简介
仓颉编程语言是一种面向全场景应用开发的通用编程语言,可以兼顾开发效率和运行性能,并提供良好的编程体验,主要具有如下特点:
- 语法简明高效:仓颉编程语言提供了一系列简明高效的语法,旨在减少冗余书写、提升开发效率,例如插值字符串、主构造函数、Flow 表达式、
match、if-let、while-let和重导出等语法,让开发者可以用较少编码表达相关逻辑。 - 多范式编程:仓颉编程语言支持函数式、命令式和面向对象等多范式编程,融合了高阶函数、代数数据类型、模式匹配、泛型等函数式语言的先进特性,还有封装、接口、继承、子类型多态等支持模块化开发的面向对象语言特性,以及值类型、全局函数等简洁高效的命令式语言特性。开发者可以根据开发偏好或应用场景,选用不同的编程范式。
- 类型安全:仓颉编程语言是静态强类型语言,通过编译时类型检查尽早识别程序错误,降低运行时风险,也便于代码维护。同时,仓颉编译器提供了强大的类型推断能力,可以减少类型标注工作,提高开发效率。
- 内存安全:仓颉编程语言支持自动内存管理,并在运行时进行数组下标越界检查、溢出检查等,确保运行时内存安全。
- 高效并发:仓颉编程语言提供了用户态轻量化线程(原生协程),以及简单易用的并发编程机制,保证并发场景的高效开发和运行。
- 兼容语言生态:仓颉编程语言支持和 C 等主流编程语言的互操作,并采用便捷的声明式编程范式,可实现对其他语言库的高效复用和生态兼容。
- 领域易扩展:仓颉编程语言提供了基于词法宏的元编程能力,支持在编译时变换代码,此外,还提供了尾随
lambda、属性、操作符重载、部分关键字可省略等特性,开发者可由此深度定制程序的语法和语义,有利于内嵌式领域专用语言(Embedded Domain Specific Languages,EDSL)的构建。 - 助力 UI 开发:UI 开发是构建端侧应用的重要环节,基于仓颉编程语言的元编程和尾随
lambda等特性,可以搭建声明式 UI 开发框架,提升 UI 开发效率和体验。 - 助力 AI 开发:AI 是当今重要的研究与应用领域,仓颉编程语言为此提供了原生自动微分支持,可有效减少 AI 开发中数学运算相关的编码,结合元编程等能力,开发者还能快速搭建 AI 开发框架,可参考仓颉 AI 项目。
- 内置库功能丰富:仓颉编程语言提供了功能丰富的内置库,涉及数据结构、常用算法、数学计算、正则匹配、系统交互、文件操作、网络通信、数据库访问、日志打印、解压缩、编解码、加解密和序列化等功能。
仓颉编程语言的特性较为丰富繁多,但却易于入门和上手,适合渐进式学习与实践。本手册的各章节内容如下:
- 第一章:仓颉编程语言简介。
- 第二章:介绍如何安装仓颉编译器工具链,并指导读者编译运行第一个仓颉程序。
- 第三章:介绍仓颉编程语言的基本概念,包括变量、表达式、作用域和程序基本结构等。
- 第四章:介绍基础数据类型,包括整数、浮点数、字符串、元组和区间等类型。
- 第五章:介绍自定义类型,包括
enum类型、struct类型、class类型和interface类型,以及子类型关系、类型转换和类型别名。 - 第六章:介绍常用的 Collection 数据类型,包括
Array、ArrayList、HashSet和HashMap等。 - 第七章:介绍错误处理,包括异常类和
try表达式,以及Option类型在错误处理中的应用。 - 第八章:介绍函数,包括函数的基本概念、函数作为一等公民的相关特性、
lambda表达式、闭包、函数调用语法糖、函数重载、操作符重载和mut函数等。 - 第九章:介绍模式匹配,包括
match表达式和六种基本模式,以及模式的 Refutability 属性。 - 第十章:介绍泛型编程,包括泛型参数、自定义泛型类型、泛型接口、泛型函数和泛型约束等。
- 第十一章:介绍属性,包括属性的定义和使用。
- 第十二章:介绍扩展,包括扩展的定义、扩展的孤儿规则、扩展的访问与遮盖、扩展的导入导出。
- 第十三章:介绍并发,包括仓颉线程的创建和执行,以及三种常用的同步机制(原子操作、互斥锁和条件变量)。
- 第十四章:介绍元编程,包括 Tokens 相关类型、
quote表达式和仓颉宏的相关语法,并结合实例介绍仓颉宏的编译和使用方式。 - 第十五章:介绍自动微分,包括可微类型和不可微类型,以及可微函数和微分表达式等。
- 第十六章:介绍包管理,包括包与模块的概念,以及包的声明与导入方式等。
- 第十七章:介绍跨语言互操作,目前只涉及仓颉与 C 语言的互操作,包括类型映射、声明与调用 C 函数、
CType类型约束、CFunc类型函数和inout引用传参等特性。 - 第十八章:介绍仓颉编译器
cjc的使用方法及编译选项。 - 第十九章:介绍仓颉运行时相关的环境变量。
- 第二十章:介绍条件编译,包括如何使用内置条件和自定义条件等。
- 第二十一章:介绍常量求值,即仓颉允许某些特定形式的表达式在编译时求值,可以提高程序运行时效率。
- 第二十二章:介绍注解,即仓颉针对某些特殊场景给开发者提供的内置属性宏。
- 第二十三章:介绍仓颉动态特性,包括反射和动态加载特性。
- 第二十四章:本章为附录,介绍仓颉中的关键字、操作符和
TokenKind类型等。
入门指南
跟随本章的指导,您将学会如何安装仓颉工具链,并尝试编译运行第一个仓颉程序。
安装仓颉工具链
在开发仓颉程序时,必用的工具之一是仓颉编译器,它可以将仓颉源代码编译为可运行的二进制文件,但现代编程语言的配套工具并不止于此,实际上,我们为开发者提供了编译器、调试器、包管理器、静态检查工具、格式化工具和覆盖率统计工具等一整套仓颉开发工具链,同时提供了友好的安装和使用方式,基本能做到“开箱即用”。
目前仓颉工具链已适配部分版本的 Linux 和 Windows 平台,但是仅针对部分 Linux 发行版做了完整功能测试,详情可参阅附录“Linux 版本工具链的支持与安装”章节,在暂未进行过完整功能测试的平台上,仓颉工具链的功能完整性不受到保证。此外,当前 Windows 平台上的仓颉编译器基于 MinGW 实现,相较于 Linux 版本的仓颉编译器,功能会有部分欠缺,二者的具体差异请见版本 Release Note。
Linux
环境准备
Linux
Linux 版仓颉工具链的系统环境要求如下:
| 架构 | 环境要求 |
|---|---|
| x86_64 | glibc 2.22,Linux Kernel 4.12 或更高版本,系统安装 libstdc++ 6.0.24 或更高版本 |
| aarch64 | glibc 2.27,Linux Kernel 4.15 或更高版本,系统安装 libstdc++ 6.0.24 或更高版本 |
除此之外,对于不同的 Linux 发行版,还需要安装相应的依赖软件包:
Ubuntu 18.04
$ apt-get install binutils libc-dev libc++-dev libgcc-7-dev
EulerOS R11
$ yum install binutils glibc-devel gcc
此外,仓颉工具链还依赖 OpenSSL 3 组件,由于该组件可能无法从以上发行版的默认软件源直接安装,因此你需要自行手动安装,安装方式请参考附录[编译安装依赖工具]小节。
其他 Linux 发行版
您可以在附录“Linux 版本工具链的支持与安装”章节找到更多 Linux 发行版的依赖安装命令。
安装指导
首先请前往仓颉官方发布渠道,下载适配您平台架构的安装包:
Cangjie-x.y.z-linux_x64.tar.gz:适用于 x86_64 架构 Linux 系统的仓颉工具链Cangjie-x.y.z-linux_aarch64.tar.gz:适用于 aarch64 架构 Linux 系统的仓颉工具链
假设这里选择了 Cangjie-x.y.z-linux_x64.tar.gz,下载到本地后,请执行如下命令解压:
tar xvf Cangjie-x.y.z-linux_x64.tar.gz
解压完成,您会在当前工作路径下看到一个名为 cangjie 的目录,其中存放了仓颉工具链的全部内容,请执行如下命令完成仓颉工具链的安装配置:
source cangjie/envsetup.sh
为了验证是否安装成功,可以执行如下命令:
cjc -v
其中 cjc 是仓颉编译器的可执行文件名,如果您在命令行中看到了仓颉编译器版本信息,那么恭喜您,已经成功安装了仓颉工具链。值得说明的是,envsetup.sh 脚本只是在当前 shell 环境中配置了工具链相关的环境变量,所以仓颉工具链仅在当前 shell 环境中可用,在新的 shell 环境中,您需要重新执行 envsetup.sh 脚本配置环境。
卸载与更新
在 Linux 平台,删除上述仓颉工具链的安装包目录,同时移除上述环境变量(最简单的,您可以新开一个 shell 环境),即可完成卸载。
$ rm -rf <path>/<to>/cangjie
若需要更新仓颉工具链,您需要先卸载当前版本,然后按上述指导重新安装最新版本的仓颉工具链。
Windows
本节以 Windows 10 平台为例,介绍仓颉工具链的安装方式。
安装指导
在 Windows 平台上,我们为开发者提供了 exe 和 zip 两种格式的安装包,请前往仓颉官方发布渠道,选择和下载适配您平台架构的 Windows 版安装包。
如果您选择了 exe 格式的安装包(例如 Cangjie-x.y.z-windows_x64.exe),请直接执行此文件,跟随安装向导点击操作,即可完成安装。
如果您选择了 zip 格式的安装包(例如 Cangjie-x.y.z-windows_x64.zip),请将它解压到适当目录,在安装包中,我们为开发者提供了三种不同格式的安装脚本,分别是 envsetup.bat,envsetup.ps1 和 envsetup.sh,您可以根据使用习惯及环境配置,选择一种执行:
若使用 Windows 命令提示符(CMD)环境,请执行:
path\to\cangjie\envsetup.bat
若使用 PowerShell 环境,请执行:
. path\to\cangjie\envsetup.ps1
若使用 MSYS shell、bash 等环境,请执行:
source path/to/cangjie/envsetup.sh
为了验证是否安装成功,请在以上命令环境中继续执行 cjc -v 命令,如果输出了仓颉编译器版本信息,那么恭喜您,已经成功安装了仓颉工具链。
注意:基于
zip安装包和执行脚本的安装方式,类似于 Linux 平台,即envsetup脚本所配置的环境变量,只在当前命令行环境中有效,如果打开新的命令行窗口,需要重新执行envsetup脚本配置环境。
卸载与更新
运行仓颉安装目录下的 unins000.exe 可执行文件,跟随卸载向导点击操作,即可完成卸载。
若需要更新仓颉工具链,您需要先卸载当前版本,然后按上述指导重新安装最新版本的仓颉工具链。
运行第一个仓颉程序
万事俱备,让我们编写和运行第一个仓颉程序吧!
首先,请在适当目录下新建一个名为 hello.cj 的文本文件,并向文件中写入以下仓颉代码:
// hello.cj
main() {
println("你好,仓颉")
}
在这段代码中,使用了仓颉的注释语法,您可以在
//符号之后写单行注释,也可以在一对/*和*/符号之间写多行注释,这与 C/C++ 等语言的注释语法相同。注释内容不影响程序的编译和运行。
然后,请在此目录下执行如下命令:
cjc hello.cj -o hello
这里仓颉编译器会将 hello.cj 中的源代码编译为此平台上的可执行文件 hello,在命令行环境中运行此文件,您将看到程序输出了如下内容:
你好,仓颉
以上编译命令是针对 Linux 平台的,如果您使用 Windows 平台,只需要将编译命令改为
cjc hello.cj -o hello.exe即可。
基本概念
大多数编程语言都有一些共通的概念或元素,例如变量和表达式等,因为它们是逻辑表达的要素,同时和计算机的存储及指令有较为直接的对应关系。此外,还有程序入口、作用域、全局/局部变量等概念,这些概念和相关的规则,将作为开发者编写程序的基本章法。本章将介绍仓颉编程语言中的这些基本概念。
标识符
在仓颉编程语言中,开发者可以给一些程序元素命名,这些名字也被称为“标识符”,标识符分为普通标识符和原始标识符两类,它们分别遵从不同的命名规则。
普通标识符不能和仓颉关键字相同,可以取自以下两类字符序列:
- 由英文字母开头,后接零至多个英文字母、数字或下划线“_”。
- 由一至多个下划线“_”开头,后接一个英文字母,最后可接零至多个英文字母、数字或下划线“_”。
例如,以下每行字符串都是合法的普通标识符:
abc
_abc
abc_
a1b2c3
a_b_c
a1_b2_c3
以下每行字符串都是不合法的普通标识符:
ab&c // 使用了非法字符 “&”
_123 // 起始下划线 “_” 后不能接数字
3abc // 数字不能出现在头部
while // 不能使用仓颉关键字
原始标识符是在普通标识符或仓颉关键字的外面加上一对反引号,主要用于将仓颉关键字作为标识符的场景。
例如,以下每行字符串都是合法的原始标识符:
abc
_abc
a1b2c3
if
while
以下每行字符串,由于反引号内的部分是不合法的普通标识符,所以它们整体也是不合法的原始标识符:
ab&c
_123
3abc
变量
在仓颉编程语言中,一个变量由对应的变量名、数据(值)和若干属性构成,开发者通过变量名访问变量对应的数据,但访问操作需要遵从相关属性的约束(如数据类型、可变性和可见性等)。当程序被编译运行时,一个变量可以具化为一份可操作的存储空间。
因此,在定义一个仓颉变量时,就需要指定变量名、初始值和相关属性。变量定义的具体形式为:
修饰符 变量名: 变量类型 = 初始值
其中修饰符用于设置变量的各类属性,可以有一个或多个,常用的修饰符包括:
- 可变性修饰符:
let与var,分别对应不可变和可变属性,可变性决定了变量被初始化后其值还能否改变,仓颉变量也由此分为不可变变量和可变变量两类。 - 可见性修饰符:
private与public等,影响全局变量和成员变量的可引用范围,详见后续章节的相关介绍。 - 静态性修饰符:
static,影响成员变量的存储和引用方式,详见后续章节的相关介绍。
在定义仓颉变量时,可变性修饰符是必要的,在此基础上,还可以根据需要添加其他修饰符。
变量名应是一个合法的仓颉标识符。
变量类型指定了变量所持有数据的类型。当初始值具有明确类型时,可以省略变量类型标注,此时编译器可以自动推断出变量类型。
初始值是一个仓颉表达式,用于初始化变量,如果标注了变量类型,需要保证初始值类型和变量类型一致。在定义全局变量或静态成员变量时,必须指定初始值。在定义局部变量或实例成员变量时,可以省略初始值,但需要标注变量类型,同时要在此变量被引用前完成初始化,否则编译会报错。
例如,下列程序定义了两个 Int64 类型的不可变变量 a 和可变变量 b,随后修改了变量 b 的值,并调用仓颉标准库中的 println 函数打印 a 与 b 的值。
main() {
let a: Int64 = 20
var b: Int64 = 12
b = 23
println("${a}${b}")
}
编译运行此程序,将输出:
2023
如果尝试修改不可变变量,编译时会报错,例如:
main() {
let pi: Float64 = 3.14159
pi = 2.71828 // error: cannot assign to immutable value
}
当初始值具有明确类型时,可以省略变量类型标注,例如:
main() {
let a: Int64 = 2023
let b = a
println("a - b = ${a - b}")
}
其中变量 b 的类型可以由其初值 a 的类型自动推断为 Int64,所以此程序也可以被正常编译和运行,将输出:
a - b = 0
在定义局部变量时,可以不进行初始化,但一定要在变量被引用前赋予初值,例如:
main() {
let text: String
text = "仓颉造字"
println(text)
}
编译运行此程序,将输出:
仓颉造字
在定义全局变量和静态成员变量时必须初始化,否则编译会报错,例如:
// example.cj
let global: Int64 // error: variable in top-level scope must be initialized
// example.cj
class Player {
static let score: Int32 // error: static variable 'score' needs to be initialized when declaring
}
值类型和引用类型变量
程序在运行阶段,只有指令流转和数据变换,仓颉程序中的各种标识符已不复存在。由此可见,编译器使用了一些机制,将这些名字和编程所取用的数据实体/存储空间绑定起来。
从编译器实现层面看,任何变量总会关联一个值(一般是通过内存地址/寄存器关联),只是在使用时,对有些变量,我们将直接取用这个值本身,这被称为值类型变量,而对另一些变量,我们把这个值作为索引、取用这个索引指示的数据,这被称为引用类型变量。值类型变量通常在线程栈上分配,每个变量都有自己的数据副本;引用类型变量通常在进程堆中分配,多个变量可引用同一数据对象,对一个变量执行的操作可能会影响其他变量。
从语言层面看,值类型变量对它所绑定的数据/存储空间是独占的,而引用类型变量所绑定的数据/存储空间可以和其他引用类型变量共享。
基于上述原理,在使用值类型变量和引用类型变量时,会存在一些行为差异,值得注意以下几点:
- 在给值类型变量赋值时,一般会产生拷贝操作,且原来绑定的数据/存储空间被覆写。在给引用类型变量赋值时,只是改变了引用关系,原来绑定的数据/存储空间不会被覆写。
- 用
let定义的变量,要求变量被初始化后都不能再赋值。对于引用类型,这只是限定了引用关系不可改变,但是所引用的数据是可以被修改的。
在仓颉编程语言中,基础数据类型和 struct 等类型属于值类型,而 class 和 Array 等类型属于引用类型。
例如,以下程序演示了 struct 和 class 类型变量的行为差异:
struct Copy {
var data = 2012
}
class Share {
var data = 2012
}
main() {
let c1 = Copy()
var c2 = c1
c2.data = 2023
println("${c1.data}, ${c2.data}")
let s1 = Share()
let s2 = s1
s2.data = 2023
println("${s1.data}, ${s2.data}")
}
运行以上程序,将输出:
2012, 2023
2023, 2023
由此可以看出,对于值类型的 Copy 类型变量,在赋值时总是获取 Copy 实例的拷贝,如 c2 = c1,随后对 c2 成员的修改并不影响 c1。对于引用类型的 Share 类型变量,在赋值时将建立变量和实例之间的引用关系,如 s2 = s1,随后对 s2 成员的修改会影响 s1。
如果将以上程序中的 var c2 = c1 改成 let c2 = c1,则编译会报错,例如:
struct Copy {
var data = 2012
}
main() {
let c1 = Copy()
let c2 = c1
c2.data = 2023 // error: cannot assign to immutable value
}
表达式
在一些传统编程语言中,一个表达式由一个或多个操作数(operand)通过零个或多个操作符(operator)组合而成,表达式总是隐含着一个计算过程,因此每个表达式都会有一个计算结果,对于只有操作数而没有操作符的表达式,其计算结果就是操作数自身,对于包含操作符的表达式,计算结果是对操作数执行操作符定义的计算而得到的值。在这种定义下的表达式也被称为算术运算表达式。
在仓颉编程语言中,我们简化并延伸了表达式的传统定义——凡是可求值的语言元素都是表达式。因此,仓颉不仅有传统的算术运算表达式,还有条件表达式、循环表达式和 try 表达式等,它们都可以被求值,并作为值去使用,如作为变量定义的初值和函数实参等。此外,因为仓颉是强类型的编程语言,所以仓颉表达式不仅可求值,还有确定的类型。
仓颉编程语言的各种表达式将在后续章节中逐一介绍,本节只介绍最常用的条件表达式和循环表达式。
我们知道,任何一段程序的执行流程,只会涉及三种基本结构——顺序结构、分支结构和循环结构。实际上,分支结构和循环结构,是由某些指令控制当前顺序执行流产生跳转而得到的,它们让程序能够表达更复杂的逻辑,在仓颉中,这种用来控制执行流的语言元素就是条件表达式和循环表达式。
在仓颉编程语言中,条件表达式分为 if 表达式和 if-let 表达式两种,它们的值与类型需要根据使用场景来确定。循环表达式有四种:for-in 表达式、while 表达式、do-while 表达式和 while-let 表达式,它们的类型都是 Unit、值为 ()。其中 if-let 表达式和 while-let 表达式都与模式匹配相关,请参见模式匹配章节,本节只介绍以上提及的其他几种表达式。
在仓颉程序中,由一对大括号“{}”包围起来的一组表达式,被称为“代码块”,它将作为程序的一个顺序执行流,其中的表达式将按编码顺序依次执行。如果代码块中有至少一个表达式,我们规定此代码块的值与类型等于其中最后一个表达式的值与类型,如果代码块中没有表达式,规定这种空代码块的类型为
Unit、值为()。请注意,代码块本身不是一个表达式,不能被单独使用,它将依附于函数、条件表达式和循环表达式等执行和求值。
if 表达式
if 表达式的基本形式为:
if (条件) {
分支 1
} else {
分支 2
}
其中“条件”是布尔类型表达式,“分支 1”和“分支 2”是两个代码块。if 表达式将按如下规则执行:
- 计算“条件”表达式,如果值为
true则转到第 2 步,值为false则转到第 3 步。 - 执行“分支 1”,转到第 4 步。
- 执行“分支 2”,转到第 4 步。
- 继续执行
if表达式后面的代码。
在一些场景中,我们可能只关注条件成立时该做些什么,所以 else 和对应的代码块是允许省略的。
如下程序演示了 if 表达式的基本用法:
from std import random.*
main() {
let number: Int8 = Random().nextInt8()
println(number)
if (number % 2 == 0) {
println("偶数")
} else {
println("奇数")
}
}
在这段程序中,我们使用仓颉标准库的 random 包生成了一个随机整数,然后使用 if 表达式判断这个整数是否能被 2 整除,并在不同的条件分支中打印“偶数”或“奇数”。
仓颉编程语言是强类型的,if 表达式的条件只能是布尔类型,不能使用整数或浮点数等类型,和 C 语言等不同,仓颉不以条件取值是否为 0 作为分支选择依据,例如以下程序将编译报错:
main() {
let number = 1
if (number) { // error: mismatched types
println("非零数")
}
}
在许多场景中,当一个条件不成立时,我们可能还要判断另一个或多个条件、再执行对应的动作,仓颉允许在 else 之后跟随新的 if 表达式,由此支持多级条件判断和分支执行,例如:
from std import random.*
main() {
let speed = Random().nextFloat64() * 20.0
println("${speed} km/s")
if (speed > 16.7) {
println("第三宇宙速度,鹊桥相会")
} else if (speed > 11.2) {
println("第二宇宙速度,嫦娥奔月")
} else if (speed > 7.9) {
println("第一宇宙速度,腾云驾雾")
} else {
println("脚踏实地,仰望星空")
}
}
if 表达式的值与类型,需要根据使用形式与场景来确定:
-
当含
else分支的if表达式被求值时,需要根据求值上下文确定if表达式的类型:-
如果上下文明确要求值类型为
T,则if表达式各分支代码块的类型必须是T的子类型,这时if表达式的类型被确定为T,如果不满足子类型约束,编译会报错。 -
如果上下文没有明确的类型要求,则
if表达式的类型是其各分支代码块类型的最小公共父类型,如果最小公共父类型不存在,编译会报错。
如果编译通过,则
if表达式的值就是所执行分支代码块的值。 -
-
如果含
else分支的if表达式没有被求值,在这种场景里,开发者一般只想在不同分支里做不同操作,不会关注各分支最后一个表达式的值与类型,为了不让上述类型检查规则影响这一思维习惯,仓颉规定这种场景下的if表达式类型为Unit、值为(),且各分支不参与上述类型检查。 -
对于不含
else分支的if表达式,由于if分支也可能不被执行,所以我们规定这类if表达式的类型为Unit、值为()。
例如,以下程序基于 if 表达式求值,模拟一次简单的模数转换过程:
main() {
let zero: Int8 = 0
let one: Int8 = 1
let voltage = 5.0
let bit = if (voltage < 2.5) {
zero
} else {
one
}
}
在以上程序中,if 表达式作为变量定义的初值使用,由于变量 bit 没有被标注类型、需要从初值中推导,所以 if 表达式的类型取为两个分支代码块类型的最小公共父类型,根据前文对“代码块”的介绍,可知两个分支代码块类型都是 Int8,所以 if 表达式的类型被确定为 Int8,其值为所执行分支即 else 分支代码块的值,所以变量 bit 的类型为 Int8、值为 1。
while 表达式
while 表达式的基本形式为:
while (条件) {
循环体
}
其中“条件”是布尔类型表达式,“循环体”是一个代码块。while 表达式将按如下规则执行:
- 计算“条件”表达式,如果值为
true则转第 2 步,值为false转第 3 步。 - 执行“循环体”,转第 1 步。
- 结束循环,继续执行
while表达式后面的代码。
例如,以下程序使用 while 表达式,基于二分法,近似计算数字 2 的平方根:
main() {
var root = 0.0
var min = 1.0
var max = 2.0
var error = 1.0
let tolerance = 0.1 ** 10
while (error ** 2 > tolerance) {
root = (min + max) / 2.0
error = root ** 2 - 2.0
if (error > 0.0) {
max = root
} else {
min = root
}
}
println("2 的平方根约等于:${root}")
}
运行以上程序,将输出:
2 的平方根约等于:1.414215
do-while 表达式
do-while 表达式的基本形式为:
do {
循环体
} while (条件)
其中“条件”是布尔类型表达式,“循环体”是一个代码块。do-while 表达式将按如下规则执行:
- 执行“循环体”,转第 2 步。
- 计算“条件”表达式,如果值为
true则转第 1 步,值为false转第 3 步。 - 结束循环,继续执行
do-while表达式后面的代码。
例如,以下程序使用 do-while 表达式,基于蒙特卡洛算法,近似计算圆周率的值:
from std import random.*
main() {
let random = Random()
var totalPoints = 0
var hitPoints = 0
do {
// 在 ((0, 0), (1, 1)) 这个正方形中随机取点
let x = random.nextFloat64()
let y = random.nextFloat64()
// 判断是否落在正方形内接圆里
if ((x - 0.5) ** 2 + (y - 0.5) ** 2 < 0.25) {
hitPoints++
}
totalPoints++
} while (totalPoints < 1000000)
let pi = 4.0 * Float64(hitPoints) / Float64(totalPoints)
println("圆周率近似值为:${pi}")
}
运行以上程序,将输出:
圆周率近似值为:3.141872
由于算法涉及随机数,所以每次运行程序输出的数值可能都不同,但都会约等于 3.14。
for-in 表达式
for-in 表达式可以遍历那些扩展了迭代器接口 Iterable<T> 的类型实例。for-in 表达式的基本形式为:
for (迭代变量 in 序列) {
循环体
}
其中“循环体”是一个代码块。“迭代变量”是单个标识符或由多个标识符构成的元组,用于绑定每轮遍历中由迭代器指向的数据,可以作为“循环体”中的局部变量使用。“序列”是一个表达式,它只会被计算一次,遍历是针对此表达式的值进行的,其类型必须扩展了迭代器接口 Iterable<T>。for-in 表达式将按如下规则执行:
- 计算“序列”表达式,将其值作为遍历对象,并初始化遍历对象的迭代器。
- 更新迭代器,如果迭代器终止,转第 4 步,否则转第 3 步。
- 将当前迭代器指向的数据与“迭代变量”绑定,并执行“循环体”,转第 2 步。
- 结束循环,继续执行
for-in表达式后面的代码。
仓颉内置的区间和数组等类型已经扩展了
Iterable<T>接口。
例如,以下程序使用 for-in 表达式,遍历中国地支字符构成的数组 noumenonArray,输出农历 2024 年各月的干支纪法:
main() {
let metaArray = ['甲', '乙', '丙', '丁', '戊',
'己', '庚', '辛', '壬', '癸']
let noumenonArray = ['寅', '卯', '辰', '巳', '午', '未',
'申', '酉', '戌', '亥', '子', '丑']
let year = 2024
// 年份对应的天干索引
let metaOfYear = ((year % 10) + 10 - 4) % 10
// 此年首月对应的天干索引
var index = (2 * metaOfYear + 3) % 10 - 1
println("农历 2024 年各月干支:")
for (noumenon in noumenonArray) {
print("${metaArray[index]}${noumenon} ")
index = (index + 1) % 10
}
}
运行以上程序,将输出:
农历 2024 年各月干支:
丙寅 丁卯 戊辰 己巳 庚午 辛未 壬申 癸酉 甲戌 乙亥 丙子 丁丑
遍历区间
for-in 表达式可以遍历区间类型实例,例如:
main() {
var sum = 0
for (i in 1..=100) {
sum += i
}
println(sum)
}
运行以上程序,将输出:
5050
关于区间类型的详细内容,请参阅“基本数据类型”章节。
遍历元组构成的序列
如果一个序列的元素是元组类型,则使用 for-in 表达式遍历时,“迭代变量”可以写成元组形式,以此实现对序列元素的解构,例如:
main() {
let array = [(1, 2), (3, 4), (5, 6)]
for ((x, y) in array) {
println("${x}, ${y}")
}
}
运行以上程序,将输出:
1, 2
3, 4
5, 6
迭代变量不可修改
在 for-in 表达式的循环体中,不能修改迭代变量,例如以下程序在编译时会报错:
main() {
for (i in 0..5) {
i = i * 10 // error: cannot assign to value which is an initialized 'let' constant
println(i)
}
}
使用通配符_代替迭代变量
在一些应用场景中,我们只需要循环执行某些操作,但并不使用迭代变量,这时您可以使用通配符 _ 代替迭代变量,例如:
main() {
var number = 2
for (_ in 0..5) {
number *= number
}
println(number)
}
运行以上程序,将输出:
4294967296
在这种场景下,如果您使用普通的标识符定义迭代变量,编译会输出“unused variable”告警,使用通配符
_则可以避免这一告警。
where 条件
在部分循环遍历场景中,对于特定取值的迭代变量,我们可能需要直接跳过、进入下一轮循环,虽然可以使用 if 表达式和 continue 表达式在循环体中实现这一逻辑,但仓颉为此提供了更便捷的表达方式——可以在所遍历的“序列”之后用 where 关键字引导一个布尔表达式,这样在每次将进入循环体执行前,会先计算此表达式,如果值为 true 则执行循环体,反之直接进入下一轮循环。例如:
main() {
for (i in 0..8 where i % 2 == 1) { // i 为奇数才会执行循环体
println(i)
}
}
运行以上程序,将输出:
1
3
5
7
break 与 continue 表达式
在循环结构的程序中,有时我们需要根据特定条件提前结束循环或跳过本轮循环,为此仓颉引入了 break 与 continue 表达式,它们可以出现在循环表达式的循环体中,break 用于终止当前循环表达式的执行、转去执行循环表达式之后的代码,continue 用于提前结束本轮循环、进入下一轮循环。break 与 continue 表达式的类型都是 Nothing。
例如,以下程序使用 for-in 表达式和 break 表达式,在给定的整数数组中,找到第一个能被 5 整除的数字:
main() {
let numbers = [12, 18, 25, 36, 49, 55]
for (number in numbers) {
if (number % 5 == 0) {
println(number)
break
}
}
}
当 for-in 迭代至 numbers 数组的第三个数 25 时,由于 25 可以被 5 整除,所以将执行 if 分支中的 println 和 break,break 将终止 for-in 循环,numbers中的后续数字不会被遍历到,因此运行以上程序,将输出:
25
以下程序使用 for-in 表达式和 continue 表达式,将给定整数数组中的奇数打印出来:
main() {
let numbers = [12, 18, 25, 36, 49, 55]
for (number in numbers) {
if (number % 2 == 0) {
continue
}
println(number)
}
}
在循环迭代中,当 number 是偶数时,continue 将被执行,这会提前结束本轮循环、进入下一轮循环,println 不会被执行,因此运行以上程序,将输出:
25
49
55
作用域
在前文中,我们初步介绍了如何给仓颉程序元素命名,实际上,除了变量,我们还可以给函数和自定义类型等命名,在程序中将使用这些名字访问对应的程序元素。
但在实际应用中,需要考虑一些特殊情况:
- 当程序规模较大时,那些简短的名字很容易重复,即产生命名冲突。
- 结合运行时考虑,在有些代码片段中,另一些程序元素是无效的,对它们的引用会导致运行时错误。
- 在某些逻辑构造中,为了表达元素之间的包含关系,不应通过名字直接访问子元素,而是要通过其父元素名间接访问。
为了应对这些问题,现代编程语言引入了“作用域”的概念及设计,将名字和程序元素的绑定关系限制在一定范围里。不同作用域之间可以是并列或无关的,也可以是嵌套或包含关系。一个作用域将明确我们能用哪些名字访问哪些程序元素,具体规则是:
- 当前作用域中定义的程序元素与名字的绑定关系,在当前作用域和其内层作用域中是有效的,可以通过此名字直接访问对应的程序元素。
- 内层作用域中定义的程序元素与名字的绑定关系,在外层作用域中无效。
- 内层作用域可以使用外层作用域中的名字重新定义绑定关系,根据规则 1,此时内层作用域中的命名相当于遮盖了外层作用域中的同名定义,对此我们称内层作用域的级别比外层作用域的级别高。
在仓颉编程语言中,用一对大括号“{}”包围一段仓颉代码,即构造了一个新的作用域,其中可以继续使用大括号“{}”包围仓颉代码,由此产生了嵌套作用域,这些作用域均服从上述规则。特别的,在一个仓颉源文件中,不被任何大括号“{}”包围的代码,它们所属的作用域被称为“顶层作用域”,即当前文件中“最外层”的作用域,按上述规则,其作用域级别最低。
用大括号“{}”包围代码构造作用域时,其中不限于使用表达式,还可以定义函数和自定义类型等,这不同于前文中提到的“代码块”概念,当然“代码块”也是一个作用域。
例如在以下名为 test.cj 的仓颉源文件里,在顶层作用域中定义了名字 element,它和字符串“仓颉”绑定,而 main 和 if 引导的代码块中也定义了名字 element,分别对应整数 9 和整数 2023。由上述作用域规则,在第 4 行,element 的值为“仓颉”,在第 8 行,element 的值为 2023,在第 10 行,element 的值为 9。
// test.cj
let element = "仓颉"
main() {
println(element)
let element = 9
if (element > 0) {
let element = 2023
println(element)
}
println(element)
}
运行以上程序,将输出:
仓颉
2023
9
程序结构
通常,我们都会在扩展名为 .cj 的文本文件中编写仓颉程序,这些程序和文件也被称为源代码和源文件,在程序开发的最后阶段,这些源代码将被编译为特定格式的二进制文件。
在仓颉程序的顶层作用域中,可以定义一系列的变量、函数和自定义类型(如 struct、class、enum 和 interface 等),其中的变量和函数分别被称为全局变量和全局函数。如果要将仓颉程序编译为可执行文件,您需要在顶层作用域中定义一个 main 函数作为程序入口,它可以有 Array<String> 类型的参数,也可以没有参数,它的返回值类型可以是整数类型或 Unit 类型。
定义
main函数时,不需要写func修饰符。此外,如果需要获取程序启动时的命令行参数,可以声明和使用Array<String>类型参数。
例如在以下程序中,我们在顶层作用域定义了全局变量 a 和全局函数 b,还有自定义类型 C、D 和 E,以及作为程序入口的 main 函数。
// example.cj
let a = 2023
func b() {}
struct C {}
class D {}
enum E { F | G }
main() {
println(a)
}
在非顶层作用域中不能定义上述自定义类型,但可以定义变量和函数,称之为局部变量和局部函数。特别地,对于定义在自定义类型中的变量和函数,称之为成员变量和成员函数。
enum和interface中仅支持定义成员函数。
例如在以下程序中,我们在顶层作用域定义了全局函数 a 和自定义类型 A,在函数 a 中定义了局部变量 b 和局部函数 c,在自定义类型 A 中定义了成员变量 b 和成员函数 c。
// example.cj
func a() {
let b = 2023
func c() {
println(b)
}
c()
}
class A {
let b = 2024
public func c() {
println(b)
}
}
main() {
a()
A().c()
}
运行以上程序,将输出:
2023
2024
基本数据类型
本章介绍仓颉中的基本数据类型以及它们支持的基本操作,包括:整数类型、浮点类型、布尔类型、字符类型、字符串类型、Unit 类型、元组类型、区间类型、Nothing 类型。
整数类型
整数类型分为有符号(signed)整数类型和无符号(unsigned)整数类型。
有符号整数类型包括 Int8、Int16、Int32、Int64 和 IntNative,分别用于表示编码长度为 8-bit、16-bit、32-bit、64-bit 和平台相关大小的有符号整数值的类型。
无符号整数类型包括 UInt8、UInt16、UInt32、UInt64 和 UIntNative,分别用于表示编码长度为 8-bit、16-bit、32-bit、64-bit 和平台相关大小的无符号整数值的类型。
对于编码长度为 N 的有符号整数类型,其表示范围为:$$-2^{N-1} \sim 2^{N-1}-1$$;对于编码长度为 N 的无符号整数类型,其表示范围为:$$0 \sim 2^{N}-1$$。下表列出了所有整数类型的表示范围:
| 类型 | 表示范围 |
|---|---|
| Int8 | $$-2^7 \sim 2^7-1 (-128 \sim 127)$$ |
| Int16 | $$-2^{15} \sim 2^{15}-1 (-32,768 \sim 32,767)$$ |
| Int32 | $$-2^{31} \sim 2^{31}-1 (-2,147,483,648 \sim 2,147,483,647)$$ |
| Int64 | $$-2^{63} \sim 2^{63}-1 (-9,223,372,036,854,775,808 \sim 9,223,372,036,854,775,807)$$ |
| IntNative | platform dependent |
| UInt8 | $$0 \sim 2^8-1 (0 \sim 255)$$ |
| UInt16 | $$0 \sim 2^{16}-1 (0 \sim 65,535)$$ |
| UInt32 | $$0 \sim 2^{32}-1 (0 \sim 4,294,967,295)$$ |
| UInt64 | $$0 \sim 2^{64}-1 (0 \sim 18,446,744,073,709,551,615)$$ |
| UIntNative | platform dependent |
程序具体使用哪种整数类型,取决于该程序中需要处理的整数的性质和范围。在 Int64 类型适合的情况下,首选 Int64 类型,因为 Int64 的表示范围足够大,并且整数字面量(在下一节介绍)在没有类型上下文的情况下默认推断为 Int64 类型,可以避免不必要的类型转换。
整数类型字面量
整数类型字面量有 4 种进制表示形式:二进制(使用 0b 或 0B 前缀)、八进制(使用 0o 或 0O 前缀)、十进制(没有前缀)、十六进制(使用 0x 或 0X 前缀)。例如,对于十进制数 24,表示成二进制是 0b00011000(或 0B00011000),表示成八进制是 0o30(或 0O30),表示成十六进制是 0x18(或 0X18)。
在各进制表示中,可以使用下划线 _ 充当分隔符的作用,方便识别数值的位数,如 0b0001_1000。
对于整数类型字面量,如果它的值超出了上下文要求的整数类型的表示范围,编译器将会报错。
let x: Int8 = 128 // Error: 128 out of the range of Int8
let y: UInt8 = 256 // Error: 256 out of the range of UInt8
let z: Int32 = 0x8000_0000 // Error: 0x8000_0000 out of the range of Int32
在使用整数类型字面量时,可以通过加入后缀来明确整数字面量的类型,后缀与类型的对应为:
| 后缀 | 类型 | 后缀 | 类型 |
|---|---|---|---|
| i8 | Int8 | u8 | UInt8 |
| i16 | Int16 | u16 | UInt16 |
| i32 | Int32 | u32 | UInt32 |
| i64 | Int64 | u64 | UInt64 |
加入了后缀的整数字面量可以像下面的方式来使用:
var x = 100i8 // x is 100 with type Int8
var y = 0x10u64 // y is 16 with type UInt64
var z = 0o432i32 // z is 282 with type Int32
整数类型支持的操作
整数类型默认支持的操作符包括:算术操作符、位操作符、关系操作符、自增和自减操作符、赋值操作符、复合赋值操作符。各操作符的优先级和用法参见附录中的[操作符]。
-
算术操作符包括:一元负号(
-)、加法(+)、减法(-)、乘法(*)、除法(/)、取模(%)、幂运算(**)。注意:
-
除了一元负号(
-)和幂运算(**),其他操作符要求左右操作数是相同的类型。 -
*,/,+和-的操作数可以是整数类型或浮点类型。 -
%的操作数只支持整数类型。 -
**的左操作数只能为Int64类型或Float64类型,并且:- 当左操作数类型为
Int64时,右操作数只能为UInt64类型,表达式的类型为Int64。 - 当左操作数类型为
Float64时,右操作数只能为Int64类型或Float64类型,表达式的类型为Float64。
- 当左操作数类型为
幂运算的使用,见如下示例:
let p1 = 2 ** 3 // p1 = 8 let p2 = 2 ** UInt64(3 ** 2) // p2 = 512 let p3 = 2.0 ** 3.0 // p3 = 8.0 let p4 = 2.0 ** 3 ** 2 // p4 = 512.0 let p5 = 2.0 ** 3.0 // p5 = 8.0 let p6 = 2.0 ** 3.0 ** 2.0 // p6 = 512.0 -
-
位操作符包括:按位求反(
!)、左移(<<)、右移(>>)、按位与(&)、按位异或(^)、按位或(|)。注意,按位与、按位异或和按位或操作符要求左右操作数是相同的整数类型。 -
关系操作符包括:小于(
<)、大于(>)、小于等于(<=)、大于等于(>=)、相等(==)、不等(!=)。要求关系操作符的左右操作数是相同的整数类型。 -
自增和自减操作符包括:自增(
++)和自减(--)。注意,仓颉中的自增和自减操作符只能作为一元后缀操作符使用。 -
赋值操作符即
=,复合赋值操作符包括:+=、-=、*=、/=、%=、**=、<<=、>>=、&=、^=、|=。
注:本章中我们所提及的某个类型支持的操作,均是指在没有[操作符重载]的前提下。
字符字节字面量
仓颉编程语言引入了字符字节字面量来更为方便地用 ASCII 码来表示 UInt8 类型的值,由字符 b 和被单引号引用的值组成。例如:
var a = b'x' // a is 120 with type UInt8
var b = b'\n' // b is 10 with type UInt8
var c = b'\u{78}' // c is 120 with type UInt8
对于 \u 转义的字符不支持 Unicode,所以内部最多有两位 16 进制数。
浮点类型
浮点类型包括 Float16、 Float32 和 Float64,分别用于表示编码长度为 16-bit、 32-bit 和 64-bit 的浮点数(带小数部分的数字,如 3.14159、8.24 和 0.1 等)的类型。Float16、 Float32 和 Float64 分别对应 IEEE 754 中的半精度格式(即 binary16)、单精度格式(即 binary32)和双精度格式(即 binary64)。
Float64 的精度约为小数点后 15 位,Float32 的精度约为小数点后 6 位,Float16 的精度约为小数点后 3 位。使用哪种浮点类型,取决于代码中需要处理的浮点数的性质和范围。在多种浮点类型都适合的情况下,首选精度高的浮点类型,因为精度低的浮点类型的累计计算误差很容易扩散,并且它能精确表示的整数范围也很有限。
浮点类型字面量
浮点类型字面量有两种进制表示形式:十进制、十六进制。在十进制表示中,一个浮点字面量至少要包含一个整数部分或一个小数部分,没有小数部分时必须包含指数部分(以 e 或 E 为前缀,底数为 10)。在十六进制表示中,一个浮点字面量除了至少要包含一个整数部分或小数部分(以 0x 或 0X 为前缀),同时必须包含指数部分(以 p 或 P 为前缀,底数为 2)。
下面的例子展示了浮点字面量的使用:
let a: Float32 = 3.14
let b: Float32 = 2e3
let c: Float32 = 2.4e-1
let d: Float64 = .123e2
let e: Float64 = 0x1.1p0
let f: Float64 = 0x1p2
let g: Float64 = 0x.2p4
在使用十进制浮点数字面量时,可以通过加入后缀来明确浮点数字面量的类型,后缀与类型的对应为:
| 后缀 | 类型 |
|---|---|
| f16 | Float16 |
| f32 | Float32 |
| f64 | Float64 |
加入了后缀的浮点数字面量可以像下面的方式来使用:
let a = 3.14f32 // a is 3.14 with type Float32
let b = 2e3f32 // b is 2e3 with type Float32
let c = 2.4e-1f64 // c is 2.4e-1 with type Float64
let d = .123e2f64 // d is .123e2 with type Float64
浮点类型支持的操作
浮点类型默认支持的操作符包括:算术操作符、关系操作符、赋值操作符、复合赋值操作符。浮点类型不支持自增和自减操作符。
布尔类型
布尔类型使用 Bool 表示,用来表示逻辑中的真和假。
布尔类型字面量
布尔类型只有两个字面量:true 和 false。
下面的例子展示了布尔字面量的使用:
let a: Bool = true
let b: Bool = false
布尔类型支持的操作
布尔类型支持的操作符包括:逻辑操作符(逻辑非 !,逻辑与 &&,逻辑或 ||)、部分关系操作符(== 和 !=)、赋值操作符、部分复合赋值操作符(&&= 和 ||=)。
字符类型
字符类型使用 Char 表示,可以表示 Unicode 字符集中的所有字符。
当前,仓颉已经引入了 Rune。Rune 是 Char 的 类型别名,定义为 type Rune = Char。
Rune 的语义与 Char 相同,都是 Unicode Scalar Value。目前 Rune 与 Char 短期共存,但是将来 Char 将会被删除,建议需要使用字符类型的地方使用 Rune。
字符类型字面量
字符类型字面量有三种形式:单个字符、转义字符和通用字符,它们均使用一对单引号定义。
单个字符的字符字面量举例:
let a: Char = 'a'
let b: Char = 'b'
转义字符是指在一个字符序列中对后面的字符进行另一种解释的字符。转义字符使用转义符号 \ 开头,后面加需要转义的字符。举例如下:
let slash: Char = '\\'
let newLine: Char = '\n'
let tab: Char = '\t'
通用字符以 \u 开头,后面加上定义在一对花括号中的 1~8 个十六进制数,即可表示对应的 Unicode 值代表的字符。举例如下:
main() {
let he: Char = '\u{4f60}'
let llo: Char = '\u{597d}'
print(he)
print(llo)
}
编译并执行上述代码,输出结果为:
你好
字符类型支持的操作
字符类型仅支持关系操作符:小于(<)、大于(>)、小于等于(<=)、大于等于(>=)、相等(==)、不等(!=)。比较的是字符的 Unicode 值。
字符串类型
字符串类型使用 String 表示,用于表达文本数据,由一串 Unicode 字符组合而成。
字符串字面量
字符串字面量分为三类:单行字符串字面量,多行字符串字面量,多行原始字符串字面量。
单行字符串字面量的内容定义在一对双引号之内,双引号中的内容可以是任意数量的(除了非转义的双引号和单独出现的 \ 之外的)任意字符。单行字符串字面量只能写在同一行,不能跨越多行。举例如下:
let s1: String = ""
let s2 = "Hello Cangjie Lang"
let s3 = "\"Hello Cangjie Lang\""
let s4 = "Hello Cangjie Lang\n"
多行字符串字面量以三个双引号开头,并以三个双引号结尾,并且开头的三个双引号之后需要换行(否则编译报错)。字面量的内容从开头的三个双引号换行后的第一行开始,到结尾的三个双引号之前为止,之间的内容可以是任意数量的(除单独出现的 \ 之外的)任意字符。不同于单行字符串字面量,多行字符串字面量可以跨越多行。举例如下:
let s1: String = """
"""
let s2 = """
Hello,
Cangjie Lang"""
多行原始字符串字面量以一个或多个井号(#)加上一个双引号开始,并以一个双引号加上和开始相同个数的 # 结束。开始的双引号和结束的双引号之间的内容可以是任意数量的任意合法字符。不同于(普通)多行字符串字面量,多行原始字符串字面量中的内容会维持原样(转义字符不会被转义,如下例中 s2 中的 \n 不是换行符,而是由 \ 和 n 组成的字符串 \n)。举例如下:
let s1: String = #""#
let s2 = ##"\n"##
let s3 = ###"
Hello,
Cangjie
Lang"###
插值字符串
插值字符串是一种包含一个或多个插值表达式的字符串字面量(不适用于多行原始字符串字面量),通过将表达式插入到字符串中,可以有效避免字符串拼接的问题。虽然我们直到现在才介绍它,但其实它早已经出现在之前的示例代码中,因为我们经常在 println 函数中输出非字符串类型的变量值,例如 println("${x}")。
插值表达式必须用花括号 {} 包起来,并在 {} 之前加上 $ 前缀。{} 中可以包含一个或者多个声明或表达式。
当插值字符串求值时,每个插值表达式所在位置会被 {} 中的最后一项的值替换,整个插值字符串最终仍是一个字符串。
下面是插值字符串的简单示例:
main() {
let fruit = "apples"
let count = 10
let s = "There are ${count * count} ${fruit}"
println(s)
let r = 2.4
let area = "The area of a circle with radius ${r} is ${let PI = 3.141592; PI * r * r}"
println(area)
}
编译并执行上述代码,输出结果为:
There are 100 apples
The area of a circle with radius 2.400000 is 18.095570
字符串类型支持的操作
字符串类型支持使用关系操作符进行比较,支持使用 + 进行拼接。下面的例子展示了字符串类型的判等和拼接:
main() {
let s1 = "abc"
var s2 = "ABC"
let r1 = s1 == s2
println("The result of 'abc' == 'ABC' is: ${r1}")
let r2 = s1 + s2
println("The result of 'abc' + 'ABC' is: ${r2}")
}
编译并执行上述代码,输出结果为:
The result of 'abc' == 'ABC' is: false
The result of 'abc' + 'ABC' is: abcABC
字符串还支持其他常见操作,例如拆分、替换等,可参见标准库文档。
字节数组字面量
仓颉编程语言引入了字节数组字面量来方便地表达 Array<UInt8> 类型的值,由字符 b 、一对用双引号引用的 ASCII 字符串组成。例如:
var a = b"hello"
表示一个长度为 5,类型为 Array<UInt8> 的数组,其中的每个元素的值为对应字符的 ASCII 的数值,即 [104, 101, 108, 108, 111]。
同时也支持转义字符,例如:
var b = b"\u{78}\n\r"
表示一个长度为 3,类型为 Array<UInt8> 的数组,其中的元素的值为 [120, 10, 13]。
这里 \u 转义的字符和字符字节字面量相同,也不支持 Unicode,所以内部最多有两位 16 进制数。
值类型数组 VArray
仓颉编程语言引入了值类型数组 VArray<T, $N> ,其中 T 表示该值类型数组的元素类型,$N 是一个固定的语法,通过 $ 加上一个数值字面量表示这个值类型数组的长度。需要注意的是,VArray<T, $N> 不能省略 <T, $N>,且使用类型别名时,不允许拆分 VArray 关键字与其泛型参数。
type varr1 = VArray<Int64, $3> // ok
type varr2 = VArray // error
注意: 由于运行时后端限制,当前 VArray<T, $N> 的元素类型 T 或 T 的成员不能包含引用类型、枚举类型、Lambda 表达式(CFunc 除外)以及未实例化的泛型类型。
VArray 可以由一个数组的字面量来进行初始化,左值 a 必须标识出 VArray 的实例化类型:
var a: VArray<Int64, $3> = [1, 2, 3]
同时,它拥有两个构造函数:
// VArray<T, $N>(initElement: (Int64) -> T)
let b = VArray<Int64, $5>({ i => i}) // [0, 1, 2, 3, 4]
// VArray<T, $N>(item!: T)
let c = VArray<Int64, $5>(item: 0) // [0, 0, 0, 0, 0]
除此之外,VArray<T, $N> 类型提供了两个成员方法:
1、用于下标访问和修改的 [] 操作符方法:
var a: VArray<Int64, $3> = [1, 2, 3]
let i = a[1] // i is 2
a[2] = 4 // a is [1, 2, 4]
2、用于获取 VArray 长度的 size 成员:
var a: VArray<Int64, $3> = [1, 2, 3]
let s = a.size // s is 3
Unit 类型
对于那些只关心副作用而不关心值的表达式,它们的类型是 Unit。例如,print 函数、赋值表达式、复合赋值表达式、自增和自减表达式、循环表达式,它们的类型都是 Unit。
Unit 类型只有一个值,也是它的字面量:()。除了赋值、判等和判不等外,Unit 类型不支持其他操作。
元组类型
元组(Tuple)可以将多个不同的类型组合在一起,成为一个新的类型。元组类型使用 (T1, T2, ..., TN) 表示,其中 T1 到 TN 可以是任意类型,不同类型间使用逗号(,)连接。元组至少是二元以上,例如,(Int64, Float64) 表示一个二元组类型,(Int64, Float64, String) 表示一个三元组类型。
元组的长度是固定的,即一旦定义了一个元组类型的实例,它的长度不能再被更改。
元组类型是不可变类型,即一旦定义了一个元组类型的实例,它的内容不能再被更新。例如
var tuple = (true, false)
tuple[0] = false // Error: 'tuple element' can not be assigned
元组类型的字面量
元组类型的字面量使用 (e1, e2, ..., eN) 表示,其中 e1 到 eN 是表达式,多个表达式之间使用逗号分隔。下面的例子中,分别定义了一个 (Int64, Float64) 类型的变量 x,以及一个 (Int64, Float64, String) 类型的变量 y,并且使用元组类型的字面量为它们定义了初值:
let x: (Int64, Float64) = (3, 3.141592)
let y: (Int64, Float64, String) = (3, 3.141592, "PI")
元组支持通过 t[index] 的方式访问某个具体位置的元素,其中 t 是一个元组,index 是下标,并且 index 只能是从 0 开始且小于元组元素个数的整数类型字面量,否则,编译报错。下面的例子中,使用 pi[0] 和 pi[1] 可以分别访问二元组 pi 的第一个元素和第二个元素。
main() {
var pi = (3.14, "PI")
println(pi[0])
println(pi[1])
}
编译并执行上述代码,输出结果为:
3.140000
PI
在赋值表达式中,可使用元组字面量对表达式的右值进行解构,这要求赋值表达式等号左边必须是一个元组字面量,这个元组字面量里面的元素必须都是左值(左值即出现在赋值操作符左边的,可保存值的表达式,具体参见各章节对赋值操作的描述)或者一个元组字面量,当元组字面量中出现 _ 时,表示忽略等号右侧 tuple 对应位置处的求值结果(意味着这个位置处的类型检查总是可以通过的),等号右边的表达式也必须是 tuple 类型,右边 tuple 每个元素的类型必须是对应位置左值类型的子类型。注意,复合赋值不支持这种解构方式。求值顺序上先计算等号右边表达式的值,再对左值部分从左往右逐个赋值,例如
var a: Int64
var b: String
var c: Unit
var f = { => ((1, "abc"), ())}
((a, b), c) = f() // value of a is 1, value of b is "abc", value of c is '()'
((a, b), _) = ((2, "def"), 3.0) // value of a is 2, value of b is "def", 3.0 is ignored
元组类型的类型参数
可以为元组类型标记显式的类型参数名,下面例子中的 name 和 price 就是 类型参数名。
func getFruitPrice (): (name: String, price: Int64) {
return ("banana", 10)
}
对于一个元组类型,只允许统一写类型参数名,或者统一不写类型参数名,不允许交替存在。
let c: (name: String, Int64) = ("banana", 5) // error
区间类型
区间类型用于表示拥有固定步长的序列,区间类型是一个泛型(详见泛型章节),使用 Range<T> 表示。当 T 被实例化不同的类型时(要求此类型必须支持关系操作符,并且可以和 Int64 类型的值做加法),会得到不同的区间类型,如最常用的 Range<Int64> 用于表示整数区间。
每个区间类型的实例都会包含 start、end 和 step 三个值。其中,start 和 end 分别表示序列的起始值和终止值,step 表示序列中前后两个元素之间的差值(即步长);start 和 end 的类型相同(即 T 被实例化的类型),step 类型是 Int64。
区间类型字面量
区间字面量有两种形式:“左闭右开”区间和“左闭右闭”区间。其中,“左闭右开”区间的格式是 start..end : step,它表示一个从 start 开始,以 step 为步长,到 end(不包含 end)为止的区间;“左闭右闭”区间的格式是 start..=end : step,它表示一个从 start 开始,以 step 为步长,到 end(包含 end)为止的区间。
下面的例子定义了若干区间类型的变量:
let n = 10
let r1 = 0..10 : 1 // r1 contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
let r2 = 0..=n : 1 // r2 contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
let r3 = n..0 : -2 // r3 contains 10, 8, 6, 4, 2
let r4 = 10..=0 : -2 // r4 contains 10, 8, 6, 4, 2, 0
区间字面量中,可以不写 step,此时 step 默认等于 1,但是注意,step 的值不能等于 0。另外,区间也有可能是空的(即不包含任何元素的空序列),举例如下:
let r5 = 0..10 // the step of r5 is 1, and it contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
let r6 = 0..10 : 0 // Error: step cannot be 0
let r7 = 10..0 : 1 // r7 to r10 are empty ranges
let r8 = 0..10 : -1
let r9 = 10..=0 : 1
let r10 = 0..=10 : -1
注:表达式 start..end : step 中,当 step > 0 且 start >= end,或者 step < 0 且 start <= end 时,start..end : step 是一个空区间;表达式 start..=end : step 中,当 step > 0 且 start > end,或者 step < 0 且 start < end 时,start..=end : step 是一个空区间。
Nothing 类型
Nothing 是一种特殊的类型,它不包含任何值,并且 Nothing 类型是所有类型的子类型。
break、continue、return 和 throw 表达式的类型是 Nothing,程序执行到这些表达式时,它们之后的代码将不会被执行。其中 break、continue 只能在循环体中使用,return 只能在函数体中使用。
包围着的循环体”无法穿越“函数边界。在下面的例子中,break 出现在函数 f 中,外层的 while 循环体不被视作包围着它的循环体;continue 出现在 lambda 表达式 中,外层的 while 循环体不被视作包围着它的循环体。
while (true) {
func f() {
break // Error: break must be used directly inside a loop
}
let g = { =>
continue // Error: continue must be used directly inside a loop
}
}
由于函数的形参和其默认值不属于该函数的函数体,所以下面例子中的 return 表达式缺少包围它的函数体——它既不属于外层函数 f(因为内层函数定义 g 已经开始),也不在内层函数 g 的函数体中:
func f() {
func g(x!: Int64 = return) { // Error: return must be used inside a function body
0
}
1
}
注:目前编译器还不允许在使用类型的地方显式地使用 Nothing 类型。
自定义类型
struct 类型
struct 是一种自定义类型,可以将若干不同类型的值组合在一起,成为一个新类型。本节依次介绍如何定义 struct 类型,如何创建 struct 实例,以及 struct 中的 mut 函数。
定义 struct 类型
struct 类型的定义以关键字 struct 开头,后跟 struct 的名字,接着是定义在一对花括号中的 struct 定义体。struct 定义体中可以定义一系列的成员变量、成员属性(参见[属性])、静态初始化器、构造函数和成员函数。
struct Rectangle {
let width: Int64
let height: Int64
public init(width: Int64, height: Int64) {
this.width = width
this.height = height
}
public func area() {
width * height
}
}
上例中定义了名为 Rectangle 的 struct 类型,它有两个 Int64 类型的成员变量 width 和 height,一个有两个 Int64 类型参数的构造函数(使用关键字 init 定义,函数体中通常是对成员变量的初始化),以及一个成员函数 area(返回 width 和 height 的乘积)。
注:struct 只能定义在源文件顶层。
struct 成员变量
struct 成员变量分为实例成员变量和静态成员变量(使用 static 修饰符修饰,且必须有初值),二者的区别在于实例成员变量只能通过 struct 实例(我们说 a 是 T 类型的实例,指的是 a 是一个 T 类型的值)访问,静态成员变量只能通过 struct 类型名访问。
实例成员变量定义时可以不设置初值(但必须标注类型,如上例中的 width 和 height),也可以设置初值,例如:
struct Rectangle {
let width = 10
let height = 20
}
struct 静态初始化器
struct 支持定义静态初始化器,并在静态初始化器中通过赋值表达式来对静态成员变量进行初始化。
静态初始化器以关键字组合 static init 开头,后跟无参参数列表和函数体,且不能被可见性修饰符修饰。函数体中必须完成对所有未初始化的静态成员变量的初始化,否则编译报错。
struct Rectangle {
static let degree: Int64
static init() {
degree = 180
}
}
一个 struct 中最多允许定义一个静态初始化器,否则报重定义错误。
struct Rectangle {
static let degree: Int64
static init() {
degree = 180
}
static init() { // Error: redefinition with the previous static init function
degree = 180
}
}
struct 构造函数
struct 支持两类构造函数:普通构造函数和主构造函数。
普通构造函数以关键字 init 开头,后跟参数列表和函数体,函数体中必须完成对所有未初始化的实例成员变量的初始化(如果参数名和成员变量名无法区分,可以在成员变量前使用 this 加以区分,this 表示 struct 的当前实例),否则编译报错。
struct Rectangle {
let width: Int64
let height: Int64
public init(width: Int64, height: Int64) { // Error: 'height' is not initialized in the constructor
this.width = width
}
}
一个 struct 中可以定义多个普通构造函数,但它们必须构成重载(参见[函数重载]),否则报重定义错误。
struct Rectangle {
let width: Int64
let height: Int64
public init(width: Int64) {
this.width = width
this.height = width
}
public init(width: Int64, height: Int64) { // Ok: overloading with the first init function
this.width = width
this.height = height
}
public init(height: Int64) { // Error: redefinition with the first init function
this.width = height
this.height = height
}
}
除了可以定义若干普通的以 init 为名字的构造函数外,struct 内还可以定义(最多)一个主构造函数。主构造函数的名字和 struct 类型名相同,它的参数列表中可以有两种形式的形参:普通形参和成员变量形参(需要在参数名前加上 let 或 var),成员变量形参同时扮演定义成员变量和构造函数参数的功能。
使用主构造函数通常可以简化 struct 的定义,例如,上述包含一个 init 构造函数的 Rectangle 可以简化为如下定义:
struct Rectangle {
public Rectangle(let width: Int64, let height: Int64) {}
}
主构造函数的参数列表中也可以定义普通形参,例如:
struct Rectangle {
public Rectangle(name: String, let width: Int64, let height: Int64) {}
}
如果 struct 定义中不存在自定义构造函数(包括主构造函数),并且所有实例成员变量都有初始值,则会自动为其生成一个无参构造函数(调用此无参构造函数会创建一个所有实例成员变量的值均等于其初值的对象);否则,不会自动生成此无参构造函数。例如,对于如下 struct 定义,注释中给出了自动生成的无参构造函数:
struct Rectangle {
let width: Int64 = 10
let height: Int64 = 10
/* Auto-generated memberwise constructor:
public init() {
}
*/
}
struct 成员函数
struct 成员函数分为实例成员函数和静态成员函数(使用 static 修饰符修饰),二者的区别在于:实例成员函数只能通过 struct 实例访问,静态成员函数只能通过 struct 类型名访问;静态成员函数中不能访问实例成员变量,也不能调用实例成员函数,但在实例成员函数中可以访问静态成员变量以及静态成员函数。
下例中,area 是实例成员函数,typeName 是静态成员函数。
struct Rectangle {
let width: Int64 = 10
let height: Int64 = 20
public func area() {
this.width * this.height
}
public static func typeName(): String {
"Rectangle"
}
}
实例成员函数中可以通过 this 访问实例成员变量,例如:
struct Rectangle {
let width: Int64 = 1
let height: Int64 = 1
public func area() {
this.width * this.height
}
}
struct 成员的可见修饰符
struct 的成员(包括成员变量、成员属性、构造函数、成员函数、操作符函数(详见操作符重载章节))用两种可见性修饰符修饰:public 和 private,缺省的含义是仅包内可见。
使用 public 修饰的成员在 struct 定义内部和外部均可见;使用 private 修饰的成员仅在 struct 定义内部可见,外部无法访问。
下面的例子中,width 是 public 修饰的成员,在类外可以访问,height 是缺省可见修饰符的成员,仅在本包可见,包外部无法访问。
package a
public struct Rectangle {
public var width: Int64
var height: Int64
private var area: Int64
...
}
func samePkgFunc() {
var r = Rectangle(10, 20)
r.width = 8 // Ok: public 'width' can be accessed here
r.height = 24 // Ok: 'height' has no modifier and can be accessed here
r.area = 30 // Error: private 'area' can't be accessed here
}
package b
import a.*
main() {
var r = Rectangle(10, 20)
r.width = 8 // Ok: public 'width' can be accessed here
r.height = 24 // Error: no modifier 'height' can't be accessed here
r.area = 30 // Error: private 'area' can't be accessed here
}
禁止递归 struct
递归和互递归定义的 struct 均是非法的。例如:
struct R1 { // Error: 'R1' recursively references itself
let other: R1
}
struct R2 { // Error: 'R2' and 'R3' are mutually recursive
let other: R3
}
struct R3 { // Error: 'R2' and 'R3' are mutually recursive
let other: R2
}
使用 struct 构造函数创建 struct 实例
定义了 struct 类型后,即可通过调用 struct 的构造函数来创建 struct 实例。在 struct 定义之外,通过 struct 类型名调用构造函数。例如,下例中定义了一个 Rectangle 类型的变量 r。
let r = Rectangle(10, 20)
创建了 struct 实例之后,可以通过实例访问它的(public 修饰的)实例成员变量和实例成员函数。例如,下例中通过 r.width 和 r.height 可分别访问 r 中 width 和 height 的值,通过 r.area() 可以调用 r 的成员函数 area。
let r = Rectangle(10, 20)
let width = r.width // width = 10
let height = r.height // height = 20
let a = r.area() // a = 200
如果希望通过 struct 实例去修改成员变量的值,需要将 struct 类型的变量定义为可变变量,并且被修改的成员变量也必须是可变成员变量(使用 var 定义)。举例如下:
struct Rectangle {
public var width: Int64
public var height: Int64
public init(width: Int64, height: Int64) {
this.width = width
this.height = height
}
public func area() {
width * height
}
}
main() {
var r = Rectangle(10, 20) // r.width = 10, r.height = 20
r.width = 8 // r.width = 8
r.height = 24 // r.height = 24
let a = r.area() // a = 192
}
在赋值或传参时,会对 struct 实例进行复制,生成新的实例,对其中一个实例的修改并不会影响另外一个实例。以赋值为例,下面的例子中,将 r1 赋值给 r2 之后,修改 r1 的 width 和 height 的值,并不会影响 r2 的 width 和 height 值。
struct Rectangle {
public var width: Int64
public var height: Int64
public init(width: Int64, height: Int64) {
this.width = width
this.height = height
}
public func area() {
width * height
}
}
main() {
var r1 = Rectangle(10, 20) // r1.width = 10, r1.height = 20
var r2 = r1 // r2.width = 10, r2.height = 20
r1.width = 8 // r1.width = 8
r1.height = 24 // r1.height = 24
let a1 = r1.area() // a1 = 192
let a2 = r2.area() // a2 = 200
}
struct 中的 mut 函数
默认情况下,struct 中的实例成员函数是无法修改它的实例成员变量和实例成员属性的。如果需要修改,可以在定义实例成员函数时使用关键字 mut 修饰,使之成为 mut 函数。mut 函数是一种特殊的实例成员函数,mut 函数内部可以“原地”修改当前实例,以实现 struct 通过调用函数修改自身的目的。
语法上,定义 mut 实例成员函数是在 func 关键字之前加上 mut 修饰符。例如,可以在 Rectangle 中定义一个用于修改 width 值的 mut 函数 setW:
struct Rectangle {
public var width: Int64
public var height: Int64
public init(width!: Int64, height!: Int64) {
this.width = width
this.height = height
}
public mut func setW(v: Int64): Unit {
width = v
}
public func area() {
width * height
}
}
调用 mut 函数时,mut 函数允许修改当前实例的成员值,例如,下例中通过调用 setW 将 r 的 width 值设置为 8。
main() {
var r = Rectangle(width: 10, height: 20) // r.width = 10, r.height = 20
r.setW(8) // r.width = 8
let a = r.area() // a = 160
}
注意,上例中 r 如果使用 let 定义,则不能调用 Rectangle 中的 mut 函数。
enum 类型
本节介绍仓颉中的 enum 类型。enum 类型提供了通过列举一个类型的所有可能取值来定义此类型的方式。
在很多语言中都有 enum 类型(或者称枚举类型),但是不同语言中的 enum 类型的使用方式和表达能力均有所差异,仓颉中的 enum 类型可以理解为函数式编程语言中的代数数据类型(Algebraic Data Types)。
接下来,首先介绍如何定义和使用 enum,然后介绍如何使用模式匹配使得 enum 取不同值时执行不同的操作,最后介绍一个名为 Option 的常用 enum 类型,用于表示某个类型的实例要么有值要么没值。
enum 的定义和使用
定义 enum 时需要把它所有可能的取值一一列出,我们称这些值为 enum 的构造器(或者 constructor)。
enum RGBColor {
| Red | Green | Blue
}
enum 类型的定义以关键字 enum 开头,接着是 enum 的名字,之后是定义在一对花括号中的 enum 体,enum 体中定义了若干构造器,多个构造器之间使用 | 进行分隔(第一个构造器之前的 | 是可选的)。上例中定义了一个名为 RGBColor 的 enum 类型,它有 3 个构造器:Red、Green 和 Blue,分别表示 RGB 色彩模式中的红色、绿色和蓝色。
上述 enum 中的构造器还可以携带若干(至少一个)参数,称为有参构造器。例如,可以为 Red、Green 和 Blue 设置一个 UInt8 的类型的参数,用来表示每个颜色的亮度级别:
enum RGBColor {
| Red(UInt8) | Green(UInt8) | Blue(UInt8)
}
仓颉支持同一个 enum 中定义多个同名构造器,但是要求这些构造器的参数个数不同(认为没有参数的构造器的参数个数等于 0),例如:
enum RGBColor {
| Red | Green | Blue
| Red(UInt8) | Green(UInt8) | Blue(UInt8)
}
enum 支持递归定义,例如,下面的例子中使用 enum 定义了一种表达式(即 Expr),此表达式只能有 3 种形式:单独的一个数字 Num(携带一个 Int64 类型的参数)、加法表达式 Add(携带两个 Expr 类型的参数)、减法表达式 Sub(携带两个 Expr 类型的参数)。对于 Add 和 Sub 这两个构造器,其参数中递归地使用到了 Expr 自身。
enum Expr {
| Num(Int64)
| Add(Expr, Expr)
| Sub(Expr, Expr)
}
另外,在 enum 体中还可以定义一系列成员函数、操作符函数(详见操作符重载章节)和成员属性(详见属性章节),但是要求构造器、成员函数、成员属性之间不能重名。例如,下面的例子在 RGBColor 中定义了一个名为 printType 的函数,它会输出字符串 RGBColor:
enum RGBColor {
| Red | Green | Blue
public static func printType() {
print("RGBColor")
}
}
注:enum 只能定义在源文件顶层。
使用限制:当 enum 和 struct 类型存在互递归关系时,且 enum 类型作为 Option 的类型参数, 可能存在编译错误。
enum 值
定义了 enum 类型之后,就可以创建此类型的实例(即 enum 值),enum 值只能取 enum 类型定义中的一个构造器。enum 没有构造函数,可以通过 类型名.构造器,或者直接使用构造器的方式来构造一个 enum 值(对于有参构造器,需要传实参)。
下例中,RGBColor 中定义了三个构造器,其中有两个无参构造器(Red 和 Green)和一个有参构造器(Blue(UInt8)),main 中定义了三个 RGBColor 类型的变量 r,g 和 b,其中,r 的值使用 RGBColor.Red 进行初始化,g 的值直接使用 Green 进行初始化,b 的值使用 Blue(100) 进行初始化:
enum RGBColor {
| Red | Green | Blue(UInt8)
}
main() {
let r = RGBColor.Red
let g = Green
let b = Blue(100)
}
当省略类型名时,enum 构造器的名字可能和类型名、变量名、函数名发生冲突。此时必须加上 enum 类型名来使用 enum 构造器,否则只会选择同名的类型、变量、函数定义。
下面的例子中,只有构造器 Blue(UInt8) 可以不带类型名使用,Red 和 Green(UInt8) 皆会因为名字冲突而不能直接使用,必须加上类型名 RGBColor。
let Red = 1
func Green(g: UInt8) {
return g
}
enum RGBColor {
| Red | Green(UInt8) | Blue(UInt8)
}
let r1 = Red // Will choose 'let Red'
let r2 = RGBColor.Red // Ok: constructed by enum type name
let g1 = Green(100) // Will choose 'func Green'
let g2 = RGBColor.Green(100) // Ok: constructed by enum type name
let b = Blue(100) // Ok: can be uniquely identified as an enum constructor
如下的例子中,只有构造器 Blue 会因为名称冲突而不能直接使用,必须加上类型名 RGBColor。
class Blue {}
enum RGBColor {
| Red | Green(UInt8) | Blue(UInt8)
}
let r = Red // Ok: constructed by enum type name
let g = Green(100) // Ok: constructed by enum type name
let b = Blue(100) // Will choose constructor of 'class Blue' and report an error
enum 的模式匹配
对于一个 enum 值,我们通常希望它是不同的构造器时执行不同的操作,在仓颉中,可以通过模式匹配来实现。本节只是对 enum 的模式匹配做一个简单的介绍,关于模式匹配的更多内容,会在之后的[模式匹配]章节中详细说明。
对于如下使用 enum 定义的 RGBColor,如果希望 enum 值是不同构造器时分别输出其字符串表示,则可以使用 match 表达式和 enum 模式实现(关于 match 表达式和模式的详细介绍,参见[模式匹配]):
enum RGBColor {
| Red | Green | Blue
}
main() {
let c = Green
let cs = match (c) {
case Red => "Red"
case Green => "Green" // Matched
case Blue => "Blue"
}
print(cs)
}
上例中,Red,Green 和 Blue 分别用于匹配 RGBColor 中不同的构造器,上述代码的执行结果为:
Green
对于 enum 中的有参构造器,同样可以使用 match 表达式来匹配,并且可以解构出有参构造器中参数的值,举例如下:
enum RGBColor {
| Red(UInt8) | Green(UInt8) | Blue(UInt8)
}
main() {
let c = Green(100)
let cs = match (c) {
case Red(r) => "Red = ${r}"
case Green(g) => "Green = ${g}" // Matched
case Blue(b) => "Blue = ${b}"
}
print(cs)
}
上例中,RGBColor 的三个构造器均有一个 UInt8 类型的参数,在匹配变量 c 的值时,case 之后使用 enum 模式来匹配不同的构造器,并将参数值分别与变量 r,g 和 b 进行绑定,一旦某条 case 匹配成功(本例中会与第二条 case 匹配),则返回对应的字符串。
上述代码的执行结果为:
Green = 100
Option 类型
Option 类型使用 enum 定义,它包含两个构造器:Some 和 None。其中,Some 会携带一个参数,表示有值,None 不带参数,表示无值。当需要表示某个类型可能有值,也可能没有值的时候,可选择使用 Option 类型。
Option 类型被定义为一个泛型 enum 类型,定义如下(这里我们仅需要知道尖括号中的 T 是一个类型形参,当 T 为不同类型时会得到不同的 Option 类型即可。关于泛型的详细介绍,可参见[泛型]。):
enum Option<T> {
| Some(T)
| None
}
其中,Some 构造器的参数类型就是类型形参 T,当 T 被实例化为不同的类型时,会得到不同的 Option 类型,例如:Option<Int64>、Option<String>等。
Option 类型还有一种简单的写法:在类型名前加 ?。也就是说,对于任意类型 Ty,?Ty 等价于 Option<Ty>。例如,?Int64 等价于 Option<Int64>,?String 等价于 Option<String> 等等。
下面的例子展示了如何定义 Option 类型的变量:
let a: Option<Int64> = Some(100)
let b: ?Int64 = Some(100)
let c: Option<String> = Some("Hello")
let d: ?String = None
另外,虽然 T 和 Option<T> 是不同的类型,但是当明确知道某个位置需要的是 Option<T> 类型的值时,可以直接传一个 T 类型的值,编译器会用 Option<T> 类型的 Some 构造器将 T 类型的值封装成 Option<T> 类型的值(注意:这里并不是类型转换)。例如,下面的定义是合法的(等价于上例中变量 a,b 和 c 的定义):
let a: Option<Int64> = 100
let b: ?Int64 = 100
let c: Option<String> = "100"
在上下文没有明确的类型要求时,无法使用 None 直接构造出想要的类型,此时应使用 None<T> 这样的语法来构造 Option<T> 类型的数据,例如
let a = None<Int64> // a: Option<Int64>
let b = None<Bool> // b: Option<Bool>
最后,关于 Option 的使用,请参见“错误处理”中“Option 类型用于错误处理”的内容。
class 类型
class 类型是面向对象编程中的经典概念,仓颉中同样支持使用 class 来实现面向对象编程。class 与上面介绍的 struct 的主要区别在于:class 是引用类型,struct 是值类型,它们在赋值或传参时行为是不同的(下文会有介绍);class 之间可以继承,但 struct 之间不能继承。
本节依次介绍如何定义 class 类型,如何创建对象,以及 class 的继承。
定义 class 类型
class 类型的定义以关键字 class 开头,后跟 class 的名字,接着是定义在一对花括号中的 class 定义体。class 定义体中可以定义一系列的成员变量、成员属性(参见[属性])、静态初始化器、构造函数、成员函数和操作符函数(详见操作符重载章节)。
class Rectangle {
let width: Int64
let height: Int64
public init(width: Int64, height: Int64) {
this.width = width
this.height = height
}
public func area() {
width * height
}
}
上例中定义了名为 Rectangle 的 class 类型,它有两个 Int64 类型的成员变量 width 和 height,一个有两个 Int64 类型参数的构造函数,以及一个成员函数 area(返回 width 和 height 的乘积)。
注:class 只能定义在源文件顶层。
class 成员变量
class 成员变量分为实例成员变量和静态成员变量(使用 static 修饰符修饰,且必须有初值)。实例成员变量只能通过对象(即 class 的实例)访问,静态成员变量只能通过类型名访问。
class Rectangle {
let width = 10
static let height = 20
}
let l = Rectangle.height // l = 20
实例成员变量定义时可以不设置初值(但必须标注类型),也可以设置初值,例如:
class Rectangle {
let width = 10
let height = 20
}
class 静态初始化器
class 支持定义静态初始化器,并在静态初始化器中通过赋值表达式来对静态成员变量进行初始化。
静态初始化器以关键字组合 static init 开头,后跟无参参数列表和函数体,且不能被可见性修饰符修饰。函数体中必须完成对所有未初始化的静态成员变量的初始化,否则编译报错。
class Rectangle {
static let degree: Int64
static init() {
degree = 180
}
}
一个 class 中最多允许定义一个静态初始化器,否则报重定义错误。
class Rectangle {
static let degree: Int64
static init() {
degree = 180
}
static init() { // Error: redefinition with the previous static init function
degree = 180
}
}
class 构造函数
和 struct 一样,class 中也支持定义普通构造函数和主构造函数。
普通构造函数以关键字 init 开头,后跟参数列表和函数体,函数体中必须完成所有未初始化实例成员变量的初始化,否则编译报错。
class Rectangle {
let width: Int64
let height: Int64
public init(width: Int64, height: Int64) { // Error: 'height' is not initialized in the constructor
this.width = width
}
}
一个 class 中可以定义多个普通构造函数,但它们必须构成重载(参见[函数重载]),否则报重定义错误。
class Rectangle {
let width: Int64
let height: Int64
public init(width: Int64) {
this.width = width
this.height = width
}
public init(width: Int64, height: Int64) { // Ok: overloading with the first init function
this.width = width
this.height = height
}
public init(height: Int64) { // Error: redefinition with the first init function
this.width = height
this.height = height
}
}
除了可以定义若干普通的以 init 为名字的构造函数外,class 内还可以定义(最多)一个主构造函数。主构造函数的名字和 class 类型名相同,它的参数列表中可以有两种形式的形参:普通形参和成员变量形参(需要在参数名前加上 let 或 var),成员变量形参同时具有定义成员变量和构造函数参数的功能。
使用主构造函数通常可以简化 class 的定义,例如,上述包含一个 init 构造函数的 Rectangle 可以简化为如下定义:
class Rectangle {
public Rectangle(let width: Int64, let height: Int64) {}
}
主构造函数的参数列表中也可以定义普通形参,例如:
class Rectangle {
public Rectangle(name: String, let width: Int64, let height: Int64) {}
}
如果 class 定义中不存在自定义构造函数(包括主构造函数),并且所有实例成员变量都有初始值,则会自动为其生成一个无参构造函数(调用此无参构造函数会创建一个所有实例成员变量的值均等于其初值的对象);否则,不会自动生成此无参构造函数。例如,对于如下 class 定义,编译器会为其自动生成一个无参构造函数:
class Rectangle {
let width = 10
let height = 20
/* Auto-generated parameterless constructor:
public init() {
}
*/
}
// Invoke the auto-generated parameterless constructor
let r = Rectangle() // r.width = 10,r.height = 20
class 终结器
class 支持定义终结器,这个函数在类的实例被垃圾回收的时候被调用。终结器的函数名固定为 ~init。终结器一般被用于释放系统资源:
class C {
var p: CString
init(s: String) {
p = unsafe { LibC.mallocCString(s) }
println(s)
}
~init() {
unsafe { LibC.free(p) }
}
}
使用终结器有些限制条件,需要开发者注意:
- 终结器没有参数,没有返回类型,没有泛型类型参数,没有任何修饰符,也不可以被显式调用。
- 带有终结器的类不可被
open修饰,只有非open的类可以拥有终结器。 - 一个类最多只能定义一个终结器。
- 终结器不可以定义在扩展中。
- 终结器被触发的时机是不确定的。
- 终结器可能在任意一个线程上执行。
- 多个终结器的执行顺序是不确定的。
- 终结器向外抛出未捕获异常属于未定义行为。
- 终结器中创建线程或者使用线程同步功能属于未定义行为。
- 终结器执行结束之后,如果这个对象还可以被继续访问,则属于未定义行为。
class 成员函数
class 成员函数同样分为实例成员函数和静态成员函数(使用 static 修饰符修饰),实例成员函数只能通过对象访问,静态成员函数只能通过 class 类型名访问;静态成员函数中不能访问实例成员变量,也不能调用实例成员函数,但在实例成员函数中可以访问静态成员变量以及静态成员函数。
下例中,area 是实例成员函数,typeName 是静态成员函数。
class Rectangle {
let width: Int64 = 10
let height: Int64 = 20
public func area() {
this.width * this.height
}
public static func typeName(): String {
"Rectangle"
}
}
根据有没有函数体,实例成员函数又可以分为抽象成员函数和非抽象成员函数。抽象成员函数没有函数体,只能定义在抽象类或接口(详见接口章节)中。例如,下例中在抽象类 AbRectangle(使用关键字 abstract 修饰)中定义了抽象函数 foo。
abstract class AbRectangle {
public func foo(): Unit
}
需要注意的是,抽象实例成员函数默认具有 open 的语义,open 修饰符是可选的,且必须使用 public 或 protected 进行修饰。
非抽象函数必须有函数体,在函数体中可以通过 this 访问实例成员变量,例如:
class Rectangle {
let width: Int64 = 10
let height: Int64 = 20
public func area() {
this.width * this.height
}
}
class 成员的可见修饰符
对于 class 的成员(包括成员变量、成员属性、构造函数、成员函数),可以使用的可见性修饰符有三种:public、protected 和 private,缺省的含义是仅包内可见。
使用 public 修饰的成员在 class 定义内部和外部均可见,成员变量、成员属性和成员函数在 class 外部可以通过对象访问;使用 protected 修饰的成员在本包、本 class 及其子类中可见,外部无法访问;使用 private 修饰的成员仅在本 class 定义内部可见,外部无法访问;缺省可见修饰符的成员仅在本包可见,外部无法访问。
package a
public open class Rectangle {
public var width: Int64
protected var height: Int64
private var area: Int64
public init(width: Int64, height: Int64) {
this.width = width
this.height = height
this.area = this.width * this.height
}
init(width: Int64, height: Int64, multiple: Int64) {
this.width = width
this.height = height
this.area = width * height * multiple
}
}
func samePkgFunc() {
var r = Rectangle(10, 20) // Ok: constructor 'Rectangle' can be accessed here
r.width = 8 // Ok: public 'width' can be accessed here
r.height = 24 // Ok: protected 'height' can be accessed here
r.area = 30 // Error: private 'area' cannot be accessed here
}
package b
import a.*
public class Cuboid <: Rectangle {
private var length: Int64
public init(width: Int64, height: Int64, length: Int64) {
super(width, height)
this.length = length
}
public func volume() {
this.width * this.height * this.length // Ok: protected 'height' can be accessed here
}
}
main() {
var r = Rectangle(10, 20, 2) // Error: Rectangle has no `public` constructor with three parameters
var c = Cuboid(20, 20, 20)
c.width = 8 // Ok: public 'width' can be accessed here
c.height = 24 // Error: protected 'height' cannot be accessed here
c.area = 30 // Error: private 'area' cannot be accessed here
}
This 类型
在类内部,我们支持 This 类型占位符,代指当前类的类型。它只能被作为实例成员函数的返回类型来使用,当使用子类对象调用在父类中定义的返回 This 类型的函数时,该函数调用的类型会被识别为子类类型,而非定义所在的父类类型。
如果实例成员函数没有声明返回类型,并且只存在返回 This 类型表达式时,当前函数的返回类型会推断为 This。示例如下:
open class C1 {
func f(): This { // its type is `() -> C1`
return this
}
func f2() { // its type is `() -> C1`
return this
}
public open func f3(): C1 {
return this
}
}
class C2 <: C1 {
// member function f is inherited from C1, and its type is `() -> C2` now
public override func f3(): This { // ok
return this
}
}
var obj1: C2 = C2()
var obj2: C1 = C2()
var x = obj1.f() // During compilation, the type of x is C2
var y = obj2.f() // During compilation, the type of y is C1
创建对象
定义了 class 类型后,即可通过调用 class 的构造函数来创建对象(通过 class 类型名调用构造函数)。例如,下例中通过 Rectangle(10, 20) 创建 Rectangle 类型的对象并赋值给变量 r。
let r = Rectangle(10, 20)
创建对象之后,可以通过对象访问(public 修饰的)实例成员变量和实例成员函数。例如,下例中通过 r.width 和 r.height 可分别访问 r 中 width 和 height 的值,通过 r.area() 可以调用成员函数 area。
let r = Rectangle(10, 20) // r.width = 10, r.height = 20
let width = r.width // width = 10
let height = r.height // height = 20
let a = r.area() // a = 200
如果希望通过对象去修改成员变量的值(不鼓励这种方式,最好还是通过成员函数去修改),需要将 class 类型中的成员变量定义为可变成员变量(即使用 var 定义)。举例如下:
class Rectangle {
public var width: Int64
public var height: Int64
...
}
main() {
let r = Rectangle(10, 20) // r.width = 10, r.height = 20
r.width = 8 // r.width = 8
r.height = 24 // r.height = 24
let a = r.area() // a = 192
}
不同于 struct,对象在赋值或传参时,不会将对象进行复制,多个变量指向的是同一个对象,通过一个变量去修改对象中成员的值,其他变量中对应的成员变量也会被修改。以赋值为例,下面的例子中,将 r1 赋值给 r2 之后,修改 r1 的 width 和 height 的值,r2 的 width 和 height 值也同样会被修改。
main() {
var r1 = Rectangle(10, 20) // r1.width = 10, r1.height = 20
var r2 = r1 // r2.width = 10, r2.height = 20
r1.width = 8 // r1.width = 8
r1.height = 24 // r1.height = 24
let a1 = r1.area() // a1 = 192
let a2 = r2.area() // a2 = 192
}
class 的继承
像大多数支持 class 的编程语言一样,仓颉中的 class 同样支持继承。如果 class B 继承 class A,则我们称 A 为父类,B 为子类。子类将继承父类中除 private 成员和构造函数以外的所有成员。
抽象 class 总是可被继承的,故抽象类定义时的 open 修饰符是可选的,也可以使用 sealed 修饰符修饰抽象类,表示该抽象类只能在本包被继承。但非抽象的 class 可被继承是有条件的:定义时必须使用修饰符 open 修饰。当带 open 修饰的实例成员被 class 继承时,该 open 的修饰符也会被继承。当非 open 修饰的类中存在 open 修饰的成员时,编译器会给出告警。
可以在子类定义处通过 <: 指定其继承的父类,但要求父类必须是可继承的。例如,下面的例子中,class A 使用 open 修饰,是可以被 class B 继承的,但是因为 class B 是不可继承的,所以 C 在继承 B 的时候会报错。
open class A {
let a: Int64 = 10
}
class B <: A { // Ok: 'B' Inheritance 'A'
let b: Int64 = 20
}
class C <: B { // Error: 'B' is not inheritable
let c: Int64 = 30
}
class 仅支持单继承,因此下面这样一个 class 继承两个 class 的代码是不合法的(& 是 class 实现多个接口时的语法,详见接口章节)。
open class A {
let a: Int64 = 10
}
open class B {
let b: Int64 = 20
}
class C <: A & B { // Error: 'C' can only inherit one class
let c: Int64 = 30
}
因为 class 是单继承的,所以任何 class 都最多只能有一个直接父类。对于定义时指定了父类的 class,它的直接父类就是定义时指定的类,对于定义时未指定父类的 class,它的直接父类是 Object 类型。Object 是所有 class 的父类(注意,Object 没有直接父类,并且 Object 中不包含任何成员)。
因为子类是继承自父类的,所以子类的对象天然可以当做父类的对象使用,但是反之不然。例如,下例中 B 是 A 的子类,那么 B 类型的对象可以赋值给 A 类型的变量,但是 A 类型的对象不能赋值给 B 类型的变量。
open class A {
let a: Int64 = 10
}
class B <: A {
let b: Int64 = 20
}
let a: A = B() // Ok: subclass objects can be assigned to superclass variables
open class A {
let a: Int64 = 10
}
class B <: A {
let b: Int64 = 20
}
let b: B = A() // Error: superclass objects can not be assigned to subclass variables
class 定义的类型不允许继承类型本身。
class A <: A {} // Error, 'A' inherits itself.
sealed 修饰符只能修饰抽象类,表示被修饰的 class 定义只能在本定义所在的包内被其他 class 继承。sealed 已经蕴含了 public/open 的语义,因此定义 sealed abstract class 时若提供 public/open 修饰符,编译器将会告警。sealed 的子类可以不是 sealed 类,仍可被 open/sealed 修饰,或不使用任何继承性修饰符。若 sealed 类的子类被 open 修饰,则其子类可在包外被继承。sealed 的子类可以不被 public 修饰。
package A
public sealed abstract class C1 {} // Warning, redundant modifier, 'sealed' implies 'public'
sealed open abstract class C2 {} // Warning, redundant modifier, 'sealed' implies 'open'
sealed abstract class C3 {} // OK, 'public' is optional when 'sealed' is used
class S1 <: C1 {} // OK
public open class S2 <: C1 {} // OK
public sealed abstract class S3 <: C1 {} // OK
open class S4 <: C1 {} // OK
package B
import A.*
class SS1 <: S2 {} // OK
class SS2 <: S3 {} // Error, S3 is sealed class, cannot be inherited here.
sealed class SS3 {} // Error, 'sealed' cannot be used on non-abstract class.
父类构造函数调用
子类的 init 构造函数可以使用 super(args) 的形式调用父类构造函数,或使用 this(args) 的形式调用本类其它构造函数,但两者之间只能调用一个。如果调用,必须在构造函数体内的第一个表达式处,在此之前不能有任何表达式或声明。
open class A {
A(let a: Int64) {}
}
class B <: A {
let b: Int64
init(b: Int64) {
super(30)
this.b = b
}
init() {
this(20)
}
}
子类的主构造函数中,可以使用 super(args) 的形式调用父类构造函数,但不能使用 this(args) 的形式调用本类其它构造函数。
如果子类的构造函数没有显式调用父类构造函数,也没有显式调用其他构造函数,编译器会在该构造函数体的开始处插入直接父类的无参构造函数的调用。如果此时父类没有无参构造函数,则会编译报错;
open class A {
let a: Int64
init() {
a = 100
}
}
open class B <: A {
let b: Int64
init(b: Int64) {
// OK, `super()` added by compiler
this.b = b
}
}
open class C <: B {
let c: Int64
init(c: Int64) { // Error, there is no non-parameter constructor in super class
this.c = c
}
}
覆盖和重定义
子类中可以覆盖(override)父类中的同名非抽象实例成员函数,即在子类中为父类中的某个实例成员函数定义新的实现。覆盖时,要求父类中的成员函数使用 open 修饰,子类中的同名函数使用 override 修饰,其中 override 是可选的。例如,下面的例子中,子类 B 中的函数 f 覆盖了父类 A 中的函数 f。
open class A {
public open func f(): Unit {
println("I am superclass")
}
}
class B <: A {
public override func f(): Unit {
println("I am subclass")
}
}
main() {
let a: A = A()
let b: A = B()
a.f()
b.f()
}
对于被覆盖的函数,调用时将根据变量的运行时类型(由实际赋给该变量的对象决定)确定调用的版本(即所谓的动态派发)。例如,上例中 a 的运行时类型是 A,因此 a.f() 调用的是父类 A 中的函数 f;b 的运行时类型是 B(编译时类型是 A),因此 b.f() 调用的是子类 B 中的函数 f。所以程序会输出:
I am superclass
I am subclass
对于静态函数,子类中可以重定义父类中的同名非抽象静态函数,即在子类中为父类中的某个静态函数定义新的实现。重定义时,要求子类中的同名静态函数使用 redef 修饰,其中 redef 是可选的。例如,下面的例子中,子类 D 中的函数 foo 重定义了父类 C 中的函数 foo。
open class C {
public static func foo(): Unit {
println("I am class C")
}
}
class D <: C {
public redef static func foo(): Unit {
println("I am class D")
}
}
main() {
C.foo()
D.foo()
}
对于被重定义的函数,调用时将根据 class 的类型决定调用的版本。例如,上例中 C.foo() 调用的是父类 C 中的函数 foo,D.foo() 调用的是子类 D 中的函数 foo。
I am class C
I am class D
如果抽象函数或 open 修饰的函数有命名形参,那么实现函数或 override 修饰的函数也需要保持同样的命名形参。
open class A {
public open func f(a!: Int32): Int32 {
a + 1
}
}
class B <: A {
public override func f(a!: Int32): Int32 { // ok
a + 2
}
}
class C <: A {
public override func f(b!: Int32): Int32 { // error
b + 3
}
}
main() {
B().f(a: 0)
C().f(b: 0)
}
还需要注意的是,当实现或重定义的函数为泛型函数时,子类型函数的类型变元约束需要比父类型中对应函数更宽松或相同。
open class A {}
open class B <: A {}
open class C <: B {}
open class Base {
static func f<T>(a: T): Unit where T <: B {}
static func g<T>(): Unit where T <: B {}
}
class D <: Base {
redef static func f<T>(a: T): Unit where T <: C {} // Error: stricter constraint
redef static func g<T>(): Unit where T <: C {} // Error: stricter constraint
}
class E <: Base {
redef static func f<T>(a: T): Unit where T <: A {} // OK: looser constraint
redef static func g<T>(): Unit where T <: A {} // OK: looser constraint
}
class F <: Base {
redef static func f<T>(a: T): Unit where T <: B {} // OK: same constraint
redef static func g<T>(): Unit where T <: B {} // OK: same constraint
}
接口
接口用来定义一个抽象类型,它不包含数据,但可以定义类型的行为。一个类型如果声明实现某接口,并且实现了该接口中所有的成员,就被称为实现了该接口。
接口的成员可以包含:
- 成员函数
- 操作符重载函数
- 成员属性
这些成员都是抽象的,要求实现类型必须拥有对应的成员实现。
接口的定义
一个简单的接口定义如下:
/*'open' is optional */ interface I {
func f(): Unit
}
接口使用关键字 interface 声明,其后是接口的标识符 I 和接口的成员。接口成员可被 open 修饰符修饰,并且 open 修饰符是可选的。
当接口 I 声明了一个成员函数 f 之后,当我们要为一个类型实现 I 时,就必须要在该类型中实现一个对应的 f 函数。
因为 interface 默认具有 open 语义,所以 interface 定义时的 open 修饰符是可选的。
如下面的代码所示,我们定义了一个 class Foo,使用 Foo <: I 的形式声明了 Foo 实现 I 接口。
在 Foo 中必须包含 I 声明的所有成员的实现,即需要定义一个相同签名的 f,否则会由于没有实现接口而编译报错。
class Foo <: I {
public func f(): Unit {
println("Foo")
}
}
main() {
let a = Foo()
let b: I = a
b.f() // "Foo"
}
当某个类型实现了某个接口之后,该类型就会成为该接口的子类型。
对于上面的例子,我们就可以认为 Foo 是 I 的子类型,因此任何一个 Foo 类型的实例,都可以当作 I 类型的实例使用。
在 main 中我们将一个 Foo 类型的变量 a,赋值给一个 I 类型的变量 b。然后我们再调用 b 中的函数 f,就会打印出 Foo 实现的 f 版本。程序的输出结果为:
Foo
interface 也可以使用 sealed 修饰符表示只能在 interface 定义所在的包内继承、实现或扩展该 interface。sealed 已经蕴含了 public/open 的语义,因此定义 sealed interface 时若提供 public/open 修饰符,编译器将会告警。继承 sealed 接口的子接口或实现 sealed 接口的类仍可被 sealed 修饰或不使用 sealed 修饰。若 sealed 接口的子接口被 public 修饰,且不被 sealed 修饰,则其子接口可在包外被继承、实现或扩展。继承、实现 sealed 接口的类型可以不被 public 修饰。
package A
public interface I1 {}
sealed interface I2 {} // OK
public sealed interface I3 {} // Warning, redundant modifier, 'sealed' implies 'public'
sealed open interface I4 {} // Warning, redundant modifier, 'sealed' implies 'open'
class C1 <: I1 {}
public open class C2 <: I1 {}
sealed class C3 <: I2 {}
extend Int64 <: I2 {}
package B
import A.*
class S1 <: I1 {} // OK
class S2 <: I2 {} // Error, I2 is sealed interface, cannot be inherited here.
通过接口的这种约束能力,我们可以对一系列的类型约定共同的功能,达到对功能进行抽象的目的。
例如下面的代码,我们可以定义一个 Flyable 接口,并且让其他具有 Flyable 属性的类实现它。
interface Flyable {
func fly(): Unit
}
class Bird <: Flyable {
public func fly(): Unit {
println("Bird flying")
}
}
class Bat <: Flyable {
public func fly(): Unit {
println("Bat flying")
}
}
class Airplane <: Flyable {
public func fly(): Unit {
println("Airplane flying")
}
}
func fly(item: Flyable): Unit {
item.fly()
}
main() {
let bird = Bird()
let bat = Bat()
let airplane = Airplane()
fly(bird)
fly(bat)
fly(airplane)
}
编译并执行上面的代码,我们会看到如下输出:
Bird flying
Bat flying
Airplane flying
接口的成员可以是实例的或者静态的,以上的例子已经展示过实例成员函数的作用,接下来我们来看看静态成员函数的作用。
静态成员函数和实例成员函数类似,都要求实现类型提供实现。
例如下面的例子,我们定义了一个 NamedType 接口,这个接口含有一个静态成员函数 typename 用来获得每个类型的字符串名称。
这样其它类型在实现 NamedType 接口时就必须实现 typename 函数,之后我们就可以安全地在 NamedType 的子类型上获得类型的名称。
interface NamedType {
static func typename(): String
}
class A <: NamedType {
public static func typename(): String {
"A"
}
}
class B <: NamedType {
public static func typename(): String {
"B"
}
}
main() {
println("the type is ${ A.typename() }")
println("the type is ${ B.typename() }")
}
程序输出结果为:
the type is A
the type is B
接口中的静态成员函数(或属性)可以没有默认实现,也可以拥有默认实现。
当其没有默认实现时,将无法通过接口类型名对其进行访问。例如下面的代码,直接访问 NamedType 的 typename 函数会发生编译报错,因为 NamedType 不具有 typename 函数的实现。
main() {
NamedType.typename() // error
}
接口中的静态成员函数(或属性)也可以拥有默认实现,当另一个类型继承拥有默认静态函数(或属性)实现的接口时,该类型可以不再实现这个静态成员函数(或属性),该函数(或属性)可以通过接口名和该类型名直接访问。如下用例,NamedType 的成员函数 typename 拥有默认实现,且在 A 中都可以不用再重新实现它,同时,也可以通过接口名和该类型名对其进行直接访问。
interface NamedType {
static func typename(): String {
"interface NamedType"
}
}
class A <: NamedType {}
main() {
println(NamedType.typename())
println(A.typename())
0
}
程序输出结果为:
interface NamedType
interface NamedType
通常我们会通过泛型约束,在泛型函数中使用这类静态成员。
例如下面的 printTypeName 函数,当我们约束泛型变元 T 是 NamedType 的子类型时,我们需要保证 T 的实例化类型中所有的静态成员函数(或属性)都必须拥有实现,以保证可以使用 T.typename 的方式访问泛型变元的实现,达到了我们对静态成员抽象的目的。详见泛型章节。
interface NamedType {
static func typename(): String
}
interface I <: NamedType {
static func typename(): String {
f()
}
static func f(): String
}
class A <: NamedType {
public static func typename(): String {
"A"
}
}
class B <: NamedType {
public static func typename(): String {
"B"
}
}
func printTypeName<T>() where T <: NamedType {
println("the type is ${ T.typename() }")
}
main() {
printTypeName<A>() // Ok
printTypeName<B>() // Ok
printTypeName<I>() // Error: 'I' must implement all static function. Otherwise, an unimplemented 'f' is called, causing problems.
}
需要注意的是,接口的成员默认就被 public 修饰,不可以声明额外的访问控制修饰符,同时也要求实现类型必须使用 public 实现。
interface I {
func f(): Unit
}
open class C <: I {
protected func f() {} // Compiler error, f needs to be public semantics
}
接口继承
当我们想为一个类型实现多个接口,可以在声明处使用 & 分隔多个接口,实现的接口之间没有顺序要求。
例如下面的例子,我们可以让 MyInt 同时实现 Addable 和 Subtractable 两个接口。
interface Addable {
func add(other: Int64): Int64
}
interface Subtractable {
func sub(other: Int64): Int64
}
class MyInt <: Addable & Subtractable {
var value = 0
public func add(other: Int64): Int64 {
value + other
}
public func sub(other: Int64): Int64 {
value - other
}
}
接口可以继承一个或多个接口,但不能继承类。与此同时,接口继承的时候可以添加新的接口成员。
例如下面的例子,Calculable 接口继承了 Addable 和 Subtractable 两个接口,并且增加了乘除两种运算符重载。
interface Addable {
func add(other: Int64): Int64
}
interface Subtractable {
func sub(other: Int64): Int64
}
interface Calculable <: Addable & Subtractable {
func mul(other: Int64): Int64
func div(other: Int64): Int64
}
这样实现类型实现 Calculable 接口时就必须同时实现加减乘除四种运算符重载,不能缺少任何一个成员。
class MyInt <: Calculable {
var value = 0
public func add(other: Int64): Int64 {
value + other
}
public func sub(other: Int64): Int64 {
value - other
}
public func mul(other: Int64): Int64 {
value * other
}
public func div(other: Int64): Int64 {
value / other
}
}
MyInt 实现 Calculable 的同时,也同时实现了 Calculable 继承的所有接口,因此 MyInt 也实现了 Addable 和 Subtractable,即同时是它们的子类型。
main() {
let myInt = MyInt()
let add: Addable = myInt
let sub: Subtractable = myInt
let calc: Calculable = myInt
}
对于 interface 的继承,子接口如果继承了父接口中有默认实现的函数或属性,则在子接口中不允许仅写此函数或属性的声明(即没有默认实现),而是必须要给出新的默认实现,并且函数定义前的 override 修饰符(或 redef 修饰符)是可选的;子接口如果继承了父接口中没有默认实现的函数或属性,则在子接口中允许仅写此函数或属性的声明(当然也允许定义默认实现),并且函数声明或定义前的 override 修饰符(或 redef 修饰符)是可选的。
interface I1 {
func f(a: Int64) {
a
}
static func g(a: Int64) {
a
}
func f1(a: Int64): Unit
static func g1(a: Int64): Unit
}
interface I2 <: I1 {
/*'override' is optional*/ func f(a: Int64) {
a + 1
}
override func f(a: Int32) {} // error: override function 'f' does not have an overridden function from its supertypes
static /*'redef' is optional*/ func g(a: Int64) {
a + 1
}
/*'override' is optional*/ func f1(a: Int64): Unit {}
static /*'redef' is optional*/ func g1(a: Int64): Unit {}
}
接口实现
仓颉所有的类型都可以实现接口,包括数值类型、Char、String、struct、class、enum、Tuple、函数以及其它类型。
一个类型实现接口有三种途径:
- 在定义类型时就声明实现接口,在以上的内容中我们已经见过相关例子。
- 通过扩展实现接口,这种方式详见扩展章节。
- 由语言内置实现,具体详见仓颉内置类型及库的相关文档。
实现类型声明实现接口时,需要实现接口中要求的所有成员,为此需要满足下面一些规则。
- 对于成员函数和操作符重载函数,要求实现类型提供的函数实现与接口对应的函数名称相同、参数列表相同、返回类型相同。
- 对于成员属性,要求是否被
mut修饰保持一致,并且属性的类型相同。
所以大部分情况都如同上面的例子,我们需要让实现类型中包含与接口要求的一样的成员的实现。
但有个地方是个例外,如果接口中的成员函数或操作符重载函数的返回值类型是 class 类型,那么允许实现函数的返回类型是其子类型。
例如下面这个例子,I 中的 f 返回类型是一个 class 类型 Base,因此 C 中实现的 f 返回类型可以是 Base 的子类型 Sub。
open class Base {}
class Sub <: Base {}
interface I {
func f(): Base
}
class C <: I {
public func f(): Sub {
Sub()
}
}
除此以外,接口的成员还可以为 class 类型提供默认实现。拥有默认实现的接口成员,当实现类型是 class 的时候,class 可以不提供自己的实现而继承接口的实现。
需要注意的是,默认实现只对类型是 class 的实现类型有效,对其它类型无效。
例如下面的代码中,SayHi 中的 say 拥有默认实现,因此 A 实现 SayHi 时可以继承 say 的实现,而 B 也可以选择提供自己的 say 实现。
interface SayHi {
func say() {
"hi"
}
}
class A <: SayHi {}
class B <: SayHi {
public func say() {
"hi, B"
}
}
特别地,如果一个类型在实现多个接口时,多个接口中包含同一个成员的默认实现,这时会发生多重继承的冲突,语言无法选择最适合的实现,因此这时接口中的默认实现也会失效,需要实现类型提供自己的实现。
例如下面的例子,SayHi 和 SayHello 中都包含了 say 的实现,Foo 在实现这两个接口时就必须提供自己的实现,否则会出现编译错误。
interface SayHi {
func say() {
"hi"
}
}
interface SayHello {
func say() {
"hello"
}
}
class Foo <: SayHi & SayHello {
public func say() {
"Foo"
}
}
struct、enum 和 class 在实现接口时,函数或属性定义前的 override 修饰符(或 redef 修饰符)是可选的,无论接口中的函数或属性是否存在默认实现。
interface I {
func foo(): Int64 {
return 0
}
}
enum E <: I{
elem
public override func foo(): Int64 {
return 1
}
}
struct S <: I {
public override func foo(): Int64 {
return 1
}
}
Any 类型
Any 类型是一个内置的接口,它的定义如下面。
interface Any {}
仓颉中所有接口都默认继承它,所有非接口类型都默认实现它,因此所有类型都可以作为 Any 类型的子类型使用。
如下面的代码,我们可以将一系列不同类型的变量赋值给 Any 类型的变量。
main() {
var any: Any = 1
any = 2.0
any = "hello, world!"
}
子类型关系
与其他面向对象语言一样,仓颉语言提供子类型关系和子类型多态。举例说明(不限于下述用例):
- 假设函数的形参是类型
T,则函数调用时传入的参数的实际类型既可以是T也可以是T的子类型(严格地说,T的子类型已经包括T自身,下同)。 - 假设赋值表达式
=左侧的变量的类型是T,则=右侧的表达式的实际类型既可以是T也可以是T的子类型。 - 假设函数定义中用户标注的返回类型是
T,则函数体的类型(以及函数体内所有return表达式的类型)既可以是T也可以是T的子类型。
那么如何判定两个类型是否存在子类型关系呢?下面我们对此展开说明。
继承 class 带来的子类型关系
继承 class 后,子类即为父类的子类型。如下代码中, Sub 即为 Super 的子类型。
open class Super { }
class Sub <: Super { }
实现接口带来的子类型关系
实现接口(含扩展实现)后,实现接口的类型即为接口的子类型。如下代码中,I3 是 I1 和 I2 的子类型, C 是 I1 的子类型, Int64 是 I2 的子类型:
interface I1 { }
interface I2 { }
interface I3 <: I1 & I2 { }
class C <: I1 { }
extend Int64 <: I2 { }
需要注意的是,部分跨扩展类型赋值后的类型向下转换场景(is 或 as)支持不完善,可能出现判断失败,计划在未来版本修复,见如下示例:
// file1.cj
package p1
public class A{}
public func get(): Any {
return A()
}
// =====================
// file2.cj
import p1.*
interface I0 {}
extend A <: I0 {}
main() {
let v: Any = get()
println(v is I0) // 无法正确判断类型,打印内容不确定
}
元组类型的子类型关系
仓颉语言中的元组类型也有子类型关系。直观的,如果一个元组 t1 的每个元素的类型都是另一个元组 t2 的对应位置元素类型的子类型,那么元组 t1 的类型也是元组 t2 的类型的子类型。例如下面的代码中,由于 C2 <: C1 和 C4 <: C3,因此也有 (C2, C4) <: (C1, C3) 以及 (C4, C2) <: (C3, C1)。
open class C1 { }
class C2 <: C1 { }
open class C3 { }
class C4 <: C3 { }
let t1: (C1, C3) = (C2(), C4()) // OK
let t2: (C3, C1) = (C4(), C2()) // OK
函数类型的子类型关系
仓颉语言中,函数是一等公民,而函数类型亦有子类型关系:给定两个函数类型 (U1) -> S2 和 (U2) -> S1,(U1) -> S2 <: (U2) -> S1 当且仅当 U2 <: U1 且 S2 <: S1(注意顺序)。例如下面的代码定义了两个函数 f : (U1) -> S2 和 g : (U2) -> S1,且 f 的类型是 g 的类型的子类型。由于 f 的类型是 g 的子类型,所以代码中使用到 g 的地方都可以换为 f。
open class U1 { }
class U2 <: U1 { }
open class S1 { }
class S2 <: S1 { }
func f(a: U1): S2 { S2() }
func g(a: U2): S1 { S1() }
func call1() {
g(U2()) // OK.
f(U2()) // OK.
}
func h(lam: (U2) -> S1): S1 {
lam(U2())
}
func call2() {
h(g) // OK.
h(f) // OK.
}
对于上面的规则,S2 <: S1 部分很好理解:函数调用产生的结果数据会被后续程序使用,函数 g 可以产生 S1 类型的结果数据,函数 f 可以产生 S2 类型的结果,而 g 产生的结果数据的应当能被 f 产生的结果数据替代,因此要求 S2 <: S1。
对于 U2 <: U1 的部分,可以这样理解:在函数调用产生结果前,它本身应当能够被调用,函数调用的实参类型固定不变,同时形参类型要求更宽松时,依然可以被调用,而形参类型要求更严格时可能无法被调用——例如给定上述代码中的定义 g(U2()) 可以被换为 f(U2()),正是因为实参类型 U2 的要求更严格于形参类型 U1 。
永远成立的子类型关系
仓颉语言中,有些预设的子类型关系是永远成立的:
- 一个类型
T永远是自身的子类型,即T <: T。 Nothing类型永远是其他任意类型T的子类型,即Nothing <: T。- 任意类型
T都是Any类型的子类型,即T <: Any。 - 任意
class定义的类型都是Object的子类型,即如果有class C {},则C <: Object。
传递性带来的子类型关系
子类型关系具有传递性。如下代码中,虽然只描述了 I2 <: I1,C <: I2,以及 Bool <: I2,但根据子类型的传递性,也隐式存在 C <: I1 以及 Bool <: I1 这两个子类型关系。
interface I1 { }
interface I2 <: I1 { }
class C <: I2 { }
extend Bool <: I2 { }
泛型类型的子类型关系
泛型类型间也有子类型关系,详见泛型章节。
类型转换
仓颉不支持不同类型之间的隐式转换(我们认为子类型天然是父类型,所以子类型到父类型的转换不是隐式类型转换),类型转换必须显式地进行。下面将依次介绍数值类型之间的转换,Char 到 UInt32 和整数类型到 Char 的转换,以及 is 和 as 操作符。
数值类型之间的转换
对于数值类型(包括:Int8,Int16,Int32,Int64,IntNative,UInt8,UInt16,UInt32,UInt64,UIntNative,Float16,Float32,Float64),仓颉支持使用 T(e) 的方式得到一个值等于 e,类型为 T 的值。其中,表达式 e 的类型和 T 可以是上述任意数值类型。
下面的例子展示了数值类型之间的类型转换:
main() {
let a: Int8 = 10
let b: Int16 = 20
let r1 = Int16(a)
println("The type of r1 is 'Int16', and r1 = ${r1}")
let r2 = Int8(b)
println("The type of r2 is 'Int8', and r2 = ${r2}")
let c: Float32 = 1.0
let d: Float64 = 1.123456789
let r3 = Float64(c)
println("The type of r3 is 'Float64', and r3 = ${r3}")
let r4 = Float32(d)
println("The type of r4 is 'Float32', and r4 = ${r4}")
let e: Int64 = 1024
let f: Float64 = 1024.1024
let r5 = Float64(e)
println("The type of r5 is 'Float64', and r5 = ${r5}")
let r6 = Int64(f)
println("The type of r6 is 'Int64', and r6 = ${r6}")
}
上述代码的执行结果为:
The type of r1 is 'Int16', and r1 = 10
The type of r2 is 'Int8', and r2 = 20
The type of r3 is 'Float64', and r3 = 1.000000
The type of r4 is 'Float32', and r4 = 1.123457
The type of r5 is 'Float64', and r5 = 1024.000000
The type of r6 is 'Int64', and r6 = 1024
Char 到 UInt32 和整数类型到 Char 的转换
Char 到 UInt32 的转换使用 UInt32(e) 的方式,其中 e 是一个 Char 类型的表达式,UInt32(e) 的结果是 e 的 Unicode scalar value 对应的 UInt32 类型的整数值。
整数类型到 Char 的转换使用 Char(num) 的方式,其中 num 的类型可以是任意的整数类型,且仅当 num 的值落在 [0x0000, 0xD7FF] 或 [0xE000, 0x10FFFF] (即 Unicode scalar value)中时,返回对应的 Unicode scalar value 表示的字符,否则,编译报错(编译时可确定 num 的值)或运行时抛异常。
下面的例子展示了 Char 和 UInt32 之间的类型转换:
main() {
let x: Char = 'a'
let y: UInt32 = 65
let r1 = UInt32(x)
let r2 = Char(y)
println("The type of r1 is 'UInt32', and r1 = ${r1}")
println("The type of r2 is 'Char', and r2 = ${r2}")
}
上述代码的执行结果为:
The type of r1 is 'UInt32', and r1 = 97
The type of r2 is 'Char', and r2 = A
is 和 as 操作符
仓颉支持使用 is 操作符来判断某个表达式的类型是否是指定的类型(或其子类型)。具体而言,对于表达式 e is T(e 可以是任意表达式,T 可以是任何类型),当 e 的运行时类型是 T 的子类型时,e is T 的值为 true,否则 e is T 的值为 false。
下面的例子展示了 is 操作符的使用:
open class Base {
var name: String = "Alice"
}
class Derived <: Base {
var age: UInt8 = 18
}
main() {
let a = 1 is Int64
println("Is the type of 1 'Int64'? ${a}")
let b = 1 is String
println("Is the type of 1 'String'? ${b}")
let b1: Base = Base()
let b2: Base = Derived()
var x = b1 is Base
println("Is the type of b1 'Base'? ${x}")
x = b1 is Derived
println("Is the type of b1 'Derived'? ${x}")
x = b2 is Base
println("Is the type of b2 'Base'? ${x}")
x = b2 is Derived
println("Is the type of b2 'Derived'? ${x}")
}
上述代码的执行结果为:
Is the type of 1 'Int64'? true
Is the type of 1 'String'? false
Is the type of b1 'Base'? true
Is the type of b1 'Derived'? false
Is the type of b2 'Base'? true
Is the type of b2 'Derived'? true
as 操作符可以用于将某个表达式的类型转换为指定的类型。因为类型转换有可能会失败,所以 as 操作返回的是一个 Option 类型。具体而言,对于表达式 e as T(e 可以是任意表达式,T 可以是任何类型),当 e 的运行时类型是 T 的子类型时,e as T 的值为 Option<T>.Some(e),否则 e as T 的值为 Option<T>.None。
下面的例子展示了 as 操作符的使用(注释中标明了 as 操作的结果):
open class Base {
var name: String = "Alice"
}
class Derived <: Base {
var age: UInt8 = 18
}
let a = 1 as Int64 // a = Option<Int64>.Some(1)
let b = 1 as String // b = Option<String>.None
let b1: Base = Base()
let b2: Base = Derived()
let d: Derived = Derived()
let r1 = b1 as Base // r1 = Option<Base>.Some(b1)
let r2 = b1 as Derived // r2 = Option<Derived>.None
let r3 = b2 as Base // r3 = Option<Base>.Some(b2)
let r4 = b2 as Derived // r4 = Option<Derived>.Some(b2)
let r5 = d as Base // r5 = Option<Base>.Some(d)
let r6 = d as Derived // r6 = Option<Derived>.Some(d)
类型别名
当某个类型的名字比较复杂或者在特定场景中不够直观时,可以选择使用类型别名的方式为此类型设置一个别名。
type I64 = Int64
类型别名的定义以关键字 type 开头,接着是类型的别名(如上例中的 I64),然后是等号 =,最后是原类型(即被取别名的类型,如上例中的 Int64)。
只能在源文件顶层定义类型别名,并且原类型必须在别名定义处可见。例如,下例中 Int64 的别名定义在 main 中将报错,LongNameClassB 类型在为其定义别名时不可见,同样报错。
main() {
type I64 = Int64 // Error: type aliases can only be defined at the top level of the source file
}
class LongNameClassA { }
type B = LongNameClassB // Error: type 'LongNameClassB' is not defined
一个(或多个)类型别名定义中禁止出现(直接或间接的)循环引用。
type A = (Int64, A) // Error: 'A' refered itself
type B = (Int64, C) // Error: 'B' and 'C' are circularly refered
type C = (B, Int64)
类型别名并不会定义一个新的类型,它仅仅是为原类型定义了另外一个名字,它有如下几种使用场景:
-
作为类型使用,例如:
type A = B class B {} var a: A = B() // Use typealias A as type B -
当类型别名实际指向的类型为 class、struct 时,可以作为构造器名称使用:
type A = B class B {} func foo() { A() } // Use type alias A as constructor of B -
当类型别名实际指向的类型为 class、interface、struct 时,可以作为访问内部静态成员变量或函数的类型名:
type A = B class B { static var b : Int32 = 0; static func foo() {} } func foo() { A.foo() // Use A to access static method in class B A.b } -
当类型别名实际指向的类型为 enum 时,可以作为 enum 声明的构造器的类型名:
enum TimeUnit { Day | Month | Year } type Time = TimeUnit var a = Time.Day var b = Time.Month // Use type alias Time to access constructors in TimeUnit
需要注意的是,当前用户自定义的类型别名暂不支持在类型转换表达式中使用,参考如下示例:
type MyInt = Int32
MyInt(0) // Error: no matching function for operator '()' function call
基础 Collection 类型
本章我们来看看仓颉中常用的几种基础 Collection 类型,包含 Array、ArrayList、HashSet、HashMap。
我们可以在不同的场景中选择适合我们业务的类型:
- Array:如果我们不需要增加和删除元素,但需要修改元素,就应该使用它。
- ArrayList:如果我们需要频繁对元素增删查改,就应该使用它。
- HashSet:如果我们希望每个元素都是唯一的,就应该使用它。
- HashMap:如果我们希望存储一系列的映射关系,就应该使用它。
下表是这些类型的基础特性:
| 类型名称 | 元素可变 | 增删元素 | 元素唯一性 | 有序序列 |
|---|---|---|---|---|
Array<T> | Y | N | N | Y |
ArrayList<T> | Y | Y | N | Y |
HashSet<T> | N | Y | Y | N |
HashMap<K, V> | K: N, V: Y | Y | K: Y, V: N | N |
Array
我们可以使用 Array 类型来构造单一元素类型,有序序列的数据。
仓颉使用 Array<T> 来表示 Array 类型。T 表示 Array 的元素类型,T 可以是任意类型。
var a: Array<Int64> = ... // Array whose element type is Int64
var b: Array<String> = ... // Array whose element type is String
元素类型不相同的 Array 是不相同的类型,所以它们之间不可以互相赋值。
因此以下例子是不合法的。
b = a // Type mismatch
我们可以轻松使用字面量来初始化一个 Array,只需要使用方括号将逗号分隔的值列表括起来即可。
编译器会根据上下文自动推断 Array 字面量的类型。
let a: Array<String> = [] // Created an empty Array whose element type is String
let b = [1, 2, 3, 3, 2, 1] // Created a Array whose element type is Int64, containing elements 1, 2, 3, 3, 2, 1
也可以使用构造函数的方式构造一个指定元素类型的 Array。
需要注意的是,当通过 item 指定的初始值初始化 Array 时,该构造函数不会拷贝 item,如果 item 是一个引用类型,构造后数组的每一个元素都将指向相同的引用。
let a = Array<Int64>() // Created an empty Array whose element type is Int64
let b = Array<Int64>(a) // Use another Array to initialize b
let c = Array<Int64>(3, item: 0) // Created an Array whose element type is Int64, length is 3 and all elements are initialized as 0
let d = Array<Int64>(3, {i => i + 1}) /* Created an Array whose element type is Int64, length is 3 and all elements are initialized by the initialization function */
访问 Array 成员
当我们需要对 Array 的所有元素进行访问时,可以使用 for-in 循环遍历 Array 的所有元素。
Array 是按元素插入顺序排列的,因此对 Array 遍历的顺序总是恒定的。
main() {
let arr = [0, 1, 2]
for (i in arr) {
println("The element is ${i}")
}
}
编译并执行上面的代码,会输出:
The element is 0
The element is 1
The element is 2
当我们需要知道某个 Array 包含的元素个数时,可以使用 size 属性获得对应信息。
main() {
let arr = [0, 1, 2]
if (arr.size == 0) {
println("This is an empty array")
} else {
println("The size of array is ${arr.size}")
}
}
编译并执行上面的代码,会输出:
The size of array is 3
当我们想访问单个指定位置的元素时,可以使用下标语法访问(下标的类型必须是 Int64)。非空 Array 的第一个元素总是从位置 0 开始的。我们可以从 0 开始访问 Array 的任意一个元素,直到最后一个位置(Array 的 size - 1)。索引值不能使用负数或者大于等于 size,当编译期能检查出索引值非法时,会在编译时报错,否则会在运行时抛异常。
main() {
let arr = [0, 1, 2]
let a = arr[0] // a == 0
let b = arr[1] // b == 1
let c = arr[-1] // array size is '3', but access index is '-1', which would overflow
}
如果我们想获取某一段 Array 的元素,可以在下标中传入 Range 类型的值,就可以一次性取得 Range 对应范围的一段 Array。
let arr1 = [0, 1, 2, 3, 4, 5, 6]
let arr2 = arr1[0..5]
// arr2 contains the elements 0, 1, 2, 3, 4
当 Range 字面量在下标语法中使用时,我们可以省略 start 或 end。
当省略 start 时,Range 会从 0 开始;当省略 end 时,Range 的 end 会延续到最后一位。
let arr1 = [0, 1, 2, 3, 4, 5, 6]
let arr2 = arr1[..3]
// arr2 contains elements 0, 1, 2
let arr3 = arr1[2..]
// arr3 contains elements 2, 3, 4, 5, 6
修改 Array
Array 是一种长度不变的 Collection 类型,因此 Array 没有提供添加和删除元素的成员函数。
但是 Array 允许我们对其中的元素进行修改,同样使用下标语法。
main() {
let arr = [0, 1, 2, 3, 4, 5]
arr[0] = 3
println("The first element is ${arr[0]}")
}
编译并执行上面的代码,会输出:
The first element is 3
Array 是引用类型,因此 Array 在作为表达式使用时不会拷贝副本,同一个 Array 实例的所有引用都会共享同样的数据。
因此对 Array 元素的修改会影响到该实例的所有引用。
let arr1 = [0, 1, 2]
let arr2 = arr1
arr2[0] = 3
// arr1 contains elements 3, 1, 2
// arr2 contains elements 3, 1, 2
ArrayList
使用 ArrayList 类型需要导入 collection 包:
from std import collection.*
仓颉使用 ArrayList<T> 表示 ArrayList 类型,T 表示 ArrayList 的元素类型,T 可以是任意类型。
ArrayList 具备非常好的扩容能力,适合于需要频繁增加和删除元素的场景。
相比 Array,ArrayList 既可以原地修改元素,也可以原地增加和删除元素。
ArrayList 的可变性是一个非常有用的特征,我们可以让同一个 ArrayList 实例的所有引用都共享同样的元素,并且对它们统一进行修改。
var a: ArrayList<Int64> = ... // ArrayList whose element type is Int64
var b: ArrayList<String> = ... // ArrayList whose element type is String
元素类型不相同的 ArrayList 是不相同的类型,所以它们之间不可以互相赋值。
因此以下例子是不合法的。
b = a // Type mismatch
仓颉中可以使用构造函数的方式构造一个指定的 ArrayList。
let a = ArrayList<String>() // Created an empty ArrayList whose element type is String
let b = ArrayList<String>(100) // Created an ArrayList whose element type is String, and allocate a space of 100
let c = ArrayList<Int64>([0, 1, 2]) // Created an ArrayList whose element type is Int64, containing elements 0, 1, 2
let d = ArrayList<Int64>(c) // Use another Collection to initialize an ArrayList
let e = ArrayList<String>(2, {x: Int64 => x.toString()}) // Created an ArrayList whose element type is String and size is 2. All elements are initialized by specified rule function
访问 ArrayList 成员
当我们需要对 ArrayList 的所有元素进行访问时,可以使用 for-in 循环遍历 ArrayList 的所有元素。
from std import collection.*
main() {
let list = ArrayList<Int64>([0, 1, 2])
for (i in list) {
println("The element is ${i}")
}
}
编译并执行上面的代码,会输出:
The element is 0
The element is 1
The element is 2
当我们需要知道某个 ArrayList 包含的元素个数时,可以使用 size 属性获得对应信息。
from std import collection.*
main() {
let list = ArrayList<Int64>([0, 1, 2])
if (list.size == 0) {
println("This is an empty arraylist")
} else {
println("The size of arraylist is ${list.size}")
}
}
编译并执行上面的代码,会输出:
The size of arraylist is 3
当我们想访问单个指定位置的元素时,可以使用下标语法访问(下标的类型必须是 Int64)。非空 ArrayList 的第一个元素总是从位置 0 开始的。我们可以从 0 开始访问 ArrayList 的任意一个元素,直到最后一个位置(ArrayList 的 size - 1)。使用负数或大于等于 size 的索引会触发运行时异常。
let a = list[0] // a == 0
let b = list[1] // b == 1
let c = list[-1] // Runtime exceptions
ArrayList 也支持下标中使用 Range 的语法,详见 Array 章节。
修改 ArrayList
我们可以使用下标语法对某个位置的元素进行修改。
let list = ArrayList<Int64>([0, 1, 2])
list[0] = 3
ArrayList 是引用类型,ArrayList 在作为表达式使用时不会拷贝副本,同一个 ArrayList 实例的所有引用都会共享同样的数据。
因此对 ArrayList 元素的修改会影响到该实例的所有引用。
let list1 = ArrayList<Int64>([0, 1, 2])
let list2 = list1
list2[0] = 3
// list1 contains elements 3, 1, 2
// list2 contains elements 3, 1, 2
如果需要将单个元素添加到 ArrayList 的末尾,请使用 append 函数。如果希望同时添加多个元素到末尾,可以使用 appendAll 函数,这个函数可以接受其它相同元素类型的 Collection 类型(例如 Array)。
from std import collection.*
main() {
let list = ArrayList<Int64>()
list.append(0) // list contains element 0
list.append(1) // list contains elements 0, 1
let li = [2, 3]
list.appendAll(li) // list contains elements 0, 1, 2, 3
}
我们可以通过 insert 和 insertAll 函数将指定的单个元素或相同元素类型的 Collection 值插入到我们指定索引的位置。该索引处的元素和后面的元素会被挪后以腾出空间。
let list = ArrayList<Int64>([0, 1, 2]) // list contains elements 0, 1, 2
list.insert(1, 4) // list contains elements 0, 4, 1, 2
从 ArrayList 中删除元素,可以使用 remove 函数,需要指定删除的索引。该索引处后面的元素会挪前以填充空间。
let list = ArrayList<String>(["a", "b", "c", "d"]) // list contains the elements "a", "b", "c", "d"
list.remove(1) // Delete the element at subscript 1, now the list contains elements "a", "c", "d"
增加 ArrayList 的大小
每个 ArrayList 都需要特定数量的内存来保存其内容。当我们向 ArrayList 添加元素并且该 ArrayList 开始超出其保留容量时,该 ArrayList 会分配更大的内存区域并将其所有元素复制到新内存中。这种增长策略意味着触发重新分配内存的添加操作具有性能成本,但随着 ArrayList 的保留内存变大,它们发生的频率会越来越低。
如果我们知道大约需要添加多少个元素,可以在添加之前预备足够的内存以避免中间重新分配,这样可以提升性能表现。
from std import collection.*
main() {
let list = ArrayList<Int64>(100) // Allocate space at once
for (i in 0..100) {
list.append(i) // Does not trigger reallocation of space
}
list.reserve(100) // Prepare more space
for (i in 0..100) {
list.append(i) // Does not trigger reallocation of space
}
}
Iterable 和 Collections
前面我们已经了解过 Range、Array、ArrayList,它们都可以使用 for-in 进行遍历操作
那么对一个用户自定义类型,能不能实现类似的遍历操作呢?
答案是可以的。
Range、Array、ArrayList 其实都是通过 Iterable 来支持 for-in 语法的。
Iterable 是如下形式(只展示了核心代码)的一个内置 interface。
interface Iterable<T> {
func iterator(): Iterator<T>
...
}
iterator 函数要求返回的 Iterator 类型是如下形式(只展示了核心代码)的另一个内置 interface。
interface Iterator<T> <: Iterable<T> {
mut func next(): Option<T>
...
}
我们可以使用 for-in 语法来遍历任何一个实现了 Iterable 接口类型的实例。
假设有这样一个 for-in 代码。
let list = [1, 2, 3]
for (i in list) {
println(i)
}
那么它等价于如下形式的 while 代码。
let list = [1, 2, 3]
var it = list.iterator()
while (true) {
match (it.next()) {
case Some(i) => println(i)
case None => break
}
}
另外一种常见的遍历 Iterable 类型的方法是使用 while-let,比如上面 while 代码的另一种等价写法是:
let list = [1, 2, 3]
var it = list.iterator()
while (let Some(i) <- it.next()) {
println(i)
}
Array、ArrayList、HashSet、HashMap 类型都实现了 Iterable,因此我们都可以将其用在 for-in 或者 while-let 中。
HashSet
使用 HashSet 类型需要导入 collection 包:
from std import collection.*
我们可以使用 HashSet 类型来构造只拥有不重复元素的 Collection。
仓颉使用 HashSet<T> 表示 HashSet 类型,T 表示 HashSet 的元素类型,T 必须是实现了 Hashable 和 Equatable<T> 接口的类型,例如数值或 String。
var a: HashSet<Int64> = ... // HashSet whose element type is Int64
var b: HashSet<String> = ... // HashSet whose element type is String
元素类型不相同的 HashSet 是不相同的类型,所以它们之间不可以互相赋值。
因此以下例子是不合法的。
b = a // Type mismatch
仓颉中可以使用构造函数的方式构造一个指定的 HashSet。
let a = HashSet<String>() // Created an empty HashSet whose element type is String
let b = HashSet<String>(100) // Created a HashSet whose capacity is 100
let c = HashSet<Int64>([0, 1, 2]) // Created a HashSet whose element type is Int64, containing elements 0, 1, 2
let d = HashSet<Int64>(c) // Use another Collection to initialize a HashSet
let e = HashSet<Int64>(10, {x: Int64 => (x * x)}) // Created a HashSet whose element type is Int64 and size is 10. All elements are initialized by specified rule function
访问 HashSet 成员
当我们需要对 HashSet 的所有元素进行访问时,可以使用 for-in 循环遍历 HashSet 的所有元素。
需要注意的是,HashSet 并不保证按插入元素的顺序排列,因此遍历的顺序和插入的顺序可能不同。
from std import collection.*
main() {
let mySet = HashSet<Int64>([0, 1, 2])
for (i in mySet) {
println("The element is ${i}")
}
}
编译并执行上面的代码,有可能会输出:
The element is 0
The element is 1
The element is 2
当我们需要知道某个 HashSet 包含的元素个数时,可以使用 size 属性获得对应信息。
from std import collection.*
main() {
let mySet = HashSet<Int64>([0, 1, 2])
if (mySet.size == 0) {
println("This is an empty hashset")
} else {
println("The size of hashset is ${mySet.size}")
}
}
编译并执行上面的代码,会输出:
The size of hashset is 3
当我们想判断某个元素是否被包含在某个 HashSet 中时,可以使用 contains 函数。如果该元素存在会返回 true,否则返回 false。
let mySet = HashSet<Int64>([0, 1, 2])
let a = mySet.contains(0) // a == true
let b = mySet.contains(-1) // b == false
修改 HashSet
HashSet 是一种可变的引用类型,HashSet 类型提供了添加元素、删除元素的功能。
HashSet 的可变性是一个非常有用的特征,我们可以让同一个 HashSet 实例的所有引用都共享同样的元素,并且对它们统一进行修改。
如果需要将单个元素添加到 HashSet,请使用 put 函数。如果希望同时添加多个元素,可以使用 putAll 函数,这个函数可以接受另一个相同元素类型的 Collection 类型(例如 Array)。当元素不存在时,put 函数会执行添加的操作,当 HashSet 中存在相同元素时,put 函数将不会有效果。
let mySet = HashSet<Int64>()
mySet.put(0) // mySet contains elements 0
mySet.put(0) // mySet contains elements 0
mySet.put(1) // mySet contains elements 0, 1
let li = [2, 3]
mySet.putAll(li) // mySet contains elements 0, 1, 2, 3
HashSet 是引用类型,HashSet 在作为表达式使用时不会拷贝副本,同一个 HashSet 实例的所有引用都会共享同样的数据。
因此对 HashSet 元素的修改会影响到该实例的所有引用。
let set1 = HashSet<Int64>([0, 1, 2])
let set2 = set1
set2.put(3)
// set1 contains elements 0, 1, 2, 3
// set2 contains elements 0, 1, 2, 3
从 HashSet 中删除元素,可以使用 remove 函数,需要指定删除的元素。
let mySet = HashSet<Int64>([0, 1, 2, 3])
mySet.remove(1) // mySet contains elements 0, 2, 3
HashMap
使用 HashMap 类型需要导入 collection 包:
from std import collection.*
我们可以使用 HashMap 类型来构造元素为键值对的 Collection。
HashMap 是一种哈希表,提供对其包含的元素的快速访问。表中的每个元素都使用其键作为标识,我们可以使用键来访问相应的值。
仓颉使用 HashMap<K, V> 表示 HashMap 类型,K 表示 HashMap 的键类型,K 必须是实现了 Hashable 和 Equatable<K> 接口的类型,例如数值或 String。V 表示 HashMap 的值类型,V 可以是任意类型。
var a: HashMap<Int64, Int64> = ... // HashMap whose key type is Int64 and value type is Int64
var b: HashMap<String, Int64> = ... // HashMap whose key type is String and value type is Int64
元素类型不相同的 HashMap 是不相同的类型,所以它们之间不可以互相赋值。
因此以下例子是不合法的。
b = a // Type mismatch
仓颉中可以使用构造函数的方式构造一个指定的 HashMap。
let a = HashMap<String, Int64>() // Created an empty HashMap whose key type is String and value type is Int64
let b = HashMap<String, Int64>([("a", 0), ("b", 1), ("c", 2)]) // whose key type is String and value type is Int64, containing elements ("a", 0), ("b", 1), ("c", 2)
let c = HashMap<String, Int64>(b) // Use another Collection to initialize a HashMap
let d = HashMap<String, Int64>(10) // Created a HashMap whose key type is String and value type is Int64 and capacity is 10
let e = HashMap<Int64, Int64>(10, {x: Int64 => (x, x * x)}) // Created a HashMap whose key and value type is Int64 and size is 10. All elements are initialized by specified rule function
访问 HashMap 成员
当我们需要对 HashMap 的所有元素进行访问时,可以使用 for-in 循环遍历 HashMap 的所有元素。
需要注意的是,HashMap 并不保证按插入元素的顺序排列,因此遍历的顺序和插入的顺序可能不同。
from std import collection.*
main() {
let map = HashMap<String, Int64>([("a", 0), ("b", 1), ("c", 2)])
for ((k, v) in map) {
println("The key is ${k}, the value is ${v}")
}
}
编译并执行上面的代码,有可能会输出:
The key is a, the value is 0
The key is b, the value is 1
The key is c, the value is 2
当我们需要知道某个 HashMap 包含的元素个数时,可以使用 size 属性获得对应信息。
from std import collection.*
main() {
let map = HashMap<String, Int64>([("a", 0), ("b", 1), ("c", 2)])
if (map.size == 0) {
println("This is an empty hashmap")
} else {
println("The size of hashmap is ${map.size}")
}
}
编译并执行上面的代码,会输出:
The size of hashmap is 3
当我们想判断某个键是否被包含 HashMap 中时,可以使用 contains 函数。如果该键存在会返回 true,否则返回 false。
let map = HashMap<String, Int64>([("a", 0), ("b", 1), ("c", 2)])
let a = map.contains("a") // a == true
let b = map.contains("d") // b == false
当我们想访问指定键对应的元素时,可以使用下标语法访问(下标的类型必须是键类型)。使用不存在的键作为索引会触发运行时异常。
let map = HashMap<String, Int64>([("a", 0), ("b", 1), ("c", 2)])
let a = map["a"] // a == 0
let b = map["b"] // b == 1
let c = map["d"] // Runtime exceptions
修改 HashMap
HashMap 是一种可变的引用类型,HashMap 类型提供了修改元素、添加元素、删除元素的功能。
HashMap 的可变性是一个非常有用的特征,我们可以让同一个 HashMap 实例的所有引用都共享同样的元素,并且对它们统一进行修改。
我们可以使用下标语法对某个键对应的值进行修改。
let map = HashMap<String, Int64>([("a", 0), ("b", 1), ("c", 2)])
map["a"] = 3
HashMap 是引用类型,HashMap 在作为表达式使用时不会拷贝副本,同一个 HashMap 实例的所有引用都会共享同样的数据。
因此对 HashMap 元素的修改会影响到该实例的所有引用。
let map1 = HashMap<String, Int64>([("a", 0), ("b", 1), ("c", 2)])
let map2 = map1
map2["a"] = 3
// map1 contains the elements ("a", 3), ("b", 1), ("c", 2)
// map2 contains the elements ("a", 3), ("b", 1), ("c", 2)
如果需要将单个键值对添加到 HashMap,请使用 put 函数。如果希望同时添加多个键值对,可以使用 putAll 函数。当键不存在时,put 函数会执行添加的操作,当键存在时,put 函数会将新的值覆盖旧的值。
let map = HashMap<String, Int64>()
map.put("a", 0) // map contains the element ("a", 0)
map.put("b", 1) // map contains the elements ("a", 0), ("b", 1)
let map2 = HashMap<String, Int64>([("c", 2), ("d", 3)])
map.putAll(map2) // map contains the elements ("a", 0), ("b", 1), ("c", 2), ("d", 3)
除了使用 put 函数以外,我们也可以使用赋值的方式直接将新的键值对添加到 HashMap。
let map = HashMap<String, Int64>([("a", 0), ("b", 1), ("c", 2)])
map["d"] = 3 // map contains the elements ("a", 0), ("b", 1), ("c", 2), ("d", 3)
从 HashMap 中删除元素,可以使用 remove 函数,需要指定删除的键。
let map = HashMap<String, Int64>([("a", 0), ("b", 1), ("c", 2), ("d", 3)])
map.remove("d") // map contains the elements ("a", 0), ("b", 1), ("c", 2)
错误处理
异常
异常是一类特殊的可以被程序员捕获并处理的错误,是程序执行时出现的一系列不正常行为的统称,例如,数组越界、除零错误、计算溢出、非法输入等。为了保证系统的正确性和健壮性,很多软件系统中都包含大量的代码用于错误检测和错误处理。
异常不属于程序的正常功能,一旦发生异常,要求程序必须立即处理,即将程序的控制权从正常功能的执行处转移至处理异常的部分。仓颉编程语言提供异常处理机制用于处理程序运行时可能出现的各种异常情况。
定义异常
在仓颉中,异常类有 Exception 和 Error :
Error类描述仓颉语言运行时,系统内部错误和资源耗尽错误,应用程序不应该抛出这种类型错误,如果出现内部错误,只能通知给用户,尽量安全终止程序。Exception类描述的是程序运行时的逻辑错误或者 IO 错误导致的异常,例如数组越界或者试图打开一个不存在的文件等,这类异常需要在程序中捕获处理。
用户不可以通过继承仓颉语言内置的 Error 或其子类类来自定义异常,但是可以继承内置的 Exception 或其子类来自定义异常,例如
open class FatherException <: Exception {
public open func printException() {
print("I am a FatherException")
}
}
class ChildException <: FatherException {
public override func printException() {
print("I am a ChildException")
}
}
下面列表展示了 Exception 的主要函数及其说明
| 函数种类 | 函数及说明 |
|---|---|
| 构造函数 | init() 默认构造函数 |
| 构造函数 | init(message: String) 可以设置异常消息的构造函数 |
| 成员属性 | open prop message: String 返回发生异常的详细信息。该消息在异常类构造函数中初始化,默认空字符串。 |
| 成员函数 | open func toString(): String 返回异常类型名以及异常的详细信息,其中,异常的详细信息会默认调用 message。 |
| 成员函数 | func printStackTrace(): Unit 打印堆栈信息至标准错误流。 |
下面列表展示了 Error 的主要函数及其说明
| 函数种类 | 函数及说明 |
|---|---|
| 成员属性 | open prop message: String 返回发生错误的详细信息。该消息在错误发生时,内部初始化,默认空字符串。 |
| 成员函数 | open func toString(): String 返回错误类型名以及错误的详细信息,其中,错误的详细信息会默认调用 message。 |
| 成员函数 | func printStackTrace(): Unit 打印堆栈信息至标准错误流。 |
创建和抛出异常
上文介绍了如何自定义异常,接下来我们学习如何创建和抛出异常。
- 由于异常是 class 类型,只需要按 class 对象的构建方式去创建异常即可。如表达式
FatherException()即创建了一个类型为FatherException的异常。 - 仓颉语言提供
throw关键字,用于抛出异常。用throw来抛出异常时,throw之后的表达式必须是Exception的子类型(同为异常的Error不可以手动throw),如throw ArithmeticException("I am an Exception!")(被执行到时)会抛出一个算术运算异常。 throw关键字抛出的异常需要被捕获处理。若异常没有被捕获,则由系统调用默认的异常处理函数。
具体的创建、处理示例,请参考下一小节 [异常处理]。
异常处理
异常处理由 try 表达式完成,可分为:
- 不涉及资源自动管理的普通 try 表达式;
- 会进行资源自动管理 try-with-resources 表达式。
普通 try 表达式
普通 try 表达式包括三个部分:try 块,catch 块和 finally 块。
-
Try 块,以关键字
try开始,后面紧跟一个由表达式与声明组成的块(用一对花括号括起来,定义了新的局部作用域,可以包含任意表达式和声明,后简称“块”),try 后面的块内可以抛出异常,并被紧随的 catch 块所捕获并处理(如果不存在 catch 块或未被捕获,则在执行完 finally 块后,该异常继续被抛出)。 -
Catch 块,一个普通 try 表达式可以包含零个或多个 catch 块(当没有 catch 块时必须有 finally 块)。每个 catch 块以关键字
catch开头,后跟一条(catchPattern)和一个块,catchPattern通过模式匹配的方式匹配待捕获的异常。一旦匹配成功,则交由其后跟随的块进行处理,并且忽略它后面的其他 catch 块。当某个 catch 块可捕获的异常类型均可被定义在它前面的某个 catch 块所捕获时,会在此 catch 块处报“catch 块不可达”的 warning。 -
Finally 块,以关键字
finally开始,后面紧跟一个块。原则上,finally 块中主要实现一些“善后”的工作,如释放资源等,且要尽量避免在 finally 块中再抛异常。并且无论异常是否发生(即无论 try 块中是否抛出异常),finally 块内的内容都会被执行(若异常未被处理,执行完 finally 块后,继续向外抛出异常)。一个 try 表达式在包含 catch 块时可以不包含 finally 块,否则必须包含 finally 块。
try 后面紧跟的块以及每个 catch 块的的作用域互相独立。
下面是一个只有 try 块和 catch 块的简单示例:
main() {
try {
throw NegativeArraySizeException("I am an Exception!")
} catch (e: NegativeArraySizeException) {
println(e)
println("NegativeArraySizeException is caught!")
}
println("This will also be printed!")
}
执行结果为
NegativeArraySizeException: I am an Exception!
NegativeArraySizeException is caught!
This will also be printed!
(catchPattern) 中引入的变量作用域级别与 catch 后面的块中变量作用域级别相同,在 catch 块中再次引入相同名字会触发重定义错。例如:
main() {
try {
throw NegativeArraySizeException("I am an Exception!")
} catch (e: NegativeArraySizeException) {
println(e)
let e = 0 // Error, redefinition
println(e)
println("NegativeArraySizeException is caught!")
}
println("This will also be printed!")
}
下面是带有 finally 块的 try 表达式的简单示例:
main() {
try {
throw NegativeArraySizeException("NegativeArraySizeException")
} catch (e: NegativeArraySizeException) {
println("Exception info: ${e}.")
} finally {
println("The finally block is executed.")
}
}
执行结果为
Exception info: NegativeArraySizeException: NegativeArraySizeException.
The finally block is executed.
普通 try 表达式的类型
Try 表达式可以出现在任何允许使用表达式的地方。Try 表达式的类型的确定方式,与 if、match 表达式等多分支语法结构的类型的确定方式相似(参见[if 表达式的类型],[match 表达式的类型]),即为 finally 分支除外的所有分支的类型的最小公共父类型。例如下面代码中的 try 表达式和变量 x 的类型均为 E 和 D 的最小公共父类型 D;finally 分支中的 C() 并不参与公共父类型的计算(若参与,则最小公共父类型会变为 C)。
另外,当 Try 表达式的值没有被使用时,其类型为 Unit,不要求各分支的类型有最小公共父类型。
open class C { }
open class D <: C { }
class E <: D { }
main () {
let x = try {
E()
} catch (e: Exception) {
D()
} finally {
C()
}
0
}
Try-with-resources 表达式
Try-with-resources 表达式主要是为了自动释放非内存资源。不同于普通 try 表达式,try-with-resources 表达式中的 catch 块和 finally 块均是可选的,并且 try 关键字其后的块之间可以插入一个或者多个 ResourceSpecification 用来申请一系列的资源(ResourceSpecification 并不会影响整个 try 表达式的类型)。这里所讲的资源对应到语言层面即指对象,因此 ResourceSpecification 其实就是实例化一系列的对象(多个实例化之间使用“,”分隔)。使用 try-with-resources 表达式的例子如下所示:
class R <: Resource {
public func isClosed(): Bool {
true
}
public func close(): Unit {
print("R is closed")
}
}
main() {
try (r = R()) {
println("Get the resource")
}
}
程序输出结果为:
Get the resource
try 关键字和 {} 之间引入的名字,其作用域与 {} 中引入的变量作用域级别相同,在 {} 中再次引入相同名字会触发重定义错。
class R <: Resource {
public func isClosed(): Bool {
true
}
public func close(): Unit {
print("R is closed")
}
}
main() {
try (r = R()) {
println("Get the resource")
let r = 0 // Error, redefinition
println(r)
}
}
Try-with-resources 表达式中的 ResourceSpecification 的类型必须实现 Resource 接口,并且尽量保证其中的 isClosed 函数不要再抛异常:
interface Resource {
func isClosed(): Bool
func close(): Unit
}
需要说明的是,try-with-resources 表达式中一般没有必要再包含 catch 块和 finally 块,也不建议用户再手动释放资源。因为 try 块执行的过程中无论是否发生异常,所有申请的资源都会被自动释放,并且执行过程中产生的异常均会被向外抛出。但是,如果需要显式地捕获 try 块或资源申请和释放过程中可能抛出的异常并处理,仍可在 try-with-resources 表达式中包含 catch 块和 finally 块:
class R <: Resource {
public func isClosed(): Bool {
true
}
public func close(): Unit {
print("R is closed")
}
}
main() {
try (r = R()) {
println("Get the resource")
} catch (e: Exception) {
println("Exception happened when executing the try-with-resources expression")
} finally {
println("End of the try-with-resources expression")
}
}
程序输出结果如下:
Get the resource
End of the try-with-resources expression
Try-with-resources 表达式的类型是 Unit。
CatchPattern 进阶介绍
大多数时候,我们只想捕获某一类型和其子类型的异常,这时候我们使用 CatchPattern 的类型模式来处理;但有时也需要所有异常做统一处理(如此处不该出现异常,出现了就统一报错),这时可以使用 CatchPattern 的通配符模式来处理。
类型模式在语法上有两种格式:
Identifier: ExceptionClass。此格式可以捕获类型为ExceptionClass及其子类的异常,并将捕获到的异常实例转换成ExceptionClass,然后与Identifier定义的变量进行绑定,接着就可以在 catch 块中通过 Identifier 定义的变量访问捕获到的异常实例。Identifier: ExceptionClass_1 | ExceptionClass_2 | ... | ExceptionClass_n。此格式可以通过连接符|将多个异常类进行拼接,连接符|表示“或”的关系:可以捕获类型为ExceptionClass_1及其子类的异常,或者捕获类型为ExceptionClass_2及其子类的异常,依次类推,或捕获类型为ExceptionClass_n及其子类的异常(假设 n 大于 1)。当待捕获异常的类型属于上述“或”关系中的任一类型或其子类型时,此异常将被捕获。但是由于无法静态地确定被捕获异常的类型,所以被捕获异常的类型会被转换成由|连接的所有类型的最小公共父类,并将异常实例与Identifier定义的变量进行绑定。因此在此类模式下,catch 块内只能通过Identifier定义的变量访问ExceptionClass_i(1 <= i <= n)的最小公共父类中的成员变量和成员函数。当然,也可以使用通配符代替类型模式中的Identifier,差别仅在于通配符不会进行绑定操作。
示例如下:
main(): Int64 {
try {
throw IllegalArgumentException("This is an Exception!")
} catch (e: OverflowException) {
println(e.message)
println("OverflowException is caught!")
} catch (e: IllegalArgumentException | NegativeArraySizeException) {
println(e.message)
println("IllegalArgumentException or NegativeArraySizeException is caught!")
} finally {
println("finally is executed!")
}
return 0
}
执行结果:
This is an Exception!
IllegalArgumentException or NegativeArraySizeException is caught!
finally is executed!
关于“被捕获异常的类型是由|连接的所有类型的最小公共父类”的示例:
open class Father <: Exception {
var father: Int32 = 0
}
class ChildOne <: Father {
var childOne: Int32 = 1
}
class ChildTwo <: Father {
var childTwo: Int32 = 2
}
main() {
try {
throw ChildOne()
} catch (e: ChildTwo | ChildOne) {
println("ChildTwo or ChildOne?")
}
}
通配符模式的语法是 _,它可以捕获同级 try 块内抛出的任意类型的异常,等价于类型模式中的 e: Exception,即捕获 Exception 子类所定义的异常。示例:
// Catch with wildcardPattern.
try {
throw OverflowException()
} catch (_) {
println("catch an exception!")
}
常见运行时异常
在仓颉语言中内置了最常见的异常类,开发人员可以直接使用。
| 异常 | 描述 |
|---|---|
ConcurrentModificationException | 并发修改产生的异常 |
IllegalArgumentException | 传递不合法或不正确参数时抛出的异常 |
NegativeArraySizeException | 创建大小为负的数组时抛出的异常 |
NoneValueException | 值不存在时产生的异常,如 Map 中不存在要查找的 key |
OverflowException | 算术运算溢出异常 |
Option 类型用于错误处理
在[Option 类型]中我们介绍了 Option 类型的定义,因为 Option 类型可以同时表示有值和无值两种状态,而无值在某些情况下也可以理解为一种错误,所以 Option 类型也可以用作错误处理。
例如,在下例中,如果函数 getOrThrow 的参数值等于 Some(v) 则将 v 的值返回,如果参数值等于 None 则抛出异常。
func getOrThrow(a: ?Int64) {
match (a) {
case Some(v) => v
case None => throw NoneValueException()
}
}
因为 Option 是一种非常常用的类型,所以仓颉为其提供了多种解构方式,以方便 Option 类型的使用,具体包括:模式匹配、getOrThrow 函数、coalescing 操作符(??),以及问号操作符(?)。下面将对这些方式逐一介绍。
-
模式匹配:因为 Option 类型是一种 enum 类型,所以可以使用上文提到的 enum 的模式匹配来实现对
Option值的解构。例如,下例中函数getString接受一个?Int64类型的参数,当参数是Some值时,返回其中数值的字符串表示,当参数是None值时,返回字符串"none"。func getString(p: ?Int64): String{ match (p) { case Some(x) => "${x}" case None => "none" } } main() { let a = Some(1) let b: ?Int64 = None let r1 = getString(a) let r2 = getString(b) println(r1) println(r2) }上述代码的执行结果为:
1 none -
coalescing操作符(??):对于?T类型的表达式e1,如果希望e1的值等于None时同样返回一个T类型的值e2,可以使用??操作符。对于表达式e1 ?? e2,当e1的值等于Some(v)时返回v的值,否则返回e2的值。举例如下:main() { let a = Some(1) let b: ?Int64 = None let r1: Int64 = a ?? 0 let r2: Int64 = b ?? 0 println(r1) println(r2) }上述代码的执行结果为:
1 0 -
问号操作符(
?):?需要和.或()或[]或{}(特指尾随 lambda 调用的场景)一起使用,用以实现Option类型对.,(),[]和{}的支持。以.为例((),[]和{}同理),对于?T1类型的表达式e,当e的值等于Some(v)时,e?.b的值等于Option<T2>.Some(v.b),否则e?.b的值等于Option<T2>.None,其中T2是v.b的类型。举例如下:struct R { public var a: Int64 public init(a: Int64) { this.a = a } } let r = R(100) let x = Some(r) let y = Option<R>.None let r1 = x?.a // r1 = Option<Int64>.Some(100) let r2 = y?.a // r2 = Option<Int64>.None问号操作符(
?)支持多层访问,以a?.b.c?.d为例((),[]和{}同理)。表达式a的类型需要是某个Option<T1>且T1包含实例成员b,b的类型中包含实例成员变量c且c的类型是某个Option<T2>,T2包含实例成员d;表达式a?.b.c?.d的类型为Option<T3>,其中T3是T2的实例成员d的类型;当a的值等于Some(va)且va.b.c的值等于Some(vc)时,a?.b.c?.d的值等于Option<T3>.Some(vc.d);当a的值等于Some(va)且va.b.c的值等于None时,a?.b.c?.d的值等于Option<T3>.None(d不会被求值);当a的值等于None时,a?.b.c?.d的值等于Option<T3>.None(b,c和d都不会被求值)。struct A { let b: B = B() } struct B { let c: Option<C> = C() let c1: Option<C> = Option<C>.None } struct C { let d: Int64 = 100 } let a = Some(A()) let a1 = a?.b.c?.d // a1 = Option<Int64>.Some(100) let a2 = a?.b.c1?.d // a2 = Option<Int64>.None -
getOrThrow函数:对于?T类型的表达式e,可以通过调用getOrThrow函数实现解构。当e的值等于Some(v)时,getOrThrow()返回v的值,否则抛出异常。举例如下:main() { let a = Some(1) let b: ?Int64 = None let r1 = a.getOrThrow() println(r1) try { let r2 = b.getOrThrow() } catch (e: NoneValueException) { println("b is None") } }上述代码的执行结果为:
1 b is None
函数
函数定义
仓颉使用关键字 func 来表示函数定义的开始,func 之后依次是函数名、参数列表、可选的函数返回值类型、函数体。其中,函数名可以是任意的合法标识符,参数列表定义在一对圆括号内(多个参数间使用逗号分隔),参数列表和函数返回值类型(如果存在)之间使用冒号分隔,函数体定义在一对花括号内。
函数定义举例:
func add(a: Int64, b: Int64): Int64 {
return a + b
}
上例中定义了一个名为 add 的函数,其参数列表由两个 Int64 类型的参数 a 和 b 组成,函数返回值类型为 Int64,函数体中将 a 和 b 相加并返回。
下面依次对函数定义中的参数列表、函数返回值类型和函数体作进一步介绍。
参数列表
一个函数可以拥有 0 个或多个参数,这些参数均定义在函数的参数列表中。根据函数调用时是否需要给定参数名,可以将参数列表中的参数分为两类:非命名参数和命名参数。
非命名参数的定义方式是 p: T,其中 p 表示参数名,T 表示参数 p 的类型,参数名和其类型间使用冒号连接。例如,上例中 add 函数的两个参数 a 和 b 均为非命名参数。
命名参数的定义方式是 p!: T,与非命名参数的不同是在参数名 p 之后多了一个 !。可以将上例中 add 函数的两个非命名参数修改为命名参数,如下所示:
func add(a!: Int64, b!: Int64): Int64 {
return a + b
}
命名参数还可以设置默认值,通过 p!: T = e 方式将参数 p 的默认值设置为表达式 e 的值。例如,可以将上述 add 函数的两个参数的默认值都设置为 1:
func add(a!: Int64 = 1, b!: Int64 = 1): Int64 {
return a + b
}
注:只能为命名参数设置默认值,不能为非命名参数设置默认值。
参数列表中可以同时定义非命名参数和命名参数,但是需要注意的是,非命名参数只能定义在命名参数之前,也就意味着命名参数之后不能再出现非命名参数。例如,下例中 add 函数的参数列表定义是不合法的:
func add(a!: Int64, b: Int64): Int64 { // Error: named parameter 'a' must be defined after non-named parameter 'b'
return a + b
}
非命名参数和命名参数的主要差异在于调用时的不同,具体可参见下文[函数调用]中的介绍。
函数参数均为不可变变量,在函数定义内不能对其赋值。
func add(a: Int64, b: Int64): Int64 {
a = a + b // error
return a
}
函数参数作用域从定义处起至函数体结束:
func add(a: Int64, b: Int64): Int64 {
var a_ = a // OK
var b = b // Error: redefinition of declaration 'b'
return a
}
函数返回值类型
函数返回值类型是函数被调用后得到的值的类型。函数定义时,返回值类型是可选的:可以显式地定义返回值类型(返回值类型定义在参数列表和函数体之间),也可以不定义返回值类型,交由编译器推导确定。
当显式地定义了函数返回值类型时,就要求函数体的类型(关于如何确定函数体的类型可参见下节[函数体])、函数体中所有 return e 表达式中 e 的类型是返回值类型的子类型。例如,对于上述 add 函数,显式地定义了它的返回值类型为 Int64,如果将函数体中的 return a + b 修改为 return (a, b),则会因为类型不匹配而报错:
// Error: the type of the expression after return does not match the return type of the function
func add(a: Int64, b: Int64): Int64 {
return (a, b)
}
在函数定义时如果未显式定义返回值类型,编译器将根据函数体的类型以及函数体中所有的 return 表达式来共同推导出函数的返回值类型。例如,下例中 add 函数的返回值类型虽然被省略,但编译器可以根据 return a + b 推导出 add 函数的返回值类型是 Int64:
func add(a: Int64, b: Int64) {
return a + b
}
注:函数的返回值类型并不是任何情况下都可以被推导出来的,如果返回值类型推导失败,编译器会报错。
函数体
函数体中定义了函数被调用时执行的操作,通常包含一系列的变量定义和表达式,也可以包含新的函数定义(即嵌套函数)。如下 add 函数的函数体中首先定义了 Int64 类型的变量 r(初始值为 0),接着将 a + b 的值赋值给 r,最后将 r 的值返回:
func add(a: Int64, b: Int64) {
var r = 0
r = a + b
return r
}
在函数体的任意位置都可以使用 return 表达式来终止函数的执行并返回。return 表达式有两种形式:return 和 return expr(expr 是一个表达式)。
对于 return expr,要求 expr 的类型与函数定义中的返回值类型保持一致。例如,下例中会因为 return 100 中 100 类型(Int64)和函数 foo 的返回值类型(String)不同而报错。
// error: cannot convert an integer literal to type 'Struct-String'
func foo(): String {
return 100
}
对于 return,其等价于 return (),所以要求函数的返回值类型为 Unit。
func add(a: Int64, b: Int64) {
var r = 0
r = a + b
return r
}
func foo(): Unit {
add(1, 2)
return
}
注:return 表达式作为一个整体,其类型并不由后面跟随的表达式决定,而是 Nothing 类型。
在函数体内定义的变量属于局部变量的一种(如上例中的 r 变量),它的作用域从其定义之后开始到函数体结束。
对于一个局部变量,允许在其外层作用域中定义同名变量,并且在此局部变量的作用域内,局部变量会“遮盖”外层作用域的同名变量。例如:
let r = 0
func add(a: Int64, b: Int64) {
var r = 0
r = a + b
return r
}
上例中,add 函数之前定义了 Int64 类型的全局变量 r,同时 add 函数体内定义了同名的局部变量 r,那么在函数体内,所有使用变量 r 的地方(如 r = a + b),用到的将是局部变量 r,即(在函数体内)局部变量 r “遮盖”了全局变量 r。
上节中我们提到函数体也是有类型的,函数体的类型是函数体内最后一“项”的类型:若最后一项为表达式,则函数体的类型是此表达式的类型,若最后一项为变量定义或函数声明,或函数体为空,则函数体的类型为 Unit。例如:
func add(a: Int64, b: Int64): Int64 {
a + b
}
上例中,因为函数体的最后一“项”是 Int64 类型的表达式(即 a + b),所以函数体的类型也是 Int64,与函数定义的返回值类型相匹配。又如,下例中函数体的最后一项是 print 函数调用,所以函数体的类型是 Unit,同样与函数定义的返回值类型相匹配:
func foo(): Unit {
let s = "Hello"
print(s)
}
函数调用
函数调用的形式为 f(arg1, arg2, ..., argn)。其中,f 是要调用的函数的名字,arg1 到 argn 是 n 个调用时的参数(称为实参),要求每个实参的类型必须是对应参数类型的子类型。实参可以有 0 个或多个,当实参个数为 0 时,调用方式为 f()。
根据函数定义时参数是非命名参数还是命名参数的不同,函数调用时传实参的方式也有所不同:对于非命名参数,它对应的实参是一个表达式,对于命名参数,它对应的实参需要使用 p: e 的形式,其中 p 是命名参数的名字,e 是表达式(即传递给参数 p 的值)。
非命名参数调用举例:
func add(a: Int64, b: Int64) {
return a + b
}
main() {
let x = 1
let y = 2
let r = add(x, y)
println("The sum of x and y is ${r}")
}
执行结果为:
The sum of x and y is 3
命名参数调用举例:
func add(a: Int64, b!: Int64) {
return a + b
}
main() {
let x = 1
let y = 2
let r = add(x, b: y)
println("The sum of x and y is ${r}")
}
执行结果为:
The sum of x and y is 3
对于多个命名参数,调用时的传参顺序可以和定义时的参数顺序不同。例如,下例中调用 add 函数时 b 可以出现在 a 之前:
func add(a!: Int64, b!: Int64) {
return a + b
}
main() {
let x = 1
let y = 2
let r = add(b: y, a: x)
println("The sum of x and y is ${r}")
}
执行结果为:
The sum of x and y is 3
对于拥有默认值的命名参数,调用时如果没有传实参,那么此参数将使用默认值作为实参的值。例如,下例中调用 add 函数时没有为参数 b 传实参,那么参数 b 的值等于其定义时的默认值 2:
func add(a: Int64, b!: Int64 = 2) {
return a + b
}
main() {
let x = 1
let r = add(x)
println("The sum of x and y is ${r}")
}
执行结果为:
The sum of x and y is 3
对于拥有默认值的命名参数,调用时也可以为其传递新的实参,此时命名参数的值等于新的实参的值,即定义时的默认值将失效。例如,下例中调用 add 函数时为参数 b 传了新的实参值 20,那么参数 b 的值就等于 20:
func add(a: Int64, b!: Int64 = 2) {
return a + b
}
main() {
let x = 1
let r = add(x, b: 20)
println("The sum of x and y is ${r}")
}
执行结果为:
The sum of x and y is 21
函数是一等公民
仓颉编程语言中,函数是一等公民(first-class citizens),可以作为函数的参数或返回值,也可以赋值给变量。因此函数本身也有类型,称之为函数类型。
函数类型
函数类型由函数的参数类型和返回类型组成,参数类型和返回类型之间使用 -> 连接。参数类型使用圆括号 () 括起来,可以有 0 个或多个参数,如果参数超过两个,参数类型之间使用逗号 , 分隔。
例如:
func hello(): Unit {
println("Hello!")
}
上述示例定义了一个函数,函数名为 hello,其类型是 () -> Unit,表示该函数没有参数,返回类型为 Unit。
以下给出另一些示例:
-
示例:函数名为
display,其类型是(Int64) -> Unit,表示该函数有一个参数,参数类型为Int64,返回类型为Unit。func display(a: Int64): Unit { println(a) } -
示例:函数名为
add,其类型是(Int64, Int64) -> Int64,表示该函数有两个参数,两个参数类型均为Int64,返回类型为Int64。func add(a: Int64, b: Int64): Int64 { a + b } -
示例:函数名为
returnTuple,其类型是(Int64, Int64) -> (Int64, Int64),两个参数类型均为Int64, 返回类型为元组类型:(Int64, Int64)。func returnTuple(a: Int64, b: Int64): (Int64, Int64) { (a, b) }
函数类型的类型参数
可以为函数类型标记显式的类型参数名,下面例子中的 name 和 price 就是 类型参数名。
main() {
let fruitPriceHandler: (name: String, price: Int64) -> Unit
fruitPriceHandler = {n, p => println("fruit: ${n} price: ${p} yuan")}
fruitPriceHandler("banana", 10)
}
另外对于一个函数类型,只允许统一写类型参数名,或者统一不写类型参数名,不能交替存在。
let handler: (name: String, Int64) -> Int64 // error
函数类型作为参数类型
-
示例:函数名为
printAdd,其类型是((Int64, Int64) -> Int64, Int64, Int64) -> Unit,表示该函数有三个参数,参数类型分别为函数类型(Int64, Int64) -> Int64和两个Int64,返回类型为Unit。func printAdd(add: (Int64, Int64) -> Int64, a: Int64, b: Int64): Unit { println(add(a, b)) }
函数类型作为返回类型
函数类型可以作为另一个函数的返回类型。
如下示例中,函数名为 returnAdd,其类型是 () -> (Int64, Int64) -> Int64,表示该函数无参数,返回类型为函数类型 (Int64, Int64) -> Int64。注意,-> 是右结合的。
func add(a: Int64, b: Int64): Int64 {
a + b
}
func returnAdd(): (Int64, Int64) -> Int64 {
add
}
main() {
var a = returnAdd()
println(a(1,2))
}
函数类型作为变量类型
函数名本身也是表达式,它的类型为对应的函数类型。
func add(p1: Int64, p2: Int64): Int64 {
p1 + p2
}
let f: (Int64, Int64) -> Int64 = add
上述示例中,函数名是 add,其类型为 (Int64, Int64) -> Int64。变量 f 的类型与 add 类型相同, add 被用来初始化 f。
若一个函数在当前作用域中被重载(见[函数重载])了,那么直接使用该函数名作为表达式可能产生歧义,如果产生歧义编译器会报错,例如:
func add(i: Int64, j: Int64) {
i + j
}
func add(i: Float64, j: Float64) {
i + j
}
main() {
var f = add // Error: ambiguous function 'add'
var plus: (Int64, Int64) -> Int64 = add // OK
}
嵌套函数
定义在源文件顶层的函数被称为全局函数。定义在函数体内的函数被称为嵌套函数。
示例,函数 foo 内定义了一个嵌套函数 nestAdd,可以在 foo 内调用该嵌套函数 nestAdd,也可以将嵌套函数 nestAdd 作为返回值返回,在 foo 外对其进行调用:
func foo() {
func nestAdd(a: Int64, b: Int64) {
a + b + 3
}
println(nestAdd(1, 2)) // 6
return nestAdd
}
main() {
let f = foo()
let x = f(1, 2)
println("result: ${x}")
}
程序会输出:
6
result: 6
Lambda 表达式
Lambda 表达式定义
Lambda 表达式的语法为如下形式:
{ p1: T1, ..., pn: Tn => expressions | declarations }。
其中,=> 之前为参数列表,多个参数之间使用 , 分隔,每个参数名和参数类型之间使用 : 分隔。=> 之前也可以没有参数。=> 之后为 lambda 表达式体,是一组表达式或声明序列。Lambda 表达式的参数名的作用域与函数的相同,为 lambda 表达式的函数体部分,其作用域级别可视为与 lambda 表达式的函数体内定义的变量等同。
let f1 = { a: Int64, b: Int64 => a + b }
var display = { => println("Hello") } // Parameterless lambda expression.
Lambda 表达式不管有没有参数,都不可以省略 =>,除非其作为尾随 lambda。例如:
var display = { => println("Hello") }
func f2(lam: () -> Unit) { }
let f2Res = f2{ println("World") } // OK to omit the =>
Lambda 表达式中参数的类型标注可缺省。以下情形中,若参数类型省略,编译器会尝试进行类型推断,当编译器无法推断出类型时会编译报错:
- Lambda 表达式赋值给变量时,其参数类型根据变量类型推断;
- Lambda 表达式作为函数调用表达式的实参使用时,其参数类型根据函数的形参类型推断。
// The parameter types are inferred from the type of the variable sum1
var sum1: (Int64, Int64) -> Int64 = { a, b => a + b }
var sum2: (Int64, Int64) -> Int64 = { a: Int64, b => a + b }
func f(a1: (Int64) -> Int64): Int64 {
a1(1)
}
main(): Int64 {
// The parameter type of lambda is inferred from the type of function f
f({ a2 => a2 + 10 })
}
Lambda 表达式中不支持声明返回类型,其返回类型总是从上下文中推断出来,若无法推断则报错。
-
若上下文明确指定了 lambda 表达式的返回类型,则其返回类型为上下文指定的类型。
- Lambda 表达式赋值给变量时,其返回类型根据变量类型推断返回类型:
let f: () -> Unit = { ... }- Lambda 表达式作为参数使用时,其返回类型根据使用处所在的函数调用的形参类型推断:
func f(a1: (Int64) -> Int64): Int64 { a1(1) } main(): Int64 { f({ a2: Int64 => a2 + 10 }) }- Lambda 表达式作为返回值使用时,其返回类型根据使用处所在函数的返回类型推断:
func f(): (Int64) -> Int64 { { a: Int64 => a } } -
若上下文中类型未明确,与推导函数的返回值类型类似,编译器会根据 lambda 表达式体中所有 return 表达式 'return xxx' 中 xxx 的类型,以及 lambda 表达式体的类型,来共同推导出 lambda 表达式的返回类型。
=>右侧的内容与普通函数体的规则一样。let sum1 = { a: Int64, b: Int64 => a + b } -
若
=>的右侧为空,返回类型为Unit。let f = { => }
Lambda 表达式调用
Lambda 表达式支持立即调用,例如:
let r1 = { a: Int64, b: Int64 => a + b }(1, 2) // r1 = 3
let r2 = { => 123 }() // r2 = 123
Lambda 表达式也可以赋值给一个变量,使用变量名进行调用,例如:
func f() {
var g = { x: Int64 => println("x = ${x}") }
g(2)
}
闭包
一个函数或 lambda 从定义它的静态作用域中捕获了变量,函数或 lambda 和捕获的变量一起被称为一个闭包,这样即使脱离了闭包定义所在的作用域,闭包也能正常运行。
函数或 lambda 的定义中对于以下几种变量的访问,称为变量捕获:
-
函数的参数缺省值中访问了本函数之外定义的局部变量;
-
函数或 lambda 内访问了本函数或本 lambda 之外定义的局部变量;
-
class/struct内定义的不是成员函数的函数或 lambda 访问了实例成员变量或this;
以下情形的变量访问不是变量捕获:
-
对定义在本函数或本 lambda 内的局部变量的访问;
-
对本函数或本 lambda 的形参的访问;
-
对全局变量和静态成员变量的访问;
-
对实例成员变量在实例成员函数或属性中的访问。由于实例成员函数或属性将
this作为参数传入,在实例成员函数或属性内通过this访问所有实例成员变量。
变量的捕获发生在闭包定义时,因此变量捕获有以下规则:
-
被捕获的变量必须在闭包定义时可见,否则编译报错;
-
被捕获的变量必须在闭包定义时已经完成初始化,否则编译报错;
示例 1:闭包 add,捕获了 let 声明的局部变量 num,之后通过返回值返回到 num 定义的作用域之外,调用 add 时仍可正常访问 num。
func returnAddNum(): (Int64) -> Int64 {
let num: Int64 = 10
func add(a: Int64) {
return a + num
}
add
}
main() {
let f = returnAddNum()
println(f(10))
}
程序输出的结果为:
20
示例 2:捕获的变量必须在闭包定义时可见
func f() {
let x = 99
func f1() {
println(x)
}
let f2 = { =>
println(y) // Error: cannot capture 'y' which is not defined yet
}
let y = 88
f1() // Print 99.
f2()
}
示例 3:捕获的变量必须在闭包定义前完成初始化
func f() {
let x: Int64
func f1() {
println(x) // Error: x is not initialized yet.
}
x = 99
f1()
}
如果捕获的变量是引用类型,可修改其可变实例成员变量的值。
class C {
public var num: Int64 = 0
}
func returnIncrementer(): () -> Unit {
let c: C = C()
func incrementer() {
c.num++
}
incrementer
}
main() {
let f = returnIncrementer()
f() // c.num increases by 1
}
为了防止捕获了 var 声明变量的闭包逃逸,这类闭包只能被调用,不能作为一等公民使用,包括不能赋值给变量,不能作为实参或返回值使用,不能直接将闭包的名字作为表达式使用。
func f() {
var x = 1
let y = 2
func g() {
println(x) // OK, captured a mutable variable.
}
let b = g // Error, g cannot be assigned to a variable
g // Error, g cannot be used as an expression
g() // OK, g can be invoked
g // Error, g cannot be used as a return value.
}
需要注意的是,捕获具有传递性,如果一个函数 f 调用了捕获 var 变量的函数 g,且存在 g 捕获的 var 变量不在函数 f 内定义,那么函数 f 同样捕获了 var 变量,此时,f 也不能作为一等公民使用。
以下示例中,g 捕获了 var 声明的变量 x,f 调用了 g,且 g 捕获的 x 不在 f 内定义,f 同样不能作为一等公民使用:
func h(){
var x = 1
func g() { x } // captured a mutable variable
func f() {
g() // invoked g
}
return f // error
}
以下示例中,g 捕获了 var 声明的变量 x,f 调用了 g。但 g 捕获的 x 在 f 内定义,f 没有捕获其它 var 声明的变量。因此,f 仍作为一等公民使用:
func h(){
func f() {
var x = 1
func g() { x } // captured a mutable variable
g()
}
return f // ok
}
静态成员变量和全局变量的访问,不属于变量捕获,因此访问了 var 修饰的全局变量、静态成员变量的函数或 lambda 仍可作为一等公民使用。
class C {
static public var a: Int32 = 0
static public func foo() {
a++ // OK
return a
}
}
var globalV1 = 0
func countGlobalV1() {
globalV1++
C.a = 99
let g = C.foo // OK
}
func g(){
let f = countGlobalV1 // OK
f()
}
函数调用语法糖
尾随 lambda
尾随 lambda 可以使函数的调用看起来像是语言内置的语法一样,增加语言的可扩展性。
当函数最后一个形参是函数类型,并且函数调用对应的实参是 lambda 时,我们可以使用尾随 lambda 语法,将 lambda 放在函数调用的尾部,圆括号外面。
例如,下例中我们定义了一个 myIf 函数,它的第一个参数是 Bool 类型,第二个参数是函数类型。当第一个参数的值为 true 时,返回第二个参数调用后的值,否则返回 0。调用 myIf 时可以像普通函数一样调用,也可以使用尾随 lambda 的方式调用。
func myIf(a: Bool, fn: () -> Int64) {
if(a) {
fn()
} else {
0
}
}
func test() {
myIf(true, { => 100 }) // General function call
myIf(true) { // Trailing closure call
100
}
}
当函数调用有且只有一个 lambda 实参时,我们还可以省略 (),只写 lambda。
示例:
func f(fn: (Int64) -> Int64) { fn(1) }
func test() {
f { i => i * i }
}
Flow 表达式
流操作符包括两种:表示数据流向的中缀操作符 |> (称为 pipeline)和表示函数组合的中缀操作符 ~> (称为 composition)。
Pipeline 表达式
当需要对输入数据做一系列的处理时,可以使用 pipeline 表达式来简化描述。
pipeline 表达式的语法形式如下:
e1 |> e2
等价于如下形式的语法糖:
let v = e1; e2(v) 。
其中 e2 是函数类型的表达式,e1 的类型是 e2 的参数类型的子类型;
示例:
func inc(x: Array<Int64>): Array<Int64> { // Increasing the value of each element in the array by '1'
let s = x.size
var i = 0
for (e in x where i < s) {
x[i] = e + 1
i++
}
x
}
func sum(y: Array<Int64>): Int64 { // Get the sum of elements in the array.
var s = 0
for (j in y) {
s += j
}
s
}
let arr: Array<Int64> = Array<Int64>([1, 3, 5])
let res = arr |> inc |> sum // res = 12
Composition 表达式
composition 表达式表示两个单参函数的组合。composition 表达式语法如下:
f ~> g
等价于如下形式:
{ x => g(f(x)) }
其中 f,g 均为只有一个参数的函数类型的表达式。
f 和 g 组合,则要求 f(x) 的返回类型是 g(...) 的参数类型的子类型。
示例 1:
func f(x: Int64): Float64 {
Float64(x)
}
func g(x: Float64): Float64 {
x
}
var fg = f ~> g // The same as { x: Int64 => g(f(x)) }
示例 2:
func f(x: Int64): Float64 {
Float64(x)
}
let lambdaComp = ({x: Int64 => x}) ~> f // The same as { x: Int64 => f({x: Int64 => x}(x)) }
示例 3:
func h1<T>(x: T): T { x }
func h2<T>(x: T): T { x }
var hh = h1<Int64> ~> h2<Int64> // The same as { x: Int64 => h2<Int64>(h1<Int64>(x)) }
注:表达式 f ~> g 中,会先对 f 求值,然后对 g 求值,最后才会进行函数的组合。
需要注意的是,流操作符不能与无默认值的命名形参函数直接一同使用,这是因为无默认值的命名形参函数必须给出命名实参才可以调用。例如:
func f(a!: Int64): Unit {}
var a = 1 |> f // error
如果需要使用,用户可以通过 lambda 表达式传入 f 函数的命名实参:
func f(a!: Int64): Unit {}
var x = 1 |> { x: Int64 => f(a: x) } // ok
由于相同的原因,当 f 的参数有默认值时,直接与流运算符一起使用也是错误的,例如:
func f(a!: Int64 = 2): Unit {}
var a = 1 |> f // error
但是当命名形参都存在默认值时,不需要给出命名实参也可以调用该函数,函数仅需要传入非命名形参,那么这种函数是可以同流运算符一起使用的,例如:
func f(a: Int64, b!: Int64 = 2): Unit {}
var a = 1 |> f // ok
当然,如果想要在调用f时,为参数 b 传入其他参数,那么也需要借助 lambda 表达式:
func f(a: Int64, b!: Int64 = 2): Unit {}
var a = 1 |> {x: Int64 => f(x, b: 3)} // ok
变长参数
变长参数是一种特殊的函数调用语法糖。当形参最后一个非命名参数是 Array 类型时,实参中对应位置可以直接传入参数序列代替 Array 字面量(参数个数可以是 0 个或多个)。示例如下:
func sum(arr: Array<Int64>) {
var total = 0
for (x in arr) {
total += x
}
return total
}
main() {
println(sum())
println(sum(1, 2, 3))
}
程序输出:
0
6
需要注意,只有最后一个非命名参数可以作为变长参数,命名参数不能使用这个语法糖。
func length(arr!: Array<Int64>) {
return arr.size
}
main() {
println(length()) // error: expected 1 argument, found 0
println(length(1, 2, 3)) // error: expected 1 argument, found 3
}
变长参数可以出现在全局函数、静态成员函数、实例成员函数、局部函数、构造函数、函数变量、lambda、函数调用操作符重载、索引操作符重载的调用处。不支持其他操作符重载、compose、pipeline 这几种调用方式。示例如下:
class Counter {
var total = 0
init(data: Array<Int64>) { total = data.size }
operator func ()(data: Array<Int64>) { total += data.size }
}
main() {
let counter = Counter(1, 2)
println(counter.total)
counter(3, 4, 5)
println(counter.total)
}
程序输出:
2
5
函数重载决议总是会优先考虑不使用变长参数就能匹配的函数,只有在所有函数都不能匹配,才尝试使用变长参数解析。示例如下:
func f<T>(x: T) where T <: ToString {
println("item: ${x}")
}
func f(arr: Array<Int64>) {
println("array: ${arr}")
}
main() {
f()
f(1)
f(1, 2)
}
程序输出:
array: []
item: 1
array: [1, 2]
当编译器无法决议时会报错:
func f(arr: Array<Int64>) { arr.size }
func f(first: Int64, arr: Array<Int64>) { first + arr.size }
main() {
println(f(1, 2, 3)) // error
}
函数重载
函数重载定义
在仓颉编程语言中,如果一个作用域中,一个函数名对应多个函数定义,这种现象称为函数重载。
- 函数名相同,函数参数不同(是指参数个数不同,或者参数个数相同但参数类型不同)的两个函数构成重载。示例如下:
// Scenario 1
func f(a: Int64): Unit {
}
func f(a: Float64): Unit {
}
func f(a: Int64, b: Float64): Unit {
}
- 对于两个同名泛型函数,如果重命名一个函数的泛型形参后,其非泛型部分与另一个函数的非泛型部分函数参数不同,则两个函数构成重载,否则这两个泛型函数构成重复定义错误(类型变元的约束不参与判断)。示例如下:
interface I1{}
interface I2{}
func f1<X, Y>(a: X, b: Y) {}
func f1<Y, X>(a: X, b: Y) {} // Ok: after rename generic type parameter, it will be 'func f1<X, Y>(a: Y, b: X)'
func f2<T>(a: T) where T <: I1 {}
func f2<T>(a: T) where T <: I2 {} // Error: not overloading
- 同一个类内的两个构造函数参数不同,构成重载。示例如下:
// Scenario 2
class C {
var a: Int64
var b: Float64
public init(a: Int64, b: Float64) {
this.a = a
this.b = b
}
public init(a: Int64) {
b = 0.0
this.a = a
}
}
- 同一个类内的主构造函数和
init构造函数参数不同,构成重载(认为主构造函数和init函数具有相同的名字)。示例如下:
// Scenario 3
class C {
C(var a!: Int64, var b!: Float64) {
this.a = a
this.b = b
}
public init(a: Int64) {
b = 0.0
this.a = a
}
}
- 两个函数定义在不同的作用域,在两个函数可见的作用域中构成重载。示例如下:
// Scenario 4
func f(a: Int64): Unit {
}
func g() {
func f(a: Float64): Unit {
}
}
- 两个函数分别定义在父类和子类中,在两个函数可见的作用域中构成重载。示例如下:
// Scenario 5
open class Base {
public func f(a: Int64): Unit {
}
}
class Sub <: Base {
public func f(a: Float64): Unit {
}
}
只允许函数声明引入的函数重载,但是以下情形不构成重载,不构成重载的两个名字不能定义或声明在同一个作用域内:
- class、interface、struct 类型的静态成员函数和实例成员函数之间不能重载
- enum 类型的 constructor、静态成员函数和实例成员函数之间不能重载
如下示例,两个变量均为函数类型且函数参数类型不同,但由于它们不是函数声明所以不能重载,如下示例将编译报错(重定义错):
main() {
var f: (Int64) -> Unit
var f: (Float64) -> Unit
}
如下示例,虽然变量 f 为函数类型,但由于变量和函数之间不能同名,如下示例将编译报错(重定义错):
main() {
var f: (Int64) -> Unit
func f(a: Float64): Unit { // Error: functions and variables cannot have the same name.
}
}
如下示例,静态成员函数 f 与实例成员函数 f 的参数类型不同,但由于类内静态成员函数和实例成员函数之间不能重载,如下示例将编译报错:
class C {
public static func f(a: Int64): Unit {
}
public func f(a: Float64): Unit {
}
}
函数重载决议
函数调用时,所有可被调用的函数(是指当前作用域可见且能通过类型检查的函数)构成候选集,候选集中有多个函数,究竟选择候选集中哪个函数,需要进行函数重载决议,有如下规则:
-
优先选择作用域级别高的作用域内的函数。在嵌套的表达式或函数中,越是内层作用域级别越高。
如下示例中在
inner函数体内调用g(Sub())时,候选集包括inner函数内定义的函数g和inner函数外定义的函数g,函数决议选择作用域级别更高的inner函数内定义的函数g。open class Base {} class Sub <: Base {} func outer() { func g(a: Sub) { print("1") } func inner() { func g(a: Base) { print("2") } g(Sub()) // Output: 2 } } -
如果作用域级别相对最高的仍有多个函数,则需要选择最匹配的函数(对于函数 f 和 g 以及给定的实参,如果 f 可以被调用时 g 也总是可以被调用的,但反之不然,则我们称 f 比 g 更匹配)。如果不存在唯一最匹配的函数,则报错。
如下示例中,两个函数
g定义在同一作用域,选择更匹配的函数g(a: Sub): Unit。open class Base {} class Sub <: Base {} func outer() { func g(a: Sub) { print("1") } func g(a: Base) { print("2") } g(Sub()) // Output: 1 } -
子类和父类认为是同一作用域。如下示例中,一个函数
g定义在父类中,另一个函数g定义在子类中,在调用s.g(Sub())时,两个函数g当成同一作用域级别决议,则选择更匹配的父类中定义的函数g(a: Sub): Unit。open class Base { public func g(a: Sub) { print("1") } } class Sub <: Base { public func g(a: Base) { print("2") } } func outer() { let s: Sub = Sub() s.g(Sub()) // Output: 1 }
操作符重载
如果希望在某个类型上支持此类型默认不支持的操作符,可以使用操作符重载实现。
如果需要在某个类型上重载某个操作符,可以通过为类型定义一个函数名为此操作符的函数的方式实现,这样,在该类型的实例使用该操作符时,就会自动调用此操作符函数。
操作符函数定义与普通函数定义相似,区别如下:
- 定义操作符函数时需要在
func关键字前面添加operator修饰符; - 操作符函数的参数个数需要匹配对应操作符的要求(详见附录[操作符]);
- 操作符函数只能定义在 class、interface、struct、enum 和 extend 中;
- 操作符函数具有实例成员函数的语义,所以禁止使用
static修饰符; - 操作符函数不能为泛型函数。
另外,需要注意:
- 被重载后的操作符不改变它们固有的优先级和结合性(详见附录[操作符])。
操作符重载函数定义和使用
定义操作符函数有两种方式:
- 对于可以直接包含函数定义的类型 (包括
struct、enum、class和interface),可以直接在其内部定义操作符函数的方式实现操作符的重载。 - 使用
extend的方式为其添加操作符函数,从而实现操作符在这些类型上的重载。对于无法直接包含函数定义的类型(是指除struct、class、enum和interface之外其他的类型)或无法改变其实现的类型,比如第三方定义的struct、class、enum和interface,只能采用这种方式(参见[扩展的定义]);
操作符函数对参数类型的约定如下:
-
对于一元操作符,操作符函数没有参数,对返回值的类型没有要求。
-
对于二元操作符,操作符函数只有一个参数,对返回值的类型没有要求。
如下示例中介绍了一元操作符和二元操作符的定义和使用:
-实现对一个Point实例中两个成员变量x和y取负值,然后返回一个新的Point对象,+实现对两个Point实例中两个成员变量x和y分别求和,然后返回一个新的Point对象。open class Point { var x: Int64 = 0 var y: Int64 = 0 public init (a: Int64, b: Int64) { x = a y = b } public operator func -(): Point { Point(-x, -y) } public operator func +(right: Point): Point { Point(this.x + right.x, this.y + right.y) } }接下来,就可以在
Point的实例上直接使用一元-操作符和二元+操作符:main() { let p1 = Point(8, 24) let p2 = -p1 // p2 = Point(-8, -24) let p3 = p1 + p2 // p3 = Point(0, 0) } -
索引操作符(
[])分为取值let a = arr[i]和赋值arr[i] = a两种形式,它们通过是否存在特殊的命名参数 value 来区分不同的重载。索引操作符重载不要求同时重载两种形式,可以只重载赋值不重载取值,反之亦可。索引操作符取值形式
[]内的参数序列对应操作符重载的非命名参数,可以是 1 个或多个,可以是任意类型。不可以有其它命名参数。返回类型可以是任意类型。class A { operator func [](arg1: Int64, arg2: String): Int64 { return 0 } } func f() { let a = A() let b: Int64 = a[1, "2"] // b == 0 }索引操作符赋值形式
[]内的参数序列对应操作符重载的非命名参数,可以是 1 个或多个,可以是任意类型。=右侧的表达式对应操作符重载的命名参数,有且只能有一个命名参数,该命名参数的名称必须是 value, 不能有默认值,value 可以是任意类型。返回类型必须是 Unit 类型。需要注意的是,value 只是一种特殊的标记,在索引操作符赋值时并不需要使用命名参数的形式调用。
class A { operator func [](arg1: Int64, arg2: String, value!: Int64): Unit { return } } func f() { let a = A() a[1, "2"] = 0 }特别的,除
enum外的不可变类型不支持重载索引操作符赋值形式。 -
函数调用操作符(
())重载函数,输入参数和返回值类型可以是任意类型。示例如下:open class A { public init() {} public operator func ()(): Unit {} } func test1() { let a = A() // ok, A() is call the constructor of A. a() // ok, a() is to call the operator () overloading function. }不能使用
this或super调用()操作符重载函数。示例如下:open class A { public init() {} public init(x: Int64) { this() // ok, this() calls the constructor of A. } public operator func ()(): Unit {} public func foo() { this() // error, this() calls the constructor of A. super() // error } } class B <: A { public init() { super() // ok, super() calls the constuctor of the super class. } public func goo() { super() // error } }对于枚举类型,当构造器形式和
()操作符重载函数形式都满足时,优先匹配构造器形式。示例如下:enum E { Y | X | X(Int64) public operator func ()(p: Int64) {} public operator func ()(p: Float64) {} } main() { let e = X(1) // ok, X(1) is to call the constructor X(Int64). X(1.0) // ok, X(1.0) is to call the operator () overloading function. let e1 = X e1(1) // ok, e1(1) is to call the operator () overloading function. Y(1) // oK, Y(1) is to call the operator () overloading function. }
可以被重载的操作符
下表列出了所有可以被重载的操作符(优先级从高到低):
| Operator | Description |
|---|---|
() | Function call |
[] | Indexing |
! | NOT |
- | Negative |
** | Power |
* | Multiply |
/ | Divide |
% | Remainder |
+ | Add |
- | Subtract |
<< | Bitwise left shift |
>> | Bitwise right shift |
< | Less than |
<= | Less than or equal |
> | Greater than |
>= | Greater than or equal |
== | Equal |
!= | Not equal |
& | Bitwise AND |
^ | Bitwise XOR |
| | Bitwise OR |
需要注意的是:
- 一旦在某个类型上重载了除关系操作符(
<、<=、>、>=、==和!=)之外的其他二元操作符,并且操作符函数的返回类型与左操作数的类型一致或是其子类型,那么此类型支持对应的复合赋值操作符。当操作符函数的返回类型与左操作数的类型不一致且不是其子类型时,在使用对应的复合赋值符号时将报类型不匹配错误; - 仓颉编程语言不支持自定义操作符,即不允许定义除上表中所列
operator之外的其他操作符函数。 - 对于类型
T, 如果T已经默认支持了上述若干可重载操作符,那么通过扩展的方式再次为其实现同签名的操作符函数时将报重定义错误。例如,为数值类型重载其已支持的同签名算术操作符、位操作符或关系操作符等操作符时,为Char重载同签名的关系操作符时,为Bool类型重载同签名的逻辑操作符、判等或不等操作符时,等等这些情况,均会报重定义错。
Mut 函数
Struct 类型是值类型,其实例成员函数无法修改实例本身。例如,下例中,成员函数 g 中不能修改成员变量 i 的值。
struct Foo {
var i = 0
public func g() {
i += 1 // Error: the value of a instance member variable cannot be modified in an instance member function
}
}
Mut 函数是一种可以修改 struct 实例本身的特殊的实例成员函数。在 mut 函数内部,this 的语义是特殊的,这种 this 拥有原地修改字段的能力。
只允许在 interface、struct 和 struct 的扩展内定义 mut 函数(class 是引用类型,实例成员函数不需要加 mut 也可以修改实例成员变量,所以禁止在 class 中定义 mut 函数)。
Mut 函数定义
Mut 函数与普通的实例成员函数相比,多一个 mut 关键字来修饰。
例如,下例中在函数 g 之前增加 mut 修饰符之后,即可在函数体内修改成员变量 i 的值。
struct Foo {
var i = 0
public mut func g() {
i += 1 // ok
}
}
mut 只能修饰实例成员函数,不能修饰静态成员函数。
struct A {
public mut func f(): Unit {} // ok
public mut operator func +(rhs: A): A { // ok
A()
}
public mut static func g(): Unit {} // Error: static member functions cannot be modified with 'mut'
}
Mut 函数中的 this 不能被捕获,也不能作为表达式。不能在 mut 函数中对 struct 的实例成员变量进行捕获。
示例:
struct Foo {
var i = 0
public mut func f(): Foo {
let f1 = { => this } // Error: 'this' in mut functions cannot be captured
let f2 = { => this.i = 2 } // Error: instance member variables in mut functions cannot be captured
let f3 = { => this.i } // Error: instance member variables in mut functions cannot be captured
let f4 = { => i } // Error: instance member variables in mut functions cannot be captured
this // Error: 'this' in mut functions cannot be used as expressions
}
}
接口中的 mut 函数
接口中的实例成员函数,也可以使用 mut 修饰。
struct 类型在实现 interface 的函数时必须保持一样的 mut 修饰。struct 以外的类型实现 interface 的函数时不能使用 mut 修饰。
示例:
interface I {
mut func f1(): Unit
func f2(): Unit
}
struct A <: I {
public mut func f1(): Unit {} // Ok: as in the interface, the 'mut' modifier is used
public func f2(): Unit {} // Ok: as in the interface, the 'mut' modifier is not used
}
struct B <: I {
public func f1(): Unit {} // Error: 'f1' is modified with 'mut' in interface, but not in struct
public mut func f2(): Unit {} // Error: 'f2' is not modified with 'mut' in interface, but did in struct
}
class C <: I {
public func f1(): Unit {} // ok
public func f2(): Unit {} // ok
}
当 struct 的实例赋值给 interface 类型时是拷贝语义,因此 interface 的 mut 函数并不能修改 struct 实例的值。
示例:
interface I {
mut func f(): Unit
}
struct Foo <: I {
public var v = 0
public mut func f(): Unit {
v += 1
}
}
main() {
var a = Foo()
var b: I = a
b.f() // Calling 'f' via 'b' cannot modify the value of 'a'
println(a.v) // 0
}
程序输出结果为:
0
Mut 函数的使用限制
因为 struct 是值类型,所以如果一个变量是 struct 类型且使用 let 声明,那么不能通过这个变量访问该类型的 mut 函数。
示例:
interface I {
mut func f(): Unit
}
struct Foo <: I {
public var i = 0
public mut func f(): Unit {
i += 1
}
}
main() {
let a = Foo()
a.f() // Error: 'a' is of type struct and is declared with 'let', the 'mut' function cannot be accessed via 'a'
var b = Foo()
b.f() // ok
let c: I = Foo()
c.f() // ok
}
为避免逃逸,如果一个变量的类型是 struct 类型,那么这个变量不能将该类型使用 mut 修饰的函数作为一等公民来使用,只能调用这些 mut 函数。
示例:
interface I {
mut func f(): Unit
}
struct Foo <: I {
var i = 0
public mut func f(): Unit {
i += 1
}
}
main() {
var a = Foo()
var fn = a.f // Error: mut function 'f' of 'a' cannot be used as a first class citizen.
var b: I = Foo()
fn = b.f // ok
}
为避免逃逸,非 mut 的实例成员函数(包括 lambda 表达式)不能直接访问所在类型的 mut 函数,反之可以。
示例:
struct Foo {
var i = 0
public mut func f(): Unit {
i += 1
g() // ok
}
public func g(): Unit {
f() // Error: mut functions cannot be invoked in non-mut functions
}
}
interface I {
mut func f(): Unit {
g() // ok
}
func g(): Unit {
f() // Error: mut functions cannot be invoked in non-mut functions
}
}
模式匹配
本章主要介绍仓颉中的模式匹配(pattern matching),首先介绍 match 表达式和模式,然后介绍模式的 refutability(即某个模式是否一定能匹配成功),最后介绍模式匹配在 match 表达式之外的使用。
match 表达式
仓颉支持两种 match 表达式,第一种是包含待匹配值的 match 表达式,第二种是不含待匹配值的 match 表达式。
含匹配值的 match 表达式举例:
main() {
let x = 0
match (x) {
case 1 => let r1 = "x = 1"
print(r1)
case 0 => let r2 = "x = 0" // Matched.
print(r2)
case _ => let r3 = "x != 1 and x != 0"
print(r3)
}
}
match 表达式以关键字 match 开头,后跟要匹配的值(如上例中的 x,x 可以是任意表达式),接着是定义在一对花括号内的若干 case 分支。
每个 case 分支以关键字 case 开头,case 之后是一个模式或多个由 | 连接的相同种类的模式(如上例中的 1、0、_ 都是模式,详见模式章节);模式之后可以接一个可选的 pattern guard,表示本条 case 匹配成功后额外需要满足的条件;接着是一个 =>,=> 之后即本条 case 分支匹配成功后需要执行的操作,可以是一系列表达式、变量和函数定义(新定义的变量或函数的作用域从其定义处开始到下一个 case 之前结束),如上例中的变量定义和 print 函数调用。
match 表达式执行时依次将 match 之后的表达式与每个 case 中的模式进行匹配,一旦匹配成功(如果有 pattern guard,也需要 where 之后的表达式的值为 true;如果 case 中有多个由 | 连接的模式,只要待匹配值和其中一个模式匹配则认为匹配成功)则执行 => 之后的代码然后退出 match 表达式的执行(意味着不会再去匹配它之后的 case),如果匹配不成功则继续与它之后的 case 中的模式进行匹配,直到匹配成功(match 表达式可以保证一定存在匹配的 case 分支)。
上例中,因为 x 的值等于 0,所以会和第二条 case 分支匹配(此处使用的是常量模式,匹配的是值是否相等,详见常量模式章节),最后输出 x = 0。
编译并执行上述代码,输出结果为:
x = 0
match 表达式要求所有匹配必须是穷尽(exhaustive)的,意味着待匹配表达式的所有可能取值都应该被考虑到。当 match 表达式非穷尽,或者编译器判断不出是否穷尽时,均会编译报错,换言之,所有 case 分支(包含 pattern guard)所覆盖的取值范围的并集,应该包含待匹配表达式的所有可能取值。常用的确保 match 表达式穷尽的方式是在最后一个 case 分支中使用通配符模式 _,因为 _ 可以匹配任何值。
match 表达式的穷尽性保证了一定存在和待匹配值相匹配的 case 分支。下面的例子将编译报错,因为所有的 case 并没有覆盖 x 的所有可能取值:
func nonExhaustive(x: Int64) {
match (x) {
case 0 => print("x = 0")
case 1 => print("x = 1")
case 2 => print("x = 2")
}
}
在 case 分支的模式之后,可以使用 pattern guard 进一步对匹配出来的结果进行判断。pattern guard 使用 where cond 表示,要求表达式 cond 的类型为 Bool。
在下面的例子中(使用到了 enum 模式,详见 Enum 模式章节),当 RGBColor 的构造器的参数值大于等于 0 时,输出它们的值,当参数值小于 0 时,认为它们的值等于 0:
enum RGBColor {
| Red(Int16) | Green(Int16) | Blue(Int16)
}
main() {
let c = RGBColor.Green(-100)
let cs = match (c) {
case Red(r) where r < 0 => "Red = 0"
case Red(r) => "Red = ${r}"
case Green(g) where g < 0 => "Green = 0" // Matched.
case Green(g) => "Green = ${g}"
case Blue(b) where b < 0 => "Blue = 0"
case Blue(b) => "Blue = ${b}"
}
print(cs)
}
编译执行上述代码,输出结果为:
Green = 0
没有匹配值的 match 表达式举例:
main() {
let x = -1
match {
case x > 0 => print("x > 0")
case x < 0 => print("x < 0") // Matched.
case _ => print("x = 0")
}
}
与包含待匹配值的 match 表达式相比,关键字 match 之后并没有待匹配的表达式,并且 case 之后不再是 pattern,而是类型为 Bool 的表达式(上述代码中的 x > 0 和 x < 0)或者 _(表示 true),当然,case 中也不再有 pattern guard。
无匹配值的 match 表达式执行时依次判断 case 之后的表达式的值,直到遇到值为 true 的 case 分支;一旦某个 case 之后的表达式值等于 true,则执行此 case 中 => 之后的代码,然后退出 match 表达式的执行(意味着不会再去判断该 case 之后的其他 case)。
上例中,因为 x 的值等于 -1,所以第二条 case 分支中的表达式(即 x < 0)的值等于 true,执行 print("x < 0")。
编译并执行上述代码,输出结果为:
x < 0
match 表达式的类型
对于 match 表达式(无论是否有匹配值),
-
在上下文有明确的类型要求时,要求每个
case分支中=>之后的代码块的类型是上下文所要求的类型的子类型; -
在上下文没有明确的类型要求时,
match表达式的类型是每个case分支中=>之后的代码块的类型的最小公共父类型。 -
当
match表达式的值没有被使用时,其类型为Unit,不要求各分支的类型有最小公共父类型。
下面分别举例说明。
let x = 2
let s: String = match (x) {
case 0 => "x = 0"
case 1 => "x = 1"
case _ => "x != 0 and x != 1" // Matched.
}
上面的例子中,定义变量 s 时,显式地标注了其类型为 String,属于上下文类型信息明确的情况,因此要求每个 case 的 => 之后的代码块的类型均是 String 的子类型,显然上例中 => 之后的字符串类型的字面量均满足要求。
再来看一个没有上下文类型信息的例子:
let x = 2
let s = match (x) {
case 0 => "x = 0"
case 1 => "x = 1"
case _ => "x != 0 and x != 1" // Matched.
}
上例中,定义变量 s 时,未显式标注其类型,因为每个 case 的 => 之后的代码块的类型均是 String,所以 match 表达式的类型是 String,进而可确定 s 的类型也是 String。
模式
对于包含匹配值的 match 表达式,case 之后支持哪些模式决定了 match 表达式的表达能力,本节中我们将依次介绍仓颉支持的模式,包括:常量模式、通配符模式、绑定模式、tuple 模式、类型模式和 enum 模式。
常量模式
常量模式可以是整数字面量、浮点数字面量、字符字面量、布尔字面量、字符串字面量(不支持字符串插值)、Unit 字面量。
在包含匹配值的 match 表达式中使用常量模式时,要求常量模式表示的值的类型与待匹配值的类型相同,匹配成功的条件是待匹配的值与常量模式表示的值相等。
下面的例子中,根据 score 的值(假设 score 只能取 0 到 100 间被 10 整除的值),输出考试成绩的等级:
main() {
let score = 90
let level = match (score) {
case 0 | 10 | 20 | 30 | 40 | 50 => "D"
case 60 => "C"
case 70 | 80 => "B"
case 90 | 100 => "A" // Matched.
case _ => "Not a valid score"
}
println(level)
}
编译执行上述代码,输出结果为:
A
通配符模式
通配符模式使用下划线 _ 表示,可以匹配任意值。通配符模式通常作为最后一个 case 中的模式,用来匹配其他 case 未覆盖到的情况,如上节中匹配 score 值的示例中,最后一个 case 中使用 _ 来匹配无效的 score 值。
绑定模式
绑定模式使用 id 表示,id 是一个合法的标识符。与通配符模式相比,绑定模式同样可以匹配任意值,但绑定模式会将匹配到的值与 id 进行绑定,在 => 之后可以通过 id 访问其绑定的值。
下面的例子中,最后一个 case 中使用了绑定模式,用于绑定非 0 值:
main() {
let x = -10
let y = match (x) {
case 0 => "zero"
case n => "x is not zero and x = ${n}" // Matched.
}
println(y)
}
编译执行上述代码,输出结果为:
x is not zero and x = -10
使用 | 连接多个模式时不能使用绑定模式,也不可嵌套出现在其它模式中,否则会报错:
main() {
let opt = Some(0)
match (opt) {
case x | x => {} // Error: variable cannot be introduced in patterns connected by '|'
case Some(x) | Some(x) => {} // Error: variable cannot be introduced in patterns connected by '|'
case x: Int64 | x: String => {} // Error: variable cannot be introduced in patterns connected by '|'
}
}
绑定模式 id 相当于新定义了一个名为 id 的不可变变量(其作用域从引入处开始到该 case 结尾处),因此在 => 之后无法对 id 进行修改。例如,下例中最后一个 case 中对 n 的修改是不允许的。
main() {
let x = -10
let y = match (x) {
case 0 => "zero"
case n => n = n + 0 // Error: 'n' cannot be modified.
"x is not zero"
}
println(y)
}
对于每个 case 分支,=> 之后变量作用域级别与 case 后 => 前引入的变量作用域级别相同,在 => 之后再次引入相同名字会触发重定义错。例如:
main() {
let x = -10
let y = match (x) {
case 0 => "zero"
case n => let n = 0 // Error, redefinition
println(n)
"x is not zero"
}
println(y)
}
注:当模式的 identifier 为 enum 构造器时,该模式会被当成 enum 模式进行匹配,而不是绑定模式(关于 enum 模式,详见 Enum 模式章节)。
enum RGBColor {
| Red | Green | Blue
}
main() {
let x = Red
let y = match (x) {
case Red => "red" // The 'Red' is enum mode here.
case _ => "not red"
}
println(y)
}
编译执行上述代码,输出结果为:
red
Tuple 模式
Tuple 模式用于 tuple 值的匹配,它的定义和 tuple 字面量类似:(p_1, p_2, ..., p_n),区别在于这里的 p_1 到 p_n(n 大于等于 2)是模式(可以是模式章节中介绍的任何模式,多个模式间使用逗号分隔)而不是表达式。
例如,(1, 2, 3) 是一个包含三个常量模式的 tuple 模式,(x, y, _) 是一个包含两个绑定模式,一个通配符模式的 tuple 模式。
给定一个 tuple 值 tv 和一个 tuple 模式 tp,当且仅当 tv 每个位置处的值均能与 tp 中对应位置处的模式相匹配,才称 tp 能匹配 tv。例如,(1, 2, 3) 仅可以匹配 tuple 值 (1, 2, 3),(x, y, _) 可以匹配任何三元 tuple 值。
下面的例子中,展示了 tuple 模式的使用:
main() {
let tv = ("Alice", 24)
let s = match (tv) {
case ("Bob", age) => "Bob is ${age} years old"
case ("Alice", age) => "Alice is ${age} years old" // Matched, "Alice" is a constant pattern, and 'age' is a variable pattern.
case (name, 100) => "${name} is 100 years old"
case (_, _) => "someone"
}
println(s)
}
编译执行上述代码,输出结果为:
Alice is 24 years old
同一个 tuple 模式中不允许引入多个名字相同的绑定模式。例如,下例中最后一个 case 中的 case (x, x) 是不合法的。
main() {
let tv = ("Alice", 24)
let s = match (tv) {
case ("Bob", age) => "Bob is ${age} years old"
case ("Alice", age) => "Alice is ${age} years old"
case (name, 100) => "${name} is 100 years old"
case (x, x) => "someone" // Error: Cannot introduce a variable pattern with the same name, which will be a redefinition error.
}
println(s)
}
类型模式
类型模式用于判断一个值的运行时类型是否是某个类型的子类型。类型模式有两种形式:_: Type(嵌套一个通配符模式 _)和 id: Type(嵌套一个绑定模式 id),它们的差别是后者会发生变量绑定,而前者并不会。
对于待匹配值 v 和类型模式 id: Type(或 _: Type),首先判断 v 的运行时类型是否是 Type 的子类型,若成立则视为匹配成功,否则视为匹配失败;如匹配成功,则将 v 的类型转换为 Type 并与 id 进行绑定(对于 _: Type,不存在绑定这一操作)。
假设有如下两个类,Base 和 Derived,并且 Derived 是 Base 的子类,Base 的无参构造函数中将 a 的值设置为 10,Derived 的无参构造函数中将 a 的值设置为 20:
open class Base {
var a: Int64
public init() {
a = 10
}
}
class Derived <: Base {
public init() {
a = 20
}
}
下面的代码展示了使用类型模式并匹配成功的例子:
main() {
var d = Derived()
var r = match (d) {
case b: Base => b.a // Matched.
case _ => 0
}
println("r = ${r}")
}
编译执行上述代码,输出结果为:
r = 20
下面的代码展示了使用类型模式但类型模式匹配失败的例子:
open class Base {
var a: Int64
public init() {
a = 10
}
}
class Derived <: Base {
public init() {
a = 20
}
}
main() {
var b = Base()
var r = match (b) {
case d: Derived => d.a // Type pattern match failed.
case _ => 0 // Matched.
}
println("r = ${r}")
}
编译执行上述代码,输出结果为:
r = 0
Enum 模式
Enum 模式用于匹配 enum 类型的实例,它的定义和 enum 的构造器类似:无参构造器 C 或有参构造器 C(p_1, p_2, ..., p_n),构造器的类型前缀可以省略,区别在于这里的 p_1 到 p_n(n 大于等于 1)是模式。例如,Some(1) 是一个包含一个常量模式的 enum 模式,Some(x) 是一个包含一个绑定模式的 enum 模式。
给定一个 enum 实例 ev 和一个 enum 模式 ep,当且仅当 ev 的构造器名字和 ep 的构造器名字相同,且 ev 参数列表中每个位置处的值均能与 ep 中对应位置处的模式相匹配,才称 ep 能匹配 ev。例如,Some("one") 仅可以匹配 Option<String> 类型的Some 构造器 Option<String>.Some("one"),Some(x) 可以匹配任何 Option 类型的 Some 构造器。
下面的例子中,展示了 enum 模式的使用,因为 x 的构造器是 Year,所以会和第一个 case 匹配:
enum TimeUnit {
| Year(UInt64)
| Month(UInt64)
}
main() {
let x = Year(2)
let s = match (x) {
case Year(n) => "x has ${n * 12} months" // Matched.
case TimeUnit.Month(n) => "x has ${n} months"
}
println(s)
}
编译执行上述代码,输出结果为:
x has 24 months
使用 | 连接多个 enum 模式:
enum TimeUnit {
| Year(UInt64)
| Month(UInt64)
}
main() {
let x = Year(2)
let s = match (x) {
case Year(0) | Year(1) | Month(_) => "ok" // Ok
case Year(2) | Month(m) => "invalid" // Error: Variable cannot be introduced in patterns connected by '|'
case Year(n: UInt64) | Month(n: UInt64) => "invalid" // Error: Variable cannot be introduced in patterns connected by '|'
}
println(s)
}
使用 match 表达式匹配 enum 值时,要求 case 之后的模式要覆盖待匹配 enum 类型中的所有构造器,如果未做到完全覆盖,编译器将报错:
enum RGBColor {
| Red | Green | Blue
}
main() {
let c = Green
let cs = match (c) { // Error: Not all constructors of RGBColor are covered.
case Red => "Red"
case Green => "Green"
}
println(cs)
}
我们可以通过加上 case Blue 来实现完全覆盖,也可以在 match 表达式的最后通过使用 case _ 来覆盖其他 case 未覆盖的到的情况,如:
enum RGBColor {
| Red | Green | Blue
}
main() {
let c = Blue
let cs = match (c) {
case Red => "Red"
case Green => "Green"
case _ => "Other" // Matched.
}
println(cs)
}
上述代码的执行结果为:
Other
模式的嵌套组合
Tuple 模式和 enum 模式可以嵌套任意模式。下面的代码展示了不同模式嵌套组合使用:
enum TimeUnit {
| Year(UInt64)
| Month(UInt64)
}
enum Command {
| SetTimeUnit(TimeUnit)
| GetTimeUnit
| Quit
}
main() {
let command = SetTimeUnit(Year(2022))
match (command) {
case SetTimeUnit(Year(year)) => println("Set year ${year}")
case SetTimeUnit(Month(month)) => println("Set month ${month}")
case _ => ()
}
}
编译执行上述代码,输出结果为:
Set year 2022
模式的 Refutability
模式可以分为两类:refutable 模式和 irrefutable 模式。在类型匹配的前提下,当一个模式有可能和待匹配值不匹配时,称此模式为 refutable 模式;反之,当一个模式总是可以和待匹配值匹配时,称此模式为 irrefutable 模式。
对于上述介绍的各种模式,规定如下:
常量模式是 refutable 模式。例如,下例中第一个 case 中的 1 和第二个 case 中的 2 都有可能和 x 的值不相等。
func constPat(x: Int64) {
match (x) {
case 1 => "one"
case 2 => "two"
case _ => "_"
}
}
通配符模式是 irrefutable 模式。例如,下例中无论 x 的值是多少,_ 总能和其匹配。
func wildcardPat(x: Int64) {
match (x) {
case _ => "_"
}
}
绑定模式是 irrefutable 模式。例如,下例中无论 x 的值是多少,绑定模式 a 总能和其匹配。
func varPat(x: Int64) {
match (x) {
case a => "x = ${a}"
}
}
Tuple 模式是 irrefutable 模式,当且仅当其包含的每个模式都是 irrefutable 模式。例如,下例中 (1, 2) 和 (a, 2) 都有可能和 x 的值不匹配,所以它们是 refutable 模式,而 (a, b) 可以匹配任何 x 的值,所以它是 irrefutable 模式。
func tuplePat(x: (Int64, Int64)) {
match (x) {
case (1, 2) => "(1, 2)"
case (a, 2) => "(${a}, 2)"
case (a, b) => "(${a}, ${b})"
}
}
类型模式是 refutable 模式。例如,下例中(假设 Base 是 Derived 的父类,并且 Base 实现了接口 I),x 的运行时类型有可能既不是 Base 也不是 Derived,所以 a: Derived 和 b: Base 均是 refutable 模式。
interface I {}
open class Base <: I {}
class Derived <: Base {}
func typePat(x: I) {
match (x) {
case a: Derived => "Derived"
case b: Base => "Base"
case _ => "Other"
}
}
Enum 模式是 irrefutable 模式,当且仅当它对应的 enum 类型中只有一个有参构造器,且 enum 模式中包含的其他模式也是 irrefutable 模式。例如,对于下例中的 E1 和 E2 定义,函数 enumPat1 中的 A(1) 是 refutable 模式,A(a) 是 irrefutable 模式;而函数 enumPat2 中的 B(b) 和 C(c) 均是 refutable 模式。
enum E1 {
A(Int64)
}
enum E2 {
B(Int64) | C(Int64)
}
func enumPat1(x: E1) {
match (x) {
case A(1) => "A(1)"
case A(a) => "A(${a})"
}
}
func enumPat2(x: E2) {
match (x) {
case B(b) => "B(${b})"
case C(c) => "C(${c})"
}
}
if-let 与 while-let 表达式
在一些应用场景中,我们只关注一个表达式是否为某种特定模式,是则将其解构,取出对应值做相关操作。虽然可以用 match 表达式实现这一逻辑,但书写上可能比较冗长,为此,仓颉提供了更便捷的表达方式——允许在 if 表达式和 while 表达式的条件部分,使用 let 修饰符匹配和解构模式,这时它们被称为 if-let 表达式和 while-let 表达式。
在条件部分使用 let 匹配模式的形式为:
let 模式 <- 表达式
这里的“模式”可以是常量模式、通配符模式、绑定模式、Tuple 模式和 enum 模式,如果模式中含有占位标识符,则此处等同于定义了一个不可变变量(这正是使用 let 表达此语义的原因),如果模式被匹配,这个变量就会与解构后的值绑定,可以作为 if 分支或 while 循环体中的局部变量使用。
if-let 表达式
if-let 表达式首先对条件中 let 等号右侧的表达式进行求值,如果此值能匹配 let 等号左侧的模式,则执行 if 分支,否则执行 else 分支(可省略)。例如:
main() {
let result = Option<Int64>.Some(2023)
if (let Some(value) <- result) {
println("操作成功,返回值为:${value}")
} else {
println("操作失败")
}
}
运行以上程序,将输出:
操作成功,返回值为:2023
对于以上程序,如果将 result 的初始值修改为 Option<Int64>.None,则 if-let 的模式匹配会失败,将执行 else 分支:
main() {
let result = Option<Int64>.None
if (let Some(value) <- result) {
println("操作成功,返回值为:${value}")
} else {
println("操作失败")
}
}
运行以上程序,将输出:
操作失败
while-let 表达式
while-let 表达式首先对条件中 let 等号右侧的表达式进行求值,如果此值能匹配 let 等号左侧的模式,则执行循环体,然后重复执行此过程。如果模式匹配失败,则结束循环,继续执行 while-let 表达式之后的代码。例如:
from std import random.*
// 此函数模拟在通信中接收数据,获取数据可能失败
func recv(): Option<UInt8> {
let number = Random().nextUInt8()
if (number < 128) {
return Some(number)
}
return None
}
main() {
// 模拟循环接收通信数据,如果失败就结束循环
while (let Some(data) <- recv()) {
println(data)
}
println("receive failed")
}
运行以上程序,可能的输出为:
73
94
receive failed
其他使用模式的地方
模式除了可以在 match 表达式中使用外,还可以使用在变量定义(等号左侧是个模式)和 for in 表达式(for 关键字和 in 关键字之间是个模式)中。
但是,并不是所有的模式都能使用在变量定义和 for in 表达式中,只有 irrefutable 的模式才能在这两处被使用,所以只有通配符模式、绑定模式、irrefutable tuple 模式和 irrefutable enum 模式是允许的。
-
变量定义和
for in表达式中使用通配符模式的例子如下:main() { let _ = 100 for (_ in 1..5) { println("0") } }上例中,变量定义时使用了通配符模式,表示定义了一个没有名字的变量(当然此后也就没办法对其进行访问),
for in表达式中使用了通配符模式,表示不会将1..5中的元素与某个变量绑定(当然循环体中就无法访问1..5中元素值)。编译执行上述代码,输出结果为:0 0 0 0 -
变量定义和
for in表达式中使用绑定模式的例子如下:main() { let x = 100 println("x = ${x}") for (i in 1..5) { println(i) } }上例中,变量定义中的
x以及for in表达式中的i都是绑定模式。编译执行上述代码,输出结果为:x = 100 1 2 3 4 -
变量定义和
for in表达式中使用irrefutabletuple 模式的例子如下:main() { let (x, y) = (100, 200) println("x = ${x}") println("y = ${y}") for ((i, j) in [(1, 2), (3, 4), (5, 6)]) { println("Sum = ${i + j}") } }上例中,变量定义时使用了 tuple 模式,表示对
(100, 200)进行解构并分别和x与y进行绑定,效果上相当于定义了两个变量x和y。for in表达式中使用了 tuple 模式,表示依次将[(1, 2), (3, 4), (5, 6)]中的 tuple 类型的元素取出,然后解构并分别和i与j进行绑定,循环体中输出i + j的值。编译执行上述代码,输出结果为:x = 100 y = 200 Sum = 3 Sum = 7 Sum = 11 -
变量定义和
for in表达式中使用irrefutableenum 模式的例子如下:enum RedColor { Red(Int64) } main() { let Red(red) = Red(0) println("red = ${red}") for (Red(r) in [Red(10), Red(20), Red(30)]) { println("r = ${r}") } }上例中,变量定义时使用了 enum 模式,表示对
Red(0)进行解构并将构造器的参数值(即0)与red进行绑定。for in表达式中使用了 enum 模式,表示依次将[Red(10), Red(20), Red(30)]中的元素取出,然后解构并将构造器的参数值与r进行绑定,循环体中输出r的值。编译执行上述代码,输出结果为:red = 0 r = 10 r = 20 r = 30
泛型
在仓颉编程语言中,泛型指的是参数化类型,参数化类型是一个在声明时未知并且需要在使用时指定的类型。类型声明与函数声明可以是泛型的。最为常见的例子就是 Array<T>、Set<T> 等容器类型。以数组类型为例,当使用数组类型 Array 时,会需要其中存放的是不同的类型,我们不可能定义所有类型的数组,通过在类型声明中声明类型形参,在应用数组时再指定其中的类型,这样就可以减少在代码上的重复。
术语
为了方便讨论我们先定义以下几个常用的术语:
- 类型形参:一个类型或者函数声明可能有一个或者多个需要在使用处被指定的类型,这些类型就被称为类型形参。在声明形参时,需要给定一个标识符,以便在声明体中引用。
- 类型变元:在声明类型形参后,当我们通过标识符来引用这些类型时,这些标识符被称为类型变元。
- 类型实参:当我们在使用泛型声明的类型或函数时指定了泛型参数,这些参数被称为类型实参。
- 类型构造器:一个需要零个、一个或者多个类型作为实参的类型称为类型构造器。
类型形参在声明时一般在类型名称的声明或者函数名称的声明后,使用尖括号 <...> 括起来。例如泛型列表可声明为:
class List<T> {
var elem: Option<T> = None
var tail: Option<List<T>> = None
}
func sumInt(a: List<Int64>) { }
其中 List<T> 中的 T 被称为类型形参。对于 elem: Option<T> 中对 T 的引用称为类型变元,同理 tail: Option<List<T>> 中的 T 也称为类型变元。函数 sumInt 的参数中 List<Int64> 的 Int64 被称为 List 的类型实参。 List 就是类型构造器,List<Int64> 通过 Int64 类型实参构造出了一个类型 Int64 的列表类型。
泛型接口
泛型可以用来定义泛型接口,以标准库中定义的 Iterable 为例,它需要返回一个 Iterator 类型,这一类型是一个容器的遍历器。 Iterator 是一个泛型接口,Iterator 内部有一个从容器类型中返回下一个元素的 next 成员函数,next 成员函数返回的类型是一个需要在使用时指定的类型,所以 Iterator 需要声明泛型参数。
public interface Iterable<E> {
func iterator(): Iterator<E>
}
public interface Iterator<E> <: Iterable<E> {
func next(): Option<E>
}
public interface Collection<T> <: Iterable<T> {
prop size: Int64
func isEmpty(): Bool
}
泛型类型
在仓颉编程语言中,class、struct 与 enum 的声明都可以声明类型形参,也就是说它们都可以是泛型的。
泛型 class
[泛型接口]中介绍了泛型接口的定义和使用,本节我们介绍泛型类的定义和使用。如 Map 的键值对就是使用泛型类来定义的:
可以看一下 Map 类型中的键值对 Node 类型就可以使用泛型类来定义:
public open class Node<K, V> where K <: Hashable & Equatable<K> {
public var key: Option<K> = Option<K>.None
public var value: Option<V> = Option<V>.None
public init() {}
public init(key: K, value: V) {
this.key = Option<K>.Some(key)
this.value = Option<V>.Some(value)
}
}
由于键与值的类型有可能不相同,且可以为任意满足条件的类型,所以 Node 需要两个类型形参 K 与 V ,K <: Hashable, K <: Equatable<K> 是对于键类型的约束,意为 K 要实现 Hashable 与 Equatable<K> 接口,也就是 K 需要满足的条件。对于泛型约束,详见泛型约束章节。
泛型 struct
struct 类型的泛型与 class 是类似的,下面我们可以使用 struct 定义一个类似于二元元组的类型:
struct Pair<T, U> {
let x: T
let y: U
public init(a: T, b: U) {
x = a
y = b
}
public func first(): T {
return x
}
public func second(): U {
return y
}
}
main() {
var a: Pair<String, Int64> = Pair<String, Int64>("hello", 0)
println(a.first())
println(a.second())
}
程序输出的结果为:
hello
0
在 Pair 中我们提供了 first 与 second 两个函数来取得元组的第一个与第二个元素。
泛型 enum
在仓颉编程语言中,泛型 enum 声明的类型里被使用得最广泛的例子之一就是 Option 类型了,关于 Option 详细描述可以详见 Option 类型章节。 Option 类型是用来表示在某一类型上的值可能是个空的值。这样,Option 就可以用来表示在某种类型上计算的失败。这里是何种类型上的失败是不确定的,所以很明显,Option 是一个泛型类型,需要声明类型形参。
package core // `Option` is defined in core.
public enum Option<T> {
Some(T)
| None
public func getOrThrow(): T {
match (this) {
case Some(v) => v
case None => throw NoneValueException()
}
}
...
}
可以看到,Option<T> 分成两种情况,一种是 Some(T),用来表示一个正常的返回结果,另一种是 None 用来表示一个空的结果。其中的 getOrThrow 函数会是将 Some(T) 内部的值返回出来的函数,返回的结果就是 T 类型,而如果参数是 None,那么直接抛出异常。
例如:如果我们想定义一个安全的除法,因为在除法上的计算是可能失败的。如果除数为 0,那么返回 None ,否则返回一个用 Some 包装过的结果:
func safeDiv(a: Int64, b: Int64): Option<Int64> {
var res: Option<Int64> = match (b) {
case 0 => None
case _ => Some(a/b)
}
return res
}
这样,在除数为 0 时,程序运行的过程中不会因除以 0 而抛出算术运算异常。
泛型类型的子类型关系
实例化后的泛型类型间也有子类型关系。例如当我们写出下列代码时,
interface I<X, Y> { }
class C<Z> <: I<Z, Z> { }
根据第 3 行,便知 C<Bool> <: I<Bool, Bool> 以及 C<D> <: I<D, D> 等。这里的第 3 行可以解读为“于所有的(不含类型变元的) Z 类型,都有 C<Z> <: I<Z, Z> 成立”。
但是对于下列代码
open class C { }
class D <: C { }
interface I<X> { }
I<D> <: I<C> 是不成立的(即使 D <: C 成立),这是因为在仓颉语言中,用户定义的类型构造器在其类型参数处是不型变的。
型变的具体定义为:如果 A 和 B 是(实例化后的)类型,T 是类型构造器,设有一个类型参数 X(例如 interface T<X>),那么
- 如果
T(A) <: T(B)当且仅当A = B,则T是不型变的。 - 如果
T(A) <: T(B)当且仅当A <: B,则T在X处是协变的。 - 如果
T(A) <: T(B)当且仅当B <: A,则T在X处是逆变的。
因为现阶段的仓颉中,所有用户自定义的泛型类型在其所有的类型变元处都是不变的,所以给定 interface I<X> 和类型 A、B,只有 A = B,我们才能得到 I<A> <: I<B>;反过来,如果知道了 I<A> <: I<B>,也可推出 A = B(内建类型除外:内建的元组类型对其每个元素类型来说,都是协变的;内建的函数类型在其入参类型处是逆变的,在其返回类型处是协变的。)
不型变限制了一些语言的表达能力,但也避免了一些安全问题,例如“协变数组运行时抛异常”的问题(Java 便有这个问题)。
泛型的类型别名
类型别名也是可以声明类型形参的,但是不能对其形参使用 where 声明约束,对于泛型变元的约束我们会在后面给出解释。
当一个泛型类型的名称过长时,我们就可以使用类型别名来为其声明一个更短的别名。例如,有一个类型为 RecordData ,我们可以把他用类型别名简写为 RD :
struct RecordData<T> {
var a: T
public init(x: T){
a = x
}
}
type RD<T> = RecordData<T>
main(): Int64 {
var struct1: RD<Int32> = RecordData<Int32>(2)
return 1
}
在使用时就可以用 RD<Int32> 来代指 RecordData<Int32> 类型。
泛型函数
如果一个函数声明了一个或多个类型形参,则将其称为泛型函数。语法上,类型形参紧跟在函数名后,并用 <> 括起,如果有多个类型形参,则用 , 分离。
全局泛型函数
在声明全局泛型函数时,只需要在函数名后使用尖括号声明类型形参,然后就可以在函数形参、返回类型及函数体中对这一类型形参进行引用。例如 id 函数定义为:
func id<T>(a: T): T {
return a
}
其中 (a: T) 是函数声明的形参,其中使用到了 id 函数声明的类型形参 T,并且在 id 函数的返回类型使用。
再比如另一个复杂的例子,定义如下一个泛型函数 composition,该函数声明了 3 个类型形参,分别是 T1, T2, T3,其功能是把两个函数 f: (T1) -> T2, g: (T2) -> T3 复合成类型为 (T1) -> T3 的函数。
func composition<T1, T2, T3>(f: (T1) -> T2, g: (T2) -> T3): (T1) -> T3 {
return {x: T1 => g(f(x))}
}
因为被用来复合的函数可以是任意类型,例如可以是 (Int32) -> Bool, (Bool) -> Int64 的复合,也可以是 (Int64) -> Char, (Char) -> Int8 的复合,所以才需要使用泛型函数。
func times2(a: Int64): Int64 {
return a * 2
}
func plus10(a: Int64): Int64 {
return a + 10
}
func times2plus10(a: Int64) {
return composition<Int64, Int64, Int64>(times2, plus10)(a)
}
main() {
println(times2plus10(9))
return 0
}
这里,我们复合两个 (Int64) -> Int64 的函数,将 9 先乘以 2,再加 10,结果会是 28。
28
局部泛型函数
局部函数也可以是泛型函数。例如泛型函数 id 可以嵌套定义在其它函数中:
func foo(a: Int64) {
func id<T>(a: T): T { a }
func double(a: Int64): Int64 { a + a }
return (id<Int64> ~> double)(a) == (double ~> id<Int64>)(a)
}
main() {
println(foo(1))
return 0
}
这里由于 id 的单位元性质,函数 id<Int64> ~> double 和 double ~> id<Int64> 是等价的,结果是 true。
true
泛型成员函数
class、struct 与 enum 的成员函数可以是泛型的。例如:
class A {
func foo<T>(a: T): Unit where T <: ToString {
println("${a}")
}
}
struct B {
func bar<T>(a: T): Unit where T <: ToString {
println("${a}")
}
}
enum C {
| X | Y
func coo<T>(a: T): Unit where T <: ToString {
println("${a}")
}
}
main() {
var a = A()
var b = B()
var c = C.X
a.foo<Int64>(10)
b.bar<String>("abc")
c.coo<Bool>(false)
return 0
}
程序输出的结果为:
10
abc
false
这里需要注意的是,class 中声明的泛型成员函数不能被 open 修饰,如果被 open 修饰则会报错,例如:
class A {
public open func foo<T>(a: T): Unit where T <: ToString { // Error: open generic function is not allowed
println("${a}")
}
}
在为类型使用 extend 声明进行扩展时,扩展中的函数也可以是泛型的,例如我们可以为 Int64 类型增加一个泛型成员函数:
extend Int64 {
func printIntAndArg<T>(a: T) where T <: ToString {
println(this)
println("${a}")
}
}
main() {
var a: Int64 = 12
a.printIntAndArg<String>("twelve")
}
程序输出的结果将为:
12
twelve
静态泛型函数
interface、class、struct、enum 与 extend 中可以定义静态泛型函数,例如下例 ToPair class 中从 ArrayList 中返回一个元组:
from std import collection.*
class ToPair {
public static func fromArray<T>(l: ArrayList<T>): (T, T) {
return (l[0], l[1])
}
}
main() {
var res: ArrayList<Int64> = ArrayList([1,2,3,4])
var a: (Int64, Int64) = ToPair.fromArray<Int64>(res)
return 0
}
泛型约束
泛型约束的作用是在函数、class、enum、struct 声明时明确泛型形参所具备的操作与能力。只有声明了这些约束才能调用相应的成员函数。在很多场景下泛型形参是需要加以约束的。以 id 函数为例:
func id<T>(a: T) {
return a
}
我们唯一能做的事情就是将函数形参 a 这个值返回,而不能进行 a + 1,println("${a}") 等操作,因为它可能是一个任意的类型,比如 (Bool) -> Bool,这样就无法与整数相加,同样因为是函数类型,也不能通过 println 函数来输出在命令行上。而如果这一泛型形参上有了约束,那么就可以做更多操作了。
约束大致分为接口约束与子类型约束。语法为在函数、类型的声明体之前使用 where 关键字来声明,对于声明的泛型形参 T1, T2,可以使用 where T1 <: Interface, T2 <: Type 这样的方式来声明泛型约束,同一个类型变元的多个约束可以使用 & 连接。例如:where T1 <: Interface1 & Interface2。
例如,仓颉中的 println 函数能接受类型为字符串的参数,如果我们需要把一个泛型类型的变量转为字符串后打印在命令行上,可以对这个泛型类型变元加以约束,这个约束是 core 中定义的 ToString 接口,显然它是一个接口约束:
package core // `ToString` is defined in core.
public interface ToString {
func toString(): String
}
这样我们就可以利用这个约束,定义一个名为 genericPrint 的函数:
func genericPrint<T>(a: T) where T <: ToString {
println(a)
}
main() {
genericPrint<Int64>(10)
return 0
}
结果为:
10
如果 genericPrint 函数的类型实参没有实现 ToString 接口,那么编译器会报错。例如我们传入一个函数做为参数时:
func genericPrint<T>(a: T) where T <: ToString {
println(a)
}
main() {
genericPrint<(Int64) -> Int64>({ i => 0 })
return 0
}
如果我们对上面的文件进行编译,那么编译器会抛出泛型类型参数与满足约束的错误。因为 genericPrint 函数的泛型的类型实参不满足约束 (Int64) -> Int64 <: ToString。
除了上述通过接口来表示约束,还可以使用子类型来约束一个泛型类型变元。例如:当我们要声明一个动物园类型 Zoo<T>,但是我们需要这里声明的类型形参 T 受到约束,这个约束就是 T 需要是动物类型 Animal 的子类型, Animal 类型中声明了 run 成员函数。这里我们声明两个子类型 Dog 与 Fox 都实现了 run 成员函数,这样在 Zoo<T> 的类型中,我们就可以对于 animals 数组列表中存放的动物实例调用 run 成员函数:
from std import collection.*
abstract class Animal {
public func run(): String
}
class Dog <: Animal {
public func run(): String {
return "dog run"
}
}
class Fox <: Animal {
public func run(): String {
return "fox run"
}
}
class Zoo<T> where T <: Animal {
var animals: ArrayList<Animal> = ArrayList<Animal>()
public func addAnimal(a: T) {
animals.append(a)
}
public func allAnimalRuns() {
for(a in animals) {
println(a.run())
}
}
}
main() {
var zoo: Zoo<Animal> = Zoo<Animal>()
zoo.addAnimal(Dog())
zoo.addAnimal(Fox())
zoo.allAnimalRuns()
return 0
}
程序的输出为:
dog run
fox run
属性
属性(Properties)提供了一个 getter 和一个可选的 setter 来间接检索和设置值。
使用属性的时候与普通变量无异,我们只需要对数据操作,对内部的实现无感知,可以更便利地实现访问控制、数据监控、跟踪调试、数据绑定等机制。
属性在使用时可以作为表达式或被赋值。
以下是一个简单的例子,b 是一个典型的属性,封装了外部对 a 的访问:
class Foo {
private var a = 0
public mut prop b: Int64 {
get() {
println("get")
a
}
set(value) {
println("set")
a = value
}
}
}
main() {
var x = Foo()
let y = x.b + 1 // get
x.b = y // set
}
此处 Foo 提供了一个名为 b 的属性,针对 getter/setter 这两个功能,我们提供了 get 和 set 两种语法来定义。当一个类型为 Foo 的变量 x 在访问 b 时,会调用 b 的 get 操作返回类型为 Int64 的值,因此可以用来与 1 相加;而当 x 在对 b 进行赋值时,会调用 b 的 set 操作,将 y 的值传给 set 的 value,最终将 value 的值赋值给 a。
通过属性 b,外部对 Foo 的成员变量 a 完全不感知,但却可以通过 b 做到同样的访问和修改操作,实现了有效的封装性。所以程序的输出如下:
get
set
定义属性
属性可以在 interface,class,struct,enum,extend 中定义。
一个典型的属性语法结构如下:
class Foo {
public prop a: Int64 {
get() { 0 }
}
public mut prop b: Int64 {
get() { 0 }
set(v) {}
}
}
其中使用 prop 声明的 a 和 b 都是属性,a 和 b 的类型都是 Int64。a 是无 mut 修饰符的属性,这类属性有且仅有定义 getter(对应取值)实现。b 是使用 mut 修饰的属性,这类属性必须分别定义 getter(对应取值)和 setter(对应赋值)的实现。
属性的 getter 和 setter 分别对应两个不同的函数。
- getter 函数类型是
() -> T,T 是该属性的类型,当使用该属性作为表达式时会执行 getter 函数。 - setter 函数类型是
(T) -> Unit,T 是该属性的类型,形参名需要显式指定,当对该属性赋值时会执行 setter 函数。
getter 和 setter 的实现中可以和函数体一样包含声明和表达式,与函数体的规则一样,详见函数体章节。
setter 中的参数对应的是赋值时传入的值。
class Foo {
private var j = 0
public mut prop i: Int64 {
get() {
j
}
set(v) {
j = v
}
}
}
需要注意的是,在属性的 getter 和 setter 中访问属性自身属于递归调用,与函数调用一样可能会出现死循环的情况。
修饰符
我们可以在 prop 前面声明需要的修饰符。
class Foo {
public prop a: Int64 {
get() {
0
}
}
private prop b: Int64 {
get() {
0
}
}
}
和成员函数一样,成员属性也支持 open、override、redef 修饰,所以我们也可以在子类型中 override/redef 父类型属性的实现。
子类型覆盖父类型的属性时,如果父类型属性带有 mut 修饰符,则子类型属性也需要带有 mut 修饰符,同时也必须保持一样的类型。
如下代码所示,A 中定义了 x 和 y 两个属性,B 中可以分别对 x 和 y 进行 override/redef:
open class A {
private var valueX = 0
private static var valueY = 0
public open prop x: Int64 {
get() { valueX }
}
public static mut prop y: Int64 {
get() { valueY }
set(v) {
valueY = v
}
}
}
class B <: A {
private var valueX2 = 0
private static var valueY2 = 0
public override prop x: Int64 {
get() { valueX2 }
}
public redef static mut prop y: Int64 {
get() { valueY2 }
set(v) {
valueY2 = v
}
}
}
抽象属性
类似于抽象函数,我们在 interface 和抽象类中也可以声明抽象属性,这些抽象属性没有实现。
interface I {
prop a: Int64
}
abstract class C {
public prop a: Int64
}
当实现类型实现 interface 或者非抽象子类继承抽象类时,必须要实现这些抽象属性。
与覆盖的规则一样,实现类型或子类在实现这些属性时,如果父类型属性带有 mut 修饰符,则子类型属性也需要带有 mut 修饰符,同时也必须保持一样的类型。
interface I {
prop a: Int64
mut prop b: Int64
}
class C <: I {
private var value = 0
public prop a: Int64 {
get() { value }
}
public mut prop b: Int64 {
get() { value }
set(v) {
value = v
}
}
}
通过抽象属性,我们可以让接口和抽象类对一些数据操作能以更加易用的方式进行约定,相比函数的方式要更加直观。
如下代码所示,如果我们要对一个 size 值的获取和设置进行约定,使用属性的方式 (I1) 相比使用函数的方式 (I2) 代码更少,也更加符合对数据操作的意图。
interface I1 {
mut prop size: Int64
}
interface I2 {
func getSize(): Int64
func setSize(value: Int64): Unit
}
class C <: I1 & I2 {
private var mySize = 0
public mut prop size: Int64 {
get() {
mySize
}
set(value) {
mySize = value
}
}
public func getSize() {
mySize
}
public func setSize(value: Int64) {
mySize = value
}
}
main() {
let a: I1 = C()
a.size = 5
println(a.size)
let b: I2 = C()
b.setSize(5)
println(b.getSize())
}
5
5
使用属性
属性分为实例成员属性和静态成员属性。成员属性的使用和成员变量的使用方式一样,详见成员变量章节。
class A {
public prop x: Int64 {
get() {
123
}
}
public static prop y: Int64 {
get() {
321
}
}
}
main() {
var a = A()
println(a.x) // 123
println(A.y) // 321
}
结果为:
123
321
无 mut 修饰符的属性类似 let 声明的变量,不可以被赋值。
class A {
private let value = 0
public prop i: Int64 {
get() {
value
}
}
}
main() {
var x = A()
println(x.i) // OK
x.i = 1 // Error
}
带有 mut 修饰符的属性类似 var 声明的变量,可以取值也可以被赋值。
class A {
private var value: Int64 = 0
public mut prop i: Int64 {
get() {
value
}
set(v) {
value = v
}
}
}
main() {
var x = A()
println(x.i) // OK
x.i = 1 // OK
}
0
扩展
扩展可以为在当前 package 可见的类型(除函数、元组、接口)添加新功能。
当我们不能破坏原有类型的封装性,但希望添加额外的功能时,可以使用扩展。
可以添加的功能包括:
- 添加成员函数
- 添加操作符重载函数
- 添加成员属性
- 实现接口
扩展虽然可以添加额外的功能,但不能变更原有类型的封装性,因此扩展不支持以下功能:
- 扩展不能增加成员变量。
- 扩展的函数和属性必须拥有实现。
- 扩展的函数和属性不能使用
open、override、redef修饰。 - 扩展不能访问原类型
private的成员。
扩展的定义
一个简单的扩展语法结构示例如下:
extend String {
public func printSize() {
println("the size is ${this.size}")
}
}
如上例所示,扩展使用 extend 关键字声明,其后跟着被扩展的类型 String 和扩展的功能。
当为 String 扩展了 printSize 函数之后,我们就能在当前 package 内对 String 的实例访问该函数,就像是 String 本身具备该函数。
main() {
let a = "123"
a.printSize() // the size is 3
}
编译执行上述代码,输出结果为:
the size is 3
被扩展类型处的泛型变元的名称不需要与原来定义处的相同(但个数要相同)。被扩展类型中的类型变元会隐式引入被扩展类型定义时的泛型约束。
例如下面所示的 MyList<T>。
class MyList<T> {
public let data: Array<T> = Array<T>()
}
extend MyList<T> {} // OK
extend MyList<R> {} // OK
extend MyList {} // error
extend MyList<T, R> {} // error
对于泛型类型的扩展,我们可以在其中声明额外的泛型约束,来实现一些有限情况下才能使用的函数。
例如我们可以定义一个叫 Pair 的类型,这个类型可以让我们方便的存储两个元素(类似于 Tuple)。
我们希望 Pair 类型可以容纳任何类型,因此两个泛型变元不应该有任何约束,这样才能保证 Pair 能容纳所有类型。
但同时我们又希望当两个元素可以判等的时候,让 Pair 也可以判等,这时就可以用扩展来实现这个功能。
如下面的代码所示,我们使用扩展语法,约束了 T1 和 T2 在支持 equals 的情况下,Pair 也可以实现 equals 函数。
class Pair<T1, T2> {
var first: T1
var second: T2
public init(a: T1, b: T2) {
first = a
second = b
}
}
interface Eq<T> {
func equals(other: T): Bool
}
extend Pair<T1, T2> where T1 <: Eq<T1>, T2 <: Eq<T2> {
public func equals(other: Pair<T1, T2>) {
first.equals(other.first) && second.equals(other.second)
}
}
class Foo <: Eq<Foo> {
public func equals(other: Foo): Bool {
true
}
}
main() {
let a = Pair(Foo(), Foo())
let b = Pair(Foo(), Foo())
println(a.equals(b)) // true
}
编译执行上述代码,输出结果为:
true
根据扩展有没有实现新的接口,扩展可以分为 直接扩展 和 接口扩展 两种用法,直接扩展即不包含额外接口的扩展,以上我们看到的例子都属于直接扩展;接口扩展即包含接口的扩展,接口扩展可以用来为现有的类型添加新功能并实现接口,增强抽象灵活性。
例如下面的例子,类型 Array 本身没有实现接口 PrintSizeable,但我们可以通过扩展的方式为 Array 增加额外的成员函数 printSize,并实现 PrintSizeable。
interface PrintSizeable {
func printSize(): Unit
}
extend Array<T> <: PrintSizeable {
public func printSize() {
println("The size is ${this.size}")
}
}
当使用扩展为 Array 实现 PrintSizeable 之后,就相当于在 Array 定义时实现接口 PrintSizeable。
因此我们可以将 Array 作为 PrintSizeable 的实现类型来使用了,如以下代码所示。
main() {
let a: PrintSizeable = Array<Int64>()
a.printSize() // 0
}
编译执行上述代码,输出结果为:
The size is 0
我们可以在同一个扩展内同时实现多个接口,多个接口之间使用 & 分开,接口的顺序没有先后关系。
如下面代码所示,我们可以在扩展中为 Foo 同时实现 I1、I2、I3。
interface I1 {
func f1(): Unit
}
interface I2 {
func f2(): Unit
}
interface I3 {
func f3(): Unit
}
class Foo {}
extend Foo <: I1 & I2 & I3 {
public func f1(): Unit {}
public func f2(): Unit {}
public func f3(): Unit {}
}
我们也可以在接口扩展中声明额外的泛型约束,来实现一些特定约束下才能满足的接口。
例如我们可以让上面的 Pair 类型实现 Eq 接口,这样 Pair 自己也能成为一个符合 Eq 约束的类型,如下代码所示。
class Pair<T1, T2> {
var first: T1
var second: T2
public init(a: T1, b: T2) {
first = a
second = b
}
}
interface Eq<T> {
func equals(other: T): Bool
}
extend Pair<T1, T2> <: Eq<Pair<T1, T2>> where T1 <: Eq<T1>, T2 <: Eq<T2> {
public func equals(other: Pair<T1, T2>) {
first.equals(other.first) && second.equals(other.second)
}
}
class Foo <: Eq<Foo> {
public func equals(other: Foo): Bool {
true
}
}
main() {
let a = Pair(Foo(), Foo())
let b = Pair(Foo(), Foo())
println(a.equals(b)) // true
}
编译执行上述代码,输出结果为:
true
如果被扩展的类型已经包含接口要求的函数或属性,那么我们在扩展中不需要并且也不能重新实现这些函数或属性。
例如下面的例子,我们定义了一个新接口 Sizeable,目的是获得某个类型的 size,而我们已经知道 Array 中包含了这个函数,因此我们就可以通过扩展让 Array 实现 Sizeable,而不需要添加额外的函数。
interface Sizeable {
prop size: Int64
}
extend Array<T> <: Sizeable {}
main() {
let a: Sizeable = Array<Int64>()
println(a.size)
}
编译执行上述代码,输出结果为:
0
扩展的修饰符
扩展本身不能使用修饰符修饰。
例如,下面的例子中对 A 的直接扩展前使用了 public 修饰,将编译报错。
public class A {}
public extend A {} // error, expected no modifier before extend
扩展成员可使用的修饰符有:static、public、protected(仅限于被扩展类型是 class 类型)、private、mut。
- 使用
private修饰的成员只能在本扩展内使用,外部不可见。 - 使用
protected修饰的成员除了能在本包内被访问,对包外的当前 class 子类也可以访问。 - 没有使用
private,protected或public修饰的成员只能在本包内使用。 - 使用
static修饰的成员,只能通过类型名访问,不能通过实例对象访问。 - 对
struct类型的扩展可以定义mut函数。
package p1
public open class A {}
extend A {
public func f1() {}
protected func f2() {}
private func f3() {}
static func f4() {}
}
main() {
A.f4()
var a = A()
a.f1()
a.f2()
}
扩展内的成员定义不支持使用 open、override、redef 修饰。
class Foo {
public open func f() {}
static func h() {}
}
extend Foo {
public override func f() {} // error
public open func g() {} // error
redef static func h() {} // error
}
扩展的孤儿规则
为一个其它 package 的类型实现另一个 package 的接口,可能造成理解上的困扰。
为了防止一个类型被意外实现不合适的接口,我们不允许定义孤儿扩展,指的是既不与接口(包含接口继承链上的所有接口)定义在同一个包中,也不与被扩展类型定义在同一个包中的接口扩展。
如下代码所示,我们不能在 package c 中,为 package a 里的 Foo 实现 package b 里的 Bar。
我们只能在 package a 或者在 package b 中为 Foo 实现 Bar。
// package a
public class Foo {}
// package b
public interface Bar {}
// package c
import a.Foo
import b.Bar
extend Foo <: Bar {} // Error
扩展的访问和遮盖
扩展的实例成员与类型定义处一样可以使用 this,this 的功能保持一致。同样也可以省略 this 访问成员。扩展的实例成员不能使用 super。
class A {
var v = 0
}
extend A {
func f() {
print(this.v) // ok
print(v) // ok
}
}
扩展不能访问被扩展类型的 private 修饰的成员(意味着非 private 修饰的成员均能被访问)。
class A {
private var v1 = 0
protected var v2 = 0
}
extend A {
func f() {
print(v1) // error
print(v2) // ok
}
}
扩展不能遮盖被扩展类型的任何成员。
class A {
func f() {}
}
extend A {
func f() {} // error
}
扩展也不允许遮盖其它扩展增加的任何成员。
class A {}
extend A {
func f() {}
}
extend A {
func f() {} // error
}
在同一个 package 内对同一类型可以扩展多次。
在扩展中可以直接调用(不加任何前缀修饰)其它对同一类型的扩展中的非 private 修饰的函数。
class Foo {}
extend Foo { // OK
private func f() {}
func g() {}
}
extend Foo { // OK
func h() {
g() // OK
f() // Error
}
}
扩展泛型类型时,可以使用额外的泛型约束。泛型类型的任意两个扩展之间的可见性规则如下:
- 如果两个扩展的约束相同,则两个扩展相互可见,即两个扩展内可以直接使用对方内的函数或属性;
- 如果两个扩展的约束不同,且两个扩展的约束有包含关系,约束更宽松的扩展对约束更严格的扩展可见,反之,不可见;
- 当两个扩展的约束不同时,且两个约束不存在包含关系,则两个扩展均互相不可见。
示例:假设对同一个类型 E<X> 的两个扩展分别为扩展 1 和扩展 2 ,X 的约束在扩展 1 中比扩展 2 中更严格,那么扩展 1 中的函数和属性对扩展 2 均不可见,反之,扩展 2 中的函数和属性对扩展 1 可见。
// B <: A
class E<X> {}
interface I1 {
func f1(): Unit
}
interface I2 {
func f2(): Unit
}
extend E<X> <: I1 where X <: B { // extension 1
public func f1(): Unit {
f2() // OK
}
}
extend E<X> <: I2 where X <: A { // extension 2
public func f2(): Unit {
f1() // Error
}
}
扩展的导入导出
扩展也是可以被导入和导出的,但是扩展本身不能使用 public 修饰,扩展的导出有一套特殊的规则。
对于直接扩展,只有当扩展与被扩展的类型在同一个 package,并且被扩展的类型和扩展中添加的成员都使用 public 或 protected 修饰时,扩展的功能才会被导出。
除此以外的直接扩展均不能被导出,只能在当前 package 使用。
如以下代码所示,Foo 是使用 public 修饰的类型,并且 f 与 Foo 在同一个 package 内,因此 f 会跟随 Foo 一起被导出。而 g 和 Foo 不在同一个 package,因此 g 不会被导出。
package a
public class Foo {}
extend Foo {
public func f() {}
}
///////
package b
extend Foo {
public func g() {}
}
///////
package c
import a.*
import b.*
main() {
let a = Foo()
a.f() // OK
a.g() // Error
}
对于接口扩展则分为两种情况:
- 如果接口扩展和被扩展类型在同一个
package,但接口是来自导入的,只有当被扩展类型使用public修饰时,扩展的功能才会被导出。 - 如果接口扩展与接口在同一个
package,则只有当接口是使用public修饰时,扩展的功能才会被导出。
如下代码所示,Foo 和 I 都使用了 public 修饰,因此对 Foo 的扩展就可以被导出。
package a
public class Foo {}
public interface I {
func g(): Unit
}
extend Foo <: I {
public func g(): Unit {}
}
///////
package b
import a.*
main() {
let a: I = Foo()
a.g()
}
与扩展的导出类似,扩展的导入也不需要显式地用 import 导入,扩展的导入只需要导入被扩展的类型和接口,就可以导入可访问的所有扩展。
如下面的代码所示,在 package b 中,只需要导入 Foo 就可以使用 Foo 对应的扩展中的函数 f。
而对于接口扩展,需要同时导入被扩展的类型和扩展的接口才能使用,因此在 package c 中,需要同时导入 Foo 和 I 才能使用对应扩展中的函数 g。
package a
public class Foo {}
extend Foo {
public func f() {}
}
///////
package b
import a.Foo
public interface I {
func g(): Unit
}
extend Foo <: I {
public func g() {
this.f() // OK
}
}
///////
package c
import a.Foo
import b.I
func test() {
let a = Foo()
a.f() // OK
a.g() // OK
}
并发
并发编程是现代编程语言中不可或缺的特性,仓颉编程语言提供抢占式的线程模型作为并发编程机制。在谈及编程语言和线程时,线程其实可以细化为两种不同概念,语言线程和 native 线程。
- 前者是编程语言中并发模型的基本执行单位,语言线程的目的是屏蔽底层实现细节。例如,仓颉编程语言希望给开发者提供一个友好、高效、统一的并发编程界面,让开发者无需关心操作系统线程、用户态线程等差异,因此提供仓颉线程的概念。开发者在大多数情况下只需面向仓颉线程编写并发代码。
- 后者指语言实现中所使用到的线程(一般是操作系统线程),他们作为语言线程的具体实现载体。不同编程语言会以不同的方式实现语言线程。例如,一些编程语言直接通过操作系统调用来创建线程,这意味着每个语言线程对应一个 native 线程,这种实现方案一般被称之为
1:1线程模型。此外,另有一些编程语言提供特殊的线程实现,他们允许多个语言线程在多个 native 线程上切换执行,这种也被称为M:N线程模型,即 M 个语言线程在 N 个 native 线程上调度执行,其中 M 和 N 不一定相等。当前,仓颉语言的实现同样采用M:N线程模型;因此,仓颉线程本质上是一种用户态的轻量级线程,支持抢占且相比操作系统线程更轻量化。
注:本文档在没有歧义的情况下将直接以线程一词简化对仓颉线程的指代。
创建仓颉线程
当开发者希望并发执行某一段代码时,只需创建一个仓颉线程即可。要创建一个新的仓颉线程,可以使用关键字 spawn 并传递一个无形参的 lambda 表达式,该 lambda 表达式即为在新线程中执行的代码。
下方示例代码中,主线程和新线程均会尝试打印一些文本:
from std import sync.*
from std import time.*
main(): Int64 {
spawn { =>
println("New thread before sleeping")
sleep(100 * Duration.millisecond) // sleep for 100ms.
println("New thread after sleeping")
}
println("Main thread")
return 0
}
注意:在上面的例子中,新线程会在主线程结束时一起停止,无论这个新线程是否已完成运行。上方示例的输出每次可能略有不同,有可能会输出类似如下的内容:
New thread before sleeping
Main thread
注意:sleep() 函数会让当前线程睡眠指定的时长,之后再恢复执行,其时间由指定的 Duration 类型决定,详细介绍请参考下方章节。
使用 Future<T> 等待线程结束并获取返回值
在上面的例子中,新创建的线程会由于主线程结束而提前结束,在缺乏顺序保证的情况下,甚至可能会出现新创建的线程还来不及得到执行就退出了。我们可以通过 spawn 表达式的返回值,来等待线程执行结束。
spawn 表达式的返回类型是 Future<T>,其中 T 是类型变元,其类型与 lambda 表达式的返回类型一致。当我们调用 Future<T> 的 get() 成员函数时,它将等待它的线程执行完成。
Future<T> 的原型声明如下:
public class Future<T> {
// Blocking the current thread, waiting for the result of the thread corresponding to the current Future object.
// If an exception occurs in the corresponding thread, the method will throw the exception.
public func get(): T
// Blocking the current thread, waiting for the result of the thread corresponding to the current Future object.
// If the corresponding thread has not completed execution within ns nanoseconds, the method will return a Option<T>.None.
// If `ns` <= 0, its behavior is the same as `get()`.
public func get(ns: Int64): Option<T>
// Non-blocking method that immediately returns Option<T>.None if thread has not finished execution.
// Returns the computed result otherwise.
// If an exception occurs in the corresponding thread, the method will throw the exception.
public func tryGet(): Option<T>
}
下方示例代码演示了如何使用 Future<T> 在 main 中等待新创建的线程执行完成:
from std import sync.*
from std import time.*
main(): Int64 {
let fut: Future<Unit> = spawn { =>
println("New thread before sleeping")
sleep(100 * Duration.millisecond) // sleep for 100ms.
println("New thread after sleeping")
}
println("Main thread")
fut.get() // wait for the thread to finish.
return 0
}
调用 Future<T> 实例的 get() 会阻塞当前运行的线程,直到 Future<T> 实例所代表的线程运行结束。因此,上方示例有可能会输出类似如下内容:
New thread before sleeping
Main thread
New thread after sleeping
主线程在完成打印后会因为调用 get() 而等待新创建的线程执行结束。但主线程和新线程的打印顺序具有不确定性。
但是,如果我们将 fut.get() 移动到主线程的打印之前,会出现什么结果呢?就像下方这样:
from std import sync.*
from std import time.*
main(): Int64 {
let fut: Future<Unit> = spawn { =>
println("New thread before sleeping")
sleep(100 * Duration.millisecond) // sleep for 100ms.
println("New thread after sleeping")
}
fut.get() // wait for the thread to finish.
println("Main thread")
return 0
}
主线程将等待新创建的线程执行完成,然后再执行打印,因此程序的输出将变得确定,如下所示:
New thread before sleeping
New thread after sleeping
Main thread
可见,get() 的调用位置会影响线程是否能同时运行。
Future<T> 除了可以用于阻塞等待线程执行结束以外,还可以获取线程执行的结果。现在,我们来看一下它提供的具体成员函数:
-
get(): T:阻塞等待线程执行结束,并返回执行结果,如果该线程已经结束,则直接返回执行结果。示例代码如下:
from std import sync.* from std import time.* main(): Int64 { let fut: Future<Int64> = spawn { sleep(Duration.second) // sleep for 1s. return 1 } try { // wait for the thread to finish, and get the result. let res: Int64 = fut.get() println("result = ${res}") } catch (_) { println("oops") } return 0 }输出结果如下:
result = 1 -
get(ns: Int64): Option<T>:阻塞等待该Future<T>所代表的线程执行结束,并返回执行结果,当到达超时时间ns时,如果该线程还没有执行结束,将会返回Option<T>.None。如果ns <= 0,其行为与get()相同。示例代码如下:
from std import sync.* from std import time.* main(): Int64 { let fut = spawn { sleep(Duration.second) // sleep for 1s. return 1 } // wait for the thread to finish, but only for 1ms. let res: Option<Int64> = fut.get(1000 * 1000) match (res) { case Some(val) => println("result = ${val}") case None => println("oops") } return 0 }输出结果如下:
oops
访问线程属性
每个 Future<T> 对象都有一个对应的仓颉线程,以 Thread 对象为表示。Thread 类主要被用于访问线程的属性信息,例如线程标识等。需要注意的是,Thread 无法直接被实例化构造对象,仅能从 Future<T> 的 thread 成员属性获取对应的 Thread 对象,或是通过 Thread 的静态成员属性 currentThread 得到当前正在执行线程对应的 Thread 对象。
Thread 类的部分方法定义如下(完整的方法描述可参考标准库用户手册)。
class Thread {
... ...
// Get the currently running thread
static prop currentThread: Thread
// Get the unique identifier (represented as an integer) of the thread object
prop id: Int64
// Check whether the thread has any cancellation request
prop hasPendingCancellation: Bool
}
下列示例代码在创建新线程后分别通过两种方式获取线程标识。由于主线程和新线程获取的是同一个 Thread 对象,所以他们能够打印出相同的线程标识。
main(): Unit {
let fut = spawn {
println("Current thread id: ${Thread.currentThread.id}")
}
println("New thread id: ${fut.thread.id}")
fut.get()
}
终止线程
可以通过 Future<T> 的 cancel() 方法向对应的线程发送终止请求,该方法不会停止线程执行。开发者需要使用 Thread 的 hasPendingCancellation 属性来检查线程是否存在终止请求。
一般而言,如果线程存在终止请求,那么开发者可以实施相应的线程终止逻辑。因此,如何终止线程都交由开发者自行处理,如果开发者忽略终止请求,那么线程继续执行直到正常结束。
示例代码如下:
from std import sync.SyncCounter
main(): Unit {
let syncCounter = SyncCounter(1)
let fut = spawn {
syncCounter.waitUntilZero()
// Check cancellation request
if (Thread.currentThread.hasPendingCancellation) {
println("cancelled")
return
}
println("hello")
}
fut.cancel() // Send cancellation request
syncCounter.dec()
fut.get() // Join thread
}
输出结果如下:
cancelled
线程睡眠指定时长 sleep
sleep 函数会阻塞当前运行的线程,该线程会主动睡眠一段时间,之后再恢复执行,其参数类型为 Duration 类型。函数原型为:
func sleep(dur: Duration): Unit // Sleep for at least `dur`.
注意:如果dur <= Duration.Zero, 那么当前线程只会让出执行资源,并不会进入睡眠。
以下是使用 sleep 的示例:
from std import sync.*
from std import time.*
main(): Int64 {
println("Hello")
sleep(Duration.second) // sleep for 1s.
println("World")
return 0
}
输出结果如下:
Hello
World
同步机制
在并发编程中,如果缺少同步机制来保护多个线程共享的变量,很容易会出现数据竞争问题(data race)。
仓颉编程语言提供三种常见的同步机制来确保数据的线程安全:原子操作,互斥锁以及条件变量。
原子操作 Atomic
仓颉提供整数类型、Bool 类型和引用类型的原子操作。
其中整数类型包括: Int8、Int16、Int32、Int64、UInt8、UInt16、UInt32、UInt64。
整数类型的原子操作支持基本的读写、交换以及算术运算操作:
| 操作 | 功能 |
|---|---|
load | 读取 |
store | 写入 |
swap | 交换,返回交换前的值 |
compareAndSwap | 比较再交换,交换成功返回 true,否则返回 false |
fetchAdd | 加法,返回执行加操作之前的值 |
fetchSub | 减法,返回执行减操作之前的值 |
fetchAnd | 与,返回执行与操作之前的值 |
fetchOr | 或,返回执行或操作之前的值 |
fetchXor | 异或,返回执行异或操作之前的值 |
需要注意的是:
- 交换操作和算数操作的返回值是修改前的值。
- compareAndSwap 是判断当前原子变量的值是否等于 old 值,如果等于,则使用 new 值替换;否则不替换。
以 Int8 类型为例,对应的原子操作类型声明如下:
class AtomicInt8 {
public func load(): Int8
public func store(val: Int8): Unit
public func swap(val: Int8): Int8
public func compareAndSwap(old: Int8, new: Int8): Bool
public func fetchAdd(val: Int8): Int8
public func fetchSub(val: Int8): Int8
public func fetchAnd(val: Int8): Int8
public func fetchOr(val: Int8): Int8
public func fetchXor(val: Int8): Int8
}
上述每一种原子类型的方法都有一个对应的方法可以接收内存排序参数,目前内存排序参数仅支持顺序一致性。
类似的,其他整数类型对应的原子操作类型有:
class AtomicInt16 {...}
class AtomicInt32 {...}
class AtomicInt64 {...}
class AtomicUInt8 {...}
class AtomicUInt16 {...}
class AtomicUInt32 {...}
class AtomicUInt64 {...}
下方示例演示了如何在多线程程序中,使用原子操作实现计数:
from std import sync.*
from std import time.*
from std import collection.*
let count = AtomicInt64(0)
main(): Int64 {
let list = ArrayList<Future<Int64>>()
// create 1000 threads.
for (i in 0..1000) {
let fut = spawn {
sleep(Duration.millisecond) // sleep for 1ms.
count.fetchAdd(1)
}
list.append(fut)
}
// Wait for all threads finished.
for (f in list) {
f.get()
}
let val = count.load()
println("count = ${val}")
return 0
}
输出结果应为:
count = 1000
以下是使用整数类型原子操作的一些其他正确示例:
var obj: AtomicInt32 = AtomicInt32(1)
var x = obj.load() // x: 1, the type is Int32
x = obj.swap(2) // x: 1
x = obj.load() // x: 2
var y = obj.compareAndSwap(2, 3) // y: true, the type is Bool.
y = obj.compareAndSwap(2, 3) // y: false, the value in obj is no longer 2 but 3. Therefore, the CAS operation fails.
x = obj.fetchAdd(1) // x: 3
x = obj.load() // x: 4
Bool 类型和引用类型的原子操作只提供读写和交换操作:
| 操作 | 功能 |
|---|---|
load | 读取 |
store | 写入 |
swap | 交换,返回交换前的值 |
compareAndSwap | 比较再交换,交换成功返回 true,否则返回 false |
注意,引用类型原子操作只对引用类型有效。
原子引用类型是 AtomicReference,以下是使用 Bool 类型、引用类型原子操作的一些正确示例:
from std import sync.*
class A {}
main() {
var obj = AtomicBool(true)
var x1 = obj.load() // x1: true, the type is Bool
println(x1)
var t1 = A()
var obj2 = AtomicReference(t1)
var x2 = obj2.load() // x2 and t1 are the same object
var y1 = obj2.compareAndSwap(x2, t1) // x2 and t1 are the same object, y1: true
println(y1)
var t2 = A()
var y2 = obj2.compareAndSwap(t2, A()) // x and t1 are not the same object, CAS fails, y2: false
println(y2)
y2 = obj2.compareAndSwap(t1, A()) // CAS successes, y2: true
println(y2)
}
编译执行上述代码,输出结果为:
true
true
false
true
可重入互斥锁 ReentrantMutex
可重入互斥锁的作用是对临界区加以保护,使得任意时刻最多只有一个线程能够执行临界区的代码。当一个线程试图获取一个已被其他线程持有的锁时,该线程会被阻塞,直到锁被释放,该线程才会被唤醒,可重入是指线程获取该锁后可再次获得该锁。
注意:ReentrantMutex 是内置的互斥锁,开发者需要保证不继承它。
使用可重入互斥锁时,必须牢记两条规则:
- 在访问共享数据之前,必须尝试获取锁;
- 处理完共享数据后,必须进行解锁,以便其他线程可以获得锁。
ReentrantMutex 提供的主要成员函数如下:
public open class ReentrantMutex {
// Create a ReentrantMutex.
public init()
// Locks the mutex, blocks if the mutex is not available.
public func lock(): Unit
// Unlocks the mutex. If there are other threads blocking on this
// lock, then wake up one of them.
public func unlock(): Unit
// Tries to lock the mutex, returns false if the mutex is not
// available, otherwise returns true.
public func tryLock(): Bool
}
下方示例演示了如何使用 ReentrantMutex 来保护对全局共享变量 count 的访问,对 count 的操作即属于临界区:
from std import sync.*
from std import time.*
from std import collection.*
var count: Int64 = 0
let mtx = ReentrantMutex()
main(): Int64 {
let list = ArrayList<Future<Unit>>()
// creat 1000 threads.
for (i in 0..1000) {
let fut = spawn {
sleep(Duration.millisecond) // sleep for 1ms.
mtx.lock()
count++
mtx.unlock()
}
list.append(fut)
}
// Wait for all threads finished.
for (f in list) {
f.get()
}
println("count = ${count}")
return 0
}
输出结果应为:
count = 1000
下方示例演示了如何使用 tryLock:
from std import sync.*
main(): Int64 {
let mtx: ReentrantMutex = ReentrantMutex()
var future: Future<Unit> = spawn {
mtx.lock()
while (true) {}
mtx.unlock()
}
let res: Option<Unit> = future.get(10*1000*1000)
match (res) {
case Some(v) => ()
case None =>
if (mtx.tryLock()) {
return 1
}
return 0
}
return 2
}
输出结果应为空。
以下是互斥锁的一些错误示例:
错误示例 1:线程操作临界区后没有解锁,导致其他线程无法获得锁而阻塞。
var sum: Int64 = 0
let mutex = ReentrantMutex()
main() {
for (i in 0..100) {
spawn { =>
mutex.lock()
sum = sum + 1
// Error: Because the thread is not unlocked, other threads waiting to obtain the current mutex will be blocked and cannot continue to run.
}
}
}
错误示例 2:在本线程没有持有锁的情况下调用 unlock 将会抛出异常。
var sum: Int64 = 0
let mutex = ReentrantMutex()
main() {
for (i in 0..100) {
spawn { =>
sum = sum + 1
mutex.unlock() // Error: Unlock without obtaining the lock and throw an exception.
}
}
}
错误示例 3:tryLock() 并不保证获取到锁,可能会造成不在锁的保护下操作临界区和在没有持有锁的情况下调用 unlock 抛出异常等行为。
var sum: Int64 = 0
let mutex = ReentrantMutex()
main() {
for (i in 0..100) {
spawn { =>
mutex.tryLock() // Error: `tryLock()` just trying to acquire a lock, there is no guarantee that the lock will be acquired, and this can lead to abnormal behavior.
sum = sum + 1
mutex.unlock()
}
}
}
另外,ReentrantMutex 在设计上是一个可重入锁,也就是说:在某个线程已经持有一个 ReentrantMutex 锁的情况下,再次尝试获取同一个 ReentrantMutex 锁,永远可以立即获得该 ReentrantMutex 锁。注意:虽然 ReentrantMutex 是一个可重入锁,但是调用 unlock() 的次数必须和调用 lock() 的次数相同,才能成功释放该锁。
下方示例代码演示了 ReentrantMutex 可重入的特性:
from std import sync.*
from std import time.*
var count: Int64 = 0
let mtx = ReentrantMutex()
func foo() {
mtx.lock()
count += 10
bar()
mtx.unlock()
}
func bar() {
mtx.lock()
count += 100
mtx.unlock()
}
main(): Int64 {
let fut = spawn {
sleep(Duration.millisecond) // sleep for 1ms.
foo()
}
foo()
fut.get()
println("count = ${count}")
return 0
}
输出结果应为:
count = 220
在上方示例中,无论是主线程还是新创建的线程,如果在 foo() 中已经获得了锁,那么继续调用 bar() 的话,在 bar() 函数中由于是对同一个 ReentrantMutex 进行加锁,因此也是能立即获得该锁的,不会出现死锁。
Monitor
Monitor 是一个内置的数据结构,它绑定了互斥锁和单个与之相关的条件变量(也就是等待队列)。Monitor 可以使线程阻塞并等待来自另一个线程的信号以恢复执行。这是一种利用共享变量进行线程同步的机制,主要提供如下方法:
public class Monitor <: ReentrantMutex {
// Create a monitor.
public init()
// Wait for a signal, blocking the current thread.
public func wait(timeout!: Duration = Duration.Max): Bool
// Wake up one thread of those waiting on the monitor, if any.
public func notify(): Unit
// Wake up all threads waiting on the monitor, if any.
public func notifyAll(): Unit
}
调用 Monitor 对象的 wait、notify 或 notifyAll 方法前,需要确保当前线程已经持有对应的 Monitor 锁。wait 方法包含如下动作:
- 添加当前线程到该
Monitor对应的等待队列中; - 阻塞当前线程,同时完全释放该
Monitor锁,并记录锁的重入次数; - 等待某个其它线程使用同一个
Monitor实例的notify或notifyAll方法向该线程发出信号; - 当前线程被唤醒后,会自动尝试重新获取
Monitor锁,且持有锁的重入状态与第 2 步记录的重入次数相同;但是如果尝试获取Monitor锁失败,则当前线程会阻塞在该Monitor锁上。
注意:wait 方法接受一个可选参数 timeout。需要注意的是,业界很多常用的常规操作系统不保证调度的实时性,因此无法保证一个线程会被阻塞“精确的 N 纳秒”——可能会观察到与系统相关的不精确情况。此外,当前语言规范明确允许实现产生虚假唤醒——在这种情况下,wait 返回值是由实现决定的——可能为 true 或 false。因此鼓励开发者始终将 wait 包在一个循环中:
synchronized (obj) {
while (<condition is not true>) {
obj.wait()
}
}
以下是使用 Monitor 的一个正确示例:
from std import sync.*
from std import time.*
var mon = Monitor()
var flag: Bool = true
main(): Int64 {
let fut = spawn {
mon.lock()
while (flag) {
println("New thread: before wait")
mon.wait()
println("New thread: after wait")
}
mon.unlock()
}
// Sleep for 10ms, to make sure the new thread can be executed.
sleep(10 * Duration.millisecond)
mon.lock()
println("Main thread: set flag")
flag = false
mon.unlock()
mon.lock()
println("Main thread: notify")
mon.notifyAll()
mon.unlock()
// wait for the new thread finished.
fut.get()
return 0
}
输出结果应为:
New thread: before wait
Main thread: set flag
Main thread: notify
New thread: after wait
Monitor 对象执行 wait 时,必须在锁的保护下进行,否则 wait 中释放锁的操作会抛出异常。
以下是使用条件变量的一些错误示例:
from std import sync.*
var m1 = Monitor()
var m2 = ReentrantMutex()
var flag: Bool = true
var count: Int64 = 0
func foo1() {
spawn {
m2.lock()
while (flag) {
m1.wait() // Error:The lock used together with the condition variable must be the same lock and in the locked state. Otherwise, the unlock operation in `wait` throws an exception.
}
count = count + 1
m2.unlock()
}
m1.lock()
flag = false
m1.notifyAll()
m1.unlock()
}
func foo2() {
spawn {
while (flag) {
m1.wait() // Error:The `wait` of a conditional variable must be called with a lock held.
}
count = count + 1
}
m1.lock()
flag = false
m1.notifyAll()
m1.unlock()
}
main() {
foo1()
foo2()
m1.wait()
return 0
}
MultiConditionMonitor
MultiConditionMonitor 是一个内置的数据结构,它绑定了互斥锁和一组与之相关的动态创建的条件变量。该类应仅当在 Monitor 类不足以满足复杂的线程间同步的场景下使用。主要提供如下方法:
public class MultiConditionMonitor <: ReentrantMutex {
// Constructor.
init()
// Returns a new ConditionID associated with this monitor. May be used to implement
// "single mutex -- multiple wait queues" concurrent primitives.
// Throws IllegalSynchronizationStateException("Mutex is not locked by the current thread") if the current thread does not hold this mutex.
func newCondition(): ConditionID
// Blocks until either a paired `notify` is invoked or `timeout` nanoseconds pass.
// Returns `true` if the specified condition was signalled by another thread or `false` on timeout.
// Spurious wakeups are allowed.
// Throws IllegalSynchronizationStateException("Mutex is not locked by the current thread") if the current thread does not hold this mutex.
// Throws IllegalSynchronizationStateException("Invalid condition") if `id` was not returned by `newCondition` of this MultiConditionMonitor instance.
func wait(id: ConditionID, timeout!: Duration = Duration.Max): Bool
// Wakes up a single thread waiting on the specified condition, if any (no particular admission policy implied).
// Throws IllegalSynchronizationStateException("Mutex is not locked by the current thread") if the current thread does not hold this mutex.
// Throws IllegalSynchronizationStateException("Invalid condition") if `id` was not returned by `newCondition` of this MultiConditionMonitor instance.
func notify(id: ConditionID): Unit
// Wakes up all threads waiting on the specified condition, if any (no particular admission policy implied).
// Throws IllegalSynchronizationStateException("Mutex is not locked by the current thread") if the current thread does not hold this mutex.
// Throws IllegalSynchronizationStateException("Invalid condition") if `id` was not returned by `newCondition` of this MultiConditionMonitor instance.
func notifyAll(id: ConditionID): Unit
}
newCondition(): ConditionID:创建一个新的条件变量并与当前对象关联,返回一个特定的ConditionID标识符wait(id: ConditionID, timeout!: Duration = Duration.Max): Bool:等待信号,阻塞当前线程notify(id: ConditionID): Unit:唤醒一个在Monitor上等待的线程(如果有)notifyAll(id: ConditionID): Unit:唤醒所有在Monitor上等待的线程(如果有)
初始化时,MultiConditionMonitor 没有与之相关的 ConditionID 实例。每次调用 newCondition 都会将创建一个新的条件变量并与当前对象关联,并返回如下类型作为唯一标识符:
public struct ConditionID {
private init() { ... } // constructor is intentionally private to prevent
// creation of such structs outside of MultiConditionMonitor
}
请注意使用者不可以将一个 MultiConditionMonitor 实例返回的 ConditionID 传给其它实例,或者手动创建 ConditionID(例如使用 unsafe)。由于 ConditionID 所包含的数据(例如内部数组的索引,内部队列的直接地址,或任何其他类型数据等)和创建它的 MultiConditionMonitor 相关,所以将“外部” conditonID 传入 MultiConditionMonitor 中会导致 IllegalSynchronizationStateException。
以下是使用 MultiConditionMonitor 去实现一个长度固定的有界 FIFO 队列,当队列为空,get() 会被阻塞;当队列满了时,put() 会被阻塞。
from std import sync.*
class BoundedQueue {
// Create a MultiConditionMonitor, two Conditions.
let m: MultiConditionMonitor = MultiConditionMonitor()
var notFull: ConditionID
var notEmpty: ConditionID
var count: Int64 // Object count in buffer.
var head: Int64 // Write index.
var tail: Int64 // Read index.
// Queue's length is 100.
let items: Array<Object> = Array<Object>(100, {i => Object()})
init() {
count = 0
head = 0
tail = 0
synchronized(m) {
notFull = m.newCondition()
notEmpty = m.newCondition()
}
}
// Insert an object, if the queue is full, block the current thread.
public func put(x: Object) {
// Acquire the mutex.
synchronized(m) {
while (count == 100) {
// If the queue is full, wait for the "queue notFull" event.
m.wait(notFull)
}
items[head] = x
head++
if (head == 100) {
head = 0
}
count++
// An object has been inserted and the current queue is no longer
// empty, so wake up the thread previously blocked on get()
// because the queue was empty.
m.notify(notEmpty)
} // Release the mutex.
}
// Pop an object, if the queue is empty, block the current thread.
public func get(): Object {
// Acquire the mutex.
synchronized(m) {
while (count == 0) {
// If the queue is empty, wait for the "queue notEmpty" event.
m.wait(notEmpty)
}
let x: Object = items[tail]
tail++
if (tail == 100) {
tail = 0
}
count--
// An object has been popped and the current queue is no longer
// full, so wake up the thread previously blocked on put()
// because the queue was full.
m.notify(notFull)
return x
} // Release the mutex.
}
}
synchronized 关键字
互斥锁 ReentrantMutex 提供了一种便利灵活的加锁的方式,同时因为它的灵活性,也可能引起忘了解锁,或者在持有互斥锁的情况下抛出异常不能自动释放持有的锁的问题。因此,仓颉编程语言提供一个 synchronized 关键字,搭配ReentrantMutex一起使用,可以在其后跟随的作用域内自动进行加锁解锁操作,用来解决类似的问题。
下方示例代码演示了如何使用 synchronized 关键字来保护共享数据:
from std import sync.*
from std import time.*
from std import collection.*
var count: Int64 = 0
let mtx = ReentrantMutex()
main(): Int64 {
let list = ArrayList<Future<Unit>>()
// creat 1000 threads.
for (i in 0..1000) {
let fut = spawn {
sleep(Duration.millisecond) // sleep for 1ms.
// Use synchronized(mtx), instead of mtx.lock() and mtx.unlock().
synchronized(mtx) {
count++
}
}
list.append(fut)
}
// Wait for all threads finished.
for (f in list) {
f.get()
}
println("count = ${count}")
return 0
}
输出结果应为:
count = 1000
通过在 synchronized 后面加上一个 ReentrantMutex 实例,对其后面修饰的代码块进行保护,可以使得任意时刻最多只有一个线程可以执行被保护的代码:
- 一个线程在进入
synchronized修饰的代码块之前,会自动获取ReentrantMutex实例对应的锁,如果无法获取锁,则当前线程被阻塞; - 一个线程在退出
synchronized修饰的代码块之前,会自动释放该ReentrantMutex实例的锁;
对于控制转移表达式(如 break、continue、return、throw),在导致程序的执行跳出 synchronized 代码块时,也符合上面第 2 条的说明,也就说也会自动释放 synchronized 表达式对应的锁。
下方示例演示了在 synchronized 代码块中出现 break 语句的情况:
from std import sync.*
from std import collection.*
var count: Int64 = 0
var mtx: ReentrantMutex = ReentrantMutex()
main(): Int64 {
let list = ArrayList<Future<Unit>>()
for (i in 0..10) {
let fut = spawn {
while (true) {
synchronized(mtx) {
count = count + 1
break
println("in thread")
}
}
}
list.append(fut)
}
// Wait for all threads finished.
for (f in list) {
f.get()
}
synchronized(mtx) {
println("in main, count = ${count}")
}
return 0
}
输出结果应为:
in main, count = 10
实际上 in thread 这行不会被打印,因为 break 语句实际上会让程序执行跳出 while 循环(当然,在跳出 while 循环之前,是先跳出 synchronized 代码块)。
线程局部变量 ThreadLocal
使用 core 包中的 ThreadLocal 可以创建并使用线程局部变量,每一个线程都有它独立的一个存储空间来保存这些线程局部变量,因此,在每个线程可以安全地访问他们各自的线程局部变量,而不受其他线程的影响。
public class ThreadLocal<T> {
/*
* 构造一个携带空值的仓颉线程局部变量
*/
public init()
/*
* 获得仓颉线程局部变量的值,如果值不存在,则返回 Option<T>.None
* 返回值 Option<T> - 仓颉线程局部变量的值
*/
public func get(): Option<T>
/*
* 通过 value 设置仓颉线程局部变量的值
* 如果传入 Option<T>.None,该局部变量的值将被删除,在线程后续操作中将无法获取
* 参数 value - 需要设置的局部变量的值
*/
public func set(value: Option<T>): Unit
}
下方示例代码演示了如何通过 ThreadLocal 类来创建并使用各自线程的局部变量
代码如下:
from std import sync.ThreadLocal
main(): Int64 {
let tl = ThreadLocal<Int64>()
let fut1 = spawn {
tl.set(123)
println("tl in spawn1 = ${tl.get().getOrThrow()}")
}
let fut2 = spawn {
tl.set(456)
println("tl in spawn2 = ${tl.get().getOrThrow()}")
}
fut1.get()
fut2.get()
0
}
可能的输出结果如下:
tl in spawn1 = 123
tl in spawn2 = 456
或者
tl in spawn2 = 456
tl in spawn1 = 123
仓颉线程和 native 线程
仓颉线程本质上是用户态的轻量级线程,每个仓颉线程都受到底层 native 线程的调度执行,并且多个仓颉线程可以由一个 native 线程执行。每个 native 线程会不断地选择一个就绪的仓颉线程完成执行,如果仓颉线程在执行过程中发生阻塞(例如等待互斥锁的释放),那么 native 线程会将当前的仓颉线程挂起,并继续选择下一个就绪的仓颉线程。发生阻塞的仓颉线程在重新就绪后会继续被 native 线程调度执行。
在大多数情况下,开发者只需要面向仓颉线程进行并发编程而不需要考虑这些细节。但在进行跨语言编程时,开发者需要谨慎调用可能发生阻塞的 foreign 函数,例如 IO 相关的操作系统调用等。例如,下列示例代码中的新线程会调用 foreign 函数 socket_read。在程序运行过程中,某一 native 线程将调度并执行该仓颉线程,在进入到 foreign 函数中后,系统调用会直接阻塞当前 native 线程直到函数执行完成。由于 native 线程被阻塞而不仅仅是仓颉线程,所以当前 native 线程在阻塞期间将无法调度其他仓颉线程来执行,这会降低程序执行的吞吐量。
foreign socket_read(sock: Int64): CPointer<Int8>
let fut = spawn {
let sock: Int64 = ...
let ptr = socket_read(sock)
}
元编程
元编程是一种将计算机程序(代码)当做数据的编程技术,从而修改,更新,替换已有的程序。例如可以将一些计算过程从运行时挪到编译时,并在编译期进行代码生成。仓颉语言提供的元编程能力,能支持代码复用,操作语法树,编译期求值,甚至自定义文法等功能。
下面是一个利用元编程解决具体问题的例子,利用仓颉宏为某些需要递归计算的函数进行记忆优化。
// macro_definition.cj
macro package memory
from std import ast.*
func checkBooleanAttr(attr: Tokens): Bool {
// true or false
if (attr.size != 1 || attr[0].kind != TokenKind.BOOL_LITERAL) {
throw IllegalArgumentException("Attribute for memoize should be true or false")
}
return attr[0].value == "true"
}
public macro memoize(attr: Tokens, input: Tokens): Tokens {
let memoized: Bool = checkBooleanAttr(attr)
// no memorization
if (!memoized) {
return input
}
// optimizing with memory
let fd = parseDecl(input)
return quote(
var memoMap: HashMap<Int64, Int64> = HashMap<Int64, Int64>()
func $(fd.identifier)(n: Int64): Int64 {
if (memoMap.contains(n)) {
return memoMap.get(n).getOrThrow()
}
if (n == 0 || n == 1) {
return n
}
let ret = Fib(n-1) + Fib(n-2)
memoMap.put(n, ret)
return ret
}
)
}
// macro_call.cj
import memory.*
from std import time.*
from std import collection.*
@memoize[true]
func Fib(n: Int64): Int64 {
if (n == 0 || n == 1) {
return n
}
return Fib(n-1) + Fib(n-2)
}
main() {
println("Fibonacci:")
let start1 = DateTime.now()
let f1 = Fib(20)
let end1 = DateTime.now()
println("Fib(20): ${f1}")
println("execution time: ${(end1 - start1).toMicroseconds()} us")
let start2 = DateTime.now()
let f2 = Fib(15)
let end2 = DateTime.now()
println("Fib(15): ${f2}")
println("execution time: ${(end2 - start2).toMicroseconds()} us")
let start3 = DateTime.now()
let f3 = Fib(22)
let end3 = DateTime.now()
println("Fib(22): ${f3}")
println("execution time: ${(end3 - start3).toMicroseconds()} us")
0
}
上述代码中,memoize 是一个用户自定义的宏,它修饰一个函数,这个函数用来计算 Fibonacci 序列的第 n 个位置上的值。如果没有 memoize 这个宏修饰,每次调用 Fib 函数时,都会递归执行,耗时较长。使用 memoize 后,这个宏为 Fib 函数在编译期生成一些代码,记录下已经计算出的函数入参对应的函数返回值,下次可直接查表得到函数返回值,而不需要再次递归。
使用仓颉宏时,需要先编译宏定义文件,再编译宏调用文件生成可执行文件,最终运行可执行文件的输出结果如下:
// output when use @memoize[true]
Fibonacci:
Fib(20): 6765
execution time: 146 us
Fib(15): 610
execution time: 3 us
Fib(22): 17711
execution time: 16 us
当然,记忆优化的代价是额外使用了哈希表,若开发者不希望进行这样的优化,可以将 memoize 宏的属性入参设置为 false,即使用 @memoize[false] 修饰 Fib 函数,程序的运行结果如下:
// output when use @memoize[false]
Fibonacci:
Fib(20): 6765
execution time: 570 us
Fib(15): 610
execution time: 51 us
Fib(22): 17711
execution time: 1487 us
由以上运行结果可以看出,使用 @memoize[true] 时,Fib(15), Fib(22) 的计算时间显著减少,特别是 Fib(22) 的计算耗时,使用记忆优化后时长由 1487 us 减少到 16 us。
观察 memoize 宏定义,我们看到 memoize 宏使用了 Tokens 作为入参和返回值的类型,同时返回了一个 quote 表达式。为了使用仓颉宏,我们需要了解 Token, Tokens, quote, 以及宏的编译期执行(先编译宏定义文件,再编译宏调用文件)的概念,下面将分别介绍它们,最终我们能理解 memoize 宏的工作原理。
Tokens 相关类型和 quote 表达式
仓颉语言的元编程是基于语法实现的。编译器在语法分析的阶段可以完成编写或操作目标程序的工作,用于操作目标程序的程序我们称为元程序。元程序的输入输出都是词法单元(token),为此,仓颉提供了 Token 类型,Tokens 类型和 quote 表达式。其中,Token 类型是单个词法单元的类型,Tokens 类型是多个词法单元组成的结构的类型,quote 表达式是构造 Tokens 实例的一种表达式,下面依次对它们进行介绍。
Token 类型
Token 是元编程提供给用户可操作的词法单元,含义上等同编译器中词法分析器输出的 token。一个 Token 类型中包括的信息有:Token 类型(TokenKind)、构成 Token 的字符串、Token 的位置。
可以通过传入具体的 TokenKind 来构建单个 Token 对象:
Token(TokenKind.ADD) // Token representing `+`
这里的 TokenKind 是用于表示 Token 类型的 enum,即用于表示各种 Token。使用 TokenKind 的构造器可以构造出仓颉所有的 Token (TokenKind 可用值详见附录) 。
需要注意的是,由多个字符组成的 Token 与对应相同字符的多个 Token,含义不同。例如:
let a0: Unit = ()
let a1 = String()
此处第一行的 () 可以是 一个类型为 TokenKind.UNIT_LITERAL(Unit 类型的字面值常量)的 Token,或者两个 Token,其类型分别为 TokenKind.LPAREN(左括号)和 TokenKind.RPAREN(右括号),而第二行的 (),则只能是 TokenKind.LPAREN 和 TokenKind.RPAREN。
注:TokenKind、Token 类型皆由仓颉标准库 ast 包提供,使用时需要导入
from std import ast.TokenKind
from std import ast.Token
本章中为了方便描述,使用 from std import ast.* 将整个 ast 包导入。
还存在其他构造 Token 的方式,如下:
Token() // Return illegal Token.
Token(k: TokenKind)
Token(k: TokenKind, v: String)
例如,有以下方式可以构造 Token
let tk1 = Token()
let tk2 = Token(TokenKind.FUNC) // Construct a Token, which is the keyword func
let tk3 = Token(TokenKind.IDENTIFIER, "foo") // Construct an identifier Token with value foo
Tokens 类型
Tokens 类型是用仓颉编写元程序必须的输入输出类型。存在如下 3 种构造 Tokens 实例的方式:
Tokens()
Tokens(tokArr: Array<Token>)
Tokens(tokArrList: ArrayList<Token>)
除了以上构造 Tokens 的方式外,还有 quote 表达式可以构造 Tokens,详见下一小节。简单来说,Tokens 可以理解为是由词素(Token)组成的数组,同时 Tokens 类型支持如下操作:
size: 返回 Tokens 中所包含 Token 的数目。
get(index: Int64): 用于获取指定下标的 Token 元素。
[]: 返回下标索引指定的 Token。
+: 拼接两个 Tokens 或者拼接 Tokens 和 Token。
dump(): 打印包含的所有 Token,供调试使用。
下面的例子中包含了上述的所有操作:
from std import ast.*
main() {
let ts1: Tokens = quote(1 + 2)
let ts2: Tokens = quote(3)
// ts includes Token: '1', '+', '2', '+' and '3'
let ts: Tokens = ts1 + Token(TokenKind.ADD) + ts2
println("ts.size = ${ts.size}")
println("ts.dump():")
ts.dump()
let index0 = ts.get(0)
println("ts.get(0): ${index0.value}")
let index1 = ts[1]
println("ts[1]: ${index1.value}")
0
}
这个例子中,通过 quote 表达式获取了仓颉代码(如 1 + 2 + 3)的 Tokens 对象
quote 表达式
quote 是仓颉的一个关键字,quote 表达式可以将代码表示为 Tokens 对象。具体来说,对于上一节的例子:
let ts1: Tokens = quote(1 + 2)
这里 quote 的作用是:将1 + 2这行代码转换成由 '1','+','2' 这 3 个 Token 组成的 Tokens。
插值运算符
在 quote 表达式中,仓颉支持代码插值操作,使用插值运算符 $ 表示。这里的插值表达式类似于某种占位符,会被最终替换成相应的值,即 toTokens 后的结果。
说明:
插值运算符修饰的表达式必须实现 ast 包中的
toTokens接口,否则无法正常给出插值结果并给出报错信息。关于 ast 包的介绍及其 API,请参见《仓颉库使用指南》中“ast 包”的内容。
默认情况下,插值运算符后面的表达式,需要使用小括号限定作用域,如 $(foo)。但是当后面只跟单个标识符的时候,小括号可省略,即可写为:$foo。下面是有关 quote 和插值的一个示例,这个例子中,展示了将二元表达式 (1+2) 转换为 Tokens 对象,然后调用 ast 包提供的 parseExpr 接口将其变成 AST 类型,即 BinaryExpr,通过 quote 和插值可以将这个 AST 类型变成 Tokens 对象。
from std import ast.*
main() {
let tokens: Tokens = quote(1 + 2)
// parseExpr is API provided by libast to parse input Tokens.
// BinaryExpr is type provided by libast.
var ast: BinaryExpr = match (parseExpr(tokens) as BinaryExpr) {
case Some(v) => v
case None => throw Exception()
}
let a = quote($ast) // without parentheses
let b = quote($(ast)) // with parentheses
let c = quote($ast.leftExpr) // without parentheses
let d = quote($(ast.leftExpr)) // with parentheses
println("$ast.leftExpr:")
c.dump()
println("===================")
println("$(ast.leftExpr):")
d.dump()
return 0
}
其中 BinaryExpr 和 parseExpr 是 ast 包提供的类型和成员函数。
$ 只定界到紧跟它的一个标识符。例如,quote($ast.leftExpr) 将返回 '1','+','2','.','getLeftExpr','(' 和 ')' 这 7 个 Token,ast 之后的 .leftExpr 均被解释为 Token。
quote的入参可以为任意合法的仓颉代码且可以为空,但当前编译器不支持传入代码中有宏调用表达式。
宏
仓颉实现元编程的主要方式是使用宏。仓颉的宏是语法宏,其定义形式上类似于函数,也和函数一样可以被调用。不同点是:
- 宏定义所在的
package需使用macro package来声明。 - 宏定义需要使用关键字
macro。 - 宏定义的输入和输出类型必须是 Tokens。
- 宏调用需要使用
@。
从输入代码序列到输出新的代码序列的这个映射过程称为宏展开。宏在仓颉代码编译时进行展开,一直展开到目标代码中没有宏为止。宏展开的过程会实际执行宏定义体,即宏是在编译期完成求值,展开后的结果重新作用于仓颉的语法树,继续后面的编译和执行流程。
macro package
仓颉宏的定义需要放在由 macro package 声明的包中,被 macro package 限定的包仅允许宏定义对外可见(注:也允许重导出的声明对外可见),其他声明包内可见。宏定义允许返回空 Tokens 对象,不包含任何代码(Tokens)。但是如果该(返回空 Tokens 对象的)宏调用是其他表达式的一部分,编译将报错,因为空的 Tokens 对象无法构成有效的表达式。
- 示例
// file define.cj
macro package define // 编译 define.cjo 携带 macro 属性
from std import ast.*
public func A() {} // error: 宏包不允许定义外部可见的非宏定义,此处需报错
public macro M(input: Tokens): Tokens { // macro M 外部可见
return input
}
需要特殊说明的是,在 macro package 中允许 macro package 和非 macro package 被重导出,在非 macro package 中仅允许非 macro package 被重导出。
- 示例
// A.cj -- cjc A.cj --compile-macro
macro package A
from std import ast.*
public macro M1(input: Tokens): Tokens {
return input
}
// B.cj -- cjc B.cj --output-type=dylib -o libB.so
package B
// public import A.* // error: it is not allowed to re-export a macro package in a package.
public func F1(input: Int64): Int64 {
return input
}
// C.cj -- cjc C.cj --compile-macro -L. -lB
macro package C
public import A.* // correct: macro package is allowed to re-exprot in a macro package.
public import B.* // correct: non-macro package is also allowed to re-exprot in a macro package.
from std import ast.*
public macro M2(input: Tokens): Tokens {
return @M1(input) + Token(TokenKind.NL) + quote(F1(1))
}
// main.cj -- cjc main.cj -o main -L. -lB
import C.*
main() {
@M2(let a = 1)
}
其中 main.cj 中 M2 宏展开后得到
let a = 1
F1(1)
这里在 package C 中重导出 B 包里的符号是因为宏扩展中使用了 quote(F1(1)),方便宏的使用者仅需导入宏包,就可以正确的编译宏展开后的代码。
这里有两点需要关注
- 当前编译 package C 和 main 时,都需要显式的链接 libB.so;
main.cj中需要使用import C.*导入宏和重导出符号,如果仅使用import C.M2依旧会报undeclared identifier 'F1'的错误信息。
仓颉的宏系统分为两种:非属性宏和属性宏。非属性宏只有一个入参,其输入是被宏修饰的代码。属性宏有两个入参,其增加的属性入参赋予开发者向仓颉宏传入额外信息的能力。
非属性宏
非属性宏的定义格式如下:
public macro MacroName(args: Tokens): Tokens {
... // Macro body
}
宏的调用格式如下:
@MacroName(...)
宏调用使用 () 括起来。括号里面可以是任意合法 tokens,也可以是空。
以下地方的宏调用可省略括号。
@MacroName func name() {} // Before a FuncDecl
@MacroName struct name {} // Before a StructDecl
@MacroName class name {} // Before a ClassDecl
@MacroName var a = 1 // Before a VarDecl
@MacroName enum e {} // Before a Enum
@MacroName interface i {} // Before a InterfaceDecl
@MacroName extend e <: i {} // Before a ExtendDecl
@MacroName mut prop i: Int64 {} // Before a PropDecl
@MacroName @AnotherMacro(input) // Before a macro call
此外,可省略括号的宏调用,只能出现在被修饰的声明允许出现的位置。
如前面提到的,宏展开过程作用于仓颉语法树,宏展开后,编译器会继续进行后续的编译过程,因此,用户需要保证宏展开后的代码依然是合法的仓颉代码,否则可能引发编译问题。
Tokens 类型定义位于 ast 包中,而宏定义的输入和输出都是 Tokens,因此宏定义必须导入 ast 包。宏定义必须比宏调用点先编译。编译器约束宏的定义与宏的调用不允许在同一包里。即存在宏调用的包中,不允许出现任意宏的定义。由于宏需在包中导出给另一个包使用,因此编译器约束宏定义必须使用 public 修饰。
以在 Linux 平台编译本章开头的示例为例(--compile-macro 的使用方式将在"宏的编译和调试"中进行说明):
# 编译宏定义
cjc macro_definition.cj --compile-macro
# 编译宏调用
cjc macro_call.cj -o main.out
若在 Windows 平台编译本章开头的示例:
# 编译宏定义
cjc macro_definition.cj --compile-macro
# 编译宏调用
cjc macro_call.cj -o main.exe
若用 CJVM 虚拟机则需要用解释器编译本章开头的示例:
# 编译宏定义
cjc macro_definition.cj --compile-macro
# 编译宏调用
cjc macro_call.cj --interp-macro -o main.cbc
下面是几个宏应用的典型示例。
- 示例 1
// file macro_definition.cj
macro package macro_definition
from std import ast.*
public macro TestDef(input: Tokens): Tokens {
println("I'm in macro body")
return input
}
// file macro_call.cj
package macro_calling
import macro_definition.*
main(): Int64 {
println("I'm in function body")
let a: Int64 = @TestDef(1 + 2)
println("a = ${a}")
return 0
}
上述两段代码分别位于不同文件中,优先编译宏定义文件:macro_definition.cj。在 Linux 系统中,将生成用于包管理的 macro_definition.cjo 和实际的动态库文件。macro_call.cj 的编译需要依赖这两个文件。
我们在用例中添加了打印信息,其中宏定义中的 I'm in macro body 将在编译 macro_call.cj 的期间输出,即对宏定义求值。同时,宏调用点被展开,即在编译
let a: Int64 = @TestDef(1 + 2)
时,将宏返回的 Tokens 更新到调用点的语法树上,得到如下代码:
let a: Int64 = 1 + 2
也就是说,可执行程序中的代码实际变为了:
main(): Int64 {
println("I'm in function body")
let a: Int64 = 1 + 2
println("a = ${a}")
return 0
}
a 经过计算得到的值为 3,在打印 a 的值时插值为 3。至此,上述程序的运行结果为:
I'm in function body
a = 3
下面看一个更有意义的用宏处理函数的例子,这个宏 ModifyFunc 宏的作用是给 MyFunc 增加 Composer 参数,并在counter++前后插入一段代码。
- 示例 2
// file macro_definition.cj
macro package macro_definition
from std import ast.*
public macro ModifyFunc(input: Tokens): Tokens {
println("I'm in macro body")
return quote(
func MyFunc(composer: Composer) {
composer.start(123)
counter++
composer.end()
})
}
// file macro_call.cj
package macro_calling
import macro_definition.*
struct Composer {
public init() { }
public func start (id: Int32) { println("start ${id}") }
public func end () { println("end") }
}
var counter = 0
@ModifyFunc
func MyFunc() {
counter++
}
main(): Int64 {
println("I'm in function body")
let comp = Composer()
MyFunc(comp)
println("MyFunc called: ${counter} times")
return 0
}
同样的,上述两段代码分别位于不同文件中,先编译宏定义文件 macro_definition.cj,再编译宏调用 macro_call.cj 生成可执行文件。
这个例子中,ModifyFunc 宏的输入是一个函数声明,因此可以省略括号:
@ModifyFunc
func MyFunc() {
counter++
}
经过宏展开后,得到如下代码:
func MyFunc(composer: Composer) {
composer.start(123)
counter++
composer.end()
}
MyFunc 会在 main 中调用,它接受的实参也是在 main 中定义的,从而形成了一段合法的仓颉程序。运行时打印如下:
I'm in function body
start 123
end
MyFunc called: 1 times
属性宏
和非属性宏相比,属性宏的定义会增加一个 Tokens 类型的输入,这个增加的入参可以让开发者输入额外的信息。比如开发者可能希望在不同的调用场景下使用不同的宏展开策略,则可以通过这个属性入参进行标记位设置。同时,这个属性入参也可以传入任意 Tokens,这些 Tokens 可以与被宏修饰的代码进行组合拼接等。下面是一个简单的例子:
// Macro definition with attribute
public macro Foo(attrTokens: Tokens, inputTokens: Tokens): Tokens {
return attrTokens + inputTokens // Concatenate attrTokens and inputTokens.
}
如上面的宏定义,属性宏的入参数量为 2,入参类型为 Tokens,在宏定义内,可以对 attrTokens 和 inputTokens 进行一系列的组合,拼接等变换操作,最后返回新的 Tokens。
带属性的宏与不带属性的宏的调用类似,属性宏调用时新增的入参 attrTokens 通过 [] 传入,其调用形式为:
// attribute macro with parentheses
var a: Int64 = @Foo[1+](2+3)
// attribute macro without parentheses
@Foo[public]
struct Data {
var count: Int64 = 100
}
- 宏 Foo 调用,当参数是
2+3时,与[]内的属性1+进行拼接,经过宏展开后,得到var a: Int64 = 1+2+3。 - 宏 Foo 调用,当参数是 struct Data 时,与
[]内的属性public进行拼接,经过宏展开后,得到
public struct Data {
var count: Int64 = 100
}
关于属性宏,需要注意以下几点:
-
带属性的宏,与不带属性的宏相比,能修饰的 AST 是相同的,可以理解为带属性的宏对可传入参数做了增强。
-
要求属性宏调用时,
[]内中括号匹配,且可以为空。中括号内只允许对中括号的转义\[或\],该转义中括号不计入匹配规则,其他字符会被作为 Token,不能进行转义。@Foo[[miss one](2+3) // Illegal @Foo[[matched]](2+3) // Legal @Foo[](2+3) // Legal, empty in [] @Foo[\[](2+3) // Legal, use escape for [ @Foo[\(](2+3) // Illegal, only [ and ] allowed in [] -
宏的定义和调用的类型要保持一致:如果宏定义有两个入参,即为属性宏定义,调用时必须加上
[],且内容可以为空;如果宏定义有一个入参,即为非属性宏定义,调用时不能使用[]。
宏导入时的别名
如果有两个宏定义的包 p1 和 p2,p1 p2 中都定义了一个宏,叫 Foo,我们在使用宏的文件中,同时导入了 p1 和 p2,那如何使用这个宏 Foo? 一种解决方法就是,在导入宏时使用别名。
// f1.cj
macro package p1
from std import ast.*
public macro Foo(input: Tokens) {
return input
}
// f2.cj
macro package p2
from std import ast.*
public macro Foo(input: Tokens) {
return input
}
// use.cj
import p1.Foo as Foo1
import p2.Foo as Foo2
@Foo1 // call Foo in p1
class A{}
@Foo2 // call Foo in p2
class B{}
main() {
let a = A()
let b = B()
0
}
如果,开发者在 use.cj 中直接使用 @Foo,而不使用别名,编译器会报错,提示 "ambiguous match"。
另外,支持包名 + 宏名的方式调用宏。如下:
import p1.Foo
import p2.Foo
@p1.Foo
class A{}
@p2.Foo
class A{}
也支持对包名使用别名,如:
import p0.* as p1.* // p0 is a macro package
@p1.Foo // p1 is an alias for p0
class A{}
嵌套宏
仓颉语言不支持宏定义的嵌套;有条件地支持在宏定义和宏调用中进行宏调用。
宏调用在宏定义内
下面是一个宏定义中包含其他宏调用的例子。
// file pkg1.cj
macro package pkg1
from std import ast.*
public macro GetIdent(attr:Tokens, input:Tokens):Tokens {
return quote(
let decl = (parseDecl(input) as VarDecl).getOrThrow()
let name = decl.identifier.value
let size = name.size - 1
let $(attr) = Token(TokenKind.IDENTIFIER, name[0..size])
)
}
// file pkg2.cj
macro package pkg2
from std import ast.*
import pkg1.*
public macro Prop(input:Tokens):Tokens {
let v = parseDecl(input)
@GetIdent[ident](input)
return quote(
$(input)
public prop $(ident): $(decl.declType) {
get() {
this.$(v.identifier)
}
}
)
}
// file pkg3.cj
package pkg3
import pkg2.*
class A {
@Prop
private let a_: Int64 = 1
}
main() {
let b = A()
println("${b.a}")
}
注意,按照宏定义必须比宏调用点先编译的约束,上述 3 个文件的编译顺序必须是:pkg1 -> pkg2 -> pkg3。如下宏定义:
public macro Prop(input:Tokens):Tokens {
let v = parseDecl(input)
@GetIdent[ident](input)
return quote(
$(input)
public prop $(ident): $(decl.declType) {
get() {
this.$(v.identifier)
}
}
)
}
会先被展开成如下代码,再进行编译。
public macro Prop(input: Tokens): Tokens {
let v = parseDecl(input)
let decl = (parseDecl(input) as VarDecl).getOrThrow()
let name = decl.identifier.value
let size = name.size - 1
let ident = Token(TokenKind.IDENTIFIER, name[0 .. size])
return quote(
$(input)
public prop $(ident): $(decl.declType) {
get() {
this.$(v.identifier)
}
}
)
}
宏调用在宏调用中
嵌套宏的常见场景,是宏修饰的代码块中,出现了宏调用。一个具体的例子如下:
// file pkg1.cj
macro package pkg1
from std import ast.*
public macro Foo(input: Tokens): Tokens {
return input
}
public macro Bar(input: Tokens): Tokens {
return input
}
// file pkg2.cj
macro package pkg2
from std import ast.*
public macro AddToMul(inputTokens: Tokens): Tokens {
var expr: BinaryExpr = match (parseExpr(inputTokens) as BinaryExpr) {
case Some(v) => v
case None => throw Exception()
}
var op0: Expr = expr.leftExpr
var op1: Expr = expr.rightExpr
return quote(($(op0)) * ($(op1)))
}
// file pkg3.cj
package pkg3
import pkg1.*
import pkg2.*
@Foo
struct Data {
let a = 2
let b = @AddToMul(2+3)
@Bar
public func getA() {
return a
}
public func getB() {
return b
}
}
main(): Int64 {
let data = Data()
var a = data.getA() // a = 2
var b = data.getB() // b = 6
println("a: ${a}, b: ${b}")
return 0
}
如上代码所示,宏 Foo 修饰了 struct Data,而在 struct Data 内,出现了宏调用 AddToMul 和 Bar。这种嵌套场景下,代码变换的规则是:将嵌套内层的宏 (AddToMul 和 Bar) 展开后,再去展开外层的宏 (Foo)。允许出现多层宏嵌套,代码变换的规则总是由内向外去依次展开宏。
嵌套宏可以出现在带括号和不带括号的宏调用中,二者可以组合,但用户需要保证没有歧义,且明确宏的展开顺序:
var a = @Foo(@Foo1(2 * 3)+@Foo2(1 + 3)) // Foo1, Foo2 have to be defined.
@Foo1 // Foo2 expands first, then Foo1 expands.
@Foo2[attr: struct] // Attribute macro can be used in nested macro.
struct Data{
@Foo3 @Foo4[123] var a = @Bar1(@Bar2(2 + 3) + 3) // Bar2, Bar1, Foo4, Foo3 expands in order.
public func getA() {
return @Foo(a + 2)
}
}
在嵌套场景下,存在多个宏时,有时不同宏间需要共享一些信息,往往通过在宏定义文件里定义某些全局变量的方式实现。不同的宏均可以访问、修改这些变量,其访问顺序与宏调用展开的顺序一致。
内层宏可以调用库函数 AssertParentContext 来保证内层宏调用一定嵌套在特定的外层宏调用中。如果内层宏调用这个函数时没有嵌套在给定的外层宏调用中,该函数将抛出一个错误。库函数 InsideParentContext 同样用于检查内层宏调用是否嵌套在特定的外层宏调用中,该函数返回一个布尔值。下面是一个简单的例子:
宏定义如下:
public macro Outer(input: Tokens): Tokens {
return input
}
public macro Inner(input: Tokens): Tokens {
AssertParentContext("Outer")
return input
}
宏调用如下:
@Outer var a = 0
@Inner var b = 0 // error: The macro call 'Inner' should with the surround code contains a call 'Outer'.
如上代码所示,Inner 宏在定义时使用了 AssertParentContext 函数用于检查其在调用阶段是否位于 Outer 宏中,在代码示例的宏调用场景下,由于 Outer 和 Inner 在调用时不存在这样的嵌套关系,因此编译器将报告一个错误。
内层宏也可以通过发送键/值对的方式与外层宏通信。当内层宏执行时,通过调用标准库函数 SetItem 向外层宏发送信息;随后,当外层宏执行时,调用标准库函数 GetChildMessages 接收每一个内层宏发送的信息(一组键/值对映射)。下面是一个简单的例子:
宏定义如下:
public macro Outer(input: Tokens): Tokens {
let messages = GetChildMessages("Inner")
for (m in messages) {
let value1 = m.getString("key1") // get value: "value1"
let value2 = m.getString("key2") // get value: "value2"
}
return input
}
public macro Inner(input: Tokens): Tokens {
AssertParentContext("Outer")
SetItem("key1", "value1")
SetItem("key2", "value2")
return input
}
宏调用如下:
@Outer(
@Inner var cnt = 0
)
在上面的代码中,内层宏 Inner 通过 SetItem 向外层宏发送信息;Outer 宏通过 GetChildMessages 函数接收到 Inner 发送的一组信息对象(Outer 中可以调用多次 Inner);最后通过该信息对象的 getString 函数接收对应的值。
内置宏
Attribute
仓颉语言内部提供 Attribute,开发者通过内置的 Attribute 来对某个声明设置属性值,从而达到标记声明的目的。属性值可以是 identifier 或者 string。下面是一个简单的例子:
@Attribute[State] var cnt = 0
@Attribute["Binding"] var bcnt = 0
同时,libast 提供了 getAttrs() 方法用于获取节点的属性,以及 hasAttr(attrs: String) 方法用于判断当前节点是否具有某个属性。下面是一个具体的例子:
宏定义如下:
public macro Component(input: Tokens): Tokens {
var varDecl = parseDecl(input)
if (varDecl.hasAttr("State")) { // 如果改节点被标记了属性且值为 “State” 返回 true, 否则返回 false
var attrs = varDecl.getAttrs() // 返回一组 Tokens
println(attrs[0].value)
}
return input
}
宏调用如下:
@Component(
@Attribute[State] var cnt = 0
)
源码位置
仓颉语言内部提供了如下三个内置宏,用于在编译阶段获取源码的相关信息。
@sourcePackage()展开后是一个String类型的字面量,内容为当前宏所在的源码的包名。@sourceFile()展开后是一个String类型的字面量,内容为当前宏所在的源码的文件名。@sourceLine()展开后是一个Int64类型的字面量,内容为当前宏所在的源码的代码行。
下面是相关示例:
// source.cj
package default
main() {
var pkgName = @sourcePackage() // pkgName 的值为 "default"
var fileName = @sourceFile() // fileName 的值为 "source.cj"
var line = @sourceLine() // line 的值为 7 (假设该语句位于文件的第 7 行)
return 0
}
memoize 宏分析
至此,关于 Tokens,quote,以及宏定义,宏调用的概念已经介绍完毕。再回到记忆优化宏 memoize 这个例子,可以较清楚地理解其背后的工作原理。
在 macro_definition.cj 这个文件中,我们定义一个宏 memoize,其使用了 Tokens 类型,以及 parseDecl API,它们都是在标准库 ast 包中定义的,需要导入 ast 包。
我们使用了属性宏,这样可以让用户传入标记位(@memoize[true] 里的 true 即是标记位),选择是否进行记忆优化。memoize 宏定义的入参和返回值类型都是 Tokens,即表示一段代码块,对于宏来说代码即数据。在宏定义内部,若不进行优化,则将输入的代码原样返回;若进行优化,则重新构造一段代码,这段代码里有函数 Fib 前添加的记录函数入参 - 函数值的 HashMap 变量,Fib 函数也被重新设计,增加了查表优化功能。这段代码是放在 quote 表达式里的,表示要将其转为 Tokens 返回。
宏调用 @memoize[true] 修饰后的 Fib 函数最终会在编译期被展开为如下代码:
var memoMap: HashMap<Int64, Int64> = HashMap<Int64, Int64>()
func Fib(n: Int64): Int64 {
if (memoMap.contains(n)) {
return memoMap.get(n).getOrThrow()
}
if (n == 0 || n == 1) {
return n
}
let ret = Fib(n-1) + Fib(n-2)
memoMap.put(n, ret)
return ret
}
可以看到,memoize 这个宏的主要作用是在编译期做一些代码生成的工作,让原程序执行效率更高,且优化细节不直接暴露在宏调用处,代码简洁,可读性高。
我们在使用时,先编译好宏定义文件,再编译宏调用文件。宏定义编译一次后,可被多个宏调用文件使用。若只是宏调用文件发生变动,宏定义不变,无需重新编译宏定义文件。
这里请注意,我们的宏 memoize 目前只能修饰 Fib 函数,函数名可以不同,但是不能用来修饰参数列表和返回值类型不同的函数,即 memoize 宏目前并不是通用的。开发者可以针对自己的需求,去写一个更通用的版本,比如解析函数的参数列表获取入参,解析返回值类型,根据这些信息去构造 HashMap,另外需要解析函数体获取最后的函数返回值,这些信息均可以通过 ast 包提供的 API 获取。
宏的编译和调试
宏的编译和使用流程
编译调用宏的文件,要求预先编译好宏定义文件,宏定义和宏调用要在不同的 package 中,下面是个简单的例子。
同普通仓颉工程一样,建议将源码放在 src 目录下,目录结构如下:
// Directory layout.
src
`-- macros
|-- m.cj
`-- demo.cj
宏定义放在 macros(用户自定义) 子目录下:
// m.cj
// In this file, we define the macro Inner, Outer.
macro package define
from std import ast.*
public macro Inner(input: Tokens) {
return input
}
public macro Outer(input: Tokens) {
return input
}
实际调用宏的文件如下:
// demo.cj
import define.*
@Outer
class Demo {
@Inner var state = 1
var cnt = 42
}
@Outer
main() {
println("test macro")
0
}
以下为 Linux 平台的编译命令(具体编译选项会随着 cjc 更新而演进,以最新 cjc 的编译选项为准):
# 当前目录: src
# 先编译宏定义文件在当前目录产生默认的动态库文件(允许指定动态库的路径,但不能指定动态库的名字)
cjc macros/m.cj --compile-macro
# 编译使用宏的文件,宏替换完成,产生可执行文件
cjc demo.cj -o demo
# 编译时增加 --parallel-macro-expansion 选项
# 两个 @Outer 宏调用可以并行展开,从而缩短编译时间
cjc --parallel-macro-expansion demo.cj -o demo
# 运行可执行文件
./demo
宏的调试
借助宏在编译期做代码生成时,如果发生错误,处理起来十分棘手,这是开发者经常遇到但一般很难定位的问题。这是因为,开发者写的源码,经过宏的变换后变成了不同的代码片段。编译器抛出的错误信息是基于宏最终生成的代码进行提示的,但这些代码在开发者的源码中没有体现。
为了解决这个问题,仓颉宏提供 debug 模式,在这个模式下,开发者可以从编译器为宏生成的 debug 文件中看到完整的宏展开后的代码,如下所示:
// code before macro expansion
// demo.cj
@Outer
class Demo {
@Inner var state = 1
var cnt = 42
}
在编译使用宏的文件时,在选项中,增加 --debug-macro,即使用仓颉宏的 debug 模式。
cjc --debug-macro demo.cj
在 debug 模式下,会生成临时文件 demo.cj.macrocall,对应宏展开的部分如下:
// demo.cj.macrocall
// ===== Emitted by Macro Outer at line 3 =====
class Demo {
var stateNew = 1
var cnt = 42
func getcnt( ) {
return cnt
}
}
// ===== End of the Emit =====
如果宏展开后的代码有语义错误,则编译器的错误信息会溯源到宏展开后代码的具体行列号。仓颉宏的 debug 模式有以下注意事项:
- 宏的 debug 模式会重排源码的行列号信息,不适用于某些特殊的换行场景。比如
// before expansion
@M{} - 2 // macro M return 2
// after expansion
// ===== Emmitted my Macro M at line 1 ===
2
// ===== End of the Emit =====
- 2
这些因换行符导致语义改变的情形,不应使用 debug 模式。
- 不支持宏调用在宏定义内的调试,会编译报错。
public macro M(input: Tokens) {
let a = @M2(1+2) // M2 is in macro M, not suitable for debug mode.
return input + quote($a)
}
- 不支持带括号宏的调试。
// main.cj
main() {
// For macro with parenthesis, newline introduced by debug will change the semantics
// of the expression, so it is not suitable for debug mode.
let t = @M(1+2)
0
}
自动微分
前言
自动微分是一种对程序中的函数计算导数的技术。相比符号微分,其避免了表达式膨胀的性能问题;而相比数值微分,其解决了近似误差的正确性问题。
关于自动微分技术本身的相关背景知识,我们将不在本手册中进行详细介绍。推荐用户阅读以下参考文献进行详细了解。
- How to Differentiate with a Computer
- Automatic Differentiation in Machine Learning: a Survey
- Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation
在仓颉编程语言中,自动微分将作为原生语言特性被提供给用户,用户可以通过配置编译选项 --enable-ad 来开启自动微分特性。
cjc --enable-ad helloworld.cj
需要说明的是,目前仓颉自动微分特性仅支持反向模式自动微分。
可微类型
在仓颉自动微分的库中,我们提供了Differentiable interface 用于定义仓颉中数据类型的微分规则。所有参与自动微分中导数计算的数据类型均应实现该 interface 以确保被自动微分系统认为是合法的可微类型。
// Defined in the AD library
public interface Differentiable<T> where T <: Differentiable<T> {
// Initialize a zero tangent
func TangentZero(): T
// Sum up the tangent value `y`
func TangentAdd(y: T): T
}
对于可微类型(例如浮点数类型、元组类型、struct类型),编译器会自动生成合理的 interface 实例,对于可微struct类型,用户也可以通过手动实现该 interface 实例。
可微数值类型
仓颉中的可微数值类型包括三种:
Float16Float32Float64
可微元组类型
当元组中所有元素均为可微类型时,则该元组是可微元组类型。
let a: (Float64, Float64) = (1.0, 1.0) // differentiable
let b: (Float64, String) = (1.0, "foo") // NOT differentiable
可微 struct 类型
默认情况下,struct 类型不可微,当 struct 类型不包含静态成员变量时,用户可在 struct 类型定义上方增加 @Differentiable 标注,将其定义为可微并通过 except 列表配置该 struct 类型的微分行为。
给定 except 列表后,该 struct 类型的成员变量将分为两类。
- 不在
except列表中的成员变量,必须为不可变变量,并且其类型为可微类型,成员变量将参与该struct类型对象的微分过程 - 在
except列表中的成员变量将不参与该struct类型对象的微分过程。在微分过程中,该成员变量将被保持为未初始化状态。因此用户应确保不访问微分结果中的这些成员变量值,否则将导致未定义行为
// Differentiable
@Differentiable
struct Point {
let x: Float64
let y: Float64
init(x: Float64, y: Float64) {
this.x = x
this.y = y
}
}
// Differentiable, but no back-propagation will happen in the excepted field `tag`
@Differentiable [except: [tag]]
struct TaggedPoint {
let x: Float64
let y: Float64
let tag: String
init(x: Float64, y: Float64, tag: String) {
this.x = x
this.y = y
this.tag = tag
}
}
// Compilation Error: variable `tag` has non-differentiable type String,
// but it does not appear in an except list
@Differentiable
struct TaggedWrong {
let x: Float64
let y: Float64
let tag: String
init(x: Float64, y: Float64, tag: String) {
this.x = x
this.y = y
this.tag = tag
}
}
我们也提供了定义 except 列表的另外一个语法糖版本,用户可以通过以下语法定义 struct 类型的 include 列表。此时,struct 所有不在该 include 列表中的成员变量都被定义为在 except 列表中。
// Differentiable, but no back-propagation will happen in the excepted field `tag`
@Differentiable [include: [x, y]]
struct TaggedPoint {
let x: Float64
let y: Float64
let tag: String
init(x: Float64, y: Float64, tag: String) {
this.x = x
this.y = y
this.tag = tag
}
}
可微 unit 类型
Unit 类型是一种特殊的可微类型。对任何 Unit 类型对象的微分操作所得结果均仍是 Unit 类型。
不可微类型
仓颉自动微分暂不支持对 String、Array、enum、Class、 Int16、 Int32 、 Int64和 Interface 类型数据的微分,故这些类型均为不可微类型。
可微函数
默认情况下,函数均为不可微,但用户可以在函数定义上方增加 @Differentiable 标注,将其定义为可微并通过 except 列表配置该函数的微分行为。
给定 except 列表后,该函数的参数将分为两类。
- 不在
except列表中的参数,必须为可微类型。该参数将参与函数的微分过程,微分结果中将包含函数相对该参数的导数 - 在
except列表中的参数将不参与函数的微分过程。在微分过程中,该类参数及依赖该参数的中间变量均将被忽略,微分结果中将不包含函数相对该参数的导数
// Differentiable function, its derivatives will be calculated with respect to `x` and `y`
@Differentiable
func f(x: Float64, y: Float64) {
return x * y
}
// Differentiable function, its derivative will only be calculated with respect to `x`
@Differentiable [except: [y]]
func f(x: Float64, y: Float64) {
return x * y
}
// Compilation Error: input `z` has non-differentiable type String,
// but it does not appear in an except list
@Differentiable
func f(x: Float64, y: Float64, z: String) {
return x + y
}
相似地,我们也提供了定义 except 列表的另外一个语法糖版本,用户可以通过以下语法定义函数的 include 列表。此时,函数所有不在该 include 列表中的参数都被定义为在 except 列表中。except 和 include 只能出现一个。
// Differentiable function, its derivative will only be calculated with respect to `x`
@Differentiable [include: [x]]
func f(x: Float64, y: Float64) {
return x * y
}
在使用上述语法进行可微函数定义时,用户还需要确保函数满足以下条件。
- 函数的返回类型为可微类型
- 函数参数为可微类型,且不在
except列表中(或在include列表中) - 函数中未使用全局变量
- 函数中未使用静态变量
- 函数体中所有表达式均为可微函数合法表达式,即表达式需满足以下任一条件
- 表达式可微,即其微分规则已知。目前仓颉支持的可微表达式如下:
- 赋值表达式
- 算术表达式
- 流表达式
- 条件表达式(
if) - 循环表达式(仅
while,do-while),并且不支持使用continue,break,return - lambda 表达式
- 可微
Tuple类型对象的初始化表达式 - 可微
Tuple类型对象的解构和下标访问表达式 - 对可微函数的函数调用表达式,且在编译期可以确定哪一个可微函数定义被调用
- 表达式不直接或间接地与不在
except列表中的函数参数(包括嵌套函数的外层作用域函数参数)有数据依赖关系。若必须产生数据依赖关系,则可以使用 [stopGradient函数接口] 来中止梯度传播 - 可微函数(嵌套函数或匿名函数)中
return表达式(包括自动插入的return表达式)只能出现一次 - 嵌套函数或匿名函数未捕获可变变量
- 表达式可微,即其微分规则已知。目前仓颉支持的可微表达式如下:
// Not differentiable
func f1(x: Float64, y: Float64): Float64 {
return x + y
}
// Compilation Error: expression x is marked for back-propagation,
// but is used in a context that cannot be back-propagated
@Differentiable
func f2(x: Float64, y: Float64): Float64 {
return f1(x, y)
}
// Compilation Error: match expression is not supported in differentiable function
@Differentiable
func f3(x: Float64) {
var a = match (x) {
case _ => 1.0
}
return a
}
@Differentiable
func f4 (x: Float64) {
var y = 1.0
// Compilation Error: capture mutable variable y in nested function is not supported by AD yet
func nested (x: Float64) {
y = y + x
}
nested(x)
}
@Differentiable [except: [n]]
func g(m: Float64, n: Float64) {
return m + n
}
@Differentiable
func f5(x: Float64, y: Float64) {
// Use `stopGradient` to stop the gradient propagation so we can
// pass the `y` in `f5` to `n` in `g` even `n` is marked as `except`
return g(x, stopGradient<Float64>(y))
}
func g(m: Float64) {
return m == 1.0
}
@Differentiable
func f6(x: Float64) {
// Use `stopGradient` to stop the gradient propagation so we can
// pass the `x` in `f6` to non-differentiable function `g`
let cond = g(stopGradient<Float64>(x))
if (cond) {
x * 2.0
} else {
x * 3.0
}
}
注意:为了方便计算 lambda 表达式捕获变量的导数,我们在仓颉自动微分的库中预定义了以下两个接口,这两个接口将被仓颉的自动微分实现模块调用,不建议用户直接使用。
/* lambda 表达式捕获变量的导数组成的环境变量类型的基类 */
public abstract class EnvironmentTangent {
/* 合并两部分环境变量导数 */
public func TangentAdd(other: EnvironmentTangent): EnvironmentTangent
}
/* 环境变量类型对应的 0 梯度类型 */
public class EnvironmentZero <: EnvironmentTangent {
public func TangentAdd(other: EnvironmentTangent): EnvironmentTangent {
return other
}
}
自定义函数微分规则
用户还可以通过手动提供伴随函数来为可微函数自定义微分规则。给定一个可微的全局函数 f (称为:源函数),用户可通过在另一个函数 g 的函数定义上方添加 @Adjoint 标注,将其指定为 f 的自定义伴随函数。
伴随函数需满足以下条件:
- 伴随函数的输入参数的数量、类型和顺序与原可微函数完全一致
- 伴随函数的输出是一个包含两个子元素的元组
- 元组第一个子元素为原可微函数在当前伴随函数的参数输入下的输出结果
- 元组第二个子元素为一个函数,作为原可微函数的梯度反向传播器
- 梯度反向传播器的输入类型与原可微函数的输出数量、类型和顺序一致
- 梯度反向传播器的输出类型与原可微函数的输入数量、类型和顺序一致
// Function `f` is differentiable and its custom adjoint function is `g`
@Differentiable
func f(x: Float64): Float64 {
return x * x * x
}
@Adjoint [primal: f]
func g(x: Float64): ((Float64), ((Float64) -> Float64)) {
let xSquare = x * x
return (
xSquare * x,
{ dy: Float64 =>
return dy * xSquare * 3.0
}
)
}
当用户通过上述语法为源函数自定义伴随函数后,自动微分系统将直接使用该自定义伴随函数进行微分求导。需要注意的是我们当前暂不支持用户对参数或返回值包含函数类型的可微函数自定义伴随函数。
非全局可微函数
需要注意的是,上述可微函数规则默认应用于全局函数。事实上,仓颉编程语言中存在多种非全局函数。在自动微分系统中,我们支持以下非全局函数被定义为可微函数,其他类型的非全局函数均不支持定义为可微函数。
struct 构造函数和成员函数
用户可以使用相同的可微函数标注 @Differentiable 将 struct 中的构造函数和成员函数定义为可微。
struct构造函数标注为可微。定义构造函数为可微的前提是struct类型本身可微。在这种情况下,调用该构造函数的struct初始化表达式可微。相反地,若构造函数未被标注为可微,则调用该构造函数的struct初始化表达式不可微struct成员函数标注为可微。根据仓颉语言定义,struct成员函数隐藏包含了一个标识符为this的函数参数用于表示struct对象本身,故用户也可以在except列表中配置this参数来决定是否需要对this进行微分。
@Differentiable
struct Point {
let a: Float64
let b: Float64
// Differentiable constructor
@Differentiable
init(x: Float64) {
a = x
b = x
}
}
@Differentiable
func foo(x: Float64) {
// The initialization will call the differentiable constructor.
// Therefore it is differentiable here.
return Point(x)
}
@Differentiable
struct Point {
let a: Float64
let b: Float64
init(x: Float64) {
a = x
b = x
}
// Differentiable method
@Differentiable
public func sum(bias: Float64): Float64 {
return a + b + bias
}
}
Class 成员函数
用户也可以使用相同的可微函数标注 @Differentiable 将 class 中的非open成员函数定义为可微。同样根据仓颉语言定义,class 成员函数隐藏包含了一个标识符为 this 的函数参数用于表示 class 对象本身。由于在仓颉中由于 class 类型本身不可微,故除静态成员函数外,用户必须将 this 加入到可微成员函数的 except 列表中。另外需要注意的是,返回类型为This的成员函数因返回类型不可微,所以无法被定义成可微。
class Point {
let a: Float64
let b: Float64
init(x: Float64) {
a = x
b = x
}
// Function foo can not be defined as differentiable
func foo(): This {
return this
}
// Differentiable method. But user must add `this` in the `except` list here.
@Differentiable [except: [this]]
func sum(bias: Float64): Float64 {
return a + b + bias
}
}
拓展的成员函数
用户也可以使用相同的可微函数标注语法将扩展的成员函数定义为可微,支持直接扩展和接口扩展。
interface I {
func goo(a: Float64, b: Float64): Float64
}
@Differentiable
struct Foo {}
// direct extensions
extend Foo {
@Differentiable
func foo(a: Float64, b: Float64) {
return a + b
}
}
// interface extensions
extend Foo <: I {
@Differentiable
public func goo(a: Float64, b: Float64) {
return a + b
}
}
如果需要扩展的类型不可微,用户必须将this加入到扩展的可微成员函数的except列表中。
interface I {
func goo(a: Float64, b: Float64): Float64
}
struct Foo {}
// direct extensions
extend Foo {
@Differentiable[except: [this]]
func foo(a: Float64, b: Float64) {
return a + b
}
}
// interface extensions
extend Foo <: I {
@Differentiable[except: [this]]
public func goo(a: Float64, b: Float64) {
return a + b
}
}
微分表达式
@Grad表达式
给定一个可微函数和相应的输入参数值,用户可使用 @Grad 表达式来获取该函数在该输入值处的梯度值。
@Differentiable [except: [negate]]
func product(x: Float64, y: Float64, negate: Bool): Float64 {
return if (negate) { - x * y } else { x * y }
}
main(): Int64 {
// Since `negate` is excepted, the gradient of product only has two components
let productGrad = @Grad(product, 2.0, 3.0, true)
print(productGrad[0].toString()) // Prints -3.000000
print(productGrad[1].toString()) // Prints -2.000000
return 0
}
使用@Grad表达式时有以下注意事项
@Grad表达式只能作为初始值用于 var 或 let 变量初始化表达式中- 给定的
diffFunc标识符必须表示一个函数,且满足以下条件- 必须是全局函数
- 必须是可微函数
- 函数不能有命名参数和参数默认值
- 函数的返回类型只能是一下类型之一:
Float16,Float32,Float64
inputVal组成的集合必须与diffFunc表示的函数的参数匹配,匹配规则与形为diffFunc(inputVal, ...)的函数调用匹配规则相同- 给定上述类型为
(X1, X2, ..., Xm)->Y的函数diffFunc- 若其
except列表为空,则@Grad表达式的类型为(X1, X2, ..., Xm)。若该Tuple类型元素数量为 0,则退化为Unit类型,若该Tuple类型仅包含一个元素Xj,则退化为Xj类型 - 若其
except列表不为空,则@Grad表达式的类型中需相应地剔除在except列表中的函数参数类型。假定except列表中包含的参数为Xj,则@Grad表达式的类型为(X1, X2, ..., Xj-1, Xj+1, Xm)
- 若其
@Differentiable
func foo(x: Float64, y: Float64): Float64 {
return x * y
}
main() {
let res = @Grad(foo, 2.0, 3.0) // Ok
// Compilation Error: @Grad expr must be used in var decl with an identifier
print(@Grad(foo, 2.0, 3.0)[0].toString())
// Compilation Error: @Grad expr must be used in var decl with an identifier
let (gradx, grady) = @Grad(foo, 2.0, 3.0)
return 0
}
@Differentiable
struct A {
@Differentiable
public func foo(x: Float64, y: Float64) {
return x + y
}
}
main() {
let a = A()
// Compilation Error: the function is not a top-level differentiable function identifier
let temp = @Grad(a.foo, 1.0, 1.0)
return 0
}
@ValWithGrad表达式
给定一个可微函数和相应的输入参数值,用户可使用 @ValWithGrad 表达式来获取该函数在该输入值处的结果和梯度值。
@Differentiable [except: [negate]]
func product(x: Float64, y: Float64, negate: Bool): Float64 {
return if (negate) { - x * y } else { x * y }
}
main(): Int64 {
let productValWithGrad = @ValWithGrad(product, 2.0, 3.0, true)
let (productRes, productGrad) = productValWithGrad
print(productRes.toString()) // Prints -6.000000
print(productGrad[0].toString()) // Prints -3.000000
print(productGrad[1].toString()) // Prints -2.000000
return 0
}
使用@ValWithGrad表达式时有以下注意事项。
@ValWithGrad表达式只能作为初始值用于 var 或 let 变量初始化表达式中- 给定的
diffFunc标识符必须表示一个函数,且满足以下条件- 必须是全局函数
- 必须是可微函数
- 函数不能有命名参数和参数默认值
- 函数的返回类型只能是一下类型之一:
Float16,Float32,Float64
inputVal组成的集合必须与diffFunc表示的函数的参数匹配,匹配规则与形为diffFunc(inputVal, ...)的函数调用匹配规则相同- 给定上述类型为
(X1, X2, ..., Xm)->Y的函数diffFunc- 若其
except列表为空,则@ValWithGrad表达式的类型为(Y, (X1, X2, ..., Xm))。若该Tuple类型元素数量为 0,则退化为(Y, Unit)类型,若该Tuple类型仅包含一个元素Xj,则退化为(Y, Xj)类型 - 若其
except列表不为空,则@ValWithGrad表达式的类型中需相应地剔除在except列表中的函数参数类型。假定except列表中包含的参数为Xj,则@ValWithGrad表达式的类型为(Y, (X1, X2, ..., Xj-1, Xj+1, Xm))
- 若其
@Differentiable
func foo(x: Float64, y: Float64): Float64 {
return x * y
}
main() {
let res = @ValWithGrad(foo, 2.0, 3.0) // Ok
// Compilation Error: @ValWithGrad expr must be used in var decl with an identifier
print(@ValWithGrad(foo, 2.0, 3.0)[0].toString())
// Compilation Error: @ValWithGrad expr must be used in var decl with an identifier
let (res, (gradx, grady)) = @ValWithGrad(foo, 2.0, 3.0)
return 0
}
@Differentiable
struct A {
@Differentiable
public func foo(x: Float64, y: Float64) {
return x + y
}
}
main() {
let a = A()
// Compilation Error: the function is not a top-level differentiable function identifier
let temp = @ValWithGrad(a.foo, 1.0, 1.0)
return 0
}
@AdjointOf表达式
给定一个可微函数,用户还可以使用 @AdjointOf 表达式来获取对该函数微分产生的伴随函数。
@AdjointOf表达式只能作为初始值用于 var 或 let 变量初始化表达式中- 给定的
diffFunc标识符必须表示一个函数,且满足以下条件- 必须是全局函数
- 必须是可微函数
- 函数不能有命名参数和参数默认值
- 给定上述类型为
(X1, X2, ..., Xm)->Y的函数diffFunc- 若其
except列表为空,则@AdjointOf表达式的类型为(X1, X2, ..., Xm)->(Y, (Y) -> (X1, X2, ..., Xm))。若该Tuple类型元素数量为 0,则退化为(X1, X2, ..., Xm)->(Y, (Y) -> Unit)类型,若该Tuple类型仅包含一个元素Xj,则退化为(X1, X2, ..., Xm)->(Y, (Y) -> Xj)类型 - 若其
except列表不为空,则@AdjointOf表达式的类型中需相应地剔除在except列表中的函数参数类型。假定except列表中包含的参数为Xj,则@AdjointOf表达式的类型为(X1, X2, ..., Xm)->(Y, (Y) -> (X1, X2, ..., Xj-1, Xj+1, Xm))
- 若其
@Differentiable
func foo(x: Float64, y: Float64): Float64 {
return x * y
}
main() {
// Get the adjoint function of `foo`
let fooAdj = @AdjointOf(foo)
// Given the value of `x` as 2.0 and `y` as 3.0, the adjoint function
// will return:
// 1) the result of `foo` when `x = 2.0` and `y = 3.0`
// 2) an back-propagator which propagates the gradient from output to input for `foo`
let res = fooAdj(2.0, 3.0)
let fooRes = res[0] // Prints 6.000000
let fooBP = res[1] // The back-propagator
let (dx, dy) = fooBP(1.0)
print(dx.toString()) // Prints 3.000000
print(dy.toString()) // Prints 2.000000
}
@VJP表达式
给定一个可微函数和相应的输入参数值,用户可使用@VJP表达式来获取该函数在该输入值处的结果和反向传播函数。
使用@VJP表达式时有以下注意事项。
- 给定的
diffFunc标识符必须表示一个函数,且满足以下条件- 必须是全局函数
- 必须是可微函数
- 函数不能有命名参数和参数默认值
inputVal组成的集合必须与diffFunc表示的函数的参数匹配,匹配规则与形为diffFunc(inputVal, ...)的函数调用匹配规则相同- 给定上述类型为
(X1, X2, ..., Xm)->Y的函数diffFunc- 若其
except列表为空,则@VJP表达式的类型为(Y, (Y) -> (X1, X2, ..., Xm))。若该Tuple类型元素数量为 0,则退化为(Y, (Y) -> Unit)类型,若该Tuple类型仅包含一个元素Xj,则退化为(Y, (Y) -> Xj)类型 - 若其
except列表不为空,则@VJP表达式的类型中需相应地剔除在except列表中的函数参数类型。假定except列表中包含的参数为Xj,则@VJP表达式的类型为(Y, (Y) -> (X1, X2, ..., Xj-1, Xj+1, Xm))
- 若其
@Differentiable [except: [negate]]
func product(x: Float64, y: Float64, negate: Bool): Float64 {
return if (negate) { - x * y } else { x * y }
}
main(): Int64 {
let productVJP = @VJP(product, 2.0, 3.0, true)
let (productRes, productBP) = productVJP
print(productRes.toString()) // Prints -6.000000
let productGrad = productBP(1.0)
print(productGrad[0].toString()) // Prints -3.000000
print(productGrad[1].toString()) // Prints -2.000000
return 0
}
stopGradient函数接口
在可微函数中,用户还可以使用 stopGradient 函数接口来强制中止某个变量或中间结果上的梯度传播。stopGradient 函数实现为一个泛型函数,可接受任意类型数据输入并将其直接返回。因此,该函数接口的使用不影响原可微函数的执行逻辑,但自动微分系统将识别该函数接口,并中止函数参数 x 对应变量或中间结果的梯度传播。此外,stopGradient 函数作用于函数时,可以把可微函数变成不可微函数。
public func stopGradient<T>(x: T) {
return x
}
@Differentiable
func foo(x: Float64) {
let t0 = x * 2.0
let t1 = x * 3.0
return t0 + t1 // Both `t0` and `t1` will propagate gradient to `x`
}
@Differentiable
func goo(x: Float64) {
let t0 = x * 2.0
let t1 = x * 3.0
return t0 + stopGradient<Float64>(t1) // Only `t0` will propagate gradient to `x`
}
main() {
let res0 = @Grad(foo, 1.0) // `res0` will be 5.0
let res1 = @Grad(goo, 1.0) // `res1` will be 2.0
}
伴随函数的导入/导出
给定一个在包中定义的源函数,自动微分系统将对其微分并在该包中生成它的伴随函数。该伴随函数将具有和源函数相同的 public 属性。用户可以通过使用 import a.* 确保伴随函数与源函数拥有一致的导入/导出行为,即当用户导入源函数时其伴随函数将一并被导入,从而允许用户在当前包对该函数进行微分操作。
//================================= file A
package a
// AD system will generate `fooAdj` as the adjoint of `foo`
// `fooAdj` also has `public` attribute
@Differentiable
public func foo(x: Float64) {
return x
}
//================================= file B
package b
// Will also import a.fooAdj implicitly
import a.*
main() {
// The AD system will use the `a.fooAdj` as the adjoint of `a.foo` for differentiation
let gradRes = @Grad(foo, 2.0)
print(gradRes.toString()) // Prints 1.000000
0
}
需要注意的是,若用户实现了自定义伴随函数,则也需要为该伴随函数手动配置 public 属性,从而确保该伴随函数也会被同步导入。除此之外,在导入/导出场景下,给定一个源函数,多个来自不同来源的伴随函数有可能同时出现。在这种情况下,我们定义了如下规则来确定不同版本伴随函数的优先级和使用规则。
- 当前包内定义的本地伴随函数比从其他包导入的伴随函数优先级更高,后者将被前者屏蔽
- 若出现多个从其他包导入的不同版本伴随函数且无本地伴随函数时,将触发编译器报错
//================================= file A
package a
@Differentiable
public func foo(x: Float64): Float64 {
return x
}
@Adjoint [primal: foo]
public func dfoo(x: Float64): (Float64, (Float64)->Float64) {
return (
x,
{ dy: Float64 =>
return 1.0 * dy
}
)
}
//================================= file B
import a.*
@Adjoint [primal: foo]
func localDFoo(x: Float64): (Float64, (Float64)->Float64) {
return (
x,
{ dy: Float64 =>
return 1.0 * dy
}
)
}
main() {
// The AD system will use the `localDFoo` as the
// adjoint of `a.foo` for differentiation, since
// it has higher priority than the `a.dfoo`
let gradRes = @Grad(foo, 2.0)
print(gradRes.toString()) // Prints 1.000000
0
}
//================================= file A
package a
@Differentiable
public func foo(x: Float64): Float64 {
return x
}
//================================= file B
package b
import a.*
@Adjoint [primal: foo]
public func dfooB(x: Float64): (Float64, (Float64)->Float64) {
return (
x,
{ dy: Float64 =>
return 1.0 * dy
}
)
}
//================================= file C
package c
import a.*
@Adjoint [primal: foo]
public func dfooC(x: Float64): (Float64, (Float64)->Float64) {
return (
x,
{ dy: Float64 =>
return 1.0 * dy
}
)
}
//================================= file D
import a.*, b.*, c.*
main() {
// Compilation Error: multiple imported adjoint for function foo are found
let grad_res = @Grad(foo, 2.0)
0
}
高阶微分
用户可以在微分函数中使用 @Grad,@ValWithGrad,@AdjointOf ,@VJP等表达式来实现高阶微分的效果。
此时用户需要在 @Differentiable 标注中额外提供 stage 信息来标记该微分函数的最高微分阶数(若未提供则默认最高微分阶数为一阶),若阶数信息不正确则将引发编译器报错。
注:目前高阶微分最高支持 2 阶,即
stage取值只能是1和2。 阶数检查规则:
stage=1的函数中可以使用stage=1,2的可微函数调用表达式,可以包含stage=2的函数的微分表达式stage=2的函数中可以使用stage=2的函数调用表达式
@Differentiable [stage: 2]
func f1(x: Float64) {
x * x * x // Will be differentiated as `df1/dx = 3 * x * x`
}
@Differentiable
func f2(x: Float64) {
let dx = @Grad(f1, x) // Will be differentiated as `df2/dx = d(df1/dx)/dx = 6 * x`
dx
}
main() {
let x: Float64 = 1.0
let firstOrderGrad = @Grad(f1, x)
let secondOrderGrad = @Grad(f2, x)
println(firstOrderGrad.toString()) // Prints 3.000000
println(secondOrderGrad.toString()) // Prints 6.000000
return 0
}
需要注意的是,不允许在微分函数中对函数本身或将调用函数本身的函数使用 @Grad,@ValWithGrad,@AdjointOf, @VJP 表达式,否则将产生循环依赖从而引发编译器报错。
包管理
随着项目的规模不断地扩大,仅在一个超大文件中管理源代码会变得十分困难。这时可以将源代码根据功能进行分组,并将不同功能的代码分开管理,每组独立管理的代码会生成一个输出文件。在使用时,通过导入对应的输出文件使用相应的功能,或者通过不同功能的交互与组合实现更加复杂的特性,使得项目管理更加高效。
在仓颉编程语言中,包是编译的最小单元,每个包可以单独输出 AST 文件、静态库文件、动态库文件等产物。每个包有自己的名字空间,在同一个包内不允许有同名的顶层定义或声明(函数重载除外)。一个包中可以包含多个源文件。
模块是若干包的集合,是第三方开发者发布的最小单元。一个模块的程序入口只能在其根目录下,它的顶层最多只能有一个作为程序入口的 main ,该 main 没有参数或参数类型为 Array<String>,返回类型为整数类型或 Unit 类型。
仓颉语言提供 CJPM 作为包管理工具,详见工具用户手册 Cangjie Tools User Guide 的对应章节。仓颉提供了包编译的方式对一个包进行编译,形如:
cjc --package path_to_package_directory --module-name moduleName --output path_to_output_directory
其中,命令各部分解析如下:
| 命令内容 | 命令含义 |
|---|---|
--package | 表示编译方式,--package 为包编译(默认为文件编译) |
path_to_package_directory | 包所在目录 |
--module-name | 用来指定输出模块名 |
moduleName | 输出模块名 |
--output | 用来指定输出路径 |
path_to_output_directory | 输出文件路径 |
对于当前包所依赖的包,编译器会先后在 --import-path 指定的路径、当前路径、CANGJIE_PATH 指定的路径和CANGJIE_HOME 指定的路径下查询依赖的相关文件。其中 CANGJIE_PATH 和 CANGJIE_HOME 是用户设置的环境变量,可以效仿[入门指南]进行设置,它们分别是第三方库所在目录和仓颉编译器及标准库所在目录。
可以通过 --scan-dependency 指令获得指定包源码或者一个包的 cjo 文件对于其他包的直接依赖以及其他信息,标准库相关依赖不会输出,以 json 格式输出到命令行。
// this file is placed under directory pkgA
macro package pkgA
import pkgB.*
from std import io.*
from module2 import pkgB.*
cjc --scan-dependency --package pkgA --module-name module1
{"packageName":"module1/pkgA","isMacroPackage":true,"dependencies":[{"moduleName":"module1","packageName":"pkgB"},{"moduleName":"module2","packageName":"pkgB"}]}
cjc --scan-dependency pkgA.cjo
{"packageName":"module1/pkgA","isMacroPackage":true,"dependencies":[{"moduleName":"module1","packageName":"pkgB"},{"moduleName":"module2","packageName":"pkgB"}]}
仓颉命令行指令的详细解析,可以通过 --help 指令获得:
cjc --help
声明包的名字
在仓颉编程语言中,可以通过形如 package name 的方式声明名为 name 的包,其中 package 为关键字,name 须为仓颉的合法标识符。包声明必须在源文件的非空非注释的首行,且同一个包中的不同源文件的包声明必须保持一致。如
// file 1
// Comments are accepted
package test
// declarations...
// file 2
let a = 1 // Error, package declaration must appear first in a file
package test
// declarations...
仓颉的包名需反映当前源文件相对于项目源码根目录 src 的路径,并将其中的路径分隔符替换为小数点。例如包的源代码位于 src/directory_0/directory_1 下,则其源代码中的包声明应为 package directory_0.directory_1。
注意:
- 包所在的文件夹名也必须是合法标识符,不能包含
.等其他符号。 - 源码根目录默认名为
src。 - 源码根目录下的包可以没有包声明,此时编译器将默认为其指定包名
default。
假设源代码目录结构如下:
// The directory structure is as follows:
src
`-- directory_0
|-- directory_1
| |-- a.cj
| `-- b.cj
`-- c.cj
`-- main.cj
则 a.cj、b.cj、c.cj、main.cj 中的包声明可以为
// a.cj
// in file a.cj, the declared package name must correspond to relative path directory_0/directory_1.
package directory_0.directory_1
// b.cj
// in file b.cj, the declared package name must correspond to relative path directory_0/directory_1.
package directory_0.directory_1
// c.cj
// in file c.cj, the declared package name must correspond to relative path directory_0.
package directory_0
// main.cj
// file main.cj is in the module root directory and may omit package declaration.
main() {
return 0
}
另外,包声明不能引起命名冲突:
-
包名与当前包的顶层声明不能重名。
-
当前包的顶层声明不能与子目录的包名同名。
以下是一些错误示例:
// a.cj
package c // Error, package name conflicts with top-level class name.
class c {}
// b.cj
package a
public class B {
/* Error, top-level declaration "B" conflicts with the sub-directory of the same name */
public func f() {}
}
// c.cj
/* Error, package "a.B" conflicts with the top-level declaration "B" in package "a".*/
package a.B
public func f {}
// main.cj
import a.*
import a.B
main() {
/* Error, cannot distinguish a.B is the package a.B or the class B in package b. */
a.B.f()
return 0
}
顶层声明的可见性
顶层声明可见性为包内可见
如果希望包中某个顶层声明仅在包内被使用,顶层声明前不需要加任何修饰。所有顶层声明的可见性默认是包内可见的(internal)。
// a.cj
package a
// if top-level declaration C has no modifier,
// it's not accessible to other packages except package a.
class C {}
顶层声明可见性为包外可见
如果希望包中的某个顶层声明被导出,从而能被其他包使用,应当在顶层声明前加 public 修饰。被 public 修饰的顶层声明的可见性被认为是包外可见的(external)。
// a.cj
package a
public interface I {}
public 修饰的顶层声明不能使用包外不可见的类型
-
函数声明中的参数与返回值
// a.cj package a class C {} public func f1(a1: C) // Error, external declaration f1 cannot use internal type C. { return 0 } public func f2(a1: Int8): C // Error, external declaration f2 cannot use internal type C. { return C() } public func f3 (a1: Int8) // Error, external declaration f3 cannot use internal type C. { return C() } -
变量声明
// a.cj package a class C {} public let v1: C = C() // Error, external declaration v1 cannot use internal type C. public let v2 = C() // Error, external declaration v2 cannot use internal type C. -
类声明中继承的类
// a.cj package a open class C1 {} public class C2 <: C1 {} // Error, external declaration C2 cannot use internal type C1. -
类型实现的接口
// a.cj package a interface I {} public enum E <: I {} // Error, external declaration uses internal types. -
泛型类型的类型实参
// a.cj package a public class C1<T> {} class C2 {} public let v1 = C1<C2>() // Error, external declaration v1 cannot use internal type C2. -
where约束中的类型上界// a.cj package a interface I {} public class B<T> where T <: I {} // Error, external declaration B cannot use internal type I.
值得注意的是:
-
public修饰的声明在其初始化表达式或者函数体里面可以使用本包可见的任意类型,包括public修饰的类型和没有public修饰的类型。// a.cj package a class C1 {} func f1(a1: C1) { return 0 } public func f2(a1: Int8) // ok. { var v1 = C1() return 0 } public let v1 = f1(C1()) // ok. public class C2 // ok. { var v2 = C1() } -
public修饰的顶层声明能使用匿名函数,或者任意顶层函数,包括public修饰的类型和没有public修饰的顶层函数。public var t1: () -> Unit = { => } // Ok. func f1(): Unit {} public let t2 = f1 // Ok. public func f2() // Ok. { return f1 } -
内置类型诸如
Char、Int64等也都默认是public的。var num = 5 public var t3 = num // Ok.
包的导入
使用 import 语句导入其它包中的声明或定义
在仓颉编程语言中,可以通过 from moduleName import packageName.itemName 的语法导入其他包中的一个顶层声明或定义,其中 moduleName 为模块名,packageName 为包名,itemName 为声明的名字。导入当前模块中的内容时,可以省略 from moduleName;跨模块导入时,必须使用 from moduleName 指定模块。导入语句在源文件中的位置必须在包声明之后,其他声明或定义之前。例如:
package a
from std import math.*
from module_name import package1.foo
from module_name import package1.foo, package2.bar
如果要导入的多个 itemName 同属于一个 packageName,可以使用 from moduleName import packageName.{itemName[, itemName]*} 语法,例如:
from module_name import package1.{foo, bar, fuzz}
这等价于:
from module_name import package1.foo, package1.bar, package1.fuzz
除了通过 import packagename.itemName 语法导入一个特定的顶层声明或定义外,还可以使用 import packageName.* 语法将 packageName 包中所有 public 修饰的顶层声明或定义全部导入。例如:
from module_name import package1.*
from module_name import package1.*, package2.*
from module_name import package1 // Error.
需要注意:
- 当前源文件中导入的内容在源文件所属包的所有其他源文件中也可见。
- 当已导出的包的模块名或者包名被篡改,使其与导出时指定的模块名或包名不一致,在导入时,即使通过修改相应的
from ... import语句找到了对应的包,也会报错。 - 只允许导入使用
public修饰的顶层声明或定义,导入无public修饰的声明或定义将会在导入处报错。 - 可以直接使用导入的名字访问导入的声明或定义,也可以通过形如
moduleName.packageName.itemName的带路径限定的名字访问导入的声明或定义。 - 支持使用形如
curPackageName.itemName的带路径限定的名字访问当前包的内容,但禁止通过import导入当前源文件所在包的声明或定义。 - 禁止包间的循环依赖导入,如果包之间存在循环依赖,编译器会报错。
示例如下:
// pkga/a.cj
package pkga // Error, packages pkga pkgb are in circular dependencies.
import pkgb.*
class C {}
public struct R {}
// pkgb/b.cj
package pkgb
import pkga.*
// pkgc/c1.cj
package pkgc
import pkga.C // Error, 'C' is not accessible in package 'pkga'.
import pkga.R // OK, R is an external top-level declaration of package pkga.
import pkgc.f1 // Error, package 'pkgc' should not import itself.
public func f1() {}
// pkgc/c2.cj
package pkgc
func f2() {
/* OK, the imported declaration is visible to all source files of the same package
* and accessing import declaration by its name is supported.
*/
R()
// OK, accessing imported declaration by fully qualified name is supported.
pkga.R()
// OK, the declaration of current package can be accessed directly.
f1()
// OK, accessing declaration of current package by fully qualified name is supported.
pkgc.f1()
}
在仓颉编程语言中,导入的声明或定义如果和当前包中的顶层声明或定义重名且不构成函数重载,则导入的声明和定义会被遮盖;导入的声明或定义如果和当前包中的顶层声明或定义重名且构成函数重载,函数调用时将会根据函数重载的规则进行函数决议。
// pkga/a.cj
package pkga
public struct R {} // R1
public func f(a: Int32) {} // f1
public func f(a: Bool) {} // f2
// pkgb/b.cj
package pkgb
import pkga.*
func f(a: Int32) {} // f3
struct R {} // R2
func bar() {
R() // OK, R2 shadows R1.
f(1) // OK, invoke f3 in current package.
f(true) // OK, invoke f2 in the imported package
}
隐式导入 core 包
诸如 String、Range 等类型能直接使用,并不是因为这些类型是内置类型,而是因为编译器会自动为源码隐式的导入 core 包中所有的 public 修饰的声明。
使用 import as 对导入的名字重命名
不同包的名字空间是分隔的,因此在不同的包之间可能存在同名的顶层声明。在导入不同包的同名顶层声明时,我们支持使用 import packageName.name as newName 的方式进行重命名来避免冲突。没有名字冲突的情况下仍然可以通过 import as 来重命名导入的内容。import as具有如下规则:
-
使用
import as对导入的声明进行重命名后,当前包只能使用重命名后的新名字,原名无法使用。 -
同一个声明只能重命名一次。
-
使用
import as重命名的新名字的作用域级别和当前包顶层作用域级别一致。(注意,不使用as时引入的名字的作用域级别比当前包顶层作用域级别低。) -
如果重命名后的名字与当前包顶层作用域的其它名字存在冲突,且这些名字对应的声明均为函数类型,则参与函数重载,否则报重定义的错误。
-
支持
import pkg.* as newPkgName.*的形式对包名进行重命名,以解决不同模块中同名包的命名冲突问题。// a.cj in module1/p1 package p1 public func f1() {} // d.cj in module2/p2 package p2 public func f3() {} // b.cj in module2/p1 package p1 public func f2() {} // c.cj in module3/pkgc package pkgc public func f1() {} // main.cj in module3 from module1 import p1.* as A.* from module2 import p1.* as B.* from module1 import p2.f3 as f // OK import pkgc.f1 as a import pkgc.f1 as b // Error, 'pkgc.f1' cannot be redefined here. func f(a: Int32) {} main() { A.f1() // OK, package name conflict is resolved by renaming package name. B.f2() // OK, package name conflict is resolved by renaming package name. p1.f1() // Error, the original package name cannot be used. a() // OK. b() // OK. pkgc.f1() // Error, the original name cannot be used. } -
如果没有对导入的存在冲突的名字进行重命名,在
import语句处不报错;在使用处,只能使用带路径限定的名字来访问,仅使用冲突的名字来访问将会报错。// a.cj in module1 package p1 public class C {} // b.cj in module2 package p1 public class C {} // c.cj in module2 package pkgc public class C {} // main.cj in module2 package pkgd from module1 import p1.C from module2 import p1.C import pkgc.C main() { C() // Error. pkgc.C() // OK. p1.C() // Error. module1.p1.C() // OK. module2.p1.C() // OK. }
使用 public import 重导出一个导入的名字
在功能繁多的大型项目的开发过程中,这样的场景是非常常见的:包 p2 大量地使用从包 p1 中导入的声明,当包 p3 导入包 p2 并使用其中的功能时,p1 中的声明同样需要对包 p3 可见。如果要求包 p3 自行导入 p2 中使用到的 p1 中的声明,这个过程将过于繁琐。因此希望能够在 p2 被导入时一并导入 p2 使用到的 p1 中的声明。
在仓颉编程语言中,可以在导入包的时候使用 public import 指定被重导出的声明。其它包可以直接导入并使用本包中用 public import 重导出的内容,无需从原包中导入这些内容。
需要注意的是,当导入的名字出现在当前包被 public 修饰的函数的参数类型或返回类型中时,它们必须被重导出。在如下例子的 pkg2 中,f 是一个 public 修饰的函数,它的返回值类型是导入的类型 C1,另一个包 pkg3 导入了 pkg2 的函数 f。若 pkg3 未手动导入 pkg1 中的类 C1,或者在 pkg2 中没有使用 public import 指明类 C1 被重导出,则 pkg3 在使用函数 f 时将会因为找不到类 C1 而报错。强行限制 pkg2 重导出类 C1,可以使 pkg3 在使用 pkg2 中函数 f 时无需手动导入 pkg1 中的类 C1。
使用 public import 导入的名字相当于是在本包内定义了一个新的名字,因此,public import 导入的名字和 import as 重命名的名字具有相同的规则。
// a.cj
package pkg1
public class C1 {}
public class C2 {}
// b.cj
package pkg2
public import pkg1.C1 // class C1 of pkg1 must be re-exported.
public func f() {
let c = C1()
return c
}
public class C2 {}
// main.cj
package pkg3
import pkg2.*
public import pkg1.C2 // Error, C2 is redefined.
public import pkg2.C2 // Error, C2 is redefined.
public class C2{} // Error, C2 is redefined.
main(): Int64 {
let obj1 = f() // OK.
let obj2: C1 = f() // OK, class C1 is visible to current package.
return 0
}
程序入口
仓颉程序入口为 main,源文件根目录下的包的顶层最多只能有一个 main。
如果模块采用生成可执行文件的编译方式,编译器只在源文件根目录下的顶层查找main。如果没有找到,编译器将会报错;如果找到main,编译器会进一步对其参数和返回值类型进行检查。需要注意的是,main不可被访问修饰符修饰,当一个包被导入时,包中定义的main不会被导入。
作为程序入口的 main 可以没有参数或参数类型为 Array<String>,返回值类型为 Unit 或整数类型。
没有参数的 main:
// main.cj
main(): Int64 { // OK.
return 0
}
参数类型为 Array<String> 的 main:
// main.cj
main(args: Array<String>): Unit { // OK.
for (arg in args) {
println(arg)
}
}
使用 cjc main.cj 编译完成后,通过命令行执行:./main Hello, World,将会得到如下输出:
Hello,
World
以下是一些错误示例:
// main.cj
main(): String { // Error, return type of 'main' is not 'Integer' or 'Unit'.
return ""
}
// main.cj
main(args: Array<Int8>): Int64 { // Error, 'main' cannot be defined with parameter whose type is not Array<String>.
return 0
}
// main.cj
// Error, multiple 'main's are found in source files.
main(args: Array<String>): Int32 {
return 0
}
main(): Int8 {
return 0
}
跨语言互操作
Foreign Function Interfaces (FFI) 是一种机制,通过该机制,一种编程语言写的程序可以调用另外一种编程语言编写的函数。
与 C 语言互操作
为了兼容已有的生态,仓颉支持调用 C 语言的函数,也支持 C 语言调用仓颉的函数。
仓颉调用 C 的函数
在仓颉中要调用 C 的函数,需要在仓颉语言中用 @C 和 foreign 关键字声明这个函数,但 @C 在修饰 foreign 声明的时候,可以省略。
举个例子,假设我们要调用 C 的 rand 和 printf 函数,它的函数签名是这样的:
// stdlib.h
int rand();
// stdio.h
int printf (const char *fmt, ...);
那么在仓颉中调用这两个函数的方式如下:
// declare the function by `foreign` keyword, and omit `@C`
foreign func rand(): Int32
foreign func printf(fmt: CString, ...): Int32
main() {
// call this function by `unsafe` block
let r = unsafe { rand() }
println("random number ${r}")
unsafe {
var fmt = LibC.mallocCString("Hello, No.%d\n")
printf(fmt, 1)
LibC.free(fmt)
}
}
需要注意的是:
foreign修饰函数声明,代表该函数为外部函数。被foreign修饰的函数只能有函数声明,不能有函数实现。foreign声明的函数,参数和返回类型必须符合 C 和仓颉数据类型之间的映射关系(详见下节:类型映射)。- 由于 C 侧函数很可能产生不安全操作,所以调用
foreign修饰的函数需要被unsafe块包裹,否则会发生编译错误。 @C修饰的foreign关键字只能用来修饰函数声明,不可用来修饰其他声明,否则会发生编译错误。@C只支持修饰foreign函数、top-level作用域中的非泛型函数和struct类型。foreign函数不支持命名参数和参数默认值。foreign函数允许变长参数,使用...表达,只能用于参数列表的最后。变长参数均需要满足CType约束,但不必是同一类型。- 仓颉虽然提供了栈扩容能力,但是由于 C 侧函数实际使用栈大小仓颉无法感知,所以 ffi 调用进入 C 函数后,仍然存在栈溢出的风险,需要开发者根据实际情况,修改
cjStackSize的配置。
一些不合法的 foreign 声明的示例代码如下:
foreign func rand(): Int32 { // compiler error
return 0
}
@C
foreign var a: Int32 = 0 // compiler error
@C
foreign class A{} // compiler error
@C
foreign interface B{} // compiler error
CFunc
仓颉中的 CFunc 指可以被 C 语言代码调用的函数,共有以下三种形式:
@C修饰的foreign函数@C修饰的仓颉函数- 类型为
CFunc的lambda表达式- 与普通的 lambda 表达式不同,
CFunc lambda不能捕获变量。
- 与普通的 lambda 表达式不同,
// Case 1
foreign func free(ptr: CPointer<Int8>): Unit
// Case 2
@C
func callableInC(ptr: CPointer<Int8>) {
print("This function is defined in Cangjie.")
}
// Case 3
let f1: CFunc<(CPointer<Int8>) -> Unit> = { ptr =>
print("This function is defined with CFunc lambda.")
}
以上三种形式声明/定义的函数的类型均为 CFunc<(CPointer<Int8>) -> Unit>。CFunc 对应 C 语言的函数指针类型。这个类型为泛型类型,其泛型参数表示该 CFunc 入参和返回值类型,使用方式如下:
foreign func atexit(cb: CFunc<() -> Unit>)
与 foreign 函数一样,其他形式的 CFunc 的参数和返回类型必须满足 CType 约束,且不支持命名参数和参数默认值。
CFunc 在仓颉代码中被调用时,需要处在 unsafe 上下文中。
仓颉语言支持将一个 CPointer<T> 类型的变量类型转换为一个具体的 CFunc,其中 CPointer 的泛型参数 T 可以是满足 CType 约束的任意类型,使用方式如下:
main() {
var ptr = CPointer<Int8>()
var f = CFunc<() -> Unit>(ptr)
unsafe { f() } // core dumped when running, because the pointer is nullptr.
}
注意:将一个指针强制类型转换为 CFunc 并进行函数调用是危险行为,需要用户保证指针指向的是一个切实可用的函数地址,否则将发生运行时错误。
inout 参数
在仓颉中调用 CFunc 时,其实参可以使用 inout 关键字修饰,组成引用传值表达式,此时,该参数按引用传递。引用传值表达式的类型为 CPointer<T>,其中 T 为 inout 修饰的表达式的类型。
引用传值表达式具有以下约束:
- 仅可用于对
CFunc的调用处; - 其修饰对象的类型必须满足
CType约束,但不可以是CString; - 其修饰对象不可以是用
let定义的,不可以是字面量、入参、其他表达式的值等临时变量; - 通过仓颉侧引用传值表达式传递到 C 侧的指针,仅保证在函数调用期间有效,即此种场景下 C 侧不应该保存指针以留作后用。
inout 修饰的变量,可以是定义在 top-level 作用域中的变量、局部变量、struct 中的成员变量,但不能直接或间接来源于 class 的实例成员变量。
下面是一个例子:
foreign func foo1(ptr: CPointer<Int32>): Unit
@C
func foo2(ptr: CPointer<Int32>): Unit {
let n = unsafe { ptr.read() }
println("*ptr = ${n}")
}
let foo3: CFunc<(CPointer<Int32>) -> Unit> = { ptr =>
let n = unsafe { ptr.read() }
println("*ptr = ${n}")
}
struct Data {
var n: Int32 = 0
}
class A {
var data = Data()
}
main() {
var n: Int32 = 0
unsafe {
foo1(inout n) // OK
foo2(inout n) // OK
foo3(inout n) // OK
}
var data = Data()
var a = A()
unsafe {
foo1(inout data.n) // OK
foo1(inout a.data.n) // Error, n is derived indirectly from instance member variables of class A
}
}
**注意:**使用宏扩展特性时,在宏的定义中,暂时不能使用 inout 参数特性。
unsafe
在引入与 C 语言的互操作过程中,同时也引入了 C 的许多不安全因素,因此在仓颉中使用 unsafe 关键字,用于对跨 C 调用的不安全行为进行标识。
关于 unsafe 关键字,有以下几点说明:
unsafe可以修饰函数、表达式,也可以修饰一段作用域。- 被
@C修饰的函数,被调用处需要在unsafe上下文中。 - 在调用
CFunc时,使用处需要在unsafe上下文中。 foreign函数在仓颉中进行调用,被调用处需要在unsafe上下文中。- 当被调用函数被
unsafe修饰时,被调用处需要在unsafe上下文中。
使用方式如下:
foreign func rand(): Int32
@C
func foo(): Unit {
println("foo")
}
var foo1: CFunc<() -> Unit> = { =>
println("foo1")
}
main(): Int64 {
unsafe {
rand() // Call foreign func.
foo() // Call @C func.
foo1() // Call CFunc var.
}
0
}
注意: 普通 lambda 无法传递 unsafe 属性,当 unsafe 的 lambda 逃逸后,可以不在 unsafe 上下文中直接调用而未产生任何编译错误。当需要在 lambda 中调用 unsafe 函数时,建议在 unsafe 块中进行调用,参考如下用例:
unsafe func A(){}
unsafe func B(){
var f = { =>
unsafe { A() } // Avoid calling A() directly without unsafe in a normal lambda.
}
return f
}
main() {
var f = unsafe{ B() }
f()
println("Hello World")
}
调用约定
函数调用约定描述调用者和被调用者双方如何进行函数调用(如参数如何传递、栈由谁清理等),函数调用和被调用双方必须使用相同的调用约定才能正常运行。仓颉编程语言通过 @CallingConv 来表示各种调用约定,支持的调用约定如下:
- CDECL,
CDECL表示 clang 的 C 编译器在不同平台上默认使用的调用约定。 - STDCALL,
STDCALL表示 Win32 API 使用的调用约定。
通过 C 语言互操作机制调用的 C 函数,未指定调用约定时将采用默认的 CDECL 调用约定。如下调用 C 标准库函数 rand 示例:
@CallingConv[CDECL] // Can be omitted in default.
foreign func rand(): Int32
main() {
println(rand())
}
@CallingConv 只能用于修饰 foreign 块、单个 foreign 函数和 top-level 作用域中的 CFunc 函数。当 @CallingConv 修饰 foreign 块时,会为 foreign 块中的每个函数分别加上相同的 @CallingConv 修饰。
类型映射
基础类型
仓颉与 C 语言支持基本数据类型的映射,总体原则是:
- 仓颉的类型不包含指向托管内存的引用类型;
- 仓颉的类型和 C 的类型具有同样的内存布局。
比如说,一些基本的类型映射关系如下:
| Cangjie Type | C Type | Size (byte) |
|---|---|---|
Unit | void | 0 |
Bool | bool | 1 |
UInt8 | char | 1 |
Int8 | int8_t | 1 |
UInt8 | uint8_t | 1 |
Int16 | int16_t | 2 |
UInt16 | uint16_t | 2 |
Int32 | int32_t | 4 |
UInt32 | uint32_t | 4 |
Int64 | int64_t | 8 |
UInt64 | uint64_t | 8 |
IntNative | ssize_t | platform dependent |
UIntNative | size_t | platform dependent |
Float32 | float | 4 |
Float64 | double | 8 |
注:int 类型、long 类型等由于其在不同平台上的不确定性,需要程序员自行指定对应仓颉编程语言类型。在 C 互操作场景中,与 C 语言类似,Unit 类型仅可作为 CFunc 中的返回类型和 CPointer 的泛型参数。
仓颉也支持与 C 语言的结构体和指针类型的映射。
结构体
对于结构体类型,仓颉用 @C 修饰的 struct 来对应。比如说 C 语言里面有这样的一个结构体:
typedef struct {
long long x;
long long y;
long long z;
} Point3D;
那么它对应的仓颉类型可以这么定义:
@C
struct Point3D {
var x: Int64 = 0
var y: Int64 = 0
var z: Int64 = 0
}
如果 C 语言里有这样的一个函数:
Point3D addPoint(Point3D p1, Point3D p2);
那么对应的,在仓颉里面可以这样声明这个函数:
foreign func addPoint(p1: Point3D, p2: Point3D): Point3D
用 @C 修饰的 struct 必须满足以下限制:
- 成员变量的类型必须满足
CType约束 - 不能实现或者扩展
interfaces - 不能作为
enum的关联值类型 - 不允许被闭包捕获
- 不能具有泛型参数
用 @C 修饰的 struct 自动满足 CType 约束。
指针
对于指针类型,仓颉提供 CPointer<T> 类型来对应 C 侧的指针类型,其泛型参数 T 需要满足 CType 约束。
比如对于 malloc 函数,在 C 里面的签名为:
void* malloc(size_t size);
那么在仓颉中,它可以声明为:
foreign func malloc(size: UIntNative): CPointer<Unit>
CPointer 可以进行读写、偏移计算、判空以及转为指针的整型形式等,详细 API 可以参考 core 包标准库文档。其中读写和偏移计算为不安全行为,当不合法的指针调用这些函数时,可能发生未定义行为,这些 unsafe 函数需要在 unsafe 块中调用。
CPointer 的使用示例如下:
foreign func malloc(size: UIntNative): CPointer<Unit>
foreign func free(ptr: CPointer<Unit>): Unit
@C
struct Point3D {
var x: Int64
var y: Int64
var z: Int64
init(x: Int64, y: Int64, z: Int64) {
this.x = x
this.y = y
this.z = z
}
}
main() {
let p1 = CPointer<Point3D>() // create a CPointer with null value
if (p1.isNull()) { // check if the pointer is null
print("p1 is a null pointer")
}
let sizeofPoint3D: UIntNative = 24
var p2 = unsafe { malloc(sizeofPoint3D) } // malloc a Point3D in heap
var p3 = unsafe { CPointer<Point3D>(p2) } // pointer type cast
unsafe { p3.write(Point3D(1, 2, 3)) } // write data through pointer
let p4: Point3D = unsafe { p3.read() } // read data through pointer
let p5: CPointer<Point3D> = unsafe { p3 + 1 } // offset of pointer
unsafe { free(p2) }
}
仓颉语言支持 CPointer 之间的强制类型转换,转换前后的 CPointer 的泛型参数 T 均需要满足 CType 的约束,使用方式如下:
main() {
var pInt8 = CPointer<Int8>()
var pUInt8 = CPointer<UInt8>(pInt8) // CPointer<Int8> convert to CPointer<UInt8>
0
}
仓颉语言支持将一个 CFunc 类型的变量类型转换为一个具体的 CPointer,其中 CPointer 的泛型参数 T 可以是满足 CType 约束的任意类型,使用方式如下:
foreign func rand(): Int32
main() {
var ptr = CPointer<Int8>(rand)
0
}
注意:将一个 CFunc 强制类型转换为指针通常是安全的,但是不应该对转换后的指针执行任何的 read,write 操作,可能会导致运行时错误。
数组
仓颉使用 VArray 类型与 C 的数组类型映射,VArray 可以用户作为函数参数和 @C struct 成员。当 VArray<T, $N> 中的元素类型 T 满足 CType 约束时, VArray<T, $N> 类型也满足 CType 约束。
作为函数参数类型:
当 VArray 作为 CFunc 的参数时, CFunc 的函数签名仅可以是 CPointer<T> 类型或 VArray<T, $N> 类型。当函数签名中的参数类型为 VArray<T, $N> 时,传递的参数仍以 CPointer<T> 形式传递。
VArray 作为参数的使用示例如下:
foreign func cfoo1(a: CPointer<Int32>):Unit
foreign func cfoo2(a: VArray<Int32, $3): Unit
对应的 C 侧函数定义可以是:
void cfoo1(int *a) { ... }
void cfoo2(int a[3]) { ... }
调用 CFunc 时,需要通过 inout 修饰 VArray 类型变量:
var a: VArray<Int32, $3> = [1, 2, 3]
unsafe {
cfoo1(inout a)
cfoo2(inout a)
}
VArray 不允许作为 CFunc 的返回值类型。
作为 @C struct 成员:
当 VArray 作为 @C struct 成员时,它的内存布局与 C 侧的结构体排布一致,需要保证仓颉侧声明长度与类型也与 C 完全一致:
struct S {
int a[2];
int b[0];
}
在仓颉中,可以声明为如下结构体与 C 代码对应:
@C
struct S {
var a = VArray<Int32, $2>(item: 0)
var b = VArray<Int32, $0>(item: 0)
}
注意:C 语言中允许结构体的最后一个字段为未指明长度的数组类型,该数组被称为柔性数组(flexible array),仓颉不支持包含柔性数组的结构体的映射。
字符串
特别地,对于 C 语言中的字符串类型,仓颉中设计了一个 CString 类型来对应。为简化为 C 语言字符串的操作,CString 提供了以下成员函数:
init(p: CPointer<UInt8>)通过 CPointer 构造一个 CStringfunc getChars()获取字符串的地址,类型为CPointer<UInt8>func size(): Int64计算该字符串的长度func isEmpty(): Bool判断该字符串的长度是否为 0,如果字符串的指针为空返回 truefunc isNotEmpty(): Bool判断该字符串的长度是否不为 0,如果字符串的指针为空返回 falsefunc isNull(): Bool判断该字符串的指针是否为 nullfunc startsWith(str: CString): Bool判断该字符串是否以 str 开头func endsWith(str: CString): Bool判断该字符串是否以 str 结尾func equals(rhs: CString): Bool判断该字符串是否与 rhs 相等func equalsLower(rhs: CString): Bool判断该字符串是否与 rhs 相等,忽略大小写func subCString(start: UInt64): CString从 start 开始截取子串,返回的子串存储在新分配的空间中func subCString(start: UInt64, len: UInt64): CString从 start 开始截取长度为 len 的子串,返回的子串存储在新分配的空间中func compare(str: CString): Int32该字符串与 str 比较,返回结果与 C 语言的strcmp(this, str)一样func toString(): String用该字符串构造一个新的 String 对象func asResource(): CStringResource获取 CString 的 Resource 类型
另外,将 String 类型转换为 CString 类型,可以通过调用 LibC 中的 mallocCString 接口,使用完成后需要对 CString 进行释放。
CString 的使用示例如下:
foreign func strlen(s: CString): UIntNative
main() {
var s1 = unsafe { LibC.mallocCString("hello") }
var s2 = unsafe { LibC.mallocCString("world") }
let t1: Int64 = s1.size()
let t2: Bool = s2.isEmpty()
let t3: Bool = s1.equals(s2)
let t4: Bool = s1.startsWith(s2)
let t5: Int32 = s1.compare(s2)
let length = unsafe { strlen(s1) }
unsafe {
LibC.free(s1)
LibC.free(s2)
}
}
sizeOf/alignOf
在仓颉标准库中,提供了 sizeOf 和 alignOf 两个函数,用于获取上述 C 互操作类型的内存占用和内存对齐数值(单位:字节),函数声明如下:
public func sizeOf<T>(): UIntNative where T <: CType
public func alignOf<T>(): UIntNative where T <: CType
使用示例:
@C
struct Data {
var a: Int64 = 0
var b: Float32 = 0.0
}
main() {
println(sizeOf<Data>())
println(alignOf<Data>())
}
在 64 位机器上运行,将输出:
16
8
CType
除类型映射一节提供的与 C 侧类型进行映射的类型外,仓颉还提供了一个 CType 接口,接口本身不包含任何方法,它可以作为所有 C 互操作支持的类型的父类型,便于在泛型约束中使用。
需要注意的是:
CType接口是仓颉中的一个接口类型,它本身不满足CType约束;CType接口不允许被继承、扩展;CType接口不会突破子类型的使用限制。
CType 的使用示例如下:
func foo<T>(x: T): Unit where T <: CType {
match (x) {
case i32: Int32 => println(i32)
case ptr: CPointer<Int8> => println(ptr.isNull())
case f: CFunc<() -> Unit> => unsafe { f() }
case _ => println("match failed")
}
}
main() {
var i32: Int32 = 1
var ptr = CPointer<Int8>()
var f: CFunc<() -> Unit> = { => println("Hello") }
var f64 = 1.0
foo(i32)
foo(ptr)
foo(f)
foo(f64)
}
执行结果如下:
1
true
Hello
match failed
C 调用仓颉的函数
仓颉提供 CFunc 类型来对应 C 侧的函数指针类型。C 侧的函数指针可以传递到仓颉,仓颉也可以构造出对应 C 的函数指针的变量传递到 C 侧。
假设一个 C 的库 API 如下:
typedef void (*callback)(int);
void set_callback(callback cb);
对应的,在仓颉里面这个函数可以声明为:
foreign func set_callback(cb: CFunc<(Int32) -> Unit>): Unit
CFunc 类型的变量可以从 C 侧传递过来,也可以在仓颉侧构造出来。在仓颉侧构造 CFunc 类型有两种办法,一个是用 @C 修饰的函数,另外一个是标记为 CFunc 类型的闭包。
@C 修饰的函数,表明它的函数签名是满足 C 的调用规则的,定义还是写在仓颉这边。foreign 修饰的函数定义是在 C 侧的。
注意:foreign 修饰的函数与 @C 修饰的函数,这两种 CFunc 的命名不建议使用 CJ_(不区分大小写)作为前缀,否则可能与标准库及运行时等编译器内部符号出现冲突,导致未定义行为。
示例如下:
@C
func myCallback(s: Int32): Unit {
println("handle ${s} in callback")
}
main() {
// the argument is a function qualified by `@C`
unsafe { set_callback(myCallback) }
// the argument is a lambda with `CFunc` type
let f: CFunc<(Int32) -> Unit> = { i => "handle ${i} in callback" }
unsafe { set_callback(f) }
}
假设 C 函数编译出来的库是 "libmyfunc.so",那么需要使用 cjc -L. -lmyfunc test.cj -o test.out 编译命令,使仓颉编译器去链接这个库。最终就能生成想要的可执行程序。
另外,在编译 C 代码时,请打开 -fstack-protector-all/-fstack-protector-strong 栈保护选项,仓颉侧代码默认拥有溢出检查与栈保护功能。在引入 C 代码后,需要同步保证 unsafe 块中的溢出的安全性。
编译选项
使用 C 互操作通常需要手动链接 C 的库,仓颉编译器提供了相应的编译选项。
-
--library-path <value>,-L <value>,-L<value>:指定要链接的库文件所在的目录。--library-path <value>指定的路径会被加入链接器的库文件搜索路径。另外环境变量LIBRARY_PATH中指定的路径也会被加入链接器的库文件搜索路径中,通过--library-path指定的路径会比LIBRARY_PATH中的路径拥有更高的优先级。 -
--library <value>,-l <value>,-l<value>:指定要链接的库文件。给定的库文件会被直接传给链接器,库文件名的格式应为
lib[arg].[extension]。
关于仓颉编译器支持的所有编译选项,详见仓颉编译器手册一章。
示例
假设我们有一个 C 库 libpaint.so,其头文件如下:
#include <stdint.h>
typedef struct {
int64_t x;
int64_t y;
} Point;
typedef struct {
int64_t x;
int64_t y;
int64_t r;
} Circle;
int32_t DrawPoint(const Point* point);
int32_t DrawCircle(const Circle* circle);
在仓颉代码中使用该 C 库的示例代码如下:
// main.cj
foreign {
func DrawPoint(point: CPointer<Point>): Int32
func DrawCircle(circle: CPointer<Circle>): Int32
func malloc(size: UIntNative): CPointer<Int8>
func free(ptr: CPointer<Int8>): Unit
}
@C
struct Point {
var x: Int64 = 0
var y: Int64 = 0
}
@C
struct Circle {
var x: Int64 = 0
var y: Int64 = 0
var r: Int64 = 0
}
main() {
let SIZE_OF_POINT: UIntNative = 16
let SIZE_OF_CIRCLE: UIntNative = 24
let ptr1 = unsafe { malloc(SIZE_OF_POINT) }
let ptr2 = unsafe { malloc(SIZE_OF_CIRCLE) }
let pPoint = CPointer<Point>(ptr1)
let pCircle = CPointer<Circle>(ptr2)
var point = Point()
point.x = 10
point.y = 20
unsafe { pPoint.write(point) }
var circle = Circle()
circle.r = 1
unsafe { pCircle.write(circle) }
unsafe {
DrawPoint(pPoint)
DrawCircle(pCircle)
free(ptr1)
free(ptr2)
}
}
编译仓颉代码的命令如下:
cjc -L . -l paint ./main.cj
其中编译命令中 -L . 表示链接库时从当前目录查找(假设 libpaint.so 存在于当前目录),-l paint 表示链接的库的名字,编译成功后默认生成二进制文件 main,执行二进制文件的命令如下:
LD_LIBRARY_PATH=.:$LD_LIBRARY_PATH ./main
与 Python 语言互操作
为了兼容强大的计算和 AI 生态,仓颉支持与 Python 语言的互操作调用。Python 的互操作通过 std 模块中的 ffi.python 库为用户提供能力。
目前 Python 互操作仅支持在 Linux 平台使用,并且仅支持仓颉编译器的 llvmgc 后端。
Python 的全局资源及使用
提供内建函数类以及全局资源
代码原型:
public class PythonBuiltins {
...
}
public let Python = PythonBuiltins()
Python 库提供的接口不能保证并发安全,当对 Python 进行异步调用时(系统线程 ID 不一致)会抛出 PythonException 异常。
在 Python 初始化时,GIL 全局解释器锁基于当前所在 OS 线程被锁定,如果执行的代码所在的 Cangjie 线程(包括
main所在 Cangjie 线程)在 OS 线程上发生调度(OS 线程ID发生变化),Python 内部再次尝试检查 GIL 时会对线程状态进行校验,发现 GIL 状态中保存的 OS 线程ID与当前执行的 OS 线程ID不一致,此时会触发内部错误,导致程序崩溃。
**注意:**由于 Python 互操作使用到大量 Python 库的 native 代码,这部分代码在仓颉侧无法对其进行相应的栈保护。仓颉栈保护默认大小为 64KB,在对 Python C API 进行调用过程中,容易造成 native 代码超出默认栈大小,发生溢出,会触发不可预期的结果。建议用户在执行 Python 互操作相关代码前,配置仓颉默认栈大小至少为 1MB:export cjStackSize=1MB 。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
Python.unload()
return 0
}
提供 Python 库日志类 PythonLogger
代码原型:
public class PythonLogger <: Logger {
mut prop level: LogLevel {...}
public func setOutput(output: io.File): Unit {} // do nothing
public func trace(msg: String): Unit {...}
public func debug(msg: String): Unit {...}
public func info(msg: String): Unit {...}
public func warn(msg: String): Unit {...}
public func error(msg: String): Unit {...}
public func log(level: LogLevel, msg: String): Unit {...}
}
public let PYLOG = PythonLogger()
Logger 类的几点声明:
PythonLogger实现Logger接口仅做打印输出以及打印等级控制,不做日志转储到 log 文件;setOutput为空实现,不支持 log 转储文件;info/warn/error等接口输出打印以对应前缀开头,其他不做区分;PythonLogger默认打印等级为LogLevel.WARN;PYLOG.error(msg)和log(LogLevel.ERROR, msg)接口会抛出PythonException异常。
使用示例:
from std import ffi.python.*
from std import log.*
main(): Int64 {
PYLOG.level = LogLevel.WARN // Only logs of the warn level and above are printed.
PYLOG.info("log info")
PYLOG.warn("log warn")
try {
PYLOG.error("log error")
} catch(e: PythonException) {}
PYLOG.log(LogLevel.INFO, "loglevel info")
PYLOG.log(LogLevel.WARN, "loglevel warn")
try {
PYLOG.log(LogLevel.ERROR, "loglevel error")
} catch(e: PythonException) {}
return 0
}
执行结果:
WARN: log warn
ERROR: log error
WARN: loglevel warn
ERROR: loglevel error
提供 Python 库异常类 PythonException
代码原型:
public class PythonException <: Exception {
public init() {...}
public init(message: String) {...}
}
PythonException 有以下说明:
PythonException与被继承的Exception除了异常前缀存在差异,其他使用无差异;- 当 Python 内部出现异常时,外部可以通过
try-catch进行捕获,如果不进行捕获会打印异常堆栈并退出程序,返回值为 1。
使用示例:
from std import ffi.python.*
from std import log.*
main(): Int64 {
try {
Python.load("/usr/lib/", loglevel: LogLevel.INFO)
} catch(e: PythonException) {
print("${e}") // PythonException: "/usr/lib/" does not exist or the file path is invalid.
}
return 0
}
提供 Python 库的版本信息类 Version
代码原型:
public struct Version <: ToString {
public init(major: Int64, minor: Int64, micro: Int64)
public func getMajor(): Int64
public func getMinor(): Int64
public func getMicro(): Int64
public func getVersion(): (Int64, Int64, Int64)
public func toString(): String
}
关于 Version 类的几点声明:
Version版本信息包含三个部分:major version,minor version,micro version。Version版本仅通过构造函数进行初始化,一旦定义,后续无法修改。- 提供
toString接口,可以直接进行打印。 - 提供
getVersion接口,可以获取版本的 tuple 形式。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
var version = Python.getVersion()
print("${version}")
var tuple_version = version.getVersion()
Python.unload()
return 0
}
PythonBuiltins 内建函数类
Python 库的导入和加载
代码原型:
public class PythonBuiltins {
public func load(loglevel!: LogLevel = LogLevel.WARN): Unit
public func load(path: String, loglevel!: LogLevel = LogLevel.WARN): Unit
public func isLoad(): Bool
public func unload(): Unit
}
public let Python = PythonBuiltins()
关于加载与卸载有以下几点声明:
load函数使用重载的方式实现,同时支持无参加载和指定动态库路径加载,提供可选参数配置PythonLogger的打印等级,如果不配置,会将PYLOG重置为warn打印等级;load()函数进行了 Python 相关的准备工作,在进行 Python 互操作前必须调用,其中动态库查询方式请见:动态库的加载策略;load(path: String)函数需要用户配置动态库路径path,path指定到动态库文件(如:/usr/lib/libpython3.9.so),不可以配置为目录或者非动态库文件;load函数失败时会抛出PythonException异常,如果程序仍然需要继续执行,请注意try-catch;unload函数在进行完 Python 互操作时调用,否则会造成相关资源泄露;- 加载和卸载操作仅需要调用一次,并且一一对应,多次调用仅第一次生效;
isload()函数用于判断 Python 库是否被加载。
使用示例:
load 与 unload :
from std import ffi.python.*
main(): Int64 {
Python.load()
Python.unload()
Python.load("/usr/lib/libpython3.9.so")
Python.unload()
return 0
}
isLoad 函数:
from std import ffi.python.*
main(): Int64 {
print("${Python.isLoad()}\n") // false
Python.load()
print("${Python.isLoad()}\n") // true
Python.unload()
return 0
}
动态库的加载策略
Python 库需要依赖 Python 的官方动态链接库: libpython3.x.so ,推荐版本:3.9.2,支持读取 Python3.0 以上版本。
从 Python 源码编译获取动态库:
# 在Python源码路径下:
$ ./configure --enable-shared --with-system-ffi --prefix=/usr
$ make
$ make install
Python 的动态库按照以下方式进行自动查找:
1、使用指定的环境变量:
$ export PYTHON_DYNLIB=".../libpython3.9.so"
2、如果环境变量未指定,从可执行文件的依赖中查找:
- 需要保证可执行文件
python3可正常执行(所在路径已添加值 PATH 环境变量中),通过对 python3 可执行文件的动态库依赖进行查询。 - 非动态库依赖的 Python 可执行文件无法使用(源码编译未使用
--enable-shared编译的 Python 可执行文件,不会对动态库依赖)。
$ ldd $(which python3)
...
libpython3.9d.so.1.0 => /usr/local/lib/libpython3.9d.so.1.0 (0x00007f499102f000)
...
3、如果无法找到可执行文件依赖,尝试从系统默认动态库查询路径中查找:
["/lib", "/usr/lib", "/usr/local/lib"]
- 所在路径下查询的动态库名称必须满足
libpythonX.Y.so的命名方式,其中XY分别为主版本号以及次版本号,并且支持的后缀有:d.so,m.so,dm.so,.so,支持的版本高于 python3.0,低于或等于 python3.10。如:
libpython3.9.so
libpython3.9d.so
libpython3.9m.so
libpython3.9dm.so
使用示例:
from std import ffi.python.*
from std import log.*
main(): Int64 {
Python.load(loglevel: LogLevel.INFO)
print("${Python.getVersion()}\n")
Python.unload()
return 0
}
可以开启 Python 的 INFO 级打印,查看 Python 库路径的搜索过程:
# Specifying .so by Using Environment Variables
$ export PYTHON_DYNLIB=/root/code/python_source_code/Python-3.9.2/libpython3.9d.so
$ cjc ./main.cj -o ./main && ./main
INFO: Try to get libpython path.
INFO: Found PYTHON_DYNLIB value: /root/code/python_source_code/Python-3.9.2/libpython3.9d.so
...
# Find dynamic libraries by executable file dependency.
INFO: Try to get libpython path.
INFO: Can't get path from environment PYTHON_DYNLIB, try to find it from executable file path.
INFO: Exec cmd: "ldd $(which python3)":
INFO: ...
libpython3.9d.so.1.0 => /usr/local/lib/libpython3.9d.so.1.0 (0x00007fbbb5014000)
...
INFO: Found lib: /usr/local/lib/libpython3.9d.so.1.0.
INFO: Found exec dependency: /usr/local/lib/libpython3.9d.so.1.0
...
# Search for the dynamic library in the system path.
$ unset PYTHON_DYNLIB
$ cjc ./main.cj -o ./main && ./main
INFO: Can't get path from environment PYTHON_DYNLIB, try to find it from executable file path.
INFO: Can't get path from executable file path, try to find it from system lib path.
INFO: Find in /lib.
INFO: Found lib: /lib/libpython3.9.so.
...
# Failed to find the dynamic library.
$ cjc ./main.cj -o ./main && ./main
INFO: Can't get path from environment PYTHON_DYNLIB, try to find it from executable file path.
INFO: Can't get path from executable file path, try to find it from system lib path.
INFO: Find in /lib.
INFO: Can't find lib in /lib.
INFO: Find in /usr/lib.
INFO: Can't find lib in /usr/lib.
INFO: Find in /usr/local/lib.
INFO: Can't find lib in /usr/local/lib.
An exception has occurred:
PythonException: Can't get path from system lib path, load exit.
at std/ffi/python.std/ffi/python::(PythonException::)init(std/core::String)(stdlib/std/ffi/python/Python.cj:82)
at std/ffi/python.std/ffi/python::(PythonBuiltins::)load(std/log::LogLevel)(stdlib/std/ffi/python/Python.cj:127)
at default.default::main()(/root/code/debug/src/main.cj:5)
getVersion() 函数
函数原型:
public func getVersion(): Version
接口描述:
getVersion()函数用于获取当前使用的 Python 版本;
入参返回值:
getVersion()函数无参数,返回Version类对象;
异常情况:
getVersion()函数需要保证load函数已被调用,否则返回的版本信息号为0.0.0。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
var version = Python.getVersion()
print("${version}")
var tuple_version = version.getVersion()
Python.unload()
return 0
}
Import() 函数
函数原型:
public func Import(module: String): PyModule
入参返回值:
Import函数接受一个String类型入参,即模块名,并且返回一个PyModule类型的对象;
异常情况:
Import函数需要保证 load 函数已被调用,否则返回的PyModule类型对象不可用(isAvaliable()为false);- 如果找不到对应的模块,仅会报错,且返回的
PyModule类型对象不可用(isAvaliable()为false)。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
var sys = Python.Import("sys")
if (sys.isAvailable()) {
print("Import sys success\n")
}
// Import the test.py file in the current folder.
var test = Python.Import("test")
if (test.isAvailable()) {
print("Import test success\n")
}
var xxxx = Python.Import("xxxx")
if (!xxxx.isAvailable()) {
print("Import test failed\n")
}
Python.unload()
return 0
}
执行结果:
Import sys success
Import test success
Import test failed
Eval() 函数
函数原型:
public func Eval(cmd: String, module!: String = "__main__"): PyObj
接口描述:
Eval()函数用于创建一个 Python 数据类型;
入参返回值:
Eval()接受一个String类型的命令cmd,并返回该指令的结果的PyObj形式;Eval()接受一个String类型的指定域,默认域为"__main__";
异常情况:
Eval()接口需要保证load函数已被调用,否则返回的PyObj类型对象不可用(isAvaliable()为false);Eval()如果接收的命令执行失败,Python 侧会进行报错,并且返回的PyObj类型对象不可用(isAvaliable()为false)。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
var a = Python.Eval("123")
if (a.isAvailable()) {
Python["print"]([a])
}
var b = Python.Eval("x = 123") // The expression in `Eval` needs have a return value.
if (!b.isAvailable()) {
print("b is unavailable.\n")
}
Python.unload()
return 0
}
执行结果:
123
b is unavailable.
index [] 运算符重载
接口描述:
[]函数提供了其他 Python 的内置函数调用能力;
入参返回值:
[]函数入参接受String类型的内建函数名,返回类型为PyObj;
异常处理:
[]函数需要保证load函数已被调用,否则返回的PyObj类型对象不可用(isAvaliable()为false);- 如果指定的函数名未找到,则会报错,且返回的
PyObj类型对象不可用(isAvaliable()为false)。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
if (Python["type"].isAvailable()) {
print("find type\n")
}
if (!Python["type1"].isAvailable()) {
print("cant find type1\n")
}
Python.unload()
return 0
}
执行结果:
find type
WARN: Dict key "type1" not found!
cant find type1
类型映射
由于 Python 与仓颉互操作基于 C API 开发,Python 与 C 的数据类型映射统一通过 PyObject 结构体指针完成,并且具有针对不同数据类型的一系列接口。对比 C 语言,仓颉具有面向对象的编程优势,因此将 PyObject 结构体指针统一封装为父类,并且被不同的数据类型进行继承。
类型映射表
仓颉类型到 Python 类型映射
| Cangjie Type | Python Type |
|---|---|
| Bool | PyBool |
| UInt8/Int8/Int16/UInt16/Int32/UInt32/Int64/UInt64 | PyLong |
| Float32/Float64 | PyFloat |
| Char/String | PyString |
| Array< PyObj > | PyTuple |
| Array | PyList |
| HashMap | PyDict |
| HashSet | PySet |
Python 类型到仓颉类型映射
| Python Type | Cangjie Type |
|---|---|
| PyBool | Bool |
| PyLong | Int64/UInt64 |
| PyFloat | Float64 |
| PyString | String |
| PyTuple | - |
| PyList | Array |
| PyDict | HashMap |
| PySet | HashSet |
Python FFI 库泛型约束的接口 PyFFIType
public interface PyFFIType { }
- 由于部分类引入了泛型,为了对用户在泛型使用过程中进行约束,引入了抽象接口
PyFFIType; - 该接口无抽象成员函数,其仅被
PyObj和CjObj实现或继承,该接口不允许在包外进行实现,如果用户自定义类并实现改接口,可能发生未定义行为。
PyObj 类
与 Python 库中的结构体 PyObject 对应,对外提供细分数据类型通用的接口,如成员变量访问、函数访问、到仓颉字符串转换等。
类原型:
public open class PyObj <: ToString & PyFFIType {
public func isAvailable(): Bool { ... }
public open operator func [](key: String): PyObj { ... }
public open operator func [](key: String, value!: PyObj): Unit { ... }
public operator func ()(): PyObj { ... }
public operator func ()(kargs: HashMap<String, PyObj>): PyObj { ... }
public operator func ()(args: Array<PyObj>): PyObj { ... }
public operator func ()(args: Array<PyObj>, kargs: HashMap<String, PyObj>): PyObj { ... }
public operator func ()(args: Array<CjObj>): PyObj { ... }
public operator func ()(args: Array<CjObj>, kargs: HashMap<String, PyObj>): PyObj { ... }
public operator func +(b: PyObj): PyObj { ... }
public operator func -(b: PyObj): PyObj { ... }
public operator func *(b: PyObj): PyObj { ... }
public operator func /(b: PyObj): PyObj { ... }
public operator func **(b: PyObj): PyObj { ... }
public operator func %(b: PyObj): PyObj { ... }
public open func toString(): String { ... }
public func hashCode(): Int64 { ... }
public operator func ==(right: PyObj): Bool { ... }
public operator func !=(right: PyObj): Bool { ... }
}
关于 PyObj 类的几点说明
-
PyObj不对外提供创建的构造函数,该类不能在包外进行继承,如果用户自定义类并实现改接口,可能发生未定义行为; -
public func isAvailable(): Bool { ... }:isAvailable接口用于判断该PyObj是否可用(即封装的 C 指针是否为NULL)。
-
public open operator func [](key: String): PyObj { ... }:[](key)用于访问 Python 类的成员或者模块中的成员等;- 如果
PyObj本身不可用(isAvaliable()为false),将抛出异常; - 如果
PyObj中不存在对应的key,此时由 Python 侧打印对应的错误,并返回不可用的PyObj类对象(isAvaliable()为false)。
-
public open operator func [](key: String, value!: PyObj): Unit { ... }:[](key, value)设置 Python 类、模块的成员变量值为value;- 如果
PyObj本身不可用(isAvaliable()为false),将抛出异常; - 如果
PyObj中不存在对应的key,此时由 Python 侧打印对应的错误; - 如果
value值为一个不可用的对象(isAvaliable()为false),此时会将对应的key从模块或类中删除。
-
()括号运算符重载,可调用对象的函数调用:- 如果
PyObj本身不可用(isAvaliable()为false),将抛出异常; - 如果
PyObj本身为不可调用对象,将由 Python 侧报错,且返回不可用的PyObj类对象(isAvaliable()为false); ()接受无参的函数调用;([...])接受大于等于 1 个参数传递,参数类型支持仓颉类型CjObj和 Python 数据类型PyObj,需要注意的是,多个参数传递时,CjObj和PyObj不可混用;- 如果参数中包含不可用对象(
isAvaliable()为false),此时将会抛出异常,避免发生在 Python 侧出现不可预测的程序崩溃; ()运算符支持kargs,即对应 Python 的可变命名参数设计,其通过一个HashMap进行传递,其key类型String配置为变量名,value类型为 PyObj 配置为参数值。
- 如果
-
二元运算符重载:
-
+两变量相加:- 基础数据类型:
PyString与PyBool/PyLong/PyFloat不支持相加,其他类型均可相互相加; - 高级数据类型:
PyDict/PySet与所有类型均不支持相加,PyTuple/PyList仅能与自身相加。
- 基础数据类型:
-
-两变量相减:- 基础数据类型:
PyString与PyBool/PyLong/PyFloat/PyString不支持相减,其他类型均可相互相减; - 高级数据类型:
PyDict/PySet/PyTuple/PyList与所有类型均不支持相减。
- 基础数据类型:
-
*两变量相乘:- 基础数据类型:
PyString与PyFloat/PyString不支持相乘,其他类型均可相乘; - 高级数据类型:
PyDict/PySet与所有类型均不支持相乘,PyTuple/PyList仅能与PyLong/PyBool相乘。
- 基础数据类型:
-
/两变量相除:- 基础数据类型:
PyString与PyBool/PyLong/PyFloat/PyString不支持相除,其他类型均可相互相除;如果除数为 0(False在 Python 侧解释为 0,不可作为除数),会在 Python 侧进行错误打印; - 高级数据类型:
PyDict/PySet/PyTuple/PyList与所有类型均不支持相除。
- 基础数据类型:
-
**指数运算:- 基础数据类型:
PyString与PyBool/PyLong/PyFloat/PyString不支持指数运算,其他类型均可进行指数运算; - 高级数据类型:
PyDict/PySet/PyTuple/PyList与所有类型均不支持指数运算。
- 基础数据类型:
-
%取余:- 基础数据类型:
PyString与PyBool/PyLong/PyFloat/PyString不支持取余运算,其他类型均可进行取余运算;如果除数为 0(False在 Python 侧解释为 0,不可作为除数),会在 Python 侧进行错误打印; - 高级数据类型:
PyDict/PySet/PyTuple/PyList与所有类型均不支持取余运算。
- 基础数据类型:
-
以上所有错误情况均会进行 warn 级别打印,并且返回的
PyObj不可用(isAvaliable()为false)。
-
-
public open func toString(): String { ... }:toString函数可以将 Python 数据类型以字符串形式返回,基础数据类型将以 Python 风格返回;- 如果
PyObj本身不可用(isAvaliable()为false),将抛出异常。
-
hashCode函数为封装的 Pythonhash算法,其返回一个 Int64 的哈希值; -
==操作符用于判定两个PyObj对象是否相同,!=与之相反,如果接口比较失败,==返回为false并捕获 Python 侧报错,如果被比较的两个对象存在不可用,会抛出异常。
使用示例:
test01.py 文件:
a = 10
def function():
print("a is", a)
def function02(b, c = 1):
print("function02 call.")
print("b is", b)
print("c is", c)
同级目录下的仓颉文件 main.cj:
from std import ffi.python.*
from std import collection.*
main(): Int64 {
Python.load()
// Create an unavailable value.
var a = Python.Eval("a = 10") // SyntaxError: invalid syntax
print("${a.isAvailable()}\n") // false
// Uncallable value `b` be invoked
var b = Python.Eval("10")
b() // TypeError: 'int' object is not callable
// Import .py file.
var test = Python.Import("test01")
// `get []` get value of `a`.
var p_a = test["a"]
print("${p_a}\n") // 10
// `set []` set the value of a to 20.
test["a"] = Python.Eval("20")
test["function"]() // a is 20
// Call function02 with a named argument.
test["function02"]([1], HashMap<String, PyObj>([("c", 2.toPyObj())]))
// Set `a` in test01 to an unavailable value, and `a` will be deleted.
test["a"] = a
test["function"]() // NameError: name 'a' is not defined
Python.unload()
0
}
CjObj 接口
接口原型及类型扩展:
public interface CjObj <: PyFFIType {
func toPyObj(): PyObj
}
extend Bool <: CjObj {
public func toPyObj(): PyBool { ... }
}
extend Char <: CjObj {
public func toPyObj(): PyString { ... }
}
extend Int8 <: CjObj {
public func toPyObj(): PyLong { ... }
}
extend UInt8 <: CjObj {
public func toPyObj(): PyLong { ... }
}
extend Int16 <: CjObj {
public func toPyObj(): PyLong { ... }
}
extend UInt16 <: CjObj {
public func toPyObj(): PyLong { ... }
}
extend Int32 <: CjObj {
public func toPyObj(): PyLong { ... }
}
extend UInt32 <: CjObj {
public func toPyObj(): PyLong { ... }
}
extend Int64 <: CjObj {
public func toPyObj(): PyLong { ... }
}
extend UInt64 <: CjObj {
public func toPyObj(): PyLong { ... }
}
extend Float32 <: CjObj {
public func toPyObj(): PyFloat { ... }
}
extend Float64 <: CjObj {
public func toPyObj(): PyFloat { ... }
}
extend String <: CjObj {
public func toPyObj(): PyString { ... }
}
extend Array<T> <: CjObj where T <: PyFFIType {
public func toPyObj(): PyList<T> { ... }
}
extend HashMap<K, V> <: CjObj where K <: Hashable & Equatable<K> & PyFFIType {
public func toPyObj(): PyDict<K, V> { ... }
}
extend HashSet<T> <: CjObj where T <: Hashable, T <: Equatable<T> & PyFFIType {
public func toPyObj(): PySet<T> { ... }
}
关于 CjObj 类的几点说明
CjObj接口被所有基础数据类型实现并完成toPyObj扩展,分别支持转换为与之对应的 Python 数据类型。
PyBool 与 Bool 的映射
类原型:
public class PyBool <: PyObj {
public init(bool: Bool) { ... }
public func toCjObj(): Bool { ... }
}
关于 PyBool 类的几点说明
PyBool类继承自PyObj类,PyBool具有所有父类拥有的接口;PyBool仅允许用户使用仓颉的Bool类型进行构造;toCjObj接口将PyBool转换为仓颉数据类型Bool。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
// Creation of `PyBool`.
var a = PyBool(true) // The type of `a` is `PyBool`.
var b = Python.Eval("True") // The type of `b` is `PyObj` and needs to be matched to `PyBool`.
var c = true.toPyObj() // The type of `c` is `PyBool`, which is the same as `a`.
print("${a}\n")
if (a.toCjObj()) {
print("success\n")
}
if (b is PyBool) {
print("b is PyBool\n")
}
Python.unload()
0
}
执行效果:
True
success
b is PyBool
PyLong 与整型的映射
类原型:
public class PyLong <: PyObj {
public init(value: Int64) { ... }
public init(value: UInt64) { ... }
public init(value: Int32) { ... }
public init(value: UInt32) { ... }
public init(value: Int16) { ... }
public init(value: UInt16) { ... }
public init(value: Int8) { ... }
public init(value: UInt8) { ... }
public func toCjObj(): Int64 { ... }
public func toInt64(): Int64 { ... }
public func toUInt64(): UInt64 { ... }
}
关于 PyLong 类的几点说明
-
PyLong类继承自PyObj类,PyLong具有所有父类拥有的接口; -
PyLong支持来自所有仓颉整数类型的入参构造; -
toCjObj与toInt64接口将PyLong转换为Int64类型; -
toUInt64接口将PyLong转换为UInt64类型; -
PyLong类型向仓颉类型转换统一转换为 8 字节类型,不支持转换为更低字节类型; -
溢出问题:
toInt64原数值(以UInt64赋值,赋值不报错)超出Int64范围判定为溢出;toUInt64原数值(以Int64赋值,赋值不报错)超出UInt64范围判定为溢出;
-
PyLong暂不支持大数处理。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
// Creation of `PyLong`.
var a = PyLong(10) // The type of `a` is `PyLong`.
var b = Python.Eval("10") // The type of `b` is `PyObj` and needs to be matched to `PyLong`.
var c = 10.toPyObj() // The type of `c` is `PyLong`, which is the same as `a`.
print("${a}\n")
if (a.toCjObj() == 10 && a.toUInt64() == 10) {
print("success\n")
}
if (b is PyLong) {
print("b is PyLong\n")
}
Python.unload()
0
}
执行效果:
10
success
b is PyLong
PyFloat 与浮点的映射
类原型:
public class PyFloat <: PyObj {
public init(value: Float32) { ... }
public init(value: Float64) { ... }
public func toCjObj(): Float64 { ... }
}
关于 PyFloat 类的几点说明
PyFloat类继承自PyObj类,PyFloat具有所有父类拥有的接口;PyBool支持使用仓颉Float32/Float64类型的数据进行构造;toCjObj接口为了保证精度,将PyFloat转换为仓颉数据类型Float64。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
// Creation of `PyLong`.
var a = PyFloat(3.14) // The type of `a` is `PyFloat`.
var b = Python.Eval("3.14") // The type of `b` is `PyObj` and needs to be matched to `PyFloat`.
var c = 3.14.toPyObj() // The type of `c` is `PyFloat`, which is the same as `a`.
print("${a}\n")
if (a.toCjObj() == 3.14) {
print("success\n")
}
if (b is PyFloat) {
print("b is PyFloat\n")
}
Python.unload()
0
}
执行效果:
3.14
success
b is PyFloat
PyString 与字符、字符串的映射
类原型:
public class PyString <: PyObj {
public init(value: String) { ... }
public init(value: Char) { ... }
public func toCjObj(): String { ... }
public override func toString(): String { ... }
}
关于 PyString 类的几点说明
PyString类继承自PyObj类,PyString具有所有父类拥有的接口;PyString支持使用仓颉Char/String类型的数据进行构造;toCjObj/toString接口为将PyString转换为仓颉数据类型String。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
// Creation of `PyString`.
var a = PyString("hello python") // The type of `a` is `PyString`.
var b = Python.Eval("\"hello python\"") // The type of `b` is `PyObj` and needs to be matched to `PyString`.
var c = "hello python".toPyObj() // The type of `c` is `PyString`, which is the same as `a`.
print("${a}\n")
if (a.toCjObj() == "hello python") {
print("success\n")
}
if (b is PyString) {
print("b is PyString\n")
}
Python.unload()
0
}
执行结果:
hello python
success
b is PyString
PyTuple 类型
类原型:
public class PyTuple <: PyObj {
public init(args: Array<PyObj>) { ... }
public operator func [](key: Int64): PyObj { ... }
public func size(): Int64 { ... }
public func slice(begin: Int64, end: Int64): PyTuple { ... }
}
关于 PyTuple 类的几点说明
-
PyTuple与 Python 中的元组类型一致,即 Python 代码中使用(...)的变量; -
PyTuple类继承自PyObj类,PyTuple具有所有父类拥有的接口; -
PyTuple支持使用仓颉Array来进行构造,Array的元素类型必须为PyObj(Python 不同数据类型均可以使用PyObj传递,即兼容Tuple中不同元素的不同数据类型),当成员中包含不可用对象时,会抛出异常; -
[]操作符重载:- 父类
PyObj中[]入参类型为String类型,该类对象调用时能够访问或设置Python元组类型内部成员变量或者函数; - 子类
PyTuple支持使用[]对元素进行访问,如果角标key超出 [0, size()) 区间,会进行报错,并且返回不可用的PyObj对象; - 由于 Python 的元组为不可变对象,未进行
set []操作符重载。
- 父类
-
size函数用于获取PyTuple的长度; -
slice函数用于对源PyTuple进行剪裁,并返回一个新的PyTuple, 如果slice的入参begin和end不在 [0, size()) 区间内,仍会正常裁切。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
// Creation of `PyTuple`.
var a = PyTuple(["Array".toPyObj(), 'a'.toPyObj(), 1.toPyObj(), 1.1.toPyObj()])
var b = match (Python.Eval("('Array', 'a', 1, 1.1)")) {
case val: PyTuple => val
case _ => throw PythonException()
}
// Usage of size
println(a.size()) // 4
// Usage of slice
println(a.slice(1, 2)) // ('a',). This print is same as Python code `a[1: 2]`.
println(a.slice(-1, 20)) // ('Array', 'a', 'set index 3 to String', 1.1)
Python.unload()
return 0
}
执行结果:
4
('a',)
('Array', 'a', 1, 1.1)
PyList 与 Array 的映射
类原型:
public class PyList<T> <: PyObj where T <: PyFFIType {
public init(args: Array<T>) { ... }
public operator func [](key: Int64): PyObj { ... }
public operator func [](key: Int64, value!: T): Unit { ... }
public func toCjObj(): Array<PyObj> { ... }
public func size(): Int64 { ... }
public func insert(index: Int64, value: T): Unit { ... }
public func append(item: T): Unit { ... }
public func slice(begin: Int64, end: Int64): PyList<T> { ... }
}
关于 PyList 类的几点说明
-
PyList类与 Python 中的列表类型一致,即 Python 代码中使用[...]的变量; -
PyList类继承自PyObj类,PyList具有所有父类拥有的接口,该类由于对仓颉的 Array 进行映射,因此该类引入了泛型T,T类型约束为PyFFIType接口的子类; -
PyList类可以通过仓颉的Array类型进行构造,Array的成员类型同样约束为PyFFIType接口的子类; -
[]操作符重载:- 父类
PyObj中[]入参类型为String类型,该类对象调用时仅能访问或设置Python内部成员变量或者函数; - 该类中的
[]入参类型为Int64,即对应Array的角标值,其范围为 [0, size()),如果入参不在范围内,将进行报错,并且返回的对象为不可用; []同样支持get以及set,并且set时,value类型为T,如果value其中包含不可用的 Python 对象时,会抛出异常。
- 父类
-
toCjObj函数支持将PyList转换为仓颉的Array<PyObj>,请注意,此时并不会转换为Array<T>; -
size函数返回PyList的长度; -
insert函数将在index位置插入value,其后元素往后移,index 不在 [0, size()) 可以正常插入,如果value为不可用对象,将会抛出异常; -
append函数将item追加在PyList最后,如果value为不可用对象,将会抛出异常; -
slice函数用于截取 [begin, end) 区间内的数据并且返回一个新的PyList,begin和end不在 [0, size()) 也可以正常截取。
使用示例:
from std import ffi.python.*
main(): Int64 {
Python.load()
// Creation of `PyList`.
var a = PyList<Int64>([1, 2, 3])
var b = match (Python.Eval("[1, 2, 3]")) {
case val: PyList<PyObj> => val
case _ => throw PythonException()
}
var c = [1, 2, 3].toPyObj()
// Usage of `[]`
println(a["__add__"]([b])) // [1, 2, 3, 1, 2, 3]
a[1]
b[1]
a[2] = 13
b[2] = 15.toPyObj()
// Usage of `toCjObj`
var cjArr = a.toCjObj()
for (v in cjArr) {
print("${v} ") // 1 2 13
}
print("\n")
// Usage of `size`
println(a.size()) // 3
// Usage of `insert`
a.insert(1, 4) // [1, 4, 2, 13]
a.insert(-100, 5) // [5, 1, 4, 2, 13]
a.insert(100, 6) // [5, 1, 4, 2, 13, 6]
b.insert(1, 4.toPyObj()) // [1, 4, 2, 15]
// Usage of `append`
a.append(7) // [5, 1, 4, 2, 13, 6, 7]
b.append(5.toPyObj()) // [1, 4, 2, 15, 5]
// Usage of `slice`
a.slice(1, 2) // [1]
a.slice(-100, 100) // [5, 1, 4, 2, 13, 6, 7]
b.slice(-100, 100) // [1, 4, 2, 15, 5]
return 0
}
执行结果:
[1, 2, 3, 1, 2, 3]
1 2 13
3
PyDict 与 HashMap 的映射
类原型:
public class PyDict<K, V> <: PyObj where K <: Hashable & Equatable<K> & PyFFIType {
public init(args: HashMap<K, V>) { ... }
public func getItem(key: K): PyObj { ... }
public func setItem(key: K, value: V): Unit { ... }
public func toCjObj(): HashMap<PyObj, PyObj> { ... }
public func contains(key: K): Bool { ... }
public func copy(): PyDict<K, V> { ... }
public func del(key: K): Unit { ... }
public func size(): Int64 { ... }
public func empty(): Unit { ... }
public func items(): PyList<PyObj> { ... }
public func values(): PyList<PyObj> { ... }
public func keys(): PyList<PyObj> { ... }
}
关于 PyDict 类的几点说明
-
PyDict与 Python 的字典类型一致,即 Python 代码中使用{ a: b }的变量; -
PyDict类继承自PyObj类,PyDict具有所有父类拥有的接口,该类由于对仓颉的 HashMap 进行映射,因此该类引入了泛型<K, V>,其中K类型约束为PyFFIType接口的子类,且可被Hash计算以及重载了==与!=运算符; -
PyDict接受来自仓颉类型HashMap的数据进行构造:K仅接受CjObj或PyObj类型或其子类;- 相同的 Python 数据其值也相同,例如
Python.Eval("1")与1.toPyObj()为==关系。
-
getItem函数用于获取PyDict对应键值的value,如果键值无法找到,会进行报错并返回不可用的PyObj,如果配置的值key或为value为PyObj类型且不可用,此时抛出异常;; -
setItem函数用于配置PyDict对应键值的value,如果对应键值无法找到,会进行插入,如果配置的值key或为value为PyObj类型且不可用,此时抛出异常; -
toCjObj函数用于将PyDict转换为HashMap<PyObj, PyObj>类型; -
contains函数用于判断key值是否包含在当前字典中,返回类型为 Bool 型,如果接口失败,进行报错,并且返回 false; -
copy函数用于拷贝当前字典,并返回一个新的PyDict<T>类型,如果拷贝失败,返回的 PyDict 不可用; -
del函数用于删除对应key的值,如果 key 值为 PyObj 类型且不可用,会抛出异常; -
size函数用于返回当前字典的长度; -
empty函数用于清空当前字典内容; -
items函数用于获取一个 Pythonlist类型的键值对列表,可以被迭代访问; -
values函数用于获取一个 Pythonlist类型的值列表,可以被迭代访问; -
keys函数用于获取一个 Pythonlist类型的键列表,可以被迭代访问。
使用示例:
from std import ffi.python.*
from std import collection.*
main() {
Python.load()
// Creation of `PyDict`
var a = PyDict(HashMap<Int64, Int64>([(1, 1), (2, 2)])) // The key type is `CjObj`.
var b = PyDict(HashMap<PyObj, Int64>([(Python.Eval("1"), 1), (Python.Eval("2"), 2)])) // The key type is `PyObj`.
var c = match (Python.Eval("{'pydict': 1, 'hashmap': 2, 3: 3, 3.1: 4}")) {
case val: PyDict<PyObj, PyObj> => val // Python side return `PyDict<PyObj, PyObj>`
case _ => throw PythonException()
}
var d = HashMap<Int64, Int64>([(1, 1), (2, 2)]).toPyObj()
// Usage of `getItem`
println(a.getItem(1)) // 1
println(b.getItem(1.toPyObj())) // 1
// Usage of `setItem`
a.setItem(1, 10)
b.setItem(1.toPyObj(), 10)
println(a.getItem(1)) // 10
println(b.getItem(1.toPyObj())) // 10
// Usage of `toCjObj`
var hashA = a.toCjObj()
for ((k, v) in hashA) {
print("${k}: ${v}, ") // 1: 10, 2: 2,
}
print("\n")
var hashB = b.toCjObj()
for ((k, v) in hashB) {
print("${k}: ${v}, ") // 1: 10, 2: 2,
}
print("\n")
// Usage of `contains`
println(a.contains(1)) // true
println(a.contains(3)) // false
println(b.contains(1.toPyObj())) // true
// Usage of `copy`
println(a.copy()) // {1: 10, 2: 2}
// Usage of `del`
a.del(1) // Delete the key-value pair (1: 1).
// Usage of `size`
println(a.size()) // 1
// Usage of `empty`
a.empty() // Clear all elements in dict.
// Usage of `items`
for (i in b.items()) {
print("${i} ") // (1, 10) (2, 2)
}
print("\n")
// Usage of `values`
for (i in b.values()) {
print("${i} ") // 10 2
}
print("\n")
// Usage of `keys`
for (i in b.keys()) {
print("${i} ") // 1, 2
}
print("\n")
Python.unload()
}
PySet 与 HashSet 的映射
类原型:
public class PySet<T> <: PyObj where T <: Hashable, T <: Equatable<T> & PyFFIType {
public init(args: HashSet<T>) { ... }
public func toCjObj(): HashSet<PyObj> { ... }
public func contains(key: T): Bool { ... }
public func add(key: T): Unit { ... }
public func pop(): PyObj { ... }
public func del(key: T): Unit { ... }
public func size(): Int64 { ... }
public func empty(): Unit { ... }
}
关于 PySet 类的几点说明
-
PySet对应的是 Python 中的集合的数据类型,当元素插入时会使用 Python 内部的 hash 算法对集合元素进行排序(并不一定按照严格升序,一些方法可能因此每次运行结果不一致)。 -
PySet类继承自PyObj类,PySet具有所有父类拥有的接口,该类由于对仓颉的HashSet进行映射,因此该类引入了泛型T,T类型约束为PyFFIType接口的子类,且可被Hash计算以及重载了==与!=运算符; -
PySet接受来自仓颉类型HashMap的数据进行构造:K仅接受CjObj或PyObj类型或其子类;- 相同的 Python 数据其值也相同,例如
Python.Eval("1")与1.toPyObj()为==关系。
-
toCjObj函数用于将PySet<T>转为HashSet<PyObj>需要注意的是此处只能转为元素类型为PyObj类型; -
contains函数用于判断key是否在当前字典中存在,key类型为T; -
add函数可以进行值插入,当PySet中已存在键值,则插入不生效,如果key为PyObj且不可用,则会抛出异常; -
pop函数将PySet中的第一个元素取出; -
del删除对应的键值,如果key不在PySet中,则会报错并正常退出,如果key为PyObj且不可用,则会抛出异常; -
size用于返回PySet的长度; -
empty用于清空当前PySet。
注意:调用
toCjObj完后,所有元素将被pop出来,此时原PySet将会为空(size为 0,原PySet仍然可用);
使用示例:
from std import ffi.python.*
from std import collection.*
main() {
Python.load()
// Creation of `PySet`
var a = PySet<Int64>(HashSet<Int64>([1, 2, 3]))
var b = match (Python.Eval("{'PySet', 'HashSet', 1, 1.1, True}")) {
case val: PySet<PyObj> => val
case _ => throw PythonException()
}
var c = HashSet<Int64>([1, 2, 3]).toPyObj()
// Usage of `toCjObj`
var cja = a.toCjObj()
println(a.size()) // 0
// Usage of `contains`
println(b.contains("PySet".toPyObj())) // true
// Usage of `add`
a.add(2)
println(a.size()) // 1
a.add(2) // Insert same value, do nothing.
println(a.size()) // 1
a.add(1) // Insert `1`.
// Usage of `pop`
println(a.pop()) // 1. Pop the first element.
println(a.size()) // 1
// Usage of `del`
c.del(2)
println(c.contains(2)) // false
// Usage of `empty`
println(c.size()) // 2
c.empty()
println(c.size()) // 0
Python.unload()
}
PySlice 类型
PySlice 类型与 Python 内建函数 slice() 的返回值用法一致,可以被用来标识一段区间及步长,可以用来作为可被切片的类型下标值来剪裁获取子串。为了方便从仓颉侧构造, PySlice 类可以与仓颉的 Range 区间类型进行互相转换,详细描述见以下。
类原型:
public class PySlice<T> <: PyObj where T <: Countable<T> & Comparable<T> & Equatable<T> & CjObj {
public init(args: Range<T>) { ... }
public func toCjObj(): Range<Int64> { ... }
}
关于 PySlice 的几点说明:
PySlice可以使用仓颉的Range类型来进行构造,并且支持Range的语法糖,其中泛型T在原有Range约束的同时,加上约束在来自CjObj的实现,不支持PyObj类型;toCjObj函数支持将PySlice转为仓颉Range的接口,应注意此时Range的泛型类型为Int64类型的整型;- 如果希望把
PySlice类型传递给PyString/PyList/PyTuple或者是其他可被slice的PyObj类型,可以通过其成员函数__getitem__进行传递,详情见示例。
使用示例:
from std import ffi.python.*
main() {
Python.load()
var range = 1..6:2
// Create a PySlice.
var slice1 = PySlice(range)
var slice2 = match (Python["slice"]([0, 6, 2])) {
case val: PySlice<Int64> => val
case _ => throw PythonException()
}
var slice3 = range.toPyObj()
// Use PySlice in PyString.
var str = PyString("1234567")
println(str["__getitem__"]([range])) // 246
println(str["__getitem__"]([slice1])) // 246
// Use PySlice in PyList.
var list = PyList(["a", "b", "c", "d", "e", "f", "g", "h"])
println(list["__getitem__"]([range])) // ['b', 'd', 'f']
println(list["__getitem__"]([slice1])) // ['b', 'd', 'f']
// Use PySlice in PyTuple.
var tup = PyTuple(list.toCjObj())
println(tup["__getitem__"]([range])) // ('b', 'd', 'f')
println(tup["__getitem__"]([slice1])) // ('b', 'd', 'f')
Python.unload()
0
}
执行结果:
246
246
['b', 'd', 'f']
['b', 'd', 'f']
('b', 'd', 'f')
('b', 'd', 'f')
PyObj 的迭代器类型 PyObjIterator
代码原型:
PyObj 的扩展:
extend PyObj <: Iterable<PyObj> {
public func iterator(): Iterator<PyObj> { ... }
}
PyObjIterator 类型:
public class PyObjIterator <: Iterator<PyObj> {
public init(obj: PyObj) { ... }
public func next(): Option<PyObj> { ... }
public func iterator(): Iterator<PyObj> { ... }
}
关于 PyObjIterator 的几点说明:
-
获取
PyObjIterator可以通过PyObj的 iterator 方法获取; -
PyObjIterator允许被外部构造,如果提供的PyObj不可以被迭代或提供的PyObj不可用,则会直接抛出异常;- 可以被迭代的对象有:
PyString/PyTuple/PyList/PySet/PyDict; - 注意,直接对
PyDict进行迭代时,迭代的为其键key的值。
- 可以被迭代的对象有:
-
next函数用于对该迭代器进行迭代; -
iterator方法用于返回本身。
使用示例:
from std import ffi.python.*
from std import collection.*
main() {
Python.load()
// iter of PyString
var S = PyString("Str")
for (s in S) {
print("${s} ") // S t r
}
print("\n")
// iter of PyTuple
var T = PyTuple(["T".toPyObj(), "u".toPyObj(), "p".toPyObj()])
for (t in T) {
print("${t} ") // T u p
}
print("\n")
// iter of PyList
var L = PyList(["L", "i", "s", "t"])
for (l in L) {
print("${l} ") // L i s t
}
print("\n")
// iter of PyDict
var D = PyDict(HashMap<Int64, String>([(1, "D"), (2, "i"), (3, "c"), (4, "t")]))
for (d in D) {
print("${d} ") // 1 2 3 4, dict print keys.
}
print("\n")
// iter of PySet
var Se = PySet(HashSet<Int64>([1, 2, 3]))
for (s in Se) {
print("${s} ") // 1 2 3
}
print("\n")
0
}
执行结果:
S t r
T u p
L i s t
1 2 3 4
1 2 3
仓颉与 Python 的注册回调
Python 互操作库支持简单的函数注册及 Python 对仓颉函数调用。
Python 回调仓颉代码通过需要通过 C 作为介质进行调用,并且使用到了 Python 的三方库: ctypes 以及 _ctypes 。
类型映射
基础数据对照如下表:
| Cangjie Type | CType | Python Type |
|---|---|---|
Bool | PyCBool | PyBool |
Char | PyCWchar | PyString |
Int8 | PyCByte | PyLong |
UInt8 | PyCUbyte/PyCChar | PyLong |
Int16 | PyCShort | PyLong |
UInt16 | PyCUshort | PyLong |
Int32 | PyCInt | PyLong |
UInt32 | PyCUint | PyLong |
Int64 | PyCLonglong | PyLong |
UInt64 | PyCUlonglong | PyLong |
Float32 | PyCFloat | PyFloat |
Float64 | PyCDouble | PyFloat |
[unsupport CPointer as param] CPointer<T> | PyCPointer | ctypes.pointer |
[unsupport CString as param] CString | PyCCpointer | ctypes.c_char_p |
[unsupport CString as param] CString | PyCWcpointer | ctypes.c_wchar_p |
Unit | PyCVoid | - |
Cangjie Type是在仓颉侧修饰的变量类型,无特殊说明则支持传递该类型参数给 Python 代码,并且支持从 Python 传递给仓颉;PyCType为仓颉侧对应的PyCFunc接口配置类型,详细见类原型以及示例展示;Python Type是在仓颉侧的类型映射,无指针类型映射,不支持从仓颉侧调用 Python 带有指针的函数;PyCCpointer与PyCWcpointer同样都是映射到CString,两者区别为PyCCpointer为 C 中的字符串,PyCWcpointer仅为字符指针,即使传递多个字符,也只取第一个字符;- 类型不匹配将会导致不可预测的结果。
PyCFunc 类原型
PyCFunc 是基于 Python 互操作库和 Python 三方库 ctype/_ctype 的一个 PyObj 子类型,该类型可以直接传递给 Python 侧使用。 PyCFunc 为用户提供了注册仓颉的 CFunc 函数给 Python 侧,并且支持由 Python 回调 CFunc 函数的能力。
代码原型:
public enum PyCType {
PyCBool |
PyCChar |
PyCWchar |
PyCByte |
PyCUbyte |
PyCShort |
PyCUshort |
PyCInt |
PyCUint |
PyCLonglong |
PyCUlonglong |
PyCFloat |
PyCDouble |
PyCPointer |
PyCCpointer |
PyCWcpointer |
PyCVoid
}
public class PyCFunc <: PyObj {
public init(f: CPointer<Unit>, argsTy!: Array<PyCType> = [], retTy!: PyCType = PyCType.PyCVoid) { ... }
public func setArgTypes(args: Array<PyCType>): PyCFunc { ... }
public func setRetTypes(ret: PyCType): PyCFunc { ... }
}
关于类的几点说明:
-
PyCFunc继承自PyObj,可以使用父类的部分接口(如果不支持的接口会相应报错); -
init允许外部用户构造,必须提供函数指针作为第一个参数(仓颉侧需要将CFunc类型转换为CPointer<Unit>类型),后面两个可选参数分别为入参类型的数组、返回值类型;这里特别声明,如果传入的指针并非函数指针会导致函数调用时程序崩溃(库层面无法进行拦截);
-
setArgTypes/setRetTypes函数用于配置参数和返回值类型,支持的参数见PyCType枚举; -
父类中的
()操作符,支持在仓颉侧调用该注册的CFunc函数; -
该类可以直接传递给 Python 侧使用,也可以在仓颉侧直接调用(如果该类构造时使用非函数指针,这里调用将会崩溃);
-
该类支持类似 Js 的链式调用。
示例
1、准备仓颉的 CFunc 函数:
@C
func cfoo(a: Bool, b: Int32, c: Int64): CPointer<Unit> {
print("cfoo called.\n")
print("${a}, ${b}, ${c}\n")
return CPointer<Unit>()
}
2、构造 PyCFunc 类对象:
from std import ffi.python.*
// Define the @C function.
@C
func cfoo(a: Bool, b: Int32, c: Int64): CPointer<Unit> {
print("cfoo called.\n")
print("${a}, ${b}, ${c}\n")
return CPointer<Unit>()
}
main() {
Python.load()
/*
Construct PyCFunc class.
Set args type: Bool -> PyCBool
Int32 -> PyCInt
Int64 -> PyCLonglong
CPointer<Unit> -> PyCPointer
*/
var f1 = PyCFunc(unsafe {CPointer<Unit>(cfoo)},
argsTy: [PyCBool, PyCInt, PyCLonglong],
retTy: PyCPointer)
// You also can use it by chain-call.
var f2 = PyCFunc(unsafe {CPointer<Unit>(cfoo)})
.setArgTypes([PyCBool, PyCInt, PyCLonglong])
.setRetTypes(PyCPointer)([true, 1, 2])
// Call f1
f1([true, 1, 2])
f1([PyBool(true), PyLong(1), PyLong(2)])
Python.unload()
0
}
编译仓颉文件并执行:
$ cjc ./main.cj -o ./main && ./main
cfoo called.
true, 1, 2
cfoo called.
true, 1, 2
cfoo called.
true, 1, 2
3、将函数注册给 Python 并且由 Python 进行调用:
Python 代码如下:
# File test.py
# `foo` get a function pointer and call it.
def foo(func):
func(True, 10, 40)
对上面仓颉 main 进行修改:
main() {
Python.load()
var f1 = PyCFunc(unsafe {CPointer<Unit>(cfoo)},
argsTy: [PyCBool, PyCInt, PyCLonglong],
retTy: PyCPointer)
// Import test.py
var cfunc01 = Python.Import("test")
// Call `foo` and transfer `f1`
cfunc01["foo"]([f1])
Python.unload()
0
}
4、Python 侧传递指针到仓颉侧:
为 Python 文件增加函数:
# File test.py
# If you want transfer pointer type to Cangjie CFunc, you need import ctypes.
from ctypes import *
# `foo` get a function pointer and call it.
def foo(func):
func(True, 10, 40)
# `fooptr` get a function pointer and call it with pointer type args.
def fooptr(func):
a = c_int(10)
# c_char_p will get whole symbols, but c_wchar_p only get first one symbol 'd'.
func(pointer(a), c_char_p(b'abc'), c_wchar_p('def'))
修改仓颉代码:
from std import ffi.python.*
var x = Python.load()
// Modify the `foo` param type to pointer.
@C
func foo(a: CPointer<Int64>, b: CString, c: CString): Unit {
print("${unsafe {a.read(0)}}, ${b.toString()}, ${c.toString()}\n")
}
main(): Int64 {
var f1 = PyCFunc(unsafe {CPointer<Unit>(foo)},
argsTy: [PyCPointer, PyCCpointer, PyCWcpointer],
retTy: PyCVoid)
// Import test.py
var test = Python.Import("test")
// Call `fooptr` and transfer `f1`
test["fooptr"]([f1])
return 0
}
- 由于仓颉侧调用函数不能将指针类型传递给 Python 库,所以该处仅支持在 Python 侧进行调用。
对其编译并执行:
$ cjc ./main.cj -o ./main && ./main
10, abc, d
cjc 编译器手册
本章会介绍 cjc(仓颉编译器)的基本使用方法并列出 cjc 所提供的编译选项。
cjc 基本使用方法
想必你已经在学习仓颉的过程中尝试着使用 cjc 了,我们先来看一下 cjc 的基本使用方法,如果你想了解编译选项的相关内容,请查阅本章第二节。
cjc 的使用方式如下:
cjc [option] file...
假如我们有一个名为 hello.cj 的仓颉文件:
main() {
println("Hello, World!")
}
我们可以使用以下命令来编译此文件:
$ cjc hello.cj
此时工作目录下会新增可执行文件 main ,
cjc 默认会将给定源代码文件编译成可执行文件,并将可执行文件命名为 main。
以上为不给任何编译选项时 cjc 的默认行为,
我们可以通过使用编译选项来控制 cjc 的行为,例如让 cjc 进行整包编译,
又或者是指定输出文件的名字。
cjc-frontend
cjc-frontend (仓颉前端编译器)会随 cjc 一起通过 Cangjie SDK 提供,该程序能够将仓颉源码编译至仓颉的中间表示 (LLVM IR)。 cjc-frontend 仅进行仓颉代码的前端编译,虽然该程序和 cjc 共享部分编译选项,但编译流程会在前端编译结束时中止。使用 cjc 时仓颉编译器会自动进行前端、后端的编译以及链接工作。该程序仅作为前端编译器的实体体现提供,除编译器开发者外,仓颉代码的编译应优先使用 cjc 。
cjc 编译选项
接下来会介绍一些常用的 cjc 编译选项。若某一选项同时适用于 cjc-frontend,则该选项会有 [frontend] 上标;若该选项在 cjc-frontend 下行为与 cjc 不同,选项会有额外说明。
两个横杠开头的选项为长选项,如 --xxxx。
一个横杠开头的选项为短选项,如 -x。
对于长选项,如果其后有参数,选项和参数之前既可以用空格隔开,也可以用等号连接,如 --xxxx <value> 与 --xxxx=<value> 等价。
基本选项
--output-type=[exe|staticlib|dylib] [frontend]
指定输出文件的类型,exe 模式下会生成可执行文件,staticlib 模式下会生成静态库文件( .a 文件),dylib 模式下会生成 动态库文件(Linux 平台为 .so 文件、Windows 平台为 .dll 文件)。
cjc 默认为 exe 模式。
我们除了可以将 .cj 文件编译成一个可执行文件以外,也可以将其编译成一个静态或者是动态的链接库,
例如使用
$ cjc tool.cj --output-type=dylib
可以将 tool.cj 编译成一个动态链接库,在 Linux 平台 cjc 会生成一个名为 libtool.so 的动态链接库文件。
[frontend] 在 cjc-frontend 中,编译流程仅进行至 LLVM IR,因此输出总是 .bc 文件,但是不同的 --output-type 类型仍会影响前端编译的策略。
--package, -p [frontend]
编译包,使用此选项时需要指定一个目录作为输入,目录中的源码文件需要属于同一个包。
假如我们有文件 log/printer.cj:
package log
public func printLog(message: String) {
println("[Log]: ${message}")
}
与文件 main.cj:
import log.*
main() {
printLog("Everything is great")
}
我们可以使用
$ cjc -p log --output-type=staticlib
来编译 log 包,cjc 会在当前目录下生成一个 liblog.a 文件。
然后我们可以使用 liblog.a 文件来编译 main.cj ,编译命令如下:
$ cjc main.cj liblog.a
cjc 会将 main.cj 与 liblog.a 一同编译成一个可执行文件 main 。
--module-name <value> [frontend]
指定要编译的模块的名字。
假如我们有文件 MyModule/src/log/printer.cj:
package log
public func printLog(message: String) {
println("[Log]: ${message}")
}
与文件 main.cj:
from MyModule import log.*
main() {
printLog("Everything is great")
}
我们可以使用
$ cjc -p MyModule/src/log --module-name MyModule --output-type=staticlib -o MyModule/liblog.a
来编译 log 包并指定其模块名为 MyModule,cjc 会在 MyModule 目录下生成一个 MyModule/liblog.a 文件。
然后我们可以使用 liblog.a 文件来编译导入了 log 包的 main.cj ,编译命令如下:
$ cjc main.cj MyModule/liblog.a
cjc 会将 main.cj 与 liblog.a 一同编译成一个可执行文件 main 。
--output <value>, -o <value>, -o<value> [frontend]
指定输出文件的路径,编译器的输出将被写入指定的文件。
例如以下命令会将输出的可执行文件名字指定为 a.out 。
cjc main.cj -o a.out
--library <value>, -l <value>, -l<value>
指定要链接的库文件。
给定的库文件会被直接传给链接器,此编译选项一般需要和 --library-path <value> 配合使用。
文件名的格式应为 lib[arg].[extension]。
当我们需要链接库 a 时,我们可以使用选项 -l a,库文件搜索目录下的 liba.a、
liba.so (或链接 Windows 目标程序时会搜索 liba.dll) 等文件会被链接器搜索到并根据需要被链接至最终输出中。
--library-path <value>, -L <value>, -L<value>
指定要链接的库文件所在的目录。
使用 --library <value> 选项时,一般也需要使用此选项来指定要链接的库文件所在的目录。
--library-path <value> 指定的路径会被加入链接器的库文件搜索路径。
另外环境变量 LIBRARY_PATH 中指定的路径也会被加入链接器的库文件搜索路径中,
通过 --library-path 指定的路径会比 LIBRARY_PATH 中的路径拥有更高的优先级。
假如我们有从以下 c 语言源文件通过 c 语言编译器编译得到的动态库文件 libcProg.so,
#include <stdio.h>
void printHello() {
printf("Hello World\n");
}
与仓颉文件 main.cj:
foreign func printHello(): Unit
main(): Int64 {
unsafe {
printHello()
}
return 0
}
我们可以使用
cjc main.cj -L . -l cProg
来编译 main.cj 并指定要链接的 cProg 库,这里 cjc 会输出一个可执行文件 main 。
执行 main 会有如下输出:
$ LD_LIBRARY_PATH=.:$LD_LIBRARY_PATH ./main
Hello World
请注意,由于使用了动态库文件,这里需要将库文件所在目录加入 $LD_LIBRARY_PATH 以保证
main 可以在执行时进行动态链接。
-g [frontend]
生成带有调试信息的可执行文件或者是库文件。
注:
-g只能配合-O0使用,如果使用更高的优化级别可能会导致调试功能出现异常。
--trimpath <value> [frontend]
移除调试信息中源文件路径信息的前缀。
编译仓颉代码时 cjc 会保存源文件( .cj 文件)的绝对路径信息以在运行时提供调试与异常信息。
使用此选项可以将指定的路径前缀从源文件路径信息中移除,cjc 的输出文件中的源文件路径信息不会包含用户指定的部分。
可以多次使用 --trimpath 指定多个不同的路径前缀;对于每个源文件路径,编译器会将第一个匹配到的前缀从路径中移除。
--coverage [frontend]
生成支持统计代码覆盖率的可执行程序。编译器会为每一个编译单元都生成一个后缀名为 gcno 的代码信息文件。在执行程序后,每一个编译单元都会得到一个后缀名为 gcda 的执行统计文件。根据这两个文件,配合使用 cjcov 工具可以生成本次执行下的代码覆盖率报表。
注:
--coverage只能配合-O0使用,如果使用更高的优化级别,编译器将告警并强制使用-O0。--coverage用于编译生成可执行程序,如果用于生成静态库或者动态库,那么在最终使用该库时可能出现链接错误。
--int-overflow=[throwing|wrapping|saturating] [frontend]
指定固定精度整数运算的溢出策略,默认为 throwing。
throwing策略下整数运算溢出时会抛出异常wrapping策略下整数运算溢出时会回转至对应固定精度整数的另外一端saturating策略下整数运算溢出时会选择对应固定精度的极值作为结果
--diagnostic-format=[default|noColor|json] [frontend]
Windows 版本暂不支持输出带颜色渲染的错误信息。
指定错误信息的输出格式,默认为 default 。
default错误信息默认格式输出(带颜色)noColor错误信息默认格式输出(无颜色)json错误信息json格式输出
--verbose, -V [frontend]
cjc 会打印出编译器版本信息,工具链依赖的相关信息以及编译过程中执行的命令。
--help, -h [frontend]
打印可用的编译选项。
使用此选项时编译器仅会打印编译选项相关信息,不会对任何输入文件进行编译。
--version, -v [frontend]
打印编译器版本信息。
使用此选项时编译器仅会打印版本信息,不会对任何输入文件进行编译。
--save-temps <value>
保留编译过程中生成的中间文件并保存至 <value> 路径下。
编译器会保留编译过程中生成的 .bc, .o 等中间文件。
--import-path <value> [frontend]
指定导入模块的 AST 文件的搜索路径。
假如我们已经有以下目录结构,libs/myModule 目录中包含 myModule 模块的库文件和 log 包的 AST 导出文件,
.
├── libs
| └── myModule
| ├── log.cjo
| └── libmyModule.a
└── main.cj
且我们有代码如下的 main.cj 文件,
from myModule import log.printLog
main() {
printLog("Everything is great")
}
我们可以通过使用 --import-path ./libs 来将 ./libs 加入导入模块的 AST 文件搜索路径,cjc 会使用 ./libs/myModule/log.cjo 文件来对 main.cj 文件进行语义检查与编译。
--import-path 提供与 CANGJIE_PATH 环境变量相同的功能,但通过 --import-path 设置的路径拥有更高的优先级。
--scan-dependency [frontend]
打印当前编译的包对于其他包的依赖信息。
使用示例请参考 包管理 章节。
--warn-off, -Woff <value> [frontend]
关闭编译期出现的全部或部分警告。
<value> 可以为 all 或者一个设定好的警告组别。当参数为 all 时,对于编译过程中生成的所有警告,编译器都不会打印;
当参数为其他设定好的组别时,编译器将不会打印编译过程中生成的该组别警告。
在打印每个警告时,会有一行 #note 提示该警告属于什么组别并如何关闭它,
我们可以通过 --help 打印所有可用的编译选项参数,来查阅具体的组别名称。
--warn-on, -Won <value> [frontend]
开启编译期出现的全部或部分警告。
--warn-on 的 <value> 与 --warn-off 的 <value> 取值范围相同,--warn-on 通常与 --warn-off 组合使用;
比如,我们可以通过设定 -Woff all -Won <value> 来仅允许组别为 <value> 的警告被打印。
特别要注意的是,--warn-on 与 --warn-off 在使用上顺序敏感;针对同一组别,后设定的选项会覆盖之前选项的设定,
比如,调换上例中两个编译选项的位置,使其变为 -Won <value> -Woff all,其效果将变为关闭所有警告。
--error-count-limit <value> [frontend]
限制编译器打印错误个数的上限。
参数 <value> 可以为 all 或一个非负整数。当参数为 all 时,编译器会打印编译过程中生成的所有错误;
当参数为非负整数 N 时,编译器最多会打印 N 个错误。此选项默认值为 8。
--output-dir <value> [frontend]
控制编译器生成的中间文件与最终文件的保存目录。
控制编译器生成的中间文件的保存目录,例如 .cjo 文件。当指定 --output-dir <path1> 时也指定了 --output <path2>,则最终输出会被保存至 <path1>/<path2> 。
同时指定此选项与
--output选项时,--output选项的参数必须是一个相对路径。
--static-std
静态链接仓颉库的 std 模块。
此选项仅在编译动态链接库或可执行文件时生效。cjc 默认静态链接仓颉库的 std 模块。
--dy-std
动态链接仓颉库的 std 模块。
此选项仅在编译动态链接库或可执行文件时生效。
--static-libs
静态链接仓颉库非 std 的其他模块。
此选项仅在编译动态链接库或可执行文件时生效。cjc 默认静态链接仓颉库的非 std 的其他模块。
--dy-libs
动态链接仓颉库非 std 的其他模块。
此选项仅在编译动态链接库或可执行文件时生效。
注:
--static-std和--dy-std选项一起叠加使用,仅最后的那个选项生效;--static-libs和--dy-libs选项一起叠加使用,仅最后的那个选项生效;--static-std与--dy-libs选项不可一起使用,否则会报错;--dy-std与--static-libs选项不可一起使用,否则会报错;--dy-std单独使用时,会默认生效--dy-libs选项,并有相关告警信息提示;--dy-libs单独使用时,会默认生效--dy-std选项,并有相关告警信息提示。
--stack-trace-format=[default|simple|all]
指定异常调用栈打印格式,用来控制异常抛出时的栈帧信息显示,默认为 default 格式。
异常调用栈的格式说明如下:
default格式:省略泛型参数的函数名(文件名:行号)simple格式:文件名:行号all格式:完整的函数名(文件名:行号)
--lto=[full|thin]
使能且指定 LTO (Link Time Optimization 链接时优化)优化编译模式。
注:支持编译可执行文件和
LTO模式下的静态库(.bc文件),不支持编译生成动态库,即如果在LTO模式下指定--output-type=dylib则会编译报错。 注:Windows平台不支持该功能。 注:当使能且指定LTO(Link Time Optimization链接时优化)优化编译模式时,不允许同时使用如下优化编译选项:-Os、-Oz。
LTO 优化支持两种编译模式:
-
--lto=full:full LTO将所有编译模块合并到一起,在全局上进行优化,这种方式可以获得最大的优化潜力,同时也需要更长的编译时间。 -
--lto=thin:相比于full LTO,thin LTO在多模块上使用并行优化,同时默认支持链接时增量编译,编译时间比full LTO短,因为失去了更多的全局信息,所以优化效果不如full LTO。- 通常情况下优化效果对比:
full LTO>thin LTO> 常规静态链接编译。 - 通常情况下编译时间对比:
full LTO>thin LTO> 常规静态链接编译。
- 通常情况下优化效果对比:
LTO 优化使用场景:
-
使用以下命令编译可执行文件
$ cjc test.cj --lto=full or $ cjc test.cj --lto=thin -
使用以下命令编译
LTO模式下需要的静态库(.bc文件),并且使用该库文件参与可执行文件编译# 生成的静态库为 .bc 文件 $ cjc pkg.cj --lto=full --output-type=staticlib -o libpkg.bc # .bc 文件和源文件一起输入给仓颉编译器编译可执行文件 $ cjc test.cj libpkg.bc --lto=full注:
LTO模式下的静态库(.bc文件)输入的时候需要将该文件的路径输入仓颉编译器。 -
在
LTO模式下,静态链接标准库(--static-std&-static-libs)时,标准库的代码也会参与LTO优化,并静态链接到可执行文件;动态链接标准库(--dy-std&-dy-libs)时,在LTO模式下依旧使用标准库中的动态库参与链接。# 静态链接,标准库代码也参与 LTO 优化 $ cjc test.cj --lto=full --static-std # 动态链接,依旧使用动态库参与链接,标准库代码不会参与 LTO 优化 $ cjc test.cj --lto=full --dy-std
--pgo-instr-gen
使能插桩编译,生成携带插桩信息的可执行程序。
PGO (全称Profile-Guided Optimization)是一种常用编译优化技术,通过使用运行时 profiling 信息进一步提升程序性能。Instrumentation-based PGO 是使用插桩信息的一种 PGO 优化手段,它通常包含三个步骤:
- 编译器对源码插桩编译,生成插桩后的可执行程序(instrumented program);
- 运行插桩后的可执行程序,生成配置文件;
- 编译器使用配置文件,再次对源码进行编译。
# 生成支持源码执行信息统计(携带插桩信息)的可执行程序 test
$ cjc test.cj --pgo-instr-gen -o test
# 运行可执行程序 test 结束后,生成 test.profraw 配置文件
$ LLVM_PROFILE_FILE="test.profraw" ./test
注意,运行程序时使用环境变量 LLVM_PROFILE_FILE="test%c.profraw" 可开启连续模式,即在程序崩溃或被信号杀死的情况下也能生成配置文件,可使用 llvm-profdata 工具对其进行查看分析。但是,目前 PGO 不支持连续模式下进行后续的优化步骤。
--pgo-instr-use=<.profdata>
使用指定 profdata 配置文件指导编译并生成优化后的可执行程序。
注意,--pgo-instr-use 编译选项仅支持格式为 profdata 的配置文件。可使用 llvm-profdata 工具可将 profraw 配置文件转换为 profdata 配置文件。
# 将 `profraw` 文件转换为 `profdata` 文件。
$ LD_LIBRARY_PATH=$CANGJIE_HOME/third_party/llvm/lib:$LD_LIBRARY_PATH $CANGJIE_HOME/third_party/llvm/bin/llvm-profdata merge test.profraw -o test.profdata
# 使用指定 `test.profdata` 配置文件指导编译并生成优化后的可执行程序 `testOptimized`
$ cjc test.cj --pgo-instr-use=test.profdata -o testOptimized
--target <value> [frontend]
指定编译的目标平台的 triple。
参数 <value> 一般为符合以下格式的字符串:<arch>(-<vendor>)-<os>(-<env>)。其中:
<arch>表示目标平台的系统架构,例如aarch64,x86_64等;<vendor>表示开发目标平台的厂商,常见的例如pc,apple等,在没有明确平台厂商或厂商不重要的情况下也经常写作unknown或直接省略;<os>表示目标平台的操作系统,例如linux,win32等;<env>表示目标平台的 ABI 或标准规范,用于更细粒度地区分同一操作系统的不同运行环境,例如gnu,musl等。在操作系统不需要根据<env>进行更细地区分的时候,此项也可以省略。
目前,cjc 已支持交叉编译的本地平台和目标平台如下表所示:
| 本地平台 (host) | 目标平台 (target) |
|---|---|
| x86_64-linux-gnu | aarch64-hm-gnu |
在使用 --target 指定目标平台进行交叉编译之前,请准备好对应目标平台的交叉编译工具链,以及可以在本地平台上运行的、向该目标平台编译的对应 Cangjie SDK 版本。
--target-cpu <value>
注意:该选项为实验性功能,使用该功能生成的二进制有可能会存在潜在的运行时问题,请注意使用该选项的风险。此选项必须配合
--experimental选项一同使用。
指定编译目标的 CPU 类型。
指定编译目标的 CPU 类型时,编译器在生成二进制时会尝试使用该 CPU 类型特有的扩展指令集,并尝试应用适用于该 CPU 类型的优化。为某个特定 CPU 类型生成的二进制通常会失去可移植性,该二进制可能无法在其他(拥有相同架构指令集的)CPU 上运行。
该选项支持以下可选值:
x86-64 架构:
- generic
aarch64 架构:
- generic
- tsv110
generic 为通用 CPU 类型,指定 generic 时编译器会生成适用于该架构的通用指令,这样生成的二进制在操作系统和二进制本身的动态依赖一致的前提下,可以在基于该架构的各种 CPU 上运行,无关于具体的 CPU 类型。--target-cpu 选项的默认值为 generic。
以上可选值为经过测试的 CPU 类型。该选项还支持以下可选值,但以下 CPU 类型未经过测试验证,请注意使用以下 CPU 类型生成的二进制可能会存在运行时问题。
x86-64 架构:
- alderlake
- amdfam10
- athlon
- athlon-4
- athlon-fx
- athlon-mp
- athlon-tbird
- athlon-xp
- athlon64
- athlon64-sse3
- atom
- barcelona
- bdver1
- bdver2
- bdver3
- bdver4
- bonnell
- broadwell
- btver1
- btver2
- c3
- c3-2
- cannonlake
- cascadelake
- cooperlake
- core-avx-i
- core-avx2
- core2
- corei7
- corei7-avx
- geode
- goldmont
- goldmont-plus
- haswell
- i386
- i486
- i586
- i686
- icelake-client
- icelake-server
- ivybridge
- k6
- k6-2
- k6-3
- k8
- k8-sse3
- knl
- knm
- lakemont
- nehalem
- nocona
- opteron
- opteron-sse3
- penryn
- pentium
- pentium-m
- pentium-mmx
- pentium2
- pentium3
- pentium3m
- pentium4
- pentium4m
- pentiumpro
- prescott
- rocketlake
- sandybridge
- sapphirerapids
- silvermont
- skx
- skylake
- skylake-avx512
- slm
- tigerlake
- tremont
- westmere
- winchip-c6
- winchip2
- x86-64
- x86-64-v2
- x86-64-v3
- x86-64-v4
- yonah
- znver1
- znver2
- znver3
aarch64 架构:
- a64fx
- ampere1
- apple-a10
- apple-a11
- apple-a12
- apple-a13
- apple-a14
- apple-a7
- apple-a8
- apple-a9
- apple-latest
- apple-m1
- apple-s4
- apple-s5
- carmel
- cortex-a34
- cortex-a35
- cortex-a510
- cortex-a53
- cortex-a55
- cortex-a57
- cortex-a65
- cortex-a65ae
- cortex-a710
- cortex-a72
- cortex-a73
- cortex-a75
- cortex-a76
- cortex-a76ae
- cortex-a77
- cortex-a78
- cortex-a78c
- cortex-r82
- cortex-x1
- cortex-x1c
- cortex-x2
- cyclone
- exynos-m3
- exynos-m4
- exynos-m5
- falkor
- kryo
- neoverse-512tvb
- neoverse-e1
- neoverse-n1
- neoverse-n2
- neoverse-v1
- saphira
- thunderx
- thunderx2t99
- thunderx3t110
- thunderxt81
- thunderxt83
- thunderxt88
特殊 CPU 类型:
x86-64 以及 aarch64 架构:
- native
native 为当前 CPU 类型,编译器会尝试识别当前机器的 CPU 类型并使用该 CPU 类型作为目标类型生成二进制。
--toolchain <value>, -B <value>, -B<value>
指定编译工具链中,二进制文件存放的路径。
二进制文件包括:编译器,链接器,工具链提供的 C 运行时目标文件(例如 crt0.o, crti.o)等。
我们在准备好编译工具链后,可以在将其存放在一个自定义路径,然后通过 --toolchain <value> 向编译器传入该路径,即可让编译器调用到该路径下的二进制文件进行交叉编译。
--sysroot <value>
指定编译工具链的根目录路径。
对于目录结构固定的交叉编译工具链,如果我们没有指定该目录以外的二进制和动态库、静态库文件路径的需求,可以直接使用 --sysroot <value> 向编译器传入工具链的根目录路径,编译器会根据目标平台种类分析对应的目录结构,自动搜索所需的二进制文件和动态库、静态库文件。使用该选项后,我们无需再指定 --toolchain、--library-path 参数。
假如我们向 triple 为 arch-os-env 的平台进行交叉编译,同时我们的交叉编译工具链有以下目录结构:
/usr/sdk/arch-os-env
├── bin
| ├── arch-os-env-gcc (交叉编译器)
| ├── arch-os-env-ld (链接器)
| └── ...
├── lib
| ├── crt1.o (C 运行时目标文件)
| ├── crti.o
| ├── crtn.o
| ├── libc.so (动态库)
| ├── libm.so
| └── ...
└── ...
我们有仓颉源文件 hello.cj ,那么我们可以使用以下命令,将 hello.cj 交叉编译至 arch-os-env 平台:
cjc --target=arch-os-env --toolchain /usr/sdk/arch-os-env/bin --toolchain /usr/sdk/arch-os-env/lib --library-path /usr/sdk/arch-os-env/lib hello.cj -o hello
也可以使用简写的参数:
cjc --target=arch-os-env -B/usr/sdk/arch-os-env/bin -B/usr/sdk/arch-os-env/lib -L/usr/sdk/arch-os-env/lib hello.cj -o hello
如果该工具链的目录符合惯例的目录结构,也可以无需使用 --toolchain、--library-path 参数,而使用以下的命令:
cjc --target=arch-os-env --sysroot /usr/sdk/arch-os-env hello.cj -o hello
--strip-all, -s
编译可执行文件或动态库时,指定该选项以删除输出文件中的符号表。
--discard-eh-frame
编译可执行文件或动态库时,指定该选项可以删除 eh_frame 段以及 eh_frame_hdr 段中的部分信息(涉及到 crt 的相关信息不作处理),减少可执行文件或动态库的大小,但会影响调试信息。
--link-options <value>1
指定链接器选项。
cjc 会将该选项的参数透传给链接器。可用的参数会因(系统或指定的)链接器的不同而不同。
可以多次使用 --link-options 指定多个链接器选项。
单元测试选项
--test [frontend]
unittest 测试框架提供的入口,由宏自动生成,当使用 cjc --test 选项编译时,程序入口不再是 main,而是 test_entry。测试使用方法详见 unittest 库使用文档。
对于 pkgc 目录下仓颉文件 a.cj:
from std import unittest.*
from std import unittest.testmacro.*
@Test
public class TestA {
@TestCase
public func case1(): Unit {
print("case1\n")
}
}
我们可以在 pkgc 目录下使用:
cjc a.cj --test
来编译 a.cj ,执行 main 会有如下输出:
注:不保证用例每次执行的用时都相同
case1
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 29710 ns, Result:
TCS: TestA, time elapsed: 26881 ns, RESULT:
[ PASSED ] CASE: case1 (16747 ns)
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
--------------------------------------------------------------------------------------------------
对于如下目录结构 :
application
├── src
├── pkgc
| ├── a1.cj
| └── a2.cj
└── a3.cj
我们可以在 application目录下使用 -p 编译选项配合编译整包:
cjc pkgc --test -p
来编译整个 pkgc 包下的测试用例
a1.cj 和 a2.cj。
/*a1.cj*/
package a
from std import unittest.*
from std import unittest.testmacro.*
@Test
public class TestA {
@TestCase
public func caseA(): Unit {
print("case1\n")
}
}
/*a2.cj*/
package a
from std import unittest.*
from std import unittest.testmacro.*
@Test
public class TestB {
@TestCase
public func caseB(): Unit {
throw IndexOutOfBoundsException()
}
}
执行 main 会有如下输出(输出信息仅供参考):
case1
--------------------------------------------------------------------------------------------------
TP: a, time elapsed: 367800 ns, Result:
TCS: TestA, time elapsed: 16802 ns, RESULT:
[ PASSED ] CASE: caseA (14490 ns)
TCS: TestB, time elapsed: 347754 ns, RESULT:
[ ERROR ] CASE: caseB (345453 ns)
REASON: An exception has occurred:IndexOutOfBoundsException
at std/core.Exception::init()(std/core/exception.cj:23)
at std/core.IndexOutOfBoundsException::init()(std/core/index_out_of_bounds_exception.cj:9)
at a.TestB::caseB()(/home/houle/cjtest/application/pkgc/a2.cj:7)
at a.lambda.1()(/home/houle/cjtest/application/pkgc/a2.cj:7)
at std/unittest.TestCases::execute()(std/unittest/test_case.cj:92)
at std/unittest.UT::run(std/unittest::UTestRunner)(std/unittest/test_runner.cj:194)
at std/unittest.UTestRunner::doRun()(std/unittest/test_runner.cj:78)
at std/unittest.UT::run(std/unittest::UTestRunner)(std/unittest/test_runner.cj:200)
at std/unittest.UTestRunner::doRun()(std/unittest/test_runner.cj:78)
at std/unittest.UT::run(std/unittest::UTestRunner)(std/unittest/test_runner.cj:200)
at std/unittest.UTestRunner::doRun()(std/unittest/test_runner.cj:75)
at std/unittest.entryMain(std/unittest::TestPackage)(std/unittest/entry_main.cj:11)
Summary: TOTAL: 2
PASSED: 1, SKIPPED: 0, ERROR: 1
FAILED: 0
--------------------------------------------------------------------------------------------------
--mock <on|off|runtime-error> [frontend]
如果传递了 on ,则该包将使能 mock 编译,该选项允许在测试用例中 mock 该包中的类。off 是一种显式禁用 mock 的方法。
请注意,在测试模式下(当使能 --test )自动启用对此包的 mock 支持,不需要显式传递 --mock 选项。
runtime-error 仅在测试模式下可用(当使能 --test 时),它允许编译带有 mock 代码的包,但不在编译器中做任何 mock 相关的处理(这些处理可能会造成一些开销并影响测试的运行时性能)。这对于带有 mock 代码用例进行基准测试时可能是有用的。使用此编译选项时,避免编译带有 mock 代码的用例并运行测试,否则将抛出运行时异常。
宏选项
cjc 支持以下宏选项,关于宏的更多内容请参阅 元编程 章节。
--compile-macro [frontend]
编译宏定义文件,生成默认的宏定义动态库文件。
--debug-macro [frontend]
生成宏展开后的仓颉代码文件。该选项可用于调试宏展开功能。
--parallel-macro-expansion [frontend]
开启宏展开并行。该选项可用于缩短宏展开编译时间。
条件编译选项
cjc 支持以下条件编译选项,关于条件编译的更多内容请参阅 条件编译 章节。
--conditional-compilation-config <value> [frontend]
指定自定义编译条件。
并行编译选项
cjc 支持以下并行编译选项以获得更高的编译效率。
--jobs <value>, -j <value> [frontend]
设置并行编译时所允许的最大并行数。其中 value 必须是一个合理的正整数,当 value 大于硬件支持最大并行能力时,编译器将会按基于硬件支持并行能力计算出的默认设置执行并行编译。
如果该编译选项未设置,编译器将会按基于硬件支持并行能力计算出的默认设置执行并行编译。
注意,--jobs 1表示完全使用串行方式进行编译。
---aggressive-parallel-compile, --apc [frontend]
开启此选项后,编译器会采用更加激进的策略(可能会对优化造成影响)执行并行编译,以便获得更高的编译效率。
注意,--aggressive-parallel-compile选项在一些场景下会由编译器强制开启/关闭。
在以下场景中--aggressive-parallel-compile选项将由编译器强制开启:
-O0-g
在以下场景中--aggressive-parallel-compile选项将由编译器强制关闭:
--fobf-string--fobf-const--fobf-layout--fobf-cf-flatten--fobf-cf-bogus--lto--coverage- 交叉编译
优化选项
chir 为 cjc 编译器前端的一种中间表示,基于该中间表示 cjc 提供以下优化选项:
--fchir-constant-propagation [frontend]
开启 chir 常量传播优化。
--fno-chir-constant-propagation [frontend]
关闭 chir 常量传播优化。
--fchir-function-inlining [frontend]
开启 chir 函数内联优化。
--fno-chir-function-inlining [frontend]
关闭 chir 函数内联优化。
--fchir-devirtualization [frontend]
开启 chir 去虚函数调用优化。
--fno-chir-devirtualization [frontend]
关闭 chir 去虚函数调用优化。
除了基于 chir 的优化外,cjc 还提供以下优化选项。
--fast-math [frontend]
开启此选项后,编译器会对浮点数作一些激进且有可能损失精度的假设,以便优化浮点数运算。
-O<N> [frontend]
使用参数指定的代码优化级别。
指定越高的优化级别,编译器会越多地进行代码优化以生成更高效的程序,同时也可能会需要更长的编译时间。
cjc 默认使用 O0 级别的代码优化。当前 cjc 支持如下优化级别:O0、O1、O2、Os、Oz。
当优化等级等于 2 时,cjc 除了进行对应的优化外,还会开启以下选项:
--fchir-constant-propagation--fchir-function-inlining--fchir-devirtualization
当优化等级等于 s 时, cjc除了进行 O2 级别优化外,将针对 code size 进行优化。
当优化等级等于 z 时, cjc除了进行 Os 级别优化外,还将进一步缩减 code size 大小。
注:当优化等级等于 s 或 z 时,不允许同时使用链接时优化编译选项
--lto=[full|thin]。
-O [frontend]
使用 O1 级别的代码优化,等价于 -O1。
代码混淆选项
Windows 版本暂不支持本节介绍的代码混淆选项。
cjc 支持代码混淆功能以提供对代码的额外安全保护,代码混淆功能默认不开启。
cjc 支持以下代码混淆选项:
--fobf-string
开启字符串混淆。
混淆代码中出现的字符串常量,攻击者无法静态直接读取二进制程序中的字符串数据。
--fno-obf-string
关闭字符串混淆。
--fobf-const
开启常量混淆。
混淆代码中使用的数值常量,将的数值运算指令替换成等效的、更复杂的数值运算指令序列。
--fno-obf-const
关闭常量混淆。
--fobf-layout
开启外形混淆。
混淆代码中的符号(包括函数名和全局变量名)以及函数排布顺序。注意,--fobf-layout不会混淆对外导出的符号,否则可能会导致链接错误。
使用该选项编译代码后 cjc 会在当前(或 --output-dir 指定的)目录生成副产物 obf_global_file 与 obf_func_file 文件。obf_global_file 与 obf_func_file 中包含混淆的符号映射信息。使用符号映射信息我们可以进行解混淆或导入被混淆的包。
--fno-obf-layout
关闭外形混淆。
--fobf-cf-flatten
开启控制流平坦化混淆。
混淆代码中既存的控制流,使其转移逻辑变得复杂。
--fno-obf-cf-flatten
关闭控制流平坦化混淆。
--fobf-cf-bogus
开启虚假控制流混淆。
在代码中插入虚假的控制流,使代码逻辑变得复杂。
--fno-obf-cf-bogus
关闭虚假控制流混淆。
--fobf-all
开启所有混淆功能。
指定该选项等同于同时指定以下选项:
--fobf-string--fobf-const--fobf-layout--fobf-cf-flatten--fobf-cf-bogus
--obf-config <file>
指定代码混淆配置文件路径。
在配置文件中我们可以禁止混淆工具对某些函数或者符号进行混淆。 配置文件的具体格式如下:
obf_func1 name1
obf_func2 name2
...
其中 obf_func 可以是具体的混淆功能:
control-flow-boguscontrol-flow-flattenobf-constobf-layout
也可以用 * 来匹配所有混淆功能。 name 是符号名称,包含包名、类名、函数名等,比如 pro0/zoo::(Triangle::)init(Int64, Int64) ,其中每个字段都可以用 * 匹配所有,比如 pro0/zoo::(Triangle::)*(Int64, Int64) 会匹配 pro0/zoo 包下 Triangle 类中所有形参为 (Int64, Int64) 的成员函数。
以下是一份合法的配置文件示例:
obf-const pro0_zoo_global_init
obf-const for_keeping_some_types
* pro0/zoo::(Triangle::)init(Int64, Int64)
control-flow-flatten pro0/zoo::(Rectangle::)*(Int64)
control-flow-flatten pro0/zoo::(*)print(Int64, Int64)
* */*::g1()
obf-const test/*::g2()
obf-layout test/koo::g3()
obf-layout test/default::*()
--obf-level <value>
指定混淆功能强度级别。
可指定 1-9 强度级别。默认强度级别为 5。级别数字越大,强度则越高,该选项会影响输出文件的大小以及执行开销。
--obf-seed <value>
指定混淆算法的随机数种子。
通过指定混淆算法的随机数种子,我们可以使同一份仓颉代码在不同构建时有不同的混淆结果。默认场景下,对于同一份仓颉代码,在每次混淆后都拥有相同的混淆结果。
自动微分选项
cjc 支持以下自动微分选项,关于自动微分的更多内容请参阅第十四章。
--enable-auto-differentiation, --enable-ad [frontend]
开启自动微分特性。
安全编译选项
Windows 版本暂不支持安全编译选项。
cjc 默认生成地址无关代码,在编译可执行文件时默认生成地址无关可执行文件。
cjc 支持通过 --link-options 设置以下安全相关的链接器选项:
--link-options "-z noexecstack"1
设置线程栈不可执行。
--link-options "-z relro"1
设置 GOT 表重定位只读。
--link-options "-z now"1
设置立即绑定。
代码覆盖率插桩选项
Windows 版本暂不支持代码覆盖率插桩选项。
仓颉支持对代码覆盖率插桩(SanitizerCoverage,以下简称 SanCov),提供与 LLVM 的 SanitizerCoverage 一致的接口,编译器在函数级或 BasicBlock 级插入覆盖率反馈函数,用户只需要实现约定好的回调函数即可在运行过程中感知程序运行状态。
仓颉提供的 SanCov 功能以 package 为单位,即整个 package 只有全部插桩和全部不插桩两种情况。
--sanitizer-coverage-level=0/1/2
插桩等级:0 表示不插桩;1 表示函数级插桩,只在函数入口处插入回调函数;2 表示 BasicBlock 级插桩,在各个 BasicBlock 处插入回调函数。
如不指定,默认值为 2。
该编译选项只影响 --sanitizer-coverage-trace-pc-guard、--sanitizer-coverage-inline-8bit-counters、--sanitizer-coverage-inline-bool-flag 的插桩等级。
--sanitizer-coverage-trace-pc-guard
开启该选项,会在每个 Edge 插入函数调用 __sanitizer_cov_trace_pc_guard(uint32_t *guard_variable),受 sanitizer-coverage-level 影响。
注意,该功能存在与 gcc/llvm 实现不一致的地方:不会在 constructor 插入 void __sanitizer_cov_trace_pc_guard_init(uint32_t *start, uint32_t *stop),而是在 package 初始化阶段插入函数调用 uint32_t *__cj_sancov_pc_guard_ctor(uint64_t edgeCount)。
__cj_sancov_pc_guard_ctor 回调函数需要开发者自行实现,开启 SanCov 的 package 会尽可能早地调用该回调函数,入参是该 Package 的 Edge 个数,返回值是通常是 calloc 创建的内存区域。
如果需要调用 __sanitizer_cov_trace_pc_guard_init,建议在 __cj_sancov_pc_guard_ctor 中调用,使用动态创建的缓冲区计算该函数的入参和返回值。
一个标准的__cj_sancov_pc_guard_ctor参考实现如下:
uint32_t *__cj_sancov_pc_guard_ctor(uint64_t edgeCount) {
uint32_t *p = (uint32_t *) calloc(edgeCount, sizeof(uint32_t));
__sanitizer_cov_trace_pc_guard_init(p, p + edgeCount);
return p;
}
--sanitizer-coverage-inline-8bit-counters
开启该选项后,会在每个 Edge 插入一个累加器,每经历过一次,该累加器加一,受 sanitizer-coverage-level 影响。
注意,该功能存在与 gcc/llvm 实现不一致的地方:不会在 constructor 插入 void __sanitizer_cov_8bit_counters_init(char *start, char *stop),而是在 package 初始化阶段插入函数调用 uint8_t *__cj_sancov_8bit_counters_ctor(uint64_t edgeCount)。
__cj_sancov_pc_guard_ctor 回调函数需要开发者自行实现,开启 SanCov 的 package 会尽可能早地调用该回调函数,入参是该 Package 的 Edge 个数,返回值是通常是 calloc 创建的内存区域。
如果需要调用 __sanitizer_cov_8bit_counters_init,建议在 __cj_sancov_8bit_counters_ctor 中调用,使用动态创建的缓冲区计算该函数的入参和返回值。
一个标准的__cj_sancov_8bit_counters_ctor参考实现如下:
uint8_t *__cj_sancov_8bit_counters_ctor(uint64_t edgeCount) {
uint8_t *p = (uint8_t *) calloc(edgeCount, sizeof(uint8_t));
__sanitizer_cov_8bit_counters_init(p, p + edgeCount);
return p;
}
--sanitizer-coverage-inline-bool-flag
开启该选项后,会在每个 Edge 插入布尔值,经历过的 Edge 对应的布尔值会被设置为 True,受 sanitizer-coverage-level 影响。
注意,该功能存在与 gcc/llvm 实现不一致的地方:不会在 constructor 插入 void __sanitizer_cov_bool_flag_init(bool *start, bool *stop),而是在 package 初始化阶段插入函数调用 bool *__cj_sancov_bool_flag_ctor(uint64_t edgeCount)。
__cj_sancov_bool_flag_ctor 回调函数需要开发者自行实现,开启 SanCov 的 package 会尽可能早地调用该回调函数,入参是该 Package 的 Edge 个数,返回值是通常是 calloc 创建的内存区域。
如果需要调用 __sanitizer_cov_bool_flag_init,建议在 __cj_sancov_bool_flag_ctor 中调用,使用动态创建的缓冲区计算该函数的入参和返回值。
一个标准的__cj_sancov_8bit_counters_ctor参考实现如下:
bool *__cj_sancov_bool_flag_ctor(uint64_t edgeCount) {
bool *p = (bool *) calloc(edgeCount, sizeof(bool));
__sanitizer_cov_bool_flag_init(p, p + edgeCount);
return p;
}
--sanitizer-coverage-pc-table
该编译选项用于提供插桩点和源码之间的对应关系,当前只提供精确到函数级的对应关系。需要与 --sanitizer-coverage-trace-pc-guard、--sanitizer-coverage-inline-8bit-counters、--sanitizer-coverage-inline-bool-flag 共用,至少需要开启其中一项,可以同时开启多项。
注意,该功能存在与 gcc/llvm 实现不一致的地方:不会在 constructor 插入 void __sanitizer_cov_pcs_init(const uintptr_t *pcs_beg, const uintptr_t *pcs_end);,而是在 package 初始化阶段插入函数调用 void __cj_sancov_pcs_init(int8_t *packageName, uint64_t n, int8_t **funcNameTable, int8_t **fileNameTable, uint64_t *lineNumberTable),各入参含义如下:
int8_t *packageName: 字符串,表示包名(插桩用 c 风格的 int8 数组作为入参来表达字符串,下同)。uint64_t n: 共有 n 个函数被插桩。int8_t **funcNameTable: 长度为 n 的字符串数组,第 i 个插桩点对应的函数名为 funcNameTable[i]。int8_t **fileNameTable: 长度为 n 的字符串数组,第 i 个插桩点对应的文件名为 fileNameTable[i]。uint64_t *lineNumberTable: 长度为 n 的 uint64 数组,第 i 个插桩点对应的行号为 lineNumberTable[i]。
如果需要调用 __sanitizer_cov_pcs_init,需要自行完成仓颉 pc-table 到 C 语言 pc-table 的转化。
--sanitizer-coverage-stack-depth
开启该编译选项后,由于仓颉无法获取 SP 指针的值,只能在每个函数入口处插入调用 __updateSancovStackDepth,在 C 侧实现该函数即可获得 SP 指针。
一个标准的 updateSancovStackDepth 实现如下:
thread_local void* __sancov_lowest_stack;
void __updateSancovStackDepth()
{
register void* sp = __builtin_frame_address(0);
if (sp < __sancov_lowest_stack) {
__sancov_lowest_stack = sp;
}
}
--sanitizer-coverage-trace-compares
开启该选项后,会在所有的 compare 指令和 match 指令调用前插入函数回调函数,具体列表如下,与 LLVM 系的 API 功能一致。参考 Tracing data flow
void __sanitizer_cov_trace_cmp1(uint8_t Arg1, uint8_t Arg2);
void __sanitizer_cov_trace_const_cmp1(uint8_t Arg1, uint8_t Arg2);
void __sanitizer_cov_trace_cmp2(uint16_t Arg1, uint16_t Arg2);
void __sanitizer_cov_trace_const_cmp2(uint16_t Arg1, uint16_t Arg2);
void __sanitizer_cov_trace_cmp4(uint32_t Arg1, uint32_t Arg2);
void __sanitizer_cov_trace_const_cmp4(uint32_t Arg1, uint32_t Arg2);
void __sanitizer_cov_trace_cmp8(uint64_t Arg1, uint64_t Arg2);
void __sanitizer_cov_trace_const_cmp8(uint64_t Arg1, uint64_t Arg2);
void __sanitizer_cov_trace_switch(uint64_t Val, uint64_t *Cases);
--sanitizer-coverage-trace-memcmp
该编译选项用于在 String 、 Array 等比较中反馈前缀比较信息。开启该选项后,会对 String 和 Array 的比较函数前插入函数回调函数。具体对于以下对各 String 和 Array 的 API,分别插入对应桩函数:
- String==: __sanitizer_weak_hook_memcmp
- String.startsWith: __sanitizer_weak_hook_memcmp
- String.endsWith: __sanitizer_weak_hook_memcmp
- String.indexOf: __sanitizer_weak_hook_strstr
- String.replace: __sanitizer_weak_hook_strstr
- String.contains: __sanitizer_weak_hook_strstr
- CString==: __sanitizer_weak_hook_strcmp
- CString.startswith: __sanitizer_weak_hook_memcmp
- CString.endswith: __sanitizer_weak_hook_strncmp
- CString.compare: __sanitizer_weak_hook_strcmp
- CString.equalsLower: __sanitizer_weak_hook_strcasecmp
- Array==: __sanitizer_weak_hook_memcmp
- ArrayList==: __sanitizer_weak_hook_memcmp
CFFI 内存安全检测
Windows 版本暂不支持本节介绍的 CFFI 内存安全检测。
cjc 支持 CFFI 内存安全检测功能以提供检测仓颉代码与 C 代码互操作过程中,可能出现的时间、空间内存安全问题。
例如:
-
仓颉 unsafe 代码导致的空间安全问题:堆(
acquireRawData接口)、栈、全局变量(inout语义)溢出,例如:unsafe { let array = Array<UInt8>(4, item: 0) let cp = acquireArrayRawData(array) cp.pointer.read(5) // 仓颉堆溢出 } -
仓颉 unsafe 代码导致的时间安全问题:释放后使用、返回后使用、双重释放,例如:
unsafe { let array = Array<UInt8>(4, item: 0) let cp = acquireArrayRawData(array) releaseArrayRawData(cp) array = Array<UInt8>(1, item: 0) ...... // GC 回收第一个 array cp.pointer.read() // 释放后使用 }
--sanitize=address
使能内存安全检测功能。
仓颉的内存安全检测功能是利用 Address Sanitizer 实现。支持仓颉作为主程序和 C 代码作为主程序。
用户使能该功能时,C 代码编译时建议使能 ASan 检测(通过 -fsanitize=address 开启)以获得更精准的检查。
该功能依赖 ASan 运行库,该包由仓颉或者用户系统提供,优先级如下:
-
仓颉提供的 ASan 运行库
$CANGJIE_HOME/lib/<system>_<arch>_llvm/libclang-rt_asan.a -
用户通过
-L,环境变量LIBRARY_PATH或--toolchain/-B指定的路径下搜索 ASan 运行库clang-rt.asan-<arch>.a -
使用 gnu 提供的独立 ASan 运行库
libasan.so
注意:
-
当用户使用 C 代码作为主程序时,还需要链接
$CANGJIE_HOME/lib/<system>_<arch>_llvm/cjasan_options.o以防止内存泄露漏报的问题。 -
当用户使用 ASan 的动态链接库时,需要使用
LD_PRELOAD或verify_asan_link_order=0保证 ASan 运行库是第一个被加载的,以保证 ASan 的检测正确地运行。 -
建议用户使用
ASAN_SYMBOLIZER_PATH=$CANGJIE_HOME/third_party/llvm/bin/llvm-symbolizer指定 ASan 运行库使用仓颉提供的 symbolizer,以保证函数符号的正常解析。
局限性
- 不支持仓颉宏选项。
- 在协程 A 调用
releaseArrayRawData接口后,若协程 B 仍持有该段数据的引用时,协程 A 再访问该段数据会产生漏报。 - 仓颉内存释放后使用的场景中,若该片内存再次被分配且设置为可访问后,原来的野指针(产生释放后使用的指针)访问该片内存则会产生漏报。
- 仓颉检测内存泄露中,若 C 内存在仓颉类中初始化,但没有在仓颉 class 的
~init()中释放的场景中,会产生漏报。 - 从仓颉堆内存回收到程序结束退出这一段时期程序产生的内存泄露会漏报。
数据竞争检测
Windows 版本暂不支持本节介绍的数据竞争检测。
cjc 支持 数据竞争检测功能,用来检测并发的仓颉程序中存在的数据竞争缺陷。
例如:
main() {
let x: Box<Int64> = Box<Int64>(0)
let fut = spawn { =>
x.value = 11 // data race
}
x.value = 10 // data race
fut.get()
}
上述代码中同时有两个协程修改 x 的值,而协程之间没有通过锁等同步机制进行保护,因此存在数据竞争的风险。数据竞争检测功能可以帮助用户发现和定位程序中该类数据竞争缺陷,方便用户修补该类代码缺陷。
--sanitize=thread
使能数据竞争检测功能。 开启该编译选项后,在程序运行时如果发生数据竞争,程序会打印出发生数据竞争的代码位置、调用栈和相关的协程信息。
仓颉的数据竞争检测功能是利用 Thread Sanitizer 实现,但是对原始 Thread Sanitizer 进行了修改以适配仓颉的协程并发模型,因此只能检测仓颉侧代码访问仓颉对象时产生的数据竞争,无法检测 C 侧的数据竞争以及 C 侧代码访问仓颉对象时产生的数据竞争。
注意:当用户使用 C 代码作为主程序调用仓颉库时,如果仓颉库开启了 --sanitize=thread 选项,则 C 代码在编译时需要添加以下参数来链接相关依赖:
-L $CANGJIE_HOME/lib/<system>_<arch>_llvm -lcangjie-runtime_tsan -lgcc_s -Wl,--whole-archive -lpthread -l:libclang_rt-tsan.a -Wl,--no-whole-archive -Wl,--dynamic-list=$CANGJIE_HOME/lib/<system>_<arch>_llvm/libclang_rt-tsan.a.syms
其他功能
编译器报错信息显示颜色
对于 Windows 版本的仓颉编译器,只有运行于 Windows10 version 1511(Build 10586) 或更高版本的系统,编译器报错信息才显示颜色,否则不显示颜色。
设置 build-id
通过 --link-options "--build-id=<arg>"1 可以透传链接器选项以设置 build-id。
编译 Windows 目标时不支持此功能。
设置 rpath
通过 --link-options "-rpath=<arg>"1 可以透传链接器选项以设置 rpath。
编译 Windows 目标时不支持此功能。
1 链接器透传选项可能会因为链接器的不同而不同,具体支持的选项请查阅链接器文档。
增量编译
通过 --incremental-compile[frontend]开启增量编译。开启后,cjc会在编译时根据前次编译的缓存文件加快此次编译的速度。
cjc 用到的环境变量
这里介绍一些仓颉编译器在编译代码的过程中可能使用到的环境变量。
TMPDIR 或者 TMP
仓颉编译器会将编译过程中产生的临时文件放置到临时目录中。默认情况下 Linux 操作系统会放在 /tmp 目录下;Windows 操作系统会放在 C:\Windows\Temp 目录下。仓颉编译器也支持自行设置临时文件存放目录,Linux 操作系统上通过设置环境变量 TMPDIR 来更改临时文件目录,Windows 操作系统上通过设置环境变量 TMP 来更改临时文件目录。
例如: 在 Linux shell 中
export TMPDIR=/home/xxxx
在 Windows cmd 中
set TMP=D:\\xxxx
runtime 环境变量使用手册
本章介绍 runtime(运行时)所提供的环境变量。
在 Linux shell 中,您可以使用以下方式设置仓颉运行时提供的环境变量:
$ export VARIABLE=value
在 Windows cmd 中,您可以使用以下方式设置仓颉运行时提供的环境变量:
> set VARAIBLE=value
本节后续的示例都为 Linux shell 中的设置方式,若与您的运行平台不符,请根据您的运行平台选择合适的环境变量设置方式。
runtime 初始化可选配置
注意:
- 所有整型参数为 Int64 类型,浮点型参数为 Float64 类型;
- 所有参数如果未显式规定最大值,默认隐式最大值为该类型最大值;
- 所有参数若超出范围则设置无效,自动使用默认值。
cjHeapSize
指定仓颉堆的最大值,支持单位为 kb(KB)、mb(MB)、gb(GB),支持设置范围为[4MB, 系统物理内存],超出范围的设置无效,仍旧使用默认值。 默认值设置:若物理内存低于 1GB,默认值为 64 MB,否则为 256 MB。
例如:
export cjHeapSize=32GB
cjRegionSize
指定 region 分配器 thread local buffer 的大小,支持设置范围为[4, 64],单位为 KB,超出范围的设置无效,仍旧使用默认值。 默认值设置:默认为 64 KB。
例如:
export cjRegionSize=64
cjExemptionThreshold
指定存活 region 的水线值,取值 (0,1],该值与 region 的大小相乘,若 region 中存活对象数量大于相乘后的值,则该 region 不会被回收 (其中死亡对象继续占用内存)。 该值指定得越大,region 被回收的概率越大,堆中的碎片空间就越少,但频繁回收 region 也会影响性能。 默认值设定:默认为 0.8,即 80%。
例如:
export cjExemptionThreshold=0.8
cjHeapUtilization
指定仓颉堆的利用率,该参数用于 GC 后更新堆水线的参考依据之一,取值 (0, 1],堆水线是指当堆中对象总大小达到水线值时则进行 GC。 该参数指定越小,则更新后的堆水线会越高,则触发 GC 的概率会相对变低。 默认值设定:默认值为 0.8,即 80%。
例如:
export cjHeapUtilization=0.8
cjHeapGrowth
指定仓颉堆的增长率,该参数用于 GC 后更新堆水线的参考依据之一,取值必须大于 0。 增长率的计算方式为 1 + cjHeapGrowth. 该参数指定越大,则更新后的堆水线会越高,则触发 GC 的概率会相对变低。 默认值设定:默认值为 0.15,表示增长率为 1.15。
例如:
export cjHeapGrowth=0.15
cjAlloctionRate
指定仓颉运行时分配对象的速率,该值必须大于 0,单位为 MB/s,表示每秒可分配对象的数量。 默认值设定:默认值为 10240,表示每秒可分配 10240 MB 对象。
例如:
export cjAlloctionRate=10240
cjAlloctionWaitTime
指定仓颉运行时分配对象时的等待时间,该值必须大于 0,支持单位为 s、ms、us、ns,推荐单位为纳秒(ns)。若本次分配对象距离上一次分配对象的时间间隔小于此值,则将等待。 默认值设定:默认值为 1000 ns。
例如:
export cjAlloctionWaitTime=1000ns
cjGCThreshold
指定仓颉堆的参考水线值,支持单位为 kb(KB)、mb(MB)、gb(GB), 取值必须为大于 0 的整数。当仓颉堆大小超过该值时,触发 GC。
默认值设定:默认值为堆大小。
例如:
export cjGCThreshold=20480KB
cjGarbageThreshold
当 GC 发生时,如果 region 中死亡对象所占比率大于此环境变量,此 region 会被放入回收候选集中,后续可被回收(如果受到其它策略影响也可能不被回收),默认值为 0.5,无量纲,支持设置的区间为[0.0, 1.0]。
例如:
export cjGarbageThreshold=0.5
cjGCInterval
指定 2 次 GC 的间隔时间值,取值必须大于 0,支持单位为 s、ms、us、ns,推荐单位为毫秒(ms)。若本次 GC 距离上次 GC 的间隔小于此值,则本次 GC 将被忽略。该参数可以控制 GC 的频率。 默认值设定:默认值为 150 ms。
例如:
export cjGCInterval=150ms
cjBackupGCInterval
指定 backup GC 的间隔值,取值必须大于 0,支持单位为 s、ms、us、ns,推荐单位为秒(s),当仓颉运行时在该参数设定时间内未触发 GC,则触发一次 backup GC。 默认值设定:默认值为 240 秒,即 4 分钟。
例如:
export cjBackupGCInterval=240s
cjGCThreads
指定影响 GC 线程数的因数,取值必须大于 0。 GC 线程数的计算方式为:(系统支持的并发线程数 / cjGCThreads) - 1。 默认值设定:默认值为 8。
例如:
export cjGCThreads=8
cjProcessorNum
指定仓颉线程的最大并发数,支持设置范围为 (0, CPU 核数 * 2],超出范围的设置无效,仍旧使用默认值。 默认值设置:调用系统 API 获取 cpu 核数,若成功设为 cpu 核数,否则设为 8。
例如:
export cjProcessorNum=2
cjStackSize
指定仓颉线程的栈大小,支持单位为 kb(KB)、mb(MB)、gb(GB),支持设置范围为 Linux 平台下[64KB, 1GB],Windows 平台下[128KB, 1GB],超出范围的设置无效,仍旧使用默认值。 默认值设置:Linux 平台下默认值为 64KB,Windows 平台下为 128KB。
例如:
export cjStackSize=100kb
运维日志可选配置
MRT_LOG_FILE_SIZE
指定 runtime 运维日志的文件大小,默认值为 10 MB,支持单位为 kb(KB)、mb(MB)、gb(GB),设置值需大于 0。
日志大小超过该值时,会重新回到日志开头进行打印。
最终生成日志大小略大于 MRT_LOG_FILE_SIZE。
例如:
export MRT_LOG_FILE_SIZE=100kb
MRT_LOG_PATH
指定 runtime 运维日志的输出路径,若该环境变量未设置或路径设置失败,则运维日志默认打印到 stdout(标准输出)或 stderr(标准错误)中。
例如:
export MRT_LOG_PATH="/home/cangjie/runtime/runtime_log.txt"
MRT_LOG_LEVEL
指定 runtime 运维日志的最小输出级别,大于等于这个级别的日志会被打印,默认值为 e,支持设置值为[v|d|i|w|e|f|s]。 v(VERBOSE)、d(DEBUGY)、i(INFO)、w(WARNING)、e(ERROR)、f(FATAL)、s(FATAL_WITHOUT_ABORT)
例如:
export MRT_LOG_LEVEL="v"
MRT_REPORT
指定 runtime GC 日志的输出路径,若该环境变量未设置或路径设置失败,该日志默认不打印。
例如:
export MRT_REPORT="/home/cangjie/runtime/gc_log.txt"
MRT_LOG_COROUTINE
指定 coroutine 日志的输出路径,若该环境变量未设置或路径设置失败,该日志默认不打印。
例如:
export MRT_LOG_COROUTINE="/home/cangjie/runtime/coroutine_log.txt"
运行环境可选配置
MRT_STACK_CHECK
开启 native stack overflow 检查,默认不开启,支持设置值为 1、true、TRUE 开启功能。
例如:
export MRT_STACK_CHECK=true
CJ_SOF_SIZE
当 StackOverflowError 发生时,将自动进行异常栈折叠方便用户阅读,折叠后栈帧层数默认值是 32。可以通过配置此环境变量控制折叠栈长度,支持设置为 int 范围内的整数。 CJ_SOF_SIZE = 0,打印所有调用栈; CJ_SOF_SIZE < 0,从栈底开始打印环境变量配置层数; CJ_SOF_SIZE > 0,从栈顶开始打印环境变量配置层数; CJ_SOF_SIZE 未配置,默认打印栈顶开始 32 层调用栈;
例如:
export CJ_SOF_SIZE=30
条件编译
开发者可以通过预定义或自定义的条件完成条件编译;仓颉目前支持顶层条件编译。
顶层条件编译
仓颉支持除 package 声明以外的 Top Level 条件编译。
使用方法
以内置 os 编译条件为例,其 Top Level 使用方法如下:
@When[os == "linux"]
class mc{}
main(): Int64 {
var a = mc()
return 0
}
在上面代码中,开发者在 linux 系统中可以正确编译执行;在 非 linux 系统中,则会遇到找不到 mc 类定义的编译错误。
注:仓颉不支持顶层编译条件嵌套,以下写法均不允许
// 错误示例
@When[os == "windows"]
@When[os == "linux"] // error: illegal nested when conditional compilation macro
from std import ast.*
@When[os == "windows"]
@When[os == "linux"] // error: illegal nested when conditional compilation macro
func A(){}
内置条件
仓颉内置了一些条件供开发者直接使用。所有条件的变量都是以字符串的形式存在的。
os
os 是仓颉内置的条件,支持 == 和 != 两种操作符。支持的系统有:windows、linux、macOS、hm。
使用方式如下:
@When[os == "linux"]
func foo() {
print("linux, ")
}
@When[os == "windows"]
func foo() {
print("windows, ")
}
@When[os != "windows"]
func fee() {
println("NOT windows")
}
@When[os != "linux"]
func fee() {
println("NOT linux")
}
main() {
foo()
fee()
}
如果在 windows 环境下编译执行,会得到 windows, NOT linux 的信息;如果是在 linux 环境下,则会得到 linux, NOT windows 的信息。
backend
backend 是仓颉内置的条件。仓颉是多后端语言,支持多种后端条件编译。backend 条件支持 == 和 != 两种操作符。
支持的后端有:llvm、llvm-x86、llvm-x86_64、llvm-arm、llvm-aarch64、cjvm、cjvm-x86、cjvm-x86_64、cjvm-arm、cjvm-aarch64。
当用户使用的条件为 llvm/cjvm 时,arch 信息将会按编译器执行时环境信息自动补全。
使用方式如下:
@When[backend == "llvm"]
func foo() {
print("llvm backend, ")
}
@When[backend == "cjvm"]
func foo() {
print("cjvm backend, ")
}
@When[backend != "llvm"]
func fee() {
println("NOT llvm backend")
}
@When[backend != "cjvm"]
func fee() {
println("NOT cjvm backend")
}
main() {
foo()
fee()
}
用 llvm 后端的发布包编译执行,会得到 llvm backend, NOT cjvm backend 的信息;用 cjvm 后端的发布包编译执行,则会得到 cjvm backend, NOT llvm backend 的信息。
cjc_version
cjc_version 是仓颉内置的条件,开发者可以根据当前仓颉编译器的版本选择要编译的代码。cjc_version 条件支持 ==、!=、>、<、>=、<= 六种操作符,格式为 xx.xx.xx 支持每个 xx 支持 1-2 位数字,计算规则为补位 (补齐 2 位) 比较,例如:0.18.8 < 0.18.11, 0.18.8 == 0.18.08。
使用方式如下:
@When[cjc_version == "0.18.6"]
func foo() {
println("cjc_version equals 0.18.6")
}
@When[cjc_version != "0.18.6"]
func foo() {
println("cjc_version is NOT equal to 0.18.6")
}
@When[cjc_version > "0.18.6"]
func fnn() {
println("cjc_version is greater than 0.18.6")
}
@When[cjc_version <= "0.18.6"]
func fnn() {
println("cjc_version is less than or equal to 0.18.6")
}
@When[cjc_version < "0.18.6"]
func fee() {
println("cjc_version is less than 0.18.6")
}
@When[cjc_version >= "0.18.6"]
func fee() {
println("cjc_version is greater than or equal to 0.18.6")
}
main() {
foo()
fnn()
fee()
}
根据 cjc 的版本,上面代码的执行输出结果会有不同。
debug
debug 是仓颉内置的条件。debug 条件仅支持一元运算。
使用方式如下:
@When[debug]
func foo() {
println("cjc debug")
}
@When[!debug]
func foo() {
println("cjc NOT debug")
}
main() {
foo()
}
根据 cjc 是否是 debug 的版本,上面代码的执行输出结果会有不同。
如果是 debug 版本的 cjc 会输出 cjc debug,如果是 release 版本的 cjc 则会输出 cjc NOT debug。
自定义条件
仓颉允许开发者自定义编译的条件。
自定义的条件拥有和内置条件一样的作用,不同点在于自定义的条件需要开发者在编译程序时写在编译选项中。自定义条件支持 == 和 != 两种运算符。
假如开发者自定义条件为 feature,使用方式和内置条件没有什么不同。使用如下:
//source.cj
@When[feature == "tiger"]
func foo() {
println("feature tiger")
}
@When[feature == "lion"]
func foo() {
println("feature lion")
}
main() {
foo()
}
上面这段代码,开发者想要顺利编译这段代码需要使用这段编译选项:
可以选择 feature == "tiger" 分支
cjc --conditional-compilation-config="(feature=tiger)" source.cj -o runner.out
或者选择 feature == "lion" 分支
cjc --conditional-compilation-config="(feature=lion)" source.cj -o runner.out
根据 feature 的值不同,编译运行上段代码的结果也会不同。
--conditional-compilation-config
此编译选项里的内容表示当前编译流程中 cjc 传递的自定义条件,cjc 会根据此编译选项的值来选择编译哪段代码。
这个选项中的值是以 key-value 来映射的,一个 key 只可以对应一个 value;此选项也支持多个 key-value 结构,用 逗号 (,) 分割,例如:
cjc --conditional-compilation-config="(feature=lion, target=dsp)" source.cj -o runner.out
开发者编写的条件编译代码需要和 --conditional-compilation-config 里的值对应上,否则条件编译不会生效。例如:
//source.cj
@When[feature == "lion"]
func foo() {
print("feature lion, ")
}
@When[target == "dsp"]
func fee() {
println("target dsp")
}
main() {
foo()
fee()
}
使用如下编译命令编译运行上段代码,会得到输出结果:feature lion, target dsp。
cjc --conditional-compilation-config="(feature=lion,target=dsp)" source.cj -o runner.out
而使用如下编译命令编译运行上段代码,会报错:error: undeclared identifier 'foo'。
cjc --conditional-compilation-config="(feature=dsp,target=dsp)" source.cj -o runner.out
多条件
仓颉条件编译允许开发者自由组合多个条件编译选项。支持逻辑运算符组合多个条件,支持括号运算符明确优先级。
使用方式如下:
//source.cj
@When[feature == "tiger" || os == "windows"]
func foo() {
print("feature tiger, ")
}
@When[(debug || os == "linux") && cjc_version >= "0.18.6"]
func fee() {
println("feature lion")
}
main() {
foo()
fee()
}
使用如下编译命令编译运行上段代码,
cjc --conditional-compilation-config="(feature=tiger)" source.cj -o runner.out
会得到输出结果如下:
feature tiger, feature lion
常量求值
常量求值允许某些特定形式的表达式在编译时求值,可以减少程序运行时需要的计算。本章主要介绍常量求值的使用方法与规则。
const 变量
const 变量是一种特殊的变量,它以关键字 const 修饰,定义在编译时完成求值,并且在运行时不可改变的变量。例如,下面的例子定义了万有引力常数 G:
const G = 6.674e-11
const 变量可以省略类型标注,但是不可省略初始化表达式。const 变量可以是全局变量,局部变量,静态成员变量,实例成员变量。但是 const 变量不能在扩展中定义。
const 变量可以访问对应类型的所有实例成员,也可以调用对应类型的所有非 mut 实例成员函数。
下例定义了一个 struct,记录行星的质量和半径,同时定义了一个 const 成员函数 gravity 用来计算该行星对距离为 r 质量为 m 的物体的万有引力:
struct Planet {
const Planet(let mass: Float64, let radius: Float64) {}
const func gravity(m: Float64, r: Float64) {
G * mass * m / r**2
}
}
main() {
const myMass = 71.0
const earth = Planet(5.972e24, 6.378e6)
println(earth.gravity(myMass, earth.radius))
}
编译执行得到地球对地面上一个质量为 71 kg 的成年人的万有引力:
695.657257
const 变量初始化后该类型实例的所有成员都是 const 的(深度 const,包含成员的成员),因此不能被用于左值。
main() {
const myMass = 71.0
myMass = 70.0 // error: cannot assign to immutable value
}
const 上下文与 const 表达式
const 上下文是指 const 变量初始化表达式,这些表达式始终在编译时求值。因此需要对 const 上下文中允许的表达式加以限制,避免修改全局状态、I/O 等副作用,确保其可以在编译时求值。
const 表达式具备了可以在编译时求值的能力。满足如下规则的表达式是 const 表达式:
- 数值类型、
Bool、Unit、Char、String类型的字面量(不包含插值字符串)。 - 所有元素都是
const表达式的Array字面量(不能是Array类型,可以使用VArray类型),tuple字面量。 const变量,const函数形参,const函数中的局部变量。const函数,包含使用const声明的函数名、符合const函数要求的lambda、以及这些函数返回的函数表达式。const函数调用(包含const构造函数),该函数的表达式必须是const表达式,所有实参必须都是const表达式。- 所有参数都是
const表达式的enum构造器调用,和无参数的enum构造器。 - 数值类型、
Bool、Unit、Char、String类型的算数表达式、关系表达式、位运算表达式,所有操作数都必须是const表达式。 if、match、try、控制转移表达式(包含return、break、continue、throw)、is、as。这些表达式内的表达式必须都是const表达式。const表达式的成员访问(不包含属性的访问),tuple的索引访问。const init和const函数中的this和super表达式。const表达式的const实例成员函数调用,且所有实参必须都是const表达式。
const 函数
const 函数是一类特殊的函数,这些函数具备了可以在编译时求值的能力。在 const 上下文中调用这种函数时,这些函数会在编译时执行计算。而在其它非 const 上下文,const 函数会和普通函数一样在运行时执行。
下例是一个计算平面上两点距离的 const 函数,distance 中使用 let 定义了两个局部变量 dx 和 dy:
struct Point {
const Point(let x: Float64, let y: Float64) {}
}
const func distance(a: Point, b: Point) {
let dx = a.x - b.x
let dy = a.y - b.y
(dx**2 + dy**2)**0.5
}
main() {
const a = Point(3.0, 0.0)
const b = Point(0.0, 4.0)
const d = distance(a, b)
println(d)
}
编译运行输出:
5.000000
需要注意:
const函数声明必须使用const修饰。- 全局
const函数和static const函数中只能访问const声明的外部变量,包含const全局变量、const静态成员变量,其它外部变量都不可访问。const init函数和const实例成员函数除了能访问const声明的外部变量,还可以访问当前类型的实例成员变量。 const函数中的表达式都必须是const表达式,const init函数除外。const函数中可以使用let、const声明新的局部变量。但不支持var。const函数中的参数类型和返回类型没有特殊规定。如果该函数调用的实参不符合const表达式要求,那这个函数调用不能作为const表达式使用,但仍然可以作为普通表达式使用。const函数不一定都会在编译时执行,例如可以在非const函数中运行时调用。const函数与非const函数重载规则一致。- 数值类型、
Bool、Unit、Char、String类型 和enum支持定义const实例成员函数。 - 对于
struct和class,只有定义了const init才能定义const实例成员函数。class中的const实例成员函数不能是open的。struct中的const实例成员函数不能是mut的。
另外,接口中也可以定义 const 函数,但会受到以下规则限制:
- 接口中的
const函数,实现类型必须也用const函数才算实现接口。 - 接口中的非
const函数,实现类型使用const或非const函数都算实现接口。 - 接口中的
const函数与接口的static函数一样,只有在该接口作为泛型约束的时候,受约束的泛型变元或变量才能使用这些const函数。
在下面的例子中,在接口 I 里定义了两个 const 函数,类 A 实现了接口 I,泛型函数 g 的形参类型上界是 I。
interface I {
const func f(): Int64
const static func f2(): Int64
}
class A <: I {
public const func f() { 0 }
public const static func f2() { 1 }
const init() {}
}
const func g<T>(i: T) where T <: I {
return i.f() + T.f2()
}
main() {
println(g(A()))
}
编译执行上述代码,输出结果为:
1
const init
如果一个 struct 或 class 定义了 const 构造器,那么这个 struct/class 实例可以用在 const 表达式中。
- 如果当前类型是
class,则不能具有var声明的实例成员变量,否则不允许定义const init。如果当前类型具有父类,当前的const init必须调用父类的const init(可以显式调用或者隐式调用无参const init),如果父类没有const init则报错。 - 当前类型的实例成员变量如果有初始值,初始值必须要是
const表达式,否则不允许定义const init。 const init内可以使用赋值表达式对实例成员变量赋值,除此以外不能有其它赋值表达式。
const init 与 const 函数的区别是 const init 内允许对实例成员变量进行赋值(需要使用赋值表达式)
注解
仓颉中提供了一些属性宏用来支持一些特殊情况的处理。
确保正确使用整数运算溢出策略的注解
仓颉中提供三种属性宏来控制整数溢出的处理策略,即 @OverflowThrowing,@OverflowWrapping 和 @OverflowSaturating ,这些属性宏当前只能标记于函数声明之上,作用于函数内的整数运算和整型转换。它们分别对应以下三种溢出处理策略:
(1) 抛出异常(throwing):当整数运算溢出时,抛出异常。
@OverflowThrowing
main() {
let res: Int8 = Int8(100) + Int8(29)
/* 100 + 29 在数学上等于 129,
* 在 Int8 的表示范围上发生了上溢出,
* 程序抛出异常
*/
let con: UInt8 = UInt8(-132)
/* -132 在 UInt8 的表示范围上发生了下溢出,
* 程序抛出异常
*/
0
}
(2) 高位截断(wrapping):当整数运算的结果超出用于接收它的内存空间所能表示的数据范围时,则截断超出该内存空间的部分。
@OverflowWrapping
main() {
let res: Int8 = Int8(105) * Int8(4)
/* 105 * 4 在数学上等于 420,
* 对应的二进制为 1 1010 0100,
* 超过了用于接收该结果的 8 位内存空间,
* 截断后的结果在二进制上表示为 1010 0100,
* 对应为有符号整数 -92
*/
let temp: Int16 = Int16(-132)
let con: UInt8 = UInt8(temp)
/* -132 对应的二进制为 1111 1111 0111 1100,
* 超过了用于接收该结果的 8 位内存空间,
* 截断后的结果在二进制上表示为 0111 1100
* 对应为有符号整数 124
*/
0
}
(3) 饱和(saturating):当整数运算溢出时,选择对应固定精度的极值作为结果。
@OverflowSaturating
main() {
let res: Int8 = Int8(-100) - Int8(45)
/* -100 - 45 在数学上等于 -145,
* 在 Int8 的表示范围上发生了下溢出,
* 选择 Int8 的最小值 -128 作为结果
*/
let con: Int8 = Int8(1024)
/* 1024 在 Int8 的表示范围上发生了上溢出,
* 选择 Int8 的最大值 127 作为结果
*/
0
}
默认情况下(即未标注该类属性宏时),采取抛出异常(@OverflowThrowing)的处理策略。
实际情况下需要根据业务场景的需求正确选择溢出策略。例如要在 Int32 上实现某种安全运算,使得计算结果和计算过程在数学上相等,就需要使用抛出异常的策略。
【反例】
// 计算结果被高位截断
@OverflowWrapping
func operation(a: Int32, b: Int32): Int32 {
a + b // No exception will be thrown when overflow occurs
}
该错误例子使用了高位截断的溢出策略,比如当传入的参数 a 和 b 较大导致结果溢出时,会产生高位截断的情况,导致函数返回结果和计算表达式 a + b 在数学上不是相等关系。
【正例】
// 安全
@OverflowThrowing
func operation(a: Int32, b: Int32): Int32 {
a + b
}
main() {
try {
operation(a, b)
} catch (e: ArithmeticException) {
//Handle error
}
0
}
该正确例子使用了抛出异常的溢出策略,当传入的参数 a 和 b 较大导致整数溢出时,operation 函数会抛出异常。
下面总结了可能造成整数溢出的数学操作符。
| 操作符 | 溢出 | 操作符 | 溢出 | 操作符 | 溢出 | 操作符 | 溢出 |
|---|---|---|---|---|---|---|---|
+ | Y | -= | Y | << | N | < | N |
- | Y | *= | Y | >> | N | > | N |
* | Y | /= | Y | & | N | >= | N |
/ | Y | %= | N | | | N | <= | N |
% | N | <<= | N | ^ | N | == | N |
++ | Y | >>= | N | **= | Y | ||
-- | Y | &= | N | ! | N | ||
= | N | |= | N | != | N | ||
+= | Y | ^= | N | ** | Y |
性能优化注解
为了提升与 C 语言互操作的性能,仓颉提供属性宏 @FastNative 控制 cjnative 后端优化对于 C 函数的调用。值得注意的是,属性宏 @FastNative 只能用于 foreign 声明的函数。
@FastNative 使用限制
开发者在使用 @FastNative 修饰 foreign 函数时,应确保对应的 C 函数满足以下两点要求。
- 首先,函数的整体执行时间不宜太长。例如:
- 不允许函数内部存在很大的循环;
- 不允许函数内部产生阻塞行为,如,调用
sleep、wait等函数。
- 其次,函数内部不能调用仓颉方法。
自定义注解
自定义注解机制用来让反射(详见反射章节)获取标注内容,目的是在类型元数据之外提供更多的有用信息,以支持更复杂的逻辑。
开发者可以通过自定义类型标注 @Annotation 方式创建自己的自定义注解。@Annotation 只能修饰 class,并且不能是 abstract 或 open 或 sealed 修饰的 class。当一个 class 声明它标注了 @Annotation,那么它必须要提供至少一个 const init 函数,否则编译器会报错。
下面的例子定义了一个自定义注解 @Version,并用其修饰 A, B 和 C。在 main 中,我们通过反射获取到类上的 @Version 注解信息,并将其打印出来。
package pkg
from std import reflect.TypeInfo
@Annotation
public class Version {
let code: String
const init(code: String) {
this.code = code
}
}
@Version["1.0"]
class A {}
@Version["1.1"]
class B {}
main() {
let objects = [A(), B()]
for (obj in objects) {
let annOpt = TypeInfo.of(obj).findAnnotation("pkg.Version")
if (let Some(ann) <- annOpt) {
if (let Some(version) <- ann as Version) {
println(version.code)
}
}
}
}
编译并执行上述代码,输出结果为:
1.0
1.1
注解信息需要在编译时生成信息并绑定到类型上,自定义注解在使用时必须使用 const init 构建出合法的实例。注解声明语法与声明宏语法一致,后面的 [] 括号中需要按顺序或命名参数规则传入参数,且参数必须是 const 表达式(详见常量求值章节)。对于拥有无参构造函数的注解类型,声明时允许省略括号。
下面的例子中定义了一个拥有无参 const init 的自定义注解 @Deprecated,使用时 @Deprecated 和 @Deprecated[] 这两种写法均可。
package pkg
from std import reflect.TypeInfo
@Annotation
public class Deprecated {
const init() {}
}
@Deprecated
class A {}
@Deprecated[]
class B {}
main() {
if (TypeInfo.of(A()).findAnnotation("pkg.Deprecated").isSome()) {
println("A is deprecated")
}
if (TypeInfo.of(B()).findAnnotation("pkg.Deprecated").isSome()) {
println("B is deprecated")
}
}
编译并执行上述代码,输出结果为:
A is deprecated
B is deprecated
对于同一个注解目标,同一个注解类不允许声明多次,即不可重复。
@Deprecated
@Deprecated // error
class A {}
Annotation 不会被继承,因此一个类型的注解元数据只会来自它定义时声明的注解。如果需要父类型的注解元数据信息,需要开发者自己用反射接口查询。
下面的例子中,A 被 @Deprecated 注解修饰,B 继承 A,但是 B 没有 A 的注解。
package pkg
from std import reflect.TypeInfo
@Annotation
public class Deprecated {
const init() {}
}
@Deprecated
open class A {}
class B <: A {}
main() {
if (TypeInfo.of(A()).findAnnotation("pkg.Deprecated").isSome()) {
println("A is deprecated")
}
if (TypeInfo.of(B()).findAnnotation("pkg.Deprecated").isSome()) {
println("B is deprecated")
}
}
编译并执行上述代码,输出结果为:
A is deprecated
自定义注解可以用在类型声明(class、struct、enum、interface)、成员函数/构造函数中的参数、构造函数声明、成员函数声明、成员变量声明、成员属性声明。也可以限制自己可以使用的位置,这样可以减少开发者的误用,这类注解需要在声明 @Annotation 时标注 target 参数,参数类型为 Array<AnnotationKind>。其中,AnnotationKind 是标准库中定义的 enum。当没有限定 target 的时候,该自定义注解可以用在以上全部位置。当限定 target 时,只能用在声明的列表中。
public enum AnnotaitionKind {
| Type
| Parameter
| Init
| MemberProperty
| MemberFunction
| MemberVariable
}
下面的例子中,自定义注解通过 target 限定只能用在成员函数上,用在其他位置会编译报错。
@Annotation[target: [MemberFunction]]
public class Deprecated {
const init() {}
}
class A {
@Deprecated // ok, member funciton
func deprecated() {}
}
@Deprecated // error, type
class B {}
main() {}
动态特性
本章我们来介绍 Cangjie 的动态特性,应用动态特性开发者能够更为优雅的实现一些功能。仓颉的动态特性主要包含反射、动态加载。
仓颉反射基本介绍
反射指程序可以访问、检测和修改它本身状态或行为的一种机制。
反射这一动态特性有以下的优点:
-
提高了程序的灵活性和扩展性。
-
程序能够在运行时获悉各种对象的类型,对其成员进行枚举、调用等操作。
-
允许在运行时创建新类型,无需提前硬编码。
但使用反射调用,其性能通常低于直接调用,因此反射机制主要应用于对灵活性和拓展性要求很高的系统框架上。
如何获得 TypeInfo
对于仓颉的反射特性,我们需要知道 TypeInfo 这一类型,这个核心类型中记录任意类型的类型信息,并且定义了方法用于获取类型信息、设置值等。当然为了便于用户操作我们还提供了 ClassTypeInfo、PrimitiveTypeInfo、ParameterInfo 等一系列的信息类型。
我们可以使用三种静态的 of 方法来生成 TypeInfo 信息类。
public class TypeInfo {
public static func of(a: Any): TypeInfo
public static func of(a: Object): ClassTypeInfo
public static func of<T>(): TypeInfo
}
当采用入参为 Any 和 Object 类型的 of 函数,输出为该实例的运行时类型信息,采用泛型参数的 of 函数则会返回传入参数的静态类型信息。两种方法产生的信息完全相同,但不保证一定对应同一对象。
例如我们可以用反射来获取一个自定义类型的类型信息。
from std import reflect.*
class Foo {}
main() {
let a: Foo = Foo()
let info: TypeInfo = TypeInfo.of(a)
let info2: TypeInfo = TypeInfo.of<Foo>()
println(info)
println(info2)
}
编译并执行上面的代码,会输出:
default.Foo
default.Foo
此外,为配合动态加载使用,TypeInfo 还提供了静态函数 get,该接口可通过传入的类型名称获取 TypeInfo。
public class TypeInfo {
public static func get(qualifiedName: String): TypeInfo
}
请注意,传入参数需要符合 module/package.type 的完全限定模式规则。对于编译器预导入的类型,包含 core 包中的类型和编译器内置类型,例如 primitive type、Option、Iterable 等,查找的字符串需要直接使用其类型名,不能带包名和模块名前缀。当运行时无法查询到对应类型的实例,则会抛出 InfoNotFoundException。
let t1: TypeInfo = TypeInfo.get("Int64")
let t1: TypeInfo = TypeInfo.get("default.Foo")
let t2: TypeInfo = TypeInfo.get("std/socket.TcpSocket")
let t3: TypeInfo = TypeInfo.get("net/http.ServerBuilder")
采用这种方式时无法获取一个未实例化的泛型类型。
from std import collection.*
from std import reflect.*
class A<T> {
A(public let t: T) {}
}
class B<T> {
B(public let t: T) {}
}
main() {
let aInfo: TypeInfo = TypeInfo.get("default.A<Int64>")// error `default.A<Int64>` is not instantiated,will throw InfoNotFoundException
let b: B<Int64> = B<Int64>(1)
let bInfo: TypeInfo = TypeInfo.get("default.B<Int64>")// ok `default.B<Int64>` has been performed.
}
如何使用反射访问成员
在获取到对应的类型信息类即 TypeInfo,我们便可以通过其相应接口访问对应类的实例成员以及静态成员。此外 TypeInfo 的子类 ClassTypeInfo 还提供了接口用于访问类公开的构造函数以及它的成员变量、属性、函数。仓颉的反射被设计为只能访问到类型内 public 的成员,意味着 private、protected 和 default 修饰的成员在反射中是不可见的。
例如当我们想要在运行时对类的某一实例成员变量进行获取与修改。
from std import reflect.*
public class Foo {
public static var param1 = 20
public var param2 = 10
}
main(): Unit{
let obj = Foo()
let info = TypeInfo.of(obj)
let staticVarInfo = info.getStaticVariable("param1")
let instanceVarInfo = info.getInstanceVariable("param2")
println("成员变量初始值")
print("Foo 的静态成员变量 ${staticVarInfo} = ")
println((staticVarInfo.getValue() as Int64).getOrThrow())
print("obj 的实例成员变量 ${instanceVarInfo} = ")
println((instanceVarInfo.getValue(obj) as Int64).getOrThrow())
println("更改成员变量")
staticVarInfo.setValue(8)
instanceVarInfo.setValue(obj, 25)
print("Foo 的静态成员变量 ${staticVarInfo} = ")
println((staticVarInfo.getValue() as Int64).getOrThrow())
print("obj 的实例成员变量 ${instanceVarInfo} = ")
println((instanceVarInfo.getValue(obj) as Int64).getOrThrow())
return
}
编译并执行上面的代码,会输出:
成员变量初始值
Foo 的静态成员变量 static param1: Int64 = 20
obj 的实例成员变量 param2: Int64 = 10
更改成员变量
Foo 的静态成员变量 static param1: Int64 = 8
obj 的实例成员变量 param2: Int64 = 25
同时我们也可以通过反射对属性进行检查以及修改。
from std import reflect.*
public class Foo {
public let _p1: Int64 = 1
public prop p1: Int64 {
get() { _p1 }
}
public var _p2: Int64 = 2
public mut prop p2: Int64 {
get() { _p2 }
set(v) { _p2 = v }
}
}
main(): Unit{
let obj = Foo()
let info = TypeInfo.of(obj)
let instanceProps = info.instanceProperties.toArray()
println("obj的实例成员属性包含${instanceProps}")
let PropInfo1 = info.getInstanceProperty("p1")
let PropInfo2 = info.getInstanceProperty("p2")
println((PropInfo1.getValue(obj) as Int64).getOrThrow())
println((PropInfo2.getValue(obj) as Int64).getOrThrow())
if (PropInfo1.isMutable()) {
PropInfo1.setValue(obj, 10)
}
if (PropInfo2.isMutable()) {
PropInfo2.setValue(obj, 20)
}
println((PropInfo1.getValue(obj) as Int64).getOrThrow())
println((PropInfo2.getValue(obj) as Int64).getOrThrow())
return
}
编译并执行上面的代码,会输出:
obj 的实例成员属性包含[prop p1: Int64, mut prop p2: Int64]
1
2
1
20
我们还可以通过反射机制进行函数调用。
from std import reflect.*
public class Foo {
public static func f1(v0: Int64, v1: Int64): Int64 {
return v0 + v1
}
}
main(): Unit {
var num = 0
let intInfo = TypeInfo.of<Int64>()
let funcInfo = TypeInfo.of<default.Foo>().getStaticFunction("f1", intInfo, intInfo)
num = (funcInfo.apply([1, 1]) as Int64).getOrThrow()
println(num)
}
编译并执行上面的代码,会输出:
2
动态加载
编译时刻加载称之为静态加载,而动态加载指的是仓颉程序可以在运行过程中通过特定函数来访问仓颉动态模块,以此读写全局变量、调用全局函数、获取类型信息的能力。仓颉中主要通过 ModuleInfo 和 PackageInfo 这两个类型来提供动态加载的能力。
例如我们存在一个 module0 模块下的 package0 包含一个公开的类型 Foo,其对应的仓颉动态模块路径为 "./module_package.so" 。应用动态加载我们便可以在运行时得到这个 Foo 的类型信息。
let m = ModuleInfo.load(./module_package)
let p = m.getPackageInfo("package0").getOrThrow()
let at = TypeInfo.get("module0/package0.Foo")
附录
Linux 版本工具链的支持与安装
仓颉工具链当前基于以下 Linux 发行版进行了完整功能测试: | Linux 发行版 | | -- | | SLES 12-SP5 | | Ubuntu 18.04 | | Ubuntu 20.04 | | EulerOS R11 |
适用于各 Linux 发行版的仓颉工具链依赖安装命令
注:当前仓颉工具链依赖的部分工具在一些 Linux 发行版上可能无法通过系统默认软件源直接安装,你可以参考下一节[编译安装依赖工具]进行手动安装。
SLES 12-SP5
$ zypper install \
binutils \
glibc-devel \
gcc-c++
此外,还需要安装以下工具,安装方法请参考下一节。
- OpenSSL 3
Ubuntu 18.04
$ apt-get install \
binutils \
libc-dev \
libc++-dev \
libgcc-7-dev \
此外,还需要安装以下工具,安装方法请参考下一节。
- OpenSSL 3
Ubuntu 20.04
$ apt-get install \
binutils \
libc-dev \
libc++-dev \
libgcc-9-dev \
此外,还需要安装以下工具,安装方法请参考下一节。
- OpenSSL 3
EulerOS R11
$ yum install binutils \
glibc-devel \
gcc
其他 Linux 发行版
根据使用的 Linux 发行版的不同,你可能需要参考以上系统的依赖安装命令,使用你的系统包管理工具安装对应依赖。若你使用的系统没有提供相关软件包,你可能需要自行安装链接工具、C 语言开发工具、C++ 开发工具、GCC 编译器、以及 OpenSSL 3 以正常使用仓颉工具链。
编译安装依赖工具
当前仓颉工具链中的部分标准库(以及部分工具)使用了 OpenSSL 3 开源软件。对于系统包管理工具未提供 OpenSSL 3 的场景,用户可能需要源码编译安装 OpenSSL 3,本节提供了 OpenSSL 3 源码编译的方法和步骤。
OpenSSL 3
从以下链接可以下载到 OpenSSL 3 的源码:
- https://www.openssl.org/source/
- https://www.openssl.org/source/old/
建议使用 openssl-3.0.7 或更高版本。
注意:请在执行以下编译和安装命令前仔细阅读注意事项,并根据实际情况调整命令。不正确的配置和安装可能会导致系统其他软件不可用。 如果在编译安装过程中遇到问题或希望进行额外的安装配置,请参考 OpenSSL 源码中的
INSTALL文件或 OpenSSL 的 FAQ:https://www.openssl.org/docs/faq.html。
此处以 openssl-3.0.7 为例,下载后使用以下命令解压压缩包:
$ tar xf openssl-3.0.7.tar.gz
解压完成后进入目录:
$ cd openssl-3.0.7
编译 OpenSSL:
注意:如果你的系统已经安装了 OpenSSL,建议使用
--prefix=<path>选项指定一个自定义安装路径,例如--prefix=/usr/local/openssl-3.0.7或你的个人目录。在系统目录已经存在 OpenSSL 的场景下直接使用以下命令编译安装可能会使系统 OpenSSL 被覆盖,并导致依赖系统 OpenSSL 的应用不可用。
$ ./Configure --libdir=lib
$ make
测试 OpenSSL:
$ make test
将 OpenSSL 安装至系统目录(或你先前指定的 --prefix 目录),你可能需要提供 root 权限以成功执行以下命令:
$ make install
或
$ sudo make install
如果先前编译 OpenSSL 时没有通过 --prefix 设置自定义安装路径,你的 OpenSSL 安装已经完成了。如果先前通过 --prefix 指定了自定义的安装路径,你还需要设置以下变量,以使仓颉工具链可以找到 OpenSSL 3。
注意:如果你的系统中原先存在其他版本的 OpenSSL,通过以下方式配置后,除了仓颉工具链外,你的其他编译开发工具默认使用的 OpenSSL 版本也可能受到影响。如果使用其他编译开发工具时出现 OpenSSL 不兼容的情况,请仅为仓颉开发环境配置以下变量。
请将 <prefix> 替换为你指定的自定义安装路径。
$ export LIBRARY_PATH=<prefix>/lib:$LIBRARY_PATH
$ export LD_LIBRARY_PATH=<prefix>/lib:$LD_LIBRARY_PATH
通过以上方式所配置的环境变量仅在当前执行命令的 shell 会话窗口有效。若希望 shell 每次启动时都自动配置,你可以在 $HOME/.bashrc、$HOME/.zshrc 或其他 shell 配置文件(依你的 shell 种类而定)加入以上命令。
若希望配置可以默认对所有用户生效,你可以执行以下命令:
请将 <prefix> 替换为你指定的自定义安装路径。
$ echo "export LIBRARY_PATH=<prefix>/lib:$LIBRARY_PATH" >> /etc/profile
$ echo "<prefix>/lib" >> /etc/ld.so.conf
$ ldconfig
执行完毕后重新打开 shell 会话窗口即可生效。
至此,OpenSSL 3 已经成功安装,你可以回到原来的章节继续阅读或尝试运行仓颉编译器了。
关键字
关键字是不能作为标识符使用的特殊字符串,仓颉语言的关键字如下表所示:
| as | abstract | break |
| Bool | case | catch |
| class | const | continue |
| Char | do | else |
| enum | extend | for |
| from | func | false |
| finally | foreign | Float16 |
| Float32 | Float64 | if |
| in | is | init |
| import | interface | Int8 |
| Int16 | Int32 | Int64 |
| IntNative | let | mut |
| main | macro | match |
| Nothing | open | operator |
| override | prop | public |
| package | private | protected |
| quote | redef | return |
| spawn | super | static |
| struct | synchronized | try |
| this | true | type |
| throw | This | unsafe |
| Unit | UInt8 | UInt16 |
| UInt32 | UInt64 | UIntNative |
| var | VArray | where |
| while |
操作符
下表列出了仓颉支持的所有操作符的优先级及结合性,其中优先级一栏数值越小,对应操作符的优先级越高。
| 操作符 | 优先级 | 含义 | 示例 | 结合方向 |
|---|---|---|---|---|
@ | 0 | 宏调用 | @id | 右结合 |
. | 1 | 成员访问 | expr.id | 左结合 |
[] | 1 | 索引 | expr[expr] | 左结合 |
() | 1 | 函数调用 | expr(expr) | 左结合 |
++ | 2 | 自增 | var++ | 无 |
-- | 2 | 自减 | var-- | 无 |
? | 2 | 问号 | expr?.id, expr?[expr], expr?(expr), expr?{expr} | 无 |
! | 3 | 按位求反、逻辑非 | !expr | 右结合 |
- | 3 | 一元负号 | -expr | 右结合 |
** | 4 | 幂运算 | expr ** expr | 右结合 |
*, / | 5 | 乘法,除法 | expr * expr, expr / expr | 左结合 |
% | 5 | 取模 | expr % expr | 左结合 |
+, - | 6 | 加法,减法 | expr + expr, expr - expr | 左结合 |
<< | 7 | 按位左移 | expr << expr | 左结合 |
>> | 7 | 按位右移 | expr >> expr | 左结合 |
.. | 8 | 区间操作符 | expr..expr | 无 |
..= | 8 | expr..=expr | 无 | |
< | 9 | 小于 | expr < expr | 无 |
<= | 9 | 小于等于 | expr <= expr | 无 |
> | 9 | 大于 | expr > expr | 无 |
>= | 9 | 大于等于 | expr >= expr | 无 |
is | 9 | 类型检查 | expr is Type | 无 |
as | 9 | 类型转换 | expr as Type | 无 |
== | 10 | 判等 | expr == expr | 无 |
!= | 10 | 判不等 | expr != expr | 无 |
& | 11 | 按位与 | expr & expr | 左结合 |
^ | 12 | 按位异或 | expr ^ expr | 左结合 |
| | 13 | 按位或 | expr | expr | 左结合 |
&& | 14 | 逻辑与 | expr && expr | 左结合 |
|| | 15 | 逻辑或 | expr || expr | 左结合 |
?? | 16 | coalescing 操作符 | expr ?? expr | 右结合 |
|> | 17 | pipeline 操作符 | id |> expr | 左结合 |
~> | 17 | composition 操作符 | expr ~> expr | 左结合 |
= | 18 | 赋值 | id = expr | 无 |
**= | 18 | 复合赋值 | id **= expr | 无 |
*= | 18 | id *= expr | 无 | |
/= | 18 | id /= expr | 无 | |
%= | 18 | id %= expr | 无 | |
+= | 18 | id += expr | 无 | |
-= | 18 | id -= expr | 无 | |
<<= | 18 | id <<= expr | 无 | |
>>= | 18 | id >>= expr | 无 | |
&= | 18 | id &= expr | 无 | |
^= | 18 | id ^= expr | 无 | |
|= | 18 | id |= expr | 无 | |
&&= | 18 | id &&= expr | 无 | |
||= | 18 | id ||= expr | 无 |
操作符函数
下表列出了仓颉支持的所有操作符函数。
| 操作符函数 | 函数签名 | 示例 |
|---|---|---|
[] (索引取值) | operator func [](index1: T1, index2: T2, ...): R | this[index1, index2, ...] |
[] (索引赋值) | operator func [](index1: T1, index2: T2, ..., value!: TN): R | this[index1, index2, ...] = value |
() | operator func ()(param1: T1, param2: T2, ...): R | this(param1, param2, ...) |
! | operator func !(): R | !this |
** | operator func **(other: T): R | this ** other |
* | operator func *(other: T): R | this * other |
/ | operator func /(other: T): R | this / other |
% | operator func %(other: T): R | this % other |
+ | operator func +(other: T): R | this + other |
- | operator func -(other: T): R | this - other |
<< | operator func <<(other: T): R | this << other |
>> | operator func >>(other: T): R | this >> other |
< | operator func <(other: T): R | this < other |
<= | operator func <=(other: T): R | this <= other |
> | operator func >(other: T): R | this > other |
>= | operator func >=(other: T): R | this >= other |
== | operator func ==(other: T): R | this == other |
!= | operator func !=(other: T): R | this != other |
& | operator func &(other: T): R | this & other |
^ | operator func ^(other: T): R | this ^ other |
| | operator func |(other: T): R | this | other |
TokenKind 类型
public enum TokenKind <: ToString {
DOT| /* "." */
COMMA| /* "," */
LPAREN| /* "(" */
RPAREN| /* ")" */
LSQUARE| /* "[" */
RSQUARE| /* "]" */
LCURL| /* "{" */
RCURL| /* "}" */
EXP| /* "**" */
MUL| /* "*" */
MOD| /* "%" */
DIV| /* "/" */
ADD| /* "+" */
SUB| /* "-" */
INCR| /* "++" */
DECR| /* "--" */
AND| /* "&&" */
OR| /* "||" */
COALESCING| /* "??" */
PIPELINE| /* "|>" */
COMPOSITION| /* "~>" */
NOT| /* "!" */
BITAND| /* "&" */
BITOR| /* "|" */
BITXOR| /* "^" */
BITNOT| /* "~" */
LSHIFT| /* "<<" */
RSHIFT| /* ">>" */
COLON| /* ":" */
SEMI| /* ";" */
ASSIGN| /* "=" */
ADD_ASSIGN| /* "+=" */
SUB_ASSIGN| /* "-=" */
MUL_ASSIGN| /* "*=" */
EXP_ASSIGN| /* "**=" */
DIV_ASSIGN| /* "/=" */
MOD_ASSIGN| /* "%=" */
AND_ASSIGN| /* "&&=" */
OR_ASSIGN| /* "||=" */
BITAND_ASSIGN| /* "&=" */
BITOR_ASSIGN| /* "|=" */
BITXOR_ASSIGN| /* "^=" */
LSHIFT_ASSIGN| /* "<<=" */
RSHIFT_ASSIGN| /* ">>=" */
ARROW| /* "->" */
BACKARROW| /* "<-" */
DOUBLE_ARROW| /* "=>" */
RANGEOP| /* ".." */
CLOSEDRANGEOP| /* "..=" */
ELLIPSIS| /* "..." */
HASH| /* "#" */
AT| /* "@" */
QUEST| /* "?" */
LT| /* "<" */
GT| /* ">" */
LE| /* "<=" */
GE| /* ">=" */
IS| /* "is" */
AS| /* "as" */
NOTEQ| /* "!=" */
EQUAL| /* "==" */
WILDCARD| /* "_" */
INT8| /* "Int8" */
INT16| /* "Int16" */
INT32| /* "Int32" */
INT64| /* "Int64" */
INTNATIVE| /* "IntNative" */
UINT8| /* "UInt8" */
UINT16| /* "UInt16" */
UINT32| /* "UInt32" */
UINT64| /* "UInt64" */
UINTNATIVE| /* "UIntNative" */
FLOAT16| /* "Float16" */
FLOAT32| /* "Float32" */
FLOAT64| /* "Float64" */
CHAR| /* "Char" */
BOOLEAN| /* "Bool" */
NOTHING| /* "Nothing" */
UNIT| /* "Unit" */
STRUCT| /* "struct" */
ENUM| /* "enum" */
CFUNC| /* "CFunc" */
VARRAY| /* "VArray" */
THISTYPE| /* "This" */
PACKAGE| /* "package" */
IMPORT| /* "import" */
CLASS| /* "class" */
INTERFACE| /* "interface" */
FUNC| /* "func" */
MACRO| /* "macro" */
QUOTE| /* "quote" */
DOLLAR| /* "$" */
LET| /* "let" */
VAR| /* "var" */
CONST| /* "const" */
TYPE| /* "type" */
INIT| /* "init" */
THIS| /* "this" */
SUPER| /* "super" */
IF| /* "if" */
ELSE| /* "else" */
CASE| /* "case" */
TRY| /* "try" */
CATCH| /* "catch" */
FINALLY| /* "finally" */
FOR| /* "for" */
DO| /* "do" */
WHILE| /* "while" */
THROW| /* "throw" */
RETURN| /* "return" */
CONTINUE| /* "continue" */
BREAK| /* "break" */
IN| /* "in" */
NOT_IN| /* "!in" */
MATCH| /* "match" */
FROM| /* "from" */
WHERE| /* "where" */
EXTEND| /* "extend" */
WITH| /* "with" */
PROP| /* "prop" */
STATIC| /* "static" */
PUBLIC| /* "public" */
PRIVATE| /* "private" */
PROTECTED| /* "protected" */
OVERRIDE| /* "override" */
REDEF| /* "redef" */
ABSTRACT| /* "abstract" */
SEALED| /* "sealed" */
OPEN| /* "open" */
FOREIGN| /* "foreign" */
INOUT| /* "inout" */
MUT| /* "mut" */
UNSAFE| /* "unsafe" */
OPERATOR| /* "operator" */
SPAWN| /* "spawn" */
SYNCHRONIZED| /* "synchronized */
UPPERBOUND| /* "<:" */
MAIN| /* "main" */
IDENTIFIER| /* "x" */
INTEGER_LITERAL| /* e.g. "1" */
CHAR_BYTE_LITERAL| /* e.g. "b'x'" */
FLOAT_LITERAL| /* e.g. "'1.0'" */
COMMENT| /* e.g. "/*xx*/" */
NL| /* newline */
END| /* end of file */
SENTINEL| /* ";" */
CHAR_LITERAL| /* e.g. "'x'" */
STRING_LITERAL| /* e.g. ""xx"" */
JSTRING_LITERAL| /* e.g. "J"xx"" */
BYTE_STRING_ARRAY_LITERAL /* e.g. "b"xx"" */
MULTILINE_STRING| /* e.g. """"aaa"""" */
MULTILINE_RAW_STRING| /* e.g. "#"aaa"#" */
BOOL_LITERAL| /* "true" or "false" */
UNIT_LITERAL| /* "()" */
DOLLAR_IDENTIFIER| /* e.g. "$x" */
ANNOTATION| /* e.g. "@When" */
ILLEGAL
}
core 包
介绍
此包包括一些常用接口 ToString、 Hashable、 Equatable 等,以及 String、 Range、 Array、 Option 等常用数据结构,包括预定义的异常、错误类型等。
主要接口
interface Any
public interface Any
Any 是所有类型的父类型,所有 interface 都默认继承它,所有非 interface 类型都默认实现它。
class Object
public open class Object <: Any {
public const init()
}
Object 是所有 class 的父类,所有 class 都默认继承它。
init
public const init()
功能:构造一个 object 实例。
interface CharExtension
public interface CharExtension
CharExtension 是 Char 相关的辅助接口。
interface Hasher
public interface Hasher {
func finish(): Int64
mut func reset(): Unit
mut func write(value: Bool): Unit
mut func write(value: Char): Unit
mut func write(value: Int8): Unit
mut func write(value: Int16): Unit
mut func write(value: Int32): Unit
mut func write(value: Int64): Unit
mut func write(value: UInt8): Unit
mut func write(value: UInt16): Unit
mut func write(value: UInt32): Unit
mut func write(value: UInt64): Unit
mut func write(value: Float16): Unit
mut func write(value: Float32): Unit
mut func write(value: Float64): Unit
mut func write(value: String): Unit
}
Hasher 是用来处理哈希组合运算的接口。
func finish
func finish(): Int64
功能:返回哈希运算的结果。
返回值:经过计算后的哈希值
func reset
mut func reset(): Unit
功能:重置哈希值。
func write
mut func write(value: Bool): Unit
功能:通过该函数把想要哈希运算的 Bool 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Char): Unit
功能:通过该函数把想要哈希运算的 Char 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Int8): Unit
功能:通过该函数把想要哈希运算的 Int8 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Int16): Unit
功能:通过该函数把想要哈希运算的 Int16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Int32): Unit
功能:通过该函数把想要哈希运算的 Int32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Int64): Unit
功能:通过该函数把想要哈希运算的 Int64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: UInt8): Unit
功能:通过该函数把想要哈希运算的 UInt8 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: UInt16): Unit
功能:通过该函数把想要哈希运算的 UInt16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: UInt32): Unit
功能:通过该函数把想要哈希运算的 UInt32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: UInt64): Unit
功能:通过该函数把想要哈希运算的 UInt64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Float16): Unit
功能:通过该函数把想要哈希运算的 Float16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Float32): Unit
功能:通过该函数把想要哈希运算的 Float32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Float64): Unit
功能:通过该函数把想要哈希运算的 Float64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: String): Unit
功能:通过该函数把想要哈希运算的 String 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
class ArithmeticException
public open class ArithmeticException <: Exception {
public init()
public init(message: String)
}
ArithmeticException 为算术异常类,用于在发生算术异常时使用。
init
public init()
功能:构造一个默认的 ArithmeticException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 ArithmeticException 实例。
参数:
- message:异常信息
func getClassName
protected open override func getClassName(): String
功能:获得类名。
返回值:类名字符串
class ArrayIterator
public class ArrayIterator<T> <: Iterator<T> {
public init(data: Array<T>)
}
数组迭代器。
init
public init(data: Array<T>)
功能:创建一个数组迭代器。
参数:
- data:数组
func next
public func next(): Option<T>
功能:返回迭代器中的下一个值。
返回值:Option
func iterator
public func iterator(): Iterator<T>
功能:返回迭代器。
返回值:Iterator
class Box
public class Box<T> {
public var value: T
public init(v: T)
}
Box 泛型提供了将所有的类型包装成引用类型的能力。
value
public var value: T
功能:获取或修改被包装的值。
init
public init(v: T)
功能:构造函数。
参数:
- v:任意仓颉支持的类型参数
extend Box <: Hashable
extend Box<T> <: Hashable where T <: Hashable
func hashCode
public func hashCode(): Int64
功能:获取 Box 对象的 hashCode 值。
返回值:hashCode 值
extend Box <: Comparable
extend Box<T> <: Comparable<Box<T>> where T <: Comparable<T>
为 Box<T> 类扩展 Comparable<Box<T>> 接口,其中 T 必须是 Comparable<T> 类型。Box<T> 实例的大小关系与其封装的 T 实例大小关系相同。
operator func >
public operator func >(that: Box<T>): Bool
功能:比较 Box 对象的大小。
参数:
- that:比较的另外一个 Box 对象
返回值:原 Box 对象大于 that Box 对象返回 true,否则返回 false
operator func <
public operator func <(that: Box<T>): Bool
功能:比较 Box 对象的大小。
参数:
- that:比较的另外一个 Box 对象
返回值:原 Box 对象小于 that Box 对象返回 true,否则返回 false
operator func >=
public operator func >=(that: Box<T>): Bool
功能:比较 Box 对象的大小。
参数:
- that:比较的另外一个 Box 对象
返回值:原 Box 对象大于等于 that Box 对象返回 true,否则返回 false
operator func <=
public operator func <=(that: Box<T>): Bool
功能:比较 Box 对象的大小。
参数:
- that:比较的另外一个 Box 对象
返回值:原 Box 对象小于等于 that Box 对象返回 true,否则返回 false
operator func ==
public operator func ==(that: Box<T>): Bool
功能:比较 Box 对象是否相等。
参数:
- that:比较的另外一个 Box 对象
返回值:相等返回 true,不相等返回 false
operator func !=
public operator func !=(that: Box<T>): Bool
功能:比较 Box 对象是否不相等。
参数:
- that:比较的另外一个 Box 对象
返回值:不相等返回 true,相等返回 false
func compare
public func compare(that: Box<T>): Ordering
功能:判断当前 Box 实例与另一个 Box 实例的大小关系。
参数:
- that:比较的另外一个 Box 对象
返回值:如果当前 Box 实例大于 that,返回 Ordering.GT,等于返回 Ordering.EQ,小于返回 Ordering.LT
extend Box <: ToString
extend Box<T> <: ToString where T <: ToString
func toString
public func toString(): String
功能:获取 Box 对象的字符串表示。
返回值:转换后的字符串
class SpawnException
public class SpawnException <: Exception {
public init()
public init(message: String)
}
SpawnException 为线程异常类,用于在线程处理过程中发生异常时使用。
init
public init()
功能:构造一个默认的 SpawnException 实例,默认错误信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 SpawnException 实例。
参数:
- message:预定义消息
class Error
public open class Error <: ToString
Error 是所有错误类的基类。该类不可被继承,不可初始化,但是可以被捕获到。
prop message
public open prop message: String
功能:获取错误信息。
func toString
public open func toString(): String
功能:获取当前 Error 实例的字符串值,包括类名和错误信息。
返回值:错误信息字符串
func printStackTrace
public open func printStackTrace(): Unit
功能:向控制台打印堆栈信息。
func getStackTrace
public func getStackTrace(): Array<StackTraceElement>
功能:获取堆栈信息,每一条堆栈信息用一个 StackTraceElement 实例表示,最终返回一个 StackTraceElement 的数组。
返回值:堆栈信息数组
class Exception
public open class Exception <: ToString {
public init()
public init(message: String)
}
Exception 是所有异常类的基类。
init
public init()
功能:构造一个默认的 Exception 实例,默认异常信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 Exception 实例。
参数:
- message:异常信息
prop message
public open prop message: String
功能:获取异常信息。
func toString
public open func toString(): String
功能:获取当前 Exception 实例的字符串值,包括类名和异常信息。
返回值:异常信息字符串
func printStackTrace
public func printStackTrace(): Unit
功能:向控制台打印堆栈信息。
func getStackTrace
public func getStackTrace(): Array<StackTraceElement>
功能:获取堆栈信息,每一条堆栈信息用一个 StackTraceElement 实例表示,最终返回一个 StackTraceElement 的数组。
返回值:堆栈信息数组
func getClassName
protected open func getClassName(): String
功能:获得类名,用字符串表示。
返回值:类名
class IllegalArgumentException
public class IllegalArgumentException <: Exception {
public init()
public init(message: String)
}
IllegalArgumentException 为参数非法异常。
init
public init()
功能:构造一个默认的 IllegalArgumentException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 IllegalArgumentException 实例。
参数:
- message:异常信息
class IllegalStateException
public class IllegalStateException <: Exception {
public init()
public init(message: String)
}
IllegalStateException 为非法状态异常。
init
public init()
功能:构造一个默认的 IllegalStateException 实例,默认异常信息为空。
init
public init(message: String)
参数:
功能:根据异常信息构造一个 IllegalStateException 实例。
- message:异常信息
class IndexOutOfBoundsException
public class IndexOutOfBoundsException <: Exception {
public init()
public init(message: String)
}
IndexOutOfBoundsException 为索引越界异常。
init
public init()
功能:构造一个默认的 IndexOutOfBoundsException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 IndexOutOfBoundsException 实例。
参数:
- message:异常信息
class NegativeArraySizeException
public class NegativeArraySizeException <: Exception {
public init()
public init(message: String)
}
NegativeArraySizeException 为数组索引值为负数异常。
init
public init()
功能:构造一个默认的 NegativeArraySizeException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 NegativeArraySizeException 实例。
参数:
- message:异常信息
class NoneValueException
public class NoneValueException <: Exception {
public init()
public init(message: String)
}
表示 OptionNone 的异常类。
init
public init()
功能:构造一个默认的 NoneValueException 实例,默认异常信息为空。。
init
public init(message: String)
功能:根据异常信息构造一个 NoneValueException 实例。
参数:
- message:异常信息
class UnsupportedException
public class UnsupportedException <: Exception {
public init()
public init(message: String)
}
表示功能未支持的异常类。
init
public init()
功能:构造一个默认的 UnsupportedException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据指定异常信息构造 UnsupportedException 实例。
参数:
- message:异常消息
class InternalError
public class InternalError <: Error
InternalError 继承了 Error,表示内部错误,该类不可初始化,但是可以被捕获到
class OutOfMemoryError
public class OutOfMemoryError <: Error
OutOfMemoryError 继承了 Error,表示内存不足错误,该类不可被继承,不可初始化,但是可以被捕获到
class OverflowException
public class OverflowException <: ArithmeticException {
public init()
public init(message: String)
}
OverflowException 为算术运算溢出异常。
init
public init()
功能:构造一个默认的 OverflowException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据指定异常信息构造 OverflowException 实例。
参数:
- message:异常信息
class IllegalMemoryException
public class IllegalMemoryException <: Exception {
public init()
public init(message: String)
}
IllegalMemoryException 为内存操作错误异常。
init
public init()
功能:构造一个默认的 IllegalMemoryException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据指定异常信息构造 IllegalMemoryException 实例。
参数:
- message:异常信息
class Future
public class Future<T>
spawn 表达式的返回类型是 Future<T> ,其中 T 是类型变元,其类型与闭包表达式的返回类型一致。当我们调用 Future<T> 的 get() 函数时,阻塞当前运行的线程,直到 Future<T> 实例所代表的线程运行结束。
prop thread
public prop thread: Thread
功能:获得当前线程的 Thread 实例
func get
public func get(): T
功能:阻塞当前线程,等待当前 Future 对象对应的线程的结果。
返回值:当前 Future<T> 实例代表的线程运行结束后的返回值
func get
public func get(ns: Int64): Option<T>
功能:阻塞当前线程,等待当前 Future<T> 对象对应的线程的返回值。如果相应的线程在指定时间内未完成执行,则该函数将返回 None。
参数:
- ns:传入等待时间,单位为纳秒
返回值:如果改线程未完成,返回 None;如果 ns <= 0,等同于 get();如果线程抛出异常退出执行,在 get 调用处将继续抛出该异常
func tryGet
public func tryGet(): Option<T>
功能:尝试获取结果,不会阻塞当前线程。如果相应的线程未执行完成,则该函数返回 None,否则返回 Some。
返回值:如果未完成返回 None,否则返回 Some
func cancel
public func cancel(): Unit
功能:给当前 Future 对象对应的线程发送取消请求。该方法不会立即停止线程执行,仅发送请求,相应地,函数 hasPendingCancellation 可用于检查线程是否存在取消请求。
interface ThreadContext
public interface ThreadContext {
func end(): Unit
func hasEnded(): Bool
}
用户创建 thread 时,除了缺省 spawn 表达式入参,也可以通过传入不同 ThreadContext 类型的实例,选择不同的线程上下文,然后一定程度上控制并发行为。
目前不允许用户自行实现 ThreadContext 接口,仓颉语言根据使用场景,提供了MainThreadContext, 具体定义可在终端框架库中查阅。
func end
func end(): Unit
功能:结束方法,用于向当前 context 发送结束请求。
func hasEnded
func hasEnded(): Bool
功能:检查方法,用于检查当前 context 是否已结束。
返回值:如果结束返回 true,否则返回 false
class Thread
public class Thread
Thread 类为用户提供获取线程 ID 及名字、查询线程是否存在取消请求、注册线程未处理异常的处理函数等功能。
该类型实例无法通过构造得到,仅能通过 Future 对象的 thread 属性或是 Thread 类的 currentThread 静态属性获取。
prop currentThread
public static prop currentThread: Thread
功能:获取当前执行线程的 Thread 对象。
prop id
public prop id: Int64
功能:获取当前执行线程的标识,以 Int64 表示,所有存活的线程都有不同标识,但不保证当线程执行结束后复用它的标识。
prop name
public mut prop name: String
功能:获取或是设置线程的名称,获取设置都具有原子性。
prop hasPendingCancellation
public prop hasPendingCancellation: Bool
功能:线程是否存在取消请求,即是否通过 future.cancel() 发送过取消请求。
常见使用方法:Thread.currentThread.hasPendingCancellation。
func handleUncaughtExceptionBy
public static func handleUncaughtExceptionBy(exHandler: (Thread, Exception) -> Unit): Unit
功能:注册线程未处理异常的处理函数当某一线程因异常而提前终止后,如果全局的未处理异常函数被注册,那么将调用该函数并结束线程,在该函数内抛出异常时,将向终端打印提示信息并结束线程,但不会打印异常调用栈信息;如果没有注册全局异常处理函数,那么默认会向终端打印异常调用栈信息。多次注册处理函数时,后续的注册函数将覆盖之前的处理函数。当有多个线程同时因异常而终止时,处理函数将被并发执行,因而开发者需要在处理函数中确保并发正确性。处理函数的参数第一个参数类型为 Thread,是发生异常的线程第二个参数类型为 Exception,是线程未处理的异常。
class ThreadLocal
public class ThreadLocal<T>
使用 ThreadLocal 可以在每个仓颉线程安全地访问他们各自的 “全局变量”。
func get
public func get(): ?T
功能:获得仓颉线程局部变量的值。
返回值:如果当前线程局部变量不为空值,返回该值,如果为空值,返回 Option<T>.None
func set
public func set(value: ?T): Unit
功能:通过 value 设置仓颉线程局部变量的值,如果传入 Option
参数:
- value:需要设置的局部变量的值
struct Range
public struct Range<T> <: Iterable<T> where T <: Countable<T> & Comparable<T> & Equatable<T> {
public let start: T
public let end: T
public let step: Int64
public let hasStart: Bool
public let hasEnd: Bool
public let isClosed: Bool
public const init(start: T, end: T, step: Int64, hasStart: Bool, hasEnd: Bool, isClosed: Bool)
}
Range 类用于表示拥有固定步长的序列,区间类型是一个泛型,使用 Range<T> 表示。
start
public let start: T
功能:表示开始值。
end
public let end: T
功能:表示结束值。
step
public let step: Int64
功能:表示步长。
hasStart
public let hasStart: Bool
功能:表示是否包含开始值。
hasEnd
public let hasEnd: Bool
功能:表示是否包含结束值。
isClosed
public let isClosed: Bool
功能:表示区间开闭情况,为 true 表示左闭右闭,为 false 表示左闭右开。
init
public const init(start: T, end: T, step: Int64, hasStart: Bool, hasEnd: Bool, isClosed: Bool)
功能:使用该构造函数创建 Range 序列。
参数:
- start:开始值
- end:结束值
- step:步长
- hasStart:是否有开始值
- hasEnd:是否有结束值
- isClosed:true 代表左闭右闭,false 代表左闭右开
异常:
- IllegalArgumentException:当 step 等于 0 时, 抛出异常
func iterator
public func iterator(): Iterator<T>
功能:获取当前区间的迭代器。
返回值:当前区间的迭代器
func isEmpty
public const func isEmpty(): Bool
功能:判断该区间是否为空。
返回值:如果为空,返回 true,否则返回 false
class RangeIterator
public class RangeIterator<T> <: Iterator<T> where T <: Countable<T> & Comparable<T> & Equatable<T>
RangeIterator 类为 Range 类型的迭代器。
func next
public func next(): Option<T>
功能:获取迭代器中的下一个值。
返回值:迭代器中的下一个值。
func iterator
public func iterator(): Iterator<T>
功能:获取当前迭代器实例。
返回值:当前迭代器实例
class StackOverflowError
public class StackOverflowError <: Error {}
StackOverflowError 类继承了 Error,表示堆栈溢出错误,该类不可被继承,不可初始化,但是可以被捕获到。
func printStackTrace
public override func printStackTrace(): Unit
功能:向控制台打印堆栈信息。
class StackTraceElement
public open class StackTraceElement {
public let declaringClass: String
public let methodName: String
public let fileName: String
public let lineNumber: Int64
public init(declaringClass: String, methodName: String, fileName: String, lineNumber: Int64)
}
StackTraceElement 类用于提供具体的堆栈信息。
declaringClass
public let declaringClass: String
类名
methodName
public let methodName: String
函数名
fileName
public let fileName: String
文件名
lineNumber
public let lineNumber: Int64
行号
init
public init(declaringClass: String, methodName: String, fileName: String, lineNumber: Int64)
参数:
- declaringClass:类名
- methodName:函数名
- fileName:文件名
- lineNumber:行号
struct Array
public struct Array<T> {
public const init()
public init(size: Int64, item!: T)
public init(elements: Collection<T>)
public init(size: Int64, initElement: (Int64) -> T)
}
Array 类为仓颉数组类型。
init
public const init()
功能:无参构造函数,创建一个空数组。
init
public init(size: Int64, item!: T)
功能:构造一个指定长度的数组,其中元素都用指定初始值进行初始化。
注意:该构造函数不会拷贝 item, 如果 item 是一个引用类型,构造后数组的每一个元素都将指向相同的引用。
参数:
- size:数组大小
- item:数组元素初始值
异常:
- NegativeArraySizeException:当 size 小于 0,抛出异常
init
public init(elements: Collection<T>)
功能:根据 Collection 实例创建数组,把 Collection 实例中所有元素存入数组。
参数:
- elements:根据该 Collection 实例创建数组
init
public init(size: Int64, initElement: (Int64) -> T)
功能:创建指定长度的数组,其中元素根据初始化函数计算获取。即:将 [0, size) 范围内的值分别传入初始化函数 initElement,执行得到数组对应下标的元素。
参数:
- size:数组大小
- initElement:初始化函数
异常:
- NegativeArraySizeException:当 size 小于 0,抛出异常
func slice
public func slice(start: Int64, len: Int64): Array<T>
功能:返回切片后数组。
参数:
- start:切片的起始位置
- len:切片的长度
返回值:返回切片后的数组
异常:
- IndexOutOfBoundsException:如果 start 小于 0 ,或者 len 小于 0 ,或者 (start + len)的值大于 Array 的长度,抛出异常
func get
public func get(index: Int64): Option<T>
功能:返回数组下标 index 对应的值。
参数:
- index:要获取值的下标
返回值:Option 类型的值,可以使用 match 解构
func set
public func set(index: Int64, element: T): Unit
功能:修改数组中下标 index 对应的值。
参数:
- index:需要修改的值的下标
- element:修改的目标值
异常:
- IndexOutOfBoundsException:如果 index 小于 0 或者大于或等于 Array 的长度,抛出异常
operator func []
public operator func [](index: Int64): T
功能:获取数组下标 index 对应的值。
参数:
- index:要获取值的下标
返回值:获取得到的值
异常:
- IndexOutOfBoundsException:如果 index 小于 0,或大于等于数组长度,抛出异常
operator func []
public operator func [](index: Int64, value!: T): Unit
功能:修改数组中下标 index 对应的值。
参数:
- index:需要修改值的下标
- value:修改的目标值
异常:
- IndexOutOfBoundsException:如果 index 小于 0,或大于等于数组长度,抛出异常
operator func []
public operator func [](range: Range<Int64>): Array<T>
功能:返回切片后的数组。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:
- start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响
- hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响
参数:
- range:切片的范围,注意这里 range 的步长只能为 1
返回值:新的数组
异常:
- IllegalArgumentException:如果 range 的步长不等于 1,抛出异常
- IndexOutOfBoundsException:如果 range 表示的数组范围无效,抛出异常
operator func []
public operator func [](range: Range<Int64>, value!: T): Unit
功能:用指定的值对本数组一个连续范围的元素赋值。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:
- start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响
- hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响
参数:
- range:数组范围,注意这里 range 的步长只能为 1
- value:修改的目标值
异常:
- IllegalArgumentException:如果 range 的步长不等于 1,抛出异常
- IndexOutOfBoundsException:如果 range 表示的数组范围无效,抛出异常
operator func []
public operator func [](range: Range<Int64>, value!: Array<T>): Unit
功能:用指定的数组对本数组一个连续范围的元素赋值。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:
- start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响
- hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响
参数:
- range:数组范围,注意这里 range 的步长只能为 1
- value:修改的目标值
异常:
- IllegalArgumentException:如果 range 的步长不等于 1,或 range 长度不等于 value 长度,抛出异常
- IndexOutOfBoundsException:如果 range 表示的数组范围无效,抛出异常
func reverse
public func reverse(): Unit
功能:反转数组,将数组中元素的顺序进行反转。
func clone
public func clone(): Array<T>
功能:克隆数组。
返回值:新的数组
func clone
public func clone(range: Range<Int64>) : Array<T>
功能:按 Range 克隆数组。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:
- start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响
- hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响
参数:
- range:切片的范围
返回值:新的数组
异常:
- IndexOutOfBoundsException:range 超出数组范围则抛出此异常
func copyTo
public func copyTo(dst: Array<T>, srcStart: Int64, dstStart: Int64, copyLen: Int64): Unit
功能:将当前数组中的一段数据拷贝到目标数组中。
参数:
- dst:目标数组
- srcStart:从 this 数组的 srcStart 下标开始拷贝
- dstStart:从目标数组的 dstStart 下标开始拷贝
- copyLen:拷贝数组的长度
异常:
- IllegalArgumentException:copyLen 小于 0 则抛出此异常
- IndexOutOfBoundsException:如果 srcStart 或 dstStart 小于 0,或 srcStart 大于或等于 this 数组大小,或 dstStart 大于或等于目标数组大小,或 copyLen 超出范围则抛出此异常。
struct DefaultHasher
public struct DefaultHasher <: Hasher {
public init(res!: Int64 = 0)
}
DefaultHasher 是 struct 类型,提供了默认的哈希算法实现。
init
public init(res!: Int64 = 0)
功能:构造函数,创建一个 DefaultHasher。
参数:
- res:哈希结果,默认为 0
func reset
public mut func reset(): Unit
功能:重置哈希值为 0。
func finish
public func finish(): Int64
功能:获取哈希运算的结果。
返回值:哈希运算的结果
func write
public mut func write(value: Bool): Unit
功能:通过该函数把想要哈希运算的 Bool 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Char): Unit
功能:通过该函数把想要哈希运算的 Char 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Int8): Unit
功能:通过该函数把想要哈希运算的 Int8 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Int16): Unit
功能:通过该函数把想要哈希运算的 Int16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Int32): Unit
功能:通过该函数把想要哈希运算的 Int32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Int64): Unit
功能:通过该函数把想要哈希运算的 Int64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: UInt8): Unit
功能:通过该函数把想要哈希运算的 UInt8 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: UInt16): Unit
功能:通过该函数把想要哈希运算的 UInt16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: UInt32): Unit
功能:通过该函数把想要哈希运算的 UInt32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: UInt64): Unit
功能:通过该函数把想要哈希运算的 UInt64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Float16): Unit
功能:通过该函数把想要哈希运算的 Float16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Float32): Unit
功能:通过该函数把想要哈希运算的 Float32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Float64): Unit
功能:通过该函数把想要哈希运算的 Float64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: String): Unit
功能:通过该函数把想要哈希运算的 String 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
struct LibC
public struct LibC
LibC 是一个 struct 类型,提供了仓颉中较为高频使用的 C 接口。
func malloc
public static func malloc<T>(count!: Int64 = 1): CPointer<T> where T <: CType
功能:在堆中申请对应长度的内存。泛型参数 T 需要是 CType 的子类型。
参数:
- count:为可选参数,默认为1,表示申请 T 类型的个数
返回值:如果申请成功返回非空指针,内存长度为 sizeOf
func free
public static unsafe func free<T>(p: CPointer<T>): Unit where T <: CType
功能:释放堆内存。
参数:
- p:表示被释放的内存地址
func mallocCString
public static unsafe func mallocCString(str: String): CString
功能:通过 String 申请与之字符内容相同的 C 风格字符串。
参数:
- str:仓颉 String 类型
返回值:返回 C 风格字符串,以 '\0' 结束
func free
public static unsafe func free(cstr: CString): Unit
功能:释放 C 风格字符串。
参数:
- cstr:需要释放的 C 风格字符串
enum Ordering
public enum Ordering {
| LT
| GT
| EQ
}
Ordering 表示一个比较结果的 enum 类型,它包含三种情况小于,大于和等于。
LT
LT
功能:构造一个 Ordering 实例,表示小于。
GT
GT
功能:构造一个 Ordering 实例,表示大于。
EQ
EQ
功能:构造一个 Ordering 实例,表示等于。
enum Option
public enum Option<T> {
| Some<T>
| None
}
Option 是一个泛型 enum 类型,它包含两个构造器:Some 和 None。其中,Some 会携带一个参数,表示有值,None 不带参数,表示无值。当需要表示某个类型可能有值,也可能没有值的时候,可选择使用 Option 类型。
Some
Some(T)
功能:构造一个携带参数的 Option<T> 实例,表示有值。
None
None
功能:构造一个不带参数的 Option<T> 实例,表示无值。
func getOrThrow
public func getOrThrow(): T
功能:获得值或抛出异常。
返回值:如果当前实例值是 Some<T>,返回类型为 T 的实例
异常:
- NoneValueException:如果当前实例是
None,抛出异常
func getOrThrow
public func getOrThrow(exception: ()->Exception): T
功能:获得值或抛出指定异常。
参数:
- exception:异常函数,如果当前实例值是
None,将执行该函数并将其返回值作为异常抛出
返回值:如果当前实例值是 Some<T>,返回类型为 T 的实例
异常:
- Exception:如果当前实例是
None,抛出异常函数返回的异常
func getOrDefault
public func getOrDefault(other: ()->T): T
功能:获得值或返回默认值。如果 Option 值是 Some,则返回类型为 T 的实例,如果 Option 值是 None,则调用入参,返回类型 T 的值。
参数:
- other:默认函数,如果当前实例的值是
None,调用该函数得到类型为T的实例,并将其返回
返回值:如果当前实例的值是 Some<T>,则返回当前实例携带的类型为 T 的实例,如果 Option 值是 None,调用入参指定的函数,得到类型为 T 的实例,并将其返回
func isNone
public func isNone(): Bool
功能:判断当前实例值是否为 None。
返回值:如果当前实例值是 None,则返回 true,否则返回 false
func isSome
public func isSome(): Bool
功能:判断当前实例值是否为 Some。
返回值:如果当前实例值是 Some,则返回 true,否则返回 false
extend Option <: ToString
extend Option<T> <: ToString where T <: ToString
为 Option<T> 枚举实现 ToString 接口。
func toString
public func toString(): String
功能:将 Option 转换为可输出的 String。
返回值:转化后的 String
extend Option <: Equatable
extend Option<T> <: Equatable<Option<T>> where T <: Equatable<T>
为 Option<T> 枚举实现 Equatable<Option<T>> 接口。
operator func ==
public operator func ==(that: Option<T>): Bool
功能:判断当前实例与指定 Option<T> 实例是否相等。
参数:
- that:用于与当前实例比较的
Option<T>实例
返回值:如果相等,则返回 true,否则返回 false
operator func !=
public operator func !=(that: Option<T>): Bool
功能:判断当前实例与指定 Option<T> 实例是否不等。
参数:
- that:用于与当前实例比较的
Option<T>实例
返回值:如果不相等,则返回 true,否则返回 false
extend Option <: Hashable
extend Option<T> <: Hashable where T <: Hashable
为 Option 类型扩展 Hashable。
其中, Some(T) 的 hashCode 等于 T 的值对应的 hashCode,None 的 hashCode 等于 Int64(0)。
func hashCode
public func hashCode(): Int64
功能:获取哈希值。
返回值:哈希值
extend Array <: ToString
extend Array<T> <: ToString where T <: ToString
为 Array<T> 类型扩展 ToString 接口实现。
func toString
public func toString(): String
功能:将数组转换为可输出的 String。
返回值:转化后的 String
extend Array <: Equatable
extend Array<T> <: Equatable<Array<T>> where T <: Equatable<T>
为 Array<T> 类型扩展 Equatable<Array<T>> 接口实现。
operator func ==
public const operator func ==(that: Array<T>): Bool
功能:判断当前实例与指定 Array<T> 实例是否相等。
参数:
- that:用于与当前实例比较的
Array<T>实例
返回值:如果相等,则返回 true,否则返回 false
operator func !=
public const operator func !=(that: Array<T>): Bool
功能:判断当前实例与指定 Array<T> 实例是否不等。
参数:
- that:用于与当前实例比较的
Array<T>实例
返回值:如果不相等,则返回 true;相等则返回 false
func contains
public func contains(element: T): Bool
功能:判断 Array 是否包含指定元素。
参数:
- element:需要判断的元素
返回值:如果存在,则返回 true,否则返回 false
extend Array <: Collection
extend Array<T> <: Collection<T>
func iterator
public func iterator(): Iterator<T>
功能:获取当前数组的迭代器,用于遍历数组。
返回值:当前数组的迭代器
prop size
public prop size: Int64
功能:获取元素数量。
func isEmpty
public func isEmpty(): Bool
功能:判断数组是否为空。
返回值:如果数组为空,返回 true,否则,返回 false
func toArray
public func toArray(): Array<T>
功能:根据当前 Array 生成新 Array 实例。
返回值:与原 Array 完全相同的另一个 Array 对象
struct CPointerHandle
public struct CPointerHandle<T> where T <: CType {
public let pointer: CPointer<T>
public let array: Array<T>
public init()
public init(ptr: CPointer<T>, arr: Array<T>)
}
CPointerHandle 用来表示获取 Array 原始指针的实例,该类型中的泛型参数应该满足 CType 约束。
pointer
public let pointer: CPointer<T>
功能:获取 Array 对应的原始指针。
array
public let array: Array<T>
功能:原始指针对应的 Array。
init
public init()
功能:默认初始化函数,初始化一个空指针和空数组。
init
public init(ptr: CPointer<T>, arr: Array<T>)
功能:通过传入的 CPointer 和 Array 初始化一个 CPointerHandle。
参数:
- ptr:CPointer 指针
- arr:指针对应的 Array
interface ByteExtension
public interface ByteExtension
此接口用于扩展 Byte 类型
extend Byte <: ByteExtension
extend Byte <: ByteExtension
Byte 类型为内置类型,这里是对其添加的一些在 Ascii 字符集范围内的函数。
func isAscii
public func isAscii(): Bool
功能:判断 Byte 是否是在 Ascii 范围内。
返回值:如果 Byte 在 Ascii 范围内返回 true,否则返回 false
func isAsciiLetter
public func isAsciiLetter(): Bool
功能:判断 Byte 是否是在 Ascii 拉丁字母范围内。
返回值:如果 Byte 在 Ascii 拉丁字母范围内返回 true,否则返回 false
func isAsciiNumber
public func isAsciiNumber(): Bool
功能:判断 Byte 是否是在 Ascii 十进制数字范围内。
返回值:如果 Byte 在 Ascii 十进制数字范围内返回 true,否则返回 false
func isAsciiLowerCase
public func isAsciiLowerCase(): Bool
功能:判断 Byte 是否是在 Ascii 小写拉丁字母范围内。
返回值:如果 Byte 在 Ascii 小写拉丁字母范围内返回 true,否则返回 false
func isAsciiUpperCase
public func isAsciiUpperCase(): Bool
功能:判断 Byte 是否是在 Ascii 大写拉丁字母范围内。
返回值:如果 Byte 在 Ascii 大写拉丁字母范围内返回 true,否则返回 false
func isAsciiWhiteSpace
public func isAsciiWhiteSpace(): Bool
功能:判断 Byte 是否是在 Ascii 空白字符范围内。其取值范围为 $[09, 0D] \cup 20$。
返回值:如果 Byte 在 Ascii 空白字符范围内返回 true,否则返回 false
func isAsciiHex
public func isAsciiHex(): Bool
功能:判断 Byte 是否是在 Ascii 十六进制数字范围内。
返回值:如果 Byte 在 Ascii 十六进制数字范围内返回 true,否则返回 false
func isAsciiOct
public func isAsciiOct(): Bool
功能:判断 Byte 是否是在 Ascii 八进制数字范围内。
返回值:如果 Byte 在 Ascii 八进制数字范围内返回 true,否则返回 false
func isAsciiPunctuation
public func isAsciiPunctuation(): Bool
功能:判断 Byte 是否是在 Ascii 标点符号范围内。其取值范围为 $[21, 2F] \cup [3A, 40] \cup [5B, 60] \cup [7B, 7E]$。
返回值:如果 Byte 在 Ascii 标点符号范围内返回 true,否则返回 false
func isAsciiGraphic
public func isAsciiGraphic(): Bool
功能:判断 Byte 是否是在 Ascii 图形字符范围内。其取值范围为 $[21, 7E]$。
返回值:如果 Byte 在 Ascii 图形字符范围内返回 true,否则返回 false
func isAsciiControl
public func isAsciiControl(): Bool
功能:判断 Byte 是否是在 Ascii 控制字符范围内。其取值范围为 $[00, 1F] \cup 7F$。
返回值:如果 Byte 在 Ascii 控制字符范围内返回 true,否则返回 false
func isAsciiNumberOrLetter
public func isAsciiNumberOrLetter(): Bool
功能:判断 Byte 是否是在 Ascii 十进制数字和拉丁字母范围内。
返回值:如果 Byte 在 Ascii 十进制数字和拉丁字母范围内返回 true,否则返回 false
func toAsciiUpperCase
public func toAsciiUpperCase(): Byte
功能:将 Byte 换为对应的 Ascii 大写字符 Byte,如果无法转换则保持现状。
返回值:转换后的 Byte,如果无法转换则返回原来的 Byte
func toAsciiLowerCase
public func toAsciiLowerCase(): Byte
功能:将 Byte 换为对应的 Ascii 小写字符 Byte,如果无法转换则保持现状。
返回值:转换后的 Byte,如果无法转换则返回原来的 Byte
extend Char <: CharExtension
extend Char <: CharExtension
Char 类型为内置类型,这里是对其添加的一些在 Ascii 字符集范围内的函数。
func isAscii
public func isAscii(): Bool
功能:判断字符是否是 Ascii 中的字符。
返回值:如果是 Ascii 字符返回 true,否则返回 false
func isAsciiLetter
public func isAsciiLetter(): Bool
功能:判断字符是否是 Ascii 字母字符。
返回值:如果是 Ascii 字母字符返回 true,否则返回 false
func isAsciiNumber
public func isAsciiNumber(): Bool
功能:判断字符是否是 Ascii 数字字符。
返回值:如果是 Ascii 数字字符返回 true,否则返回 false
func isAsciiLowerCase
public func isAsciiLowerCase(): Bool
功能:判断字符是否是 Ascii 小写字符。
返回值:如果是 Ascii 小写字符返回 true,否则返回 false
func isAsciiUpperCase
public func isAsciiUpperCase(): Bool
功能:判断字符是否是 Ascii 大写字符。
返回值:如果是 Ascii 大写字符返回 true,否则返回 false
func isAsciiWhiteSpace
public func isAsciiWhiteSpace(): Bool
功能:判断字符是否是 Ascii 空白字符。其取值范围为 $[09, 0D] \cup 20$。
返回值:如果是 Ascii 空白字符返回 true,否则返回 false
func isAsciiHex
public func isAsciiHex(): Bool
功能:判断字符是否是 Ascii 十六进制字符。
返回值:如果是 Ascii 十六进制字符返回 true,否则返回 false
func isAsciiOct
public func isAsciiOct(): Bool
功能:判断字符是否是 Ascii 八进制字符。
返回值:如果是 Ascii 八进制字符返回 true,否则返回 false
func isAsciiPunctuation
public func isAsciiPunctuation(): Bool
功能:判断字符是否是 Ascii 标点符号字符。其取值范围为 $[21, 2F] \cup [3A, 40] \cup [5B, 60] \cup [7B, 7E]$。
返回值:如果是 Ascii 标点符号字符返回 true,否则返回 false
func isAsciiGraphic
public func isAsciiGraphic(): Bool
功能:判断字符是否是 Ascii 图形字符。其取值范围为 $[21, 7E]$。
返回值:如果是 Ascii 图形字符返回 true,否则返回 false
func isAsciiControl
public func isAsciiControl(): Bool
功能:判断字符是否是 Ascii 控制字符。其取值范围为 $[00, 1F] \cup 7F$。
返回值:如果是 Ascii 控制字符返回 true,否则返回 false
func isAsciiNumberOrLetter
public func isAsciiNumberOrLetter(): Bool
功能:判断字符是否是 Ascii 数字或拉丁字母字符。
返回值:如果是 Ascii 数字或拉丁字母字符返回 true,否则返回 false
func toAsciiUpperCase
public func toAsciiUpperCase(): Char
功能:将字符转换为 Ascii 大写字符,如果无法转换则保持现状。
返回值:转换后的字符,如果无法转换则返回原来的 Char
func toAsciiLowerCase
public func toAsciiLowerCase(): Char
功能:将字符转换为 Ascii 小写字符,如果无法转换则保持现状。
返回值:转换后的字符,如果无法转换则返回原来的 Char
func fromUtf8
public static func fromUtf8(arr: Array<UInt8>, index: Int64): (Char, Int64)
功能:将 UInt8 数组中的某个元素,通过 UTF-8 转换成字符,并告知字符占用字节长度。
参数:
- arr:UInt8 数组
- index:UInt8 数组的下标
返回值:数组中 index 下标元素对应于 UTF-8 所表示的字符 字符字节所占的大小
func intoUtf8Array
public static func intoUtf8Array(c: Char, arr: Array<UInt8>, index: Int64): Int64
功能:该函数会把字符转成字节码序列然后覆盖 Array 数组内指定位置的字节码。
参数:
- c:字符
- arr:待覆盖的 Array 数组
- index:目标位置的起始索引
返回值:字符的字节码长度,例如中文是三个字节码长度
func utf8Size
public static func utf8Size(arr: Array<UInt8>, index: Int64): Int64
功能:该函数会返回指定索引位置字节码对应 UTF-8 字符字节码应有的长度。准确来说,除了 ASCII 码,其他长度的字节码都有首位字节码,首位字节码开头 1 的个数表明了该字符对应的字节码长度,这个函数就用来扫描这个字节码的,如果不是首位字节码,就会抛出异常。
参数:
- arr:Array 数组
- index:指定字符的索引
返回值:字符的字节码长度,例如中文是三个字节码长度
异常:
- IllegalArgumentException:如果索引位置的字节码不符合首位字节码规则,会抛出异常
func utf8Size
public static func utf8Size(c: Char): Int64
功能:返回字符对应的 UTF-8 的字节码长度,例如中文字符是 3 个长度。
参数:
- c:字符
返回值:字符的字节码长度
func getPreviousFromUtf8
public static func getPreviousFromUtf8(arr: Array<UInt8>, index: Int64): (Char, Int64)
功能:当指定了一个索引,那么函数会找到数组对应索引位置并且根据 UTF-8 规则,查看该字节码是否是字符的首位字节码,如果不是就继续向前遍历,直到该字节码是首位字节码,然后利用字节码序列找到对应的字符。
参数:
- arr:Array 数组
- index:指定的索引
返回值:找到的字符 该字符首位字节码在数组中的索引
异常:
- IllegalArgumentException:如果找不到首位字节码,就会抛出异常
extend Char <: Comparable
extend Char <: Comparable<Char>
func compare
public func compare(rhs: Char): Ordering
功能:判断当前 Char 实例与指定 Char 实例的关系。
参数:
- rhs:另一个 Char 实例,用于与当前 Char 实例进行比较
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Char <: ToString
extend Char <: ToString
Char 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Char 转换为可输出的 String。
返回值:转化后的 String
extend Char <: Hashable
extend Char <: Hashable
Char 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:获取哈希值。
返回值:哈希值
extend Char <: Countable
extend Char <: Countable<Char>
Char 类型为内置类型,这里为其扩展 Countable<Char> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): Char
功能:与 Int64 数进行加法运算,返回值是 Char 类型。
参数:
- right:Int64 数
返回值:算数结果
异常:
- OverflowException:如果与 Int64 数进行加法运算后为不合法的 Unicode 值,抛出异常
extend Int64 <: ToString
extend Int64 <: ToString
Int64 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Int64 转换为可输出的 String。
返回值:转化后的 String
extend Int64 <: Comparable
extend Int64 <: Comparable<Int64>
Int64 类型为内置类型,这里为其扩展 Comparable<Int64> 接口。
func compare
public func compare(rhs: Int64): Ordering
功能:判断 Int64 与另一个 Int64 的关系。如果等于,返回 Ordering.EQ如果小于,返回 Ordering.LT。
参数:
- rhs:另一个 Int64 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ如果小于,返回 Ordering.LT
extend Int64 <: Hashable
extend Int64 <: Hashable
Int64 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:获取哈希值。
返回值:哈希值
extend Int64 <: Countable
extend Int64 <: Countable<Int64>
Int64 类型为内置类型,这里为其扩展 Countable<Int64>。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): Int64
功能:与 Int64 数进行加法运算,返回值是 Int64 类型。
参数:
- right:Int64 数
返回值:算数结果
extend Int32 <: ToString
extend Int32 <: ToString
Int32 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Int32 转换为可输出的 String。
返回值:转化后的 String
extend Int32 <: Comparable
extend Int32 <: Comparable<Int32>
Int32 类型为内置类型,这里为其扩展 Comparable<Int32> 接口。
func compare
public func compare(rhs: Int32): Ordering
功能:判断 Int32 与另一个 Int32 的关系。
参数:
- rhs:另一个 Int32 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Int32 <: Hashable
extend Int32 <: Hashable
Int32 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Int32 <: Countable
extend Int32 <: Countable<Int32>
Int32 类型为内置类型,这里为其扩展 Countable<Int32>。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): Int32
功能:与 Int64 数进行加法运算,返回值是 Int32 类型。
参数:
- right:Int64 数
返回值:算数结果
extend Int16 <: ToString
extend Int16 <: ToString
Int16 类型为内置类型,这里为其扩展向 String 类型的转换。
func toString
public func toString(): String
功能:将 Int16 转换为可输出的 String。
返回值:转化后的 String
extend Int16 <: Comparable
extend Int16 <: Comparable<Int16>
Int16 类型为内置类型,这里为其扩展 Comparable<Int16> 接口。
func compare
public func compare(rhs: Int16): Ordering
功能:判断 Int16 与另一个 Int16 的关系。
参数:
- rhs:另一个 Int16 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Int16 <: Hashable
extend Int16 <: Hashable
Int16 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Int16 <: Countable
extend Int16 <: Countable<Int16>
Int16 类型为内置类型,这里为其扩展 Countable<Int16>。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): Int16
功能:与 Int64 数进行加法运算,返回值是 Int16 类型。
参数:
- right:Int64 数
返回值:算数结果
extend Int8 <: ToString
extend Int8 <: ToString
Int8 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Int8 转换为可输出的 String。
返回值:转化后的 String
extend Int8 <: Comparable
extend Int8 <: Comparable<Int8>
Int8 类型为内置类型,这里为其扩展 Comparable<Int8> 接口。
func compare
public func compare(rhs: Int8): Ordering
功能:判断 Int8 与另一个 Int8 的关系。
参数:
- rhs:另一个 Int8 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ如果小于,返回 Ordering.LT。
extend Int8 <: Hashable
extend Int8 <: Hashable
Int8 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Int8 <: Countable
extend Int8 <: Countable<Int8>
Int8 类型为内置类型,这里为其扩展 Countable<Int8> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): Int8
功能:与 Int64 数进行加法运算,返回值是 Int8 类型。
参数:
- right:Int64 数
返回值:算数结果
extend IntNative <: ToString
extend IntNative <: ToString
IntNative 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 IntNative 转换为可输出的 String。
返回值:转化后的 String
extend IntNative <: Comparable
extend IntNative <: Comparable<IntNative>
IntNative 类型为内置类型,这里为其扩展 Comparable<IntNative> 接口。
func compare
public func compare(rhs: IntNative): Ordering
功能:判断 IntNative 与另一个 IntNative 的关系。
参数:
- rhs:另一个 IntNative 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ如果小于,返回 Ordering.LT
extend IntNative <: Hashable
extend IntNative <: Hashable
IntNative 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
extend IntNative <: Countable
extend IntNative <: Countable<IntNative>
IntNative 类型为内置类型,这里为其扩展 Countable<IntNative> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): IntNative
功能:与 Int64 数进行加法运算,返回值是 IntNative 类型。
参数:
- right:Int64 数
返回值:算数结果
extend UInt64 <: ToString
extend UInt64 <: ToString
UInt64 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 UInt64 转换为可输出的 String。
返回值:转化后的 String
extend UInt64 <: Comparable
extend UInt64 <: Comparable<UInt64>
UInt64 类型为内置类型,这里为其扩展 Comparable<UInt64> 接口。
func compare
public func compare(rhs: UInt64): Ordering
功能:判断 UInt64 与另一个 UInt64 的关系。
参数:
- rhs:另一个 UInt64 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT。
extend UInt64 <: Hashable
extend UInt64 <: Hashable
UInt64 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend UInt64 <: Countable
extend UInt64 <: Countable<UInt64>
UInt64 类型为内置类型,这里为其扩展 Countable<UInt64> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): UInt64
功能:与 Int64 数进行加法运算,返回值是 UInt64 类型。
参数:
- right:Int64 数
返回值:算数结果
extend UInt32 <: ToString
extend UInt32 <: ToString
UInt32 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 UInt32 转换为可输出的 String。
返回值:转化后的 String
extend UInt32 <: Comparable
extend UInt32 <: Comparable<UInt32>
UInt32 类型为内置类型,这里为其扩展 Comparable<UInt32> 接口。
func compare
public func compare(rhs: UInt32): Ordering
功能:判断 UInt32 与另一个 UInt32 的关系。
参数:
- rhs:另一个 UInt32 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT。
extend UInt32 <: Hashable
extend UInt32 <: Hashable
UInt32 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend UInt32 <: Countable
extend UInt32 <: Countable<UInt32>
UInt32 类型为内置类型,这里为其扩展 Countable<UInt32> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): UInt32
功能:与 Int64 数进行加法运算,返回值是 UInt32 类型。
参数:
- right:Int64 数
返回值:算数结果
extend UInt16 <: ToString
extend UInt16 <: ToString
UInt16 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 UInt16 转换为可输出的 String。
返回值:转化后的 String
extend UInt16 <: Comparable
extend UInt16 <: Comparable<UInt16>
UInt16 类型为内置类型,这里为其扩展 Comparable<UInt16> 接口。
func compare
public func compare(rhs: UInt16): Ordering
功能:判断 UInt16 与另一个 UInt16 的关系如果等于,返回 Ordering.EQ如果小于,返回 Ordering.LT。
参数:
- rhs:另一个 UInt16 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT。
extend UInt16 <: Hashable
extend UInt16 <: Hashable
UInt16 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend UInt16 <: Countable
extend UInt16 <: Countable<UInt16>
UInt16 类型为内置类型,这里为其扩展 Countable<UInt16> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): UInt16
功能:与 Int64 数进行加法运算,返回值是 UInt16 类型。
参数:
- right:Int64 数
返回值:算数结果
extend UInt8 <: ToString
extend UInt8 <: ToString
UInt8 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 UInt8 转换为可输出的 String。
返回值:转化后的 String
extend UInt8 <: Comparable
extend UInt8 <: Comparable<UInt8>
UInt8 类型为内置类型,这里为其扩展 Comparable<UInt8> 接口。
func compare
public func compare(rhs: UInt8): Ordering
功能:判断 UInt8 与另一个 UInt8 的关系。
参数:
- rhs:另一个 UInt8 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend UInt8 <: Hashable
extend UInt8 <: Hashable
UInt8 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend UInt8 <: Countable
extend UInt8 <: Countable<UInt8>
UInt8 类型为内置类型,这里为其扩展 Countable<UInt8> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): UInt8
功能:与 Int64 数进行加法运算,返回值是 UInt8 类型。
参数:
- right:Int64 数
返回值:算数结果
extend UIntNative <: ToString
extend UIntNative <: ToString
UIntNative 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 UIntNative 转换为可输出的 String。
返回值:转化后的 String
extend UIntNative <: Comparable
extend UIntNative <: Comparable<UIntNative>
UIntNative 类型为内置类型,这里为其扩展 Comparable<UIntNative> 接口。
func compare
public func compare(rhs: UIntNative): Ordering
功能:判断 UIntNative 与另一个 UIntNative 的关系。
参数:
- rhs:另一个 UIntNative 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend UIntNative <: Hashable
extend UIntNative <: Hashable
UIntNative 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend UIntNative <: Countable
extend UIntNative <: Countable<UIntNative>
UIntNative 类型为内置类型,这里为其扩展 Countable<UIntNative> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): UIntNative
功能:与 Int64 数进行加法运算,返回值是 UIntNative 类型。
参数:
- right:Int64 数
返回值:算数结果
extend Float64 <: ToString
extend Float64 <: ToString
Float64 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换,默认保留 6 位小数,如需其他精度 String 请参考 Formatter 扩展。
func toString
public func toString(): String
功能:将 Float64 转换为可输出的 String。
返回值:转化后的 String
extend Float64 <: Comparable
extend Float64 <: Comparable<Float64>
Float64 类型为内置类型,这里为其扩展 Comparable<Float64> 接口。
func compare
public func compare(rhs: Float64): Ordering
功能:判断 Float64 与另一个 Float64 的关系。
参数:
- rhs:另一个 Float64 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Float64 <: Hashable
extend Float64 <: Hashable
Float64 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Float32 <: ToString
extend Float32 <: ToString
Float32 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换,默认保留 6 位小数,如需其他精度 String 请参考 Formatter 扩展。
func toString
public func toString(): String
功能:将 Float32 转换为可输出的 String。
返回值:转化后的 String
extend Float32 <: Comparable
extend Float32 <: Comparable<Float32>
Float32 类型为内置类型,这里为其扩展 Comparable<Float32> 接口。
func compare
public func compare(rhs: Float32): Ordering
功能:判断 Float32 与另一个 Float32 的关系。
参数:
- rhs:另一个 Float32 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Float32 <: Hashable
extend Float32 <: Hashable
Float32 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Float16 <: ToString
extend Float16 <: ToString
Float16 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换,默认保留 6 位小数,如需其他精度 String 请参考 Formatter 扩展。
func toString
public func toString(): String
功能:将 Float16 转换为可输出的 String。
返回值:转化后的 String
extend Float16 <: Comparable
extend Float16 <: Comparable<Float16>
Float16 类型为内置类型,这里为其扩展 Comparable<Float16> 接口。
func compare
public func compare(rhs: Float16): Ordering
功能:判断 Float16 与另一个 Float16 的关系。
参数:
- rhs:另一个 Float16 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Float16 <: Hashable
extend Float16 <: Hashable
Float16 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Ordering <: ToString
extend Ordering <: ToString
Ordering 类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Ordering 转换为可输出的 String。
返回值:转化后的 String
extend Ordering <: Comparable
extend Ordering <: Comparable<Ordering>
Ordering 类型,这里为其扩展 Comparable<Ordering> 接口。
func compare
public func compare(that: Ordering): Ordering
功能:判断 Ordering 与另一个 Ordering 的关系。
参数:
- that:另一个 Ordering 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
operator func ==
public operator func ==(that: Ordering): Bool
功能:判断两个 Ordering 是否相等。
参数:
- that:传入 Ordering
返回值:如果相等,则返回 true,否则返回 false
operator func !=
public operator func !=(that: Ordering): Bool
功能:判断两个 Ordering 是否不相等。
参数:
- that:传入 Ordering
返回值:如果不相等,则返回 true,否则返回 false
operator func <=
public operator func <=(that: Ordering): Bool
功能:判断两个 Ordering 是否为小于等于关系。
参数:
- that:传入 Ordering
返回值:如果为小于等于关系,则返回 true,否则返回 false
operator func <
public operator func <(that: Ordering): Bool
功能:判断两个 Ordering 是否为小于关系。
参数:
- that:传入 Ordering
返回值:如果为小于关系,则返回 true,否则返回 false
operator func >=
public operator func >=(that: Ordering): Bool
功能:判断两个 Ordering 是否为大于等于关系。
参数:
- that:传入 Ordering
返回值:如果为大于等于关系,则返回 true,否则返回 false
operator func >
public operator func >(that: Ordering): Bool
功能:判断两个 Ordering 是否为大于关系。
参数:
- that:传入 Ordering
返回值:如果为大于关系,则返回 true,否则返回 false
extend Ordering <: Hashable
extend Ordering <: Hashable
Ordering 类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:获取哈希码。
返回值:哈希值,Ordering.GT 的哈希值是 3,Ordering.EQ 的哈希值是 2,Ordering.LT 的哈希值是 1
extend Range <: Hashable
extend Range<T> <: Hashable where T <: Hashable & Countable<T> & Comparable<T> & Equatable<T>
Range 类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:获取哈希值。
返回值:哈希值
extend Range <: Equatable
extend Range<T> <: Equatable<Range<T>> where T <: Countable<T> & Comparable<T> & Equatable<T>
Range 类型,这里为其扩展 Equatable<Range<T>> 接口。
operator func ==
public operator func ==(that: Range<T>): Bool
功能:判断两个 Range 是否相等。
返回值:true 代表相等,false 代表不相等
operator func !=
public operator func !=(that: Range<T>): Bool
功能:判断两个 Range 是否不相等。
返回值:true 代表不相等,false 代表相等
extend Bool <: ToString
extend Bool <: ToString
Bool 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Bool 转换为可输出的 String。
返回值:转化后的 String
extend Bool <: Hashable
extend Bool <: Hashable
Bool 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
extend Bool <: Equatable
extend Bool <: Equatable<Bool>
Bool 类型为内置类型,这里为其扩展 Equatable<Bool> 接口。
extend Unit <: ToString
extend Unit <: ToString
Unit 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Unit 转换为可输出的 String,其值为 "()"。
返回值:转化后的 String
extend Unit <: Hashable
extend Unit <: Hashable
Unit 类型为内置类型,这里为其扩展 Hashable 接口,其函数返回值为 0。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值,为 0
extend CPointer
extend CPointer<T>
CPointer 类型为内置类型,在与 C 互操作中,该数据类型映射为 C 语言中的指针类型。这里扩展一些必要的指针使用相关接口,包含判空、读写数据等接口。其中泛型 T 为指针类型,其满足 CType 约束( CType 接口描述见后面 interface CType 章节)。对 CPointer 做运算需要在 unsafe 上下文中进行。
func isNull
public func isNull(): Bool
功能:判断指针是否是空。
返回值:如果是空返回 true,否则返回 false
func isNotNull
public func isNotNull(): Bool
功能:判断指针是否不是空。
返回值:如果不是空返回 true,否则返回 false
func toUIntNative
public func toUIntNative(): UIntNative
功能:获取该指针的整型形式。
返回值:返回该指针的整型形式
func read
public unsafe func read(): T
功能:读取第一个数据,该接口需要用户保证指针的合法性,否则发生未定义行为。
返回值:返回该对象类型的第一个数据
func write
public unsafe func write(value: T): Unit
功能:写入一个数据,该数据总是在第一个,该接口需要用户保证指针的合法性,否则发生未定义行为。
参数:
- value:要写入的数据
func read
public unsafe func read(idx: Int64): T
功能:根据下标读取对应的数据,该接口需要用户保证指针的合法性,否则发生未定义行为。
参数:
- idx:要获取数据的下标
返回值:输入下标对应的数据
func write
public unsafe func write(idx: Int64, value: T): Unit
功能:在指定下标位置写入一个数据,该接口需要用户保证指针的合法性,否则发生未定义行为。
参数:
- idx:指定的下标位置
- value:写入的数据
operator func +
public unsafe operator func +(offset: Int64): CPointer<T>
功能:CPointer 对象指针后移,同 C 语言的指针加法操作。
参数:
- offset:偏移量
返回值:返回地址变动后的对象
operator func -
public unsafe operator func -(offset: Int64): CPointer<T>
功能:CPointer 对象指针前移,同 C 语言的指针减法操作。
参数:
- offset:偏移量
返回值:返回地址变动后的对象
func asResource
public func asResource(): CPointerResource<T>
功能:获取 CPointerResource 对象。
返回值:表示 CPointerResource 对象
struct CPointerResource
public struct CPointerResource<T> <: Resource where T <: CType {
public var value: CPointer<T>
}
CPointer 对应的资源管理类型,其实例可以通过 CPointer 的成员函数 asResource 获取。
value
public var value: CPointer<T>
功能:表示当前实例管理的 CPointer<T> 类型实例。
func isClosed
public func isClosed(): Bool
功能:判断该指针内容是否已被释放。
返回值:返回 true 为已释放。
func close
public func close(): Unit
功能:释放其管理的 CPointer<T> 实例指向的内容。
extend CString
extend CString
CString 类型是内置类型,在与 C 互操作中,该数据类型映射为 C 语言中的字符串 char* 类型。这里扩展一些必要的字符串使用相关接口,包含判空、获取长度、截取等接口。 CString 提供了一个内建构造函数,接受 CPointer<UInt8> 类型的参数。
注意:如果使用 CString 需要将 \0 当做结束符。
init
public init(p: CPointer<UInt8>)
功能:通过字符串指针进行构造 CString ,该接口需要用户保证指针的合法性。
参数:
- p:使用已有的 UInt8 类型字符串指针进行构造
extend CString <: ToString
extend CString <: ToString
CString 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func getChars
public func getChars(): CPointer<UInt8>
功能:获取字符串的指针。
返回值:该字符串的指针
func isNull
public func isNull(): Bool
功能:判断字符串指针是否为空。
返回值:如果字符串指针为空,返回 true,否则返回 false
func size
public func size(): Int64
功能:返回该字符串长度,同 C 语言中的 strlen。
返回值:字符串长度
func isEmpty
public func isEmpty(): Bool
功能:判断字符串是否为空字符串。
返回值:如果为空字符串或字符串指针为空,返回 true,否则返回 false
func isNotEmpty
public func isNotEmpty(): Bool
功能:判断字符串是否不为空字符串。
返回值:如果不为空字符串,返回 true,如果字符串指针为空,返回 false
func startsWith
public func startsWith(prefix: CString): Bool
功能:判断字符串是否包含指定前缀。
参数:
- prefix:匹配的目标前缀字符串
返回值:如果该字符串包含 prefix 前缀,返回 true,如果该字符串不包含 prefix 前缀,返回 false,特别地,如果原字符串或者 prefix 前缀字符串指针为空,均返回 false
func endsWith
public func endsWith(suffix: CString): Bool
功能:判断字符串是否包含指定后缀。
参数:
- suffix:匹配的目标后缀字符串
返回值:如果该字符串包含 suffix 后缀,返回 true,如果该字符串不包含 suffix 后缀,返回 false,特别地,如果原字符串或者 suffix 后缀字符串指针为空,均返回 false
func equals
public func equals(rhs: CString): Bool
功能:判断字符串两个字符串是否相等。
参数:
- rhs:比较的目标字符串
返回值:如果两个字符串相等,返回 true,否则返回 false
func equalsLower
public func equalsLower(rhs: CString): Bool
功能:判断字符串两个字符串是否相等,且忽略大小写。
参数:
- rhs:匹配的目标字符串
返回值:如果两个字符串忽略大小写相等,返回 true,否则返回 false
func subCString
public func subCString(beginIndex: UIntNative): CString
功能:截取指定位置开始至字符串结束的子串,需要注意,该接口返回为字符串的副本,返回的子串使用完后需要手动 free。
参数:
- beginIndex:截取的起始位置
返回值:截取的子串,如果 beginIndex 与字符串长度相等,返回空字符串(空指针)
异常:
- IndexOutOfBoundsException:如果 beginIndex 大于字符串长度,抛出异常
- IllegalMemoryException:如果内存申请失败或内存拷贝失败时,抛出异常
func subCString
public func subCString(beginIndex: UIntNative, subLen: UIntNative): CString
功能:截取字符串的子串,指定起始位置和截取长度,如果截取的末尾位置超出字符串长度,截取至字符串末尾,需要注意,该接口返回为字符串的副本,返回的子串使用完后需要手动 free。
参数:
- beginIndex:截取的起始位置
- subLen:截取长度
返回值:截取的子串,如果 beginIndex 与字符串长度相等,返回空字符串(空指针)
异常:
- IndexOutOfBoundsException:如果 beginIndex 大于字符串长度,抛出异常
- IllegalMemoryException:如果内存申请失败或内存拷贝失败时,抛出异常
func compare
public func compare(str: CString): Int32
功能:按字典序比较两个字符串,同 C 语言中的 strcmp ,如果被比较的两个 CString 中存在空指针,该接口会抛出异常。
参数:
- str:比较的目标字符串
返回值:整数结果,相等时返回0,当该字符串比 str 小时,返回 -1,否则返回 1
异常:
- Exception:如果自身的数据指针或 str 为 null,抛出异常
func toString
public func toString(): String
功能:将 CString 类型转为仓颉的 String 类型。
返回值:转换后的字符串
func asResource
public func asResource(): CStringResource
功能:获取 CStringResource 对象。
返回值:表示 CStringResource 对象
struct CStringResource
public struct CStringResource <: Resource {
public let value: CString
}
CString 对应的资源管理类型,其实例可以通过 CString 的成员函数 asResource 获取。
value
public let value: CString
功能:表示当前实例管理的 CString 资源。
func isClosed
public func isClosed(): Bool
功能:判断该字符串是否被释放。
返回值:返回 true 为已释放。
func close
public func close(): Unit
功能:释放当前实例管理的 CString 类型实例指向的内容。
type Byte
public type Byte = UInt8
Byte 类型是内置类型 UInt8 的别名。
type Int
public type Int = Int64
Int 类型是内置类型 Int64 的别名。
type UInt
public type UInt = UInt64
UInt 类型是内置类型 UInt64 的别名。
func print
public func print(str: String, flush!: Bool = false): Unit
功能:向控制台输出数据。
注意:下列 print、 println、 eprint、 eprintln 函数默认为 UTF-8 编码,windows 环境需手动执行命令 chcp 65001(将 cmd 更改为 UTF-8 编码)。
参数:
- str:待输出的 String 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(str: String): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- str:待输出的 String 类型
func print
public func print<T>(arg: T, flush!: Bool = false): Unit where T <: ToString
功能:向控制台输出数据。
参数:
- arg:待输出的数据,支持实现了 ToString 接口的类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println<T>(arg: T): Unit where T <: ToString
功能:向控制台输出数据,输出末尾换行。
参数:
- arg:待输出的数据,支持实现了 ToString 接口的类型
func print
public func print(b: Bool, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- b:待输出的 Bool 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(b: Bool): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- b:待输出的 Bool 类型
func print
public func print(c: Char, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- c:待输出的 Char 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(c: Char): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- c:待输出的 Char 类型
func print
public func print(f: Float16, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- f:待输出的 Float16 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(f: Float16): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- f:待输出的 Float16 类型
func print
public func print(f: Float32, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- f:待输出的 Float32 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(f: Float32): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- f:待输出的 Float32 类型
func print
public func print(f: Float64, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- f:待输出的 Float64 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(f: Float64): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- f:待输出的 Float64 类型
func print
public func print(i: Int8, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 Int8 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: Int8): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 Int8 类型
func print
public func print(i: Int16, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 Int16 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: Int16): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 Int16 类型
func print
public func print(i: Int32, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 Int32 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: Int32): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 Int32 类型
func print
public func print(i: Int64, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 Int64 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: Int64): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 Int64 类型
func print
public func print(i: UInt8, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 UInt8 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: UInt8): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 UInt8 类型
func print
public func print(i: UInt16, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 UInt16 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: UInt16): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 UInt16 类型
func print
public func print(i: UInt32, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 UInt32 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: UInt32): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 UInt32 类型
func print
public func print(i: UInt64, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 UInt64 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: UInt64): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 UInt64 类型
func eprintln
public func eprintln(str: String): Unit
功能:eprintln 用于打印错误消息,如抛出异常,消息将打印到标准错误文本流,而不是标准输出,输出末尾换行。
参数:
- str:待输出的字符串
func eprint
public func eprint(str: String, flush!: Bool = true): Unit
功能:eprint 用于打印错误消息,如抛出异常,消息将打印到标准错误文本流,而不是标准输出。
参数:
- str:待输出的字符串
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(): Unit
功能:向标准输出(stdout)输出换行字符。
func ifSome
public func ifSome<T>(o: Option<T>, action: (T) -> Unit): Unit
功能:如果输入是 Option.Some 类型数据,则执行 action 函数。
参数:
- o:Option 类型输入
- action:待执行函数
func ifNone
public func ifNone<T>(o: Option<T>, action: () -> Unit): Unit
功能:如果输入是 Option.None 类型数据,则执行 action 函数。
参数:
- o:Option 类型输入
- action:待执行函数
func acquireArrayRawData
public unsafe func acquireArrayRawData<T>(arr: Array<T>): CPointerHandle<T> where T <: CType
功能:获取 Array
返回值:返回的原始指针实例
func releaseArrayRawData
public unsafe func releaseArrayRawData<T>(handle: CPointerHandle<T>): Unit where T <: CType
功能:释放 acquireArrayRawData 获取的原始指针实例。
参数:
- handle:待释放的指针实例
func refEq
public func refEq(a: Object, b: Object): Bool
功能:判断两个 Object 对象的内存地址是否是同一个。
参数:
- a:一个 Object 对象
- b:另一个 Object 对象
返回值:同一个返回 true,否则返回 false
func CJ_CORE_AddAtexitCallback
public func CJ_CORE_AddAtexitCallback(callback: () -> Unit): Unit
功能:注册退出函数,此处建议使用 os 库内 Process.atexit 函数,除非有制作进程管理框架的需要,否则不建议使用。
参数:
- callback:回调函数
func CJ_CORE_ExecAtexitCallbacks
public func CJ_CORE_ExecAtexitCallbacks(): Unit
功能:执行注册函数, 此处建议使用 os 库内 Process.exit 函数,除非有制作进程管理框架的需要,否则不建议使用。
func zeroValue
public unsafe func zeroValue<T>(): T
功能:获取一个已全零初始化的 T 类型实例,这个实例一定要赋值为正常初始化的值,再使用。
返回值:一个已全零初始化的 T 类型实例
func sizeOf
public func sizeOf<T>(): UIntNative where T <: CType
功能:获取类型 T 所占用的内存空间大小。
返回值:类型 T 所占用内存空间的字节数
func alignOf
public func alignOf<T>(): UIntNative where T <: CType
功能:获取类型 T 的内存对齐值。
返回值:对类型 T 做内存对齐的字节数
interface Countable
public interface Countable<T> {
func next(right: Int64): T
func position(): Int64
}
该接口表示类型可数。
func next
func next(right: Int64): T
功能:返回两个实例的和。
参数:
- right:另一个为 Int64 类型的实例
返回值:返回两个实例和的 T 类型
func position
func position(): Int64
功能:将对象转为 Int64 类型。
返回值:转换后的 Int64 整型
interface Collection
public interface Collection<T> <: Iterable<T> {
prop size: Int64
func isEmpty(): Bool
func toArray(): Array<T>
}
该接口用来表示集合。
prop size
prop size: Int64
功能:获取当前实例的长度。
返回值:列表的容量
func isEmpty
func isEmpty(): Bool
功能:判断当前实例是否为空。
返回值:如果为空返回 true,否则返回 false
func toArray
func toArray(): Array<T>
功能:将当前实例转为数组类型。
返回值:转换后的数组
interface Less
public interface Less<T> {
operator func <(rhs: T): Bool
}
该接口表示小于计算。
operator func <
operator func <(rhs: T): Bool
功能:判断一个实例是否小于另一个实例。
参数:
- rhs:另一个实例
返回值:如果小于,返回 true,否则返回 false
interface Greater
public interface Greater<T> {
operator func >(rhs: T): Bool
}
该接口表示大于计算。
operator func >
operator func >(rhs: T): Bool
功能:判断一个实例是否大于另一个实例。
参数:
- rhs:另一个实例
返回值:如果大于,返回 true,否则返回 false
interface LessOrEqual
public interface LessOrEqual<T> {
operator func <=(rhs: T): Bool
}
该接口表示小于等于计算。
operator func <=
operator func <=(rhs: T): Bool
功能:判断一个实例是否小于等于另一个实例。
参数:
- rhs:另一个实例
返回值:如果小于等于,返回 true,否则返回 false
interface GreaterOrEqual
public interface GreaterOrEqual<T> {
operator func >=(rhs: T): Bool
}
该接口表示大于等于计算。
operator func >=
operator func >=(rhs: T): Bool
功能:判断一个实例是否大于等于另一个实例。
参数:
- rhs:另一个实例
返回值:如果大于等于,返回 true,否则返回 false
interface Comparable
public interface Comparable<T> <: Equatable<T> & Less<T> & Greater<T> & LessOrEqual<T> & GreaterOrEqual<T> {
func compare(that: T): Ordering
}
该接口表示比较运算。
func compare
func compare(that: T): Ordering
功能:判断一个实例与另一个实例的关系。
参数:
- that:另一个实例
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
interface Equal
public interface Equal<T> {
operator func ==(rhs: T): Bool
}
该接口用来提供 Bool 、Char、Int64、Int32、Int16、Int8、UIntNative、UInt64、UInt32、UInt16、UInt8、Float64、Float32、Float16、String、Array、Box、ArrayList、HashSet 的直接判等操作。
operator func ==
operator func ==(rhs: T): Bool
功能:判断两个实例是否相等。
参数:
- rhs:另一个实例
返回值:如果相等,返回 true,否则返回 false
interface NotEqual
public interface NotEqual<T> {
operator func !=(rhs: T): Bool
}
该接口表示判不等运算。
operator func !=
operator func !=(rhs: T): Bool
功能:判断两个实例是否不相等。
参数:
- rhs:另一个实例
返回值:如果不相等,返回 true,否则返回 false
interface Equatable
public interface Equatable<T> <: Equal<T> & NotEqual<T>
该接口表示判等和判不等两种运算。
interface Hashable
public interface Hashable {
func hashCode(): Int64
}
该接口用来提供 Bool、Char、IntNative、Int64、Int32、Int16、Int8、UIntNative、UInt64、UInt32、UInt16、UInt8、Float64、Float32、Float16、String、Box 的哈希值。
func hashCode
func hashCode(): Int64
功能:获得实例类型的哈希值。
返回值:返回实例类型的哈希值
interface Iterable
public interface Iterable<E> {
func iterator(): Iterator<E>
}
该接口用来提供具体类型的迭代器。
func iterator
func iterator(): Iterator<E>
功能:返回实例类型的迭代器。
返回值:返回实例类型的迭代器
interface Iterator
public interface Iterator<E> <: Iterable<E> {
func next(): Option<E>
}
该接口用来返回迭代过程中的下一个元素。
func next
func next(): Option<E>
功能:返回迭代过程中的下一个元素。
返回值:迭代过程中的下一个元素
interface Resource
public interface Resource {
func isClosed(): Bool
func close(): Unit
}
该接口用于资源管理,需要用 close 释放资源的类可实现该接口。
func isClosed
func isClosed(): Bool
功能:判断资源是否关闭。
返回值:如果已经关闭返回 true,否则返回 false
func close
func close(): Unit
功能:关闭资源。
interface ToString
public interface ToString {
func toString(): String
}
该接口用来提供具体类型的字符串表示。
func toString
func toString(): String
功能:返回实例类型的字符串表示。
返回值:返回实例类型的字符串表示
interface CType
sealed interface CType
此接口不包含任何函数,它可以作为所有 C 互操作支持的类型的父类型,便于在泛型约束中使用。
需要注意的是:
CType接口是仓颉中的一个接口类型,它本身不满足CType约束;CType接口不允许被继承、扩展;CType接口不会突破子类型的使用限制。
type Rune
public type Rune = Char
重命名 Char 类型。
struct String
public struct String <: Collection<Byte> & Equatable<String> & Comparable<String> & Hashable & ToString {
public static let empty: String
public const init()
public init(value: Array<Rune>)
public init(value: Collection<Rune>)
}
此类主要用于实现 String 数据结构及相关操作函数。
empty
public static let empty: String
功能:创建一个空的字符串并返回。
init
public const init()
功能:无参构造函数,创建一个空的字符串。
init
public init(value: Array<Rune>)
功能:通过 Rune 数组创建一个字符串。
参数:
- value:Rune 数组
init
public init(value: Collection<Rune>)
功能:通过 Rune 列表创建一个字符串。
参数:
- value:Rune 列表
func getRaw
public unsafe func getRaw(): CPointerHandle<UInt8>
功能:返回当前 String 的原始指针,用于和C语言交互,使用完后需要 releaseRaw 函数释放该指针。
约束:getRaw() 与 releaseRaw() 之间仅可包含简单的 foreign C 函数调用等逻辑,不构造例如 CString 等的仓颉对象,否则可能造成不可预知的错误。
返回值:返回的原始指针实例
func releaseRaw
public unsafe func releaseRaw(cp: CPointerHandle<UInt8>): Unit
功能:释放 getRaw 函数获取的指针。
注意:释放时只能释放同一个 String 获取的指针,如果释放了其他 String 获取的指针,会出现不可预知的错误。
参数:
- cp:待释放的指针实例
func iterator
public func iterator(): Iterator<Byte>
功能:获得字符串的 UTF-8 编码字节迭代器,可用于支持 for-in 循环。
返回值:字符串的 UTF-8 编码字节迭代器
func runes
public func runes(): Iterator<Rune>
功能:获得字符串的 Rune 迭代器。
返回值:字符串的 Rune 迭代器
func tryGet
public func tryGet(index: Int64): Option<Byte>
功能:返回字符串下标 index 对应的 UTF-8 编码字节值。
参数:
- index:要获取的字节值的下标
返回值:获取得到下标对应的 UTF-8 编码字节值,当 index 小于 0 或者大于等于字符串长度,则返回 Option<Byte>.None
func toRuneArray
public func toRuneArray(): Array<Rune>
功能:返回字符串的 Rune 数组。如果原字符串为空字符串,则返回空数组。
返回值:字符串的 Rune 数组
func toString
public func toString(): String
功能:获得字符串本身。
返回值:返回字符串本身
func clone
public func clone(): String
功能:返回原字符串的拷贝。
返回值:拷贝得到的新字符串
prop size
public prop size: Int64
功能:返回字符串 UTF-8 编码后的字节长度
返回值:字符串 UTF-8 编码后的字节长度
func isEmpty
public func isEmpty(): Bool
功能:判断原字符串是否为空字符串。
返回值:如果为空返回 true,否则返回 false
func isAsciiBlank
public func isAsciiBlank(): Bool
功能:判断字符串是否为空或者字符串中的所有 Rune 都是 ascii 码的空白字符(包括:0x09、0x10、0x11、0x12、0x13、0x20)。
返回值:如果是返回 true,否则返回 false
func hashCode
public func hashCode(): Int64
功能:获得字符串的哈希值。
返回值:返回字符串的哈希值
func indexOf
public func indexOf(b: Byte): Option<Int64>
功能:返回指定字节 b 第一次出现的在原字符串内的索引。
参数:
- b:搜索的 UTF-8 编码字节
返回值:如果原字符串中包含指定字节,返回其第一次出现的索引,如果原字符串中没有此字节,返回 Option<Int64>.None
func indexOf
public func indexOf(b: Byte, fromIndex: Int64): Option<Int64>
功能:从原字符串指定索引开始搜索,获取指定 UTF-8 编码字节第一次出现的在原字符串内的索引。
参数:
- b:搜索的 UTF-8 编码字节
- fromIndex:以指定的索引 fromIndex 开始搜索
返回值:如果搜索成功,返回指定字节第一次出现的索引,否则返回 Option<Int64>.None。特别地,当 fromIndex 小于零,效果同 0,当 fromIndex 大于等于原字符串长度,返回 Option<Int64>.None
func indexOf
public func indexOf(str: String): Option<Int64>
功能:返回指定字符串 str 在原字符串中第一次出现的起始索引。
参数:
- str:搜索的字符串
返回值:如果原字符串包含 str 字符串,返回其第一次出现的索引,如果原字符串中没有 str 字符串,返回 None
func indexOf
public func indexOf(str: String, fromIndex: Int64): Option<Int64>
功能:从原字符串 fromIndex 索引开始搜索,获取指定字符串 str 第一次出现的在原字符串的起始索引。
参数:
- str:待搜索的字符串
- fromIndex:以指定的索引 fromIndex 开始搜索。
返回值:如果搜索成功,返回 str 第一次出现的索引,否则返回 None。特别地,当 str 是空字符串时,如果fromIndex 大于 0,返回 None,否则返回 Some(0)。当 fromIndex 小于零,效果同 0,当 fromIndex 大于等于原字符串长度返回 None
func lastIndexOf
public func lastIndexOf(b: Byte): Option<Int64>
功能:返回指定 UTF-8 编码字节 b 最后一次出现的在原字符串内的索引。
参数:
- b:搜索的 UTF-8 编码字节
返回值:如果原字符串中包含此字节,返回其最后一次出现的索引,否则返回 Option<Int64>.None
func lastIndexOf
public func lastIndexOf(b: Byte, fromIndex: Int64): Option<Int64>
功能:从原字符串 fromIndex 索引开始搜索,返回指定 UTF-8 编码字节 b 最后一次出现的在原字符串内的索引。
参数:
- b:搜索的 UTF-8 编码字节
- fromIndex:以指定的索引 fromIndex 开始搜索
返回值:如果搜索成功,返回指定字节最后一次出现的索引,否则返回 Option<Int64>.None。特别地,当 fromIndex 小于零,效果同 0,当 fromIndex 大于等于原字符串长度,返回 Option<Int64>.None
func lastIndexOf
public func lastIndexOf(str: String): Option<Int64>
功能:返回指定字符串 str 最后一次出现的在原字符串的起始索引。
参数:
- str:搜索的字符串
返回值:如果原字符串中包含 str 字符串,返回其最后一次出现的索引,否则返回 Option<Int64>.None
func lastIndexOf
public func lastIndexOf(str: String, fromIndex: Int64): Option<Int64>
功能:从原字符串指定索引开始搜索,获取指定字符串 str 最后一次出现的在原字符串的起始索引。
参数:
- str:待搜索的字符串
- fromIndex:以指定的索引 fromIndex 开始搜索
返回值:如果这个字符串在位置 fromIndex 及其之后没有出现,则返回 Option<Int64>.None。特别地,当 str 是空字符串时,如果 fromIndex 大于 0,返回 Option<Int64>.None,否则返回 Option<Int64>.Some(0),当 fromIndex 小于零,效果同 0,当 fromIndex 大于等于原字符串长度返回 Option<Int64>.None
func isAscii
public func isAscii(): Bool
功能:判断字符串是否是一个 Ascii 字符串,如果字符串为空或没有 Ascii 以外的字符,则返回 true。
返回值:是则返回 true,不是则返回 false
func toArray
public func toArray(): Array<Byte>
功能:返回字符串的 UTF-8 编码的字节数组。
返回值:Byte 类型的 Array
func count
public func count(str: String): Int64
功能:返回子字符串 str 在原字符串中出现的次数。
参数:
- str:被搜索的子字符串
返回值:出现的次数,当 str 为空字符串时,返回原字符串中 Rune 的数量加一
func split
public func split(str: String, removeEmpty!: Bool = false): Array<String>
功能:对原字符串按照字符串 str 分隔符分割。当 str 未出现在原字符串中,返回长度为 1 的字符串数组,唯一的元素为原字符串。
参数:
- str:字符串分隔符
- removeEmpty:移除分割结果中的空字符串,默认值为 false
返回值:分割后的字符串数组
func split
public func split(str: String, maxSplits: Int64, removeEmpty!: Bool = false): Array<String>
功能:对原字符串按照字符串 str 分隔符分割。当 maxSplit 为 0 时,返回空的字符串数组;当 maxSplit 为 1 时,返回长度为 1 的字符串数组,唯一的元素为原字符串;当 maxSplit 为负数时,返回完整分割后的字符串数组;当 maxSplit 大于完整分割出来的子字符串数量时,返回完整分割的字符串数组;当 str 未出现在原字符串中,返回长度为 1 的字符串数组,唯一的元素为原字符串;当 str 为空时,对每个字符进行分割;当原字符串和分隔符都为空时,返回空字符串数组。
参数:
- str:字符串分隔符
- maxSplit:最多分割为 maxSplit 个子字符串
- removeEmpty:移除分割结果中的空字符串,默认值为 false
返回值:分割后的字符串数组
func lazySplit
public func lazySplit(str: String, removeEmpty!: Bool = false): Iterator<String>
功能:对原字符串按照字符串 str 分隔符分割。当 str 未出现在原字符串中,返回大小为 1 的字符串迭代器,唯一的元素为原字符串。
参数:
- str:字符串分隔符
- removeEmpty:移除分割结果中的空字符串,默认值为 false
返回值:分割后的字符串迭代器
func lazySplit
public func lazySplit(str: String, maxSplits: Int64, removeEmpty!: Bool = false): Iterator<String>
功能:对原字符串按照字符串 str 分隔符分割。当 maxSplit 为 0 时,返回空的字符串迭代器;当 maxSplit 为 1 时,返回大小为 1 的字符串迭代器,唯一的元素为原字符串;当 maxSplit 为负数时,直接返回分割后的字符串迭代器;当 maxSplit 大于完整分割出来的子字符串数量时,返回完整分割的字符串迭代器当 str 未出现在原字符串中,返回大小为 1 的字符串迭代器,唯一的元素为原字符串;当 str 为空时,对每个字符进行分割;当原字符串和分隔符都为空时,返回空字符串迭代器。
参数:
- str:字符串分隔符
- maxSplit:最多分割为 maxSplit 个子字符串
- removeEmpty:移除分割结果中的空字符串,默认值为 false
返回值:分割后的字符串迭代器
func replace
public func replace(old: String, new: String): String
功能:使用新字符串替换原字符串中旧字符串。
参数:
- old:旧字符串
- new:新字符串
返回值:替换后的新字符串
异常:
- OutOfMemoryError:如果此函数分配内存时产生错误,抛出异常
func toAsciiLower
public func toAsciiLower(): String
功能:将该字符串中所有 Ascii 大写字母转化为 Ascii 小写字母。
返回值:转换后的新字符串
func toAsciiUpper
public func toAsciiUpper(): String
功能:将该字符串中所有 Ascii 小写字母转化为 Ascii 大写字母。
返回值:转换后的新字符串
func toAsciiTitle
public func toAsciiTitle(): String
功能:将该字符串标题化,只转换 Ascii 字符,当该英文字符是字符串中第一个字符或者该字符的前一个字符不是英文字符,则该字符大写,其他英文字符小写,非英文字符不变。
返回值:转换后的新字符串
func trimAscii
public func trimAscii(): String
功能:去除原字符串开头结尾以 whitespace 字符组成的子字符串(Ascii whitespace)。
返回值:转换后的新字符串
func trimAsciiLeft
public func trimAsciiLeft(): String
功能:去除原字符串开头以 whitespace 字符组成的子字符串(Ascii whitespace)。
返回值:转换后的新字符串
func trimAsciiRight
public func trimAsciiRight(): String
功能:去除原字符串结尾以 whitespace 字符组成的子字符串(Ascii whitespace)。
返回值:转换后的新字符串
func trimLeft
public func trimLeft(prefix: String): String
功能:去除前缀是 prefix 的字符串。
参数:
- prefix:如果字符串的前缀是 prefix,则去除
返回值:转换后的新字符串
func trimRight
public func trimRight(suffix: String): String
功能:去除后缀是 suffix 的字符串。
参数:
- suffix:如果字符串的后缀是 suffix,则去除
返回值:转换后的新字符串
func contains
public func contains(str: String): Bool
功能:判断原字符串中是否包含字符串 str。
参数:
- str:被判断的字符串,如果 str 字符串长度为 0,返回 true
返回值:如果字符串 str 在原字符串中,返回 true,否则返回 false
func startsWith
public func startsWith(prefix: String): Bool
功能:判断原字符串是否以 prefix 字符串为前缀开始。
参数:
- str:被判断的前缀字符串,如果 str 长度为 0,返回 true
返回值:如果字符串 str 是原字符串的前缀,返回 true,否则返回 false
func endsWith
public func endsWith(suffix: String): Bool
功能:判断原字符串是否以 suffix 字符串为后缀结尾。
参数:
- str:被判断的后缀字符串,当 str 长度为 0 时,返回 true
返回值:如果字符串 str 是原字符串的后缀,返回 true,否则返回 false
func padLeft
public func padLeft(totalWidth: Int64, padding!: String = " "): String
功能:按指定长度右对齐原字符串,如果原字符串长度小于指定长度,在其左侧添加指定字符串。
参数:
- totalWidth:按指定长度 totalWidth 右对齐
- padding:当长度不够时,在左侧用指定的字符串 padding 进行填充
返回值:填充后的字符串,当指定长度小于字符串长度时,返回字符串本身,不会发生截断;当指定长度大于字符串长度时,在左侧添加 padding 字符串,当 padding 长度大于 1 时,返回字符串的长度可能大于指定长度
异常:
- IllegalArgumentException:如果 totalWidth 小于 0,抛出异常
func padRight
public func padRight(totalWidth: Int64, padding!: String = " "): String
功能:按指定长度左对齐原字符串,如果原字符串长度小于指定长度,在其右侧添加指定字符串。
参数:
- totalWidth:按指定长度 totalWidth 左对齐
- padding:当长度不够时,在右侧用指定的字符串 padding 进行填充
返回值:填充后的字符串,当指定长度小于字符串长度时,返回字符串本身,不会发生截断;当指定长度大于字符串长度时,在右侧添加 padding 字符串,当 padding 长度大于 1 时,返回字符串的长度可能大于指定长度
异常:
- IllegalArgumentException:如果 totalWidth 小于 0,抛出异常
func compare
public func compare(str: String): Ordering
功能:按字典序比较原字符串和 str 字符串,比较基于每个byte,按照UTF-8编码的byte进行比较。Ordering.GT 表示原字符串字典序大于 str 字符串,Ordering.LT 表示原字符串字典序小于 str 字符串,Ordering.EQ 表示两个字符串字典序相等。
参数:
- str:被比较的字符串
返回值:返回 enum 值 Ordering 表示结果,
异常:
- IllegalArgumentException:如果两个字符串的原始数据中存在无效的 UTF-8 编码,抛出异常
operator func ==
public const operator func ==(right: String): Bool
功能:判断两个字符串是否相等。
返回值:相等返回 true,不相等返回 false
operator func !=
public const operator func !=(right: String): Bool
功能:判断两个字符串是否不相等。
返回值:不相等返回 true,相等返回 false
operator func >
public const operator func >(right: String): Bool
功能:判断两个字符串大小。
返回值:原字符串字典序大于 right 时,返回 true,否则返回 false
operator func >=
public const operator func >=(right: String): Bool
功能:判断两个字符串大小。
返回值:原字符串字典序大于或等于 right 时,返回 true,否则返回 false
operator func <
public const operator func <(right: String): Bool
功能:判断两个字符串大小。
返回值:原字符串字典序小于 right 时,返回 true,否则返回 false
operator func <=
public const operator func <=(right: String): Bool
功能:判断两个字符串大小。
返回值:原字符串字典序小于或等于 right 时,返回 true,否则返回 false
operator func +
public const operator func +(right: String): String
功能:两个字符串相加,将 right 字符串拼接在原字符串的末尾。
返回值:返回拼接后的字符串
operator func *
public const operator func *(count: Int64): String
功能:原字符串重复 count 次。
返回值:返回重复 count 次后的新字符串
operator func []
public const operator func [](index: Int64): Byte
功能:返回指定索引 index 处的 UTF-8 编码字节。
参数:
- index:要获取 UTF-8 编码字节的下标
返回值:获取得到下标对应的 UTF-8编码字节
异常:
- IndexOutOfBoundsException:如果 index 小于 0 或大于等于字符串长度,抛出异常
operator func []
public const operator func [](range: Range<Int64>): String
功能:获取切片后的字符串。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:
- start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响
- hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响
参数:
- range:切片的范围
返回值:新的字符串
异常:
- IndexOutOfBoundsException:如果切片范围超过原字符串边界,抛出异常
- IllegalArgumentException:如果 range.step 不等于 1,抛出异常
- IllegalArgumentException:如果范围起止点不是字符边界,抛出异常
func join
public static func join(strArray: Array<String>, delimiter!: String = String.empty): String
功能:连接字符串列表中的所有字符串。
参数:
- value:需要被连接的字符串数组,当数组为空时,返回空字符串
- delimiter:用于连接的中间字符串,其默认值为 String.empty
返回值:连接后的新字符串
func rawData
public unsafe func rawData(): Array<Byte>
功能:返回字符串的 UTF-8 编码的原始字节数组,开发者如果对该数组修改会破坏字符串的并发安全
返回值:Byte 类型的 Array
func fromUtf8
public static func fromUtf8(utf8Data: Array<UInt8>): String
功能:根据 UTF-8 数组创建一个字符串。
参数:
- utf8Data:需要构造字符串的 UTF-8 数组
返回值:创建的字符串
异常:
- IllegalArgumentException:入参不符合 utf-8 序列规则,抛出异常
func fromUtf8Unchecked
public static unsafe func fromUtf8Unchecked(utf8Data: Array<UInt8>): String
功能:根据 UTF-8 数组创建一个字符串,相较于 fromUtf8 函数,它并没有针对于字节数组进行 UTF-8 相关规则的检查,所以它所构建的字符串并不一定保证是合法的,甚至出现非预期的异常,如果不是某些场景下的速度考虑,请优先使用安全的 fromUtf8 函数。
参数:
- utf8Data:需要构造字符串的 UTF-8 数组
返回值:创建的字符串
class StringBuilder
public class StringBuilder <: ToString {
public init()
public init(str: String)
public init(r: Rune, n: Int64)
public init(value: Array<Char>)
public init(capacity: Int64)
}
该类主要用于字符串的构建,其中实现了 StringBuilder 相关接口;StringBuilder 在字符串的构建上效率高于 String,当需要多种类型和多个值构建 String 时推荐使用 StringBuilder。
init
public init()
功能:构造一个初始容量为 32 的空 StringBuilder 实例。
init
public init(str: String)
功能:使用参数 str 指定的字符串初始化 StringBuilder 实例。
参数:
- str:初始化
StringBuilder实例的字符串
init
public init(r: Rune, n: Int64)
功能:使用 n 个 r 字符初始化 StringBuilder 实例。
参数:
- r:初始化
StringBuilder实例的字符 - n:字符
r的数量
异常:
- IllegalArgumentException: 当参数
n小于 0 时,抛出异常
init
public init(value: Array<Rune>)
功能:使用参数 value 指定的字符数组初始化一个 StringBuilder 实例。
参数:
- value:初始化
StringBuilder实例的字符数组
init
public init(capacity: Int64)
功能:使用参数 capacity 指定的容量初始化一个空 StringBuilder 实例。
参数:
- capacity:初始化
StringBuilder的字节容量
异常:
- IllegalArgumentException: 当参数
capacity的值小于等于 0 时,抛出异常
prop size
public prop size: Int64
功能:返回 StringBuilder 实例中字符串 UTF-8 编码后的字节长度。
返回值 Int64 - StringBuilder 实例中字符串 UTF-8 编码后的字节长度
prop capacity
public prop capacity: Int64
功能:返回 StringBuilder 实例能容纳字符串 UTF-8 编码后的字节长度。
返回值 Int64 - StringBuilder 实例中能容纳字符串 UTF-8 编码后的字节长度
func reserve
public func reserve(additional: Int64): Unit
功能:将 StringBuilder 扩容 additional 大小。当 additional 小于等于零,或剩余容量大于等于 additional 时,不发生扩容;当剩余容量小于 additional 时,扩容至当前容量的 1.5 倍(向下取整)与 size + additional 的最大值。
参数:
- additional:指定
StringBuilder的扩容大小
func reset
public func reset(capacity!: Option<Int64> = None): Unit
功能:清空当前 StringBuilder,并将容量重置为 capacity 指定的值。
参数:
- capacity:重置后
StringBuilder实例的容量大小,默认值None表示采用默认大小容量(32)。
异常:
- IllegalArgumentException: 当参数
capacity的值小于等于 0 时,抛出异常
func toString
public func toString(): String
功能:返回 StringBuilder 实例中的字符串。
返回值:StringBuilder 实例中的字符串
func append
public func append(r: Rune): Unit
功能:在 StringBuilder 末尾插入参数 r 指定的字符。
参数:
- r:插入的字符
func append
public func append(str: String): Unit
功能:在 StringBuilder 末尾插入参数 str 指定的字符串。
参数:
- str:插入的字符串
func append
public func append(sb: StringBuilder): Unit
功能:在 StringBuilder 末尾插入参数 sb 指定的 StringBuilder 中的内容。
参数:
- sb:插入的
StringBuilder实例
func append
public func append(runeArr: Array<Rune>): Unit
功能:在 StringBuilder 末尾插入一个 Rune 数组中所有字符。
参数:
- runeArr:插入的
Rune数组
func append
public func append(cstr: CString): Unit
功能:在 StringBuilder 末尾插入参数 cstr 指定 CString 中的内容。
参数:
- cstr:插入的
CString
func append
public func append<T>(v: T): Unit where T <: ToString
功能:在 StringBuilder 末尾插入参数 v 指定 T 类型的字符串表示,类型 T 需要实现 ToString 接口。
参数:
- v:插入的
T类型实例
func append
public func append<T>(val: Array<T>): Unit where T <: ToString
功能:在 StringBuilder 末尾插入参数 val 指定的 Array<T> 的字符串表示,类型 T 需要实现 ToString 接口。
参数:
- val:插入的
Array<T>类型实例
func append
public func append(b: Bool): Unit
功能:在 StringBuilder 末尾插入参数 b 的字符串表示。
参数:
- b:插入的
Bool类型的值,取值 "true" 或者 "false"
func append
public func append(n: Int64): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Int64类型的值
func append
public func append(n: Int32): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Int32类型的值
func append
public func append(n: Int16): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Int16类型的值
func append
public func append(n: Int8): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Int8类型的值
func append
public func append(n: UInt64): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
UInt64类型的值
func append
public func append(n: UInt32): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
UInt32类型的值
func append
public func append(n: UInt16): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
UInt16类型的值
func append
public func append(n: UInt8): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
UInt8类型的值
func append
public func append(n: Float64): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Float64类型的值
func append
public func append(n: Float32): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Float32类型的值
func append
public func append(n: Float16): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Float16类型的值
func appendFromUtf8
public func appendFromUtf8(arr: Array<Byte>): Unit
功能:在 StringBuilder 末尾插入参数 arr 指定 utf8 编码的字节数组。
参数:
- arr:插入的 utf8 字节数组
异常:
- IllegalArgumentException:当字节数组不符合 utf8 编码规则时,抛出异常
func appendFromUtf8Unchecked
public unsafe func appendFromUtf8Unchecked(arr: Array<Byte>): Unit
功能:在 StringBuilder 末尾插入参数 arr 指定 utf8 编码的字节数组, 相较于 appendFromUtf8 函数,它并没有针对于字节数组进行 utf8 相关规则的检查,所以它所构建的字符串并不一定保证是合法的,甚至出现非预期的异常,如果不是某些场景下的速度考虑,请优先使用安全的 appendFromUtf8 函数。
参数:
- arr:插入的 utf8 字节数组
enum AnnotationKind
public enum AnnotationKind {
| Type
| Parameter
| Init
| MemberProperty
| MemberFunction
| MemberVariable
}
枚举类型 AnnotationKind 表示自定义注解希望支持的位置。
Type
Type
功能:类型声明(class、struct、enum、interface)。
Parameter
Parameter
功能:成员函数/构造函数中的参数。
Init
Init
功能:构造函数声明。
MemberProperty
MemberProperty
功能:成员属性声明
MemberFunction
MemberFunction
功能:成员函数声明
MemberVariable
MemberVariable
功能:成员变量声明
示例
Future 的使用
主线程和新线程同时尝试打印一些文本。
代码如下:
from std import sync.sleep
from std import time.{Duration, DurationExtension}
main(): Int64 {
spawn { =>
for (i in 0..10) {
println("New thread, number = ${i}")
sleep(100 * Duration.millisecond) /* 睡眠 100 毫秒 */
}
}
for (i in 0..5) {
println("Main thread, number = ${i}")
sleep(100 * Duration.millisecond) /* 睡眠 100 毫秒 */
}
return 0
}
运行结果如下:
Main thread, number = 0
New thread, number = 0
Main thread, number = 1
New thread, number = 1
Main thread, number = 2
New thread, number = 2
Main thread, number = 3
New thread, number = 3
Main thread, number = 4
New thread, number = 4
New thread, number = 5
- 注意,上述打印信息仅做参考。
Future 的 get 的使用
主线程等待创建线程执行完再执行。
代码如下:
from std import sync.sleep
from std import time.{Duration, DurationExtension}
main(): Int64 {
let fut: Future<Unit> = spawn { =>
for (i in 0..10) {
println("New thread, number = ${i}")
sleep(100 * Duration.millisecond) /* 睡眠 100 毫秒 */
}
}
fut.get() /* 等待线程完成 */
for (i in 0..5) {
println("Main thread, number = ${i}")
sleep(100 * Duration.millisecond) /* 睡眠 100 毫秒 */
}
return 0
}
运行结果如下:
New thread, number = 0
New thread, number = 1
New thread, number = 2
New thread, number = 3
New thread, number = 4
New thread, number = 5
New thread, number = 6
New thread, number = 7
New thread, number = 8
New thread, number = 9
Main thread, number = 0
Main thread, number = 1
Main thread, number = 2
Main thread, number = 3
Main thread, number = 4
创建 Array 并取值
下面是创建 Array,使用下标取值的示例。
代码如下:
main() {
var array: Array<Int64> = [1, 2, 3, 4, 5]
println("array[1] = ${array[1]}")
return 0
}
运行结果如下:
array[1] = 2
创建 String 并访问每个字符
下面是创建 String 并且通过 for-in 访问每个 UTF-8 编码字节的示例。
代码如下:
main() {
var str = "仓颉" // E4BB93 E9A289
for (c in str) {
println(c)
}
}
运行结果如下:
228
187
147
233
162
137
CString 与 C 代码交互
C 代码中分别提供两个函数: getCString 函数,用于返回一个 C 侧的字符串指针; printCString 函数,用于打印来自仓颉侧 CString 。
#include <stdio.h>
char *str = "CString in C code.";
char *getCString() { return str; }
void printCString(char *s) { printf("%s\n", s); }
在仓颉代码中,创建一个 CString 对象,传递给 C 侧打印。并且获取 C 侧字符串,在仓颉侧打印:
foreign func getCString(): CString
foreign func printCString(s: CString): Unit
main() {
// Construct by a Cangjie String.
unsafe {
let s: CString = LibC.mallocCString("CString in Cangjie code.")
printCString(s)
LibC.free(s)
}
unsafe {
// Get a CString from C code and use `toString` convert to cangjie String.
let cs = getCString()
println(cs.toString())
}
// Use CStringResource by try-with-resource
let cs = unsafe { LibC.mallocCString("CString in Cangjie code.") }
try (csr = cs.asResource()) {
unsafe { printCString(csr.value) }
}
0
}
示例输出:
CString in Cangjie code.
CString in C code.
CString in Cangjie code.
core 包
介绍
此包包括一些常用接口 ToString、 Hashable、 Equatable 等,以及 String、 Range、 Array、 Option 等常用数据结构,包括预定义的异常、错误类型等。
主要接口
interface Any
public interface Any
Any 是所有类型的父类型,所有 interface 都默认继承它,所有非 interface 类型都默认实现它。
class Object
public open class Object <: Any {
public const init()
}
Object 是所有 class 的父类,所有 class 都默认继承它。
init
public const init()
功能:构造一个 object 实例。
interface CharExtension
public interface CharExtension
CharExtension 是 Char 相关的辅助接口。
interface Hasher
public interface Hasher {
func finish(): Int64
mut func reset(): Unit
mut func write(value: Bool): Unit
mut func write(value: Char): Unit
mut func write(value: Int8): Unit
mut func write(value: Int16): Unit
mut func write(value: Int32): Unit
mut func write(value: Int64): Unit
mut func write(value: UInt8): Unit
mut func write(value: UInt16): Unit
mut func write(value: UInt32): Unit
mut func write(value: UInt64): Unit
mut func write(value: Float16): Unit
mut func write(value: Float32): Unit
mut func write(value: Float64): Unit
mut func write(value: String): Unit
}
Hasher 是用来处理哈希组合运算的接口。
func finish
func finish(): Int64
功能:返回哈希运算的结果。
返回值:经过计算后的哈希值
func reset
mut func reset(): Unit
功能:重置哈希值。
func write
mut func write(value: Bool): Unit
功能:通过该函数把想要哈希运算的 Bool 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Char): Unit
功能:通过该函数把想要哈希运算的 Char 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Int8): Unit
功能:通过该函数把想要哈希运算的 Int8 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Int16): Unit
功能:通过该函数把想要哈希运算的 Int16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Int32): Unit
功能:通过该函数把想要哈希运算的 Int32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Int64): Unit
功能:通过该函数把想要哈希运算的 Int64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: UInt8): Unit
功能:通过该函数把想要哈希运算的 UInt8 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: UInt16): Unit
功能:通过该函数把想要哈希运算的 UInt16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: UInt32): Unit
功能:通过该函数把想要哈希运算的 UInt32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: UInt64): Unit
功能:通过该函数把想要哈希运算的 UInt64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Float16): Unit
功能:通过该函数把想要哈希运算的 Float16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Float32): Unit
功能:通过该函数把想要哈希运算的 Float32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: Float64): Unit
功能:通过该函数把想要哈希运算的 Float64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
mut func write(value: String): Unit
功能:通过该函数把想要哈希运算的 String 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
class ArithmeticException
public open class ArithmeticException <: Exception {
public init()
public init(message: String)
}
ArithmeticException 为算术异常类,用于在发生算术异常时使用。
init
public init()
功能:构造一个默认的 ArithmeticException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 ArithmeticException 实例。
参数:
- message:异常信息
func getClassName
protected open override func getClassName(): String
功能:获得类名。
返回值:类名字符串
class ArrayIterator
public class ArrayIterator<T> <: Iterator<T> {
public init(data: Array<T>)
}
数组迭代器。
init
public init(data: Array<T>)
功能:创建一个数组迭代器。
参数:
- data:数组
func next
public func next(): Option<T>
功能:返回迭代器中的下一个值。
返回值:Option
func iterator
public func iterator(): Iterator<T>
功能:返回迭代器。
返回值:Iterator
class Box
public class Box<T> {
public var value: T
public init(v: T)
}
Box 泛型提供了将所有的类型包装成引用类型的能力。
value
public var value: T
功能:获取或修改被包装的值。
init
public init(v: T)
功能:构造函数。
参数:
- v:任意仓颉支持的类型参数
extend Box <: Hashable
extend Box<T> <: Hashable where T <: Hashable
func hashCode
public func hashCode(): Int64
功能:获取 Box 对象的 hashCode 值。
返回值:hashCode 值
extend Box <: Comparable
extend Box<T> <: Comparable<Box<T>> where T <: Comparable<T>
为 Box<T> 类扩展 Comparable<Box<T>> 接口,其中 T 必须是 Comparable<T> 类型。Box<T> 实例的大小关系与其封装的 T 实例大小关系相同。
operator func >
public operator func >(that: Box<T>): Bool
功能:比较 Box 对象的大小。
参数:
- that:比较的另外一个 Box 对象
返回值:原 Box 对象大于 that Box 对象返回 true,否则返回 false
operator func <
public operator func <(that: Box<T>): Bool
功能:比较 Box 对象的大小。
参数:
- that:比较的另外一个 Box 对象
返回值:原 Box 对象小于 that Box 对象返回 true,否则返回 false
operator func >=
public operator func >=(that: Box<T>): Bool
功能:比较 Box 对象的大小。
参数:
- that:比较的另外一个 Box 对象
返回值:原 Box 对象大于等于 that Box 对象返回 true,否则返回 false
operator func <=
public operator func <=(that: Box<T>): Bool
功能:比较 Box 对象的大小。
参数:
- that:比较的另外一个 Box 对象
返回值:原 Box 对象小于等于 that Box 对象返回 true,否则返回 false
operator func ==
public operator func ==(that: Box<T>): Bool
功能:比较 Box 对象是否相等。
参数:
- that:比较的另外一个 Box 对象
返回值:相等返回 true,不相等返回 false
operator func !=
public operator func !=(that: Box<T>): Bool
功能:比较 Box 对象是否不相等。
参数:
- that:比较的另外一个 Box 对象
返回值:不相等返回 true,相等返回 false
func compare
public func compare(that: Box<T>): Ordering
功能:判断当前 Box 实例与另一个 Box 实例的大小关系。
参数:
- that:比较的另外一个 Box 对象
返回值:如果当前 Box 实例大于 that,返回 Ordering.GT,等于返回 Ordering.EQ,小于返回 Ordering.LT
extend Box <: ToString
extend Box<T> <: ToString where T <: ToString
func toString
public func toString(): String
功能:获取 Box 对象的字符串表示。
返回值:转换后的字符串
class SpawnException
public class SpawnException <: Exception {
public init()
public init(message: String)
}
SpawnException 为线程异常类,用于在线程处理过程中发生异常时使用。
init
public init()
功能:构造一个默认的 SpawnException 实例,默认错误信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 SpawnException 实例。
参数:
- message:预定义消息
class Error
public open class Error <: ToString
Error 是所有错误类的基类。该类不可被继承,不可初始化,但是可以被捕获到。
prop message
public open prop message: String
功能:获取错误信息。
func toString
public open func toString(): String
功能:获取当前 Error 实例的字符串值,包括类名和错误信息。
返回值:错误信息字符串
func printStackTrace
public open func printStackTrace(): Unit
功能:向控制台打印堆栈信息。
func getStackTrace
public func getStackTrace(): Array<StackTraceElement>
功能:获取堆栈信息,每一条堆栈信息用一个 StackTraceElement 实例表示,最终返回一个 StackTraceElement 的数组。
返回值:堆栈信息数组
class Exception
public open class Exception <: ToString {
public init()
public init(message: String)
}
Exception 是所有异常类的基类。
init
public init()
功能:构造一个默认的 Exception 实例,默认异常信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 Exception 实例。
参数:
- message:异常信息
prop message
public open prop message: String
功能:获取异常信息。
func toString
public open func toString(): String
功能:获取当前 Exception 实例的字符串值,包括类名和异常信息。
返回值:异常信息字符串
func printStackTrace
public func printStackTrace(): Unit
功能:向控制台打印堆栈信息。
func getStackTrace
public func getStackTrace(): Array<StackTraceElement>
功能:获取堆栈信息,每一条堆栈信息用一个 StackTraceElement 实例表示,最终返回一个 StackTraceElement 的数组。
返回值:堆栈信息数组
func getClassName
protected open func getClassName(): String
功能:获得类名,用字符串表示。
返回值:类名
class IllegalArgumentException
public class IllegalArgumentException <: Exception {
public init()
public init(message: String)
}
IllegalArgumentException 为参数非法异常。
init
public init()
功能:构造一个默认的 IllegalArgumentException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 IllegalArgumentException 实例。
参数:
- message:异常信息
class IllegalStateException
public class IllegalStateException <: Exception {
public init()
public init(message: String)
}
IllegalStateException 为非法状态异常。
init
public init()
功能:构造一个默认的 IllegalStateException 实例,默认异常信息为空。
init
public init(message: String)
参数:
功能:根据异常信息构造一个 IllegalStateException 实例。
- message:异常信息
class IndexOutOfBoundsException
public class IndexOutOfBoundsException <: Exception {
public init()
public init(message: String)
}
IndexOutOfBoundsException 为索引越界异常。
init
public init()
功能:构造一个默认的 IndexOutOfBoundsException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 IndexOutOfBoundsException 实例。
参数:
- message:异常信息
class NegativeArraySizeException
public class NegativeArraySizeException <: Exception {
public init()
public init(message: String)
}
NegativeArraySizeException 为数组索引值为负数异常。
init
public init()
功能:构造一个默认的 NegativeArraySizeException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据异常信息构造一个 NegativeArraySizeException 实例。
参数:
- message:异常信息
class NoneValueException
public class NoneValueException <: Exception {
public init()
public init(message: String)
}
表示 OptionNone 的异常类。
init
public init()
功能:构造一个默认的 NoneValueException 实例,默认异常信息为空。。
init
public init(message: String)
功能:根据异常信息构造一个 NoneValueException 实例。
参数:
- message:异常信息
class UnsupportedException
public class UnsupportedException <: Exception {
public init()
public init(message: String)
}
表示功能未支持的异常类。
init
public init()
功能:构造一个默认的 UnsupportedException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据指定异常信息构造 UnsupportedException 实例。
参数:
- message:异常消息
class InternalError
public class InternalError <: Error
InternalError 继承了 Error,表示内部错误,该类不可初始化,但是可以被捕获到
class OutOfMemoryError
public class OutOfMemoryError <: Error
OutOfMemoryError 继承了 Error,表示内存不足错误,该类不可被继承,不可初始化,但是可以被捕获到
class OverflowException
public class OverflowException <: ArithmeticException {
public init()
public init(message: String)
}
OverflowException 为算术运算溢出异常。
init
public init()
功能:构造一个默认的 OverflowException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据指定异常信息构造 OverflowException 实例。
参数:
- message:异常信息
class IllegalMemoryException
public class IllegalMemoryException <: Exception {
public init()
public init(message: String)
}
IllegalMemoryException 为内存操作错误异常。
init
public init()
功能:构造一个默认的 IllegalMemoryException 实例,默认异常信息为空。
init
public init(message: String)
功能:根据指定异常信息构造 IllegalMemoryException 实例。
参数:
- message:异常信息
class Future
public class Future<T>
spawn 表达式的返回类型是 Future<T> ,其中 T 是类型变元,其类型与闭包表达式的返回类型一致。当我们调用 Future<T> 的 get() 函数时,阻塞当前运行的线程,直到 Future<T> 实例所代表的线程运行结束。
prop thread
public prop thread: Thread
功能:获得当前线程的 Thread 实例
func get
public func get(): T
功能:阻塞当前线程,等待当前 Future 对象对应的线程的结果。
返回值:当前 Future<T> 实例代表的线程运行结束后的返回值
func get
public func get(ns: Int64): Option<T>
功能:阻塞当前线程,等待当前 Future<T> 对象对应的线程的返回值。如果相应的线程在指定时间内未完成执行,则该函数将返回 None。
参数:
- ns:传入等待时间,单位为纳秒
返回值:如果改线程未完成,返回 None;如果 ns <= 0,等同于 get();如果线程抛出异常退出执行,在 get 调用处将继续抛出该异常
func tryGet
public func tryGet(): Option<T>
功能:尝试获取结果,不会阻塞当前线程。如果相应的线程未执行完成,则该函数返回 None,否则返回 Some。
返回值:如果未完成返回 None,否则返回 Some
func cancel
public func cancel(): Unit
功能:给当前 Future 对象对应的线程发送取消请求。该方法不会立即停止线程执行,仅发送请求,相应地,函数 hasPendingCancellation 可用于检查线程是否存在取消请求。
interface ThreadContext
public interface ThreadContext {
func end(): Unit
func hasEnded(): Bool
}
用户创建 thread 时,除了缺省 spawn 表达式入参,也可以通过传入不同 ThreadContext 类型的实例,选择不同的线程上下文,然后一定程度上控制并发行为。
目前不允许用户自行实现 ThreadContext 接口,仓颉语言根据使用场景,提供了MainThreadContext, 具体定义可在终端框架库中查阅。
func end
func end(): Unit
功能:结束方法,用于向当前 context 发送结束请求。
func hasEnded
func hasEnded(): Bool
功能:检查方法,用于检查当前 context 是否已结束。
返回值:如果结束返回 true,否则返回 false
class Thread
public class Thread
Thread 类为用户提供获取线程 ID 及名字、查询线程是否存在取消请求、注册线程未处理异常的处理函数等功能。
该类型实例无法通过构造得到,仅能通过 Future 对象的 thread 属性或是 Thread 类的 currentThread 静态属性获取。
prop currentThread
public static prop currentThread: Thread
功能:获取当前执行线程的 Thread 对象。
prop id
public prop id: Int64
功能:获取当前执行线程的标识,以 Int64 表示,所有存活的线程都有不同标识,但不保证当线程执行结束后复用它的标识。
prop name
public mut prop name: String
功能:获取或是设置线程的名称,获取设置都具有原子性。
prop hasPendingCancellation
public prop hasPendingCancellation: Bool
功能:线程是否存在取消请求,即是否通过 future.cancel() 发送过取消请求。
常见使用方法:Thread.currentThread.hasPendingCancellation。
func handleUncaughtExceptionBy
public static func handleUncaughtExceptionBy(exHandler: (Thread, Exception) -> Unit): Unit
功能:注册线程未处理异常的处理函数当某一线程因异常而提前终止后,如果全局的未处理异常函数被注册,那么将调用该函数并结束线程,在该函数内抛出异常时,将向终端打印提示信息并结束线程,但不会打印异常调用栈信息;如果没有注册全局异常处理函数,那么默认会向终端打印异常调用栈信息。多次注册处理函数时,后续的注册函数将覆盖之前的处理函数。当有多个线程同时因异常而终止时,处理函数将被并发执行,因而开发者需要在处理函数中确保并发正确性。处理函数的参数第一个参数类型为 Thread,是发生异常的线程第二个参数类型为 Exception,是线程未处理的异常。
class ThreadLocal
public class ThreadLocal<T>
使用 ThreadLocal 可以在每个仓颉线程安全地访问他们各自的 “全局变量”。
func get
public func get(): ?T
功能:获得仓颉线程局部变量的值。
返回值:如果当前线程局部变量不为空值,返回该值,如果为空值,返回 Option<T>.None
func set
public func set(value: ?T): Unit
功能:通过 value 设置仓颉线程局部变量的值,如果传入 Option
参数:
- value:需要设置的局部变量的值
struct Range
public struct Range<T> <: Iterable<T> where T <: Countable<T> & Comparable<T> & Equatable<T> {
public let start: T
public let end: T
public let step: Int64
public let hasStart: Bool
public let hasEnd: Bool
public let isClosed: Bool
public const init(start: T, end: T, step: Int64, hasStart: Bool, hasEnd: Bool, isClosed: Bool)
}
Range 类用于表示拥有固定步长的序列,区间类型是一个泛型,使用 Range<T> 表示。
start
public let start: T
功能:表示开始值。
end
public let end: T
功能:表示结束值。
step
public let step: Int64
功能:表示步长。
hasStart
public let hasStart: Bool
功能:表示是否包含开始值。
hasEnd
public let hasEnd: Bool
功能:表示是否包含结束值。
isClosed
public let isClosed: Bool
功能:表示区间开闭情况,为 true 表示左闭右闭,为 false 表示左闭右开。
init
public const init(start: T, end: T, step: Int64, hasStart: Bool, hasEnd: Bool, isClosed: Bool)
功能:使用该构造函数创建 Range 序列。
参数:
- start:开始值
- end:结束值
- step:步长
- hasStart:是否有开始值
- hasEnd:是否有结束值
- isClosed:true 代表左闭右闭,false 代表左闭右开
异常:
- IllegalArgumentException:当 step 等于 0 时, 抛出异常
func iterator
public func iterator(): Iterator<T>
功能:获取当前区间的迭代器。
返回值:当前区间的迭代器
func isEmpty
public const func isEmpty(): Bool
功能:判断该区间是否为空。
返回值:如果为空,返回 true,否则返回 false
class RangeIterator
public class RangeIterator<T> <: Iterator<T> where T <: Countable<T> & Comparable<T> & Equatable<T>
RangeIterator 类为 Range 类型的迭代器。
func next
public func next(): Option<T>
功能:获取迭代器中的下一个值。
返回值:迭代器中的下一个值。
func iterator
public func iterator(): Iterator<T>
功能:获取当前迭代器实例。
返回值:当前迭代器实例
class StackOverflowError
public class StackOverflowError <: Error {}
StackOverflowError 类继承了 Error,表示堆栈溢出错误,该类不可被继承,不可初始化,但是可以被捕获到。
func printStackTrace
public override func printStackTrace(): Unit
功能:向控制台打印堆栈信息。
class StackTraceElement
public open class StackTraceElement {
public let declaringClass: String
public let methodName: String
public let fileName: String
public let lineNumber: Int64
public init(declaringClass: String, methodName: String, fileName: String, lineNumber: Int64)
}
StackTraceElement 类用于提供具体的堆栈信息。
declaringClass
public let declaringClass: String
类名
methodName
public let methodName: String
函数名
fileName
public let fileName: String
文件名
lineNumber
public let lineNumber: Int64
行号
init
public init(declaringClass: String, methodName: String, fileName: String, lineNumber: Int64)
参数:
- declaringClass:类名
- methodName:函数名
- fileName:文件名
- lineNumber:行号
struct Array
public struct Array<T> {
public const init()
public init(size: Int64, item!: T)
public init(elements: Collection<T>)
public init(size: Int64, initElement: (Int64) -> T)
}
Array 类为仓颉数组类型。
init
public const init()
功能:无参构造函数,创建一个空数组。
init
public init(size: Int64, item!: T)
功能:构造一个指定长度的数组,其中元素都用指定初始值进行初始化。
注意:该构造函数不会拷贝 item, 如果 item 是一个引用类型,构造后数组的每一个元素都将指向相同的引用。
参数:
- size:数组大小
- item:数组元素初始值
异常:
- NegativeArraySizeException:当 size 小于 0,抛出异常
init
public init(elements: Collection<T>)
功能:根据 Collection 实例创建数组,把 Collection 实例中所有元素存入数组。
参数:
- elements:根据该 Collection 实例创建数组
init
public init(size: Int64, initElement: (Int64) -> T)
功能:创建指定长度的数组,其中元素根据初始化函数计算获取。即:将 [0, size) 范围内的值分别传入初始化函数 initElement,执行得到数组对应下标的元素。
参数:
- size:数组大小
- initElement:初始化函数
异常:
- NegativeArraySizeException:当 size 小于 0,抛出异常
func slice
public func slice(start: Int64, len: Int64): Array<T>
功能:返回切片后数组。
参数:
- start:切片的起始位置
- len:切片的长度
返回值:返回切片后的数组
异常:
- IndexOutOfBoundsException:如果 start 小于 0 ,或者 len 小于 0 ,或者 (start + len)的值大于 Array 的长度,抛出异常
func get
public func get(index: Int64): Option<T>
功能:返回数组下标 index 对应的值。
参数:
- index:要获取值的下标
返回值:Option 类型的值,可以使用 match 解构
func set
public func set(index: Int64, element: T): Unit
功能:修改数组中下标 index 对应的值。
参数:
- index:需要修改的值的下标
- element:修改的目标值
异常:
- IndexOutOfBoundsException:如果 index 小于 0 或者大于或等于 Array 的长度,抛出异常
operator func []
public operator func [](index: Int64): T
功能:获取数组下标 index 对应的值。
参数:
- index:要获取值的下标
返回值:获取得到的值
异常:
- IndexOutOfBoundsException:如果 index 小于 0,或大于等于数组长度,抛出异常
operator func []
public operator func [](index: Int64, value!: T): Unit
功能:修改数组中下标 index 对应的值。
参数:
- index:需要修改值的下标
- value:修改的目标值
异常:
- IndexOutOfBoundsException:如果 index 小于 0,或大于等于数组长度,抛出异常
operator func []
public operator func [](range: Range<Int64>): Array<T>
功能:返回切片后的数组。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:
- start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响
- hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响
参数:
- range:切片的范围,注意这里 range 的步长只能为 1
返回值:新的数组
异常:
- IllegalArgumentException:如果 range 的步长不等于 1,抛出异常
- IndexOutOfBoundsException:如果 range 表示的数组范围无效,抛出异常
operator func []
public operator func [](range: Range<Int64>, value!: T): Unit
功能:用指定的值对本数组一个连续范围的元素赋值。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:
- start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响
- hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响
参数:
- range:数组范围,注意这里 range 的步长只能为 1
- value:修改的目标值
异常:
- IllegalArgumentException:如果 range 的步长不等于 1,抛出异常
- IndexOutOfBoundsException:如果 range 表示的数组范围无效,抛出异常
operator func []
public operator func [](range: Range<Int64>, value!: Array<T>): Unit
功能:用指定的数组对本数组一个连续范围的元素赋值。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:
- start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响
- hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响
参数:
- range:数组范围,注意这里 range 的步长只能为 1
- value:修改的目标值
异常:
- IllegalArgumentException:如果 range 的步长不等于 1,或 range 长度不等于 value 长度,抛出异常
- IndexOutOfBoundsException:如果 range 表示的数组范围无效,抛出异常
func reverse
public func reverse(): Unit
功能:反转数组,将数组中元素的顺序进行反转。
func clone
public func clone(): Array<T>
功能:克隆数组。
返回值:新的数组
func clone
public func clone(range: Range<Int64>) : Array<T>
功能:按 Range 克隆数组。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:
- start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响
- hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响
参数:
- range:切片的范围
返回值:新的数组
异常:
- IndexOutOfBoundsException:range 超出数组范围则抛出此异常
func copyTo
public func copyTo(dst: Array<T>, srcStart: Int64, dstStart: Int64, copyLen: Int64): Unit
功能:将当前数组中的一段数据拷贝到目标数组中。
参数:
- dst:目标数组
- srcStart:从 this 数组的 srcStart 下标开始拷贝
- dstStart:从目标数组的 dstStart 下标开始拷贝
- copyLen:拷贝数组的长度
异常:
- IllegalArgumentException:copyLen 小于 0 则抛出此异常
- IndexOutOfBoundsException:如果 srcStart 或 dstStart 小于 0,或 srcStart 大于或等于 this 数组大小,或 dstStart 大于或等于目标数组大小,或 copyLen 超出范围则抛出此异常。
struct DefaultHasher
public struct DefaultHasher <: Hasher {
public init(res!: Int64 = 0)
}
DefaultHasher 是 struct 类型,提供了默认的哈希算法实现。
init
public init(res!: Int64 = 0)
功能:构造函数,创建一个 DefaultHasher。
参数:
- res:哈希结果,默认为 0
func reset
public mut func reset(): Unit
功能:重置哈希值为 0。
func finish
public func finish(): Int64
功能:获取哈希运算的结果。
返回值:哈希运算的结果
func write
public mut func write(value: Bool): Unit
功能:通过该函数把想要哈希运算的 Bool 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Char): Unit
功能:通过该函数把想要哈希运算的 Char 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Int8): Unit
功能:通过该函数把想要哈希运算的 Int8 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Int16): Unit
功能:通过该函数把想要哈希运算的 Int16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Int32): Unit
功能:通过该函数把想要哈希运算的 Int32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Int64): Unit
功能:通过该函数把想要哈希运算的 Int64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: UInt8): Unit
功能:通过该函数把想要哈希运算的 UInt8 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: UInt16): Unit
功能:通过该函数把想要哈希运算的 UInt16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: UInt32): Unit
功能:通过该函数把想要哈希运算的 UInt32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: UInt64): Unit
功能:通过该函数把想要哈希运算的 UInt64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Float16): Unit
功能:通过该函数把想要哈希运算的 Float16 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Float32): Unit
功能:通过该函数把想要哈希运算的 Float32 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: Float64): Unit
功能:通过该函数把想要哈希运算的 Float64 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
func write
public mut func write(value: String): Unit
功能:通过该函数把想要哈希运算的 String 值传入,然后进行哈希组合运算。
参数:
- value:待运算的值
struct LibC
public struct LibC
LibC 是一个 struct 类型,提供了仓颉中较为高频使用的 C 接口。
func malloc
public static func malloc<T>(count!: Int64 = 1): CPointer<T> where T <: CType
功能:在堆中申请对应长度的内存。泛型参数 T 需要是 CType 的子类型。
参数:
- count:为可选参数,默认为1,表示申请 T 类型的个数
返回值:如果申请成功返回非空指针,内存长度为 sizeOf
func free
public static unsafe func free<T>(p: CPointer<T>): Unit where T <: CType
功能:释放堆内存。
参数:
- p:表示被释放的内存地址
func mallocCString
public static unsafe func mallocCString(str: String): CString
功能:通过 String 申请与之字符内容相同的 C 风格字符串。
参数:
- str:仓颉 String 类型
返回值:返回 C 风格字符串,以 '\0' 结束
func free
public static unsafe func free(cstr: CString): Unit
功能:释放 C 风格字符串。
参数:
- cstr:需要释放的 C 风格字符串
enum Ordering
public enum Ordering {
| LT
| GT
| EQ
}
Ordering 表示一个比较结果的 enum 类型,它包含三种情况小于,大于和等于。
LT
LT
功能:构造一个 Ordering 实例,表示小于。
GT
GT
功能:构造一个 Ordering 实例,表示大于。
EQ
EQ
功能:构造一个 Ordering 实例,表示等于。
enum Option
public enum Option<T> {
| Some<T>
| None
}
Option 是一个泛型 enum 类型,它包含两个构造器:Some 和 None。其中,Some 会携带一个参数,表示有值,None 不带参数,表示无值。当需要表示某个类型可能有值,也可能没有值的时候,可选择使用 Option 类型。
Some
Some(T)
功能:构造一个携带参数的 Option<T> 实例,表示有值。
None
None
功能:构造一个不带参数的 Option<T> 实例,表示无值。
func getOrThrow
public func getOrThrow(): T
功能:获得值或抛出异常。
返回值:如果当前实例值是 Some<T>,返回类型为 T 的实例
异常:
- NoneValueException:如果当前实例是
None,抛出异常
func getOrThrow
public func getOrThrow(exception: ()->Exception): T
功能:获得值或抛出指定异常。
参数:
- exception:异常函数,如果当前实例值是
None,将执行该函数并将其返回值作为异常抛出
返回值:如果当前实例值是 Some<T>,返回类型为 T 的实例
异常:
- Exception:如果当前实例是
None,抛出异常函数返回的异常
func getOrDefault
public func getOrDefault(other: ()->T): T
功能:获得值或返回默认值。如果 Option 值是 Some,则返回类型为 T 的实例,如果 Option 值是 None,则调用入参,返回类型 T 的值。
参数:
- other:默认函数,如果当前实例的值是
None,调用该函数得到类型为T的实例,并将其返回
返回值:如果当前实例的值是 Some<T>,则返回当前实例携带的类型为 T 的实例,如果 Option 值是 None,调用入参指定的函数,得到类型为 T 的实例,并将其返回
func isNone
public func isNone(): Bool
功能:判断当前实例值是否为 None。
返回值:如果当前实例值是 None,则返回 true,否则返回 false
func isSome
public func isSome(): Bool
功能:判断当前实例值是否为 Some。
返回值:如果当前实例值是 Some,则返回 true,否则返回 false
extend Option <: ToString
extend Option<T> <: ToString where T <: ToString
为 Option<T> 枚举实现 ToString 接口。
func toString
public func toString(): String
功能:将 Option 转换为可输出的 String。
返回值:转化后的 String
extend Option <: Equatable
extend Option<T> <: Equatable<Option<T>> where T <: Equatable<T>
为 Option<T> 枚举实现 Equatable<Option<T>> 接口。
operator func ==
public operator func ==(that: Option<T>): Bool
功能:判断当前实例与指定 Option<T> 实例是否相等。
参数:
- that:用于与当前实例比较的
Option<T>实例
返回值:如果相等,则返回 true,否则返回 false
operator func !=
public operator func !=(that: Option<T>): Bool
功能:判断当前实例与指定 Option<T> 实例是否不等。
参数:
- that:用于与当前实例比较的
Option<T>实例
返回值:如果不相等,则返回 true,否则返回 false
extend Option <: Hashable
extend Option<T> <: Hashable where T <: Hashable
为 Option 类型扩展 Hashable。
其中, Some(T) 的 hashCode 等于 T 的值对应的 hashCode,None 的 hashCode 等于 Int64(0)。
func hashCode
public func hashCode(): Int64
功能:获取哈希值。
返回值:哈希值
extend Array <: ToString
extend Array<T> <: ToString where T <: ToString
为 Array<T> 类型扩展 ToString 接口实现。
func toString
public func toString(): String
功能:将数组转换为可输出的 String。
返回值:转化后的 String
extend Array <: Equatable
extend Array<T> <: Equatable<Array<T>> where T <: Equatable<T>
为 Array<T> 类型扩展 Equatable<Array<T>> 接口实现。
operator func ==
public const operator func ==(that: Array<T>): Bool
功能:判断当前实例与指定 Array<T> 实例是否相等。
参数:
- that:用于与当前实例比较的
Array<T>实例
返回值:如果相等,则返回 true,否则返回 false
operator func !=
public const operator func !=(that: Array<T>): Bool
功能:判断当前实例与指定 Array<T> 实例是否不等。
参数:
- that:用于与当前实例比较的
Array<T>实例
返回值:如果不相等,则返回 true;相等则返回 false
func contains
public func contains(element: T): Bool
功能:判断 Array 是否包含指定元素。
参数:
- element:需要判断的元素
返回值:如果存在,则返回 true,否则返回 false
extend Array <: Collection
extend Array<T> <: Collection<T>
func iterator
public func iterator(): Iterator<T>
功能:获取当前数组的迭代器,用于遍历数组。
返回值:当前数组的迭代器
prop size
public prop size: Int64
功能:获取元素数量。
func isEmpty
public func isEmpty(): Bool
功能:判断数组是否为空。
返回值:如果数组为空,返回 true,否则,返回 false
func toArray
public func toArray(): Array<T>
功能:根据当前 Array 生成新 Array 实例。
返回值:与原 Array 完全相同的另一个 Array 对象
struct CPointerHandle
public struct CPointerHandle<T> where T <: CType {
public let pointer: CPointer<T>
public let array: Array<T>
public init()
public init(ptr: CPointer<T>, arr: Array<T>)
}
CPointerHandle 用来表示获取 Array 原始指针的实例,该类型中的泛型参数应该满足 CType 约束。
pointer
public let pointer: CPointer<T>
功能:获取 Array 对应的原始指针。
array
public let array: Array<T>
功能:原始指针对应的 Array。
init
public init()
功能:默认初始化函数,初始化一个空指针和空数组。
init
public init(ptr: CPointer<T>, arr: Array<T>)
功能:通过传入的 CPointer 和 Array 初始化一个 CPointerHandle。
参数:
- ptr:CPointer 指针
- arr:指针对应的 Array
interface ByteExtension
public interface ByteExtension
此接口用于扩展 Byte 类型
extend Byte <: ByteExtension
extend Byte <: ByteExtension
Byte 类型为内置类型,这里是对其添加的一些在 Ascii 字符集范围内的函数。
func isAscii
public func isAscii(): Bool
功能:判断 Byte 是否是在 Ascii 范围内。
返回值:如果 Byte 在 Ascii 范围内返回 true,否则返回 false
func isAsciiLetter
public func isAsciiLetter(): Bool
功能:判断 Byte 是否是在 Ascii 拉丁字母范围内。
返回值:如果 Byte 在 Ascii 拉丁字母范围内返回 true,否则返回 false
func isAsciiNumber
public func isAsciiNumber(): Bool
功能:判断 Byte 是否是在 Ascii 十进制数字范围内。
返回值:如果 Byte 在 Ascii 十进制数字范围内返回 true,否则返回 false
func isAsciiLowerCase
public func isAsciiLowerCase(): Bool
功能:判断 Byte 是否是在 Ascii 小写拉丁字母范围内。
返回值:如果 Byte 在 Ascii 小写拉丁字母范围内返回 true,否则返回 false
func isAsciiUpperCase
public func isAsciiUpperCase(): Bool
功能:判断 Byte 是否是在 Ascii 大写拉丁字母范围内。
返回值:如果 Byte 在 Ascii 大写拉丁字母范围内返回 true,否则返回 false
func isAsciiWhiteSpace
public func isAsciiWhiteSpace(): Bool
功能:判断 Byte 是否是在 Ascii 空白字符范围内。其取值范围为 $[09, 0D] \cup 20$。
返回值:如果 Byte 在 Ascii 空白字符范围内返回 true,否则返回 false
func isAsciiHex
public func isAsciiHex(): Bool
功能:判断 Byte 是否是在 Ascii 十六进制数字范围内。
返回值:如果 Byte 在 Ascii 十六进制数字范围内返回 true,否则返回 false
func isAsciiOct
public func isAsciiOct(): Bool
功能:判断 Byte 是否是在 Ascii 八进制数字范围内。
返回值:如果 Byte 在 Ascii 八进制数字范围内返回 true,否则返回 false
func isAsciiPunctuation
public func isAsciiPunctuation(): Bool
功能:判断 Byte 是否是在 Ascii 标点符号范围内。其取值范围为 $[21, 2F] \cup [3A, 40] \cup [5B, 60] \cup [7B, 7E]$。
返回值:如果 Byte 在 Ascii 标点符号范围内返回 true,否则返回 false
func isAsciiGraphic
public func isAsciiGraphic(): Bool
功能:判断 Byte 是否是在 Ascii 图形字符范围内。其取值范围为 $[21, 7E]$。
返回值:如果 Byte 在 Ascii 图形字符范围内返回 true,否则返回 false
func isAsciiControl
public func isAsciiControl(): Bool
功能:判断 Byte 是否是在 Ascii 控制字符范围内。其取值范围为 $[00, 1F] \cup 7F$。
返回值:如果 Byte 在 Ascii 控制字符范围内返回 true,否则返回 false
func isAsciiNumberOrLetter
public func isAsciiNumberOrLetter(): Bool
功能:判断 Byte 是否是在 Ascii 十进制数字和拉丁字母范围内。
返回值:如果 Byte 在 Ascii 十进制数字和拉丁字母范围内返回 true,否则返回 false
func toAsciiUpperCase
public func toAsciiUpperCase(): Byte
功能:将 Byte 换为对应的 Ascii 大写字符 Byte,如果无法转换则保持现状。
返回值:转换后的 Byte,如果无法转换则返回原来的 Byte
func toAsciiLowerCase
public func toAsciiLowerCase(): Byte
功能:将 Byte 换为对应的 Ascii 小写字符 Byte,如果无法转换则保持现状。
返回值:转换后的 Byte,如果无法转换则返回原来的 Byte
extend Char <: CharExtension
extend Char <: CharExtension
Char 类型为内置类型,这里是对其添加的一些在 Ascii 字符集范围内的函数。
func isAscii
public func isAscii(): Bool
功能:判断字符是否是 Ascii 中的字符。
返回值:如果是 Ascii 字符返回 true,否则返回 false
func isAsciiLetter
public func isAsciiLetter(): Bool
功能:判断字符是否是 Ascii 字母字符。
返回值:如果是 Ascii 字母字符返回 true,否则返回 false
func isAsciiNumber
public func isAsciiNumber(): Bool
功能:判断字符是否是 Ascii 数字字符。
返回值:如果是 Ascii 数字字符返回 true,否则返回 false
func isAsciiLowerCase
public func isAsciiLowerCase(): Bool
功能:判断字符是否是 Ascii 小写字符。
返回值:如果是 Ascii 小写字符返回 true,否则返回 false
func isAsciiUpperCase
public func isAsciiUpperCase(): Bool
功能:判断字符是否是 Ascii 大写字符。
返回值:如果是 Ascii 大写字符返回 true,否则返回 false
func isAsciiWhiteSpace
public func isAsciiWhiteSpace(): Bool
功能:判断字符是否是 Ascii 空白字符。其取值范围为 $[09, 0D] \cup 20$。
返回值:如果是 Ascii 空白字符返回 true,否则返回 false
func isAsciiHex
public func isAsciiHex(): Bool
功能:判断字符是否是 Ascii 十六进制字符。
返回值:如果是 Ascii 十六进制字符返回 true,否则返回 false
func isAsciiOct
public func isAsciiOct(): Bool
功能:判断字符是否是 Ascii 八进制字符。
返回值:如果是 Ascii 八进制字符返回 true,否则返回 false
func isAsciiPunctuation
public func isAsciiPunctuation(): Bool
功能:判断字符是否是 Ascii 标点符号字符。其取值范围为 $[21, 2F] \cup [3A, 40] \cup [5B, 60] \cup [7B, 7E]$。
返回值:如果是 Ascii 标点符号字符返回 true,否则返回 false
func isAsciiGraphic
public func isAsciiGraphic(): Bool
功能:判断字符是否是 Ascii 图形字符。其取值范围为 $[21, 7E]$。
返回值:如果是 Ascii 图形字符返回 true,否则返回 false
func isAsciiControl
public func isAsciiControl(): Bool
功能:判断字符是否是 Ascii 控制字符。其取值范围为 $[00, 1F] \cup 7F$。
返回值:如果是 Ascii 控制字符返回 true,否则返回 false
func isAsciiNumberOrLetter
public func isAsciiNumberOrLetter(): Bool
功能:判断字符是否是 Ascii 数字或拉丁字母字符。
返回值:如果是 Ascii 数字或拉丁字母字符返回 true,否则返回 false
func toAsciiUpperCase
public func toAsciiUpperCase(): Char
功能:将字符转换为 Ascii 大写字符,如果无法转换则保持现状。
返回值:转换后的字符,如果无法转换则返回原来的 Char
func toAsciiLowerCase
public func toAsciiLowerCase(): Char
功能:将字符转换为 Ascii 小写字符,如果无法转换则保持现状。
返回值:转换后的字符,如果无法转换则返回原来的 Char
func fromUtf8
public static func fromUtf8(arr: Array<UInt8>, index: Int64): (Char, Int64)
功能:将 UInt8 数组中的某个元素,通过 UTF-8 转换成字符,并告知字符占用字节长度。
参数:
- arr:UInt8 数组
- index:UInt8 数组的下标
返回值:数组中 index 下标元素对应于 UTF-8 所表示的字符 字符字节所占的大小
func intoUtf8Array
public static func intoUtf8Array(c: Char, arr: Array<UInt8>, index: Int64): Int64
功能:该函数会把字符转成字节码序列然后覆盖 Array 数组内指定位置的字节码。
参数:
- c:字符
- arr:待覆盖的 Array 数组
- index:目标位置的起始索引
返回值:字符的字节码长度,例如中文是三个字节码长度
func utf8Size
public static func utf8Size(arr: Array<UInt8>, index: Int64): Int64
功能:该函数会返回指定索引位置字节码对应 UTF-8 字符字节码应有的长度。准确来说,除了 ASCII 码,其他长度的字节码都有首位字节码,首位字节码开头 1 的个数表明了该字符对应的字节码长度,这个函数就用来扫描这个字节码的,如果不是首位字节码,就会抛出异常。
参数:
- arr:Array 数组
- index:指定字符的索引
返回值:字符的字节码长度,例如中文是三个字节码长度
异常:
- IllegalArgumentException:如果索引位置的字节码不符合首位字节码规则,会抛出异常
func utf8Size
public static func utf8Size(c: Char): Int64
功能:返回字符对应的 UTF-8 的字节码长度,例如中文字符是 3 个长度。
参数:
- c:字符
返回值:字符的字节码长度
func getPreviousFromUtf8
public static func getPreviousFromUtf8(arr: Array<UInt8>, index: Int64): (Char, Int64)
功能:当指定了一个索引,那么函数会找到数组对应索引位置并且根据 UTF-8 规则,查看该字节码是否是字符的首位字节码,如果不是就继续向前遍历,直到该字节码是首位字节码,然后利用字节码序列找到对应的字符。
参数:
- arr:Array 数组
- index:指定的索引
返回值:找到的字符 该字符首位字节码在数组中的索引
异常:
- IllegalArgumentException:如果找不到首位字节码,就会抛出异常
extend Char <: Comparable
extend Char <: Comparable<Char>
func compare
public func compare(rhs: Char): Ordering
功能:判断当前 Char 实例与指定 Char 实例的关系。
参数:
- rhs:另一个 Char 实例,用于与当前 Char 实例进行比较
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Char <: ToString
extend Char <: ToString
Char 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Char 转换为可输出的 String。
返回值:转化后的 String
extend Char <: Hashable
extend Char <: Hashable
Char 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:获取哈希值。
返回值:哈希值
extend Char <: Countable
extend Char <: Countable<Char>
Char 类型为内置类型,这里为其扩展 Countable<Char> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): Char
功能:与 Int64 数进行加法运算,返回值是 Char 类型。
参数:
- right:Int64 数
返回值:算数结果
异常:
- OverflowException:如果与 Int64 数进行加法运算后为不合法的 Unicode 值,抛出异常
extend Int64 <: ToString
extend Int64 <: ToString
Int64 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Int64 转换为可输出的 String。
返回值:转化后的 String
extend Int64 <: Comparable
extend Int64 <: Comparable<Int64>
Int64 类型为内置类型,这里为其扩展 Comparable<Int64> 接口。
func compare
public func compare(rhs: Int64): Ordering
功能:判断 Int64 与另一个 Int64 的关系。如果等于,返回 Ordering.EQ如果小于,返回 Ordering.LT。
参数:
- rhs:另一个 Int64 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ如果小于,返回 Ordering.LT
extend Int64 <: Hashable
extend Int64 <: Hashable
Int64 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:获取哈希值。
返回值:哈希值
extend Int64 <: Countable
extend Int64 <: Countable<Int64>
Int64 类型为内置类型,这里为其扩展 Countable<Int64>。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): Int64
功能:与 Int64 数进行加法运算,返回值是 Int64 类型。
参数:
- right:Int64 数
返回值:算数结果
extend Int32 <: ToString
extend Int32 <: ToString
Int32 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Int32 转换为可输出的 String。
返回值:转化后的 String
extend Int32 <: Comparable
extend Int32 <: Comparable<Int32>
Int32 类型为内置类型,这里为其扩展 Comparable<Int32> 接口。
func compare
public func compare(rhs: Int32): Ordering
功能:判断 Int32 与另一个 Int32 的关系。
参数:
- rhs:另一个 Int32 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Int32 <: Hashable
extend Int32 <: Hashable
Int32 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Int32 <: Countable
extend Int32 <: Countable<Int32>
Int32 类型为内置类型,这里为其扩展 Countable<Int32>。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): Int32
功能:与 Int64 数进行加法运算,返回值是 Int32 类型。
参数:
- right:Int64 数
返回值:算数结果
extend Int16 <: ToString
extend Int16 <: ToString
Int16 类型为内置类型,这里为其扩展向 String 类型的转换。
func toString
public func toString(): String
功能:将 Int16 转换为可输出的 String。
返回值:转化后的 String
extend Int16 <: Comparable
extend Int16 <: Comparable<Int16>
Int16 类型为内置类型,这里为其扩展 Comparable<Int16> 接口。
func compare
public func compare(rhs: Int16): Ordering
功能:判断 Int16 与另一个 Int16 的关系。
参数:
- rhs:另一个 Int16 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Int16 <: Hashable
extend Int16 <: Hashable
Int16 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Int16 <: Countable
extend Int16 <: Countable<Int16>
Int16 类型为内置类型,这里为其扩展 Countable<Int16>。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): Int16
功能:与 Int64 数进行加法运算,返回值是 Int16 类型。
参数:
- right:Int64 数
返回值:算数结果
extend Int8 <: ToString
extend Int8 <: ToString
Int8 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Int8 转换为可输出的 String。
返回值:转化后的 String
extend Int8 <: Comparable
extend Int8 <: Comparable<Int8>
Int8 类型为内置类型,这里为其扩展 Comparable<Int8> 接口。
func compare
public func compare(rhs: Int8): Ordering
功能:判断 Int8 与另一个 Int8 的关系。
参数:
- rhs:另一个 Int8 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ如果小于,返回 Ordering.LT。
extend Int8 <: Hashable
extend Int8 <: Hashable
Int8 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Int8 <: Countable
extend Int8 <: Countable<Int8>
Int8 类型为内置类型,这里为其扩展 Countable<Int8> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): Int8
功能:与 Int64 数进行加法运算,返回值是 Int8 类型。
参数:
- right:Int64 数
返回值:算数结果
extend IntNative <: ToString
extend IntNative <: ToString
IntNative 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 IntNative 转换为可输出的 String。
返回值:转化后的 String
extend IntNative <: Comparable
extend IntNative <: Comparable<IntNative>
IntNative 类型为内置类型,这里为其扩展 Comparable<IntNative> 接口。
func compare
public func compare(rhs: IntNative): Ordering
功能:判断 IntNative 与另一个 IntNative 的关系。
参数:
- rhs:另一个 IntNative 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ如果小于,返回 Ordering.LT
extend IntNative <: Hashable
extend IntNative <: Hashable
IntNative 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
extend IntNative <: Countable
extend IntNative <: Countable<IntNative>
IntNative 类型为内置类型,这里为其扩展 Countable<IntNative> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): IntNative
功能:与 Int64 数进行加法运算,返回值是 IntNative 类型。
参数:
- right:Int64 数
返回值:算数结果
extend UInt64 <: ToString
extend UInt64 <: ToString
UInt64 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 UInt64 转换为可输出的 String。
返回值:转化后的 String
extend UInt64 <: Comparable
extend UInt64 <: Comparable<UInt64>
UInt64 类型为内置类型,这里为其扩展 Comparable<UInt64> 接口。
func compare
public func compare(rhs: UInt64): Ordering
功能:判断 UInt64 与另一个 UInt64 的关系。
参数:
- rhs:另一个 UInt64 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT。
extend UInt64 <: Hashable
extend UInt64 <: Hashable
UInt64 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend UInt64 <: Countable
extend UInt64 <: Countable<UInt64>
UInt64 类型为内置类型,这里为其扩展 Countable<UInt64> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): UInt64
功能:与 Int64 数进行加法运算,返回值是 UInt64 类型。
参数:
- right:Int64 数
返回值:算数结果
extend UInt32 <: ToString
extend UInt32 <: ToString
UInt32 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 UInt32 转换为可输出的 String。
返回值:转化后的 String
extend UInt32 <: Comparable
extend UInt32 <: Comparable<UInt32>
UInt32 类型为内置类型,这里为其扩展 Comparable<UInt32> 接口。
func compare
public func compare(rhs: UInt32): Ordering
功能:判断 UInt32 与另一个 UInt32 的关系。
参数:
- rhs:另一个 UInt32 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT。
extend UInt32 <: Hashable
extend UInt32 <: Hashable
UInt32 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend UInt32 <: Countable
extend UInt32 <: Countable<UInt32>
UInt32 类型为内置类型,这里为其扩展 Countable<UInt32> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): UInt32
功能:与 Int64 数进行加法运算,返回值是 UInt32 类型。
参数:
- right:Int64 数
返回值:算数结果
extend UInt16 <: ToString
extend UInt16 <: ToString
UInt16 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 UInt16 转换为可输出的 String。
返回值:转化后的 String
extend UInt16 <: Comparable
extend UInt16 <: Comparable<UInt16>
UInt16 类型为内置类型,这里为其扩展 Comparable<UInt16> 接口。
func compare
public func compare(rhs: UInt16): Ordering
功能:判断 UInt16 与另一个 UInt16 的关系如果等于,返回 Ordering.EQ如果小于,返回 Ordering.LT。
参数:
- rhs:另一个 UInt16 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT。
extend UInt16 <: Hashable
extend UInt16 <: Hashable
UInt16 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend UInt16 <: Countable
extend UInt16 <: Countable<UInt16>
UInt16 类型为内置类型,这里为其扩展 Countable<UInt16> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): UInt16
功能:与 Int64 数进行加法运算,返回值是 UInt16 类型。
参数:
- right:Int64 数
返回值:算数结果
extend UInt8 <: ToString
extend UInt8 <: ToString
UInt8 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 UInt8 转换为可输出的 String。
返回值:转化后的 String
extend UInt8 <: Comparable
extend UInt8 <: Comparable<UInt8>
UInt8 类型为内置类型,这里为其扩展 Comparable<UInt8> 接口。
func compare
public func compare(rhs: UInt8): Ordering
功能:判断 UInt8 与另一个 UInt8 的关系。
参数:
- rhs:另一个 UInt8 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend UInt8 <: Hashable
extend UInt8 <: Hashable
UInt8 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend UInt8 <: Countable
extend UInt8 <: Countable<UInt8>
UInt8 类型为内置类型,这里为其扩展 Countable<UInt8> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): UInt8
功能:与 Int64 数进行加法运算,返回值是 UInt8 类型。
参数:
- right:Int64 数
返回值:算数结果
extend UIntNative <: ToString
extend UIntNative <: ToString
UIntNative 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 UIntNative 转换为可输出的 String。
返回值:转化后的 String
extend UIntNative <: Comparable
extend UIntNative <: Comparable<UIntNative>
UIntNative 类型为内置类型,这里为其扩展 Comparable<UIntNative> 接口。
func compare
public func compare(rhs: UIntNative): Ordering
功能:判断 UIntNative 与另一个 UIntNative 的关系。
参数:
- rhs:另一个 UIntNative 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend UIntNative <: Hashable
extend UIntNative <: Hashable
UIntNative 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend UIntNative <: Countable
extend UIntNative <: Countable<UIntNative>
UIntNative 类型为内置类型,这里为其扩展 Countable<UIntNative> 接口。
func position
public func position(): Int64
功能:转成 Int64 类型。
返回值:转换后的 Int64 值
func next
public func next(right: Int64): UIntNative
功能:与 Int64 数进行加法运算,返回值是 UIntNative 类型。
参数:
- right:Int64 数
返回值:算数结果
extend Float64 <: ToString
extend Float64 <: ToString
Float64 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换,默认保留 6 位小数,如需其他精度 String 请参考 Formatter 扩展。
func toString
public func toString(): String
功能:将 Float64 转换为可输出的 String。
返回值:转化后的 String
extend Float64 <: Comparable
extend Float64 <: Comparable<Float64>
Float64 类型为内置类型,这里为其扩展 Comparable<Float64> 接口。
func compare
public func compare(rhs: Float64): Ordering
功能:判断 Float64 与另一个 Float64 的关系。
参数:
- rhs:另一个 Float64 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Float64 <: Hashable
extend Float64 <: Hashable
Float64 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Float32 <: ToString
extend Float32 <: ToString
Float32 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换,默认保留 6 位小数,如需其他精度 String 请参考 Formatter 扩展。
func toString
public func toString(): String
功能:将 Float32 转换为可输出的 String。
返回值:转化后的 String
extend Float32 <: Comparable
extend Float32 <: Comparable<Float32>
Float32 类型为内置类型,这里为其扩展 Comparable<Float32> 接口。
func compare
public func compare(rhs: Float32): Ordering
功能:判断 Float32 与另一个 Float32 的关系。
参数:
- rhs:另一个 Float32 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Float32 <: Hashable
extend Float32 <: Hashable
Float32 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Float16 <: ToString
extend Float16 <: ToString
Float16 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换,默认保留 6 位小数,如需其他精度 String 请参考 Formatter 扩展。
func toString
public func toString(): String
功能:将 Float16 转换为可输出的 String。
返回值:转化后的 String
extend Float16 <: Comparable
extend Float16 <: Comparable<Float16>
Float16 类型为内置类型,这里为其扩展 Comparable<Float16> 接口。
func compare
public func compare(rhs: Float16): Ordering
功能:判断 Float16 与另一个 Float16 的关系。
参数:
- rhs:另一个 Float16 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
extend Float16 <: Hashable
extend Float16 <: Hashable
Float16 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值
extend Ordering <: ToString
extend Ordering <: ToString
Ordering 类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Ordering 转换为可输出的 String。
返回值:转化后的 String
extend Ordering <: Comparable
extend Ordering <: Comparable<Ordering>
Ordering 类型,这里为其扩展 Comparable<Ordering> 接口。
func compare
public func compare(that: Ordering): Ordering
功能:判断 Ordering 与另一个 Ordering 的关系。
参数:
- that:另一个 Ordering 对象
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
operator func ==
public operator func ==(that: Ordering): Bool
功能:判断两个 Ordering 是否相等。
参数:
- that:传入 Ordering
返回值:如果相等,则返回 true,否则返回 false
operator func !=
public operator func !=(that: Ordering): Bool
功能:判断两个 Ordering 是否不相等。
参数:
- that:传入 Ordering
返回值:如果不相等,则返回 true,否则返回 false
operator func <=
public operator func <=(that: Ordering): Bool
功能:判断两个 Ordering 是否为小于等于关系。
参数:
- that:传入 Ordering
返回值:如果为小于等于关系,则返回 true,否则返回 false
operator func <
public operator func <(that: Ordering): Bool
功能:判断两个 Ordering 是否为小于关系。
参数:
- that:传入 Ordering
返回值:如果为小于关系,则返回 true,否则返回 false
operator func >=
public operator func >=(that: Ordering): Bool
功能:判断两个 Ordering 是否为大于等于关系。
参数:
- that:传入 Ordering
返回值:如果为大于等于关系,则返回 true,否则返回 false
operator func >
public operator func >(that: Ordering): Bool
功能:判断两个 Ordering 是否为大于关系。
参数:
- that:传入 Ordering
返回值:如果为大于关系,则返回 true,否则返回 false
extend Ordering <: Hashable
extend Ordering <: Hashable
Ordering 类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:获取哈希码。
返回值:哈希值,Ordering.GT 的哈希值是 3,Ordering.EQ 的哈希值是 2,Ordering.LT 的哈希值是 1
extend Range <: Hashable
extend Range<T> <: Hashable where T <: Hashable & Countable<T> & Comparable<T> & Equatable<T>
Range 类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:获取哈希值。
返回值:哈希值
extend Range <: Equatable
extend Range<T> <: Equatable<Range<T>> where T <: Countable<T> & Comparable<T> & Equatable<T>
Range 类型,这里为其扩展 Equatable<Range<T>> 接口。
operator func ==
public operator func ==(that: Range<T>): Bool
功能:判断两个 Range 是否相等。
返回值:true 代表相等,false 代表不相等
operator func !=
public operator func !=(that: Range<T>): Bool
功能:判断两个 Range 是否不相等。
返回值:true 代表不相等,false 代表相等
extend Bool <: ToString
extend Bool <: ToString
Bool 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Bool 转换为可输出的 String。
返回值:转化后的 String
extend Bool <: Hashable
extend Bool <: Hashable
Bool 类型为内置类型,这里为其扩展 Hashable 接口。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
extend Bool <: Equatable
extend Bool <: Equatable<Bool>
Bool 类型为内置类型,这里为其扩展 Equatable<Bool> 接口。
extend Unit <: ToString
extend Unit <: ToString
Unit 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func toString
public func toString(): String
功能:将 Unit 转换为可输出的 String,其值为 "()"。
返回值:转化后的 String
extend Unit <: Hashable
extend Unit <: Hashable
Unit 类型为内置类型,这里为其扩展 Hashable 接口,其函数返回值为 0。
func hashCode
public func hashCode(): Int64
功能:返回哈希值。
返回值:哈希值,为 0
extend CPointer
extend CPointer<T>
CPointer 类型为内置类型,在与 C 互操作中,该数据类型映射为 C 语言中的指针类型。这里扩展一些必要的指针使用相关接口,包含判空、读写数据等接口。其中泛型 T 为指针类型,其满足 CType 约束( CType 接口描述见后面 interface CType 章节)。对 CPointer 做运算需要在 unsafe 上下文中进行。
func isNull
public func isNull(): Bool
功能:判断指针是否是空。
返回值:如果是空返回 true,否则返回 false
func isNotNull
public func isNotNull(): Bool
功能:判断指针是否不是空。
返回值:如果不是空返回 true,否则返回 false
func toUIntNative
public func toUIntNative(): UIntNative
功能:获取该指针的整型形式。
返回值:返回该指针的整型形式
func read
public unsafe func read(): T
功能:读取第一个数据,该接口需要用户保证指针的合法性,否则发生未定义行为。
返回值:返回该对象类型的第一个数据
func write
public unsafe func write(value: T): Unit
功能:写入一个数据,该数据总是在第一个,该接口需要用户保证指针的合法性,否则发生未定义行为。
参数:
- value:要写入的数据
func read
public unsafe func read(idx: Int64): T
功能:根据下标读取对应的数据,该接口需要用户保证指针的合法性,否则发生未定义行为。
参数:
- idx:要获取数据的下标
返回值:输入下标对应的数据
func write
public unsafe func write(idx: Int64, value: T): Unit
功能:在指定下标位置写入一个数据,该接口需要用户保证指针的合法性,否则发生未定义行为。
参数:
- idx:指定的下标位置
- value:写入的数据
operator func +
public unsafe operator func +(offset: Int64): CPointer<T>
功能:CPointer 对象指针后移,同 C 语言的指针加法操作。
参数:
- offset:偏移量
返回值:返回地址变动后的对象
operator func -
public unsafe operator func -(offset: Int64): CPointer<T>
功能:CPointer 对象指针前移,同 C 语言的指针减法操作。
参数:
- offset:偏移量
返回值:返回地址变动后的对象
func asResource
public func asResource(): CPointerResource<T>
功能:获取 CPointerResource 对象。
返回值:表示 CPointerResource 对象
struct CPointerResource
public struct CPointerResource<T> <: Resource where T <: CType {
public var value: CPointer<T>
}
CPointer 对应的资源管理类型,其实例可以通过 CPointer 的成员函数 asResource 获取。
value
public var value: CPointer<T>
功能:表示当前实例管理的 CPointer<T> 类型实例。
func isClosed
public func isClosed(): Bool
功能:判断该指针内容是否已被释放。
返回值:返回 true 为已释放。
func close
public func close(): Unit
功能:释放其管理的 CPointer<T> 实例指向的内容。
extend CString
extend CString
CString 类型是内置类型,在与 C 互操作中,该数据类型映射为 C 语言中的字符串 char* 类型。这里扩展一些必要的字符串使用相关接口,包含判空、获取长度、截取等接口。 CString 提供了一个内建构造函数,接受 CPointer<UInt8> 类型的参数。
注意:如果使用 CString 需要将 \0 当做结束符。
init
public init(p: CPointer<UInt8>)
功能:通过字符串指针进行构造 CString ,该接口需要用户保证指针的合法性。
参数:
- p:使用已有的 UInt8 类型字符串指针进行构造
extend CString <: ToString
extend CString <: ToString
CString 类型为内置类型,这里为其扩展 ToString 接口,实现向 String 类型的转换。
func getChars
public func getChars(): CPointer<UInt8>
功能:获取字符串的指针。
返回值:该字符串的指针
func isNull
public func isNull(): Bool
功能:判断字符串指针是否为空。
返回值:如果字符串指针为空,返回 true,否则返回 false
func size
public func size(): Int64
功能:返回该字符串长度,同 C 语言中的 strlen。
返回值:字符串长度
func isEmpty
public func isEmpty(): Bool
功能:判断字符串是否为空字符串。
返回值:如果为空字符串或字符串指针为空,返回 true,否则返回 false
func isNotEmpty
public func isNotEmpty(): Bool
功能:判断字符串是否不为空字符串。
返回值:如果不为空字符串,返回 true,如果字符串指针为空,返回 false
func startsWith
public func startsWith(prefix: CString): Bool
功能:判断字符串是否包含指定前缀。
参数:
- prefix:匹配的目标前缀字符串
返回值:如果该字符串包含 prefix 前缀,返回 true,如果该字符串不包含 prefix 前缀,返回 false,特别地,如果原字符串或者 prefix 前缀字符串指针为空,均返回 false
func endsWith
public func endsWith(suffix: CString): Bool
功能:判断字符串是否包含指定后缀。
参数:
- suffix:匹配的目标后缀字符串
返回值:如果该字符串包含 suffix 后缀,返回 true,如果该字符串不包含 suffix 后缀,返回 false,特别地,如果原字符串或者 suffix 后缀字符串指针为空,均返回 false
func equals
public func equals(rhs: CString): Bool
功能:判断字符串两个字符串是否相等。
参数:
- rhs:比较的目标字符串
返回值:如果两个字符串相等,返回 true,否则返回 false
func equalsLower
public func equalsLower(rhs: CString): Bool
功能:判断字符串两个字符串是否相等,且忽略大小写。
参数:
- rhs:匹配的目标字符串
返回值:如果两个字符串忽略大小写相等,返回 true,否则返回 false
func subCString
public func subCString(beginIndex: UIntNative): CString
功能:截取指定位置开始至字符串结束的子串,需要注意,该接口返回为字符串的副本,返回的子串使用完后需要手动 free。
参数:
- beginIndex:截取的起始位置
返回值:截取的子串,如果 beginIndex 与字符串长度相等,返回空字符串(空指针)
异常:
- IndexOutOfBoundsException:如果 beginIndex 大于字符串长度,抛出异常
- IllegalMemoryException:如果内存申请失败或内存拷贝失败时,抛出异常
func subCString
public func subCString(beginIndex: UIntNative, subLen: UIntNative): CString
功能:截取字符串的子串,指定起始位置和截取长度,如果截取的末尾位置超出字符串长度,截取至字符串末尾,需要注意,该接口返回为字符串的副本,返回的子串使用完后需要手动 free。
参数:
- beginIndex:截取的起始位置
- subLen:截取长度
返回值:截取的子串,如果 beginIndex 与字符串长度相等,返回空字符串(空指针)
异常:
- IndexOutOfBoundsException:如果 beginIndex 大于字符串长度,抛出异常
- IllegalMemoryException:如果内存申请失败或内存拷贝失败时,抛出异常
func compare
public func compare(str: CString): Int32
功能:按字典序比较两个字符串,同 C 语言中的 strcmp ,如果被比较的两个 CString 中存在空指针,该接口会抛出异常。
参数:
- str:比较的目标字符串
返回值:整数结果,相等时返回0,当该字符串比 str 小时,返回 -1,否则返回 1
异常:
- Exception:如果自身的数据指针或 str 为 null,抛出异常
func toString
public func toString(): String
功能:将 CString 类型转为仓颉的 String 类型。
返回值:转换后的字符串
func asResource
public func asResource(): CStringResource
功能:获取 CStringResource 对象。
返回值:表示 CStringResource 对象
struct CStringResource
public struct CStringResource <: Resource {
public let value: CString
}
CString 对应的资源管理类型,其实例可以通过 CString 的成员函数 asResource 获取。
value
public let value: CString
功能:表示当前实例管理的 CString 资源。
func isClosed
public func isClosed(): Bool
功能:判断该字符串是否被释放。
返回值:返回 true 为已释放。
func close
public func close(): Unit
功能:释放当前实例管理的 CString 类型实例指向的内容。
type Byte
public type Byte = UInt8
Byte 类型是内置类型 UInt8 的别名。
type Int
public type Int = Int64
Int 类型是内置类型 Int64 的别名。
type UInt
public type UInt = UInt64
UInt 类型是内置类型 UInt64 的别名。
func print
public func print(str: String, flush!: Bool = false): Unit
功能:向控制台输出数据。
注意:下列 print、 println、 eprint、 eprintln 函数默认为 UTF-8 编码,windows 环境需手动执行命令 chcp 65001(将 cmd 更改为 UTF-8 编码)。
参数:
- str:待输出的 String 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(str: String): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- str:待输出的 String 类型
func print
public func print<T>(arg: T, flush!: Bool = false): Unit where T <: ToString
功能:向控制台输出数据。
参数:
- arg:待输出的数据,支持实现了 ToString 接口的类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println<T>(arg: T): Unit where T <: ToString
功能:向控制台输出数据,输出末尾换行。
参数:
- arg:待输出的数据,支持实现了 ToString 接口的类型
func print
public func print(b: Bool, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- b:待输出的 Bool 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(b: Bool): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- b:待输出的 Bool 类型
func print
public func print(c: Char, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- c:待输出的 Char 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(c: Char): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- c:待输出的 Char 类型
func print
public func print(f: Float16, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- f:待输出的 Float16 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(f: Float16): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- f:待输出的 Float16 类型
func print
public func print(f: Float32, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- f:待输出的 Float32 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(f: Float32): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- f:待输出的 Float32 类型
func print
public func print(f: Float64, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- f:待输出的 Float64 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(f: Float64): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- f:待输出的 Float64 类型
func print
public func print(i: Int8, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 Int8 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: Int8): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 Int8 类型
func print
public func print(i: Int16, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 Int16 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: Int16): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 Int16 类型
func print
public func print(i: Int32, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 Int32 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: Int32): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 Int32 类型
func print
public func print(i: Int64, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 Int64 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: Int64): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 Int64 类型
func print
public func print(i: UInt8, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 UInt8 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: UInt8): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 UInt8 类型
func print
public func print(i: UInt16, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 UInt16 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: UInt16): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 UInt16 类型
func print
public func print(i: UInt32, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 UInt32 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: UInt32): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 UInt32 类型
func print
public func print(i: UInt64, flush!: Bool = false): Unit
功能:向控制台输出数据。
参数:
- i:待输出的 UInt64 类型
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(i: UInt64): Unit
功能:向控制台输出数据,输出末尾换行。
参数:
- i:待输出的 UInt64 类型
func eprintln
public func eprintln(str: String): Unit
功能:eprintln 用于打印错误消息,如抛出异常,消息将打印到标准错误文本流,而不是标准输出,输出末尾换行。
参数:
- str:待输出的字符串
func eprint
public func eprint(str: String, flush!: Bool = true): Unit
功能:eprint 用于打印错误消息,如抛出异常,消息将打印到标准错误文本流,而不是标准输出。
参数:
- str:待输出的字符串
- flush:是否清空缓存,true 清空,false 不清空,默认 false
func println
public func println(): Unit
功能:向标准输出(stdout)输出换行字符。
func ifSome
public func ifSome<T>(o: Option<T>, action: (T) -> Unit): Unit
功能:如果输入是 Option.Some 类型数据,则执行 action 函数。
参数:
- o:Option 类型输入
- action:待执行函数
func ifNone
public func ifNone<T>(o: Option<T>, action: () -> Unit): Unit
功能:如果输入是 Option.None 类型数据,则执行 action 函数。
参数:
- o:Option 类型输入
- action:待执行函数
func acquireArrayRawData
public unsafe func acquireArrayRawData<T>(arr: Array<T>): CPointerHandle<T> where T <: CType
功能:获取 Array
返回值:返回的原始指针实例
func releaseArrayRawData
public unsafe func releaseArrayRawData<T>(handle: CPointerHandle<T>): Unit where T <: CType
功能:释放 acquireArrayRawData 获取的原始指针实例。
参数:
- handle:待释放的指针实例
func refEq
public func refEq(a: Object, b: Object): Bool
功能:判断两个 Object 对象的内存地址是否是同一个。
参数:
- a:一个 Object 对象
- b:另一个 Object 对象
返回值:同一个返回 true,否则返回 false
func CJ_CORE_AddAtexitCallback
public func CJ_CORE_AddAtexitCallback(callback: () -> Unit): Unit
功能:注册退出函数,此处建议使用 os 库内 Process.atexit 函数,除非有制作进程管理框架的需要,否则不建议使用。
参数:
- callback:回调函数
func CJ_CORE_ExecAtexitCallbacks
public func CJ_CORE_ExecAtexitCallbacks(): Unit
功能:执行注册函数, 此处建议使用 os 库内 Process.exit 函数,除非有制作进程管理框架的需要,否则不建议使用。
func zeroValue
public unsafe func zeroValue<T>(): T
功能:获取一个已全零初始化的 T 类型实例,这个实例一定要赋值为正常初始化的值,再使用。
返回值:一个已全零初始化的 T 类型实例
func sizeOf
public func sizeOf<T>(): UIntNative where T <: CType
功能:获取类型 T 所占用的内存空间大小。
返回值:类型 T 所占用内存空间的字节数
func alignOf
public func alignOf<T>(): UIntNative where T <: CType
功能:获取类型 T 的内存对齐值。
返回值:对类型 T 做内存对齐的字节数
interface Countable
public interface Countable<T> {
func next(right: Int64): T
func position(): Int64
}
该接口表示类型可数。
func next
func next(right: Int64): T
功能:返回两个实例的和。
参数:
- right:另一个为 Int64 类型的实例
返回值:返回两个实例和的 T 类型
func position
func position(): Int64
功能:将对象转为 Int64 类型。
返回值:转换后的 Int64 整型
interface Collection
public interface Collection<T> <: Iterable<T> {
prop size: Int64
func isEmpty(): Bool
func toArray(): Array<T>
}
该接口用来表示集合。
prop size
prop size: Int64
功能:获取当前实例的长度。
返回值:列表的容量
func isEmpty
func isEmpty(): Bool
功能:判断当前实例是否为空。
返回值:如果为空返回 true,否则返回 false
func toArray
func toArray(): Array<T>
功能:将当前实例转为数组类型。
返回值:转换后的数组
interface Less
public interface Less<T> {
operator func <(rhs: T): Bool
}
该接口表示小于计算。
operator func <
operator func <(rhs: T): Bool
功能:判断一个实例是否小于另一个实例。
参数:
- rhs:另一个实例
返回值:如果小于,返回 true,否则返回 false
interface Greater
public interface Greater<T> {
operator func >(rhs: T): Bool
}
该接口表示大于计算。
operator func >
operator func >(rhs: T): Bool
功能:判断一个实例是否大于另一个实例。
参数:
- rhs:另一个实例
返回值:如果大于,返回 true,否则返回 false
interface LessOrEqual
public interface LessOrEqual<T> {
operator func <=(rhs: T): Bool
}
该接口表示小于等于计算。
operator func <=
operator func <=(rhs: T): Bool
功能:判断一个实例是否小于等于另一个实例。
参数:
- rhs:另一个实例
返回值:如果小于等于,返回 true,否则返回 false
interface GreaterOrEqual
public interface GreaterOrEqual<T> {
operator func >=(rhs: T): Bool
}
该接口表示大于等于计算。
operator func >=
operator func >=(rhs: T): Bool
功能:判断一个实例是否大于等于另一个实例。
参数:
- rhs:另一个实例
返回值:如果大于等于,返回 true,否则返回 false
interface Comparable
public interface Comparable<T> <: Equatable<T> & Less<T> & Greater<T> & LessOrEqual<T> & GreaterOrEqual<T> {
func compare(that: T): Ordering
}
该接口表示比较运算。
func compare
func compare(that: T): Ordering
功能:判断一个实例与另一个实例的关系。
参数:
- that:另一个实例
返回值:如果大于,返回 Ordering.GT,如果等于,返回 Ordering.EQ,如果小于,返回 Ordering.LT
interface Equal
public interface Equal<T> {
operator func ==(rhs: T): Bool
}
该接口用来提供 Bool 、Char、Int64、Int32、Int16、Int8、UIntNative、UInt64、UInt32、UInt16、UInt8、Float64、Float32、Float16、String、Array、Box、ArrayList、HashSet 的直接判等操作。
operator func ==
operator func ==(rhs: T): Bool
功能:判断两个实例是否相等。
参数:
- rhs:另一个实例
返回值:如果相等,返回 true,否则返回 false
interface NotEqual
public interface NotEqual<T> {
operator func !=(rhs: T): Bool
}
该接口表示判不等运算。
operator func !=
operator func !=(rhs: T): Bool
功能:判断两个实例是否不相等。
参数:
- rhs:另一个实例
返回值:如果不相等,返回 true,否则返回 false
interface Equatable
public interface Equatable<T> <: Equal<T> & NotEqual<T>
该接口表示判等和判不等两种运算。
interface Hashable
public interface Hashable {
func hashCode(): Int64
}
该接口用来提供 Bool、Char、IntNative、Int64、Int32、Int16、Int8、UIntNative、UInt64、UInt32、UInt16、UInt8、Float64、Float32、Float16、String、Box 的哈希值。
func hashCode
func hashCode(): Int64
功能:获得实例类型的哈希值。
返回值:返回实例类型的哈希值
interface Iterable
public interface Iterable<E> {
func iterator(): Iterator<E>
}
该接口用来提供具体类型的迭代器。
func iterator
func iterator(): Iterator<E>
功能:返回实例类型的迭代器。
返回值:返回实例类型的迭代器
interface Iterator
public interface Iterator<E> <: Iterable<E> {
func next(): Option<E>
}
该接口用来返回迭代过程中的下一个元素。
func next
func next(): Option<E>
功能:返回迭代过程中的下一个元素。
返回值:迭代过程中的下一个元素
interface Resource
public interface Resource {
func isClosed(): Bool
func close(): Unit
}
该接口用于资源管理,需要用 close 释放资源的类可实现该接口。
func isClosed
func isClosed(): Bool
功能:判断资源是否关闭。
返回值:如果已经关闭返回 true,否则返回 false
func close
func close(): Unit
功能:关闭资源。
interface ToString
public interface ToString {
func toString(): String
}
该接口用来提供具体类型的字符串表示。
func toString
func toString(): String
功能:返回实例类型的字符串表示。
返回值:返回实例类型的字符串表示
interface CType
sealed interface CType
此接口不包含任何函数,它可以作为所有 C 互操作支持的类型的父类型,便于在泛型约束中使用。
需要注意的是:
CType接口是仓颉中的一个接口类型,它本身不满足CType约束;CType接口不允许被继承、扩展;CType接口不会突破子类型的使用限制。
type Rune
public type Rune = Char
重命名 Char 类型。
struct String
public struct String <: Collection<Byte> & Equatable<String> & Comparable<String> & Hashable & ToString {
public static let empty: String
public const init()
public init(value: Array<Rune>)
public init(value: Collection<Rune>)
}
此类主要用于实现 String 数据结构及相关操作函数。
empty
public static let empty: String
功能:创建一个空的字符串并返回。
init
public const init()
功能:无参构造函数,创建一个空的字符串。
init
public init(value: Array<Rune>)
功能:通过 Rune 数组创建一个字符串。
参数:
- value:Rune 数组
init
public init(value: Collection<Rune>)
功能:通过 Rune 列表创建一个字符串。
参数:
- value:Rune 列表
func getRaw
public unsafe func getRaw(): CPointerHandle<UInt8>
功能:返回当前 String 的原始指针,用于和C语言交互,使用完后需要 releaseRaw 函数释放该指针。
约束:getRaw() 与 releaseRaw() 之间仅可包含简单的 foreign C 函数调用等逻辑,不构造例如 CString 等的仓颉对象,否则可能造成不可预知的错误。
返回值:返回的原始指针实例
func releaseRaw
public unsafe func releaseRaw(cp: CPointerHandle<UInt8>): Unit
功能:释放 getRaw 函数获取的指针。
注意:释放时只能释放同一个 String 获取的指针,如果释放了其他 String 获取的指针,会出现不可预知的错误。
参数:
- cp:待释放的指针实例
func iterator
public func iterator(): Iterator<Byte>
功能:获得字符串的 UTF-8 编码字节迭代器,可用于支持 for-in 循环。
返回值:字符串的 UTF-8 编码字节迭代器
func runes
public func runes(): Iterator<Rune>
功能:获得字符串的 Rune 迭代器。
返回值:字符串的 Rune 迭代器
func tryGet
public func tryGet(index: Int64): Option<Byte>
功能:返回字符串下标 index 对应的 UTF-8 编码字节值。
参数:
- index:要获取的字节值的下标
返回值:获取得到下标对应的 UTF-8 编码字节值,当 index 小于 0 或者大于等于字符串长度,则返回 Option<Byte>.None
func toRuneArray
public func toRuneArray(): Array<Rune>
功能:返回字符串的 Rune 数组。如果原字符串为空字符串,则返回空数组。
返回值:字符串的 Rune 数组
func toString
public func toString(): String
功能:获得字符串本身。
返回值:返回字符串本身
func clone
public func clone(): String
功能:返回原字符串的拷贝。
返回值:拷贝得到的新字符串
prop size
public prop size: Int64
功能:返回字符串 UTF-8 编码后的字节长度
返回值:字符串 UTF-8 编码后的字节长度
func isEmpty
public func isEmpty(): Bool
功能:判断原字符串是否为空字符串。
返回值:如果为空返回 true,否则返回 false
func isAsciiBlank
public func isAsciiBlank(): Bool
功能:判断字符串是否为空或者字符串中的所有 Rune 都是 ascii 码的空白字符(包括:0x09、0x10、0x11、0x12、0x13、0x20)。
返回值:如果是返回 true,否则返回 false
func hashCode
public func hashCode(): Int64
功能:获得字符串的哈希值。
返回值:返回字符串的哈希值
func indexOf
public func indexOf(b: Byte): Option<Int64>
功能:返回指定字节 b 第一次出现的在原字符串内的索引。
参数:
- b:搜索的 UTF-8 编码字节
返回值:如果原字符串中包含指定字节,返回其第一次出现的索引,如果原字符串中没有此字节,返回 Option<Int64>.None
func indexOf
public func indexOf(b: Byte, fromIndex: Int64): Option<Int64>
功能:从原字符串指定索引开始搜索,获取指定 UTF-8 编码字节第一次出现的在原字符串内的索引。
参数:
- b:搜索的 UTF-8 编码字节
- fromIndex:以指定的索引 fromIndex 开始搜索
返回值:如果搜索成功,返回指定字节第一次出现的索引,否则返回 Option<Int64>.None。特别地,当 fromIndex 小于零,效果同 0,当 fromIndex 大于等于原字符串长度,返回 Option<Int64>.None
func indexOf
public func indexOf(str: String): Option<Int64>
功能:返回指定字符串 str 在原字符串中第一次出现的起始索引。
参数:
- str:搜索的字符串
返回值:如果原字符串包含 str 字符串,返回其第一次出现的索引,如果原字符串中没有 str 字符串,返回 None
func indexOf
public func indexOf(str: String, fromIndex: Int64): Option<Int64>
功能:从原字符串 fromIndex 索引开始搜索,获取指定字符串 str 第一次出现的在原字符串的起始索引。
参数:
- str:待搜索的字符串
- fromIndex:以指定的索引 fromIndex 开始搜索。
返回值:如果搜索成功,返回 str 第一次出现的索引,否则返回 None。特别地,当 str 是空字符串时,如果fromIndex 大于 0,返回 None,否则返回 Some(0)。当 fromIndex 小于零,效果同 0,当 fromIndex 大于等于原字符串长度返回 None
func lastIndexOf
public func lastIndexOf(b: Byte): Option<Int64>
功能:返回指定 UTF-8 编码字节 b 最后一次出现的在原字符串内的索引。
参数:
- b:搜索的 UTF-8 编码字节
返回值:如果原字符串中包含此字节,返回其最后一次出现的索引,否则返回 Option<Int64>.None
func lastIndexOf
public func lastIndexOf(b: Byte, fromIndex: Int64): Option<Int64>
功能:从原字符串 fromIndex 索引开始搜索,返回指定 UTF-8 编码字节 b 最后一次出现的在原字符串内的索引。
参数:
- b:搜索的 UTF-8 编码字节
- fromIndex:以指定的索引 fromIndex 开始搜索
返回值:如果搜索成功,返回指定字节最后一次出现的索引,否则返回 Option<Int64>.None。特别地,当 fromIndex 小于零,效果同 0,当 fromIndex 大于等于原字符串长度,返回 Option<Int64>.None
func lastIndexOf
public func lastIndexOf(str: String): Option<Int64>
功能:返回指定字符串 str 最后一次出现的在原字符串的起始索引。
参数:
- str:搜索的字符串
返回值:如果原字符串中包含 str 字符串,返回其最后一次出现的索引,否则返回 Option<Int64>.None
func lastIndexOf
public func lastIndexOf(str: String, fromIndex: Int64): Option<Int64>
功能:从原字符串指定索引开始搜索,获取指定字符串 str 最后一次出现的在原字符串的起始索引。
参数:
- str:待搜索的字符串
- fromIndex:以指定的索引 fromIndex 开始搜索
返回值:如果这个字符串在位置 fromIndex 及其之后没有出现,则返回 Option<Int64>.None。特别地,当 str 是空字符串时,如果 fromIndex 大于 0,返回 Option<Int64>.None,否则返回 Option<Int64>.Some(0),当 fromIndex 小于零,效果同 0,当 fromIndex 大于等于原字符串长度返回 Option<Int64>.None
func isAscii
public func isAscii(): Bool
功能:判断字符串是否是一个 Ascii 字符串,如果字符串为空或没有 Ascii 以外的字符,则返回 true。
返回值:是则返回 true,不是则返回 false
func toArray
public func toArray(): Array<Byte>
功能:返回字符串的 UTF-8 编码的字节数组。
返回值:Byte 类型的 Array
func count
public func count(str: String): Int64
功能:返回子字符串 str 在原字符串中出现的次数。
参数:
- str:被搜索的子字符串
返回值:出现的次数,当 str 为空字符串时,返回原字符串中 Rune 的数量加一
func split
public func split(str: String, removeEmpty!: Bool = false): Array<String>
功能:对原字符串按照字符串 str 分隔符分割。当 str 未出现在原字符串中,返回长度为 1 的字符串数组,唯一的元素为原字符串。
参数:
- str:字符串分隔符
- removeEmpty:移除分割结果中的空字符串,默认值为 false
返回值:分割后的字符串数组
func split
public func split(str: String, maxSplits: Int64, removeEmpty!: Bool = false): Array<String>
功能:对原字符串按照字符串 str 分隔符分割。当 maxSplit 为 0 时,返回空的字符串数组;当 maxSplit 为 1 时,返回长度为 1 的字符串数组,唯一的元素为原字符串;当 maxSplit 为负数时,返回完整分割后的字符串数组;当 maxSplit 大于完整分割出来的子字符串数量时,返回完整分割的字符串数组;当 str 未出现在原字符串中,返回长度为 1 的字符串数组,唯一的元素为原字符串;当 str 为空时,对每个字符进行分割;当原字符串和分隔符都为空时,返回空字符串数组。
参数:
- str:字符串分隔符
- maxSplit:最多分割为 maxSplit 个子字符串
- removeEmpty:移除分割结果中的空字符串,默认值为 false
返回值:分割后的字符串数组
func lazySplit
public func lazySplit(str: String, removeEmpty!: Bool = false): Iterator<String>
功能:对原字符串按照字符串 str 分隔符分割。当 str 未出现在原字符串中,返回大小为 1 的字符串迭代器,唯一的元素为原字符串。
参数:
- str:字符串分隔符
- removeEmpty:移除分割结果中的空字符串,默认值为 false
返回值:分割后的字符串迭代器
func lazySplit
public func lazySplit(str: String, maxSplits: Int64, removeEmpty!: Bool = false): Iterator<String>
功能:对原字符串按照字符串 str 分隔符分割。当 maxSplit 为 0 时,返回空的字符串迭代器;当 maxSplit 为 1 时,返回大小为 1 的字符串迭代器,唯一的元素为原字符串;当 maxSplit 为负数时,直接返回分割后的字符串迭代器;当 maxSplit 大于完整分割出来的子字符串数量时,返回完整分割的字符串迭代器当 str 未出现在原字符串中,返回大小为 1 的字符串迭代器,唯一的元素为原字符串;当 str 为空时,对每个字符进行分割;当原字符串和分隔符都为空时,返回空字符串迭代器。
参数:
- str:字符串分隔符
- maxSplit:最多分割为 maxSplit 个子字符串
- removeEmpty:移除分割结果中的空字符串,默认值为 false
返回值:分割后的字符串迭代器
func replace
public func replace(old: String, new: String): String
功能:使用新字符串替换原字符串中旧字符串。
参数:
- old:旧字符串
- new:新字符串
返回值:替换后的新字符串
异常:
- OutOfMemoryError:如果此函数分配内存时产生错误,抛出异常
func toAsciiLower
public func toAsciiLower(): String
功能:将该字符串中所有 Ascii 大写字母转化为 Ascii 小写字母。
返回值:转换后的新字符串
func toAsciiUpper
public func toAsciiUpper(): String
功能:将该字符串中所有 Ascii 小写字母转化为 Ascii 大写字母。
返回值:转换后的新字符串
func toAsciiTitle
public func toAsciiTitle(): String
功能:将该字符串标题化,只转换 Ascii 字符,当该英文字符是字符串中第一个字符或者该字符的前一个字符不是英文字符,则该字符大写,其他英文字符小写,非英文字符不变。
返回值:转换后的新字符串
func trimAscii
public func trimAscii(): String
功能:去除原字符串开头结尾以 whitespace 字符组成的子字符串(Ascii whitespace)。
返回值:转换后的新字符串
func trimAsciiLeft
public func trimAsciiLeft(): String
功能:去除原字符串开头以 whitespace 字符组成的子字符串(Ascii whitespace)。
返回值:转换后的新字符串
func trimAsciiRight
public func trimAsciiRight(): String
功能:去除原字符串结尾以 whitespace 字符组成的子字符串(Ascii whitespace)。
返回值:转换后的新字符串
func trimLeft
public func trimLeft(prefix: String): String
功能:去除前缀是 prefix 的字符串。
参数:
- prefix:如果字符串的前缀是 prefix,则去除
返回值:转换后的新字符串
func trimRight
public func trimRight(suffix: String): String
功能:去除后缀是 suffix 的字符串。
参数:
- suffix:如果字符串的后缀是 suffix,则去除
返回值:转换后的新字符串
func contains
public func contains(str: String): Bool
功能:判断原字符串中是否包含字符串 str。
参数:
- str:被判断的字符串,如果 str 字符串长度为 0,返回 true
返回值:如果字符串 str 在原字符串中,返回 true,否则返回 false
func startsWith
public func startsWith(prefix: String): Bool
功能:判断原字符串是否以 prefix 字符串为前缀开始。
参数:
- str:被判断的前缀字符串,如果 str 长度为 0,返回 true
返回值:如果字符串 str 是原字符串的前缀,返回 true,否则返回 false
func endsWith
public func endsWith(suffix: String): Bool
功能:判断原字符串是否以 suffix 字符串为后缀结尾。
参数:
- str:被判断的后缀字符串,当 str 长度为 0 时,返回 true
返回值:如果字符串 str 是原字符串的后缀,返回 true,否则返回 false
func padLeft
public func padLeft(totalWidth: Int64, padding!: String = " "): String
功能:按指定长度右对齐原字符串,如果原字符串长度小于指定长度,在其左侧添加指定字符串。
参数:
- totalWidth:按指定长度 totalWidth 右对齐
- padding:当长度不够时,在左侧用指定的字符串 padding 进行填充
返回值:填充后的字符串,当指定长度小于字符串长度时,返回字符串本身,不会发生截断;当指定长度大于字符串长度时,在左侧添加 padding 字符串,当 padding 长度大于 1 时,返回字符串的长度可能大于指定长度
异常:
- IllegalArgumentException:如果 totalWidth 小于 0,抛出异常
func padRight
public func padRight(totalWidth: Int64, padding!: String = " "): String
功能:按指定长度左对齐原字符串,如果原字符串长度小于指定长度,在其右侧添加指定字符串。
参数:
- totalWidth:按指定长度 totalWidth 左对齐
- padding:当长度不够时,在右侧用指定的字符串 padding 进行填充
返回值:填充后的字符串,当指定长度小于字符串长度时,返回字符串本身,不会发生截断;当指定长度大于字符串长度时,在右侧添加 padding 字符串,当 padding 长度大于 1 时,返回字符串的长度可能大于指定长度
异常:
- IllegalArgumentException:如果 totalWidth 小于 0,抛出异常
func compare
public func compare(str: String): Ordering
功能:按字典序比较原字符串和 str 字符串,比较基于每个byte,按照UTF-8编码的byte进行比较。Ordering.GT 表示原字符串字典序大于 str 字符串,Ordering.LT 表示原字符串字典序小于 str 字符串,Ordering.EQ 表示两个字符串字典序相等。
参数:
- str:被比较的字符串
返回值:返回 enum 值 Ordering 表示结果,
异常:
- IllegalArgumentException:如果两个字符串的原始数据中存在无效的 UTF-8 编码,抛出异常
operator func ==
public const operator func ==(right: String): Bool
功能:判断两个字符串是否相等。
返回值:相等返回 true,不相等返回 false
operator func !=
public const operator func !=(right: String): Bool
功能:判断两个字符串是否不相等。
返回值:不相等返回 true,相等返回 false
operator func >
public const operator func >(right: String): Bool
功能:判断两个字符串大小。
返回值:原字符串字典序大于 right 时,返回 true,否则返回 false
operator func >=
public const operator func >=(right: String): Bool
功能:判断两个字符串大小。
返回值:原字符串字典序大于或等于 right 时,返回 true,否则返回 false
operator func <
public const operator func <(right: String): Bool
功能:判断两个字符串大小。
返回值:原字符串字典序小于 right 时,返回 true,否则返回 false
operator func <=
public const operator func <=(right: String): Bool
功能:判断两个字符串大小。
返回值:原字符串字典序小于或等于 right 时,返回 true,否则返回 false
operator func +
public const operator func +(right: String): String
功能:两个字符串相加,将 right 字符串拼接在原字符串的末尾。
返回值:返回拼接后的字符串
operator func *
public const operator func *(count: Int64): String
功能:原字符串重复 count 次。
返回值:返回重复 count 次后的新字符串
operator func []
public const operator func [](index: Int64): Byte
功能:返回指定索引 index 处的 UTF-8 编码字节。
参数:
- index:要获取 UTF-8 编码字节的下标
返回值:获取得到下标对应的 UTF-8编码字节
异常:
- IndexOutOfBoundsException:如果 index 小于 0 或大于等于字符串长度,抛出异常
operator func []
public const operator func [](range: Range<Int64>): String
功能:获取切片后的字符串。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:
- start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响
- hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响
参数:
- range:切片的范围
返回值:新的字符串
异常:
- IndexOutOfBoundsException:如果切片范围超过原字符串边界,抛出异常
- IllegalArgumentException:如果 range.step 不等于 1,抛出异常
- IllegalArgumentException:如果范围起止点不是字符边界,抛出异常
func join
public static func join(strArray: Array<String>, delimiter!: String = String.empty): String
功能:连接字符串列表中的所有字符串。
参数:
- value:需要被连接的字符串数组,当数组为空时,返回空字符串
- delimiter:用于连接的中间字符串,其默认值为 String.empty
返回值:连接后的新字符串
func rawData
public unsafe func rawData(): Array<Byte>
功能:返回字符串的 UTF-8 编码的原始字节数组,开发者如果对该数组修改会破坏字符串的并发安全
返回值:Byte 类型的 Array
func fromUtf8
public static func fromUtf8(utf8Data: Array<UInt8>): String
功能:根据 UTF-8 数组创建一个字符串。
参数:
- utf8Data:需要构造字符串的 UTF-8 数组
返回值:创建的字符串
异常:
- IllegalArgumentException:入参不符合 utf-8 序列规则,抛出异常
func fromUtf8Unchecked
public static unsafe func fromUtf8Unchecked(utf8Data: Array<UInt8>): String
功能:根据 UTF-8 数组创建一个字符串,相较于 fromUtf8 函数,它并没有针对于字节数组进行 UTF-8 相关规则的检查,所以它所构建的字符串并不一定保证是合法的,甚至出现非预期的异常,如果不是某些场景下的速度考虑,请优先使用安全的 fromUtf8 函数。
参数:
- utf8Data:需要构造字符串的 UTF-8 数组
返回值:创建的字符串
class StringBuilder
public class StringBuilder <: ToString {
public init()
public init(str: String)
public init(r: Rune, n: Int64)
public init(value: Array<Char>)
public init(capacity: Int64)
}
该类主要用于字符串的构建,其中实现了 StringBuilder 相关接口;StringBuilder 在字符串的构建上效率高于 String,当需要多种类型和多个值构建 String 时推荐使用 StringBuilder。
init
public init()
功能:构造一个初始容量为 32 的空 StringBuilder 实例。
init
public init(str: String)
功能:使用参数 str 指定的字符串初始化 StringBuilder 实例。
参数:
- str:初始化
StringBuilder实例的字符串
init
public init(r: Rune, n: Int64)
功能:使用 n 个 r 字符初始化 StringBuilder 实例。
参数:
- r:初始化
StringBuilder实例的字符 - n:字符
r的数量
异常:
- IllegalArgumentException: 当参数
n小于 0 时,抛出异常
init
public init(value: Array<Rune>)
功能:使用参数 value 指定的字符数组初始化一个 StringBuilder 实例。
参数:
- value:初始化
StringBuilder实例的字符数组
init
public init(capacity: Int64)
功能:使用参数 capacity 指定的容量初始化一个空 StringBuilder 实例。
参数:
- capacity:初始化
StringBuilder的字节容量
异常:
- IllegalArgumentException: 当参数
capacity的值小于等于 0 时,抛出异常
prop size
public prop size: Int64
功能:返回 StringBuilder 实例中字符串 UTF-8 编码后的字节长度。
返回值 Int64 - StringBuilder 实例中字符串 UTF-8 编码后的字节长度
prop capacity
public prop capacity: Int64
功能:返回 StringBuilder 实例能容纳字符串 UTF-8 编码后的字节长度。
返回值 Int64 - StringBuilder 实例中能容纳字符串 UTF-8 编码后的字节长度
func reserve
public func reserve(additional: Int64): Unit
功能:将 StringBuilder 扩容 additional 大小。当 additional 小于等于零,或剩余容量大于等于 additional 时,不发生扩容;当剩余容量小于 additional 时,扩容至当前容量的 1.5 倍(向下取整)与 size + additional 的最大值。
参数:
- additional:指定
StringBuilder的扩容大小
func reset
public func reset(capacity!: Option<Int64> = None): Unit
功能:清空当前 StringBuilder,并将容量重置为 capacity 指定的值。
参数:
- capacity:重置后
StringBuilder实例的容量大小,默认值None表示采用默认大小容量(32)。
异常:
- IllegalArgumentException: 当参数
capacity的值小于等于 0 时,抛出异常
func toString
public func toString(): String
功能:返回 StringBuilder 实例中的字符串。
返回值:StringBuilder 实例中的字符串
func append
public func append(r: Rune): Unit
功能:在 StringBuilder 末尾插入参数 r 指定的字符。
参数:
- r:插入的字符
func append
public func append(str: String): Unit
功能:在 StringBuilder 末尾插入参数 str 指定的字符串。
参数:
- str:插入的字符串
func append
public func append(sb: StringBuilder): Unit
功能:在 StringBuilder 末尾插入参数 sb 指定的 StringBuilder 中的内容。
参数:
- sb:插入的
StringBuilder实例
func append
public func append(runeArr: Array<Rune>): Unit
功能:在 StringBuilder 末尾插入一个 Rune 数组中所有字符。
参数:
- runeArr:插入的
Rune数组
func append
public func append(cstr: CString): Unit
功能:在 StringBuilder 末尾插入参数 cstr 指定 CString 中的内容。
参数:
- cstr:插入的
CString
func append
public func append<T>(v: T): Unit where T <: ToString
功能:在 StringBuilder 末尾插入参数 v 指定 T 类型的字符串表示,类型 T 需要实现 ToString 接口。
参数:
- v:插入的
T类型实例
func append
public func append<T>(val: Array<T>): Unit where T <: ToString
功能:在 StringBuilder 末尾插入参数 val 指定的 Array<T> 的字符串表示,类型 T 需要实现 ToString 接口。
参数:
- val:插入的
Array<T>类型实例
func append
public func append(b: Bool): Unit
功能:在 StringBuilder 末尾插入参数 b 的字符串表示。
参数:
- b:插入的
Bool类型的值,取值 "true" 或者 "false"
func append
public func append(n: Int64): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Int64类型的值
func append
public func append(n: Int32): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Int32类型的值
func append
public func append(n: Int16): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Int16类型的值
func append
public func append(n: Int8): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Int8类型的值
func append
public func append(n: UInt64): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
UInt64类型的值
func append
public func append(n: UInt32): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
UInt32类型的值
func append
public func append(n: UInt16): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
UInt16类型的值
func append
public func append(n: UInt8): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
UInt8类型的值
func append
public func append(n: Float64): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Float64类型的值
func append
public func append(n: Float32): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Float32类型的值
func append
public func append(n: Float16): Unit
功能:在 StringBuilder 末尾插入参数 n 的字符串表示。
参数:
- n:插入的
Float16类型的值
func appendFromUtf8
public func appendFromUtf8(arr: Array<Byte>): Unit
功能:在 StringBuilder 末尾插入参数 arr 指定 utf8 编码的字节数组。
参数:
- arr:插入的 utf8 字节数组
异常:
- IllegalArgumentException:当字节数组不符合 utf8 编码规则时,抛出异常
func appendFromUtf8Unchecked
public unsafe func appendFromUtf8Unchecked(arr: Array<Byte>): Unit
功能:在 StringBuilder 末尾插入参数 arr 指定 utf8 编码的字节数组, 相较于 appendFromUtf8 函数,它并没有针对于字节数组进行 utf8 相关规则的检查,所以它所构建的字符串并不一定保证是合法的,甚至出现非预期的异常,如果不是某些场景下的速度考虑,请优先使用安全的 appendFromUtf8 函数。
参数:
- arr:插入的 utf8 字节数组
enum AnnotationKind
public enum AnnotationKind {
| Type
| Parameter
| Init
| MemberProperty
| MemberFunction
| MemberVariable
}
枚举类型 AnnotationKind 表示自定义注解希望支持的位置。
Type
Type
功能:类型声明(class、struct、enum、interface)。
Parameter
Parameter
功能:成员函数/构造函数中的参数。
Init
Init
功能:构造函数声明。
MemberProperty
MemberProperty
功能:成员属性声明
MemberFunction
MemberFunction
功能:成员函数声明
MemberVariable
MemberVariable
功能:成员变量声明
示例
Future 的使用
主线程和新线程同时尝试打印一些文本。
代码如下:
from std import sync.sleep
from std import time.{Duration, DurationExtension}
main(): Int64 {
spawn { =>
for (i in 0..10) {
println("New thread, number = ${i}")
sleep(100 * Duration.millisecond) /* 睡眠 100 毫秒 */
}
}
for (i in 0..5) {
println("Main thread, number = ${i}")
sleep(100 * Duration.millisecond) /* 睡眠 100 毫秒 */
}
return 0
}
运行结果如下:
Main thread, number = 0
New thread, number = 0
Main thread, number = 1
New thread, number = 1
Main thread, number = 2
New thread, number = 2
Main thread, number = 3
New thread, number = 3
Main thread, number = 4
New thread, number = 4
New thread, number = 5
- 注意,上述打印信息仅做参考。
Future 的 get 的使用
主线程等待创建线程执行完再执行。
代码如下:
from std import sync.sleep
from std import time.{Duration, DurationExtension}
main(): Int64 {
let fut: Future<Unit> = spawn { =>
for (i in 0..10) {
println("New thread, number = ${i}")
sleep(100 * Duration.millisecond) /* 睡眠 100 毫秒 */
}
}
fut.get() /* 等待线程完成 */
for (i in 0..5) {
println("Main thread, number = ${i}")
sleep(100 * Duration.millisecond) /* 睡眠 100 毫秒 */
}
return 0
}
运行结果如下:
New thread, number = 0
New thread, number = 1
New thread, number = 2
New thread, number = 3
New thread, number = 4
New thread, number = 5
New thread, number = 6
New thread, number = 7
New thread, number = 8
New thread, number = 9
Main thread, number = 0
Main thread, number = 1
Main thread, number = 2
Main thread, number = 3
Main thread, number = 4
创建 Array 并取值
下面是创建 Array,使用下标取值的示例。
代码如下:
main() {
var array: Array<Int64> = [1, 2, 3, 4, 5]
println("array[1] = ${array[1]}")
return 0
}
运行结果如下:
array[1] = 2
创建 String 并访问每个字符
下面是创建 String 并且通过 for-in 访问每个 UTF-8 编码字节的示例。
代码如下:
main() {
var str = "仓颉" // E4BB93 E9A289
for (c in str) {
println(c)
}
}
运行结果如下:
228
187
147
233
162
137
CString 与 C 代码交互
C 代码中分别提供两个函数: getCString 函数,用于返回一个 C 侧的字符串指针; printCString 函数,用于打印来自仓颉侧 CString 。
#include <stdio.h>
char *str = "CString in C code.";
char *getCString() { return str; }
void printCString(char *s) { printf("%s\n", s); }
在仓颉代码中,创建一个 CString 对象,传递给 C 侧打印。并且获取 C 侧字符串,在仓颉侧打印:
foreign func getCString(): CString
foreign func printCString(s: CString): Unit
main() {
// Construct by a Cangjie String.
unsafe {
let s: CString = LibC.mallocCString("CString in Cangjie code.")
printCString(s)
LibC.free(s)
}
unsafe {
// Get a CString from C code and use `toString` convert to cangjie String.
let cs = getCString()
println(cs.toString())
}
// Use CStringResource by try-with-resource
let cs = unsafe { LibC.mallocCString("CString in Cangjie code.") }
try (csr = cs.asResource()) {
unsafe { printCString(csr.value) }
}
0
}
示例输出:
CString in Cangjie code.
CString in C code.
CString in Cangjie code.
argopt 包
介绍
argopt 包主要用于帮助解析命令行参数。
主要接口
class ArgOpt
public class ArgOpt {
public init(shortArgFormat: String)
public init(longArgList: Array<String>)
public init(shortArgFormat: String, longArgList: Array<String>)
public init(args: Array<String>, shortArgFormat: String, longArgList: Array<String>)
}
ArgOpt 类主要用于帮助解析命令行参数(包括参数的特殊含义,如形式为 "-" 和 "--"),该类使用了 String 类和 Char 类的一些函数来辅助实现,提供了一组针对命令行参数字符串或数组的解析函数。
一个命令行参数是由前缀符号、参数名、参数值组成,其中 "-" 表示短参(短命令行参数)的前缀,"--" 表示长参(长命令行参数)的前缀。 可解析的短参参数名只能是字母,可解析长参参数名字符串需满足:以字母开头,字符串中不能包含 "="。
对于以下函数中短参名字符串,和长参名字符串数组入参,需要注意以下几点:
- 短参名字符串的入参,格式为:"a:",规范为:一位字母和 ":" 的组合,例如:"ab:",该例仅解析 b 作为短参名。
- 长参名字符串数组入参,字符串格式为:"--testA=" 或 "testA=",规范为:"--" + 长参参数名 + "="(前缀"--"可省略)。
- 其它情况会可造成不解析或者异常。
init
public init(shortArgFormat: String)
功能:构造 ArgOpt 实例,并从短参名字符串中解析短参名。
参数:
- shortArgFormat:包含短参名的字符串
异常:
- IllegalArgumentException:短参名字符串不符合规范
init
public init(longArgList: Array<String>)
功能:构造 ArgOpt 实例,并从列表的字符串中解析长参名。
参数:
- longArgList:包含长参名的字符串数组
异常:
- IllegalArgumentException:字符串数组中的长参名字符串不符合规范
init
public init(shortArgFormat: String, longArgList: Array<String>)
功能:构造 ArgOpt 实例,并从短参名字符串中解析短参名、从列表的字符串中解析长参名。
参数:
- shortArgFormat:包含短参名的字符串
- longArgList:包含长参名的字符串数组
异常:
- IllegalArgumentException:短参名字符串不符合规范,或字符串数组中的长参名字符串不符合规范
init
public init(args: Array<String>, shortArgFormat: String, longArgList: Array<String>)
功能:构造 ArgOpt 实例,并从短参名字符串中解析短参名、从列表的字符串中解析长参名,若解析成功,则依据解析出的参数名从参数 args 指定的命令行参数中解析参数名的对应取值。
参数:
- args:待解析的命令行参数字符串数组
- shortArgFormat:包含短参名的字符串
- longArgList:包含长参名的字符串数组
异常:
- IllegalArgumentException:短参名字符串不符合规范,或字符串数组中的长参名字符串不符合规范
func getArg
public func getArg(arg: String): Option<String>
功能:返回入参 arg 指定参数的解析值。
参数:
- arg:前缀和参数名组成的字符串(可省略前缀)
返回值:参数解析值
func getUnparseArgs
public func getUnparseArgs(): Array<String>
功能:返回没有被解析的字符串集合。
返回值:存放没有被解析的字符串的数组
func getArgumentsMap
public func getArgumentsMap(): HashMap<String, String>
功能:获取所有已解析的参数名和取值,参数名包含前缀符号。
返回值:存放解析出键值对的哈希表
示例
ArgOpt 构造异常
抛异常示例。
代码如下:
from std import argopt.*
main() {
/* IllegalArgumentException: Invalid character string: please check */
let arg: String = "ab:-~"
try {
/* the parameter: ab:-~ */
let ao: ArgOpt = ArgOpt(arg)
let p: Option<String> = ao.getArg("-b")
match (p) {
case Some(v) => println(v)
case _ => println("NONE")
}
} catch (e: Exception) {
print(e.toString())
}
return 0
}
运行结果如下:
IllegalArgumentException: Invalid string, please check the parameter: ab:-~
ArgOpt 构造成功
构造成功示例。
代码如下:
from std import argopt.*
main() {
var a: Array<String> = Array<String>(["-a123", "-bofo", "-cfoo", "-d789",
"bar","--condition=foo", "--testing=456",
"--output-file", "--abc.def","-p","-k123","bbb","a1", "a2"])
let lof: Array<String> = Array<String>(["condition=", "output-file=", "testing", "testing"])
let str: String = "ab:c:d:k:u:x"
let ao: ArgOpt = ArgOpt(a, str, lof)
a = ao.getUnparseArgs()
let p: Option<String> = ao.getArg("-b")
match (p) {
case Some(v) => println(v)
case _ => println("NONE")
}
0
}
运行结果如下:
ofo
未解析参数
未解析参数示例。
代码如下:
from std import argopt.*
main() {
var a: Array<String> = Array<String>(["-a123", "-bofo", "-cfoo", "-d789",
"bar","--condition=foo", "--testing=456",
"--output-file", "--abc.def", "-p", "-k123", "bbb", "a1", "a2"])
let lof: Array<String> = Array<String>(["condition=", "output-file=", "testing", "testing"])
let str: String = "ab:c:d:k:u:x"
let ao: ArgOpt = ArgOpt(a, str, lof)
a = ao.getUnparseArgs()
for (i in 0..a.size) {
print("${a[i]},")
}
0
}
运行结果如下:
-a123,bar,--testing=456,-p,bbb,a1,a2,
成功解析参数
成功解析参数示例。
代码如下:
from std import argopt.*
from std import collection.*
main() {
let args: Array<String> = Array<String>(["-a123", "-bofo", "-cfoo", "-d789", "bar",
"--condition=foo", "--testing=456", "--output-file",
"abc.def", "-p", "-k123", "bbb", "a1", "a2"])
let longArgList: Array<String> = Array<String>(["condition=", "output-file=", "testing", "testing"])
let str: String = "a:b:c:d:e"
let ao: ArgOpt = ArgOpt(args, str, longArgList)
let map: HashMap<String, String> = ao.getArgumentsMap()
let value: Option<String> = map.get("--output-file")
match (value) {
/* abc.def */
case Some(v) => println(v)
case _ => print("NOPASS")
}
0
}
运行结果如下:
abc.def
ast 包
介绍
仓颉 ast 包内主要包含了仓颉源码的语法解析器和仓颉语法树节点。
基本类型
struct Position
public struct Position {
public init()
public init(fileID: UInt32, line: Int32, column: Int32)
public let fileID: UInt32
public let line: Int32
public let column: Int32
public func isEmpty(): Bool
public func dump(): Unit
public operator func ==(pos: Position): Bool
public operator func !=(pos: Position): Bool
}
Position 类型是一个表示位置信息的数据结构。用于表示某个语法树节点的文件 ID, 行列号等位置信息。
init
public init()
功能:构造一个默认的 Position 实例。
init
public init(fileID: UInt32, line: Int32, column: Int32)
功能:构造 Position 实例。
参数:
- fileID:文件ID
- line:行号
- column:列号
fileID
public let fileID: UInt32
功能:获取文件 ID 信息。
line
public let line: UInt32
功能:获取行号信息。
column
public let column: UInt32
功能:获取列号信息。
func isEmpty
public func isEmpty(): Bool
功能:判断行号和列号是否为 0。
返回值:布尔类型。
operator func ==
public operator func == (pos: Position): Bool
功能:重载等号操作符,用于比较两个实例是否相等。
参数:
- pos:与当前位置比较的另一个位置实例。
返回值:布尔类型。
operator func !=
public operator func != (pos: Position): Bool
功能:重载不等号操作符,用于比较两个实例是否相等。
参数:
- pos:与当前位置比较的另一个位置实例。
返回值:布尔类型。
struct Token
public struct Token {
public let kind: TokenKind
public let value: String
public let pos: Position
public var delimiterNum: UInt16 = 1
public init()
public init(kind: TokenKind)
public init(kind: TokenKind, value: String)
public func addPosition(fileID: UInt32, line: Int32, colum: Int32)
public operator func ==(token: Token): Bool
public operator func !=(token: Token): Bool
public operator func +(tokens: Tokens): Tokens
public operator func +(token: Token): Tokens
public func dump(): Unit
}
Token 表示词法单元类型。词法单元是构成仓颉源码的最小单元,一组合法的词法单元列表经过语法解析后可生成一个语法树节点。例如,var bar = 0 可以视为 var, bar, = 和 0 四个词法单元。
kind
public let kind: TokenKind
功能:词法单元的类型。词法单元类型有关键字、标识符、运算符、常量值等,具体见 [TokenKind] 章节。
value
public let value: String
功能:词法单元的字面量值。
pos
public let pos: Position
功能:词法单元在源码中的位置信息。
delimiterNum
public var delimiterNum: UInt16 = 1
功能:多行字符串的 '#' 符号个数。
init
public init()
功能:构造一个默认的词法单元实例,其中 TokenKind 类型为 ILLEGAL,value 为空字符串,Position 成员变量均为 0。
init
public init(kind: TokenKind)
功能:构造一个新的词法单元。
参数:
- kind:构建词法单元的类型。
init
public init(kind: TokenKind, value: String)
功能:创建一个新的词法单元,使用 TokenKind 类型作为 kind,String 类型作为 value。
参数:
-
kind:要构建词法单元的类型。
-
value: 要构建词法单元的
value值。
异常:
- IllegalArgumentException:输入的
kind与value不匹配时抛出异常点。
func addPosition
public func addPosition(fileID: UInt32, line: Int32, colum: Int32)
功能:补充词法单元的位置信息。
参数:
-
fileID:UInt32 类型,
Token所在的 fileID。 -
line: Int32 类型,
Token所在的行号。 -
colum: Int32 类型,
Token所在的列号。
operator func ==
public operator func ==(token: Token): Bool
功能:判断两个 Token 对象是否相等。
参数:
- token: 待比较的另一个
Token对象。
返回值:布尔类型,两个词法单元的种类 ID、值、位置相同时,返回 true。
operator func !=
public operator func !=(token: Token): Bool
功能:判断两个 Token 对象是否不相等。
参数:
- token: 待比较的另一个
Token对象。
返回值:布尔类型,两个词法单元的种类 ID、值、位置不相同时,返回 true。
operator func +
public operator func +(tokens: Tokens): Tokens
功能:使用当前 Token 添加多个 Token 以获取新的 Tokens。
参数:
- token: 待添加的另一组
Token对象集合。
返回值:添加新的 Tokens 后的词法单元集合。
operator func +
public operator func +(token: Token): Tokens
功能:使用当前 Token 添加一个 Token 以获取新的 Tokens。
参数:
- token: 待添加的另一个
Token对象。
返回值:添加新的 Tokens 后的词法单元集合。
func dump
public func dump(): Unit
功能:将 Token 的信息打印出来。
class Tokens
public open class Tokens <: ToString & Iterable<Token> {
public init()
public init(tokArray: Array<Token>)
public init(tokArrayList: ArrayList<Token>)
public prop size: Int64
public open func get(index: Int64): Token
public func iterator(): TokensIterator
public func concat(tokens: Tokens): Tokens
public func append(tokens: Tokens): Tokens
public func append(token: Token): Tokens
public func append(node: Node): Tokens
public func remove(index: Int64): Tokens
public operator func [](index: Int64): Token
public operator func [](range: Range<Int64>): Tokens
public operator func +(tokens: Tokens): Tokens
public operator func +(token: Token): Tokens
public func dump(): Unit
public func toString(): String
}
Tokens 是一个对 Token 序列进行封装的类型。
init
public init()
功能:构造一个空的 Tokens 对象。
init
public init(tokArray: Array<Token>)
功能:构造一个新的 Tokens 对象。
参数:
- tokArray:一组包含
Token的Array类型。
init
public init(tokArrayList: ArrayList<Token>)
功能:构造一个新的 Tokens 对象。
参数:
- tokArrayList:一组包含
Token的ArrayList类型。
prop size
public prop size: Int64
功能:获取 Tokens 对象中 Token 类型的数量。
func get
public open func get(index: Int64): Token
功能:通过索引值获取 Token 元素。
参数:
- index:待索引的数值
返回值:指定索引的 Token
func iterator
public func iterator(): TokensIterator
功能:获取 Tokens 对象中的一个迭代器对象。
func concat
public func concat(tokens: Tokens): Tokens
功能:将当前的 Tokens 与传入的 Tokens 进行拼接。
参数:
- tokens:待拼接的
Tokens对象。
返回值:拼接后的 Tokens。
func append
public func append(tokens: Tokens): Tokens
功能:在当前的 Tokens 后追加传入的 Tokens 进行拼接(该接口性能较其他拼接函数表现更好)。
参数:
- tokens:待拼接的
Tokens对象。
返回值:拼接后的 Tokens 类型。
func append
public func append(token: Token): Tokens
功能:将当前的 Tokens 与传入的 Token 进行拼接。
参数:
- tokens:待拼接的
Token对象。
返回值:拼接后的 Tokens
func append
public func append(node: Node): Tokens
功能:将当前的 Tokens 与传入节点所转换得到的 Tokens 进行拼接。
参数:
- Node:待拼接的
Node对象。
返回值:拼接后的 Tokens
func remove
public func remove(index: Int64): Tokens
功能:删除指定位置的 Token 对象。
参数:
- index:被删除的
Token的索引
返回值:删除指定位置的 Token 后的 Tokens 对象
operator func +
public operator func +(tokens: Tokens): Tokens
功能:使用当前 Token 与 Tokens 相加以获取新的 Tokens 类型。
参数:
- token: 待操作的一组
Tokens对象。
返回值:新拼接 Tokens 后的词法单元集合。
operator func +
public operator func +(token: Token): Tokens
功能:使用当前 Token 与另一个 Token 相加以获取新的 Tokens。
参数:
- token: 待操作的另一个
Token对象。
返回值:新拼接 Tokens 后的词法单元集合。
operator func []
public operator func [](index: Int64): Token
功能:操作符重载,通过索引值获取对应 Token。
参数:
- index: 待索引的数值。
返回值:返回索引对应的 Token。
operator func []
public operator func [](range: Range<Int64>): Tokens
功能:操作符重载,通过 range 获取对应 Tokens 切片。
参数:
- range: 待索引的切片范围
返回值:返回切片索引对应的 Tokens。
异常:
- IllegalArgumentException:当 range.step 不等于 1 时,抛出异常
- IndexOutOfBoundsException:当 range 无效时,抛出异常
func dump
public func dump(): Unit
功能:将 Tokens 内所有 Token 的信息打印出来。
func toString
public func toString(): String
功能:将 Tokens 转化为 String 类型。
class Node
sealed abstract class Node <: ToTokens {
public mut prop beginPos: Position
public mut prop endPos: Position
public func toTokens(): Tokens
public func traverse(v: Visitor): Unit
public func dump(): Unit
}
Node 是所有仓颉语法树节点的父类,该类提供了所有数据类型通用的操作接口。
prop beginPos
public mut prop beginPos: Position
功能:获取或设置当前节点的起始的位置信息。
prop endPos
public mut prop endPos: Position
功能:获取或设置当前节点的终止的位置信息。
func toTokens
public func toTokens(): Tokens
功能:将节点转化为 Tokens 类型,实现语法树树节点与 Tokens 类型之间的转化。
func traverse
public func traverse(v: Visitor): Unit
功能:遍历当前语法树节点及其子节点。若提前终止遍历子节点的行为,可重写 visit 函数并调用 breakTraverse 函数提前终止遍历行为,详细见[visit] 章节。
参数:
v:Visitor类型的实例
func dump
public func dump(): Unit
功能:将当前语法树节点转为为树形结构的形态并进行打印。
具体使用方式和运行结果如下所示:
from std import ast.*
main() {
let input = quote(var demo: Int64 = 1) // 假设当前代码所在行数为:3
let varDecl = parseDecl(input)
varDecl.dump()
}
运行结果如下:
VarDecl {
-keyword: Token {
value: "var"
kind: VAR
pos: 3: 23
}
-identifier: Token {
value: "demo"
kind: IDENTIFIER
pos: 3: 27
}
-declType: PrimitiveType {
-keyword: Token {
value: "Int64"
kind: INT64
pos: 3: 33
}
}
-assign: Token {
value: "="
kind: ASSIGN
pos: 3: 39
}
-expr: LitConstExpr {
-literal: Token {
value: "1"
kind: INTEGER_LITERAL
pos: 3: 41
}
}
}
说明:
-字符串:表示当前节点的公共属性, 如-keyword,-identifier;- 节点属性后紧跟该节点的具体类型, 如
-declType: PrimitiveType表示节点类型是一个PrimitiveType节点; - 每个类型使用大括号表示类型的作用区间;
class Program
public class Program <: Node {
public init()
public init(input: Tokens)
public mut prop packageHeader: PackageHeader
public mut prop importLists: ArrayList<ImportList>
public mut prop decls: ArrayList<Decl>
}
Program 类型表示一个仓颉源码文件节点。一个仓颉源码文件节点主要包括包定义节点,包导入节点和 TopLevel 作用域内的所有声明节点。
说明:任何一个仓颉源码文件都可以被解析为一个 Program 类型。
init
public init()
功能:构造一个默认的 Program 实例。
init
public init(input: Tokens)
功能:构造 Program 实例。
参数:
- input:将要构造
Program类型的词法单元集合 (Tokens) 序列。
异常:
- ASTException:输入的
Tokens类型无法构造为一个文件节点。
prop packageHeader
public mut prop packageHeader: PackageHeader
功能:获取或设置仓颉源码文件中包的声明节点 PackageHeader。
返回值:一个 PackageHeader 类型的节点。
prop importLists
public mut prop importLists: ArrayList<ImportList>
功能:获取或设置仓颉源码文件中包导入节点 ImportList。
返回值:当前源码文件中包导入节点的列表。
prop decls
public mut prop decls: ArrayList<Decl>
功能:获取或设置仓颉源码文件中 toplevel 作用域内定义的节点。
返回值:当前源码文件中 toplevel 作用域内定义的声明节点列表。
class PackageHeader
public class PackageHeader <: Node {
public init()
public init(input: Tokens)
public mut prop keywordM: Token
public mut prop keywordP: Token
public mut prop packageIdentifier: Token
}
PackageHeader 类型用来表示包声明节点。
说明:包声明以关键字 package 或 macro package 开头,后面紧跟包名,且包声明必须在源文件的首行。
- 一个
PackageHeader节点:package define或者macro package define
init
public init()
功能:构造一个默认的 PackageHeader 实例。
init
public init(input: Tokens)
功能:构造 PackageHeader 实例。
参数:
- input:将要构造
PackageHeader类型的词法单元集合 (Tokens) 序列。
异常:
- ASTException:输入的 Tokens 类型无法构造为目标节点。
prop keywordM
public mut prop keywordM: Token
功能:获取或设置 PackageHeader 节点中的 macro 关键字的词法单元(M 为关键字首字母,下同)。
返回值:macro 关键字的词法单元类型,可能为空的词法单元。
prop keywordP
public mut prop keywordP: Token
功能:获取或设置 PackageHeader 节点中的 package 关键字的词法单元。
返回值:package 关键字的词法单元类型。
prop packageIdentifier
public mut prop packageIdentifier: Token
功能:获取或设置 PackageHeader 节点中的紧跟在 package 后包的名字。
返回值:包名的词法单元类型。
class ImportList
public class ImportList <: Node {
public init()
public init(input: Tokens)
public mut prop keywordF: Token
public mut prop moduleIdentifier: Token
public mut prop keywordI: Token
public mut prop importAll: Tokens
public mut prop importSpecified: Tokens
public mut prop importAlias: Tokens
}
ImportList 类型用来表示包导入节点。
说明:导入节点以关键字 from 或 import 开头。以 import pkga.pkgb.item 为例,pkga.pkgb 为导入的顶级定义或声明所在的包的名字,item 为导入的顶级定义或声明。
- 一个
ImportList节点:from module import package.foo as bar
init
public init()
功能:构造一个默认的 ImportList 实例。
init
public init(input: Tokens)
功能:构造 ImportList 实例。
参数:
- input:将要构造
ImportList类型的词法单元集合 (Tokens) 序列。
异常:
- ASTException:输入的 Tokens 类型无法构造为目标节点。
prop keywordF
public mut prop keywordF: Token
功能:获取或设置 ImportList 节点中的 from 关键字的词法单元, F 为关键字首字母。
返回值:from 关键字的词法单元类型,可能为空的词法单元。
prop moduleIdentifier
public mut prop moduleIdentifier: Token
功能:获取或设置 ImportList 节点中的导入模块名的词法单元。
返回值:模块名的词法单元类型,可能为空的词法单元。
prop keywordI
public mut prop keywordI: Token
功能:获取或设置 ImportList 节点中的 import 关键字的词法单元, I 为关键字首字母。
返回值:import 关键字的词法单元类型。
prop packageIdentifier
public mut prop packageIdentifier: Token
功能:获取或设置 ImportList 节点中导入的顶级定义或声明所在的包的名字。
返回值:通配符导入形式词法单元序列。如:import packageName.* 中的 packageName。
prop dot
public mut prop dot: Token
功能:获取或设置 ImportList 节点中的 . 操作符。
返回值:. 操作符词法单元。
prop importedItem
public mut prop importedItem: Token
功能:获取或设置 ImportList 节点中导入的顶级定义或声明的词法单元。
返回值:导入的顶级定义或声明的词法单元。
prop importAlias
public mut prop importAlias: Tokens
功能:获取或设置 ImportList 节点导入的定义或声明的别名。
返回值:导入定义或声明的别名词法单元序列。如:import packageName.xxx as yyy 中的 as yyy。
class Annotation
public class Annotation <: Node {
public init()
public init(input: Tokens)
public mut prop at: Token
public mut prop identifier: Token
public mut prop arguments: ArrayList<Argument>
public mut prop stageValue: UInt16
public mut prop configKind: Token
public mut prop configParam: ArrayList<RefExpr>
public mut prop adjointExpr: RefExpr
public mut prop attributes: Tokens
public mut prop condition: Expr
}
说明:Annotation 表示编译器内置的注解节点。
一个 Annotation 节点:@CallingConv[xxx], @Attribute[xxx], @Differentiable[except: [xx]], @When[condition]等
init
public init()
功能:构造一个默认的 Annotation 实例。
init
public init(input: Token)
功能:构造 Annotation 实例。
参数:
- input:将要构造
Annotation类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为目标节点。
prop at
public mut prop at: Token
功能:获取或设置 Annotation 节点中的 @ 操作符。
返回值:Annotation 节点中的 @ 的词法单元类型。
prop identifier
public mut prop identifier: Token
功能:获取或设置 Annotation 节点的标识符。
返回值:Annotation 节点中的标识符,如 @CallingConv 中的 CallingConv。
prop arguments
public mut prop arguments: ArrayList<Argument>
功能:获取或设置 Annotation 中的参数。
返回值:Annotation 节点中的参数序列,如 @CallingConv[xxx] 中的 xxx。
prop stageValue
public mut prop stageValue: UInt16
功能:获取或设置 AD Annotation 的阶值,仅用于自动微分注解。
返回值:AD Annotation 的阶值,如 @Differentiable [stage: 2] 中的 2。
prop configKind
public mut prop configKind: Token
功能:获取或设置 AD Annotation 的配置项,仅用于自动微分注解。
返回值:AD Annotation 的配置项的词法单元,如 @Differentiable[except: [xx]] 中的 except。
prop configParam
public mut prop configParam: ArrayList<RefExpr>
功能:获取或设置 AD Annotation 配置项的成员,仅用于自动微分注解。
返回值:AD Annotation 的配置列表,如 @Differentiable[except: [xx]] 中的 xx。
prop adjointExpr
public mut prop adjointExpr: RefExpr
功能:获取或设置 AD Annotation 中的自定义伴随函数,仅用于自动微分的自定义伴随函数注解。
返回值:AD Annotation 的自定义伴随函数,如 @adjoint [primal: f] 中的 f。
prop attributes
public mut prop attributes: Tokens
功能:获取或设置 Attribute 中设置的属性值,仅用于 @Attribute。
返回值:Attribute 设置的属性值的词法单元,如 @Attribute[xxx] 中的 xxx。
prop condition
public mut prop condition: Expr
功能:获取或设置条件编译中的条件表达式,用于 @When。
返回值:@When 的条件表达式,如 @When[xxx] 中的 xxx。
class Modifier
public class Modifier <: Node {
public init()
public init(keyword: Token)
public mut prop keyword: Token
}
说明:Modifier 通常放在定义处的最前端,用来表示该定义具备某些特性。
- 一个
Modifier节点:public func foo()中的public
init
public init()
功能:构造一个默认的 Modifier 实例。
init
public init(keyword: Token)
功能:构造 Modifier 实例。
参数:
- keyword:将要构造
Modifier类型的词法单元。
prop keyword
public mut prop keyword: Token
功能:获取或设置 Modifier 节点中的修饰符。
返回值:Modifier 节点中的修饰符词法单元类型。
class GenericParam
public class GenericParam <: Node {
public init()
public init(input: Tokens)
public mut prop lAngle: Token
public mut prop parameters: Tokens
public mut prop rAngle: Token
}
说明:GenericParam 表示一个类型形参节点,类型形参用 <> 括起并用 , 分隔多个类型形参名称。
- 一个
GenericParam节点:<T1, T2, T3>
init
public init()
功能:构造一个默认的 GenericParam 实例。
init
public init(input: Tokens)
功能:构造 GenericParam 实例。
参数:
- input:将要构造
GenericParam的类型形参的词法单元集合 (Tokens)。
prop lAngle
public mut prop lAngle: Token
功能:获取或设置 GenericParam 节点中的左尖括号。
返回值:左尖括号词法单元。
prop parameters
public mut prop parameters: Tokens
功能:获取或设置 GenericParam 节点中的类型形参。
返回值:类型形参的 Tokens 类型,可能为空,如 <T1, T2, T3> 中的 T1 T2 和 T3。
prop rAngle
public mut prop rAngle: Token
功能:获取或设置 GenericParam 节点中的右尖括号。
返回值:右尖括号词法单元。
class GenericConstraint
public class GenericConstraint <: Node {
public init()
public mut prop keyword: Token
public mut prop typeArgument: TypeNode
public mut prop upperBound: Token
public mut prop upperBounds: ArrayList<TypeNode>
}
说明:GenericConstraint 表示一个泛型约束节点,通过 where 之后的 <: 运算符来声明,由一个下界与一个上界来组成。其中 <: 左边称为约束的下界,下界只能为类型变元。<: 右边称为约束上界,约束上界可以为类型。
- 一个
GenericConstraint节点:interface Enumerable<U> where U <: Bounded {}中的where where U <: Bounded。
init
public init()
功能:构造一个默认的 GenericConstraint 实例。
prop keyword
public mut prop keyword: Token
功能:获取或设置 GenericConstraint 节点中关键字 where。
返回值:关键字 where 词法单元, 可能为空。
prop typeArgument
public mut prop typeArgument: Token
功能:获取或设置 GenericConstraint 节点中的约束下界。
返回值:类型变元的 Token。
prop upperBound
public mut prop upperBound: Token
功能:获取或设置 GenericConstraint 节点中的 <: 运算符。
返回值:<: 词法单元。
prop upperBounds
public mut prop upperBounds: ArrayList<RefType>
功能:获取或设置 GenericConstraint 节点中的约束上界。
返回值:一组 RefType 类型节点的集合。
class Body
public class Body <: Node {
public init()
public mut prop lBrace: Token
public mut prop decls: ArrayList<Decl>
public mut prop rBrace: Token
}
说明:Body 表示 Class 类型、 Struct 类型、 Interface 类型以及扩展中由 {} 和 内部的一组声明节点组成的结构。
init
public init()
功能:构造一个默认的 Body 实例。
prop lBrace
public mut prop lBrace: Token
功能:获取或设置 { 。
返回值:{ 词法单元。
prop decls
public mut prop decls: ArrayList<Decl>
功能:获取或设置 Body 内的声明节点集合。
返回值:一组声明节点的集合。
prop rBrace
public mut prop rBrace: Token
功能:获取或设置 } 。
返回值:} 词法单元。
class MatchCase
public class MatchCase <: Node {
public init()
public mut prop keywordC: Token
public mut prop expr: Expr
public mut prop patterns: ArrayList<Pattern>
public mut prop keywordW: Token
public mut prop patternGuard: Expr
public mut prop arrow: Token
public mut prop block: Block
}
说明:MatchCase 表示一个 MatchCase 类型。MatchCase 以关键字 case 开头,后跟 Expr 或者一个或多个由 | 分隔的相同种类的 pattern,一个可选的 patternguard,一个 => 和一系列声明或表达式。该节点与 MatchExpr 存在强绑定关系。
一个 MatchCase 节点:case failScore where score > 0 => 0
init
public init()
功能:构造一个默认的 MatchCase 实例。
prop keywordC
public mut prop keywordC: Token
功能:获取或设置 MatchCase 内的 case 关键字。
返回值:case 关键字的词法单元。
prop expr
public mut prop expr: Expr
功能:获取或设置 MatchCase 中位于 case 后的表达式节点。
返回值:一个表达式节点。
异常:
- ASTException:当前
MatchCase节点中不存在表达式节点。
prop patterns
public mut prop patterns: ArrayList<Pattern>
功能:获取或设置 MatchCase 中位于 case 后的 pattern 列表。
返回值:一组 pattern 节点的结合。
prop keywordW
public mut prop keywordW: Token
功能:获取或设置 MatchCase 中可选的关键字 where。
返回值:关键字 where 的词法单元,可能为空。
prop patternGuard
public mut prop patternGuard: Expr
功能:获取或设置 MatchCase 中可选的 pattern guard 表达式。
返回值:一个表达式节点。
异常:
- ASTException:当前
MatchCase节点中不存在 pattern guard 表达式。
prop arrow
public mut prop arrow: Token
功能:获取或设置 MatchCase 中的 => 操作符。
返回值:=> 的词法单元。
prop block
public mut prop block: Block
功能:获取或设置 MatchCase 中的一系列声明或表达式节点。
返回值:一个块节点。
class Constructor
public class Constructor <: Node {
public init()
public mut prop identifier: Token
public mut prop lParen: Token
public mut prop typeArguments: ArrayList<TypeNode>
public mut prop rParen: Token
}
说明:Constructor 表示 enum 类型中的 Constructor 节点。每个 Constructor 可以没有参数,也可以有一组不同类型的参数。
一个 Constructor 节点:enum TimeUnit { Year | Month(Float32, Float32)} 中的 Year 和 Month(Float32, Float32)。
init
public init()
功能:构造一个默认的 Constructor 实例。
prop identifier
public mut prop identifier: Token
功能:获取或设置 Constructor 的标识符。
返回值:标识符词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 Constructor 节点中的左括号。
返回值:左括号词法单元。
prop typeArguments
public mut prop typeArguments: ArrayList<TypeNode>
功能:获取或设置 Constructor 节点可选的参数类型。
返回值:一组类型节点的集合。
prop rParen
public mut prop rParen: Token
功能:获取或设置 Constructor 节点中的右括号。
返回值:右括号词法单元。
class Argument
public class Argument <: Node {
public init()
public mut prop keyword: Token
public mut prop identifier: Token
public mut prop colon: Token
public mut prop expr: Expr
}
说明:Argument 表示函数调用的实参节点,例如 foo(arg:value) 中的 arg:value。
init
public init()
功能:构造一个默认的 Argument 实例。
prop keyword
public mut prop keyword: Token
功能:获取或设置 Argument 节点中的关键字 inout。
返回值:inout 词法单元,可能为空。
prop identifier
public mut prop identifier: Token
功能:获取或设置 Argument 节点中的标识符。
返回值:标识符词法单元,如 arg:value 中的 arg,可能为空。
prop identifier
public mut prop identifier: Token
功能:获取或设置 Argument 节点中的操作符 :。
返回值:: 词法单元,可能为空。
prop expr
public mut prop expr: Expr
功能:获取或设置 Argument 节点中的表达式。
返回值:表达式节点,如 arg:value 中的 value。
class Decl
public open class Decl <: Node {
public mut prop annotations: ArrayList<Annotation>
public mut prop modifiers: ArrayList<Modifier>
public mut prop keyword: Token
public open mut prop identifier: Token
public mut prop genericParam: GenericParam
public mut prop genericConstraint: ArrayList<GenericConstraint>
public func hasAttr(attr: String): Bool
public func getAttrs(): Tokens
}
Decl 是所有声明节点的父类,继承自 Node 节点,提供了所有声明节点的通用接口。
类定义、接口定义、函数定义、变量定义、枚举定义、结构体定义、扩展定义、类型别名定义、宏定义等都属于 Decl 节点。
prop annotations
public mut prop annotations: ArrayList<Annotation>
功能:获取或设置作用于 Decl 节点的注解列表。
返回值:一组 Annotation 节点列表,可能为空。
prop modifiers
public mut prop modifiers: ArrayList<Modifier>
功能:获取或设置修饰节点的修饰符列表。
返回值:一组 Modifier 节点列表,可能为空,如 open public func foo() {} 中的 open 和 public。
prop keyword
public mut prop keyword: Token
功能:获取或设置定义节点的关键字。
返回值:一个关键字词法单元,如 func foo() {} 中的 func。
prop identifier
public open mut prop identifier: Token
功能:获取或设置定义节点的标识符。
返回值:一个标识符词法单元,如 class foo {} 中的 foo。
prop genericParam
public mut prop genericParam: GenericParam
功能:获取或设置形参列表,类型形参列表由 <> 括起,多个类型形参之间用逗号分隔。
返回值:一个类型形参节点,如 func foo<T1, T2, T3>() {} 中的 <T1, T2, T3>。
异常:
- ASTException:当前节点未定义类型形参列表。
prop genericConstraint
public mut prop genericConstraint: ArrayList<GenericConstraint>
功能:获取或设置定义节点的泛型约束。
返回值:一个组泛型约束节点,可能为空,如 func foo<T>() where T <: Comparable<T> {} 中的 where T <: Comparable<T>。
func getAttrs
public func getAttrs(): Tokens
功能:获取当前节点的属性(一般通过内置的 Attribute 来设置某个声明设置属性值)。
func hasAttr
public func hasAttr(attr: String): Bool
功能:判断当前节点是否具有某个属性(一般通过内置的 Attribute 来设置某个声明设置属性值)。
class ClassDecl
public class ClassDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop upperBound: Token
public mut prop superTypes: ArrayList<TypeNode>
public mut prop body: Body
}
ClassDecl 表示类定义节点。类的定义使用 class 关键字,定义依次为:可缺省的修饰符、class 关键字、class 名、可选的类型参数、是否指定父类或父接口、可选的泛型约束、类体的定义。
init
public init()
功能:构造一个默认的 ClassDecl 实例。
init
public init(input: Tokens)
功能:构造 ClassDecl 实例。
参数:
- input:将要构造
ClassDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ClassDecl节点。
prop upperBound
public mut prop upperBound: Token
功能:获取或设置 <: 操作符。
返回值:<: 操作符的词法单元。
prop superTypes
public mut prop superTypes: ArrayList<TypeNode>
功能:获取或设置 ClassDecl 节点的父类或者父接口。
返回值:ClassDecl 节点的父类或者父接口类型的列表,如:class B <: A {} 中的 A。
prop body
public mut prop body: Body
功能:获取或设置 ClassDecl 节点的类体。
返回值:ClassDecl 节点的 Body 节点(大括号及大括号内的节点)。
class StructDecl
public class StructDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop upperBound: Token
public mut prop superTypes: ArrayList<TypeNode>
public mut prop body: Body
}
StructDecl 表示一个 Struct 节点。Struct 的定义使用 struct 关键字,定义依次为:可缺省的修饰符、struct 关键字、struct 名、可选的类型参数、是否指定父接口、可选的泛型约束、struct 体的定义。
init
public init()
功能:构造一个默认的 StructDecl 实例。
init
public init(input: Tokens)
功能:构造 StructDecl 实例。
参数:
- input:将要构造
StructDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
StructDecl节点。
prop upperBound
public mut prop upperBound: Token
功能:获取或设置 <: 操作符。
返回值:<: 操作符的词法单元。
prop superTypes
public mut prop superTypes: ArrayList<TypeNode>
功能:获取或设置 StructDecl 节点的父接口。
返回值:StructDecl 节点的父接口类型的列表,如:struct B <: A {} 中的 A。
prop body
public mut prop body: Body
功能:获取或设置 StructDecl 节点的类体。
返回值:StructDecl 节点的 Body 节点(大括号及大括号内的节点)。
class InterfaceDecl
public class InterfaceDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop upperBound: Token
public mut prop superTypes: ArrayList<TypeNode>
public mut prop body: Body
}
InterfaceDecl 表示接口定义节点。接口的定义使用 interface 关键字,接口定义依次为:可缺省的修饰符、interface 关键字、接口名、可选的类型参数、是否指定父接口、可选的泛型约束、接口体的定义。
init
public init()
功能:构造一个默认的 InterfaceDecl 实例。
init
public init(input: Tokens)
功能:构造 InterfaceDecl 实例。
参数:
- input:将要构造
InterfaceDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
InterfaceDecl节点。
prop upperBound
public mut prop upperBound: Token
功能:获取或设置 <: 操作符。
返回值:<: 操作符的词法单元。
prop superTypes
public mut prop superTypes: ArrayList<TypeNode>
功能:获取或设置 InterfaceDecl 节点的父接口。
返回值:InterfaceDecl 节点的父接口类型的列表,如:interface B <: A {} 中的 A。
prop body
public mut prop body: Body
功能:获取或设置 InterfaceDecl 节点的类体。
返回值:InterfaceDecl 节点的 Body 节点(大括号及大括号内的节点)。
class ExtendDecl
public class ExtendDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop extendType: TypeNode
public mut prop upperBound: Token
public mut prop superTypes: ArrayList<TypeNode>
public mut prop body: Body
public override mut prop identifier: Token
}
ExtendDecl 表示一个扩展定义节点。扩展的定义使用 extend 关键字,扩展定义依次为:extend 关键字、扩展类型、是否指定父接口、可选的泛型约束、扩展体的定义。
init
public init()
功能:构造一个默认的 ExtendDecl 实例。
init
public init(input: Tokens)
功能:构造 ExtendDecl 实例。
参数:
- input:将要构造
ExtendDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ExtendDecl节点。
prop extendType
public mut prop extendType: TypeNode
功能:获取或设置被扩展的类型。
返回值:一个类型节点,如:extend B <: A{} 中的 B。
prop upperBound
public mut prop upperBound: Token
功能:获取或设置 <: 操作符。
返回值:<: 操作符的词法单元。
prop superTypes
public mut prop superTypes: ArrayList<TypeNode>
功能:获取或设置 ExtendDecl 节点的父接口。
返回值:ExtendDecl 节点的父接口类型的列表,如:extend B <: A {} 中的 A。
prop body
public mut prop body: Body
功能:获取或设置 ExtendDecl 节点的类体。
返回值:ExtendDecl 节点的 Body 节点(大括号及大括号内的节点)。
prop identifier
public override mut prop identifier
功能:ExtendDecl 节点继承 Decl 节点,但是不支持 identifier 属性,使用时会抛出异常。
异常:
- ASTException:当前节点未定义标识符。
class EnumDecl
public class EnumDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop upperBound: Token
public mut prop superTypes: ArrayList<TypeNode>
public mut prop lBrace: Token
public mut prop constructors: ArrayList<Constructor>
public mut prop decls: ArrayList<Decl>
public mut prop rBrace: Token
}
EnumDecl 表示一个 Enum 定义节点。Enum 的定义使用 enum 关键字,定义依次为:可缺省的修饰符、enum 关键字、enum 名、可选的类型参数、是否指定父接口、可选的泛型约束、enum 体的定义。
init
public init()
功能:构造一个默认的 EnumDecl 实例。
init
public init(input: Tokens)
功能:构造 EnumDecl 实例。
参数:
- input:将要构造
EnumDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
EnumDecl节点。
prop upperBound
public mut prop upperBound: Token
功能:获取或设置 <: 操作符。
返回值:<: 操作符的词法单元。
prop superTypes
public mut prop superTypes: ArrayList<TypeNode>
功能:获取或设置 EnumDecl 节点的父接口。
返回值:EnumDecl 节点的父接口类型的列表,如:enum B <: A { X| Y } 中的 A。
prop lBrace
public mut prop lBrace: Token
功能:获取或设置 EnumDecl 节点的 { 词法单元类型。
prop constructors
public mut prop constructors: ArrayList<Constructor>
功能:获取或设置 EnumDecl 节点内 constructor 的成员。
返回值:EnumDecl 节点的 constructor 的列表,如:enum B <: A { X | Y } 中的 X 和 Y。
prop decls
public mut prop decls: ArrayList<Decl>
功能:获取或设置 EnumDecl 节点内除 constructor 的其它成员。
返回值:EnumDecl 节点的其它成员, 包含成员函数、操作符重载函数等节点。
prop rBrace
public mut prop rBrace: Token
功能:获取或设置 EnumDecl 节点的 } 词法单元类型。
class FuncDecl
public class FuncDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop overloadOp: Tokens
public mut prop lParen: Token
public mut prop funcParams: ArrayList<FuncParam>
public mut prop rParen: Token
public mut prop colon: Token
public mut prop declType: TypeNode
public mut prop block: Block
public func isConst(): Bool
}
FuncDecl 表示一个函数定义节点。由可选的函数修饰符,关键字 func ,函数名,可选的类型形参列表,函数参数,可缺省的函数返回类型来定义一个函数,函数定义时必须有函数体,函数体是一个块。
init
public init()
功能:构造一个默认的 FuncDecl 实例。
init
public init(input: Tokens)
功能:构造 FuncDecl 实例。
参数:
- input:将要构造
FuncDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
FuncDecl节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 FuncDecl 节点的左括号。
返回值:FuncDecl 节点的左括号词法单元。
prop funcParams
public mut prop funcParams: ArrayList<FuncParam>
功能:获取或设置 FuncDecl 节点的函数参数。
返回值:FuncDecl 节点内的函数参数节点列表。
prop rParen
public mut prop rParen: Token
功能:获取或设置 FuncDecl 节点的右括号。
返回值:FuncDecl 节点的右括号词法单元。
prop colon
public mut prop colon: Token
功能:获取或设置 FuncDecl 节点的冒号。
返回值:FuncDecl 节点的冒号词法单元,可能为空。
prop declType
public mut prop declType: TypeNode
功能:获取或设置 FuncDecl 节点的函数返回类型。
返回值:FuncDecl 节点的类型节点。
异常:
- ASTException:
FuncDecl节点的函数返回类型是一个缺省值。
prop block
public mut prop block: Block
功能:获取或设置 FuncDecl 节点的函数体。
返回值:FuncDecl 节点的函数体节点(块)。
prop overloadOp
public mut prop overloadOp: Tokens
功能:获取或设置 FuncDecl 节点的重载操作符。
返回值:FuncDecl 节点中重载的操作符词法单元。
func isConst
public func isConst(): Bool
功能:判断是否是一个 Const 类型的节点。
返回值:是一个 Const 类型的节点返回 true。
class MainDecl
public class MainDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop lParen: Token
public mut prop funcParams: ArrayList<FuncParam>
public mut prop rParen: Token
public mut prop colon: Token
public mut prop declType: TypeNode
public mut prop block: Block
}
MainDecl 表示一个 main 函数定义节点。
一个 MainDecl 节点:main() {}
init
public init()
功能:构造一个默认的 MainDecl 实例。
init
public init(input: Tokens)
功能:构造 MainDecl 实例。
参数:
- input:将要构造
MainDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
MainDecl节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 MainDecl 节点的左括号。
返回值:MainDecl 节点的左括号词法单元。
prop funcParams
public mut prop funcParams: ArrayList<FuncParam>
功能:获取或设置 MainDecl 节点的函数参数。
返回值:MainDecl 节点内的函数参数节点列表。
prop rParen
public mut prop rParen: Token
功能:获取或设置 MainDecl 节点的右括号。
返回值:MainDecl 节点的右括号词法单元。
prop colon
public mut prop colon: Token
功能:获取或设置 MainDecl 节点的冒号。
返回值:MainDecl 节点的冒号词法单元,可能为空。
prop declType
public mut prop declType: TypeNode
功能:获取或设置 MainDecl 节点的函数返回类型。
返回值:MainDecl 节点的类型节点。
异常:
- ASTException:
MainDecl节点的函数返回类型是一个缺省值。
prop block
public mut prop block: Block
功能:获取或设置 MainDecl 节点的函数体。
返回值:MainDecl 节点的函数体节点(块)。
class MacroDecl
public class MacroDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop lParen: Token
public mut prop funcParams: ArrayList<FuncParam>
public mut prop rParen: Token
public mut prop colon: Token
public mut prop declType: TypeNode
public mut prop block: Block
}
MacroDecl 表示一个宏定义节点。
一个 MacroDecl 节点:public macro M(input: Tokens): Tokens {...}
init
public init()
功能:构造一个默认的 MacroDecl 实例。
init
public init(input: Tokens)
功能:构造 MacroDecl 实例。
参数:
- input:将要构造
MacroDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
MacroDecl节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 MacroDecl 节点的左括号。
返回值:MacroDecl 节点的左括号词法单元。
prop funcParams
public mut prop funcParams: ArrayList<FuncParam>
功能:获取或设置 MacroDecl 节点的参数。
返回值:MacroDecl 节点的参数列表。
prop rParen
public mut prop rParen: Token
功能:获取或设置 MacroDecl 节点的右括号。
返回值:MacroDecl 节点的右括号词法单元。
prop colon
public mut prop colon: Token
功能:获取或设置 MacroDecl 节点的冒号。
返回值:MacroDecl 节点的冒号词法单元,可能为空。
prop declType
public mut prop declType: TypeNode
功能:获取或设置 MacroDecl 节点的函数返回类型。
返回值:MacroDecl 节点的类型节点。
异常:
- ASTException:
MacroDecl节点的函数返回类型是一个缺省值。
prop block
public mut prop block: Block
功能:获取或设置 MacroDecl 节点的函数体。
返回值:MacroDecl 节点的函数体节点。
class PrimaryCtorDecl
public class PrimaryCtorDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop lParen: Token
public mut prop funcParams: ArrayList<FuncParam>
public mut prop rParen: Token
public mut prop block: Block
public func isConst(): Bool
}
PrimaryCtorDecl 表示一个主构造函数节点。主构造函数节点由修饰符,主构造函数名,形参列表和主构造函数体构成。
init
public init()
功能:构造一个默认的 PrimaryCtorDecl 实例。
init
public init(input: Tokens)
功能:构造 PrimaryCtorDecl 实例。
参数:
- input:将要构造
PrimaryCtorDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
PrimaryCtorDecl节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 PrimaryCtorDecl 节点的左括号。
返回值:PrimaryCtorDecl 节点的左括号词法单元。
prop funcParams
public mut prop funcParams: ArrayList<FuncParam>
功能:获取或设置 PrimaryCtorDecl 节点的参数。
返回值:PrimaryCtorDecl 节点的参数列表。
prop rParen
public mut prop rParen: Token
功能:获取或设置 PrimaryCtorDecl 节点的右括号。
返回值:PrimaryCtorDecl 节点的右括号词法单元。
prop block
public mut prop block: Block
功能:获取或设置 PrimaryCtorDecl 节点的主构造函数体。
返回值:PrimaryCtorDecl 节点的主构造函数体节点。
func isConst
public func isConst(): Bool
功能:判断是否是一个 Const 类型的节点。
返回值:是一个 Const 类型的节点返回 true。
class PropDecl
public class PropDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop colon: Token
public mut prop declType : TypeNode
public mut prop lBrace: Token
public mut prop getter: FuncDecl
public mut prop setter: FuncDecl
public mut prop rBrace: Token
}
PropDecl 表示一个属性定义节点。
一个 PropDecl 节点:prop var X: Int64 { get() { 0 } }
init
public init()
功能:构造一个默认的 PropDecl 实例。
init
public init(input: Tokens)
功能:构造 PropDecl 实例。
参数:
- input:将要构造
PropDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
PropDecl节点。
prop colon
public mut prop colon: Token
功能:获取或设置 PropDecl 节点的冒号。
返回值:PropDecl 节点中冒号词法单元。
prop declType
public mut prop declType : TypeNode
功能:获取或设置 PropDecl 节点的返回类型。
返回值:PropDecl 节点的返回类型。
prop lBrace
public mut prop lBrace: Token
功能:获取或设置 PropDecl 节点的左大括号。
返回值:PropDecl 节点的左大括号词法单元。
prop getter
public mut prop getter: FuncDecl
功能:获取或设置 PropDecl 节点的 getter 函数。
返回值:一个函数节点。
异常:
-ASTException:当前 PropDecl 节点不存在 getter 函数。
prop setter
public mut prop setter: FuncDecl
功能:获取或设置 PropDecl 节点的 setter 函数。
返回值:一个函数节点。
异常:
-ASTException:当前 PropDecl 节点不存在 setter 函数。
prop rBrace
public mut prop rBrace: Token
功能:获取或设置 PropDecl 节点的右大括号。
返回值:PropDecl 节点的右大括号词法单元。
class VarDecl
public class VarDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop pattern: Pattern
public mut prop colon: Token
public mut prop declType: TypeNode
public mut prop assign: Token
public mut prop expr: Expr
public func isConst(): Bool
}
VarDecl 表示变量定义节点。变量的定义主要包括四个部分:修饰符、关键字、patternsMaybeIrrefutable、变量类型和变量初始值。
一个 VarDecl 节点: var a: String,var b: Int64 = 1
init
public init()
功能:构造一个默认的 VarDecl 实例。
init
public init(input: Tokens)
功能:构造 VarDecl 实例。
参数:
- input:将要构造
VarDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
VarDecl节点。
prop pattern
public mut prop pattern: Pattern
功能:获取或设置 VarDecl 节点的 pattern 节点。
返回值:pattern 节点,如 var (a, b) = (1, 2) 中的 (a, b)。
prop colon
public mut prop colon: Token
功能:获取或设置 VarDecl 节点中的冒号位置信息。
返回值:冒号的词法单元类型(由于变量类型是可选的,所以该属性的值可能为空的 Token)。
prop declType
public mut prop declType: TypeNode
功能:获取或设置 VarDecl 节点的变量类型。
返回值:当前节点的变量类型节点。
异常:
- ASTException:
VarDecl节点没有声明变量类型。
prop assign
public mut prop assign: Token
功能:获取或设置 VarDecl 节点中的赋值操作符的位置信息。
返回值:赋值操作符的词法单元类型(由于变变量初始化是可选的,所以该属性的值可能为空的 Token)。
prop expr
public mut prop expr: Expr
功能:获取或设置 VarDecl 节点的变量初始化节点。
返回值:变量初始化节点。
异常:
- ASTException:
VarDecl节点没有对变量进行初始化。
func isConst
public func isConst(): Bool
功能:判断是否是一个 Const 类型的节点。
返回值:是一个 Const 类型的节点返回 true。
class FuncParam
public class FuncParam <: Decl {
public init()
public init(inputs: Tokens)
public mut prop not: Token
public mut prop colon: Token
public mut prop paramType: TypeNode
public mut prop assign: Token
public mut prop expr: Expr
public func isMemberParam(): Bool
}
FuncParam 表示函数参数节点,包括非命名参数和命名参数。
一个 FuncParam 节点: func foo(a: Int64, b: Float64) {...} 中的 a: Int64 和 b: Float64
init
public init()
功能:构造一个默认的 FuncParam 实例。
init
public init(input: Tokens)
功能:构造 FuncParam 实例。
参数:
- input:将要构造
FuncParam类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
FuncParam节点。
prop not
public mut prop not: Token
功能:获取或设置命名形参中的 !。
返回值:! 词法单元类型(该属性的值可能为空的 Token)。
prop colon
public mut prop colon: Token
功能:获取或设置置形参中的 :。
返回值:冒号的词法单元类型。
prop paramType
public mut prop paramType: TypeNode
功能:获取或设置函数参数的类型。
返回值:当前函数参数的类型节点。
prop assign
public mut prop assign: Token
功能:获取或设置具有默认值的函数参数中的 =。
返回值:赋值操作符的词法单元类型(该属性的值可能为空的 Token)。
prop expr
public mut prop expr: Expr
功能:获取或设置具有默认值的函数参数的变量初始化节点。
返回值:变量初始化节点。
异常:
- ASTException:函数参数没有进行初始化。
func isMemberParam
public func isMemberParam(): Bool
功能:当前的函数参数是否是主构造函数中的参数。
返回值:布尔类型,如果是主构造函数中的参数,返回 true。
class MacroExpandParam
public class MacroExpandParam <: FuncParam {
public init()
public init(inputs: Tokens)
public mut prop at: Token
public mut prop identifier: Token
public mut prop fullIdentifier: Token
public mut prop lSquare: Token
public mut prop macroAttrs: Tokens
public mut prop rSquare: Token
public mut prop lParen: Token
public mut prop macroInputs: Tokens
public mut prop rParen: Token
public mut prop macroInputDecl: Decl
}
MacroExpandParam 表示宏调用节点。
一个 MacroExpandDecl 节点: func foo (@M a: Int64) 中的 @M a: Int64。
init
public init()
功能:构造一个默认的 MacroExpandParam 实例。
prop at
public mut prop at: Token
功能:获取或设置宏调用节点的关键字 at。
返回值:关键字 at 的词法单元,例如 @pkg.M 中的 @。
prop identifier
public mut prop identifier: Token
功能:获取或设置宏调用节点的标识符。
返回值:一个包含完整标识符的词法单元类型,例如 @pkg.M 中的 M。
prop fullIdentifier
public mut prop fullIdentifier: Token
功能:获取或设置宏调用节点的完整标识符。
返回值:一个包含完整标识符的词法单元类型,例如 @pkg.M 中的 pkg.M。
prop lSquare
public mut prop lSquare: Token
功能:获取或设置 MacroExpandParam 属性宏调用的左中括号。
返回值:左中括号词法单元。
prop macroAttrs
public mut prop macroAttrs: Tokens
功能:获取或设置 MacroExpandParam 属性宏调用的输入。
返回值:宏调用的输入的词法单元集合。
prop rSquare
public mut prop rSquare: Token
功能:获取或设置 MacroExpandParam 属性宏调用的右中括号。
返回值:右中括号词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 MacroExpandParam 属性宏调用的左小括号。
返回值:左小括号词法单元。
prop macroInputs
public mut prop macroInputs: Tokens
功能:获取或设置 MacroExpandParam 宏调用的输入。
返回值:宏调用的输入的词法单元集合。
prop rParen
public mut prop rParen: Token
功能:获取或设置 MacroExpandParam 宏调用的右小括号。
返回值:右小括号词法单元。
prop macroInputDecl
public mut prop macroInputDecl: Decl
功能:获取或设置 MacroExpandParam 中的声明节点。
返回值:不带括号的宏调用的声明节点。
class TypeAliasDecl
public class TypeAliasDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop assign: Token
public mut prop aliasType: TypeNode
}
TypeAliasDecl 表示类型别名节点。该节点中 type 作为关键字,紧跟任意的合法标识符,其后的 type 是任意的 top-level 可见的类型,标识符和 type 之间使用 = 进行连接。
一个 TypeAliasDecl 节点: type Point2D = Float64
init
public init()
功能:构造一个默认的 TypeAliasDecl 实例。
init
public init(input: Tokens)
功能:构造 TypeAliasDecl 实例。
参数:
- input:将要构造
TypeAliasDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
TypeAliasDecl节点。
prop assign
public mut prop assign: Token
功能:获取或设置标识符和 type 之间的 = 。
返回值:= 的词法单元类型。
prop aliasType
public mut prop aliasType: TypeNode
功能:获取或设置将要别名的类型。
返回值:一个类型节点,如 type Point2D = Float64 中的 Float64。
class MacroExpandDecl
public class MacroExpandDecl <: Decl {
public init()
public init(inputs: Tokens)
public mut prop fullIdentifier: Token
public mut prop lSquare: Token
public mut prop macroAttrs: Tokens
public mut prop rSquare: Token
public mut prop lParen: Token
public mut prop macroInputs: Tokens
public mut prop rParen: Token
public mut prop macroInputDecl: Decl
}
MacroExpandDecl 表示宏调用节点。
一个 MacroExpandDecl 节点: @M class A {}
init
public init()
功能:构造一个默认的 MacroExpandDecl 实例。
init
public init(input: Tokens)
功能:构造 MacroExpandDecl 实例。
参数:
- input:将要构造
MacroExpandDecl类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
MacroExpandDecl节点。
prop fullIdentifier
public mut prop fullIdentifier: Token
功能:获取或设置宏调用节点的完整标识符。
返回值:一个包含完整标识符的词法单元类型,例如 @pkg.M 中的 pkg.M。
prop lSquare
public mut prop lSquare: Token
功能:获取或设置 MacroExpandDecl 属性宏调用的左中括号。
返回值:左中括号词法单元。
prop macroAttrs
public mut prop macroAttrs: Tokens
功能:获取或设置 MacroExpandDecl 属性宏调用的输入。
返回值:宏调用的输入的词法单元集合。
prop rSquare
public mut prop rSquare: Token
功能:获取或设置 MacroExpandDecl 属性宏调用的右中括号。
返回值:右中括号词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 MacroExpandDecl 属性宏调用的左小括号。
返回值:左小括号词法单元。
prop macroInputs
public mut prop macroInputs: Tokens
功能:获取或设置 MacroExpandDecl 宏调用的输入。
返回值:宏调用的输入的词法单元集合。
prop rParen
public mut prop rParen: Token
功能:获取或设置 MacroExpandDecl 宏调用的右小括号。
返回值:右小括号词法单元。
prop macroInputDecl
public mut prop macroInputDecl: Decl
功能:获取或设置 MacroExpandDecl 中的声明节点。
返回值:不带括号的宏调用的声明节点。
class Expr
public open class Expr <: Node {
}
Expr 是所有表达式节点的父类,继承自 Node 节点。
class Block
public class Block <: Expr {
public init()
public mut prop lBrace: Token
public mut prop nodes: ArrayList<Node>
public mut prop rBrace: Token
}
Block 表示块节点,Block 由一对匹配的大括号及其中可选的表达式声明序列组成的结构,简称 “块”。
init
public init()
功能:构造一个默认的 Block 实例。
说明:Block 节点无法脱离表达式或声明节点单独存在,因此不提供其他的构造函数。
prop nodes
public mut prop nodes: ArrayList<Node>
功能:获取或设置 Block 中的表达式或声明序列。
返回值: Block 中的表达式或声明序列,可以为空。
prop lBrace
public mut prop lBrace: Token
功能:获取或设置 Block 的左大括号。
返回值:一个左大括号节点词法单元类型。
prop rBrace
public mut prop rBrace: Token
功能:获取或设置 Block 的右大括号。
返回值:一个右大括号节点词法单元类型。
class BinaryExpr
public class BinaryExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop leftExpr: Expr
public mut prop op: Token
public mut prop rightExpr: Expr
}
BinaryExpr 表示一个二元操作表达式节点。
一个 BinaryExpr 节点:a + b, a - b 等
init
public init()
功能:构造一个默认的 BinaryExpr 实例。
init
public init(input: Tokens)
功能:构造 BinaryExpr 实例。
参数:
- input:将要构造
BinaryExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
BinaryExpr节点。
prop leftExpr
public mut prop leftExpr: Expr
功能:获取或设置 BinaryExpr 节点中操作符左侧的表达式节点。
返回值:BinaryExpr 节点中左表达式节点,如: a + b 中的 a。
prop op
public mut prop op: Token
功能:获取或设置 BinaryExpr 节点中的二元操作符。
返回值:BinaryExpr 节点中二元操作符词法单元,如: a + b 中的 +。
prop rightExpr
public mut prop rightExpr: Expr
功能:获取或设置 BinaryExpr 节点中操作符右侧的表达式节点。
返回值:BinaryExpr 节点中右表达式节点,如: a + b 中的 b。
class UnaryExpr
public class UnaryExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop op: Token
public mut prop expr: Expr
}
UnaryExpr 表示一个一元操作表达式节点。
init
public init()
功能:构造一个默认的 UnaryExpr 实例。
init
public init(input: Tokens)
功能:构造 UnaryExpr 实例。
参数:
- input:将要构造
UnaryExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
UnaryExpr节点。
prop op
public mut prop op: Token
功能:获取或设置 UnaryExpr 节点中的一元操作符。
返回值:UnaryExpr 节点中一元操作符词法单元,如:-b 中的 -。
prop expr
public mut prop expr: Expr
功能:获取或设置 UnaryExpr 节点中的操作数。
返回值:UnaryExpr 节点中表达式,如:-b 中的 b。
class IsExpr
public class IsExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop expr: Expr
public mut prop keyword: Token
public mut prop shiftType: TypeNode
}
IsExpr 表示一个类型检查表达式。
一个 IsExpr 表达式:e is T,类型为 Bool。其中 e 可以是任何类型的表达式,T 可以是任何类型。
init
public init()
功能:构造一个默认的 IsExpr 实例。
init
public init(input: Tokens)
功能:构造 IsExpr 实例。
参数:
- input:将要构造
IsExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
IsExpr节点。
prop expr
public mut prop expr: Expr
功能:获取或设置 IsExpr 节点中的表达式节点。
返回值:表达式节点,如:e is T 中的 e。
prop keyword
public mut prop keyword: Token
功能:获取或设置 IsExpr 节点中的 is 操作符。
返回值:is 操作符词法单元。
prop shiftType
public mut prop shiftType: TypeNode
功能:获取或设置 IsExpr 节点中的目标类型。
返回值:目标类型节点,如:e is T 中的 T。
class AsExpr
public class AsExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop expr: Expr
public mut prop keyword: Token
public mut prop shiftType: TypeNode
}
AsExpr 表示一个类型检查表达式。
一个 AsExpr 表达式:e as T,类型为 Option<T>。其中 e 可以是任何类型的表达式,T 可以是任何类型。
init
public init()
功能:构造一个默认的 AsExpr 实例。
init
public init(input: Tokens)
功能:构造 AsExpr 实例。
参数:
- input:将要构造
AsExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
AsExpr节点。
prop expr
public mut prop expr: Expr
功能:获取或设置 AsExpr 节点中的表达式节点。
返回值:表达式节点,如:e as T 中的 e。
prop keyword
public mut prop keyword: Token
功能:获取或设置 AsExpr 节点中的 as 操作符。
返回值:as 操作符词法单元。
prop shiftType
public mut prop shiftType: TypeNode
功能:获取或设置 AsExpr 节点中的目标类型。
返回值:目标类型节点,如:e as T 中的 T。
class ParenExpr
public class ParenExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop lParen: Token
public mut prop parenthesizedExpr: Expr
public mut prop rParen: Token
}
ParenExpr 表示一个括号表达式节点,是指使用圆括号括起来的表达式。
一个 ParenExpr 节点:(1 + 2)
init
public init()
功能:构造一个默认的 ParenExpr 实例。
init
public init(input: Tokens)
功能:构造 ParenExpr 实例。
参数:
- input:将要构造
ParenExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ParenExpr节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 ParenExpr 节点中的左括号。
返回值:左括号的词法单元。
prop parenthesizedExpr
public mut prop parenthesizedExpr: Expr
功能:获取或设置 ParenExpr 节点中由圆括号括起来的子表达式。
返回值:表达式节点,如:(a) 中的 a。
prop rParen
public mut prop rParen: Token
功能:获取或设置 ParenExpr 节点中的右括号。
返回值:右括号的词法单元。
class LitConstExpr
public class LitConstExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop literal: Token
}
LitConstExpr 表示一个常量表达式节点。
一个 LitConstExpr 表达式:"abc",123 等。
init
public init()
功能:构造一个默认的 LitConstExpr 实例。
init
public init(input: Tokens)
功能:构造 LitConstExpr 实例。
参数:
- input:将要构造
LitConstExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ParenExpr节点。
prop literal
public mut prop literal: Token
功能:获取或设置 LitConstExpr 节点中的字面量。
返回值:字面量值的词法单元。
class RefExpr
public class RefExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop identifier: Token
public mut prop lAngle: Token
public mut prop typeArguments: ArrayList<TypeNode>
public mut prop rAngle: Token
}
RefExpr 表示一个使用自定义类型节点相关的表达式节点。
一个 RefExpr 节点:var ref = refNode + 1 中的 refNode 是一个 RefExpr。
init
public init()
功能:构造一个默认的 RefExpr 实例。
init
public init(input: Tokens)
功能:构造 RefExpr 实例。
参数:
- input:将要构造
RefExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
RefExpr节点。
prop identifier
public mut prop identifier: Token
功能:获取或设置 RefExpr 节点中的自定义类型的标识符。
返回值:自定义类型标识符的词法单元,如 refNode + 1 中的 refNode。
prop lAngle
public mut prop lAngle: Token
功能:获取或设置 RefExpr 节点中的左尖括号。
返回值:左尖括号词法单元,可能为空的 Token。
prop typeArguments
public mut prop typeArguments: ArrayList<TypeNode>
功能:获取或设置 RefExpr 节点中的实例化类型。
返回值:实例化类型的列表,可能为空,如 refNode<Int32, A> + 1 中的 Int32 和 A。
prop rAngle
public mut prop rAngle: Token
功能:获取或设置 RefExpr 节点中的右尖括号。
返回值:右尖括号词法单元,可能为空的 Token。
class ReturnExpr
public class ReturnExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
public mut prop expr: Expr
}
ReturnExpr 表示 return 表达式节点。
一个 ReturnExpr 节点:return 1。
init
public init()
功能:构造一个默认的 ReturnExpr 实例。
init
public init(input: Tokens)
功能:构造 ReturnExpr 实例。
参数:
- input:将要构造
ReturnExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ReturnExpr节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置 ReturnExpr 节点中的关键字。
返回值:return 关键字词法单元。
prop expr
public mut prop expr: Expr
功能:获取或设置 ReturnExpr 节点中的表达式节点。
返回值:一个表达式节点。
异常:
- ASTException:当前的
ReturnExpr节点没有表达式。
class ThrowExpr
public class ThrowExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
public mut prop expr: Expr
}
ThrowExpr 表示 throw 表达式节点。
一个 ThrowExpr 节点:throw Exception()。
init
public init()
功能:构造一个默认的 ThrowExpr 实例。
init
public init(input: Tokens)
功能:构造 ThrowExpr 实例。
参数:
- input:将要构造
ThrowExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ThrowExpr节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置 ThrowExpr 节点中的关键字。
返回值:throw 关键字词法单元。
prop expr
public mut prop expr: Expr
功能:获取或设置 ThrowExpr 节点中的表达式节点。
返回值:一个表达式节点。
class AssignExpr
public class AssignExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop leftExpr: Expr
public mut prop assign: Token
public mut prop rightExpr: Expr
}
AssignExpr 表示赋值表达式节点,用于将左操作数的值修改为右操作数的值。
一个 AssignExpr 节点:a = b。
init
public init()
功能:构造一个默认的 AssignExpr 实例。
init
public init(input: Tokens)
功能:构造 AssignExpr 实例。
参数:
- input:将要构造
AssignExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
AssignExpr节点。
prop leftExpr
public mut prop leftExpr: Expr
功能:获取或设置 AssignExpr 节点中的左操作数。
返回值:AssignExpr 节点中的左操作数表达式,如 a = b 中的 a。
prop assign
public mut prop assign: Token
功能:获取或设置 AssignExpr 节点中的 = 操作符。
返回值:= 操作符的词法单元。
prop rightExpr
public mut prop rightExpr: Expr
功能:获取或设置 AssignExpr 节点中的右操作数。
返回值:AssignExpr 节点中的右操作数表达式,如 a = b 中的 b。
class CallExpr
public class CallExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop callFunc: Expr
public mut prop lParen: Token
public mut prop arguments: ArrayList<Argument>
public mut prop rParen: Token
}
CallExpr 表示函数调用节点节点。
一个 CallExpr 节点包括一个表达式后面紧跟参数列表,例如 foo(100)。
init
public init()
功能:构造一个默认的 CallExpr 实例。
init
public init(input: Tokens)
功能:构造 CallExpr 实例。
参数:
- input:将要构造
CallExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
CallExpr节点。
prop callFunc
public mut prop callFunc: Expr
功能:获取或设置 CallExpr 节点中的函数调用节点。
返回值:函数调用的表达式,如 foo(a, b) 中的 foo。
prop lParen
public mut prop lParen: Token
功能:获取或设置 CallExpr 节点中的左括号。
返回值:左括号的词法单元。
prop arguments
public mut prop arguments: ArrayList<Argument>
功能:获取或设置 CallExpr 节点中函数参数。
返回值:函数调用节点的入参。如 foo(a, b) 中的 a, b。
prop rParen
public mut prop rParen: Token
功能:获取或设置 CallExpr 节点中的右括号。
返回值:右括号的词法单元。
class MemberAccess
public class MemberAccess <: Expr {
public init()
public init(input: Tokens)
public mut prop baseExpr: Expr
public mut prop dot: Token
public mut prop field: Token
public mut prop lAngle: Token
public mut prop typeArguments: ArrayList<TypeNode>
public mut prop rAngle: Token
}
MemberAccess 表示成员访问表达式,可以用于访问 class、interface、struct 等类型的成员。
一个 MemberAccess 节点的形式为 T.a,T 为成员访问表达式的主体,a 表示成员的名字。
init
public init()
功能:构造一个默认的 MemberAccess 实例。
init
public init(input: Tokens)
功能:构造 MemberAccess 实例。
参数:
- input:将要构造
MemberAccess类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
MemberAccess节点。
prop baseExpr
public mut prop baseExpr: Expr
功能:获取或设置 MemberAccess 节点的成员访问表达式主体。
返回值:一个表达式节点,如 T.a 中的 T。
prop dot
public mut prop dot: Token
功能:获取或设置 MemberAccess 节点中的 . 。
返回值:. 的词法单元。
prop field
public mut prop field: Token
功能:获取或设置 MemberAccess 节点成员的名字。
返回值:成员名字的词法单元,如 T.a 中的 a。
prop lAngle
public mut prop lAngle: Token
功能:获取或设置 MemberAccess 节点中的左尖括号。
返回值:左尖括号词法单元,可能为空的 Token。
prop typeArguments
public mut prop typeArguments: ArrayList<TypeNode>
功能:获取或设置 MemberAccess 节点中的实例化类型。
返回值:实例化类型的列表,可能为空,如 T.a<Int32> 中的 Int32。
prop rAngle
public mut prop rAngle: Token
功能:获取或设置 MemberAccess 节点中的右尖括号。
返回值:右尖括号词法单元,可能为空的 Token。
class OptionalExpr
public class OptionalExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop baseExpr: Expr
public mut prop quest: Token
}
OptionalExpr 表示一个带有问号操作符的表达式节点。
一个 OptionalExpr 节点:a?.b, a?(b), a?[b] 中的 a?。
init
public init()
功能:构造一个默认的 OptionalExpr 实例。
init
public init(input: Tokens)
功能:构造 OptionalExpr 实例。
参数:
- input:将要构造
OptionalExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
OptionalExpr节点。
prop baseExpr
public mut prop baseExpr: Expr
功能:获取或设置 OptionalExpr 的表达式节点。
返回值:一个表达式节点。
prop quest
public mut prop quest: Token
功能:获取或设置 OptionalExpr 中的问号操作符。
返回值:问号操作符的词法单元。
class IfExpr
public class IfExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keywordI: Token
public mut prop lParen: Token
public mut prop condition: Expr
public mut prop rParen: Token
public mut prop ifBlock: Block
public mut prop keywordE: Token
public mut prop elseExpr: Expr
}
IfExpr 表示条件表达式,可以根据判定条件是否成立来决定执行哪条代码分支。
一个 IfExpr 节点中 if 是关键字,if 之后是一个小括号,小括号内可以是一个表达式或者一个 let 声明的解构匹配,接
着是一个 Block,Block 之后是可选的 else 分支。 else 分支以 else 关键字开始,后接新的 if 表达式或一个 Block。
init
public init()
功能:构造一个默认的 IfExpr 实例。
init
public init(input: Tokens)
功能:构造 IfExpr 实例。
参数:
- input:将要构造
IfExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
IfExpr节点。
prop keywordI
public mut prop keywordI: Token
功能:获取或设置 IfExpr 节点中的 if 关键字。
返回值:if 关键字的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 IfExpr 节点中的 if 后的左括号。
返回值:左括号的词法单元。
prop condition
public mut prop condition: Expr
功能:获取或设置 IfExpr 节点中的 if 后的条件表达式。
返回值:一个表达式节点,如 if (a == 1) 中的 a == 1。
prop rParen
public mut prop rParen: Token
功能:获取或设置 IfExpr 节点中的 if 后的右括号。
返回值:右括号的词法单元。
prop ifBlock
public mut prop ifBlock: Block
功能:获取或设置 IfExpr 节点中的 if 后的 block 节点。
返回值:一个 Block 类型的节点。
prop keywordE
public mut prop keywordE: Token
功能:获取或设置 IfExpr 节点中 else 关键字。
返回值:else 关键字的词法单元。
prop elseExpr
public mut prop elseExpr: Expr
功能:获取或设置 IfExpr 节点中 else 分支节点。
返回值:Expr 类型的节点,该节点可能为空,节点的具体类型为 IfExpr 或 Block。
异常:
- ASTException:当前
IfExpr节点没有 else 分支节点。
class LetPatternExpr
public class LetPatternExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
public mut prop pattern: Pattern
public mut prop backArrow: Token
public mut prop expr: Expr
}
LetPatternExpr 表示 let 声明的解构匹配节点。
一个 LetPatternExpr 节点:if (let Some(v) <- x) 中的 let Some(v) <- x。
init
public init()
功能:构造一个默认的 LetPatternExpr 实例。
init
public init(input: Tokens)
功能:构造 LetPatternExpr 实例。
参数:
- input:将要构造
LetPatternExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
LetPatternExpr节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置 LetPatternExpr 节点中 let 关键字。
返回值:let 关键字的词法单元。
prop pattern
public mut prop pattern: Pattern
功能:获取或设置 LetPatternExpr 节点中 let 之后的 pattern。
返回值:Pattern 类型的节点。
prop backArrow
public mut prop backArrow: Token
功能:获取或设置 LetPatternExpr 节点中 <- 操作符。
返回值:<- 操作符的词法单元。
prop expr
public mut prop expr: Expr
功能:获取或设置 LetPatternExpr 节点中 <- 操作符之后的表达式。
返回值:Expr 类型的节点。
class MatchExpr
public class MatchExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
public mut prop lParen: Token
public mut prop selector: Expr
public mut prop rParen: Token
public mut prop lBrace: Token
public mut prop matchCases: ArrayList<MatchCase>
public mut prop rBrace: Token
}
MatchExpr 表示模式匹配表达式实现模式匹配。模式匹配表达式分为带 selector 的 match 表达式和不带 selector 的 match 表达式。
init
public init()
功能:构造一个默认的 MatchExpr 实例。
init
public init(input: Tokens)
功能:构造 MatchExpr 实例。
参数:
- input:将要构造
MatchExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
MatchExpr节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置 MatchExpr 节点中 match 关键字。
返回值:match 关键字的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 MatchExpr 之后的左括号。
返回值:左括号的词法单元,可能为空的 Token。
prop selector
public mut prop selector: Expr
功能:获取或设置关键字 match 之后的 Expr。
返回值:一个表达式节点。
异常:
- ASTException:该表达式是一个不带 selector 的
match表达式。
prop rParen
public mut prop rParen: Token
功能:获取或设置 MatchExpr 之后的右括号。
返回值:右括号的词法单元,可能为空的 Token。
prop lBrace
public mut prop lBrace: Token
功能:获取或设置 MatchExpr 之后的左大括号。
返回值:左大括号的词法单元。
prop matchCases
public mut prop matchCases: ArrayList<MatchCase>
功能:获取或设置 MatchExpr 内的 matchCase, matchCase 以关键字 case 开头,后跟一个或者多个由 Pattern 或 Expr节点,具体见 [matchCase]。
返回值:一组 matchCase 节点列表。
prop rBrace
public mut prop rBrace: Token
功能:获取或设置 MatchExpr 之后的右大括号。
返回值:右大括号的词法单元。
class WhileExpr
public class WhileExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
public mut prop lParen: Token
public mut prop condition: Expr
public mut prop rParen: Token
public mut prop block: Block
}
WhileExpr 表示 while 表达式。 while 是关键字,while 之后是一个小括号,小括号内可以是一个表达式或者一个 let 声明的解构匹配,接着是一个 Block 节点。
init
public init()
功能:构造一个默认的 WhileExpr 实例。
init
public init(input: Tokens)
功能:构造 WhileExpr 实例。
参数:
- input:将要构造
WhileExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
WhileExpr节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置 WhileExpr 节点中 while 关键字。
返回值:while 关键字的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 WhileExpr 中 while 关键字之后的左括号。
返回值:左括号的词法单元。
prop condition
public mut prop condition: Expr
功能:获取或设置关键字 WhileExpr 中的条件表达式。
返回值:一个表达式节点。
prop rParen
public mut prop rParen: Token
功能:获取或设置 WhileExpr 中 while 关键字之后的右括号。
返回值:右括号的词法单元。
prop block
public mut prop block: Block
功能:获取或设置 WhileExpr 中的块节点。
返回值:一个 Block 节点。
class DoWhileExpr
public class DoWhileExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keywordD: Token
public mut prop block: Block
public mut prop keywordW: Token
public mut prop lParen: Token
public mut prop condition: Expr
public mut prop rParen: Token
}
DoWhileExpr 表示 do-while 表达式。
init
public init()
功能:构造一个默认的 DoWhileExpr 实例。
init
public init(input: Tokens)
功能:构造 DoWhileExpr 实例。
参数:
- input:将要构造
DoWhileExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
DoWhileExpr节点。
prop keywordD
public mut prop keywordD: Token
功能:获取或设置 DoWhileExpr 节点中 do 关键字,D 为关键字前缀的大写表示。
返回值:do 关键字的词法单元。
prop block
public mut prop block: Block
功能:获取或设置 DoWhileExpr 中的块表达式。
返回值:一个 Block 节点。
prop keywordW
public mut prop keywordW: Token
功能:获取或设置 DoWhileExpr 节点中 while 关键字,W 为关键字前缀的大写表示。
返回值:while 关键字的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 DoWhileExpr 中 while 关键字之后的左括号。
返回值:左括号的词法单元。
prop condition
public mut prop condition: Expr
功能:获取或设置关键字 DoWhileExpr 中的条件表达式。
返回值:一个表达式节点。
prop rParen
public mut prop rParen: Token
功能:获取或设置 DoWhileExpr 中 while 关键字之后的右括号。
返回值:右括号的词法单元。
class LambdaExpr
public class LambdaExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop lBrace: Token
public mut prop funcParams: ArrayList<FuncParam>
public mut prop doubleArrow: Token
public mut prop nodes: ArrayList<Node>
public mut prop rBrace: Token
}
LambdaExpr 表示 Lambda 表达式,是一个匿名的函数。
一个 LambdaExpr 节点有两种形式,一种是有形参的 {a: Int64 => e1; e2 },另一种是无形参的 { => e1; e2 }。
init
public init()
功能:构造一个默认的 LambdaExpr 实例。
init
public init(input: Tokens)
功能:构造 LambdaExpr 实例。
参数:
- input:将要构造
LambdaExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
LambdaExpr节点。
prop lBrace
public mut prop lBrace: Token
功能:获取或设置 LambdaExpr 中的左大括号。
返回值:左大括号的词法单元。
prop funcParams
public mut prop funcParams: ArrayList<FuncParam>
功能:获取或设置 LambdaExpr 中的参数列表。
返回值:函数参数列表。
prop doubleArrow
public mut prop doubleArrow: Token
功能:获取或设置 LambdaExpr 中的 =>。
返回值:=> 操作符的词法单元。
prop nodes
public mut prop nodes: ArrayList<Node>
功能:获取或设置 LambdaExpr 中的表达式或声明节点。
返回值:一组表达式或声明列表。
prop rBrace
public mut prop rBrace: Token
功能:获取或设置 LambdaExpr 中的右大括号。
返回值:右大括号的词法单元。
class SpawnExpr
public class SpawnExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
public mut prop lParen: Token
public mut prop threadContext: Expr
public mut prop rParen: Token
public mut prop lambdaExpr: LambdaExpr
}
SpawnExpr 表示 Spawn 表达式。
一个 SpawnExpr 节点由 spawn 关键字和一个不包含形参的闭包组成,例如:spawn { add(1, 2) }。
init
public init()
功能:构造一个默认的 SpawnExpr 实例。
init
public init(input: Tokens)
功能:构造 SpawnExpr 实例。
参数:
- input:将要构造
SpawnExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
SpawnExpr节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 SpawnExpr 中的左括号。
返回值:左括号的词法单元,可以为空。
prop threadContext
public mut prop threadContext: Expr
功能:获取或设置 SpawnExpr 中的线程上下文环境表达式。
返回值:一个表达式节点,如:spwan (ctx) 中的 (ctx)。
异常:
- ASTException:
SpawnExpr中不含有上下文表达式。
prop rParen
public mut prop rParen: Token
功能:获取或设置 SpawnExpr 中的右括号。
返回值:右括号的词法单元,可以为空。
prop keyword
public mut prop keyword: Token
功能:获取或设置 SpawnExpr 中的 spawn 关键字。
返回值:spawn 关键字的词法单元。
prop lambdaExpr
public mut prop lambdaExpr: LambdaExpr
功能:获取或设置 SpawnExpr 中的不含形参的闭包。
返回值:不含形参的 LambdaExpr 表达式。
class SynchronizedExpr
public class SynchronizedExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
public mut prop lParen: Token
public mut prop structuredMutex: Expr
public mut prop rParen: Token
public mut prop block: Block
}
SynchronizedExpr 表示 synchronized 表达式。
一个 SynchronizedExpr 节点由 synchronized 关键字和 StructuredMutex 对以及后面的代码块组成, 例如 synchronized(m) { foo() }。
init
public init()
功能:构造一个默认的 SynchronizedExpr 实例。
init
public init(input: Tokens)
功能:构造 SynchronizedExpr 实例。
参数:
- input:将要构造
SynchronizedExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
SynchronizedExpr节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置 SynchronizedExpr 中的 synchronized 关键字。
返回值:synchronized 关键字的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 SynchronizedExpr 中的左括号。
返回值:左括号词法单元。
prop structuredMutex
public mut prop structuredMutex: Expr
功能:获取或设置 SynchronizedExpr 中的 StructuredMutex 的对象。
返回值:一个 RefExpr 节点。
prop rParen
public mut prop rParen: Token
功能:获取或设置 SynchronizedExpr 中的右括号。
返回值:右括号词法单元。
prop block
public mut prop block: Block
功能:获取或设置 SynchronizedExpr 修饰的代码块。
返回值:代码块节点。
class TrailingClosureExpr
public class TrailingClosureExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop expr: Expr
public mut prop lambdaExpr: LambdaExpr
}
TrailingClosureExpr 表示尾随 Lambda 节点。
一个 TrailingClosureExpr 节点将 lambda 表达式放在函数调用的尾部,括号外面,如 f(a){ i => i * i }。
init
public init()
功能:构造一个默认的 TrailingClosureExpr 实例。
init
public init(input: Tokens)
功能:构造 TrailingClosureExpr 实例。
参数:
- input:将要构造
TrailingClosureExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
TrailingClosureExpr节点。
prop expr
public mut prop expr: Expr
功能:获取或设置 TrailingClosureExpr 中的表达式。
返回值:表达式节点,可能为 RefExpr 或 CallExpr 类型。
prop expr
public mut prop lambdaExpr: LambdaExpr
功能:获取或设置 TrailingClosureExpr 中的尾随 lambda 。
返回值:LambdaExpr 表达式节点。
class TypeConvExpr
public class TypeConvExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop targetType: PrimitiveType
public mut prop lParen: Token
public mut prop expr: Expr
public mut prop rParen: Token
}
TypeConvExpr 表示类型转换表达式,用于实现若干数值类型间的转换。
一个 TypeConvExpr 节点:Int8(32)
init
public init()
功能:构造一个默认的 TypeConvExpr 实例。
init
public init(input: Tokens)
功能:构造 TypeConvExpr 实例。
参数:
- input:将要构造
TypeConvExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
TypeConvExpr节点。
prop targetType
public mut prop targetType: PrimitiveType
功能:获取或设置 TypeConvExpr 中将要转换到的目标类型。
返回值:基本类型节点,如 Int8, Int16。
prop lParen
public mut prop lParen: Token
功能:获取或设置 TypeConvExpr 中的左括号。
返回值:左括号词法单元。
prop expr
public mut prop expr: Expr
功能:获取或设置 TypeConvExpr 中进行类型转化的原始表达式。
返回值:表达式节点,如 Int8(a) 中的 a。
prop rParen
public mut prop rParen: Token
功能:获取或设置 TypeConvExpr 中的右括号。
返回值:右括号词法单元。
class ForInExpr
public class ForInExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keywordF: Token
public mut prop lParen: Token
public mut prop pattern: Pattern
public mut prop keywordI: Token
public mut prop expr: Expr
public mut prop keywordW: Token
public mut prop patternGuard: Expr
public mut prop rParen: Token
public mut prop block: Block
}
ForInExpr 表示 for-in 表达式。
ForInExpr 类型中,关键字 for 之后是 Pattern, 此后是一个 in 关键字和表达式节点,最后是一个执行循环体 Block。
init
public init()
功能:构造一个默认的 ForInExpr 实例。
init
public init(input: Tokens)
功能:构造 ForInExpr 实例。
参数:
- input:将要构造
ForInExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ForInExpr节点。
prop keywordF
public mut prop keywordF: Token
功能:获取或设置 ForInExpr 中的关键字 for。
返回值:for 关键字的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 ForInExpr 中关键字 for 后的左括号。
返回值:左括号的词法单元。
prop pattern
public mut prop pattern: Pattern
功能:获取或设置 ForInExpr 中的 Pattern 节点。
返回值:Pattern 节点。
prop keywordI
public mut prop keywordI: Token
功能:获取或设置 ForInExpr 中的关键字 in。
返回值:in 关键字词法单元。
prop expr
public mut prop expr: Expr
功能:获取或设置 ForInExpr 中的表达式。
返回值:表达式节点,如 for (i in children) 中的 children。
prop keywordW
public mut prop keywordW: Token
功能:获取或设置 ForInExpr 中的关键字 where。
返回值:where 关键字词法单元,可能为空。
prop patternGuard
public mut prop patternGuard: Expr
功能:获取或设置 ForInExpr 中的 patternGuard 条件表达式。
返回值:patternGuard 表达式节点。
异常:
- ASTException:
ForInExpr节点中不存在patternGuard表达式。
prop rParen
public mut prop rParen: Token
功能:获取或设置 ForInExpr 中的右括号。
返回值:右括号的词法单元。
prop block
public mut prop block: Block
功能:获取或设置 ForInExpr 中的循环体。
返回值:代码块 Block 节点。
class PrimitiveTypeExpr
public class PrimitiveTypeExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
}
PrimitiveTypeExpr 表示基本类型表达式节点。
PrimitiveTypeExpr 节点:编译器内置的基本类型作为表达式出现在节点中。如 Int64.toSting() 中的 Int64。
init
public init()
功能:构造一个默认的 PrimitiveTypeExpr 实例。
init
public init(input: Tokens)
功能:构造 PrimitiveTypeExpr 实例。
参数:
- input:将要构造
PrimitiveTypeExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
PrimitiveTypeExpr节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置 PrimitiveTypeExpr 中的基本类型关键字。
返回值:基本类型关键字的词法单元。
class ArrayLiteral
public class ArrayLiteral <: Expr {
public init()
public init(input: Tokens)
public mut prop lSquare: Token
public mut prop elements: ArrayList<Expr>
public mut prop rSquare: Token
}
ArrayLiteral 表示 Array 字面量节点。
ArrayLiteral 节点:使用格式 [element1, element2, ... , elementN] 表示, 每个 element 是一个表达式。
init
public init()
功能:构造一个默认的 ArrayLiteral 实例。
init
public init(input: Tokens)
功能:构造 ArrayLiteral 实例。
参数:
- input:将要构造
ArrayLiteral类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ArrayLiteral节点。
prop lSquare
public mut prop lSquare: Token
功能:获取或设置 ArrayLiteral 中的左中括号。
返回值:左中括号的词法单元。
prop elements
public mut prop elements: ArrayList<Expr>
功能:获取或设置 ArrayLiteral 中的表达式列表。
返回值:一组表达式列表。
prop rSquare
public mut prop rSquare: Token
功能:获取或设置 ArrayLiteral 中的右中括号。
返回值:右中括号的词法单元。
class TupleLiteral
public class TupleLiteral <: Expr {
public init()
public init(input: Tokens)
public mut prop lParen: Token
public mut prop elements: ArrayList<Expr>
public mut prop rParen: Token
}
TupleLiteral 表示元组字面量节点。
TupleLiteral 节点:使用格式 (expr1, expr2, ... , exprN) 表示, 每个 expr 是一个表达式。
init
public init()
功能:构造一个默认的 TupleLiteral 实例。
init
public init(input: Tokens)
功能:构造 TupleLiteral 实例。
参数:
- input:将要构造
TupleLiteral类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
TupleLiteral节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 TupleLiteral 中的左括号。
返回值:左中括号的词法单元。
prop elements
public mut prop elements: ArrayList<Expr>
功能:获取或设置 TupleLiteral 中的表达式列表。
返回值:一组表达式列表。
prop rParen
public mut prop rParen: Token
功能:获取或设置 TupleLiteral 中的右括号。
返回值:右括号的词法单元。
class RangeExpr
public class RangeExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop start: Expr
public mut prop op: Token
public mut prop end: Expr
public mut prop colon: Token
public mut prop step: Expr
}
RangeExpr 表示包含区间操作符的表达式。
RangeExpr 节点:存在两种 Range 操作符:.. 和 ..=,分别用于创建左闭右开和左闭右闭的 Range 实例。它们的使用方式分别为 start..end:step 和 start..=end:step。
init
public init()
功能:构造一个默认的 RangeExpr 实例。
init
public init(input: Tokens)
功能:构造 RangeExpr 实例。
参数:
- input:将要构造
RangeExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
RangeExpr节点。
prop start
public mut prop start: Expr
功能:获取或设置 RangeExpr 中的起始值。
返回值:一个表达式节点,如:0..10:1 中的 0。
异常:
- ASTException:起始表达式省略。只有在
Range<Int64>类型的实例用在下标操作符[]为空的场景。
prop op
public mut prop op: Token
功能:获取或设置 RangeExpr 中的 Range 的操作符。
返回值:一个操作符的词法单元,如 .. 或 ..=。
prop end
public mut prop end: Expr
功能:获取或设置 RangeExpr 中的终止值。
返回值:一个表达式节点,如:0..10:1 中的 10。
异常:
- ASTException:终止表达式省略。只有在
Range<Int64>类型的实例用在下标操作符[]为空的场景。
prop colon
public mut prop colon: Token
功能:获取或设置 RangeExpr 中的 : 操作符。
返回值:一个 : 操作符的词法单元,可以为空。
prop step
public mut prop step: Expr
功能:获取或设置 RangeExpr 中序列中前后两个元素之间的差值。
返回值:一个表达式节点,如:0..10:1 中的 1。
异常:
- ASTException:
RangeExpr中未设置序列前后两个元素之间的差值。
class SubscriptExpr
public class SubscriptExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop baseExpr: Expr
public mut prop lSquare: Token
public mut prop indexList: ArrayList<Expr>
public mut prop rSquare: Token
}
SubscriptExpr 表示索引访问表达式。
SubscriptExpr 节点:用于那些支持索引访问的类型(包括 Array 类型和 Tuple 类型)通过下标来访问其具体位置的元素,如 arr[0]。
init
public init()
功能:构造一个默认的 SubscriptExpr 实例。
init
public init(input: Tokens)
功能:构造 SubscriptExpr 实例。
参数:
- input:将要构造
SubscriptExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
SubscriptExpr节点。
prop baseExpr
public mut prop baseExpr: Expr
功能:获取或设置 SubscriptExpr 中的表达式。
返回值:一个表达式节点,如:e[a] 中的 e。
prop lSquare
public mut prop lSquare: Token
功能:获取或设置 SubscriptExpr 中的左中括号。
返回值:左中括号词法单元。
prop indexList
public mut prop indexList: ArrayList<Expr>
功能:获取或设置 SubscriptExpr 中的索引表达式序列。
返回值:表达式节点的序列,如 arr[1] 中的 1。
prop rSquare
public mut prop rSquare: Token
功能:获取或设置 SubscriptExpr 中的右中括号。
返回值:右中括号词法单元。
class JumpExpr
public class JumpExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
}
JumpExpr 表示循环表达式的循环体中的 break 和 continue。
init
public init()
功能:构造一个默认的 JumpExpr 实例。
init
public init(input: Tokens)
功能:构造 JumpExpr 实例。
参数:
- input:将要构造
JumpExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
JumpExpr节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置关键字。
返回值:关键字的词法单元,如:break。
class IncOrDecExpr
public class IncOrDecExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop op: Token
public mut prop expr: Expr
}
IncOrDecExpr 表示包含自增操作符(++)或自减操作符(--)的表达式。
init
public init()
功能:构造一个默认的 IncOrDecExpr 实例。
init
public init(input: Tokens)
功能:构造 IncOrDecExpr 实例。
参数:
- input:将要构造
IncOrDecExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
IncOrDecExpr节点。
prop op
public mut prop op: Token
功能:获取或设置 IncOrDecExpr 中的操作符。
返回值:操作符的词法单元。
prop expr
public mut prop expr: Expr
功能:获取或设置 IncOrDecExpr 中的表达式。
返回值:一个表达式节点。
class TryExpr
public class TryExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keywordT: Token
public mut prop resourceSpec: ArrayList<VarDecl>
public mut prop tryBlock: Block
public mut prop keywordsC: Tokens
public mut prop catchPatterns: ArrayList<Pattern>
public mut prop catchBlocks: ArrayList<Block>
public mut prop keywordF: ArrayList<Pattern>
public mut prop finallyBlock: Block
}
TryExpr 表示 try 表达式节点。try 表达式包括三个部分:try 块,catch 块和 finally 块。
init
public init()
功能:构造一个默认的 TryExpr 实例。
init
public init(input: Tokens)
功能:构造 TryExpr 实例。
参数:
- input:将要构造
TryExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
TryExpr节点。
prop keywordT
public mut prop keywordT: Token
功能:获取或设置 TryExpr 中的 try 关键字。
返回值:try 关键字的词法单元。
prop resourceSpec
public mut prop resourceSpec: ArrayList<VarDecl>
功能:获取或设置 TryExpr 中 Try-with-resources 类型表达式的实例化对象序列。
返回值:一组实例化对象节点。
prop tryBlock
public mut prop tryBlock: Block
功能:获取或设置 TryExpr 中由表达式与声明组成的块。
返回值:一个 Block 类型的节点。
prop keywordsC
public mut prop keywordsC: Tokens
功能:获取或设置 TryExpr 中的关键字 catch。
返回值:一组 catch 关键字词法单元。
prop catchPatterns
public mut prop catchPatterns: ArrayList<Pattern>
功能:获取或设置 TryExpr 中通过模式匹配的方式匹配待捕获的异常序列。
返回值:一组模式匹配序列。
prop catchBlocks
public mut prop catchBlocks: ArrayList<Block>
功能:获取或设置 TryExpr 中的 Catch 块。
返回值:由表达式与声明组成块的序列。
prop keywordF
public mut prop keywordF: Token
功能:获取或设置 TryExpr 中的 finally 关键字。
返回值:finally 关键字词法单元,可以为空。
prop finallyBlock
public mut prop finallyBlock: Block
功能:获取或设置 TryExpr 中的关键字 Finally 块。
返回值:由表达式与声明组成块。
异常:
- ASTException:
TryExpr节点无Finally块节点。
class QuoteExpr
public class QuoteExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
public mut prop lParen: Token
public mut prop exprs: ArrayList<Expr>
public mut prop rParen: Token
}
QuoteExpr 表示 quote 表达式节点。
一个 QuoteExpr 节点: quote(var ident = 0)
init
public init()
功能:构造一个默认的 QuoteExpr 实例。
init
public init(input: Tokens)
功能:构造 QuoteExpr 实例。
参数:
- input:将要构造
QuoteExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
QuoteExpr节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 QuoteExpr 中的左括号。
返回值:左括号节点的词法单元。
prop exprs
public mut prop exprs: ArrayList<Expr>
功能:获取或设置 QuoteExpr 中由 () 括起的内部引用表达式节点。
返回值:一组表达式序列。
prop rParen
public mut prop rParen: Token
功能:获取或设置 QuoteExpr 中的右括号。
返回值:右括号节点的词法单元。
class QuoteToken
public class QuoteToken <: Expr {
public mut prop tokens: Tokens
}
QuoteToken 表示 quote 表达式节点内任意合法的 token。
tokens
public mut prop tokens: Tokens
功能:获取 QuoteToken 内的 tokens。
返回值:一组词法单元序列,如 quote(1 + 2) 中的 1 + 2。
class MacroExpandExpr
public class MacroExpandExpr <: Expr {
public init()
public init(inputs: Tokens)
public mut prop at: Token
public mut prop identifier: Token
public mut prop lSquare: Token
public mut prop macroAttrs: Tokens
public mut prop rSquare: Token
public mut prop lParen: Token
public mut prop macroInputs: Tokens
public mut prop rParen: Token
}
MacroExpandExpr 表示宏调用节点。
一个 MacroExpandExpr 节点: @M (a is Int64)
init
public init()
功能:构造一个默认的 MacroExpandExpr 实例。
init
public init(input: Tokens)
功能:构造 MacroExpandExpr 实例。
参数:
- input:将要构造
MacroExpandExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
MacroExpandExpr节点。
public mut prop at: Token
功能:获取或设置宏调用节点的关键字 at。
返回值:关键字 at 的词法单元,例如 @pkg.M 中的 @。
public mut prop identifier: Token
功能:获取或设置宏调用节点的标识符。
返回值:一个包含完整标识符的词法单元类型,例如 @pkg.M 中的 M。
prop lSquare
public mut prop lSquare: Token
功能:获取或设置 MacroExpandExpr 属性宏调用的左中括号。
返回值:左中括号词法单元。
prop macroAttrs
public mut prop macroAttrs: Tokens
功能:获取或设置 MacroExpandExpr 属性宏调用的输入。
返回值:宏调用的输入的词法单元集合。
prop rSquare
public mut prop rSquare: Token
功能:获取或设置 MacroExpandExpr 属性宏调用的右中括号。
返回值:右中括号词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 MacroExpandExpr 属性宏调用的左小括号。
返回值:左小括号词法单元。
prop macroInputs
public mut prop macroInputs: Tokens
功能:获取或设置 MacroExpandExpr 宏调用的输入。
返回值:宏调用的输入的词法单元集合。
prop rParen
public mut prop rParen: Token
功能:获取或设置 MacroExpandExpr 宏调用的右小括号。
返回值:右小括号词法单元。
class WildcardExpr
public class WildcardExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop keyword: Token
}
WildcardExpr 表示通配符表达式节点。
init
public init()
功能:构造一个默认的 WildcardExpr 实例。
init
public init(input: Tokens)
功能:构造 WildcardExpr 实例。
参数:
- input:将要构造
WildcardExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
WildcardExpr节点。
token
public mut prop keyword: Token
功能:获取 WildcardExpr 的通配符关键字。
返回值:一个通配符词法单元。
class VArrayExpr
public class VArrayExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop vArrayType: VArrayType
public mut prop lParen: Token
public mut prop arguments: ArrayList<Argument>
public mut prop rParen: Token
}
VArrayExpr 表示 VArray 的实例节点。
一个 VArrayExpr 节点:let arr: VArray<Int64, $5> = VArray<Int64, $5> { i => i} 中的 VArray<Int64, $5> { i => i}
init
public init()
功能:构造一个默认的 VArrayExpr 实例。
init
public init(input: Tokens)
功能:构造 VArrayExpr 实例。
参数:
- input:将要构造
VArrayExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
VArrayExpr节点。
prop vArrayType
public mut prop vArrayType: VArrayType
功能:获取或设置 VArrayExpr 的 VArray 类型节点。
返回值:一个 VArrayType 类型的节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 VArrayExpr 中的左括号。
返回值:左括号节点的词法单元。
prop exprs
public mut prop exprs: ArrayList<Expr>
功能:获取或设置 VArrayExpr 中的初始化表达式。
返回值:一组表达式序列。
prop rParen
public mut prop rParen: Token
功能:获取或设置 VArrayExpr 中的右括号。
返回值:右括号节点的词法单元。
class AdjointExpr
public class AdjointExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop at: Token
public mut prop identifier: Token
public mut prop lParen: Token
public mut prop diffFunc: Expr
public mut prop rParen: Token
}
AdjointExpr 用于表示AdjointExpr 节点,给定一个可微函数,可以使用 @AdjointOf 表达式来获取对该函数微分产生的伴随函数。
一个 AdjointExpr 节点:@AdjointOf(foo) ,其中括号内的标识符必须表示一个函数。
init
public init()
功能:构造一个默认的 AdjointExpr 实例。
init
public init(input: Tokens)
功能:构造 AdjointExpr 实例。
参数:
- input:将要构造
AdjointExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
AdjointExpr节点。
prop at
public mut prop at: Token
功能:设置或获取 AdjointExpr 的 @ 操作符。
返回值:@ 操作符的词法单元。
prop identifier
public mut prop identifier: Token
功能:获取或设置 AdjointExpr 中的标识符 AdjointOf。
返回值:标识符 AdjointOf 的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 AdjointExpr 中的左括号。
返回值:左括号节点的词法单元。
prop diffFunc
public mut prop diffFunc: Expr
功能:获取或设置 AdjointExpr 中的可微函数表达式。
返回值:一个可微函数的表达式节点。
prop rParen
public mut prop rParen: Token
功能:获取或设置 AdjointExpr 中的右括号。
返回值:右括号节点的词法单元。
class GradExpr
public class GradExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop at: Token
public mut prop identifier: Token
public mut prop lParen: Token
public mut prop diffFunc: Expr
public mut prop inputValue: ArrayList<Expr>
public mut prop rParen: Token
}
GradExpr 表示 GradExpr 节点,给定一个可微函数和相应的输入参数,可使用 @Grad 表达式来获取该函数在该输入值处的梯度值。
一个 GradExpr 节点:@Grad(foo, 2.0, 3.0) ,其中括号内的标识符必须表示一个函数。
init
public init()
功能:构造一个默认的 GradExpr 实例。
init
public init(input: Tokens)
功能:构造 GradExpr 实例。
参数:
- input:将要构造
GradExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
GradExpr节点。
prop at
public mut prop at: Token
功能:设置或获取 GradExpr 内的 @ 操作符。
返回值:@ 操作符的词法单元。
prop identifier
public mut prop identifier: Token
功能:获取或设置 GradExpr 中的标识符 Grad。
返回值:标识符 Grad 的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 GradExpr 中的左括号。
返回值:左括号节点的词法单元。
prop diffFunc
public mut prop diffFunc: Expr
功能:获取或设置 GradExpr 中的可微函数表达式。
返回值:一个可微函数的表达式节点。
prop inputValue
public mut prop inputValue: ArrayList<Expr>
功能:获取或设置 GradExpr 中的输入参数。
返回值:输入参数的表达式节点结合,如 @Grad(foo, 2.0, 3.0) 中的 2.0, 3.0。
prop rParen
public mut prop rParen: Token
功能:获取或设置 GradExpr 中的右括号。
返回值:右括号节点的词法单元。
class ValWithGradExpr
public class ValWithGradExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop at: Token
public mut prop identifier: Token
public mut prop lParen: Token
public mut prop diffFunc: Expr
public mut prop inputValue: ArrayList<Expr>
public mut prop rParen: Token
}
ValWithGradExpr 表示 ValWithGradExpr 节点,给定一个可微函数和相应的输入参数值,用户可使用 @ValWithGrad 表达式来获取该函数在该输入值处的结果和梯度值。
一个 VJPExpr 节点:@ValWithGrad(foo, 2.0, 3.0),其中括号内的标识符必须表示一个函数。
init
public init()
功能:构造一个默认的 ValWithGradExpr 实例。
init
public init(input: Tokens)
功能:构造 ValWithGradExpr 实例。
参数:
- input:将要构造
ValWithGradExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ValWithGradExpr节点。
prop at
public mut prop at: Token
功能:设置或获取 ValWithGradExpr 内的 @ 操作符。
返回值:@ 操作符的词法单元。
prop identifier
public mut prop identifier: Token
功能:获取或设置 ValWithGradExpr 中的标识符。
返回值:标识符 ValWithGrad 的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 ValWithGradExpr 中的左括号。
返回值:左括号节点的词法单元。
prop diffFunc
public mut prop diffFunc: Expr
功能:获取或设置 ValWithGradExpr 中的可微函数表达式。
返回值:一个可微函数的表达式节点。
prop inputValue
public mut prop inputValue: ArrayList<Expr>
功能:获取或设置 ValWithGradExpr 中的输入参数。
返回值:输入参数的表达式节点结合,如 @ValWithGrad(foo, 2.0, 3.0) 中的 2.0, 3.0。
prop rParen
public mut prop rParen: Token
功能:获取或设置 ValWithGradExpr 中的右括号。
返回值:右括号节点的词法单元。
class VJPExpr
public class VJPExpr <: Expr {
public init()
public init(input: Tokens)
public mut prop at: Token
public mut prop identifier: Token
public mut prop lParen: Token
public mut prop diffFunc: Expr
public mut prop inputValue: ArrayList<Expr>
public mut prop rParen: Token
}
VJPExpr 表示 VJPExpr 节点,给定一个可微函数和相应的输入参数值,使用 @VJP 表达式来获取该函数在该输入值处的结果和反向传播函数。
一个 VJPExpr 节点:@VJP(product, 2.0, 3.0, true) ,其中括号内的标识符必须表示一个函数。
init
public init()
功能:构造一个默认的 VJPExpr 实例。
init
public init(input: Tokens)
功能:构造 VJPExpr 实例。
参数:
- input:将要构造
VJPExpr类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
VJPExpr节点。
prop at
public mut prop at: Token
功能:设置或获取 VJPExpr 内的 @ 操作符。
返回值:@ 操作符的词法单元。
prop identifier
public mut prop identifier: Token
功能:获取或设置 VJPExpr 中的标识符 VJP。
返回值:标识符 VJP 的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 VJPExpr 中的左括号。
返回值:左括号节点的词法单元。
prop diffFunc
public mut prop diffFunc: Expr
功能:获取或设置 VJPExpr 中的可微函数表达式。
返回值:一个可微函数的表达式节点。
prop inputValue
public mut prop inputValue: ArrayList<Expr>
功能:获取或设置 VJPExpr 中的输入参数。
返回值:输入参数的表达式节点结合,如 @VJP(product, 2.0, 3.0, true) 中的 2.0, 3.0, true。
prop rParen
public mut prop rParen: Token
功能:获取或设置 VJPExpr 中的右括号。
返回值:右括号节点的词法单元。
class TypeNode
public open class TypeNode <: Node {
public mut prop typeParameterName: Token
}
TypeNode 是所有类型节点的父类,继承自 Node。
prop typeParameterName
public mut prop typeParameterName: Token
功能:获取或设置类型节点的参数。
返回值:类型参数的词法单元,如:(p1:Int64, p2:Int64) 中的 p1 和 p2,并且可以为空。
class PrimitiveType
public class PrimitiveType <: TypeNode {
public init()
public init(input: Tokens)
public mut prop keyword: Token
}
PrimitiveType 表示一个基本类型节点,如数值类型,Char 类型,布尔类型等。
init
public init()
功能:构造一个默认的 PrimitiveType 实例。
init
public init(input: Tokens)
功能:构造 PrimitiveType 实例。
参数:
- input:将要构造
PrimitiveType类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
PrimitiveType节点。
keyword
public mut prop keyword: Token
功能:构造 PrimitiveType 类型的关键字。
返回值:一个基本类型关键字词法单元,如 Int8。
class RefType
public class RefType <: TypeNode {
public init()
public init(input: Tokens)
public mut prop identifier: Token
public mut prop lAngle: Token
public mut prop typeArguments: ArrayList<TypeNode>
public mut prop rAngle: Token
}
RefType 表示一个用户自定义类型节点,如 var a : A = A() 中的 A。
init
public init()
功能:构造一个默认的 RefType 实例。
init
public init(input: Tokens)
功能:构造 RefType 实例。
参数:
- input:将要构造
RefType类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
RefType节点。
prop identifier
public mut prop identifier: Token
功能:构造 RefType 类型的关键字。
返回值:一个基本类型关键字词法单元,如 var a : A = A() 中的 A。
prop lAngle
public mut prop lAngle: Token
功能:获取或设置 RefType 节点中的左尖括号。
返回值:左尖括号词法单元,可能为空的 Token。
prop typeArguments
public mut prop typeArguments: ArrayList<TypeNode>
功能:获取或设置 RefType 节点中的实例化类型。
返回值:实例化类型的列表,可能为空,如 var a : Array<Int32> 中的 Int32。
prop rAngle
public mut prop rAngle: Token
功能:获取或设置 RefType 节点中的右尖括号。
返回值:右尖括号词法单元,可能为空的 Token。
class QualifiedType
public class QualifiedType <: TypeNode {
public init()
public init(input: Tokens)
public mut prop baseType: TypeNode
public mut prop dot: Token
public mut prop identifier: Token
public mut prop lAngle: Token
public mut prop typeArguments: ArrayList<TypeNode>
public mut prop rAngle: Token
}
QualifiedType 表示一个用户自定义成员类型,如 var a : T.a 中的 T.a, 其中 T 是包名,a 是从 T 包中导入的类型。
init
public init()
功能:构造一个默认的 QualifiedType 实例。
init
public init(input: Tokens)
功能:构造 QualifiedType 实例。
参数:
- input:将要构造
QualifiedType类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
QualifiedType节点。
prop baseType
public mut prop baseType: Expr
功能:获取或设置 QualifiedType 节点的成员访问类型主体。
返回值:一个表达式节点,如 var a : T.a 中的 T。
prop dot
public mut prop dot: Token
功能:获取或设置 QualifiedType 节点中的 . 。
返回值:. 的词法单元。
prop identifier
public mut prop identifier: Token
功能:获取或设置 QualifiedType 节点成员的标识符。
返回值:节点成员标识符的词法单元,如 var a : T.a 中的 a。
prop lAngle
public mut prop lAngle: Token
功能:获取或设置 QualifiedType 节点中的左尖括号。
返回值:左尖括号词法单元,可能为空的 Token。
prop typeArguments
public mut prop typeArguments: ArrayList<TypeNode>
功能:获取或设置 QualifiedType 节点中的实例化类型。
返回值:实例化类型的列表,可能为空,如 T.a<Int32> 中的 Int32。
prop rAngle
public mut prop rAngle: Token
功能:获取或设置 QualifiedType 节点中的右尖括号。
返回值:右尖括号词法单元,可能为空的 Token。
class ParenType
public class ParenType <: TypeNode {
public init()
public init(input: Tokens)
public mut prop lParen: Token
public mut prop parenthesizedType: TypeNode
public mut prop rParen: Token
}
ParenType 表示括号类型节点,如 var a: (Int64) 中的 (Int64)。
init
public init()
功能:构造一个默认的 ParenType 实例。
init
public init(input: Tokens)
功能:构造 ParenType 实例。
参数:
- input:将要构造
ParenType类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ParenType节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 ParenType 节点中的左括号。
返回值:左括号词法单元。
prop parenthesizedType
public mut prop parenthesizedType: TypeNode
功能:获取或设置 ParenType 节点中括起来的类型。
返回值:一个表达式节点,如 (Int64) 中的 Int64。
prop rParen
public mut prop rParen: Token
功能:获取或设置 ParenType 节点中的右括号。
返回值:右括号词法单元。
class TupleType
public class TupleType <: TypeNode {
public init()
public init(input: Tokens)
public mut prop lParen: Token
public mut prop types: ArrayList<TypeNode>
public mut prop rParen: Token
}
TupleType 表示元组类型节点,如 var a : (Int64, Int32) 中的 (Int64, Int32)。
init
public init()
功能:构造一个默认的 TupleType 实例。
init
public init(input: Tokens)
功能:构造 TupleType 实例。
参数:
- input:将要构造
TupleType类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
TupleType节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 TupleType 节点中的左括号。
返回值:左括号词法单元。
prop types
public mut prop types: ArrayList<TypeNode>
功能:获取或设置 TupleType 节点中的类型节点列表。
返回值:类型节点序列。
prop rParen
public mut prop rParen: Token
功能:获取或设置 TupleType 节点中的右括号。
返回值:右括号词法单元。
class ThisType
public class ThisType <: TypeNode {
public init()
public init(input: Tokens)
public mut prop keyword: Token
}
ThisType 表示 This 类型节点。
init
public init()
功能:构造一个默认的 ThisType 实例。
init
public init(input: Tokens)
功能:构造 ThisType 实例。
参数:
- input:将要构造
ThisType类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ThisType节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置 ThisType 节点关键字 This。
返回值:This 关键字的词法单元。
class PrefixType
public class PrefixType <: TypeNode {
public init()
public init(input: Tokens)
public mut prop prefixOps: Tokens
public mut prop baseType: TypeNode
}
PrefixType 表示带问号的前缀类型节点,如:var a : ?A 中的 ?A。
init
public init()
功能:构造一个默认的 PrefixType 实例。
init
public init(input: Tokens)
功能:构造 PrefixType 实例。
参数:
- input:将要构造
PrefixType类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
PrefixType节点。
prop prefixOps
public mut prop prefixOps: Tokens
功能:获取或设置 PrefixType 节点中前缀操作符集合。
返回值:包含多个问号的词法单元集合。
prop baseType
public mut prop baseType: TypeNode
功能:获取或设置 PrefixType 节点中的类型节点。
返回值:一个类型节点,如 var a: ?A 中的 A。
class FuncType
public class FuncType <: TypeNode {
public init()
public init(input: Tokens)
public mut prop lParen: Token
public mut prop types: ArrayList<TypeNode>
public mut prop rParen: Token
public mut prop arrow: Token
public mut prop returnType: TypeNode
}
FuncType 表示函数类型节点,由函数的参数类型和返回类型组成,参数类型与返回类型之间用 -> 分隔如:(Int32) -> Unit。
init
public init()
功能:构造一个默认的 FuncType 实例。
init
public init(input: Tokens)
功能:构造 FuncType 实例。
参数:
- input:将要构造
FuncType类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
FuncType节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置 FuncType 节点的中的关键字 CFunc。
返回值:关键字 CFunc 的词法单元, 若不是一个 CFunc 类型,则获取一个空的词法单元。
prop lParen
public mut prop lParen: Token
功能:获取或设置 FuncType 节点的左括号。
返回值:左括号的词法单元。
prop types
public mut prop types: ArrayList<TypeNode>
功能:获取或设置 FuncType 节点中函数的参数类型。
返回值:一组类型列表。
prop rParen
public mut prop rParen: Token
功能:获取或设置 FuncType 节点的右括号。
返回值:右括号的词法单元。
prop arrow
public mut prop arrow: Token
功能:获取或设置 FuncType 节点参数类型与返回类型之间的 ->。
返回值:-> 操作符的词法单元。
prop returnType
public mut prop returnType: TypeNode
功能:获取或设置 FuncType 节点返回类型。
返回值:函数类型节点。
class VArrayType
public class VArrayType <: TypeNode {
public init()
public init(input: Tokens)
public mut prop keyword: Token
public mut prop lAngle: Token
public mut prop elementTy: TypeNode
public mut prop dollar: Token
public mut prop size: Token
public mut prop rAngle: Token
}
VArrayType 表示 VArray 类型节点,使用泛型 VArray<T, size: Int64> 表示 VArray 类型。
init
public init()
功能:构造一个默认的 VArrayType 实例。
init
public init(input: Tokens)
功能:构造 VArrayType 实例。
参数:
- input:将要构造
VArrayType类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
VArrayType节点。
prop keyword
public mut prop keyword: Token
功能:获取或设置 VArrayType 节点的关键字 VArray。
返回值:VArray 关键字的词法单元。
prop lAngle
public mut prop lAngle: Token
功能:获取或设置 VArrayType 节点左尖括号。
返回值:左尖括号的词法单元。
prop elementTy
public mut prop elementTy: TypeNode
功能:获取或设置 VArrayType 节点中的类型变元。
返回值:一个类型节点,如 VArray<Int16, $0> 中的 Int16。
prop dollar
public mut prop dollar: Token
功能:获取或设置 VArrayType 节点中的操作符 $。
返回值:操作符 $ 的词法单元。
prop size
public mut prop size: Token
功能:获取或设置 VArrayType 节点中类型的长度。
返回值:类型长度的词法单元。
prop rAngle
public mut prop rAngle: Token
功能:获取或设置 VArrayType 节点右尖括号。
返回值:右尖括号的词法单元。
class Pattern
public open class Pattern <: Node {
}
Pattern 是所有模式匹配节点的父类,继承自 Node 节点。
class ConstPattern
public class ConstPattern <: Pattern {
public init()
public init(input: Tokens)
public mut prop litConstExpr: LitConstExpr
}
ConstPattern 表示常量模式节点,常量模式可以是整数字面量、字符字节字面量、浮点数字面量、字符字面量、布尔字面量、字符串字面量等字面量。
一个 ConstPattern 节点:case 1 => 0 中的 1。
init
public init()
功能:构造一个默认的 ConstPattern 实例。
init
public init(input: Tokens)
功能:构造 ConstPattern 实例。
参数:
- input:将要构造
ConstPattern类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ConstPattern节点。
prop litConstExpr
public mut prop litConstExpr: LitConstExpr
功能:获取或设置 ConstPattern 节点中的字面量表达式。
返回值:LitConstExpr 类型的字面量表达式节点。
class WildcardPattern
public class WildcardPattern <: Pattern {
public init()
public init(input: Tokens)
public mut prop wildcard: Token
}
WildcardPattern 表示通配符模式节点,使用下划线 _ 表示,可以匹配任意值。通配符模式通常作为最后一个 case 中的模式,用来匹配其他 case 未覆盖到的情况。
init
public init()
功能:构造一个默认的 WildcardPattern 实例。
init
public init(input: Tokens)
功能:构造 WildcardPattern 实例。
参数:
- input:将要构造
WildcardPattern类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
WildcardPattern节点。
prop wildcard
public mut prop wildcard: Token
功能:获取或设置 WildcardPattern 节点中的 _ 操作符。
返回值:_ 操作符的词法单元。
class VarPattern
public class VarPattern <: Pattern {
public init()
public init(input: Tokens)
public mut prop identifier: Token
}
VarPattern 表示绑定模式节点,使用一个合法的标识符表示,一般适用于声明节点中。
一个 节点: case n => 0 中的 n。
init
public init()
功能:构造一个默认的 VarPattern 实例。
init
public init(input: Tokens)
功能:构造 VarPattern 实例。
参数:
- input:将要构造
VarPattern类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
VarPattern节点。
prop identifier
public mut prop identifier: Token
功能:获取或设置 VarPattern 节点中的标识符。
返回值:标识符的词法单元。
class VarOrEnumPattern
public class VarOrEnumPattern <: Pattern {
public init()
public init(input: Tokens)
public mut prop identifier: Token
}
VarOrEnumPattern 表示当模式的标识符为 Enum 构造器时的节点,如 case RED 中的 RED 为 Enum 构造器。
init
public init()
功能:构造一个默认的 VarOrEnumPattern 实例。
init
public init(input: Tokens)
功能:构造 VarOrEnumPattern 实例。
参数:
- input:将要构造
VarOrEnumPattern类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
VarOrEnumPattern节点。
prop identifier
public mut prop identifier: Token
功能:获取或设置 VarOrEnumPattern 节点中的标识符。
返回值:标识符的词法单元。
class TypePattern
public class TypePattern <: Pattern {
public init()
public init(input: Tokens)
public mut prop pattern: Pattern
public mut prop colon: Token
public mut prop patternType: TypeNode
}
TypePattern 表示当类型模式节点。用于判断一个值的运行时类型是否是某个类型的子类型。
一个 TypePattern 节点:case b: Base => 0 中的 b: Base。
init
public init()
功能:构造一个默认的 TypePattern 实例。
init
public init(input: Tokens)
功能:构造 TypePattern 实例。
参数:
- input:将要构造
TypePattern类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
TypePattern节点。
prop pattern
public mut prop pattern: Pattern
功能:获取或设置 TypePattern 节点中的模式。
返回值:一个模式节点。
prop colon
public mut prop colon: Token
功能:获取或设置 TypePattern 节点中的 : 操作符。
返回值:: 操作符的词法单元节点。
prop patternType
public mut prop patternType: TypeNode
功能:获取或设置 TypePattern 节点中的待匹配的模式类型。
返回值:一个类型节点。
class EnumPattern
public class EnumPattern <: Pattern {
public init()
public init(input: Tokens)
public mut prop constructor: Expr
public mut prop lParen: Token
public mut prop patterns: ArrayList<Pattern>
public mut prop rParen: Token
}
EnumPattern 表示当 enum 模式节点。用于匹配 enum 的 constructor。
一个 EnumPattern 节点:case Year(n) => 1 中的 Year(n)。
init
public init()
功能:构造一个默认的 EnumPattern 实例。
init
public init(input: Tokens)
功能:构造 EnumPattern 实例。
参数:
- input:将要构造
EnumPattern类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
EnumPattern节点。
prop constructor
public mut prop constructor: Expr
功能:获取或设置 EnumPattern 节点中的构造器。
返回值:一个构造器表达式节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 EnumPattern 节点中的左括号。
返回值:左括号的词法单元。
prop patterns
public mut prop patterns: ArrayList<Pattern>
功能:获取或设置 EnumPattern 节点中有参构造器内的模式节点列表。
返回值:一组模式节点集合。
prop lParen
public mut prop lParen: Token
功能:获取或设置 EnumPattern 节点中的右括号。
返回值:右括号的词法单元。
class TuplePattern
public class TuplePattern <: Pattern {
public init()
public init(input: Tokens)
public mut prop lParen: Token
public mut prop patterns: ArrayList<Pattern>
public mut prop rParen: Token
}
TuplePattern 表示当 Tuple 模式节点。用于 tuple 值的匹配。
一个 TuplePattern 节点:case ("Bob", age) => 1 中的 ("Bob", age)
init
public init()
功能:构造一个默认的 TuplePattern 实例。
init
public init(input: Tokens)
功能:构造 TuplePattern 实例。
参数:
- input:将要构造
TuplePattern类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
TuplePattern节点。
prop lParen
public mut prop lParen: Token
功能:获取或设置 TuplePattern 节点中的左括号。
返回值:左括号的词法单元。
prop patterns
public mut prop patterns: ArrayList<Pattern>
功能:获取或设置 TuplePattern 节点中的多个 pattern。
返回值:一组 pattern 节点。
prop rParen
public mut prop rParen: Token
功能:获取或设置 TuplePattern 节点中的右括号。
返回值:右括号的词法单元。
class ExceptTypePattern
public class ExceptTypePattern <: Pattern {
public init()
public init(input: Tokens)
public mut prop pattern: Pattern
public mut prop colon: Token
public mut prop types: ArrayList<TypeNode>
}
ExceptTypePattern 表示一个用于的异常模式状态下的节点,如: e: Exception1 | Exception2。
init
public init()
功能:构造一个默认的 ExceptTypePattern 实例。
init
public init(input: Tokens)
功能:构造 ExceptTypePattern 实例。
参数:
- input:将要构造
ExceptTypePattern类型的词法单元集合 (Tokens)。
异常:
- ASTException:输入的 Tokens 类型无法构造为
ExceptTypePattern节点。
prop pattern
public mut prop pattern: Pattern
功能:获取或设置 ExceptTypePattern 节点中的模式节点。
返回值:一个模式节点。
prop colon
public mut prop colon: Token
功能:获取或设置 ExceptTypePattern 节点中的 : 。
返回值:: 操作符的词法单元。
prop types
public mut prop types: ArrayList<TypeNode>
功能:获取或设置 ExceptTypePattern 节点中有类型列表。
返回值:一组类型节点集合。
interface ToTokens
public interface ToTokens {
func toTokens(): Tokens
}
功能:实现仓颉基本类型或自定义类型到 Tokens 的转换接口,作为支持quote插值操作必须实现的接口,本库中目前提供以下类型的 ToTokens 扩展
+ Token, Tokens
+ Int64, Int32, Int16, Int8
+ UInt64, UInt32, UInt16, UInt8
+ Float64, Float32, Float16
+ Bool, Char, String
extend Token <: ToTokens
extend Token <: ToTokens
此扩展用于实现 Token 的 toTokens 函数。
extend Tokens <: ToTokens
extend Tokens <: ToTokens
此扩展用于实现 Tokens 的 toTokens 函数。
extend Int64 <: ToTokens
extend Int64 <: ToTokens
此扩展用于实现 Int64 的 toTokens 函数。
extend Int32 <: ToTokens
extend Int32 <: ToTokens
此扩展用于实现 Int32 的 toTokens 函数。
extend Int16 <: ToTokens
extend Int16 <: ToTokens
此扩展用于实现 Int16 的 toTokens 函数。
extend Int8 <: ToTokens
extend Int8 <: ToTokens
此扩展用于实现 Int8 的 toTokens 函数。
extend UInt64 <: ToTokens
extend UInt64 <: ToTokens
此扩展用于实现 UInt64 的 toTokens 函数。
extend UInt32 <: ToTokens
extend UInt32 <: ToTokens
此扩展用于实现 UInt32 的 toTokens 函数。
extend UInt16 <: ToTokens
extend UInt16 <: ToTokens
此扩展用于实现 UInt16 的 toTokens 函数。
extend UInt8 <: ToTokens
extend UInt8 <: ToTokens
此扩展用于实现 UInt8 的 toTokens 函数。
extend Float64 <: ToTokens
extend Float64 <: ToTokens
此扩展用于实现 Float64 的 toTokens 函数。
extend Float32 <: ToTokens
extend Float32 <: ToTokens
此扩展用于实现 Float32 的 toTokens 函数。
extend Float16 <: ToTokens
extend Float16 <: ToTokens
此扩展用于实现 Float16 的 toTokens 函数。
extend Bool <: ToTokens
extend Bool <: ToTokens
此扩展用于实现 Bool 的 toTokens 函数。
extend Char <: ToTokens
extend Char <: ToTokens
此扩展用于实现 Char 的 toTokens 函数。
extend String <: ToTokens
extend String <: ToTokens
此扩展用于实现 String 的 toTokens 函数。
extend ArrayList <: ToTokens
extend ArrayList<T> <: ToTokens
此扩展主要用于实现 ArrayList 的 toTokens 函数, 目前支持的类型有 Decl, Node, Constructor, Argument, FuncParam, MatchCase, Modifier, Annotation, ImportList, Pattern, TypeNode等。
extend Array <: ToTokens
extend Array<T> <: ToTokens
此扩展主要用于实现 Array 的 toTokens 函数,仅支持数值类型,Char 类型,Bool 类型,String 类型等。
class ASTException
public class ASTException <: Exception {
public init()
public init(message: String)
}
Ast库的异常类,在ast库调用过程中发生异常时使用。
init
public init()
功能:无参构造函数。
init
public init(message: String)
参数:
- message:异常信息
class ParseASTException
public class ParseASTException <: Exception {
public init()
public init(message: String)
}
Ast库的解析异常类,在节点解析过程中发生异常时使用。
init
public init()
功能:无参构造函数。
init
public init(message: String)
参数:
- message:异常信息
enum TokenKind
public enum TokenKind <: ToString {
DOT| /* "." */
COMMA| /* "," */
LPAREN| /* "(" */
RPAREN| /* ")" */
LSQUARE| /* "[" */
RSQUARE| /* "]" */
LCURL| /* "{" */
RCURL| /* "}" */
EXP| /* "**" */
MUL| /* "*" */
MOD| /* "%" */
DIV| /* "/" */
ADD| /* "+" */
SUB| /* "-" */
INCR| /* "++" */
DECR| /* "--" */
AND| /* "&&" */
OR| /* "||" */
COALESCING| /* "??" */
PIPELINE| /* "|>" */
COMPOSITION| /* "~>" */
NOT| /* "!" */
BITAND| /* "&" */
BITOR| /* "|" */
BITXOR| /* "^" */
BITNOT| /* "~" */
LSHIFT| /* "<<" */
RSHIFT| /* ">>" */
COLON| /* ":" */
SEMI| /* ";" */
ASSIGN| /* "=" */
ADD_ASSIGN| /* "+=" */
SUB_ASSIGN| /* "-=" */
MUL_ASSIGN| /* "*=" */
EXP_ASSIGN| /* "**=" */
DIV_ASSIGN| /* "/=" */
MOD_ASSIGN| /* "%=" */
AND_ASSIGN| /* "&&=" */
OR_ASSIGN| /* "||=" */
BITAND_ASSIGN| /* "&=" */
BITOR_ASSIGN| /* "|=" */
BITXOR_ASSIGN| /* "^=" */
LSHIFT_ASSIGN| /* "<<=" */
RSHIFT_ASSIGN| /* ">>=" */
ARROW| /* "->" */
BACKARROW| /* "<-" */
DOUBLE_ARROW| /* "=>" */
RANGEOP| /* ".." */
CLOSEDRANGEOP| /* "..=" */
ELLIPSIS| /* "..." */
HASH| /* "#" */
AT| /* "@" */
QUEST| /* "?" */
LT| /* "<" */
GT| /* ">" */
LE| /* "<=" */
GE| /* ">=" */
IS| /* "is" */
AS| /* "as" */
NOTEQ| /* "!=" */
EQUAL| /* "==" */
WILDCARD| /* "_" */
INT8| /* "Int8" */
INT16| /* "Int16" */
INT32| /* "Int32" */
INT64| /* "Int64" */
INTNATIVE| /* "IntNative" */
UINT8| /* "UInt8" */
UINT16| /* "UInt16" */
UINT32| /* "UInt32" */
UINT64| /* "UInt64" */
UINTNATIVE| /* "UIntNative" */
FLOAT16| /* "Float16" */
FLOAT32| /* "Float32" */
FLOAT64| /* "Float64" */
CHAR| /* "Char" */
BOOLEAN| /* "Bool" */
NOTHING| /* "Nothing" */
UNIT| /* "Unit" */
STRUCT| /* "struct" */
ENUM| /* "enum" */
CFUNC| /* "CFunc" */
VARRAY| /* "VArray" */
THISTYPE| /* "This" */
PACKAGE| /* "package" */
IMPORT| /* "import" */
CLASS| /* "class" */
INTERFACE| /* "interface" */
FUNC| /* "func" */
MACRO| /* "macro" */
QUOTE| /* "quote" */
DOLLAR| /* "$" */
LET| /* "let" */
VAR| /* "var" */
CONST| /* "const" */
TYPE| /* "type" */
INIT| /* "init" */
THIS| /* "this" */
SUPER| /* "super" */
IF| /* "if" */
ELSE| /* "else" */
CASE| /* "case" */
TRY| /* "try" */
CATCH| /* "catch" */
FINALLY| /* "finally" */
FOR| /* "for" */
DO| /* "do" */
WHILE| /* "while" */
THROW| /* "throw" */
RETURN| /* "return" */
CONTINUE| /* "continue" */
BREAK| /* "break" */
IN| /* "in" */
NOT_IN| /* "!in" */
MATCH| /* "match" */
FROM| /* "from" */
WHERE| /* "where" */
EXTEND| /* "extend" */
WITH| /* "with" */
PROP| /* "prop" */
STATIC| /* "static" */
PUBLIC| /* "public" */
PRIVATE| /* "private" */
PROTECTED| /* "protected" */
OVERRIDE| /* "override" */
REDEF| /* "redef" */
ABSTRACT| /* "abstract" */
SEALED| /* "sealed" */
OPEN| /* "open" */
FOREIGN| /* "foreign" */
INOUT| /* "inout" */
MUT| /* "mut" */
UNSAFE| /* "unsafe" */
OPERATOR| /* "operator" */
SPAWN| /* "spawn" */
SYNCHRONIZED| /* "synchronized */
UPPERBOUND| /* "<:" */
MAIN| /* "main" */
IDENTIFIER| /* "x" */
INTEGER_LITERAL| /* e.g. "1" */
CHAR_BYTE_LITERAL| /* e.g. "b'x'" */
FLOAT_LITERAL| /* e.g. "'1.0'" */
COMMENT| /* e.g. "/*xx*/" */
NL| /* newline */
END| /* end of file */
SENTINEL| /* ";" */
CHAR_LITERAL| /* e.g. "'x'" */
STRING_LITERAL| /* e.g. ""xx"" */
JSTRING_LITERAL| /* e.g. "J"xx"" */
BYTE_STRING_ARRAY_LITERAL /* e.g. "b"xx"" */
MULTILINE_STRING| /* e.g. """"aaa"""" */
MULTILINE_RAW_STRING| /* e.g. "#"aaa"#" */
BOOL_LITERAL| /* "true" or "false" */
UNIT_LITERAL| /* "()" */
DOLLAR_IDENTIFIER| /* e.g. "$x" */
ANNOTATION| /* e.g. "@When" */
ILLEGAL
public operator func ==(right: TokenKind): Bool
public operator func !=(right: TokenKind): Bool
public func toString(): String
}
枚举类型 TokenKind 内部的构造器列举了仓颉编译内部所有的词法结构,包括符号、关键字、标识符、换行等。
operator func ==
public operator func == (r: Position): Bool
功能:重载等号操作符,用于比较两个 TokenKind 是否相等。
返回值:布尔类型。
operator func !=
public operator func != (r: Position): Bool
功能:重载不等号操作符,用于比较两个 TokenKind 是否相等。
返回值:布尔类型。
func toString
public func toString(): String
功能:将 TokenKind 类型转化为字符串类型表示。
返回值:String 类型的字面量值。
func getTokenKind
public func getTokenKind(no: UInt16): TokenKind
功能:将词法单元种类序号转化为 TokenKind。
参数:
- no:需要转换的
UInt16序号
class TokensIterator
public class TokensIterator <: Iterator<Token> {
public init(tokens: Tokens)
public func peek(): Option<Token>
public func seeing(kind: TokenKind): Bool
public func next(): Option<Token>
public func iterator(): Iterator<Token>
}
此类主要实现 Tokens 的迭代器功能。
init
public init(tokens: Tokens)
功能:创建 TokensIterator 实例。
参数:
- tokens:传入 Tokens
func peek
public func peek(): Option<Token>
功能:获取迭代器中的当前值。
返回值:返回 Option<Token> 类型,当遍历结束后,返回 None
func seeing
public func seeing(kind: TokenKind): Bool
功能:判断当前节点的 Token 类型是否是传入的类型。
参数:
- kind:需要判断的
TokenKind类型
返回值:如果当前节点的 TokenKind 与传入类型相同 ,返回 true,否则返回 false
func next
public func next(): Option<Token>
功能:获取迭代器中的下一个值。
返回值:返回 Option<Token> 类型,当遍历结束后,返回 None
func iterator
public func iterator(): Iterator<Token>
功能:获取当前迭代器实例。
返回值:当前迭代器实例
func compareTokens
public func compareTokens(tokens1: Tokens, tokens2: Tokens): Bool
功能:用于比较两个Tokens是否一致
参数:
- tokens1:需要比较的第一个
Tokens - tokens2:需要比较的第二个
Tokens
返回值:如果两个 Tokens 内容相同(除了换行符、结束符和位置信息)则返回 true
总结:仓颉 AST 包提供了丰富的语法树节点用于表示仓颉源码。由于节点种类丰富、不同节点间属性不同,使用过程可能会发生混淆不清的情况,为此我们为每个 AST 节点实现了 dump 函数(具体见 [func dump] 章节)方便实时查看语法树节点的整体结构,避免重复查看该手册带来的困扰。
仓颉源码解析函数
仓颉 ast 包提供语法解析函数可将仓颉源码的词法单元 (Tokens) 解析为 AST 节点对象。
func cangjieLex
public func cangjieLex(code: String): Tokens
功能:将字符串转换为 Tokens 类型。
参数:
- code: 待词法解析的字符串。
返回值:词法解析得到的 Tokens。
异常:
- IllegalMemoryException:申请内存失败,抛出异常。
- IllegalArgumentException:输入的 code 无法被正确的解析为
Tokens抛出异常。
func parseProgram
public func parseProgram(input: Tokens): Program
功能:用于解析单个仓颉文件的源码,获取一个 Program 类型的节点。
参数:
- input: 待解析源码的词法单元(Tokens)。
返回值:一个 Program 类型的节点。
异常:
- ParseASTException:输入的 Tokens 类型无法构造为 Program 节点。
func parseDecl
public func parseDecl(input: Tokens, astKind !: String = ""): Decl
功能:用于解析一组词法单元,获取一个 Decl 类型的节点。
参数:
- input: 待解析源码的词法单元(Tokens)。
- astKind: 用于指定解析特定的节点类型,有效支持的值为:PrimaryCtorDecl 和 PropMemberDecl。
返回值:一个 Decl 类型的节点。
异常:
- ParseASTException:输入的 Tokens 类型无法构造为 Decl 节点。
func parseDeclFragment
public func parseDeclFragment(input: Tokens, startFrom !: Int64 = 0): (Decl, Int64)
功能:用于解析一组词法单元,获取一个 Decl 类型的节点和继续解析节点的索引。
参数:
- input: 待解析源码的词法单元(Tokens)。
- startFrom: 起始位置
返回值:语法树节点,继续解析的位置。
异常:
- ParseASTException:输入的 Tokens 类型无法构造为 Decl 节点。
func parseExpr
public func parseExpr(input: Tokens): Expr
功能:用于解析一组词法单元,获取一个 Expr 类型的节点。
参数:
- input: 待解析源码的词法单元(Tokens)。
返回值:一个 Expr 类型的节点。
异常:
- ParseASTException:输入的 Tokens 类型无法构造为 Expr 节点。
func parseExprFragment
public func parseExprFragment(input: Tokens, startFrom !: Int64 = 0): (Expr, Int64)
功能:用于解析一组词法单元,获取一个 Expr 类型的节点和继续解析节点的索引。
参数:
- input: 待解析源码的词法单元(Tokens)。
- startFrom: 起始位置
返回值:语法树节点,继续解析的位置。
异常:
- ParseASTException:输入的 Tokens 类型无法构造为 Expr 节点。
Visitor
public open abstract class Visitor {
public func breakTraverse(): Unit
open protected func visit(_: Node): Unit
open protected func visit(_: Expr) : Unit
open protected func visit(_: Program): Unit
open protected func visit(_: PackageHeader): Unit
open protected func visit(_: Argument): Unit
open protected func visit(_: Annotation): Unit
open protected func visit(_: Modifier): Unit
...
}
Visitor 是一个抽象类,其内部默认定义了访问不同类型 AST 节点访问(visit)函数,visit 函数搭配 traverse 一起使用,可实现对节点的访问和修改, 所有 visit 函数都有默认为空的实现,可以按需实现需要的 visit 方法。该类需要被继承使用,并允许子类重新定义访问函数。
func breakTraverse
public func breakTraverse(): Unit
功能:用于重写 visit 函数中,通过调用该函数来终止继续遍历子节点的行为。
使用示例
将仓颉源码解析为 AST 对象示例
如下有一个类 Data,它的代码如下:
class Data {
var a: Int32
init(a_: Int32) {
a = a_
}
}
利用解析函数将上述代码解析为一个 Decl 对象,代码如下所示:
from std import ast.*
main() {
let input: Tokens = quote(
class Data {
var a: Int32
init(a_: Int32) {
a = a_
}
}
)
let decl = parseDecl(input) // 获取一个 Decl 声明节点
var classDecl = match (decl as ClassDecl) { // decl 的具体类型为 ClassDecl, 将其进行类型转化。
case Some(v) => v
case None => throw Exception()
}
0
}
操作 AST 对象示例
获取 ClassDecl 类型的节点后,可以对该节点进行增、删、改、查等操作。代码如下所示:
from std import ast.*
main() {
let input: Tokens = quote(
class Data {
var a: Int32
init(a_: Int32) {
a = a_
}
}
)
let decl = parseDecl(input) // 获取一个 Decl 声明节点
var classDecl = match (decl as ClassDecl) { // decl 的具体类型为 ClassDecl, 将其进行类型转化。
case Some(v) => v
case None => throw Exception()
}
var identifier = classDecl.identifier
// 为该节点增加一个成员函数用于获取a的值
var funcdecl = FuncDecl(quote(func getValue() {a}))
classDecl.body.decls.append(funcdecl)
println("Identifier value is ${identifier.value}")
println("ClassDecl body size is ${classDecl.body.decls.size}")
0
}
运行结果:
Identifier value is Data
ClassDecl body size is 3
自定义访问函数遍历 AST 对象示例
定义访问变量声明节点的行为:继承 Visitor 并重写访问函数,找到未定义变量,将他的变量词法单元存起来。
class MyVisitor <: Visitor {
public var unitializedVars = Tokens() // 存储变量词法单元
override public func visit(varDecl: VarDecl) {
match (varDecl.expr) {
case Some(s) => ()
case None => unitializedVars.append(varDecl.identifier)
}
breakTraverse() // 不会继续遍历 varDecl 的子节点
return
}
}
main(): Int64 {
let input = quote(
var a : Int64
)
let varDecl = parseDecl(input)
let visitor = MyVisitor() /* MyVisitor中定义了对 varDecl 节点的处理*/
varDecl.traverse(visitor) /* 实现对 varDecl 节点的处理 */
println("Unitialized VarDecl size is {visitor.unitializedVars.size}")
0
}
运行结果:
Unitialized VarDecl size is 1
Macro With Context
仓颉 ast 包提供了 Macro With Context 的相关函数,用于在宏展开时可以获取展开过程中的上下文相关信息。
在嵌套宏场景下,内层宏可以调用库函数 AssertParentContext 来保证内层宏调用一定嵌套在特定的外层宏调用中。如果内层宏调用这个函数时没有嵌套在给定的外层宏调用中,该函数将抛出一个错误。同时,函数 InsideParentContext 也用于检查内层宏调用是否嵌套在特定的外层宏调用,但是返回一个布尔值。
func AssertParentContext
public func AssertParentContext(parentMacroName: String): Unit
功能:检查当前宏调用是否在特定的宏调用内;若检查不符合预期,编译器出现一个错误提示。
参数:
- parentMacroName: 待检查的外层宏调用的名字。
func InsideParentContext
public func InsideParentContext(parentMacroName: String): Bool
功能:检查当前宏调用是否在特定的宏调用内,返回一个布尔值。
参数:
- parentMacroName: 待检查的外层宏调用的名字。
返回值:若当前宏嵌套在特定的宏调用内,返回 true。
在嵌套宏场景下,内层宏也可以通过发送键/值对的方式与外层宏通信。当内层宏执行时,通过调用标准库函数 SetItem 向外层宏发送信息;随后,当外层宏执行时,调用标准库函数 GetChildMessages 接收每一个内层宏发送的信息(一组键/值对映射)。
func SetItem
public func SetItem(key:String, value:String):Unit
功能:内层宏通过该接口发送 string 类型的信息到外层宏。
参数:
- key: 发送的关键字,用于检索信息。
- value: 要发送的 String 类型的信息。
func SetItem
public func SetItem(key:String, value:Int64):Unit
功能:内层宏通过该接口发送 Int64 类型的信息到外层宏。
参数:
- key: 发送的关键字,用于检索信息。
- value: 要发送的 Int64 类型的信息。
func SetItem
public func SetItem(key:String, value:Bool):Unit
功能:内层宏通过该接口发送 Bool 类型的信息到外层宏。
参数:
- key: 发送的关键字,用于检索信息。
- value: 要发送的 Bool 类型的信息。
class MacroMessage
public class MacroMessage {
public func hasItem(key: String): Bool
public func getString(key: String): String
public func getInt64(key: String): Int64
public func getBool(key: String):Bool
}
func hasItem
public func hasItem(key:String): Bool
功能:检查是否有 key 值对应的相关信息。
参数:
- key: 用于检索的关键字名字。
返回值:若存在 key 值对应的相关信息,返回 true。
func getString
public func getString(key:String): String
功能:获取对应 key 值的 String 类型信息。
参数:
- key: 用于检索的关键字的名字。
返回值:返回存在 key 值对应的 String 类型的信息。
异常:
- 不存在 key 值对应的 String 类型的信息。
func getInt64
public func getInt64(key:String): Int64
功能:获取对应 key 值的 Int64 类型信息。
参数:
- key: 用于检索的关键字的名字。
返回值:返回存在 key 值对应的 Int64 类型的信息。
异常:
- 不存在 key 值对应的 Int64 类型的信息。
func getBool
public func getBool(key:String): Bool
功能:获取对应 key 值的 Bool 类型信息。
参数:
- key: 用于检索的关键字的名字。
返回值:返回存在 key 值对应的 Bool 类型的信息。
异常:
- 不存在 key 值对应的 Bool 类型的信息。
func GetChildMessages
public func GetChildMessages(children:String): ArrayList<MacroMessage>
功能:获取特定内层宏发送的信息。
参数:
- children: 待接收信息的内层宏名称。
返回值:返回一组 MacroMessage 的对象。
需要注意的是, Macro With Context 的相关函数只能作为函数被直接调用,不能作为赋值给变量,不能作为实参或返回值使用。
示例
宏定义如下:
public macro Outter(input: Tokens): Tokens {
return input
}
public macro Inner(input: Tokens): Tokens {
AssertParentContext("Outter")
return input
}
宏调用如下:
@Outter var a = 0
@Inner var b = 0 // error: The macro call 'Inner' should with the surround code contains a call 'Outer'.
如上代码所示,Inner 宏在定义时使用了 AssertParentContext 函数用于检查其在调用阶段是否位于 Outter 宏中,在代码示例的宏调用场景下,由于 Outter 和 Inner 在调用时不存在这样的嵌套关系,因此编译器将报告一个错误。
宏定义如下:
public macro Outter(input: Tokens): Tokens {
let messages = GetChildMessages("Inner")
for (m in messages) {
let value1 = m.getString("key1") // get value: "value1"
let value2 = m.getString("key2") // get value: "value2"
}
return input
}
public macro Inner(input: Tokens): Tokens {
AssertParentContext("Outer")
SetItem("key1", "value1")
SetItem("key2", "value2")
return input
}
宏调用如下:
@Outter(
@Inner var cnt = 0
)
在上面的代码中,内层宏 Inner 通过 SetItem 向外层宏发送信息;Outter 宏通过 GetChildMessages 函数接收到 Inner 发送的一组信息对象(Outter 中可以调用多次 Inner);最后通过该信息对象的 getString 函数接收对应的值。
自定义报错接口
仓颉 ast 包提供了自定义报错接口。方便定义宏的用户,在解析传入tokens时,对错误tokens内容进行自定义报错。
自定义报错接口提供同原生编译器报错一样的输出格式,允许用户报 warning 和 error 两类错误提示信息。
enum DiagReportLevel
public enum DiagReportLevel {
| ERROR | WARNING
public func level(): Int32
}
该枚举表示报错接口的信息等级。
func level
public func level(): Int32
功能:返回枚举值对应的整型。ERROR 返回 1,WARNING 返回 2。
返回值:枚举值对应的整型
func diagReport
public func diagReport(level: DiagReportLevel, tokens: Tokens, message: String, hint: String): Unit
功能:报错接口,在编译过程的宏展开阶段输出错误提示信息,支持 WARNING 和 ERROR 两个等级的报错。 注意该接口在 错误等级为 ERROR 时会终止编译过程,但不会终止宏展开过程,建议用户调用接口后直接 return 或者抛出异常来终止宏展开过程。
参数:
- level: 报错信息等级
- tokens: 报错信息中所引用源码内容对应的 tokens
- message: 报错的主信息
- hint: 辅助提示信息
异常:
- ASTException: 当输入的 tokens 存在以下错误时抛出异常
-
- 输入的 tokens 为空
-
- 输入的 tokens 中的 token 来自于不同的源文件
-
- 输入的 tokens 中首位 token 位置早于末位 token 位置
-
- 输入的 tokens 中的 token 位置范围超出了宏调用的位置范围
特殊说明:
- 该接口会按照 cjc 标准报错的接口,将传入的 tokens 所在行的代码列出,并对 tokens 的内容用波浪线进行标注, message 信息将展示在首行, hint 信息将紧跟波浪线进行展示
- 报错引用的源码内容目前仅依据第一个 token 的开始位置和最后一个 token 的结束位置确定,不校验中间 token 位置信息的一致性
- 该接口目前不支持在非宏函数中进行调用,参见下面代码示例
示例
正确使用示例
宏定义文件
// macro_definition.cj
macro package macro_definition
from std import ast.*
public macro TestDef(input: Tokens): Tokens {
for (i in 0..input.size) {
if (input[i].kind == IDENTIFIER) {
diagReport(DiagReportLevel.ERROR, input[i..(i + 1)], "This expression is not allowed to contain identifier", "Here is the illegal identifier")
}
}
return input
}
执行文件
// macro_call.cj
package macro_calling
from std import ast.*
import macro_definition.*
main(): Int64 {
let a = @TestDef(1)
let b = @TestDef(a)
let c = @TestDef(1 + a)
return 0
}
报错提示信息如下
error: This expression is not allowed to contain identifier
==> call.cj:9:22:
|
9 | let b = @TestDef(a)
| ^ Here is the illegal identifier
|
error: This expression is not allowed to contain identifier
==> call.cj:10:26:
|
10 | let c = @TestDef(1 + a)
| ^ Here is the illegal identifier
|
2 errors generated, 2 errors printed.
在非宏函数中调用
// macro_definition.cj
macro package macro_definition
from std import ast.*
func A(input: Tokens) {
diagReport(DiagReportLevel.ERROR, input, ...) // 该调用处在普通函数 A 中,diagReport 实际不会执行任何操作
}
public macro M(input: Tokens): Tokens {
A(input)
}
collection 包
介绍
Collection 包提供可变的元素集合, 分为有序和无序的集合。
有序集合,可以根据元素的整数索引(在列表中的位置)访问元素, 列表中的元素可以重复。
无序集合,通过使用迭代器上可以遍历集合中的元素。无序集合不允许重复元素。
注意:
- 如果在迭代器迭代过程中, 通过集合修改、增加、删除了某些元素, 迭代器会抛出 ConcurrentModificationException。
主要接口
class ArrayList
public class ArrayList<T> <: Collection<T> {
public init()
public init(capacity: Int64)
public init(size: Int64, initElement: (Int64) -> T)
public init(elements: Array<T>)
public init(elements: Collection<T>)
}
此类主要用于实现 ArrayList 数据结构及相关操作函数。
类的主要函数如下所示:
init
public init()
功能:构造一个初始容量为默认值的空 ArrayList构造一个具有默认初始容量 16 的空 ArrayList。
init
public init(capacity: Int64)
功能:构造具有指定初始容量的空 ArrayList。容量是用于存储 ArrayList 中元素的数组的大小,在向 ArrayList 中添加元素时,其容量会自动增长,可以通过对应实例的 capacity() 函数获取容量大小。
参数:
- capacity:初始容量大小
异常:
- IllegalArgumentException:如果 capacity 小于 0 则抛出异常
init
public init(size: Int64, initElement: (Int64) -> T)
功能:构造具有指定初始元素个数和指定规则函数的 ArrayList。该构造函数根据参数 size 设置 ArrayList 的容量。
参数:
- size:初始化函数元素个数
- initElement:传入初始化函数
异常:
- IllegalArgumentException:如果 size 小于 0 则抛出异常
init
public init(elements: Array<T>)
功能:使用指定数组构造 ArrayList。该构造函数根据传入数组 elements 的 size 设置 ArrayList 的容量。
注意,当 T 的类型是 Int64 时,此构造函数的变长参数语法糖版本可能会和 public init(capacity: Int64) 产生歧义,比如 ArrayList<Int64>(8, 9) 是构造一个包含两个元素的 ArrayList, 而 ArrayList<Int64>(8) 是构造一个容量为 8 的 ArrayList。
参数:
- elements:传入数组
init
public init(elements: Collection<T>)
功能:使用指定集合构造 ArrayList。该构造函数根据传入集合 elements 的 size 设置 ArrayList 的容量。
参数:
- elements:传入集合
func get
public func get(index: Int64): Option<T>
功能:返回此 ArrayList 中指定位置的元素。
参数:
- index:index 表示 get 接口的索引
返回值:返回指定位置的元素
func set
public func set(index: Int64, element: T): Unit
功能:将此 ArrayList 中指定位置的元素替换为指定的元素。
参数:
- index:要设置的索引值
- element:T 类型元素
异常:
- IndexOutOfBoundsException:当 index 小于 0 或者大于等于 ArrayList 的 size,抛出异常
func append
public func append(element: T): Unit
功能:将指定的元素附加到此 ArrayList 的末尾。
参数:
- element:插入元素,类型为 T
func appendAll
public func appendAll(elements: Collection<T>): Unit
功能:将指定集合中的所有元素附加到此 ArrayList 的末尾,按指定集合的迭代器返回的顺序排列。
参数:
- elements:导入元素集合
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
func insert
public func insert(index: Int64, element: T): Unit
功能:在此 ArrayList 中的指定位置插入指定元素。
参数:
- index:插入元素的目标索引
- element:要插入的 T 类型元素
异常:
- IndexOutOfBoundsException,当 index 超出范围时,抛出异常
func insertAll
public func insertAll(index: Int64, elements: Collection<T>): Unit
功能:从指定位置开始,将指定集合中的所有元素插入此 ArrayList。
参数:
- index:插入集合的目标索引
- elements:要插入的 T 类型元素集合
异常:
- IndexOutOfBoundsException,当 index 超出范围时,抛出异常
func prepend
public func prepend(element: T): Unit
功能:在起始位置,将指定元素插入此 ArrayList。
参数:
- element:插入 T 类型元素
func prependAll
public func prependAll(elements: Collection<T>): Unit
功能:从起始位置开始,将指定集合中的所有元素插入此 ArrayList。
参数:
- elements:要插入的 T 类型元素集合
func remove
public func remove(index: Int64): T
功能:删除此 ArrayList 中指定位置的元素。
参数:
- index:被删除元素的索引
返回值:被移除的元素
异常:
- IndexOutOfBoundsException,当 index 超出范围时,抛出异常
func remove
public func remove(range: Range<Int64>): Unit
功能:删除此 ArrayList 中 Range 范围所包含的所有元素。
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响。 参数:
- range:从 range 的 start 开始,删除到 end 位置
异常:
- IllegalArgumentException:当 range 的 step 不等于 1 时抛出异常
- IndexOutOfBoundsException:当 range 的 start 或 end 小于 0,或 end 大于 Array 的长度时抛出
func removeIf
public func removeIf(predicate: (T) -> Bool): Unit
功能:删除此 ArrayList 中满足给定 lambda 表达式或函数的所有元素。
参数:
- predicate:传递判断删除的条件
func clear
public func clear(): Unit
功能:从此 ArrayList 中删除所有元素。
func reverse
public func reverse(): Unit
功能:反转此 ArrayList 中元素的顺序。
func sortBy
public func sortBy(stable!: Bool = false, comparator!: (T, T) -> Ordering): Unit
功能:通过传入的比较函数,根据其返回值 Ordering 类型的结果,可对数组进行自定义排序comparator: (t1: T, t2: T) -> Ordering,如果 comparator 的返回值为 Ordering.GT,排序后 t1 在 t2后;如果 comparator 的返回值为 Ordering.LT,排序后 t1 在t2 前;如果 comparator 的返回值为 Ordering.EQ,且为稳定排序,那么 t1 在 t2 之前; 如果 comparator 的返回值为 Ordering.EQ,且为不稳定排序,那么 t1,t2 顺序不确定。
参数:
- stable:是否使用稳定排序
- comparator:(T, T) -> Ordering 类型
func reserve
public func reserve(additional: Int64): Unit
功能:将 ArrayList 扩容 additional 大小,当 additional 小于等于零时,不发生扩容,当 ArrayList 剩余容量大于等于 additional 时,不发生扩容,当 ArrayList 剩余容量小于 additional 时,取(原始容量的1.5倍向下取整)与(additional + 已使用容量)两个值中的最大值进行扩容。
参数:
- additional:将要扩容的大小
func toArray
public func toArray(): Array<T>
功能:转成数组。
返回值:T 类型数组
func capacity
public func capacity(): Int64
功能:返回此 ArrayList 的容量大小
返回值:此 ArrayList 的容量大小
func iterator
public func iterator(): Iterator<T>
功能:在适当的集合中返回此 ArrayList 中元素的迭代器。
返回值:返回迭代器 Iterator
prop size
public prop size: Int64
功能:返回此 ArrayList 中的元素个数 返回值 Int64 - 元素个数
func isEmpty
public func isEmpty(): Bool
功能:判断 ArrayList 是否为空。
返回值:如果为空,则返回 true, 否则,返回 false
func slice
public func slice(range: Range<Int64>): ArrayList<T>
功能:传入参数 range 作为索引,返回索引对应的 ArrayList
注意:如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:1)start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响2)hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响。
参数:
- range:传递切片的范围
异常:
- IllegalArgumentException:当 range.step 不等于 1 时,抛出异常
- IndexOutOfBoundsException:当 range 无效时,抛出异常
func clone
public func clone(): ArrayList<T>
功能:克隆新 ArrayList。
返回值:返回新 ArrayList
operator func []
public operator func [](index: Int64): T
功能:操作符重载 - get。
参数:
- index:表示 get 接口的索引
返回值:索引位置的元素的值
异常:
- IndexOutOfBoundsException:当 index 超出范围时,抛出异常
operator func []
public operator func [](index: Int64, value!: T): Unit
功能:操作符重载 - set。
参数:
- index:要设置的索引值
- value:要设置的 T 类型的值
异常:
- IndexOutOfBoundsException:当 index 超出范围时,抛出异常
operator func []
public operator func [](range: Range<Int64>): ArrayList<T>
功能:运算符重载 - 切片。
注意:
- 如果参数 range 是使用 Range 构造函数构造的 Range 实例,有如下行为:1)start 的值就是构造函数传入的值本身,不受构造时传入的 hashStart 的值的影响2)hasEnd 为 false 时,该 Range 实例为开区间,不受构造时传入的 isClosed 的值的影响。
- 切片操作返回的ArrayList为全新的对象,与原ArrayList无引用关系。
参数:
- range:传递切片的范围
异常:
- IllegalArgumentException:当 range.step 不等于 1 时,抛出异常
- IndexOutOfBoundsException:当 range 无效时,抛出异常
func getRawArray
public unsafe func getRawArray(): Array<T>
功能:返回 ArrayList 的原始数据。
class LinkedList
public class LinkedList<T> <: Collection<T> {
public init()
public init(elements: Collection<T>)
public init(elements: Array<T>)
public init(size: Int64, initElement: (Int64)-> T)
}
LinkedList 是一个由双向链表实现的集合,它支持在集合的任何地方插入和删除元素,不支持快速随机访问。
LinkedList 不支持并发操作,并且对集合中元素的修改不会使迭代器失效,只有在添加和删除元素的时候会使迭代器失效。
init
public init()
功能:构造一个空的链表
init
public init(elements: Collection<T>)
功能:按照集合迭代器返回元素的顺序构造一个包含指定集合元素的链表。
参数:
- elements:将要放入此链表中的元素集合
init
public init(elements: Array<T>)
功能:按照数组的遍历顺序构造一个包含指定集合元素的 LinkedList 实例。
参数:
- elements:将要放入此链表中的元素数组
init
public init(size: Int64, initElement: (Int64)-> T)
功能:创建一个包含 size 个元素,且第 n 个元素满足 (Int64)-> T 条件的链表。
参数:
- size:要创建的链表元素数量
- initElement:元素的初始化参数
prop size
public prop size: Int64
功能:链表中的元素数量。
prop first
public prop first: Option<T>
功能:链表中第一个元素的值,如果是空链表则返回 None。
prop last
public prop last: Option<T>
功能:链表中最后一个元素的值,如果是空链表则返回 None。
func toArray
public func toArray(): Array<T>
功能:返回一个数组,数组包含该链表中的所有元素,并且顺序与链表的顺序相同。
返回值:T 类型数组
func prepend
public func prepend(element: T): LinkedListNode<T>
功能:在链表的头部位置插入一个元素,并且返回该元素的节点。
参数:
- element:要添加到链表中的元素
返回值:指向该元素的节点
func append
public func append(element: T): LinkedListNode<T>
功能:在链表的尾部位置添加一个元素,并且返回该元素的节点。
参数:
- element:要添加到链表中的元素
返回值:指向该元素的节点
func insertBefore
public func insertBefore(node: LinkedListNode<T>, element: T): LinkedListNode<T>
功能:在链表中指定节点的前面插入一个元素,并且返回该元素的节点。
参数:
- node:指定的节点
- element:要添加到链表中的元素
返回值:指向被插入元素的节点
异常:
- IllegalArgumentException:如果指定的节点不属于该链表,则抛此异常
func insertAfter
public func insertAfter(node: LinkedListNode<T>, element: T): LinkedListNode<T>
功能:在链表中指定节点的后面插入一个元素,并且返回该元素的节点。
参数:
- node:指定的节点
- element:要添加到链表中的元素
返回值:指向被插入元素的节点
异常:
- IllegalArgumentException:如果指定的节点不属于该链表,则抛此异常
func remove
public func remove(node: LinkedListNode<T>): T
功能:删除链表中指定节点
参数:
- node:要被删除的节点
异常:
- IllegalArgumentException:如果指定的节点不属于该链表,则抛此异常
func removeIf
public func removeIf(predicate: (T)-> Bool): Unit
功能:删除此链表中满足给定 lambda 表达式或函数的所有元素
参数:
- predicate:对于要删除的元素,返回值为 true
func clear
public func clear(): Unit
功能:删除链表中的所有元素
func isEmpty
public func isEmpty(): Bool
功能:返回此链表是否为空链表的判断
返回值:如果此链表中不包含任何元素,返回 true
func iterator
public func iterator(): Iterator<T>
功能:返回当前集合中元素的迭代器,其顺序是从链表的第一个节点到链表的最后一个节点
返回值:当前集合中元素的迭代器
func reverse
public func reverse(): Unit
功能:反转此链表中的元素顺序
func popFirst
public func popFirst() : Option<T>
功能:移除链表的第一个元素,并返回该元素的值
返回值:被删除的元素的值,若链表为空则返回 None
func popLast
public func popLast() : Option<T>
功能:移除链表的最后一个元素,并返回该元素的值
返回值:被删除的元素的值,若链表为空则返回 None
func nodeAt
public func nodeAt(index: Int64): Option<LinkedListNode<T>>
功能:获取链表中的第 index 个元素的节点,编号从 0 开始
参数:
- index:指定获取第 index 个元素的节点
返回值:编号为 index 的节点,如果没有则返回 None
func firstNode
public func firstNode(): Option<LinkedListNode<T>>
功能:获取链表中的第一个元素的节点
返回值:第一个元素的节点,如果链表为空链表则返回 None
func lastNode
public func lastNode(): Option<LinkedListNode<T>>
功能:获取链表中的最后一个元素的节点
返回值:最后一个元素的节点,如果链表为空链表则返回 None
func splitOff
public func splitOff(node: LinkedListNode<T>): LinkedList<T>
功能:从指定的节点 node 开始,将链表分割为两个链表,如果分割成功,node 不在当前的链表内,而是作为首个节点存在于新的链表内部。
参数:
- node:要分割的位置
返回值:原链表分割后新产生的链表
异常:
- IllegalArgumentException:如果指定的节点不属于该链表,则抛此异常
extend LinkedList <: ToString
extend LinkedList<T> <: ToString where T <: ToString
此扩展主要用于实现 LinkedList 的 toString() 函数。
func toString
public func toString(): String
功能:返回此链表的字符串形式,包含了链表中每个元素的字符串形式。
返回值:此链表的字符串形式
extend LinkedList <: Equatable
extend LinkedList<T> <: Equatable<LinkedList<T>> where T <: Equatable<T>
此扩展主要用于实现 LinkedList 的判等函数。
operator func ==
public operator func ==(right: LinkedList<T>): Bool
功能:判断当前链表与目标链表是否相等,如果两个链表中相同位置的元素都相同,则两个链表相等。
参数:
- right:与当前链表相比较的链表
返回值:如果两个链表相等,返回 true
operator func !=
public operator func !=(right: LinkedList<T>): Bool
功能:判断当前链表与目标链表是否不相等,如果两个链表中相同位置的元素都相同,则两个链表相等。
参数:
- right:与当前链表相比较的链表
返回值:如果两个链表不相等,返回 true
class LinkedListNode
public class LinkedListNode<T>
LinkedListNode 是 LinkedList 上的节点,可以通过 LinkedListNode 对 LinkedList 进行前向后向遍历操作,也可以访问和修改元素的值。
LinkedListNode 只能通过对应 LinkedList 的 'nodeAt'、'firstNode'、'lastNode' 获得,当 LinkedList 删除掉对应的节点时,会造成一个悬空的节点,对悬空的节点进行任何操作都会抛 'IllegalStateException' 异常。
prop value
public mut prop value: T
功能:获取或者修改元素的值。
异常:
- IllegalStateException:如果该节点不属于任何链表实例,抛此异常
prop next
public prop next: Option<LinkedListNode<T>>
功能:获取当前节点的下一个节点,如果没有则返回 None。
异常:
- IllegalStateException:如果该节点不属于任何链表实例,抛此异常
prop prev
public prop prev: Option<LinkedListNode<T>>
功能:获取当前节点的前一个节点,如果没有则返回 None。
异常:
- IllegalStateException:如果该节点不属于任何链表实例,抛此异常
func backward
public func backward(): Iterator<T>
功能:获取一个从当前节点开始,到所对应链表的尾部节点的所有元素的迭代器。
返回值:对应元素的迭代器
异常:
- IllegalStateException:如果该节点不属于任何链表实例,抛此异常
func forward
public func forward(): Iterator<T>
功能:获取一个从当前节点开始,到所对应链表的头部节点的所有元素的迭代器。
返回值:对应元素的迭代器
异常:
- IllegalStateException:如果该节点不属于任何链表实例,抛此异常
interface Map
该接口是用于 Map 集合中所有 K 和 V 的展示。
public interface Map<K, V> <: Collection<(K, V)> where K <: Equatable<K> {
func get(key: K): Option<V>
func contains(key: K): Bool
func containsAll(keys: Collection<K>): Bool
mut func put(key: K, value: V): Option<V>
mut func putAll(elements: Collection<(K, V)>): Unit
mut func remove(key: K): Option<V>
mut func removeAll(keys: Collection<K>): Unit
mut func removeIf(predicate: (K, V) -> Bool): Unit
mut func clear(): Unit
func clone(): Map<K, V>
operator func [](key: K): V
operator func [](key: K, value!: V): Unit
func keys(): EquatableCollection<K>
func values(): Collection<V>
prop size: Int64
func isEmpty(): Bool
func iterator(): Iterator<(K, V)>
}
func get
func get(key: K): Option<V>
功能:根据 key 得到 Map 中映射的值。
参数:
- key:传递 key,获取 value
返回值:key 对应的值是用 Option 封装的
func contains
func contains(key: K): Bool
功能:判断是否包含指定键的映射。
参数:
- key:传递要判断的 key
返回值:如果存在,则返回 true;否则,返回 false
func containsAll
func containsAll(keys: Collection<K>): Bool
功能:判断是否包含指定集合键的映射。
参数:
- keys:传递待判断的 keys
返回值:如果存在,则返回 true;否则,返回 false
func put
mut func put(key: K, value: V): Option<V>
功能:将传入的键值对放入该 Map 中。对于 Map 中已有的键,该键映射的值将被新值替换。
参数:
- key:要放置的键
- value:要分配的值
返回值:如果赋值之前 key 存在,旧的 value 用 Option 封装;否则,返回 Option
func putAll
mut func putAll(elements: Collection<(K, V)>): Unit
功能:将新的键值对放入 Map 中。对于 Map 中已有的键,该键映射的值将被新值替换。
参数:
- elements:需要放入到 Map 中的键值对集合
func remove
mut func remove(key: K): Option<V>
功能:从此 Map 中删除指定键的映射(如果存在)。
参数:
- key:传入要删除的 key
返回值:从 Map 中移除的键对应的值。用 Option 封装
func removeAll
mut func removeAll(keys: Collection<K>): Unit
功能:从此映射中删除指定集合的映射(如果存在)。
参数:
- keys:传入要删除的集合
func removeIf
mut func removeIf(predicate: (K, V) -> Bool): Unit
功能:传入 lambda 表达式,如果满足条件,则删除对应的键值对。
参数:
- predicate:传递一个 lambda 表达式进行判断
func clear
mut func clear(): Unit
功能:清除所有键值对。
func clone
func clone(): Map<K, V>
功能:克隆 Map。
返回值:返回一个 Map<K, V>
operator func []
operator func [](key: K): V
功能:运算符重载集合,如果键存在,返回键对应的值,如果不存在,抛出异常。
参数:
- key:需要进行查找的键
返回值:与键对应的值
operator func []
operator func [](key: K, value!: V): Unit
功能:运算符重载集合,如果键存在,新 value 覆盖旧 value,如果键不存在,添加此键值对。
参数:
- key:需要进行设置的键
- value:传递要设置的值
func keys
func keys(): EquatableCollection<K>
功能:返回 Map 中所有的 key,并将所有 key 存储在一个 EquatableCollection
返回值:保存所有返回的 key
func values
func values(): Collection<V>
功能:返回 Map 中所有的 value,并将所有 value 存储在一个 Collection
返回值:保存所有返回的 value
prop size
prop size: Int64
功能:返回 Map 中所有的键值对的个数
返回值:键值对的个数
func isEmpty
func isEmpty(): Bool
功能:检查 Map 是否为空。
返回值:如果 Map 为空,返回 true; 否则,返回 false
func iterator
func iterator(): Iterator<(K, V)>
功能:返回 Map 的迭代器。
返回值:Map 的迭代器
struct EntryView
public struct EntryView<K, V> where K <: Hashable & Equatable<K>
此类主要用于插入不存在的键值对时,返回指定的键值在 HashMap 中的引用视图。 在使用视图的过程中,如果集合修改、增加、删除了某些元素, 视图会无效并抛出 ConcurrentModificationException。
类的主要函数如下所示:
func isAbsent
public func isAbsent(): Bool
功能:判断视图是否为空。
返回值:如果视图为空,则返回 true;否则,返回 false
func getKey
public func getKey(): K
功能:获取视图中的键,时间复杂度为 O(1)。
返回值:视图的键
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
func getValue
public func getValue(): ?V
功能:获取视图中的值,时间复杂度为 O(1)。如果视图为空,返回 None;否则,返回键对应的值。
返回值:视图的值
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
func setValue
public mut func setValue(v: V): V
功能:设置视图中的值,时间复杂度为 O(1)。如果视图为空,则插入指定的键值对,并返回插入的值;否则,返回设置前的值。
返回值:视图的值
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
class HashMap
public class HashMap<K, V> <: Map<K, V> where K <: Hashable & Equatable<K> {
public init()
public init(elements: Collection<(K, V)>)
public init(elements: Array<(K, V)>)
public init(capacity: Int64)
public init(size: Int64, initElement: (Int64) -> (K, V))
}
此类主要用于实现 HashMap 数据结构及相关操作函数。
类的主要函数如下所示:
init
public init()
功能:构造一个具有默认初始容量 (16) 和默认负载因子为空的 HashMap。
init
public init(elements: Collection<(K, V)>)
功能:通过传入的键值对集合构造一个 HashMap。该构造函数根据传入集合 elements 的 size 设置 HashMap 的容量。
参数:
- elements:初始化该 HashMap 的键值对集合
异常:
- NegativeArraySizeException: 如果内部数组超过了平台允许的大小上限,抛出异常
init
public init(elements: Array<(K, V)>)
功能:通过传入的键值对数组构造一个 HashMap。该构造函数根据传入数组的 size 设置 HashMap 的容量。
参数:
- elements:初始化该 HashMap 的键值对数组
异常:
- NegativeArraySizeException: 如果内部数组超过了平台允许的大小上限,抛出异常
init
public init(capacity: Int64)
功能:构造一个带有传入容量大小的 HashMap。
参数:
- capacity:初始化容量大小
异常:
-
IllegalArgumentException:如果 capacity 小于 0 则抛出异常
-
NegativeArraySizeException: 如果内部数组超过了平台允许的大小上限,抛出异常
init
public init(size: Int64, initElement: (Int64) -> (K, V))
功能:通过传入的元素个数 size 和函数规则来构造 HashMap。构造出的 HashMap 的容量受 size 大小影响。
参数:
- size:初始化该 HashMap 的函数规则
- initElement:初始化该 HashMap 的函数规则
异常:
-
IllegalArgumentException:如果 size 小于 0 则抛出异常
-
NegativeArraySizeException: 如果内部数组超过了平台允许的大小上限,抛出异常
func get
public func get(key: K): Option<V>
功能:返回指定键映射到的值,如果 HashMap 不包含指定键的映射,则返回 Option
参数:
- key:传入的键
返回值:键对应的值。用 Option 封装
func contains
public func contains(key: K): Bool
功能:判断是否包含指定键的映射。
参数:
- key:传递要判断的 key
返回值:如果存在,则返回 true;否则,返回 false
func containsAll
public func containsAll(keys: Collection<K>): Bool
功能:判断是否包含指定集合中所有键的映射。
参数:
- keys:键传递待判断的 keys
返回值:如果都包含,则返回 true;否则,返回 false
func put
public func put(key: K, value: V): Option<V>
功能:将新的键值对放入 HashMap 中。对于 HashMap 中已有的键,该键的值将被新值替换。
参数:
- key:要放置的键
- value:要分配的值
返回值:如果赋值之前 key 存在,旧的 value 用 Option 封装;否则,返回 Option
func putIfAbsent
public func putIfAbsent(key: K, value: V): Bool
功能:当此 HashMap 中不存在键 @p key 时,在 HashMap 中添加指定的值 @p value 与指定的键 @p key 的关联。如果 HashMap 已经包含键 @p key,则不执行赋值操作。
参数:
- key:要放置的键
- value:要分配的值
返回值:如果赋值之前 @p key 存在,则返回false,且不执行赋值操作;当赋值前 @p key 不存在时,执行插值操作,并返回 true。
func putAll
public func putAll(elements: Collection<(K, V)>): Unit
功能:将新的键值对集合放入 HashMap 中。对于 HashMap 中已有的键,该键的值将被新值替换。
参数:
- elements:需要添加进 HashMap 的键值对集合
func remove
public func remove(key: K): Option<V>
功能:从此 HashMap 中删除指定键的映射(如果存在)。
参数:
- key:传入要删除的 key
返回值:被从 HashMap 中移除的键对应的值。用 Option 封装
func removeAll
public func removeAll(keys: Collection<K>): Unit
功能:从此 HashMap 中删除指定集合中键的映射(如果存在)。
参数:
- keys:传入要删除的键的集合
func removeIf
public func removeIf(predicate: (K, V) -> Bool): Unit
功能:传入 lambda 表达式,如果满足条件,则删除对应的键值对。
参数:
- predicate:传递一个 lambda 表达式进行判断
func entryView
public func entryView(key: K): EntryView<K, V>
功能:如果不包含特定键,返回一个空的引用视图。如果包含特定键,则返回该键对应的元素的引用视图。
参数:
- key:要添加的键值对的键
返回值:一个引用视图
func clear
public func clear(): Unit
功能:清除所有键值对。
func reserve
public func reserve(additional: Int64): Unit
功能:将 HashMap 扩容 additional 大小当 additional 小于等于零时,不发生扩容;当 HashMap 剩余容量大于等于 additional 时,不发生扩容当 HashMap 剩余容量小于 additional 时,取(原始容量的1.5倍向下取整)与(additional + 已使用容量)中的最大值进行扩容。
参数:
- additional:将要扩容的大小
func capacity
public func capacity(): Int64
功能:返回 HashMap 的容量。
返回值:HashMap 的容量
func clone
public func clone(): HashMap<K, V>
功能:克隆 HashMap。
返回值:返回一个 HashMap<K, V>
func toArray
public func toArray(): Array<(K, V)>
功能:构造一个包含 HashMap 内键值对的数组,并返回
返回值:包含容器内所有键值对的数组
func keys
public func keys(): EquatableCollection<K>
功能:返回 HashMap 中所有的 key,并将所有 key 存储在一个 Keys 容器中。
返回值:保存所有返回的 key
func values
public func values(): Collection<V>
功能:返回 HashMap 中包含的值,并将所有的 value 存储在一个 Values 容器中。
返回值:保存所有返回的 value
func iterator
public func iterator(): HashMapIterator<K, V>
功能:返回 Hashmap 的迭代器。
返回值:返回 HashMap 的迭代器
prop size
public prop size: Int64
功能:返回键值对的个数 返回值 Int64 - 键值对的个数
func isEmpty
public func isEmpty(): Bool
功能:判断 HashMap 是否为空,如果是,则返回 true;否则,返回 false。
返回值:如果 HashMap 为空,则返回 true;否则,返回 false
operator func []
public operator func [](key: K, value!: V): Unit
功能:运算符重载集合,如果键存在,新 value 覆盖旧 value,如果键不存在,添加此键值对。
参数:
- key:传递值进行判断
- value:传递要设置的值
operator func []
public operator func [](key: K): V
功能:运算符重载集合,如果键存在,返回键对应的值。
参数:
- key:传递值进行判断
返回值:与键对应的值
异常:
- NoneValueException:如果该 HashMap 不存在该键
interface Set
public interface Set<T> <: Collection<T> where T <: Equatable<T> {
func contains(element: T): Bool
func subsetOf(other: Set<T>): Bool
func containsAll(elements: Collection<T>): Bool
mut func put(element: T): Bool
mut func putAll(elements: Collection<T>): Unit
mut func remove(element: T): Bool
mut func removeAll(elements: Collection<T>): Unit
mut func removeIf(predicate: (T) -> Bool): Unit
mut func clear(): Unit
mut func retainAll(elements: Set<T>): Unit
func clone(): Set<T>
}
该接口是用于 Set 集合中所有元素的展示。
func contains
func contains(element: T): Bool
功能:如果该集合包含指定元素,则返回 true。
参数:
- element:需要判断的元素
返回值:如果包含,则返回 true;否则,返回 false
func subsetOf
func subsetOf(other: Set<T>): Bool
功能:检查该集合是否为其他集合的子集。
参数:
- other:其他集合
返回值:果该集合是指定集合的子集,则返回 true;否则,返回 false
func containsAll
func containsAll(elements: Collection<T>): Bool
功能:检查该集合是否包含其他集合。
参数:
- elements:其他集合
返回值:如果该集合包含指定集合,则返回 true;否则,返回 false
func put
mut func put(element: T): Bool
功能:添加元素操作。如果元素已经存在,则不会添加它。
参数:
- element:要添加的元素
返回值:如果添加成功,则返回 true;否则,返回 false
func putAll
mut func putAll(elements: Collection<T>): Unit
功能:添加 Collection 中的所有元素至此 Set 中,如果元素存在,则不添加。
参数:
- elements:需要被添加的元素的集合
func remove
mut func remove(element: T): Bool
功能:从该结合中移除指定元素(如果存在)。
参数:
- element:要删除的元素
func removeAll
mut func removeAll(elements: Collection<T>): Unit
功能:移除此 Set 中那些也包含在指定 Collection 中的所有元素。
参数:
- elements:传入 Collection
func removeIf
mut func removeIf(predicate: (T) -> Bool): Unit
功能:传入 lambda 表达式,如果满足 true 条件,则删除对应的元素。
参数:
- predicate:传入一个 lambda 表达式进行判断
func clear
mut func clear(): Unit
功能:清除所有键值对。
func retainAll
mut func retainAll(elements: Set<T>): Unit
功能:仅保留该 Set 与入参 Set 中重复的元素。
参数:
- elements:要保存的元素集合
func clone
func clone(): Set<T>
功能:克隆此 Set,并返回克隆出的新的 Set。
class HashSet
public class HashSet<T> <: Set<T> where T <: Hashable & Equatable<T> {
public init()
public init(elements: Collection<T>)
public init(elements: Array<T>)
public init(capacity: Int64)
public init(size: Int64, initElement: (Int64) -> T)
}
此类主要用于实现 HashSet 数据结构及相关操作函数。
类的主要函数如下所示:
init
public init()
功能:构造一个具有默认初始容量 (16) 和默认负载因子为 (0.75) 的 HashSet。
init
public init(elements: Collection<T>)
功能:使用传入的集合构造 HashSet。该构造函数根据传入集合 elements 的 size 设置 HashSet 的容量。
参数:
- elements:初始化 HashSet 的集合
异常:
- NegativeArraySizeException: 如果内部数组超过了平台允许的大小上限,抛出异常
init
public init(elements: Array<T>)
功能:使用传入的数组构造 HashSet。该构造函数根据传入数组 elements 的 size 设置 HashSet 的容量。
参数:
- elements:初始化 HashSet 的数组
异常:
- NegativeArraySizeException: 如果内部数组超过了平台允许的大小上限,抛出异常
init
public init(capacity: Int64)
功能:使用传入的容量构造一个 HashSet。
参数:
- capacity:初始化容量大小
异常:
-
IllegalArgumentException:如果 capacity 小于 0,抛出异常
-
NegativeArraySizeException: 如果内部数组超过了平台允许的大小上限,抛出异常
init
public init(size: Int64, initElement: (Int64) -> T)
功能:通过传入的函数元素个数 size 和函数规则来构造 HashSet。构造出的 HashSet 的容量受 size 大小影响。
参数:
- size:初始化函数中元素的个数
- initElement:初始化函数规则
异常:
-
IllegalArgumentException:如果 size 小于 0,抛出异常
-
NegativeArraySizeException: 如果内部数组超过了平台允许的大小上限,抛出异常
func contains
public func contains(element: T): Bool
功能:判断 HashSet 是否包含指定元素。
参数:
- element:T
返回值:如果包含指定元素,则返回 true;否则,返回 false
func containsAll
public func containsAll(elements: Collection<T>): Bool
功能:判断 HashSet 是否包含指定 Collection 中的所有元素。
参数:
- elements:传入 Collection
返回值:如果此 HashSet 包含 Collection 中的所有元素,则返回 true;否则,返回 false
func put
public func put(element: T): Bool
功能:添加元素, 若添加的元素在 HashSet 中存在, 则添加失败。
参数:
- element:T
返回值:如果添加成功,则返回 true;否则,返回 false
func putAll
public func putAll(elements: Collection<T>): Unit
功能:添加 Collection 中的所有元素至此 HashSet 中,如果元素存在,则不添加。
参数:
- elements:需要被添加的元素的集合
func subsetOf
public func subsetOf(other: Set<T>): Bool
功能:检查该集合是否为其他集合的子集。
参数:
- other:传入集合,此函数将判断当前集合是否为 other 的子集
返回值:如果该 Set 是指定 Set 的子集,则返回 true;否则返回 false
func remove
public func remove(element: T): Bool
功能:如果指定元素存在于此 HashSet 中,则将其移除。
参数:
- element:需要被移除的元素
返回值:true,表示移除成功;false,表示移除失败
func removeAll
public func removeAll(elements: Collection<T>): Unit
功能:移除此 HashSet 中那些也包含在指定 Collection 中的所有元素。
参数:
- elements:需要从此 HashSet 中移除的元素的集合
func removeIf
public func removeIf(predicate: (T) -> Bool): Unit
功能:传入 lambda 表达式,如果满足 true 条件,则删除对应的元素。
参数:
- predicate:(T) -> Bool 表达式
func clear
public func clear(): Unit
功能:从此 HashSet 中移除所有元素。
func retainAll
public func retainAll(elements: Set<T>): Unit
功能:从此 HashSet 中保留 Set 中的元素。
参数:
- elements:需要保留的 Set
func toArray
public func toArray(): Array<T>
功能:返回一个包含容器内所有元素的数组
返回值:T 类型数组
func clone
public func clone(): HashSet<T>
功能:克隆 HashSet。
返回值:返回克隆到的 HashSet
func reserve
public func reserve(additional: Int64): Unit
功能:将 HashSet 扩容 additional 大小,当 additional 小于等于零时,不发生扩容,当 HashSet 剩余容量大于等于 additional 时,不发生扩容,当 HashSet 剩余容量小于 additional 时,取(原始容量的1.5倍向下取整)与(additional + 已使用容量)中的最大值进行扩容。
参数:
- additional:将要扩容的大小
func capacity
public func capacity(): Int64
功能:返回此 HashSet 的内部数组容量大小。
注意: 容量大小不一定等于 HashSet 的 size。
返回值:返回此 HashSet 的内部数组容量大小
func iterator
public func iterator(): Iterator<T>
功能:返回此 HashSet 的迭代器。
返回值:返回此 HashSet 的迭代器
prop size
public prop size: Int64
功能:返回此 HashSet 的元素个数 返回值:元素个数
func isEmpty
public func isEmpty(): Bool
功能:判断 HashSet 是否为空。
返回值:如果为空,则返回 true;否则,返回 false
interface EquatableCollection
public interface EquatableCollection<T> <: Collection<T> where T <: Equatable<T> {
func contains(element: T): Bool
func containsAll(elements: Collection<T>): Bool
}
该接口用于 HashMap 集合中 所有 K 的展示。
func contains
func contains(element: T): Bool
功能:判断 Keys 是否包含指定元素。
参数:
- element:指定元素,待判断 Keys 是否包含该元素
返回值:包含返回 true,否则返回 false
func containsAll
func containsAll(elements: Collection<T>): Bool
功能:判断 Keys 是否包含指定集合的所有元素。
参数:
- 待判断的集合 elements
返回值:包含则返回 true,否则返回 false
class ArrayListIterator
public class ArrayListIterator<T> <: Iterator<T> {
public init(data: ArrayList<T>)
}
此类主要实现 ArrayList 的迭代器功能。
init
public init(data: ArrayList<T>)
功能:创建 ArrayListIterator
参数:
- date:传入 ArrayList
func next
public func next(): Option<T>
功能:返回迭代中的下一个元素。
返回值:Option
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
func iterator
public func iterator(): Iterator<T>
功能:返回迭代器。
返回值:Iterator
class HashMapIterator
public class HashMapIterator<K, V> <: Iterator<(K, V)> where K <: Hashable & Equatable<K> {
public init(map: HashMap<K, V>)
}
此类主要实现 HashMap 的迭代器功能。
init
public init(map: HashMap<K, V>)
功能:创建 HashMapIterator<K, V> 实例。
参数:
- map:传入 HashMap<K, V>
func next
public func next(): Option<(K, V)>
功能:返回迭代中的下一个元素。
返回值:Option<(K,V)> 类型
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
func iterator
public func iterator(): Iterator<(K, V)>
功能:返回迭代器。
返回值:Iterator<(K,V)> 类型
func remove
public func remove(): Option<(K, V)>
功能:删除此 HashMap 迭代器的 next 函数返回的元素,此函数只能在 next 函数调用时调用一次。
返回值:返回被删除的元素
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
class ConcatIterator
public class ConcatIterator<T> <: Iterator<T> {
public init(it: Iterable<T>, other: Iterable<T>)
}
这个类 ConcatIterator 用于连接两个 Iterable
init
public init(it: Iterable<T>, other: Iterable<T>)
功能:创建 ConcatIterator
参数:
- it:Iterable
- other:Iterable
func next
public func next(): Option<T>
功能:返回迭代中的下一个元素。
返回值:Option
func iterator
public func iterator(): Iterator<T>
功能:返回迭代器。
返回值:Iterator
class FilterIterator
public class FilterIterator<T> <: Iterator<T> {
public init(it: Iterable<T>, predicate: (T) -> Bool)
}
此类 FilterIterator 使用闭包来确定是否应生成元素,按过滤函数过滤 Iterable。
init
public init(it: Iterable<T>, predicate: (T) -> Bool)
功能:创建 FilterIterator
参数:
- it:Iterable
- predicate:过滤函数
func next
public func next(): Option<T>
功能:返回迭代中的下一个元素。
返回值:Option
func iterator
public func iterator(): Iterator<T>
功能:返回迭代器。
返回值:Iterator
class FlatMapIterator
public class FlatMapIterator<T, R> <: Iterator<R> {
public init(it: Iterable<T>, transform: (T) -> Iterable<R>)
}
这个类 FlatMapIterator 用于转换和扁平化 Iterable,所有元素都通过转换函数转换为 Iterator
init
public init(it: Iterable<T>, transform: (T) -> Iterable<R>)
功能:创建 FlatMapIterator<T, R> 实例。
参数:
- it:Iterable
- transform:转换函数
func next
public func next(): Option<R>
功能:返回迭代中的下一个元素。
返回值:Option
func iterator
public func iterator(): Iterator<R>
功能:返回迭代器。
返回值:Iterator
class FlattenIterator
public class FlattenIterator<T, R> <: Iterator<R> where T <: Iterable<R> {
public init(it: Iterable<T>)
}
该类 FlattenIterator 用于扁平化 Iterable
init
public init(it: Iterable<T>)
功能:创建 FlattenIterator<T, R> 实例。
参数:
- it:Iterable
func next
public func next(): Option<R>
功能:返回迭代中的下一个元素。
返回值:Option
func iterator
public func iterator(): Iterator<R>
功能:返回迭代器。
返回值:Iterator
class LimitIterator
public class LimitIterator<T> <: Iterator<T> {
public init(it: Iterable<T>, count: Int64)
}
此限制迭代器类用于生成 Iterablecount元素
切片 Iterable
init
public init(it: Iterable<T>, count: Int64)
功能:创建 LimitIterator
参数:
- it:Iterable
- count:限制计数元素
func next
public func next(): Option<T>
功能:返回迭代中的下一个元素。
返回值:Option
func iterator
public func iterator(): Iterator<T>
功能:返回迭代器。
返回值:Iterator
class MapIterator
public class MapIterator<T, R> <: Iterator<R> {
public init(it: Iterable<T>, transform: (T) -> R)
}
这个类 MapIterator 用于将 Iterable 转换为另一个 Iterable, 通过转换函数将 Iterable
init
public init(it: Iterable<T>, transform: (T) -> R)
功能:将 Iterator 转换为另一个类型。
参数:
- it:Iterable
- transform:转换函数
func next
public func next(): Option<R>
功能:返回迭代中的下一个元素。
返回值:Option
func iterator
public func iterator(): Iterator<R>
功能:返回迭代器。
返回值:Iterator
class SkipIterator
public class SkipIterator<T> <: Iterator<T> {
public init(it: Iterable<T>, count: Int64)
}
此类是一个跳过迭代器类,跳过 Iterable
init
public init(it: Iterable<T>, count: Int64)
功能:构建 SkipIterator
参数:
- it:Iterable
- count:跳过的元素数量
func next
public func next(): Option<T>
功能:返回迭代中的下一个元素。
返回值:Option
func iterator
public func iterator(): Iterator<T>
功能:返回迭代器。
返回值:Iterator
class StepIterator
public class StepIterator<T> <: Iterator<T> {
public init(it: Iterable<T>, count: Int64)
}
此类是一个跳跃迭代器类,按照步距为 n 的大小构造 Iterable
init
public init(it: Iterable<T>, count: Int64)
功能:构建 SkipIterator
参数:
- it:Iterable
- count:步距大小
func next
public func next(): Option<T>
功能:返回迭代中的下一个元素。
返回值:Option
func iterator
public func iterator(): Iterator<T>
功能:返回迭代器。
返回值:Iterator
class WithIndexIterator
public class WithIndexIterator<T> <: Iterator<(Int64, T)> {
public init(it: Iterable<T>)
}
这个类 WithIndexIterator 是可迭代的索引和元素
init
public init(it: Iterable<T>)
功能:构建 SkipIterator
参数:
- it:Iterable
func next
public func next(): Option<(Int64, T)>
功能:返回迭代中的下一个元素。
返回值:Option<(Int64, T) 类型, 其中 Int64 是迭代元素的索引,T 是内部元素
func iterator
public func iterator(): Iterator<(Int64, T)>
功能:返回迭代器。
返回值:Iterator
class ZipIterator
public class ZipIterator<T, R> <: Iterator<(T, R)> {
public init(itt: Iterable<T>, itr: Iterable<R>)
}
这个类 ZipIterator 用于压缩两个 Iterable,新的 Iterator<T*R> 大小由短 Iterable 控制
init
public init(itt: Iterable<T>, itr: Iterable<R>)
功能:构建 ZipIterator<T, R> 对象。
参数:
- itt:Iterable
- itr:Iterable
func next
public func next(): Option<(T, R)>
功能:返回迭代中的下一个元素。
返回值:Option<(T, R)> 类型
func iterator
public func iterator(): Iterator<(T, R)>
功能:返回迭代器。
返回值:Iterator<(T, R)> 类型
extend ArrayList <: ToString
extend ArrayList<T> <: ToString where T <: ToString
此扩展主要用于实现 ArrayList 的 toString() 函数。
func toString
public func toString(): String
功能:实现 ArrayList 的 toString() 函数。
返回值:字符串类型
extend ArrayList <: SortExtension
extend ArrayList<T> <: SortExtension where T <: Comparable<T>
此扩展主要用于实现 ArrayList 的排序函数。
func sort
public func sort(stable!: Bool = false): Unit
功能:以升序的方式排序 ArrayList。
参数:
- stable:是否使用稳定排序
func sortDescending
public func sortDescending(stable!: Bool = false): Unit
功能:以降序的方式排序 ArrayList。
参数:
- stable:是否使用稳定排序
extend ArrayList <: Equatable
extend ArrayList<T> <: Equatable<ArrayList<T>> where T <: Equatable<T>
此扩展主要用于实现 ArrayList 的判等和 contains() 函数。
operator func ==
public operator func ==(that: ArrayList<T>): Bool
功能:判断 ArrayList 是否相等。
参数:
- that:传入 ArrayList
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public operator func !=(that: ArrayList<T>): Bool
功能:判断 ArrayList 是否不相等。
参数:
- that:传入 ArrayList
返回值:如果不相等,则返回 true;否则,返回 false
func contains
public func contains(element: T): Bool
功能:判断 ArrayList 是否包含指定元素。
参数:
- element:T
返回值:如果存在,则返回 true;否则,返回 false
extend HashMap <: ToString
extend HashMap<K, V> <: ToString where V <: ToString, K <: ToString & Hashable & Equatable<K>
此扩展主要用于实现 HashMap 的 toString() 函数。
func toString
public func toString(): String
功能:实现 HashMap 的 toString() 函数。
返回值:字符串类型
extend HashMap <: Equatable
extend HashMap<K, V> <: Equatable<HashMap<K, V>> where V <: Equatable<V>
此扩展主要用于实现 HashMap 的 Equatable 函数。
operator func ==
public operator func ==(right: HashMap<K, V>): Bool
功能:判断 HashMap 是否相等。
参数:
- right:传入 HashMap<K, V>
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public operator func !=(right: HashMap<K, V>): Bool
功能:判断 HashMap 是否不相等。
参数:
- right:传入 HashMap<K, V>
返回值:如果不相等,则返回 true;否则,返回 false
extend HashSet <: ToString
extend HashSet<T> <: ToString where T <: Hashable & Equatable<T> & ToString
此扩展主要用于实现 HashSet 的 toString() 函数。
func toString
public func toString(): String
功能:实现 HashSet 的 toString() 函数。
返回值:字符串类型
extend HashSet <: Equatable
extend HashSet<T> <: Equatable<HashSet<T>> where T <: Hashable & Equatable<T>
此扩展主要用于实现 HashSet 的判等功能。
operator func ==
public operator func ==(that: HashSet<T>): Bool
功能:判断 HashSet 是否相等。
参数:
- that:传入 HashSet
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public operator func !=(that: HashSet<T>): Bool
功能:判断 HashSet 是否不相等。
参数:
- that:传入 HashSet
返回值:如果不相等,则返回 true;否则,返回 false
class TreeMap
public class TreeMap<K, V> <: Map<K, V> where K <: Comparable<K> {
public init()
public init(elements: Collection<(K, V)>)
public init(elements: Array<(K,V)>)
public init(size: Int64, initElement: (Int64) -> (K, V))
}
此类主要用于实现 TreeMap 数据结构及相关操作函数。TreeMap 提供有序的 map 实现,它的顺序由 Comparable 接口保证:小的元素总是在左边,大的元素总是在右边。
init
public init()
功能:构造一个空的 TreeMap。
init
public init(elements: Collection<(K, V)>)
功能:通过传入的键值对集合构造一个 TreeMap。
参数:
- elements:初始化该
TreeMap的键值对集合
init
public init(elements: Array<(K,V)>)
功能:通过传入的键值对数组构造一个 TreeMap。
参数:
- elements:初始化该
TreeMap的键值对数组
init
public init(size: Int64, initElement: (Int64) -> (K, V))
功能:通过传入的元素个数 size 和函数规则来构造 TreeMap。
参数:
- size:传入的元素个数
- initElement:初始化该
TreeMap的函数规则
异常:
- IllegalArgumentException:如果 size 小于 0 则抛出异常
func firstEntry
public func firstEntry(): Option<(K, V)>
功能:获取 TreeMap 的第一个元素。
返回值:如果存在第一个元素,用 Option 封装该元素并返回;否则返回 Option<(K, V)>.None
func popFirstEntry
public func popFirstEntry(): Option<(K, V)>
功能:删除 TreeMap 的第一个元素。
返回值:如果存在第一个元素,那么删除该元素,用 Option 封装该元素并返回;否则返回 Option<(K, V)>.None
func lastEntry
public func lastEntry(): Option<(K, V)>
功能:获取 TreeMap 的最后一个元素。
返回值:如果存在最后一个元素,用 Option 封装该元素并返回;否则返回 Option<(K, V)>.None
func popLastEntry
public func popLastEntry(): Option<(K, V)>
功能:删除 TreeMap 的最后一个元素。
返回值:如果存在最后一个元素,那么删除该元素,用 Option 封装该元素并返回;否则返回 Option<(K, V)>.None
func findUpper
public func findUpper(bound: K, inclusive!: Bool = false): Option<TreeMapNode<K, V>>
功能:返回比传入的键大的最小元素。
参数:
- bound:传入的键
- inclusive:是否包含传入的键本身,默认为 false ,即不包含
返回值:如果存在这样一个元素,用 Option<TreeMapNode<K, V>> 封装该元素并返回;否则,返回 Option<TreeMapNode<K, V>>.None
func findLower
public func findLower(bound: K, inclusive!: Bool = false): Option<TreeMapNode<K, V>>
功能:返回比传入的键小的最大元素。
参数:
- bound:传入的键
- inclusive:是否包含传入的键本身,默认为 false ,即不包含
返回值:如果存在这样一个元素,用 Option<TreeMapNode<K, V>> 封装该元素并返回;否则,返回 Option<TreeMapNode<K, V>>.None
func get
public func get(key: K): Option<V>
功能:返回指定键映射的值。
参数:
- key:传递键,获取值
返回值:如果存在这样一个值,用 Option
func contains
public func contains(key: K): Bool
功能:判断是否包含指定键的映射。
参数:
- key:传递要判断的 key
返回值:如果存在,则返回 true;否则,返回 false
func containsAll
public func containsAll(keys: Collection<K>): Bool
功能:判断是否包含指定集合键的映射。
参数:
- keys:键的集合 keys
返回值:如果存在,则返回 true;否则,返回 false
func put
public func put(key: K, value: V): Option<V>
功能:将新的键值对放入 TreeMap 中。对于 TreeMap 中已有的键,该键的值将被新值替换。
参数:
- key:要放置的键
- value:要分配的值
返回值:如果赋值之前 key 存在,旧的 value 用 Option
func putAll
public func putAll(elements: Collection<(K, V)>): Unit
功能:将新的键值对集合放入 TreeMap 中。对于 TreeMap 中已有的键,该键的值将被新值替换。
参数:
- elements:需要添加进
TreeMap的键值对集合
func remove
public func remove(key: K): Option<V>
功能:从此映射中删除指定键的映射(如果存在)。
参数:
- key:传入要删除的 key
返回值:被移除映射的值用 Option
func removeAll
public func removeAll(keys: Collection<K>): Unit
功能:从此映射中删除指定集合的映射(如果存在)。
参数:
- keys:传入要删除的键的集合
func removeIf
public func removeIf(predicate: (K, V) -> Bool): Unit
功能:传入 lambda 表达式,如果满足条件,则删除对应的键值。
参数:
- predicate:传递一个 lambda 表达式进行判断
func clear
public func clear(): Unit
功能:清除所有键值对。
func clone
public func clone(): TreeMap<K, V>
功能:克隆 TreeMap。
返回值:返回一个 TreeMap 实例
operator func []
public operator func [](key: K): V
功能:运算符重载集合,如果键存在,返回键对应的值。
参数:
- key:传递值进行判断
返回值:与键对应的值
异常:
- NoneValueException:如果该 HashMap 不存在该键
operator func []
public operator func [](key: K, value!: V): Unit
功能:运算符重载集合,如果键存在,新 value 覆盖旧 value,如果键不存在,添加此键值对。
参数:
- key:传递值进行判断
- value:传递要设置的值
func keys
public func keys(): EquatableCollection<K>
功能:返回 TreeMap 中所有的 key,并将所有 key 存储在一个容器中。
返回值:保存所有返回的 key
func values
public func values(): Collection<V>
功能:返回 TreeMap 中包含的值,并将所有的 value 存储在一个容器中。
返回值:保存所有返回的 value
prop size
public prop size: Int64
功能:返回键值的个数
返回值:键值的个数
func isEmpty
public func isEmpty(): Bool
功能:判断 TreeMap 是否为空。
返回值:如果为空,返回 true,否则返回 false
func iterator
public func iterator(): Iterator<(K, V)> {}
功能:返回 TreeMap 的迭代器,迭代器按 Key 值从小到大的顺序迭代。
返回值:TreeMap 的迭代器
extend TreeMap <: ToString
extend TreeMap<K, V> <: ToString where V <: ToString, K <: ToString & Comparable<K>
此扩展主要用于实现 TreeMap 的 toString() 函数。
func toString
public func toString(): String
功能:获取当前 TreeMap 实例的字符串值。
返回值:当前 TreeMap 实例的字符串值
extend TreeMap <: Equatable
此扩展主要用于实现 TreeMap 的 Equatable 接口。
extend TreeMap<K, V> <: Equatable<TreeMap<K, V>> where V <: Equatable<V>, K <: Comparable<K>
operator func ==
public operator func ==(right: TreeMap<K, V>): Bool
功能:判断 TreeMap 是否相等。
参数:
- right:传入 TreeMap<K, V>
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public operator func !=(right: TreeMap<K, V>): Bool
功能:判断 TreeMap 是否不相等。
参数:
- right:传入 TreeMap<K, V>
返回值:如果不相等,则返回 true;否则,返回 false
struct TreeMapNode
public struct TreeMapNode<K, V> where K <: Comparable<K>
此类主要用于实现 TreeMap 的节点操作。
在使用 TreeMapNode 进行节点操作时,如果此时对 TreeMap 进行插入或删除操作,将会导致 TreeMapNode 的方法抛出异常。
prop key
public prop key: K
功能:获取当前节点的键。
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
prop value
public mut prop value: V
功能:获取或设置当前节点的值。
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
func next
public func next(): Option<TreeMapNode<K, V>>
功能:访问后继节点。
返回值:如果存在后继节点,用 Option<TreeMapNode<K, V>> 封装并返回;否则,返回 Option<TreeMapNode<K, V>>.None
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
func prev
public func prev(): Option<TreeMapNode<K, V>>
功能:访问前继节点。
返回值:如果存在前继节点,用 Option<TreeMapNode<K, V>> 封装并返回;否则,返回 Option<TreeMapNode<K, V>>.None
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
func backward
public func backward(bound: K, inclusive!:Bool = true): Iterator<(K, V)>
功能:从当前节点开始,到 bound 结束,生成一个正序的迭代器。
参数:
- bound:传入的键
- inclusive:是否包含传入的键本身,默认为 true ,即包含传入的键本身
返回值:返回从当前节点开始,到 bound 结束的一个正序的迭代器
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
func forward
public func forward(bound: K, inclusive!:Bool = true): Iterator<(K, V)>
功能:从当前节点开始,到 bound 结束,生成一个逆序的迭代器。
参数:
- bound:传入的键
- inclusive:是否包含传入的键本身,默认为 true ,即包含传入的键本身
返回值:返回从当前节点开始,到 bound 结束的一个逆序的迭代器
异常:
- ConcurrentModificationException:当函数检测到不同步的并发修改,抛出异常
class ConcurrentModificationException
public class ConcurrentModificationException <: Exception {
public init()
public init(message: String)
}
此类为并发修改异常类。当函数检测到不同步的并发修改,抛出异常。
init
public init()
功能:无参构造函数。
init
public init(message: String)
功能:根据异常信息构造异常实例。
参数:
- message:预定义消息
func withIndex
public func withIndex<T>(it: Iterable<T>): Iterator<(Int64, T)>
功能:以下是以柯里化函数形式提供一系列迭代器操作函数,此函数用于获取带索引的迭代器。
参数:
- it:给定的迭代器
返回值:返回一个带索引的迭代器
func filter
public func filter<T>(predicate: (T) -> Bool): (Iterable<T>) -> Iterator<T>
功能:筛选出满足条件的元素。
参数:
- predicate:给定的条件
返回值:返回一个筛选函数
func map
public func map<T, R>(transform: (T) -> R): (Iterable<T>) -> Iterator<R>
功能:创建一个映射。
参数:
- transform:给定的映射函数
返回值:返回一个映射函数
func flatten
public func flatten<T, R>(it: Iterable<T>): Iterator<R> where T <: Iterable<R>
功能:将嵌套的迭代器展开一层。
参数:
- it:给定的迭代器
返回值:返回展开一层后的迭代器
func flatMap
public func flatMap<T, R>(transform: (T) -> Iterable<R>): (Iterable<T>) -> Iterator<R>
功能:创建一个带 flatten 功能的映射。
参数:
- transform:给定的映射函数
返回值:返回一个带 flatten 功能的映射函数
func zip
public func zip<T, R>(other: Iterable<R>): (Iterable<T>) -> Iterator<(T, R)>
功能:将两个迭代器合并成一个(以短的为主)。
参数:
- other:要合并的其中一个迭代器
返回值:返回一个合并函数
func concat
public func concat<T>(other: Iterable<T>): (Iterable<T>) -> Iterator<T>
功能:串联两个迭代器。
参数:
- other:要串联在后面的迭代器
返回值:返回一个串联函数
func skip
public func skip<T>(count: Int64): (Iterable<T>) -> Iterator<T>
功能:从迭代器跳过特定个数当 count < 0 时,抛异常当 count == 0 时,相当没有跳过任何元素,返回原迭代器当 0 < count < size 时,跳过 count 个元素后,返回含有剩下的元素的新迭代器当 count >= size 时,跳过所有元素,返回空迭代器。
参数:
- count:要跳过的个数
返回值:返回一个跳过指定数量元素的函数,执行逻辑如下:
异常:
- IllegalArgumentException:当 count < 0 时,抛出异常
func limit
public func limit<T>(count: Int64): (Iterable<T>) -> Iterator<T>
功能:从迭代器取出特定个数当 count < 0 时,抛异常当 count == 0 时,不取元素,返回空迭代器当 0 < count < size 时,取前 count 个元素,返回新迭代器当 count >= size 时,取所有元素,返回原迭代器。
参数:
- count:要取出的个数
返回值:> Iterator
异常:
- IllegalArgumentException:当 count < 0 时,抛出异常
func step
public func step<T>(count: Int64): (Iterable<T>) -> Iterator<T>
功能:迭代器每次调用 next() 跳过特定个数当 count <= 0 时,抛异常当 count > 0 时,每次调用 next() 跳过 count 次,直到迭代器为空。
参数:
- count:每次调用 next() 要跳过的个数
返回值:> Iterator
异常:
- IllegalArgumentException:当 count < 0 时,抛出异常
func forEach
public func forEach<T>(action: (T) -> Unit): (Iterable<T>) -> Unit
功能:遍历所有元素,指定给定的操作。
参数:
- action:给定的操作函数
返回值:返回一个执行遍历操作的函数
func isEmpty
public func isEmpty<T>(it: Iterable<T>): Bool
功能:判断迭代器是否为空。
参数:
- it:给定的迭代器
返回值:返回迭代器是否为空
func count
public func count<T>(it: Iterable<T>): Int64
功能:统计迭代器包含元素数量。
参数:
- it:给定的迭代器
返回值:返回迭代器包含元素数量
func contains
public func contains<T>(element: T): (Iterable<T>) -> Bool where T <: Equatable<T>
功能:遍历所有元素,判断是否包含指定元素并返回该元素。
参数:
- element:要查找的元素
返回值:返回一个查找函数
func max
public func max<T>(it: Iterable<T>): Option<T> where T <: Comparable<T>
功能:筛选最大的元素。
参数:
- it:给定的迭代器
返回值:返回最大的元素,若为空则返回 None
func min
public func min<T>(it: Iterable<T>): Option<T> where T <: Comparable<T>
功能:筛选最小的元素。
参数:
- it:给定的迭代器
返回值:返回最小的元素,若为空则返回 None
func all
public func all<T>(predicate: (T) -> Bool): (Iterable<T>) -> Bool
功能:判断迭代器所有元素是否都满足条件。
参数:
- predicate:给定的条件
返回值:返回一个判断全部满足条件的函数
func any
public func any<T>(predicate: (T) -> Bool): (Iterable<T>) -> Bool
功能:判断迭代器是否存在任意一个满足条件的元素。
参数:
- predicate:给定的条件
返回值:返回一个判断存在任意一个满足条件的函数
func none
public func none<T>(predicate: (T) -> Bool): (Iterable<T>) -> Bool
功能:判断迭代器是否都不满足条件。
参数:
- predicate:给定的条件
返回值:返回一个判断都不满足条件的函数
func first
public func first<T>(it: Iterable<T>): Option<T>
功能:获取头部元素。
参数:
- it:给定的迭代器
返回值:返回头部元素,若为空则返回 None
func last
public func last<T>(it: Iterable<T>): Option<T>
功能:获取尾部元素。
参数:
- it:给定的迭代器
返回值:返回尾部元素,若为空则返回 None
func at
public func at<T>(n: Int64): (Iterable<T>) -> Option<T>
功能:获取第 n 个 元素。
参数:
- n:给定的个数
返回值:返回获取对应位置元素的函数,若迭代器为空则该函数返回 None
func reduce
public func reduce<T, R>(initial: R, operation: (T, R) -> R): (Iterable<T>) -> R
功能:使用指定初始值,从左向右计算。
参数:
- initial:给定的 R 类型的初始值
返回值:返回一个规并函数
func fold
public func fold<T, R>(initial: R, operation: (T, R) -> R): (Iterable<T>) -> R
功能:使用指定初始值,从右向左计算。
参数:
- initial:给定的 R 类型的初始值
返回值:返回一个折叠函数
func collectString
public func collectString<T>(delimiter!: String = ""): (Iterable<T>) -> String where T <: ToString
功能:将一个对应元素实现了 ToString 接口的迭代器转换成 String 类型。
参数:
- delimiter:字符串拼接分隔符
返回值:返回一个转换函数
func collectArray
public func collectArray<T>(it: Iterable<T>): Array<T>
功能:将一个迭代器转换成 Array 类型。
参数:
- it:给定的迭代器
返回值:返回一个数组
func collectArrayList
public func collectArrayList<T>(it: Iterable<T>): ArrayList<T>
功能:将一个迭代器转换成 ArrayList 类型。
参数:
- it:给定的迭代器
返回值:返回一个 ArrayList
func collectHashSet
public func collectHashSet<T>(it: Iterable<T>): HashSet<T> where T <: Hashable & Equatable<T>
功能:将一个迭代器转换成 HashSet 类型。
参数:
- it:给定的迭代器
返回值:返回一个 HashSet
func collectHashMap
public func collectHashMap<K, V>(it: Iterable<(K, V)>): HashMap<K, V> where K <: Hashable & Equatable<K>
功能:将一个迭代器转换成 HashMap 类型。
参数:
- it:给定的迭代器
返回值:返回一个 HashMap
示例
ArrayList 的 get/set 函数
下面是 ArrayList 的 get/set 函数示例。
代码如下:
from std import collection.*
main() {
var a: ArrayList<Int64> = ArrayList<Int64>(10)
a.append(97)
a.append(100)
a.set(1, 120)
var b = a.get(1)
print("b=${b.getOrThrow()}")
return 0
}
运行结果如下:
b=120
ArrayList 的 append/insert 函数
下面是 ArrayList 的 append/insert 函数示例。
代码如下:
from std import collection.*
main() {
var a: ArrayList<Int64> = ArrayList<Int64>(10)
var arr: Array<Int64> = [1,2,3]
a.appendAll(arr)
a.set(1, 120)
var b = a.get(2)
print("b=${b.getOrThrow()},")
a.insert(1, 12)
var c = a.get(2)
print("c=${c.getOrThrow()},")
var arr1: Array<Int64> = [1,2,3]
a.insertAll(1, arr1)
var d = a.get(2)
print("d=${d.getOrThrow()}")
return 0
}
运行结果如下:
b=3,c=120,d=2
ArrayList 的 remove/clear/slice 函数
下面是 ArrayList 的 remove/clear/slice 函数示例。
代码如下:
from std import collection.*
main() {
var a: ArrayList<Int64> = ArrayList<Int64>(97, 100, 99) // Function call syntactic sugar of variable-length
a.remove(1)
var b = a.get(1)
print("b=${b.getOrThrow()}")
a.clear()
a.append(11)
var arr: Array<Int64> = [1,2,3]
a.insertAll(0, arr)
var g = a.get(0)
print("g=${g.getOrThrow()}")
let r: Range<Int64> = 1..=2 : 1
var mu: ArrayList<Int64> = a.slice(r)
var m = mu.get(0)
print("m=${m.getOrThrow()}")
return 0
}
运行结果如下:
b=99g=1m=2
Hashmap 的 get/put/contains 函数
下面是 Hashmap 的 get/put/contains 函数示例。
代码如下:
from std import collection.*
main() {
var m: HashMap<String, Int64> = HashMap<String, Int64>()
m.put("a", 99)
m.put("b", 100)
var a = m.get("a")
var bool = m.contains("a")
print("a=${a.getOrThrow()} ")
print("bool=${bool.toString()}")
return 0
}
运行结果如下:
a=99 bool=true
HashMap 的 putAll/remove/clear 函数
下面是 HashMap 的 putAll/remove/clear 函数示例。
代码如下:
from std import collection.*
main() {
var m: HashMap<String, Int64> = HashMap<String, Int64>()
var arr: Array<(String, Int64)> = [("d", 11), ("e", 12)]
m.putAll(arr)
var d = m.get("d")
print("d=${d.getOrThrow()} ")
m.remove("d")
var bool = m.contains("d")
print("bool=${bool.toString()} ")
m.clear()
var bool1 = m.contains("e")
print("bool1=${bool1.toString()}")
return 0
}
运行结果如下:
d=11 bool=false bool1=false
HashSet 的 put/iterator/remove 函数
下面是 HashSet 的 put/iterator/remove 函数示例。
代码如下:
from std import collection.*
/* 测试 */
main() {
var set: HashSet<String> = HashSet<String>()
set.put("apple")
set.put("banana")
set.put("orange")
set.put("peach")
var itset = set.iterator()
while(true) {
var value = itset.next()
match(value) {
case Some(v) =>
if (!set.contains(v)) {
print("Operation failed")
return 1
} else { println(v) }
case None => break
}
}
set.remove("apple")
println(set)
println("Successful operation")
return 0
}
运行结果如下:
apple
banana
orange
peach
[banana, orange, peach]
Successful operation
迭代器操作函数
下面是 HashSet 的 put/iterator/remove 函数示例。
代码如下:
from std import collection.*
main() {
let arr = [-1, 2, 3, 4, 5, 6, 7, 8, 9]
arr |> filter{a: Int64 => a > 0} // filter -1
|> step<Int64>(2) // [2, 4, 6, 8]
|> skip<Int64>(2) // [6, 8]
|> forEach<Int64>(println)
let str = arr |> filter{a: Int64 => a % 2 == 1} |> collectString<Int64>(delimiter: ">")
println(str)
println(arr |> contains(6_i64))
return 0
}
运行结果如下:
6
8
3>5>7>9
true
collection.concurrent 包
介绍
仓颉 collection.concurrent 包中提供了并发场景下线程安全的数据结构。
主要接口
interface ConcurrentMap
public interface ConcurrentMap<K, V> where K <: Hashable & Equatable<K> {
func get(key: K): Option<V>
func contains(key: K): Bool
mut func put(key: K, value: V): Option<V>
mut func putIfAbsent(key: K, value: V): Option<V>
mut func remove(key: K): Option<V>
mut func remove(key: K, predicate: (V) -> Bool): Option<V>
mut func replace(key: K, value: V): Option<V>
mut func replace(key: K, eval: (V) -> V): Option<V>
mut func replace(key: K, predicate: (V) -> Bool, eval: (V) -> V): Option<V>
}
ConcurrentMap 接口中声明了并发场景下线程安全的 Map 必须保证原子性的方法,我们希望定义的线程安全 Map 类都能实现 ConcurrentMap 接口。例如我们在该包中定义的 ConcurrentHashMap 就实现了 ConcurrentMap 接口,并提供了 ConcurrentMap 中所声明方法的保证原子性的实现。
ConcurrentMap 接口中声明了并发 Map 在并发场景下需要保证原子性的方法。
并发 Map 为“键”到“值”的映射,其中 K 为键的类型,V 为值的类型。
func get
func get(key: K): Option<V>
功能:返回 Map 中键 @p key 所关联的值。
参数:
- key:传递 key,获取 value。
返回值:当 @p key 存在时,返回其关联的值 Some(v);当 @p key 不存在时,返回 None
func contains
func contains(key: K): Bool
功能:判断 Map 中是否包含指定键 @p key 的关联。
参数:
- key:传递要判断的 key。
返回值:当 @p key 存在时返回 true;当 @p key 不存在时返回 false
func put
mut func put(key: K, value: V): Option<V>
功能:将指定的值 @p value 与此 Map 中指定的键 @p key 关联。如果 Map 中已经包含键 @p key 的关联,则旧值将被替换;如果 Map 中不包含键 @p key 的关联,则添加键 @p key 与值 @p value 的关联。
参数:
- key:要放置的键;
- value:要关联的值。
返回值:如果赋值之前 @p key 存在,则返回旧的值 Some(v);当赋值前 @p key 不存在时,返回 None。
func putIfAbsent
mut func putIfAbsent(key: K, value: V): Option<V>
功能:当此 Map 中不存在键 @p key 时,在 Map 中添加指定的值 @p value 与指定的键 @p key 的关联。如果 Map 已经包含键 @p key,则不执行赋值操作。
参数:
- key:要放置的键;
- value:要分配的值。
返回值:如果赋值之前 @p key 存在,则返回当前 @p key 对应的值 Some(v),且不执行赋值操作;当赋值前 @p key 不存在时,返回 None。
func remove
mut func remove(key: K): Option<V>
功能:从此映射中删除指定键 @p key 的映射(如果存在)。
参数:
- key:传入要删除的 key
返回值:如果移除之前 @p key 存在,则返回 @p key 对应的值 Some(v);当移除时 @p key 不存在时,返回 None。
func remove
mut func remove(key: K, predicate: (V) -> Bool): Option<V>
功能:如果 Map 中存在键 @p key 且 @p key 所关联的值 v 满足条件 @p predicate,则从 Map 中删除 @p key 的关联。
参数:
- key:传入要删除的 key;
- predicate:传递一个 lambda 表达式进行判断。
返回值:如果 Map 中存在 @p key,则返回 @p key 对应的旧值 Some(v);当 Map 中不存在 @p key 时,或者 @p key 关联的值不满足 @p predicate 时,返回 None。
func replace
mut func replace(key: K, value: V): Option<V>
功能:如果 Map 中存在 @p key,则将 Map 中键 @p key 关联的值替换为 @p value;如果 Map 中不存在 @p key,则不对 Map 做任何修改。
参数:
- key:传入要替换所关联值的键;
- value:传入要替换成的新值。
返回值:如果 @p key 存在,则返回 @p key 对应的旧值 Some(v);当 @p key 不存在时,返回 None。
func replace
mut func replace(key: K, eval: (V) -> V): Option<V>
功能:如果 Map 中存在键 @p key(假设其关联的值为 v),则将 Map 中键 @p key 关联的值替换为 @p eval(v) 的计算结果;如果 Map 中不存在键 @p key,则不对 Map 做任何修改。
参数:
- key:传入要替换所关联值的键;
- eval:传入计算用于替换的新值的函数。
返回值:如果 @p key 存在,则返回 @p key 对应的旧值 Some(v);当 @p key 不存在时,返回 None。
func replace
mut func replace(key: K, predicate: (V) -> Bool, eval: (V) -> V): Option<V>
功能:如果 Map 中存在键 @p key(假设其关联的值为 v),且 v 满足条件 @p predicate,则将 Map 中键 @p key 关联的值替换为 @p eval(v) 的计算结果;如果 Map 中不存在键 @p key,或者存在键 @p key 但关联的值不满足 @p predicate,则不对 Map 做任何修改。
参数:
- key:传入要替换所关联值的键;
- predicate:传递一个 lambda 表达式进行判断;
- eval:传入计算用于替换的新值的函数。
返回值:如果 @p key 存在,则返回 @p key 对应的旧值 Some(v);None:当 @p key 不存在时,或者 @p key 关联的值不满足 @p predicate 时,返回 None。
class ConcurrentHashMap
public class ConcurrentHashMap<K, V> <: ConcurrentMap<K, V> & Collection<(K, V)> where K <: Hashable & Equatable<K> {
public init(concurrencyLevel!: Int64 = DEFAULT_CONCUR_LEVEL)
public init(capacity: Int64, concurrencyLevel!: Int64 = DEFAULT_CONCUR_LEVEL)
public init(elements: Collection<(K, V)>, concurrencyLevel!: Int64 = DEFAULT_CONCUR_LEVEL)
public init(size: Int64, initElement: (Int64) -> (K, V), concurrencyLevel!: Int64 = DEFAULT_CONCUR_LEVEL)
}
此类用于实现并发场景下线程安全的哈希表 ConcurrentHashMap 数据结构及相关操作函数。当 ConcurrentHashMap 中出现键值对数量大于“桶”数量的情况时,会进行“扩容”。
构造函数中的参数 concurrencyLevel 表示“并发度”,即:最多允许多少个线程并发修改 ConcurrentHashMap。查询键值对的操作是非阻塞的,不受所指定的并发度 concurrencyLevel 的限制。参数 concurrencyLevel 默认等于 16,即:DEFAULT_CONCUR_LEVEL 的值。它只影响 ConcurrentHashMap 在并发场景下的性能,不影响功能。
注意:concurrencyLevel 并非越大越好,更大的 concurrencyLevel 会导致更大的内存开销(甚至可能导致 out of memory 异常),用户需要在内存开销和运行效率之间进行平衡。
init
public init(concurrencyLevel!: Int64 = DEFAULT_CONCUR_LEVEL)
功能:构造一个具有默认初始容量(16)和指定并发度(默认等于 16)的 ConcurrentHashMap。
参数:
- concurrencyLevel:用户指定的并发度
注意:
- 如果用户传入的 concurrencyLevel 小于 16,则并发度会被设置为 16。
init
public init(capacity: Int64, concurrencyLevel!: Int64 = DEFAULT_CONCUR_LEVEL)
功能:构造一个带有传入容量大小和指定并发度(默认等于 16)的 ConcurrentHashMap。
参数:
- capacity:初始化容量大小
- concurrencyLevel:用户指定的并发度
异常:
- IllegalArgumentException:如果 capacity 小于 0 则抛出异常
注意:
- 如果用户传入的 concurrencyLevel 小于 16,则并发度会被设置为 16。
init
public init(elements: Collection<(K, V)>, concurrencyLevel!: Int64 = DEFAULT_CONCUR_LEVEL)
功能:构造一个带有传入迭代器和指定并发度的 ConcurrentHashMap。该构造函数根据传入迭代器元素 elements 的 size 设置 ConcurrentHashMap 的容量。
参数:
- elements:初始化迭代器元素
- concurrencyLevel:用户指定的并发度
注意:
- 如果用户传入的 concurrencyLevel 小于 16,则并发度会被设置为 16。
init
public init(size: Int64, initElement: (Int64) -> (K, V), concurrencyLevel!: Int64 = DEFAULT_CONCUR_LEVEL)
功能:构造具有传入大小和初始化函数元素以及指定并发度的 ConcurrentHashMap。该构造函数根据参数 size 设置 ConcurrentHashMap 的容量。
参数:
- size:初始化函数元素的大小
- initElement:初始化函数元素
- concurrencyLevel:用户指定并发度
异常:
- IllegalArgumentException:如果 size 小于 0 则抛出异常
注意:
- 如果用户传入的 concurrencyLevel 小于 16,则并发度会被设置为 16。
func get
public func get(key: K): Option<V>
功能:返回此映射中键 @p key 所关联的值。
参数:
- key:传递 key,获取 value
返回值:Option
func contains
public func contains(key: K): Bool
功能:判断此映射中是否包含指定键 @p key 的映射。
参数:
- key:传递要判断的 key
返回值:Bool: true: 当 @p key 存在时; false: 当 @p key 不存在时
func put
public func put(key: K, value: V): Option<V>
功能:将指定的值 @p value 与此 Map 中指定的键 @p key 关联。如果 Map 中已经包含键 @p key 的关联,则旧值将被替换;如果 Map 中不包含键 @p key 的关联,则添加键 @p key 与值 @p value 的关联。
参数:
- key:要放置的键
- value:要关联的值
返回值:如果赋值之前 @p key 存在,则返回旧的值 Some(v);当赋值前 @p key 不存在时,返回 None
func putIfAbsent
public func putIfAbsent(key: K, value: V): Option<V>
功能:当此 Map 中不存在键 @p key 时,在 Map 中添加指定的值 @p value 与指定的键 @p key 的关联。如果 Map 已经包含键 @p key,则不执行赋值操作。
参数:
- key:要放置的键
- value:要分配的值
返回值:如果赋值之前 @p key 存在,则返回当前 @p key 对应的值 Some(v),且不执行赋值操作;当赋值前 @p key 不存在时,返回 None
func remove
public func remove(key: K): Option<V>
功能:从此映射中删除指定键 @p key 的映射(如果存在)。
参数:
- key:传入要删除的 key
返回值:如果移除之前 @p key 存在,则返回 @p key 对应的值 Some(v);None:当移除时 @p key 不存在时,返回 None
func remove
public func remove(key: K, predicate: (V) -> Bool): Option<V>
功能:如果此映射中存在键 @p key 且 @p key 所映射的值 v 满足条件 @p predicate,则从此映射中删除 @p key 的映射。
参数:
- key:传入要删除的 key
- predicate:传递一个 lambda 表达式进行判断
返回值:如果映射中存在 @p key,则返回 @p key 对应的旧值;当映射中不存在 @p key 时,或者 @p key 关联的值不满足 @p predicate 时,返回 None
func replace
public func replace(key: K, value: V): Option<V>
功能:如果 Map 中存在 @p key,则将 Map 中键 @p key 关联的值替换为 @p value;如果 Map 中不存在 @p key,则不对 Map 做任何修改。
参数:
- key:传入要替换所关联值的键
- value:传入要替换成的新值
返回值:如果 @p key 存在,则返回 @p key 对应的旧值 Some(v);None:当 @p key 不存在时,返回 None
func replace
public func replace(key: K, eval: (V) -> V): Option<V>
功能:如果 Map 中存在键 @p key(假设其关联的值为 v),则将 Map 中键 @p key 关联的值替换为 @p eval(v) 的计算结果;如果 Map 中不存在键 @p key,则不对 Map 做任何修改。
参数:
- key:传入要替换所关联值的键
- eval:传入计算用于替换的新值的函数
返回值:如果 @p key 存在,则返回 @p key 对应的旧值 Some(V);None:当 @p key 不存在时,返回 None
func replace
public func replace(key: K, predicate: (V) -> Bool, eval: (V) -> V): Option<V>
功能:如果 Map 中存在键 @p key(假设其关联的值为 v),且 v 满足条件 @p predicate,则将 Map 中键 @p key 关联的值替换为 @p eval(v) 的计算结果;如果 Map 中不存在键 @p key,或者存在键 @p key 但关联的值不满足 @p predicate,则不对 Map 做任何修改。 参数:
- key:传入要替换所关联值的键
- predicate:传递一个 lambda 表达式进行判断
- eval:传入计算用于替换的新值的函数
返回值:如果 @p key 存在,则返回 @p key 对应的旧值 Some(V);当 @p key 不存在时,或者 @p key 关联的值不满足 @p predicate 时,返回 None
operator func []
public operator func [](key: K, value!: V): Unit
功能:运算符重载集合,如果键 @p key 存在,新 value 覆盖旧 value;如果键不存在,添加此键值对。
参数:
- key:传递值进行判断
- value:传递要设置的值
operator func []
public operator func [](key: K): V
功能:运算符重载集合,如果键存在,返回键对应的值;如果不存在,抛出异常。 参数:
- key:传递值进行判断
返回值:与键对应的值
异常:
- NoneValueException:关联中不存在键 @p key
prop size
public prop size: Int64
功能:返回键值的个数。
注意:此方法不保证并发场景下的原子性,建议在环境中没有其它线程并发地修改 Concurrent HashMap 时调用。
func isEmpty
public func isEmpty(): Bool
功能:判断 Concurrent HashMap 是否为空;如果是,则返回 true;否则,返回 false。
注意:此方法不保证并发场景下的原子性,建议在环境中没有其它线程并发地修改 Concurrent HashMap 时调用。
返回值:如果是,则返回 true,否则,返回 false
func iterator
public func iterator(): ConcurrentHashMapIterator<K, V>
功能:获取 Concurrent HashMap 的迭代器。
返回值:Concurrent HashMap 的迭代器
class ConcurrentHashMapIterator
public class ConcurrentHashMapIterator<K, V> <: Iterator<(K, V)> where K <: Hashable & Equatable<K> {
public init(cmap: ConcurrentHashMap<K, V>)
}
此类主要实现 Concurrent HashMap 的迭代器功能。
注意,这里定义的 Concurrent HashMap 迭代器:
- 不保证迭代结果为并发 HashMap 某一时刻的 “快照”,建议在环境中没有其它线程并发地修改 Concurrent HashMap 时调用;
- 迭代器在迭代过程中,不保证可以感知环境线程对目标 Concurrent HashMap 的修改。
init
public init(cmap: ConcurrentHashMap<K, V>)
功能:创建 ConcurrentHashMapIterator<K, V> 实例。
参数:
- cmap:待获取其迭代器的 ConcurrentHashMap<K, V> 实例
func next
public func next(): Option<(K, V)>
功能:返回迭代中的下一个元素。
返回值:Option<(K,V)> 类型
func iterator
public func iterator(): Iterator<(K, V)>
功能:获取 ConcurrentHashMap<K, V> 实例的迭代器。
返回值:ConcurrentHashMap<K, V> 实例的迭代器
class BlockingQueue
public class BlockingQueue<E> {
public init()
public init(capacity: Int64)
public init(capacity: Int64, elements: Array<E>)
public init(capacity: Int64, elements: Collection<E>)
}
此类用于实现 BlockingQueue 数据结构及相关操作函数。 BlockingQueue 是带阻塞机制并支持用户指定容量上界的并发队列。
类的主要函数如下所示:
init
public init()
功能:构造一个具有默认初始容量 (Int64.Max) 的 BlockingQueue。
init
public init(capacity: Int64)
功能:构造一个带有传入容量大小的 BlockingQueue。
参数:
- capacity:初始化容量大小
异常:
- IllegalArgumentException:如果 capacity 小于等于 0 则抛出异常
init
public init(capacity: Int64, elements: Array<E>)
功能:构造一个带有传入容量大小,并带有传入数组元素的 BlockingQueue。
参数:
- capacity:初始化容量大小
- elements:初始化数组元素
异常:
- IllegalArgumentException:如果 capacity 小于等于 0 或小于数组元素elements 的 size 则抛出异常
init
public init(capacity: Int64, elements: Collection<E>)
功能:构造一个带有传入容量大小,并带有传入迭代器的 BlockingQueue。
参数:
- capacity:初始化容量大小
- elements:初始化迭代器元素
异常:
- IllegalArgumentException:如果 capacity 小于等于 0 或小于迭代器元素elements 的 size 则抛出异常
capacity
public let capacity: Int64
功能:返回此 BlockingQueue 的容量。
prop size
public prop size: Int64
功能:返回此 BlockingQueue 的元素个数。
注意:此方法不保证并发场景下的原子性,建议在环境中没有其它线程并发地修改 BlockingQueue 时调用。
func enqueue
public func enqueue(element: E): Unit
功能:阻塞的入队操作,将元素添加到队列尾部
参数:
- element:要添加的元素
func enqueue
public func enqueue(element: E, timeout: Duration): Bool
功能:阻塞的入队操作,将元素添加到队列尾部,如果队列满了,将等待指定的时间。
参数:
- element:要添加的元素
- timeout:等待时间
返回值:成功添加元素返回 true。超出等待时间还未成功添加元素返回 false
func dequeue
public func dequeue(): E
功能:阻塞的出队操作,获得队首元素并删除。
返回值:返回队首元素
func dequeue
public func dequeue(timeout: Duration): Option<E>
功能:阻塞的出队操作,获得队首元素并删除。如果队列为空,将等待指定的时间。
参数:
- timeout:等待时间
返回值:返回队首元素。如果超出等待时间还未成功获取队首元素,则返回 None
func head
public func head(): Option<E>
功能:获取队首元素。
注意:该函数是非阻塞的。
返回值:返回队首元素,队列为空时返回 None
func tryEnqueue
public func tryEnqueue(element: E): Bool
功能:非阻塞的入队操作,将元素添加到队列尾部。
参数:
- element:要添加的元素
返回值:成功添加返回 true;如果队列满了,添加失败返回 false
func tryDequeue
public func tryDequeue(): Option<E>
功能:非阻塞的出队操作,获得队首元素并删除。
返回值:返回队首元素,队列为空时返回 None
class NonBlockingQueue
public class NonBlockingQueue<E> {
public init()
public init(elements: Collection<E>)
}
此类用于实现 NonBlockingQueue 数据结构及相关操作函数。
NonBlockingQueue 是无界非阻塞并发队列。
init
public init()
功能:构造一个默认的 NonBlockingQueue 实例。
init
public init(elements: Collection<E>)
功能:根据 Collection
参数:
- elements:将该容器中元素放入新构造的 NonBlockingQueue 实例中
prop size
public prop size: Int64
功能:获取此 NonBlockingQueue 的元素个数。
注意:此方法不保证并发场景下的原子性,建议在环境中没有其它线程并发地修改 NonBlockingQueue 时调用。
func enqueue
public func enqueue(element: E): Bool
功能:非阻塞的入队操作,将元素添加到队列尾部。
注意:该函数不会返回 false。
参数:
- element:要添加的元素
返回值:成功添加元素则返回 true
func dequeue
public func dequeue(): Option<E>
功能:获取并删除队首元素。
返回值:成功删除则返回队首元素,队列为空则返回 None
func head
public func head(): Option<E>
功能:获取队首元素,不会删除该元素。
返回值:成功获取则返回队首元素,队列为空则返回 None
class ArrayBlockingQueue
public class ArrayBlockingQueue<E> {
public init(capacity: Int64)
public init(capacity: Int64, elements: Collection<E>)
}
此类为基于数组实现的 Blocking Queue 数据结构及相关操作函数。 ArrayBlockingQueue 是带阻塞机制且需要用户指定容量上界的并发队列。
类的主要函数如下所示:
init
public init(capacity: Int64)
功能:构造一个带有传入容量大小的 ArrayBlockingQueue。
参数:
- capacity:初始化容量大小
异常:
- IllegalArgumentException:如果 capacity 小于等于 0 则抛出异常
init
public init(capacity: Int64, elements: Collection<E>)
功能:构造一个带有传入容量大小,并带有传入迭代器的 ArrayBlockingQueue。
参数:
- capacity:初始化容量大小
- elements:初始化迭代器元素
异常:
- IllegalArgumentException:如果 capacity 小于等于 0 或小于迭代器元素 elements 的 size 则抛出异常
capacity
public let capacity: Int64
功能:返回此 ArrayBlockingQueue 的容量。
prop size
public prop size: Int64
功能:返回此 ArrayBlockingQueue 的元素个数。
注意:此方法不保证并发场景下的原子性,建议在环境中没有其它线程并发地修改 ArrayBlockingQueue 时调用。
func enqueue
public func enqueue(element: E): Unit
功能:阻塞的入队操作,将元素添加到队列尾部。
参数:
- element:要添加的元素
func enqueue
public func enqueue(element: E, timeout: Duration): Bool
功能:阻塞的入队操作,将元素添加到队列尾部,如果队列满了,将等待指定的时间。
参数:
- element:要添加的元素
- timeout:等待时间
返回值:成功添加元素返回 true,超出等待时间还未成功添加元素返回 false
func dequeue
public func dequeue(): E
功能:阻塞的出队操作,获得队首元素并删除。
返回值:返回队首元素
func dequeue
public func dequeue(timeout: Duration): Option<E>
功能:阻塞的出队操作,获得队首元素并删除,如果队列为空,将等待指定的时间。
参数:
- timeout:等待时间
返回值:返回队首元素。如果超出等待时间还未成功获取队首元素,则返回 None
func head
public func head(): Option<E>
功能:获取队首元素。
注意:该函数是非阻塞的。
返回值:返回队首元素,队列为空时返回 None
func tryEnqueue
public func tryEnqueue(element: E): Bool
功能:非阻塞的入队操作,将元素添加到队列尾部。
参数:
- element:要添加的元素
返回值:成功添加返回 true;如果队列满了,添加失败返回 false
func tryDequeue
public func tryDequeue(): Option<E>
功能:非阻塞的出队操作,获得队首元素并删除。
返回值:返回队首元素,队列为空时返回 None
console 包
介绍
console 提供从控制台读取和向控制台打印的功能。
console 默认为 UTF-8 编码,windows 环境需手动执行 chcp 65001(将 windows 终端更改为 UTF-8 编码)。
主要接口
class Console
public class Console
此类提供标准输入、标准输出和标准错误 Stream 的获取接口
类的主要函数如下所示:
prop stdIn
public static prop stdIn: ConsoleReader
功能:该成员属性为 ConsoleReader 类,它提供标准输入的获取接口
prop stdOut
public static prop stdOut: ConsoleWriter
功能:该成员属性为 ConsoleWriter 类,它提供标准输出的获取接口
prop stdErr
public static prop stdErr: ConsoleWriter
功能:该成员属性为 ConsoleWriter 类,它提供标准错误的获取接口
class ConsoleReader
public class ConsoleReader <: InputStream
提供从控制台读出数据并转换成字符或字符串的功能。 读操作是同步的,内部设有缓冲区来保存控制台输入的内容,当到达控制台输入流的结尾时,控制台读取函数将返回 None, 例如在 Unix 上键入 control-D 或在 Windows 上键入 control-Z。如果稍后在控制台的输入设备上输入其他字符,则后续读取操作将成功。
func read
public func read(): Option<Rune>
功能:从标准输入中读取一个字符。
返回值:读取到字符,返回 Option<Rune>,否则返回 Option<Rune>.None。
func readln
public func readln(): Option<String>
功能:从标准输入中读取一行字符读取到字符,返回 Option<String>,结果不包含末尾换行符。
返回值:读取到的行信息,读取失败返回 Option<String>.None
func readToEnd
public func readToEnd(): Option<String>
功能:从标准输入中读取所有字符,以 Option<String> 的形式返回。读取到字符,返回 Option<String>,否则返回 Option<String>.None。读取失败时会返回 Option<String>.None。
返回值:将输入的所有行信息以 Option<String> 的形式返回
func readUntil
public func readUntil(ch: Char): Option<String>
功能:从标准输入中读取数据直到读取到字符 ch 结束, ch 包含在结果中,如果读取到文件结束符 EOF,将返回读取到的所有信息读取失败时会返回 Option<String>.None。
返回值:将输入的信息以 Option<String> 的形式返回
func readUntil
public func readUntil(predicate: (Char) -> Bool): Option<String>
功能:从标准输入中读取数据直到读取到的字符满足 predicate 条件结束,满足 predicate: (Char) -> Bool 条件的字符包含在结果中,如果读取到文件结束符 EOF,将返回读取到的所有信息输入失败时会返回 Option<String>.None。
参数:
- predicate:终止读取的条件
返回值:将输入的信息以 Option<String> 的形式返回
func read
public func read(arr: Array<Byte>): Int64
功能:从标准输入中读取并放入 arr 中,该函数存在风险,可能读取出来的结果恰好把 UTF-8 code point 从中截断。
参数:
- arr:目标 Array
返回值:返回读取到的字节长度
class ConsoleWriter
public class ConsoleWriter <: OutputStream
此类提供保证线程安全的标准输出功能,每次 write 调用写到控制台的结果是完整的,不 同的 write 函数调用的结果不会混合到一起。
func flush
public func flush(): Unit
功能:刷新输出流。
func write
public func write(buffer: Array<Byte>): Unit
功能:将字节数组 buffer 写入标准输出流中。
参数:
- buffer:要被写入的数组
func writeln
public func writeln(buffer: Array<Byte>): Unit
功能:将字节数组 buffer 写入标准输出流中,并换行。
参数:
- buffer:要被写入的数组
func write
public func write(v: String): Unit
功能:将 String 类型入参 v 写入标准输出流中。
参数:
- v:要被写入的 String 类型的值
func write
public func write<T>(v: T): Unit where T <: ToString
功能:将实现了 ToString 接口的数据类型写入标准输出流中。
参数:
- v:要被写入的 ToString 类型的实例
func write
public func write(v: Bool): Unit
功能:将 Bool 类型写入标准输出流中。
参数:
- v:要被写入的 Bool 类型的数据
func write
public func write(v: Int8): Unit
功能:将 Int8 类型写入标准输出流中。
参数:
- v:要被写入的 Int8 类型的值
func write
public func write(v: Int16): Unit
功能:将 Int16 类型写入标准输出流中。
参数:
- v:要被写入的 Int16 类型的值
func write
public func write(v: Int32): Unit
功能:将 Int32 类型写入标准输出流中。
参数:
- v:要被写入的 Int32 类型的值
func write
public func write(v: Int64): Unit
功能:将 Int64 类型写入标准输出流中。
参数:
- v:要被写入的 Int64 类型的值
func write
public func write(v: UInt8): Unit
功能:将 UInt8 类型写入标准输出流中。
参数:
- v:要被写入的 UInt8 类型的值
func write
public func write(v: UInt16): Unit
功能:将 UInt16 类型写入标准输出流中。
参数:
- v:要被写入的 UInt16 类型的值
func write
public func write(v: UInt32): Unit
功能:将 UInt32 类型写入标准输出流中。
参数:
- v:要被写入的 UInt32 类型的值
func write
public func write(v: UInt64): Unit
功能:将 UInt64 类型写入标准输出流中。
参数:
- v:要被写入的 UInt64 类型的值
func write
public func write(v: Float16): Unit
功能:将 Float16 类型写入标准输出流中。
参数:
- v:要被写入的 Float16 类型的值
func write
public func write(v: Float32): Unit
功能:将 Float32 类型写入标准输出流中。
参数:
- v:要被写入的 Float32 类型的值
func write
public func write(v: Float64): Unit
功能:将 Float64 类型写入标准输出流中。
参数:
- v:要被写入的 Float64 类型的值
func write
public func write(v: Char): Unit
功能:将 Char 类型写入标准输出流中。
参数:
- v:要被写入的 Char 类型的值
func writeln
public func writeln(v: String): Unit
功能:将 String 写入标准输出流中,并换行。
参数:
- v:要被写入的 String 类型的值
func writeln
public func writeln<T>(v: T): Unit where T <: ToString
功能:将 ToString 写入标准输出流中,并换行。
参数:
- v:要被写入的 ToString 类型的实例
func writeln
public func writeln(v: Bool): Unit
功能:将 Bool 写入标准输出流中,并换行。
参数:
- v:要被写入的 Bool 类型的值
func writeln
public func writeln(v: Int8): Unit
功能:将 Int8 写入标准输出流中,并换行。
参数:
- v:要被写入的 Int8 类型的值
func writeln
public func writeln(v: Int16): Unit
功能:将 Int16 写入标准输出流中,并换行。
参数:
- v:要被写入的 Int16 类型的值
func writeln
public func writeln(v: Int32): Unit
功能:将 Int32 写入标准输出流中,并换行。
参数:
- v:要被写入的 Int32 类型的值
func writeln
public func writeln(v: Int64): Unit
功能:将 Int64 写入标准输出流中,并换行。
参数:
- v:要被写入的 Int64 类型的值
func writeln
public func writeln(v: UInt8): Unit
功能:将 UInt8 写入标准输出流中,并换行。
参数:
- v:要被写入的 UInt8 类型的值
func writeln
public func writeln(v: UInt16): Unit
功能:将 UInt16 写入标准输出流中,并换行。
参数:
- v:要被写入的 UInt16 类型的值
func writeln
public func writeln(v: UInt32): Unit
功能:将 UInt32 写入标准输出流中,并换行。
参数:
- v:要被写入的 UInt32 类型的值
func writeln
public func writeln(v: UInt64): Unit
功能:将 UInt64 写入标准输出流中,并换行。
参数:
- v:要被写入的 UInt64 类型的值
func writeln
public func writeln(v: Float16): Unit
功能:将 Float16 写入标准输出流中,并换行。
参数:
- v:要被写入的 Float16 类型的值
func writeln
public func writeln(v: Float32): Unit
功能:将 Float32 写入标准输出流中,并换行。
参数:
- v:要被写入的 Float32 类型的值
func writeln
public func writeln(v: Float64): Unit
功能:将 Float64 写入标准输出流中,并换行。
参数:
- v:要被写入的 Float64 类型的值
func writeln
public func writeln(v: Char): Unit
功能:将 Char 写入标准输出流中,并换行。
参数:
- v:要被写入的 Char 类型的值
示例
Console 示例
下面是 Console 的使用示例。
代码如下:
from std import console.*
main() {
Console.stdOut.write("请输入信息1:")
var c = Console.stdIn.readln()
var r = c.getOrThrow()
Console.stdOut.writeln("输入的信息1为:" + r)
Console.stdOut.write("请输入信息2:")
c = Console.stdIn.readln()
r = c.getOrThrow()
var a = Console.stdOut
a.writeln("输入的信息2为:" + r)
return 0
}
运行结果如下:
请输入信息1:你好,请问今天星期几?
输入的信息1为:你好,请问今天星期几?
请输入信息2:你好,请问今天几号?
输入的信息2为:你好,请问今天几号?
convert 包
介绍
主要提供从字符串转到特定类型的 Convert 系列函数。
主要接口
interface Parsable
public interface Parsable<T> {
static func parse(value: String): T
static func tryParse(value: String): Option<T>
}
此接口主要提供统一的抽象,以支持字符串中的特定类型的解析
func parse
static func parse(value: String): T
功能:提供一个抽象函数,以支持从字符串中解析特定类型。
参数:
- value:待解析的字符串
返回值:转换后的值
func tryParse
static func tryParse(value: String): Option<T>
功能:提供一个抽象函数,以支持从字符串中解析特定类型。
参数:
- value:待解析的字符串
返回值:转换后值,转换失败返回 Option<T>.None
extend Bool <: Parsable
extend Bool <: Parsable<Bool>
此扩展主要用于实现将 Bool 类型字面量的字符串转换为 Bool 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): Bool
功能:将 Bool 类型字面量的字符串转换为 Bool 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Bool 值
异常:
- IllegalArgumentException:当字符串为空或转换失败时,抛出异常
func tryParse
public static func tryParse(data: String): Option<Bool>
功能:将 Bool 类型字面量的字符串转换为 Option<Bool> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<Bool> 值,转换失败返回 Option<Bool>.None
extend Char <: Parsable
extend Char <: Parsable<Char>
此扩展主要用于实现将 Char 类型字面量的字符串转换为 Char 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): Char
功能:将 Char 类型字面量的字符串转换为 Char 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Char 值
异常:
- IllegalArgumentException:当字符串为空,或转换失败时,或字符串中含有无效的 UTF-8 字符时,抛出异常
func tryParse
public static func tryParse(data: String): Option<Char>
功能:将 Char 类型字面量的字符串转换为 Option<Char> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<Char> 值,转换失败返回 Option<Char>.None
异常:
- IllegalArgumentException:当字符串中含有无效的 UTF-8 字符时,抛出异常
extend Int8 <: Parsable
extend Int8 <: Parsable<Int8>
此扩展主要用于实现将 Int8 类型字面量的字符串转换为 Int8 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): Int8
功能:将 Int8 类型字面量的字符串转换为 Int8 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Int8 值
异常:
- IllegalArgumentException:当字符串为空,首位为“+”,转换失败,或转换后超出 Int8 范围,或字符串中含有无效的 UTF-8 字符时,抛出异常
func tryParse
public static func tryParse(data: String): Option<Int8>
功能:将 Int8 类型字面量的字符串转换为 Option<Int8> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<Int8> 值,转换失败返回 Option<Int8>.None
异常:
- IllegalArgumentException:当字符串中含有无效的 UTF-8 字符时,抛出异常
extend UInt8 <: Parsable
extend UInt8 <: Parsable<UInt8>
此扩展主要用于实现将 UInt8 类型字面量的字符串转换为 UInt8 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): UInt8
功能:将 UInt8 类型字面量的字符串转换为 UInt8 值。
参数:
- data:要转换的字符串
返回值:返回转换后 UInt8 值
异常:
- IllegalArgumentException:当字符串为空,首位为“+”或“-”,转换失败,或转换后超出 UInt8 范围,或字符串中含有无效的 UTF-8 字符时,抛出异常
func tryParse
public static func tryParse(data: String): Option<UInt8>
功能:将 UInt8 类型字面量的字符串转换为 Option<UInt8> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<UInt8> 值,转换失败返回 Option<UInt8>.None
异常:
- IllegalArgumentException:当字符串中含有无效的 UTF-8 字符时,抛出异常
extend Int16 <: Parsable
extend Int16 <: Parsable<Int16>
此扩展主要用于实现将 Int16 类型字面量的字符串转换为 Int16 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): Int16
功能:将 Int16 类型字面量的字符串转换为 Int16 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Int16 值
异常:
- IllegalArgumentException:当字符串为空,首位为“+”,转换失败,或转换后超出 Int16 范围,或字符串中含有无效的 UTF-8 字符时,抛出异常
func tryParse
public static func tryParse(data: String): Option<Int16>
功能:将 Int16 类型字面量的字符串转换为 Option<Int16> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<Int16> 值,转换失败返回 Option<Int16>.None
异常:
- IllegalArgumentException:当字符串中含有无效的 UTF-8 字符时,抛出异常
extend UInt16 <: Parsable
extend UInt16 <: Parsable<UInt16>
此扩展主要用于实现将 UInt16 类型字面量的字符串转换为 UInt16 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): UInt16
功能:将 UInt16 类型字面量的字符串转换为 UInt16 值。
参数:
- data:要转换的字符串
返回值:返回转换后 UInt16 值
异常:
- IllegalArgumentException:当字符串为空,首位为“+”或“-”,转换失败,或转换后超出 UInt16 范围,或字符串中含有无效的 UTF-8 字符时,抛出异常
func tryParse
public static func tryParse(data: String): Option<UInt16>
功能:将 UInt16 类型字面量的字符串转换为 Option<UInt16> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<UInt16> 值,转换失败返回 Option<UInt16>.None
异常:
- IllegalArgumentException:当字符串中含有无效的 UTF-8 字符时,抛出异常
extend Int32 <: Parsable
extend Int32 <: Parsable<Int32>
此扩展主要用于实现将 Int32 类型字面量的字符串转换为 Int32 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): Int32
功能:将 Int32 类型字面量的字符串转换为 Int32 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Int32 值
异常:
- IllegalArgumentException:当字符串为空,首位为“+”,转换失败,或转换后超出 Int32 范围,或字符串中含有无效的 UTF-8 字符时,抛出异常
func tryParse
public static func tryParse(data: String): Option<Int32>
功能:将 Int32 类型字面量的字符串转换为 Option<Int32> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<Int32> 值,转换失败返回 Option<Int32>.None
异常:
- IllegalArgumentException:当字符串中含有无效的 UTF-8 字符时,抛出异常
extend UInt32 <: Parsable
extend UInt32 <: Parsable<UInt32>
此扩展主要用于实现将 UInt32 类型字面量的字符串转换为 UInt32 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): UInt32
功能:将 UInt32 类型字面量的字符串转换为 UInt32 值。
参数:
- data:要转换的字符串
返回值:返回转换后 UInt32 值
异常:
- IllegalArgumentException:当字符串为空,首位为“+”或“-”,转换失败,或转换后超出 UInt32 范围,或字符串中含有无效的 UTF-8 字符时,抛出异常常
func tryParse
public static func tryParse(data: String): Option<UInt32>
功能:将 UInt32 类型字面量的字符串转换为 Option<UInt32> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<UInt32> 值,转换失败返回 Option<UInt32>.None
异常:
- IllegalArgumentException:当字符串中含有无效的 UTF-8 字符时,抛出异常
extend Int64 <: Parsable
extend Int64 <: Parsable<Int64>
此扩展主要用于实现将 Int64 类型字面量的字符串转换为 Int64 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): Int64
功能:将 Int64 类型字面量的字符串转换为 Int64 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Int64 值
异常:
- IllegalArgumentException:当字符串为空,首位为“+”,转换失败,或转换后超出 Int64 范围,或字符串中含有无效的 UTF-8 字符时,抛出异常
func tryParse
public static func tryParse(data: String): Option<Int64>
功能:将 Int64 类型字面量的字符串转换为 Option<Int64> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<Int64> 值,转换失败返回 Option<Int64>.None
异常:
- IllegalArgumentException:当字符串中含有无效的 UTF-8 字符时,抛出异常
extend UInt64 <: Parsable
extend UInt64 <: Parsable<UInt64>
此扩展主要用于实现将 UInt64 类型字面量的字符串转换为 UInt64 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): UInt64
功能:将 UInt64 类型字面量的字符串转换为 UInt64 值。
参数:
- data:要转换的字符串
返回值:返回转换后 UInt64 值
异常:
- IllegalArgumentException:当字符串为空,首位为“+”或“-”,转换失败,或转换后超出 UInt64 范围,或字符串中含有无效的 UTF-8 字符时,抛出异常
func tryParse
public static func tryParse(data: String): Option<UInt64>
功能:将 UInt64 类型字面量的字符串转换为 Option<UInt64> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<UInt64> 值,转换失败返回 Option<UInt64>.None
异常:
- IllegalArgumentException:当字符串中含有无效的 UTF-8 字符时,抛出异常
extend Float16 <: Parsable
extend Float16 <: Parsable<Float16>
此扩展主要用于实现将 Float16 类型字面量的字符串转换为 Float16 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): Float16
功能:将 Float16 类型字面量的字符串转换为 Float16 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Float16 值
异常:
- IllegalArgumentException:当字符串不符合浮点数语法时,抛出异常
func tryParse
public static func tryParse(data: String): Option<Float16>
功能:将 Float16 类型字面量的字符串转换为 Option<Float16> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<Float16> 值,转换失败返回 Option<Float16>.None
extend Float32 <: Parsable
extend Float32 <: Parsable<Float32>
此扩展主要用于实现将 Float32 类型字面量的字符串转换为 Float32 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): Float32
功能:将 Float32 类型字面量的字符串转换为 Float32 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Float32 值
异常:
- IllegalArgumentException:当字符串不符合浮点数语法时,抛出异常
func tryParse
public static func tryParse(data: String): Option<Float32>
功能:将 Float32 类型字面量的字符串转换为 Option<Float32> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<Float32> 值,转换失败返回 Option<Float32>.None
extend Float64 <: Parsable
extend Float64 <: Parsable<Float64>
此扩展主要用于实现将 Float64 类型字面量的字符串转换为 Float64 值的相关操作函数。
扩展的主要函数如下所示:
func parse
public static func parse(data: String): Float64
功能:将 Float64 类型字面量的字符串转换为 Float64 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Float64 值
异常:
- IllegalArgumentException:当字符串不符合浮点数语法时,抛出异常
func tryParse
public static func tryParse(data: String): Option<Float64>
功能:将 Float64 类型字面量的字符串转换为 Option<Float64> 值。
参数:
- data:要转换的字符串
返回值:返回转换后 Option<Float64> 值,转换失败返回 Option<Float64>.None
示例
covert 包使用示例
代码如下:
from std import convert.*
main():Int64 {
var strBool_parse : String = "true"
var strBool_tryParse : String = "false"
var strChar_parse : String = "'a'"
var strChar_tryParse : String = "'\\u{00e2}'"
var strInt8_parse : String = "-128"
var strInt8_tryParse : String = "127"
var strInt16_parse : String = "-32768"
var strInt16_tryParse : String = "32767"
var strInt32_parse : String = "-2147483648"
var strInt32_tryParse : String = "2147483647"
var strInt64_parse : String = "-9223372036854775808"
var strInt64_tryParse : String = "9223372036854775807"
var strFloat16_parse : String = "-65504.0"
var strFloat16_tryParse : String = "65504.0"
var strFloat32_parse : String = "-3.14159"
var strFloat32_tryParse : String = "3.14159"
var strFloat64_parse : String = "-3.1415926"
var strFloat64_tryParse : String = "3.1415926"
var strUInt8_parse : String = "255"
var strUInt8_tryParse : String = "255"
var strUInt16_parse : String = "65535"
var strUInt16_tryParse : String = "65535"
var strUInt32_parse : String = "4294967295"
var strUInt32_tryParse : String = "4294967295"
var strUInt64_parse : String = "18446744073709551615"
var strUInt64_tryParse : String = "18446744073709551615"
println("After the conversion of parse, \"true\" became ${Bool.parse(strBool_parse)}")
println("After the conversion of tryParse, \"false\" became ${Bool.tryParse(strBool_tryParse)}")
println("After the conversion of parse, \"'a'\" became ${Char.parse(strChar_parse)}")
println("After the conversion of tryParse, \"'\\u{00e2}'\" became ${Char.tryParse(strChar_tryParse)}")
println("After the conversion of parse, \"-128\" became ${Int8.parse(strInt8_parse)}")
println("After the conversion of tryParse, \"127\" became ${Int8.tryParse(strInt8_tryParse)}")
println("After the conversion of parse, \"-32768\" became ${Int16.parse(strInt16_parse)}")
println("After the conversion of tryParse, \"32767\" became ${Int16.tryParse(strInt16_tryParse)}")
println("After the conversion of parse, \"-2147483648\" became ${Int32.parse(strInt32_parse)}")
println("After the conversion of tryParse, \"2147483647\" became ${Int32.tryParse(strInt32_tryParse)}")
println("After the conversion of parse, \"-9223372036854775808\" became ${Int64.parse(strInt64_parse)}")
println("After the conversion of tryParse, \"9223372036854775807\" became ${Int64.tryParse(strInt64_tryParse)}")
println("After the conversion of parse, \"-65504.0\" became ${Float16.parse(strFloat16_parse)}")
println("After the conversion of tryParse, \"65504.0\" became ${Float16.tryParse(strFloat16_tryParse)}")
println("After the conversion of parse, \"-3.14159\" became ${Float32.parse(strFloat32_parse)}")
println("After the conversion of tryParse, \"3.14159\" became ${Float32.tryParse(strFloat32_tryParse)}")
println("After the conversion of parse, \"-3.1415926\" became ${Float64.parse(strFloat64_parse)}")
println("After the conversion of tryParse, \"3.1415926\" became ${Float64.tryParse(strFloat64_tryParse)}")
println("After the conversion of parse, \"255\" became ${UInt8.parse(strUInt8_parse)}")
println("After the conversion of tryParse, \"255\" became ${UInt8.tryParse(strUInt8_tryParse)}")
println("After the conversion of parse, \"65535\" became ${UInt16.parse(strUInt16_parse)}")
println("After the conversion of tryParse, \"65535\" became ${UInt16.tryParse(strUInt16_tryParse)}")
println("After the conversion of parse, \"4294967295\" became ${UInt32.parse(strUInt32_parse)}")
println("After the conversion of tryParse, \"4294967295\" became ${UInt32.tryParse(strUInt32_tryParse)}")
println("After the conversion of parse, \"18446744073709551615\" became ${UInt64.parse(strUInt64_parse)}")
println("After the conversion of tryParse, \"18446744073709551615\" became ${UInt64.tryParse(strUInt64_tryParse)}")
return 0
}
运行结果如下:
After the conversion of parse, "true" became true
After the conversion of tryParse, "false" became Some(false)
After the conversion of parse, "'a'" became a
After the conversion of tryParse, "'\u{00e2}'" became Some(â)
After the conversion of parse, "-128" became -128
After the conversion of tryParse, "127" became Some(127)
After the conversion of parse, "-32768" became -32768
After the conversion of tryParse, "32767" became Some(32767)
After the conversion of parse, "-2147483648" became -2147483648
After the conversion of tryParse, "2147483647" became Some(2147483647)
After the conversion of parse, "-9223372036854775808" became -9223372036854775808
After the conversion of tryParse, "9223372036854775807" became Some(9223372036854775807)
After the conversion of parse, "-65504.0" became -65504.000000
After the conversion of tryParse, "65504.0" became Some(65504.000000)
After the conversion of parse, "-3.14159" became -3.141590
After the conversion of tryParse, "3.14159" became Some(3.141590)
After the conversion of parse, "-3.1415926" became -3.141593
After the conversion of tryParse, "3.1415926" became Some(3.141593)
After the conversion of parse, "255" became 255
After the conversion of tryParse, "255" became Some(255)
After the conversion of parse, "65535" became 65535
After the conversion of tryParse, "65535" became Some(65535)
After the conversion of parse, "4294967295" became 4294967295
After the conversion of tryParse, "4294967295" became Some(4294967295)
After the conversion of parse, "18446744073709551615" became 18446744073709551615
After the conversion of tryParse, "18446744073709551615" became Some(18446744073709551615)
crypto 包
crypto 包提供常用的密码算法、密钥生成和签名验证功能。
digest 包
介绍
digest 包提供常用摘要算法的通用接口。
主要接口
interface Digest
public interface Digest {
prop size: Int64
prop blockSize: Int64
mut func write(buffer: Array<Byte>): Unit
func finish(): Array<Byte>
mut func reset(): Unit
}
接口 Digest,摘要算法接口,继承该接口的 class、interface、struct 也需要遵守该接口中函数的入参及返回值定义。
prop size
prop size: Int64
功能:生成的摘要信息长度,单位字节。
prop blockSize
prop blockSize: Int64
功能:digest 块长度,单位字节。
func write
mut func write(buffer: Array<Byte>): Unit
功能:使用给定的 buffer 更新 digest 对象。
func finish
func finish(): Array<Byte>
功能:返回生成的 digest 值。
func reset
mut func reset(): Unit
功能:重置 digest 对象到初始状态。
func digest
public func digest<T>(algorithm: T, data: String): Array<Byte> where T <: Digest
功能:提供 digest 泛型函数,实现用指定的摘要算法进行摘要运算。
参数:
- algorithm:具体的摘要算法
- data:待进行摘要运算的数据
返回值:摘要运算结果
func digest
public func digest<T>(algorithm: T, data: Array<Byte>): Array<Byte> where T <: Digest
功能:提供 digest 泛型函数,实现用指定的摘要算法进行摘要运算。
参数:
- algorithm:具体的摘要算法
- data:待进行摘要运算的数据
返回值:摘要运算结果
database 包
database 包提供仓颉访问数据库的接口,当前仅支持 SQL/CLI 接口。
注意:当前 database 包本身没有对外接口,因此无法被引入。使用 SQL/CLI 接口时需引入 database.sql 包。
sql 包
介绍
sql 包提供了 SQL/CLI 的通用接口,配合数据库驱动 Driver 完成对数据库的各项操作。
数据类型对应表
Sql 数据类型和仓颉数据类型对应表。
| SQL | CDBC/Cangjie | SqlDataType | 说明 |
|---|---|---|---|
CHAR | String | SqlChar | |
VARCHAR | String | SqlVarchar | |
CLOB | io.InputStream | SqlClob | |
BINARY | Array<Byte> | SqlBinary | |
VARBINARY | Array<Byte> | SqlVarBinary | |
BLOB | io.InputStream | SqlBlob | |
NUMERIC | / | / | 仓颉无对应原生类型, 用户可使用 SqlBinary 扩展 |
DECIMAL | / | / | 仓颉无对应原生类型, 用户可使用 SqlBinary 扩展 |
BOOLEAN | Bool | SqlBool | |
TINYINT | Int8 | SqlByte | |
SMALLINT | Int16 | SqlSmallInt | |
INTEGER | Int32 | SqlInteger | |
BIGINT | Int64 | SqlBigInt | |
REAL | Float32 | SqlReal | |
DOUBLE | Float64 | SqlDouble | |
DATE | time.DateTime | SqlDate | YEAR, MONTH, and DAY |
TIME | time.DateTime | SqlTime | HOUR, MINUTE, and SECOND 不包含 TIME ZONE |
TIMETZ | time.DateTime | SqlTimeTz | HOUR, MINUTE, and SECOND 包含 TIME ZONE |
TIMESTAMP | time.DateTime | SqlTimestamp | YEAR, MONTH, DAY, HOUR, MINUTE, SECOND and TIME ZONE |
INTERVAL | time.Duration | SqlInterval | year-month interval or a day-time interval |
主要接口
interface Driver
public interface Driver {
prop name: String
prop version: String
prop preferredPooling: Bool
func open(connectionString: String, opts: Array<(String, String)>): Datasource
}
接口 Driver,数据库驱动接口,继承该接口的 class、interface、struct 也需要遵守该接口中函数的入参及返回值定义。
prop name
prop name: String
功能:驱动名称
prop version
prop version: String
功能:驱动版本
prop preferredPooling
prop preferredPooling: Bool
功能:指示驱动程序是否与连接池亲和。
如果否,则不建议使用连接池。
比如 sqlite 驱动连接池化的收益不明显,不建议使用连接池。
func open
func open(connectionString: String, opts: Array<(String, String)>): Datasource
功能:通过 connectionString 和选项打开数据源。
参数:
- connectionString:数据库连接字符串
- opts:key,value 的 tuple 数组,打开数据源的选项
返回值:数据源实例
interface Datasource
public interface Datasource <: Resource {
func setOption(key: String, value: String): Unit
func connect(): Connection
}
接口 Datasource,数据源接口,继承该接口的 class、interface、struct 也需要遵守该接口中函数的入参及返回值定义。
func setOption
func setOption(key: String, value: String): Unit
功能:设置连接选项。
参数:
- key:连接选项名称
- value:连接选项的值
func connect
func connect(): Connection
功能:返回一个可用的连接。
返回值:数据库连接实例
interface Connection
public interface Connection <: Resource {
prop state: ConnectionState
func getMetaData(): Map<String, String>
func prepareStatement(sql: String): Statement
func createTransaction(): Transaction
}
接口 Connection ,数据库连接接口,继承该接口的 class、interface、struct 也需要遵守该接口中函数的入参及返回值定义。
prop state
prop state: ConnectionState
功能:描述与数据源连接的当前状态
func getMetaData
func getMetaData(): Map<String, String>
功能:返回连接到的数据源元数据。
返回值:数据源元数据
func prepareStatement
func prepareStatement(sql: String): Statement
功能:通过传入的 sql 语句,返回一个预执行的 Statement 对象实例。
参数:
- sql:预执行的 sql 语句,sql 语句的参数只支持 ? 符号占位符
返回值:一个可以执行 sql 语句的实例对象
异常:
- SqlException:语法错误, sql 语句包含不认识的字符
func createTransaction
func createTransaction(): Transaction
功能:创建事务对象。
返回值:事务对象
异常:
- SqlException:已经处于事务状态,不支持并行事务。
interface Statement
public interface Statement <: Resource {
prop parameterColumnInfos: Array<ColumnInfo>
func setOption(key: String, value: String): Unit
func update(params: Array<SqlDbType>): UpdateResult
func query(params: Array<SqlDbType>): QueryResult
}
接口 Statement ,sql 语句预执行接口,它绑定了一个 Connection , 继承该接口的 class、interface、struct 也需要遵守该接口中函数的入参及返回值定义。
prop parameterColumnInfos
prop parameterColumnInfos: Array<ColumnInfo>
功能:预执行 sql 语句中,占位参数的列信息,比如列名,列类型,列长度,是否允许数据库 Null 值等
func setOption
func setOption(key: String, value: String): Unit
功能:设置预执行 sql 语句选项。
参数:
- key:连接选项名称
- value:连接选项的值
func update
func update(params: Array<SqlDbType>): UpdateResult
功能:执行 sql 语句,得到更新结果。
参数:
- params:sql 数据类型的数据列表,用于替换 sql 语句中的 ?占位符
返回值:更新结果。
异常:
- SqlException:执行过程中发生了异常,比如网络中断,服务器超时,参数个数不正确
func query
func query(params: Array<SqlDbType>): QueryResult
功能:执行 sql 语句,得到查询结果。
参数:
- params:sql 数据类型的数据列表,用于替换 sql 语句中的 ?占位符
返回值:查询结果。
异常:
- SqlException:执行过程中发生了异常,比如网络中断,服务器超时,参数个数不正确
interface UpdateResult
public interface UpdateResult {
prop rowCount: Int64
prop lastInsertId: Int64
}
接口 UpdateResult,它是执行 Insert、Update、Delete 语句产生的结果接口。继承该接口的 class、interface、struct 也需要遵守该接口中函数的入参及返回值定义。
prop rowCount
prop rowCount: Int64
功能:执行 Insert, Update, Delete 语句影响的行数
prop lastInsertId
prop lastInsertId: Int64
功能:执行 Insert 语句自动生成的最后 row ID ,如果不支持则为 0
interface ColumnInfo
public interface ColumnInfo {
prop name: String
prop typeName: String
prop displaySize: Int64
prop length: Int64
prop scale: Int64
prop nullable: Bool
}
接口 ColumnInfo,它一般是执行 Select/Query 语句返回结果的列信息,通过这个信息,可以支持数据库服务侧扩展的数据类型值解析
prop name
prop name: String
功能:列名或者别名
prop typeName
prop typeName: String
功能:获取列类型名称,如果在 SqlDataType 中定义,返回 SqlDataType.toString(), 如果未在 SqlDataType 中定义,由数据库驱动定义
prop displaySize
prop displaySize: Int64
功能:获取列值的最大显示长度,如果无限制,则应该返回 Int64.Max (仍然受数据库的限制)
prop length
prop length: Int64
功能:获取列值大小。
- 对于数值数据,这是最大精度。
- 对于字符数据,这是以字符为单位的长度。
- 对于日期时间数据类型,这是字符串表示形式的最大字符长度。
- 对于二进制数据,这是以字节为单位的长度。
- 对于 RowID 数据类型,这是以字节为单位的长度。
- 对于列大小不适用的数据类型,返回 0。
prop scale
prop scale: Int64
功能:获取列值的小数长度,如果无小数部分,返回 0。
prop nullable
prop nullable: Bool
功能:列值是否允许数据库 Null 值
interface QueryResult
public interface QueryResult <: Resource {
prop columnInfos: Array<ColumnInfo>
func next(values: Array<SqlDbType>): Bool
}
接口 QueryResult,它是执行 Select 语句产生的结果接口。继承该接口的 class、interface、struct 也需要遵守该接口中函数的入参及返回值定义。
prop columnInfos
prop columnInfos: Array<ColumnInfo>
功能:返回结果集的列信息,比如列名,列类型,列长度,是否允许数据库 Null 值等
func next
func next(values: Array<SqlDbType>): Bool
功能:向后移动一行,必须先调用一次 next 才能移动到第一行,第二次调用移动到第二行,依此类推。当返回 true 时,驱动会在 values 中填入行数据;当返回 false 时结束,且不会修改 values 的内容。
参数:
- params:
返回值:存在下一行则返回 true,否则返回 false
interface Transaction
public interface Transaction {
mut prop isoLevel: TransactionIsoLevel
mut prop accessMode: TransactionAccessMode
mut prop deferrableMode: TransactionDeferrableMode
func begin(): Unit
func commit(): Unit
func rollback(): Unit
func save(savePointName: String): Unit
func rollback(savePointName: String): Unit
func release(savePointName: String): Unit
}
接口 Transaction,定义数据库事务的核心行为。继承该接口的 class、interface、struct 也需要遵守该接口中函数的入参及返回值定义。
prop isoLevel
mut prop isoLevel: TransactionIsoLevel
功能:获取数据库事务隔离级别。
prop accessMode
mut prop accessMode: TransactionAccessMode
功能:获取数据库事务访问模式。
prop deferrableMode
mut prop deferrableMode: TransactionDeferrableMode
功能:获取数据库事务延迟模式。
func begin
func begin(): Unit
功能:开始数据库事务。
异常:
- SqlException:提交事务时服务器端发生错误。
- SqlException:事务已提交或回滚或连接已断开。
func commit
func commit(): Unit
功能:提交数据库事务。
异常:
- SqlException:提交事务时服务器端发生错误。
- SqlException:事务已提交或回滚或连接已断开。
func rollback
func rollback(): Unit
功能:从挂起状态回滚事务。
异常:
- SqlException:回滚事务时服务器端发生错误。
- SqlException:事务已提交或回滚或连接已断开。
func save
func save(savePointName: String): Unit
功能:在事务中创建一个指定名称的保存点,可用于回滚此保存点之后的事务。
参数:
- savePointName:保存点名称
异常:
- SqlException:提交事务时服务器端发生错误。
- SqlException:事务已提交或回滚或连接已断开。
func rollback
func rollback(savePointName: String): Unit
功能:回滚事务至指定保存点名称。
参数:
- savePointName:保存点名称
异常:
- SqlException:提交事务时服务器端发生错误。
- SqlException:事务已提交或回滚或连接已断开。
func release
func release(savePointName: String): Unit
功能:销毁先前在当前事务中定义的保存点。这允许系统在事务结束之前回收一些资源。
参数:
- savePointName:保存点名称
异常:
- SqlException:提交事务时服务器端发生错误。
- SqlException:事务已提交或回滚或连接已断开。
enum ConnectionState
public enum ConnectionState <: Equatable<ConnectionState> {
| Broken
| Closed
| Connecting
| Connected
}
枚举 ConnectionState ,描述与数据源连接的当前状态
Broken
| Broken
功能:表示与数据源的连接已中断。只有在 Connected 之后才可能发生这种情况。
Closed
| Closed
功能:表示连接对象已关闭
Connecting
| Connecting
功能:表示连接对象正在与数据源连接
Connected
| Connected
功能:表示连接对象已与数据源连接上
operator func ==
public operator func ==(rhs: ConnectionState): Bool
功能:判断数据源连接状态是否相同。
参数:
- rhs:数据源连接状态
返回值:传入数据源连接状态与当前状态相同则返回 true ,否则返回 false
operator func !=
public operator func !=(rhs: ConnectionState): Bool
功能:判断数据源连接状态是否不同。
参数:
- rhs:数据源连接状态
返回值:传入数据源连接状态与当前状态相同则返回 false ,否则返回 true
enum TransactionIsoLevel
public enum TransactionIsoLevel <: ToString & Hashable & Equatable<TransactionIsoLevel> {
| Unspecified
| ReadCommitted
| ReadUncommitted
| RepeatableRead
| Snapshot
| Serializable
| Linearizable
| Chaos
}
事务隔离定义了数据库系统中,一个事务中操作的结果在何时以何种方式对其他并发事务操作可见。
Unspecified
Unspecified
功能:未指定的事务隔离级别,其行为取决于特定的数据库服务器。
ReadCommitted
ReadCommitted
功能:表示事务等待,直到其他事务写锁定的行被解锁;这将防止它读取任何“脏”数据。
ReadUncommitted
ReadUncommitted
功能:表示事务之间不隔离。
RepeatableRead
RepeatableRead
功能:表示事务等待,直到其他事务写锁定的行被解锁;这将防止它读取任何“脏”数据。
Snapshot
Snapshot
功能:表示快照隔离通过使用行版本控制避免了大多数锁定和阻止。
Serializable
Serializable
功能:表示事务等待,直到其他事务写锁定的行被解锁;这将防止它读取任何“脏”数据。
Linearizable
Linearizable
功能:表示当您查看单个对象(即 db 行或 nosql 记录)上的操作子集时,线性化是相关的。
Chaos
Chaos
功能:表示无法覆盖来自高度隔离事务的挂起更改。
func toString
public func toString(): String
功能:返回事务隔离级别的字符串表示。
返回值:事务隔离级别的字符串
func hashCode
public func hashCode(): Int64
功能:获取事务隔离级别的哈希值。
返回值:事务隔离级别的哈希值
operator func ==
public operator func == (rhs: TransactionIsoLevel): Bool
功能:判断两个 TransactionIsoLevel 是否相等。
参数:
- that:传入
TransactionIsoLevel
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public operator func != (rhs: TransactionIsoLevel): Bool
功能:判断两个 TransactionIsoLevel 是否不相等。
参数:
- that:传入
TransactionIsoLevel
返回值:如果不相等,则返回 true;否则,返回 false
enum TransactionAccessMode
public enum TransactionAccessMode <: ToString & Hashable & Equatable<TransactionAccessMode> {
| Unspecified
| ReadWrite
| ReadOnly
}
事务读写模式
Unspecified
Unspecified
功能:未指定的事务读写模式,其行为取决于特定的数据库服务器。
ReadWrite
ReadWrite
功能:表示读 + 写模式
ReadOnly
ReadOnly
功能:表示只读模式
func toString
public func toString(): String
功能:返回事务读写模式的字符串表示。
返回值:事务读写模式的字符串
func hashCode
public func hashCode(): Int64
功能:获取事务读写模式的哈希值。
返回值:事务读写模式的哈希值
operator func ==
public operator func == (rhs: TransactionAccessMode): Bool
功能:判断两个 TransactionAccessMode 是否相等。
参数:
- that:传入
TransactionAccessMode
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public operator func != (rhs: TransactionAccessMode): Bool
功能:判断两个 TransactionAccessMode 是否不相等。
参数:
- that:传入
TransactionAccessMode
返回值:如果不相等,则返回 true;否则,返回 false
enum TransactionDeferrableMode
public enum TransactionDeferrableMode <: ToString & Hashable & Equatable<TransactionDeferrableMode> {
| Unspecified
| Deferrable
| NotDeferrable
}
事务的延迟模式
Unspecified
Unspecified
功能:未指定的事务延迟模式,其行为取决于特定的数据库服务器。
Deferrable
Deferrable
功能:延迟事务是指在前滚阶段结束时未提交的事务,并且遇到了阻止其回滚的错误。因为事务无法回滚,所以它被推迟。
NotDeferrable
NotDeferrable
功能:表示不可延迟
func toString
public func toString(): String
功能:返回事务延迟模式的字符串表示。
返回值:事务延迟模式的字符串
func hashCode
public func hashCode(): Int64
功能:获取事务延迟模式的哈希值。
返回值:事务延迟模式的哈希值
operator func ==
public operator func == (rhs: TransactionDeferrableMode): Bool
功能:判断两个 TransactionDeferrableMode 是否相等。
参数:
- that:传入
TransactionDeferrableMode
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public operator func != (rhs: TransactionDeferrableMode): Bool
功能:判断两个 TransactionDeferrableMode 是否不相等。
参数:
- that:传入
TransactionDeferrableMode
返回值:如果不相等,则返回 true;否则,返回 false
class DriverManager
public class DriverManager
类 DriverManager ,支持运行时根据驱动名获取数据库驱动实例
func register
public static func register(driverName: String, driver: Driver): Unit
功能:按名称注册数据库驱动。如果名称重复,会抛出 SqlException。本方法并发安全。
参数:
- driverName:驱动名称
- driver:驱动实例
异常:
- SqlException:driverName 已经注册
func deregister
public static func deregister(driverName: String): Unit
功能:按名称去注册数据库驱动(如果存在)。本函数并发安全。
参数:
- driverName:驱动名称
func getDriver
public static func getDriver(driverName: String): Option<Driver>
功能:按名称获取已注册的数据库驱动,如果不存在返回 None。本函数并发安全。
参数:
- driverName:驱动名称
返回值:若驱动存在返回 Option 包装的驱动实例,否则返回 None
func drivers
public static func drivers(): Array<String>
功能:返回已注册数据库驱动名称的列表(已排序)。本方法并发安全。
返回值:数据库驱动名称的列表
class PooledDatasource
public class PooledDatasource <: Datasource {
public init(datasource: Datasource)
}
数据库连接池类,提供数据库连接池能力,以下是连接池属性。
init
public init(datasource: Datasource)
功能:构造函数,入参必须为 Datasource 对象。
prop idleTimeout
public mut prop idleTimeout: Duration
功能:允许连接在池中闲置的最长时间,超过这个时间的空闲连接可能会被回收。
prop maxLifeTime
public mut prop maxLifeTime: Duration
功能:自连接创建以来的持续时间,在该持续时间之后,连接将自动关闭。
prop connectionTimeout
public mut prop connectionTimeout: Duration
功能:从池中获取连接的超时时间,超时后抛出 TimeoutException。
prop keepaliveTime
public mut prop keepaliveTime: Duration
功能:检查空闲连接健康状况的间隔时间,防止它被数据库或网络基础设施超时。
prop maxSize
public mut prop maxSize: Int32
功能:连接池最大连接数量,负数表示无限制。
prop maxIdleSize
public mut prop maxIdleSize: Int32
功能:最大空闲连接数量,超过这个数量的空闲连接会被关闭,负数表示无限制。
func setOption
public func setOption(key: String, value: String): Unit
功能:设置数据库驱动连接选项(公钥在 SqlOption 中预定义)。
func connect
public func connect(): Connection
功能:获取一个连接。
func isClosed
public func isClosed(): Bool
功能:判断连接是否关闭。
func close
public func close(): Unit
功能:关闭连接池中的所有连接并阻止其它连接请求调用该方法会阻塞至所有连接关闭并归还到连接池。
class SqlException
public open class SqlException <: Exception {
public init()
public init(message: String)
public init(message: String, sqlState: String, errorCode: Int64)
}
类 SqlException,继承了 Exception 用于处理 SQL 相关的异常。
init
public init()
功能:无参构造函数。
init
public init(message: String)
参数:
- message:预定义消息
init
public init(message: String, sqlState: String, errorCode: Int64)
参数:
- message: 预定义消息
- sqlState: 长度为五个字符的字符串,是数据库系统返回的最后执行的 SQL 语句状态。
- errorCode: 数据库供应商返回的整数错误代码。
prop sqlState
public prop sqlState: String
功能:长度为五个字符的字符串,是数据库系统返回的最后执行的 SQL 语句状态。
prop errorCode
public prop errorCode: Int64
功能:数据库供应商返回的整数错误代码。
prop message
public override prop message: String
功能:获取异常信息字符串。
class SqlOption
public class SqlOption {
public static let URL = "url"
public static let Host = "host"
public static let Username = "username"
public static let Password = "password"
public static let Driver = "driver"
public static let Database = "database"
public static let Encoding = "encoding"
public static let ConnectionTimeout = "connection_timeout"
public static let UpdateTimeout = "update_timeout"
public static let QueryTimeout = "query_timeout"
public static let FetchRows = "fetch_rows"
public static let SSLMode = "ssl.mode"
public static let SSLModePreferred = "ssl.mode.preferred"
public static let SSLModeDisabled = "ssl.mode.disabled"
public static let SSLModeRequired = "ssl.mode.required"
public static let SSLModeVerifyCA = "ssl.mode.verify_ca"
public static let SSLModeVerifyFull = "ssl.mode.verify_full"
public static let SSLCA = "ssl.ca"
public static let SSLCert = "ssl.cert"
public static let SSLKey = "ssl.key"
public static let SSLKeyPassword = "ssl.key.password"
public static let SSLSni = "ssl.sni"
public static let Tls12Ciphersuites = "tls1.2.ciphersuites"
public static let Tls13Ciphersuites = "tls1.3.ciphersuites"
public static let TlsVersion = "tls.version"
}
预定义的 SQL 选项名称和值。如果需要扩展,请不要与这些名称和值冲突。
URL
public static let URL = "url"
功能:获取 URL 数据库连接字符串
Host
public static let Host = "host"
功能:获取 Host 数据库服务器主机名或者 IP 地址
Username
public static let Username = "username"
功能:获取 Username 连接数据库的用户名
Password
public static let Password = "password"
功能:获取 Password 连接数据库的密码
Driver
public static let Driver = "driver"
功能:获取 Driver 数据库驱动名称,比如 postgres, opengauss
Database
public static let Database = "database"
功能:获取 Database 数据库名称
Encoding
public static let Encoding = "encoding"
功能:获取 Encoding 数据库字符集编码类型
ConnectionTimeout
public static let ConnectionTimeout = "connection_timeout"
功能:获取 ConnectionTimeout connect 操作的超时时间,单位 ms
UpdateTimeout
public static let UpdateTimeout = "update_timeout"
功能:获取 UpdateTimeout update 操作的超时时间,单位 ms
QueryTimeout
public static let QueryTimeout = "query_timeout"
功能:获取 QueryTimeout query 操作的超时时间,单位 ms
FetchRows
public static let FetchRows = "fetch_rows"
功能:获取 FetchRows 指定需要获取额外行时从数据库中提取的行数
SSLMode
public static let SSLMode = "ssl.mode"
功能:获取 SSLMode 传输层加密模式 key
SSLModePreferred
public static let SSLModePreferred = "ssl.mode.preferred"
功能:SSLModePreferred 如果服务器支持加密连接,则建立加密连接; 如果无法建立加密连接,则回退到未加密连接,这是 SSLMode 的默认值
SSLModeDisabled
public static let SSLModeDisabled = "ssl.mode.disabled"
功能:SSLModeDisabled 建立未加密的连接
SSLModeRequired
public static let SSLModeRequired = "ssl.mode.required"
功能:SSLModeRequired 如果服务器支持加密连接,则建立加密连接。如果无法建立加密连接,则连接失败。
SSLModeVerifyCA
public static let SSLModeVerifyCA = "ssl.mode.verify_ca"
功能:SSLModeVerifyCA 和 SSLModeRequired 类似,但是增加了校验服务器证书,如果校验失败,则连接失败。
SSLModeVerifyFull
public static let SSLModeVerifyFull = "ssl.mode.verify_full"
功能:SSLModeVerifyFull 和 SSLModeVerifyCA 类似,但通过对照服务器发送给客户端的证书中的标识检查客户端用于连接到服务器的主机名来执行主机名身份验证。
SSLCA
public static let SSLCA = "ssl.ca"
功能:SSLCA 证书颁发机构( CA )证书文件的路径名
SSLCert
public static let SSLCert = "ssl.cert"
功能:SSLCert 客户端 SSL 公钥证书文件的路径名
SSLKey
public static let SSLKey = "ssl.key"
功能:SSLKey 客户端 SSL 私钥文件的路径名
SSLKeyPassword
public static let SSLKeyPassword = "ssl.key.password"
功能:SSLKeyPassword 客户端 SSL 私钥文件的密码
SSLSni
public static let SSLSni = "ssl.sni"
功能:SSLSni 客户端通过该标识在握手过程开始时试图连接到哪个主机名
Tls12Ciphersuites
public static let Tls12Ciphersuites = "tls1.2.ciphersuites"
功能:Tls12Ciphersuites 此选项指定客户端允许使用 TLSv1.2 及以下的加密连接使用哪些密码套件。 值为冒号分隔的字符串,比如 "TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256:TLS_DHE_RSA_WITH_AES_128_CBC_SHA"
Tls13Ciphersuites
public static let Tls13Ciphersuites = "tls1.3.ciphersuites"
功能:Tls13Ciphersuites 此选项指定客户端允许使用 TLSv1.3 的加密连接使用哪些密码套件。 值为冒号分隔的字符串,比如 "TLS_AES_256_GCM_SHA384:TLS_CHACHA20_POLY1305_SHA256"
TlsVersion
public static let TlsVersion = "tls.version"
功能:TlsVersion 支持的 TLS 版本号,值为逗号分隔的字符串,比如 "TLSv1.2,TLSv1.3"
interface SqlDbType
public interface SqlDbType {
prop name: String
}
SqlDbType 接口和 SqlNullableDbType 接口是所有 Sql 数据类型的基类。要扩展用户定义的类型,请继承 SqlDbType 或 SqlNullableDbType。
每种 Sql 数据类型实现类,同时满足以下条件:
- 只有一个参数的构造函数,参数类型为
T(T为仓颉语言支持的类型) public修饰的value属性,其类型必须上一条中使用的参数类型一致,其值为对应仓颉类型的值- 如果数据类型允许
null值,继承SqlNullableDbType,null值时,value字段的值为Option<T>.None
SqlDbType 接口所有实现类型都必须具有公共 value 属性。
prop name
prop name: String
功能:获取类型名称
interface SqlNullableDbType
public interface SqlNullableDbType <: SqlDbType
允许 null 值的类型基类,如果为 null 值,value 属性值为 Option.None
class SqlChar
public class SqlChar <: SqlDbType {
public init(v: String)
}
定长字符串,对应仓颉 String 类型
init
public init(v: String)
prop value
public mut prop value: String
prop name
public prop name: String
功能:类型名称 SqlChar
class SqlNullableChar
public class SqlNullableChar <: SqlNullableDbType {
public init(v: ?String)
}
定长字符串,对应仓颉 String 类型,可为数据库 Null 值
init
public init(v: ?String)
prop value
public mut prop value: ?String
prop name
public prop name: String
功能:类型名称 SqlNullableChar
class SqlVarchar
public class SqlVarchar <: SqlDbType {
public init(v: String)
}
变长字符串,对应仓颉 String 类型
init
public init(v: String)
prop value
public mut prop value: String
prop name
public prop name: String
功能:类型名称 SqlVarchar
class SqlNullableVarchar
public class SqlNullableVarchar <: SqlNullableDbType {
public init(v: ?String)
}
变长字符串,对应仓颉 String 类型,可为数据库 Null 值
init
public init(v: ?String)
prop value
public mut prop value: ?String
prop name
public prop name: String
功能:类型名称 SqlNullableVarchar
class SqlBinary
public class SqlBinary <: SqlDbType {
public init(v: Array<Byte>)
}
定长二进制字符串,对应仓颉 Array<Byte> 类型
init
public init(v: Array<Byte>)
prop value
public mut prop value: Array<Byte>
prop name
public prop name: String
功能:类型名称 SqlBinary
class SqlNullableBinary
public class SqlNullableBinary <: SqlNullableDbType {
public init(v: ?Array<Byte>)
}
定长二进制字符串,对应仓颉 Array<Byte> 类型,可为数据库 Null 值
init
public init(v: ?Array<Byte>)
prop value
public mut prop value: ?Array<Byte>
prop name
public prop name: String
功能:类型名称 SqlNullableBinary
class SqlVarBinary
public class SqlVarBinary <: SqlDbType {
public init(v: Array<Byte>)
}
变长二进制字符串,对应仓颉 Array<Byte> 类型
init
public init(v: Array<Byte>)
prop value
public mut prop value: Array<Byte>
prop name
public prop name: String
功能:类型名称 SqlVarBinary
class SqlNullableVarBinary
public class SqlNullableVarBinary <: SqlNullableDbType {
public init(v: ?Array<Byte>)
}
变长二进制字符串,对应仓颉 Array<Byte> 类型,可为数据库 Null 值
init
public init(v: ?Array<Byte>)
prop value
public mut prop value: ?Array<Byte>
prop name
public prop name: String
功能:类型名称 SqlNullableVarBinary
class SqlClob
public class SqlClob <: SqlDbType {
public init(v: InputStream)
}
变长超大字符串(CHAR LARGE OBJECT),对应仓颉 InputStream 类型
init
public init(v: InputStream)
prop value
public mut prop value: InputStream
prop name
public prop name: String
功能:类型名称 SqlClob
class SqlNullableClob
public class SqlNullableClob <: SqlNullableDbType {
public init(v: ?InputStream)
}
变长超大字符串(CHAR LARGE OBJECT),对应仓颉 InputStream 类型,可为数据库 Null 值
init
public init(v: ?InputStream)
prop value
public mut prop value: ?InputStream
prop name
public prop name: String
功能:类型名称 SqlNullableClob
class SqlBlob
public class SqlBlob <: SqlDbType {
public init(v: InputStream)
}
变长超大二进制字符串(BINARY LARGE OBJECT),对应仓颉 InputStream 类型
init
public init(v: InputStream)
prop value
public mut prop value: InputStream
prop name
public prop name: String
功能:类型名称 SqlBlob
class SqlNullableBlob
public class SqlNullableBlob <: SqlNullableDbType {
public init(v: ?InputStream)
}
变长超大二进制字符串(BINARY LARGE OBJECT),对应仓颉 InputStream 类型,可为数据库 Null 值
init
public init(v: ?InputStream)
prop value
public mut prop value: ?InputStream
prop name
public prop name: String
功能:类型名称 SqlNullableBlob
class SqlBool
public class SqlBool <: SqlDbType {
public init(v: Bool)
}
布尔类型,对应仓颉 Bool 类型
init
public init(v: Bool)
prop value
public mut prop value: Bool
prop name
public prop name: String
功能:类型名称 SqlBool
class SqlNullableBool
public class SqlNullableBool <: SqlNullableDbType {
public init(v: ?Bool)
}
布尔类型,对应仓颉 Bool 类型,可为数据库 Null 值
init
public init(v: ?Bool)
prop value
public mut prop value: ?Bool
prop name
public prop name: String
功能:类型名称 SqlNullableBool
class SqlByte
public class SqlByte <: SqlDbType {
public init(v: Int8)
}
字节,对应仓颉 Int8 类型
init
public init(v: Int8)
prop value
public mut prop value: Int8
prop name
public prop name: String
功能:类型名称 SqlByte
class SqlNullableByte
public class SqlNullableByte <: SqlNullableDbType {
public init(v: ?Int8)
}
字节,对应仓颉 Int8 类型,可为数据库 Null 值
init
public init(v: ?Int8)
prop value
public mut prop value: ?Int8
prop name
public prop name: String
功能:类型名称 SqlNullableByte
class SqlSmallInt
public class SqlSmallInt <: SqlDbType {
public init(v: Int16)
}
小整数,对应仓颉 Int16 类型
init
public init(v: Int16)
prop value
public mut prop value: Int16
prop name
public prop name: String
功能:类型名称 SqlSmallInt
class SqlNullableSmallInt
public class SqlNullableSmallInt <: SqlNullableDbType {
public init(v: ?Int16)
}
小整数,对应仓颉 Int16 类型,可为数据库 Null 值
init
public init(v: ?Int16)
prop value
public mut prop value: ?Int16
prop name
public prop name: String
功能:类型名称 SqlNullableSmallInt
class SqlInteger
public class SqlInteger <: SqlDbType {
public init(v: Int32)
}
中整数,对应仓颉 Int32 类型
init
public init(v: Int32)
prop value
public mut prop value: Int32
prop name
public prop name: String
功能:类型名称 SqlInteger
class SqlNullableInteger
public class SqlNullableInteger <: SqlNullableDbType {
public init(v: ?Int32)
}
中整数,对应仓颉 Int32 类型,可为数据库 Null 值
init
public init(v: ?Int32)
prop value
public mut prop value: ?Int32
prop name
public prop name: String
功能:类型名称 SqlNullableInteger
class SqlBigInt
public class SqlBigInt <: SqlDbType {
public init(v: Int64)
}
大整数,对应仓颉 Int64 类型
init
public init(v: Int64)
prop value
public mut prop value: Int64
prop name
public prop name: String
功能:类型名称 SqlBigInt
class SqlNullableBigInt
public class SqlNullableBigInt <: SqlNullableDbType {
public init(v: ?Int64)
}
大整数,对应仓颉 Int64 类型,可为数据库 Null 值
init
public init(v: ?Int64)
prop value
public mut prop value: ?Int64
prop name
public prop name: String
功能:类型名称 SqlNullableBigInt
class SqlReal
public class SqlReal <: SqlDbType {
public init(v: Float32)
}
浮点数,对应仓颉 Float32 类型
init
public init(v: Float32)
prop value
public mut prop value: Float32
prop name
public prop name: String
功能:类型名称 SqlReal
class SqlNullableReal
public class SqlNullableReal <: SqlNullableDbType {
public init(v: ?Float32)
}
浮点数,对应仓颉 Float32 类型,可为数据库 Null 值
init
public init(v: ?Float32)
prop value
public mut prop value: ?Float32
prop name
public prop name: String
功能:类型名称 SqlNullableReal
class SqlDouble
public class SqlDouble <: SqlDbType {
public init(v: Float64)
}
双精度数,对应仓颉 Float64 类型,可为数据库 Null 值
init
public init(v: Float64)
prop value
public mut prop value: Float64
prop name
public prop name: String
功能:类型名称 SqlDouble
class SqlNullableDouble
public class SqlNullableDouble <: SqlNullableDbType {
public init(v: ?Float64)
}
双精度数,对应仓颉 Float64 类型,可为数据库 Null 值
init
public init(v: ?Float64)
prop value
public mut prop value: ?Float64
prop name
public prop name: String
功能:类型名称 SqlNullableDouble
class SqlDate
public class SqlDate <: SqlDbType {
public init(v: DateTime)
}
日期,仅年月日有效,对应仓颉 DateTime 类型
init
public init(v: DateTime)
prop value
public mut prop value: DateTime
prop name
public prop name: String
功能:类型名称 SqlDate
class SqlNullableDate
public class SqlNullableDate <: SqlNullableDbType {
public init(v: ?DateTime)
}
日期,仅年月日有效,对应仓颉 DateTime 类型,可为数据库 Null 值
init
public init(v: ?DateTime)
prop value
public mut prop value: ?DateTime
prop name
public prop name: String
功能:类型名称 SqlNullableDate
class SqlTime
public class SqlTime <: SqlDbType {
public init(v: DateTime)
}
时间,仅时分秒毫秒有效,对应仓颉 DateTime 类型
init
public init(v: DateTime)
prop value
public mut prop value: DateTime
prop name
public prop name: String
功能:类型名称 SqlTime
class SqlNullableTime
public class SqlNullableTime <: SqlNullableDbType {
public init(v: ?DateTime)
}
时间,仅时分秒毫秒有效,对应仓颉 DateTime 类型,可为数据库 Null 值
init
public init(v: ?DateTime)
prop value
public mut prop value: ?DateTime
prop name
public prop name: String
功能:类型名称 SqlNullableTime
class SqlTimeTz
public class SqlTimeTz <: SqlDbType {
public init(v: DateTime)
}
带时区的时间,仅时分秒毫秒时区有效,对应仓颉 DateTime 类型
init
public init(v: DateTime)
prop value
public mut prop value: DateTime
prop name
public prop name: String
功能:类型名称 SqlTimeTz
class SqlNullableTimeTz
public class SqlNullableTimeTz <: SqlNullableDbType {
public init(v: ?DateTime)
}
带时区的时间,仅时分秒毫秒时区有效,对应仓颉 DateTime 类型,可为数据库 Null 值
init
public init(v: ?DateTime)
prop value
public mut prop value: ?DateTime
prop name
public prop name: String
功能:类型名称 SqlNullableTimeTz
class SqlTimestamp
public class SqlTimestamp <: SqlDbType {
public init(v: DateTime)
}
时间戳,对应仓颉 DateTime 类型
init
public init(v: DateTime)
prop value
public mut prop value: DateTime
prop name
public prop name: String
功能:类型名称 SqlTimestamp
class SqlNullableTimestamp
public class SqlNullableTimestamp <: SqlNullableDbType {
public init(v: ?DateTime)
}
时间戳,对应仓颉 DateTime 类型,可为数据库 Null 值
init
public init(v: ?DateTime)
prop value
public mut prop value: ?DateTime
prop name
public prop name: String
功能:类型名称 SqlNullableTimestamp
class SqlInterval
public class SqlInterval <: SqlDbType {
public init(v: Duration)
}
时间间隔,对应仓颉 Duration 类型
init
public init(v: Duration)
prop value
public mut prop value: Duration
prop name
public prop name: String
功能:类型名称 SqlInterval
class SqlNullableInterval
public class SqlNullableInterval <: SqlNullableDbType {
public init(v: ?Duration)
}
时间间隔,对应仓颉 Duration 类型,可为数据库 Null 值
init
public init(v: ?Duration)
prop value
public mut prop value: ?Duration
prop name
public prop name: String
功能:类型名称 SqlNullableInterval
class SqlDecimal
public class SqlDecimal <: SqlDbType {
public init(v: Decimal)
}
时间间隔,对应仓颉 Decimal 类型
init
public init(v: Decimal)
prop value
public mut prop value: Decimal
prop name
public prop name: String
功能:类型名称 SqlDecimal
class SqlNullableDecimal
public class SqlNullableDecimal <: SqlNullableDbType {
public init(v: ?Decimal)
}
时间间隔,对应仓颉 Decimal 类型,可为数据库 Null 值
init
public init(v: ?Decimal)
prop value
public mut prop value: ?Decimal
prop name
public prop name: String
功能:类型名称 SqlNullableDecimal
示例
获取数据库连接
下面是获取数据库连接示例:
func test_opengauss() {
let drv = DriverManager.getDriver("opengauss") ?? return
let opts = [
("cachePrepStmts", "true"),
("prepStmtCacheSize", "250"),
("prepStmtCacheSqlLimit", "2048")
]
let ds = drv.open("opengauss://testuser:testpwd@localhost:5432/testdb", opts)
ds.setOption(SqlOption.SSLMode, SqlOption.SSLModeVerifyCA)
ds.setOption(SqlOption.SSLCA, "ca.crt")
ds.setOption(SqlOption.SSLCert, "server.crt")
ds.setOption(SqlOption.SSLKey, "server.key")
ds.setOption(SqlOption.SSLKeyPassword, "key_password")
ds.setOption(SqlOption.TlsVersion, "TLSv1.2,TLSv1.3")
let conn = ds.connect()
}
执行数据库定义语句
下面是删除表,创建表的示例:
var stmt = conn.prepareStatement("DROP TABLE IF EXISTS test")
var ur = stmt.update()
println("Update Result: ${ur.rowCount} ${ur.lastInsertId}")
stmt.close()
stmt = conn.prepareStatement("CREATE TABLE test(id SERIAL PRIMARY KEY, name VARCHAR(20) NOT NULL, age INT)")
ur = stmt.update()
println("Update Result: ${ur.rowCount} ${ur.lastInsertId}")
stmt.close()
执行数据库操作语句
插入数据
var stmt = conn.prepareStatement("INSERT INTO test VALUES(?, ?)")
var name = SqlVarchar("li lei")
var age = SqlNullableInteger(12)
var ur = stmt.update(name, age)
println("Update Result: ${ur.rowCount} ${ur.lastInsertId}")
name.value = "han meimei"
age.value = 13
ur = stmt.update(name, age)
println("Update Result: ${ur.rowCount} ${ur.lastInsertId}")
stmt.close()
如果需要在插入数据后返回插入的 id 值,可以参考如下方式:
let sql = "INSERT INTO test (name, age) VALUES (?,?) RETURNING id, name"
try (stmt = cn.prepareStatement(sql)) {
var name = SqlVarchar("li hua")
var age = SqlNullableInteger(12)
let qr = stmt.query(name, age)
let id = SqlInteger(0)
while (qr.next(id, name)) {
println("id = ${id.value}, name=${name.value}")
}
} catch (e: Exception) {
logger.error(e.message)
e.printStackTrace()
}
查询数据
var stmt = conn.prepareStatement("select * from test where name = ?")
var name = SqlNullableVarchar("li lei")
let id = SqlInteger(0)
let qr = stmt.query(name)
var age = SqlNullableInteger(0)
while (qr.next(id, name, age)) {
println("id = ${id.value}, name = ${name.value}, age=${age.value}")
}
stmt.close()
更新数据
var stmt = conn.prepareStatement("update test set age = ? where name = ?")
var age = SqlNullableInteger(15)
var name = SqlNullableVarchar("li lei")
var ur = stmt.update(age, name)
println("Update Result: ${ur.rowCount} ${ur.lastInsertId}")
stmt.close()
删除数据
var stmt = conn.prepareStatement("delete from test where name = ?")
var name = SqlNullableVarchar("li lei")
var ur = stmt.update(name)
println("Update Result: ${ur.rowCount} ${ur.lastInsertId}")
stmt.close()
执行事务控制语句
普通数据库事务
func test_transaction() {
let SQL_INSERT = "INSERT INTO EMPLOYEE (NAME, SALARY, CREATED_DATE) VALUES (?, ?, ?)"
let SQL_UPDATE = "UPDATE EMPLOYEE SET SALARY=? WHERE NAME=?"
let drv = DriverManager.getDriver("opengauss").getOrThrow()
let db = drv.open("opengauss://localhost:5432/testdb")
try(cn = db.connect()) {
let psInsert = cn.prepareStatement(SQL_INSERT)
let psUpdate = cn.prepareStatement(SQL_UPDATE)
// 创建事务对象
let tx = cn.createTransaction()
try {
psInsert.update(SqlChar("mkyong"), SqlBinary(Array<Byte>([10])), SqlTime(DateTime.now()))
psInsert.update(SqlChar("kungfu"), SqlBinary(Array<Byte>([20])), SqlTime(DateTime.now()))
// error, test rollback SQLException: No value specified for parameter 3.
psInsert.update(SqlVarchar("mkyong"), SqlBinary(Array<Byte>([1, 2, 3, 4, 5])))
// 提交事务
tx.commit()
} catch (e1: SqlException) {
e1.printStackTrace()
try {
// 发生异常,回滚所有事务
tx.rollback()
} catch (e2: SqlException) {
e2.printStackTrace()
}
}
} catch (e: SqlException) {
e.printStackTrace()
}
}
事务保存点
如果数据库事务支持保存点,可以参考如下样例:
func test_savepoint() {
let SQL_INSERT = "INSERT INTO EMPLOYEE (NAME, SALARY, CREATED_DATE) VALUES (?, ?, ?)"
let SQL_UPDATE = "UPDATE EMPLOYEE SET SALARY=? WHERE NAME=?"
let drv = DriverManager.getDriver("opengauss").getOrThrow()
let db = drv.open("opengauss://localhost:5432/testdb")
try(cn = db.connect()) {
let psInsert = cn.prepareStatement(SQL_INSERT)
let psUpdate = cn.prepareStatement(SQL_UPDATE)
let tx = cn.createTransaction()
try {
// 创建保存点 1
tx.save("save1")
psInsert.update([SqlChar("mkyong"), SqlBinary(Array<Byte>([10])), SqlTime(DateTime.now())])
// 创建保存点 2
tx.save("save2")
psInsert.update([SqlChar("kungfu"), SqlBinary(Array<Byte>([20])), SqlTime(DateTime.now())])
// 创建保存点 3
tx.save("save3")
psInsert.update([SqlVarchar("mkyong"), SqlBinary(Array<Byte>([1, 2, 3, 4, 5]))])
// 回滚到保存点 2
tx.rollback("save2")
// 提交事务
tx.commit()
} catch (e1: SqlException) {
e1.printStackTrace()
try {
// 发生异常,回滚所有事务
tx.rollback()
} catch (e2: SqlException) {
e2.printStackTrace()
}
}
} catch (e: SqlException) {
e.printStackTrace()
}
}
实现数据库驱动查询功能参考
对于数据库驱动提供者,此处给出实现查询功能的样例代码:
public class Rows <: QueryResult {
public func next(values: Array<SqlDbType>): Bool {
for (idx in 0..values.size) {
match (values[idx]) {
case v: SqlBigInt => v.value = 100
case v: SqlVarchar => v.value = "foo"
case v: SqlNullableTimestamp => v.value = None
case v: MySqlExtXmlType => v.value = "<element></element>"
case _ => ()
}
}
return false
}
}
ffi 包
与 Python 语言的互操作
介绍
为了兼容强大的计算和 AI 生态,仓颉支持与 Python 语言的互操作调用。Python 的互操作通过 std 模块中的 ffi.python 库为用户提供能力。
本包暂不支持 macOS 平台。
功能介绍
Python 的全局资源及使用
Python 库为用户提供了全局解释器对象 Python ,其类型为 PythonBuiltins ,通过该解释器对象可以:
- 加载、卸载解释器资源;
- 获取当前使用的 Python 解释器版本;
- 导入及使用 Python 的三方模块。
详细介绍及使用请参见用户手册中【与 Python 语言互操作/PythonBuiltins 内建函数类】章节。
类型映射
Python 库提供了 Python 数据类型与仓颉类型之间的互相转换。如 PyBool/PyLong/PyFloat/PyString/PyTuple/PyList/PyDict/PySet, 它们均继承自 PyObject 类型,PyObject 类型提供了所有类型的通用接口,如成员变量访问、函数访问、到仓颉类型转换等。PyObject 类型的子类提供了每个类型独有的函数接口。
详细映射关系介绍及使用请参见用户手册中【与 Python 语言互操作/类型映射表】章节。
仓颉与 Python 的注册回调
Python 互操作库支持简单的函数注册及 Python 对仓颉函数调用。
Python 回调仓颉代码需要通过 C 作为中间层进行调用,并且使用到了 Python 的三方库: ctypes 以及 _ctypes 。
用户手册【与 Python 语言互操作/仓颉与 Python 的注册回调】章节详细介绍了在回调过程中,两边参数和返回值的类型映射情况以及调用方式。
format 包
介绍
format 包提供根据格式化参数将指定类型的实例转换成对应格式的字符串的功能。
格式化参数及其含义参见“格式化参数的语法”章节。
format 包提供了统一的格式化接口,并为 Char、Int8 等基本类型实现了该接口。
主要接口
interface Formatter
public interface Formatter {
func format(fmt: String): String
}
format 包提供 Formatter interface 以及对于基本类型的实现。由基本类型 Int,UInt,Char 和 Float 继承 Formatter 接口。
该接口定义了格式化函数,即根据格式化参数将指定类型实例转换为对应格式的字符串。其他类型可通过实现该接口提供格式化功能。
func format
func format(fmt: String): String
功能:根据格式化参数将当前实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前实例格式化后得到的字符串
extend Char <: Formatter
extend Char <: Formatter
为 Char 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 Char 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 Char 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend Int8 <: Formatter
extend Int8 <: Formatter
为 Int8 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 Int8 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 Int8 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend Int16 <: Formatter
extend Int16 <: Formatter
为 Int16 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 Int16 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 Int16 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend Int32 <: Formatter
extend Int32 <: Formatter
为 Int32 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 Int32 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 Int32 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend Int64 <: Formatter
extend Int64 <: Formatter
为 Int64 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 Int64 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 Int64 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend UInt8 <: Formatter
extend UInt8 <: Formatter
为 UInt8 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 UInt8 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 UInt8 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend UInt16 <: Formatter
extend UInt16 <: Formatter
为 UInt16 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 UInt16 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 UInt16 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend UInt32 <: Formatter
extend UInt32 <: Formatter
为 UInt32 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 UInt32 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 UInt32 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend UInt64 <: Formatter
extend UInt64 <: Formatter
为 UInt64 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 UInt64 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 UInt64 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend Float16 <: Formatter
extend Float16 <: Formatter
为 Float16 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 Float16 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 Float16 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend Float32 <: Formatter
extend Float32 <: Formatter
为 Float32 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 Float32 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 Float32 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
extend Float64 <: Formatter
extend Float64 <: Formatter
为 Float64 扩展 Formatter 接口,以实现格式化字符串。
func format
public func format(fmt: String): String
功能:根据格式化参数将当前 Float64 类型实例格式化为对应格式的字符串。
参数:
- fmt:格式化参数
返回值:将当前 Float64 类型实例格式化后得到的字符串
异常:
- IllegalArgumentException:当 fmt 不合法时抛出异常
格式化参数的语法
format_spec := [flags][width][.precision][specifier]
flags := '-' | '+' | '#' | '0'
width := integer
precision := integer
specifier := 'b' | 'B' | 'o' | 'O' | 'x' | 'X' | 'e' | 'E' | 'g' | 'G'
参数 flags:
-
'-' 适用于 Int,UInt,Char 和 Float,表示左对齐。
代码如下:
from std import format.* main() { var c : Int32 = -20 print("\"${c.format("-10")}\"") }运行结果如下:
"-20 " -
'+' 适用于 Int,UInt 和 Float,如果数值为正数则打出 '+' 符号,如果数值为负数则忽略。
代码如下:
from std import format.* main() { var c: Int32 = 20 print("\"${c.format("+10")}\"") }运行结果如下:
" +20" -
'#' 是针对进制打印的,对于二进制打印会补充一个 '0b' 或者 '0B',对于八进制打印会补充一个 '0o' 或者 '0O',对于十六进制会补充 '0x' 或者 '0X'。
代码如下:
from std import format.* main() { var c: Int32 = 1 print("\"${c.format("#10x")}\"") }运行结果如下:
" 0x1" -
'0' 适用于 Int,UInt 和 Float,在空位补充 0。
代码如下:
from std import format.* main() { var c: Int32 = -20 print("\"${c.format("010")}\"") }运行结果如下:
"-000000020"
参数 width 宽度:
-
宽度为正整数,适用于 Int,UInt,Char 和 Float,宽度前有负号则表示左对齐,没有负号则是右对齐,如果数值小于数值本身的长度,不会发生截断。 如果前缀有
+或-符号会占用一个字符位,如果前缀有0x或0o等会占用两个字符位。代码如下:
from std import format.* main() { var c: Int32 = 20 println("\"${c.format("1")}\"") println("\"${c.format("+4")}\"") }运行结果如下:
"20" " +20"
参数 precision 精度:
-
精度为正整数,适用于 Int,UInt 和 Float。 对于浮点数表示小数点后的有效数字位数,如果不指定,那么则打印六位小数,如果小于数值本身有效数字的长度,那就四舍五入,如果大于就补全,补全的不一定是 0。
-
对于整数类型,不指定或者指定的数字小于数值本身的长度,则无效果,如果大于数值本身的长度,则在前面补全'0'。
代码如下:
from std import format.* main() { var e: Float32 = 1234.1 println("\"${e.format("20.20")}\"") var c: Int32 = -20 println("\"${c.format("10.8")}\"") }运行结果如下:
"1234.09997558593750000000" " -00000020"
参数 specifier:
-
'b' | 'B' | 'o' | 'O' | 'x' | 'X' 适用于 Int 和 UInt 类型。
'b' | 'B' : 表示二进制格式打印
'o' | 'O' : 表示八进制格式打印
'x' | 'X' : 表示十六进制格式打印
代码如下:
from std import format.* main() { var a = 20 println("\"${a.format("b")}\"") println("\"${a.format("o")}\"") println("\"${a.format("x")}\"") println("\"${a.format("X")}\"") println("\"${a.format("#X")}\"") }运行结果如下:
"10100" "24" "14" "14" "0X14" -
'e' | 'E' | 'g' | 'G' 适用于 Float 类型。
'e' | 'E' : 科学计数法,小写和大写
'g' | 'G' : general,用十进制或者科学计数法表示,会选择精简的表示方式进行打印
代码如下:
from std import format.* main() { var f: Float32 = 1234.1 var c: Float32 = 123412341234.1 println("\"${f.format("20.2e")}\"") println("\"${f.format("20G")}\"") println("\"${c.format("20G")}\"") println("\"${f.format("20")}\"") println("\"${c.format("20")}\"") }运行结果如下:
" 1.23e+03" " 1234.1" " 1.23412E+11" " 1234.099976" " 123412340736.000000"
示例
格式化整型
下面是格式化整型示例。
代码如下:
from std import format.*
main(): Int64 {
var a: Int32 = -20
var res1 = a.format("-10")
var res2 = a.format("+10")
var res3 = (-20).format("10")
var res4 = a.format("-")
println("\"${res1}\"")
println("\"${res2}\"")
println("\"${res3}\"")
println("\"${res4}\"")
return 0
}
运行结果如下:
"-20 "
" -20"
" -20"
"-20"
格式化浮点型
下面是格式化浮点型示例。
代码如下:
from std import format.*
/* flags '-' */
main(): Int64 {
var a: Float16 = -0.34
var b: Float32 = .34
var c: Float64 = 3_0.3__4_
var d: Float64 = 20.00
/* left align */
var res1 = a.format("-20")
/* right align */
var res2 = b.format("+20")
/* left align */
var res3 = c.format("10")
/* left align */
var res4 = d.format("-10")
/* left align */
var res5 = d.format("-")
println("\"${res1}\"")
println("\"${res2}\"")
println("\"${res3}\"")
println("\"${res4}\"")
println("\"${res5}\"")
return 0
}
运行结果如下:
"-0.340088 "
" +0.340000"
" 30.340000"
"20.000000 "
"20.000000"
格式化字符型
下面是格式化字符型示例。
代码如下:
from std import format.*
main(): Int64 {
var a: Char = 'a'
var b = '-'
/* left align */
var res1 = a.format("-10")
/* right align */
var res2 = b.format("-10")
/* left align */
var res3 = a.format("10")
/* left align */
var res4 = b.format("10")
println("\"${res1}\"")
println("\"${res2}\"")
println("\"${res3}\"")
println("\"${res4}\"")
return 0
}
运行结果如下:
"a "
"- "
" a"
" -"
fs 包
介绍
fs 包提供对文件、目录、路径、文件元数据信息的一些操作函数。 目前支持 Linux,macOS 和 Windows 平台下使用。
主要接口
struct Path
public struct Path <: Equatable<Path> & Hashable & ToString {
public init(rawPath: String)
}
Path 用来表示本地路径(Windows 平台已支持 DOS 设备路径和 UNC 路径,长度限制跟随系统)。
路径的字符串最大支持 4096 个字节(包括结束符 \0)。
init
public init(rawPath: String)
功能:创建 Path 实例初始化时不检查路径字符串是否合法。
参数:
- rawPath:路径的字符串
prop directoryName
public prop directoryName: Option<Path>
功能:获得 Path 的目录部分,以 Option
- 对于路径 "/a/b/c",此属性返回 Some(Path("/a/b"))
- 对于路径 "/a/b/",此属性返回 Some(Path("/a/b"))
- 对于路径 "/a",此属性返回 Some(Path("/"))
- 对于路径 "/",此属性返回 Some(Path("/"))
- 对于路径 "./a/b",此属性返回 Some(Path("./a"))
- 对于路径 "./",此属性返回 Some(Path("."))
- 对于路径 ".",此属性返回 None
- 对于路径 ".gitignore",此属性返回 None
- 对于路径 "a.txt",此属性返回 None
- 对于路径 "C:\a\b\c",此属性返回 Some(Path("C:\a\b"))
- 对于路径 "C:\a\b",此属性返回 Some(Path("C:\a\b"))
返回值:返回构造时传入的路径中的目录部分,构造时传入的路径中无目录部分时返回 None
异常:
- IllegalArgumentException:当路径为空,或包含字符串结束符则抛出异常
prop fileName
public prop fileName: Option<String>
功能:获得 Path 的文件名(含扩展名)部分,以 Option
- 对于路径 "./NewFile.txt",此属性返回 Some("NewFile.txt")
- 对于路径 "./.gitignore",此属性返回 Some(".gitignore")
- 对于路径 "./noextension",此属性返回 Some("noextension")
- 对于路径 "./a.b.c",此属性返回 Some("a.b.c")
- 对于路径 "./NewDir/",此属性返回 None
返回值:返回构造时传入的路径中的文件名(含扩展名)部分,构造时传入的路径中无文件名(含扩展名)部分时返回 None
异常:
- IllegalArgumentException:当路径为空,或包含字符串结束符则抛出异常
prop extensionName
public prop extensionName: Option<String>
功能:获得 Path 的文件扩展名部分,以 Option
- 对于路径 "./NewFile.txt",此属性返回 Some("txt")
- 对于路径 "./.gitignore",此属性返回 Some("gitignore")
- 对于路径 "./noextension",此属性返回 None
- 对于路径 "./a.b.c",此属性返回 Some("c")
- 对于路径 "./NewDir/",此属性返回 None
- 对于路径 "./NewDir/NewFile.",此属性返回 None
返回值:返回构造时传入的路径中的文件扩展名部分,构造时传入的路径中无文件扩展名部分时返回 None
异常:
- IllegalArgumentException:当路径为空,或包含字符串结束符则抛出异常
prop fileNameWithoutExtension
public prop fileNameWithoutExtension: Option<String>
功能:获得 Path 的文件名(不含扩展名)部分,以 Option
- 对于路径 "./NewFile.txt",此属性返回 Some("NewFile")
- 对于路径 "./.gitignore",此属性返回 None
- 对于路径 "./noextension",此属性返回 Some("noextension")
- 对于路径 "./a.b.c",此属性返回 Some("a.b")
- 对于路径 "./NewDir/",此属性返回 None
返回值:返回构造时传入的路径中的文件名(不含扩展名)部分,构造时传入的路径中无文件名(不含扩展名)部分时返回 None
异常:
- IllegalArgumentException:当路径为空,或包含字符串结束符则抛出异常
func isAbsolute
public func isAbsolute(): Bool
功能:判断 Path 是否是绝对路径。在 Unix 中,以 "/" 开头的路径为绝对路径。
返回值:true,是绝对路径;false,不是绝对路径
异常:
- IllegalArgumentException:当路径为空,或包含字符串结束符则抛出异常
func isRelative
public func isRelative(): Bool
功能:判断 Path 是否是相对路径与 isAbsolute 结果相反。
返回值:true,是相对路径;false,不是相对路径
异常:
- IllegalArgumentException:当路径为空,或包含字符串结束符则抛出异常
func isSymbolicLink
public func isSymbolicLink(): Bool
功能:判断 Path 是否是软链接,与 isFile, isDirectory 互斥。
返回值:true,是软链接;false,不是软链接
异常:
- FSException:如果路径不存在,或者判断过程中底层调用的系统接口发生错误,则抛异常
- IllegalArgumentException:当路径为空,或包含字符串结束符则抛出异常
func isFile
public func isFile(): Bool
功能:判断 Path 是否是文件,与 isSymbolicLink, isDirectory 互斥。
返回值:true,是文件;false,不是文件
异常:
- FSException:如果路径不存在,或者判断过程中底层调用的系统接口发生错误,则抛异常
- IllegalArgumentException:当路径为空,或包含字符串结束符则抛出异常
func isDirectory
public func isDirectory(): Bool
功能:判断 Path 是否是目录,与 isFile, isSymbolicLink 互斥。
返回值:true,是目录;false,不是目录
异常:
- FSException:如果路径不存在,或者判断过程中底层调用的系统接口发生错误,则抛异常
- IllegalArgumentException:当路径为空,或包含字符串结束符则抛出异常
func split
public func split(): (Option<Path>, Option<String>)
功能:将 Path 分割成目录和文件名两部分以元组形式返回分割结果 (directoryName, fileName) 获取目录失败,返回 Option
返回值:返回值为元组类型,第一个元素表示路径,路径获取成功,返回 Option
异常:
- IllegalArgumentException:当路径为空,或包含字符串结束符则抛出异常
func join
public func join(path: String): Path
功能:在当前路径后拼接另一个路径字符串形成新路径对于路径 "a/b", "c",返回 "a/b/c" 对于路径 "a", "b/c",返回 "a/b/c"。
返回值:新路径的 Path 实例
异常:
- FSException:如果参数 path 是绝对路径则抛异常
- IllegalArgumentException:当前路径为空,或当前路径、入参路径非法时抛出异常
func join
public func join(path: Path): Path
功能:在当前路径后拼接另一个路径形成新路径对于路径 "a/b", "c",返回 "a/b/c" 对于路径 "a", "b/c",返回 "a/b/c"。
返回值:新路径的 Path 实例
异常:
- FSException:如果参数 path 是绝对路径则抛异常
- IllegalArgumentException:当前路径为空,或当前路径、入参路径非法时抛出异常
func toCanonical
public func toCanonical(): Path
功能:将 Path 规范化返回绝对路径形式的规范化路径,所有的中间引用和软链接都会处理 (UNC 路径下的软链接无法被规范化)对于路径 "/foo/test/../test/bar.txt",该函数会返回 "/foo/test/bar.txt"。
返回值:规范化路径的 Path 实例
异常:
- FSException:路径不存在或无法规范化时抛出异常
- IllegalArgumentException:路径为空,或包含字符串结束符时抛出异常
operator func ==
public operator func ==(that: Path): Bool
功能:判断 Path 是否是同一路径。
返回值:true,是同一路径;false,不是同一路径
operator func !=
public operator func !=(that: Path): Bool
功能:判断 Path 是否不是同一路径。
返回值:true,不是同一路径;false,是同一路径
func hashCode
public func hashCode(): Int64
功能:获得 Path 的哈希值。
返回值:Path 的哈希值
func toString
public func toString(): String
功能:获得 Path 的路径字符串。
返回值:Path 的路径字符串
enum OpenOption
public enum OpenOption {
| Append
| Create(Bool)
| Truncate(Bool)
| Open(Bool, Bool)
| CreateOrTruncate(Bool)
| CreateOrAppend
}
OpenOption 枚举类型表示不同的文件打开选项。
Append
Append
功能:构造一个 OpenOption 实例,指定文件系统应打开现有文件并查找到文件尾,用这个选项创建的 File 默认只具有 Write 权限,试图查找文件尾之前的位置时会引发 FSException 异常,并且任何试图读取的操作都会失败并引发异常,如果文件不存在,则将引发异常。
Create
Create(Bool)
功能:构造一个 OpenOption 实例,指定文件系统应创建新文件,用这个选项创建的 File 默认具有 Write 权限,可以通过参数指定是否具有 Read 权限。如果文件已存在,则将引发异常。
Truncate
Truncate(Bool)
功能:构造一个 OpenOption 实例,指定文件系统应打开现有文件,该文件被打开时,将被截断为零字节大小。用这个选项创建的 File 默认具有 Write 权限,可以通过参数指定是否具有 Read 权限。如果文件不存在,则将引发异常。
Open
Open(Bool, Bool)
功能:构造一个 OpenOption 实例,指定文件系统应打开现有文件,第一个参数指定文件是否具有 Read 权限,第二个参数指定文件具有 Write 权限。如果文件不存在,则将引发异常。
CreateOrTruncate
CreateOrTruncate(Bool)
功能:构造一个 OpenOption 实例,指定文件系统应创建新文件,如果此文件已存在,则会将其覆盖。用这个选项创建的 File 默认具有 Write 权限,可以通过参数指定是否具有 Read 权限。分为两种情况:如果文件不存在,则使用 Create;否则使用 Truncate。
CreateOrAppend
CreateOrAppend
功能:构造一个 OpenOption 实例,指定文件系统应打开文件(如果文件存在),否则,应创建新文件。用这个选项创建的 File 默认只具有 Write 权限,并且试图查找文件尾之前的位置时会引发 FSException 异常。分为两种情况:如果文件不存在,则使用 Create;否则使用 Append。
struct FileDescriptor
public struct FileDescriptor
此类用于获取文件句柄信息。
prop fileHandle
public prop fileHandle: CPointer<Unit>
功能:Windows 下获取文件句柄信息。
prop fileHandle
public prop fileHandle: Int32
功能:Linux 下获取文件句柄信息。
class File
public class File <: Resource & InputStream & OutputStream & Seekable {
public init(path: String, openOption: OpenOption)
public init(path: Path, openOption: OpenOption)
}
此类提供一些对文件进行操作的函数,包括文件的流式读写操作和一些常用的辅助函数等。
注:创建的 File 对象会默认打开对应的文件,当使用结束后需要及时调用 close 函数关闭文件, 否则会造成资源泄露。
init
public init(path: String, openOption: OpenOption)
功能:创建 File 对象。
参数:
- path:文件路径字符串
- openOption:文件打开选项
异常:
- FSException:如果创建操作时文件已存在、进行操作时文件不存在、文件的父目录不存在,或其他原因导致无法打开文件,则抛异常
- IllegalArgumentException:如果 path 是空字符串或者 path 包含 '\0',则抛出异常
init
public init(path: Path, openOption: OpenOption)
功能:创建一个 File 对象。
参数:
- path:文件路径
- openOption:文件打开选项
异常:
- FSException:如果创建操作时文件已存在、进行操作时文件不存在、文件的父目录不存在,或其他原因导致无法打开文件,则抛异常
- IllegalArgumentException:如果 path 为空路径或者 path 路径中包含 '\0',则抛出异常
prop length
public prop length: Int64
功能:获取文件头至文件尾的数据字节数。
prop remainLength
public prop remainLength: Int64
功能:获取文件当前光标位置至文件尾的数据字节数。
prop position
public prop position: Int64
功能:获取文件当前光标位置。
prop info
public prop info: FileInfo
功能:获取文件元数据信息。
prop fileDescriptor
public prop fileDescriptor: FileDescriptor
功能:获取文件描述符信息。
func read
public func read(buffer: Array<Byte>): Int64
功能:从文件中读出数据到 buffer 中。
参数:
- buffer:读取数据存放的缓冲区
返回值:读取成功,返回读取字节数,如果文件被读完,返回 0
异常:
- IllegalArgumentException:如果 buffer 为空,则抛出异常
- FSException:读取失败、文件已关闭,或文件不可读,则抛出异常
func write
public func write(buffer: Array<Byte>): Unit
功能:将 buffer 中的数据写入到文件中。
参数:
- buffer:待写入数据的缓冲区,若 buffer 为空则直接返回
异常:
- FSException:如果写入失败或者只写入了部分数据,或文件已关闭、文件不可写,则抛出异常
func seek
public func seek(sp: SeekPosition): Int64
功能:将光标跳转到指定位置,指定的位置不能位于文件头部之前,指定位置可以超过文件末尾,但指定位置到文件头部的最大偏移量不能超过当前文件系统允许的最大值,这个最大值接近当前文件系统的所允许的最大文件大小,一般为最大文件大小减去 4096 个字节。
参数:
- sp:指定光标跳转后的位置
返回值:返回文件头部到跳转后位置的偏移量(以字节为单位)
异常:
- FSException:指定位置不满足以上情况时,或如果文件不能seek,seek 操作均会抛异常
func canRead
public func canRead(): Bool
功能:判断当前 File 对象是否可读,该函数返回值由创建文件对象的 openOption 所决定,文件对象关闭后返回 false。
返回值:返回 false 表示不可读或文件对象已关闭,返回 true 表示可读
func canWrite
public func canWrite(): Bool
功能:判断当前 File 对象是否可写,该函数返回值由创建文件对象的 openOption 所决定,文件对象关闭后返回 falsefalse:不可写或文件对象已关闭。
返回值:返回 true 表示可写
func readToEnd
public func readToEnd(): Array<Byte>
功能:读取当前 File 所有剩余数据,以 Array
返回值:文件内剩余的 bytes
异常:
- FSException:如果读取失败,或文件不可读,则抛异常
func copyTo
public func copyTo(out: OutputStream): Unit
功能:将当前 File 还没读取的数据全部写入到指定的 OutputStream 中。
参数:
- out:待写入的 OutputStream
异常:
- FSException:文件读取时未被打开或文件没有读取权限,则抛出异常
func close
public func close(): Unit
功能:关闭当前 File 对象。
异常:
- FSException:如果关闭失败,则抛异常
func isClosed
public func isClosed(): Bool
功能:判断当前 File 对象是否已关闭。
返回值:false 表示未关闭,true 表示已关闭
func exists
public static func exists(path: String): Bool
功能:判断路径对应的文件是否存在。
参数:
- path:文件路径字符串
返回值:false 表示路径不存在或者路径对应的不是文件,true 表示路径对应的是文件或指向文件的软链接
func exists
public static func exists(path: Path): Bool
功能:判断路径对应的文件是否存在。
参数:
- path:文件路径
返回值:false 表示路径不存在或者路径对应的不是文件,true 表示路径对应的是文件或指向文件的软链接
func openRead
public static func openRead(path: String): File
功能:以只读模式打开指定路径的文件。
参数:
- path:文件路径字符串
返回值:File 实例,该实例需要及时调用 close 函数关闭文件
异常:
- FSException:如果文件不存在,或文件不可读,则抛异常
- IllegalArgumentException:文件路径包含空字符则抛出异常
func openRead
public static func openRead(path: Path): File
功能:以只读模式打开指定路径的文件。
参数:
- path:文件路径
返回值:File 实例,该实例需要手动调用 close 函数关闭文件
异常:
- FSException:如果文件不存在,或文件不可读,则抛异常
- IllegalArgumentException:文件路径包含空字符则抛出异常
func create
public static func create(path: String): File
功能:以只写模式创建指定路径的文件。
参数:
- path:文件路径字符串
返回值:File 实例
异常:
- FSException:如果路径指向的文件的上级目录不存在或文件已存在,则抛出异常
- IllegalArgumentException:如果文件路径为空字符串或包含空字符,则抛出异常
func create
public static func create(path: Path): File
功能:以只写模式创建指定路径的文件。
参数:
- path:文件路径
返回值:File 实例
异常:
- FSException:如果路径指向的文件的上级目录不存在或文件已存在,则抛出异常
- IllegalArgumentException:如果文件路径为空或包含空字符,则抛出异常
func createTemp
public static func createTemp(directoryPath: String): File
功能:在指定目录下创建临时文件创建的文件名称是 tmpFileXXXXXX 形式,不使用的临时文件应手动删除。
参数:
- directoryPath:目录路径字符串
返回值:临时文件 File 实例
异常:
- FSException:创建文件失败或路径不存在则抛出异常
- IllegalArgumentException:如果文件路径为空字符串或包含空字符,则抛出异常
func createTemp
public static func createTemp(directoryPath: Path): File
功能:在指定目录下创建临时文件创建的文件名称是 tmpFileXXXXXX 形式,不使用的临时文件应手动删除。
参数:
- path:目录路径
返回值:临时文件 File 实例
异常:
- FSException:创建文件失败或路径不存在则抛出异常
- IllegalArgumentException:如果文件路径为空或包含空字符,则抛出异常
func readFrom
public static func readFrom(path: String): Array<Byte>
功能:直接读取指定路径的文件,以 Array
参数:
- path:文件路径字符串
返回值:文件内所有 bytes
异常:
- FSException:文件读取失败、文件关闭失败、文件路径为空、文件不可读,则抛出异常
- IllegalArgumentException:文件路径包含空字符则抛出异常
func readFrom
public static func readFrom(path: Path): Array<Byte>
功能:直接读取指定路径的文件,以 Array
参数:
- path:文件路径
返回值:文件内所有 bytes
异常:
- FSException:文件路径为空、文件不可读、文件读取失败,则抛出异常
- IllegalArgumentException:文件路径包含空字符则抛出异常
func writeTo
public static func writeTo(path: String, buffer: Array<Byte>, openOption!: OpenOption = CreateOrAppend): Unit
功能:按照 openOption 打开指定路径的文件并将 buffer 写入。
参数:
- path:文件路径字符串
- buffer:待写入的 bytes
- openOption:文件打开选项,默认为 CreateOrAppend
异常:
- FSException:文件路径为空则抛出异常
- IllegalArgumentException:如果文件路径为空字符串或包含空字符,则抛出异常
func writeTo
public static func writeTo(path: Path, buffer: Array<Byte>, openOption!: OpenOption = CreateOrAppend): Unit
功能:按照 openOption 打开指定路径的文件并将 buffer 写入。
参数:
- path:文件路径
- buffer:待写入的 bytes
- openOption:文件打开选项,默认为 CreateOrAppend
异常:
- FSException:文件路径为空则抛出异常
- IllegalArgumentException:如果文件路径为空或包含空字符,则抛出异常
func delete
public static func delete(path: String): Unit
功能:删除指定路径下的文件,删除文件前需保证文件已关闭,否则可能删除失败。
参数:
- path:文件路径字符串
异常:
- FSException:如果指定文件不存在,或删除失败,则抛异常
func delete
public static func delete(path: Path): Unit
功能:删除指定路径下的文件,删除文件前需保证文件已关闭,否则可能删除失败。
参数:
- path:文件路径
异常:
- FSException:如果指定文件不存在,或删除失败,则抛异常
func move
public static func move(sourcePath: String, destinationPath: String, overwrite: Bool): Unit
功能:移动文件,当 overwrite 为 true,如果指定路径中已有同名的文件,则会覆盖已存在的文件。 参数:
- sourcePath:文件原路径
- destinationPath:文件目标路径
- overwrite:是否覆盖
异常:
- IllegalArgumentException:目标目录名为空,或目标目录名包含空字符
- FSException:源目录不存在,或 overwrite 为 false 时目标目录已存在,或移动失败
func move
public static func move(sourcePath: Path, destinationPath: Path, overwrite: Bool): Unit
功能:移动文件当 overwrite 为 true,如果指定路径中已有同名的文件,则会覆盖已存在的文件。 参数:
- sourcePath:文件原路径
- destinationPath:文件目标路径
- overwrite:是否覆盖
异常:
- IllegalArgumentException:目标目录名为空,或目标目录名包含空字符
- FSException:源目录不存在,或 overwrite 为 false 时目标目录已存在,或移动失败
func copy
public static func copy(sourcePath: String, destinationPath: String, overwrite: Bool): Unit
功能:将文件拷贝到新的位置,不成功则抛异常。
参数:
- sourcePath:文件原路径
- destinationPath:文件目标路径
- overwrite:是否覆盖
异常:
- FSException:文件路径为空,或源路径文件无读权限,或目标路径文件已存在且无写权限则抛出异常
- IllegalArgumentException:文件路径包含空字符则抛出异常
func copy
public static func copy(sourcePath: Path, destinationPath: Path, overwrite: Bool): Unit
功能:将文件拷贝到新的位置,不成功则抛异常。
参数:
- sourcePath:文件原路径
- destinationPath:文件目标路径
- overwrite:是否覆盖
异常:
- FSException:文件路径为空,或源路径文件无读权限,或目标路径文件已存在且无写权限则抛出异常
- IllegalArgumentException:文件路径包含空字符则抛出异常
func flush
public func flush(): Unit
功能:清空缓存区,该函数提供默认实现,默认实现为空。
class Directory
Directory 对应文件系统中的目录,它提供了常规目录操作,以及遍历目录的能力。
public class Directory <: Iterable<FileInfo> {
public init(path: String)
public init(path: Path)
}
init
public init(path: String)
功能:创建 Directory 实例,路径非法抛异常。
参数:
- path:String 形式的目录路径
异常:
- FSException:当路径不存在时或路径为空时,抛出异常
init
public init(path: Path)
功能:创建 Directory 实例。
参数:
- path:Path 形式的目录路径
异常:
- FSException:如果路径非法,则抛异常
func exists
public static func exists(path: String): Bool
功能:判断路径对应的目录是否存在。
参数:
- path:String 形式的目录路径
返回值:false 表示路径不存在,或者路径对应的不是目录,true 表示路径对应的是目录或指向目录的软链接
func exists
public static func exists(path: Path): Bool
功能:判断路径对应的目录是否存在。
参数:
- path:Path 形式的目录路径
返回值:false 表示路径不存在或者路径对应的不是目录,true 表示路径对应的是目录或指向目录的软链接
func create
public static func create(path: String, recursive!: Bool = false): Directory
功能:创建目录,可指定是否递归创建,如果需要递归创建,将逐级创建路径中不存在的目录,否则仅创建最后一级目录。
参数:
- path:待创建的目录路径
- recursive:是否递归创建目录,默认 false
返回值:新创建的 Directory 实例
异常:
- FSException:目录已存在时,抛出异常;非递归时中间有不存在的目录时抛出异常
- IllegalArgumentException:目录为空、目录为当前目录、目录为根目录,或目录中存在空字符时抛出异常
func create
public static func create(path: Path, recursive!: Bool = false): Directory
功能:创建目录,可指定是否递归创建,如果需要递归创建,将逐级创建路径中不存在的目录,否则仅创建最后一级目录。
参数:
- path:待创建的目录路径
- recursive:是否递归创建目录,默认 false
返回值:新创建的 Directory 实例
异常:
- FSException:目录已存在时,抛出异常;非递归时中间有不存在的目录时抛出异常
- IllegalArgumentException:目录为空、目录为当前目录、目录为根目录,或目录中存在空字符时抛出异常
func createTemp
public static func createTemp(directoryPath: String): Directory
功能:在指定目录下创建临时目录。
参数:
- directoryPath:String 形式的目录路径
返回值:临时目录的 Directory 实例
异常:
- FSException:目录不存在或创建失败时抛出异常
- IllegalArgumentException:目录为空或包含空字符时抛出异常
func createTemp
public static func createTemp(directoryPath: Path): Directory
功能:在指定目录下创建临时目录。
参数:
- directoryPath:Path 对象形式的目录路径
返回值:临时目录的 Directory 实例
异常:
- FSException:目录不存在或创建失败时抛出异常
- IllegalArgumentException:目录为空或包含空字符时抛出异常
func delete
public static func delete(path: String, recursive!: Bool = false): Unit
功能:删除目录,可指定是否递归删除,如果需要递归删除,将逐级删除目录,否则仅删除最后一级目录。
参数:
- path:String 形式的指定目录路径
- recursive:是否递归,默认不递归
异常:
- FSException:如果目录不存在或递归删除失败,则抛出异常
- IllegalArgumentException:如果 path 为空字符串或包含空字符或长度大于 4096 ,则出抛异常
func delete
public static func delete(path: Path, recursive!: Bool = false): Unit
功能:删除目录,可指定是否递归删除,如果需要递归删除,将逐级删除目录,否则仅删除最后一级目录。
参数:
- path:String 形式的指定目录路径
- recursive:是否递归,默认不递归
异常:
- FSException:如果目录不存在或递归删除失败,则抛出异常
- IllegalArgumentException:如果 path 为空字符串或包含空字符或长度大于 4096 ,则出抛异常
func move
public static func move(sourceDirPath: String, destinationDirPath: String, overwrite: Bool): Unit
功能:将该目录以及文件、子文件夹都移动到指定路径。
参数:
- sourceDirPath:String 形式的源目录路径
- destinationDirPath:String 形式的目标目录路径
- overwrite:是否覆盖, 为 true 时将覆盖目标路径中的所有子文件夹和文件
异常:
- IllegalArgumentException:目标目录名为空,或目标目录名包含空字符
- FSException:源目录不存在,或 overwrite 为 false 时目标目录已存在,或移动失败
func move
public static func move(sourceDirPath: Path, destinationDirPath: Path, overwrite: Bool): Unit
功能:将该目录以及文件、子文件夹都移动到指定路径。
参数:
- sourceDirPath:String 形式的源目录路径
- destinationDirPath:String 形式的目标目录路径
- overwrite:是否覆盖, 为 true 时将覆盖目标路径中的所有子文件夹和文件
异常:
- IllegalArgumentException:目标目录名为空,或目标目录名包含空字符
- FSException:源目录不存在,或 overwrite 为 false 时目标目录已存在,或移动失败
func copy
public static func copy(sourceDirPath: String, destinationDirPath: String, overwrite: Bool): Unit
功能:将该目录以及文件、子文件夹都拷贝到新的位置,不成功则抛异常。
参数:
- sourceDirPath:String 形式的源目录路径
- destinationDirPath:String 形式的目标目录路径
- overwrite:是否覆盖
异常:
- FSException:源目录不存在,或 overwrite 为 false 时目标目录已存在,或目标目录在源目录中,或复制失败,抛出异常
- IllegalArgumentException:源目录或目标目录名包含空字符则抛出异常
func copy
public static func copy(sourceDirPath: Path, destinationDirPath: Path, overwrite: Bool): Unit
功能:将该目录以及文件、子文件夹都拷贝到新的位置。
参数:
- sourceDirPath:Path 形式的源目录路径
- destinationDirPath:Path 形式的目标目录路径
- overwrite:是否覆盖
异常:
- FSException:源目录不存在,或 overwrite 为 false 时目标目录已存在,或目标目录在源目录中,或复制失败,抛出异常
- IllegalArgumentException:源目录或目标目录名包含空字符则抛出异常
func createSubDirectory
public func createSubDirectory(name: String): Directory
功能:在当前 Directory 下创建指定名字的子目录。
参数:
- name:子目录名,参数只接受不带路径前缀的字符串
返回值:子目录的 Directory 实例
异常:
- FSException:当子目录名中含有路径信息,路径已存在,或创建目录失败时,抛出异常
- IllegalArgumentException:当目录名中含有空字符时,抛出异常
func createFile
public func createFile(name: String): File
功能:在当前 Directory 下创建指定名字的子文件。
参数:
- name:子文件名,参数只接受不带路径前缀的字符串
返回值:子文件的 File 实例,该实例需要手动调用 close 函数关闭文件
异常:
- FSException:当子文件名中含有路径信息,文件名已存在,抛出异常
- IllegalArgumentException:当文件名包含空字符时抛出异常
prop info
public prop info: FileInfo
功能:当前目录元数据信息
func isEmpty
public func isEmpty(): Bool
功能:判断当前目录是否为空。
异常:
- FSException:如果判断过程中底层调用的系统接口发生错误,则抛异常
func iterator
public func iterator(): Iterator<FileInfo>
功能:返回当前目录的文件或子目录迭代器。
返回值:当前目录的文件或子目录迭代器
异常:
- FSException:获取目录的成员信息失败时,抛出异常
func directories
public func directories(): Iterator<FileInfo>
功能:返回当前目录的子目录迭代器。
返回值:当前目录的子目录迭代器
异常:
- FSException:获取目录的成员信息失败时,抛出异常
func files
public func files(): Iterator<FileInfo>
功能:返回当前目录的子文件迭代器。
返回值:当前目录的子文件迭代器
异常:
- FSException:获取目录的成员信息失败时,抛出异常
func entryList
public func entryList(): ArrayList<FileInfo>
功能:返回当前目录的文件或子目录列表。
返回值:当前目录的文件或子目录列表
异常:
- FSException:获取目录的成员信息失败时,抛出异常
func directoryList
public func directoryList(): ArrayList<FileInfo>
功能:返回当前目录的子目录列表。
返回值:当前目录的所有子目录列表
异常:
- FSException:获取目录的成员信息失败时,抛出异常
func fileList
public func fileList(): ArrayList<FileInfo>
功能:返回当前目录的子文件列表。
返回值:当前目录的子文件列表
异常:
- FSException:获取目录的成员信息失败时,抛出异常
struct FileInfo
public struct FileInfo <: Equatable<FileInfo> {
public init(path: String)
public init(path: Path)
}
FileInfo 对应文件系统中的文件元数据,提供一些文件属性的查询和操作。
FileInfo 的底层实现是没有直接缓存文件属性的,每次通过 FileInfo 的 API 都是现场获取的最新的文件属性。
因此这里有需要注意的情况,对于创建的同一 FileInfo 实例,如果在两次获取其文件属性操作期间,对应的文件实体可能会被其他用户或进程做了修改或者替换等不期望的操作,就会导致后一次获取的可能不是期望的文件属性。 如果有特殊文件操作需求需要避免上述情况的产生,可以采用设置文件权限或者给关键文件操作加锁的方式来保证。
init
public init(path: String)
功能:创建 FileInfo 实例。
参数:
- path:String 形式的目录路径
异常:
- FSException:路径非法
init
public init(path: Path)
功能:创建 FileInfo 实例。
参数:
- path:Path 形式的目录路径
异常:
- FSException:路径非法
prop parentDirectory
public prop parentDirectory: Option<FileInfo>
功能:获得父级目录元数据,以 Option
prop path
public prop path: Path
功能:获得当前文件路径,以 Path 形式返回
prop symbolicLinkTarget
public prop symbolicLinkTarget: Option<Path>
功能:获得链接目标路径,以 Option
prop creationTime
public prop creationTime: DateTime
功能:获取创建时间。
异常 FSException - 如果判断过程中底层调用的系统接口发生错误,则抛异常
prop lastAccessTime
public prop lastAccessTime: DateTime
功能:获取最后访问时间。
异常 FSException - 如果判断过程中底层调用的系统接口发生错误,则抛异常
prop lastModificationTime
public prop lastModificationTime: DateTime
功能:获取最后修改时间。
异常 FSException - 如果判断过程中底层调用的系统接口发生错误,则抛异常
prop length
public prop length: Int64
功能:返回当前文件大小。
- 当前是文件时,表示单个文件占用磁盘空间的大小
- 当前是目录时,表示当前目录的所有文件占用磁盘空间的大小
异常:
- FSException:如果判断过程中底层调用的系统接口发生错误,则抛异常
func isSymbolicLink
public func isSymbolicLink(): Bool
功能:判断当前文件是否是软链接。
异常:
- FSException:如果判断过程中底层调用的系统接口发生错误,则抛异常
func isFile
public func isFile(): Bool
功能:判断当前文件是否是普通文件。
异常:
- FSException:如果判断过程中底层调用的系统接口发生错误,则抛异常
func isDirectory
public func isDirectory(): Bool
功能:判断当前文件是否是目录。
异常:
- FSException:如果判断过程中底层调用的系统接口发生错误,则抛异常
func isReadOnly
public func isReadOnly(): Bool
功能:判断当前文件是否只读。
- 在 Windows 环境下,用户对于文件的只读权限正常使用;用户始终拥有对于目录的删除修改权限,该函数不生效,返回 false
- 在 Linux 和 macOS 环境下,该函数正常使用
异常:
- FSException:如果判断过程中底层调用的系统接口发生错误,则抛异常
func isHidden
public func isHidden(): Bool
功能:判断当前文件是否隐藏。
func canExecute
public func canExecute(): Bool
功能:判断当前用户是否有权限执行该实例对应的文件。
- 对文件而言,判断用户是否有执行文件的权限
- 对目录而言,判断用户是否有进入目录的权限
- 在 Windows 环境下,用户对于文件的执行权限由文件扩展名决定;用户始终拥有对于目录的执行权限,该函数不生效,返回 true
- 在 Linux 和 macOS 环境下,该函数正常使用
异常:
- FSException:如果判断过程中底层调用的系统接口发生错误,则抛异常
func canRead
public func canRead(): Bool
功能:判断当前用户是否有权限读取该实例对应的文件。
- 对文件而言,判断用户是否有读取文件的权限
- 对目录而言,判断用户是否有浏览目录的权限
- 在 windows 环境下,用户始终拥有对于文件和目录的可读权限,该函数不生效,返回 true
- 在 Linux 和 macOS 环境下,该函数正常使用
异常:
- FSException:如果判断过程中底层调用的系统接口发生错误,或文件不可读,则抛异常
func canWrite
public func canWrite(): Bool
功能:判断当前用户是否有权限写入该实例对应的文件。
- 对文件而言,判断用户是否有写入文件的权限
- 对目录而言,判断用户是否有删除、移动、创建目录内文件的权限
- 在 Windows 环境下,用户对于文件的可写权限正常使用,用户始终拥有对于目录的可写权限,该函数不生效,返回 true
- 在 Linux 和 macOS 环境下,该函数正常使用
异常:
- FSException:如果判断过程中底层调用的系统接口发生错误,则抛异常
func setExecutable
public func setExecutable(executable: Bool): Bool
功能:对当前实例对应的文件设置当前用户是否可执行的权限,当前用户没有权限修改抛异常。
- 对文件而言,设置用户是否有执行文件的权限,对目录而言,设置用户是否有进入目录的权限
- 在 Windows 环境下,用户对于文件的执行权限由文件扩展名决定,用户始终拥有对于目录的执行权限该函数不生效,返回 false
- 在 Linux 和 macOS 环境下,该函数正常使用如果在此函数调用期间,该 FileInfo 对应的文件实体被其它用户或者进程修改,有可能因为竞争条件(Race Condition)导致其它修改不能生效
参数:
- executable:是否设置可执行
返回值:true,操作成功;false,操作失败
func setReadable
public func setReadable(readable: Bool): Bool
功能:对当前实例对应的文件设置当前用户是否可读取的权限,当前用户没有权限修改抛异常。
- 对文件而言,设置用户是否有读取文件的权限
- 对目录而言,设置用户是否有浏览目录的权限
- 在 Windows 环境下,用户始终拥有对于文件以及目录的可读权限,不可更改,该函数不生效当 readable 为 true 时,函数返回 true,当 readable 为 false 时,函数返回 false
- 在 Linux 和 macOS 环境下,该函数正常使用如果在此函数调用期间,该 FileInfo 对应的文件实体被其它用户或者进程修改,有可能因为竞争条件(Race Condition)导致其它修改不能生效。
参数:
- readable:是否设置可读
返回值:true,操作成功;false,操作失败
func setWritable
public func setWritable(writable: Bool): Bool
功能:对当前实例对应的文件设置当前用户是否可写入的权限,当前用户没有权限修改抛异常。
- 对文件而言,设置用户是否有写入文件的权限对
- 目录而言,设置用户是否有删除、移动、创建目录内文件的权限
- 在 Windows 环境下,用户对于文件的可写权限正常使用;用户始终拥有对于目录的可写权限,不可更改,该函数不生效,返回 false
- 在 Linux 和 macOS 环境下,该函数正常使用如果在此函数调用期间,该 FileInfo 对应的文件实体被其它用户或者进程修改,有可能因为竞争条件(Race Condition)导致其它修改不能生效
参数:
- writable:是否设置可写
返回值:true,操作成功;false,操作失败
operator func ==
public operator func ==(that: FileInfo): Bool
功能:判断当前 FileInfo 和另一个 FileInfo 是否对应同一文件。
返回值:true,是同一文件;false,不是同一文件
operator func !=
public operator func !=(that: FileInfo): Bool
功能:判断当前 FileInfo 和另一个 FileInfo 是否对应非同一文件。
返回值:true,不是同一文件;false,是同一文件
class FSException
此类是文件流异常类,继承了异常类
public class FSException <: Exception {
public init()
public init(message: String)
}
init
public init()
功能:无参构造函数。
init
public init(message: String)
参数:
- message:错误信息
示例
Path 示例
不同 Path 实例的属性信息展示
打印 Path 实例的目录部分、文件全名(有扩展名)、扩展名、文件名(无扩展名),并判断 Path 实例是绝对路径还是相对路径
代码如下:
from std import fs.Path
main() {
let pathStrArr: Array<String> = [
// 绝对路径
"/a/b/c",
"/a/b/",
"/a/b/c.cj",
"/a",
"/",
// 相对路径
"./a/b/c",
"./a/b/",
"./a/b/c.cj",
"./",
".",
"123."
]
for (i in 0..pathStrArr.size) {
let path: Path = Path(pathStrArr[i])
// 打印 path 的整个路径字符串
println("Path${i}: ${path.toString()}")
// 打印 path 的目录路径
println("Path.directoryName: ${path.directoryName}")
// 打印 path 的文件全名(有扩展名)
println("Path.fileName: ${path.fileName}")
// 打印 path 的扩展名
println("Path.extensionName: ${path.extensionName}")
// 打印 path 的文件名(无扩展名)
println("Path.fileNameWithoutExtension: ${path.fileNameWithoutExtension}")
// 打印 path 的拆分成的目录路径和文件全名
var (directoryName, fileName): (Option<Path>, Option<String>) = path.split()
println("Path.split: (${directoryName}, ${fileName})")
// 打印 path 的是否是符号链接、普通文件、目录
println("Path.isAbsolute: ${path.isAbsolute()}; Path.isRelative: ${path.isRelative()}")
println()
}
return 0
}
运行结果如下:
Path0: /a/b/c
Path.directoryName: Some(/a/b)
Path.fileName: Some(c)
Path.extensionName: None
Path.fileNameWithoutExtension: Some(c)
Path.split: (Some(/a/b), Some(c))
Path.isAbsolute: true; Path.isRelative: false
Path1: /a/b/
Path.directoryName: Some(/a/b)
Path.fileName: None
Path.extensionName: None
Path.fileNameWithoutExtension: None
Path.split: (Some(/a/b), None)
Path.isAbsolute: true; Path.isRelative: false
Path2: /a/b/c.cj
Path.directoryName: Some(/a/b)
Path.fileName: Some(c.cj)
Path.extensionName: Some(cj)
Path.fileNameWithoutExtension: Some(c)
Path.split: (Some(/a/b), Some(c.cj))
Path.isAbsolute: true; Path.isRelative: false
Path3: /a
Path.directoryName: Some(/)
Path.fileName: Some(a)
Path.extensionName: None
Path.fileNameWithoutExtension: Some(a)
Path.split: (Some(/), Some(a))
Path.isAbsolute: true; Path.isRelative: false
Path4: /
Path.directoryName: Some(/)
Path.fileName: None
Path.extensionName: None
Path.fileNameWithoutExtension: None
Path.split: (Some(/), None)
Path.isAbsolute: true; Path.isRelative: false
Path5: ./a/b/c
Path.directoryName: Some(./a/b)
Path.fileName: Some(c)
Path.extensionName: None
Path.fileNameWithoutExtension: Some(c)
Path.split: (Some(./a/b), Some(c))
Path.isAbsolute: false; Path.isRelative: true
Path6: ./a/b/
Path.directoryName: Some(./a/b)
Path.fileName: None
Path.extensionName: None
Path.fileNameWithoutExtension: None
Path.split: (Some(./a/b), None)
Path.isAbsolute: false; Path.isRelative: true
Path7: ./a/b/c.cj
Path.directoryName: Some(./a/b)
Path.fileName: Some(c.cj)
Path.extensionName: Some(cj)
Path.fileNameWithoutExtension: Some(c)
Path.split: (Some(./a/b), Some(c.cj))
Path.isAbsolute: false; Path.isRelative: true
Path8: ./
Path.directoryName: Some(.)
Path.fileName: None
Path.extensionName: None
Path.fileNameWithoutExtension: None
Path.split: (Some(.), None)
Path.isAbsolute: false; Path.isRelative: true
Path9: .
Path.directoryName: None
Path.fileName: Some(.)
Path.extensionName: None
Path.fileNameWithoutExtension: None
Path.split: (None, Some(.))
Path.isAbsolute: false; Path.isRelative: true
Path10: 123.
Path.directoryName: None
Path.fileName: Some(123.)
Path.extensionName: None
Path.fileNameWithoutExtension: Some(123)
Path.split: (None, Some(123.))
Path.isAbsolute: false; Path.isRelative: true
Path 的拼接、判等、转规范化路径等操作
代码如下:
from std import fs.*
main() {
let dirPath: Path = Path("./a/b/c")
if (!Directory.exists(dirPath)) {
Directory.create(dirPath, recursive: true)
}
let filePath: Path = dirPath.join("d.cj") // ./a/b/c/d.cj
if (filePath == Path("./a/b/c/d.cj")) {
println("filePath.join: success")
}
if (!File.exists(filePath)) {
File.create(filePath).close()
}
let curNormalizedPath: Path = Path(".").toCanonical()
let fileNormalizedPath: Path = Path("././././a/./../a/b/../../a/b/c/.././../../a/b/c/d.cj").toCanonical()
if (fileNormalizedPath == filePath &&
fileNormalizedPath.toString() == curNormalizedPath.toString() + "/a/b/c/d.cj") {
println("filePath.toCanonical: success")
}
Directory.delete(dirPath, recursive: true)
return 0
}
运行结果如下:
filePath.join: success
filePath.toCanonical: success
通过 Path 创建文件和目录
代码如下:
from std import fs.*
main() {
let curPath: Path = Path("./")
let dirPath: Path = curPath.join("tempDir")
let filePath: Path = dirPath.join("tempFile.txt")
if (Directory.exists(dirPath)) {
Directory.delete(dirPath, recursive: true)
}
Directory.create(dirPath)
if (Directory.exists(dirPath)) {
println("Directory 'tempDir' is created successfully.")
}
File.create(filePath).close()
if (File.exists(filePath)) {
println("File 'tempFile.txt' is created successfully in directory 'tempDir'.")
}
Directory.delete(dirPath, recursive: true)
return 0
}
运行结果如下:
Directory 'tempDir' is created successfully.
File 'tempFile.txt' is created successfully in directory 'tempDir'.
File 示例
File 常规操作:创建、删除、读写、关闭
代码如下:
from std import fs.*
from std import io.SeekPosition
main() {
let filePath: Path = Path("./tempFile.txt")
if (File.exists(filePath)) {
File.delete(filePath)
}
/* 在当前目录以 只写模式 创建新文件 'tempFile.txt',写入三遍 "123456789\n" 并关闭文件 */
var file: File = File(filePath, OpenOption.Create(false))
if (File.exists(filePath)) {
println("The file 'tempFile.txt' is created successfully in current directory.\n")
}
let bytes: Array<Byte> = b"123456789\n"
for (_ in 0..3) {
file.write(bytes)
}
file.close()
/* 以 追加模式 打开文件 './tempFile.txt',写入 "abcdefghi\n" 并关闭文件 */
file = File(filePath, OpenOption.Append)
file.write(b"abcdefghi\n")
file.close()
/* 以 只读模式 打开文件 './tempFile.txt',按要求读出数据并关闭文件 */
file = File(filePath, OpenOption.Open(true, false))
let bytesBuf: Array<Byte> = Array<Byte>(10, item: 0)
// 从文件头开始的第 10 个字节后开始读出 10 个字节的数据
file.seek(SeekPosition.Begin(10))
file.read(bytesBuf)
println("Data of the 10th byte after the 10th byte: ${String.fromUtf8(bytesBuf)}")
// 读出文件尾的 10 个字节的数据
file.seek(SeekPosition.End(-10))
file.read(bytesBuf)
println("Data of the last 10 bytes: ${String.fromUtf8(bytesBuf)}")
file.close()
/* 以 截断模式 打开文件 './tempFile.txt',写入 "The file was truncated to an empty file!" 并关闭文件 */
file = File(filePath, OpenOption.Truncate(true))
file.write(b"The file was truncated to an empty file!")
file.seek(SeekPosition.Begin(0))
let allBytes: Array<Byte> = file.readToEnd()
file.close()
println("Data written newly: ${String.fromUtf8(allBytes)}")
File.delete(filePath)
return 0
}
运行结果如下:
The file 'tempFile.txt' is created successfully in current directory.
Data of the 10th byte after the 10th byte: 123456789
Data of the last 10 bytes: abcdefghi
Data written newly: The file was truncated to an empty file!
File 的一些 static 函数演示
代码如下:
from std import fs.*
main() {
let filePath: Path = Path("./tempFile.txt")
if (File.exists(filePath)) {
File.delete(filePath)
}
/* 以 只写模式 创建文件,并写入 "123456789\n" 并关闭文件 */
var file: File = File.create(filePath)
file.write(b"123456789\n")
file.close()
/* 以 追加模式 写入 "abcdefghi\n" 到文件 */
File.writeTo(filePath, b"abcdefghi", openOption: OpenOption.Append)
/* 直接读取文件中所有数据 */
let allBytes: Array<Byte> = File.readFrom(filePath)
println(String.fromUtf8(allBytes))
File.delete(filePath)
return 0
}
运行结果如下:
123456789
abcdefghi
Directory 示例
Directory 一些基础操作演示
代码如下:
from std import fs.*
main() {
let testDirPath: Path = Path("./testDir")
let subDirPath: Path = Path("./testDir/subDir")
if (Directory.exists(testDirPath)) {
Directory.delete(testDirPath, recursive: true)
}
/* 递归创建目录 和 "./testDir/subDir" */
let subDir: Directory = Directory.create(subDirPath, recursive: true)
if (Directory.exists(subDirPath)) {
println("The directory './testDir/subDir' is successfully created recursively in current directory.")
}
/* 在 "./testDir/subDir" 下创建子目录 "dir1" */
subDir.createSubDirectory("dir1")
if (Directory.exists("./testDir/subDir/dir1")) {
println("The directory 'dir1' is created successfully in directory './testDir/subDir'.")
}
/* 在 "./testDir/subDir" 下创建子文件 "file1" */
subDir.createFile("file1")
if (File.exists("./testDir/subDir/file1")) {
println("The file 'file1' is created successfully in directory './testDir/subDir'.")
}
/* 在 "./testDir" 下创建临时目录 */
let tempDir: Directory = Directory.createTemp(testDirPath)
let tempDirPath: Path = tempDir.info.path
if (Directory.exists(tempDirPath)) {
println("The temporary directory is created successfully in directory './testDir'.")
}
/* 将 "subDir" 移动到临时目录下并重命名为 "subDir_new" */
let newSubDirPath: Path = tempDirPath.join("subDir_new")
Directory.move(subDirPath, newSubDirPath, false)
if (Directory.exists(newSubDirPath) && !Directory.exists(subDirPath)) {
println("The directory './testDir/subDir' is moved successfully to the temporary directory and renamed 'subDir_new'.")
}
/* 将 "subDir_new" 拷贝到 "./testDir" 下并重命名为 "subDir" */
Directory.copy(newSubDirPath, subDirPath, false)
if (Directory.exists(subDirPath) && Directory.exists(newSubDirPath)) {
println("The directory 'subDir_new' is copied successfully to directory './testDir' and renamed 'subDir'.")
}
Directory.delete(testDirPath, recursive: true)
return 0
}
运行结果如下:
The directory './testDir/subDir' is successfully created recursively in current directory.
The directory 'dir1' is created successfully in directory './testDir/subDir'.
The file 'file1' is created successfully in directory './testDir/subDir'.
The temporary directory is created successfully in directory './testDir'.
The directory './testDir/subDir' is moved successfully to the temporary directory and renamed 'subDir_new'.
The directory 'subDir_new' is copied successfully to directory './testDir' and renamed 'subDir'.
FileInfo 示例
FileInfo 一些基础操作演示
代码如下:
from std import fs.*
from std import time.DateTime
main() {
// 在当前目录下创建个临时文件以便下面 FileInfo 的演示
let curDirPath: Path = Path("./").toCanonical()
let file: File = File.createTemp(curDirPath)
file.write(b"123456789\n")
let fileInfo: FileInfo = file.info
file.close()
/* 获得这个文件父级目录的 FileInfo,这个文件的父目录是当前目录 */
let parentDirectory: Option<FileInfo> = fileInfo.parentDirectory
checkResult(parentDirectory == Some(FileInfo(curDirPath)), "The 'parentFileInfo' is obtained successfully.")
/* 获得这个文件的路径 */
/*
let filePath: Path = fileInfo.path
*/
/* 如果文件是软链接,获得其链接文件的 Path,这里的文件不是软链接故是 Option<Path>.None */
let symbolicLinkTarget: Option<Path> = fileInfo.symbolicLinkTarget
checkResult(symbolicLinkTarget == None, "It's not a symbolic link, there's no `symbolicLinkTarget`.")
/* 获取这个文件的创建时间、最后访问时间、最后修改时间 */
/*
let creationTime: DateTime = fileInfo.creationTime
let lastAccessTime: DateTime = fileInfo.lastAccessTime
let lastModificationTime: DateTime = fileInfo.lastModificationTime
*/
/*
* 获取这个文件的 length
* 如果是文件代表这个文件占用磁盘空间的大小
* 如果是目录代表这个目录的所有文件占用磁盘空间的大小(不包含子目录)
*/
/*
let length: Int64 = fileInfo.length
*/
/* 判断这个文件是否是软链接、普通文件、目录 */
checkResult(fileInfo.isSymbolicLink(), "The file is a symbolic link.")
checkResult(fileInfo.isFile(), "The file is a common file.")
checkResult(fileInfo.isDirectory(), "The file is a directory.")
/* 判断这个文件对于当前用户是否是只读、隐藏、可执行、可读、可写 */
checkResult(fileInfo.isReadOnly(), "This file is read-only.")
checkResult(fileInfo.isHidden(), "The file is hidden.")
checkResult(fileInfo.canExecute(), "The file is executable.")
checkResult(fileInfo.canRead(), "The file is readable.")
checkResult(fileInfo.canWrite(), "The file is writable.")
/* 修改当前用户对这个文件的权限,这里设置为对当前用户只读 */
checkResult(fileInfo.setExecutable(false), "The file was successfully set to executable.")
checkResult(fileInfo.setReadable(true), "The file was successfully set to readable.")
checkResult(fileInfo.setWritable(false), "The file was successfully set to writable.")
checkResult(fileInfo.isReadOnly(), "This file is now read-only.")
return 0
}
func checkResult(result: Bool, message: String): Unit {
if (result) {
println(message)
}
}
运行结果如下:
The 'parentFileInfo' is obtained successfully.
It's not a symbolic link, there's no `symbolicLinkTarget`.
The file is a common file.
The file is readable.
The file is writable.
The file was successfully set to executable.
The file was successfully set to readable.
The file was successfully set to writable.
This file is now read-only.
io 包
介绍
io 包提供对字符串、缓冲区、字节数组等进行读写操作的流。
主要接口
interface InputStream
public interface InputStream {
func read(buffer: Array<Byte>): Int64
}
接口 InputStream,输入流接口,继承该接口的 class、interface、struct 需要遵守该接口中函数的入参及返回值定义。
func read
func read(buffer: Array<Byte>): Int64
功能:从输入流中读取数据放到 buffer 中。没有数据可读,返回 0;读取失败,抛出异常。
参数:
- buffer:读取数据存放的缓冲区,若 buffer 为空则抛出异常
返回值:读取成功,返回读取字节数
interface OutputStream
public interface OutputStream {
func write(buffer: Array<Byte>): Unit
func flush(): Unit
}
接口 OutputStream,输出流接口,继承该接口的 class、interface、struct 需要遵守该接口中函数的入参及返回值定义。
func write
func write(buffer: Array<Byte>): Unit
功能:将 buffer 中的数据写入到输出流中,当数据全部成功写入则函数返回,写入失败或者只写入了部分数据,则抛出异常。
参数:
- buffer:待写入数据的缓冲区,若 buffer 为空则直接返回
func flush
func flush(): Unit
功能:清空缓存区,该函数提供默认实现,默认实现为空。
interface IOStream
public interface IOStream <: InputStream & OutputStream {}
接口 IOStream,输入输出流接口,继承该接口的 class、interface、struct 需要遵守该接口中函数的入参及返回值定义。
interface Seekable
public interface Seekable {
func seek(sp: SeekPosition): Int64
prop length: Int64
prop position: Int64
prop remainLength: Int64
}
接口 Seekable,移动光标接口,继承该接口的 class、interface、struct 需要遵守该接口中函数的入参及返回值定义。
func seek
func seek(sp: SeekPosition): Int64
参数:
- sp:指定光标跳转后的位置
返回值:返回流中数据头部到跳转后位置的偏移量(以字节为单位)
prop length
prop length: Int64
功能:返回当前流中的总数据量。
prop remainLength
prop remainLength: Int64
功能:获取当前流中可读的数据量。
prop position
prop position: Int64
功能:获取流当前光标位置。
class IOException
public class IOException <: Exception {
public init()
public init(message: String)
}
异常处理类,继承了 Exception 类,用于处理 io 流相关的异常。
init
public init()
功能:创建 IOException 实例。
init
public init(message: String)
功能:创建带有异常信息 message 的 IOException 实例。
class ContentFormatException
public class ContentFormatException <: Exception
异常处理类,继承了 Exception 类,用于处理字符格式相关的异常。
enum SeekPosition
public enum SeekPosition {
| Current(Int64)
| Begin(Int64)
| End(Int64)
}
SeekPosition 枚举类型表示光标在文件中的位置。
Current
Current(Int64)
功能:构造 SeekPosition 枚举实例,表示在当前实际位置基础上偏移后的位置,偏移量为入参值。
Begin
Begin(Int64)
功能:构造 SeekPosition 枚举实例,表示在文件开始位置基础上偏移后的位置,偏移量为入参值。
End
End(Int64)
功能:构造 SeekPosition 枚举实例,表示在文件结束位置基础上偏移后的位置,偏移量为入参值。
class ByteArrayStream
public class ByteArrayStream <: InputStream & OutputStream & Seekable {
public init()
public init(capacity: Int64)
}
此类基于 Array
init
public init()
功能:默认构造函数,默认的 capacity 是 32。
init
public init(capacity: Int64)
功能:使用传入的 capacity 初始化 ByteArrayStream。
参数:
- capacity:指定的初始容量
异常:
- IllegalArgumentException:当 capacity 小于 0 时,抛出异常
func seek
public func seek(sp: SeekPosition): Int64
功能:将光标跳转到指定位置,指定的位置不能位于流中数据头部之前,指定位置可以超过流中数据末尾。
参数:
- sp:指定光标跳转后的位置
返回值:返回流中数据头部到跳转后位置的偏移量(以字节为单位)
异常:
- IOException:指定的位置位于流中数据头部之前
prop length
public prop length: Int64
功能:返回当前流中的总数据量。
prop remainLength
public prop remainLength: Int64
功能:获取当前流中可读的数据量。
prop position
public prop position: Int64
功能:获取流当前光标位置。
func capacity
public func capacity(): Int64
功能:返回当前缓冲区总容量。
返回值:返回一个 Int64 类型的值
func isEmpty
public func isEmpty(): Bool
功能:返回当前 ByteArrayStream 中是否为空。
返回值:为空返回 true,否则返回 false
func clone
public func clone(): ByteArrayStream
功能:将当前 ByteArrayStream 中的数据拷贝一份,重新构造一个新的 ByteArrayStream。
返回值:拷贝的 ByteArrayStream
func clear
public func clear(): Unit
功能:清除掉当前 ByteArrayStream 中所有数据。
func bytes
public func bytes(): Array<Byte>
功能:返回当前 ByteArrayStream 中没有被读取的所有数据的切片。这个切片会在缓冲区进行读取,写入或重置等修改操作之后变的无效;同时,对切片的修改也会影响缓冲区的内容。
返回值:返回剩余数据的切片
func readToEnd
public func readToEnd(): Array<Byte>
功能:返回当前 ByteArrayStream 中没有被读取的所有数据。
返回值:返回剩余数据的拷贝
func copyTo
public func copyTo(output: OutputStream): Unit
功能:将当前 ByteArrayStream 中没有被读取的所有数据拷贝到 output 流中。
参数:
- output:将要拷贝到的流
func read
public func read(buffer: Array<Byte>): Int64
功能:从输入流中读取数据放到 buffer 中。如果没有数据可读,返回 0 。读取失败,则抛出异常。
参数:
- buffer:读取数据存放的缓冲区
返回值:读取成功,返回读取字节数
异常:
- IllegalArgumentException:当 buffer 为空时, 抛出异常
func write
public func write(buffer: Array<Byte>): Unit
功能:将 buffer 中的数据写入到输出流中,当数据全部成功写入则函数返回。
参数:
- buffer:待写入数据的缓冲区,若 buffer 为空则直接返回
异常:
- IllegalArgumentException:如果 buffer 写入失败或者只写入了部分数据,则抛出异常
func reserve
public func reserve(additional: Int64): Unit
功能:将缓冲区扩容 additional 大小,缓冲区剩余字节数量大于等于 additional 时不发生扩容,当缓冲区剩余字节数量小于 additional 时,取(additional + capacity)与(capacity的1.5倍向下取整)两个值中的最大值进行扩容。
参数:
- additional:将要扩容的大小
异常:
- IllegalArgumentException:当 additional 小于 0 时抛出异常
- OverflowException:当扩容后的缓冲区大小超过 Int64 的最大值时抛出异常
class BufferedInputStream
public class BufferedInputStream<T> <: InputStream where T <: InputStream {
public init(input: T)
public init(input: T, capacity: Int64)
}
此类用于为其他 InputStream 提供指定容量的缓冲区的功能。
init
public init(input: T)
功能:创建一个 BufferedInputStream 实例。
参数:
- input:绑定一个输入流
init
public init(input: T, capacity: Int64)
功能:创建一个 BufferedInputStream 实例。
参数:
- input:绑定一个输入流
- capacity:内部缓冲区容量
异常:
- IllegalArgumentException:当 capacity 小于等于 0 时,抛出异常
func read
public func read(buffer: Array<Byte>): Int64
功能:从绑定的输入流读出数据到 buffer 中。如果没有数据可读,返回 0 。读取失败,抛出异常。
参数:
- buffer:存放读取的数据的缓冲区
返回值:读取成功,返回读取字节数
异常:
- IllegalArgumentException:当 buffer 为空时, 抛出异常
func reset
public func reset(input: T): Unit
功能:绑定新的输入流,重置状态,但不重置 capacity。
参数:
- input:待绑定的输入流
extend BufferedInputStream <: Resource
extend BufferedInputStream<T> <: Resource where T <: Resource
此扩展主要用于实现 BufferedInputStream 的 Resource 接口。
func close
public func close(): Unit
功能:关闭当前流。调用此方法后不可再调用 BufferedInputStream 的其他接口,否则会造成不可期现象。
func isClosed
public func isClosed(): Bool
功能:判断当前流是否关闭。
返回值:如果当前流已经被关闭,返回 true,否则返回 false
extend BufferedInputStream <: Seekable
extend BufferedInputStream<T> <: Seekable where T <: Seekable
此扩展主要用于实现 BufferedInputStream 的 Seekable 接口。
func seek
public func seek(sp: SeekPosition): Int64
功能:将光标跳转到指定位置,指定的位置不能位于流中数据头部之前,指定位置可以超过流中数据末尾。调用该函数会先清空流的缓存区,再移动光标的位置。
参数:
- sp:指定光标跳转后的位置
返回值:返回流中数据头部到跳转后位置的偏移量(以字节为单位)
异常:
- IOException:指定的位置位于流中数据头部之前
prop length
public prop length: Int64
功能:返回当前流中的总数据量。
prop remainLength
public prop remainLength: Int64
功能:获取当前流中可读的数据量。
prop position
public prop position: Int64
功能:获取流当前光标位置。
class BufferedOutputStream
public class BufferedOutputStream<T> <: OutputStream where T <: OutputStream {
public init(output: T)
public init(output: T, capacity: Int64)
}
此类是用于为其他 OutputStream 提供指定容量的缓冲区的功能。
init
public init(output: T)
功能:创建一个 BufferedOutputStream 实例。
参数:
- output:绑定一个输出流
init
public init(output: T, capacity: Int64)
功能:创建一个 BufferedOutputStream 实例。
参数:
- output:绑定一个输出流
- capacity:内部缓冲区容量
异常:
- IllegalArgumentException:当 capacity 小于等于 0 时,抛出异常
func write
public func write(buffer: Array<Byte>): Unit
功能:将 buffer 中的数据写入到绑定的输出流中,当数据全部成功写入则函数返回,写入失败或者只写入了部分数据,则抛出异常。
参数:
- buffer:待写入数据的缓冲区,若 buffer 为空则直接返回
func flush
public func flush(): Unit
功能:刷新 BufferedOutputStream:将内部缓冲区的剩余数据写入绑定的输出流,并刷新绑定的输出流。
func reset
public func reset(output: T): Unit
功能:绑定新的输出流,重置状态,但不重置 capacity。
参数:
- output:待绑定的输出流
extend BufferedOutputStream <: Resource
extend BufferedOutputStream<T> <: Resource where T <: Resource
此扩展主要用于实现 BufferedOutputStream 的 Resource 接口。
func close
public func close(): Unit
功能:关闭当前流。调用此方法后不可再调用 BufferedOutputStream 的其他接口,否则会造成不可期现象。
func isClosed
public func isClosed(): Bool
功能:判断当前流是否关闭。
返回值:如果当前流已经被关闭,返回 true,否则返回 false
extend BufferedOutputStream <: Seekable
extend BufferedOutputStream<T> <: Seekable where T <: Seekable
此扩展主要用于实现 BufferedOutputStream 的 Seekable 接口。
func seek
public func seek(sp: SeekPosition): Int64
功能:将光标跳转到指定位置,指定的位置不能位于流中数据头部之前,指定位置可以超过流中数据末尾。调用该函数会先将缓存区内的数据写到绑定的输出流里,再移动光标的位置。
参数:
- sp:指定光标跳转后的位置
返回值:返回流中数据头部到跳转后位置的偏移量(以字节为单位)
异常:
- IOException:指定的位置位于流中数据头部之前
prop length
public prop length: Int64
功能:返回当前流中的总数据量。
prop remainLength
public prop remainLength: Int64
功能:获取当前流中可读的数据量。
prop position
public prop position: Int64
功能:获取流当前光标位置。
enum StringEncoding
public enum StringEncoding {
| UTF8
| UTF16
| UTF32
}
StringEncoding 枚举类型表示字符串的编码格式。
UTF8
UTF8
UTF16
UTF16
UTF32
UTF32
enum Endian
public enum Endian {
| Little
| Big
}
Endian 枚举类型表示字节序,只对 UTF16、UTF32 有效。
Little
Little
功能:构造一个 Endian 枚举实例,表示小端字节序。
Big
Big
功能:构造一个 Endian 枚举实例,表示大端字节序。
CURRENT_ENDIAN
public let CURRENT_ENDIAN: Endian = getCurrentEndian()
功能:获取运行时所在系统的字节序。
func getCurrentEndian
public func getCurrentEndian(): Endian
功能:获取运行时所在系统的字节序。
class StringReader
public class StringReader<T> where T <: InputStream {
public init(input: T, encoding!: StringEncoding = UTF8, endian!: Endian = CURRENT_ENDIAN)
}
提供从 InputStream 输入流中读出数据并转换成字符或字符串的功能
StringReader 内部默认有缓冲区,缓冲区容量 4096 个字节
StringReader 目前仅支持 UTF-8 编码,暂不支持 UTF-16、UTF-32
init
public init(input: T, encoding!: StringEncoding = UTF8, endian!: Endian = CURRENT_ENDIAN)
功能:创建一个 StringReader 实例。
参数:
- input:待读取数据的输入流
- encoding:指定 input 的编码格式,默认是 UTF-8 编码
- endian:指定 input 的字节序配置,默认使用运行时所在系统的 endian 配置
异常:
- IllegalArgumentException:当 encoding 传入 UTF16/UTF32 时抛出异常
func read
public func read(): ?Char
功能:按字符读,从流内读出单个字符流结束后再调用此函数,返回 Option
返回值:读取成功,返回 Option
异常:
- ContentFormatException:如果读取到不合法字符,则抛出异常
func readln
public func readln(): Option<String>
功能:按行读,从流内读出一行的字符串(尾部不含换行符)流结束后再调用此函数,返回 Option
返回值:读取成功,返回 Option
异常:
- ContentFormatException:如果读取到不合法字符,则抛出异常
func readToEnd
public func readToEnd(): String
功能:从流内读出所有剩余数据,以字符串形式返回。
返回值:返回读出的字符串
异常:
- ContentFormatException:如果读取到不合法字符,则抛出异常
func readUntil
public func readUntil(v: Char): Option<String>
功能:从流内读出到指定字符之前(包含指定字符)或者流结束位置之前的数据,以 Option
返回值:读取成功,返回 Option
异常:
- ContentFormatException:如果读取到不合法字符,则抛出异常
func readUntil
public func readUntil(predicate: (Char)->Bool): Option<String>
功能:从流内读出到使 predicate 返回 true 的字符位置之前(包含这个字符)或者流结束位置之前的数据,以 Option
返回值:读取成功,返回 Option
异常:
- ContentFormatException:如果读取到不合法字符,则抛出异常
extend StringReader <: Resource
extend StringReader<T> <: Resource where T <: Resource
此扩展主要用于实现 StringReader 的 Resource 接口。
func close
public func close(): Unit
功能:关闭当前流。调用此方法后不可再调用 StringReader 的其他接口,否则会造成不可期现象。
func isClosed
public func isClosed(): Bool
功能:判断当前流是否关闭。
返回值:如果当前流已经被关闭,返回 true,否则返回 false
extend StringReader <: Seekable
extend StringReader<T> <: Seekable where T <: Seekable
此扩展主要用于实现 StringReader 的 Seekable 接口。
func seek
public func seek(sp: SeekPosition): Int64
功能:将光标跳转到指定位置,指定的位置不能位于流中数据头部之前,指定位置可以超过流中数据末尾。
参数:
- sp:指定光标跳转后的位置
返回值:返回流中数据头部到跳转后位置的偏移量(以字节为单位)
异常:
- IOException:指定的位置位于流中数据头部之前
prop length
public prop length: Int64
功能:返回当前流中的总数据量。
prop remainLength
public prop remainLength: Int64
功能:获取当前流中可读的数据量。
prop position
public prop position: Int64
功能:获取流当前光标位置。
class StringWriter
public class StringWriter<T> where T <: OutputStream {
public init(output: T, encoding!: StringEncoding = UTF8, endian!: Endian = CURRENT_ENDIAN)
}
提供将 String 以及一些 ToString 类型转换成指定编码格式和字节序配置的字符串并写入到输出流的功能。
StringWriter 内部默认有缓冲区,缓冲区容量 4096 个字节。
StringWriter 目前仅支持 UTF-8 编码,暂不支持 UTF-16、UTF-32。
init
public init(output: T, encoding!: StringEncoding = UTF8, endian!: Endian = CURRENT_ENDIAN)
功能:创建一个 StringWriter 实例。
参数:
- output:待写入数据的输出流
- encoding:指定 output 编码格式,默认是 UTF-8 编码
- endian:指定 output 的字节序配置,默认使用运行时所在系统的 endian 配置
异常:
- IllegalArgumentException:当 encoding 传入 UTF16/UTF32 时抛出异常
func flush
public func flush(): Unit
功能:刷新内部缓冲区,将缓冲区数据写入 output 中,并刷新 output。
func write
public func write(v: String): Unit
功能:写入字符串。
参数:
- v:待写入的字符串
func write
public func write<T>(v: T): Unit where T <: ToString
功能:写入 ToString 类型。
参数:
- v:ToString 类型的实例
func write
public func write(v: Bool): Unit
功能:写入 Bool 类型。
参数:
- v:Bool 类型的实例
func write
public func write(v: Int8): Unit
功能:写入 Int8 类型。
参数:
- v:Int8 类型的实例
func write
public func write(v: Int16): Unit
功能:写入 Int16 类型。
参数:
- v:Int16 类型的实例
func write
public func write(v: Int32): Unit
功能:写入 Int32 类型。
参数:
- v:Int32 类型的实例
func write
public func write(v: Int64): Unit
功能:写入 Int64 类型。
参数:
- v:Int64 类型的实例
func write
public func write(v: UInt8): Unit
功能:写入 UInt8 类型。
参数:
- v:UInt8 类型的实例
func write
public func write(v: UInt16): Unit
功能:写入 UInt16 类型。
参数:
- v:UInt16 类型的实例
func write
public func write(v: UInt32): Unit
功能:写入 UInt32 类型。
参数:
- v:UInt32 类型的实例
func write
public func write(v: UInt64): Unit
功能:写入 UInt64 类型。
参数:
- v:UInt64 类型的实例
func write
public func write(v: Float16): Unit
功能:写入 Float16 类型。
参数:
- v:Float16 类型的实例
func write
public func write(v: Float32): Unit
功能:写入 Float32 类型。
参数:
- v:Float32 类型的实例
func write
public func write(v: Float64): Unit
功能:写入 Float64 类型。
参数:
- v:Float64 类型的实例
func write
public func write(v: Char): Unit
功能:写入 Char 类型。
参数:
- v:Char 类型的实例
func writeln
public func writeln(): Unit
功能:写入换行符。
func writeln
public func writeln(v: String): Unit
功能:写入字符串 + 换行符。
参数:
- v:待写入的字符串
func writeln
public func writeln<T>(v: T): Unit where T <: ToString
功能:写入 ToString 类型 + 换行符。
参数:
- v:ToString 类型的实例
func writeln
public func writeln(v: Bool): Unit
功能:写入 Bool 类型 + 换行符。
参数:
- v:Bool 类型的实例
func writeln
public func writeln(v: Int8): Unit
功能:写入 Int8 类型 + 换行符。
参数:
- v:Int8 类型的实例
func writeln
public func writeln(v: Int16): Unit
功能:写入 Int16 类型 + 换行符。
参数:
- v:Int16 类型的实例
func writeln
public func writeln(v: Int32): Unit
功能:写入 Int32 类型 + 换行符。
参数:
- v:Int32 类型的实例
func writeln
public func writeln(v: Int64): Unit
功能:写入 Int64 类型 + 换行符。
参数:
- v:Int64 类型的实例
func writeln
public func writeln(v: UInt8): Unit
功能:写入 UInt8 类型 + 换行符。
参数:
- v:UInt8 类型的实例
func writeln
public func writeln(v: UInt16): Unit
功能:写入 UInt16 类型 + 换行符。
参数:
- v:UInt16 类型的实例
func writeln
public func writeln(v: UInt32): Unit
功能:写入 UInt32 类型 + 换行符。
参数:
- v:UInt32 类型的实例
func writeln
public func writeln(v: UInt64): Unit
功能:写入 UInt64 类型 + 换行符。
参数:
- v:UInt64 类型的实例
func writeln
public func writeln(v: Float16): Unit
功能:写入 Float16 类型 + 换行符。
参数:
- v:Float16 类型的实例
func writeln
public func writeln(v: Float32): Unit
功能:写入 Float32 类型 + 换行符。
参数:
- v:Float32 类型的实例
func writeln
public func writeln(v: Float64): Unit
功能:写入 Float64 类型 + 换行符。
参数:
- v:Float64 类型的实例
func writeln
public func writeln(v: Char): Unit
功能:写入 Char 类型 + 换行符。
参数:
- v:Char 类型的实例
extend StringWriter <: Resource
extend StringWriter<T> <: Resource where T <: Resource
此扩展主要用于实现 StringWriter 的 Resource 接口。
func close
public func close(): Unit
功能:关闭当前流。调用此方法后不可再调用 StringWriter 的其他接口,否则会造成不可期现象。
func isClosed
public func isClosed(): Bool
功能:判断当前流是否关闭。
返回值:如果当前流已经被关闭,返回 true,否则返回 false
extend StringWriter <: Seekable
extend StringWriter<T> <: Seekable where T <: Seekable
此扩展主要用于实现 StringWriter 的 Seekable 接口。
func seek
public func seek(sp: SeekPosition): Int64
功能:将光标跳转到指定位置,指定的位置不能位于流中数据头部之前,指定位置可以超过流中数据末尾。
参数:
- sp:指定光标跳转后的位置
返回值:返回流中数据头部到跳转后位置的偏移量(以字节为单位)
异常:
- IOException:指定的位置位于流中数据头部之前
prop length
public prop length: Int64
功能:返回当前流中的总数据量。
prop remainLength
public prop remainLength: Int64
功能:获取当前流中可读的数据量。
prop position
public prop position: Int64
功能:获取流当前光标位置。
class ChainedInputStream
public class ChainedInputStream <: InputStream {
public init(input: Array<InputStream>)
}
此类提供了顺序从 InputStream 数组中读取数据的功能。
init
public init(input: Array<InputStream>)
功能:创建一个 ChainedInputStream 实例。
参数:
- input:绑定一个输入流数组
异常:
- IllegalArgumentException:当 input 为空时, 抛出异常
func read
public func read(buffer: Array<Byte>): Int64
功能:依次从绑定 InputStream 数组中读出数据到 buffer 中。若所有 InputStream 均已读完,则返回 0。
参数:
- buffer:存储读出数据的缓冲区
返回值:读取成功,返回读取字节数
异常:
- IllegalArgumentException:当 buffer 为空时, 抛出异常
class MultiOutputStream
public class MultiOutputStream <: OutputStream {
public init(output: Array<OutputStream>)
}
此类提供了将数据同时写入到 OutputStream 数组中每个输出流中的功能。
init
public init(output: Array<OutputStream>)
功能:创建一个 MultiOutputStream 实例。
参数:
- output:绑定一个输出流数组
异常:
- IllegalArgumentException:当 output 为空时,抛出异常
func write
public func write(buffer: Array<Byte>): Unit
功能:将 buffer 同时写入到绑定的 OutputStream 数组里的每个输出流中。
参数:
- buffer:存储待写入数据的缓冲区
func flush
public func flush(): Unit
功能:刷新绑定的输出流数组里的每个输出流。
func indexOf
public func indexOf(src: Array<Byte>, byte: Byte, start!: Int64 = 0): Option<Int64>
功能:查找字节 byte 在字节数组 src 中首次出现位置的下标。
参数:
- src:要查找的字节数组
- byte:待查找的字节
- start:从 src 数组 start 位置开始查找,默认为 0
返回值:若查找到,返回 Some(下标位置),否则返回 None
异常:
- IllegalArgumentException:当 start 小于 0 时, 抛出异常
func indexOf
public func indexOf(src: Array<Byte>, bytes: Array<Byte>, start!: Int64 = 0): Option<Int64>
功能:查找字节数组 bytes 在字节数组 src 中首次出现位置的下标。
参数:
- src:要查找的字节数组
- byte:待查找的字节数组,当 bytes 是空数组时,如果 start 大于 0,返回 None, 否则返回 Some(0)
- start:从 src 数组 start 位置开始查找,默认为 0,当 start 小于零正常返回,当 start 大于等于原数组长度时返回 Option
.None
返回值:若查找到,返回 Some(下标位置),否则返回 None
func trim
public func trim(src: Array<Byte>, trimBytes: Array<Byte>): Array<Byte>
功能:修剪 src 两侧的字节,如果 src 两侧的字节包含在 trimBytes 中就将其修剪掉,直到遇到第一个不包含在 trimBytes 中的字符。
参数:
- src:待修剪的数组
- byte:要修剪掉的字节的数组
返回值:修剪后的数组
示例
ByteArrayStream 示例
from std import io.*
main(): Unit {
let arr1 = b"test case"
let byteArrayStream = ByteArrayStream()
/* 将 arr1 中的数据写入到流中 */
byteArrayStream.write(arr1)
/* 读取 4 个字节的数据到 arr2 中 */
let arr2 = Array<Byte>(4, item: 0)
byteArrayStream.read(arr2)
println(String.fromUtf8(arr2))
/* 将流的索引指向起点 */
byteArrayStream.seek(Begin(0))
/* 读取流中全部数据 */
let arr3 = byteArrayStream.readToEnd()
println(String.fromUtf8(arr3))
}
运行结果如下:
test
test case
BufferedInputStream 示例
from std import io.*
main(): Unit {
let arr1 = b"0123456789"
let byteArrayStream = ByteArrayStream()
byteArrayStream.write(arr1)
let bufferedInputStream = BufferedInputStream(byteArrayStream)
let arr2 = Array<Byte>(20, item: 0)
/* 读取流中数据,返回读取到的数据的长度 */
let readLen = bufferedInputStream.read(arr2)
println(String.fromUtf8(arr2[..readLen]))
}
运行结果如下:
0123456789
BufferedOutputStream 示例
from std import io.*
main(): Unit {
let arr1 = b"01234"
let byteArrayStream = ByteArrayStream()
byteArrayStream.write(arr1)
let bufferedInputStream = BufferedOutputStream(byteArrayStream)
let arr2 = b"56789"
/* 向流中写入数据,此时数据在外部流的缓冲区中 */
bufferedInputStream.write(arr2)
/* 调用 flush 函数,真正将数据写入内部流中 */
bufferedInputStream.flush()
println(String.fromUtf8(byteArrayStream.readToEnd()))
}
运行结果如下:
0123456789
ChainedInputStream 示例
from std import io.*
from std import collection.ArrayList
main(): Unit {
const size = 2
/* 创建两个 ByteArrayStream 并写入数据 */
let streamArr = Array<InputStream>(size, {_ => ByteArrayStream()})
for (i in 0..size) {
match (streamArr[i]) {
case v: OutputStream =>
let str = "now ${i}"
v.write(str.toArray())
case _ => throw Exception()
}
}
/* 将两个 ByteArrayStream 绑定到 ChainedInputStream */
let chainedInputStream = ChainedInputStream(streamArr)
let res = ArrayList<Byte>()
let buffer = Array<Byte>(20, item: 0)
var readLen = chainedInputStream.read(buffer)
/* 循环读取 chainedInputStream 中数据 */
while (readLen != 0) {
res.appendAll(buffer[..readLen])
readLen = chainedInputStream.read(buffer)
}
println(String.fromUtf8(res.toArray()))
}
运行结果如下:
now 0now 1
MultiOutputStream 示例
from std import io.*
main(): Unit {
const size = 2
/* 将两个 ByteArrayStream 绑定到 MultiOutputStream */
let streamArr = Array<OutputStream>(size, {_ => ByteArrayStream()})
let multiOutputStream = MultiOutputStream(streamArr)
/* 往 MultiOutputStream 写入数据,会同时写入绑定的两个 ByteArrayStream */
multiOutputStream.write(b"test")
/* 读取 ByteArrayStream 中数据,验证结果 */
for (i in 0..size) {
match (streamArr[i]) {
case v: ByteArrayStream =>
println(String.fromUtf8(v.readToEnd()))
case _ => throw Exception()
}
}
}
运行结果如下:
test
test
StringReader 示例
from std import io.*
main(): Unit {
let arr1 = b"012\n346789"
let byteArrayStream = ByteArrayStream()
byteArrayStream.write(arr1)
let stringReader = StringReader(byteArrayStream)
/* 读取一个字节 */
let ch = stringReader.read()
println(ch ?? 'a')
/* 读取一行数据 */
let line = stringReader.readln()
println(line ?? "error")
/* 读取数据直到遇到字符6 */
let until = stringReader.readUntil('6')
println(until ?? "error")
/* 读取全部数据 */
let all = stringReader.readToEnd()
println(all)
}
运行结果如下:
0
12
346
789
StringWriter 示例
from std import io.*
main(): Unit {
let byteArrayStream = ByteArrayStream()
let stringWriter = StringWriter(byteArrayStream)
/* 写入字符串 */
stringWriter.write("number")
/* 写入字符串并自动转行 */
stringWriter.writeln(" is:")
/* 写入数字 */
stringWriter.write(100.0f32)
stringWriter.flush()
println(String.fromUtf8(byteArrayStream.readToEnd()))
}
运行结果如下:
number is:
100.000000
log 包
介绍
Log 包提供日志管理和打印功能。
依赖 io 包中的 OutputStream 作为输出流。
主要接口
interface Logger
public interface Logger {
mut prop level: LogLevel
func setOutput(output: OutputStream): Unit
func trace(msg: String): Unit
func debug(msg: String): Unit
func info(msg: String): Unit
func warn(msg: String): Unit
func error(msg: String): Unit
func log(level: LogLevel, msg: String): Unit
}
此接口用于管理和打印日志。
prop level
mut prop level: LogLevel
功能:获取和修改日志打印级别,只有级别小于等于该值的日志会被打印。
func setOutput
func setOutput(output: OutputStream): Unit
功能:设置日志输出流,日志将被打印到该输出流。
参数:
output:输出流
func trace
func trace(msg: String): Unit
功能:打印 TRACE 级别的日志的便捷函数。如果设置的打印级别小于 TRACE,将忽略这条日志信息,否则打印到输出流。以下日志打印函数均使用该规则。
参数:
msg:日志内容
func debug
func debug(msg: String): Unit
功能:打印 DEBUG 级别的日志的便捷函数。
参数:
msg:日志内容
func info
func info(msg: String): Unit
功能:打印 INFO 级别的日志的便捷函数。
参数:
msg:日志内容
func warn
func warn(msg: String): Unit
功能:打印 WARN 级别的日志的便捷函数。
参数:
msg:日志内容
func error
func error(msg: String): Unit
功能:打印 ERROR 级别的日志的便捷函数。
参数:
msg:日志内容
func log
func log(level: LogLevel, msg: String): Unit
功能:打印日志的通用函数,需指定日志级别。
参数:
level:日志级别msg:日志内容
class SimpleLogger
public class SimpleLogger <: Logger {
public init()
public init(name: String, level: LogLevel, output: OutputStream)
}
此类实现了 Logger 接口,提供基础的日志打印和管理功能,包括自定义日志名称,控制日志打印级别,自定义输出流,默认情况下,日志名称为 “Logger”,打印级别为 INFO,输出流为 stdOut。
init
public init()
功能:创建一个默认的 SimpleLogger 实例。
init
public init(name: String, level: LogLevel, output: OutputStream)
功能:创建一个 SimpleLogger 实例,指定日志名称,日志打印级别和输出流。
参数:
name:日志名称level:日志级别output:输出流
func flush
public func flush(): Unit
功能:刷新输出流。
prop level
public mut prop level: LogLevel
功能:获取和修改日志打印级别。
func setOutput
public func setOutput(output: OutputStream): Unit
功能:设置输出流,日志信息将打印到该输出流中。
参数:
output:输出流
func trace
public func trace(msg: String): Unit
功能:打印 TRACE 级别的日志的便捷函数。
参数:
msg:日志内容
func debug
public func debug(msg: String): Unit
功能:打印 DEBUG 级别的日志的便捷函数。
参数:
msg:日志内容
func info
public func info(msg: String): Unit
功能:打印 INFO 级别的日志的便捷函数。
参数:
msg:日志内容
func warn
public func warn(msg: String): Unit
功能:打印 WARN 级别的日志的便捷函数。
参数:
msg:日志内容
func error
public func error(msg: String): Unit
功能:打印 ERROR 级别的日志的便捷函数。
参数:
msg:日志内容
func log
public func log(level: LogLevel, msg: String): Unit
功能:打印日志的通用函数,需指定日志级别。
参数:
level:日志级别msg:日志内容
enum LogLevel
public enum LogLevel <: ToString {
| OFF
| ERROR
| WARN
| INFO
| DEBUG
| TRACE
| ALL
}
该枚举类用于表示打印级别,定义了日志打印的七个级别,级别从低到高分别为 OFF、ERROR、WARN、INFO、DEBUG、TRACE、ALL。
SimpleLogger 类的实现中,指定了日志打印级别,以及每一条日志的级别,只有级别小于等于指定打印级别的日志条目会被打印到输出流中。
OFF
OFF
功能:构造一个日志打印级别的枚举实例,等级为禁用。
ERROR
ERROR
功能:构造一个日志打印级别的枚举实例,等级为错误。
WARN
WARN
功能:构造一个日志打印级别的枚举实例,等级为警告。
INFO
INFO
功能:构造一个日志打印级别的枚举实例,等级为通知。
DEBUG
DEBUG
功能:构造一个日志打印级别的枚举实例,等级为调试。
TRACE
TRACE
功能:构造一个日志打印级别的枚举实例,等级为跟踪。
ALL
ALL
功能:构造一个日志打印级别的枚举实例,等级为所有。
func level
public func level(): Int64
功能:获取日志级别对应的数字,OFF 为 1,ERROR 为 2,此后依次加一。
返回值:当前的日志级别对应的数字
func toString
public func toString(): String
功能:获取日志级别对应的名称。
返回值:当前的日志级别的名称
operator func >=
public operator func >=(target: LogLevel): Bool
功能:比较日志级别高低。
参数:
target:将当前日志级别和target进行比较
返回值:如果当前日志级别大于等于 target,返回 true,否则返回 false
示例
ALL 级别日志打印
下面是 ALL 级别日志打印示例。
代码如下:
from std import log.*
main(): Int64 {
let logger: SimpleLogger = SimpleLogger()
logger.level = LogLevel.ALL
logger.log(LogLevel.ALL, "============== 日志级别为 ALL================")
logger.log(LogLevel.TRACE,
"=============="+logger.level.toString()+"================")
logger.log(LogLevel.OFF, "OFF 打印出来!")
logger.log(LogLevel.ERROR, "error 打印出来!")
logger.log(LogLevel.WARN, "warn 打印出来!")
logger.log(LogLevel.INFO, "INFO 打印出来!")
logger.log(LogLevel.DEBUG, "DEBUG 打印出来!")
logger.log(LogLevel.TRACE, "trace 打印出来!")
logger.log(LogLevel.ALL, "ALL 打印出来!")
logger.flush()
0
}
运行结果如下:
2021/08/05 08:20:42.692770 ALL Logger ============== 日志级别为 ALL================
2021/08/05 08:20:42.696645 TRACE Logger ==============ALL================
2021/08/05 08:20:42.700188 ERROR Logger error 打印出来!
2021/08/05 08:20:42.703576 WARN Logger warn 打印出来!
2021/08/05 08:20:42.706920 INFO Logger INFO 打印出来!
2021/08/05 08:20:42.710268 DEBUG Logger DEBUG 打印出来!
2021/08/05 08:20:42.713602 TRACE Logger trace 打印出来!
2021/08/05 08:20:42.716940 ALL Logger ALL 打印出来!
ERROR 和 WARN 级别日志打印
下面是 ERROR 和 WARN 级别日志打印示例。
代码如下:
from std import fs.*
from std import log.*
main(): Int64 {
let logger: SimpleLogger = SimpleLogger()
logger.level = LogLevel.ERROR
var s = File("./stdout1.log", OpenOption.CreateOrTruncate(false))
logger.setOutput(s)
logger.log(LogLevel.ERROR, "============== 日志级别为 ERROR================")
logger.log(LogLevel.ERROR,
"=============="+logger.level.toString()+"================")
logger.log(LogLevel.OFF, "OFF 打印出来!")
logger.log(LogLevel.ERROR, "error 打印出来!")
logger.log(LogLevel.WARN, "warn 打印出来!")
logger.log(LogLevel.INFO, "INFO 打印出来!")
logger.log(LogLevel.DEBUG, "DEBUG 打印出来!")
logger.log(LogLevel.TRACE, "trace 打印出来!")
logger.log(LogLevel.ALL, "ALL 打印出来!")
logger.flush()
logger.level = LogLevel.WARN
s.close()
s = File("./stdout2.log", OpenOption.CreateOrTruncate(false))
logger.setOutput(s)
logger.log(LogLevel.WARN, "============== 日志级别为 WARN================")
logger.log(LogLevel.WARN,
"=============="+logger.level.toString()+"================")
logger.log(LogLevel.OFF, "OFF 打印出来!")
logger.log(LogLevel.ERROR, "error 打印出来!")
logger.log(LogLevel.WARN, "warn 打印出来!")
logger.log(LogLevel.INFO, "INFO 打印出来!")
logger.log(LogLevel.DEBUG, "DEBUG 打印出来!")
logger.log(LogLevel.TRACE, "trace 打印出来!")
logger.log(LogLevel.ALL, "ALL 打印出来!")
logger.flush()
s.close()
0
}
运行结果如下:
$ cat stdout1.log
2021/08/05 08:28:29.667441 ERROR Logger ============== 日志级别为 ERROR================
2021/08/05 08:28:29.671402 ERROR Logger ==============ERROR================
2021/08/05 08:28:29.674891 ERROR Logger error 打印出来!
$ cat stdout2.log
2021/08/05 08:28:29.678978 WARN Logger ============== 日志级别为 WARN================
2021/08/05 08:28:29.682635 WARN Logger ==============WARN================
2021/08/05 08:28:29.686126 ERROR Logger error 打印出来!
2021/08/05 08:28:29.689561 WARN Logger warn 打印出来!
math 包
介绍
math 包提供常见的数学运算,常数定义,浮点数处理等功能。包括了以下能力:
- 科学常数与类型常数定义;
- 浮点数的判断,规整;
- 常用的位运算;
- 通用的数学函数,如绝对值,三角函数,指数,对数计算;
- 最大公约数与最小公倍数。
主要接口
interface MathExtension
public interface MathExtension
为了导出 prop 而作辅助接口,内部为空。
extend Float64 <: MathExtension
extend Float64 <: MathExtension
拓展双精度浮点数以支持一些数学常数。
prop NaN
public static prop NaN: Float64
功能:获取双精度浮点数的非数。
prop Inf
public static prop Inf: Float64
功能:获取双精度浮点数的无穷数。
prop PI
public static prop PI: Float64
功能:获取双精度浮点数的圆周率常数。
prop E
public static prop E: Float64
功能:获取双精度浮点数的自然常数。
prop Max
public static prop Max: Float64
功能:获取双精度浮点数的最大值。
prop Min
public static prop Min: Float64
功能:获取双精度浮点数的最小值。
prop MinDenormal
public static prop MinDenormal: Float64
功能:获取双精度浮点数的最小次正规数。
prop MinNormal
public static prop MinNormal: Float64
功能:获取双精度浮点数的最小正规数。
func isInf
public func isInf(): Bool
功能:根据返回的 Bool 值,判断某个浮点数 Float64 是否为无穷数值。
返回值:如果 Float64 的值正无穷大或负无穷大,则返回 true;否则,返回 false
func isNaN
public func isNaN(): Bool
功能:根据返回的 Bool 值,判断某个浮点数 Float64 是否为非数值。
返回值:如果 Float64 的值为非数值,则返回 true;否则,返回 false
func isNormal
public func isNormal(): Bool
功能:根据返回的 Bool 值,判断某个浮点数 Float64 是否为常规数值。
返回值:如果 Float64 的值是正常的浮点数,返回 true;否则,返回 false
extend Float32 <: MathExtension
extend Float32 <: MathExtension
拓展单精度浮点数以支持一些数学常数。
prop NaN
public static prop NaN: Float32
功能:获取单精度浮点数的非数。
prop Inf
public static prop Inf: Float32
功能:获取单精度浮点数的无穷数。
prop PI
public static prop PI: Float32
功能:获取单精度浮点数的圆周率常数。
prop E
public static prop E: Float32
功能:获取单精度浮点数的自然常数。
prop Max
public static prop Max: Float32
功能:获取单精度浮点数的最大值。
prop Min
public static prop Min: Float32
功能:获取单精度浮点数的最小值。
prop MinDenormal
public static prop MinDenormal: Float32
功能:获取单精度浮点数的最小次正规数。
prop MinNormal
public static prop MinNormal: Float32
功能:获取单精度浮点数的最小正规数。
func isInf
public func isInf(): Bool
功能:根据返回的 Bool 值,判断某个浮点数 Float32 是否为无穷数值。
返回值:如果 Float32 的值正无穷大或负无穷大,则返回 true;否则,返回 false
func isNaN
public func isNaN(): Bool
功能:根据返回的 Bool 值,判断某个浮点数 Float32 是否为非数值。
返回值:如果 Float32 的值为非数值,则返回 true;否则,返回 false
func isNormal
public func isNormal(): Bool
功能:根据返回的 Bool 值,判断某个浮点数 Float32 是否为常规数值。
返回值:如果 Float32 的值是正常的浮点数,返回 true;否则,返回 false
extend Float16 <: MathExtension
extend Float16 <: MathExtension
拓展半精度浮点数以支持一些数学常数。
prop NaN
public static prop NaN: Float16
功能:获取半精度浮点数的非数。
prop Inf
public static prop Inf: Float16
功能:获取半精度浮点数的无穷数。
prop PI
public static prop PI: Float16
功能:获取半精度浮点数的圆周率常数。
prop E
public static prop E: Float16
功能:获取半精度浮点数的自然常数。
prop Max
public static prop Max: Float16
功能:获取半精度浮点数的最大值。
prop Min
public static prop Min: Float16
功能:获取半精度浮点数的最小值。
prop MinDenormal
public static prop MinDenormal: Float16
功能:获取半精度浮点数的最小次正规数。
prop MinNormal
public static prop MinNormal: Float16
功能:获取半精度浮点数的最小正规数。
func isInf
public func isInf(): Bool
功能:根据返回的 Bool 值,判断某个浮点数 Float16 是否为无穷数值。
返回值:如果 Float16 的值正无穷大或负无穷大,则返回 true;否则,返回 false
func isNaN
public func isNaN(): Bool
功能:根据返回的 Bool 值,判断某个浮点数 Float16 是否为非数值。
返回值:如果 Float16 的值为非数值,则返回 true;否则,返回 false
func isNormal
public func isNormal(): Bool
功能:根据返回的 Bool 值,判断某个浮点数 Float16 是否为常规数值。
返回值:如果 Float16 的值是正常的浮点数,返回 true;否则,返回 false
extend Int64 <: MathExtension
extend Int64 <: MathExtension
拓展 64 位有符号整数以支持一些数学常数。
prop Max
public static prop Max: Int64
功能:获取 64 位有符号整数的最大值。
prop Min
public static prop Min: Int64
功能:获取 64 位有符号整数的最小值。
extend Int32 <: MathExtension
extend Int32 <: MathExtension
拓展 32 位有符号整数以支持一些数学常数。
prop Max
public static prop Max: Int32
功能:获取 32 位有符号整数的最大值。
prop Min
public static prop Min: Int32
功能:获取 32 位有符号整数的最小值。
extend Int16 <: MathExtension
extend Int16 <: MathExtension
拓展 16 位有符号整数以支持一些数学常数。
prop Max
public static prop Max: Int16
功能:获取 16 位有符号整数的最大值。
prop Min
public static prop Min: Int16
功能:获取 16 位有符号整数的最小值。
extend Int8 <: MathExtension
extend Int8 <: MathExtension
拓展 8 位有符号整数以支持一些数学常数。
prop Max
public static prop Max: Int8
功能:获取 8 位有符号整数的最大值。
prop Min
public static prop Min: Int8
功能:获取 8 位有符号整数的最小值。
extend UInt64 <: MathExtension
extend UInt64 <: MathExtension
拓展 64 位无符号整数以支持一些数学常数。
prop Max
public static prop Max: UInt64
功能:获取 64 位无符号整数的最大值。
prop Min
public static prop Min: UInt64
功能:获取 64 位无符号整数的最小值。
extend UInt32 <: MathExtension
extend UInt32 <: MathExtension
拓展 32 位无符号整数以支持一些数学常数。
prop Max
public static prop Max: UInt32
功能:获取 32 位无符号整数的最大值。
prop Min
public static prop Min: UInt32
功能:获取 32 位无符号整数的最小值。
extend UInt16 <: MathExtension
extend UInt16 <: MathExtension
拓展 16 位无符号整数以支持一些数学常数。
prop Max
public static prop Max: UInt16
功能:获取 16 位无符号整数的最大值。
prop Min
public static prop Min: UInt16
功能:获取 16 位无符号整数的最小值。
extend UInt8 <: MathExtension
extend UInt8 <: MathExtension
拓展 8 位无符号整数以支持一些数学常数。
prop Max
public static prop Max: UInt8
功能:获取 8 位无符号整数的最大值。
prop Min
public static prop Min: UInt8
功能:获取 8 位无符号整数的最小值。
extend IntNative <: MathExtension
extend IntNative <: MathExtension
拓展平台相关有符号整数以支持一些数学常数。
prop Max
public static prop Max: IntNative
功能:获取平台相关有符号整数的最大值。
prop Min
public static prop Min: IntNative
功能:获取平台相关有符号整数的最小值。
extend UIntNative <: MathExtension
extend UIntNative <: MathExtension
拓展平台相关无符号整数以支持一些数学常数。
prop Max
public static prop Max: UIntNative
功能:获取平台相关无符号整数的最大值。
prop Min
public static prop Min: UIntNative
功能:获取平台相关无符号整数的最小值。
func throwIllegalArgumentException
public func throwIllegalArgumentException(): Int64
功能:此函数用于抛出非法参数异常。
func abs
public func abs(x: Int64): Int64
功能:此函数用于求一个 64 位有符号整数的绝对值。
参数:
x:传入的 64 位有符号整数
返回值:返回传入参数的绝对值
异常:
OverflowException:当输入参数是有符号整数的最小值,抛出异常
func abs
public func abs(x: Int32): Int32
功能:此函数用于求一个 32 位有符号整数的绝对值。
参数:
x:传入的 32 位有符号整数
返回值:返回传入参数的绝对值
异常:
OverflowException:当输入参数是有符号整数的最小值,抛出异常
func abs
public func abs(x: Int16): Int16
功能:此函数用于求一个 16 位有符号整数的绝对值。
参数:
x:传入的 16 位有符号整数
返回值:返回传入参数的绝对值
异常:
OverflowException:当输入参数是有符号整数的最小值,抛出异常
func abs
public func abs(x: Int8): Int8
功能:此函数用于求一个 8 位有符号整数的绝对值。
参数:
x:传入的 8 位有符号整数
返回值:返回传入参数的绝对值
异常:
OverflowException:当输入参数是有符号整数的最小值,抛出异常
func abs
public func abs(x: Float64): Float64
功能:此函数用于求一个双精度浮点数的绝对值。
参数:
x:传入的双精度浮点数
返回值:返回传入参数的绝对值
func abs
public func abs(x: Float32): Float32
功能:此函数用于求一个单精度浮点数的绝对值。
参数:
x:传入的单精度浮点数
返回值:返回传入参数的绝对值
func abs
public func abs(x: Float16): Float16
功能:此函数用于求一个半精度浮点数的绝对值。
参数:
x:传入的半精度浮点数
返回值:返回传入参数的绝对值
func checkedAbs
public func checkedAbs(x: Int64): Option<Int64>
功能:此函数检查并返回整数绝对值的 Option 类型,若参数是有符号整数的最小值,返回 None;否则,返回 Some(abs(x))
参数:
x:传入一个整数
返回值:若参数是有符号整数的最小值,返回 None;否则,返回 Some(abs(x))
func checkedAbs
public func checkedAbs(x: Int32): Option<Int32>
功能:此函数检查并返回整数绝对值的 Option 类型,若参数是有符号整数的最小值,返回 None;否则,返回 Some(abs(x))
参数:
x:传入一个整数
返回值:若参数是有符号整数的最小值,返回 None;否则,返回 Some(abs(x))
func checkedAbs
public func checkedAbs(x: Int16): Option<Int16>
功能:此函数检查并返回整数绝对值的 Option 类型,若参数是有符号整数的最小值,返回 None;否则,返回 Some(abs(x))
参数:
x:传入一个整数
返回值:若参数是有符号整数的最小值,返回 None;否则,返回 Some(abs(x))
func checkedAbs
public func checkedAbs(x: Int8): Option<Int8>
功能:此函数检查并返回整数绝对值的 Option 类型,若参数是有符号整数的最小值,返回 None;否则,返回 Some(abs(x))
参数:
x:传入一个整数
返回值:若参数是有符号整数的最小值,返回 None;否则,返回 Some(abs(x))
func cbrt
public func cbrt(x: Float64): Float64
功能:此函数用于求浮点数的立方根。
参数:
x:传入的浮点数
返回值:浮点数的立方根
func cbrt
public func cbrt(x: Float32): Float32
功能:此函数用于求浮点数的立方根。
参数:
x:传入的浮点数
返回值:浮点数的立方根
func cbrt
public func cbrt(x: Float16): Float16
功能:此函数用于求浮点数的立方根。
参数:
x:传入的浮点数
返回值:浮点数的立方根
func ceil
public func ceil(x: Float64): Float64
功能:此函数用于求浮点数的向上取整值。
参数:
x:传入的浮点数
返回值:返回传入浮点数的向上取整值
func ceil
public func ceil(x: Float32): Float32
功能:此函数用于求浮点数的向上取整值。
参数:
x:传入的浮点数
返回值:返回传入浮点数的向上取整值
func ceil
public func ceil(x: Float16): Float16
功能:此函数用于求浮点数的向上取整值。
参数:
x:传入的浮点数
返回值:返回传入浮点数的向上取整值
func clamp
public func clamp(v: Float64, min: Float64, max: Float64): Float64
功能:此函数用于求浮点数的范围区间数。如果此浮点数在该范围区间则返回此浮点数;如果此浮点数小于这个范围区间,则返回该范围区间的最小值;如果此浮点数大于这个范围区间,则返回该范围区间的最大值;如果是 NaN 则返回 NaN。
参数:
v:传入一个浮点数min:指定最小值max:指定最大值
返回值:如果 v 在 min 与 max 之间则返回 v,如果 v 小于 min 则返回 min,如果 v 大于 max,则返回 max,如果是 NaN 则需要返回 NaN
异常:
IllegalArgumentException:当参数min或参数max为NaN,或参数min大于参数max时,抛出异常
func clamp
public func clamp(v: Float32, min: Float32, max: Float32): Float32
功能:此函数用于求浮点数的范围区间数。如果此浮点数在该范围区间则返回此浮点数;如果此浮点数小于这个范围区间,则返回该范围区间的最小值;如果此浮点数大于这个范围区间,则返回该范围区间的最大值;如果是 NaN 则返回 NaN。
参数:
v:传入一个浮点数min:指定最小值max:指定最大值
返回值:如果 v 在 min 与 max 之间则返回 v,如果 v 小于 min 则返回 min,如果 v 大于 max,则返回 max,如果是 NaN 则需要返回 NaN
异常:
IllegalArgumentException:当参数min或参数max为NaN,或参数min大于参数max时,抛出异常
func clamp
public func clamp(v: Float16, min: Float16, max: Float16): Float16
功能:此函数用于求浮点数的范围区间数。如果此浮点数在该范围区间则返回此浮点数;如果此浮点数小于这个范围区间,则返回该范围区间的最小值;如果此浮点数大于这个范围区间,则返回该范围区间的最大值;如果是 NaN 则返回 NaN。
参数:
v:传入一个浮点数min:指定最小值max:指定最大值
返回值:如果 v 在 min 与 max 之间则返回 v,如果 v 小于 min 则返回 min,如果 v 大于 max,则返回 max,如果是 NaN 则需要返回 NaN
异常:
IllegalArgumentException:当参数min或参数max为NaN,或参数min大于参数max时,抛出异常
func countOne
public func countOne(x: Int64): Int8
功能:此函数用于求二进制表达中值为 1 的位的个数。
参数:
x:传入一个整数
返回值:返回值为 1 的位个数
func countOne
public func countOne(x: Int32): Int8
功能:此函数用于求二进制表达中值为 1 的位的个数。
参数:
x:传入一个整数
返回值:返回值为 1 的位个数
func countOne
public func countOne(x: Int16): Int8
功能:此函数用于求二进制表达中值为 1 的位的个数。
参数:
x:传入一个整数
返回值:返回值为 1 的位个数
func countOne
public func countOne(x: Int8): Int8
功能:此函数用于求二进制表达中值为 1 的位的个数。
参数:
x:传入一个整数
返回值:返回值为 1 的位个数
func countOne
public func countOne(x: UInt64): Int8
功能:此函数用于求二进制表达中值为 1 的位的个数。
参数:
x:传入一个整数
返回值:返回值为 1 的位个数
func countOne
public func countOne(x: UInt32): Int8
功能:此函数用于求二进制表达中值为 1 的位的个数。
参数:
x:传入一个整数
返回值:返回值为 1 的位个数
func countOne
public func countOne(x: UInt16): Int8
功能:此函数用于求二进制表达中值为 1 的位的个数。
参数:
x:传入一个整数
返回值:返回值为 1 的位个数
func countOne
public func countOne(x: UInt8): Int8
功能:此函数用于求二进制表达中值为 1 的位的个数。
参数:
x:传入一个整数
返回值:返回值为 1 的位个数
func erf
public func erf(x: Float64): Float64
功能:此函数用于求浮点数的误差值。相关定义是:$$erf(x) = \frac{2}{\sqrt{\pi}}\int_0^xe^{-t^2}dt$$
参数:
x:传入一个浮点数
返回值:返回传入浮点数的误差值
func erf
public func erf(x: Float32): Float32
功能:此函数用于求浮点数的误差值。相关定义是:$$erf(x) = \frac{2}{\sqrt{\pi}}\int_0^xe^{-t^2}dt$$
参数:
x:传入一个浮点数
返回值:返回传入浮点数的误差值
func erf
public func erf(x: Float16): Float16
功能:此函数用于求浮点数的误差值。相关定义是:$$erf(x) = \frac{2}{\sqrt{\pi}}\int_0^xe^{-t^2}dt$$
参数:
x:传入一个浮点数
返回值:返回传入浮点数的误差值
func pow
public func pow(base: Float64, exponent: Float64): Float64
功能:此函数用于求浮点数 base 的 exponent 次幂。
参数:
base:传入一个浮点数exponent:指定计算幂的次数
返回值:返回传入浮点数 base 的 exponent 次幂
func pow
public func pow(base: Float32, exponent: Float32): Float32
功能:此函数用于求浮点数 base 的 exponent 次幂。
参数:
base:传入一个浮点数exponent:指定计算幂的次数
返回值:返回传入浮点数 base 的 exponent 次幂
func pow
public func pow(base: Float64, exponent: Int64): Float64
功能:此函数用于求浮点数 base 的 exponent 次幂。
参数:
base:传入一个浮点数exponent:指定计算幂的次数
返回值:返回传入浮点数 base 的 exponent 次幂
func pow
public func pow(base: Float32, exponent: Int32): Float32
功能:此函数用于求浮点数 base 的 exponent 次幂。
参数:
base:传入一个浮点数exponent:指定计算幂的次数
返回值:返回传入浮点数 base 的 exponent 次幂
func exp
public func exp(x: Float64): Float64
功能:此函数用于求自然常数 e 的 x 次幂。
参数:
x:传入一个浮点数
返回值:返回自然常数 e 的 x 次幂
func exp
public func exp(x: Float32): Float32
功能:此函数用于求自然常数 e 的 x 次幂。
参数:
x:传入一个浮点数
返回值:返回自然常数 e 的 x 次幂
func exp
public func exp(x: Float16): Float16
功能:此函数用于求自然常数 e 的 x 次幂。
参数:
x:传入一个浮点数
返回值:返回自然常数 e 的 x 次幂
func exp2
public func exp2(x: Float64): Float64
功能:此函数用于求 2 的 x 次幂。
参数:
x:传入一个浮点数
返回值:返回 2 的 x 次幂
func exp2
public func exp2(x: Float32): Float32
功能:此函数用于求 2 的 x 次幂。
参数:
x:传入一个浮点数
返回值:返回 2 的 x 次幂
func exp2
public func exp2(x: Float16): Float16
功能:此函数用于求 2 的 x 次幂。
参数:
x:传入一个浮点数
返回值:返回 2 的 x 次幂
func floor
public func floor(x: Float64): Float64
功能:此函数用于求浮点数的向下取整值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的向下取整值
func floor
public func floor(x: Float32): Float32
功能:此函数用于求浮点数的向下取整值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的向下取整值
func floor
public func floor(x: Float16): Float16
功能:此函数用于求浮点数的向下取整值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的向下取整值
func gamma
public func gamma(x: Float64): Float64
功能:此函数用于求浮点数的 Gamma 值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的 Gamma 值
func gamma
public func gamma(x: Float32): Float32
功能:此函数用于求浮点数的 Gamma 值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的 Gamma 值
func gamma
public func gamma(x: Float16): Float16
功能:此函数用于求浮点数的 Gamma 值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的 Gamma 值
func gcd
public func gcd(x: Int64, y: Int64): Int64
功能:此函数用于求两数的最大公约数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最大公约数
异常:
IllegalArgumentException:当两参数为有符号整数最小值,或一个参数为有符号整数最小值且另一个参数为 0 时,抛出异常
func gcd
public func gcd(x: Int32, y: Int32): Int32
功能:此函数用于求两数的最大公约数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最大公约数
异常:
IllegalArgumentException:当两参数为有符号整数最小值,或一个参数为有符号整数最小值且另一个参数为 0 时,抛出异常
func gcd
public func gcd(x: Int16, y: Int16): Int16
功能:此函数用于求两数的最大公约数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最大公约数
异常:
IllegalArgumentException:当两参数为有符号整数最小值,或一个参数为有符号整数最小值且另一个参数为 0 时,抛出异常
func gcd
public func gcd(x: Int8, y: Int8): Int8
功能:此函数用于求两数的最大公约数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最大公约数
异常:
IllegalArgumentException:当两参数为有符号整数最小值,或一个参数为有符号整数最小值且另一个参数为 0 时,抛出异常
func gcd
public func gcd(x: UInt64, y: UInt64): UInt64
功能:此函数用于求两数的最大公约数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最大公约数
func gcd
public func gcd(x: UInt32, y: UInt32): UInt32
功能:此函数用于求两数的最大公约数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最大公约数
func gcd
public func gcd(x: UInt16, y: UInt16): UInt16
功能:此函数用于求两数的最大公约数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最大公约数
func gcd
public func gcd(x: UInt8, y: UInt8): UInt8
功能:此函数用于求两数的最大公约数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最大公约数
func lcm
public func lcm(x: Int64, y: Int64): Int64
功能:此函数用于求两数的最小公倍数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最小公倍数
异常:
IllegalArgumentException:当返回值超出有符号整数类型值对应范围
func lcm
public func lcm(x: Int32, y: Int32): Int32
功能:此函数用于求两数的最小公倍数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最小公倍数
异常:
IllegalArgumentException:当返回值超出有符号整数类型值对应范围
func lcm
public func lcm(x: Int16, y: Int16): Int16
功能:此函数用于求两数的最小公倍数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最小公倍数
异常:
IllegalArgumentException:当返回值超出有符号整数类型值对应范围
func lcm
public func lcm(x: Int8, y: Int8): Int8
功能:此函数用于求两数的最小公倍数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最小公倍数
异常:
IllegalArgumentException:当返回值超出有符号整数类型值对应范围
func lcm
public func lcm(x: UInt64, y: UInt64): UInt64
功能:此函数用于求两数的最小公倍数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最小公倍数
异常:
IllegalArgumentException:当返回值超出整数类型值对应范围时,抛出异常
func lcm
public func lcm(x: UInt32, y: UInt32): UInt32
功能:此函数用于求两数的最小公倍数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最小公倍数
异常:
IllegalArgumentException:当返回值超出整数类型值对应范围时,抛出异常
func lcm
public func lcm(x: UInt16, y: UInt16): UInt16
功能:此函数用于求两数的最小公倍数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最小公倍数
异常:
IllegalArgumentException:当返回值超出整数类型值对应范围时,抛出异常
func lcm
public func lcm(x: UInt8, y: UInt8): UInt8
功能:此函数用于求两数的最小公倍数。
参数:
x:传入第一个整数y:传入第二个整数
返回值:返回两个整数最小公倍数
异常:
IllegalArgumentException:当返回值超出整数类型值对应范围时,抛出异常
func leadingZeros
public func leadingZeros(x: Int64): Int8
功能:此函数用于返回整数的二进制表达中从最高位算起,连续为 0 的位数。如果最高位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回从最高位算起,连续 0 的位数
func leadingZeros
public func leadingZeros(x: Int32): Int8
功能:此函数用于返回整数的二进制表达中从最高位算起,连续为 0 的位数。如果最高位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回从最高位算起,连续 0 的位数
func leadingZeros
public func leadingZeros(x: Int16): Int8
功能:此函数用于返回整数的二进制表达中从最高位算起,连续为 0 的位数。如果最高位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回从最高位算起,连续 0 的位数
func leadingZeros
public func leadingZeros(x: Int8): Int8
功能:此函数用于返回整数的二进制表达中从最高位算起,连续为 0 的位数。如果最高位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回从最高位算起,连续 0 的位数
func leadingZeros
public func leadingZeros(x: UInt64): Int8
功能:此函数用于返回整数的二进制表达中从最高位算起,连续为 0 的位数。如果最高位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回从最高位算起,连续 0 的位数
func leadingZeros
public func leadingZeros(x: UInt32): Int8
功能:此函数用于返回整数的二进制表达中从最高位算起,连续为 0 的位数。如果最高位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回从最高位算起,连续 0 的位数
func leadingZeros
public func leadingZeros(x: UInt16): Int8
功能:此函数用于返回整数的二进制表达中从最高位算起,连续为 0 的位数。如果最高位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回从最高位算起,连续 0 的位数
func leadingZeros
public func leadingZeros(x: UInt8): Int8
功能:此函数用于返回整数的二进制表达中从最高位算起,连续为 0 的位数。如果最高位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回从最高位算起,连续 0 的位数
func log
public func log(x: Float64): Float64
功能:此函数用于求以 e 为底 x 的对数。
参数:
x:传入一个浮点数
返回值:返回以 e 为底 x 的对数
异常:
IllegalArgumentException:当输入值不为正时,抛出异常
func log
public func log(x: Float32): Float32
功能:此函数用于求以 e 为底 x 的对数。
参数:
x:传入一个浮点数
返回值:返回以 e 为底 x 的对数
异常:
IllegalArgumentException:当输入值不为正时,抛出异常
func log
public func log(x: Float16): Float16
功能:此函数用于求以 e 为底 x 的对数。
参数:
x:传入一个浮点数
返回值:返回以 e 为底 x 的对数
异常:
IllegalArgumentException:当输入值不为正时,抛出异常
func log2
public func log2(x: Float64): Float64
功能:此函数用于求以 2 为底 x 的对数。
参数:
x:传入一个浮点数
返回值:返回以 2 为底 x 的对数
异常:
IllegalArgumentException:当输入值不为正时,抛出异常
func log2
public func log2(x: Float32): Float32
功能:此函数用于求以 2 为底 x 的对数。
参数:
x:传入一个浮点数
返回值:返回以 2 为底 x 的对数
异常:
IllegalArgumentException:当输入值不为正时,抛出异常
func log2
public func log2(x: Float16): Float16
功能:此函数用于求以 2 为底 x 的对数。
参数:
x:传入一个浮点数
返回值:返回以 2 为底 x 的对数
异常:
IllegalArgumentException:当输入值不为正时,抛出异常
func log10
public func log10(x: Float64): Float64
功能:此函数用于求以 10 为底 x 的对数。
参数:
x:传入一个浮点数
返回值:返回以 10 为底 x 的对数
异常:
IllegalArgumentException:当输入值不为正时,抛出异常
func log10
public func log10(x: Float32): Float32
功能:此函数用于求以 10 为底 x 的对数。
参数:
x:传入一个浮点数
返回值:返回以 10 为底 x 的对数
异常:
IllegalArgumentException:当输入值不为正时,抛出异常
func log10
public func log10(x: Float16): Float16
功能:此函数用于求以 10 为底 x 的对数。
参数:
x:传入一个浮点数
返回值:返回以 10 为底 x 的对数
异常:
IllegalArgumentException:当输入值不为正时,抛出异常
func logBase
public func logBase(x: Float64, base: Float64): Float64
功能:此函数用于求以 e 为底 x 的对数与以 e 为底 base 的对数的商。
参数:
x:传入一个浮点数base:传入第二个浮点数
返回值:返回以 e 为底 x 的对数与以 e 为底 base 的对数的商
异常:
IllegalArgumentException:当参数x或参数base不为正,或参数base为 1.0 时,抛出异常
func logBase
public func logBase(x: Float32, base: Float32): Float32
功能:此函数用于求以 e 为底 x 的对数与以 e 为底 base 的对数的商。
参数:
x:传入一个浮点数base:传入第二个浮点数
返回值:返回以 e 为底 x 的对数与以 e 为底 base 的对数的商
异常:
IllegalArgumentException:当参数x或参数base不为正,或参数base为 1.0 时,抛出异常
func logBase
public func logBase(x: Float16, base: Float16): Float16
功能:此函数用于求以 e 为底 x 的对数与以 e 为底 base 的对数的商。
参数:
x:传入一个浮点数base:传入第二个浮点数
返回值:返回以 e 为底 x 的对数与以 e 为底 base 的对数的商
异常:
IllegalArgumentException:当参数x或参数base不为正,或参数base为 1.0 时,抛出异常
func max
public func max(a: Int64, b: Int64): Int64
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func max
public func max(a: Int32, b: Int32): Int32
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func max
public func max(a: Int16, b: Int16): Int16
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func max
public func max(a: Int8, b: Int8): Int8
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func max
public func max(a: UInt64, b: UInt64): UInt64
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func max
public func max(a: UInt32, b: UInt32): UInt32
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func max
public func max(a: UInt16, b: UInt16): UInt16
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func max
public func max(a: UInt8, b: UInt8): UInt8
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func max
public func max(a: Float64, b: Float64): Float64
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func max
public func max(a: Float32, b: Float32): Float32
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func max
public func max(a: Float16, b: Float16): Float16
功能:此函数用于求两个数的最大值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最大值
func maxNaN
public func maxNaN(a: Float64, b: Float64): Float64
功能:此函数用于求两个浮点数的最大值,有非数返回非数。
参数:
a:传入的第一个浮点数b: 传入的第二个浮点数
返回值:返回两个浮点数最大值, 有非数返回非数
func maxNaN
public func maxNaN(a: Float32, b: Float32): Float32
功能:此函数用于求两个浮点数的最大值,有非数返回非数。
参数:
a:传入的第一个浮点数b: 传入的第二个浮点数
返回值:返回两个浮点数最大值, 有非数返回非数
func maxNaN
public func maxNaN(a: Float16, b: Float16): Float16
功能:此函数用于求两个浮点数的最大值,有非数返回非数。
参数:
a:传入的第一个浮点数b: 传入的第二个浮点数
返回值:返回两个浮点数最大值, 有非数返回非数
func min
public func min(a: Int64, b: Int64): Int64
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func min
public func min(a: Int32, b: Int32): Int32
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func min
public func min(a: Int16, b: Int16): Int16
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func min
public func min(a: Int8, b: Int8): Int8
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func min
public func min(a: UInt64, b: UInt64): UInt64
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func min
public func min(a: UInt32, b: UInt32): UInt32
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func min
public func min(a: UInt16, b: UInt16): UInt16
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func min
public func min(a: UInt8, b: UInt8): UInt8
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func min
public func min(a: Float64, b: Float64): Float64
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func min
public func min(a: Float32, b: Float32): Float32
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func min
public func min(a: Float16, b: Float16): Float16
功能:此函数用于求两个数的最小值。
参数:
a:传入的第一个数b:传入的第二个数
返回值:返回两个数的最小值
func minNaN
public func minNaN(a: Float64, b: Float64): Float64
功能:此函数用于求两个浮点数的最小值, 有非数返回非数。
参数:
a:传入第一个浮点数b:传入第二个浮点数
返回值:返回两个浮点数最小值, 有非数返回非数
func minNaN
public func minNaN(a: Float32, b: Float32): Float32
功能:此函数用于求两个浮点数的最小值, 有非数返回非数。
参数:
a:传入第一个浮点数b:传入第二个浮点数
返回值:返回两个浮点数最小值, 有非数返回非数
func minNaN
public func minNaN(a: Float16, b: Float16): Float16
功能:此函数用于求两个浮点数的最小值, 有非数返回非数。
参数:
a:传入第一个浮点数b:传入第二个浮点数
返回值:返回两个浮点数最小值, 有非数返回非数
func reverse
public func reverse(x: UInt64): UInt64
功能:此函数用于无符号数的按位反转,返回反转结果对应的无符号数。
参数:
x:传入一个无符号整数
返回值:返回反转结果对应的无符号数
func reverse
public func reverse(x: UInt32): UInt32
功能:此函数用于无符号数的按位反转,返回反转结果对应的无符号数。
参数:
x:传入一个无符号整数
返回值:返回反转结果对应的无符号数
func reverse
public func reverse(x: UInt16): UInt16
功能:此函数用于无符号数的按位反转,返回反转结果对应的无符号数。
参数:
x:传入一个无符号整数
返回值:返回反转结果对应的无符号数
func reverse
public func reverse(x: UInt8): UInt8
功能:此函数用于无符号数的按位反转,返回反转结果对应的无符号数。
参数:
x:传入一个无符号整数
返回值:返回反转结果对应的无符号数
func rotate
public func rotate(num: Int64, d: Int8): Int64
功能:此函数用于整数的按位旋转,返回旋转结果对应的整数。
参数:
num:传入一个整数d:旋转位数,负数右移,正数左移
返回值:返回旋转后的整数
func rotate
public func rotate(num: Int32, d: Int8): Int32
功能:此函数用于整数的按位旋转,返回旋转结果对应的整数。
参数:
num:传入一个整数d:旋转位数,负数右移,正数左移
返回值:返回旋转后的整数
func rotate
public func rotate(num: Int16, d: Int8): Int16
功能:此函数用于整数的按位旋转,返回旋转结果对应的整数。
参数:
num:传入一个整数d:旋转位数,负数右移,正数左移
返回值:返回旋转后的整数
func rotate
public func rotate(num: Int8, d: Int8): Int8
功能:此函数用于整数的按位旋转,返回旋转结果对应的整数。
参数:
num:传入一个整数d:旋转位数,负数右移,正数左移
返回值:返回旋转后的整数
func rotate
public func rotate(num: UInt64, d: Int8): UInt64
功能:此函数用于整数的按位旋转,返回旋转结果对应的整数。
参数:
num:传入一个整数d:旋转位数,负数右移,正数左移
返回值:返回旋转后的整数
func rotate
public func rotate(num: UInt32, d: Int8): UInt32
功能:此函数用于整数的按位旋转,返回旋转结果对应的整数。
参数:
num:传入一个整数d:旋转位数,负数右移,正数左移
返回值:返回旋转后的整数
func rotate
public func rotate(num: UInt16, d: Int8): UInt16
功能:此函数用于整数的按位旋转,返回旋转结果对应的整数。
参数:
num:传入一个整数d:旋转位数,负数右移,正数左移
返回值:返回旋转后的整数
func rotate
public func rotate(num: UInt8, d: Int8): UInt8
功能:此函数用于整数的按位旋转,返回旋转结果对应的整数。
参数:
num:传入一个整数d:旋转位数,负数右移,正数左移
返回值:返回旋转后的整数
func sqrt
public func sqrt(x: Float64): Float64
功能:此函数用于求浮点数的算术平方根。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的算术平方根
异常:
IllegalArgumentException:当输入值为负数时,抛出异常
func sqrt
public func sqrt(x: Float32): Float32
功能:此函数用于求浮点数的算术平方根。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的算术平方根
异常:
IllegalArgumentException:当输入值为负数时,抛出异常
func sqrt
public func sqrt(x: Float16): Float16
功能:此函数用于求浮点数的算术平方根。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的算术平方根
异常:
IllegalArgumentException:当输入值为负数时,抛出异常
func trailingZeros
public func trailingZeros(x: Int64): Int8
功能:此函数用于返回整数的二进制表达中从最低位算起,连续 0 的个数。如果最低位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回最低位算起,有多少位连续为 0
func trailingZeros
public func trailingZeros(x: Int32): Int8
功能:此函数用于返回整数的二进制表达中从最低位算起,连续 0 的个数。如果最低位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回最低位算起,有多少位连续为 0
func trailingZeros
public func trailingZeros(x: Int16): Int8
功能:此函数用于返回整数的二进制表达中从最低位算起,连续 0 的个数。如果最低位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回最低位算起,有多少位连续为 0
func trailingZeros
public func trailingZeros(x: Int8): Int8
功能:此函数用于返回整数的二进制表达中从最低位算起,连续 0 的个数。如果最低位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回最低位算起,有多少位连续为 0
func trailingZeros
public func trailingZeros(x: UInt64): Int8
功能:此函数用于返回整数的二进制表达中从最低位算起,连续 0 的个数。如果最低位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回最低位算起,有多少位连续为 0
func trailingZeros
public func trailingZeros(x: UInt32): Int8
功能:此函数用于返回整数的二进制表达中从最低位算起,连续 0 的个数。如果最低位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回最低位算起,有多少位连续为 0
func trailingZeros
public func trailingZeros(x: UInt16): Int8
功能:此函数用于返回整数的二进制表达中从最低位算起,连续 0 的个数。如果最低位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回最低位算起,有多少位连续为 0
func trailingZeros
public func trailingZeros(x: UInt8): Int8
功能:此函数用于返回整数的二进制表达中从最低位算起,连续 0 的个数。如果最低位不是 0,则返回 0。
参数:
x:传入一个整数
返回值:返回最低位算起,有多少位连续为 0
func trunc
public func trunc(x: Float64): Float64
功能:此函数用于浮点数的截断取整。
参数:
x:传入一个浮点数
返回值:返回传入浮点数截断后取整值
func trunc
public func trunc(x: Float32): Float32
功能:此函数用于浮点数的截断取整。
参数:
x:传入一个浮点数
返回值:返回传入浮点数截断后取整值
func trunc
public func trunc(x: Float16): Float16
功能:此函数用于浮点数的截断取整。
参数:
x:传入一个浮点数
返回值:返回传入浮点数截断后取整值
func sin
public func sin(x: Float64): Float64
功能:此函数用于计算浮点数的正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的正弦函数值
func sin
public func sin(x: Float32): Float32
功能:此函数用于计算浮点数的正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的正弦函数值
func sin
public func sin(x: Float16): Float16
功能:此函数用于计算浮点数的正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的正弦函数值
func cos
public func cos(x: Float64): Float64
功能:此函数用于计算浮点数的余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的余弦函数值
func cos
public func cos(x: Float32): Float32
功能:此函数用于计算浮点数的余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的余弦函数值
func cos
public func cos(x: Float16): Float16
功能:此函数用于计算浮点数的余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的余弦函数值
func tan
public func tan(x: Float64): Float64
功能:此函数用于计算浮点数的正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的正切函数值
func tan
public func tan(x: Float32): Float32
功能:此函数用于计算浮点数的正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的正切函数值
func tan
public func tan(x: Float16): Float16
功能:此函数用于计算浮点数的正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的正切函数值
func asin
public func asin(x: Float64): Float64
功能:此函数用于计算浮点数的反正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反正弦函数值
异常:
IllegalArgumentException:当参数x大于 1.0 或小于 -1.0 时,抛出异常
func asin
public func asin(x: Float32): Float32
功能:此函数用于计算浮点数的反正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反正弦函数值
异常:
IllegalArgumentException:当参数x大于 1.0 或小于 -1.0 时,抛出异常
func asin
public func asin(x: Float16): Float16
功能:此函数用于计算浮点数的反正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反正弦函数值
异常:
IllegalArgumentException:当参数x大于 1.0 或小于 -1.0 时,抛出异常
func acos
public func acos(x: Float64): Float64
功能:此函数用于计算浮点数的反余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反余弦函数值
异常:
IllegalArgumentException:当参数x大于 1.0 或小于 -1.0 时,抛出异常
func acos
public func acos(x: Float32): Float32
功能:此函数用于计算浮点数的反余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反余弦函数值
异常:
IllegalArgumentException:当参数x大于 1.0 或小于 -1.0 时,抛出异常
func acos
public func acos(x: Float16): Float16
功能:此函数用于计算浮点数的反余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反余弦函数值
异常:
IllegalArgumentException:当参数x大于 1.0 或小于 -1.0 时,抛出异常
func atan
public func atan(x: Float64): Float64
功能:此函数用于计算浮点数的反正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反正切函数值
func atan
public func atan(x: Float32): Float32
功能:此函数用于计算浮点数的反正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反正切函数值
func atan
public func atan(x: Float16): Float16
功能:此函数用于计算浮点数的反正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反正切函数值
func sinh
public func sinh(x: Float64): Float64
功能:此函数用于计算浮点数的双曲正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的双曲正弦函数值
func sinh
public func sinh(x: Float32): Float32
功能:此函数用于计算浮点数的双曲正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的双曲正弦函数值
func sinh
public func sinh(x: Float16): Float16
功能:此函数用于计算浮点数的双曲正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的双曲正弦函数值
func cosh
public func cosh(x: Float64): Float64
功能:此函数用于计算浮点数的双曲余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的双曲余弦函数值
func cosh
public func cosh(x: Float32): Float32
功能:此函数用于计算浮点数的双曲余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的双曲余弦函数值
func cosh
public func cosh(x: Float16): Float16
功能:此函数用于计算浮点数的双曲余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的双曲余弦函数值
func tanh
public func tanh(x: Float64): Float64
功能:此函数用于计算浮点数的双曲正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的双曲正切函数值
func tanh
public func tanh(x: Float32): Float32
功能:此函数用于计算浮点数的双曲正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的双曲正切函数值
func tanh
public func tanh(x: Float16): Float16
功能:此函数用于计算浮点数的双曲正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的双曲正切函数值
func asinh
public func asinh(x: Float64): Float64
功能:此函数用于计算浮点数的反双曲正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反双曲正弦函数值
func asinh
public func asinh(x: Float32): Float32
功能:此函数用于计算浮点数的反双曲正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反双曲正弦函数值
func asinh
public func asinh(x: Float16): Float16
功能:此函数用于计算浮点数的反双曲正弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反双曲正弦函数值
func acosh
public func acosh(x: Float64): Float64
功能:此函数用于计算浮点数的反双曲余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反双曲余弦函数值
异常:
IllegalArgumentException:当参数x小于 1.0 时,抛出异常
func acosh
public func acosh(x: Float32): Float32
功能:此函数用于计算浮点数的反双曲余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反双曲余弦函数值
异常:
IllegalArgumentException:当参数x小于 1.0 时,抛出异常
func acosh
public func acosh(x: Float16): Float16
功能:此函数用于计算浮点数的反双曲余弦函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反双曲余弦函数值
异常:
IllegalArgumentException:当参数x小于 1.0 时,抛出异常
func atanh
public func atanh(x: Float64): Float64
功能:此函数用于计算浮点数的反双曲正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反双曲正切函数值
异常:
IllegalArgumentException:当参数x大于等于 1.0 或小于等于 -1.0 时,抛出异常
func atanh
public func atanh(x: Float32): Float32
功能:此函数用于计算浮点数的反双曲正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反双曲正切函数值
异常:
IllegalArgumentException:当参数x大于等于 1.0 或小于等于 -1.0 时,抛出异常
func atanh
public func atanh(x: Float16): Float16
功能:此函数用于计算浮点数的反双曲正切函数值。
参数:
x:传入一个浮点数
返回值:返回传入浮点数的反双曲正切函数值
异常:
IllegalArgumentException:当参数x大于等于 1.0 或小于等于 -1.0 时,抛出异常
func round
public func round(x: Float64): Float64
功能:此函数采用 IEEE-754 的向最近舍入规则,计算浮点数的舍入值。如果该浮点数有两个最近整数,则向偶数舍入。
参数:
x:传入一个浮点数
返回值:返回浮点数向最近整数方向的舍入值。如果该浮点数有两个最近整数,则向偶数舍入
func round
public func round(x: Float32): Float32
功能:此函数采用 IEEE-754 的向最近舍入规则,计算浮点数的舍入值。如果该浮点数有两个最近整数,则向偶数舍入。
参数:
x:传入一个浮点数
返回值:返回浮点数向最近整数方向的舍入值。如果该浮点数有两个最近整数,则向偶数舍入
func round
public func round(x: Float16): Float16
功能:此函数采用 IEEE-754 的向最近舍入规则,计算浮点数的舍入值。如果该浮点数有两个最近整数,则向偶数舍入。
参数:
x:传入一个浮点数
返回值:返回浮点数向最近整数方向的舍入值。如果该浮点数有两个最近整数,则向偶数舍入
示例
rotate 函数的位旋转运算 1
下面是 rotate 函数的位旋转运算示例:
代码如下:
from std import math.rotate
main(): Unit {
let a: Int8 = rotate(Int8(92), Int8(4))
/* a=-59 */
println("a=${a}")
}
运行结果如下:
a=-59
rotate 函数的位旋转运算 2
下面是 rotate 函数的位旋转运算示例:
代码如下:
from std import math.rotate
main(): Unit {
let a: Int32 = rotate(Int32(1), Int8(4))
/* a=16 */
println("a=${a}")
}
运行结果如下:
a=16
clamp 范围截断函数
下面是 clamp 范围截断函数示例:
代码如下:
from std import math.clamp
main(): Unit {
let min: Float16 = -0.123
let max: Float16 = 0.123
let v: Float16 = 0.121
let c = clamp(v, min, max)
/* true */
print("${c==v}")
let min2: Float16 = -0.999
let max2: Float16 = 10.123
let v2: Float16 = 11.121
let c2 = clamp(v2, min2, max2)
/* true */
print("${c2==max2}")
let min3: Float16 = -0.999
let max3: Float16 = 10.123
let v3: Float16 = -1.121
let c3 = clamp(v3, min3, max3)
/* true */
print("${c3==min3}")
}
运行结果如下:
truetruetrue
最小公倍数函数
下面是最小公倍数函数示例:
代码如下:
from std import math.lcm
main(): Unit {
let a: Int8 = lcm(Int8(-3), Int8(5))
/* a=15 */
println("a=${a}")
}
运行结果如下:
a=15
最大公约数函数
下面是最大公约数函数示例:
代码如下:
from std import math.gcd
main(): Unit {
let c2 = gcd(0, -60)
/* 60 */
println("c2=${c2}")
let c4 = gcd(-33, 27)
/* 3 */
print("c4=${c4}")
}
运行结果如下:
c2=60
c4=3
math.numeric 包
介绍
math.numeric 包对基础类型可表达范围之外提供扩展能力,当前支持大整数(BigInt)、高精度十进制数(Decimal)类型,提供常见的数学运算能力。
主要接口
struct BigInt
public struct BigInt <: Comparable<BigInt> & Hashable & ToString {
public init(bytes: Array<Byte>)
public init(sign: Bool, magnitude: Array<Byte>)
public init(n: Int8)
public init(n: Int16)
public init(n: Int32)
public init(n: Int64)
public init(n: IntNative)
public init(n: UInt8)
public init(n: UInt16)
public init(n: UInt32)
public init(n: UInt64)
public init(n: UIntNative)
public init(sign: Bool, bitLen: Int64, rand!: Random = Random())
public init(s: String, base!: Int64 = 10)
public static func randomProbablePrime(bitLen: Int64, certainty: UInt64, rand!: Random = Random()): BigInt
}
BigInt 定义为任意精度(二进制)的有符号整数。仓颉的 struct BigInt 用于任意精度有符号整数的计算,类型转换等。
init
public init(bytes: Array<Byte>)
功能: 通过大端的 Byte 数组以补码形式构建 BigInt。
参数:
- bytes:大端二进制补码数组,数组长度不能为空
异常:
- IllegalArgumentException:当传入空数组时,抛此异常
init
public init(sign: Bool, magnitude: Array<Byte>)
功能:通过符号位和真值的绝对值来构造 BigInt。视空数组为 0。
参数:
-
sign:符号。true 表示非负数,false 表示负数
-
magnitude:真值绝对值的二进制原码
异常:
- IllegalArgumentException:当 sign 为 false 且传入的数组为 0 时,抛此异常
init
public init(n: Int8)
功能:通过有符号整数来构建 BigInt。
参数:
- n:有符号整数
init
public init(n: Int16)
功能:通过有符号整数来构建 BigInt。
参数:
- n:有符号整数
init
public init(n: Int32)
功能:通过有符号整数来构建 BigInt。
参数:
- n:有符号整数
init
public init(n: Int64)
功能:通过有符号整数来构建 BigInt。
参数:
- n:有符号整数
init
public init(n: IntNative)
功能:通过有符号整数来构建 BigInt。
参数:
- n:有符号整数
init
public init(n: UInt8)
功能:通过无符号整数来构建 BigInt。
参数:
- n:无符号整数
init
public init(n: UInt16)
功能:通过无符号整数来构建 BigInt。
参数:
- n:无符号整数
init
public init(n: UInt32)
功能:通过无符号整数来构建 BigInt。
参数:
- n:无符号整数
init
public init(n: UInt64)
功能:通过无符号整数来构建 BigInt。
参数:
- n:无符号整数
init
public init(n: UIntNative)
功能:通过无符号整数来构建 BigInt。
参数:
- n:无符号整数
init
public init(sign: Bool, bitLen: Int64, rand!: Random = Random())
功能:通过指定正负,bit 长度,和随机数种子来构建一个随机的 BigInt。bit 长度需要大于 0。
参数:
-
sign:指定随机 BigInt 的正负
-
bitLen:指定随机 BigInt 的 bit 长度上限
-
rand:指定的随机数种子
异常:
- IllegalArgumentException:如果指定的 bit 长度小于等于 0,则抛此异常
init
public init(s: String, base!: Int64 = 10)
功能:通过字符串和进制来构建 BigInt。支持 2 进制到 36 进制。字符串的规则如下:
IntegerString : (SignString)? ValueString
SignString : + | -
ValueString : digit digits
digit : '0' ~ '9' | 'A' ~ 'Z' | 'a' ~ 'z'
如果 digit 在 '0' ~ '9' 内, 需要满足 (digit - '0') < base;
如果 digit 在 'A' ~ 'Z' 内, 需要满足 (digit - 'A') + 10 < base;
如果 digit 在 'a' ~ 'z' 内, 需要满足 (digit - 'A') + 10 < base。
参数:
-
s:字符串,用来构建 BigInt 的字符串。字符串规则为,开头可选一个正号(+)或者负号(-)。接下来必选非空阿拉伯数字或大小写拉丁字母的字符序列,大小写字符含义一样,'a' 和 'A' 的大小等于十进制的 10, 'b' 和 'B' 的大小等于十进制的 11, 以此类推。序列中的字符大小不得大于等于进制大小。如果入参字符串不符合上述要求,则抛出 IllegalArgumentException
-
base:进制,字符串所表示的进制,范围为 [2, 36]
异常:
- IllegalArgumentException:如果入参字符串不符合上述规则,或入参进制不在 [2, 36] 区间内,抛此异常
func randomProbablePrime
public static func randomProbablePrime(bitLen: Int64, certainty: UInt64, rand!: Random = Random()): BigInt
功能:通过可选的随机数种子构建一个随机的 BigInt 素数,素数的 bit 长度不超过入参 bitLen。显然,素数必定是大于等于 2 的整数,因此 bitLen 必须大于等于 2。素数检测使用 Miller-Rabin 素数测试算法。Miller-Rabin 测试会有概率将一个合数判定为素数,其出错概率随着入参 certainty 的增加而减少。
参数:
-
bitLen:所要生成的随机素数的 bit 长度的上限
-
certainty:生成的随机素数通过 Miller-Rabin 素数测试算法的次数,通过的次数越多,将合数误判为素数的概率越低
-
rand:指定的随机数种子
返回值:返回生成的随机素数
异常:
- IllegalArgumentException:如果指定的 bit 长度小于等于 1,则抛此异常
prop sign
public prop sign: Int64
功能:获取此 BigInt 的符号。如果此 BigInt 大于 0,则返回 1;等于 0,则返回 0;小于 0,则返回 -1。
prop bitLen
public prop bitLen: Int64
功能:获取此 BigInt 的最短 bit 长度。如 -3 (101) 返回 3,-1 (11) 返回 2,0 (0) 返回 1。
func testBit
public func testBit(index: Int64): Bool
功能:返回指定位置的 bit 信息。如果指定位置的 bit 为 0,则返回 false;为 1,则返回 true。
参数:
- index:需要知道的 bit 的索引。index 需要大于等于 0
返回值:指定位置的 bit 信息
异常:
- IllegalArgumentException:如果入参 index 小于 0,则抛此异常
func lowestOneBit
public func lowestOneBit(): Int64
功能:返回为 1 的最低位的 bit 的位置。
返回值:返回为 1 的最低位的 bit 的位置。如果 bit 全为 0,则返回 -1
func setBit
public func setBit(index: Int64): BigInt
功能:通过将指定索引位置的 bit 修改为 1 来构造一个新 BigInt。
参数:
- index:需要设置的 bit 位置的索引。index 需要大于等于 0
返回值:一个新的 BigInt,它是将原 BigInt index 处的 bit 改为 1 的产物
异常:
- IllegalArgumentException:如果入参 index 小于 0,则抛此异常
func clearBit
public func clearBit(index: Int64): BigInt
功能:通过将指定索引位置的 bit 修改为 0 来构造一个新 BigInt。
参数:
- index:需要设置的 bit 位置的索引。index 需要大于等于 0
返回值:一个新的 BigInt,它是将原 BigInt index 处的 bit 改为 0 的产物
异常:
- IllegalArgumentException:如果入参 index 小于 0,则抛此异常
func flipBit
public func flipBit(index: Int64): BigInt
功能:通过翻转指定索引位置的 bit 来构造一个新 BigInt。
参数:
- index:需要翻转的 bit 位置的索引。index 需要大于等于 0
返回值:一个新的 BigInt,它是将原 BigInt index 处的 bit 翻转后的产物
异常:
- IllegalArgumentException:如果入参 index 小于 0,则抛此异常
func isProbablePrime
public func isProbablePrime(certainty: UInt64): Bool
功能:判断一个数是不是素数,使用了 Miller-Rabin 测试算法,此算法的准确率会随着 certainty 参数的增加而增加。如果该数是素数,那么 Miller-Rabin 测试必定返回 true;如果该数是合数(期待返回 false),那么会有低于 $1/4^{certainty}$ 概率返回 true。注意,素数只对大于等于 2 的正整数有意义,即负数,0,1 都不是素数。
参数:
- certainty:需要执行 Miller-Rabin 测试的次数,注意,如果测试次数为 0,表示不测试,那么总是返回 true(即不是素数的数也必定返回 true)
返回值:测试该数是否是素数的结果,如果是,则返回 true;如果不是,则返回 false
operator func +
public operator func +(that: BigInt): BigInt
功能:与另一个 BigInt 相加,返回结果。
参数:
- that:另外一个 BigInt
返回值:一个新 BigInt,它是此 BigInt 与另外一个 BigInt 相加后的结果
operator func -
public operator func -(that: BigInt): BigInt
功能:与另一个 BigInt 相减,返回结果。
参数:
- that:另外一个 BigInt
返回值:一个新 BigInt,它是此 BigInt 与另外一个 BigInt 相减后的结果
operator func *
public operator func *(that: BigInt): BigInt
功能:与另一个 BigInt 相乘,返回结果。
参数:
- that:另外一个 BigInt
返回值:一个新 BigInt,它是此 BigInt 与另外一个 BigInt 相乘后的结果
operator func /
public operator func /(that: BigInt): BigInt
功能:与另一个 BigInt 相除,返回结果。此除法运算的行为与基础类型保持一致,即结果向靠近 0 的方向取整。
参数:
- that:另外一个 BigInt。入参不得为 0
返回值:一个新 BigInt,它是此 BigInt 与另外一个 BigInt 相除后的结果,结果向靠近 0 的方向取整
异常:
- ArithmeticException:除数为 0 抛此异常
operator func %
public operator func %(that: BigInt): BigInt
功能:与另一个 BigInt 相模,返回结果。此取模运算的行为与基础类型保持一致,即符号与被除数保持一致。
参数:
- that:另外一个 BigInt。入参不得为 0
返回值:一个新 BigInt,它是此 BigInt 与另外一个 BigInt 相模后的结果,其符号与被除数保持一致
异常:
- ArithmeticException:除数为 0 抛此异常
func divAndMod
public func divAndMod(that: BigInt): (BigInt, BigInt)
功能:与另一个 BigInt 相除,返回商和模。此除法运算的行为与基础类型保持一致,即商向靠近 0 的方向取整,模的符号与被除数保持一致。
参数:
- that:另外一个 BigInt。入参不得为 0
返回值:商和模
异常:
- ArithmeticException:除数为 0 抛此异常
func quo
public func quo(that: BigInt): BigInt
功能:与另一个 BigInt 相除,返回结果。此除法运算的行为与运算符重载函数区别于,如果被除数为负数,此函数的结果向着远离 0 的方向取整,保证余数大于等于 0。
参数:
- that:另外一个 BigInt。入参不得为 0
返回值:一个新 BigInt,它是此 BigInt 与另外一个 BigInt 相除后的结果
异常:
- ArithmeticException:除数为 0 抛此异常
func rem
public func rem(that: BigInt): BigInt
功能:与另一个 BigInt 相除,返回余数。余数的结果总是大于等于 0。
参数:
- that:另外一个 BigInt。入参不得为 0
返回值:一个新 BigInt,它是此 BigInt 与另外一个 BigInt 相除后的余数
异常:
- ArithmeticException:除数为 0 抛此异常
func quoAndRem
public func quoAndRem(that: BigInt): (BigInt, BigInt)
功能:与另一个 BigInt 相除,返回商和余数。此除法运算的行为与 divAndMod 函数区别于,如果被除数为负数,此函数的结果向着远离 0 的方向取整,保证余数总是大于等于 0。
参数:
- that:另外一个 BigInt。入参不得为 0
返回值:商和余数
异常:
- ArithmeticException:除数为 0 抛此异常
func modInverse
public func modInverse(that: BigInt): BigInt
功能:求模逆元,使得结果 r 满足 (this * r) % that == 1。显然,this 和 that 必须互质。当 that 为 正负 1 时,结果总是 0。
参数:
- that:另外一个 BigInt。入参不得为 0,且需要与 this 互质
返回值:返回模逆元
异常:
- IllegalArgumentException:当 this 和 that 不互质或 that 为 0 时,抛此异常
operator func -
public operator func -(): BigInt
功能:返回此 BigInt 的相反数。
返回值:此 BigInt 的相反数
operator func **
public operator func **(n: UInt64): BigInt
功能:计算此 BigInt 的 n 次幂,返回计算结果。
参数:
- n:指数参数
返回值:幂运算结果
func modPow
public func modPow(n: BigInt, m!: ?BigInt = None): BigInt
功能:计算此 BigInt 的 n 次幂模 m 的结果,并返回。模的规则与基础类型一致,即模的符号与被除数保持一致。
参数:
-
n:指数参数,必须为非负数
-
m:除数,此入参不得为 0
返回值:乘方后取模的运算结果
异常:
-
ArithmeticException:除数为 0 抛此异常
-
IllegalArgumentException:指数为负数时抛此异常
operator func &
public operator func &(that: BigInt): BigInt
功能:与另一个 BigInt 按位与,返回计算结果。
参数:
- that:另外一个 BigInt
返回值:返回与另一个 BigInt 的按位与的结果
operator func |
public operator func |(that: BigInt): BigInt
功能:与另一个 BigInt 按位或,返回计算结果。
参数:
- that:另外一个 BigInt
返回值:返回与另一个 BigInt 的按位或的结果
operator func ^
public operator func ^(that: BigInt): BigInt
功能:与另一个 BigInt 按位异或,返回计算结果。
参数:
- that:另外一个 BigInt
返回值:返回与另一个 BigInt 的按位异或的结果
operator func !
public operator func !(): BigInt
功能:按位非,返回结果。
返回值:返回此 BigInt 按位非的结果
operator func >>
public operator func >>(n: Int64): BigInt
功能:右移 n 位,并返回移位后的结果。
参数:
- n:右移 n 位,n 需要大于等于 0
返回值:返回此 BigInt 右移 n 位的结果
异常:
- ArithmeticException:入参小于 0 时抛此异常
operator func <<
public operator func <<(n: Int64): BigInt
功能:左移 n 位,并返回移位后的结果。
参数:
- n:左移 n 位,n 需要大于等于 0
返回值:返回此 BigInt 左移 n 位的结果
异常:
- ArithmeticException:入参小于 0 时抛此异常
operator func ==
public operator func ==(that: BigInt): Bool
功能:判断两个 BigInt 是否相等。
参数:
- that:另一个 BigInt
返回值:判等的结果。相等返回 true,不等返回 false
operator func !=
public operator func !=(that: BigInt): Bool
功能:判断两个 BigInt 是否不等。
参数:
- that:另一个 BigInt
返回值:判不等的结果。不等返回 true,相等返回 false
operator func >
public operator func >(that: BigInt): Bool
功能:判断此 BigInt 是否大于另一个 BigInt
参数:
- that:另一个 BigInt
返回值:比较的结果。大于返回 true,否则返回 false
operator func >=
public operator func >=(that: BigInt): Bool
功能:判断此 BigInt 是否大于等于另一个 BigInt
参数:
- that:另一个 BigInt
返回值:比较的结果。大于等于返回 true,否则返回 false
operator func <
public operator func <(that: BigInt): Bool
功能:判断此 BigInt 是否小于另一个 BigInt
参数:
- that:另一个 BigInt
返回值:比较的结果。小于返回 true,否则返回 false
operator func <=
public operator func <=(that: BigInt): Bool
功能:判断此 BigInt 是否小于等于另一个 BigInt
参数:
- that:另一个 BigInt
返回值:比较的结果。小于等于返回 true,否则返回 false
func compare
public func compare(that: BigInt): Ordering
功能:判断 BigInt 与另一个 BigInt 的关系。如果等于,返回 Ordering.EQ;如果小于,返回 Ordering.LT;如果大于,返回 Ordering.GT。
参数:
- that:另一个 BigInt 对象
返回值:返回此 BigInt 与另一个 BigInt 的关系。如果等于,返回 Ordering.EQ;如果小于,返回 Ordering.LT;如果大于,返回 Ordering.GT
func hashCode
public func hashCode(): Int64
功能:计算并返回此 BigInt 的哈希值。
返回值:返回此 BigInt 的哈希值
func toString
public func toString(): String
功能:计算并返回此 BigInt 的十进制字符串表示。
返回值:返回此 BigInt 的十进制字符串
func toBytes
public func toBytes(): Array<Byte>
功能:计算并返回此 BigInt 的大端补码字节数组。字节数组最低索引的最低位为符号位,如 128 返回 [0, 128](符号位为 0),-128 返回 [128](符号位为 1)。
返回值:返回此 BigInt 的大端补码字节数组
func toString
public func toString(base: Int64): String
功能:计算并返回此 BigInt 的任意进制字符串表示。
参数:
- base:进制,字符串所表示的进制,范围为 [2, 36]
返回值:返回此 BigInt 的 base 进制字符串
func toInt8
public func toInt8(overflowHandling!: OverflowStrategy = throwing): Int8
功能:将当前 BigInt 对象转化为 Int8 类型,支持自定义溢出策略。
参数:
- overflowHandling:转换溢出策略
返回值:返回转换后的 Int8 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toInt16
public func toInt16(overflowHandling!: OverflowStrategy = throwing): Int16
功能:将当前 BigInt 对象转化为 Int16 类型,支持自定义溢出策略。
参数:
- overflowHandling:转换溢出策略
返回值:返回转换后的 Int16 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toInt32
public func toInt32(overflowHandling!: OverflowStrategy = throwing): Int32
功能:将当前 BigInt 对象转化为 Int32 类型,支持自定义溢出策略。
参数:
- overflowHandling:转换溢出策略
返回值:返回转换后的 Int32 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toInt64
public func toInt64(overflowHandling!: OverflowStrategy = throwing): Int64
功能:将当前 BigInt 对象转化为 Int64 类型,支持自定义溢出策略。
参数:
- overflowHandling:转换溢出策略
返回值:返回转换后的 Int64 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toIntNative
public func toIntNative(overflowHandling!: OverflowStrategy = throwing): IntNative
功能:将当前 BigInt 对象转化为 IntNative 类型,支持自定义溢出策略。
参数:
- overflowHandling:转换溢出策略
返回值:返回转换后的 IntNative 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toUInt8
public func toUInt8(overflowHandling!: OverflowStrategy = throwing): UInt8
功能:将当前 BigInt 对象转化为 UInt8 类型,支持自定义溢出策略。
参数:
- overflowHandling:转换溢出策略
返回值:返回转换后的 UInt8 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toUInt16
public func toUInt16(overflowHandling!: OverflowStrategy = throwing): UInt16
功能:将当前 BigInt 对象转化为 UInt16 类型,支持自定义溢出策略。
参数:
- overflowHandling:转换溢出策略
返回值:返回转换后的 UInt16 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toUInt32
public func toUInt32(overflowHandling!: OverflowStrategy = throwing): UInt32
功能:将当前 BigInt 对象转化为 UInt32 类型,支持自定义溢出策略。
参数:
- overflowHandling:转换溢出策略
返回值:返回转换后的 UInt32 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toUInt64
public func toUInt64(overflowHandling!: OverflowStrategy = throwing): UInt64
功能:将当前 BigInt 对象转化为 UInt64 类型,支持自定义溢出策略。
参数:
- overflowHandling:转换溢出策略
返回值:返回转换后的 UInt64 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toUIntNative
public func toUIntNative(overflowHandling!: OverflowStrategy = throwing): UIntNative
功能:将当前 BigInt 对象转化为 UIntNative 类型,支持自定义溢出策略。
参数:
- overflowHandling:转换溢出策略
返回值:返回转换后的 UIntNative 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func abs
public func abs(i: BigInt): BigInt
功能:计算并返回入参 BigInt 的绝对值。
参数:
- i:需要计算绝对值的 BigInt
返回值:返回入参 BigInt 的绝对值
func sqrt
public func sqrt(i: BigInt): BigInt
功能:计算并返回入参 BigInt 的算数平方根,向下取整。
参数:
- i:需要计算算数平方根的 BigInt,入参需要非负
返回值:返回入参 BigInt 的算数平方根,向下取整
异常:
- IllegalArgumentException:如果入参为负数,则抛此异常
func gcd
public func gcd(i1: BigInt, i2: BigInt): BigInt
功能:计算并返回 i1 和 i2 的最大公约数,总是返回非负数(相当于绝对值的最大公约数)。
参数:
-
i1:需要计算最大公约数的第一个入参
-
i2:需要计算最大公约数的第二个入参
返回值:返回 i1 和 i2 的最大公约数,总是返回非负数(相当于绝对值的最大公约数)
func lcm
public func lcm(i1: BigInt, i2: BigInt): BigInt
功能:计算并返回 i1 和 i2 的最小公倍数,除了入参有 0 时返回 0 外,总是返回正数(相当于绝对值的最小公倍数)。
参数:
-
i1:需要计算最小公倍数的第一个入参
-
i2:需要计算最小公倍数的第二个入参
返回值:返回 i1 和 i2 的最小公倍数,当入参有 0 时返回 0,其余情况返回正数(相当于绝对值的最小公倍数)
func max
public func max(i1: BigInt, i2: BigInt): BigInt
功能:计算并返回两个 BigInt 中较大的那个。
参数:
-
i1:需要比较的 BigInt
-
i2:需要比较的 BigInt
返回值:返回 i1,i2 中较大的 BigInt
func min
public func min(i1: BigInt, i2: BigInt): BigInt
功能:计算并返回两个 BigInt 中较小的那个。
参数:
-
i1:需要比较的 BigInt
-
i2:需要比较的 BigInt
返回值:返回 i1,i2 中较小的 BigInt
func countOne
public func countOne(i: BigInt): Int64
功能:计算并返回入参 BigInt 的二进制补码中 1 的个数。
参数:
- i:需要计算二进制补码中 1 的个数的 BigInt
返回值:返回入参 BigInt 的二进制补码中 1 的个数
struct DecimalContext
public struct DecimalContext {
public init(precision: Int64, roundingMode: RoundingMode)
}
DecimalContext 对象作用于用户对 Decimal 操作过程中,对生成结果指定上下文,设定结果的精度与对应舍入规则。
init
public init(precision: Int64, roundingMode: RoundingMode)
功能:指定精度与舍入规则构建生成上下文对象,可作用于 Decimal 操作结果。
参数:
-
precision:精度值,限制
Decimal结果有效数值位数 -
roundingMode:舍入规则,
Decimal结果有效位超出精度限制时舍入操作遵循该指定规则
异常:
- IllegalArgumentException:当传入精度小于0时,抛出此异常
precision
public let precision: Int64
功能:获取上下文中指定的精度值。
roundingMode
public let roundingMode: RoundingMode
功能:获取上下文中指定的舍入规则。
enum RoundingMode
public enum RoundingMode {
| UP
| DOWN
| CEILING
| FLOOR
| HALF_UP
| HALF_EVEN
}
舍入规则枚举类,共包含 6 中舍入规则。除包含 IEEE 754 浮点数规定约定的 5 种舍入规则外,提供使用较多的 “四舍五入” 舍入规则。
| 十进制数 | UP | DOWN | CEILING | FLOOR | HALF_UP | HALF_EVEN |
|---|---|---|---|---|---|---|
| 7.5 | 8 | 7 | 8 | 7 | 8 | 8 |
| 4.5 | 5 | 4 | 5 | 4 | 5 | 4 |
| -1.1 | -2 | -1 | -1 | -2 | -1 | -1 |
| -4.5 | -5 | -4 | -4 | -5 | -5 | -4 |
| -7.5 | -8 | -7 | -7 | -8 | -8 | -8 |
UP
UP
功能:向远离零的方向舍入。
DOWN
DOWN
功能:向靠近零的方向舍入。
CEILING
CEILING
功能:向正无穷方向舍入。
FLOOR
FLOOR
功能:向负无穷方向舍入。
HALF_UP
HALF_UP
功能:四舍五入。
HALF_EVEN
HALF_EVEN
功能:四舍六入五取偶,又称 “银行家舍入”。
enum OverflowStrategy
public enum OverflowStrategy {
| throwing
| wrapping
| saturating
}
溢出策略枚举类,共包含 3 种溢出策略。BigInt 类型、Decimal 类型转换为整数类型时,允许指定不同的溢出处理策略。
throwing
throwing
功能:出现溢出,抛出异常。
wrapping
wrapping
功能:出现溢出,高位截断。
saturating
saturating
功能:出现溢出,当前值大于目标类型的 MAX 值,返回目标类型 MAX 值,当前值小于目标类型的 MIN 值,返回目标类型 MIN 值。
struct Decimal
public struct Decimal <: Comparable<Decimal> & Hashable & ToString {
public init(val: BigInt, scale: Int32, ctx!: DecimalContext = defaultDecimalContext)
public init(val: String, ctx!: DecimalContext = defaultDecimalContext)
public init(val: Int8, ctx!: DecimalContext = defaultDecimalContext)
public init(val: Int16, ctx!: DecimalContext = defaultDecimalContext)
public init(val: Int32, ctx!: DecimalContext = defaultDecimalContext)
public init(val: Int64, ctx!: DecimalContext = defaultDecimalContext)
public init(val: IntNative, ctx!: DecimalContext = defaultDecimalContext)
public init(val: UInt8, ctx!: DecimalContext = defaultDecimalContext)
public init(val: UInt16, ctx!: DecimalContext = defaultDecimalContext)
public init(val: UInt32, ctx!: DecimalContext = defaultDecimalContext)
public init(val: UInt64, ctx!: DecimalContext = defaultDecimalContext)
public init(val: UIntNative, ctx!: DecimalContext = defaultDecimalContext)
public init(val: Float16, ctx!: DecimalContext = defaultDecimalContext)
public init(val: Float32, ctx!: DecimalContext = defaultDecimalContext)
public init(val: Float64, ctx!: DecimalContext = defaultDecimalContext)
}
Decimal 用于表示任意精度的有符号的十进制数。允许操作过程指定上下文,指定结果精度及舍入规则。提供基础类型 (Int、UInt、String、Float等) 与 BigInt 类型互相转换能力,支持 Decimal 对象基本属性查询等能力,支持基础数学运算操作,提供对象比较、hash、字符串打印等基础能力。
init
public init(val: BigInt, scale: Int32, ctx!: DecimalContext = defaultDecimalContext)
功能:通过有符号大整数 BigInt 和标度值构建 Deciaml 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:有符号大整数值
-
scale:标度值
-
ctx:
Deciaml上下文
异常:
- OverflowException:当构建值范围超过
[-(maxValue(ctx.precision) * (10 ^ {Int32.MAX})), maxValue(ctx.precision) * (10 ^ {Int32.MAX})]时,抛出此异常
init
public init(val: String, ctx!: DecimalContext = defaultDecimalContext)
功能:通过规定格式字符串构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
字符串需满足格式如下:
Decimal 字符串: (SignString)? ValueString (ExponentString)?
SignString: + | -
ValueString:IntegerPart.(FractionPart)? | .FractionPart | IntegerPart
IntegerPart:Digits
FractionPart:Digits
ExponentString:ExponentIndicator (SignString)? IntegerPart
ExponentIndicator:e | E
Digits:Digit | Digit Digits
Digit:0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
参数:
-
val:规定格式字符串
-
ctx:
Deciaml上下文
异常:
-
IllegalArgumentException:当入参字符串不满足规定格式时,抛此异常
-
OverflowException:当构建值范围超过
[-(maxValue(ctx.precision) * (10 ^ {Int32.MAX})), maxValue(ctx.precision) * (10 ^ {Int32.MAX})]时,抛出此异常
init
public init(val: Int8, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 8 位有符号整数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:8 位有符号整数
-
ctx:
Decimal上下文
init
public init(val: Int16, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 16 位有符号整数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:16 位有符号整数
-
ctx:
Decimal上下文
init
public init(val: Int32, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 32 位有符号整数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:32 位有符号整数
-
ctx:
Decimal上下文
init
public init(val: Int64, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 64 位有符号整数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:64 位有符号整数
-
ctx:
Decimal上下文
init
public init(val: IntNative, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 32 位或 64 位 (具体长度与平台相关) 有符号整数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:32 位或 64位有符号整数
-
ctx:
Decimal上下文
init
public init(val: UInt8, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 8 位无符号整数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:8 位无符号整数
-
ctx:
Decimal上下文
init
public init(val: UInt16, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 16 位无符号整数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:16 位无符号整数
-
ctx:
Decimal上下文
init
public init(val: UInt32, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 32 位无符号整数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:32 位无符号整数
-
ctx:
Decimal上下文
init
public init(val: UInt64, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 64 位无符号整数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:64 位无符号整数
-
ctx:
Decimal上下文
init
public init(val: UIntNative, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 32 位或 64 位 (具体长度与平台相关) 无符号整数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
参数:
-
val:32 位或 64位无符号整数
-
ctx:
Decimal上下文
init
public init(val: Float16, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 16 位有符号浮点数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
注意:由于部分十进制小数无法通过二进制浮点数精确表示,此构造函数以精确值构建 Decimal 对象,传入浮点数值可能与最终构建 Decimal 对象字符串打印值不一致。
参数:
-
val:16 位有符号二进制浮点数
-
ctx:
Decimal上下文
异常:
- IllegalArgumentException:当入参为
inf、-inf或nan时,抛出此异常
init
public init(val: Float32, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 32 位有符号浮点数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
注意:由于部分十进制小数无法通过二进制浮点数精确表示,此构造函数以精确值构建 Decimal 对象,传入浮点数值可能与最终构建 Decimal 对象字符串打印值不一致。
参数:
-
val:32 位有符号二进制浮点数
-
ctx:
Decimal上下文
异常:
- IllegalArgumentException:当入参为
inf、-inf或nan时,抛出此异常
init
public init(val: Float64, ctx!: DecimalContext = defaultDecimalContext)
功能:通过 64 位有符号浮点数构建 Decimal 对象。允许自行指定上下文,对构建结果限制精度,按指定舍入规则进行舍入操作。默认采用 defaultDecimalContext 即无限精度进行构建。
注意:由于部分十进制小数无法通过二进制浮点数精确表示,此构造函数以精确值构建 Decimal 对象,传入浮点数值可能与最终构建 Decimal 对象字符串打印值不一致。
参数:
-
val:64 位有符号二进制浮点数
-
ctx:
Decimal上下文
异常:
- IllegalArgumentException:当入参为
inf、-inf或nan时,抛出此异常
defaultDecimalContext
public static let defaultDecimalContext
功能:默认上下文,精度值为 0,舍入规则为 “银行家舍入”。即无精度限制,保留操作结果实际精度,在操作结果为无限小数场景下,默认遵循 IEEE 754-2019 decimal128 规则,精度保留 34 位 “银行家” 规则舍入。
返回值:DecimalContext 默认值
prop sign
public prop sign: Int64
功能:获取 Decimal 实例符号值。
Decimal值大于 0,返回 1;Decimal值等于 0,返回 0;Decimal值小于 0,返回 -1。
prop scale
public prop scale: Int32
功能:获取 Decimal 标度值。
prop value
public prop value: BigInt
功能:获取 Decimal 无标度整数值,BigInt 承载。
prop precision
public prop precision: Int64
功能:获取 Decimal 精度值,即无标度整数部分十进制有效数字位数,非负数。
func add
public func add(d: Decimal): Decimal
功能:加法运算,加上入参 Decimal 对象,返回结果值。上下文默认 defaultDecimalContext 保留加合结果实际精度值。
参数:
- d:
Decimal加数对象
返回值:生成一个新的 Decimal 对象,用于存储两个加数的加合结果值
异常:
- OverflowException:当两个加数标度值相减值溢出时,抛出此异常
func add
public func add(d: Decimal, ctx: DecimalContext): Decimal
功能:加法运算,支持自定义运算上下文,加上入参 Decimal 对象,返回结果值,如果结果精度超过上下文指定精度,则根据指定的上下文对加合结果进行舍入。
参数:
-
d:
Decimal加数对象 -
ctx:
Decimal上下文
返回值:生成一个新的 Decimal 对象,用于存储两个加数的加合结果值
异常:
- OverflowException:当两个加数标度值相减值溢出时,抛出此异常
operator func +
public operator func +(d: Decimal): Decimal
功能:加法运算,加法运算符重载,行为与 add 函数相同,加上入参 Decimal 对象,返回结果值。上下文默认 defaultDecimalContext 保留加合结果实际精度值。
参数:
- d:
Decimal加数对象
返回值:生成一个新的 Decimal 对象,用于存储两个加数的加合结果值
异常:
- OverflowException:当两个加数标度值相减溢出时,抛出此异常
func sub
public func sub(d: Decimal): Decimal
功能:减法运算,减去入参 Decimal 对象,返回结果值。上下文默认 defaultDecimalContext 保留减法运算结果实际精度值。
参数:
- d:
Decimal减数对象
返回值:生成一个新的 Decimal 对象,用于存储减法运算结果值
异常:
- OverflowException:当被减数与减数标度值相减溢出时,抛出此异常
func sub
public func sub(d: Decimal, ctx: DecimalContext): Decimal
功能:减法运算,支持自定义运算上下文,减去入参 Decimal 对象,返回结果值,如果结果精度超过上下文指定精度,则根据指定的上下文对减法运算结果进行舍入。
参数:
-
d:
Decimal减数对象 -
ctx:
Decimal上下文
返回值:生成一个新的 Decimal 对象,用于存储减法运算结果值
异常:
- OverflowException:当被减数与减数标度值相减溢出时,抛出此异常
operator func -
public operator func -(d: Decimal): Decimal
功能:减法运算,减法运算符重载,行为与 sub 函数相同,减去入参 Decimal 对象,返回结果值。上下文默认 defaultDecimalContext 保留减法运算结果实际精度值。
参数:
- d:
Decimal减数对象
返回值:生成一个新的 Decimal 对象,用于存储减法运算结果值
异常:
- OverflowException:当被减数与减数标度值相减溢出时,抛出此异常
func mul
public func mul(d: Decimal): Decimal
功能:乘法运算,乘以入参 Decimal 对象,返回结果值。上下文默认 defaultDecimalContext 保留乘法运算结果实际精度值。
参数:
- d:
Decimal乘数对象
返回值:生产一个新的 Decimal 对象,用于存储乘法运算结果值
异常:
- OverflowException:当两个乘数标度值相加溢出时,抛出此异常
func mul
public func mul(d: Decimal, ctx: DecimalContext): Decimal
功能:乘法运算,支持自定义运算上下文,乘以入参 Decimal 对象,返回结果值,如果结果精度超过上下文指定精度,则根据指定的上下文对乘法运算结果进行舍入。
参数:
- d:
Decimal乘数对象
返回值:生成一个新的 Decimal 对象,用于存储乘法运算结果值
异常:
- OverflowException:当两个乘数标度值相加溢出时,抛出此异常
operator func *
public operator func *(d: Decimal): Decimal
功能:乘法运算,乘法运算符重载,行为与 mul 函数相同,乘以入参 Decimal 对象,返回结果值。上下文默认 defaultDecimalContext 保留乘法运算结果实际精度值。
参数:
- d:
Decimal乘数对象
返回值:生成一个新的 Decimal 对象,用于存储乘法运算结果值
异常:
- OverflowException:当两个乘数标度值相加溢出时,抛出此异常
func div
public func div(d: Decimal): Decimal
功能:除法运算,除以入参 Decimal 对象,返回结果值。上下文默认 defaultDecimalContext 保留除法运算结果实际精度值。
注意:结果为无限小数场景时,默认采用 IEEE 754-2019 decimal128 对结果进行舍入。
参数:
- d:
Decimal除数对象
返回值:生成一个新的 Decimal 对象,用于存储除法运算结果值
异常:
-
IllegalArgumentException:当除数为 0 时,抛出此异常
-
OverflowException:当除法结果值范围超过
[-(maxValue(ctx.precision) * (10 ^ {Int32.MAX})), maxValue(ctx.precision) * (10 ^ {Int32.MAX})]时,抛出此异常
func div
public func div(d: Decimal, ctx: DecimalContext): Decimal
功能:除法运算,支持自定义运算上下文,除以入参 Decimal 对象,返回结果值,如果结果精度超过上下文指定精度,则根据指定的上下文对除法运算结果进行舍入。
参数:
-
d:
Decimal除数对象 -
ctx:
Decimal上下文
返回值:生成一个新的 Decimal 对象,用于存储除法运算结果值
异常:
-
IllegalArgumentException:当除数为 0 时,抛出此异常
-
OverflowException:当除法结果值范围超过
[-(maxValue(ctx.precision) * (10 ^ {Int32.MAX})), maxValue(ctx.precision) * (10 ^ {Int32.MAX})]时,抛出此异常
operator func /
public operator func /(d: Decimal): Decimal
功能:除法运算,除法运算符重载,行为与 div 函数相同,除以入参 Decimal 对象,返回结果值。上下文默认 defaultDecimalContext 保留除法运算结果实际精度值。
注意:结果为无限小数场景时,默认采用 IEEE 754-2019 decimal128 对结果进行舍入。
参数:
- d:
Decimal除数对象
返回值:生成一个新的 Decimal 对象,用于存储除法运算结果值
异常:
-
IllegalArgumentException:当除数为 0 时,抛出此异常
-
OverflowException:当除法结果值范围超过
[-(maxValue(ctx.precision) * (10 ^ {Int32.MAX})), maxValue(ctx.precision) * (10 ^ {Int32.MAX})]时,抛出此异常
func divAndRem
public func divAndRem(d: Decimal): (BigInt, Decimal)
功能:除法取商和余数运算,除以入参 Decimal 对象,返回整数商值和余数值。上下文默认 defaultDecimalContext 保留结果实际精度值。
参数:
- d:
Decimal除数对象
返回值:生成一个元组对象,分别用于存储整数商值结果和余数结果值
异常:
-
IllegalArgumentException:当除数为 0 时,抛出此异常
-
OverflowException:当除法结果值范围超过
[-(maxValue(ctx.precision) * (10 ^ {Int32.MAX})), maxValue(ctx.precision) * (10 ^ {Int32.MAX})]时,抛出此异常
func divAndRem
public func divAndRem(d: Decimal, ctx: DecimalContext): (BigInt, Decimal)
功能:除法取商和余数运算,支持自定义运算上下文,除以入参 Decimal 对象,返回整数商值和余数值。如果结果精度超过上下文指定精度,则根据指定的上下文对除法运算结果进行舍入。特别注意,这里传入的舍入规则是无效的,默认使用 RoundingMode.DOWN。
参数:
-
d:
Decimal除数对象 -
ctx:
Decimal上下文
返回值:生成一个元组对象,分别用于存储整数商值结果和余数结果值
异常:
-
IllegalArgumentException:当除数为 0 时,抛出此异常
-
OverflowException:当除法结果值范围超过
[-(maxValue(ctx.precision) * (10 ^ {Int32.MAX})), maxValue(ctx.precision) * (10 ^ {Int32.MAX})]时,抛出此异常
func neg
public func neg(): Decimal
功能:取反运算,对当前 Decimal 对象取反,返回结果值。上下文默认 defaultDecimalContext 保留取反运算结果实际精度值。
返回值:生成一个新的 Decimal 对象,用于存储取反结果值
func neg
public func neg(ctx: DecimalContext): Decimal
功能:取反运算,支持自定义运算上下文,对当前 Decimal 对象取反,返回结果值。如果结果精度超过上下文指定精度,则根据指定的上下文对取反运算结果进行舍入。
参数:
- ctx:
Decimal上下文
返回值:生成一个新的 Decimal 对象,用于存储取反结果值
operator func -
public operator func -(): Decimal
功能:取反运算,一元负数运算符重载,行为与 neg 函数相同,对当前 Decimal 对象取反,返回结果值。上下文默认 defaultDecimalContext 保留取反运算结果实际精度值。
返回值:生成一个新的 Decimal 对象,用于存储取反结果值
operator func <
public operator func <(d: Decimal): Bool
功能:小于比较运算,小于运算符重载,判断入参 Decimal 对象是否小于当前对象,返回比较结果值。
参数:
- d:
Decimal待比较对象
返回值:返回小于比较运算结果。当前对象小于入参时,返回 true,否则返回 false
operator func >
public operator func >(d: Decimal): Bool
功能:大于比较运算,大于运算符重载,判断入参 Decimal 对象是否大于当前对象,返回比较结果值。
参数:
- d:
Decimal待比较对象
返回值:返回大于比较运算结果。当前对象大于入参时,返回 true,否则返回 false
operator func <=
public operator func <=(d: Decimal): Bool
功能:小于等于比较运算,小于等于运算符重载,判断入参 Decimal 对象是否小于等于当前对象,返回比较结果值。
参数:
- d:
Decimal待比较对象
返回值:返回小于等于比较运算结果。当前对象小于等于入参时,返回 true,否则返回 false
operator func >=
public operator func >=(d: Decimal): Bool
功能:大于等于比较运算,大于等于运算符重载,判断入参 Decimal 对象是否大于等于当前对象,返回比较结果值。
参数:
- d:
Decimal待比较对象
返回值:返回大于等于比较运算结果。当前对象大于等于入参时,返回 true,否则返回 false
operator func ==
public operator func ==(d: Decimal): Bool
功能:等于比较运算,等于运算符重载,判断入参 Decimal 对象与当前对象是否相等,返回比较结果值。
参数:
- d:
Decimal待比较对象
返回值:返回等于比较运算结果。当前对象等于入参时,返回 true,否则返回 false
operator func !=
public operator func !=(d: Decimal): Bool
功能:不等比较运算,不等运算符重载,判断入参 Decimal 对象与当前对象是否不相等,返回比较结果值。
参数:
- d:
Decimal待比较对象
返回值:返回不等比较运算结果。当前对象不等于入参时,返回 true,否则返回 false
func compare
public func compare(d: Decimal): Ordering
功能:比较当前对象与入参 Decimal 对象,返回比较结果值。
参数:
- d:
Decimal待比较对象
返回值:返回比较结果,当前对象小于入参时,返回 Ordering.LT,大于入参时,返回 Ordering.GT,否则返回 Ordering.EQ
func hashCode
public func hashCode(): Int64
功能:获取当前对象哈希值。
返回值:返回当前对象哈希值
func toString
public func toString(): String
功能:以不带指数形式打印输出 Decimal 对象,小于 0 时以 “-” 开头后跟十进制数字,大于等于 0 时,直接打印输出数字,不额外添加 “+”。
返回值:不带指数形式的 Decimal 字符串
func reScale
public func reScale(newScale: Int32, rm!: RoundingMode = HALF_EVEN): Decimal
功能:调整 Decimal 对象标度值,允许指定舍入规则,返回标度调整后新的 Decimal 对象。
参数:
-
newScale:新的标度值
-
rm:舍入规则
返回值:新的标度值的 Decimal 对象
func removeTrailingZeros
public func removeTrailingZeros(): Decimal
功能:对当前 Decimal 对象移除尾部零,不改变对象数值。
返回值:新的无尾部零的 Decimal 对象
func scaleUnit
public func scaleUnit(): Decimal
功能:对当前 Decimal 对象返回标度单位,即数值为 1 ,标度值与当前对象相等的 Decimal 对象。
返回值:标度单位 Decimal 对象
func isInteger
public func isInteger(): Bool
功能:判断当前 Decimal 对象是否为整数。
返回值:返回当前对象是否为整数判断结果。当前对象为整数时返回 true,否则返回 false
func pow
public func pow(n: Int64): Decimal
功能:乘方运算,获取当前对象为底数,入参 Int64 为指数的乘方运算结果。
注意:指数为负值且结果为无限小数场景时,默认采用 IEEE 754-2019 decimal128 对结果进行舍入。
参数:
- n:乘方运算的指数值
返回值:生成一个新的 Decimal 对象,用于存储乘方运算结果值
异常:
- OverflowException:当乘方运算结果标度值溢出时,抛出此异常
func pow
public func pow(n: Int64, ctx: DecimalContext): Decimal
功能:乘方运算,支持自定义运算上下文,获取当前对象为底数,入参 Int64 为指数的乘方运算结果,如果运算结果超过上下文指定精度,则根据指定的上下文对乘方结果进行舍入。
参数:
-
n:乘方运算的指数值
-
ctx:
Decimal上下文
返回值:生成一个新的 Decimal 对象,用于存储乘方运算结果值
异常:
- OverflowException:当乘方运算结果标度值溢出时,抛出此异常
operator func **
public operator func **(n: Int64): Decimal
功能:乘方运算,乘方运算符重载,行为与 pow 函数相同,获取当前对象为底数,入参 Int64 为指数的乘方运算结果,其中指数为入参 Decimal 对象的整数部分。
注意:指数为负值且结果为无限小数场景时,默认采用 IEEE 754-2019 decimal128 对结果进行舍入。
参数:
- n:乘方运算的指数值
返回值:生成一个新的 Decimal 对象,用于存储乘方运算结果值
异常:
- OverflowException:当乘方运算结果标度值溢出时,抛出此异常
func shiftPoint
public func shiftPoint(n: Int32): Decimal
功能:移动当前 Decimal 对象小数点 abs(n) 位返回结果对象,当 n 为正数时,左移小数点,n 为负数时,右移小数点,n 为零时,返回当前对象。
参数:
- n:指定小数点移动位数及方向
返回值:对当前对象小数点移动指定位数后生成新的 Decimal 对象
func round
public func round(ctx: DecimalContext): Decimal
功能:按照指定上下文(舍入精度、舍入规则)对当前 Decimal 对象进行舍入操作。
参数:
- ctx:
Decimal上下文
返回值:舍入操作生成的新的 Decimal 对象
异常:
- OverflowException:当舍入操作结果标度值溢出时,抛出此异常
func abs
public func abs(): Decimal
功能:获取当前 Decimal 对象的绝对值。
返回值:返回当前 Decimal 对象的绝对值
func sqrt
public func sqrt(ctx!: DecimalContext = defaultDecimalContext): Decimal
功能:开方运算,支持自定义运算上下文,获取当前对象开方结果,如果运算结果超过上下文指定精度,则根据指定的上下文对开方结果进行舍入。
入参:
- ctx:
Decimal上下文
返回值:生成一个新的 Decimal 对象,用于存储开方运算结果值
异常:
- IllegalArgumentException:当前
Decimal对象为负数时,抛出此异常
func toInt8
public func toInt8(overflowHandling!: OverflowStrategy = throwing): Int8
功能:将当前 Decimal 对象转化为 Int8 类型,支持自定义溢出策略。
入参:
- overflowHandling:转换溢出策略
返回值:转换后的 Int8 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toInt16
public func toInt16(overflowHandling!: OverflowStrategy = throwing): Int16
功能:将当前 Decimal 对象转化为 Int16 类型,支持自定义溢出策略。
入参:
- overflowHandling:转换溢出策略
返回值:转换后的 Int16 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toInt32
public func toInt32(overflowHandling!: OverflowStrategy = throwing): Int32
功能:将当前 Decimal 对象转化为 Int32 类型,支持自定义溢出策略。
入参:
- overflowHandling:转换溢出策略
返回值:转换后的 Int32 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toInt64
public func toInt64(overflowHandling!: OverflowStrategy = throwing): Int64
功能:将当前 Decimal 对象转化为 Int64 类型,支持自定义溢出策略。
入参:
- overflowHandling:转换溢出策略
返回值:转换后的 Int64 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toIntNative
public func toIntNative(overflowHandling!: OverflowStrategy = throwing): IntNative
功能:将当前 Decimal 对象转化为 IntNative 类型,支持自定义溢出策略。
入参:
- overflowHandling:转换溢出策略
返回值:转换后的 IntNative 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toUInt8
public func toUInt8(overflowHandling!: OverflowStrategy = throwing): UInt8
功能:将当前 Decimal 对象转化为 UInt8 类型,支持自定义溢出策略。
入参:
- overflowHandling:转换溢出策略
返回值:转换后的 UInt8 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toUInt16
public func toUInt16(overflowHandling!: OverflowStrategy = throwing): UInt16
功能:将当前 Decimal 对象转化为 UInt16 类型,支持自定义溢出策略。
入参:
- overflowHandling:转换溢出策略
返回值:转换后的 UInt16 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toUInt32
public func toUInt32(overflowHandling!: OverflowStrategy = throwing): UInt32
功能:将当前 Decimal 对象转化为 UInt32 类型,支持自定义溢出策略。
入参:
- overflowHandling:转换溢出策略
返回值:转换后的 UInt32 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toUInt64
public func toUInt64(overflowHandling!: OverflowStrategy = throwing): UInt64
功能:将当前 Decimal 对象转化为 UInt64 类型,支持自定义溢出策略。
入参:
- overflowHandling:转换溢出策略
返回值:转换后的 UInt64 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toUIntNative
public func toUIntNative(overflowHandling!: OverflowStrategy = throwing): UIntNative
功能:将当前 Decimal 对象转化为 UIntNative 类型,支持自定义溢出策略。
入参:
- overflowHandling:转换溢出策略
返回值:转换后的 UIntNative 值
异常:
- OverflowException:当不指定溢出策略或溢出策略为
throwing转换溢出时,抛出此异常
func toFloat16
public func toFloat16(): Float16
功能:将当前 Decimal 对象转化为 Float16 类型。
返回值:转换后的 Float16 值,溢出时,当前值为正数,返回 inf,当前值为负数,返回 -inf
func toFloat32
public func toFloat32(): Float32
功能:将当前 Decimal 对象转化为 Float32 类型。
返回值:转换后的 Float32 值,溢出时,当前值为正数,返回 inf,当前值为负数,返回 -inf
func toFloat64
public func toFloat64(): Float64
功能:将当前 Decimal 对象转化为 Float64 类型。
返回值:转换后的 Float64 值,溢出时,当前值为正数,返回 inf,当前值为负数,返回 -inf
func toBigInt
public func toBigInt(): BigInt
功能:将当前 Decimal 对象转化为 BigInt 类型。
返回值:转换后的 BigInt 值
func toEngString
public func toEngString(): String
功能:以工程计数法的形式打印输出 Decimal 对象,指数为 3 的倍数, 当值小于 0 时以 “-” 开头后跟十进制数字,大于等于 0 时,直接打印输出数字,不额外添加 “+”。指数小于 0 时同样遵循以上规则。
返回值:工程计数法形式的 Decimal 字符串
func toSciString
public func toSciString(): String
功能:以科学计数法的形式打印输出 Decimal 对象,当值小于 0 时以 “-” 开头后跟十进制数字,大于等于 0 时,直接打印输出数字,不额外添加 “+”。指数小于 0 时同样遵循以上规则。
返回值:科学计数法形式的 Decimal 字符串
示例
Decimal 基础运算操作
以下为通过不同构造函数初始化 Decimal 对象的,并进行基础数学运算示例:
代码如下:
from std import math.numeric.*
main() {
let decimal1: Decimal = Decimal("12345.6789")
let decimal2: Decimal = Decimal(BigInt("987654321"), 6)
println("without ctx:")
println("${decimal1} + ${decimal2} = ${decimal1 + decimal2}")
println("${decimal1} - ${decimal2} = ${decimal1 - decimal2}")
println("${decimal1} * ${decimal2} = ${decimal1 * decimal2}")
println("${decimal1} / ${decimal2} = ${decimal1 / decimal2}")
let (quo, rem) = decimal1.divAndRem(decimal2)
println("${decimal1} / ${decimal2} = ${quo} .. ${rem}")
println("with ctx(precision: 8, HALF_EVEN):")
let baseOperCtx = DecimalContext(8, HALF_EVEN)
println("${decimal1} + ${decimal2} = ${decimal1.add(decimal2, baseOperCtx)}")
println("${decimal1} - ${decimal2} = ${decimal1.sub(decimal2, baseOperCtx)}")
println("${decimal1} * ${decimal2} = ${decimal1.mul(decimal2, baseOperCtx)}")
println("${decimal1} / ${decimal2} = ${decimal1.div(decimal2, baseOperCtx)}")
let (quoWithCtx, remWithCtx) = decimal1.divAndRem(decimal2, baseOperCtx)
println("${decimal1} / ${decimal2} = ${quoWithCtx} .. ${remWithCtx}")
return 0
}
运行结果如下:
without ctx:
12345.6789 + 987.654321 = 13333.333221
12345.6789 - 987.654321 = 11358.024579
12345.6789 * 987.654321 = 12193263.1112635269
12345.6789 / 987.654321 = 12.49999988609375000142382812498220
12345.6789 / 987.654321 = 12 .. 493.827048
with ctx(precision: 8, HALF_EVEN):
12345.6789 + 987.654321 = 13333.333
12345.6789 - 987.654321 = 11358.025
12345.6789 * 987.654321 = 12193263
12345.6789 / 987.654321 = 12.500000
12345.6789 / 987.654321 = 12 .. 493.827048
Decimal 基本属性操作
以下为初始化 Decimal 对象的,并查询对象的基本属性的示例:
代码如下:
from std import math.numeric.*
main() {
let decimalProperties = Decimal("-123456.7890123456789")
println("deciaml: ${decimalProperties}")
println("decimal sign: ${decimalProperties.sign}")
println("decimal scale: ${decimalProperties.scale}")
println("decimal value: ${decimalProperties.value}")
println("decimal precision: ${decimalProperties.precision}")
return 0
}
运行结果如下:
deciaml: -123456.7890123456789
decimal sign: -1
decimal scale: 13
decimal value: -1234567890123456789
decimal precision: 19
Decimal 比较操作
以下为初始化多个 Decimal 对象,相互之间大小比较的示例:
代码如下:
from std import math.numeric.*
main() {
let decimal1 = Decimal("12345.6789")
let decimal2 = Decimal("987.654321")
println("${decimal1} > ${decimal2} = ${decimal1 > decimal2}")
println("${decimal1} < ${decimal2} = ${decimal1 < decimal2}")
println("${decimal1} == ${decimal2} = ${decimal1 == decimal2}")
println("${decimal1} != ${decimal2} = ${decimal1 != decimal2}")
println("${decimal1} <= ${decimal2} = ${decimal1 <= decimal2}")
println("${decimal1} >= ${decimal2} = ${decimal1 >= decimal2}")
println("${decimal1}.compare(${decimal2}) = ${decimal1.compare(decimal2)}")
return 0
}
运行结果如下:
12345.6789 > 987.654321 = true
12345.6789 < 987.654321 = false
12345.6789 == 987.654321 = false
12345.6789 != 987.654321 = true
12345.6789 <= 987.654321 = false
12345.6789 >= 987.654321 = true
12345.6789.compare(987.654321) = Ordering.GT
BigInt 基础运算操作
以下为通过不同构造函数初始化 BigInt 对象的,并进行基础数学运算示例:
代码如下:
from std import math.numeric.*
main() {
let int1: BigInt = BigInt("123456789")
let int2: BigInt = BigInt("987654321")
println("${int1} + ${int2} = ${int1 + int2}")
println("${int1} - ${int2} = ${int1 - int2}")
println("${int1} * ${int2} = ${int1 * int2}")
println("${int1} / ${int2} = ${int1 / int2}")
let (quo, mod) = int1.divAndMod(int2)
println("${int1} / ${int2} = ${quo} .. ${mod}")
return 0
}
运行结果如下:
123456789 + 987654321 = 1111111110
123456789 - 987654321 = -864197532
123456789 * 987654321 = 121932631112635269
123456789 / 987654321 = 0
123456789 / 987654321 = 0 .. 123456789
BigInt 基本属性操作
以下为初始化 BigInt 对象的,并查询对象的基本属性的示例:
代码如下:
from std import math.numeric.*
main() {
let int = BigInt("-123456")
println("BigInt: ${int}")
println("BigInt sign: ${int.sign}")
println("BigInt bitLen: ${int.bitLen}")
return 0
}
运行结果如下:
BigInt: -123456
BigInt sign: -1
BigInt bitLen: 18
BigInt 比较操作
以下为初始化多个 BigInt 对象,相互之间大小比较的示例:
代码如下:
from std import math.numeric.*
main() {
let int1 = BigInt("123456789")
let int2 = BigInt("987654321")
println("${int1} > ${int2} = ${int1 > int2}")
println("${int1} < ${int2} = ${int1 < int2}")
println("${int1} == ${int2} = ${int1 == int2}")
println("${int1} != ${int2} = ${int1 != int2}")
println("${int1} <= ${int2} = ${int1 <= int2}")
println("${int1} >= ${int2} = ${int1 >= int2}")
println("${int1}.compare(${int2}) = ${int1.compare(int2)}")
return 0
}
运行结果如下:
123456789 > 987654321 = false
123456789 < 987654321 = true
123456789 == 987654321 = false
123456789 != 987654321 = true
123456789 <= 987654321 = true
123456789 >= 987654321 = false
123456789.compare(987654321) = Ordering.LT
objectpool 包
介绍
objectpool 包提供了一个并发安全的对象缓存类型 ObjectPool。
主要接口
class ObjectPool
public class ObjectPool<T> where T <: Object {
public init(newFunc: () -> T, resetFunc!: Option<(T) -> T> = None)
}
此类提供了一个并发安全的对象缓存类型,该类型可以储存已经分配内存但未使用的对象。
当一个对象不需要使用时可以将对象存入 ObjectPool,当需要使用对象时再从该 ObjectPool 中取出。
储存在一个 ObjectPool 中的对象只能是同一种类型。
在一个 ObjectPool 对象的生命周期结束前,该 ObjectPool 对象中存储的对象不会被释放。
init
public init(newFunc: () -> T, resetFunc!: Option<(T) -> T> = None)
功能:创建新的 ObjectPool 对象。
参数:
- newFunc:当调用 get 方法时,若从 ObjectPool 中获取对象失败,则调用 newFn 创建一个新对象, newFunc 应保证并发安全
- resetFunc:调用 get 方法时会调用 resetFunc 重置对象状态,resetFunc 为 None 表示不重置, resetFunc 应保证并发安全
func get
public func get(): T
功能:尝试从 ObjectPool 中获取对象, 若从 ObjectPool 中获取对象失败,则调用 newFunc 创建新的对象并返回该对象get 的对象不使用之后应该通过 put 归还给 ObjectPool。
返回值:从 ObjectPool 中获取到的对象或调用 newFunc 新建的对象
func put
public func put(item: T): Unit
功能:尝试将对象放入 ObjectPool 中,不保证一定会将对象放入 ObjectPool在对一个对象调用 put 后不应该再对该对象进行任何操作,否则可能导致不可期问题。
参数:
- item:需要放入 ObjectPool 的对象
示例
ObjectPool 的使用示例
下面是 ObjectPool 的使用示例。
代码如下:
from std import objectpool.*
class City {
var id: Int64 = 0
var name: String = ""
}
func resetCity(c: City): City {
let city = c
city.id = 0
city.name = ""
return city
}
main() {
let cityPool = ObjectPool({ => City()}, resetFunc: resetCity)
let cityA = cityPool.get()
cityA.id = 30
cityA.name = "A"
println("id: ${cityA.id}, name: ${cityA.name}")
cityPool.put(cityA)
}
运行结果如下:
id: 30, name: A
os 包
介绍
os 包提供了对 Linux,macOS 与 Windows 平台操作系统 POSIX 、Process 与部分 OS 相关能力的支持。平台具体支持能力详见兼容性说明章节表格。 操作系统 OS 支持能力主要包括获取或操作当前进程相关信息(如进程参数、环境变量、目录信息等),注册回调函数及退出当前进程,相关实现在 os 包中。操作系统 POSIX 相关能力实现在 os.posix 包中。Process 相关能力实现在 os.process 包中。
主要接口
func getArgs
public func getArgs(): Array<String>
功能:返回命令行参数列表,例如在命令行中执行 a.out ab cd ef,其中 a.out 是程序名,返回的列表包含三个元素 ab cd ef。
需要注意的是,使用 c 语言调用仓颉动态库方式时,通过 int SetCJCommandLineArgs(int argc, const char* argv[]) 设置的命令行参数,在使用 getArgs() 获取时将会被舍弃掉第一个参数。
返回值:返回命令行参数列表
func envVars
public func envVars(): HashMap<String, String>
功能:获取所有环境变量。 返回值为 HashMap,它以 key 和 value 的形式存储环境变量。
返回值:返回所有环境变量值
func getEnv
public func getEnv(k: String): Option<String>
功能:获取指定名称的环境变量值。 返回 Option<String> 类型的字符串。
参数:
- k:环境变量名称
返回值:返回环境变量值
异常:
- IllegalArgumentException:如果 k 包含空字符则抛出异常
func setEnv
public func setEnv(k: String, v: String): Unit
功能:用于设置一对环境变量。如果设置了同名环境变量,原始环境变量值将被覆盖。
参数:
- k:环境变量名称
- v:环境变量值
异常:
- IllegalArgumentException:如果 k 或 v 包含空字符则抛出异常
func removeEnv
public func removeEnv(k: String): Unit
功能:用于通过环境变量名称移除环境变量。
参数:
- k:环境变量名称
异常:
- IllegalArgumentException:如果 k 包含空字符则抛出异常
func currentDir
public func currentDir(): Directory
功能:获取当前工作目录。返回值为 Directory 类型,可以使用 Directory.info.path.toString() 获取路径的字符串。
返回值:返回 Directory 类型值
func homeDir
public func homeDir(): Directory
功能:获取 home 目录。
返回值:返回 Directory 类型值
func tempDir
public func tempDir(): Directory
功能:获取临时目录。从环境变量中获取 TMPDIR、TMP、TEMP 和 TEMPDIR 环境变量。如果以上值在环境变量中均不存在,则默认返回 /tmp 目录。
返回值:返回 Directory 类型值
func processorCount
public func processorCount(): Int64
功能:获取处理器数量。 返回值:处理器数量
示例
获取参数、环境变量及相关目录信息
from std import os.*
from std import fs.*
from std import collection.*
main(): Unit {
let args: Array<String> = getArgs()
let envs: HashMap<String, String> = envVars()
let currentDir: Directory = currentDir()
let homeDir: Directory = homeDir()
let tempDir: Directory = tempDir()
let processorCount: Int64 = processorCount()
println("args: ${args}")
println("envs: ${envs}")
println("currentDir: ${currentDir.info.path.toString()}")
println("homeDir: ${homeDir.info.path.toString()}")
println("tempDir: ${tempDir.info.path.toString()}")
println("processorCount: ${processorCount}")
return
}
运行结果如下(根据系统与运行环境不同返回结果可能不同):
args: []
envs: [(USER, root),(PWD, /root/code/cangjie)]
currentDir: /root/code/cangjie
homeDir: /root
tempDir: /tmp
processorCount: 96
os.posix 包
介绍
本包主要适配 POSIX 系统接口,提供多平台统一操控能力,目前支持 Linux 平台,macOS 平台与 Windows 平台。
主要接口
常量具体说明详见常量信息说明章节。
AT_EMPTY_PATH
public const AT_EMPTY_PATH: Int32
AT_REMOVEDIR
public const AT_REMOVEDIR :Int32
F_OK
public const F_OK: Int32
O_CLOEXEC
public const O_CLOEXEC: Int32
O_DIRECTORY
public const O_DIRECTORY: Int32
O_EXCL
public const O_EXCL: Int32
O_NOFOLLOW
public const O_NOFOLLOW: Int32
O_RDONLY
public const O_RDONLY: Int32
O_RSYNC
public const O_RSYNC: Int32
O_TRUNC
public const O_TRUNC: Int32
R_OK
public const R_OK: Int32
SEEK_END
public const SEEK_END: Int32
SIGABRT
public const SIGABRT: Int32
SIGBUS
public const SIGBUS: Int32
SIGCONT
public const SIGCONT: Int32
SIGHUP
public const SIGHUP: Int32
SIGINT
public const SIGINT: Int32
SIGIOT
public const SIGIOT: Int32
SIGPIPE
public const SIGPIPE: Int32
SIGPWR
public const SIGPWR: Int32
SIGSEGV
public const SIGSEGV: Int32
SIGSTOP
public const SIGSTOP: Int32
SIGTERM
public const SIGTERM: Int32
SIGTSTP
public const SIGTSTP: Int32
SIGTTOU
public const SIGTTOU: Int32
SIGUSR1
public const SIGUSR1: Int32
SIGVTALRM
public const SIGVTALRM: Int32
SIGXCPU
public const SIGXCPU: Int32
S_IFBLK
public const S_IFBLK: UInt32
S_IFDIR
public const S_IFDIR: UInt32
S_IFLNK
public const S_IFLNK: UInt32
S_IFSOCK
public const S_IFSOCK: UInt32
S_IROTH
public const S_IROTH: UInt32
S_IRWXG
public const S_IRWXG: UInt32
S_IRWXU
public const S_IRWXU: UInt32
S_IWOTH
public const S_IWOTH: UInt32
S_IXGRP
public const S_IXGRP: UInt32
S_IXUSR
public const S_IXUSR: UInt32
X_OK
public const X_OK: Int32
func getos
public func getos(): String
功能:从 /proc/version 文件中获取 Linux 系统的信息。例如: Linux version 4.15.0-142-generic (buildd@lgw01-amd64-036) (gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)) #146-Ubuntu SMP Tue Apr 13 01:11:19 UTC 2021。
返回值:获取到的 Linux 系统的信息字符串
func gethostname
public func gethostname(): String
功能:获取主机名称,此名称通常是 TCP/IP 网络上主机的名称。
返回值:获取到的主机的名称字符串, 获取失败则返回空字符串
func sethostname
public func sethostname(buf: String): Int32
功能:设置主机名,仅超级用户可以调用。
参数:
- buf:需要设置的主机名
返回值:设置成功,返回 0,设置失败, 返回 -1
异常:
- IllegalArgumentException:如果参数 buf 包含空字符则抛出异常
func getlogin
public func getlogin(): String
功能:获取当前登录名。
返回值:如果操作成功,则返回 String 类型的登录名,失败时返回空的 String
func chdir
public func chdir(path: String): Int32
功能:通过指定路径的方式,更改调用进程的当前工作目录。
参数:
- path:改变后的路径
返回值:设置成功,返回 0,设置失败, 返回 -1
func fchdir
public func fchdir(fd: Int32): Int32
功能:通过指定文件路径的描述符,更改调用进程的当前工作目录。
参数:
- fd:改变后的文件路径的描述符
返回值:设置成功,返回 0,设置失败, 返回 -1
func getcwd
public func getcwd(): String
功能:获取当前执行进程工作目录的绝对路径。
返回值:操作成功,返回包含路径信息的字符串,操作失败则返回空字符串
func getgid
public func getgid(): UInt32
功能:获取用户组 ID。
返回值:当前用户组 ID
func getuid
public func getuid(): UInt32
功能:获取调用进程的真实用户 ID。
返回值:当前真实用户 ID
func setgid
public func setgid(id: UInt32): Int32
功能:设置调用进程的有效组 ID,需要适当的权限。
参数:
- id:调用进程的有效组 ID 号
返回值:设置成功,返回 0,设置失败, 返回 -1
func setuid
public func setuid(id: UInt32): Int32
功能:设置调用进程的有效用户 ID,需要适当的权限。
参数:
- id:调用进程的有效用户 ID 号
返回值:设置成功,返回 0,设置失败, 返回 -1
func getpgid
public func getpgid(pid: Int32): Int32
功能:获取 pid 指定的进程的 PGID,如果 pid 为零,返回调用进程的进程 ID。
参数:
- pid:目标进程 ID
返回值:执行成功,返回进程组 ID,执行失败, 返回 -1
func getgroups
public unsafe func getgroups(size: Int32, gidArray: CPointer<UInt32>): Int32
功能:该函数用于获取当前用户所属组的代码。size 的值为 gidArray 可以容纳的 gid 的数量,gidArray 存放 gid,如果参数大小的值为零,则此函数仅返回表示用户所属的组数,不会像 gidArray 中放入 gid。获取当前用户所属组的代码。
参数:
- size:gidArray 可以容纳的 gid 的数量
- gidArray:组信息
返回值:执行成功,返回组代码,执行失败, 返回 -1
func getpid
public func getpid(): Int32
功能:获取调用进程的进程 ID (PID)。
返回值:返回调用进程的进程 ID (PID)
func getppid
public func getppid(): Int32
功能:此函数获取调用进程的父进程 ID。
返回值:返回调用进程的父进程 ID
func getpgrp
public func getpgrp(): Int32
功能:此函数用于获取当前进程所属的组 ID。 此函数等效于调用 getpgid(0);返回值返回当前进程所属的组 ID。
返回值:返回调用进程父级的进程 ID
func setpgrp
public func setpgrp(): Int32
功能:此函数将当前进程所属的组 ID 设置为当前进程的进程 ID。 此函数相当于调用 setpgid(0, 0)。
返回值:执行成功,返回当前进程的组 ID,执行失败, 返回 -1
func setpgid
public func setpgid(pid: Int32, pgrp: Int32): Int32
功能:此函数将参数 pid 指定的组 ID 设置为参数 pgrp 指定的组 ID。 如果 pid 为 0,则使用当前进程的组 ID。
参数:
- pid:进程 id
- pgrp:进程组 id
返回值:执行成功,返回组 id,执行失败, 返回 -1
func `open`
public func `open`(path: String, oflag: Int32, flag: UInt32): Int32
功能:此函数功能为打开文件并为其返回新的文件描述符,或在失败时返回 -1。当文件打开方式参数设置为 O_CREAT 时,可以通过参数设置文件权限。path 代表文件路径,oflag 代表文件打开的方式,其中 O_RDONLY、O_RDWR、O_WRONLY 作为 oflag 取值为互斥关系,但可以与其他操作标识一起使用,如 O_APPEND 进程 | 操作。如果 oflag 中设置了 O_CREAT,且需要创建新文件,则 flag 参数标识对新文件的权限,否则 flag 不改变文件权限。
参数:
- path:文件路径
- oflag:文件打开的方式,O_RDONLY、O_RDWR、O_WRONLY 是一个互斥的条件
- flag:如果 oflag 设置了 O_CREAT 并且需要创建新文件,则 flag 参数标识对新文件的权限,否则 flag 不改变文件权限
返回值:返回新的文件描述符,执行失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func `open`
public func `open`(path: String, oflag: Int32): Int32
功能:打开文件并为其返回新的文件描述符,或在失败时返回 -1。
参数:
- path:文件路径
- oflag:文件打开的方式,O_RDONLY、O_RDWR、O_WRONLY 是一个互斥的条件
返回值:返回新的文件描述符,执行失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func open64
public func open64(path: String, oflag: Int32, flag: UInt32): Int32
功能:此函数功能为打开文件并为其返回新的文件描述符,或在失败时返回 -1。当文件打开方式参数设置为 O_CREAT 时,可以通过参数设置文件权限。path 代表文件路径,oflag 代表文件打开的方式,其中 O_RDONLY、O_RDWR、O_WRONLY 作为 oflag 取值为互斥关系,但可以与其他操作标识一起使用,如 O_APPEND 进程 | 操作。如果 oflag 中设置了 O_CREAT,且需要创建新文件,则 flag 参数标识对新文件的权限,否则 flag 不改变文件权限。
参数:
- path:文件路径
- oflag:文件打开的方式,O_RDONLY、O_RDWR、O_WRONLY 是一个互斥的条件
- flag:如果 oflag 设置了 O_CREAT 并且需要创建新文件,则 flag 参数标识对新文件的权限,否则 flag 不改变文件权限
返回值:返回新的文件描述符,执行失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func open64
public func open64(path: String, oflag: Int32): Int32
功能:打开文件并为其返回新的文件描述符,或在失败时返回 -1。
参数:
- path:文件路径
- oflag:文件打开的方式,O_RDONLY、O_RDWR、O_WRONLY 是一个互斥的条件
返回值:返回新的文件描述符,执行失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func openat
public func openat(fd: Int32, path: String, oflag: Int32, flag: UInt32): Int32
功能:此函数功能为打开文件并为其返回新的文件描述符,或在失败时返回 -1。当文件打开方式参数设置为 O_CREAT 时,可以通过参数设置文件权限。path 代表文件路径,oflag 代表文件打开的方式,其中 O_RDONLY、O_RDWR、O_WRONLY 作为 oflag 取值为互斥关系,但可以与其他操作标识一起使用,如 O_APPEND 进程 | 操作。如果 oflag 中设置了 O_CREAT,且需要创建新文件,则 flag 参数标识对新文件的权限,否则 flag 不改变文件权限。
参数:
- fd:路径的文件描述符
- path:文件路径
- oflag:文件打开的方式,O_RDONLY、O_RDWR、O_WRONLY 是一个互斥的条件
- flag:如果 oflag 设置了 O_CREAT 并且需要创建新文件,则 flag 参数标识对新文件的权限,否则 flag 不改变文件权限
返回值:返回新的文件描述符,执行失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func openat
public func openat(fd: Int32, path: String, oflag: Int32): Int32
功能:打开文件并为其返回新的文件描述符,或在失败时返回 -1。
参数:
- fd:路径的文件描述符
- path:文件路径
- oflag:文件打开的方式,O_RDONLY、O_RDWR、O_WRONLY 是一个互斥的条件
返回值:返回新的文件描述符,执行失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func openat64
public func openat64(fd: Int32, path: String, oflag: Int32, flag: UInt32): Int32
功能:打开文件并为其返回新的文件描述符,或在失败时返回 -1。
参数:
- fd:路径的文件描述符
- path:文件路径
- oflag:文件打开的方式,O_RDONLY、O_RDWR、O_WRONLY 是一个互斥的条件
- flag:如果 oflag 设置了 O_CREAT 并且需要创建新文件,则 flag 参数标识对新文件的权限,否则 flag 不改变文件权限
返回值:返回新的文件描述符,执行失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func openat64
public func openat64(fd: Int32, path: String, oflag: Int32): Int32
功能:打开文件并为其返回新的文件描述符,或在失败时返回 -1。 参数:
- fd:路径的文件描述符
- path:文件路径
- oflag:文件打开的方式,O_RDONLY、O_RDWR、O_WRONLY 是一个互斥的条件
返回值:返回新的文件描述符,执行失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func creat
public func creat(path: String, flag: UInt32): Int32
功能:创建文件并为其返回文件描述符,或在失败时返回 -1。
参数:
- path:文件路径
- flag:创建文件的权限
返回值:返回文件描述符,执行失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func close
public func close(fd: Int32): Int32
功能:关闭文件,close 将会触发数据写回磁盘,并释放文件占用的资源。
参数:
- fd:文件描述符
返回值:成功时返回 0,失败时返回 -1
func lseek
public func lseek(fd: Int32, offset: Int64, whence: Int32): Int64
功能:当文件进行读或写时,读 / 写位置相应增加。本函数用于控制文件的读 / 写位置。调用成功时,返回当前读写位置,即从文件开头开始的字节数。 如果发生错误,返回 -1。
参数:
- fd:打开文件的文件描述符
- offset:偏移量
- whence:表示控制模式
返回值:调用成功时,返回当前读写位置,即从文件开头开始的字节数
func read
public unsafe func read(fd: Int32, buffer: CPointer<UInt8>, nbyte: UIntNative): IntNative
功能:将 fd 指向的文件的 nbyte 字节传输到 buffer 指向的内存中。如果 nbyte 为 0,则函数无效果,并返回 0。返回值是实际读取的字节数。返回值为 0 表示到达文件末尾或无法读取数据。 此外,文件的读写位置随着读取字节的变化而变化。 注意: 建议 nbyte 的大小与 buffer 的大小相同,且 buffer 的大小小于或等于 150000 字节。
参数:
- fd:待读取文件的文件描述符
- buffer:缓冲区容器
- nbyte:读取字节数,建议采用buffer.size
返回值:返回实际读取字节数,读取无效时返回 -1
func pread
public unsafe func pread(fd: Int32, buffer: CPointer<UInt8>, nbyte: UIntNative, offset: Int32): IntNative
功能:将 fd 指向的文件从指定偏移位置开始的 nbyte 字节传输到 buffer 指向的内存中。offset 表示读取位置的偏移量。如果 nbyte 为 0,则函数无效果,并返回 0。返回值是实际读取的字节数。返回值为 0 表示到达文件末尾或无法读取数据。此外,文件的读写位置随着读取字节的变化而变化。 注意: 建议 nbyte 的大小与 buffer 的大小相同,且 buffer 的大小小于或等于 150000 字节。
参数:
- fd:待读取文件的文件描述符
- buffer:缓冲区容器
- nbyte:读取字节数,建议采用buffer.size
- offset:读取位置的偏移量
返回值:返回实际读取数,执行失败时返回 -1
func write
public unsafe func write(fd: Int32, buffer: CPointer<UInt8>, nbyte: UIntNative): IntNative
功能:将 buffer 指向的内存中 nbyte 字节写入到 fd 指向的文件。指定文件的读写位置会随之移动。 注意: 建议 nbyte 的大小与 buffer 的大小相同,且 buffer 的大小小于或等于 150000 字节。
参数:
- fd:待写入文件的文件描述符
- buffer:缓冲区容器
- nbyte:写入字节数,建议采用buffer.size
返回值:返回实际写入数,执行失败时返回 -1
func pwrite
public unsafe func pwrite(fd: Int32, buffer: CPointer<UInt8>, nbyte: UIntNative, offset: Int32): IntNative
功能:将 buffer 指向的内存中 nbyte 字节从指定偏移位置开始写入到 fd 指向的文件。指定文件的读写位置会随之移动。 注意: 建议 nbyte 的大小与 buffer 的大小相同,且 buffer 的大小小于或等于 150000 字节。
参数:
- fd:待写入文件的文件描述符
- buffer:缓冲区容器
- nbyte:写入字节数,建议采用buffer.size
- offset:写入位置的偏移量
返回值:返回实际写入数,执行失败时返回 -1
func dup
public func dup(fd: Int32): Int32
功能:用于复制旧 fd 参数指定的文件描述符并返回。此新文件描述符和旧的参数 fd 引用同一文件,共享文件各种状态。共享所有的锁定、读写位置和各项权限或标志等。
参数:
- fd:文件描述符
返回值:返回最小且未使用的文件描述符,执行失败时返回 -1
func dup2
public func dup2(fd: Int32, fd2: Int32): Int32
功能:用于复制 oldfd 参数指定的文件描述符,并将其返回到 newfd 参数。如果参数 newfd 是打开的文件描述符,则 newfd 指定的文件将首先关闭。
参数:
- fd:oldfd 参数指定的文件描述符
- fd2:newfd 参数指定的文件描述符
返回值:fd2 文件描述符
func isType
public func isType(path: String, mode: UInt32): Bool
功能:检查文件是否为指定模式的文件。如果是,返回 ture,否则返回 false。根据模式的不同值确定不同的类型。
参数:
- path:文件路径
- mode:判断参数
返回值:如果是指定模式的文件,返回 true,否则返回 false
func isReg
public func isReg(path: String): Bool
功能:检查传入对象是否为普通文件,返回布尔类型。
参数:
- path:文件路径
返回值:如果是,返回 true,否则返回 false
func isDir
public func isDir(path: String): Bool
功能:检查传入对象是否为文件夹,返回布尔类型。
参数:
- path:文件路径
返回值:如果是,返回 true,否则返回 false
func isChr
public func isChr(path: String): Bool
功能:检查传入对象是否为字符设备,返回布尔类型。
参数:
- path:文件路径
返回值:如果是,返回 true,否则返回 false
func isBlk
public func isBlk(path: String): Bool
功能:检查传入对象是否为块设备,并返回布尔类型。
参数:
- path:文件路径
返回值:如果是,返回 true,否则返回 false
func isFIFO
public func isFIFO(path: String): Bool
功能:检查传入对象是否为 FIFO 文件,返回布尔类型。
参数:
- path:文件路径
返回值:如果是,返回 true,否则返回 false
func isLnk
public func isLnk(path: String): Bool
功能:检查传入对象是否为软链路,返回布尔类型。
参数:
- path:文件路径
返回值:如果是,返回 true,否则返回 false
func isSock
public func isSock(path: String): Bool
功能:检查传入对象是否为套接字文件,返回布尔类型。
参数:
- path:文件路径
返回值:如果是,返回 true,否则返回 false
func access
public func access(path: String, mode: Int32): Int32
功能:判断某个文件是否具有某种权限,具有返回 0,否则返回 -1。 mode 为指定权限,传入类型 R_OK、W_OK、X_OK、F_OK。
参数:
- path:文件路径
- mode:待检查的权限
返回值:文件具有待检查的权限返回 0,否则返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func faccessat
public func faccessat(fd: Int32, path: String, mode: Int32, flag: Int32): Int32
功能:判断 fd 对应的文件是否具有某种权限,具有返回 0,否则返回 -1 mode 为指定权限,传入类型 R_OK、W_OK、X_OK、F_OK。 如果操作成功,返回 0;否则,返回 -1。
参数:
- fd:文件描述符
- path:文件路径
- mode:待检查的权限
- flag:将以下一个或多个值按位或运算获取。(512)使用有效的用户和组 ID 执行访问检查,默认情况下使用有效 ID;(256)如果路径名是符号链接,不会取消引用而是返回有关链接本身信息
返回值:文件具有待检查的权限返回 0,否则返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func umask
public func umask(cmask: UInt32): UInt32
功能:设置权限掩码。
参数:
- cmask:文件权限参数
返回值:返回文件上一个掩码的值
func chown
public func chown(path: String, owner: UInt32, group: UInt32): Int32
功能:修改文件所有者和文件所有者所属组。
参数:
- path:文件路径
- owner:所有者 uid
- group:指定 gid 参数
返回值:操作成功时返回 0,失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func fchown
public func fchown(fd: Int32, owner: UInt32, group: UInt32): Int32
功能:修改 fd 对应的文件所有者和文件所有者所属组。
参数:
- fd:文件描述符
- owner:所有者 uid
- group:指定 gid 参数
返回值:操作成功时返回 0,失败时返回 -1
func lchown
public func lchown(path: String, owner: UInt32, group: UInt32): Int32
功能:修改文件链接本身所有者和所有者所属组。 成功时返回零,失败时返回 -1,错误号设置为指示错误。
参数:
- path:字符串类型的文件路径
- owner:所有者 uid
- group:指定 gid 参数
返回值:操作成功时返回 0,失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func fchownat
public func fchownat(fd: Int32, path: String, owner: UInt32, group: UInt32, flag: Int32): Int32
功能:修改文件描述符对应的文件所有者和文件所有者所属组。
- path 为相对路径且 fd 为特殊值 AT_FDCWD 时,则路径将相对于调用进程的当前工作目录
- path 为相对路径且 fd 非 AT_FDCWD 时,则路径将相对于 fd 引用的文件所属目录
- path 为绝对路径时 fd 参数将被忽略
参数:
- fd:文件描述符
- path:文件路径
- owner:所有者 uid
- group:指定 gid 参数
- flag:取值可为 0,或(256)如果路径名是符号链接,不会取消引用它,而是返回有关链接本身的信息
返回值:操作成功时返回 0,失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func chmod
public func chmod(path: String, mode: UInt32): Int32
功能:修改文件访问权限。在 Windows 环境下, chmod() 函数使用说明:1. 所有文件和目录都是可读的,chmod() 不能更改文件的可读权限;2. 文件的可执行权限通过文件扩展名设置,所有目录都是可执行的,chmod() 不能更改文件和目录的可执行权限。
参数:
- path:文件路径
- mode:要修改的权限
返回值:成功时返回 0,失败时返回 -1;当 mode 为非法参数时,chmod 会忽略该参数,返回 0
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func fchmod
public func fchmod(fd: Int32, mode: UInt32): Int32
功能:修改文件描述符对应的文件访问权限。
参数:
- fd:文件描述符
- mode:要修改的权限
返回值:操作成功时返回 0,失败时返回 -1
func fchmodat
public func fchmodat(fd: Int32, path: String, mode: UInt32, flag: Int32): Int32
功能:修改文件描述符对应的文件访问权限。
- path 为相对路径且 fd 为特殊值 AT_FDCWD 时,则路径将相对于调用进程的当前工作目录
- path 为相对路径且 fd 非 AT_FDCWD 时,则路径将相对于 fd 引用的文件所属目录
- path 为绝对路径时 fd 参数将被忽略
参数:
- fd:文件描述符
- path:文件路径
- mode:要修改的权限
- flag:取值可为 0,或(256)如果路径名是符号链接,不会取消引用它,而是返回有关链接本身的信息
返回值:操作成功时返回 0,失败时返回 -1
异常:
- IllegalArgumentException:如果 path 包含空字符则抛出异常
func nice
public func nice(inc: Int32): Int32
功能:更改当前线程的优先级。 只有超级用户才能使用负的 inc 值,表示优先级高,进程执行得更快。 inc 代表当前进程的优先级,取值的范围是 + 19(低优先级)到 - 20。 成功时返回新值,失败时返回 -1。 inc 在值大于 19 时,返回最大值 19。
参数:
- inc:当前进程的优先级, 值的范围是 + 19(低优先级)到 - 20
返回值:返回新优先级值
func kill
public func kill(pid: Int32, sig: Int32): Int32
功能:系统调用可用于向任何进程组或进程发送任何信号。
- 如果 pid 大于 0,则信号 sig 将发送到 pid 对应的进程
- 如果 pid 等于 0,然后 sig 被发送到调用进程的进程组中的每个进程
- 如果 pid 等于 -1,则 sig 被发送到调用进程有权发送信号的每个进程
- 如果 pid 小于 -1,则将 sig 发送到 ID 为 - pid 的进程组中的每个进程
参数:
- pid:进程 ID
- sig:信号 ID
返回值:操作成功时返回 0,否则返回 -1
func killpg
public func killpg(pgid: Int32, sig: Int32): Int32
功能:将信号 sig 发送到进程组 pgrp,如果 pgrp 为 0,则 killpg() 将信号发送到调用进程的进程组。
参数:
- pgid:组 ID
- sig:信号 ID
返回值:执行成功,返回 0,如果失败,返回 -1
func ttyname
public func ttyname(fd: Int32): String
功能:返回终端名称。
参数:
- fd:文件描述符
返回值:操作成功时返回指向路径名的指针,失败时,返回 NULL
func isatty
public func isatty(fd: Int32): Bool
功能:用于测试文件描述符是否引用终端,成功时返回 true,否则返回 false。
参数:
- fd:文件描述符
返回值:操作成功时返回 true,否则返回 false
func link
public func link(path: String, newpath: String): Int32
功能:为存在的文件创建链接,一个文件可以有多个指向其 i-node 的目录条目。
参数:
- path:文件路径
- newpath:其他文件路径
返回值:成功返回 0,错误返回 -1
异常:
- IllegalArgumentException:在 path 或 newPath 包含空字符时抛出异常
func linkat
public func linkat(fd: Int32, path: String, nfd: Int32, newPath: String, lflag: Int32): Int32
功能:创建相对于目录文件描述符的文件链接。
- path 为相对路径且 fd 为特殊值 AT_FDCWD 时,则路径将相对于调用进程的当前工作目录
- path 为相对路径且 fd 非 AT_FDCWD 时,则路径将相对于 fd 引用的文件所属目录
- path 为绝对路径时 fd 参数将被忽略
- newPath 的场景与 path 相同,只是当 newPath 为相对路径时是相对于 nfd 引用的文件所属目录
参数:
- fd:文件描述符
- path:文件路径
- nfd:其他文件描述符
- newPath:其他文件路径,如果 newpath 存在,则不会覆盖
- lflag:AT_EMPTY_PATH 或 AT_SYMLINK_FOLLOW 或 0
返回值:成功返回 0,错误返回 -1
异常:
- IllegalArgumentException:在 path 或 newPath 包含空字符时抛出异常
func remove
public func remove(path: String): Int32
功能:删除文件或目录。对于文件,remove() 等同于 unlink()。对于目录,remove() 等同于 rmdir()。
参数:
- path:文件路径
返回值:成功返回 0,错误返回 -1
异常:
- IllegalArgumentException:在 path 包含空字符时抛出异常
func rename
public func rename(oldName: String, newName: String): Int32
功能:重命名文件,如果需要将会移动文件所在目录。文件的任何其他硬链接不受影响。旧路径打开的文件描述符也不受影响。 各种限制将决定重命名操作是否成功,具体场景如下:
- 如果 newName 已经存在,它将被原子替换,这样另一个尝试访问 newName 的进程就不会发现它丢失,但是,可能会有一个窗口,其中旧路径和新路径都引用要重命名的文件
- 如果旧路径和新路径是引用同一文件的现有硬链接,则重命名不做任何操作,并返回成功状态
- 如果 newName 存在,但操作因某种原因失败,则重命名保证保留 newName 的实例
- oldName 可以指定目录。在这种情况下,newName 必须不存在,或者它必须指定空目录
- 如果旧路径引用符号链接,则链接将重命名;如果新路径引用符号链接,则链接将被覆盖
参数:
- oldName:文件名(含路径)
- newName:文件名(含路径)
返回值:成功返回 0,错误返回 -1
异常:
- IllegalArgumentException:在 oldName 或 newName 包含空字符时抛出异常
func renameat
public func renameat(oldfd: Int32, oldName: String, newfd: Int32, newName: String): Int32
功能:重命名文件,如果需要将会移动文件所在目录。renameat() 与 rename() 处理相同,此处仅描述两者差异点:
- oldName 为相对路径且 oldfd 为特殊值 AT_FDCWD 时,则路径将相对于调用进程的当前工作目录
- oldName 为相对路径且 oldfd 非 AT_FDCWD 时,则路径将相对于 oldfd 引用的文件所属目录
- oldName 为绝对路径时 oldfd 参数将被忽略
- newName 的场景与 oldName 相同,只是当 newName 为相对路径时是相对于 newfd 引用的文件所属目录
参数:
- oldfd:文件描述符
- oldName:文件名
- newName:文件名
- newfd:文件描述符
返回值:成功返回 0,错误返回 -1
异常:
- IllegalArgumentException:在 oldName 或 newName 包含空字符时抛出异常
func symlink
public func symlink(path: String, symPath: String): Int32
功能:创建一个名为 symPath 链接到 path 所指定的文件。
- 符号链接在运行时被解释为链接的内容已被替换到要查找文件或目录的路径中
- 符号链接可能包含..路径组件,这些组件(如果在链接的开头使用)引用链接所在目录的父目录
- 符号链接(也称为软链接)可以指向现有文件或不存在的文件,后者被称为悬空链接
- 符号链接的权限是不相关的,在跟踪链接时,所有权将被忽略,但当请求删除或重命名链接并且链接位于设置了粘滞位的目录中时,所有权将被检查
- 如果 symPath 已存在,则不会被覆盖
参数:
- path:文件路径
- symPath:链接文件路径
返回值:成功返回 0,错误返回 -1
异常:
- IllegalArgumentException:在 path 或 symPath 包含空字符时抛出异常
func symlinkat
public func symlinkat(path: String, fd: Int32, symPath: String): Int32
功能:创建一个名为 symPath 链接到 path 与 fd 所指定的文件。
- symPath 为相对路径且 fd 为特殊值 AT_FDCWD 时,则路径将相对于调用进程的当前工作目录
- symPath 为相对路径且 fd 非 AT_FDCWD 时,则路径将相对于 fd 引用的文件所属目录
- symPath 为绝对路径时 fd 参数将被忽略
参数:
- path:文件路径
- fd:文件描述符
- symPath:链接文件路径
返回值:成功返回 0,错误返回 -1
异常:
- IllegalArgumentException:在 path 或 symPath 包含空字符时抛出异常
func unlink
public func unlink(path: String): Int32
功能:从文件系统中删除文件。
- 如果 path 是指向文件的最后一个链接,并且没有进程打开该文件,则该文件将被删除,它使用的空间可供重复使用
- 如果 path 是指向文件的最后一个链接,但仍然有进程打开该文件,该文件将一直存在,直到引用它的最后一个文件描述符关闭
- 如果 path 引用了符号链接,则该链接将被删除
- 如果 path 引用了套接字、FIFO 或设备,则该文件将被删除,但打开对象的进程可能会继续使用它
参数:
- path:文件路径
返回值:成功返回 0,错误返回 -1
异常:
- IllegalArgumentException:在 path 包含空字符时抛出异常
func unlinkat
public func unlinkat(fd: Int32, path: String, ulflag: Int32): Int32
功能:该函数系统调用的操作方式与 unlink 函数完全相同,但此处描述的差异除外:
- path 为相对路径且 fd 为特殊值 AT_FDCWD 时,则路径将相对于调用进程的当前工作目录
- path 为相对路径且 fd 非 AT_FDCWD 时,则路径将相对于 fd 引用的文件所属目录
- path 为绝对路径时 fd 参数将被忽略
参数:
- fd:文件描述符
- path:文件路径
- ulflag:可以指定为 0,或者可以设置为控制 unlinkat() 操作的标志值按位或运算。标志值当前取值仅支持 AT_REMOVEDIR
返回值:成功返回 0,错误返回 -1
异常:
- IllegalArgumentException:在 path 包含空字符时抛出异常
常量信息说明
| 常量名称 | 说明 | 适用 api | 所属参数 |
|---|---|---|---|
| O_RDONLY | 以只读方式打开文件 | open,open64,openat,openat64 | oflag |
| O_RDWR | 以读写模式打开文件 | open,open64,openat,openat64 | oflag |
| O_WRONLY | 以只写方式打开文件 | open,open64,openat,openat64 | oflag |
| O_APPEND | 读取或写入文件时,数据将从文件末尾移动。即,写入的数据将附加到文件的末尾 | open,open64,openat,openat64 | oflag |
| O_CLOEXEC | 在某些多线程程序中,使用此标志是必不可少的。因为在一个线程同时打开文件描述符,而另一个线程执行 fork(2) 加 execve(2) 场景下使用单独的 fcntl(2) F_SETFD 操作设置 FD_CLOEXEC 标志并不足以避免竞争条件 | open,open64,openat,openat64 | oflag |
| O_CREAT | 如果要打开的文件不存在,则自动创建该文件 | open,open64,openat,openat64 | oflag |
| O_DIRECTORY | 如果 pathname 指定的文件不是目录,则打开文件失败 | open,open64,openat,openat64 | oflag |
| O_DSYNC | 每次写入都会等待物理 I/O 完成,但如果写操作不影响读取刚写入的数据,则不等待文件属性更新 | open,open64,openat,openat64 | oflag |
| O_EXCL | 如果还设置了 O_CREAT,则此指令检查文件是否存在。如果文件不存在,则创建文件。否则,打开文件出错。此外,如果同时设置了 O_CREAT 和 O_EXCL,并且要打开的文件是符号链接,则打开文件失败 | open,open64,openat,openat64 | oflag |
| O_NOCTTY | 如果要打开的文件是终端设备,则该文件不会成为这个进程的控制终端 | open,open64,openat,openat64 | oflag |
| O_NOFOLLOW | 如果 pathname 指定的文件是单符号连接,则打开文件失败 | open,open64,openat,openat64 | oflag |
| O_NONBLOCK | 以非阻塞的方式打开文件,即 I/O 操作不会导致调用进程等待 | open,open64,openat,openat64 | oflag |
| O_SYNC | 同步打开文件 | open,open64,openat,openat64 | oflag |
| O_TRUNC | 如果文件存在且打开可写,则此标志将文件长度清除为 0,文件中以前存储的数据消失 | open,open64,openat,openat64 | oflag |
| O_RSYNC | 此标志仅影响读取操作,必须与 O_SYNC 或 O_DSYNC 结合使用。如果有必要,它将导致读取调用阻塞,直到正在读取的数据(可能还有元数据)刷新到磁盘 | open,open64,openat,openat64 | oflag |
| S_IRUSR | 表示文件所有者具有读权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IWUSR | 表示文件所有者具有写权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IXUSR | 表示文件所有者具有执行权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IRWXU | 表示文件所有者具有读、写和执行权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IRGRP | 表示文件用户组具有读权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IWGRP | 表示文件用户组具有写权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IXGRP | 表示文件用户组具有执行权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IRWXG | 表示文件用户组具有读、写、执行权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IROTH | 表示其他用户对文件具有读权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IWOTH | 表示其他用户对文件具有写权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IXOTH | 表示其他用户对文件具有执行权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| S_IRWXO | 表示其他用户对文件具有读、写和执行权限 | open,open64,openat,openat64,chmod(mode),fchmod(mode),fchmodat(mode),creat | flag |
| SEEK_SET | 偏移参数表示新的读写位置 | lseek | whence |
| SEEK_CUR | 向当前读 / 写位置添加偏移量 | lseek | whence |
| SEEK_END | 将读写位置设置为文件末尾,并添加偏移量 | lseek | whence |
| S_IFREG | 一般文件 | isType | mode |
| S_IFDIR | 目录 | isType | mode |
| S_IFCHR | 字符设备 | isType | mode |
| S_IFBLK | 块设备 | isType | mode |
| S_IFIFO | FIFO 文件 | isType | mode |
| S_IFLNK | 软连接 | isType | mode |
| S_IFSOCK | 套接字文件 | isType | mode |
| R_OK | 测试读取权限 | access,faccessat | mode |
| W_OK | 测试写权限 | access,faccessat | mode |
| X_OK | 测试执行权限 | access,faccessat | mode |
| F_OK | 测试存在 | access,faccessat | mode |
| SIGHUP | 连接已断开;默认操作已终止 | kill,killpg | sig |
| SIGINT | 终端中断字符;默认动作终止 | kill,killpg | sig |
| SIGQUIT | 终端退出字符;默认动作终止 | kill,killpg | sig |
| SIGIL | 硬件指令无效;默认动作终止 | kill,killpg | sig |
| SIGTRAP | 硬件故障;默认操作终止 + 核心 | kill,killpg | sig |
| SIGTRAP | 异常终止;默认动作终止 + 核心 | kill,killpg | sig |
| SIGIOT | 硬件故障;默认操作终止 + 核心 | kill,killpg | sig |
| SIGBUS | 硬件故障;默认操作终止 + 核心 | kill,killpg | sig |
| SIGFPE | 算术错误;默认动作终止 + 核心 | kill,killpg | sig |
| SIGKILL | 终止;默认操作终止 | kill,killpg | sig |
| SIGUSR1 | 用户定义的信号;默认操作终止 | kill,killpg | sig |
| SIGSEGV | 内存引用无效;默认操作终止 + 核心 | kill,killpg | sig |
| SIGUSR2 | 用户定义的信号;默认操作终止 | kill,killpg | sig |
| SIGPIPE | 写入未读进程的管道;默认操作终止 | kill,killpg | sig |
| SIGALRM | 计时器到期;默认动作终止 | kill,killpg | sig |
| SIGTERM | 终止;默认操作终止 | kill,killpg | sig |
| SIGSTKFLT | 协处理器堆栈故障;默认操作终止 | kill,killpg | sig |
| SIGCHLD | 子进程状态更改;忽略默认操作 | kill,killpg | sig |
| SIGCONT | 暂停过程的继续;默认操作继续 / 忽略 | kill,killpg | sig |
| SIGSTOP | 停止;默认操作停止 | kill,killpg | sig |
| SIGTSTP | 终端停止符号;默认操作停止进程 | kill,killpg | sig |
| SIGTTIN | 后台读取控件 tty;默认操作停止进程 | kill,killpg | sig |
| SIGTTO | 后台写控制 tty;默认操作停止进程 | kill,killpg | sig |
| SIGURG | 紧急情况(套接字);忽略默认操作 | kill,killpg | sig |
| SIGXCPU | CPU 占用率超过上限;默认操作终止或终止 + 核心 | kill,killpg | sig |
| SIGXFSZ | 文件长度超过上限;默认操作终止或终止 + 核心 | kill,killpg | sig |
| SIGVTALRM | 虚拟时间警报;默认操作已终止 | kill,killpg | sig |
| SIGPROF | 摘要超时;默认操作已终止 | kill,killpg | sig |
| SIGWINCH | 终端窗口大小更改;忽略默认操作 | kill,killpg | sig |
| SIGIO | 异步 IO;默认操作终止 / 忽略 | kill,killpg | sig |
| SIGPWR | 电源故障或重启;默认操作终止 / 忽略 | kill,killpg | sig |
| SIGSYS | 系统调用无效;默认操作终止 + 核心 | kill,killpg | sig |
示例
获取各类系统信息
下面是获取各类系统信息示例。
代码如下:
from std import os.posix.*
main(): Int64 {
/* 系统名称相关 */
var os_info = getos()
println("os info ==> ${os_info}")
var hostname = gethostname()
println("hostname ==> ${hostname}")
var logname: String = getlogin()
println("logname ==> ${logname}")
/* 程序运行路径相关函数 */
var chagePath = "/"
var chdir_restlt = chdir(chagePath)
println("chdir_restlt ==> ${chdir_restlt}")
var cwd_path: String = getcwd()
println("cwd_path ==> ${cwd_path}")
/* 系统 id 相关函数 getpgid */
var arr: CString = unsafe { LibC.mallocCString(" ") }
var a: CPointer<UInt8> = arr.getChars()
var cp: CPointer<UInt32> = CPointer<UInt32>(a)
var getg = unsafe{ getgroups(0, cp)}
var s: String = " "
for (_ in 0..getg) {
s = s + "\0"
}
println(getg)
var local: UInt32 = 0
for (temp in 0..getg) {
unsafe { local = cp.read(Int64(temp)) }
println("getgroups ==> ${local.toString()}")
}
unsafe { LibC.free(arr)}
return 0
}
运行结果如下(根据系统不同返回结果可能不同):
Linux version 4.15.0-159-generic (buildd@lgw01-amd64-055) (gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)) #167-Ubuntu SMP Tue Sep 21 08:55:05 UTC 2021
hostname ==> e124e6e0fe0f
logname ==> root
chdir_restlt ==> 0
cwd_path ==> /
1
getgroups ==> 1309868064
文件内容相关操作
下面是文件内容相关操作示例。
代码如下:
from std import os.posix.*
main(): Int64 {
var fd = `open`("textcase.txt", O_RDWR | O_APPEND | O_CREAT, S_IRWXU)
println("fd ==> ${fd}")
close(fd)
var fd2 = `open`("textcase.txt", O_RDWR)
var len = lseek(fd2, 0, SEEK_END)
println("len ==> ${len}")
close(fd2)
var str1 = unsafe{LibC.mallocCString(" ")}
var buf = str1.getChars()
var fd3 = `open`("textcase.txt", O_RDWR)
var readNum = unsafe { read(fd3, buf, 2) }
unsafe{ LibC.free(str1)}
println("readNum ==> ${readNum}")
close(fd3)
var str2 = unsafe{LibC.mallocCString("123456")}
var buf2 = str2.getChars()
var fd4 = `open`("textcase.txt", O_RDWR)
var fd5 = dup(fd4)
var writeNum = unsafe { write(fd5, buf2, UIntNative(str2.size())) }
unsafe { LibC.free(str2)}
println("writeNum ==> ${writeNum}")
close(fd4)
return 0
}
可能出现的运行结果如下:
fd ==> 3
len ==> 6
readNum ==> 2
writeNum ==> 6
文件信息相关操作
下面是文件信息相关操作示例。
代码如下:
from std import os.posix.*
main(): Int64 {
var result1: Bool = isType("/notdirs", S_IFDIR)
println("result ==> ${result1}")
var result2: Bool = isDir("/dev")
println("result ==> ${result2}")
var result3 = access("./oscfg.cfg", F_OK)
println("result ==> ${result3}")
var result4 = chmod("oscfg.cfg", UInt32(S_IXUSR))
println("result ==> ${result4}")
return 0
}
运行结果如下:
result ==> false
result ==> true
result ==> -1
result ==> -1
进程相关信息操作
下面是进程相关信息操作示例。
代码如下:
from std import os.posix.*
main(): Int64 {
var result = nice(200)
print("${result}")
var result1 = kill(0, SIGCHLD)
println(result1)
var result2 = killpg(0, SIGURG)
println("result ==> ${result2}")
if (isatty(0) && isatty(1) && isatty(2)) {
print("true01 ")
} else {
print("false01 ")
}
if (isatty(-23) || isatty(4) || isatty(455) || isatty(43332)) {
print("true02 ")
} else {
println("false02")
}
return 0
}
运行结果如下:
190
result ==> 0
true01 false02
os.process 包
介绍
本包主要提供 Process 进程操作接口,主要包括进程创建,标准流获取,进程等待,进程信息查询等,提供多平台统一操控能力,支持 Linux 平台、 Windows 平台。
主要接口
class Process
public open class Process
此类为进程类,提供进程操作相关功能。
使用 Process 类需要导入 os.process 包。
提供功能具体如下:
- 提供获取当前进程实例的功能;
- 提供根据进程 id 绑定进程实例的功能;
- 提供根据输入信息创建子进程的功能;
- 提供获取进程信息的功能;
- 提供关闭进程的功能,允许设置是否强制关闭进程;
prop current
public static prop current: CurrentProcess
功能:获取当前进程实例。
prop pid
public prop pid: Int64
功能:获取进程 id。
prop name
public prop name: String
功能:获取进程名。
异常:
ProcessException:如果进程不存在或对应进程为僵尸进程,无法获取进程名,则抛出异常
prop command
public prop command: String
功能:获取进程命令。
异常:
ProcessException:如果进程不存在或对应进程为僵尸进程,无法获取进程命令,则抛出异常
prop arguments
public prop arguments: Array<String>
功能:获取进程参数。Windows 平台下无法在非特权 API 下获取到本属性,暂不支持获取。
异常:
ProcessException:如果进程不存在或对应进程为僵尸进程,或在 Windows 平台下暂不支持场景,无法获取进程参数,则抛出异常
prop commandLine
public prop commandLine: Array<String>
功能:获取进程命令行。Windows 平台当前进程可获取,其他场景下无法在非特权 API 下获取到本属性,暂不支持获取。
异常:
ProcessException:如果进程不存在或对应进程为僵尸进程,或在 Windows 平台下暂不支持场景,无法获取进程命令行,则抛出异常
prop workingDirectory
public prop workingDirectory: Path
功能:获取进程工作路径。Windows 平台当前进程可获取,其他场景下无法在非特权 API 下获取到本属性,暂不支持获取。
异常:
ProcessException:如果进程不存在或对应进程为僵尸进程,或在 Windows 平台下暂不支持场景,无法获取进程工作路径,则抛出异常
prop environment
public prop environment: Map<String, String>
功能:获取进程环境变量。Windows 平台当前进程可获取,其他场景下无法在非特权 API 下获取到本属性,暂不支持获取。
异常:
ProcessException:如果进程不存在或对应进程为僵尸进程,或在 Windows 平台下暂不支持场景,无法获取进程环境变量,则抛出异常
func of
public static func of(pid: Int64): Process
功能:根据输入进程 id 绑定一个进程实例。
参数:
pid: 进程 id
返回值:
Process:返回进程 id 对应的进程实例
异常:
-
IllegalArgumentException:当输入进程 id 大于 Int32 最大值或小于 0,抛出异常 -
ProcessException:如果内存分配失败或 pid 对应的进程不存在,则抛出异常
func start
public static func start(command: String,
arguments: Array<String>,
workingDirectory!: ?Path = None,
environment!: ?Map<String, String> = None,
stdIn!: ProcessRedirect = Inherit,
stdOut!: ProcessRedirect = Inherit,
stdErr!: ProcessRedirect = Inherit): SubProcess
功能:根据输入参数创建并运行一个子进程,并返回一个子进程实例。调用该函数创建子进程后,需要调用 wait 或 waitOutput 函数,否则该子进程结束后成为的僵尸进程的资源不会被回收。
参数:
-
command:指定子进程命令,command 不允许包含空字符 -
arguments:指定子进程参数,arguments 不允许数组中字符串中包含空字符 -
workingDirectory:命名可选参数,指定子进程的工作路径,默认继承当前进程工作路径,路径必须为存在的目录且不允许为空路径或包含空字符 -
environment:命名可选参数,指定子进程环境变量,默认继承当前进程环境变量,key 不允许字符串中包含空字符或 '=',value 不允许字符串中包含空字符 -
stdIn:命名可选参数,指定子进程重定向标准输入,默认继承当前进程标准输入 -
stdOut:命名可选参数,指定子进程重定向标准输出,默认继承当前进程标准输出 -
stdErr:命名可选参数,指定子进程重定向标准错误,默认继承当前进程标准错误
返回值:
SubProcess:返回一个子进程实例
异常:
-
IllegalArgumentException:如果 command 包含空字符,或者 arguments 数组中字符串中包含空字符,或者 workingDirectory 不是存在的目录或为空路径或包含空字符,或者 environment 表中 key 字符串中包含空字符或 '=',或 value 字符串中包含空字符,或者 stdIn、stdOut、stdErr 输入为文件模式时,输入的文件已被关闭或删除,则抛出异常 -
ProcessException:如果内存分配失败或 command 对应的命令不存在,则抛出异常
func run
public static func run(command: String,
arguments: Array<String>,
workingDirectory!: ?Path = None,
environment!: ?Map<String, String> = None,
stdIn!: ProcessRedirect = Inherit,
stdOut!: ProcessRedirect = Inherit,
stdErr!: ProcessRedirect = Inherit,
timeout!: ?Duration = None): Int64
功能:根据输入参数创建并运行一个子进程,等待该子进程运行完毕并返回子进程退出状态。
参数:
-
command:指定子进程命令,command 不允许包含空字符 -
arguments:指定子进程参数,arguments 不允许数组中字符串中包含空字符 -
workingDirectory:命名可选参数,指定子进程的工作路径,默认继承当前进程工作路径,路径必须为存在的目录且不允许为空路径或包含空字符 -
environment:命名可选参数,指定子进程环境变量,默认继承当前进程环境变量,key 不允许字符串中包含空字符或 '=',value 不允许字符串中包含空字符 -
stdIn:命名可选参数,指定子进程重定向标准输入,默认继承当前进程标准输入 -
stdOut:命名可选参数,指定子进程重定向标准输出,默认继承当前进程标准输出 -
stdErr:命名可选参数,指定子进程重定向标准错误,默认继承当前进程标准错误 -
timeout:命名可选参数,指定等待子进程超时时间,默认为不超时, timeout 指定为 0 或负值时表示不超时
返回值:
Int64:返回子进程退出状态,若子进程正常退出,返回子进程退出码,若子进程被信号杀死,返回导致子进程终止的信号编号
异常:
-
IllegalArgumentException:如果 command 包含空字符,或者 arguments 数组中字符串中包含空字符,或者 workingDirectory 不是存在的目录或为空路径或包含空字符,或者 environment 表中 key 字符串中包含空字符或 '=',或 value 字符串中包含空字符,或者 stdIn、stdOut、stdErr 输入为文件模式时,输入的文件已被关闭或删除,则抛出异常 -
ProcessException:如果内存分配失败或 command 对应的命令不存在或等待超时,则抛出异常
func runOutput
public static func runOutput(command: String,
arguments: Array<String>,
workingDirectory!: ?Path = None,
environment!: ?Map<String, String> = None,
stdIn!: ProcessRedirect = Inherit,
stdOut!: ProcessRedirect = Pipe,
stdErr!: ProcessRedirect = Pipe): (Int64, Array<Byte>, Array<Byte>)
功能:根据输入参数创建并运行一个子进程,等待该子进程运行完毕并返回子进程退出状态、标准输出和标准错误。输出流、错误流中包含大量输出的场景不适用于本函数,建议通过 SubProcess 中提供的标准流属性结合 wait 函数自行处理。
参数:
-
command:指定子进程命令,command 不允许包含空字符 -
arguments:指定子进程参数,arguments 不允许数组中字符串中包含空字符 -
workingDirectory:命名可选参数,指定子进程的工作路径,默认继承当前进程工作路径,路径必须为存在的目录且不允许为空路径或包含空字符 -
environment:命名可选参数,指定子进程环境变量,默认继承当前进程环境变量,key 不允许字符串中包含空字符或 '=',value 不允许字符串中包含空字符 -
stdIn:命名可选参数,指定子进程重定向标准输入,默认继承当前进程标准输入 -
stdOut:命名可选参数,指定子进程重定向标准输出,默认继承当前进程标准输出 -
stdErr:命名可选参数,指定子进程重定向标准错误,默认继承当前进程标准错误
返回值:
(Int64, Array<Byte>, Array<Byte>):子进程执行返回结果,包含子进程退出状态(若子进程正常退出,返回子进程退出码,若子进程被信号杀死,返回导致子进程终止的信号编号),进程标准输出结果和进程错误结果
异常:
-
IllegalArgumentException:如果 command 包含空字符,或者 arguments 数组中字符串中包含空字符,或者 workingDirectory 不是存在的目录或为空路径或包含空字符,或者 environment 表中 key 字符串中包含空字符或 '=',或 value 字符串中包含空字符,或者 stdIn、stdOut、stdErr 输入为文件模式时,输入的文件已被关闭或删除,则抛出异常 -
ProcessException:如果内存分配失败,或者 command 对应的命令不存在,或者子进程不存在,或者标准流读取异常,则抛出异常
func terminate
public func terminate(force!: Bool = false): Unit
功能:终止进程
参数:
force:命名可选参数,指定是否强制关闭进程,默认为 false,若设置为 false,对应进程可以在释放资源后结束;若设置为 true,对应进程将被直接杀死。Windows 平台实现为强制关闭进程。
异常:
ProcessException:如果进程不存在,不允许终止,则抛出异常
enum ProcessRedirect
public enum ProcessRedirect
此 enum 类用于在创建进程时设置子进程标准流的重定向模式。
Inherit
Inherit
功能:构造一个标准流重定向枚举实例,表示子进程标准流将继承当前进程的标准流。此模式下标准流属性不可读取或写入
Pipe
Pipe
功能:构造一个标准流重定向枚举实例,表示子进程标准流将被重定向至管道,并通过管道与当前进程连接。重定向标准输入流可通过管道向子进程写入数据,重定向标准输出流或标准错误流可通过管道读取子进程输出结果。此模式下可通过标准流属性读取或写入数据
FromFile
FromFile(File)
功能:构造一个标准流重定向枚举实例,表示子进程标准流将被重定向至指定的文件。重定向标准输入流将从指定文件读取,重定向标准输出流或标准错误流将写入至指定文件。重定向文件需保证存在且未关闭,否则不允许重定向。此模式下标准流属性不可读取或写入
参数:
File:指定存在且未关闭文件实例,创建子进程时,重定向标准流至该指定文件
Discard
Discard
功能:构造一个标准流重定向枚举实例,表示子进程标准流将被丢弃。此模式下标准流属性不可读取或写入
class CurrentProcess
public class CurrentProcess <: Process
此类为当前进程类,继承 Process 类,提供对当前进程操作相关功能。
使用 CurrentProcess 类需要导入 os.process 包。
提供功能具体如下:
- 提供获取当前进程标准流(stdIn、stdOut、stdErr)机制;
- 提供当前进程退出注册回调函数机制;
- 提供当前进程退出机制,允许设置退出状态码。
prop stdIn
public prop stdIn: InputStream
功能:获取当前进程标准输入流。
prop stdOut
public prop stdOut: OutputStream
功能:获取当前进程标准输出流。
prop stdErr
public prop stdErr: OutputStream
功能:获取当前进程标准错误流。
func atExit
public func atExit(callback: () -> Unit): Unit
功能:注册回调函数,当前进程退出时执行注册函数。注意请不要使用C语言 atexit 函数,避免出现不可期问题。
参数:
() -> Unit:需要被注册回调的函数
func exit
public func exit(code: Int64): Nothing
功能:进程退出函数,执行到此函数直接结束当前进程,并且通过入参 code 设置返回状态码。
参数:
Int64:当前进程退出状态码
class SubProcess
public class SubProcess <: Process
此类为子进程类,继承 Process 类,提供对子进程操作相关功能。
使用 SubProcess 类需要导入 os.process 包。
提供功能具体如下:
- 提供获取子进程标准流(stdIn、stdOut、stdErr)机制;
- 提供等待子进程执行返回退出状态码机制,允许设置等待超时时长;
- 提供等待子进程执行返回输出结果(包含运行正常、异常结果)机制,允许设置等待超时时长。
prop stdIn
public prop stdIn: OutputStream
功能:获取输出流,连接到子进程标准输入流。
prop stdOut
public prop stdOut: InputStream
功能:获取输入流,连接到子进程标准输出流。
prop stdErr
public prop stdErr: InputStream
功能:获取输入流,连接到子进程标准错误流。
func wait
public func wait(timeout!: ?Duration = None): Int64
功能:阻塞当前进程等待子进程任务执行完成并返回子进程退出状态码,允许指定等待超时时间。对于需要操作标准流的场景(Pipe 模式),使用者需要优先处理标准流,避免子进程标准流缓冲区满后调用本函数产生死锁。
超时时间处理机制:
- 未传参、
timeout值为None或值小于等于Duration.Zero时,阻塞等待直至子进程执行返回。 timeout值大于Duration.Zero时,阻塞等待子进程执行返回或等待超时后抛出超时异常。
参数:
timeout:命名可选参数,设置等待子进程超时时间,默认为None
返回值:
Int64:返回子进程退出状态。若子进程正常退出,返回子进程退出码,若子进程被信号杀死,返回导致子进程终止的信号编号
异常:
ProcessException:如果等待超时,子进程未退出,则抛出异常
func waitOutput
public func waitOutput(): (Int64, Array<Byte>, Array<Byte>)
功能:阻塞当前进程等待子进程任务执行完成,并返回子进程退出状态码、返回结果(包含输出流和错误流返回结果)。输出流、错误流中包含大量输出的场景不适用于本函数,建议通过 SubProcess 中提供的标准流属性结合 wait 函数自行处理。
返回值:
(Int64, Array<Byte>, Array<Byte>):子进程执行返回结果,包含子进程退出状态(若子进程正常退出,返回子进程退出码,若子进程被信号杀死,返回导致子进程终止的信号编号),进程标准输出结果和进程错误结果
异常:
ProcessException:如果子进程不存在,或者标准流读取异常,则抛出异常
class ProcessException
public class ProcessException <: Exception
os.process 包的异常类。
init
public init(message: String)
功能:创建 ProcessException 实例。
参数:
message:异常提示信息
示例
子进程相关操作
下面是子进程相关操作示例。
代码如下:
from std import os.process.*
from std import io.*
from std import fs.*
// 以Linux平台相关命令举例说明, 以下用例需要提前创建 “/root/code/Process/test” 目录
main(): Int64 {
let sleepProcess: SubProcess = Process.start("sleep", "10s", workingDirectory: Path("/root/code/Process/test"))
println(sleepProcess.pid)
println(sleepProcess.name)
println(sleepProcess.command)
println(sleepProcess.arguments.toString())
println(sleepProcess.commandLine.toString())
println(sleepProcess.workingDirectory.toString())
sleepProcess.terminate(force: true)
let rtnCode = sleepProcess.wait()
println("sleepProcess rtnCode: ${rtnCode}")
let echoProcess: SubProcess = Process.start("echo", "hello cangjie!", stdOut: ProcessRedirect.Pipe)
let strReader: StringReader<InputStream> = StringReader(echoProcess.stdOut)
println(strReader.readToEnd())
return 0
}
运行结果可能如下:
45090
sleep 10s
sleep
[10s]
[sleep, 10s]
/root/code/Process/test
sleepProcess rtnCode: 9
hello cangjie!
当前进程相关操作
下面是当前进程相关操作示例。
代码如下:
from std import os.process.*
main(): Int64 {
let curProcess = Process.current
println(curProcess.pid)
println(curProcess.name)
println(curProcess.command)
println(curProcess.arguments.toString())
println(curProcess.commandLine.toString())
println(curProcess.workingDirectory.toString())
curProcess.atExit(printText)
curProcess.exit(0)
return 0
}
func printText(): Unit {
println("hello cangjie!")
}
运行结果可能如下(输出结果中mian为当前进程执行命令名,回调执行完成后当前进程会退出):
75590
./main
./main
[]
[./main]
/root/code/Process/test
hello cangjie!
任意进程相关操作
下面是任意进程相关操作示例。
代码如下:
from std import os.process.*
from std import fs.*
main(): Int64 {
let echoProcess: SubProcess = Process.start("sleep", "10s")
let ofProcess: Process = Process.of(echoProcess.pid)
println(ofProcess.pid)
println(ofProcess.name)
println(ofProcess.command)
println(ofProcess.arguments.toString())
println(ofProcess.commandLine.toString())
ofProcess.terminate(force: true)
return 0
}
运行结果可能如下:
78980
sleep
sleep
[10s]
[sleep, 10s]
兼容性说明
os
| 函数 | linux | windows | macOS |
|---|---|---|---|
| public func getArgs(): Array<String> | 支持 | 支持 | 支持 |
| public func envVars(): HashMap<String, String> | 支持 | 支持 | 支持 |
| public func getEnv(k: String): Option<String> | 支持 | 支持 | 支持 |
| public func setEnv(k: String, v: String): Unit | 支持 | 支持 | 支持 |
| public func removeEnv(k: String): Unit | 支持 | 支持 | 支持 |
| public func currentDir(): Directory | 支持 | 支持 | 支持 |
| public func homeDir(): Directory | 支持 | 支持 | 支持 |
| public func tempDir(): Directory | 支持 | 支持 | 支持 |
| public func processorCount(): Int64 | 支持 | 支持 | 支持 |
os.posix
| 不可变变量 | linux | windows | macOS |
|---|---|---|---|
| AT_EMPTY_PATH: Int32 | 支持 | 支持 | 不支持 |
| AT_FDCWD: Int32 | 支持 | 支持 | 支持 |
| AT_REMOVEDIR :Int32 | 支持 | 支持 | 支持 |
| AT_SYMLINK_FOLLOW: Int32 | 支持 | 支持 | 支持 |
| F_OK: Int32 | 支持 | 支持 | 支持 |
| O_APPEND: Int32 | 支持 | 支持 | 支持 |
| O_CLOEXEC: Int32 | 支持 | 不支持 | 支持 |
| O_CREAT: Int32 | 支持 | 支持 | 支持 |
| O_DIRECTORY: Int32 | 支持 | 不支持 | 支持 |
| O_DSYNC: Int32 | 支持 | 不支持 | 支持 |
| O_EXCL: Int32 | 支持 | 支持 | 支持 |
| O_NOCTTY: Int32 | 支持 | 不支持 | 支持 |
| O_NOFOLLOW: Int32 | 支持 | 不支持 | 支持 |
| O_NONBLOCK: Int32 | 支持 | 不支持 | 支持 |
| O_RDONLY: Int32 | 支持 | 支持 | 支持 |
| O_RDWR: Int32 | 支持 | 支持 | 支持 |
| O_RSYNC: Int32 | 支持 | 不支持 | 不支持 |
| O_SYNC: Int32 | 支持 | 不支持 | 支持 |
| O_TRUNC: Int32 | 支持 | 支持 | 支持 |
| O_WRONLY: Int32 | 支持 | 支持 | 支持 |
| R_OK: Int32 | 支持 | 支持 | 支持 |
| SEEK_CUR: Int32 | 支持 | 支持 | 支持 |
| SEEK_END: Int32 | 支持 | 支持 | 支持 |
| SEEK_SET: Int32 | 支持 | 支持 | 支持 |
| SIGABRT: Int32 | 支持 | 支持 | 支持 |
| SIGALRM: Int32 | 支持 | 支持 | 支持 |
| SIGBUS: Int32 | 支持 | 支持 | 支持 |
| SIGCHLD: Int32 | 支持 | 支持 | 支持 |
| SIGCONT: Int32 | 支持 | 支持 | 支持 |
| SIGFPE: Int32 | 支持 | 支持 | 支持 |
| SIGHUP: Int32 | 支持 | 支持 | 支持 |
| SIGILL: Int32 | 支持 | 支持 | 支持 |
| SIGINT: Int32 | 支持 | 支持 | 支持 |
| SIGIO: Int32 | 支持 | 支持 | 支持 |
| SIGIOT: Int32 | 支持 | 支持 | 支持 |
| SIGKILL: Int32 | 支持 | 支持 | 支持 |
| SIGPIPE: Int32 | 支持 | 支持 | 支持 |
| SIGPROF: Int32 | 支持 | 支持 | 支持 |
| SIGPWR: Int32 | 支持 | 支持 | 不支持 |
| SIGQUIT: Int32 | 支持 | 支持 | 支持 |
| SIGSEGV: Int32 | 支持 | 支持 | 支持 |
| SIGSTKFLT: Int32 | 支持 | 支持 | 不支持 |
| SIGSTOP: Int32 | 支持 | 支持 | 支持 |
| SIGSYS: Int32 | 支持 | 支持 | 支持 |
| SIGTERM: Int32 | 支持 | 支持 | 支持 |
| SIGTRAP: Int32 | 支持 | 支持 | 支持 |
| SIGTSTP: Int32 | 支持 | 支持 | 支持 |
| SIGTTIN: Int32 | 支持 | 支持 | 支持 |
| SIGTTOU: Int32 | 支持 | 支持 | 支持 |
| SIGURG: Int32 | 支持 | 支持 | 支持 |
| SIGUSR1: Int32 | 支持 | 支持 | 支持 |
| SIGUSR2: Int32 | 支持 | 支持 | 支持 |
| SIGVTALRM: Int32 | 支持 | 支持 | 支持 |
| SIGWINCH: Int32 | 支持 | 支持 | 支持 |
| SIGXCPU: Int32 | 支持 | 支持 | 支持 |
| SIGXFSZ: Int32 | 支持 | 支持 | 支持 |
| S_IFBLK: UInt32 | 支持 | 支持 | 支持 |
| S_IFCHR: UInt32 | 支持 | 支持 | 支持 |
| S_IFDIR: UInt32 | 支持 | 支持 | 支持 |
| S_IFIFO: UInt32 | 支持 | 支持 | 支持 |
| S_IFLNK: UInt32 | 支持 | 支持 | 支持 |
| S_IFREG: UInt32 | 支持 | 支持 | 支持 |
| S_IFSOCK: UInt32 | 支持 | 支持 | 支持 |
| S_IRGRP: UInt32 | 支持 | 支持 | 支持 |
| S_IROTH: UInt32 | 支持 | 支持 | 支持 |
| S_IRUSR: UInt32 | 支持 | 支持 | 支持 |
| S_IRWXG: UInt32 | 支持 | 支持 | 支持 |
| S_IRWXO: UInt32 | 支持 | 支持 | 支持 |
| S_IRWXU: UInt32 | 支持 | 支持 | 支持 |
| S_IWGRP: UInt32 | 支持 | 支持 | 支持 |
| S_IWOTH: UInt32 | 支持 | 支持 | 支持 |
| S_IWUSR: UInt32 | 支持 | 支持 | 支持 |
| S_IXGRP: UInt32 | 支持 | 支持 | 支持 |
| S_IXOTH: UInt32 | 支持 | 支持 | 支持 |
| S_IXUSR: UInt32 | 支持 | 支持 | 支持 |
| W_OK: Int32 | 支持 | 支持 | 支持 |
| X_OK: Int32 | 支持 | 支持 | 支持 |
| 函数 | linux | windows | macOS |
|---|---|---|---|
| public func getos(): String | 支持 | 不支持 | 不支持 |
| public func gethostname(): String | 支持 | 不支持 | 支持 |
| public func sethostname(buf: String): Int32 | 支持 | 不支持 | 支持 |
| public func getlogin(): String | 支持 | 不支持 | 支持 |
| public func chdir(path: String): Int32 | 支持 | 支持 | 支持 |
| public func fchdir(fd: Int32): Int32 | 支持 | 不支持 | 支持 |
| public func getcwd(): String | 支持 | 支持 | 支持 |
| public func getgid(): UInt32 | 支持 | 不支持 | 支持 |
| public func getuid(): UInt32 | 支持 | 不支持 | 支持 |
| public func setgid(id: UInt32): Int32 | 支持 | 不支持 | 支持 |
| public func setuid(id: UInt32): Int32 | 支持 | 不支持 | 支持 |
| public func getpgid(pid: Int32): Int32 | 支持 | 不支持 | 支持 |
| public unsafe func getgroups(size: Int32, gidArray: CPointer<UInt32>): Int32 | 支持 | 不支持 | 支持 |
| public func getpid(): Int32 | 支持 | 支持 | 支持 |
| public func getppid(): Int32 | 支持 | 不支持 | 支持 |
| public func getpgrp(): Int32 | 支持 | 不支持 | 支持 |
| public func setpgrp(): Int32 | 支持 | 不支持 | 支持 |
| public func setpgid(pid: Int32, pgrp: Int32): Int32 | 支持 | 不支持 | 支持 |
| public func open(path: String, oflag: Int32, flag: UInt32): Int32 | 支持 | 支持 | 支持 |
| public func open(path: String, oflag: Int32): Int32 | 支持 | 支持 | 支持 |
| public func open64(path: String, oflag: Int32, flag: UInt32): Int32 | 支持 | 不支持 | 不支持 |
| public func open64(path: String, oflag: Int32): Int32 | 支持 | 不支持 | 不支持 |
| public func openat(fd: Int32, path: String, oflag: Int32, flag: UInt32): Int32 | 支持 | 不支持 | 支持 |
| public func openat(fd: Int32, path: String, oflag: Int32): Int32 | 支持 | 不支持 | 支持 |
| public func openat64(fd: Int32, path: String, oflag: Int32, flag: UInt32): Int32 | 支持 | 不支持 | 不支持 |
| public func openat64(fd: Int32, path: String, oflag: Int32): Int32 | 支持 | 不支持 | 不支持 |
| public func creat(path: String, flag: UInt32): Int32 | 支持 | 支持 | 支持 |
| public func close(fd: Int32): Int32 | 支持 | 支持 | 支持 |
| public func lseek(fd: Int32, offset: Int64, whence: Int32): Int64 | 支持 | 支持 | 支持 |
| public unsafe func read(fd: Int32, buffer: CPointer<UInt8>, nbyte: UIntNative): IntNative | 支持 | 支持 | 支持 |
| public unsafe func pread(fd: Int32, buffer: CPointer<UInt8>, nbyte: UIntNative, offset: Int32): IntNative | 支持 | 不支持 | 支持 |
| public unsafe func write(fd: Int32, buffer: CPointer<UInt8>, nbyte: UIntNative): IntNative | 支持 | 支持 | 支持 |
| public unsafe func pwrite(fd: Int32, buffer: CPointer<UInt8>, nbyte: UIntNative, offset: Int32): IntNative | 支持 | 不支持 | 支持 |
| public func dup(fd: Int32): Int32 | 支持 | 支持 | 支持 |
| public func dup2(fd: Int32, fd2: Int32): Int32 | 支持 | 支持 | 支持 |
| public func isType(path: String, mode: UInt32): Bool | 支持 | 不支持 | 支持 |
| public func isReg(path: String): Bool | 支持 | 支持 | 支持 |
| public func isDir(path: String): Bool | 支持 | 支持 | 支持 |
| public func isChr(path: String): Bool | 支持 | 支持 | 支持 |
| public func isBlk(path: String): Bool | 支持 | 支持 | 支持 |
| public func isFIFO(path: String): Bool | 支持 | 不支持 | 支持 |
| public func isLnk(path: String): Bool | 支持 | 不支持 | 支持 |
| public func isSock(path: String): Bool | 支持 | 不支持 | 支持 |
| public func access(path: String, mode: Int32): Int32 | 支持 | 支持 | 支持 |
| public func faccessat(fd: Int32, path: String, mode: Int32, flag: Int32): Int32 | 支持 | 不支持 | 支持 |
| public func umask(cmask: UInt32): UInt32 | 支持 | 支持 | 支持 |
| public func chown(path: String, owner: UInt32, group: UInt32): Int32 | 支持 | 不支持 | 支持 |
| public func fchown(fd: Int32, owner: UInt32, group: UInt32): Int32 | 支持 | 不支持 | 支持 |
| public func lchown(path: String, owner: UInt32, group: UInt32): Int32 | 支持 | 不支持 | 支持 |
| public func fchownat(fd: Int32, path: String, owner: UInt32, group: UInt32, flag: Int32): Int32 | 支持 | 不支持 | 支持 |
| public func chmod(path: String, mode: UInt32): Int32 | 支持 | 支持 | 支持 |
| public func fchmod(fd: Int32, mode: UInt32): Int32 | 支持 | 不支持 | 支持 |
| public func fchmodat(fd: Int32, path: String, mode: UInt32, flag: Int32): Int32 | 支持 | 不支持 | 支持 |
| public func nice(inc: Int32): Int32 | 支持 | 不支持 | 支持 |
| public func kill(pid: Int32, sig: Int32): Int32 | 支持 | 不支持 | 支持 |
| public func killpg(pgid: Int32, sig: Int32): Int32 | 支持 | 不支持 | 支持 |
| public func ttyname(fd: Int32): String | 支持 | 不支持 | 支持 |
| public func isatty(fd: Int32): Bool | 支持 | 支持 | 支持 |
| public func link(path: String, newpath: String): Int32 | 支持 | 不支持 | 支持 |
| public func linkat(fd: Int32, path: String, nfd: Int32, newPath: String, lflag: Int32): Int32 | 支持 | 不支持 | 支持 |
| public func remove(path: String): Int32 | 支持 | 支持 | 支持 |
| public func rename(oldName: String, newName: String): Int32 | 支持 | 支持 | 支持 |
| public func renameat(oldfd: Int32, oldName: String, newfd: Int32, newName: String): Int32 | 支持 | 不支持 | 支持 |
| public func symlink(path: String, symPath: String): Int32 | 支持 | 不支持 | 支持 |
| public func symlinkat(path: String, fd: Int32, symPath: String): Int32 | 支持 | 不支持 | 支持 |
| public func unlink(path: String): Int32 | 支持 | 不支持 | 支持 |
| public func unlinkat(fd: Int32, path: String, ulflag: Int32): Int32 | 支持 | 不支持 | 支持 |
os.process
public open class Process
| 成员 | linux | windows | macOS |
|---|---|---|---|
| static prop current | 支持 | 支持 | 支持 |
| prop pid | 支持 | 支持 | 支持 |
| prop name | 支持 | 支持 | 支持 |
| prop command | 支持 | 支持 | 支持 |
| prop arguments | 支持 | 不支持 | 支持 |
| prop commandLine | 支持 | 不支持 | 支持 |
| prop workingDirectory | 支持 | 不支持 | 支持 |
| prop environment | 支持 | 不支持 | 不支持 |
| static func of | 支持 | 支持 | 支持 |
| static func start | 支持 | 支持 | 支持 |
| static func run | 支持 | 支持 | 支持 |
| static func runOutput | 支持 | 支持 | 支持 |
| func terminate | 支持 | 支持 | 支持 |
class CurrentProcss
| 成员 | linux | windows | macOS |
|---|---|---|---|
| prop stdIn | 支持 | 支持 | 支持 |
| prop stdOut | 支持 | 支持 | 支持 |
| prop stdErr | 支持 | 支持 | 支持 |
| func atExit | 支持 | 支持 | 支持 |
| func exit | 支持 | 支持 | 支持 |
class SubProcess
| 成员 | linux | windows | macOS |
|---|---|---|---|
| prop stdIn | 支持 | 支持 | 支持 |
| prop stdOut | 支持 | 支持 | 支持 |
| prop stdErr | 支持 | 支持 | 支持 |
| func wait | 支持 | 支持 | 支持 |
| func waitOutput | 支持 | 支持 | 支持 |
overflow 包
介绍
在整数运算时,若运算结果大于其类型最大值或小于其类型最小值既是溢出,默认情况下,在出现溢出时会抛出异常。
overflow 包提供了四种溢出处理策略,并定义了对应的 interface,四种策略列举如下:
| 策略 | 接口 | 描述 |
|---|---|---|
| 抛出异常 | public interface ThrowingOp | 出现溢出,抛出异常 |
| 高位截断 | public interface WrappingOp | 出现溢出,高位截断 |
| 饱和 | public interface SaturatingOp | 当计算结果大于目标类型的 MAX 值,返回 MAX 值;当计算结果小于目标类型的 MIN 值,返回 MIN 值 |
| 返回 Option 类型 | public interface CheckedOp | 出现溢出,返回 Option |
overflow 包中通过扩展为所有的整数类型提供了这些接口的实现,用户可以用同样的方式为其他类型实现 overflow 接口。
主要接口
interface ThrowingOp
public interface ThrowingOp<T> {
func throwingAdd(y: T): T
func throwingSub(y: T): T
func throwingMul(y: T): T
func throwingDiv(y: T): T
func throwingMod(y: T): T
func throwingInc(): T
func throwingDec(): T
func throwingNeg(): T
}
当整数运算出现溢出,抛出异常。
func throwingAdd
func throwingAdd(y: T): T
功能:加法运算。
参数:
y:加数
返回值:算数结果
异常:
OverflowException:当加法运算出现溢出时,抛出异常
func throwingSub
func throwingSub(y: T): T
功能:减法运算。
参数:
y:减数
返回值:算数结果
异常:
OverflowException:当减法运算出现溢出时,抛出异常
func throwingMul
func throwingMul(y: T): T
功能:乘法运算。
参数:
y:乘数
返回值:算数结果
异常:
OverflowException:当乘法运算出现溢出时,抛出异常
func throwingDiv
func throwingDiv(y: T): T
功能:除法运算。
参数:
y:除数
返回值:算数结果
异常:
OverflowException:当除法运算出现溢出时,抛出异常
func throwingMod
func throwingMod(y: T): T
功能:取余运算。
参数:
y:除数
返回值:算数结果
异常:
OverflowException:当取余运算出现溢出时,抛出异常
func throwingInc
func throwingInc(): T
功能:自增运算。
返回值:算数结果
异常:
OverflowException:当自增运算出现溢出时,抛出异常
func throwingDec
func throwingDec(): T
功能:自减运算。
返回值:算数结果
异常:
OverflowException:当自减运算出现溢出时,抛出异常
func throwingNeg
func throwingNeg(): T
功能:负号运算。
返回值:算数结果
异常:
OverflowException:当负号运算出现溢出时,抛出异常
interface WrappingOp
public interface WrappingOp<T> {
func wrappingAdd(y: T): T
func wrappingSub(y: T): T
func wrappingMul(y: T): T
func wrappingDiv(y: T): T
func wrappingMod(y: T): T
func wrappingInc(): T
func wrappingDec(): T
func wrappingNeg(): T
}
当整数运算出现溢出,高位截断。
func wrappingAdd
func wrappingAdd(y: T): T
功能:加法运算加法运算出现溢出,高位截断。
参数:
y:加数
返回值:算数结果
func wrappingSub
func wrappingSub(y: T): T
功能:减法运算减法运算出现溢出,高位截断。
参数:
y:减数
返回值:算数结果
func wrappingMul
func wrappingMul(y: T): T
功能:乘法运算乘法运算出现溢出,高位截断。
参数:
y:乘数
返回值:算数结果
func wrappingDiv
func wrappingDiv(y: T): T
功能:除法运算除法运算出现溢出,高位截断。
参数:
y:除数
返回值:算数结果
func wrappingMod
func wrappingMod(y: T): T
功能:取余运算取余运算出现溢出,高位截断。
参数:
y:除数
返回值:算数结果
func wrappingInc
func wrappingInc(): T
功能:自增运算自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
func wrappingDec(): T
功能:自减运算自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
func wrappingNeg(): T
功能:负号运算负号运算出现溢出,高位截断。
返回值:算数结果
interface SaturatingOp
public interface SaturatingOp<T> {
func saturatingAdd(y: T): T
func saturatingSub(y: T): T
func saturatingMul(y: T): T
func saturatingDiv(y: T): T
func saturatingMod(y: T): T
func saturatingInc(): T
func saturatingDec(): T
func saturatingNeg(): T
}
当整数运算出现溢出,饱和处理。
func saturatingAdd
func saturatingAdd(y: T): T
功能:加法运算加法运算出现溢出,饱和处理。
参数:
y:加数
返回值:算数结果
func saturatingSub
func saturatingSub(y: T): T
功能:减法运算减法运算出现溢出,饱和处理。
参数:
y:减数
返回值:算数结果
func saturatingMul
func saturatingMul(y: T): T
功能:乘法运算乘法运算出现溢出,饱和处理。
参数:
y:乘数
返回值:算数结果
func saturatingDiv
func saturatingDiv(y: T): T
功能:除法运算除法运算出现溢出,饱和处理。
参数:
y:除数
返回值:算数结果
func saturatingMod
func saturatingMod(y: T): T
功能:取余运算取余运算出现溢出,饱和处理。
参数:
y:除数
返回值:算数结果
func saturatingInc
func saturatingInc(): T
功能:自增运算自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
func saturatingDec(): T
功能:自减运算自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
func saturatingNeg(): T
功能:负号运算负号运算出现溢出,饱和处理。
返回值:算数结果
interface CheckedOp
public interface CheckedOp<T> {
func checkedAdd(y: T): Option<T>
func checkedSub(y: T): Option<T>
func checkedMul(y: T): Option<T>
func checkedDiv(y: T): Option<T>
func checkedMod(y: T): Option<T>
func checkedInc(): Option<T>
func checkedDec(): Option<T>
func checkedNeg(): Option<T>
}
当整数运算出现溢出,返回 Option
func checkedAdd
func checkedAdd(y: T): Option<T>
功能:加法运算加法运算出现溢出,返回 Option
参数:
y:加数
返回值:算数结果
func checkedSub
func checkedSub(y: T): Option<T>
功能:减法运算减法运算出现溢出,返回 Option
参数:
y:减数
返回值:算数结果
func checkedMul
func checkedMul(y: T): Option<T>
功能:乘法运算乘法运算出现溢出,返回 Option
参数:
y:乘数
返回值:算数结果
func checkedDiv
func checkedDiv(y: T): Option<T>
功能:除法运算除法运算出现溢出,返回 Option
参数:
y:除数
返回值:算数结果
func checkedMod
func checkedMod(y: T): Option<T>
功能:取余运算取余运算出现溢出,返回 Option
参数:
y:除数
返回值:算数结果
func checkedInc
func checkedInc(): Option<T>
功能:自增运算自增运算出现溢出,返回 Option
返回值:算数结果
func checkedDec
func checkedDec(): Option<T>
功能:自减运算自减运算出现溢出,返回 Option
返回值:算数结果
func checkedNeg
func checkedNeg(): Option<T>
功能:负号运算负号运算出现溢出,返回 Option
返回值:算数结果
extend Int8 <: ThrowingOp
extend Int8 <: ThrowingOp<Int8>
Int8 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是抛出异常的策略
func throwingAdd
public func throwingAdd(y: Int8): Int8
功能:加法运算出现溢出,抛异常。
参数:
y:另一个Int8数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingSub
public func throwingSub(y: Int8): Int8
功能:减法运算出现溢出,抛异常。
参数:
y:另一个Int8数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMul
public func throwingMul(y: Int8): Int8
功能:乘法运算出现溢出,抛异常。
参数:
y:另一个Int8数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDiv
public func throwingDiv(y: Int8): Int8
功能:除法运算出现溢出,抛异常。
参数:
y:另一个Int8数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMod
public func throwingMod(y: Int8): Int8
功能:取余运算出现溢出,抛异常。
参数:
y:另一个Int8数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingInc
public func throwingInc(): Int8
功能:自增运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDec
public func throwingDec(): Int8
功能:自减运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingNeg
public func throwingNeg(): Int8
功能:负号运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
extend Int8 <: WrappingOp
extend Int8 <: WrappingOp<Int8>
Int8 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是高位截断的策略
func wrappingAdd
public func wrappingAdd(y: Int8): Int8
功能:加法运算出现溢出,高位截断。
参数:
y:另一个Int8数
返回值:算数结果
func wrappingSub
public func wrappingSub(y: Int8): Int8
功能:减法运算出现溢出,高位截断。
参数:
y:另一个Int8数
返回值:算数结果
func wrappingMul
public func wrappingMul(y: Int8): Int8
功能:乘法运算出现溢出,高位截断。
参数:
y:另一个Int8数
返回值:算数结果
func wrappingDiv
public func wrappingDiv(y: Int8): Int8
功能:除法运算出现溢出,高位截断。
参数:
y:另一个Int8数
返回值:算数结果
func wrappingMod
public func wrappingMod(y: Int8): Int8
功能:取余运算出现溢出,高位截断。
参数:
y:另一个Int8数
返回值:算数结果
func wrappingInc
public func wrappingInc(): Int8
功能:自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
public func wrappingDec(): Int8
功能:自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
public func wrappingNeg(): Int8
功能:负号运算出现溢出,高位截断。
返回值:算数结果
extend Int8 <: SaturatingOp
extend Int8 <: SaturatingOp<Int8>
Int8 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是饱和的策略
func saturatingAdd
public func saturatingAdd(y: Int8): Int8
功能:加法运算出现溢出,饱和处理。
参数:
y:另一个Int8数
返回值:算数结果
func saturatingSub
public func saturatingSub(y: Int8): Int8
功能:减法运算出现溢出,饱和处理。
参数:
y:另一个Int8数
返回值:算数结果
func saturatingMul
public func saturatingMul(y: Int8): Int8
功能:乘法运算出现溢出,饱和处理。
参数:
y:另一个Int8数
返回值:算数结果
func saturatingDiv
public func saturatingDiv(y: Int8): Int8
功能:除法运算出现溢出,饱和处理。
参数:
y:另一个Int8数
返回值:算数结果
func saturatingMod
public func saturatingMod(y: Int8): Int8
功能:取余运算出现溢出,饱和处理。
参数:
y:另一个Int8数
返回值:算数结果
func saturatingInc
public func saturatingInc(): Int8
功能:自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
public func saturatingDec(): Int8
功能:自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
public func saturatingNeg(): Int8
功能:负号运算出现溢出,饱和处理。
返回值:算数结果
extend Int8 <: CheckedOp
extend Int8 <: CheckedOp<Int8>
Int8 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是返回 Option 类型的策略
func checkedAdd
public func checkedAdd(y: Int8): Option<Int8>
功能:加法运算出现溢出,返回 Option
参数:
y:另一个Int8数
返回值:Option
func checkedSub
public func checkedSub(y: Int8): Option<Int8>
功能:减法运算出现溢出,返回 Option
参数:
y:另一个Int8数
返回值:Option
func checkedMul
public func checkedMul(y: Int8): Option<Int8>
功能:乘法运算出现溢出,返回 Option
参数:
y:另一个Int8数
返回值:Option
func checkedDiv
public func checkedDiv(y: Int8): Option<Int8>
功能:除法运算出现溢出,返回 Option
参数:
y:另一个Int8数
返回值:Option
func checkedMod
public func checkedMod(y: Int8): Option<Int8>
功能:取余运算出现溢出,返回 Option
参数:
y:另一个Int8数
返回值:Option
func checkedInc
public func checkedInc(): Option<Int8>
功能:自增运算出现溢出,返回 Option
返回值:Option
func checkedDec
public func checkedDec(): Option<Int8>
功能:自减运算出现溢出,返回 Option
返回值:Option
func checkedNeg
public func checkedNeg(): Option<Int8>
功能:负号运算出现溢出,返回 Option
返回值:Option
extend Int16 <: ThrowingOp
extend Int16 <: ThrowingOp<Int16>
Int16 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是抛出异常的策略
func throwingAdd
public func throwingAdd(y: Int16): Int16
功能:加法运算出现溢出,抛异常。
参数:
y:另一个Int16数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingSub
public func throwingSub(y: Int16): Int16
功能:减法运算出现溢出,抛异常。
参数:
y:另一个Int16数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMul
public func throwingMul(y: Int16): Int16
功能:乘法运算出现溢出,抛异常。
参数:
y:另一个Int16数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDiv
public func throwingDiv(y: Int16): Int16
功能:除法运算出现溢出,抛异常。
参数:
y:另一个Int16数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMod
public func throwingMod(y: Int16): Int16
功能:取余运算出现溢出,抛异常。
参数:
y:另一个Int16数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingInc
public func throwingInc(): Int16
功能:自增运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDec
public func throwingDec(): Int16
功能:自减运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingNeg
public func throwingNeg(): Int16
功能:负号运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
extend Int16 <: WrappingOp
extend Int16 <: WrappingOp<Int16>
Int16 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是高位截断的策略
func wrappingAdd
public func wrappingAdd(y: Int16): Int16
功能:加法运算出现溢出,高位截断。
参数:
y:另一个Int16数
返回值:算数结果
func wrappingSub
public func wrappingSub(y: Int16): Int16
功能:减法运算出现溢出,高位截断。
参数:
y:另一个Int16数
返回值:算数结果
func wrappingMul
public func wrappingMul(y: Int16): Int16
功能:乘法运算出现溢出,高位截断。
参数:
y:另一个Int16数
返回值:算数结果
func wrappingDiv
public func wrappingDiv(y: Int16): Int16
功能:除法运算出现溢出,高位截断。
参数:
y:另一个Int16数
返回值:算数结果
func wrappingMod
public func wrappingMod(y: Int16): Int16
功能:取余运算出现溢出,高位截断。
参数:
y:另一个Int16数
返回值:算数结果
func wrappingInc
public func wrappingInc(): Int16
功能:自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
public func wrappingDec(): Int16
功能:自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
public func wrappingNeg(): Int16
功能:负号运算出现溢出,高位截断。
返回值:算数结果
extend Int16 <: SaturatingOp
extend Int16 <: SaturatingOp<Int16>
Int16 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是饱和的策略
func saturatingAdd
public func saturatingAdd(y: Int16): Int16
功能:加法运算出现溢出,饱和处理。
参数:
y:另一个Int16数
返回值:算数结果
func saturatingSub
public func saturatingSub(y: Int16): Int16
功能:减法运算出现溢出,饱和处理。
参数:
y:另一个Int16数
返回值:算数结果
func saturatingMul
public func saturatingMul(y: Int16): Int16
功能:乘法运算出现溢出,饱和处理。
参数:
y:另一个Int16数
返回值:算数结果
func saturatingDiv
public func saturatingDiv(y: Int16): Int16
功能:除法运算出现溢出,饱和处理。
参数:
y:另一个Int16数
返回值:算数结果
func saturatingMod
public func saturatingMod(y: Int16): Int16
功能:取余运算出现溢出,饱和处理。
参数:
y:另一个Int16数
返回值:算数结果
func saturatingInc
public func saturatingInc(): Int16
功能:自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
public func saturatingDec(): Int16
功能:自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
public func saturatingNeg(): Int16
功能:负号运算出现溢出,饱和处理。
返回值:算数结果
extend Int16 <: CheckedOp
extend Int16 <: CheckedOp<Int16>
Int16 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是返回 Option 类型的策略
func checkedAdd
public func checkedAdd(y: Int16): Option<Int16>
功能:加法运算出现溢出,返回 Option
参数:
y:另一个Int16数
返回值:Option
func checkedSub
public func checkedSub(y: Int16): Option<Int16>
功能:减法运算出现溢出,返回 Option
参数:
y:另一个Int16数
返回值:Option
func checkedMul
public func checkedMul(y: Int16): Option<Int16>
功能:乘法运算出现溢出,返回 Option
参数:
y:另一个Int16数
返回值:Option
func checkedDiv
public func checkedDiv(y: Int16): Option<Int16>
功能:除法运算出现溢出,返回 Option
参数:
y:另一个Int16数
返回值:Option
func checkedMod
public func checkedMod(y: Int16): Option<Int16>
功能:取余运算出现溢出,返回 Option
参数:
y:另一个Int16数
返回值:Option
func checkedInc
public func checkedInc(): Option<Int16>
功能:自增运算出现溢出,返回 Option
返回值:Option
func checkedDec
public func checkedDec(): Option<Int16>
功能:自减运算出现溢出,返回 Option
返回值:Option
func checkedNeg
public func checkedNeg(): Option<Int16>
功能:负号运算出现溢出,返回 Option
返回值:Option
extend Int32 <: ThrowingOp
extend Int32 <: ThrowingOp<Int32>
Int32 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是抛出异常的策略
func throwingAdd
public func throwingAdd(y: Int32): Int32
功能:加法运算出现溢出,抛异常。
参数:
y:另一个Int32数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingSub
public func throwingSub(y: Int32): Int32
功能:减法运算出现溢出,抛异常。
参数:
y:另一个Int32数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMul
public func throwingMul(y: Int32): Int32
功能:乘法运算出现溢出,抛异常。
参数:
y:另一个Int32数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDiv
public func throwingDiv(y: Int32): Int32
功能:除法运算出现溢出,抛异常。
参数:
y:另一个Int32数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMod
public func throwingMod(y: Int32): Int32
功能:取余运算出现溢出,抛异常。
参数:
y:另一个Int32数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingInc
public func throwingInc(): Int32
功能:自增运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDec
public func throwingDec(): Int32
功能:自减运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingNeg
public func throwingNeg(): Int32
功能:负号运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
extend Int32 <: WrappingOp
extend Int32 <: WrappingOp<Int32>
Int32 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是高位截断的策略
func wrappingAdd
public func wrappingAdd(y: Int32): Int32
功能:加法运算出现溢出,高位截断。
参数:
y:另一个Int32数
返回值:算数结果
func wrappingSub
public func wrappingSub(y: Int32): Int32
功能:减法运算出现溢出,高位截断。
参数:
y:另一个Int32数
返回值:算数结果
func wrappingMul
public func wrappingMul(y: Int32): Int32
功能:乘法运算出现溢出,高位截断。
参数:
y:另一个Int32数
返回值:算数结果
func wrappingDiv
public func wrappingDiv(y: Int32): Int32
功能:除法运算出现溢出,高位截断。
参数:
y:另一个Int32数
返回值:算数结果
func wrappingMod
public func wrappingMod(y: Int32): Int32
功能:取余运算出现溢出,高位截断。
参数:
y:另一个Int32数
返回值:算数结果
func wrappingInc
public func wrappingInc(): Int32
功能:自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
public func wrappingDec(): Int32
功能:自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
public func wrappingNeg(): Int32
功能:负号运算出现溢出,高位截断。
返回值:算数结果
extend Int32 <: SaturatingOp
extend Int32 <: SaturatingOp<Int32>
Int32 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是饱和的策略
func saturatingAdd
public func saturatingAdd(y: Int32): Int32
功能:加法运算出现溢出,饱和处理。
参数:
y:另一个Int32数
返回值:算数结果
func saturatingSub
public func saturatingSub(y: Int32): Int32
功能:减法运算出现溢出,饱和处理。
参数:
y:另一个Int32数
返回值:算数结果
func saturatingMul
public func saturatingMul(y: Int32): Int32
功能:乘法运算出现溢出,饱和处理。
参数:
y:另一个Int32数
返回值:算数结果
func saturatingDiv
public func saturatingDiv(y: Int32): Int32
功能:除法运算出现溢出,饱和处理。
参数:
y:另一个Int32数
返回值:算数结果
func saturatingMod
public func saturatingMod(y: Int32): Int32
功能:取余运算出现溢出,饱和处理。
参数:
y:另一个Int32数
返回值:算数结果
func saturatingInc
public func saturatingInc(): Int32
功能:自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
public func saturatingDec(): Int32
功能:自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
public func saturatingNeg(): Int32
功能:负号运算出现溢出,饱和处理。
返回值:算数结果
extend Int32 <: CheckedOp
extend Int32 <: CheckedOp<Int32>
Int32 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是返回 Option 类型的策略
func checkedAdd
public func checkedAdd(y: Int32): Option<Int32>
功能:加法运算出现溢出,返回 Option
参数:
y:另一个Int32数
返回值:Option
func checkedSub
public func checkedSub(y: Int32): Option<Int32>
功能:减法运算出现溢出,返回 Option
参数:
y:另一个Int32数
返回值:Option
func checkedMul
public func checkedMul(y: Int32): Option<Int32>
功能:乘法运算出现溢出,返回 Option
参数:
y:另一个Int32数
返回值:Option
func checkedDiv
public func checkedDiv(y: Int32): Option<Int32>
功能:除法运算出现溢出,返回 Option
参数:
y:另一个Int32数
返回值:Option
func checkedMod
public func checkedMod(y: Int32): Option<Int32>
功能:取余运算出现溢出,返回 Option
参数:
y:另一个Int32数
返回值:Option
func checkedInc
public func checkedInc(): Option<Int32>
功能:自增运算出现溢出,返回 Option
返回值:Option
func checkedDec
public func checkedDec(): Option<Int32>
功能:自减运算出现溢出,返回 Option
返回值:Option
func checkedNeg
public func checkedNeg(): Option<Int32>
功能:负号运算出现溢出,返回 Option
返回值:Option
extend Int64 <: ThrowingOp
extend Int64 <: ThrowingOp<Int64>
Int64 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是抛出异常的策略
func throwingAdd
public func throwingAdd(y: Int64): Int64
功能:加法运算出现溢出,抛异常。
参数:
y:另一个Int64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingSub
public func throwingSub(y: Int64): Int64
功能:减法运算出现溢出,抛异常。
参数:
y:另一个Int64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMul
public func throwingMul(y: Int64): Int64
功能:乘法运算出现溢出,抛异常。
参数:
y:另一个Int64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDiv
public func throwingDiv(y: Int64): Int64
功能:除法运算出现溢出,抛异常。
参数:
y:另一个Int64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMod
public func throwingMod(y: Int64): Int64
功能:取余运算出现溢出,抛异常。
参数:
y:另一个Int64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingPow
public func throwingPow(y: UInt64): Int64
功能:幂运算出现溢出,抛异常。
参数:
y:另一个UInt64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingInc
public func throwingInc(): Int64
功能:自增运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDec
public func throwingDec(): Int64
功能:自减运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingNeg
public func throwingNeg(): Int64
功能:负号运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
extend Int64 <: WrappingOp
extend Int64 <: WrappingOp<Int64>
Int64 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是高位截断的策略
func wrappingAdd
public func wrappingAdd(y: Int64): Int64
功能:加法运算出现溢出,高位截断。
参数:
y:另一个Int64数
返回值:算数结果
func wrappingSub
public func wrappingSub(y: Int64): Int64
功能:减法运算出现溢出,高位截断。
参数:
y:另一个Int64数
返回值:算数结果
func wrappingMul
public func wrappingMul(y: Int64): Int64
功能:乘法运算出现溢出,高位截断。
参数:
y:另一个Int64数
返回值:算数结果
func wrappingDiv
public func wrappingDiv(y: Int64): Int64
功能:除法运算出现溢出,高位截断。
参数:
y:另一个Int64数
返回值:算数结果
func wrappingMod
public func wrappingMod(y: Int64): Int64
功能:取余运算出现溢出,高位截断。
参数:
y:另一个Int64数
返回值:算数结果
func wrappingPow
public func wrappingPow(y: UInt64): Int64
功能:幂运算出现溢出,高位截断。
参数:
y:另一个UInt64数
返回值:算数结果
func wrappingInc
public func wrappingInc(): Int64
功能:自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
public func wrappingDec(): Int64
功能:自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
public func wrappingNeg(): Int64
功能:负号运算出现溢出,高位截断。
返回值:算数结果
extend Int64 <: SaturatingOp
extend Int64 <: SaturatingOp<Int64>
Int64 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是饱和的策略
func saturatingAdd
public func saturatingAdd(y: Int64): Int64
功能:加法运算出现溢出,饱和处理。
参数:
y:另一个Int64数
返回值:算数结果
func saturatingSub
public func saturatingSub(y: Int64): Int64
功能:减法运算出现溢出,饱和处理。
参数:
y:另一个Int64数
返回值:算数结果
func saturatingMul
public func saturatingMul(y: Int64): Int64
功能:乘法运算出现溢出,饱和处理。
参数:
y:另一个Int64数
返回值:算数结果
func saturatingDiv
public func saturatingDiv(y: Int64): Int64
功能:除法运算出现溢出,饱和处理。
参数:
y:另一个Int64数
返回值:算数结果
func saturatingMod
public func saturatingMod(y: Int64): Int64
功能:取余运算出现溢出,饱和处理。
参数:
y:另一个Int64数
返回值:算数结果
func saturatingPow
public func saturatingPow(y: UInt64): Int64
功能:幂运算出现溢出,饱和处理。
参数:
y:另一个UInt64数
返回值:算数结果
func saturatingInc
public func saturatingInc(): Int64
功能:自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
public func saturatingDec(): Int64
功能:自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
public func saturatingNeg(): Int64
功能:负号运算出现溢出,饱和处理。
返回值:算数结果
extend Int64 <: CheckedOp
extend Int64 <: CheckedOp<Int64>
Int64 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是返回 Option 类型的策略
func checkedAdd
public func checkedAdd(y: Int64): Option<Int64>
功能:加法运算出现溢出,返回 Option
参数:
y:另一个Int64数
返回值:Option
func checkedSub
public func checkedSub(y: Int64): Option<Int64>
功能:减法运算出现溢出,返回 Option
参数:
y:另一个Int64数
返回值:Option
func checkedMul
public func checkedMul(y: Int64): Option<Int64>
功能:乘法运算出现溢出,返回 Option
参数:
y:另一个Int64数
返回值:Option
func checkedDiv
public func checkedDiv(y: Int64): Option<Int64>
功能:除法运算出现溢出,返回 Option
参数:
y:另一个Int64数
返回值:Option
func checkedMod
public func checkedMod(y: Int64): Option<Int64>
功能:取余运算出现溢出,返回 Option
参数:
y:另一个Int64数
返回值:Option
func checkedPow
public func checkedPow(y: UInt64): Option<Int64>
功能:幂运算出现溢出,返回 Option
参数:
y:另一个UInt64数
返回值:Option
func checkedInc
public func checkedInc(): Option<Int64>
功能:自增运算出现溢出,返回 Option
返回值:Option
func checkedDec
public func checkedDec(): Option<Int64>
功能:自减运算出现溢出,返回 Option
返回值:Option
func checkedNeg
public func checkedNeg(): Option<Int64>
功能:负号运算出现溢出,返回 Option
返回值:Option
extend IntNative <: ThrowingOp
extend IntNative <: ThrowingOp<IntNative>
IntNative 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是抛出异常的策略
func throwingAdd
public func throwingAdd(y: IntNative): IntNative
功能:加法运算出现溢出,抛异常。
参数:
y:另一个 IntNative 数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingSub
public func throwingSub(y: IntNative): IntNative
功能:减法运算出现溢出,抛异常。
参数:
y:另一个 IntNative 数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMul
public func throwingMul(y: IntNative): IntNative
功能:乘法运算出现溢出,抛异常。
参数:
y:另一个 IntNative 数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDiv
public func throwingDiv(y: IntNative): IntNative
功能:除法运算出现溢出,抛异常。
参数:
y:另一个 IntNative 数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMod
public func throwingMod(y: IntNative): IntNative
功能:取余运算出现溢出,抛异常。
参数:
y:另一个 IntNative 数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingInc
public func throwingInc(): IntNative
功能:自增运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDec
public func throwingDec(): IntNative
功能:自减运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingNeg
public func throwingNeg(): IntNative
功能:负号运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
extend IntNative <: WrappingOp
extend IntNative <: WrappingOp<IntNative>
IntNative 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是高位截断的策略
func wrappingAdd
public func wrappingAdd(y: IntNative): IntNative
功能:加法运算出现溢出,高位截断。
参数:
y:另一个 IntNative 数
返回值:算数结果
func wrappingSub
public func wrappingSub(y: IntNative): IntNative
功能:减法运算出现溢出,高位截断。
参数:
y:另一个 IntNative 数
返回值:算数结果
func wrappingMul
public func wrappingMul(y: IntNative): IntNative
功能:乘法运算出现溢出,高位截断。
参数:
y:另一个 IntNative 数
返回值:算数结果
func wrappingDiv
public func wrappingDiv(y: IntNative): IntNative
功能:除法运算出现溢出,高位截断。
参数:
y:另一个 IntNative 数
返回值:算数结果
func wrappingMod
public func wrappingMod(y: IntNative): IntNative
功能:取余运算出现溢出,高位截断。
参数:
y:另一个 IntNative 数
返回值:算数结果
func wrappingInc
public func wrappingInc(): IntNative
功能:自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
public func wrappingDec(): IntNative
功能:自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
public func wrappingNeg(): IntNative
功能:负号运算出现溢出,高位截断。
返回值:算数结果
extend IntNative <: SaturatingOp
extend IntNative <: SaturatingOp<IntNative>
IntNative 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是饱和的策略
func saturatingAdd
public func saturatingAdd(y: IntNative): IntNative
功能:加法运算出现溢出,饱和处理。
参数:
y:另一个 IntNative 数
返回值:算数结果
func saturatingSub
public func saturatingSub(y: IntNative): IntNative
功能:减法运算出现溢出,饱和处理。
参数:
y:另一个 IntNative 数
返回值:算数结果
func saturatingMul
public func saturatingMul(y: IntNative): IntNative
功能:乘法运算出现溢出,饱和处理。
参数:
y:另一个 IntNative 数
返回值:算数结果
func saturatingDiv
public func saturatingDiv(y: IntNative): IntNative
功能:除法运算出现溢出,饱和处理。
参数:
y:另一个 IntNative 数
返回值:算数结果
func saturatingMod
public func saturatingMod(y: IntNative): IntNative
功能:取余运算出现溢出,饱和处理。
参数:
y:另一个 IntNative 数
返回值:算数结果
func saturatingInc
public func saturatingInc(): IntNative
功能:自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
public func saturatingDec(): IntNative
功能:自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
public func saturatingNeg(): IntNative
功能:负号运算出现溢出,饱和处理。
返回值:算数结果
extend IntNative <: CheckedOp
extend IntNative <: CheckedOp<IntNative>
IntNative 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是返回 Option 类型的策略
func checkedAdd
public func checkedAdd(y: IntNative): Option<IntNative>
功能:加法运算出现溢出,返回 Option
参数:
y:另一个 IntNative 数
返回值:Option
func checkedSub
public func checkedSub(y: IntNative): Option<IntNative>
功能:减法运算出现溢出,返回 Option
参数:
y:另一个 IntNative 数
返回值:Option
func checkedMul
public func checkedMul(y: IntNative): Option<IntNative>
功能:乘法运算出现溢出,返回 Option
参数:
y:另一个 IntNative 数
返回值:Option
func checkedDiv
public func checkedDiv(y: IntNative): Option<IntNative>
功能:除法运算出现溢出,返回 Option
参数:
y:另一个 IntNative 数
返回值:Option
func checkedMod
public func checkedMod(y: IntNative): Option<IntNative>
功能:取余运算出现溢出,返回 Option
参数:
y:另一个 IntNative 数
返回值:Option
func checkedInc
public func checkedInc(): Option<IntNative>
功能:自增运算出现溢出,返回 Option
返回值:Option
func checkedDec
public func checkedDec(): Option<IntNative>
功能:自减运算出现溢出,返回 Option
返回值:Option
func checkedNeg
public func checkedNeg(): Option<IntNative>
功能:负号运算出现溢出,返回 Option
返回值:Option
extend UInt8 <: ThrowingOp
extend UInt8 <: ThrowingOp<UInt8>
UInt8 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是抛出异常的策略
func throwingAdd
public func throwingAdd(y: UInt8): UInt8
功能:加法运算出现溢出,抛异常。
参数:
y:另一个UInt8数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingSub
public func throwingSub(y: UInt8): UInt8
功能:减法运算出现溢出,抛异常。
参数:
y:另一个UInt8数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMul
public func throwingMul(y: UInt8): UInt8
功能:乘法运算出现溢出,抛异常。
参数:
y:另一个UInt8数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDiv
public func throwingDiv(y: UInt8): UInt8
功能:除法运算出现溢出,抛异常。
参数:
y:另一个UInt8数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMod
public func throwingMod(y: UInt8): UInt8
功能:取余运算出现溢出,抛异常。
参数:
y:另一个UInt8数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingInc
public func throwingInc(): UInt8
功能:自增运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDec
public func throwingDec(): UInt8
功能:自减运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingNeg
public func throwingNeg(): UInt8
功能:负号运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
extend UInt8 <: WrappingOp
extend UInt8 <: WrappingOp<UInt8>
UInt8 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是高位截断的策略
func wrappingAdd
public func wrappingAdd(y: UInt8): UInt8
功能:加法运算出现溢出,高位截断。
参数:
y:另一个UInt8数
返回值:算数结果
func wrappingSub
public func wrappingSub(y: UInt8): UInt8
功能:减法运算出现溢出,高位截断。
参数:
y:另一个UInt8数
返回值:算数结果
func wrappingMul
public func wrappingMul(y: UInt8): UInt8
功能:乘法运算出现溢出,高位截断。
参数:
y:另一个UInt8数
返回值:算数结果
func wrappingDiv
public func wrappingDiv(y: UInt8): UInt8
功能:除法运算出现溢出,高位截断。
参数:
y:另一个UInt8数
返回值:算数结果
func wrappingMod
public func wrappingMod(y: UInt8): UInt8
功能:取余运算出现溢出,高位截断。
参数:
y:另一个UInt8数
返回值:算数结果
func wrappingInc
public func wrappingInc(): UInt8
功能:自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
public func wrappingDec(): UInt8
功能:自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
public func wrappingNeg(): UInt8
功能:负号运算出现溢出,高位截断。
返回值:算数结果
extend UInt8 <: SaturatingOp
extend UInt8 <: SaturatingOp<UInt8>
UInt8 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是饱和的策略
func saturatingAdd
public func saturatingAdd(y: UInt8): UInt8
功能:加法运算出现溢出,饱和处理。
参数:
y:另一个UInt8数
返回值:算数结果
func saturatingSub
public func saturatingSub(y: UInt8): UInt8
功能:减法运算出现溢出,饱和处理。
参数:
y:另一个UInt8数
返回值:算数结果
func saturatingMul
public func saturatingMul(y: UInt8): UInt8
功能:乘法运算出现溢出,饱和处理。
参数:
y:另一个UInt8数
返回值:算数结果
func saturatingDiv
public func saturatingDiv(y: UInt8): UInt8
功能:除法运算出现溢出,饱和处理。
参数:
y:另一个UInt8数
返回值:算数结果
func saturatingMod
public func saturatingMod(y: UInt8): UInt8
功能:取余运算出现溢出,饱和处理。
参数:
y:另一个UInt8数
返回值:算数结果
func saturatingInc
public func saturatingInc(): UInt8
功能:自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
public func saturatingDec(): UInt8
功能:自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
public func saturatingNeg(): UInt8
功能:负号运算出现溢出,饱和处理。
返回值:算数结果
extend UInt8 <: CheckedOp
extend UInt8 <: CheckedOp<UInt8>
UInt8 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是返回 Option 类型的策略
func checkedAdd
public func checkedAdd(y: UInt8): Option<UInt8>
功能:加法运算出现溢出,返回 Option
参数:
y:另一个UInt8数
返回值:Option
func checkedSub
public func checkedSub(y: UInt8): Option<UInt8>
功能:减法运算出现溢出,返回 Option
参数:
y:另一个UInt8数
返回值:Option
func checkedMul
public func checkedMul(y: UInt8): Option<UInt8>
功能:乘法运算出现溢出,返回 Option
参数:
y:另一个UInt8数
返回值:Option
func checkedDiv
public func checkedDiv(y: UInt8): Option<UInt8>
功能:除法运算出现溢出,返回 Option
参数:
y:另一个UInt8数
返回值:Option
func checkedMod
public func checkedMod(y: UInt8): Option<UInt8>
功能:取余运算出现溢出,返回 Option
参数:
y:另一个UInt8数
返回值:Option
func checkedInc
public func checkedInc(): Option<UInt8>
功能:自增运算出现溢出,返回 Option
返回值:Option
func checkedDec
public func checkedDec(): Option<UInt8>
功能:自减运算出现溢出,返回 Option
返回值:Option
func checkedNeg
public func checkedNeg(): Option<UInt8>
功能:负号运算出现溢出,返回 Option
返回值:Option
extend UInt16 <: ThrowingOp
extend UInt16 <: ThrowingOp<UInt16>
UInt16 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是抛出异常的策略
func throwingAdd
public func throwingAdd(y: UInt16): UInt16
功能:加法运算出现溢出,抛异常。
参数:
y:另一个UInt16数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingSub
public func throwingSub(y: UInt16): UInt16
功能:减法运算出现溢出,抛异常。
参数:
y:另一个UInt16数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMul
public func throwingMul(y: UInt16): UInt16
功能:乘法运算出现溢出,抛异常。
参数:
y:另一个UInt16数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDiv
public func throwingDiv(y: UInt16): UInt16
功能:除法运算出现溢出,抛异常。
参数:
y:另一个UInt16数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMod
public func throwingMod(y: UInt16): UInt16
功能:取余运算出现溢出,抛异常。
参数:
y:另一个UInt16数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingInc
public func throwingInc(): UInt16
功能:自增运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDec
public func throwingDec(): UInt16
功能:自减运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingNeg
public func throwingNeg(): UInt16
功能:负号运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
extend UInt16 <: WrappingOp
extend UInt16 <: WrappingOp<UInt16>
UInt16 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是高位截断的策略
func wrappingAdd
public func wrappingAdd(y: UInt16): UInt16
功能:加法运算出现溢出,高位截断。
参数:
y:另一个UInt16数
返回值:算数结果
func wrappingSub
public func wrappingSub(y: UInt16): UInt16
功能:减法运算出现溢出,高位截断。
参数:
y:另一个UInt16数
返回值:算数结果
func wrappingMul
public func wrappingMul(y: UInt16): UInt16
功能:乘法运算出现溢出,高位截断。
参数:
y:另一个UInt16数
返回值:算数结果
func wrappingDiv
public func wrappingDiv(y: UInt16): UInt16
功能:除法运算出现溢出,高位截断。
参数:
y:另一个UInt16数
返回值:算数结果
func wrappingMod
public func wrappingMod(y: UInt16): UInt16
功能:取余运算出现溢出,高位截断。
参数:
y:另一个UInt16数
返回值:算数结果
func wrappingInc
public func wrappingInc(): UInt16
功能:自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
public func wrappingDec(): UInt16
功能:自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
public func wrappingNeg(): UInt16
功能:负号运算出现溢出,高位截断。
返回值:算数结果
extend UInt16 <: SaturatingOp
extend UInt16 <: SaturatingOp<UInt16>
UInt16 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是饱和的策略
func saturatingAdd
public func saturatingAdd(y: UInt16): UInt16
功能:加法运算出现溢出,饱和处理。
参数:
y:另一个UInt16数
返回值:算数结果
func saturatingSub
public func saturatingSub(y: UInt16): UInt16
功能:减法运算出现溢出,饱和处理。
参数:
y:另一个UInt16数
返回值:算数结果
func saturatingMul
public func saturatingMul(y: UInt16): UInt16
功能:乘法运算出现溢出,饱和处理。
参数:
y:另一个UInt16数
返回值:算数结果
func saturatingDiv
public func saturatingDiv(y: UInt16): UInt16
功能:除法运算出现溢出,饱和处理。
参数:
y:另一个UInt16数
返回值:算数结果
func saturatingMod
public func saturatingMod(y: UInt16): UInt16
功能:取余运算出现溢出,饱和处理。
参数:
y:另一个UInt16数
返回值:算数结果
func saturatingInc
public func saturatingInc(): UInt16
功能:自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
public func saturatingDec(): UInt16
功能:自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
public func saturatingNeg(): UInt16
功能:负号运算出现溢出,饱和处理。
返回值:算数结果
extend UInt16 <: CheckedOp
extend UInt16 <: CheckedOp<UInt16>
UInt16 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是返回 Option 类型的策略
func checkedAdd
public func checkedAdd(y: UInt16): Option<UInt16>
功能:加法运算出现溢出,返回 Option
参数:
y:另一个UInt16数
返回值:Option
func checkedSub
public func checkedSub(y: UInt16): Option<UInt16>
功能:减法运算出现溢出,返回 Option
参数:
y:另一个UInt16数
返回值:Option
func checkedMul
public func checkedMul(y: UInt16): Option<UInt16>
功能:乘法运算出现溢出,返回 Option
参数:
y:另一个UInt16数
返回值:Option
func checkedDiv
public func checkedDiv(y: UInt16): Option<UInt16>
功能:除法运算出现溢出,返回 Option
参数:
y:另一个UInt16数
返回值:Option
func checkedMod
public func checkedMod(y: UInt16): Option<UInt16>
功能:取余运算出现溢出,返回 Option
参数:
y:另一个UInt16数
返回值:Option
func checkedInc
public func checkedInc(): Option<UInt16>
功能:自增运算出现溢出,返回 Option
返回值:Option
func checkedDec
public func checkedDec(): Option<UInt16>
功能:自减运算出现溢出,返回 Option
返回值:Option
func checkedNeg
public func checkedNeg(): Option<UInt16>
功能:负号运算出现溢出,返回 Option
返回值:Option
extend UInt32 <: ThrowingOp
extend UInt32 <: ThrowingOp<UInt32>
UInt32 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是抛出异常的策略
func throwingAdd
public func throwingAdd(y: UInt32): UInt32
功能:加法运算出现溢出,抛异常。
参数:
y:另一个UInt32数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingSub
public func throwingSub(y: UInt32): UInt32
功能:减法运算出现溢出,抛异常。
参数:
y:另一个UInt32数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMul
public func throwingMul(y: UInt32): UInt32
功能:乘法运算出现溢出,抛异常。
参数:
y:另一个UInt32数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDiv
public func throwingDiv(y: UInt32): UInt32
功能:除法运算出现溢出,抛异常。
参数:
y:另一个UInt32数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMod
public func throwingMod(y: UInt32): UInt32
功能:取余运算出现溢出,抛异常。
参数:
y:另一个UInt32数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingInc
public func throwingInc(): UInt32
功能:自增运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDec
public func throwingDec(): UInt32
功能:自减运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingNeg
public func throwingNeg(): UInt32
功能:负号运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
extend UInt32 <: WrappingOp
extend UInt32 <: WrappingOp<UInt32>
UInt32 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是高位截断的策略
func wrappingAdd
public func wrappingAdd(y: UInt32): UInt32
功能:加法运算出现溢出,高位截断。
参数:
y:另一个UInt32数
返回值:算数结果
func wrappingSub
public func wrappingSub(y: UInt32): UInt32
功能:减法运算出现溢出,高位截断。
参数:
y:另一个UInt32数
返回值:算数结果
func wrappingMul
public func wrappingMul(y: UInt32): UInt32
功能:乘法运算出现溢出,高位截断。
参数:
y:另一个UInt32数
返回值:算数结果
func wrappingDiv
public func wrappingDiv(y: UInt32): UInt32
功能:除法运算出现溢出,高位截断。
参数:
y:另一个UInt32数
返回值:算数结果
func wrappingMod
public func wrappingMod(y: UInt32): UInt32
功能:取余运算出现溢出,高位截断。
参数:
y:另一个UInt32数
返回值:算数结果
func wrappingInc
public func wrappingInc(): UInt32
功能:自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
public func wrappingDec(): UInt32
功能:自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
public func wrappingNeg(): UInt32
功能:负号运算出现溢出,高位截断。
返回值:算数结果
extend UInt32 <: SaturatingOp
extend UInt32 <: SaturatingOp<UInt32>
UInt32 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是饱和的策略
func saturatingAdd
public func saturatingAdd(y: UInt32): UInt32
功能:加法运算出现溢出,饱和处理。
参数:
y:另一个UInt32数
返回值:算数结果
func saturatingSub
public func saturatingSub(y: UInt32): UInt32
功能:减法运算出现溢出,饱和处理。
参数:
y:另一个UInt32数
返回值:算数结果
func saturatingMul
public func saturatingMul(y: UInt32): UInt32
功能:乘法运算出现溢出,饱和处理。
参数:
y:另一个UInt32数
返回值:算数结果
func saturatingDiv
public func saturatingDiv(y: UInt32): UInt32
功能:除法运算出现溢出,饱和处理。
参数:
y:另一个UInt32数
返回值:算数结果
func saturatingMod
public func saturatingMod(y: UInt32): UInt32
功能:取余运算出现溢出,饱和处理。
参数:
y:另一个UInt32数
返回值:算数结果
func saturatingInc
public func saturatingInc(): UInt32
功能:自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
public func saturatingDec(): UInt32
功能:自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
public func saturatingNeg(): UInt32
功能:负号运算出现溢出,饱和处理。
返回值:算数结果
extend UInt32 <: CheckedOp
extend UInt32 <: CheckedOp<UInt32>
UInt32 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是返回 Option 类型的策略
func checkedAdd
public func checkedAdd(y: UInt32): Option<UInt32>
功能:加法运算出现溢出,返回 Option
参数:
y:另一个UInt32数
返回值:Option
func checkedSub
public func checkedSub(y: UInt32): Option<UInt32>
功能:减法运算出现溢出,返回 Option
参数:
y:另一个UInt32数
返回值:Option
func checkedMul
public func checkedMul(y: UInt32): Option<UInt32>
功能:乘法运算出现溢出,返回 Option
参数:
y:另一个UInt32数
返回值:Option
func checkedDiv
public func checkedDiv(y: UInt32): Option<UInt32>
功能:除法运算出现溢出,返回 Option
参数:
y:另一个UInt32数
返回值:Option
func checkedMod
public func checkedMod(y: UInt32): Option<UInt32>
功能:取余运算出现溢出,返回 Option
参数:
y:另一个UInt32数
返回值:Option
func checkedInc
public func checkedInc(): Option<UInt32>
功能:自增运算出现溢出,返回 Option
返回值:Option
func checkedDec
public func checkedDec(): Option<UInt32>
功能:自减运算出现溢出,返回 Option
返回值:Option
func checkedNeg
public func checkedNeg(): Option<UInt32>
功能:负号运算出现溢出,返回 Option
返回值:Option
extend UInt64 <: ThrowingOp
extend UInt64 <: ThrowingOp<UInt64>
UInt64 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是抛出异常的策略
func throwingAdd
public func throwingAdd(y: UInt64): UInt64
功能:加法运算出现溢出,抛异常。
参数:
y:另一个UInt64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingSub
public func throwingSub(y: UInt64): UInt64
功能:减法运算出现溢出,抛异常。
参数:
y:另一个UInt64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMul
public func throwingMul(y: UInt64): UInt64
功能:乘法运算出现溢出,抛异常。
参数:
y:另一个UInt64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDiv
public func throwingDiv(y: UInt64): UInt64
功能:除法运算出现溢出,抛异常。
参数:
y:另一个UInt64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMod
public func throwingMod(y: UInt64): UInt64
功能:取余运算出现溢出,抛异常。
参数:
y:另一个UInt64数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingInc
public func throwingInc(): UInt64
功能:自增运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDec
public func throwingDec(): UInt64
功能:自减运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingNeg
public func throwingNeg(): UInt64
功能:负号运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
extend UInt64 <: WrappingOp
extend UInt64 <: WrappingOp<UInt64>
UInt64 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是高位截断的策略
func wrappingAdd
public func wrappingAdd(y: UInt64): UInt64
功能:加法运算出现溢出,高位截断。
参数:
y:另一个UInt64数
返回值:算数结果
func wrappingSub
public func wrappingSub(y: UInt64): UInt64
功能:减法运算出现溢出,高位截断。
参数:
y:另一个UInt64数
返回值:算数结果
func wrappingMul
public func wrappingMul(y: UInt64): UInt64
功能:乘法运算出现溢出,高位截断。
参数:
y:另一个UInt64数
返回值:算数结果
func wrappingDiv
public func wrappingDiv(y: UInt64): UInt64
功能:除法运算出现溢出,高位截断。
参数:
y:另一个UInt64数
返回值:算数结果
func wrappingMod
public func wrappingMod(y: UInt64): UInt64
功能:取余运算出现溢出,高位截断。
参数:
y:另一个UInt64数
返回值:算数结果
func wrappingInc
public func wrappingInc(): UInt64
功能:自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
public func wrappingDec(): UInt64
功能:自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
public func wrappingNeg(): UInt64
功能:负号运算出现溢出,高位截断。
返回值:算数结果
extend UInt64 <: SaturatingOp
extend UInt64 <: SaturatingOp<UInt64>
UInt64 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是饱和的策略
func saturatingAdd
public func saturatingAdd(y: UInt64): UInt64
功能:加法运算出现溢出,饱和处理。
参数:
y:另一个UInt64数
返回值:算数结果
func saturatingSub
public func saturatingSub(y: UInt64): UInt64
功能:减法运算出现溢出,饱和处理。
参数:
y:另一个UInt64数
返回值:算数结果
func saturatingMul
public func saturatingMul(y: UInt64): UInt64
功能:乘法运算出现溢出,饱和处理。
参数:
y:另一个UInt64数
返回值:算数结果
func saturatingDiv
public func saturatingDiv(y: UInt64): UInt64
功能:除法运算出现溢出,饱和处理。
参数:
y:另一个UInt64数
返回值:算数结果
func saturatingMod
public func saturatingMod(y: UInt64): UInt64
功能:取余运算出现溢出,饱和处理。
参数:
y:另一个UInt64数
返回值:算数结果
func saturatingInc
public func saturatingInc(): UInt64
功能:自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
public func saturatingDec(): UInt64
功能:自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
public func saturatingNeg(): UInt64
功能:负号运算出现溢出,饱和处理。
返回值:算数结果
extend UInt64 <: CheckedOp
extend UInt64 <: CheckedOp<UInt64>
UInt64 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是返回 Option 类型的策略
func checkedAdd
public func checkedAdd(y: UInt64): Option<UInt64>
功能:加法运算出现溢出,返回 Option
参数:
y:另一个UInt64数
返回值:Option
func checkedSub
public func checkedSub(y: UInt64): Option<UInt64>
功能:减法运算出现溢出,返回 Option
参数:
y:另一个UInt64数
返回值:Option
func checkedMul
public func checkedMul(y: UInt64): Option<UInt64>
功能:乘法运算出现溢出,返回 Option
参数:
y:另一个UInt64数
返回值:Option
func checkedDiv
public func checkedDiv(y: UInt64): Option<UInt64>
功能:除法运算出现溢出,返回 Option
参数:
y:另一个UInt64数
返回值:Option
func checkedMod
public func checkedMod(y: UInt64): Option<UInt64>
功能:取余运算出现溢出,返回 Option
参数:
y:另一个UInt64数
返回值:Option
func checkedInc
public func checkedInc(): Option<UInt64>
功能:自增运算出现溢出,返回 Option
返回值:Option
func checkedDec
public func checkedDec(): Option<UInt64>
功能:自减运算出现溢出,返回 Option
返回值:Option
func checkedNeg
public func checkedNeg(): Option<UInt64>
功能:负号运算出现溢出,返回 Option
返回值:Option
extend UIntNative <: ThrowingOp
extend UIntNative <: ThrowingOp<UIntNative>
UIntNative 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是抛出异常的策略
func throwingAdd
public func throwingAdd(y: UIntNative): UIntNative
功能:加法运算出现溢出,抛异常。
参数:
y:另一个 UIntNative 数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingSub
public func throwingSub(y: UIntNative): UIntNative
功能:减法运算出现溢出,抛异常。
参数:
y:另一个 UIntNative 数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMul
public func throwingMul(y: UIntNative): UIntNative
功能:乘法运算出现溢出,抛异常。
参数:
y:另一个 UIntNative 数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDiv
public func throwingDiv(y: UIntNative): UIntNative
功能:除法运算出现溢出,抛异常。
参数:
y:另一个 UIntNative 数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingMod
public func throwingMod(y: UIntNative): UIntNative
功能:取余运算出现溢出,抛异常。
参数:
y:另一个 UIntNative 数
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingInc
public func throwingInc(): UIntNative
功能:自增运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingDec
public func throwingDec(): UIntNative
功能:自减运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
func throwingNeg
public func throwingNeg(): UIntNative
功能:负号运算出现溢出,抛异常。
返回值:算数结果
异常:
OverflowException:溢出时抛出异常
extend UIntNative <: WrappingOp
extend UIntNative <: WrappingOp<UIntNative>
UIntNative 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是高位截断的策略
func wrappingAdd
public func wrappingAdd(y: UIntNative): UIntNative
功能:加法运算出现溢出,高位截断。
参数:
y:另一个 UIntNative 数
返回值:算数结果
func wrappingSub
public func wrappingSub(y: UIntNative): UIntNative
功能:减法运算出现溢出,高位截断。
参数:
y:另一个 UIntNative 数
返回值:算数结果
func wrappingMul
public func wrappingMul(y: UIntNative): UIntNative
功能:乘法运算出现溢出,高位截断。
参数:
y:另一个 UIntNative 数
返回值:算数结果
func wrappingDiv
public func wrappingDiv(y: UIntNative): UIntNative
功能:除法运算出现溢出,高位截断。
参数:
y:另一个 UIntNative 数
返回值:算数结果
func wrappingMod
public func wrappingMod(y: UIntNative): UIntNative
功能:取余运算出现溢出,高位截断。
参数:
y:另一个 UIntNative 数
返回值:算数结果
func wrappingInc
public func wrappingInc(): UIntNative
功能:自增运算出现溢出,高位截断。
返回值:算数结果
func wrappingDec
public func wrappingDec(): UIntNative
功能:自减运算出现溢出,高位截断。
返回值:算数结果
func wrappingNeg
public func wrappingNeg(): UIntNative
功能:负号运算出现溢出,高位截断。
返回值:算数结果
extend UIntNative <: SaturatingOp
extend UIntNative <: SaturatingOp<UIntNative>
UIntNative 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是饱和的策略
func saturatingAdd
public func saturatingAdd(y: UIntNative): UIntNative
功能:加法运算出现溢出,饱和处理。
参数:
y:另一个 UIntNative 数
返回值:算数结果
func saturatingSub
public func saturatingSub(y: UIntNative): UIntNative
功能:减法运算出现溢出,饱和处理。
参数:
y:另一个 UIntNative 数
返回值:算数结果
func saturatingMul
public func saturatingMul(y: UIntNative): UIntNative
功能:乘法运算出现溢出,饱和处理。
参数:
y:另一个 UIntNative 数
返回值:算数结果
func saturatingDiv
public func saturatingDiv(y: UIntNative): UIntNative
功能:除法运算出现溢出,饱和处理。
参数:
y:另一个 UIntNative 数
返回值:算数结果
func saturatingMod
public func saturatingMod(y: UIntNative): UIntNative
功能:取余运算出现溢出,饱和处理。
参数:
y:另一个 UIntNative 数
返回值:算数结果
func saturatingInc
public func saturatingInc(): UIntNative
功能:自增运算出现溢出,饱和处理。
返回值:算数结果
func saturatingDec
public func saturatingDec(): UIntNative
功能:自减运算出现溢出,饱和处理。
返回值:算数结果
func saturatingNeg
public func saturatingNeg(): UIntNative
功能:负号运算出现溢出,饱和处理。
返回值:算数结果
extend UIntNative <: CheckedOp
extend UIntNative <: CheckedOp<UIntNative>
UIntNative 类型为内置类型,这里为其扩展算数运算溢出策略的实现,此处是返回 Option 类型的策略
func checkedAdd
public func checkedAdd(y: UIntNative): Option<UIntNative>
功能:加法运算出现溢出,返回 Option
参数:
y:另一个 UIntNative 数
返回值:Option
func checkedSub
public func checkedSub(y: UIntNative): Option<UIntNative>
功能:减法运算出现溢出,返回 Option
参数:
y:另一个 UIntNative 数
返回值:Option
func checkedMul
public func checkedMul(y: UIntNative): Option<UIntNative>
功能:乘法运算出现溢出,返回 Option
参数:
y:另一个 UIntNative 数
返回值:Option
func checkedDiv
public func checkedDiv(y: UIntNative): Option<UIntNative>
功能:除法运算出现溢出,返回 Option
参数:
y:另一个 UIntNative 数
返回值:Option
func checkedMod
public func checkedMod(y: UIntNative): Option<UIntNative>
功能:取余运算出现溢出,返回 Option
参数:
y:另一个 UIntNative 数
返回值:Option
func checkedInc
public func checkedInc(): Option<UIntNative>
功能:自增运算出现溢出,返回 Option
返回值:Option
func checkedDec
public func checkedDec(): Option<UIntNative>
功能:自减运算出现溢出,返回 Option
返回值:Option
func checkedNeg
public func checkedNeg(): Option<UIntNative>
功能:负号运算出现溢出,返回 Option
返回值:Option
示例
抛出异常策略的示例
下面是 Int64 类型抛出异常策略的使用示例。
代码如下:
from std import overflow.*
from std import math.*
main() {
let a: Int64 = Int64.Max
println(a.throwingAdd(1))
return 0
}
运行结果如下:
An exception has occurred:
OverflowException: add
高位截断策略的示例
下面是 Int8 类型高位截断策略的使用示例。
代码如下:
from std import overflow.*
from std import math.*
main() {
let a: Int8 = Int8.Max
println(a.wrappingMul(5))
return 0
}
运行结果如下:
123
饱和策略的示例
下面是 UInt16 类型饱和策略的使用示例。
代码如下:
from std import overflow.*
from std import math.*
main() {
let a:UInt16 = UInt16.Max / 8 + 1
println(a.saturatingMul(16))
return 0
}
运行结果如下:
65535
返回Option策略的示例
下面是 Int64 类型返回Option策略的使用示例。
代码如下:
from std import overflow.*
from std import math.*
main() {
let a:Int64 = Int64.Max / 8 + 1
println(a.checkedPow(UInt64(2)))
return 0
}
运行结果如下:
None
random 包
介绍
random 包提供用于生成伪随机数的类 Random。
主要接口
class Random
public open class Random {
public init()
public init(seed: UInt64)
}
此类主要用于伪随机数的生成。
Random 类的主要函数如下所示:
init
public init()
功能:默认无参构造函数创建新的 Random 对象。
init
public init(seed: UInt64)
功能:创建新的 Random 对象。
参数:
- seed:UInt64 类型的种子,如果设置相同随机种子,生成的伪随机数列表相同
prop seed
public open mut prop seed: UInt64
功能:设置或者获取种子的大小,如果设置相同随机种子,生成的伪随机数列表相同
func next
public open func next(bits: UInt64): UInt64
功能:生成一个用户指定位长的随机整数。
参数:
- bits:要生成的伪随机数的位数
返回值:用户指定位长的伪随机数
异常:
- IllegalArgumentException:如果 bits 等于 0 ,或大于 64,超过所能截取的 UInt64 长度,则抛出异常
func nextBool
public open func nextBool(): Bool
功能:获取一个布尔类型的伪随机值。
返回值:返回一个布尔类型的伪随机数
func nextUInt8
public open func nextUInt8(): UInt8
功能:获取一个 UInt8 类型的伪随机数。
返回值:返回一个 UInt8 类型的伪随机数
func nextUInt16
public open func nextUInt16(): UInt16
功能:获取一个 UInt16 类型的伪随机数。
返回值:返回一个 UInt16 类型的伪随机数
func nextUInt32
public open func nextUInt32(): UInt32
功能:获取一个 UInt32 类型的伪随机数。
返回值:返回一个 UInt32 类型的伪随机数
func nextUInt64
public open func nextUInt64(): UInt64
功能:获取一个 UInt64 类型的伪随机数。
返回值:返回一个 UInt64 类型的伪随机数
func nextInt8
public open func nextInt8(): Int8
功能:获取一个 Int8 类型的伪随机数。
返回值:返回一个 Int8 类型的伪随机数
func nextInt16
public open func nextInt16(): Int16
功能:获取一个 Int16 类型的伪随机数。
返回值:返回一个 Int16 类型的伪随机数
func nextInt32
public open func nextInt32(): Int32
功能:获取一个 Int32 类型的伪随机数。
返回值:返回一个 Int32 类型的伪随机数
func nextInt64
public open func nextInt64(): Int64
功能:获取一个 Int64 类型的伪随机数。
返回值:返回一个 Int64 类型的伪随机数
func nextUInt8
public open func nextUInt8(upper: UInt8): UInt8
功能:获取一个范围在 [0, upper) 的 UInt8 类型的伪随机数。
参数:
- upper:生成的伪随机数范围上界(不包括 upper)
返回值:返回一个 UInt8 类型的伪随机数
异常:
- IllegalArgumentException:如果 upper 等于 0,抛出异常
func nextUInt16
public open func nextUInt16(upper: UInt16): UInt16
功能:获取一个范围在 [0, upper) 的 UInt16 类型的伪随机数。
参数:
- upper:生成的伪随机数范围上界(不包括 upper)
返回值:返回一个 UInt16 类型的伪随机数
异常:
- IllegalArgumentException:如果 upper 等于 0,抛出异常
func nextUInt32
public open func nextUInt32(upper: UInt32): UInt32
功能:获取一个范围在 [0, upper) 的 UInt32 类型的伪随机数。
参数:
- upper:生成的伪随机数范围上界(不包括 upper)
返回值:返回一个 UInt32 类型的伪随机数
异常:
- IllegalArgumentException:如果 upper 等于 0,抛出异常
func nextUInt64
public open func nextUInt64(upper: UInt64): UInt64
功能:获取一个范围在 [0, upper) 的 UInt64 类型的伪随机数。
参数:
- upper:生成的伪随机数范围上界(不包括 upper)
返回值:返回一个 UInt64 类型的伪随机数
异常:
- IllegalArgumentException:如果 upper 等于 0,抛出异常
func nextInt8
public open func nextInt8(upper: Int8): Int8
功能:获取一个范围在 [0, upper) 的 Int8 类型的伪随机数。
参数:
- upper:生成的伪随机数范围上界(不包括 upper)
返回值:返回一个 Int8 类型的伪随机数
异常:
- IllegalArgumentException:如果 upper 小于等于 0,抛出异常
func nextInt16
public open func nextInt16(upper: Int16): Int16
功能:获取一个范围在 [0, upper) 的 Int16 类型的伪随机数。
参数:
- upper:表示生成的伪随机数范围上界(不包括 upper)
返回值:返回一个 Int16 类型的伪随机数
异常:
- IllegalArgumentException:如果 upper 小于等于 0,抛出异常
func nextInt32
public open func nextInt32(upper: Int32): Int32
功能:获取一个范围在 [0, upper) 的 Int32 类型的伪随机数。
参数:
- upper:表示生成的伪随机数范围上界(不包括 upper)
返回值:返回一个 Int32 类型的伪随机数
异常:
- IllegalArgumentException:如果 upper 小于等于 0,抛出异常
func nextInt64
public open func nextInt64(upper: Int64): Int64
功能:获取一个范围在 [0, upper) 的 Int64 类型的伪随机数。
参数:
- upper:生成的伪随机数范围上界(不包括 upper)
返回值:返回一个 Int64 类型的伪随机数
异常:
- IllegalArgumentException:如果 upper 小于等于 0,抛出异常
func nextUInt8s
public open func nextUInt8s(array: Array<UInt8>): Array<UInt8>
功能:生成随机数替换入参数组中的每个元素。
参数:
- array:被替换的数组
返回值:返回替换后的 Array
func nextFloat16
public open func nextFloat16(): Float16
功能:获取一个 Float16 类型的伪随机数,其范围为 [0.0, 1.0)。
返回值:Float16 类型的伪随机数
func nextFloat32
public open func nextFloat32(): Float32
功能:获取一个 Float32 类型的伪随机数,其范围为 [0.0, 1.0)。
返回值:Float32 类型的伪随机数
func nextFloat64
public open func nextFloat64(): Float64
功能:获取一个 Float64 类型的伪随机数,其范围为 [0.0, 1.0)。
返回值:Float64 类型的伪随机数
func nextGaussianFloat16
public func nextGaussianFloat16(mean!: Float16 = 0.0, sigma!: Float16 = 1.0): Float16
功能:默认获取一个 Float16 类型且符合均值为 0.0 标准差为 1.0 的高斯分布的随机数。其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。此函数调用了函数 nextGaussianFloat16Implement 得到返回值,所以当子类继承 Random 并覆写 nextGaussianFloat64Implement 函数时,调用子类的该函数将会返回覆写的函数的返回值。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float16 类型的随机数
func nextGaussianFloat32
public func nextGaussianFloat32(mean!: Float32 = 0.0, sigma!: Float32 = 1.0): Float32
功能:默认获取一个 Float32 类型且符合均值为 0.0 标准差为 1.0 的高斯分布的随机数。其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。此函数调用了函数 nextGaussianFloat32Implement 得到返回值,所以当子类继承 Random 并覆写 nextGaussianFloat64Implement 函数时,调用子类的该函数将会返回覆写的函数的返回值。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float32 类型的随机数
func nextGaussianFloat64
public func nextGaussianFloat64(mean!: Float64 = 0.0, sigma!: Float64 = 1.0): Float64
功能:默认获取一个 Float64 类型且符合均值为 0.0 标准差为 1.0 的高斯分布的随机数。其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。此函数调用了函数 nextGaussianFloat64Implement 得到返回值,所以当子类继承 Random 并覆写 nextGaussianFloat64Implement 函数时,调用子类的该函数将会返回覆写的函数的返回值。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float64 类型的随机数
func nextGaussianFloat16Implement
protected open func nextGaussianFloat16Implement(mean: Float16, sigma: Float16): Float16
功能:获取一个 Float16 类型, 且符合均值为 mean 标准差为 sigma 的高斯分布的随机数。其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。此函数是 nextGaussianFloat16 的实现函数,非公开,当子类继承 Random 并覆写此函数时,调用子类的 nextGaussianFloat16 函数将会返回此函数的返回值。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float16 类型的随机数
func nextGaussianFloat32Implement
protected open func nextGaussianFloat32Implement(mean: Float32, sigma: Float32): Float32
功能:获取一个 Float32 类型, 且符合均值为 mean 标准差为 sigma 的高斯分布的随机数。其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。此函数是 nextGaussianFloat32 的实现函数,非公开,当子类继承 Random 并覆写此函数时,调用子类的 nextGaussianFloat32 函数将会返回此函数的返回值。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float32 类型的随机数
func nextGaussianFloat64Implement
protected open func nextGaussianFloat64Implement(mean: Float64, sigma: Float64): Float64
功能:获取一个 Float64 类型, 且符合均值为 mean 标准差为 sigma 的高斯分布的随机数。其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。此函数是 nextGaussianFloat64 的实现函数,非公开,当子类继承 Random 并覆写此函数时,调用子类的 nextGaussianFloat32 函数将会返回此函数的返回值。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float64 类型的随机数
示例
Random 使用
下面是 Random 创建随机数对象的示例。
代码如下:
from std import random.*
main() {
let m: Random = Random()
/* 创建 Random 对象并设置种子来获取随机对象 */
m.seed = 3
let b: Bool = m.nextBool()
let c: Int8 = m.nextInt8()
print("b=${b is Bool},")/* 对象也可以是 Bool 类型 */
println("c=${c is Int8}")
return 0
}
运行结果如下:
b=true,c=true
reflect 包
介绍
reflect 包为用户提供了反射功能,使得程序在运行时能够获取到各种实例的类型信息,并进行各种读写和调用操作。
本包暂不支持 macOS 平台。
注意:
- 仓颉的反射功能只能访问公开的全局变量和全局函数。
- 对于当前所在包,仓颉的反射功能可以访问所有全局定义的类型,而对于外部导入的包或动态加载的模块,则只能访问其中公开的全局定义的类型。
- 仓颉的反射功能只能访问类型内的公开成员(实例/静态成员变量/属性/函数),使用非
public修饰符修饰的或缺省修饰符的成员均是不可见的。 - 目前,仓颉的反射功能尚不支持
Nothing类型、函数类型、元组类型、enum类型和带有泛型的struct类型。
主要接口
func parseParameterTypes
public func parseParameterTypes(parameterTypes: String): Array<TypeInfo>
功能:将字符串转换为包含具体类型信息的函数签名,以便getStaticFunction等函数使用。
参数:
parameterTypes: 函数参数类型字符串。
返回值:字符串对应的参数类型信息。
异常:
- 如果无法将字符串格式错误,则会抛出
IllegalArgumentException。 - 如果无法获得参数中的类型信息,则会抛出
InfoNotFoundException异常。
注意:
- 参数类型需要使用限定名称。
parameterTypes只需要传入函数类型的参数类型部分,不包含参数名、默认值,也不包含最外层的()。
因此对于下面的一个仓颉函数:
from m1 import p1.T1
func f(a: Int64, b: T1, c!: Int64, d!: Int64 = 0): Int64 { ... }
其 parameterTypes 参数应该为"Int64, m1/p1.T1, Int64, Int64"。对于无参函数的 parameterTypes 参数应该为 ""
class TypeInfo
sealed abstract class TypeInfo <: Equatable<TypeInfo> & Hashable & ToString
TypeInfo 提供了所有数据类型通用的操作接口,使得开发者通常无需向下转型为更具体的数据类型,如 ClassTypeInfo 等,就能进行反射操作。
TypeInfo 的子类包括 PrimitiveTypeInfo、StructTypeInfo、ClassTypeInfo 和 InterfaceTypeInfo,分别对应基本数据类型,struct 数据类型,class 数据类型和 interface 数据类型的类型信息。
func of
public static func of<T>(): TypeInfo
功能:获取给定类型对应的类型信息。
泛型:
T:将被获取其类型信息的任意类型。
返回值:T 类型对应的类型信息
异常:
- 如果无法获得类型
T所对应的类型信息,则会抛出InfoNotFoundException异常
注意:
- 目前,
T不支持Nothing类型、函数类型,元组类型,enum类型和带有泛型的struct类型。 T支持传入类型别名,包括内置类型别名(如Int、UInt和Rune等)与用户自定义类型别名。
func of
public static func of(a: Any): TypeInfo
功能:获取给定的任意类型的实例的运行时类型所对应的类型信息。
参数:
a:实例
返回值:实例 a 的运行时类型所对应的类型信息
异常:
- 如果无法获得实例
a的运行时类型所对应的类型信息,则会抛出InfoNotFoundException异常
注意:
- 目前,实例
a不支持运行时类型为函数类型,元组类型,enum类型和带有泛型的struct类型的实例。
func of
public static func of(a: Object): ClassTypeInfo
功能:获取给定的 class 类型的实例的运行时类型所对应的 class 类型信息。
参数:
a:class类型的实例
返回值:class 类型的实例 a 的运行时类型所对应的 class 类型信息
异常:
- 如果无法获得实例
a的运行时类型所对应的class类型信息,则会抛出InfoNotFoundException异常
func get
public static func get(qualifiedName: String): TypeInfo
功能:获取给定的类型的限定名称所对应的类型的类型信息。
参数:
qualifiedName:类型的限定名称
返回值:类型的限定名称 qualifiedName 所对应的类型的类型信息
异常:
- 如果无法获取与给定类型的限定名称
qualifiedName匹配的类型所对应的类型信息,则将抛出InfoNotFoundException异常
注意:
- 未实例化的泛型类型的类型信息无法被获取。
- 目前, 类型的限定名称
qualifiedName不支持Nothing类型、函数类型、元组类型、enum类型和带有泛型的struct类型的限定名称。
prop name
public prop name: String
功能:获取该类型信息所对应的类型的名称。
注意:
- 该名称不包含任何模块名和包名前缀。
- 类型别名的类型信息就是实际类型其本身的类型信息,所以该函数并不会返回类型别名本身的名称而是实际类型的名称,如类型别名
Rune的类型信息的名称是Char而不是Rune。
prop qualifiedName
public prop qualifiedName: String
功能:获取该类型信息所对应的类型的限定名称。
注意:
- 限定名称包含模块名和包名前缀。
- 特别地,仓颉内置数据类型,以及位于
std模块core包下的所有类型的限定名称都是不带有任何模块名和包名前缀的。 - 在缺省模块名和包名的上下文中定义的所有类型,均无模块名前缀,但拥有包名前缀"
default",如:"default.MyType"。
prop instanceFunctions
public prop instanceFunctions: Collection<InstanceFunctionInfo>
功能:获取该类型信息所对应的类型所拥有的所有公开实例成员函数的信息所组成的集合。
注意:
- 如果该类型信息所对应的类型无任何公开实例成员函数,则返回空集合。
- 该集合不保证遍历顺序恒定。
- 如果该类型信息所对应的类型是
struct或class类型,则该集合包含从其他interface类型继承而来的非抽象的实例成员函数的信息。
prop staticFunctions
public prop staticFunctions: Collection<StaticFunctionInfo>
功能:获取该类型信息所对应的类型所拥有的所有公开静态成员函数的信息所组成的集合。
注意:
- 如果该类型信息所对应的类型无任何公开静态成员函数,则返回空集合。
- 该集合不保证遍历顺序恒定。
- 如果该类型信息所对应的类型是
struct、class或interface类型,则该集合包含从其他interface类型继承而来的非抽象的静态成员函数的信息。
prop instanceProperties
public prop instanceProperties: Collection<InstancePropertyInfo>
功能:获取该类型信息所对应的类型所拥有的所有公开实例成员属性的信息所组成的集合。
注意:
- 如果该类型信息所对应的类型无任何公开实例成员属性,则返回空集合。
- 该集合不保证遍历顺序恒定。
- 如果该类型信息所对应的类型是
struct或class类型,则该集合包含从其他interface类型继承而来的非抽象的实例成员属性的信息。
prop staticProperties
public prop staticProperties: Collection<StaticPropertyInfo>
功能:获取该类型信息所对应的类型所拥有的所有公开静态成员属性的信息所组成的集合。
注意:
- 如果该类型信息所对应的类型无任何公开静态成员属性,则返回空集合。
- 该集合不保证遍历顺序恒定。
- 如果该类型信息所对应的类型是
struct、class或interface类型,则该集合包含从其他interface类型继承而来的非抽象的静态成员属性的信息。
prop superInterfaces
public prop superInterfaces: Collection<InterfaceTypeInfo>
功能:获取该类型信息所对应的类型所直接实现的所有 interface 类型的 interface 类型信息所组成的集合。
注意:
- 所有类型均默认直接实现
interface Any类型。 - 该集合不保证遍历顺序恒定。
- 目前,
struct类型只支持获取到interface Any类型。
prop modifiers
public prop modifiers: Collection<ModifierInfo>
功能:获取该类型信息所对应的类型所拥有的所有修饰符的信息所组成的集合。
注意:
- 如果该类型无任何修饰符,则返回空集合。
- 该集合不保证遍历顺序恒定。
interface类型默认拥有open语义,故返回的集合总是包含open修饰符。- 由于反射功能只能对所有被
public访问控制修饰符所修饰的类型进行操作,故将忽略所有访问控制修饰符。
prop annotations
public prop annotations: Collection<Annotation>
功能:获取所有作用于该类型信息所对应的类型的注解所组成的集合。
注意:
- 如果无任何注解作用于该类型信息所对应的类型,则返回空集合。
- 该集合不保证遍历顺序恒定。
func isSubtypeOf
public func isSubtypeOf(supertype: TypeInfo): Bool
功能:判断该类型信息所对应的类型是否是给定类型信息所对应的类型的子类型。
参数:
supertype:目标类型的类型信息
返回值:如果该类型信息所对应的类型是 supertype 所对应的类型的子类型则返回 true,否则返回 false
注意:
- 由于目前所有
struct类型均无法获得其实现的interface类型,所以在做struct是否为某interface的子类型的判断时总是返回false。
func getInstanceFunction
public func getInstanceFunction(name: String, parameterTypes: Array<TypeInfo>): InstanceFunctionInfo
功能:给定函数名称与函数形参类型列表所对应的类型信息列表,尝试获取该类型中匹配的实例成员函数的信息。
参数:
name:函数名称parameterTypes:函数形参类型列表所对应的类型信息列表
返回值:如果成功匹配则返回该实例成员函数的信息
func getStaticFunction
public func getStaticFunction(name: String, parameterTypes: Array<TypeInfo>): StaticFunctionInfo
功能:给定函数名称与函数形参类型列表所对应的类型信息列表,尝试获取该类型中匹配的静态成员函数的信息。
参数:
name: 函数名称parameterTypes: 函数形参类型列表所对应的类型信息列表
返回值:如果成功匹配则返回该静态成员函数的信息
func getInstanceProperty
public func getInstanceProperty(name: String): InstancePropertyInfo
功能:尝试获取该类型中与给定属性名称匹配的实例成员属性的信息。
参数:
name: 属性名称
返回值:如果成功匹配则返回该实例成员属性的信息
func getStaticProperty
public func getStaticProperty(name: String): StaticPropertyInfo
功能:尝试获取该类型中与给定属性名称匹配的静态成员属性的信息。
参数:
name: 属性名称
返回值:如果成功匹配则返回该静态成员属性的信息
func findAnnotation
public func findAnnotation<T>(): Option<T> where T <: Annotation
功能:尝试获取作用于该类型信息所对应的类型且拥有给定限定名称的注解。
参数:
name:注解的限定名称
返回值:如果成功匹配则返回该注解
func hashCode
public func hashCode(): Int64
功能:获取该类型信息的哈希值。
返回值:该类型信息的哈希值
注意:
- 内部实现为该类型信息的限定名称字符串的哈希值。
func toString
public func toString(): String
功能:获取字符串形式的该类型信息。
返回值:字符串形式的该类型信息
注意:
- 内部实现为该类型信息的限定名称字符串。
operator func ==
public operator func ==(that: TypeInfo): Bool
功能:判断该类型信息与给定的另一个类型信息是否相等。
参数:
that: 被比较相等性的另一个类型信息
返回值:如果该类型信息与 that 相等则返回 true,否则返回 false
注意:
- 内部实现为比较两个类型信息的限定名称是否相等。
operator func !=
public operator func !=(that: TypeInfo): Bool
功能:判断该类型信息与给定的另一个类型信息是否不等。
参数:
that: 被比较相等性的另一个类型信息
返回值:如果该类型信息与 that 不等则返回 true,否则返回 false
注意:
- 内部实现为比较两个类型信息的限定名称字符串是否不等。
class ClassTypeInfo
public class ClassTypeInfo <: TypeInfo
class 类型的类型信息。
prop constructors
public prop constructors: Collection<ConstructorInfo>
功能:获取该 class 类型信息所对应的 class 类型所拥有的所有公开构造函数的信息所组成的集合。
注意:
- 如果该
class类型无任何公开构造函数,则返回空集合。 - 该集合不保证遍历顺序恒定。
prop instanceVariables
public prop instanceVariables: Collection<InstanceVariableInfo>
功能:获取该 class 类型信息所对应的 class 类型所拥有的所有公开实例成员变量的信息所组成的集合。
注意:
- 如果该
class类型无任何公开实例成员变量,则返回空集合。 - 该集合不保证遍历顺序恒定。
- 该集合不包含任何继承而来的公开实例成员变量。
prop staticVariables
public prop staticVariables: Collection<StaticVariableInfo>
功能:获取该 class 类型信息所对应的 class 类型所拥有的所有公开静态成员变量的信息所组成的集合。
注意:
- 如果该
class类型无任何公开静态成员变量,则返回空集合。 - 该集合不保证遍历顺序恒定。
- 该集合不包含任何继承而来的公开静态成员变量。
prop superClass
public prop superClass: Option<ClassTypeInfo>
功能:获取该 class 类型信息所对应的 class 类型的直接父类,如果存在的话。
注意:
- 理论上只有
class Object没有直接父类。
prop sealedSubclasses
public prop sealedSubclasses: Collection<ClassTypeInfo>
功能:如果该 class 类型信息所对应的 class 类型拥有 sealed 语义,则获取该 class 类型所在包内的所有子类的类型信息所组成的集合。
注意:
- 如果该
class类型不拥有sealed语义,则返回空集合。 - 如果该
class类型拥有sealed语义,那么获得的集合必不可能是空集合,因为该class类型本身就是自己的子类。
func construct
public func construct(args: Array<Any>): Any
功能:在该 class 类型信息所对应的 class 类型中根据实参列表搜索匹配的构造函数并调用,传入实参列表,返回调用结果。
参数:
args:实参列表
返回值:该 class 类型的实例
异常:
- 如果该
class类型拥有abstract语义,调用construct则会抛出IllegalTypeException异常,因为抽象类不可被实例化 - 如果
args未能成功匹配任何该class类型的公开构造函数,则会抛出MisMatchException异常 - 在被调用的构造函数内部抛出的任何异常均将被封装为
InvocationTargetException异常并抛出
func isOpen
public func isOpen(): Bool
功能:判断该 class 类型信息所对应的 class 类型是否拥有 open 语义。
返回值:如果该 class 类型信息所对应的 class 类型拥有 open 语义则返回 true,否则返回 false
注意:
- 并不是只有被
open修饰符所修饰的class类型定义才拥有open语义,如:abstract class无论是否被open修饰符修饰都会拥有open语义。
func isAbstract
public func isAbstract(): Bool
功能:判断该 class 类型信息所对应的 class 类型是否是抽象类。
返回值:如果该 class 类型信息所对应的 class 类型是抽象类则返回 true,否则返回 false
func isSealed
public func isSealed(): Bool
功能:判断该 class 类型信息所对应的 class 类型是否拥有 sealed 语义。
返回值:如果该 class 类型信息所对应的 class 类型拥有 sealed 语义则返回 true,否则返回 false
func getConstructor
public func getConstructor(parameterTypes: Array<TypeInfo>): ConstructorInfo
功能:尝试在该 class 类型信息所对应的 class 类型中获取与给定形参类型信息列表匹配的公开构造函数的信息。
参数:
parameterTypes: 形参类型信息列表
返回值:如果成功匹配则返回该公开构造函数的信息
func getInstanceVariable
public func getInstanceVariable(name: String): InstanceVariableInfo
功能:给定变量名称,尝试获取该 class 类型信息所对应的 class 类型中匹配的实例成员变量的信息。
参数:
name: 变量名称
返回值:如果成功匹配则返回该实例成员变量的信息
func getStaticVariable
public func getStaticVariable(name: String): StaticVariableInfo
功能:给定变量名称,尝试获取该 class 类型信息所对应的 class 类型中匹配的静态成员变量的信息。
参数:
name: 变量名称
返回值:如果成功匹配则返回该静态成员变量的信息
class InterfaceTypeInfo
public class InterfaceTypeInfo <: TypeInfo
interface 类型的类型信息。
prop sealedSubtypes
public prop sealedSubtypes: Collection<TypeInfo>
功能:如果该 interface 类型信息所对应的 interface 类型拥有 sealed 语义,则获取该 interface 类型所在包内的所有子类型的类型信息所组成的集合。
注意:
- 如果该
interface类型不拥有sealed语义,则返回空集合。 - 如果该
interface类型拥有sealed语义,那么获得的集合必不可能是空集合,因为该interface类型本身就是自己的子类型。
func isSealed
public func isSealed(): Bool
功能:判断该 interface 类型信息所对应的 interface 类型是否拥有 sealed 语义。
返回值:如果该 interface 类型拥有 sealed 语义则返回 true,否则返回 false
class PrimitiveTypeInfo
public class PrimitiveTypeInfo <: TypeInfo
原始数据类型的类型信息。
原始数据类型包括无类型(Nothing)、单元类型(Unit)、字符类型(Char)、布尔类型(Bool),整形类型(Int8,Int16,Int32,Int64,IntNative,UInt8,UInt16,UInt32,UInt64,UIntNative)和浮点类型(Float16,Float32,Float64)。
注意:
- 目前尚不支持
Nothing原始数据类型。
class StructTypeInfo
public class StructTypeInfo <: TypeInfo
struct 类型的类型信息。
prop constructors
public prop constructors: Collection<ConstructorInfo>
功能:获取该 struct 类型信息所对应的 struct 类型所拥有的所有公开构造函数的信息所组成的集合。
注意:
- 如果该
struct类型无任何公开构造函数,则返回空集合。 - 该集合不保证遍历顺序恒定。
prop instanceVariables
public prop instanceVariables: Collection<InstanceVariableInfo>
功能:获取该 struct 类型信息所对应的 struct 类型所拥有的所有公开实例成员变量的信息所组成的集合。
注意:
- 如果该
struct类型无任何公开实例成员变量,则返回空集合。 - 该集合不保证遍历顺序恒定。
prop staticVariables
public prop staticVariables: Collection<StaticVariableInfo>
功能:获取该 struct 类型信息所对应的 struct 类型所拥有的所有公开静态成员变量的信息所组成的集合。
注意:
- 如果该
struct类型无任何公开静态成员变量,则返回空集合。 - 该集合不保证遍历顺序恒定。
func construct
public func construct(args: Array<Any>): Any
功能:在该 struct 类型信息所对应的 struct 类型中根据实参列表搜索匹配的构造函数并调用,传入实参列表,返回调用结果。
参数:
args:实参列表
返回值:该 struct 类型的实例
异常:
- 如果
args未能成功匹配任何该struct类型的公开构造函数,则会抛出MisMatchException异常 - 在被调用的构造函数内部抛出的任何异常均将被封装为
InvocationTargetException异常并抛出 - 由于
construct函数本质上调用的是apply函数,而目前struct类型中定义的构造函数不支持被调用apply函数,故该函数目前无法正常使用
func getConstructor
public func getConstructor(parameterTypes: Array<TypeInfo>): ConstructorInfo
功能:尝试在该 struct 类型信息所对应的 struct 类型中获取与给定形参类型信息列表匹配的公开构造函数的信息。
参数:
parameterTypes: 形参类型信息列表
返回值:如果成功匹配则返回该公开构造函数的信息
func getInstanceVariable
public func getInstanceVariable(name: String): InstanceVariableInfo
功能:给定变量名称,尝试获取该 struct 类型信息所对应的 struct 类型中匹配的实例成员变量的信息。
参数:
name: 变量名称
返回值:如果成功匹配则返回该实例成员变量的信息
func getStaticVariable
public func getStaticVariable(name: String): StaticVariableInfo
功能:给定变量名称,尝试获取该 struct 类型信息所对应的 struct 类型中匹配的静态成员变量的信息。
参数:
name: 变量名称
返回值:如果成功匹配则返回该静态成员变量的信息
class InfoList
public class InfoList<T> <: Collection<T>
信息列表,用于保存只读的反射信息。
prop size
public prop size: Int64
功能:获取该信息列表中的元素个数。
func get
public func get(index: Int64): ?T
功能:尝试获取该信息列表指定位置上的元素。
参数:
index:位置索引
返回值:该信息列表指定位置上的元素
operator func []
public operator func [](index: Int64): T
功能:获取该信息列表指定位置上的元素。
参数:
index:位置索引
返回值:该信息列表指定位置上的元素
异常:
- 如果
index超出索引范围,则抛出IndexOutOfBoundsException异常
func isEmpty
public func isEmpty(): Bool
功能:判断该信息列表是否为空。
返回值:如果该信息列表为空则返回 true,否则返回 false
func iterator
public func iterator(): Iterator<T>
功能:获取该信息列表的迭代器。
返回值:该信息列表的迭代器
class ConstructorInfo
public class ConstructorInfo <: Equatable<ConstructorInfo> & Hashable & ToString
构造函数信息,实现了运行时构造指定类型的实例的能力。
prop parameters
public prop parameters: InfoList<ParameterInfo>
功能:获取该构造函数信息所对应的构造函数的形参类型列表。
prop annotations
public prop annotations: Collection<Annotation>
功能:获取所有作用于该构造函数信息所对应的构造函数的注解所组成的集合。
注意:
- 如果无任何注解作用于该构造函数信息所对应的构造函数,则返回空集合。
- 该集合不保证遍历顺序恒定。
func apply
public func apply(args: Array<Any>): Any
功能:调用该构造函数信息所对应的构造函数,传入实参列表,并返回调用结果。
参数:
args: 实参列表
返回值:由该构造函数构造得到的类型实例
异常:
- 如果该构造函数信息所对应的构造函数所属的类型是抽象类,则会抛出
InvocationTargetException异常 - 如果实参列表
args中的实参的数目与该构造函数信息所对应的构造函数的形参列表中的形参的数目不等,则会抛出IllegalArgumentException异常 - 如果实参列表
args中的任何一个实参的运行时类型不是该构造函数信息所对应的构造函数的对应形参的声明类型的子类型,则会抛出IllegalTypeException异常 - 如果被调用的构造函数信息所对应的构造函数内部抛出异常,则该异常将被封装为
Exception异常并抛出
注意:
- 目前,实参不支持
struct类型的实例。 - 目前,
struct类型中定义的构造函数不支持被调用。
func findAnnotation
public func findAnnotation<T>(): Option<T> where T <: Annotation
功能:尝试获取作用于该构造函数信息所对应的构造函数且拥有给定限定名称的注解。
参数:
name:注解的限定名称
返回值:如果成功匹配则返回该注解
func hashCode
public func hashCode(): Int64
功能:获取该构造器信息的哈希值。
返回值:该构造器信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该构造函数信息。
返回值:字符串形式的该构造函数信息
operator func ==
public operator func ==(that: ConstructorInfo): Bool
功能:判断该构造器信息与给定的另一个构造器信息是否相等。
参数:
that: 被比较相等性的另一个构造器信息
返回值:如果该构造器信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: ConstructorInfo): Bool
功能:判断该构造器信息与给定的另一个构造器信息是否不等。
参数:
that: 被比较相等性的另一个构造器信息
返回值:如果该构造器信息与 that 不等则返回 true,否则返回 false
class ParameterInfo
public class ParameterInfo <: Equatable<ParameterInfo> & Hashable & ToString
函数形参信息。
prop index
public prop index: Int64
功能:获知该函数形参信息所对应的形参是其所在函数的第几个形参。
注意:
index从0开始计数。
prop name
public prop name: String
功能:获取该函数形参信息所对应的形参的名称。
prop typeInfo
public prop typeInfo: TypeInfo
功能:获取该函数形参信息所对应的函数形参的声明类型所对应的类型信息。
prop annotations
public prop annotations: Collection<Annotation>
功能:获取所有作用于该函数形参信息所对应的函数形参的注解所组成的集合。
注意:
- 如果无任何注解作用于该函数形参信息所对应的函数形参,则返回空集合。
- 该集合不保证遍历顺序恒定。
func findAnnotation
public func findAnnotation<T>(): Option<T> where T <: Annotation
功能:尝试获取作用于该函数形参信息所对应的函数形参且拥有给定限定名称的注解。
参数:
name:注解的限定名称
返回值:如果成功匹配则返回该注解
func hashCode
public func hashCode(): Int64
功能:获取该函数形参信息的哈希值。
返回值:该函数形参信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该函数形参信息。
返回值:字符串形式的该函数形参信息
operator func ==
public operator func ==(that: ParameterInfo): Bool
功能:判断该函数形参信息与给定的另一个函数形参信息是否相等。
参数:
that: 被比较相等性的另一个函数形参信息
返回值:如果该函数形参信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: ParameterInfo): Bool
功能:判断该函数形参信息与给定的另一个函数形参信息是否不等。
参数:
that: 被比较相等性的另一个函数形参信息
返回值:如果该函数形参信息与 that 不等则返回 true,否则返回 false
enum ModifierInfo
public enum ModifierInfo <: Equatable<ModifierInfo> & Hashable & ToString {
| Open
| Override
| Redef
| Abstract
| Sealed
| Mut
| Static
}
修饰符信息。
注意:
- 由于开发者通过反射功能获取到的类型信息均来自于公开的类型,这些类型都必定拥有
public的访问控制语义,因此修饰符信息并不包含任何访问控制相关的修饰符。
Open
open 修饰符。
Override
override 修饰符。
Redef
redef 修饰符。
Abstract
abstract 修饰符。
Sealed
sealed 修饰符。
Mut
mut 修饰符。
Static
static 修饰符。
func hashCode
public func hashCode(): Int64
功能:获取该修饰符信息的哈希值。
返回值:该修饰符信息的哈希值
注意:
- 内部实现为该修饰符关键字字符串的哈希值。
operator func ==
public operator func ==(that: ModifierInfo): Bool
功能:判断该修饰符信息与给定的另一个修饰符信息是否相等。
参数:
that:被比较相等性的另一个修饰符信息
返回值:如果该修饰符信息与 that 相等则返回 true,否则返回 false
注意:
- 修饰符信息的相等性的语义等价于
enum类型实例的相等性的语义。
operator func !=
public operator func !=(that: ModifierInfo): Bool
功能:判断该修饰符信息与给定的另一个修饰符信息是否不等。
参数:
that:被比较相等性的另一个修饰符信息
返回值:如果该修饰符信息与 that 不等则返回 true,否则返回 false
注意:
- 修饰符信息的相等性的语义等价于
enum类型实例的相等性的语义。
func toString
public func toString(): String
功能:获取字符串形式的该修饰符信息。
返回值:字符串形式的该修饰符信息
注意:
- 字符串形式的修饰符信息即为修饰符关键字的标识符。
class InstanceFunctionInfo
public class InstanceFunctionInfo <: Equatable<InstanceFunctionInfo> & Hashable & ToString
实例成员函数信息。
prop name
public prop name: String
功能:获取该实例成员函数信息所对应的实例成员函数的名称。
注意:
- 构成重载的所有实例成员函数将拥有相同的名称。
- 操作符重载函数的名称就是该操作符本身的符号内容,如"
+","*","[]"。
prop parameters
public prop parameters: InfoList<ParameterInfo>
功能:获取该实例成员函数信息所对应的实例成员函数的形参信息列表。
prop returnType
public prop returnType: TypeInfo
功能:获取该实例成员函数信息所对应的实例成员函数的返回值类型的类型信息。
prop modifiers
public prop modifiers: Collection<ModifierInfo>
功能:获取该实例成员函数信息所对应的实例成员函数所拥有的所有修饰符的信息所组成的集合。
注意:
- 如果该实例成员函数无任何修饰符,则返回空集合。
- 该集合不保证遍历顺序恒定。
- 即便未被某修饰符修饰,如果拥有该修饰符的语义,该修饰符信息也将被包括在该集合中。
prop annotations
public prop annotations: Collection<Annotation>
功能:获取所有作用于该实例成员函数信息所对应的实例成员函数的注解所组成的集合。
注意:
- 如果无任何注解作用于该实例成员函数信息所对应的实例成员函数,则返回空集合。
- 该集合不保证遍历顺序恒定。
func isOpen
public func isOpen(): Bool
功能:判断该实例成员函数信息所对应的实例成员函数是否拥有 open 语义。
返回值:如果该实例成员函数拥有 open 语义则返回 true,否则返回 false
注意:
interface类型中的实例成员函数默认均拥有open语义。
func isAbstract
public func isAbstract(): Bool
功能:判断该实例成员函数信息所对应的实例成员函数是否拥有 abstract 语义。
返回值:如果该实例成员函数拥有 abstract 语义则返回 true,否则返回 false
func apply
public func apply(instance: Any, args: Array<Any>): Any
功能:调用该实例成员函数信息所对应实例成员函数,指定实例并传入实参列表,返回调用结果。
参数:
instance:实例args:实参列表
返回值:该实例成员函数的调用结果
异常:
- 如果该实例成员函数信息所对应的实例成员函数是抽象的,则会抛出
InvocationTargetException异常 - 如果实例
instance的运行时类型与该实例成员函数信息所对应的实例成员函数所属的类型不严格相同,则会抛出IllegalTypeException异常 - 如果实参列表
args中的实参的数目与该实例成员函数信息所对应的实例成员函数的形参列表中的形参的数目不等,则会抛出IllegalArgumentException异常 - 如果实参列表
args中的任何一个实参的运行时类型不是该实例成员函数信息所对应的实例成员函数的对应形参的声明类型的子类型,则会抛出IllegalTypeException异常 - 如果被调用的实例成员函数信息所对应的实例成员函数内部抛出异常,则该异常将被封装为
Exception异常并抛出
注意:
- 目前,实例
instance不支持struct类型的实例。 - 目前,实参不支持
struct类型的实例。
func findAnnotation
public func findAnnotation<T>(): Option<T> where T <: Annotation
功能:尝试获取作用于该实例成员函数信息所对应的实例成员函数且拥有给定限定名称的注解。
参数:
name:注解的限定名称
返回值:如果成功匹配则返回该注解
func hashCode
public func hashCode(): Int64
功能:获取该实例成员函数信息的哈希值。
返回值:该实例成员函数信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该实例成员函数信息。
返回值:字符串形式的该实例成员函数信息
operator func ==
public operator func ==(that: InstanceFunctionInfo): Bool
功能:判断该实例成员函数信息与给定的另一个实例成员函数信息是否相等。
参数:
that: 被比较相等性的另一个实例成员函数信息
返回值:如果该实例成员函数信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: InstanceFunctionInfo): Bool
功能:判断该实例成员函数信息与给定的另一个实例成员函数信息是否不等。
参数:
that: 被比较相等性的另一个实例成员函数信息
返回值:如果该实例成员函数信息与 that 不等则返回 true,否则返回 false
class StaticFunctionInfo
public class StaticFunctionInfo <: Equatable<StaticFunctionInfo> & Hashable & ToString
静态成员函数信息。
prop name
public prop name: String
功能:获取该静态成员函数信息所对应的静态成员函数的名称。
注意:
- 构成重载的所有静态成员函数将拥有相同的名称。
prop parameters
public prop parameters: InfoList<ParameterInfo>
功能:获取该静态成员函数信息所对应的静态成员函数的形参信息列表。
prop returnType
public prop returnType: TypeInfo
功能:获取该静态成员函数信息所对应的静态成员函数的返回值类型的类型信息。
prop modifiers
public prop modifiers: Collection<ModifierInfo>
功能:获取该静态成员函数信息所对应的静态成员函数所拥有的所有修饰符的信息所组成的集合。
注意:
- 如果该静态成员函数无任何修饰符,则返回空集合。
- 该集合不保证遍历顺序恒定。
- 即便未被某修饰符修饰,如果拥有该修饰符的语义,该修饰符信息也将被包括在该集合中。
prop annotations
public prop annotations: Collection<Annotation>
功能:获取所有作用于该静态成员函数信息所对应的静态成员函数的注解所组成的集合。
注意:
- 如果无任何注解作用于该静态成员函数信息所对应的静态成员函数,则返回空集合。
- 该集合不保证遍历顺序恒定。
func apply
public func apply(args: Array<Any>): Any
功能:调用该静态成员函数信息所对应静态成员函数,传入实参列表并返回调用结果。
参数:
args:实参列表
返回值:该静态成员函数的调用结果
异常:
- 如果实参列表
args中的实参的数目与该静态成员函数信息所对应的静态成员函数的形参列表中的形参的数目不等,则会抛出IllegalArgumentException异常 - 如果实参列表
args中的任何一个实参的运行时类型不是该静态成员函数信息所对应的静态成员函数的对应形参的声明类型的子类型,则会抛出IllegalTypeException异常 - 如果被调用的静态成员函数信息所对应的静态成员函数内部抛出异常,则该异常将被封装为
Exception异常并抛出
注意:
- 目前,实参不支持
struct类型的实例。
func findAnnotation
public func findAnnotation<T>(): Option<T> where T <: Annotation
功能:尝试获取作用于该静态成员函数信息所对应的静态成员函数且拥有给定限定名称的注解。
参数:
name:注解的限定名称。
返回值:如果成功匹配则返回该注解
func hashCode
public func hashCode(): Int64
功能:获取该静态成员函数信息的哈希值。
返回值:该静态成员函数信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该静态成员函数信息。
返回值:字符串形式的该静态成员函数信息
operator func ==
public operator func ==(that: StaticFunctionInfo): Bool
功能:判断该静态成员函数信息与给定的另一个静态成员函数信息是否相等。
参数:
that: 被比较相等性的另一个静态成员函数信息
返回值:如果该静态成员函数信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: StaticFunctionInfo): Bool
功能:判断该静态成员函数信息与给定的另一个静态成员函数信息是否不等。
参数:
that: 被比较相等性的另一个静态成员函数信息
返回值:如果该静态成员函数信息与 that 不等则返回 true,否则返回 false
class InstancePropertyInfo
public class InstancePropertyInfo <: Equatable<InstancePropertyInfo> & Hashable & ToString
实例成员属性信息。
prop name
public prop name: String
功能:获取该实例成员属性信息所对应的实例成员属性的名称。
prop typeInfo
public prop typeInfo: TypeInfo
功能:获取该实例成员属性信息所对应的实例成员属性的声明类型的类型信息。
prop modifiers
public prop modifiers: Collection<ModifierInfo>
功能:获取该实例成员属性信息所对应的实例成员属性所拥有的所有修饰符的信息所组成的集合。
注意:
- 如果该实例成员属性无任何修饰符,则返回空集合。
- 该集合不保证遍历顺序恒定。
- 即便未被某修饰符修饰,如果拥有该修饰符的语义,该修饰符信息也将被包括在该集合中。
prop annotations
public prop annotations: Collection<Annotation>
功能:获取所有作用于该实例成员属性信息所对应的实例成员属性的注解所组成的集合。
注意:
- 如果无任何注解作用于该实例成员属性信息所对应的实例成员属性,则返回空集合。
- 该集合不保证遍历顺序恒定。
func isMutable
public func isMutable(): Bool
功能:判断该实例成员属性信息所对应的实例成员属性是否可修改。
返回值:如果该实例成员属性信息所对应的实例成员属性可被修改则返回 true ,否则返回 false
注意:
- 如果实例成员属性被
mut修饰符所修饰,则该实例成员属性可被修改,否则不可被修改。 - 任何
struct类型的实例的任何实例成员属性均不可修改。 - 任何类型为
struct的实例成员属性均不可修改。
func getValue
public func getValue(instance: Any): Any
功能:获取该实例成员属性信息所对应的实例成员属性在给定实例中的值。
参数:
instance:实例
返回值:该实例成员属性在实例 instance 中的值
异常:
- 如果实例
instance的运行时类型与该实例成员属性信息所对应的实例成员属性所属的类型不严格相同,则会抛出IllegalTypeException异常
注意:
- 目前,实例
instance不支持struct类型的实例。
func setValue
public func setValue(instance: Any, newValue: Any): Unit
功能:设置该实例成员属性信息所对应的实例成员属性在给定实例中的值。
参数:
instance:实例newValue:新值
异常:
- 如果该实例成员属性信息所对应的实例成员属性不可修改,则会抛出
IllegalSetException异常 - 如果实例
instance的运行时类型与该实例成员属性信息所对应的实例成员属性所属的类型不严格相同,则会抛出IllegalTypeException异常 - 如果新值
newValue的运行时类型不是该实例成员属性信息所对应的实例成员属性的声明类型的子类型,则会抛出IllegalTypeException异常。
注意:
- 目前,实例
instance不支持struct类型的实例。
func findAnnotation
public func findAnnotation<T>(): Option<T> where T <: Annotation
功能:尝试获取作用于该实例成员属性信息所对应的实例成员属性且拥有给定限定名称的注解。
参数:
name:注解的限定名称
返回值:如果成功匹配则返回该注解
func hashCode
public func hashCode(): Int64
功能:获取该实例成员属性信息的哈希值。
返回值:该实例成员属性信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该实例成员属性信息
返回值:字符串形式的该实例成员属性信息
operator func ==
public operator func ==(that: InstancePropertyInfo): Bool
功能:判断该实例成员属性信息与给定的另一个实例成员属性信息是否相等。
参数:
that: 被比较相等性的另一个实例成员属性信息
返回值:如果该实例成员属性信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: InstancePropertyInfo): Bool
功能:判断该实例成员属性信息与给定的另一个实例成员属性信息是否不等。
参数:
that: 被比较相等性的另一个实例成员属性信息
返回值:如果该实例成员属性信息与 that 不等则返回 true,否则返回 false
class StaticPropertyInfo
public class StaticPropertyInfo <: Equatable<StaticPropertyInfo> & Hashable & ToString
静态成员属性信息。
prop name
public prop name: String
功能:获取该静态成员属性信息所对应的静态成员属性的名称。
prop typeInfo
public prop typeInfo: TypeInfo
功能:获取该静态成员属性信息所对应的静态成员属性的声明类型的类型信息。
prop modifiers
public prop modifiers: Collection<ModifierInfo>
功能:获取该静态成员属性信息所对应的静态成员属性所拥有的所有修饰符的信息所组成的集合。
注意:
- 如果该静态成员属性无任何修饰符,则返回空集合。
- 该集合不保证遍历顺序恒定。
- 目前获取到的修饰符集合内容较为混乱,尚未统一。
prop annotations
public prop annotations: Collection<Annotation>
功能:获取所有作用于该静态成员属性信息所对应的静态成员属性的注解所组成的集合。
注意:
- 如果无任何注解作用于该静态成员属性信息所对应的静态成员属性,则返回空集合。
- 该集合不保证遍历顺序恒定。
func isMutable
public func isMutable(): Bool
功能:判断该静态成员属性信息所对应的静态成员属性是否可修改。
返回值:如果该静态成员属性信息所对应的静态成员属性可被修改则返回 true ,否则返回 false
注意:
- 如果静态成员属性被
mut修饰符所修饰,则该静态成员属性可被修改,否则不可被修改。 - 任何
struct类型的任何静态成员属性均不可修改。 - 任何类型为
struct的静态成员属性均不可修改。
func getValue
public func getValue(): Any
功能:获取该静态成员属性信息所对应的静态成员属性的值。
返回值:该静态成员属性的值
注意:
- 如果该静态成员属性缺少合法实现,如
interface类型中的抽象静态成员属性,则应抛出UnsupportedException异常,但由于后端尚未支持,故尚未实现。
func setValue
public func setValue(newValue: Any): Unit
功能:设置该静态成员属性信息所对应的静态成员属性的值。
参数:
newValue:新值
异常:
- 如果该静态成员属性信息所对应的静态成员属性不可修改,则会抛出
IllegalSetException异常 - 如果新值
newValue的运行时类型不是该静态成员属性信息所对应的静态成员属性的声明类型的子类型,则会抛出IllegalTypeException异常
注意:
- 如果该静态成员属性缺少合法实现,如
interface类型中的抽象静态成员属性,则应抛出UnsupportedException异常,但由于后端尚未支持,故尚未实现。
func findAnnotation
public func findAnnotation<T>(): Option<T> where T <: Annotation
功能:尝试获取作用于该静态成员属性信息所对应的静态成员属性且拥有给定限定名称的注解。
参数:
name:注解的限定名称
返回值:如果成功匹配则返回该注解
func hashCode
public func hashCode(): Int64
功能:获取该静态成员属性信息的哈希值。
返回值:该静态成员属性信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该静态成员属性信息。
返回值:字符串形式的该静态成员属性信息
operator func ==
public operator func ==(that: StaticPropertyInfo): Bool
功能:判断该静态成员属性信息与给定的另一个静态成员属性信息是否相等。
参数:
that: 被比较相等性的另一个静态成员属性信息
返回值:如果该静态成员属性信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: StaticPropertyInfo): Bool
功能:判断该静态成员属性信息与给定的另一个静态成员属性信息是否不等。
参数:
that: 被比较相等性的另一个静态成员属性信息
返回值:如果该静态成员属性信息与 that 不等则返回 true,否则返回 false
class InstanceVariableInfo
public class InstanceVariableInfo <: Equatable<InstanceVariableInfo> & Hashable & ToString
实例成员变量信息。
prop name
public prop name: String
功能:获取该实例成员变量信息所对应的实例成员变量的名称。
prop typeInfo
public prop typeInfo: TypeInfo
功能:获取该实例成员变量信息所对应的实例成员变量的声明类型的类型信息。
prop modifiers
public prop modifiers: Collection<ModifierInfo>
功能:获取该实例成员变量信息所对应的实例成员变量所拥有的所有修饰符的信息所组成的集合。
注意:
- 如果该实例成员变量无任何修饰符,则返回空集合。
- 该集合不保证遍历顺序恒定。
- 即便未被某修饰符修饰,如果拥有该修饰符的语义,该修饰符信息也将被包括在该集合中。
prop annotations
public prop annotations: Collection<Annotation>
功能:获取所有作用于该实例成员变量信息所对应的实例成员变量的注解所组成的集合。
注意:
- 如果无任何注解作用于该实例成员变量信息所对应的实例成员变量,则返回空集合。
- 该集合不保证遍历顺序恒定。
func isMutable
public func isMutable(): Bool
功能:判断该实例成员变量信息所对应的实例成员变量是否可修改。
返回值:如果该实例成员变量信息所对应的实例成员变量可被修改则返回 true ,否则返回 false 。
注意:
- 如果实例成员变量被
var修饰符所修饰,则该实例成员变量可被修改。 - 如果实例成员变量被
let修饰符所修饰,则该实例成员变量不可被修改。 - 任何
struct类型的实例的任何实例成员变量均不可修改。 - 任何类型为
struct的实例成员变量均不可修改。
func getValue
public func getValue(instance: Any): Any
功能:获取该实例成员变量信息所对应的实例成员变量在给定实例中的值。
参数:
instance:实例
返回值:该实例成员变量在实例 instance 中的值
异常:
- 如果实例
instance的运行时类型与该实例成员变量信息所对应的实例成员变量所属的类型不严格相同,则会抛出IllegalTypeException异常
注意:
- 目前,实例
instance不支持struct类型的实例。 - 目前,返回值不支持为
struct类型的实例。
func setValue
public func setValue(instance: Any, newValue: Any): Unit
功能:设置该实例成员变量信息所对应的实例成员变量在给定实例中的值。
参数:
instance:实例newValue:新值
异常:
- 如果该实例成员变量信息所对应的实例成员变量不可修改,则会抛出
IllegalSetException异常 - 如果实例
instance的运行时类型与该实例成员变量信息所对应的实例成员变量所属的类型不严格相同,则会抛出IllegalTypeException异常 - 如果新值
newValue的运行时类型不是该实例成员变量信息所对应的实例成员变量的声明类型的子类型,则会抛出IllegalTypeException异常
注意:
- 目前,实例
instance不支持struct类型的实例。
func findAnnotation
public func findAnnotation<T>(): Option<T> where T <: Annotation
功能:尝试获取作用于该实例成员变量信息所对应的实例成员变量且拥有给定限定名称的注解。
参数:
name:注解的限定名称
返回值:如果成功匹配则返回该注解
func hashCode
public func hashCode(): Int64
功能:获取该实例成员变量信息的哈希值。
返回值:该实例成员变量信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该实例成员变量信息。
返回值:字符串形式的该实例成员变量信息
operator func ==
public operator func ==(that: InstanceVariableInfo): Bool
功能:判断该实例成员变量信息与给定的另一个实例成员变量信息是否相等。
参数:
that: 被比较相等性的另一个实例成员变量信息
返回值:如果该实例成员变量信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: InstanceVariableInfo): Bool
功能:判断该实例成员变量信息与给定的另一个实例成员变量信息是否不等。
参数:
that: 被比较相等性的另一个实例成员变量信息
返回值:如果该实例成员变量信息与 that 不等则返回 true,否则返回 false
class StaticVariableInfo
public class StaticVariableInfo <: Equatable<StaticVariableInfo> & Hashable & ToString
静态成员变量信息。
prop name
public prop name: String
功能:获取该静态成员变量信息所对应的静态成员变量的名称。
prop typeInfo
public prop typeInfo: TypeInfo
功能:获取该静态成员变量信息所对应的静态成员变量的声明类型的类型信息。
prop modifiers
public prop modifiers: Collection<ModifierInfo>
功能:获取该静态成员变量信息所对应的静态成员变量所拥有的所有修饰符的信息所组成的集合。
注意:
- 如果该静态成员变量无任何修饰符,则返回空集合。
- 该集合不保证遍历顺序恒定。
- 目前获取到的修饰符集合内容较为混乱,尚未统一。
prop annotations
public prop annotations: Collection<Annotation>
功能:获取所有作用于该静态成员变量信息所对应的静态成员变量的注解所组成的集合。
注意:
- 如果无任何注解作用于该静态成员变量信息所对应的静态成员变量,则返回空集合。
- 该集合不保证遍历顺序恒定。
func isMutable
public func isMutable(): Bool
功能:判断该静态成员变量信息所对应的静态成员变量是否可修改。
返回值:如果该静态成员变量信息所对应的静态成员变量可被修改则返回 true ,否则返回 false
注意:
- 如果静态成员变量被
var修饰符所修饰,则该静态成员变量可被修改。 - 如果静态成员变量被
let修饰符所修饰,则该静态成员变量不可被修改。 - 任何
struct类型的任何静态成员变量均不可修改。 - 任何类型为
struct的静态成员变量均不可修改。
func getValue
public func getValue(): Any
功能:获取该静态成员变量信息所对应的静态成员变量的值。
返回值:该静态成员变量的值
注意:
- 返回值不支持为
struct类型。
func setValue
public func setValue(newValue: Any): Unit
功能:设置该静态成员变量信息所对应的静态成员变量的值。
参数:
newValue:新值
异常:
- 如果该静态成员变量信息所对应的静态成员变量不可修改,则会抛出
IllegalSetException异常 - 如果新值
newValue的运行时类型不是该静态成员变量信息所对应的静态成员变量的声明类型的子类型,则会抛出IllegalTypeException异常
func findAnnotation
public func findAnnotation<T>(): Option<T> where T <: Annotation
功能:尝试获取作用于该静态成员变量信息所对应的静态成员变量且拥有给定限定名称的注解。
参数:
name:注解的限定名称
返回值:如果成功匹配则返回该注解
func hashCode
public func hashCode(): Int64
功能:获取该静态成员变量信息的哈希值。
返回值:该静态成员变量信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该静态成员变量信息。
返回值:字符串形式的该静态成员变量信息
operator func ==
public operator func ==(that: StaticVariableInfo): Bool
功能:判断该静态成员变量信息与给定的另一个静态成员变量信息是否相等。
参数:
that: 被比较相等性的另一个静态成员变量信息
返回值:如果该静态成员变量信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: StaticVariableInfo): Bool
功能:判断该静态成员变量信息与给定的另一个静态成员变量信息是否不等。
参数:
that: 被比较相等性的另一个静态成员变量信息
返回值:如果该静态成员变量信息与 that 不等则返回 true,否则返回 false
class ModuleInfo
public class ModuleInfo <: Equatable<ModuleInfo> & Hashable & ToString
模块信息,提供了仓颉动态模块加载、缓存能力以及模块内包信息查询能力。
仓颉动态模块是仓颉编译器生成的一种特殊二进制文件,这种文件可以被外部的仓颉程序在运行时被加载与使用。
仓颉动态库模块在不同操作系统中以共享库(.so 文件)、动态链接库(.dll 文件)等文件形式存在。
注意:
- 任一模块下不允许包含拥有相同限定名称的包。
prop name
public prop name: String
功能:获取该模块信息所对应的模块的名称。
注意:
- 模块的名称由被加载的模块的文件名决定,该文件名的格式为
lib<module_name>_<package_name>(.<package_name>)*。 <module_name>和<package_name>均不允许为空。- 由于当前实现的局限性,
<module_name>中如果包含下划线 "_" 字符,可能出现非预期的加载错误。
prop version
public prop version: String
功能:获取该模块信息所对应的模块的版本号。
注意:
- 由于目前动态库中尚无版本信息,获取到的版本号总是
1.0。
prop packages
public prop packages: Collection<PackageInfo>
功能:获取该模块中包含的所有包。
func load
public static func load(path: String): ModuleInfo
功能:运行时动态加载指定路径下的一个仓颉动态库模块并获得该模块的信息。
参数:
path:共享库文件的绝对路径或相对路径
异常:
- 如果共享库加载失败,则会抛出
ReflectException异常 - 如果具有相同模块名称的共享库被重复加载,则会抛出
UnsupportedException异常
注意:
- 为了提升兼容性,路径
path中的共享库文件名不需要后缀名(如.so和.dll等)。 - 由于当前实现局限性,具有相同模块名称的动态库不能被同时加载,否则将抛出异常。如
m/a、m/a.b、m/a.c这三个包所对应的共享库的加载是互斥的。
func find
public static func find(moduleName: String): Option<ModuleInfo>
功能:尝试在所有已加载的仓颉动态库模块中获取与给定模块名称匹配的模块的信息。
参数:
moduleName:仓颉动态库模块名称
返回值:如果匹配成功则返回该模块的信息
func getPackageInfo
public func getPackageInfo(packageName: String): PackageInfo
功能:尝试在该模块信息所对应的模块中获取与给定包的名称或限定名称匹配的包的信息。
参数:
packageName:包的名称或限定名称
返回值:如果匹配成功则返回该包的信息
func hashCode
public func hashCode(): Int64
功能:获取该模块信息的哈希值。
返回值:该模块信息的哈希值
注意:
-内部实现为该模块信息的名称和版本号字符串的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该模块信息。
返回值:字符串形式的该模块信息
注意:
- 内容为该模块的名称和版本号。
operator func ==
public operator func ==(that: ModuleInfo): Bool
功能:判断该模块信息与给定的另一个模块信息是否相等。
参数:
that: 被比较相等性的另一个模块信息
返回值:如果该模块信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: ModuleInfo): Bool
功能:判断该模块信息与给定的另一个模块信息是否不等。
参数:
that: 被比较相等性的另一个模块信息
返回值:如果该模块信息与 that 不等则返回 true,否则返回 false
class PackageInfo
public class PackageInfo <: Equatable<PackageInfo> & Hashable & ToString
包信息。
prop name
public prop name: String
功能:获取该包信息所对应的包的名称。
注意:
- 包的名称不包含其所在的模块名称和其父包的名称,例如限定名称为
a/b.c.d的包的名称是d。
prop qualifiedName
public prop qualifiedName: String
功能:获取该包信息所对应的包的限定名称。
注意:
- 包的限定名称的格式是
(module_name/)?(default|package_name)(.package_name)*,例如限定名称为a/b.c.d的包位于模块a下的b包里的c包里。
prop typeInfos
public prop typeInfos: Collection<TypeInfo>
功能:获取该包信息所对应的包中所有全局定义的公开类型的类型信息所组成的列表。
注意:
- 目前该列表不包含所有反射尚未支持的类型。
prop variables
public prop variables: Collection<GlobalVariableInfo>
功能:获取该包信息所对应的包中所有公开全局变量的信息所组成的列表。
prop functions
public prop functions: Collection<GlobalFunctionInfo>
功能:获取该包信息所对应的包中所有公开全局函数的信息所组成的列表。
func getTypeInfo
public func getTypeInfo(qualifiedName: String): TypeInfo
功能:尝试在该包信息所对应的包中获取拥有给定类型名称的全局定义的公开类型的类型信息。
参数:
qualifiedName:类型的限定名称
返回值:如果成功匹配则返回该全局定义的公开类型的类型信息
func getVariable
public func getVariable(name: String): GlobalVariableInfo
功能:尝试在该包信息所对应的包中获取拥有给定变量名称的公开全局变量的信息。
参数:
name:全局变量的名称
func getFunction
public func getFunction(name: String, parameterTypes: Array<TypeInfo>): GlobalFunctionInfo
功能:尝试在该包信息所对应的包中获取拥有给定函数名称且与给定形参类型信息列表匹配的公开全局函数的信息。
参数:
name:全局函数的名称parameterTypes:形参类型信息列表
operator func ==
public operator func ==(that: PackageInfo): Bool
功能:判断该包信息与给定的另一个包信息是否相等。
参数:
that:被比较相等性的另一个包信息
返回值:如果该包信息与 that 相等则返回 true,否则返回 false
注意:
- 内部实现为比较两个包信息的限定名称是否相等。
operator func !=
public operator func !=(that: PackageInfo): Bool
功能:判断该包信息与给定的另一个包信息是否不等。
参数:
that:被比较相等性的另一个包信息
返回值:如果该包信息与 that 不等则返回 true,否则返回 false
注意:
- 内部实现为比较两个包信息的限定名称是否相等。
func hashCode
public func hashCode(): Int64
功能:获取该包信息的哈希值。
返回值:该包信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该包信息。
返回值:字符串形式的该包信息
注意:
- 内部实现为该包信息的限定名称字符串。
class GlobalFunctionInfo
public class GlobalFunctionInfo <: Equatable<GlobalFunctionInfo> & Hashable & ToString
全局函数信息。
prop name
public prop name: String
功能:获取该全局函数信息所对应的全局函数的名称。
注意:
- 构成重载的所有全局函数将拥有相同的名称。
prop parameters
public prop parameters: InfoList<ParameterInfo>
功能:获取该全局函数信息所对应的全局函数的形参信息列表。
prop returnType
public prop returnType: TypeInfo
功能:获取该全局函数信息所对应的全局函数的返回类型的类型信息。
func apply
public func apply(args: Array<Any>): Any
功能:调用该全局函数信息所对应的全局函数,传入实参列表,返回调用结果。
参数:
args:实参列表
返回值:该全局函数的调用结果
异常:
- 如果实参列表
args中的实参的数目与该全局函数信息所对应的全局函数的形参列表中的形参的数目不等,则会抛出IllegalArguemntException异常 - 如果实参列表
args中的任何一个实参的运行时类型不是该全局函数信息所对应的全局函数的对应形参的声明类型的子类型,则会抛出IllegalTypeException异常 - 如果被调用的全局函数信息所对应全局函数内部抛出异常,则该异常将被封装为
Exception异常并抛出
注意:
- 目前,实参不支持
struct类型的实例。
func hashCode
public func hashCode(): Int64
功能:获取该全局函数信息的哈希值。
返回值:该全局函数信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该全局函数信息。
返回值:字符串形式的该全局函数信息
operator func ==
public operator func ==(that: GlobalFunctionInfo): Bool
功能:判断该全局函数信息与给定的另一个全局函数信息是否相等。
参数:
that: 被比较相等性的另一个全局函数信息
返回值:如果该全局函数信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: GlobalFunctionInfo): Bool
功能:判断该全局函数信息与给定的另一个全局函数信息是否不等。
参数:
that: 被比较相等性的另一个全局函数信息
返回值:如果该全局函数信息与 that 不等则返回 true,否则返回 false
class GlobalVariableInfo
public class GlobalVariableInfo <: Equatable<GlobalVariableInfo> & Hashable & ToString
全局变量信息。
prop name
public prop name: String
功能:获取该全局变量信息所对应的全局变量的名称。
prop typeInfo
public prop typeInfo: TypeInfo
功能:获取该全局变量信息所对应的全局变量的声明类型的类型信息。
func getValue
public func getValue(): Any
功能:获取该全局变量信息所对应的全局变量的值。
返回值:该全局变量的值
func setValue
public func setValue(newValue: Any): Unit
功能:设置该全局变量信息所对应的全局变量的值。
参数:
newValue:新的值
异常:
- 如果该全局变量信息所对应的全局变量不可修改,则会抛出
IllegalSetException异常 - 如果新值
newValue的运行时类型不是全局变量信息所对应的全局变量的声明类型的子类型,则会抛出IllegalTypeException异常
func hashCode
public func hashCode(): Int64
功能:获取该全局变量信息的哈希值。
返回值:该全局变量信息的哈希值
func toString
public func toString(): String
功能:获取字符串形式的该全局变量信息。
返回值:字符串形式的该全局变量信息
operator func ==
public operator func ==(that: GlobalVariableInfo): Bool
功能:判断该全局变量信息与给定的另一个全局变量信息是否相等。
参数:
that: 被比较相等性的另一个全局变量信息
返回值:如果该全局变量信息与 that 相等则返回 true,否则返回 false
operator func !=
public operator func !=(that: GlobalVariableInfo): Bool
功能:判断该全局变量信息与给定的另一个全局变量信息是否不等。
参数:
that: 被比较相等性的另一个全局变量信息
返回值:如果该全局变量信息与 that 不等则返回 true,否则返回 false
class ReflectException
public open class ReflectException <: Exception {
public init()
public init(message: String)
}
ReflectException 为 Reflect 包的基异常类。
init
public init()
功能:无参构造函数。
init
public init(message: String)
参数:
- message:异常信息
class InfoNotFoundException
public class InfoNotFoundException <: ReflectException {
public init()
public init(message: String)
}
InfoNotFoundException 为无法找到对应信息异常。
init
public init()
功能:无参构造函数。
init
public init(message: String)
参数:
- message:异常信息
class MisMatchException
public class MisMatchException <: ReflectException {
public init()
public init(message: String)
}
MisMatchException 为调用对应函数抛出异常。
init
public init()
功能:无参构造函数。
init
public init(message: String)
参数:
- message:异常信息
class IllegalSetException
public class IllegalSetException <: ReflectException {
public init()
public init(message: String)
}
IllegalSetException 为对不可变类型进行更改异常。
init
public init()
功能:无参构造函数。
init
public init(message: String)
参数:
- message:异常信息
class IllegalTypeException
public class IllegalTypeException <: ReflectException {
public init()
public init(message: String)
}
IllegalTypeException 为类型不匹配异常。
init
public init()
功能:无参构造函数。
init
public init(message: String)
参数:
- message:异常信息
class InvocationTargetException
public class InvocationTargetException <: ReflectException {
public init()
public init(message: String)
}
InvocationTargetException 为调用函数包装异常。
init
public init()
功能:无参构造函数。
init
public init(message: String)
参数:
- message:异常信息
示例
使用 TypeInfo 的例子
通过反射获取实例类型的类型名以及实例成员函数个数。
代码如下:
package Demo
from std import reflect.*
public class Foo {
public let item = 0
public func f() {}
}
main() {
let a = Foo()
let ty: TypeInfo = TypeInfo.of(a)
println(ty.name)
println(ty.qualifiedName)
println(ty.instanceFunctions.size)
}
运行结果如下:
Foo
Demo.Foo
1
使用成员信息的例子
通过反射动态获取实例类型参数名并进行动态设置。
代码如下:
from std import reflect.*
public class Rectangular {
public var length = 4
public var width = 5
public func area(): Int64 {
return length * width
}
}
main(): Unit {
let a = Rectangular()
let ty = TypeInfo.of(a)
const zl = 3
let members = ty.instanceVariables.toArray()
println((members[0].getValue(a) as Int64).getOrThrow())
println((members[1].getValue(a) as Int64).getOrThrow())
members[0].setValue(a, zl)
members[1].setValue(a, zl)
println((members[0].getValue(a) as Int64).getOrThrow())
println((members[1].getValue(a) as Int64).getOrThrow())
println(a.area())
let funcs = ty.instanceFunctions.toArray()
if (funcs[0].returnType.name == "Int64"){
println("The area of the square is ${zl**2}")
}
return
}
运行结果如下:
4
5
3
3
9
The area of the square is 9
动态加载的例子
在项目根目录 myProject 下分别创建两个目录 myModuleDirectory 和 myExecutableDirectory,分别在其中使用 cjpm 构建仓颉动态库模块和可执行文件,该可执行文件将在动态加载该仓颉动态库模块后通过反射对动态库模块中的全局变量进行操作。
$ mkdir -p myProject && cd myProject
$ mkdir -p myModuleDirectory && cd myModuleDirectory
# 在 myModuleDirectory 目录下执行该命令初始化该仓颉动态库模块的目录结构,如此创建了一个名称为 myModule 的仓颉动态库模块。
$ cjpm init myOrganization myModule --type=dynamic
cjpm init success
$ mkdir -p src/myPackage/mySubPackage
$ cat << EOF > src/myPackage/mySubPackage/myImplementation.cj
package myPackage.mySubPackage
public var myPublicGlobalVariable0: Int64 = 2333
public let myPublicGlobalVariable1 = MyPublicType("Initializing myPublicGlobalVariable1 in myModule/myPackage.mySubPackage")
public class MyPublicType {
public MyPublicType(message: String) {
println(message)
}
public static func myPublicStaticMemeberFunction() {
println("myModule/myPackage.mySubPackage.MyPublicType.myPublicStaticMemeberFunction is called.")
}
static let myStaticVariable = MyPublicType("Initializing myStaticle in myModule/myPackage.mySubPackage.MyPublicType")
}
EOF
# 使用 cjpm 构建该仓颉动态库模块。
$ cjpm build
cjpm build success
$ cd .. && mkdir -p myExecutableDirectory && cd myExecutableDirectory
$ cjpm init myOrganization myExecutable
$ cat << EOF > src/main.cj
from std import reflect.*
main(): Unit {
// 加载仓颉动态库。
let myModule = ModuleInfo.load("../myModuleDirectory/build/release/myModule/libmyModule_myPackage.mySubPackage.so")
println(myModule.name)
let mySubPackage = myModule.findPackageInfo("myPackage.mySubPackage").getOrThrow()
println(mySubPackage.name)
TypeInfo.find("myModule/myPackage.mySubPackage.MyPublicType") |> println
let myPublicGlobalVariable0 = mySubPackage.getVariable("myPublicGlobalVariable0").getOrThrow()
(myPublicGlobalVariable0.getValue() as Int64).getOrThrow() |> println
myPublicGlobalVariable0.setValue(666)
(myPublicGlobalVariable0.getValue() as Int64).getOrThrow() |> println
}
EOF
# 构建并运行可执行程序。
$ cjpm run
Initializing myPublicGlobalVariable1 in myModule/myPackage.mySubPackage
Initializing myStaticVariable in myModule/myPackage.mySubPackage.MyPublicType
myModule
mySubPackage
myModule/myPackage.mySubPackage.MyPublicType
2333
666
cjpm run finished
$ tree ..
..
├── myExecutableDirectory
│ ├── build
│ │ └── release
│ │ ├── bin
│ │ │ ├── default.bchir
│ │ │ ├── default.cjo
│ │ │ └── main
│ │ ├── myExecutable
│ │ │ └── incremental-cache.json
│ │ └── myExecutable-cache.json
│ ├── module.json
│ ├── module-lock.json
│ └── src
│ └── main.cj
└── myModuleDirectory
├── build
│ └── release
│ ├── bin
│ ├── myModule
│ │ ├── incremental-cache.json
│ │ ├── libmyModule_myPackage.mySubPackage.so
│ │ ├── myPackage.mySubPackage.bchir
│ │ └── myPackage.mySubPackage.cjo
│ └── myModule-cache.json
├── module.json
├── module-lock.json
└── src
└── myPackage
└── mySubPackage
└── myImplementation.cj
14 directories, 16 files
注意,由于当前 ModuleInfo.load 函数根据文件名来判断包名,因此不允许修改该文件名,否则将抛出无法找到仓颉动态库模块文件的异常。
使用注解的例子
通过反射获取实例上注解的值。
代码如下:
from std import reflect.*
main() {
let ti = TypeInfo.of(Test())
let annotation = ti.findAnnotation<A>().getOrThrow()
match (annotation) {
case annotation: A => println(annotation.name)
case _ => println("annotation not found")
}
}
@A["Annotation"]
public class Test {}
@Annotation
public class A {
const A(let name: String) {}
}
运行结果如下:
Annotation
S
regex 包
介绍
该包使用正则表达式分析处理文本(仅支持 Ascii 编码字符串),支持查找、分割、替换、验证等功能。
主要接口
class Regex
public class Regex {
public init(s: String)
public init(s: String, option: RegexOption)
}
Regex 用来指定编译类型和输入序列。
正则匹配规则详见 regex 规则集。
Regex 类提供的 API 如下所示:
init
public init(s: String)
功能:创建一个 Regex 实例, 匹配模式为普通模式。
参数:
- s:正则表达式
异常:
- RegexException:如果初始化失败,则抛异常
- IllegalArgumentException:s 中包含空字符时,则抛出异常
init
public init(s: String, option: RegexOption)
功能:创建一个 Regex 实例。
参数:
- s:正则表达式
- option:当前有三种模式可选,分别是普通模式、忽略大小写模式和多行文本模式(忽略大小写模式和多行文本模式可同时支持)
异常:
- RegexException:如果初始化失败,则抛异常
- IllegalArgumentException:s 中包含空字符时,则抛出异常
func matcher
public func matcher(input: String): Matcher
功能:创建匹配器。
参数:
- input:要匹配的字符串, 字符串长度最大2^31 - 1
返回值:返回创建的匹配器
异常:
- RegexException:如果初始化失败,抛出异常
- IllegalArgumentException:input 中包含空字符时,抛出异常
func matches
public func matches(input: String): Option<MatchData>
功能:创建匹配器,并将入参 input 与正则表达式进行完全匹配。
参数:
- input:要匹配的字符串
返回值:匹配到结果,返回 Option
异常:
- RegexException:如果初始化失败,抛出异常
- IllegalArgumentException:input 中包含空字符时,抛出异常
func string
public func string(): String
功能:返回正则的输入序列。
返回值:返回输入序列
class Matcher
public class Matcher {
public init(re: Regex, input: String)
}
Regex 的匹配器,用于扫描输入序列并进行匹配。
要匹配的字符串最大长度不得超过 2^31-1。
要使用 replaceAll 替换的字符串最大长度不得超过 2^30-2。
init
public init(re: Regex, input: String)
功能:创建一个 Matcher 实例。
参数:
- re:正则表达式
- input:要匹配的字符串
异常:
- RegexException:如果初始化失败,则抛异常
- IllegalArgumentException:input 中包含空字或长度大于2^31-1时,则抛出异常
func fullMatch
public func fullMatch(): Option<MatchData>
功能:对整个输入序列进行匹配。
返回值:全部匹配才会返回对应的 Option
func matchStart
public func matchStart(): Option<MatchData>
功能:对输入序列的头部进行匹配。
返回值:匹配到结果返回 Option
异常:
- RegexException:如果重置匹配器时内存分配失败,抛出异常
func allCount
public func allCount(): Int64
功能:获取匹配正则表示式的结果总数默认是从头到尾匹配的结果,使用了 setRegion 后只会在设置的范围内查找。
返回值:匹配结果总数
func find
public func find(): Option<MatchData>
功能:自当前字符串偏移位置起,返回匹配到的第一个子序列, find 调用一次,当前偏移位置为最新一次匹配到的子序列后第一个字符位置,再次调用, find 从当前位置开始匹配。
返回值:匹配到结果返回 Option
异常:
- RegexException:如果重置匹配器时内存分配失败,抛出异常
func find
public func find(index: Int64): Option<MatchData>
功能:重置该匹配器索引位置,从 index 对应的位置处开始对输入序列进行匹配, 返回匹配到的子序列。
返回值:匹配到结果返回 Option
异常:
- IndexOutOfBoundsException:如果 index 小于0,或 index 大于等于输入序列的 size ,则抛异常
- RegexException:如果重置匹配器时内存分配失败,或匹配失败,抛出异常
func findAll
public func findAll(): Option<Array<MatchData>>
功能:对整个输入序列进行匹配, 找到所有匹配到的子序列生成一个包含所有可匹配子序列的Array
返回值:匹配到结果返回 Option<Array
异常:
- RegexException:如果获取失败,则抛异常
- RegexException:如果重置匹配器时内存分配失败,抛出异常
- RegexException:如果申请内存失败,抛出异常
func replace
public func replace(replacement: String): String
功能:自当前字符串偏移位置起,匹配到的第一个子序列替换为目标字符串, 并将当前索引位置设置到匹配子序列的下一个位置。返回替换后的字符串。 参数:
- replacement:指定替换字符串
返回值:返回替换后字符串
异常:
- RegexException:如果重置匹配器时内存分配失败,则抛出异常
- IllegalArgumentException:如果 replacement 长度大于2^30-2,或者 replacement 包含空字符,则抛出异常
func replace
public func replace(replacement: String, index: Int64): String
功能:从输入序列的 Index 位置起匹配正则,将匹配到的第一个子序列替换为目标字符串,返回替换后的字符串。
参数:
- replacement:指定替换字符串
- index:匹配开始位置
返回值:返回替换后字符串
异常:
- IndexOutOfBoundsException:如果index值不符合规定,则抛异常
- RegexException:如果重置匹配器时内存分配失败,则抛出异常
- IllegalArgumentException:如果 replacement 长度大于2^30-2,或者 replacement 包含空字符,则抛出异常
func replaceAll
public func replaceAll(replacement: String): String
功能:将输入序列中所有与正则匹配的子序列替换为给定的目标字符串,返回替换后的字符串。
参数:
- replacement:指定替换字符串
返回值:String 是替换后的字符串
异常:
- RegexException:如果重置匹配器时内存分配失败,或者 c 侧申请内存失败,或者替换字符串时发生了 GC,则抛出异常
- IllegalArgumentException:如果 replacement 长度大于2^30-2,或者 replacement 包含空字符,则抛出异常
func replaceAll
public func replaceAll(replacement: String, limit: Int64): String
功能:将输入序列中与正则匹配的前 limit 个子序列替换为给定的替换字符串,返回替换后的字符串。
参数:
- limit:替换次数. 如果 limit 等于 0, 返回原来的序列;如果 limit 为负数, 将尽可能多次的替换
- replacement:指定替换字符串
返回值:返回替换后字符串
异常:
- RegexException:如果重置匹配器时内存分配失败,或者 c 侧申请内存失败,或者替换字符串时发生了 GC,则抛出异常
- IllegalArgumentException:如果 replacement 长度大于2^30-2,或者 replacement 包含空字符,则抛出异常
func split
public func split(): Array<String>
功能:将给定的输入序列根据正则尽可能的分割成多个子序列。
返回值:子序列数组
func split
public func split(limit: Int64): Array<String>
功能:将给定的输入序列根据正则尽可能的分割成多个子序列 (最多分割成 limit 个子串)。
参数:
- limit:传入最多分割的子串个数
返回值:如果 limit>0, 返回最多 limit 个子串;如果 limit<=0, 返回最大可分割数个子串
异常:
- RegexException:如果重置匹配器时内存分配失败,抛出异常
func setRegion
public func setRegion(beginIndex: Int64, endIndex: Int64): Matcher
功能:设置匹配器可搜索区域的位置信息,具体位置由指定的 begin 和 end 决定。
参数:
- beginIndex:区域开始位置
- endIndex:区域结束位置
返回值:返回匹配器自身
异常:
- IndexOutOfBoundsException:如果 beginIndex 小于0,或 beginIndex 大于输入序列的 size ,则抛异常
- IndexOutOfBoundsException:如果 endIndex 小于0,或 endIndex 大于输入序列的 size ,则抛异常
- IndexOutOfBoundsException:如果 beginIndex 大于 endIndex ,则抛异常
- RegexException:如果匹配失败,则抛异常
func region
public func region(): Position
功能:返回匹配器的区域设置。
返回值:返回匹配器的区域设置
func resetRegion
public func resetRegion(): Matcher
功能:重置匹配器开始位置和结束位置。
返回值:返回匹配器自身
异常:
- RegexException:如果重置匹配器时内存分配失败,或匹配失败,则抛异常
func resetString
public func resetString(input: String): Matcher
功能:重设匹配序列,并重置匹配器。
参数:
- input:要匹配的字符串
返回值:返回匹配器自身
异常:
- RegexException:如果重置匹配器时内存分配失败,抛出异常
- IllegalArgumentException:input 长度大于2^31-1时,则抛出异常
func getString
public func getString(): String
功能:获取要匹配的字符串。
返回值:返回匹配序列
class RegexOption
public class RegexOption <: ToString {
public init()
}
RegexOption 类用于指定正则匹配的模式。默认的正则匹配算法为 NFA ,匹配运行次数上限为 1000000。 提供的 API 如下所示:
init
public init()
功能:创建一个 RegexOption 实例, 匹配模式为普通模式(NORMAL)。
func ignoreCase
public func ignoreCase(): RegexOption
功能:修改 RegexOption, 修改匹配模式为忽略大小写(IGNORECASE)。
返回值:返回修改后的 RegexOption
func multiLine
public func multiLine(): RegexOption
功能:修改 RegexOption, 修改匹配模式为多行文本模式(MULTILINE)。
返回值:返回修改后的 RegexOption
func toString
public func toString(): String
功能:获取 RegexOption 当前表示的正则匹配模式。
返回值:返回正则匹配模式
class MatchData
public class MatchData
存储正则表达式匹配结果,并提供对正则匹配结果进行查询的函数。
func matchStr
public func matchStr(): String
功能:返回上一次匹配到的子字符串,结果与调用 matchStr(0) 相同。
返回值:返回子字符串
异常:
- IndexOutOfBoundsException:如果匹配字符串数组长度小于1,抛出异常
func matchStr
public func matchStr(group: Int64): String
功能:根据给定的索引获取上一次匹配中该捕获组匹配到的子字符串捕获组的索引从 1 开始,索引为 0 表示整个正则表达式的匹配结果。
参数:
- group:指定组
返回值:返回子字符串
异常:
- IndexOutOfBoundsException:如果输入值不符合规定,则抛异常
func matchPosition
public func matchPosition(): Position
功能:返回上一次匹配到的子字符串在输入字符串中起始位置的索引和最后一个字符匹配后的偏移索引。
返回值:Position – 返回匹配结果位置信息
异常:
- IndexOutOfBoundsException:如果捕获数组长度小于1,抛出异常
func matchPosition
public func matchPosition(group: Int64): Position
功能:根据给定的索引获取上一次匹配中该捕获组匹配到的子字符串在输入字符串中的位置信息。
参数:
- group:指定组
返回值:返回对应捕获组的位置信息
异常:
- IndexOutOfBoundsException:如果输入值不符合规定,则抛异常
func groupNumber
public func groupNumber(): Int64
功能:返回捕获组的个数。
返回值:返回捕获组的个数
struct Position
public struct Position
Position 用来存储位置信息,表示的是一个前闭后开区间。
prop start
public prop start: Int64
功能:区间开始位置
prop end
public prop end: Int64
功能:区间结束位置
class RegexException
public class RegexException <: Exception {
public init()
public init(message: String)
}
RegexException 类提供的 API 如下所示:
init
public init()
功能:创建 RegexException。
init
public init(message: String)
功能:创建 RegexException。
参数:
- message:异常提示字符串
regex 规则集
当前仓颉的正则表达式仅支持以下规则,使用不支持的规则会导致输出结果与预期不符。
| 字符 | 描述 |
|---|---|
\ | 将下一个字符标记为一个特殊字符(File Format Escape,清单见本表)、或一个原义字符(Identity Escape,有^$()*+?.[{\|共计 12 个)、或一个向后引用(backreferences)。例如,“n”匹配字符“n”。\n匹配一个换行符。序列\匹配\,而(则匹配(。 |
^ | 匹配输入字符串的开始位置。如果设置了 RegexOption 中的多行模式 multiLine(),^也匹配\n或\r之后的位置。 |
$ | 匹配输入字符串的结束位置。 |
* | 匹配前面的子表达式零次或多次。例如,zo*能匹配z,zo以及zoo。*等价于{0,}。 |
+ | 匹配前面的子表达式一次或多次。例如,zo+能匹配zo以及zoo,但不能匹配z。+等价于{1,}。 |
? | 匹配前面的子表达式零次或一次。例如,do(es)?可以匹配does中的do和does。?等价于{0,1}。 |
{n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2}不能匹配Bob中的o,但是能匹配food中的两个o。 |
{n,} | n 是一个非负整数。至少匹配 n 次。例如,o{2,}不能匹配Bob中的o,但能匹配foooood中的所有o。o{1,}等价于o+。o{0,}则等价于o*。 |
{n,m} | m 和 n 均为非负整数,其中 n<=m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3}将匹配fooooood中的前三个o。o{0,1}等价于o?。请注意在逗号和两个数之间不能有空格。 |
? | 非贪心量化(Non-greedy quantifiers):当该字符紧跟在任何一个其他重复修饰符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串oooo,o+?将匹配单个o,而o+将匹配所有o。 |
. | 匹配除\n之外的任何单个字符。要匹配包括\n在内的任何字符,请使用像(.\|\n)的模式。 |
(pattern) | 匹配 pattern 并获取这一匹配的子字符串。该子字符串用于向后引用。所获取的匹配可以从产生的 Matches 集合中得到。要匹配圆括号字符,请使用\(或\)。可带数量后缀。 |
x\|y | 没有包围在()里,其范围是整个正则表达式。例如,z|food 能匹配z或food。(?:z|f)ood 则匹配zood或food。 |
[xyz] | 字符集合(character class)。匹配所包含的任意一个字符。例如,[abc]可以匹配plain中的a。特殊字符仅有反斜线\保持特殊含义,用于转义字符。其它特殊字符如星号、加号、各种括号等均作为普通字符。脱字符^如果出现在首位则表示负值字符集合;如果出现在字符串中间就仅作为普通字符。连字符 - 如果出现在字符串中间表示字符范围描述;如果如果出现在首位(或末尾)则仅作为普通字符。右方括号应转义出现,也可以作为首位字符出现。 |
[^xyz] | 排除型字符集合(negated character classes)。匹配未列出的任意字符。例如,[^abc]可以匹配plain中的plin。 |
[a-z] | 字符范围。匹配指定范围内的任意字符。例如,[a-z]可以匹配a到z范围内的任意小写字母字符。 |
[^a-z] | 排除型的字符范围。匹配任何不在指定范围内的任意字符。例如,[^a-z]可以匹配任何不在a到z范围内的任意字符。 |
\b | 匹配一个单词边界,也就是指单词和空格间的位置。例如,er\b可以匹配never中的er,但不能匹配verb中的er。 |
\B | 匹配非单词边界。er\B能匹配verb中的er,但不能匹配never中的er。 |
\d | 匹配一个数字字符。等价于[0-9]。 |
\D | 匹配一个非数字字符。等价于[^0-9]。 |
\f | 匹配一个换页符。等价于\x0c。 |
\n | 匹配一个换行符。等价于\x0a。 |
\r | 匹配一个回车符。等价于\x0d。 |
\s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]。 |
\S | 匹配任何非空白字符。等价于[^\f\n\r\t\v]。 |
\t | 匹配一个制表符。等价于\x09。 |
\v | 匹配\n\v\f\r\x85。 |
\w | 匹配包括下划线的任何单词字符。等价于[A-Za-z0-9_]。 |
\W | 匹配任何非单词字符。等价于[^A-Za-z0-9_]。 |
\xnm | 十六进制转义字符序列。匹配两个十六进制数字 nm 表示的字符。例如,\x41匹配A。正则表达式中可以使用 ASCII 码。 |
\num | 向后引用(back-reference)一个子字符串(substring),该子字符串与正则表达式的第 num 个用括号围起来的捕捉群(capture group)子表达式(subexpression)匹配。其中 num 是从 1 开始的十进制正整数,Regex 捕获组上限为 63。例如:(.)\1匹配两个连续的相同字符。 |
(?:pattern) | 匹配 pattern 但不获取匹配的子字符串(shy groups),也就是说这是一个非获取匹配,不存储匹配的子字符串用于向后引用。这在使用或字符(\|)来组合一个模式的各个部分是很有用。 |
(?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,Windows(?=95\|98\|NT\|2000)能匹配Windows2000中的Windows,但不能匹配Windows3.1中的Windows。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
(?!pattern) | 正向否定预查(negative assert),在任何不匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如Windows(?!95\|98\|NT\|2000)能匹配Windows3.1中的Windows,但不能匹配Windows2000中的Windows。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
(?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,(?<=95\|98\|NT\|2000)Windows能匹配2000Windows中的Windows,但不能匹配3.1Windows中的Windows。 |
(?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如(?<!95\|98\|NT\|2000)Windows能匹配3.1Windows中的Windows,但不能匹配2000Windows中的Windows。 |
(?i) | 通过规则指定部分规则忽略大小写。当前 Regex 仅支持全局忽略大小写,当该选项被指定时,会被当做全局忽略大小写对待。 |
(?-i) | 通过规则指定部分规则大小写敏感。 当前 Regex 默认大小写敏感,该选项仅做编译兼容处理,不做敏感处理。 |
+ | 单独一个加号,不是转义的\+ |
* | 单独一个星号,不是转义的\* |
- | 单独一个减号,不是转义的\- |
] | 单独一个右中括号,不是转义的\] |
} | 单独一个右大括号,不是转义的\} |
[[:alpha:]] | 表示任意大小写字母。 |
[[:^alpha:]] | 表示除大小写字母以外的任意字符。 |
[[:lower:]] | 表示任意小写字母。 |
[[:^lower:]] | 表示除小写字母以外的任意字符。 |
[[:upper:]] | 表示任意大写字母。 |
[[:^upper:]] | 表示除大写字母以外的任意字符。 |
[[:digit:]] | 表示0到9之间的任意单个数字。 |
[[:^digit:]] | 表示除0到9之间的单个数字以外的任意字符。 |
[[:xdigit:]] | 表示十六进制的字母和数字。 |
[[:^xdigit:]] | 表示除十六进制的字母和数字以外的任意字符。 |
[[:alnum:]] | 表示任意数字或字母。 |
[[:^alnum:]] | 表示除数字或字母以外的任意字符。 |
[[:space:]] | 表示任意空白字符,包括"空格"、"tab键"等。 |
[[:^space:]] | 表示除空白字符以外的任意字符。 |
[[:punct:]] | 表示任意标点符号。 |
[[:^punct:]] | 表示除任意标点符号以外的任意字符。 |
在仓颉中,还存在一些特殊的规则:
-
?、+、*前面的字符不可量化时, 会被忽略; 特例:(*、|*、*开头时*会被视为普通字符。 -
*?在匹配全部*?之前的字符组成的字符串时,会匹配不到该字符。 -
正则表达式的捕获组的最大个数为 63,编译后的最大规则长度为 65535。
-
暂不支持的场景:((pattern1){m1,n1}pattern2){m2,n2},即: a:组定义 1 被{m1,n1}修饰; b:组定义 1 被组定义 2 包裹; c:组定义 2 被{m2,n2}修饰。
示例
Regex 匹配大小写
创建 Regex 正则类,并简单匹配大小写, 使用 matches() 进行匹配。
代码如下:
from std import regex.*
main() {
let r1 = Regex("ab")
let r2 = Regex("ab", RegexOption().ignoreCase())
match (r1.matches("aB")) {
case Some(r) => println(r.matchStr())
case None => println("None")
}
match (r2.matches("aB")) {
case Some(r) => println(r.matchStr())
case None => println("None")
}
return 0
}
运行结果如下:
None
aB
Matcher 中 resetString/fullMatch/matchStart 函数
使用 Regex 的 matcher 创建匹配器 Matcher 实例,使用 resetString 重新设值匹配序列,使用 fullMatch 和 matchStart 进行匹配。
代码如下:
from std import regex.*
main() {
let r = Regex("\\d+")
let m = r.matcher("13588123456")
let matchData1 = m.fullMatch()
m.resetString("13588abc")
let matchData2 = m.matchStart()
m.resetString("abc13588123abc")
let matchData3 = m.matchStart()
match (matchData1) {
case Some(md) => println(md.matchStr())
case None => println("None")
}
match (matchData2) {
case Some(md) => println(md.matchStr())
case None => println("None")
}
match (matchData3) {
case Some(md) => println(md.matchStr())
case None => println("None")
}
return 0
}
运行结果如下:
13588123456
13588
None
Matcher 和 MatchData 的使用
正则匹配贪婪量词,使用 find() 查看多次的匹配结果,使用 MatchData 的 matchPosition() 查看匹配的偏移值。
代码如下:
from std import regex.*
main() {
let r = Regex(#"a\wa"#).matcher("1aba12ada555")
for (i in 0..2) {
let matchData = r.find()
match (matchData) {
case Some(md) =>
println(md.matchStr())
let pos = md.matchPosition()
println("[${pos.start}, ${pos.end})")
case None => println("None")
}
}
return 0
}
运行结果如下:
aba
[1, 4)
ada
[6, 9)
Matcher 中 replace/replaceAll 函数
下面是使用 replace 和 replaceAll 示例。
代码如下:
from std import regex.*
main() {
let r = Regex("\\d").matcher("a1b1c2d3f4")
println(r.replace("X")) //replace a digit once with X
println(r.replace("X", 2)) //replace once from index 4
println(r.replaceAll("X")) //replace all digit with X
println(r.replaceAll("X", 2)) //replace all at most 2 times
println(r.replaceAll("X", -1)) //replace all digit with X
return 0
}
运行结果如下:
aXb1c2d3f4
a1bXc2d3f4
aXbXcXdXfX
aXbXc2d3f4
aXbXcXdXfX
MatchOption 指定多行模式匹配
MatchOption 指定多行模式匹配。
代码如下:
from std import regex.*
main(): Int64 {
let rule = ##"^(\w+)\s(\d+)*$"##
let pattern: String = """
Joe 164
Sam 208
Allison 211
Gwen 171
"""
let r1 = Regex(rule, RegexOption().multiLine())
var arr = r1.matcher(pattern).findAll() ?? Array<MatchData>()
for (md in arr) {
println(md.matchStr())
}
return 0
}
运行结果如下:
Joe 164
Sam 208
Allison 211
Gwen 171
RegexOption 获取当前正则匹配模式
RegexOption 类可以获取当前正则匹配模式。
代码如下:
from std import regex.*
main()
{
var a = RegexOption()
println(a.toString())
a = RegexOption().ignoreCase()
println(a.toString())
a = RegexOption().multiLine()
println(a.toString())
a = RegexOption().multiLine().ignoreCase()
println(a.toString())
return 0
}
运行结果如下:
NORMAL,NFA
IGNORECASE,NFA
MULTILINE,NFA
MULTILINE,IGNORECASE,NFA
MatchData 中 groupNumber 函数
调用 groupNumber() 查询 group 数,获取每个 group 的 MatchData 信息。
代码如下:
from std import regex.*
main() {
var r = Regex("(a+c)(a?b)()(()?c+((e|s([a-h]*))))")
var m = r.matcher("aacbcsdedd")
var matchData = m.find()
match (matchData) {
case Some(s) =>
println("groupNum : ${s.groupNumber()}")
if (s.groupNumber() > 0) {
for (i in 1..=s.groupNumber() ) {
println("group[${i}] : ${s.matchStr(i)}")
var pos = s.matchPosition(i)
println("position : [${pos.start}, ${pos.end})")
}
}
case None => ()
}
return 0
}
运行结果如下:
groupNum : 8
group[1] : aac
position : [0, 3)
group[2] : b
position : [3, 4)
group[3] :
position : [4, 4)
group[4] : csdedd
position : [4, 10)
group[5] :
position : [10, 10)
group[6] : sdedd
position : [5, 10)
group[7] : sdedd
position : [5, 10)
group[8] : dedd
position : [6, 10)
Matcher 获取匹配总数
Matcher 类可以获取正则表达式匹配总数。
代码如下:
from std import regex.*
main() {
var matcher = Regex("a+b").matcher("1ab2aab3aaab4aaaab")
println(matcher.allCount())
return 0
}
运行结果如下:
4
runtime 包
介绍
该包用于提供内存管理功能,包括一些内存数据的读取。
术语表
| 术语 | 说明 |
|---|---|
| 仓颉堆 | 仓颉运行时管理的堆内存, 是仓颉做动态内存分配的内存空间。 |
| 水线值 | 当仓颉堆分配的对象大小大于此值时,则进行一次 GC。 |
主要接口
struct MemoryInfo
public struct MemoryInfo
MemoryInfo 用于提供获取一些堆内存统计数据的接口。
prop maxHeapSize
public static prop maxHeapSize: Int64
功能:获取仓颉堆可以使用的最大值, 单位为 byte。
prop allocatedHeapSize
public static prop allocatedHeapSize: Int64
功能:获取仓颉堆已被使用的大小, 单位为 byte。
prop heapPhysicalMemory
public static prop heapPhysicalMemory: Int64
功能:获取仓颉堆实际占用的物理内存大小, 单位为 byte。
struct ThreadInfo
public struct ThreadInfo
ThreadInfo 用于提供获取一些仓颉线程统计数据的接口。
prop threadCount
public static prop threadCount: Int64
功能:获取仓颉当前的线程数量。
prop blockingThreadCount
public static prop blockingThreadCount: Int64
功能:获取阻塞的仓颉线程数。
prop nativeThreadCount
public static prop nativeThreadCount : Int64
功能:获取物理线程数。
func GC
public func GC(heavy!: Bool = false): Unit
功能:执行 GC。
参数:
- heavy:如果为 true,执行会慢,收集的多一些,默认为 false
func SetGCThreshold
public func SetGCThreshold(value: UInt64) : Unit
功能:修改用户期望的 GC 的水线值,当仓颉堆大小超过该值时,触发 GC。单位为 KB。
参数:
- value:用户期望的 GC 的水线值
示例
获取仓颉堆可以使用的最大值
获取仓颉堆可以使用的最大值。
代码如下:
from std import runtime.*
main() {
println(MemoryInfo.maxHeapSize)
}
运行结果如下(以实际环境为准):
268435456
设置用户期望的 GC 的水线值
设置用户期望的 GC 的水线值为 2MB,代码如下:
from std import runtime.*
main() {
SetGCThreshold(2048)
}
socket 包
介绍
用于进行网络通信,提供启动 Socket 服务器、连接 Socket 服务器、发送数据、接收数据等功能。
我们支持 UDP/TCP/UDS 三种 Socket 类型,用户可按需选用。
如下为本库提供 Socket 的类继承关系:
Hierarchy
Resource
├StreamingSocket
│ ├TcpSocket
│ └UnixSocket
│
├DatagramSocket
│ ├UdpSocket
│ └UnixDatagramSocket
│
└ServerSocket
├TcpServerSocket
└UnixServerSocket
主要接口
IPV4_BROADCAST
public let IPV4_BROADCAST: Array<UInt8>
功能:IPV4 广播地址。
IPV4_ALL_SYSTEM
public let IPV4_ALL_SYSTEM: Array<UInt8>
功能:IPV4 多播地址,用于向同一局域网中的所有主机发送多播数据包。
IPV4_ALL_ROUTER
public let IPV4_ALL_ROUTER: Array<UInt8>
功能:IPV4 预留的组播地址,用于向所有本地网络上的所有路由器发送路由信息。
IPV4_ZERO
public let IPV4_ZERO: Array<UInt8>
功能:IPV4 通用地址。
IPV4_LOCAL_HOST
public let IPV4_LOCAL_HOST: Array<UInt8>
功能:IPV4 本地地址。
IPV6_ZERO
public let IPV6_ZERO: Array<UInt8>
功能:IPV6 通用地址。
IPV6_LOOPBACK
public let IPV6_LOOPBACK: Array<UInt8>
功能:IPV6 环回地址(本地地址)。
IPV6_INTERFACE_LOCAL_ALL_NODES
public let IPV6_INTERFACE_LOCAL_ALL_NODES: Array<UInt8>
功能:IPv6 在节点本地范围的所有节点多播地址。
IPV6_LINK_LOCAL_ALL_NODES
public let IPV6_LINK_LOCAL_ALL_NODES: Array<UInt8>
功能:IPv6 在链路本地范围的所有节点多播地址。
IPV6_LINK_LOCAL_ALL_ROUTERS
public let IPV6_LINK_LOCAL_ALL_ROUTERS: Array<UInt8>
功能:IPv6 链路本地范围的所有路由器多播地址。
interface StreamingSocket
public interface StreamingSocket <: IOStream & Resource & ToString {
prop localAddress: SocketAddress
prop remoteAddress: SocketAddress
mut prop readTimeout: ?Duration
mut prop writeTimeout: ?Duration
}
双工流模式下的运行的 Socket,可被读写。
StreamingSocket 可以被绑定 (bind) 和连接 (connect), 用户可以通过属性设置绑定和连接的远端和本地地址。
StreamingSocket 可以有序分包传输字节流。我们会使用一段缓存空间存储读写的字节流。读取接口 (read()) 默认在无数据到来时阻塞式等待,直到下一次数据到达,或超时。写操作 (write()) 会写入缓存中的数据并在后续被发出,如果缓存不足,或者写入速度快于转发速度,写操作将会阻塞等待缓存空闲,或超时。
读写字符始终保持有序, 但不保证传输过程中的分包策略及大小与发包时一致。例如:一端发送 10 字节报文后,又发送了 15 字节报文,对端可能分别收到 10 字节 和 15 字节报文,也可能一次性收到 25 字节的一个报文。
当收到一段异常报文时,将返回报文长度为 -1 。
prop localAddress
prop localAddress: SocketAddress
功能:Socket 将要或已经被绑定的本地地址
异常:
SocketException:当Socket已经被关闭或无可用的本地地址(本地地址未配置并且套接字未连接)时抛出异常
prop remoteAddress
prop remoteAddress: SocketAddress
功能:Socket 将要或已经连接的远端地址。
异常:
SocketException:当Socket已经被关闭时抛出异常
prop readTimeout
mut prop readTimeout: ?Duration
功能:设置和读取读超时时间。
返回值:超时时间或 None,如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间((263-1) 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
prop writeTimeout
mut prop writeTimeout: ?Duration
功能:设置和读取写超时时间。
返回值:超时时间或 None,如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间((263-1) 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
interface DatagramSocket
public interface DatagramSocket <: Resource & ToString {
prop localAddress: SocketAddress
prop remoteAddress: ?SocketAddress
mut prop receiveTimeout: ?Duration
mut prop sendTimeout: ?Duration
func receiveFrom(buffer: Array<Byte>): (SocketAddress, Int64)
func sendTo(address: SocketAddress, payload: Array<Byte>): Unit
}
DatagramSocket 是一种接受和读取数据包的套接字,一个数据包通常有有限的大小,可能为空。不同的数据包套接字类型有不同的数据包最大值。例如 UDP 套接字一次可以处理最大 64KB 的数据包。
数据包传输不是一种可靠的传输,不保证传输顺序。数据包大小在发送端决定,例如:一端发送了 10 字节和 15 字节的报文,对端将收到相同大小的对应报文,10 字节和 15 字节。
prop localAddress
prop localAddress: SocketAddress
功能:Socket 将要或已经被绑定的本地地址。
异常:
SocketException:当Socket已经被关闭或无可用的本地地址(本地地址未配置并且套接字未连接)时抛出异常
prop remoteAddress
prop remoteAddress: ?SocketAddress
功能:Socket 已经连接的远端地址,当 Socket 未连接时返回 None。
异常:
SocketException:当Socket已经被关闭时抛出异常
prop receiveTimeout
mut prop receiveTimeout: ?Duration
功能:设置和读取 receiveFrom 超时时间, 无超时时间设置为 None。
返回值:超时时间或 None,如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间(263-1 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
prop sendTimeout
mut prop sendTimeout: ?Duration
功能:设置和读取 sendTo 超时时间, 默认设置为 None。
返回值:超时时间或 None,如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间((263-1) 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
func receiveFrom
func receiveFrom(buffer: Array<Byte>): (SocketAddress, Int64)
功能:阻塞式等待收取报文到 buffer 中。
参数:
buffer:存储报文内容的缓存空间,buffer应当有一个合适的大小,否则可能导致收取报文时报文被截断,并且返回的报文大小值大于buffer的大小
返回值:报文发送地址和收取到的报文大小(可能为 0,或大于参数 buffer 大小)。
异常:
SocketException:本机缓存过小无法读取报文时,抛出异常SocketTimeoutException:读取超时时抛出异常
func sendTo
func sendTo(address: SocketAddress, payload: Array<Byte>): Unit
功能:发送报文到指定的远端地址,当对端无足够缓存时此操作可能被阻塞,报文可能被丢弃。
参数:
address:需要发送的远端地址payload:需要发送的报文内容
interface ServerSocket
public interface ServerSocket <: Resource & ToString {
prop localAddress: SocketAddress
func bind(): Unit
func accept(timeout!: ?Duration): StreamingSocket
func accept(): StreamingSocket
}
prop localAddress
prop localAddress: SocketAddress
功能:Socket 将要或已经被绑定的本地地址。
异常:
SocketException:当Socket已经被关闭时抛出异常
func bind
func bind(): Unit
功能:绑定套接字,当没有设置 reuse 属性,本地端口、地址、文件路径已被占用时,或还有上次绑定套接字的连接将绑定失败失败后需要 close 套接字,不支持多次重试此操作后可执行 accept() 操作。
异常:
SocketException:当因系统原因绑定失败时抛出异常
func accept
func accept(timeout!: ?Duration): StreamingSocket
功能:接受一个客户端套接字的连接请求,阻塞式等待连接请求。
参数:
timeout:等待连接超时的时间
返回值:连接成功的客户端套接字
异常:
SocketTimeoutException:等待连接请求超时IllegalArgumentException:当超时时间小于 0 时,抛出异常
func accept
func accept(): StreamingSocket
功能:接受一个客户端套接字的连接请求,阻塞式等待连接请求。
返回值:连接成功的客户端套接字
class TcpSocket
public class TcpSocket <: StreamingSocket & Equatable<TcpSocket> & Hashable {
public init(address: String, port: UInt16)
public init(address: SocketAddress)
public init(address: SocketAddress, localAddress!: ?SocketAddress)
}
TCP 套接字,当实例对象被创建后,可使用 connect 函数创建连接,并在结束时显式执行 close 操作。
该类型继承自 StreamingSocket, 可参阅 StreamingSocket 章节获取更多信息。
init
public init(address: String, port: UInt16)
功能:创建一个未连接的套接字。
参数:
address:即将要连接的地址,当前仅支持 IPv4 地址port:即将要连接的端口。
异常:
SocketException:当address参数不合法时抛出异常,规格同SocketAddress实例创建时的要求SocketException:Windows 平台下地址为全零地址时将抛出异常
init
public init(address: SocketAddress)
功能:创建一个未连接的套接字。
参数:
address:即将要连接的地址,当前仅支持 IPv4 地址
异常:
SocketException:当address参数不合法时抛出异常,规格同SocketAddress实例创建时的要求SocketException:Windows 平台下地址为全零地址时将抛出异常
init
public init(address: SocketAddress, localAddress!: ?SocketAddress)
功能:创建一个未连接的套接字,并且绑定到指定本地地址,本地地址为 None 时,将随机选定地址去绑定。此接口当 localAddress 不为 None 时,将默认设置 SO_REUSEADDR 为 true,否则可能导致 "address already in use" 的错误。如果需要变更此配置,可以通过调用 setSocketOptionBool(SocketOptions.SOL_SOCKET, SocketOptions.SO_REUSEADDR, false)。另外,本地地址和远端地址需要均为 IPv4。
参数:
address:即将要连接的地址localAddress:绑定的本地地址
异常:
SocketException:当address参数不合法时抛出异常,规格同SocketAddress实例创建时的要求SocketException:Windows 平台下地址为全零地址时将抛出异常
prop remoteAddress
public override prop remoteAddress: SocketAddress
功能:Socket 已经或将要连接的远端地址。
异常:
SocketException:当Socket已经被关闭时抛出异常
prop localAddress
public override prop localAddress: SocketAddress
功能:Socket 将要或已经被绑定的本地地址。
异常:
SocketException:当Socket已经被关闭或无可用的本地地址(本地地址未配置并且套接字未连接)时抛出异常
prop bindToDevice
public mut prop bindToDevice: ?String
功能:设置和读取绑定网卡。
prop readTimeout
public override mut prop readTimeout: ?Duration
功能:设置和读取读操作超时时间。
返回值:超时时间或 None,如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间((263-1) 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
prop writeTimeout
public override mut prop writeTimeout: ?Duration
功能:设置和读取写操作超时时间。
返回值:超时时间或 None,如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间((263-1) 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
prop keepAlive
public mut prop keepAlive: ?SocketKeepAliveConfig
功能:设置和读取保活属性,None 表示关闭保活。用户未设置时将使用系统默认配置。设置此配置可能会被延迟或被系统忽略,取决于系统的处理能力。
prop noDelay
public mut prop noDelay: Bool
功能:设置和读取 TCP_NODELAY 属性,默认为 true。这个选项将禁用 Nagel 算法,所有写入字节被无延迟得转发。当属性设置为 false 时,Nagel 算法将在发包前引入延时时间
prop quickAcknowledge
public mut prop quickAcknowledge: Bool
功能:设置和读取 TCP_QUICKACK 属性,默认为 false。这个选项类似于 noDelay,但仅影响 TCP ACK 和第一次响应。不支持 Windows 和 macOS 系统。
prop linger
public mut prop linger: ?Duration
功能:设置和读取 SO_LINGER 属性,默认值取决于系统,None 表示禁用此选项 。
- 如果
SO_LINGER被设置为Some(v),当套接字关闭时,如果还有等待的字节流,我们将在关闭连接前等待v时间,如果超过时间,字节流还未被发送,连接将会被异常终止(通过 RST 报文关闭)。 - 如果
SO_LINGER被设置为None,当套接字关闭时,连接将被立即关闭,如果当前等待发送的字符,使用 FIN-ACK 关闭连接, 当还有剩余待发送的字符时,使用 RST 关闭连接。
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
prop sendBufferSize
public mut prop sendBufferSize: Int64
功能:设置和读取 SO_SNDBUF 属性,提供一种方式指定发包缓存大小。选项的生效情况取决于系统。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
prop receiveBufferSize
public mut prop receiveBufferSize: Int64
功能:设置和读取 SO_RCVBUF 属性,提供一种方式指定收包缓存大小。选项的生效情况取决于系统。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
func read
public override func read(buffer: Array<Byte>): Int64
功能:读取报文。超时情况按 readTimeout 决定, 详见 readTimeout。
参数:
buffer:读取的数据存储变量
返回值:读取的数据长度
异常:
SocketException:当buffer大小为 0 时抛出异常,当因系统原因读取失败时,抛出异常
注:由于系统底层接口差异,如果连接被对端关闭,read 和 write 接口的行为也有相应的差异
- Windows 系统上,对端关闭连接后,如果本端调用一次
write,会导致清空缓冲区内容,在此基础上再调用read会抛出连接关闭异常 - Linux\macOS 系统上,对端关闭连接后,先调用
write再调用read函数仍会读出缓冲区中的内容
func write
public override func write(payload: Array<Byte>): Unit
功能:读取写入。超时情况按 writeTimeout 决定, 详见 writeTimeout。
参数:
payload:写入的数据存储变量
异常:
SocketException:当buffer大小为 0 时抛出异常,当因系统原因写入失败时,抛出异常
func connect
public func connect(timeout!: ?Duration = None): Unit
功能:连接远端套接字, 会自动绑定本地地址,因此不需要进行额外的绑定操作。
参数:
timeout:连接超时时间,None表示无超时时间,并且连接操作无重试,当服务端拒绝连接时,将返回连接失败。并且此操作包含了绑定操作,因此无需重复调用bind接口
异常:
IllegalArgumentException:当远端地址不合法时抛出异常IllegalArgumentException:当连接超时时间小于 0 时,抛出异常SocketException:当连接因系统原因(例如:套接字已关闭,没有访问权限,系统错误等)无法建立时抛出异常。再次调用可能成功SocketTimeoutException:当连接超时时抛出异常IllegalArgumentException:当超时时间小于 0 时,抛出异常
func getSocketOption
public func getSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: CPointer<UIntNative>
): Unit
功能:读取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当getsockopt返回失败时抛出异常
func setSocketOption
public func setSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: UIntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionIntNative
public func getSocketOptionIntNative(
level: Int32,
option: Int32
): IntNative
功能:读取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:参数值
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常
func setSocketOptionIntNative
public func setSocketOptionIntNative(
level: Int32,
option: Int32,
value: IntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常。
func getSocketOptionBool
public func getSocketOptionBool(
level: Int32,
option: Int32
): Bool
功能:读取指定的套接字参数。从 IntNative 强转而来。0 => false,非 0 => true。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:读取到的参数值
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常。
func setSocketOptionBool
public func setSocketOptionBool(
level: Int32,
option: Int32,
value: Bool
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常
func close
public func close(): Unit
功能:关闭套接字,所有操作除了 close/isClosed 之外,均不允许再调用。接口允许多次调用。
func isClosed
public func isClosed(): Bool
功能:判断套接字是否通过调用 close 显式关闭。
返回值:返回套接字是否已经调用 close 显式关闭。是则返回 true;否则返回 false
operator func ==
public override operator func ==(other: TcpSocket): Bool
功能:判断两个 TcpSocket 实例是否相等。
参数:
other:参与比较的TcpSocket实例。
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public override operator func !=(other: TcpSocket): Bool
功能:判断两个 TcpSocket 实例是否不等。
参数:
other:参与比较的TcpSocket实例。
返回值:如果不等,则返回 true;否则,返回 false
func hashCode
public override func hashCode(): Int64
功能:获取当前 TcpSocket 实例的哈希值。
返回值:返回当前 TcpSocket 实例的哈希值
func toString
public override func toString(): String
功能:返回当前 TcpSocket 的状态信息。
返回值:包含当前 TcpSocket 状态信息的字符串。
class TcpServerSocket
public class TcpServerSocket <: ServerSocket {
public init(bindAt!: UInt16)
public init(bindAt!: SocketAddress)
}
TcpServerSocket 将监听 TCP 连接。套接字被创建后,可通过属性和 setSocketOptionXX 接口配置属性。
启动监听需要调用 bind() 将套接字绑定到本地端口。accept() 接口将接受 TCP 连接,阻塞等待连接,若队列中已有连接,则可立即返回。
套接字需要通过 close 显式关闭。
当前仅支持 IPv4 协议。
init
public init(bindAt!: UInt16)
功能:创建一个 TcpServerSocket 对象,尚未绑定,因此客户端无法连接。
参数:
bindAt:指定本地绑定端口,0 表示随机绑定空闲的本地端口
init
public init(bindAt!: SocketAddress)
功能:创建一个 TcpServerSocket 对象,尚未绑定,因此客户端无法连接。
参数:
bindAt:指定本地绑定地址,0 表示随机绑定空闲的本地地址
prop localAddress
public override prop localAddress: SocketAddress
功能:Socket 将要或已经被绑定的本地地址。
异常:
SocketException:当Socket已经被关闭时抛出异常
prop reuseAddress
public mut prop reuseAddress: Bool
功能:设置和读取 SO_REUSEADDR 属性,默认设置为 true。
属性生效后的行为取决于系统,使用前,请参阅不同系统针对此属性 SO_REUSEADDR/SOCK_REUSEADDR 的说明文档。
prop reusePort
public mut prop reusePort: Bool
功能:设置和读取 SO_REUSEPORT 属性。仅可在绑定前被修改。Windows 上可使用 SO_REUSEADDR,无该属性,抛出异常。
属性默认及配置生效后的行为取决于系统,使用前,请参阅不同系统针对此属性 SO_REUSEPORT 的说明文档。
同时开启 SO_REUSEADDR/SO_REUSEPORT 会导致不可预知的系统错误,用户需谨慎配置次值。
异常:
SocketException: Windows 上不支持此类型,抛出异常
prop sendBufferSize
public mut prop sendBufferSize: Int64
功能:设置和读取 SO_SNDBUF 属性。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
prop receiveBufferSize
public mut prop receiveBufferSize: Int64
功能:设置和读取 SO_RCVBUF 属性。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
prop bindToDevice
public mut prop bindToDevice: ?String
功能:设置和读取绑定网卡。
prop backlogSize
public mut prop backlogSize: Int64
功能:设置和读取 backlog 大小。仅可在调用 bind 前调用,否则将抛出异常。
变量是否生效取决于系统行为,可能不可预知得被忽略。
异常:
SocketException:当在bind后调用,将抛出异常
func bind
public override func bind(): Unit
功能:绑定本地端口失败后需要 close 套接字,不支持多次重试。
异常:
SocketException:当因系统原因绑定失败时抛出异常
func accept
public override func accept(timeout!: ?Duration): TcpSocket
功能:监听或接受客户端连接。
参数:
timeout:超时时间
返回值:客户端套接字
异常:
SocketTimeoutException:连接超时SocketException:当因系统原因监听失败时抛出异常IllegalArgumentException:当超时时间小于 0 时,抛出异常
func accept
public override func accept(): TcpSocket
功能:监听或接受客户端连接。阻塞等待。
返回值:客户端套接字
异常:
SocketException:当因系统原因监听失败时抛出异常
func close
public override func close(): Unit
功能:关闭套接字。接口允许多次调用。
func isClosed
public override func isClosed(): Bool
功能:检查套接字是否关闭。
返回值:如果已经关闭,返回 true,否则返回 false。
func getSocketOption
public func getSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: CPointer<UIntNative>
): Unit
功能:获取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当getsockopt返回失败时抛出异常
func setSocketOption
public func setSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: UIntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionIntNative
public func getSocketOptionIntNative(
level: Int32,
option: Int32
): IntNative
功能:获取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:获取的套接字参数值
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常。
func setSocketOptionIntNative
public func setSocketOptionIntNative(
level: Int32,
option: Int32,
value: IntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionBool
public func getSocketOptionBool(
level: Int32,
option: Int32
): Bool
功能:获取指定的套接字参数。从 IntNative 强转而来。0 => false, 非 0 => true。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:返回指定的套接字参数。从 IntNative 强转而来。0 => false, 非 0 => true
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常
func setSocketOptionBool
public func setSocketOptionBool(
level: Int32,
option: Int32,
value: Bool
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常。
func toString
public override func toString(): String
功能:返回当前 TcpServerSocket 的状态信息。
返回值:包含当前 TcpServerSocket 状态信息的字符串。
class UdpSocket
public class UdpSocket <: DatagramSocket {
public init(bindAt!: UInt16)
public init(bindAt!: SocketAddress)
}
UDPSocket 创建实例后,需要调用 bind() 绑定,可在不与远端建连的前提下接受报文。不过,UDPSocket 也可以通过 connect()/disconnect() 接口进行建连。
UDP 协议要求传输报文大小不可超过 64KB 。
UDPSocket 需要被显式 close() 。可以参阅 DatagramSocket 获取更多信息。
init
public init(bindAt!: UInt16)
功能:创建一个未绑定的 UDPSocket。
参数:
bindAt:绑定端口
init
public init(bindAt!: SocketAddress)
功能:创建一个未绑定的 UDPSocket。
参数:
bindAt:绑定地址及端口
prop remoteAddress
public override prop remoteAddress: ?SocketAddress
功能:Socket 已经连接的远端地址,当 Socket 未连接时返回 None。
异常:
SocketException:当Socket已经被关闭时抛出异常
prop localAddress
public override prop localAddress: SocketAddress
功能:Socket 将要或已经被绑定的本地地址。
异常:
SocketException:当Socket已经被关闭或无可用的本地地址(本地地址未配置并且套接字未连接)时抛出异常
prop receiveTimeout
public override mut prop receiveTimeout: ?Duration
功能:设置和读取 receive/receiveFrom 操作超时时间。
返回值:超时时间或 None,如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间((263-1) 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
prop sendTimeout
public override mut prop sendTimeout: ?Duration
功能:设置和读取 send/sendTo 操作超时时间。
返回值:超时时间或 None,如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间((263-1) 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
func close
public override func close(): Unit
功能:关闭套接字,所有操作除了 close/isClosed 之外,均不允许再调用。接口允许多次调用。
func isClosed
public override func isClosed(): Bool
功能:判断套接字是否通过调用 close 显式关闭。
返回值:如果该套接字已调用 close 显示关闭,则返回 true;否则,返回 false。
func bind
public func bind()
功能:绑定本地端口失败后需要 close 套接字,不支持多次重试。
异常:
SocketException:当因系统原因绑定失败时抛出异常
func connect
public func connect(remote: SocketAddress): Unit
功能:连接特定远端地址,可通过 disconnect 撤销配置。仅接受该远端地址的报文。必须在调用 bind 后执行。此操作执行后,端口将开始接收 ICMP 报文,若收到异常报文后,可能导致 send/sendTo 执行失败。
参数:
remote:远端地址,需要与本地地址都在 IPv4 协议下
异常:
IllegalArgumentException:当远端地址不合法时抛出异常SocketException:当端口未绑定时抛出异常SocketException:当连接因系统原因无法建立时抛出异常SocketException:Windows 平台下远端地址为全零地址时, 将抛出异常
func disconnect
public func disconnect(): Unit
功能:停止连接。取消仅收取特定对端报文。可在 connect 前调用,可多次调用。
func receiveFrom
public override func receiveFrom(buffer: Array<Byte>): (SocketAddress, Int64)
功能:收取报文。
参数:
buffer:存储收取到报文的缓存地址
返回值:收取到的报文的发送端地址,及实际收取到的报文大小,可能为 0 或者大于参数 buffer 的大小
异常:
SocketException:本机缓存过小无法读取报文时,抛出异常SocketTimeoutException:读取超时时抛出异常
func sendTo
public override func sendTo(recipient: SocketAddress, payload: Array<Byte>): Unit
功能:发送报文。当没有足够的缓存地址时可能会被阻塞。
参数:
recipient:发送的对端地址payload:发送报文内容
异常:
SocketException:当payload的大小超出系统限制SocketException:系统发送失败,例如:当connect被调用,并且收到异常 ICMP 报文时,发送将失败SocketException:Windows 平台下远端地址为全零地址时, 将抛出异常SocketException:macOS 平台下当connect被调用后调用sendTo, 将抛出异常
func send
public func send(payload: Array<Byte>): Unit
功能:发送报文到 connect 连接到的地址。
参数:
payload:发送报文内容
异常:
SocketException:当payload的大小超出系统限制SocketException:系统发送失败,例如:当connect被调用,并且收到异常 ICMP 报文时,发送将失败
func receive
public func receive(buffer: Array<Byte>): Int64
功能:从 connect 连接到的地址收取报文。
参数:
payload:存储收取到的报文的地址
返回值:收取到的报文大小
prop reusePort
public mut prop reusePort: Bool
功能:设置和读取 SO_REUSEPORT 属性。Windows 上可使用 SO_REUSEADDR,但无 SO_REUSEPORT 属性,因此会抛出异常。
属性默认以及配置生效后的行为取决于系统,使用前,请参阅不同系统针对此属性 SO_REUSEPORT 的说明文档。
异常:
SocketException:Windows 上不支持此类型,抛出异常
prop reuseAddress
public mut prop reuseAddress: Bool
功能:设置和读取 SO_REUSEADDR 属性
属性默认以及生效后的行为取决于系统,使用前,请参阅不同系统针对此属性 SO_REUSEADDR/SOCK_REUSEADDR 的说明文档。
prop sendBufferSize
public mut prop sendBufferSize: Int64
功能:设置和读取 SO_SNDBUF 属性。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
prop receiveBufferSize
public mut prop receiveBufferSize: Int64
功能:设置和读取 SO_RCVBUF 属性。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
func getSocketOption
public func getSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: CPointer<UIntNative>
): Unit
功能:获取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当getsockopt返回失败时抛出异常
func setSocketOption
public func setSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: UIntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionIntNative
public func getSocketOptionIntNative(
level: Int32,
option: Int32
): IntNative
功能:获取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:指定的套接字参数值
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常
func setSocketOptionIntNative
public func setSocketOptionIntNative(
level: Int32,
option: Int32,
value: IntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionBool
public func getSocketOptionBool(
level: Int32,
option: Int32
): Bool
功能:获取指定的套接字参数。从 IntNative 强转而来。0 => false, 非 0 => true。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:返回指定的套接字参数。从 IntNative 强转而来。0 => false, 非 0 => true
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常
func setSocketOptionBool
public func setSocketOptionBool(
level: Int32,
option: Int32,
value: Bool
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常
func toString
public override func toString(): String
功能:返回当前 UdpSocket 的状态信息。
返回值:包含当前 UdpSocket 状态信息的字符串。
class UnixSocket
public class UnixSocket <: StreamingSocket {
public init(path: String)
public init(address: SocketAddress)
}
UnixSocket 实例创建后应调用 connect() 接口创建连接,并且在结束时显式调用 close() 回收资源。可参阅 StreamingSocket 获取更多信息。
注:该类型不支持在 Windows 平台上运行。
init
public init(path: String)
功能:创建一个未连接的 UnixSocket 实例此文件类型可通过 isSock() 判断是否存在,可通过 unlink() 接口删除。
参数:
path:连接的文件地址
init
public init(address: SocketAddress)
功能:创建一个未连接的 UnixSocket 实例。
参数:
address:连接的套接字地址
prop remoteAddress
public override prop remoteAddress: SocketAddress
功能:Socket 已经或将要连接的远端地址。
异常:
SocketException:当Socket已经被关闭时抛出异常
prop localAddress
public override prop localAddress: SocketAddress
功能:Socket 将要或已经被绑定的本地地址。
异常:
SocketException:当Socket已经被关闭或无可用的本地地址(本地地址未配置并且套接字未连接)时抛出异常
prop readTimeout
public override mut prop readTimeout: ?Duration
功能:设置和读取读操作超时时间。
返回值:超时时间或 None。如果设置的时间过小将会设置为最小时钟周期值,过大时将设置为None,默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
prop writeTimeout
public override mut prop writeTimeout: ?Duration
功能:设置和读取写操作超时时间。
返回值:超时时间或 None。如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间((263-1) 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
prop sendBufferSize
public mut prop sendBufferSize: Int64
功能:设置和读取 SO_SNDBUF 属性。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
prop receiveBufferSize
public mut prop receiveBufferSize: Int64
功能:设置和读取 SO_RCVBUF 属性。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
func read
public override func read(buffer: Array<Byte>): Int64
功能:读取报文。超时情况按 readTimeout 决定, 详见 readTimeout。
参数:
buffer:读取的数据存储变量
返回值:读取的数据长度
异常:
SocketException:当buffer大小为 0 时抛出异常,当因系统原因读取失败时,抛出异常
func write
public override func write(buffer: Array<Byte>): Unit
功能:读取写入。超时情况按 writeTimeout 决定,详见 writeTimeout。
参数:
buffer:写入的数据存储变量
异常:
SocketException:当buffer大小为 0 时抛出异常,当因系统原因写入失败时,抛出异常
func connect
public func connect(timeout!: ?Duration = None)
功能:建立远端连接,对端拒绝时连接失败,会自动绑定本地地址,因此不需要进行额外的绑定操作。
参数:
timeout:超时时间,None表示无超时时间。Unix 与 Tcp 不同,队列已满时,调用将理解返回错误,而非重试阻塞等待
异常:
IllegalArgumentException:当远端地址不合法时抛出异常SocketException:当连接因系统原因无法建立时抛出异常SocketTimeoutException:当连接超时时抛出异常IllegalArgumentException:当超时时间小于 0 时,抛出异常
func getSocketOption
public func getSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: CPointer<UIntNative>
): Unit
功能:获取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当getsockopt返回失败时抛出异常
func setSocketOption
public func setSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: UIntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionIntNative
public func getSocketOptionIntNative(
level: Int32,
option: Int32
): IntNative
功能:获取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:返回指定的套接字参数值
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常
func setSocketOptionIntNative
public func setSocketOptionIntNative(
level: Int32,
option: Int32,
value: IntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionBool
public func getSocketOptionBool(
level: Int32,
option: Int32
): Bool
功能:获取指定的套接字参数。从 IntNative 强转而来。0 => false,非 0 => true。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:返回指定的套接字参数值。从 IntNative 强转而来。0 => false,非 0 => true
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常
func setSocketOptionBool
public func setSocketOptionBool(
level: Int32,
option: Int32,
value: Bool
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常
func close
public func close(): Unit
功能:关闭套接字,所有操作除了 close/isClosed 之外,均不允许再调用。接口允许多次调用。
func isClosed
public func isClosed(): Bool
功能:判断套接字是否通过调用 close 显式关闭。
返回值:返回套接字是否已经调用 close 显示关闭。是则返回 true;否则,返回 false
func toString
public override func toString(): String
功能:返回当前 UnixSocket 的状态信息。
返回值:包含当前 UnixSocket 状态信息的字符串。
class UnixServerSocket
public class UnixServerSocket <: ServerSocket
UnixServerSocket 监听连接,创建后可以通过属性和 setSocketOptionXX 接口配置属性值。需要调用 bind() 接口绑定本地地址开始监听连接。可以通过 accept() 接口接受连接。
注:该类型不支持在 Windows 平台上运行。
prop localAddress
public override prop localAddress: SocketAddress
功能:Socket 将要或已经被绑定的本地地址。
异常:
SocketException:当Socket已经被关闭时抛出异常
init
public init(bindAt!: String)
功能:创建一个未连接的 UnixServerSocket 实例此文件类型可通过 isSock() 判断是否存在,可通过 unlink() 接口删除。
参数:
path:连接的文件地址
init
public init(bindAt!: SocketAddress)
功能:创建一个未连接的 UnixServerSocket 实例。
参数:
address:连接的套接字地址
prop sendBufferSize
public mut prop sendBufferSize: Int64
功能:设置和读取 SO_SNDBUF 属性。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
prop receiveBufferSize
public mut prop receiveBufferSize: Int64
功能:设置和读取 SO_RCVBUF 属性。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
prop backlogSize
public mut prop backlogSize: Int64
功能:设置和读取 backlog 大小。仅可在调用 bind 前调用,否则将抛出异常。
变量是否生效取决于系统行为,可能不可预知得被忽略。
异常:
SocketException:当在bind后调用,将抛出异常
func bind
public override func bind(): Unit
功能:绑定一个 Unix domain 套接字,并创建监听队列此接口自动在本地地址中创建一个套接字文件,如该文件已存在则会绑定失败此文件类型可通过 isSock() 接口判断是否存在,可通过 unlink() 接口删除失败后需要 close 套接字,不支持多次重试。
异常:
SocketException:当因系统原因绑定失败时抛出异常
func accept
public override func accept(timeout!: ?Duration): UnixSocket
功能:等待接受一个客户端的连接,或从队列中读取连接。
参数:
timeout:超时时间
返回值:连接的客户端套接字
异常:
SocketTimeoutException:连接超时IllegalArgumentException:当超时时间小于 0 时,抛出异常
func accept
public override func accept(): UnixSocket
功能:等待接受一个客户端的连接,或从队列中读取连接。
返回值:连接的客户端套接字
func close
public override func close(): Unit
功能:关闭套接字,该套接字的所有操作除了 close/isClosed 之外,均不允许再调用。此接口允许多次调用。
func isClosed
public override func isClosed(): Bool
功能:判断套接字是否通过调用 close 显式关闭。
func getSocketOption
public func getSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: CPointer<UIntNative>
): Unit
功能:获取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当getsockopt返回失败时抛出异常
func setSocketOption
public func setSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: UIntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionIntNative
public func getSocketOptionIntNative(
level: Int32,
option: Int32
): IntNative
功能:获取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:返回指定的套接字参数值
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常
func setSocketOptionIntNative
public func setSocketOptionIntNative(
level: Int32,
option: Int32,
value: IntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionBool
public func getSocketOptionBool(
level: Int32,
option: Int32
): Bool
功能:获取指定的套接字参数。从 IntNative 强转而来。0 => false, 非 0 => true。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:返回指定的套接字参数。从 IntNative 强转而来。0 => false, 非 0 => true
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常
func setSocketOptionBool
public func setSocketOptionBool(
level: Int32,
option: Int32,
value: Bool
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常
func toString
public override func toString(): String
功能:返回当前 UnixServerSocket 的状态信息。
返回值:包含当前 UnixServerSocket 状态信息的字符串。
class UnixDatagramSocket
public class UnixDatagramSocket <: DatagramSocket {
public init(bindAt!: String)
public init(bindAt!: SocketAddress)
}
UnixDatagramSocket 实例创建后,应当显式调用 bind() 接口绑定。Unix 数据包套接字不需要连接,不需要与远端握手多次。不过用户也可以通过 connect/disconnect 接口与远端建连和断连。
不同于 UDP, UDS 没有数据包大小限制,限制来源于操作系统和接口实现。
套接字资源需要用 close 接口显式回收。可参阅 DatagramSocket 获取更多信息。
注:该类型不支持在 Windows 平台上运行。
init
public init(bindAt!: String)
功能:创建一个未连接的 UnixDatagramSocket 实例此文件类型可通过 isSock() 判断是否存在,可通过 unlink() 接口删除。
参数:
bindAt:连接的文件地址。文件地址应当不存在,在bind时会创建
异常:
SocketException:当路径为空或已存在时,抛出异常
init
public init(bindAt!: SocketAddress)
功能:创建一个未连接的 UnixDatagramSocket 实例。
参数:
bindAt:连接的套接字地址。地址应当不存在,在bind时会创建
异常:
SocketException:当路径为空或已存在时,抛出异常
prop remoteAddress
public override prop remoteAddress: ?SocketAddress
功能:Socket 已经连接的远端地址,当 Socket 未连接时返回 None。
异常:
SocketException:当Socket已经被关闭时抛出异常
prop localAddress
public override prop localAddress: SocketAddress
功能:socket 将要或已经绑定的本地地址。
异常:
SocketException:当socket已经关闭将抛出异常
prop receiveTimeout
public override mut prop receiveTimeout: ?Duration
功能:设置和读取 receive/receiveFrom 操作超时时间。
返回值:超时时间或 None,如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间((263-1) 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
prop sendTimeout
public override mut prop sendTimeout: ?Duration
功能:设置和读取 send/sendTo 操作超时时间。
返回值:超时时间或 None,如果设置的时间过小将会设置为最小时钟周期值;过大时将设置为最大超时时间((263-1) 纳秒);默认值为 None
异常:
IllegalArgumentException:当超时时间小于 0 时,抛出异常
func close
public override func close(): Unit
功能:关闭套接字,所有操作除了 close/isClosed 之外,均不允许再调用。接口允许多次调用。
func isClosed
public override func isClosed(): Bool
功能:判断套接字是否通过调用 close 显式关闭。
返回值:返回套接字是否已经通过调用 close 显式关闭。是则返回 true;否则,返回 false
func bind
public func bind(): Unit
功能:绑定一个 Unix datagram 套接字,并创建监听队列。此接口自动在本地地址中创建一个套接字文件,如该文件已存在则会绑定失败此文件类型可通过 isSock() 判断是否存在,可通过 unlink() 接口删除失败后需要 close 套接字,不支持多次重试。
异常:
SocketException:当文件地址已存在,或文件创建失败将抛出异常
func connect
public func connect(remotePath: String): Unit
功能:连接特定远端地址,可通过 disconnect 撤销配置。仅接受该远端地址的报文。必须在 bind 后调用。此操作执行后,端口将开始接收 ICMP 报文,若收到异常报文后,可能导致 send/sendTo 执行失败。
参数:
remotePath:远端文件地址
异常:
SocketException:当地址未绑定时,将抛出异常
func connect
public func connect(remote: SocketAddress): Unit
功能:连接特定远端地址,可通过 disconnect 撤销配置。仅接受该远端地址的报文。默认执行 bind,因此不需额外调用 bind。此操作执行后,端口将开始接收 ICMP 报文,若收到异常报文后,可能导致 send/sendTo 执行失败。
参数:
remote:远端套接字地址
异常:
SocketException:当地址未绑定时,将抛出异常
func disconnect
public func disconnect(): Unit
功能:停止连接。取消仅收取特定对端报文。可在 connect 前调用,可多次调用。
异常:
SocketException:当未绑定时抛出异常
func receiveFrom
public override func receiveFrom(buffer: Array<Byte>): (SocketAddress, Int64)
功能:收取报文。
参数:
buffer:存储收取到报文的地址
返回值:收取到的报文的发送端地址,及实际收取到的报文大小,可能为 0 或者大于参数 buffer 的大小
异常:
SocketException:本机缓存过小无法读取报文时,抛出异常SocketTimeoutException:读取超时时抛出异常
func sendTo
public override func sendTo(recipient: SocketAddress, payload: Array<Byte>): Unit
功能:发送报文。当没有足够的缓存地址时可能会被阻塞。
参数:
recipient:发送的对端地址payload:发送报文内容
异常:
SocketException:当payload的大小超出系统限制SocketException:系统发送失败,例如:当connect被调用,并且收到异常 ICMP 报文时,发送将失败SocketException:macOS 平台下当connect被调用后调用sendTo, 将抛出异常
func send
public func send(payload: Array<Byte>): Unit
功能:发送报文到 connect 连接到的地址。
参数:
payload:发送报文内容
异常:
SocketException:当payload的大小超出系统限制SocketException:系统发送失败,例如:当connect被调用,并且收到异常 ICMP 报文时,发送将失败
func receive
public func receive(buffer: Array<Byte>): Int64
功能:从 connect 连接到的地址收取报文。
参数:
buffer:存储收取到的报文的地址
返回值:收取到的报文大小
prop sendBufferSize
public mut prop sendBufferSize: Int64
功能:设置和读取 SO_SNDBUF 属性,提供一种方式指定发包缓存大小。选项的生效情况取决于系统。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
prop receiveBufferSize
public mut prop receiveBufferSize: Int64
功能:设置和读取 SO_RCVBUF 属性,提供一种方式指定发包缓存大小。选项的生效情况取决于系统。
异常:
IllegalArgumentException:当size小于等于 0 时,抛出异常SocketException:当Socket已关闭时,抛出异常
func getSocketOption
public func getSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: CPointer<UIntNative>
): Unit
功能:获取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当getsockopt返回失败时抛出异常
func setSocketOption
public func setSocketOption(
level: Int32,
option: Int32,
value: CPointer<Unit>,
valueLength: UIntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值valueLength:参数值长度
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionIntNative
public func getSocketOptionIntNative(
level: Int32,
option: Int32
): IntNative
功能:获取指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:返回指定的套接字参数值
异常:
SocketException:当getsockopt返回失败时或参数大小超过IntNative的阈值时抛出异常
func setSocketOptionIntNative
public func setSocketOptionIntNative(
level: Int32,
option: Int32,
value: IntNative
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败时抛出异常
func getSocketOptionBool
public func getSocketOptionBool(
level: Int32,
option: Int32
): Bool
功能:获取指定的套接字参数。从 IntNative 强转而来。0 => false, 非 0 => true。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVE
返回值:返回指定的套接字参数值。从 IntNative 强转而来。0 => false, 非 0 => true
异常:
SocketException:当getsockopt返回失败时抛出异常
func setSocketOptionBool
public func setSocketOptionBool(
level: Int32,
option: Int32,
value: Bool
): Unit
功能:设置指定的套接字参数。
参数:
level:层级,例如SOL_SOCKEToption:参数,例如SO_KEEPALIVEvalue:参数值
异常:
SocketException:当setsockopt返回失败抛出异常
func toString
public override func toString(): String
功能:返回当前 UDS 的状态信息。
返回值:包含当前 UDS 状态信息的字符串。
enum SocketNet
public enum SocketNet <: ToString & Equatable<SocketNet> {
| TCP
| UDP
| UNIX
}
传输层协议类型。
TCP
TCP
功能:TCP。
UDP
UDP
功能:UDP。
UNIX
UNIX
功能:UNIX。
func toString
public func toString(): String
功能:将枚举值转换为字符串。
返回值:返回转换后字符串
operator func ==
public operator func ==(that: SocketNet): Bool
功能:判断两个 SocketNet 是否相等。
参数:
that:传入SocketNet
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public operator func !=(that: SocketNet): Bool
功能:判断两个 SocketNet 是否不相等。
参数:
that:传入SocketNet
返回值:如果不相等,则返回 true;否则,返回 false
enum SocketAddressKind
public enum SocketAddressKind <: ToString & Equatable<SocketAddressKind> {
| IPv4
| IPv6
| Unix
}
互联网通信协议种类。
IPv4
IPv4
功能:IPv4。
IPv6
IPv6
功能:IPv6。
Unix
Unix
功能:Unix。
func toString
public func toString(): String
功能:将枚举值转换为字符串。
返回值:返回转换后字符串
operator func ==
public operator func ==(that: SocketAddressKind): Bool
功能:判断两个 SocketAddressKind 是否相等。
参数:
that:传入SocketAddressKind
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public operator func !=(that: SocketAddressKind): Bool
功能:判断两个 SocketAddressKind 是否不相等。
参数:
that:传入SocketAddressKind
返回值:如果不相等,则返回 true;否则,返回 false
struct SocketKeepAliveConfig
public struct SocketKeepAliveConfig <: ToString & Equatable<SocketKeepAliveConfig> {
public let idle: Duration
public let interval: Duration
public let count: UInt32
public init(
idle!: Duration = Duration.second * 45,
interval!: Duration = Duration.second * 5,
count!: UInt32 = 5
)
public init(
idleSeconds: UInt32,
intervalSeconds: UInt32,
count: UInt32
)
}
TCP KeepAlive 属性配置
init
public init(
idle!: Duration = Duration.second * 45,
interval!: Duration = Duration.second * 5,
count!: UInt32 = 5
)
功能:初始化 SocketKeepAliveConfig 实例对象。
参数:
idle:允许空闲的时长,默认 45 秒interval:保活报文发送周期,默认 45 秒count:查询连接是否失效的报文个数, 默认 5 个
异常:
IllegalArgumentException:当配置为空闲状态或设置间隔小于 0 时抛出异常
idle
public let idle: Duration
功能:允许连接空闲的时长,空闲超长将关闭连接。
interval
public let interval: Duration
功能:保活报文发送周期。
count
public let count: UInt32
功能:查询连接是否失效的报文个数。
func toString
public override func toString(): String
功能:将 TCP KeepAlive 属性配置转换为字符串。
返回值:返回转换后字符串
operator func ==
public override operator func ==(other: SocketKeepAliveConfig): Bool
功能:判断两个 SocketKeepAliveConfig 实例是否相等。
参数:
other:参与比较的SocketKeepAliveConfig实例。
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public override operator func !=(other: SocketKeepAliveConfig): Bool
功能:判断两个 SocketKeepAliveConfig 实例是否不等。
参数:
other:参与比较的SocketKeepAliveConfig实例。
返回值:如果不等,则返回 true;否则,返回 false
class SocketAddress
public open class SocketAddress <: ToString & Hashable & Equatable<SocketAddress> {
public init(kind: SocketAddressKind, address: Array<UInt8>, port: UInt16)
public init(hostAddress: String, port: UInt16)
public init(unixPath!: String)
}
具有特定类型、地址和端口的套接字地址。
init
public init(kind: SocketAddressKind, address: Array<UInt8>, port: UInt16)
功能:初始化 SocketAddress。
参数:
kind:套接字地址类型address:IP 地址port:端口号
异常:
SocketException:当地址长度不符合地址类型要求时抛出异常
init
public init(hostAddress: String, port: UInt16)
功能:初始化 SocketAddress。
参数:
hostAddress:IP 地址port:端口号
异常:
SocketException:当地址无法解析成 IP 格式,或不符合地址类型要求时抛出异常
init
public init(unixPath!: String)
功能:初始化 SocketAddress。
参数:
unixPath:连接的文件地址
异常:
SocketException:当地址无法解析成 IP 格式,或不符合地址类型要求时抛出异常
prop address
public prop address: Array<UInt8>
功能:获取地址。
返回值:获取存储在数组中的地址
prop hostAddress
public prop hostAddress: String
功能:获取主机地址。
返回值:获取由字符串表示的主机地址
prop hostName
public prop hostName: Option<String>
功能:获取名称,不存在时返回 None。
prop kind
public prop kind: SocketAddressKind
功能:获取地址类型。
返回值:返回地址类型
prop port
public prop port: UInt16
功能:获取端口。
返回值:返回端口
prop zone
public prop zone: Option<String>
功能:获取 IPv6 地址族。
返回值:如果 IPv6 地址族存在,返回 IPv6 地址族,否则返回 None
prop defaultMask
public prop defaultMask: Option<IPMask>
功能:获取默认掩码。
返回值:如果默认掩码存在,返回默认掩码,否则返回 None
func mask
public func mask(mask: IPMask): SocketAddressWithMask
功能:使用掩码处理地址。
参数:
mask:掩码
返回值:被处理后的地址
异常:
SocketException:当掩码长度不符合地址长度时,抛出异常IllegalArgumentException:当缓存空间不符合 IPv4/IPv6 要求时
func toString
public open func toString(): String
功能:获取地址对象字符串,格式为:"127.0.0.1:2048", "[::]:2048","[212c:3742::ffff:5863:6f00]:2048" 等。
异常:
SocketException:地址不合法时,抛出异常
func hashCode
public open func hashCode(): Int64
功能:获取 hashcode 值。
返回值:返回 hashcode 值
operator func ==
public operator func ==(that: SocketAddress): Bool
功能:判断两个 SocketAddress 是否相等。
参数:
that:传入SocketAddress
返回值:如果相等,则返回 true;否则,返回 false
operator func !=
public operator func != (that: SocketAddress): Bool
功能:判断两个 SocketAddress 是否不相等。
参数:
that:传入SocketAddress
返回值:如果不相等,则返回 true;否则,返回 false
func kapString
public func kapString(): String
功能:获取 IP 协议、地址和端口字符串。
返回值:返回 IP 协议、地址和端口字符串
异常:
SocketException:地址的大小与 IPv4 或 IPv6 不匹配时,抛出异常
func setHostName
public func setHostName(name: String): Unit
功能:设置主机名。
func resolve
public static func resolve(domain: String, port: UInt16): ?SocketAddress
功能:解析域和端口,并构造 SocketAddress 的实例。
当传入 IP 地址时,不包含 DNS 能力。当传入域名地址时,通过 getaddrinfo 解析得到 IP 地址,其中优先解析 IPv4 地址,并仅返回获取到的首个 IP 地址。
参数:
domain:域port:端口
返回值:如果解析域和端口成功,返回 SocketAddress 实例,否则返回 None
class SocketAddressWithMask
public class SocketAddressWithMask <: SocketAddress {
public init(kind: SocketAddressKind, address: Array<UInt8>, port: UInt16, mask: IPMask)
public init(hostAddress: String, port: UInt16, mask: IPMask)
public init(socketAddr: SocketAddress, mask: IPMask)
}
带有掩码的 SocketAddress。
init
public init(kind: SocketAddressKind, address: Array<UInt8>, port: UInt16, mask: IPMask)
功能:初始化 SocketAddressWithMask。
参数:
kind:SocketAddress类型address:符合kind所指定类型的地址port:端口mask:掩码
异常:
SocketException:当参数address传入的地址不符合参数kind地址类型的要求时,抛出异常
init
public init(hostAddress: String, port: UInt16, mask: IPMask)
功能:初始化 SocketAddressWithMask。
参数:
hostAddress:IP 地址字符串port:端口mask:掩码
异常:
SocketException:当参数address无法解析成合法的 IP 地址
init
public init(socketAddr: SocketAddress, mask: IPMask)
功能:初始化 SocketAddressWithMask。
参数:
socketAddr:地址mask:掩码
异常:
SocketException:当参数socketAddr不合法
prop ipMask
public mut prop ipMask: IPMask
功能:设置/获取 IP 掩码。
返回值:返回 IP 掩码
func clone
public func clone(): SocketAddressWithMask
功能:使用绑定的掩码处理地址,复制一个地址。
返回值:复制生成的 SocketAddressWithMask 实例
异常:
SocketException:当掩码长度不符合地址长度IllegalArgumentException:当缓存长度不足
func toString
public override func toString(): String
功能:将 SocketAddressWithMask 转换为字符串。
返回值:返回转换后字符串
func hashCode
public override func hashCode(): Int64
功能:获取 SocketAddressWithMask 的 hashcode 值。
返回值:返回 SocketAddressWithMask 的 hashcode 值
class IPMask
public class IPMask <: ToString {
public init(buf: Array<UInt8>)
public init(ones: Int64, bits: Int64)
public init(a: UInt8, b: UInt8, c: UInt8, d: UInt8)
}
IP 掩码,操作 IP 地址和路由地址。
init
public init(buf: Array<UInt8>)
功能:初始化掩码值。
参数:
buf:掩码值
异常:
IllegalArgumentException:当buffer值超出阈值,不符合 IPv4/IPv6 要求
init
public init(ones: Int64, bits: Int64)
功能:初始化掩码值。
参数:
ones:高位 1 的个数bits:bit位总个数
异常:
IllegalArgumentException:当bits值超出阈值,不符合 IPv4/IPv6 要求
init
public init(a: UInt8, b: UInt8, c: UInt8, d: UInt8)
功能:初始化掩码值,参数值分别是 IPv4 的 4 个字节 a.b.c.d。
参数:
a:最高字节b:次高字节c:次低字节d:最低字节
func size
public func size(): (Int64, Int64)
功能:获取高位 1 的个数,以及总 bit 位数。
返回值:高位 1 的个数,以及总 bit 位数,若掩码格式不符合高位均为 1 的格式,返回 (0, 0)
func toString
public func toString(): String
功能:将IP 掩码转换为字符串。
返回值:返回转换后字符串
struct SocketOptions
public struct SocketOptions {
public static const SOL_SOCKET: Int32 = SOL_SOCKET
public static const IPPROTO_TCP: Int32 = IPPROTO_TCP
public static const IPPROTO_UDP: Int32 = IPPROTO_UDP
public static const SO_KEEPALIVE: Int32 = SOCK_KEEPALIVE
public static const TCP_NODELAY: Int32 = SOCK_TCP_NODELAY
public static const TCP_QUICKACK: Int32 = SOCK_TCP_QUICKACK
public static const SO_LINGER: Int32 = SOCK_LINGER
public static const SO_SNDBUF: Int32 = SOCK_SNDBUF
public static const SO_RCVBUF: Int32 = SOCK_RCVBUF
public static const SO_REUSEADDR: Int32 = SOCK_REUSEADDR
public static const SO_REUSEPORT: Int32 = SOCK_REUSEPORT
public static const SO_BINDTODEVICE: Int32 = SOCK_BINDTODEVICE
}
struct SocketOptions 存储了设置套接字选项的一些参数常量方便后续调用。
SOL_SOCKET
public static const SOL_SOCKET: Int32 = SOL_SOCKET
常数,用于将套接字选项的 level 层级设为 SOL_SOCKET。
IPPROTO_TCP
public static const IPPROTO_TCP: Int32 = IPPROTO_TCP
常数,用于将套接字选项的 level 层级设为 IPPROTO_TCP。
IPPROTO_UDP
public static const IPPROTO_UDP: Int32 = IPPROTO_UDP
常数,用于将套接字选项的 level 层级设为 IPPROTO_UDP。
SO_KEEPALIVE
public static const SO_KEEPALIVE: Int32 = SOCK_KEEPALIVE
常数,用于将套接字选项的 optname 设为 SO_KEEPALIVE。
TCP_NODELAY
public static const TCP_NODELAY: Int32 = SOCK_TCP_NODELAY
常数,用于将套接字选项的 optname 设为 TCP_NODELAY。
TCP_QUICKACK
public static const TCP_QUICKACK: Int32 = SOCK_TCP_QUICKACK
常数,用于将套接字选项的 optname 设为 TCP_QUICKACK。
SO_LINGER
public static const SO_LINGER: Int32 = SOCK_LINGER
常数,用于将套接字选项的 optname 设为 SO_LINGER。
SO_SNDBUF
public static const SO_SNDBUF: Int32 = SOCK_SNDBUF
常数,用于将套接字选项的 optname 设为 SO_SNDBUF。
SO_RCVBUF
public static const SO_RCVBUF: Int32 = SOCK_RCVBUF
常数,用于将套接字选项的 optname 设为 SO_RCVBUF。
SO_REUSEADDR
public static const SO_REUSEADDR: Int32 = SOCK_REUSEADDR
常数,用于将套接字选项的 optname 设为 SO_REUSEADDR。
SO_REUSEPORT
public static const SO_REUSEPORT: Int32 = SOCK_REUSEPORT
常数,用于将套接字选项的 optname 设为 SO_REUSEPORT。
SO_BINDTODEVICE
public static const SO_BINDTODEVICE: Int32 = SOCK_BINDTODEVICE
常数,用于将套接字选项的 optname 设为 SO_BINDTODEVICE。
class RawSocket
public class RawSocket {
public init(domain: SocketDomain, `type`: SocketType, protocol: ProtocolType)
}
RawSocket 提供了套接字的基本功能,可以访问特定通信域(domain)、类型(type)和协议(protocol)组合的套接字。Socket 包已经提供了 TCP、 UDP 等常用网络协议的支持,因此,该类型适用于已经支持以外的网络编程需求。
注意:当前 RawSocket 已经验证的功能包括 TCP、UDP、UDS 以及 ICMP 协议套接字,其它类型使用上可能存在预期之外的问题。此外,由于接口的开放性,可以使用 connect 再 listen 的组合,部分场景可能存在预期外的问题,请开发者使用时遵循正常的调用逻辑,避免产生问题。
init
public init(domain: SocketDomain, `type`: SocketType, protocol: ProtocolType)
功能:创建特定通信域、类型、协议组合的套接字。
参数:
domain:通信域type:套接字类型protocol:协议类型
异常:
SocketException:通信域、类型、协议组合无法创建套接字
prop localAddr
public prop localAddr: RawAddress
功能:获取当前 RawSocket 实例的本地地址。
返回值:当前 RawSocket 实例的本地地址
异常:
SocketException:当前RawSocket实例已经关闭,或无法获取本地地址
prop remoteAddr
public prop remoteAddr: RawAddress
功能:获取当前 RawSocket 实例的对端地址。
返回值:当前 RawSocket 实例的对端地址
异常:
SocketException:当前RawSocket实例已经关闭,或无法获取对端地址
prop readTimeout
public mut prop readTimeout: ?Duration
功能:获取或设置当前 RawSocket 实例的读超时时间。
异常:
SocketException:当前RawSocket实例已经关闭IllegalArgumentException:设置的读超时时间为负
prop writeTimeout
public mut prop writeTimeout: ?Duration
功能:获取或设置当前 RawSocket 实例的写超时时间。
异常:
SocketException:当前RawSocket实例已经关闭IllegalArgumentException:设置的写超时时间为负
func bind
public func bind(addr: RawAddress): Unit
功能:将当前 RawSocket 实例与指定的套接字地址进行绑定。
参数:
addr:套接字地址
异常:
SocketException:当前RawSocket实例已经关闭,或绑定失败
func listen
public func listen(backlog: Int32): Unit
功能:监听当前 RawSocket 实例绑定的地址。
参数:
backlog:等待队列增长的最大长度
异常:
SocketException:当前RawSocket实例已经关闭,或监听失败
func accept
public func accept(timeout!: ?Duration = None): RawSocket
功能:接收当前 RawSocket 实例监听时挂起连接队列上的第一个连接请求,返回一个用于通信的 RawSocket。
参数:
timeout:等待连接请求的最大时间,默认值None表示一直等待
异常:
SocketException:当前RawSocket实例已经关闭,或接收失败SocketTimeoutException:等待超时
返回值:用于通信的新 RawSocket 实例
func connect
public func connect(addr: RawAddress, timeout!: ?Duration = None): Unit
功能:向目标地址发送连接请求。
参数:
addr:发送连接请求的目标地址timeout:等待连接接收的最大时间,默认值None表示一直等待
异常:
SocketException:当前RawSocket实例已经关闭,或请求失败SocketTimeoutException:等待超时
func close
public func close(): Unit
功能:关闭。
func sendTo
public func sendTo(addr: RawAddress, buffer: Array<Byte>, flags: Int32): Unit
功能:向目标地址发送数据。若 RawSocket 是 DATAGRAM 类型,发送的数据包大小不允许超过 65507 字节。
参数:
addr:发送数据的目标地址buffer:数据flags:指定函数行为的标志
异常:
SocketException:当前RawSocket实例已经关闭,或发送数据失败SocketTimeoutException:超过指定的写超时时间SocketException:macOS 平台下当connect被调用后调用sendTo, 将抛出异常
func receiveFrom
public func receiveFrom(buffer: Array<Byte>, flags: Int32): (RawAddress, Int64)
功能:接收来自其它 RawSocket 实例的数据。
参数:
buffer:存储接收数据的数组flags:指定函数行为的标志
返回值:数据来源的地址和数据长度
异常:
SocketException:当前RawSocket实例已经关闭,或接收数据失败SocketTimeoutException:超过指定的读超时时间
func send
public func send(buffer: Array<Byte>, flags: Int32): Unit
功能:向连接的对端发送数据。
参数:
buffer:数据flags:指定函数行为的标志
异常:
SocketException:当前RawSocket实例已经关闭,或发送数据失败SocketTimeoutException:超过指定的写超时时间
func receive
public func receive(buffer: Array<Byte>, flags: Int32): Int64
功能:接收来自连接对端发送的数据。
参数:
buffer:存储接收数据的数组flags:指定函数行为的标志
返回值:数据长度
异常:
SocketException:当前RawSocket实例已经关闭,或发送数据失败SocketTimeoutException:超过指定的读超时时间
func setSocketOption
public unsafe func setSocketOption(level: Int32, option: Int32, value: CPointer<Byte>, len: Int32): Unit
功能:设置套接字选项。
参数:
level:套接字选项级别option:套接字选项名value:套接字选项值len:套接字选项字节长度
异常:
SocketException:当前RawSocket实例已经关闭,或设置套接字选项失败
func getSocketOption
public unsafe func getSocketOption(level: Int32, option: Int32, value: CPointer<Byte>, len: CPointer<Int32>): Unit
功能:获取套接字选项的值。
参数:
level:套接字选项级别option:套接字选项名value:存储套接字选项值的指针len:套接字选项值的长度
异常:
SocketException:当前RawSocket实例已经关闭,或获取套接字选项失败
struct SocketDomain
public struct SocketDomain <: Equatable<SocketDomain> & ToString & Hashable {
public static let IPV4: SocketDomain
public static let IPV6: SocketDomain
public static let UNIX: SocketDomain
public static let NETLINK: SocketDomain
public static let PACKET: SocketDomain
public init(domain: Int32)
}
提供了常用的套接字通信域,以及通过指定 Int32 值来构建套接字通信域的功能。
IPV4
public static let IPV4: SocketDomain
功能:IPV4 通信域。
IPV6
public static let IPV6: SocketDomain
功能:IPV6 通信域。
UNIX
public static let UNIX: SocketDomain
功能:本机通信。
NETLINK
public static let NETLINK: SocketDomain
功能:内核和用户空间进程之间通信。
注意:该常量在 Windows 平台不提供。
PACKET
public static let PACKET: SocketDomain
功能:允许用户空间程序直接访问网络数据包。
注意:该常量在 Windows 平台不提供。
init
public init(domain: Int32)
功能:根据指定通信域值创建套接字通信域。
operator func ==
public operator func ==(r: SocketDomain): Bool
功能:比较两个 SocketDomain 实例是否相等。
返回值:当二者代表的 Int32 值相等时,返回 true;否则,返回 false。
operator func !=
public operator func !=(r: SocketDomain): Bool
功能:比较两个 SocketDomain 实例是否不等。
返回值:当二者代表的 Int32 值不等时,返回 true;否则,返回 false。
func toString
public func toString(): String
功能:返回当前 SocketDomain 实例的字符串表示。
返回值:当前 SocketDomain 实例的字符串表示
func hashCode
public func hashCode(): Int64
功能:返回当前 SocketDomain 实例的哈希值。
返回值:当前 SocketDomain 实例的哈希值
struct SocketType
public struct SocketType <: Equatable<SocketType> & ToString & Hashable {
public static let STREAM: SocketType
public static let DATAGRAM: SocketType
public static let RAW: SocketType
public static let SEQPACKET: SocketType
public init(`type`: Int32)
}
提供了常用的套接字类型,以及通过指定 Int32 值来构建套接字类型的功能。
STREAM
public static let STREAM: SocketType
功能:流式套接字类型。
DATAGRAM
public static let DATAGRAM: SocketType
功能:数据报套接字类型。
RAW
public static let RAW: SocketType
功能:原始套接字类型。
SEQPACKET
public static let SEQPACKET: SocketType
功能:有序数据包套接字类型。
init
public init(`type`: Int32)
功能:通过指定套接字类型值创建套接字类型。
operator func ==
public operator func ==(r: SocketType): Bool
功能:判断两个 SocketType 实例是否相等。
返回值:当二者代表的 Int32 值相等时,返回 true;否则,返回 false
operator func !=
public operator func !=(r: SocketType): Bool
功能:判断两个 SocketType 实例是否不等。
返回值:当二者代表的 Int32 值不等时,返回 true;否则,返回 false
func toString
public func toString(): String
功能:返回当前 SocketType 实例的字符串表示。
返回值:当前 SocketType 实例的字符串表示
func hashCode
public func hashCode(): Int64
功能:返回当前 SocketType 实例的哈希值。
返回值:当前 SocketType 实例的哈希值
struct ProtocolType
public struct ProtocolType <: Equatable<ProtocolType> & ToString & Hashable {
public static let Unspecified: ProtocolType
public static let IPV4: ProtocolType
public static let IPV6: ProtocolType
public static let ICMP: ProtocolType
public static let TCP: ProtocolType
public static let UDP: ProtocolType
public static let RAW: ProtocolType
public init(protocol: Int32)
}
提供了常用的套接字协议,以及通过指定 Int32 值来构建套接字协议的功能。
Unspecified
public static let Unspecified: ProtocolType
功能:不指定协议。
IPV4
public static let IPV4: ProtocolType
功能:指定协议类型为 IPV4 。
IPV6
public static let IPV6: ProtocolType
功能:指定协议类型为 IPV6。
ICMP
public static let ICMP: ProtocolType
功能:指定协议类型为 ICMP。
TCP
public static let TCP: ProtocolType
功能:指定协议类型为 TCP。
UDP
public static let UDP: ProtocolType
功能:指定协议类型为 UDP。
RAW
public static let RAW: ProtocolType
功能:指定协议类型为 RAW。
init
public init(protocol: Int32)
功能:通过指定套接字协议值创建协议。
operator func ==
public operator func ==(r: ProtocolType): Bool
功能:判断两个 ProtocolType 实例是否相等。
返回值:当二者代表的 Int32 值相等时,返回 true;否则,返回 false
operator func !=
public operator func !=(r: ProtocolType): Bool
功能:判断两个 ProtocolType 实例是否不等。
返回值:当二者代表的 Int32 值不等时,返回 true;否则,返回 false
func toString
public func toString(): String
功能:返回当前 ProtocolType 实例的字符串表示。
返回值:当前 ProtocolType 实例的字符串表示
func hashCode
public func hashCode(): Int64
功能:返回当前 ProtocolType 实例的哈希值。
返回值:当前 ProtocolType 实例的哈希值
struct OptionLevel
public struct OptionLevel {
public static const IP: Int32
public static const TCP: Int32
public static const UDP: Int32
public static const ICMP: Int32
public static const RAW: Int32
public static const SOCKET: Int32
}
提供了常用的套接字选项级别。
IP
public static const IP: Int32
功能:控制 IP 协议行为的套接字选项级别。
TCP
public static const TCP: Int32
功能:控制 TCP 协议行为的套接字选项级别。
UDP
public static const UDP: Int32
功能:控制 UDP 协议行为的套接字选项级别。
ICMP
public static const ICMP: Int32
功能:控制 ICMP 协议行为的套接字选项级别。
RAW
public static const RAW: Int32
功能:控制 IP 协议行为的套接字选项级别。
SOCKET
public static const SOCKET: Int32
功能:控制基本套接字行为的套接字选项级别。
struct OptionName
public struct OptionName {
public static const IP_HDRINCL: Int32
public static const IP_TOS: Int32
public static const IP_TTL: Int32
public static const TCP_KEEPCNT: Int32
public static const TCP_KEEPIDLE: Int32
public static const TCP_KEEPINTVL: Int32
public static const TCP_NODELAY: Int32
public static const SO_DEBUG: Int32
public static const SO_ACCEPTCONN: Int32
public static const SO_REUSEADDR: Int32
public static const SO_KEEPALIVE: Int32
public static const SO_DONTROUTE: Int32
public static const SO_BROADCAST: Int32
public static const SO_LINGER: Int32
public static const SO_OOBINLINE: Int32
public static const SO_SNDBUF: Int32
public static const SO_RCVBUF: Int32
public static const SO_SNDTIMEO: Int32
public static const SO_RCVTIMEO: Int32
public static const SO_ERROR: Int32
}
提供了常用的套接字选项。
IP_HDRINCL
public static const IP_HDRINCL: Int32
功能:用于在发送数据包时指定 IP 头部是否由应用程序提供的套接字选项。
IP_TOS
public static const IP_TOS: Int32
功能:用于指定数据包服务类型和优先级的套接字选项。
IP_TTL
public static const IP_TTL: Int32
功能:用于限制IP数据包在网络中传输最大跳数的套接字选项。
TCP_KEEPCNT
public static const TCP_KEEPCNT: Int32
功能:用于控制 TCP 连接中发送保持存活探测报文次数的套接字选项。
TCP_KEEPIDLE
public static const TCP_KEEPIDLE: Int32
功能:用于设置在没有收到对端确认的情况下,TCP 保持连接最大次数的套接字选项。
TCP_KEEPINTVL
public static const TCP_KEEPINTVL: Int32
功能:用于设置 TCP 保持连接时发送探测报文时间间隔的套接字选项。
TCP_NODELAY
public static const TCP_NODELAY: Int32
功能:用于控制 TCP 协议延迟行为的套接字选项。
SO_DEBUG
public static const SO_DEBUG: Int32
功能:用于启用或禁用调试模式的套接字选项。
SO_ACCEPTCONN
public static const SO_ACCEPTCONN: Int32
功能:用于查询套接字是否处于监听状态的套接字选项。
SO_REUSEADDR
public static const SO_REUSEADDR: Int32
功能:用于在套接字关闭后立即释放其绑定端口,以便其他套接字可以立即绑定该端口的套接字选项。
SO_KEEPALIVE
public static const SO_KEEPALIVE: Int32
功能:用于检测 TCP 连接是否仍然处于活动状态的套接字选项。
SO_DONTROUTE
public static const SO_DONTROUTE: Int32
功能:用于在连接套接字时,不路由套接字数据包的套接字选项。
SO_BROADCAST
public static const SO_BROADCAST: Int32
功能:用于设置套接字是否允许发送广播消息的套接字选项。
SO_LINGER
public static const SO_LINGER: Int32
功能:用于设置套接字关闭时行为的套接字选项。
SO_OOBINLINE
public static const SO_OOBINLINE: Int32
功能:用于控制接收带外数据方式的套接字选项。
SO_SNDBUF
public static const SO_SNDBUF: Int32
功能:用于设置套接字发送缓冲区大小的套接字选项。
SO_RCVBUF
public static const SO_RCVBUF: Int32
功能:用于设置套接字接收缓冲区大小的套接字选项。
SO_SNDTIMEO
public static const SO_SNDTIMEO: Int32
功能:用于设置套接字发送数据超时时间的套接字选项。
SO_RCVTIMEO
public static const SO_RCVTIMEO: Int32
功能:用于设置套接字接收数据超时时间的套接字选项。
SO_ERROR
public static const SO_ERROR: Int32
功能:获取和清除套接字上错误状态的套接字选项。
struct RawAddress
public struct RawAddress {
public init(addr: Array<Byte>)
}
提供了 RawSocket 的通信地址创建和获取功能。
init
public init(addr: Array<Byte>)
功能:创建地址。
参数:
addr:存储地址的字节数组
prop addr
public prop addr: Array<Byte>
功能:获取地址。
class SocketException
public class SocketException <: Exception {
public init()
public init(message: String)
}
在出现套接字异常时抛出的异常。
init
public init()
功能:创建 SocketException 实例
init
public init(message: String)
功能:创建 SocketException 实例
参数:
message:异常提示信息
class SocketTimeoutException
public class SocketTimeoutException <: Exception {
public init()
public init(message: String)
}
在套接字操作超时时抛出的异常。
init
public init()
功能:创建 SocketTimeoutException 实例
init
public init(message: String)
功能:创建 SocketTimeoutException 实例
参数:
message:异常提示信息
示例
TCP 的使用
简单的 TCP 服务端和客户端示例
from std import socket.*
from std import time.*
from std import sync.*
let SERVER_PORT: UInt16 = 33333
func runTcpServer() {
try (serverSocket = TcpServerSocket(bindAt: SERVER_PORT)) {
serverSocket.bind()
try (client = serverSocket.accept()) {
let buf = Array<Byte>(10, item: 0)
let count = client.read(buf)
// Server read 3 bytes: [1, 2, 3, 0, 0, 0, 0, 0, 0, 0]
println("Server read ${count} bytes: ${buf}")
}
}
}
main(): Int64 {
spawn {
runTcpServer()
}
sleep(Duration.millisecond * 500)
try (socket = TcpSocket("127.0.0.1", SERVER_PORT)) {
socket.connect()
socket.write(Array<Byte>([1, 2, 3]))
}
return 0
}
运行结果如下:
Server read 3 bytes: [1, 2, 3, 0, 0, 0, 0, 0, 0, 0]
UDP 的使用
from std import socket.*
from std import time.*
from std import sync.*
let SERVER_PORT: UInt16 = 33333
func runUpdServer() {
try (serverSocket = UdpSocket(bindAt: SERVER_PORT)) {
serverSocket.bind()
let buf = Array<Byte>(3, item: 0)
let (clientAddr, count) = serverSocket.receiveFrom(buf)
let sender = clientAddr.hostAddress
// Server receive 3 bytes: [1, 2, 3] from 127.0.0.1
println("Server receive ${count} bytes: ${buf} from ${sender}")
}
}
main(): Int64 {
spawn {
runUpdServer()
}
sleep(Duration.second)
try (udpSocket = UdpSocket(bindAt: 0)) { // random port
udpSocket.sendTimeout = Duration.second * 2
udpSocket.bind()
udpSocket.sendTo(
SocketAddress("127.0.0.1", SERVER_PORT),
Array<Byte>([1, 2, 3])
)
}
return 0
}
运行结果如下:
Server receive 3 bytes: [1, 2, 3] from 127.0.0.1
Unix 的使用
from std import socket.*
from std import time.*
from std import sync.*
let SOCKET_PATH = "/tmp/tmpsock"
func runUnixServer() {
try (serverSocket = UnixServerSocket(bindAt: SOCKET_PATH)) {
serverSocket.bind()
try (client = serverSocket.accept()) {
client.write(b"hello")
}
}
}
main(): Int64 {
spawn {
runUnixServer()
}
sleep(Duration.second)
try (socket = UnixSocket(SOCKET_PATH)) {
socket.connect()
let buf = Array<Byte>(10, item: 0)
socket.read(buf)
println(String.fromUtf8(buf)) // hello
}
return 0
}
运行结果如下:
hello
UnixDatagram 的使用
from std import socket.*
from std import time.*
from std import sync.*
from std import fs.*
from std import os.*
from std import random.*
func createTempFile(): String {
let tempDir: Path = tempDir().info.path
let index: String = Random().nextUInt64().toString()
return tempDir.join("tmp${index}").toString()
}
func runUnixDatagramServer(serverPath: String, clientPath: String) {
try (serverSocket = UnixDatagramSocket(bindAt: serverPath)) {
serverSocket.bind()
let buf = Array<Byte>(3, item: 0)
let (clientAddr, read) = serverSocket.receiveFrom(buf)
if (read == 3 && buf == Array<Byte>([1, 2, 3])) {
println("server received")
}
if (clientAddr.toString() == clientPath) {
println("client address correct")
}
}
}
main(): Int64 {
let clientPath = createTempFile()
let serverPath = createTempFile()
spawn {
runUnixDatagramServer(serverPath, clientPath)
}
sleep(Duration.second)
try (unixSocket = UnixDatagramSocket(bindAt: clientPath)) {
unixSocket.sendTimeout = Duration.second * 2
unixSocket.bind()
unixSocket.connect(serverPath)
unixSocket.send(Array<Byte>([1, 2, 3]))
sleep(Duration.second)
}
return 0
}
运行结果如下:
server received
client address correct
增加自定义属性
from std import socket.*
let TCP_KEEPCNT: Int32 = 6
extend TcpSocket {
public mut prop customNoDelay: Int64 {
get() {
Int64(getSocketOptionIntNative(SocketOptions.IPPROTO_TCP, SocketOptions.TCP_NODELAY))
}
set(value) {
setSocketOptionIntNative(SocketOptions.IPPROTO_TCP, SocketOptions.TCP_NODELAY, IntNative(value))
}
}
}
main() {
let socket = TcpSocket("127.0.0.1", 0)
socket.customNoDelay = 1
println(socket.customNoDelay)
}
运行结果如下:
1
属性配置
from std import socket.*
from std import time.*
from std import sync.*
main (){
try (tcpSocket = TcpSocket("127.0.0.1", 80)) {
tcpSocket.readTimeout = Duration.second
tcpSocket.noDelay = false
tcpSocket.linger = Duration.minute
tcpSocket.keepAlive = SocketKeepAliveConfig(
interval: Duration.second * 7,
count: 15
)
}
}
sort 包
介绍
sort 包提供数组类型的排序函数。
主要接口
interface SortExtension
public interface SortExtension
此接口作为排序相关的辅助接口,内部为空。
interface SortByExtension
public interface SortByExtension
此接口作为排序相关的辅助接口,内部为空。
extend Array <: SortByExtension
extend Array<T> <: SortByExtension
此扩展用于实现 Array 的 sortBy 函数。
func sortBy
public func sortBy(stable!: Bool = false, comparator!: (T, T) -> Ordering): Unit
功能:通过传入的比较函数,根据其返回值 Ordering 类型的结果,可对数组进行自定义排序。
参数:
stable:是否使用稳定排序comparator:用户传入的比较函数,如,comparator: (t1: T, t2: T) -> Ordering,如果comparator的返回值为Ordering.GT,排序后t1在t2后;如果comparator的返回值为Ordering.LT,排序后t1在t2前;如果comparator的返回值为Ordering.EQ,且为稳定排序那么t1与t2的位置较排序前保持不变; 如果comparator的返回值为Ordering.EQ,且为不稳定排序,那么t1,t2顺序不确定
extend Array <: SortExtension
extend Array<T> <: SortExtension where T <: Comparable<T>
此扩展用于实现 Array 的 sort/sortDescending 函数。
func sort
public func sort(stable!: Bool = false): Unit
功能:以升序的方式排序 Array。
参数:
stable:是否使用稳定排序
func sortDescending
public func sortDescending(stable!: Bool = false): Unit
功能:以降序的方式排序 Array。
参数:
stable:是否使用稳定排序
func unstableSort
public func unstableSort<T>(data: Array<T>): Unit where T <: Comparable<T>
功能:对数组进行不稳定升序排序。
参数:
data:需要排序的数组
func unstableSort
public func unstableSort<T>(data: Array<T>, comparator: (T, T) -> Ordering): Unit
功能:对数组进行不稳定排序。
参数:
data:需要排序的数组comparator:用户传入的比较函数,如,comparator: (t1: T, t2: T) -> Ordering,如果comparator的返回值为Ordering.GT,排序后t1在t2后;如果comparator的返回值为Ordering.LT,排序后t1在t2前;如果comparator的返回值为Ordering.EQ,排序后t1,t2顺序不确定
func stableSort
public func stableSort<T>(data: Array<T>): Unit where T <: Comparable<T>
功能:对数组进行稳定升序排序。
参数:
data:需要排序的数组
func stableSort
public func stableSort<T>(data: Array<T>, comparator: (T, T) -> Ordering): Unit
功能:对数组进行稳定排序。
参数:
data:需要排序的数组comparator:用户传入的比较函数,如,comparator: (t1: T, t2: T) -> Ordering,如果comparator的返回值为Ordering.GT,排序后t1在t2后;如果comparator的返回值为Ordering.LT,排序后t1在t2前;如果comparator的返回值为Ordering.EQ,排序后t1与t2的位置较排序前保持不变
示例
对 Array 进行排序
下面是创建 Array,并使用 random 库提供的随机数来得到一个无序 Array; 对这个 Array 进行升序排序,利用 isAse 判断排序后是否为升序。
代码如下:
from std import sort.*
from std import random.*
main(): Unit {
let r: Random = Random()
let arr: Array<Int64> = Array<Int64>(70000, { _ => r.nextInt64() })
arr.sortBy(stable: true){ rht: Int64, lht: Int64 =>
if (rht < lht) {
return Ordering.LT
}
if (rht > lht) {
return Ordering.GT
}
return Ordering.EQ
}
println(isAse(arr))
}
func isAse(t: Array<Int64>) {
var item: Int64 = t[0]
for (i in 1..t.size) {
if (item > t[i]) {
return false
}
item = t[i]
}
return true
}
运行结果如下:
true
sync 包
介绍
随着越来越多的计算机开始使用多核处理器,要充分发挥多核的优势,并发编程也变得越来越重要。
不同编程语言会以不同的方式实现线程。一些编程语言通过调用操作系统 API 来创建线程,意味着每个语言线程对应一个操作系统线程,一般称之为 1:1 的线程模型;也有一些编程语言提供特殊的线程实现,允许多个语言线程在不同数量的操作系统线程的上下文中切换执行,这种也被称为 M:N 的线程模型,即 M 个语言线程在 N 个操作系统线程上调度执行,其中 M 和 N 不一定相等。
仓颉编程语言希望给开发者提供一个友好、高效、统一的并发编程界面,让开发者无需关心操作系统线程、用户态线程等概念上的差异,同时屏蔽底层实现细节,因此我们只提供一个仓颉线程的概念。仓颉线程采用的是 M:N 线程模型的实现,因此本质上它是一种用户态的轻量级线程,支持抢占,且相比操作系统线程内存资源占用更小。
当开发者希望并发执行某一段代码时,只需创建一个仓颉线程即可。
要创建一个新的仓颉线程,可以使用关键字 spawn 并传递一个无形参的 lambda 表达式,该 lambda 表达式即为我们想在新线程中执行的代码。
sync 包主要提供了不同类型的原子操作,可重入互斥锁及其接口,利用共享变量的线程同步机制以及定时器的功能。
原子操作提供了包括整数类型、Bool 类型和引用类型的原子操作。
其中整数类型包括:Int8、Int16、Int32、Int64、UInt8、UInt16、UInt32、UInt64。
整数类型的原子操作支持基本的读写、交换以及算术运算操作,需要注意的是:
-
交换操作和算数操作的返回值是修改前的值。
-
compareAndSwap 是判断当前原子变量的值是否等于 old 值,如果等于,则使用 new 值替换;否则不替换。
Bool 类型和引用类型的原子操作只提供读写和交换操作,需要注意的是:
引用类型原子操作只对引用类型有效。
主要接口
enum MemoryOrder
public enum MemoryOrder {
| SeqCst
}
内存顺序枚举类型。
SeqCst
SeqCst
功能:构造顺序一致性内存顺序枚举类型实例。
DefaultMemoryOrder
public let DefaultmemoryOrder!: MemoryOrder = MemoryOrder.SeqCst
默认内存排序
class AtomicInt8
public class AtomicInt8 {
public init(val: Int8)
}
此类是封装了 Int8 类型数据的原子类型,可以通过该类型实例执行与 Int8 类型数据相关的原子操作。
init
public init(val: Int8)
功能:构造一个封装 Int8 数据类型的原子类型 AtomicInt8 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): Int8
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): Int8
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: Int8): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: Int8, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: Int8): Int8
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: Int8, memoryOrder!: MemoryOrder): Int8
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: Int8, new: Int8): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: Int8, new: Int8, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
func fetchAdd
public func fetchAdd(val: Int8): Int8
功能:加操作,采用默认内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加操作前的值。
参数:
- val:与原子类型进行加操作的值
返回值:执行加操作前的值
func fetchAdd
public func fetchAdd(val: Int8, memoryOrder!: MemoryOrder): Int8
功能:加操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加法运算前的值。
参数:
- val:与原子类型进行加操作的值
- memoryOrder:内存排序方式
返回值:执行加操作前的值
func fetchSub
public func fetchSub(val: Int8): Int8
功能:减操作,采用默认内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
返回值:执行减操作前的值
func fetchSub
public func fetchSub(val: Int8, memoryOrder!: MemoryOrder): Int8
功能:减操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
- memoryOrder:内存排序方式
返回值:执行减操作前的值
func fetchAnd
public func fetchAnd(val: Int8): Int8
功能:与操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
返回值:执行与操作前的值
func fetchAnd
public func fetchAnd(val: Int8, memoryOrder!: MemoryOrder): Int8
功能:与操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
- memoryOrder:内存排序方式
返回值:执行与操作前的值
func fetchOr
public func fetchOr(val: Int8): Int8
功能:或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
返回值:执行或操作前的值
func fetchOr
public func fetchOr(val: Int8, memoryOrder!: MemoryOrder): Int8
功能:或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
- memoryOrder:内存排序方式
返回值:执行或操作前的值
func fetchXor
public func fetchXor(val: Int8): Int8
功能:异或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
返回值:执行异或操作前的值
func fetchXor
public func fetchXor(val: Int8, memoryOrder!: MemoryOrder): Int8
功能:异或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
- memoryOrder:内存排序方式
返回值:执行异或操作前的值
class AtomicInt16
public class AtomicInt16 {
public init(val: Int16)
}
此类提供 Int16 类型的原子操作相关函数。
init
public init(val: Int16)
功能:构造一个封装 Int16 数据类型的原子类型 AtomicInt16 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): Int16
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): Int16
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: Int16): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: Int16, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: Int16): Int16
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: Int16, memoryOrder!: MemoryOrder): Int16
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: Int16, new: Int16): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: Int16, new: Int16, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
func fetchAdd
public func fetchAdd(val: Int16): Int16
功能:加操作,采用默认内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加操作前的值。
参数:
- val:与原子类型进行加操作的值
返回值:执行加操作前的值
func fetchAdd
public func fetchAdd(val: Int16, memoryOrder!: MemoryOrder): Int16
功能:加操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加法运算前的值。
参数:
- val:与原子类型进行加操作的值
- memoryOrder:内存排序方式
返回值:执行加操作前的值
func fetchSub
public func fetchSub(val: Int16): Int16
功能:减操作,采用默认内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
返回值:执行减操作前的值
func fetchSub
public func fetchSub(val: Int16, memoryOrder!: MemoryOrder): Int16
功能:减操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
- memoryOrder:内存排序方式
返回值:执行减操作前的值
func fetchAnd
public func fetchAnd(val: Int16): Int16
功能:与操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
返回值:执行与操作前的值
func fetchAnd
public func fetchAnd(val: Int16, memoryOrder!: MemoryOrder): Int16
功能:与操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
- memoryOrder:内存排序方式
返回值:执行与操作前的值
func fetchOr
public func fetchOr(val: Int16): Int16
功能:或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
返回值:执行或操作前的值
func fetchOr
public func fetchOr(val: Int16, memoryOrder!: MemoryOrder): Int16
功能:或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
- memoryOrder:内存排序方式
返回值:执行或操作前的值
func fetchXor
public func fetchXor(val: Int16): Int16
功能:异或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
返回值:执行异或操作前的值
func fetchXor
public func fetchXor(val: Int16, memoryOrder!: MemoryOrder): Int16
功能:异或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
- memoryOrder:内存排序方式
返回值:执行异或操作前的值
class AtomicInt32
public class AtomicInt32 {
public init(val: Int32)
}
此类提供 Int32 类型的原子操作相关函数。
init
public init(val: Int32)
功能:构造一个封装 Int32 数据类型的原子类型 AtomicInt32 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): Int32
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): Int32
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: Int32): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: Int32, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: Int32): Int32
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: Int32, memoryOrder!: MemoryOrder): Int32
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: Int32, new: Int32): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: Int32, new: Int32, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
func fetchAdd
public func fetchAdd(val: Int32): Int32
功能:加操作,采用默认内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加操作前的值。
参数:
- val:与原子类型进行加操作的值
返回值:执行加操作前的值
func fetchAdd
public func fetchAdd(val: Int32, memoryOrder!: MemoryOrder): Int32
功能:加操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加法运算前的值。
参数:
- val:与原子类型进行加操作的值
- memoryOrder:内存排序方式
返回值:执行加操作前的值
func fetchSub
public func fetchSub(val: Int32): Int32
功能:减操作,采用默认内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
返回值:执行减操作前的值
func fetchSub
public func fetchSub(val: Int32, memoryOrder!: MemoryOrder): Int32
功能:减操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
- memoryOrder:内存排序方式
返回值:执行减操作前的值
func fetchAnd
public func fetchAnd(val: Int32): Int32
功能:与操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
返回值:执行与操作前的值
func fetchAnd
public func fetchAnd(val: Int32, memoryOrder!: MemoryOrder): Int32
功能:与操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
- memoryOrder:内存排序方式
返回值:执行与操作前的值
func fetchOr
public func fetchOr(val: Int32): Int32
功能:或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
返回值:执行或操作前的值
func fetchOr
public func fetchOr(val: Int32, memoryOrder!: MemoryOrder): Int32
功能:或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
- memoryOrder:内存排序方式
返回值:执行或操作前的值
func fetchXor
public func fetchXor(val: Int32): Int32
功能:异或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
返回值:执行异或操作前的值
func fetchXor
public func fetchXor(val: Int32, memoryOrder!: MemoryOrder): Int32
功能:异或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
- memoryOrder:内存排序方式
返回值:执行异或操作前的值
class AtomicInt64
public class AtomicInt64 {
public init(val: Int64)
}
此类提供 Int64 类型的原子操作相关函数。
init
public init(val: Int64)
功能:构造一个封装 Int64 数据类型的原子类型 AtomicInt64 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): Int64
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): Int64
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: Int64): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: Int64, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: Int64): Int64
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: Int64, memoryOrder!: MemoryOrder): Int64
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: Int64, new: Int64): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: Int64, new: Int64, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
func fetchAdd
public func fetchAdd(val: Int64): Int64
功能:加操作,采用默认内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加操作前的值。
参数:
- val:与原子类型进行加操作的值
返回值:执行加操作前的值
func fetchAdd
public func fetchAdd(val: Int64, memoryOrder!: MemoryOrder): Int64
功能:加操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加法运算前的值。
参数:
- val:与原子类型进行加操作的值
- memoryOrder:内存排序方式
返回值:执行加操作前的值
func fetchSub
public func fetchSub(val: Int64): Int64
功能:减操作,采用默认内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
返回值:执行减操作前的值
func fetchSub
public func fetchSub(val: Int64, memoryOrder!: MemoryOrder): Int64
功能:减操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
- memoryOrder:内存排序方式
返回值:执行减操作前的值
func fetchAnd
public func fetchAnd(val: Int64): Int64
功能:与操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
返回值:执行与操作前的值
func fetchAnd
public func fetchAnd(val: Int64, memoryOrder!: MemoryOrder): Int64
功能:与操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
- memoryOrder:内存排序方式
返回值:执行与操作前的值
func fetchOr
public func fetchOr(val: Int64): Int64
功能:或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
返回值:执行或操作前的值
func fetchOr
public func fetchOr(val: Int64, memoryOrder!: MemoryOrder): Int64
功能:或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
- memoryOrder:内存排序方式
返回值:执行或操作前的值
func fetchXor
public func fetchXor(val: Int64): Int64
功能:异或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
返回值:执行异或操作前的值
func fetchXor
public func fetchXor(val: Int64, memoryOrder!: MemoryOrder): Int64
功能:异或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
- memoryOrder:内存排序方式
返回值:执行异或操作前的值
class AtomicUInt8
public class AtomicUInt8 {
public init(val: UInt8)
}
此类是封装了 UInt8 类型数据的原子类型,可以通过该类型实例执行与 UInt8 类型数据相关的原子操作。
init
public init(val: UInt8)
功能:构造一个封装 UInt8 数据类型的原子类型 AtomicUInt8 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): UInt8
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): UInt8
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: UInt8): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: UInt8, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: UInt8): UInt8
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: UInt8, memoryOrder!: MemoryOrder): UInt8
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: UInt8, new: UInt8): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: UInt8, new: UInt8, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
func fetchAdd
public func fetchAdd(val: UInt8): UInt8
功能:加操作,采用默认内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加操作前的值。
参数:
- val:与原子类型进行加操作的值
返回值:执行加操作前的值
func fetchAdd
public func fetchAdd(val: UInt8, memoryOrder!: MemoryOrder): UInt8
功能:加操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加法运算前的值。
参数:
- val:与原子类型进行加操作的值
- memoryOrder:内存排序方式
返回值:执行加操作前的值
func fetchSub
public func fetchSub(val: UInt8): UInt8
功能:减操作,采用默认内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
返回值:执行减操作前的值
func fetchSub
public func fetchSub(val: UInt8, memoryOrder!: MemoryOrder): UInt8
功能:减操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
- memoryOrder:内存排序方式
返回值:执行减操作前的值
func fetchAnd
public func fetchAnd(val: UInt8): UInt8
功能:与操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
返回值:执行与操作前的值
func fetchAnd
public func fetchAnd(val: UInt8, memoryOrder!: MemoryOrder): UInt8
功能:与操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
- memoryOrder:内存排序方式
返回值:执行与操作前的值
func fetchOr
public func fetchOr(val: UInt8): UInt8
功能:或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
返回值:执行或操作前的值
func fetchOr
public func fetchOr(val: UInt8, memoryOrder!: MemoryOrder): UInt8
功能:或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
- memoryOrder:内存排序方式
返回值:执行或操作前的值
func fetchXor
public func fetchXor(val: UInt8): UInt8
功能:异或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
返回值:执行异或操作前的值
func fetchXor
public func fetchXor(val: UInt8, memoryOrder!: MemoryOrder): UInt8
功能:异或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
- memoryOrder:内存排序方式
返回值:执行异或操作前的值
class AtomicUInt16
public class AtomicUInt16 {
public init(val: UInt16)
}
此类提供 UInt16 类型的原子操作相关函数。
init
public init(val: UInt16)
功能:构造一个封装 UInt16 数据类型的原子类型 AtomicUInt16 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): UInt16
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): UInt16
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: UInt16): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: UInt16, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: UInt16): UInt16
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: UInt16, memoryOrder!: MemoryOrder): UInt16
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: UInt16, new: UInt16): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: UInt16, new: UInt16, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
func fetchAdd
public func fetchAdd(val: UInt16): UInt16
功能:加操作,采用默认内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加操作前的值。
参数:
- val:与原子类型进行加操作的值
返回值:执行加操作前的值
func fetchAdd
public func fetchAdd(val: UInt16, memoryOrder!: MemoryOrder): UInt16
功能:加操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加法运算前的值。
参数:
- val:与原子类型进行加操作的值
- memoryOrder:内存排序方式
返回值:执行加操作前的值
func fetchSub
public func fetchSub(val: UInt16): UInt16
功能:减操作,采用默认内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
返回值:执行减操作前的值
func fetchSub
public func fetchSub(val: UInt16, memoryOrder!: MemoryOrder): UInt16
功能:减操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
- memoryOrder:内存排序方式
返回值:执行减操作前的值
func fetchAnd
public func fetchAnd(val: UInt16): UInt16
功能:与操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
返回值:执行与操作前的值
func fetchAnd
public func fetchAnd(val: UInt16, memoryOrder!: MemoryOrder): UInt16
功能:与操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
- memoryOrder:内存排序方式
返回值:执行与操作前的值
func fetchOr
public func fetchOr(val: UInt16): UInt16
功能:或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
返回值:执行或操作前的值
func fetchOr
public func fetchOr(val: UInt16, memoryOrder!: MemoryOrder): UInt16
功能:或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
- memoryOrder:内存排序方式
返回值:执行或操作前的值
func fetchXor
public func fetchXor(val: UInt16): UInt16
功能:异或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
返回值:执行异或操作前的值
func fetchXor
public func fetchXor(val: UInt16, memoryOrder!: MemoryOrder): UInt16
功能:异或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
- memoryOrder:内存排序方式
返回值:执行异或操作前的值
class AtomicUInt32
public class AtomicUInt32 {
public init(val: UInt32)
}
此类提供 UInt32 类型的原子操作相关函数。
init
public init(val: UInt32)
功能:构造一个封装 UInt32 数据类型的原子类型 AtomicUInt32 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): UInt32
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): UInt32
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: UInt32): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: UInt32, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: UInt32): UInt32
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: UInt32, memoryOrder!: MemoryOrder): UInt32
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: UInt32, new: UInt32): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: UInt32, new: UInt32, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
func fetchAdd
public func fetchAdd(val: UInt32): UInt32
功能:加操作,采用默认内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加操作前的值。
参数:
- val:与原子类型进行加操作的值
返回值:执行加操作前的值
func fetchAdd
public func fetchAdd(val: UInt32, memoryOrder!: MemoryOrder): UInt32
功能:加操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加法运算前的值。
参数:
- val:与原子类型进行加操作的值
- memoryOrder:内存排序方式
返回值:执行加操作前的值
func fetchSub
public func fetchSub(val: UInt32): UInt32
功能:减操作,采用默认内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
返回值:执行减操作前的值
func fetchSub
public func fetchSub(val: UInt32, memoryOrder!: MemoryOrder): UInt32
功能:减操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
- memoryOrder:内存排序方式
返回值:执行减操作前的值
func fetchAnd
public func fetchAnd(val: UInt32): UInt32
功能:与操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
返回值:执行与操作前的值
func fetchAnd
public func fetchAnd(val: UInt32, memoryOrder!: MemoryOrder): UInt32
功能:与操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
- memoryOrder:内存排序方式
返回值:执行与操作前的值
func fetchOr
public func fetchOr(val: UInt32): UInt32
功能:或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
返回值:执行或操作前的值
func fetchOr
public func fetchOr(val: UInt32, memoryOrder!: MemoryOrder): UInt32
功能:或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
- memoryOrder:内存排序方式
返回值:执行或操作前的值
func fetchXor
public func fetchXor(val: UInt32): UInt32
功能:异或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
返回值:执行异或操作前的值
func fetchXor
public func fetchXor(val: UInt32, memoryOrder!: MemoryOrder): UInt32
功能:异或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
- memoryOrder:内存排序方式
返回值:执行异或操作前的值
class AtomicUInt64
public class AtomicUInt64 {
public init(val: UInt64)
}
此类提供 UInt64 类型的原子操作相关函数。
init
public init(val: UInt64)
功能:构造一个封装 UInt64 数据类型的原子类型 AtomicUInt64 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): UInt64
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): UInt64
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: UInt64): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: UInt64, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: UInt64): UInt64
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: UInt64, memoryOrder!: MemoryOrder): UInt64
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: UInt64, new: UInt64): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: UInt64, new: UInt64, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
func fetchAdd
public func fetchAdd(val: UInt64): UInt64
功能:加操作,采用默认内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加操作前的值。
参数:
- val:与原子类型进行加操作的值
返回值:执行加操作前的值
func fetchAdd
public func fetchAdd(val: UInt64, memoryOrder!: MemoryOrder): UInt64
功能:加操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行加操作,将结果写入当前原子类型实例,并返回加法运算前的值。
参数:
- val:与原子类型进行加操作的值
- memoryOrder:内存排序方式
返回值:执行加操作前的值
func fetchSub
public func fetchSub(val: UInt64): UInt64
功能:减操作,采用默认内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
返回值:执行减操作前的值
func fetchSub
public func fetchSub(val: UInt64, memoryOrder!: MemoryOrder): UInt64
功能:减操作,采用参数 memoryOrder 指定的内存排序方式,将原子类型的值与参数 val 进行减操作,将结果写入当前原子类型实例,并返回减操作前的值。
参数:
- val:与原子类型进行减操作的值
- memoryOrder:内存排序方式
返回值:执行减操作前的值
func fetchAnd
public func fetchAnd(val: UInt64): UInt64
功能:与操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
返回值:执行与操作前的值
func fetchAnd
public func fetchAnd(val: UInt64, memoryOrder!: MemoryOrder): UInt64
功能:与操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行与操作,将结果写入当前原子类型实例,并返回与操作前的值。
参数:
- val:与原子类型进行与操作的值
- memoryOrder:内存排序方式
返回值:执行与操作前的值
func fetchOr
public func fetchOr(val: UInt64): UInt64
功能:或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
返回值:执行或操作前的值
func fetchOr
public func fetchOr(val: UInt64, memoryOrder!: MemoryOrder): UInt64
功能:或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行或操作,将结果写入当前原子类型实例,并返回或操作前的值。
参数:
- val:与原子类型进行或操作的值
- memoryOrder:内存排序方式
返回值:执行或操作前的值
func fetchXor
public func fetchXor(val: UInt64): UInt64
功能:异或操作,采用默认内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
返回值:执行异或操作前的值
func fetchXor
public func fetchXor(val: UInt64, memoryOrder!: MemoryOrder): UInt64
功能:异或操作,采用参数 memoryOrder 指定的内存排序方式,将当前原子类型实例的值与参数 val 进行异或操作,将结果写入当前原子类型实例,并返回异或操作前的值。
参数:
- val:与原子类型进行异或操作的值
- memoryOrder:内存排序方式
返回值:执行异或操作前的值
class AtomicBool
public class AtomicBool {
public init(val: Bool)
}
此类提供 Bool 类型的原子操作相关函数。
init
public init(val: Bool)
功能:构造一个封装 Bool 数据类型的原子类型 AtomicBool 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): Bool
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): Bool
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: Bool): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: Bool, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: Bool): Bool
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: Bool, memoryOrder!: MemoryOrder): Bool
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: Bool, new: Bool): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: Bool, new: Bool, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
class AtomicReference
public class AtomicReference<T> where T <: Object {
public init(val: T)
}
引用类型原子操作,该引用类型必须是 Object 的子类。
init
public init(val: T)
功能:构造一个封装 T 数据类型的原子类型 AtomicReference 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): T
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): T
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: T): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: T, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: T): T
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: T, memoryOrder!: MemoryOrder): T
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: T, new: T): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: T, new: T, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
class AtomicOptionReference
public class AtomicOptionReference<T> where T <: Object {
public init()
public init(val: Option<T>)
}
引用类型原子操作,该引用类型必须是 Object 的子类。
init
public init()
功能:构造一个空的 AtomicOptionReference 实例。
init
public init(val: Option<T>)
功能:构造一个封装 Option<T> 数据类型的原子类型 AtomicOptionReference 的实例,其内部数据初始值为入参 val 的值。
参数:
- val:原子类型的初始值
func load
public func load(): Option<T>
功能:获取操作,采用默认内存排序方式,读取原子类型的值。
返回值:当前原子类型的值
func load
public func load(memoryOrder!: MemoryOrder): Option<T>
功能:获取操作,采用参数 memoryOrder 指定的内存排序方式,读取原子类型的值。
参数:
- memoryOrder:内存排序方式
返回值:当前原子类型的值
func store
public func store(val: Option<T>): Unit
功能:写入操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
func store
public func store(val: Option<T>, memoryOrder!: MemoryOrder): Unit
功能:写入操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
func swap
public func swap(val: Option<T>): Option<T>
功能:交换操作,采用默认内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
返回值:写入前的值
func swap
public func swap(val: Option<T>, memoryOrder!: MemoryOrder): Option<T>
功能:交换操作,采用参数 memoryOrder 指定的内存排序方式,将参数 val 指定的值写入原子类型,并返回写入前的值。
参数:
- val:写入原子类型的值
- memoryOrder:内存排序方式
返回值:写入前的值
func compareAndSwap
public func compareAndSwap(old: Option<T>, new: Option<T>): Bool
功能:比较后交换操作,采用默认内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
返回值:比较后交换成功返回 true,否则返回 false
func compareAndSwap
public func compareAndSwap(old: Option<T>, new: Option<T>, successOrder!: MemoryOrder, failureOrder!: MemoryOrder): Bool
功能:比较后交换操作,采用参数 successOrder 和 failureOrder 指定的内存排序方式,比较当前原子类型的值与参数 old 指定的值是否相等:若相等,则写入参数 new 指定的值,并返回 true;否则,不写入值,并返回 false。
参数:
- old:与当前原子类型进行比较的值
- new:比较结果相等时写入原子类型的值
- successOrder:内存排序方式
- failureOrder:内存排序方式
返回值:比较后交换成功返回 true,否则返回 false
interface IReentrantMutex
public interface IReentrantMutex {
func lock(): Unit
func tryLock(): Bool
func unlock(): Unit
}
IReentrantMutex 是一个可重入互斥锁的公共接口,提供如下三个函数,开发者可通过该接口实现自己的可重入互斥锁。
注意:
- 开发者在实现该接口时需要保证底层互斥锁确实支持嵌套锁。
- 开发者在实现该接口时需要保证在当前线程时抛出
IllegalSynchronizationStateException。
func lock
func lock(): Unit
功能:锁定互斥体,如果互斥体已被锁定,则阻塞。
func tryLock
func tryLock(): Bool
功能:尝试锁定互斥体。
返回值:如果互斥体已被锁定,则返回 false;反之,则锁定互斥体并返回 true
func unlock
func unlock(): Unit
功能:解锁互斥体,如果互斥体被重复加锁了 N 次,那么需要调用 N 次该函数来完全解锁,一旦互斥体被完全解锁,如果有其他线程阻塞在此锁上,那么唤醒他们中的一个。
异常:
- IllegalSynchronizationStateException:如果当前线程没有持有该互斥体,抛出异常
class ReentrantMutex
public open class ReentrantMutex <: IReentrantMutex {
public init()
}
可重入互斥锁的作用是对临界区加以保护,使得任意时刻最多只有一个线程能够执行临界区的代码。当一个线程试图获取一个已被其他线程持有的锁时,该线程会被阻塞,直到锁被释放,该线程才会被唤醒,可重入是指线程获取该锁后可再次获得该锁。
注意:ReentrantMutex 是内置的互斥锁,开发者需要保证不继承它。
使用可重入互斥锁时,必须牢记两条规则:
- 在访问共享数据之前,必须尝试获取锁
- 处理完共享数据后,必须进行解锁,以便其他线程可以获得锁
init
public init()
功能:创建可重入互斥锁。
异常:
- IllegalSynchronizationStateException:当出现系统错误时,抛出异常
func lock
public open func lock(): Unit
功能:锁定互斥体,如果互斥体已被锁定,则阻塞。
func tryLock
public open func tryLock(): Bool
功能:尝试锁定互斥体。
返回值:如果互斥体已被锁定,则返回 false;反之,则锁定互斥体并返回 true
func unlock
public open func unlock(): Unit
功能:解锁互斥体,如果互斥体被重复加锁了 N 次,那么需要调用 N 次该函数来完全解锁,一旦互斥体被完全解锁,如果有其他线程阻塞在此锁上,那么唤醒他们中的一个。
异常:
- IllegalSynchronizationStateException:如果当前线程没有持有该互斥体,抛出异常
class IllegalSynchronizationStateException
public class IllegalSynchronizationStateException <: Exception {
public init()
public init(message: String)
}
此类为非法同步状态异常。
init
public init()
功能:创建一个 IllegalSynchronizationStateException 实例。
init
public init(message: String)
功能:创建一个 IllegalSynchronizationStateException 实例,其信息由参数 message 指定。
参数:
- message:预定义消息
synchronized 关键字
ReentrantMutex 在使用的时候仍然有诸多不便,比如稍不注意会忘了解锁,或者在持有互斥锁的情况下抛出异常不能自动释放持有的锁,等等。因此,仓颉编程语言提供一个 synchronized 关键字,搭配 ReentrantMutex 一起使用,来解决类似的问题。
通过在 synchronized 后面加上一个 ReentrantMutex 实例,对其后面修饰的代码块进行保护,可以使得任意时刻最多只有一个线程可以执行被保护的代码:
- 一个线程在进入
synchronized修饰的代码块之前,会自动获取ReentrantMutex实例对应的锁,如果无法获取锁,则当前线程被阻塞; - 一个线程在退出
synchronized修饰的代码块之前,会自动释放该ReentrantMutex实例的锁;
对于控制转移表达式(如 break、continue、return、throw),在导致程序的执行跳出 synchronized 代码块时,也符合上面第 2 条的说明,也就说也会自动释放 synchronized 表达式对应的锁。
注意:synchronized 关键字与 IReentrantMutex 接口不兼容。
class Monitor
public class Monitor <: ReentrantMutex {
public init()
}
Monitor 可以使线程阻塞并等待来自另一个线程的信号以恢复执行,这是一种利用共享变量进行线程同步的机制。
当一些线程因等待共享变量的某个条件成立而挂起时,另一些线程改变共享的变量,使条件成立,然后执行唤醒操作。这使得挂起的线程被唤醒后可以继续执行。
init
public init()
功能:通过默认构造函数创建 Monitor。
func wait
public func wait(timeout!: Duration = Duration.Max): Bool
功能:当前线程挂起,直到对应的 notify 函数被调用,或者挂起时间超过 timeout。
参数:
- timeout:
Duration类型,挂起时间,其默认值为Duration.Max
返回值:如果 Monitor 被其它线程唤醒,返回 true;如果超时,则返回 false
异常:
- IllegalArgumentException:如果
timeout <= Duration.Zero,抛出异常。 - IllegalSynchronizationStateException:如果当前线程没有持有该互斥体,抛出异常
func notify
public func notify(): Unit
功能:唤醒等待在该 Montior 上的线程。
返回值:Unit
异常:
- IllegalSynchronizationStateException:如果当前线程没有持有该互斥体,抛出异常
func notifyAll
public func notifyAll(): Unit
功能:唤醒所有等待在该 Montior 上的线程。
返回值:Unit
异常:
- IllegalSynchronizationStateException:如果当前线程没有持有该互斥体,抛出异常
struct ConditionID
public struct ConditionID
ConditionID 实例表示线程间的共享变量。
class MultiConditionMonitor
public class MultiConditionMonitor <: ReentrantMutex {
public init()
}
MultiConditionMonitor 用于绑定一个互斥锁和多个条件变量。
注意:该类应仅当在 Monitor 类不足以实现高级并发算法时被使用。
初始化时,MultiConditionMonitor 没有与之相关的条件变量。每次调用 newCondition 将创建一个新的等待队列并与当前对象关联,并返回如下类型作为唯一标识符:
init
public init()
功能:通过默认构造函数创建 MultiConditionMonitor。
func newCondition
public func newCondition(): ConditionID
功能:创建一个与该 Monitor 相关的 ConditionID,可能被用来实现 “单互斥体多等待队列” 的并发原语。
返回值:新的 ConditionID
异常:
- IllegalSynchronizationStateException:如果当前线程没有持有该互斥体,抛出异常
func wait
public func wait(condID: ConditionID, timeout!: Duration = Duration.Max): Bool
功能:当前线程挂起,直到对应的 notify 函数被调用。
参数:
- condID:ConditionID 类型, 指定的条件变量
- timeout:Duration 类型,挂起时间,其默认值为
Duration.Max。
返回值:如果该 Monitor 指定的条件变量被其它线程唤醒,返回 true;如果超时,则返回 false
异常:
- IllegalSynchronizationStateException:如果当前线程没有持有该互斥体,或者挂起时间超过
timeout或condID不是由该MultiConditionMonitor实例通过newCondition函数创建时,抛出异常 - IllegalArgumentException:如果
timeout <= Duration.Zero,抛出异常。
func notify
public func notify(condID: ConditionID): Unit
功能:唤醒等待在所指定的条件变量的线程(如果有)。
参数:
- condID:ConditionID 类型, 指定的条件变量
异常:
- IllegalSynchronizationStateException:如果当前线程没有持有该互斥体,或
condID不是由该MultiConditionMonitor实例通过newCondition函数创建时,抛出异常。
func notifyAll
public func notifyAll(condID: ConditionID): Unit
功能:唤醒所有等待在所指定的条件变量的线程(如果有)。
参数:
- condID:ConditionID 类型, 指定的条件变量
异常:
- IllegalSynchronizationStateException:如果当前线程没有持有该互斥体,或
condID不是由该MultiConditionMonitor实例通过newCondition函数创建时,抛出异常。
class SyncCounter
public class SyncCounter {
public init(count: Int64)
}
SyncCounter 提供倒数计数器功能,线程可以等待计数器变为零。
init
public init(count: Int64)
功能:创建倒数计数器
参数:
- count:倒数计数器的初始值
异常:
- IllegalArgumentException:如果参数
count为负数
prop count
public prop count: Int64
功能:获取计数器的当前值
func dec
public func dec(): Unit
功能:计数器减一。如果计数器变为零,那么唤醒所有等待的线程;如果计数器已经为零,那么数值保持不变。
func waitUntilZero
public func waitUntilZero(timeout!: Duration = Duration.Max): Unit
功能:当前线程等待直到计数器变为零,或等待时间超过 timeout。
参数:
- timeout:阻塞时等待的最大时长,其默认值为
Duration.Max
class Barrier
public class Barrier {
public init(count: Int64)
}
Barrier 用于协调多个线程一起执行到某一个程序点。率先达到程序点的线程将进入阻塞状态,当所有线程都达到程序点后,才一起继续执行。
init
public init(count: Int64)
功能:创建 Barrier 对象。
参数:
- count:表示需要协调的线程数
异常:
- IllegalArgumentException:参数
count为负数
func wait
public func wait(timeout!: Duration = Duration.Max): Unit
功能:线程进入 Barrier 等待点。如果 Barrier 对象所有调用 wait 的次数(即进入等待点的线程数)等于初始值,那么唤醒所有等待的线程;如果调用 wait 方法次数仍小于初始值,那么当前线程进入阻塞状态直到被唤醒或者等待时间超过 timeout;如果调用 wait 次数已大于初始值,那么线程继续执行。
参数:
- timeout:阻塞时等待的最大时长,其默认值为
Duration.Max
异常:
- IllegalArgumentException:参数
count为负数
class Semaphore
public class Semaphore {
public init(count: Int64)
}
Semaphore 可以被视为携带计数器的 Monitor,常用于控制并发访问共享资源的线程数量。
init
public init(count: Int64)
功能:创建一个 Semaphore 对象并初始化内部计数器的值。
参数:
- count:计数器初始值
异常:
- IllegalArgumentException:参数
count为负数
prop count
public prop count: Int64
功能:返回当前内部计数器的值。
func acquire
public func acquire(amount!: Int64 = 1): Unit
功能:向 Semaphore 对象获取指定值,如果当前计数器小于要求的数值,那么当前线程将被阻塞,直到获取满足数量的值后才被唤醒。
参数:
- amount:向对象内部计数器中获取的数值,默认值为 1
异常:
- IllegalArgumentException:参数
amount为负数,或大于初始值
func tryAcquire
public func tryAcquire(amount!: Int64 = 1): Bool
功能:尝试向 Semaphore 对象获取指定值,该方法不会阻塞线程。如果有多个线程并发执行获取操作,则无法保证线程间的获取顺序。
参数:
- amount:向对象内部计数器中获取的数值,默认值为 1
返回值:如果当前计数器小于要求的数值,则获取失败并返回 false;成功获取值时返回 true。
异常:
- IllegalArgumentException:参数
amount为负数,或大于初始值
func release
public func release(amount!: Int64 = 1): Unit
功能:向 Semaphore 对象释放指定值。如果内部计数器在累加释放值后能够满足当前阻塞在 Semaphore 对象的线程,那么将得到满足的线程唤醒;内部计数器的值不会大于初始值,即如果计数器的值在累加后大于初始值,那么仍被设置为初始值。所有在调用 release 之前的操作都先发生于调用 acquire/tryAcquire 之后的操作。
参数:
- amount:向对象内部计数器中释放的数值,默认值为 1
返回值:如果当前计数器小于要求的数值,则获取失败并返回 false;成功获取值时返回 true。
异常:
- IllegalArgumentException:参数
amount为负数,或大于初始值
class ReentrantReadWriteMutex
public class ReentrantReadWriteMutex {
public init(mode!: ReadWriteMutexMode = ReadWriteMutexMode.Unfair)
}
ReentrantReadWriteMutex 是内置的可重入读写锁,它和普通互斥锁的差异在于:读写锁同时携带两个互斥锁,分别为“读锁”以及“写锁”,并且它允许多个线程同时持有读锁。读写锁有如下的特殊性质:
- 写互斥性:只有唯一的线程能够持有写锁。当一个线程持有写锁,而其他线程再次获取锁(读锁或是写锁)时将被阻塞。
- 读并发性:允许多个线程同时持有读锁。当一个线程持有读锁,其他线程仍然可以获取读锁。但其他线程获取写锁时将被阻塞。
- 可重入性:一个线程可以重复获取锁。
- 当线程已持有写锁时,它可以继续获取写锁或者读锁。只有当锁释放操作和获取操作一一对应时,锁才被完全释放。
- 当线程已持有读锁时,它可以继续获取读锁。当锁释放操作和获取操作一一对应时,锁才被完全释放。注意,不允许在持有读锁的情况下获取写锁,这将抛出异常。
- 锁降级:一个线程在经历“持有写锁--持有读锁--释放写锁”后,它持有的是读锁而不再是写锁。
- 读写公平性:读写锁支持两种不同的模式,分别为“公平”及“非公平”模式。
- 在非公平模式下,读写锁对线程获取锁的顺序不做任何保证。
- 在公平模式下,当线程获取读锁时(当前线程未持有读锁),如果写锁已被获取或是存在线程等待写锁,那么当前线程无法获取读锁并进入等待。
- 在公平模式下,写锁释放会优先唤醒所有读线程、读锁释放会优先唤醒一个等待写锁的线程。当存在多个线程等待写锁,他们之间被唤醒的先后顺序并不做保证。
init
public init(mode!: ReadWriteMutexMode = ReadWriteMutexMode.Unfair)
功能:构造读写锁。
参数:
- mod:读写锁模式;默认值为
Unfair,即构造“非公平”的读写锁
prop readMutex
public prop readMutex: ReentrantReadMutex
功能:获取读锁。
prop writeMutex
public prop writeMutex: ReentrantWriteMutex
功能:获取写锁。
enum ReadWriteMutexMode
public enum ReadWriteMutexMode {
| Unfair
| Fair
}
Unfair
Unfair
功能:读写锁非公平模式。
Fair
Unfair
功能:读写锁公平模式。
ReentrantReadMutex 和 ReentrantWriteMutex 分别是读锁和写锁类型,他们支持如下方法。
class ReentrantReadMutex
public class ReentrantReadMutex <: ReentrantMutex
ReentrantReadMutex 表示 ReentrantReadWriteMutex 中的读锁类型。
func lock
public func lock(): Unit
功能:获取读锁。
注意:
- 在公平模式下,如果没有其他线程持有或等待写锁,或是当前线程已持有读锁,则立即持有读锁;否则,当前线程进入等待状态。
- 在非公平模式下,如果没有其他线程持有或等待写锁,则立即持有读锁;如果有其他线程持有写锁,当前线程进入等待状态;否则,线程是否能立即持有读锁不做保证。
- 多个线程可以同时持有读锁并且一个线程可以重复多次持有读锁;如果一个线程持有写锁,那么它仍可以持有读锁。
func tryLock
public func tryLock(): Bool
功能:尝试获取读锁。该方法获取读锁时并不遵循公平模式。
返回值:若成功获取读锁,返回 true;若未能获取读锁,返回 false。
func unlock
public func unlock(): Unit
功能:释放读锁。如果一个线程多次持有读锁,那么仅当释放操作和获取操作数量相同时才释放读锁;如果读锁被释放并且存在线程等待写锁,那么唤醒其中一个线程。
异常:
- IllegalSynchronizationStateException:当前线程未持有读锁,那么将抛出异常。
class ReentrantWriteMutex
public class ReentrantWriteMutex <: ReentrantMutex
ReentrantWriteMutex 表示 ReentrantReadWriteMutex 中的写锁类型。
func lock
public func lock(): Unit
功能:获取写锁。只允许唯一线程能够持有写锁,且该线程能多次重复持有写锁。如果存在其他线程持有写锁或是读锁,那么当前线程进入等待状态。
异常:
- IllegalSynchronizationStateException:当前线程已持有读锁
func tryLock
public func tryLock(): Bool
功能:尝试获取写锁。该方法获取读锁时并不遵循公平模式。
返回值:若成功获取写锁,返回 true;若未能获取写锁,返回 false。
func unlock
public func unlock(): Unit
功能:释放写锁。
注意:
- 如果一个线程多次持有读锁,那么仅当释放操作和获取操作数量相同时才释放读锁;如果读锁被释放并且存在线程等待写锁,那么唤醒其中一个线程。
- 在公平模式下,如果写锁被释放并且存在线程等待读锁,那么优先唤醒这些等待线程;如果没有线程等待读锁,但存在线程等待写锁,那么唤醒其中一个线程。
- 在非公平模式下,如果写锁被释放,优先唤醒等待写锁的线程还是等待读锁的线程不做保证,交由具体实现决定。
异常:
- IllegalSynchronizationStateException:当前线程未持有写锁
class Timer
public class Timer <: Equatable<Timer>
Timer 表示定时器,用于在指定时间点或指定时间间隔后,执行指定任务一次或多次。
需要注意的是:
Timer隐式包含了spawn操作,即,每个Timer会创建一个线程用于执行该Timer关联的 Task。- 每个
Timer只能在初始化时绑定一个 Task,初始化完成后,无法重置关联的 Task。 - 只有关联 Task 执行完毕,或 使用
cancel接口主动取消Timer,Timer的生命周期才会结束,之后才能被 GC 回收。换句话说,在Timer关联的 Task 执行完毕或Timer被主动取消前,Timer实例均不会被 GC 回收,从而确保关联 Task 可以被正常执行。 - 系统繁忙时,Task 的触发时间可能会被影响。
Timer不保证 Task 的触发时间一定准时。Timer保证 Task 的触发时间小于等于当前时间时,会执行 Task,后续 Task 会被顺延。 Timer不会主动捕获关联 Task 抛出的异常。只要 Task 有未被捕获的异常,Timer就会失效。
func at
public static func at(dt: DateTime, task: () -> Option<Duration>): Timer
功能:初始化一个 Timer,关联的 Task 被调度执行的次数取决于它的返回值。如果定时器第一次触发的时间点小于当前时间,关联的 Task 会立刻被调度执行。如果关联 Task 的返回值为 Option.None,该 Timer 将会失效,并停止调度关联 Task。如果关联 Task 的返回值为 Option.Some(v) 且 v > Duration.Zero,下次运行前的最小时间间隔将被设置为 v。否则,关联 Task 会立刻再次被调度执行。
参数:
- dt:关联 Task 首次被调度执行的时间点
- task:该
Timer调度执行的 Task
返回值:一个 Timer 实例
异常:
- IllegalArgumentException:参数
dt晚于当前时间时,抛此异常
func after
public static func after(delay: Duration, task: () -> Option<Duration>): Timer
功能:初始化一个 Timer,关联的 Task 被调度执行的次数取决于它的返回值。如果定时器第一次触发的时间点小于当前时间,关联的 Task 会立刻被调度执行。如果关联 Task 的返回值为 Option.None,该 Timer 将会失效,并停止调度关联 Task。如果关联 Task 的返回值为 Option.Some(v) 且 v > Duration.Zero,下次运行前的最小时间间隔将被设置为 v。否则,关联 Task 会立刻再次被调度执行。
参数:
- delay:从现在开始到关联 Task 首次被调度执行的时间间隔
- task:该
Timer调度执行的 Task
返回值:一个 Timer 实例
init
public init(start!: DateTime, task!: () -> Unit)
功能:初始化一个一次性 Timer,关联的 Task 只会被调度执行一次。如果参数 start 的时间点小于当前时间,关联的 Task 会立刻被调度执行。
参数:
- start:关联 Task 首次被调度执行的时间点
- task:该
Timer调度执行的 Task
异常:
- IllegalArgumentException:参数
start晚于当前时间,抛此异常
init
public init(start!: Duration, task!: () -> Unit)
功能:初始化一个一次性 Timer,关联的 Task 只会被调度执行一次。如果参数 start 的时间间隔为负值,关联的 Task 会立刻被调度执行。
参数:
- start:从现在开始到关联 Task 首次被调度执行的时间间隔
- task:该
Timer调度执行的 Task
init
public init(start!: DateTime, period!: Duration, task!: () -> Unit)
功能:初始化一个周期性 Timer,关联的 Task 只会被重复调度执行。如果参数 start 的时间点小于当前时间,关联的 Task 会立刻被调度执行。
参数:
- start:关联 Task 首次被调度执行的时间点
- period:关联 Task 两次执行的最小时间间隔
- task:该
Timer调度执行的 Task
异常:
- IllegalArgumentException:参数
start晚于当前时间,或period <= Duration.Zero时,抛此异常
init
public init(start!: Duration, period!: Duration, task!: () -> Unit)
功能:初始化一个周期性 Timer,关联的 Task 只会被重复调度执行。如果参数 start 的时间间隔为负值,关联的 Task 会立刻被调度执行。
参数:
- start:从现在开始到关联 Task 首次被调度执行的时间间隔
- period:关联 Task 两次执行的最小时间间隔
- task:该
Timer调度执行的 Task
异常:
- IllegalArgumentException:当
period <= Duration.Zero时,抛此异常
init
public init(start!: DateTime, end!: DateTime, period!: Duration, task!: () -> Unit)
功能:初始化一个周期性 Timer,关联的 Task 只会被重复调度执行。如果参数 start 的时间点小于当前时间,关联的 Task 会立刻被调度执行。
参数:
- start:关联 Task 首次被调度执行的时间点
- end:
Timer被取消,关联 Task 不再被调度执行的时间点 - period:关联 Task 两次执行的最小时间间隔
- task:该
Timer调度执行的 Task
异常:
- IllegalArgumentException:参数
start晚于当前时间,或参数end小于等于参数start或当前时间,或period <= Duration.Zero时,抛此异常
init
public init(start!: Duration, count!: Int64, period!: Duration, task!: () -> Unit)
功能:初始化一个周期性 Timer,关联的 Task 只会被重复调度执行。如果参数 start 的时间点小于当前时间,关联的 Task 会立刻被调度执行。
参数:
- start:从现在开始到关联 Task 首次被调度执行的时间间隔
- count:关联 Task 被调度执行的次数
- period:关联 Task 两次执行的最小时间间隔
- task:该
Timer调度执行的 Task
异常:
- IllegalArgumentException:当
count <= 0,或period <= Duration.Zero时,抛此异常
func cancel
public func cancel(): Unit
功能:取消该 Timer,关联 Task 将不再被调度执行。如果调用该函数时关联 Task 正在执行,不会打断当前运行。该函数不会阻塞当前线程。调用该函数多次等同于只调用一次。
operator func ==
public operator func ==(rhs: Timer): Bool
功能:判断当前 Timer 与入参 rhs 指定的 Timer 是否是同一个实例。
返回值:若两个 Timer 是同一个实例,则返回 true,否则返回 false
operator func !=
public operator func !=(rhs: Timer): Bool
功能:判断当前 Timer 与入参 rhs 指定的 Timer 是否不是同一个实例。
返回值:若两个 Timer 不是同一个实例,则返回 true,否则返回 false
func sleep
public func sleep(dur: Duration): Unit
功能:使得当前线程进入睡眠。若 dur <= Duration.Zero,当前线程会让出运行权。
参数:
- dur:线程睡眠的时长。
示例
Atomic 的使用
如何在多线程程序中,使用原子操作实现计数。
代码如下:
from std import sync.*
from std import time.*
from std import collection.*
let count = AtomicInt64(0)
main(): Int64 {
let list = ArrayList<Future<Int64>>()
/* 创建 1000 个线程 */
for (i in 0..1000) {
let fut = spawn {
sleep(Duration.millisecond) /* 睡眠 1 毫秒 */
count.fetchAdd(1)
}
list.append(fut)
}
/* 等待所有线程完成 */
for (f in list) {
f.get()
}
var val = count.load()
println("count = ${val}")
return 0
}
输出结果如下:
count = 1000
Monitor 的使用
下面是 Monitor 实例使用示例。
代码如下:
from std import sync.*
from std import time.{Duration, DurationExtension}
var mon = Monitor()
var flag: Bool = true
main(): Int64 {
let fut = spawn {
mon.lock()
while (flag) {
println("New thread: before wait")
mon.wait()
println("New thread: after wait")
}
mon.unlock()
}
/* 睡眠 10 毫秒,以确保新线程可以执行 */
sleep(10 * Duration.millisecond)
mon.lock()
println("Main thread: set flag")
flag = false
mon.unlock()
println("Main thread: notify")
mon.lock()
mon.notifyAll()
mon.unlock()
/* 等待新线程完成 */
fut.get()
return 0
}
输出结果如下:
New thread: before wait
Main thread: set flag
Main thread: notify
New thread: after wait
Timer 的使用
下面是 Timer 实例使用示例。
代码如下:
from std import sync.*
from std import time.{Duration, DurationExtension}
main(): Int64 {
let count = AtomicInt8(0)
Timer(start: 50 * Duration.millisecond, task: { =>
println("run only once")
count.fetchAdd(1)
})
let timer = Timer(start: 100 * Duration.millisecond, period: 200 * Duration.millisecond, task: { =>
println("run repetitively")
count.fetchAdd(10)
})
sleep(Duration.second)
timer.cancel()
sleep(500 * Duration.millisecond)
println("count = ${count.load()}")
0
}
输出结果如下:
run only once
run repetitively
run repetitively
run repetitively
run repetitively
run repetitively
count = 51
time 包
介绍
time 包提供了时间操作相关的能力,包括时间的读取、时间计算、基于时区的时间转换、时间的序列化和反序列化等功能。
主要接口
struct Duration
public struct Duration <: ToString & Hashable & Comparable<Duration>
Duration 用以表示一段时间间隔,其精度为纳秒,可表示范围为 Duration.Min 至 Duration.Max,数值表示为[-263, 263)(单位为秒)。提供了一些常用时间间隔的静态成员实例、时间间隔的计算以及比较函数等。
Duration 中的规则:
每个时间单位(小时、分、秒等)均用整数表示,如果实际值不为整数,则向绝对值小的方向取整,向绝对值小的方向取整:例如,2.8 小时取整为 2小时,-2.8 小时取整为 -2小时,0.5 分钟取整为 0 分钟,-0.7 秒取整为 0 秒。
Duration 提供的 API 如下所示:
prop nanosecond
public static prop nanosecond: Duration
功能:表示 1 纳秒时间间隔的 Duration 实例。
prop microsecond
public static prop microsecond: Duration
功能:表示 1 微秒时间间隔的 Duration 实例。
prop millisecond
public static prop millisecond: Duration
功能:表示 1 毫秒时间间隔的 Duration 实例。
prop second
public static prop second: Duration
功能:表示 1 秒时间间隔的 Duration 实例。
prop minute
public static prop minute: Duration
功能:表示 1 分钟时间间隔的 Duration 实例。
prop hour
public static prop hour: Duration
功能:表示 1 小时时间间隔的 Duration 实例。
prop day
public static prop day: Duration
功能:表示 1 天时间间隔的 Duration 实例。
prop Zero
public static prop Zero: Duration
功能:表示 0 纳秒时间间隔的 Duration 实例。
prop Max
public static prop Max: Duration
功能:表示最大时间间隔的 Duration 实例,其值为 “9223372036854775807秒999999999纳秒”。
prop Min
public static prop Min: Duration
功能:表示最小时间间隔的 Duration 实例,其值为 “-9223372036854775807秒”。
func since
public static func since(t: DateTime): Duration
功能:计算从参数 t 开始到当前时间为止的时间间隔。
参数:
- t:
DateTime实例
返回值:Duration 实例
func until
public static func until(t: DateTime): Duration
功能:计算从当前时间开始到参数 t 为止的时间间隔。
参数:
- t:
DateTime实例
返回值:Duration 实例
func toDays
public func toDays(): Int64
功能:获得当前 Duration 实例以“天”为单位的整数大小,向绝对值小的方向取整。
返回值:当前 Duration 实例以“天”为单位的大小
func toHours
public func toHours(): Int64
功能:获得当前 Duration 实例以“小时”为单位的整数大小,向绝对值小的方向取整。
返回值:当前 Duration 实例以“小时”为单位的大小
func toMinutes
public func toMinutes(): Int64
功能:获得当前 Duration 实例以“分钟”为单位的整数大小,向绝对值小的方向取整。
返回值:当前 Duration 实例以“分钟”为单位的大小
func toSeconds
public func toSeconds(): Int64
功能:获得当前 Duration 实例以“秒”为单位的整数大小,向绝对值小的方向取整。
返回值:当前 Duration 实例以“秒”为单位的大小
func toMilliseconds
public func toMilliseconds(): Int64
功能:获得当前 Duration 实例以“毫秒”为单位的整数大小,向绝对值小的方向取整。
返回值:当前 Duration 实例以“毫秒”为单位的大小
异常:
- ArithmeticException:当
Duration实例以“毫秒”为单位的大小超过Int64表示范围时,抛出异常。
func toMicroseconds
public func toMicroseconds(): Int64
功能:获得当前 Duration 实例以“微秒”为单位的整数大小,向绝对值小的方向取整。
返回值:当前 Duration 实例以“微秒”为单位的大小
异常:
- ArithmeticException:当
Duration实例以“微秒”为单位的大小超过Int64表示范围时,抛出异常。
func toNanoseconds
public func toNanoseconds(): Int64
功能:获得当前 Duration 实例以“纳秒”为单位的整数大小,向绝对值小的方向取整。
返回值:当前 Duration 实例以“纳秒”为单位的大小
异常:
- ArithmeticException:当
Duration实例以“纳秒”为单位的大小超过Int64表示范围时,抛出异常。
func toString
public func toString(): String
功能:获得当前 Duration 实例的字符串表示,格式形如:"1d2h3m4s5ms6us7ns",表示“1天2小时3分钟4秒5毫秒6微秒7纳秒”。某个单位下数值为 0 时此项会被省略,特别地,当所有单位下数值都为 0 时,返回 "0s"。
返回值:当前 Duration 实例的字符串表示
func hashCode
public func hashCode(): Int64
功能:获得当前 Duration 实例的哈希值。
返回值:当前 Duration 实例的哈希值
func abs
public func abs(): Duration
功能:返回一个新的 Duration 实例,其值大小为当前 Duration 实例绝对值。
返回值:当前 Duration 实例取绝对值的结果
异常:
- ArithmeticException:如果当前
Duration实例等于Duration.Min,会因为取绝对值超出Duration表示范围而抛异常
operator func +
public operator func +(r: Duration): Duration
功能:重载操作符 +,实现 "Duration + Duration = Duration",返回新的 Duration 实例表示和。
参数:
- r:
Duration实例,加法的右操作数
返回值:加法运算的结果
异常:
- ArithmeticException:当相加后的结果超出
Duration的表示范围时,抛出异常
operator func -
public operator func -(r: Duration): Duration
功能:重载操作符 -,实现 "Duration - Duration = Duration",返回新的 Duration 实例表示差。
参数:
- r:
Duration实例,减法的右操作数
返回值:减法运算的结果
异常:
- ArithmeticException:当相减后的结果超出
Duration的表示范围时,抛出异常
operator func *
public operator func *(r: Int64): Duration
功能:重载操作符 *,实现 "Duration * Int64 = Duration",返回新的 Duration 实例表示积。
参数:
- r:
Int64类型,乘法的右操作数
返回值:乘法运算的结果
异常:
- ArithmeticException:当相乘后的结果超出
Duration的表示范围时,抛出异常
operator func *
public operator func *(r: Float64): Duration
功能:重载操作符 *,实现 "Duration * Float64 = Duration",返回新的 Duration 实例表示积。由于 Float64 的精度受限,当 Duration 超过一定范围时,结果会不准确。
参数:
- r:
Float64类型,乘法的右操作数
返回值:乘法运算的结果,最小精度为纳秒,不足一纳秒部分向绝对值小的方向取整
异常:
- ArithmeticException:当相乘后的结果超出
Duration的表示范围时,抛出异常
operator func /
public operator func /(r: Int64): Duration
功能:重载操作符 /,实现 "Duration / Int64 = Duration",返回新的 Duration 实例表示商。
参数:
- r:
Int64类型,除法的右操作数
返回值:除法运算的结果
异常:
- IllegalArgumentException:当
r等于 0 时,抛出异常 - ArithmeticException:当相除后的结果超出
Duration的表示范围时,抛出异常
operator func /
public operator func /(r: Float64): Duration
功能:重载操作符 /,实现 "Duration / Float64 = Duration",返回新的 Duration 实例表示商。由于 Float64 的精度受限,当 Duration 超过一定范围时,结果会不准确。
参数:
- r:
Float64类型,除法的右操作数
返回值:除法运算的结果
异常:
- IllegalArgumentException:当
r等于 0 时,抛出异常 - ArithmeticException:当相除后的结果超出
Duration的表示范围时,抛出异常
operator func /
public operator func /(r: Duration): Float64
功能:重载操作符 /,实现 "Duration / Duration = Float64",返回一个浮点数表示商。
参数:
- r:
Duration实例,除法的右操作数
返回值:除法运算的结果
异常:
- IllegalArgumentException:当
r等于Duration.Zero时,抛出异常
operator func ==
public operator func ==(r: Duration): Bool
功能:重载操作符 ==,实现 "Duration == Duration" 的判断,返回当前 Duration 实例是否等于 r。
参数:
- r:
Duration实例,==运算的右操作数
返回值:当前 Duration 实例是否等于 r
operator func !=
public operator func !=(r: Duration): Bool
功能:重载操作符 !=,实现 "Duration != Duration" 的判断,返回当前 Duration 实例是否不等于 r。
参数:
- r:
Duration实例,!=运算的右操作数
返回值:当前 Duration 实例是否不等于 r
operator func >=
public operator func >=(r: Duration): Bool
功能:重载操作符 >=,实现 "Duration >= Duration" 的判断,返回当前 Duration 实例是否大于等于 r。
参数:
- r:
Duration实例,>=运算的右操作数
返回值:当前 Duration 实例是否大于等于 r
operator func >
public operator func >(r: Duration): Bool
功能:重载操作符 >,实现 "Duration > Duration" 的判断,返回当前 Duration 实例是否大于 r。
参数:
- r:
Duration实例,>运算的右操作数
返回值:当前 Duration 实例是否大于 r
operator func <=
public operator func <=(r: Duration): Bool
功能:重载操作符 <=,实现 "Duration <= Duration" 的判断,返回当前 Duration 实例是否小于等于 r。
参数:
- r:
Duration实例,<=运算的右操作数
返回值:当前 Duration 实例是否小于等于 r
operator func <
public operator func <(r: Duration): Bool
功能:重载操作符 <,实现 "Duration < Duration" 的判断,返回当前 Duration 实例是否小于 r。
参数:
- r:
Duration实例,<运算的右操作数
返回值:当前 Duration 实例是否小于 r
func compare
public func compare(rhs: Duration): Ordering
功能:比较当前 Duration 实例与另一个 Duration 实例的关系,如果大于,返回 Ordering.GT;如果等于,返回 Ordering.EQ;如果小于,返回 Ordering.LT。
参数:
- rhs:参与比较的
Duration实例
返回值:当前 Duration 实例与 rhs 的大小关系
interface DurationExtension
public interface DurationExtension {
operator func *(r: Duration): Duration
}
DurationExtension 用于拓展 Duration 实例作为右操作数时,返回积为新 Duration 实例的乘法运算。
operator func *
operator func *(r: Duration): Duration
功能:重载操作符 *,实现 "T * Duration = Duration",返回新的 Duration 实例表示积。
参数:
- r:
Duration实例,乘法的右操作数
返回值:乘法运算的结果
异常:
- ArithmeticException:当相乘后的结果超出
Duration的表示范围时,抛出异常
extend Int64 <: DurationExtension
extend Int64 <: DurationExtension
拓展了 Int64 类型作为左操作数和 Duration 类型作为右操作数的乘法运算。
operator func *
public operator func *(r: Duration): Duration
功能:重载操作符 *,实现 "Int64 * Duration = Duration",返回新的 Duration 实例表示积。
例如 2 * Duration.second 返回表示时间间隔为 2 秒的 Duration 实例。
参数:
- r:
Duration实例,乘法的右操作数
返回值:乘法运算的结果
异常:
- ArithmeticException:当相乘后的结果超出
Duration的表示范围时,抛出异常
extend Float64 <: DurationExtension
extend Float64 <: DurationExtension
拓展了 Float64 类型作为左操作数和 Duration 类型作为右操作数的乘法运算。
operator func *
public operator func *(r: Duration): Duration
功能:重载操作符 *,实现 "Float64 * Duration = Duration",返回新的 Duration 实例表示积。由于 Float64 的精度受限,当 Duration 超过一定范围时,结果会不准确。
参数:
- r:
Duration实例,乘法的右操作数
返回值:乘法运算的结果
异常:
- ArithmeticException:当相乘后的结果超出
Duration的表示范围时,抛出异常
class TimeZone
public class TimeZone <: ToString & Equatable<TimeZone> {
public static let UTC: TimeZone
public static let Local: TimeZone
public init(id: String, offset: Duration)
}
类 TimeZone 表示了具体的时区信息,提供从系统加载时区、自定义时区等功能。
时区信息包含对应地区的夏令时、时区偏移量等信息。
类 TimeZone 提供的 API 如下所示:
init
public init(id: String, offset: Duration)
功能:使用参数 id 和 offset 指定的时区 id 和偏移构造一个自定义 TimeZone 实例。其中,offset 精度为秒,相对于 UTC 时区向东为正,有效区间为 [-24:59:59, 25:59:59]。
参数:
- id:时区 id
- offset:时区偏移
异常:
- IllegalArgumentException:输入
id为空字符串,或offset无效时抛出异常
prop id
public prop id: String
功能:获取当前 TimeZone 实例所关联的时区 id。
UTC
public static let UTC: TimeZone
功能:获取 UTC 时区。
Local
public static let Local: TimeZone
功能:获取本地时区。
此函数根据系统环境变量 TZ 获取时区 id,并从系统时区文件中加载时区;若未设置 TZ 环境变量或 TZ 环境变量为空,则加载名为 localtime 的本地时区。
环境变量 TZ 的取值为时区 id 格式,如 "Asia/Shanghai",该格式中使用的正斜杠符合标准时区 id 规范,不因操作系统不同而改变。
系统时区文件依赖路径 "/usr/share/zoneinfo",本地时区文件依赖 "/etc/localtime",若系统中上述依赖的路径不存在,则返回 UTC;
通过时区 id 方式加载时区时,若无法从相应路径中找到 id 对应的时区文件时,则返回 UTC;
通过本地时区文件方式加载时区时,若本地时区文件未链接到时区文件时,则返回 UTC 。
func load
public static func load(id: String): TimeZone
功能:从系统中加载参数 id 指定的时区,其格式举例 "Asia/Shanghai",该格式中使用的正斜杠符合标准时区 id 规范,不因操作系统不同而改变(windows 需要用户自行下载 IANA 时区文件)如果存在名为 CJ_TZPATH 的环境变量,则优先使用环境变量指定的根路径加载时区文件如果通过分隔符(Linux 是 ":" ; Windows 是 ";" )设定了多个环境变量值,将会按照分隔路径的先后顺序依次查找时区文件,并加载第一个找到的时区文件。需要注意的是,如果设定了有效的环境变量,将不会去查找系统的时区文件,环境变量中查找不到,将会抛出异常环境变量未定义又或者指向一个空字符串时,该环境变量视作无效,按照默认路径 "/usr/share/zoneinfo" 寻找时区文件当参数 id 为 "UTC" 时,返回 TimeZone.UTC;当参数 id 为 "Local" 时,返回 TimeZone.Local。此函数加载成功时获得 TimeZone 实例,否则抛出异常。
参数:
- id:时区 id 的字符串表示
返回值:加载的时区
异常:
- IllegalArgumentException:当参数
id为空,或长度超过 4096,或不合法时,抛出异常 - InvalidDataException:如果时区文件加载失败,则抛出异常(如找不到文件,文件解析失败等)
func loadFromPaths
public static func loadFromPaths(id: String, tzpaths: Array<String>): TimeZone
功能:从参数 tzpaths 指定的路径中加载参数 id 指定的时区。由参数 tzpaths 指定根路径(Linux 系统例如 "/root/user/location/",Windows 系统例如 "C:\Users\location"),由参数 id 指定时区 id,其格式举例 "Asia/Shanghai",该格式中使用的正斜杠符合标准时区 id 规范,不因操作系统不同而改变。加载时区文件时,将按照 ArrayTimeZone 实例,否则抛出异常。
参数:
- tzpaths:时区文件存放的路径集合,其包内时区文件需要满足 IANA 时区文件格式:https://datatracker.ietf.org/doc/html/rfc8536
- id:存在的时区 id
返回值:加载的时区
异常:
- IllegalArgumentException:当
id为空,或长度超过 4096,或不合法时,抛出异常 - InvalidDataException:如果时区文件加载失败,则抛出异常(如找不到文件,文件解析失败等)
func loadFromTZData
public static func loadFromTZData(id: String, data: Array<UInt8>): TimeZone
功能:使用参数 id 和 data 指定的时区 id 和时区数据构造一个自定义 TimeZone 实例,id 可以是任何合法字符串,data 需要满足 IANA 时区文件格式,加载成功时获得 TimeZone 实例,否则抛出异常。
参数:
- id:时区 id
- data:满足 IANA 时区数据库格式的数据
返回值:加载的时区
异常:
- IllegalArgumentException:当 id 为空时,抛出异常
- InvalidDataException:如果 data 解析失败,则抛出异常
func toString
public func toString(): String
功能:获取本 TimeZone 实例时区 id 的字符串表示。
返回值:时区 id 的字符串表示
operator func ==
public operator func ==(r: TimeZone): Bool
功能:判断当前 TimeZone 实例是否等于 r,两个 TimeZone 的引用相同时,返回 true;反之,返回 false。
参数:
- r:
TimeZone实例,==运算的右操作数
返回值:当前 TimeZone 实例是否等于 r
operator func !=
public operator func !=(r: TimeZone): Bool
功能:判断当前 TimeZone 实例是否不等于 r,两个 TimeZone 的引用相同时,返回 false;反之,返回 true。
参数:
- r:
TimeZone实例,!=运算的右操作数
返回值:当前 TimeZone 实例是否不等于 r
class TimeParseException
public class TimeParseException <: Exception {
public init()
public init(message: String)
}
异常类,表示解析时间字符串发生错误。
init
public init()
功能:构造一个 TimeParseException 实例。
init
public init(message: String)
功能:根据参数 message 指定的异常信息,构造一个 TimeParseException 实例。
参数:
- message:预定义消息
class InvalidDataException
public class InvalidDataException <: Exception {
public init()
public init(message: String)
}
异常类,表示加载时区发生错误。
init
public init()
功能:构造一个 InvalidDataException 实例。
init
public init(message: String)
功能:根据参数 message 指定的异常信息,构造一个 InvalidDataException 实例。
参数:
- message:预定义消息
struct DateTime
public struct DateTime <: ToString & Hashable & Comparable<DateTime>
DateTime 表示日期时间,可表示至纳秒,受时区影响。可表示的时间区间为 [-999,999,999-01-01T00:00:00.000000000, 999,999,999-12-31T23:59:59.999999999],该表示范围不受时区影响。主要提供了时间的读取和计算、基于时区的时间转换、序列化和反序列化等功能。
DateTime 的比较是基于去除时区影响的时间,即实例对应的零时区的时间。如表示东8区(+8)2023年4月13日8时0分0秒 与西5区(-5)2023年4月12日19时0分0秒 的 DateTime 实例是相等的。
以下为 DateTime 中 now 函数获取当前时间使用的系统调用函数:
| 系统 | 系统调用函数 | 时钟类型 |
|---|---|---|
| Linux | clock_gettime | CLOCK_REALTIME |
| Windows | clock_gettime | CLOCK_REALTIME |
| macOS | clock_gettime | CLOCK_REALTIME |
DateTime 提供的 API 如下所示:
prop UnixEpoch
public static prop UnixEpoch: DateTime
功能:Unix 时间纪元 - 1970-01-01T00:00:00Z。
prop year
public prop year: Int64
功能:获取当前 DateTime 实例的年份。
返回值:当前 DateTime 实例的年份
prop month
public prop month: Month
功能:获取当前 DateTime 实例的月份。
返回值:当前 DateTime 实例的月
prop monthValue
public prop monthValue: Int64
功能:获取当前 DateTime 实例的月份取值。
返回值:当前 DateTime 实例的月份取值
prop dayOfMonth
public prop dayOfMonth: Int64
功能:获取当前 DateTime 实例以月算的天数。
返回值:当前 DateTime 实例以月算的天数
prop dayOfWeek
public prop dayOfWeek: DayOfWeek
功能:获取当前 DateTime 实例以周算的天数。
返回值:当前 DateTime 实例以周算的天数
prop dayOfYear
public prop dayOfYear: Int64
功能:获取当前 DateTime 实例以年算的天数。
返回值:当前 DateTime 实例以年算的天数
prop hour
public prop hour: Int64
功能:获取当前 DateTime 实例的小时。
返回值:当前 DateTime 实例的小时
prop minute
public prop minute: Int64
功能:获取当前 DateTime 实例的分钟。
返回值:当前 DateTime 实例的分钟
prop second
public prop second: Int64
功能:获取当前 DateTime 实例的秒。
返回值:当前 DateTime 实例的秒
prop nanosecond
public prop nanosecond: Int64
功能:获取当前 DateTime 实例的纳秒。
返回值:当前 DateTime 实例的纳秒
prop isoWeek
public prop isoWeek: (Int64, Int64)
功能:获取基于 ISO8601 标准的年份和基于年的周数。
返回值:基于 ISO8601 标准的年份和基于年的周数
prop zone
public prop zone: TimeZone
功能:获取当前 DateTime 实例所关联的时区。
返回值:前 DateTime 实例所关联的时区
prop zoneId
public prop zoneId: String
功能:获取当前 DateTime 实例所关联的 TimeZone 实例的时区 id。
返回值:时区 id 的字符串表示
prop zoneOffset
public prop zoneOffset: Duration
功能:获取当前 DateTime 实例所关联的 TimeZone 实例的时间偏移。
返回值:时间偏移表示的时间间隔
func now
public static func now(timeZone!: TimeZone = TimeZone.Local): DateTime
功能:获取参数 timeZone 指定时区的当前时间。该方法获取的当前时间受系统时间影响,如存在使用不受系统时间影响的计时场景,可使用 MonoTime.now() 替代。
参数:
- timeZone:时区,默认为本地时区
返回值:返回指定时区当前时间
func nowUTC
public static func nowUTC(): DateTime
功能:获取 UTC 时区的当前时间。该方法获取的当前时间受系统时间影响,如存在使用不受系统时间影响的计时场景,可使用 MonoTime.now() 替代。
返回值:UTC 时区当前时间
func fromUnixTimeStamp
public static func fromUnixTimeStamp(d: Duration): DateTime
功能:获取自 UnixEpoch 开始参数 d 指定时间间隔后的日期时间。
参数:
- d:时间间隔
返回值:自 UnixEpoch 开始的指定 d 后的日期时间
异常:
- ArithmeticException:当结果超过日期时间的表示范围时,抛出异常
func ofEpoch
public static func ofEpoch(second!: Int64, nanosecond!: Int64): DateTime
功能:根据入参 second 和 nanosecond 构造 DateTime 实例。入参 second 表示 unix 时间的秒部分,nanosecond 表示 unix 时间的纳秒部分。unix 时间以 UnixEpoch 开始计算,nanosecond 的范围不可以超过[0, 999,999,999],否则抛出异常。
参数:
- second:unix 时间的秒部分
- nanosecond:unix 时间的纳秒部分,范围不可以超过[0, 999,999,999]
返回值:返回自 UnixEpoch 开始的指定 second 和 nanosecond 后的时间
异常:
- IllegalArgumentException:当
nanosecond值超出指定范围时,抛出异常 - ArithmeticException:当结果超过日期时间的表示范围时,抛出异常
func of
public static func of(
year!: Int64,
month!: Int64,
dayOfMonth!: Int64,
hour!: Int64 = 0,
minute!: Int64 = 0,
second!: Int64 = 0,
nanosecond!: Int64 = 0,
timeZone!: TimeZone = TimeZone.Local
): DateTime
功能:根据参数指定的年、月、日、时、分、秒、纳秒、时区构造 DateTime 实例。
参数:
- year:年,范围[-999,999,999, 999,999,999]
- month:月,范围[1, 12]
- dayOfMonth:日,范围[1, 31],最大取值需要跟 month 匹配,可能是 28、29、30、31
- hour:时,范围[0, 23]
- minute:分,范围[0, 59]
- second:秒,范围[0, 59]
- nanosecond:纳秒,范围[0, 999,999,999]
- timeZone:时区
返回值:根据指定参数构造的 DateTime 实例
异常:
- IllegalArgumentException:当参数值超出指定范围,抛出异常
func of
public static func of(
year!: Int64,
month!: Month,
dayOfMonth!: Int64,
hour!: Int64 = 0,
minute!: Int64 = 0,
second!: Int64 = 0,
nanosecond!: Int64 = 0,
timeZone!: TimeZone = TimeZone.Local
): DateTime
功能:根据参数指定的年、月、日、时、分、秒、纳秒、时区构造 DateTime 实例。
参数:
- year:年,范围[-999,999,999, 999,999,999]
- month:月,Month 类型
- dayOfMonth:日,范围[1, 31],最大取值需要跟 month 匹配,可能是 28、29、30、31
- hour:时,范围[0, 23]
- minute:分,范围[0, 59]
- second:秒,范围[0, 59]
- nanosecond:纳秒,范围[0, 999,999,999]
- timeZone:时区
返回值:根据指定参数构造的 DateTime 实例
异常:
- IllegalArgumentException:当参数值超出指定范围,抛出异常
func ofUTC
public static func ofUTC(
year!: Int64,
month!: Int64,
dayOfMonth!: Int64,
hour!: Int64 = 0,
minute!: Int64 = 0,
second!: Int64 = 0,
nanosecond!: Int64 = 0
): DateTime
功能:根据参数指定的年、月、日、时、分、秒、纳秒构造 UTC 时区 DateTime 实例。
参数:
- year:年,范围[-999,999,999, 999,999,999]
- month:月,范围[1, 12]
- dayOfMonth:日,范围[1, 31],最大取值需要跟 month 匹配,可能是 28、29、30、31
- hour:时,范围[0, 23]
- minute:分,范围[0, 59]
- second:秒,范围[0, 59]
- nanosecond:纳秒,范围[0, 999,999,999]
返回值:根据指定参数构造的 UTC 时区 DateTime 实例
异常:
- IllegalArgumentException:当参数值超出指定范围时,抛出异常
func ofUTC
public static func ofUTC(
year!: Int64,
month!: Month,
dayOfMonth!: Int64,
hour!: Int64 = 0,
minute!: Int64 = 0,
second!: Int64 = 0,
nanosecond!: Int64 = 0
): DateTime
功能:根据参数指定的年、月、日、时、分、秒、纳秒构造 UTC 时区 DateTime 实例。
参数:
- year:年,范围[-999,999,999, 999,999,999]
- month:月,Month 类型
- dayOfMonth:日, 范围[1, 31],最大取值需要跟 month 匹配,可能是 28、29、30、31
- hour:时,范围[0, 23]
- minute:分,范围[0, 59]
- second:秒,范围[0, 59]
- nanosecond:纳秒,范围[0, 999,999,999]
返回值:根据指定参数构造的 UTC 时区 DateTime 实例
异常:
- IllegalArgumentException:当参数值超出指定范围时,抛出异常
func parse
public static func parse(str: String): DateTime
功能:从参数 str 中解析得到时间,解析成功时返回 DateTime 实例。
参数:
- str:时间字符串,格式为
RFC3339中date-time格式,可包含小数秒,如 "2023-04-10T08:00:00[.123456]+08:00"([]中的内容表示可选项)
返回值:从参数 str 中解析出的 DateTime 实例
异常:
- TimeParseException:无法正常解析时,抛出异常
func parse
public static func parse(str: String, format: String): DateTime
功能:根据 format 指定的时间格式,从字符串 str 中解析得到时间,解析成功时返回 DateTime 实例,解析具体规格可见下文“从字符串中解析得到时间”模块。
参数:
- str:时间字符串,例如:"2023/04/10 08:00:00 +08:00"
- format:时间字符串的格式,例如:"yyyy/MM/dd HH:mm:ss OOOO"
返回值:根据参数 format 指定的时间格式,从参数 str 中解析出的 DateTime 实例
异常:
- TimeParseException:当无法正常解析时,或存在同一
format的多次取值时,抛出异常 - IllegalArgumentException:当
format格式不正确时,抛出异常
func inUTC
public func inUTC(): DateTime
功能:获取当前 DateTime 实例在 UTC 时区的时间。
返回值:当前 DateTime 实例在 UTC 时区的时间
异常:
- ArithmeticException:当返回的
DateTime实例表示的日期时间超过表示范围时,抛出异常
func inLocal
public func inLocal(): DateTime
功能:获取当前 DateTime 实例在本地时区的时间。
返回值:当前 DateTime 实例在本地时区的时间
异常:
- ArithmeticException:当返回的
DateTime实例表示的日期时间超过表示范围时,抛出异常
func inTimeZone
public func inTimeZone(timeZone: TimeZone): DateTime
功能:获取当前 DateTime 实例在参数 timeZone 指定时区的时间。
参数:
- timeZone:目标时区
返回值:当前 DateTime 实例在参数 timezone 指定时区的时间
异常:
- ArithmeticException:当返回的
DateTime实例表示的日期时间超过表示范围时,抛出异常
func toUnixTimeStamp
public func toUnixTimeStamp(): Duration
功能:获取当前实例自 UnixEpoch 的时间间隔。
返回值:当前实例自 UnixEpoch 的时间间隔
func toString
public func toString(): String
功能:返回一个表示当前 DateTime 实例的字符串,其格式为 RFC3339 中 date-time 格式,如果时间包含纳秒信息(不为零),会打印出小数秒。
返回值:当前 DateTime 实例的字符串表示
func toString
public func toString(format: String): String
功能:返回一个表示当前 DateTime 实例的字符串,其格式由参数 format 指定。
参数:
- format:返回字符串的格式,其格式可为 "yyyy/MM/dd HH:mm:ss OOOO"
返回值:当前 DateTime 实例在 format 指定格式下的字符串
异常:
- IllegalArgumentException:当
format格式不正确时,抛出异常
func hashCode
public func hashCode(): Int64
功能:获取当前 DateTime 实例的哈希值。
返回值:哈希值
func addYears
public func addYears(n: Int64): DateTime
功能:获取当前 DateTime 实例 n 年之后的时间,返回新的 DateTime 实例。
注意:由于年的间隔不固定,若设 dt 表示 “2020年2月29日”,dt.addYears(1) 不会返回非法日期“2021年2月29日”。为了尽量返回有效的日期,会偏移到当月最后一天,返回 “2021年2月28日”。
参数:
- n:自当前
DateTime实例后多少年的数量
返回值:当前 DateTime 实例 n 年后的时间
异常:
- ArithmeticException:当前
DateTime实例n年后的日期时间超过表示范围时,抛出异常
func addMonths
public func addMonths(n: Int64): DateTime
功能:获取当前 DateTime 实例 n 月之后的时间,返回新的 DateTime 实例。
注意:由于月的间隔不固定,若设 dt 表示 “2020年3月30日”,dt.addMonths(1) 不会返回非法日期“2020年3月31日”。为了尽量返回有效的日期,会偏移到当月最后一天,返回“2020年4月30日”。
参数:
- n:自当前
DateTime实例后多少月的数量
返回值:当前 DateTime 实例 n 月后的时间
异常:
- ArithmeticException:当前
DateTime实例n月后的日期时间超过表示范围时,抛出异常
func addWeeks
public func addWeeks(n: Int64): DateTime
功能:获取当前 DateTime 实例 n 周之后的时间,返回新的 DateTime 实例。
参数:
- n:自当前
DateTime实例后多少周的数量
返回值:当前 DateTime 实例 n 周后的时间
异常:
功能:获取入参 n 周之后的时间,返回新的 DateTime 实例。
func addDays
public func addDays(n: Int64): DateTime
功能:获取当前 DateTime 实例 n 天之后的时间,返回新的 DateTime 实例。
参数:
- n:自当前
DateTime实例后多少天的数量
返回值:当前 DateTime 实例 n 天后的时间
异常:
- ArithmeticException:当前
DateTime实例n天后的日期时间超过表示范围时,抛出异常
func addHours
public func addHours(n: Int64): DateTime
功能:获取当前 DateTime 实例 n 小时之后的时间,返回新的 DateTime 实例。
参数:
- n:自当前
DateTime实例后多少小时的数量
返回值:当前 DateTime 实例 n 小时后的时间
异常:
- ArithmeticException:当前
DateTime实例n小时后的日期时间超过表示范围时,抛出异常
func addMinutes
public func addMinutes(n: Int64): DateTime
功能:获取当前 DateTime 实例 n 分钟之后的时间,返回新的 DateTime 实例。
参数:
- n:自当前
DateTime实例后多少分钟的数量
返回值:当前 DateTime 实例 n 分钟后的时间
异常:
- ArithmeticException:当前
DateTime实例n分钟后的日期时间超过表示范围时,抛出异常
func addSeconds
public func addSeconds(n: Int64): DateTime
功能:获取当前 DateTime 实例 n 秒之后的时间,返回新的 DateTime 实例。
参数:
- n:自当前
DateTime实例后多少秒的数量
返回值:当前 DateTime 实例 n 秒后的时间
异常:
- ArithmeticException:当前
DateTime实例n秒后的日期时间超过表示范围时,抛出异常
func addNanoseconds
public func addNanoseconds(n: Int64): DateTime
功能:获取当前 DateTime 实例 n 纳秒之后的时间,返回新的 DateTime 实例。
参数:
- n:自当前
DateTime实例后多少纳秒的数量
返回值:当前 DateTime 实例 n 纳秒后的时间
异常:
- ArithmeticException:当前
DateTime实例n纳秒后时间的日期时间超过表示范围时,抛出异常
operator func +
public operator func +(r: Duration): DateTime
功能:重载操作符 +,实现 "DateTime + Duration = DateTime",返回一个新的 DateTime 实例表示参数 r 指定时间间隔后的日期时间。
参数:
- r:时间间隔,加法的右操作数
返回值:参数 r 指定时间间隔后的日期时间
异常:
- ArithmeticException:当结果超过日期时间的表示范围时,抛出异常
operator func -
public operator func -(r: Duration): DateTime
功能:重载操作符 -,实现 "DateTime - Duration = DateTime",返回一个新的 DateTime 实例表示参数 r 指定时间间隔前的时间。
参数:
- r:时间间隔,减法的右操作数
返回值:参数 r 指定时间间隔前的时间
异常:
- ArithmeticException:当结果超过日期时间的表示范围时,抛出异常
operator func -
public operator func -(r: DateTime): Duration
功能:重载操作符 -,实现 "DateTime - DateTime = Duration",返回一个 Duration 实例表示两个 DateTime 实例相距的时间间隔。若参数 r 表示的时间早于当前 DateTime 实例,结果为正,晚于为负,等于为 0。
参数:
- r:时间,减法的右操作数
返回值:当前 DateTime 实例与参数 r 相距的时间间隔
operator func ==
public operator func ==(r: DateTime): Bool
功能:重载操作符 ==,实现 "DateTime == DateTime" 运算,返回当前 DateTime 实例是否等于 r。
参数:
- r:
DateTime实例,==运算的右操作数
返回值:当前 DateTime 实例是否等于 r
operator func !=
public operator func !=(r: DateTime): Bool
功能:重载操作符 !=,实现 "DateTime != DateTime" 运算,返回当前 DateTime 实例是否不等于 r。
参数:
- r:
DateTime实例,!=运算的右操作数
返回值:当前 DateTime 实例是否不等于 r
operator func >=
public operator func >=(r: DateTime): Bool
功能:重载操作符 >=,实现 "DateTime >= DateTime" 运算,返回当前 DateTime 实例是否晚于或等于 r。
参数:
- r:
DateTime实例,>=运算的右操作数
返回值:当前 DateTime 实例是否晚于或等于 r
operator func >
public operator func >(r: DateTime): Bool
功能:重载操作符 >,实现 "DateTime > DateTime" 运算,返回当前 DateTime 实例是否晚于 r。
参数:
- r:
DateTime实例,>运算的右操作数
返回值:当前 DateTime 实例是否晚于 r
operator func <=
public operator func <=(r: DateTime): Bool
功能:重载操作符 <=,实现 "DateTime <= DateTime" 运算,返回当前 DateTime 实例是否早于或等于 r。
参数:
- r:
DateTime实例,<=运算的右操作数
返回值:当前 DateTime 实例是否早于或等于 r
operator func <
public operator func <(r: DateTime): Bool
功能:重载操作符 <,实现 "DateTime < DateTime" 运算,返回当前 DateTime 实例是否早于 r。
参数:
- r:
DateTime实例,<运算的右操作数
返回值:当前 DateTime 实例是否早于 r
func compare
public func compare(rhs: DateTime): Ordering
功能:判断一个 DateTime 实例与参数 rhs 的大小关系。如果大于,返回 Ordering.GT;如果等于,返回 Ordering.EQ;如果小于,返回 Ordering.LT。
参数:
- rhs:参与比较的
DateTime实例
返回值:当前 DateTime 实例与 rhs 大小关系
struct MonoTime
public struct MonoTime <: Hashable & Comparable<MonoTime>
MonoTime 表示单调时间,是一个用来衡量经过时间的时钟,类似于一直运行的秒表,精度为纳秒。可表示的范围为 Duration.Zero 至 Duration.Max,数值表示为[0, 263)(单位为秒)。
通过 now 方法创建的 MonoTime 总是晚于先使用该方式创建的 MonoTime,常用于性能测试和时间优先的任务队列。
以下为 MonoTime 中 now 函数获取当前时间使用的系统调用函数:
| 系统 | 系统调用函数 | 时钟类型 |
|---|---|---|
| Linux | clock_gettime | CLOCK_MONOTONIC |
| Windows | clock_gettime | CLOCK_MONOTONIC |
| macOS | clock_gettime | CLOCK_MONOTONIC |
MonoTime 提供的 API 如下所示:
func now
public static func now(): MonoTime
功能:获取与当前时间对应的 MonoTime。
返回值:与当前时间对应的 MonoTime
operator func +
public operator func +(r: Duration): MonoTime
功能:重载操作符 +,实现 "MonoTime + Duration = MonoTime",返回经过 r 表示时间间隔后的单调时间。
参数:
- r:时间间隔,加法的右操作数
返回值:参数 r 表示时间间隔后的单调时间
异常:
- ArithmeticException:当结果超过单调时间的表示范围时,抛出异常
operator func -
public operator func -(r: Duration): MonoTime
功能:重载操作符 -,实现 "MonoTime - Duration = MonoTime",返回经过 r 表示时间间隔前的单调时间。
参数:
- r:时间间隔,减法的右操作数
返回值:参数 r 表示时间间隔前的单调时间
异常:
- ArithmeticException:当结果超过单调时间的表示范围时,抛出异常
operator func -
public operator func -(r: MonoTime): Duration
功能:重载操作符 -,实现 "MonoTime - MonoTime = Duration",返回当前实例距 r 经过的时间间隔。
参数:
- r:单调时间,减法的右操作数
返回值:当前实例距 r 经过的时间间隔
operator func ==
public operator func ==(r: MonoTime): Bool
功能:重载操作符 ==,实现 "MonoTime == MonoTime" 运算,返回当前 MonoTime 实例是否等于 r。
参数:
- r:单调时间,
==运算的右操作数
返回值:当前 MonoTime 实例是否等于 r,若等于,则返回 ture;否则,返回 false
operator func !=
public operator func !=(r: MonoTime): Bool
功能:重载操作符 !=,实现 "MonoTime != MonoTime" 运算,返回当前 MonoTime 实例是否不等于 r。
参数:
- r:单调时间,
!=运算的右操作数
返回值:当前 MonoTime 实例是否不等于 r,若不等于,则返回 true;否则,返回 false
operator func >=
public operator func >=(r: MonoTime): Bool
功能:重载操作符 >=,实现 "MonoTime >= MonoTime" 运算,返回当前 MonoTime 实例是否晚于或等于 r。
参数:
- r:单调时间,
>=运算的右操作数
返回值:当前 MonoTime 实例是否晚于或等于 r,若晚于或等于,则返回 true;否则,返回 false
operator func >
public operator func >(r: MonoTime): Bool
功能:重载操作符 >,实现 "MonoTime > MonoTime" 运算,返回当前 MonoTime 实例是否晚于 r。
参数:
- r:单调时间,
>运算的右操作数
返回值:当前 MonoTime 实例是否早于 r,若晚于,则返回 true;否则,返回 false
operator func <=
public operator func <=(r: MonoTime): Bool
功能:重载操作符 <=,实现 "MonoTime <= MonoTime" 运算,返回当前 MonoTime 实例是否晚于或等于 r。
参数:
- r:单调时间,
<=运算的右操作数
返回值:当前 MonoTime 实例是否晚于或等于 r,若晚于或等于,则返回 true;否则,返回 false
operator func <
public operator func <(r: MonoTime): Bool
功能:重载操作符 <,实现 "MonoTime < MonoTime" 运算,返回当前 MonoTime 实例是否晚于 r。
参数:
- r:单调时间,
<运算的右操作数
返回值:当前 MonoTime 实例是否晚于 r,若晚于,则返回 true;否则,返回 false
func compare
public func compare(rhs: MonoTime): Ordering
功能:判断一个 MonoTime 实例与参数 rhs 的大小关系。如果大于,返回 Ordering.GT;如果等于,返回 Ordering.EQ;如果小于,返回 Ordering.LT。
参数:
- rhs:参与比较的
MonoTime实例
返回值:当前 MonoTime 实例与 rhs 大小关系
func hashCode
public func hashCode(): Int64
功能:获取当前 MonoTime 实例的哈希值。
返回值:哈希值
enum Month
public enum Month <: ToString {
| January
| February
| March
| April
| May
| June
| July
| August
| September
| October
| November
| December
}
枚举类型 Month 用以表示月份,并提供与 Int64 类型的相互转换功能。
枚举类型 Month 提供的 API 如下所示:
January
January
功能:构造一个 Month 实例,表示一月。
February
February
功能:构造一个 Month 实例,表示二月。
March
March
功能:构造一个 Month 实例,表示三月。
April
April
功能:构造一个 Month 实例,表示四月。
May
May
功能:构造一个 Month 实例,表示五月。
June
June
功能:构造一个 Month 实例,表示六月。
July
July
功能:构造一个 Month 实例,表示七月。
August
August
功能:构造一个 Month 实例,表示八月。
September
September
功能:构造一个 Month 实例,表示九月。
October
October
功能:构造一个 Month 实例,表示十月。
November
November
功能:构造一个 Month 实例,表示十一月。
December
December
功能:构造一个 Month 实例,表示十二月。
func of
public static func of(mon: Int64): Month
功能:获取参数 mon 对应 Month 类型实例。
参数:
- mon:整数形式的月,合法范围为 [1, 12],分别表示一年中的十二个月
返回值:参数 mon 对应的 Month 类型实例
异常:
- IllegalArgumentException:当参数
mon不在 [1, 12] 范围内时,抛出异常
func value
public func value(): Int64
功能:获取当前 Month 实例的整数表示,一月至十二月分别表示为 1 至 12。
返回值:当前 Month 实例的整数表示
func toString
public func toString(): String
功能:返回当前 Month 实例的字符串表示。
返回值:当前 Month 实例的字符串表示
operator func +
public operator func +(n: Int64): Month
功能:重载操作符 +,实现 "Month + Int64 = Month",表示 n 月之后的日历月份。例如,一月的 12 个月后为一月。
参数:
- n:后多少月的数量,加法的右操作数
返回值:n 月后的月份
operator func -
public operator func -(n: Int64): Month
功能:重载操作符 -,实现 "Month - Int64 = Month",表示 n 月前的日历月份。例如,一月的 12 个月前为一月。
参数:
- n:前多少月的数量,减法的右操作数
返回值:n 月前的月份
operator func ==
public operator func ==(r: Month): Bool
功能:重载操作符 ==,实现 "Month == Month" 运算,返回当前 Month 实例是否等于 r。
参数:
- r:
Month实例,==运算的右操作数`
返回值:当前 Month 实例是否等于 r
operator func !=
public operator func !=(r: Month): Bool
功能:重载操作符 !=,实现 "Month != Month" 运算,返回当前 Month 实例是否不等于 r。
参数:
- r:Month 实例,
!=运算的右操作数
返回值:当前 Month 实例是否不等于 r
enum DayOfWeek
public enum DayOfWeek <: ToString {
| Sunday
| Monday
| Tuesday
| Wednesday
| Thursday
| Friday
| Saturday
}
枚举类型 DayOfWeek 用以表示一周中的某一天,并提供与 Int64 类型的相互转换功能。
枚举类型 DayOfWeek 提供的 API 如下所示:
Sunday
Sunday
功能:构造一个 DayOfWeek 实例,表示星期天。
Monday
Monday
功能:构造一个 DayOfWeek 实例,表示星期一。
Tuesday
Tuesday
功能:构造一个 DayOfWeek 实例,表示星期二。
Wednesday
Wednesday
功能:构造一个 DayOfWeek 实例,表示星期三。
Thursday
Thursday
功能:构造一个 DayOfWeek 实例,表示星期四。
Friday
Friday
功能:构造一个 DayOfWeek 实例,表示星期五。
Saturday
Saturday
功能:构造一个 DayOfWeek 实例,表示星期六。
func of
public static func of(dayOfWeek: Int64): DayOfWeek
功能:获取参数 dayOfWeek 对应 DayOfWeek 实例。
参数:
- dayOfWeek:周几的整数表示,合法范围为 [0, 6]。其中,0 表示周日,1 至 6 表示周一至周六。
返回值:参数 dayOfWeek 对应的 DayOfWeek 实例
异常:
- IllegalArgumentException:当
dayOfWeek不在 [0, 6] 范围内时,抛出异常
func value
public func value(): Int64
功能:获取当前 DayOfWeek 实例的整数表示,周日表示为 0,周一至周六表示为 1 至 6。
返回值:当前 DayOfWeek 实例的整数表示
func toString
public func toString(): String
功能:返回当前 DayOfWeek 实例的字符串表示。
返回值:当前 DayOfWeek 实例的字符串表示
operator func ==
public operator func ==(r: DayOfWeek): Bool
功能:重载操作符 ==,实现 "DayOfWeek == DayOfWeek" 运算,返回当前 DayOfWeek 实例是否等于 r。
参数:
- r:
DayOfWeek实例,==的右操作数
返回值:当前 DayOfWeek 实例是否等于 r
operator func !=
public operator func !=(r: DayOfWeek): Bool
功能:重载操作符 !=,实现 "DayOfWeek != DayOfWeek" 运算,返回当前 DayOfWeek 实例是否不等于 r。
参数:
- r:
DayOfWeek实例,!=的右操作数
返回值:当前 DayOfWeek 实例是否不等于 r
enum FormatStyle
public enum FormatStyle {
| RFC3339
| RFC1123
}
枚举类型 FormatStyle 用以表示时间标准化格式,并提供打印标准时间格式功能。
枚举类型 Month 提供的 API 如下所示:
RFC3339
RFC3339
功能:构造一个 FormatStyle 实例,表示 RFC3339 时间格式。
RFC1123
RFC1123
功能:构造一个 FormatStyle 实例,表示 RFC1123 时间格式。
func value
public func value(): String
功能:获取当前 FormatStyle 时间格式的字符串表示。
返回值:时间格式的字符串表示
示例
获取时间的详细信息
读取当前时间,分别获取年、月、日、时、分、秒、纳秒、时区 id、时区偏移、序列化字符串等信息示例。
代码如下:
from std import time.*
main(): Int64 {
var now = DateTime.now()
var yr = now.year
var mon = now.month
var day = now.dayOfMonth
var hr = now.hour
var min = now.minute
var sec = now.second
var ns = now.nanosecond
var zoneId = now.zoneId
var offset = now.zoneOffset
var dayOfWeek = now.dayOfWeek
var dayOfYear = now.dayOfYear
var (isoYear, isoWeek) = now.isoWeek
println("Now is ${yr}, ${mon}, ${day}, ${hr}, ${min}, ${sec}, ${ns}, ${zoneId}, ${offset}")
println("now.toString() = ${now}")
println("${dayOfWeek}, ${dayOfYear}th day, ${isoWeek}th week of ${isoYear}")
return 0
}
运行结果如下:
Now is 2021, August, 5, 21, 8, 4, 662859318, CST, 8h
now.toString() = 2021-08-05T21:08:04+08:00
Thursday, 217th day, 31th week of 2021
同一时间在不同时区的墙上时间
初始化指定时间,并进行时区转换,打印同一时间在不同时区下的墙上时间。
代码如下:
from std import time.*
main(): Int64 {
var t = DateTime.of(year: 2021, month: Month.August, dayOfMonth: 5)
println("local zone: ${t}")
println("utc zone: ${t.inUTC()}")
return 0
}
运行结果如下:
local zone: 2021-08-05T00:00:00+08:00
utc zone: 2021-08-04T16:00:00Z
从字符串中解析得到时间
字符串解析时间有以下要求和说明:
-
字符串必须包含描述具体年月日的信息:如公元年(y)+ 月(M)和日(d),或公元年(y)和一年中的第几天(D);
-
如果不包含时分秒的描述信息,则均默认为 0;时区信息如果不包含,则默认为 TimeZone.Local;
-
对同一字母表示的格式不允许两次取值,如不允许两次对公元年(y)格式的赋值;表示时区的 O 和 Z 两种格式同样不允许一起出现;
-
其余的部分字母的格式会作为辅助信息验证,如 "2023-04-24-Mon" 使用格式 "yyyy-MM-dd-www" 进行解析时,会验证"Mon"的正确性。
以下为 parse 函数中参数 format 中字符解析的范围
-
基于 ISO-8601 标准的年:1 ~ 9 位 Y 表示
case 1 | 3 | 4 解析 4 位数年份,如 2023, 0001等
case 2 解析 2 位数年份,如 23, 69等,其中 xx >= 69的会解析为 19xx,否则为 20xx,负数同理
case 5 ~ 9 解析 length 位数年份
case _ 异常
-
月:1 ~ 4 位 M 表示
case 1 解析 1 ~ 2 位数字,如 1, 01, 11 等
case 2 解析 2 位数字,如 01, 11 等
case 3 解析简写的月,如 Jan, Dec 等
case 4 解析完整书写的月,如 January, December 等
case _ 异常
-
日:1 ~ 2 位 d 表示
case 1 解析 1 ~ 2 位数字,如 1, 01, 11 等
case 2 解析 2 位数字,如 01, 11 等
case _ 异常
-
时(24小时制):1 ~ 2 位 H 表示
case 1 解析 1 ~ 2 位数字,如 0, 00, 23 等
case 2 解析 2 位数字,如 00, 23 等
case _ 异常
-
时(12小时制):1 ~ 2 位 h 表示
case 1 解析 1 ~ 2 位数字,如 1, 01, 12 等
case 2 解析 2 位数字,如 01, 12 等
case _ 异常
-
分:1 ~ 2 位 m 表示
case 1 解析 1 ~ 2 位数字,如 0, 00, 08, 59 等
case 2 解析 2 位数字,如 00, 08, 59 等
case _ 异常
-
秒:1 ~ 2 位 s 表示
case 1 解析 1 ~ 2 位数字,如 0, 00, 08, 59 等
case 2 解析 2 位数字,如 00, 08, 59 等
case _ 异常
-
纳秒:1 ~ 3 位 S 表示
case 1 解析 3 位数字,如 001, 123 等作为毫秒
case 2 解析 6 位数字,如 000001, 123456 等作为微秒
case 3 解析 9 位数字,如 000000001, 123456789 等作为纳秒
case _ 异常
-
时区(偏移形式):1 ~ 4 位 O 表示,范围:[-24:59:59, 25:59:59]
case 1 解析格式如:+08, -08 等
case 2 解析格式如:+08:00, -08:59 等
case 3 解析格式如:+08:00:00, -08:59:59 等
case 4 解析格式如:case2 或 case3 以及 Z
case _ 异常
-
时区(时区名和地点形式):1 ~ 4 位 z 表示
case 1 解析格式如:CST, GMT 等可以通过 TimeZone.load("XXX") 得到
case 2 解析格式如:case1
case 3 解析格式如:case1
case 4 解析格式如:Asia/Shanghai, America/New_York 等可以通过 TimeZone.load("XXX") 得到
case _ 异常
-
时区(GMT偏移形式):1 ~ 4 位 Z 表示
case 1 解析格式如:GMT+0, GMT+10 等
case 2 解析格式如:GMT+00:00, GMT+10:00 等
case 3 解析格式如:GMT+00:00:00, GMT+10:00:00 等
case 4 解析格式如:case2 或 case3
case _ 异常
-
一年中的第几天:1 ~ 2 位 D 表示
case 1 解析格式如:1, 01, 001 等 1 ~ 3 位数字
case 2 解析格式如:01, 001 等 2 ~ 3 位数字
case _ 异常
-
基于 ISO-8601 标准的周:1 ~ 2 位 W 表示
case 1 解析格式如:1, 01 等 1 ~ 2 位数字
case 2 解析格式如:01, 12 等 2 位数字
case _ 异常
-
一周的第几天:1 ~ 4 位 w 表示
case 1 解析 1 位数字,如 0, 6 等, 0 表示周日,其余表示周一至周六
case 2 解析 2 位数字,如 00, 06 等,00 表示周日,其余表示周一至周六
case 3 解析简写的周,如 Sun, Sat 等
case 4 解析完整书写的周,如 Sunday, Saturday 等
case _ 异常
-
纪年:1 ~ 3 位 G 表示
case 1 解析 A
case 2 解析 AD
case 3 解析 Anno Domini
case _ 异常
-
上下午:1 位 a 表示
case 1 解析 AM 或 PM
case _ 异常
下面是从字符串中解析得到时间,并输出的示例。
代码如下:
from std import time.*
main(): Int64 {
var customPtn = "yyyy/MM/dd HH:mm:ss OO"
var t1 = DateTime.parse("2021-08-05T21:08:04+08:00")
var t2 = DateTime.parse("2021/08/05 21:08:04 +10:00", customPtn)
println("t1.toString(customPtn) = ${t1.toString(customPtn)}")
println("t2.toString() = ${t2}")
return 0
}
运行结果如下:
t1.toString(customPtn) = 2021/08/05 21:08:04 +08:00
t2.toString() = 2021-08-05T21:08:04 +10:00
时间实例转换为字符串格式
以下为 toString 函数中参数 format 中字符输出的结果
-
公元年:1 ~ 9 位 y 表示
-
基于 ISO-8601 标准的年:1 ~ 9 位 Y 表示
case 1 | 3 | 4 输出最少 4 位数年份,如 2023, 0001,99999 等,不足 4 位则补 0
case 2 输出 2 位或 4 位以上个数年份,如 23, 69等,其中 [1969, 1999] 会输出为 [69, 99],[2000, 2068] 会输出为 [00, 68],负数同理,其余情况至少输出 4 位,不足 4 位则补 0
case 5 ~ 9 输出 length 位数年份,不足则补 0
case _ 异常
-
月:1 ~ 4 位 M 表示
case 1 输出 1 ~ 2 位数字,如 1, 11 等
case 2 输出 2 位数字,如 01, 11 等
case 3 输出简写的月,如 Jan, Dec 等
case 4 输出完整书写的月,如 January, December 等
case _ 异常
-
日:1 ~ 2 位 d 表示
case 1 输出 1 ~ 2 位数字,如 1, 11 等
case 2 解析 2 位数字,如 01, 11 等
case _ 异常
-
时(24小时制):1 ~ 2 位 H 表示
case 1 输出 1 ~ 2 位数字,如 0, 23 等
case 2 输出 2 位数字,如 00, 23 等
case _ 异常
-
时(12小时制):1 ~ 2 位 h 表示
case 1 输出 1 ~ 2 位数字,如 1, 12 等
case 2 输出 2 位数字,如 01, 12 等
case _ 异常
-
分:1 ~ 2 位 m 表示
case 1 输出 1 ~ 2 位数字,如 0, 59 等
case 2 解析 2 位数字,如 00, 08, 59 等
case _ 异常
-
秒:1 ~ 2 位 s 表示
case 1 输出 1 ~ 2 位数字,如 0, 59 等
case 2 输出 2 位数字,如 00, 08, 59 等
case _ 异常
-
纳秒:1 ~ 3 位 S 表示
case 1 输出 3 位数字,如 001, 123 等作为毫秒
case 2 输出 6 位数字,如 000001, 123456 等作为微秒
case 3 输出 9 位数字,如 000000001, 123456789 等作为纳秒
case _ 异常
-
时区(偏移形式):1 ~ 4 位 O 表示
case 1 输出格式如:+08, -08 等,若偏移量不为整小时,则会截断
case 2 输出格式如:+08:00, -08:59 等,偏移量不为整分钟,则会截断
case 3 输出格式如:+08:00:00, -08:59:59 等
case 4 输出格式如:case2 或 case3, 偏移量为 0 时, 输出 Z
case _ 异常
-
时区(时区名和地点形式):1 ~ 4 位 z 表示
case 1 输出格式如:CST, GMT 等
case 2 输出格式如:case1
case 3 输出格式如:case1
case 4 输出格式如:Asia/Shanghai, America/New_York 等
case _ 异常
-
时区(GMT偏移形式):1 ~ 4 位 Z 表示
case 1 输出格式如:GMT+0, GMT+10 等
case 2 输出格式如:GMT+00:00, GMT+10:00 等
case 3 输出格式如:GMT+00:00:00, GMT+10:00:00 等
case 4 输出格式如:case2 或 case3
case _ 异常
-
一年中的第几天:1 ~ 2 位 D 表示
case 1 输出格式如:1, 12, 123 等 1 ~ 3 位数字
case 2 输出格式如:001, 012, 123 等 2 ~ 3 位数字
case _ 异常
-
基于 ISO-8601 标准的周:1 ~ 2 位 W 表示
case 1 输出格式如:1, 12 等 1 ~ 2 位数字
case 2 输出格式如:01, 12 等 2 位数字
case _ 异常
-
一周的第几天:1 ~ 4 位 w 表示
case 1 输出 1 位数字,如 0, 6 等, 0 表示周日,其余表示周一至周六
case 2 输出 2 位数字,如 00, 06 等, 00 表示周日,其余表示周一至周六
case 3 输出简写的周,如 Sun, Sat 等
case 4 输出完整书写的周,如 Sunday, Saturday 等
case _ 异常
-
纪年:1 ~ 3 位 G 表示
case 1 输出 A
case 2 输出 AD
case 3 输出 Anno Domini
case _ 异常
-
上下午:1 位 a 表示
case 1 输出 AM 或 PM
case _ 异常
下面是时间示例转为字符串,并输出的示例。
代码如下:
from std import time.*
main(): Int64 {
var customPtn = "yyyy/MM/dd HH:mm:ss OO"
var t = DateTime.of(
year: 2023,
month: 1,
dayOfMonth: 23,
hour: 4,
minute: 56,
second: 7,
nanosecond: 89,
timeZone: TimeZone.load("Asia/Shanghai")
)
println("t.toString(customPtn) = ${t.toString(customPtn)}")
println("t.toString() = ${t}")
return 0
}
运行结果如下:
t.toString(customPtn) = 2023/01/23 04:56:07 +08:00
t.toString() = 2023-01-23T04:56:07.89+08:00
DayOfWeek 的使用
初始化不同的 DayOfWeek,进行与 Int64 类型的互转、比较大小,打印其字符串表示等。
代码如下:
from std import time.*
main(): Int64 {
var sat = DayOfWeek.Saturday
var sun = DayOfWeek.of(0)
println("sat.toString() = ${sat}")
println("sun.toString() = ${sun}")
println("sat.value() = ${sat.value()}")
println("sun.value() = ${sun.value()}")
println("sat == sun ? ${sat == sun}")
return 0
}
运行结果如下:
sat.toString() = Saturday
sun.toString() = Sunday
sat.value() = 6
sun.value() = 0
sat == sun ? false
Month 的使用
初始化不同的 Month,进行与 Int64 类型的互转、算数运算、比较大小,打印其字符串表示等。
代码如下:
from std import time.*
main(): Int64 {
var jan = Month.January
var feb = Month.of(2)
println("jan.toString() = ${jan}")
println("feb.toString() = ${feb}")
println("jan.value() = ${jan.value()}")
println("feb.value() = ${feb.value()}")
println("jan + 1 = ${jan + 1}")
println("feb - 1 = ${feb - 1}")
println("jan == feb ? ${jan == feb}")
return 0
}
运行结果如下:
jan.toString() = January
feb.toString() = February
jan.value() = 1
feb.value() = 2
jan + 1 = February
feb - 1 = January
jan == feb ? false
Duration 的使用
初始化不同的 Duration,打印其字符串表示,并对其比较大小。
代码如下:
from std import time.*
main(): Int64 {
var d1 = Duration.nanosecond * 10000
var d2 = Duration.microsecond * 100
var d3 = Duration.millisecond * 10
var d4 = Duration.second
var d5 = Duration.minute * 2
var d6 = Duration.hour * 3
println("d1 = ${d1}")
println("d2 = ${d2}")
println("d3 = ${d3}")
println("d4 = ${d4}")
println("d5 = ${d5}")
println("d6 = ${d6}")
println("in nanosecond, d1 = ${d1.toNanoseconds()}")
println("in nanosecond, d2 = ${d2.toNanoseconds()}")
println("in nanosecond, d3 = ${d3.toNanoseconds()}")
println("in second, d4 = ${d4.toSeconds()}")
println("in second, d4 = ${d5.toSeconds()}")
println("in second, d4 = ${d6.toSeconds()}")
println("d1 > d2 ? ${d1 > d2}")
return 0
}
运行结果如下:
d1 = 10us
d2 = 100us
d3 = 10ms
d4 = 1s
d5 = 2m
d6 = 3h
in nanosecond, d1 = 10000
in nanosecond, d2 = 100000
in nanosecond, d3 = 10000000
in second, d4 = 1
in second, d4 = 120
in second, d4 = 10800
d1 > d2 ? false
TimeZone 的使用
通过不同方式初始化时区,对指定时间进行时区转换,打印同一时间在不同时区下的墙上时间。
代码如下:
from std import time.*
main(): Int64 {
var utc = TimeZone.load("UTC")
var local = TimeZone.load("Local")
var newYork = TimeZone.load("America/New_York")
println("utc.toString() = ${utc}")
println("local.toString() = ${local}")
println("newYork.toString() = ${newYork}")
var t = DateTime.of(year: 2021, month: Month.August, dayOfMonth: 5)
println("in utc zone, ${t.inTimeZone(utc)}")
println("in local zone, ${t.inTimeZone(local)}")
println("in newYork zone, ${t.inTimeZone(newYork)}")
return 0
}
运行结果如下:
utc.toString() = UTC
local.toString() = Asia/Shanghai
newYork.toString() = America/New_York
in utc zone, 2021-08-04T16:00:00Z
in local zone, 2021-08-05T00:00:00+08:00
in newYork zone, 2021-08-04T12:00:00-04:00
unicode 包
介绍
unicode 包提供了 Char 和 String 类型的一些扩展函数,包括在 Unicode 字符集范围内的大小写转换、空白字符修剪等功能。
主要接口
interface UnicodeExtension
public interface UnicodeExtension
UnicodeExtension 为一个空接口,方便为 Char 和 String 类型增加一系列与 Unicode 编码相关的扩展函数。
extend Char <: UnicodeExtension
extend Char <: UnicodeExtension
Char 类型为内置类型,此处实现了该类型的一些扩展函数,包括 Unicode 字符集范围内的字符类型判断,字符大小写转换。
func isLetter
public func isLetter(): Bool
功能:判断字符是否是 Unicode 字母字符。
返回值:如果该字符是 Unicode 字母字符,返回 true,否则返回 false
func isNumber
public func isNumber(): Bool
功能:判断字符是否是 Unicode 数字字符。
返回值:如果该字符是 Unicode 数字字符,返回 true,否则返回 false
func isLowerCase
public func isLowerCase(): Bool
功能:判断字符是否是 Unicode 小写字符。
返回值:如果该字符是 Unicode 小写字符,返回 true,否则返回 false
func isUpperCase
public func isUpperCase(): Bool
功能::判断字符是否是 Unicode 大写字符。
返回值:如果该字符是 Unicode 大写字符,返回 true,否则返回 false
func isTitleCase
public func isTitleCase(): Bool
功能:判断字符是否是 Unicode 标题大写字符。
返回值:如果该字符是 Unicode 标题大写字符,返回 true,否则返回 false
func isWhiteSpace
public func isWhiteSpace(): Bool
功能:判断字符是否是 Unicode 空白字符。空白字符包括 0x0009、0x000A、0x000B、0x000C、0x000D、
0x0020、0x0085、0x00A0、0X1680、0X2000、0X2001、0X2002、0X2003、0X2004、0X2005、0X2006、0X2007、0X2008、0X2009、0X200A、0X2028、0X2029、0X202F、0X205F、0X3000。
返回值:如果该字符是 Unicode 空白字符,返回 true,否则返回 false
func toUpperCase
public func toUpperCase(): Char
功能:获取该字符对应的 Unicode 大写字符。
返回值:当前字符对应的小写字符
func toLowerCase
public func toLowerCase(): Char
功能:获取该字符对应的 Unicode 小写字符。
返回值:当前字符对应的小写字符
func toTitleCase
public func toTitleCase(): Char
功能:获取该字符对应的 Unicode 标题大写字符。
返回值:当前字符对应的标题大写字符。
extend String <: UnicodeExtension
extend String <: UnicodeExtension
实现了 String 类型的一些扩展函数,包括 Unicode 字符集范围内的字符类型判断,字符大小写转换,以及去除前后空白字符。
func isBlank
public func isBlank(): Bool
功能:判断当前字符串是否为空,或仅包含 Unicode 字符集中的空字符,空字符定义见 Char 类型的扩展函数 isWhiteSpace。
返回值:如果字符串为空,或仅包含空字符,返回 true,否则返回 false。
func toLower
public func toLower(): String
功能:将当前字符串中所有 Unicode 字符集范围内的大写字符转化为小写字符。
返回值:转换后的全小写字符串
异常:
IllegalArgumentException:如果字符串中存在无效的 UTF-8 编码,抛出异常
func toUpper
public func toUpper(): String
功能:将当前字符串中所有 Unicode 字符集范围内的小写字符转化为大写字符。
返回值:转换后的全大写字符串
异常:
IllegalArgumentException:如果字符串中存在无效的 UTF-8 编码,抛出异常
func toTitle
public func toTitle(): String
功能:将当前字符串中 Unicode 字符集范围内可以转换为标题大写字符的转换为标题大写字符。
返回值:转换后的标题大写字符串
异常:
IllegalArgumentException:如果字符串中存在无效的 UTF-8 编码,抛出异常
func trim
public func trim(): String
功能:去除原字符串开头结尾以空字符组成的子字符串,空字符定义见 Char 类型的扩展函数 isWhiteSpace。
返回值:去除首尾空字符后的字符串
异常:
IllegalArgumentException:如果字符串中不存在有效的 UTF-8 编码,抛出异常
func trimLeft
public func trimLeft(): String
功能:去除原字符串开头以空字符组成的子字符串,空字符定义见 Char 类型的扩展函数 isWhiteSpace。
返回值:去除开头空字符后的字符串
异常:
IllegalArgumentException:如果字符串中不存在有效的 UTF-8 编码,抛出异常
func trimRight
public func trimRight(): String
功能:去除原字符串结尾以空字符组成的子字符串,空字符定义见 Char 类型的扩展函数 isWhiteSpace。
返回值:去除结尾空字符后的字符串
异常:
IllegalArgumentException:如果字符串中不存在有效的 UTF-8 编码,抛出异常
unittest 包
介绍
unittest 包使用元编程语法来支持单元测试功能,用于编写和运行可重复的测试用例,并进行结构化测试。
仓颉编译器提供 --test 编译选项来自动组织源码中的测试用例以及生成可执行程序的入口函数。
宏功能介绍
@Test 宏
@Test 宏应用于顶级函数或顶级类,使该函数或类转换为单元测试类。
如果是顶级函数,则该函数新增一个具有单个测试用例的类提供给框架使用,同时该函数仍旧可被作为普通函数调用。
标有 @Test 的类必须满足以下条件:
- 它必须有一个无参构造函数
- 不能从其他类继承
实现说明:
@Test宏为任何用它标记的类引入了一个新的基类:unittest.TestCases。unittest.TestCases的所有公共和受保护成员(请参阅下面的 API 概述)将在标有@Test的类或函数中变得可用,包括两个字段: 1. 包含此测试的TestContext实例的ctx。 2. 包含类的名称的name。 单元测试框架的用户不应修改这些字段,因为这可能会导致不可预期的错误。
@TestCase 宏
@TestCase 宏用于标记单元测试类内的函数,使这些函数成为单元测试的测试用例。
标有 @TestCase 的函数必须满足以下条件:
- 该类必须用
@Test标记 - 该函数返回类型必须是
Unit
@Test
class Tests {
@TestCase
func fooTest(): Unit {...}
}
测试用例可能有参数,在这种情况下,开发人员必须使用参数化测试 DSL 指定这些参数的值:
@Test[x in source1, y in source2, z in source3]
func test(x: Int64, y: String, z: Float64): Unit {}
此 DSL 可用于 @Test、@RawBench、@Bench 和 @TestCase 宏,其中 @Test 仅在顶级函数上时才可用。如果测试函数中同时存在 @Bench 和 @TestCase ,则只有 @Bench 可以包含 DSL 。
在 DSL 语法中,in 之前的标识符(在上面的示例中为 x 、y 和 z )必须直接对应于函数的参数,参数源(在上面的示例中为source1 、source2 和 source3 ) 是任何有效的仓颉表达式(该表达式类型必须实现接口 DataStrategy<T> ,详见下文)。
参数源的元素类型(此类型作为泛型参数 T 提供给接口 DataStrategy<T> )必须与相应函数参数的类型严格相同。
目前,参数化测试最多支持 5 个参数,支持的参数源类型如下:
- Arrays:
x in [1,2,3,4] - Ranges:
x in 0..14 - 随机生成的值:
x in random() - 从 json 文件中读取到的值:
x in json("filename.json") - 从 csv 文件中读取到的值:
x in csv("filename.csv")
高级用户可以通过定义自己的类型并且实现
DataStrategy<T>接口来引入自己的参数源类型。有关详细信息,请参阅 “高级特性” 章节。
使用 random() 的随机生成函数默认支持以下类型:
UnitBool- 所有内置的 integer 类型(包含有符号和无符号)
- 所有内置的 float 类型
Ordering- 所有已支持类型的数组类型
- 所有已支持类型的 Option 类型
若需要新增其他的类型支持
random(),可以让该类型扩展unittest.prop_test.Arbitrary。有关详细信息,请参阅 “高级特性” 章节。
在参数有多个值时,
beforeEach/afterEach不会在不同值下重复执行而仅会执行一次。若确实需要在每个值下做初始化和去初始化,需要在测试主体中写。对于性能测试场景,应使用@RawBench。暂时不对此类情况提供特殊 API ,因为大多数情况下,此类代码取决于具体参数值。
@Bench 宏
@Bench 宏用于标记要执行多次的函数并计算该函数的预期执行时间
此类函数将分批执行,并针对整个批次测量执行时间。这种测量将重复多次以获得结果的统计分布,并将计算该分布的各种统计参数。 当前支持的参数如下:
- 中位数
- 用作误差估计的中位数 99% 置信区间的绝对值
- 中位数 99% 置信区间的相对值
- 平均值
参数化的 DSL 与 @Bench 结合的示例如下,具体语法与规则详见《 @TestCase 宏》章节:
func sortArray<T>(arr: Array<T>): Unit
where T <: Comparable<T> {
if (arr.size < 2) { return }
var minIndex = 0
for (i in 1..arr.size) {
if (arr[i] < arr[minIndex]) {
minIndex = i
}
}
(arr[0], arr[minIndex]) = (arr[minIndex], arr[0])
sortArray(arr[1..])
}
@Test
@Configure[baseline: "test1"]
class ArrayBenchmarks{
@Bench
func test1(): Unit
{
let arr = Array(10) { i: Int64 => i }
sortArray(arr)
}
@Bench[x in 10..20]
func test2(x:Int64): Unit
{
let arr = Array(x) { i: Int64 => i.toString() }
sortArray(arr)
}
}
输出如下, 增加 Args 列,列举不同参数下的测试数据,每个参数值将作为一个性能测试用例输出测试结果,多个参数时将列举全组合场景:
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 68610430659 ns, Result:
TCS: ArrayBenchmarks, time elapsed: 68610230100 ns, RESULT:
| Case | Args | Median | Err | Err% | Mean |
|:-------|:-------|---------:|----------:|-------:|---------:|
| test1 | - | 4.274 us | ±2.916 ns | ±0.1% | 4.507 us |
| | | | | | |
| test2 | 10 | 6.622 us | ±5.900 ns | ±0.1% | 6.670 us |
| test2 | 11 | 7.863 us | ±5.966 ns | ±0.1% | 8.184 us |
| test2 | 12 | 9.087 us | ±10.74 ns | ±0.1% | 9.918 us |
| test2 | 13 | 10.34 us | ±6.363 ns | ±0.1% | 10.28 us |
| test2 | 14 | 11.63 us | ±9.219 ns | ±0.1% | 11.67 us |
| test2 | 15 | 13.05 us | ±7.520 ns | ±0.1% | 13.24 us |
| test2 | 16 | 14.66 us | ±11.59 ns | ±0.1% | 15.53 us |
| test2 | 17 | 16.21 us | ±8.972 ns | ±0.1% | 16.35 us |
| test2 | 18 | 17.73 us | ±6.288 ns | ±0.0% | 17.88 us |
| test2 | 19 | 19.47 us | ±5.819 ns | ±0.0% | 19.49 us |
Summary: TOTAL: 11
PASSED: 11, SKIPPED: 0, ERROR: 0
FAILED: 0
--------------------------------------------------------------------------------------------------
@RawBench 宏
与 @Bench 相同,但可以访问更高级的 API 。被 @RawBench 修饰的函数主体将被执行一次,并且应使用 RawBencher 类进行相关配置。 @RawBench 宏不能与 @TestCase 和 @Bench 一起应用在同一个测试用例上。
@Configure 宏
@Configure 宏为测试类或测试函数提供配置参数。它可以放置在测试类或测试函数上。它具有以下形式:
@Configure[parameter1: <value1>,parameter2: <value2>]
其中 parameter1 是仓颉标识符,value 是任何有效的仓颉表达式。
value 可以是常量或在标有 @Configure 的声明范围内有效的任何仓颉表达式。
如果多个参数具有不同的类型,则它们可以有相同的名称。如果指定了多个具有相同名称和类型的参数,则使用最新的一个。
目前支持的配置参数有:
randomSeed: 类型为Int64, 为所有使用随机生成的函数设置起始随机种子。generationSteps: 类型为Int64:参数化测试算法中的生成值的最大步数。reductionSteps:类型为Int64: 参数化测试算法中的缩减值的最大步数。 注意:以下参数一般用于被@Bench修饰的 Benchmark 测试函数。explicitGC:类型为ExplicitGcType: Benchmark 函数测试期间如何调用 GC。默认值为ExplicitGcType.Lightbaseline:类型为String: 参数值为 Benchmark 函数的名称,作为比较 Benchmark 函数执行结果的基线。该结果值将作为附加列添加到输出中,其中将包含比较结果。batchSize:类型为Int64或者Range<Int64>: 为 Benchmark 函数配置批次大小。默认值是由框架在预热期间计算得到。minBatches:类型为Int64: 配置 Benchmark 函数测试执行期间将执行多少个批次。默认值为10。minDuration:类型为Duration: 配置重复执行 Benchmark 函数以获得更好结果的时间。默认值为Duration.second * 5。warmup:类型为Duration或者Int64: 配置在收集结果之前重复执行 Benchmark 函数的时间或次数。默认值为Duration.second。当值为 0 时,表示没有 warmup , 此时执行次数按用户输入的batchSize乘minBatches计算得到,当batchSize未指定时将抛出异常。measurement:类型为Measurement:描述性能测试需要收集的信息。默认值为TimeNow(),它在内部使用DateTime.now()进行测量。
用户可以在 @Configure 宏中指定其他配置参数,这些参数将来可能会用到。
如果测试类使用 @Configure 宏指定配置,则该类中的所有测试函数都会继承此配置参数。
如果此类中的测试函数也标有 @Configure 宏,则配置参数将从类和函数合并,其中函数级宏优先。
@Types 宏
@Types 宏为测试类或测试函数提供类型参数。它可以放置在测试类或测试函数上。它具有以下形式:
@Types[Id1 in <Type1, Type2, Type3>, Id2 in <Type4, Type5> ...]
其中 Id1、Id2... 是有效类型参数标识符,Type1、Type2、Type3...是有效的仓颉类型。
@Types 宏有以下限制:
- 必须与
@Test,@TestCase或@Bench宏共同使用。 - 一个声明只能有一个
@Types宏修饰。 - 该声明必须是具有与
@Types宏中列出的相同类型参数的泛型类或函数。 - 类型列表中列出的类型不能相互依赖,例如
@Types[A in <Int64, String>, B in <List<A>>]将无法正确编译。但是,在为该类内的测试函数提供类型时,可以使用为测试类提供的类型。例如:
@Test
@Types[T in <...>]
class TestClass<T> {
@TestCase
@Types[U in <Array<T>>]
func testfunc<U>() {}
}
该机制可以与其他测试框架功能一起使用,例如 @Configure 等。
@Skip 宏
@Skip[expr] 修饰已经被 @TestCase 修饰的函数
expr暂只支持true,表达式为true时,跳过该测试,其他均为false- 默认
expr为true即@Skip[true]==@Skip
@Timeout 宏
@Timeout[expr] 指示测试应在指定时间后终止。它有助于测试可能运行很长时间或陷入无限循环的复杂算法。 expr 的类型应为 std.time.Duration 。
其修饰测试类时为每个相应的测试用例提供超时时间。
@Parallel 宏
@Parallel 宏可以修饰测试类。被 @Parallel 修饰的测试类中的测试用例,将被分别独立到不同的进程中并行运行。
- 所有相关的测试用例应该各自独立,不依赖于任何可变的共享的状态值。
beforeAll()和afterAll()应该是可重入的,以便可以在不同的进程中多次运行。- 需要并行化的测试用例本身应耗时较长。否则并行化引入的多次
beforeAll()和afterAll()可能会超过并行化的收益。 - 不允许与
@Bench同时使用。由于性能用例对底层资源敏感,用例是否并行执行,将影响性能用例的结果,因此禁止与@Bench同时使用。
@Assert 宏
@Assert 声明 Assert 断言,测试函数内部使用,断言失败停止用例
@Assert(leftExpr, rightExpr),比较leftExpr和rightExpr值是否相同@Assert(condition: Bool),比较condition是否为true,即@Assert(condition: Bool)等同于@Assert(condition: Bool, true)
@PowerAssert 宏
@PowerAssert 与 @Assert 类似, 但是将打印更详细的中间值和异常信息。
打印的详细信息如下:
REASON: `foo(10, y: test + s) == foo(s.size, y: s) + bar(a)` has been evaluated to false
Assert Failed: `(foo(10, y: test + s) == foo(s.size, y: s) + bar(a))`
| | |_|| | |_| | |_|| | |_||
| | "123" | "123" | "123" | 1 |
| |__________|| | |______| | |______|
| "test123" | | 3 | 33 |
|______________________| |_________________| |
0 | 1 |
|__________________________|
34
--------------------------------------------------------------------------------------------------
@Expect 宏
@Expect 声明 Expect 断言,测试函数内部使用,断言失败继续执行用例
@Expect(leftExpr, rightExpr),比较leftExpr和rightExpr是否相同@Expect(condition: Bool),比较condition是否为true,即@Expect(condition: Bool)等同于@Expect(condition: Bool, true)
编译选项 --test 介绍
--test 是仓颉编译器 cjc 的内置编译选项
- 测试用例编译,配合 unittest 库使用
- 条件编译,测试代码应放在以 _test.cj 结尾的文件中,如果包编译时未使用
--test则忽略该文件
使用方法
使用 --test 编译测试文件
例如,有如下一段测试代码:
@Test
public class TestA {
@TestCase
public func case1(): Unit {
print("case1\n")
}
}
cjc test.cj -o test --test && ./test
test.cj是含有测试用例的仓颉文件test是编译输出的可执行程序--test是编译选项,当使用--test选项编译时,程序入口不再是main,而是由编译器生成的入口函数。./test执行测试用例
使用 --test 组织包测试
目录结构:
application
├── pkgc
| ├── a1.cj
| └── a1_test.cj
| └── a2.cj
| └── a2_test.cj
- a1_test.cj 是 a1.cj 的单元测试
- a2_test.cj 是 a2.cj 的单元测试
cjc -p pkgc -o test --test && ./test
-p整包编译选项pkgc是含有测试用例的包路径test是编译输出的可执行程序--test是编译选项,当使用--test选项编译时,-程序入口不再是main,而是由编译器生成的入口函数./test执行所有测试用例
unittest 没有严格限制只能测试同 package 的内容,但通常情况下由于单元测试需要测试仅包内可见的内容,推荐使用如上形式组织 package 的单元测试。
编译器约束 (仅在使能 --test 时生效)
@Test宏不能修饰非 TopLevel 的函数。@Test宏不能修饰泛型类。@Test宏修饰的类必须包含一个无参数的构造函数。@Testcase宏只能修饰返回值类型为Unit的成员函数。@Testcase宏不能修饰foreign函数。@Testcase宏不能修饰泛型函数。
运行选项介绍
使用方法
运行 cjc 编译的可执行文件 test ,添加参数选项
./test --bench --filter MyTest.*Test,-stringTest
--bench
默认情况下,只有被 @TestCase 修饰的函数会被执行。在使用 --bench 的情况下只执行 @Bench 宏修饰的用例。
--filter
如果您希望以测试类和测试用例过滤出测试的子集,可以使用 --filter=测试类名.测试用例名 的形式来筛选匹配的用例,例如:
--filter=*匹配所有测试类--filter=*.*匹配所有测试类所有测试用例(结果和*相同)--filter=*.*Test,*.*case*匹配所有测试类中以 Test 结尾的用例,或者所有测试类中名字中带有 case 的测试用例--filter=MyTest*.*Test,*.*case*,-*.*myTest匹配所有 MyTest 开头测试类中以 Test 结尾的用例,或者名字中带有 case的用例,或者名字中不带有 myTest 的测试用例
另外,--filter 后有 = 和无 = 均支持。
--timeout-each=timeout
使用 --timeout-each=timeout 选项等同于对所有的测试类使用 @Timeout[timeout] 修饰。若代码中已有 @Timeout[timeout] ,则将被代码中的超时时间覆盖,即选项的超时时间配置优先级低于代码中超时时间配置。
timeout 的值应符合以下语法:
number ('millis' | 's' | 'm' | 'h')
例如: 10s, 9millis 等。
- millis : 毫秒
- s : 秒
- m : 分钟
- h : 小时
--parallel
打开 --parallel 选项将使测试框架在单独的多个进程中并行执行不同的测试类。
测试类之间应该是相互独立的,不依赖于共享的可变的状态值。
程序静态初始化可能会发生多次。
不允许与 --bench 同时使用。由于性能用例对底层资源敏感,用例是否并行执行,将影响性能用例的结果,因此禁止与 --bench 同时使用。
--parallel=<BOOL><BOOL>可为true或false,指定为true时,测试类可被并行运行,并行进程个数将受运行系统上的CPU核数控制。另外,--parallel可省略=true。--parallel=nCores指定了并行的测试进程个数应该等于可用的 CPU 核数。--parallel=NUMBER指定了并行的测试进程个数值。该数值应该为正整数。--parallel=NUMBERnCores指定了并行的测试进程个数值为可用的 CPU 核数的指定数值倍。该数值应该为正数(支持浮点数或整数)。
--option=value
以 --option=value 形式提供的任何非上述的选项均按以下规则处理并转换为配置参数(类似于 @Configure 宏处理的参数),并按顺序应用:
option 与 value 为任意自定义的运行配置选项键值对,option 可以为任意通过 - 连接的英文字符,转换到 @Configure 时将转换为小驼峰格式。value 的格式规则如下:
注:当前未检查 option 与 value 的合法性,并且选项的优先级低于代码中 @Configure 的优先级。
- 如果省略
=value部分,则该选项被视为Bool值true, 例如:--no-color生成配置条目noColor = true。 - 如果``value
严格为true或false,则该选项被视为具有相应含义的Bool值:--no-color=false生成配置条目noColor = false` 。 - 如果
value是有效的十进制整数,则该选项被视为Int64值 , 例如:--random-seed=42生成配置条目randomSeed = 42。 - 如果
value是有效的十进制小数,则该选项被视为Float64值 , 例如:--angle=42.0生成配置条目angle = 42。 - 如果
value是带引号的字符串文字(被"符号包围),则该选项将被视为String类型,并且该值是通过解码"符号之间的字符串值来生成的,并处理转义符号,例如\n、\t、\"作为对应的字符值。例如,选项--mode="ABC \"2\""生成配置条目mode = "ABC \"2\""; - 除上述情况外
value值将被视为String类型,该值从所提供的选项中逐字获取。例如,--mode=ABC23[1,2,3]生成配置条目mode = "ABC23[1,2,3]"。
package unittest
enum TimeoutInfo
public enum TimeoutInfo {
| NoTimeout
| Timeout(Duration)
指定测试超时的信息。目前,可以通过两种方式提供此超时信息:
- 在执行测试文件时打开
--timeout-each选项。 - 在测试类或测试用例上使用
@Timeout[expr]宏。
NoTimeout
没有提供超时信息。
Timeout(Duration)
指定超时时间。
func fromDefaultConfiguration
public static func fromDefaultConfiguration(): TimeoutInfo
功能:返回测试过程的 CLI 参数中提供的超时信息。
返回值:超时信息。
func applyDefault
public func applyDefault(default: TimeoutInfo): TimeoutInfo
功能:返回根据默认值更新的超时信息。
参数:
- default :来自于 CLI 参数或测试类上的超时信息,作为默认值
返回值:超时信息。
interface Measurement
public interface Measurement {
func measure(f: () -> Unit): Float64
func toString(f: Float64): String
}
功能:在性能测试过程中可以收集和分析各种数据的接口。性能测试框架使用的特定实例由 @Configure 宏的 measurement 参数指定。
func measure
func measure(f: () -> Unit): Float64
功能: 返回将用于统计分析的测量数据的表示。
参数:
- f : 是一个 lambda,应该测量它的执行信息。
返回值:测量得到的数据
func toString
func toString(f: Float64): String
功能:将测量数据的浮点表示转换为将在性能测试输出中使用的字符串。
参数:
- f : 测量数据的浮点表示
返回值:按规则转换后的字符串
class RawBench
public class RawBencher<T> {
public init()
public init(initial: T)
public func beforeInvocation(before: () -> T)
public func afterInvocation(after: (T) -> Unit )
public func runBench(bench: (T) -> Unit )
}
extend RawBencher<T> where T <: Unit {
public func afterInvocation(after: () -> Unit )
public func runBench(bench: () -> Unit )
}
提供较低级别的性能测试 API ,以便对性能测试过程进行更细粒度的控制。使用时应小心,因为如果使用不当,可能会产生误导性结果。
init
public init()
功能:默认构造函数。只应在 @RawBench 注释的性能测试用例中调用。
异常:
- IllegalStateException : 如果不是在
@RawBench注释的性能测试用例中创建的,则抛出IllegalStateException
init
public init(initial: T)
功能:带初始化值的默认构造函数。只应在 @RawBench 注释的性能测试用例中调用。
参数:
- initial : 测试用例会使用的初始化值
异常:
- IllegalStateException : 如果不是在
@RawBench注释的性能测试用例中创建的,则抛出IllegalStateException
func beforeInvocation
beforeInvocation(before: () -> T)
功能:提供在每次调用 runBench 之前执行并且不统计入性能测试结果的代码。
为了提供可靠的性能测试结果,before 的执行应该尽可能具有确定性,并且它应该比实际的性能测试函数花费更少的时间。如果可能的话,堆分配的数量也应该最小化。
参数:
- before: 带有入参的被注册的函数。
异常:
- IllegalStateException: 当在
runBench调用后或者其内部调用时将抛出异常。
func afterInvocation
public func afterInvocation(after: (T) -> Unit)
功能:提供在每次调用 runBench 之后执行并且不统计入性能测试结果的代码。
为了提供可靠的性能测试结果,after 的执行应该尽可能具有确定性,并且它应该比实际的性能测试函数花费更少的时间。如果可能的话,堆分配的数量也应该最小化。
特别是,即使它是在 beforeInvocation 回调之后立即执行而不在其间调用 runBench ,它也应该以相同的方式工作。
参数:
- after: 带有入参的被注册的函数。
异常:
- IllegalStateException :当在
runBench调用后或者其内部调用时将抛出异常。
func afterInvocation
public func afterInvocation(after: () -> Unit)
功能:提供在每次调用 runBench 之后执行并且不统计入性能测试结果的代码。
为了提供可靠的性能测试结果,after 的执行应该尽可能具有确定性,并且它应该比实际的性能测试函数花费更少的时间。如果可能的话,堆分配的数量也应该最小化。
特别是,即使它是在 beforeInvocation 回调之后立即执行而不在其间调用 runBench ,它也应该以相同的方式工作。
参数:
- after: 无入参的被注册的函数。
异常:
- IllegalStateException :当在
runBench调用后或者其内部调用时将抛出异常。
func runBench
public func runBench(bench: (T) -> Unit)
功能:执行实际的性能测试流程。所有设置都继承自包含测试用例的 @Configure 。
性能测试用例的输入数据来自构造函数或前一个 beforeInvocation 调用。
参数:
- bench: 带有入参的被注册的函数。
func runBench
public func runBench(bench: () -> Unit)
功能:执行实际的性能测试流程。所有设置都继承自包含测试用例的 @Configure 。
性能测试用例的输入数据来自构造函数或前一个 beforeInvocation 调用。
参数:
- bench: 无入参的被注册的函数。
示例
如何对 Array.sort 进行性能测试:
@Test
class BenchSort {
@RawBench[len in [1,100,10000]]
func sort(len: Int64): Unit {
let b = RawBencher<Array<Int64>>()
b.beforeInvocation{ => Array(len,{ i: Int64 => len-i}) }
b.runBench { x =>
x.sort()
}
}
}
请注意,上例每次都会分配新数组,这可能会导致后台进行大量 GC 工作,从而导致结果不太精确。
如何更好得对 Array.sort 进行性能测试,消除过多对象分配:
@Test
class BenchSort {
@RawBench[len in [1,100,10000]]
func sort(len: Int64): Unit {
let b = RawBencher<Array<Int64>>()
let array = Array(len,{ i: Int64 => len-i})
b.beforeInvocation{ => array.clone() }
b.runBench { x =>
x.sort()
}
}
}
请记住,并不总是可以在 beforeInvocation 中将对象恢复到其原始状态的同时满足 beforeInvocation 的所有要求。
例如,如下即为不正确的方式对 ArrayList.append 进行性能测试:
@Test
class BenchAppend {
@RawBench
func append(): Unit {
let b = RawBencher<ArrayList<Int64>>()
let data = ArrayList()
b.beforeInvocation{ =>
data.clear()
data
}
b.runBench { x =>
x.append(1)
}
}
}
上例看起来正确,但是它并不满足 beforeInvocation 的要求。
它的问题是,根据是否调用基准测试,ArrayList.clear() 的工作方式有所不同。
一种正确的,但依然不够好的对 ArrayList.append 的性能测试方案:
@Test
class BenchAppend {
@RawBench
func append(): Unit {
let b = RawBencher<ArrayList<Int64>>()
b.beforeInvocation{ =>
ArrayList()
}
b.runBench { x =>
x.append(1)
}
}
}
这里的问题是 ArrayList 的创建比 ArrayList.append 花费更多的时间,因此 append 的实际时间可能会在测量噪声中丢失。
如下为一种更好的方式对 ArrayList.append 进行测试:
@Test
class BenchAppend {
@RawBench[times in [10,100]]
func append(times: Int64): Unit {
let b = RawBencher<ArrayList<Int64>>()
b.beforeInvocation{ =>
ArrayList()
}
b.runBench { x =>
for i in 0..times {
x.append(1)
}
}
}
}
这仍然不是最好的方法,因为性能测试结果将包括循环本身的执行时间。但目前在很多场景上它都比其他选择更好。
class TimeNow
public struct TimeNow <: Measurement {
public init(unit: ?TimeUnit)
public init()
public func measure(f: () -> Unit): Float64
public func toString(duration: Float64): String
}
功能: Measurement 的实现,用于测量执行一个函数所花费的时间。
init
public init(unit: ?TimeUnit)
功能: unit 参数用于指定打印结果时将使用的时间单位。
参数:
- unit: 指定的时间单位
init
public init()
功能:自动选择输出格式的默认构造函数。
func measure
public func measure(f: () -> Unit): Float64
功能:计算将用于统计分析的测量数据
参数:
- f :被计算时间的执行体
返回值:
计算得到的数据,用于统计分析
func toString
public func toString(duration: Float64): String
功能:按时间单位打印传入的时间值
参数:
- duration: 需要被打印的时间数值
返回值:按指定单位输出的时间数字字符串
enum TimeUnit
public enum TimeUnit {
| Nanos
| Micros
| Millis
| Seconds
}
功能:可以在 TimeNow 类构造函数中使用的时间单位。
Nanos
Nanos
功能: 单位为纳秒
Micros
Micros
功能: 单位为微秒
Millis
Millis
功能: 单位为毫秒
Seconds
Seconds
功能: 单位为秒
enum ExplicitGcType
public enum ExplicitGcType{
Disabled |
Light |
Heavy
}
功能:用于指定 @Configure 宏的 explicitGC 配置参数。表示 GC 执行的三种不同方式。
Disabled
Disabled
功能: GC不会被框架显式调用。
Light
Light
功能: std.runtime.GC(heavy: false) 将在 Benchmark 函数执行期间由框架显式调用。这是默认设置。
Heavy
Heavy
功能: std.runtime.GC(heavy: true) 将在性能测试执行期间由框架显式调用。
class JsonStrategy
public class JsonStrategy<T> <: DataStrategy<T> where T <: Serializable<T> {
public override func provider(configuration: Configuration): SerializableProvider<T>
}
功能:DataStrategy 对 JSON 数据格式的序列化实现
func provider
public override func provider(configuration: Configuration): SerializableProvider<T>
功能:生成序列化数据迭代器
参数:
- configuration: 数据配置信息
返回值:序列化迭代器对象
func json
public func json<T>(fileName: String): JsonStrategy<T> where T <: Serializable<T>
功能:
返回一个 JsonStrategy<T> 对象, T 可被序列化,数据值从 JSON 文件中读取。
参数:
- fileName : JSON 格式的文件地址,可为相对地址
返回值:一个 JsonStrategy<T> 对象, T 可被序列化,数据值从 JSON 文件中读取。
class CsvStrategy
public class CsvStrategy<T> <: DataStrategy<T> where T <: Serializable<T> {
public override func provider(configuration: Configuration): SerializableProvider<T>
}
功能:DataStrategy 对 CSV 数据格式的序列化实现
func provider
public override func provider(configuration: Configuration): SerializableProvider<T>
功能:生成序列化数据迭代器
参数:
- configuration: 数据配置信息
返回值:序列化迭代器对象
func csv
public func csv<T>(
fileName: String,
delimiter!: Char = ',',
quoteChar!: Char = '"',
escapeChar!: Char = '"',
commentChar!: Option<Char> = None,
header!: Option<Array<String>> = None,
skipRows!: Array<UInt64> = [],
skipColumns!: Array<UInt64> = [],
skipEmptyLines!: Bool = false
): CsvStrategy<T> where T <: Serializable<T>
功能:
返回一个 CsvStrategy<T> 对象, T 可被序列化,数据值从 CSV 文件中读取。
参数:
- fileName : CSV 格式的文件地址,可为相对地址,不限制后缀名。
- delimiter :一行中作为元素分隔符的符号。默认值为
,(逗号)。 - quoteChar :- 括住元素的符号。默认值为
"(双引号)。 - escapeChar :转义括住元素的符号。默认值为
"(双引号)。 - commentChar :注释符号,跳过一行。必须在一行的最左侧。默认值是
None(不存在注释符号)。 - header :提供一种方式覆盖第一行。
- 当 header 被指定时,文件的第一行将被作为数据行,指定的 header 将被使用。
- 当 header 被指定,同时第一行通过指定
skipRows被跳过时,第一行将被忽略,指定的 header 将被使用。 - 当 header 未被指定时,即值为
None时,文件的第一行将被作为表头。此为默认值。
- skipRows :指定需被跳过的数据行号,行号从 0 开始。默认值为空数组
[]。 - skipColumns :指定需被跳过的数据列号,列号从 0 开始。当有数据列被跳过,并且用户指定了自定义的 header 时,该 header 将按照跳过后的实际数据列对应。默认值为空数据
[]。 - skipEmptyLines :指定是否需要跳过空行。默认值为
false。
返回值:CsvStrategy<T> 对象, T 可被序列化,数据值从 CSV 文件中读取。
func tsv
public func tsv<T>(
fileName: String,
quoteChar!: Char = '"',
escapeChar!: Char = '"',
commentChar!: Option<Char> = None,
header!: Option<Array<String>> = None,
skipRows!: Array<UInt64> = [],
skipColumns!: Array<UInt64> = [],
skipEmptyLines!: Bool = false
): CsvStrategy<T> where T <: Serializable<T>
功能:
返回一个 CsvStrategy<T> 对象, T 可被序列化,数据值从 TSV 文件中读取。
Parameters:
- fileName : TSV 格式的文件地址,可为相对地址,不限制后缀名。
- quoteChar :- 括住元素的符号。默认值为
"(双引号)。 - escapeChar :转义括住元素的符号。默认值为
"(双引号)。 - commentChar :注释符号,跳过一行。必须在一行的最左侧。默认值是
None(不存在注释符号)。 - header :提供一种方式覆盖第一行。
- 当 header 被指定时,文件的第一行将被作为数据行,指定的 header 将被使用。
- 当 header 被指定,同时第一行通过指定
skipRows被跳过时,第一行将被忽略,指定的 header 将被使用。 - 当 header 未被指定时,即值为
None时,文件的第一行(跳过后的实际数据)将被作为表头。此为默认值。
- skipRows :指定需被跳过的数据行号,行号从 0 开始。默认值为空数组
[]。 - skipColumns :指定需被跳过的数据列号,列号从 0 开始。当有数据列被跳过,并且用户指定了自定义的 header 时,该 header 将按照跳过后的实际数据列对应。默认值为空数据
[]。 - skipEmptyLines :指定是否需要跳过空行。默认值为
false。
返回值:CsvStrategy<T> 对象, T 可被序列化,数据值从 TSV 文件中读取。
如何使用 json 文件进行参数化测试
用例示例:
@Test[user in json("users.json")]
func test_user_age(user: User): Unit {
@Expect(user.age, 100)
}
json 文件示例:
[
{
"age": 100
},
{
"age": 100
}
]
创建一种被用作测试函数参数的类,该类实现接口 Serializable 。
class User <: Serializable<User> {
User(let age: Int64) {}
public func serialize(): DataModel {
DataModelStruct()
.add(Field("age", DataModelInt(age)))
}
public static func deserialize(dm: DataModel): User {
if (let Some(dms) <- dm as DataModelStruct) {
if (let Some(age) <- dms.get("age") as DataModelInt) {
return User(age.getValue())
}
}
throw Exception("Can't deserialize user.")
}
}
任何实现 Serializable 的类型都可以用作参数类型,包括默认值:
@Test[user in json("numbers.json")]
func test(value: Int64)
@Test[user in json("names.json")]
func test(name: String)
如何使用 csv/tsv 文件进行参数化测试
在单元测试中,可以通过传入 csv/tsv 文件地址进行参数化测试。
CSV 文件每一行的数据应当被表示成一个 Serializable<T> 对象,它的成员名是文件每一列头的值,成员值是 DataModelString 类型的对应列号上的值。
举例来说,有一个 testdata.csv 文件,具有如下内容:
username,age
Alex Great,21
Donald Sweet,28
有几种方式可以序列化上述数据:
- 将数据表示为
HashMap<String, String>类型。
具体示例为:
from std import collection.HashMap
from std import unittest.*
from std import unittest.testmacro.*
@Test[user in csv("testdata.csv")]
func testUser(user: HashMap<String, String>) {
@Assert(user["username"] == "Alex Great" || user["username"] == "Donald Sweet")
@Assert(user["age"] == "21" || user["age"] == "28")
}
- 将数据表示为
Serializable<T>类型数据,其String类型的数据可被反序列化为DataModelStruct格式对象。
具体示例为:
from serialization import serialization.*
from std import convert.*
from std import unittest.*
from std import unittest.testmacro.*
public class User <: Serializable<User> {
public User(let name: String, let age: UInt32) {}
public func serialize(): DataModel {
let dms = DataModelStruct()
dms.add(Field("username", DataModelString(name)))
dms.add(Field("age", DataModelString(age.toString())))
return dms
}
static public func deserialize(dm: DataModel): User {
var data: DataModelStruct = match (dm) {
case dms: DataModelStruct => dms
case _ => throw DataModelException("this data is not DataModelStruct")
}
let name = String.deserialize(data.get("username"))
let age = String.deserialize(data.get("age"))
return User(name, UInt32.parse(age))
}
}
@Test[user in csv("testdata.csv")]
func testUser(user: User) {
@Assert(user.name == "Alex Great" || user.name == "Donald Sweet")
@Assert(user.age == 21 || user.age == 28)
}
Re-exported declarations
unittest 重导出了下列类型:
public import unittest.common.checkDataStrategy
public from std import unittest.common.Configuration
public from std import unittest.common.ConfigurationKey
public from std import unittest.common.DataProvider
public from std import unittest.common.DataStrategy
public from std import unittest.common.DataShrinker
public from std import unittest.common.DataFinisher
public import unittest.prop_test.random
public import unittest.prop_test.Arbitrary
public import unittest.prop_test.Shrink
package unittest.testmacro
macro Bench
public macro Bench(input: Tokens): Tokens
功能:@Bench 宏的实现, @Bench 可用于在 @Test 宏内声明的函数。可以使用 @Configure 宏来配置 @Bench 宏的行为。
参数:
- input :
@Bench修饰的函数的 Tokens
返回值:经过处理后的 Tokens ,该用例将作为性能测试用例
异常 MacroException - 如果 input 不是 FuncDecl ,抛出异常
macro Bench
public macro Bench(dslArguments: Tokens, input: Tokens): Tokens
功能: @Bench 宏的实现, @Bench 可用于在 @Test 宏内声明的函数。可以使用 @Configure 宏来配置 @Bench 宏的行为。
参数:
- input :
@Bench修饰的 Tokens - dslArguments - 参数的配置 DSL
返回值:经过处理后的 Tokens ,该用例将作为性能测试用例
异常 MacroException : 如果 input 不是 FuncDecl ,抛出异常
macro RawBench
public macro RawBench(input: Tokens): Tokens
功能: @RawBench 宏的实现, @RawBench 可用于在 @Test 宏内声明的函数。可以使用 @Configure 宏来配置 @RawBench 宏的行为。提供比 @Bench 宏更细粒度的 API 。
参数:
- input :
@RawBench修饰的 Tokens
返回值:经过处理后的 Tokens ,该用例将作为性能测试用例
异常 MacroException : 如果 input 不是 FuncDecl ,抛出异常
macro RawBench
public macro RawBench(dslArguments: Tokens, input: Tokens): Tokens
功能: @RawBench 宏的实现, @RawBench 可用于在 @Test 宏内声明的函数。可以使用 @Configure 宏来配置 @RawBench 宏的行为。提供比 @Bench 宏更细粒度的 API 。
参数:
- input :
@RawBench修饰的 Tokens - dslArguments - 参数的配置 DSL
返回值:经过处理后的 Tokens ,该用例将作为性能测试用例
异常 MacroException : 如果 input 不是 FuncDecl ,抛出异常
macro Expect
public macro Expect(input: Tokens): Tokens
@Expect 宏的实现, @Testcase 宏声明的函数内部使用, 用于断言。@Expect(expr1, expr2) 接受两个表达式,左边是实际执行的值,右边是期望的值。@Expect(condition: Bool) 比较 condition 是否为 true 。比较左右两边是否相同,与 @Assert 不同的是断言失败继续执行用例。
参数:
- input :
@Expect修饰的 Tokens
返回值:经过处理后的 Tokens ,用于判断测试中的变量是否符合预期
macro Assert
public macro Assert(input: Tokens): Tokens
@Assert 宏的实现, @Testcase 宏声明的函数内部使用,用于断言。@Assert(expr1, expr2) 接受两个表达式,左边是实际执行的值,右边是期望的值。@Assert(condition: Bool) 比较 condition 是否为 true 。比较左右两边是否相同,与 @Expect 不同的是断言失败停止用例。
参数:
- input :
@Assert修饰的 Tokens
返回值:经过处理后的 Tokens ,用于判断测试中的变量是否符合预期
macro PowerAssert
public macro PowerAssert(input: Tokens): Tokens
功能:@PowerAssert(condition: Bool) 检查传递的表达式是否为真,并显示包含传递表达式的中间值和异常的详细图表。
请注意,现在并非所有 AST 节点都受支持。支持的节点如下:
- 任何二进制表达式
- 算术表达式,如
a + b == p % b - 布尔表达式,如
a || b == a && b - 位表达式,如
a | b == a ^ b
- 算术表达式,如
- 成员访问如
a.b.c == foo.bar - 括号化的表达式,如
(foo) == ((bar)) - 调用表达式,如
foo(bar()) == Zoo() - 引用表达式,如
x == y - 赋值表达式,如
a = foo,实际上总是Unit(表示为()),请注意,赋值表达式的左值不支持打印 - 一元表达式,如
!myBool is表达式,如myExpr is Fooas表达式,如myExpr as Foo如果传递了其他节点,则图中不会打印它们的值 返回的 Tokens 是初始表达式,但包装到一些内部包装器中,这些包装器允许进一步打印中间值和异常。
参数:
- input :
@Assert修饰的 Tokens
返回值:经过处理后的 Tokens ,初始表达式,但包装到一些内部包装器中,这些包装器允许进一步打印中间值和异常。
macro Skip
public macro Skip(input: Tokens): Tokens
功能:@Skip 宏的实现,只在用于测试类内使用 @Testcase 宏声明的函数,@Skip 修饰使用 @Testcase 宏声明的函数后,执行测试会跳过该用例。
参数:
- input :
@Skip修饰的 Tokens
返回值:经过处理后的 Tokens,用于跳过该测试用例
异常 MacroException : 如果 input 不是 ClassDecl 或者 FuncDecl ,抛出异常
macro Skip
public macro Skip(attr: Tokens, input: Tokens): Tokens
功能:@Skip 宏的实现,只在用于测试类内使用 @Testcase 宏声明的函数,@Skip 修饰使用 @Testcase 宏声明的函数后,执行测试会跳过该用例。
参数:
- input :
@Skip修饰的 Tokens - attr -
@Skip[attr]中的 attr ,只支持为 true ,其他参数用例不跳过。
返回值:经过处理后的 Tokens,用于跳过该测试用例
异常 MacroException : 如果 input 不是 ClassDecl 或者 FuncDecl ,抛出异常
macro Timeout
public macro Timeout(attr: Tokens, input: Tokens): Tokens
@Timeout 宏可以与 @TestCase 和 @Test 。指定超时值。
参数:
- attr : 类型为
std.time.Duration的表达式,作为用例执行的超时时间 - input :
@Timeout修饰的 Tokens
返回值:经过处理后的 Token
异常 MacroException : 如果 input 不是 ClassDecl 或者 FuncDecl ,抛出异常
macro Parallel
public macro Parallel(input: Tokens): Tokens
@Parallel 宏可以与 @Test 共同使用,指定该用例类中所有用例可并行执行。
参数:
- input :
@Parallel修饰的 Tokens
返回值:经过处理后的 Token
macro TestCase
public macro TestCase(input: Tokens): Tokens
功能: @Testcase 宏的实现,只在 @Test 修饰的 class 内部生效, 修饰非测试类成员函数时无效。@Testcase 修饰的函数必须为返回值类型为 Unit 的函数
参数:
- input :
@Testcase修饰的 Tokens
返回值:经过处理后的 Tokens ,用于将测试类中的函数变为测试用例
异常 MacroException : 如果 input 不是 FuncDecl ,抛出异常
macro TestCase
public macro TestCase(dslArguments: Tokens, input: Tokens): Tokens
功能: @Testcase 宏的实现,只在 @Test 修饰的 class 内部生效, 修饰非测试类成员函数时无效。@Testcase 修饰的函数必须为返回值类型为 Unit 的函数
参数:
- input :
@Testcase修饰的 Tokens - dslArguments - 参数的配置 DSL
返回值:经过处理后的 Tokens ,用于将测试类中的函数变为测试用例
异常 MacroException : 如果 input 不是 FuncDecl ,抛出异常
macro Test
public macro Test(input: Tokens): Tokens
功能: @Test 宏的实现,修饰 Top-Level 类或者 Top-Level 的函数(此时也会宏展开为测试类)。 @Test 修饰的类不能是泛型类且必须有无参构造函数。 @Test 修饰的 Top-Level 的函数必须为返回值类型为 Unit 的函数
参数:
- input :
@Test修饰的 Tokens
返回值:经过处理后的 Tokens ,用于将修饰的类和函数变为测试类
异常:
- MacroException : 如果 input 不是 ClassDecl 或 FuncDecl ,抛出异常
- IllegalArgumentException - 如果输入是 ClassDecl ,并且在类体内中找到了 PrimaryCtorDecl ,并且 PrimaryCtorDecl 体内为空,抛出异常
macro Test
public macro Test(dslArguments: Tokens, input: Tokens): Tokens
功能: @Test 宏的实现,修饰 Top-Level 类或者 Top-Level 的函数(此时也会宏展开为测试类)。 @Test 修饰的类不能是泛型类且必须有无参构造函数。 @Test 修饰的 Top-Level 的函数必须为返回值类型为 Unit 的函数
参数:
- input :
@Test修饰的 Tokens - dslArguments - 参数的配置 DSL
返回值:经过处理后的 Tokens ,用于将修饰的类和函数变为测试类
异常:
- MacroException : 如果 input 不是 ClassDecl 或 FuncDecl ,或者 classDecl 的无携带参数的构造函数,抛出异常
macro Configure
public macro Configure(dslArguments: Tokens, input: Tokens): Tokens
功能: @Configure 与 @Test 或 @TestCase 或 @Bench 宏一起放置在声明上。如果与 @Test 宏一起使用,必须放在 @Test 宏之后。用于设置测试用例的配置参数。
语法:@Configure(parameter1:value1,parameter2:value2) 。
@Configure 宏仅用于设置内部配置参数,在单元测试框架中的使用方式请参阅各组件文档。
参数:
- input :
@Configure修饰的 Tokens - dslArguments - 参数的配置 DSL
返回值:通常返回 input 相同的值。
异常:
- MacroException : 如果 dslArguments 格式不正确,则抛出异常。
macro Types
public macro Types(dslArguments: Tokens, input: Tokens): Tokens
功能:@Types 与 @Test 或 @TestCase 或 @Bench 宏一起放置在声明上。用于设置带泛型参数的测试用例的类型参数。
语法:@Types[T in <Int64, String, Array<Int64>>, U in <SomeClass, SomeClass2>].
更多信息,详见 《带类型参数的参数化测试》章节。
参数:
- input :
@Types修饰的 Tokens - dslArguments - 类型参数 DSL
返回值:返回使用传入的类型参数替换泛型参数的类或函数声明 Tokens 。
异常:
- MacroException : 如果 dslArguments 格式不正确,则抛出异常。
package unittest.common
class Configuration
public class Configuration <: ToString
public init()
public func get<T>(key: String): ?T
public func set<T>(key: String, value: T): Unit
public func remove<T>(key: String): ?T
public func clone(): Configuration
public func toString(): String
}
存储 @Configure 宏生成的 unittest 配置数据的对象。Configuration 是一个类似 HashMap 的类,但它的键不是键和值类型,而是 String 类型,和任何给定类型的值
init
public init()
功能:构造一个空的实例。
func get
public func get<T>(key: String): ?T
功能:获取 key 对应的值。
参数:
- key : 键名称
- T : 泛型参数,用于在对象中查找对应类型的值
返回值:未找到时返回 None ,找到对应类型及名称的值时返回 Some() 。
func set
public func set<T>(key: String, value: T): Unit
功能:给对应键名称和类型设置值。
参数:
- key :键名称
- T :类型名称
func remove
public func remove<T>(key: String): ?T
功能:删除对应键名称和类型的值。
参数:
- key :键名称
- T :类型名称
返回值:当存在该值时返回该值,当不存在时返回 None 。
func clone
public func clone(): Configuration
功能:拷贝一份对象
返回值:拷贝的对象
func toString
public func toString(): String
功能:该对象的字符化对象,当内部对象未实现 ToString 接口时,输出 '
返回值:字符串
interface DataProvider
public interface DataProvider<T> {
func provide(): Iterable<T>
prop isInfinite: Bool
}
DataStrategy 的组件,用于提供测试数据, T 指定提供者提供的数据类型。
func provide()
func provide(): Iterable<T>
功能:获取数据迭代器。
返回值:数据迭代器
prop isInfinite
prop isInfinite: Bool
功能:是否无法穷尽。
interface DataShrinker
public interface DataShrinker<T> {
func shrink(value: T): Iterable<T>
}
DataStrategy 的组件,用于在测试期间缩减数据,T 指定该收缩器处理的数据类型。
func shrink
func shrink(value: T): Iterable<T>
功能:获取类型 T 的值并生成较小值的集合。什么被认为是“较小”取决于数据的类型。
参数:
- value : 被缩减的值
返回值:较小值的集合,当数据无法再被缩减时返回空集合。
interface DataFinisher
public interface DataFinisher<T> {
func finish(value: T): Unit
}
DataStrategy 的组件,用于在测试完成后对数据进行后处理。
func finish
func finish(value: T): Unit
功能:对值进行后处理步骤
参数:
- value : 被处理的值
interface DataStrategy
public interface DataStrategy<T> {
func provider(configuration: Configuration): DataProvider<T>
func shrinker(configuration: Configuration): DataShrinker<T>
func finisher(configuration: Configuration): DataFinisher<T>
}
为参数化测试提供数据的策略,T 指定该策略操作的数据类型。
func provider
func provider(configuration: Configuration): DataProvider<T>
功能:获取提供测试数据组件。
参数:
- configuration : 配置信息
返回值:提供测试数据的组件对象。
func shrinker
func shrinker(configuration: Configuration): DataShrinker<T>
功能:获取缩减测试数据的组件。
参数:
- configuration : 配置信息
返回值:缩减测试数据的组件对象。
func finisher
func finisher(configuration: Configuration): DataFinisher<T>
功能:获取对测试数据进行测试后操作的组件。
参数:
- configuration : 配置信息
返回值:对测试数据进行测试后操作测试数据的组件对象。
extend Array
extend Array<T> <: DataStrategy<T> & DataProvider<T>
为 Array 实现了 DataStrategy
@Test[x in [1,2,3]]
func test(x: Int64) {}
extend Range
extend Range<T> <: DataStrategy<T> & DataProvider<T>
为 Range 实现了 DataStrategy
@Test[x in (0..5)]
func test(x: Int64) {}
package unittest.prop_test
interface Generator
public interface Generator<T> {
func next(): T
}
生成器生成 T 类型的值。
func next
func next(): T
功能:获取生成出来的 T 类型的值。
返回值:生成的 T 类型的值
interface Arbitrary
public interface Arbitrary<T> {
static func arbitrary(random: Random): Generator<T>
}
生成 T 类型随机值的接口
func arbitrary
static func arbitrary(random: Random): Generator<T>
功能:获取生成 T 类型随机值生成器。
参数:
- random :随机数
返回值:生成 T 类型随机值生成器。
extend Types by Arbitrary
extend Unit <: Arbitrary<Unit> {}
extend Bool <: Arbitrary<Bool> {}
extend UInt8 <: Arbitrary<UInt8> {}
extend UInt16 <: Arbitrary<UInt16> {}
extend UInt32 <: Arbitrary<UInt32> {}
extend UInt64 <: Arbitrary<UInt64> {}
extend Int8 <: Arbitrary<Int8> {}
extend Int16 <: Arbitrary<Int16> {}
extend Int32 <: Arbitrary<Int32> {}
extend Int64 <: Arbitrary<Int64> {}
extend IntNative <: Arbitrary<IntNative> {}
extend UIntNative <: Arbitrary<UIntNative> {}
extend Float16 <: Arbitrary<Float16> {}
extend Float32 <: Arbitrary<Float32> {}
extend Float64 <: Arbitrary<Float64> {}
extend Ordering <: Arbitrary<Ordering> {}
extend Char <: Arbitrary<Char> {}
extend String <: Arbitrary<String> {}
extend Array<T> <: Arbitrary<Array<T>> where T <: Arbitrary<T> {}
extend Option<T> <: Arbitrary<Option<T>> where T <: Arbitrary<T> {}
extend Ordering <: Arbitrary<Ordering> {}
interface Shrink
public interface Shrink<T> {
func shrink(): Iterable<T>
}
将 T 类型的值缩减到多个“更小的”值
func shrink
func shrink(): Iterable<T>
功能:将该值缩小为一组可能的“较小”值
返回值:一组可能的“较小”值的迭代器
extend Types by Shrink
extend Unit <: Shrink<Unit> {}
extend Bool <: Shrink<Bool> {}
extend UInt8 <: Shrink<UInt8> {}
extend UInt16 <: Shrink<UInt16> {}
extend UInt32 <: Shrink<UInt32> {}
extend UInt64 <: Shrink<UInt64> {}
extend UIntNative <: Shrink<UIntNative> {}
extend Int8 <: Shrink<Int8> {}
extend Int16 <: Shrink<Int16> {}
extend Int32 <: Shrink<Int32> {}
extend Int64 <: Shrink<Int64> {}
extend IntNative <: Shrink<IntNative> {}
extend Float16 <: Shrink<Float16> {}
extend Float32 <: Shrink<Float32> {}
extend Float64 <: Shrink<Float64> {}
extend Ordering <: Shrink<Ordering> {}
extend Array<T> <: Shrink<Array<T>> where T <: Shrink<T> {}
extend Option<T> <: Shrink<Option<T>> where T <: Shrink<T> {}
extend Char <: Shrink<Char> {}
extend String <: Shrink<String> {}
class RandomDataProvider
public class RandomDataProvider<T> <: DataProvider<T> where T <: Arbitrary<T> {
public init(configuration:Configuration)
public override func provide(): Iterable<T>
public override prop isInfinite: Bool
}
使用随机数据生成的 DataProvider 接口的实现。
init
public init(configuration:Configuration)
功能:构造一个随机数据提供者的对象。
参数:
- configuration :配置对象,必须包含一个随机生成器,名称为
random,类型为random.Random
异常 IllegalArgumentException:当 configuration 不包含 random 实例时,抛出异常。
func provide
public override func provide(): Iterable<T>
功能:提供随机化生成的数据。
返回值:从 T 的任意实例创建的无限迭代器
prop isInfinite
public override prop isInfinite: Bool
功能:是否生成无限的数据。
返回值:始终返回 true
class RandomDataShrinker
public class RandomDataShrinker<T> <: DataShrinker<T> {
public override func shrink(value: T): Iterable<T>
}
使用随机数据生成的 DataShrinker 接口的实现。
func shrinker
public override func shrink(value: T): Iterable<T>
功能:获取值的缩减器。
参数:
- value:参数值
返回值: 如果参数实现了 Shrink 接口,则返回缩减后的迭代器,如果未实现,则返回空的数组。
class RandomDataStrategy
public class RandomDataStrategy<T> <: DataStrategy<T> where T <: Arbitrary<T> {
public override func provider(configuration: Configuration): RandomDataProvider<T>
public override func shrinker(_: Configuration): RandomDataShrinker<T>
}
使用随机数据生成的 DataStrategy 接口的实现。
func provider
public override func provider(configuration: Configuration): RandomDataProvider<T>
功能:获取随机数据的提供者。
参数:
- configuration:参数配置信息
返回值: RandomDataProvider 的实例
func shrinker
public override func shrinker(_: Configuration): RandomDataShrinker<T>
功能:获取随机数据的缩减器。
参数:
- configuration:参数配置信息
返回值: RandomDataShrinker 的实例
func random
public func random<T>(): RandomDataStrategy<T> where T <: Arbitrary<T>
功能:使用随机数据生成的 RandomDataStrategy 接口的实现。
返回值:使用随机数据生成的 RandomDataStrategy 接口的实例
示例
简单示例
// Function under test
func concat(s1: String, s2: String): String {
return s1 + s2
}
// Test itself
@Test
class Tests {
@TestCase
func testConcat(): Unit {
//期望 concat("1", "2") 运行结果为 "12"
@Assert(concat("1", "2"), "12")
}
}
执行命令
cjc --test test.cj && ./main
输出内容:
TCS: TestCCC, time elapsed: 0 ns, RESULT:
[ PASSED ] CASE: sayhi (0 ns)
--------------------------------------------------------------------------------------------------
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
使用 TopLevel 函数:
// Function under test
func concat(s1: String, s2: String): String {
return s1 + s2
}
// Test itself
@Test
func testConcat(): Unit {
//期望 concat("1", "2") 运行结果为 "12"
@Assert(concat("1", "2"), "12")
}
执行命令
cjc --test test.cj && ./main
输出内容:
TCS: TestCase_sayhi, time elapsed: 0 ns, RESULT:
[ PASSED ] CASE: sayhi (0 ns)
--------------------------------------------------------------------------------------------------
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
@Test 修饰类的使用
@Test 修饰类,展开的测试类使用 @Bench 、 @TestCase 和 @Skip 的功能。
代码如下:
@Test
class MySimpleTest {
//无 @TestCase 修饰非测试函数
func test1(): Unit {
println("hi1")
}
// TestCase 跟 Bench 可以同时修饰一个函数。此时函数既可以为单个测试用例,也可以作为 Benchmark 被多次执行,通过 --bench 打开 Bench 执行模式
@Bench
@TestCase
//跳过
@Skip
func test2(): Unit {
println("hi2")
}
// 最简单的 Benchmark 用例函数,输出 Benchmark 测试结果数据。
@Bench
//不跳过
@Skip[false]
func test3(): Unit {
println("hi3")
}
@TestCase
func test4(): Unit {
println("hi4")
}
}
运行结果如下:
hi3
hi3
hi3
hi3
hi3
...
hi3
hi3
hi3
hi3
hi4
TCS: MySimpleTest, time elapsed: 6580329566 ns, RESULT:
| Case | Median | Err | Err% |
|------ |----------:|-----------:|--------:|
| test3 | 30.23 us | ±5.148 us | ±17.0% |
[ PASSED ] CASE: test4 (50300 ns)
--------------------------------------------------------------------------------------------------
Summary: TOTAL: 4
PASSED: 2, SKIPPED: 2, ERROR: 0
FAILED: 0
自定义逻辑函数的使用
用户可以通过重写 afterAll , afterEach , beforeAll , beforeEach 在测试函数调用前后处理自定义的逻辑。
代码如下:
@Test
class MySimpleTest {
@TestCase
func test1(): Unit {
println("test1")
}
@TestCase
func test2(): Unit {
println("test2")
}
@TestCase
func test3(): Unit {
println("test3")
}
public override func afterAll(): Unit {
println("afterAll")
}
public override func afterEach(): Unit {
println("afterEach")
}
public override func beforeAll(): Unit {
println("beforeAll")
}
public override func beforeEach(): Unit {
println("beforeEach")
}
}
运行结果如下:
beforeAll
beforeEach
ccc1
afterEach
beforeEach
ccc2
afterEach
beforeEach
ccc3
afterEach
afterAll
TCS: MySimpleTest, time elapsed: 0 ns, RESULT:
[ PASSED ] CASE: ccc1 (0 ns)
[ PASSED ] CASE: ccc2 (0 ns)
[ PASSED ] CASE: ccc3 (0 ns)
--------------------------------------------------------------------------------------------------
Summary: TOTAL: 3
PASSED: 3, SKIPPED: 0, ERROR: 0
FAILED: 0
@PowerAssert 示例
@Test 修饰类,展开的测试类使用 @TestCase 的功能以及 @PowerAssert 的断言用法。
代码如下:
func foo(x: Int64, y!: String = "foo") { y.size / x }
func bar(_: Int64) { 33 }
@Test
class TestA {
@TestCase
func case1(): Unit {
let s = "123"
let a = 1
@PowerAssert(foo(10, y: "test" + s) == foo(s.size, y: s) + bar(a))
}
}
运行结果如下:
TCS: TestA_case1, time elapsed: 176000000 ns, RESULT:
[ FAILED ] CASE: case1 (175000000 ns)
REASON: `foo(10, y: test + s) == foo(s.size, y: s) + bar(a)` has been evaluated to false
Assert Failed: `(foo(10, y: test + s) == foo(s.size, y: s) + bar(a))`
| | |_|| | |_| | |_|| | |_||
| | "123" | "123" | "123" | 1 |
| |__________|| | |______| | |______|
| "test123" | | 3 | 33 |
|______________________| |_________________| |
0 | 1 |
|__________________________|
34
--------------------------------------------------------------------------------------------------
Summary: TOTAL: 1
PASSED: 0, SKIPPED: 0, ERROR: 0
FAILED: 1, listed below:
TCS: TestA_case1, CASE: case1
参数化测试简单示例
想象一下,您有一个 String 的 reverse 实现,并且您想在许多不同的字符串上测试它。
您不需要为此编写单独的测试,您可以使用参数化测试 DSL 来代替:
func reverse(s: String) {
let temp = s.toRuneArray()
temp.reverse()
return String(temp)
}
@Test
func testA(): Unit {
@Expect("cba", reverse("abc"))
}
@Test[s in ["ab", "bc", "Hello", ""]]
func testB(s: String): Unit {
@Expect(s != reverse(s))
}
输出如下:
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 250236 ns, Result:
TCS: TestCase_testA, time elapsed: 65077 ns, RESULT:
[ PASSED ] CASE: testA (51004 ns)
TCS: TestCase_testB, time elapsed: 71557 ns, RESULT:
[ FAILED ] CASE: testB (45465 ns)
REASON: After 4 generation steps:
s =
with randomSeed = 1706690422527775114
Expect Failed: `(s != reverse ( s ) == true)`
left: false
right: true
Summary: TOTAL: 2
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 1, listed below:
TCS: TestCase_testB, CASE: testB
--------------------------------------------------------------------------------------------------
可以使用 random() 生成器来测试函数在随机值下的行为:
func reverse(s: String) {
let temp = s.toRuneArray()
temp.reverse()
return String(temp)
}
@Test[s in random()]
func testC(s: String): Unit {
@Expect(s != reverse(s))
}
输出如下:
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 170350 ns, Result:
TCS: TestCase_testC, time elapsed: 166996 ns, RESULT:
[ FAILED ] CASE: testC (160175 ns)
REASON: After 3 generation steps and 1 reduction steps:
s =
with randomSeed = 1691464803229918621
Expect Failed: `(s != reverse ( s ) == true)`
left: false
right: true
Summary: TOTAL: 1
PASSED: 0, SKIPPED: 0, ERROR: 0
FAILED: 1, listed below:
TCS: TestCase_testC, CASE: testC
--------------------------------------------------------------------------------------------------
请注意,由于随机生成的性质,每次运行测试时随机测试可能会给出不同的结果。 如果你想获得更稳定、可重复的结果,强烈建议配置随机生成的种子:
func reverse(s: String) {
let temp = s.toRuneArray()
temp.reverse()
return String(temp)
}
@Test[s in random()]
@Configure[randomSeed: 1] // randomSeed is set to 1
func testC(s: String): Unit {
@Expect(s != reverse(s))
}
如果配置了随机种子,随机生成器将在每次运行测试时生成相同的值:
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 297568 ns, Result:
TCS: TestCase_testC, time elapsed: 293383 ns, RESULT:
[ FAILED ] CASE: testC (284963 ns)
REASON: After 4 generation steps and 1 reduction steps:
s =
with randomSeed = 1
Expect Failed: `(s != reverse ( s ) == true)`
left: false
right: true
Summary: TOTAL: 1
PASSED: 0, SKIPPED: 0, ERROR: 0
FAILED: 1, listed below:
TCS: TestCase_testC, CASE: testC
--------------------------------------------------------------------------------------------------
请注意,输出包含运行测试时使用的 randomSeed 值。如果您将此值作为 randomSeed 参数值放入测试代码中,它应该产生完全相同的结果。
带多个参数的参数化测试
如果测试函数包含多个参数,则所有参数都可以通过参数化测试 DSL 提供。当前支持的最大参数数量为 5。
@Test[a in ["Hello", "a", ""], b in (0..4)]
func testB(a: String, b: Int64): Unit {
println("${a}, ${b}")
@Expect(a.size != b)
}
测试框架应用此值的不同组合来检查给定条件:
Hello, 0
Hello, 1
Hello, 2
Hello, 3
a, 0
a, 1
a, 2
a, 3
, 0
, 1
, 2
, 3
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 334280 ns, Result:
TCS: TestCase_testB, time elapsed: 236204 ns, RESULT:
[ FAILED ] CASE: testB (142534 ns)
REASON: After 6 generation steps:
a = a
b = 1
with randomSeed = 1706691095691478341
Expect Failed: `(a . size != b == true)`
left: false
right: true
[ FAILED ] CASE: testB (188789 ns)
REASON: After 9 generation steps:
a =
b = 0
with randomSeed = 1706691095691478341
Expect Failed: `(a . size != b == true)`
left: false
right: true
Summary: TOTAL: 1
PASSED: 0, SKIPPED: 0, ERROR: 0
FAILED: 1, listed below:
TCS: TestCase_testB, CASE: testB
--------------------------------------------------------------------------------------------------
这也可以与随机生成的值一起使用:
@Test[a in ["Hello", "a", ""], b in random()]
@Configure[randomSeed: 0]
func testB(a: String, b: Int64): Unit {
println("${a}, ${b}")
@Expect(a.size != b)
}
输出结果为:
Hello, -144895307711186549
a, 1
a, 0
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 118190 ns, Result:
TCS: TestCase_testB, time elapsed: 114702 ns, RESULT:
[ FAILED ] CASE: testB (108172 ns)
REASON: After 2 generation steps and 1 reduction steps:
a = a
b = 1
with randomSeed = 0
Expect Failed: `(a . size != b == true)`
left: false
right: true
Summary: TOTAL: 1
PASSED: 0, SKIPPED: 0, ERROR: 0
FAILED: 1, listed below:
TCS: TestCase_testB, CASE: testB
--------------------------------------------------------------------------------------------------
如果需要,所有参数都可以随机化(在本例中我们不执行 println ,因为我们不建议将随机字符串打印到标准输出,它可能会破坏您的终端):
@Test[a in random(), b in random()]
@Configure[randomSeed: 0]
func testB(a: String, b: Int64): Unit {
@Expect(a.size != b)
}
输出如下:
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 3226316 ns, Result:
TCS: TestCase_testB, time elapsed: 3222958 ns, RESULT:
[ FAILED ] CASE: testB (3214676 ns)
REASON: After 53 generation steps and 2 reduction steps:
a = _
b = 1
with randomSeed = 0
Expect Failed: `(a . size != b == true)`
left: false
right: true
Summary: TOTAL: 1
PASSED: 0, SKIPPED: 0, ERROR: 0
FAILED: 1, listed below:
TCS: TestCase_testB, CASE: testB
--------------------------------------------------------------------------------------------------
带类型参数的参数化测试
如果您需要在不同类型上运行测试类或函数,您可以使用类型参数进行测试。
这些测试与普通仓颉泛型类型和函数类似:您只需将测试类或测试函数设为泛型类或函数,然后使用特殊的 @Types 宏列出要运行测试的类型。
from std import collection.*
@Test
@Types[T in <String, Char, Int64>]
class HashSetTest<T> where T <: Hashable & Equatable<T> {
@TestCase
func testFoo(): Unit {
@Expect(HashSet<T>().size, 0)
}
}
当与 --test 编译器选项一起使用时,此测试的工作方式与三个对应声明为 HashSetTest<String>、HashSetTest<Char> 和 HashSetTest<Int64> 类型的测试类相同:。示例输出如下所示:
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 33645 ns, Result:
TCS: HashSetTest<String>, time elapsed: 15947 ns, RESULT:
[ PASSED ] CASE: testFoo (9520 ns)
TCS: HashSetTest<Char>, time elapsed: 7644 ns, RESULT:
[ PASSED ] CASE: testFoo (5852 ns)
TCS: HashSetTest<Int64>, time elapsed: 6175 ns, RESULT:
[ PASSED ] CASE: testFoo (2570 ns)
Summary: TOTAL: 3
PASSED: 3, SKIPPED: 0, ERROR: 0
FAILED: 0
--------------------------------------------------------------------------------------------------
相同的机制可以应用于测试函数:
from std import collection.*
@Test
class HashSetTest {
@TestCase
@Types[T in <String, Char, Int64>]
func testFoo<T>(): Unit where T <: Hashable & Equatable<T> {
@Expect(HashSet<T>().size, 0)
}
}
当与 --test 编译器选项一起使用时,此测试将像测试类包含三个测试函数 testFoo<String>、 testFoo<Char> 和 testFoo<Int64> 一样工作。示例输出如下所示:
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 30664 ns, Result:
TCS: HashSetTest, time elapsed: 27987 ns, RESULT:
[ PASSED ] CASE: testFoo<String> (13846 ns)
[ PASSED ] CASE: testFoo<Char> (3044 ns)
[ PASSED ] CASE: testFoo<Int64> (4612 ns)
Summary: TOTAL: 3
PASSED: 3, SKIPPED: 0, ERROR: 0
FAILED: 0
--------------------------------------------------------------------------------------------------
带超时信息的测试用例
from std import time.*
@Test
@Timeout[Duration.second]
func test(): Unit {
println("Hello from test")
while (true) {}
}
测试用例进入无限循环,但框架在一秒钟后中断它并打印报告:
Hello from test
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 1005261753 ns, Result:
TCS: TestCase_test, time elapsed: 1005255775 ns, RESULT:
[ FAILED ] CASE: test (1005191011 ns)
REASON: Wait timeout, process not exit.
Summary: TOTAL: 1
PASSED: 0, SKIPPED: 0, ERROR: 0
FAILED: 1, listed below:
TCS: TestCase_test, CASE: test
--------------------------------------------------------------------------------------------------
如果没有 @Timeout ,测试过程本身就会陷入无限循环。
高级特性
基于属性的随机化测试(实验特性)
基于属性的随机化测试是仓颉单元测试框架的一项实验性功能,允许您使用随机生成的值编写测试。
为了使用基于属性的随机化测试,您需要使用 random() 函数作为参数化值生成器:
@Test
class RandomTests {
@TestCase[p in random()]
func sayhi2(p: Int64): Unit {
@Assert(p > 0)
}
}
@Test[v in random()]
func ttt(v: String) {
@Assert(v[0] != v[1])
}
在这种模式下,相应的函数参数必须全部实现接口 Arbitrary 和 Shrink (请参阅 unittest.prop_test 文档部分)。当运行这样的测试时,这些参数是随机生成的,并自动缩减到较小的值。
基于属性的随机测试对于根据大量随机数据快速测试代码非常有用,但您需要小心,因为生成/缩减过程是随机的,每次都可能会得到不同的结果。
随机数据生成使用以下配置参数:
generationSteps: Int64用于随机生成值的步数(默认为 200)reductionSteps: Int64用于缩减值的步数(默认为 200)randomSeed: Int64框架内使用的随机值生成器的种子值。
增加 generationSteps 和, 或 reductionSteps 的值将提高生成的质量和,或缩减测试过程中使用的值,但也可能会增加测试的运行时间。建议谨慎。
randomSeed 可以显式设置此参数以使测试可重现,使用相同此参数的相同测试保证每次运行时都会产生相同的结果,如果不提供此参数,结果可能每次都会改变。
随机数生成支持自定义类型
要使用 random() 使自定义类型可用于随机生成,需要执行以下步骤:
- 该类型必须实现
unittest.prop_test包中的Arbitrary接口 - 如果您还想支持缩减值,则还必须实现
unittest.prop_test包中的Shrink接口
示例如下:
from std import unittest.prop_test.*
from std import random.Random
class SimpleClass <: ToString {
SimpleClass(let name: String, let number: Int64) {}
public func toString(): String {
"SimpleClass(${name}, ${number})"
}
}
extend SimpleClass <: Arbitrary<SimpleClass> {
public static func arbitrary(random: Random): Generator<SimpleClass> {
let stringGenerator = String.arbitrary(random)
let numberGenerator = Int64.arbitrary(random)
return Generators.generate {
SimpleClass(stringGenerator.next(), numberGenerator.next())
}
}
}
@Test[x in random()]
@Configure[randomSeed: 0]
func foo(x: SimpleClass): Unit {
// we can now write tests for SimpleClass
@Expect(x.name.size != x.number)
}
输出如下
--------------------------------------------------------------------------------------------------
TP: default, time elapsed: 2600034 ns, Result:
TCS: TestCase_foo, time elapsed: 2596678 ns, RESULT:
[ FAILED ] CASE: foo (2587608 ns)
REASON: After 53 generation steps
x = SimpleClass(_, 1)
with randomSeed = 0
Expect Failed: `(x . name . size != x . number == true)`
left: false
right: true
Summary: TOTAL: 1
PASSED: 0, SKIPPED: 0, ERROR: 0
FAILED: 1, listed below:
TCS: TestCase_foo, CASE: foo
--------------------------------------------------------------------------------------------------
请注意,随机生成不一定实现 ToString,但如果没有它,它将无法在测试输出中打印生成的值。
增加新的数据生成策略
为了为参数化测试创建新的数据值源,需要执行以下步骤:
- 相应的类型必须实现
unittest.common包中的DataStrategy<T>接口,其中T是您要支持的参数类型。 - 涉及此类类型的任何表达式都可以在数据 DSL 中用作值源。
示例如下:
class SimpleStorage {
SimpleStorage() {}
let v1: String = "1"
let v2: String = "2"
let v3: String = "3"
let v4: String = "4"
}
extend SimpleStorage <: DataProvider<String> {
public func provide(): Iterable<String> {
return [v1, v2, v3, v4]
}
public prop isInfinite: Bool {
get() { false }
}
}
extend SimpleStorage <: DataStrategy<String> {
public func provider(_: Configuration): DataProvider<String> {
return this
}
}
// SimpleStorage can now be used in data DSL as a source of String
@Test[x in SimpleStorage()]
func foo(x: String): Unit {
@Expect(x.size > 0)
}
附录
API list
在框架中,部分 API 由于整体实现结构要求,属性为对外可见,但用户不应直接使用如下 API 。因此此处仅列举 API 列表,而不详细说明对应 API 使用方式。
package unittest
public class AssertException <: Exception {
public init()
public init(message: String)
}
public class AssertIntermediateException <: Exception {
public let expression: String
public let position: Int64
public let originalException: Exception
public func getOriginalStackTrace(): String
}
public open class UnittestException <: Exception
public class UnittestCliOptionsFormatException <: UnittestException
public func assertEqual<T>(leftStr:String, rightStr:String, expected: T, actual: T): Unit where T <: Equatable<T>
public func assertEqual<T, C>(leftStr:String, rightStr:String, expected: C, actual: C): Unit where T <: Equatable<T>, C <: Array<T>
public func expectEqual<T>(leftStr:String, rightStr:String, expected: T, actual: T): Unit where T <: Equatable<T>
public func expectEqual<T, C>(leftStr:String, rightStr:String, expected: C, actual: C): Unit where T <: Equatable<T>, C <: Array<T>
public class BenchParameterTestCase<T> <: ParameterTestCase<T>{
public init(
isSkip!: Bool,
caseName!: String,
argumentNames!: Array<String>,
doRunBatch!: (T, Int64, Int64) -> Unit,
strategy!: DataStrategy<T>,
configuration!: Configuration,
timeout!: TimeoutInfo
)
}
public class CombinedDataFinisher2<T0, T1> <: DataFinisher<(T0, T1)> {
public override func finish(value: (T0, T1))
}
public class CombinedDataFinisher3<T0, T1, T2> <: DataFinisher<(T0, T1, T2)> {
public override func finish(value: (T0, T1, T2))
}
public class CombinedDataFinisher4<T0, T1, T2, T3> <: DataFinisher<(T0, T1, T2, T3)> {
public override func finish(value: (T0, T1, T2, T3))
}
public class CombinedDataFinisher5<T0, T1, T2, T3, T4> <: DataFinisher<(T0, T1, T2, T3, T4)> {
public override func finish(value: (T0, T1, T2, T3, T4))
}
public class CombinedDataProvider2<T0, T1> <: DataProvider<(T0, T1)> {
public func positions(): Array<Int64>
public prop isInfinite: Bool
public func provide(): Iterator<(T0, T1)>
}
public class CombinedDataProvider3<T0, T1, T2> <: DataProvider<(T0, T1, T2)> {
public func positions(): Array<Int64>
public prop isInfinite: Bool
public func provide(): Iterator<(T0, T1, T2)>
}
public class CombinedDataProvider4<T0, T1, T2, T3> <: DataProvider<(T0, T1, T2, T3)> {
public func positions(): Array<Int64> { pos }
public prop isInfinite: Bool
public func provide(): Iterator<(T0, T1, T2, T3)>
}
public class CombinedDataProvider5<T0, T1, T2, T3, T4> <: DataProvider<(T0, T1, T2, T3, T4)> {
public func positions(): Array<Int64> { pos }
public prop isInfinite: Bool
public func provide(): Iterator<(T0, T1, T2, T3, T4)>
}
public class CombinedDataShrinker2<T0, T1> <: DataShrinker<(T0, T1)> {
public override func shrink(value: (T0, T1)): Iterable<(T0, T1)>
}
public class CombinedDataShrinker3<T0, T1, T2> <: DataShrinker<(T0, T1, T2)> {
public override func shrink(value: (T0, T1, T2)): Iterable<(T0, T1, T2)>
}
public class CombinedDataShrinker4<T0, T1, T2, T3> <: DataShrinker<(T0, T1, T2, T3)> {
public override func shrink(value: (T0, T1, T2, T3)): Iterable<(T0, T1, T2, T3)>
}
public class CombinedDataShrinker5<T0, T1, T2, T3, T4> <: DataShrinker<(T0, T1, T2, T3, T4)> {
public override func shrink(value: (T0, T1, T2, T3, T4)): Iterable<(T0, T1, T2, T3, T4)>
}
public class CombinedDataStrategy2<T0, T1> <: FormattedDataStrategy<(T0, T1)> {
public init(t0Strategy: DataStrategy<T0>, t1Strategy: DataStrategy<T1>)
public override func provider(configuration: Configuration)
public override func shrinker(configuration: Configuration)
public override func finisher(configuration: Configuration)
}
public class CombinedDataStrategy3<T0, T1, T2> <: FormattedDataStrategy<(T0, T1, T2)> {
public init(
t0Strategy: DataStrategy<T0>,
t1Strategy: DataStrategy<T1>,
t2Strategy: DataStrategy<T2>)
public override func provider(configuration: Configuration)
public override func shrinker(configuration: Configuration)
public override func finisher(configuration: Configuration)
}
public class CombinedDataStrategy4<T0, T1, T2, T3> <: FormattedDataStrategy<(T0, T1, T2, T3)> {
public init(
t0Strategy: DataStrategy<T0>,
t1Strategy: DataStrategy<T1>,
t2Strategy: DataStrategy<T2>,
t3Strategy: DataStrategy<T3>)
public override func provider(configuration: Configuration)
public override func shrinker(configuration: Configuration)
public override func finisher(configuration: Configuration)
}
public class CombinedDataStrategy5<T0, T1, T2, T3, T4> <: FormattedDataStrategy<(T0, T1, T2, T3, T4)> {
public init(
t0Strategy: DataStrategy<T0>,
t1Strategy: DataStrategy<T1>,
t2Strategy: DataStrategy<T2>,
t3Strategy: DataStrategy<T3>,
t4Strategy: DataStrategy<T4>)
public override func provider(configuration: Configuration)
public override func shrinker(configuration: Configuration)
public override func finisher(configuration: Configuration)
}
public func checkDataStrategy<T>(strategy: DataStrategy<T>): DataStrategy<T>{
public func provider(configuration: Configuration): DataProvider<T>{ val.provider(configuration) }
public func shrinker(configuration: Configuration): DataShrinker<T> { val.shrinker(configuration) }
public func finisher(configuration: Configuration): DataFinisher<T> { val.finisher(configuration) }
}
public sealed abstract class FormattedDataStrategy<T> <: DataStrategy<T>
public func defaultConfiguration(): Configuration
public func entryMain(cases: TestPackage): Int64
public class SerializableProvider<T> <: DataProvider<T> where T <: Serializable<T> {
public override func provide(): Iterable<T>
public prop isInfinite: Bool
}
/**********************************/
public open class ParameterTestCase<T> <: UTestCase {
public override func run(ctx: TestCaseContext): Unit
}
public func makeParameterTestCase<T>(
caseName!: String,
isSkip!: Bool,
argumentNames!: Array<String>,
doRun!: (T) -> Unit,
strategy!: DataStrategy<T>,
configuration!: Configuration,
timeout!: TimeoutInfo
): ParameterTestCase<T>
public class PowerAssertDiagramBuilder {
public init(expression: String, initialPosition: Int64)
public func r<T>(value: T, exprAsText: String, position: Int64): T
public func r(value: String, exprAsText: String, position: Int64): String
public func h(exception: Exception, exprAsText: String, position: Int64): Nothing
public func w(result: Bool)
}
public func pprint(pp: PrettyPrinter): PrettyPrinter
public abstract class UTestCase <: Hashable & Equatable<UTestCase>{
public init(caseName: String, isSkip!: Bool, isBench!: Bool, timeout!: TimeoutInfo)
public func run(ctx: TestCaseContext): Unit
public func hashCode() : Int64
public operator func ==(rhs: UTestCase): Bool
public operator func !=(rhs: UTestCase): Bool
}
public class SimpleTestCase <: UTestCase {
public init(
isSkip: Bool, caseName: String, doRun: () -> Unit,
times!: Int64 = 1, isBench!: Bool = false, timeout!: TimeoutInfo = NoTimeout)
public init(
caseName: String, doRun: () -> Unit, times!: Int64 = 1,
isBench!: Bool = false, timeout!: TimeoutInfo = NoTimeout)
public override func run(ctx: TestCaseContext): Unit
}
public open class TestCases <: UTest {
public func addCase(t: UTestCase): Unit
public func withName(name: String): This
public init()
public init(name: String)
public init(name: String, isParallel!: Bool)
public func loadCases(): Unit
}
public open class TestInfo <: Serializable<TestInfo> & PrettyPrintable {
public var config: Configuration = Configuration()
public var name: String
public prop errorCount: Int64
public prop caseCount: Int64
public prop passedCount: Int64
public prop failedCount: Int64
public prop timeoutCount: Int64
public prop skippedCount: Int64
public func recordStartTime(): Unit
public func recordTimeDuration(): Unit
public func printResult(): Unit
public open override func pprint(pp: PrettyPrinter): PrettyPrinter
public func getBenchResults(): HashMap<String, (Float64,Float64)>
public open func serialize(): DataModel
public static func deserialize(dm: DataModel): TestInfo
public func addCheckResult(check: CheckResult)
public func serialize(): DataModel
public static func deserialize(dm: DataModel): TestResult
public override func pprint(pp: PrettyPrinter): PrettyPrinter
}
public open class CheckResult <: Serializable<CheckResult> {
public func serialize(): DataModel
public static func deserialize(dm: DataModel): addCheckResult
}
public class TestCaseContext {}
public class TestPackage <: UTest {
public init(packageName: String)
public func add(t: TestCases): TestPackage
public func add(elements: Collection<TestCases>): TestPackage
public func runCases(): UnittestCliOptionsFormatException
}
public class TestModule <: UTest {
public init(moduleName: String)
public func add(t: TestPackage): TestModule
public func add(elements: Collection<TestPackage>): TestModule
public func runCases(): Unit
}
public class TestPackageInfo <: TestInfo & Serializable<TestPackageInfo> {
public override func serialize(): DataModel
static public redef func deserialize(dm: DataModel): TestPackageInfo
public override func pprint(pp: PrettyPrinter): PrettyPrinter
}
public class TestModuleInfo <: TestInfo & Serializable<TestModuleInfo> {
public override func serialize(): DataMode
static public redef func deserialize(dm: DataModel): TestModuleInfo
public override func pprint(pp: PrettyPrinter): PrettyPrinter
}
public abstract class UTest {
public func execute(): Unit
public func printResult(): Unit
public open func jsonReport(): JsonValue
public open func getTestInfo(): TestInfo
public open prop ctx: TestCaseContext
}
public class Configuration <: ToString {
public init()
public func get<T>(key: String): ?T
public func set<T>(key: String, value: T)
public func remove<T>(key: String): ?T
public func clone(): Configuration
public func toString(): string
}
package unittest.common
public interface DataProvider<T> {
func provide(): Iterable<T>
func positions(): Array<Int64> /* users should not implement this API */
prop isInfinite: Bool
}
public enum Color {
| RED
| GREEN
| YELLOW
| BLUE
| CYAN
| MAGENTA
| GRAY
| DEFAULT_COLOR
}
public abstract class PrettyPrinter {
public init(indentationSize!: UInt64 = 4, startingIndent!: UInt64 = 0)
public prop isTopLevel: Bool
public func indent(body: () -> Unit): PrettyPrinter
public func indent(indents: UInt64, body: () -> Unit): PrettyPrinter
public func customOffset(symbols: UInt64, body: () -> Unit): PrettyPrinter
public func colored(color: Color, body: () -> Unit): PrettyPrinter
public func colored(color: Color, text: String): PrettyPrinter
public func append(text: String): PrettyPrinter
public func appendCentered(text: String, space: UInt64): PrettyPrinter
public func append<PP>(value: PP): PrettyPrinter where PP <: PrettyPrintable
public func newLine(): PrettyPrinter
public func appendLine(text: String): PrettyPrinter
public func appendLine<PP>(value: PP): PrettyPrinter where PP <: PrettyPrintable
}
public class PrettyText <: PrettyPrinter & PrettyPrintable & ToString {
public init()
public init(string: String)
public static func of<PP>(pp: PP) where PP <: PrettyPrintable
public func isEmpty(): Bool
public func pprint(to: PrettyPrinter): PrettyPrinter
public func toString(): String
}
public interface PrettyPrintable {
func pprint(to: PrettyPrinter): PrettyPrinter
}
extend Array<T> <: PrettyPrintable where T <: PrettyPrintable
extend ArrayList<T> <: PrettyPrintable where T <: PrettyPrintable
package unittest.prop_test
public func emptyIterable<T>(): Iterable<T>
public interface Generator<T> {
func next(): T
}
public class Generators {
public static func single<T>(value: T): Generator<T>
public static func generate<T>(body: () -> T): Generator<T>
public static func iterable<T>(random: Random, collection: Array<T>): Generator<T>
public static func weighted<T>(random: Random, variants: Array<(UInt64, Generator<T>)>): Generator<T>
public static func pick<T>(random: Random, variants: Array<Generator<T>>): Generator<T>
public static func lookup<T>(random: Random): Generator<T> where T <: Arbitrary<T>
public static func mapped<T, R>(random: Random, body: (T) -> R): Generator<R> where T <: Arbitrary<T>
public static func mapped<T1, T2, R>(random: Random, body: (T1, T2) -> R): Generator<R> where T1 <: Arbitrary<T1>, T2 <: Arbitrary<T2>
public static func mapped<T1, T2, T3, R>(random: Random, body: (T1, T2, T3) -> R): Generator<R>
where T1 <: Arbitrary<T1>, T2 <: Arbitrary<T2>, T3 <: Arbitrary<T3>
public static func mapped<T1, T2, T3, T4, R>(random: Random, body: (T1, T2, T3, T4) -> R): Generator<R>
where T1 <: Arbitrary<T1>, T2 <: Arbitrary<T2>, T3 <: Arbitrary<T3>, T4 <: Arbitrary<T4>
}
public class LazySeq<T> <: Iterable<T> {
public static func of(iterable: Iterable<T>)
public static func of(array: Array<T>)
public init(element: T)
public init()
public func iterator(): Iterator<T>
public func concat(other: LazySeq<T>): LazySeq<T>
public func prepend(element: T): LazySeq<T>
public func append(element: T): LazySeq<T>
public func mixWith(other: LazySeq<T>): LazySeq<T>
public static func mix(l1: LazySeq<T>, l2: LazySeq<T>)
public static func mix(l1: LazySeq<T>, l2: LazySeq<T>, l3: LazySeq<T>)
public static func mix(l1: LazySeq<T>, l2: LazySeq<T>, l3: LazySeq<T>, l4: LazySeq<T>)
public static func mix(l1: LazySeq<T>, l2: LazySeq<T>, l3: LazySeq<T>, l4: LazySeq<T>, l5: LazySeq<T>)
public func map<U>(body: (T) -> U): LazySeq<U>
}
public class ShrinkHelpers {
public static func shrinkTuple<T0, T1>
public static func shrinkTuple<T0, T1, T2>
public static func shrinkTuple<T0, T1, T2, T3>
public static func shrinkTuple<T0, T1, T2, T3, T4>
}
public interface IndexAccess {
func getElementAsAny(index: Int64): ?Any
}
public struct Function0Wrapper<R> {
public Function0Wrapper(public let function: () -> R) {}
public operator func () (): R { function() }
}
public struct TupleWrapper2<T0, T1> {
public TupleWrapper2(public let tuple: (T0, T1))
public func apply<R>(f: (T0, T1) -> R): R
}
public struct TupleWrapper3<T0, T1, T2> {
public TupleWrapper3(public let tuple: (T0, T1, T2))
public func apply<R>(f: (T0, T1, T2) -> R): R
}
public struct TupleWrapper4<T0, T1, T2, T3> {
public TupleWrapper4(public let tuple: (T0, T1, T2, T3))
public func apply<R>(f: (T0, T1, T2, T3) -> R): R
}
public struct TupleWrapper5<T0, T1, T2, T3, T4> {
public TupleWrapper5(public let tuple: (T0, T1, T2, T3, T4))
public func apply<R>(f: (T0, T1, T2, T3, T4) -> R): R
}
/* how to describe the specification for function and tuples?*/
extend Function0Wrapper<R> <: Arbitrary<Function0Wrapper<R>> where R <: Arbitrary<R>
extend TupleWrapper2<T0, T1> <: Arbitrary<TupleWrapper2<T0, T1>>
extend TupleWrapper3<T0, T1, T3> <: Arbitrary<TupleWrapper3<T0, T1, T3>>
extend TupleWrapper4<T0, T1, T3, T4> <: Arbitrary<TupleWrapper4<T0, T1, T3, T4>>
extend TupleWrapper5<T0, T1, T3, T4, T5> <: Arbitrary<TupleWrapper5<T0, T1, T3, T4, T5>>
extend Function0Wrapper<R> <: Shrink<Function0Wrapper<R>> {}
extend TupleWrapper2<T0, T1> <: Shrink<TupleWrapper2<T0, T1>>
extend TupleWrapper3<T0, T1, T3> <: Shrink<TupleWrapper3<T0, T1, T3>>
extend TupleWrapper4<T0, T1, T3, T4> <: Shrink<TupleWrapper4<T0, T1, T3, T4>>
extend TupleWrapper5<T0, T1, T3, T4, T5> <: Shrink<TupleWrapper5<T0, T1, T3, T4, T5>>
extend TupleWrapper2<T0, T1> <: IndexAccess
extend TupleWrapper3<T0, T1, T3> <: IndexAccess
extend TupleWrapper4<T0, T1, T3, T4> <: IndexAccess
extend TupleWrapper5<T0, T1, T3, T4, T5> <: IndexAccess
package unittest.testmacro
class MacroException <: Exception {
public init()
public init(message: String)
}
概述
Unittest 库用于编写仓颉项目单元测试代码,提供包括代码编写、运行和调测在内的基本功能,以及为有经验的用户提供的一些高级功能。 仓颉单元测试支持 cjc 编译器(单包编译模式)和 cjpm 包管理器( 多包模式)。
快速入门
先编写一个简单的仓颉函数:
package example
func add(left: Int64, right: Int64) {
return left + right
}
将这个函数保存在 add.cj 文件中,开始编写该函数的测试代码:
package example
@Test
func addTest() {
@Expect(add(2, 3), 5)
}
测试包含如下组件:
@Test宏,配置在addTest函数上,表示这是一个测试函数。@Expect宏,作为断言,检查输入的两个参数是否相等。在这个例子中,两个参数分别是add函数的结果add(2, 3)和预期值5。
将这个测试函数保存在 add_test.cj 文件中,和代码函数一起在 add.cj 中运行。
cjc add.cj add_test.cj --test -o add_test
./add_test
正常情况下,将得到如下类似输出:
-------------------------------------------------------------------------------------------------
TP: default, time elapsed: 59363 ns, Result:
TCS: TestCase_addTest, time elapsed: 32231 ns, RESULT:
[ PASSED ] CASE: addTest (28473 ns)
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
--------------------------------------------------------------------------------------------------
至此,我们就完成了测试的构建和运行。
下面我们来详细介绍一下用来构建测试的 cjc 命令。
待测试的代码文件
↓
cjc add.cj add_test.cj --test -o add_test
↑ ↑
| --test 表明在测试模式下构建生成二进制文件
测试文件
注意,对于复杂项目来说,不建议直接运行 cjc 编译器。
对于结构庞大的大型项目,建议使用 cjpm 包管理器。
以 cjpm 项目测试为例。
首先创建一个简单的 cjpm 项目,其中包含一个名为 example 的包。
项目的文件结构如下所示(借用 cjc 示例中的文件):
- src
|
+- example
|
+- add.cj
+- add_test.cj
原文件已指明它们属于 example 包,因此只需运行以下命令即可初始化 cjpm 项目:
cjpm init example example
cjpm 包管理器内置支持运行单元测试,所以直接运行即可:
cjpm test
此命令会运行项目所有包中的测试,统一生成如下类似输出:
--------------------------------------------------------------------------------------------------
TP: example/example, time elapsed: 60989 ns, Result:
TCS: TestCase_addTest, time elapsed: 32804 ns, RESULT:
[ PASSED ] CASE: addTest (29195 ns)
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
--------------------------------------------------------------------------------------------------
注意,无需指定 --test 或任何其他特殊选项。
默认情况下,cjpm 使用项目中的文件名来确认文件应该在测试模式还是正常模式下编译。
示例包中, add_test.cj 是测试文件,文件名以 _test.cj 结尾。
正常构建时,二进制文件或库的构建不包含这些文件。
单元测试框架 API 已经存在于 std 模块的 unittest 包中,宏也存在于 std 模块的 unittest.testmacro 包中,因此不需要在测试文件中显式导入。
如需了解更多关于 unittest 框架的基本概念,请参考单元测试基础。
Unittest相关概念
测试及测试用例
测试是用 @Test 宏标记的实体,会在测试过程中执行。
仓颉 unittest 框架中有两种测试:测试类和测试函数。
测试函数相对简单,每个函数包含全部测试运行的代码。
测试类适用于为测试引入更深层次的结构,或者覆盖测试生命周期行为的场景。
每个测试类由若干个测试用例组成,每个测试用例用 @TestCase 宏标记。
每个测试用例都是测试类内部的一个函数。
上一节中的示例,相同的测试可以改写为如下所示的测试类:
@Test
class AddTests {
@TestCase
func addTest() {
@Expect(add(2, 3), 5)
}
@TestCase
func addZero() {
@Expect(add(2, 0), 2)
}
}
测试函数即函数中包含单个测试用例的测试。这种情况下不需要使用 @TestCase 宏。
cjpm test 中运行这个新的测试类会生成如下类似输出:
--------------------------------------------------------------------------------------------------
TP: example/example, time elapsed: 67369 ns, Result:
TCS: AddTests, time elapsed: 31828 ns, RESULT:
[ PASSED ] CASE: addTest (25650 ns)
[ PASSED ] CASE: addZero (4312 ns)
Summary: TOTAL: 2
PASSED: 2, SKIPPED: 0, ERROR: 0
FAILED: 0
--------------------------------------------------------------------------------------------------
cjpm test success
断言
断言是在测试用例函数体内执行的单个条件检查,用以判断代码是否正常运行。
断言有两种:@Expect 和 @Assert 。
创建一个错误的测试来说明两者的区别:
@Test
func testAddIncorrect() {
@Expect(add(3, 3), 5)
}
运行测试失败,并生成以下结果(仅展示与此测试相关的部分):
TCS: TestCase_testAddIncorrect, time elapsed: 4236 ns, RESULT:
[ FAILED ] CASE: testAddIncorrect (3491 ns)
Expect Failed: `(add ( 3 , 3 ) == 5)`
left: 6
right: 5
在这个例子中,用 @Assert 替换 @Expect 不会有什么变化。添加一个检查项后,再次运行:
@Test
func testAddIncorrect() {
@Expect(add(3, 3), 5)
@Expect(add(5, 3), 9)
}
运行测试失败,并生成以下结果(仅展示与此测试相关的部分):
TCS: TestCase_testAddIncorrect, time elapsed: 5058 ns, RESULT:
[ FAILED ] CASE: testAddIncorrect (4212 ns)
Expect Failed: `(add ( 3 , 3 ) == 5)`
left: 6
right: 5
Expect Failed: `(add ( 5 , 3 ) == 9)`
left: 8
right: 9
可以在输出中看到这两个检查的结果。
但是,如果用 @Assert 替换 @Expect :
@Test
func testAddIncorrectAssert() {
@Assert(add(3, 3), 5)
@Assert(add(5, 3), 9)
}
可以得到以下输出:
TCS: TestCase_testAddIncorrectAssert, time elapsed: 31653 ns, RESULT:
[ FAILED ] CASE: testAddIncorrectAssert (30893 ns)
Assert Failed: `(add ( 3 , 3 ) == 5)`
left: 6
right: 5
可以看到,只有第一个 @Assert 检查失败了,其余的测试甚至都没有运行。
这是因为 @Assert 宏采用的是快速失败(fail-fast)机制:一旦首次断言失败,整个测试用例都失败,后续的断言不再检查。
在涉及大量断言的大型测试中,这一点非常重要,尤其是在循环中使用断言时。 并不需要等到全部失败,首次失败后用户即可感知。
在测试中选择 @Assert 还是 @Expect 取决于测试场景的复杂程度,以及是否需要采用快速失败机制。
使用 unittest 提供的两种断言宏时,可采用如下方式:
- 相等断言,其中
@Assert(a, b)或@Expect(a, b)的两个参数a和b,检查他们的参数值是否相等;假设a的类型为A,b的类型为B,A必须实现了Equatable<B>。 - 布尔断言
@Assert(c)或@Expect(c),其参数c为Bool类型,参数值true或false。
断言的第二种形式 @Assert(c) 可以视为 @Assert(c, true) 的简写形式。
测试生命周期
测试用例之间有时可以共享创建或清理代码。测试框架支持4个生命周期步骤,分别通过相应的宏来设置。只能为 @Test 测试类指定生命周期步骤,不能为 @Test 顶层函数指定生命周期步骤。
| @BeforeAll | 在任何测试用例之前运行 |
| @BeforeEach | 在每个测试用例之前运行一次 |
| @AfterEach | 在每个测试用例之后运行一次 |
| @AfterAll | 在所有测试用例完成后运行 |
这些宏必须配置在 @Test 测试类的成员或静态函数上。@BeforeAll 和 @AfterAll 函数不能声明任何参数。 @BeforeEach 和 @AfterEach 函数可以声明一个 String 类型的参数(或者不声明参数)。
@Test
class FooTest {
@BeforeAll
func setup() {
//在测试执行前运行这段代码。
}
}
每个宏可以应用于单个测试类内的多个函数。可以在单个函数上配置多个生命周期宏。生命周期宏不能配置在标有 @TestCase 或类似宏的函数上。
如果多个函数被标记为相同的生命周期步骤,则可以按照它们在代码中声明的顺序(从上到下)执行。
测试框架确保:
- 标记为 Before all 的步骤在任何测试用例运行之前,至少运行一次。
- 对于测试类中的每个测试用例
TC: 1) 标记为 Before each 的步骤在TC之前运行一次。 2) 运行TC。 3) 标记为 After each 的步骤在TC之后运行一次。 - 在测试类中的所有测试用例之后运行标记为 After all 的步骤。
注意,如果没有运行测试用例,上述并不适用。
简单场景中,标识为 before all 和 after all 的步骤只运行一次。但也有例外:
- 对于类型参数化测试,标识为 before/after all 的步骤运行的数量为每个类型参数的组合数。
- 如果多个测试用例在不同的进程中并行执行,则每个进程中标识为 before/after all 的步骤都将运行一次。
@BeforeEach 和 @AfterEach 可以访问正在创建或删除的测试用例,只需要在相应的函数中指定一个 String 类型的参数即可。
@Test
class Foo {
@BeforeEach
func prepareData(testCaseName: String) {
//测试用例函数的名称作为参数
//本例中的"bar"
}
@AfterEach
func cleanup() {
//不指定参数也可以
}
@TestCase
func bar() {}
}
为参数化测试或参数化性能测试配置生命周期时,注意标识为 before each 或 after each 的步骤仅在执行测试用例或基准之前或之后为其所有参数执行一次。也就是说,从生命周期的角度看,使用不同参数执行多次的测试主体会被视为单个测试用例。
如果参数化测试的每个参数都需要单独创建清理,需要将相应的代码配置在测试用例主体本身中。此外,还可以访问参数本身。
测试配置
单元测试框架中其他更高级的功能可能需要额外配置。 参考如下三种方式配置测试:
- 使用
@Configure宏 - 直接在运行测试时或在
cjpm test测试中使用命令行参数 - 使用
cjpm配置文件
参数化测试
参数化测试入门
仓颉 unittest 框架支持参数化测试,格式为数据 DSL ,测试中框架自动插入输入参数。
如下为复杂代码示例,用函数对数组排序:
package example
func sort(array: Array<Int64>): Unit {
for (i in 0..array.size) {
var minIndex = i
for (j in i..array.size) {
if (array[j] < array[minIndex]) {
minIndex = j
}
}
(array[i], array[minIndex]) = (array[minIndex], array[i])
}
}
这个函数不是最优最高效的排序实现,但仍可以达成目的。 我们来测试一下。
package example
@Test
func testSort() {
let arr = [45, 5, -1, 0, 1, 2]
sort(arr)
@Expect(arr, [-1, 0, 1, 2, 5, 45])
}
测试结果显示,函数在单个输入的情况下可用。 接下来测试,如果数组只包含等值元素,排序函数还是否可用。
@Test
func testAllEqual() {
let arr = [0, 0, 0, 0]
let expected = [0, 0, 0, 0]
sort(arr)
@Expect(expected, arr)
}
测试结果显示函数可用,但还是不能确认是否适用于所有大小的数组。 接下来测试参数化数组的大小。
@Test[size in [0, 1, 50, 100, 1000]]
func testAllEqual(size: Int64) {
let arr = Array(size, item: 0)
let expected = Array(size, item: 0)
sort(arr)
@Expect(expected, arr)
}
至此,参数化测试已完成。 这种是最简单的参数化测试,即值驱动测试,直接在代码中列出测试运行的值。 参数化测试的参数可以不止一个。 不仅可以指定排序函数的大小,还可以指定待测试的元素。
@Test[
size in [0, 1, 50, 100, 1000],
item in (-1..20)
]
func testAllEqual(size: Int64, item: Int64) {
let arr = Array(size, item: item)
let expected = Array(size, item: item)
sort(arr)
@Expect(expected, arr)
}
注意,item 的取值范围为 -1..20 ,不是一个数组。
那么,运行这个测试,结果会如何?
参数 size 和 item 的取值会进行组合再测试和返回结果。
因此,测试函数时,不要配置过多参数;否则组合数量过大,导致测试变慢。
上述例子中,size 参数值有5个,item 参数值有21个,共有21×5=105种组合。
注意,值驱动测试不限于整型或内置类型。 也可以和任何仓颉类型一起使用。 参考如下测试:
@Test[
array in [
[],
[1, 2, 3],
[1, 2, 3, 4, 5],
[5, 4, 3, 2, 1],
[-1, 0],
[-20]
]
]
func testDifferentArrays(array: Array<Int64>) {
//测试数组是否已排序
for (i in 0..(array.size - 1)) {
@Expect(array[i] <= array[i + 1])
}
}
这里,直接以参数的形式提供测试的数据。
当然,用数组来测试代码可能过于笨重。
有时,对于这样的泛型函数,随机生成数据可能会更容易些。
接下来,我们来看一种更高级的参数化测试:随机测试。
通过调用函数 unittest.random<T>() 替换值驱动测试的数组或范围来创建随机测试:
@Test[
array in random()
]
func testRandomArrays(array: Array<Int64>) {
//测试数组是否已排序
for (i in 0..(array.size - 1)) {
@Expect(array[i] <= array[i + 1])
}
}
这个测试本质上是生成大量完全随机的数值(默认为200个),用这些值来测试代码。 数值并不完全随机,偏向于边界值,如特定类型的零、最大值和最小值、空集合等。
特别注明:通常建议随机化测试与手工编写的测试混用,实践表明可以互为补充。
为了更好地描述随机测试,让我们先把排序函数放一边,编写下面这样一个测试:
@Test[
array in random()
]
func testNonsense(array: Array<Int64>) {
if (array.size < 2) { return }
@Expect(array[0] <= array[1] + 500)
}
运行后,会生成如下类似输出:
[ FAILED ] CASE: testNonsense (1159229 ns)
REASON: After 4 generation steps and 200 reduction steps:
array = [0, -453923686263, 0]
with randomSeed = 1702373121372171563
Expect Failed: `(array [ 0 ] <= array [ 1 ] + 500 == true)`
left: false
right: true
结果可见,数组[0, -453923686263, 0]测试失败。
再运行一次:
[ FAILED ] CASE: testNonsense (1904718 ns)
REASON: After 5 generation steps and 200 reduction steps:
array = [0, -1196768422]
with randomSeed = 1702373320782980551
Expect Failed: `(array [ 0 ] <= array [ 1 ] + 500 == true)`
left: false
right: true
同样,测试失败,但值都不同。 为什么会这样呢? 因为随机测试本质上是随机的,所以每次都会生成新的随机值。 在各种不同的数据上测试函数,可能很好用;但是对于某些测试,这意味着多次运行中,有时成功,有时失败,不利于共享测试结果。 随机测试是一个强大的工具,但在使用时也需要了解这些弊端。
测试结果每次都不一样,如何向其他开发者展示结果呢? 答案很简单,就在运行测试时得到的输出中:
with randomSeed = 1702373320782980551
以上提供了一个随机种子,可以在测试中用作配置项。 改写测试如下:
@Test[
array in random()
]
@Configure[randomSeed: 1702373320782980551]
func testNonsense(array: Array<Int64>) {
if (array.size < 2) { return }
@Expect(array[0] <= array[1] + 500)
}
运行如下代码:
[ FAILED ] CASE: testNonsense (1910109 ns)
REASON: After 5 generation steps and 200 reduction steps:
array = [0, -1196768422]
with randomSeed = 1702373320782980551
Expect Failed: `(array [ 0 ] <= array [ 1 ] + 500 == true)`
left: false
right: true
注意,此次运行生成的值、生成值所用的步骤和随机种子与上次运行完全相同。
这种机制让随机测试可重复,可以保存在测试套件中与其他开发人员共享。
您也可以只从随机测试中获取数据(如本例中的数组值[0, -1196768422]),用这些值编写新测试。
让我们快速看看失败的测试生成的输出。
REASON: After 5 generation steps and 200 reduction steps:
array = [0, -1196768422]
with randomSeed = 1702373320782980551
输出中包含几个重要信息:
- 测试失败前数据生成的步骤数:即测试失败前运行的迭代次数。
- 数据减量的步骤数:随机测试有缩减测试数据的机制,数据量减小后更方便操作,且提升了可读性。
- 导致测试失败的实际数据:按顺序列出所有参数(在本例中,只有一个参数
array)以及它们实际导致测试失败的值。 - 以及前面提到的随机种子,用于重现随机测试。
有些测试比较棘手,需要调整随机生成的步骤数。
可以通过如下两个配置项控制:generationSteps 和 reductionSteps 。
随机测试一个最大的优点是,只要设置了足够多的步骤,它可以运行很长时间,这样就可以检查数百万个值。
为了不使测试太耗时,默认 generationSteps 和 reductionSteps 的最大值都是200。
通过这两个配置参数,我们就可以设置框架的最大步骤数。
例如,对于上面的这个小测试,参数设置为一个大的数值可能没有多大意义。我们之前的运行已经表明,通常不到10步,测试就会失败。
类型参数化测试
虽然当前排序实现仅针对整型数组排序,但本质上也可以对其他任何类型排序。
我们可以改写 sort 函数变成泛型函数,允许它对任意类型进行排序。
注意,元素必须是可比较的,这样才能排序。
package example
func sort<T>(array: Array<T>): Unit where T <: Comparable<T> {
for (i in 0..array.size) {
var minIndex = i
for (j in i..array.size) {
if (array[j] < array[minIndex]) {
minIndex = j
}
}
(array[i], array[minIndex]) = (array[minIndex], array[i])
}
}
所有测试均继续正常运行,可知排序函数已广泛适用。 但是,是否真的适用于整型以外的类型呢?
用示例中的 testDifferentArrays 编写一个新的测试,对其他类型(如字符串)进行测试:
@Test[
array in [
[],
["1","2","3"],
["1","2","3","4","5"],
["5","4","3","2","1"]
]
]
func testDifferentArraysString(array: Array<String>) {
//测试数组是否已排序
let sorted = array.clone()
sort(sorted)
for (i in 0..(sorted.size - 1)) {
@Expect(sorted[i] <= sorted[i + 1])
}
}
运行测试可知,测试正常。 注意,两个测试的主体和断言完全相同。 试想,如果泛型函数的测试也可以泛型,不是更方便吗?
回到之前的随机测试示例:
@Test[array in random()]
func testRandomArrays(array: Array<Int64>) {
let sorted = array.clone()
sort(sorted)
for (i in 0..(sorted.size - 1)) {
@Expect(sorted[i] <= sorted[i + 1])
}
}
测试是广泛适用的,可以看到元素类型不限于 Int64 ,也可以是任何类型 T ,例如:
- 可以比较:需要实现
Comparable<T>; - 可以随机生成实例:需要实现
Arbitrary<T>;
将这个测试改写为一个泛型函数:
@Test[array in random()]
func testRandomArrays<T>(array: Array<T>) where T <: Comparable<T> & Arbitrary<T> {
let sorted = array.clone()
sort(sorted)
for (i in 0..(sorted.size - 1)) {
@Expect(sorted[i] <= sorted[i + 1])
}
}
编译运行后,遇到了一个问题:
An exception has occurred:
MacroException: Generic function testRandomArrays requires a @Types macro to set up generic arguments
当然,要运行测试某些类型,需要先有这些类型。
用 @Types 宏设置测试,这样就可以运行测试 Int64、 Float64 和 String 这些类型了。
@Test[array in random()]
@Types[T in <Int64, Float64, String>]
func testRandomArrays<T>(array: Array<T>) where T <: Comparable<T> & Arbitrary<T> {
let sorted = array.clone()
sort(sorted)
for (i in 0..(sorted.size - 1)) {
@Expect(sorted[i] <= sorted[i + 1])
}
}
现在,运行测试,将编译并生成以下输出:
TCS: TestCase_testRandomArrays, time elapsed: 2491737752 ns, RESULT:
[ PASSED ] CASE: testRandomArrays<Int64> (208846446 ns)
[ PASSED ] CASE: testRandomArrays<Float64> (172845910 ns)
[ PASSED ] CASE: testRandomArrays<String> (2110037787 ns)
注意,每个类型,测试都是单独运行的,因为行为可能大不相同。
@Types 宏可以用于任何参数化的测试用例,包括测试函数和测试类。
mock 框架入门
mock 框架是仓颉单元测试框架,提供 API 用于创建和配置mock 对象 (也可称为“骨架对象”,即 API 函数体为空的对象),这些 mock 对象与真实对象拥有签名一致的 API 。mock 测试技术支持隔离测试代码,测试用例使用 mock 对象编码,实现外部依赖消除。
本文概述了如何使用 mock 框架测试及测试中所需的核心 API 。
概述
mock 框架具有以下特性:
- 创建 mock 对象和 spy 对象:测试时无需修改生产代码。
- API 配置简单:可配置 mock/spy 对象的行为。
- 单元测试框架部分:无缝集成单元测试框架的其他特性,错误输出可读。
- 自动验证配置行为:大多数情况下不需要多余的验证代码。
- 提供验证 API:用于测试系统内部的复杂交互。
用户使用场景包括:
- 简化测试设置和代码。
- 测试异常场景。
- 用轻量级 mock 对象替换代价高的依赖,提高测试性能。
- 验证测试复杂场景,如调用的顺序/数量。
使用 mock 框架
mock 框架本身是仓颉标准库中单元测试的一部分。使用 mock 框架前,需将 unittest.mock.* 和 unittest.mock.mockmacro.* 导入到测试文件中。
如果使用 cjpm 工具,仅需运行 cjpm test 命令即可自动启用 mock 框架。
如果直接使用 cjc ,参见[使用 cjc](#使用 cjc)。
示例
常见 mock 测试用例:
- 调用[mock 构造函数](#创建 mock 对象)创建 mock/spy 对象。
- 调用[配置 API](#配置 api)设置 mock 行为。
- 使用 mock 对象替代测试代码依赖。
- (可选)调用验证API来验证测试代码与 mock/spy 对象之间的交互。
以如下简单API为例:
public interface Repository {
func requestData(id: UInt64, timeoutMs: Int): String
}
public class Controller {
public Controller(
private let repo: Repository
) {}
public func findData(id: UInt64): ?String {
try {
return repo.requestData(id, 100)
}
catch (e: TimeoutException) {
return None
}
}
}
public class TimeoutException <: Exception {}
如果 Repository 实现不理想,比如可能包含复杂的依赖关系,实现在其他包中,或者测试太慢,mock 框架可以在不创建依赖的情况下测试 Controller 。
测试 findData 方法。
//导入mock框架包
from std import unittest.mock.*
from std import unittest.mock.mockmacro.*
@Test
class ControllerTest {
let testId: UInt64 = 100
let testResponse = "foo"
@TestCase
func testFindSuccessfully() {
//只需要创建mock,不用创建真正的Repository
let repository = mock<Repository>()
//使用@On宏配置testData行为
@On(repository.requestData(testId, _)).returns(testResponse)
//创建真正的Controller测试以便测试实际的实现
let controller = Controller(repository)
//运行测试代码
let result = controller.findData(testId)
//对结果运行断言
@Assert(result == Some(testResponse))
}
@TestCase
func testTimeout() {
let repository = mock<Repository>()
//设置getData抛出异常
@On(repository.requestData(testId, _)).throws(TimeoutException())
let controller = Controller(repository)
//底层实现抛出异常时,测试行为
let result = controller.findData(testId)
//对结果运行断言
@Assert(result == None)
}
}
创建 mock 对象
mock 构造函数可以通过调用 mock<T> 和 spy<T> 函数来创建两种对象:mock和spy,其中 T 表示被 mock 的类或接口。
public func mock<T>(): T
public func spy<T>(objectToSpyOn: T): T
mock 作为骨架对象,默认不对成员进行任何操作。 spy 作为一种特殊的 mock 对象用于封装某个类或接口的当前实例。默认情况下,spy 对象将其成员调用委托给底层对象。 其他方面,spy 和 mock 对象非常相似。
只有类(包括 final 类和 sealed 类)和接口支持 mock 。
参阅[使用 mock 和 spy 对象](#使用 spy 和 mock 对象)。
配置 API
配置 API 是框架的核心,可以定义 mock/spy 对象成员的行为(或重新定义 spy 对象)。
配置 API 的入口是 @On 宏调用。
@On(storage.getComments(testId)).returns(testComments)
示例中,如果 mock 对象 storage 接收到 getComments 方法的调用,并且指定了参数 testId ,则返回 testComment 。
如上行为即为打桩,桩(Stub, 模拟还未实现或无法在测试环境中执行的组件)需在测试用例主体内部先定义。
只有类和接口的实例成员(包括 final 成员)才能打桩。以下实体不能打桩:
- 静态成员
- 扩展成员
- 顶层函数,包括外部函数
一个完整的桩声明包含以下部分:
@On宏调用中描述的桩签名。- 用于描述桩行为的[操作](#操作 API)。
- (可选)用于设置预期的基数说明符( cardinality specifier, 指定预期执行次数的表达式)。
- (可选)续体( continuation, 支持链式调用的表达式)。
mock 框架拦截匹配桩签名的调用,并执行桩声明中指定的操作。只能拦截 spy 对象和 mock 对象的成员。
桩签名
桩签名定义了与特定调用子集匹配的一组条件,包括以下部分:
- mock/spy 对象的引用,必须是单个标识符
- 成员调用
- 特定格式的参数调用,参见参数匹配器。
签名可以匹配以下实体:
- 方法
- 属性 getter
- 属性 setter
- 字段读操作
- 字段写操作
只要 mock/spy 对象调用相应的成员,并且所有参数(若有)都与相应的参数匹配器匹配时,桩签名就会匹配调用。
方法的桩的签名结构:<mock object name>.<method name>(<argument matcher>*)。
@On(foo.method(0, 1)) // 带参数 0 和 1 的方法调用
@On(foo.method(param1: 0, param2: 1)) // 带命名参数的方法调用
当桩属性 getter/setter 或字段读/写操作时,使用 <mock object name>.<property or field name> 或 <mock object name>.<property or field name> = <argument matcher> 。
@On(foo.prop) //属性 getter
@On(foo.prop = 3) //参数为3的属性 setter
对运算符函数打桩时,运算符的接收者必须是对 mock/spy 对象的单个引用,而运算符的参数必须是参数匹配器。
@On(foo + 3) // 'operator func +',参数为3
@On(foo[0]) // 'operator func []',参数为0
参数匹配器
每个桩签名必须包含所有参数的参数匹配器。单个参数匹配器定义了一个条件,用于接受所有可能参数值的某个子集。
每个匹配器都是通过调用 Matchers 类的静态方法来定义的。
例如 Matchers.any() 是一个允许任何参数的有效匹配器。为了方便起见,提供省略 Matcher. 前缀的语法糖。
预定义的匹配器包括:
| 匹配器 | 描述 | 语法糖 |
|---|---|---|
any() | 任何参数 | _ 符号 |
eq(value: Equatable) | value 结构相等( structural equality ,对象的值相等,不一定内存相同)的参数 | 允许使用单个 identifier 和常量字面量 |
same(reference: Object) | reference 引用相等(referential equality, 对象的引用相等,内存相同)的参数 | 允许单个identifier |
ofType<T>() | 仅匹配 T 类型的值 | |
argThat(predicate: (T) -> Bool) | 仅匹配由 predicate 筛选出的 T 类型的值 | |
none() | 匹配选项类型的 None 值 |
如果使用单个标识符作为参数匹配器,则优先选择结构相等的参数。
如果方法有默认参数,并且没有显式指定该参数,则使用 any() 匹配器。
示例:
let p = mock<Printer>() //假设print采用ToString类型的单个参数
@On(p.print(_)) //可以使用“_”特殊字符代替any()
@On(p.print(eq("foo"))) //只匹配“foo”参数
@On(p.print("foo")) //常量字符串可以省略显式匹配器
let predefined = "foo" //可以传递单个标识符,而不是参数匹配器
@On(p.print(predefined)) //如果类型相等,则使用结构相等来匹配
@On(p.print(ofType<Bar>())) //仅匹配Bar类型的参数
//对于更复杂的匹配器,鼓励使用以下模式
let hasQuestionMark = { arg: String => arg.contains("?") }
@On(p.print(argThat(hasQuestionMark))) //只匹配包含问号的字符串
正确选择函数重载依赖仓颉类型推断机制。可以使用 ofType 来解决与类型推断有关的编译时问题。
重要规则:函数调用作为参数匹配器时,会视为对匹配器的调用。
@On(foo.bar(calculateArgument())) //不正确,calculateArgument()不是匹配器
let expectedArgument = calculateArgument()
@On(foo.bar(expectedArgument)) //正确,只要 'expectedArgument' 是可等价的和/或引用类型
操作 API
mock 框架提供 API 来指定桩操作。触发桩后,打桩成员会执行指定的操作。如果调用与相应的 @On 宏调用指定的签名匹配,则会触发桩。
每个桩函数必须指定一个操作。
@On 宏调用返回的 ActionSelector 子类型会定义可用操作。操作列表取决于所打桩的实体。
通用(操作)
适用于所有桩的操作。
throws(exception: Exception):抛出exception。throws(exceptionFactory: () -> Exception):调用exceptionFactory去构造桩触发时抛出的异常。fails():如果触发了桩,则测试失败。
throws用于测试桩成员抛出异常时的系统行为。fails用于测试桩成员是否未被调用。
@On(service.request()).throws(TimeoutException())
方法和属性/字段 Getter
R 表示对应成员的返回类型。
returns():不做任何操作并返回(),仅当R为Unit时可用。returns(value: R):返回value。returns(valueFactory: () -> R):调用valueFactory去构造桩触发时抛出的异常。returnsConsecutively(values: Array<R>),returnsConsecutively(values: ArrayList<R>):触发桩时,返回values中的下一个元素。
@On(foo.bar()).returns(2) //返回 0
@On(foo.bar()).returnsConsecutively(1, 2, 3) //依次返回 1,2,3
属性/字段 Setter
doesNothing():忽略调用,不做任何操作。类似于返回 Unit 的函数的returns()。 更多信息详见这里.
spy 操作
对于 spy 对象,可以使用其他操作来委托监控实例。
callsOriginal():调用原始方法。getsOriginal():调用原始属性 getter 或获取原始实例中的字段值。setsOriginal():调用原始属性 setter 或设置原始实例中的字段值。
预期
定义桩时会隐式或显式地向桩附加预期。桩可以定义期望的基数。操作( fails 和 returnsConcesecutively 除外)返回CardinalitySelector 的实例,该实例可以使用基数说明符自定义预期。
CardinalitySelector 定义了如下函数:
once()atLeastOnce()anyTimes()times(expectedTimes: Int64)times(min!: Int64, max!: Int64)atLeastTimes(minTimesExpected: Int64)
anyTimes 说明符用于提升预期,即如果桩从未被触发,测试也不会失败。其他说明符都暗示了测试代码中特定桩的调用次数上下限。只要桩被触发的次数比预期的多,测试就会立即失败。下限在测试代码执行完毕后进行检查。
示例:
// example_test.cj
@Test
func tooFewInvocations() {
let foo = mock<Foo>()
@On(foo.bar()).returns().times(2)
foo.bar()
}
输出:
Expectation failed
Too few invocations for stub foo.bar() declared at example_test.cj:9.
Required: exactly 2 times
Actual: 1
Invocations handled by this stub occured at:
example_test.cj:6
如果没有自定义预期,mock框架使用默认预期:
| 操作 | 默认期望基数 | 允许自定义基数 |
|---|---|---|
| fails | 不可调用 | 否 |
| returns | atLeastOnce | 是 |
| returnsConsecutively | times(values.size) | 否 |
| throws | atLeastOnce | 是 |
| doesNothing | atLeastOnce | 是 |
| (calls/gets/sets)Original | atLeastOnce | 是 |
桩链
returnsConsecutively 操作,once 和 times(n) 基数说明符返回一个续体实例。顾名思义,续体表示可以继续使用链,即指定某操作在前一个操作完全完成时立即执行。
续体本身只提供了一个返回新 ActionSelector 的 then() 函数。链上的所有操作都适用相同的规则。如果调用了 then() ,则必须指定新的操作。
总预期为各个链预期之和。如果在测试中指定了一个复杂的链,那么链的所有部分都会被触发。
@On(foo.bar()).returnsConsecutively(1, 2, 3, 4)
//同下
@On(foo.bar()).returnsConsecutively(1, 2).then().returnsConsecutively(3, 4)
//指定了一个桩,总共必须调用 NUM_OF_RETRIES 次
@On(service.request()).throws(TimeoutException()).times(NUM_OF_RETRIES - 1). //请求会先超时几次
then().returns(response).once() //第一个成功响应之后,停止发送请求
使用 spy 和 mock 对象
spy 对象和 mock 对象在配置上是类似的,只不过 spy 对象监控的是当前实例。
主要区别如下:成员调用没有触发任何桩时,spy 对象调用底层实例的原始实现,mock 对象抛出运行时错误(并且测试失败)。
mock 对象无需创建真正的依赖来测试 API ,只需配置特定测试场景所需的行为。
spy 对象支持重写真实实例的可观察行为。只有通过 spy 对象引用的调用才会被拦截。创建 spy 对象对原始 spy 实例的引用无影响。spy 调用自己的方法不会被拦截。
let serviceSpy = spy(service)
//模拟超时,继续使用真正的实现
@On(serviceSpy.request()).throws(TimeoutException()).once().then().callsOriginal()
//测试代码必须使用'serviceSpy'引用
mock 依赖
接口始终可以被 mock 。从另一个包 mock 一个类时,类本身和它的超类必须按特定方式编译, 即只能 mock 预编译库(如 stdlib )中的接口,不能 mock 类。
使用 cjc 编译
对于 cjc 来说,mock 是通过 --mock 标志来控制的。
如果想 mock 特定包中的类 p ,添加 --mock=on 标志到 cjc 进行调用。
在编译依赖
p的包时,也必须添加此标志。
在测试中使用mock对象( cjc--test )不需要额外的标志。
使用 cjpm 编译
cjpm 会自动检测 mock 使用,并生成正确的 cjc 调用,确保可以从任何从源代码编译的包中 mock 类。
还可以使用 cjpm 配置文件控制哪些包支持 mock 。
桩使用指南
mock/spy 对象和桩的使用方法多种多样。本文介绍了不同的模式和用例,便于用户编写 mock 框架的可维护且简洁的测试用例。
桩的工作原理
桩 通过在测试用例内部调用 @On 宏来声明,该声明在特定测试用例执行完成之前有效。多个测试用例之间可以共享桩。
mock 框架处理 mock/spy 对象成员调用时的顺序如下:
- 查找特定成员的桩。后声明的桩优先于之前声明的桩。测试用例主体内部声明的桩优先于共享桩。
- 应用每个桩的参数匹配器。如果所有参数都成功匹配,则执行该桩定义的操作。
- 如果找不到桩,或者没有与实际参数匹配的桩,则应用默认行为:对于 mock 对象,上报未打桩调用错误;对于 spy 对象,调用监控实例的原始成员。
无论是否为单个成员定义了多个桩,每个桩都有自己的预期,需要满足这些预期才能通过测试。
@On(foo.bar(1)).returns(1)
@On(foo.bar(2)).returns(2)
foo.bar(2)
//第一个桩已定义但从未使用,测试失败
重新定义桩
如果希望在测试中更改桩的行为,可以重新定义桩。
@On(service.request()).returns(testData)
//使用服务
@On(service.request()).throws(Exception())
//测试服务开始失败时会发生什么事情
同一成员定义多个桩
根据不同参数,可以使用多个桩来定义不同的行为。
示例:
@On(storage.get(_)).returns(None) // 1
@On(storage.get(TEST_ID)).returns(Some(TEST_DATA)) // 2
示例中,storage 为除 TEST_ID 之外的所有参数返回 None 。
如果从未使用 TEST_ID 参数调用 get ,则测试失败,因为桩 2 未使用。如果始终使用 TEST_ID 参数调用 get ,则测试失败,因为桩 1 未使用。这些限制确保测试代码是纯净的,让开发人员知道桩何时变为未使用。如果用例不需要此功能,则使用 anyTimes() 基数说明符来提升这些预期。
//实现经常更改,但不希望测试中断
//使用 anyTimes 提升与测试本身无关的预期
@On(storage.get(_)).returns(None).anyTimes()
@On(storage.get(TEST_ID)).returns(Some(TEST_DATA)) // 测试必须调用正在测试的内容
鉴于桩优先级是从下到上,以下用法都不正确。
@On(storage.get(TEST_ID)).returns(Some(TEST_DATA)) // 不正确,这个桩永远不会被触发
@On(storage.get(_)).returns(None) // 在上面的桩始终会被隐藏
您还可以使用预期来检查调用的参数。
let renderer = spy(Renderer())
@On(renderer.render(_)).fails()
let isVisible = { c: Component => c.isVisible }
@On(renderer.render(argThat(isVisible))).callsOriginal() // 只允许可见的组件
共享 mock 对象和桩
测试需要大量使用 mock 对象时可以多个测试用例共享 mock 对象和/或桩。 可以在任何位置创建 mock 或 spy 对象。然而,如果误将 mock 对象从一个测试用例泄漏到另一个测试用例,可能导致顺序依赖问题或测试不稳定。因此,不建议这样操作,mock 框架也会检测这类情况。 在同一测试类下的测试用例之间共享 mock 或 spy 对象时,可以将它们放在该类的实例变量中。
桩声明中隐含了预期,因此更难处理共享桩。测试用例之间不能共享预期。 只有2个位置可以声明桩:
- 测试用例主体(无论是
@Test函数还是@Test类中的@TestCase):检查预期。 - 在
@Test类中的beforeAll中:在测试用例之间共享桩。这样的桩不能声明预期,预期也不会被检查。不允许使用基数说明符。只允许returns(value)、throws(exception)、fails()、callsOriginal()等无状态操作。可以将这些桩视为具有隐式anyTimes()基数。
如果测试用例的预期相同,则可以在测试用例主体中提取和调用函数(测试类中非测试用例的成员函数)。
使用 beforeAll :
@Test
class TestFoo {
let foo = mock<Foo>()
//单元测试框架会在执行测试用例之前调用以下内容
public func beforeAll(): Unit {
//在所有测试用例之间共享默认行为
//此桩无需在每个测试用例中使用
@On(foo.bar(_)).returns("default")
}
@TestCase
func testZero() {
@On(foo.bar(0)).returns("zero") //本测试用例中需要使用此桩
foo.bar(0) //返回 "zero"
foo.bar(1) //返回 "default"
}
@TestCase
func testOne() {
@On(foo.bar(0)).returns("one")
foo.bar(0) //返回 "one"
}
}
使用函数:
@Test
class TestFoo {
let foo = mock<Foo>()
func setupDefaultStubs() {
@On(foo.bar(_)).returns("default")
}
@TestCase
func testZero() {
setupDefaultStubs()
@On(foo.bar(0)).returns("zero")
foo.bar(0) //返回"zero"
foo.bar(1) //返回"default"
}
@TestCase
func testOne() {
setupDefaultStubs()
@On(foo.bar(0)).returns("zero")
foo.bar(0) //返回"zero"
//预期失败,桩已声明但从未使用
}
}
不要在测试类构造函数中声明桩。无法保证何时调用测试类构造函数。
捕获参数
mock 框架使用 captor(ValueListener) 参数匹配器捕获参数来检查传递到桩成员的实际参数。只要触发了桩,ValueListener 就会拦截相应的参数,并检查参数和/或添加验证参数。
每次调用时,还可以使用 ValueListener.onEach 静态函数来验证某个条件。接受 lambda 后,触发桩时都会调用这个 lambda 。lambda 用于接收参数的值。
let renderer = spy(TextRenderer())
let markUpRenderer = MarkupRenderer(renderer)
// 创建验证器
let validator = ValueListener.onEach { str: String =>
@Assert(str == "must be bold")
}
// 使用 'capture' 参数匹配器绑定参数到验证器
@On(renderer.renderBold(capture(validator))).callsOriginal() // 如果从来没有调用过,则测试失败
markUpRenderer.render("text inside tag <b>must be bold</b>")
另外 ValueListener 还提供了 allValues() 和 lastValue() 函数来检查参数。模式如下:
//创建捕获器
let captor = ValueListener<String>.new()
//使用'capture'参数匹配器绑定参数到捕获器
@On(renderer.renderBold(capture(captor))).callsOriginal()
markUpRenderer.render("text inside tag <b>must be bold</b>")
let argumentValues = captor.allValues()
@Assert(argumentValues.size == 1 && argumentValues[0] == "must be bold")
argThat 匹配器是一个结合了参数过滤和捕获的重载函数。argThat(listener, filter) 接受 ValueListener 实例和 filter 谓词。listener 只收集通过 filter 检查的参数。
let filter = { arg: String => arg.contains("bold") }
let captor = ValueListener<String>.new()
// 失败,除非参数被拦截,但下面已经声明了桩
@On(renderer.renderBold(_)).fails()
// 只收集包含 "bold" 的字符串
@On(renderer.renderBold(argThat(captor, filter))).callsOriginal()
markUpRenderer.render("text inside tag <b>must be bold</b>")
// 可以使用 'captor' 对象检查所有过滤参数
@Assert(captor.lastValue() == "must be bold")
参数捕获器可以与 mock 和 spy 对象一起使用。但是,在 @Called 宏中不允许使用此类参数匹配器。
自定义和使用参数匹配器
为了避免重复使用相同的参数匹配器,可以自定义参数匹配器。
如下示例为在测试用例之间共享匹配器:
@On(foo.bar(oddNumbers())).returns("Odd")
@On(foo.bar(evenNumbers())).returns("Even")
foo.bar(0) // "Even"
foo.bar(1) // "Odd"
由于每个匹配器都只是 Matchers 类的静态函数,因此可以使用扩展来自定义参数匹配器。新参数匹配器需要调用现有的(实例)。
extend Matchers {
static func evenNumbers(): TypedMatcher<Int> {
argThat { arg: Int => arg % 2 == 0}
}
static func oddNumbers(): TypedMatcher<Int> {
argThat { arg: Int => arg % 2 == 1}
}
}
函数参数匹配器可以包含参数。
extend Matchers {
//只接受Int参数。
static func isDivisibleBy(n: Int): TypedMatcher<Int> {
argThat { arg: Int => arg % n == 0}
}
}
大多数匹配器函数都指定了返回类型 TypedMatcher<T> 。这样的匹配器只接受类型为 T 。在桩声明中使用参数匹配器调用时,类型为 T 的值应该是被打桩函数或属性 setter 的有效参数。换句话说,类型 T 应该是参数子类型或与参数实际类型相同。
设置属性和字段
字段和属性打桩的方式与方法相同,可以依相同操作来配置返回值。
setter 类似于返回 Unit 的函数。特殊操作 doesNothing() 可用于 setter。
可变属性打桩的常用模式如下:
@On(foo.prop).returns("value") //配置getter
@On(foo.prop = _).doesNothing() //忽略setter调用
极少场景下,我们期望可变属性的行为与字段的行为相同。要创建合成字段(框架生成的字段),请使用 SyntheticField.create 静态函数。合成字段存储由 mock 框架来管理。适用于 mock 含有可变属性和字段的接口或抽象类的场景。
执行 getsField 和 setsField 桩操作将字段绑定到特定的调用,这些操作可以将预期配置为任何其他操作。
interface Foo {
mut prop bar: String
}
@Test
func test() {
let foo = mock<Foo>()
let syntheticField = SyntheticField.create(initialValue: "initial")
@On(foo.bar).getsField(syntheticField) // 对属性的读取访问即为读取合成字段
@On(foo.bar = _).setsField(syntheticField) // 为属性写入新值
//此时'bar'属性表现为字段
}
如果多个测试用例之间共享
SyntheticField对象,则该字段本身的值会在每个测试用例之前重置为initialValue,避免在测试之间共享可变状态。
桩的模式
通常,当一些调用匹配不到任何桩时将抛出异常。
但是,对于某些常见情况, mock 对象可以配置增加默认行为,此时,当匹配不到任何桩时,将执行默认行为。这通过启用桩模式来实现。
有两种可用的模式 ReturnsDefaults 和 SyntheticFields 。
这些模式通过枚举类型 StubMode 表示。可以通过在创建 mock 对象时将其传递给 mock 函数来为特定的 mock 对象启用桩模式。
public func mock<T>(modes: Array<StubMode>): T
桩模式可用于在配置 mock 对象时减少代码,并且它们可以与显式桩自由组合。显式的桩始终优先于其默认行为。 请注意,使用桩模式不会对 mock 对象的成员强加任何期望。 当用例是检查是否仅调用 mock 对象的某些特定成员,则应谨慎使用桩模式。被测对象的行为可能会以不期望的方式发生变化,但测试仍可能通过。
ReturnsDefaults 模式
在此模式下,当成员的返回类型在如下表格中时,无需显式配置桩,即可调用。
let foo = mock<Foo>(ReturnsDefaults)
@Assert(foo.isPretty(), false)
此类成员返回的默认值也如如下表格所示。
| 类型 | 默认值 |
|---|---|
| Bool | false |
| numbers | 0 |
| String | empty string |
| Option | None |
| ArrayList, HashSet, Array | new empty collection |
| HashMap | new empty map |
ReturnsDefaults 模式仅对如下成员生效:
- 返回值为支持类型(如上表)的成员函数。
- 类型为支持类型(如上表)的属性读取器和字段。
SyntheticFields 模式
SyntheticFields 模式可简化对 SyntheticField 的配置动作,详见 stubbing properties and fields 章节。
SyntheticFields 将通过 mock 框架为所有属性和字段隐式创建对应类型的合成字段。但是,这些字段只能在被赋值后读取。仅对可变属性和字段生效。
let foo = mock<Foo>(SyntheticFields)
// can simply assign a value to a mutable property
foo.bar = "Hello"
@Assert(foo.bar, "Hello")
赋给属性和字段的值仅在相应的测试用例中可见。
当同时启用 SyntheticFields 和 ReturnsDefaults 时,赋的值优先于默认值。但是,只要字段或属性尚未被赋值,就可以使用默认值。
let foo = mock<Foo>(ReturnsDefaults, SyntheticFields)
@Assert(foo.bar, "")
foo.bar = "Hello"
@Assert(foo.bar, "Hello")
mock 框架验证 API
验证 API 是 mock 框架的一部分,其功能如下:
- 验证是否进行了某些调用。
- 验证特定调用的次数。
- 验证是否使用特定参数进行调用。
- 验证调用是否按特定顺序进行。
验证通过检查在执行测试期间构建的调用日志来运行断言。调用日志涵盖让 mock 和 spy 对象在测试中可访问的所有调用。只能验证在 mock/spy 对象上进行的调用。
Verify 类是验证 API 的入口。
@Called 宏用于构建关于代码的断言。
@Called 宏调用构造了一个 验证语句 ,即根据调用日志检查代码的单个断言。
Verify 类本身是静态方法的集合。诸如 that 、 ordered 、 unordered 等方法可构造验证块。
示例
let foo = mock<Foo>()
//配置foo
@On(foo.bar()).returns()
foo.bar()
Verify.that(@Called(foo.bar())) //验证bar至少被调用一次
验证语句和 @Called 宏
验证语句由 VerifyStatement 类表示。 VerifyStatement 实例由 @Called 宏创建。
@Called 宏调用接受桩签名,类似于 @On 宏,并且适用参数匹配器的规则。
示例:
@Called(foo.bar(1, _)) //匹配bar方法调用的验证语句,其中第一个参数为'1'
@Called(foo.baz) //匹配baz属性getter调用的验证语句
VerifyStatement 类提供的 API 类似于桩配置时可用的基数说明符。
基数函数为:
once()atLeastOnce()times(expectedTimes: Int64)times(min!: Int64, max!: Int64)atLeastTimes(minTimesExpected: Int64)never()
调用这些函数会返回相同的 VerifyStatement 实例。同一语句不能重置基数,且必须在语句传递到验证块生成器函数之前设置基数。如果没有显式设置基数,则使用默认基数。
Verify.that(@Called(foo.bar()).atLeastOnce())
Verify.that(@Called(foo.bar()).once())
验证块
验证块通常包含一个或多个验证语句,且检查块中的语句会构成更复杂的断言。
在调用验证块时会立即验证,不验证之后发生的任何调用。 验证块不会改变调用日志的状态:日志中的每个调用都可以被任意数量的块检查。独立检查各个块,前后块之间没有依赖关系。除非在块之间发生了一些调用,或者手动清除了调用日志,否则调用验证块的顺序并不重要。
验证语句本身不执行任何类型的验证,必须传递到验证块中进行验证。
单个验证块仅检查在块内验证语句中提到的 mock/spy 对象上的调用,忽略对其他对象的调用。
Verify 类包含几个构建验证块的静态方法。有序验证块用于检查调用的确切顺序。无序验证块只验证调用的次数。
有序
如需检查一个或多个对象的调用顺序,使用 ordered 验证块生成器。
ordered 静态函数接收一个验证语句数组。
for (i in 0..4) {
foo.bar(i % 2)
}
Verify.ordered(
@Called(foo.bar(0)),
@Called(foo.bar(1)),
@Called(foo.bar(0)),
@Called(foo.bar(1))
)
允许检查多个对象的调用顺序。
for (i in 0..4) {
if (i % 2 == 0) {
fooEven.bar(i)
}
else {
forOdd.bar(i)
}
}
Verify.ordered(
@Called(fooEven.bar(0)),
@Called(fooOdd.bar(1)),
@Called(fooEven.bar(2)),
@Called(fooOdd.bar(3)),
)
有序验证的默认基数说明符是 once() 。如有需要,可使用其他基数说明符。
for (i in 0..4) {
foo1.bar(i)
}
for (i in 0..4) {
foo2.bar(i)
}
Verify.ordered(
@Called(foo1.bar(_).times(4)),
@Called(foo2.bar(_).times(4))
)
对于有序验证,须列出对(块中提到的) mock/spy 对象的所有调用。任何未列出的调用都会导致验证失败。
foo.bar(0)
foo.bar(10)
foo.bar(1000)
Verify.ordered(
@Called(foo.bar(0)),
@Called(foo.bar(10))
)
输出:
验证失败
以下调用未匹配到任何语句:
foo.bar(...) at example_test.cj:6
无序
无序验证只检查其验证语句的调用次数。
对于无序验证,除非显式指定,否则使用 atLeastOnce() 基数,即检查至少进行了一次的调用。
for (i in 0..4) {
foo.bar(i % 2)
}
//验证是否至少调用了一次使用参数0和参数1的bar
Verify.unordered(
@Called(foo.bar(0)),
@Called(foo.bar(1))
)
//验证是否调用了两次使用参数0和参数1的bar
Verify.unordered(
@Called(foo.bar(0)).times(2),
@Called(foo.bar(1)).times(2)
)
//验证是否总共调用了四次bar
Verify.unordered(
@Called(foo.bar(_)).times(4)
)
无序验证包括 Partial 和 Exhaustive 。
默认为 Exhaustive ,需要列出验证语句所提到的 mock/spy 对象的所有调用。 Partial 只列出部分调用。
for (i in 0..4) {
foo.bar(i)
}
//失败,foo.bar()的两次调用未在块中列出
Verify.unordered(
@Called(foo.bar(0)).once(),
@Called(foo.bar(1)).once()
)
//忽略无关调用
Verify.unordered(Partial,
@Called(foo.bar(0)).once(),
@Called(foo.bar(1)).once()
)
动态构建验证块
ordered 和 unordered 函数为接受 lambda 的重载函数。可使用 checkThat(statement: VerifyStatement) 函数动态添加语句。
示例:
let totalTimes = 40
for (i in 0..totalTimes) {
foo.bar(i % 2)
}
Verify.ordered { v =>
for (j in 0..totalTimes) {
v.checkThat(@Called(foo.bar(eq(j % 2))))
}
}
其他 API
另外,Verify 类还提供了以下工具。
that(statement: VerifyStatement)为Verify.unordered(Paritial, statement)的别名,用于检查单个语句,不需要列出对应 mock/spy 对象的所有调用。noInteractions(mocks: Array<Object>)用于检查没有进行调用的 mock/spy 对象。clearInvocationLog()将日志重置为空状态。这会影响后面的所有验证块,但并不影响桩预期。
示例:
foo.bar()
Verify.that(@Called(foo.bar())) // OK
Verify.noInteractions(foo) // 失败,foo.bar() 调用在日志中
Verify.clearInvocationLog() // 清除日志
Verify.noInteractions(foo) // 从日志中清除所有与 foo 的交互
Verify.that(@Called(foo.bar())) // 失败
Verify 类 API
public static func that(statement: VerifyStatement): Unit
public static func unordered(
exhaustive: Exhaustiveness,
collectStatements: (UnorderedVerifier) -> Unit
): Unit
public static func unordered(
collectStatements: (UnorderedVerifier) -> Unit
): Unit
public static func unordered(statements: Array<VerifyStatement>): Unit
public static func unordered(
exhaustive: Exhaustiveness,
statements: Array<VerifyStatement>
): Unit
public static func ordered(
collectStatements: (OrderedVerifier) -> Unit
): Unit
public static func ordered(statements: Array<VerifyStatement>): Unit
public static func clearInvocationLog(): Unit
public static func noInteractions(mocks: Array<Object>): Unit
验证错误
验证失败时,会抛出 VerificationFailedException ,mock 框架会给出报告。不要捕获该异常。
失败类型如下:
- 调用次数太少或调用次数太多:调用次数与块中的语句不匹配。
- 语句不匹配:块中存在与日志中的调用不匹配的语句。
- 调用不匹配:日志中存在与块中的语句不匹配的调用。
- 意外调用:有序验证块需要的是其他的调用。
- 无用交互: noInteractions 检测到意外调用。
还有另一种失败类型不相交的语句,不一定是测试代码本身有问题。调用匹配到多个语句时,就会上报这种失败类型。在单个验证块中使用具有不相交参数匹配器的语句可能会导致此错误。不允许在语句和调用之间进行模糊匹配。
示例和模式
使用验证 API 的常见模式是验证测试代码(无论是函数、类还是整个包)与外部对象之间的交互。 如下所示:
- 创建 spy 对象。
- 将这些 spy 对象传递给测试代码。
- 验证代码和 spy 对象之间的交互。
验证调用数量
func testDataCaching() {
// 创建必要的spy或mock对象
let uncachedRepo = spy(Repository())
let invalidationTracker = mock<InvalidationTracker>()
@On(invalidationTracker.getTimestamp()).returns(0)
// 准备测试数据
let cachedRepo = CachedRepistory(uncachedRepo, invalidationTracker)
// 运行测试代码
for (i in 0..10) {
cachedRepo.get(TEST_ID)
}
// 验证得出只查询了一次基础repo,没有对未缓存repo的其他调用
Verify.unordered(Exhaustive,
@Called(uncachedRepo.get(TEST_ID)).once()
)
// 清除日志
Verify.clearInvocationLog()
// 设置其他行为
@On(invalidationTracker.getTimestamp()).returns(1)
for (i in 0..10) {
cachedRepo.get(TEST_ID)
}
// 自上次清除后只进行了一次调用
Verify.unordered(Exhaustive,
@Called(uncachedRepo.get(TEST_ID)).once()
)
}
验证带特定参数的调用
func testDrawingTriangle() {
// 创建必要的 spy 或 mock 对象
let canvas = spy(Canvas())
// 运行代码
canvas.draw(Triangle())
// 测试三角形由3条线和3个点组成
// 使用 'that' 块
Verify.that(
@Called(canvas.draw(ofType<Dot>())).times(3)
)
Verify.that(
@Called(canvas.draw(ofType<Line>())).times(3)
)
//或者使用部分无序验证块
Verify.unordered(Partial, // 未知线条和点实际绘制的顺序
@Called(canvas.draw(ofType<Dot>())).times(3),
@Called(canvas.draw(ofType<Line>())).times(3)
)
// 使用枚举块时,必须枚举出所有调用
Verify.unordered(Exhaustive,
@Called(canvas.draw(ofType<Triangle>())).once(),
@Called(canvas.draw(ofType<Dot>())).times(3),
@Called(canvas.draw(ofType<Line>())).times(3)
)
// 验证用例从未调用入参为 Square 类型的 draw 函数
Verify.that(
@Called(canvas.draw(ofType<Square>)).never()
)
// 如果想通过更复杂的条件来区分参数
// 可以使用下面的模式
let isDot = { f: Figure =>
f is Dot //此为更复杂的逻辑
}
Verify.that(
@Called(canvas.draw(argThat(isDot))).times(3)
)
// 注意,属于同一个块的语句必须明确只匹配了一个调用
// 以下为反例,有些调用匹配了两个语句
Verify.unordered(
@Called(canvas.draw(_)).times(7),
@Called(canvas.draw(ofType<Dot>())).times(3)
)
}
验证调用顺序
func testBuildFlight() {
let plane = spy(Plane())
FlightBuilder(plane).planFlight(Shenzhen, Shanghai, Beijing).execute()
Verify.ordered(
@Called(plane.takeOffAt(Shenzhen)),
@Called(plane.landAt(Shanghai)),
@Called(plane.takeOffAt(Shanghai)),
@Called(plane.landAt(Beijing))
)
}
预期与验证 API
配置桩时,可以设置预期和验证API覆盖测试代码的一些断言。这种情况别无他法,只能选择更能反映测试意图的方法。
一般情况下,建议避免重复验证块中的配置步骤。
let foo = mock<Foo>()
@On(foo.bar(_)).returns() //如果从未使用此桩,测试失败
foo.bar(1)
foo.bar(2)
Verify.that(
//不需要,自动验证
@Called(foo.bar(_)).atLeastOnce()
)
//但可以检查调用的数量和具体的参数
Verify.unordered(
@Called(foo.bar(1)).once(),
@Called(foo.bar(2)).once()
)
上面的示例可以使用预期重写:
let foo = mock<Foo>()
@On(foo.bar(1)).returns().once() //预期只被调用一次,参数为`1`
@On(foo.bar(2)).returns().once() //预期只被调用一次,参数为`2`
foo.bar(1)
foo.bar(2)
//如果没有桩被触发,则测试失败
unittest.mock 包
主要接口
构造对象
func mock
public func mock<T>(): T
创建类型 T 的 mock object, 这个对象默认情况下,所有的成员函数、属性或运算符重载函数没有任何具体实现。
可以通过 @On 指定这个对象的成员函数、属性或运算符重载函数的行为。
返回值:类型 T 的 mock object
enum StubMode
public enum StubMode {
| ReturnsDefaults
| SyntheticFields
}
功能:为 mock object 指定额外的默认行为,显示的桩行为优先级高于此默认行为。
ReturnsDefaults
ReturnsDefaults
mock object 的返回支持类型的成员,指定其默认返回空或者 false 等值。
SyntheticFields
SyntheticFields
mock object 将会简化合成字段的赋值流程。
func mock
public func mock<T>(modes: Array<StubMode>): T
创建类型 T 的 mock object 并指定其桩模式。
可以通过 @On 指定这个对象的成员函数、属性或运算符重载函数的行为。未通过 @On 指定的函数将应用对应桩模式下的行为。
参数:
- modes:
mock对象的桩模式
返回值:类型 T 的 mock object
func spy
public func spy<T>(objectToSpyOn: T): T
创建类型 T 的 spy object ( mock object 的扩展,对象的成员拥有默认实现的“骨架”对象)。 这个对象包装了所传入的对象,并且默认情况下成员函数、属性或运算符重载函数实现为对这个传入的实例对象的对应成员函数、属性或运算符重载函数的调用。
可以通过 @On 重载这个对象的成员函数、属性或运算符重载函数的行为。
返回值:类型 T 的 spy object 。
行为定义
interface ActionSelector
public interface ActionSelector<R> {
func returns(value: R): CardinalitySelector<R>
func returns(valueFactory: () -> R): CardinalitySelector<R>
func returnsConsecutively(values: Array<R>): Continuation<R>
func returnsConsecutively(values: ArrayList<R>): Continuation<R>
func throws(exception: Exception): CardinalitySelector<R>
func throws(exceptionFactory: () -> Exception): CardinalitySelector<R>
func fails(): Unit
func callsOriginal(): CardinalitySelector<R>
}
此接口提供了为成员函数指定一个行为的 API ,并允许链式调用。
入参为 mock object 或 spy object 的某个成员函数的调用表达式的 @On 宏调用表达式,将返回 ActionSelector<R> 的实例(其中 R 代表正在配置的函数成员的返回值类型)。
即,此接口中的 API 可为成员函数插入桩代码。
另,为方便起见,后文将 @On 表达式的入参中的成员函数调用表达式称为“桩表达式”。
func returns
func returns(value: R): CardinalitySelector<R>
功能:定义“桩表达式”返回指定值的行为。
参数:
- values: 预期“桩表达式”的返回值
返回值:定义了“桩表达式”返回行为的 CardinalitySelector
func returns
func returns(valueFactory: () -> R): CardinalitySelector<R>
功能:定义“桩表达式”返回指定的值的行为,该值由传入的闭包生成。
参数:
- values: 生成预期返回值的闭包函数(生成器)
返回值:定义了“桩表达式”返回指定值的行为的 CardinalitySelector
func returnsConsecutively
func returnsConsecutively(values: Array<R>): Continuation<R>
功能:定义“桩表达式”按列表顺序返回指定的值的行为。“桩表达式”将被调用多次,次数与数组内值的个数相同。
参数:
- values: “桩表达式”的返回值列表
返回值:定义了“桩表达式”按序返回指定值的行为的 Continuation
异常:
- IllegalArgumentException 当参数列表为空时,抛出异常
func returnsConsecutively
func returnsConsecutively(values: ArrayList<R>): Continuation<R>
功能:定义“桩表达式”按列表顺序返回指定的值的行为。“桩表达式”将被连续调用多次,次数与数组列表内值的个数相同。
参数:
- values: “桩表达式”的返回值列表
返回值:定义了“桩表达式”按序返回指定值的 Continuation
异常:
- IllegalArgumentException 当参数列表为空时,抛出异常
func throws
func throws(exception: Exception): CardinalitySelector<R>
功能:定义“桩表达式”抛出异常的行为。
参数:
- exception: 预期“桩表达式”抛出的异常对象
返回值:定义了“桩表达式”抛出异常的行为的 CardinalitySelector
func throws
func throws(exceptionFactory: () -> Exception): CardinalitySelector<R>
功能:定义“桩表达式”抛出异常的行为,异常由参数闭包函数生成。
参数:
- exceptionFactory: 构造预期“桩表达式”抛出的异常对象的闭包函数(生成器)
返回值:定义了“桩表达式”抛出异常行为的 CardinalitySelector
func fails
func fails(): Unit
功能:定义“桩表达式”抛出 AssertionException 异常的行为。
func callsOriginal(): CardinalitySelector
func callsOriginal(): CardinalitySelector<R>
功能:定义“桩表达式”执行原始代码逻辑的行为。
返回值:定义了“桩表达式”执行原始代码逻辑的 CardinalitySelector
interface CardinalitySelector
public interface CardinalitySelector<R> {
func anyTimes(): Unit
func once(): Continuation<R>
func atLeastOnce(): Unit
func times(expectedTimes: Int64): Continuation<R>
func times(min!: Int64, max!: Int64): Unit
func atLeastTimes(minTimesExpected: Int64): Unit
}
此接口提供了可定义“桩表达式”的最近一次行为的执行次数的 API 。
该实例仅可被 ActionSelector<R> 的 API 生成(其中 R 代表“桩表达式”的返回类型)。例如:@On(foo.bar()).returns("Predefined value").atLeastOnce() 。
为方便表达,后文将“桩表达式”的最近一次行为称为“桩行为”。
此接口提供的 API 提供的验证能力如下:
- “桩表达式”的调用次数超过指定次数将立即抛出 ExpectationFailedException
- “桩表达式”的调用次数不足时,框架将在测试用例执行完成后抛出 ExceptionFailedException
func anyTimes
func anyTimes(): Unit
功能:定义“桩行为”可以执行任意次数。此函数对“桩表达式”的调用次数不做任何校验。
func once
func once(): Continuation<R>
功能:定义“桩行为”仅被执行一次。此函数将在验证“桩表达式”执行次数超出一次时,抛出异常。
返回值:定义了验证“桩行为”仅被执行一次的行为的 Continuation
异常:
- ExpectationFailedException: 验证“桩行为”执行次数超过一次时,立即抛出异常
func atLeastOnce
func atLeastOnce(): Unit
功能:定义“桩行为”最少被执行一次。验证不到一次时,抛出异常。
异常:
- ExpectationFailedException: 验证“桩行为”执行次数不到一次时,抛出异常
func times
func times(expectedTimes: Int64): Continuation<R>
功能:定义“桩行为”被执行指定次数。验证不是指定次数时,抛出异常。
参数:
- expectedTimes :预期“桩行为”被执行的次数
返回值:定义了验证“桩行为”被执行指定次数的行为的 Continuation
异常:
- ExpectationFailedException: 验证“桩行为”执行次数不是指定次数时,抛出异常
func times
func times(min!: Int64, max!: Int64): Unit
功能:定义“桩行为”执行指定次数范围。验证超出指定次数范围时,抛出异常。
参数:
- min :预期“桩行为”被执行的最小次数
- max :预期“桩行为”被执行的最大次数
异常:
- ExpectationFailedException: 验证“桩行为”执行次数不是指定次数范围时,抛出异常
func atLeastTimes
func atLeastTimes(minTimesExpected: Int64): Unit
功能:定义“桩行为”最少被执行指定次数的行为。验证实际执行次数低于最少指定次数时,抛出异常。
参数:
- minTimesExpected :预期“桩行为”最少被执行的次数
异常:
- ExpectationFailedException: 验证“桩行为”执行少于指定次数时,抛出异常
interface ContinuationSelector
public interface Continuation<R> {
func then(): ActionSelector<R>
}
此接口提供了可继续定义“桩表达式”的行为的 API 。
该实例可由ActionSelector<R> 或 CardinalitySelector<R> 的 API 调用后生成。
此接口提供的接口能力如下:
- 允许当先前的操作得到满足时,“桩表达式”将执行额外的操作。仅当后面跟着一个行为定义时,
Continuation实例才有意义。 - 当先前的操作未得到满足时,将抛出 MockFrameworkException 异常。并不保证抛出此异常的确切位置。
func then
func then(): ActionSelector<R>
功能: 当链中的先前操作完成时,返回 ActionSelector
返回值:ActionSelector
异常 MockFrameworkException:当先前的操作未得到满足时,将抛出异常。
参数匹配器
class Matchers
public class Matchers {
public static func argThat<T>(predicate: (T) -> Bool): TypedMatcher<T>
public static func argThatNot<T>(predicate: (T) -> Bool): TypedMatcher<T>
public static func same<T>(target: T): TypedMatcher<T> where T <: Object
public static func eq<T>(target: T): TypedMatcher<T> where T <: Equatable<T>
public static func ofType<T>(): TypedMatcher<T>
public static func any(): AnyMatcher
public static func default<T>(target: T): TypedMatcher<T>
}
该类提供生成匹配器的静态函数。匹配器对象仅可通过此处的静态函数生成。匹配器可在 Stubs 链中使用。
例如:@On(foo.bar(ofType<Int64>())).returns(1)
func argThat
public static func argThat<T>(predicate: (T) -> Bool): TypedMatcher<T>
功能:根据提供的过滤器闭包过滤输入值。
参数:
- predicate : 过滤器
返回值:参数过滤类型匹配器实例
func argThatNot
public static func argThatNot<T>(predicate: (T) -> Bool): TypedMatcher<T>
功能:根据提供的过滤器闭包,满足 'predicate(value) == false' 时过滤输入值。
参数:
- predicate : 过滤器
返回值:参数过滤类型匹配器实例
func same
public static func same<T>(target: T): TypedMatcher<T> where T <: Object
功能:根据与所提供对象的引用相等性来过滤输入值。
参数:
- target : 匹配对象
返回值:仅允许与给定对象引用相等的参数的参数匹配器
func eq
public static func eq<T>(target: T): TypedMatcher<T> where T <: Equatable<T>
功能:根据与提供的值的结构相等性过滤输入值。
参数:
- target : 匹配对象
返回值:仅允许结构上等于给定值的参数匹配器
func ofType
public static func ofType<T>(): TypedMatcher<T>
功能:根据类型过滤输入值。
参数:
- target : 匹配对象
返回值:仅允许特定类型的类型匹配器
func any()
public static func any(): AnyMatcher
功能:允许将任何值作为参数。
返回值:允许任意值的参数匹配器
func default
public static func default<T>(target: T): TypedMatcher<T>
功能:根据结构(更高优先级)或引用相等性来匹配值。如果传入的参数既不是 Equatable<T> 也不是引用类型,则会在运行时抛出异常(编译期不做检查)。
参数:
- target : 必须通过结构或引用相等来匹配的匹配对象
返回值:默认类型匹配器
异常:
- MockFrameworkException : 如果参数 target 既不是
Equatable<T>类型也不是引用类型,则抛出异常
macro On
public macro On(tokens: Tokens): Tokens
@On 宏调用表达式创建了“桩表达式”的“桩行为”定义的表达式链的头。
@On 的参数即为“桩表达式”,由 mock object 或 spy object 的引用表达式、其成员函数的调用表达式,以及参数匹配器(用于描述该“桩表达式”接受哪些参数,仅可为对 Matchers 类的静态函数的调用表达式)组成。
参数:
- input :符合
@On语法规则定义的Tokens
返回值:被框架处理后的 Tokens
异常:
- MockFrameworkException : 当“桩行为”执行出错时,将抛出异常
行为验证
class Verify
public class Verify {
public static func that(statement: VerifyStatement): Unit
public static func unordered(exhaustive: Exhaustiveness, collectStatements: (UnorderedVerifier) -> Unit): Unit
public static func unordered(collectStatements: (UnorderedVerifier) -> Unit): Unit
public static func unordered(statements: Array<VerifyStatement>): Unit
public static func unordered(exhaustive: Exhaustiveness, statements: Array<VerifyStatement>): Unit
public static func ordered(collectStatements: (OrderedVerifier) -> Unit): Unit
public static func ordered(statements: Array<VerifyStatement>): Unit
public static func clearInvocationLog(): Unit
public static func noInteractions(mocks: Array<Object>): Unit
}
Verify 提供了一系列静态方法来支持定义所需验证的动作,如 that 、 ordered 以及 unorder 。
一个验证动作可以包含多个由 @Called 生成的“动作语句”,来描述需要验证的动作。
通常验证的范围为所在测试用例的函数体,但 Verify 提供了 clearInvocationLog 函数来清除此前的执行记录,以缩小验证范围。
func that
public static func that(statement: VerifyStatement): Unit
验证是否正确执行了传入的单个“动作语句”。
参数:
- statement :所需验证的“动作语句”
异常:
- VerificationFailedException :验证不通过时,将抛出异常
func unordered
public static func unordered(statements: Array<VerifyStatement>): Unit
此函数支持验证“动作语句”是否被执行或执行的次数是否符合定义,并且不校验执行顺序。默认情况下,“动作语句”的执行次数为至少一次。
传入列表中的“动作语句”必须是不相交的(即当单个调用行为,可以匹配多个“动作语句”时,将抛出异常)。
验证模式为 exhaustive (全量匹配,验证范围内的所有执行情况都应在验证动作中被指定)
举例来说:
let foo = mock<Foo>()
for (i in 0..4) {
foo.bar(i % 2)
}
// 验证 bar() 在传入参数为 0 或 1 的情况下均至少执行一次
Verify.unordered(
@Called(foo.bar(0)),
@Called(foo.bar(1))
)
// 此处的验证动作将抛出异常,因为 `foo.bar(_)` 包含了 `foo.bar(1)`
Verify.unordered(
@Called(foo.bar(_)).times(2),
@Called(foo.bar(1)).times(2)
)
// 可以通过如下方式进行验证
// 验证入参为 1 的调用表达式执行了2次
Verify.that(@Called(foo.bar(1)).times(2))
// 验证任意入参的调用表达式执行了2次
Verify.that(@Called(foo.bar(_)).times(2)) // called four times in total
参数:
- statements :待验证的多条“动作语句”,变长参数语法支持参数省略
[]
异常:
- VerificationFailedException :验证不通过时,抛出异常
func unordered
public static func unordered(exhaustive: Exhaustiveness, statements: Array<VerifyStatement>): Unit
此函数支持验证“动作语句”是否被执行或执行的次数是否符合定义,并且不校验执行顺序。默认情况下,“动作语句”的执行次数为至少一次。 传入列表中的“动作语句”必须是不相交的(即当单个调用行为,可以匹配多个“动作语句”时,将抛出异常)。
参数:
- statements :待验证的多条“动作语句”,变长参数语法支持参数省略
[] - exhaustive :验证模式,详见《 enum Exhaustiveness 》章节
异常:
- VerificationFailedException :验证不通过时,抛出异常
func unordered
public static func unordered(collectStatements: (UnorderedVerifier) -> Unit): Unit
此函数支持验证“动作语句”是否被执行或执行的次数是否符合定义,并且不校验执行顺序。默认情况下,“动作语句”的执行次数为至少一次。
传入列表中的“动作语句”必须是不相交的(即当单个调用行为,可以匹配多个“动作语句”时,将抛出异常)。
验证模式为 exhaustive (全量匹配,验证范围内的所有执行情况都应在验证动作中被指定)
“动作语句”通过入参中的闭包动态增加。举例来说:
let totalTimes = getTimes()
for (i in 0..totalTimes) {
foo.bar(i % 2)
}
// 通过闭包使得“动作语句”可以通过 totalTimes 的值确定内容
Verify.unordered { v =>
for (j in 0..totalTimes) {
v.checkThat(@Called(foo.bar(eq(j % 2))))
}
}
参数:
- collectStatements :支持可动态增加“动作语句”的闭包
异常:
- VerificationFailedException :验证不通过时,抛出异常
func unordered
public static func unordered(exhaustive: Exhaustiveness, collectStatements: (UnorderedVerifier) -> Unit): Unit
此函数支持验证“动作语句”是否被执行或执行的次数是否符合定义,并且不校验执行顺序。默认情况下,“动作语句”的执行次数为至少一次。 传入列表中的“动作语句”必须是不相交的(即当单个调用行为,可以匹配多个“动作语句”时,将抛出异常)。 “动作语句”通过入参中的闭包动态增加。
参数:
- collectStatements :支持可动态增加“动作语句”的闭包
- exhaustive :验证模式,详见《 enum Exhaustiveness 》章节
异常:
- VerificationFailedException :验证不通过时,抛出异常
func ordered
public static func ordered(statements: Array<VerifyStatement>): Unit
此函数支持验证“动作语句”是否被执行或执行的次数是否符合定义,并且校验执行顺序。默认情况下,“动作语句”的执行次数为一次。
传入列表中的“动作语句”必须是不相交的(即当单个调用行为,可以匹配多个“动作语句”时,将抛出异常)。
验证模式为 exhaustive (全量匹配,验证范围内的所有执行情况都应在验证动作中被指定)
举例来说:
for (i in 0..4) {
foo.bar(i % 2)
}
Verify.ordered(
@Called(foo.bar(0)),
@Called(foo.bar(1)),
@Called(foo.bar(0)),
@Called(foo.bar(1)),
)
// 将抛出异常,验证范围内有 4 次 foo.bar() 表达式的执行动作,此处只验证了2次执行。
Verify.ordered(
@Called(foo.bar(0)),
@Called(foo.bar(_)),
)
func ordered
public static func ordered( collectStatements: (OrderedVerifier) -> Unit): Unit
此函数支持验证“动作语句”是否被执行或执行的次数是否符合定义,并且校验执行顺序。默认情况下,“动作语句”的执行次数为一次。
传入列表中的“动作语句”必须是不相交的(即当单个调用行为,可以匹配多个“动作语句”时,将抛出异常)。
“动作语句”通过入参中的闭包动态增加。
验证模式为 exhaustive (全量匹配,验证范围内的所有执行情况都应在验证动作中被指定)
参数:
- collectStatements :支持可动态增加“动作语句”的闭包
异常:
- VerificationFailedException :验证不通过时,抛出异常
func noInteractions
public static func noInteractions(mocks: Array<Object>): Unit
在验证范围内,对象没有任何执行动作时,验证通过。
参数:
- mocks :被验证的对象列表
异常
- VerificationFailedException :验证不通过时,抛出异常
func clearInvocationLog
public static func clearInvocationLog(): Unit
清除前序的执行记录,以缩小验证范围。
enum Exhaustiveness
public enum Exhaustiveness {
Exhaustive | Partial
}
此枚举类型用于指定 unordered 函数的验证模式,包含两种模式。
Exhaustive 模式要求对于验证范围内的所有“桩表达式”,均需在验证动作中定义。
Partial 模式的要求较松,可以忽略“桩表达式”在验证范围内未被验证动作定义的执行行为。
举例来说:
for (i in 0..6) {
foo.bar(i % 3)
}
// 此处验证动作将抛出异常,因为 foo.bar()在验证范围内一共执行了 6 次,而此处的验证动作仅指定了 4 次执行行为。
Verify.unordered(
@Called(foo.bar(1)).times(2),
@Called(foo.bar(2)).times(2)
)
// 此处验证动作可以成功,指定了 Partial 模式后,2 次未在验证动作中定义的执行行为将被忽略。
Verify.unordered(Partial,
@Called(foo.bar(1)).times(2),
@Called(foo.bar(2)).times(2)
)
Exhaustive
要求在验证范围内的每一次“桩表达式”的调用均需在验证动作中被定义。
Partial
允许验证范围内存在未在验证动作中被定义的“桩表达式”的调用行为。
class UnorderedVerifier
public class UnorderedVerifier{
public func checkThat(statement: VerifyStatement):UnorderedVerifier
}
此类型用于收集 “动作语句”, 可在 unordered 函数中动态传入验证行为。
func checkThat
public func checkThat(statement: VerifyStatement):UnorderedVerifier
添加一条 “动作语句”。
参数:
- statement:待被添加的“动作语句”
返回值:
- UnorderedVerifier : 返回对象自身
class OrderedVerifier
public class OrderedVerifier {
public func checkThat(statement: VerifyStatement): OrderedVerifier
}
此类型用于收集 “动作语句”, 可在 ordered 函数中动态传入验证行为。
func checkThat
public func checkThat(statement: VerifyStatement): OrderedVerifier
添加一条 “动作语句”。
参数:
- statement:待被添加的“动作语句”
返回值:
- OrderedVerifier : 返回对象自身
class VerifyStatement
public class VerifyStatement {
public func once(): VerifyStatement
public func atLeastOnce(): VerifyStatement
public func times(expectedTimes: Int64): VerifyStatement
public func times(min!: Int64, max!: Int64): VerifyStatement
public func atLeastTimes(minTimesExpected: Int64): VerifyStatement
public func never(): VerifyStatement
}
此类型表示对“桩表达式”在验证范围内的单个验证动作语句(即上文中的“动作语句”),提供了成员函数指定“桩表达式”的执行次数。
该类型的对象仅可通过 @Called 宏调用表达式创建。
对一个对象连续调用多个成员函数没有意义,并且会抛出异常。即,执行次数仅可被指定一次。
当未调用成员函数指定执行次数时,将基于语句所在的验证动作类型定义默认的执行次数验证值。例如在 Verify.ordered() 中的“动作语句”默认为验证执行一次。
func once
public func once(): VerifyStatement
指定此“动作语句”验证在验证范围内“桩表达式”仅被执行一次
返回值:
- VerifyStatement :返回对象自身
异常:
- MockFrameworkException : 当对象已被指定过执行次数或已被传入过“验证动作”中时,将抛出异常
func atLeastOnce
public func atLeastOnce(): VerifyStatement
指定此“动作语句”验证在验证范围内“桩表达式”最少被执行一次
返回值:
- VerifyStatement :返回对象自身
异常:
- MockFrameworkException : 当对象已被指定过执行次数或已被传入过“验证动作”中时,将抛出异常
func times
public func times(expectedTimes: Int64): VerifyStatement
指定此“动作语句”验证在验证范围内“桩表达式”被执行指定次数。
参数:
- expectedTimes :预期验证的执行次数
返回值:
- VerifyStatement :返回对象自身
异常:
- MockFrameworkException : 当对象已被指定过执行次数或已被传入过“验证动作”中时,将抛出异常
func times
public func times(min!: Int64, max!: Int64): VerifyStatement
指定此“动作语句”验证在验证范围内“桩表达式”的执行次数在指定范围内。
参数:
- min :预期验证的最小执行次数
- max :预期验证的最大执行次数
返回值:
- VerifyStatement :返回对象自身
异常:
- MockFrameworkException : 当对象已被指定过执行次数或已被传入过“验证动作”中时,将抛出异常
func atLeastTimes
public func atLeastTimes(minTimesExpected: Int64): VerifyStatement
指定此“动作语句”验证在验证范围内“桩表达式”最少执行指定的次数。
参数:
- minTimesExpected :预期验证的执行最少次数
返回值:
- VerifyStatement :返回对象自身
异常:
- MockFrameworkException : 当对象已被指定过执行次数或已被传入过“验证动作”中时,将抛出异常
func never
public func never(): VerifyStatement
指定此“动作语句”验证在验证范围内“桩表达式”不会被执行
返回值:
- VerifyStatement :返回对象自身
异常:
- MockFrameworkException : 当对象已被传入过“验证动作”中时,将抛出异常
macro Called
public macro Called(tokens: Tokens): Tokens
创建一个“动作语句”对象。宏调用表达式的入参的语法要求和 @On 相同。详见《 macro On 》章节。
值监听器与参数捕获器
interface ValueListener
public interface ValueListener<T> {
func lastValue(): Option<T>
func allValues(): Array<T>
func addCallback(callback: (T) -> Unit): Unit
static func new(): ValueListener<T>
static func onEach(callback: (T) -> Unit): ValueListener<T>
}
此接口提供了多个成员函数以支持“监听”传入给“桩表达式”的参数,即对每次调用中传入“桩表达式”的参数进行指定的操作( addCallback() 或 onEach 中的闭包函数即为对参数进行的操作内容)。
一般与参数匹配器生成函数 argThat 或者 capture 配合使用。
func lastValue
func lastValue(): Option<T>
返回当前“值监听器”对象所处理的最后一个值。
返回值:
- Option
:返回“值监听器”对象所处理的最后一个值,不存在时,返回 None
func allValues
func allValues(): Array<T>
返回当前“值监听器”对象已所处理的所有值。
返回值:
- Array
:返回“值监听器”对象所处理的所有值列表
func addCallback
func addCallback(callback: (T) -> Unit): Unit
为当前“值监听器”对象增加闭包函数,该函数将处理传入的参数值。
参数:
- callback :处理参数值的闭包函数
func new
static func new(): ValueListener<T>
创建一个新的“值监听器”对象,不包含任何处理参数的闭包方法。
返回值:
- ValueListener
:“值监听器”对象
func onEach
static func onEach(callback: (T) -> Unit): ValueListener<T>
创建一个新的“值监听器”对象,带有一个处理参数的闭包方法。
返回值:
- ValueListener
:“值监听器”对象
参数:
- callback :处理参数值的闭包函数
class Matchers
public class Matchers {
public static func argThat<T>(listener: ValueListener<T>, predicate: (T) -> Bool): TypedMatcher<T>
public static func capture<T>(listener: ValueListener<T>): TypedMatcher<T>
}
此处增加列举 Matcher 类两个可传入“值监听器”的静态函数,可用于生成带有值监听器的参数匹配器,其他函数说明详见 《行为定义》章节中《参数匹配器》章节里的《 class Matchers 》章节。
func argThat
public static func argThat<T>(listener: ValueListener<T>, predicate: (T) -> Bool): TypedMatcher<T>
通过传入的 predicate 闭包函数过滤传入的参数值,允许 listener 值监听器对满足条件的传入参数值进行处理。
参数:
- listener :值监听器
- predicate :过滤器,可通过此函数定义过滤参数值的匹配条件
返回值:
- TypedMatcher
:拥有值监听器和过滤器的类型匹配器
func capture
public static func capture<T>(listener: ValueListener<T>): TypedMatcher<T>
允许 listener 值监听器对类型为 T 的传入参数值进行处理。当 capture 的类型参数未指定时,将使用值监听器的类型参数值。
参数:
- listener :值监听器
返回值:
- TypedMatcher
:拥有值监听器的类型匹配器
注意:值监听器不允许在 @Called 的参数范围内使用。
附录
API list
在框架中,部分 API 由于整体实现结构要求,属性为对外可见,但用户不应直接使用如下 API 。因此此处仅列举 API 列表,而不详细说明对应 API 使用方式。
package unittest.mock
public abstract class ArgumentMatcher {
public func withDescription(description: String): ArgumentMatcher
public func forParameter(name: String): ArgumentMatcher
public func matchesAny(arg: Any): Bool
}
public abstract class TypedMatcher<T> <: ArgumentMatcher {
public func matches(arg: T): Bool
public override func matchesAny(arg: Any): Bool
public override func matches(arg: T): Bool
public prop valueListener: Option<ListenerInternal>
}
public class AnyMatcher <: ArgumentMatcher {
public func matchesAny(_: Any)
}
extend TypedMatcher<T> {
public func value(): T
}
extend AnyMatcher {
public func value<T>(): T
}
public class ConfigureMock {
public static func stub<T, R>
}
public abstract class PrettyException <: Exception & PrettyPrintable {
public func pprint(to: PrettyPrinter): PrettyPrinter
}
public class MockFrameworkInternalError <: PrettyException
public class MockFrameworkException <: PrettyException
public open class ExpectationFailedException <: PrettyException
public class UnnecessaryStubbingException <: PrettyException
public class UnstubbedInvocationException <: PrettyException
public class UnhandledCallException <: PrettyException
public class VerificationFailedException <: PrettyException
public class MockFramework {
public static func openSession(name!: String): Unit
public static func openSession(): Unit
public static func closeSession(verifyExpectations!: Bool = true): Unit
public func onCall(call: Call): OnCall
}
@Intrinsic
public unsafe func createMock<T>(handler: CallHandler): T
@Intrinsic
public unsafe func createSpy<T>(handler: CallHandler, objectToSpyOn: T): T
public interface CallHandler {
func onCall(call: Call): OnCall
}
public enum OnCall {
ReturnZero | Return(Any) | Throw(Exception) | CallBase | ReturnDefault
}
public struct Call {
public Call(
public let funcInfo: FuncInfo,
public let receiver: Object,
public let args: Array<Any>
) {}
}
public struct FuncInfo {
public FuncInfo(
public let id: DeclId,
public let params: Array<ParameterInfo>,
public let hasImplementation: Bool,
public let location: (String, Int64, Int64),
public let outerDeclId: DeclId
) {}
}
public struct ParameterInfo {
public ParameterInfo(
public let name: String,
public let position: Int64,
public let isNamed: Bool,
public let hasDefaultValue: Bool
) {}
}
public struct DeclId <: Equatable<DeclId> & Hashable {
public DeclId(
public let mangledName: String,
public let shortName: String
)
public operator func ==(that: DeclId): Bool
public operator func !=(that: DeclId): Bool
public func hashCode(): Int64
}
public class NoneMatcher <: ArgumentMatcher {
public override func matchesAny(arg: Any): Bool
}
extend Matchers {
public static func none(): NoneMatcher
}
extend NoneMatcher {
public func value<T>(): Option<T>
}
public class VerifyStatement {
public static func fromStub<T, R> (
stubCall: () -> R,
matchers: Array<ArgumentMatcher>,
objectReference: T,
objectName: String,
declarationName: String,
callDescription: String,
lineNumber: Int64
): VerifyStatement // users should not use this API directly
}
public enum MockSessionKind {
| Forbidden
| Stateless
| Verifiable
}
public sealed class ActionSelector {
public func fails(): Unit
}
public sealed class MethodActionSelector<TRet> <: ActionSelector {
public func throws(exception: Exception): CardinalitySelector<MethodActionSelector<TRet>>
public func throws(exceptionFactory: () -> Exception): CardinalitySelector<MethodActionSelector<TRet>>
public func returns(value: TRet): CardinalitySelector<MethodActionSelector<TRet>>
public func returns(valueFactory: () -> TRet): CardinalitySelector<MethodActionSelector<TRet>>
public func returnsConsecutively(values: Array<TRet>): Continuation<MethodActionSelector<TRet>>
public func returnsConsecutively(values: ArrayList<TRet>): Continuation<MethodActionSelector<TRet>>
public func callsOriginal(): CardinalitySelector<MethodActionSelector<TRet>>
}
public sealed class GetterActionSelector<TRet> <: ActionSelector {
public func throws(exception: Exception): CardinalitySelector<GetterActionSelector<TRet>>
public func throws(exceptionFactory: () -> Exception): CardinalitySelector<GetterActionSelector<TRet>>
public func returns(value: TRet): CardinalitySelector<GetterActionSelector<TRet>>
public func returns(valueFactory: () -> TRet): CardinalitySelector<GetterActionSelector<TRet>>
public func returnsConsecutively(values: Array<TRet>): Continuation<GetterActionSelector<TRet>>
public func returnsConsecutively(values: ArrayList<TRet>): Continuation<GetterActionSelector<TRet>>
public func getsOriginal(): CardinalitySelector<GetterActionSelector<TRet>>
public func getsField(field: SyntheticField<TRet>): CardinalitySelector<GetterActionSelector<TRet>>
}
public sealed class SetterActionSelector<TArg> <: ActionSelector {
public func throws(exception: Exception): CardinalitySelector<SetterActionSelector<TArg>>
public func throws(exceptionFactory: () -> Exception): CardinalitySelector<SetterActionSelector<TArg>>
public func doesNothing(): CardinalitySelector<SetterActionSelector<TArg>>
public func setsOriginal(): CardinalitySelector<SetterActionSelector<TArg>>
public func setsField(field: SyntheticField<TArg>): CardinalitySelector<SetterActionSelector<TArg>>
public func returns(): CardinalitySelector<MethodActionSelector<TRet>>
}
public interface ValueListener<T> {
public override func supplyValue(value: Any)
}
public class ConfigureMock {
public static func stubMethod<TObj, TRet>(
stubCall: () -> TRet,
matchers: Array<ArgumentMatcher>,
objectReference: TObj,
objectName: String,
methodName: String,
callDescription: String,
lineNumber: Int64
): MethodActionSelector<TRet>
public static func stubGetter<TObj, TRet>(
stubCall: () -> TRet,
objectReference: TObj,
objectName: String,
fieldOrPropertyName: String,
callDescription: String,
lineNumber: Int64
): GetterActionSelector<TRet>
public static func stubSetter<TObj, TArg>(
stubCall: () -> Unit,
_: () -> TArg, // capturing type of property/field
matcher: ArgumentMatcher,
objectReference: TObj,
objectName: String,
fieldOrPropertyName: String,
callDescription: String,
lineNumber: Int64
): SetterActionSelector<TArg>
}
public class SyntheticField<T> {
SyntheticField(let description: SyntheticFieldDescription)
public static func create(initialValue!: T): SyntheticField<T>
@OverflowWrapping
public func hashCode(): Int64
public operator func ==(that: AutoFieldId): Bool
public operator func !=(that: AutoFieldId): Bool
}
public class CardinalitySelector<A> where A <: ActionSelector{
public func anyTimes(): Unit
public func once(): Continuation<A>
public func atLeastOnce(): Unit
public func times(expectedTimes: Int64): Continuation<A>
public func times(min!: Int64, max!: Int64): Unit
public func atLeastTimes(minTimesExpected: Int64): Unit
}
public class Continuation<A> where A <: ActionSelector {
public func then(): A
}
public enum DeclKind {
| Method(/*name:*/ String)
| FieldGetter(/*fieldName: */String, /*hasSetter: */Bool)
| FieldSetter(/*fieldName:*/ String)
| PropertyGetter(/*propertyName:*/String, /*hasSetter:*/ Bool)
| PropertySetter(/*propertyName:*/ String)
}
public interface HasDefaultValueForStub<T> {
static func defaultValueForStub(): T
}
extend Unit <: HasDefaultValueForStub<Unit>
extend Int8 <: HasDefaultValueForStub<Int8>
extend Int16 <: HasDefaultValueForStub<Int16>
extend Int32 <: HasDefaultValueForStub<Int32>
extend Int64 <: HasDefaultValueForStub<Int64>
extend Float16 <: HasDefaultValueForStub<Float16>
extend Float32 <: HasDefaultValueForStub<Float32>
extend Float64 <: HasDefaultValueForStub<Float64>
extend Bool <: HasDefaultValueForStub<Bool>
extend String <: HasDefaultValueForStub<String>
extend Option<T> <: HasDefaultValueForStub<Option<T>>
extend Array<T> <: HasDefaultValueForStub<Array<T>>
extend ArrayList<T> <: HasDefaultValueForStub<ArrayList<T>>
extend HashSet<T> <: HasDefaultValueForStub<HashSet<T>>
extend HashMap<K, V> <: HasDefaultValueForStub<HashMap<K, V>>
public class IllegalMockCallException <: Exception
public class NoDefaultValueForMockException <: Exception
public class MockReturnValueTypeMismatchException <: Exception
zlib 包
介绍
提供流式压缩和解压功能,支持从输入流读取数据,将其压缩或解压,并写入字节数组,或从字节数组中读取数据,将其压缩或解压,并写入输出流。
压缩和解压使用自研 deflate 算法,压缩和解压数据格式支持 gzip 格式和 deflate raw 格式。
压缩时可指定压缩等级,支持默认快速、默认、高压缩率三个等级,压缩速度依次下降,压缩率依次提升。
主要接口
enum WrapType
public enum WrapType {
| DeflateFormat
| GzipFormat
}
该枚举类用于表示压缩数据格式,目前支持 DeflateFormat 和 GzipFormat两种格式。
DeflateFormat
DeflateFormat
功能:构造一个表示 Deflate 压缩数据格式的枚举实例。
GzipFormat
GzipFormat
功能:构造一个表示 Gzip 压缩数据格式的枚举实例。
enum CompressLevel
public enum CompressLevel {
| BestSpeed
| DefaultCompression
| BestCompression
}
该枚举类用于表示压缩等级,压缩等级决定了压缩率和压缩速度,目前支持三种压缩等级,压缩率由小到大,压缩速度由快到慢依次为:BestSpeed、DefaultCompression、 BestCompression。
BestSpeed
BestSpeed
功能:构造一个压缩等级枚举实例,表示压缩速度最快,压缩率相对较低。
DefaultCompression
DefaultCompression
功能:构造一个压缩等级枚举实例,表示默认压缩等级。
BestCompression
BestCompression
功能:构造一个压缩等级枚举实例,表示压缩率最高,压缩速度相对降低。
class CompressInputStream
public class CompressInputStream <: InputStream {
public init(inputStream: InputStream, wrap!: WrapType = DeflateFormat, compressLevel!: CompressLevel = DefaultCompression, bufLen!: Int64 = 512)
}
该类实现了一个压缩输入流。可将其绑定到指定的 InputStream 类型输入流,读取、压缩其中的数据,并将压缩后数据输出到指定字节数组。
init
public init(inputStream: InputStream, wrap!: WrapType = DeflateFormat, compressLevel!: CompressLevel = DefaultCompression, bufLen!: Int64 = 512)
功能:构造一个压缩输入流。需绑定一个输入流,可设置压缩数据格式、压缩等级、内部缓冲区大小(每次从输入流中读取多少数据进行压缩)。
参数:
inputStream:待压缩的输入流wrap:压缩数据格式,默认值为DeflateFormatcompressLevel:压缩等级,默认值为DefaultCompressionbufLen:输入流缓冲区的大小,默认 512 字节
异常:
ZlibException:如果bufLen小于等于 0,输入流分配内存失败,或压缩资源初始化失败,抛出异常
func read
public func read(outBuf: Array<Byte>): Int64
功能:从绑定的输入流中读取数据并压缩,压缩后数据放入指定的字节数组中。
参数:
outBuf:用来存放压缩后数据的缓冲区
返回值:如果压缩成功,返回压缩后字节数,如果绑定的输入流中数据已经全部压缩完成,或者该压缩输入流被关闭,返回 0
异常:
ZlibException:当outBuf为空,或压缩数据失败,抛出异常
func close
public func close(): Unit
功能:关闭压缩输入流。当前 CompressInputStream 实例使用完毕后必须调用此接口来释放其所占内存资源,以免造成内存泄漏。调用该函数前需确保 read 函数已返回 0,否则可能导致绑定的 InputStream 并未被全部压缩。
异常:
ZlibException:如果释放压缩资源失败,抛出异常
class CompressOutputStream
public class CompressOutputStream <: OutputStream {
public init(outputStream: OutputStream, wrap!: WrapType = DeflateFormat, compressLevel!: CompressLevel = DefaultCompression, bufLen!: Int64 = 512)
}
该类实现了一个压缩输出流。可将其绑定到指定的 OutputStream 类型输出流,读取、压缩指定字节数组中的数据,并将压缩后数据输出到绑定的输出流。
init
public init(outputStream: OutputStream, wrap!: WrapType = DeflateFormat, compressLevel!: CompressLevel = DefaultCompression, bufLen!: Int64 = 512)
功能:构造一个压缩输出流,需绑定一个输出流,可设置压缩数据类型、压缩等级、内部缓冲区大小(每得到多少压缩后数据往输出流写一次)
参数:
outputStream:绑定的输出流,压缩后数据将写入该输出流wrap:压缩数据格式,默认值为DeflateFormatcompressLevel:压缩等级,默认值为DefaultCompressionbufLen:输出流缓冲区的大小,默认 512 字节
异常:
ZlibException:如果bufLen小于等于 0,输出流分配内存失败,或压缩资源初始化失败,抛出异常
func write
public func write(inBuf: Array<Byte>): Unit
功能:将指定字节数组中的数据进行压缩,并写入输出流,当数据全部压缩完成并写入输出流,函数返回。
参数:
inBuf:待压缩的字节数组
异常:
ZlibException:如果当前压缩输出流已经被关闭,或压缩数据失败,抛出异常
func flush
public func flush(): Unit
功能:刷新压缩输出流。将内部缓冲区里已压缩的数据刷出并写入绑定的输出流,然后刷新绑定的输出流。
异常:
ZlibException:如果当前压缩输出流已经被关闭,抛出异常
func close
public func close(): Unit
功能:关闭当前压缩输出流实例。写入剩余压缩数据(包括缓冲区中数据,以及压缩尾部信息),并释放其所占内存资源。当前压缩输出流使用完毕后必须调用此接口来释放其所占内存资源,以免造成内存泄漏。在调用 close 函数前,绑定的输出流里已写入的数据并不是一段完整的压缩数据,调用 close 函数后,才会把剩余压缩数据写入绑定的输出流,使其完整。
异常:
ZlibException:如果当前压缩输出流已经被关闭,或释放压缩资源失败,抛出异常
class DecompressInputStream
public class DecompressInputStream <: InputStream {
public init(inputStream: InputStream, wrap!: WrapType = DeflateFormat, bufLen!: Int64 = 512)
}
该类实现了一个解压输入流。可将其绑定到指定的 InputStream 类型输入流,读取、解压其中的数据,并将解压后数据输出到指定字节数组。
init
public init(inputStream: InputStream, wrap!: WrapType = DeflateFormat, bufLen!: Int64 = 512)
功能:构造一个解压输入流。需绑定一个输入流,可设置待解压数据格式、内部缓冲区大小(每次从输入流中读取多少数据进行解压)。
参数:
inputStream:待压缩的输入流wrap:待解压数据格式,默认值为DeflateFormatbufLen:输入流缓冲区的大小,默认 512 字节
异常:
ZlibException:如果bufLen小于等于 0,输入流分配内存失败,或待解压资源初始化失败,抛出异常
func read
public func read(outBuf: Array<Byte>): Int64
功能:从绑定的输入流中读取数据并解压,解压后数据放入指定的字节数组中。
参数:
outBuf:用来存放解压后数据的缓冲区
返回值:如果解压成功,返回解压后字节数,如果绑定的输入流中数据已经全部解压完成,或者该解压输入流被关闭,返回 0
异常:
ZlibException:当outBuf为空,或解压数据失败,抛出异常
func close
public func close(): Unit
功能:关闭解压输入流。当前 DecompressInputStream 实例使用完毕后必须调用此接口来释放其所占内存资源,以免造成内存泄漏。调用该函数前需确保 read 函数已返回 0,否则可能导致绑定的 InputStream 并未被全部解压。
异常:
ZlibException,如果释放解压资源失败,抛出异常
class DecompressOutputStream
public class DecompressOutputStream <: OutputStream {
public init(outputStream: OutputStream, wrap!: WrapType = DeflateFormat, bufLen!: Int64 = 512)
}
该类实现了一个解压输出流。可将其绑定到指定的 OutputStream 类型输出流,读取、解压指定字节数组中的数据,并将解压后数据输出到绑定的输出流。
init
public init(outputStream: OutputStream, wrap!: WrapType = DeflateFormat, bufLen!: Int64 = 512)
功能:构造一个解压输出流,需绑定一个输出流,可设置压缩数据类型、压缩等级、内部缓冲区大小(解压后数据会存入内部缓冲区,缓冲区存满后再写到输出流)。
参数:
outputStream:绑定的输出流,解压后数据将写入该输出流wrap:待解压数据格式,默认值为DeflateFormatbufLen:输出流缓冲区的大小,默认 512 字节
异常:
ZlibException:如果bufLen小于等于 0,输出流分配内存失败,或解压资源初始化失败,抛出异常
func write
public func write(inBuf: Array<Byte>): Unit
功能:将指定字节数组中的数据进行解压,并写入输出流,当数据全部解压完成并写入输出流,函数返回。
参数:
inBuf:待解压的字节数组
异常:
ZlibException:如果当前解压输出流已经被关闭,或解压数据失败,抛出异常
func flush
public func flush(): Unit
功能:刷新解压输出流。将内部缓冲区里已解压的数据刷出并写入绑定的输出流,然后刷新绑定的输出流。
异常:
ZlibException:如果当前解压输出流已经被关闭,抛出异常
func close
public func close(): Unit
功能:关闭当前解压输出流实例。写入剩余解压后数据,并释放其所占内存资源。当前压缩输出流使用完毕后必须调用此接口来释放其所占内存资源,以免造成内存泄漏。如果之前 write 函数已处理的压缩数据不完整,调用 close 函数时会因为解压数据不全而抛出异常。
异常:
ZlibException:如果当前压缩输出流已经被关闭,通过write函数传入的待解压数据不完整,或释放压缩资源失败,抛出异常
class ZlibException
public class ZlibException <: Exception {
public init(message: String)
}
zlib 包的异常类。
init
public init(message: String)
功能:创建 ZlibException 实例。
参数:
message:异常提示信息
示例
Gzip 格式数据的压缩和解压
from compress import zlib.*
from std import fs.*
main() {
var arr: Array<Byte> = Array<Byte>(1024 * 1024, {i => UInt8(i % 256)})
File.writeTo("./zlib.txt", arr, openOption: Create(false))
if (compressFile("./zlib.txt", "./zlib_copmressed.zlib") <= 0) {
println("Failed to compress file!")
}
if (decompressFile("./zlib_copmressed.zlib", "./zlib_decopmressed.txt") != arr.size) {
println("Failed to decompress file!")
}
if (compareFile("./zlib.txt", "./zlib_decopmressed.txt")) {
println("success")
} else {
println("failed")
}
File.delete("./zlib.txt")
File.delete("./zlib_copmressed.zlib")
File.delete("./zlib_decopmressed.txt")
return 0
}
func compressFile(srcFileName: String, destFileName: String): Int64 {
var count: Int64 = 0
var srcFile: File = File(srcFileName, OpenOption.Open(true, false))
var destFile: File = File(destFileName, OpenOption.Create(false))
var tempBuf: Array<UInt8> = Array<UInt8>(1024, item: 0)
var compressOutputStream: CompressOutputStream = CompressOutputStream(destFile, wrap: GzipFormat, bufLen: 10000)
while (true) {
var readNum = srcFile.read(tempBuf)
if (readNum > 0) {
compressOutputStream.write(tempBuf.slice(0, readNum).toArray())
count += readNum
} else {
break
}
}
compressOutputStream.flush()
compressOutputStream.close()
srcFile.close()
destFile.close()
return count
}
func decompressFile(srcFileName: String, destFileName: String): Int64 {
var count: Int64 = 0
var srcFile: File = File(srcFileName, OpenOption.Open(true, false))
var destFile: File = File(destFileName, OpenOption.Create(false))
var tempBuf: Array<UInt8> = Array<UInt8>(1024, item: 0)
var decompressInputStream: DecompressInputStream = DecompressInputStream(srcFile, wrap: GzipFormat, bufLen: 10000)
while (true) {
var readNum = decompressInputStream.read(tempBuf)
if (readNum <= 0) {
break
}
destFile.write(tempBuf.slice(0, readNum).toArray())
count += readNum
}
decompressInputStream.close()
srcFile.close()
destFile.close()
return count
}
func compareFile(fileName1: String, fileName2: String): Bool {
return File.readFrom(fileName1) == File.readFrom(fileName2)
}
运行结果:
success
Deflate 格式数据的压缩和解压
from compress import zlib.*
from std import fs.*
main() {
var arr: Array<Byte> = Array<Byte>(1024 * 1024, {i => UInt8(i % 256)})
File.writeTo("./zlib1.txt", arr, openOption: Create(false))
if (compressFile("./zlib1.txt", "./zlib_copmressed1.zlib") <= 0) {
println("Failed to compress file!")
}
if (decompressFile("./zlib_copmressed1.zlib", "./zlib_decopmressed1.txt") != arr.size) {
println("Failed to decompress file!")
}
if (compareFile("./zlib1.txt", "./zlib_decopmressed1.txt")) {
println("success")
} else {
println("failed")
}
File.delete("./zlib1.txt")
File.delete("./zlib_copmressed1.zlib")
File.delete("./zlib_decopmressed1.txt")
return 0
}
func compressFile(srcFileName: String, destFileName: String): Int64 {
var count: Int64 = 0
var srcFile: File = File(srcFileName, OpenOption.Open(true, false))
var destFile: File = File(destFileName, OpenOption.Create(false))
var tempBuf: Array<UInt8> = Array<UInt8>(1024, item: 0)
var compressOutputStream: CompressOutputStream = CompressOutputStream(destFile, wrap: DeflateFormat)
while (true) {
var readNum = srcFile.read(tempBuf)
if (readNum > 0) {
compressOutputStream.write(tempBuf.slice(0, readNum).toArray())
count += readNum
} else {
break
}
}
compressOutputStream.flush()
compressOutputStream.close()
srcFile.close()
destFile.close()
return count
}
func decompressFile(srcFileName: String, destFileName: String): Int64 {
var count: Int64 = 0
var srcFile: File = File(srcFileName, OpenOption.Open(true, false))
var destFile: File = File(destFileName, OpenOption.Create(false))
var tempBuf: Array<UInt8> = Array<UInt8>(1024, item: 0)
var decompressInputStream: DecompressInputStream = DecompressInputStream(srcFile, wrap: DeflateFormat)
while (true) {
var readNum = decompressInputStream.read(tempBuf)
if (readNum <= 0) {
break
}
destFile.write(tempBuf.slice(0, readNum).toArray())
count += readNum
}
decompressInputStream.close()
srcFile.close()
destFile.close()
return count
}
func compareFile(fileName1: String, fileName2: String): Bool {
return File.readFrom(fileName1) == File.readFrom(fileName2)
}
运行结果
success
zlib 包
介绍
提供流式压缩和解压功能,支持从输入流读取数据,将其压缩或解压,并写入字节数组,或从字节数组中读取数据,将其压缩或解压,并写入输出流。
压缩和解压使用自研 deflate 算法,压缩和解压数据格式支持 gzip 格式和 deflate raw 格式。
压缩时可指定压缩等级,支持默认快速、默认、高压缩率三个等级,压缩速度依次下降,压缩率依次提升。
主要接口
enum WrapType
public enum WrapType {
| DeflateFormat
| GzipFormat
}
该枚举类用于表示压缩数据格式,目前支持 DeflateFormat 和 GzipFormat两种格式。
DeflateFormat
DeflateFormat
功能:构造一个表示 Deflate 压缩数据格式的枚举实例。
GzipFormat
GzipFormat
功能:构造一个表示 Gzip 压缩数据格式的枚举实例。
enum CompressLevel
public enum CompressLevel {
| BestSpeed
| DefaultCompression
| BestCompression
}
该枚举类用于表示压缩等级,压缩等级决定了压缩率和压缩速度,目前支持三种压缩等级,压缩率由小到大,压缩速度由快到慢依次为:BestSpeed、DefaultCompression、 BestCompression。
BestSpeed
BestSpeed
功能:构造一个压缩等级枚举实例,表示压缩速度最快,压缩率相对较低。
DefaultCompression
DefaultCompression
功能:构造一个压缩等级枚举实例,表示默认压缩等级。
BestCompression
BestCompression
功能:构造一个压缩等级枚举实例,表示压缩率最高,压缩速度相对降低。
class CompressInputStream
public class CompressInputStream <: InputStream {
public init(inputStream: InputStream, wrap!: WrapType = DeflateFormat, compressLevel!: CompressLevel = DefaultCompression, bufLen!: Int64 = 512)
}
该类实现了一个压缩输入流。可将其绑定到指定的 InputStream 类型输入流,读取、压缩其中的数据,并将压缩后数据输出到指定字节数组。
init
public init(inputStream: InputStream, wrap!: WrapType = DeflateFormat, compressLevel!: CompressLevel = DefaultCompression, bufLen!: Int64 = 512)
功能:构造一个压缩输入流。需绑定一个输入流,可设置压缩数据格式、压缩等级、内部缓冲区大小(每次从输入流中读取多少数据进行压缩)。
参数:
inputStream:待压缩的输入流wrap:压缩数据格式,默认值为DeflateFormatcompressLevel:压缩等级,默认值为DefaultCompressionbufLen:输入流缓冲区的大小,默认 512 字节
异常:
ZlibException:如果bufLen小于等于 0,输入流分配内存失败,或压缩资源初始化失败,抛出异常
func read
public func read(outBuf: Array<Byte>): Int64
功能:从绑定的输入流中读取数据并压缩,压缩后数据放入指定的字节数组中。
参数:
outBuf:用来存放压缩后数据的缓冲区
返回值:如果压缩成功,返回压缩后字节数,如果绑定的输入流中数据已经全部压缩完成,或者该压缩输入流被关闭,返回 0
异常:
ZlibException:当outBuf为空,或压缩数据失败,抛出异常
func close
public func close(): Unit
功能:关闭压缩输入流。当前 CompressInputStream 实例使用完毕后必须调用此接口来释放其所占内存资源,以免造成内存泄漏。调用该函数前需确保 read 函数已返回 0,否则可能导致绑定的 InputStream 并未被全部压缩。
异常:
ZlibException:如果释放压缩资源失败,抛出异常
class CompressOutputStream
public class CompressOutputStream <: OutputStream {
public init(outputStream: OutputStream, wrap!: WrapType = DeflateFormat, compressLevel!: CompressLevel = DefaultCompression, bufLen!: Int64 = 512)
}
该类实现了一个压缩输出流。可将其绑定到指定的 OutputStream 类型输出流,读取、压缩指定字节数组中的数据,并将压缩后数据输出到绑定的输出流。
init
public init(outputStream: OutputStream, wrap!: WrapType = DeflateFormat, compressLevel!: CompressLevel = DefaultCompression, bufLen!: Int64 = 512)
功能:构造一个压缩输出流,需绑定一个输出流,可设置压缩数据类型、压缩等级、内部缓冲区大小(每得到多少压缩后数据往输出流写一次)
参数:
outputStream:绑定的输出流,压缩后数据将写入该输出流wrap:压缩数据格式,默认值为DeflateFormatcompressLevel:压缩等级,默认值为DefaultCompressionbufLen:输出流缓冲区的大小,默认 512 字节
异常:
ZlibException:如果bufLen小于等于 0,输出流分配内存失败,或压缩资源初始化失败,抛出异常
func write
public func write(inBuf: Array<Byte>): Unit
功能:将指定字节数组中的数据进行压缩,并写入输出流,当数据全部压缩完成并写入输出流,函数返回。
参数:
inBuf:待压缩的字节数组
异常:
ZlibException:如果当前压缩输出流已经被关闭,或压缩数据失败,抛出异常
func flush
public func flush(): Unit
功能:刷新压缩输出流。将内部缓冲区里已压缩的数据刷出并写入绑定的输出流,然后刷新绑定的输出流。
异常:
ZlibException:如果当前压缩输出流已经被关闭,抛出异常
func close
public func close(): Unit
功能:关闭当前压缩输出流实例。写入剩余压缩数据(包括缓冲区中数据,以及压缩尾部信息),并释放其所占内存资源。当前压缩输出流使用完毕后必须调用此接口来释放其所占内存资源,以免造成内存泄漏。在调用 close 函数前,绑定的输出流里已写入的数据并不是一段完整的压缩数据,调用 close 函数后,才会把剩余压缩数据写入绑定的输出流,使其完整。
异常:
ZlibException:如果当前压缩输出流已经被关闭,或释放压缩资源失败,抛出异常
class DecompressInputStream
public class DecompressInputStream <: InputStream {
public init(inputStream: InputStream, wrap!: WrapType = DeflateFormat, bufLen!: Int64 = 512)
}
该类实现了一个解压输入流。可将其绑定到指定的 InputStream 类型输入流,读取、解压其中的数据,并将解压后数据输出到指定字节数组。
init
public init(inputStream: InputStream, wrap!: WrapType = DeflateFormat, bufLen!: Int64 = 512)
功能:构造一个解压输入流。需绑定一个输入流,可设置待解压数据格式、内部缓冲区大小(每次从输入流中读取多少数据进行解压)。
参数:
inputStream:待压缩的输入流wrap:待解压数据格式,默认值为DeflateFormatbufLen:输入流缓冲区的大小,默认 512 字节
异常:
ZlibException:如果bufLen小于等于 0,输入流分配内存失败,或待解压资源初始化失败,抛出异常
func read
public func read(outBuf: Array<Byte>): Int64
功能:从绑定的输入流中读取数据并解压,解压后数据放入指定的字节数组中。
参数:
outBuf:用来存放解压后数据的缓冲区
返回值:如果解压成功,返回解压后字节数,如果绑定的输入流中数据已经全部解压完成,或者该解压输入流被关闭,返回 0
异常:
ZlibException:当outBuf为空,或解压数据失败,抛出异常
func close
public func close(): Unit
功能:关闭解压输入流。当前 DecompressInputStream 实例使用完毕后必须调用此接口来释放其所占内存资源,以免造成内存泄漏。调用该函数前需确保 read 函数已返回 0,否则可能导致绑定的 InputStream 并未被全部解压。
异常:
ZlibException,如果释放解压资源失败,抛出异常
class DecompressOutputStream
public class DecompressOutputStream <: OutputStream {
public init(outputStream: OutputStream, wrap!: WrapType = DeflateFormat, bufLen!: Int64 = 512)
}
该类实现了一个解压输出流。可将其绑定到指定的 OutputStream 类型输出流,读取、解压指定字节数组中的数据,并将解压后数据输出到绑定的输出流。
init
public init(outputStream: OutputStream, wrap!: WrapType = DeflateFormat, bufLen!: Int64 = 512)
功能:构造一个解压输出流,需绑定一个输出流,可设置压缩数据类型、压缩等级、内部缓冲区大小(解压后数据会存入内部缓冲区,缓冲区存满后再写到输出流)。
参数:
outputStream:绑定的输出流,解压后数据将写入该输出流wrap:待解压数据格式,默认值为DeflateFormatbufLen:输出流缓冲区的大小,默认 512 字节
异常:
ZlibException:如果bufLen小于等于 0,输出流分配内存失败,或解压资源初始化失败,抛出异常
func write
public func write(inBuf: Array<Byte>): Unit
功能:将指定字节数组中的数据进行解压,并写入输出流,当数据全部解压完成并写入输出流,函数返回。
参数:
inBuf:待解压的字节数组
异常:
ZlibException:如果当前解压输出流已经被关闭,或解压数据失败,抛出异常
func flush
public func flush(): Unit
功能:刷新解压输出流。将内部缓冲区里已解压的数据刷出并写入绑定的输出流,然后刷新绑定的输出流。
异常:
ZlibException:如果当前解压输出流已经被关闭,抛出异常
func close
public func close(): Unit
功能:关闭当前解压输出流实例。写入剩余解压后数据,并释放其所占内存资源。当前压缩输出流使用完毕后必须调用此接口来释放其所占内存资源,以免造成内存泄漏。如果之前 write 函数已处理的压缩数据不完整,调用 close 函数时会因为解压数据不全而抛出异常。
异常:
ZlibException:如果当前压缩输出流已经被关闭,通过write函数传入的待解压数据不完整,或释放压缩资源失败,抛出异常
class ZlibException
public class ZlibException <: Exception {
public init(message: String)
}
zlib 包的异常类。
init
public init(message: String)
功能:创建 ZlibException 实例。
参数:
message:异常提示信息
示例
Gzip 格式数据的压缩和解压
from compress import zlib.*
from std import fs.*
main() {
var arr: Array<Byte> = Array<Byte>(1024 * 1024, {i => UInt8(i % 256)})
File.writeTo("./zlib.txt", arr, openOption: Create(false))
if (compressFile("./zlib.txt", "./zlib_copmressed.zlib") <= 0) {
println("Failed to compress file!")
}
if (decompressFile("./zlib_copmressed.zlib", "./zlib_decopmressed.txt") != arr.size) {
println("Failed to decompress file!")
}
if (compareFile("./zlib.txt", "./zlib_decopmressed.txt")) {
println("success")
} else {
println("failed")
}
File.delete("./zlib.txt")
File.delete("./zlib_copmressed.zlib")
File.delete("./zlib_decopmressed.txt")
return 0
}
func compressFile(srcFileName: String, destFileName: String): Int64 {
var count: Int64 = 0
var srcFile: File = File(srcFileName, OpenOption.Open(true, false))
var destFile: File = File(destFileName, OpenOption.Create(false))
var tempBuf: Array<UInt8> = Array<UInt8>(1024, item: 0)
var compressOutputStream: CompressOutputStream = CompressOutputStream(destFile, wrap: GzipFormat, bufLen: 10000)
while (true) {
var readNum = srcFile.read(tempBuf)
if (readNum > 0) {
compressOutputStream.write(tempBuf.slice(0, readNum).toArray())
count += readNum
} else {
break
}
}
compressOutputStream.flush()
compressOutputStream.close()
srcFile.close()
destFile.close()
return count
}
func decompressFile(srcFileName: String, destFileName: String): Int64 {
var count: Int64 = 0
var srcFile: File = File(srcFileName, OpenOption.Open(true, false))
var destFile: File = File(destFileName, OpenOption.Create(false))
var tempBuf: Array<UInt8> = Array<UInt8>(1024, item: 0)
var decompressInputStream: DecompressInputStream = DecompressInputStream(srcFile, wrap: GzipFormat, bufLen: 10000)
while (true) {
var readNum = decompressInputStream.read(tempBuf)
if (readNum <= 0) {
break
}
destFile.write(tempBuf.slice(0, readNum).toArray())
count += readNum
}
decompressInputStream.close()
srcFile.close()
destFile.close()
return count
}
func compareFile(fileName1: String, fileName2: String): Bool {
return File.readFrom(fileName1) == File.readFrom(fileName2)
}
运行结果:
success
Deflate 格式数据的压缩和解压
from compress import zlib.*
from std import fs.*
main() {
var arr: Array<Byte> = Array<Byte>(1024 * 1024, {i => UInt8(i % 256)})
File.writeTo("./zlib1.txt", arr, openOption: Create(false))
if (compressFile("./zlib1.txt", "./zlib_copmressed1.zlib") <= 0) {
println("Failed to compress file!")
}
if (decompressFile("./zlib_copmressed1.zlib", "./zlib_decopmressed1.txt") != arr.size) {
println("Failed to decompress file!")
}
if (compareFile("./zlib1.txt", "./zlib_decopmressed1.txt")) {
println("success")
} else {
println("failed")
}
File.delete("./zlib1.txt")
File.delete("./zlib_copmressed1.zlib")
File.delete("./zlib_decopmressed1.txt")
return 0
}
func compressFile(srcFileName: String, destFileName: String): Int64 {
var count: Int64 = 0
var srcFile: File = File(srcFileName, OpenOption.Open(true, false))
var destFile: File = File(destFileName, OpenOption.Create(false))
var tempBuf: Array<UInt8> = Array<UInt8>(1024, item: 0)
var compressOutputStream: CompressOutputStream = CompressOutputStream(destFile, wrap: DeflateFormat)
while (true) {
var readNum = srcFile.read(tempBuf)
if (readNum > 0) {
compressOutputStream.write(tempBuf.slice(0, readNum).toArray())
count += readNum
} else {
break
}
}
compressOutputStream.flush()
compressOutputStream.close()
srcFile.close()
destFile.close()
return count
}
func decompressFile(srcFileName: String, destFileName: String): Int64 {
var count: Int64 = 0
var srcFile: File = File(srcFileName, OpenOption.Open(true, false))
var destFile: File = File(destFileName, OpenOption.Create(false))
var tempBuf: Array<UInt8> = Array<UInt8>(1024, item: 0)
var decompressInputStream: DecompressInputStream = DecompressInputStream(srcFile, wrap: DeflateFormat)
while (true) {
var readNum = decompressInputStream.read(tempBuf)
if (readNum <= 0) {
break
}
destFile.write(tempBuf.slice(0, readNum).toArray())
count += readNum
}
decompressInputStream.close()
srcFile.close()
destFile.close()
return count
}
func compareFile(fileName1: String, fileName2: String): Bool {
return File.readFrom(fileName1) == File.readFrom(fileName2)
}
运行结果
success
crypto 包
介绍
crypto 包提供生成安全随机数功能。
使用本包需要外部依赖 OpenSSL 3 的 crypto 动态库文件,故使用前需安装相关工具:
- 对于
Linux操作系统,可参考以下方式:- 如果系统的包管理工具支持安装
OpenSSL 3开发工具包,可通过这个方式安装,并确保系统安装目录下含有libcrypto.so和libcrypto.so.3这两个动态库文件,例如Ubuntu 22.04系统上可使用sudo apt install libssl-dev命令安装libssl-dev工具包; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.so和libcrypto.so.3这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
LD_LIBRARY_PATH以及LIBRARY_PATH中。
- 如果系统的包管理工具支持安装
- 对于
Windows操作系统,可按照以下步骤:- 自行下载
OpenSSL 3.x.x源码编译安装 x64 架构软件包或者自行下载安装第三方预编译的供开发人员使用的OpenSSL 3.x.x软件包; - 确保安装目录下含有
libcrypto.dll.a(或libcrypto.lib)、libcrypto-3-x64.dll这两个库文件; - 将
libcrypto.dll.a(或libcrypto.lib) 所在的目录路径设置到环境变量LIBRARY_PATH中,将libcrypto-3-x64.dll所在的目录路径设置到环境变量PATH中。
- 自行下载
- 对于
macOS操作系统,可参考以下方式:- 使用
brew install openssl@3安装,并确保系统安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
DYLD_LIBRARY_PATH以及LIBRARY_PATH中。
- 使用
如果未安装OpenSSL 3软件包或者安装低版本的软件包,程序可能无法使用并抛出相关异常 SecureRandomException:Can not load openssl library or function xxx.。
主要接口
class SecureRandomException
public class SecureRandomException <: Exception {
public init()
public init(message: String)
}
crypto 包的异常类。
init
public init()
功能:创建默认的 SecureRandomException 实例,异常提示消息为空。
init
public init(message: String)
功能:根据异常提示消息创建 SecureRandomException 实例。
参数:
- message:异常提示字符串
class SecureRandom
public class SecureRandom {
public init(priv!: Bool = false)
}
该类用于生成加密安全的伪随机数。
和 std.random.Random 相比,主要有三个方面不同:
- 随机数种子:
Random使用系统时钟作为默认的种子,时间戳一样,结果就相同,SecureRandom使用操作系统或者硬件提供的随机数种子,生成的几乎是真随机数。 - 随机数生成:
Random使用了梅森旋转伪随机生成器,SecureRandom则使用了 openssl 库提供的 MD5 等随机算法,使用熵源生成真随机数。如果硬件支持,还可以使用硬件随机数生成器来生成安全性更强的随机数。 - 安全性:
Random不能用于加密安全的应用或者隐私数据的保护。
init
public init(priv!: Bool = false)
功能:创建 SecureRandom 实例,可指定是否使用更加安全的加密安全伪随机生成器,加密安全伪随机生成器可用于会话密钥和证书私钥等加密场景。
参数:
- priv:为 true 表示使用加密安全伪随机生成器
func nextBytes
public func nextBytes(length: Int32): Array<Byte>
功能:获取一个指定长度的随机字节的数组。
参数:
- length:要生成的随机字节数组的长度
返回值:一个随机字节数组
异常:
- 异常 IllegalArgumentException:当参数 length 小于等于 0,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextBool
public func nextBool(): Bool
功能:获取一个随机的 Bool 类型实例。
返回值:一个随机的 Bool 类型实例
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt8
public func nextUInt8(): UInt8
功能:获取一个 UInt8 类型的随机数。
返回值:一个 UInt8 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt16
public func nextUInt16(): UInt16
功能:获取一个 UInt16 类型的随机数。
返回值:一个 UInt16 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt32
public func nextUInt32(): UInt32
功能:获取一个 UInt32 类型的随机数。
返回值:一个 UInt32 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt64
public func nextUInt64(): UInt64
功能:获取一个 UInt64 类型的随机数。
返回值:一个 UInt64 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt8
public func nextInt8(): Int8
功能:获取一个 Int8 类型的随机数。
返回值:一个 Int8 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt16
public func nextInt16(): Int16
功能:获取一个 Int16 类型的随机数。
返回值:一个 Int16 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt32
public func nextInt32(): Int32
功能:获取一个 Int32 类型的随机数。
返回值:一个 Int32 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt64
public func nextInt64(): Int64
功能:获取一个 Int64 类型的随机数。
返回值:一个 Int64 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt8
public func nextUInt8(max: UInt8): UInt8
功能:获取一个 UInt8 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 UInt8 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为 0 时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt16
public func nextUInt16(max: UInt16): UInt16
功能:获取一个 UInt16 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 UInt16 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为 0 时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt32
public func nextUInt32(max: UInt32): UInt32
功能:获取一个 UInt32 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 UInt32 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为 0 时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt64
public func nextUInt64(max: UInt64): UInt64
功能:获取一个 UInt64 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 UInt64 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为 0 时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt8
public func nextInt8(max: Int8): Int8
功能:获取一个 Int8 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 Int8 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为非正数时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt16
public func nextInt16(max: Int16): Int16
功能:获取一个 Int16 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 Int16 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为非正数时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt32
public func nextInt32(max: Int32): Int32
功能:获取一个 Int32 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 Int32 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为非正数时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt64
public func nextInt64(max: Int64): Int64
功能:获取一个 Int64 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 Int64 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为非正数时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextFloat16
public func nextFloat16(): Float16
功能:获取一个 Float16 类型且在区间 [0.0, 1.0) 内的随机数。
返回值:一个 Float16 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextFloat32
public func nextFloat32(): Float32
功能:获取一个 Float32 类型且在区间 [0.0, 1.0) 内的随机数。
返回值:一个 Float32 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextFloat64
public func nextFloat64(): Float64
功能:获取一个 Float64 类型且在区间 [0.0, 1.0) 内的随机数。
返回值:一个 Float64 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextGaussianFloat16
public func nextGaussianFloat16(mean!: Float16 = 0.0, sigma!: Float16 = 1.0): Float16
功能:默认获取一个 Float16 类型且符合均值为 0.0 标准差为 1.0 的高斯分布的随机数,其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float16 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextGaussianFloat32
public func nextGaussianFloat32(mean!: Float32 = 0.0, sigma!: Float32 = 1.0): Float32
功能:默认获取一个 Float32 类型且符合均值为 0.0 标准差为 1.0 的高斯分布的随机数,其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float32 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextGaussianFloat64
public func nextGaussianFloat64(mean!: Float64 = 0.0, sigma!: Float64 = 1.0): Float64
功能:默认获取一个 Float64 类型且符合均值为 0.0 标准差为 1.0 的高斯分布的随机数,其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float64 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
示例
SecureRandom 使用
下面是 Random 创建随机数对象的示例。
代码如下:
from crypto import crypto.*
main() {
let r = SecureRandom()
for (i in 0..10) {
let flip = r.nextBool()
println(flip)
}
return 0
}
可能出现的运行结果如下(true/false 的选择是随机的):
false
true
false
false
false
true
true
false
false
true
crypto 包
介绍
crypto 包提供生成安全随机数功能。
使用本包需要外部依赖 OpenSSL 3 的 crypto 动态库文件,故使用前需安装相关工具:
- 对于
Linux操作系统,可参考以下方式:- 如果系统的包管理工具支持安装
OpenSSL 3开发工具包,可通过这个方式安装,并确保系统安装目录下含有libcrypto.so和libcrypto.so.3这两个动态库文件,例如Ubuntu 22.04系统上可使用sudo apt install libssl-dev命令安装libssl-dev工具包; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.so和libcrypto.so.3这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
LD_LIBRARY_PATH以及LIBRARY_PATH中。
- 如果系统的包管理工具支持安装
- 对于
Windows操作系统,可按照以下步骤:- 自行下载
OpenSSL 3.x.x源码编译安装 x64 架构软件包或者自行下载安装第三方预编译的供开发人员使用的OpenSSL 3.x.x软件包; - 确保安装目录下含有
libcrypto.dll.a(或libcrypto.lib)、libcrypto-3-x64.dll这两个库文件; - 将
libcrypto.dll.a(或libcrypto.lib) 所在的目录路径设置到环境变量LIBRARY_PATH中,将libcrypto-3-x64.dll所在的目录路径设置到环境变量PATH中。
- 自行下载
- 对于
macOS操作系统,可参考以下方式:- 使用
brew install openssl@3安装,并确保系统安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
DYLD_LIBRARY_PATH以及LIBRARY_PATH中。
- 使用
如果未安装OpenSSL 3软件包或者安装低版本的软件包,程序可能无法使用并抛出相关异常 SecureRandomException:Can not load openssl library or function xxx.。
主要接口
class SecureRandomException
public class SecureRandomException <: Exception {
public init()
public init(message: String)
}
crypto 包的异常类。
init
public init()
功能:创建默认的 SecureRandomException 实例,异常提示消息为空。
init
public init(message: String)
功能:根据异常提示消息创建 SecureRandomException 实例。
参数:
- message:异常提示字符串
class SecureRandom
public class SecureRandom {
public init(priv!: Bool = false)
}
该类用于生成加密安全的伪随机数。
和 std.random.Random 相比,主要有三个方面不同:
- 随机数种子:
Random使用系统时钟作为默认的种子,时间戳一样,结果就相同,SecureRandom使用操作系统或者硬件提供的随机数种子,生成的几乎是真随机数。 - 随机数生成:
Random使用了梅森旋转伪随机生成器,SecureRandom则使用了 openssl 库提供的 MD5 等随机算法,使用熵源生成真随机数。如果硬件支持,还可以使用硬件随机数生成器来生成安全性更强的随机数。 - 安全性:
Random不能用于加密安全的应用或者隐私数据的保护。
init
public init(priv!: Bool = false)
功能:创建 SecureRandom 实例,可指定是否使用更加安全的加密安全伪随机生成器,加密安全伪随机生成器可用于会话密钥和证书私钥等加密场景。
参数:
- priv:为 true 表示使用加密安全伪随机生成器
func nextBytes
public func nextBytes(length: Int32): Array<Byte>
功能:获取一个指定长度的随机字节的数组。
参数:
- length:要生成的随机字节数组的长度
返回值:一个随机字节数组
异常:
- 异常 IllegalArgumentException:当参数 length 小于等于 0,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextBool
public func nextBool(): Bool
功能:获取一个随机的 Bool 类型实例。
返回值:一个随机的 Bool 类型实例
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt8
public func nextUInt8(): UInt8
功能:获取一个 UInt8 类型的随机数。
返回值:一个 UInt8 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt16
public func nextUInt16(): UInt16
功能:获取一个 UInt16 类型的随机数。
返回值:一个 UInt16 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt32
public func nextUInt32(): UInt32
功能:获取一个 UInt32 类型的随机数。
返回值:一个 UInt32 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt64
public func nextUInt64(): UInt64
功能:获取一个 UInt64 类型的随机数。
返回值:一个 UInt64 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt8
public func nextInt8(): Int8
功能:获取一个 Int8 类型的随机数。
返回值:一个 Int8 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt16
public func nextInt16(): Int16
功能:获取一个 Int16 类型的随机数。
返回值:一个 Int16 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt32
public func nextInt32(): Int32
功能:获取一个 Int32 类型的随机数。
返回值:一个 Int32 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt64
public func nextInt64(): Int64
功能:获取一个 Int64 类型的随机数。
返回值:一个 Int64 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt8
public func nextUInt8(max: UInt8): UInt8
功能:获取一个 UInt8 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 UInt8 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为 0 时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt16
public func nextUInt16(max: UInt16): UInt16
功能:获取一个 UInt16 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 UInt16 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为 0 时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt32
public func nextUInt32(max: UInt32): UInt32
功能:获取一个 UInt32 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 UInt32 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为 0 时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextUInt64
public func nextUInt64(max: UInt64): UInt64
功能:获取一个 UInt64 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 UInt64 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为 0 时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt8
public func nextInt8(max: Int8): Int8
功能:获取一个 Int8 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 Int8 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为非正数时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt16
public func nextInt16(max: Int16): Int16
功能:获取一个 Int16 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 Int16 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为非正数时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt32
public func nextInt32(max: Int32): Int32
功能:获取一个 Int32 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 Int32 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为非正数时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextInt64
public func nextInt64(max: Int64): Int64
功能:获取一个 Int64 类型且在区间 [0, max) 内的随机数。
参数:
- max:区间最大值
返回值:一个 Int64 类型的随机数
异常:
- 异常 IllegalArgumentException:当 max 为非正数时,抛出异常
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextFloat16
public func nextFloat16(): Float16
功能:获取一个 Float16 类型且在区间 [0.0, 1.0) 内的随机数。
返回值:一个 Float16 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextFloat32
public func nextFloat32(): Float32
功能:获取一个 Float32 类型且在区间 [0.0, 1.0) 内的随机数。
返回值:一个 Float32 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextFloat64
public func nextFloat64(): Float64
功能:获取一个 Float64 类型且在区间 [0.0, 1.0) 内的随机数。
返回值:一个 Float64 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextGaussianFloat16
public func nextGaussianFloat16(mean!: Float16 = 0.0, sigma!: Float16 = 1.0): Float16
功能:默认获取一个 Float16 类型且符合均值为 0.0 标准差为 1.0 的高斯分布的随机数,其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float16 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextGaussianFloat32
public func nextGaussianFloat32(mean!: Float32 = 0.0, sigma!: Float32 = 1.0): Float32
功能:默认获取一个 Float32 类型且符合均值为 0.0 标准差为 1.0 的高斯分布的随机数,其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float32 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
func nextGaussianFloat64
public func nextGaussianFloat64(mean!: Float64 = 0.0, sigma!: Float64 = 1.0): Float64
功能:默认获取一个 Float64 类型且符合均值为 0.0 标准差为 1.0 的高斯分布的随机数,其中均值是期望值,可解释为位置参数,决定了分布的位置,标准差可解释为尺度参数,决定了分布的幅度。
参数:
- mean:均值
- sigma:标准差
返回值:一个 Float64 类型的随机数
异常:
- 异常 SecureRandomException:当生成器不能正确生成随机数或生成随机数失败时,抛出异常
示例
SecureRandom 使用
下面是 Random 创建随机数对象的示例。
代码如下:
from crypto import crypto.*
main() {
let r = SecureRandom()
for (i in 0..10) {
let flip = r.nextBool()
println(flip)
}
return 0
}
可能出现的运行结果如下(true/false 的选择是随机的):
false
true
false
false
false
true
true
false
false
true
digest 包
介绍
digest 包提供常用的消息摘要算法
使用本包需要外部依赖 OpenSSL 3 的 crypto 动态库文件,故使用前需安装相关工具:
- 对于
Linux操作系统,可参考以下方式:- 如果系统的包管理工具支持安装
OpenSSL 3开发工具包,可通过这个方式安装,并确保系统安装目录下含有libcrypto.so和libcrypto.so.3这两个动态库文件,例如Ubuntu 22.04系统上可使用sudo apt install libssl-dev命令安装libssl-dev工具包; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.so和libcrypto.so.3这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
LD_LIBRARY_PATH以及LIBRARY_PATH中。
- 如果系统的包管理工具支持安装
- 对于
Windows操作系统,可按照以下步骤:- 自行下载
OpenSSL 3.x.x源码编译安装 x64 架构软件包或者自行下载安装第三方预编译的供开发人员使用的OpenSSL 3.x.x软件包; - 确保安装目录下含有
libcrypto.dll.a(或libcrypto.lib)、libcrypto-3-x64.dll这两个库文件; - 将
libcrypto.dll.a(或libcrypto.lib) 所在的目录路径设置到环境变量LIBRARY_PATH中,将libcrypto-3-x64.dll所在的目录路径设置到环境变量PATH中。
- 自行下载
- 对于
macOS操作系统,可参考以下方式:- 使用
brew install openssl@3安装,并确保系统安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
DYLD_LIBRARY_PATH以及LIBRARY_PATH中。
- 使用
如果未安装OpenSSL 3软件包或者安装低版本的软件包,程序可能无法使用并抛出相关异常 CryptoException: Can not load openssl library or function xxx.。
主要接口
class MD5
提供 MD5 算法的实现接口。
public class MD5 <: Digest {
public init()
}
init
public init()
功能:无参构造函数,创建 MD5 对象。
prop size
public prop size: Int64
功能:MD5 摘要信息长度,单位字节。
返回值: MD5 摘要信息的字节长度,长度为16
prop blockSize
public prop blockSize: Int64
功能:MD5 信息块长度,单位字节。
返回值:MD5 信息块的字节长度,长度为64
func write
public func write(buffer: Array<Byte>): Unit
功能:使用给定的 buffer 更新 MD5 对象,在调用 finish 前可以多次更新。
参数:
- buffer:更新后的 MD5 字节序列
异常:
- CryptoException: 已经调用 finish 进行摘要计算后未重置上下文,抛此异常
func finish
public func finish(): Array<Byte>
功能:返回生成的 MD5 值,注意调用 finish 后 MD5 上下文会发生改变,finish 后不可以再进行摘要计算,如重新计算需要 reset 重置上下文。
返回值:生成的 MD5 字节序列
异常:
- CryptoException: 未重置上下文再次调用 finish 进行摘要计算,抛此异常
func reset
public func reset(): Unit
功能:重置 MD5 对象到初始状态,清理 MD5 上下文。
class SHA1
提供 SHA1 算法的实现接口。
public class SHA1 <: Digest {
public init()
}
init
public init()
功能:无参构造函数,创建 SHA1 对象。
prop size
public prop size: Int64
功能:SHA1 摘要信息长度,单位字节。
返回值: SHA1 摘要信息的字节长度,长度为20
prop blockSize
public prop blockSize: Int64
功能:SHA1 信息块长度,单位字节。
返回值:SHA1 信息块的字节长度,长度为64
func write
public func write(buffer: Array<Byte>): Unit
功能:使用给定的 buffer 更新 SHA1 对象,在调用 finish 前可以多次更新。
参数:
- buffer:更新后的 SHA1 字节序列
异常:
- CryptoException: 已经调用 finish 进行摘要计算后未重置上下文,抛此异常
func finish
public func finish(): Array<Byte>
功能:返回生成的 SHA1 值,注意调用 finish 后 SHA224 上下文会发生改变,finish 后不可以再进行摘要计算,如重新计算需要 reset 重置上下文。
返回值:生成的 SHA1 字节序列
异常:
- CryptoException: 未重置上下文再次调用 finish 进行摘要计算,抛此异常
func reset
public func reset(): Unit
功能:重置 SHA1 对象到初始状态,清理 SHA1 上下文。
class SHA224
提供 SHA224 算法的实现接口。
public class SHA224 <: Digest {
public init()
}
init
public init()
功能:无参构造函数,创建 SHA224 对象。
prop size
public prop size: Int64
功能:SHA224 摘要信息长度,单位字节。
返回值: SHA224 摘要信息的字节长度,长度为28
prop blockSize
public prop blockSize: Int64
功能:SHA224 信息块长度,单位字节。
返回值:SHA224 信息块的字节长度,长度为64
func write
public func write(buffer: Array<Byte>): Unit
功能:使用给定的 buffer 更新 SHA224 对象,在调用 finish 前可以多次更新。
参数:
- buffer: 更新后的 SHA224 字节序列
异常:
- CryptoException: 已经调用 finish 进行摘要计算后未重置上下文,抛此异常
func finish
public func finish(): Array<Byte>
功能:返回生成的 SHA224 值,注意调用 finish 后 SHA224 上下文会发生改变,finish 后不可以再进行摘要计算,如重新计算需要 reset 重置上下文。
返回值:生成的 SHA224 字节序列
异常:
- CryptoException: 未重置上下文再次调用 finish 进行摘要计算,抛此异常
func reset
public func reset(): Unit
功能:重置 SHA224 对象到初始状态,清理 SHA224 上下文。
class SHA256
提供 SHA256 算法的实现接口。
public class SHA256 <: Digest {
public init()
}
init
public init()
功能:无参构造函数,创建 SHA256 对象。
prop size
public prop size: Int64
功能:SHA256 摘要信息长度,单位字节。
返回值: SHA256 摘要的信息字节长度,长度为32
prop blockSize
public prop blockSize: Int64
功能:SHA256 信息块长度,单位字节。
返回值:SHA256 信息块的字节长度,长度为64
func write
public func write(buffer: Array<Byte>): Unit
功能:使用给定的 buffer 更新 SHA256 对象,在调用 finish 前可以多次更新。
参数:
- buffer: 更新后的 SHA256 字节序列
异常:
- CryptoException: 已经调用 finish 进行摘要计算后未重置上下文,抛此异常
func finish
public func finish(): Array<Byte>
功能:返回生成的 SHA256 值,注意调用 finish 后 SHA256 上下文会发生改变,finish 后不可以再进行摘要计算,如重新计算需要 reset 重置上下文。
返回值:生成的 SHA256 字节序列
异常:
- CryptoException: 未重置上下文再次调用 finish 进行摘要计算,抛此异常
func reset
public func reset(): Unit
功能:重置 SHA256 对象到初始状态,清理 SHA256 上下文。
class SHA384
提供 SHA384 算法的实现接口。
public class SHA384 <: Digest {
public init()
}
init
public init()
功能:无参构造函数,创建 SHA384 对象。
prop size
public prop size: Int64
功能:SHA384 摘要信息长度,单位字节。
返回值: SHA384 摘要的信息字节长度,长度为48
prop blockSize
public prop blockSize: Int64
功能:SHA384 信息块长度,单位字节。
返回值:SHA384 信息块的字节长度,长度为128
func write
public func write(buffer: Array<Byte>): Unit
功能:使用给定的 buffer 更新 SHA384 对象,在调用 finish 前可以多次更新。
参数:
- buffer:更新后的 SHA384 字节序列
异常:
- CryptoException: 已经调用 finish 进行摘要计算后未重置上下文,抛此异常
func finish
public func finish(): Array<Byte>
功能:返回生成的 SHA384 值,注意调用 finish 后 SHA384 上下文会发生改变,finish 后不可以再进行摘要计算,如重新计算需要 reset 重置上下文。
返回值:生成的 SHA384 字节序列
异常:
- CryptoException: 未重置上下文再次调用 finish 进行摘要计算,抛此异常
func reset
public func reset(): Unit
功能:重置 SHA384 对象到初始状态,清理 SHA384 上下文。
class SHA512
提供 SHA512 算法的实现接口。
public class SHA512 <: Digest {
public init()
}
init
public init()
功能:无参构造函数,创建 SHA512 对象。
prop size
public prop size: Int64
功能:SHA512 摘要信息长度,单位字节。
返回值: SHA512 摘要信息的字节长度,长度为64
prop blockSize
public prop blockSize: Int64
功能:SHA512 信息块长度,单位字节。
返回值:SHA512 信息块的字节长度,长度为128
func write
public func write(buffer: Array<Byte>): Unit
功能:使用给定的 buffer 更新 SHA512 对象,在调用 finish 前可以多次更新。
参数:
- buffer:更新后的 SHA512 字节序列
异常:
- CryptoException: 已经调用 finish 进行摘要计算后未重置上下文,抛此异常
func finish
public func finish(): Array<Byte>
功能:返回生成的 SHA512 值,注意调用 finish 后 SHA512 上下文会发生改变,finish 后不可以再进行摘要计算,如重新计算需要 reset 重置上下文。
返回值:生成的 SHA512 字节序列
异常:
- CryptoException: 未重置上下文再次调用 finish 进行摘要计算,抛此异常
func reset
public func reset(): Unit
功能:重置 SHA512 对象到初始状态,清理 SHA512 上下文。
class HMAC
提供 HMAC 算法的实现接口。
public class HMAC <: Digest {
public init(key: Array<Byte>, algorithm: HashType)
}
init
public init(key: Array<Byte>, algorithm: HashType)
功能:构造函数,创建 HMAC 对象。
参数:key 为密钥,建议该参数不小于所选Hash算法摘要的长度,algorithm 为 hash 算法,目前仅支持 SHA512 算法
异常:
- CryptoException: 使用 SHA512 以外的 hash 算法或 key 值为空时,抛出异常
prop size
public prop size: Int64
功能:HMAC 所选 Hash 算法的摘要信息长度,单位字节。
返回值: HMAC 所选 Hash 算法摘要信息的字节长度
prop blockSize
public prop blockSize: Int64
功能:HMAC 所选 Hash 算法信息块长度,单位字节。
返回值:HMAC 所选 Hash 算法信息块的字节长度
func write
public func write(buffer: Array<Byte>): Unit
功能:使用给定的 buffer 更新 HMAC 对象,在调用 finish 前可以多次更新。
参数:
- buffer:需要追加的字节序列
异常:
- CryptoException: 当 buffer 为空、finish 已经调用生成信息摘要场景,抛此异常
func finish
public func finish(): Array<Byte>
功能:返回生成的信息摘要值,注意调用 finish 后不可以再进行摘要计算,如重新计算需要 reset 重置上下文。
返回值:生成的信息摘要字节序列
异常:
- CryptoException: 未重置上下文再次调用 finish 进行摘要计算,抛此异常
func reset
public func reset(): Unit
功能:重置 HMAC 对象到初始状态,清理 HMAC 上下文。
异常:
- CryptoException: 当内部错误,重置失败,抛此异常
func equal
public static func equal(mac1: Array<Byte>, mac2: Array<Byte>): Bool
功能:比较两个信息摘要是否相等,且不泄露比较时间,即比较不采用传统短路原则,从而防止 timing attack 类型的攻击。
参数:
- mac1:需要比较的信息摘要序列
- mac2:需要比较的信息摘要序列
返回值:信息摘要是否相同, true 相同, false 不相同
struct HashType
public struct HashType
此类为 Hash 算法类。
prop MD5
public static prop MD5: HashType
功能:返回 MD5 类型。
prop SHA1
public static prop SHA1: HashType
功能:返回 SHA1 类型。
prop SHA224
public static prop SHA224: HashType
功能:返回 SHA224 类型。
prop SHA256
public static prop SHA256: HashType
功能:返回 SHA256 类型。
prop SHA384
public static prop SHA384: HashType
功能:返回 SHA384 类型。
prop SHA512
public static prop SHA512: HashType
功能:返回 SHA512 类型。
func toString
public func toString(): String
功能:获取 Hash 算法名称。
class SM3
提供 SM3 算法的实现接口。
public class SM3 <: Digest {
public init()
}
init
public init()
功能:无参构造函数,创建 SM3 对象。
prop size
public prop size: Int64
功能:SM3 摘要信息长度,单位字节。
返回值: SM3 摘要信息的字节长度,长度为32
prop blockSize
public prop blockSize: Int64
功能:SM3 信息块长度,单位字节。
返回值:SM3 信息块的字节长度,长度为64
func write
public func write(buffer: Array<Byte>): Unit
功能:使用给定的 buffer 更新 SM3 对象,在调用 finish 前可以多次更新。
参数:
- buffer:更新后的 SM3 字节序列
异常:
- CryptoException: 已经调用 finish 进行摘要计算后未重置上下文,抛此异常
func finish
public func finish(): Array<Byte>
功能:返回生成的 SM3 值,注意调用 finish 后 SM3 上下文会发生改变,finish 后不可以再进行摘要计算,如重新计算需要 reset 重置上下文。
返回值:生成的 SM3 字节序列
异常:
- CryptoException: 未重置上下文再次调用 finish 进行摘要计算,抛此异常
func reset
public func reset(): Unit
功能:重置 SM3 对象到初始状态,清理 SM3 上下文。
class CryptoException
public class CryptoException <: Exception {
public init()
public init(message: String)
}
此类为 crypto 库出现错误时抛出的异常。
init
public init()
功能:无参构造函数,构造异常。
init
public init(message: String)
功能:构造异常。
参数:
- message:异常信息
示例
MD5 算法示例
使用 MD5 算法计算摘要示例。
调用仓颉标准库提供的通用 digest 函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var md5Instance = MD5()
var md: Array<Byte> = digest(md5Instance, str)
var result: String = toHexString(md)
println(result)
return 0
}
调用 MD5 成员函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var md5Instance = MD5()
md5Instance.write(str.toArray())
var md: Array<Byte> = md5Instance.finish()
var result: String = toHexString(md)
println(result)
return 0
}
运行结果如下:
fc5e038d38a57032085441e7fe7010b0
SHA1 算法示例
使用 SHA1 算法计算摘要示例。
调用仓颉标准库提供的通用 digest 函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sha1Instance = SHA1()
var md: Array<Byte> = digest(sha1Instance, str)
var result: String = toHexString(md)
println(result)
return 0
}
调用 SHA1 成员函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sha1Instance = SHA1()
sha1Instance.write(str.toArray())
var md: Array<Byte> = sha1Instance.finish()
var result: String = toHexString(md)
println(result)
return 0
}
运行结果如下:
6adfb183a4a2c94a2f92dab5ade762a47889a5a1
SHA224 算法示例
使用 SHA224 算法计算摘要示例。
调用仓颉标准库提供的通用 digest 函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sha224Instance = SHA224()
var md: Array<Byte> = digest(sha224Instance, str)
var result: String = toHexString(md)
println(result)
return 0
}
调用 SHA224 成员函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sha224Instance = SHA224()
sha224Instance.write(str.toArray())
var md: Array<Byte> = sha224Instance.finish()
var result: String = toHexString(md)
println(result)
return 0
}
运行结果如下:
b033d770602994efa135c5248af300d81567ad5b59cec4bccbf15bcc
SHA256 算法示例
使用 SHA256 算法计算摘要示例。
调用仓颉标准库提供的通用 digest 函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sha256Instance = SHA256()
var md: Array<Byte> = digest(sha256Instance, str)
var result: String = toHexString(md)
println(result)
return 0
}
调用 SHA256 成员函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sha256Instance = SHA256()
sha256Instance.write(str.toArray())
var md: Array<Byte> = sha256Instance.finish()
var result: String = toHexString(md)
println(result)
return 0
}
运行结果如下:
936a185caaa266bb9cbe981e9e05cb78cd732b0b3280eb944412bb6f8f8f07af
SHA384 算法示例
使用 SHA384 算法计算摘要示例。
调用仓颉标准库提供的通用 digest 函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sha384Instance = SHA384()
var md: Array<Byte> = digest(sha384Instance, str)
var result: String = toHexString(md)
println(result)
return 0
}
调用 SHA384 成员函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sha384Instance = SHA384()
sha384Instance.write(str.toArray())
var md: Array<Byte> = sha384Instance.finish()
var result: String = toHexString(md)
println(result)
return 0
}
运行结果如下:
97982a5b1414b9078103a1c008c4e3526c27b41cdbcf80790560a40f2a9bf2ed4427ab1428789915ed4b3dc07c454bd9
SHA512 算法示例
使用 SHA512 算法计算摘要示例。
调用仓颉标准库提供的通用 digest 函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sha512Instance = SHA512()
var md: Array<Byte> = digest(sha512Instance, str)
var result: String = toHexString(md)
println(result)
return 0
}
调用 SHA512 成员函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sha512Instance = SHA512()
sha512Instance.write(str.toArray())
var md: Array<Byte> = sha512Instance.finish()
var result: String = toHexString(md)
println(result)
return 0
}
运行结果如下:
1594244d52f2d8c12b142bb61f47bc2eaf503d6d9ca8480cae9fcf112f66e4967dc5e8fa98285e36db8af1b8ffa8b84cb15e0fbcf836c3deb803c13f37659a60
HMAC 算法示例
使用 HMAC-SHA512 算法计算摘要示例。
调用仓颉标准库提供的通用 digest 函数
from crypto import digest.*
from encoding import hex.*
from std import crypto.digest.*
main() {
var algorithm: HashType = HashType.SHA512
var key: Array<UInt8> = "cangjie".toArray()
var data: Array<UInt8> = "123456789".toArray()
var hmac= HMAC(key,algorithm)
var md: Array<Byte> = digest(hmac, data)
var result: String = toHexString(md)
println(result)
return 0
}
运行结果如下:
2bafeb53b60a119d38793a886c7744f5027d7eaa3702351e75e4ff9bf255e3ce296bf41f80adda2861e81bd8efc52219df821852d84a17fb625e3965ebf2fdd9
调用 HMAC-SHA512 成员函数
from crypto import digest.*
from encoding import hex.*
main() {
var algorithm: HashType = HashType.SHA512
var key: Array<UInt8> = "cangjie".toArray()
var data1: Array<UInt8> = "123".toArray()
var data2: Array<UInt8> = "456".toArray()
var data3: Array<UInt8> = "789".toArray()
var data4: Array<UInt8> = "123456789".toArray()
var hmac= HMAC(key,algorithm)
hmac.write(data1)
hmac.write(data2)
hmac.write(data3)
var md1: Array<Byte>= hmac.finish()
var result1: String = toHexString(md1)
println(result1)
hmac.reset()
hmac.write(data4)
var md2: Array<Byte>= hmac.finish()
var result2: String = toHexString(md2)
println(result2)
println(HMAC.equal(md1,md2))
return 0
}
运行结果如下:
2bafeb53b60a119d38793a886c7744f5027d7eaa3702351e75e4ff9bf255e3ce296bf41f80adda2861e81bd8efc52219df821852d84a17fb625e3965ebf2fdd9
2bafeb53b60a119d38793a886c7744f5027d7eaa3702351e75e4ff9bf255e3ce296bf41f80adda2861e81bd8efc52219df821852d84a17fb625e3965ebf2fdd9
true
SM3 算法示例
使用 SM3 算法计算摘要示例。
调用仓颉标准库提供的通用 digest 函数
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
from encoding import hex.*
main() {
var str: String = "helloworld"
var sm3Instance = SM3()
var md: Array<Byte> = digest(sm3Instance, str)
var result: String = toHexString(md)
println(result)
return 0
}
keys 包
介绍
keys 包提供非对称加密算法
使用本包需要外部依赖 OpenSSL 3 的 crypto 动态库文件,故使用前需安装相关工具:
- 对于
Linux操作系统,可参考以下方式:- 如果系统的包管理工具支持安装
OpenSSL 3开发工具包,可通过这个方式安装,并确保系统安装目录下含有libcrypto.so和libcrypto.so.3这两个动态库文件,例如Ubuntu 22.04系统上可使用sudo apt install libssl-dev命令安装libssl-dev工具包; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.so和libcrypto.so.3这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
LD_LIBRARY_PATH以及LIBRARY_PATH中。
- 如果系统的包管理工具支持安装
- 对于
Windows操作系统,可按照以下步骤:- 自行下载
OpenSSL 3.x.x源码编译安装 x64 架构软件包或者自行下载安装第三方预编译的供开发人员使用的OpenSSL 3.x.x软件包; - 确保安装目录下含有
libcrypto.dll.a(或libcrypto.lib)、libcrypto-3-x64.dll这两个库文件; - 将
libcrypto.dll.a(或libcrypto.lib) 所在的目录路径设置到环境变量LIBRARY_PATH中,将libcrypto-3-x64.dll所在的目录路径设置到环境变量PATH中。
- 自行下载
- 对于
macOS操作系统,可参考以下方式:- 使用
brew install openssl@3安装,并确保系统安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
DYLD_LIBRARY_PATH以及LIBRARY_PATH中。
- 使用
如果未安装OpenSSL 3软件包或者安装低版本的软件包,程序可能无法使用并抛出相关异常 CryptoException: Can not load openssl library or function xxx.。
主要接口
class RSAPrivateKey
public class RSAPrivateKey <: PrivateKey{
public init(bits: Int32)
public init(bits: Int32, e: BigInt)
}
RSA 私钥类,提供生成 RSA 私钥能力,RSA 私钥支持签名和解密操作,支持 PEM 和 DER 格式的编码解码,符合 PKCS1 标准,详见 rfc8017。
init
public init(bits: Int32)
功能:init 初始化生成私钥, 公共指数默认值为 65537,业界推荐。
参数:
- bits:密钥长度,需要大于等于 512 位,并且小于等于 16384 位
异常:
- CryptoException - 密钥长度不符合要求或初始化失败,抛出异常
init
public init(bits: Int32, e: BigInt)
功能:init 初始化生成私钥,允许用户指定公共指数。
参数:
- bits:密钥长度,需要大于等于 512 位,并且小于等于 16384 位,推荐使用的密钥长度不小于 3072 位
- e:公钥公共指数,范围是 [3, 2^256-1] 的奇数
异常:
- CryptoException - 密钥长度不符合要求、公钥公共指数值不符合要求或初始化失败,抛出异常
func sign
public func sign(hash: Digest, digest: Array<Byte>, padType!: PadOption): Array<Byte>
功能:sign 对数据的摘要结果进行签名。
参数:
- hash:摘要方法,获取 digest 结果使用的摘要方法
- digest:数据的摘要结果
- padType:填充模式,可以选择 PKCS1 或 PSS 模式,不支持 OAEP 模式,在对安全场景要求较高的情况下,推荐使用 PSS 填充模式
返回值:签名后的数据
异常:
- CryptoException:设置摘要方法失败、设置填充模式失败或签名失败,抛出异常
func decrypt
public func decrypt(input: InputStream, output: OutputStream, padType!: PadOption): Unit
功能:decrypt 解密出原始数据。
参数:
- input:加密的数据
- digest:解密后的数据
- padType:填充模式,可以选择 PKCS1 或 OAEP 模式,不支持 PSS 模式,在对安全场景要求较高的情况下,推荐使用 OAEP 填充模式
异常:
- CryptoException - 设置填充模式失败或解密失败,抛出异常
func encodeToDer
public override func encodeToDer(): DerBlob
功能:将私钥编码为 DER 格式。
返回值:Derblob 对象
异常:
- CryptoException:编码失败,抛出异常
func encodeToDer
public func encodeToDer(password!: ?String): DerBlob
功能:使用 AES-256-CBC 加密私钥,将私钥编码为 DER 格式。
参数:
- password:加密私钥需要提供的密码,密码为 None 时则不加密
返回值:Derblob 对象
异常:
- CryptoException:编码失败、加密失败或者参数密码为空字符串,抛出异常
func encodeToPem
public override func encodeToPem(): PemEntry
功能:将私钥编码为 PEM 格式。
返回值:PemEntry 对象
异常:
- CryptoException:编码失败,抛出异常
func decodeDer
public static func decodeDer(blob: DerBlob): RSAPrivateKey
功能:将私钥从 DER 格式解码。
参数:
- password:二进制格式的私钥对象
返回值:解码出的 RSA 私钥
异常:
- CryptoException:解码失败,抛出异常
func decodeDer
public static func decodeDer(blob: DerBlob, password!: ?String): RSAPrivateKey
功能:将加密的私钥从 DER 格式解码。
参数:
- blob:二进制格式的私钥对象
- password:解密私钥需要提供的密码,密码为 None 时则不解密
返回值:解码出的 RSA 私钥
异常:
- CryptoException:解码失败、解密失败或者参数密码为空字符串,抛出异常
func decodeFromPem
public static func decodeFromPem(text: String): RSAPrivateKey
功能:将私钥从 PEM 格式解码。
参数:
- text:PEM 格式的私钥字符流
返回值:解码出的 RSA 私钥
异常:
- CryptoException:解码失败、解密失败、字符流不符合 PEM 格式或文件头不符合私钥头标准时,抛出异常
func decodeFromPem
public static func decodeFromPem(text: String, password!: ?String): RSAPrivateKey
功能:将私钥从 PEM 格式解码。
参数:
- text:PEM 格式的私钥字符流
- password:解密私钥需要提供的密码,密码为 None 时则不解密
返回值:解码出的 RSA 私钥
异常:
- CryptoException:解码失败、解密失败、参数密码为空字符串、字符流不符合 PEM 格式或文件头不符合私钥头标准时,抛出异常
func toString
public override func toString(): String
功能:输出私钥种类。
class RSAPublicKey
public class RSAPublicKey <: PublicKey {
public init(pri: RSAPrivateKey)
}
RSA 公钥类,提供生成 RSA 公钥能力,RSA 公钥支持验证签名和加密操作,支持 PEM 和 DER 格式的编码解码。
init
public init(pri: RSAPrivateKey)
功能:init 初始化公钥,从私钥中获取对应的公钥。
参数:
- pri:RSA私钥
异常:
- CryptoException:初始化失败,抛出异常
func verify
public func verify(hash: Digest, digest: Array<Byte>, sig: Array<Byte>, padType!: PadOption): Bool
功能:verify 验证签名结果。
参数:
- hash:摘要方法,获取 digest 结果使用的摘要方法
- digest:数据的摘要结果
- sig:数据的签名结果
- padType:填充模式,可以选择 PKCS1 或 PSS 模式,不支持 OAEP 模式,在对安全场景要求较高的情况下,推荐使用 PSS 填充模式
返回值:返回 true 表示验证成功,false 失败
异常:
- CryptoException:设置填充模式失败或验证失败,抛出异常
func encrypt
public func encrypt(input: InputStream, output: OutputStream, padType!: PadOption): Unit
功能:encrypt 给一段数据进行加密。
参数:
- input:需要加密的数据
- output:加密后的数据
- padType:填充模式,可以选择 PKCS1 或 OAEP 模式,不支持 PSS 模式,在对安全场景要求较高的情况下,推荐使用 OAEP 填充模式
异常:
- CryptoException:设置填充模式失败或加密失败,抛出异常
func encodeToDer
public override func encodeToDer(): DerBlob
功能:将公钥编码为 DER 格式。
返回值:返回 Derblob 对象
异常:
- CryptoException:编码失败,抛出异常
func encodeToPem
public override func encodeToPem(): PemEntry
功能:将公钥编码为 PEM 格式。
返回值:返回 PemEntry 对象
异常:
- CryptoException:编码失败,抛出异常
func decodeDer
public static func decodeDer(blob: DerBlob): RSAPublicKey
功能:将公钥从 DER 格式解码。
参数:
- blob:二进制格式的公钥对象
返回值:解码出的 RSA 公钥
异常:
- CryptoException:解码失败,抛出异常
func decodeFromPem
public static func decodeFromPem(text: String): RSAPublicKey
功能:将公钥从PEM 格式解码。
参数:
- text:PEM 格式的公钥字符流
返回值:解码出的 RSA 公钥
异常:
- CryptoException:解码失败、字符流不符合 PEM 格式或文件头不符合公钥头标准时,抛出异常
func toString
public override func toString(): String
功能:输出公钥种类
enum PadOption
public enum PadOption {
| OAEP(OAEPOption) | PSS(PSSOption) | PKCS1
}
枚举类型 PadOption 用于设置 RSA 的填充模式,RSA 有三种常用的填充模式,OAEP 为最优非对称加密填充,只能用于加密解密;PSS 为概率签名方案, 只能用于签名和验证,PKCS1 是一种普通的填充模式,用于填充数据长度,可以用于加密、解密、签名和验证。RSA 的 PKCS1 填充模式是在早期的 PKCS #1 v1.5 规范中定义的填充模式,当前对使用 PKCS1 填充模式的攻击较为成熟,容易被攻击者解密或伪造签名,建议采用 PKCS #1 v2 版本中更加安全的 PSS 或 OAEP 填充模式。
OAEP
OAEP(OAEPOption)
功能:使用最优非对称加密初始化 PadOption 实例。
PSS
PSS(PSSOption)
功能:使用概率签名方案初始化 PadOption 实例。
PKCS1
PKCS1
功能:使用 PKCS #1 公钥密码学标准初始化 PadOption 实例。
struct OAEPOption
public struct OAEPOption {
public init(hash: Digest, mgfHash: Digest, label!: String = "")
}
此结构体为 OAEP 填充模式需要设置的参数。
init
public init(hash: Digest, mgfHash: Digest, label!: String = "")
功能:初始化 OAEP 填充参数。
参数:
hash:摘要方法,用于对 label 进行摘要mgfHash:摘要方法,用于设置 MGF1 函数中的摘要方法label: 摘要方法,label 是可选参数,默认为空字符串,可以通过设置 lable 来区分不同的加密操作
init
public init(hash: Digest, mgfHash: Digest, label!: String = "")
功能:初始化 OAEP 填充参数。
参数:
hash:摘要方法,用于对 label 进行摘要mgfHash:摘要方法,用于设置 MGF1 函数中的摘要方法label:label 是可选参数,默认为空字符串,可以通过设置 lable 来区分不同的加密操作
struct PSSOption
public struct PSSOption {
public init(saltLen: Int32)
}
此结构体为 PSS 填充模式需要设置的参数。
init
public init(saltLen: Int32)
功能:初始化 PSS 填充参数。
参数:
- saltLen:随机盐长度,长度应大于等于 0,小于等于(RSA 长度 - 摘要长度 - 2),长度单位为字节,长度过长会导致签名失败
异常:
- CryptoException:随机盐长度小于 0,抛出异常
enum Curve
public enum Curve {
| P224 | P256 | P384 | P521 | BP256 | BP320 | BP384 | BP512
}
枚举类型 Curve 用于选择生成 ECDSA 密钥时使用的椭圆曲线类型,支持 NIST P-224,NIST P-256,NIST P-384,NIST P-521,Brainpool P-256,Brainpool P-320,Brainpool P-384,Brainpool P-512 八种椭圆曲线。
P224
P224
功能:使用 NIST P-224 椭圆曲线初始化 Curve 实例。
P256
P256
功能:使用 NIST P-256 椭圆曲线初始化 Curve 实例。
P384
P384
功能:使用 NIST P-384 椭圆曲线初始化 Curve 实例。
P521
P521
功能:使用 NIST P-521 椭圆曲线初始化 Curve 实例。
BP256
BP256
功能:使用 Brainpool P-256 椭圆曲线初始化 Curve 实例。
BP320
BP320
功能:使用 Brainpool P-320 椭圆曲线初始化 Curve 实例。
BP384
BP384
功能:使用 Brainpool P-384 椭圆曲线初始化 Curve 实例。
BP512
BP512
功能:使用 Brainpool P-512 椭圆曲线初始化 Curve 实例。
class ECDSAPrivateKey
public class ECDSAPrivateKey <: PrivateKey {
public init(curve: Curve)
}
ECDSA 私钥类,提供生成 ECDSA 私钥能力,ECDSA 的私钥支持签名操作,同时支持 PEM 和 DER 格式的编码解码,详见 FIPS 186-4。
init
public init(curve: Curve)
功能:init 初始化生成私钥。
参数:
- curve:椭圆曲线类型
异常:
- CryptoException:初始化失败,抛出异常
func sign
public func sign(digest: Array<Byte>): Array<Byte>
功能:sign 对数据的摘要结果进行签名。
参数:
- digest:数据的摘要结果
返回值:签名后的数据
异常:
- CryptoException:签名失败,抛出异常
func encodeToDer
public override func encodeToDer(): DerBlob
功能:将私钥编码为 DER 格式。
返回值:返回 Derblob 对象
异常:
- CryptoException:编码失败,抛出异常
func encodeToDer
public func encodeToDer(password!: ?String): DerBlob
功能:使用 AES-256-CBC 加密私钥,将私钥编码为 DER 格式。
参数:
- password:加密私钥需要提供的密码,密码为 None 时则不加密
返回值:Derblob 对象
异常:
- CryptoException:编码失败、加密失败或者参数密码为空字符串,抛出异常
func encodeToPem
public override func encodeToPem(): PemEntry
功能:将私钥编码为 PEM 格式。
返回值:PemEntry 对象
异常:
- CryptoException:编码失败,抛出异常
func decodeDer
public static func decodeDer(blob: DerBlob): ECDSAPrivateKey
功能:将私钥从 DER 格式解码。
参数:
- blob:二进制格式的私钥对象
返回值:解码出的 ECDSA 私钥
异常:
- CryptoException:解码失败,抛出异常
func decodeDer
public static func decodeDer(blob: DerBlob, password!: ?String): ECDSAPrivateKey
功能:将加密的私钥从 DER 格式解码。
参数:
- blob:二进制格式的私钥对象
- password:解密私钥需要提供的密码,密码为 None 时则不解密
返回值:解码出的 ECDSA 私钥
异常:
- CryptoException:解码失败、解密失败或者参数密码为空字符串,抛出异常
func decodeFromPem
public static func decodeFromPem(text: String): ECDSAPrivateKey
功能:将私钥从 PEM 格式解码。
参数:
- text:PEM 格式的私钥字符流
返回值:解码出的 ECDSA 私钥
异常:
- CryptoException:解码失败、字符流不符合 PEM 格式或文件头不符合私钥头标准时,抛出异常
func decodeFromPem
public static func decodeFromPem(text: String, password!: ?String): ECDSAPrivateKey
功能:将私钥从PEM 格式解码。
参数:
- text:PEM 格式的私钥字符流
- password:解密私钥需要提供的密码,密码为 None 时则不解密
返回值:解码出的 ECDSA 私钥
异常:
- CryptoException:解码失败、解密失败、参数密码为空字符串、字符流不符合 PEM 格式或文件头不符合私钥头标准时,抛出异常
func toString
public override func toString(): String
功能:输出私钥种类。
class ECDSAPublicKey
public class ECDSAPublicKey <: PublicKey {
public init(pri: ECDSAPrivateKey)
}
ECDSA 公钥类,提供生成 ECDSA 公钥能力,ECDSA 公钥支持验证签名操作,支持 PEM 和 DER 格式的编码解码。
init
public init(pri: ECDSAPrivateKey)
功能:init 初始化公钥,从私钥中获取对应的公钥。
参数:
- pri:ECDSA 私钥
异常:
- CryptoException:初始化失败,抛出异常
func verify
public func verify(digest: Array<Byte>, sig: Array<Byte>): Bool
功能:verify 验证签名结果。
参数:
- digest:数据的摘要结果
- sig:数据的签名结果
返回值:返回 true 表示验证成功,false 失败
func encodeToDer
public override func encodeToDer(): DerBlob
功能:将公钥编码为 DER 格式。
返回值:返回 Derblob 对象
异常:
- CryptoException:编码失败,抛出异常
func encodeToPem
public override func encodeToPem(): PemEntry
功能:将公钥编码为 PEM 格式。
返回值:PemEntry 对象
异常:
- CryptoException:编码失败,抛出异常
func decodeDer
public static func decodeDer(blob: DerBlob): ECDSAPublicKey
功能:将公钥从 DER 格式解码。
参数:
- blob:二进制格式的公钥对象
返回值:解码出的 ECDSA 公钥
异常:
- CryptoException:编码失败,抛出异常
func decodeFromPem
public static func decodeFromPem(text: String): ECDSAPublicKey
功能:将公钥从 PEM 格式解码。
参数:
- text:PEM 格式的公钥字符流
返回值:解码出的 ECDSA 公钥
异常:
- CryptoException:解码失败、字符流不符合 PEM 格式或文件头不符合公钥头标准时,抛出异常
func toString
public override func toString(): String
功能:输出公钥种类。
示例
RSA 密钥示例
使用 RSA 密钥使用示例。
生成 rsa 公钥及私钥,并使用公钥的 OAEP 填充模式加密,用私钥的 OAEP 填充模式解密。
from crypto import keys.*
from crypto import digest.*
from std import io.*
from std import crypto.digest.*
main() {
var rsaPri = RSAPrivateKey(2048)
var rsaPub = RSAPublicKey(rsaPri)
var str: String = "hello world, hello cangjie"
var bas1 = ByteArrayStream()
var bas2 = ByteArrayStream()
var bas3 = ByteArrayStream()
bas1.write(str.toArray())
var encOpt = OAEPOption(SHA1(), SHA256())
rsaPub.encrypt(bas1, bas2, padType: OAEP(encOpt))
var encOpt2 = OAEPOption(SHA1(), SHA256())
rsaPri.decrypt(bas2, bas3, padType: OAEP(encOpt2))
var buf = Array<Byte>(str.size, item:0)
bas3.read(buf)
if (str.toArray() == buf){
println("success")
} else {
println("fail")
}
}
从文件中读取 rsa 公钥和私钥,并使用私钥的 PKCS1 填充模式签名,用公钥的 PKCS1 填充模式验证签名结果。
from crypto import keys.*
from crypto import digest.*
from std import crypto.digest.*
from std import fs.*
main() {
var pemPri = String.fromUtf8(File("./files/rsaPri.pem", OpenOption.Open(true, false)).readToEnd())
var rsaPri = RSAPrivateKey.decodeFromPem(pemPri)
var pemPub = String.fromUtf8(File("./files/rsaPub.pem", OpenOption.Open(true, false)).readToEnd())
var rsaPub = RSAPublicKey.decodeFromPem(pemPub)
var str: String = "helloworld"
var sha512Instance = SHA512()
var md: Array<Byte> = digest(sha512Instance, str)
var sig = rsaPri.sign(sha512Instance, md, padType: PKCS1)
if (rsaPub.verify(sha512Instance, md, sig, padType: PKCS1)){
println("verify successful")
}
}
ECDSA 密钥示例
使用 ECDSA 密钥使用示例。
生成 ECDSA 公钥及私钥,并使用私钥签名,公钥验证签名结果。
from crypto import keys.*
from crypto import digest.*
from std import convert.*
from std import crypto.digest.*
main() {
var ecPri = ECDSAPrivateKey(P224)
var ecPub = ECDSAPublicKey(ecPri)
var str: String = "helloworld"
var sha512Instance = SHA512()
var md: Array<Byte> = digest(sha512Instance, str)
var sig = ecPri.sign(md)
println(sig)
if (ecPub.verify(md, sig)){
println("verify successful")
}
}
x509 包
介绍
x509 包提供处理数字证书功能。
使用本包需要外部依赖 OpenSSL 3 的 ssl 和 crypto 动态库文件,故使用前需安装相关工具:
- 对于
Linux操作系统,可参考以下方式:- 如果系统的包管理工具支持安装
OpenSSL 3开发工具包,可通过这个方式安装,并确保系统安装目录下含有libssl.so、libssl.so.3、libcrypto.so和libcrypto.so.3这些动态库文件,例如Ubuntu 22.04系统上可使用sudo apt install libssl-dev命令安装libssl-dev工具包; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libssl.so、libssl.so.3、libcrypto.so和libcrypto.so.3这些动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
LD_LIBRARY_PATH以及LIBRARY_PATH中。
- 如果系统的包管理工具支持安装
- 对于
Windows操作系统,可按照以下步骤:- 自行下载
OpenSSL 3.x.x源码编译安装 x64 架构软件包或者自行下载安装第三方预编译的供开发人员使用的OpenSSL 3.x.x软件包; - 确保安装目录下含有
libssl.dll.a(或libssl.lib)、libssl-3-x64.dll、libcrypto.dll.a(或libcrypto.lib)、libcrypto-3-x64.dll这些库文件; - 将
libssl.dll.a(或libssl.lib)、libcrypto.dll.a(或libcrypto.lib) 所在的目录路径设置到环境变量LIBRARY_PATH中,将libssl-3-x64.dll、libcrypto-3-x64.dll所在的目录路径设置到环境变量PATH中。
- 自行下载
- 对于
macOS操作系统,可参考以下方式:- 使用
brew install openssl@3安装,并确保系统安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
DYLD_LIBRARY_PATH以及LIBRARY_PATH中。
- 使用
如果未安装OpenSSL 3软件包或者安装低版本的软件包,程序可能无法使用并抛出相关异常 X509Exception: Can not load openssl library or function xxx.。
主要接口
interface Key
public interface Key <: ToString {
func encodeToDer(): DerBlob
func encodeToPem(): PemEntry
static func decodeDer(encoded: DerBlob): Key
static func decodeFromPem(text: String): Key
}
公钥用于签名验证或加密,私钥用于签名或解密,公钥和私钥必须相互匹配并形成一对。
该类为密钥类,无具体实现,供 PrivateKey/PublicKey 及用户扩展接口。
func encodeToDer
func encodeToDer(): DerBlob
功能:将密钥编码为 DER 格式。
返回值:密钥数据 DER 格式编码生成的对象
func encodeToPem
func encodeToPem(): PemEntry
功能:将密钥编码为 PEM 格式。
返回值:密钥数据 PEM 格式编码生成的对象
func decodeDer
static func decodeDer(encoded: DerBlob): Key
功能:将密钥从 DER 格式解码。
参数:
- encoded:DER 格式的对象
返回值:由 DER 格式解码出的密钥
异常:
- X509Exception : 当 DER 格式的私钥内容不正确,无法解析时抛出异常
func decodeFromPem
static func decodeFromPem(text: String): Key
功能:将密钥从 PEM 格式解码。
参数:
- text:PEM 格式的字符流
返回值:由 PEM 格式解码出的密钥
interface PublicKey
public interface PublicKey <: Key {
override func encodeToPem(): PemEntry
static func decodeDer(blob: DerBlob): PublicKey
static func decodeFromPem(text: String): PublicKey
}
func encodeToPem
override func encodeToPem(): PemEntry
功能:将公钥编码为 PEM 格式。
返回值:公钥数据 PEM 格式编码生成的对象
func decodeDer
static func decodeDer(blob: DerBlob): PublicKey
功能:将公钥从 DER 格式解码。
参数:
- blob:DER 格式的公钥对象
返回值:由 DER 格式解码出的公钥
异常:
- X509Exception : 当 DER 格式的私钥内容不正确,无法解析时抛出异常
func decodeFromPem
static func decodeFromPem(text: String): PublicKey
功能:将公钥从 PEM 格式解码。
参数:
- text:PEM 格式的公钥字符流
返回值:由 PEM 格式解码出的公钥
异常:
- X509Exception:字符流不符合 PEM 格式时,或文件头不符合公钥头标准时抛出异常
interface DHParamters
public interface DHParamters <: Key {
override func encodeToPem(): PemEntry
static func decodeDer(blob: DerBlob): DHParamters
static func decodeFromPem(text: String): DHParamters
}
func encodeToPem
override func encodeToPem(): PemEntry
功能:将 DH 密钥参数编码为 PEM 格式。
返回值: DH 密钥参数数据 PEM 格式编码生成的对象
func decodeDer
static func decodeDer(blob: DerBlob): DHParamters
功能:将 DH 密钥参数从 DER 格式解码。
参数:
- blob:DER 格式的 DH 密钥参数对象
返回值:由 DER 格式解码出的 DH 密钥参数
异常:
- X509Exception : 当 DER 格式的 DH 密钥参数内容不正确,无法解析时抛出异常
func decodeFromPem
static func decodeFromPem(text: String): DHParamters
功能:将 DH 密钥参数从 PEM 格式解码。
参数:
- text:PEM 格式的 DH 密钥参数字符流
返回值:由 PEM 格式解码出的 DH 密钥参数
异常:
- X509Exception:字符流不符合 PEM 格式时,或文件头不符合 DH 密钥参数头标准时抛出异常
interface PrivateKey
public interface PrivateKey <: Key {
static func decodeDer(blob: DerBlob): PrivateKey
static func decodeFromPem(text: String): PrivateKey
static func decodeDer(blob: DerBlob, password!: ?String): PrivateKey
static func decodeFromPem(text: String, password!: ?String): PrivateKey
func encodeToDer(password!: ?String): DerBlob
override func encodeToPem(): PemEntry
func encodeToPem(password!: ?String): PemEntry
}
func decodeDer
static func decodeDer(blob: DerBlob): PrivateKey
功能:将私钥从 DER 格式解码。
参数:
- blob:DER 格式的私钥对象
返回值:由 DER 格式解码出的私钥
异常:
- X509Exception : 当 DER 格式的私钥内容不正确,无法解析时抛出异常
func decodeDer
static func decodeDer(blob: DerBlob, password!: ?String): PrivateKey
功能:将 DER 格式的私钥解密解码成 PrivateKey 对象,密码为 None 时则不解密。
参数:
-
blob:DER 格式的私钥
-
password:解密密码
返回值:解密解码后的私钥对象
异常:
- X509Exception:解密解码失败,或者参数密码为空字符串
func decodeFromPem
static func decodeFromPem(text: String): PrivateKey
功能:将私钥从 PEM 格式解码。
参数:
- text:PEM 格式的私钥字符流
返回值:由 PEM 格式解码出的私钥
异常:
- X509Exception:字符流不符合 PEM 格式时,或文件头不符合公钥头标准时抛出异常
func decodeFromPem
static func decodeFromPem(text: String, password!: ?String): PrivateKey
功能:将 PEM 格式的私钥解密解码成 PrivateKey 对象,密码为 None 时则不解密。
参数:
-
text:PEM 格式的私钥
-
password:解密密码
返回值:解密解码后的私钥对象
异常:
- X509Exception:解密解码失败,或者参数密码为空字符串
func encodeToDer
func encodeToDer(password!: ?String): DerBlob
功能:将私钥加密编码成 DER 格式,密码为 None 时则不加密。
参数:
- password:加密密码
返回值:加密后的 DER 格式的私钥
异常:
- X509Exception:加密失败,或者参数密码为空字符串
func encodeToPem
func encodeToPem(password!: ?String): PemEntry
功能:将私钥加密编码成 PEM 格式,密码为 None 时则不加密。
参数:
- password:加密密码
返回值:加密后的 PEM 格式的私钥
异常:
- X509Exception:加密失败,或者参数密码为空字符串
func encodeToPem
override func encodeToPem(): PemEntry
功能:将私钥编码成 PEM 格式。
返回值:编码后的 PEM 格式的私钥
异常:
- X509Exception:编码失败
type IP
public type IP = Array<Byte>
x509包用 Array<Byte> 来记录 IP
struct SerialNumber
public struct SerialNumber <: Equatable<SerialNumber> & Hashable & ToString {
public init(length!: UInt8 = 16)
}
结构体 SerialNumber 为数字证书的序列号,是数字证书中的一个唯一标识符,用于标识数字证书的唯一性。根据规范,证书序列号的长度不应超过 20 字节。详见rfc5280。
init
public init(length!: UInt8 = 16)
功能:生成指定长度的随机序列号。
参数:
- length:序列号长度,单位为字节,类型为 UInt8,默认值为 16
异常:
- X509Exception:length 等于 0 或大于 20 时,抛出异常
func toString
public override func toString(): String
功能:生成证书序列号字符串,格式为 16 进制。
返回值:证书序列号字符串
operator func ==
public override operator func ==(other: SerialNumber): Bool
功能:判等。
参数:
- other:被比较的证书序列号对象
返回值:若序列号相同,返回 true;否则,返回 false
operator func !=
public override operator func !=(other: SerialNumber): Bool
功能:判不等。
参数:
- other:被比较的证书序列号对象
返回值:若序列号不同,返回 true;否则,返回 false
func hashCode
public override func hashCode(): Int64
功能:返回证书序列号哈希值。
返回值:对证书序列号对象进行哈希计算后得到的结果
struct X509CertificateInfo
public struct X509CertificateInfo {
public var serialNumber: SerialNumber
public var notBefore: DateTime
public var notAfter: DateTime
public var subject: ?X509Name
public var dnsNames: Array<String>
public var emailAddresses: Array<String>
public var IPAddresses: Array<IP>
public var keyUsage: ?KeyUsage
public var extKeyUsage: ?ExtKeyUsage
public init(
serialNumber!: ?SerialNumber = None,
notBefore!: ?DateTime = None,
notAfter!: ?DateTime = None,
subject!: ?X509Name = None,
dnsNames!: Array<String> = Array<String>(),
emailAddresses!: Array<String> = Array<String>(),
IPAddresses!: Array<IP> = Array<IP>(),
keyUsage!: ?KeyUsage = None,
extKeyUsage!: ?ExtKeyUsage = None
)
}
X509CertificateInfo 结构包含了证书信息,包括证书序列号、有效期、实体可辨识名称、域名、email 地址、IP 地址、密钥用法和扩展密钥用法。
serialNumber
public var serialNumber: SerialNumber
功能:记录证书的序列号
notBefore
public var notBefore: DateTime
功能:记录证书有效期的起始日期
notAfter
public var notAfter: DateTime
功能:记录证书有效期的结束日期
subject
public var subject: ?X509Name
功能:记录证书实体可辨识名称
dnsNames
public var dnsNames: Array<String>
功能:记录证书的 DNS 域名
emailAddresses
public var emailAddresses: Array<String>
功能:记录证书的 email 地址
IPAddresses
public var IPAddresses: Array<IP>
功能:记录证书的 IP 地址
keyUsage
public var keyUsage: ?KeyUsage
功能:记录证书的密钥用法
extKeyUsage
public var extKeyUsage: ?ExtKeyUsage
功能:记录证书的扩展密钥用法
init
public init(
serialNumber!: ?SerialNumber = None,
notBefore!: ?DateTime = None,
notAfter!: ?DateTime = None,
subject!: ?X509Name = None,
dnsNames!: Array<String> = Array<String>(),
emailAddresses!: Array<String> = Array<String>(),
IPAddresses!: Array<IP> = Array<IP>(),
keyUsage!: ?KeyUsage = None,
extKeyUsage!: ?ExtKeyUsage = None
)
功能:构造 X509CertificateInfo 对象。
参数:
- serialNumber:数字证书序列号,默认值为 None,使用默认值时默认的序列号长度为 128 比特
- notBefore:数字证书有效期开始时间,默认值为 None,使用默认值时默认的时间为 X509CertificateInfo 创建的时间
- notAfter:数字证书有效期截止时间,默认值为 None,使用默认值时默认的时间为 notBefore 往后 1 年的时间
- subject:数字证书使用者信息,默认值为 None
- dnsNames:域名列表,需要用户保证输入域名的有效性,默认值为空的字符串数组
- emailAddresses:email 地址列表,需要用户保证输入 email 的有效性,默认值为空的字符串数组
- IPAddresses:IP 地址列表,默认值为空的 IP 数组
- keyUsage:密钥用法,默认值为 None
- extKeyUsage:扩展密钥用法,默认值为 None
异常:
- X509Exception:输入的 IP 地址列表中包含无效的 IP 地址,则抛出异常
class X509Certificate
public class X509Certificate <: Equatable<X509Certificate> & Hashable & ToString {
public init(
certificateInfo: X509CertificateInfo,
parent!: X509Certificate,
publicKey!: PublicKey,
privateKey!: PrivateKey,
signatureAlgorithm!: ?SignatureAlgorithm = None
)
public func encodeToDer(): DerBlob
public func encodeToPem(): PemEntry
public static func decodeFromDer(der: DerBlob): X509Certificate
public static func decodeFromPem(pem: String): Array<X509Certificate>
public static func systemRootCerts(): Array<X509Certificate>
public prop serialNumber: SerialNumber
public prop signatureAlgorithm: SignatureAlgorithm
public prop signature: Signature
public prop issuer: X509Name
public prop subject: X509Name
public prop notBefore: DateTime
public prop notAfter: DateTime
public prop publicKeyAlgorithm: PublicKeyAlgorithm
public prop publicKey: PublicKey
public prop dnsNames: Array<String>
public prop emailAddresses: Array<String>
public prop IPAddresses: Array<IP>
public prop keyUsage: KeyUsage
public prop extKeyUsage: ExtKeyUsage
public func verify(verifyOption: VerifyOption): Bool
public override func toString(): String
public override operator func ==(other: X509Certificate): Bool
public override operator func !=(other: X509Certificate): Bool
public override func hashCode(): Int64
}
X509 数字证书是一种用于加密通信的数字证书,它是公钥基础设施(PKI)的核心组件之一。X509 数字证书包含了一个实体的公钥和身份信息,用于验证该实体的身份和确保通信的安全性。
init
public init(
certificateInfo: X509CertificateInfo,
parent!: X509Certificate,
publicKey!: PublicKey,
privateKey!: PrivateKey,
signatureAlgorithm!: ?SignatureAlgorithm = None
)
功能:创建数字证书对象。
参数:
- certificateInfo:数字证书配置信息,类型为 X509CertificateInfo
- parent:颁发者证书,类型为 X509Certificate
- publicKey:申请人公钥,类型为 PublicKey,仅支持 RSA、ECDSA 和 DSA 公钥
- privateKey:颁发者私钥,类型为 PrivateKey,仅支持 RSA、ECDSA 和 DSA 私钥
- signatureAlgorithm:证书签名算法,默认值为 None,使用默认值时默认的摘要类型是 SHA256
异常:
- X509Exception: 公钥或私钥类型不支持、私钥类型和证书签名算法中的私钥类型不匹配或数字证书信息设置失败时,抛出异常
func encodeToDer
public func encodeToDer(): DerBlob
功能:将数字证书编码成 Der 格式。
返回值:编码后的 Der 格式的数字证书
func encodeToPem
public func encodeToPem(): PemEntry
功能:将数字证书编码成 PEM 格式。
返回值:编码后的 PEM 格式的数字证书
func decodeFromDer
public static func decodeFromDer(der: DerBlob): X509Certificate
功能:将 DER 格式的数字证书解码。
参数:
- der:DER 格式的二进制数据
返回值:由 DER 格式解码出的数字证书
异常:
- X509Exception:数据为空时,或数据不是有效的数字证书 DER 格式时抛出异常
func decodeFromPem
public static func decodeFromPem(pem: String): Array<X509Certificate>
功能:将数字证书从 PEM 格式解码。
参数:
- pem:PEM 格式的数字证书字符流
返回值:由 PEM 格式解码出的数字证书数组
异常:
- X509Exception:字符流不符合 PEM 格式时,或文件头不符合数字证书头标准时抛出异常
func systemRootCerts
public static func systemRootCerts(): Array<X509Certificate>
功能:返回操作系统的根证书链。支持 linux,macOS 和 windows 平台。
返回值:操作系统的根证书链
prop serialNumber
public prop serialNumber: SerialNumber
功能:解析数字证书的序列号。
返回值:数字证书的序列号,类型为 SerialNumber
prop signatureAlgorithm
public prop signatureAlgorithm: SignatureAlgorithm
功能:解析数字证书的签名算法。
返回值:数字证书的签名算法,类型为 SignatureAlgorithm
prop signature
public prop signature: Signature
功能:解析数字证书的签名。
返回值:数字证书的签名,类型为 Signature
prop issuer
public prop issuer: X509Name
功能:解析数字证书的颁发者信息。
返回值:数字证书的颁发者信息,类型为 X509Name
prop subject
public prop subject: X509Name
功能:解析数字证书的使用者信息。
返回值:数字证书的使用者信息,类型为 X509Name
prop notBefore
public prop notBefore: DateTime
功能:解析数字证书的有效期开始时间。
返回值:数字证书的有效期开始时间,类型为 DateTime
prop notAfter
public prop notAfter: DateTime
功能:解析数字证书的有效期截止时间。
返回值:数字证书的有效期截止时间,类型为 DateTime
prop publicKeyAlgorithm
public prop publicKeyAlgorithm: PublicKeyAlgorithm
功能:解析数字证书的公钥算法。
返回值:数字证书的公钥算法,类型为 PublicKeyAlgorithm
prop publicKey
public prop publicKey: PublicKey
功能:解析数字证书的公钥。
返回值:数字证书的公钥,类型为 PublicKey
prop dnsNames
public prop dnsNames: Array<String>
功能:解析数字证书备选名称中的域名。
返回值:数字证书备选名称中的域名,类型为 Array
prop emailAddresses
public prop emailAddresses: Array<String>
功能:解析数字证书备选名称中的 email 地址。
返回值:数字证书备选名称中的 email 地址,类型为 Array
prop IPAddresses
public prop IPAddresses: Array<IP>
功能:解析数字证书备选名称中的 IP 地址。
返回值:数字证书备选名称中的 IP 地址,类型为 Array
prop keyUsage
public prop keyUsage: KeyUsage
功能:解析数字证书中的密钥用法。
返回值:数字证书中的密钥用法,类型为 KeyUsage
prop extKeyUsage
public prop extKeyUsage: ExtKeyUsage
功能:解析数字证书中的扩展密钥用法。
返回值:数字证书中的扩展密钥用法,类型为 ExtKeyUsage
func verify
public func verify(verifyOption: VerifyOption): Bool
功能:根据验证选项验证当前证书的有效性,验证优先级:
- 优先验证有效期;
- 可选验证DNS域名;
- 最后根据根证书和中间证书验证其有效性。
参数:
- verifyOption:证书验证选项
返回值:证书有效返回 true,否则返回 false
异常:
- X509Exception:检验过程中失败,比如内存分配异常等内部错误,则抛出异常
func toString
public override func toString(): String
功能:生成证书名称字符串,包含证书的使用者信息、有效期以及颁发者信息。
返回值:证书名称字符串
operator func ==
public override operator func ==(other: X509Certificate): Bool
功能:判等。
参数:
- other:被比较的证书对象
返回值:若证书相同,返回 true;否则,返回 false
operator func !=
public override operator func !=(other: X509Certificate): Bool
功能:判不等。
参数:
- other:被比较的证书对象
返回值:若证书不同,返回 true;否则,返回 false
func hashCode
public override func hashCode(): Int64
功能:返回证书哈希值。
返回值:对证书对象进行哈希计算后得到的结果
struct X509CertificateRequestInfo
public struct X509CertificateRequestInfo {
public var subject: ?X509Name
public var dnsNames: Array<String>
public var emailAddresses: Array<String>
public var IPAddresses: Array<IP>
public init(
subject!: ?X509Name = None,
dnsNames!: Array<String> = Array<String>(),
emailAddresses!: Array<String> = Array<String>(),
IPAddresses!: Array<IP> = Array<IP>()
)
X509CertificateRequestInfo 结构包含了证书请求信息,包括证书实体可辨识名称、域名、email 地址和 IP 地址。
subject
public var subject: ?X509Name
功能:记录证书签名请求的实体可辨识名称
dnsNames
public var dnsNames: Array<String>
功能:记录证书签名请求的 DNS 域名
emailAddresses
public var emailAddresses: Array<String>
功能:记录证书签名请求的 email 地址
IPAddresses
public var IPAddresses: Array<IP>
功能:记录证书签名请求的 IP 地址
init
public init(
subject!: ?X509Name = None,
dnsNames!: Array<String> = Array<String>(),
emailAddresses!: Array<String> = Array<String>(),
IPAddresses!: Array<IP> = Array<IP>()
)
功能:构造 X509CertificateRequestInfo 对象。
参数:
- subject:数字证书的使用者信息,默认值为 None
- dnsNames:域名列表,需要用户保证输入域名的有效性,默认值为空的字符串数组
- emailAddresses:email 地址列表,需要用户保证输入 email 的有效性,默认值为空的字符串数组
- IPAddresses:IP 地址列表,默认值为空的 IP 数组
异常:
- X509Exception:输入的 IP 地址列表中包含无效的 IP 地址,则抛出异常
class X509CertificateRequest
public class X509CertificateRequest <: Hashable & ToString {
public init(
privateKey: PrivateKey,
certificateRequestInfo!: ?X509CertificateRequestInfo = None,
signatureAlgorithm!: ?SignatureAlgorithm = None
)
public func encodeToDer(): DerBlob
public func encodeToPem(): PemEntry
public static func decodeFromDer(der: DerBlob): X509CertificateRequest
public static func decodeFromPem(pem: String): Array<X509CertificateRequest>
public prop signatureAlgorithm: SignatureAlgorithm
public prop signature: Signature
public prop publicKeyAlgorithm: PublicKeyAlgorithm
public prop publicKey: PublicKey
public prop subject: X509Name
public prop dnsNames: Array<String>
public prop emailAddresses: Array<String>
public prop IPAddresses: Array<IP>
public override func toString(): String
public override func hashCode(): Int64
init
public init(
privateKey: PrivateKey,
certificateRequestInfo!: ?X509CertificateRequestInfo = None,
signatureAlgorithm!: ?SignatureAlgorithm = None
)
功能:创建数字证书签名请求对象。
参数:
- privateKey:私钥,仅支持 RSA、ECDSA 和 DSA 私钥
- certificateRequestInfo:数字证书签名信息,默认值为 None
- signatureAlgorithm:证书签名算法,默认值为 None,使用默认值时默认的摘要类型是 SHA256
异常:
- X509Exception:私钥类型不支持、私钥类型和证书签名算法中的私钥类型不匹配或数字证书签名信息设置失败时,抛出异常
func encodeToDer
public func encodeToDer(): DerBlob
功能:将数字证书签名请求编码成 Der 格式。
返回值:编码后的 Der 格式的数字证书签名请求
func encodeToPem
public func encodeToPem(): PemEntry
功能:将数字证书签名请求编码成 PEM 格式。
返回值:编码后的 PEM 格式的数字证书签名请求
func decodeFromDer
public static func decodeFromDer(der: DerBlob): X509CertificateRequest
功能:将 DER 格式的数字证书签名请求解码。
参数:
- der:DER 格式的二进制数据
返回值:由 DER 格式解码出的数字证书签名请求
异常:
- X509Exception:数据为空时,或数据不是有效的数字证书签名请求 DER 格式时抛出异常
func decodeFromPem
public static func decodeFromPem(pem: String): Array<X509CertificateRequest>
功能:将数字证书签名请求从 PEM 格式解码。
参数:
- pem:PEM 格式的数字证书签名请求字符流
返回值:由 PEM 格式解码出的数字证书签名请求数组
异常:
- X509Exception:字符流不符合 PEM 格式时,或文件头不符合数字证书签名请求头标准时抛出异常
prop signatureAlgorithm
public prop signatureAlgorithm: SignatureAlgorithm
功能:解析数字证书签名请求的签名算法。
返回值:数字证书签名请求的签名算法,类型为 SignatureAlgorithm
prop signature
public prop signature: Signature
功能:解析数字证书签名请求的签名。
返回值:数字证书签名请求的签名,类型为 Signature
prop publicKeyAlgorithm
public prop publicKeyAlgorithm: PublicKeyAlgorithm
功能:解析数字证书签名请求的公钥算法。
返回值:数字证书签名请求的公钥算法,类型为 PublicKeyAlgorithm
prop publicKey
public prop publicKey: PublicKey
功能:解析数字证书签名请求的公钥。
返回值:数字证书签名请求的公钥,类型为 PublicKey
prop subject
public prop subject: X509Name
功能:解析数字证书签名请求的使用者信息。
返回值:数字证书签名请求的使用者信息,类型为 X509Name
prop dnsNames
public prop dnsNames: Array<String>
功能:解析数字证书签名请求备选名称中的域名。
返回值:数字证书签名请求备选名称中的域名,类型为 Array
prop emailAddresses
public prop emailAddresses: Array<String>
功能:解析数字证书签名请求备选名称中的 email 地址。
返回值:数字证书签名请求备选名称中的 email 地址,类型为 Array
prop IPAddresses
public prop IPAddresses: Array<IP>
功能:解析数字证书签名请求备选名称中的 IP 地址。
返回值:数字证书签名请求备选名称中的 IP 地址,类型为 Array
func toString
public override func toString(): String
功能:生成证书签名请求名称字符串,包含证书签名请求的使用者信息。
返回值:证书签名请求名称字符串
func hashCode
public override func hashCode(): Int64
功能:返回证书签名请求哈希值。
返回值:对证书签名请求对象进行哈希计算后得到的结果
class X509Name
public class X509Name <: ToString {
public init(
countryName!: ?String = None,
provinceName!: ?String = None,
localityName!: ?String = None,
organizationName!: ?String = None,
organizationalUnitName!: ?String = None,
commonName!: ?String = None,
email!: ?String = None
)
public prop countryName: ?String
public prop provinceName: ?String
public prop localityName: ?String
public prop organizationName: ?String
public prop organizationalUnitName: ?String
public prop commonName: ?String
public prop email: ?String
public override func toString(): String
}
证书实体可辨识名称(Distinguished Name)是数字证书中的一个重要组成部分,作用是确保证书的持有者身份的真实性和可信度,同时也是数字证书验证的重要依据之一。
X509Name 通常包含证书实体的国家或地区名称(Country Name)、州或省名称(State or Province Name)、城市名称(Locality Name)、组织名称(Organization Name)、组织单位名称(Organizational Unit Name)、通用名称(Common Name)。有时也会包含 email 地址。
init
public init(
countryName!: ?String = None,
provinceName!: ?String = None,
localityName!: ?String = None,
organizationName!: ?String = None,
organizationalUnitName!: ?String = None,
commonName!: ?String = None,
email!: ?String = None
)
功能:构造 X509Name 对象。
参数:
- countryName:国家或地区名称,默认值为 None
- provinceName:州或省名称,默认值为 None
- localityName:城市名称,默认值为 None
- organizationName:组织名称,默认值为 None
- organizationalUnitName:组织单位名称,默认值为 None
- commonName:通用名称,默认值为 None
- email:email 地址,默认值为 None
异常:
- X509Exception:设置证书实体可辨识名称时失败,比如内存分配异常等内部错误,则抛出异常
prop countryName
public prop countryName: ?String
功能:返回证书实体的国家或地区名称。
返回值:Option
prop provinceName
public prop provinceName: ?String
功能:返回证书实体的州或省名称。
返回值:Option
prop localityName
public prop localityName: ?String
功能:返回证书实体的城市名称。
返回值:Option
prop organizationName
public prop organizationName: ?String
功能:返回证书实体的组织名称。
返回值:Option
prop organizationalUnitName
public prop organizationalUnitName: ?String
功能:返回证书实体的组织单位名称。
返回值:Option
prop commonName
public prop commonName: ?String
功能:返回证书实体的通用名称。
返回值:Option
prop email
public prop email: ?String
功能:返回证书实体的 email 地址。
返回值:Option
func toString
public override func toString(): String
功能:生成证书实体名称字符串。
返回值:证书实体名称字符串,包含实体名称中存在的字段信息
class X509Exception
public class X509Exception <: Exception {
public init()
public init(message: String)
}
此异常为 X509 包抛出的异常类型。
init
public init()
功能:构造 X509Exception 对象。
init
public init(message: String)
功能:构造 X509Exception 对象。
参数:
- message:异常的信息
enum SignatureAlgorithm
public enum SignatureAlgorithm <: Equatable<SignatureAlgorithm> & ToString {
| MD2WithRSA | MD5WithRSA | SHA1WithRSA | SHA256WithRSA | SHA384WithRSA
| SHA512WithRSA | DSAWithSHA1 | DSAWithSHA256 | ECDSAWithSHA1 | ECDSAWithSHA256
| ECDSAWithSHA384 | ECDSAWithSHA512 | UnknownSignatureAlgorithm
}
证书签名算法(Signature Algorithm)是用于数字证书签名的算法,它是一种将数字证书中的公钥和其他信息进行加密的算法,以确保数字证书的完整性和真实性。
目前支持签名算法的种类包括:MD2WithRSA 、MD5WithRSA 、SHA1WithRSA 、SHA256WithRSA 、SHA384WithRSA、SHA512WithRSA、DSAWithSHA1、DSAWithSHA256、ECDSAWithSHA1、ECDSAWithSHA256、ECDSAWithSHA384 和 ECDSAWithSHA512。
MD2WithRSA
MD2WithRSA
功能:MD2withRSA 签名算法。
MD5WithRSA
MD5WithRSA
功能:MD5withRSA 签名算法。
SHA1WithRSA
SHA1WithRSA
功能:SHA1withRSA签名算法。
SHA256WithRSA
SHA256WithRSA
功能:SHA256withRSA 签名算法。
SHA384WithRSA
SHA384WithRSA
功能:SHA384withRSA 签名算法。
SHA512WithRSA
SHA512WithRSA
功能:SHA512withRSA 签名算法。
DSAWithSHA1
DSAWithSHA1
功能:DSAwithSHA1 签名算法。
DSAWithSHA256
DSAWithSHA256
功能:DSAwithSHA256 签名算法。
ECDSAWithSHA1
ECDSAWithSHA1
功能:ECDSAwithSHA1 签名算法。
ECDSAWithSHA256
ECDSAWithSHA256
功能:ECDSAwithSHA256 签名算法。
ECDSAWithSHA384
ECDSAWithSHA384
功能:ECDSAwithSHA384 签名算法。
ECDSAWithSHA512
ECDSAWithSHA512
功能:ECDSAwithSHA512 签名算法。
UnknownSignatureAlgorithm
UnknownSignatureAlgorithm
功能:未知签名算法。
operator func ==
public override operator func ==(other: SignatureAlgorithm): Bool
功能:判等。
参数:
- other:被比较的签名算法
返回值:若签名算法相同,返回 true;否则,返回 false
operator func !=
public override operator func !=(other: SignatureAlgorithm): Bool
功能:判不等。
参数:
- other:被比较的签名算法
返回值:若签名算法不同,返回 true;否则,返回 false
func toString
public override func toString(): String
功能:生成证书签名算法名称字符串。
返回值:证书签名算法名称字符串
struct Signature
public struct Signature <: Equatable<Signature> & Hashable {
}
数字证书的签名,用来验证身份的正确性。
prop signatureValue
public prop signatureValue: DerBlob
功能:返回证书签名的二进制。
返回值:证书签名的二进制,类型为 DerBlob
operator func ==
public override operator func ==(other: Signature): Bool
功能:判等。
参数:
- other:被比较的证书签名
返回值:若证书签名相同,返回 true;否则,返回 false
operator func !=
public override operator func !=(other: Signature): Bool
功能:判不等。
参数:
- other:被比较的证书签名
返回值:若证书签名不同,返回 true;否则,返回 false
func hashCode
public override func hashCode(): Int64
功能:返回证书签名哈希值。
返回值:对证书签名对象进行哈希计算后得到的结果
enum PublicKeyAlgorithm
public enum PublicKeyAlgorithm <: Equatable<PublicKeyAlgorithm> & ToString {
RSA | DSA | ECDSA | UnknownPublicKeyAlgorithm
}
数字证书中包含的公钥信息,目前支持的种类有:RSA、DSA、ECDSA。
RSA
RSA
功能:RSA 公钥算法。
DSA
DSA
功能:DSA 公钥算法。
ECDSA
ECDSA
功能:ECDSA 公钥算法。
UnknownPublicKeyAlgorithm
UnknownPublicKeyAlgorithm
功能:未知公钥算法。
operator func ==
public override operator func ==(other: PublicKeyAlgorithm): Bool
功能:判等。
参数:
- other:被比较的公钥算法
返回值:若公钥算法相同,返回 true;否则,返回 false
operator func !=
public override operator func !=(other: PublicKeyAlgorithm): Bool
功能:判不等。
参数:
- other:被比较的公钥算法
返回值:若公钥算法不同,返回 true;否则,返回 false
func toString
public override func toString(): String
功能:生成证书携带的公钥算法名称字符串。
返回值:证书携带的公钥算法名称字符串
struct KeyUsage
public struct KeyUsage <: ToString {
public static let DigitalSignature = 0x0080u16
public static let NonRepudiation = 0x0040u16
public static let KeyEncipherment = 0x0020u16
public static let DataEncipherment = 0x0010u16
public static let KeyAgreement = 0x0008u16
public static let CertSign = 0x0004u16
public static let CRLSign = 0x0002u16
public static let EncipherOnly = 0x0001u16
public static let DecipherOnly = 0x0100u16
public init(keys: UInt16)
public override func toString(): String
}
数字证书扩展字段中通常会包含携带公钥的用法说明,目前支持的用途有:DigitalSignature、NonRepudiation、KeyEncipherment、DataEncipherment、KeyAgreement、CertSign、CRLSign、EncipherOnly、DecipherOnly。
DigitalSignature
public static let DigitalSignature = 0x0080u16
功能:表示私钥可以用于除了签发证书、签发 CRL 和非否认性服务的各种数字签名操作,而公钥用来验证这些签名
NonRepudiation
public static let NonRepudiation = 0x0040u16
功能:表示私钥可以用于进行非否认性服务中的签名,而公钥用来验证签名
KeyEncipherment
public static let KeyEncipherment = 0x0020u16
功能:表示密钥用来加密传输其他的密钥
DataEncipherment
public static let DataEncipherment = 0x0010u16
功能:表示公钥用于直接加密数据
KeyAgreement
public static let KeyAgreement = 0x0008u16
功能:表示密钥用于密钥协商
CertSign
public static let CertSign = 0x0004u16
功能:表示私钥用于证书签名,而公钥用于验证证书签名,专用于 CA 证书
CRLSign
public static let CRLSign = 0x0002u16
功能:表示私钥可用于对 CRL 签名,而公钥可用于验证 CRL 签名
EncipherOnly
public static let EncipherOnly = 0x0001u16
功能:表示证书中的公钥在密钥协商过程中,仅仅用于加密计算,配合 key Agreement 使用才有意义
DecipherOnly
public static let DecipherOnly = 0x0100u16
功能:表示证书中的公钥在密钥协商过程中,仅仅用于解密计算,配合 key Agreement 使用才有意义
init
public init(keys: UInt16)
参数:
- keys:密钥的用法,建议使用本结构中所提供的密钥用法变量通过按位或的方式传入参数
功能:构造指定用途的密钥用法,需要注意同一个密钥可以有多种用途。
func toString
public override func toString(): String
功能:生成密钥用途字符串。
返回值:证书密钥用途字符串
struct ExtKeyUsage
public struct ExtKeyUsage <: ToString {
public static let AnyKey = 0u16
public static let ServerAuth = 1u16
public static let ClientAuth = 2u16
public static let EmailProtection = 3u16
public static let CodeSigning = 4u16
public static let OCSPSigning = 5u16
public static let TimeStamping = 6u16
public init(keys: Array<UInt16>)
public override func toString(): String
}
数字证书扩展字段中通常会包含携带扩展密钥用法说明,目前支持的用途有:ServerAuth、ClientAuth、EmailProtection、CodeSigning、OCSPSigning、TimeStamping。
AnyKey
public static let AnyKey = 0u16
功能:表示应用于任意用途
ServerAuth
public static let ServerAuth = 1u16
功能:表示用于 SSL 的服务端验证
ClientAuth
public static let ClientAuth = 2u16
功能:表示用于 SSL 的客户端验证
EmailProtection
public static let EmailProtection = 3u16
功能:表示用于电子邮件的加解密、签名等
CodeSigning
public static let CodeSigning = 4u16
功能:表示用于代码签名
OCSPSigning
public static let OCSPSigning = 5u16
功能:用于对 OCSP 响应包进行签名
TimeStamping
public static let TimeStamping = 6u16
功能:用于将对象摘要值与时间绑定
init
public init(keys: Array<UInt16>)
功能:构造指定用途的扩展密钥用法,需要注意同一个密钥可以有多种用途。
func toString
public override func toString(): String
功能:生成扩展密钥用途字符串。
返回值:证书扩展密钥用途字符串
struct VerifyOption
public struct VerifyOption {
public var time: DateTime = DateTime.now()
public var dnsName: String = ""
public var roots: Array<X509Certificate> = X509Certificate.systemRootCerts()
public var intermediates: Array<X509Certificate> = Array<X509Certificate>()
}
time
public var time: DateTime = DateTime.now()
校验时间,默认为创建选项的时间。
dnsName
public var dnsName: String = ""
校验域名,默认为空,只有设置域名时才会进行此处校验。
roots
public var roots: Array<X509Certificate> = X509Certificate.systemRootCerts()
根证书链,默认为系统根证书链。
intermediates
public var intermediates: Array<X509Certificate> = Array<X509Certificate>()
中间证书链,默认为空。
struct DerBlob
public struct DerBlob <: Equatable<DerBlob> & Hashable {
public init(content: Array<Byte>)
}
Crypto 支持配置二进制证书流,用户读取二进制证书数据并创建 DerBlob 对象后可将其解析成 X509Certificate / X509CertificateRequest / PublicKey / PrivateKey 对象。
init
public init(content: Array<Byte>)
功能:构造 DerBlob 对象。
参数:
- content:二进制字符序列
prop size
public prop size: Int64
功能:DerBlob 对象中字符序列的大小。
prop body
public prop body: Array<Byte>
功能:DerBlob 对象中的字符序列。
operator func ==
public override operator func ==(other: DerBlob): Bool
功能:判等。
参数:
- other:被比较的 DerBlob 对象
返回值:若对象相同,返回 true;否则,返回 false
operator func !=
public override operator func !=(other: DerBlob): Bool
功能:判不等。
参数:
- other:被比较的 DerBlob 对象
返回值:若对象不同,返回 true;否则,返回 false
func hashCode
public override func hashCode(): Int64
功能:返回 DerBlob 对象哈希值。
返回值:对 DerBlob 对象进行哈希计算后得到的结果
struct PemEntry
public struct PemEntry <: ToString {
public PemEntry(
public let label: String,
public let headers: Array<(String, String)>,
public let body: ?DerBlob
)
public init(label: String, body: DerBlob)
}
PEM 文本格式经常用于存储证书和密钥,PEM 编码结构包含以下几个部分:第一行是 “-----BEGIN”,标签和 “-----” 组成的utf8编码的字符串;最后一行是 “-----END”,标签和 “-----” 组成的 utf8 编码的字符串;中间是正文,是实际二进制内容经过 base64 编码得到的可打印字符串, 详细的 PEM 编码规范可参考 rfc7468。在旧版的 PEM 编码标准中在第一行和正文之间还包含条目头,详见 rfc1421
单个 PEM 文件可能包含多个条目,单个条目可以是证书、密钥、请求或其他安全相关内容的 PEM 基础结构。密钥和证书链可以分别存储在多个 PEM 文件中,也可以存储在同一个 PEM 文件中。
为了支持不同的用户场景,我们提供了 PemEntry 和 Pem 类型,PemEntry 用于存储单个PEM 基础结构。
label
public let label: String
功能:PemEntry 实例的标签。
headers
public let headers: Array<(String, String)>
功能:PemEntry 实例的条目头。
body
public let body: ?DerBlob
功能:PemEntry 实例的二进制内容。
PemEntry
public PemEntry(
public let label: String,
public let headers: Array<(String, String)>,
public let body: ?DerBlob
)
功能:构造 PemEntry 对象。
参数:
-
label:标签
-
headers:条目头
-
body:二进制内容
init
public init(label: String, body: DerBlob)
功能:构造 PemEntry 对象。
参数:
-
label:标签
-
body:二进制内容
func header
public func header(name: String): Iterator<String>
功能:通过条目头名称,找到对应条目内容。
参数:
- name:条目头名称
返回值:条目头名称对应内容的迭代器
func encode
public func encode(): String
功能:返回PEM格式的字符串。行结束符将根据当前操作系统生成。
返回值:PEM 格式的字符串
func toString
public override func toString(): String
功能:返回 PEM 对象的标签和二进制内容的长度。
返回值:PEM 对象的标签和二进制内容的长度
LABEL_CERTIFICATE
public static let LABEL_CERTIFICATE = "CERTIFICATE"
功能:记录条目类型为证书
LABEL_X509_CRL
public static let LABEL_X509_CRL = "X509 CRL"
功能:记录条目类型为证书吊销列表
LABEL_CERTIFICATE_REQUEST
public static let LABEL_CERTIFICATE_REQUEST = "CERTIFICATE REQUEST"
功能:记录条目类型为证书签名请求
LABEL_PRIVATE_KEY
public static let LABEL_PRIVATE_KEY = "PRIVATE KEY"
功能:记录条目类型为 PKCS #8 标准未加密的私钥
LABEL_EC_PRIVATE_KEY
public static let LABEL_EC_PRIVATE_KEY = "EC PRIVATE KEY"
功能:记录条目类型为椭圆曲线私钥
LABEL_ENCRYPTED_PRIVATE_KEY
public static let LABEL_ENCRYPTED_PRIVATE_KEY = "ENCRYPTED PRIVATE KEY"
功能:记录条目类型为 PKCS #8 标准加密的私钥
LABEL_RSA_PRIVATE_KEY
public static let LABEL_RSA_PRIVATE_KEY = "RSA PRIVATE KEY"
功能:记录条目类型为 RSA 私钥
LABEL_PUBLIC_KEY
public static let LABEL_PUBLIC_KEY = "PUBLIC KEY"
功能:记录条目类型为公钥
LABEL_EC_PARAMETERS
public static let LABEL_EC_PARAMETERS = "EC PARAMETERS"
功能:记录条目类型为椭圆曲线参数
LABEL_DH_PARAMETERS
public static let LABEL_DH_PARAMETERS = "DH PARAMETERS"
功能:记录条目类型为 DH 密钥参数
struct Pem
public struct Pem <: Collection<PemEntry> & ToString {
public Pem(private let items: Array<PemEntry>)
}
结构体 Pem 为条目序列,可以包含多个 PemEntry。
Pem
public Pem(private let items: Array<PemEntry>)
功能:构造 Pem 对象。
参数:
- items:多个 PemEntry 对象
func encode
public func encode(): String
功能:返回PEM格式的字符串。行结束符将根据当前操作系统生成。
返回值:PEM 格式的字符串
func decode
public static func decode(text: String): Pem
功能:将 PEM 文本解码为条目序列。
参数:
- text:PEM 字符串
返回值:PEM 条目序列
func toString
public override func toString(): String
功能:返回一个字符串,字符串内容是包含每个条目序列的标签。
返回值:包含每个条目序列的标签的字符串
func isEmpty
public override func isEmpty(): Bool
功能:判断 PEM 文本解码为条目序列是否为空。
返回值:PEM 文本解码为条目序列为空返回 true;否则,返回 false
func iterator
public override func iterator(): Iterator<PemEntry>
功能:生成 PEM 文本解码为条目序列的迭代器。
返回值:PEM 文本解码为条目序列的迭代器
prop size
public override prop size: Int64
功能:条目序列的数量。
示例
读取、解析证书
from std import fs.File
from crypto import x509.*
let readPath = "./files/root_rsa.cer"
main() {
// 读取本地证书
let pem = String.fromUtf8(File.readFrom(readPath))
let certificates = X509Certificate.decodeFromPem(pem)
// 解析证书中的必选字段
let cert = certificates[0]
println(cert)
println("Serial Number: ${cert.serialNumber}")
println("Issuer: ${cert.issuer}")
println("NotBefore: ${cert.notBefore}")
println("NotAfter: ${cert.notAfter}")
println(cert.signatureAlgorithm)
let signature = cert.signature
println(signature.hashCode())
println(cert.publicKeyAlgorithm)
let pubKey = cert.publicKey
println(pubKey.encodeToPem().encode())
// 解析证书中的扩展字段
println("DNSNames: ${cert.dnsNames}")
println("EmailAddresses: ${cert.emailAddresses}")
println("IPAddresses: ${cert.IPAddresses}")
println("KeyUsage: ${cert.keyUsage}")
println("ExtKeyUsage: ${cert.extKeyUsage}")
// 解析证书使用者的可辨识名称
println("Subject: ${cert.subject}")
return 0
}
读取、验证证书
from std import fs.File
from crypto import x509.*
from std import time.DateTime
let prefixPath = "./files/"
let certFile = "servers.crt"
let rootFile = "roots.crt"
let middleFile = "middles.crt"
func getX509Cert(path: String)
{
let pem = String.fromUtf8(File.readFrom(path))
X509Certificate.decodeFromPem(pem)
}
func testVerifyByTime(cert: X509Certificate, roots: Array<X509Certificate>, middles: Array<X509Certificate>)
{
var opt = VerifyOption()
opt.roots = roots
opt.intermediates = middles
cert.verify(opt)
println("Verify result: ${cert.verify(opt)}")
opt.time = DateTime.of(year: 2023, month: 7, dayOfMonth: 1)
println("Verify result:: ${cert.verify(opt)}")
}
func testVerifyByDNS(cert: X509Certificate)
{
var opt = VerifyOption()
opt.dnsName = "www.example.com"
println("cert DNS names: ${cert.dnsNames}")
let res = cert.verify(opt)
println("Verify result: ${res}")
}
/**
* The relation of certs.
* root[0] root[1]
* / \ |
* mid[0] mid[1] mid[2]
* | |
* server[0] server[1]
*/
func testVerify(cert: X509Certificate, roots: Array<X509Certificate>, middles: Array<X509Certificate>)
{
var opt = VerifyOption()
opt.roots = roots
opt.intermediates = middles
let res = cert.verify(opt)
println("Verify result: ${res}")
}
main() {
// 2 server certs
let certs = getX509Cert(prefixPath + certFile)
// 2 root certs
let roots = getX509Cert(prefixPath + rootFile)
// 3 middle certs
let middles = getX509Cert(prefixPath + middleFile)
// Verify by time: true, false
testVerifyByTime(certs[0], [roots[0]], [middles[0]])
// Verify by dns: false
testVerifyByDNS(certs[0])
// cert0 <- root0: false
testVerify(certs[0], [roots[0]], [])
// cert0 <- middle0 <- root0: true
testVerify(certs[0], [roots[0]], [middles[0]])
// cert0 <- (middle0, middle1, middle2) <- (root0, root1) : true
testVerify(certs[0], roots, middles)
// cert1 <- middle0 <- root0: false
testVerify(certs[1], [roots[0]], [middles[0]])
// cert1 <- middle2 <- root1: true
testVerify(certs[1], [roots[1]], [middles[2]])
// cert1 <- (middle0, middle1, middle2) <- (root0, root1) : true
testVerify(certs[1], roots, middles)
return 0
}
创建、解析证书
from std import fs.*
from crypto import x509.*
main(){
let x509Name = X509Name(
countryName: "CN",
provinceName: "beijing",
localityName: "haidian",
organizationName: "organization",
organizationalUnitName: "organization unit",
commonName: "x509",
email: "test@email.com"
)
let serialNumber = SerialNumber(length: 20)
let startTime: DateTime = DateTime.now()
let endTime: DateTime = notBefore.addYears(1)
let ip1: IP = Array<Byte>([8, 8, 8, 8])
let ip2: IP = Array<Byte>([0, 1, 0, 1, 0, 1, 0, 1, 0, 8, 0, 8, 0, 8, 0, 8])
let parentCertPem = String.fromUtf8(File("./certificate.pem", OpenOption.Open(true, false)).readToEnd())
let parentCert = X509Certificate.decodeFromPem(parentCertPem)[0]
let parentKeyPem = String.fromUtf8(File("./rsa_private_key.pem", OpenOption.Open(true, false)).readToEnd())
let parentPrivateKey = PrivateKey.decodeFromPem(parentKeyPem)
let usrKeyPem = String.fromUtf8(File("./ecdsa_public_key.pem", OpenOption.Open(true, false)).readToEnd())
let usrPublicKey = PublicKey.decodeFromPem(usrKeyPem)
let certInfo = X509CertificateInfo(serialNumber: serialNumber, notBefore: startTime, notAfter: endTime, subject: x509Name, dnsNames: Array<String>(["b.com"]), IPAddresses: Array<IP>([ip1, ip2]));
let cert = X509Certificate(info, parent: parentCert, publicKey: usrPublicKey, privateKey: parentPrivateKey)
println(cert)
println("Serial Number: ${cert.serialNumber}")
println("Issuer: ${cert.issuer}")
println("Subject: ${cert.subject}")
println("NotBefore: ${cert.notBefore}")
println("NotAfter: ${cert.notAfter}")
println(cert.signatureAlgorithm)
println("DNSNames: ${cert.dnsNames}")
println("IPAddresses: ${cert.IPAddresses}")
return 0
}
创建、解析证书签名请求
from std import fs.*
from crypto import x509.*
main(){
let x509Name = X509Name(
countryName: "CN",
provinceName: "beijing",
localityName: "haidian",
organizationName: "organization",
organizationalUnitName: "organization unit",
commonName: "x509",
email: "test@email.com"
)
let ip1:IP = Array<Byte>([8, 8, 8, 8])
let ip2:IP = Array<Byte>([0, 1, 0, 1, 0, 1, 0, 1, 0, 8, 0, 8, 0, 8, 0, 8])
let rsaPem = String.fromUtf8(File("./rsa_private_key.pem", OpenOption.Open(true, false)).readToEnd())
let rsa = PrivateKey.decodeFromPem(rsaPem)
let csrInfo = X509CertificateRequestInfo(subject: x509Name, dnsNames: Array<String>(["b.com"]), IPAddresses: Array<IP>([ip1, ip2]));
let csr = X509CertificateRequest(rsa, certificateRequestInfo:csrInfo, signatureAlgorithm: SHA256WithRSA)
println("Subject: ${csr.subject.toString()}")
println("IPAddresses: ${csr.IPAddresses}")
println("dnsNames: ${csr.dnsNames}")
return 0
}
base64 包
介绍
主要提供字符串的 Base64 编码及解码。
主要接口
func fromBase64String
public func fromBase64String(data: String): Option<Array<Byte>>
功能:此函数用于 Base64 编码的字符串的解码。
参数:
data:要转换的 Base64String
返回值:返回转换后的 Option<Array<Byte>>,输入空字符串会返回Option<Array<Byte>>.Some(Array<Byte>()),解码失败会返回 Option<Array<Byte>>.None。
func toBase64String
public func toBase64String(data: Array<Byte>): String
功能:此函数将字符串的 ascii 编码数组转换成 Base64 编码的字符串。
参数:
data:要转换的Array<Byte>
返回值:返回转换后的 Base64 编码的字符串
示例
Byte 数组和 Base 互转
下面是 Byte 数组和 Base 互转示例。
代码如下:
from encoding import base64.*
main(): Int64 {
var arr = Array<Byte>([77, 97, 110])
var str = toBase64String(arr)
print("${str},")
var opArr: Option<Array<Byte>> = fromBase64String(str)
var arr2: Array<Byte> = match (opArr) {
case Some(s) => s
case None => Array<Byte>()
}
for (i in 0..arr2.size) {
print("${arr2[i]},")
}
return 0
}
运行结果如下:
TWFu,77,97,110,
base64 包
介绍
主要提供字符串的 Base64 编码及解码。
主要接口
func fromBase64String
public func fromBase64String(data: String): Option<Array<Byte>>
功能:此函数用于 Base64 编码的字符串的解码。
参数:
data:要转换的 Base64String
返回值:返回转换后的 Option<Array<Byte>>,输入空字符串会返回Option<Array<Byte>>.Some(Array<Byte>()),解码失败会返回 Option<Array<Byte>>.None。
func toBase64String
public func toBase64String(data: Array<Byte>): String
功能:此函数将字符串的 ascii 编码数组转换成 Base64 编码的字符串。
参数:
data:要转换的Array<Byte>
返回值:返回转换后的 Base64 编码的字符串
示例
Byte 数组和 Base 互转
下面是 Byte 数组和 Base 互转示例。
代码如下:
from encoding import base64.*
main(): Int64 {
var arr = Array<Byte>([77, 97, 110])
var str = toBase64String(arr)
print("${str},")
var opArr: Option<Array<Byte>> = fromBase64String(str)
var arr2: Array<Byte> = match (opArr) {
case Some(s) => s
case None => Array<Byte>()
}
for (i in 0..arr2.size) {
print("${arr2[i]},")
}
return 0
}
运行结果如下:
TWFu,77,97,110,
hex 包
介绍
主要提供字符串的 Hex 编码及解码。
主要接口
func fromHexString
public func fromHexString(data: String): Option<Array<Byte>>
功能:此函数用于 Hex 编码的字符串的解码。
参数:
data:要转换的字符串
返回值:返回解码后字节数组,用 Option<Array<Byte>> 类型表示,输入空字符串会返回Option<Array<Byte>>.Some(Array<Byte>()),解码失败会返回Option<Array<Byte>>.None。
func toHexString
public func toHexString(data: Array<Byte>): String
功能:此函数将字符串的 ascii 编码数组转换成 Hex 编码的字符串。
参数:
data:要转换的字节数组
返回值:返回转换后的 Hex 编码的字符串
示例
Byte 数组和 Hex 互转
下面是 Byte 数组和 Hex 互转示例。
代码如下:
from encoding import hex.*
main(): Int64 {
var arr = Array<Byte>([65, 66, 94, 97])
var str = toHexString(arr)
print("${str},")
var opArr: Option<Array<Byte>> = fromHexString(str)
var arr2: Array<Byte> = match (opArr) {
case Some(s) => s
case None => Array<Byte>()
}
for (i in 0..arr2.size) {
print("${arr2[i]},")
}
return 0
}
运行结果如下:
41425e61,65,66,94,97,
json 包
介绍
主要用于对 json 数据的处理,实现 String, JsonValue, DataModel 之间的相互转换。
JsonValue 是对 Json 数据格式的封装,包括 object, array, string, number, true, false 和 null。
DataModel 详细信息可参考 serialization 包文档。
json 语法规则可参考:介绍 JSON。
json 数据转换标准可参考:ECMA-404 The JSON Data Interchange Standard。
主要接口
enum JsonKind
public enum JsonKind {
| JsNull
| JsBool
| JsInt
| JsFloat
| JsString
| JsArray
| JsObject
}
JsonKind 枚举类型表示 JsonValue 的所有类型。
JsNull
JsNull
JsBool
JsBool
JsInt
JsInt
JsFloat
JsFloat
JsString
JsString
JsArray
JsArray
JsObject
JsObject
class JsonValue
sealed abstract class JsonValue <: ToString
此类为 json 数据层, 主要用于 JsonValue 和 String 数据之间的互相转换。
func fromStr
public static func fromStr(s: String): JsonValue
功能:将字符串数据解析为 JsonValue,对于整数,支持前导 '0b', '0o', '0x'(不区分大小写),分别表示二进制,八进制和十六进制。字符串解析失败时将打印错误字符及其行数和列数,其中列数从错误字符所在行的非空格字符起开始计算。
参数:
- s:传入字符串,s 暂不支持 ? 和特殊字符
返回值:转换后 JsonValue
异常:
- 异常 JsonException:如果内存分配失败,或解析字符串出错,抛出异常
func toString
public func toString(): String
功能:将 JsonValue 转换为字符串。
返回值:转换后字符串
异常:
- 异常 JsonException:如果 json 值不能转换为字符串, 抛出异常
func toJsonString
public func toJsonString(): String
功能:将 JsonValue 转换为 json 格式 (带有空格换行符) 字符串。
返回值:转换后 json 格式字符串
异常:
- 异常 JsonException:如果 json 值不能转换为字符串, 抛出异常
func kind
public func kind(): JsonKind
功能:返回当前 JsonValue 所属的 JsonKind 类型。
返回值:当前 JsonValue 所属的 JsonKind 类型
func asNull
public func asNull(): JsonNull
功能:将 JsonValue 转换为 JsonNull 格式。
返回值:转换后 JsonNull
异常:
- 异常 JsonException:如果转换失败,抛出异常
func asBool
public func asBool(): JsonBool
功能:将 JsonValue 转换为 JsonBool 格式。
返回值:转换后 JsonBool
异常:
- 异常 JsonException:如果转换失败,抛出异常
func asInt
public func asInt(): JsonInt
功能:将 JsonValue 转换为 JsonInt 格式。
返回值:转换后 JsonInt
异常:
- 异常 JsonException:如果转换失败,抛出异常
func asFloat
public func asFloat(): JsonFloat
功能:将 JsonValue 转换为 JsonFloat 格式。
返回值:转换后 JsonFloat
异常:
- 异常 JsonException:如果转换失败,抛出异常
func asString
public func asString(): JsonString
功能:将 JsonValue 转换为 JsonString 格式。
返回值:转换后 JsonString
异常:
- 异常 JsonException:如果转换失败,抛出异常
func asArray
public func asArray(): JsonArray
功能:将 JsonValue 转换为 JsonArray 格式。
返回值:转换后 JsonArray
异常:
- 异常 JsonException:如果转换失败,抛出异常
func asObject
public func asObject(): JsonObject
功能:将 JsonValue 转换为 JsonObject 格式。
返回值:转换后 JsonObject
异常:
- 异常 JsonException:如果转换失败,抛出异常
class JsonNull
public class JsonNull <: JsonValue
此类为 JsonValue 实现子类, 主要用于封装 null 的 JSON 数据。
func toString
public func toString(): String
功能:将 JsonNull 转换为字符串。
返回值:转换后字符串
func toJsonString
public func toJsonString(): String
功能:将 JsonNull 转换为 json 格式 (带有空格换行符) 字符串。
返回值:转换后 json 格式字符串
func kind
public func kind(): JsonKind
功能:返回当前 JsonNull 所属的 JsonKind 类型(JsNull)。
返回值:当前 JsonNull 所属的 JsonKind 类型(JsNull)
class JsonBool
public class JsonBool <: JsonValue {
public init(bv: Bool)
}
此类为 JsonValue 实现子类, 主要用于封装 true 或者 false 的 JSON 数据。
init
public init(bv: Bool)
功能:将指定的 Bool 类型实例封装成 JsonBool 实例。
func getValue
public func getValue(): Bool
功能:获取 JsonBool 中 value 的实际值。
返回值:value 的实际值
func toString
public func toString(): String
功能:将 JsonBool 转换为字符串。
返回值:转换后字符串
func toJsonString
public func toJsonString(): String
功能:将 JsonBool 转换为 json 格式 (带有空格换行符) 字符串。
返回值:转换后 json 格式字符串
func kind
public func kind(): JsonKind
功能:返回当前 JsonBool 所属的 JsonKind 类型(JsBool)。
返回值:当前 JsonBool 所属的 JsonKind 类型(JsBool)
class JsonInt
public class JsonInt <: JsonValue {
public init(iv: Int64)
}
此类为 JsonValue 实现子类, 主要用于封装整数类型的 JSON 数据。
init
public init(iv: Int64)
功能:将指定的 Int64 类型实例封装成 JsonInt 实例。
func getValue
public func getValue(): Int64
功能:获取 JsonInt 中 value 的实际值。
返回值:value 的实际值
func toString
public func toString(): String
功能:将 JsonInt 转换为字符串。
返回值:转换后字符串
func toJsonString
public func toJsonString(): String
功能:将 JsonInt 转换为 json 格式 (带有空格换行符) 字符串。
返回值:转换后 json 格式字符串
func kind
public func kind(): JsonKind
功能:返回当前 JsonInt 所属的 JsonKind 类型(JsInt)。
返回值:当前 JsonInt 所属的 JsonKind 类型(JsInt)
class JsonFloat
public class JsonFloat <: JsonValue {
public init(fv: Float64)
public init(v: Int64)
}
此类为 JsonValue 实现子类, 主要用于封装浮点类型的 JSON 数据。
init
public init(fv: Float64)
功能:将指定的 Float64 类型实例封装成 JsonFloat 实例。
参数:
- fv:Float64 类型
init
public init(v: Int64)
功能:将指定的 Int64 类型实例封装成 JsonFloat 实例。
参数:
- v:Int64 类型
func getValue
public func getValue(): Float64
功能:获取 JsonFloat 中 value 的实际值。
返回值:value 的实际值
func toString
public func toString(): String
功能:将 JsonFloat 转换为字符串。
返回值:转换后字符串
func toJsonString
public func toJsonString(): String
功能:将 JsonFloat 转换为 json 格式 (带有空格换行符) 字符串。
返回值:转换后 json 格式字符串
func kind
public func kind(): JsonKind
功能:返回当前 JsonFloat 所属的 JsonKind 类型(JsFloat)。
返回值:当前 JsonFloat 所属的 JsonKind 类型(JsFloat)
class JsonString
public class JsonString <: JsonValue {
public init(sv: String)
}
此类为 JsonValue 实现子类, 主要用于封装字符串类型的 JSON 数据。
init
public init(sv: String)
功能:将指定的 String 类型实例封装成 JsonString 实例。
func getValue
public func getValue(): String
功能:获取 JsonString 中 value 的实际值。
返回值:value 的实际值
func toString
public func toString(): String
功能:将 JsonString 转换为字符串。
返回值:转换后字符串
func toJsonString
public func toJsonString(): String
功能:将 JsonString 转换为 json 格式 (带有空格换行符) 字符串。
返回值:转换后 json 格式字符串
func kind
public func kind(): JsonKind
功能:返回当前 JsonString 所属的 JsonKind 类型(JsString)。
返回值:当前 JsonString 所属的 JsonKind 类型(JsString)
class JsonArray
public class JsonArray <: JsonValue {
public init()
public init(list: ArrayList<JsonValue>)
public init(list: Array<JsonValue>)
}
此类为 JsonValue 实现子类, 主要用于封装数组类型的 JSON 数据。
init
public init()
功能:创建空 JsonArray。
init
public init(list: ArrayList<JsonValue>)
功能:将指定的 ArrayList 类型实例封装成 JsonArray 实例。
init
public init(list: Array<JsonValue>)
功能:将指定的 Array 类型实例封装成 JsonArray 实例。
func toJsonString
public func toJsonString(): String
功能:将 JsonArray 转换为 json 格式 (带有空格换行符) 字符串。
返回值:转换后 json 格式字符串
异常:
- 异常 JsonException:如果数组中存在 JsonValue 元素无法转为字符串,抛出异常
func toJsonString
public func toJsonString(depth: Int64, bracketInNewLine!: Bool = false): String
功能:将 JsonArray 转换为 Json-String。
参数:
- depth:JSON 格式缩进深度
- bracketInNewLine:如果是 false, 第一个括号将不会缩进,其他所有行都会缩进指定深度,true,所有行按照缩进深度跟随缩进,默认是 false
返回值:json 转换的字符串是项字符串数据
异常:
- 异常 JsonException:如果存在无法转换为字符串的 JsonArray, 则抛出异常
func toString
public func toString(): String
功能:将 JsonString 转换为字符串。
返回值:转换后字符串
异常:
- 异常 JsonException:如果数组中存在 JsonValue 元素无法转为字符串,抛出异常
func kind
public func kind(): JsonKind
功能:返回当前 JsonArray 所属的 JsonKind 类型(JsArray)。
返回值:当前 JsonArray 所属的 JsonKind 类型(JsArray)
func size
public func size(): Int64
功能:获取 JsonArray 中 JsonValue 的数量。
返回值:JsonArray 中 items 的大小
func add
public func add(jv: JsonValue): JsonArray
功能:向 JsonArray 中加入 JsonValue 数据。
参数:
jv:需要加入的JsonValue
func get
public func get(index: Int64): Option<JsonValue>
功能:获取 JsonArray 中指定索引的 JsonValue,并用 Option
参数:
- index:指定的索引
返回值:对应索引的 JsonValue 数据的封装形式
operator func []
public operator func [](index: Int64): JsonValue
功能:获取 JsonArray 中指定索引的 JsonValue。
参数:
- index:指定的索引
返回值:对应索引的 JsonValue
异常:
- 异常 JsonException:如果 index 不是 JsonArray 的有效索引,抛出异常
func getItems
public func getItems(): ArrayList<JsonValue>
功能:获取 JsonArray 中的 items 数据。
返回值:JsonArray 的 items 数据
class JsonObject
public class JsonObject <: JsonValue {
public init()
public init(map: HashMap<String, JsonValue>)
}
此类为 JsonValue 实现子类, 主要用于封装 object 类型的 JSON 数据。
init
public init()
功能:创建空 JsonObject。
init
public init(map: HashMap<String, JsonValue>)
功能:将指定的 HashMap 类型实例封装成 JsonObject 实例。
func toJsonString
public func toJsonString(): String
功能:将 JsonObject 转换为 json 格式 (带有空格换行符) 字符串。
返回值:转换后 json 格式字符串
异常:
- 异常 JsonException:如果 JsonObject 中存在 JsonValue 元素无法转为字符串,抛出异常
func toJsonString
public func toJsonString(depth: Int64, bracketInNewLine!: Bool = false): String
功能:将 JsonObject 转换为 Json-String。
参数:
- depth:JSON 格式缩进深度
- bracketInNewLine:如果是 false,第一个括号将不会缩进,其他所有行都会缩进指定深度,true,所有行按照缩进深度跟随缩进,默认是 false
返回值:json 转换的字符串是项字符串数据
异常:
- 异常 JsonException:如果存在无法转换为字符串的 JsonObject,则抛出异常
func toString
public func toString(): String
功能:将 JsonObject 转换为字符串。
返回值:转换后字符串
异常:
- 异常 JsonException:如果 JsonObject 中存在 JsonValue 元素无法转为字符串,抛出异常
func kind
public func kind(): JsonKind
功能:返回当前 JsonObject 所属的 JsonKind 类型(JsObject)。
返回值:当前 JsonObject 所属的 JsonKind 类型(JsObject)
func size
public func size(): Int64
功能:获取 JsonObject 中 fields 存入 string-JsonValue 的数量。
返回值:JsonObject 中 fields 的大小
func containsKey
public func containsKey(key: String): Bool
功能:判断 JsonObject 中是否存在 key。
参数:
- key:指定的 key
返回值:存在返回 true,不存在返回 false
func put
public func put(key: String, v: JsonValue)
功能:向 JsonObject 中加入 key-JsonValue 数据。
参数:
- key:需要加入的 key
- v:对应 key 的 JsonValue
func get
public func get(key: String): Option<JsonValue>
功能:获取 JsonObject 中 key 对应的 JsonValue, 并用 Option
参数:
- key:指定的 key
返回值:key 对应的 JsonValue 的封装形式
operator func []
public operator func [](key: String): JsonValue
功能:获取 JsonObject 中 key 对应的 JsonValue。
参数:
- key:指定的 key
返回值:key 对应的 JsonValue
异常:
- 异常 JsonException:如果 key 不是 JsonObject 的有效键,抛出异常
func getFields
public func getFields(): HashMap<String, JsonValue>
功能:获取 JsonObject 中的 fields 数据。
返回值:JsonObject 的 fields 数据
interface ToJson
public interface ToJson {
func toJson(): JsonValue
static func fromJson(jv: JsonValue): DataModel
}
此接口用于实现 JsonValue 和 DataModel 的相互转换,DataModel 依赖 serialization 包,DataModel 为数据中间层, 可以通过序列化和反序列化的函数实现 DataModel 和对象的相互转换,支持的对象类型包括:
基本数据类型:整数类型、浮点类型、布尔类型、字符类型、字符串类型。
Collection 类型:Array、ArrayList、HashSet、HashMap、Option。
用户自定义的实现了 Serializable 接口的类型。
JsonValue 与 DataModel 的对应关系如下:
| JsonValue | DataModel |
|---|---|
| JsonBool | DataModelBool |
| JsonInt | DataModelInt |
| JsonFloat | DataModelFloat |
| JsonString | DataModelString |
| JsonArray | DataModelSeq |
| JsonObject | DataModelStruct |
| JsonNull | DataModelNull |
func toJson
func toJson(): JsonValue
功能:将自身转化为 JsonValue。
异常:
- 异常 JsonException:如果转换失败,抛出异常
func fromJson
static func fromJson(jv: JsonValue): DataModel
功能:将 JsonValue 转化为对象 DataModel。
异常:
- 异常 JsonException:如果转换失败,抛出异常
class JsonException
public class JsonException <: Exception {
public init()
public init(message: String)
}
Json 包的异常类
init
public init()
功能:创建 JsonException。
init
public init(message: String)
功能:创建 JsonException。
参数:
- message:异常提示字符串
extend DataModel <: ToJson
extend DataModel <: ToJson
此扩展主要用于实现 DataModel 的 ToJson 接口
func fromJson
public static func fromJson(jv: JsonValue): DataModel
功能:将 JsonValue 数据解析为 DataModel。
参数:
- jv:Json 数据格式的 JsonValue
返回值:解析的数据模型
func toJson
public func toJson(): JsonValue
功能:将 DataModel 转换为 JsonValue。
返回值:json 转换的 JsonValue
示例
JsonValue 的 fromStr/toJsonString 函数
下面是实现 String 和 JsonValue 相互转换的示例。
代码如下:
from encoding import json.*
main() {
var str = ##"[true,"kjjjke\"eed",{"sdfd":"ggggg","eeeee":[341,false,{"nnnn":55.87}]},3422,22.341,false,[22,22.22,true,"ddd"],43]"##
var jv: JsonValue = JsonValue.fromStr(str)
var res = jv.toString()
var prettyres = jv.toJsonString()
println(res)
println(prettyres)
var strO = ##"{"name":"Tom","age":"18","version":"0.1.1"}"##
var kO = JsonValue.fromStr(strO)
var resO = kO.asObject().get("name").getOrThrow()
println(resO)
0
}
运行结果如下:
[true,"kjjjke\"eed",{"sdfd":"ggggg","eeeee":[341,false,{"nnnn":55.870000}]},3422,22.341000,false,[22,22.220000,true,"ddd"],43]
[
true,
"kjjjke\"eed",
{
"sdfd": "ggggg",
"eeeee": [
341,
false,
{
"nnnn": 55.870000
}
]
},
3422,
22.341000,
false,
[
22,
22.220000,
true,
"ddd"
],
43
]
"Tom"
JsonValue 添加多种数据并转 String
下面是 JsonValue 添加多种数据并转换成 String 的示例。
代码如下:
from encoding import json.*
from std import collection.*
main() {
var a: JsonValue = JsonNull()
var b: JsonValue = JsonBool(true)
var c: JsonValue = JsonBool(false)
var d: JsonValue = JsonInt(7363)
var e: JsonValue = JsonFloat(736423.546)
var list: ArrayList<JsonValue> = ArrayList<JsonValue>()
var list2: ArrayList<JsonValue> = ArrayList<JsonValue>()
var map = JsonObject()
var map1 = JsonObject()
map1.put("a", JsonString("jjjjjj"))
map1.put("b", b)
map1.put("c", JsonString("hhhhh"))
list2.append(b)
list2.append(JsonInt(3333333))
list2.append(map1)
list2.append(JsonString("sdfghgfasd"))
list.append(b)
list.append(a)
list.append(map)
list.append(c)
list.append(JsonArray(list2))
list.append(d)
list.append(JsonString("ddddddd"))
list.append(e)
var result: JsonValue = JsonArray(list)
println(result.toString())
println(result.toJsonString())
0
}
运行结果如下:
[true,null,{},false,[true,3333333,{"a":"jjjjjj","b":true,"c":"hhhhh"},"sdfghgfasd"],7363,"ddddddd",736423.546000]
[
true,
null,
{},
false,
[
true,
3333333,
{
"a": "jjjjjj",
"b": true,
"c": "hhhhh"
},
"sdfghgfasd"
],
7363,
"ddddddd",
736423.546000
]
Json 字符串与自定义类型间的转换
下面是 Json 字符串与自定义类型间的转换的示例。
代码如下:
from serialization import serialization.*
from encoding import json.*
class Person <: Serializable<Person> {
var name: String = ""
var age: Int64 = 0
var loc: Option<Location> = Option<Location>.None
public func serialize(): DataModel {
return DataModelStruct().add(field<String>("name", name)).add(field<Int64>("age", age)).add(field<Option<Location>>("loc", loc))
}
public static func deserialize(dm: DataModel): Person {
var dms = match (dm) {
case data: DataModelStruct => data
case _ => throw Exception("this data is not DataModelStruct")
}
var result = Person()
result.name = String.deserialize(dms.get("name"))
result.age = Int64.deserialize(dms.get("age"))
result.loc = Option<Location>.deserialize(dms.get("loc"))
return result
}
}
class Location <: Serializable<Location>{
var country: String = ""
var province: String = ""
public func serialize(): DataModel {
return DataModelStruct().add(field<String>("country", country)).add(field<String>("province", province))
}
public static func deserialize(dm: DataModel): Location {
var dms = match (dm) {
case data: DataModelStruct => data
case _ => throw Exception("this data is not DataModelStruct")
}
var result = Location()
result.country = String.deserialize(dms.get("country"))
result.province = String.deserialize(dms.get("province"))
return result
}
}
main() {
var js = ##"{
"name": "A",
"age": 30,
"loc": {
"country": "China",
"province": "Beijing"
}
}"##
var jv = JsonValue.fromStr(js)
var dm = DataModel.fromJson(jv)
var A = Person.deserialize(dm)
println("name == ${A.name}")
println("age == ${A.age}")
println("country == ${A.loc.getOrThrow().country}")
println("province == ${A.loc.getOrThrow().province}")
println("====================") // 上部分实现从 Json 字符串到自定义类型的转换,下部分实现从自定义类型到 Json 字符串的转换。
dm = A.serialize()
var jo = dm.toJson().asObject()
println(jo.toJsonString())
0
}
运行结果如下:
name == A
age == 30
country == China
province == Beijing
====================
{
"name": "A",
"age": 30,
"loc": {
"country": "China",
"province": "Beijing"
}
}
Json 中转义字符处理
Json 在解析 String 转换为 JsonValue 时,转义字符 \ 之后只能对应 json 支持的转义字符(b、f、n、r、t、u、\、"、/),其中 \u 的格式为:\uXXXX,X 为十六进制数,例:\u0041 代表字符 'A'
代码如下:
from encoding import json.*
main() {
println(JsonString("\b | \f | \n | \r | \t | A | \\ | \" | /").toString())
println(JsonValue.fromStr("\"\\b\"").toString())
println(JsonValue.fromStr("\"\\f\"").toString())
println(JsonValue.fromStr("\"\\n\"").toString())
println(JsonValue.fromStr("\"\\r\"").toString())
println(JsonValue.fromStr("\"\\t\"").toString())
println(JsonValue.fromStr("\"\\u0041\"").toString())
println(JsonValue.fromStr("\"\\\\\"").toString())
println(JsonValue.fromStr("\"\\\"\"").toString())
println(JsonValue.fromStr("\"\\/\"").toString())
}
运行结果如下:
"\b | \f | \n | \r | \t | A | \\ | \" | /"
"\b"
"\f"
"\n"
"\r"
"\t"
"A"
"\\"
"\""
"/"
Json 中转义字符错误处理
json 转义错误示例,\ 后面加上数字 (非 json 支持的转义字符)。
代码如下:
from encoding import json.*
main() {
var s1 = JsonValue.fromStr("\"\\1\"").toString()
println(s1)
}
运行结果如下:会抛出异常
An exception has occurred:
JsonException: the json data is Non-standard, please check:
Parse Error: [Line]: 1, [Pos]: 3, [Error]: Unexpected character: '1'.
json.stream 包
介绍
本包主要用于仓颉对象和 JSON 数据流之间的互相转换。
本包提供了 JsonWriter 和 JsonReader 类,JsonWriter 用于提供仓颉对象转 JSON 数据流的序列化能力;JsonReader 用于提供 JSON 数据流转仓颉对象的反序列化能力。
主要接口
enum JsonToken
public enum JsonToken <: Equatable<JsonToken> & Hashable{
| JsonNull
| JsonBool
| JsonNumber
| JsonString
| BeginArray
| EndArray
| BeginObject
| EndObject
| Name
}
JsonNull
JsonNull
功能:表示 JSON 的 null 类型。如果 JsonReader.peek() 返回的是该类型,可以使用 JsonReader.readValue<Option
JsonBool
JsonBool
功能:表示 JSON 的 bool 类型。如果 JsonReader.peek() 返回的是该类型,可以使用 JsonReader.readValue
JsonNumber
JsonNumber
功能:表示 JSON 的 number 类型。如果 JsonReader.peek() 返回的是该类型,可以使用 JsonReader.readValue
JsonString
JsonString
功能:表示 JSON 的 string 类型。如果 JsonReader.peek() 返回的是该类型,可以使用 JsonReader.readValue
BeginArray
BeginArray
功能:表示 JSON 中 array 的开始。如果 JsonReader.peek() 返回的是该类型,可以使用 JsonReader.startArray() 读取。
EndArray
EndArray
功能:表示 JSON 中 array 的结束。如果 JsonReader.peek() 返回的是该类型,可以使用 JsonReader.endArray() 读取。
BeginObject
BeginObject
功能:表示 JSON 中 object 的开始。如果 JsonReader.peek() 返回的是该类型,可以使用 JsonReader.startObject() 读取。
EndObject
EndObject
功能:表示 JSON 中 object 的结束。如果 JsonReader.peek() 返回的是该类型,可以使用 JsonReader.endObject() 读取。
Name
Name
功能:表示 object 中的 name。如果 JsonReader.peek() 返回的是该类型,可以使用 JsonReader.readName() 读取。
operator func ==
public operator func ==(that: JsonToken): Bool
功能:判等。
参数:
- that:被比较的 JsonToken 对象
返回值:当前实例与 that 相等返回 true,否则返回 false
operator func !=
public operator func !=(that: JsonToken): Bool
功能:判不等。
参数:
- that:被比较的 JsonToken 对象
返回值:当前实例与 that 不相等返回 true,否则返回 false
func hashCode
public func hashCode(): Int64
功能:获取 JsonToken 对象的 hashCode 值。
返回值:hashCode 值
class JsonReader
public class JsonReader {
public init(inputStream: InputStream)
}
此类提供 JSON 数据流转仓颉对象的反序列化能力。
init
public init(inputStream: InputStream)
功能:根据输入流创建一个 JsonReader, JsonReader 从输入流中读取数据时,将跳过非 JsonString 中的空字符('\0', '\t', '\n', '\r')。
参数:
inputStream: 输入的 JSON 数据流
func peek
public func peek(): Option<JsonToken>
功能:获取输入流的下一个 JsonToken 的类型,不保证下一个 JsonToken 的格式一定正确。
例:如果输入流中的下一个字符为 't',获取的 JsonToken 将为 JsonToken.Bool,但调用 readValue
返回值:
Option<JsonToken>: 获取到的下一个 JsonToken 的类型,如果到了输入流的结尾返回 None。
异常:
- 异常 IllegalStateException:如果输入流的下一个字符不在一下范围内:(n, t, f, ", 0~9, -, {, }, [, ]),读取下一字符时,将根据 JSON 规则跳过逗号。
func readName
public func readName(): String
功能:从输入流的当前位置读取一个 name。
返回值:
String: 读取出的 name 值
异常:
- 异常 IllegalStateException:如果输入流的 JSON 数据不符合格式,抛出异常
func readValue
public func readValue<T>(): T where T <: JsonDeserializable<T>
功能:从输入流的当前位置读取一个 value。
返回值:
T: 读取出的 value 值
异常:
- 异常 IllegalStateException:如果输入流的 JSON 数据不符合格式,抛出异常
func startArray
public func startArray(): Unit
功能:从输入流的当前位置跳过空白字符后消耗一个 '[' 字符。
异常:
- 异常 IllegalStateException:如果输入流的 JSON 数据不符合格式,抛出异常
func endArray
public func endArray(): Unit
功能:从输入流的当前位置跳过空白字符后消耗一个 ']' 字符,endArray 必须有一个 startArray 与之对应。
异常:
- 异常 IllegalStateException:如果输入流的 JSON 数据不符合格式,抛出异常
func startObject
public func startObject(): Unit
功能:从输入流的当前位置跳过空白字符后消耗一个 '{' 字符。
异常:
- 异常 IllegalStateException:如果输入流的 JSON 数据不符合格式,抛出异常
func endObject
public func endObject(): Unit
功能:从输入流的当前位置跳过空白字符后消耗一个 '}' 字符,endObject 必须有一个 startObject 与之对应。
异常:
- 异常 IllegalStateException:如果输入流的 JSON 数据不符合格式,抛出异常
func skip
public func skip(): Unit
功能:从输入流的当前位置跳过一组数据。
如果 next token 是 value,跳过这个 value, 跳过 value 时不检查该 value 格式是否正确。
如果 next token 是 Name,跳过 (name + value) 这一个组合。
如果 next token 是 BeginArray,跳过这个 array。
如果 next token 是 BeginObject,跳过这个 object。
如果 next token 是 EndArray 或者 EndObject 或者 None,不做任何操作,peek 仍返回 EndArray 或者 EndObject 或者 None。
异常:
- 异常 IllegalStateException:如果输入流的 JSON 数据不符合格式,抛出异常
interface JsonDeserializable
public interface JsonDeserializable<T> {
static func fromJson(r: JsonReader): T
}
此接口用于实现从 JsonReader 中读取一个仓颉对象,支持的对象类型包括:
基本数据类型:整数类型、浮点类型、布尔类型、字符串类型。
Collection 类型:Array、ArrayList、HashMap、Option。
func fromJson
static func fromJson(r: JsonReader): T
功能:从参数 r 指定的 JsonReader 实例中读取一个 T 类型对象。
参数:
r:读取反序列化结果的JsonReader实例
返回值:T 类型的实例
extend Int64 <: JsonDeserializable
extend Int64 <: JsonDeserializable<Int64>
此扩展为 Int64 类型实现 JsonDeserializable 接口。
func fromJson
public static func fromJson(r: JsonReader): Int64
功能:从参数 r 指定的 JsonReader 实例中读取出 Int64 类型实例。支持前导 '0b', '0o', '0x'(不区分大小写),分别表示二进制,八进制和十六进制。
参数:
r:读取反序列化结果的JsonReader实例
返回值:Int64 类型的实例
extend UInt64 <: JsonDeserializable
extend UInt64 <: JsonDeserializable<UInt64>
此扩展为 UInt64 类型实现 JsonDeserializable 接口。
func fromJson
public static func fromJson(r: JsonReader): UInt64
功能:从参数 r 指定的 JsonReader 实例中读取出 UInt64 类型实例。
参数:
r:读取反序列化结果的JsonReader实例
返回值:UInt64 类型的实例
extend Float64 <: JsonDeserializable
extend Float64 <: JsonDeserializable<Float64>
此扩展为 Float64 类型实现 JsonDeserializable 接口。
func fromJson
public static func fromJson(r: JsonReader): Float64
功能:从参数 r 指定的 JsonReader 实例中读取出 Float64 类型实例。
参数:
r:读取反序列化结果的JsonReader实例
返回值:Float64 类型的实例
extend Bool <: JsonDeserializable
extend Bool <: JsonDeserializable<Bool>
此扩展为 Bool 类型实现 JsonDeserializable 接口。
func fromJson
public static func fromJson(r: JsonReader): Bool
功能:从参数 r 指定的 JsonReader 实例中读取出 Bool 类型实例。
参数:
r:读取反序列化结果的JsonReader实例
返回值:Bool 类型的实例
extend String <: JsonDeserializable
extend String <: JsonDeserializable<String>
此扩展为 String 类型实现 JsonDeserializable 接口。
根据下一个 JsonToken`` 的不同, String` 的反序列化结果将会不同:
- 当下一个
JsonToken是JsonString时, 反序列化过程会按照标准ECMA-404 The JSON Data Interchange Standard对读到的String进行转义。 - 当下一个
JsonToken是JsonNumberJsonBoolJsonNull其中一个时,将会读取下一个value字段的原始字符串并返回。 - 当下一个
JsonToken是其它类型时,调用此接口会抛异常。
func fromJson
public static func fromJson(r: JsonReader): String
功能:从参数 r 指定的 JsonReader 中读取 String。
参数:
r:读取反序列化结果的JsonReader实例
返回值:String 类型的实例
extend Option <: JsonDeserializable
extend Option<T> <: JsonDeserializable<Option<T>> where T <: JsonDeserializable<T>
此扩展为 Option 类型实现 JsonDeserializable 接口。
func fromJson
public static func fromJson(r: JsonReader): Option<T>
功能:从参数 r 指定的 JsonReader 中读取 String。如果 JSON 数据流的下一 token 为 null,返回 None。
参数:
r:读取反序列化结果的Option实例
返回值:Option 类型的实例
extend Array <: JsonDeserializable
extend Array<T> <: JsonDeserializable<Array<T>> where T <: JsonDeserializable<T>
此扩展为 Array 类型实现 JsonDeserializable 接口。
func fromJson
public static func fromJson(r: JsonReader): Array<T>
功能:从参数 r 指定的 JsonReader 中读取 Array<T>。调用该函数前后不需要调用 startArray 和 endArray 函数。
参数:
r:读取反序列化结果的JsonReader实例
返回值:Array<T> 类型的实例
extend ArrayList <: JsonDeserializable
extend ArrayList<T> <: JsonDeserializable<ArrayList<T>> where T <: JsonDeserializable<T>
为 ArrayList 类型扩展实现 JsonDeserializable 接口。
func fromJson
public static func fromJson(r: JsonReader): ArrayList<T>
功能:从参数 r 指定的 JsonReader 实例中读取出 ArrayList<T> 类型实例。调用该函数前后不需要调用 startArray 和 endArray 函数。
参数:
r:读取反序列化结果的JsonReader实例
返回值:ArrayList<T> 类型的实例
extend HashMap <: JsonDeserializable
extend HashMap<K, T> <: JsonDeserializable<HashMap<K, T>> where T <: JsonDeserializable<T>, K <: String
此扩展为 HashMap 类型实现 JsonDeserializable 接口。
func fromJson
public static func fromJson(r: JsonReader): HashMap<K, T>
功能:从参数 r 指定的 JsonReader 实例中读取出 HashMap<K, T> 类型实例。调用该函数前后不需要调用 startObject 和 endObject 函数。
参数:
r:读取反序列化结果的JsonReader实例
返回值:HashMap<K, T> 类型的实例
extend BigInt <: JsonDeserializable
extend BigInt <: JsonDeserializable<BigInt>
此扩展为 BigInt 类型实现 JsonDeserializable 接口。
func fromJson
public static func fromJson(r: JsonReader): BigInt
功能:从参数 r 指定的 JsonReader 实例中读取出 BigInt 类型实例。
参数:
r:读取反序列化结果的JsonReader实例
返回值:BigInt 类型的实例
extend Decimal <: JsonDeserializable
extend Decimal <: JsonDeserializable<Decimal>
此扩展为 Decimal 类型实现 JsonDeserializable 接口。
func fromJson
public static func fromJson(r: JsonReader): Decimal
功能:从参数 r 指定的 JsonReader 实例中读取出 Decimal 类型实例。
参数:
r:读取反序列化结果的JsonReader实例
返回值:Decimal 类型的实例
class JsonWriter
public class JsonWriter {
public init(out: OutputStream)
}
JsonWriter 提供了将仓颉对象序列化到 OutputStream 的能力。
JsonWriter 需要和 interface JsonSerializable 搭配使用,JsonWriter 可以通过 writeValue 来将实现了 JsonSerializable 接口的类型写入到 Stream 中。
JsonWriter 中使用缓存来减少写入 Stream 时的 IO 次数,在结束使用 JsonWriter 之前需要调用 flush 函数来确保缓存中的数据全部写入 Stream。
init
public init(out: OutputStream)
功能:构造函数,构造一个将数据写入 out 的实例。
参数:
out:目标流
func writeNullValue
public func writeNullValue(): JsonWriter
功能:向流中写入 JSON value null。
返回值:为方便链式调用,返回值为当前 JsonWriter 的引用。
异常:
- IllegalStateException: 当前 writer 的状态不应该写入 value 时
func jsonValue
public func jsonValue(value: String): JsonWriter
功能: 将符合JSON value规范的原始字符串写入stream,此函数不会对值 value 进行转义。如果使用者能够保证输入的值 value 符合数据转换标准ECMA-404 The JSON Data Interchange Standard, 建议使用该函数。
返回值:为方便链式调用,返回值为当前 JsonWriter 的引用。
异常:
- IllegalStateException: 当前 writer 的状态不应该写入 value 时。
func flush
public func flush(): Unit
功能:将缓存中的数据写入 out,并且调用 out 的 flush 方法。
func writeValue
public func writeValue<T>(v: T): JsonWriter where T <: JsonSerializable
功能:将实现了 JsonSerializable 接口的类型写入到 Stream 中。该接口会调用泛型 T 的 toJson 方法向输出流中写入数据
json.stream 包已经为基础类型 Int64、UInt64、Float64、Bool、String类型扩展实现了 JsonSerializable, 并且为 Collection 类型 Array、ArrayList和 HashMap 扩展实现了 JsonSerializable。
返回值:返回当前 JsonWriter 的引用。
异常:
- IllegalStateException: 当前 writer 的状态不应该写入 value 时。
func writeName
public func writeName(name: String): JsonWriter
功能:在 object 结构中写入 name。
返回值:当前 JsonWriter 引用
异常:
- IllegalStateException:当前
JsonWriter的状态不应写入参数name指定字符串时。
func startArray
public func startArray(): Unit
功能:开始序列化一个新的 JSON 数组,每一个 startArray 都必须有一个 endArray 对应。
异常:
- IllegalStateException: 当前 writer 的状态不应该写入 JSON array 时。
func endArray
public func endArray(): Unit
功能:结束序列化当前的 JSON 数组。
异常:
- IllegalStateException: 当前 writer 没有匹配的 startArray 时。
func startObject
public func startObject(): Unit
功能:开始序列化一个新的 JSON object,每一个 startObject 都必须有一个 endObject 对应。
异常:
- IllegalStateException: 当前 writer 的状态不应该写入 JSON object 时。
func endObject
public func endObject(): Unit
功能:结束序列化当前的 JSON object。
异常:
- IllegalStateException: 当前 writer 的状态不应该结束一个 JSON object 时。
interface JsonSerializable
public interface JsonSerializable {
func toJson(w: JsonWriter): Unit
}
功能:为类型提供序列化成 JSON 的接口,与 JsonWriter 搭配使用,JsonWriter 可以通过 writeValue 来将实现了 JsonSerializable 接口的类型写入到 Stream 中。
func toJson
func toJson(w: JsonWriter): Unit
功能:将实现了 JsonSerializable 接口的类型写入参数 w 指定的 JsonWriter 实例中。
参数:
w:写入序列化结果的JsonWriter实例
extend Int64 <: JsonSerializable
extend Int64 <: JsonSerializable
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 Int64 的序列化结果写入参数 w 指定的 JsonWriter。
参数:
w:写入序列化结果的JsonWriter实例。
extend UInt64 <: JsonSerializable
extend UInt64 <: JsonSerializable
功能:为 UInt64 类型扩展实现 JsonSerializable 接口。
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 UInt64 的序列化结果写入参数 w 指定的 JsonWriter。
参数:
w:写入序列化结果的JsonWriter实例。
extend Float64 <: JsonSerializable
extend Float64 <: JsonSerializable
功能:为 Float64 类型扩展实现 JsonSerializable 接口。
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 Float64 的序列化结果写入参数 w 指定的 JsonWriter。
参数:
w:写入序列化结果的JsonWriter实例。
extend Bool <: JsonSerializable
extend Bool <: JsonSerializable
功能:为 Bool 类型扩展实现 JsonSerializable 接口。
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 Bool 的序列化结果写入参数 w 指定的 JsonWriter。
参数:
w:写入序列化结果的JsonWriter实例。
extend String <: JsonSerializable
extend String <: JsonSerializable
为 String 类型扩展实现 JsonSerializable 接口。String 的序列化过程会按照标准ECMA-404 The JSON Data Interchange Standard进行转义。为了追求更好的序列化性能,如果能够确保 String 符合 ECMA-404 规定的转义后的标准,可以调用 JsonWriter 的 jsonValue 方法。
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 String 的序列化结果写入参数 w 指定的 JsonWriter。
参数:
w:写入序列化结果的JsonWriter实例。
extend Option <: JsonSerializable
extend Option<T> <: JsonSerializable where T <: JsonSerializable
功能:为 Option 类型扩展实现 JsonSerializable 接口。
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 Option 的序列化结果写入参数 w 指定的 JsonWriter。如果 Option 的值是 Some(v),将会调用 T 类型的 toJson 方法进行序列化,如果 Option 的值是 None,将会向输出流中写入 null。
参数:
w:写入序列化结果的JsonWriter实例。
extend Array <: JsonSerializable
extend Array<T> <: JsonSerializable where T <: JsonSerializable
功能:为 Array 类型扩展实现了 JsonSerializable 接口。
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 Array 的序列化结果写入参数 w 指定的 JsonWriter。该接口直接向输出流中写入 JSON array,调用该函数前后不需要调用 startArray 和 endArray 函数。
参数:
w:写入序列化结果的JsonWriter实例。
extend ArrayList <: JsonSerializable
extend ArrayList<T> <: JsonSerializable where T <: JsonSerializable
功能:为 ArrayList 类型扩展实现了 JsonSerializable 接口。
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 ArrayList 的序列化结果写入参数 w 指定的 JsonWriter。
参数:
w:写入序列化结果的JsonWriter实例。该接口直接向输出流中写入 JSON array,调用该函数前后不需要调用startArray和endArray函数。
extend HashMap <: JsonSerializable
extend HashMap<K, V> <: JsonSerializable where V <: JsonSerializable, K <: String
功能:为 HashMap 类型扩展实现了 JsonSerializable 接口。
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 HashMap 的序列化结果写入参数 w 指定的 JsonWriter。该函数直接向输出流中写入 JSON object,JSON object 中 name-value 对应着 HashMap 中的 key-value。调用该函数前后不需要调用 startObject 和 endObject 函数。
参数:
w:写入序列化结果的JsonWriter实例。
extend BigInt <: JsonSerializable
extend BigInt <: JsonSerializable
功能:为 BigInt 类型扩展实现 JsonSerializable 接口。
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 BigInt 的序列化结果写入参数 w 指定的 JsonWriter。
参数:
w:写入序列化结果的JsonWriter实例。
extend Decimal <: JsonSerializable
extend Decimal <: JsonSerializable
功能:为 Decimal 类型扩展实现 JsonSerializable 接口。
func toJson
public func toJson(w: JsonWriter): Unit
功能:将 Decimal 的序列化结果写入参数 w 指定的 JsonWriter。
参数:
w:写入序列化结果的JsonWriter实例。
示例
反序列化
代码如下:
from encoding import json.stream.*
from std import io.*
from std import collection.*
class A <: JsonDeserializable<A> {
var key1: Option<String> = None
var key2: Bool = false
var key3: Float64 = 0.0
var key4: String = ""
var key5: Array<Int64> = Array<Int64>()
var key6: HashMap<String, String> = HashMap<String, String>()
public static func fromJson(r: JsonReader): A {
var res = A()
while (let Some(v) <- r.peek()) {
match(v) {
case BeginObject =>
r.startObject()
while(r.peek() != EndObject) {
let n = r.readName()
match (n) {
case "key1" => res.key1 = r.readValue<Option<String>>()
case "key2" => res.key2 = r.readValue<Bool>()
case "key3" => res.key3 = r.readValue<Float64>()
case "key4" => res.key4 = r.readValue<String>()
case "key5" => res.key5 = r.readValue<Array<Int64>>()
case "key6" => res.key6 = r.readValue<HashMap<String, String>>()
case _ => ()
}
}
r.endObject()
break
case _ => throw Exception()
}
}
return res
}
func toString(): String {
return "${key1}\n${key2}\n${key3}\n${key4}\n${key5}\n${key6}"
}
}
main() {
let jsonStr = ##"{"key1": null, "key2": true, "key3": 123.456, "key4": "string", "key5": [123, 456], "key6": {"key7": " ", "key8": "\\a"}}"##
var bas = ByteArrayStream()
unsafe { bas.write(jsonStr.rawData()) }
var reader = JsonReader(bas)
var obj = A.fromJson(reader)
println(obj.toString())
}
运行结果可能如下:
None
true
123.456000
string
[123, 456]
[(key7, ), (key8, \a)]
序列化
from encoding import json.stream.*
from std import io.ByteArrayStream
class Image <: JsonSerializable {
var width: Int64
var height: Int64
var title: String
var ids: Array<Int64>
public init() {
width = 0
height = 0
title = ""
ids = Array<Int64>()
}
public func toJson(w: JsonWriter): Unit {
w.startObject() // start encoding an object
w.writeName("Width").writeValue(width) // write name and value pair in current object
w.writeName("Height").writeValue(height)
w.writeName("Title").writeValue(title)
w.writeName("Ids").writeValue<Array<Int64>>(ids) //use class Array's func toJson
w.endObject()// end current object
}
}
main(){
let image = Image()
image.width = 800
image.height = 600
image.title = "View from 15th Floor"
image.ids = [116, 943, 234, 38793]
let stream = ByteArrayStream() // output
let writer = JsonWriter(stream) // init a JsonWriter
writer.writeValue(image) // serialize image to JSON
writer.flush()
println(String.fromUtf8(stream.readToEnd()))
}
运行结果如下:
{"Width":800,"Height":600,"Title":"View from 15th Floor","Ids":[116,943,234,38793]}
HashMap 序列化的使用方式
与 Array 不同的是,HashMap 中的每一条数据都是 name-value 组合, 所以 HashMap 的序列化时会序列化成 JSON object。
from encoding import json.stream.*
from std import io.ByteArrayStream
from std import collection.HashMap
main(){
let map = HashMap<String, Int64>()
map.put("Width", 800)
map.put("Height", 600)
let stream = ByteArrayStream()
let writer = JsonWriter(stream)
writer.writeValue(map)
writer.flush()
println(String.fromUtf8(stream.readToEnd()))
}
运行结果如下
{"Width":800,"Height":600}
url 包
介绍
该包提供 url 数据解析功能。
主要接口
class URL
public class URL <: ToString
该类提供接口解析 URL,其中的 % 编码会被解码,保存在相应的组件之中,而初始值保存在相应的 raw 属性之中。(暂时不支持 IPv6 主机形式的 URL 解析,暂时未提供各组件的编解码功能。)URL 中的用户名和密码部分(如果存在的话)也会按照 rfc3986 协议的说明被解析,但是该协议也明确说明了,在任何场景下,明文保存用户信息都有被泄露的风险,所以我们不建议您在 URL 中明文保存用户信息,这不安全!
init
public init(scheme!: String, hostName!: String, path!: String)
功能:构造一个 URL 实例。
参数:
scheme:协议hostName:不包含端口号的主机名path:路径
异常:
- 异常
UrlSyntaxException: 当出现以下任何情况之一时,会抛出异常。- 在没有协议
scheme的情况下,拥有主机名hostName - 只有协议
scheme - 存在协议和路径的情况下,路径
path不是绝对路径 - 存在非法字符
- 在没有协议
prop scheme
public prop scheme: String
功能:获取 URL 中协议部分,用字符串表示。
prop opaque
public prop opaque: String
功能:获取 URL 中不透明部分,用字符串表示。
prop userInfo
public prop userInfo: UserInfo
功能:获取解码后的用户名和密码信息,用 UserInfo 实例表示。
prop rawUserInfo
public prop rawUserInfo: UserInfo
功能:获取解码前的用户名和密码信息,用 UserInfo 实例表示。
prop hostName
public prop hostName: String
功能:获取解码后的主机名,用字符串表示。
prop port
public prop port: String
功能:获取端口号,用字符串表示,空字符串表示无端口号。
prop path
public prop path: String
功能:获取解码后路径,用字符串表示。
prop rawPath
public prop rawPath: String
功能:获取解码前路径,用字符串表示。
prop query
public prop query: ?String
功能:获取解码后查询组件,用字符串表示。
prop rawQuery
public prop rawQuery: ?String
功能:获取解码前查询组件,用字符串表示。
prop fragment
public prop fragment: ?String
功能:获取解码后锚点组件,用字符串表示。
prop rawFragment
public prop rawFragment: ?String
功能:获取解码前锚点组件,用字符串表示。
prop queryForm
public prop queryForm: Form
功能:获取解码后查询组件,用 Form 实例表示。
func parse
public static func parse(rawUrl: String): URL
功能:将原始字符串解析成 URL 对象,相对路径或绝对路径均可。该函数可以解析 url 中的用户名和密码(如果内部存在的话),这是符合 rfc3986 协议的解析功能,但是该协议也明确说明了,在任何场景下,明文保存用户信息都有被泄露的风险,所以我们不建议您在 url 中明文保存用户信息,这不安全!
参数:
- rawUrl:URL 字符串
返回值:解析字符串得到的 URL 实例
异常:
- 异常 UrlSyntaxException:当 URL 字符串中包含非法字符时,抛出异常
- 异常 IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
func isAbsoluteURL
public func isAbsoluteURL(): Bool
功能:判断 url 是否为绝对 URL,scheme 存在时,URL 是绝对 URL。
返回值:是否为绝对 URL
func resolveURL
public func resolveURL(ref: URL): URL
功能:以当前 URL 实例为基础 URL,以传入的 URL 为参考 URL,根据协议生成一个新的 URL 实例。
例如:http://a/b/c/d;p?q 为基础 URL,以下 = 左边为参考 URL,右边为生成的新 URL:
- "g" = "http://a/b/c/g"
- "/g" = "http://a/g"
- "g?y" = "http://a/b/c/g?y"
- "g?y#s" = "http://a/b/c/g?y#s"
- "../" = "http://a/b/"
更详细行为,参见 rfc3986。
参数:
- ref:参考 URL 对象
返回值:新的 URL 实例
func mergePaths
public static func mergePaths(basePath: String, refPath: String): String
功能:合并有效的两个路径,并消除合并后的 path 中的"."字符,".."字符,将多个连续的"/"替换为单个"/",例如:
- "/a/b/c" 合并 "/d" 输出 "/d"
- "/a/b/c" 合并 "d" 输出 "/a/b/d"
- "/a/b/" 合并 "d/e/../f" 输出 "/a/b/d/f"
- "/a/b/c/" 合并 "./../../g" 输出 "/a/g"
参数:
- basePath:基础路径
- refPath:引用路径
返回值:合并且标准化后的路径
func toString
public func toString(): String
功能:获取当前 URL 实例的字符串值。
返回值:当前 URL 实例的字符串值
func replace
public func replace(scheme!: Option<String> = None, userInfo!: Option<String> = None,
hostName!: Option<String> = None, port!: Option<String> = None, path!: Option<String> = None,
query!: Option<String> = None, fragment!: Option<String> = None): URL
功能:替换 URL 对象的各组件,并且返回一个新的 URL 对象。 参数:
- scheme:方案部分
- userInfo:用户信息
- hostName:主机名
- port:端口号
- path:路径
- query:查询部分
- fragment:锚点部分
返回值:新的 URL 对象
异常:
- 异常 UrlSyntaxException:
当出现以下任何情况之一时,会抛出异常。
- 方案 scheme 为空而主机名不为空时。
- 主机名为空而用户信息或端口号不为空时。
- 方案 scheme 不为空而主机名和路径同时为空时。
- 方案 scheme 不为空而路径不是绝对路径时。
- 任意组件不合法时。
class UserInfo
public class UserInfo <: ToString {
public init()
public init(userName: String)
public init(userName: String, passWord: String)
public init(userName: String, passWord: Option<String>)
}
UserInfo 表示 url 中用户名和密码信息, URL.parse 可以解析 url 中的用户名和密码,这是符合 rfc3986 协议的解析功能,但是该协议也明确说明了,在任何场景下,明文保存用户信息都有被泄露的风险,所以我们不建议您在 url 中明文保存用户信息,这不安全!
init
public init()
功能:创建 UserInfo 实例。
init
public init(userName: String)
功能:根据用户名创建 UserInfo 实例。 参数:
- userName:用户名
init
public init(userName: String, passWord: String)
功能:根据用户名和密码创建 UserInfo 实例。 参数:
- userName:用户名
- passWord:密码
init
public init(userName: String, passWord: Option<String>)
功能:根据用户名和 Option
- userName:用户名
- passWord:密码,用 Option
类型表示
func toString
public func toString(): String
功能:将当前 UserInfo 实例转换为字符串。
返回值:当前 UserInfo 示例的字符串表示
func password
public func password(): Option<String>
功能:获取密码信息(不建议在 url 中明文保存用户信息!详情参上!)。
返回值:将密码以 Option
func username
public func username(): String
功能:获取用户名信息。
返回值:字符串类型返回用户名
class Form
public class Form {
public init()
public init(queryComponent: String)
}
Form 以 key-value 键值对形式存储 http 请求的参数, 同一个 key 可以对应多个 value, value 以数组形式存储。
init
public init()
功能:构造一个默认的 Form 实例。
init
public init(queryComponent: String)
功能:根据 URL 编码的查询字符串,即 URL 实例的 query 部分构造 Form 实例,解析 URL 编码的查询字符串,得到若干键值对,并将其添加到新构造的 Form 实例中。 参数:
- queryCompoent:'&' 符号分隔多个键值对;'=' 分隔的左侧作为 key 值,右侧作为 value 值(没有 '=' 或者 value 为空,均是允许的)
异常:
- 异常 UrlSyntaxException:当 URL 字符串中包含非法转义字符时,抛出异常
func isEmpty
public func isEmpty(): Bool
功能:判断 Form 是否为空。
返回值:如果为空,则返回 true;否则,返回 false
func get
public func get(key: String): Option<String>
功能:根据 key 获取第一个关联的 value。
参数:
- key:指定键
返回值:根据指定键获取的第一个值,用 Option
func getAll
public func getAll(key: String): ArrayList<String>
功能:根据 key - 获取所有关联的 value。
参数:
- key:根据该键获取值
返回值:根据指定键获取的全部值
func set
public func set(key: String, value: String): Unit
功能:重置指定 key 对应的 value。
参数:
- key:指定键
- value:将指定键的值设置为 value
func add
public func add(key: String, value: String): Unit
功能:新增 key-value 映射, 如果 key 已存在,则将 value 添加到原来 value 数组的最后面。
参数:
- key:指定键,可以是新增的
- value:将该值添加到指定键对应的值数组中
func remove
public func remove(key: String): Unit
功能:删除 key 及其对应 value。
参数:
- key:删除的键
func clone
public func clone(): Form
功能:克隆 Form。
返回值:克隆得到的新 Form 实例
func toEncodeString
public func toEncodeString(): String
功能:对表单中的键值对进行编码。未保留字符 unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~" 不会被编码,空格将编码为 '+'。
返回值:编码后的字符串
class UrlSyntaxException
public class UrlSyntaxException <: Exception {
public init(reason: String)
public init(input: String, reason: String)
}
url 解析异常类
init
public init(reason: String)
功能:根据错误原因构造 UrlSyntaxException 实例。
参数:
- reason:解析错误的原因
init
public init(input: String, reason: String)
功能:根据 url 及错误原因构造 UrlSyntaxException 实例,其内部的 message 整合了 url 和错误原因。
参数:
- input:原生 url 或其片段
- reason:解析错误的原因
示例
parse 的使用
使用 parse 函数解析 URL 字符串,生成 URL 对象。
代码如下:
from encoding import url.*
main(): Int64 {
var url = URL.parse("http://www.example.com:80/path%E4%BB%93%E9%A2%89?key=value%E4%BB%93%E9%A2%89#%E4%BD%A0%E5%A5%BD")
println("url.scheme = ${url.scheme}")
println("url.opaque = ${url.opaque}")
println("url.userInfo = ${url.userInfo}")
println("url.rawUserInfo = ${url.rawUserInfo}")
println("url.hostName = ${url.hostName}")
println("url.port = ${url.port}")
println("url.path = ${url.path}")
println("url.rawPath = ${url.rawPath}")
println("url.query = ${url.query.getOrThrow()}")
println("url.rawQuery = ${url.rawQuery.getOrThrow()}")
println("url.fragment = ${url.fragment.getOrThrow()}")
println("url.rawfragment = ${url.rawFragment.getOrThrow()}")
println("url = ${url}")
return 0
}
运行结果形如下:
url.scheme = http
url.opaque =
url.userInfo =
url.rawUserInfo =
url.hostName = www.example.com
url.port = 80
url.path = /path仓颉
url.rawPath = /path%E4%BB%93%E9%A2%89
url.query = key=value仓颉
url.rawQuery = key=value%E4%BB%93%E9%A2%89
url.fragment = 你好
url.rawfragment = %E4%BD%A0%E5%A5%BD
url = http://www.example.com:80/path%E4%BB%93%E9%A2%89?key=value%E4%BB%93%E9%A2%89#%E4%BD%A0%E5%A5%BD
Form 的构造使用 1
创建 Form 类,并通过 get 获取 key 对应映射的 value。
代码如下:
from encoding import url.*
main(): Int64 {
var s = Form("1=2&2=3&1=2&&")
print(s.get("1").getOrThrow())
return 0
}
运行结果如下:
2
Form 的构造使用 2
创建 Form 正则类,并通过 get 获取 key 对应映射的 value。
代码如下:
from encoding import url.*
main(): Int64 {
var s = Form("2=3&1=%6AD&1=2")
// 对于 %6A 解码成 j,重复的 key 调用 get 获取第一个 value 值 jD
print(s.get("1").getOrThrow())
return 0
}
运行结果如下:
jD
Form 的构造使用 3
分别调用 add,set,clone,打印输出前后变化。
代码如下:
from encoding import url.*
main(): Int64 {
var f = Form()
f.add("k", "v1")
f.add("k", "v2")
println(f.get("k").getOrThrow())
f.set("k", "v")
println(f.get("k").getOrThrow())
let clone_f = f.clone()
clone_f.add("k1", "v1")
println(clone_f.get("k1").getOrThrow())
println(f.get("k1") ?? "kkk")
0
}
运行结果如下:
v1
v
v1
kkk
xml 包
介绍
提供基于标准的 XML 文本处理,暂不支持外部实体功能,以及 形式的指令声明
主要接口
interface SaxHandler
public interface SaxHandler {
func startDocument(): Unit
func endDocument(): Unit
func startElement(name: String, attrs: ArrayList<XmlAttr>): Unit
func endElement(name: String): Unit
func characters(content: String): Unit
}
提供 SAX 模式的回调函数接口。
func startDocument
func startDocument(): Unit
功能:开始解析 XML 文本时执行的回调函数。
func endDocument
func endDocument(): Unit
功能:结束解析 XML 文本时执行的回调函数。
func startElement
func startElement(name: String, attrs: ArrayList<XmlAttr>): Unit
功能:开始解析 XML 元素时执行的回调函数。
参数:
- name:元素名称
- attrs:元素属性列表
func endElement
func endElement(name: String): Unit
功能:结束解析 XML 元素时执行的回调函数。
参数:
- name:元素名称
func characters
func characters(content: String): Unit
功能:解析得到 XML 字符数据时执行的回调函数。
参数:
- content:元素文本内容
class XmlParser
public class XmlParser {
public init()
public init(handler: SaxHandler)
}
此类提供 XML 解析功能,目前支持两种模式:文档对象模型(DOM)模式和 XML 简单 API(SAX)模式,暂不支持外部实体功能,以及 形式的指令声明。
支持 5 个内置符号的解析,如下表所示:
| 符号 | 字符 |
| --- | --- |
| < | <, <, < |
| > | >, >, > |
| & | &, &, & |
| ' | ', ', ' |
| " | ", ", " |
init
public init()
功能:创建 XML 文档对象模型(DOM)模式解析器。
异常:
- XmlException:如果初始化失败,抛出异常
init
public init(handler: SaxHandler)
功能:创建 XML 简单 API(SAX)模式解析器。
参数:
- handler:实现了 SaxHandler 的一组回调函数
异常:
- XmlException:初始化失败
func parse
public func parse(str: String): Option<XmlElement>
功能:解析字符串类型的 XML 文本。
参数:
- str:XML 文本,最大解析长度 2^32 - 1, 即 UInt32 的最大值
返回值:DOM模式下解析成功则返回 Option
异常:
- XmlException:内存分配失败,或解析文本出错,或存在空指针
- IllegalArgumentException:XML 文本中包含字符串结束符
class XmlAttr
public class XmlAttr <: ToString {
public init(name: String, content: String)
}
此类存储 XML 元素节点属性,并提供查询其内容的函数。
如需使用 XmlAttr 构造 XML 文档,请注意符合 XML 规范,具体规范请查阅 W3C 官网。
部分接口提供了有限的检查功能,例如节点名称为空,首字母为 '-' 、 '.' 、 '[0-9]' 等。
init
public init(name: String, content: String)
功能:创建新的 XmlAttr 对象。
参数:
- name:属性名称
- content:属性值
异常:
- XmlException:属性名称为空,或首字母为 '-' 、 '.' 、 '[0-9]'
prop name
public mut prop name: String
功能:获取或设置属性名称
异常:
- XmlException:设置属性名称为空,或首字母为 '-' 、 '.' 、 '[0-9]'
prop content
public mut prop content: String
功能:获取或设置属性值
func toString
public func toString(): String
功能:将 XmlAttr 转换成字符串。
返回值:当前 XmlAttr 实例的字符串值
class XmlElement
public class XmlElement <: ToString {
public init(name: String, content: String)
}
此类存储 XML 元素节点,并提供查询其内容的函数。
如需使用 XmlELement 构造 XML 文档,请注意符合 XML 规范,具体规范请查阅 W3C 官网。
部分接口提供了有限的检查功能,例如节点名称为空,首字母为 '-' 、 '.' 、 '[0-9]',属性名称必须保证唯一等。
init
public init(name: String, content: String)
功能:创建新的 XmlElement 对象。
参数:
- name:节点名称
- content:节点文本内容
异常:
- XmlException:节点名称为空,或首字母为 '-' 、 '.' 、 '[0-9]'
prop name
public mut prop name: String
功能:获取或设置节点名称
异常:
- XmlException:设置节点名称为空,或首字母为 '-' 、 '.' 、 '[0-9]'
prop content
public mut prop content: String
功能:获取或设置节点文本内容
prop isClosed
public prop isClosed: Bool
功能:判断节点是否闭合
prop childrenNum
public prop childrenNum: Int64
功能:获取节点的子节点个数
prop childrenElements
public mut prop childrenElements: ArrayList<XmlElement>
功能:获取或设置节点所有子节点
prop attributesNum
public prop attributesNum: Int64
功能:获取节点属性个数
prop attributes
public mut prop attributes: ArrayList<XmlAttr>
功能:获取节点的属性,返回节点属性的深拷贝,设置节点的属性。
异常:
- XmlException:设置节点属性时,如果传入的属性列表中有重复字段,抛出异常
func toString
public func toString(): String
功能:返回 XML 字符串,该字符串会在一行显示,其中的实体引用将会被解析,例如: '<' 将替换成 '<'。
返回值:解析得到的字符串
func toXmlString
public func toXmlString(): String
功能:返回格式化后的 XML 字符串,该字符串会以 XML 的格式体现,其中的实体引用将会被解析,例如: '<' 将替换成 '<'。
返回值:解析并且格式化后的字符串
class XmlException
public class XmlException <: Exception {
public init()
public init(message: String)
}
XML 异常类。
init
public init()
功能:创建 XmlException 实例。
init
public init(message: String)
功能:创建 XmlException 实例,可指定异常信息。
参数:
- message:异常提示字符串
示例
Xml DOM 模式使用
下面是 XML 解析的示例。
代码如下:
from encoding import xml.*
main() {
let x: XmlParser = XmlParser()
var ret = x.parse("<myxml>Some data </myxml>")
match (ret) {
case Some(root) => println(root.name)
case None => println("XML Parse error.")
}
return 0
}
运行结果如下:
myxml
Xml SAX 解析模式使用
下面是 XML SAX 解析模式使用的示例。
代码如下:
from std import collection.*
from encoding import xml.*
let latestMovie = """
<collection shelf="New Arrivals">
<movie title="Movie 2021">
<score>7.4</score>
<year>2021-3</year>
<description>This is a virtual film released in 2021 for testing.</description>
</movie>
<movie title="Movie 2022">
<type>Anime, Science Fiction</type>
<score>7</score>
<year>2022-2</year>
<description>This is a virtual film released in 2022 for testing.</description>
</movie>
<movie title="Movie 2023">
<score>6.5</score>
<year>2023-4</year>
<description>This is a virtual film released in 2023 for testing.</description>
</movie>
</collection>
"""
class MovieHandler <: SaxHandler {
private var curTag: String
private var title: String
private var score: String
private var year: String
init() {
curTag = ""
title = ""
score = ""
year = ""
}
public func startDocument(): Unit {
println("Start Parsing.")
}
public func endDocument(): Unit {
println("End Parsing.")
}
public func startElement(name: String, attrs: ArrayList<XmlAttr>): Unit {
curTag = name
if (name == "movie") {
title = attrs[0].content
println("Title: ${title}")
}
}
public func endElement(name: String): Unit {
if (curTag == "score") {
println("Score: ${score}")
} else if (curTag == "year") {
println("Year: ${year}")
}
}
public func characters(content: String): Unit {
if (curTag == "score") {
score = content
} else if (curTag == "year") {
year = content
}
}
}
main() {
var handler = MovieHandler()
let x: XmlParser = XmlParser(handler)
x.parse(latestMovie)
return 0
}
运行结果如下:
Start Parsing.
Title: Movie 2021
Score: 7.4
Year: 2021-3
Title: Movie 2022
Score: 7
Year: 2022-2
Title: Movie 2023
Score: 6.5
Year: 2024-4
End Parsing.
fuzz 包
介绍
提供仓颉 fuzz 引擎及对应的接口,需配合覆盖率反馈插桩(SanitizerCoverage)功能使用,编写代码对 API 进行测试。使用此包需要开发者对 fuzz 测试有一定的了解,初学者建议先学习 C 语言的 Fuzz 工具 libFuzzer
使用本包需要外部依赖 LLVM 套件 compiler-rt 提供的 libclang_rt.fuzzer_no_main.a 静态库,当前支持 Linux 以及 macOS,不支持 Windows,对 cjnative 后端支持最好,对 cjvm 后端的测试需要重新链接依赖库。
通常使用包管理工具即可完成安装,例如 Ubuntu 22.04 系统上可使用 sudo apt install clang 进行安装,安装后可以在 clang -print-runtime-dir 指向的目录下找到对应的 libclang_rt.fuzzer_no_main.a 文件,例如 /usr/lib/llvm-14/lib/clang/14.0.0/lib/linux/libclang_rt.fuzzer_no_main-x86_64.a,将来在链接时会用到它。
主要接口
FUZZ_VERSION
public let FUZZ_VERSION = "1.0.0"
功能:Fuzz 版本。
class Fuzzer
public class Fuzzer {
public init(targetFunction: (Array<UInt8>) -> Int32)
public init(targetFunction: (Array<UInt8>) -> Int32, args: Array<String>)
public init(targetFunction: (DataProvider) -> Int32)
public init(targetFunction: (DataProvider) -> Int32, args: Array<String>)
}
Fuzzer 类提供了 fuzz 工具的创建.
init
public init(targetFunction: (Array<UInt8>) -> Int32)
功能:根据以 UInt8 数组为参数,以 Int32 为返回值的目标函数,创建 Fuzzer 实例。
参数:
targetFunction:以UInt8数组为参数,以Int32为返回值的目标函数
init
public init(targetFunction: (Array<UInt8>) -> Int32, args: Array<String>)
功能:根据以 UInt8 数组为参数,以 Int32 为返回值的目标函数,以及 Fuzz 运行参数,创建 Fuzzer 实例。
参数:
targetFunction:以UInt8数组为参数,以Int32为返回值的目标函数args:Fuzz 运行参数
init
public init(targetFunction: (DataProvider) -> Int32)
功能:根据以 DataProvider 为参数,以 Int32 为返回值的目标函数,创建 Fuzzer 实例。
参数:
targetFunction:以DataProvider为参数,以Int32为返回值的目标函数
init
public init(targetFunction: (DataProvider) -> Int32, args: Array<String>)
功能:根据以 DataProvider 为参数,以 Int32 为返回值的目标函数,以及 Fuzz 运行参数,创建 Fuzzer 实例。
参数:
targetFunction:以DataProvider为参数,以Int32为返回值的目标函数args:Fuzz 运行参数
func getArgs
public func getArgs(): Array<String>
功能:获取 Fuzz 运行参数。
返回值:当前 Fuzz 运行参数
func setArgs
public func setArgs(args: Array<String>): Unit
功能:设置 Fuzz 运行参数。
参数:
args:Fuzz 运行参数。
func setTargetFunction
public func setTargetFunction(targetFunction: (Array<UInt8>) -> Int32): Unit
功能:设置 Fuzz 目标函数。
参数:
targetFunction:以UInt8数组为参数,以Int32为返回值的目标函数
func setTargetFunction
public func setTargetFunction(targetFunction: (DataProvider) -> Int32): Unit
功能:设置 Fuzz 目标函数。
参数:
targetFunction:以DataProvider为参数,以Int32为返回值的目标函数
func startFuzz
public func startFuzz(): Unit
功能:执行 Fuzz。
func enableFakeCoverage
public func enableFakeCoverage(): Unit
功能:创建一块虚假的覆盖率反馈区域,保持 Fuzz 持续进行。在 DataProvider 模式下,前几轮运行时可能由于数据不足而导致没有覆盖率,libfuzzer 会退出。该功能默认为关闭。
func disableFakeCoverage
public func disableFakeCoverage(): Unit
功能:关闭调用 enableFakeCoverage 对 Fuzz 的影响。
func enableDebugDataProvider
public func enableDebugDataProvider(): Unit
功能:启用调试信息打印功能,当 DataProvider.consumeXXX 被调用时,返回值将被打印到 stdout。该功能默认为关闭。
func disableDebugDataProvider
public func disableDebugDataProvider(): Unit
功能:关闭调试信息打印功能,当 DataProvider.consumeXXX 被调用时,返回值将不被打印到 stdout。
class FuzzerBuilder
public class FuzzerBuilder {
public init(targetFunction: (Array<UInt8>) -> Int32)
public init(targetFunction: (DataProvider) -> Int32)
}
此类用于 Fuzzer 类的构建。
init
public init(targetFunction: (Array<UInt8>) -> Int32)
功能:根据以 UInt8 数组为参数,以 Int32 为返回值的目标函数,创建 FuzzerBuilder 实例。
参数:
targetFunction:以UInt8数组为参数,以Int32为返回值的目标函数
init
public init(targetFunction: (DataProvider) -> Int32)
功能:根据以 DataProvider 为参数,以 Int32 为返回值的目标函数,创建 FuzzerBuilder 实例。
参数:
targetFunction:以DataProvider为参数,以Int32为返回值的目标函数
func setArgs
public func setArgs(args: Array<String>): FuzzerBuilder
功能:设置 Fuzz 运行参数。
参数:
args:Fuzz 运行参数
返回值:当前 FuzzerBuilder 实例。
func setTargetFunction
public func setTargetFunction(targetFunction: (Array<UInt8>) -> Int32): FuzzerBuilder
功能:设置 Fuzz 目标函数。
参数:
targetFunction:以UInt8数组为参数,以Int32为返回值的目标函数
返回值:当前 FuzzerBuilder 实例。
func setTargetFunction
public func setTargetFunction(targetFunction: (DataProvider) -> Int32): FuzzerBuilder
功能:设置 Fuzz 目标函数。
参数:
targetFunction:以DataProvider为参数,以Int32为返回值的目标函数
返回值:当前 FuzzerBuilder 实例。
func build
public func build(): Fuzzer
功能:生成一个 Fuzzer 实例。
返回值:Fuzzer 实例
class DataProvider
public open class DataProvider {
public let data: Array<UInt8>
public var remainingBytes: Int64
public var offset: Int64
}
DataProvider 是一个工具类,目的是将变异数据的字节流转化为标准的仓颉基本数据,当前支持的数据结构如下:
| 目标类型 | API | 说明 |
|---|---|---|
| Bool | consumeBool() | 获取1个Bool,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeBools(count: Int64) | 获取N个Bool,变异数据长度不足时,抛出ExhaustedException |
| Byte | consumeByte() | 获取1个Byte,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeBytes(count: Int64) | 获取N个Byte,变异数据长度不足时,抛出ExhaustedException |
| UInt8 | consumeUInt8() | 获取1个UInt8,变异数据长度不足时,抛出ExhaustedException |
| UInt16 | consumeUInt16() | 获取1个UInt16,变异数据长度不足时,抛出ExhaustedException |
| UInt32 | consumeUInt32() | 获取1个UInt32,变异数据长度不足时,抛出ExhaustedException |
| UInt64 | consumeUInt64() | 获取1个UInt64,变异数据长度不足时,抛出ExhaustedException |
| Int8 | consumeInt8() | 获取1个Int8,变异数据长度不足时,抛出ExhaustedException |
| Int16 | consumeInt16() | 获取1个Int16,变异数据长度不足时,抛出ExhaustedException |
| Int32 | consumeInt32() | 获取1个Int32,变异数据长度不足时,抛出ExhaustedException |
| Int32 | consumeInt32() | 获取1个Int32,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeUInt8s(count: Int64) | 获取N个UInt8,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeUInt16s(count: Int64) | 获取N个UInt16,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeUInt32s(count: Int64) | 获取N个UInt32,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeUInt64s(count: Int64) | 获取N个UInt64,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeInt8s(count: Int64) | 获取N个Int8,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeInt16s(count: Int64) | 获取N个Int16,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeInt32s(count: Int64) | 获取N个Int32,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeInt32s(count: Int64) | 获取N个Int32,变异数据长度不足时,抛出ExhaustedException |
| Char | consumeChar() | 获取1个Char,变异数据长度不足时,抛出ExhaustedException |
| String | consumeAsciiString(maxLength: Int64) | 获取1个纯ASCII的String,长度为0到maxLength,可以为0 |
| String | consumeString(maxLength: Int64) | 获取1个UTF8 String,长度为0到maxLength,可以为0 |
| Array | consumeAll() | 将DataProvider中的剩余内容全部转化为字节数组 |
| String | consumeAllAsAscii() | 将DataProvider中的剩余内容全部转化为纯ASCII的String |
| String | consumeAllAsString() | 将DataProvider中的剩余内容全部转化为UTF8 String,末尾多余的字符不会被消耗 |
不支持Float32和Float64
在数据长度不足时,调用上述大部分虽然会抛出 ExhaustedException,但编写 fuzz 函数时通常并不需要对它进行处理,ExhaustedException 默认会被 fuzz 框架捕获,告诉 libfuzzer 该次运行无效,请继续下一轮变异。随着执行时间的变长,变异数据也会逐渐变长,直到满足 DataProvider 的需求。
如果达到了 max_len 仍无法满足 DataProvider 的需求,则进程退出,请修改 fuzz 测试用例(推荐) 或 增大 max_len(不推荐)。
data
public let data: Array<UInt8>
功能:变异数据。
remainingBytes
public var remainingBytes: Int64
功能:剩余字节数。
offset
public var offset: Int64
功能:已转化的字节数。
func withCangjieData
public static func withCangjieData(data: Array<UInt8>): DataProvider
功能:根据 UInt8 数组创建 DataProvider 实例。
参数:
data:字节流的变异数据
func withNativeData
public static unsafe func withNativeData(data: CPointer<UInt8>, length: Int64): DataProvider
功能:根据 UInt8 指针,以及数据长度,创建 DataProvider 实例。
参数:
data:利用指针存储的变异数据length:数据长度
func consumeBool
public open func consumeBool(): Bool
功能:将数据转换成 Bool 类型实例。
返回值:Bool 类型实例
func consumeBools
public open func consumeBools(count: Int64): Array<Bool>
功能:将指定数量的数据转换成 Bool 类型数组。
参数:
count:指定转换的数据量
返回值:Bool 类型数组
func consumeByte
public open func consumeByte(): Byte
功能:将数据转换成 Byte 类型实例。
返回值:Byte 类型实例
func consumeBytes
public open func consumeBytes(count: Int64): Array<Byte>
功能:将指定数量的数据转换成 Byte 类型数组。
参数:
count:指定转换的数据量
返回值:Byte 类型数组
func consumeUInt8
public open func consumeUInt8(): UInt8
功能:将数据转换成 UInt8 类型实例。
返回值:UInt8 类型实例
func consumeUInt16
public open func consumeUInt16(): UInt16
功能:将数据转换成 UInt16 类型实例。
返回值:UInt16 类型实例
func consumeUInt32
public open func consumeUInt32(): UInt32
功能:将数据转换成 UInt32 类型实例。
返回值:UInt32 类型实例
func consumeUInt64
public open func consumeUInt64(): UInt64
功能:将数据转换成 UInt64 类型实例。
返回值:UInt64 类型实例
func consumeInt8
public open func consumeInt8(): Int8
功能:将数据转换成 Int8 类型实例。
返回值:Int8 类型实例
func consumeInt16
public open func consumeInt16(): Int16
功能:将数据转换成 Int16 类型实例。
返回值:Int16 类型实例
func consumeInt32
public open func consumeInt32(): Int32
功能:将数据转换成 Int32 类型实例。
返回值:Int32 类型实例
func consumeInt64
public open func consumeInt64(): Int64
功能:将数据转换成 Int64 类型实例。
返回值:Int64 类型实例
func consumeUInt8s
public open func consumeUInt8s(count: Int64): Array<UInt8>
功能:将指定数量的数据转换成 UInt8 类型数组。
参数:
count:指定转换的数据量
返回值:UInt8 类型数组
func consumeUInt16s
public open func consumeUInt16s(count: Int64): Array<UInt16>
功能:将指定数量的数据转换成 UInt16 类型数组。
参数:
count:指定转换的数据量
返回值:UInt16 类型数组
func consumeUInt32s
public open func consumeUInt32s(count: Int64): Array<UInt32>
功能:将指定数量的数据转换成 UInt32 类型数组。
参数:
count:指定转换的数据量
返回值:UInt32 类型数组
func consumeUInt64s
public open func consumeUInt64s(count: Int64): Array<UInt64>
功能:将指定数量的数据转换成 UInt64 类型数组。
参数:
count:指定转换的数据量
返回值:UInt64 类型数组
func consumeInt8s
public open func consumeInt8s(count: Int64): Array<Int8>
功能:将指定数量的数据转换成 Int8 类型数组。
参数:
count:指定转换的数据量
返回值:Int8 类型数组
func consumeInt16s
public open func consumeInt16s(count: Int64): Array<Int16>
功能:将指定数量的数据转换成 Int16 类型数组。
参数:
count:指定转换的数据量
返回值:Int16 类型数组
func consumeInt32s
public open func consumeInt32s(count: Int64): Array<Int32>
功能:将指定数量的数据转换成 Int32 类型数组。
参数:
count:指定转换的数据量
返回值:Int32 类型数组
func consumeInt64s
public open func consumeInt64s(count: Int64): Array<Int64>
功能:将指定数量的数据转换成 Int64 类型数组。
参数:
count:指定转换的数据量
返回值:Int64 类型数组
func consumeFloat32
public open func consumeFloat32(): Float32
功能:将数据转换成 Float32 类型实例(保留接口,功能暂未实现,当前为抛出异常UnsupportException)。
返回值:Float32 类型实例
func consumeFloat64
public open func consumeFloat64(): Float64
功能:将数据转换成 Float64 类型实例(保留接口,功能暂未实现,当前为抛出异常UnsupportException)。
返回值:Float64 类型实例
func consumeChar
public open func consumeChar(): Char
功能:将数据转换成 Char 类型实例。
返回值:Char 类型实例
func consumeAsciiString
public open func consumeAsciiString(maxLength: Int64): String
功能:将数据转换成 Ascii String 类型实例。
参数:
maxLength:String类型的最大长度
返回值:String 类型实例
func consumeString
public open func consumeString(maxLength: Int64): String
功能:将数据转换成 utf8 String 类型实例。
参数:
maxLength:String类型的最大长度
返回值:String 类型实例
func consumeAll
public open func consumeAll(): Array<UInt8>
功能:将所有数据转换成 UInt8 类型数组。
返回值:UInt8 类型数组
func consumeAllAsAscii
public open func consumeAllAsAscii(): String
功能:将所有数据转换成 Ascii String 类型。
返回值:Ascii String 类型实例
func consumeAllAsString
public open func consumeAllAsString(): String
功能:将所有数据转换成 utf8 String 类型。
返回值:utf8 String 类型实例
class DebugDataProvider
public class DebugDataProvider <: DataProvider
此类继承了 DataProvider 类型,额外增加了调试信息。
data
public let data: Array<UInt8>
功能:变异数据。
remainingBytes
public var remainingBytes: Int64
功能:剩余字节数。
offset
public var offset: Int64
功能:已转化的字节数。
func wrap
public static func wrap(dp: DataProvider): DebugDataProvider
功能:根据 DataProvider 实例创建 DebugDataProvider 实例。
参数:
data:DataProvider类型实例
func consumeBool
public override func consumeBool(): Bool
功能:将数据转换成 Bool 类型实例。
返回值:Bool 类型实例
func consumeBools
public override func consumeBools(count: Int64): Array<Bool>
功能:将指定数量的数据转换成 Bool 类型数组。
参数:
count:指定转换的数据量
返回值:Bool 类型数组
func consumeByte
public override func consumeByte(): Byte
功能:将数据转换成 Byte 类型实例。
返回值:Byte 类型实例
func consumeBytes
public override func consumeBytes(count: Int64): Array<Byte>
功能:将指定数量的数据转换成 Byte 类型数组。
参数:
count:指定转换的数据量
返回值:Byte 类型数组
func consumeUInt8
public override func consumeUInt8(): UInt8
功能:将数据转换成 UInt8 类型实例。
返回值:UInt8 类型实例
func consumeUInt16
public override func consumeUInt16(): UInt16
功能:将数据转换成 UInt16 类型实例。
返回值:UInt16 类型实例
func consumeUInt32
public override func consumeUInt32(): UInt32
功能:将数据转换成 UInt32 类型实例。
返回值:UInt32 类型实例
func consumeUInt64
public override func consumeUInt64(): UInt64
功能:将数据转换成 UInt64 类型实例。
返回值:UInt64 类型实例
func consumeInt8
public override func consumeInt8(): Int8
功能:将数据转换成 Int8 类型实例。
返回值:Int8 类型实例
func consumeInt16
public override func consumeInt16(): Int16
功能:将数据转换成 Int16 类型实例。
返回值:Int16 类型实例
func consumeInt32
public override func consumeInt32(): Int32
功能:将数据转换成 Int32 类型实例。
返回值:Int32 类型实例
func consumeInt64
public override func consumeInt64(): Int64
功能:将数据转换成 Int64 类型实例。
返回值:Int64 类型实例
func consumeUInt8s
public override func consumeUInt8s(count: Int64): Array<UInt8>
功能:将指定数量的数据转换成 UInt8 类型数组。
参数:
count:指定转换的数据量
返回值:UInt8 类型数组
func consumeUInt16s
public override func consumeUInt16s(count: Int64): Array<UInt16>
功能:将指定数量的数据转换成 UInt16 类型数组。
参数:
count:指定转换的数据量
返回值:UInt16 类型数组
func consumeUInt32s
public override func consumeUInt32s(count: Int64): Array<UInt32>
功能:将指定数量的数据转换成 UInt32 类型数组。
参数:
count:指定转换的数据量
返回值:UInt32 类型数组
func consumeUInt64s
public override func consumeUInt64s(count: Int64): Array<UInt64>
功能:将指定数量的数据转换成 UInt64 类型数组。
参数:
count:指定转换的数据量
返回值:UInt64 类型数组
func consumeInt8s
public override func consumeInt8s(count: Int64): Array<Int8>
功能:将指定数量的数据转换成 Int8 类型数组。
参数:
count:指定转换的数据量
返回值:Int8 类型数组
func consumeInt16s
public override func consumeInt16s(count: Int64): Array<Int16>
功能:将指定数量的数据转换成 Int16 类型数组。
参数:
count:指定转换的数据量
返回值:Int16 类型数组
func consumeInt32s
public override func consumeInt32s(count: Int64): Array<Int32>
功能:将指定数量的数据转换成 Int32 类型数组。
参数:
count:指定转换的数据量
返回值:Int32 类型数组
func consumeInt64s
public override func consumeInt64s(count: Int64): Array<Int64>
功能:将指定数量的数据转换成 Int64 类型数组。
参数:
count:指定转换的数据量
返回值:Int64 类型数组
func consumeFloat32
public override func consumeFloat32(): Float32
功能:将数据转换成 Float32 类型实例(保留接口,功能暂未实现,当前为抛出异常UnsupportException)。
返回值:Float32 类型实例
func consumeFloat64
public override func consumeFloat64(): Float64
功能:将数据转换成 Float64 类型实例(保留接口,功能暂未实现,当前为抛出异常UnsupportException)。
返回值:Float64 类型实例
func consumeChar
public override func consumeChar(): Char
功能:将数据转换成 Char 类型实例。
返回值:Char 类型实例
func consumeAsciiString
public override func consumeAsciiString(maxLength: Int64): String
功能:将数据转换成 Ascii String 类型实例。
参数:
maxLength:String类型的最大长度
返回值:String 类型实例
func consumeString
public override func consumeString(maxLength: Int64): String
功能:将数据转换成 utf8 String 类型实例。
参数:
maxLength:String类型的最大长度
返回值:String 类型实例
func consumeAll
public override func consumeAll(): Array<UInt8>
功能:将所有数据转换成 UInt8 类型数组。
返回值:UInt8 类型数组
func consumeAllAsAscii
public override func consumeAllAsAscii(): String
功能:将所有数据转换成 Ascii String 类型。
返回值:Ascii String 类型实例
func consumeAllAsString
public override func consumeAllAsString(): String
功能:将所有数据转换成 utf8 String 类型。
返回值:utf8 String 类型实例
class UnsupportException
public class UnsupportException <: Exception {
public init()
public init(message: String)
}
此异常为转换数据时,不支持该数据类型时抛出的异常。
init
public init()
功能:创建 UnsupportException 实例。
init
public init(message: String)
功能:创建 UnsupportException 实例。
参数:
message:异常提示信息
class ExhaustedException
public class ExhaustedException <: Exception {
public init()
public init(message: String)
}
此异常为转换数据时,剩余数据不足以转换时抛出的异常。
init
public init()
功能:创建 ExhaustedException 实例。
init
public init(message: String)
功能:创建 ExhaustedException 实例。
参数:
message:异常提示信息
示例
对字符猜测功能进行测试
- 编写被测 API,当且仅当输入数组长度是 8、内容是 "Cangjie!" 对应的 ASCII 时抛出异常,纯随机的情况下最差需要
2**64次猜测才会触发异常。 - 创建 Fuzzer 并且调用待测 API,进入主流程
// 导入依赖的类
from fuzz import fuzz.Fuzzer
main() {
// 创建Fuzzer并启动fuzz流程
Fuzzer(api).startFuzz()
return 0
}
// 被测函数,在满足特定条件会抛出异常,该异常会被 Fuzzer 捕获
public func api(data: Array<UInt8>): Int32 {
if (data.size == 8 && data[0] == b'C' && data[1] == b'a' && data[2] == b'n' && data[3] == b'g' && data[4] == b'j' &&
data[5] == b'i' && data[6] == b'e' && data[7] == b'!') {
throw Exception("TRAP")
}
return 0
}
Linux 的编译命令是:cjc fuzz_main.cj --link-options="--whole-archive $CANGJIE_HOME/lib/linux_x86_64_llvm/libclang_rt.fuzzer_no_main.a -no-whole-archive -lstdc++" --sanitizer-coverage-inline-8bit-counters
macOS 的编译命令是:cjc fuzz_main.cj --link-options="$CANGJIE_HOME/lib/linux_x86_64_llvm/libclang_rt.fuzzer_no_main.a -lc++" --sanitizer-coverage-inline-8bit-counters
释义:
link-options是链接时选项,fuzz 库本身依赖符号LLVMFuzzerRunDriver,该符号需要开发者自行解决- 仓颉语言在 $CANGJIE_HOME/lib/linux_x86_64_llvm/libclang_rt.fuzzer_no_main.a 存放一份 修改过 的 libfuzzer,对标准的 libfuzzer 进行了增强,见 覆盖率信息打印-实验性特性
- 可以使用
find $(clang -print-runtime-dir) -name "libclang_rt.fuzzer_no_main*.a"寻找本地安装好的静态库文件。
- 向 Linux 编译需要使用
whole-archive libfuzzer.a是因为 cjc 调用 ld 后端时,从左到右顺序是libfuzzer.a、libcangjie-fuzz-fuzz.a、 libc 等基础库,该顺序会导致libcangjie-fuzz-fuzz.a依赖的LLVMFuzzerRunDriver符号未被找到。解决方案有- 将
libfuzzer.a放到libcangjie-fuzz-fuzz.a后面 - 使用
whole-archive libfuzzer.a来规避符号找不到的问题
- 将
-lstdc++(Linux) /-lc++(macOS) 用于链接 libfuzzer 依赖的 std 库--sanitizer-coverage-inline-8bit-counters是cjc的编译选项,它会对当前package执行覆盖率反馈插桩,详见 cjc 编译器使用手册- 其他高级的参数有:
--sanitizer-coverage-trace-compares(提高Fuzz变异的效率)、--sanitizer-coverage-pc-table(Fuzz结束后打印覆盖率信息)
- 其他高级的参数有:
与 libfuzzer 体验类似,可以直接运行,数秒后(取决于 CPU 性能)可获得 crash,且输入的数据是 "Cangjie!"
$ ./main
INFO: Seed: 246468919
INFO: Loaded 1 modules (15 inline 8-bit counters): 15 [0x55bb7c76dcb0, 0x55bb7c76dcbf),
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED ft: 4 corp: 1/1b exec/s: 0 rss: 28Mb
#420 NEW ft: 5 corp: 2/9b lim: 8 exec/s: 0 rss: 28Mb L: 8/8 MS: 3 CrossOver-InsertByte-InsertRepeatedBytes-
#1323 NEW ft: 6 corp: 3/17b lim: 14 exec/s: 0 rss: 28Mb L: 8/8 MS: 3 InsertByte-InsertByte-CrossOver-
#131072 pulse ft: 6 corp: 3/17b lim: 1300 exec/s: 65536 rss: 35Mb
#262144 pulse ft: 6 corp: 3/17b lim: 2600 exec/s: 65536 rss: 41Mb
#295225 NEW ft: 7 corp: 4/25b lim: 2930 exec/s: 73806 rss: 43Mb L: 8/8 MS: 2 ShuffleBytes-ChangeByte-
#514006 NEW ft: 8 corp: 5/33b lim: 4096 exec/s: 73429 rss: 53Mb L: 8/8 MS: 1 ChangeByte-
#524288 pulse ft: 8 corp: 5/33b lim: 4096 exec/s: 74898 rss: 53Mb
#1048576 pulse ft: 8 corp: 5/33b lim: 4096 exec/s: 61680 rss: 78Mb
#1064377 NEW ft: 9 corp: 6/41b lim: 4096 exec/s: 62610 rss: 79Mb L: 8/8 MS: 1 ChangeByte-
#1287268 NEW ft: 10 corp: 7/49b lim: 4096 exec/s: 61298 rss: 90Mb L: 8/8 MS: 1 ChangeByte-
#2097152 pulse ft: 10 corp: 7/49b lim: 4096 exec/s: 59918 rss: 128Mb
#2875430 NEW ft: 11 corp: 8/57b lim: 4096 exec/s: 61179 rss: 165Mb L: 8/8 MS: 2 ChangeBinInt-ChangeByte-
#4194304 pulse ft: 11 corp: 8/57b lim: 4096 exec/s: 59918 rss: 227Mb
#4208258 NEW ft: 12 corp: 9/65b lim: 4096 exec/s: 60117 rss: 228Mb L: 8/8 MS: 3 CrossOver-CrossOver-ChangeBit-
[WARNING]: Detect uncatched exception, maybe caused by bugs, exit now
An exception has occurred:
Exception: TRAP
at default.api(std/core::Array<...>)(/data/Cangjie/fuzz_main.cj:14)
at _ZN7default3apiER_ZN8std$core5ArrayIhE_cc_wrapper(/data/Cangjie/fuzz_main.cj:0)
at libfuzzerCallback(fuzz/fuzz/callback.cj:20)
[INFO]: data is: [67, 97, 110, 103, 106, 105, 101, 33]
[INFO]: data base64: Q2FuZ2ppZSE=
crash file will stored with libfuzzer
==899957== ERROR: libFuzzer: fuzz target exited
SUMMARY: libFuzzer: fuzz target exited
MS: 1 ChangeByte-; base unit: 7d8b0108ce76a937161065eafcde95bbf3d47dbf
0x43,0x61,0x6e,0x67,0x6a,0x69,0x65,0x21,
Cangjie!
artifact_prefix='./'; Test unit written to ./crash-555e7af32a2ceb585cdd9ce810c4804e65d41cea
Base64: Q2FuZ2ppZSE=
也可以使用 -help=1 打印帮助,-seed=246468919 指定随机数的种子。
$ ./main -help=1 exit 130
Usage:
To run fuzzing pass 0 or more directories.
program_name [-flag1=val1 [-flag2=val2 ...] ] [dir1 [dir2 ...] ]
To run individual tests without fuzzing pass 1 or more files:
program_name [-flag1=val1 [-flag2=val2 ...] ] file1 [file2 ...]
使用 DataProvider 功能进行测试
上文介绍了使用字节流对 API 进行测试的方法,除此之外,fuzz 包提供了 DataProvider 类,用于更友好地从变异的数据源产生仓颉的标准数据类型,方便对 API 进行测试。
public func api2(dp: DataProvider): Int32 {
if(dp.consumeBool() && dp.consumeByte() == b'A' && dp.consumeuint32() == 0xdeadbeef){
throw Exception("TRAP")
}
return 0
}
此案例中,开启 --sanitizer-coverage-trace-compares 可有效提高 fuzz 效率。
DataProvider 模式下,无法直观地判断各个 API 返回值分别是什么,因此提供了 Fuzzer.enableDebugDataProvider() 和 DebugDataProvider,在 startFuzz 前调用 enableDebugDataProvider() 即可令本次 fuzz 每次调用 consumeXXX 时打印日志。
例如,上文代码触发异常后,添加 enableDebugDataProvider 重新编译,效果如下。
from fuzz import fuzz.*
main() {
let fuzzer = Fuzzer(api2)
fuzzer.enableDebugDataProvider()
fuzzer.startFuzz()
return 0
}
./main crash-d7ece8e77ff25769a5d55eb8d3093d4bace78e1b
Running: crash-d7ece8e77ff25769a5d55eb8d3093d4bace78e1b
[DEBUG] consumeBool return true
[DEBUG] consumeByte return 65
[DEBUG] consumeUInt32 return 3735928559
[WARNING]: Detect uncatched exception, maybe caused by bugs, exit now
An exception has occurred:
Exception: TRAP
at default.api2(fuzz/fuzz::DataProvider)(/tmp/test.cj:12)
at _ZN7default4api2EC_ZN9fuzz$fuzz12DataProviderE_cc_wrapper(/tmp/test.cj:0)
at libfuzzerCallback(fuzz/fuzz/callback.cj:0)
[INFO]: data is: [191, 65, 239, 190, 173, 222]
FakeCoverage 模式
在链接了 libfuzzer <= 14 的情况下,且处于 DataProvider 模式下,遇到了类似如下的错误,可能需要阅读此章节:
ERROR: no interesting inputs were found. Is the code instrumented for coverage? Exiting.
libfuzzer 15 起,修复了该 feature,即使初始化时拒绝了输入,也不会停止执行。
注意:请确认被测试的库确实被插入了覆盖率反馈,因为在没有覆盖率反馈插桩的情况下,也会出现该错误!
当前 fuzz 后端对接到了 libfuzzer,而 libfuzzer 在启动时会先输入空字节流、再输入仅包含一个 '\n' 的字节流对待测函数进行试探,在两轮结束后检测覆盖率是否新增。在 DataProvider 模式下,如果先消耗数据,再调用待测库的 API,会导致消耗数据时长度不足而提前返回,从而 libfuzzer 认为覆盖率信息为零。
例如下方代码,会触发该错误
触发的代码:
// main.cj
from fuzz import fuzz.*
main() {
let f = Fuzzer(api)
f.disableFakeCoverage()
f.startFuzz()
return 0
}
// fuzz_target.cj, with sancov
public func api(dp: DataProvider): Int32 {
if (dp.consumeBool() && dp.consumeBool()) {
throw Exception("TRAP!")
}
return 0
}
因此,需要使用 Fake Coverage 创建虚假的覆盖率信息,让 libfuzzer 在初始化期间认为待测模块确实被插桩,等到 DataProvider 收集到足够数据后,再进行有效的 fuzz 测试。该模式被称为 Fake Coverage 模式。
将上文的 disableFakeCoverage() 替换为 enableFakeCoverage() 即可继续运行,最终触发 TRAP。
此外,除了使用 Fake Coverage 模式,还可以在测试用例中主动调用待测函数的某些不重要的API来将覆盖率信息传递给 libfuzzer,也能起到让 fuzz 继续下去的作用。
栈回溯缺失的处理方案
WARNING: Failed to find function "__sanitizer_acquire_crash_state".
WARNING: Failed to find function "__sanitizer_print_stack_trace".
WARNING: Failed to find function "__sanitizer_set_death_callback".
在启动 fuzz 时默认会有这三条 WARNING,因为当前 cj-fuzz 没有对它们进行实现。在 fuzz 过程中,可能会因为
- 抛出异常
- 超时
- 在 C 代码中 crash
而结束 fuzz 流程。
其中“抛出异常”的情况,fuzz 框架对异常进行捕获后会打印栈回溯,不会造成栈回溯缺失的现象。
“超时”和“在 C 代码中 crash”实际是在 native 代码中触发了 SIGNAL,不属于仓颉异常,因此会造成栈回溯的缺失。
libfuzzer 会尝试使用 __sanitizer_acquire_crash_state、__sanitizer_print_stack_trace、__sanitizer_set_death_callback 等函数处理异常情况,其中 __sanitizer_print_stack_trace 会打印栈回溯,目前成熟的实现在 llvm compiler-rt 中的 asan 等模块中。
因此,建议的解决方案是在链接时额外加入如下的静态库文件和链接选项,释义如下
/usr/lib/llvm-14/lib/clang/14.0.0/lib/linux/libclang_rt.asan-x86_64.a -lgcc_s --eh-frame-hdr
/usr/lib/llvm-14/lib/clang/14.0.0/lib/linux/libclang_rt.asan-x86_64.a因为该 .a 文件实现了__sanitizer_print_stack_trace,出于方便就直接用它。-lgcc_s栈回溯依赖 gcc_s--eh-frame-hdrld 链接时生成 eh_frame_hdr 节,帮助完成栈回溯
可选的环境变量:ASAN_SYMBOLIZER_PATH=$CANGJIE_HOME/third_party/llvm/bin/llvm-symbolizer,可能在某些情况下有用。
最终会得到两套栈回溯,一套是 Exception.printStackTrace,一套是 __sanitizer_print_stack_trace,内容如下:
[WARNING]: Detect uncatched exception, maybe caused by bugs, exit now
An exception has occurred:
Exception: TRAP!
at default.ttt(std/core::Array<...>)(/data/cangjie/libs/fuzz/ci_fuzzer0.cj:11)
at _ZN7default3tttER_ZN8std$core5ArrayIhE_cc_wrapper(/data/cangjie/libs/fuzz/ci_fuzzer0.cj:0)
at libfuzzerCallback(/data/cangjie/libs/fuzz/fuzz/callback.cj:34)
[INFO]: data is: [0, 202, 0, 0, 0, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255]
[INFO]: crash file will stored with libfuzzer
==425243== ERROR: libFuzzer: fuzz target exited
#0 0x563a233fadf1 in __sanitizer_print_stack_trace (/data/cangjie/libs/fuzz/main+0x280df1)
#1 0x563a2337c0b8 in fuzzer::PrintStackTrace() (/data/cangjie/libs/fuzz/main+0x2020b8)
#2 0x563a2338726c in fuzzer::Fuzzer::ExitCallback() (/data/cangjie/libs/fuzz/main+0x20d26c)
#3 0x7f485cf36494 in __run_exit_handlers stdlib/exit.c:113:8
#4 0x7f485cf3660f in exit stdlib/exit.c:143:3
#5 0x563a23224e68 in libfuzzerCallback$real /data/cangjie/libs/fuzz/fuzz/callback.cj:62:18
#6 0x7f485d22718b in CJ_MCC_N2CStub (/data/cangjie/output/runtime/lib/linux_x86_64_llvm/libcangjie-runtime.so+0x2718b)
#7 0x563a2322fc26 in libfuzzerCallback /data/cangjie/libs/fuzz/fuzz/callback.cj:20
#8 0x563a23387883 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) (/data/cangjie/libs/fuzz/main+0x20d883)
#9 0x563a2338a3f9 in fuzzer::Fuzzer::RunOne(unsigned char const*, unsigned long, bool, fuzzer::InputInfo*, bool, bool*) (/data/cangjie/libs/fuzz/main+0x2103f9)
#10 0x563a23387e49 in fuzzer::Fuzzer::MutateAndTestOne() (/data/cangjie/libs/fuzz/main+0x20de49)
#11 0x563a2338a2b5 in fuzzer::Fuzzer::Loop(std::vector<fuzzer::SizedFile, std::allocator<fuzzer::SizedFile>>&) (/data/cangjie/libs/fuzz/main+0x2102b5)
#12 0x563a23377a12 in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) (/data/cangjie/libs/fuzz/main+0x1fda12)
#13 0x563a231ad2b6 in fuzz_fake$fuzz::Fuzzer::startFuzz() /data/cangjie/libs/fuzz/fuzz/fuzzer.cj:200:13
#14 0x563a23405fad in default::main() /data/cangjie/libs/fuzz/ci_fuzzer0.cj:5:5
#15 0x563a23405fe7 in user.main /data/cangjie/libs/fuzz/<stdin>
#16 0x563a234060e1 in cj_entry$ (/data/cangjie/libs/fuzz/main+0x28c0e1)
#17 0x7f485d227220 (/data/cangjie/output/runtime/lib/linux_x86_64_llvm/libcangjie-runtime.so+0x27220)
#18 0x7f485d223898 (/data/cangjie/output/runtime/lib/linux_x86_64_llvm/libcangjie-runtime.so+0x23898)
#19 0x7f485d2607b9 in CJ_CJThreadEntry (/data/cangjie/output/runtime/lib/linux_x86_64_llvm/libcangjie-runtime.so+0x607b9)
覆盖率信息打印 实验性特性
仓颉 fuzzer 支持使用 -print_coverage=1 作为启动参数运行 fuzzer,用于统计各函数的测试情况,该特性在持续完善中,只与输出覆盖率报告有关,不影响 fuzz 过程。
由于该功能需要对 libfuzzer 进行侵入式修改,使用该功能需要链接仓颉自带的 libfuzzer,路径是:$CANGJIE_HOME/lib/{linux_x86_64_llvm, linux_aarch64_llvm}/libclang_rt-fuzzer_no_main.a。
编译时需要同时启用--sanitizer-coverage-inline-8bit-counters 和 --sanitizer-coverage-pc-table。
C 语言 libfuzzer 输出举例
./a.out -print_coverage=1
COVERAGE:
COVERED_FUNC: hits: 5 edges: 6/8 LLVMFuzzerTestOneInput /tmp/test.cpp:5
UNCOVERED_PC: /tmp/test.cpp:6
UNCOVERED_PC: /tmp/test.cpp:9
仓颉语言 cj-fuzz 输出举例
./main -print_coverage=1 -runs=100
Done 100 runs in 0 second(s)
COVERAGE:
COVERED_FUNC: hits: 1 edges: 3/12 ttt <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_FUNC: hits: 0 edges: 0/2 main <unknown cj filename>:<unknown cj line number>
COVERED_FUNC: hits: 1 edges: 1/1 ttt_cc_wrapper <unknown cj filename>:<unknown cj line number>
cjvm 使用 cj-fuzz 功能
差异说明:cjvm 无法加载 .a 文件,只能加载 .so 文件。
cj-fuzz 运行时依赖 libclang_rt.fuzzer_no_main.a 和 libcangjie-fuzz-fuzzFFI.a,因此需要将它们链接为动态链接库的格式,命令如下:
clang++ -shared -Wl,--whole-archive libclang_rt.fuzzer_no_main.a ${CANGJIE_HOME}/lib/linux_x86_64_jet/libcangjie-fuzz-fuzzFFI.a -Wl,--no-whole-archive -o libcangjie-fuzz-fuzzFFI.so
运行 cj-fuzz
- 通过上述命令,获得
libcangjie-fuzz-fuzzFFI.so cjc fuzz_main.cj --sanitizer-coverage-inline-8bit-counters ${CANGJIE_HOME}/modules/linux_x86_64_jet/fuzz/fuzz.bc -lcangjie-fuzz-fuzzFFI--sanitizer-coverage-inline-8bit-counters启用覆盖率插桩${CANGJIE_HOME}/modules/linux_x86_64_jet/fuzz/fuzz.bc主动链接 fuzz 模块的 fuzz 包的字节码-lcangjie-fuzz-fuzzFFI指定依赖库的名称,运行时会搜索 libcangjie-fuzz-fuzzFFI.so 进行动态加载
LD_LIBRARY_PATH=/path/to/lib:${LD_LIBRARY_PATH} cj main.cbc- 按需修改 LD_LIBRARY_PATH
- 执行 cbc 文件
实际效果如下:
cp /usr/lib/llvm-14/lib/clang/14.0.0/lib/linux/libclang_rt.fuzzer_no_main-x86_64.a .
clang++ -shared -Wl,--whole-archive libclang_rt.fuzzer_no_main-x86_64.a ${CANGJIE_HOME}/lib/linux_x86_64_jet/libcangjie-fuzz-fuzzFFI.a -Wl,--no-whole-archive -o libcangjie-fuzz-fuzzFFI.so
cjc --sanitizer-coverage-inline-8bit-counters fuzz_main.cj ${CANGJIE_HOME}/modules/linux_x86_64_jet/fuzz/fuzz.bc -lcangjie-fuzz-fuzzFFI
LD_LIBRARY_PATH=/path/to/lib:${LD_LIBRARY_PATH} cj main.cbc
>>>>
WARNING: Failed to find function "__sanitizer_acquire_crash_state".
WARNING: Failed to find function "__sanitizer_print_stack_trace".
WARNING: Failed to find function "__sanitizer_set_death_callback".
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 3156944264
INFO: Loaded 1 modules (21 inline 8-bit counters): 21 [0x5627041690a0, 0x5627041690b5),
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED ft: 4 corp: 1/1b exec/s: 0 rss: 52Mb
#488 NEW ft: 5 corp: 2/9b lim: 8 exec/s: 0 rss: 53Mb L: 8/8 MS: 1 InsertRepeatedBytes-
#12303 NEW ft: 6 corp: 3/17b lim: 122 exec/s: 0 rss: 54Mb L: 8/8 MS: 5 CrossOver-ChangeBit-ShuffleBytes-ShuffleBytes-ChangeByte-
#20164 NEW ft: 7 corp: 4/25b lim: 198 exec/s: 0 rss: 54Mb L: 8/8 MS: 1 ChangeByte-
#180030 NEW ft: 8 corp: 5/33b lim: 1780 exec/s: 180030 rss: 55Mb L: 8/8 MS: 1 ChangeByte-
#524288 pulse ft: 8 corp: 5/33b lim: 4096 exec/s: 174762 rss: 55Mb
#671045 NEW ft: 9 corp: 6/41b lim: 4096 exec/s: 167761 rss: 55Mb L: 8/8 MS: 5 InsertByte-ChangeByte-ChangeBit-ChangeByte-EraseBytes-
#758816 NEW ft: 10 corp: 7/49b lim: 4096 exec/s: 151763 rss: 55Mb L: 8/8 MS: 1 ChangeByte-
#1048576 pulse ft: 10 corp: 7/49b lim: 4096 exec/s: 149796 rss: 55Mb
#1947938 NEW ft: 11 corp: 8/57b lim: 4096 exec/s: 162328 rss: 55Mb L: 8/8 MS: 2 InsertByte-EraseBytes-
#2097152 pulse ft: 11 corp: 8/57b lim: 4096 exec/s: 161319 rss: 55Mb
#3332055 NEW ft: 12 corp: 9/65b lim: 4096 exec/s: 151457 rss: 55Mb L: 8/8 MS: 2 ChangeByte-ChangeBit-
[WARNING]: Detect uncatched exception, maybe caused by bugs, exit now
An exception has occurred:
Exception: TRAP
at default.api(/cjvm_demo/test.cj:20)
at default.api(/cjvm_demo/test.cj:0)
at fuzz/fuzz.libfuzzerCallback(/cangjie/lib/src/fuzz/fuzz/callback.cj:34)
at fuzz/fuzz.Fuzzer.startFuzz(/cangjie/lib/src/fuzz/fuzz/fuzzer.cj:223)
at default.<main>(/cjvm_demo/test.cj:5)
at default.user.main(<unknown>:0)
[INFO]: data is: [67, 97, 110, 103, 106, 105, 101, 33]
[INFO]: crash file will stored with libfuzzer
==33946== ERROR: libFuzzer: fuzz target exited
SUMMARY: libFuzzer: fuzz target exited
MS: 1 ChangeByte-; base unit: 1719c2c0bbc676f5b436528c183e4743a455d66a
0x43,0x61,0x6e,0x67,0x6a,0x69,0x65,0x21,
Cangjie!
artifact_prefix='./'; Test unit written to ./crash-555e7af32a2ceb585cdd9ce810c4804e65d41cea
Base64: Q2FuZ2ppZSE=
fuzz 包
介绍
提供仓颉 fuzz 引擎及对应的接口,需配合覆盖率反馈插桩(SanitizerCoverage)功能使用,编写代码对 API 进行测试。使用此包需要开发者对 fuzz 测试有一定的了解,初学者建议先学习 C 语言的 Fuzz 工具 libFuzzer
使用本包需要外部依赖 LLVM 套件 compiler-rt 提供的 libclang_rt.fuzzer_no_main.a 静态库,当前支持 Linux 以及 macOS,不支持 Windows,对 cjnative 后端支持最好,对 cjvm 后端的测试需要重新链接依赖库。
通常使用包管理工具即可完成安装,例如 Ubuntu 22.04 系统上可使用 sudo apt install clang 进行安装,安装后可以在 clang -print-runtime-dir 指向的目录下找到对应的 libclang_rt.fuzzer_no_main.a 文件,例如 /usr/lib/llvm-14/lib/clang/14.0.0/lib/linux/libclang_rt.fuzzer_no_main-x86_64.a,将来在链接时会用到它。
主要接口
FUZZ_VERSION
public let FUZZ_VERSION = "1.0.0"
功能:Fuzz 版本。
class Fuzzer
public class Fuzzer {
public init(targetFunction: (Array<UInt8>) -> Int32)
public init(targetFunction: (Array<UInt8>) -> Int32, args: Array<String>)
public init(targetFunction: (DataProvider) -> Int32)
public init(targetFunction: (DataProvider) -> Int32, args: Array<String>)
}
Fuzzer 类提供了 fuzz 工具的创建.
init
public init(targetFunction: (Array<UInt8>) -> Int32)
功能:根据以 UInt8 数组为参数,以 Int32 为返回值的目标函数,创建 Fuzzer 实例。
参数:
targetFunction:以UInt8数组为参数,以Int32为返回值的目标函数
init
public init(targetFunction: (Array<UInt8>) -> Int32, args: Array<String>)
功能:根据以 UInt8 数组为参数,以 Int32 为返回值的目标函数,以及 Fuzz 运行参数,创建 Fuzzer 实例。
参数:
targetFunction:以UInt8数组为参数,以Int32为返回值的目标函数args:Fuzz 运行参数
init
public init(targetFunction: (DataProvider) -> Int32)
功能:根据以 DataProvider 为参数,以 Int32 为返回值的目标函数,创建 Fuzzer 实例。
参数:
targetFunction:以DataProvider为参数,以Int32为返回值的目标函数
init
public init(targetFunction: (DataProvider) -> Int32, args: Array<String>)
功能:根据以 DataProvider 为参数,以 Int32 为返回值的目标函数,以及 Fuzz 运行参数,创建 Fuzzer 实例。
参数:
targetFunction:以DataProvider为参数,以Int32为返回值的目标函数args:Fuzz 运行参数
func getArgs
public func getArgs(): Array<String>
功能:获取 Fuzz 运行参数。
返回值:当前 Fuzz 运行参数
func setArgs
public func setArgs(args: Array<String>): Unit
功能:设置 Fuzz 运行参数。
参数:
args:Fuzz 运行参数。
func setTargetFunction
public func setTargetFunction(targetFunction: (Array<UInt8>) -> Int32): Unit
功能:设置 Fuzz 目标函数。
参数:
targetFunction:以UInt8数组为参数,以Int32为返回值的目标函数
func setTargetFunction
public func setTargetFunction(targetFunction: (DataProvider) -> Int32): Unit
功能:设置 Fuzz 目标函数。
参数:
targetFunction:以DataProvider为参数,以Int32为返回值的目标函数
func startFuzz
public func startFuzz(): Unit
功能:执行 Fuzz。
func enableFakeCoverage
public func enableFakeCoverage(): Unit
功能:创建一块虚假的覆盖率反馈区域,保持 Fuzz 持续进行。在 DataProvider 模式下,前几轮运行时可能由于数据不足而导致没有覆盖率,libfuzzer 会退出。该功能默认为关闭。
func disableFakeCoverage
public func disableFakeCoverage(): Unit
功能:关闭调用 enableFakeCoverage 对 Fuzz 的影响。
func enableDebugDataProvider
public func enableDebugDataProvider(): Unit
功能:启用调试信息打印功能,当 DataProvider.consumeXXX 被调用时,返回值将被打印到 stdout。该功能默认为关闭。
func disableDebugDataProvider
public func disableDebugDataProvider(): Unit
功能:关闭调试信息打印功能,当 DataProvider.consumeXXX 被调用时,返回值将不被打印到 stdout。
class FuzzerBuilder
public class FuzzerBuilder {
public init(targetFunction: (Array<UInt8>) -> Int32)
public init(targetFunction: (DataProvider) -> Int32)
}
此类用于 Fuzzer 类的构建。
init
public init(targetFunction: (Array<UInt8>) -> Int32)
功能:根据以 UInt8 数组为参数,以 Int32 为返回值的目标函数,创建 FuzzerBuilder 实例。
参数:
targetFunction:以UInt8数组为参数,以Int32为返回值的目标函数
init
public init(targetFunction: (DataProvider) -> Int32)
功能:根据以 DataProvider 为参数,以 Int32 为返回值的目标函数,创建 FuzzerBuilder 实例。
参数:
targetFunction:以DataProvider为参数,以Int32为返回值的目标函数
func setArgs
public func setArgs(args: Array<String>): FuzzerBuilder
功能:设置 Fuzz 运行参数。
参数:
args:Fuzz 运行参数
返回值:当前 FuzzerBuilder 实例。
func setTargetFunction
public func setTargetFunction(targetFunction: (Array<UInt8>) -> Int32): FuzzerBuilder
功能:设置 Fuzz 目标函数。
参数:
targetFunction:以UInt8数组为参数,以Int32为返回值的目标函数
返回值:当前 FuzzerBuilder 实例。
func setTargetFunction
public func setTargetFunction(targetFunction: (DataProvider) -> Int32): FuzzerBuilder
功能:设置 Fuzz 目标函数。
参数:
targetFunction:以DataProvider为参数,以Int32为返回值的目标函数
返回值:当前 FuzzerBuilder 实例。
func build
public func build(): Fuzzer
功能:生成一个 Fuzzer 实例。
返回值:Fuzzer 实例
class DataProvider
public open class DataProvider {
public let data: Array<UInt8>
public var remainingBytes: Int64
public var offset: Int64
}
DataProvider 是一个工具类,目的是将变异数据的字节流转化为标准的仓颉基本数据,当前支持的数据结构如下:
| 目标类型 | API | 说明 |
|---|---|---|
| Bool | consumeBool() | 获取1个Bool,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeBools(count: Int64) | 获取N个Bool,变异数据长度不足时,抛出ExhaustedException |
| Byte | consumeByte() | 获取1个Byte,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeBytes(count: Int64) | 获取N个Byte,变异数据长度不足时,抛出ExhaustedException |
| UInt8 | consumeUInt8() | 获取1个UInt8,变异数据长度不足时,抛出ExhaustedException |
| UInt16 | consumeUInt16() | 获取1个UInt16,变异数据长度不足时,抛出ExhaustedException |
| UInt32 | consumeUInt32() | 获取1个UInt32,变异数据长度不足时,抛出ExhaustedException |
| UInt64 | consumeUInt64() | 获取1个UInt64,变异数据长度不足时,抛出ExhaustedException |
| Int8 | consumeInt8() | 获取1个Int8,变异数据长度不足时,抛出ExhaustedException |
| Int16 | consumeInt16() | 获取1个Int16,变异数据长度不足时,抛出ExhaustedException |
| Int32 | consumeInt32() | 获取1个Int32,变异数据长度不足时,抛出ExhaustedException |
| Int32 | consumeInt32() | 获取1个Int32,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeUInt8s(count: Int64) | 获取N个UInt8,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeUInt16s(count: Int64) | 获取N个UInt16,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeUInt32s(count: Int64) | 获取N个UInt32,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeUInt64s(count: Int64) | 获取N个UInt64,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeInt8s(count: Int64) | 获取N个Int8,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeInt16s(count: Int64) | 获取N个Int16,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeInt32s(count: Int64) | 获取N个Int32,变异数据长度不足时,抛出ExhaustedException |
| Array | consumeInt32s(count: Int64) | 获取N个Int32,变异数据长度不足时,抛出ExhaustedException |
| Char | consumeChar() | 获取1个Char,变异数据长度不足时,抛出ExhaustedException |
| String | consumeAsciiString(maxLength: Int64) | 获取1个纯ASCII的String,长度为0到maxLength,可以为0 |
| String | consumeString(maxLength: Int64) | 获取1个UTF8 String,长度为0到maxLength,可以为0 |
| Array | consumeAll() | 将DataProvider中的剩余内容全部转化为字节数组 |
| String | consumeAllAsAscii() | 将DataProvider中的剩余内容全部转化为纯ASCII的String |
| String | consumeAllAsString() | 将DataProvider中的剩余内容全部转化为UTF8 String,末尾多余的字符不会被消耗 |
不支持Float32和Float64
在数据长度不足时,调用上述大部分虽然会抛出 ExhaustedException,但编写 fuzz 函数时通常并不需要对它进行处理,ExhaustedException 默认会被 fuzz 框架捕获,告诉 libfuzzer 该次运行无效,请继续下一轮变异。随着执行时间的变长,变异数据也会逐渐变长,直到满足 DataProvider 的需求。
如果达到了 max_len 仍无法满足 DataProvider 的需求,则进程退出,请修改 fuzz 测试用例(推荐) 或 增大 max_len(不推荐)。
data
public let data: Array<UInt8>
功能:变异数据。
remainingBytes
public var remainingBytes: Int64
功能:剩余字节数。
offset
public var offset: Int64
功能:已转化的字节数。
func withCangjieData
public static func withCangjieData(data: Array<UInt8>): DataProvider
功能:根据 UInt8 数组创建 DataProvider 实例。
参数:
data:字节流的变异数据
func withNativeData
public static unsafe func withNativeData(data: CPointer<UInt8>, length: Int64): DataProvider
功能:根据 UInt8 指针,以及数据长度,创建 DataProvider 实例。
参数:
data:利用指针存储的变异数据length:数据长度
func consumeBool
public open func consumeBool(): Bool
功能:将数据转换成 Bool 类型实例。
返回值:Bool 类型实例
func consumeBools
public open func consumeBools(count: Int64): Array<Bool>
功能:将指定数量的数据转换成 Bool 类型数组。
参数:
count:指定转换的数据量
返回值:Bool 类型数组
func consumeByte
public open func consumeByte(): Byte
功能:将数据转换成 Byte 类型实例。
返回值:Byte 类型实例
func consumeBytes
public open func consumeBytes(count: Int64): Array<Byte>
功能:将指定数量的数据转换成 Byte 类型数组。
参数:
count:指定转换的数据量
返回值:Byte 类型数组
func consumeUInt8
public open func consumeUInt8(): UInt8
功能:将数据转换成 UInt8 类型实例。
返回值:UInt8 类型实例
func consumeUInt16
public open func consumeUInt16(): UInt16
功能:将数据转换成 UInt16 类型实例。
返回值:UInt16 类型实例
func consumeUInt32
public open func consumeUInt32(): UInt32
功能:将数据转换成 UInt32 类型实例。
返回值:UInt32 类型实例
func consumeUInt64
public open func consumeUInt64(): UInt64
功能:将数据转换成 UInt64 类型实例。
返回值:UInt64 类型实例
func consumeInt8
public open func consumeInt8(): Int8
功能:将数据转换成 Int8 类型实例。
返回值:Int8 类型实例
func consumeInt16
public open func consumeInt16(): Int16
功能:将数据转换成 Int16 类型实例。
返回值:Int16 类型实例
func consumeInt32
public open func consumeInt32(): Int32
功能:将数据转换成 Int32 类型实例。
返回值:Int32 类型实例
func consumeInt64
public open func consumeInt64(): Int64
功能:将数据转换成 Int64 类型实例。
返回值:Int64 类型实例
func consumeUInt8s
public open func consumeUInt8s(count: Int64): Array<UInt8>
功能:将指定数量的数据转换成 UInt8 类型数组。
参数:
count:指定转换的数据量
返回值:UInt8 类型数组
func consumeUInt16s
public open func consumeUInt16s(count: Int64): Array<UInt16>
功能:将指定数量的数据转换成 UInt16 类型数组。
参数:
count:指定转换的数据量
返回值:UInt16 类型数组
func consumeUInt32s
public open func consumeUInt32s(count: Int64): Array<UInt32>
功能:将指定数量的数据转换成 UInt32 类型数组。
参数:
count:指定转换的数据量
返回值:UInt32 类型数组
func consumeUInt64s
public open func consumeUInt64s(count: Int64): Array<UInt64>
功能:将指定数量的数据转换成 UInt64 类型数组。
参数:
count:指定转换的数据量
返回值:UInt64 类型数组
func consumeInt8s
public open func consumeInt8s(count: Int64): Array<Int8>
功能:将指定数量的数据转换成 Int8 类型数组。
参数:
count:指定转换的数据量
返回值:Int8 类型数组
func consumeInt16s
public open func consumeInt16s(count: Int64): Array<Int16>
功能:将指定数量的数据转换成 Int16 类型数组。
参数:
count:指定转换的数据量
返回值:Int16 类型数组
func consumeInt32s
public open func consumeInt32s(count: Int64): Array<Int32>
功能:将指定数量的数据转换成 Int32 类型数组。
参数:
count:指定转换的数据量
返回值:Int32 类型数组
func consumeInt64s
public open func consumeInt64s(count: Int64): Array<Int64>
功能:将指定数量的数据转换成 Int64 类型数组。
参数:
count:指定转换的数据量
返回值:Int64 类型数组
func consumeFloat32
public open func consumeFloat32(): Float32
功能:将数据转换成 Float32 类型实例(保留接口,功能暂未实现,当前为抛出异常UnsupportException)。
返回值:Float32 类型实例
func consumeFloat64
public open func consumeFloat64(): Float64
功能:将数据转换成 Float64 类型实例(保留接口,功能暂未实现,当前为抛出异常UnsupportException)。
返回值:Float64 类型实例
func consumeChar
public open func consumeChar(): Char
功能:将数据转换成 Char 类型实例。
返回值:Char 类型实例
func consumeAsciiString
public open func consumeAsciiString(maxLength: Int64): String
功能:将数据转换成 Ascii String 类型实例。
参数:
maxLength:String类型的最大长度
返回值:String 类型实例
func consumeString
public open func consumeString(maxLength: Int64): String
功能:将数据转换成 utf8 String 类型实例。
参数:
maxLength:String类型的最大长度
返回值:String 类型实例
func consumeAll
public open func consumeAll(): Array<UInt8>
功能:将所有数据转换成 UInt8 类型数组。
返回值:UInt8 类型数组
func consumeAllAsAscii
public open func consumeAllAsAscii(): String
功能:将所有数据转换成 Ascii String 类型。
返回值:Ascii String 类型实例
func consumeAllAsString
public open func consumeAllAsString(): String
功能:将所有数据转换成 utf8 String 类型。
返回值:utf8 String 类型实例
class DebugDataProvider
public class DebugDataProvider <: DataProvider
此类继承了 DataProvider 类型,额外增加了调试信息。
data
public let data: Array<UInt8>
功能:变异数据。
remainingBytes
public var remainingBytes: Int64
功能:剩余字节数。
offset
public var offset: Int64
功能:已转化的字节数。
func wrap
public static func wrap(dp: DataProvider): DebugDataProvider
功能:根据 DataProvider 实例创建 DebugDataProvider 实例。
参数:
data:DataProvider类型实例
func consumeBool
public override func consumeBool(): Bool
功能:将数据转换成 Bool 类型实例。
返回值:Bool 类型实例
func consumeBools
public override func consumeBools(count: Int64): Array<Bool>
功能:将指定数量的数据转换成 Bool 类型数组。
参数:
count:指定转换的数据量
返回值:Bool 类型数组
func consumeByte
public override func consumeByte(): Byte
功能:将数据转换成 Byte 类型实例。
返回值:Byte 类型实例
func consumeBytes
public override func consumeBytes(count: Int64): Array<Byte>
功能:将指定数量的数据转换成 Byte 类型数组。
参数:
count:指定转换的数据量
返回值:Byte 类型数组
func consumeUInt8
public override func consumeUInt8(): UInt8
功能:将数据转换成 UInt8 类型实例。
返回值:UInt8 类型实例
func consumeUInt16
public override func consumeUInt16(): UInt16
功能:将数据转换成 UInt16 类型实例。
返回值:UInt16 类型实例
func consumeUInt32
public override func consumeUInt32(): UInt32
功能:将数据转换成 UInt32 类型实例。
返回值:UInt32 类型实例
func consumeUInt64
public override func consumeUInt64(): UInt64
功能:将数据转换成 UInt64 类型实例。
返回值:UInt64 类型实例
func consumeInt8
public override func consumeInt8(): Int8
功能:将数据转换成 Int8 类型实例。
返回值:Int8 类型实例
func consumeInt16
public override func consumeInt16(): Int16
功能:将数据转换成 Int16 类型实例。
返回值:Int16 类型实例
func consumeInt32
public override func consumeInt32(): Int32
功能:将数据转换成 Int32 类型实例。
返回值:Int32 类型实例
func consumeInt64
public override func consumeInt64(): Int64
功能:将数据转换成 Int64 类型实例。
返回值:Int64 类型实例
func consumeUInt8s
public override func consumeUInt8s(count: Int64): Array<UInt8>
功能:将指定数量的数据转换成 UInt8 类型数组。
参数:
count:指定转换的数据量
返回值:UInt8 类型数组
func consumeUInt16s
public override func consumeUInt16s(count: Int64): Array<UInt16>
功能:将指定数量的数据转换成 UInt16 类型数组。
参数:
count:指定转换的数据量
返回值:UInt16 类型数组
func consumeUInt32s
public override func consumeUInt32s(count: Int64): Array<UInt32>
功能:将指定数量的数据转换成 UInt32 类型数组。
参数:
count:指定转换的数据量
返回值:UInt32 类型数组
func consumeUInt64s
public override func consumeUInt64s(count: Int64): Array<UInt64>
功能:将指定数量的数据转换成 UInt64 类型数组。
参数:
count:指定转换的数据量
返回值:UInt64 类型数组
func consumeInt8s
public override func consumeInt8s(count: Int64): Array<Int8>
功能:将指定数量的数据转换成 Int8 类型数组。
参数:
count:指定转换的数据量
返回值:Int8 类型数组
func consumeInt16s
public override func consumeInt16s(count: Int64): Array<Int16>
功能:将指定数量的数据转换成 Int16 类型数组。
参数:
count:指定转换的数据量
返回值:Int16 类型数组
func consumeInt32s
public override func consumeInt32s(count: Int64): Array<Int32>
功能:将指定数量的数据转换成 Int32 类型数组。
参数:
count:指定转换的数据量
返回值:Int32 类型数组
func consumeInt64s
public override func consumeInt64s(count: Int64): Array<Int64>
功能:将指定数量的数据转换成 Int64 类型数组。
参数:
count:指定转换的数据量
返回值:Int64 类型数组
func consumeFloat32
public override func consumeFloat32(): Float32
功能:将数据转换成 Float32 类型实例(保留接口,功能暂未实现,当前为抛出异常UnsupportException)。
返回值:Float32 类型实例
func consumeFloat64
public override func consumeFloat64(): Float64
功能:将数据转换成 Float64 类型实例(保留接口,功能暂未实现,当前为抛出异常UnsupportException)。
返回值:Float64 类型实例
func consumeChar
public override func consumeChar(): Char
功能:将数据转换成 Char 类型实例。
返回值:Char 类型实例
func consumeAsciiString
public override func consumeAsciiString(maxLength: Int64): String
功能:将数据转换成 Ascii String 类型实例。
参数:
maxLength:String类型的最大长度
返回值:String 类型实例
func consumeString
public override func consumeString(maxLength: Int64): String
功能:将数据转换成 utf8 String 类型实例。
参数:
maxLength:String类型的最大长度
返回值:String 类型实例
func consumeAll
public override func consumeAll(): Array<UInt8>
功能:将所有数据转换成 UInt8 类型数组。
返回值:UInt8 类型数组
func consumeAllAsAscii
public override func consumeAllAsAscii(): String
功能:将所有数据转换成 Ascii String 类型。
返回值:Ascii String 类型实例
func consumeAllAsString
public override func consumeAllAsString(): String
功能:将所有数据转换成 utf8 String 类型。
返回值:utf8 String 类型实例
class UnsupportException
public class UnsupportException <: Exception {
public init()
public init(message: String)
}
此异常为转换数据时,不支持该数据类型时抛出的异常。
init
public init()
功能:创建 UnsupportException 实例。
init
public init(message: String)
功能:创建 UnsupportException 实例。
参数:
message:异常提示信息
class ExhaustedException
public class ExhaustedException <: Exception {
public init()
public init(message: String)
}
此异常为转换数据时,剩余数据不足以转换时抛出的异常。
init
public init()
功能:创建 ExhaustedException 实例。
init
public init(message: String)
功能:创建 ExhaustedException 实例。
参数:
message:异常提示信息
示例
对字符猜测功能进行测试
- 编写被测 API,当且仅当输入数组长度是 8、内容是 "Cangjie!" 对应的 ASCII 时抛出异常,纯随机的情况下最差需要
2**64次猜测才会触发异常。 - 创建 Fuzzer 并且调用待测 API,进入主流程
// 导入依赖的类
from fuzz import fuzz.Fuzzer
main() {
// 创建Fuzzer并启动fuzz流程
Fuzzer(api).startFuzz()
return 0
}
// 被测函数,在满足特定条件会抛出异常,该异常会被 Fuzzer 捕获
public func api(data: Array<UInt8>): Int32 {
if (data.size == 8 && data[0] == b'C' && data[1] == b'a' && data[2] == b'n' && data[3] == b'g' && data[4] == b'j' &&
data[5] == b'i' && data[6] == b'e' && data[7] == b'!') {
throw Exception("TRAP")
}
return 0
}
Linux 的编译命令是:cjc fuzz_main.cj --link-options="--whole-archive $CANGJIE_HOME/lib/linux_x86_64_llvm/libclang_rt.fuzzer_no_main.a -no-whole-archive -lstdc++" --sanitizer-coverage-inline-8bit-counters
macOS 的编译命令是:cjc fuzz_main.cj --link-options="$CANGJIE_HOME/lib/linux_x86_64_llvm/libclang_rt.fuzzer_no_main.a -lc++" --sanitizer-coverage-inline-8bit-counters
释义:
link-options是链接时选项,fuzz 库本身依赖符号LLVMFuzzerRunDriver,该符号需要开发者自行解决- 仓颉语言在 $CANGJIE_HOME/lib/linux_x86_64_llvm/libclang_rt.fuzzer_no_main.a 存放一份 修改过 的 libfuzzer,对标准的 libfuzzer 进行了增强,见 覆盖率信息打印-实验性特性
- 可以使用
find $(clang -print-runtime-dir) -name "libclang_rt.fuzzer_no_main*.a"寻找本地安装好的静态库文件。
- 向 Linux 编译需要使用
whole-archive libfuzzer.a是因为 cjc 调用 ld 后端时,从左到右顺序是libfuzzer.a、libcangjie-fuzz-fuzz.a、 libc 等基础库,该顺序会导致libcangjie-fuzz-fuzz.a依赖的LLVMFuzzerRunDriver符号未被找到。解决方案有- 将
libfuzzer.a放到libcangjie-fuzz-fuzz.a后面 - 使用
whole-archive libfuzzer.a来规避符号找不到的问题
- 将
-lstdc++(Linux) /-lc++(macOS) 用于链接 libfuzzer 依赖的 std 库--sanitizer-coverage-inline-8bit-counters是cjc的编译选项,它会对当前package执行覆盖率反馈插桩,详见 cjc 编译器使用手册- 其他高级的参数有:
--sanitizer-coverage-trace-compares(提高Fuzz变异的效率)、--sanitizer-coverage-pc-table(Fuzz结束后打印覆盖率信息)
- 其他高级的参数有:
与 libfuzzer 体验类似,可以直接运行,数秒后(取决于 CPU 性能)可获得 crash,且输入的数据是 "Cangjie!"
$ ./main
INFO: Seed: 246468919
INFO: Loaded 1 modules (15 inline 8-bit counters): 15 [0x55bb7c76dcb0, 0x55bb7c76dcbf),
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED ft: 4 corp: 1/1b exec/s: 0 rss: 28Mb
#420 NEW ft: 5 corp: 2/9b lim: 8 exec/s: 0 rss: 28Mb L: 8/8 MS: 3 CrossOver-InsertByte-InsertRepeatedBytes-
#1323 NEW ft: 6 corp: 3/17b lim: 14 exec/s: 0 rss: 28Mb L: 8/8 MS: 3 InsertByte-InsertByte-CrossOver-
#131072 pulse ft: 6 corp: 3/17b lim: 1300 exec/s: 65536 rss: 35Mb
#262144 pulse ft: 6 corp: 3/17b lim: 2600 exec/s: 65536 rss: 41Mb
#295225 NEW ft: 7 corp: 4/25b lim: 2930 exec/s: 73806 rss: 43Mb L: 8/8 MS: 2 ShuffleBytes-ChangeByte-
#514006 NEW ft: 8 corp: 5/33b lim: 4096 exec/s: 73429 rss: 53Mb L: 8/8 MS: 1 ChangeByte-
#524288 pulse ft: 8 corp: 5/33b lim: 4096 exec/s: 74898 rss: 53Mb
#1048576 pulse ft: 8 corp: 5/33b lim: 4096 exec/s: 61680 rss: 78Mb
#1064377 NEW ft: 9 corp: 6/41b lim: 4096 exec/s: 62610 rss: 79Mb L: 8/8 MS: 1 ChangeByte-
#1287268 NEW ft: 10 corp: 7/49b lim: 4096 exec/s: 61298 rss: 90Mb L: 8/8 MS: 1 ChangeByte-
#2097152 pulse ft: 10 corp: 7/49b lim: 4096 exec/s: 59918 rss: 128Mb
#2875430 NEW ft: 11 corp: 8/57b lim: 4096 exec/s: 61179 rss: 165Mb L: 8/8 MS: 2 ChangeBinInt-ChangeByte-
#4194304 pulse ft: 11 corp: 8/57b lim: 4096 exec/s: 59918 rss: 227Mb
#4208258 NEW ft: 12 corp: 9/65b lim: 4096 exec/s: 60117 rss: 228Mb L: 8/8 MS: 3 CrossOver-CrossOver-ChangeBit-
[WARNING]: Detect uncatched exception, maybe caused by bugs, exit now
An exception has occurred:
Exception: TRAP
at default.api(std/core::Array<...>)(/data/Cangjie/fuzz_main.cj:14)
at _ZN7default3apiER_ZN8std$core5ArrayIhE_cc_wrapper(/data/Cangjie/fuzz_main.cj:0)
at libfuzzerCallback(fuzz/fuzz/callback.cj:20)
[INFO]: data is: [67, 97, 110, 103, 106, 105, 101, 33]
[INFO]: data base64: Q2FuZ2ppZSE=
crash file will stored with libfuzzer
==899957== ERROR: libFuzzer: fuzz target exited
SUMMARY: libFuzzer: fuzz target exited
MS: 1 ChangeByte-; base unit: 7d8b0108ce76a937161065eafcde95bbf3d47dbf
0x43,0x61,0x6e,0x67,0x6a,0x69,0x65,0x21,
Cangjie!
artifact_prefix='./'; Test unit written to ./crash-555e7af32a2ceb585cdd9ce810c4804e65d41cea
Base64: Q2FuZ2ppZSE=
也可以使用 -help=1 打印帮助,-seed=246468919 指定随机数的种子。
$ ./main -help=1 exit 130
Usage:
To run fuzzing pass 0 or more directories.
program_name [-flag1=val1 [-flag2=val2 ...] ] [dir1 [dir2 ...] ]
To run individual tests without fuzzing pass 1 or more files:
program_name [-flag1=val1 [-flag2=val2 ...] ] file1 [file2 ...]
使用 DataProvider 功能进行测试
上文介绍了使用字节流对 API 进行测试的方法,除此之外,fuzz 包提供了 DataProvider 类,用于更友好地从变异的数据源产生仓颉的标准数据类型,方便对 API 进行测试。
public func api2(dp: DataProvider): Int32 {
if(dp.consumeBool() && dp.consumeByte() == b'A' && dp.consumeuint32() == 0xdeadbeef){
throw Exception("TRAP")
}
return 0
}
此案例中,开启 --sanitizer-coverage-trace-compares 可有效提高 fuzz 效率。
DataProvider 模式下,无法直观地判断各个 API 返回值分别是什么,因此提供了 Fuzzer.enableDebugDataProvider() 和 DebugDataProvider,在 startFuzz 前调用 enableDebugDataProvider() 即可令本次 fuzz 每次调用 consumeXXX 时打印日志。
例如,上文代码触发异常后,添加 enableDebugDataProvider 重新编译,效果如下。
from fuzz import fuzz.*
main() {
let fuzzer = Fuzzer(api2)
fuzzer.enableDebugDataProvider()
fuzzer.startFuzz()
return 0
}
./main crash-d7ece8e77ff25769a5d55eb8d3093d4bace78e1b
Running: crash-d7ece8e77ff25769a5d55eb8d3093d4bace78e1b
[DEBUG] consumeBool return true
[DEBUG] consumeByte return 65
[DEBUG] consumeUInt32 return 3735928559
[WARNING]: Detect uncatched exception, maybe caused by bugs, exit now
An exception has occurred:
Exception: TRAP
at default.api2(fuzz/fuzz::DataProvider)(/tmp/test.cj:12)
at _ZN7default4api2EC_ZN9fuzz$fuzz12DataProviderE_cc_wrapper(/tmp/test.cj:0)
at libfuzzerCallback(fuzz/fuzz/callback.cj:0)
[INFO]: data is: [191, 65, 239, 190, 173, 222]
FakeCoverage 模式
在链接了 libfuzzer <= 14 的情况下,且处于 DataProvider 模式下,遇到了类似如下的错误,可能需要阅读此章节:
ERROR: no interesting inputs were found. Is the code instrumented for coverage? Exiting.
libfuzzer 15 起,修复了该 feature,即使初始化时拒绝了输入,也不会停止执行。
注意:请确认被测试的库确实被插入了覆盖率反馈,因为在没有覆盖率反馈插桩的情况下,也会出现该错误!
当前 fuzz 后端对接到了 libfuzzer,而 libfuzzer 在启动时会先输入空字节流、再输入仅包含一个 '\n' 的字节流对待测函数进行试探,在两轮结束后检测覆盖率是否新增。在 DataProvider 模式下,如果先消耗数据,再调用待测库的 API,会导致消耗数据时长度不足而提前返回,从而 libfuzzer 认为覆盖率信息为零。
例如下方代码,会触发该错误
触发的代码:
// main.cj
from fuzz import fuzz.*
main() {
let f = Fuzzer(api)
f.disableFakeCoverage()
f.startFuzz()
return 0
}
// fuzz_target.cj, with sancov
public func api(dp: DataProvider): Int32 {
if (dp.consumeBool() && dp.consumeBool()) {
throw Exception("TRAP!")
}
return 0
}
因此,需要使用 Fake Coverage 创建虚假的覆盖率信息,让 libfuzzer 在初始化期间认为待测模块确实被插桩,等到 DataProvider 收集到足够数据后,再进行有效的 fuzz 测试。该模式被称为 Fake Coverage 模式。
将上文的 disableFakeCoverage() 替换为 enableFakeCoverage() 即可继续运行,最终触发 TRAP。
此外,除了使用 Fake Coverage 模式,还可以在测试用例中主动调用待测函数的某些不重要的API来将覆盖率信息传递给 libfuzzer,也能起到让 fuzz 继续下去的作用。
栈回溯缺失的处理方案
WARNING: Failed to find function "__sanitizer_acquire_crash_state".
WARNING: Failed to find function "__sanitizer_print_stack_trace".
WARNING: Failed to find function "__sanitizer_set_death_callback".
在启动 fuzz 时默认会有这三条 WARNING,因为当前 cj-fuzz 没有对它们进行实现。在 fuzz 过程中,可能会因为
- 抛出异常
- 超时
- 在 C 代码中 crash
而结束 fuzz 流程。
其中“抛出异常”的情况,fuzz 框架对异常进行捕获后会打印栈回溯,不会造成栈回溯缺失的现象。
“超时”和“在 C 代码中 crash”实际是在 native 代码中触发了 SIGNAL,不属于仓颉异常,因此会造成栈回溯的缺失。
libfuzzer 会尝试使用 __sanitizer_acquire_crash_state、__sanitizer_print_stack_trace、__sanitizer_set_death_callback 等函数处理异常情况,其中 __sanitizer_print_stack_trace 会打印栈回溯,目前成熟的实现在 llvm compiler-rt 中的 asan 等模块中。
因此,建议的解决方案是在链接时额外加入如下的静态库文件和链接选项,释义如下
/usr/lib/llvm-14/lib/clang/14.0.0/lib/linux/libclang_rt.asan-x86_64.a -lgcc_s --eh-frame-hdr
/usr/lib/llvm-14/lib/clang/14.0.0/lib/linux/libclang_rt.asan-x86_64.a因为该 .a 文件实现了__sanitizer_print_stack_trace,出于方便就直接用它。-lgcc_s栈回溯依赖 gcc_s--eh-frame-hdrld 链接时生成 eh_frame_hdr 节,帮助完成栈回溯
可选的环境变量:ASAN_SYMBOLIZER_PATH=$CANGJIE_HOME/third_party/llvm/bin/llvm-symbolizer,可能在某些情况下有用。
最终会得到两套栈回溯,一套是 Exception.printStackTrace,一套是 __sanitizer_print_stack_trace,内容如下:
[WARNING]: Detect uncatched exception, maybe caused by bugs, exit now
An exception has occurred:
Exception: TRAP!
at default.ttt(std/core::Array<...>)(/data/cangjie/libs/fuzz/ci_fuzzer0.cj:11)
at _ZN7default3tttER_ZN8std$core5ArrayIhE_cc_wrapper(/data/cangjie/libs/fuzz/ci_fuzzer0.cj:0)
at libfuzzerCallback(/data/cangjie/libs/fuzz/fuzz/callback.cj:34)
[INFO]: data is: [0, 202, 0, 0, 0, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255]
[INFO]: crash file will stored with libfuzzer
==425243== ERROR: libFuzzer: fuzz target exited
#0 0x563a233fadf1 in __sanitizer_print_stack_trace (/data/cangjie/libs/fuzz/main+0x280df1)
#1 0x563a2337c0b8 in fuzzer::PrintStackTrace() (/data/cangjie/libs/fuzz/main+0x2020b8)
#2 0x563a2338726c in fuzzer::Fuzzer::ExitCallback() (/data/cangjie/libs/fuzz/main+0x20d26c)
#3 0x7f485cf36494 in __run_exit_handlers stdlib/exit.c:113:8
#4 0x7f485cf3660f in exit stdlib/exit.c:143:3
#5 0x563a23224e68 in libfuzzerCallback$real /data/cangjie/libs/fuzz/fuzz/callback.cj:62:18
#6 0x7f485d22718b in CJ_MCC_N2CStub (/data/cangjie/output/runtime/lib/linux_x86_64_llvm/libcangjie-runtime.so+0x2718b)
#7 0x563a2322fc26 in libfuzzerCallback /data/cangjie/libs/fuzz/fuzz/callback.cj:20
#8 0x563a23387883 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) (/data/cangjie/libs/fuzz/main+0x20d883)
#9 0x563a2338a3f9 in fuzzer::Fuzzer::RunOne(unsigned char const*, unsigned long, bool, fuzzer::InputInfo*, bool, bool*) (/data/cangjie/libs/fuzz/main+0x2103f9)
#10 0x563a23387e49 in fuzzer::Fuzzer::MutateAndTestOne() (/data/cangjie/libs/fuzz/main+0x20de49)
#11 0x563a2338a2b5 in fuzzer::Fuzzer::Loop(std::vector<fuzzer::SizedFile, std::allocator<fuzzer::SizedFile>>&) (/data/cangjie/libs/fuzz/main+0x2102b5)
#12 0x563a23377a12 in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) (/data/cangjie/libs/fuzz/main+0x1fda12)
#13 0x563a231ad2b6 in fuzz_fake$fuzz::Fuzzer::startFuzz() /data/cangjie/libs/fuzz/fuzz/fuzzer.cj:200:13
#14 0x563a23405fad in default::main() /data/cangjie/libs/fuzz/ci_fuzzer0.cj:5:5
#15 0x563a23405fe7 in user.main /data/cangjie/libs/fuzz/<stdin>
#16 0x563a234060e1 in cj_entry$ (/data/cangjie/libs/fuzz/main+0x28c0e1)
#17 0x7f485d227220 (/data/cangjie/output/runtime/lib/linux_x86_64_llvm/libcangjie-runtime.so+0x27220)
#18 0x7f485d223898 (/data/cangjie/output/runtime/lib/linux_x86_64_llvm/libcangjie-runtime.so+0x23898)
#19 0x7f485d2607b9 in CJ_CJThreadEntry (/data/cangjie/output/runtime/lib/linux_x86_64_llvm/libcangjie-runtime.so+0x607b9)
覆盖率信息打印 实验性特性
仓颉 fuzzer 支持使用 -print_coverage=1 作为启动参数运行 fuzzer,用于统计各函数的测试情况,该特性在持续完善中,只与输出覆盖率报告有关,不影响 fuzz 过程。
由于该功能需要对 libfuzzer 进行侵入式修改,使用该功能需要链接仓颉自带的 libfuzzer,路径是:$CANGJIE_HOME/lib/{linux_x86_64_llvm, linux_aarch64_llvm}/libclang_rt-fuzzer_no_main.a。
编译时需要同时启用--sanitizer-coverage-inline-8bit-counters 和 --sanitizer-coverage-pc-table。
C 语言 libfuzzer 输出举例
./a.out -print_coverage=1
COVERAGE:
COVERED_FUNC: hits: 5 edges: 6/8 LLVMFuzzerTestOneInput /tmp/test.cpp:5
UNCOVERED_PC: /tmp/test.cpp:6
UNCOVERED_PC: /tmp/test.cpp:9
仓颉语言 cj-fuzz 输出举例
./main -print_coverage=1 -runs=100
Done 100 runs in 0 second(s)
COVERAGE:
COVERED_FUNC: hits: 1 edges: 3/12 ttt <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_PC: <unknown cj filename>:<unknown cj line number>
UNCOVERED_FUNC: hits: 0 edges: 0/2 main <unknown cj filename>:<unknown cj line number>
COVERED_FUNC: hits: 1 edges: 1/1 ttt_cc_wrapper <unknown cj filename>:<unknown cj line number>
cjvm 使用 cj-fuzz 功能
差异说明:cjvm 无法加载 .a 文件,只能加载 .so 文件。
cj-fuzz 运行时依赖 libclang_rt.fuzzer_no_main.a 和 libcangjie-fuzz-fuzzFFI.a,因此需要将它们链接为动态链接库的格式,命令如下:
clang++ -shared -Wl,--whole-archive libclang_rt.fuzzer_no_main.a ${CANGJIE_HOME}/lib/linux_x86_64_jet/libcangjie-fuzz-fuzzFFI.a -Wl,--no-whole-archive -o libcangjie-fuzz-fuzzFFI.so
运行 cj-fuzz
- 通过上述命令,获得
libcangjie-fuzz-fuzzFFI.so cjc fuzz_main.cj --sanitizer-coverage-inline-8bit-counters ${CANGJIE_HOME}/modules/linux_x86_64_jet/fuzz/fuzz.bc -lcangjie-fuzz-fuzzFFI--sanitizer-coverage-inline-8bit-counters启用覆盖率插桩${CANGJIE_HOME}/modules/linux_x86_64_jet/fuzz/fuzz.bc主动链接 fuzz 模块的 fuzz 包的字节码-lcangjie-fuzz-fuzzFFI指定依赖库的名称,运行时会搜索 libcangjie-fuzz-fuzzFFI.so 进行动态加载
LD_LIBRARY_PATH=/path/to/lib:${LD_LIBRARY_PATH} cj main.cbc- 按需修改 LD_LIBRARY_PATH
- 执行 cbc 文件
实际效果如下:
cp /usr/lib/llvm-14/lib/clang/14.0.0/lib/linux/libclang_rt.fuzzer_no_main-x86_64.a .
clang++ -shared -Wl,--whole-archive libclang_rt.fuzzer_no_main-x86_64.a ${CANGJIE_HOME}/lib/linux_x86_64_jet/libcangjie-fuzz-fuzzFFI.a -Wl,--no-whole-archive -o libcangjie-fuzz-fuzzFFI.so
cjc --sanitizer-coverage-inline-8bit-counters fuzz_main.cj ${CANGJIE_HOME}/modules/linux_x86_64_jet/fuzz/fuzz.bc -lcangjie-fuzz-fuzzFFI
LD_LIBRARY_PATH=/path/to/lib:${LD_LIBRARY_PATH} cj main.cbc
>>>>
WARNING: Failed to find function "__sanitizer_acquire_crash_state".
WARNING: Failed to find function "__sanitizer_print_stack_trace".
WARNING: Failed to find function "__sanitizer_set_death_callback".
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 3156944264
INFO: Loaded 1 modules (21 inline 8-bit counters): 21 [0x5627041690a0, 0x5627041690b5),
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED ft: 4 corp: 1/1b exec/s: 0 rss: 52Mb
#488 NEW ft: 5 corp: 2/9b lim: 8 exec/s: 0 rss: 53Mb L: 8/8 MS: 1 InsertRepeatedBytes-
#12303 NEW ft: 6 corp: 3/17b lim: 122 exec/s: 0 rss: 54Mb L: 8/8 MS: 5 CrossOver-ChangeBit-ShuffleBytes-ShuffleBytes-ChangeByte-
#20164 NEW ft: 7 corp: 4/25b lim: 198 exec/s: 0 rss: 54Mb L: 8/8 MS: 1 ChangeByte-
#180030 NEW ft: 8 corp: 5/33b lim: 1780 exec/s: 180030 rss: 55Mb L: 8/8 MS: 1 ChangeByte-
#524288 pulse ft: 8 corp: 5/33b lim: 4096 exec/s: 174762 rss: 55Mb
#671045 NEW ft: 9 corp: 6/41b lim: 4096 exec/s: 167761 rss: 55Mb L: 8/8 MS: 5 InsertByte-ChangeByte-ChangeBit-ChangeByte-EraseBytes-
#758816 NEW ft: 10 corp: 7/49b lim: 4096 exec/s: 151763 rss: 55Mb L: 8/8 MS: 1 ChangeByte-
#1048576 pulse ft: 10 corp: 7/49b lim: 4096 exec/s: 149796 rss: 55Mb
#1947938 NEW ft: 11 corp: 8/57b lim: 4096 exec/s: 162328 rss: 55Mb L: 8/8 MS: 2 InsertByte-EraseBytes-
#2097152 pulse ft: 11 corp: 8/57b lim: 4096 exec/s: 161319 rss: 55Mb
#3332055 NEW ft: 12 corp: 9/65b lim: 4096 exec/s: 151457 rss: 55Mb L: 8/8 MS: 2 ChangeByte-ChangeBit-
[WARNING]: Detect uncatched exception, maybe caused by bugs, exit now
An exception has occurred:
Exception: TRAP
at default.api(/cjvm_demo/test.cj:20)
at default.api(/cjvm_demo/test.cj:0)
at fuzz/fuzz.libfuzzerCallback(/cangjie/lib/src/fuzz/fuzz/callback.cj:34)
at fuzz/fuzz.Fuzzer.startFuzz(/cangjie/lib/src/fuzz/fuzz/fuzzer.cj:223)
at default.<main>(/cjvm_demo/test.cj:5)
at default.user.main(<unknown>:0)
[INFO]: data is: [67, 97, 110, 103, 106, 105, 101, 33]
[INFO]: crash file will stored with libfuzzer
==33946== ERROR: libFuzzer: fuzz target exited
SUMMARY: libFuzzer: fuzz target exited
MS: 1 ChangeByte-; base unit: 1719c2c0bbc676f5b436528c183e4743a455d66a
0x43,0x61,0x6e,0x67,0x6a,0x69,0x65,0x21,
Cangjie!
artifact_prefix='./'; Test unit written to ./crash-555e7af32a2ceb585cdd9ce810c4804e65d41cea
Base64: Q2FuZ2ppZSE=
http 包
介绍
http 包提供 HTTP/1.1,HTTP/2,WebSocket 协议的 server、client 端实现,关于协议的详细内容可参考 RFC 9110、9112、9113、9218、7541 等。
使用本包需要外部依赖 OpenSSL 3 的 ssl 和 crypto 动态库文件,故使用前需安装相关工具:
- 对于
Linux操作系统,可参考以下方式:- 如果系统的包管理工具支持安装
OpenSSL 3开发工具包,可通过这个方式安装,并确保系统安装目录下含有libssl.so、libssl.so.3、libcrypto.so和libcrypto.so.3这些动态库文件,例如Ubuntu 22.04系统上可使用sudo apt install libssl-dev命令安装libssl-dev工具包; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libssl.so、libssl.so.3、libcrypto.so和libcrypto.so.3这些动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
LD_LIBRARY_PATH以及LIBRARY_PATH中。
- 如果系统的包管理工具支持安装
- 对于
Windows操作系统,可按照以下步骤:- 自行下载
OpenSSL 3.x.x源码编译安装 x64 架构软件包或者自行下载安装第三方预编译的供开发人员使用的OpenSSL 3.x.x软件包; - 确保安装目录下含有
libssl.dll.a(或libssl.lib)、libssl-3-x64.dll、libcrypto.dll.a(或libcrypto.lib)、libcrypto-3-x64.dll这些库文件; - 将
libssl.dll.a(或libssl.lib)、libcrypto.dll.a(或libcrypto.lib) 所在的目录路径设置到环境变量LIBRARY_PATH中,将libssl-3-x64.dll、libcrypto-3-x64.dll所在的目录路径设置到环境变量PATH中。
- 自行下载
- 对于
macOS操作系统,可参考以下方式:- 使用
brew install openssl@3安装,并确保系统安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
DYLD_LIBRARY_PATH以及LIBRARY_PATH中。
- 使用
如果未安装OpenSSL 3软件包或者安装低版本的软件包,程序可能无法使用并抛出相关异常 WebSocketException: Can not load openssl library or function xxx.。
http
用户可以选择 http 协议的版本,如 HTTP/1.1、HTTP/2,http 包的多数 API 并不区分这两种协议版本,只有当用户用到某个版本的特有功能时,才需要做这种区分,如 HTTP/1.1 中的 chunked 的 transfer-encoding,HTTP/2 中的 server push。
http 库默认使用 HTTP/1.1 版本。当开发者需要使用 HTTP/2 协议时,需要为 Client/Server 配置 tls,并且设置 alpn 的值为 h2;不支持 HTTP/1.1 通过 Upgrade: h2c 协议升级的方式升级到 HTTP/2。
如果创建 HTTP/2 连接握手失败,Client/Server 会自动将协议退回 HTTP/1.1。
用户通过 ClientBuilder 构建一个 Client 实例,构建过程可以指定多个参数,如 httpProxy、logger、cookieJar、是否自动 redirect、连接池大小等,详情参见 ClientBuilder。
用户通过 ServerBuilder 构建一个 Server 实例,构建过程可以指定多个参数,如 addr、port、logger、distributor 等,详情参见 ServerBuilder。
用户如果需要自己设置 Logger,需要保证它是线程安全的。
Client、Server 的大多数参数在构建后便不允许修改,如果想要更改,用户需要重新构建一个新的 Client 或 Server 实例;如果该参数支持动态修改,本实现会提供显式的功能,如 Server 端 cert、CA 的热更新。
通过 Client 实例,用户可以发送 http request、接收 http response。
通过 Server 实例,用户可以配置 request 转发处理器,启动 http server。在 server handler 中,用户可以通过 HttpContext 获取 client 发来的 request 的详细信息,构造发送给 client 的 response。 Server 端根据 Client 端请求,创建对应的 ProtocolService 实例,同一个 Server 实例可同时支持两种协议:HTTP/1.1、HTTP/2。
在 client 端,用户通过 HttpRequestBuilder 构造 request,构建过程可以指定多个参数,如 method、url、version、headers、body、trailers 等等;构建之后的request 不允许再进行修改。 在 server 端,用户通过 HttpResponseBuilder 构造 response,构建过程可以指定多个参数,如 status、headers、body、trailers 等等;构建之后的 response 不允许再进行修改。
另外,本实现提供一些工具类,方便用户构造一些常用 response,如 RedirectHandler 构造 redirect response,NotFoundHandler 构造 404 response。
WebSocket
本实现为 WebSocket 提供 sub-protocol 协商,基础的 frame 解码、读取、消息发送、frame 编码、ping、pong、关闭等功能。
用户通过 WebSocket.upgradeFromClient 从一个 HTTP/1.1 或 HTTP/2 Client 实例升级到 WebSocket 协议,之后通过返回的 WebSocket 实例进行 WebSocket 通讯。
用户在一个 server 端的 handler 中,通过 WebSocket.upgradeFromServer 从 HTTP/1.1 或 HTTP/2 协议升级到 WebSocket 协议,之后通过返回的 WebSocket 实例进行 WebSocket 通讯。
按照协议,HTTP/1.1 中,升级后的 WebSocket 连接是建立在 tcp 连接(https 则还会多一层 TLS)之上;HTTP/2 中,升级后的 WebSocket 连接是建立在 HTTP/2 connection 的一个 stream 之上。HTTP/1.1 中,close 最终会直接关闭 tcp 连接;HTTP/2 中,close 只会关闭 connection 上的一个 stream。
主要接口
class ServerBuilder
public class ServerBuilder
提供 Server 实例构建器。 支持通过如下参数构造一个 Http Server:
- 地址、端口;
- 线程安全的 logger;
- HttpRequestDistributor,用于注册 handler、分发 request;
- HTTP/2 的 settings;
- shutdown 回调;
- transport:listener、连接及其配置;
- protocol service:http 协议解析服务;
除地址端口、shutdown 回调外,均提供默认实现,用户在构造 server 过程中可不指定其他构建参数。 ServerBuilder 文档中未明确说明支持版本的配置,在 HTTP/1.1 与 HTTP/2 都会生效
init
public init()
功能:创建 ServerBuilder 实例。
func addr
public func addr(addr: String): ServerBuilder
功能:设置服务端监听地址,若 listener 被设定,此值被忽略。
参数:
- addr:地址值,格式为 IP 或者 域名
返回值:当前 ServerBuilder 的引用
func port
public func port(port: UInt16): ServerBuilder
功能:设置服务端监听端口,若 listener 被设定,此值被忽略。
参数:
- port:端口值
返回值:当前 ServerBuilder 的引用
func listener
public func listener(listener: ServerSocket): ServerBuilder
功能:服务端调用此函数对指定 socket 进行绑定监听。
参数:
- listener:所绑定的socket
返回值:当前 ServerBuilder 的引用
func logger
public func logger(logger: Logger): ServerBuilder
功能:设定服务器的 logger,默认 logger 级别为 INFO,logger 内容将写入 Console.stdout。
参数:
- logger:需要是线程安全的,默认使用内置线程安全 logger
返回值:当前 ServerBuilder 的引用
func distributor
public func distributor(distributor: HttpRequestDistributor): ServerBuilder
功能:设置请求分发器,请求分发器会根据 url 将请求分发给对应的 handler不设置时使用默认请求分发器。
参数:
- distributor:自定义请求分发器实例
返回值:当前 ServerBuilder 的引用
func protocolServiceFactory
public func protocolServiceFactory(factory: ProtocolServiceFactory): ServerBuilder
功能:设置协议服务工厂,服务协议工厂会生成每个协议所需的服务实例,不设置时使用默认工厂。
参数:
- factory:自定义工厂实例
返回值:当前 ServerBuilder 的引用
func transportConfig
public func transportConfig(config: TransportConfig): ServerBuilder
功能:设置传输层配置,默认配置详见 TransportConfig 结构体说明。
参数:
- config:设定的传输层配置信息
返回值:当前 ServerBuilder 的引用
func tlsConfig
public func tlsConfig(config: TlsServerConfig): ServerBuilder
功能:设置 TLS 层配置,默认不对其进行设置。
参数:
- config:设定支持 tls 服务所需要的配置信息
返回值:当前 ServerBuilder 的引用
func readTimeout
public func readTimeout(timeout: Duration): ServerBuilder
功能:设定服务端读取一个请求的最大时长,超过该时长将不再进行读取并关闭连接,默认不进行限制。
参数:
- timeout:设定读请求的超时时间,如果传入时间为负值将被替换为 Duration.Zero
返回值:当前 ServerBuilder 的引用
func writeTimeout
public func writeTimeout(timeout: Duration): ServerBuilder
功能:设定服务端发送一个响应的最大时长,超过该时长将不再进行写入并关闭连接,默认不进行限制。
参数:
- timeout:设定写响应的超时时间,如果传入时间为负值将被替换为 Duration.Zero
返回值:当前 ServerBuilder 的引用
func readHeaderTimeout
public func readHeaderTimeout(timeout: Duration): ServerBuilder
功能:设定服务端读取客户端发送一个请求的请求头最大时长,超过该时长将不再进行读取并关闭连接,默认不进行限制。
参数:
- timeout:设定的读请求头超时时间,如果传入负的 Duration 将被替换为 Duration.Zero
返回值:
- ServerBuilder:当前 ServerBuilder 的引用
func httpKeepAliveTimeout
public func httpKeepAliveTimeout(timeout: Duration): ServerBuilder
功能:HTTP/1.1 专用,设定服务端连接保活时长,该时长内客户端未再次发送请求,服务端将关闭长连接,默认不进行限制。
参数:
- timeout:设定保持长连接的超时时间,如果传入负的 Duration 将被替换为 Duration.Zero
返回值:当前 ServerBuilder 的引用
func maxRequestHeaderSize
public func maxRequestHeaderSize(size: Int64): ServerBuilder
功能:设定服务端允许客户端发送单个请求的请求头部分最大值,请求头部分大小超过该值时,将返回状态码为 431 的响应仅对 HTTP/1.1 生效,HTTP/2 中有专门的配置 maxHeaderListSize,默认值为 8192。
参数:
- size:设定允许接收请求的请求头大小最大值,值为 0 代表不作限制
返回值:当前 ServerBuilder 的引用
异常:
- IllegalArgumentException:size < 0
func maxRequestBodySize
public func maxRequestBodySize(size: Int64): ServerBuilder
功能:设置服务端允许客户端发送单个请求的请求体部分最大值,请求体部分大小超过该值时,将返回状态码为 413 的响应仅对于 HTTP/1.1 且未设置 "Transfer-Encoding: chunked" 的请求生效,默认值为 2M。
参数:
- size:设定允许接收请求的请求体大小最大值,值为 0 代表不作限制
返回值:当前 ServerBuilder 的引用
异常:
- IllegalArgumentException:size < 0
func headerTableSize
public func headerTableSize(size: UInt32): ServerBuilder
功能:HTTP/2 专用,设置本端对响应头编码时使用的压缩表的最大大小,默认值为 4096。
参数:
- size:本端对响应头编码时使用的最大
table size
返回值:当前 ServerBuilder 的引用
func maxConcurrentStreams
public func maxConcurrentStreams(size: UInt32): ServerBuilder
功能:HTTP/2 专用,设置本端同时处理的最大请求数量,限制对端并发发送请求的数量,默认值为 100。
参数:
- size:本端同时处理的最大请求数量
返回值:当前 ServerBuilder 的引用
func initialWindowSize
public func initialWindowSize(size: UInt32): ServerBuilder
功能:HTTP/2 专用,设置本端一个 stream 上接收报文的初始流量窗口大小,默认值为 65535. 取值范围为 0 至 2^31 - 1。
参数:
- size:本端一个 stream 上接收报文的初始流量窗口大小
返回值:当前 ServerBuilder 的引用
func maxFrameSize
public func maxFrameSize(size: UInt32): ServerBuilder
功能:HTTP/2 专用,设置本端接收的一个帧的最大长度,用来限制对端发送帧的长度,默认值为 16384. 取值范围为 2^14 至 2^24 - 1。
参数:
- size:本端接收的一个帧的最大长度
返回值:当前 ServerBuilder 的引用
func maxHeaderListSize
public func maxHeaderListSize(size: UInt32): ServerBuilder
功能:HTTP/2 专用,设置本端接收的报文头最大长度,用来限制对端发送的报文头最大长度。报文头长度计算方法:所有 header field 长度之和(所有 name 长度 + value 长度 + 32,包括自动添加的 HTTP/2 伪头),默认值为 8192。
参数:
- size:本端接收的报文头最大长度
返回值:当前 ServerBuilder 的引用
func enableConnectProtocol
public func enableConnectProtocol(flag: Bool): ServerBuilder
功能:HTTP/2 专用,设置本端是否接收 CONNECT 请求,默认 false。
参数:
- flag:本端是否接收 CONNECT 请求
返回值:当前 ServerBuilder 的引用
func afterBind
public func afterBind(f: ()->Unit): ServerBuilder
功能:注册服务器启动时的回调函数,服务内部 ServerSocket 实例 bind 之后,accept 之前将调用该函数。重复调用将覆盖之前注册的函数。
参数:
- f:回调函数,入参为空,返回值为 Unit 类型
返回值:当前 ServerBuilder 的引用
func onShutdown
public func onShutdown(f: ()->Unit): ServerBuilder
功能:注册服务器关闭时的回调函数,服务器关闭时将调用该回调函数,重复调用将覆盖之前注册的函数。
参数:
- f:回调函数,入参为空,返回值为 Unit 类型
返回值:当前 ServerBuilder 的引用
func servicePoolConfig
public func servicePoolConfig(cfg: ServicePoolConfig): ServerBuilder
功能:服务过程中使用的协程池相关设置,具体说明见 servicePoolConfig 结构体。
参数:
- cfg:协程池相关设置。
返回值:当前 ServerBuilder 的引用
func build
public func build(): Server
功能:构建 Server 实例。
返回值:根据设置的属性生成的 Server 实例
异常:
- IllegalArgumentException:设置的参数非法
class Server
public class Server
提供 HTTP 服务的 Server 类包含如下功能:
- 启动服务,在指定地址及端口等待用户连接、服务用户的 http request;
- 关闭服务,包括关闭所有已有连接;
- 提供注册处理 http request 的 handler 的机制,根据注册信息分发 request 到相应的 handler;
- 提供 tls 证书热机制;
- 提供 shutdown 回调机制;
- 通过 Logger.level 开启、关闭日志打印,包括按照用户要求打印相应级别的日志;
- Server 文档中未明确说明支持版本的配置,在 HTTP/1.1 与 HTTP/2 都会生效
prop addr
public prop addr: String
功能:获取服务端监听地址,格式为 IP 或者 域名。
prop port
public prop port: UInt16
功能:获取服务端监听端口。
prop listener
public prop listener: ServerSocket
功能:获取服务器绑定 socket。
prop logger
public prop logger: Logger
功能:获取服务器日志记录器,设置 logger.level 将立即生效,记录器应该是线程安全的。
prop distributor
public prop distributor: HttpRequestDistributor
功能:获取请求分发器,请求分发器会根据 url 将请求分发给对应的 handler。
prop protocolServiceFactory
public prop protocolServiceFactory: ProtocolServiceFactory
功能:获取协议服务工厂,服务协议工厂会生成每个协议所需的服务实例。
prop transportConfig
public prop transportConfig: TransportConfig
功能:获取服务器设定的传输层配置。
func getTlsConfig
public func getTlsConfig(): ?TlsServerConfig
功能:获取服务器设定的 TLS 层配置。
返回值:
prop readTimeout
public prop readTimeout: Duration
功能:获取服务器设定的读取整个请求的超时时间。
prop writeTimeout
public prop writeTimeout: Duration
功能:获取服务器设定的写响应的超时时间。
prop readHeaderTimeout
public prop readHeaderTimeout: Duration
功能:获取服务器设定的读取请求头的超时时间。
prop httpKeepAliveTimeout
public prop httpKeepAliveTimeout: Duration
功能:HTTP/1.1 专用,获取服务器设定的保持长连接的超时时间。
prop maxRequestHeaderSize
public prop maxRequestHeaderSize: Int64
功能:获取服务器设定的读取请求的请求头最大值。仅对 HTTP/1.1 生效,HTTP/2 中有专门的配置 maxHeaderListSize。
prop maxRequestBodySize
public prop maxRequestBodySize: Int64
功能:获取服务器设定的读取请求的请求体最大值,仅对于 HTTP/1.1 且未设置 "Transfer-Encoding: chunked" 的请求生效。
prop headerTableSize
public prop headerTableSize: UInt32
功能:HTTP/2 专用,用来限制对端发送的报文。
hpack encoder/decoder 的最大 table size
prop maxConcurrentStreams
public prop maxConcurrentStreams: UInt32
功能:HTTP/2 专用,用来限制对端发送的报文。
同时处理的最大请求数量
prop initialWindowSize
public prop initialWindowSize: UInt32
功能:HTTP/2 专用,用来限制对端发送的报文stream 初始流量窗口大小。默认值为 65535 ,取值范围为 0 至 2^31 - 1。
prop maxFrameSize
public prop maxFrameSize: UInt32
功能:HTTP/2 专用,用来限制对端发送的报文一个帧的最大长度。默认值为 16384. 取值范围为 2^14 至 2^24 - 1。
prop maxHeaderListSize
public prop maxHeaderListSize: UInt32
功能:HTTP/2 专用,用来限制对端发送的报文请求 headers 最大长度,为所有 header field 长度之和(所有 name 长度 + value 长度 + 32,包括自动添加的 h2 伪头),默认值为 UInt32.Max。
prop enableConnectProtocol
public prop enableConnectProtocol: Bool
功能:HTTP/2 专用,用来限制对端发送的报文是否支持通过 connect 方法升级协议,true 表示支持。
prop servicePoolConfig
public prop servicePoolConfig: ServicePoolConfig
功能:获取协程池配置实例。
func serve
public func serve(): Unit
功能:启动服务端进程不支持重复启动h1 request 检查和处理:
- request-line 不符合 rfc9112 中 request-line = method SP request-target SP HTTP-version 的规则,将会返回 400 响应
- method 由 tokens 组成,且大小写敏感,request-target 为能够被解析的 url,HTTP-version 为 HTTP/1.0 或 HTTP/1.1 否则将会返回 400 响应headers name 和 value 需符合特定规则,详见 HttpHeaders 类说明,否则返回 400 响应
- 当 headers 的大小超出 server 设定的 maxRequestHeaderSize 时将自动返回 431 响应
- headers 中必须包含 "host" 请求头,且值唯一,否则返回 400 响应headers 中不允许同时存在 "content-length" 与 "transfer-encoding" 请求头,否则返回 400 响应
- 请求头 "transfer-encoding" 的 value 经过 "," 分割后最后一个 value 必须为 "chunked",且之前的 value 不允许存在 "chunked",否则返回 400 响应
- 请求头 "content-length" 其 value 必须能解析为 Int64 类型,且不能为负值,否则返回 400 响应,当其 value 值超出 server 设定maxRequestBodySize,将返回 413 响应
- headers 中若不存在 "content-length" 和 "transfer-encoding: chunked" 时默认不存在 body
- 请求头 "trailer" 中,value 不允许存在 "transfer-encoding","trailer","content-length"
- 请求头 "expect" 中,value 中存在非 "100-continue" 的值,将会返回 417 响应
- HTTP/1.0 默认短连接,若想保持长连接需要包含请求头 "connection: keep-alive" 与 "keep-alive: timeout = XX, max = XX",将会自动保持 timeout 时长的连接。HTTP/1.1 默认长连接,当解析 request 失败则关闭连接
- 仅允许在 chunked 模式下存在 trailers,且 trailer 中条目的 name 必须被包含在 "trailers" 请求头中,否则将自动删除
h1 response 检查和处理:
- 若用户不对 response 进行配置,将会自动返回 200 响应
- 若接收到的 request 包含请求头 "connection: close" 而配置 response 未添加响应头 "connection" 或响应头 "connection" 的 value 不包含 "close",将自动添加 "connection: close",若接收到的 request 不包含请求头 "connection: close" 且响应头不存在 "connection: keep-alive",将会自动添加
- 如果 headers 包含逐跳响应头:"proxy-connection","keep-alive","te","transfer-encoding","upgrade",将会在响应头 "connection" 自动添加这些头作为 value
- 将自动添加 "date" field,用户提供的 "date" 将被忽略
- 若请求方法为 "HEAD" 或响应状态码为 "1XX\204\304" body将配置为空
- 若已知提供 body 的大小时,将会与响应头 "content-length" 进行比较,若不存在响应头 "content-length",将自动添加此响应头,其 value 值为 body 大小。若响应头 "content-length" 大小大于 body 大小将会在 handler 中抛出 HttpException,若小于 body 大小,将对 body 进行截断处理,发送的 body 大小将为 "content-length" 的值
- response 中 "set-cookie" header 将分条发送,其他 headers 同名条目将合成一条发送
- 在处理包含请求头:"Expect: 100-continue"的request时,在调用 request 的 body.read() 时将会自动发送状态码为100的响应给客户端。不允许用户主动发送状态码为100的response,若进行发送则被认定为服务器异常
启用 h2 服务:tlsConfig 中 supportedAlpnProtocols 需包含 "h2",此后如果 tls 层 alpn 协商结果为 h2,则启用 h2 服务
h2 request 检查和处理:
- headers name 和 value 需符合特定规则,详见 HttpHeaders 类说明,此外 name 不能包含大写字符,否则发送 RST 帧关闭流,即无法保证返回响应
- trailers name 和 value 需符合同样规则,否则关闭流
- headers 不能包含 "connection","transfer-encoding","keep-alive","upgrade","proxy-connection",否则关闭流
- 如果有 "te" header,其值只能为 "trailers",否则关闭流
- 如果有 "host" header 和 ":authority" pseudo header,"host" 值必须与 ":authority" 一致,否则关闭流
- 如果有 "content-length" header,需符合 "content-length" 每个值都能解析为 Int64 类型,且如果有多个值,必须相等,否则关闭流
- 如果有 "content-length" header,且有 body 大小,则 content-length 值与 body 大小必须相等,否则关闭流
- 如果有 "trailer" header,其值不能包含 "transfer-encoding","trailer","content-length",否则关闭流
- 仅在升级 WebSocket 场景下支持 CONNECT 方法,否则关闭流
- pseudo headers 中,必须包含 ":method"、":scheme"、":path",其中 ":method" 值必须由 tokens 字符组成,":scheme" 值必须为 "https",":path" 不能为空,否则关闭流
- trailer 中条目的 name 必须被包含在 "trailers" 头中,否则将自动删除
- request headers 大小不能超过 maxHeaderListSize,否则关闭连接
h2 response 检查和处理:
- 如果 HEAD 请求的响应包含 body,将自动删除
- 将自动添加 "date" field,用户提供的 "date" 将被忽略
- 如果 headers 包含 "connection","transfer-encoding","keep-alive","upgrade","proxy-connection",将自动删除
- response 中 "set-cookie" header 将分条发送,其他 headers 同名条目将合成一条发送
- 如果 headers 包含 "content-length",且 method 不为 "HEAD","content-length" 将被删除
- 如果 method 为 "HEAD",则
- headers 包含 "content-length",但 "content-length" 不合法(无法被解析为 Int64 值,或包含多个不同值),如果用户调用 HttpResponseWriter 类的 write 函数,将抛出 HttpException,如果用户 handler 已经结束,将打印日志
- headers 包含 "content-length",同时 response.body.length 不为 -1,"content-length" 值与 body.length 不符,同 6.1 处理
- headers 包含 "content-length",同时 response.body.length 为 -1,或 body.length 与 "content-length" 值一致,则保留 "content-length" header
- trailer 中条目必须被包含在 "trailers" 头中,否则将自动删除
- 如果 handler 中抛出异常,且用户未调用 write 发送部分响应,将返回 500 响应。如果用户已经调用 write 发送部分响应,将发送 RST 帧关闭 stream
h2 server 发完 response 之后,如果 stream 状态不是 CLOSED,会发送带 NO_ERROR 错误码的 RST 帧关闭 stream,避免已经处理完毕的 stream 继续占用服务器资源
h2 流量控制:
- connection 流量窗口初始值为 65535,每次收到 DATA 帧将返回一个 connection 层面的 WINDOW-UPDATE,发送 DATA 时,如果 connection 流量窗口值为负数,将阻塞至其变为正数
- stream 流量窗口初始值可由用户设置,默认值为 65535,每次收到 DATA 帧将返回一个 stream 层面的 WINDOW-UPDATE,发送 DATA 时,如果 stream 流量窗口值为负数,将阻塞至其变为正数
h2 请求优先级:
- 支持按 urgency 处理请求,h2 服务默认并发处理请求,当并发资源不足时,请求将按 urgency 处理,优先级高的请求优先处理
默认 ProtocolServiceFactory 协议选择:
- 如果连接是 tcp,使用 HTTP/1.1 server
- 如果连接是 tls,根据 alpn 协商结果确定 http 协议版本,如果协商结果为 "http/1.0","http/1.1" 或 "",使用 HTTP/1.1 server,如果协商结果为 "h2",使用 HTTP/2 server,否则不处理此次请求,打印日志关连接。
异常:
- SocketException:端口监听失败
func close
public func close(): Unit
功能:关闭服务器,服务器关闭后将不再对请求进行读取与处理重复关闭将只有第一次生效(包括 close 和 closeGracefully)。
func closeGracefully
public func closeGracefully(): Unit
功能:关闭服务器,服务器关闭后将不再对请求进行读取,当前正在进行处理的服务器待处理结束后进行关闭。
func afterBind
public func afterBind(f: ()->Unit): Unit
功能:注册服务器启动时的回调函数,服务内部 ServerSocket 实例 bind 之后,accept 之前将调用该函数。重复调用将覆盖之前注册的函数。
参数:
- f:回调函数,入参为空,返回值为 Unit 类型
func onShutdown
public func onShutdown(f: ()->Unit): Unit
功能:注册服务器关闭时的回调函数,服务器关闭时将调用该回调函数,重复调用将覆盖之前注册的函数。
参数:
- f:回调函数,入参为空,返回值为 Unit 类型
func updateCert
public func updateCert(certificateChainFile: String, privateKeyFile: String): Unit
功能:对 TLS 证书进行热更新。
参数:
- certificateChainFile:证书链文件
- privateKeyFile:证书匹配的私钥文件
异常:
- IllegalArgumentException:参数包含空字符
- HttpException:服务端未配置 tlsConfig
func updateCert
public func updateCert(certChain: Array<X509Certificate>, certKey: PrivateKey): Unit
功能:对 TLS 证书进行热更新。
参数:
- certChain:证书链
- certKey:证书匹配的私钥
异常:
- HttpException:服务端未配置 tlsConfig
func updateCA
public func updateCA(newCaFile: String): Unit
功能:对 CA 证书进行热更新。
参数:
- newCaFile:CA证书文件
异常:
- IllegalArgumentException:参数包含空字符
- HttpException:服务端未配置 tlsConfig
func updateCA
public func updateCA(newCa: Array<X509Certificate>): Unit
功能:对 CA 证书进行热更新。
参数:
- newCa:CA证书
异常:
- IllegalArgumentException:参数包含空字符
- HttpException:服务端未配置 tlsConfig
struct ServicePoolConfig
public struct ServicePoolConfig {
public let capacity: Int64
public let queueCapacity: Int64
public let preheat: Int64
public init(
capacity!: Int64 = 10 ** 4,
queueCapacity!: Int64 = 10 ** 4,
preheat!: Int64 = 0
)
}
Server 协程池配置类。
Server 每次收到一个请求,将从协程池取出一个协程进行处理,如果任务等待队列已满,将拒绝服务该次请求,并断开连接。
特别地,HTTP/2 Service 处理过程中会从协程池取出若干协程进行处理,如果任务等待队列已满,将阻塞直至有协程空闲。
capacity
public let capacity: Int64
功能:获取协程池容量,协程被创建后将循环从 queue 中获取任务并执行,直至协程池关闭
queueCapacity
public let queueCapacity: Int64
功能:获取缓冲区等待任务的最大数量
preheat
public let preheat: Int64
功能:获取服务启动时预先启动的协程数量
init
public init(
capacity!: Int64 = 10 ** 4,
queueCapacity!: Int64 = 10 ** 4,
preheat!: Int64 = 0
)
功能:构造一个 ServicePoolConfig 实例。
参数:
capacity:协程池容量,默认值为 10000queueCapacity:缓冲区等待任务的最大数量,默认值为 10000preheat:服务启动时预先启动的协程数量,默认值为 0
异常:
- IllegalArgumentException:参数 capacity 小于 0,或参数 queueCapacity 小于0,或参数preheat小于 0,或大于 capacity
interface ProtocolServiceFactory
public interface ProtocolServiceFactory {
func create(protocol: Protocol, socket: StreamingSocket): ProtocolService
}
Http 服务实例工厂,用于生成 ProtocolService 实例。
ServerBuilder 提供默认的实现,默认实现提供仓颉标准库中 HTTP/1.1、HTTP/2 的 ProtocolService 实例。
func create
func create(protocol: Protocol, socket: StreamingSocket): ProtocolService
功能:根据协议创建协议服务实例。
参数:
protocol:协议版本,如 HTTP1_0、HTTP1_1、HTTP2_0socket:来自客户端的套接字
返回值:协议服务实例
abstract class ProtocolService
Http协议服务实例,为单个客户端连接提供 Http 服务,包括对客户端 request 报文的解析、 request 的分发处理、 response 的发送等。
public abstract class ProtocolService
prop server
open protected mut prop server: Server
Server 实例,提供默认实现,设置为绑定的 Server 实例
func serve
protected func serve(): Unit
功能:处理来自客户端连接的请求,不提供默认实现。
func closeGracefully
open protected func closeGracefully(): Unit
功能:优雅关闭连接,提供默认实现,无任何行为。
func close
open protected func close(): Unit
功能:强制关闭连接,提供默认实现,无任何行为。
interface HttpRequestDistributor
public interface HttpRequestDistributor {
func register(path: String, handler: HttpRequestHandler): Unit
func register(path: String, handler: (HttpContext) -> Unit): Unit
func distribute(path: String): HttpRequestHandler
}
Http request 分发器,将一个 request 按照 url 中的 path 分发给对应的 HttpRequestHandler 处理。 本实现提供一个默认的 HttpRequestDistributor,该 distributor 非线程安全,且只能在启动 server 前 register,启动后再次 register,结果未定义。 如果用户希望在启动 server 后还能够 register,需要自己提供一个线程安全的 HttpRequestDistributor 实现。
func register
func register(path: String, handler: HttpRequestHandler): Unit
功能:注册请求处理器。
参数:
- path:请求路径
- handler:请求处理器
异常:
- HttpException:请求路径已注册请求处理器
func register
func register(path: String, handler: (HttpContext) -> Unit): Unit
功能:注册请求处理函数,将调用 register(String, HttpRequestHandler): Unit 函数注册请求处理器。
参数:
- path:请求路径
- handler:请求处理函数
异常:
- HttpException:请求路径已注册请求处理器
func distribute
func distribute(path: String): HttpRequestHandler
功能:分发请求处理器,未找到对应请求处理器时,将返回 NotFoundHandler 以返回 404 状态码。 参数:
- path:请求路径
返回值:返回请求处理器
class HttpContext
Http 请求上下文,作为 HttpRequestHandler.handle 函数的参数在服务端使用。
public class HttpContext
prop request
public prop request: HttpRequest
功能:获取 Http 请求
prop responseBuilder
public prop responseBuilder: HttpResponseBuilder
功能:获取 Http 响应构建器
prop clientCertificate
public prop clientCertificate: ?Array<X509Certificate>
功能:获取 Http 客户端证书
func upgrade
public func upgrade(ctx: HttpContext): StreamingSocket
功能:在 handler 内获取 StreamingSocket,可用于支持协议升级和处理 CONNECT 请求。
- 调用该函数时,将首先根据 ctx.responseBuilder 发送响应,仅发送状态码和响应头。
- 调用该函数时,将把 ctx.request.body 置空,后续无法通过 body.read(...) 读数据,未读完的 body 数据将留存在返回的 StreamingSocket 中
注意:
-
对于 HTTP/1.1 或 HTTP/1.0
- 获取的 StreamingSocket 是底层连接,可直接读写连接上的数据
- 如果请求方法为 CONNECT,响应状态码必须是 2XX,否则报错,响应头中 content-length 和 transfer-encoding 头将被删除
- 如果请求方法不为 CONNECT,响应状态码必须是 101,如果用户未设置,将自动置为 101,如果用户设置了状态码且非 101,将报错
-
对于 HTTP/2
- 获取的 StreamingSocket 是一个 stream 上的读写流,后续读写数据将由 stream 封装成 data 帧收发
- 请求方法必须为 CONNECT,响应状态码必须为 2XX,否则将报错
参数:
- ctx:请求上下文
返回值:底层连接(对于 HTTP/2 是一个 stream),可用于后续读写
异常:
- HttpException:获取底层连接(对于 HTTP/2 是一个 stream)失败
interface HttpRequestHandler
public interface HttpRequestHandler {
func handle(ctx: HttpContext): Unit
}
Http request 处理器。 http server 端通过 handler 处理来自客户端的 http request;在 handler 中用户可以获取 http request 的详细信息,包括 header、body;在 handler 中,用户可以构造 http response,包括 header、body,并且可以直接发送 response 给客户端,也可交由 server 发送。 用户在构建 http server 时,需手动通过 server 的 HttpRequestDistributor 注册一个或多个 handler,当一个客户端 http request 被接收,distributor 按照request 中 url 的 path 分发给对应的 handler 处理。
func handle
func handle(ctx: HttpContext): Unit
功能:处理 Http 请求。
参数:
- ctx:Http 请求上下文
class FuncHandler
public class FuncHandler <: HttpRequestHandler {
public FuncHandler(let handler: (HttpContext) -> Unit)
}
HttpRequestHandler 接口包装类,把单个函数包装成 HttpRequestHandler。
FuncHandler
public FuncHandler(let handler: (HttpContext) -> Unit)
功能:FuncHandler 的构造函数。
参数:
- handler:是调用 handle 的处理函数,其入参为 HttpContext ,返回值类型为 Unit 的函数类型
func handle
public func handle(ctx: HttpContext): Unit
功能:处理 Http 请求。
参数:
- ctx:Http 请求上下文
class NotFoundHandler
public class NotFoundHandler <: HttpRequestHandler
便捷的 Http 请求处理器,404 Not Found 处理器。
func handle
public func handle(ctx: HttpContext): Unit
功能:处理 Http 请求,回复 404 响应。
参数:
- ctx:Http 请求上下文
func notFound
public func notFound(ctx: HttpContext): Unit
功能:便捷的 Http 请求处理函数,用于回复 404 响应。处理 Http 请求,回复 404 响应。
参数:
- ctx:Http 请求上下文
func handleError
public func handleError(ctx: HttpContext, code: UInt16): Unit
功能:便捷的 Http 请求处理函数,用于回复错误请求。处理 Http 请求,回复响应。
参数:
- ctx:Http 请求上下文
- code:Http 响应码
class OptionsHandler
public class OptionsHandler <: HttpRequestHandler
便捷的 Http 处理器,用于处理 OPTIONS 请求。 固定返回 "Allow: OPTIONS,GET,HEAD,POST,PUT,DELETE" 响应头
func handle
public func handle(ctx: HttpContext): Unit
功能:处理 Http OPTIONS 请求。
参数:
- ctx:Http 请求上下文
class RedirectHandler
public class RedirectHandler <: HttpRequestHandler {
public init(url: String, code: UInt16)
}
便捷的 Http 处理器,用于回复重定向响应。
init
public init(url: String, code: UInt16)
功能:RedirectHandler 的构造函数。
参数:
- url:重定向响应中 Location 头部的 url
- code:重定向响应的响应码
异常:
- HttpException:url 为空或响应码不是除 304 以外的 3XX 状态码时抛出异常
func handle
public func handle(ctx: HttpContext): Unit
功能:处理 Http 请求,回复重定向响应。
参数:
- ctx:Http 请求上下文
enum FileHandlerType
public enum FileHandlerType {
| DownLoad
| UpLoad
}
此枚举类用于设置 FileHandler 是上传还是下载模式。
DownLoad
DownLoad
功能:创建一个 FileHandler 类型的枚举实例,表示下载模式。
UpLoad
UpLoad
功能:创建一个 FileHandler 类型的枚举实例,表示上传模式。
class FileHandler
public class FileHandler <: HttpRequestHandler {
public init(path: String, handlerType!: FileHandlerType = DownLoad, bufferSize!: Int64 = 64 * 1024)
}
用于处理文件下载或者文件上传。
- 文件下载:
- 构造
FileHandler时需要传入待下载文件的路径,目前一个FileHandler只能处理一个文件的下载; - 下载文件只能使用 GET 请求,其他请求返回 400 状态码;
- 文件如果不存在,将返回 404 状态码;
- 构造
- 文件上传:
- 构造
FileHandler时需要传入一个存在的目录路径,上传到服务端的文件将保存在这个目录中; - 上传文件时只能使用 POST 请求,其他请求返回 400 状态码;
- 上传数据的 http 报文必须是
multipart/form-data格式的,Content-Type头字段的值为multipart/form-data; boundary=----XXXXX; - 上传文件的文件名存放在
form-data数据报文中,报文数据格式为Content-Disposition: form-data; name="xxx"; filename="xxxx",文件名是filename字段的值; - 目前 form-data 中必须包含 filename 字段;
- 如果请求报文不正确,将返回 400 状态码;
- 如果出现其他异常,例如文件处理异常,将返回 500 状态码;
- 构造
init
public init(path: String, handlerType!: FileHandlerType = DownLoad, bufferSize!: Int64 = 64 * 1024)
功能:FileHandler 的构造函数。
参数:
- path:FileHandler 构造时需要传入的文件或者目录路径字符串,上传模式中只能传入存在的目录路径;路径中存在../时,用户需要确认标准化后的绝对路径是期望传入的路径
- handlerType:构造 FileHandler 时指定当前 FileHandler 的工作模式,默认为 DownLoad 下载模式
- bufferSize:内部从网络读取或者写入的缓冲区大小,默认值为 64*1024(64k),若小于 4096,则使用 4096 作为缓冲区大小
异常:
- HttpException:当 path 不存在时,抛出异常
func handle
public func handle(ctx: HttpContext): Unit
功能:根据请求对响应数据进行处理。
参数:
- ctx:Http 请求上下文
class Client
public class Client
Client 类,用户可以通过 Client 实例发送 HTTP/1.1 或 HTTP/2 请求。
主要提供功能:发送 Http request、随时关闭等。
Client 文档中未明确说明支持版本的配置,在 HTTP/1.1 与 HTTP/2 都会生效。
prop httpProxy
public prop httpProxy: String
功能:获取客户端 http 代理,默认使用系统环境变量 http_proxy 的值,用字符串表示,格式为:"http://host:port",例如:"http://192.168.1.1:80"
prop httpsProxy
public prop httpsProxy: String
功能:获取客户端 https 代理,默认使用系统环境变量 https_proxy 的值,用字符串表示,格式为:"http://host:port",例如:"http://192.168.1.1:443"
prop connector
public prop connector: (String) -> StreamingSocket
功能:客户端调用此函数获取到服务器的连接
prop logger
public prop logger: Logger
功能:获取客户端日志记录器,设置 logger.level 将立即生效,记录器应该是线程安全的
prop cookieJar
public prop cookieJar: ?CookieJar
功能:用于存储客户端所有 Cookie,如果配置为 None,则不会启用 Cookie
prop poolSize
public prop poolSize: Int64
功能:HTTP/1.1 客户端使用连接池大小,表示对同一个主机(host:port)同时存在的连接数的最大值
prop autoRedirect
public prop autoRedirect: Bool
功能:获取客户端是否会自动进行重定向,304 状态码默认不重定向
func getTlsConfig
public func getTlsConfig(): ?TlsClientConfig
功能:获取客户端设定的 TLS 层配置。
返回值:
prop readTimeout
public prop readTimeout: Duration
功能:获取客户端设定的读取整个响应的超时时间,默认值为 15s
prop writeTimeout
public prop writeTimeout: Duration
功能:获取客户端设定的写请求的超时时间,默认值为 15s
prop headerTableSize
public prop headerTableSize: UInt32
功能:获取客户端 HTTP/2 Hpack 动态表初始值,默认值为 4096
prop enablePush
public prop enablePush: Bool
功能:获取客户端 HTTP/2 是否支持服务器推送,默认值为 true
prop maxConcurrentStreams
public prop maxConcurrentStreams: UInt32
功能:获取客户端 HTTP/2 初始最大并发流数量,默认值为 2^31 - 1
prop initialWindowSize
public prop initialWindowSize: UInt32
功能:获取客户端 HTTP/2 流控窗口初始值,默认值为 65535 ,取值范围为 0 至 2^31 - 1。
prop maxFrameSize
public prop maxFrameSize: UInt32
功能:获取客户端 HTTP/2 初始最大帧大小。默认值为 16384. 取值范围为 2^14 至 2^24 - 1
prop maxHeaderListSize
public prop maxHeaderListSize: UInt32
功能:获取客户端 HTTP/2 最大 header 大小。响应 headers 最大长度,为所有 header field 长度之和(所有 name 长度 + value 长度 + 32,包括自动添加的 h2 伪头),默认值为 UInt32.Max
func send
public func send(req: HttpRequest): HttpResponse
功能:通用请求函数,发送 HttpRequest 到 url 中的服务器,接收 HttpResponse注意:
- 对于 HTTP/1.1,如果请求中有 body 要发,那么需要保证 Content-Length 和 Transfer-Encoding: chunked必有且只有一个,以 chunked 形式发时,每段 chunk 最大为 8192 字节:如果用户发送的 body 为自己实现的 InputStream 类,则需要自己保证 Content-Length和 Transfer-Encoding: chunked 设置且只设置了一个;如果用户采用默认的 body 发送,Content-Length 和 Transfer-Encoding: chunked都缺失时,我们会为其补上 Content-Length header,值为 body.size
- 用户如果设置了 Content-Length,则需要保证其正确性:如果所发 body 的内容大于等于 Content-Length 的值,我们会发送长度为 Content-Length 值的数据;如果所发 body 的内容小于 Content-Length 的值,此时如果 body 是默认的 body,则会抛出 HttpException,如果 body是用户自己实现的 InputStream 类,其行为便无法保证(可能会造成服务器端的读 request 超时或者客户端的收 response 超时)
- 升级函数通过 WebSocket 的 upgradeFromClient 或 Client 的 upgrade 接口发出,调用 client 的其他函数发送 upgrade 请求会抛出异常
- 协议规定 TRACE 请求无法携带内容,故用户发送带有 body 的 TRACE 请求时会抛出异常
- HTTP/1.1 默认对同一个服务器的连接数不超过 10 个。response 的 body 需要用户调用
body.read(buf: Array<Byte>)函数去读。body 被读完后,连接才能被客户端对象复用,否则请求相同的服务器也会新建连接。新建连接时如果连接数超出限制则会抛出 HttpException - body.read 函数将 body 读完之后返回 0,如果读的时候连接断开会抛出 ConnectionException
- HTTP/1.1 的升级请求如果收到 101 响应,则表示切换协议,此连接便不归 client 管理
- 下文的快捷请求函数的注意点相同一次请求重定向超出一定次数时抛此异常客户端解析报文出错时抛此异常一次性收到的 1xx 响应超过一定数量抛此异常对同一个服务器的连接超过一定数量抛此异常使用 send 函数升级协议抛此异常发送带有 body 的 TRACE 请求抛此异常。
参数:
- HttpRequest:发送的请求
返回值:服务端返回处理该请求的响应
异常:
- UrlSyntaxException:请求中 URL 错误时抛此异常
- SocketException:Socket 连接出现错误时抛此异常
- ConnectionException:从连接中读数据时对端已关闭连接抛此异常
- SocketTimeoutException:Socket 连接超时抛此异常
- TlsException:Tls 连接建立失败或通信异常抛此异常
- HttpException:当用户未使用 http 库提供的 API 升级 WebSocket 时抛此异常
- HttpTimeoutException:请求超时或读 HttpResponse.body 超时抛此异常
func get
public func get(url: String): HttpResponse
功能:请求方法为 GET 的便捷请求函数。
参数:
- url:请求的 url
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func head
public func head(url: String): HttpResponse
功能:请求方法为 HEAD 的便捷请求函数。
参数:
- url:请求的 url
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func put
public func put(url: String, body: InputStream): HttpResponse
功能:请求方法为 PUT 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func put
public func put(url: String, body: String): HttpResponse
功能:请求方法为 PUT 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func put
public func put(url: String, body: Array<UInt8>): HttpResponse
功能:请求方法为 PUT 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func post
public func post(url: String, body: InputStream): HttpResponse
功能:请求方法为 POST 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func post
public func post(url: String, body: String): HttpResponse
功能:请求方法为 POST 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func post
public func post(url: String, body: Array<UInt8>): HttpResponse
功能:请求方法为 POST 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func delete
public func delete(url: String): HttpResponse
功能:请求方法为 DELETE 的便捷请求函数。
参数:
- url:请求的 url
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func connect
public func connect(url: String, header!: HttpHeaders = HttpHeaders(), version!: Protocol = HTTP1_1): (HttpResponse, ?StreamingSocket)
功能:发送 CONNECT 请求与服务器建立隧道,返回建连成功后的连接,连接由用户负责关闭。服务器返回 2xx 表示建连成功,否则建连失败(不支持自动重定向,3xx 也视为失败)。
参数:
- url:请求的 url
- headers:请求头,默认为空请求头
- version:请求的协议,默认为 HTTP1_1
返回值:返回元组类型,其中 HttpResponse 实例表示服务器返回的响应体,Option<StreamingSocket> 实例表示请求成功时返回 headers 之后连接
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func options
public func options(url: String): HttpResponse
功能:请求方法为 OPTIONS 的便捷请求函数。
参数:
- url:请求的 url
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func upgrade
public func upgrade(req: HttpRequest): (HttpResponse, ?StreamingSocket)
功能:发送请求并升级协议,用户设置请求头,返回升级后的连接(如果升级成功),连接由用户负责关闭。
- 服务器返回 101 表示升级成功,获取到了 StreamingSocket
- 必选请求头:
- Upgrade: protocol-name ["/" protocol-version]
- Connection: Upgrade (Connection: Upgrade 在有 Upgrade 时会自动补上)
- 不支持 HTTP/1.0、HTTP/2
- 不支持 HTTP/1.1 CONNECT 方法的 HttpRequest
参数:
- req:升级时发送的请求
返回值:返回一个元组,HttpResponse 实例表示服务器返回的响应,?StreamingSocket 实例表示获取的底层连接,升级失败时为 None
异常:
- HttpException:
- 请求报文或响应报文不符合协议
- 请求报文不含 Upgrade 头
- 发送 CONNECT 请求
- 发送带 body 的 TRACE 请求
- SocketException,ConnectionException:Socket 连接出现异常或被关闭
- SocketTimeoutException:Socket 连接超时
- TlsException: Tls 连接建立失败或通信异常
func close
public func close(): Unit
功能:关闭客户端建立的所有连接,调用后不能继续发送请求。
class ClientBuilder
public class ClientBuilder
ClientBuilder 类,用于 Client 实例的构建,Client 没有公开的构造函数,用户只能通过 ClientBuilder 得到 Client 实例。ClientBuilder 文档中未明确说明支持版本的配置,在 HTTP/1.1 与 HTTP/2 都会生效。
init
public init()
功能:创建新的 ClientBuilder 实例。
func httpProxy
public func httpProxy(addr: String): ClientBuilder
功能:设置客户端 http 代理,默认使用系统环境变量 http_proxy 的值。
参数:
- addr:格式为:"http://host:port",例如:"http://192.168.1.1:80"
返回值:当前 ClientBuilder 实例的引用
func httpsProxy
public func httpsProxy(addr: String): ClientBuilder
功能:设置客户端 https 代理,默认使用系统环境变量 https_proxy 的值。
参数:
- addr:格式为:"http://host:port",例如:"http://192.168.1.1:443"
返回值:当前 ClientBuilder 实例的引用
func noProxy
public func noProxy(): ClientBuilder
功能:调用此函数后,客户端不使用任何代理。
返回值:当前 ClientBuilder 实例的引用
func connector
public func connector(connector: (String)->StreamingSocket): ClientBuilder
功能:客户端调用此函数获取到服务器的连接。
参数:
- connector:入参为字符串,返回值类型为 Unit 的函数类型字符串返回
返回值:当前 ClientBuilder 实例的引用
func logger
public func logger(logger: Logger): ClientBuilder
功能:设定客户端的 logger,默认 logger 级别为 INFO,logger 内容将写入 Console.stdout。
参数:
- logger:需要是线程安全的,默认使用内置线程安全 logger
返回值:当前 ClientBuilder 实例的引用
func cookieJar
public func cookieJar(cookieJar: ?CookieJar): ClientBuilder
功能:用于存储客户端所有 Cookie。
参数:
- cookieJar:默认使用一个空的 CookieJar,如果配置为 None 则不会启用 Cookie
返回值:当前 ClientBuilder 实例的引用
func poolSize
public func poolSize(size: Int64): ClientBuilder
功能:HTTP/1.1 客户端使用连接池大小,表示对同一个主机(host:port)同时存在的连接数的最大值。
参数:
- size:默认 10,poolSize 需要大于 0
异常:
- HttpException:如果传参小于等于 0,则会抛出该异常
返回值:当前 ClientBuilder 实例的引用
func autoRedirect
public func autoRedirect(auto: Bool): ClientBuilder
功能:配置客户端是否会自动进行重定向,重定向会请求 Location 头的资源,协议规定,Location 只能包含一个 URI 引用Location = URI-reference详见 RFC 9110 10.2.2.。304 状态码默认不重定向。
参数:
- autoRedirect,默认 true
返回值:当前 ClientBuilder 实例的引用
func tlsConfig
public func tlsConfig(config: TlsClientConfig): ClientBuilder
功能:设置 TLS 层配置,默认不对其进行设置。
参数:
- config:设定支持 tls 客户端需要的配置信息
返回值:当前 ClientBuilder 实例的引用
func readTimeout
public func readTimeout(timeout: Duration): ClientBuilder
功能:设定客户端读取一个响应的最大时长。
参数:
- timeout:默认 15s,Duration.Max 代表不限制,如果传入负的 Duration 将被替换为 Duration.Zero
返回值:当前 ClientBuilder 实例的引用
func writeTimeout
public func writeTimeout(timeout: Duration): ClientBuilder
功能:设定客户端发送一个请求的最大时长。
参数:
- timeout,默认 15s,Duration.Max 代表不限制,如果传入负的 Duration 将被替换为 Duration.Zero
返回值:当前 ClientBuilder 实例的引用
func headerTableSize
public func headerTableSize(size: UInt32): ClientBuilder
功能:配置客户端 HTTP/2 Hpack 动态表初始值。
参数:
- size:默认值 4096
返回值:当前 ClientBuilder 实例的引用
func enablePush
public func enablePush(enable: Bool): ClientBuilder
功能:配置客户端 HTTP/2 是否支持服务器推送。
参数:
- enable:默认值 true
返回值:当前 ClientBuilder 实例的引用
func maxConcurrentStreams
public func maxConcurrentStreams(size: UInt32): ClientBuilder
功能:配置客户端 HTTP/2 初始最大并发流数量。
参数:
- size:默认值为 2^31 - 1
返回值:当前 ClientBuilder 实例的引用
func initialWindowSize
public func initialWindowSize(size: UInt32): ClientBuilder
功能:配置客户端 HTTP/2 流控窗口初始值。
参数:
- size:默认值 65535 , 取值范围为 0 至 2^31 - 1
返回值:当前 ClientBuilder 实例的引用
func maxFrameSize
public func maxFrameSize(size: UInt32): ClientBuilder
功能:配置客户端 HTTP/2 初始最大帧大小。
参数:
- size:默认值为 16384. 取值范围为 2^14 至 2^24 - 1
返回值:当前 ClientBuilder 实例的引用
func maxHeaderListSize
public func maxHeaderListSize(size: UInt32): ClientBuilder
功能:配置客户端接收的 HTTP/2 响应 headers 最大长度,为所有 header field 长度之和(所有 name 长度 + value 长度 + 32,包括自动添加的 h2 伪头),默认值为 UInt32.Max。
参数:
- size:客户端接收的 HTTP/2 响应 headers 最大长度
返回值:当前 ClientBuilder 实例的引用
func build
public func build(): Client
功能:构造 Client 实例。
返回值:用当前 ClientBuilder 实例构造数来的 Client 实例。
异常:
- IllegalArgumentException:配置项有非法参数时抛出此异常
class WebSocket
public class WebSocket
提供 WebSocket 服务的相关类,用户通过 upgradeFrom 函数以获取 WebSocket 连接。
提供 WebSocket 连接的读、写、关闭等函数。
调用 read() 即读取一个 WebSocketFrame,用户可通过 WebSocketFrame.frameType 来知晓帧的类型,通过 WebSocketFrame.fin 来知晓是否是分段帧。
调用 write(frameType: WebSocketFrameType, byteArray: Array<UInt8>),传入message的类型,和 message 的 byte 来发送 WebSocket 信息,如果写的是控制帧,则不会分段发送,如果写的是数据帧(Text、Binary),则会将 message 按底层 buffer 的大小分段(分成多个 fragment)发送。
详细说明见下文接口说明,接口行为以 RFC 6455 为准。
prop subProtocol
public prop subProtocol: String
功能:获取与对端协商到的 subProtocol,协商时,客户端提供一个按偏好排名的 subProtocols 列表,服务器从中选取一个或零个子协议
prop logger
public prop logger: Logger
功能:日志记录器
func read
public func read(): WebSocketFrame
功能:从连接中读取一个帧,如果连接上数据未就绪会阻塞,非线程安全(即对同一个 WebSocket 对象不支持多线程读)
说明:read 函数返回一个帧对象 WebSocketFrame ,用户可以调用 WebSocketFrame 的 frameType,fin 属性确定其帧类型和是否是分段帧调用 WebSocketFrame 的 payload 函数得到原始二进制数据数组:Array<UInt8>
- 分段帧的首帧为 fin == false,frameType == TextWebFrame 或 BinaryWebFrame中间帧 fin == false,frameType == ContinuationWebFrame尾帧 fin == true, frameType == ContinuationWebFrame
- 非分段帧为 fin == true, frameType != ContinuationWebFrame
注意:
- 数据帧(Text,Binary)可以分段,用户需要多次调用 read 将所有分段帧读完(以下称为接收到完整的 message),再将分段帧的 payload 按接收序拼接Text 帧的 payload 为 UTF-8 编码,用户在接收到完整的 message 后,调用 String.fromUtf8函数将拼接后的 payload 转成字符串Binary 帧的 payload 的意义由使用其的应用确定,用户在接收到完整的 message 后,将拼接后的 payload 传给上层应用
- 控制帧(Close,Ping,Pong)不可分段
- 控制帧本身不可分段,但其可以穿插在分段的数据帧之间。分段的数据帧之间不可出现其他数据帧,如果用户收到穿插的分段数据帧,则需要当作错误处理
- 客户端收到 masked 帧,服务器收到 unmasked 帧,断开底层连接并抛出异常
- rsv1、rsv2、rsv3 位被设置(暂不支持 extensions,因此 rsv 位必须为 0),断开底层连接并抛出异常
- 收到无法理解的帧类型(只支持 Continuation,Text,Binary,Close,Ping,Pong),断开底层连接并抛出异常
- 收到分段或 payload 长度大于 125 bytes 的控制帧(Close,Ping,Pong),断开底层连接并抛出异常
- 收到 payload 长度大于 20M 的帧,断开底层连接并抛出异常
- closeConn 关闭连接后继续调用读,抛出异常。
返回值:读到的 WebSocketFrame 对象
异常:
- SocketException:底层连接错误
- WebSocketException:收到不符合协议规定的帧,此时会给对端发送 Close 帧说明错误信息,并断开底层连接
- ConnectionException:从连接中读数据时对端已关闭连接抛此异常
func write
public func write(frameType: WebSocketFrameType, byteArray: Array<UInt8>, frameSize!: Int64 = FRAMESIZE)
功能:发送数据,非线程安全(即对同一个 WebSocket 对象不支持多线程写)
说明:write 函数将数据以 WebSocket 帧的形式发送给对端
- 如果发送数据帧(Text,Binary),传入的 byteArray 如果大于 frameSize (默认 4 * 1024 bytes),我们会将其分成小于等于 frameSize 的 payload 以分段帧的形式发送,否则不分段
- 如果发送控制帧(Close,Ping,Pong),传入的 byteArray 的大小需要小于等于 125 bytes,Close 帧的前两个字节为状态码,可用的状态码见 RFC 6455 7.4. Status Codes协议规定,Close 帧发送之后,禁止再发送数据帧,如果发送则会抛出异常
- 用户需要自己保证其传入的 byteArray 符合协议,如 Text 帧的 payload 需要是 UTF-8 编码,如果数据帧设置了 frameSize,那么需要大于 0,否则抛出异常
- 发送数据帧时,frameSize 小于等于 0,抛出异常
- 用户发送控制帧时,传入的数据大于 125 bytes,抛出异常
- 用户传入非 Text,Binary,Close,Ping,Pong 类型的帧类型,抛出异常
- 发送 Close 帧时传入非法的状态码,或 reason 数据超过 123 bytes,抛出异常
- 发送完 Close 帧后继续发送数据帧,抛出异常
- closeConn 关闭连接后调用写,抛出异常
参数:
- frameType:所需发送的帧的类型
- byteArray:所需发送的帧的 payload(二进制形式)
- frameSize:分段帧的大小,默认为 4 * 1024 bytes,frameSize 不会对控制帧生效(控制帧设置了无效)
异常:
- SocketException:底层连接错误
- WebSocketException:传入非法的帧类型,或者数据时抛出异常
func writeCloseFrame
public func writeCloseFrame(status!: ?UInt16 = None, reason!: String = ""): Unit
功能:发送 Close 帧
注意:协议规定,Close 帧发送之后,禁止再发送数据帧如果用户不设置 status,那么 reason 不会被发送(即有 reason 必有 status);控制帧的 payload 不超过 125 bytes,Close 帧的前两个 bytes 为 status,因此 reason 不能超过 123 bytes,closeConn 关闭连接后调用写,抛出异常。
参数:
- status:发送的 Close 帧的状态码,默认为 None,表示不发送状态码和 reason
- reason:关闭连接的说明,默认为空字符串,发送时会转成 UTF-8,不保证可读,debug 用,
异常:
- WebSocketException:传入非法的状态码,或 reason 数据超过 123 bytes
func writePingFrame
public func writePingFrame(byteArray: Array<UInt8>): Unit
功能:提供发送 Ping 帧的快捷函数,closeConn 关闭连接后调用写,抛出异常。
参数:
- byteArray:所需发送的帧的 payload(二进制形式)
异常:
- SocketException:底层连接错误
- WebSocketException:传入的数据大于 125 bytes,抛出异常
func writePongFrame
public func writePongFrame(byteArray: Array<UInt8>): Unit
功能:提供发送 Pong 帧的快捷函数,closeConn 关闭连接后调用写,抛出异常。
参数:
- byteArray:所需发送的帧的 payload(二进制形式)
异常:
- SocketException:底层连接错误
- WebSocketException:传入的数据大于 125 bytes,抛出异常
func closeConn
public func closeConn(): Unit
功能:提供关闭底层 WebSocket 连接的函数
说明:直接关闭底层连接。正常的关闭流程需要遵循协议规定的握手流程,即先发送 Close 帧给对端,并等待对端回应的 Close 帧。握手流程结束后方可关闭底层连接。
func upgradeFromServer
public static func upgradeFromServer(ctx: HttpContext, subProtocols!: ArrayList<String> = ArrayList<String>(),
origins!: ArrayList<String> = ArrayList<String>(),
userFunc!:(HttpRequest) -> HttpHeaders = {_: HttpRequest => HttpHeaders()}): WebSocket
功能:提供服务端升级到 WebSocket 协议的函数,通常在 handler 中使用
说明:服务端升级的流程为,收到客户端发来的升级请求,验证请求,如果验证通过,则回复 101 响应并返回 WebSocket 对象用于 WebSocket 通讯
- 用户通过 subProtocols,origins 参数来配置其支持的 subprotocol 和 origin 白名单,subProtocols如果不设置,则表示不支持子协议,origins 如果不设置,则表示接受所有 origin 的握手请求
- 用户通过 userFunc 来自定义处理升级请求的行为,如处理 cookie 等,传入的 userFunc 要求返回一个 HttpHeaders 对象,其会通过 101 响应回给客户端(升级失败的请求则不会)
- 暂不支持 WebSocket 的 extensions,因此如果握手过程中出现 extensions 协商则会抛 WebSocketException
- 只支持 HTTP1_1 和 HTTP2_0 向 WebSocket 升级
参数:
- ctx:Http 请求上下文,将传入给 handler 的直接传给 upgradeFromServer 即可
- subProtocols:用户配置的子协议列表,默认值为空,表示不支持。如果用户配置了,则会选取升级请求中最靠前的且出现在配置列表中的子协议作为升级后的 WebSocket 的子协议,用户可通过调用返回的 WebSocket 的 subProtocol 查看子协议
- origins:用户配置的同意握手的 origin 的白名单,如果不配置,则同意来自所有 origin 的握手,如果配置了,则只接受来自配置 origin 的握手
- userFunc:用户配置的自定义处理升级请求的函数,该函数返回一个 HttpHeaders,
返回值:
- WebSocket:升级得到的 WebSocket 实例
func upgradeFromClient
public static func upgradeFromClient(client: Client, url: URL,
version!: Protocol = HTTP1_1,
subProtocols!: ArrayList<String> = ArrayList<String>(),
headers!: HttpHeaders = HttpHeaders()): (WebSocket, HttpHeaders)
功能:提供客户端升级到 WebSocket 协议的函数
说明:客户端的升级流程为,传入 client 对象,url 对象,构建升级请求,请求服务器后验证其响应,如果握手成功,则返回 WebSocket 对象用于 WebSocket 通讯,并返回 101 响应头的 HttpHeaders 对象给用户,暂不支持 extensions如果子协议协商成功,用户可通过调用返回的 WebSocket 的 subProtocol 查看子协议。
参数:
- client:用于请求的 client 对象
- version:创建 socket 使用的 HTTP 版本,只支持 HTTP1_1 和 HTTP2_0 向 WebSocket 升级
- url:用于请求的 url 对象,WebSocket 升级时要注意 url 的 scheme 为 ws 或 wss
- subProtocols:用户配置的子协议列表,按偏好排名,默认为空。若用户配置了,则会随着升级请求发送给服务器。
- headers:需要随着升级请求一同发送的非升级必要头,如 cookie 等
返回值:升级成功,则返回 WebSocket 对象用于通讯和 101 响应的头
异常:
- SocketException:底层连接错误
- HttpException:握手时 HTTP 请求过程中出现错误
- WebSocketException:升级失败,升级响应验证不通过
class WebSocketFrame
public class WebSocketFrame
WebSocket 用于读的基本单元。
说明:WebSocketFrame 提供了三个属性,其中 fin 和 frameType 共同说明了帧是否分段和帧的类型。payload 为帧的载荷。 分段帧的首帧为 fin == false,frameType == TextWebFrame 或 BinaryWebFrame 中间帧 fin == false,frameType == ContinuationWebFrame 尾帧 fin == true, frameType == ContinuationWebFrame 非分段帧为 fin == true, frameType != ContinuationWebFrame 用户仅能通过 WebSocket 对象的 read 函数得到 WebSocketFrame。数据帧可分段,如果用户收到分段帧,则需要多次调用 read 函数直到收到完整的 message,并将所有分段的 payload 按接收顺序拼接。 注意,由于控制帧可以穿插在分段帧之间,用户在拼接分段帧的 payload 时需要单独处理控制帧。分段帧之间仅可穿插控制帧,如果用户在分段帧之间接收到其他数据帧,则需要当作错误处理。
prop fin
public prop fin: Bool
功能:获取 WebSocketFrame 的 fin 属性,fin 与 frameType 共同说明了帧是否分段和帧的类型
prop frameType
public prop frameType: WebSocketFrameType
功能:获取 WebSocketFrame 的帧类型,fin 与 frameType 共同说明了帧是否分段和帧的类型
prop payload
public prop payload: Array<UInt8>
功能:获取 WebSocketFrame 的帧载荷,如果是分段数据帧,用户需要在接收完完整的 message 后将所有分段的 payload 按接收序拼接
enum WebSocketFrameType
public enum WebSocketFrameType <: Equatable<WebSocketFrameType> & ToString {
| ContinuationWebFrame
| TextWebFrame
| BinaryWebFrame
| CloseWebFrame
| PingWebFrame
| PongWebFrame
| UnknownWebFrame
}
WebSocketFrame 的枚举类型。
ContinuationWebFrame
ContinuationWebFrame
功能:表示 continuation 帧类型,对应 Opcode 为 %x0 的情形。
TextWebFrame
TextWebFrame
功能:表示 text 帧类型,对应 Opcode 为 %x1 的情形。
BinaryWebFrame
BinaryWebFrame
功能:表示 binary 帧类型,对应 Opcode 为 %x2 的情形。
CloseWebFrame
CloseWebFrame
功能:表示 close 帧类型,对应 Opcode 为 %x8 的情形。
PingWebFrame
PingWebFrame
功能:表示 ping 帧类型,对应 Opcode 为 %x9 的情形。
PongWebFrame
PongWebFrame
功能:表示 pong 帧类型,对应 Opcode 为 %xA 的情形。
UnknownWebFrame
UnknownWebFrame
功能:表示 其余帧类型,暂不支持,对应 Opcode 为上述值之外的情形。
operator func ==
public override operator func == (that: WebSocketFrameType): Bool
功能:判等。
参数:
- WebSocketFrameType:被比较的对象
返回值:当前实例与 that 相等返回 true,否则返回 false
operator func !=
public override operator func != (that: WebSocketFrameType): Bool
功能:判不等。
参数:
- WebSocketFrameType:被比较的对象
返回值:当前实例与 that 不等返回 true,否则返回 false
func toString
public override func toString(): String
功能:获取 WebSocket 帧类型字符串。
返回值:WebSocket 帧类型字符串
enum Protocol
public enum Protocol <: Equatable<Protocol> & ToString {
| HTTP1_0
| HTTP1_1
| HTTP2_0
| UnknownProtocol(String)
}
HTTP 协议类型枚举。
HTTP1_0
HTTP1_0
功能:创建一个 HTTP1_0 类型的枚举实例,表示采用 http/1.0 协议版本。
HTTP1_1
HTTP1_1
功能:创建一个 HTTP1_1 类型的枚举实例,表示采用 http/1.1 协议版本。
HTTP2_0
HTTP2_0
功能:创建一个 HTTP2_0 类型的枚举实例,表示采用 http/2.0 协议版本。
UnknownProtocol
UnknownProtocol(String)
operator func ==
public override operator func == (that: Protocol): Bool
功能:判等。
参数:
- WebSocketFrameType:被比较的对象
返回值:当前实例与 that 相等返回 true,否则返回 false
operator func !=
public override operator func != (that: Protocol): Bool
功能:判不等。
参数:
- WebSocketFrameType:被比较的对象
返回值:当前实例与 that 不等返回 true,否则返回 false
func toString
public override func toString(): String
功能:获取 Http 协议版本对象字符串。
返回值:Http 协议版本对象字符串
class HttpHeaders
public class HttpHeaders <: Iterable<(String, Collection<String>)>
此类用于表示 Http 报文中的 header 和 trailer,定义了相关增、删、改、查操作。 header 和 trailer 为键值映射集,由若干 field-line 组成,每一个 field-line 包含一个键 (field -name) 和若干值 (field-value)。 field-name 由 token 字符组成,不区分大小写,在该类中将转为小写保存。 field-value 由 vchar,SP 和 HTAB 组成,vchar 表示可见的 US-ASCII 字符,不得包含前后空格,不得为空值。 详见 rfc 9110 https://www.rfc-editor.org/rfc/rfc9110.html#name-fields 示例: Example-Field: Foo, Bar key: Example-Field, value: Foo, Bar field-name = token token = 1tchar tchar = "!" / "#" / "$" / "%" / "&" / "'" / "" / "+" / "-" / "." / "^" / "_" / "`" / "|" / "~" / DIGIT / ALPHA ; any VCHAR, except delimiters
func add
public func add(name: String, value: String): Unit
功能:添加指定键值对 name: value如果 name 已经存在,将在其对应的值列表中添加 value,如果 name 不存在,则添加 name 字段及其值 value。
参数:
- name:HttpHeaders 的字段名称
- value:HttpHeaders 的字段值
异常:
- HttpException:如果传入的name/value包含不合法元素,将抛出此异常
func set
public func set(name: String, value: String): Unit
功能:设置指定键值对 name: value 如果 name 已经存在,传入的 value 将会覆盖之前的值。
参数:
- name:HttpHeaders 的字段名称
- value:HttpHeaders 的字段值
异常:
- HttpException:如果传入的 name/values 包含不合法元素,将抛出此异常
func get
public func get(name: String): Collection<String>
功能:获取指定 name 对应的 value 值。
参数:
- name:字段名称,不区分大小写
返回值:name 对应的 value 集合,如果指定 name 不存在,返回空集合
func getFirst
public func getFirst(name: String): ?String
功能:获取指定 name 对应的第一个 value 值。
参数:
- name:字段名称,不区分大小写
返回值:name 对应的第一个 value 值,如果指定 name 不存在,返回 None
func del
public func del(name: String): Unit
功能:删除指定 name 对应的键值对。
参数:
- name:删除的字段名称
func iterator
public func iterator(): Iterator<(String, Collection<String>)>
功能:获取迭代器,可用于遍历所有键值对。
返回值:该键值集的迭代器
func isEmpty
public func isEmpty(): Bool
功能:判断当前实例是否为空,即没有任何键值对。
返回值:如果当前实例为空,返回 true,否则返回 false
class HttpRequestBuilder
public class HttpRequestBuilder
HttpRequestBuilder 类用于构造 HttpRequest 实例。
init
public init()
功能:构造一个新 HttpRequestBuilder。
init
public init(request: HttpRequest)
功能: 通过 request 构造一个具有 request 属性的 HttpRequestBuilder。由于 body 成员是一个 InputStream,对原始的 request 的 body 的操作会影响到复制得到的 HttpRequest 的 body。HttpRequestBuilder 的 headers 和 trailers 是入参 request 的深拷贝。其余元素都是入参 request 的浅拷贝(因为是不可变对象,无需深拷贝)。
参数:
- request:传入的 HttpRequest 对象
func method
public func method(method: String): HttpRequestBuilder
功能:设置请求 method,默认请求 method 为 "GET"。
参数:
- method:请求方法,必须由 token 字符组成,如果传入空字符串,method 值将自动设置为 "GET"
返回值:当前 HttpRequestBuilder 实例的引用
异常:
- HttpException:参数 method 非法时抛出此异常
func url
public func url(rawUrl: String): HttpRequestBuilder
功能:设置请求 url,默认 url 为空的 URL 对象,即 URL.parse("")。
参数:
- 待解析成 url 对象的字符串,该字符串格式详见 url 包 parse 函数
返回值:当前 HttpRequestBuilder 实例的引用
异常:
- IllegalArgumentException - 当被编码的字符不符合 UTF8 的字节序列规则时,抛出异常
func url
public func url(url: URL): HttpRequestBuilder
功能:设置请求 url,默认 url 为空的 URL 对象,即 URL.parse("")。
返回值:当前 HttpRequestBuilder 实例的引用
func version
public func version(version: Protocol): HttpRequestBuilder
功能:设置请求的 http 协议版本,默认为 UnknownProtocol(""),客户端会根据 tls 配置自动选择协议。
返回值:当前 HttpRequestBuilder 实例的引用
func header
public func header(name: String, value: String): HttpRequestBuilder
功能:向请求 header 添加指定键值对 name: value,规则同 HttpHeaders 类的 add 函数。
返回值:当前 HttpRequestBuilder 实例的引用
异常:
- HttpException:如果传入的 name 或 value 包含不合法元素,将抛出此异常
func addHeaders
public func addHeaders(headers: HttpHeaders): HttpRequestBuilder
功能:向请求 header 添加参数 HttpHeaders 中的键值对。
返回值:当前 HttpRequestBuilder 实例的引用
func setHeaders
public func setHeaders(headers: HttpHeaders): HttpRequestBuilder
功能:设置请求 header,如果已经设置过,调用该函数将替换原 header。
返回值:当前 HttpRequestBuilder 实例的引用
func body
public func body(body: Array<UInt8>): HttpRequestBuilder
功能:设置请求 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 将以内置的 InputStream 实现类表示,其大小已知默认请求 body 为空的 InputStream 对象,即其 read 函数总是返回 0body 大小是否已知将影响 HttpRequest 类属性 bodySize 的取值,及客户端发送请求的行为。
返回值:当前 HttpRequestBuilder 实例的引用
func body
public func body(body: String): HttpRequestBuilder
功能:设置请求 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 将以内置的 InputStream 实现类表示,其大小已知。
返回值:当前 HttpRequestBuilder 实例的引用
func body
public func body(body: InputStream): HttpRequestBuilder
功能:设置请求 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 以用户自定义的 InputStream 实现类表示,其大小未知。
返回值:当前 HttpRequestBuilder 实例的引用
func trailer
public func trailer(name: String, value: String): HttpRequestBuilder
功能:向请求 trailer 添加指定键值对 name: value,规则同 HttpHeaders 类的 add 函数。
返回值:当前 HttpRequestBuilder 实例的引用
异常:
- HttpException:如果传入的 name 或 value 包含不合法元素,将抛出此异常
func addTrailers
public func addTrailers(trailers: HttpHeaders): HttpRequestBuilder
功能:向请求 trailer 添加参数 HttpHeaders 中的键值对。
返回值:当前 HttpRequestBuilder 实例的引用
func setTrailers
public func setTrailers(trailers: HttpHeaders): HttpRequestBuilder
功能:设置请求 trailer,如果已经设置过,调用该函数将替换原 trailer。
返回值:当前 HttpRequestBuilder 实例的引用
func priority
public func priority(urg: Int64, inc: Bool): HttpRequestBuilder
功能:设置 priority 头的便捷函数,调用此函数后,将生成 priority 头,形如:"priority: urgency=x, i"如果通过设置请求头的函数设置了 priority 字段,调用此函数无效。如果多次调用此函数,以最后一次为准。
参数:
- urg:表示请求优先级,取值范围为 0~7,0 表示最高优先级
- inc:表示请求是否需要增量处理,为 true 表示希望服务器并发处理与之同 urg 同 inc 的请求,为 false 表示不希望服务器并发处理
返回值:当前 HttpRequestBuilder 实例的引用
func readTimeout
public func readTimeout(timeout: Duration): HttpRequestBuilder
功能:设置此请求的读超时时间。如果传入的 Duration 为负,则会自动转为 0。如果用户设置了此读超时时间,那么该请求的读超时以此为准;如果用户没有设置,那么该请求的读超时以 Client 为准。
参数:
- timeout:用户设置的此请求的读超时时间
返回值:当前 HttpRequestBuilder 实例的引用
func writeTimeout
public func writeTimeout(timeout: Duration): HttpRequestBuilder
功能:设置此请求的写超时时间。如果传入的 Duration 为负,则会自动转为 0。如果用户设置了此写超时时间,那么该请求的写超时以此为准;如果用户没有设置,那么该请求的写超时以 Client 为准。
参数:
- timeout:用户设置的此请求的写超时时间
返回值:当前 HttpRequestBuilder 实例的引用
func get
public func get(): HttpRequestBuilder
功能:构造 method 为 "GET" 的请求的便捷函数。
返回值:当前 HttpRequestBuilder 实例的引用
func head
public func head(): HttpRequestBuilder
功能:构造 method 为 "HEAD" 的请求的便捷函数。
返回值:当前 HttpRequestBuilder 实例的引用
func options
public func options(): HttpRequestBuilder
功能:构造 method 为 "OPTIONS" 的请求的便捷函数。
func trace
public func trace(): HttpRequestBuilder
功能:构造 method 为 "TRACE" 的请求的便捷函数。
func delete
public func delete(): HttpRequestBuilder
功能:构造 method 为 "DELETE" 的请求的便捷函数。
func post
public func post(): HttpRequestBuilder
功能:构造 method 为 "POST" 的请求的便捷函数。
func put
public func put(): HttpRequestBuilder
功能:构造 method 为 "PUT" 的请求的便捷函数。
func connect
public func connect(): HttpRequestBuilder
功能:构造 method 为 "CONNECT" 的请求的便捷函数。
func build
public func build(): HttpRequest
功能:根据 HttpRequestBuilder 实例生成一个 HttpRequest 实例。
返回值:根据当前 HttpRequestBuilder 实例构造出来的 HttpRequest 实例
class HttpRequest
public class HttpRequest <: ToString
此类为 Http 请求类。
客户端发送请求时,需要构造一个 HttpRequest 实例,再编码成字节报文发出。
服务端处理请求时,需要把收到的请求解析成 HttpRequest 实例,并传给 handler 处理函数。
prop method
public prop method: String
功能:获取 method,如 "GET", "POST",request 实例的 method 无法修改
prop url
public prop url: URL
功能:获取 url,表示客户端访问的 url
prop version
public prop version: Protocol
功能:获取 http 版本,如 HTTP1_1 和 HTTP2_0,request 实例的 version 无法修改
prop headers
public prop headers: HttpHeaders
功能:获取 headers,headers 详述见 HttpHeaders 类,获取后,可通过调用 HttpHeaders 实例成员函数,修改该请求的 headers
prop body
public prop body: InputStream
功能:获取 body 注意
- body 不支持并发读取
- 默认 InputStream 实现类的 read 函数不支持多次读取
prop trailers
public prop trailers: HttpHeaders
功能:获取 trailers,trailers 详述见 HttpHeaders 类,获取后,可通过调用 HttpHeaders 实例成员函数,修改该请求的 trailers
prop bodySize
public prop bodySize: Option<Int64>
功能:获取请求 body 长度
- 如果未设置 body,则 bodySize 为 Some(0)
- 如果 body 长度已知,即通过
Array<UInt8>或 String 传入 body,或传入的 InputStream 有确定的 length (length >= 0),则 bodySize 为 Some(Int64) - 如果 body 长度未知,即通过用户自定义的 InputStream 实例传入 body 且 InputStream 实例没有确定的 length (length < 0),则 bodySize 为 None
prop form
public prop form: Form
功能:获取请求中的表单信息
- 如果请求方法为 POST,PUT,PATCH,且 content-type 包含 application/x-www-form-urlencoded,获取请求 body 部分,用 form 格式解析
- 如果请求方法不为 POST,PUT,PATCH,获取请求 url 中 query 部分 注意
- 如果用该接口读取了 body,body 已被消费完,后续将无法通过 body.read 读取 body
- 如果 form 不符合 Form 格式,抛 UrlSyntaxException 异常
prop remoteAddr
public prop remoteAddr: String
功能:用于服务端,获取对端地址,即客户端地址,格式为 ip: port,用户无法设置,自定义的 request 对象调用该属性返回 "",服务端 handler 中调用该属性返回客户端地址
prop close
public prop close: Bool
功能:表示该请求 header 是否包含 Connection: close
- 对于服务端,close 为 true 表示处理完该请求应该关闭连接
- 对于客户端,close 为 true 表示如果收到响应后服务端未关闭连接,客户端应主动关闭连接
prop readTimeout
public prop readTimeout: ?Duration
功能:表示该请求的请求级读超时时间,None 表示没有设置;Some(Duration) 表示设置了。
prop writeTimeout
public prop writeTimeout: ?Duration
功能:表示该请求的请求级写超时时间,None 表示没有设置;Some(Duration) 表示设置了。
func toString
public override func toString(): String
功能:把请求转换为字符串,包括 start line,headers,body size,trailers例如:GET /path HTTP/1.1\r\nhost: <www.example.com\r\n\r\nbody> size: 5\r\nbar: foo\r\n。
返回值:请求的字符串表示
class HttpResponseBuilder
public class HttpResponseBuilder
HttpResponseBuilder 类用于构造 HttpResponse 实例。
init
public init()
功能:构造一个新 HttpResponseBuilder。
func version
public func version(version: Protocol): HttpResponseBuilder
功能:设置 http 响应协议版本。
func status
public func status(status: UInt16): HttpResponseBuilder
功能:设置 http 响应状态码。
异常:
- HttpException:如果设置响应状态码不在 100~599 这个区间内,则抛出此异常
func header
public func header(name: String, value: String): HttpResponseBuilder
功能:向响应 header 添加指定键值对 name: value,规则同 HttpHeaders 类的 add 函数。
异常:
- HttpException:如果传入的 name 或 value 包含不合法元素,将抛出此异常
func addHeaders
public func addHeaders (headers: HttpHeaders): HttpResponseBuilder
功能:向响应 header 添加参数 HttpHeaders 中的键值对。
func setHeaders
public func setHeaders (headers: HttpHeaders): HttpResponseBuilder
功能:设置响应 header,如果已经设置过,调用该函数将替换原 header。
func body
public func body(body: Array<UInt8>): HttpResponseBuilder
功能:设置响应 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 将以内置的 InputStream 实现类表示,其大小已知默认请求 body 为空的 InputStream 对象,即其 read 函数总是返回 0。
func body
public func body(body: String): HttpResponseBuilder
功能:设置响应 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 将以内置的 InputStream 实现类表示,其大小已知。
func body
public func body(body: InputStream): HttpResponseBuilder
功能:设置响应 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 以用户自定义的 InputStream 实现类表示,其大小未知。
func trailer
public func trailer(name: String, value: String): HttpResponseBuilder
功能:向响应 trailer 添加指定键值对 name: value,规则同 HttpHeaders 类的 add 函数。
异常:
- HttpException:如果传入的 name 或 value 包含不合法元素,将抛出此异常
func addTrailers
public func addTrailers (trailers: HttpHeaders): HttpResponseBuilder
功能:向响应 trailer 添加参数 HttpHeaders 中的键值对。
func setTrailers
public func setTrailers (trailers: HttpHeaders): HttpResponseBuilder
功能:设置响应 trailer,如果已经设置过,调用该函数将替换原 trailer。
func request
public func request(request: HttpRequest): HttpResponseBuilder
功能:设置响应对应的请求。
func build
public func build(): HttpResponse
功能:根据 HttpResponseBuilder 实例生成一个 HttpResponse 实例。
返回值:根据当前 HttpResponseBuilder 实例构造出来的 HttpResponse 实例
class HttpResponse
public class HttpResponse <: ToString
Http 响应类。
此类定义了 http 中响应 Response 的相关接口,客户端用该类读取服务端返回的响应。
prop version
public prop version: Protocol
功能:获取响应的协议版本,默认值为Http1_1
prop status
public prop status: UInt16
功能:获取响应的状态码,默认值为 200。状态码由 100~599 的三位数字组成,状态码所反映的具体信息可参考 rfc9110 https://httpwg.org/specs/rfc9110.html#status.codes。
prop headers
public prop headers: HttpHeaders
功能:获取 headers,headers 详述见 HttpHeaders 类,获取后,可通过调用 HttpHeaders 实例成员函数,修改该请求的 headers
prop body
public prop body: InputStream
功能:获取 body 注意
- body 不支持并发读取
- 默认 InputStream 实现类的 read 函数不支持多次读取
prop trailers
public prop trailers: HttpHeaders
功能:获取 trailers,trailers 详述见 HttpHeaders 类,获取后,可通过调用 HttpHeaders 实例成员函数,修改该请求的 trailers
prop bodySize
public prop bodySize: Option<Int64>
功能:获取响应 body 长度
- 如果未设置 body,则 bodySize 为 Some(0)
- 如果 body 长度已知,即通过
Array<UInt8>或 String 传入 body,或传入的 InputStream 有确定的 length (length >= 0),则 bodySize 为 Some(Int64) - 如果 body 长度未知,即通过用户自定义的 InputStream 实例传入 body 且 InputStream 实例没有确定的 length (length < 0),则 bodySize 为 None
prop request
public prop request: Option<HttpRequest>
功能:获取该响应对应的请求,默认为 None
prop close
public prop close: Bool
功能:表示该响应 header 是否包含 Connection: close
- 对于服务端,close 为 true 表示处理完该请求应该关闭连接
- 对于客户端,close 为 true 表示如果收到响应后服务端未关闭连接,客户端应主动关闭连接
func getPush
public func getPush(): Option<ArrayList<HttpResponse>>
功能:获取服务器推送的响应,返回 None 代表未开启服务器推送功能,返回空 ArrayList 代表无服务器推送的响应。
func toString
public override func toString(): String
功能:把响应转换为字符串,包括 status-line,headers,body size, trailers例如:HTTP/1.1 200 OK\r\ncontent-length: 5\r\n\r\nbody size: 5\r\nbar: foo\r\n。
struct HttpStatusCode
public struct HttpStatusCode {
public static const STATUS_CONTINUE = 100
public static const STATUS_SWITCHING_PROTOCOLS = 101
public static const STATUS_PROCESSING = 102
public static const STATUS_EARLY_HINTS = 103
public static const STATUS_OK = 200
public static const STATUS_CREATED = 201
public static const STATUS_ACCEPTED = 202
public static const STATUS_NON_AUTHORITATIVE_INFO = 203
public static const STATUS_NO_CONTENT = 204
public static const STATUS_RESET_CONTENT = 205
public static const STATUS_PARTIAL_CONTENT = 206
public static const STATUS_MULTI_STATUS = 207
public static const STATUS_ALREADY_REPORTED = 208
public static const STATUS_IM_USED = 226
public static const STATUS_MULTIPLE_CHOICES = 300
public static const STATUS_MOVED_PERMANENTLY = 301
public static const STATUS_FOUND = 302
public static const STATUS_SEE_OTHER = 303
public static const STATUS_NOT_MODIFIED = 304
public static const STATUS_USE_PROXY = 305
public static const STATUS_TEMPORARY_REDIRECT = 307
public static const STATUS_PERMANENT_REDIRECT = 308
public static const STATUS_BAD_REQUEST = 400
public static const STATUS_UNAUTHORIZED = 401
public static const STATUS_PAYMENT_REQUIRED = 402
public static const STATUS_FORBIDDEN = 403
public static const STATUS_NOT_FOUND = 404
public static const STATUS_METHOD_NOT_ALLOWED = 405
public static const STATUS_NOT_ACCEPTABLE = 406
public static const STATUS_PROXY_AUTH_REQUIRED = 407
public static const STATUS_REQUEST_TIMEOUT = 408
public static const STATUS_CONFLICT = 409
public static const STATUS_GONE = 410
public static const STATUS_LENGTH_REQUIRED = 411
public static const STATUS_PRECONDITION_FAILED = 412
public static const STATUS_REQUEST_CONTENT_TOO_LARGE = 413
public static const STATUS_REQUEST_URI_TOO_LONG = 414
public static const STATUS_UNSUPPORTED_MEDIA_TYPE = 415
public static const STATUS_REQUESTED_RANGE_NOT_SATISFIABLE = 416
public static const STATUS_EXPECTATION_FAILED = 417
public static const STATUS_TEAPOT = 418
public static const STATUS_MISDIRECTED_REQUEST = 421
public static const STATUS_UNPROCESSABLE_ENTITY = 422
public static const STATUS_LOCKED = 423
public static const STATUS_FAILED_DEPENDENCY = 424
public static const STATUS_TOO_EARLY = 425
public static const STATUS_UPGRADE_REQUIRED = 426
public static const STATUS_PRECONDITION_REQUIRED = 428
public static const STATUS_TOO_MANY_REQUESTS = 429
public static const STATUS_REQUEST_HEADER_FIELDS_TOO_LARGE = 431
public static const STATUS_UNAVAILABLE_FOR_LEGAL_REASONS = 451
public static const STATUS_INTERNAL_SERVER_ERROR = 500
public static const STATUS_NOT_IMPLEMENTED = 501
public static const STATUS_BAD_GATEWAY = 502
public static const STATUS_SERVICE_UNAVAILABLE = 503
public static const STATUS_GATEWAY_TIMEOUT = 504
public static const STATUS_HTTP_VERSION_NOT_SUPPORTED = 505
public static const STATUS_VARIANT_ALSO_NEGOTIATES = 506
public static const STATUS_INSUFFICIENT_STORAGE = 507
public static const STATUS_LOOP_DETECTED = 508
public static const STATUS_NOT_EXTENDED = 510
public static const STATUS_NETWORK_AUTHENTICATION_REQUIRED = 511
}
用以表示网页服务器超文本传输协议响应状态的 3 位数字代码。它由 RFC 9110 规范定义的,并得到 RFC2518、RFC 3229、RFC 4918、RFC 5842、RFC 7168 与 RFC 8297 等规范扩展。所有状态码的第一个数字代表了响应的五种状态之一。
- 状态代码的 1xx(信息)指示在完成请求的操作并发送最终响应之前通信连接状态或请求进度的临时响应;
- 状态代码的 2xx(成功)指示客户端的请求已成功接收、理解和接受;
- 状态代码的 3xx(重定向)指示用户代理需要采取进一步的操作才能完成请求;
- 状态代码的 4xx(客户端错误)指示客户端似乎出错;
- 状态代码的 5xx(服务器错误)指示服务器意识到它出错或无法执行请求的方法;
HttpStatusCode 类结构和主要函数如下:
STATUS_CONTINUE
public static const STATUS_CONTINUE = 100
HTTP 标准状态码 客户端继续发送请求时。这个临时响应是用来通知客户端它的部分请求已经被 服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请 求已经完成,忽略这个响应。服务器必须在请求完成后向客户端发送一个最终响应
STATUS_SWITCHING_PROTOCOLS
public static const STATUS_SWITCHING_PROTOCOLS = 101
服务器已经理解了客户端的请求,并将通过 Upgrade 消息头通知客户端采用不同的 协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到在 Upgrade 消息头中定义的那些协议
STATUS_PROCESSING
public static const STATUS_PROCESSING = 102
处理将被继续执行
STATUS_EARLY_HINTS
public static const STATUS_EARLY_HINTS = 103
提前预加载 (css、js) 文档
STATUS_OK
public static const STATUS_OK = 200
2 开头的状态码,代表请求已成功被服务器接收、理解、并接受,正常状态, 请求已成功,请求所希望的响应头或数据体将随此响应返回
STATUS_CREATED
public static const STATUS_CREATED = 201
请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其 URI 已经 随 Location 头信息返回
STATUS_ACCEPTED
public static const STATUS_ACCEPTED = 202
服务器已接受请求,但尚未处理
STATUS_NON_AUTHORITATIVE_INFO
public static const STATUS_NON_AUTHORITATIVE_INFO = 203
服务器已成功处理了请求。返回的实体头部元信息不是在原始服务器上有效的 确定集合,而是来自本地或者第三方的拷贝
STATUS_NO_CONTENT
public static const STATUS_NO_CONTENT = 204
服务器成功处理,但未返回内容
STATUS_RESET_CONTENT
public static const STATUS_RESET_CONTENT = 205
服务器成功处理了请求,且没有返回任何内容,希望请求者重置文档视图
STATUS_PARTIAL_CONTENT
public static const STATUS_PARTIAL_CONTENT = 206
服务器已经成功处理了部分 GET 请求
STATUS_MULTI_STATUS
public static const STATUS_MULTI_STATUS = 207
DAV 绑定的成员已经在(多状态)响应之前的部分被列举,且未被再次包含
STATUS_ALREADY_REPORTED
public static const STATUS_ALREADY_REPORTED = 208
消息体将是一个 XML 消息
STATUS_IM_USED
public static const STATUS_IM_USED = 226
服务器已完成对资源的请求,并且响应是应用于当前实例的一个或多个实例操作的结果 的表示
STATUS_MULTIPLE_CHOICES
public static const STATUS_MULTIPLE_CHOICES = 300
被请求的资源有一系列可供选择的回馈信息,每个都有自己特定的地址和浏览器驱动的 商议信息。用户或浏览器能够自行选择一个首选的地址进行重定向
STATUS_MOVED_PERMANENTLY
public static const STATUS_MOVED_PERMANENTLY = 301
永久移动 请求的资源已被永久的移动到新 URI,返回信息会包括新的 URI,浏览器会自动定向到 新 URI。
STATUS_FOUND
public static const STATUS_FOUND = 302
临时移动 请求的资源已被临时的移动到新 URI,客户端应当继续向原有地址发送以后的请求
STATUS_SEE_OTHER
public static const STATUS_SEE_OTHER = 303
对应当前请求的响应可以在另一个 URL 上被找到,而且客户端应当采用 GET 的 方式访问那个资源
STATUS_NOT_MODIFIED
public static const STATUS_NOT_MODIFIED = 304
请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访 问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源
STATUS_USE_PROXY
public static const STATUS_USE_PROXY = 305
使用代理,所请求的资源必须通过代理访问
STATUS_TEMPORARY_REDIRECT
public static const STATUS_TEMPORARY_REDIRECT = 307
临时重定向
STATUS_PERMANENT_REDIRECT
public static const STATUS_PERMANENT_REDIRECT = 308
请求和所有将来的请求应该使用另一个 URI
STATUS_BAD_REQUEST
public static const STATUS_BAD_REQUEST = 400
- 语义有误,当前请求无法被服务器理解
- 请求参数有误
STATUS_UNAUTHORIZED
public static const STATUS_UNAUTHORIZED = 401
当前请求需要用户验证
STATUS_PAYMENT_REQUIRED
public static const STATUS_PAYMENT_REQUIRED = 402
为了将来可能的需求而预留的状态码
STATUS_FORBIDDEN
public static const STATUS_FORBIDDEN = 403
服务器已经理解请求,但是拒绝执行
STATUS_NOT_FOUND
public static const STATUS_NOT_FOUND = 404
请求失败,请求所希望得到的资源未被在服务器上发现
STATUS_METHOD_NOT_ALLOWED
public static const STATUS_METHOD_NOT_ALLOWED = 405
请求行中指定的请求函数不能被用于请求响应的资源
STATUS_NOT_ACCEPTABLE
public static const STATUS_NOT_ACCEPTABLE = 406
请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体
STATUS_PROXY_AUTH_REQUIRED
public static const STATUS_PROXY_AUTH_REQUIRED = 407
必须在代理服务器上进行身份验证
STATUS_REQUEST_TIMEOUT
public static const STATUS_REQUEST_TIMEOUT = 408
请求超时。客户端没有在服务器预备等待的时间内完成一个请求的发送
STATUS_CONFLICT
public static const STATUS_CONFLICT = 409
由于和被请求的资源的当前状态之间存在冲突,请求无法完成
STATUS_GONE
public static const STATUS_GONE = 410
被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址
STATUS_LENGTH_REQUIRED
public static const STATUS_LENGTH_REQUIRED = 411
服务器拒绝在没有定义 Content-Length 头的情况下接受请求
STATUS_PRECONDITION_FAILED
public static const STATUS_PRECONDITION_FAILED = 412
服务器在验证在请求的头字段中给出先决条件时,没能满足其中的一个或多个
STATUS_REQUEST_CONTENT_TOO_LARGE
public static const STATUS_REQUEST_CONTENT_TOO_LARGE = 413
请求提交的实体数据大小超过了服务器愿意或者能够处理的范围
STATUS_REQUEST_URI_TOO_LONG
public static const STATUS_REQUEST_URI_TOO_LONG = 414
请求的 URI 长度超过了服务器能够解释的长度
STATUS_UNSUPPORTED_MEDIA_TYPE
public static const STATUS_UNSUPPORTED_MEDIA_TYPE = 415
服务器无法处理请求附带的媒体格式,对于当前请求的函数和所请求的资源,请求中提 交的实体并不是服务器中所支持的格式
STATUS_REQUESTED_RANGE_NOT_SATISFIABLE
public static const STATUS_REQUESTED_RANGE_NOT_SATISFIABLE = 416
客户端请求的范围无效 请求中包含了 Range 请求头,并且 Range 中指定的任何数据范围都与当前资源的可 用范围不重合同时请求中又没有定义 If-Range 请求头
STATUS_EXPECTATION_FAILED
public static const STATUS_EXPECTATION_FAILED = 417
服务器无法满足 Expect 的请求头信息
STATUS_TEAPOT
public static const STATUS_TEAPOT = 418
服务端无法处理请求,一个愚弄客户端的状态码,被称为“我是茶壶”错误码,不应被认真对待
STATUS_MISDIRECTED_REQUEST
public static const STATUS_MISDIRECTED_REQUEST = 421
请求被指向到无法生成响应的服务器
STATUS_UNPROCESSABLE_ENTITY
public static const STATUS_UNPROCESSABLE_ENTITY = 422
请求格式正确,但是由于含有语义错误,无法响应
STATUS_LOCKED
public static const STATUS_LOCKED = 423
当前资源被锁定
STATUS_FAILED_DEPENDENCY
public static const STATUS_FAILED_DEPENDENCY = 424
由于之前的某个请求发生的错误,导致当前请求失败
STATUS_TOO_EARLY
public static const STATUS_TOO_EARLY = 425
服务器不愿意冒风险来处理该请求
STATUS_UPGRADE_REQUIRED
public static const STATUS_UPGRADE_REQUIRED = 426
客户端应当切换到 TLS/1.0
STATUS_PRECONDITION_REQUIRED
public static const STATUS_PRECONDITION_REQUIRED = 428
客户端发送 HTTP 请求时,必须要满足的一些预设条件
STATUS_TOO_MANY_REQUESTS
public static const STATUS_TOO_MANY_REQUESTS = 429
请求过多
STATUS_REQUEST_HEADER_FIELDS_TOO_LARGE
public static const STATUS_REQUEST_HEADER_FIELDS_TOO_LARGE = 431
请求头字段太大
STATUS_UNAVAILABLE_FOR_LEGAL_REASONS
public static const STATUS_UNAVAILABLE_FOR_LEGAL_REASONS = 451
该请求因法律原因不可用
STATUS_INTERNAL_SERVER_ERROR
public static const STATUS_INTERNAL_SERVER_ERROR = 500
服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理
STATUS_NOT_IMPLEMENTED
public static const STATUS_NOT_IMPLEMENTED = 501
服务器不支持当前请求所需要的某个功能
STATUS_BAD_GATEWAY
public static const STATUS_BAD_GATEWAY = 502
作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应
STATUS_SERVICE_UNAVAILABLE
public static const STATUS_SERVICE_UNAVAILABLE = 503
临时的服务器维护或者过载
STATUS_GATEWAY_TIMEOUT
public static const STATUS_GATEWAY_TIMEOUT = 504
从上游服务器(URI 标识出的服务器,例如 HTTP、FTP、LDAP)或者辅助服务 器(例如 DNS)收到响应超时
STATUS_HTTP_VERSION_NOT_SUPPORTED
public static const STATUS_HTTP_VERSION_NOT_SUPPORTED = 505
服务器不支持,或者拒绝支持在请求中使用的 HTTP 版本
STATUS_VARIANT_ALSO_NEGOTIATES
public static const STATUS_VARIANT_ALSO_NEGOTIATES = 506
服务器存在内部配置错误
STATUS_INSUFFICIENT_STORAGE
public static const STATUS_INSUFFICIENT_STORAGE = 507
服务器无法存储完成请求所必须的内容
STATUS_LOOP_DETECTED
public static const STATUS_LOOP_DETECTED = 508
服务器在处理请求时检测到无限递归
STATUS_NOT_EXTENDED
public static const STATUS_NOT_EXTENDED = 510
获取资源所需要的策略并没有被满足
STATUS_NETWORK_AUTHENTICATION_REQUIRED
public static const STATUS_NETWORK_AUTHENTICATION_REQUIRED = 511
要求网络认证
class HttpResponseWriter
public class HttpResponseWriter {
public HttpResponseWriter(let ctx: HttpContext)
}
HTTP response消息体 Writer,支持用户控制消息体的发送过程。
第一次调用 write 函数时,将立即发送 header 和通过参数传入的 body,此后每次调用 write,发送通过参数传入的 body。 对于 HTTP/1.1,如果设置了 transfer-encoding: chunked,用户每调用一次 write,将发送一个 chunk。 对于 HTTP/2,用户每调用一次 write,将把指定数据封装并发出。
HttpResponseWriter
public HttpResponseWriter(let ctx: HttpContext)
功能:构造一个 HttpResponseWriter 实例
func write
public func write(buf: Array<Byte>): Unit
功能:发送 buf 中数据到客户端。以下情况调用该函数将会抛出 HttpException 若服务端不进行捕捉将返回状态码为500的响应连接升级为 WebSocket ,或连接关闭response 协议版本为 HTTP/1.0若请求方法为 "HEAD" 或响应状态码为 "1XX\204\304"。
class HttpResponsePusher
public class HttpResponsePusher
HTTP/2 服务器推送。
如果服务器收到请求后,认为客户端后续还需要某些关联资源,可以将其提前推送到客户端。 服务端推送包括推送请求和推送响应。 启用服务端推送需要先调用 push 函数发送推送请求,并向服务器注册该请求对应的 handler,用以生成推送响应。 客户端可设置拒绝服务端推送。 不允许嵌套推送,即不允许在推送请求对应的 handler 中再次推送。这种情况下,服务端将不执行推送,并打印日志进行提示。
func getPusher
public static func getPusher(ctx: HttpContext): ?HttpResponsePusher
功能:获取 HttpResponsePusher 实例,如果客户端拒绝推送,将返回 None。
返回值:获得的 HttpResponsePusher
func push
public func push(path: String, method: String, header: HttpHeaders): Unit
功能:向客户端发送推送请求,path 为请求地址,method 为请求方法,header 为请求头。
struct TransportConfig
public struct TransportConfig
传输层配置,对应服务器调用serve()之后的建立连接传输层配置。
prop readTimeout
public mut prop readTimeout: Duration
功能:设定和读取传输层 socket 的读取时间,如果设置的时间小于 0 将置为 0,默认值为 Duration.Max。
prop writeTimeout
public mut prop writeTimeout: Duration
功能:设定和读取传输层 socket 的写入时间,如果设置的时间为负将置为 0,默认值为 Duration.Max。
prop writeBufferSize
public mut prop writeBufferSize: ?Int64
功能:设定和读取传输层 socket 的写缓冲区大小,默认值为 None ,若设置的值小于 0,将在服务器进行服务建立连接后抛出 IllegalArgumentException。
prop readBufferSize
public mut prop readBufferSize: ?Int64
功能:设定和读取传输层 socket 的读缓冲区大小,默认值为 None ,若设置的值小于 0,将在服务器进行服务建立连接后抛出 IllegalArgumentException。
prop keepAliveConfig
public mut prop keepAliveConfig: SocketKeepAliveConfig
功能:设定和读取传输层 socket 的消息保活配置,默认配置空闲时间为 45s,发送探测报文的时间间隔为 5s,在连接被认为无效之前发送的探测报文数 5 次,实际时间粒度可能因操作系统而异。
class Cookie
public class Cookie
HTTP 本身是无状态的,server 为了知道 client 的状态,提供个性化的服务,便可以通过 Cookie 来维护一个有状态的会话。
用户首次访问某站点时,server 通过 Set-Cookie header 将 name/value 对,以及 attribute-value 传给用户代理;用户代理随后的对该站点的请求中便可以将 name/value 包含进 Cookie header 中传给 server。
Cookie 类提供了构建 Cookie 对象,并将 Cookie 对象转成 Set-Cookie header 值的函数,提供了获取 Cookie 对象各属性值的函数。
Cookie 的各个属性的要求和作用见 RFC 6265。
prop cookieName
public prop cookieName: String
功能:获取 Cookie 对象的 cookie-name 值。
注意:cookie-name,cookie-value,expires-av 等名字采用 RFC 6265 中的名字,详情请见协议。
prop cookieValue
public prop cookieValue: String
功能:获取 Cookie 对象的 cookie-value 值。
prop expires
public prop expires: ?DateTime
功能:获取 Cookie 对象的 expires-av 值。
prop maxAge
public prop maxAge: ?Int64
功能:获取 Cookie 对象的 max-age-av 值。
prop domain
public prop domain: String
功能:获取 Cookie 对象的 domain-av 值。
prop path
public prop path: String
功能:获取 Cookie 对象的 path-av 值。
prop secure
public prop secure: Bool
功能:获取 Cookie 对象的 secure-av 值。
prop httpOnly
public prop httpOnly: Bool
功能:获取 Cookie 对象的 httpOnly-av 值。
prop others
public prop others: ArrayList<String>
功能:获取未被解析的属性。
func toSetCookieString
public func toSetCookieString(): String
功能:提供将 Cookie 转成字符串形式的函数,方便 server 设置 Set-Cookie header说明:服务器设置 Set-Cookie header 时,可以先创建一个 Cookie 对象,再对其调用该函数获得 Set-Cookie value,将 Set-Cookie value 设置为 Set-Cookie header 的值并发送给客户端注意:
- Cookie 各属性(包含 name,value)在对象创建时就被检查了,因此对 Cookie 对象调用 toSetCookieString 函数不会产生异常
- Cookie 必需的属性是 cookie-pair 即 cookie-name "=" cookie-value,cookie-value 可以为空字符串,toSetCookieString 函数只会将设置过的属性写入字符串,即只有 "cookie-name=" 是必有的,其余部分是否存在取决于是否设置。
返回值:字符串对象,用于设置 Set-Cookie header
init
public init(name: String, value: String, expires!: ?DateTime = None, maxAge!: ?Int64 = None,
domain!: String = "", path!: String = "", secure!: Bool = false, httpOnly!: Bool = false)
功能:提供 Cookie 对象的公开构造器说明:该构造器会检查传入的各项属性是否满足协议要求,如果不满足则会产生 IllegalArgumentException。 具体要求见 RFC 6265 4.1.1.
注意:Cookie 各属性中只有 cookie-name,cookie-value 是必需的,必须传入 name,value 参数,但 value 参数可以传入空字符串。
参数:
- name:cookie-name 属性
name = token
token = 1*tchar
tchar = "!" / "#" / "$" / "%" / "&" / "'" / "*"
/ "+" / "-" / "." / "^" / "_" / "`" / "|" / "~"
/ DIGIT / ALPHA
- value:cookie-value 属性
value = *cookie-octet / ( DQUOTE *cookie-octet DQUOTE )
cookie-octet = %x21 / %x23-2B / %x2D-3A / %x3C-5B / %x5D-7E
; US-ASCII characters excluding CTLs,
; whitespace DQUOTE, comma, semicolon,
; and backslash
- expires:设置 Cookie 的过期时间,默认为 None,时间必须在 1601 年之后
- maxAge:Cookie 的最大生命周期,默认为 None,如果 Cookie 既有 expires 属性,也有 maxAge,则表示该 Cookie 只维护到会话结束(维护到 Client 关闭之前,Client 关闭之后设置了过期的 Cookie 也不再维护)
max-age-av = "Max-Age=" non-zero-digit *DIGIT
non-zero-digit = %x31-39
; digits 1 through 9
DIGIT = %x30-39
; digits 0 through 9
- domain:默认为空字符串,表示该收到该 Cookie 的客户端只会发送该 Cookie 给原始服务器。如果设置了合法的 domain,则收到该 Cookie 的客户端只会发送该 Cookie 给所有该 domain 的子域(且满足其他属性条件要求才会发)
domain = <subdomain> | " "
<subdomain> ::= <label> | <subdomain> "." <label>
<label> ::= <letter> [ [ <ldh-str> ] <let-dig> ]
<ldh-str> ::= <let-dig-hyp> | <let-dig-hyp> <ldh-str>
<let-dig-hyp> ::= <let-dig> | "-"
<let-dig> ::= <letter> | <digit>
<letter> ::= any one of the 52 alphabetic characters A through Z in upper case and a through z in lower case
<digit> ::= any one of the ten digits 0 through 9
RFC 1035 2.3.1.
而 RFC 1123 2.1. 放松了对 label 首字符必须是 letter 的限制
因此,对 domain 的要求为:
1、总长度小于等于 255,由若干个 label 组成
2、label 与 label 之间通过 "." 分隔,每个 label 长度小于等于 63
3、label 的开头和结尾必须是数字或者字母,label 的中间字符必须是数字、字母或者 "-"
- path:默认为空字符串,客户端会根据 url 计算出默认的 path 属性,见 RFC 6265 5.1.4. 收到该 Cookie 的客户端只会发送该 Cookie 给所有该 path 的子目录(且满足其他属性条件要求才会发)
path = <any CHAR except CTLs or ";">
CHAR = <any [USASCII] character>
CTLs = <controls>
- secure:默认为 false,如果设置为 true,该 Cookie 只会在安全协议请求中发送
- httpOnly:默认为 false,如果设置为 true,该 Cookie 只会在 HTTP 协议请求中发送
返回值:构造的 Cookie 对象
异常:
- IllegalArgumentException:传入的参数不符合协议要求
interface CookieJar
public interface CookieJar {
prop rejectPublicSuffixes: ArrayList<String>
prop isHttp: Bool
func storeCookies(url: URL, cookies: ArrayList<Cookie>): Unit
func getCookies(url: URL): ArrayList<Cookie>
func removeCookies(domain: String): Unit
func clear(): Unit
static func toCookieString(cookies: ArrayList<Cookie>): String
static func parseSetCookieHeader(response: HttpResponse): ArrayList<Cookie>
static func createDefaultCookieJar(rejectPublicSuffixes: ArrayList<String>, isHttp: Bool): CookieJar
}
CookieJar 是 Client 用来管理 Cookie 的工具,其有两个静态函数,toCookieString 用于将 ArrayList<Cookie> 转成字符串以便设置请求的 Cookie header;
parseSetCookieHeader 用于解析收到 response 中的 Set-Cookie header;如果 Client 配置了 CookieJar,那么 Cookie 的解析收发都是自动的;
用户可以实现自己的 CookieJar,实现自己的管理逻辑。
createDefaultCookieJar 函数返回一个默认的 CookieJar 实例。
CookieJar 的管理要求见 RFC 6265。
prop rejectPublicSuffixes
prop rejectPublicSuffixes: ArrayList<String>
功能:获取 public suffixes 配置,该配置是一个 domain 黑名单,会拒绝 domain 值为 public suffixes 的 Cookie (除非该 Cookie 来自于与 domain 相同的 host) public suffixes 见 https://publicsuffix.org/
prop isHttp
prop isHttp: Bool
功能:该 CookieJar 是否用于 HTTP 协议 isHttp 为 true 则只会存储来自于 HTTP 协议的 Cookie isHttp 为 false 则只会存储来自非 HTTP 协议的 Cookie,且不会存储发送设置了 httpOnly 的 Cookie
func storeCookies
func storeCookies(url: URL, cookies: ArrayList<Cookie>): Unit
功能:将 ArrayList<Cookie> 存进 CookieJar
说明:默认实现的 cookieJarImpl 中的 Cookie 是以 CookieEntry (包访问权限) 对象的形式存进 CookieJar 中的,具体要求见 RFC 6265 5.3.,如果往 CookieJar 中存 Cookie 时超过了上限(3000 条),那么至少清除 CookieJar 中 1000 条 Cookie 再往里存清除 CookieJar 中 Cookie 的优先级见 RFC 6265 5.3.12.
- 过期的 Cookie
- 相同 domain 中超过 50 条以上的部分
- 所有 Cookie具有相同优先级的 Cookie 则优先删除 last-access 属性更早的。
参数:
- url:产生该 Cookie 的 url
- cookies:需要存储的
ArrayList<Cookie>
func getCookies
func getCookies(url: URL): ArrayList<Cookie>
功能:从 CookieJar 中取出 ArrayList<Cookie>
说明:默认实现 cookieJarImpl 的取 ArrayList<Cookie> 函数的具体要求见 RFC 6265 5.4.,对取出的 ArrayList<Cookie> 调用 toCookieString 可以将取出的 ArrayList<Cookie> 转成 Cookie header 的 value 字符串。
参数:
- url:所要取出
ArrayList<Cookie>的 url
返回值:CookieJar 中存储的对应此 url 的 ArrayList<Cookie>
func removeCookies
func removeCookies(domain: String): Unit
功能:从 CookieJar 中移除某个 domain 的 Cookie说明:默认实现 CookieJarImpl 的移除某个 domain 的 Cookie 只会移除特定 domain 的 Cookie,domain 的 subdomain 的 Cookie 并不会移除。
参数:
- domain:所要移除 Cookie 的域名
异常:
- IllegalArgumentException:如果传入的 domain 为空字符串或者非法,则抛出该异常,合法的 domain 规则见 Cookie 的参数文档
func clear
func clear(): Unit
功能:清除全部 Cookie说明:默认实现 CookieJarImpl 会清除 CookieJar 中的所有 Cookie。
func toCookieString
static func toCookieString(cookies: ArrayList<Cookie>): String
功能:静态函数,将 ArrayList<Cookie> 转成字符串,用于 Cookie header说明:该函数会将传入的 ArrayList<Cookie> 数组转成协议规定的 Cookie header 的字符串形式,见 RFC 6265 5.4.4.。
参数:
- cookies:所需转成 Cookie header 字符串的
ArrayList<Cookie>
返回值:用于 Cookie header 的字符串
func parseSetCookieHeader
static func parseSetCookieHeader(response: HttpResponse): ArrayList<Cookie>
功能:静态函数,解析 response 中的 Set-Cookie header说明:该函数解析 response 中的 Set-Cookie header,并返回解析出的 ArrayList<Cookie>,解析 Set-Cookie header 的具体规则见 RFC 6265 5.2.。
参数:
- response:所需要解析的 response
返回值:从 response 中解析出的 ArrayList<Cookie> 数组
func createDefaultCookieJar
static func createDefaultCookieJar(rejectPublicSuffixes: ArrayList<String>, isHttp: Bool): CookieJar
功能:静态函数,构建默认的管理 Cookie 的 CookieJar 实例说明:默认的 CookieJar 的管理要求参考 RFC 6265 5.3.isHttp 为 false 则只会存储来自非 HTTP 协议的 Cookie,且不会存储发送设置了 httpOnly 的 Cookie。
参数:
- rejectPublicSuffixes:用户配置的 public suffixes,Cookie 管理为了安全会拒绝 domain 值为 public suffixes 的 cookie(除非该 Cookie 来自于与 domain 相同的 host),public suffixes 见 https://publicsuffix.org/
- isHttp:该 CookieJar 是否用于 HTTP 协议,isHttp 为 true 则只会存储来自于 HTTP 协议的 Cookie;
返回值:默认的 CookieJar 实例
class HttpException
public class HttpException <: Exception
Http 的异常类。
class HttpTimeoutException
public class HttpTimeoutException <: Exception
class HttpStatusException
public class HttpStatusException <: Exception
class WebSocketException
public class WebSocketException <: Exception
class ConnectionException
public class ConnectionException <: Exception {
public init(message: String)
}
init
public init(message: String)
参数:
- message:异常提示信息
异常:
- 类初始化函数
class CoroutinePoolRejectException
public class CoroutinePoolRejectException <: Exception {
public init(message: String)
}
init
public init(message: String)
参数:
- message:异常提示信息
异常:
- 异常类初始化函数
示例
server
Hello 仓颉
from net import http.ServerBuilder
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
// 2. 注册 HttpRequestHandler
server.distributor.register("/index", {httpContext =>
httpContext.responseBuilder.body("Hello 仓颉!")
})
// 3. 启动服务
server.serve()
}
通过 request distributor注册处理器
from net import http.{ServerBuilder, HttpRequestHandler, FuncHandler}
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
var a: HttpRequestHandler = FuncHandler({ httpContext =>
httpContext.responseBuilder.body("index")
})
var b: HttpRequestHandler = FuncHandler({ httpContext =>
httpContext.responseBuilder.body("id")
})
var c: HttpRequestHandler = FuncHandler({ httpContext =>
httpContext.responseBuilder.body("help")
})
server.distributor.register("/index", a)
server.distributor.register("/id", b)
server.distributor.register("/help", c)
// 2. 启动服务
server.serve()
}
自定义 request distributor与处理器
from net import http.*
from std import collection.HashMap
class NaiveDistributor <: HttpRequestDistributor {
let map = HashMap<String, HttpRequestHandler>()
public func register(path: String, handler: HttpRequestHandler): Unit {
map.put(path, handler)
}
public func distribute(path: String): HttpRequestHandler {
if (path == "/index") {
return PageHandler()
}
return NotFoundHandler()
}
}
// 返回一个简单的 HTML 页面
class PageHandler <: HttpRequestHandler {
public func handle(httpContext: HttpContext): Unit {
httpContext.responseBuilder.body(b"<html></html>")
}
}
class NotFoundHandler <: HttpRequestHandler {
public func handle(httpContext: HttpContext): Unit {
httpContext.responseBuilder
.status(404)
.body(b"404 Not Found")
}
}
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.distributor(NaiveDistributor()) // 自定义分发器
.build()
// 2. 启动服务
server.serve()
}
自定义 server 网络配置
from std import fs.*
from net import tls.*
from crypto import x509.{X509Certificate, PrivateKey}
from net import http.*
//该程序需要用户配置存在且合法的文件路径才能执行
main () {
// 1. 自定义配置
// tcp 配置
var transportCfg = TransportConfig()
transportCfg.readBufferSize = 8192
// tls 配置 需要传入配套的证书与私钥文件路径
let pem0 = String.fromUtf8(File("/certPath", OpenOption.Open(true, false)).readToEnd())
let pem02 = String.fromUtf8(File("/keyPath", OpenOption.Open(true, false)).readToEnd())
var tlsConfig = TlsServerConfig(X509Certificate.decodeFromPem(pem0), PrivateKey.decodeFromPem(pem02))
tlsConfig.supportedAlpnProtocols = ["h2"]
// 2. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.transportConfig(transportCfg)
.tlsConfig(tlsConfig)
.headerTableSize(10 * 1024)
.maxRequestHeaderSize(1024 * 1024)
.build()
// 3. 注册 HttpRequestHandler
server.distributor.register("/index", {httpContext =>
httpContext.responseBuilder.body("Hello 仓颉!")
})
// 4. 启动服务
server.serve()
}
response中的 chunked与trailer
from net import http.*
from std import io.*
from std import collection.HashMap
func checksum(chunk: Array<UInt8>): Int64 {
var sum = 0
for (i in chunk) {
if (i == b'\n') {
sum += 1
}
}
return sum / 2
}
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
// 2. 注册 HttpRequestHandler
server.distributor.register("/index", {httpContext =>
let responseBuilder = httpContext.responseBuilder
responseBuilder.header("transfer-encoding", "chunked") // 设置response头
responseBuilder.header("trailer", "checkSum")
let writer = HttpResponseWriter(httpContext)
var sum = 0
for (_ in 0..10) {
let chunk = Array<UInt8>(10, item: 0)
sum += checksum(chunk)
writer.write(chunk) // 立即发送
}
responseBuilder.trailer("checkSum", "${sum}") // handler结束后发送
})
// 3. 启动服务
server.serve()
}
处理重定向 request
from net import http.*
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
// 2. 注册 HttpRequestHandler
server.distributor.register("/redirecta",RedirectHandler("/movedsource", 308))
server.distributor.register("/redirectb",RedirectHandler("http://www.example.com", 308))
// 3. 启动服务
server.serve()
}
tls 证书热加载
from std import fs.*
from net import tls.*
from crypto import x509.{X509Certificate, PrivateKey}
from net import http.*
//该程序需要用户配置存在且合法的文件路径才能执行
main() {
// 1. tls 配置
let pem0 = String.fromUtf8(File("/certPath", OpenOption.Open(true, false)).readToEnd())
let pem02 = String.fromUtf8(File("/keyPath", OpenOption.Open(true, false)).readToEnd())
var tlsConfig = TlsServerConfig(X509Certificate.decodeFromPem(pem0), PrivateKey.decodeFromPem(pem02))
tlsConfig.supportedAlpnProtocols = ["http/1.1"]
let pem = String.fromUtf8(File("/rootCerPath", OpenOption.Open(true, false)).readToEnd())
tlsConfig.verifyMode = CustomCA(X509Certificate.decodeFromPem(pem))
// 2. 构建 Server 实例,并启动服务
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.tlsConfig(tlsConfig)
.build()
spawn {
server.serve()
}
// 3. 更新 tls 证书和私钥,之后收到的 request将使用新的证书和私钥
server.updateCert("/newCerPath", "/newKeyPath")
// 4. 更新 CA, 双向认证时使用,之后收到的 request将使用新的CA
server.updateCA("/newRootCerPath")
}
client
Hello World
from net import http.*
main () {
// 1. 构建 client 实例
let client = ClientBuilder().build()
// 2. 发送 request
let rsp = client.get("http://example.com/hello")
// 3. 读取response
println(rsp)
// 4. 关闭连接
client.close()
}
自定义 client 网络配置
from std import socket.TcpSocket
from std import convert.Parsable
from std import fs.*
from net import tls.*
from crypto import x509.X509Certificate
from net import http.*
//该程序需要用户配置存在且合法的文件路径才能执行
main () {
// 1. 自定义配置
// tls 配置
var tlsConfig = TlsClientConfig()
let pem = String.fromUtf8(File("/rootCerPath", OpenOption.Open(true, false)).readToEnd())
tlsConfig.verifyMode = CustomCA(X509Certificate.decodeFromPem(pem))
tlsConfig.alpnProtocolsList = ["h2"]
// connector
let TcpSocketConnector = { authority: String =>
let words = authority.split(":")
let addr = words[0]
let port = UInt16.parse(words[1])
let socket = TcpSocket(addr, port)
socket.connect()
return socket
}
// 2. 构建 client 实例
let client = ClientBuilder()
.tlsConfig(tlsConfig)
.enablePush(false)
.connector(TcpSocketConnector)
.build()
// 3. 发送 request
let rsp = client.get("https://example.com/hello")
// 4. 读取response
let buf = Array<UInt8>(1024, item: 0)
let len = rsp.body.read(buf)
println(String.fromUtf8(buf.slice(0, len)))
// 5. 关闭连接
client.close()
}
request中的 chunked 与 trailer
from std import io.*
from std import fs.*
from net import http.*
func checksum(chunk: Array<UInt8>): Int64 {
var sum = 0
for (i in chunk) {
if (i == b'\n') {
sum += 1
}
}
return sum / 2
}
//该程序需要用户配置存在且合法的文件路径才能执行
main () {
// 1. 构建 client 实例
let client = ClientBuilder().build()
var requestBuilder = HttpRequestBuilder()
let file = File("./res.jpg", OpenOption.Open(true, false))
let sum = checksum(file.readToEnd())
let req = requestBuilder
.method("PUT")
.url("https://example.com/src/")
.header("Transfer-Encoding","chunked")
.header("Trailer","checksum")
.body(FileBody("./res.jpg"))
.trailer("checksum", sum.toString())
.build()
let rsp = client.send(req)
println(rsp)
client.close()
}
class FileBody <: InputStream {
var file: File
init(path: String) { file = File(path, OpenOption.Open(true, false))}
public func read(buf: Array<UInt8>): Int64 {
file.read(buf)
}
}
配置代理
from net import http.*
main () {
// 1. 构建 client 实例
let client = ClientBuilder()
.httpProxy("http://192.168.0.1:8080")
.build()
// 2. 发送 request,所有 request都会被发送至192.168.0.1地址的8080端口,而不是example.com
let rsp = client.get("http://example.com/hello")
// 3. 读取response
println(rsp)
// 4. 关闭连接
client.close()
}
cookie
Client
from net import http.*
from encoding import url.*
from std import socket.*
from std import time.*
from std import sync.*
main() {
// 1、启动socket服务器
let serverSocket = TcpServerSocket(bindAt: 0)
serverSocket.bind()
let fut = spawn {
serverPacketCapture(serverSocket)
}
sleep(Duration.millisecond * 10)
// 客户端一般从 response 中的 Set-Cookie header 中读取 cookie,并将其存入 cookieJar 中,
// 下次发起 request时,将其放在 request 的 Cookie header 中发送
// 2、启动客户端
let client = ClientBuilder().build()
let port = serverSocket.localAddress.port
var u = URL.parse("http://127.0.0.1:${port}/a/b/c")
var r = HttpRequestBuilder()
.url(u)
.build()
// 3、发送request
client.send(r)
sleep(Duration.second * 2)
r = HttpRequestBuilder()
.url(u)
.build()
// 4、发送新 request,从 CookieJar 中取出 cookie,并转成 Cookie header 中的值
// 此时 cookie 2=2 已经过期,因此只发送 1=1 cookie
client.send(r)
// 5、关闭客户端
client.close()
fut.get()
serverSocket.close()
}
func serverPacketCapture(serverSocket: TcpServerSocket) {
let buf = Array<UInt8>(500, item: 0)
let server = serverSocket.accept()
var i = server.read(buf)
println(String.fromUtf8(buf[..i]))
// GET /a/b/c HTTP/1.1
// host: 127.0.0.1:44649
// user-agent: CANGJIEUSERAGENT_1_1
// connection: keep-alive
// content-length: 0
//
// 过期时间为 4 秒的 cookie1
let cookie1 = Cookie("1", "1", maxAge: 4, domain: "127.0.0.1", path: "/a/b/")
let setCookie1 = cookie1.toSetCookieString()
// 过期时间为 2 秒的 cookie2
let cookie2 = Cookie("2", "2", maxAge: 2, path: "/a/")
let setCookie2 = cookie2.toSetCookieString()
// 服务器发送 Set-Cookie 头,客户端解析并将其存进 CookieJar 中
server.write("HTTP/1.1 204 ok\r\nSet-Cookie: ${setCookie1}\r\nSet-Cookie: ${setCookie2}\r\nConnection: close\r\n\r\n".toArray())
let server2 = serverSocket.accept()
i = server2.read(buf)
// 接收客户端的带 cookie 的请求
println(String.fromUtf8(buf[..i]))
// GET /a/b/c HTTP/1.1
// host: 127.0.0.1:34857
// cookie: 1=1
// user-agent: CANGJIEUSERAGENT_1_1
// connection: keep-alive
// content-length: 0
//
server2.write("HTTP/1.1 204 ok\r\nConnection: close\r\n\r\n".toArray())
server2.close()
}
Server
from net import http.*
main () {
// 服务器设置 cookie 时将 cookie 放在 Set-Cookie header 中发给客户端
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
// 2. 注册 HttpRequestHandler
server.distributor.register("/index", {httpContext =>
let cookie = Cookie("name", "value")
httpContext.responseBuilder.header("Set-Cookie", cookie.toSetCookieString()).body("Hello 仓颉!")
})
// 3. 启动服务
server.serve()
}
server push
仅用于 HTTP/2
client:
from std import fs.*
from std import collection.ArrayList
from net import tls.*
from crypto import x509.X509Certificate
from net import http.*
//该程序需要用户配置存在且合法的文件路径才能执行
// client:
main() {
// 1. tls 配置
var tlsConfig = TlsClientConfig()
let pem = String.fromUtf8(File("/rootCerPath", OpenOption.Open(true, false)).readToEnd())
tlsConfig.verifyMode = CustomCA(X509Certificate.decodeFromPem(pem))
tlsConfig.alpnProtocolsList = ["h2"]
// 2. 构建 Client 实例
let client = ClientBuilder()
.tlsConfig(tlsConfig)
.build()
// 3. 发送 request,收response
let response = client.get("https://example.com/index.html")
// 4. 收 pushResponse,此例中相当于 client.get("http://example.com/picture.png") 的response
let pushResponses: Option<ArrayList<HttpResponse>> = response.getPush()
client.close()
}
server:
from std import fs.*
from net import tls.*
from crypto import x509.{X509Certificate, PrivateKey}
from net import http.*
//该程序需要用户配置存在且合法的文件路径才能执行
main() {
// 1. tls 配置
let pem0 = String.fromUtf8(File("/certPath", OpenOption.Open(true, false)).readToEnd())
let pem02 = String.fromUtf8(File("/keyPath", OpenOption.Open(true, false)).readToEnd())
var tlsConfig = TlsServerConfig(X509Certificate.decodeFromPem(pem0), PrivateKey.decodeFromPem(pem02))
tlsConfig.supportedAlpnProtocols = ["h2"]
// 2. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.tlsConfig(tlsConfig)
.build()
// 3. 注册原 request 的 handler
server.distributor.register("/index.html", {httpContext =>
let pusher = HttpResponsePusher.getPusher(httpContext)
match (pusher) {
case Some(pusher) =>
pusher.push("/picture.png", "GET", httpContext.request.headers)
case None =>
()
}
})
// 4. 注册 pushRequest 的 handler
server.distributor.register("/picture.png", {httpContext =>
httpContext.responseBuilder.body(b"picture.png")
})
// 4. 启动服务
server.serve()
}
webSocket
from net import http.*
from encoding import url.*
from std import time.*
from std import sync.*
from std import collection.*
from std import log.*
let server = ServerBuilder()
.addr("127.0.0.1")
.port(0)
.build()
// client:
main() {
// 1 启动服务器
spawn { startServer() }
sleep(Duration.millisecond * 200)
let client = ClientBuilder().build()
let u = URL.parse("ws://127.0.0.1:${server.port}/webSocket")
let subProtocol = ArrayList<String>(["foo1", "bar1"])
let headers = HttpHeaders()
headers.add("test", "echo")
// 2 完成 WebSocket 握手,获取 WebSocket 实例
let websocket: WebSocket
let respHeaders: HttpHeaders
(websocket, respHeaders) = WebSocket.upgradeFromClient(client, u, subProtocols: subProtocol, headers: headers)
client.close()
println("subProtocol: ${websocket.subProtocol}") // fool1
println(respHeaders.getFirst("rsp") ?? "") // echo
// 3 消息收发
// 发送 hello
websocket.write(TextWebFrame, b"hello")
// 收
let data = ArrayList<UInt8>()
var frame = websocket.read()
while(true) {
match(frame.frameType) {
case ContinuationWebFrame =>
data.appendAll(frame.payload)
if (frame.fin) {
break
}
case TextWebFrame | BinaryWebFrame =>
if (!data.isEmpty()) {
throw Exception("invalid frame")
}
data.appendAll(frame.payload)
if (frame.fin) {
break
}
case CloseWebFrame =>
websocket.write(CloseWebFrame, frame.payload)
break
case PingWebFrame =>
websocket.writePongFrame(frame.payload)
case _ => ()
}
frame = websocket.read()
}
println("data size: ${data.size}") // 4097
println("last item: ${String.fromUtf8(Array(data)[4096])}") // a
// 4 关闭 websocket,
// 收发 CloseFrame
websocket.writeCloseFrame(status: 1000)
let websocketFrame = websocket.read()
println("close frame type: ${websocketFrame.frameType}") // CloseWebFrame
println("close frame payload: ${websocketFrame.payload}") // 3, 232
// 关闭底层连接
websocket.closeConn()
server.close()
}
func startServer() {
// 1 注册 handler
server.distributor.register("/webSocket", handler1)
server.logger.level = OFF
server.serve()
}
// server:
func handler1(ctx: HttpContext): Unit {
// 2 完成 websocket 握手,获取 websocket 实例
let websocketServer = WebSocket.upgradeFromServer(ctx, subProtocols: ArrayList<String>(["foo", "bar", "foo1"]),
userFunc: {request: HttpRequest =>
let value = request.headers.getFirst("test") ?? ""
let headers = HttpHeaders()
headers.add("rsp", value)
headers
})
// 3 消息收发
// 收 hello
let data = ArrayList<UInt8>()
var frame = websocketServer.read()
while(true) {
match(frame.frameType) {
case ContinuationWebFrame =>
data.appendAll(frame.payload)
if (frame.fin) {
break
}
case TextWebFrame | BinaryWebFrame =>
if (!data.isEmpty()) {
throw Exception("invalid frame")
}
data.appendAll(frame.payload)
if (frame.fin) {
break
}
case CloseWebFrame =>
websocketServer.write(CloseWebFrame, frame.payload)
break
case PingWebFrame =>
websocketServer.writePongFrame(frame.payload)
case _ => ()
}
frame = websocketServer.read()
}
println("data: ${String.fromUtf8(Array(data))}") // hello
// 发 4097 个 a
websocketServer.write(TextWebFrame, Array<UInt8>(4097, item: 97))
// 4 关闭 websocket,
// 收发 CloseFrame
let websocketFrame = websocketServer.read()
println("close frame type: ${websocketFrame.frameType}") // CloseWebFrame
println("close frame payload: ${websocketFrame.payload}") // 3, 232
websocketServer.write(CloseWebFrame, websocketFrame.payload)
// 关闭底层连接
websocketServer.closeConn()
}
运行结果如下:
subProtocol: foo1
echo
data: hello
data size: 4097
last item: a
close frame type: CloseWebFrame
close frame payload: [3, 232]
close frame type: CloseWebFrame
close frame payload: [3, 232]
log
from std import log.*
from net import http.*
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
// 2. 注册 HttpRequestHandler
server.distributor.register("/index", {httpContext =>
httpContext.responseBuilder.body("Hello 仓颉!")
})
// 3. 开启日志
server.logger.level = DEBUG
// client端通过client.logger.level = DEBUG 开启
// 4. 启动服务
server.serve()
}
运行结果如下所示:
2024/01/25 17:23:54.344205 DEBUG Logger [Server#serve] bindAndListen(127.0.0.1, 8080)
http 包
介绍
http 包提供 HTTP/1.1,HTTP/2,WebSocket 协议的 server、client 端实现,关于协议的详细内容可参考 RFC 9110、9112、9113、9218、7541 等。
使用本包需要外部依赖 OpenSSL 3 的 ssl 和 crypto 动态库文件,故使用前需安装相关工具:
- 对于
Linux操作系统,可参考以下方式:- 如果系统的包管理工具支持安装
OpenSSL 3开发工具包,可通过这个方式安装,并确保系统安装目录下含有libssl.so、libssl.so.3、libcrypto.so和libcrypto.so.3这些动态库文件,例如Ubuntu 22.04系统上可使用sudo apt install libssl-dev命令安装libssl-dev工具包; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libssl.so、libssl.so.3、libcrypto.so和libcrypto.so.3这些动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
LD_LIBRARY_PATH以及LIBRARY_PATH中。
- 如果系统的包管理工具支持安装
- 对于
Windows操作系统,可按照以下步骤:- 自行下载
OpenSSL 3.x.x源码编译安装 x64 架构软件包或者自行下载安装第三方预编译的供开发人员使用的OpenSSL 3.x.x软件包; - 确保安装目录下含有
libssl.dll.a(或libssl.lib)、libssl-3-x64.dll、libcrypto.dll.a(或libcrypto.lib)、libcrypto-3-x64.dll这些库文件; - 将
libssl.dll.a(或libssl.lib)、libcrypto.dll.a(或libcrypto.lib) 所在的目录路径设置到环境变量LIBRARY_PATH中,将libssl-3-x64.dll、libcrypto-3-x64.dll所在的目录路径设置到环境变量PATH中。
- 自行下载
- 对于
macOS操作系统,可参考以下方式:- 使用
brew install openssl@3安装,并确保系统安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
DYLD_LIBRARY_PATH以及LIBRARY_PATH中。
- 使用
如果未安装OpenSSL 3软件包或者安装低版本的软件包,程序可能无法使用并抛出相关异常 WebSocketException: Can not load openssl library or function xxx.。
http
用户可以选择 http 协议的版本,如 HTTP/1.1、HTTP/2,http 包的多数 API 并不区分这两种协议版本,只有当用户用到某个版本的特有功能时,才需要做这种区分,如 HTTP/1.1 中的 chunked 的 transfer-encoding,HTTP/2 中的 server push。
http 库默认使用 HTTP/1.1 版本。当开发者需要使用 HTTP/2 协议时,需要为 Client/Server 配置 tls,并且设置 alpn 的值为 h2;不支持 HTTP/1.1 通过 Upgrade: h2c 协议升级的方式升级到 HTTP/2。
如果创建 HTTP/2 连接握手失败,Client/Server 会自动将协议退回 HTTP/1.1。
用户通过 ClientBuilder 构建一个 Client 实例,构建过程可以指定多个参数,如 httpProxy、logger、cookieJar、是否自动 redirect、连接池大小等,详情参见 ClientBuilder。
用户通过 ServerBuilder 构建一个 Server 实例,构建过程可以指定多个参数,如 addr、port、logger、distributor 等,详情参见 ServerBuilder。
用户如果需要自己设置 Logger,需要保证它是线程安全的。
Client、Server 的大多数参数在构建后便不允许修改,如果想要更改,用户需要重新构建一个新的 Client 或 Server 实例;如果该参数支持动态修改,本实现会提供显式的功能,如 Server 端 cert、CA 的热更新。
通过 Client 实例,用户可以发送 http request、接收 http response。
通过 Server 实例,用户可以配置 request 转发处理器,启动 http server。在 server handler 中,用户可以通过 HttpContext 获取 client 发来的 request 的详细信息,构造发送给 client 的 response。 Server 端根据 Client 端请求,创建对应的 ProtocolService 实例,同一个 Server 实例可同时支持两种协议:HTTP/1.1、HTTP/2。
在 client 端,用户通过 HttpRequestBuilder 构造 request,构建过程可以指定多个参数,如 method、url、version、headers、body、trailers 等等;构建之后的request 不允许再进行修改。 在 server 端,用户通过 HttpResponseBuilder 构造 response,构建过程可以指定多个参数,如 status、headers、body、trailers 等等;构建之后的 response 不允许再进行修改。
另外,本实现提供一些工具类,方便用户构造一些常用 response,如 RedirectHandler 构造 redirect response,NotFoundHandler 构造 404 response。
WebSocket
本实现为 WebSocket 提供 sub-protocol 协商,基础的 frame 解码、读取、消息发送、frame 编码、ping、pong、关闭等功能。
用户通过 WebSocket.upgradeFromClient 从一个 HTTP/1.1 或 HTTP/2 Client 实例升级到 WebSocket 协议,之后通过返回的 WebSocket 实例进行 WebSocket 通讯。
用户在一个 server 端的 handler 中,通过 WebSocket.upgradeFromServer 从 HTTP/1.1 或 HTTP/2 协议升级到 WebSocket 协议,之后通过返回的 WebSocket 实例进行 WebSocket 通讯。
按照协议,HTTP/1.1 中,升级后的 WebSocket 连接是建立在 tcp 连接(https 则还会多一层 TLS)之上;HTTP/2 中,升级后的 WebSocket 连接是建立在 HTTP/2 connection 的一个 stream 之上。HTTP/1.1 中,close 最终会直接关闭 tcp 连接;HTTP/2 中,close 只会关闭 connection 上的一个 stream。
主要接口
class ServerBuilder
public class ServerBuilder
提供 Server 实例构建器。 支持通过如下参数构造一个 Http Server:
- 地址、端口;
- 线程安全的 logger;
- HttpRequestDistributor,用于注册 handler、分发 request;
- HTTP/2 的 settings;
- shutdown 回调;
- transport:listener、连接及其配置;
- protocol service:http 协议解析服务;
除地址端口、shutdown 回调外,均提供默认实现,用户在构造 server 过程中可不指定其他构建参数。 ServerBuilder 文档中未明确说明支持版本的配置,在 HTTP/1.1 与 HTTP/2 都会生效
init
public init()
功能:创建 ServerBuilder 实例。
func addr
public func addr(addr: String): ServerBuilder
功能:设置服务端监听地址,若 listener 被设定,此值被忽略。
参数:
- addr:地址值,格式为 IP 或者 域名
返回值:当前 ServerBuilder 的引用
func port
public func port(port: UInt16): ServerBuilder
功能:设置服务端监听端口,若 listener 被设定,此值被忽略。
参数:
- port:端口值
返回值:当前 ServerBuilder 的引用
func listener
public func listener(listener: ServerSocket): ServerBuilder
功能:服务端调用此函数对指定 socket 进行绑定监听。
参数:
- listener:所绑定的socket
返回值:当前 ServerBuilder 的引用
func logger
public func logger(logger: Logger): ServerBuilder
功能:设定服务器的 logger,默认 logger 级别为 INFO,logger 内容将写入 Console.stdout。
参数:
- logger:需要是线程安全的,默认使用内置线程安全 logger
返回值:当前 ServerBuilder 的引用
func distributor
public func distributor(distributor: HttpRequestDistributor): ServerBuilder
功能:设置请求分发器,请求分发器会根据 url 将请求分发给对应的 handler不设置时使用默认请求分发器。
参数:
- distributor:自定义请求分发器实例
返回值:当前 ServerBuilder 的引用
func protocolServiceFactory
public func protocolServiceFactory(factory: ProtocolServiceFactory): ServerBuilder
功能:设置协议服务工厂,服务协议工厂会生成每个协议所需的服务实例,不设置时使用默认工厂。
参数:
- factory:自定义工厂实例
返回值:当前 ServerBuilder 的引用
func transportConfig
public func transportConfig(config: TransportConfig): ServerBuilder
功能:设置传输层配置,默认配置详见 TransportConfig 结构体说明。
参数:
- config:设定的传输层配置信息
返回值:当前 ServerBuilder 的引用
func tlsConfig
public func tlsConfig(config: TlsServerConfig): ServerBuilder
功能:设置 TLS 层配置,默认不对其进行设置。
参数:
- config:设定支持 tls 服务所需要的配置信息
返回值:当前 ServerBuilder 的引用
func readTimeout
public func readTimeout(timeout: Duration): ServerBuilder
功能:设定服务端读取一个请求的最大时长,超过该时长将不再进行读取并关闭连接,默认不进行限制。
参数:
- timeout:设定读请求的超时时间,如果传入时间为负值将被替换为 Duration.Zero
返回值:当前 ServerBuilder 的引用
func writeTimeout
public func writeTimeout(timeout: Duration): ServerBuilder
功能:设定服务端发送一个响应的最大时长,超过该时长将不再进行写入并关闭连接,默认不进行限制。
参数:
- timeout:设定写响应的超时时间,如果传入时间为负值将被替换为 Duration.Zero
返回值:当前 ServerBuilder 的引用
func readHeaderTimeout
public func readHeaderTimeout(timeout: Duration): ServerBuilder
功能:设定服务端读取客户端发送一个请求的请求头最大时长,超过该时长将不再进行读取并关闭连接,默认不进行限制。
参数:
- timeout:设定的读请求头超时时间,如果传入负的 Duration 将被替换为 Duration.Zero
返回值:
- ServerBuilder:当前 ServerBuilder 的引用
func httpKeepAliveTimeout
public func httpKeepAliveTimeout(timeout: Duration): ServerBuilder
功能:HTTP/1.1 专用,设定服务端连接保活时长,该时长内客户端未再次发送请求,服务端将关闭长连接,默认不进行限制。
参数:
- timeout:设定保持长连接的超时时间,如果传入负的 Duration 将被替换为 Duration.Zero
返回值:当前 ServerBuilder 的引用
func maxRequestHeaderSize
public func maxRequestHeaderSize(size: Int64): ServerBuilder
功能:设定服务端允许客户端发送单个请求的请求头部分最大值,请求头部分大小超过该值时,将返回状态码为 431 的响应仅对 HTTP/1.1 生效,HTTP/2 中有专门的配置 maxHeaderListSize,默认值为 8192。
参数:
- size:设定允许接收请求的请求头大小最大值,值为 0 代表不作限制
返回值:当前 ServerBuilder 的引用
异常:
- IllegalArgumentException:size < 0
func maxRequestBodySize
public func maxRequestBodySize(size: Int64): ServerBuilder
功能:设置服务端允许客户端发送单个请求的请求体部分最大值,请求体部分大小超过该值时,将返回状态码为 413 的响应仅对于 HTTP/1.1 且未设置 "Transfer-Encoding: chunked" 的请求生效,默认值为 2M。
参数:
- size:设定允许接收请求的请求体大小最大值,值为 0 代表不作限制
返回值:当前 ServerBuilder 的引用
异常:
- IllegalArgumentException:size < 0
func headerTableSize
public func headerTableSize(size: UInt32): ServerBuilder
功能:HTTP/2 专用,设置本端对响应头编码时使用的压缩表的最大大小,默认值为 4096。
参数:
- size:本端对响应头编码时使用的最大
table size
返回值:当前 ServerBuilder 的引用
func maxConcurrentStreams
public func maxConcurrentStreams(size: UInt32): ServerBuilder
功能:HTTP/2 专用,设置本端同时处理的最大请求数量,限制对端并发发送请求的数量,默认值为 100。
参数:
- size:本端同时处理的最大请求数量
返回值:当前 ServerBuilder 的引用
func initialWindowSize
public func initialWindowSize(size: UInt32): ServerBuilder
功能:HTTP/2 专用,设置本端一个 stream 上接收报文的初始流量窗口大小,默认值为 65535. 取值范围为 0 至 2^31 - 1。
参数:
- size:本端一个 stream 上接收报文的初始流量窗口大小
返回值:当前 ServerBuilder 的引用
func maxFrameSize
public func maxFrameSize(size: UInt32): ServerBuilder
功能:HTTP/2 专用,设置本端接收的一个帧的最大长度,用来限制对端发送帧的长度,默认值为 16384. 取值范围为 2^14 至 2^24 - 1。
参数:
- size:本端接收的一个帧的最大长度
返回值:当前 ServerBuilder 的引用
func maxHeaderListSize
public func maxHeaderListSize(size: UInt32): ServerBuilder
功能:HTTP/2 专用,设置本端接收的报文头最大长度,用来限制对端发送的报文头最大长度。报文头长度计算方法:所有 header field 长度之和(所有 name 长度 + value 长度 + 32,包括自动添加的 HTTP/2 伪头),默认值为 8192。
参数:
- size:本端接收的报文头最大长度
返回值:当前 ServerBuilder 的引用
func enableConnectProtocol
public func enableConnectProtocol(flag: Bool): ServerBuilder
功能:HTTP/2 专用,设置本端是否接收 CONNECT 请求,默认 false。
参数:
- flag:本端是否接收 CONNECT 请求
返回值:当前 ServerBuilder 的引用
func afterBind
public func afterBind(f: ()->Unit): ServerBuilder
功能:注册服务器启动时的回调函数,服务内部 ServerSocket 实例 bind 之后,accept 之前将调用该函数。重复调用将覆盖之前注册的函数。
参数:
- f:回调函数,入参为空,返回值为 Unit 类型
返回值:当前 ServerBuilder 的引用
func onShutdown
public func onShutdown(f: ()->Unit): ServerBuilder
功能:注册服务器关闭时的回调函数,服务器关闭时将调用该回调函数,重复调用将覆盖之前注册的函数。
参数:
- f:回调函数,入参为空,返回值为 Unit 类型
返回值:当前 ServerBuilder 的引用
func servicePoolConfig
public func servicePoolConfig(cfg: ServicePoolConfig): ServerBuilder
功能:服务过程中使用的协程池相关设置,具体说明见 servicePoolConfig 结构体。
参数:
- cfg:协程池相关设置。
返回值:当前 ServerBuilder 的引用
func build
public func build(): Server
功能:构建 Server 实例。
返回值:根据设置的属性生成的 Server 实例
异常:
- IllegalArgumentException:设置的参数非法
class Server
public class Server
提供 HTTP 服务的 Server 类包含如下功能:
- 启动服务,在指定地址及端口等待用户连接、服务用户的 http request;
- 关闭服务,包括关闭所有已有连接;
- 提供注册处理 http request 的 handler 的机制,根据注册信息分发 request 到相应的 handler;
- 提供 tls 证书热机制;
- 提供 shutdown 回调机制;
- 通过 Logger.level 开启、关闭日志打印,包括按照用户要求打印相应级别的日志;
- Server 文档中未明确说明支持版本的配置,在 HTTP/1.1 与 HTTP/2 都会生效
prop addr
public prop addr: String
功能:获取服务端监听地址,格式为 IP 或者 域名。
prop port
public prop port: UInt16
功能:获取服务端监听端口。
prop listener
public prop listener: ServerSocket
功能:获取服务器绑定 socket。
prop logger
public prop logger: Logger
功能:获取服务器日志记录器,设置 logger.level 将立即生效,记录器应该是线程安全的。
prop distributor
public prop distributor: HttpRequestDistributor
功能:获取请求分发器,请求分发器会根据 url 将请求分发给对应的 handler。
prop protocolServiceFactory
public prop protocolServiceFactory: ProtocolServiceFactory
功能:获取协议服务工厂,服务协议工厂会生成每个协议所需的服务实例。
prop transportConfig
public prop transportConfig: TransportConfig
功能:获取服务器设定的传输层配置。
func getTlsConfig
public func getTlsConfig(): ?TlsServerConfig
功能:获取服务器设定的 TLS 层配置。
返回值:
prop readTimeout
public prop readTimeout: Duration
功能:获取服务器设定的读取整个请求的超时时间。
prop writeTimeout
public prop writeTimeout: Duration
功能:获取服务器设定的写响应的超时时间。
prop readHeaderTimeout
public prop readHeaderTimeout: Duration
功能:获取服务器设定的读取请求头的超时时间。
prop httpKeepAliveTimeout
public prop httpKeepAliveTimeout: Duration
功能:HTTP/1.1 专用,获取服务器设定的保持长连接的超时时间。
prop maxRequestHeaderSize
public prop maxRequestHeaderSize: Int64
功能:获取服务器设定的读取请求的请求头最大值。仅对 HTTP/1.1 生效,HTTP/2 中有专门的配置 maxHeaderListSize。
prop maxRequestBodySize
public prop maxRequestBodySize: Int64
功能:获取服务器设定的读取请求的请求体最大值,仅对于 HTTP/1.1 且未设置 "Transfer-Encoding: chunked" 的请求生效。
prop headerTableSize
public prop headerTableSize: UInt32
功能:HTTP/2 专用,用来限制对端发送的报文。
hpack encoder/decoder 的最大 table size
prop maxConcurrentStreams
public prop maxConcurrentStreams: UInt32
功能:HTTP/2 专用,用来限制对端发送的报文。
同时处理的最大请求数量
prop initialWindowSize
public prop initialWindowSize: UInt32
功能:HTTP/2 专用,用来限制对端发送的报文stream 初始流量窗口大小。默认值为 65535 ,取值范围为 0 至 2^31 - 1。
prop maxFrameSize
public prop maxFrameSize: UInt32
功能:HTTP/2 专用,用来限制对端发送的报文一个帧的最大长度。默认值为 16384. 取值范围为 2^14 至 2^24 - 1。
prop maxHeaderListSize
public prop maxHeaderListSize: UInt32
功能:HTTP/2 专用,用来限制对端发送的报文请求 headers 最大长度,为所有 header field 长度之和(所有 name 长度 + value 长度 + 32,包括自动添加的 h2 伪头),默认值为 UInt32.Max。
prop enableConnectProtocol
public prop enableConnectProtocol: Bool
功能:HTTP/2 专用,用来限制对端发送的报文是否支持通过 connect 方法升级协议,true 表示支持。
prop servicePoolConfig
public prop servicePoolConfig: ServicePoolConfig
功能:获取协程池配置实例。
func serve
public func serve(): Unit
功能:启动服务端进程不支持重复启动h1 request 检查和处理:
- request-line 不符合 rfc9112 中 request-line = method SP request-target SP HTTP-version 的规则,将会返回 400 响应
- method 由 tokens 组成,且大小写敏感,request-target 为能够被解析的 url,HTTP-version 为 HTTP/1.0 或 HTTP/1.1 否则将会返回 400 响应headers name 和 value 需符合特定规则,详见 HttpHeaders 类说明,否则返回 400 响应
- 当 headers 的大小超出 server 设定的 maxRequestHeaderSize 时将自动返回 431 响应
- headers 中必须包含 "host" 请求头,且值唯一,否则返回 400 响应headers 中不允许同时存在 "content-length" 与 "transfer-encoding" 请求头,否则返回 400 响应
- 请求头 "transfer-encoding" 的 value 经过 "," 分割后最后一个 value 必须为 "chunked",且之前的 value 不允许存在 "chunked",否则返回 400 响应
- 请求头 "content-length" 其 value 必须能解析为 Int64 类型,且不能为负值,否则返回 400 响应,当其 value 值超出 server 设定maxRequestBodySize,将返回 413 响应
- headers 中若不存在 "content-length" 和 "transfer-encoding: chunked" 时默认不存在 body
- 请求头 "trailer" 中,value 不允许存在 "transfer-encoding","trailer","content-length"
- 请求头 "expect" 中,value 中存在非 "100-continue" 的值,将会返回 417 响应
- HTTP/1.0 默认短连接,若想保持长连接需要包含请求头 "connection: keep-alive" 与 "keep-alive: timeout = XX, max = XX",将会自动保持 timeout 时长的连接。HTTP/1.1 默认长连接,当解析 request 失败则关闭连接
- 仅允许在 chunked 模式下存在 trailers,且 trailer 中条目的 name 必须被包含在 "trailers" 请求头中,否则将自动删除
h1 response 检查和处理:
- 若用户不对 response 进行配置,将会自动返回 200 响应
- 若接收到的 request 包含请求头 "connection: close" 而配置 response 未添加响应头 "connection" 或响应头 "connection" 的 value 不包含 "close",将自动添加 "connection: close",若接收到的 request 不包含请求头 "connection: close" 且响应头不存在 "connection: keep-alive",将会自动添加
- 如果 headers 包含逐跳响应头:"proxy-connection","keep-alive","te","transfer-encoding","upgrade",将会在响应头 "connection" 自动添加这些头作为 value
- 将自动添加 "date" field,用户提供的 "date" 将被忽略
- 若请求方法为 "HEAD" 或响应状态码为 "1XX\204\304" body将配置为空
- 若已知提供 body 的大小时,将会与响应头 "content-length" 进行比较,若不存在响应头 "content-length",将自动添加此响应头,其 value 值为 body 大小。若响应头 "content-length" 大小大于 body 大小将会在 handler 中抛出 HttpException,若小于 body 大小,将对 body 进行截断处理,发送的 body 大小将为 "content-length" 的值
- response 中 "set-cookie" header 将分条发送,其他 headers 同名条目将合成一条发送
- 在处理包含请求头:"Expect: 100-continue"的request时,在调用 request 的 body.read() 时将会自动发送状态码为100的响应给客户端。不允许用户主动发送状态码为100的response,若进行发送则被认定为服务器异常
启用 h2 服务:tlsConfig 中 supportedAlpnProtocols 需包含 "h2",此后如果 tls 层 alpn 协商结果为 h2,则启用 h2 服务
h2 request 检查和处理:
- headers name 和 value 需符合特定规则,详见 HttpHeaders 类说明,此外 name 不能包含大写字符,否则发送 RST 帧关闭流,即无法保证返回响应
- trailers name 和 value 需符合同样规则,否则关闭流
- headers 不能包含 "connection","transfer-encoding","keep-alive","upgrade","proxy-connection",否则关闭流
- 如果有 "te" header,其值只能为 "trailers",否则关闭流
- 如果有 "host" header 和 ":authority" pseudo header,"host" 值必须与 ":authority" 一致,否则关闭流
- 如果有 "content-length" header,需符合 "content-length" 每个值都能解析为 Int64 类型,且如果有多个值,必须相等,否则关闭流
- 如果有 "content-length" header,且有 body 大小,则 content-length 值与 body 大小必须相等,否则关闭流
- 如果有 "trailer" header,其值不能包含 "transfer-encoding","trailer","content-length",否则关闭流
- 仅在升级 WebSocket 场景下支持 CONNECT 方法,否则关闭流
- pseudo headers 中,必须包含 ":method"、":scheme"、":path",其中 ":method" 值必须由 tokens 字符组成,":scheme" 值必须为 "https",":path" 不能为空,否则关闭流
- trailer 中条目的 name 必须被包含在 "trailers" 头中,否则将自动删除
- request headers 大小不能超过 maxHeaderListSize,否则关闭连接
h2 response 检查和处理:
- 如果 HEAD 请求的响应包含 body,将自动删除
- 将自动添加 "date" field,用户提供的 "date" 将被忽略
- 如果 headers 包含 "connection","transfer-encoding","keep-alive","upgrade","proxy-connection",将自动删除
- response 中 "set-cookie" header 将分条发送,其他 headers 同名条目将合成一条发送
- 如果 headers 包含 "content-length",且 method 不为 "HEAD","content-length" 将被删除
- 如果 method 为 "HEAD",则
- headers 包含 "content-length",但 "content-length" 不合法(无法被解析为 Int64 值,或包含多个不同值),如果用户调用 HttpResponseWriter 类的 write 函数,将抛出 HttpException,如果用户 handler 已经结束,将打印日志
- headers 包含 "content-length",同时 response.body.length 不为 -1,"content-length" 值与 body.length 不符,同 6.1 处理
- headers 包含 "content-length",同时 response.body.length 为 -1,或 body.length 与 "content-length" 值一致,则保留 "content-length" header
- trailer 中条目必须被包含在 "trailers" 头中,否则将自动删除
- 如果 handler 中抛出异常,且用户未调用 write 发送部分响应,将返回 500 响应。如果用户已经调用 write 发送部分响应,将发送 RST 帧关闭 stream
h2 server 发完 response 之后,如果 stream 状态不是 CLOSED,会发送带 NO_ERROR 错误码的 RST 帧关闭 stream,避免已经处理完毕的 stream 继续占用服务器资源
h2 流量控制:
- connection 流量窗口初始值为 65535,每次收到 DATA 帧将返回一个 connection 层面的 WINDOW-UPDATE,发送 DATA 时,如果 connection 流量窗口值为负数,将阻塞至其变为正数
- stream 流量窗口初始值可由用户设置,默认值为 65535,每次收到 DATA 帧将返回一个 stream 层面的 WINDOW-UPDATE,发送 DATA 时,如果 stream 流量窗口值为负数,将阻塞至其变为正数
h2 请求优先级:
- 支持按 urgency 处理请求,h2 服务默认并发处理请求,当并发资源不足时,请求将按 urgency 处理,优先级高的请求优先处理
默认 ProtocolServiceFactory 协议选择:
- 如果连接是 tcp,使用 HTTP/1.1 server
- 如果连接是 tls,根据 alpn 协商结果确定 http 协议版本,如果协商结果为 "http/1.0","http/1.1" 或 "",使用 HTTP/1.1 server,如果协商结果为 "h2",使用 HTTP/2 server,否则不处理此次请求,打印日志关连接。
异常:
- SocketException:端口监听失败
func close
public func close(): Unit
功能:关闭服务器,服务器关闭后将不再对请求进行读取与处理重复关闭将只有第一次生效(包括 close 和 closeGracefully)。
func closeGracefully
public func closeGracefully(): Unit
功能:关闭服务器,服务器关闭后将不再对请求进行读取,当前正在进行处理的服务器待处理结束后进行关闭。
func afterBind
public func afterBind(f: ()->Unit): Unit
功能:注册服务器启动时的回调函数,服务内部 ServerSocket 实例 bind 之后,accept 之前将调用该函数。重复调用将覆盖之前注册的函数。
参数:
- f:回调函数,入参为空,返回值为 Unit 类型
func onShutdown
public func onShutdown(f: ()->Unit): Unit
功能:注册服务器关闭时的回调函数,服务器关闭时将调用该回调函数,重复调用将覆盖之前注册的函数。
参数:
- f:回调函数,入参为空,返回值为 Unit 类型
func updateCert
public func updateCert(certificateChainFile: String, privateKeyFile: String): Unit
功能:对 TLS 证书进行热更新。
参数:
- certificateChainFile:证书链文件
- privateKeyFile:证书匹配的私钥文件
异常:
- IllegalArgumentException:参数包含空字符
- HttpException:服务端未配置 tlsConfig
func updateCert
public func updateCert(certChain: Array<X509Certificate>, certKey: PrivateKey): Unit
功能:对 TLS 证书进行热更新。
参数:
- certChain:证书链
- certKey:证书匹配的私钥
异常:
- HttpException:服务端未配置 tlsConfig
func updateCA
public func updateCA(newCaFile: String): Unit
功能:对 CA 证书进行热更新。
参数:
- newCaFile:CA证书文件
异常:
- IllegalArgumentException:参数包含空字符
- HttpException:服务端未配置 tlsConfig
func updateCA
public func updateCA(newCa: Array<X509Certificate>): Unit
功能:对 CA 证书进行热更新。
参数:
- newCa:CA证书
异常:
- IllegalArgumentException:参数包含空字符
- HttpException:服务端未配置 tlsConfig
struct ServicePoolConfig
public struct ServicePoolConfig {
public let capacity: Int64
public let queueCapacity: Int64
public let preheat: Int64
public init(
capacity!: Int64 = 10 ** 4,
queueCapacity!: Int64 = 10 ** 4,
preheat!: Int64 = 0
)
}
Server 协程池配置类。
Server 每次收到一个请求,将从协程池取出一个协程进行处理,如果任务等待队列已满,将拒绝服务该次请求,并断开连接。
特别地,HTTP/2 Service 处理过程中会从协程池取出若干协程进行处理,如果任务等待队列已满,将阻塞直至有协程空闲。
capacity
public let capacity: Int64
功能:获取协程池容量,协程被创建后将循环从 queue 中获取任务并执行,直至协程池关闭
queueCapacity
public let queueCapacity: Int64
功能:获取缓冲区等待任务的最大数量
preheat
public let preheat: Int64
功能:获取服务启动时预先启动的协程数量
init
public init(
capacity!: Int64 = 10 ** 4,
queueCapacity!: Int64 = 10 ** 4,
preheat!: Int64 = 0
)
功能:构造一个 ServicePoolConfig 实例。
参数:
capacity:协程池容量,默认值为 10000queueCapacity:缓冲区等待任务的最大数量,默认值为 10000preheat:服务启动时预先启动的协程数量,默认值为 0
异常:
- IllegalArgumentException:参数 capacity 小于 0,或参数 queueCapacity 小于0,或参数preheat小于 0,或大于 capacity
interface ProtocolServiceFactory
public interface ProtocolServiceFactory {
func create(protocol: Protocol, socket: StreamingSocket): ProtocolService
}
Http 服务实例工厂,用于生成 ProtocolService 实例。
ServerBuilder 提供默认的实现,默认实现提供仓颉标准库中 HTTP/1.1、HTTP/2 的 ProtocolService 实例。
func create
func create(protocol: Protocol, socket: StreamingSocket): ProtocolService
功能:根据协议创建协议服务实例。
参数:
protocol:协议版本,如 HTTP1_0、HTTP1_1、HTTP2_0socket:来自客户端的套接字
返回值:协议服务实例
abstract class ProtocolService
Http协议服务实例,为单个客户端连接提供 Http 服务,包括对客户端 request 报文的解析、 request 的分发处理、 response 的发送等。
public abstract class ProtocolService
prop server
open protected mut prop server: Server
Server 实例,提供默认实现,设置为绑定的 Server 实例
func serve
protected func serve(): Unit
功能:处理来自客户端连接的请求,不提供默认实现。
func closeGracefully
open protected func closeGracefully(): Unit
功能:优雅关闭连接,提供默认实现,无任何行为。
func close
open protected func close(): Unit
功能:强制关闭连接,提供默认实现,无任何行为。
interface HttpRequestDistributor
public interface HttpRequestDistributor {
func register(path: String, handler: HttpRequestHandler): Unit
func register(path: String, handler: (HttpContext) -> Unit): Unit
func distribute(path: String): HttpRequestHandler
}
Http request 分发器,将一个 request 按照 url 中的 path 分发给对应的 HttpRequestHandler 处理。 本实现提供一个默认的 HttpRequestDistributor,该 distributor 非线程安全,且只能在启动 server 前 register,启动后再次 register,结果未定义。 如果用户希望在启动 server 后还能够 register,需要自己提供一个线程安全的 HttpRequestDistributor 实现。
func register
func register(path: String, handler: HttpRequestHandler): Unit
功能:注册请求处理器。
参数:
- path:请求路径
- handler:请求处理器
异常:
- HttpException:请求路径已注册请求处理器
func register
func register(path: String, handler: (HttpContext) -> Unit): Unit
功能:注册请求处理函数,将调用 register(String, HttpRequestHandler): Unit 函数注册请求处理器。
参数:
- path:请求路径
- handler:请求处理函数
异常:
- HttpException:请求路径已注册请求处理器
func distribute
func distribute(path: String): HttpRequestHandler
功能:分发请求处理器,未找到对应请求处理器时,将返回 NotFoundHandler 以返回 404 状态码。 参数:
- path:请求路径
返回值:返回请求处理器
class HttpContext
Http 请求上下文,作为 HttpRequestHandler.handle 函数的参数在服务端使用。
public class HttpContext
prop request
public prop request: HttpRequest
功能:获取 Http 请求
prop responseBuilder
public prop responseBuilder: HttpResponseBuilder
功能:获取 Http 响应构建器
prop clientCertificate
public prop clientCertificate: ?Array<X509Certificate>
功能:获取 Http 客户端证书
func upgrade
public func upgrade(ctx: HttpContext): StreamingSocket
功能:在 handler 内获取 StreamingSocket,可用于支持协议升级和处理 CONNECT 请求。
- 调用该函数时,将首先根据 ctx.responseBuilder 发送响应,仅发送状态码和响应头。
- 调用该函数时,将把 ctx.request.body 置空,后续无法通过 body.read(...) 读数据,未读完的 body 数据将留存在返回的 StreamingSocket 中
注意:
-
对于 HTTP/1.1 或 HTTP/1.0
- 获取的 StreamingSocket 是底层连接,可直接读写连接上的数据
- 如果请求方法为 CONNECT,响应状态码必须是 2XX,否则报错,响应头中 content-length 和 transfer-encoding 头将被删除
- 如果请求方法不为 CONNECT,响应状态码必须是 101,如果用户未设置,将自动置为 101,如果用户设置了状态码且非 101,将报错
-
对于 HTTP/2
- 获取的 StreamingSocket 是一个 stream 上的读写流,后续读写数据将由 stream 封装成 data 帧收发
- 请求方法必须为 CONNECT,响应状态码必须为 2XX,否则将报错
参数:
- ctx:请求上下文
返回值:底层连接(对于 HTTP/2 是一个 stream),可用于后续读写
异常:
- HttpException:获取底层连接(对于 HTTP/2 是一个 stream)失败
interface HttpRequestHandler
public interface HttpRequestHandler {
func handle(ctx: HttpContext): Unit
}
Http request 处理器。 http server 端通过 handler 处理来自客户端的 http request;在 handler 中用户可以获取 http request 的详细信息,包括 header、body;在 handler 中,用户可以构造 http response,包括 header、body,并且可以直接发送 response 给客户端,也可交由 server 发送。 用户在构建 http server 时,需手动通过 server 的 HttpRequestDistributor 注册一个或多个 handler,当一个客户端 http request 被接收,distributor 按照request 中 url 的 path 分发给对应的 handler 处理。
func handle
func handle(ctx: HttpContext): Unit
功能:处理 Http 请求。
参数:
- ctx:Http 请求上下文
class FuncHandler
public class FuncHandler <: HttpRequestHandler {
public FuncHandler(let handler: (HttpContext) -> Unit)
}
HttpRequestHandler 接口包装类,把单个函数包装成 HttpRequestHandler。
FuncHandler
public FuncHandler(let handler: (HttpContext) -> Unit)
功能:FuncHandler 的构造函数。
参数:
- handler:是调用 handle 的处理函数,其入参为 HttpContext ,返回值类型为 Unit 的函数类型
func handle
public func handle(ctx: HttpContext): Unit
功能:处理 Http 请求。
参数:
- ctx:Http 请求上下文
class NotFoundHandler
public class NotFoundHandler <: HttpRequestHandler
便捷的 Http 请求处理器,404 Not Found 处理器。
func handle
public func handle(ctx: HttpContext): Unit
功能:处理 Http 请求,回复 404 响应。
参数:
- ctx:Http 请求上下文
func notFound
public func notFound(ctx: HttpContext): Unit
功能:便捷的 Http 请求处理函数,用于回复 404 响应。处理 Http 请求,回复 404 响应。
参数:
- ctx:Http 请求上下文
func handleError
public func handleError(ctx: HttpContext, code: UInt16): Unit
功能:便捷的 Http 请求处理函数,用于回复错误请求。处理 Http 请求,回复响应。
参数:
- ctx:Http 请求上下文
- code:Http 响应码
class OptionsHandler
public class OptionsHandler <: HttpRequestHandler
便捷的 Http 处理器,用于处理 OPTIONS 请求。 固定返回 "Allow: OPTIONS,GET,HEAD,POST,PUT,DELETE" 响应头
func handle
public func handle(ctx: HttpContext): Unit
功能:处理 Http OPTIONS 请求。
参数:
- ctx:Http 请求上下文
class RedirectHandler
public class RedirectHandler <: HttpRequestHandler {
public init(url: String, code: UInt16)
}
便捷的 Http 处理器,用于回复重定向响应。
init
public init(url: String, code: UInt16)
功能:RedirectHandler 的构造函数。
参数:
- url:重定向响应中 Location 头部的 url
- code:重定向响应的响应码
异常:
- HttpException:url 为空或响应码不是除 304 以外的 3XX 状态码时抛出异常
func handle
public func handle(ctx: HttpContext): Unit
功能:处理 Http 请求,回复重定向响应。
参数:
- ctx:Http 请求上下文
enum FileHandlerType
public enum FileHandlerType {
| DownLoad
| UpLoad
}
此枚举类用于设置 FileHandler 是上传还是下载模式。
DownLoad
DownLoad
功能:创建一个 FileHandler 类型的枚举实例,表示下载模式。
UpLoad
UpLoad
功能:创建一个 FileHandler 类型的枚举实例,表示上传模式。
class FileHandler
public class FileHandler <: HttpRequestHandler {
public init(path: String, handlerType!: FileHandlerType = DownLoad, bufferSize!: Int64 = 64 * 1024)
}
用于处理文件下载或者文件上传。
- 文件下载:
- 构造
FileHandler时需要传入待下载文件的路径,目前一个FileHandler只能处理一个文件的下载; - 下载文件只能使用 GET 请求,其他请求返回 400 状态码;
- 文件如果不存在,将返回 404 状态码;
- 构造
- 文件上传:
- 构造
FileHandler时需要传入一个存在的目录路径,上传到服务端的文件将保存在这个目录中; - 上传文件时只能使用 POST 请求,其他请求返回 400 状态码;
- 上传数据的 http 报文必须是
multipart/form-data格式的,Content-Type头字段的值为multipart/form-data; boundary=----XXXXX; - 上传文件的文件名存放在
form-data数据报文中,报文数据格式为Content-Disposition: form-data; name="xxx"; filename="xxxx",文件名是filename字段的值; - 目前 form-data 中必须包含 filename 字段;
- 如果请求报文不正确,将返回 400 状态码;
- 如果出现其他异常,例如文件处理异常,将返回 500 状态码;
- 构造
init
public init(path: String, handlerType!: FileHandlerType = DownLoad, bufferSize!: Int64 = 64 * 1024)
功能:FileHandler 的构造函数。
参数:
- path:FileHandler 构造时需要传入的文件或者目录路径字符串,上传模式中只能传入存在的目录路径;路径中存在../时,用户需要确认标准化后的绝对路径是期望传入的路径
- handlerType:构造 FileHandler 时指定当前 FileHandler 的工作模式,默认为 DownLoad 下载模式
- bufferSize:内部从网络读取或者写入的缓冲区大小,默认值为 64*1024(64k),若小于 4096,则使用 4096 作为缓冲区大小
异常:
- HttpException:当 path 不存在时,抛出异常
func handle
public func handle(ctx: HttpContext): Unit
功能:根据请求对响应数据进行处理。
参数:
- ctx:Http 请求上下文
class Client
public class Client
Client 类,用户可以通过 Client 实例发送 HTTP/1.1 或 HTTP/2 请求。
主要提供功能:发送 Http request、随时关闭等。
Client 文档中未明确说明支持版本的配置,在 HTTP/1.1 与 HTTP/2 都会生效。
prop httpProxy
public prop httpProxy: String
功能:获取客户端 http 代理,默认使用系统环境变量 http_proxy 的值,用字符串表示,格式为:"http://host:port",例如:"http://192.168.1.1:80"
prop httpsProxy
public prop httpsProxy: String
功能:获取客户端 https 代理,默认使用系统环境变量 https_proxy 的值,用字符串表示,格式为:"http://host:port",例如:"http://192.168.1.1:443"
prop connector
public prop connector: (String) -> StreamingSocket
功能:客户端调用此函数获取到服务器的连接
prop logger
public prop logger: Logger
功能:获取客户端日志记录器,设置 logger.level 将立即生效,记录器应该是线程安全的
prop cookieJar
public prop cookieJar: ?CookieJar
功能:用于存储客户端所有 Cookie,如果配置为 None,则不会启用 Cookie
prop poolSize
public prop poolSize: Int64
功能:HTTP/1.1 客户端使用连接池大小,表示对同一个主机(host:port)同时存在的连接数的最大值
prop autoRedirect
public prop autoRedirect: Bool
功能:获取客户端是否会自动进行重定向,304 状态码默认不重定向
func getTlsConfig
public func getTlsConfig(): ?TlsClientConfig
功能:获取客户端设定的 TLS 层配置。
返回值:
prop readTimeout
public prop readTimeout: Duration
功能:获取客户端设定的读取整个响应的超时时间,默认值为 15s
prop writeTimeout
public prop writeTimeout: Duration
功能:获取客户端设定的写请求的超时时间,默认值为 15s
prop headerTableSize
public prop headerTableSize: UInt32
功能:获取客户端 HTTP/2 Hpack 动态表初始值,默认值为 4096
prop enablePush
public prop enablePush: Bool
功能:获取客户端 HTTP/2 是否支持服务器推送,默认值为 true
prop maxConcurrentStreams
public prop maxConcurrentStreams: UInt32
功能:获取客户端 HTTP/2 初始最大并发流数量,默认值为 2^31 - 1
prop initialWindowSize
public prop initialWindowSize: UInt32
功能:获取客户端 HTTP/2 流控窗口初始值,默认值为 65535 ,取值范围为 0 至 2^31 - 1。
prop maxFrameSize
public prop maxFrameSize: UInt32
功能:获取客户端 HTTP/2 初始最大帧大小。默认值为 16384. 取值范围为 2^14 至 2^24 - 1
prop maxHeaderListSize
public prop maxHeaderListSize: UInt32
功能:获取客户端 HTTP/2 最大 header 大小。响应 headers 最大长度,为所有 header field 长度之和(所有 name 长度 + value 长度 + 32,包括自动添加的 h2 伪头),默认值为 UInt32.Max
func send
public func send(req: HttpRequest): HttpResponse
功能:通用请求函数,发送 HttpRequest 到 url 中的服务器,接收 HttpResponse注意:
- 对于 HTTP/1.1,如果请求中有 body 要发,那么需要保证 Content-Length 和 Transfer-Encoding: chunked必有且只有一个,以 chunked 形式发时,每段 chunk 最大为 8192 字节:如果用户发送的 body 为自己实现的 InputStream 类,则需要自己保证 Content-Length和 Transfer-Encoding: chunked 设置且只设置了一个;如果用户采用默认的 body 发送,Content-Length 和 Transfer-Encoding: chunked都缺失时,我们会为其补上 Content-Length header,值为 body.size
- 用户如果设置了 Content-Length,则需要保证其正确性:如果所发 body 的内容大于等于 Content-Length 的值,我们会发送长度为 Content-Length 值的数据;如果所发 body 的内容小于 Content-Length 的值,此时如果 body 是默认的 body,则会抛出 HttpException,如果 body是用户自己实现的 InputStream 类,其行为便无法保证(可能会造成服务器端的读 request 超时或者客户端的收 response 超时)
- 升级函数通过 WebSocket 的 upgradeFromClient 或 Client 的 upgrade 接口发出,调用 client 的其他函数发送 upgrade 请求会抛出异常
- 协议规定 TRACE 请求无法携带内容,故用户发送带有 body 的 TRACE 请求时会抛出异常
- HTTP/1.1 默认对同一个服务器的连接数不超过 10 个。response 的 body 需要用户调用
body.read(buf: Array<Byte>)函数去读。body 被读完后,连接才能被客户端对象复用,否则请求相同的服务器也会新建连接。新建连接时如果连接数超出限制则会抛出 HttpException - body.read 函数将 body 读完之后返回 0,如果读的时候连接断开会抛出 ConnectionException
- HTTP/1.1 的升级请求如果收到 101 响应,则表示切换协议,此连接便不归 client 管理
- 下文的快捷请求函数的注意点相同一次请求重定向超出一定次数时抛此异常客户端解析报文出错时抛此异常一次性收到的 1xx 响应超过一定数量抛此异常对同一个服务器的连接超过一定数量抛此异常使用 send 函数升级协议抛此异常发送带有 body 的 TRACE 请求抛此异常。
参数:
- HttpRequest:发送的请求
返回值:服务端返回处理该请求的响应
异常:
- UrlSyntaxException:请求中 URL 错误时抛此异常
- SocketException:Socket 连接出现错误时抛此异常
- ConnectionException:从连接中读数据时对端已关闭连接抛此异常
- SocketTimeoutException:Socket 连接超时抛此异常
- TlsException:Tls 连接建立失败或通信异常抛此异常
- HttpException:当用户未使用 http 库提供的 API 升级 WebSocket 时抛此异常
- HttpTimeoutException:请求超时或读 HttpResponse.body 超时抛此异常
func get
public func get(url: String): HttpResponse
功能:请求方法为 GET 的便捷请求函数。
参数:
- url:请求的 url
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func head
public func head(url: String): HttpResponse
功能:请求方法为 HEAD 的便捷请求函数。
参数:
- url:请求的 url
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func put
public func put(url: String, body: InputStream): HttpResponse
功能:请求方法为 PUT 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func put
public func put(url: String, body: String): HttpResponse
功能:请求方法为 PUT 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func put
public func put(url: String, body: Array<UInt8>): HttpResponse
功能:请求方法为 PUT 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func post
public func post(url: String, body: InputStream): HttpResponse
功能:请求方法为 POST 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func post
public func post(url: String, body: String): HttpResponse
功能:请求方法为 POST 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func post
public func post(url: String, body: Array<UInt8>): HttpResponse
功能:请求方法为 POST 的便捷请求函数。
参数:
- url:请求的 url
- body:请求体
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func delete
public func delete(url: String): HttpResponse
功能:请求方法为 DELETE 的便捷请求函数。
参数:
- url:请求的 url
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func connect
public func connect(url: String, header!: HttpHeaders = HttpHeaders(), version!: Protocol = HTTP1_1): (HttpResponse, ?StreamingSocket)
功能:发送 CONNECT 请求与服务器建立隧道,返回建连成功后的连接,连接由用户负责关闭。服务器返回 2xx 表示建连成功,否则建连失败(不支持自动重定向,3xx 也视为失败)。
参数:
- url:请求的 url
- headers:请求头,默认为空请求头
- version:请求的协议,默认为 HTTP1_1
返回值:返回元组类型,其中 HttpResponse 实例表示服务器返回的响应体,Option<StreamingSocket> 实例表示请求成功时返回 headers 之后连接
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func options
public func options(url: String): HttpResponse
功能:请求方法为 OPTIONS 的便捷请求函数。
参数:
- url:请求的 url
返回值:服务端返回的响应
异常:
- UrlSyntaxException:当参数 url 不符合 URL 解析规范时,抛出异常
- IllegalArgumentException:当被编码的字符不符合 UTF-8 的字节序列规则时,抛出异常
- 其余同 func send
func upgrade
public func upgrade(req: HttpRequest): (HttpResponse, ?StreamingSocket)
功能:发送请求并升级协议,用户设置请求头,返回升级后的连接(如果升级成功),连接由用户负责关闭。
- 服务器返回 101 表示升级成功,获取到了 StreamingSocket
- 必选请求头:
- Upgrade: protocol-name ["/" protocol-version]
- Connection: Upgrade (Connection: Upgrade 在有 Upgrade 时会自动补上)
- 不支持 HTTP/1.0、HTTP/2
- 不支持 HTTP/1.1 CONNECT 方法的 HttpRequest
参数:
- req:升级时发送的请求
返回值:返回一个元组,HttpResponse 实例表示服务器返回的响应,?StreamingSocket 实例表示获取的底层连接,升级失败时为 None
异常:
- HttpException:
- 请求报文或响应报文不符合协议
- 请求报文不含 Upgrade 头
- 发送 CONNECT 请求
- 发送带 body 的 TRACE 请求
- SocketException,ConnectionException:Socket 连接出现异常或被关闭
- SocketTimeoutException:Socket 连接超时
- TlsException: Tls 连接建立失败或通信异常
func close
public func close(): Unit
功能:关闭客户端建立的所有连接,调用后不能继续发送请求。
class ClientBuilder
public class ClientBuilder
ClientBuilder 类,用于 Client 实例的构建,Client 没有公开的构造函数,用户只能通过 ClientBuilder 得到 Client 实例。ClientBuilder 文档中未明确说明支持版本的配置,在 HTTP/1.1 与 HTTP/2 都会生效。
init
public init()
功能:创建新的 ClientBuilder 实例。
func httpProxy
public func httpProxy(addr: String): ClientBuilder
功能:设置客户端 http 代理,默认使用系统环境变量 http_proxy 的值。
参数:
- addr:格式为:"http://host:port",例如:"http://192.168.1.1:80"
返回值:当前 ClientBuilder 实例的引用
func httpsProxy
public func httpsProxy(addr: String): ClientBuilder
功能:设置客户端 https 代理,默认使用系统环境变量 https_proxy 的值。
参数:
- addr:格式为:"http://host:port",例如:"http://192.168.1.1:443"
返回值:当前 ClientBuilder 实例的引用
func noProxy
public func noProxy(): ClientBuilder
功能:调用此函数后,客户端不使用任何代理。
返回值:当前 ClientBuilder 实例的引用
func connector
public func connector(connector: (String)->StreamingSocket): ClientBuilder
功能:客户端调用此函数获取到服务器的连接。
参数:
- connector:入参为字符串,返回值类型为 Unit 的函数类型字符串返回
返回值:当前 ClientBuilder 实例的引用
func logger
public func logger(logger: Logger): ClientBuilder
功能:设定客户端的 logger,默认 logger 级别为 INFO,logger 内容将写入 Console.stdout。
参数:
- logger:需要是线程安全的,默认使用内置线程安全 logger
返回值:当前 ClientBuilder 实例的引用
func cookieJar
public func cookieJar(cookieJar: ?CookieJar): ClientBuilder
功能:用于存储客户端所有 Cookie。
参数:
- cookieJar:默认使用一个空的 CookieJar,如果配置为 None 则不会启用 Cookie
返回值:当前 ClientBuilder 实例的引用
func poolSize
public func poolSize(size: Int64): ClientBuilder
功能:HTTP/1.1 客户端使用连接池大小,表示对同一个主机(host:port)同时存在的连接数的最大值。
参数:
- size:默认 10,poolSize 需要大于 0
异常:
- HttpException:如果传参小于等于 0,则会抛出该异常
返回值:当前 ClientBuilder 实例的引用
func autoRedirect
public func autoRedirect(auto: Bool): ClientBuilder
功能:配置客户端是否会自动进行重定向,重定向会请求 Location 头的资源,协议规定,Location 只能包含一个 URI 引用Location = URI-reference详见 RFC 9110 10.2.2.。304 状态码默认不重定向。
参数:
- autoRedirect,默认 true
返回值:当前 ClientBuilder 实例的引用
func tlsConfig
public func tlsConfig(config: TlsClientConfig): ClientBuilder
功能:设置 TLS 层配置,默认不对其进行设置。
参数:
- config:设定支持 tls 客户端需要的配置信息
返回值:当前 ClientBuilder 实例的引用
func readTimeout
public func readTimeout(timeout: Duration): ClientBuilder
功能:设定客户端读取一个响应的最大时长。
参数:
- timeout:默认 15s,Duration.Max 代表不限制,如果传入负的 Duration 将被替换为 Duration.Zero
返回值:当前 ClientBuilder 实例的引用
func writeTimeout
public func writeTimeout(timeout: Duration): ClientBuilder
功能:设定客户端发送一个请求的最大时长。
参数:
- timeout,默认 15s,Duration.Max 代表不限制,如果传入负的 Duration 将被替换为 Duration.Zero
返回值:当前 ClientBuilder 实例的引用
func headerTableSize
public func headerTableSize(size: UInt32): ClientBuilder
功能:配置客户端 HTTP/2 Hpack 动态表初始值。
参数:
- size:默认值 4096
返回值:当前 ClientBuilder 实例的引用
func enablePush
public func enablePush(enable: Bool): ClientBuilder
功能:配置客户端 HTTP/2 是否支持服务器推送。
参数:
- enable:默认值 true
返回值:当前 ClientBuilder 实例的引用
func maxConcurrentStreams
public func maxConcurrentStreams(size: UInt32): ClientBuilder
功能:配置客户端 HTTP/2 初始最大并发流数量。
参数:
- size:默认值为 2^31 - 1
返回值:当前 ClientBuilder 实例的引用
func initialWindowSize
public func initialWindowSize(size: UInt32): ClientBuilder
功能:配置客户端 HTTP/2 流控窗口初始值。
参数:
- size:默认值 65535 , 取值范围为 0 至 2^31 - 1
返回值:当前 ClientBuilder 实例的引用
func maxFrameSize
public func maxFrameSize(size: UInt32): ClientBuilder
功能:配置客户端 HTTP/2 初始最大帧大小。
参数:
- size:默认值为 16384. 取值范围为 2^14 至 2^24 - 1
返回值:当前 ClientBuilder 实例的引用
func maxHeaderListSize
public func maxHeaderListSize(size: UInt32): ClientBuilder
功能:配置客户端接收的 HTTP/2 响应 headers 最大长度,为所有 header field 长度之和(所有 name 长度 + value 长度 + 32,包括自动添加的 h2 伪头),默认值为 UInt32.Max。
参数:
- size:客户端接收的 HTTP/2 响应 headers 最大长度
返回值:当前 ClientBuilder 实例的引用
func build
public func build(): Client
功能:构造 Client 实例。
返回值:用当前 ClientBuilder 实例构造数来的 Client 实例。
异常:
- IllegalArgumentException:配置项有非法参数时抛出此异常
class WebSocket
public class WebSocket
提供 WebSocket 服务的相关类,用户通过 upgradeFrom 函数以获取 WebSocket 连接。
提供 WebSocket 连接的读、写、关闭等函数。
调用 read() 即读取一个 WebSocketFrame,用户可通过 WebSocketFrame.frameType 来知晓帧的类型,通过 WebSocketFrame.fin 来知晓是否是分段帧。
调用 write(frameType: WebSocketFrameType, byteArray: Array<UInt8>),传入message的类型,和 message 的 byte 来发送 WebSocket 信息,如果写的是控制帧,则不会分段发送,如果写的是数据帧(Text、Binary),则会将 message 按底层 buffer 的大小分段(分成多个 fragment)发送。
详细说明见下文接口说明,接口行为以 RFC 6455 为准。
prop subProtocol
public prop subProtocol: String
功能:获取与对端协商到的 subProtocol,协商时,客户端提供一个按偏好排名的 subProtocols 列表,服务器从中选取一个或零个子协议
prop logger
public prop logger: Logger
功能:日志记录器
func read
public func read(): WebSocketFrame
功能:从连接中读取一个帧,如果连接上数据未就绪会阻塞,非线程安全(即对同一个 WebSocket 对象不支持多线程读)
说明:read 函数返回一个帧对象 WebSocketFrame ,用户可以调用 WebSocketFrame 的 frameType,fin 属性确定其帧类型和是否是分段帧调用 WebSocketFrame 的 payload 函数得到原始二进制数据数组:Array<UInt8>
- 分段帧的首帧为 fin == false,frameType == TextWebFrame 或 BinaryWebFrame中间帧 fin == false,frameType == ContinuationWebFrame尾帧 fin == true, frameType == ContinuationWebFrame
- 非分段帧为 fin == true, frameType != ContinuationWebFrame
注意:
- 数据帧(Text,Binary)可以分段,用户需要多次调用 read 将所有分段帧读完(以下称为接收到完整的 message),再将分段帧的 payload 按接收序拼接Text 帧的 payload 为 UTF-8 编码,用户在接收到完整的 message 后,调用 String.fromUtf8函数将拼接后的 payload 转成字符串Binary 帧的 payload 的意义由使用其的应用确定,用户在接收到完整的 message 后,将拼接后的 payload 传给上层应用
- 控制帧(Close,Ping,Pong)不可分段
- 控制帧本身不可分段,但其可以穿插在分段的数据帧之间。分段的数据帧之间不可出现其他数据帧,如果用户收到穿插的分段数据帧,则需要当作错误处理
- 客户端收到 masked 帧,服务器收到 unmasked 帧,断开底层连接并抛出异常
- rsv1、rsv2、rsv3 位被设置(暂不支持 extensions,因此 rsv 位必须为 0),断开底层连接并抛出异常
- 收到无法理解的帧类型(只支持 Continuation,Text,Binary,Close,Ping,Pong),断开底层连接并抛出异常
- 收到分段或 payload 长度大于 125 bytes 的控制帧(Close,Ping,Pong),断开底层连接并抛出异常
- 收到 payload 长度大于 20M 的帧,断开底层连接并抛出异常
- closeConn 关闭连接后继续调用读,抛出异常。
返回值:读到的 WebSocketFrame 对象
异常:
- SocketException:底层连接错误
- WebSocketException:收到不符合协议规定的帧,此时会给对端发送 Close 帧说明错误信息,并断开底层连接
- ConnectionException:从连接中读数据时对端已关闭连接抛此异常
func write
public func write(frameType: WebSocketFrameType, byteArray: Array<UInt8>, frameSize!: Int64 = FRAMESIZE)
功能:发送数据,非线程安全(即对同一个 WebSocket 对象不支持多线程写)
说明:write 函数将数据以 WebSocket 帧的形式发送给对端
- 如果发送数据帧(Text,Binary),传入的 byteArray 如果大于 frameSize (默认 4 * 1024 bytes),我们会将其分成小于等于 frameSize 的 payload 以分段帧的形式发送,否则不分段
- 如果发送控制帧(Close,Ping,Pong),传入的 byteArray 的大小需要小于等于 125 bytes,Close 帧的前两个字节为状态码,可用的状态码见 RFC 6455 7.4. Status Codes协议规定,Close 帧发送之后,禁止再发送数据帧,如果发送则会抛出异常
- 用户需要自己保证其传入的 byteArray 符合协议,如 Text 帧的 payload 需要是 UTF-8 编码,如果数据帧设置了 frameSize,那么需要大于 0,否则抛出异常
- 发送数据帧时,frameSize 小于等于 0,抛出异常
- 用户发送控制帧时,传入的数据大于 125 bytes,抛出异常
- 用户传入非 Text,Binary,Close,Ping,Pong 类型的帧类型,抛出异常
- 发送 Close 帧时传入非法的状态码,或 reason 数据超过 123 bytes,抛出异常
- 发送完 Close 帧后继续发送数据帧,抛出异常
- closeConn 关闭连接后调用写,抛出异常
参数:
- frameType:所需发送的帧的类型
- byteArray:所需发送的帧的 payload(二进制形式)
- frameSize:分段帧的大小,默认为 4 * 1024 bytes,frameSize 不会对控制帧生效(控制帧设置了无效)
异常:
- SocketException:底层连接错误
- WebSocketException:传入非法的帧类型,或者数据时抛出异常
func writeCloseFrame
public func writeCloseFrame(status!: ?UInt16 = None, reason!: String = ""): Unit
功能:发送 Close 帧
注意:协议规定,Close 帧发送之后,禁止再发送数据帧如果用户不设置 status,那么 reason 不会被发送(即有 reason 必有 status);控制帧的 payload 不超过 125 bytes,Close 帧的前两个 bytes 为 status,因此 reason 不能超过 123 bytes,closeConn 关闭连接后调用写,抛出异常。
参数:
- status:发送的 Close 帧的状态码,默认为 None,表示不发送状态码和 reason
- reason:关闭连接的说明,默认为空字符串,发送时会转成 UTF-8,不保证可读,debug 用,
异常:
- WebSocketException:传入非法的状态码,或 reason 数据超过 123 bytes
func writePingFrame
public func writePingFrame(byteArray: Array<UInt8>): Unit
功能:提供发送 Ping 帧的快捷函数,closeConn 关闭连接后调用写,抛出异常。
参数:
- byteArray:所需发送的帧的 payload(二进制形式)
异常:
- SocketException:底层连接错误
- WebSocketException:传入的数据大于 125 bytes,抛出异常
func writePongFrame
public func writePongFrame(byteArray: Array<UInt8>): Unit
功能:提供发送 Pong 帧的快捷函数,closeConn 关闭连接后调用写,抛出异常。
参数:
- byteArray:所需发送的帧的 payload(二进制形式)
异常:
- SocketException:底层连接错误
- WebSocketException:传入的数据大于 125 bytes,抛出异常
func closeConn
public func closeConn(): Unit
功能:提供关闭底层 WebSocket 连接的函数
说明:直接关闭底层连接。正常的关闭流程需要遵循协议规定的握手流程,即先发送 Close 帧给对端,并等待对端回应的 Close 帧。握手流程结束后方可关闭底层连接。
func upgradeFromServer
public static func upgradeFromServer(ctx: HttpContext, subProtocols!: ArrayList<String> = ArrayList<String>(),
origins!: ArrayList<String> = ArrayList<String>(),
userFunc!:(HttpRequest) -> HttpHeaders = {_: HttpRequest => HttpHeaders()}): WebSocket
功能:提供服务端升级到 WebSocket 协议的函数,通常在 handler 中使用
说明:服务端升级的流程为,收到客户端发来的升级请求,验证请求,如果验证通过,则回复 101 响应并返回 WebSocket 对象用于 WebSocket 通讯
- 用户通过 subProtocols,origins 参数来配置其支持的 subprotocol 和 origin 白名单,subProtocols如果不设置,则表示不支持子协议,origins 如果不设置,则表示接受所有 origin 的握手请求
- 用户通过 userFunc 来自定义处理升级请求的行为,如处理 cookie 等,传入的 userFunc 要求返回一个 HttpHeaders 对象,其会通过 101 响应回给客户端(升级失败的请求则不会)
- 暂不支持 WebSocket 的 extensions,因此如果握手过程中出现 extensions 协商则会抛 WebSocketException
- 只支持 HTTP1_1 和 HTTP2_0 向 WebSocket 升级
参数:
- ctx:Http 请求上下文,将传入给 handler 的直接传给 upgradeFromServer 即可
- subProtocols:用户配置的子协议列表,默认值为空,表示不支持。如果用户配置了,则会选取升级请求中最靠前的且出现在配置列表中的子协议作为升级后的 WebSocket 的子协议,用户可通过调用返回的 WebSocket 的 subProtocol 查看子协议
- origins:用户配置的同意握手的 origin 的白名单,如果不配置,则同意来自所有 origin 的握手,如果配置了,则只接受来自配置 origin 的握手
- userFunc:用户配置的自定义处理升级请求的函数,该函数返回一个 HttpHeaders,
返回值:
- WebSocket:升级得到的 WebSocket 实例
func upgradeFromClient
public static func upgradeFromClient(client: Client, url: URL,
version!: Protocol = HTTP1_1,
subProtocols!: ArrayList<String> = ArrayList<String>(),
headers!: HttpHeaders = HttpHeaders()): (WebSocket, HttpHeaders)
功能:提供客户端升级到 WebSocket 协议的函数
说明:客户端的升级流程为,传入 client 对象,url 对象,构建升级请求,请求服务器后验证其响应,如果握手成功,则返回 WebSocket 对象用于 WebSocket 通讯,并返回 101 响应头的 HttpHeaders 对象给用户,暂不支持 extensions如果子协议协商成功,用户可通过调用返回的 WebSocket 的 subProtocol 查看子协议。
参数:
- client:用于请求的 client 对象
- version:创建 socket 使用的 HTTP 版本,只支持 HTTP1_1 和 HTTP2_0 向 WebSocket 升级
- url:用于请求的 url 对象,WebSocket 升级时要注意 url 的 scheme 为 ws 或 wss
- subProtocols:用户配置的子协议列表,按偏好排名,默认为空。若用户配置了,则会随着升级请求发送给服务器。
- headers:需要随着升级请求一同发送的非升级必要头,如 cookie 等
返回值:升级成功,则返回 WebSocket 对象用于通讯和 101 响应的头
异常:
- SocketException:底层连接错误
- HttpException:握手时 HTTP 请求过程中出现错误
- WebSocketException:升级失败,升级响应验证不通过
class WebSocketFrame
public class WebSocketFrame
WebSocket 用于读的基本单元。
说明:WebSocketFrame 提供了三个属性,其中 fin 和 frameType 共同说明了帧是否分段和帧的类型。payload 为帧的载荷。 分段帧的首帧为 fin == false,frameType == TextWebFrame 或 BinaryWebFrame 中间帧 fin == false,frameType == ContinuationWebFrame 尾帧 fin == true, frameType == ContinuationWebFrame 非分段帧为 fin == true, frameType != ContinuationWebFrame 用户仅能通过 WebSocket 对象的 read 函数得到 WebSocketFrame。数据帧可分段,如果用户收到分段帧,则需要多次调用 read 函数直到收到完整的 message,并将所有分段的 payload 按接收顺序拼接。 注意,由于控制帧可以穿插在分段帧之间,用户在拼接分段帧的 payload 时需要单独处理控制帧。分段帧之间仅可穿插控制帧,如果用户在分段帧之间接收到其他数据帧,则需要当作错误处理。
prop fin
public prop fin: Bool
功能:获取 WebSocketFrame 的 fin 属性,fin 与 frameType 共同说明了帧是否分段和帧的类型
prop frameType
public prop frameType: WebSocketFrameType
功能:获取 WebSocketFrame 的帧类型,fin 与 frameType 共同说明了帧是否分段和帧的类型
prop payload
public prop payload: Array<UInt8>
功能:获取 WebSocketFrame 的帧载荷,如果是分段数据帧,用户需要在接收完完整的 message 后将所有分段的 payload 按接收序拼接
enum WebSocketFrameType
public enum WebSocketFrameType <: Equatable<WebSocketFrameType> & ToString {
| ContinuationWebFrame
| TextWebFrame
| BinaryWebFrame
| CloseWebFrame
| PingWebFrame
| PongWebFrame
| UnknownWebFrame
}
WebSocketFrame 的枚举类型。
ContinuationWebFrame
ContinuationWebFrame
功能:表示 continuation 帧类型,对应 Opcode 为 %x0 的情形。
TextWebFrame
TextWebFrame
功能:表示 text 帧类型,对应 Opcode 为 %x1 的情形。
BinaryWebFrame
BinaryWebFrame
功能:表示 binary 帧类型,对应 Opcode 为 %x2 的情形。
CloseWebFrame
CloseWebFrame
功能:表示 close 帧类型,对应 Opcode 为 %x8 的情形。
PingWebFrame
PingWebFrame
功能:表示 ping 帧类型,对应 Opcode 为 %x9 的情形。
PongWebFrame
PongWebFrame
功能:表示 pong 帧类型,对应 Opcode 为 %xA 的情形。
UnknownWebFrame
UnknownWebFrame
功能:表示 其余帧类型,暂不支持,对应 Opcode 为上述值之外的情形。
operator func ==
public override operator func == (that: WebSocketFrameType): Bool
功能:判等。
参数:
- WebSocketFrameType:被比较的对象
返回值:当前实例与 that 相等返回 true,否则返回 false
operator func !=
public override operator func != (that: WebSocketFrameType): Bool
功能:判不等。
参数:
- WebSocketFrameType:被比较的对象
返回值:当前实例与 that 不等返回 true,否则返回 false
func toString
public override func toString(): String
功能:获取 WebSocket 帧类型字符串。
返回值:WebSocket 帧类型字符串
enum Protocol
public enum Protocol <: Equatable<Protocol> & ToString {
| HTTP1_0
| HTTP1_1
| HTTP2_0
| UnknownProtocol(String)
}
HTTP 协议类型枚举。
HTTP1_0
HTTP1_0
功能:创建一个 HTTP1_0 类型的枚举实例,表示采用 http/1.0 协议版本。
HTTP1_1
HTTP1_1
功能:创建一个 HTTP1_1 类型的枚举实例,表示采用 http/1.1 协议版本。
HTTP2_0
HTTP2_0
功能:创建一个 HTTP2_0 类型的枚举实例,表示采用 http/2.0 协议版本。
UnknownProtocol
UnknownProtocol(String)
operator func ==
public override operator func == (that: Protocol): Bool
功能:判等。
参数:
- WebSocketFrameType:被比较的对象
返回值:当前实例与 that 相等返回 true,否则返回 false
operator func !=
public override operator func != (that: Protocol): Bool
功能:判不等。
参数:
- WebSocketFrameType:被比较的对象
返回值:当前实例与 that 不等返回 true,否则返回 false
func toString
public override func toString(): String
功能:获取 Http 协议版本对象字符串。
返回值:Http 协议版本对象字符串
class HttpHeaders
public class HttpHeaders <: Iterable<(String, Collection<String>)>
此类用于表示 Http 报文中的 header 和 trailer,定义了相关增、删、改、查操作。 header 和 trailer 为键值映射集,由若干 field-line 组成,每一个 field-line 包含一个键 (field -name) 和若干值 (field-value)。 field-name 由 token 字符组成,不区分大小写,在该类中将转为小写保存。 field-value 由 vchar,SP 和 HTAB 组成,vchar 表示可见的 US-ASCII 字符,不得包含前后空格,不得为空值。 详见 rfc 9110 https://www.rfc-editor.org/rfc/rfc9110.html#name-fields 示例: Example-Field: Foo, Bar key: Example-Field, value: Foo, Bar field-name = token token = 1tchar tchar = "!" / "#" / "$" / "%" / "&" / "'" / "" / "+" / "-" / "." / "^" / "_" / "`" / "|" / "~" / DIGIT / ALPHA ; any VCHAR, except delimiters
func add
public func add(name: String, value: String): Unit
功能:添加指定键值对 name: value如果 name 已经存在,将在其对应的值列表中添加 value,如果 name 不存在,则添加 name 字段及其值 value。
参数:
- name:HttpHeaders 的字段名称
- value:HttpHeaders 的字段值
异常:
- HttpException:如果传入的name/value包含不合法元素,将抛出此异常
func set
public func set(name: String, value: String): Unit
功能:设置指定键值对 name: value 如果 name 已经存在,传入的 value 将会覆盖之前的值。
参数:
- name:HttpHeaders 的字段名称
- value:HttpHeaders 的字段值
异常:
- HttpException:如果传入的 name/values 包含不合法元素,将抛出此异常
func get
public func get(name: String): Collection<String>
功能:获取指定 name 对应的 value 值。
参数:
- name:字段名称,不区分大小写
返回值:name 对应的 value 集合,如果指定 name 不存在,返回空集合
func getFirst
public func getFirst(name: String): ?String
功能:获取指定 name 对应的第一个 value 值。
参数:
- name:字段名称,不区分大小写
返回值:name 对应的第一个 value 值,如果指定 name 不存在,返回 None
func del
public func del(name: String): Unit
功能:删除指定 name 对应的键值对。
参数:
- name:删除的字段名称
func iterator
public func iterator(): Iterator<(String, Collection<String>)>
功能:获取迭代器,可用于遍历所有键值对。
返回值:该键值集的迭代器
func isEmpty
public func isEmpty(): Bool
功能:判断当前实例是否为空,即没有任何键值对。
返回值:如果当前实例为空,返回 true,否则返回 false
class HttpRequestBuilder
public class HttpRequestBuilder
HttpRequestBuilder 类用于构造 HttpRequest 实例。
init
public init()
功能:构造一个新 HttpRequestBuilder。
init
public init(request: HttpRequest)
功能: 通过 request 构造一个具有 request 属性的 HttpRequestBuilder。由于 body 成员是一个 InputStream,对原始的 request 的 body 的操作会影响到复制得到的 HttpRequest 的 body。HttpRequestBuilder 的 headers 和 trailers 是入参 request 的深拷贝。其余元素都是入参 request 的浅拷贝(因为是不可变对象,无需深拷贝)。
参数:
- request:传入的 HttpRequest 对象
func method
public func method(method: String): HttpRequestBuilder
功能:设置请求 method,默认请求 method 为 "GET"。
参数:
- method:请求方法,必须由 token 字符组成,如果传入空字符串,method 值将自动设置为 "GET"
返回值:当前 HttpRequestBuilder 实例的引用
异常:
- HttpException:参数 method 非法时抛出此异常
func url
public func url(rawUrl: String): HttpRequestBuilder
功能:设置请求 url,默认 url 为空的 URL 对象,即 URL.parse("")。
参数:
- 待解析成 url 对象的字符串,该字符串格式详见 url 包 parse 函数
返回值:当前 HttpRequestBuilder 实例的引用
异常:
- IllegalArgumentException - 当被编码的字符不符合 UTF8 的字节序列规则时,抛出异常
func url
public func url(url: URL): HttpRequestBuilder
功能:设置请求 url,默认 url 为空的 URL 对象,即 URL.parse("")。
返回值:当前 HttpRequestBuilder 实例的引用
func version
public func version(version: Protocol): HttpRequestBuilder
功能:设置请求的 http 协议版本,默认为 UnknownProtocol(""),客户端会根据 tls 配置自动选择协议。
返回值:当前 HttpRequestBuilder 实例的引用
func header
public func header(name: String, value: String): HttpRequestBuilder
功能:向请求 header 添加指定键值对 name: value,规则同 HttpHeaders 类的 add 函数。
返回值:当前 HttpRequestBuilder 实例的引用
异常:
- HttpException:如果传入的 name 或 value 包含不合法元素,将抛出此异常
func addHeaders
public func addHeaders(headers: HttpHeaders): HttpRequestBuilder
功能:向请求 header 添加参数 HttpHeaders 中的键值对。
返回值:当前 HttpRequestBuilder 实例的引用
func setHeaders
public func setHeaders(headers: HttpHeaders): HttpRequestBuilder
功能:设置请求 header,如果已经设置过,调用该函数将替换原 header。
返回值:当前 HttpRequestBuilder 实例的引用
func body
public func body(body: Array<UInt8>): HttpRequestBuilder
功能:设置请求 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 将以内置的 InputStream 实现类表示,其大小已知默认请求 body 为空的 InputStream 对象,即其 read 函数总是返回 0body 大小是否已知将影响 HttpRequest 类属性 bodySize 的取值,及客户端发送请求的行为。
返回值:当前 HttpRequestBuilder 实例的引用
func body
public func body(body: String): HttpRequestBuilder
功能:设置请求 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 将以内置的 InputStream 实现类表示,其大小已知。
返回值:当前 HttpRequestBuilder 实例的引用
func body
public func body(body: InputStream): HttpRequestBuilder
功能:设置请求 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 以用户自定义的 InputStream 实现类表示,其大小未知。
返回值:当前 HttpRequestBuilder 实例的引用
func trailer
public func trailer(name: String, value: String): HttpRequestBuilder
功能:向请求 trailer 添加指定键值对 name: value,规则同 HttpHeaders 类的 add 函数。
返回值:当前 HttpRequestBuilder 实例的引用
异常:
- HttpException:如果传入的 name 或 value 包含不合法元素,将抛出此异常
func addTrailers
public func addTrailers(trailers: HttpHeaders): HttpRequestBuilder
功能:向请求 trailer 添加参数 HttpHeaders 中的键值对。
返回值:当前 HttpRequestBuilder 实例的引用
func setTrailers
public func setTrailers(trailers: HttpHeaders): HttpRequestBuilder
功能:设置请求 trailer,如果已经设置过,调用该函数将替换原 trailer。
返回值:当前 HttpRequestBuilder 实例的引用
func priority
public func priority(urg: Int64, inc: Bool): HttpRequestBuilder
功能:设置 priority 头的便捷函数,调用此函数后,将生成 priority 头,形如:"priority: urgency=x, i"如果通过设置请求头的函数设置了 priority 字段,调用此函数无效。如果多次调用此函数,以最后一次为准。
参数:
- urg:表示请求优先级,取值范围为 0~7,0 表示最高优先级
- inc:表示请求是否需要增量处理,为 true 表示希望服务器并发处理与之同 urg 同 inc 的请求,为 false 表示不希望服务器并发处理
返回值:当前 HttpRequestBuilder 实例的引用
func readTimeout
public func readTimeout(timeout: Duration): HttpRequestBuilder
功能:设置此请求的读超时时间。如果传入的 Duration 为负,则会自动转为 0。如果用户设置了此读超时时间,那么该请求的读超时以此为准;如果用户没有设置,那么该请求的读超时以 Client 为准。
参数:
- timeout:用户设置的此请求的读超时时间
返回值:当前 HttpRequestBuilder 实例的引用
func writeTimeout
public func writeTimeout(timeout: Duration): HttpRequestBuilder
功能:设置此请求的写超时时间。如果传入的 Duration 为负,则会自动转为 0。如果用户设置了此写超时时间,那么该请求的写超时以此为准;如果用户没有设置,那么该请求的写超时以 Client 为准。
参数:
- timeout:用户设置的此请求的写超时时间
返回值:当前 HttpRequestBuilder 实例的引用
func get
public func get(): HttpRequestBuilder
功能:构造 method 为 "GET" 的请求的便捷函数。
返回值:当前 HttpRequestBuilder 实例的引用
func head
public func head(): HttpRequestBuilder
功能:构造 method 为 "HEAD" 的请求的便捷函数。
返回值:当前 HttpRequestBuilder 实例的引用
func options
public func options(): HttpRequestBuilder
功能:构造 method 为 "OPTIONS" 的请求的便捷函数。
func trace
public func trace(): HttpRequestBuilder
功能:构造 method 为 "TRACE" 的请求的便捷函数。
func delete
public func delete(): HttpRequestBuilder
功能:构造 method 为 "DELETE" 的请求的便捷函数。
func post
public func post(): HttpRequestBuilder
功能:构造 method 为 "POST" 的请求的便捷函数。
func put
public func put(): HttpRequestBuilder
功能:构造 method 为 "PUT" 的请求的便捷函数。
func connect
public func connect(): HttpRequestBuilder
功能:构造 method 为 "CONNECT" 的请求的便捷函数。
func build
public func build(): HttpRequest
功能:根据 HttpRequestBuilder 实例生成一个 HttpRequest 实例。
返回值:根据当前 HttpRequestBuilder 实例构造出来的 HttpRequest 实例
class HttpRequest
public class HttpRequest <: ToString
此类为 Http 请求类。
客户端发送请求时,需要构造一个 HttpRequest 实例,再编码成字节报文发出。
服务端处理请求时,需要把收到的请求解析成 HttpRequest 实例,并传给 handler 处理函数。
prop method
public prop method: String
功能:获取 method,如 "GET", "POST",request 实例的 method 无法修改
prop url
public prop url: URL
功能:获取 url,表示客户端访问的 url
prop version
public prop version: Protocol
功能:获取 http 版本,如 HTTP1_1 和 HTTP2_0,request 实例的 version 无法修改
prop headers
public prop headers: HttpHeaders
功能:获取 headers,headers 详述见 HttpHeaders 类,获取后,可通过调用 HttpHeaders 实例成员函数,修改该请求的 headers
prop body
public prop body: InputStream
功能:获取 body 注意
- body 不支持并发读取
- 默认 InputStream 实现类的 read 函数不支持多次读取
prop trailers
public prop trailers: HttpHeaders
功能:获取 trailers,trailers 详述见 HttpHeaders 类,获取后,可通过调用 HttpHeaders 实例成员函数,修改该请求的 trailers
prop bodySize
public prop bodySize: Option<Int64>
功能:获取请求 body 长度
- 如果未设置 body,则 bodySize 为 Some(0)
- 如果 body 长度已知,即通过
Array<UInt8>或 String 传入 body,或传入的 InputStream 有确定的 length (length >= 0),则 bodySize 为 Some(Int64) - 如果 body 长度未知,即通过用户自定义的 InputStream 实例传入 body 且 InputStream 实例没有确定的 length (length < 0),则 bodySize 为 None
prop form
public prop form: Form
功能:获取请求中的表单信息
- 如果请求方法为 POST,PUT,PATCH,且 content-type 包含 application/x-www-form-urlencoded,获取请求 body 部分,用 form 格式解析
- 如果请求方法不为 POST,PUT,PATCH,获取请求 url 中 query 部分 注意
- 如果用该接口读取了 body,body 已被消费完,后续将无法通过 body.read 读取 body
- 如果 form 不符合 Form 格式,抛 UrlSyntaxException 异常
prop remoteAddr
public prop remoteAddr: String
功能:用于服务端,获取对端地址,即客户端地址,格式为 ip: port,用户无法设置,自定义的 request 对象调用该属性返回 "",服务端 handler 中调用该属性返回客户端地址
prop close
public prop close: Bool
功能:表示该请求 header 是否包含 Connection: close
- 对于服务端,close 为 true 表示处理完该请求应该关闭连接
- 对于客户端,close 为 true 表示如果收到响应后服务端未关闭连接,客户端应主动关闭连接
prop readTimeout
public prop readTimeout: ?Duration
功能:表示该请求的请求级读超时时间,None 表示没有设置;Some(Duration) 表示设置了。
prop writeTimeout
public prop writeTimeout: ?Duration
功能:表示该请求的请求级写超时时间,None 表示没有设置;Some(Duration) 表示设置了。
func toString
public override func toString(): String
功能:把请求转换为字符串,包括 start line,headers,body size,trailers例如:GET /path HTTP/1.1\r\nhost: <www.example.com\r\n\r\nbody> size: 5\r\nbar: foo\r\n。
返回值:请求的字符串表示
class HttpResponseBuilder
public class HttpResponseBuilder
HttpResponseBuilder 类用于构造 HttpResponse 实例。
init
public init()
功能:构造一个新 HttpResponseBuilder。
func version
public func version(version: Protocol): HttpResponseBuilder
功能:设置 http 响应协议版本。
func status
public func status(status: UInt16): HttpResponseBuilder
功能:设置 http 响应状态码。
异常:
- HttpException:如果设置响应状态码不在 100~599 这个区间内,则抛出此异常
func header
public func header(name: String, value: String): HttpResponseBuilder
功能:向响应 header 添加指定键值对 name: value,规则同 HttpHeaders 类的 add 函数。
异常:
- HttpException:如果传入的 name 或 value 包含不合法元素,将抛出此异常
func addHeaders
public func addHeaders (headers: HttpHeaders): HttpResponseBuilder
功能:向响应 header 添加参数 HttpHeaders 中的键值对。
func setHeaders
public func setHeaders (headers: HttpHeaders): HttpResponseBuilder
功能:设置响应 header,如果已经设置过,调用该函数将替换原 header。
func body
public func body(body: Array<UInt8>): HttpResponseBuilder
功能:设置响应 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 将以内置的 InputStream 实现类表示,其大小已知默认请求 body 为空的 InputStream 对象,即其 read 函数总是返回 0。
func body
public func body(body: String): HttpResponseBuilder
功能:设置响应 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 将以内置的 InputStream 实现类表示,其大小已知。
func body
public func body(body: InputStream): HttpResponseBuilder
功能:设置响应 body,如果已经设置过,调用该函数将替换原 body调用该函数设置请求 body,则 body 以用户自定义的 InputStream 实现类表示,其大小未知。
func trailer
public func trailer(name: String, value: String): HttpResponseBuilder
功能:向响应 trailer 添加指定键值对 name: value,规则同 HttpHeaders 类的 add 函数。
异常:
- HttpException:如果传入的 name 或 value 包含不合法元素,将抛出此异常
func addTrailers
public func addTrailers (trailers: HttpHeaders): HttpResponseBuilder
功能:向响应 trailer 添加参数 HttpHeaders 中的键值对。
func setTrailers
public func setTrailers (trailers: HttpHeaders): HttpResponseBuilder
功能:设置响应 trailer,如果已经设置过,调用该函数将替换原 trailer。
func request
public func request(request: HttpRequest): HttpResponseBuilder
功能:设置响应对应的请求。
func build
public func build(): HttpResponse
功能:根据 HttpResponseBuilder 实例生成一个 HttpResponse 实例。
返回值:根据当前 HttpResponseBuilder 实例构造出来的 HttpResponse 实例
class HttpResponse
public class HttpResponse <: ToString
Http 响应类。
此类定义了 http 中响应 Response 的相关接口,客户端用该类读取服务端返回的响应。
prop version
public prop version: Protocol
功能:获取响应的协议版本,默认值为Http1_1
prop status
public prop status: UInt16
功能:获取响应的状态码,默认值为 200。状态码由 100~599 的三位数字组成,状态码所反映的具体信息可参考 rfc9110 https://httpwg.org/specs/rfc9110.html#status.codes。
prop headers
public prop headers: HttpHeaders
功能:获取 headers,headers 详述见 HttpHeaders 类,获取后,可通过调用 HttpHeaders 实例成员函数,修改该请求的 headers
prop body
public prop body: InputStream
功能:获取 body 注意
- body 不支持并发读取
- 默认 InputStream 实现类的 read 函数不支持多次读取
prop trailers
public prop trailers: HttpHeaders
功能:获取 trailers,trailers 详述见 HttpHeaders 类,获取后,可通过调用 HttpHeaders 实例成员函数,修改该请求的 trailers
prop bodySize
public prop bodySize: Option<Int64>
功能:获取响应 body 长度
- 如果未设置 body,则 bodySize 为 Some(0)
- 如果 body 长度已知,即通过
Array<UInt8>或 String 传入 body,或传入的 InputStream 有确定的 length (length >= 0),则 bodySize 为 Some(Int64) - 如果 body 长度未知,即通过用户自定义的 InputStream 实例传入 body 且 InputStream 实例没有确定的 length (length < 0),则 bodySize 为 None
prop request
public prop request: Option<HttpRequest>
功能:获取该响应对应的请求,默认为 None
prop close
public prop close: Bool
功能:表示该响应 header 是否包含 Connection: close
- 对于服务端,close 为 true 表示处理完该请求应该关闭连接
- 对于客户端,close 为 true 表示如果收到响应后服务端未关闭连接,客户端应主动关闭连接
func getPush
public func getPush(): Option<ArrayList<HttpResponse>>
功能:获取服务器推送的响应,返回 None 代表未开启服务器推送功能,返回空 ArrayList 代表无服务器推送的响应。
func toString
public override func toString(): String
功能:把响应转换为字符串,包括 status-line,headers,body size, trailers例如:HTTP/1.1 200 OK\r\ncontent-length: 5\r\n\r\nbody size: 5\r\nbar: foo\r\n。
struct HttpStatusCode
public struct HttpStatusCode {
public static const STATUS_CONTINUE = 100
public static const STATUS_SWITCHING_PROTOCOLS = 101
public static const STATUS_PROCESSING = 102
public static const STATUS_EARLY_HINTS = 103
public static const STATUS_OK = 200
public static const STATUS_CREATED = 201
public static const STATUS_ACCEPTED = 202
public static const STATUS_NON_AUTHORITATIVE_INFO = 203
public static const STATUS_NO_CONTENT = 204
public static const STATUS_RESET_CONTENT = 205
public static const STATUS_PARTIAL_CONTENT = 206
public static const STATUS_MULTI_STATUS = 207
public static const STATUS_ALREADY_REPORTED = 208
public static const STATUS_IM_USED = 226
public static const STATUS_MULTIPLE_CHOICES = 300
public static const STATUS_MOVED_PERMANENTLY = 301
public static const STATUS_FOUND = 302
public static const STATUS_SEE_OTHER = 303
public static const STATUS_NOT_MODIFIED = 304
public static const STATUS_USE_PROXY = 305
public static const STATUS_TEMPORARY_REDIRECT = 307
public static const STATUS_PERMANENT_REDIRECT = 308
public static const STATUS_BAD_REQUEST = 400
public static const STATUS_UNAUTHORIZED = 401
public static const STATUS_PAYMENT_REQUIRED = 402
public static const STATUS_FORBIDDEN = 403
public static const STATUS_NOT_FOUND = 404
public static const STATUS_METHOD_NOT_ALLOWED = 405
public static const STATUS_NOT_ACCEPTABLE = 406
public static const STATUS_PROXY_AUTH_REQUIRED = 407
public static const STATUS_REQUEST_TIMEOUT = 408
public static const STATUS_CONFLICT = 409
public static const STATUS_GONE = 410
public static const STATUS_LENGTH_REQUIRED = 411
public static const STATUS_PRECONDITION_FAILED = 412
public static const STATUS_REQUEST_CONTENT_TOO_LARGE = 413
public static const STATUS_REQUEST_URI_TOO_LONG = 414
public static const STATUS_UNSUPPORTED_MEDIA_TYPE = 415
public static const STATUS_REQUESTED_RANGE_NOT_SATISFIABLE = 416
public static const STATUS_EXPECTATION_FAILED = 417
public static const STATUS_TEAPOT = 418
public static const STATUS_MISDIRECTED_REQUEST = 421
public static const STATUS_UNPROCESSABLE_ENTITY = 422
public static const STATUS_LOCKED = 423
public static const STATUS_FAILED_DEPENDENCY = 424
public static const STATUS_TOO_EARLY = 425
public static const STATUS_UPGRADE_REQUIRED = 426
public static const STATUS_PRECONDITION_REQUIRED = 428
public static const STATUS_TOO_MANY_REQUESTS = 429
public static const STATUS_REQUEST_HEADER_FIELDS_TOO_LARGE = 431
public static const STATUS_UNAVAILABLE_FOR_LEGAL_REASONS = 451
public static const STATUS_INTERNAL_SERVER_ERROR = 500
public static const STATUS_NOT_IMPLEMENTED = 501
public static const STATUS_BAD_GATEWAY = 502
public static const STATUS_SERVICE_UNAVAILABLE = 503
public static const STATUS_GATEWAY_TIMEOUT = 504
public static const STATUS_HTTP_VERSION_NOT_SUPPORTED = 505
public static const STATUS_VARIANT_ALSO_NEGOTIATES = 506
public static const STATUS_INSUFFICIENT_STORAGE = 507
public static const STATUS_LOOP_DETECTED = 508
public static const STATUS_NOT_EXTENDED = 510
public static const STATUS_NETWORK_AUTHENTICATION_REQUIRED = 511
}
用以表示网页服务器超文本传输协议响应状态的 3 位数字代码。它由 RFC 9110 规范定义的,并得到 RFC2518、RFC 3229、RFC 4918、RFC 5842、RFC 7168 与 RFC 8297 等规范扩展。所有状态码的第一个数字代表了响应的五种状态之一。
- 状态代码的 1xx(信息)指示在完成请求的操作并发送最终响应之前通信连接状态或请求进度的临时响应;
- 状态代码的 2xx(成功)指示客户端的请求已成功接收、理解和接受;
- 状态代码的 3xx(重定向)指示用户代理需要采取进一步的操作才能完成请求;
- 状态代码的 4xx(客户端错误)指示客户端似乎出错;
- 状态代码的 5xx(服务器错误)指示服务器意识到它出错或无法执行请求的方法;
HttpStatusCode 类结构和主要函数如下:
STATUS_CONTINUE
public static const STATUS_CONTINUE = 100
HTTP 标准状态码 客户端继续发送请求时。这个临时响应是用来通知客户端它的部分请求已经被 服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请 求已经完成,忽略这个响应。服务器必须在请求完成后向客户端发送一个最终响应
STATUS_SWITCHING_PROTOCOLS
public static const STATUS_SWITCHING_PROTOCOLS = 101
服务器已经理解了客户端的请求,并将通过 Upgrade 消息头通知客户端采用不同的 协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到在 Upgrade 消息头中定义的那些协议
STATUS_PROCESSING
public static const STATUS_PROCESSING = 102
处理将被继续执行
STATUS_EARLY_HINTS
public static const STATUS_EARLY_HINTS = 103
提前预加载 (css、js) 文档
STATUS_OK
public static const STATUS_OK = 200
2 开头的状态码,代表请求已成功被服务器接收、理解、并接受,正常状态, 请求已成功,请求所希望的响应头或数据体将随此响应返回
STATUS_CREATED
public static const STATUS_CREATED = 201
请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其 URI 已经 随 Location 头信息返回
STATUS_ACCEPTED
public static const STATUS_ACCEPTED = 202
服务器已接受请求,但尚未处理
STATUS_NON_AUTHORITATIVE_INFO
public static const STATUS_NON_AUTHORITATIVE_INFO = 203
服务器已成功处理了请求。返回的实体头部元信息不是在原始服务器上有效的 确定集合,而是来自本地或者第三方的拷贝
STATUS_NO_CONTENT
public static const STATUS_NO_CONTENT = 204
服务器成功处理,但未返回内容
STATUS_RESET_CONTENT
public static const STATUS_RESET_CONTENT = 205
服务器成功处理了请求,且没有返回任何内容,希望请求者重置文档视图
STATUS_PARTIAL_CONTENT
public static const STATUS_PARTIAL_CONTENT = 206
服务器已经成功处理了部分 GET 请求
STATUS_MULTI_STATUS
public static const STATUS_MULTI_STATUS = 207
DAV 绑定的成员已经在(多状态)响应之前的部分被列举,且未被再次包含
STATUS_ALREADY_REPORTED
public static const STATUS_ALREADY_REPORTED = 208
消息体将是一个 XML 消息
STATUS_IM_USED
public static const STATUS_IM_USED = 226
服务器已完成对资源的请求,并且响应是应用于当前实例的一个或多个实例操作的结果 的表示
STATUS_MULTIPLE_CHOICES
public static const STATUS_MULTIPLE_CHOICES = 300
被请求的资源有一系列可供选择的回馈信息,每个都有自己特定的地址和浏览器驱动的 商议信息。用户或浏览器能够自行选择一个首选的地址进行重定向
STATUS_MOVED_PERMANENTLY
public static const STATUS_MOVED_PERMANENTLY = 301
永久移动 请求的资源已被永久的移动到新 URI,返回信息会包括新的 URI,浏览器会自动定向到 新 URI。
STATUS_FOUND
public static const STATUS_FOUND = 302
临时移动 请求的资源已被临时的移动到新 URI,客户端应当继续向原有地址发送以后的请求
STATUS_SEE_OTHER
public static const STATUS_SEE_OTHER = 303
对应当前请求的响应可以在另一个 URL 上被找到,而且客户端应当采用 GET 的 方式访问那个资源
STATUS_NOT_MODIFIED
public static const STATUS_NOT_MODIFIED = 304
请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访 问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源
STATUS_USE_PROXY
public static const STATUS_USE_PROXY = 305
使用代理,所请求的资源必须通过代理访问
STATUS_TEMPORARY_REDIRECT
public static const STATUS_TEMPORARY_REDIRECT = 307
临时重定向
STATUS_PERMANENT_REDIRECT
public static const STATUS_PERMANENT_REDIRECT = 308
请求和所有将来的请求应该使用另一个 URI
STATUS_BAD_REQUEST
public static const STATUS_BAD_REQUEST = 400
- 语义有误,当前请求无法被服务器理解
- 请求参数有误
STATUS_UNAUTHORIZED
public static const STATUS_UNAUTHORIZED = 401
当前请求需要用户验证
STATUS_PAYMENT_REQUIRED
public static const STATUS_PAYMENT_REQUIRED = 402
为了将来可能的需求而预留的状态码
STATUS_FORBIDDEN
public static const STATUS_FORBIDDEN = 403
服务器已经理解请求,但是拒绝执行
STATUS_NOT_FOUND
public static const STATUS_NOT_FOUND = 404
请求失败,请求所希望得到的资源未被在服务器上发现
STATUS_METHOD_NOT_ALLOWED
public static const STATUS_METHOD_NOT_ALLOWED = 405
请求行中指定的请求函数不能被用于请求响应的资源
STATUS_NOT_ACCEPTABLE
public static const STATUS_NOT_ACCEPTABLE = 406
请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体
STATUS_PROXY_AUTH_REQUIRED
public static const STATUS_PROXY_AUTH_REQUIRED = 407
必须在代理服务器上进行身份验证
STATUS_REQUEST_TIMEOUT
public static const STATUS_REQUEST_TIMEOUT = 408
请求超时。客户端没有在服务器预备等待的时间内完成一个请求的发送
STATUS_CONFLICT
public static const STATUS_CONFLICT = 409
由于和被请求的资源的当前状态之间存在冲突,请求无法完成
STATUS_GONE
public static const STATUS_GONE = 410
被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址
STATUS_LENGTH_REQUIRED
public static const STATUS_LENGTH_REQUIRED = 411
服务器拒绝在没有定义 Content-Length 头的情况下接受请求
STATUS_PRECONDITION_FAILED
public static const STATUS_PRECONDITION_FAILED = 412
服务器在验证在请求的头字段中给出先决条件时,没能满足其中的一个或多个
STATUS_REQUEST_CONTENT_TOO_LARGE
public static const STATUS_REQUEST_CONTENT_TOO_LARGE = 413
请求提交的实体数据大小超过了服务器愿意或者能够处理的范围
STATUS_REQUEST_URI_TOO_LONG
public static const STATUS_REQUEST_URI_TOO_LONG = 414
请求的 URI 长度超过了服务器能够解释的长度
STATUS_UNSUPPORTED_MEDIA_TYPE
public static const STATUS_UNSUPPORTED_MEDIA_TYPE = 415
服务器无法处理请求附带的媒体格式,对于当前请求的函数和所请求的资源,请求中提 交的实体并不是服务器中所支持的格式
STATUS_REQUESTED_RANGE_NOT_SATISFIABLE
public static const STATUS_REQUESTED_RANGE_NOT_SATISFIABLE = 416
客户端请求的范围无效 请求中包含了 Range 请求头,并且 Range 中指定的任何数据范围都与当前资源的可 用范围不重合同时请求中又没有定义 If-Range 请求头
STATUS_EXPECTATION_FAILED
public static const STATUS_EXPECTATION_FAILED = 417
服务器无法满足 Expect 的请求头信息
STATUS_TEAPOT
public static const STATUS_TEAPOT = 418
服务端无法处理请求,一个愚弄客户端的状态码,被称为“我是茶壶”错误码,不应被认真对待
STATUS_MISDIRECTED_REQUEST
public static const STATUS_MISDIRECTED_REQUEST = 421
请求被指向到无法生成响应的服务器
STATUS_UNPROCESSABLE_ENTITY
public static const STATUS_UNPROCESSABLE_ENTITY = 422
请求格式正确,但是由于含有语义错误,无法响应
STATUS_LOCKED
public static const STATUS_LOCKED = 423
当前资源被锁定
STATUS_FAILED_DEPENDENCY
public static const STATUS_FAILED_DEPENDENCY = 424
由于之前的某个请求发生的错误,导致当前请求失败
STATUS_TOO_EARLY
public static const STATUS_TOO_EARLY = 425
服务器不愿意冒风险来处理该请求
STATUS_UPGRADE_REQUIRED
public static const STATUS_UPGRADE_REQUIRED = 426
客户端应当切换到 TLS/1.0
STATUS_PRECONDITION_REQUIRED
public static const STATUS_PRECONDITION_REQUIRED = 428
客户端发送 HTTP 请求时,必须要满足的一些预设条件
STATUS_TOO_MANY_REQUESTS
public static const STATUS_TOO_MANY_REQUESTS = 429
请求过多
STATUS_REQUEST_HEADER_FIELDS_TOO_LARGE
public static const STATUS_REQUEST_HEADER_FIELDS_TOO_LARGE = 431
请求头字段太大
STATUS_UNAVAILABLE_FOR_LEGAL_REASONS
public static const STATUS_UNAVAILABLE_FOR_LEGAL_REASONS = 451
该请求因法律原因不可用
STATUS_INTERNAL_SERVER_ERROR
public static const STATUS_INTERNAL_SERVER_ERROR = 500
服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理
STATUS_NOT_IMPLEMENTED
public static const STATUS_NOT_IMPLEMENTED = 501
服务器不支持当前请求所需要的某个功能
STATUS_BAD_GATEWAY
public static const STATUS_BAD_GATEWAY = 502
作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应
STATUS_SERVICE_UNAVAILABLE
public static const STATUS_SERVICE_UNAVAILABLE = 503
临时的服务器维护或者过载
STATUS_GATEWAY_TIMEOUT
public static const STATUS_GATEWAY_TIMEOUT = 504
从上游服务器(URI 标识出的服务器,例如 HTTP、FTP、LDAP)或者辅助服务 器(例如 DNS)收到响应超时
STATUS_HTTP_VERSION_NOT_SUPPORTED
public static const STATUS_HTTP_VERSION_NOT_SUPPORTED = 505
服务器不支持,或者拒绝支持在请求中使用的 HTTP 版本
STATUS_VARIANT_ALSO_NEGOTIATES
public static const STATUS_VARIANT_ALSO_NEGOTIATES = 506
服务器存在内部配置错误
STATUS_INSUFFICIENT_STORAGE
public static const STATUS_INSUFFICIENT_STORAGE = 507
服务器无法存储完成请求所必须的内容
STATUS_LOOP_DETECTED
public static const STATUS_LOOP_DETECTED = 508
服务器在处理请求时检测到无限递归
STATUS_NOT_EXTENDED
public static const STATUS_NOT_EXTENDED = 510
获取资源所需要的策略并没有被满足
STATUS_NETWORK_AUTHENTICATION_REQUIRED
public static const STATUS_NETWORK_AUTHENTICATION_REQUIRED = 511
要求网络认证
class HttpResponseWriter
public class HttpResponseWriter {
public HttpResponseWriter(let ctx: HttpContext)
}
HTTP response消息体 Writer,支持用户控制消息体的发送过程。
第一次调用 write 函数时,将立即发送 header 和通过参数传入的 body,此后每次调用 write,发送通过参数传入的 body。 对于 HTTP/1.1,如果设置了 transfer-encoding: chunked,用户每调用一次 write,将发送一个 chunk。 对于 HTTP/2,用户每调用一次 write,将把指定数据封装并发出。
HttpResponseWriter
public HttpResponseWriter(let ctx: HttpContext)
功能:构造一个 HttpResponseWriter 实例
func write
public func write(buf: Array<Byte>): Unit
功能:发送 buf 中数据到客户端。以下情况调用该函数将会抛出 HttpException 若服务端不进行捕捉将返回状态码为500的响应连接升级为 WebSocket ,或连接关闭response 协议版本为 HTTP/1.0若请求方法为 "HEAD" 或响应状态码为 "1XX\204\304"。
class HttpResponsePusher
public class HttpResponsePusher
HTTP/2 服务器推送。
如果服务器收到请求后,认为客户端后续还需要某些关联资源,可以将其提前推送到客户端。 服务端推送包括推送请求和推送响应。 启用服务端推送需要先调用 push 函数发送推送请求,并向服务器注册该请求对应的 handler,用以生成推送响应。 客户端可设置拒绝服务端推送。 不允许嵌套推送,即不允许在推送请求对应的 handler 中再次推送。这种情况下,服务端将不执行推送,并打印日志进行提示。
func getPusher
public static func getPusher(ctx: HttpContext): ?HttpResponsePusher
功能:获取 HttpResponsePusher 实例,如果客户端拒绝推送,将返回 None。
返回值:获得的 HttpResponsePusher
func push
public func push(path: String, method: String, header: HttpHeaders): Unit
功能:向客户端发送推送请求,path 为请求地址,method 为请求方法,header 为请求头。
struct TransportConfig
public struct TransportConfig
传输层配置,对应服务器调用serve()之后的建立连接传输层配置。
prop readTimeout
public mut prop readTimeout: Duration
功能:设定和读取传输层 socket 的读取时间,如果设置的时间小于 0 将置为 0,默认值为 Duration.Max。
prop writeTimeout
public mut prop writeTimeout: Duration
功能:设定和读取传输层 socket 的写入时间,如果设置的时间为负将置为 0,默认值为 Duration.Max。
prop writeBufferSize
public mut prop writeBufferSize: ?Int64
功能:设定和读取传输层 socket 的写缓冲区大小,默认值为 None ,若设置的值小于 0,将在服务器进行服务建立连接后抛出 IllegalArgumentException。
prop readBufferSize
public mut prop readBufferSize: ?Int64
功能:设定和读取传输层 socket 的读缓冲区大小,默认值为 None ,若设置的值小于 0,将在服务器进行服务建立连接后抛出 IllegalArgumentException。
prop keepAliveConfig
public mut prop keepAliveConfig: SocketKeepAliveConfig
功能:设定和读取传输层 socket 的消息保活配置,默认配置空闲时间为 45s,发送探测报文的时间间隔为 5s,在连接被认为无效之前发送的探测报文数 5 次,实际时间粒度可能因操作系统而异。
class Cookie
public class Cookie
HTTP 本身是无状态的,server 为了知道 client 的状态,提供个性化的服务,便可以通过 Cookie 来维护一个有状态的会话。
用户首次访问某站点时,server 通过 Set-Cookie header 将 name/value 对,以及 attribute-value 传给用户代理;用户代理随后的对该站点的请求中便可以将 name/value 包含进 Cookie header 中传给 server。
Cookie 类提供了构建 Cookie 对象,并将 Cookie 对象转成 Set-Cookie header 值的函数,提供了获取 Cookie 对象各属性值的函数。
Cookie 的各个属性的要求和作用见 RFC 6265。
prop cookieName
public prop cookieName: String
功能:获取 Cookie 对象的 cookie-name 值。
注意:cookie-name,cookie-value,expires-av 等名字采用 RFC 6265 中的名字,详情请见协议。
prop cookieValue
public prop cookieValue: String
功能:获取 Cookie 对象的 cookie-value 值。
prop expires
public prop expires: ?DateTime
功能:获取 Cookie 对象的 expires-av 值。
prop maxAge
public prop maxAge: ?Int64
功能:获取 Cookie 对象的 max-age-av 值。
prop domain
public prop domain: String
功能:获取 Cookie 对象的 domain-av 值。
prop path
public prop path: String
功能:获取 Cookie 对象的 path-av 值。
prop secure
public prop secure: Bool
功能:获取 Cookie 对象的 secure-av 值。
prop httpOnly
public prop httpOnly: Bool
功能:获取 Cookie 对象的 httpOnly-av 值。
prop others
public prop others: ArrayList<String>
功能:获取未被解析的属性。
func toSetCookieString
public func toSetCookieString(): String
功能:提供将 Cookie 转成字符串形式的函数,方便 server 设置 Set-Cookie header说明:服务器设置 Set-Cookie header 时,可以先创建一个 Cookie 对象,再对其调用该函数获得 Set-Cookie value,将 Set-Cookie value 设置为 Set-Cookie header 的值并发送给客户端注意:
- Cookie 各属性(包含 name,value)在对象创建时就被检查了,因此对 Cookie 对象调用 toSetCookieString 函数不会产生异常
- Cookie 必需的属性是 cookie-pair 即 cookie-name "=" cookie-value,cookie-value 可以为空字符串,toSetCookieString 函数只会将设置过的属性写入字符串,即只有 "cookie-name=" 是必有的,其余部分是否存在取决于是否设置。
返回值:字符串对象,用于设置 Set-Cookie header
init
public init(name: String, value: String, expires!: ?DateTime = None, maxAge!: ?Int64 = None,
domain!: String = "", path!: String = "", secure!: Bool = false, httpOnly!: Bool = false)
功能:提供 Cookie 对象的公开构造器说明:该构造器会检查传入的各项属性是否满足协议要求,如果不满足则会产生 IllegalArgumentException。 具体要求见 RFC 6265 4.1.1.
注意:Cookie 各属性中只有 cookie-name,cookie-value 是必需的,必须传入 name,value 参数,但 value 参数可以传入空字符串。
参数:
- name:cookie-name 属性
name = token
token = 1*tchar
tchar = "!" / "#" / "$" / "%" / "&" / "'" / "*"
/ "+" / "-" / "." / "^" / "_" / "`" / "|" / "~"
/ DIGIT / ALPHA
- value:cookie-value 属性
value = *cookie-octet / ( DQUOTE *cookie-octet DQUOTE )
cookie-octet = %x21 / %x23-2B / %x2D-3A / %x3C-5B / %x5D-7E
; US-ASCII characters excluding CTLs,
; whitespace DQUOTE, comma, semicolon,
; and backslash
- expires:设置 Cookie 的过期时间,默认为 None,时间必须在 1601 年之后
- maxAge:Cookie 的最大生命周期,默认为 None,如果 Cookie 既有 expires 属性,也有 maxAge,则表示该 Cookie 只维护到会话结束(维护到 Client 关闭之前,Client 关闭之后设置了过期的 Cookie 也不再维护)
max-age-av = "Max-Age=" non-zero-digit *DIGIT
non-zero-digit = %x31-39
; digits 1 through 9
DIGIT = %x30-39
; digits 0 through 9
- domain:默认为空字符串,表示该收到该 Cookie 的客户端只会发送该 Cookie 给原始服务器。如果设置了合法的 domain,则收到该 Cookie 的客户端只会发送该 Cookie 给所有该 domain 的子域(且满足其他属性条件要求才会发)
domain = <subdomain> | " "
<subdomain> ::= <label> | <subdomain> "." <label>
<label> ::= <letter> [ [ <ldh-str> ] <let-dig> ]
<ldh-str> ::= <let-dig-hyp> | <let-dig-hyp> <ldh-str>
<let-dig-hyp> ::= <let-dig> | "-"
<let-dig> ::= <letter> | <digit>
<letter> ::= any one of the 52 alphabetic characters A through Z in upper case and a through z in lower case
<digit> ::= any one of the ten digits 0 through 9
RFC 1035 2.3.1.
而 RFC 1123 2.1. 放松了对 label 首字符必须是 letter 的限制
因此,对 domain 的要求为:
1、总长度小于等于 255,由若干个 label 组成
2、label 与 label 之间通过 "." 分隔,每个 label 长度小于等于 63
3、label 的开头和结尾必须是数字或者字母,label 的中间字符必须是数字、字母或者 "-"
- path:默认为空字符串,客户端会根据 url 计算出默认的 path 属性,见 RFC 6265 5.1.4. 收到该 Cookie 的客户端只会发送该 Cookie 给所有该 path 的子目录(且满足其他属性条件要求才会发)
path = <any CHAR except CTLs or ";">
CHAR = <any [USASCII] character>
CTLs = <controls>
- secure:默认为 false,如果设置为 true,该 Cookie 只会在安全协议请求中发送
- httpOnly:默认为 false,如果设置为 true,该 Cookie 只会在 HTTP 协议请求中发送
返回值:构造的 Cookie 对象
异常:
- IllegalArgumentException:传入的参数不符合协议要求
interface CookieJar
public interface CookieJar {
prop rejectPublicSuffixes: ArrayList<String>
prop isHttp: Bool
func storeCookies(url: URL, cookies: ArrayList<Cookie>): Unit
func getCookies(url: URL): ArrayList<Cookie>
func removeCookies(domain: String): Unit
func clear(): Unit
static func toCookieString(cookies: ArrayList<Cookie>): String
static func parseSetCookieHeader(response: HttpResponse): ArrayList<Cookie>
static func createDefaultCookieJar(rejectPublicSuffixes: ArrayList<String>, isHttp: Bool): CookieJar
}
CookieJar 是 Client 用来管理 Cookie 的工具,其有两个静态函数,toCookieString 用于将 ArrayList<Cookie> 转成字符串以便设置请求的 Cookie header;
parseSetCookieHeader 用于解析收到 response 中的 Set-Cookie header;如果 Client 配置了 CookieJar,那么 Cookie 的解析收发都是自动的;
用户可以实现自己的 CookieJar,实现自己的管理逻辑。
createDefaultCookieJar 函数返回一个默认的 CookieJar 实例。
CookieJar 的管理要求见 RFC 6265。
prop rejectPublicSuffixes
prop rejectPublicSuffixes: ArrayList<String>
功能:获取 public suffixes 配置,该配置是一个 domain 黑名单,会拒绝 domain 值为 public suffixes 的 Cookie (除非该 Cookie 来自于与 domain 相同的 host) public suffixes 见 https://publicsuffix.org/
prop isHttp
prop isHttp: Bool
功能:该 CookieJar 是否用于 HTTP 协议 isHttp 为 true 则只会存储来自于 HTTP 协议的 Cookie isHttp 为 false 则只会存储来自非 HTTP 协议的 Cookie,且不会存储发送设置了 httpOnly 的 Cookie
func storeCookies
func storeCookies(url: URL, cookies: ArrayList<Cookie>): Unit
功能:将 ArrayList<Cookie> 存进 CookieJar
说明:默认实现的 cookieJarImpl 中的 Cookie 是以 CookieEntry (包访问权限) 对象的形式存进 CookieJar 中的,具体要求见 RFC 6265 5.3.,如果往 CookieJar 中存 Cookie 时超过了上限(3000 条),那么至少清除 CookieJar 中 1000 条 Cookie 再往里存清除 CookieJar 中 Cookie 的优先级见 RFC 6265 5.3.12.
- 过期的 Cookie
- 相同 domain 中超过 50 条以上的部分
- 所有 Cookie具有相同优先级的 Cookie 则优先删除 last-access 属性更早的。
参数:
- url:产生该 Cookie 的 url
- cookies:需要存储的
ArrayList<Cookie>
func getCookies
func getCookies(url: URL): ArrayList<Cookie>
功能:从 CookieJar 中取出 ArrayList<Cookie>
说明:默认实现 cookieJarImpl 的取 ArrayList<Cookie> 函数的具体要求见 RFC 6265 5.4.,对取出的 ArrayList<Cookie> 调用 toCookieString 可以将取出的 ArrayList<Cookie> 转成 Cookie header 的 value 字符串。
参数:
- url:所要取出
ArrayList<Cookie>的 url
返回值:CookieJar 中存储的对应此 url 的 ArrayList<Cookie>
func removeCookies
func removeCookies(domain: String): Unit
功能:从 CookieJar 中移除某个 domain 的 Cookie说明:默认实现 CookieJarImpl 的移除某个 domain 的 Cookie 只会移除特定 domain 的 Cookie,domain 的 subdomain 的 Cookie 并不会移除。
参数:
- domain:所要移除 Cookie 的域名
异常:
- IllegalArgumentException:如果传入的 domain 为空字符串或者非法,则抛出该异常,合法的 domain 规则见 Cookie 的参数文档
func clear
func clear(): Unit
功能:清除全部 Cookie说明:默认实现 CookieJarImpl 会清除 CookieJar 中的所有 Cookie。
func toCookieString
static func toCookieString(cookies: ArrayList<Cookie>): String
功能:静态函数,将 ArrayList<Cookie> 转成字符串,用于 Cookie header说明:该函数会将传入的 ArrayList<Cookie> 数组转成协议规定的 Cookie header 的字符串形式,见 RFC 6265 5.4.4.。
参数:
- cookies:所需转成 Cookie header 字符串的
ArrayList<Cookie>
返回值:用于 Cookie header 的字符串
func parseSetCookieHeader
static func parseSetCookieHeader(response: HttpResponse): ArrayList<Cookie>
功能:静态函数,解析 response 中的 Set-Cookie header说明:该函数解析 response 中的 Set-Cookie header,并返回解析出的 ArrayList<Cookie>,解析 Set-Cookie header 的具体规则见 RFC 6265 5.2.。
参数:
- response:所需要解析的 response
返回值:从 response 中解析出的 ArrayList<Cookie> 数组
func createDefaultCookieJar
static func createDefaultCookieJar(rejectPublicSuffixes: ArrayList<String>, isHttp: Bool): CookieJar
功能:静态函数,构建默认的管理 Cookie 的 CookieJar 实例说明:默认的 CookieJar 的管理要求参考 RFC 6265 5.3.isHttp 为 false 则只会存储来自非 HTTP 协议的 Cookie,且不会存储发送设置了 httpOnly 的 Cookie。
参数:
- rejectPublicSuffixes:用户配置的 public suffixes,Cookie 管理为了安全会拒绝 domain 值为 public suffixes 的 cookie(除非该 Cookie 来自于与 domain 相同的 host),public suffixes 见 https://publicsuffix.org/
- isHttp:该 CookieJar 是否用于 HTTP 协议,isHttp 为 true 则只会存储来自于 HTTP 协议的 Cookie;
返回值:默认的 CookieJar 实例
class HttpException
public class HttpException <: Exception
Http 的异常类。
class HttpTimeoutException
public class HttpTimeoutException <: Exception
class HttpStatusException
public class HttpStatusException <: Exception
class WebSocketException
public class WebSocketException <: Exception
class ConnectionException
public class ConnectionException <: Exception {
public init(message: String)
}
init
public init(message: String)
参数:
- message:异常提示信息
异常:
- 类初始化函数
class CoroutinePoolRejectException
public class CoroutinePoolRejectException <: Exception {
public init(message: String)
}
init
public init(message: String)
参数:
- message:异常提示信息
异常:
- 异常类初始化函数
示例
server
Hello 仓颉
from net import http.ServerBuilder
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
// 2. 注册 HttpRequestHandler
server.distributor.register("/index", {httpContext =>
httpContext.responseBuilder.body("Hello 仓颉!")
})
// 3. 启动服务
server.serve()
}
通过 request distributor注册处理器
from net import http.{ServerBuilder, HttpRequestHandler, FuncHandler}
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
var a: HttpRequestHandler = FuncHandler({ httpContext =>
httpContext.responseBuilder.body("index")
})
var b: HttpRequestHandler = FuncHandler({ httpContext =>
httpContext.responseBuilder.body("id")
})
var c: HttpRequestHandler = FuncHandler({ httpContext =>
httpContext.responseBuilder.body("help")
})
server.distributor.register("/index", a)
server.distributor.register("/id", b)
server.distributor.register("/help", c)
// 2. 启动服务
server.serve()
}
自定义 request distributor与处理器
from net import http.*
from std import collection.HashMap
class NaiveDistributor <: HttpRequestDistributor {
let map = HashMap<String, HttpRequestHandler>()
public func register(path: String, handler: HttpRequestHandler): Unit {
map.put(path, handler)
}
public func distribute(path: String): HttpRequestHandler {
if (path == "/index") {
return PageHandler()
}
return NotFoundHandler()
}
}
// 返回一个简单的 HTML 页面
class PageHandler <: HttpRequestHandler {
public func handle(httpContext: HttpContext): Unit {
httpContext.responseBuilder.body(b"<html></html>")
}
}
class NotFoundHandler <: HttpRequestHandler {
public func handle(httpContext: HttpContext): Unit {
httpContext.responseBuilder
.status(404)
.body(b"404 Not Found")
}
}
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.distributor(NaiveDistributor()) // 自定义分发器
.build()
// 2. 启动服务
server.serve()
}
自定义 server 网络配置
from std import fs.*
from net import tls.*
from crypto import x509.{X509Certificate, PrivateKey}
from net import http.*
//该程序需要用户配置存在且合法的文件路径才能执行
main () {
// 1. 自定义配置
// tcp 配置
var transportCfg = TransportConfig()
transportCfg.readBufferSize = 8192
// tls 配置 需要传入配套的证书与私钥文件路径
let pem0 = String.fromUtf8(File("/certPath", OpenOption.Open(true, false)).readToEnd())
let pem02 = String.fromUtf8(File("/keyPath", OpenOption.Open(true, false)).readToEnd())
var tlsConfig = TlsServerConfig(X509Certificate.decodeFromPem(pem0), PrivateKey.decodeFromPem(pem02))
tlsConfig.supportedAlpnProtocols = ["h2"]
// 2. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.transportConfig(transportCfg)
.tlsConfig(tlsConfig)
.headerTableSize(10 * 1024)
.maxRequestHeaderSize(1024 * 1024)
.build()
// 3. 注册 HttpRequestHandler
server.distributor.register("/index", {httpContext =>
httpContext.responseBuilder.body("Hello 仓颉!")
})
// 4. 启动服务
server.serve()
}
response中的 chunked与trailer
from net import http.*
from std import io.*
from std import collection.HashMap
func checksum(chunk: Array<UInt8>): Int64 {
var sum = 0
for (i in chunk) {
if (i == b'\n') {
sum += 1
}
}
return sum / 2
}
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
// 2. 注册 HttpRequestHandler
server.distributor.register("/index", {httpContext =>
let responseBuilder = httpContext.responseBuilder
responseBuilder.header("transfer-encoding", "chunked") // 设置response头
responseBuilder.header("trailer", "checkSum")
let writer = HttpResponseWriter(httpContext)
var sum = 0
for (_ in 0..10) {
let chunk = Array<UInt8>(10, item: 0)
sum += checksum(chunk)
writer.write(chunk) // 立即发送
}
responseBuilder.trailer("checkSum", "${sum}") // handler结束后发送
})
// 3. 启动服务
server.serve()
}
处理重定向 request
from net import http.*
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
// 2. 注册 HttpRequestHandler
server.distributor.register("/redirecta",RedirectHandler("/movedsource", 308))
server.distributor.register("/redirectb",RedirectHandler("http://www.example.com", 308))
// 3. 启动服务
server.serve()
}
tls 证书热加载
from std import fs.*
from net import tls.*
from crypto import x509.{X509Certificate, PrivateKey}
from net import http.*
//该程序需要用户配置存在且合法的文件路径才能执行
main() {
// 1. tls 配置
let pem0 = String.fromUtf8(File("/certPath", OpenOption.Open(true, false)).readToEnd())
let pem02 = String.fromUtf8(File("/keyPath", OpenOption.Open(true, false)).readToEnd())
var tlsConfig = TlsServerConfig(X509Certificate.decodeFromPem(pem0), PrivateKey.decodeFromPem(pem02))
tlsConfig.supportedAlpnProtocols = ["http/1.1"]
let pem = String.fromUtf8(File("/rootCerPath", OpenOption.Open(true, false)).readToEnd())
tlsConfig.verifyMode = CustomCA(X509Certificate.decodeFromPem(pem))
// 2. 构建 Server 实例,并启动服务
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.tlsConfig(tlsConfig)
.build()
spawn {
server.serve()
}
// 3. 更新 tls 证书和私钥,之后收到的 request将使用新的证书和私钥
server.updateCert("/newCerPath", "/newKeyPath")
// 4. 更新 CA, 双向认证时使用,之后收到的 request将使用新的CA
server.updateCA("/newRootCerPath")
}
client
Hello World
from net import http.*
main () {
// 1. 构建 client 实例
let client = ClientBuilder().build()
// 2. 发送 request
let rsp = client.get("http://example.com/hello")
// 3. 读取response
println(rsp)
// 4. 关闭连接
client.close()
}
自定义 client 网络配置
from std import socket.TcpSocket
from std import convert.Parsable
from std import fs.*
from net import tls.*
from crypto import x509.X509Certificate
from net import http.*
//该程序需要用户配置存在且合法的文件路径才能执行
main () {
// 1. 自定义配置
// tls 配置
var tlsConfig = TlsClientConfig()
let pem = String.fromUtf8(File("/rootCerPath", OpenOption.Open(true, false)).readToEnd())
tlsConfig.verifyMode = CustomCA(X509Certificate.decodeFromPem(pem))
tlsConfig.alpnProtocolsList = ["h2"]
// connector
let TcpSocketConnector = { authority: String =>
let words = authority.split(":")
let addr = words[0]
let port = UInt16.parse(words[1])
let socket = TcpSocket(addr, port)
socket.connect()
return socket
}
// 2. 构建 client 实例
let client = ClientBuilder()
.tlsConfig(tlsConfig)
.enablePush(false)
.connector(TcpSocketConnector)
.build()
// 3. 发送 request
let rsp = client.get("https://example.com/hello")
// 4. 读取response
let buf = Array<UInt8>(1024, item: 0)
let len = rsp.body.read(buf)
println(String.fromUtf8(buf.slice(0, len)))
// 5. 关闭连接
client.close()
}
request中的 chunked 与 trailer
from std import io.*
from std import fs.*
from net import http.*
func checksum(chunk: Array<UInt8>): Int64 {
var sum = 0
for (i in chunk) {
if (i == b'\n') {
sum += 1
}
}
return sum / 2
}
//该程序需要用户配置存在且合法的文件路径才能执行
main () {
// 1. 构建 client 实例
let client = ClientBuilder().build()
var requestBuilder = HttpRequestBuilder()
let file = File("./res.jpg", OpenOption.Open(true, false))
let sum = checksum(file.readToEnd())
let req = requestBuilder
.method("PUT")
.url("https://example.com/src/")
.header("Transfer-Encoding","chunked")
.header("Trailer","checksum")
.body(FileBody("./res.jpg"))
.trailer("checksum", sum.toString())
.build()
let rsp = client.send(req)
println(rsp)
client.close()
}
class FileBody <: InputStream {
var file: File
init(path: String) { file = File(path, OpenOption.Open(true, false))}
public func read(buf: Array<UInt8>): Int64 {
file.read(buf)
}
}
配置代理
from net import http.*
main () {
// 1. 构建 client 实例
let client = ClientBuilder()
.httpProxy("http://192.168.0.1:8080")
.build()
// 2. 发送 request,所有 request都会被发送至192.168.0.1地址的8080端口,而不是example.com
let rsp = client.get("http://example.com/hello")
// 3. 读取response
println(rsp)
// 4. 关闭连接
client.close()
}
cookie
Client
from net import http.*
from encoding import url.*
from std import socket.*
from std import time.*
from std import sync.*
main() {
// 1、启动socket服务器
let serverSocket = TcpServerSocket(bindAt: 0)
serverSocket.bind()
let fut = spawn {
serverPacketCapture(serverSocket)
}
sleep(Duration.millisecond * 10)
// 客户端一般从 response 中的 Set-Cookie header 中读取 cookie,并将其存入 cookieJar 中,
// 下次发起 request时,将其放在 request 的 Cookie header 中发送
// 2、启动客户端
let client = ClientBuilder().build()
let port = serverSocket.localAddress.port
var u = URL.parse("http://127.0.0.1:${port}/a/b/c")
var r = HttpRequestBuilder()
.url(u)
.build()
// 3、发送request
client.send(r)
sleep(Duration.second * 2)
r = HttpRequestBuilder()
.url(u)
.build()
// 4、发送新 request,从 CookieJar 中取出 cookie,并转成 Cookie header 中的值
// 此时 cookie 2=2 已经过期,因此只发送 1=1 cookie
client.send(r)
// 5、关闭客户端
client.close()
fut.get()
serverSocket.close()
}
func serverPacketCapture(serverSocket: TcpServerSocket) {
let buf = Array<UInt8>(500, item: 0)
let server = serverSocket.accept()
var i = server.read(buf)
println(String.fromUtf8(buf[..i]))
// GET /a/b/c HTTP/1.1
// host: 127.0.0.1:44649
// user-agent: CANGJIEUSERAGENT_1_1
// connection: keep-alive
// content-length: 0
//
// 过期时间为 4 秒的 cookie1
let cookie1 = Cookie("1", "1", maxAge: 4, domain: "127.0.0.1", path: "/a/b/")
let setCookie1 = cookie1.toSetCookieString()
// 过期时间为 2 秒的 cookie2
let cookie2 = Cookie("2", "2", maxAge: 2, path: "/a/")
let setCookie2 = cookie2.toSetCookieString()
// 服务器发送 Set-Cookie 头,客户端解析并将其存进 CookieJar 中
server.write("HTTP/1.1 204 ok\r\nSet-Cookie: ${setCookie1}\r\nSet-Cookie: ${setCookie2}\r\nConnection: close\r\n\r\n".toArray())
let server2 = serverSocket.accept()
i = server2.read(buf)
// 接收客户端的带 cookie 的请求
println(String.fromUtf8(buf[..i]))
// GET /a/b/c HTTP/1.1
// host: 127.0.0.1:34857
// cookie: 1=1
// user-agent: CANGJIEUSERAGENT_1_1
// connection: keep-alive
// content-length: 0
//
server2.write("HTTP/1.1 204 ok\r\nConnection: close\r\n\r\n".toArray())
server2.close()
}
Server
from net import http.*
main () {
// 服务器设置 cookie 时将 cookie 放在 Set-Cookie header 中发给客户端
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
// 2. 注册 HttpRequestHandler
server.distributor.register("/index", {httpContext =>
let cookie = Cookie("name", "value")
httpContext.responseBuilder.header("Set-Cookie", cookie.toSetCookieString()).body("Hello 仓颉!")
})
// 3. 启动服务
server.serve()
}
server push
仅用于 HTTP/2
client:
from std import fs.*
from std import collection.ArrayList
from net import tls.*
from crypto import x509.X509Certificate
from net import http.*
//该程序需要用户配置存在且合法的文件路径才能执行
// client:
main() {
// 1. tls 配置
var tlsConfig = TlsClientConfig()
let pem = String.fromUtf8(File("/rootCerPath", OpenOption.Open(true, false)).readToEnd())
tlsConfig.verifyMode = CustomCA(X509Certificate.decodeFromPem(pem))
tlsConfig.alpnProtocolsList = ["h2"]
// 2. 构建 Client 实例
let client = ClientBuilder()
.tlsConfig(tlsConfig)
.build()
// 3. 发送 request,收response
let response = client.get("https://example.com/index.html")
// 4. 收 pushResponse,此例中相当于 client.get("http://example.com/picture.png") 的response
let pushResponses: Option<ArrayList<HttpResponse>> = response.getPush()
client.close()
}
server:
from std import fs.*
from net import tls.*
from crypto import x509.{X509Certificate, PrivateKey}
from net import http.*
//该程序需要用户配置存在且合法的文件路径才能执行
main() {
// 1. tls 配置
let pem0 = String.fromUtf8(File("/certPath", OpenOption.Open(true, false)).readToEnd())
let pem02 = String.fromUtf8(File("/keyPath", OpenOption.Open(true, false)).readToEnd())
var tlsConfig = TlsServerConfig(X509Certificate.decodeFromPem(pem0), PrivateKey.decodeFromPem(pem02))
tlsConfig.supportedAlpnProtocols = ["h2"]
// 2. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.tlsConfig(tlsConfig)
.build()
// 3. 注册原 request 的 handler
server.distributor.register("/index.html", {httpContext =>
let pusher = HttpResponsePusher.getPusher(httpContext)
match (pusher) {
case Some(pusher) =>
pusher.push("/picture.png", "GET", httpContext.request.headers)
case None =>
()
}
})
// 4. 注册 pushRequest 的 handler
server.distributor.register("/picture.png", {httpContext =>
httpContext.responseBuilder.body(b"picture.png")
})
// 4. 启动服务
server.serve()
}
webSocket
from net import http.*
from encoding import url.*
from std import time.*
from std import sync.*
from std import collection.*
from std import log.*
let server = ServerBuilder()
.addr("127.0.0.1")
.port(0)
.build()
// client:
main() {
// 1 启动服务器
spawn { startServer() }
sleep(Duration.millisecond * 200)
let client = ClientBuilder().build()
let u = URL.parse("ws://127.0.0.1:${server.port}/webSocket")
let subProtocol = ArrayList<String>(["foo1", "bar1"])
let headers = HttpHeaders()
headers.add("test", "echo")
// 2 完成 WebSocket 握手,获取 WebSocket 实例
let websocket: WebSocket
let respHeaders: HttpHeaders
(websocket, respHeaders) = WebSocket.upgradeFromClient(client, u, subProtocols: subProtocol, headers: headers)
client.close()
println("subProtocol: ${websocket.subProtocol}") // fool1
println(respHeaders.getFirst("rsp") ?? "") // echo
// 3 消息收发
// 发送 hello
websocket.write(TextWebFrame, b"hello")
// 收
let data = ArrayList<UInt8>()
var frame = websocket.read()
while(true) {
match(frame.frameType) {
case ContinuationWebFrame =>
data.appendAll(frame.payload)
if (frame.fin) {
break
}
case TextWebFrame | BinaryWebFrame =>
if (!data.isEmpty()) {
throw Exception("invalid frame")
}
data.appendAll(frame.payload)
if (frame.fin) {
break
}
case CloseWebFrame =>
websocket.write(CloseWebFrame, frame.payload)
break
case PingWebFrame =>
websocket.writePongFrame(frame.payload)
case _ => ()
}
frame = websocket.read()
}
println("data size: ${data.size}") // 4097
println("last item: ${String.fromUtf8(Array(data)[4096])}") // a
// 4 关闭 websocket,
// 收发 CloseFrame
websocket.writeCloseFrame(status: 1000)
let websocketFrame = websocket.read()
println("close frame type: ${websocketFrame.frameType}") // CloseWebFrame
println("close frame payload: ${websocketFrame.payload}") // 3, 232
// 关闭底层连接
websocket.closeConn()
server.close()
}
func startServer() {
// 1 注册 handler
server.distributor.register("/webSocket", handler1)
server.logger.level = OFF
server.serve()
}
// server:
func handler1(ctx: HttpContext): Unit {
// 2 完成 websocket 握手,获取 websocket 实例
let websocketServer = WebSocket.upgradeFromServer(ctx, subProtocols: ArrayList<String>(["foo", "bar", "foo1"]),
userFunc: {request: HttpRequest =>
let value = request.headers.getFirst("test") ?? ""
let headers = HttpHeaders()
headers.add("rsp", value)
headers
})
// 3 消息收发
// 收 hello
let data = ArrayList<UInt8>()
var frame = websocketServer.read()
while(true) {
match(frame.frameType) {
case ContinuationWebFrame =>
data.appendAll(frame.payload)
if (frame.fin) {
break
}
case TextWebFrame | BinaryWebFrame =>
if (!data.isEmpty()) {
throw Exception("invalid frame")
}
data.appendAll(frame.payload)
if (frame.fin) {
break
}
case CloseWebFrame =>
websocketServer.write(CloseWebFrame, frame.payload)
break
case PingWebFrame =>
websocketServer.writePongFrame(frame.payload)
case _ => ()
}
frame = websocketServer.read()
}
println("data: ${String.fromUtf8(Array(data))}") // hello
// 发 4097 个 a
websocketServer.write(TextWebFrame, Array<UInt8>(4097, item: 97))
// 4 关闭 websocket,
// 收发 CloseFrame
let websocketFrame = websocketServer.read()
println("close frame type: ${websocketFrame.frameType}") // CloseWebFrame
println("close frame payload: ${websocketFrame.payload}") // 3, 232
websocketServer.write(CloseWebFrame, websocketFrame.payload)
// 关闭底层连接
websocketServer.closeConn()
}
运行结果如下:
subProtocol: foo1
echo
data: hello
data size: 4097
last item: a
close frame type: CloseWebFrame
close frame payload: [3, 232]
close frame type: CloseWebFrame
close frame payload: [3, 232]
log
from std import log.*
from net import http.*
main () {
// 1. 构建 Server 实例
let server = ServerBuilder()
.addr("127.0.0.1")
.port(8080)
.build()
// 2. 注册 HttpRequestHandler
server.distributor.register("/index", {httpContext =>
httpContext.responseBuilder.body("Hello 仓颉!")
})
// 3. 开启日志
server.logger.level = DEBUG
// client端通过client.logger.level = DEBUG 开启
// 4. 启动服务
server.serve()
}
运行结果如下所示:
2024/01/25 17:23:54.344205 DEBUG Logger [Server#serve] bindAndListen(127.0.0.1, 8080)
tls 包
介绍
用于进行安全网络通信,提供启动 tls 服务器、连接 tls 服务器、发送数据、接收数据等功能。
使用本包需要外部依赖 OpenSSL 3 的 ssl 和 crypto 动态库文件,故使用前需安装相关工具:
- 对于
Linux操作系统,可参考以下方式:- 如果系统的包管理工具支持安装
OpenSSL 3开发工具包,可通过这个方式安装,并确保系统安装目录下含有libssl.so、libssl.so.3、libcrypto.so和libcrypto.so.3这些动态库文件,例如Ubuntu 22.04系统上可使用sudo apt install libssl-dev命令安装libssl-dev工具包; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libssl.so、libssl.so.3、libcrypto.so和libcrypto.so.3这些动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
LD_LIBRARY_PATH以及LIBRARY_PATH中。
- 如果系统的包管理工具支持安装
- 对于
Windows操作系统,可按照以下步骤:- 自行下载
OpenSSL 3.x.x源码编译安装 x64 架构软件包或者自行下载安装第三方预编译的供开发人员使用的OpenSSL 3.x.x软件包; - 确保安装目录下含有
libssl.dll.a(或libssl.lib)、libssl-3-x64.dll、libcrypto.dll.a(或libcrypto.lib)、libcrypto-3-x64.dll这些库文件; - 将
libssl.dll.a(或libssl.lib)、libcrypto.dll.a(或libcrypto.lib) 所在的目录路径设置到环境变量LIBRARY_PATH中,将libssl-3-x64.dll、libcrypto-3-x64.dll所在的目录路径设置到环境变量PATH中。
- 自行下载
- 对于
macOS操作系统,可参考以下方式:- 使用
brew install openssl@3安装,并确保系统安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件; - 如果无法通过上面的方式安装,可自行下载
OpenSSL 3.x.x源码编译安装软件包,并确保安装目录下含有libcrypto.dylib和libcrypto.3.dylib这两个动态库文件,然后可选择下面任意一种方式来保证系统链接器可以找到这些文件:- 在系统未安装 OpenSSL 的场景,安装时选择直接安装到系统路径下;
- 安装在自定义目录的场景,将这些文件所在目录设置到环境变量
DYLD_LIBRARY_PATH以及LIBRARY_PATH中。
- 使用
如果未安装OpenSSL 3软件包或者安装低版本的软件包,程序可能无法使用并抛出相关异常 TlsException: Can not load openssl library or function xxx.。
主要接口
struct CipherSuite
public struct CipherSuite <: ToString & Equatable<CipherSuite>
结构体 CipherSuite 为 TLS 中的密码套件。
prop allSupported
public static prop allSupported: Array<CipherSuite>
功能:返回所有支持的密码套件。
返回值:存放密码套件的数组
func toString
public func toString(): String
功能:返回密码套件名称。
返回值:密码套件名称
operator func ==
public operator func ==(that: CipherSuite): Bool
功能:判断两个密码套件是否相等。
参数:
- that:被比较的密码套件对象
返回值:若相等,则返回 true;反之,返回 false
operator func !=
public operator func !=(that: CipherSuite): Bool
功能:判断两个密码套件是否不等。
参数:
- that:被比较的密码套件对象
返回值:若不等,则返回 true;反之,返回 false
class TlsSocket
public class TlsSocket <: StreamingSocket & ToString & Equatable<TlsSocket> & Hashable
TlsSocket 用于在客户端及服务端间创建加密传输通道。
func client
public static func client(
socket: StreamingSocket,
session!: ?TlsSession = None,
clientConfig!: TlsClientConfig = TlsClientConfig()
): TlsSocket
功能:根据传入的 StreamingSocket 实例创建指定地址的客户端 tls 套接字,该套接字可用于客户端 tls 握手及会话。
参数:
- socket:已连接到服务端的客户端 tcp 套接字
- session:TLS 会话 id,若存在可用的 TLS 会话, 则可通过该 id 恢复历史 TLS 会话,省去 TLS 建立连接时间,但使用该会话依然可能协商失败。默认为 None
- clientConfig:客户端配置,默认为 TlsClientConfig()
返回值:Tls 套接字
func server
public static func server(
socket: StreamingSocket,
sessionContext!: ?TlsSessionContext = None,
serverConfig!: TlsServerConfig
): TlsSocket
功能:根据传入的 StreamingSocket 实例创建指定地址的服务端 tls 套接字,该套接字可用于服务端 tls 握手及会话。
参数:
- socket:TCP 连接建立完成后接受到套接字
- sessionContext:TLS 会话 id, 若存在可用的 TLS 会话, 则可通过该 id 恢复历史 TLS 会话,省去 TLS 建立连接时间,但使用该会话依然可能协商失败。默认为 None
- serverConfig:服务端配置,默认为 TlsServerConfig()
返回值:Tls 套接字。
prop socket
public prop socket: StreamingSocket
功能:TlsSocket 创建所使用的 StreamingSocket。
异常:
- TlsException:本端配置为TLS的套接字已关闭时,抛出异常
prop readTimeout
public override mut prop readTimeout: ?Duration
功能:读写 TlsSocket 的读超时时间。
异常:
- SocketException:本端建连的底层TCP套接字关闭,抛出异常
- TlsException:本端配置为TLS的套接字已关闭时,抛出异常
- IllegalArgumentException:设定的读超时时间为负值时,抛出异常
prop writeTimeout
public override mut prop writeTimeout: ?Duration
功能:读写 TlsSocket 的写超时时间。
异常:
- SocketException:本端建连的底层TCP套接字关闭,抛出异常
- TlsException:本端配置为TLS的套接字已关闭时,抛出异常
- IllegalArgumentException:设定的写超时时间为负值时,抛出异常
prop localAddress
public override prop localAddress: SocketAddress
功能:读取 TlsSocket 的本地地址。
异常:
- SocketException:本端建连的底层TCP套接字关闭,抛出异常
- TlsException:本端配置为TLS的套接字已关闭时,抛出异常
prop remoteAddress
public override prop remoteAddress: SocketAddress
功能:读取 TlsSocket 的远端地址。
异常:
- SocketException:本端建连的底层TCP套接字关闭,抛出异常
- TlsException:本端配置为TLS的套接字已关闭时,抛出异常
prop alpnProtocolName
public prop alpnProtocolName: ?String
功能:读取协商到的应用层协议名称。
异常:
- TlsException:当套接字未完成TLS握手或本端TLS套接字已关闭时,抛出异常
- IllegalMemoryException:内存申请失败时,抛出异常
prop tlsVersion
public prop tlsVersion: TlsVersion
功能:读取协商到的 TLS 版本。
异常:
- TlsException:当套接字未完成TLS握手或本端TLS套接字已关闭时,抛出异常
prop session
public prop session: ?TlsSession
功能:读取 Tls 会话 id , 客户端会在握手成功后捕获当前会话的 id ,可使用该 id 重用该会话,省去 TLS 建立连接时间。连接建立未成功时,返回 None。
服务端不做捕获因此始终为 None。
异常:
- TlsException:当套接字未完成TLS握手,抛出异常
prop domain
public prop domain: ?String
功能:读取协商到的服务端主机名称。
- TlsException:当套接字未完成TLS握手或本端TLS套接字已关闭时,抛出异常
prop serverCertificate
public prop serverCertificate: Array<X509Certificate>
功能:服务器证书链由服务器提供或在服务器配置中预先配置。在服务端获取时为本端证书,在客户端获取时为对端证书。
这是可选的,因为服务器可能会跳过发送证书链。
这通常无效,但可以通过提供接受此类服务器的自定义 TLS 客户端配置来允许。
- TlsException:当套接字未完成TLS握手或本端TLS套接字已关闭时,抛出异常
prop clientCertificate
public prop clientCertificate: ?Array<X509Certificate>
功能:客户端提供的客户端证书。在客户端获取时为本端证书,在服务端获取时为对端证书。
异常:
- TlsException:当套接字未完成TLS握手或本端TLS套接字已关闭时,抛出异常
注意:当客户端会话恢复时,它可能会丢失。
prop peerCertificate
public prop peerCertificate: ?Array<X509Certificate>
功能:对端证书(如果对端提供)。
注意:在客户端获取时同 serverCertificate ,在服务端获取时同 clientCertificate。
异常:
- TlsException:当套接字未完成TLS握手或本端TLS套接字已关闭时,抛出异常
prop cipherSuite
public prop cipherSuite: CipherSuite
功能:握手后协商到的加密套。
密码套件包含加密算法、用于消息认证的散列函数、密钥交换算法。
异常:
- TlsException:当套接字未完成TLS握手或本端TLS套接字已关闭时,抛出异常
func handshake
public func handshake(timeout!: ?Duration = None): Unit
功能:TLS 握手。不支持重新协商握手,因此只能被调用一次。当调用对象可以为客户端或者服务端的 TlsSocket。
参数:
- timeout:握手超时时间,默认为 None
异常:
- SocketException:本端建连的底层 TCP 套接字关闭,抛出异常
- SocketTimeoutException: 底层 TCP 套接字连接超时时,抛出异常
- TlsException:当握手已经开始或者已经结束,抛出异常或当握手阶段出现系统错误时,抛出异常
- IllegalArgumentException: 设定的握手超时时间为负值时,抛出异常
func read
public override func read(buffer: Array<Byte>): Int64
功能:TlsSocket 读取数据。
参数:
- buffer:存储读取到的数据内容的容器
返回值:读取到的数据内容字节数
异常:
- SocketException:本端建连的底层TCP套接字关闭,抛出异常
- TlsException:当 buffer 为空,或者 TlsSocket 未连接,或读取数据出现系统错误等
func write
public func write(buffer: Array<Byte>): Unit
功能:TlsSocket 发送数据。
参数:
- buffer:存储将要发送的数据内容的容器
异常:
- SocketException:本端建连的底层TCP套接字关闭,抛出异常
- TlsException:当套接字已关闭,或者 TlsSocket 未连接,或写入数据出现系统错误等
func close
public func close(): Unit
功能:关闭套接字。
异常:
- SocketException:底层连接无法关闭时,抛出异常
func isClosed
public func isClosed(): Bool
功能:返回套接字是否关闭的状态。
返回值:连接断开返回 true;否则,返回 false
func toString
public func toString(): String
功能:套接字状态。
返回值:该 tls 连接字符串
operator func ==
public override operator func ==(other: TlsSocket)
功能:套接字间判等。
参数:
- other:对比的套接字
返回值:对比的套接字相同返回 true;否则,返回 false
operator func !=
public override operator func !=(other: TlsSocket)
功能:套接字间判不等。
参数:
- other:对比的套接字
返回值:对比的套接字不同返回 true;否则,返回 false
func hashCode
public override func hashCode(): Int64
功能:返回 tls 套接字对象的哈希值。
返回值:对 tls 套接字对象进行哈希计算后得到的结果
enum TlsVersion
public enum TlsVersion <: ToString {
| V1_2
| V1_3
| Unknown
}
TLS 协议版本
V1_2
V1_2
功能:表示 TLS 1.2。
V1_3
V1_3
功能:表示 V1_3。
Unknown
Unknown
功能:表示未知协议版本。
func toString
public override func toString(): String
功能:返回当前 TlsVersion 的字符串表示。
返回值:当前 TlsVersion 的字符串表示
enum CertificateVerifyMode
public enum CertificateVerifyMode {
| Default
| TrustAll
| CustomCA(Array<X509Certificate>)
}
证书认证模式,TCP 连接建立成功后,客户端和服务端可交换证书,Default 模式使用系统证书。 在开发测试阶段,可使用 TrustAll 模式,该模式表示本端不作对对端证书的校验。此模式本端信任任意建立连接对象,一般仅在开发测试阶段使用。 CustomCA 模式可使用用户配置的证书地址,适用于用户证书无法设置为系统证书的场景。
Default
Default
功能:表示默认验证模式:根据系统CA验证证书。
TrustAll
TrustAll
功能:表示信任所有证书。
CustomCA
CustomCA(Array<X509Certificate>)
功能:表示根据提供的CA列表进行验证。
enum TlsClientIdentificationMode
public enum TlsClientIdentificationMode {
| Disabled
| Optional
| Required
}
服务端对客户端证书的认证模式。
Disabled
Disabled
功能:表示服务端不校验客户端证书,客户端可以不发送证书和公钥,即单向认证。
Optional
Optional
功能:表示服务端校验客户端证书,但客户端可以不提供证书及公钥,不提供时则单向认证,提供时则为双向认证。
Required
Required
功能:表示服务端校验客户端证书,并且要求客户端必须提供证书和公钥,即双向认证。
enum HashType
public enum HashType <: ToString & Equatable<HashType> {
| SHA512
| SHA384
| SHA256
| SHA224
| SHA1
}
功能:在签名前使用的 Hash 算法类型,参见 RFC5246 7.4.1.4.1。
SHA512
SHA512
功能:创建一个 SHA512 类型的枚举实例,表示签名前使用的 Hash 算法类型为 SHA512。
SHA384
SHA384
功能:创建一个 SHA384 类型的枚举实例,表示签名前使用的 Hash 算法类型为 SHA384。
SHA256
SHA256
功能:创建一个 SHA256 类型的枚举实例,表示签名前使用的 Hash 算法类型为 SHA256。
SHA224
SHA224
功能:创建一个 SHA224 类型的枚举实例,表示签名前使用的 Hash 算法类型为 SHA224。
SHA1
SHA1
功能:创建一个 SHA1 类型的枚举实例,表示签名前使用的 Hash 算法类型为 SHA1。
func toString
public func toString(): String
功能:转换为字符串。
返回值:转换后的字符串
operator func ==
public operator func ==(other: HashType): Bool
功能:判等。
参数:
- other: 对比的签名前使用的 Hash 算法类型
返回值:相同返回 true;否则,返回 false
operator func !=
public operator func !=(other: HashType): Bool
功能:判不等。
参数:
- other: 对比的签名前使用的 Hash 算法类型
返回值:不相同返回 true;否则,返回 false
enum SignatureType
public enum SignatureType <: ToString & Equatable<SignatureType> {
| ECDSA
| DSA
| RSA
}
功能:签名算法类型,用于认证真实性。参见 RFC5246 7.4.1.4.1。
ECDSA
ECDSA
功能:创建一个 ECDSA 类型的枚举实例,表示采用椭圆曲线数字签名算法。
DSA
DSA
功能:创建一个 DSA 类型的枚举实例,表示采用数字签名算法。
RSA
RSA
功能:创建一个 RSA 类型的枚举实例,表示采用 RSA 加密算法。
func toString
public func toString(): String
功能:转换为字符串。
返回值:转换后的字符串
operator func ==
public operator func ==(other: SignatureType) : Bool
功能:判等。
参数:
- other: 对比的签名算法类型
返回值:相同返回 true;否则,返回 false
operator func !=
public operator func !=(other: SignatureType) : Bool
功能:判不等。
参数:
- other: 对比的签名算法类型
返回值:不相同返回 true;否则,返回 false
enum SignatureSchemeType
public enum SignatureSchemeType <: ToString & Equatable<SignatureSchemeType> {
| RSA_PKCS1_SHA256
| RSA_PKCS1_SHA384
| RSA_PKCS1_SHA512
| ECDSA_SECP256R1_SHA256
| ECDSA_SECP384R1_SHA384
| ECDSA_SECP521R1_SHA512
| RSA_PSS_RSAE_SHA256
| RSA_PSS_RSAE_SHA384
| RSA_PSS_RSAE_SHA512
| ED25519
| ED448
| RSA_PSS_PSS_SHA256
| RSA_PSS_PSS_SHA384
| RSA_PSS_PSS_SHA512
}
功能: 加密算法类型,用于保护网络通信的安全性和隐私性。
RSA_PKCS1_SHA256
RSA_PKCS1_SHA256
功能:创建一个 RSA_PKCS1_SHA256 类型的枚举实例,表示加密算法类型使用 RSA_PKCS1_SHA256。
RSA_PKCS1_SHA384
RSA_PKCS1_SHA384
功能:创建一个 RSA_PKCS1_SHA384 类型的枚举实例,表示加密算法类型使用 RSA_PKCS1_SHA384。
RSA_PKCS1_SHA512
RSA_PKCS1_SHA512
功能:创建一个 RSA_PKCS1_SHA512 类型的枚举实例,表示加密算法类型使用 RSA_PKCS1_SHA512。
ECDSA_SECP256R1_SHA256
ECDSA_SECP256R1_SHA256
功能:创建一个 ECDSA_SECP256R1_SHA256 类型的枚举实例,表示加密算法类型使用 ECDSA_SECP256R1_SHA256。
ECDSA_SECP384R1_SHA384
ECDSA_SECP384R1_SHA384
功能:创建一个 ECDSA_SECP384R1_SHA384 类型的枚举实例,表示加密算法类型使用 ECDSA_SECP384R1_SHA384。
ECDSA_SECP521R1_SHA512
ECDSA_SECP521R1_SHA512
功能:创建一个 ECDSA_SECP521R1_SHA512 类型的枚举实例,表示加密算法类型使用 ECDSA_SECP521R1_SHA512。
RSA_PSS_RSAE_SHA256
RSA_PSS_RSAE_SHA256
功能:创建一个 RSA_PSS_RSAE_SHA256 类型的枚举实例,表示加密算法类型使用 RSA_PSS_RSAE_SHA256。
RSA_PSS_RSAE_SHA384
RSA_PSS_RSAE_SHA384
功能:创建一个 RSA_PSS_RSAE_SHA384 类型的枚举实例,表示加密算法类型使用 RSA_PSS_RSAE_SHA384。
RSA_PSS_RSAE_SHA512
RSA_PSS_RSAE_SHA512
功能:创建一个 RSA_PSS_RSAE_SHA512 类型的枚举实例,表示加密算法类型使用 RSA_PSS_RSAE_SHA384。
ED25519
ED25519
功能:创建一个 ED25519 类型的枚举实例,表示加密算法类型使用 ED25519
ED448
ED448
功能:创建一个 ED448 类型的枚举实例,表示加密算法类型使用 ED448。
RSA_PSS_PSS_SHA256
RSA_PSS_PSS_SHA256
功能:创建一个 RSA_PSS_PSS_SHA256 类型的枚举实例,表示加密算法类型使用 RSA_PSS_PSS_SHA256。
RSA_PSS_PSS_SHA384
RSA_PSS_PSS_SHA384
功能:创建一个 RSA_PSS_PSS_SHA384 类型的枚举实例,表示加密算法类型使用 RSA_PSS_PSS_SHA384。
RSA_PSS_PSS_SHA512
RSA_PSS_PSS_SHA512
功能:创建一个 RSA_PSS_PSS_SHA512 类型的枚举实例,表示加密算法类型使用 RSA_PSS_PSS_SHA512。
func toString
public func toString(): String
功能:转换为字符串。
返回值:转换后的字符串
operator func ==
public operator func ==(other: SignatureSchemeType): Bool
功能:判等。
参数:
- other: 对比的加密算法类型
返回值:相同返回 true;否则,返回 false
operator func !=
public operator func !=(other: SignatureSchemeType): Bool
功能:判不等。
参数:
- other: 对比的加密算法类型
返回值:不相同返回 true;否则,返回 false
功能:哈希和签名算法列表。
enum SignatureAlgorithm
public enum SignatureAlgorithm <: ToString & Equatable<SignatureAlgorithm> {
| SignatureAndHashAlgorithm(SignatureType, HashType)
| SignatureScheme(SignatureSchemeType)
}
功能: 签名算法类型,签名算法用于确保传输数据的身份验证、完整性和真实性。
SignatureAndHashAlgorithm
SignatureAndHashAlgorithm(SignatureType, HashType)
功能:自 TLS 1.2 后出现,包含签名和哈希算法类型。
SignatureScheme
SignatureScheme(SignatureSchemeType)
功能:自 TLS 1.3 后出现,更为现代的指定签名算法的方式。
func toString
public func toString():String
功能:转换为字符串。
返回值:转换后的字符串
operator func ==
public operator func ==(other: SignatureAlgorithm) : Bool
功能:判等。
参数:
- other: 对比的签名算法类型
返回值:相同返回 true;否则,返回 false
operator func !=
public operator func !=(other: SignatureAlgorithm) : Bool
功能:判不等。
参数:
- other: 对比的签名算法类型
返回值:不相同返回 true;否则,返回 false
struct TlsClientConfig
public struct TlsClientConfig {
public init()
public var verifyMode: CertificateVerifyMode = CertificateVerifyMode.Default
}
客户端配置。
verifyMode
public var verifyMode: CertificateVerifyMode = CertificateVerifyMode.Default
功能:设置或获取证书认证模式,默认为 Default。
keylogCallback
public var keylogCallback: ?(TlsSocket, String) -> Unit = None
功能:握手过程的回调函数,提供 TLS 初始秘钥数据,用于调试和解密记录使用。
init
public init()
功能:构造 TlsClientConfig。
prop clientCertificate
public mut prop clientCertificate: ?(Array<X509Certificate>, PrivateKey)
功能:客户端证书和私钥。
prop domain
public mut prop domain: ?String
功能:读写要求的服务端主机地址 (SNI), None 表示不要求。
异常:
- IllegalArgumentException:参数有 '\0' 字符时,抛出异常
prop alpnProtocolsList
public mut prop alpnProtocolsList: Array<String>
功能:要求的应用层协议名称。若列表为空,则客户将不协商应用层协议。
异常:
- IllegalArgumentException:列表元素有 '\0' 字符时,抛出异常
prop cipherSuitesV1_2
public mut prop cipherSuitesV1_2: ?Array<String>
功能:基于 TLS 1.2 协议下的加密套。
异常:
- IllegalArgumentException:列表元素有 '\0' 字符时,抛出异常
prop cipherSuitesV1_3
public mut prop cipherSuitesV1_3: ?Array<String>
功能:基于 TLS 1.3 协议下的加密套。
异常:
- IllegalArgumentException:列表元素有 '\0' 字符时,抛出异常
prop minVersion
public mut prop minVersion: TlsVersion
功能:支持的 TLS 最小的版本。
注意:当仅设置 minVersion 而未设置 maxVersion ,或设置的 minVersion 高于 maxVersion ,将会在握手阶段抛出 TlsException。
prop maxVersion
public mut prop maxVersion: TlsVersion
功能:支持的 TLS 最大的版本。
注意:当仅设置 maxVersion 而未设置 minVersion ,或设置的 maxVersion 低于 minVersion ,将会在握手阶段抛出 TlsException。
prop signatureAlgorithms
public mut prop signatureAlgorithms: ?Array<SignatureAlgorithm>
功能:指定保序的签名和哈希算法。在值为 None 或者列表为空时,客户端会使用默认的列表。指定列表后,客户端可能不会发送不合适的签名算法。 参见 RFC5246 7.4.1.4.1.(TLS 1.2), RFC8446 4.2.3. (TLS 1.3)。
prop securityLevel
public mut prop securityLevel: Int32
功能:指定客户端的安全级别,默认值为2,可选参数值在 0-5 内,参数值含义参见 openssl-SSL_CTX_set_security_level 说明。
struct TlsServerConfig
public struct TlsServerConfig {
public var verifyMode: CertificateVerifyMode = CertificateVerifyMode.Default
public var clientIdentityRequired: TlsClientIdentificationMode = Disabled
public init(certChain: Array<X509Certificate>, certKey: PrivateKey)
}
服务端配置
verifyMode
public var verifyMode: CertificateVerifyMode = CertificateVerifyMode.Default
功能:设置或获取认证模式,默认认证系统证书。
clientIdentityRequired
public var clientIdentityRequired: TlsClientIdentificationMode = Disabled
功能:设置或获取服务端要求客户端的认证模式,默认不要求客户端认证服务端证书,也不要求客户端发送本端证书。
keylogCallback
public var keylogCallback: ?(TlsSocket, String) -> Unit = None
功能:握手过程的回调函数,提供 TLS 初始秘钥数据,用于调试和解密记录使用。
init
public init(certChain: Array<X509Certificate>, certKey: PrivateKey)
功能:构造 TlsServerConfig 对象。
参数:
- certChain:证书对象
- certKey:私钥对象
prop serverCertificate
public mut prop serverCertificate: (Array<X509Certificate>, PrivateKey)
功能:服务端证书和对应的私钥文件。
prop supportedAlpnProtocols
public mut prop supportedAlpnProtocols: Array<String>
功能:应用层协商协议,若客户端尝试协商该协议,服务端将与选取其中相交的协议名称。若客户端未尝试协商协议,则该配置将被忽略。
异常:
- IllegalArgumentException:列表元素有 '\0' 字符时,抛出异常
prop cipherSuitesV1_2
public mut prop cipherSuitesV1_2: Array<String>
功能:基于 TLS 1.2 协议下的加密套。
异常:
- IllegalArgumentException:列表元素有 '\0' 字符时,抛出异常
prop cipherSuitesV1_3
public mut prop cipherSuitesV1_3: Array<String>
功能:基于 TLS 1.3 协议下的加密套。
异常:
- IllegalArgumentException:列表元素有 '\0' 字符时,抛出异常
prop minVersion
public mut prop minVersion: TlsVersion
功能:支持的最小 TLS 版本。
注意:当仅设置 minVersion 而未设置 maxVersion ,或设置的 minVersion 高于 maxVersion ,将会在握手阶段抛出 TlsException。
prop maxVersion
public mut prop maxVersion: TlsVersion
功能:支持的最大 TLS 版本。
注意:当仅设置 maxVersion 而未设置 minVersion ,或设置的 maxVersion 低于 minVersion ,将会在握手阶段抛出 TlsException。
prop securityLevel
public mut prop securityLevel: Int32
功能:指定服务端的安全级别,默认值为2,可选参数值在 0-5 内,参数值含义参见 openssl-SSL_CTX_set_security_level 说明。
异常:
- IllegalArgumentException: 当配置值不在 0-5 范围内时,抛出异常
prop dhParameters
public mut prop dhParameters: ?DHParamters
功能:指定服务端的 DH 密钥参数,默认为 None, 默认情况下使用 openssl 自动生成的参数值。
struct TlsSession
public struct TlsSession <: Equatable<TlsSession> & ToString & Hashable
当客户端 TLS 握手成功后,将会生成一个会话,当连接因一些原因丢失后,客户端可以通过这个会话 id 复用此次会话,省略握手流程。
此结构体表示已建立的客户端会话。此结构体实例用户不可创建,其内部结构对用户不可见。
operator func ==
public override operator func ==(other: TlsSession)
功能:判等。
参数:
- other:被比较的会话对象
返回值:若会话对象相同,返回 true;否则,返回 false
operator func !=
public override operator func !=(other: TlsSession)
功能:判不等。
参数:
- other:被比较的会话对象
返回值:若会话对象不同,返回 true;否则,返回 false
func toString
public override func toString(): String
功能:生成会话 id 字符串。
返回值:TlsSession(会话 id 字符串)
func hashCode
public override func hashCode(): Int64
功能:生成会话 id 哈希值。
返回值:会话 id 哈希值
class TlsSessionContext
public class TlsSessionContext <: Equatable<TlsSessionContext> & ToString
当客户端尝试恢复会话时,双方都必须确保他们正在恢复与合法对端的会话。TlsSessionContext 会做以下两件事情: 1. 验证客户端。 2. 给客户端提供信息,确保客户端所连接的服务端仍为相同实例。
func fromName
public static func fromName(name: String): TlsSessionContext
功能:通过 TlsSessionContext 保存的名称获取 TlsSessionContext 对象该名称用于区分 TLS 服务器,因此客户端依赖此名称来避免意外尝试恢复与错误的服务器的连接这里不一定使用加密安全名称,因为底层实现可以完成这项工作从此函数返回的具有相同名称的两个会话上下文可能不相等,并且不保证可替换,尽管它们是从相同的名称创建的因此,服务器实例应该在整个生命周期内创建一个会话上下文,并且在每次 TlsSocket.server() 调用中使用它。
参数:
- name:会话上下文名称
返回值:会话上下文
operator func ==
public override operator func ==(other: TlsSessionContext)
功能:判等。
参数:
- other:被比较的会话上下文对象
返回值:若 TlsSessionContext 对象相同,返回 true;否则,返回 false
operator func !=
public override operator func !=(other: TlsSessionContext)
功能:判不等。
参数:
- other:被比较的会话上下文对象
返回值:若 TlsSessionContext 对象不同,返回 true;否则,返回 false
func toString
public override func toString(): String
功能:生成会话上下文名称字符串。
返回值:TlsSessionContext(会话上下文名称字符串)
class TlsException
public class TlsException <: Exception {
public init()
public init(message: String)
}
TLS 处理出现错误时抛出的异常
init
public init()
功能:构造异常。
init
public init(message: String)
功能:构造异常。
参数:
- message:异常信息
示例
客户端示例
from std import fs.*, socket.*
from net import tls.*
from crypto import x509.{X509Certificate,PrivateKey}
main() {
var config = TlsClientConfig()
config.verifyMode = TrustAll
config.alpnProtocolsList = ["h2"]
// 用于恢复会话
var lastSession: ?TlsSession = None
while (true) { // 重新连接环路
try (socket = TcpSocket("127.0.0.1", 8443)) {
socket.connect() // 首先进行 TCP 连接
try (tls = TlsSocket.client(socket, clientConfig: config, session: lastSession)) {
try {
tls.handshake() // then we are negotiating TLS
lastSession = tls.session // 如果成功协商下一次重新连接,将记住会话
} catch (e: Exception) {
lastSession = None // 如果协商失败,将删除会话
throw e
}
// tls实例已完成
tls.write("Hello, peer! Let's discuss our personal secrets.\n".toArray())
}
} catch (e: Exception) {
println("client connection failed ${e}, retrying...")
}
}
}
服务端示例
from std import fs.*, socket.*
from net import tls.*
from crypto import x509.{X509Certificate,PrivateKey}
let certificatePath = "./files/apiserver.crt"
let certificateKeyPath = "./files/apiserver.key"
main() {
// 对证书以及私钥进行解析
let pem = readTextFromFile(certificatePath)
let keyText = readTextFromFile(certificateKeyPath)
let certificate = X509Certificate.decodeFromPem(pem)
let privateKey = PrivateKey.decodeFromPem(keyText)
let config = TlsServerConfig(certificate, privateKey)
//可选:允许恢复TLS会话
let sessions= TlsSessionContext.fromName("my-server")
try (server = TcpServerSocket(bindAt:8443)) {
server.bind()
server.acceptLoop { clientSocket =>
try (tls = TlsSocket.server(clientSocket, serverConfig: config, sessionContext: sessions)) {
tls.handshake()
let buffer = Array<Byte>(100, item: 0)
tls.read(buffer)
println(buffer) // operate received data.
}
}
}
}
// 简化示例代码的辅助函数
extend TcpServerSocket {
func acceptLoop(handler: (TcpSocket) -> Unit) {
while (true) {
let client = accept()
spawn {
try {
handler(client)
} finally {
client.close()
}
}
}
}
}
func readTextFromFile(path: String): String {
var str = ""
try (file = File(path, OpenOption.Open(true, false))) {
str = String.fromUtf8(file.readToEnd())
}
str
}
证书热更新
from std import fs.*, socket.*
from net import tls.*
from crypto import x509.{X509Certificate,PrivateKey}
class MyServer {
private var currentConfig: TlsServerConfig
init(initialConfig: TlsServerConfig) { currentConfig = initialConfig }
/**
* 更改带有密钥的证书只会影响新的连接
*/
public mut prop certificate: (Array<X509Certificate>, PrivateKey) {
get() { currentConfig.serverCertificate }
set(newCertificate) { currentConfig.serverCertificate = newCertificate }
}
public func onAcceptedConnection(client: StreamingSocket) {
try (tls = TlsSocket.server(client, serverConfig: currentConfig)) {
tls.handshake()
}
}
}
服务端证书及公钥在一份文件中
from std import fs.*, socket.*, collection.*
from net import tls.*
from crypto import x509.{X509Certificate,PrivateKey, Pem, PemEntry,DerBlob}
let certificatePath = "/etc/myserver/cert-and-key.pem"
func parsePem(text: String): (Array<X509Certificate>, PrivateKey) {
let pem = Pem.decode(text)
let chain = pem |>
filter<PemEntry> { entry => entry.label == PemEntry.LABEL_CERTIFICATE } |>
map<PemEntry, X509Certificate> { entry => X509Certificate.decodeFromDer(entry.body ?? DerBlob()) } |>
collectArray
let key = (pem |>
filter<PemEntry> { entry => entry.label == PemEntry.LABEL_PRIVATE_KEY} |>
map<PemEntry, PrivateKey> { entry => PrivateKey.decodeDer(entry.body ?? DerBlob()) } |>
first) ?? throw Exception("No private key found in the PEM file")
if (chain.isEmpty()) {
throw Exception("No certificates found in the PEM file")
}
return (chain, key)
}
func readTextFromFile(path: String): String {
var fileString = ""
try (file = File(path, OpenOption.Open(true, false))) {
fileString = String.fromUtf8(file.readToEnd())
()
}
fileString
}
main() {
// 对证书及私钥进行解析
let pem = readTextFromFile(certificatePath)
let (certificate, privateKey) = parsePem(pem)
var _ = TlsServerConfig(certificate, privateKey)
// 进行https服务,请参阅其他服务器示例
}
serialization 包
介绍
用户定义的类型,可以通过实现 Serializable 接口,来支持序列化和反序列化。
主要接口
class DataModel
public abstract class DataModel
此类为中间数据层。
class DataModelNull
public class DataModelNull <: DataModel
此类为 DataModel 的子类,实现对 Null 类型数据的封装。
class DataModelBool
public class DataModelBool <: DataModel {
public init(bv: Bool)
}
此类为 DataModel 的子类,实现对 Bool 类型数据的封装。类的主要函数如下所示:
init
public init(bv: Bool)
功能:构造一个具有初始数据的 DataModelBool。
参数:
bv:传入的Bool类型
func getValue
public func getValue(): Bool
功能:获取 DataModelBool 中的数据。
返回值:DataModelBool 中类型为 Bool 的 value 数值
class DataModelInt
public class DataModelInt <: DataModel {
public init(iv: Int64)
}
此类为 DataModel 的子类,实现对 Int64 类型数据的封装。类的主要函数如下所示:
init
public init(iv: Int64)
功能:构造一个具有初始数据的 DataModelInt。
参数:
iv:传入的Int64类型
func getValue
public func getValue(): Int64
功能:获取 DataModelInt 中的数据。
返回值:DataModelInt 中类型为 Int64 的 value 数值
class DataModelFloat
public class DataModelFloat <: DataModel {
public init(fv: Float64)
public init(v: Int64)
}
此类为 DataModel 的子类,实现对 Float64 类型数据的封装。类的主要函数如下所示:
init
public init(fv: Float64)
功能:构造一个具有初始数据的 DataModelFloat。
参数:
fv:传入的Float64类型
init
public init(v: Int64)
功能:构造一个具有初始数据的 DataModelFloat。
参数:
v:传入的Int64类型
func getValue
public func getValue(): Float64
功能:获取 DataModelFloat 中的数据。
返回值:DataModelFloat 中类型为 Float64 的 value 数值
class DataModelString
public class DataModelString <: DataModel {
public init(sv: String)
}
此类为 DataModel 的子类,实现对 String 类型数据的封装。类的主要函数如下所示:
init
public init(sv: String)
功能:构造一个具有初始数据的 DataModelString。
参数:
sv:传入的String类型
func getValue
public func getValue(): String
功能:获取 DataModelString 中的数据。
返回值:DataModelString 中类型为 String 的 value 数值
class DataModelSeq
public class DataModelSeq <: DataModel {
public init()
public init(list: ArrayList<DataModel>)
}
此类为 DataModel 的子类,实现对 ArrayList<DataModel> 类型数据的封装。类的主要函数如下所示:
init
public init()
功能:构造一个空参的 DataModelSeqitems 默认为空的 ArrayList<DataModel>。
init
public init(list: ArrayList<DataModel>)
功能:构造一个具有初始数据的 DataModelString。
参数:
list:传入的ArrayList<DataModel>类型
func getItems
public func getItems(): ArrayList<DataModel>
功能:获取 DataModelSeq 中的数据。
返回值:类型为 ArrayList<DataModel> 的 items 数据
func add
public func add(dm: DataModel)
功能:在 DataModelSeq 末尾增加一个数据 dm。
参数:
- dm:传入的
DataModel类型
class DataModelStruct
public class DataModelStruct <: DataModel {
public init()
public init(list: ArrayList<Field>)
}
此类为 DataModel 的子类,用来实现 class 对象到 DataModel 的转换。
init
public init()
功能:构造一个空参的 DataModelStructfields 默认为空的 ArrayList<Field>。
init
public init(list: ArrayList<Field>)
功能:构造一个具有初始数据的 DataModelStruct。
参数:
list:传入的ArrayList<Field>类型
func getFields
public func getFields(): ArrayList<Field>
功能:获取 DataModelStruct 的数据集合。
返回值:类型为 ArrayList<Field> 的 fields 数据
func add
public func add(fie: Field): DataModelStruct
功能:添加数据 fie 到 DataModelStruct 中。
参数:
fie:传入的Field类型
返回值:得到新的 DataModelStruct
func get
public func get(key: String): DataModel
功能:获取 key 对应的数据。
参数:
key:传入的String类型
返回值:类型为 DataModel,如未查找到对应值,则返回 DataModelNull
class Field
public class Field {
public init(name: String, data: DataModel)
}
Field 类用于存储 DataModelStruct 的元素。
init
public init(name: String, data: DataModel)
功能:Field 的构造函数。
参数:
name:name字段值,name字段为""时行为与为其它字符串时一致data:data字段值
func getName
public func getName(): String
功能:获取 name 字段。
返回值:获取 name 字段,类型为 String
func getData
public func getData(): DataModel
功能:获取 data 字段。
返回值:获取 data 字段,类型为 DataModel
func field
public func field<T>(name: String, data: T) : Field where T <: Serializable<T>
功能:此函数用于将一组数据 name 和 data 封装到 Field 对象中。处理一组数据 name 和 data,将 data 序列化为 DataModel 类型,并将二者封装到 Field 对象中。
参数:
name:String类型,name字段为""时行为与为其它字符串时一致data:T类型,T类型必须实现Serializable<T>接口
返回值:封装了 name 和 data 的 Field 对象
class DataModelException
public class DataModelException <: Exception {
public init()
public init(message: String)
}
此类为 Exception 的子类,DataModel 的异常类。类的主要函数如下所示:
init
public init()
功能:创建 DataModelException。
init
public init(message: String)
功能:创建 DataModelException。
参数:
message:异常提示字符串
interface Serializable
public interface Serializable<T> {
func serialize(): DataModel
static func deserialize(dm: DataModel): T
}
此接口用于规范序列化。接口的主要函数如下所示:
func serialize
func serialize(): DataModel
功能:将自身序列化为 DataModel。
返回值:序列化 DataModel
func deserialize
static func deserialize(dm: DataModel): T
功能:将 DataModel 反序列化为对象。
返回值:反序列化的对象
哪些类型支持实现 Serializable :
- 基本数据类型:整数类型、浮点类型、布尔类型、字符类型、字符串类型;
Collection类型:Array、ArrayList、HashSet、HashMap、Option;- 用户自定义的实现了
Serializable<T>的类型。
extend Int64 <: Serializable
extend Int64 <: Serializable<Int64>
拓展 Int64 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Int64 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): Int64
功能:将 DataModel 反序列化为 Int64。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Int64
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend Int32 <: Serializable
extend Int32 <: Serializable<Int32>
拓展 Int32 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Int32 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): Int32
功能:将 DataModel 反序列化为 Int32。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Int32
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend Int16 <: Serializable
extend Int16 <: Serializable<Int16>
拓展 Int16 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Int16 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): Int16
功能:将 DataModel 反序列化为 Int16。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Int16
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend Int8 <: Serializable
extend Int8 <: Serializable<Int8>
拓展 Int8 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Int8 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): Int8
功能:将 DataModel 反序列化为 Int8。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Int8
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend UInt64 <: Serializable
extend UInt64 <: Serializable<UInt64>
拓展 UInt64 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 UInt64 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): UInt64
功能:将 DataModel 反序列化为 UInt64。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 UInt64
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend UInt32 <: Serializable
extend UInt32 <: Serializable<UInt32>
拓展 UInt32 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 UInt32 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): UInt32
功能:将 DataModel 反序列化为 UInt32。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 UInt32
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend UInt16 <: Serializable
extend UInt16 <: Serializable<UInt16>
拓展 UInt16 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 UInt16 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): UInt16
功能:将 DataModel 反序列化为 UInt16。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 UInt16
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend UInt8 <: Serializable
extend UInt8 <: Serializable<UInt8>
拓展 UInt8 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 UInt8 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): UInt8
功能:将 DataModel 反序列化为 UInt8。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 UInt8
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend Float64 <: Serializable
extend Float64 <: Serializable<Float64>
拓展 Float64 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Float64 序列化为 DataModelFloat。
返回值:序列化的 DataModelFloat
func deserialize
static public func deserialize(dm: DataModel): Float64
功能:将 DataModel 反序列化为 Float64。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Float64
异常:
DataModelException:如果dm不是DataModelFloat,则抛出异常
extend Float32 <: Serializable
extend Float32 <: Serializable<Float32>
拓展 Float32 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Float32 序列化为 DataModelFloat。
返回值:序列化的 DataModelFloat
func deserialize
static public func deserialize(dm: DataModel): Float32
功能:将 DataModel 反序列化为 Float32。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Float32
异常:
DataModelException:如果dm不是DataModelFloat,则抛出异常
extend Float16 <: Serializable
extend Float16 <: Serializable<Float16>
拓展 Float16 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Float16 序列化为 DataModelFloat。
返回值:序列化的 DataModelFloat
func deserialize
static public func deserialize(dm: DataModel): Float16
功能:将 DataModel 反序列化为 Float16。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Float16
异常:
DataModelException:如果dm不是DataModelFloat,则抛出异常
extend Bool <: Serializable
extend Bool <: Serializable<Bool>
拓展 Bool 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Bool 序列化为 DataModelBool。
返回值:序列化的 DataModelBool
func deserialize
static public func deserialize(dm: DataModel): Bool
功能:将 DataModel 反序列化为 Bool。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Bool
异常:
DataModelException:如果dm不是DataModelBool,则抛出异常
extend String <: Serializable
extend String <: Serializable<String>
拓展 String 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 String 序列化为 DataModelString。
返回值:序列化的 DataModelString
func deserialize
static public func deserialize(dm: DataModel): String
功能:将 DataModel 反序列化为 String。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 String
异常:
DataModelException:如果dm不是DataModelString,则抛出异常
extend Char <: Serializable
extend Char <: Serializable<Char>
拓展 Char 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Char 序列化为 DataModelString。
返回值:序列化的 DataModelString
func deserialize
static public func deserialize(dm: DataModel): Char
功能:将 DataModel 反序列化为 Char。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Char
异常:
DataModelException:如果dm不是DataModelString,则抛出异常Exception:如果dm不是Char,则抛出异常
extend Option <: Serializable
extend Option<T> <: Serializable<Option<T>> where T <: Serializable<T>
拓展 Option<T> 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Option<T> 中的 T 序列化为 DataModel。
返回值:序列化的 DataModel
func deserialize
static public func deserialize(dm: DataModel): Option<T>
功能:将 DataModel 反序列化为 Option<T>。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Option<T>
extend Array <: Serializable
extend Array<T> <: Serializable<Array<T>> where T <: Serializable<T>
拓展 Array<T> 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Array<T> 序列化为 DataModelSeq。
返回值:序列化的 DataModelSeq
func deserialize
static public func deserialize(dm: DataModel): Array<T>
功能:将 DataModel 反序列化为 Array<T>。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Array<T>
异常:
DataModelException:如果dm不是DataModelSeq,则抛出异常
extend ArrayList <: Serializable
extend ArrayList<T> <: Serializable<ArrayList<T>> where T <: Serializable<T>
拓展 ArrayList<T> 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 ArrayList<T> 序列化为 DataModelSeq。
返回值:序列化的 DataModelSeq
func deserialize
static public func deserialize(dm: DataModel): ArrayList<T>
功能:将 DataModel 反序列化为 ArrayList<T>。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 ArrayList<T>
异常:
DataModelException:如果dm不是DataModelSeq,则抛出异常
extend HashSet <: Serializable
extend HashSet<T> <: Serializable<HashSet<T>> where T <: Serializable<T> & Hashable & Equatable<T>
拓展 HashSet<T> 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 HashSet<T> 序列化为 DataModelSeq。
返回值:序列化的 DataModelSeq
func deserialize
static public func deserialize(dm: DataModel): HashSet<T>
功能:将 DataModel 反序列化为 HashSet<T>。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 HashSet<T>
异常:
DataModelException:如果dm不是DataModelSeq,则抛出异常
extend HashMap <: Serializable
extend HashMap<K, V> <: Serializable<HashMap<K, V>> where K <: Serializable<K> & Hashable & Equatable<K>, V <: Serializable<V>
拓展 HashMap<K, V> 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 HashMap<K, V> 序列化为 DataModelSeq。
返回值:序列化的 DataModelSeq
异常:
DataModelException:如果当前HashMap实例中的Key不是String类型,则抛出异常
func deserialize
static public func deserialize(dm: DataModel): HashMap<K, V>
功能:将 DataModel 反序列化为 HashMap<K, V>。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 HashMap<K, V>
异常:
DataModelException:如果dm不是DataModelStruct类型或者DataModelStruct类型的dm中的Field不是String类型,则抛出异常
示例
class 序列化和反序列化
对 class Abc 进行序列化和反序列化。
代码如下:
from serialization import serialization.*
from std import math.*
from encoding import json.*
class Abc <: Serializable<Abc> {
var name: String = "Abcde"
var age: Int64 = 555
var loc: Option<Location> = Option<Location>.None
public func serialize(): DataModel {
return DataModelStruct().add(field<String>("name", name)).add(field<Int64>("age", age)).add(field<Option<Location>>("loc", loc))
}
public static func deserialize(dm: DataModel): Abc {
let dms = match (dm) {
case data: DataModelStruct => data
case _ => throw Exception("this data is not DataModelStruct")
}
let result = Abc()
result.name = String.deserialize(dms.get("name"))
result.age = Int64.deserialize(dms.get("age"))
result.loc = Option<Location>.deserialize(dms.get("loc"))
return result
}
}
class Location <: Serializable<Location> {
var time: Int64 = 666
var heheh: Char = 'T'
public func serialize(): DataModel {
return DataModelStruct().add(field<Int64>("time", time)).add(field<Char>("heheh", heheh))
}
public static func deserialize(dm: DataModel): Location {
let dms = match (dm) {
case data: DataModelStruct => data
case _ => throw Exception("this data is not DataModelStruct")
}
let result = Location()
result.time = Int64.deserialize(dms.get("time"))
result.heheh = Char.deserialize(dms.get("heheh"))
return result
}
}
main(): Unit {
let dd = Abc()
let aa: JsonValue = dd.serialize().toJson()
let bb: JsonObject = (aa as JsonObject).getOrThrow()
let v1 = (bb.get("name").getOrThrow() as JsonString).getOrThrow()
let v2 = (bb.get("age").getOrThrow() as JsonInt).getOrThrow()
let v3 = bb.get("loc").getOrThrow()
println(v1.getValue())
println(v2.getValue())
println(v3.toString())
println("===========")
let aaa = ##"{"age": 123, "loc": { "heheh": "H", "time": 45 }, "name": "zhangsan"}"##
let bbb = JsonValue.fromStr(aaa)
let ccc = (bbb as JsonObject).getOrThrow()
let v4 = (ccc.get("name").getOrThrow() as JsonString).getOrThrow()
let v5 = (ccc.get("age").getOrThrow() as JsonInt).getOrThrow()
let v6 = (ccc.get("loc").getOrThrow() as JsonObject).getOrThrow()
let v7 = (v6.get("time").getOrThrow() as JsonInt).getOrThrow()
let v8 = (v6.get("heheh").getOrThrow() as JsonString).getOrThrow()
println(v4.getValue())
println(v5.getValue())
println(v7.getValue())
println(v8.getValue())
}
运行结果如下:
Abcde
555
null
===========
zhangsan
123
45
H
HashSet 和 HashMap 序列化
对 HashSet 和 HashMap 进行序列化。
代码如下:
from std import collection.*
from serialization import serialization.*
from encoding import json.*
main(): Unit {
let s: HashSet<Values> = HashSet<Values>([Values(3), Values(5), Values(7)])
let seris: DataModel = s.serialize()
println(seris.toJson().toJsonString())
println("===========")
let m: HashMap<String, Values> = HashMap<String, Values>([("1", Values(3)), ("2", Values(6)), ("3", Values(9))])
let serim: DataModel = m.serialize()
print(serim.toJson().toJsonString())
}
class Values <: Hashable & Equatable<Values> & Serializable<Values> {
var m_data: Int64
init(m_data: Int64) {
this.m_data = m_data
}
public func hashCode(): Int64 {
return this.m_data
}
public operator func ==(right: Values): Bool {
let a = (this.m_data == right.m_data)
if (a) { return true } else { return false }
}
public operator func !=(right: Values): Bool {
let a = (this.m_data != right.m_data)
if (a) { return true } else { return false }
}
public func serialize(): DataModel {
return DataModelStruct().add(field<Int64>("m_data", m_data))
}
public static func deserialize(dm: DataModel): Values {
let dms: DataModelStruct = match (dm) {
case data: DataModelStruct => data
case _ => throw Exception("this data is not DataModelStruct")
}
let result = Values(0)
result.m_data = Int64.deserialize(dms.get("m_data"))
return result
}
}
运行结果如下:
[
{
"m_data": 3
},
{
"m_data": 5
},
{
"m_data": 7
}
]
===========
{
"1": {
"m_data": 3
},
"2": {
"m_data": 6
},
"3": {
"m_data": 9
}
}
serialization 包
介绍
用户定义的类型,可以通过实现 Serializable 接口,来支持序列化和反序列化。
主要接口
class DataModel
public abstract class DataModel
此类为中间数据层。
class DataModelNull
public class DataModelNull <: DataModel
此类为 DataModel 的子类,实现对 Null 类型数据的封装。
class DataModelBool
public class DataModelBool <: DataModel {
public init(bv: Bool)
}
此类为 DataModel 的子类,实现对 Bool 类型数据的封装。类的主要函数如下所示:
init
public init(bv: Bool)
功能:构造一个具有初始数据的 DataModelBool。
参数:
bv:传入的Bool类型
func getValue
public func getValue(): Bool
功能:获取 DataModelBool 中的数据。
返回值:DataModelBool 中类型为 Bool 的 value 数值
class DataModelInt
public class DataModelInt <: DataModel {
public init(iv: Int64)
}
此类为 DataModel 的子类,实现对 Int64 类型数据的封装。类的主要函数如下所示:
init
public init(iv: Int64)
功能:构造一个具有初始数据的 DataModelInt。
参数:
iv:传入的Int64类型
func getValue
public func getValue(): Int64
功能:获取 DataModelInt 中的数据。
返回值:DataModelInt 中类型为 Int64 的 value 数值
class DataModelFloat
public class DataModelFloat <: DataModel {
public init(fv: Float64)
public init(v: Int64)
}
此类为 DataModel 的子类,实现对 Float64 类型数据的封装。类的主要函数如下所示:
init
public init(fv: Float64)
功能:构造一个具有初始数据的 DataModelFloat。
参数:
fv:传入的Float64类型
init
public init(v: Int64)
功能:构造一个具有初始数据的 DataModelFloat。
参数:
v:传入的Int64类型
func getValue
public func getValue(): Float64
功能:获取 DataModelFloat 中的数据。
返回值:DataModelFloat 中类型为 Float64 的 value 数值
class DataModelString
public class DataModelString <: DataModel {
public init(sv: String)
}
此类为 DataModel 的子类,实现对 String 类型数据的封装。类的主要函数如下所示:
init
public init(sv: String)
功能:构造一个具有初始数据的 DataModelString。
参数:
sv:传入的String类型
func getValue
public func getValue(): String
功能:获取 DataModelString 中的数据。
返回值:DataModelString 中类型为 String 的 value 数值
class DataModelSeq
public class DataModelSeq <: DataModel {
public init()
public init(list: ArrayList<DataModel>)
}
此类为 DataModel 的子类,实现对 ArrayList<DataModel> 类型数据的封装。类的主要函数如下所示:
init
public init()
功能:构造一个空参的 DataModelSeqitems 默认为空的 ArrayList<DataModel>。
init
public init(list: ArrayList<DataModel>)
功能:构造一个具有初始数据的 DataModelString。
参数:
list:传入的ArrayList<DataModel>类型
func getItems
public func getItems(): ArrayList<DataModel>
功能:获取 DataModelSeq 中的数据。
返回值:类型为 ArrayList<DataModel> 的 items 数据
func add
public func add(dm: DataModel)
功能:在 DataModelSeq 末尾增加一个数据 dm。
参数:
- dm:传入的
DataModel类型
class DataModelStruct
public class DataModelStruct <: DataModel {
public init()
public init(list: ArrayList<Field>)
}
此类为 DataModel 的子类,用来实现 class 对象到 DataModel 的转换。
init
public init()
功能:构造一个空参的 DataModelStructfields 默认为空的 ArrayList<Field>。
init
public init(list: ArrayList<Field>)
功能:构造一个具有初始数据的 DataModelStruct。
参数:
list:传入的ArrayList<Field>类型
func getFields
public func getFields(): ArrayList<Field>
功能:获取 DataModelStruct 的数据集合。
返回值:类型为 ArrayList<Field> 的 fields 数据
func add
public func add(fie: Field): DataModelStruct
功能:添加数据 fie 到 DataModelStruct 中。
参数:
fie:传入的Field类型
返回值:得到新的 DataModelStruct
func get
public func get(key: String): DataModel
功能:获取 key 对应的数据。
参数:
key:传入的String类型
返回值:类型为 DataModel,如未查找到对应值,则返回 DataModelNull
class Field
public class Field {
public init(name: String, data: DataModel)
}
Field 类用于存储 DataModelStruct 的元素。
init
public init(name: String, data: DataModel)
功能:Field 的构造函数。
参数:
name:name字段值,name字段为""时行为与为其它字符串时一致data:data字段值
func getName
public func getName(): String
功能:获取 name 字段。
返回值:获取 name 字段,类型为 String
func getData
public func getData(): DataModel
功能:获取 data 字段。
返回值:获取 data 字段,类型为 DataModel
func field
public func field<T>(name: String, data: T) : Field where T <: Serializable<T>
功能:此函数用于将一组数据 name 和 data 封装到 Field 对象中。处理一组数据 name 和 data,将 data 序列化为 DataModel 类型,并将二者封装到 Field 对象中。
参数:
name:String类型,name字段为""时行为与为其它字符串时一致data:T类型,T类型必须实现Serializable<T>接口
返回值:封装了 name 和 data 的 Field 对象
class DataModelException
public class DataModelException <: Exception {
public init()
public init(message: String)
}
此类为 Exception 的子类,DataModel 的异常类。类的主要函数如下所示:
init
public init()
功能:创建 DataModelException。
init
public init(message: String)
功能:创建 DataModelException。
参数:
message:异常提示字符串
interface Serializable
public interface Serializable<T> {
func serialize(): DataModel
static func deserialize(dm: DataModel): T
}
此接口用于规范序列化。接口的主要函数如下所示:
func serialize
func serialize(): DataModel
功能:将自身序列化为 DataModel。
返回值:序列化 DataModel
func deserialize
static func deserialize(dm: DataModel): T
功能:将 DataModel 反序列化为对象。
返回值:反序列化的对象
哪些类型支持实现 Serializable :
- 基本数据类型:整数类型、浮点类型、布尔类型、字符类型、字符串类型;
Collection类型:Array、ArrayList、HashSet、HashMap、Option;- 用户自定义的实现了
Serializable<T>的类型。
extend Int64 <: Serializable
extend Int64 <: Serializable<Int64>
拓展 Int64 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Int64 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): Int64
功能:将 DataModel 反序列化为 Int64。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Int64
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend Int32 <: Serializable
extend Int32 <: Serializable<Int32>
拓展 Int32 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Int32 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): Int32
功能:将 DataModel 反序列化为 Int32。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Int32
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend Int16 <: Serializable
extend Int16 <: Serializable<Int16>
拓展 Int16 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Int16 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): Int16
功能:将 DataModel 反序列化为 Int16。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Int16
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend Int8 <: Serializable
extend Int8 <: Serializable<Int8>
拓展 Int8 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Int8 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): Int8
功能:将 DataModel 反序列化为 Int8。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Int8
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend UInt64 <: Serializable
extend UInt64 <: Serializable<UInt64>
拓展 UInt64 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 UInt64 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): UInt64
功能:将 DataModel 反序列化为 UInt64。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 UInt64
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend UInt32 <: Serializable
extend UInt32 <: Serializable<UInt32>
拓展 UInt32 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 UInt32 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): UInt32
功能:将 DataModel 反序列化为 UInt32。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 UInt32
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend UInt16 <: Serializable
extend UInt16 <: Serializable<UInt16>
拓展 UInt16 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 UInt16 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): UInt16
功能:将 DataModel 反序列化为 UInt16。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 UInt16
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend UInt8 <: Serializable
extend UInt8 <: Serializable<UInt8>
拓展 UInt8 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 UInt8 序列化为 DataModelInt。
返回值:序列化的 DataModelInt
func deserialize
static public func deserialize(dm: DataModel): UInt8
功能:将 DataModel 反序列化为 UInt8。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 UInt8
异常:
DataModelException:如果dm不是DataModelInt,则抛出异常
extend Float64 <: Serializable
extend Float64 <: Serializable<Float64>
拓展 Float64 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Float64 序列化为 DataModelFloat。
返回值:序列化的 DataModelFloat
func deserialize
static public func deserialize(dm: DataModel): Float64
功能:将 DataModel 反序列化为 Float64。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Float64
异常:
DataModelException:如果dm不是DataModelFloat,则抛出异常
extend Float32 <: Serializable
extend Float32 <: Serializable<Float32>
拓展 Float32 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Float32 序列化为 DataModelFloat。
返回值:序列化的 DataModelFloat
func deserialize
static public func deserialize(dm: DataModel): Float32
功能:将 DataModel 反序列化为 Float32。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Float32
异常:
DataModelException:如果dm不是DataModelFloat,则抛出异常
extend Float16 <: Serializable
extend Float16 <: Serializable<Float16>
拓展 Float16 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Float16 序列化为 DataModelFloat。
返回值:序列化的 DataModelFloat
func deserialize
static public func deserialize(dm: DataModel): Float16
功能:将 DataModel 反序列化为 Float16。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Float16
异常:
DataModelException:如果dm不是DataModelFloat,则抛出异常
extend Bool <: Serializable
extend Bool <: Serializable<Bool>
拓展 Bool 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Bool 序列化为 DataModelBool。
返回值:序列化的 DataModelBool
func deserialize
static public func deserialize(dm: DataModel): Bool
功能:将 DataModel 反序列化为 Bool。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Bool
异常:
DataModelException:如果dm不是DataModelBool,则抛出异常
extend String <: Serializable
extend String <: Serializable<String>
拓展 String 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 String 序列化为 DataModelString。
返回值:序列化的 DataModelString
func deserialize
static public func deserialize(dm: DataModel): String
功能:将 DataModel 反序列化为 String。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 String
异常:
DataModelException:如果dm不是DataModelString,则抛出异常
extend Char <: Serializable
extend Char <: Serializable<Char>
拓展 Char 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Char 序列化为 DataModelString。
返回值:序列化的 DataModelString
func deserialize
static public func deserialize(dm: DataModel): Char
功能:将 DataModel 反序列化为 Char。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Char
异常:
DataModelException:如果dm不是DataModelString,则抛出异常Exception:如果dm不是Char,则抛出异常
extend Option <: Serializable
extend Option<T> <: Serializable<Option<T>> where T <: Serializable<T>
拓展 Option<T> 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Option<T> 中的 T 序列化为 DataModel。
返回值:序列化的 DataModel
func deserialize
static public func deserialize(dm: DataModel): Option<T>
功能:将 DataModel 反序列化为 Option<T>。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Option<T>
extend Array <: Serializable
extend Array<T> <: Serializable<Array<T>> where T <: Serializable<T>
拓展 Array<T> 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 Array<T> 序列化为 DataModelSeq。
返回值:序列化的 DataModelSeq
func deserialize
static public func deserialize(dm: DataModel): Array<T>
功能:将 DataModel 反序列化为 Array<T>。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 Array<T>
异常:
DataModelException:如果dm不是DataModelSeq,则抛出异常
extend ArrayList <: Serializable
extend ArrayList<T> <: Serializable<ArrayList<T>> where T <: Serializable<T>
拓展 ArrayList<T> 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 ArrayList<T> 序列化为 DataModelSeq。
返回值:序列化的 DataModelSeq
func deserialize
static public func deserialize(dm: DataModel): ArrayList<T>
功能:将 DataModel 反序列化为 ArrayList<T>。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 ArrayList<T>
异常:
DataModelException:如果dm不是DataModelSeq,则抛出异常
extend HashSet <: Serializable
extend HashSet<T> <: Serializable<HashSet<T>> where T <: Serializable<T> & Hashable & Equatable<T>
拓展 HashSet<T> 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 HashSet<T> 序列化为 DataModelSeq。
返回值:序列化的 DataModelSeq
func deserialize
static public func deserialize(dm: DataModel): HashSet<T>
功能:将 DataModel 反序列化为 HashSet<T>。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 HashSet<T>
异常:
DataModelException:如果dm不是DataModelSeq,则抛出异常
extend HashMap <: Serializable
extend HashMap<K, V> <: Serializable<HashMap<K, V>> where K <: Serializable<K> & Hashable & Equatable<K>, V <: Serializable<V>
拓展 HashMap<K, V> 以实现 Serializable。
func serialize
public func serialize(): DataModel
功能:将 HashMap<K, V> 序列化为 DataModelSeq。
返回值:序列化的 DataModelSeq
异常:
DataModelException:如果当前HashMap实例中的Key不是String类型,则抛出异常
func deserialize
static public func deserialize(dm: DataModel): HashMap<K, V>
功能:将 DataModel 反序列化为 HashMap<K, V>。
参数:
dm:需要被反序列化的DataModel
返回值:反序列化后的 HashMap<K, V>
异常:
DataModelException:如果dm不是DataModelStruct类型或者DataModelStruct类型的dm中的Field不是String类型,则抛出异常
示例
class 序列化和反序列化
对 class Abc 进行序列化和反序列化。
代码如下:
from serialization import serialization.*
from std import math.*
from encoding import json.*
class Abc <: Serializable<Abc> {
var name: String = "Abcde"
var age: Int64 = 555
var loc: Option<Location> = Option<Location>.None
public func serialize(): DataModel {
return DataModelStruct().add(field<String>("name", name)).add(field<Int64>("age", age)).add(field<Option<Location>>("loc", loc))
}
public static func deserialize(dm: DataModel): Abc {
let dms = match (dm) {
case data: DataModelStruct => data
case _ => throw Exception("this data is not DataModelStruct")
}
let result = Abc()
result.name = String.deserialize(dms.get("name"))
result.age = Int64.deserialize(dms.get("age"))
result.loc = Option<Location>.deserialize(dms.get("loc"))
return result
}
}
class Location <: Serializable<Location> {
var time: Int64 = 666
var heheh: Char = 'T'
public func serialize(): DataModel {
return DataModelStruct().add(field<Int64>("time", time)).add(field<Char>("heheh", heheh))
}
public static func deserialize(dm: DataModel): Location {
let dms = match (dm) {
case data: DataModelStruct => data
case _ => throw Exception("this data is not DataModelStruct")
}
let result = Location()
result.time = Int64.deserialize(dms.get("time"))
result.heheh = Char.deserialize(dms.get("heheh"))
return result
}
}
main(): Unit {
let dd = Abc()
let aa: JsonValue = dd.serialize().toJson()
let bb: JsonObject = (aa as JsonObject).getOrThrow()
let v1 = (bb.get("name").getOrThrow() as JsonString).getOrThrow()
let v2 = (bb.get("age").getOrThrow() as JsonInt).getOrThrow()
let v3 = bb.get("loc").getOrThrow()
println(v1.getValue())
println(v2.getValue())
println(v3.toString())
println("===========")
let aaa = ##"{"age": 123, "loc": { "heheh": "H", "time": 45 }, "name": "zhangsan"}"##
let bbb = JsonValue.fromStr(aaa)
let ccc = (bbb as JsonObject).getOrThrow()
let v4 = (ccc.get("name").getOrThrow() as JsonString).getOrThrow()
let v5 = (ccc.get("age").getOrThrow() as JsonInt).getOrThrow()
let v6 = (ccc.get("loc").getOrThrow() as JsonObject).getOrThrow()
let v7 = (v6.get("time").getOrThrow() as JsonInt).getOrThrow()
let v8 = (v6.get("heheh").getOrThrow() as JsonString).getOrThrow()
println(v4.getValue())
println(v5.getValue())
println(v7.getValue())
println(v8.getValue())
}
运行结果如下:
Abcde
555
null
===========
zhangsan
123
45
H
HashSet 和 HashMap 序列化
对 HashSet 和 HashMap 进行序列化。
代码如下:
from std import collection.*
from serialization import serialization.*
from encoding import json.*
main(): Unit {
let s: HashSet<Values> = HashSet<Values>([Values(3), Values(5), Values(7)])
let seris: DataModel = s.serialize()
println(seris.toJson().toJsonString())
println("===========")
let m: HashMap<String, Values> = HashMap<String, Values>([("1", Values(3)), ("2", Values(6)), ("3", Values(9))])
let serim: DataModel = m.serialize()
print(serim.toJson().toJsonString())
}
class Values <: Hashable & Equatable<Values> & Serializable<Values> {
var m_data: Int64
init(m_data: Int64) {
this.m_data = m_data
}
public func hashCode(): Int64 {
return this.m_data
}
public operator func ==(right: Values): Bool {
let a = (this.m_data == right.m_data)
if (a) { return true } else { return false }
}
public operator func !=(right: Values): Bool {
let a = (this.m_data != right.m_data)
if (a) { return true } else { return false }
}
public func serialize(): DataModel {
return DataModelStruct().add(field<Int64>("m_data", m_data))
}
public static func deserialize(dm: DataModel): Values {
let dms: DataModelStruct = match (dm) {
case data: DataModelStruct => data
case _ => throw Exception("this data is not DataModelStruct")
}
let result = Values(0)
result.m_data = Int64.deserialize(dms.get("m_data"))
return result
}
}
运行结果如下:
[
{
"m_data": 3
},
{
"m_data": 5
},
{
"m_data": 7
}
]
===========
{
"1": {
"m_data": 3
},
"2": {
"m_data": 6
},
"3": {
"m_data": 9
}
}
概述
目标和适用范围
本规范参考业界标准及实践,华为编程实践总结,为提高代码的可读性,可维护性和安全性,提供编程指南,力争系统化、易使用、易检查。
本规范适用于公司内使用仓颉编程语言编写的代码。
本规范不是仓颉语言教程,在参考本规范之前,希望您具有相应的仓颉语言基础知识。
总体原则
仓颉编程遵循通用原则:
- 清晰第一:清晰性是易于维护、易于重构的程序必需具备的特征。
- 简洁为美:简洁就是易于理解并且易于实现。
- 风格一致:相比个人习惯,所有人共享同一种风格带来的好处,远远超出为统一而付出的代价。
安全编码基本思想:
编程过程中应该时刻保持以下的假设:
- 程序所处理的所有外部数据都是不可信的攻击数据
- 攻击者时刻试图监听、篡改、破坏程序运行环境、外部数据
基于以上的假设,得出安全编码基本思想:
-
程序在处理外部数据时必须经过严格的合法性校验 编程人员在处理外部数据过程中必须时刻保持这种思维意识,不能做出任何外部数据符合预期的假设,外部数据必须经过严格判断后才能使用。编码人员必须在这种严酷的攻击环境下通过遵守这一原则保证程序的执行过程符合预期结果。
-
尽量减少代码的攻击面。代码的实现应该尽量简单,避免与外部环境做多余的数据交互,过多的攻击面增加了被攻击的概率,尽量避免将程序内部的数据处理过程暴露到外部环境。
-
通过防御性的编码策略来弥补潜在的编码人员的疏忽 粗心是人类的天性。由于外部环境的不确定性,以及编码人员的经验、习惯的差异,代码的执行过程很难达到完全符合预期设想的情况。因此在编码过程中必须采取防御性的策略,尽量缓解由于编码人员疏忽导致的缺陷。
条款组织方式
每个条款一般包含标题、级别、描述等组成部分。条款内容中的 “正例”表示符合该条款要求的代码片段,“反例”表示不符合该条款要求的代码片段,但不一定造成程序错误的结果。
标题
描述本条款的内容。
规范条款分为原则和规则两个类别,原则可以评价规则内容制定的好坏并引导规则进行相应的调整;规则是需要遵从或参考的实践。通过标题前的编号标识出条款的类别为原则或规则。
标题前的编号规则为:'P' 为单词 Principle 首字母,'G' 为单词 Guideline 的首字母。原则条款的编号规则为 P.Number。规则的编号方式为 G.Element.Number,其中 Element 为领域知识中关键元素(本规范中对应的二级目录)的 3 位英文字母缩略语。Number 是从 1 开始递增的两位阿拉伯数字,不足两位时高位补 0。
级别
规则类条款分为两个级别:要求、建议。
- 要求:表示产品原则上应该遵从,但可以按照具体的产品版本计划和节奏分期实现。
- 建议:表示该条款属于最佳实践,有助于进一步消解风险,产品可结合业务情况考虑是否纳入,但要保证实施一致的代码风格。
描述
对条款的进一步描述,描述条款的原理,配合正确和错误的代码例子作为示范。有的条款还包含一些规则不适用的例外场景。
仓颉语言的安全机制
仓颉提供了很多安全机制来减少潜在的安全风险:
- 类型安全:仓颉语言是静态强类型语言,通过编译时检查尽早发现程序错误,排除运行时类型错误,能够减少整数截断、溢出、回绕的问题,同时仅非常有限地支持隐式转换。
- 自动内存管理:仓颉语言采用垃圾收集机制,支持自动内存管理,杜绝内存泄漏、多次释放等问题。
- 内存安全:仓颉语言在运行时进行数组下标越界检查、溢出检查等,确保程序内存安全。
- 无指针:仓颉语言支持枚举类型,使用由枚举类型定义的 Option 类型解决了空指针问题。同时不能对对象取地址,引用类型不能使用指针的算术运算,所以无法创造出野指针。
- 变量初始化策略:仓颉语言要求所有变量都必须初始化,并且在编译时进行检查,减少忘记赋值导致的安全风险。
仓颉在实现了上述强大的安全机制的同时,也实现了强大的兼容性:仓颉语言通过在 IR 层级上实现多语言的互通,可以高效调用其他主流编程语言,进而实现对其他语言库的复用和生态兼容。但由于仓颉的提供的安全机制仅适用于仓颉语言本身,并不适用于与其他语言交互操作的场景,因此与其他语言交互操作的安全规范请参考语言互操作章节。
代码风格
代码风格一般包含标识符的命名风格、注释风格及排版风格。一致的编码习惯与风格,会使代码更容易阅读、理解,更容易维护。
命名
有意义地、恰当地命名在编程中是一个较难的事。好的命名特征有:能清晰地表达意图,避免造成误导。 少用缩写,但常见词以及业务线的领域词汇都是允许的,比如 response:resp,request:req,message:msg。 使用仓颉语言编程建议各种形式的名字使用统一的命名风格,具体如下:
| 类别 | 命名风格 | 形式 |
|---|---|---|
| 包名和文件名 | unix_like:单词全小写,用下划线分割 | aaa_bbb |
| 接口,类,结构体,枚举和类型别名 | 大驼峰:首字母大写,单词连在一起,不同单词间通过单词首字母大写分开,可包含数字 | AaaBbb |
| 变量,函数,函数参数 | 小驼峰:首字母小写,单词连在一起,不同单词间通过单词首字母大写分开。例外:测试函数可有下划线 _,循环变量,try-catch 中的异常变量,允许单个小写字母 | aaaBbb |
| let 全局变量, static let 成员变量 | 建议全大写,下划线分割 | AAA_BBB |
| 泛型类型变量 | 单个大写字母,或单个大写字母加数字,或单个大写字母接下划线、大写字母和数字的组合,例如 E, T, T2, E_IN, E_OUT, T_CONS | A |
下表是一些易混淆的单个字符,当作为标识符时,需留意:
| 易混淆的字符 | 易误导的字符 |
|---|---|
| O (大写的 o), D (大写的 d) | 0 (zero) |
| I (大写的 i), l (小写 L) | 1 (one) |
| Z (大写的 z) | 2 (two) |
| S (大写的 s) | 5 (five) |
| b (小写的 B) | 6 (six) |
| B (大写的 b) | 8 (eight) |
| q(小写的 Q) | 9 (nine) |
| h (小写的 H) | n (小写的 N) |
| m (小写的 M) | rn (小写的 RN) |
_(下划线) | 连续多个时很难分辨究竟有几个 |
另外,在使用大、小驼峰命名风格时若遇到 JSON,HTTP 等首字母缩略词,
应将整个缩略词看做普通单词处理,服从命名风格的大小写规定,而不要维持全大写的写法。
如大驼峰风格中:XmlHttpRequest,小驼峰风格中:jsonObject。
包名和文件名
G.NAM.01 包名采用全小写单词,允许包含数字和下划线
【级别】建议
【描述】
- 包名字母全小写,如果有多个单词使用下划线分隔;
- 包名允许有数字,例如 org.apache.commons.lang3;
- 带限定前缀的包名必须和当前包与源代码根目录的相对路径对应,建议以 Internet 域名反转的规则开头,再加上产品名称和模块名称。
【正例】
| 域名 | 包名 |
|---|---|
| my_product.example.com | com.example.my_product |
| my_product.example.org | org.example.my_product |
G.NAM.02 源文件名采用全小写加下划线风格
【级别】建议
【描述】
- 文件名不采用驼峰的原因是:不同系统对文件名大小写处理不同(如 Windows 系统不区分大小写,但是 Unix/Linux, Mac 系统则默认区分)。
- 如果文件只包含一个包外部可见的顶层元素,那么选择该顶层元素的名称,以此命名。否则,选择能代表主要内容的元素名称作为文件名。源文件名称使用全小写加下划线风格。
【正例】
// my_class.cj
public class MyClass {
// CODE
}
【反例】
// MyClass.cj 文件名不符合:使用了驼峰命名
public class MyClass {
// CODE
}
接口、类、struct、enum 和类型别名
G.NAM.03 接口、类、struct、enum 类型和 enum 构造器、类型别名、采用大驼峰命名
【级别】建议
【描述】
- 类型定义通常是名词或名词短语,其中接口名还可以是形容词或形容词短语,都应采用大驼峰命名。
- enum 构造器采用大驼峰命名风格。
- 测试类命名时推荐以被测试类名开头,并以 Test 结尾。例如,HashTest 或 HashIntegrationTest。
- 建议异常类加
Exception/Error后缀。
例外:
在 UI 场景下,一些配置需要用 enum 的成员构造来实现,html 里的一些配置习惯用小驼峰,对于领域内有约定的场景,允许例外。
【正例】
// 符合:类名使用大驼峰
class MarcoPolo {
// CODE
}
// 符合:enum 类型和 enum 构造器使用大驼峰
enum ThreadState {
New | Runnable | Blocked | Terminated
}
// 符合:接口名使用大驼峰
interface TaPromotable {
// CODE
}
// 符合:类型别名使用大驼峰
type Point2D = (Float64, Float64)
// 符合:抽象类名使用大驼峰
abstract class AbstractAppContext {
// CODE
}
【反例】
// 不符合:类名使用小驼峰
class marcoPolos {
// CODE
}
// 不符合:enum 类型名使用小驼峰
enum timeUnit {
Year | Month | Day | Hour
}
函数
G.NAM.04 函数名称应采用小驼峰命名
【级别】建议
【描述】
-
函数名称采用小驼峰命名风格。例如,sendMessage 或 stopServer。
格式如下:
- 建议优先将 field 对外的接口实现成属性,而不是 getXXX/setXXX,会更简洁。
- 布尔属性名建议加 is 或 has, 例如:isEmpty。
- 函数名称建议使用以下格式:has + 名词 / 形容词 ()、动词 ()、动词 + 宾语 ()。
- 回调函数(callback)允许介词 + 动词形式命名,如: onCreate, onDestroy, toString 其中动词主要用在动作的对象自身上,如 document.print()。
-
下划线可能出现在单元测试函数名称中,用于分隔名称的逻辑组件,每个组件都使用小驼峰命名法。例如,一种典型的模式是
<methodUnderTest>_<state>,又例如pop_emptyStack,命名测试函数没有唯一的正确方法。
【正例】
// 符合:函数名使用小驼峰
func addExample(start: Int64, size: Int64) {
return start + size
}
// 符合:函数名使用小驼峰
func printAdd(add: (Int64, Int64) -> Int64): Unit {
println(add(1, 2))
}
【反例】
// 不符合:函数名使用大驼峰
func GenerateChildren(page: Int64) {
println(page.toString())
}
变量
G.NAM.05 const 变量的名称采用全大写
【级别】建议
【描述】
const 变量表示在编译时完成求值,并且在运行时不可改变的变量,使用下划线分隔的全大写单词来命名。
【反例】:
// 不符合 : const 变量没有使用下划线分隔的全大写单词命名
const MAXUSERNUM = 200
class Weight {
static const GramsPerKg = 1000
}
【正例】
// 符合 : const 变量使用下划线分隔的全大写单词命名
const MAX_USER_NUM = 200
class Weight {
static const GRAMS_PER_KG = 1000
}
G.NAM.06 变量的名称采用小驼峰
【级别】建议
【描述】
变量、属性、函数参数、pattern 等均采用小驼峰命名风格。
例外:
-
泛型类型变量,允许单个大写字母,或单个大写字母加数字,或单个大写字母接下划线、大写字母和数字的组合,例如 E, T, T2, E_IN, E_OUT, T_CONS
-
函数内使用的数值常量,不要使用魔鬼数字,用 let 声明有意义的局部变量代替,此时局部变量名可以使用全大写下划线的风格命名,强调是常量
不应该取 NUM_FIVE = 5 或 NUM_5 = 5 这样的 “魔鬼常量”。如果被粗心大意地改为 NUM_5 = 50 或 55 等,很容易出错。
【反例】:
// 不符合:变量名使用无意义单个字符
var i: Array<Item> = ...
// 不符合:类型参数使用小写字母
class Map<key, val> { ... }
【正例】
// 变量名使用小驼峰命名
let menuItems: Array<Item> = ...
let names: Array<String> = ...
let menuItemsArray: Array<Item> = ...
let menuItems: Set<Item> = ...
let rememberedSet: Set<Address> = ...
let waitingQue: Queue<Thread> = ...
let lookupTable: Array<Int64> = ...
let word2WordIdMap: Map<Stirng, Integer> = ...
class MyPage <: Page {
var pageNo = StateInt64(1) // 实例成员变量使用小驼峰命名
var imagePath = StateArray(images) // 实例成员变量使用小驼峰命名
init() {
...
}
}
// 参数名使用小驼峰命名
func getColumnMoreDataColumn(pageType: String, idxColumn: Int64, outIndex: Int64) {
...
}
// 类型参数使用大写字母
class Map<KEY, VAL> { ... }
// 类型参数使用大写字母与数字
class Pair<T1, T2> { ... }
格式
尽管有些编程的排版风格因人而异,但是我们强烈建议和要求在同一个项目中使用统一的编码风格,以便所有人都能够轻松的阅读和理解代码,增强代码的可维护性。
编码格式
G.FMT.01 源文件编码格式(包括注释)必须是 UTF-8
【级别】要求
【描述】
对于源文件,应统一采用 UTF-8 进行编码。仓颉编译器目前仅支持 UTF-8 编码。
文件
G.FMT.02 一个源文件按顺序包含版权、package、import、顶层元素四类信息,且不同类别之间用空行分隔
【级别】建议
【描述】
一个源文件会包含以下几个可选的部分,应按顺序组织,且每个部分之间用空行隔开:
- 许可证或版权信息;
- package 声明,且不换行;
- import 声明,且每个 import 不换行;
- 顶层元素。
【正例】
// 第一部分,版权信息
/*
* Copyright (c) Huawei Technologies Co., Ltd. 2020-2020. All rights reserved.
*/
// 第二部分,package 声明
package com.huawei.myproduct.mymodule
// 第三部分,import 声明
from std import collection.HashMap // 标准库
// 第四部分,public 元素定义
public class ListItem <: Component {
// ...
}
// 第五部分,internal 元素定义
class Helper {
// CODE
}
G.FMT.03 import 包应该按照包所归属的组织或分类进行分组
【级别】建议
【描述】
说明:import 导入包根据归属组织或分类进行分组:本公司 (例如华为公司 com.huawei.),其它商业组织 (com.),其它开源第三方、net/org 开源组织、标准库。两个分组之间使用空行分隔。
【正例】
import com.huawei.*; // 华为公司
import com.google.common.io.Files; // 其它商业组织
import harmonyos.*; // 开源
import mitmproxy.*; // 其它开源第三方
import textual.*; // 开源
import net.sf.json.*; // 开源组织
import org.linux.apache.server.SoapServer; // 开源组织
from std import io.*; // 标准库
from std import socket.*
G.FMT.04 一个类、接口或 struct 的声明部分应当按照静态变量、实例变量、构造函数、成员函数的顺序出现,且用空行分隔
【级别】建议
【描述】
一个类或接口的声明部分应当按照以下顺序出现:
- 静态变量
- 实例变量
- 构造函数,如果有主构造函数,则主构造函数在其它构造函数之前
- 属性
- 成员函数
实例变量、构造函数,均按访问修饰符从大到小排列:public、protected、private。静态变量要按初始化顺序来,可以不遵循按访问修饰符从大到小排列的建议。
说明:
- 对于自注释字段之间可以不加空行;
- 非自注释字段应该加注释且字段间空行隔开;
- enum 没有成员变量,按照 enum 构造器,属性,成员函数的顺序出现;
行宽
G.FMT.05 行宽不超过 120 个窄字符
【级别】建议
【描述】
一个宽字符占用两个窄字符的宽度。除非另有说明,否则任何超出此限制的行都应该换行,如 [换行](# 换行) 一节中所述。
每个 Unicode 代码点都计为一个字符,即使其显示宽度大于或小于一个字符。如果使用 全角字符,可以选择比此规则建议的位置更早地换行。
字符的 “宽” 与“窄”由它的 east asian width Unicode 属性 定义。通常,窄字符也称 “半角” 字符,ASCII 字符集中的所有字符,包括字母(如:a、A)、数字(如:0、3)、标点(如','、'{')、空格,都是窄字符;
宽字符也称 “全角” 字符,汉字(如:中、文)、中文标点(','、'、')、全角字母和数字(如 A、3)等都是宽字符,算 2 个窄字符。
例外:
package和import声明;- 对于换行导致内容截断,不方便查找、拷贝的字符(如长 URL、命令行等)可以不换行。
换行
换行是将代码分隔到多个行的行为,否则它们都会堆积到同一行。
如需换行,建议在以下位置进行换行:
- 函数参数列表(包括形参和实参),两个参数之间,在逗号后换行;
- 函数返回类型,在
:后换行; - 泛型参数列表(包括泛型形参和泛型实参),两个泛型参数之间,在逗号后换行;
- 泛型约束条件列表,两个约束条件之间,在
&或逗号后换行; - 类型声明时,父类和实现接口列表,在
&后换行; - lambda 表达式的
=>后换行; - 如果需要在二元操作符
+、-号的位置换行,应在操作符之后换行以避免歧义;
举个例子,下面这个复杂的函数声明,建议在箭头(^)所指的位置进行换行:
public func codeStyleDemo<T, M>(param1: String, param2: String): String where T <: String, M <: String { ... }
// ^ ^ ^ ^
G.FMT.06 表达式中不要插入空白行
【级别】建议
【描述】
- 当表达式过长,或者可读性不佳时,需要在合适的地方换行。表达式换行后的缩进要跟上一行的表达式开头对齐。
- 可以在表达式中间插入注释行
- 不要在表达式中间插入空白行
【正例】
func foo(s: string) {
s
}
func bar(s: string) {
s
}
/* 符合,表达式中可以插入注释进行说明 */
main() {
let s = "Hello world"
/* this is a comment */
|> foo
|> bar
}
【反例】
func foo(s: string) {
s
}
func bar(s: string) {
s
}
/* 不符合,表达式中不应插入空白行 */
main() {
let s = "Hello world"
|> foo
|> bar
}
G.FMT.07 一行只有一个声明或表达式
【级别】建议
【描述】声明或表达式应该单独占一行,更加利于阅读和理解代码。
【反例】
// 不符合:多个变量声明需要分开放在多行
var length = 0; var result = false
// 不符合: 多个表达式需分开放在多行
result = true; result
【正例】
// 符合:多个变量声明需要分开放在多行
var length = 0
var result = false
// 符合: 多个表达式分开放在多行
result = true
result
缩进
G.FMT.08 采用一致的空格缩进
【级别】建议
【描述】
建议使用空格进行缩进,每次缩进 4 个空格。避免使用制表符(\t)进行缩进。
对于 UI 等多层嵌套使用较多的产品,可以统一使用 2 个空格缩进。
【正例】
class ListItem {
var content: Array<Int64> // 符合:相对类声明缩进 4 个空格
init(
content: Array<Int64>, // 符合:函数参数相对函数声明缩进 4 个空格
isShow!: Bool = true,
id!: String = ""
) {
this.content = content
}
}
大括号
G.FMT.09 使用统一的大括号换行风格
【级别】建议
【描述】
选择并统一使用一种大括号换行风格,避免多种风格并存。
对于非空块状结构,大括号推荐使用 K&R 风格:
- 左大括号不换行;
- 右大括号独占一行,除非后面跟着同一表达式的剩余部分,如
do-while表达式中的while,或者if表达式中的else和else if等。
【正例】
enum TimeUnit { // 符合:跟随声明放行末,前置 1 空格
Year | Month | Day | Hour
} // 符合:右大括号独占一行
class A { // 符合:跟随声明放行末,前置 1 空格
var count = 1
}
func fn(a: Int64): Unit { // 符合:跟随声明放行末,前置 1 空格
if (a > 0) { // 符合:跟随声明放行末,前置 1 空格
// CODE
} else { // 符合:右大括号和 else 在同一行
// CODE
} // 符合:右大括号独占一行
}
// lambda 函数
let add = { base: Int64, bonus: Int64 => // 符合: lambda 表达式中非空块遵循 K&R 风格
print("符合 news")
base + bonus
}
【反例】
func fn(count: Int64)
{ // 不符合:左大括号不应该单独一行
if (count > 0)
{ // 不符合:左大括号不应该单独一行
// CODE
} // 不符合:右大括号后面还有跟随的 else,应该和 else 放同一行
else {
print("count <= 0")} // 不符合:右大括号后面没有跟随的部分,应该独占一行
}
例外: 对于空块既可遵循前面的 K&R 风格,也可以在大括号打开后立即关闭,产品应考虑使用统一的风格。
【正例】
open class Demo {} // 符合: 空块,左右大括号在同一行
空行和水平空格
G.FMT.10 用空格突出关键字和重要信息
【级别】建议
【描述】
水平空格应该突出关键字和重要信息。单个空格应该分隔关键字与其后的左括号、与其前面的右大括号,出现在二元操作符 / 类似操作符的两侧。行尾和空行不应用空格 space。总体规则如下:
-
建议 加空格的场景:
- 条件表达式(if 表达式),循环表达式(for-in 表达式,while 表达式和 do-while 表达式),模式匹配表达式(match 表达式)和 try 表达式中关键字与其后的左括号,或与其前面的右括号之间
- 赋值运算符(包括复合)前后,例如
=、*=等 - 逗号
,、enum 定义中的|符号、变量声明 / 函数定义 / 命名参数传值中的冒号:之后,例如let a: Int64 - 二元操作符、泛型约束的
&符号、声明父类父接口或实现 / 扩展接口的<:符号、range操作符步长的冒号:前后两侧,例如base + offset,Int64 * Int64等 - lambda 表达式中的箭头前后,例如
{str => str.length()} - 条件表达式、循环表达式等场景下的
)与{之间加空格,例如:if (i > 0) {。 - 函数、类型等声明的
{之前加空格,例如:class A {
-
不建议 加空格的场景:
- 成员访问操作符(
instance.member)前后, 问号操作符?前后 range操作符(0..num、0..=num这 2 种区间)前后- 圆括号、方括号内两侧
- 一元操作符前后,例如
cnt++ - 函数声明或者函数调用的左括号之前
- 逗号
,和变量声明 / 函数定义 / 命名参数传值中的冒号:之前 - 下标访问表达式中,
[和它之前的 token 之间
- 成员访问操作符(
推荐示例如下:
var isPresent: Bool = false // 符合:变量声明冒号之后有一个空格
func method(isEmpty!: Bool): RetType { ... } // 符合:函数定义(命名参数 / 返回类型)中的冒号之后有一个空格
method(isEmpty: isPresent) // 符合: 命名参数传值中的冒号之后有一个空格
0..MAX_COUNT : -1 // 符合: range 操作符区间前后没有空格,步长冒号前后两侧有一个空格
var hundred = 0
do { // 符合:关键字 do 和后面的括号之间有一个空格
hundred++
} while (hundred < 100) // 符合:关键字 while 和前面的括号之间有一个空格
func fn(paramName1: ArgType, paramName2: ArgType): ReturnType { // 符合:圆括号和内部相邻字符之间不出现空格
...
for (i in 1..4) { // 符合:range 操作符左右两侧不留空格
...
}
}
let listOne: Array<Int64> = [1, 2, 3, 4] // 符合:方括号和圆括号内部两侧不出现空格
let salary = base + bonus // 符合:二元操作符左右两侧留空格
x++ // 符合:一元操作符和操作数之间不留空格
G.FMT.11 减少不必要的空行,保持代码紧凑
【级别】建议
【描述】
减少不必要的空行,可以显示更多的代码,方便代码阅读。建议:
- 根据上下内容的相关程度,合理安排空行;
- 类型定义和顶层函数定义与前后顶层元素之间至少空一行;
- 函数内部、类型定义内部、表达式内部,不使用连续空行;
- 不使用连续 3 个或更多空行;
- 大括号内的代码块行首之前和行尾之后不要加空行。
【反例】
class MyApp <: App {
let album = albumCreate()
let page: Router
// 空行
// 空行
// 空行
init() { // 不符合:类型定义内部使用连续空行
this.page = Router("album", album)
}
override func onCreate(): Unit {
println( "album Init." ) // 不符合:大括号内部首尾存在空行
}
}
修饰符
G.FMT.12 修饰符关键字按照一定优先级排列
【级别】建议
【描述】
以下是推荐的所有修饰符排列的优先级:
public/protected/private
open/abstract/static/sealed
override/redef
unsafe/foreign
const/mut
另外,因为 sealed 已经蕴含了 public 和 open 的语义,不推荐 sealed 与 public 或 open 同时使用。
注释
注释是为了帮助阅读者快速读懂代码,所以要从读者的角度出发,按需注释。
注释内容要简洁、明了、无二义性,信息全面且不冗余。
注释跟代码一样重要。
CangJie 中注释的语法有以下几种:单行注释(//)、多行注释(/*...*/)。本节介绍如何规范使用这些注释。
文件头注释
G.FMT.13 文件头注释应该包含版权许可
【级别】建议
【描述】
文件头注释必须放在 package 和 import 之前,必须包含版权许可信息,如果需要在文件头注释中增加其他内容,可以在后面以相同格式补充。版本许可不应该使用单行样式的注释,必须从文件顶头开始。如果包含 “关键资产说明 “类注释,则应紧随其后。
版权许可内容及格式必须如下:
中文版:
/*
* 版权所有 (c) 华为技术有限公司 2019-2021
*/
英文版:
/*
* Copyright (c) Huawei Technologies Co., Ltd. 2019-2021. All rights reserved.
*/
关于版本说明,应注意:
-
2019-2021 根据实际需要可以修改。
2019 是文件首次创建年份,而 2021 是文件修改最后年份。二者可以一样,如 "2021-2021"。
对文件有重大修改时,必须更新后面年份,如特性扩展,重大重构等。
-
版权说明可以使用华为子公司。
如:版权所有 (c) 海思半导体 2012-2020
或英文: Copyright (c) Hisilicon Technologies Co., Ltd. 2019-2021. All rights reserved.
代码注释
G.FMT.14 代码注释放于对应代码的上方或右边
【级别】建议
【描述】
-
代码上方的注释与被注释的代码行间无空行,保持与代码一样的缩进。
-
代码右边的注释,与代码之间至少留有 1 个空格。代码右边的注释,无需插入空格使其强行对齐。
选择并统一使用如下风格:
var foo = 100 // 放右边的注释 var bar = 200 /* 放右边的注释 */ -
当右置的注释超过行宽时,请考虑将注释至于代码上方。同一个 block 中的代码注释不用插入空格使其强行对齐。
【正例】
class Column <: Div { var reverse: Bool = false var justifyContent: JustifyContent = JustifyContent.flexStart var alignItems: AlignItems = AlignItems.stretch // 注释和代码间留一个空格 var alignSelf: AlignSelf = AlignSelf.auto // 上下两行注释无需插入空格强行对齐 init() { ... } } -
if else if为了更清晰,考虑注释放在else if同行或者在块内都行,但不是在else if之前,避免以为注释是关于它所在块的。【反例】
var nr = 100 if (nr % 15 == 0) { println("fizzbuzz") // 当 nr 只能被 3 整除,不能被 5 整除不符合。 } else if (nr % 3 == 0) { println("fizz") }上述错误示例的注释是
if分支的还是else if分支的,容易造成误解。【正例】
var nr = 100 if (nr % 15 == 0) { println("fizzbuzz") } else if (nr % 3 == 0) { // 当 nr 只能被 3 整除,不能被 5 整除不符合。 println("fizz") }
编程实践
声明
G.DECL.01 避免遮盖(shadow)
【级别】建议
【描述】
由于变量、类型、函数、包名共享一个命名空间,这几类实体之间重用名字会发生遮盖 (shadow),因此,需尽量避免无关的实体之间发生遮盖 (shadow);
否则,这种源代码上的模糊性,会给维护者和检视者带来很大的困扰和负担。尤其是当代码既需要访问复用的标识符,又需要访问被覆盖的标识符时。当复用的标识符在不同的包里时,这个负担会变得更加沉重。
【反例】
main(): Unit {
var name = ""
var fn = {
var name = "Zhang" // Shadow
println(name)
}
println(name) // prints ""
fn() // prints "Zhang"
}
类似地,类型参数名称也要尽量避免遮盖。
【反例】
class Foo<T> {
static func foo<T>(a: T): T { return a }
func goo(a: T): T { return a }
}
上面代码中静态泛型函数的类型参数 T 遮盖了泛型类的类型参数 T。
函数
G.FUNC.01 函数功能要单一
【级别】建议
【描述】
过长的函数往往意味着函数功能不单一,可以进行进一步拆分或分层。过于复杂的函数不利于阅读理解,难以维护。
可以考虑从以下维度间接衡量函数功能是否单一:
-
函数行数,建议不超过 50 行(非空非注释);
-
除构造函数外,函数的参数,建议不超过 5 个;
-
函数最大代码块嵌套不要过深,建议不要超过 4 层。函数的代码块嵌套深度指的是函数中的代码控制块(例如:if、for、while、match 等)之间互相包含的深度。
G.FUNC.02 禁止函数有未被使用的参数
【级别】要求
【描述】
未被使用的参数往往是因为设计发生了变动造成的,它可能导致传参时出现不正确的参数匹配。
【反例】
func logInfo(fileName: String, lineNo: Int64): Unit {
println(fileName)
}
例外:回调函数和 interface 实现等情形,可以用_代替未被使用的参数。
let a = [1, 2, 3]
let b = a.filter{ _ => true }
G.FUNC.03 避免在无关的函数之间重用名字,构成重载
【级别】建议
【描述】
函数重载的主要作用是使用同一个函数名来接受不同的参数实现相似的任务,为了代码的可读性和可维护性,应尽量避免完成不同任务的函数之间构成重载 (overload)。如果多个函数之间有必要构成重载,那么应满足以下要求:
- 它们应在同一个类型或文件内依次定义,避免重载的多个函数出现在不同作用域层级;
- 构成重载的函数之间应尽量避免同一组实参能通过多个函数的类型检查。
以上对函数重载的建议,指的是一个团队内部自定义的函数之间构成重载的建议,以下情形可以例外:
- 如果和第三方或标准库中的函数之间有必要构成重载,可以出现在不同包;
- 如果有必要进行操作符重载,操作符重载函数可以出现在不同文件或不同包;
- 父类和子类的函数之间如果有必要成重载,可以出现在不同文件或包。
【反例】
以下例子中,在 package a 定义了函数 fn(a: Derived),在 package b 定义了 fn(a: Base) 的重载函数,由于两个重载函数在不同的作用域层级,导致在 package b 中调用 fn 时,根据作用域优先级原则,选择不是最匹配的 fn(a: Base)。
另一个不符合规范的例子是,两个构成重载的函数 g 的对应位置参数类型为被实例化的关系或父子类型关系,函数调用时两个函数均通过类型检查,但根据最匹配原则,没有最匹配函数,导致无法决议。
package a
public open class Base {
...
}
public class Derived <: Base {
...
}
public func fn(a: Derived) {
...
}
////
package b
import a.Base
import a.Derived
import a.fn
func fn(a: Base) { // 不符合:两个 fn 在不同的作用域层级
...
}
main() {
fn(Derived()) // 根据作用域优先级原则,调用的是 fn(a: Base)
g(Derived(), Derived()) // 根据最匹配原则,没有最匹配函数,无法决议
}
// 不符合: 两个 g 的对应位置参数类型为被实例化的关系或父子类型关系,很容易构造实参让两个均通过类型检查
func g<X>(a: X, b: Derived) {
...
}
func g(a: Derived, b: Base) {
...
}
【正例】
public open class Base {
// CODE
}
public class Derived <: Base {
// CODE
}
// 符合:构成重载的函数在同一层作用域内依次出现,且参数之间不存在子类型或被实例化的关系
func fn(a: Base) {
// CODE
}
func fn(a: Int64) {
// CODE
}
类
G.CLS.01 override 父类函数时不要增加函数的可访问性
【级别】建议
【描述】
增加 override 函数的可访问性,子类将拥有比预期更大的访问权限。
【反例】
open class Base {
protected open func f(a: Int64): Int64 {
return a
}
}
class Sub <: Base {
public override func f(a: Int64): Int64 {
super.f(a)
//do some sensitive operations
}
public func g(a: Int64): Int64 {
super.f(a) // 这种也算是增加可访问性。
}
}
上面的错误代码中,子类 override 了基类的 f() 函数,并增加了函数的可访问性。基类 Base 定义的 f() 函数为 protected 的,子类 Sub 定义该函数为 public 的,从而增加了 f() 的访问性。因此,任何 Sub 的使用者都可以调用此函数。
【正例】
open class Base {
protected open func f(a: Int64): Int64 {
//do some sensitive operations
return a
}
}
class Sub <: Base {
protected override func f(a: Int64): Int64 {
return a + 1
}
}
该正确示例中,子类覆写的基类 f() 函数与基类保持一致为 protected。
G.CLS.02 创建对象优先使用构造函数,慎用静态工厂方法
【级别】建议
【描述】
静态工厂方法是一种将对象的构造与使用相分离的设计模式,它使用一个(或一系列)静态函数代替构造函数来构造数据。
在仓颉中应优先使用构造函数来构造对象,除了下文提到的例外情况,尽量避免使用静态工厂方法。
首先,若必须使用,为了方便识别,静态工厂方法的名称应包含 from, of, valueOf, instance, get, new, create 等常用关键字来突出构造作用。 如果为了区别无法仅从参数中识别的多种构造方法,各个静态工厂函数的名称也应有所区别以解释具体的构造方式。
仓颉语言支持命名参数和操作符重载,在只用作区分构造方式的目的时,比起静态工厂方法, 应优先考虑带命名参数的构造函数、单位常量乘以数目等更直观的构造方式。在这些方法都难以理解时再考虑静态工厂方法。
【反例】
class Weight {
private static const G_PER_KG = 1000.0
let g: Int64
Weight(gram: Int64, kilo: Float64) {
g = gram + Int64(kilo * G_PER_KG)
}
init(gram: Int64) {
this(gram, 0.0)
}
init(kilo: Float64) {
this(0, kilo)
}
}
// 不符合,难以区分
main() {
let w1 = Weight(1)
let w2 = Weight(0.5)
let w3 = Weight(1, 2.0)
}
class Weight {
private static const G_PER_KG = 1000.0
private Weight(let g: Int64) {}
static func ofGram(gram: Int64) {
Weight(gram)
}
static func ofKilo(kilo: Float64) {
Weight(Int64(kilo * G_PER_KG))
}
static func ofGramNKilo(gram: Int64, kilo: Float64) {
Weight(gram + Int64(kilo * G_PER_KG))
}
}
// 不符合,有更直观的替代方式
main() {
let w1 = Weight.ofGram(1)
let w2 = Weight.ofKilo(0.5)
let w3 = Weight.ofGramNKilo(1, 2.0)
}
【正例】
class Weight {
private static const G_PER_KG = 1000.0
let g: Int64
Weight(gram!: Int64, kilo!: Float64) {
g = gram + Int64(kilo * G_PER_KG)
}
init(gram!: Int64) {
this(gram: gram, kilo: 0.0)
}
init(kilo!: Float64) {
this(gram: 0, kilo: kilo)
}
}
/* 符合,优先使用 */
main() {
let w1 = Weight(gram: 1)
let w2 = Weight(kilo: 0.5)
let w3 = Weight(gram: 1, kilo: 2.0)
}
class Weight {
private static const G_PER_KG = 1000
private Weight(let g: Int64) {}
static let gram = Weight(1)
static let kilo = Weight(G_PER_KG)
operator func *(rhs: Int64) {
Weight(g * rhs)
}
operator func *(rhs: Float64) {
Weight(Int64(Float64(g) * rhs))
}
operator func +(rhs: Weight) {
Weight(g + rhs.g)
}
}
extend Int64 {
operator func *(rhs: Weight) {
rhs * this
}
}
extend Float64 {
operator func *(rhs: Weight) {
rhs * this
}
}
/* 符合,优先使用 */
main() {
let w1 = 1 * Weight.gram
let w2 = 0.5 * Weight.kilo
let w3 = 1 * Weight.kilo + 2 * Weight.gram
}
from std import random.Random
class BigInteger {
/* ....... */
static func probablePrime(bitWidth: Int64, rnd: Random) {
/* some complex computation */
/* ............ */
BigInteger()
}
}
main() {
// 符合,较为复杂,仅用命名参数难以解释清楚
let rndPrime = BigInteger.probablePrime(16, Random())
}
另一种允许使用静态工厂方法的情况是在需要获得缓存的对象时,构造函数总是会构造新的对象,此时可以使用静态工厂方法来达到访问缓存的目的。 一些典型的情况包括:不可变类型、与资源绑定的类型、构造过程非常耗时的类型等
【正例】
from std import collection.HashMap
class ImmutableData {
private static let cache = HashMap<String, ImmutableData>()
// 符合,返回缓存的不可变对象
public static func getByName(name: String) {
if (cache.contains(name)) {
return cache[name]
} else {
cache[name] = ImmutableData(name)
return cache[name]
}
}
private ImmutableData(name: String) {
// some very time-consuming process
}
}
main() {
let d1 = ImmutableData.getByName("abc") // new
let d2 = ImmutableData.getByName("abc") // cached
}
最后一种情形是返回接口的实例从而将接口与实现类解耦,达到隐藏实现细节或者按需替换实现类的目的。
【正例】
sealed interface I1 {
// 符合,隐藏实现细节
static func getInstance() {
return C1() as I1
}
func Safe():Unit
}
interface I2 <: I1 {
func Safe():Unit
func Secret():Unit
}
class C1 <: I2 {
public func Safe():Unit {}
public func Secret():Unit {}
}
sealed interface I1 {
// 符合,根据输入选择实现方式
static func fromInt(i: Int64) {
if (i > 100) {
return ImplForLarge() as I1
} else {
return ImplForSmall() as I1
}
}
func foo():Unit
}
class ImplForLarge <: I1 {
public func foo():Unit {}
}
class ImplForSmall <: I1 {
public func foo():Unit {}
}
接口
G.ITF.01 对于需要原地修改对象自身的抽象函数,尽量使用 mut 修饰,以支持 struct 类型实现或扩展该接口
【级别】建议
【描述】
说明: 如果对于可能需要原地修改的函数不声明为 mut 函数,未来就不能被 struct 类型实现,会导致接口的抽象能力降低。
【正例】
interface Increasable {
mut func increase(): Unit
}
struct R <: Increasable {
var item = 0
public mut func increase(): Unit {
item += 1
}
}
【反例】
interface Increasable {
func increase(): Unit // 不符合:struct 类型实现该接口时,无法实际被修改
}
struct R <: Increasable {
var item = 0
public func increase(): Unit {
item += 1 // item 不能被实际修改
}
}
G.ITF.02 尽量在类型定义处就实现接口,而不是通过扩展实现接口
【级别】建议
【描述】
说明:
- 通过扩展实现接口不应该被滥用,如果一个类型在定义时就已知将要实现的接口信息,应该将接口直接声明出来,有利于使用者集中浏览信息。
- 通过扩展实现的接口,和类型定义处声明实现接口,在实现层面可能带来协变层面的问题。这个开发者可能不容易感知,但尽量在定义处声明实现接口,可以有效避免。
【反例】
interface I {
func f(): Unit
}
class C {}
extend C <: I {
public func f(): Unit {}
}
main() {
let i: I = C() // ok
let f1: () -> C = { => C() }
let f2: () -> I = f1 // 报错,虽然 () -> C 是 () -> I 的子类型,但 C 通过扩展实现 I,此时不能协变,导致不能赋值。
return 0
}
【正例】
interface I {
func f(): Unit
}
// 符合:类型定义处实现接口
class A <: I {
public func f(): Unit {
// CODE
}
}
G.ITF.03 类型定义时避免同时声明实现父接口和子接口
【级别】建议
【描述】
同时实现父接口和子接口时,父接口属于冗余信息,对用户甄别信息造成困扰。避免声明重复的父接口可以让声明保持简洁。
interface Base {
func f1(): Unit
}
interface Sub <: Base {
func f2(): Unit
}
// 符合
class A <: Sub {
public func f1(): Unit {
// CODE
}
public func f2(): Unit {
// CODE
}
}
// 不符合
class B <: Sub & Base {
public func f1(): Unit {
// CODE
}
public func f2(): Unit {
// CODE
}
}
G.ITF.04 尽量通过泛型约束使用接口,而不是直接将接口作为类型使用
【级别】建议
【描述】
class 以外的类型转型到 interface 可能会附带装箱操作,而作为泛型约束的方式使用 interface 可以直接静态派发,避免装箱和动态派发带来的开销,提升性能。
interface I {
func f(): Unit
}
// 符合
func g<T>(i: T): Unit where T <: I {
return i.f()
}
// 不符合
func g(i: I): Unit {
return i.f()
}
操作符重载
G.OP.01 尽量避免违反使用习惯的操作符重载
【级别】建议
【描述】
重载操作符时要有充分的理由,尽量避免改变操作符的原有使用习惯,例如使用 + 操作符来做减法运算,避免对基础类型重载已内置支持的操作符。
【正例】:
struct Point {
var x: Int64 = 0
var y: Int64 = 0
public init(x: Int64, y: Int64) {
this.x = x
this.y = y
}
operator func +(rhs: Point): Point { // 符合:为 Point 重载加法操作符
return Point(this.x + rhs.x, this.y + rhs.y)
}
}
【反例】
struct Point {
let x: Int64 = 0
let y: Int64 = 0
// 不符合:为 Point 重载加法操作符,但其实成员间做的是减法操作
operator func +(rhs: Point): Point {
return Point(this.x - rhs.x, this.y - rhs.y)
}
}
extend Int64 {
operator func +(right: Float64) { // 不符合:对基础类型重载已内置支持的操作符
// CODE
}
}
G.OP.02 尽量避免在 enum 类型内定义 () 操作符重载函数
【级别】建议
【描述】
enum 类型中定义 () 操作符重载函数,可能会和构造成员造成冲突,当两者之间发生冲突将优先调用 enum 类型的构造成员。因此建议尽量避免在 enum 类型中定义 () 操作符重载函数。
【反例】
enum E {
Y | X | X(Int64)
operator func ()(a: Int64) { // 不符合: enum 类型内定义 () 操作符重载函数,且与构造器有冲突
// CODE
}
}
let e = X(1) // 调用的是 enum 构造器:X(Int64).
enum
G.ENUM.01:避免 enum 的构造器与顶层元素同名
【级别】要求
【描述】
enum 构造器名字在类型所在作用域下总是自动引入,可以省略类型前缀使用。
- enum 构造器与顶层的除函数以外元素的同名时,两者均不能使用,都需要通过前缀限定的方式使用。
- enum 构造器与顶层可见的函数同名时,参与函数重载决议,当无法决议时,enum 构造器和函数均不能使用,均需通过前缀限定的方式使用。应尽量保证 enum 的构造器与顶层函数使用不同的名字,以避免不必要的重载所带来的困惑。
【正例】:
enum TimeUnit {
| Year(Int64)
| Month(Int64, Int64)
| Day(Int64, Int64, Int64)
}
class MyYear {
let a: Int64
init(a: Int64) {
this.a = a
}
}
main() {
let y1 = Year(100) // ok,Year(100) 调用的是 TimeUnit 中的 Year(Int64) 构造器
let y2 = MyYear(100) // ok,调用的是 class MyYear 的构造函数
return 0
}
【反例】
enum TimeUnit {
| Year(Int64) // 不符合:enum 构成成员与顶层的 class 类型同名
| Month(Int64, Int64)
| Day(Int64, Int64, Int64)
}
class Year {
let a: Int64 = 0
init(a: Int64) {
this.a = a
}
}
main() {
let y = Year(100) // error,无法决议是调用 TimeUnit 中的构造器还是调用 Year 类的构造函数
return 0
}
【反例】
enum E {
| f1(Int64) // 不符合:enum 构成成员与顶层的函数同名
| f2(Int64, Int64)
}
func f1(a: Int64) {}
func f2(a: Int64, b: Int64) {}
main() {
f1(1) // error,无法决议
f2(1, 2) // error,无法决议
return 0
}
G.ENUM.02 尽量避免不同 enum 构造器之间不必要的重载
【级别】建议
【描述】
因为 enum 构造器的名字在类型所在作用域下总是自动引入的,所以不同 enum 中定义同名且对应位置参数类型存在子类型关系的构造成员后,省略类型前缀的使用方式将不再可用。enum 构造器参与函数的重载决议,当无法决议时 enum 构造器和函数均不能直接使用,此时 enum 构造器需要使用类型前缀的方式使用,函数也需要通过前缀限定的方式使用。只要有多个 enum constructor 通过类型检查,或只要有 enum constructor 和函数同时通过类型检查,就会造成无法决议。
【正例】
enum TimeUnit1 {
| Year1(Int64)
| Month1(Int64, Int64)
| Day1(Int64, Int64, Int64)
}
enum TimeUnit2 {
| Year2(Int64)
| Month2(Int64, Int64)
| Day2(Int64, Int64, Int64)
}
main() {
let a = Year1(1) // ok:无需使用 enum 类型前缀
let b = Year2(2) // ok:无需使用 enum 类型前缀
return 0
}
【反例】
enum TimeUnit1 {
| Year(Int64)
| Month(Int64, Int64)
| Day(Int64, Int64, Int64)
}
enum TimeUnit2 {
| Year(Int64)
| Month(Int64, Int64)
| Day(Int64, Int64, Int64)
}
main() {
let a = Year(1) // error:无法决议调用的是哪个 Year(Int64)
let b = TimeUnit1.Year(1) // ok:使用 enum 类型前缀
let c = TimeUnit2.Year(2) // ok:使用 enum 类型前缀
return 0
}
【正例】
open class Base {}
class Derived <: Base {}
enum E1 {
| A1(Base)
}
enum E2 {
| A2(Derived)
}
main() {
let a1 = A1(Derived()) // ok:无需使用 enum 类型前缀
let a2 = A2(Derived()) // ok:无需使用 enum 类型前缀
return 0
}
【反例】
open class Base {}
class Derived <: Base {}
enum E1 {
| A(Base)
}
enum E2 {
| A(Derived)
}
main() {
let a = A(Derived()) // error:无法决议调用的是哪个 enum 中的 constructor
let a2 = E1.A(Derived()) // ok:使用 enum 类型前缀
let a3 = E2.A(Derived()) // ok:使用 enum 类型前缀
return 0
}
变量
G.VAR.01 优先使用不可变变量
【级别】建议
【描述】初始化后未修改的变量或属性,建议将其声明为 let 而不是 var。
G.VAR.02 保持变量的作用域尽可能小
【级别】建议
【描述】
作用域是指变量在程序内可见和可引用的范围,这个范围越大引起错误的可能性越高,对它的可控制性就越差。
例如:在变量的可见范围内新增代码,不当地修改了这个变量可能引发错误;如果可见范围过大,阅读代码的人也可能会忘记该变量应有的值,可读性差。
所以,通常应使变量的作用域尽量小,同时把变量引用点尽量集中在一起,便于对变量施加控制。
最小化作用域,可以增强代码的可读性和可维护性,并降低出错的可能性。
最小化作用域的函数:
- 尽量推迟变量定义,在变量使用时才声明并初始化
- 把相关声明和表达式放在一起或提取成单独的子函数,使函数尽量小而集中,功能单一。
G.VAR.03 避免使用全局变量
【级别】建议
【描述】
使用全局变量会导致业务代码和全局变量之间产生数据耦合,并且很难跟踪数据的变化,建议避免使用全局变量。使用全局常量通常是必要的,例如定义一些全局使用的数值。
数据类型
G.TYP.01 确保以正确的策略处理除数
【级别】建议
【描述】
在除法运算和模运算中,可能会发生除数为 0 的错误。对于整数运算,仓颉在运行时会自动检查除数,当除数为 0 时会自动抛出异常。不处理除零的情况可能会导致程序终止或拒绝服务(DoS)。捕获除零异常可能会导致性能开销较高,存在多个除法操作的时候会导致难以排查异常抛出点,因此开发者需要显式地对除数进行判断。
【反例】
func f() {
var num1: Int64
var num2: Int64
var result: Int64
// Initialize num1 and num2
...
result = num1 / num2
}
上面的示例中,有符号操作数 num1 和 num2 的除法运算,num2 可能为 0,导致除 0 错误的发生。
【正例】
func f() {
var num1: Int64
var num2: Int64
var result: Int64
// Initialize num1 and num2
...
if (num2 == 0) {
//Handle error
} else {
result = num1 / num2
}
}
该正确示例中,对除数进行了检查,从而杜绝了发生除 0 错误的发生。
【反例】
var num1: Int64
var num2: Int64
var result: Int64
// Initialize num1 and num2
...
result = num1 % num2
整数类型的操作数,模运算符会计算除法中的余数。上述不符合规则的代码示例,在进行模运算时,可能会因为 num2 为 0 导致除 0 错误的发生。
【正例】
var num1: Int64
var num2: Int64
var result: Int64
// Initialize num1 and num2
...
if (num2 == 0) {
//Handle error
} else {
result = num1 % num2
}
该正确示例中,对除数进行了检查,从而杜绝了发生除 0 错误的发生。
G.TYP.02 确保正确使用整数运算溢出策略
【级别】要求
【描述】
仓颉中提供三种属性宏来控制整数溢出的处理策略,@OverflowThrowing,@OverflowWrapping 和 @OverflowSaturating 分别对应抛出异常、高位截断以及饱和这三种溢出处理策略,默认情况下(即未使用宏),采取抛出异常的处理策略 。
实际情况下需要根据业务场景的需求正确选择溢出策略。例如要在 Int64 上实现某种安全运算,使得计算结果和计算过程在数学上相等,就需要使用抛出异常的策略。
【反例】
// 计算结果被高位截断
@OverflowWrapping
func operation(a: Int64, b: Int64): Int64 {
a + b // No exception will be thrown when overflow occurs
}
该错误例子使用了高位截断的溢出策略,当传入的参数 a 和 b 太大时,可能产生高位截断的情况,导致计算结果和计算表达式 (a + b) 在数学上不是相等关系。
【正例】
// 安全
@OverflowThrowing
func operation(a: Int32, b: Int32): Int32 {
a + b
}
...
try {
operation(a, b)
} catch (e: ArithmeticException) {
//Handle error
}
该正确例子使用了抛出异常的溢出策略,当传入的参数 a 和 b 较大导致整数溢出时,operation 函数会抛出异常。
附录 B 总结了可能造成整数溢出的数学操作符。
表达式
G.EXP.01 match 表达式同一层尽量避免不同类别的 pattern 混用
【级别】建议
【描述】
仓颉提供了丰富的模式种类,包括:常量模式、通配符模式、变量模式、tuple 模式、类型模式、enum 模式。在类型匹配的前提下,根据是否总是能匹配分为两种:refutable pattern 和 irrefutable pattern,其中 irrefutable pattern 总是可以和它所要匹配的值匹配成功。
对 pattern 的使用建议如下:
- match 表达式的不同 case 的 pattern 之间尽量保持互斥,避免依赖匹配顺序;
- match 不能互斥时,由于匹配的顺序是从前往后,要避免前面的 case 遮盖后面的 case,比如 irrefutable pattern 的 case 需要放到所有 refutable pattern 的 case 之后;
- match 表达式同一层中尽量避免混用不同判断维度的模式:
- 类型模式和其它判断的维度也不一样,比如常量模式是根据值来判断,类型模式是判断类型,混用后对 exhaustive 的可读性会有影响;
- tuple 模式、enum 模式属于解构,可以和常量模式、变量模式结合使用。
【反例】
enum TimeUnit {
| Year(Int64)
| Month(Int64, Int64)
| Day(Int64, Int64, Int64)
| Hour(Int64, Int64, Int64, Int64)
}
let oneYear = Year(1)
let howManyHours = match (oneYear) { // 不符合:enum 模式、类型模式混用
case Month(y, m) => ...
case _: TimeUnit => ...
case Day(y, m, d) => ...
case Hour(y, m, d, h) => ...
}
【正例】:
enum TimeUnit {
| Year(Int64)
| Month(Int64, Int64)
| Day(Int64, Int64, Int64)
| Hour(Int64, Int64, Int64, Int64)
}
let oneYear = Year(1)
let howManyHours = match (oneYear) {
case Year(y) => //...
case Month(y, m) => //...
case Day(y, m, d) => //...
case Hour(y, m, d, h) => //...
}
G.EXP.02 不要期望浮点运算得到精确的值
【级别】建议
【描述】
因为存储二进制浮点的 bit 位是有限的,所以二进制浮点数的表示范围也是有限的,并且无法精确地表示所有实数。因此,浮点数计算结果也不是精确值,除了可以表示为 2 的幂次以及整数数乘的浮点数可以准确表示外,其余数的值都是近似值。
实际编程中,要结合场景需求,尤其是对精度的要求,合理选择浮点数操作。
例如,对于浮点值比较,如果对比较精度有要求,通常不建议直接用 != 或 == 比较,而是要考虑对精度的要求。
【正例】
from std import math.*
func isEqual(a: Float64, b: Float64): Bool {
return abs(a - b) <= 1e-6
}
func compare(x: Float64) {
if (isEqual(x, 3.14)) {
// CODE
} else {
// CODE
}
}
【反例】
func compare(x: Float64) {
if (x == 3.14) {
// CODE
} else {
// CODE
}
}
G.EXP.03 && 、 ||、? 和 ?? 操作符的右侧操作数不要修改程序状态
【级别】要求
逻辑与(&&)、逻辑或(||)、问号操作符(?)和 coalescing(??)表达式中的右操作数是否被求值,取决于左操作数的求值结果,当左操作数的求值结果可以得到整个表达式的结果时,不会再计算右操作数的结果。如果右操作数可能修改程序状态,则不能确定该修改是否发生,因此,规定逻辑与、逻辑或、问号操作符和 coalescing 操作符的右操作数中不要修改程序状态。
这里修改程序状态主要指修改变量及其成员(如修改全局变量、取放锁)、进行 IO 操作(如读写文件,收发网络包)等。
【反例】
var count: Int64 = 0
func add(x: Int64): Int64 {
count += x // 修改了全局变量
return count
}
main(): Int64 {
let isOk = false
let num = 5
if (isOk && (add(num) != 0)) { // 不符合: && 的右操作数中修改了程序状态
return 0
} else {
return 1
}
}
【正例】:
var count: Int64 = 0
func add(x: Int64): Int64 {
count += x // 修改了全局变量
return count
}
main(): Int64 {
let isOk = false
let num = 5
if (isOk) { // 使用显式的条件判断来区分操作是否被执行
if (add(num) != 0) {
return 0
} else {
return 1
}
} else {
return 1
}
}
G.EXP.04 尽量避免副作用发生依赖于操作符的求值顺序
【级别】建议
【描述】
表达式的求值顺序会影响副作用发生的顺序,应尽量避免副作用发生依赖于操作符的求值顺序。
通常操作符或表达式的求值顺序是先左后右,但以下情形求值顺序会比较特殊,尤其要避免副作用发生依赖于表达式的求值顺序:
- 对于赋值表达式,总是先计算右边的表达式,再计算 = 左边的表达式,最后进行赋值;
- 复合赋值表达式
a op= b不能简单看做赋值表达式与其它二元操作符的组合a = a op b,a op= b中的a只会被求值一次,而a = a op b中的a会被求值两次; try {e1} catch (catchPattern) {e2} finally {e3}表达式的求值顺序,依赖e1,e2,e3是否抛出异常;- 函数调用时,参数求值顺序是按照定义时顺序从左到右,而非按照调用时的实参顺序;
- 如果函数调用的某个参数是 Nothing 类型,则该参数后面的参数不会被求值,函数调用本身也不会被执行;
【反例】
如下代码示例中,main 中的复合赋值表达式的左操作数调用了一个有副作用的函数:
class C {
var count = 0
var num = 0
}
var c = C()
func getC(): C {
c.count += 1 // 副作用
return c
}
main(): Int64 {
let num = 5
getC().count += num // 不符合:副作用依赖了表达式的求值顺序和求值次数。
return 1
}
G.EXP.05 用括号明确表达式的操作顺序,避免过分依赖默认优先级
【级别】建议
【描述】
当表达式包含不常用、优先级易混淆的操作符时,建议使用括号明确表达式的操作顺序,防止因默认的优先级与实现意图不符而导致程序出错。
然而过多的括号也会分散代码降低其可读性,下面是对如何使用括号的建议:
-
一元操作符,不需要使用括号
foo = -a // 一元操作符,不需要括号 if (var1 || !isSomeBool) // 一元操作符,不需要括号 -
涉及位操作,推荐使用括号
-
如果不涉及多种操作符,不需要括号
涉及多种操作符混合使用并且优先级容易混淆的场景,建议使用括号明确表达式操作顺序。
foo = a + b + c // 操作符相同,不需要括号 if (a && b && c) // 操作符相同,不需要括号 foo = 1 << (2 + 3) // 操作符不同,优先级易混淆,需要括号
【正例】:
main(): Int64 {
var a = 0
var b = 0
var c = 0
a = 1 << (2 + 3)
a = (1 << 2) + 3
c = (a & 0xFF) + b
if ((a & b) == 0) {
return 0
} else {
return 1
}
}
【反例】
main(): Int64 {
var a = 0
var b = 0
var c = 0
a = 1 << 2 + 3 // 涉及位操作符,需要括号
c = a & 0xFF + b // 涉及位操作符,需要括号
if (a & b == 0) { // 涉及位操作符,需要括号
return 0
} else {
return 1
}
}
对于常用、不易混淆优先级的表达式,不需要强制增加额外的括号。例如:
main(): Int64 {
var a = 0
var b = 0
var c = 0
var d = a + b + c // 操作符相同,可以不加括号
var e = (a + b, c) // 逗号两边的表达式,不需要括号
if (a > b && c > d) { // 逻辑表达式,根据子表达式的复杂情况选择是否加括号
return 0
} else {
return 1
}
}
G.EXP.06 Bool 类型比较应避免多余的 == 或 !=
【级别】建议
【描述】
在 if 表达式、while、do while 表达式等使用到 Bool 类型表达式的位置,对于 Bool 类型的判断,应该避免多余的 == 或 !=。
【正例】:
func isZero(x: Int64):Bool {
return x == 0
}
main(): Int64 {
var a = true
var b = isZero(1)
if (a && !b) {
return 1
} else {
return 0
}
}
【反例】
func isZero(x: Int64):Bool {
return (x == 0) == true
}
main(): Int64 {
var a = true
var b = isZero(1)
if (a == true && b != true) {
return 1
} else {
return 0
}
}
G.EXP.07 比较两个表达式时,左侧倾向于变化,右侧倾向于不变
【级别】建议
【描述】
当可变变量与常量比较时,如果常量放左侧,如 if (MAX == v) 不符合阅读习惯,而 if (MAX > v) 更是难于理解。
应当按人的正常阅读、表达习惯,将常量放右侧。
【反例】
const MAX_LEN = 99999
func maxIndex(arr: ArrayList<Int>) {
let len = arr.size
// 不符合,常量在左,let 修饰的变量在右
if (MAX_LEN < len) {
throw Exception("too long")
} else {
var i = 0
var maxI = 0
// 不符合,let 修饰的变量在左,var 修饰的变量在右
while (len > i) {
if (arr[i] > arr[maxI]) {
maxI = i
}
i++
}
return maxI
}
}
【正例】:
const MAX_LEN = 99999
func maxIndex(arr: ArrayList<Int>) {
let len = arr.size
if (len > MAX_LEN) {
throw Exception("too long")
} else {
var i = 0
var maxI = 0
while (i < len) {
if (arr[i] > arr[maxI]) {
maxI = i
}
i++
}
return maxI
}
}
也有例外情况,如使用 if (MIN < a && a < MAX) 用来描述区间时,前半段表达式中不可变变量在左侧也是允许的。
异常与错误处理
G.ERR.01 恰当地使用异常或错误处理机制
【级别】建议
【描述】
仓颉提供了 Exception 用来处理异常或错误:Exception 给函数提供了一条异常返回路径,用于表示函数无法正常执行完成,或无法正常返回结果的情形。
对于异常或错误处理机制的建议如下:
- Exception 应避免不加任何处理就丢掉错误信息;
- 对于会抛 Exception 的 API,须在注释中说明可能出现的 Exception 类型;
例外:
- 系统调用、FFI 可以使用返回错误码的形式,与原 API 保持一致。
G.ERR.02 防止通过异常抛出的内容泄露敏感信息
【级别】要求
【描述】
如果在传递异常的时候未对其中的敏感信息进行过滤,常常会导致信息泄露,而这可能帮助攻击者尝试发起进一步的攻击。攻击者可以通过构造恶意的输入参数来发掘应用的内部结构和机制。不管是异常中的文本消息,还是异常本身的类型都可能泄露敏感信息。因此,当异常被传递到信任边界以外时,必须同时对敏感的异常消息和敏感的异常类型进行过滤。
错误示例(异常消息和类型泄露敏感信息):
from std import io.*
func exceptionExample(path: String): Unit {
var file: File
if (!File.exist(path)) {
throw IOException("File does not exist")
}
file = File(path, AccessMode.ReadWrite, OpenMode.OpenOrCreate)
// CODE
}
当打开的源文件不存在时,程序会抛出 IOException 异常,并提示 “File does not exist”。这使得攻击者可以不断传入伪造的路径名称来重现出底层文件系统结构。
错误示例 (异常净化):
from std import io.*
func exceptionExample(path: String): Unit {
var file: File
if (!File.exist(path)) {
throw IOException()
}
file = File(path, AccessMode.ReadWrite, OpenMode.OpenOrCreate)
// CODE
}
此例中虽然报错信息并未透露错误原因,但是对于不同的错误原因仍会抛出不同类型的异常。攻击者可以根据程序的行为推断出有关文件系统的敏感信息。未对用户输入做限制,使得系统面临暴力攻击的风险,攻击者可以多次传入所有可能的文件名进行查询来发现有效文件。如果传入一个文件名后程序返回一个 IOException 异常,则表明该文件不存在,否则说明该文件是存在的。
正确示例(安全策略):
from std import io.*
func exceptionExample(path: String): Unit {
var file: File
if (!File.exist(path)) {
println("Invalide file")
}
file = File(path, AccessMode.ReadWrite, OpenMode.OpenOrCreate)
// CODE
}
正确示例(限制输入):
from std import io.*
func exceptionExample(index: Int32): Unit {
var path: String
var file: File
match (index) {
case 1 => path = "/home/test1"
case 2 => path = "/home/test2"
case _ => return
}
file = File(path, AccessMode.ReadWrite, OpenMode.OpenOrCreate)
// CODE
}
这个正确示例限制用户只能打开 /home/test1 与 /home/test2。同时,它也会过滤在 catch 块中捕获的异常中的敏感信息。
例外场景:
对出于问题定位目的,可将敏感异常信息记录到日志中,但必须做好日志的访问控制,防止日志被任意访问,导致敏感信息泄露给非授权用户。
G.ERR.03 避免对 Option 类型使用 getOrThrow 函数
【级别】建议
【描述】
仓颉使用 Option 类型来避免空指针问题,若对 Option 类型使用 getOrThrow 来获取其内容,容易导致忽略异常的处理,造成等同于空指针的效果。因此应尽量避免对 Option 类型使用 getOrThrow 函数。
【反例】
func getOne(dict: HashMap<String, Int64>, name: String): Int64 {
return dict.get(name).getOrThrow()
}
该错误示例没有考虑传入的名字可能不存在的情况,只使用了 getOrThrow 而没有处理异常。这是一种危险的编码风格,并不推荐。
【正例】
const DEFAULT_VALUE = 0
func getOne(dict: HashMap<String, Int64>, name: String): Int64 {
return dict.get(name) ?? DEFAULT_VALUE
}
该正确示例中,在 Option 中值不存在的情况下提供了默认值,而不是使用 getOrThrow。
例外场景:
对于调用开源三方件,三方件中通过 getOrThrow 抛出 NoneValueException 异常时,可以捕获 NoneValueException,并对该异常进行处理。
包和模块化
G.PKG.01 避免在 import 声明中使用通配符 *
【级别】建议
【描述】
使用 import xxx.* 会导致如下问题:
-
代码可读性问题:很难从代码中清楚地看到当前包依赖其它包的哪些实体 (类型,变量或函数等),也很难直接看出来一些实体是从哪个包来的;
-
形成意外的重载。
【反例】:
// test1.cj
package test1
public open class Base {
...
}
public class Sub <: Base {
...
}
public func f(a: Base) {
...
}
//file test2.cj
package test2
import test1.*
class Basa {
var m = Sub()
}
func f(a: Basa) {
...
}
main() {
f(Base()) // Miswriting Basa as Base, but no compiler error.
}
【正例】
// test1.cj
package test1
public open class Base {
...
}
public class Sub <: Base {
...
}
public func f(a: Base) {
...
}
//file test2.cj
package test2
import test1.Sub
class Basa {
var m = Sub()
}
func f(a: Basa) {
...
}
main() {
f(Base()) // Error,误将 Basa 写成了 Base,会编译报错
}
线程同步
G.CON.01 禁止将系统内部使用的锁对象暴露给不可信代码
【级别】要求
【描述】
在仓颉中可以通过 synchronized 关键字和一个 ReentrantMutex 对象对所修饰的代码块进行保护,使得同一时间只允许一个线程执行里面的代码。攻击者可以通过获取该 ReentrantMutex 对象来触发条件竞争与死锁,进而引起拒绝服务(DoS)。
防御这个漏洞一种方法就是使用私有锁对象。
【反例】
from std import sync.*
from std import time.*
class SomeObject {
public let mtx: ReentrantMutex = ReentrantMutex()
...
public func put(x: Object) {
synchronized(mtx) {
...
}
}
}
//Trusted code
var so = SomeObject()
...
//Untrusted code
synchronized(so.mtx) {
while (true) {
sleep(100 * Duration.nanosecond)
}
}
使用 public 修饰锁对象,攻击者可以直接无限持有 mtx 锁,使得其它调用 put 函数的线程被阻塞。
【正例】
from std import sync.*
class SomeObject {
private let mtx: ReentrantMutex = ReentrantMutex()
// CODE
public func put(x: Object) {
synchronized(mtx) {
// CODE
}
}
}
将锁对象设置为 private 类型,攻击者无法无限持有锁。
例外场景:
包私有的类可以不受该规则的约束,因为他们无法被包外的非受信代码直接访问。
对于非受信代码无法获取执行同步操作的对象的场景下,可以不受该规则的约束。
P.01 使用相同的顺序请求锁,避免死锁
【级别】要求
【描述】
为避免多线程同时操作共享变量导致冲突,必须对共享变量进行保护,防止被并行地修改和访问。进行同步操作可以使用 ReentrantMutex 对象。当两个或多个线程以不同的顺序请求锁时,就可能会发生死锁。仓颉自身不能防止死锁也不能对死锁进行检测。所以程序必须以相同的顺序来请求锁,避免产生死锁。
【反例】
from std import sync.*
class BankAccount {
private var balanceAmount: Float64 = 0.0
public let mtx: ReentrantMutex = ReentrantMutex()
// CODE
public func depositAmount(ba: BankAccount, amount: Float64) {
synchronized(mtx) {
synchronized(ba.mtx) {
if (balanceAmount> amount) {
ba.balanceAmount += amount
balanceAmount -= amount
}
}
}
}
}
上面的错误示例会存在死锁的情况。当 bankA / bankB 两个银行账户在不同线程同步互相转账时,就可能导致死锁的问题。
【正例】
from std import sync.*
class BankAccount {
private var balanceAmount: Float64 = 0.0
public let mtx: ReentrantMutex = ReentrantMutex()
private var id: Int32 = 0 // Unique for each BankAccount
// CODE
public func depositAmount(ba: BankAccount, amount: Float64) {
var former: ReentrantMutex
var latter: ReentrantMutex
if (id > ba.id) {
former = ba.mtx
latter = mtx
} else {
former = mtx
latter = ba.mtx
}
synchronized(former) {
synchronized(latter) {
if (balanceAmount > amount) {
ba.balanceAmount += amount
balanceAmount -= amount
}
}
}
}
}
上述正确示例使用了一个全局唯一的 id 来保证不同线程使用相同的顺序来申请和释放锁对象,因此不会导致死锁问题。
G.CON.02 在异常可能出现的情况下,保证释放已持有的锁
【级别】要求
【描述】
一个线程中没有正确释放持有的锁会使其他线程无法获取该锁对象,导致阻塞。在发生异常时,要确保程序正确释放当前持有的锁。注:在发生异常时,通过 synchronized 进行同步的代码块的锁会被自动释放,但是通过 mtx.lock() 获得的锁不会被自动释放,需要开发者手动释放。
【反例】
from std import sync.*
class Foo {
private let mtx: ReentrantMutex = ReentrantMutex()
public func doSomething(a: Int64, b: Int64) {
var c: Int64
try {
mtx.lock()
// CODE
c = a / b
mtx.unlock()
} catch (e: ArithmeticException) {
// Handle exception
// CODE
} finally {
// CODE
}
}
}
上述错误示例中,使用 ReentrantMutex 锁,发生算数运算错误时,catch 及 finally 代码块中没有释放锁操作,导致锁没有释放。
【正例】
from std import sync.*
class Foo {
private let mtx: ReentrantMutex = ReentrantMutex()
public func doSomething(a: Int64, b: Int64) {
var c: Int64
try {
mtx.lock()
// CODE
c = a / b
} catch (e: ArithmeticException) {
// Handle exception
// CODE
} finally {
mtx.unlock()
// CODE
}
}
}
上述正确示例中,成功执行锁定操作后,将可能抛出异常的操作封装在 try 代码块中。锁在执行可能发生异常的代码块前获取,可保证在执行 finally 代码时正确持有锁。在 finally 代码块中调用 mtx.unlock(),可以保证不管是否发生异常都可以释放锁。
G.CON.03 禁止使用非线程安全的函数来覆写线程安全的函数
【级别】要求
【描述】
使用非线程安全的函数覆写基类的线程安全函数,可能会导致不恰当的同步。比如,子类将基类的线程安全的函数覆写为非安全函数,这样就违背了覆写同步函数的要求。这样很容易导致难以定位的问题的产生。
被设计为可继承的类,这些类对应的锁策略必须要详细记录说明。方便子类继承时,沿用正确的锁策略。
【反例】
from std import sync.*
open class Base {
private let baseMtx: ReentrantMutex = ReentrantMutex()
public open func doSomething() {
synchronized(baseMtx) {
// CODE
}
}
}
class Derived <: Base {
public override func doSomething() {
// CODE
}
}
上述错误示例中,子类 Derived 覆写了基类 Base 的同步函数 doSomething() 为非线程同步函数。Base 类的 doSomething() 函数可被多线程正确使用,但 Derived 类不可以。因为接受 Base 实例的线程同时也可以接受其子类,所以可能会导致难以诊断的程序错误。
【正例】
from std import sync.*
open class Base {
private let baseMtx: ReentrantMutex = ReentrantMutex()
public open func doSomething() {
synchronized(baseMtx) {
// CODE
}
}
}
class Derived <: Base {
private let mtx: ReentrantMutex = ReentrantMutex()
public override func doSomething() {
synchronized(mtx) {
// CODE
}
}
}
上述正确示例中,通过使用一个私有的锁对象来同步的函数覆写 Base 类中的同步函数 doSomething(),确保了 Derived 类是线程安全的。
另外,上面示例中,子类与基类的 doSomething() 函数使用的是不同的锁,实际编码过程中,要考虑是否会产生影响。在设计过程中,要尽量避免类似的继承导致的同步问题。
P.02 避免数据竞争(data race)
【级别】要求
【描述】
仓颉语言中,内存模型中的每个操作都采用 happens-before 关系,来规定并发执行中,读写操作允许读到什么值,不允许读到什么值。两个线程分别对同一个变量进行访问操作,其中至少一个操作是写操作,且这两个操作之间没有 happens-before 关系,就会产生 data race。正确同步的(correctly synchronized)执行是指没有 data race 的执行。仓颉语言内存模型中规定,如果存在 data race,那么行为是未定义的,因此要求必须避免 data race。在仓颉中通常采用锁机制完成对共享资源的同步,并且同一个共享资源应该使用同一个锁来进行保护。注:happens-before 关系的正式定义见仓颉语言规范定义。
对 “同一个数据” 的定义:
- 对同一个 primitive type、enum、array 类型的变量或者 struct/class 类型的同一个 field 的访问,都算作同一个数据。
- 对 struct/class 类型的不同 field 的访问,算作不同数据 。
【反例】
from std import sync.*
from std import time.*
var res: Int64 = 0
main(): Int64 {
var i: Int64 = 0
while (i < 100) {
i++
spawn {
res = res + 1
}
}
sleep(Duration.second)
print(res.toString())
return 0
}
上述错误示例中,多个线程同时对全局变量 res 进行了读写操作,导致 data race, 最终 res 的值为一个非预期值。
【正例】
from std import sync.*
from std import time.*
var res: Int64 = 0
main(): Int64 {
var i: Int64 = 0
let mtx = ReentrantMutex()
while (i < 100) {
i++
spawn {
synchronized (mtx) {
res = res + 1
}
}
}
sleep(Duration.second)
print(res.toString())
return 0
}
上述正确示例中,通过使用 synchronized 来保护对全局变量 res 的修改。
一般来说,如果使用锁,那么读和写都要加锁,而不是写线程需要加锁,而读的线程可以不加锁。
【反例】
from std import sync.*
from std import time.*
var a: Int64 = 0
var b: Int64 = 0
main(): Int64 {
let mtx = ReentrantMutex()
spawn {
mtx.lock()
a = 1
b = 1
mtx.unlock()
}
spawn {
while (true) {
if (a == 0) {
continue
}
if (b != 1) {
print("Fail\n")
} else {
print("Success\n")
}
break
}
}
sleep(Duration.second)
return 0
}
上述错误示例中,对于 a、b 的写入是在锁的保护下进行的,但是没有在锁的保护中进行读取,可能导致读取到的值不符合预期。
【正例】
from std import sync.*
from std import time.*
var a: Int64 = 0
var b: Int64 = 0
main(): Int64 {
let mtx = ReentrantMutex()
spawn {
mtx.lock()
a = 1
b = 1
mtx.unlock()
}
spawn {
while (true) {
mtx.lock()
if (a == 0) {
mtx.unlock()
continue
}
if (b != 1) {
print("Fail\n")
} else {
print("Success\n")
}
mtx.unlock()
break
}
}
sleep(Duration.second)
return 0
}
上述正确示例中,对于 a、b 的写入和读取均是在锁的保护下进行的,结果符合预期。
G.CON.04 避免在产生阻塞操作中持有锁
【级别】建议
【描述】
在耗时严重或阻塞的操作中持有锁,可能会严重降低系统的性能。另外,无限期的阻塞相互关联的线程,会导致死锁。阻塞操作一般包括:网络、文件和控制台 I/O 等,将一个线程延时同样会形成阻塞操作。所以程序持有锁时应避免执行这些操作。
【反例】
from std import sync.*
from std import time.*
let mtx: MultiConditionMonitor = MultiConditionMonitor()
let c: ConditionID = mtx.newCondition()
func doSomething(time: Duration) {
synchronized(mtx) {
sleep(time)
}
}
上述错误示例中,doSomething() 函数是同步的,当线程挂起时,其他线程也不能使用该同步函数。
【正例】
from std import sync.*
from std import time.*
let mtx: MultiConditionMonitor = MultiConditionMonitor()
let c: ConditionID = synchronized(mtx) {
mtx.newCondition()
}
func doSomething(timeout: Duration) {
synchronized(mtx) {
while (<condition does not hold>) {
mtx.wait(c, timeout: timeout) // Immediately releases the current mutex
}
}
}
上述正确示例中,使用 mtx 对象的 wait 函数设置一个 timeout 期限并阻塞当前线程,然后将 mtx 对象锁释放。在 timeout 期限到达或者该线程被 mtx 对象的 notify() 或 notifyAll() 函数唤起时,该线程会重新尝试获取 mtx 锁。
【反例】
from std import sync.*
// Class Page is defined separately.
// It stores and returns the Page name via getName()
let pageBuff: Array<Page> = Array<Page>(MAX_PAGE_SIZE) { i => Page() }
let mtx = ReentrantMutex()
public func sendPage(socket: Socket, pageName: String): Bool {
synchronized(mtx) {
var write_bytes: Option<Int64>
var targetPage = None<Page>
// Send the Page to the server
for (p in pageBuff) {
match (p.getName().compareTo(pageName)) {
case EQUAL => targetPage = Some<Page>(p)
case _ => ...
}
}
// Requested Page does not exist
match (targetPage) {
case None => return false
case _ => ...
}
// Send the Page to the client
// (does not require any synchronization)
write_bytes = socket.write(targetPage.getOrThrow().getBuff())
...
}
return true
}
上述错误示例中,sendPage() 函数会从服务器发送一个 page 对象的数据到客户端。当多个线程并发访问时,同步函数会保护 pageBuf 队列,而 writeObject() 操作会导致延时,在高延时的网络或当网络条件本身存在丢包时,该锁会被长期无意义地持有。
【正例】
from std import sync.*
// Class Page is defined separately.
// It stores and returns the Page name via getName()
// let pageBuff: Array<Page> = Array<Page>(MAX_PAGE_SIZE) { i => Page() }
let pageBuff = ArrayList<Page>()
let mtx = ReentrantMutex()
public func sendPage(socket: Socket, pageName: String): Bool {
let targetPage = getPage(pageName)
match (targetPage) {
case None => return false
case _ => ...
}
// Send the Page to the client
// (does not require any synchronization)
deliverPage(socket, targetPage.getOrThrow())
...
return true
}
// Requires synchronization
private func getPage(pageName: String): Option<Page> {
synchronized(mtx) {
var targetPage = None<Page>
for (p in pageBuff) {
match (p.getName().compareTo(pageName)) {
case EQUAL => targetPage = Some<Page>(p)
case _ => ...
}
}
return targetPage
}
}
private func deliverPage(socket: Socket, targetPage: Page) {
var write_bytes: Option<Int64>
// Send the Page to the client
// (does not require any synchronization)
write_bytes = socket.write(targetPage.getBuff())
...
}
上述正确示例中,将原来的 sendPage() 分为三个具体步骤执行,不同步的 sendPage() 函数调用同步的 getPage() 函数来在 pageBuff 队列中获得请求的 page。在取得 page 后,会调用不同步的 deliverPage() 函数类提交 page 到客户端。
例外场景:
向调用者提供正确终止阻塞操作的类可不遵守该要求。
G.CON.05 避免使用不正确形式的双重锁定检查
【级别】建议
【描述】
双重锁定(double-checked locking idiom)是一种软件设计模式,通常用于延迟初始化单例。主要通过在进行获取锁之前先检查单例对象是否创建(第一次检查),在获取锁以后,再次检查对象是否创建(第二次检查),以此减少并发获取锁的开销。
但是取决于具体实现的内存模型,不正确的双重锁定检查使用可能会导致一个未初始化或部分初始化的对象对其它线程可见。因此只有在能为实例的完整构建建立正确的 happens-before 关系的情况下,才可以使用双重锁定检查。
【反例】
from std import sync.*
class Foo {
private var helper: Option<Helper> = None<Helper>
private let mtx: ReentrantMutex = ReentrantMutex()
public func getHelper(): Helper {
match (helper) {
case None =>
synchronized(mtx) {
match (helper) {
case None =>
let temp = Helper()
helper = Some<Helper>(temp)
return temp
case Some(h) => return h
}
}
case Some(h) => return h
}
}
}
上述错误示例中,使用了双重锁定检查的错误形式。对 Helper 对象进行初始化的写入和对 Helper 数据成员的写入,可能不按次序进行或完成。因此,一个调用 getHelper() 的线程可能会得到指向一个 helper 对象的非空引用,但该对象的数据成员为默认值而不是构造函数中设置的值。
【正例】
from std import sync.*
class Foo {
private var helper = AtomicReference<Option<Helper>>(None<Helper>)
private let mtx: ReentrantMutex = ReentrantMutex()
public func getHelper(): Helper {
match (helper.load()) {
case None =>
synchronized(mtx) {
match (helper.load()) {
case None =>
let temp = Helper()
helper = AtomicReference<Option<Helper>>(temp)
return temp
case Some(h) => return h
}
}
case Some(h) => return h
}
}
}
上述例子将使用 AtomicReference 类对 Helper 的使用进行了封装,该类型会禁用编译优化,使得对 helper 对象的操作满足 happens-before 关系。
【正例】
class Foo {
private static let helper: Helper = Helper()
public static func getHelper(): Helper {
return helper
}
}
上述正确示例中,在对静态变量的声明中完成了 helper 字段的初始化。但是该实例没有使用延迟初始化。
数据校验
G.CHK.01 跨信任边界传递的不可信数据使用前必须进行校验
【级别】要求
【描述】
程序可能会接收来自用户、网络连接或其他来源的不可信数据, 并将这些数据跨信任边界传递到目标系统(如浏览器、数据库等)。来自程序外部的数据通常被认为是不可信的,不可信数据的范围包括但不限于:网络、用户输入(包括命令行、界面)、命令行、文件(包括程序的配置文件)、环境变量、进程间通信(包括管道、消息、共享内存、socket、RPC)、跨信任域函数参数(对于 API)等。在使用这些数据前需要进行合法性校验,否则可能会导致不正确的计算结果、运行时异常、不一致的对象状态,甚至引起各种注入攻击,对系统造成严重影响。 对于外部数据的具体校验,要结合实际的业务场景采用与之相对的校验方式来消除安全隐患;对于缺少校验规则的场景,可结合其他的措施进行防护,保证不会存在安全隐患。
由于目标系统可能无法区分处理畸形的不可信数据,未经校验的不可信数据可能会引起某种注入攻击,对系统造成严重影响,因此,必须对不可信数据进行校验,且数据校验必须在信任边界以内进行(如对于 Web 应用,需要在服务端做校验)。数据校验有输入校验和输出校验,对从信任边界外传入的数据进行校验的叫输入校验,对传出到信任边界外的数据进行校验的叫输出校验。
尽管仓颉已经提供了强大的编译时和运行时检查,能拦截空指针、缓冲区溢出、整数溢出等问题,但无法保证数据的合法性和准确性,无法拦截注入攻击等,开发者仍应该关注不可信数据。
对外部数据的校验包括但不局限于:
- 校验 API 接口参数合法性;
- 校验数据长度;
- 校验数据范围;
- 校验数据类型和格式;
- 校验集合大小;
- 校验外部数据只包含可接受的字符(白名单校验),尤其需要注意一些特殊情况下的特殊字符,例如附录 A 命令注入相关字符。
对于外部数据的校验,要注意以下两点:
- 如果需要,外部数据校验前要先进行标准化:例如
\uFE64、<都可以表示<,在 web 应用中, 如果外部输入不做标准化,可以通过\uFE64绕过对<限制。 - 对外部数据的修改要在校验前完成,保证实际使用的数据与校验的数据一致。
如下描述了四种数据校验策略(任何时候,尽可能使用接收已知合法数据的 “白名单” 策略)。
接受已知好的数据
这种策略被称为 “白名单” 或者 “正向” 校验。该策略检查数据是否属于一个严格约束的、已知的、可接受的合法数据集合。例如,下面的示例代码确保 name 参数只包含字母、数字以及下划线。
...
// CODE
match (Regex("^[0-9A-Za-z_]+$").matches(name)) {
case None => throw IllegalArgumentException()
case _ => ()
}
...
拒绝已知坏的数据
这种策略被称为 “黑名单” 或者 “负向” 校验,相对于正向校验,这是一种较弱的校验方式。由于潜在的不合法数据可能是一个不受约束的无限集合,这就意味着你必须一直维护一个已知不合法字符或者模式的列表。如果不定期研究新的攻击方式并对校验的表达式进行日常更新,该校验方式就会很快过时。
from std import regex.*
func removeJavascript(input: String): String {
var matchData = Regex("javascript").matcher(input).find()
match (matchData) {
case None => return input
case _ => ""
}
}
“白名单” 方式净化
对任何不属于已验证合法字符数据中的字符进行净化,然后再使用净化后的数据,净化的方式包括删除、编码、替换。比如,如果你期望接收一个电话号码,那么你可以删除掉输入中所有的非数字字符,“(555)123-1234”,“555.123.1234”,与 “555";DROP TABLE USER;--123.1234” 全部会被转换为 “5551231234”,然后再对转换的结果进行校验。又比如,对于用户评论栏的文本输入,由于几乎所有的字符都可能被用到,确定一个合法的数据集合是非常困难的,一种解决方案是对所有非字母数字进行编码,如对“I like your web page!” 使用 URL 编码,其净化后的输出为 “I+like+your+web+page%21”。“白名单” 方式净化不仅有利于安全,它也允许接收和使用更宽泛的有效用户输入。
“黑名单” 方式净化
为了确保输入数据是 “安全” 的,可以剔除或者转换某些字符(例如,删除引号、转换成 HTML 实体)。跟 “黑名单” 校验类似,随着时间推移不合法字符的范围很可能不一样,需要对不合法字符进行日常维护。因此,执行一个单纯针对正确输入的 “正向” 校验更加简单、高效、安全。
from std import regex.*
func quoteApostrophe(input: String): String {
var m = Regex("\\\\").matcher(input)
return m.replace("’");
}
G.CHK.02 禁止直接使用外部数据记录日志
【级别】要求
【描述】
直接将外部数据记录到日志中,可能存在以下风险:
- 日志注入:恶意用户可利用回车、换行等字符注入一条完整的日志;
- 敏感信息泄露:当用户输入敏感信息时,直接记录到日志中可能会导致敏感信息泄露;
- 垃圾日志或日志覆盖:当用户输入的是很长的字符串,直接记录到日志中可能会导致产生大量垃圾日志;当日志被循环覆盖时,这样还可能会导致有效日志被恶意覆盖。
所以外部数据应尽量避免直接记录到日志中,如果必须要记录到日志中,要进行必要的校验及过滤处理,对于较长字符串可以截断。对于记录到日志中的数据含有敏感信息时,将这些敏感信息替换为固定长度的 *,对于手机号、邮箱等敏感信息,可以进行匿名化处理。
【反例】
if (loginSuccessful) {
simpleLogger.log(LogLevel.ERROR, "User login succeeded for:" + username)
} else {
simpleLogger.log(LogLevel.ERROR, "User login failed for:" + username)
}
此错误示例代码中,在接收到非法请求时,会记录用户的用户名,由于没有执行任何输入净化,这种情况下就可能会遭受日志注入攻击: 当 username 字段的值是 david 时,会生成一条标准的日志信息:
2021/06/01 2:19:10.123123 Error logger User login failed for: david
但是,如果记录日志时使用的 username 存在换行,如下所示:
2021/06/01 2:19:10.123123 Error logger User login failed for: david
INFO logger User login succeeded for: administrator
那么日志中包含了以下可能引起误导的信息:
2021/06/01 2:19:10.123123 Error logger User login failed for: david
2021/06/01 2:19:15.123123 INFO: logger User login succeeded for: administrator
【正例】
match (Regex("[A-Za-z0-9_]+").matches(username)) {
case None => simpleLogger.log(LogLevel.ERROR, "User login failed for unauthorized user")
case _ where (loginSuccessful) =>
simpleLogger.log(LogLevel.ERROR, "User login succeeded for:" + username)
case _ =>
simpleLogger.log(LogLevel.ERROR, "User login failed for:" + username)
}
说明:外部数据记录到日志中前,进行有效字符的校验。
G.CHK.03 使用外部数据构造的文件路径前必须进行校验,校验前必须对文件路径进行规范化处理
【级别】要求
【描述】
文件路径来自外部数据时,必须对其合法性进行校验,否则可能会产生路径遍历漏洞,目录遍历漏洞使得攻击者能够转移到一个特定目录进行 I/O 操作。
在文件路径校验前要对文件路径进行规范化处理,使用规范化的文件路径进行校验。由于文件路径有多种表现形式,如绝对路径、相对路径,路径中可能会含各种链接、快捷方式、影子文件等,这些都会对文件路径的校验产生影响。路径中也可能会包含如下所示的文件名,使得验证变得困难:
- “.” 指目录本身;
- 在一个目录内,“..” 指该目录的上一级目录;
除此之外,还有与特定操作系统和特定文件系统相关的命名约定,也会使验证变得困难。
【反例】
func dumpSecureFile(path: String): Int32
{
if (isInSecureDir(Path)){
//dump the file
...
}
...
}
【正例】
func dumpSecureFile(path: String): Int32
{
var di = DirectoryInfo(path)
var canPath: String = di.getCanonicalPath()
if (isInSecureDir(canPath)) {
//dump the file
...
}
...
}
这个正确示例使用了 DirectoryInfo.getCanonicalPath()函数,它能在所有的平台上对所有别名、快捷方式以及符号链接进行一致地解析。特殊的文件名,比如 “..” 会被移除,这样输入在验证之前会被简化成对应的标准形式。当使用标准形式的文件路径来做验证时,攻击者将无法使用../ 序列来跳出指定目录。
注意:如果在操作规范化后的路径发生错误(比如打开失败或者没有通过安全检查)时需要将路径打印到日志中,谨慎选择是否应该打印规范化后的路径,避免路径信息发生泄露。
G.CHK.04 禁止直接使用不可信数据构造正则表达式
【级别】要求
【描述】
正则表达式广泛用于匹配文本字符串。例如,POSIX 中 grep 实用程序支持用于查找指定文本中的模式的正则表达式。仓颉的 regex 包提供了 Regex 类,该类封装了一个编译过的正则表达式和一个 Matcher 类,通过 Matcher 类引擎,可以在字符串中进行匹配操作。
在仓颉中必须注意不能误用正则表达式的功能。攻击者可能会通过恶意构造的输入对初始化的正则表达式进行修改,比如导致正则表达式不符合程序规定要求。这种攻击称为正则注入 (regex injection), 可能会影响控制流,导致信息泄漏,或导致 ReDos 攻击。
以下是正则表达式可能被利用的方式:
匹配标志:不可信的输入可能覆盖匹配选项,然后有可能会被传给 Regex() 构造函数。
贪婪: 一个非受信的输入可能试图注入一个正则表达式,通过它来改变初始的那个正则表达式,从而匹配尽可能多的字符串,从而暴露敏感信息。
分组: 程序员会用括号包括一部分的正则表达式以完成一组动作中某些共同的部分。攻击者可能通过提供非受信的输入来改变这种分组。
非受信的输入应该在使用前净化,从而防止发生正则表达式注入。当用户必须指定正则表达式作为输入时,必须注意需要保证初始的正则表达式没有被无限制修改。在用户输入字符串提交给正则解析之前,进行白名单字符处理(比如字母和数字)是一个很好的输入净化策略。开发人员必须仅仅提供最有限的正则表达式功能给用户,从而减少被误用的可能。
ReDos 攻击是仓颉代码正则使用不当导致的常见安全风险。容易存在 ReDos 攻击的正则表达式主要有两类:
-
包含具有自我重复的重复性分组的正则,例如:
^(\d+)+$ ^(\d*)*$ ^(\d+)*$ ^(\d+|\s+)*$ -
包含替换的重复性分组,例如:
^(\d|\d\d)+$ ^(\d|\d?)+$
对于 ReDos 攻击的防护手段主要包括:
-
进行正则匹配前,先对匹配的文本的长度进行校验;
-
在编写正则时,尽量不要使用过于复杂的正则,尽量减少分组的使用,越复杂、分组越多越容易有缺陷,例如对于下面的正则:
^(([a-z])+\.)+[A-Z]([a-z])+$存在 ReDos 风险,可以将多余的分组删除,这样在不改变检查规则的前提下消除了 ReDos 风险;
^([a-z]+\.)+[A-Z][a-z]+$【反例】
let REGEX_PATTER: Regex = Regex("a(b|c+)+d") func test(arg: String) { match (REGEX_PATTER.matches(arg)) { case None => ... case _ => ... } }【正例】
let REGEX_PATTER: Regex = Regex("a[bc]+d") func test(arg: String) { match (REGEX_PATTER.matches(arg)) { case None => ... case _ => ... } } -
避免动态构建正则,当使用不可信数据构造正则时,要使用白名单进行严格校验。
【反例】
class LogSearch { func findLogEntry(search: String, log: String) { // Construct regex dynamically from user string var regex: String = "(.*? +public\\[\\d+\\] +.*" + search + ".*)" var logMatcher: Matcher = Regex(regex).matcher(log) ... } }【正例】
class LogSearch { func findLogEntry(search: String, log: String) { // Sanitize search string var ss = StringStream("") for (i in search) { if (i.isLetter() || i.isNumber() || i == '' || i =='\'') { ss.appends(i) } } var sanitized = ss.toString() // Construct regex dynamically from user string var regex: String = "(.*? +public\\[\\d+\\] +.*" + sanitized + ".*)" var logMatcher: Matcher = Regex(regex).matcher(log) ... } }
I/O 操作
G.FIO.01 临时文件使用完毕必须及时删除
【级别】要求
【描述】
程序运行时经常会需要创建临时文件。如果文件未被安全地创建或者用完后还是可访问的,具备本地文件系统访问权限的攻击者便可以利用临时文件进行恶意操作。删除已经不再需要的临时文件有助于对文件名和其他资源(如二级存储)进行回收利用。每一个程序在正常运行过程中都有责任确保已使用完毕的临时文件被删除。
【反例】
main(){
let pathName = "/mytemp/doc.txt";
let fs: File = File(pathName, AccessMode.ReadWrite, OpenMode.OpenOrCreate);
...
fs.flush()
fs.close()
print("This file already exists or created!")
...
return 0
}
这个错误示例代码在运行结束时未将临时文件删除。
【正例】
main() {
let pathName = "/mytemp/doc.txt"
let fs: File = File(pathName, AccessMode.ReadWrite, OpenMode.OpenOrCreate)
...
fs.flush()
fs.close()
print("This file already exists or created!")
File.delete(pathName)
...
return 0
}
这个正确示例代码在临时文件使用完毕之后、系统终止之前,显式地对其进行删除。
序列化和反序列化
G.SER.01 禁止序列化未加密的敏感数据
【级别】要求
【描述】
虽然序列化可以将对象的状态保存为一个字节序列,之后通过反序列化将字节序列又能重新构造出原来的对象,但是它并没有提供一种机制来保证序列化数据的安全性。因此,敏感数据序列化之后是潜在对外暴露的,可访问序列化数据的攻击者可以借此获取敏感信息并确定对象的实现细节。永远不应该被序列化的敏感信息包括:密钥、数字证书以及那些在序列化时引用敏感数据的类,防止敏感数据被无意识的序列化导致敏感信息泄露。另外,声明了可序列化标识对象的所有字段在序列化时都会被输出为字节序列,能够解析这些字节序列的代码可以获取到这些数据的值,而不依赖于该字段在类中的可访问性。因此,若其中某些字段包含敏感信息,则会造成敏感信息泄露。
【反例】
class People <: Serializable<People> {
var name: String
// 口令是敏感数据
var password: String
init(s: DataModelStruct) {
name = String.deserialize(s.get("name"))
password = String.deserialize(s.get("password"))
}
public func serialize(): DataModel {
DataModelStruct().add(field<String>("name", name))
DataModelStruct().add(field<String>("password", password))
}
public static func deserialize(s: DataModel): People {
let d = (s as DataModelStruct).getOrThrow()
People(d)
}
}
该错误示例允许将敏感成员变量 password 进行序列化和反序列化,可能会导致 password 信息泄露。
【正例】
class People <: Serializable {
var name: String
// 口令是敏感数据
var password: String
init(s: DataModelStruct) {
name = String.deserialize(s.get("name"))
password = ""
}
public func serialize(): DataModel {
DataModelStruct().add(field<String>("name", name))
}
public static func deserialize(s: DataModel): People {
let d = (s as DataModelStruct).getOrThrow()
People(d)
}
}
该正确示例在进行序列化和反序列化时跳过了 password 变量,避免了 password 信息被泄露。
G.SER.02 防止反序列化被利用来绕过构造函数中的安全操作
【级别】要求
【描述】
仓颉语言默认由用户提供序列化和反序列化函数,用户实现的反序列化函数中需要对各个字段进行校验。反序列化操作可以在绕过公开构造函数的情况下创建对象的实例,所以反序列化操作中的行为应该设计为与公开构造函数保持一致,这些行为包括: 对参数的校验、对属性赋初始值等; 否则,攻击者就可能会通过反序列化操作构造出与预期不符合的对象实例。仓颉语言使用反序列化功能时应关注此问题,需要在序列化和反序列化前后进行安全检查。
【反例】
class MySerializeDemo <: Serializable<MySerializeDemo> {
var value: Int64
init(v: Int64) {
value = if (v >= 0) { v } else { 0 }
}
private init(s: DataModelStruct) {
value = Int64.deserialize(s.get("value"))
}
public func serialize(): DataModel {
return DataModelStruct().add(field<Int64>("value", value))
}
public static func deserialize(s: DataModel): MySerializeDemo {
let d = (s as DataModelStruct).getOrThrow()
MySerializeDemo(d)
}
}
上述示例中,构造函数会对参数进行检查,保证 value 的值为非负值,但通过反序列化操作可构造 value 值为负值的对象示例。
【正例】
class MySerializeDemo <: Serializable<MySerializeDemo> {
var value: Int64
init(v: Int64) {
value = if (v >= 0) { v } else { 0 }
}
private init(s: DataModelStruct) {
let v = Int64.deserialize(s.get("value"))
value = if (v >= 0) { v } else { 0 }
}
public func serialize(): DataModel {
return DataModelStruct().add(field<Int64>("value", value))
}
public static func deserialize(s: DataModel): MySerializeDemo {
let d = (s as DataModelStruct).getOrThrow()
MySerializeDemo(d)
}
}
上述示例中, 反序列化操作中与构造函数中对 value 赋值操作保持一致,先检查后赋值。
G.SER.03 保证序列化和反序列化的变量类型一致
【级别】要求
【描述】
仓颉不会对序列化和反序列化使用的数据的数据类型进行检查,如果反序列化时使用的数据的数据类型和序列化时传入数据的数据类型不一致,则可能会造成数据错误。开发者需要保证序列化和反序列化时传入数据和接收数据的变量的变量类型一致。
【反例】
class MySerializeDemo <: Serializable<MySerializeDemo> {
var value: Int64
var msg: String
init(v: Int64) {
value = v
msg = match (value) {
case 0x0 => "zero"
case 0x7fffffff => "BIG INT"
case _ => "DEFAULT"
}
}
public func serialize() : DataModel {
DataModelStruct().add(field<Int64>("value", value))
}
private init(s: DataModelStruct) {
let v = Int32.deserialize(s.get("value"))
value = Int64(v)
msg = match (v) {
case 0x0 => "zero"
case 0x7fffffff => "BIG INT"
case _ => "DEFAULT"
}
}
public static func deserialize(s: DataModel): MySerializeDemo {
let d = (s as DataModelStruct).getOrThrow()
MySerializeDemo(d)
}
}
错误示例中序列化时传入的参数 value 是 Int64 类型,但是在接收的时候使用的是 Int32 类型的变量,因此会造成数据截断,导致反序列化的对象数据预期不一致。
【正例】
class MySerializeDemo <: Serializable<MySerializeDemo> {
var value: Int64
var msg: String
init(v: Int64) {
value = v
msg = match (value) {
case 0x0 => "zero"
case 0x7fffffff => "BIG INT"
case _ => "DEFAULT"
}
}
public func serialize(): DataModel {
DataModelStruct().add(field<Int64>("value", value))
}
private init(s: DataModelStruct) {
let v = Int64.deserialize(s.get("value"))
value = v
msg = match (v) {
case 0x0 => "zero"
case 0x7fffffff => "BIG INT"
case _ => "DEFAULT"
}
}
public static func deserialize(s: DataModel): MySerializeDemo {
let d = (s as DataModelStruct).getOrThrow()
MySerializeDemo(d)
}
}
正确示例中序列化和反序列化使用的变量的类型一致,保证了反序列化后得到的对象数据符合预期。
平台安全
G.SEC.01 进行安全检查的函数禁止声明为 open
【级别】建议
【描述】
实现安全检查功能的函数,如果可以被子类 override,恶意子类可以 override 安全检查函数,忽略这些安全检查,使安全检查失效。所以安全检查相关的函数禁止声明为 open,防止被 override。
【反例】
public open func requestPasswordAuthentication(protocol: String, prompt: String, scheme: String): Bool {
if (checkProtocol(protocol) && checkPrompt(prompt) && checkScheme(scheme)) {
...
}
}
上述示例中,requestPasswordAuthentication 被声明为了 open 类型,攻击者可以构造恶意子类将该函数覆写,忽略其中的安全检查。
【正例】
public func requestPasswordAuthentication(protocol: String, prompt: String, scheme: String): Bool {
if (checkProtocol(protocol) && checkPrompt(prompt) && checkScheme(scheme)) {
...
}
}
上述示例中,requestPasswordAuthentication 没有被声明为 open 类型,防止被子类覆写。
P.03 对外部对象进行安全检查时需要进行防御性拷贝
【级别】要求
【描述】
如果一个可信类被声明为 open,并且该类中存在 open 的涉及安全检查的函数,则会存在一定的安全隐患。攻击者可以通过继承该类并 override 其中 open 函数,来达到绕过安全检查的目的。因此,在对不可信的对象进行安全检查时,需要对其进行防御性拷贝,并且拷贝必须是深拷贝,然后对拷贝的对象进行安全检查,这样就能保证不会调用到攻击者 override 的函数。
【反例】
open class SecretFile {
var path: String
var stream: File
public open func getPath() {
return path
}
public open func getStream() {
return stream
}
...
}
class Foo {
public func getFileAsStream(file: SecretFile): File {
try {
this.securityCheck(file.getPath())
return file.getStream()
} catch (ex: IOException) {
// 处理异常
...
}
}
...
}
上述示例中,由于 SecretFile 是 open 的,并且 getPath() 函数也是 open 的,因此攻击者可以继承该类并 override getPath() 函数来绕过安全检查。如下代码所示,getPath() 函数第一次调用时会返回正常的文件路径,而之后的每次调用都会返回敏感文件路径。这样攻击者拿到的其实是 /etc/passwd 对应的 File。
class UntrustedFile <: SecretFile {
private var count: Int32 = 0
public init(path: String) {
super(path)
}
public override func getPath(): String {
return if (count == 0) {
count++
"/tmp/pub"
} else {
"/etc/passwd"
}
}
}
【正例】
public func getFileAsStream(file: SecretFile): File {
var copy = SecretFile(file.getPath())
try {
this.securityCheck(copy.getPath())
return copy.getStream()
} catch (ex: IOException) {
// 处理异常
}
}
上述示例中,通过 File 的构造函数创建了一个新的文件对象,这样可以保证在 copy 对象上调用的任何函数均来自标准类库。
其他
G.OTH.01 禁止在日志中保存口令、密钥和其他敏感数据
【级别】要求
【描述】
在日志中不能输出口令、密钥和其他敏感信息,口令包括明文口令和密文口令。对于敏感信息建议采取以下方法:
- 不在日志中打印敏感信息。
- 若因为特殊原因必须要打印日志,则用固定长度的星号(
*)代替输出的敏感信息。
【反例】
let fs: File = File("xxx.log", AccessMode.ReadWrite,
OpenMode.ForceCreate)
let logger = SimpleLogger("Login", LogLevel.INFO, fs)
...
logger.info("Login success ,user is ${userName} and password is ${encrypt(pass)}")
【正例】
let fs: File = File("xxx.log", AccessMode.ReadWrite,
OpenMode.ForceCreate)
let logger = SimpleLogger("Login", LogLevel.INFO, fs)
...
logger.info("Login success ,user is ${userName} and password is ****")
}
G.OTH.02 禁止将敏感信息硬编码在程序中
【级别】要求
【描述】
如果将敏感信息(包括口令和加密密钥)硬编码在程序中,可能会将敏感信息暴露给攻击者。任何能够访问到二进制文件的人都可以反编译二进制文件并发现这些敏感信息。因此,不能将敏感信息硬编码在程序中。同时,硬编码敏感信息会增加代码管理和维护的难度。例如,在一个已经部署的程序中修改一个硬编码的口令需要发布一个补丁才能实现。
【反例】
class DataHandler {
let pwd: String = "Huawei@123"
...
}
【正例】
class DataHandler {
public func checkPwd() {
let pwd = Array<UInt8>()
let read_bytes: Int64
let fs: File = File("serverpwd.txt", AccessMode.Read, OpenMode.Open)
read_bytes = fs.read(pwd, 0, 32)
...
for (i in 0..pwd.size) {
pwd[i] = 0
}
...
}
}
这个正确代码示例从一个安全目录下的外部文件获取密码信息,在其使用完后立即从内存中将其清除可以防止后续的信息泄露。
G.OTH.03 禁止代码中包含公网地址
【级别】要求
【描述】
代码或脚本中包含用户不可见,不可知的公网地址,可能会引起客户质疑。
对产品发布的软件(包含软件包 / 补丁包)中包含的公网地址(包括公网 IP 地址、公网 URL 地址 / 域名、 邮箱地址)要求如下:
- 禁止包含用户界面不可见、或产品资料未描述的未公开的公网地址。
- 已公开的公网地址禁止写在代码或者脚本中,可以存储在配置文件或数据库中。 对于开源 / 第三方软件自带的公网地址必须至少满足上述第 1 条公开性要求。
【例外】 对于标准协议中必须指定公网地址的场景可例外,如 soap 协议中函数的命名空间必须指定的一个组装的公网 URL、http 页面中包含 w3.org 网址、XML 解析器中的 Feature 名等。
G.OTH.04 不要使用 String 存储敏感数据,敏感数据使用结束后应立即清 0
【级别】建议
【描述】
仓颉中 String 是不可变对象(创建后无法更改)。如果使用 String 保存口令、秘钥等敏感信息时,这些敏感信息会一直在内存中直至被垃圾收集器回收,如果该进程的内存可 dump,这些敏感信息就可能被泄露。应使用可以主动立即将内容清除的数据结构存储敏感数据,如 Array<Byte> 等。敏感数据使用结束后立即将内容清除,可有效减少敏感数据在内存中的保留时间,降低敏感数据泄露的风险。
【反例】
func foo() {
let password: String = getPassword()
verifyPassword(password)
}
func verifyPassword(pwd: String): Bool {
...
}
上面的代码中,使用 String 保存密码信息,可能会导致敏感信息泄露。
【正例】
func foo() {
let password: Array<Char> = getPassword()
verifyPassword(password)
for (i in 0..password.size) {
password[i] = '\0'
}
}
func verifyPassword(pwd: Array<Char>): Bool {
...
}
上述正确示例中 password 被声明为了数组类型,并且在使用完毕后被清空,保证了后续 password 内容不会被泄露。
语言互操作
说明: 仓颉在实现了强大的安全机制的同时,也实现了强大的兼容性:仓颉语言通过在 IR 层级上实现多语言的互通,可以高效调用其他主流编程语言,进而实现对其他语言库的复用和生态兼容。但由于仓颉的提供的安全机制仅适用于仓颉语言本身,并不适用于与其他语言交互操作的场景,因此在语言交互边界上仍是不安全的,与其他语言交互操作的安全问题仍需重视。
C 语言互操作
说明: 在有些情况下,仓颉语言需要直接和操作系统交互。为了满足这种需求,仓颉提供了与 C 语言互操作的机制,例如函数调用、类型映射、内存管理等。该部分规范主要关注仓颉中已有的安全机制在 C 语言中不适用而导致安全问题被忽视的情况,同时只关注程序运行时的安全问题,编译器能静态检查的错误不会被加入到规范中。由于仓颉和 C 交互的代码都放在 unsafe 上下文中,因此 unsafe 内的代码需要关注此类规范。
FFI.C.1 声明 struct 类型时,成员变量的顺序和类型要求和 C 语言侧保持一致
【级别】要求
【描述】
当使用 struct 来声明 C 语言中的结构体类型时,要求保持变量的顺序和类型一致。若没有保持一致,可能导致数据映射地址不正确,同时也可能因为类型不一致而出现截断错误。
进行结构体参数映射时,需要按照类型映射表来保证类型相匹配,具体参见附录 C 基础类型映射关系表。
【反例】
如下仓颉和 C 结构体中定义的前两个成员变量顺序不一致,导致类型大小顺序颠倒,类型对应不正确,在仓颉中能够使用 Int64 正常容纳的数据,映射到 C 语言的 int32_t 型,可能会出现截断错误。
// CTest.c
#include<stdio.h>
#include<stdint.h>
typedef struct {
int32_t x; // int32_t 对应仓颉的 Int32
int64_t y;
int64_t z;
int64_t a;
}CStruct;
void distance(CStruct cs) {
printf("x=%d, y=%lld, z=%lld, a=%lld\n", cs.x, cs.y, cs.z, cs.a);
}
// CJTest.cj
foreign func distance(f: CStruct): Unit
@C
struct CStruct {
var y: Int64 // 此处使用 Int64 对应 int32_t,不合法
var x: Int32
var z: Int64
var a: Int64
init(yy: Int64, xx: Int32, zz: Int64, aa: Int64) {
y = yy
x = xx
z = zz
a = aa
}
}
按照如下给结构体赋值,第一个参数明显超出 Int32 最大范围,但没有超出 Int64 的范围,在仓颉中使用 Int64 可以正常使用,但映射到 C 语言中使用的是 int32_t 型接收,会出现截断错误。
main() {
var y = CStruct(214748364888, 2147483647, 4, 8)
print("yres:\n")
unsafe { distance(y) }
}
yres:
x=88, y=140615081787391, z=4, a=8
【正例】
//CJTest.cj
foreign func distance(f: CStruct): Unit
@C
struct CStruct {
var x: Int32
var y: Int64
var z: Int64
var a: Int64
init(xx: Int32, yy: Int64, zz: Int64, aa: Int64) {
x = xx
y = yy
z = zz
a = aa
}
}
main() {
var y = CStruct(214748364888, 2147483647, 4, 8)
print("yres:\n")
unsafe { distance(y) }
}
FFI.C.2 foreign 声明的函数参数类型、参数数量和返回值类型要求和 C 语言侧对应的函数参数类型、参数数量和返回值类型保持一致
【级别】要求
【描述】
仓颉使用 foreign 声明 C 语言侧函数时应保持参数数量、参数类型、返回值类型严格一致。若参数数量不一致,仓颉这边传入的参数数量不够的话,可能导致 C 语言侧变量的值未被初始化而访问到随机值;若参数类型不一致,可能会导致参数传递过去后被截断;返回值类型不一致,可能会导致仓颉接收函数返回值时出现截断问题。
同样的,在使用 CFunc<T, T> 声明函数指针时,也需要保持参数类型和类型限定符一致,若不一致,则可能出现截断错误。
【反例】
函数指针接收时参数类型和类型限定符不一致可能导致截断。如下示例中,C 语言侧函数指针为 int16_t 型,仓颉为 Int32 型,传入的参数在 Int32 范围内,但超过了 int16_t 范围,会出现截断错误。
// CTest.c
#include<stdio.h>
#include<stdint.h>
typedef int16_t(*func_t)(int16_t, int16_t);
int16_t add(int16_t a, int16_t b) {
int16_t sum = a + b;
printf("%d + %d = %d\n", a, b, sum);
return sum;
}
// Pass func ptr 'add' to CangJie.
func_t getFuncPtr() {
printf("this is from getFuncPtr. addr: %d\n", &add);
return add;
}
// CJTest.cj
foreign func getFuncPtr(): CFunc<(Int32, Int32) -> Int32>
main() {
var add: CFunc<(Int32, Int32) -> Int32> = unsafe { getFuncPtr() }
var bb = add(214748364, 2)
}
可以看到参数出现截断错误。
this is from getFuncPtr. addr: 575928392
-13108 + 2 = -13106
【正例】
仓颉侧和 C 语言侧类型保持一致,避免截断问题。
// CJTest.cj
foreign func getFuncPtr(): CFunc<(Int16, Int16) -> Int16>
main() {
var add: CFunc<(Int16, Int16) -> Int16> = unsafe { getFuncPtr() }
var bb = add(214, 2)
}
同时保持传参在类型大小范围内,将会正常执行。
this is from getFuncPtr. addr: -578103224
214 + 2 = 216
【反例】
参数类型不一致可导致截断。如下示例中,两侧互通函数 add 声明的参数类型不一致,传入后会发生截断。
//CTest.c
#include<stdio.h>
#include<stdint.h>
int add(short x, int y) { // 参数包含 short 型
printf("x = %x, y = %x\n", x, y);
return x + y;
}
// CJTest.cj
foreign func printf(fmt: CString, ...): Int32
foreign func add(x: Int32, y: Int32): Int32 // 参数全为 Int32 型
main() {
var a: Int32 = 0x1234567
var b: Int32 = 0
var res: Int32 = unsafe { add(a, b) }
unsafe {
var cstr = LibC.mallocCString("res = %x \n")
printf(cstr, res)
LibC.free(cstr)
}
}
运行结果如下,可以看到参数 x 传入后被截断,导致计算结果也被截断,仅保留了十六进制的低四位。
x = 4567, y = 0
res = 4567
【正例】
如下示例将互通函数两侧的参数都声明为 Int32 类型,避免截断问题。
// CTest.c
#include<stdio.h>
#include<stdint.h>
int add(int x, int y) {
printf("x = %x, y = %x\n", x, y);
return x + y;
}
// CJTest.cj
foreign func add(x: Int32, y: Int32): Int32
foreign func printf(fmt: CString, ...): Int32
main() {
var a: Int32 = 0x1234567
var b: Int32 = 0
var res: Int32 = unsafe { add(a, b) }
unsafe {
var cstr = LibC.mallocCString("res = %x \n")
printf(cstr, res)
LibC.free(cstr)
}
}
【反例】
参数数量不一致可导致访问任意值。互通函数两侧声明的参数数量不一致,会导致部分 C 侧变量没有得到初始化,从而访问到随机值。
// CTest.c
#include<stdio.h>
#include<stdint.h>
int add(int x, int y) {
printf("x = %x, y = %x\n", x, y);
return x + y;
}
// CJTest.cj
foreign func add(x: Int32): Int32
foreign func printf(fmt: CString, ...): Int32
main() {
var a: Int32 = 123
var res: Int32 = unsafe { add(a) } // 此处仅传递一个参数,第二个参数没有被初始化
unsafe {
var cstr = LibC.mallocCString("res = %d \n")
printf(cstr, res)
LibC.free(cstr)
}
}
运行结果如下,可以看到 y 是一个未知值,导致结果也是一个随机值。
x = 123, y = 1439015064
res = 1439015187
【正例】
// CJTest.cj
foreign func add(x: Int32, y: Int32): Int32
foreign func printf(fmt: CString, ...): Int32
main() {
var a: Int32 = 0x1234567
var b: Int32 = 0
var res: Int32 = unsafe { add(a, b) } // 此处正常传递两个参数
unsafe {
var cstr = LibC.mallocCString("res = %x \n")
printf(cstr, res)
LibC.free(cstr)
}
}
【反例】
函数返回类型不一致可导致截断。
// CTest.c
#include<stdio.h>
#include<stdint.h>
int add(int x, int y) {
printf("x = %x, y = %x\n", x, y);
return x + y;
}
// CJTest.cj
foreign func printf(fmt: CString, ...): Int32
foreign func add(x: Int32, y: Int32): Int16 // 此处返回类型和 C 侧声明不一致,可能出现截断问题
main() {
var a: Int32 = 0x12345
var b: Int32 = 0
var res: Int16 = unsafe { add(a, b) }
unsafe {
var cstr = LibC.mallocCString("res = %x \n")
printf(cstr, res)
LibC.free(cstr)
}
}
运行结果如下,可以看到计算结果仅保留十六进制的低四位,发生了截断。
x = 12345, y = 0
res = 2345
【正例】
// CJTest.cj
foreign func printf(fmt: CString, ...): Int32
foreign func add(x: Int32, y: Int32): Int32 // 此处返回类型和 C 侧声明一致
main() {
var a: Int32 = 0x12345678
var b: Int32 = 0
var res: Int32 = unsafe { add(a, b) }
unsafe {
var cstr = LibC.mallocCString("res = %x \n")
printf(cstr, res)
LibC.free(cstr)
}
}
FFI.C.3 仓颉侧接收 C 语言传递过来的指针时,如果可能接收到空指针,应在使用前检查是否为 NULL
【级别】要求
【描述】
仓颉编程语言提供 CPointer<T> 类型对应 C 语言的指针 T* 类型,CPointer<T> 可以使用类型名构造一个实例,用来接收 C 语言传递过来的指针类型,这个实例的值初始为空,相当于 C 语言的 NULL。如果传递过来的是空指针,则在仓颉侧接收到的也是空指针,没有校验就直接使用会造成空指针引用问题。
常见的场景:
- C 语言侧分配内存失败,返回空指针并传递过来;
- C 语言侧函数返回值为
NULL。
【反例】
没有处理空指针可导致程序崩溃。
//CTest.c
#include<stdio.h>
#include<stdint.h>
int *PassInt32PointerToCangjie() {
int *a = (int *)malloc(sizeof(int));
if (a == NULL)
return NULL;
*a = 1234;
return a;
}
void GetInt32PointerFromCangjie(int *a) {
int b = 12;
a = &b;
printf("value of int *a = %d\n", *a);
}
//CJTest.cj
foreign func PassInt32PointerToCangjie(): CPointer<Int32>
foreign func GetInt32PointerFromCangjie(a: CPointer<Int32>): Unit
main() {
var a = unsafe { PassInt32PointerToCangjie() } // 此处从 C 语言接收指针
if (unsafe { a.read() != 2147483647 }) { // a 未校验就直接引用成员函数 read(),可能出现空指针引用
return
}
unsafe { GetInt32PointerFromCangjie(a) }
}
【正例】
指针引用前先进行校验。
foreign func PassInt32PointerToCangjie(): CPointer<Int32>
foreign func GetInt32PointerFromCangjie(a: CPointer<Int32>): Unit
main() {
var a = unsafe { PassInt32PointerToCangjie() } // 此处从 C 语言接收指针
if (a.isNull()) { // 指针接收后先校验
print("pointer is null!\n")
return
}
if (unsafe { a.read() != 2147483647 }) { // a 未校验就直接引用成员函数 read(),可能出现空指针引用
return
}
unsafe { GetInt32PointerFromCangjie(a) }
}
FFI.C.4 资源不再使用时应予以关闭或释放
【级别】要求
【描述】
在仓颉和 C 语言交互时,可能会手动申请内存、句柄等系统资源,这些资源不再使用时应予以关闭或释放。
若需要分配或释放 C 侧的内存,需要在 C 语言侧提供内存分配和释放的接口,在仓颉侧调用对应的接口。若没有封装接口,则需要根据 C 语言规范要求,在 C 语言侧合理使用 free 或者 close 等函数进行释放。
如果是在仓颉侧直接调用 C 语言库函数分配内存,例如 LibC.malloc 等,如果分配内存成功,在使用完后也必须在仓颉侧调用 LibC.free 等内存释放函数来释放内存。
【反例】
仓颉侧自行分配和释放内存。下述示例代码中,使用完 CString 字符串,但之后没有调用相应的释放函数,导致内存泄漏。
foreign func printf(fmt: CString, ...): Int32
main() {
var str = unsafe { LibC.mallocCString("hello world!\n") }
unsafe { printf(str) }
// 使用完后没有释放 str 的内存
}
【正例】
下述示例中,使用完 CString 字符串后及时调用 LibC.free 来释放内存,消除了上述风险。
foreign func printf(fmt: CString, ...): Int32
main() {
var str = unsafe { LibC.mallocCString("hello world!\n") }
unsafe { printf(str) }
unsafe { LibC.free(str) } // 使用完后释放内存
}
【反例】
若 C 侧提供内存释放函数,则需要在仓颉侧进行调用来释放内存。
// CTest.c
#include<stdio.h>
#include<stdint.h>
#include<stdlib.h>
int* SetMem() {
// 分配内存
int* a = (int*)malloc(sizeof(int));
if (a == NULL) {
return NULL;
}
*a = 123;
return a;
}
void FreeMem(int* a) {
// 释放内存
if (a == NULL) {
printf("Pointer a is NULL!\n");
return;
}
free(a);
}
// CJTest.cj
foreign func SetMem(): CPointer<Int32>
main() {
var a: CPointer<Int32> = unsafe { SetMem() }
// do something
// 此处函数直接返回,未调用 C 侧释放函数来释放之前分配的内存
}
【正例】
// CJTest.cj
foreign func SetMem(): CPointer<Int32>
foreign func FreeMem(a: CPointer<Int32>): Unit
main() {
var a: CPointer<Int32> = unsafe { SetMem() }
// do something
unsafe { FreeMem(a) } // 使用完后及时释放内存
a = CPointer<Int32>() // 将 a 置为空
}
【影响】如果资源在结束使用前未正确地关闭或释放,会造成系统的内存泄漏、句柄泄漏等资源泄漏漏洞。如果攻击者可以有意触发资源泄漏,则可能能够通过耗尽资源来发起拒绝服务攻击。
FFI.C.5 禁止访问已经释放过的资源
【级别】要求
【描述】
如果从 C 语言侧接收到的指针已经进行过释放操作,那么禁止在仓颉侧再次使用这些指针的值,也不得再引用负责接收这些指针的变量,否则可能会造成安全问题,如解引用已释放的内存的指针、再次释放这些指针的内存等。
再次使用已释放内存的指针,可能因为访问无效内存导致程序崩溃,建议在释放内存后将指针显式置空,在下次使用前进行判空校验。
【反例】
// CTest.c
#include<stdio.h>
#include<stdint.h>
#include<stdlib.h>
int* SetMem() {
// 分配内存
int* a = (int*)malloc(sizeof(int));
*a = 123;
return a;
}
void FreeMem(int* a) {
// 释放内存
if (a == NULL) {
printf("Pointer a is NULL!\n");
return;
}
free(a);
}
// CJTest.cj
foreign func SetMem(): CPointer<Int32>
foreign func FreeMem(a: CPointer<Int32>): Unit
var a = CPointer<Int32>()
func Foo() {
a = unsafe { SetMem() }
// 指针校验和其它操作
unsafe { FreeMem(a) } // 调用 C 侧 free 之后指针实际不为空,a 为野指针
}
func Foo2() {
if (!a.isNull()) { // 此处判空校验无效,会被绕过
unsafe { a.read(0) } // 此处会被执行,访问非法地址
}
}
main() {
Foo()
Foo2()
}
【正例】
// CJTest.cj
foreign func SetMem(): CPointer<Int32>
foreign func FreeMem(a: CPointer<Int32>): Unit
var a = CPointer<Int32>()
func Foo() {
a = unsafe { SetMem() }
// 使用指针
unsafe { FreeMem(a) }
a = CPointer<Int32>() // 建议使用完后将指针置为空,避免了使用已释放内存的问题。
}
func Foo2() {
if (!a.isNull()) { // 此处校验有效,指针 a 为空,因此不会进入此分支,避免 use after free
unsafe { a.read(0) }
}
}
main() {
Foo()
Foo2()
}
FFI.C.6 外部数据作为 read() 和 write() 函数索引时必须确保在有效范围内
【级别】要求
【描述】
由于仓颉的 CPointer<T> 类的成员函数 read() 和 write() 支持设置索引,因此可能会使用来自外部的数据作为函数的索引。当使用外部数据作为函数索引时,需要确保其在索引的有效范围内, 否则可能会出现越界访问的风险。
【反例】
// CTest.c
#include<stdio.h>
#include<stdint.h>
#include<stdlib.h>
int* PassPointerToCangjie() {
int *p = (int*)malloc(sizeof(int) * 5);
if ( p == NULL) {
return NULL;
}
for (int i = 0; i < 5; i++) {
p[i] = i;
}
return p;
}
void GetPointerFromCangjie(int *a, int len)
{
if ( a == NULL) {
printf("Pointer a is null!\n");
return;
}
for (int i = 0; i < len; i++) {
printf("%d ", a[i]);
}
}
// CJTest.cj
foreign func printf(fmt: CString, ...): Int32
foreign func PassPointerToCangjie(): CPointer<Int32>
foreign func GetPointerFromCangjie(a: CPointer<Int32>, len: Int32): Unit
func Foo(index: Int64) {
var a: CPointer<Int32> = unsafe { PassPointerToCangjie() } // 接收的数组指针索引范围为 0-4
if (a.isNull()) {
return
}
var value = unsafe { LibC.mallocCString("%d\n") }
unsafe { printf(value, a.read(index)) } // 此处 index 值为函数入参,有可能为外部输入数据
unsafe { a.write(index, 123) } // 没有校验就直接作为数组索引,可能会导致越界访问
var len: Int32 = 5
unsafe { GetPointerFromCangjie(a, len) }
unsafe { LibC.free(value) }
}
main() {
var index: Int64 = 3
Foo(index) //不会越界
var index2: Int64 = 5
Foo(index2) //发生越界
}
【正例】
// CJTest.cj
foreign func printf(fmt: CString, ...): Int32
foreign func PassPointerToCangjie(): CPointer<Int32>
foreign func GetPointerFromCangjie(a: CPointer<Int32>, len: Int32): Unit
let MAX: Int64 = 4
func Foo(index: Int64) {
var a: CPointer<Int32> = unsafe { PassPointerToCangjie() } // 接收的数组指针索引范围为 0-4
let value = unsafe { LibC.mallocCString("%d\n") }
if (index < 0 || index> MAX) { // 对函数入参进行合理的校验
return
}
unsafe { printf(value, a.read(index)) }
unsafe { a.write(index, 123) }
var len: Int32 = 5
unsafe { GetPointerFromCangjie(a, len) }
unsafe { LibC.free(value) }
}
main() {
var index: Int64 = 3
Foo(index) //不会越界
var index2: Int64 = 5
Foo(index2) //校验不通过,不会发生越界
}
【影响】未对外部数据中的整数值进行限制可能导致拒绝服务,缓冲区溢出,信息泄露,甚至执行任意代码。
FFI.C.7 强制进行指针类型转换时避免出现截断错误
【级别】要求
【描述】
仓颉中的不同指针类型间相互进行强制转换时,需要注意强制类型转换前后内存中的数据是不变的,但可能出现元素的合并和拆分的情况,元素个数也可能因此发生变化,使用者必须充分了解数据的内存分布情况,否则不要使用强制指针类型转换。
【反例】
如下示例,将 Int32 类型指针强制转换成 Int16 型,会将数据截断为低两位和高两位,但内存中的数据实际并没有变化,可以通过成员函数 read() 访问,如 read(0) 访问低两位数据,read(1) 访问高两位数据,元素个数由原来的一个变成了两个,并且都可以通过索引访问到内存,但访问第二个元素的时候实际上是越界访问内存。
// CTest.c
#include<stdio.h>
#include<stdint.h>
#include<stdlib.h>
int *PassPointerToCangjie() {
int *p = (int *)malloc(sizeof(int));
if (p == NULL)
return NULL;
*p = 0x1234;
return p;
}
foreign func printf(fmt: CString, ...): Int32
foreign func PassPointerToCangjie(): CPointer<Int32>
main() {
var a: CPointer<Int32> = unsafe { PassPointerToCangjie() }
var b: CPointer<Int16> = CPointer<Int16>(a) // 此处将 Int32 类型指针强制转换成 Int16 型
if (b.isNull()) {
print("pointer is null!\n")
return
}
if (unsafe { b.read() != 0 }) {
print("Pointer was cut!\n")
var value = unsafe { LibC.mallocCString("%x\n") }
unsafe { printf(value, b.read(1)) } // read(1) 访问 Int16 的高两位数据,可能造成越界访问
unsafe { LibC.free(value) }
return
}
var value = unsafe { LibC.mallocCString("%x\n") }
unsafe { printf(value, b.read(0)) }
unsafe { LibC.free(value) }
}
【正例】
谨慎使用强制指针类型转换。
foreign func printf(fmt: CString, ...): Int32
foreign func PassPointerToCangjie(): CPointer<Int32>
main() {
var a: CPointer<Int32> = unsafe { PassPointerToCangjie() }
// 删除此处的强制类型转换
if (a.isNull()) {
print("pointer is null!\n")
return
}
if (unsafe { a.read() != 0 }) {
print("Pointer a was cut!\n")
var value = unsafe { LibC.mallocCString("%x\n") }
unsafe { printf(value, a.read(0)) }
unsafe { LibC.free(value) }
return
}
var value = unsafe { LibC.mallocCString("%x\n") }
unsafe { printf(value, a.read(0)) }
unsafe { LibC.free(value) }
}
附录
命令注入相关特殊字符
表 3 shell 脚本中常用的与命令注入相关的特殊字符。
| 分类 | 符号 | 功能描述 |
|---|---|---|
| 管道 | | | 连结上个指令的标准输出,作为下个指令的标准输入 |
| 内联命令 | ; | 连续指令符号 |
| 内联命令 | & | 单一个 & 符号,且放在完整指令列的最后端,即表示将该指令列放入后台中工作 |
| 逻辑操作符 | $ | 变量替换 (Variable Substitution) 的代表符号 |
| 表达式 | $ | 可用在 ${} 中作为变量的正规表达式 |
| 重定向操作 | > | 将命令输出写入到目标文件中 |
| 重定向操作 | < | 将目标文件的内容发送到命令当中 |
| 反引号 | ` 对 | 可在 ` 和 ` 之间构造命令内容并返回当前执行命令的结果 |
| 倒斜线 | \ | 在交互模式下的 escape 字元,有几个作用;放在指令前,有取消 aliases 的作用;放在特殊符号前,则该特殊符号的作用消失;放在指令的最末端,表示指令连接下一行 |
| 感叹号 | ! | 事件提示符 (Event Designators), 可以引用历史命令 |
| 换行符 | \n | 可以用在一行命令的结束,用于分隔不同的命令行 |
上述字符也可能以组合方式影响命令拼接,如管道符 “||”,“>>” ,“<<”,逻辑操作符 “&&” 等,由于基于单个危险字符的检测可以识别这部分组合字符,因此不再列出。另外可以表示账户的 home 目录 “~”,可以表示上层目录的符号“..”,以及文件名通配符 “?” (匹配文件名中除 null 外的单个字元),“*” (匹配文件名的任意字元) 由于只影响命令本身的语义,不会引入额外的命令,因此未列入命令注入涉及的特殊字符,需根据业务本身的逻辑进行处理。
可能产生整数溢出的数学操作符
| 操作符 | 溢出 | 操作符 | 溢出 | 操作符 | 溢出 | 操作符 | 溢出 |
|---|---|---|---|---|---|---|---|
+ | Y | -= | Y | << | N | < | N |
- | Y | *= | Y | >> | N | > | N |
* | Y | /= | Y | & | N | >= | N |
/ | Y | %= | N | | | N | <= | N |
% | N | <<= | N | ^ | N | == | N |
++ | Y | >>= | N | ~ | N | ||
-- | Y | &= | N | ! | N | ||
= | N | \|= | N | != | N | ||
+= | Y | ^= | N | ** | Y |
基础类型映射关系表
| CangJie Type | C Type | Size |
|---|---|---|
| Unit | void | 0 |
| Bool | bool | 1 |
| Int8 | int8_t | 1 |
| UInt8 | uint8_t | 1 |
| Int16 | int16_t | 2 |
| UInt16 | uint16_t | 2 |
| Int32 | int32_t | 4 |
| UInt32 | uint32_t | 4 |
| Int64 | int64_t | 8 |
| UInt64 | uint64_t | 8 |
| IntNative | - | * platform dependent |
| UIntNative | - | * platform dependent |
| Float32 | float | 4 |
| Float64 | double | 8 |
| struct | struct | field dependent |
参考文档
仓颉语言 IDE 插件使用指南
功能简介
仓颉语言 IDE 插件为用户提供了语言服务、工程管理、编译构建、调试服务、格式化、静态检查、覆盖率统计的功能。
支持在 VSCode、 VSCode-huawei、Wecode-online中使用该语言服务插件
安装说明
安装 VSCode 或 VSCode-huawei
windows 平台
下载Windows 平台 VSCode(推荐使用 version 1.67 及以上版本)
下载Windows 平台 VSCode-huawei(推荐使用 version 1.67.2 及以上版本)
按照安装包导引,将 VSCode 或 VSCode-huawei 安装在自定义路径中,然后启动。
linux 平台
下载linux 平台 VSCode(推荐使用 version 1.67 及以上版本)
下载linux 平台 VSCode-huawei(推荐使用 version 1.67.2 及以上版本)
mac 平台
下载mac 平台 VSCode(推荐使用 version 1.67 及以上版本)
本地安装
压缩包解压后,将 压缩包 如 VSCode-linux-x64 放到自定义位置,使用chmod 777 ./VSCode-linux-x64/code和chmod 777 ./VSCode-linux-x64/bin/code 命令给 code 增加可执行权限,
然后用./VSCode-linux-x64/bin/code命令启动 VSCode
(注意 VSCode-huawei 中将上述 code 改为 VSCode-huawei,操作一致)
远程安装
使用 Remote - SSH 远程连接 VSCode ( VSCode-huawei 使用 RemoteDev BETA 操作一致)
搜索 Remote - SSH,点击安装
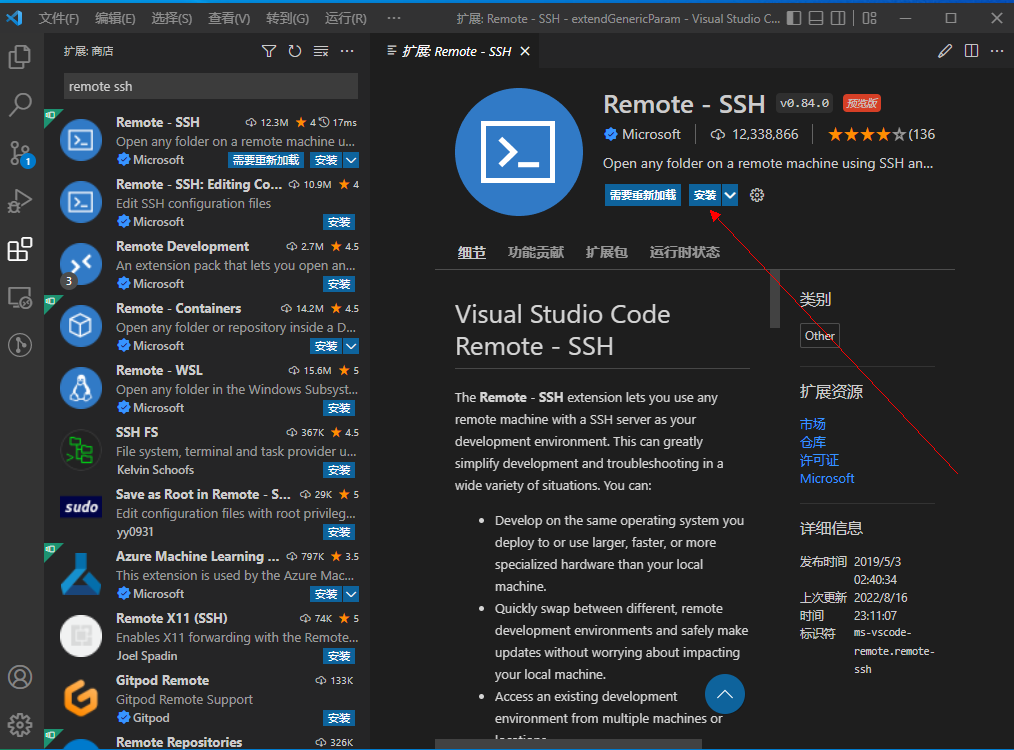 使用 Remote - SSH 进行远程工作,VSCode/VSCode-huawei 会自动在远程主机上安装 server,linux_arm64 暂时只支持使用 Remote - SSH 的方式进行操作。
使用 Remote - SSH 进行远程工作,VSCode/VSCode-huawei 会自动在远程主机上安装 server,linux_arm64 暂时只支持使用 Remote - SSH 的方式进行操作。
插件安装
首先,请在仓颉官方渠道(官网或者 Gitee)根据平台架构下载相应安装包,交付内容为压缩包:Cangjie-vscode-version.tar.gz。
下载成功后,将其解压得到文件夹:Cangjie-vscode-version。该文件夹下有下列的内容
| 解压后生成文件与文件夹 | 文件功能 |
|---|---|
| .vsix 文件 | 插件端 |
VSCode 或 VSCode-huawei 安装本地插件
按照下图所示操作,打开文件资源管理器对话框,找到要安装的插件.vsix,点击确定即可安装。
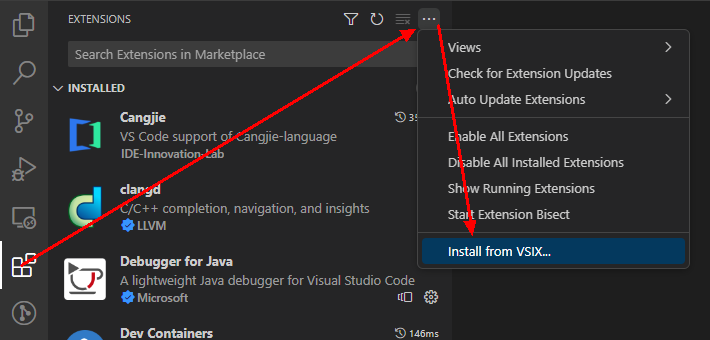
已经安装的插件可以在 INSTALLED 目录下查看
安装仓颉 SDK
仓颉 SDK 主要提供了 cjpm、cjc、cjfmt 等命令行工具,正确安装并配置仓颉 SDK 后,可使用工程管理、编译构建、格式化、静态检查和覆盖率统计等功能,开发者可以通过两种方式下载 SDK:
- 在官网下载 SDK 安装包,并在本地安装部署仓颉 SDK。
- 仓颉插件提供了仓颉 SDK 最新版本下载和更新功能,开发者可以在 VSCode 界面完成最新版本仓颉 SDK 的下载和本地环境部署。
离线手动安装和更新仓颉 SDK
开发者可以自行前往官网,手动下载需要的 SDK 版本,并在本地完成 SDK 路径配置。
windows 平台
Windows 平台的 SDK 下载内容为:Cangjie-version-windows_x64.exe或Cangjie-version-windows_x64.zip。将其下载后内容放置在本地环境中。
windows 版本的目录结构如下:

linux 平台
linux_x64 平台的 SDK 下载内容为:Cangjie-version-linux_x64.tar.gz。
linux_aarch64 平台的 SDK 下载内容为:Cangjie-version-linux_aarch64.tar.gz。
将其下载后内容放置在本地环境中。linux 版本的目录结构如下:
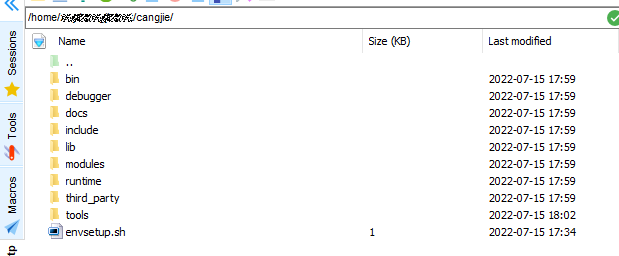
mac 平台
mac_x86_64 平台的 SDK 下载内容为:Cangjie-version-darwin_x64.tar.gz。
mac_aarch64 平台的 SDK 下载内容为:Cangjie-version-darwin_aarch64.tar.gz。
将其下载后内容放置在本地环境中。mac 版本的目录结构如下:
SDK 路径配置
插件支持 CJNative 后端和 CJVM 后端两种 SDK 的使用,目前 CJVM 后端只支持 Linux 系统。
安装完 Cangjie 插件后,即可配置 SDK 的路径。点击左下角齿轮图标,选择设置选项:
或直接右键点击插件,选择 Extension Settings,进入配置页面:
在搜索栏输入 cangjie, 然后选择侧边栏的 Cangjie Language Support 选项。
CJNative 后端的 SDK 路径配置
-
找到 Cangjie Sdk: Option 选项,选择后端类型为 CJNative(默认是此选项)
-
找到 Cangjie Sdk Path: CJNative Backend 选项,输入 CJNative 后端 SDK 文件所在绝对路径
-
重启 VScode 生效
CJVM 后端的 SDK 路径配置
-
找到 Cangjie Sdk: Option 选项,选择后端类型为 CJVM
-
找到 Cangjie Sdk Path: CJVM Backend 选项,输入 CJVM 后端 SDK 文件所在绝对路径
-
重启 VScode 生效
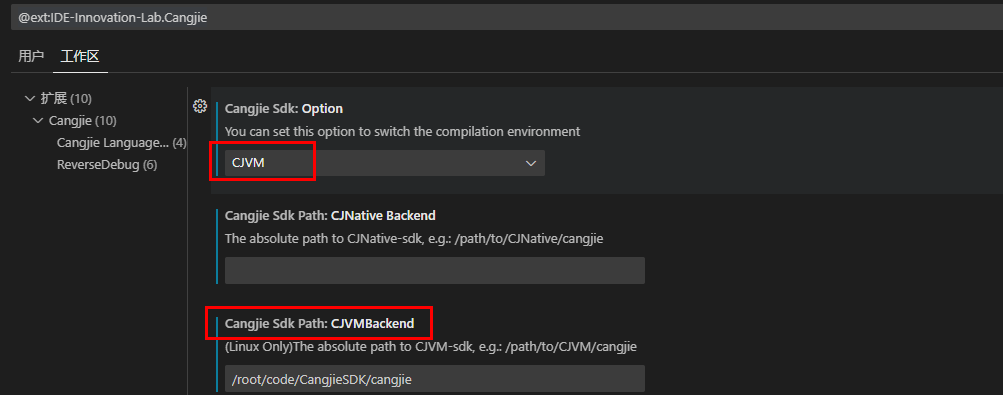
插件安装和更新仓颉 SDK
仓颉插件提供了仓颉 SDK 最新版本的下载与更新功能,开发者只需在 VSCode 界面即可完成仓颉 SDK 对应平台最新版本的下载更新与本地环境部署。
触发更新提示
当开发者进行如下操作时,仓颉插件会通过设置页面配置的仓颉 SDK 路径,获取对应 SDK 的版本信息,从而判断本地仓颉 SDK 是否为最新版本:
-
在 VSCode 界面打开仓颉源文件。
-
通过快捷键 "Ctrl + Shift + P"(mac 上快捷键为 "Command + Shift + P") 调出 VSCode 的命令面板,然后选择 "Cangjie: Install/Update Latest SDK" 命令。
当本地 VSCode 没有配置仓颉 SDK 或者仓颉 SDK 非最新版本时,VSCode 界面右下角会弹出安装或更新提示。
安装仓颉 SDK
-
如果希望直接安装最新版本 SDK,可以在更新提示框点击 “ Install “ 按钮。
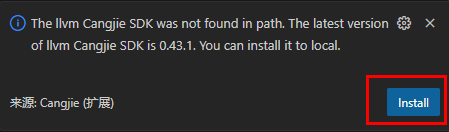
-
在弹出的窗口中选择下载和安装路径(注意路径不能存在名为
cangjie的文件夹)并单击 "Choose the SDK install path" 确定。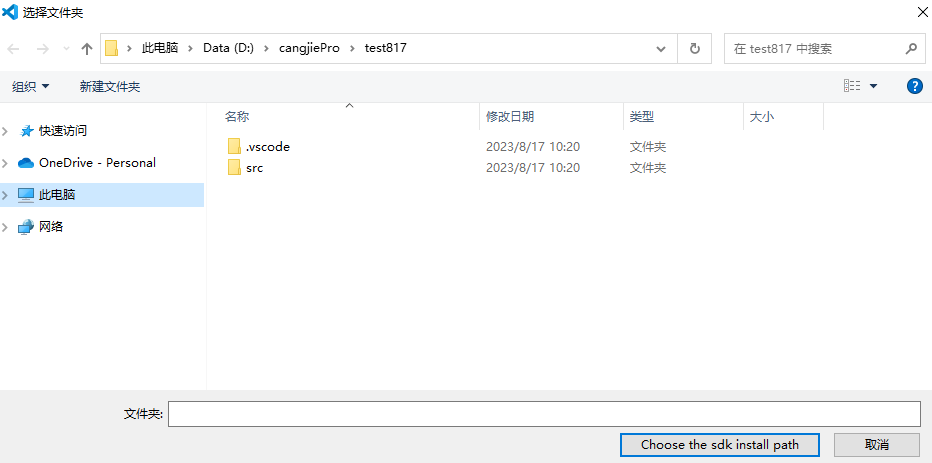
-
完成路径选择后,仓颉 SDK 开始下载:
-
下载完成后,会自动配置仓颉 SDK 的安装路径。
-
配置完成后,您可以使用最新版本的仓颉 SDK 进行本地开发。
更新仓颉 SDK
说明:
更新操作只能更新名为
cangjie文件夹中的 SDK,当目标文件夹名称不为cangjie时,会提示相关信息并取消更新操作。
-
如果本地已经安装了仓颉 SDK,但不是最新版本时,请单击更新提示界面的 “Update” 按钮。
-
单击提示界面的 “Update” 按钮,插件会自动更新开发者当前 SDK 目录下的内容(因为会覆盖该目录下的所有文件,所以请确保该目录下除了 SDK 文件外无其他冗余文件)。由于更新的内容包含语言服务,因此更新过程中语言服务(代码补全、查找引用、悬浮提示等)不可用。
-
更新完成后,会自动重启语言服务器,随后您可以使用最新版本的仓颉 SDK 进行本地开发。
使用限制
使用 VSCode 打开一个文件夹,将其中的仓颉源码分为两部分:一部分是顶层 src 目录下的仓颉源码,另一部分是非 src 目录下的仓颉源码。仓颉语言服务支持的目录结构如下:
限制一
语言服务插件仅为用户打开的文件夹下仓颉源码提供语言服务。以用户打开的文件夹为仓颉项目的根目录 PROJECTROOT(如果用户没有明确指定模块名称,默认将 PROJECTROOT 目录名称作为模块名,以方便用户导入 src 下的包),PROJECTROOT/src 为 src 下仓颉源码(支持语言服务);除了 src 下的仓颉源码,PROJECTROOT 下的所有源码称为非 src 下仓颉源码(支持语言服务);PROJECTROOT 之外的仓颉源码称为外部源码(暂不支持语言服务)。
限制二
非 src 下每个文件夹都作为一个包,包名的声明和包的编译方式与 src 下顶层包(即 default 包)处理方式保持一致。非 src 下的仓颉源码可以导入标准库的包以及 src 下用户自定义的包,非 src 下的包无法被其他包导入。
限制三
linux 、 windows 、 mac 环境下均需要先设置 Cangjie sdk 路径。
语言服务
功能简介
语言服务工具基于《Cangjie Language Guide》,为用户提供了如下功能:语法高亮、自动补全、定义跳转、查找引用、诊断报错、选中高亮、悬浮提示、签名帮助、重命名等功能。
使用说明
语法高亮介绍及使用
VSCode 打开 Cangjie 工程中的.cj 文件,即可看到效果,VSCode 不同主题显示的代码高亮颜色不同,如下所示的 dark+ 主题:关键字显示粉色,函数定义、引用符号为黄色,函数形参、变量符号为蓝色,注释为绿色等。
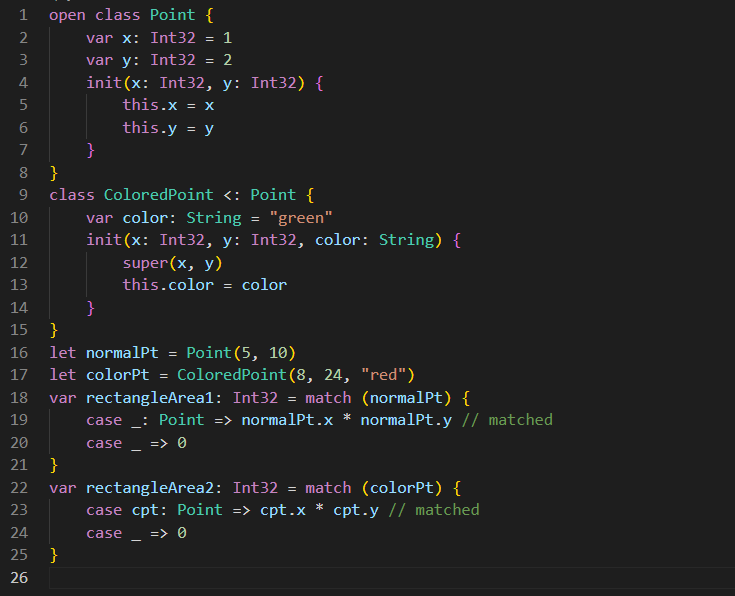
自动补全介绍及使用
VSCode 打开 Cangjie 工程中的.cj 文件,输入关键字、变量或 “.” 符号,在光标右侧提示候选内容,如下所示,可以用上下方向键快速选择想要的内容(注:需要切换为系统默认输入法),回车补全。

对于带参数的函数或者泛型提供模块化补齐,即当函数有参数或者带泛型的时候,选择函数补齐项之后会出现参数格式化补齐,如下图,填充数值之后按 tab 可以切换到下一个参数补齐直至模块化补齐结束,或者按 Esc 可以提前退出除当前选中模块外,其余模块的模块化补齐。

定义跳转介绍及使用
VSCode 打开 Cangjie 工程中的.cj 文件,鼠标悬停在目标上方 Ctrl + 单击鼠标左键触发定义跳转;或使用鼠标右键单击目标符号,选择 “Go to Definition” 执行定义跳转;或快捷键 F12 执行定义跳转,光标跳到定义处符号左端。
注意事项
- 在符号使用的地方使用定义跳转会跳转到符号定义处,支持跨文件跳转
- 在符号定义处使用定义跳转,如果此符号没被引用过,光标会跳转到符号左端
- 如果符号在其他地方被引用,会触发查找引用
跨语言跳转介绍和使用
语言服务插件支持 Cangjie 语言到 C 语言的跳转功能,VSCode 打开 Cangjie 工程中的.cj 文件,鼠标悬停在 Cangjie 互操作函数上方 Ctrl + 单击鼠标左键触发定义跳转;或使用鼠标右键单击目标符号,选择 “Go to Definition” 执行定义跳转;或快捷键 F12 执行定义跳转,光标跳到 C 语言定义处符号左端。
前置条件
- 本地安装华为自研 C++ 插件;
- 在 Cangjie 插件上设置需要跳转的 C 语言源码存放目录;
- 在当前工程下创建 build 文件夹,存放 compile_commands.json 文件 (该文件可通过 cmake 命令生成) 用于创建指定文件夹的索引文件。
跳转效果
foreign 函数会在用户设置的目录下查找对应的 C 语言函数,若找到则跳转至 C 源码的函数位置;除上述场景外均保持插件原有的定义跳转。
查找引用介绍及使用
VSCode 打开 Cangjie 工程中的.cj 文件,使用鼠标右键单击目标符号,选择 “Find All References” 执行符号引用预览,单击预览条目,可以跳转到对应引用处。
诊断报错介绍及使用
VSCode 打开 Cangjie 工程中的.cj 文件,当源码文件出现不符合 Cangjie 语法或语义规则的代码时,会在相关代码段出现红色波浪下划线,如下图所示,当鼠标悬停在上面,可以提示相应的报错信息,修改正确后,诊断报错自行消失。
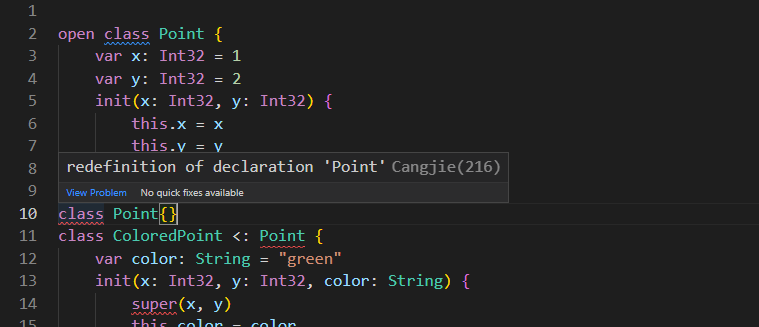
选中高亮介绍及使用
VSCode 打开 Cangjie 工程中的.cj 文件,光标定位在一个变量或函数名处,当前文件中该变量的声明处以及其使用处都会高亮显示。
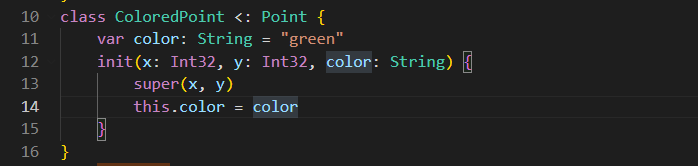
悬浮提示介绍及使用
VSCode 打开 Cangjie 工程中的.cj 文件,光标悬浮在变量处,可以提示出类型信息;悬浮在函数名处,可以提示出函数原型。
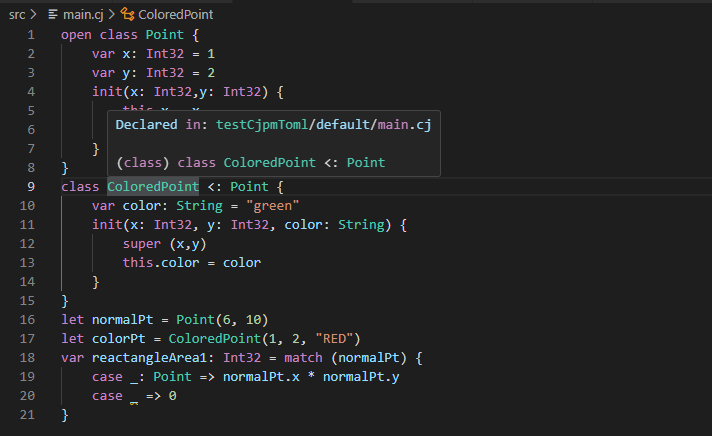
定义搜索介绍及使用
VSCode 打开 Cangjie 工程中的任意.cj 文件,按住Ctrl + T 后会出现搜索框,输入想要搜索的符号定义名,会显示出符合条件的搜索结果,单击搜索结果的条目,可以跳转到定义的对应位置处。
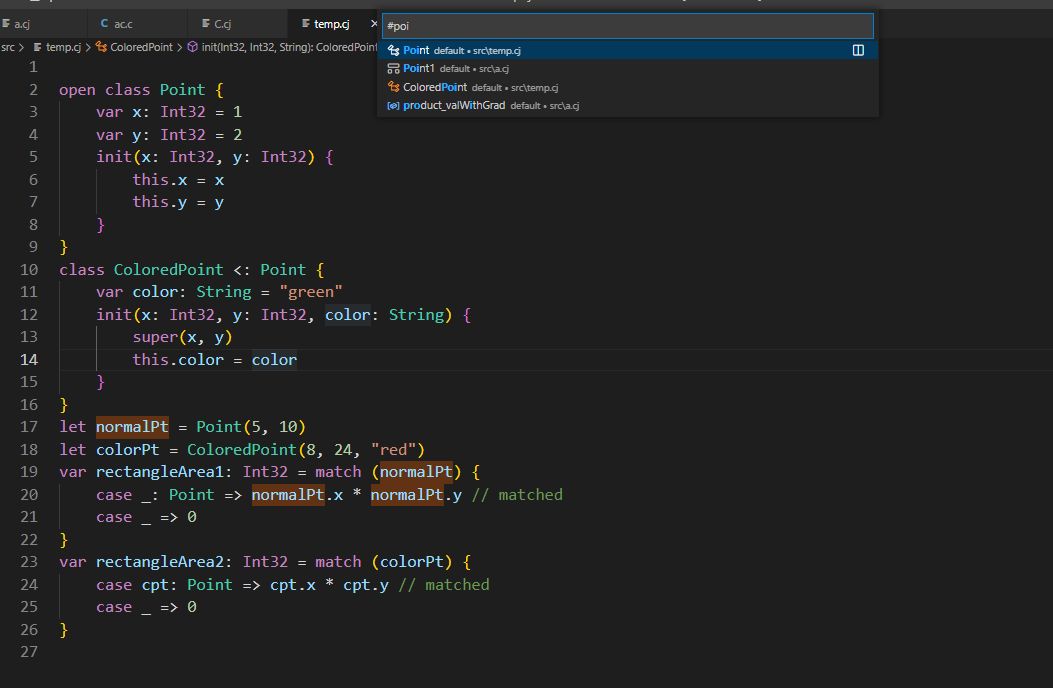
目前支持搜索的定义类型如下表格:
| class | interface | enum | struct |
| typealias | toplevel 的函数 | toplevel 的变量 | prop |
| enum 构造器 | 成员函数 | 成员变量 |
重命名介绍及使用
VSCode 打开 Cangjie 工程中的.cj 文件,光标定位在想要修改的用户自定义编写名称上,右键选择 Rename Symbol 或者快捷键 F2 方式打开重命名编辑框。
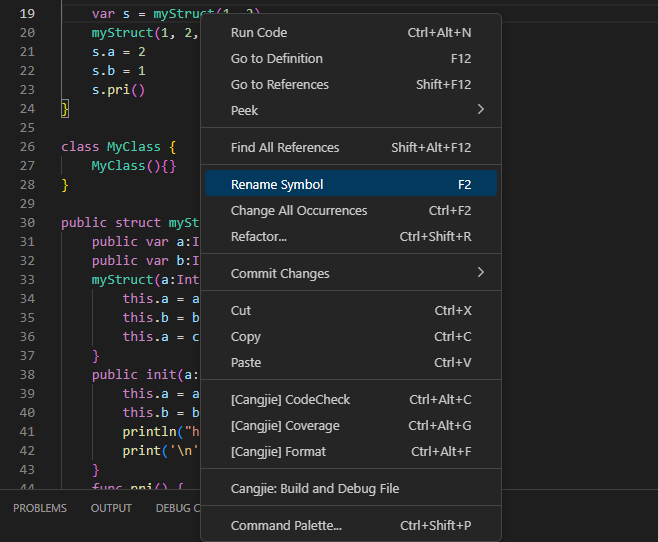
编辑完毕回车完成重命名的实现。
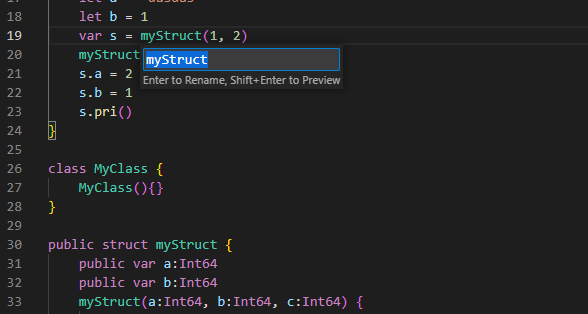
目前重命名支持的用户自定义类型如下:
| class 类名称 | struct 结构体名称 | interface 接口名称 | enum 枚举名称 | func 函数名称 |
| type 别名名称 | <T>泛型名称 | 变量名称 | 自定义宏名称 |
大纲视图显示介绍及使用
VSCode 打开 Cangjie 工程中的任意.cj 文件,在 OUTLINE 视图中显示当前文件的符号,目前支持两层结构的显示(第一层主要为 toplevel 中定义的声明,第二层主要为构造器及成员)。
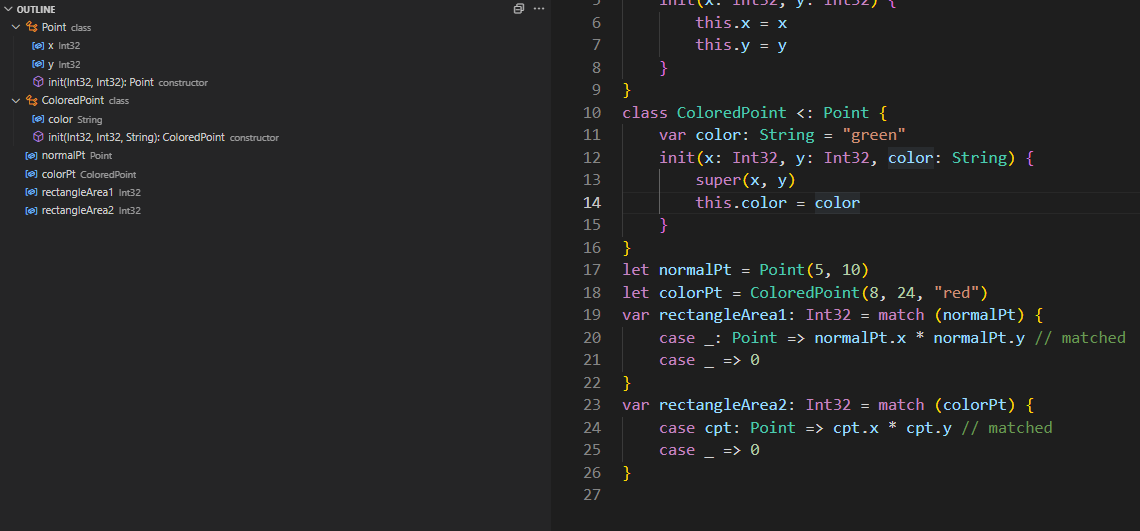
目前支持大纲视图显示的符号类型如下表格:
| class | interface | enum | struct |
| typealias | toplevel 的函数 | toplevel 的变量 | prop |
| enum 构造器 | 成员函数 | 成员变量 |
面包屑导航介绍及使用
VSCode 打开 Cangjie 工程中的任意.cj 文件,在面包屑导航中显示某个符号当前所处的位置以及该符号在整个工程中的位置路径。
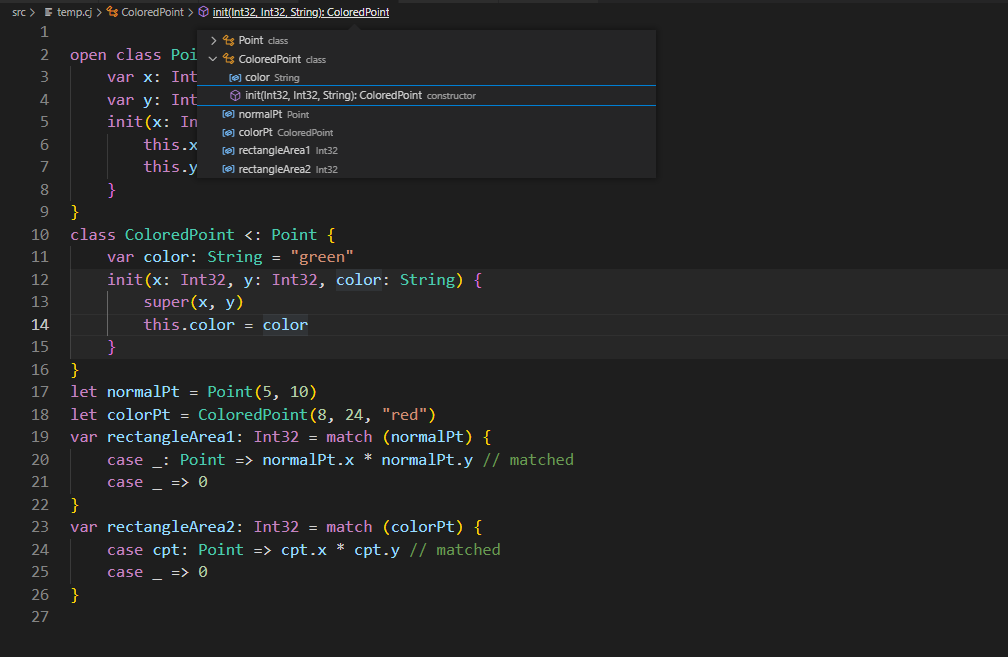
目前支持面包屑导航的符号类型如下表格:
| class | interface | enum | struct |
| typealias | toplevel 的函数 | toplevel 的变量 | prop |
| enum 构造器 | 成员函数 | 成员变量 |
签名帮助介绍及使用
VSCode 在输入左括号和逗号时会触发签名帮助,触发后只要还在函数参数范围内提示框会一直随光标移动(可与补全共存),如下图,会给用户提供当前函数参数信息,以及高亮当前函数位置参数帮助用户补充参数。

显示类型层次结构介绍及使用
VSCode 打开 Cangjie 工程中的 .cj 文件,光标定位在 class/interface/enum/struct 的名字上,右键选择 Show Type Hierarchy ,在左侧就会显示该类型层次结构。
点击下拉框可以继续显示,
在箭头所示位置可以在显示子类和父类之间切换。
调用类型层次结构介绍及使用
VSCode 打开 Cangjie 工程中的 .cj 文件,光标定位在函数的名字上,右键选择 Show Call Hierarchy ,在左侧就会显示该函数的调用类型层次结构。
点击下拉框可以继续显示
通过点击标识位置可以在显示调用函数和被调用函数之间切换。
工程管理
工程目录:
Project_name:用户输入的名称
│ └── src:代码目录
│ ├── main.cj:源码文件
│ ├── cjpm.toml:默认的 cjpm.toml 配置文件
通过 VSCode 命令面板创建仓颉工程
在 VSCode 中按 "F1" 或者 "Ctrl + Shift + P"(mac 上快捷键为 "Command + Shift + P") 打开命令面板,然后按照以下步骤创建仓颉工程:
第一步:选择创建 Cangjie 工程命令

第二步:选择 Cangjie 后端

第二步:选择 Cangjie 工程模板

第三步:选择工程路径
第四步:输入工程名称

第五步:创建完成并打开
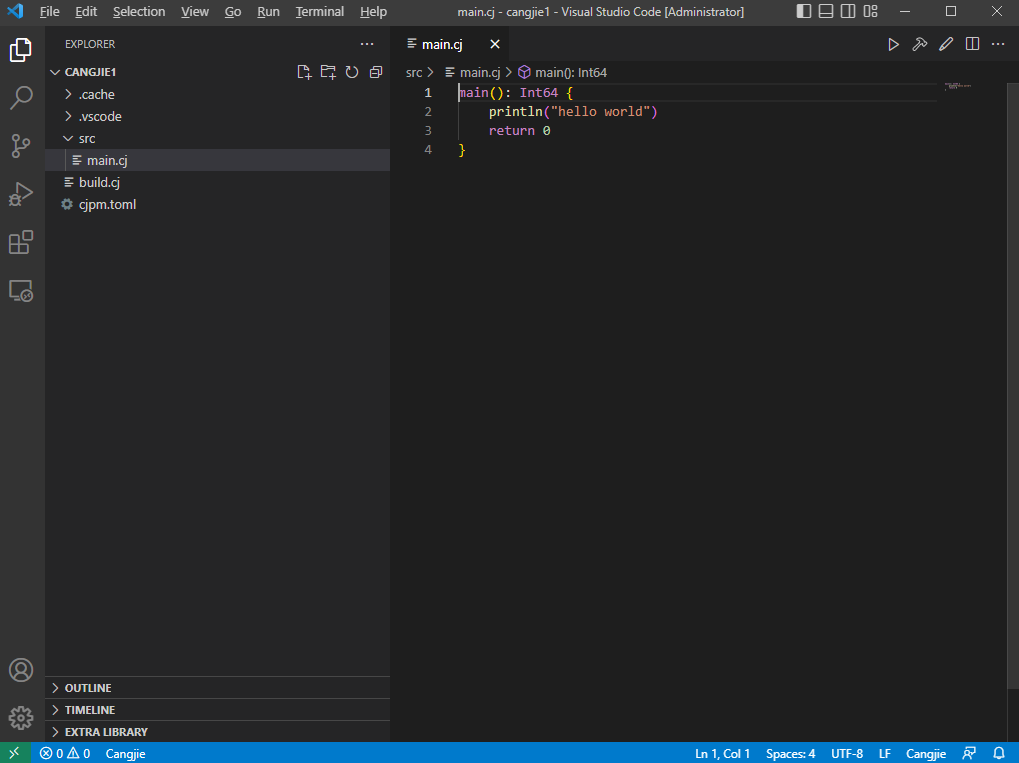
通过可视化界面创建仓颉工程
第一步:打开命令面板选择可视化创建 Cangjie 工程命令

第二步:打开可视化创建 Cangjie 工程界面
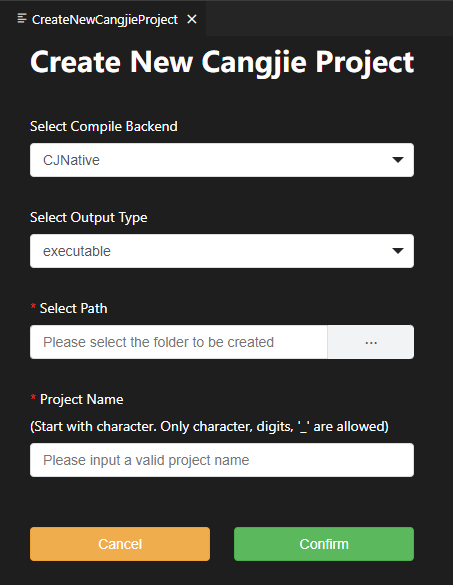
第三步:选择后端类型
第四步:选择工程类型
第五步:点击选择工程路径
第六步:输入工程名称

第七步:点击 Confirm 创建工程
编译构建
注:VSCode 中可视化方式提供的仓颉功能编译构建能力依赖 cjpm 工具,该工具要求打开的仓颉工程的模块内必须包含规范的 cjpm.toml 文件。若没有该文件仍想执行工程的编译构建,可在终端使用 cjc 命令。
在 VSCode 中提供四种方式来实现 Cangjie 工程的编译构建方式。
编译构建方式
在命令面板执行命令
打开命令面板,通过分类词Cangjie来快速找到如下编译相关命令:
-
Parallelled Build并行编译
执行并行编译后,在工程文件夹下会生成
target目录,target目录下有一个release文件夹,release文件夹下包含三个目录:.build-logs目录、bin目录、工程名同名的目录。bin目录下存放可执行文件(可执行文件只有在cjpm.toml的output-type为executable时才会生成),工程名同名目录下存放编译的中间产物。在 output Panel 上会打印编译成功与否
-
Build With Verbose编译并展示编译日志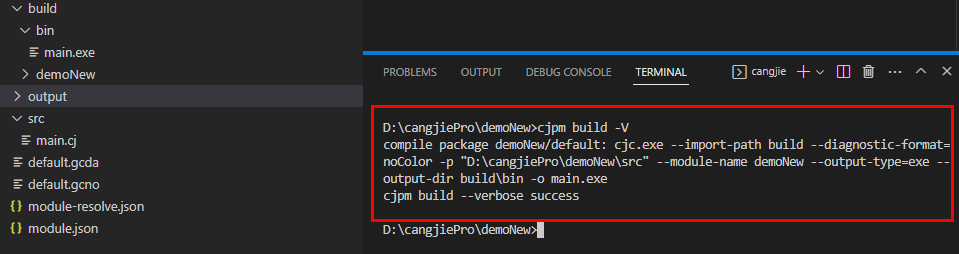
该编译参数除了执行编译外,还会打印编译日志
-
Build With Debug可生成 debug 版本的目标文件该命令的编译结果中带有 debug 信息,供调试使用
-
Build With Coverage可生成覆盖率信息该命令在编译结果中带有覆盖率的信息
-
Build With Alias编译并指定输出可执行文件的名称
执行该命令,按下回车后,会弹出一个输入栏,需要用户为工程的编译结果赋予一个新的名字。该命令只对
cjpm.toml的output-type为executable时有效。如输入的是hello,则编译后的二进制文件如下:
-
Build With Increment增量编译用来指定增量编译
-
Build With CustomizedOption按条件透传cjpm.toml中的命令。注意,这里的透传条件包括全局字段和单包配置中的所有条件。若全局条件编译选项和单包的条件编译选项出现冲突,在执行编译的过程,IDE 会提示有冲突。单包配置之间的条件编译选项可以有冲突。
使用该选项需要先在 cjpm.toml 中配置
customized-option字段。然后在命令面板输入Build With CustomizedOption,回车后可以选择需要的参数,参数可多选,选择后回车即可。
若没有在 cjpm.toml 中配置
customized-option字段,并执行了该条命令,插件会提示用户先配置改字段
-
Build With TargetDir编译并在指定路径生成编译产物选择该命令执行后,可指定编译产物的输出路径,默认不作输入操作则以 cjpm.toml 中的
target-dir字段为路径。
当输入的编译产物路径与 cjpm.toml 中的
target-dir字段不同时,会弹出提示是否覆盖 cjpm.toml 中的target-dir字段,若选择 Yes 覆盖,则会将 cjpm.toml 中target-dir字段覆盖成输入的值。
该执行命令执行成功后,会在指定的路径下生成编译产物。
-
Build With Jobs执行编译之前自定义最大并发度支持通过执行该命令在编译之前自定义最大并发度,输入参数为任意数字,设置范围为 (0, cpu 核数 * 2]。
当在输入框输入非数字时,会终止操作,并提示用户输入数字内容:Invaild input! The input should be number.
当在输入框输入的范围超出所支持的范围 (0, cpu 核数 * 2] 时,会默认采用 cpu 核数,并提示超出可选范围的 warning 信息。
-
Build With CodeCheck执行编译的时候进行 CodeCheck 静态代码检查执行该命令编译工程时,会对当前工程进行 CodeCheck 静态代码检查,如果检查到【要求】级别的代码规范违规,则编译失败,检查到【建议】级别的违规仅告警,正常完成编译。
-
Build With MultiParameter多参数编译仓颉工程的编译可以叠加多个参数,在命令面板搜索到
Build With MultiParameter命令后,选择需要叠加的参数,其中--target 参数会根据 cjpm.toml 中的cross-compile-configuration字段的设置来决定是否显示,如果用户没有配置cross-compile-configuration的内容,则--target参数选项会隐藏;--<customized-option>参数会根据 cjpm.toml 中的customized-option字段的设置来决定是否显示,如果用户没有配置customized-option的内容,则--参数选项会隐藏。 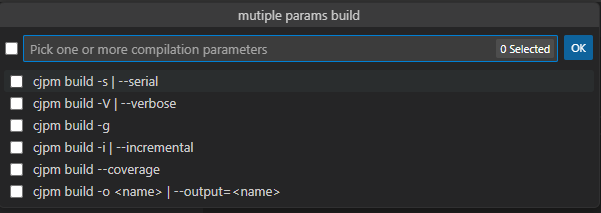
将用户想叠加的参数勾选,然后按回车键或者点击 ok 按钮。用户也可点击界面中的向左箭头,重新选择编译参数
如果叠加的参数中选择了
cjpm build -o,那么需要用户输入一个别名字符串然后按回车键执行叠加命令操作
如果叠加参数中选择了
cjpm build --target=<name>,那么用户可以选择一个想要交叉编译的平台
如果叠加参数中选择了
cjpm build --<customized-option>,那么用户可以选择透传参数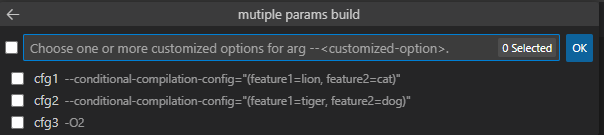
叠加命令的编译结果就是这些命令分别执行的总和。
-
Update Cjpm.toml更新 cjpm.lock 文件在修改完 cjpm.toml 文件后需要执行该命令,更新 cjpm.lock 文件。如果是通过 UI 界面修改的 cjpm.toml 文件的话,用户不需要手动执行该操作
-
Execute Test File用于编译单元测试产物并执行对应的单元测试用例,并直接打印测试结果 -
Test With NoRun用于编译对应测试产物 -
Test With SkipBuild测试产物存在的前提下,用于执行对应测试产物 -
Test With Jobs执行单元测试之前自定义最大并发度,操作与Build With Jobs相同 -
Test With MultiParameter多参数执行仓颉工程的单元测试在选择该条命令后,首先输入指定待测试的包路径,若不需要指定,则直接按 Enter 键

此步骤可通过输入多个包的路径并用空格分隔,可以实现多包并发单元测试

然后选择要叠加的参数
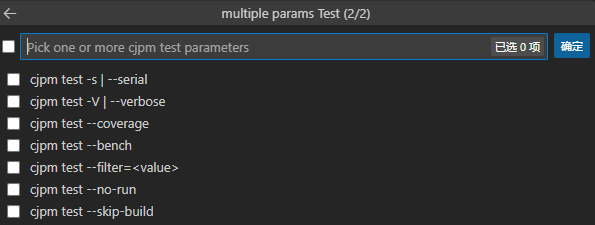
如果选择了
--filter=<value>参数,则还需要输入对应的过滤测试子集的表达式
输入过滤测试子集的表达式后便能执行 cjpm test 的完整命令。执行结果会在 output 面板输出
若是在 cjpm.toml 中配置了
cross-compile-configuration和customized-option则可选择的参数会有--target=<name>和--<customized-option>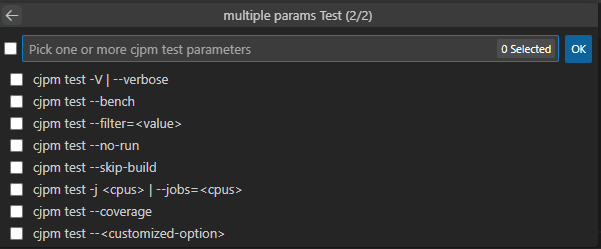
如果选择了
--target=<name>参数,则还需要选择对应的平台
--target暂时只支持在 SUSE 平台下选择aarch64-hm-gnu使用如果选择了
--<customized-option>参数,则还需要选择条件选项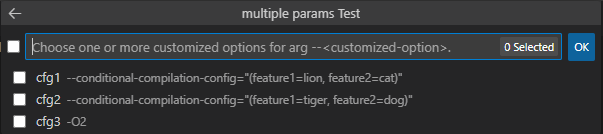
-
Clean Build Result清除编译结果(工程目录下的 build 目录) -
Check Circular Dependencies检测文件依赖 -
Edit Configuration (UI)打开 UI 配置界面
在终端进行执行编译构建命令
提供用户在 VSCode 的终端面板直接使用编译构建命令(cjpm)对仓颉工程进行编译构建。但需要用户做如下操作:
关闭新建的工程,重新打开 VSCode(reload 不行)
然后可以在终端执行 cjpm 的操作了
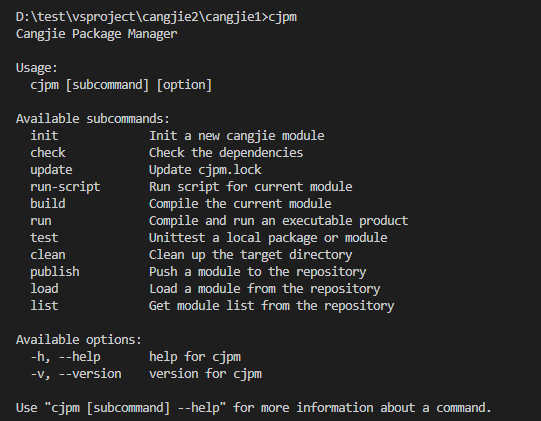
点击运行按钮运行工程
用户可以点击 cj 文件编辑区的运行按钮来运行整个仓颉工程
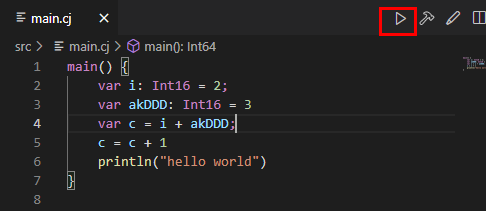
若整个工程中配置的output-type为executable时会在终端面板打印运行结果,否则只会显示编译的结果。
点击运行按钮执行的编译过程是结合当前的 cjpm.toml 和 cjpm_build_args.json 的配置来进行的
点击锤子按钮编译工程
用户可以点击 cj 文件编辑区的锤子按钮编译整个仓颉工程
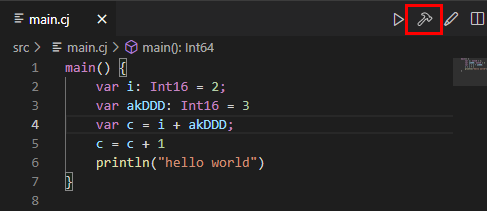
点击锤子按钮执行的编译过程与运行按钮一致,也是结合当前的 cjpm.toml 和 cjpm_build_args.json 的配置来进行的;不同的是若整个工程中配置的output-type为executable,运行按钮在编译完成后再运行整个工程,而锤子按钮只会编译工程,无后续运行动作。
可视化配置编译构建参数
在编译构建的过程中需要配置工程目录中的 toml 和 json 文件,cjpm.toml 和 cjpm_build_args.json 对这两个文件,可以直接修改 toml 和 json 文件本身,也可以点击编辑按钮或者在命令面板执行Edit Configuration (UI)命令打开可视化编辑的 UI 界面。
编译构建参数的 UI 界面如下:
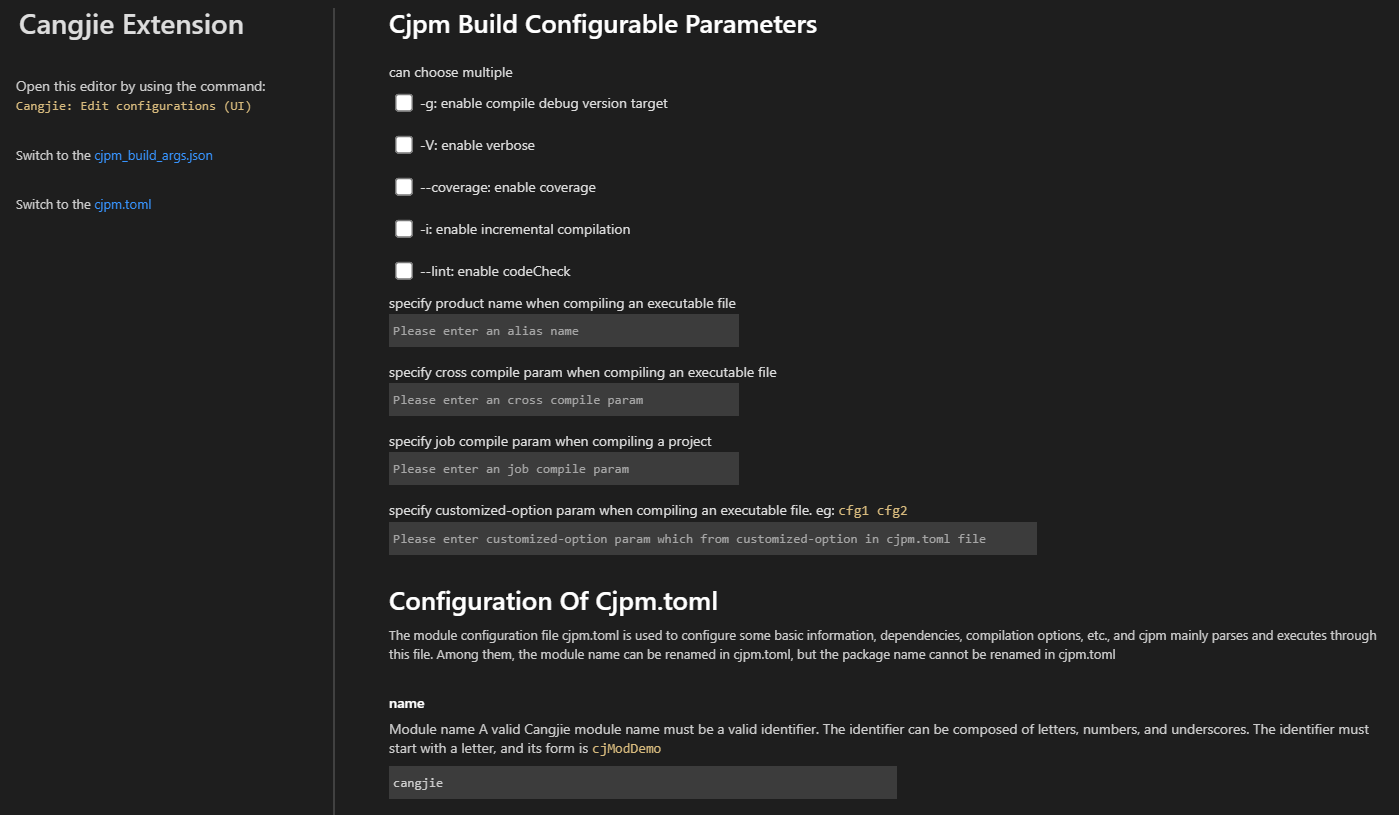
左边有两个的蓝色的链接,点击后可跳转到对应的 toml 或者 json 文件。
右边的上半部分是对工程文件中.vscode目录下的 cjpm_build_args.json 的配置,通过复选框或者输入框的形式确定编译要使用的参数,修改后会同步到 cjpm_build_args.json 文件中。
右边的下半部分是对工程中的 cjpm.toml 文件的配置,对于输入框形式的配置,用户输入内容且光标不在输入框后便生效到 cjpm.toml 文件中。
注意:
当仓颉工程中的 cjpm.toml 文件和参数配置界面同时在 VSCode 的编辑区显示时(如下图),对 toml 文件的修改不会同步到 UI 界面上。
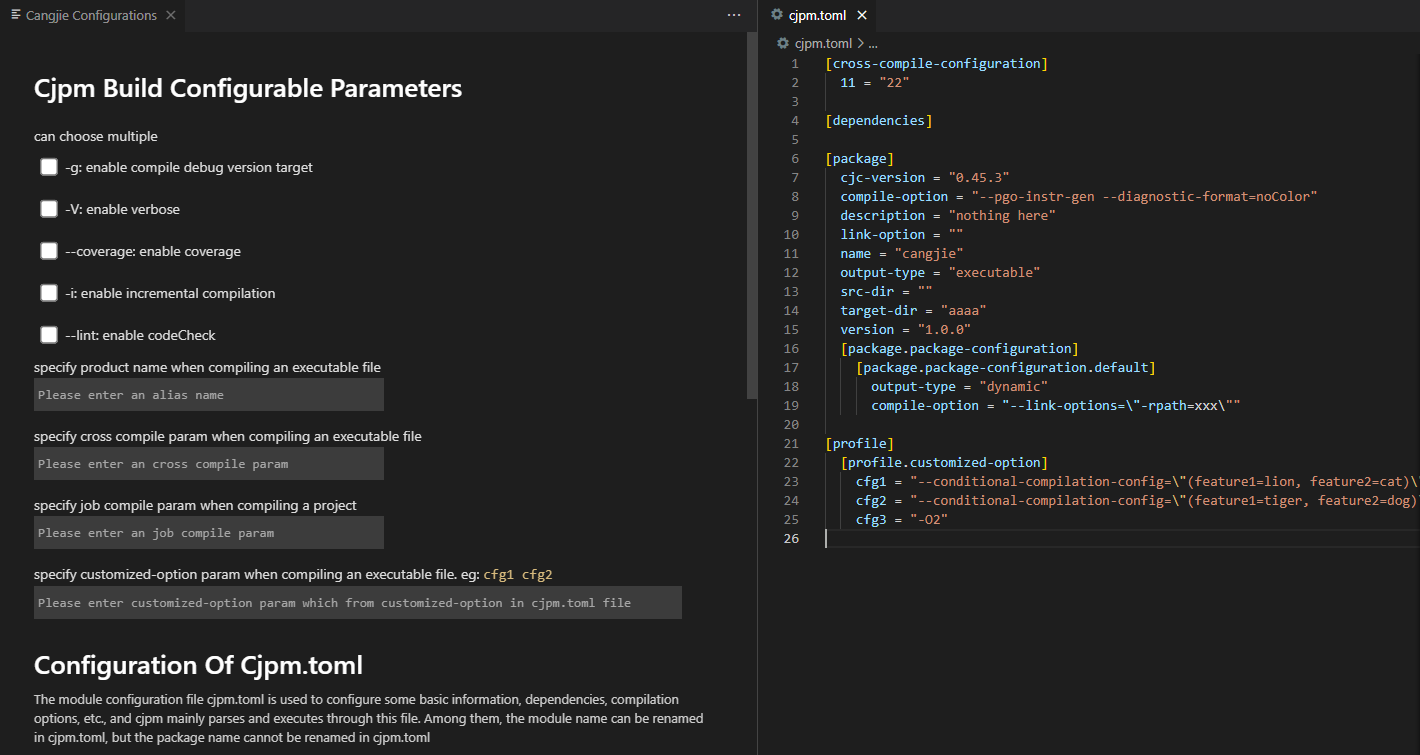
对于构建参数cross-compile-configuration,可以通过点击Add Configuration 按钮添加选项
然后在 key 和 compile-option 处填写对应的内容,点击红色圆圈圈出来的对钩按钮(也称为提交按钮)与 cjpm.toml 保持同步,点击提交按钮后,该按钮会隐藏,若用户再次修改某个字段的内容,直接点击该字段进行修改,修改完后按回车键便可以与 cjpm.toml 保持同步;若想删除该条配置,用户只需点击该条选项的叉号按钮。
添加的配置在不填写第一个字段key就直接回车或者按提交按钮,会提醒用户必须要填写第一个字段,该场景下提交的内容不会同步到 cjpm.toml 中。在 UI 界面目前不会直接删除该条配置,用户刷新 UI 界面后会自动删除,内容与 cjpm.toml 保持一致。package-configuration和cross-compile-configuration类似,如下显示为package-configuration新增配置时第一个字段为空的场景。
对于package-configuration参数,其添加和修改方式与cross-compile-configuration大致一致,其中output-type字段为下拉框选项,其可选的类型有 executable、static、dynamic、null。新添加的配置,该字段被初始化为 null,用户可以根据自己的需要选择。当选择为 null 时,该字段同步到 cjpm.toml 后会删除该字段。
对于 package-configuration 的 customized-option 字段,在 UI 可配置界面中是单独的模块,位于 package-configuration 下方
该界面每条字段的内容分别为 包名, 条件名,条件。该界面的交互操作如下:
-
用户在 cjpm.toml 文件中新增一条 package-configuration 的
apackage 配置,但是没有配置 customized-option,那么 UI 界面不会显示apackage 的 customized-option -
用户在 UI 界面新增一条 package-configuration 的
apackage 配置,界面中不会自动生成对应的 customized-option -
用户可以在 UI 界面为某个包单独配置条件编译选项
-
若新增条件对应的包并不是 package-configuration 的,那么会提示用户该包不正确,该条配置不会写入到 cjpm.toml 中,重新切换 UI,会显示正确的 cjpm.toml 对应的内容
-
若新增条件对应的包是 package-configuration 中的配置,通过回车或者对钩按钮可以正确将配置更新到 cjpm.toml 中
-
cjpm.toml 文件中的 package-configuration 中配置了包
a, 也写了 customized-option 字段,但字段中没有条件,在 UI 界面中不会显示该包的 customized-option -
可以单独在 UI 界面删除 package-configuration 中配置了包 X 的某条条件编译选项
-
在 UI 界面删除 package-configuration 中配置了包
a,其对应的 customized-option 也会在界面中被删除 -
单包配置的条件编译选项名称一旦确定后就不能再被修改,除非为空。

注:在 UI 界面配置 cjpm.toml 的内容时不需要添加转义符号,但直接在 cjpm.toml 中填写时,需要加转义符号,如在给 package-configuration 字段的 p1 配置 compile-option 时,在 UI 界面对--link-options 设置内容时只需要加引号即可,即--link-options="-rpath=xxx",而在 toml 文件中,需要填写--link-options=\"-rpath=xxx\"
对于customized-option参数,其添加修改方式与cross-compile-configuration一致。注意:customized-option 的条件不能设置内置的条件(@When[os == “linux”] 不能作为 customized-option 的条件,即"cfg1" : "--conditional-compilation-config ="(os=linux)""是不允许的),只能添加用户自定义条件。具体可以参考 Cangjie Language Guide 文档的条件编译一章。
三方库便捷导入
三方库导入方式
注 :三方库便捷导入的方式只适用于当前打开的仓颉工程的主 module,其他子 module 想要使用这种方式导入外部库的话,可以单独以工程的方式打开使用
在仓颉工程中,可以导入外部的三方库,且可以在 cjpm.toml 中进行配置,他们分别是
dependencies: 当前仓颉模块依赖项目,里面配置了当前构建所需要的其它模块的信息,包含版本号、路径。这两个选项必须全部配置且不为空,否则会执行失败并报错。在使用过程中,优先使用此方式进行项目依赖导入。
dev-dependencies: 使用方式与 dependencies 保持一致,具有与 dependencies 字段相同的格式。它用于指定仅在开发过程中使用的依赖项,而不是构建主项目所需的依赖项,例如仅在测试中使用的依赖项。如果开发者是库作者,则应将此字段用于此库的下游用户不需要使用的依赖项。
bin-dependencies :非特殊需求场景下,建议使用 dependencies的方式导入依赖。目前插件仅支持本地的 bin-dependencies 配置。
当前仓颉模块依赖的已编译好的 package。其有两种导入形式。以导入下述的 pro0 模块和 pro1 模块的三个包来举例说明。
├── test
│ └── pro0
│ ├── libpro0_xoo.so
│ └── xoo.cjo
│ ├── libpro0_yoo.so
│ └── yoo.cjo
│ └── pro1
│ ├── libpro1_zoo.so
│ └── zoo.cjo
└── src
└── main.cj
├── cjpm.toml
方式一,通过 package-option 导入:
[target]
[target.x86_64-w64-mingw32]
[target.x86_64-w64-mingw32.bin-dependencies]
[target.x86_64-w64-mingw32.bin-dependencies.package-option]
pro0_xoo = "./test/pro0/xoo.cjo"
pro0_yoo = "./test/pro0/yoo.cjo"
pro1_zoo = "./test/pro1/zoo.cjo"
这个选项是个 map 结构,pro0_xoo 名称作为 key,与 libpro0_xoo.so 相对应,前端文件 cjo 的路径作为 value,对应于该 cjo 的 .a 或 .so 需放置在相同路径下,且对应的 cjo 模块文件必须与模块名来源文件放置在相同的文件夹下,该文件夹下不能有任何其他的文件或者文件夹。
方式二,通过 path-option 导入:
[target]
[target.x86_64-w64-mingw32]
[target.x86_64-w64-mingw32.bin-dependencies]
path-option = ["./test/pro0", "./test/pro1"]
这个选项是个字符串数组结构,每个元素代表待导入的路径名称。cjpm 会自动导入该路径下所有符合规则的仓颉库包,这里的合规性是指库名称的格式为 模块名_包名。库名称不满足该规则的包只能通过 package-option 选项进行导入。
注意,如果同时通过 package-option 和 path-option 导入了相同的包,则 package-option 字段的优先级更高。
对应 IDE 上,其在导航栏视图中的呈现形式如下:
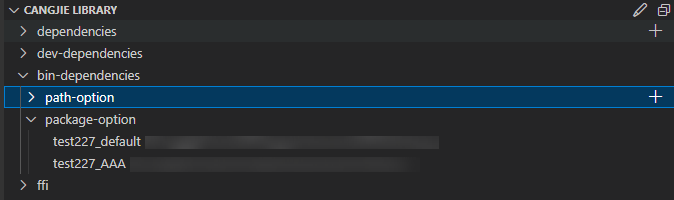
用户可以在其对应的导入方式子目录下导入或者工程需要的模块
其在 UI 界面的显示如下:
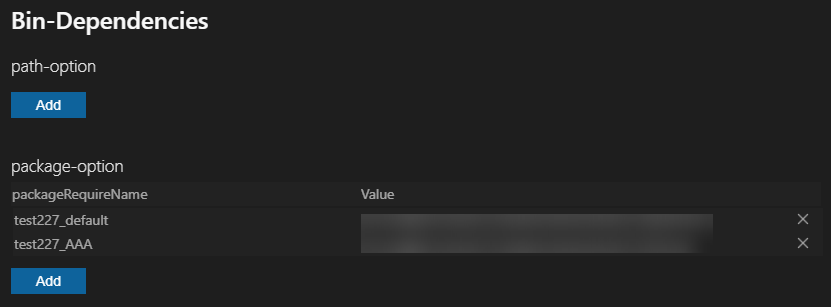
ffi:当前仓颉模块外部依赖 c 库。里面配置了依赖该库所需要的信息,包含名称、路径字段
为方便用户添加这几类外部库 ,在 IDE 的资源管理器的视图栏添加了CANGJIE LIBRARY栏
在工程初始化后,用户便可以通过点击分类栏的加号按钮添加对应的三方库。
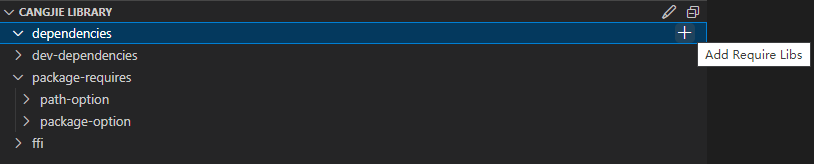
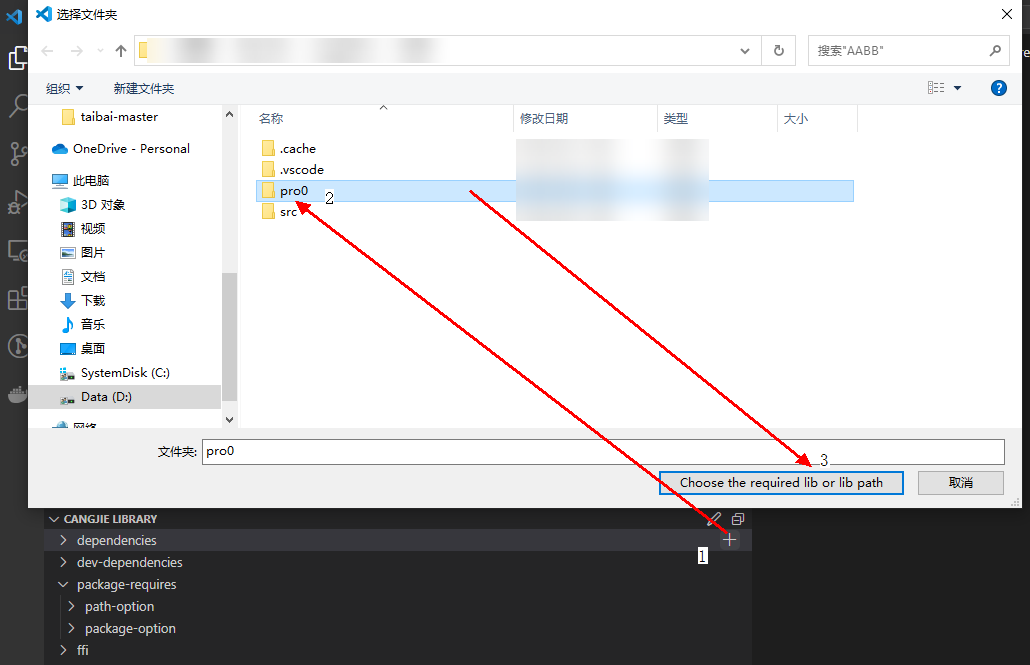
也可以通过点击三方库上的减号删除对应的库
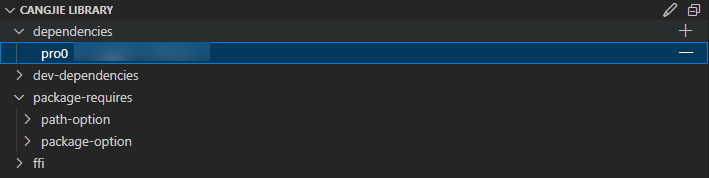
用户还可以点击视图栏的编辑按钮,打开三方库导入的可视化界面来导入或者删除三方库
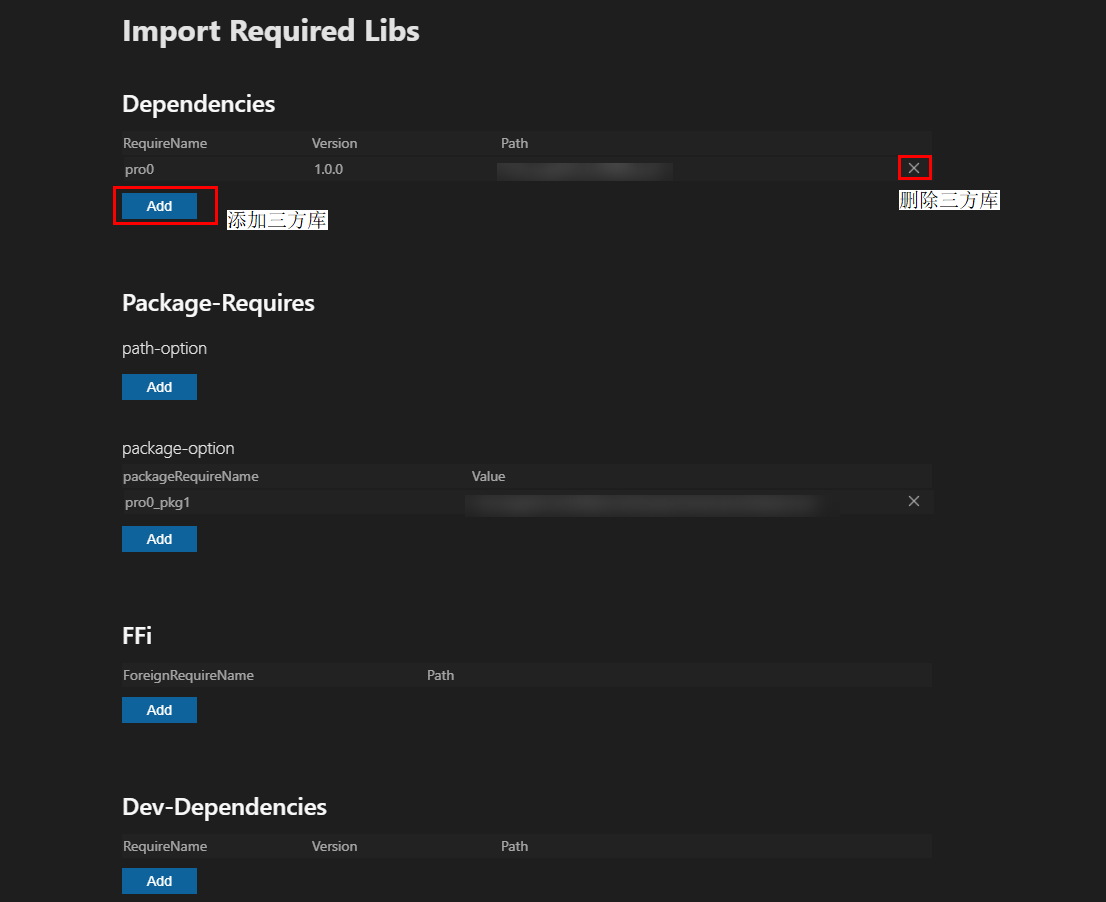
以上的删除和添加操作都会同步到工程的 module.json 中。
三方库导入限制
- 项目中需要链接动态库( c 库、仓颉库)时 ,运行时会加载不到,需自行设置 LD_LIBRARY_PATH ,执行下 export LD_LIBRARY_PATH=xxx:$LD_LIBRARY_PATH;主要的影响就是可以编译构建时会构建失败,需要用户自己设置 LD_LIBRARY_PATH。
- cjpm.toml 中修改的内容不会直接修改 treeView 和 UI 界面,需要用户更新一下,即重新点击 treeView 或者 UI 界面。
- treeView 中在库分类处添加外部库,且此时库分类目录是关闭状态,则添加后需要自己打开目录查看。
- UI 界面的字段暂不支持 hover 显示内容的功能。
- 在 UI 界面非用户添加的外部库,其路径与 cjpm.toml 保持一致。用户添加的库显示绝对路径。treeView 的路径均显示绝对路径。
调试服务
功能简介
仓颉编程语言提供了可视化调试服务,方便用户调试仓颉程序。该插件提供了如下功能:
- Launch: 启动调试进程
- Attach: 附加到已启动的进程
- 支持源码断点、函数断点、数据断点、汇编断点
- 支持源码内单步调试、运行到光标处、步入、步出、继续、暂停、重启、停止调试
- 支持汇编内单步、步入、步出
- 支持表达式求值
- 支持变量查看和修改
- 支持在调试控制台中查看变量
- 支持查看被调试程序的输出信息
- 支持反向调试
- 支持 unittest 的运行和调试
- 支持 CJVM 后端调试
使用说明
说明:
- 如果您是第一次使用 VSCode 调试功能,可以查看 VSCode 调试服务使用手册 https://code.visualstudio.com/docs/editor/debugging 。
- 调试服务当前支持 Windows 和 Linux 版本的 VSCode 中安装使用。
- 受调试器限制,循环代码中存在条件断点时,执行 PAUSE 操作可能导致后续调试无法进行。
- VARIABLES 视图修改变量时,不会触发存在依赖关系的变量的刷新。
- 调试服务依赖仓颉 SDK 包内 liblldb 动态库文件,请提前配置仓颉 SDK 路径。SDK 配置方式请参考本手册 ”安装说明“ 目录下 ”插件安装与环境配置“。
- CJVM 后端调试能力逐步支持中,在当前阶段,调试服务的说明中如未明确指出是针对 CJVM 后端,则默认其为针对 CJNative 后端的说明。
启动调试
Launch
说明:
创建仓颉工程请参考本手册 ”工程管理“ 模块介绍。
-
launch 模式仓颉工程调试
- 未创建 launch.json 文件时,点击 "Run and Debug" > "Cangjie(cjdb) Debug" 启动调试。
- 已创建 launch.json 文件时,在 launch.json 文件中点击 "Add Configuration..." > "Cangjie Debug (CJNative) : launch" > "Build And Debug Cangjie Project" 添加调试配置,选择添加的配置启动调试。
-
launch 模式单文件调试
针对单文件调试,可以选中需要调试的仓颉源文件,右键选择 “Cangjie: Build and Debug File” ,该操作会生成编译配置文件 task.json 和编译脚本,并且会根据 task.json 配置执行脚本,编译出可调试的二进制文件,然后启动调试。
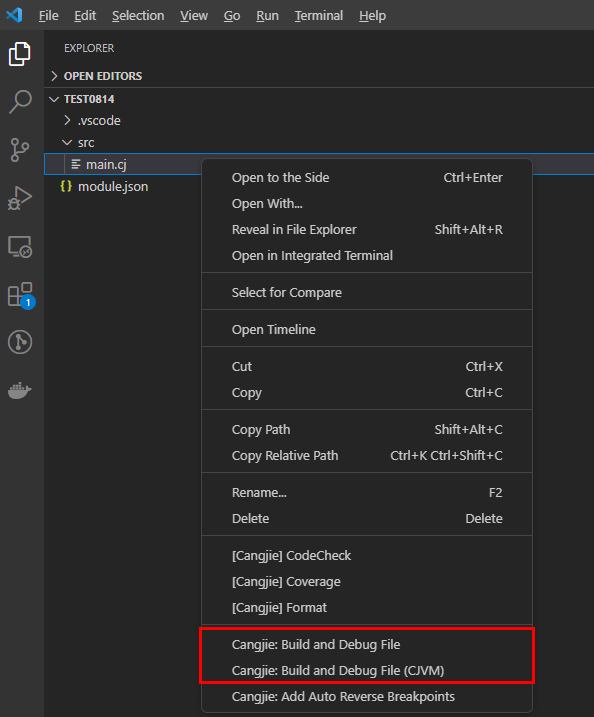
-
launch 模式调试手动编译的可执行文件
- 使用 cjc 编译器或 cjpm 手动编译出可调试的二进制文件。
- 点击 "Run and Debug" > "Cangjie(cjdb) Debug" > "Cangjie (CJNative): launch" > "Choose Executable File Later" 启动调试。
-
launch debugMacro 模式仓颉工程调试宏展开后的代码
调试宏展开后的代码文件(
.marcocall为后缀的文件),此时宏对应的原文件无法调试。 -
launch 模式调试远程进程(支持 linux 远程到 linux)
launch 模式下调试远程进程时,调试服务会将本地编译的二进制文件推送到远程平台,然后调试远程平台的二进制文件。
- 在远程平台启动 lldb-server(lldb-server 建议使用 cjdb 自带 lldb-server,路径/cangjie/third_party/llvm/lldb/bin/lldb-server),启动命令
/**/**/cangjie/third_party/llvm/lldb/bin/lldb-server p --listen "*:1234" --server - 在本地机器使用 cjc 编译器或 cjpm 手动编译出可调试的二进制文件。
- 单击 "Run and Debug" 按钮启动调试。
launch.json 配置示例
{ "name": "Cangjie Debug (cjdb): test", "program": "/**/**/test", "request": "launch", "type": "cangjieDebug", "externalConsole": false, "remote": true, "remoteCangjieSdkPath": "/**/**/cangjie", "remoteFilePath": "/**/**/test", "remoteAddress": "1.1.1.1:1234", "remotePlatform": "remote-linux" } - 在远程平台启动 lldb-server(lldb-server 建议使用 cjdb 自带 lldb-server,路径/cangjie/third_party/llvm/lldb/bin/lldb-server),启动命令
-
配置属性:
属性 类型 描述 program string 被调试进程的全路径,该文件将推送到远程平台,例如:/home/cangjieProject/build/bin/main remote boolean 启动远程 launch 进程,remote 为 true remoteCangjieSdkPath string 远程平台仓颉 SDK 路径 remoteFilePath string 远程平台存放推送文件的全路径,请确保路径 /home/test/ 合法且存在, main为推送到远程的文件名,例如:/home/cangjieProject/build/bin/mainremoteAddress string 被调试进程所在的机器 IP 和 lldb-server 监听的端口号,数据格式:ip:port remotePlatform string 远程的平台,仅支持 remote-linux(远程 linux 平台) env object 为被调试程序设置运行时的环境变量,该配置将覆盖系统环境变量。例如:“PATH”:“/home/user/bin”, “LD_LIBRARY_PATH”:“/home/user/bin”。
Attach
-
attach 模式调试本地进程
- 在 launch.json 文件中点击 "Add Configuration..." > "Cangjie Debug (CJNative) : attach" 添加调试配置,选择添加的配置启动调试
- 在弹出界面选择要调试的进程即可启动调试
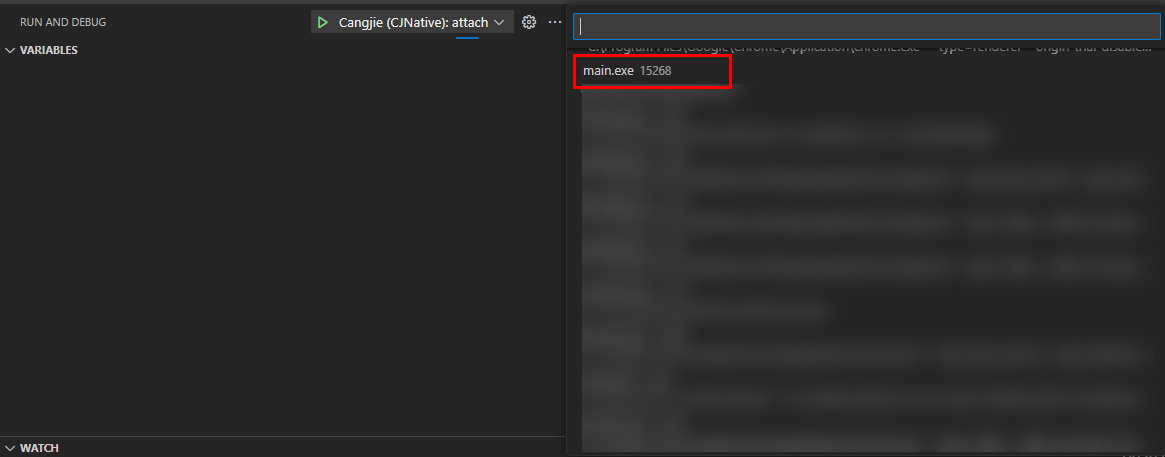
-
attach 模式调试远程进程
- 在本地机器编译出可调试二进制文件并将该文件拷贝到远程机器。
- 在远程机器启动 lldb-server(lldb-server 建议使用 cjdb 自带 lldb-server,路径/cangjie/third_party/llvm/lldb/bin/lldb-server),启动命令
/**/**/cangjie/third_party/llvm/lldb/bin/lldb-server p --listen "*:1234" --server - 在远程机器启动被调试的二进制文件
- 在本地机器配置 launch.json 文件,并启动调试
launch.json 配置属性:
{ "name": "Cangjie Debug (cjdb): test", "processId": "8888", "program": "/**/**/test", "request": "attach", "type": "cangjieDebug", "remote": true, "remoteAddress": "1.1.1.1:1234", "remotePlatform": "remote-linux" } -
配置属性:
属性 类型 描述 processId string 被调试进程的 pid(配置 pid 时优先 attach pid,未配置 pid 则 attach program) program string 被调试进程的全路径,例如:/home/cangjieProject/build/bin/main remote boolean attach 本机器进程,remote 为 false;若 attach 远程进程,将 remote 设置为 true remoteAddress string 远程调试时被调试进程所在的机器 IP 和 lldb-server 监听的端口号,数据格式:ip:port remotePlatform string 远程调试时远程的平台,仅支持 remote-linux(远程 linux 平台)
调试信息查看
当进程处于 stopped 状态时,可以在 VSCode 界面左侧查看断点、当前线程、堆栈信息和变量,并支持编辑断点和修改变量,您也可以在 Editor 窗口 将鼠标悬浮于变量名称上查看变量值。支持在TERMINAL窗口查看被调试程序的输出信息。
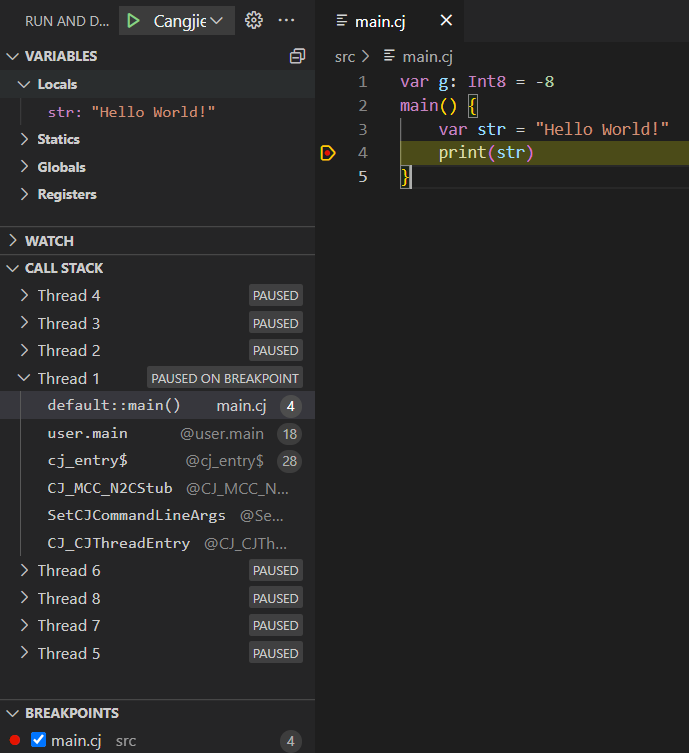
表达式求值
说明:
表达式暂不支持元组类型和基础 Collection 类型。
- 您可以在 WATCH 窗口添加按钮或空白处双击键入表达式。
- 您可以在 Debug Console 窗口键入表达式。
- 您可以在 Editor 窗口 双击选中变量,右键选择 Evaluate in Debug Console。
程序控制
- 您可以单击顶部调试工具栏上的图标控制程序,包括单步执行、步入、步出、继续、暂停、重启或停止程序。


- 您可以在鼠标光标处点击右键选择
运行到光标处。
- 您可以在源码视图右键选择
Open Disassembly View进入汇编视图。
调试控制台
说明:
cjdb 介绍请查看本手册内 ”仓颉语言命令行工具使用指南“ 目录下 ”仓颉语言调试工具使用指南“
执行 cjdb 命令
您可以在 “调试控制台” 中输入 cjdb 命令来调试程序,命令必须遵循以下格式:
命令必须以 -exec 开头,要执行的子命令必须是正确的 cjdb 命令。
使用 cjdb 命令 n 执行单步调试的示例如下:
-exec n
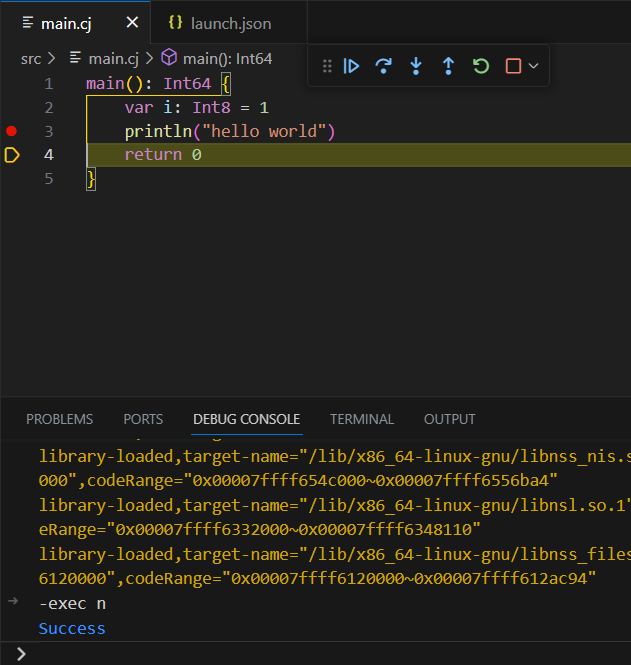
查看变量
您可以在 “调试控制台” 中输入变量名称查看变量值:
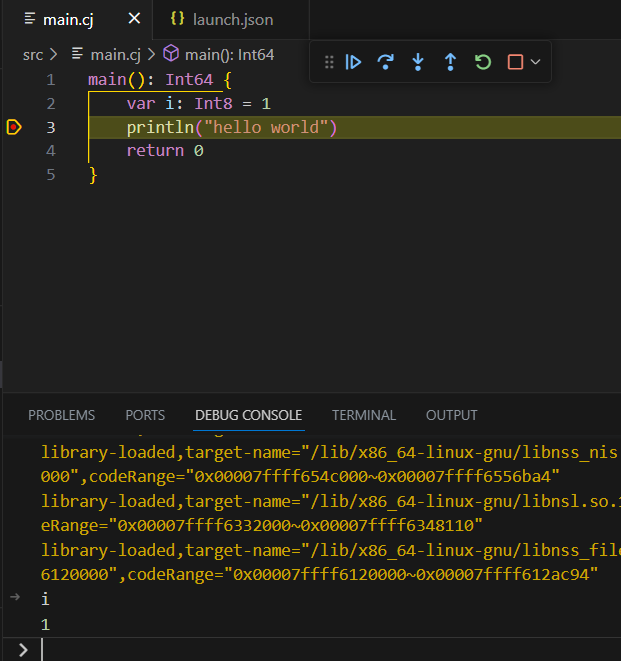
反向调试
说明:
- 反向调试基于记录重放,开启反向调试功能后,调试服务会记录用户正向调试的所有停止点(断点+单步),以及停止点的线程、堆栈、变量等调试信息。进入反向调试模式,支持查看历史记录点的调试信息。
配置
您可以通过点击左下角齿轮图标,选择设置选项,在搜索栏输入 cangjie,找到 Reverse Debug 选项,勾选 Enable reverse debug,开启程序调试历史停止点信息的自动记录,同时可以配置自动记录的线程个数、堆栈个数、变量作用域、复杂类型变量子变量的展开层数和子变量个数,配置修改后,需要重新启动仓颉调试。
工具栏
您可以单击顶部调试工具栏上的时钟图标进入反向调试模式,使用工具栏上正反向继续、正反向单步控制程序,查看历史记录的线程、堆栈、变量信息,如下图:

您可以单击顶部调试工具栏上的方块图标退出反向调试模式,调试会回到正向调试的最后停止点,如下图:

反向断点
说明:
- 反向断点是一种特殊的源码断点(Log Point),正向调试过程中不会停止,也不会输出自动生成的 Log Message(用于标记反向断点)。
- 在正向调试时,用户提前设置反向断点,调试服务后台会记录进程走过的反向断点的调试信息。
- 在进入反向调试模式时,反向断点会作为停止点(断点型),可以查看该断点处的线程堆栈变量等调试信息。
- 在进入反向调试模式时,不支持设置反向断点。
反向断点设置方式:
-
在仓颉源文件编辑器视图内右键选择
Cangjie: Add Reverse Breakpoint为光标所在行设置一个反向断点;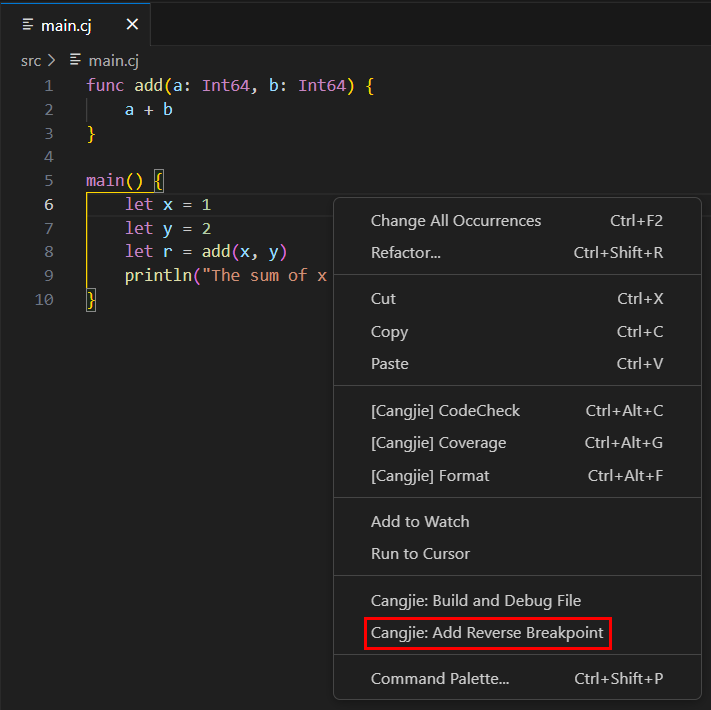
-
在仓颉源文件上右键选择
Cangjie: Add Auto Reverse Breakpoints插件会分析该文件内函数的入口和出口位置并自动设置反向断点;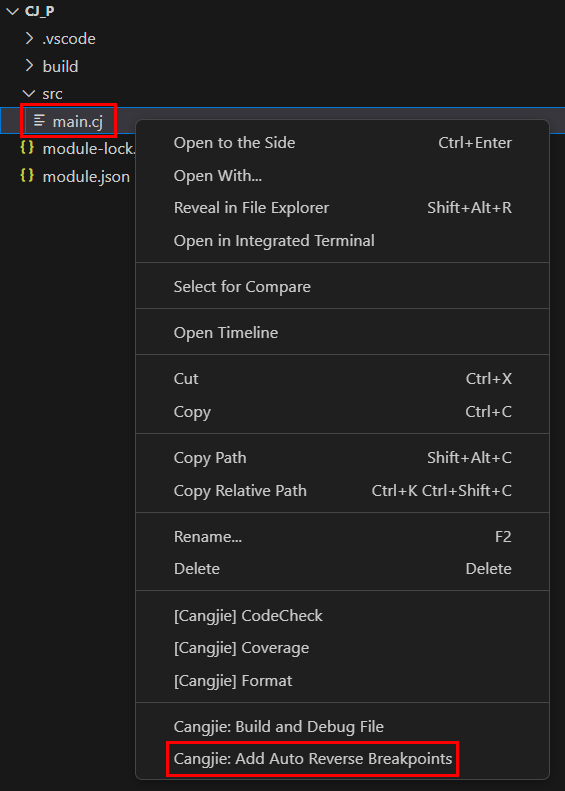
-
在文件夹上右键选择
Cangjie: Add Auto Reverse Breakpoints插件会分析该文件夹内仓颉源文件中的函数的入口和出口位置并自动设置反向断点。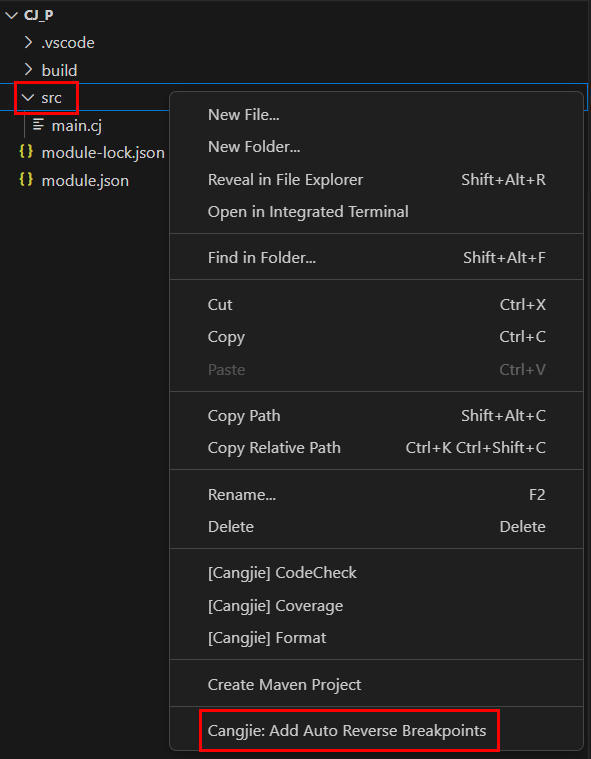
时间线
说明:
- 时间线展示了反向调试模式下记录的所有停止点(断点+单步),通过时间线拖拽,可以查看历史停止点的信息。
时间线入口位于 VSCode 右下方区域,您可以在右下方的 Tab 标签行右键将时间线 Cangjie Debug Timeline 开启或隐藏,也可以在 View 菜单中选择 Open View 开启,如下图:
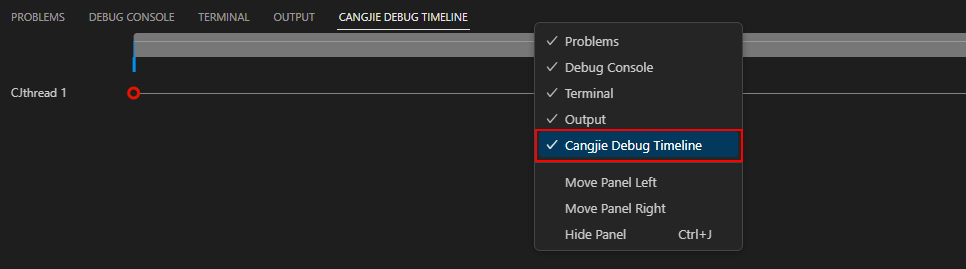
- 主时间线上有左右游标,您可以分别拖动左右游标选出某一段时间区域;在选中一段区域之后,鼠标放在选中区域上方时会变为手的形状,此时您可以左右拖动此区域;
- 将鼠标放在主时间线上,鼠标变为十字光标的形状,此时按住鼠标往前或往后拖动,您可以将鼠标滑过的区域设为新的时间区域;
- 您可以通过 Ctrl + 鼠标滚轮的方式,放大和缩小选中区域;
- 每条时间线标识一个仓颉线程或者系统线程;如下图:

您可以点击时间线上的记录点, editor 界面同步刷新(定位到源码的行),调试信息界面同步刷新(展示该记录点的线程、栈帧和变量)。
unittest 运行和调试
前置条件
模块的单元测试代码应采用如下结构,其中 xxx.cj 表示该包的源码,对应单元测试代码文件命名应以 _test.cj 结尾。具体单元测试代码的写法可参考标准库用户手册。
│ └── src
│ ├── koo
│ │ ├── koo.cj
│ │ └── koo_test.cj
│ ├── zoo
│ │ ├── zoo.cj
│ │ └── zoo_test.cj
│ ├── main.cj
│ └── main_test.cj
│ ├── cjpm.toml
使用方式
- 点击
@Test/@TestCase声明行上的 "run" 按钮,运行该单元测试类/单元测试 case; - 点击
@Test/@TestCase声明行上的 "debug" 按钮,调试该单元测试类/单元测试 case;

CJVM 后端调试
功能简介
当前仅在 linux 平台的 VSCode 上支持 CJVM 后端调试,已支持的可视化调试能力如下:
- 支持 launch 模式本地调试
- 支持源码断点、函数断点
- 支持源码内单步调试、运行到光标处、步入、步出、继续、暂停、重启、停止调试
- 支持线程堆栈信息查看
- 支持基础类型变量查看和修改
- 支持 class 、 array 类型变量展开查看和修改子变量
- 支持跨 java 调试
启动调试
当前支持仓颉工程的编译调试、单个仓颉源文件的编译调试以及调试手动编译好的仓颉可执行文件。
-
launch 模式仓颉工程调试
对仓颉工程进行编译并调试前,需要用户在 settings 设置 CJVM SDK,如下图所示:
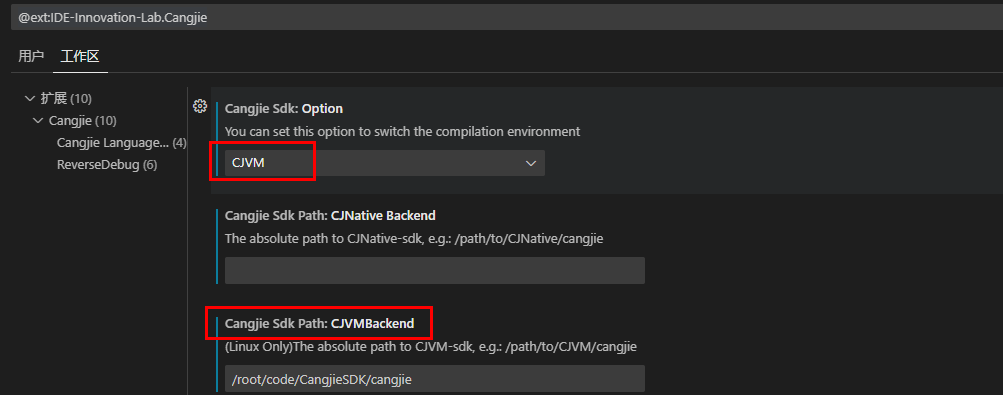
- 未创建 launch.json 文件时,点击 "Run and Debug" > "Cangjie(cjdb) Debug" 启动调试。
- 已创建 launch.json 文件时,点击 "Add Configuration..." > "Cangjie (CJVM): launch" > "Build And Debug Cangjie Project" 启动调试。
-
launch 模式单文件调试
针对单文件调试,可以选中需要调试的仓颉源文件,右键选择 “Cangjie: Build and Debug File (CJVM)” ,该操作会生成编译配置文件 task.json 和编译脚本,并且会根据 task.json 配置执行脚本,编译出可调试的二进制文件,然后启动调试。
-
launch 模式调试手动编译的可执行文件
点击 "Run and Debug" > "Cangjie(cjdb) Debug" > "Cangjie (CJVM): launch" > "Choose Executable File Later" 启动调试。
调试配置
-
在 launch.json 文件可以添加 CJVM 后端仓颉调试配置,点击 "Add Configuration...",选择 "Cangjie (CJVM): launch" ,会有如图所示的选项:
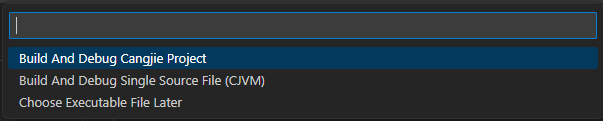
上述三个选项分别对应三种启动调试方式,会分别生成对应模板。
-
根据模板生成的 CJVM 后端仓颉调试配置示例如下:
{ "name": "Cangjie (CJVM): main", "program": "/**/**/main.cbc", "request": "launch", "type": "cangjieDebug", "vmMode": true, "vmAddress": "127.0.0.1", "vmPort": 3001 }上述配置信息中,vmMode 用以表征当前配置是否为 CJVM 后端的调试配置,vmAddress 和 vmPort 是指 CJVM 虚拟机的地址和其监听的端口号。您可以根据需要更改插件的现有调试配置。
已支持的调试功能
-
断点
当前支持源码断点、函数断点,其使用方式和结果与 CJNative 后端一致。
-
程序控制
当前支持源码内单步调试、运行到光标处、步入、步出、继续、暂停、重启、停止调试,其使用方式和结果与 CJNative 后端一致。
-
调试信息查看
- 当前支持线程堆栈信息查看,其查看方式与 CJNative 后端一致。
- 本地 launch 模式下启动 CJVM 后端调试,IDE 上会新建 terminal 用于执行仓颉程序。
- 支持基础类型变量查看和修改
- 支持 class 、 array 类型变量展开查看和修改子变量
-
跨 java 调试
在调用 java 的仓颉程序中,支持调试时跨 java 调试,包括由仓颉 stepin 到 java、由 java stepout 到仓颉、java 内单步调试、java 内设置断点、java 堆栈信息查看;暂不支持 java 变量查看。
格式化
针对仓颉文件,在 VSCode 的代码编辑区右键选择 [Cangjie] Format 或者用快捷键 Ctrl+Alt+F 执行格式化命令,可以对当前仓颉文件进行格式化。如下图:
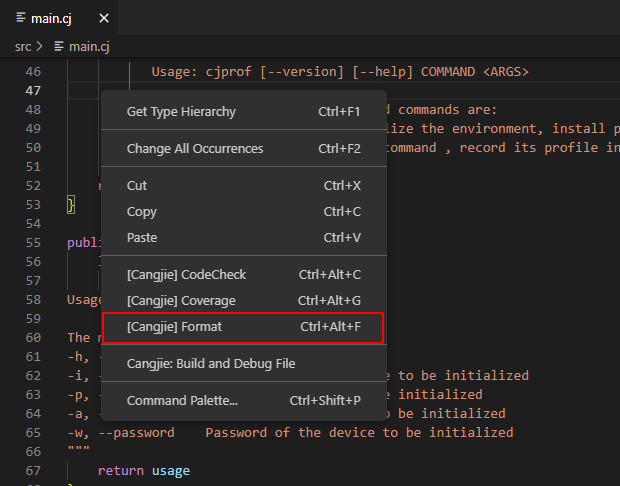
针对仓颉项目,支持在 VSCode 的资源管理器中选择文件或者文件夹右键执行 [Cangjie] Format 命令,对选择的文件或者文件夹进行格式化。如下图:
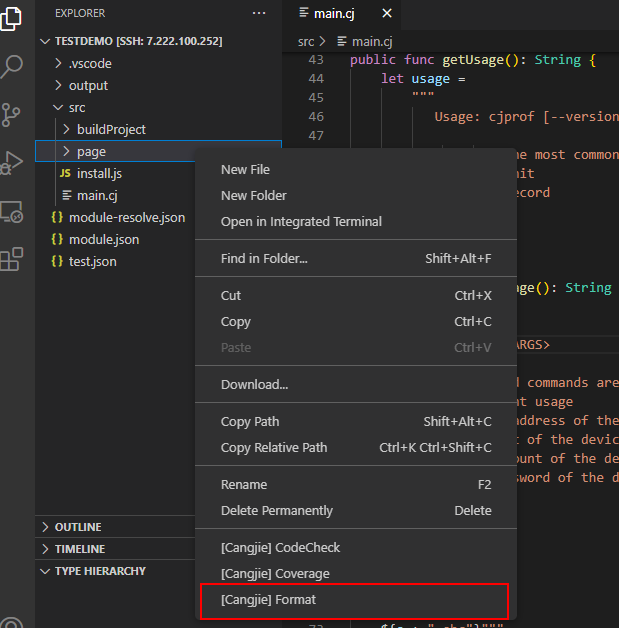
静态检查
IDE 中的静态检查功能基于静态检查工具 cjlint,该功能可以识别代码中不符合编程规范的问题,帮助开发者发现代码中的漏洞,写出满足 Clean Source 要求的仓颉代码。
说明:
静态检查目前只能检测工程目录 src 文件夹下的所有仓颉文件。
静态检查的入口有两处:
-
在 VSCode 的代码编辑区右键选择 [Cangjie] CodeCheck 或者用快捷键 Ctrl+Alt+C 执行静态检查命令 。如下图:
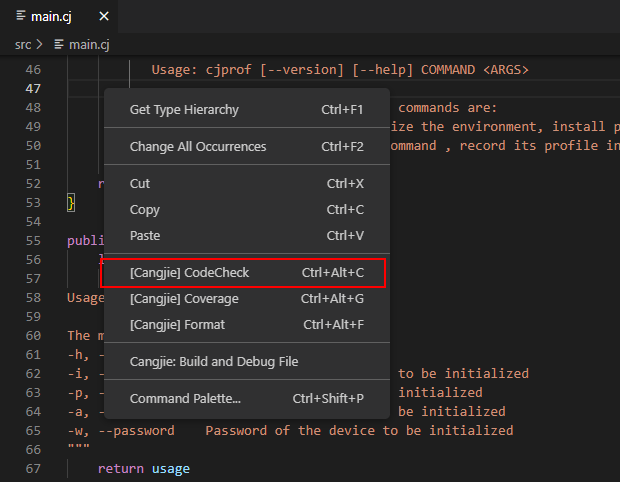
-
在 VSCode 的资源管理器处右键选择 [Cangjie] CodeCheck 执行静态检查命令。如下图:
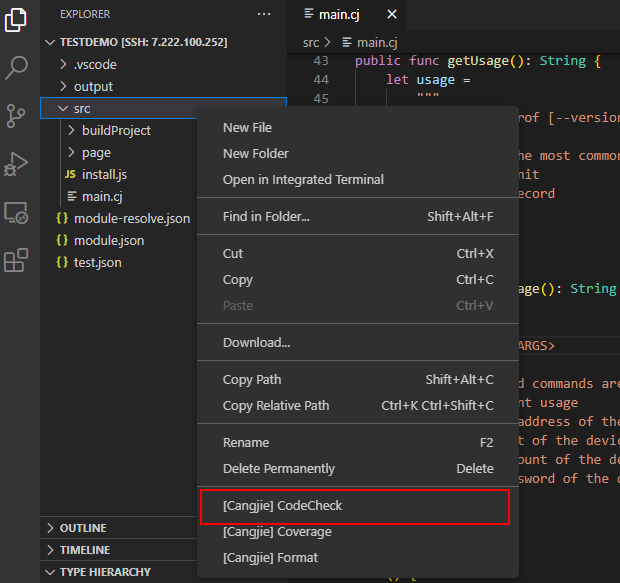
执行静态检查命令后,如果有不符合编码规范的问题会展示在右侧的表格中,点击表格中的文件链接,可以跳转到问题代码所在文件的行列:
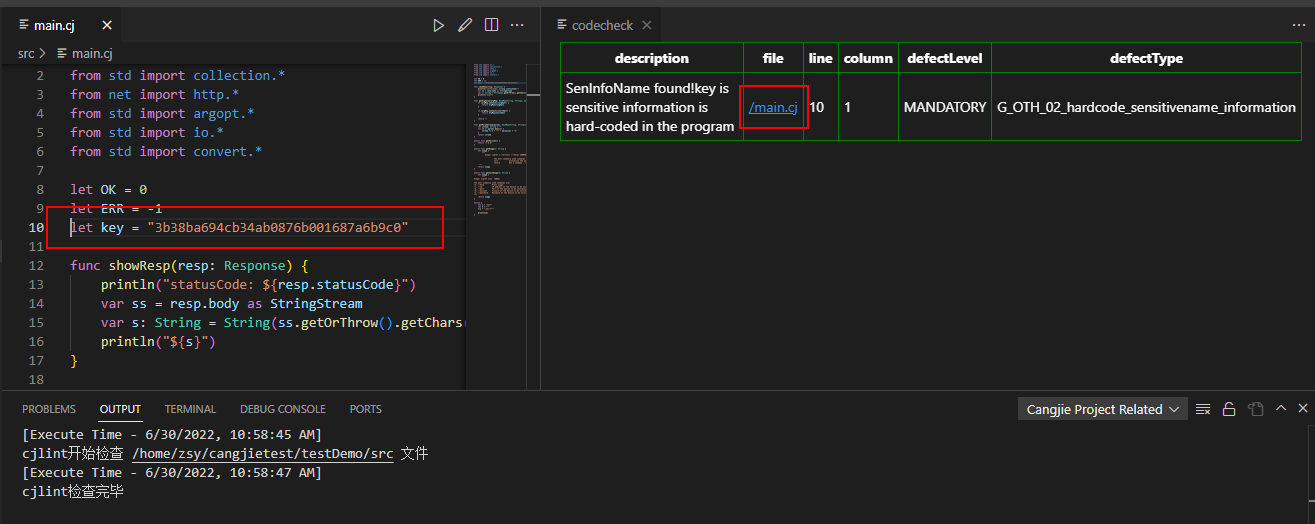
覆盖率统计
覆盖率统计功能用于生成仓颉语言程序的覆盖率报告。
覆盖率统计的入口有两处:
-
在 VSCode 的代码编辑区右键选择 [Cangjie] Coverage 或者用快捷键 Ctrl+Alt+G 执行生成当前仓颉文件覆盖率报告的命令。如下图:
-
在 VSCode 的资源管理器中选择文件或者文件夹右键执行 [Cangjie] Coverage 命令,对选择的文件或者文件夹生成覆盖率报告。如下图:
注意:当选择的文件夹中不含有仓颉文件时,将不会生成覆盖率报告。
在生成的覆盖率报告页面,点击文件名可以查看点击文件的覆盖率详情:
仓颉语言命令行工具使用指南
仓颉语言命令行工具目前包括包管理工具、调试工具、静态检查工具、格式化工具、覆盖率统计工具、性能分析工具和 API 文档生成工具。通过下载并解压对应平台的仓颉软件包,执行 source cangjie/envsetup.sh 使能配置。
仓颉语言包管理工具使用指南
功能简介
CJPM(Cangjie Package Manager) 是仓颉语言的官方包管理工具,用来管理、维护仓颉项目的模块系统,并且提供更简易统一的编译入口,支持自定义编译命令。
使用说明
通过 cjpm -h 即可查看主界面,由几个板块组成,从上到下分别是: 当前命令说明、使用示例(Usage)、支持的可用命令(Available subcommands)、支持的配置项(Available options)、更多提示内容。
Cangjie Package Manager
Usage:
cjpm [subcommand] [option]
Available subcommands:
init Init a new cangjie module
check Check the dependencies
update Update cjpm.lock
tree Display the package dependencies in the source code
build Compile the current module
run Compile and run an executable product
test Unittest a local package or module
clean Clean up the target directory
publish Push a module to the repository
load Load a module from the repository
list Get module list from the repository
Available options:
-h, --help help for cjpm
-v, --version version for cjpm
Use "cjpm [subcommand] --help" for more information about a command.
其中 cjpm publish 、 cjpm load 、 cjpm list 是 beta 版本功能,支持用户通过 cjpm 对接仓颉中心仓发布、下载和查询仓颉模块,当前仅在内部版本支持。
基本的使用操作命令如下所示:
cjpm build --help
cjpm 是主程序的名称, build 是当前执行的可用命令, --help 是当前可用命令可用的配置项(配置项通常有长和短两种写法,效果相同)。
成功执行后会显式如下结果:
Compile a local module and all of its dependencies.
Usage:
cjpm build [option]
Available options:
-h, --help help for build
-i, --incremental enable incremental compilation
-j, --jobs <N> the number of jobs to spawn in parallel during the build process
-V, --verbose enable verbose
-g enable compile debug version target
--coverage enable coverage
--cfg enable the customized option 'cfg'
-m, --member <value> specify a member module of the workspace
--target <value> generate code for the given target platform
--target-dir <value> specify target directory
-o, --output <value> specify product name when compiling an executable file
-l, --lint enable cjlint code check
--mock enable support of mocking classes in tests.
命令说明
在使用命令前,可以通过 help 选项查看当前命令的帮助信息。
help
help 用来展示 cjpm 使用的基本方法以及当前可用命令的使用帮助信息。
例如:
cjpm -h
上述命令用于展示可用命令的帮助信息,以及可选字段的使用信息。
额外的,cjpm 也为每个可用命令都配置了 --help 的配置项,因此也可以使用配置项来得到帮助信息。
例如:
cjpm init --help
Initialize a new cangjie module.
This command creates "cjpm.toml" file, along with the necessary project directory "src".
If the '--workspace' option is specified, only the default configuration file for a workspace will be initialized.
Usage:
cjpm init [option]
Available options:
-h, --help help for init
--workspace initialize a workspace's default configuration file
--name <value> module name, default as current directory name
--path <value> path to create the module, default as current directory
--type=<executable|static|dynamic> define output_type of current module.
其它命令的帮助信息与上述相似。
init
init 用来初始化一个新的仓颉模块或者工作空间。初始化模块时会默认在当前文件夹创建 cjpm.toml 文件,并且新建 src 源码文件夹,文件已存在则会跳过。如果该模块的产物为可执行类型,则会在 src 下生成默认的 main.cj 文件,并在编译后打印输出 hello world。初始化工作空间时仅会创建 cjpm.toml 文件,默认会扫描该路径下已有的仓颉模块并添加到 members 字段中,该文件已存在时则会跳过。
init 有多个可配置项:
--name <value>指定新建的模块名,不指定时默认为上一级子文件夹名称--path <value>指定新建的模块路径,不指定时默认为当前文件夹--type=<executable|static|dynamic>指定新建模块的产物类型,缺省时默认为executable--workspace新建一个工作空间配置文件,指定该选项时以上其它选项无效会自动忽略
例如:
输入: cjpm init
输出: cjpm init success
输入: cjpm init --name demo --path project
输出: cjpm init success
输入: cjpm init --type=static
输出: cjpm init success
check
check 命令用于检查项目中所需的依赖项,执行成功将会打印有效的包编译顺序。
check 有多个可配置项:
-m, --member <value>仅可在工作空间下使用,可用来指定单个模块作为检查入口--no-tests配置后,测试相关的依赖将不会被打印
例如:
输入: cjpm check
输出:
The valid serial compilation order is:
b/pkgA -> b/default
cjpm check success
输入: cjpm check
输出:
Error: cyclic dependency
b/B -> c/C (其中,`b/B` 代表 `b` 模块的 `B` 包)
c/C -> d/D
d/D -> b/B
输入: cjpm check
输出:
Error: can not find the following dependencies
pro1/xoo
pro1/yoo
pro2/zoo
update
update 用来将 cjpm.toml 里的内容更新到 cjpm.lock。当 cjpm.lock 不存在时,将会生成该文件。cjpm.lock 文件记录着 git 依赖和中心仓依赖的版本号等元信息,用于下次构建使用。
输入: cjpm update
输出: cjpm update success
tree
tree 命令用于可视化地展示仓颉源码中的包依赖关系。
tree 有多个可配置项:
-p, --package <value>指定某个包为根节点,从而展示它的子依赖包,需要配置的值是包名--invert <value>指定某个包为根节点并反转依赖树,从而展示它被哪些包所依赖,需要配置的值是包名--depth <N>指定依赖树的最大深度,可选值是非负整数。指定该选项时,默认会以所有包作为根节点。其中,N 的值代表每个依赖树的子节点最大深度--target <value>将指定目标平台的依赖项加入分析,并展示依赖关系--no-tests排除test-dependencies字段的依赖项-V, --verbose增加包节点的详细信息,包括包名、版本号和包路径
输入: cjpm tree
输出:
|-- a/default
└── a/a
└── a/c
└── a/b
└── a/c
|-- a/d
└── a/c
|-- a/e
cjpm tree success
输入: cjpm tree --depth 2 -p a/default
输出:
|-- a/default
└── a/a
└── a/c
└── a/b
└── a/c
cjpm tree success
输入: cjpm tree --depth 0
输出:
|-- a/default
|-- a/e
|-- a/a
|-- a/b
|-- a/d
|-- a/c
cjpm tree success
输入: cjpm tree --invert a/c --verbose
输出:
|-- a/c 1.2.0 (.../src/c)
└── a/a 1.1.0 (.../src/a)
└── a/default 1.0.0 (.../src)
└── a/b 1.1.0 (.../b)
└── a/default 1.0.0 (.../src)
└── a/d 1.3.0 (.../src/d)
cjpm tree success
build
build 用来构建当前仓颉项目,执行该命令前会先检查依赖项,检查通过后调用 cjc 进行构建。
build 有多个可配置项:
-i, --incremental用来指定增量编译,默认情况下是全量编译-j, --jobs <N>用来指定并行编译的最大并发数,最终的最大并发数取N和2倍 CPU 核数的最小值。-V, --verbose用来展示编译日志-g用来生成debug版本的输出产物--mock带有此选项的构建版本中的类可用于在测试中进行 mock 测试--coverage用来生成覆盖率信息,默认情况下不开启覆盖率功能--cfg指定后,能够透传cjpm.toml中的自定义cfg选项-m, --member <value>仅可在工作空间下使用,可用来指定单个模块作为编译入口--target-dir <value>用来指定输出产物的存放路径-o, --output <value>用来指定输出可执行文件的名称--target <value>指定后,可交叉编译代码到目标平台,cjpm.toml中的配置可参考cross-compile-configuration部分-l, --lint用于在编译时调用仓颉语言静态检查工具cjlint进行代码检查,如果检查到【要求】级别的代码规范违规,则编译会失败,检查到【建议】级别的违规仅报警,正常完成编译
编译生成的中间文件默认会存放在 target 文件夹,而可执行文件会根据编译模式存放到 target/release/bin 或 target/debug/bin 文件夹。为了提供可复制的构建,此命令会创建 cjpm.lock 文件,该文件包含所有可传递依赖项的确切版本,这些依赖项将用于所有后续构建,需要更新该文件时请使用 update 命令。如果有必要保证每个在项目上工作的人都有可复制的构建,那么此文件应提交到版本控制系统中。
例如:
输入: cjpm build -V
输出:
compile package module1/package1: cjc --import-path build -p "src/package1" --module-name module1 --output-type=staticlib -o build/release/module1/libmodule1_package1.a
compile package cangjie/default: cjc --import-path build -L build/release/module1 -l module1_package1 -p "src" --module-name cangjie --output-type=exe --output-dir build/release/bin -o main
cjpm build success
输入: cjpm build
输出: cjpm build success
run
run 用来运行当前项目构建出的二进制产物。
run 有多个可配置项:
--name <value>指定运行的二进制名称,不指定时默认为main,工作空间下的二进制产物默认存放在target/release/bin路径下--build-args <value>控制cjpm编译流程的参数--skip-build跳过编译流程,直接运行--run-args <value>透传参数给本次运行的二进制产物--target-dir <value>用来指定运行产物的存放路径-g用来运行debug版本的产物-V, --verbose用来展示运行日志
例如:
输入: cjpm run
输出: cjpm run success
输入: cjpm run -g // 此时会默认执行 cjpm build -i -g 命令
输出: cjpm run success
输入: cjpm run --build-args="-s -j16" --run-args="a b c" -V
输出: cjpm run success
test
test 用于执行仓颉文件的单元测试用例,并直接打印测试结果,编译产物默认存放在 target/release/unittest_bin 文件夹。
该命令可以指定待测试的单包路径(支持指定多个单包,形如 cjpm test path1 path2),不指定路径时默认执行模块级别的单元测试。test 执行前提是当前项目能够 build 编译成功。
模块的单元测试代码结构如下所示,xxx.cj 存放该包的源码,xxx_test.cj 存放单元测试代码。具体单元测试代码的写法可参考标准库用户手册。
│ └── src
│ ├── koo
│ │ ├── koo.cj
│ │ └── koo_test.cj
│ ├── zoo
│ │ ├── zoo.cj
│ │ └── zoo_test.cj
│ ├── main.cj
│ └── main_test.cj
│ ├── cjpm.toml
多模块测试场景
输入: cjpm test
输出:
---------------------------------------------------------------------------------
TP: pro0/zoo, time elapsed: 26411 ns, Result:
TCS: TestZ, time elapsed: 23483 ns, RESULT:
[ PASSED ] CASE: sayhi (17592 ns)
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
---------------------------------------------------------------------------------
---------------------------------------------------------------------------------
TP: test/default, time elapsed: 26580 ns, Result:
TCS: TestM, time elapsed: 23724 ns, RESULT:
[ PASSED ] CASE: sayhi (17937 ns)
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
---------------------------------------------------------------------------------
---------------------------------------------------------------------------------
TP: test/koo, time elapsed: 39090 ns, Result:
TCS: TestK, time elapsed: 35847 ns, RESULT:
[ PASSED ] CASE: sayhi (20907 ns)
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
---------------------------------------------------------------------------------
cjpm test success
单包测试场景
输入: cjpm test src/koo
输出:
---------------------------------------------------------------------------------
TP: test/koo, time elapsed: 25883 ns, Result:
TCS: TestK, time elapsed: 22768 ns, RESULT:
[ PASSED ] CASE: sayhi (17322 ns)
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
---------------------------------------------------------------------------------
cjpm test success
多包测试场景
输入: cjpm test src/koo src
输出:
---------------------------------------------------------------------------------
TP: test/koo, time elapsed: 25883 ns, Result:
TCS: TestK, time elapsed: 22768 ns, RESULT:
[ PASSED ] CASE: sayhi (17322 ns)
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
---------------------------------------------------------------------------------
---------------------------------------------------------------------------------
TP: test/default, time elapsed: 26580 ns, Result:
TCS: TestM, time elapsed: 23724 ns, RESULT:
[ PASSED ] CASE: sayhi (17937 ns)
Summary: TOTAL: 1
PASSED: 1, SKIPPED: 0, ERROR: 0
FAILED: 0
---------------------------------------------------------------------------------
cjpm test success
test 有多个可配置项:
--no-run用来仅编译单元测试产物--skip-build用来仅执行单元测试产物-j, --jobs <N>用来指定并行编译的最大并发数,最终的最大并发数取N和2倍 CPU 核数的最小值。-V, --verbose配置项开启后,会输出单元测试的日志-g用来生成debug版本的单元测试产物,此时的产物存放在 target/debug/unittest_bin` 文件夹。--bench用来指定只执行@bench宏修饰用例的测试结果--target-dir <value>用来指定单侧产物的存放路径--coverage配合cjcov命令可以生成单元测试的覆盖率报告。使用cjpm test --coverage统计覆盖率时,源代码中的main不会再作为程序入口执行,因此会显示为未被覆盖。建议使用cjpm test之后,不再手写多余的main。--cfg指定后,能够透传cjpm.toml中的自定义cfg选项-m, --member <value>仅可在工作空间下使用,可用来指定测试单个模块--target <value>指定后,可交叉编译生成目标平台的单元测试结果,cjpm.toml中的配置可参考cross-compile-configuration部分--filter <value>用于过滤测试的子集,value的形式如下所示:
--filter=*匹配所有测试类--filter=*.*匹配所有测试类所有测试用例(结果和*相同)--filter=*.*Test,*.*case*匹配所有测试类中以 Test 结尾的用例,或者所有测试类中名字中带有 case 的测试用例--filter=MyTest*.*Test,*.*case*,-*.*myTest匹配所有 MyTest 开头测试类中以 Test 结尾的用例,或者名字中带有 case 的用例,或者名字中不带有 myTest 的测试用例
--random-seed <N>用来指定随机种子的值--no-color关闭控制台颜色显示--timeout-each <value>value 的格式为%d[millis|s|m|h],为每个测试用例指定默认的超时时间
cjpm test 参数选项使用示例:
输入:
cjpm test src --coverage
cjcov --root=./ --html-details -o html_output
输出:
在 html_output 目录下会生成 html 文件,总的覆盖率报告文件名固定为 index.html
输入: cjpm test --bench
输出: cjpm test success
输入: cjpm test src --bench
输出: cjpm test success
输入: cjpm test src --filter=*
输出: cjpm test success
请注意,cjpm test 会自动构建所有带有 mock 支持的包,因此在测试中,您可以 mock 您的或依赖源模块的类。为了能够从一些二进制依赖中 mock 类,它应该通过cjpm build --mock来构建带有 mock 支持的类。
带有 --bench 选项的 cjpm test 并不包含完全的 mock 支持,以避免在基准测试中由于在编译器中的 mock 处理而增加的任何开销。
使用 --bench 选项时,如果使用 mock ,编译器不会报错,以便能够将常规测试和基准测试一起编译。但是要避免运行使用 mock 的基准测试,否则会抛出运行时异常。
clean
clean 用来清理构建过程中的临时产物(target 文件夹)。该命令支持通过短选项 -g 指定仅清理 debug 版本的产物。该命令支持通过长选项 --target-dir <value> 用来指定清理的产物存放路径,用户需自身保证清理该目录行为的安全性。如果使用了 cjpm build --coverage 或者 cjpm test --coverage 功能,还会清除 cov_output 文件夹,以及当前目录下的 *.gcno 文件和 *.gcda 文件。
例如:
输入: cjpm clean
输出: cjpm clean success
输入: cjpm clean --target-dir temp
输出: cjpm clean success
publish
publish 用来发布当前模块到仓颉中心仓,当前仅支持将 src 文件夹和 cjpm.toml 文件进行打包发布,后续将做成用户可配置的发布列表。由于当前仓颉中心仓没有支持用户权限管理,所以暂不支持用户删除已发布的仓颉模块,以免误删其他人的发布件。publish 支持 -m, --member <value> 的可配置项,仅可在工作空间下使用,可用来指定发布单个模块。
例如:
输入: cjpm publish
输出: ${module_name}:${version} publish success
load
load 用来手动从中心仓下载指定名称和版本的模块到本地,如果希望编译时自动下载依赖,请参考 cjpm.toml 文件中的 dependencies 配置项进行依赖配置。
例如:
输入: cjpm load charset:1.2.0
输出: charset load success
list
list 用来查询中心仓已发布的仓颉模块,用户可以通过指定模块名查询中心仓中对应模块名的所有版本。
例如:
输入: cjpm list
输出:
charset:1.2.0
test:0.0.1
zip4cj:1.0.0
zip4cj:1.1.0
输入: cjpm list zip4cj
输出:
zip4cj:1.0.0
zip4cj:1.1.0
模块配置文件说明
模块配置文件 cjpm.toml 用来配置一些基础信息、依赖项、编译选项等内容,cjpm 主要通过这个文件进行解析执行。其中,模块名可以在 cjpm.toml 中进行重命名,但是包名不能在 cjpm.toml 中进行重命名。
配置文件代码如下所示:
[package]
cjc-version = "0.49.1" # 所需 `cjc` 的最低版本要求,必须
name = "demo" # 模块名称,必须
description = "nothing here" # 描述信息,非必须
version = "1.0.0" # 模块版本信息,必须
compile-option = "" # 额外编译命令选项,非必须
link-option = "" # 链接器透传选项,可透传安全编译命令,非必须
output-type = "executable" # 编译输出产物类型,必须
src-dir = "" # 指定源码存放路径,非必须
target-dir = "" # 指定产物存放路径,非必须
package-configuration = {} # 单包配置选项,非必须
[workspace] # 工作空间管理字段,与 package 字段不能同时存在
members = []
build-members = []
test-members = []
compile-option = ""
link-option = ""
target-dir = ""
[dependencies] # 源码依赖配置项
aoo = { version = "1.0.0" } # 导入中心仓依赖
boo = "1.1.0" # 导入中心仓依赖
coo = { git = "xxx",branch = "dev" , version = "1.0.0"} # 导入 `git` 依赖,`version`字段可缺省
doo = { path = "./pro1" ,version = "1.0.0"} # 导入源码依赖,`version`字段可缺省
[test-dependencies] # 测试阶段的依赖配置项
[ffi.c] # 导入 `c` 库依赖
clib1.path = "xxx"
[profile] # 命令剖面配置项
build = {}
test = {}
customized-option = {}
[target.x86_64-unknown-linux-gnu] # 后端和平台隔离配置项
compile-option = "value1" # 额外编译命令选项,适用于特定 target 的编译流程和指定该 target 作为交叉编译目标平台的编译流程,非必须
link-option = "value2" # 链接器透传选项,适用于特定 target 的编译流程和指定该 target 作为交叉编译目标平台的编译流程,非必须
[target.x86_64-w64-mingw32.dependencies] # 适用于对应 target 的源码依赖配置项,非必须
[target.x86_64-w64-mingw32.test-dependencies] # 适用于对应 target 的测试阶段依赖配置项,非必须
[target.cjvm.bin-dependencies] # 仓颉二进制库依赖,适用于特定 target 的编译流程和指定该 target 作为交叉编译目标平台的编译流程,非必须
path-option = ["./test/pro0", "./test/pro1"]
[target.cjvm.bin-dependencies.package-option]
pro0_xoo = "./test/pro0/xoo.cjo"
pro0_yoo = "./test/pro0/yoo.cjo"
pro1_zoo = "./test/pro1/zoo.cjo"
当以上字段在 cjpm.toml 中没有使用时,默认为空(对于路径,默认为配置文件所在的路径)。
"cjc-version"
仓颉编译器最低版本要求,必须和当前环境版本兼容才可以执行,当前未进行兼容性检查。但一个合法的仓颉版本号是由三段数字组成,中间使用 . 隔开,其正确形式为 0.38.2,而 0.038.2 是不合法的 。
"name"
当前仓颉模块名称。
一个合法的仓颉模块名称必须是一个合法的标识符,标识符可由字母、数字、下划线组成,标识符的开头必须是字母,其形式为 cjModDemo。
"description"
当前仓颉模块描述信息,仅作说明用,不限制格式。
"version"
当前仓颉模块版本号,由模块所有者管理,主要供模块校验使用。
一个合法的仓颉模块版本号由三段数字组成,中间使用 . 隔开,其形式为 1.1.1 。从前往后的数字代表的版本稳定性依次递减。注意,1.01.1 是不合法的形式。
"compile-option"
传给 cjc 的额外编译选项。多模块编译时,每个模块设置的 compile-option 对该模块内的所有包生效。
例如:
-O2 -V
这里填入的命令会在 build 执行时插入到编译命令中间,多个命令可以用空格隔开。可用的命令参考仓颉用户手册的编译选项章节内容。
"link-option"
传给链接器的编译选项,可用于透传安全编译命令,如下所示。注意,这里配置的命令在编译时只会自动透传给动态库和可执行产物对应的包。
link-option = "-z noexecstack -z relro -z now --strip-all"
"output-type"
编译输出产物的类型,包含可执行程序和库两种形式,相关的输入如下表格所示。如果想生成 cjpm.toml 时该字段自动填充为 static,可使用命令 cjpm init --type=static --name=modName,不指定类型时默认生成为 executable。只有主模块的该字段可以为 executable。
| 输入 | 说明 |
|---|---|
| "executable" | 可执行程序 |
| "static" | 静态库 |
| "dynamic" | 动态库 |
| 其它 | 报错 |
"src-dir"
该字段可以指定源码的存放路径,不指定时默认为 src 文件夹。
"target-dir"
该字段可以指定编译产物的存放路径,不指定时默认为 target 文件夹。若该字段不为空,执行 cjpm clean 时会删除该字段所指向的文件夹,用户需自身保证清理该目录行为的安全性。注意,若在编译时同时指定了 --target-dir 选项,则该选项的优先级会更高。
target-dir = "temp"
"package-configuration"
每个模块的单包可配置项。该选项是个 map 结构,需要配置的包名作为 key,单包配置信息作为 value。当前可配置的信息包含输出类型、透传命令选项、条件选项,这几个选项可缺省按需配置。如下所示,aoo 包的输出类型会被指定为动态库类型,-g 命令会在编译时透传给 aoo 包。
package-configuration = {
aoo = {
output-type = "dynamic"
compile-option = "-g"
}
}
如果在不同字段配置了相互兼容的编译选项,生成命令的优先级如下所示。
compile-option = "-O1"
package-configuration = {
default = {
compile-option = "-O2"
}
}
# profile字段会在下文介绍
profile.customized-option = {
cfg1 = "-O0"
}
输入: cjpm build --cfg1 -V
输出: cjc --import-path build -O0 -O1 -O2 ...
通过配置这个字段,可以同时生成多个二进制产物(生成多个二进制产物时,-o, --output <value> 选项将会失效),示例如下:
源码结构的示例:
`-- src
|-- aoo
| `-- aoo.cj
|-- boo
| `-- boo.cj
|-- coo
| `-- coo.cj
`-- main.cj
配置方式的示例:
package-configuration = {
aoo = { output-type = "executable"}
boo = { output-type = "executable"}
}
多个二进制产物的示例:
❯ cjpm build
cjpm build success
❯ tree target/release/bin
target/release/bin
|-- b_aoo
|-- b_boo
`-- b_default
"workspace"
该字段可管理多个模块作为一个工作空间,支持以下配置项:
- members = ["aoo", "path/to/boo"] # 列举包含在此工作空间的本地源码模块,支持绝对路径和相对路径。该字段的成员必须是一个模块,不允许是另一个工作空间。
- build-members = [] # 本次编译的模块,不指定时默认编译该工作空间内的所有模块。该字段的成员必须被包含在 members 字段中。
- test-members = [] # 本次测试的模块,不指定时默认单元测试该工作空间内的所有模块。该字段的成员必须被包含在 build-members 字段中。
- compile-option = "" # 工作空间的公共编译选项,非必须。
- link-option = "" # 工作空间的公共链接选项,非必须。
- target-dir = "" # 工作空间的产物存放路径,非必须,默认为 target 。
工作空间内的公共配置项,对所有成员模块生效。例如:配置了 [dependencies] xoo = { path = "path_xoo" } 的源码依赖,则所有成员模块可以直接使用 xoo 模块,无需在每个子模块的 cjpm.toml 中再配置。注意,package 字段用于配置模块的通用信息,不允许和 workspace 字段出现在同一个 cjpm.toml 中,除 package 外的其它字段均可在工作空间中使用。
工作空间目录举例:
root_path
│ └─ aoo
│ ├─ src
│ └─ cjpm.toml
│ └─ boo
│ ├─ src
│ └─ cjpm.toml
│ └─ coo
│ ├─ src
│ └─ cjpm.toml
└─ cjpm.toml
工作空间的配置文件使用举例:
[workspace]
members = ["aoo", "boo", "coo"]
build-members = ["aoo", "boo"]
test-members = ["aoo"]
compile-option = "-Woff all"
[dependencies]
xoo = { path = "path_xoo" }
[ffi.c]
abc = { path = "libs" }
"dependencies"
该字段通过源码方式导入依赖的其它仓颉模块,里面配置了当前构建所需要的其它模块的信息。目前,该字段支持本地路径依赖、远程 git 依赖和中心仓依赖。要指定本地依赖项,请使用path字段,并且它必须包含有效的本地路径。要指定远程 git 依赖项,请使用git字段,并且它必须包含 git 支持的任何格式的有效 url。要配置 git 依赖关系,最多可以有一个branch、tag和commitId字段,这些字段允许分别选择特定的分支、标记或提交哈希。此外,还有可选的version字段,用于检查依赖项是否具有正确的版本,并且没有意外更新。要指定中心仓依赖,请使用version字段。目前,中心仓功能是 beta 版本功能,仅支持配置中心仓系统已发布的模块(中心仓外部暂时无法访问)。
通常需要一些身份验证才能访问 git 存储库。 cjpm 不要求提供所需的凭据,因此应使用现有的 git 身份验证支持。如果用于 git 的协议是 https ,则需要使用一些现有的 git 凭据帮助程序。在 windows 上,可在安装 git 时一起安装凭据帮助程序,默认使用。在 linux 上,请参阅 https://git-scm.com/docs/gitcredentials ,了解有关设置凭据帮助程序的详细信息。如果协议是 ssh 或 git ,则应使用基于密钥的身份验证。如果密钥受密码短语保护,则用户应确保 ssh-agent 正在运行,并且在使用 cjpm 之前通过 ssh-add 添加密钥。
本地源码依赖导入指导
目录结构和配置信息如下所示:
|-- pro0
| |-- cjpm.toml
| `-- src
| `-- zoo
| `-- zoo.cj
|-- pro1
| |-- cjpm.toml
| `-- src
| |-- xoo
| | `-- xoo.cj
| `-- yoo
| `-- yoo.cj
|-- cjpm.toml
`-- src
|-- aoo
| `-- aoo.cj
|-- boo
| `-- boo.cj
`-- main.cj
[dependencies]
pro0 = { path = "./pro0" }
pro1 = { path = "./pro1" }
git 源码依赖导入指导
[dependencies]
pro0 = { git = "git://github.com/org/pro0.git", tag = "v1.0.0"}
pro1 = { git = "https://gitee.com/anotherorg/pro1", branch = "dev"}
在这种情况下, cjpm 将下载对应存储库的最新版本,并将当前 commit-hash 保存在 cjpm.lock 文件中。所有后续的 cjpm 调用都将使用保存的版本,直到使用 cjpm update 。
中心仓源码依赖导入指导
例如,依赖中心仓系统中的 `charset` 和 `zip4cj` 两个模块
[dependencies]
charset = "1.2.0"
zip4cj = "1.0.0"
dependencies 字段可以通过 output-type 属性指定编译产物类型,指定的类型可以与源码依赖自身的编译产物类型不一致,且仅能为 static 或者 dynamic, 如下所示:
[dependencies]
pro0 = { path = "./pro0", output-type = "static" }
pro1 = { git = "https://gitee.com/anotherorg/pro1", output-type = "dynamic" }
"test-dependencies"
具有与 dependencies 字段相同的格式。它用于指定仅在测试过程中使用的依赖项,而不是构建主项目所需的依赖项。如果你是库作者,则应将此字段用于此库的下游用户不需要感知的依赖项。
test-dependencies 内的依赖仅可用于文件名形如 xxx_test.cj 的测试文件,在编译时这些依赖将不会被编译。test-dependencies 在 cjpm.toml 中的配置格式与 dependencies 相同。
"ffi.c"
当前仓颉模块外部依赖 c 库的配置。该字段配置了依赖该库所需要的信息,包含库名和路径。
用户需要自行编出动态库或静态库放到设置的 path 下,可参考下面的例子。
仓颉调用外部 c 动态库的方法说明:
- 自行将相应的
hello.c文件编成.so库(在该文件路径执行clang -shared -fPIC hello.c -o libhello.so) - 修改该项目的
cjpm.toml文件,配置ffi.c字段,如下所示。其中,./src/是编出的libhello.so相对当前目录的地址,hello为库名。 - 执行
cjpm build,即可编译成功。
例如:
[ffi.c]
hello = { path = "./src/" }
"profile"
profile 作为一种命令剖面配置项,用于控制某个命令执行时的默认配置项。目前支持四种场景:build、test、run 和 customized-option。
"profile.build"
[profile.build]
lto = "full" # 是否开启 LTO (Link Time Optimization 链接时优化)优化编译模式,仅 linux 平台支持该功能。
incremental = true # 是否默认开启增量编译
编译流程的控制项,所有字段均可缺省,不配置时不生效,顶层模块设置的 profile.build 项才会生效。LTO 优化支持两种编译模式:full LTO 将所有编译模块合并到一起,在全局上进行优化,这种方式可以获得最大的优化潜力,同时也需要更长的编译时间;thin LTO 在多模块上使用并行优化,同时默认支持链接时增量编译,编译时间比 full LTO 短,因为失去了更多的全局信息,所以优化效果不如 full LTO。
"profile.test"
[profile.test] # 使用举例
noColor = true
isolate-all-timeout = "4m"
randomSeed = 10
bench = true
compilation-options = {
verbose = true
no-run = false
lto = "thin"
mock = "on"
}
[profile.test.env]
MY_ENV = { value = "abc" }
cjHeapSize = { value = "32GB", splice-type = "replace" }
PATH = { value = "/usr/bin", splice-type = "prepend" }
测试配置支持指定编译和运行测试用例时的选项,所有字段均可缺省,不配置时不生效,顶层模块设置的 profile.test 项才会生效。选项列表与 cjpm test 提供的控制台执行选项一致。如果选项在配置文件和控制台中同时被配置,则控制台中的选项优先级高于配置文件中的选项。profile.test 支持的运行时选项:
isolate-all-timeout:指定用例孤立执行,并指定超时时间,参数值类型为字符串,格式需满足正整数加上单位信息 ('millis' | 's' | 'm' | 'h') 例如: "isolate-all-timeout": "10s"isolate-all:指定用例孤立执行,参数值类型为BOOL, 即值可为true或false。bench:指定用例按性能用例方式执行,参数值类型为BOOL, 即值可为true或false。filter:指定用例过滤器,参数值类型为字符串, 格式与《命令说明》章节中《test》章节中关于--filter的值格式一致。parallel用于指定测试用例并行执行的方案,value的形式如下所示:
<BOOL><BOOL>可为true或false,指定为true时,测试类可被并行运行,并行进程个数将受运行系统上的 CPU 核数控制。nCores指定了并行的测试进程个数应该等于可用的 CPU 核数。NUMBER指定了并行的测试进程个数值。该数值应该为正整数。NUMBERnCores指定了并行的测试进程个数值为可用的 CPU 核数的指定数值倍。该数值应该为正数(支持浮点数或整数)。
option:<value>与@Configuration协同定义运行选项。例如,如下选项:
randomSeed用来指定随机种子的值, 参数值类型为正整数。noColor:指定执行结果在控制台中是否无颜色显示。参数值类型为BOOL, 即值可为true或false。
compilation-options 支持的编译选项:
verbose:指定显示编译过程详细信息,参数值类型为BOOL, 即值可为true或false。no-run:指定仅编译单元测试产物,参数值类型为BOOL, 即值可为true或false。lto:是否开启 LTO 优化编译模式,该值可为thin或full,windows 平台暂不支持该功能。mock:显式设置 mock 模式,可能的选项:on、off、runtime-error。更多详细信息,请参阅用户手册。
env 支持在 test 命令时运行可执行文件时配置临时环境变量,key 值为需要配置的环境变量的名称,有如下配置项:
value: 配置环境变量值,必填。splice-type: 配置环境变量的拼接方式,非必填,不配置时默认为absent。
splice-type 共有以下四种取值:
absent: 该配置仅在环境内不存在同名环境变量时生效,若存在同名环境变量则忽略该配置。replace: 该配置会替代环境中已有的同名环境变量。prepend: 该配置会拼接在环境中已有的同名环境变量之前。append: 该配置会拼接在环境中已有的同名环境变量之后。
"profile.run"
运行可执行文件时的选项,支持配置在 run 命令时运行可执行文件时的环境变量配置 env,配置方式同 profile.test.env。
"profile.customized-option"
[profile.customized-option]
cfg1 = "--conditional-compilation-config=\"(feature1=lion, feature2=cat)\""
cfg2 = "--conditional-compilation-config=\"(feature1=tiger, feature2=dog)\""
cfg3 = "-O2"
自定义透传给 cjc 的选项,,通过 --cfg1 --cfg3 使能,每个模块设置的 customized-option 对该模块内的所有包生效。例如,执行 cjpm build --cfg1 --cfg3 命令时,透传给 cjc 的命令则为 --conditional-compilation-config="(feature1=lion, feature2=cat)" -O2。
注意:这里的条件值可由字母、数字、下划线组成,且不能以数字开头。
"target"
多后端、多平台隔离选项,用于配置不同后端、不同平台情况下的一系列不同配置项。target 配置方式如下:
[target.x86_64-unknown-linux-gnu] # 配置 cjnative 后端、linux 系统的配置
compile-option = "value1" # 额外编译命令选项
link-option = "value2" # 链接器透传选项
[target.x86_64-unknown-linux-gnu.dependencies] # 源码依赖配置项
[target.x86_64-unknown-linux-gnu.test-dependencies] # 测试阶段依赖配置项
[target.x86_64-unknown-linux-gnu.bin-dependencies] # 仓颉二进制库依赖
path-option = ["./test/pro0", "./test/pro1"]
[target.x86_64-unknown-linux-gnu.bin-dependencies.package-option]
pro0_xoo = "./test/pro0/xoo.cjo"
pro0_yoo = "./test/pro0/yoo.cjo"
pro1_zoo = "./test/pro1/zoo.cjo"
[target.x86_64-w64-mingw32] # 配置 cjnative 后端、windows 系统的配置
compile-option = "value3"
link-option = "value4"
[target.cjvm] # 配置 cjvm 后端的配置
[target.cjvm.dependencies]
[target.x86_64-unknown-linux-gnu.debug] # 配置 cjnative 后端、linux 系统的 debug 配置
[target.x86_64-unknown-linux-gnu.debug.test-dependencies]
[target.x86_64-unknown-linux-gnu.release] # 配置 cjnative 后端、linux 系统的 release 配置
[target.x86_64-unknown-linux-gnu.release.bin-dependencies]
用户可以通过配置 target.target-name 字段为某个 target 添加一系列配置项。在 cjnative 后端,target 的名称可以在相应的仓颉环境下通过命令 cjc -v 获取,命令输出中的 Target 项目即为该环境对应的 target 名称。在 cjvm 后端,target 的名称固定为 cjvm。
可为特定 target 配置的专用配置项,将会适用于该 target 下的编译流程,同时也会适用于其他 target 指定该 target 作为目标平台的交叉编译流程。配置项列表如下:
compile-option: 额外编译命令选项link-option: 链接器透传选项dependencies: 源码依赖配置项,结构同dependencies字段test-dependencies: 测试阶段依赖配置项,结构同test-dependencies字段bin-dependencies: 仓颉二进制库依赖,结构在下文中介绍compile-macros-for-target: 交叉编译时的宏包控制项,该选项不支持区分下述的debug和release编译模式
用户可以通过配置 target.target-name.debug 和 target.target-name.release 字段为该 target 额外配置在 debug 和 release 编译模式下特有的配置,可配置的配置项同上。配置于此类字段的配置项将仅应用于该 target 的对应编译模式。
"target.target-name[.debug/release].bin-dependencies"
该字段用于导入已编译好的、适用于指定 target 的仓颉库产物文件,以导入下述的 pro0 模块和 pro1 模块的三个包来举例说明。注意,非特殊需求场景,不建议使用该字段,请使用上文介绍的 dependencies 字段导入模块源码。
├── test
│ └── pro0
│ ├── libpro0_xoo.so
│ └── xoo.cjo
│ ├── libpro0_yoo.so
│ └── yoo.cjo
│ └── pro1
│ ├── libpro1_zoo.so
│ └── zoo.cjo
└── src
└── main.cj
├── cjpm.toml
方式一,通过 package-option 导入:
[target.x86_64-unknown-linux-gnu.bin-dependencies.package-option]
pro0_xoo = "./test/pro0/xoo.cjo"
pro0_yoo = "./test/pro0/yoo.cjo"
pro1_zoo = "./test/pro1/zoo.cjo"
package-option 选项为 map 结构,pro0_xoo 名称作为 key,值为 libpro0_xoo.so 。前端文件 cjo 的路径作为 value,对应于该 cjo 的 .a 或 .so 需放置在相同路径下。
方式二,通过 path-option 导入:
[target.x86_64-unknown-linux-gnu.bin-dependencies]
path-option = ["./test/pro0", "./test/pro1"]
path-option 选项为字符串数组结构,每个元素代表待导入的路径名称。cjpm 会自动导入该路径下所有符合规则的仓颉库包,这里的合规性是指库名称的格式为 模块名_包名。库名称不满足该规则的包只能通过 package-option 选项进行导入。
注意,如果同时通过 package-option 和 path-option 导入了相同的包,则 package-option 字段的优先级更高。
其中,源码main.cj 调用 xoo、yoo、zoo 包的代码示例如下所示。
from pro0 import xoo.*
from pro0 import yoo.*
from pro1 import zoo.*
main(): Int64 {
var res = xoo.x + yoo.y + zoo.z
println(res)
return 0
}
"target.target-name.compile-macros-for-target"
方式一:宏包在交叉编译时默认仅编译本地平台的产物,不编译目标平台的产物,对该模块内的所有宏包生效
[target.目标平台]
compile-macros-for-target = ""
方式二:在交叉编译时同时编译本地平台和目标平台的产物,对该模块内的所有宏包生效
[target.目标平台]
compile-macros-for-target = "all" # 配置项为字符串形式,可选值必须为 all
方式三:指定该模块内的某些宏包在交叉编译时同时编译本地平台和目标平台的产物,其它未指定的宏包采取方式一的默认模式
[target.目标平台]
compile-macros-for-target = ["pkg1", "pkg2"] # 配置项为字符串数字形式,可选值是宏包名
"target" 相关字段合并规则
target 配置项中的内容可能同时存在于 cjpm.toml 的其他选项中,例如 compile-option 字段在 package 字段中也可以存在,区别在于 package 中的该字段会应用于全部 target。cjpm 对这些重复的字段会按照特定的方式将所有可应用的配置合并。以 x86_64-unknown-linux-gnu 的 debug 编译模式为例,有如下的 target 配置:
[package]
compile-option = "compile-0"
link-option = "link-0"
[dependencies]
dep0 = { path = "./dep0" }
[test-dependencies]
devDep0 = { path = "./devDep0" }
[target.x86_64-unknown-linux-gnu]
compile-option = "compile-1"
link-option = "link-1"
[target.x86_64-unknown-linux-gnu.dependencies]
dep1 = { path = "./dep1" }
[target.x86_64-unknown-linux-gnu.test-dependencies]
devDep1 = { path = "./devDep1" }
[target.x86_64-unknown-linux-gnu.bin-dependencies]
path-option = ["./test/pro1"]
[target.x86_64-unknown-linux-gnu.bin-dependencies.package-option]
pro1_xoo = "./test/pro1/xoo.cjo"
[target.x86_64-unknown-linux-gnu.debug]
compile-option = "compile-2"
link-option = "link-2"
[target.x86_64-unknown-linux-gnu.debug.dependencies]
dep2 = { path = "./dep2" }
[target.x86_64-unknown-linux-gnu.debug.test-dependencies]
devDep2 = { path = "./devDep2" }
[target.x86_64-unknown-linux-gnu.debug.bin-dependencies]
path-option = ["./test/pro2"]
[target.x86_64-unknown-linux-gnu.debug.bin-dependencies.package-option]
pro2_xoo = "./test/pro2/xoo.cjo"
target 配置项在与 cjpm.toml 公共配置项或者相同 target 的其他级别的配置项共存时,按照如下的优先级合并:
debug/release模式下对应target的配置debug/release无关的对应target的配置- 公共配置项
以上述的 target 配置为例,target 各个配置项按照以下规则合并:
compile-option: 将所有适用的同名配置项按照优先级拼接,优先级更高的配置拼接在后方。在本例中,在x86_64-unknown-linux-gnu的debug编译模式下,最终生效的compile-option值为compile-0 compile-1 compile-2,在release编译模式下为compile-0 compile-1,在其他target中为compile-0。link-option: 同上。dependencies: 源码依赖将被直接合并,如果其中存在依赖冲突则会报错。在本例中,在x86_64-unknown-linux-gnu的debug编译模式下,最终生效的dependencies为dep0,dep1和dep2,而在release编译模式下仅有dep0和dep1生效。在其他target中,仅有dep0生效。test-dependencies: 同上。bin-dependencies: 二进制依赖将按照优先级合并,如果有冲突则仅有优先级更高的依赖将会被加入,同优先级的配置先加入package-option配置。在本例中,在x86_64-unknown-linux-gnu的debug编译模式下,./test/pro1和./test/pro2内的二进制依赖将被加入,而在release模式下仅会加入./test/pro1。由于bin-dependencies没有公共配置,因此在其他target中不会有二进制依赖生效。
在本例的交叉编译场景中,若在其他平台中指定了 x86_64-unknown-linux-gnu 作为目标 target,则 target.x86_64-unknown-linux-gnu 的配置也会按照上述规则与公共配置项合并并应用;如果处于 debug 编译模式,也将应用 target.x86_64-unknown-linux-gnu.debug 的配置项。
包管理配置文件说明
包管理配置文件 cjpm-config.toml 用来配置中心仓地址、本地仓路径、下载代理等内容,它位于仓颉开发包的 cangjie/tools/config 目录下,cjpm 主要通过此文件对接中心仓系统,管理从中心仓下载的依赖模块。
配置文件代码如下所示:
localRepository = "~/.cjpm/repository"
offline = false
[centralRepository]
url = "..."
privateKey = "generate from cangjie central repository after user logined"
[proxy]
host = "proxy.host.net"
port = "80"
username = "proxyuser"
password = "proxypwd"
noProxyHosts = "local.net,some.host.com"
active = "true"
从上往下的信息分别是:
-
centralRepository通过url指定中心仓地址,必须。privateKey是保留字段,待中心仓支持用户管理后的用户鉴权凭证。 -
localRepository本地存储路径配置,必须。用于存放从中心仓下载的仓颉模块。 -
offline当前是保留字段,后续用于支持开启离线模式功能。 -
proxy当前是保留字段,后续用于支持网络代理配置。
配置和缓存文件夹
cjpm 通过 git 下载文件的存储路径可以通过 CJPM_CONFIG 环境变量指定。如果未指定,则 Linux 上的默认位置为 $HOME/.cjpm , Windows 上的默认位置为 %LOCALAPPDATA%/.cjpm 。
其他
命令扩展
cjpm 提供命令扩展机制,用户可以通过文件名形如 cjpm-xxx(.exe) 的可执行文件扩展 cjpm 的命令。cjpm 内部已有的命令优先级更高,因此无法用此方式扩展这些命令。
针对可执行文件 cjpm-xxx (windows 系统中为 cjpm-xxx.exe),若系统环境变量 PATH 中配置了该文件所在的路径,则可以使用如下的命令运行该可执行文件:
cjpm xxx [args]
其中 args 为可能需要的输入给 cjpm-xxx(.exe) 的参数列表。上述命令等价于:
cjpm-xxx(.exe) [args]
运行 cjpm-xxx(.exe) 可能会依赖某些动态库,在这种情况下,用户需要手动将需要使用的动态库所在的目录添加到环境变量中。
下面以 cjpm-demo 为例,该可执行文件由以下仓颉代码编译得到:
from std import os.*
from std import collection.*
main(): Int64 {
var args = ArrayList<String>(os.getArgs())
if (args.size < 1) {
eprintln("Error: failed to get parameters")
return 1
}
println("Output: ${args[0]}")
return 0
}
则在将其目录添加到 PATH 之后,运行对应命令,会执行该可执行文件并获得对应的输出。
输入:cjpm demo hello,world
输出:Output: hello,world
构建脚本
cjpm 提供构建脚本机制,用户可以在构建脚本中定义需要 cjpm 在某个命令前后的行为。
构建脚本源文件固定命名为 build.cj,位于仓颉项目主目录下,即与 cjpm.toml 同级。执行 init 命令新建仓颉项目时,cjpm 默认不创建 build.cj,用户若有相关需求,可以自行按如下的模板格式在指定位置新建并编辑 build.cj。
// build.cj
from std import os.*
// Case of pre/post codes for 'cjpm build'.
/* called before `cjpm build`
* Success: return 0
* Error: return any number except 0
*/
// func stagePreBuild(): Int64 {
// // process before "cjpm build"
// 0
// }
/*
* called after `cjpm build`
*/
// func stagePostBuild(): Int64 {
// // process after "cjpm build"
// 0
// }
// Case of pre/post codes for 'cjpm clean'.
/* called before `cjpm clean`
* Success: return 0
* Error: return any number except 0
*/
// func stagePreClean(): Int64 {
// // process before "cjpm clean"
// 0
// }
/*
* called after `cjpm clean`
*/
// func stagePostClean(): Int64 {
// // process after "cjpm clean"
// 0
// }
// For other options, define stagePreXXX and stagePostXXX in the same way.
/*
* Error code:
* 0: success.
* other: cjpm will finish running command. Check target-dir/build-script-cache/module-name/script-log for error outputs defind by user in functions.
*/
main(): Int64 {
match (os.getArgs()[0]) {
// Add operation here with format: "pre-"/"post-" + optionName
// case "pre-build" => stagePreBuild()
// case "post-build" => stagePostBuild()
// case "pre-clean" => stagePreClean()
// case "post-clean" => stagePostClean()
case _ => 0
}
}
cjpm 针对所有命令(扩展命令除外)均支持使用构建脚本定义命令前后行为。例如,针对 build 命令,可在 main 函数中的 match 内定义 pre-build,执行想要在 build 命令执行前需要执行的功能函数 stagePreBuild(功能函数的命名不做要求)。build 命令后的行为可以以相同的方式通过添加 post-build 的 case 选项定义。针对其他命令的命令前后行为的定义类似,只需要添加相应的 pre/post 选项和对应的功能函数即可。
在定义某一命令前后的行为后,cjpm 在执行该命令时会首先编译 build.cj,并在执行前后执行对应的行为。同样以 build 为例,在定义了 pre-build 和 post-build 后运行 cjpm build,则会按照如下步骤运行整个 cjpm build 流程:
- 进行编译流程前,首先编译
build.cj; - 执行
pre-build对应的功能函数; - 进行
cjpm build编译流程; - 编译流程顺利结束后,
cjpm会执行post-build对应的功能函数。
构建脚本的使用说明如下:
- 功能函数的返回值需要满足一定要求:当功能函数执行成功时,需要返回
0;执行失败时返回除0以外的任意Int64类型变量。 build.cj中的所有输出都将被重定向到target-dir定义的编译目录下,路径为${target-dir}/build-script-cache/${module-name}/script-log。用户如果在功能函数中添加了一些输出内容,可在该文件中查看。- 若项目根目录下不存在
build.cj,则cjpm将按正常流程执行;若存在build.cj并定义了某一命令的前后行为,则在build.cj编译失败或者功能函数返回值不为0时,即使该命令本身能够顺利执行,命令也将异常中止。 - 多模块场景下,被依赖模块的
build.cj构建脚本会在编译和单元测试流程中生效。被依赖模块构建脚本中的输出同样重定向到${target-dir}/build-script-cache下对应模块名目录中的日志文件。
例如,下面的构建脚本 build.cj 定义了 build 前后的行为:
from std import os.*
func stagePreBuild(): Int64 {
println("PRE-BUILD")
0
}
func stagePostBuild(): Int64 {
println("POST-BUILD")
0
}
main(): Int64 {
match (os.getArgs()[0]) {
case "pre-build" => stagePreBuild()
case "post-build" => stagePostBuild()
case _ => 0
}
}
则在执行 cjpm build 命令时,cjpm 将会执行 stagePreBuild 和 stagePostBuild。cjpm build 执行完成后,script-log 日志文件内会有如下输出:
PRE-BUILD
POST-BUILD
使用示例
以下面仓颉项目的目录结构为例,介绍 cjpm 的使用方法,该目录下对应的源码文件示例可见文末。
cj_project
│ ├── pro0
│ │ ├── cjpm.toml
│ │ └── src
│ │ └── zoo
│ │ ├── zoo.cj
│ │ └── zoo_test.cj
│ └── src
│ ├── koo
│ │ ├── koo.cj
│ │ └── koo_test.cj
│ ├── main.cj
│ └── main_test.cj
│ ├── cjpm.toml
init、build 的使用
-
进入
cj_project文件夹,新建仓颉项目并编写源码xxx.cj文件,如示例结构所示的koo包和main.cj文件。cjpm init --name test --path cj_project mkdir koo此时,会自动生成
src文件夹和默认的cjpm.toml配置文件。 -
当前模块需要依赖外部的
pro0模块时,可以新建pro0模块及该模块的配置文件,接下来编写该模块的源码文件。注,这里需要自行在pro0下新建src文件夹,并将编写的仓颉包放置在src下,如示例结构所示的zoo包。mkdir pro0 && cd pro0 cjpm init --name pro0 --type=static mkdir src/zoo -
主模块依赖
pro0时,需要按照手册说明去配置主模块配置文件的dependencies字段。配置无误后,执行cjpm build即可,生成的可执行文件在target/release/bin/目录下。cd cj_project vim cjpm.toml cjpm build cjpm run
test、clean 的使用
-
按示例结构,编写完每个文件对应的
xxx_test.cj单元测试文件后,可以执行下述代码进行单元测试,生成的文件在target/release/unittest_bin目录下。cjpm test或者
cjpm test src src/koo pro/src/zoo -
想要手动删除
target、cov_output文件夹、*.gcno、*.gcda等中间件时。cjpm clean
示例的源代码
cj_project/src/main.cj
from pro0 import zoo.*
import koo.*
main(): Int64 {
let res = zoo.z + koo.k
println(res)
let res2 = concatM("a", "b")
println(res2)
return 0
}
func concatM(s1: String, s2: String): String {
return s1 + s2
}
cj_project/src/main_test.cj
from std import unittest.*//testfame
from std import unittest.testmacro.*//macro_Defintion
@Test
public class TestM{
@TestCase
func sayhi(): Unit {
@Assert(concatM("1", "2"), "12")
@Assert(concatM("1", "3"), "13")
}
}
cj_project/src/koo/koo.cj
package koo
public let k: Int32 = 12
func concatk(s1: String, s2: String): String {
return s1 + s2
}
cj_project/src/koo/koo_test.cj
package koo
from std import unittest.*//testfame
from std import unittest.testmacro.*//macro_Defintion
@Test
public class TestK{
@TestCase
func sayhi(): Unit {
@Assert(concatk("1", "2"), "12")
@Assert(concatk("1", "3"), "13")
}
}
cj_project/pro0/src/zoo/zoo.cj
package zoo
public let z: Int32 = 26
func concatZ(s1: String, s2: String): String {
return s1 + s2
}
cj_project/pro0/src/zoo/zoo_test.cj
package zoo
from std import unittest.*//testfame
from std import unittest.testmacro.*//macro_Defintion
@Test
public class TestZ{
@TestCase
func sayhi(): Unit {
@Assert(concatZ("1", "2"), "12")
@Assert(concatZ("1", "3"), "13")
}
}
cj_project/cjpm.toml
[package]
cjc-version = "0.40.2"
description = "nothing here"
version = "1.0.0"
name = "test"
output-type = "executable"
[dependencies]
pro0 = { path = "pro0" }
cj_project/pro0/cjpm.toml
[package]
cjc-version = "0.40.2"
description = "nothing here"
version = "1.0.0"
name = "pro0"
output-type = "static"
仓颉语言调试工具使用指南
功能简介
cjdb 是一款基于 llvm 后端的 Cangjie 程序命令行调试工具,为 Cangjie 开发者提供程序调试的能力,特性列表如下:
- 调试器启动被调程序(launch,attach)
- 源码断点/函数断点/条件断点(breakpoint)
- 观察点(watchpoint)
- 程序运行(s,n, finish, continue)
- 变量查看/变量修改(print,set)
- 仓颉线程查看(cjthread)
使用说明
调试器加载被调程序(launch,attach)
launch 方式加载被调程序
launch 方式有两种加载方式,如下:
<1> 启动调试器的时候,同时加载被调程序
~/0901/cangjie_test$ cjdb test
(cjdb) target create "test"
Current executable set to '/0901/cangjie-linux-x86_64-release/bin/test' (x86_64).
(cjdb)
<2> 先启动调试器,然后通过 file 命令加载被调程序
~/0901/cangjie_test$ cjdb
(cjdb) file test
Current executable set to '/0901/cangjie/test' (x86_64).
(cjdb)
attach 方式调试被调程序
针对正在运行的程序,支持 attach 方式调试被调程序,如下:
~/0901/cangjie-linux-x86_64-release/bin$ cjdb
(cjdb) attach 15325
Process 15325 stopped
* thread #1, name = 'test', stop reason = signal SIGSTOP
frame #0: 0x00000000004014cd test`default.main() at test.cj:7:9
4 var a : Int32 = 12
5 a = a + 23
6 while (true) {
-> 7 a = 1
8 }
9 a = test(10, 34)
10 return 1
thread #2, name = 'FinalProcessor', stop reason = signal SIGSTOP
frame #0: 0x00007f48c12fc065 libpthread.so.0`__pthread_cond_timedwait at futex-internal.h:205
thread #3, name = 'PoolGC_1', stop reason = signal SIGSTOP
frame #0: 0x00007f48c12fbad3 libpthread.so.0`__pthread_cond_wait at futex-internal.h:88
thread #4, name = 'MainGC', stop reason = signal SIGSTOP
frame #0: 0x00007f48c12fc065 libpthread.so.0`__pthread_cond_timedwait at futex-internal.h:205
thread #5, name = 'schmon', stop reason = signal SIGSTOP
frame #0: 0x00007f48c0fe17a0 libc.so.6`__GI___nanosleep(requested_time=0x00007f48a8ffcb70, remaining=0x0000000000000000) at nanosleep.c:28
Executable module set to "/0901/cangjie-linux-x86_64-release/bin/test".
Architecture set to: x86_64-unknown-linux-gnu.
设置断点
设置源码断点
源码断点设置:breakpoint set --line line_number
例:breakpoint set --line 2
(cjdb) b 2
Breakpoint 1: where = test`default.main() + 13 at test.cj:4:3, address = 0x0000000000401491
(cjdb) b test.cj : 4
Breakpoint 2: where = test`default.main() + 13 at test.cj:4:3, address = 0x0000000000401491
(cjdb)
对于单文件,只需要输入行号即可,对于多文件,需要加上文件名字
--line 指定行号 --file 指定文件
b test.cj:4是breakpoint set --file test.cj --line 2的缩写,是 lldb 原生命令,如需了解更多可查看 lldb 相关文档
设置函数断点
函数断点设置:breakpoint set --name function_name
例:breakpoint set --method test
(cjdb) b test
Breakpoint 3: where = test`default.test(int, int) + 19 at test.cj:12:10, address = 0x0000000000401547
(cjdb)
--name 指定要设置函数断点的函数名
设置条件断点
条件断点设置:breakpoint set --file xx.cj --line line_number --condition expression
例:breakpoint set --file test.cj --line 4 --condition 'a==12'
(cjdb) b -f test.cj -l 5 'a==12'
Breakpoint 2: where = test`default.main() + 20 at test.cj:5:7, address = 0x0000000000401498
(cjdb) r
Process 13513 launched: '/0901/cangjie-linux-x86_64-release/bin/test' (x86_64)
Process 13513 stopped
* thread #1, name = 'test', stop reason = breakpoint 2.1
frame #0: 0x0000000000401498 test`default.main() at test.cj:5:7
2 main(): Int64 {
3
4 var a : Int32 = 12
-> 5 a = a + 23
6 a = test(10, 34)
7 return 1
8 }
(cjdb)
--file 指定文件
--condition 指定条件,支持 ==, !=, >, <, >=, <=, and, or
缩写是 b -f test.cj -l 4 -c 'a==12' ,是 lldb 原生命令
仅支持基础类型变量条件设置(Int8,Int16,Int32,Int64,UInt8,UInt16,UInt32,UInt64,Float32,Float64,Bool,Char)
暂时不支持 Float16 变量类型条件设置
设置观察点
观察点设置:watchpoint set variable -w read variable_name
例:watchpoint set variable -w read a
(cjdb) wa s v -w read a
Watchpoint created: Watchpoint 1: addr = 0x7fffddffed70 size = 8 state = enabled type = r
declare @ 'test.cj:27'
watchpoint spec = 'a'
new value: 10
(cjdb)
b test是breakpoint set --name test的缩写,是 lldb 原生命令
-w 指定观察点点类型,有 read、write、read_write 三种类型
wa s v是watchpoint set variable的缩写,是 lldb 原生命令
只支持在基础类型设置观察点
启动被调程序
执行 r(run)命令
(cjdb) r
Process 2884 launched: '/0901/cangjie-linux-x86_64-release/bin/test' (x86_64)
Process 2884 stopped
* thread #1, name = 'test', stop reason = breakpoint 1.1 2.1
frame #0: 0x0000000000401491 test`default.main() at test.cj:4:3
1
2 main(): Int64 {
3
-> 4 var a : Int32 = 12
5 a = a + 23
6 a = test(10, 34)
7
可以看到程序停到初始化断点处
执行
单步执行,n(next)
(cjdb) n
Process 2884 stopped
* thread #1, name = 'test', stop reason = step over
frame #0: 0x0000000000401498 test`default.main() at test.cj:5:7
2 main(): Int64 {
3
4 var a : Int32 = 12
-> 5 a = a + 23
6 a = test(10, 34)
7 return 1
8 }
(cjdb)
从第 4 行运行到第 5 行
执行到下一个断点停止,c(continue)
(cjdb) c
Process 2884 resuming
Process 2884 stopped
* thread #1, name = 'test', stop reason = breakpoint 3.1
frame #0: 0x0000000000401547 test`default.test(a=10, b=34) at test.cj:12:10
9
10 func test(a : Int32, b : Int32) : Int32 {
11
-> 12 return a + b
13 }
14
(cjdb)
函数进入,s
(cjdb) n
Process 5240 stopped
* thread #1, name = 'test', stop reason = step over
frame #0: 0x00000000004014d8 test`default.main() at test.cj:6:7
3
4 var a : Int32 = 12
5 a = a + 23
-> 6 a = test(10, 34)
7 return 1
8 }
9
(cjdb) s
Process 5240 stopped
* thread #1, name = 'test', stop reason = step in
frame #0: 0x0000000000401547 test`default.test(a=10, b=34) at test.cj:12:10
9
10 func test(a : Int32, b : Int32) : Int32 {
11
-> 12 return a + b
13 }
14
(cjdb)
当遇到函数调用的时候,可通过s命令进入到被调函数的定义声明处
注意,如果被调函数是仓颉标准库函数,则不会进入,若该标准库函数有调用用户函数,同样也不会进入,此时执行该命令等同于n/next命令
函数退出,finish
(cjdb) s
Process 5240 stopped
* thread #1, name = 'test', stop reason = step in
frame #0: 0x0000000000401547 test`default.test(a=10, b=34) at test.cj:12:10
9
10 func test(a : Int32, b : Int32) : Int32 {
11
-> 12 return a + b
13 }
14
(cjdb) finish
Process 5240 stopped
* thread #1, name = 'test', stop reason = step out
Return value: (int) $0 = 44
frame #0: 0x00000000004014dd test`default.main() at test.cj:6:7
3
4 var a : Int32 = 12
5 a = a + 23
-> 6 a = test(10, 34)
7 return 1
8 }
9
(cjdb)
执行finish命令,退出当前函数,返回到上一个调用栈函数
变量查看
查看局部变量,locals
(cjdb) locals
(Int32) a = 12
(Int64) b = 68
(Int32) c = 13
(Array<Int64>) array = {
[0] = 2
[1] = 4
[2] = 6
}
(pkgs.Rec) newR2 = {
age = 5
name = "string"
}
(cjdb)
当调试器停到程序的某个位置时,使用locals可以看到程序当前位置所在函数生命周期范围内,所有的局部变量,只能正确查看当前位置已经初始化的变量,当前未初始化的变量无法正确查看
查看单个变量,print variable_name
例:print b
(cjdb) print b
(Int64) $0 = 110
(cjdb)
使用print命令,后跟要查看具体变量的名字,也可用简写p
查看 String 类型变量
(cjdb) print newR2.name
(String) $0 = "string"
(cjdb)
查看 struct、class 类型变量
(cjdb) print newR2
(pkgs.Rec) $0 = {
age = 5
name = "string"
}
(cjdb)
查看数组
(cjdb) print array
(Array<Int64>) $0 = {
[0] = 2
[1] = 4
[2] = 6
[3] = 8
}
(cjdb) print array[1..3]
(Array<Int64>) $1 = {
[1] = 4
[2] = 6
}
(cjdb)
支持查看基础类型(Int8,Int16,Int32,Int64,UInt8,UInt16,UInt32,UInt64,Float16,Float32,Float64,Bool,Unit,Char)
支持范围查看,区间 [start..end) 为左闭右开区间,暂不支持逆序
对于非法区间或对非数组类型查看区间会报错提示
(cjdb) print array
(Array<Int64>) $0 = {
[0] = 0
[1] = 1
}
(cjdb) print array[1..3]
error: unsupported expression
(cjdb) print array[0][0]
error: unsupported expression
查看 CString 类型变量
(cjdb) p cstr
(cro.CString) $0 = "abc"
(cjdb) p cstr
(cro.CString) $1 = null
查看全局变量,globals
(cjdb) globals
(Int64) pkgs.Rec.g_age = 100
(Int64) pkgs.g_var = 123
(cjdb)
包名为 default 的全局变量,查看时不显示 default 包名,只显示变量名
用 print 命令查看单个全局变量时,不支持 print+包名+变量名查看全局变量,仅支持 print+变量名进行查看,例如查看全局变量 g_age 应该用如下命令查看
(cjdb) p g_age
(Int64) $0 = 100
(cjdb)
变量修改
(cjdb) set a=30
(Int32) $4 = 30
(cjdb)
可以使用set修改某个局部变量的值,只支持基础数值类型(Int8,Int16,Int32,Int64,UInt8,UInt16,UInt32,UInt64,Float32,Float64)
对于 Bool 类型的变量,可以使用数值 0(false)和非 0(true)进行修改,Char 类型变量,可以使用对应的 ASCII 码进行修改
(cjdb) set b = 0
(Bool) $0 = false
(cjdb) set b = 1
(Bool) $1 = true
(cjdb) set c = 0x41
(Char) $2 = 'A'
(cjdb)
如果修改的值为非数值,或是超出变量的范围,则会报错提示
(cjdb) p c
(Char) $0 = 'A'
(cjdb) set c = 'B'
error: unsupported expression
(cjdb) p b
(Bool) $1 = false
(cjdb) set b = true
error: unsupported expression
(cjdb) p u8
(UInt8) $3 = 123
(cjdb) set u8 = 256
error: unsupported expression
(cjdb) set u8 = -1
error: unsupported expression
仓颉线程查看
支持查看仓颉线程 id 状态以及 frame 信息,暂不支持仓颉线程切换
查看所有仓颉线程
(cjdb) cjthread list
cjthread id: 1, state: running name: cjthread1
frame #0: 0x000055555557c140 main`ab::main() at varray.cj:16:1
cjthread id: 2, state: pending name: cjthread2
frame #0: 0x00007ffff7d8b9d5 libcangjie-runtime.so`CJ_CJThreadPark + 117
(cjdb)
查看仓颉线程调用栈
查看指定仓颉线程调用栈
(cjdb) cjthread backtrace 1
cjthread #1 state: pending name: cangjie
frame #0: 0x00007ffff7d8b9d5 libcangjie-runtime.so`CJ_CJThreadPark + 117
frame #1: 0x00007ffff7d97252 libcangjie-runtime.so`CJ_TimerSleep + 66
frame #2: 0x00007ffff7d51b5d libcangjie-runtime.so`CJ_MRT_FuncSleep + 33
frame #3: 0x0000555555591031 main`std/sync::sleep(std/time::Duration) + 45
frame #4: 0x0000555555560941 main`default::lambda.0() at complex.cj:9:3
frame #5: 0x000055555555f68b main`default::std/core::Future<Unit>::execute(this=<unavailable>) at future.cj:124:35
frame #6: 0x00007ffff7d514f1 libcangjie-runtime.so`___lldb_unnamed_symbol1219 + 7
frame #7: 0x00007ffff7d4dc52 libcangjie-runtime.so`___lldb_unnamed_symbol1192 + 114
frame #8: 0x00007ffff7d8b09a libcangjie-runtime.so`CJ_CJThreadEntry + 26
(cjdb)
cjthread backtrace 1 命令中 1 为指定的 cjthread ID
注意事项
-
进行调试的程序必须已经经过编译的 debug 版本,如使用下述命令编译的程序文件:
cjc -g test.cj -o test
FAQs
-
docker 环境下 cjdb 报
error: process launch failed: 'A' packet returned an error: 8root@xxx:/home/cj/cangjie-example#cjdb ./hello (cjdb) target create "./hello" Current executable set to '/home/cj/cangjie-example/hello' (x86_64). (cjdb) b main Breakpoint 1: 2 locations. (cjdb) r error: process launch failed: 'A' packet returned an error: 8 (cjdb)问题原因:docker 创建容器时,未开启 SYS_PTRACE 权限
解决方案:创建新容器时加上如下选项,并且删除已存在容器
docker run --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --security-opt apparmor=unconfined -
cjdb 报
stop reason = signal XXXProcess 32491 stopped * thread #2, name = 'PoolGC_1', stop reason = signal SIGABRT frame #0: 0x00007ffff450bfb7 lib.so.6`__GI_raise(sig=2) at raise.c:51问题原因:程序持续产生 SIG 信号触发调试器暂停
解决方案:可执行如下命令屏蔽此类信号
(cjdb) process handle --pass true --stop false --notify true SIGBUS NAME PASS STOP NOTIFY =========== ===== ===== ====== SIGBUS true false true (cjdb) -
在 spawn 或使用 sleep 语句的场景,执行
next命令,没有停在下一步(cjdb) next i number = 1 Process 22768 stopped * thread #1, name = 'cjdb_sleep', stop reason = step over frame #0: 0x00000000004015ed cjdb_sleep`default.main() at cjdb_sleep.cj:4:5 1 main() { 2 for (i in 0..5) { 3 print("i number = ${i}\n") -> 4 sleep(100 * Duration.millisecond) // sleep for 100ms. 5 } 6 var ava :Int8 = 3 7 return 0 (cjdb) next i number = 2 i number = 3 i number = 4 Process 22768 exited with status = 0 (0x00000000)问题原因:cjdb 执行
next默认是单线程模式解决方案:使用
next -m all-threads可减少此问题出现概率;或者在启动调试前设置环境变量cjProcessorNum为 1,这样做会使并发线程数量为 1,协程运行框架只有一个线程,不会涉及线程切换:export cjProcessorNum=1 -
由于仓颉 runtime 中的 GC 使用 SIGSEGV 信号实现,cjdb 在启动时会默认不捕获 SIGSEGV 信号,用户如果需要在调试时捕获此信号,可使用命令重新设置,例如
process handle -p true -s true -n true SIGSEGV将设置 Pass Stop NOTIFY 动作为 true。 -
在调试代码过程中发生异常时, 如果 catch 语句块中未包含断点,那么无法通过
next/s等调试指令进入 catch 块。其原因在于:仓颉使用 LLVM 的 LandingPad 机制的来实现异常处理, 而该机制无法通过控制流明确 try 语句块中的抛出的异常会由哪一个 catch 语句块捕获,所以无法明确执行的代码。类似问题在 clang++ 中也存在。 -
用户定义了一个泛型对象后,调试单步进入该对象的 init 函数时,栈信息显示的函数名称会包含两个包名,一个是实例化该泛型对象所在的包名,另外一个是泛型定义所在的包名。
* thread #1, name = 'main', stop reason = step in frame #0: 0x0000000000404057 main`default.p1.Pair<String, Int64>.init(a="hello", b=0) at a.cj:21:9 18 let x: T 19 let y: U 20 public init(a: T, b: U) { -> 21 x = a 22 y = b 23 } -
对于
Enum类型的显示, 如果该Enum的构造器存在参数的情况下, 会显示成如下样式:enum E { Ctor(Int64, String) | Ctor } main() { var temp = E.Ctor(10, "String") 0 } ======================================== (cjdb) p temp (E) $0 = Ctor { arg_1 = 10 arg_2 = "String" }其中
arg_x并非是一个可打印的成员变量,Enum内实际并没有命名为arg_x的成员变量。 -
仓颉
CJDB基于lldb构建, 所以支持lldb原生基础功能,详情见lldb官方文档:https://lldb.llvm.org。
附录
cjdb 独有命令
| 命令 | 简写 | 简要描述 | 参数说明 |
|---|---|---|---|
| globals | 无 | 查看全局变量 | 无参数 |
| locals | 无 | 查看局部变量 | 无参数 |
| p | 查看单个变量 | 参数为变量名称,例 print variable_name | |
| set | 无 | 修改变量 | 参数为表达式,例 set variable_name = value |
| finish | 无 | 函数退出 | 无参数 |
| cjthread | 无 | 轻量级线程查看 | 无参数 |
仓颉语言静态检查工具使用指南
功能简介
cjlint是一款静态检查工具,该工具是基于 Cangjie Programming Language CodingStyle 开发。通过它可以识别代码中不符合编程规范的问题,帮助开发者发现代码中的漏洞,写出满足 Clean Source 要求的仓颉代码。
使用说明
cjlint -f fileDir [option] fileDir...
注意:-f 后面指定的是*.cj 文件所在src目录
正例:
cjlint -f xxx/xxx/src
反例:
cjlint -f xxx/xxx/src/xxx.cj
注:上述限制来自编译器模块编译限制, 因为当前编译器编译选项正在重构,相关 API 不稳定;而模块编译较为稳定,因此工具当前仅支持模块编译方式。最终工具支持的编译选项会与编译器一致,支持其他编译方式。
命令行选项 - [option]
Options:
-h Show usage
eg: ./cjlint -h
-f <value> Detected file directory, it can be absolute path or relative path, if it is directory, default file name is cjReport
eg: ./cjlint -f fileDir -c . -m .
-e <v1:v2:...> Excluded files, directories or configurations, splitted by ':'. Regular expressions are supported
eg: ./cjlint -f fileDir -e fileDir/a/:fileDir/b/*.cj
-o <value> Output file path, it can be absolute path or relative path
eg: ./cjlint -f fileDir -o ./out
-r [csv|json] Report file format, it can be csv or json, default is json
eg: ./cjlint -f fileDir -r csv -o ./out
-c <value> Directory path where the config directory is located, it can be absolute path or relative path to the executable file
eg: ./cjlint -f fileDir -c .
-m <value> Directory path where the modules directory is located, it can be absolute path or relative path to the executable file
eg: ./cjlint -f fileDir -m .
注意事项
-
用户可以通过
-r指定生成扫描报告的格式,目前支持json格式和csv格式。-r需要与-o选项配合使用,如果没有-o指定输出到文件,即使指定了-r也不会生成扫描报告。如果指定了-o没有指定-r,那么默认生成json格式的扫描报告。例:通过 -r 选项,生成 report.csv 的扫描报告:
cjlint -f ./src -r csv -o ./report // 生成report.csv文件 cjlint -f ./src -r csv -o ./output/report // 在output目录下生成report.csv文件 -
可执行文件
cjlint同目录下,有config和modules作为默认的配置目录和依赖目录。若有需要,用户可以用命令行选项-c,-m来指定config和modules所在的目录。例:指定的 config 和 modules 文件路径为:
./xxx/xxx/config和./xxx/xxx/modules则命令应为:
cjlint -f ./src -c ./xxx/xxx -m ./xxx/xxx -
可执行文件
cjlint同目录下的config配置目录中,有cjlint_rule_list.json和exclude_lists.json两个配置文件。其中,cjlint_rule_list.json为规则列表配置文件,用户可以通过增减其中的配置信息来决定进行哪些规则的检查。exclude_lists.json为告警屏蔽配置文件,用户可以通过添加告警信息来屏蔽某一条规则的某一条告警。例: 若用户只想检查如下 5 条规则,则
cjlint_rule_list.json配置文件中只添加要检查的 5 条规则。{ "RuleList": [ "G.FMT.01", "G.ENUM.01", "G.EXP.03", "G.OTH.01", "G.OTH.02" ] }例: 若用户想要屏蔽某一条规则的某一条告警,可以在
exclude_lists.json配置文件中添加屏蔽信息。注意:
path不必填写绝对路径,但必须有xxx.cj格式,为模糊匹配。line为告警行号,为精确匹配。colum为告警列号,可选择性填写进行列号精确匹配。{ "G.OTH.01" : [ {"path":"xxx/example.cj", "line":"42"}, {"path":"xxx/example.cj", "line":"42", "colum": "2"}, {"path":"example.cj", "line":"42", "colum": "2"} ] } -
支持源代码注释屏蔽告警
特殊注释 BNF
<content of cjlint-ignore comment> ::= "cjlint-ignore" [-start] <ignore-rule>{...} [description] | cjlint-ignore <-end> [description]
<ignore-rule> ::="!"<rule-name>
<rule-name> ::= <letters>
单行屏蔽正确示例 1,屏蔽 G.CHK.04 告警
void fetctl_process(const void *para)
{
if (para == NULL)
{
return; /*cjlint-ignore !G.CHK.04 */
}
}
单行屏蔽正确示例 2,屏蔽 G.CHK.04 告警
void fetctl_process(const void *para)
{
if (para == NULL)
{
return; // cjlint-ignore !G.CHK.04 description
}
}
多行屏蔽正确示例 1,屏蔽 G.CHK.04 告警
/*cjlint-ignore -start !G.CHK.04 description */
void fetctl_process(const void *para)
{
if (para == NULL)
{
return;
}
}
/* cjlint-ignore -end description */
多行屏蔽正确示例 2,屏蔽 G.CHK.04 告警
// cjlint-ignore -start !G.CHK.04 description
void fetctl_process(const void *para)
{
if (para == NULL)
{
return;
}
}
// cjlint-ignore -end description
多行屏蔽正确示例 3,屏蔽 G.CHK.04 告警
/**
* cjlint-ignore -start !G.CHK.04 description
*/
void fetctl_process(const void *para)
{
if (para == NULL)
{
return;
}
}
// cjlint-ignore -end description
单行屏蔽错误示例 1,屏蔽 G.CHK.04 告警
void fetctl_process(const void *para)
{
if (para == NULL)
{
return; /*cjlint-ignore !G.CHK.04!G.CHK.02 */
// ERROR: 规则间没用空格隔开,屏蔽告警失败
}
}
单行屏蔽错误示例 2,屏蔽 G.CHK.04 告警
void fetctl_process(const void *para)
{
if (para == NULL)
{
return; /*cjlint-ignore !G.CHK.04description */
// ERROR: 规则与描述信息没用空格隔开,屏蔽告警失败
}
}
多行屏蔽错误示例 1,屏蔽 G.CHK.04 告警
/* cjlint-ignore -start
* !G.CHK.04 description */
void fetctl_process(const void *para)
{
if (para == NULL)
{
return;
}
}
/* cjlint-ignore -end description */
// ERROR: 屏蔽规则没与 'cjlint-ignore' 在同一行,屏蔽告警失败
注意
- 特殊注释的
cjlint-ignore与选项-start和-end以及屏蔽的规则需要写在同一行上,否则无法进行告警屏蔽。描述信息可以写在不同行。 - 单行屏蔽,屏蔽规则与屏蔽规则间需要用空格隔开,
cjlint会将特殊注释所在行的对应规则告警进行屏蔽。 - 多行屏蔽,
cjlint会以含有-start的特殊注释为起始行,以含有-end的特殊注释为结束行,将其间对应的规则进行屏蔽。含有-end的特殊注释会与其上方最近的含有-start的特殊注释相匹配。
文件级告警屏蔽
-
cjlint可以通过-e选项支持文件级别的告警屏蔽。通过在
-e后添加屏蔽规则,即可将规则匹配的仓颉文件屏蔽,不会产生关于这些文件的告警。输入的规则为相对-f源码目录的相对路径(支持正则),输入字符串需要用双引号包含,多条屏蔽规则用空格分隔。例如,下面这条命令屏蔽了src/dir1/目录内的所有仓颉文件,src/dir2/a.cj文件和src/目录下所有形如test*.cj的仓颉文件。cjlint -f src/ -e "dir1/ dir2/a.cj test*.cj" -
cjlint可以通过后缀为.cfg的配置文件批量导入屏蔽规则。通过
-e选项导入配置文件,与其他屏蔽规则或配置文件用空格分隔。例如,下面这条命令屏蔽了src/dir1目录和src/exclude_config_1.cfg、src/dir2/exclude_config_2.cfg内配置的所有屏蔽规则对应的文件。cjlint -f src/ -e "dir1/ exclude_config_1.cfg dir2/exclude_config_2.cfg".cfg配置文件中可以配置多条屏蔽规则,每行均为一条屏蔽规则,屏蔽规则为相对该配置文件所在目录的相对路径(支持正则),无需双引号包含。例如在src/dir2/exclude_config_2.cfg中有以下配置,则上述的命令会将src/dir2/subdir1/目录和src/dir2/subdir2/a.cj文件加入屏蔽。subdir1/ subdir2/a.cj -
cjlint可以通过默认配置文件批量导入屏蔽规则。cjlint屏蔽功能的默认配置文件名为cjlint_file_exclude.cfg,位置在-f源码目录下。例如,当src/目录下存在src/cjlint_file_exclude.cfg这一配置文件时,cjlint -f src/命令会屏蔽src/cjlint_file_exclude.cfg内配置的屏蔽规则对应的文件。如果用户已经在-e选项中配置了其他有效的.cfg配置文件,则cjlint不会检查默认配置文件。 -
cjlint的屏蔽规则语法对标gitignore,详见 gitignore 语法官方文档。
支持检查的规范列表(持续新增中)
cjlint 默认启用的规范列表:
- G.NAM.01 包名采用全小写单词,允许包含数字和下划线
- G.NAM.02 源文件名采用全小写加下划线风格
- G.NAM.03 接口,类,struct、枚举类型和枚举成员构造,类型别名,采用大驼峰命名
- G.NAM.04 函数名称应采用小驼峰命名
- G.NAM.05 let 的全局变量和 static let 变量的名称采用全大写
- G.FMT.01 源文件编码格式(包括注释)必须是 UTF-8
- G.FUNC.01 函数功能要单一
- G.FUNC.02 禁止函数有未被使用的参数
- G.CLS.01 override 父类函数时不要增加函数的可访问性
- G.ITF.02 尽量在类型定义处就实现接口,而不是通过扩展实现接口
- G.ITF.03 类型定义时避免同时声明实现父接口和子接口
- G.ITF.04 尽量通过泛型约束使用接口,而不是直接将接口作为类型使用
- G.OP.01 尽量避免违反使用习惯的操作符重载
- G.OP.02 尽量避免在枚举类型内定义
()操作符重载函数 - G.ENUM.01 避免枚举的构造成员与顶层元素同名
- G.ENUM.02 尽量避免不同的 enum 的 constructor 之间不必要的重载
- G.VAR.01 优先使用不可变变量(CJVM 后端暂不支持)
- G.EXP.01 match 表达式同一层尽量避免不同类别的 pattern 混用
- G.EXP.02 不要期望浮点运算得到精确的值
- G.EXP.03 && 、 ||、? 和 ?? 操作符的右侧操作数不要包含副作用
- G.EXP.05 用括号明确表达式的操作顺序,避免过分依赖默认优先级
- G.EXP.06 Bool 类型比较应避免多余的 == 或 !=
- G.EXP.07 比较两个表达式时,左侧倾向于变化,右侧倾向于不变
- G.ERR.02 防止通过异常抛出的内容泄露敏感信息
- G.ERR.03 避免对 Option 类型使用 getorthrow 函数
- G.PKG.01 避免在 import 声明中使用通配符*
- G.CON.01 禁止将系统内部使用的锁对象暴露给不可信代码
- P.01 使用相同的顺序请求锁,避免死锁
- G.CON.02 在异常可能出现的情况下,保证释放已持有的锁
- G.CON.03 禁止使用非线程安全的函数来覆写线程安全的函数
- P.02 避免数据竞争(data race)
- G.CHK.01 跨信任边界传递的不可信数据使用前必须进行校验
- G.CHK.02 禁止直接使用外部数据记录日志
- G.CHK.04 禁止直接使用不可信数据构造正则表达式
- G.FIO.01 临时文件使用完毕必须及时删除
- G.SER.01 禁止序列化未加密的敏感数据
- G.SER.02 防止反序列化被利用来绕过构造方法中的安全操作
- G.SER.03 保证序列化和反序列化的变量类型一致
- G.SEC.01 进行安全检查的方法禁止声明为
open - G.OTH.01 禁止在日志中保存口令、密钥和其他敏感数据
- G.OTH.02 禁止将敏感信息硬编码在程序中
- G.OTH.03 禁止代码中包含公网地址
- G.OTH.04 不要使用 String 存储敏感数据,敏感数据使用结束后应立即清 0
cjlint 能够检测,但默认不启用的规范列表(用户可通过将规范添加至 cjlint_rule_list.json 以启用这类规则):
- G.VAR.03 避免使用全局变量
规格说明
-
G.CON.02 在异常可能出现的情况下,保证释放已持有的锁
lock() 函数和 unlock() 函数赋值给变量,赋值后的变量再去加解锁的场景,该规则检查不覆盖。
-
G.OTH.03 暂不支持宏检查
-
只有当宏包在正确的路径下时,
cjlint才能支持宏检查例:a.cj 为宏包源码,其正确路径应为 xxx/src/a/a.cj
-
cjlint只有在宏被调用时才能对其进行检查,且无法对宏包中的冗余代码进行检查
支持语法禁用检查
-
cjlint可以通过将 G.SYN.01 添加至cjlint_rule_list.json以启用禁用语法的检查。如果使用了禁用的语法元素,cjlint将会报错。 -
当前所支持
cjlint检查的禁用语法如表中所示:禁用语法 关键词 说明 导入包 Import 不允许随意导入包 let 变量 Let 只用 var 变量,不引入不可写变量的概念 创建线程 Spawn 不允许创建线程 线程同步 Synchronized 防止死锁 主函数 Main 禁止提供入口主函数 定义宏 MacroQuote 禁止定义宏(但允许使用宏) 跨语言 Foreign 禁止跨语言混合编程 while 循环 While 防止复杂循环和死循环 扩展 Extend 禁止使用扩展语法 类型别名 Type 禁止自行定义类型别名 操作符重载 Operator 禁止重载操作符 全局变量 GlobalVariable 禁止声明和使用全局变量,防止副作用和内存泄漏 定义枚举 Enum 禁用 Enum,避免复杂代码 定义类 Class 禁用 Class,避免复杂代码 定义接口 Interface 禁用 Interface,避免复杂代码 定义结构 Struct 禁用 Struct,避免复杂代码 定义泛型 Generic 禁用 Generic,避免复杂代码 条件编译 When 禁止平台相关代码 自动微分 Differentiable 禁用 Differentiable 模式匹配 Match 函数式编程范式,开发者不易掌握 捕获异常 TryCatch 避免自行处理异常,易导致错误被忽略 高阶函数 HigherOrderFunc 函数类型的参数或返回值, 避免复杂代码 其他基础类型 PrimitiveType 不应使用 Int64、float64、bool 之外的其他基础类型 其他容器类型 ContainerType 应使用 List,Map,Set -
通过将上述表格中的关键字添加到
structural_rule_G_SYN_01.json中启用对应语法的禁用检查。举例:禁用导入包
{
"SyntaxKeyword": [
"Import"
]
}
仓颉语言格式化工具使用指南
功能简介
cjfmt仓颉格式化工具是一款基于 Cangjie Programming Language CodingStyle 开发的代码自动格式化工具。
使用说明
- 可以在 VS Code 安装本工具插件进行使用
- 使用命令行操作
cjfmt [option] file [option] file
cjfmt -h 帮助信息,选项介绍
Usage:
cjfmt -f fileName [-o fileName]
cjfmt -d fileDir [-o fileDir]
Options:
-h Show usage
eg: cjfmt -h
-d Specifies the file directory in the required format. The value can be a relative path or an absolute path.
eg: cjfmt -d test/
-o <value> Output. If a single file is formatted, '-o' is followed by the file name. Relative and absolute paths are supported;
If a file in the file directory is formatted, a path must be added after -o. The path can be a relative path or an absolute path.
eg: cjfmt -f a.cj -o ./fmta.cj
eg: cjfmt -d ~/testsrc -o ./testout
-l <region> Only format lines in the specified region for the provided file. Only valid if a single file was specified.
Region has a format of [start:end] where 'start' and 'end' are integer numbers representing first and last lines to be formated in the specified file.
Line count starts with 1.
eg: cjfmt -f a.cj -o ./fmta.cj -l 1:25
使用命令行进行格式化操作,如果没有指定-d,那么只对一个仓颉文件进行格式化,-o指定的是仓颉文件。
如果指定了-d,那么是对一个目录下的所有仓颉文件进行格式化,-o指定的是目录。
//选项-o 新建一个.cj文件导出格式化后的代码,源文件和输出文件支持相对路径和绝对路径。
例子1:
cjfmt -f ../../../test/uilang/Thread.cj -o ../../../test/formated/Thread.cj
//格式化并覆盖源文件,支持相对路径和绝对路径。
例子2:
cjfmt -f ../../../test/uilang/Thread.cj
//选项-d让用户指定扫描仓颉源代码目录,对文件夹下的仓颉源码格式化,支持相对路径和绝对路径。
//选项-o为输出目录,可以是已存在的路径,若不存在则会创建相关的目录结构,支持相对路径和绝对路径。
//目录的最大长度MAX_PATH不同的系统之间存在差异,如Windows上这个值一般不能超过260;在Linux上这个值一般建议不能超过4096。
例子1:
cjfmt -d test/ //源文件目录为相对目录。
cjfmt -d test/ -o /home/xxx/testout
例子2:
cjfmt -d /home/xxx/test //源文件目录为绝对目录。
cjfmt -d /home/xxx/test -o ../testout/
例子3:
cjfmt -d testsrc/ -o /home/../testout 源文件文件夹testsrc/不存在;报错:error: Source file path not exist!
//选项-l允许用户指定应格式化文件的哪一部分。格式化程序将仅对提供的行范围内的源代码应用规则。
//-l选项仅适用于格式化单个文件(选项-f)。如果指定了目录(选项-d),则-l选项无效。
例子:
cjfmt -f a.cj -o .cj -l 10:25 //仅格式化第10行至第25行
格式化规则
- 一个源文件按顺序包含版权、package、import、顶层元素,且用空行分隔。
【正例】
// 第一部分,版权信息
/*
* Copyright (c) Huawei Technologies Co., Ltd. 2020-2020. All rights reserved.
*/
// 第二部分,package 声明
package com.huawei.myproduct.mymodule
// 第三部分,import 声明
from std import collection.HashMap // 标准库
// 第四部分,public 元素定义
public class ListItem <: Component {
// ...
}
// 第五部分,internal 元素定义
class Helper {
// CODE
}
注意:仓颉格式化工具不会强制用空行将版权信息部分与其他部分分隔,若用户在版权信息下方留有一个或多个空行,则格式化工具会保留一个空行。
- 采用一致的空格缩进,每次缩进 4 个空格。
【正例】
class ListItem {
var content: Array<Int64> // 符合:相对类声明缩进 4 个空格
init(
content: Array<Int64>, // 符合:函数参数相对函数声明缩进 4 个空格
isShow!: Bool = true,
id!: String = ""
) {
this.content = content
}
}
- 使用统一的大括号换行风格,对于非空块状结构,大括号使用 K&R 风格。
【正例】
enum TimeUnit { // 符合:跟随声明放行末,前置 1 空格
Year | Month | Day | Hour
} // 符合:右大括号独占一行
class A { // 符合:跟随声明放行末,前置 1 空格
var count = 1
}
func fn(a: Int64): Unit { // 符合:跟随声明放行末,前置 1 空格
if (a > 0) { // 符合:跟随声明放行末,前置 1 空格
// CODE
} else { // 符合:右大括号和 else 在同一行
// CODE
} // 符合:右大括号独占一行
}
// lambda 函数
let add = { base: Int64, bonus: Int64 => // 符合: lambda 表达式中非空块遵循 K&R 风格
print("符合 news")
base + bonus
}
- 按照 Cangjie Programming Language CodingStyle 中的规则 G.FMT.10,使用空格突出关键字和重要信息。
【正例】
var isPresent: Bool = false // 符合:变量声明冒号之后有一个空格
func method(isEmpty!: Bool): RetType { ... } // 符合:函数定义(命名参数 / 返回类型)中的冒号之后有一个空格
method(isEmpty: isPresent) // 符合: 命名参数传值中的冒号之后有一个空格
0..MAX_COUNT : -1 // 符合: range 操作符区间前后没有空格,步长冒号前后两侧有一个空格
var hundred = 0
do { // 符合:关键字 do 和后面的括号之间有一个空格
hundred++
} while (hundred < 100) // 符合:关键字 while 和前面的括号之间有一个空格
func fn(paramName1: ArgType, paramName2: ArgType): ReturnType { // 符合:圆括号和内部相邻字符之间不出现空格
...
for (i in 1..4) { // 符合:range 操作符左右两侧不留空格
...
}
}
let listOne: Array<Int64> = [1, 2, 3, 4] // 符合:方括号和圆括号内部两侧不出现空格
let salary = base + bonus // 符合:二元操作符左右两侧留空格
x++ // 符合:一元操作符和操作数之间不留空格
- 减少不必要的空行,保持代码紧凑。
【反例】
class MyApp <: App {
let album = albumCreate()
let page: Router
// 空行
// 空行
// 空行
init() { // 不符合:类型定义内部使用连续空行
this.page = Router("album", album)
}
override func onCreate(): Unit {
println( "album Init." ) // 不符合:大括号内部首尾存在空行
}
}
- 按照 Cangjie Programming Language CodingStyle 中的规则 G.FMT.12 规定的优先级排列修饰符关键字。
以下是推荐的顶层元素的修饰符排列优先级:
public
open/abstract
以下是推荐的实例成员函数或实例成员属性的修饰符排序优先级:
public/protected/private
open
override
以下是推荐的静态成员函数的修饰符排序优先级:
public/protected/private
static
redef
以下是推荐的成员变量的修饰符排序优先级:
public/protected/private
static
- 多行注释的格式化行为
以 * 开头的注释, * 会互相对齐, 不以 * 开头的注释,则会保持注释原样。
// 格式化前
/*
* comment
*/
/*
comment
*/
//格式化后
/*
* comment
*/
/*
comment
*/
注意事项
仓颉格式化工具暂不支持语法错误的代码的格式化
仓颉格式化工具暂不支持元编程的格式化。
仓颉语言覆盖率统计工具使用指南
功能简介
cjcov(Cangjie Coverage)是仓颉语言的官方覆盖率统计工具,用于生成仓颉语言程序的覆盖率报告。
使用说明
通过 cjcov -h 即可查看命令使用方法,如下所示。由几个板块组成,从上到下分别是:当前命令使用形式(Usage)、当前命令用途、支持的可用参数(Options)。
Usage: cjcov [options]
A tool used to summarize the coverage in html reports.
Options:
-v, --version Print the version number, then exit.
-h, --help Show this help message, then exit.
-r ROOT, --root=ROOT The root directories of your source files, defaults to '.', the current directory.
File names are reported relative to this root.
-o OUTPUT, --output=OUTPUT The output directories of html reports, defaults to '.', the current directory.
-b, --branches Report the branch coverage. (It is an experimental feature and may generate imprecise branch coverage.)
--verbose Print some detail messages, including parsing data for the gcov file.
--html-details Generate html reports for each source file.
-x, --xml Generate a xml report.
-j, --json Generate a json report.
-k, --keep Keep gcov files after processing.
-s SOURCE, --source=SOURCE The directories of cangjie source files.
-e EXCLUDE, --exclude=EXCLUDE
The cangjie source files starts with EXCLUDE will not be showed in coverage reports.
-i INCLUDE, --include=INCLUDE
The cangjie source files starts with INCLUDE will be showed in coverage reports.
基本的使用操作命令如下所示,cjcov 是主程序的名称,--version 表示显示 cjcov 的版本号。部分配置项支持长短选项的写法,效果相同,具体可以用 cjcov --help 参考用法。
cjcov -version 或者 cjcov -v
环境要求
依赖仓颉版本包里的 cjc 和 llvm-cov,正确安装仓颉版本包即可。
使用步骤
仓颉版本包准备 --> 仓颉源码准备 --> 编译源码,cjc --coverage 或者 cjpm --coverage 编译 --> 运行编译出来的二进制 --> cjcov 生成覆盖率统计结果
下面举一个 hello world 的覆盖率的例子:
假设当前目录是 WORKPATH 。
1)仓颉版本包准备
假设仓颉版本包解压在WORKPATH目录下,则source WORKPATH/cangjie/envsetup.sh即可。使用 which cjcov 可以查看到 cjcov 命令。
2)仓颉源码准备
源码目录结构如下:
src/
└── main.cj
main.cj 源码内容:
main(): Int64 {
print("hello world\n")
return 0
}
3)编译源码,该例子用 cjpm 编译举例
在 WORKPATH 目录下执行以下命令
cjpm init cangjie test
cjpm build --coverage
编译完成之后在 WORKPATH 目录下会有一个 default.gcno
4)运行编译出来的二进制
在 WORKPATH 目录下执行 cjpm run
运行完成之后 WORKPATH 目录下会有一个 default.gcda
5)cjcov 生成 html
在 WORKPATH 目录执行 cjcov -o output --html-details,更多 cjcov 参数使用可参考下一章节 "命令介绍"。
执行完 cjcov 命令之后,在 WORKPATH/output 目录会有以下文件:
output/
├── cjcov_logs (该目录存放一些 cjcov 执行过程的详细日志,可不用关注)
│ ├── cjcov.log
│ └── gcov_parse.log
├── index.html (总的覆盖率报告,通过浏览器打开)
└── src_main.cj.html (单个文件的覆盖率,可以通过打开 index.html 自动跳转到该文件)
命令介绍
cjcov -h | --help
显示 cjcov 基本使用方法
cjcov -v | --version
显示 cjcov 的版本号,只要指定了 -v 或者 --version 参数,不管输入其他任何选项参数都不生效,只会显示版本号。如 --version 和 --help 同时使用,则显示 version 信息后退出。(参考 linux 命令的显示方法,如 grep)
cjcov --verbose
输出 cjcov 命令的一些中间信息到 cjcov_logs 目录的日志中,该参数默认不生效, 即默认不会打印中间信息。
cjcov 解析 gcov 文件的中间信息,格式如下:
==================== start: main.cj.gcov =====================
noncode line numbers:
[0, 0, 0, 0, 1, 2, 6, 7, 9, 10, 11, 15, 17, 18]
uncovered line numbers:
[5]
covered data:
[(16, 1), (3, 1), (4, 1), (8, 1), (12, 1), (13, 1), (14, 1)]
branches data:
line number: 4 ==> data: [(0, 0), (1, 1)]
===================== end: main.cj.gcov =======================
指定该选项参数,会显示每个 gcov 文件的详细覆盖率数据。
具体字段解释如下:
- start: xxx.gcov, end: xxx.gcov 两行中间的文本是对应 xxx.gcov 文件解析到的覆盖率数据。
- noncode line numbers:显示的是不统计到总代码行的行号,在 html 中是以白色底呈现,对应 gcov 中的以-开头的行数。
- uncovered line numbers:显示的是没有覆盖到的数据,在 html 中是以红色底呈现,对应 gcov 文件中以#####开头的行数。
- covered data:显示的是覆盖到的数据,以(代码行数,覆盖次数)呈现,在对应子 html 中以绿色呈现,只要覆盖次数大于 0,在 html 中的 Exec 一列中显示为 Y。对应于 gcov 文件以数字开头的行数。
- branches data:显示的分支覆盖数据,以(代码行数,分支覆盖次数)呈现,在对应子 html 中的 Branch 一列中,有一个倒三角形,显示的是分支覆盖数/总分支数。该数据对应于 gcov 文件中以 branch 开头的数据。
cjcov --html-details
如果指定该参数,表示会生成仓颉文件对应的 html。在总的 index 文件里面会有每个子 html 的索引。子 html 文件和 index.html 放在同一个目录。
子 html 文件名是由目录和文件名由下划线拼接起来。如源文件是 src/main.cj,生成的 html 名字为 src_main.cj.html 。如果源文件路径带有特殊字符会被替换成‘=’,第 6.1 节对特殊字符有详细的描述。
如果没有指定该参数,表示不会生成子 html 。在总的 index 文件里面会显示每个子 html 的覆盖率数据,但是不能跳转到对应的子 html 文件。
该参数默认不生效。即默认只会生成一个 index.html , 不会生成子 html 文件。
cjcov -x | --xml
如果指定该参数,则会在指定输出路径生成 coverage.xml 文件,coverage.xml 记录的是所有文件的覆盖率数据。
cjcov -j | --json
如果指定该参数,则会在指定输出路径生成 coverage.json 文件。
cjcov -k | --keep
该参数指定表示不会删除 gcov 中间文件。如果 gcov 文件不删除,会造成执行次数的累加,可能会影响覆盖率数据的准确性。
默认该参数不生效,即默认会删除 gcov 中间文件。
cjcov -b | --branches
分支覆盖率是一个试验阶段的功能,当前数据不是很精确,建议少用。
该参数指定表示会生成分支的覆盖率信息。不指定该参数,不会生成分支覆盖率数据,最终在 html 报告中分支覆盖率数据百分比为-。
默认该参数不生效,即默认不生成分支的覆盖率信息。
cjcov -r ROOT | --root=ROOT
该参数指定的 ROOT 参数,表示在 ROOT 目录或者在其递归子目录能找到 gcda 文件,gcda 和 gcno 文件默认会生成在一起,建议不要手动特意去把 gcda 文件和 gcno 文件分开存放,不然可能会发生程序不能运行的情况。
参数指定的 ROOT 目录如果不存在,cjcov 工具会有报错提示。
不指定该参数,默认会以当前目录为 ROOT 目录。
cjcov -o OUTPUT | --output=OUTPUT
该参数指定的 OUTPUT 参数,表示 html 覆盖率报告的输出路径。
如果该 OUTPUT 不存在,而且其父目录也不存在,cjcov 工具会有报错提示;如果 OUTPUT 目录不存在,但其父目录存在,cjcov 会帮助创建 OUTPUT 目录。
不指定该参数,默认会以当前目录为 OUTPUT 目录来存放 html 文件。
-s SOURCE | --source=SOURCE
该参数指定的 SOURCE 参数,表示仓颉源文件的代码路径,html 总覆盖率报告 index.html 会有各个源文件的索引,这些文件路径记录的是一个相对路径。如果指定 -s SOURCE |--source SOURCE 参数,优先以 SOURCE 路径列表中的路径作为相对路径的参考路径,如果没有指定该参数,则以 -r ROOT | --root=ROOT 作为相对路径的参考路径,如果都没有指定,则以当前路径作为相对路径的参考路径。
示例:
仓颉代码目录结构如下:
/work/cangjie/tests/API/test01/src/1.cj
/work/cangjie/tests/API/test01/src/2.cj
/work/cangjie/tests/LLVM/test02/src/3.cj
/work/cangjie-tools/tests/LLVM/test01/src/4.cj
/work/cangjie-tools/tests/LLVM/test02/src/5.cj
1)在 /work 目录执行命令:
cjcov --root=./ -s "/work/cangjie /work/cangjie-tools/tests" --html-details --output=html_output
最后 html 中呈现的源文件相对路径是
tests/API/test01/src/1.cj
tests/API/test01/src/2.cj
tests/LLVM/test02/src/3.cj
LLVM/test01/src/4.cj
LLVM/test02/src/5.cj
2)在 /work 目录执行命令, 没有指定 --root 参数和 --source 参数,默认当前所在路径为相对路径的参考路径,执行命令如下:
cjcov --html-details --output=html_output
最后 html 中呈现的源文件相对路径是:
cangjie/tests/API/test01/src/1.cj
cangjie/tests/API/test01/src/2.cj
cangjie/tests/LLVM/test02/src/3.cj
cangjie-tools/tests/LLVM/test01/src/4.cj
cangjie-tools/tests/LLVM/test02/src/5.cj
-e EXCLUDE | --exclude=EXCLUDE
该参数指定的 EXCLUDE 参数,表示不需要生成覆盖率信息的源文件列表,支持指定目录和文件
示例:
仓颉代码目录结构如下:
/usr1/cangjie/tests/API/test01/src/1.cj
/usr1/cangjie/tests/API/test01/src/2.cj
/usr1/cangjie/tests/LLVM/test02/src/3.cj
/usr1/cangjie-tools/tests/LLVM/test01/src/4.cj
/usr1/cangjie-tools/tests/LLVM/test02/src/5.cj
在 /usr1 目录执行命令:
cjcov --root=./ -s "/usr1/cangjie" -e "/usr1/cangjie-tools/tests/LLVM" --html-details --output=html_output
最后 html 中呈现的源文件相对路径是,其中以 /usr1/cangjie-tools/tests/LLVM 路径开头的文件不会出现在 html 的文件列表中。
tests/API/test01/src/1.cj
tests/API/test01/src/2.cj
tests/LLVM/test02/src/3.cj
-i INCLUDE | --include=INCLUDE
该参数指定的 INCLUDE 参数,表示以 INCLUDE 开头的文件会显示在 index.html 的文件列表中,支持指定目录和文件。如果 -e | --exclude 和 -i | --include 指定的参数有路径重复,会有报错提示。
示例:
目录/usr1/cangjie/tests仓颉代码目录结构如下:
.
├── API
│ └── test01
│ └── src
│ ├── 1.cj
│ └── 2.cj
└── LLVM
└── test02
└── src
└── 3.cj
在 /usr1 目录执行命令, 其中 -i 参数表示需要体现在覆盖率报告 index.html 的文件,命令如下:
cjcov --root=./ -s "/usr1/cangjie" -i "/usr1/cangjie/tests/API/test01/src/1.cj /usr1/cangjie/tests/LLVM/test02" --html-details --output=html_output
上面命令执行后, 在 index.html 中文件路径列表如下(tests/API/test01/src/2.cj 不在 -i 参数指定的列表里面,所以不会出现在 html 的文件列表中):
tests/API/test01/src/1.cj
tests/LLVM/test02/src/3.cj
特殊场景
对于常驻的网络服务程序无法正常结束并生成 gcda 覆盖率数据的场景,需要手动执行退出脚本生成 gdca 覆盖率数据
1)将以下脚本内容保存为 stop.sh (此脚本执行依赖 gdb )
#!/bin/sh
SERVER_NAME=$1
pid=`ps -ef | grep $SERVER_NAME | grep -v "grep" | awk '{print $2}'`
echo $pid
gdb -q attach $pid <<__EOF__
p exit(0)
__EOF__
2)常驻服务程序完成业务逻辑操作覆盖后,执行 stop.sh {service_name},如通过 ./main 启动常驻服务进程,通过如下方式停止进程产生 gcda 数据
sh stop.sh ./main
建议都遵循仓颉编程规范命名文件,不建议包含除[0-9a-zA-Z_]之外的字符,特殊字符会被替换成‘=’
如果文件名有特殊字符,为保证 html 跳转正确,index.html 中呈现的 html 名字和 html 本身文件名会不一致,html 文件名的特殊字符都会被替换成=。
示例如下:
代码结构:
src
├── 1file#.cj
├── file10_abc.cj
├── file11_.aaa-bbb.cj
├── file12!#aaa!bbb.cj
├── file13~####.cj
├── file14*aa.cj
├── file15`.cj
├── file16(#).cj
├── file2;aa.cj
├── file3,?.cj
├── file4@###.cj
├── file5&cc.cj
├── file6=.cj
├── file7+=.cj
├── file8$.cj
├── file9-aaa.cj
└── main.cj
生成 html 文件名,其中除了[0-9a-zA-Z_.=]之外,其他特殊字符都被替换成了'='
.
├── index.html
├── src_1file=.cj.html
├── src_file10_abc.cj.html
├── src_file11_.aaa=bbb.cj.html
├── src_file12==aaa=bbb.cj.html
├── src_file13=####.cj.html
├── src_file14=aa.cj.html
├── src_file15=.cj.html
├── src_file16===.cj.html
├── src_file2=aa.cj.html
├── src_file3==.cj.html
├── src_file4=###.cj.html
├── src_file5=cc.cj.html
├── src_file6=.cj.html
├── src_file7==.cj.html
├── src_file8=.cj.html
├── src_file9=aaa.cj.html
└── src_main.cj.html
分支覆盖率是一个试验阶段的功能,会出现分支覆盖率数据不准确的情况
目前已知会出现分支覆盖率数据不准确的场景包含以下几种表达式:
-
try-catch-finally表达式 -
循环表达式(包括
for表达式、while表达式) -
if-else表达式
部分代码不会记录到行覆盖率数据中,属于正常情况
整体而言,如果一行代码仅包含定义、声明而没有实际的可执行代码,那么这一行代码不会被统计到覆盖率中。目前已知不会统计的场景有:
-
全局变量的定义 ,示例如下:
let HIGH_1_UInt8: UInt8 = 0b10000000; -
成员变量仅声明未初始化赋值 ,示例如下:
public class StringBuilder <: Collection & ToString { private var myData: Array private var mySize: Int64 private var endIndex: Int64 } -
仅有函数声明未包含函数体(包括 foreign 函数等),示例如下:
foreign func cj_core_free(p: CPointer): Unit -
枚举类型定义 ,示例如下:
enum Numeric { NumDay | NumYearDay | NumYearWeek | NumHour12 | NumHour24 | NumMinute | NumSecond } -
class、extend 等定义,其中 extend 和 class 所在的一行不会记录到覆盖率数据中,示例如下:
extend Int8 <: Formatter { // This line wil not account for the coverage. ... } public class StringBuilder <: Collection & ToString { // This line will not account for the coverage. ... }
使用 cjc --test 编译,源代码中的 main 不会被覆盖
原因: 使用 cjc --test 编译,仓颉测试框架会生成一个新的 main 作为程序入口,源代码中的 main 不再作为程序入口并且不会被执行。
**建议:**在使用 cjc --test 之后,建议不用再手写多余的 main 。
FAQ
报错找不到 llvm-cov 命令
解决方法:
方法1:设置 CANGJIE_HOME 环境变量, cjcov 可通过 CANGJIE_HOME 环境变量找到 llvm-cov 命令,设置方法如下:
假设 which cjc 显示 /work/cangjie/bin/cjc, 并且 /work/cangjie/bin/llvm/bin和 /work/cangjie/bin/llvm/lib 目录都存在,则可设置:
export CANGJIE_HOME=/work/cangjie
方法2:在 /root/.bashrc 里面直接设置环境变量,如 cjc 放在 /work/cangjie/bin/cjc 目录下,则设置方法如下:
export PATH=/work/cangjie/bin/llvm/bin:$PATH
export LIBRARY_PATH=/work/cangjie/bin/llvm/lib:$LIBRARY_PATH
export LD_LIBRARY_PATH=/work/cangjie/bin/llvm/lib:$LD_LIBRARY_PATH
方法3:手动安装 llvm-cov 命令,如 ubuntu 上可执行命令:
apt install llvm-cov
出现 VirtualMachineError OutOfMemoryError
问题现象:
An exception has occurred:
Error VirtualMachineError OutOfMemoryError
**解决方法:**仓颉默认规格 stack 1MB,heap 256 MB,建议根据文件数量大小将堆内存调到合适的大小。一般 2GB 满足大多数情况,如果不够再视情况增加大小。
示例:
把堆内存扩大到2GB:
export cjHeapSize=2GB
仓颉性能分析工具使用指南
功能简介
cjprof(Cangjie Profile)是仓颉语言的性能分析工具,支持以下功能:
-
对仓颉语言程序进行 CPU 热点函数采样,导出采样数据。
-
对热点函数采样数据进行分析,生成 CPU 热点函数统计报告或火焰图。
-
导出仓颉语言应用程序堆内存,并对其进行分析生成分析报告。
目前 cjprof 仅支持 linux 系统。
使用说明
通过 cjprof --help 即可查看命令使用方法。支持 record,report 和 heap 子命令,分别用于采集 CPU 热点函数信息, 生成 CPU 热点函数报告(包含火焰图)和导出与分析堆内存。
cjprof --help
Usage: cjprof [--help] COMMAND [ARGS]
The supported commands are:
heap Dump heap into a dump file or analyze the heap dump file
record Run a command and record its profile data into data file
report Read profile data file (created by cjprof record) and display the profile
注意,由于 cjprof record 依赖系统的 perf 权限,因此使用需要满足以下两个条件之一:
-
使用 root 用户或 sudo 权限执行。
-
系统的
perf_event_paranoid参数(通过/proc/sys/kernel/perf_event_paranoid文件配置)配置为 -1 。
否则可能会报权限不足的问题。
采集 CPU 热点函数信息
命令
cjprof record
格式
cjprof record [<options>] [<command>]
cjprof record [<options>] -- <command> [<options>]
选项
-f, --freq <freq> 指定采样频率,单位为赫兹(Hz),即每秒采样次数,默认为 1000Hz,当指定为 max 或超过系统支持的最大频率时,取系统支持的最大频率。
-o, --output <file> 指定采样结束后生成的采样数据文件名,默认为 cjprof.data 。
-p, --pid <pid> 指定被采样应用程序的进程 ID,当指定 <command> 新启动应用程序进行采样时,该选项会被忽略。
示例
- 采样正在运行的应用程序。
cjprof record -f 10000 -p 12345 -o sample.data
说明:以 10000Hz 的采样频率对正在运行的应用程序(进程号为 12345)进行采样,采样结束后将采样数据生成在当前路径下名为 sample.data 的文件中。
- 新启动应用程序并对其进行采样。
cjprof record -f max -- ./test arg1 arg2
说明:执行当前路径下的 test 应用程序,参数为 arg1 arg2 ,并以系统支持的最大采样频率对其进行采样,采样结束后将采样数据生成在当前路径下名为 cjprof.data (默认文件名)的文件中。
说明
- 开始采样后,只有被采样程序退出后才会结束采样,如果需要提前结束采样,可以在采样过程中通过按
Ctrl+C主动停止采样。
生成 CPU 热点函数报告
命令
cjprof report
格式
cjprof report [<options>]
选项
-F, --flame-graph 生成 CPU 热点函数火焰图,而非默认的文本报告。
-i, --input <file> 采样数据文件名,默认为 cjprof.data 。
-o, --output <file> 生成的 CPU 热点函数火焰图文件名,默认为 FlameGraph.svg,仅当生成火焰图时才有效。
示例
- 生成默认的 CPU 热点函数文本报告。
cjprof report -i sample.data
说明:分析 sample.data 中的采样数据,生成 CPU 热点函数文本报告。
- 生成 CPU 热点函数火焰图。
cjprof report -F -o test.svg
说明:分析 cjprof.data (默认文件)中的采样数据,生成名为 test.svg 的 CPU 热点函数火焰图。
说明
-
文本形式的报告包含函数采样总占比(包含子函数)、函数采样占比(自身)以及函数名(如果没有对应的符号信息则显示为地址)三部分,报告结果以函数采样总占比降序排列。
-
火焰图中的横轴代表采样占比大小,越宽表示采样占比越大,即运行时间越长,纵轴表示调用栈,父函数在下,子函数在上。
导出和分析堆内存
命令
cjprof heap
格式
cjprof heap [<options>]
选项
-D, --depth <depth> 指定对象的引用/被引用关系最大展示深度,默认为 10 层,仅在指定了 --show-reference 时才能生效。
-d, --dump <pid> 导出仓颉应用程序当前时刻的堆内存,pid 为应用程序进程号,当指定为应用程序的子线程号时,同样可导出。
-i, --input <file> 指定进行分析的堆内存数据文件名,默认为 cjprof.data 。
-o, --output <file> 指定导出的堆内存数据文件名,默认为 cjprof.data 。
--show-reference[=<objnames>] 分析报告中展示对象的引用关系,objnames 为需要展示的对象名,多个对象使用 ; 隔开,不指定时默认展示所有对象。
--incoming-reference 展示对象的被引用关系,而非引用关系,需要与 --show-reference 配合使用。
-t, --show-thread 分析报告中展示仓颉线程栈,以及在栈中引用的对象。
-V, --verbose 维测选项,解析堆内存数据文件时打印解析日志。
示例
- 导出堆内存数据。
cjprof heap -d 12345 -o heap.data
说明:将正在运行的应用程序(进程号为 12345)当前时刻的堆内存导出到当前路径下名为 heap.data 的文件中。
注意,导出堆内存时会向进程发送 SIG_USR1 信号,在不确定目标进程是否为仓颉应用程序时,需要谨慎操作,否则可能会给目标进程误发送信号导致非预期错误。
- 分析堆内存数据,展示对象信息。
cjprof heap -i ~/heap.data
说明:解析并分析 ~ 目录下名为 heap.data 的堆内存数据文件,展示堆中各激活对象的对象类型名、实例个数、浅堆大小和深堆大小。效果如下:
Object Type Objects Shallow Heap Retained Heap
==================== ============= ============= =============
AAA 1 80 400
BBB 4 32 196
CCC 2 16 32
- 分析堆内存数据,展示仓颉线程栈及对象引用。
cjprof heap --show-thread
说明:解析并分析当前目录下名为 cjprof.data (默认文件)的堆内存数据文件,展示堆中各激活对象的对象类型名、实例个数、浅堆大小和深堆大小,以及仓颉线程栈与栈中引用的对象。效果如下:
Object Type Objects Shallow Heap Retained Heap
==================== ============= ============= =============
AAA 1 80 400
BBB 4 32 196
CCC 2 16 32
Object/Stack Frame Shallow Heap Retained Heap
=================================== ============= =============
thread0
at Func2() (/home/test/test.cj:10)
<local> AAA @ 0x7f1234567800 80 400
at Func1() (/home/test/test.cj:20)
<local> CCC @ 0x7f12345678c0 16 16
at main (/home/test/test.cj:30)
- 分析堆内存数据,展示仓颉线程栈及对象的引用关系。
cjprof heap --show-reference="default::Dirived;std/core::ArrayIterator<Int32>"
说明:解析并分析当前目录下名为 cjprof.data (默认文件)的堆内存数据文件,展示堆中各激活对象的对象类型名、实例个数、浅堆大小和深堆大小,以及 default::Dirived 和 std/core::ArrayIterator<Int32> 对象的引用关系。效果如下:
Object Type Objects Shallow Heap Retained Heap
==================== ============= ============= =============
AAA 1 80 400
BBB 4 128 196
CCC 2 32 32
Objects with outgoing references:
Object Type Shallow Heap Retained Heap
=================================== ============= =============
AAA @ 0x7f1234567800 80 400
BBB @ 0x7f1234567880 32 48
CCC @ 0x7f12345678c0 16 16
CCC @ 0x7f12345678e0 16 16
- 分析堆内存数据,展示仓颉线程栈及对象的被引用关系。
cjprof heap --show-reference="RawArray<std/core::String>[]" --incoming-reference
说明:解析并分析当前目录下名为 cjprof.data (默认文件)的堆内存数据文件,展示堆中各激活对象的对象类型名、实例个数、浅堆大小和深堆大小,以及 RawArray<std/core::String>[] 对象的被引用关系。效果如下:
Object Type Objects Shallow Heap Retained Heap
==================== ============= ============= =============
AAA 1 80 400
BBB 4 128 196
CCC 2 32 32
Objects with incoming references:
Object Type Shallow Heap Retained Heap
=================================== ============= =============
CCC @ 0x7f12345678c0 16 16
BBB @ 0x7f1234567880 32 48
AAA @ 0x7f1234567800 80 400
CCC @ 0x7f12345678e0 16 16
AAA @ 0x7f1234567800 80 400
说明
-
对象类型名使用
RawArray<Byte>[],RawArray<Half>[],RawArray<Word>[]和RawArray<DWord>[]分别表示 1 字节、2 字节、4 字节和 8 字节大小的基础数据类型原始数组。 -
浅堆是指对象自身所占用的堆内存大小,深堆是指对象被垃圾回收后,可以被释放的所有对象(即仅能通过该对象直接或间接引用到的对象)的浅堆大小之和。
-
当对象的引用关系层级超出最大展示深度后,或是存在循环引用出现重复对象后,会使用
...来省略后续引用。
仓颉 API 文档生成工具使用指南
cjdoc 整体介绍
cjdoc 是一个支持仓颉语言的 API 文档生成器。
cjdoc 能提取源文件的全局变量、函数、类、结构体、接口、枚举、扩展等语法的文档注释,并输出 HTML 格式的 API 接口文档。
文档注释介绍
什么是文档注释
文档注释是为自动生成文档而写的注释,它是一种带有特殊功能的注释。 cjdoc 能够识别遵循 cjdoc 风格注释的文档注释。
cjdoc 风格文档注释以 /** 开头、以 */ 结尾,并且当编辑多行注释时,每行要以星号开头。文档注释与一般注释的最大区别在于起始符号是/**而不是/*或//。
/**
* 这是文档注释
*/
/** 这是文档注释 */
/*
* 这是一般注释
*/
// 这是一般注释
文档注释格式
cjdoc 的一个文档注释由两部分组成,分别为描述部分和注解部分,描述部分又可分为简要描述和详细描述。不同的写法举例如下:
**说明:**以下写法的描述部分如果需要有换行效果,需要在换行地方加上\n
- 写法 1: 描述部分不分开
/**
* this is description (描述部分)
*
* @param parameter-name explanation (注解部分)
* @return explanation (注解部分)
*/
- 写法 2:只有描述部分
/**
* this is description (描述部分)
*/
- 写法 3:文档注释只有一行,描述部分不分开
/** this is description (描述部分)*/
- 写法 4:描述部分分简要描述和详细描述
/**
* @brief this is brief description (简要描述)
*
* this is detailed description (详细描述)
*
* @param parameter-name explanation (注解部分)
*/
- 写法 5:描述部分需要换行,需要在换行地方加上
\n
正例:
/**
* this is description.\n
* add a new line
*/
html 文档效果:
this is description
add a new line
反例:
/**
* this is description.
* add a new line
*/
html 文档效果:
this is description. add a new line
cjdoc 支持的注解
| 标签 | 描述 | 示例 |
|---|---|---|
| @file | 文件描述信息 | @file file description |
| @author | 标识作者 | @author description |
| @version | 指定版本 | @version info |
| @date | 指定日期 | @date datetime |
| @since | 标记当引入一个特定的变化时 | @since release |
| @see | 指定一个到另一个主题的链接 | @see anchor |
| @brief | 标记简要描述 | @brief brief description |
| @param | 说明一个方法的参数 | @param parameter-name explanation |
| @return | 说明返回值类型 | @return explanation |
| @throws | 和 @exception 标签一样 | The @throws tag has the same meaning as the @exception tag |
| @exception | 标志抛出的异常 | @exception exception-name explanation |
| @note | 标记提示信息 | @note note text |
| @warning | 标记告警信息 | @warning warning text |
| @attention | 标记需要注意的信息 | @attention attention text |
以下 3 个注解正式代码中不建议用,但是 cjdoc 也支持:
| 标签 | 描述 | 示例 |
|---|---|---|
| @todo | 标记后续需要做的事 | @todo paragraph describing what is to be done |
| @bug | 标记代码中未解决的 bug | @bug bug description |
| @deprecated | 标记过期的用法 | @deprecated description |
cjdoc 的使用方法
cjdoc -h 查看 cjdoc 工具的命令帮助。下面是几个常用的和配置文件相关的命令。
生成配置文件
cjdoc -g [configName] 生成配置文件模板,如果没有输入 configName ,则默认生成文件名为 Doxyfile 的配置文件
cjdoc [configName] 使用配置文件 configName 生成文档
cjdoc -x [configFile] 将 configFile 和默认配置比较,可以看到当前配置修改了哪些条目
**说明:**若使用-g命令时,configName或Doxyfile已存在,则会生成.bak配置文件以备份旧的配置文件信息,并生成新的默认配置文件configName或Doxyfile。
常用配置选项
-
建议配置的选项
配置选项 默认值 描述 RECURSIVE 默认 NO,建议配置成 YES 是否递归扫描 INPUT 配置的路径 EXTRACT_ALL 默认 NO,建议配置成 YES 如果配置 NO,只会显示带有文档注释的 API 接口 GENERATE_LATEX 默认 YES,建议配置成 NO 是否生成 latex 文件 INPUT 默认空,不配置默认当前路径 源文件路径 OUTPUT_DIRECTORY 默认空,不配置默认当前路径 文档输出路径 **说明:**若有多个源文件路径,可以在
INPUT输入多个路径(文件或目录),以空格相隔, 也可以使用INPUT +=添加多个路径
例1:添加以执行`cjdoc`所在的相对路径
INPUT = src/spirit/annotation src/spirit/dbconnection src/spirit/util/enum_enhance.cj
例2:添加绝对路径
INPUT = /home/project/src/spirit/annotation /home/project/src/spirit/dbconnection /home/project/src/spirit/util
例3:INPUT += 添加多个路径
INPUT = src/spirit/annotation
INPUT += src/spirit/dbconnection
INPUT += src/spirit/util
注:若所输入路径是不存在的路径,会在执行 cjdoc 过程中显示:
warning: source 'xxx' is not a readable file or directory... skipping.
说明:EXCLUDE配置选项可用于从INPUT中排除相应的文件或目录
例1:
EXCLUDE = src/spirit/annotation src/spirit/dbconnection src/spirit/util/enum_enhance.cj
例2:添加绝对路径
EXCLUDE = /home/project/src/spirit/annotation /home/project/src/spirit/dbconnection /home/project/src/spirit/util
例3:EXCLUDE += 添加多个路径
EXCLUDE = src/spirit/annotation
EXCLUDE += src/spirit/dbconnection
EXCLUDE += src/spirit/util
- 其他常用选项
| 配置选项 | 默认值 | 描述 |
|---|---|---|
| PROJECT_NAME | 默认空,可不配 | 工程名,最后会显示在 html 页面标题上 |
| GENERATE_HTML | 默认 YES | 生成 html 格式的 API 文档 |
| HTML_OUTPUT | 默认 html | html 文件生成在 {OUTPUT_DIRECTORY}/{HTML_OUTPUT} 目录下 |
| EXTRACT_PRIVATE | NO | 是否显示属性为 private 的接口 |
| EXTRACT_PROTECTED | NO | 是否显示属性为 protected 的接口 |
| EXTRACT_PACKAGE | NO | 是否显示属性为 package 的接口 |
| EXTRACT_STATIC | NO | 是否显示属性为 static 的接口 |
执行 cjdoc
cjdoc [configName]
使用配置文件 configName 生成 API 文档。如果没有指定 configName,默认使用当前目录下文件名为 Doxyfile 的配置文件,configName文件可以命名为任何 linux 支持的文件名。
相关资料
cjdoc 是基于开源工具 doxygen 扩展了仓颉语言。doxygen 本身功能非常庞大,资料丰富,cjdoc 中非语言相关的特性,与 doxygen 是互通的。
doxygen 的参考手册可参照: doxygen 用户手册
注意事项
Windows 版本不支持中文路径,如需对路径中包含中文的源码文件生成 API 文档,请使用 Linux 版本。
简介
仓颉 TensorBoost 使用仓颉编程语言编写,面向 AI 领域编程问题,支持语言级可微编程,基于 MindSpore 图引擎的一套完备的 AI 训练和推理框架。对用户屏蔽静态图、动态图的编程差异性,既提供基于动态图的友好调试体验,也提供基于静态图的优化加速。
- 基于仓颉语言源到源自动微分算法,支持自定义微分类型和微分规则;
- 统一前端编程接口:将前端编程抽象和底层静态图、动态图实现解耦,提供一致的编程体验,兼顾动态图开发效率和静态图性能优势;
- 生态兼容性:跨语言互操作(C/C++,Python 等);
- 基于静态类型系统的代码补全,静态检查,自动类型推导等。
入门指南
软件安装和使用
安装仓颉编译器
仓颉 TensorBoost 程序必须使用仓颉编译器进行编译,请参考《Cangjie Language Guide》入门指南中的指导安装仓颉编译器。
安装 MindSpore
仓颉 TensorBoost 已经适配 MindSpore 1.8.1 软件版本,需要用户下载 MindSpore 1.8.1 源码并编译:
$ git clone https://gitee.com/mindspore/mindspore.git
$ cd mindspore
$ git checkout v1.8.1 ## v1.8.1 commit id: 7b161d3df308c86d4618cf67c6303da5f58d036c
从源码编译 MindSpore ,在源码根目录执行如下命令:
$ # GPU平台
$ bash build.sh -e gpu
$ # 昇腾平台
$ bash build.sh -e ascend
安装 mindspore 软件包:
$ # GPU平台
$ cd build/package
$ pip install mindspore_gpu-1.8.1-cp37-cp37m-linux_x86_64.whl
$ # 昇腾平台
$ cd build/package
$ pip install mindspore_ascend-1.8.1-cp37-cp37m-linux_x86_64.whl
【备注】:
- MindSpore 编译环境准备和编译指导请参考 MindSpore 安装。
- Python 版本使用 MindSpore 推荐的 3.7.5。
安装仓颉 TensorBoost
仓颉编译器的软件包中包含仓颉 TensorBoost 的软件,通过配置环境变量即可完成安装:
- 配置仓颉 TensorBoost 环境变量
$ # GPU平台
$ source ./cangjie/envsetupTB.sh gpu
$ # 昇腾平台
$ source ./cangjie/envsetupTB.sh ascend
【说明】:仓颉程序默认栈空间大小是 1MB,堆空间大小是 256MB,程序运行时如遇栈或者堆空间不足,可通过环境变量调整修改其大小。
-
栈空间不足(运行时报“StackOverflowError”错误),可通过设置 cjStackSize 环境变量调整栈空间大小。cjStackSize 的合法取值范围是 [64KB, 1GB]。
$ export cjStackSize=4MB -
堆空间不足(运行时报“OutOfMemoryError”错误),可通过设置 cjHeapSize 环境变量调整堆空间大小。cjHeapSize 的合法取值范围是 [256MB, 256GB],且配置的数值应小于物理内存大小。
$ export cjHeapSize=32GB
配置 Python 和 CUDA (或 CANN) 环境变量:
$ # GPU平台
$ export LIBRARY_PATH=/usr/public_tool/tool/miniconda3/envs/ci3.7/lib:/usr/local/cuda-11.1/lib64:${LIBRARY_PATH}
$ export LD_LIBRARY_PATH=/usr/public_tool/tool/miniconda3/envs/ci3.7/lib:/usr/local/cuda-11.1/lib64:/usr/local/cuda-11.1/extras/CUPTI/lib64:${LD_LIBRARY_PATH}
$ export PATH=/usr/local/cuda-11.1/bin:${PATH}
$ # 昇腾平台
$ export LOCAL_ASCEND=/usr/local/Ascend/
$ export LIBRARY_PATH=/usr/public_tool/tool/miniconda3/envs/ci3.7/lib
$ export LD_LIBRARY_PATH=/usr/public_tool/tool/miniconda3/envs/ci3.7/lib:${LOCAL_ASCEND}/latest/x86_64-linux/lib64:${LOCAL_ASCEND}/latest/fwkacllib/lib64:${LOCAL_ASCEND}/driver/lib64/driver:${LOCAL_ASCEND}/driver/lib64/common/:${LOCAL_ASCEND}/latest/opp/op_impl/built-in/ai_core/tbe/op_tiling/:${LD_LIBRARY_PATH}
$ export TBE_IMPL_PATH=${LOCAL_ASCEND}/latest/opp/op_impl/built-in/ai_core/tbe/
$ export ASCEND_OPP_PATH=${LOCAL_ASCEND}/latest/opp/
$ export PATH=${LOCAL_ASCEND}/latest/fwkacllib/ccec_compiler/bin/:${PATH}
$ export PYTHONPATH=${TBE_IMPL_PATH}:${PYTHONPATH}
【说明】:
- MindSpore 的库依赖 Python 的库和 Python 环境,需要将 Python 的库添加到 LD_LIBRARY_PATH(示例命令中 /usr/public_tool/tool/miniconda3/envs/ci3.7/lib 请修改成 Python 实际对应的 lib 文件夹)。
- 对于 GPU 平台,MindSpore 的库依赖 CUDA ,需要将 CUDA 添加到 PATH 中(示例命令中 /usr/local/cuda-11.1/bin 请修改成 CUDA 实际对应的 bin 文件夹)。
- 对于昇腾平台,MindSpore 的库依赖 CANN ,需要将 CANN 添加到 PATH 中(示例命令中 /usr/local/Ascend/latest/ 请修改成 CANN 实际对应文件夹)。
第一个仓颉 TensorBoost 程序
以创建两个 Tensor,进行矩阵乘运算,并输出计算结果为例,将示例代码保存到 demo.cj 文件中。
from CangjieTB import ops.*
from CangjieTB import common.*
main(): Int64
{
let input_x = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let input_y = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
print(matmul(input_x, input_y))
print("Cangjie TensorBoost run test success!\n")
return 0
}
编译示例代码:
$ cjc --enable-ad --int-overflow=wrapping -lcangjie_tensorboost -lmindspore_wrapper ./demo.cj -o ./demo
【说明】:
- 用户可以根据需要将程序分多个源文件开发,编译时只要将多个源文件一起添加到编译命令中即可。
- 链接选项中,通过 -lcangjie_tensorboost 链接仓颉 TensorBoost 的库,通过 -lmindspore_wrapper 链接 MindSpore 的库。
运行示例程序:
$ ./demo
Tensor(shape=[2, 2], dtype=Float32, value=
[[7.00000000e+00 1.00000000e+01]
[1.50000000e+01 2.20000000e+01]])
Cangjie TensorBoost run test success!
如果输出如上结果,说明仓颉 TensorBoost 已经安装成功。
小试牛刀
本节以 LeNet 网络训练为例介绍仓颉 TensorBoost 的基础功能。本章按功能进行了导包和代码介绍,完整可运行的代码见本章最后一节。
配置运行信息
仓颉 TensorBoost 程序默认以动态图模式运行,在程序运行前,通过设置环境变量 CANGJIETB_GRAPH_MODE=true ,可设置成静态图模式运行。此外,仓颉 TensorBoost 通过[g_context](##附录 A 运行环境管理)来配置其他运行需要的信息,如后端信息、硬件信息等。
g_context 对象定义在 context 包中,使用前需要先导入context包。设置仓颉 TensorBoost 程序使用 GPU 硬件:
from CangjieTB import context.*
main(): Int64
{
// 设置运行设备为 GPU
g_context.setDeviceTarget("GPU")
// 测试代码写在此处
return 0
}
设置运行设备为昇腾:
// 设置运行设备为 Ascend
g_context.setDeviceTarget("Ascend")
加载数据集
使用仓颉 TensorBoost 加载 MNIST 数据集:
from CangjieTB import dataset.*
// 加载数据集
func createLenetDataset(path: String, batchSize!: Int32 = 32, shuffleSize!: Int32 = 10000, repeatCnt!: Int32 = 1, epoch!: Int32 = 1): Dataset
{
var ds = MnistDataset(path, epoch: epoch)
var resize = resize(Array<Int32>([32, 32]))
var rescale_nml = rescale(1.0 / 0.3081, -1.0 * 0.1307 / 0.3081)
var rescale = rescale(1.0 / 255.0, 0.0)
var hwc2chw = hwc2chw()
var typeCast = typeCast(INT32)
ds.datasetMap([resize, rescale, rescale_nml, hwc2chw], "image")
ds.datasetMap([typeCast], "label")
ds.shuffle(shuffleSize)
ds.batch(batchSize, true)
ds.repeat(repeatCnt)
return ds
}
创建模型
仓颉 TensorBoost 使用 struct 数据类型定义神经网络,@OptDifferentiable 注解用于使能仓颉 TensorBoost 自动收集网络权重。
神经网络的网络层需要在 struct 类型init()方法中初始化,通过重载 () 运算符方法来定义神经网络的前向构造。按照 LeNet 的网络结构,定义网络各层如下:
from CangjieTB import macros.*
from CangjieTB import nn.*
from CangjieTB import nn.layers.*
from CangjieTB import nn.optim.*
from CangjieTB import nn.loss.*
from CangjieTB import ops.*
from CangjieTB import common.*
@OptDifferentiable
struct LeNetModel {
let conv1: Conv2d
let conv2: Conv2d
let pool: MaxPool2d
let dense1: Dense
let dense2: Dense
let dense3: Dense
init() {
conv1 = Conv2d(1, 6, Array<Int64>([5, 5]), pad_mode: "valid")
conv2 = Conv2d(6, 16, Array<Int64>([5, 5]), pad_mode: "valid")
pool = MaxPool2d(kernel_size: Array<Int64>([2, 2]), stride: Array<Int64>([2, 2]))
dense1 = Dense(400, 120, RandomNormalInitializer(sigma: 0.02))
dense2 = Dense(120, 84, RandomNormalInitializer(sigma: 0.02))
dense3 = Dense(84, 10, RandomNormalInitializer(sigma: 0.02))
}
@Differentiable
operator func ()(input: Tensor): Tensor {
input |> this.conv1 |> relu |> this.pool
|> this.conv2 |> relu |> this.pool
|> flatten
|> this.dense1 |> relu
|> this.dense2 |> relu
|> this.dense3
}
}
创建定义好的 LeNetModel 模型:
// 创建网络模型
var net = LeNetModel()
【说明】:|> 运算符是仓颉 提供的流运算符,用于表达单输入单输出网络结构的连接关系。上述示例中 () 运算符重载函数可重写为:
@Differentiable
operator func ()(input: Tensor): Tensor {
var out = this.conv1(input)
out = relu(out)
out = this.pool(out)
out = this.conv2(out)
out = relu(out)
out = this.pool(out)
out = flatten(out)
out = this.dense1(out)
out = relu(out)
out = this.dense2(out)
out = relu(out)
out = this.dense3(out)
return out
}
优化模型参数
要训练神经网络模型,需要定义损失函数和优化器。
定义[交叉熵损失函数](####SoftmaxCrossEntropyWithLogits 层) :
// 创建损失函数对象
var lossFn = SoftmaxCrossEntropyWithLogits(sparse: true)
【说明】:自定义损失函数请参考损失函数。
仓颉 TensorBoost 支持的优化器有 [Adam](####Adam 优化器)、[Momentum](####Momentum 优化器)。这里使用Momentum优化器:
// 设置学习率和动量,创建优化器对象
let lr: Float32 = 0.01
let momentum: Float32 = 0.9
var optim: MomentumOptimizer<LeNetModel> = MomentumOptimizer<LeNetModel>(net, lr, momentum)
【说明】:更多优化器的信息见优化器
训练及保存模型
计算网络梯度
定义可微函数train,用于网络前向结果的计算:
@Differentiable[except: [lossFn, input, label]]
func train(net: LeNetModel, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor): Tensor
{
var output = net(input)
var lossTensor = lossFn(output, label)
return lossTensor
}
定义函数gradient,对train函数求微分,用于网络反向梯度的计算:
func gradient(net: LeNetModel, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor): (Tensor, LeNetModel)
{
var adj = @AdjointOf(train)
var (loss, fBackward) = adj(net, lossFn, input, label)
var gradout = fBackward(onesLike(loss))
return (loss, gradout)
}
【说明】:
- [@AdjointOf](###可微函数和微分 API)是仓颉 TensorBoost 提供的获取可微函数的反向函数的关键字。
gradient函数的输出是网络前向的结果和网络反向的梯度。
训练网络
将下载好的 MNIST 数据集文件放到./data/mnist/路径下,网络训练代码如下。
// 创建承载数据集数据的 Tensor,作为网络的输入
let input = parameter(zerosTensor(Array<Int64>([32, 1, 32, 32]), dtype: FLOAT32), "data")
let label = parameter(zerosTensor(Array<Int64>([32]), dtype: INT32), "label")
var datasetLenet = createLenetDataset("./data/mnist/train", epoch: 2)
print("============== Starting Training ==============\n")
let epoch = 2
for (i in 0..epoch) {
for (j in 1..(datasetLenet.getDatasetSize() + 1)) {
// 将数据集的数据读取到这两个 Tensor 中
datasetLenet.getNext([input, label])
// 将输入、损失函数、网络对象传入到求微分的函数中
var (loss, gradout) = gradient(net, lossFn, input, label)
// 将得到的梯度传递给优化器
optim.update(gradout)
let lossValue = loss.evaluate().toScalar<Float32>()
if (j % 100 == 0) {
print("epoch: ${i}, step: ${j}, loss is: ${lossValue}\n")
}
}
}
【说明】:
- 静态图模式下,所有的计算都是 lazy 的,网络的输出
loss是一个无值的Tensor。调用loss的 evaluate() 方法将触发计算图的执行,并返回计算结果。计算结果是一个有值的Tensor,可以用 toArrayFloat32() 方法转为数组。 - 动态图模式下,所有的计算都是立即执行的。不需要调用
loss的 evaluate() 方法,就可以直接调用 toArrayFloat32() 方法转为数组。动态图模型下调用loss的 evaluate() 方法,不产生任何影响。 - 如果不确定某个 Tensor 是否有值,可以调用 isConcrete 方法进行判断。
- LeNetModel 使用了宏功能,编译命令可参考[第一个仓颉 TensorBoost 程序](##第一个仓颉 TensorBoost 程序)。
训练过程中会打印 loss 值,类似下图。loss 值会波动,但总体来说 loss 值会逐步减小,精度逐步提高。每个人运行的 loss 值有一定随机性,不一定完全相同。 训练过程中 loss 打印示例如下:
epoch: 0, step: 100, loss is: 2.311390
epoch: 0, step: 200, loss is: 2.292652
epoch: 0, step: 300, loss is: 2.320347
epoch: 0, step: 400, loss is: 2.315219
epoch: 0, step: 500, loss is: 2.313322
epoch: 0, step: 600, loss is: 2.287148
epoch: 0, step: 700, loss is: 2.294824
epoch: 0, step: 800, loss is: 2.080675
epoch: 0, step: 900, loss is: 0.665705
epoch: 0, step: 1000, loss is: 0.486177
epoch: 0, step: 1100, loss is: 0.435502
epoch: 0, step: 1200, loss is: 0.291111
epoch: 0, step: 1300, loss is: 0.301397
epoch: 0, step: 1400, loss is: 0.139376
epoch: 0, step: 1500, loss is: 0.258150
epoch: 0, step: 1600, loss is: 0.029784
epoch: 0, step: 1700, loss is: 0.109121
epoch: 0, step: 1800, loss is: 0.023385
...
保存模型
public func saveCheckpoint(params: ArrayList<Tensor>, ckptFileName: String)
saveCheckpoint 函数可以保存网络模型和参数,以便进行后续的 Fine-tuning(微调)操作。
当训练结束时,可以调用 saveCheckpoint 来保存网络权重。
from CangjieTB import train.*
// 将训练好的模型保存
saveCheckpoint(optim.getParameters(), "./lenet.ckpt")
完成后可以看到本目录下多了一个名为lenet.ckpt的文件,网络的权重就保存在文件中。
加载模型
public func loadCheckpoint(params: ArrayList<Tensor>, ckptFileName: String)
创建 LeNet 模型对象,并获取模型中的参数,使用 loadCheckpoint 函数更新模型的参数。
// 重新创建新的网络模型
net = LeNetModel()
// 获取模型中的参数
optim = MomentumOptimizer<LeNetModel>(net, 0.01, 0.9)
var params: ArrayList<Tensor> = optim.getParameters()
// 加载 ckpt 文件中的数据到模型参数
loadCheckpoint(params, "./lenet.ckpt")
验证模型
观察加载的模型在测试集上的表现:
// 加载测试数据集
var datasetLenetTest = createLenetDataset("./data/mnist/test")
// 观察模型在测试集上的表现
for (i in 0..datasetLenetTest.getDatasetSize()) {
datasetLenetTest.getNext([input, label])
var loss = train(net, lossFn, input, label)
// 触发计算图的执行
let lossValue = loss.evaluate().toScalar<Float32>()
print("sample: ${i}, loss is: ${lossValue}\n")
}
输出如下:
sample: 6, loss is: 0.107543
sample: 7, loss is: 0.267138
sample: 8, loss is: 0.0362831
sample: 9, loss is: 0.00709512
sample: 10, loss is: 0.00440472
sample: 11, loss is: 0.00594328
sample: 12, loss is: 0.00353992
sample: 13, loss is: 0.0153856
sample: 14, loss is: 0.113814
sample: 15, loss is: 0.0211988
sample: 16, loss is: 0.0751143
sample: 17, loss is: 0.00700548
sample: 18, loss is: 0.143039
sample: 19, loss is: 0.0867741
sample: 20, loss is: 0.0273039
sample: 21, loss is: 0.00415331
sample: 22, loss is: 0.127782
sample: 23, loss is: 0.064515
sample: 24, loss is: 0.0509498
sample: 25, loss is: 0.0671479
sample: 26, loss is: 0.15785
...
可以看到加载的模型在测试集上的 loss 非常低,与测试集训练后的 loss 接近。
完整的 LeNet 网络训练代码
仓颉 TensorBoost 的 lenet_example.cj 样例代码使用了仓颉 TensorBoost 的宏,其编译命令如下:
$ cjc --enable-ad --int-overflow=wrapping -lcangjie_tensorboost -lmindspore_wrapper lenet_example.cj --import-path ${CANGJIE_TB_HOME}/modules/CangjieTB -o ./lenet
lenet_example.cj 代码如下:
from CangjieTB import context.*
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import dataset.*
from CangjieTB import nn.*
from CangjieTB import nn.optim.*
from CangjieTB import nn.loss.*
from CangjieTB import nn.layers.*
from CangjieTB import macros.*
from CangjieTB import train.*
from std import collection.ArrayList
// 加载数据集
func createLenetDataset(path: String, batchSize!: Int32 = 32, shuffleSize!: Int32 = 10000, repeatCnt!: Int32 = 1,
epoch!: Int32 = 1) {
var ds = MnistDataset(path, epoch: epoch)
var resize = resize([32, 32])
var rescale_nml = rescale(1.0 / 0.3081, -1.0 * 0.1307 / 0.3081)
var rescale = rescale(1.0 / 255.0, 0.0)
var hwc2chw = hwc2chw()
var typeCast = typeCast(INT32)
ds.datasetMap([resize, rescale, rescale_nml, hwc2chw], "image")
ds.datasetMap([typeCast], "label")
ds.shuffle(shuffleSize)
ds.batch(batchSize, true)
ds.repeat(repeatCnt)
return ds
}
@OptDifferentiable
struct LeNetModel {
let conv1: Conv2d
let conv2: Conv2d
let pool: MaxPool2d
let dense1: Dense
let dense2: Dense
let dense3: Dense
init() {
conv1 = Conv2d(1, 6, [5, 5], pad_mode: "valid")
conv2 = Conv2d(6, 16, [5, 5], pad_mode: "valid")
pool = MaxPool2d(kernel_size: [2, 2], stride: [2, 2])
dense1 = Dense(400, 120, RandomNormalInitializer(sigma: 0.02))
dense2 = Dense(120, 84, RandomNormalInitializer(sigma: 0.02))
dense3 = Dense(84, 10, RandomNormalInitializer(sigma: 0.02))
}
@Differentiable
operator func ()(input: Tensor): Tensor {
input |> this.conv1 |> relu |> this.pool |> this.conv2 |> relu |> this.pool |> flatten |> this.dense1 |> relu |>
this.dense2 |> relu |> this.dense3
}
}
@Differentiable [except: [input, label, lossFn]]
func train(net: LeNetModel, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor) {
var output = net(input)
var lossTensor = lossFn(output, label)
return lossTensor
}
func gradient(net: LeNetModel, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor) {
var adj = @AdjointOf(train)
var (loss, f_backward) = adj(net, lossFn, input, label)
var gradout = f_backward(onesLike(loss))
return (loss, gradout)
}
main(): Int64 {
// 设置运行设备为GPU
g_context.setDeviceTarget("GPU")
// 创建承载数据集数据的 Tensor,作为网络的输入
let input = parameter(zerosTensor([32, 1, 32, 32], dtype: FLOAT32), "data")
let label = parameter(zerosTensor([32], dtype: INT32), "label")
var datasetLenet = createLenetDataset("./data/mnist/train", epoch: 2)
// 创建网络模型
var net = LeNetModel()
// 创建损失函数对象
var lossFn = SoftmaxCrossEntropyWithLogits(sparse: true)
// 设置学习率和动量,创建优化器对象
let lr: Float32 = 0.01
let momentum: Float32 = 0.9
var optim: MomentumOptimizer<LeNetModel> = MomentumOptimizer<LeNetModel>(net, lr, momentum)
print("============== Starting Training ==============\n")
let epoch = 2
for (i in 0..epoch) {
for (j in 1..(datasetLenet.getDatasetSize() + 1)) {
// 将数据集的数据读取到这两个 Tensor 中
datasetLenet.getNext([input, label])
// 将输入、损失函数、网络对象传入到求微分的函数中
var (loss, gradout) = gradient(net, lossFn, input, label)
// 将得到的梯度传递给优化器
optim.update(gradout)
let lossValue = loss.evaluate().toScalar<Float32>()
if (j % 100 == 0) {
print("epoch: ${i}, step: ${j}, loss is: ${lossValue}\n")
}
}
}
saveCheckpoint(optim.getParameters(), "./lenet.ckpt")
// 重新创建新的网络模型
net = LeNetModel()
// 获取模型中的参数
optim = MomentumOptimizer<LeNetModel>(net, 0.01, 0.9)
var params: ArrayList<Tensor> = optim.getParameters()
// 加载ckpt文件中的数据到模型参数
loadCheckpoint(params, "./lenet.ckpt")
// 加载测试数据集
var datasetLenetTest = createLenetDataset("./data/mnist/test")
print("============== Starting Test ==============\n")
// 观察模型在测试集上的表现
for (i in 0..datasetLenetTest.getDatasetSize()) {
datasetLenetTest.getNext([input, label])
var loss = train(net, lossFn, input, label)
// 触发计算图的执行
let lossValue = loss.evaluate().toScalar<Float32>()
print("sample: ${i}, loss is: ${lossValue}\n")
}
return 0
}
张量 Tensor
张量(Tensor)是仓颉 TensorBoost 网络运算中的基本数据结构,张量支持的数据类型有整型、浮点型和布尔类型,目前整型支持 Int32 和 Int64,浮点型支持 Float16、Float32 和 Float64(注: 目前 Float64 的 Tensor 仅支持部分算子)。使用仓颉 TensorBoost Tensor 结构需要导入 ops 包和 common 包:
from CangjieTB import ops.*
from CangjieTB import common.*
初始化张量
张量的初始化方式有多种,构造张量时,支持传入Tensor、Float16、Float32、Float64、Int32、Int64、Bool类型。
根据数据直接生成
可以根据数据创建张量。
var x = Tensor(Float32(0.1))
print(x)
x = Tensor(Array<Float32>([1.0, 2.0, 3.0, 1.0, 2.0, 3.0]), shape: Array<Int64>([2, 3]))
print(x)
x = Tensor(Float32(0.1), dtype:FLOAT64)
print(x)
x = Tensor(Array<Float32>([1.0, 2.0, 3.0, 1.0, 2.0, 3.0]), shape: Array<Int64>([2, 3]), dtype:FLOAT64)
print(x)
输出为:
Tensor(shape=[], dtype=Float32, value= 1.00000001e-01)
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 1.00000000e+00 2.00000000e+00 3.00000000e+00]
[ 1.00000000e+00 2.00000000e+00 3.00000000e+00]])
Tensor(shape=[], dtype=Float64, value= 1.00000001e-01)
Tensor(shape=[2, 3], dtype=Float64, value=
[[ 1.00000000e+00 2.00000000e+00 3.00000000e+00]
[ 1.00000000e+00 2.00000000e+00 3.00000000e+00]])
【说明】:仓颉 TensorBoost 重载了 print 函数,可用于查看张量的数值。
继承另一个张量的属性,形成新的张量
let xZeros = zerosLike(x)
print(xZeros)
输出为:
Tensor(shape=[2, 3], dtype=Float64, value=
[[0.00000000e+00 0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00 0.00000000e+00]])
输出指定大小的恒定值或随机张量
var x = zerosTensor(Array<Int64>([2, 3]))
print("zeros x", x)
x = onesTensor(Array<Int64>([2, 3]))
print("ones x", x)
x = fillTensor(Array<Int64>([6]), 2.0)
print("fill x", x)
x = randomNormalTensor(Array<Int64>([2, 3]))
print("random x", x)
输出为:
zeros x
Tensor(shape=[2, 3], dtype=Float32, value=
[[0.00000000e+00 0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00 0.00000000e+00]])
ones x
Tensor(shape=[2, 3], dtype=Float32, value=
[[1.00000000e+00 1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00 1.00000000e+00]])
fill x
Tensor(shape=[6], dtype=Float32, value=
[2.00000000e+00 2.00000000e+00 2.00000000e+00 2.00000000e+00 2.00000000e+00 2.00000000e+00])
random x
Tensor(shape=[2, 3], dtype=Float32, value=
[[5.24295261e-03 -8.60292558e-03 -6.73894212e-03]
[-1.03433325e-03 -6.31256960e-03 2.36030575e-02]])
张量的属性
张量的属性包括形状(shape)和数据类型(dtype)。
- 形状:Tensor 的 shape,是一个 Int64 的数组。
- 数据类型:Tensor 的 dtype,是一个字符串。
获取属性的代码如下所示:
let t = onesTensor(Array<Int64>([2, 3]), dtype: INT32)
let shape: Array<Int64> = t.getShape()
let dtype: String = t.getStrDtype()
print("Shape of t: ${shape}\n")
print("DType of t: ${dtype}\n")
输出为:
Shape of t: [2, 3]
DType of t: INT32
张量运算
张量支持多种运算,包括算术、线性代数、矩阵处理(转置、索引、切片)等,张量运算的结果依然是张量。下面介绍其中几种操作:
取行/列
张量可以使用 gather 方法,根据轴或索引获取 Tensor 中的某些值。
let tensor: Tensor = randomNormalTensor(Array<Int64>([4, 4]))
print("tensor: ", tensor)
let firstRow = gather(tensor, Tensor(Int32(0), dtype: INT32), 0)
print("First row: ", firstRow)
let firstColumn = gather(tensor, Tensor(Int32(0), dtype: INT32), 1)
print("First column: ", firstColumn)
let otherColumn = gather(tensor, Tensor(Array<Int32>([1, 2]), shape: Array<Int64>([2])), 1)
print("column 2-3: ", otherColumn)
输出为:
tensor:
Tensor(shape=[4, 4], dtype=Float32, value=
[[1.57868862e-02 -4.30074194e-03 6.91929235e-05 1.57265477e-02]
[5.19612944e-03 -6.04318548e-03 -5.03292587e-03 4.90910932e-03]
[-1.76758785e-02 -8.70072190e-03 -5.10977907e-03 -7.41219288e-03]
[-3.73127405e-04 -5.04293945e-03 -7.56428868e-04 -2.82030297e-03]])
First row:
Tensor(shape=[1, 4], dtype=Float32, value=
[[1.57868862e-02 -4.30074194e-03 6.91929235e-05 1.57265477e-02]])
First column:
Tensor(shape=[4, 1], dtype=Float32, value=
[[1.57868862e-02]
[5.19612944e-03]
[-1.76758785e-02]
[-3.73127405e-04]])
column 2-3:
Tensor(shape=[4, 2], dtype=Float32, value=
[[-4.30074194e-03 6.91929235e-05]
[-6.04318548e-03 -5.03292587e-03]
[-8.70072190e-03 -5.10977907e-03]
[-5.04293945e-03 -7.56428868e-04]])
张量连接
张量可以用 concat 或 stack 方法进行连接。二者的区别是,concat 对输入的 Tensor 在指定轴上进行合并,stack 对输入的 Tensor 在指定轴上进行堆叠。
let t1: Tensor = concat([tensor, tensor, tensor], axis: 1)
print(t1)
let t2: Tensor = stack([tensor, tensor, tensor], axis: 1)
print(t2)
输出为:
Tensor(shape=[4, 12], dtype=Float32, value=
[[1.57868862e-02 -4.30074194e-03 6.91929235e-05 ... -4.30074194e-03 6.91929235e-05 1.57265477e-02]
[5.19612944e-03 -6.04318548e-03 -5.03292587e-03 ... -6.04318548e-03 -5.03292587e-03 4.90910932e-03]
[-1.76758785e-02 -8.70072190e-03 -5.10977907e-03 ... -8.70072190e-03 -5.10977907e-03 -7.41219288e-03]
[-3.73127405e-04 -5.04293945e-03 -7.56428868e-04 ... -5.04293945e-03 -7.56428868e-04 -2.82030297e-03]])
Tensor(shape=[4, 3, 4], dtype=Float32, value=
[[[1.57868862e-02 -4.30074194e-03 6.91929235e-05 1.57265477e-02]
[1.57868862e-02 -4.30074194e-03 6.91929235e-05 1.57265477e-02]
[1.57868862e-02 -4.30074194e-03 6.91929235e-05 1.57265477e-02]]
[[5.19612944e-03 -6.04318548e-03 -5.03292587e-03 4.90910932e-03]
[5.19612944e-03 -6.04318548e-03 -5.03292587e-03 4.90910932e-03]
[5.19612944e-03 -6.04318548e-03 -5.03292587e-03 4.90910932e-03]]
[[-1.76758785e-02 -8.70072190e-03 -5.10977907e-03 -7.41219288e-03]
[-1.76758785e-02 -8.70072190e-03 -5.10977907e-03 -7.41219288e-03]
[-1.76758785e-02 -8.70072190e-03 -5.10977907e-03 -7.41219288e-03]]
[[-3.73127405e-04 -5.04293945e-03 -7.56428868e-04 -2.82030297e-03]
[-3.73127405e-04 -5.04293945e-03 -7.56428868e-04 -2.82030297e-03]
[-3.73127405e-04 -5.04293945e-03 -7.56428868e-04 -2.82030297e-03]]])
数学运算
let mat = onesTensor(Array<Int64>([4, 4]), dtype: FLOAT32)
// matmul 可以进行矩阵乘法
let z1 = matmul(mat, mat)
print(z1)
// 下面两个操作等价,都是 element-wise 的乘法,得到的 z2 和 z3 结果相同
let z2 = mul(mat, mat)
let z3 = mat * mat
print(z2)
print(z3)
输出为:
Tensor(shape=[4, 4], dtype=Float32, value=
[[4.00000000e+00 4.00000000e+00 4.00000000e+00 4.00000000e+00]
[4.00000000e+00 4.00000000e+00 4.00000000e+00 4.00000000e+00]
[4.00000000e+00 4.00000000e+00 4.00000000e+00 4.00000000e+00]
[4.00000000e+00 4.00000000e+00 4.00000000e+00 4.00000000e+00]])
Tensor(shape=[4, 4], dtype=Float32, value=
[[1.00000000e+00 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00 1.00000000e+00 1.00000000e+00]])
Tensor(shape=[4, 4], dtype=Float32, value=
[[1.00000000e+00 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00 1.00000000e+00 1.00000000e+00]])
数组与张量的转换
数组转张量
根据数组构造 Tensor。
let xDataArray: Array<Float32> = Array<Float32>([1.0, 0.0, 1.0, 0.0])
let xDataTensor = Tensor(xDataArray, shape: Array<Int64>([2, 2]))
print("xDataTensor is: ", xDataTensor)
输出为:
xDataTensor is:
Tensor(shape=[2, 2], dtype=Float32, value=
[[1.00000000e+00 0.00000000e+00]
[1.00000000e+00 0.00000000e+00]])
张量转数组
使用 toArrayFloat32() 方法,将 Float32 类型的 Tensor 转为数组。
let zerosTensor: Tensor = zerosTensor(Array<Int64>([3, 2]), dtype: FLOAT32)
print("zerosTensor is: ", zerosTensor)
let zerosArray: Array<Float32> = zerosTensor.toArrayFloat32()
print("zerosArray is: ${zerosArray.toString()}\n")
输出为:
zerosTensor is:
Tensor(shape=[3, 2], dtype=Float32, value=
[[0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00]])
zerosArray is: [0.000000, 0.000000, 0.000000, 0.000000, 0.000000, 0.000000]
【说明】:
- 如果 Tensor 的 dtype 为 Int32 类型,可调用toArrayInt32(),如果为 Bool 类型,可调用toArrayBool()。
toArrayFloat32()/toArrayInt32()/toArrayBool()转数组的方法只能用于已经有值的 Tensor 上,无值的 Tensor 不能调用。如果不确定某个 Tensor 是否有值,可以调用 isConcrete 方法进行判断。
张量释放
export TENSORSIZE=100MB
考虑到在网络执行过程中会不断创建 Tensor,占用较大的内存。如遇到内存资源不足的情况,可通过配置环境变量TENSORSIZE,及时释放设备内存,等号右侧为用户希望 Tensor 占用最大内存(必须为正整数),单位支持 KB、MB 和 GB。当 Tensor 占用的内存总量超过该值时会触发自动 GC,尝试释放出一些内存。默认情况会由仓颉 GC 自动判断,对无用 Tensor 对象进行内存回收。
数据集 Dataset
仓颉 TensorBoost 提供数据加载及处理能力,支持读取多种数据集格式和自定义数据集,支持常用的数据处理、数据增强方法,数据加载和处理需要导入 dataset 包:
from CangjieTB import dataset.*
加载数据集
使用仓颉 TensorBoost 的 数据集接口可以加载数据集, 示例代码中使用MnistDataset接口加载 MNIST 数据集,并使用随机采样器获取 5 个样本。其他格式的数据集接口可参见 附录 C: 数据集
var sampler5 = RandomSampler(numSamples: 5)
let dataPath: String = "./data/mnist/train"
var mnistDs = MnistDataset(dataPath, sampler: sampler5)
// 将图像数据映射到固定的范围
var rescale = rescale(1.0 / 255.0, 0.0)
mnistDs.datasetMap([rescale], "image")
将数据集读取到 Tensor 中
调用数据集类的 getNext 方法可以将数据读取到 Tensor 中,如下所示:
var input: Tensor = parameter(zerosTensor(Array<Int64>([1, 28, 28]), dtype: FLOAT32), "data")
var label: Tensor = parameter(zerosTensor(Array<Int64>([1]), dtype: INT32), "label")
while (mnistDs.getNext([input, label])) {
print("---------------\n")
print("input: ", input)
print("label: ", label)
}
输出为:
---------------
input:
Tensor(shape=[1, 28, 28], dtype=Float32, value=
[[[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]
...
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]]])
label:
Tensor(shape=[1], dtype=Int32, value= [0])
...
【说明】:
parameter函数用于定义数据可变的 Tensor 对象,作为网络训练的 input 和 label 。- 如果数据已经取完,
getNext返回 false,循环结束。
【注意】:在定义 Parameter 时,要确保 shape 和 dtype 和数据文件中的数据一致。
自定义数据集
对于目前仓颉 TensorBoost 不支持直接加载的数据集,可以先将数据集转换成 MindRecord 或 TFRecord 格式,再用仓颉 TensorBoost 进行读取。
将数据转换成 MindRecord 格式的方法见自定义数据集转换为 MindRecord。将数据转换成 TFRecord 格式的方法见TFRecord。
读取自定义数据集./data/train.mindrecord 如下所示:
// 加载数据
let mindrecordSampler = RandomSampler(numSamples: 6)
let mindRecordDataPath: String = "./data/train.mindrecord"
let columnNames: Array<String> = ["R", "F", "E"]
var msDataset = MindDataDataset(mindRecordDataPath, columnNames, sampler: mindrecordSampler)
// 读取数据
var R = parameter(zerosTensor(Array<Int64>([9, 3])), "R")
var F = parameter(zerosTensor(Array<Int64>([9, 3])), "F")
var E = parameter(zerosTensor(Array<Int64>([1])), "E")
while (msDataset.getNext([R, F, E])) {
print("---------------\n")
print("R", R)
print("F", F)
print("E", E)
}
输出为:
---------------
R
Tensor(shape=[9, 3], dtype=Float32, value=
[[-1.95923567e-01 -5.75768769e-01 -8.86928290e-02]
[-9.65070069e-01 6.16460443e-01 5.17787218e-01]
[1.09309697e+00 -9.55241770e-02 -3.60066712e-01]
...
[-5.41572392e-01 1.01731408e+00 1.46117091e+00]
[-1.10684466e+00 1.27925050e+00 -2.28156179e-01]
[9.93210256e-01 6.73578858e-01 -9.84581828e-01]])
F
Tensor(shape=[9, 3], dtype=Float32, value=
[[-2.55999870e+01 3.66684914e+01 1.54593821e+01]
[4.35021973e+01 -5.85456161e+01 6.23012238e+01]
[2.99424801e+01 3.68474412e+00 -2.41483364e+01]
...
[7.96970320e+00 2.15402818e+00 -1.43688583e+01]
[-4.69919205e+00 6.80967560e+01 -5.65661163e+01]
[3.59104991e+00 -1.91799850e+01 1.60485039e+01]])
E
Tensor(shape=[1], dtype=Float32, value= [-9.71969688e+04])
...
和 MnistDataset 类似,使用 getNext 函数可以将输入读取到 Tensor 中。和 MnistDataset 不同的是,MindDataDataset 的构造方法中需要额外的一个列名的入参,以指定在数据文件中读取哪几列数据。
【注意】 传入 getNext 函数的 Tensor 数组元素的个数要与 MindRecord 数据集中保存的数据类别个数相同,并且对应的 shape 和 dtype 也要相同
数据处理与增强
数据处理
仓颉 TensorBoost 提供的数据集接口具备常用的数据处理方法,用户只需调用相应的函数接口即可快速进行数据处理。 如下代码展示了仓颉 TensorBoost 的数据处理过程:将数据集进行 shuffle 处理,然后将数据两两组成一个批次。
// 重新读取数据
msDataset = MindDataDataset(mindRecordDataPath, columnNames, sampler: mindrecordSampler)
let batchSize: Int32 = 2
let bufferSize: Int32 = 1000
// 随机打乱数据顺序
msDataset.shuffle(bufferSize)
// 对数据集进行分批
msDataset.batch(batchSize, true)
// 读取数据
R = parameter(zerosTensor([Int64(batchSize), 9, 3]), "R")
F = parameter(zerosTensor([Int64(batchSize), 9, 3]), "F")
E = parameter(zerosTensor([Int64(batchSize), 1]), "E")
while (msDataset.getNext([R, F, E])) {
print("---------------\n")
print("R", R)
print("F", F)
print("E", E)
}
输出为:
---------------
R
Tensor(shape=[2, 9, 3], dtype=Float32, value=
[[[-1.81845412e-01 -2.61216700e-01 -5.36276340e-01]
[-5.81744909e-02 1.27089608e+00 -2.06515580e-01]
[1.85678512e-01 -9.63150203e-01 6.43111765e-01]
...
[-6.72326028e-01 1.42653990e+00 7.66738772e-01]
[1.07878494e+00 1.39543390e+00 -3.93244214e-02]
[5.54795861e-01 -3.44734281e-01 1.29838037e+00]]
[[3.33174407e-01 4.40440863e-01 1.62186071e-01]
[-7.58461058e-01 5.63840449e-01 -8.67527306e-01]
[4.60158527e-01 -9.15827274e-01 6.33802950e-01]
...
[-1.68348837e+00 6.67325556e-01 -3.36017698e-01]
[-8.81266594e-01 1.50722134e+00 -1.51811504e+00]
[-3.96128386e-01 -1.10900962e+00 1.10739207e+00]]])
F
Tensor(shape=[2, 9, 3], dtype=Float32, value=
[[[5.50469017e+01 2.22117062e+01 -2.59304409e+01]
[-4.75894117e+00 -2.55197372e+01 6.58721209e+00]
[-6.24587297e+00 -2.03564777e+01 8.99683416e-01]
...
[2.27004929e+01 2.90634203e+00 -3.15368729e+01]
[-3.87679062e+01 1.21524820e+01 -4.42834806e+00]
[-1.44927382e+00 9.46627378e-01 -5.96580458e+00]]
[[3.88336296e+01 3.53328371e+00 5.44805384e+00]
[-1.79748745e+01 1.74029770e+01 -6.41082306e+01]
[-2.62239990e+01 -5.71368599e+00 1.24214802e+01]
...
[-2.74372044e+01 -1.68999844e+01 8.07555008e+00]
[2.52471638e+01 -1.31735935e+01 2.34950371e+01]
[2.11702538e+01 -2.78234661e-01 -1.10375137e+01]]])
E
Tensor(shape=[2, 1], dtype=Float32, value=
[[-9.71979297e+04]
[-9.71984062e+04]])
...
其中:
bufferSize:数据集中进行 shuffle 操作的缓存区的大小。batchSize:每组包含的数据个数,现设置每组包含 2 个数据。
数据增强
数据量过小或是样本场景单一等问题会影响模型的训练效果,用户可以通过数据增强操作扩充样本多样性,从而提升模型的泛化能力。
如下代码可以对数据集进行数据增强:定义数据处理算子,对数据集进行 resize,rescale 和 randomCrop 操作,然后通过 datasetMap 设置数据处理的管道,达到生成新数据的目的。
// 重新读取数据
mnistDs = MnistDataset(dataPath, sampler: sampler5)
// 定义数据增强算子
var resize = resize(Array<Int32>([16, 16]))
var randomCropOp = randomCrop(Array<Int32>([8, 8]), Array<Int32>([0, 0, 0, 0]))
// 进行数据增强操作
mnistDs.datasetMap([resize, rescale, randomCropOp], "image")
// 查看增强后的数据
input = parameter(initialize(Array<Int64>([8, 8]), initType: InitType.ZERO, dtype: FLOAT32), "data")
while (mnistDs.getNext([input, label])) {
print("---------------\n")
print("input: ", input)
print("label: ", label)
}
输出为:
---------------
input:
Tensor(shape=[8, 8], dtype=Float32, value=
[[ 0.00000000e+00 1.41176477e-01 4.50980425e-01 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 3.72549027e-01 1.00000000e+00 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 3.72549027e-01 1.00000000e+00 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]
...
[ 1.00000000e+00 1.00000000e+00 7.64705956e-01 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 1.00000000e+00 6.70588255e-01 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 6.07843161e-01 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 0.00000000e+00]])
label:
Tensor(shape=[1], dtype=Int32, value= [1])
...
构建神经网络
仓颉 TensorBoost 内置常见的神经网络结构(如 2D 卷积层、全连接层等),同时也支持用户自定义神经网络结构。
定义网络结构
网络结构包含网络构建过程参与的状态数据(如网络参数、控制属性等)。仓颉 TensorBoost 通过 struct 定义神经网络。网络结构可以包含某些权重参数(类型为 Tensor),也可以包含其他网络结构。
下面以 MyLayer 为例定义某个矩阵乘法和 bias 叠加的神经网络。MyLayer 成员变量包括用于矩阵乘法的权重参数、偏差参数和控制是否叠加偏差参数的属性。构造函数(init)根据入参里的输入通道数、输出通道数等初始化成员变量。
from CangjieTB import macros.*
from CangjieTB import ops.*
@OptDifferentiable[include: [weight, bias]]
struct MyLayer {
let weight: Tensor // 权重参数
let bias: Tensor // 偏差参数
var hasBias: Bool // 控制是否叠加 bias
init(inChannels: Int64, outChannels: Int64, hasBias: Bool)
{
this.hasBias = hasBias
this.weight = parameter(initialize([outChannels, inChannels], initType: InitType.NORMAL), "weight")
if (hasBias) {
this.bias = parameter(initialize([outChannels], initType: InitType.ZERO), "bias")
} else {
this.bias = noneTensor()
}
}
}
说明:
- @OptDifferentiable 用于修饰网络结构类型,标注该网络支持反向传播。同时,将参与反向传播梯度更新的参数变量加入到 include 列表。当网络结构类型没有成员变量或所有成员变量都是待更新的网络参数时,@OptDifferentiable 可省略不写 include。
- 要求 struct 所有成员变量必须进行初始化(声明处或构造函数处):MyLayer 即使不需要 bias ,也要给 bias 成员变量赋值。
- 使用 @OptDifferentiable 功能的编译命令可参考[第一个仓颉 TensorBoost 程序](##第一个仓颉 TensorBoost 程序)。
创建和收集 Parameter
网络结构里很重要的状态数据就是网络运算过程中用到的参数(Parameter)。可以理解为网络参数是具有全局生命周期的 Tensor ,有着明确的、唯一存储空间,支持原址修改数据(通过 assign / assignAdd等)。网络参数创建的唯一方式是调用函数 parameter(),函数声明如下:
public func parameter(data: Tensor, name: String, requiresGrad!: Bool = true): Tensor
入参说明:
- data 必须是提前构造好的有值的 Tensor ,data 不能是其他
parameter()函数返回值,也不能将同一个 data 传给两个parameter()做参数。 - name 为网络参数初始名字,网络结构里的参数经过收集之后会统一重命名。
- requiresGrad 控制网络参数是否需要更新梯度,默认是 true。如果存在增量训练或其他需要固定住部分网络参数的场景,可将该选项设置为 false。
网络结构收集参数通过实现 OptDiff 接口里的 collectParams()工作的。
public interface OptDiff {
public func collectParams(params: ArrayList<Tensor>, renamePrefix: String): Unit
}
说明:
Unit 是仓颉函数的默认返回值,调用时可不处理该返回值。
所有被 @OptDifferentiable 修饰的网络结构类型默认支持收集网络参数。因此对于 MyLayer 可直接通过下面代码收集网络参数,得到两个参数分别名为 myLayer.weight 和 myLayer.bias。
let myLayer = MyLayer(4, 4, true)
// 准备参数数组
let params: ArrayList<Tensor> = ArrayList<Tensor>()
// (递归)收集 myLayer 包含的全部网络参数到参数数组
myLayer.collectParams(params, "myLayer")
定义网络运算方法
网络运算方法定义神经网络构建过程。仓颉 TensorBoost 通过 operator() 运算符重载定义网络运算方法。方法可以调用算子函数(如 matmul、biasAdd),也可以调用其他网络结构的 operator() 方法。MyLayer 网络运算代码示意如下:
from CangjieTB import macros.*
from CangjieTB import ops.*
@OptDifferentiable[include: [weight, bias]]
struct MyLayer {
let weight: Tensor // 权重参数
let bias: Tensor // 偏差参数
var hasBias: Bool // 控制是否叠加 bias
init(inChannels: Int64, outChannels: Int64, hasBias: Bool)
{
this.hasBias = hasBias
this.weight = parameter(initialize([outChannels, inChannels], initType: InitType.NORMAL), "weight")
if (hasBias) {
this.bias = parameter(initialize([outChannels], initType: InitType.ZERO), "bias")
} else {
this.bias = noneTensor()
}
}
@Differentiable
operator func ()(input: Tensor): Tensor {
var output = matmul(input, this.weight)
if (this.hasBias) {
output = biasAdd(output, this.bias)
}
return output
}
}
说明:
- @Differentiable 修饰 MyLayer operator() 网络运算方法,标注该运算过程参与反向传播。仓颉 TensorBoost 基于用户定义的网络运算代码分析生成反向传播需要的求导代码,用于模型训练等场景下对 MyLayer 网络运算的自动求导。
- @Differentiable 默认将函数所有入参当做求导需要累计梯度的对象。如果不是,比如入参除了输入 Tensor 以外还有其他不需要求导的变量,需要将输入 Tensor 加入到 include 列表。
- 当神经网络 A 和 B 存在一些公共子结构 C,产生代码复用的编程需求,可考虑通过 struct 定义公共子结构 C,再在网络 A/B 中将 C 作为成员变量包含进来。
如果某个输入的 Tensor 可能为空(对应 python 语言中某个入参为 None 的情况),可以调用 noneTensor() 函数创建一个空的 Tensor ,并在网络的 operator() 方法中调用 isNone() 来判断该入参是否为空。示例代码如下,OptionalLayer 网络的第二个输入 optional 可能为空。当 optional 为空时,返回 inputIds 和 weight_ 之和,否则返回 inputIds 与 optional 的差:
from CangjieTB import macros.*
from CangjieTB import ops.*
@OptDifferentiable[include: [weight_]]
struct OptionalLayer {
let weight_: Tensor
init(weight: Tensor){
weight_ = parameter(weight, "weight_")
}
@Differentiable[except: [optional]]
operator func ()(inputIds: Tensor, optional: Tensor): Tensor {
if (optional.isNone()) {
inputIds + this.weight_
} else {
inputIds - optional
}
}
}
测试代码如下:
let opLayer = OptionalLayer(onesTensor(Array<Int64>([2, 2])))
let inputId = onesTensor(Array<Int64>([2, 2]))
let optional1 = onesTensor(Array<Int64>([2, 2]))
let optional2 = noneTensor()
let out1 = opLayer(inputId, optional1)
let out2 = opLayer(inputId, optional2)
print("case 1: ", out1)
print("case 2: ", out2)
输出为:
case 1:
Tensor(shape=[2, 2], dtype=Float32, value=
[[0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00]])
case 2:
Tensor(shape=[2, 2], dtype=Float32, value=
[[2.00000000e+00 2.00000000e+00]
[2.00000000e+00 2.00000000e+00]])
自动微分
神经网络的训练使用反向传播算法求梯度。仓颉 TensorBoost 提供函数式自动微分的能力,应用链式求导法则,自动微分对用户屏蔽了大量的求导细节和过程。一般而言,用户可对被 @Differentiable 修饰的任一函数进行自动求导,通过微分表达式计算函数入参对应的梯度。用户还可通过微分表达式组合进行高阶微分,完成更强大的求导功能。
可微函数和微分表达式
仓颉 TensorBoost 微分表达式作用于函数,对函数入参求取梯度。以网络模型训练过程为例:
@Differentiable
首先定义训练函数 train,使用 @Differentiable 修饰函数,include 列表包含 train 函数第一个入参(定制网络结构 MyLayer)。
@Differentiable[include: [net]]
func train(net: MyLayer, input: Tensor, label: Tensor): Tensor {
let out = net(input) // 执行 MyLayer operator() 方法
(out - label) ** 2.0
}
@AdjointOf
要对训练函数进行求导,则需要用到 @AdjointOf 表达式:
let net = MyLayer(16, 16, true)
let input = onesTensor(Array<Int64>([16, 16]))
let label = onesTensor(Array<Int64>([1]))
let adj = @AdjointOf(train)
let (out, bpFunc) = adj(net, input, label)
let netGrad: MyLayer = bpFunc(onesLike(out))
@AdjointOf 为仓颉 TensorBoost 提供的微分表达式。下面的代码是 @AdjointOf 的使用样例,假设函数 f 的输入是 x 和 y,且两个输入都可微:
let adj = @AdjointOf(f)
let (out, bpFunc) = adj(x, y)
let sensitivity = out
let (dx, dy) = bpFunc(sensitivity)
【说明】:
@AdjointOf的返回值为原函数f的伴随函数adj。- 伴随函数
adj的返回值为原函数f的正向计算结果out和微分计算函数bpFunc。 bpFunc接受和out同类型的sensitivity值,输出(dx, dy),dx/dy分别和x/y同类型,对应了x和y的梯度。- 函数
f必须为被@Differentiable修饰的全局的微分函数。
stopGradient
用户在编写可微函数时可能会涉及到一些运算操作不参与或不支持微分求导。如果这些运算操作访问到参与微分的数据,意味着链式求导过程出现中断。此时需要用户使用仓颉 TensorBoost 提供的 stopGradient 函数接口来显示标注需要停止求导的数据。
比如下面代码中,可微方法 SmartMatMul 根据输入 Tensor 维度选择合适的运算方式。获取 Tensor 维度通过 getShapeDims()。而这个方法不参与微分求导,所以需要对参与微分的 input 先进行 stopGradient() 再调用 getShapeDims()。
@Differentiable
func SmartMatMul(input: Tensor, weight: Tensor): Tensor {
return if (stopGradient(input).getShapeDims() == 2) {
// 2D Tensor:调用 matmul
matmul(input, weight)
} else {
// 超过 2D Tensor:调用 batchMatMul
batchMatMul(input, weight)
}
}
模型训练
在进行模型训练时,一般分为四个步骤。
- 构建数据集,参见数据集 Dataset。
- 定义神经网络,参见网络构建 。
- 定义超参、损失函数及优化器。
- 训练网络,参见训练及保存模型。
准备数据集和神经网络
参考前面章节数据集 Dataset和网络构建。给出如下加载数据集和定义神经网络的代码
from CangjieTB import macros.*
from CangjieTB import nn.*
from CangjieTB import nn.layers.*
from CangjieTB import nn.optim.*
from CangjieTB import nn.loss.*
from CangjieTB import ops.*
from CangjieTB import common.*
from CangjieTB import dataset.*
// 定义神经网络
@OptDifferentiable
struct LeNetModel {
let conv1: Conv2d
let conv2: Conv2d
let pool: MaxPool2d
let dense1: Dense
let dense2: Dense
let dense3: Dense
init() {
conv1 = Conv2d(1, 6, Array<Int64>([5, 5]), pad_mode: "valid")
conv2 = Conv2d(6, 16, Array<Int64>([5, 5]), pad_mode: "valid")
pool = MaxPool2d(kernel_size: Array<Int64>([2, 2]), stride: Array<Int64>([2, 2]))
dense1 = Dense(400, 120, RandomNormalInitializer(sigma: 0.02))
dense2 = Dense(120, 84, RandomNormalInitializer(sigma: 0.02))
dense3 = Dense(84, 10, RandomNormalInitializer(sigma: 0.02))
}
@Differentiable
operator func ()(input: Tensor): Tensor {
input |> this.conv1 |> relu |> this.pool
|> this.conv2 |> relu |> this.pool
|> flatten
|> this.dense1 |> relu
|> this.dense2 |> relu
|> this.dense3
}
}
func createLenetDataset() {
// 加载数据集
let dataPath: String = "./data/mnist/test"
var mnistDs = MnistDataset(dataPath, epoch: 2)
// 将图像数据映射到[0, 1]的范围
var rescale = rescale(1.0 / 255.0, 0.0)
mnistDs.datasetMap([rescale], "image")
return mnistDs
}
定义超参、损失函数及优化器
定义超参
超参是可以调整的参数,可以控制模型训练优化的过程,不同的超参数值可能会影响模型训练和收敛速度。
一般会定义以下用于训练的超参:
- 训练轮次(epoch):训练时遍历数据集的次数。
- 批次大小(batch size):数据集进行分批读取训练,设定每个批次数据的大小。
- 学习率(learning rate):如果学习率偏小,会导致收敛的速度变慢,如果学习率偏大则可能会导致训练不收敛等不可预测的结果。
为数据集设置训练轮次和批次大小,定义学习率
let epoch: Int32 = 5
let batchSize: Int32 = 32
mnistDs.batch(batchSize, true)
mnistDs.repeat(epoch)
let learningRate: Float32 = 1.0e-2
设置学习率见定义优化器 。
定义损失函数
使用损失函数需要导入 nn 包。
from CangjieTB import nn.loss.*
损失函数用来评价模型的预测值和真实值不一样的程度。给定输出值和目标值,计算损失值,使用方法如下所示:
// 创建损失函数对象
let lossFn = SoftmaxCrossEntropyWithLogits(sparse: true)
// 创建计算值与目标值
let netOutput = Tensor(Array<Float32>([0.1, 0.3, 0.5, 0.1]), shape: Array<Int64>([1, 4]))
let label = Tensor(Array<Int32>([3]), shape: Array<Int64>([1]))
// 调用损失函数对象的操作符重载方法,获取 loss 值
let loss = lossFn(netOutput, label)
print("loss", loss)
输出为:
loss
Tensor(shape=[], dtype=Float32, value= 1.55037284e+00)
除了 SoftmaxCrossEntropyWithLogits,仓颉 TensorBoost 也支持用户自定义损失函数。与自定义神经网络结构类似,自定义损失函数使用 struct 数据类型,其计算逻辑在 operator() 运算符重载函数中实现,详见构建神经网络。
定义优化器
使用优化器需要导入 nn 包。
from CangjieTB import nn.*
优化器用于计算和更新梯度,构建一个优化器对象,该对象可以基于计算得到的梯度对原模型进行参数更新。设置优化器的参数选项,比如学习率、权重衰减等等。 class MomentumOptimizer<T0> 中泛型 T0 为神经网络的类型,如 LeNetModel 或 MyLayer 等。初始化时必须显式指明泛型类型,代码如下:
let lr: Float32 = 0.01
let momentum: Float32 = 0.9
let net = LeNetModel()
var optim: MomentumOptimizer<LeNetModel> = MomentumOptimizer<LeNetModel>(net, lr, momentum)
其中,学习率可以是 Float32 类型的常数,也可以是 Tensor 类型的可变动态学习率,代码如下:
var lrArrary: Array<Float32> = Array<Float32>([0.01, 0.01, 0.005, 0.002, 0.001])
var learningRate = Tensor(lrArrary, shape: [lrArrary.size])
var net = LeNetModel()
var optim = MomentumOptimizer<LeNetModel>(net, learningRate, 0.9, weightDecay: 0.00004, lossScale: 1024.0)
训练网络
训练网络的过程可以分成两步,第一步是进行前向和反向计算分别得到模型的 loss 值和梯度;第二步是利用梯度更新模型参数。
计算 loss 值和梯度
运用仓颉 TensorBoost 提供的 @AdjointOf 接口,可以获取到网络反向计算的梯度,代码如下:
// 定义可微的训练函数
@Differentiable[except: [lossFn, input, label]]
func train(net: LeNetModel, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor): Tensor
{
var output = net(input)
var lossTensor = lossFn(output, label)
return lossTensor
}
根据训练函数,获取输入的梯度:
// 创建 train 函数的输入
var input = parameter(zerosTensor(Array<Int64>([32, 1, 32, 32]), dtype: FLOAT32), "data")
var label = parameter(zerosTensor(Array<Int64>([32]), dtype: INT32), "label")
var lossFn = SoftmaxCrossEntropyWithLogits(sparse: true)
// 获取伴随函数
let adj = @AdjointOf(train)
// 获取反向传播函数
var (loss, bpFunc) = adj(net, lossFn, input, label)
// 获取梯度
var gradient: LeNetModel = bpFunc(Tensor(Float32(1.0)))
更新参数
当完成优化器对象的初始化,并通过反向传播函数得到梯度对象之后,即可调用优化器的 update 方法,将获取到的梯度传递给优化器,代码如下:
// 更新梯度
optim.update(gradient)
此处的 gradient 的类型需要与 optim 对象的泛型一致。
执行训练
基于前面介绍的梯度计算和参数更新方法,可以写出如下训练代码:
var datasetLenetTest = createLenetDataset()
for (i in 1..(datasetLenetTest.getDatasetSize() + 1)) {
datasetLenetTest.getNext([input, label])
var (loss, bpFunc) = adj(net, lossFn, input, label)
var gradient: LeNetModel = bpFunc(Tensor(Float32(1.0)))
optim.update(gradient)
let lossValue = loss.evaluate().toScalar<Float32>() // 这里调用 `evaluate` 确保静态图模式下能够正确的执行计算
if (i % 100 == 0) {
print("step: ${i}, loss is: ${lossValue}\n")
}
}
这就是一个神经网络模型的完整训练过程了。执行如上代码,一般可以看到模型 loss 值逐步减小,代表模型收敛。如果遇到模型不收敛的情况,可以尝试调整超参。
JIT 加速
仓颉 TensorBoost 提供独立的 jit 函数对 Tensor 运算进行加速。jit 函数为高阶函数形式,入参和返回值类型都是函数。返回的新函数相比原函数使能更多底层优化。返回的新函数在第一次调用的时候,会尝试进行图编译,然后执行编译的图得到运算结果。后续调用该函数会复用之前编译的图,达到加速效果。
package ops
// 通用接口(tensorFunc入参为tensor数组,可由任意个数tensor组成)
public func jit(tensorFunc: (Array<Tensor>)->Tensor): (Array<Tensor>)->Tensor
// 特例化接口(tensorFunc入参接受1个、2个、3个、4个、5个tensor)
public func jit(tensorFunc: (Tensor)->Tensor): (Tensor)->Tensor
public func jit(tensorFunc: (Tensor, Tensor)->Tensor): (Tensor, Tensor)->Tensor
public func jit(tensorFunc: (Tensor, Tensor, Tensor)->Tensor): (Tensor, Tensor, Tensor)->Tensor
public func jit(tensorFunc: (Tensor, Tensor, Tensor, Tensor)->Tensor): (Tensor, Tensor, Tensor, Tensor)->Tensor
public func jit(tensorFunc: (Tensor, Tensor, Tensor, Tensor, Tensor)->Tensor): (Tensor, Tensor, Tensor, Tensor, Tensor)->Tensor
使用 JIT 加速功能一般分为两步。
- 将某函数(可以是个匿名函数)传给
jit函数得到新函数,新函数和原函数的输入、输出类型保持不变; - 调用新函数执行运算,调用方式跟正常函数调用一样,可以多次调用,每次传入相应的 tensor 数据。
使用示例:
// 示例1:对普通函数进行加速
func foo(x: Tensor, y: Tensor): Tensor { return x + y }
let jittedFoo = jit(foo)
// 示例2:对lambda函数进行加速
let jittedLambdaFunc = jit({x, y => x + y})
// 示例3:对包含非Tensor入参的函数进行加速(方法:封装偏函数)
func bar(x: Tensor, y: Tensor, attr: Int64): Tensor {
return if (attr > 0) { x + y } else { x - y }
}
func partialBar(attr: Int64): (Tensor, Tensor)->Tensor {
return {x: Tensor, y: Tensor => bar(x, y, attr)}
}
let jittedAddFunc = jit(partialBar(1))
let jittedSubFunc = jit(partialBar(0))
注意以下约束条件,如有违反会导致 jit 返回的新函数被调用时抛异常:
- 调用新函数之前,不能存在一些 tensor 尚未求值;
- 新函数调用的入参 tensor 必须是有值的,不能是 parameter;
- 函数返回值必须是来自某个算子,不能是常量 tensor 或 parameter。
另外,仓颉 TensorBoost 还提供更底层的加速 API runWith,可以免去jit API 产生的缓存查询开销,直接基于底层图执行加速。
package ops
public interface Jitable {
// 无参计算图
public func runWith(tensorFunc: ()->Tensor): Tensor
// 有参计算图
public func runWith(ins: Array<Tensor>, tensorFunc: (Array<Tensor>)->Tensor): Tensor
}
// 仓颉 TensorBoost 计算图数据类型
public class Graph {
public init()
}
extend Graph <: Jitable {
public func runWith(tensorFunc: ()->Tensor): Tensor
public func runWith(ins: Array<Tensor>, tensorFunc: (Array<Tensor>)->Tensor): Tensor
}
使用示例:
let g0 = Graph()
var acc = Tensor(0.0)
for (i in 0..4) {
acc = g0.runWith([acc]) {ins => ins[0] + Tensor(1.0)}
}
jit 底层调用 runWith。比较两个 API 之间异同:
【相同点】
都是高阶函数形式,支持对传入的函数以静态图方式执行,底层和某个图对象进行绑定起到图编译加速作用。
【不同点】
runWith不会从动态图切换到静态图。如果上下文是动态图模式,runWith会按照动态图方式执行。而jit不管上下文,固定对传入函数进行静态图优化。runWith基于 Graph 绑定某段 tensor 运算,绑定成功后可以直接运行该图得到结果。jit的图对象缓存在全局 hash 表,通过 tensor shape、dtype 等查找图缓存。因此,runWith比jit更高效,介意图缓存开销的可以选择用runWith。
附录 A 运行环境管理
仓颉 TensorBoost 需要设置环境变量 CANGJIETB_GRAPH_MODE 来设置运行模式,当 CANGJIETB_GRAPH_MODE=true 时,仓颉 TensorBoost 将以静态图模式运行,否则为动态图模式。如未设置此环境变量,默认以动态图模式运行。
此外仓颉 TensorBoost 提供了 Context 类型用于运行管理,并在 context 包里定义了 Context 对象 g_context。只要从 context 包中导入 g_context,即可使用 Context 类型提供的外部接口管理运行状态。
public var g_context: Context
Context 类提供的相关方法如下所述:
设置运行模式
public func setEagerMode(eagerMode: Bool): Unit
仅支持在调试版本使用,非调试版本会抛出异常提示,当 eagerMode 选择 true 时,表示动态图模式运行。
查看运行模式
public func isEagerMode(): Bool
查看当前是动态图模式运行还是静态图模式运行,如果返回 true ,表示当前在动态图模式运行。
设置 Device 类型
public func setDeviceTarget(device: String): Unit
函数 setDeviceTarget 用于设置 Device 类型,合法的输入有 "Ascend","GPU","CPU",不符合输入要求会抛出异常,目前仓颉 TensorBoost 发布的软件版本仅支持 "Ascend" 和 "GPU"。默认不显示设置的情况下,仓颉 TensorBoost 自动设置 Device 类型是 "GPU"。
获取 Device 类型
public func getDeviceTarget(): String
函数 getDeviceTarget 用于获取 Device 类型,返回值有 "Ascend" ,"GPU","CPU",分别表示 Device 类型是 Ascend,GPU 和 CPU。
获取 Tensor GC 阈值
public func getTensorSize(): Int64
Tensor 占用的内存总量超过释放阈值会自动释放不使用的 Tensor,具体详见张量释放章节。
选择 Device 编号
public func setDeviceId(deviceId: UInt32): Unit
当存在多张昇腾计算芯片时,函数 setDeviceId 用于选择设备编号,取值范围为[0, 4095],不在范围内会抛出异常。如果 Device 为 GPU 或 CPU 时此设置无效。
设置当前分布式后端
public func setBackend(backend: String): Unit
初始化通信服务需要的分布式后端,backend 是分布式后端的名称,当前仅支持输入"nccl",仅支持 GPU 硬件平台,不符合规则会抛出异常,默认值为"none"。
查询当前分布式后端
public func getBackend(): String
代码示例
以下为程序开始时设置运行信息的示例代码:
from CangjieTB import context.*
main(): Int64
{
g_context.setSaveGraphs(true) // 保存计算图
g_context.setDeviceTarget("GPU") // 运行设备为GPU
// 测试代码写在此处
return 0
}
附录 A 运行环境管理
仓颉 TensorBoost 需要设置环境变量 CANGJIETB_GRAPH_MODE 来设置运行模式,当 CANGJIETB_GRAPH_MODE=true 时,仓颉 TensorBoost 将以静态图模式运行,否则为动态图模式。如未设置此环境变量,默认以动态图模式运行。
此外仓颉 TensorBoost 提供了 Context 类型用于运行管理,并在 context 包里定义了 Context 对象 g_context。只要从 context 包中导入 g_context,即可使用 Context 类型提供的外部接口管理运行状态。
public var g_context: Context
Context 类提供的相关方法如下所述:
设置运行模式
public func setEagerMode(eagerMode: Bool): Unit
仅支持在调试版本使用,非调试版本会抛出异常提示,当 eagerMode 选择 true 时,表示动态图模式运行。
查看运行模式
public func isEagerMode(): Bool
查看当前是动态图模式运行还是静态图模式运行,如果返回 true ,表示当前在动态图模式运行。
设置 Device 类型
public func setDeviceTarget(device: String): Unit
函数 setDeviceTarget 用于设置 Device 类型,合法的输入有 "Ascend","GPU","CPU",不符合输入要求会抛出异常,目前仓颉 TensorBoost 发布的软件版本仅支持 "Ascend" 和 "GPU"。默认不显示设置的情况下,仓颉 TensorBoost 自动设置 Device 类型是 "GPU"。
获取 Device 类型
public func getDeviceTarget(): String
函数 getDeviceTarget 用于获取 Device 类型,返回值有 "Ascend" ,"GPU","CPU",分别表示 Device 类型是 Ascend,GPU 和 CPU。
获取 Tensor GC 阈值
public func getTensorSize(): Int64
Tensor 占用的内存总量超过释放阈值会自动释放不使用的 Tensor,具体详见张量释放章节。
选择 Device 编号
public func setDeviceId(deviceId: UInt32): Unit
当存在多张昇腾计算芯片时,函数 setDeviceId 用于选择设备编号,取值范围为[0, 4095],不在范围内会抛出异常。如果 Device 为 GPU 或 CPU 时此设置无效。
设置当前分布式后端
public func setBackend(backend: String): Unit
初始化通信服务需要的分布式后端,backend 是分布式后端的名称,当前仅支持输入"nccl",仅支持 GPU 硬件平台,不符合规则会抛出异常,默认值为"none"。
查询当前分布式后端
public func getBackend(): String
代码示例
以下为程序开始时设置运行信息的示例代码:
from CangjieTB import context.*
main(): Int64
{
g_context.setSaveGraphs(true) // 保存计算图
g_context.setDeviceTarget("GPU") // 运行设备为GPU
// 测试代码写在此处
return 0
}
附录 B 张量 API
创建张量
使用构造函数创建
仓颉 TensorBoost 为张量(Tensor)类型提供了多个构造函数,函数原型定义如下。其中 value 是传入的数组或者单个的值,入参 shape 是所创建 Tensor 的形状大小,dtype 用于指定 Tensor 的类型。
public struct Tensor {
public init()
public init(value: Float16, dtype!: Int32 = FLOAT16)
public init(value: Float32, dtype!: Int32 = FLOAT32)
public init(value: Float64, dtype!: Int32 = FLOAT64)
public init(value: Int32, dtype!: Int32 = INT32)
public init(value: Int64, dtype!: Int32 = INT64)
public init(value: Bool, dtype!: Int32 = BOOL)
public init(value: Array<Float16>, shape!: Array<Int64>, dtype!: Int32 = FLOAT16)
public init(value: Array<Float32>, shape!: Array<Int64>, dtype!: Int32 = FLOAT32)
public init(value: Array<Float64>, shape!: Array<Int64>, dtype!: Int32 = FLOAT64)
public init(value: Array<Int32>, shape!: Array<Int64>, dtype!: Int32 = INT32)
public init(value: Array<Int64>, shape!: Array<Int64>, dtype!: Int32 = INT64)
public init(value: Array<UInt32>, shape!: Array<Int64>, dtype!: Int32 = UINT32)
public init(value: Array<Bool>, shape!: Array<Int64>, dtype!: Int32 = BOOL)
}
当在 Tensor 构造函数中指定了 dtype 时,Tensor 类型以指定的 dtype 为准; 否则 Tensor 类型同传入的值或者 Array 类型相同。对于不同的值或者 Array 类型,可指定的 dtype 目前也做了限制,参考下表。
| 值或者 Array 类型 | dtype 可选类型 |
|---|---|
| Int32, Int64, UInt32 | INT32, INT64, UINT32 |
| Float16, Float32, Float64 | FLOAT16, FLOAT32, FLOAT64 |
| Bool | BOOL |
构造 Tensor 时,如果输入不符合要求,会抛出异常,有以下几种类型:
- 初始化数据类型不支持
- 初始化参数值不符合要求
- 初始化 Tensor 的形状不符合要求
使用仓颉数组(数据类型为 Float32)创建大小为 Array<Int64>([2, 2]) 的张量 tensor。
let tensor = Tensor(Array<Float32>([1.0, 1.0, 1.0, 1.0]), shape: Array<Int64>([2, 2]))
print(tensor)
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00]])
创建符合正态分布的张量
函数 randomNormalTensor 提供正态分布随机初始化 Tensor 的能力,函数原型定义如下,其中 dtype 是传入的 Tensor 的数据类型入参, shape 是 Tensor 的 shape 大小,sigma 是标准差,seed 是全局种子,seed2 是 op 种子,两者一起作为随机数的种子, 函数返回一个 Tensor 类型。
public func randomNormalTensor(shape: Array<Int64>, sigma!: Float32 = 0.01, dtype!: Int32 = FLOAT32, seed!: Int64 = 0, seed2!: Int64 = 0): Tensor
创建数据类型为 Float32,大小为 Array<Int64>([2, 3]) ,数值按正态分布随机初始化的张量 randTensor。
let randTensor = randomNormalTensor(Array<Int64>([2, 3]))
print(randTensor)
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[2.41499580e-02 -6.09102054e-03 1.38444267e-02]
[9.14979633e-03 -2.58914679e-02 -1.21405339e-02]])
【注意】: 全局种子和 op 种子均为 0 的情况下,随机数会使用时钟作为种子,生成每次都不相同的随机数。
创建符合均匀分布的张量
函数 uniformTensor 提供均匀分布随机初始化 Tensor 的能力,函数原型定义如下,其中 dtype 是传入的 Tensor 的数据类型,入参 shape 是 Tensor 的 shape 大小,以 0 为均值, boundary 为均匀分布的取值上限 (-boundary 为均匀分布的取值下限),函数返回一个 Tensor 类型。
public func uniformTensor(shape: Array<Int64>, boundary!: Float32 = 0.01, dtype!: Int32 = FLOAT32): Tensor
创建数据类型为 Float32,大小为 Array<Int64>([2, 3]) ,数值按均匀分布随机初始化的张量 randTensor。
let randTensor = uniformTensor(Array<Int64>([2, 3]))
print(randTensor)
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[6.29447401e-03 8.11583921e-03 -7.46026356e-03]
[8.26751627e-03 2.64718570e-03 -8.04919191e-03]])
创建数值全 1 的张量
函数 onesTensor 提供全 1 初始化 Tensor 的能力,函数原型定义如下,其中 dtype 是传入的 Tensor 的数据类型,支持 Float16\Float32\Float64\Int32\Int64\UInt32\Bool 类型;shape 是 Tensor 的 shape 大小,函数返回一个 Tensor 类型。
public func onesTensor(shape: Array<Int64>, dtype!: Int32 = FLOAT32): Tensor
创建数据类型为 Float32,大小为 Array<Int64>([2, 3]),数值全为 1 的张量 onesTensor。
let onesTensor = onesTensor(Array<Int64>([2, 3]))
print(onesTensor)
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[1.00000000e+00 1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00 1.00000000e+00]])
创建数值全 0 的张量
函数 zerosTensor 提供全 0 初始化 Tensor 的能力,函数原型定义如下,其中 dtype 是传入的 Tensor 的数据类型,支持 Float16\Float32\Float64\Int32\Int64\UInt32\Bool 类型;shape 是 Tensor 的 shape 大小,函数返回一个 Tensor 类型。
public func zerosTensor(shape: Array<Int64>, dtype!: Int32 = FLOAT32): Tensor
创建数据类型为 Float32,大小为 Array<Int64>([2, 3]),数值全为 0 的张量 zerosTensor。
let zerosTensor = zerosTensor(Array<Int64>([2, 3]))
print(zerosTensor)
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[0.00000000e+00 0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00 0.00000000e+00]])
创建指定数值和大小的张量
函数 fillTensor 提供指定数值 data 和大小的 Tensor 的能力,data 可以是 Float16\Float32\Float64\Int32\Bool 的数据类型,根据填充的数据类型不同,提供了五个接口,函数原型定义如下,其中 shape 是 Tensor 的 shape 大小,data 是填充数据,函数返回一个 Tensor 类型。
public func fillTensor(shape: Array<Int64>, data: Float16): Tensor
public func fillTensor(shape: Array<Int64>, data: Float32): Tensor
public func fillTensor(shape: Array<Int64>, data: Float64): Tensor
public func fillTensor(shape: Array<Int64>, data: Int32): Tensor
public func fillTensor(shape: Array<Int64>, data: Bool): Tensor
创建数值全是 2.0,大小为 Array<Int64>([6]) 的张量 newTensor。
let newTensor = fillTensor(Array<Int64>([6]), Float32(2.0))
print(newTensor)
输出为:
Tensor(shape=[6], dtype=Float32, value=
[2.00000000e+00 2.00000000e+00 2.00000000e+00 2.00000000e+00 2.00000000e+00 2.00000000e+00])
创建对角张量
函数 eyeTensor 提供一个对角线是 1,其他位置是 0 的 Tensor,支持的类型有 FLOAT16\FLOAT32\FLOAT64\INT32\INT64\UINT32\BOOL,函数原型定义如下:
public func eyeTensor(n: Int64, dtype!: Int32 = FLOAT32): Tensor
public func eyeTensor(n: Int64, m: Int64, dtype!: Int32 = FLOAT32): Tensor
其中,n、m 分别对应输出矩阵的 row 和 column,没有传入 m,则 m = n ,dtype 是传入的数据类型,默认值为 FLOAT32。
创建数据类型为 Float32,大小为 Array<Int64>([2, 3]),对角线 Tensor,使用以下代码:
let eyeTensor = eyeTensor(2, 3)
print(eyeTensor)
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 1.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 1.00000000e+00 0.00000000e+00]])
创建内容为空的张量
函数 noneTensor 提供空 Tensor 初始化的能力,该函数返回一个内置的 Tensor 类型的全局变量 NONETENSOR,表示 Tensor 对象中没有任何值。NONETENSOR 的 dtype 和 shape 无意义,无法调用 getDtype()、 getShape() 、 isInt32() 等方法获取属性,也无法调用 evaluate() 方法进行求值。
public func noneTensor(): Tensor
创建内容为空的张量。可以调用 Tensor 的成员函数 isNone() 来判断 Tensor 对象是否为 NONETENSOR。
let none = noneTensor()
这种初始化方式可用于函数入参类型为 Tensor,但某些情况下可能为空的场景。
使用 initialize 方法创建张量
仓颉 TensorBoost 为以上提到的各种初始化方式提供了统一的调用方法:initialize 函数,这种初始化方式常用于网络中权重的初始化,如 Dense 或 Conv2d 等,参见[附录 D](###Dense 层)。定义如下:
public func initialize(shape: Array<Int64>, initializer: BaseInitializer, dtype!: Int32 = FLOAT32): Tensor
public func initialize(shape: Array<Int64>, initType!: InitType = InitType.NORMAL, dtype!: Int32 = FLOAT32): Tensor
其中:
-
BaseInitializer 是初始化器的基类,仓颉 TensorBoost 目前提供了 4 个子类:
-
RandomNormalInitializer 可以使生成的数据满足正态分布,原型定义如下,入参 sigma 代表生成数据的标准差。
public class RandomNormalInitializer <: BaseInitializer { public init(sigma!: Float32 = 0.01) } -
TruncatedNormalInitializer 生成截断正态分布,数据要求限制在[left, right]范围内。原型定义如下,入参 sigma 代表标准差;left、right 分别代表左右数据边界。
public class TruncatedNormalInitializer <: BaseInitializer { public init() public init(sigma: Float32, left!: Float32 = -2.0, right!: Float32 = 2.0) } -
UniformInitializer 生成在[-range, range] 之间的均匀随机分布数据。原型定义如下,入参 range 代表生成数据的边界范围。
public class UniformInitializer <: BaseInitializer { public init(range!: Float32 = 0.07) } -
ReadFileInitializer 从文件生成 Tensor。
public class ReadFileInitializer <: BaseInitializer { public init(fromFile!: String = "") } -
XavierUniformInitializer 按照 xavier uniform 算法生成在 [-boundary, boundary] 之间的均匀分布的数据。原型定义如下,入参 gain 代表缩放因子。
public class XavierUniformInitializer <: BaseInitializer { public init(gain!: Float32 = 1.0) }
-
XavierUniformInitializer 按照 xavier uniform 算法生成在 [-boundary, boundary] 之间的均匀分布的数据,其中 boundary 的计算公式如下:
$$ boundary = gain * \sqrt{\frac{6}{n_{in} + n_{out}}} $$
上述公式中,$n_{in}$ 为权重的输入单元数,$n_{out}$ 为权重的输出单元数。
InitType 是枚举类型,定义如下:
public enum InitType { ZERO // "全 0" 初始化
| ONE // "全 1" 初始化
| NORMAL // "sigma 为 0.01 的正态分布" 初始化
| TRUNCNORM // "sigma 为0.01, left 为-2.0, right 为2.0的截断正态分布" 初始化
| UNIFORM // "range为0.07的均匀分布" 初始化
| XAVIERUNIFORM // "gain 为 1 的 XAVIER 均匀分布" 初始化
}
通过加载 npy 文件来初始化 Tensor
npy 是 Python 的 Numpy 模块保存 ndarray 的标准格式。仓颉 TensorBoost 提供了 NpyFile 类与其对应,支持从 npy 文件初始化 Tensor ,也支持将 Tensor 保存成 npy 文件。 首先需要创建 NpyFile 类型,NpyFile 的第一个参数为需要读写的文件名(或路径),如路径不存在会自动创建;第二个参数指定读写模式。NpyFile 类定义如下:
public class NpyFile {
public init(name: String, mode: String)
public func close()
}
可以通过 Tensor 的静态 load 方法读取 npy 文件进行初始化,仅支持读模式"rb",读取的顺序需要同保存的顺序保持一致。具体用法如下:
let npy = NpyFile("test.npy", "rb")
let a = Tensor.load(npy)
let b = Tensor.load(npy)
npy.close()
另外也可以通过 Tensor 的静态 save 方法将其保存成 npy 文件,仅支持写模式"wb"。具体用法如下:
let npy = NpyFile("test.npy", "wb")
let input0 = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]), shape: Array<Int64>([2, 3]))
let input1 = Tensor([true, false, true], shape: Array<Int64>([3]))
Tensor.save(npy, input0)
Tensor.save(npy, input1)
npy.close()
注意: close() 方法可以提前释放文件句柄。用户如果选择不调用,仓颉的 GC 也会自动进行释放,不会造成资源泄漏。
张量属性与方法
获取张量数据类型
函数 getDtype() 和 getStrDtype() 用于获取张量的数据类型。
public func getDtype(): Int32
public func getStrDtype(): String
应用示例
let input = randomNormalTensor(Array<Int64>([32, 1, 32, 32]))
let dtype = input.getDtype()
let strDtype = input.getStrDtype()
print("dtype is ${dtype}\n")
print("strDtype is ${strDtype}\n")
输出为:
dtype is 0
strDtype is FLOAT32
获取张量形状大小
函数 getShape() 用于获取张量的形状大小。
public func getShape(): Array<Int64>
应用示例
let input = randomNormalTensor(Array<Int64>([32, 1, 32, 32]))
let shape= input.getShape()
print("shape is ${shape.toString()}\n")
输出为:
shape is [32, 1, 32, 32]
获取张量维度大小
函数 getShapeDims() 用于获取张量的维度大小。
public func getShapeDims(): Int64
应用示例
let input = randomNormalTensor(Array<Int64>([32, 1, 32, 32]))
let shapeDims= input.getShapeDims()
print("shapeDims is ${shapeDims.toString()}\n")
输出为:
shapeDims is 4
判断是否是 zerosTensor 接口初始化的 Tensor
函数 isZero() 判断是否是 zerosTensor 接口初始化的 Tensor,常用于性能优化。
public func isZero(): Bool
应用示例
let zerosTensor: Tensor = zerosTensor(Array<Int64>([3, 2]), dtype: FLOAT32)
if (zerosTensor.isZero()) {
print("Zero\n")
} else {
print("not Zero\n")
}
输出为:
Zero
判断张量是否为空
函数 isNone() 用于判断张量是否为空。
public func isNone(): Bool
应用示例
let none = noneTensor()
if (none.isNone()) {
print("None\n")
} else {
print("not None\n")
}
输出为:
None
获取张量的名称
属性 name 用于获取张量的 name,默认值为空。
public prop name: String
应用示例
let input1 = parameter(onesTensor(Array<Int64>([2, 2])), "input1")
let name1 = input1.name
print("name1 is ${name1}\n")
let input2 = onesTensor(Array<Int64>([2, 2]))
let name2 = input2.name
print("name2 is ${name2}\n")
输出为:
name1 is input1
name2 is
获取对应的 Mindspore Handle 值
函数 getMsHandle() 获取对应的 Mindspore Handle 值,常用于仓颉与 Mindspore 的数据同步操作。
public func getMsHandle()
判断是否需要从主机同步数据到设备
函数 enableSyncHostToDevice() 判断是否需要从主机同步数据到设备,常用于数据集,用户无需主动调用
public func enableSyncHostToDevice()
判断张量是否需要更新梯度
属性 requiresGrad 用于控制网络参数是否需要更新梯度,默认是 false。
mut prop requiresGrad: Bool
应用示例
var input = onesTensor(Array<Int64>([2, 2]))
print("input's requiresGrad is ${input.requiresGrad}\n")
var param = parameter(input, "weight")
print("param's requiresGrad is ${param.requiresGrad}\n")
输出为:
input's requiresGrad is false
param's requiresGrad is true
判断张量数据类型
例如函数 isInt32() 、 isFloat32() 、 isFloat64() 和 isBool() 分别用于判断张量是否是 Int32、Float32、Float64 或者 Bool 数据类型。
当前提供的判断张量数据类型的接口如下:
public func isInt32(): Bool
public func isInt64(): Bool
public func isFloat16(): Bool
public func isFloat32(): Bool
public func isFloat64(): Bool
public func isBool(): Bool
public func isUInt32(): Bool
对某一个确定的 Tensor 而言,调用以上三个方法只有一个为 true,即某个确定的 Tensor 只能为一种类型。
应用示例
let a = onesTensor(Array<Int64>([1]), dtype: INT32)
print("a isInt32? : ${a.isInt32()}\n")
print("a isFloat32? : ${a.isFloat32()}\n")
print("a isBool? : ${a.isBool()}\n")
输出为:
a isInt32? : true
a isFloat32? : false
a isBool? : false
张量转为数组
例如函数 toArrayInt32() 、 toArrayFloat32() 、 toArrayFloat64() 和 toArrayBool() 分别用于将 Int32、Float32、Float64 或者 Bool 类型张量转换成对应数据类型的数组。
提供toScalar<T>(),可以将 Tensor 转化为标量,例如当一个 dtype 为 Int32 类型的 Tensor 为标量时(shape 为空数组),应调用toScalar<Int32>()方法。
当前提供的张量转数组或者标量的方法如下:
public func toArrayInt32(): Array<Int32>
public func toArrayInt64(): Array<Int64>
public func toArrayFloat16(): Array<Float16>
public func toArrayFloat32(): Array<Float32>
public func toArrayFloat64(): Array<Float64>
public func toArrayBool(): Array<Bool>
public func toArrayUInt32(): Array<UInt32>
public func toScalar<T>(): T
支持使用 toScalar<T>() 的类型受到接口 Number
public interface Number<T> {
static func size(): Int64
static func zero(): T
static func dtype(): Int32
static func dtypeName(): String
static func initArrayTensorByValue(
value: Array<T>,
shapePtr: CPointer<Int64>,
shapeDims: Int64,
dtype: Int32
): MSTensorHandle
static func copyTensorDataToCangjie(dest: Array<T>, tensorHandle: MSTensorHandle): Unit
}
应用示例:
let zerosTensor: Tensor = zerosTensor(Array<Int64>([3, 2]), dtype: FLOAT32)
print("zerosTensor is: ", zerosTensor)
let zerosArray: Array<Float32> = zerosTensor.toArrayFloat32()
print("zerosArray is: ${zerosArray.toString()}\n")
输出为:
zerosTensor is:
Tensor(shape=[3, 2], dtype=Float32, value=
[[0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00]])
zerosArray is: [0.000000, 0.000000, 0.000000, 0.000000, 0.000000, 0.000000]
【注意】:对某一个确定的 Tensor 而言,只能将其转为与数据类型相对应的数组。如果某 Tensor 对象定义为 Int32 类型,则不允许调用 toArrayFloat32() 和toArrayBool() 方法。
evaluate 方法
以静态图模式运行时,evaluate 之前计算得出的 Tensor 是无值的。需要调用 Tensor 的 evaluate() 方法触发计算图的执行之后,才能将无值的 Tensor 变为有值的 Tensor。
public func evaluate(): Tensor
如下代码以静态图模式运行时,用仓颉数组创建的t1和t2是有值的 Tensor,t5为计算得出的 Tensor 且被 evaluate 过,是有值的。t4为计算得出的 Tensor 且未被 evaluate 过,是无值的。如果不确定某个 Tensor 是否有值,可以调用 isConcrete 方法进行判断。
let t1 = Tensor(Array<Float32>([1.0, 1.0, 1.0]), shape: Array<Int64>([3]))
let t2 = Tensor(Array<Float32>([2.0, 2.0, 2.0]), shape: Array<Int64>([3]))
let t3 = t1 + t2
let t4 = t3 * t3
let t5: Tensor = t4.evaluate()
let resArr: Array<Float32> = t5.toArrayFloat32()
print("resArr: ${resArr.toString()}\n")
上述代码中,t3/t4未被 evaluate 过,不允许对t3/t4直接调用 toArrayFloat32()。
判断张量是否为 Parameter
public func isParameter(): Bool
let t1 = initialize(Array<Int64>([2]), initType:InitType.NORMAL, dtype:FLOAT32)
print("t1 is Parameter? --- ${t1.isParameter()}\n")
let t2 = parameter(initialize(Array<Int64>([2]), initType:InitType.NORMAL, dtype:FLOAT32), "param")
print("t2 is Parameter? --- ${t2.isParameter()}\n")
输出为:
t1 is Parameter? --- false
t2 is Parameter? --- true
判断张量是否有值
以静态图模式运行时,evaluate 之前计算得出的 Tensor 是无值的。可以调用 Tensor 的 isConcrete() 方法来判断 Tensor 是否需要 evaluate 操作。
public func isConcrete(): Bool
如下代码以静态图模式运行时,t3 是无值的 Tensor,t4 是有值的 Tensor:
let t1 = Tensor(Array<Float32>([1.0, 1.0, 1.0]), shape: Array<Int64>([3]))
let t2 = Tensor(Array<Float32>([2.0, 2.0, 2.0]), shape: Array<Int64>([3]))
let t3 = t1 + t2
let t4 = t3.evaluate()
print("t3 is concrete?---${t3.isConcrete()}\n")
print("t4 is concrete?---${t4.isConcrete()}\n")
输出为:
t3 is concrete?---false
t4 is concrete?---true
张量自动微分
张量支持微分,提供微分初值接口和微分累加接口供自动微分系统使用
extend Tensor <: Differentiable<Tensor> {
@Differentiable
public func TangentZero(): Tensor
@Differentiable
public func TangentAdd(y: Tensor): Tensor
}
查看张量数值
仓颉 TensorBoost 提供了多种 print 重载函数,用于查看张量数值。
查看单个张量数值
public func print(tensor: Tensor): Unit
应用示例
let input = Tensor(Array<Int32>([1, 2, 3, 4]), shape: Array<Int64>([1, 4]))
print(input)
输出为:
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
查看描述和单个张量数值
public func print(str: String, tensor: Tensor): Unit
应用示例
let input = Tensor(Array<Int32>([1, 2, 3, 4]), shape: Array<Int64>([1, 4]))
print("input:", input)
输出为:
input:
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
查看张量数组
public func print(tensors: Array<Tensor>): Unit
应用示例
let input1 = Tensor(Array<Int32>([1, 2, 3, 4]), shape: Array<Int64>([1, 4]))
let input2 = Tensor(Array<Int32>([5, 6, 7, 8]), shape: Array<Int64>([1, 4]))
print([input1, input2])
输出为:
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
Tensor(shape=[1, 4], dtype=Int32, value=
[[5 6 7 8]])
查看描述和张量数组
public func print(str: String, tensors: Array<Tensor>): Unit
应用示例
let input1 = Tensor(Array<Int32>([1, 2, 3, 4]), shape: Array<Int64>([1, 4]))
let input2 = Tensor(Array<Int32>([5, 6, 7, 8]), shape: Array<Int64>([1, 4]))
print("Print input1 and input2:", [input1, input2])
输出为:
Print input1 and input2:
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
Tensor(shape=[1, 4], dtype=Int32, value=
[[5 6 7 8]])
查看(描述, Tensor) 数组
public func print(tensors: Array<(String, Tensor)>): Unit
应用示例
let input1 = Tensor(Array<Int32>([1, 2, 3, 4]), shape: Array<Int64>([1, 4]))
let input2 = Tensor(Array<Int32>([5, 6, 7, 8]), shape: Array<Int64>([1, 4]))
print([("input1:", input1), ("input2:", input2)])
输出为:
input1:
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
input2:
Tensor(shape=[1, 4], dtype=Int32, value=
[[5 6 7 8]])
查看并存储张量信息
函数 logTensor() 把 Tensor 打印到文件中。
public func logTensor(tensor: Tensor, fileName: String, appendMode!: Bool = true): Unit
动静态图下张量输出的对比
在动态图模式下,打印总是按照代码执行的顺序进行输出;在静态图模式下,当 tensor 不需要通过 op 运算获得时,直接输出结果;否则要在 evaluate()后再进行输出操作。以下代码在动态图模式下的行为与静态图模式下不同:
func TestPrint1(): Unit
{
print("STTest: Print Begin\n")
var input1 = Tensor(Array<Int32>([1, 2, 3, 4]), shape: Array<Int64>([1, 4]))
var input2 = Tensor(Array<Int32>([5, 6, 7, 8]), shape: Array<Int64>([1, 4]))
var output1 = input1 + input2
print("input1", input1) // 第 1 次打印
print("Sum of inpu1 and input2:", output1) // 第 2 次打印
print([("input1:", input1), ("input2:", input2), ("output1:", output1)]) // 第 3 次打印
print("Print input1 and input2:", [input1, input2]) // 第 4 次打印
var res = output1.evaluate()
print("STTest: Print End\n")
}
动态图下的运行结果为:
ST-Test
STTest: Print Begin
input1
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
Sum of inpu1 and input2:
Tensor(shape=[1, 4], dtype=Int32, value=
[[6 8 10 12]])
input1:
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
input2:
Tensor(shape=[1, 4], dtype=Int32, value=
[[5 6 7 8]])
output1:
Tensor(shape=[1, 4], dtype=Int32, value=
[[6 8 10 12]])
Print input1 and input2:
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
Tensor(shape=[1, 4], dtype=Int32, value=
[[5 6 7 8]])
STTest: Print End
静态图下的运行结果为:
ST-Test
STTest: Print Begin
input1
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
Print input1 and input2:
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
Tensor(shape=[1, 4], dtype=Int32, value=
[[5 6 7 8]])
Sum of inpu1 and input2:
Tensor(shape=[1, 4], dtype=Int32, value=
[[ 6 8 10 12]])
input1:
Tensor(shape=[1, 4], dtype=Int32, value=
[[1 2 3 4]])
input2:
Tensor(shape=[1, 4], dtype=Int32, value=
[[5 6 7 8]])
output1:
Tensor(shape=[1, 4], dtype=Int32, value=
[[ 6 8 10 12]])
STTest: Print End
可以看到在动态图下是按照 1、2、3、4 的顺序进行打印;而在静态图下最终打印结果的顺序为 1、4、2、3。 这是因为:第 1 次打印中 input1 是有值的,所以结果立刻进行了输出;而第 2 次打印中 output1 需要通过运算获得,所以结果在 evaluate 之后输出;第 3 次打印中包含了 1 个需要运算获得的 output1,所以也要在 evaluate 之后输出,第 4 次打印中的 2 个 Tensor 都是有值的,可以立刻输出。
Tensor 运算符重载
在仓颉 TensorBoost 中,支持对 Tensor 进行加减乘除等操作,分别对应了算子函数,以下是 Tensor 支持的运算符重载: 当前 Scalar 作为左操作数,运算符重载支持的类型有:Float16、Float32、Float64、Int32。
| 操作符 | 操作符含义 | 替换的仓颉 TensorBoost 算子 |
|---|---|---|
- | Negative: unary | neg(input1) |
* | Multiply: binary | mul(input1, input2) |
/ | Divide: binary | realDiv(input1, input2) |
+ | Add: binary | add(input1, input2) |
- | Subtract: binary | sub(input1, input2) |
< | Less than: binary | less(input1, input2) |
<= | Less than or equal to: binary | lessEqual(input1, input2) |
> | Greater than: binary | greater(input1, input2) |
>= | Greater than or equal to: binary | greaterEqual(input1, input2) |
== | Equal: binary | equal(input1, input2) |
!= | Not equal: binary | notEqual(input1, input2) |
[] | Get Item: binary | getTupleItem(input: Tensor, index: Int64) |
** | Pow: binary (right: 2.0) | square(input1) |
** | Pow: binary (right: 0.5) | sqrt(input1) |
** | Pow: binary (right: Except for 2.0 and 0.5) | pow(input1, input2) |
附录 C Dataset API
仓颉 TensorBoost 支持加载 AI 领域常用的数据集,用户可以直接调用 dataset 包中的类实现数据集的加载。目前支持的数据集如下表所示:
| 数据集 | 数据集类 | 数据集简介 |
|---|---|---|
| MNIST | MnistDataset | MNIST 是一个大型手写数字图像数据集,拥有 60,000 张训练图像和 10,000 张测试图像,常用于训练各种图像处理系统。 |
| CIFAR-10 | Cifar10Dataset | CIFAR-10 是一个微小图像数据集,包含 10 种类别下的 60,000 张 32x32 大小彩色图像,平均每种类别 6,000 张,其中 5,000 张为训练集,1,000 张为测试集。 |
仓颉 TensorBoost 也支持加载多种存储格式下的数据集,用户可以直接调用 dataset 包中的类实现数据集的加载,目前支持的数据格式如下表所示:
| 数据集 | 数据集类 | 数据集简介 |
|---|---|---|
| TFRecord | TFRecordDataset | TFRecord 是 TensorFlow 定义的一种二进制数据文件格式。 |
| MindRecord | MindDataDataset | MindRecord 是 mindspore 定义的一种二进制数据文件格式。 |
| ImageFolder | ImageFolderDataset | ImageFolder 是图片文件格式。 |
数据集
Dataset 基类
仓颉 TensorBoost 提供数据加载与处理的基类 Dataset,Dataset 提供了统一的数据操作与管理方式,不同格式的数据集均继承自 Dataset。直接创建 Dataset 的对象是无意义的,加载数据集需要创建 Dataset 相应的子类。
public open class Dataset {
public init()
public init(epoch: Int32, columnNames: Array<String>)
public func repeat(count: Int32)
public func batch(batchSize: Int32, dropRemainder: Bool)
public func shuffle(bufferSize: Int32)
public func datasetMap(dsOpHandleList: Array<MSDsOperationHandle>, name: String)
public func getDatasetSize()
public func getNext(params: Array<Tensor>)
}
初始化参数列表:
| 名称 | 含义 |
|---|---|
| epoch | 类型为 Int32,数据集要循环的 epoch 数 |
| columnNames | 类型为 String 数组,数据集文件的列名 |
设置重复次数
public func repeat(count: Int32): Unit
设置数据集重复的次数,达到扩充数据量的目的。
参数列表:
| 名称 | 含义 |
|---|---|
| count | 类型为 Int32,数据集重复的次数 |
【注意】 repeat 和 batch 操作的顺序会影响训练 batch 的数量,建议将 repeat 置于 batch 之后。
设置 batch size
public func batch(batchSize: Int32, dropRemainder: Bool): Unit
参数列表:
| 名称 | 含义 |
|---|---|
| batchSize | 类型为 Int32,数据集读取时 mini-batch 的大小 |
| dropRemainder | 类型为 Bool,数据集数量不是 batchSize 的整数时,是否抛弃最后一组数据。 |
获取数据集大小
public func getDatasetSize(): Int64
输出:
| 名称 | 含义 |
|---|---|
| datasetSize | 数据集样本数,类型为 Int64 |
设置数据乱序读取
public func shuffle(bufferSize: Int32): Unit
参数列表:
| 名称 | 含义 |
|---|---|
| bufferSize | 类型为 Int32,数据集乱序读取的数量,当 bufferSize 等于数据集的行数时,整个数据集读取全部为乱序 |
设置数据集数据增强操作
public func datasetMap(dsOpHandleList: Array<MSDsOperationHandle>, name: String): Unit
参数列表:
| 名称 | 含义 |
|---|---|
| dsOpHandleList | 数据增强操作列表,类型为 MSDsOperationHandle 的数组,具体的操作见数据增强 |
| name | 数据增强操作所作用的列名,类型为 String |
获取下一批数据
public func getNext(params: Array<Tensor>)
参数列表:
| 名称 | 含义 |
|---|---|
| params | 网络参数列表,类型为 Tensor 的数组,需要和数据集中保存的数据类别个数相同, 并且 shape 和 dtype 也要相同 |
子类实现
MnistDataset
public class MnistDataset <: Dataset {
public init(dataPath: String, sampler!: BuildInSampler = RandomSampler(), epoch!: Int32 = 1)
}
参数列表:
| 名称 | 含义 |
|---|---|
| dataPath | 类型为 String,数据集文件路径 |
| sampler | 类型为 BuildInSampler,采样器,可指定 RandomSampler 随机采样或 SequentialSampler 顺序采样 |
| epoch | 类型为 Int32,数据集要循环的 epoch 数 |
Cifar10Dataset
public class Cifar10Dataset <: Dataset {
public init(dataPath: String, epoch!: Int32 = 1, usage!: String = "all")
}
参数列表:
| 名称 | 含义 |
|---|---|
| dataPath | 类型为 String,数据集文件路径 |
| epoch | 类型为 Int32,数据集要循环的 epoch 数 |
| usage | 类型为 String,数据集的用法,取值包括 train、test 和 all,默认值为 all |
TFRecordDataset
public class TFRecordDataset <: Dataset {
public init(dataPath: String, schemaPath: String, columnsList: Array<String>, shuffle!: Bool = true, epoch!: Int32 = 1)
}
参数列表:
| 名称 | 含义 |
|---|---|
| dataPath | 类型为 String,数据集文件路径 |
| schemaPath | 类型为 String,TFRecord 的 shema 文件路径 |
| columnsList | 类型为 String 数组,数据集文件的列名 |
| shuffle | 类型为 Bool,是否将打乱读取顺序 |
| epoch | 类型为 Int32,数据集要循环的 epoch 数 |
MindDataDataset
public class MindDataDataset <: Dataset {
public init(dataPath: String, columnsList: Array<String>, sampler!: BuildInSampler = RandomSampler(), epoch!: Int32 = 1)
}
参数列表:
| 名称 | 含义 |
|---|---|
| dataPath | 类型为 String,数据集文件路径 |
| columnsList | 类型为 String 数组,数据集文件的列名 |
| sampler | 类型为 BuildInSampler,采样器,可指定 RandomSampler 随机采样或 SequentialSampler 顺序采样 |
| epoch | 类型为 Int32,数据集要循环的 epoch 数 |
ImageFolderDataset
public class ImageFolderDataset <: Dataset {
public init(dataPath: String, decode: Bool, numShards: Int32, shardId: Int32, shuffle: Bool, epoch!: Int32 = 1)
}
参数列表:
| 名称 | 含义 |
|---|---|
| dataPath | 类型为 String,数据集文件路径 |
| decode | 类型为 Bool,读取后是否对图片进行解码 |
| numShards | 类型为 Int32,数据分片的数量 |
| shardId | 类型为 Int32,数据分片的 ID,必须在 numShards 的范围内 |
| shuffle | 类型为 Bool,是否将打乱读取顺序 |
| epoch | 类型为 Int32,数据集要循环的 epoch 数 |
示例代码
如下代码展示了如何读取 MNIST 数据集,并将数据集进行 shuffle 处理,然后将样本两两组成一个批次:
from CangjieTB import dataset.*
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let dataPath: String = "./data/mnist/train"
let ds = MnistDataset(dataPath)
let batchSize: Int32 = 2
let bufferSize: Int32 = 1000
var step: Int64 = 0
// 随机打乱数据顺序
ds.shuffle(bufferSize)
// 对数据集进行分批
ds.batch(batchSize, true)
// 将图像数据映射到固定的范围
var rescale = rescale(1.0 / 255.0, 0.0)
ds.datasetMap([rescale], "image")
// 读取数据
var input: Tensor = parameter(zerosTensor([Int64(batchSize), 28, 28], dtype: FLOAT32), "data")
var label: Tensor = parameter(zerosTensor([Int64(batchSize)], dtype: INT32), "label")
while (ds.getNext([input, label]) && step < 5) {
print("---------------\n")
print("input", input)
print("label", label)
step += 1
}
return 0
}
数据增强
仓颉 TensorBoost 目前支持的常用数据增强方法如下表所示:
vision
| 方法 | 说明 |
|---|---|
| randomCropDecodeResize | 图像裁剪。 |
| randomHorizontalFlip | 按照指定概率对图像进行水平翻转。 |
| randomColorAdjust | 调整图像的亮度,对比度,饱和度和色相。 |
| normalize | 根据均值和方差对图像正态化。 |
| hwc2chw | 转换图像的数据排列方式。 |
| rescale | 可以将图像数据映射到固定的范围。 |
| resize | 图像缩放。 |
| randomCrop | 图像裁剪。 |
| centerCrop | 从中心进行裁剪。 |
| randomResizedCrop | 随机长宽比裁剪。 |
transforms
| 方法 | 说明 |
|---|---|
| typeCast | 转换数据类型。 |
函数介绍
randomCropDecodeResize
public func randomCropDecodeResize(size: Array<Int32>, scale: Array<Float32>, ratio: Array<Float32>): MSDsOperationHandle
一个处理 JPEG 图像的高效函数。在随机位置裁剪输入的图像,将裁剪后的图像解码成 RGB 格式,并调整解码图像的尺寸大小。
参数列表:
| 名称 | 含义 |
|---|---|
| size | 输出图像的大小。 |
| scale | 要裁剪的原始范围 [最小值,最大值](默认值 = (0.08, 1.0))。 |
| ratio | 要裁剪的纵横比范围 [最小值,最大值](默认值 = (3 / 4, 4 / 3))。 |
randomHorizontalFlip
public func randomHorizontalFlip(prob: Float32): MSDsOperationHandle
对输入图像进行随机水平翻转。
参数说明 参数列表:
| 名称 | 含义 |
|---|---|
| prob | 单张图片发生翻转的概率。 |
randomColorAdjust
public func randomColorAdjust(brightness: Array<Float32>, contrast: Array<Float32>, saturation: Array<Float32>, hue: Array<Float32>): MSDsOperationHandle
调整图像的亮度,对比度,饱和度和色相。
参数列表:
| 名称 | 含义 |
|---|---|
| brightness | 亮度。 |
| contrast | 对比度。 |
| saturation | 饱和度。 |
| hue | 色相。 |
normalize
public func normalize(meanIn: Array<Float32>, stdIn: Array<Float32>): MSDsOperationHandle
根据提供的均值和标准差对输入图像进行归一化。
参数列表:
| 名称 | 含义 |
|---|---|
| meanIn | 调整后图像的均值。 |
| stdIn | 调整后图像的方差。 |
hwc2chw
public func hwc2chw(): MSDsOperationHandle
数据操作,转换图像的数据排列方式,数据的形状从 高 $\times$ 宽 $\times$ 通道 (HWC) 变为 通道 $\times$ 高 $\times$ 宽 (CHW)。
rescale
public func rescale(rescale: Float32, shift: Float32): MSDsOperationHandle
数据操作,可以将数据映射到固定的范围。
参数列表:
| 名称 | 含义 |
|---|---|
| rescale | 比例因子。 |
| shift | 偏移因子。 |
resize
public func resize(size: Array<Int32>, interpolation!: Int32 = 0): MSDsOperationHandle
对输入图像进行缩放。
参数列表:
| 名称 | 含义 |
|---|---|
| size | 缩放的目标大小。 |
| interpolation | 缩放时采用的插值方式。 |
randomCrop
public func randomCrop(size: Array<Int32>, padding: Array<Int32>, padIfNeeded!: Bool = true, fillValue!: Array<UInt8> = [0, 0, 0], paddingMode!: Int32 = 0)
对输入图像随机位置进行指定大小的裁剪。
参数列表:
| 名称 | 含义 |
|---|---|
| size | 输出图像的大小。 |
| padding | 填充的像素数量。 |
| padIfNeeded | 原图小于裁剪尺寸时,是否需要填充。 |
| fillValue | 在常量填充模式时使用的填充值。 |
| paddingMode | 填充模式。 |
centerCrop
public func centerCrop(size: Array<Int32>): MSDsOperationHandle
对输入图像从中心进行裁剪。
参数列表:
| 名称 | 含义 |
|---|---|
| size | 输出图像的大小。 |
randomResizedCrop
public func randomResizedCrop(size: Array<Int32>, scale: Array<Float32>, ratio: Array<Float32>): MSDsOperationHandle
对输入图像进行随机裁剪,最后将图像调整到设定好的尺寸。
参数列表:
| 名称 | 含义 |
|---|---|
| size | 输出图像的大小。 |
| scale | 要裁剪的原始范围 [最小值,最大值]。 |
| ratio | 要裁剪的纵横比范围 [最小值,最大值]。 |
typeCast
public func typeCast(dataType: String): MSDsOperationHandle
数据操作,转换数据类型。
参数列表:
| 名称 | 含义 |
|---|---|
| dataType | 目标数据类型。 |
示例代码
以下代码展示了对数据集进行 resize,rescale 和 randomCrop 操作,然后通过 datasetMap 设置数据处理的管道,生成新数据。
from CangjieTB import dataset.*
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let dataPath: String = "./data/mnist/train"
var step: Int64 = 0
// 读取数据
let mnistDs = MnistDataset(dataPath)
// 定义数据增强算子
var resize = resize(Array<Int32>([16, 16]))
var rescale = rescale(1.0 / 255.0, 0.0)
var randomCropOp = randomCrop(Array<Int32>([8, 8]), Array<Int32>([0, 0, 0, 0]))
// 进行数据增强操作
mnistDs.datasetMap([resize, rescale, randomCropOp], "image")
// 查看增强后的数据
let input = parameter(initialize(Array<Int64>([8, 8]), initType: InitType.ZERO, dtype: FLOAT32), "data")
let label: Tensor = parameter(zerosTensor(Array<Int64>([1]), dtype: INT32), "label")
while (mnistDs.getNext([input, label]) && step < 5) {
print("---------------\n")
print("input: ", input)
print("label: ", label)
step += 1
}
return 0
}
采样器
对于数据集对象, 可以通过设置采样器来指定随机还是顺序采样.
| 采样器类 | 采样器简介 |
|---|---|
| RandomSampler | 给定数据集对象后,按随机顺序进行采样。 |
| SequentialSampler | 给定数据集对象后,按顺序从前到后进行采样。 |
采样器类
RandomSampler
public class RandomSampler <: BuildInSampler {
public init(replacement!: Bool = false, numSamples!: Int64 = 0)
}
参数列表:
| 名称 | 含义 |
|---|---|
| replacement | 类型为 Bool,是否将样本放回。 |
| numSamples | 类型为 Int64,采样个数。 |
SequentialSampler
public class SequentialSampler <: BuildInSampler {
public init(startIndex!: Int64 = 0, numSamples!: Int64 = 0)
}
参数列表:
| 名称 | 含义 |
|---|---|
| startIndex | 类型为 Int64,采样起点。 |
| numSamples | 类型为 Int64,采样个数。 |
示例代码
以下代码展示了对数据集的前 6 个数据进行采样并打乱顺序读取:
from CangjieTB import dataset.*
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
var samplerRD = RandomSampler(numSamples: 6)
let dataPath: String = "./data/mnist/train"
let ds = MnistDataset(dataPath, sampler: samplerRD)
// 将图像数据映射到固定的范围
var rescale = rescale(1.0 / 255.0, 0.0)
ds.datasetMap([rescale], "image")
// 读取数据
var input: Tensor = parameter(zerosTensor(Array<Int64>([1, 28, 28]), dtype: FLOAT32), "data")
var label: Tensor = parameter(zerosTensor(Array<Int64>([1]), dtype: INT32), "label")
while (ds.getNext([input, label])) {
print("---------------\n")
print("input", input)
print("label", label)
}
return 0
}
附录 D Ops API
仓颉 TensorBoost 的 Operator 功能使用仓颉函数实现,用户只需要导入 operator package (from CangjieTB import ops.*) 即可直接使用仓颉 TensorBoost 已经封装好的函数。
仓颉 TensorBoost 的算子与 mindspore 算子完全一致,与 pytorch 的对照可参见 mindspore 与 pytorch 的 api 映射。
附录 D 中的示例代码,在动态图模式下可以直接运行,静态图模型下运行,需增加调用 Tensor 的evaluate 方法触发计算。
自动微分系统中,部分算子微分求解过程中需要人工定义伴随函数或反向传播函数,已在算子描述中注明,伴随函数自动微分系统会自动调用,建议用户不要直接调用。
算子的输入不符合要求时,会抛出异常,有以下几种类型:
- 输入的数据类型不支持
- 输入的值或者 Tensor 的形状不符合要求
- 运行后端或者模式不符合要求
abs
public func abs(input: Tensor): Tensor
函数 abs 实现 Abs 算子功能,用于计算 Tensor 元素的绝对值。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入的 Tensor,GPU & CPU 支持 Float16\Float32\Float64 类型; Ascend 支持 Float16\Float32\Int32。 |
输出:
| 名称 | 含义 |
|---|---|
| output | Tensor,与原始变量的类型相同。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func absGrad(input: Tensor, gradOut: Tensor): Tensor
微分伴随函数:
public func adjointAbs(input: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([2.0, -4.0, -1.4, -5.0, 6.0]), shape: Array<Int64>([5]))
let output = abs(input)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[2.00000000e+00 4.00000000e+00 1.39999998e+00 5.00000000e+00 6.00000000e+00])
acos
public func acos(input: Tensor): Tensor
函数 acos 实现 ACos 算子功能,按照 element-wise 的规则计算 Tensor 元素的 arccosine 值。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入的 Tensor,支持 Float16\Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | Tensor,与输入的 dtype 和 shape 相同。 |
支持平台:Ascend, GPU
反向函数:
public func acosGrad(x: Tensor, gradOut: Tensor): Tensor
微分伴随函数:
public func adjointAcos(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = Tensor(Array<Float32>([0.0295925457, 0.6197745800, 0.4479851723, 0.3968157172, 0.2453137785]), shape: Array<Int64>([5]))
let output = acos(x)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[1.54119945e+00 9.02340889e-01 1.10628593e+00 1.16275120e+00 1.32295299e+00])
acosh
public func acosh(input: Tensor): Tensor
计算输入元素的反向双曲余弦
$$ out_i = cosh^{-1}(input_i) $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, 支持 Float16\Float32 类型, 输入 Tensor 的秩必须在[0,7]范围内。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 与输入 的 shape 和 dtype 相同 |
支持平台:Ascend, GPU, CPU
反向函数:
public func acoshGrad(x: Tensor, y: Tensor): Tensor
微分伴随函数:
public func adjointAcosh(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 1.5, 3.0, 100.0]), shape: [4])
let output = acosh(input)
print(output)
return 0
}
输出为:
Tensor(shape=[4], dtype=Float32, value=
[0.00000000e+00 9.62423682e-01 1.76274729e+00 5.29829216e+00])
adamWeightDecay
public func adamWeightDecay(input: Tensor, m: Tensor, v: Tensor, lr: Float32, beta1: Float32, beta2: Float32, epsilon: Float32, decay: Float32, gradient: Tensor, useLocking!: Bool = false): Tensor
通过权重衰减的自适应力矩估计算法更新梯度(AdamWeightDecay)
Adam 原理详见 Adam: A Method for Stochastic Optimization, AdamWeightDecay 原理详见Decoupled Weight Decay Regularization
更新公式如下:
$$ \begin{split}\begin{array}{ll} \ m = \beta_1 * m + (1 - \beta_1) * g \ v = \beta_2 * v + (1 - \beta_2) * g * g \ update = \frac{m}{\sqrt{v} + \epsilon} \ update = \begin{cases} update + weight_decay * w & \text{ if } weight_decay > 0 \ update & \text{ otherwise } \end{cases} \ w = w - lr * update \end{array}\end{split}\ $$
公式中符号与函数入参关系为:
m 代表第一个矩阵向量 m, v 代表第二个矩阵向量 v,g 代表 gradient, β1, β2 代表 beta1, beta2, lr 代表 lr, w 代表 input, decay 代表 decay, ϵ 代表 epsilon。
输入:
| 名称 | 含义 |
|---|---|
| input | 要更新的权重,支持 Float32 类型,必须设置为 parameter |
| m | 更新公式中的第一个矩阵向量,shape,dtype 与 input 一致,必须设置为 parameter |
| v | 更新公式中的第一个矩阵向量,shape,dtype 与 input 一致,均方梯度类型也与 input 一致,必须设置为 Parameter |
| lr | 更新公式中的 lr, 论文建议值为 10 的 -8 次方,shape,dtype 与 input 一致 |
| beta1 | 第一次评估的指数衰减率,论文建议值为 0.9 |
| beta2 | 第一次评估的指数衰减率,论文建议值为 0.999 |
| epsilon | 与分母做加法提高数值稳定性 |
| decay | 权重的衰减值 |
| gradient | 梯度,shape 和 dtype 和 input 一致 |
| useLocking | 是否启用锁保护变量更新。 如果为 true, input, m, n 的更新将被保护,如果为 false,结果将不可预测。默认值:false |
输出:
| 名称 | 含义 |
|---|---|
| output0 | 更新后的 input, shape, dtype 与输入 input 相同 |
| output1 | 更新后的 m, shape, dtype 与输入 m 相同 |
| output2 | 更新后的 v, shape, dtype 与输入 v 相同 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(onesTensor(Array<Int64>([2, 2])), "input")
let m = parameter(onesTensor(Array<Int64>([2, 2])), "m")
let v = parameter(onesTensor(Array<Int64>([2, 2])), "v")
let gradient = onesTensor(Array<Int64>([2, 2]))
let output = adamWeightDecay(input, m, v, 0.001, 0.9, 0.999, 1e-8, 0.0, gradient)
print(input)
print(m)
print(v)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 9.99000013e-01 9.99000013e-01]
[ 9.99000013e-01 9.99000013e-01]])
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 1.00000000e+00 1.00000000e+00]
[ 1.00000000e+00 1.00000000e+00]])
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 1.00000000e+00 1.00000000e+00]
[ 1.00000000e+00 1.00000000e+00]])
add
public func add(input0: Tensor, input1: Tensor): Tensor
public func add(input0: Float16, input1: Tensor): Tensor
public func add(input0: Tensor, input1: Float16): Tensor
public func add(input0: Float32, input1: Tensor): Tensor
public func add(input0: Tensor, input1: Float32): Tensor
public func add(input0: Float64, input1: Tensor): Tensor
public func add(input0: Tensor, input1: Float64): Tensor
public func add(input0: Int32, input1: Tensor): Tensor
public func add(input0: Tensor, input1: Int32): Tensor
函数 add 实现 Add 算子功能,用于计算两个 Tensor 逐个元素相加。输入必须是两个 Tensor 或者一个 Tensor 和一个标量。它们的输入类型必须一致,它们的形状可以被广播。当输入是一个 Tensor 和一个标量时,这个标量只能是一个常数。
输入:
| 名称 | 含义 |
|---|---|
| input0 | Tensor 或者 Number,GPU & CPU 支持 Float16\Float32\Float64\Int32 类型,Ascend 支持 Float16\Float32\Int32, dtype 或者类型要求与 input1 一致 |
| input1 | Tensor 或者 Number,GPU & CPU 支持 Float16\Float32\Float64\Int32 类型,Ascend 支持 Float16\Float32\Int32, dtype 或者类型要求与 input0 一致 |
输出:
| 名称 | 含义 |
|---|---|
| output | 相加后的 Tensor。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input0 = Tensor(Array<Float32>([1.0, 2.0, 3.0]), shape: Array<Int64>([3]))
let input1 = Tensor(Array<Float32>([4.0, 5.0, 6.0]), shape: Array<Int64>([3]))
let output = add(input0, input1)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[5.00000000e+00 7.00000000e+00 9.00000000e+00])
adaptiveAvgPool2D
public func adaptiveAvgPool2D(input: Tensor, outputSize: Array<Int64>): Tensor
public func adaptiveAvgPool2D(input: Tensor, outputSize: Int64): Tensor
AdaptiveAvgPool2D 计算
输出 Tensor 的格式为 "NCHW" 和 "CHW",表示 [batch, channels, height, width]。
计算公式如下所示:
$$ \begin{split}\begin{align} h_{start} &= floor(i * H_{in} / H_{out})\ h_{end} &= ceil((i + 1) * H_{in} / H_{out})\ w_{start} &= floor(j * W_{in} / W_{out})\ w_{end} &= ceil((j + 1) * W_{in} / W_{out})\ Output(i,j) &= \frac{\sum Input[h_{start}:h_{end}, w_{start}:w_{end}]}{(h_{end}- h_{start}) * (w_{end}- w_{start})} \end{align}\end{split} $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入,3 维 或者 4 维的 Tensor,支持 Float32 或者 Float64 类型 |
| outputSize | 目标输出, outputSize 可以是代表 (H x W) 的 2 维数组或者代表 H 的 number,输入 number 时, 输出大小为 H x H |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,类型与 input 相同,outputSize 为二维数组时 shape 为 input_shape[:len(input_shape) - len(outputSize)] + outputSize, 为 number 时,shape 为 input_shape[:len(input_shape) - len(outputSize)] + [outputSize, outputSize] |
支持平台:GPU
反向函数:
public func adaptiveAvgPool2DGrad(x: Tensor, y: Tensor): Tensor
微分伴随函数:
public func adjointAdaptiveAvgPool2D(x: Tensor, outputSize: Array<Int64>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]), shape: [3, 3, 3])
let output = adaptiveAvgPool2D(x, Array<Int64>([2, 1]))
print(output)
return 0
}
输出为:
Tensor(shape=[3, 2, 1], dtype=Float32, value=
[[[ 3.50000000e+00]
[ 6.50000000e+00]]
[[ 3.50000000e+00]
[ 6.50000000e+00]]
[[ 3.50000000e+00]
[ 6.50000000e+00]]])
addN
public func addN(input: Tensor): Tensor
public func addN(input1: Tensor, input2: Tensor, input3: Tensor): Tensor
函数 addN 实现 AddN 算子功能,用来将输入加到一起,输入 Tensor 的 shape 必须相同。
输入:
| 名称 | 含义 |
|---|---|
| input | 多个 Tensor 合成的 Tuple, GPU & CPU 所有元素必须都为 Float32 类型; Ascend 所有元素必须都为 Float16\Float32\Int32 类型。 |
| input1 | 多个 Tensor 合成的 Tuple, GPU & CPU 所有元素必须都为 Float32 类型; Ascend 所有元素必须都为 Float16\Float32\Int32 类型。 |
| input2 | 多个 Tensor 合成的 Tuple, GPU & CPU 所有元素必须都为 Float32 类型; Ascend 所有元素必须都为 Float16\Float32\Int32 类型。 |
| input3 | 多个 Tensor 合成的 Tuple, GPU & CPU 所有元素必须都为 Float32 类型; Ascend 所有元素必须都为 Float16\Float32\Int32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出,与 input 每一项的形状和类型相同。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointAddN(input: Tensor)
public func adjointAddN(input1: Tensor, input2: Tensor, input3: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input0 = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]), shape: Array<Int64>([2, 3]))
let input1 = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]), shape: Array<Int64>([2, 3]))
let input = makeTuple([input0, input1])
let output = addN(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[2.00000000e+00 4.00000000e+00 6.00000000e+00]
[8.00000000e+00 1.00000000e+01 1.20000000e+01]])
allGather
public func allGather(input: Tensor, group!: String = "nccl_world_group"): Tensor
按照输入的 group 方式收集 Tensor
输入:
| 名称 | 含义 |
|---|---|
| input | 输入,支持 Float32,Int32 类型 |
| group | 通信组类型,GPU 设备支持输入 "nccl_world_group"。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointAllGather(input: Tensor, group!: String = "nccl_world_group")
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import context.*
main(): Int64
{
g_context.setBackend("nccl")
let x = onesTensor(Array<Int64>([3, 3]))
let output = allGather(x, group: "nccl_world_group")
print(output)
return 0
}
输出为(单 gpu):
Tensor(shape=[3, 3], dtype=Float32, value=
[[ 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[ 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[ 1.00000000e+00 1.00000000e+00 1.00000000e+00]])
allReduce
public func allReduce(input: Tensor, opType!: ReduceType = ReduceType.SUM, group!: String = "nccl_world_group"): Tensor
函数 allReduce 实现 AllReduce 算子功能,用于归并所有设备的张量数据,以保证所有设备可以获得相同的结果,通常用在并行训练中。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入,支持 Int32, Int64, Float16, Float32 类型的 Tensor。 |
| opType | 规约类型,支持四种输入,分别是 ReduceType.SUM、ReduceType.MAX、ReduceType.MIN、ReduceType.PROD。默认为 ReduceType.SUM |
| group | 通信组类型,GPU 设备支持输入 "nccl_world_group"。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与 input 具有相同的 shape 和 dtype。 |
支持平台:GPU
微分伴随函数:
public func adjointAllReduce(input: Tensor, opType!: ReduceType = ReduceType.SUM, group!: String = "nccl_world_group")
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import context.*
main(): Int64
{
g_context.setBackend("nccl")
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]), shape: Array<Int64>([2, 3]))
let output = allReduce(input, opType: ReduceType.SUM, group: "nccl_world_group")
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[1.00000000e+00 2.00000000e+00 3.00000000e+00]
[4.00000000e+00 5.00000000e+00 6.00000000e+00]])
applyCenteredRMSProp
public func applyCenteredRMSProp(input: Tensor, meanGradient: Tensor, meanSquare: Tensor, moment: Tensor, gradient: Tensor, learningRate: Tensor, decay: Float32, momentum: Float32, epsilon: Float32, useLocking!: Bool = false): Tensor
public func applyCenteredRMSProp(input: Tensor, meanGradient: Tensor, meanSquare: Tensor, moment: Tensor, gradient: Tensor, learningRate: Float32, decay: Float32, momentum: Float32, epsilon: Float32, useLocking!: Bool = false): Tensor
实现 centered RMSProp 算法的优化器
ApplyCenteredRMSProp 算法实现公式如下:
$$ g_{t} = \rho g_{t-1} + (1 - \rho)\nabla Q_{i}(w) \ s_{t} = \rho s_{t-1} + (1 - \rho)(\nabla Q_{i}(w))^2\ m_{t} = \beta m_{t-1} + \frac{\eta} {\sqrt{s_{t} - g_{t}^2 + \epsilon}} \nabla Q_{i}(w)\ w = w - m_{t}\ $$
其中:$w$ 代表将被更新的 input。$g_{t}$代表$mean_gradien$,$g_{t-1}$是$g_{t}$最后部分。$s_{t}$代表$mean_square$,$s_{t-1}$是$s_{t}$的最后一部分。$m_{t}$代表$moment$,$m_{t-1}$代表$m_{t}$的最后一部分。$\rho$代表 decay。$\beta$是动量术语,代表 momentum。$\epsilon$是避免被 0 整除的平滑项,代表 epsilon。$\eta$代表$learning_rate$。$\nabla Q_{i}(w)$代表 gradient。
输入:
| 名称 | 含义 |
|---|---|
| useLocking | 是否启用锁保护 input 的更新。 默认值:false |
| input | 要更新的权重, 支持 Float32 类型的 Tensor |
| meanGradient | 平均梯度, shape 和 dtype 和 input 一致 |
| meanSquare | 均值平方梯度,shape 和 dtype 和 input 一致 |
| moment | input 的 Delta,shape 和 dtype 和 input 一致 |
| gradient | 梯度,shape 和 dtype 和 input 一致 |
| learningRate | 学习率,支持 Float32 类型的数字和 Float32 类型的标量 Tensor |
| decay | 衰退率, 支持 Float32 类型的 number |
| momentum | 动力指标, 支持 Float32 类型的 number |
| epsilon | Ridge, 避免被 0 整除的平滑项, 支持 Float32 类型的 number |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 与输入 的 shape 和 dtype 相同 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(Tensor(Array<Float32>([2.0, 9.0, 7.0, 5.0]), shape: [2, 2]), "input")
let meanGrad = onesTensor(Array<Int64>([2, 2]), dtype: FLOAT32)
let meanSquare = onesTensor(Array<Int64>([2, 2]), dtype: FLOAT32)
let moment = onesTensor(Array<Int64>([2, 2]), dtype: FLOAT32)
let gradient = onesTensor(Array<Int64>([2, 2]), dtype: FLOAT32)
let res = applyCenteredRMSProp(input, meanGrad, meanSquare, moment, gradient, 0.01, 1e-10, 0.001, 0.9)
print(input)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 1.98845911e+00 8.98845863e+00]
[ 6.98845911e+00 4.98845911e+00]])
applyAdagrad
public func applyAdagrad(input: Tensor, accum: Tensor, lr: Tensor, gradient: Tensor, update_slots!: Bool = true): (Tensor, Tensor)
public func applyAdagrad(input: Tensor, accum: Tensor, lr: Float32, gradient: Tensor, update_slots!: Bool = true): (Tensor, Tensor)
根据 adagrad 方案更新相关实例
$$ \begin{array}\ accum += gradient * gradient \ input -= lr * gradient * \frac{1}{\sqrt{accum}} \end{array} $$
输入:
| 名称 | 含义 |
|---|---|
| update_slots | 是否启用锁保护 input 和 accum 张量不被更新。 默认值:true |
| input | 要更新的权重。 支持 Float32 类型,需要设置为 Parameter |
| accum | 平均梯度, shape 和 dtype 和 input 一致, 需要设置为 Parameter |
| lr | 学习率,支持 Float32 类型的数字和 Float32 类型的标量 Tensor |
| gradient | input 的 Delta,shape 和 dtype 和 input 一致 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与 input 的 shape 和 dtype 相同 |
| accum | 输出 Tensor,与 accum 的 shape 和 dtype 相同 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: [2, 2]), "input")
let accum = parameter(Tensor(Array<Float32>([10.0, 9.0, 8.0, 7.0]), shape: [2, 2]), "accum")
let lr = Tensor(0.001, dtype: FLOAT32)
let gradient = Tensor(Array<Float32>([1.5, 4.5, 3.7, 4.8]), shape: [2, 2])
let (out1, out2) = applyAdagrad(input, accum, lr, gradient)
print(out1)
print(out2)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 9.99571443e-01 1.99916792e+00]
[ 2.99920559e+00 3.99912429e+00]])
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 1.22500000e+01 2.92500000e+01]
[ 2.16900005e+01 3.00400009e+01]])
applyFtrl
public func applyFtrl(x: Tensor, accum: Tensor, linear: Tensor, gradOut: Tensor, lr: Tensor, l1: Tensor, l2: Tensor, lrPower: Tensor, useLocking!: Bool = false): Tensor
public func applyFtrl(x: Tensor, accum: Tensor, linear: Tensor, gradOut: Tensor, lr!: Float32 = 0.001, l1!: Float32 = 0.0, l2!: Float32 = 0.0, lrPower!: Float32 = -0.5, useLocking!: Bool = false): Tensor
根据 FTRL 方案更新输入,FTRL 表示一种在线凸优化算法,根据损失函数自适应选择正则化函数。可参考在线凸优化的自适应边界优化论文:a View from the Trenches for engineering document。其计算过程如下:
$$ \begin{aligned} m_{t+1} &= m_{t} + g^2 \ u_{t+1} &= u_{t} + g - \frac{m_{t+1}^\text{-p} - m_{t}^\text{-p}}{\alpha } * \omega_{t} \ \omega_{t+1} &= \begin{cases} \frac{(sign(u_{t+1}) * l1 - u_{t+1})}{\frac{m_{t+1}^\text{-p}}{\alpha } + 2 * l2 } & \text{ if } |u_{t+1}| > l1 \ 0.0 & \text{ otherwise } \end{cases}\ \end{aligned} $$
其中,$m$表示 accum,$g$表示 gradOut,$t$表示迭代步数,$u$表示 linear,$p$表示 lrPower,$\alpha$表示学习率 lr,$w$表示待更新的输入 x。
参数列表:
| 名称 | 含义 |
|---|---|
| useLocking | 如果为 true,x 和有累加 tensor 的更新将受到锁保护,Bool 类型,默认为 false |
输入:
| 名称 | 含义 |
|---|---|
| x | 要更新的变量。 支持 Float32 类型,需要设置为 parameter |
| accum | 梯度的均方值。与 x 的类型和 shape 一致,需要设置为 parameter |
| linear | 线性增益。与 x 的类型和 shape 一致,需要设置为 parameter |
| gradOut | 梯度。与 x 的类型和 shape 一致 |
| lr | 学习率。可以是 Float32 类型的数值或标量 Tensor, 默认值为 0.001 |
| l1 | L1 正则化强度。可以是 Float32 类型的数值或标量 Tensor,默认值为 0.0 |
| l2 | L2 正则化强度。可以是 Float32 类型的数值或标量 Tensor,默认值为 0.0 |
| lrPower | 学习率下降的速度控制参数。可以是 Float32 类型的数值或标量 Tensor,默认值为 -0.5 |
输出:
| 名称 | 含义 |
|---|---|
| output | 更新后的 input, 与 x 的类型和 shape 一致 |
支持平台:GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Float32>([0.6, 0.4, 0.1, 0.5]), shape: Array<Int64>([2, 2])), "x")
let accum = parameter(Tensor(Array<Float32>([0.6, 0.5, 0.2, 0.6]), shape: Array<Int64>([2, 2])), "accum")
let linear = parameter(Tensor(Array<Float32>([0.9, 0.1, 0.7, 0.8]), shape: Array<Int64>([2, 2])), "linear")
let gradOut = Tensor(Array<Float32>([0.3, 0.7, 0.1, 0.8]), shape: Array<Int64>([2, 2]))
let lr: Float32 = 0.001
let l1: Float32 = 0.0
let l2: Float32 = 0.0
let lrPower: Float32 = -0.5
let out = applyFtrl(x, accum, linear, gradOut, lr: lr, l1: l1, l2: l2, lrPower: lrPower)
print(x)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 3.90524976e-02 1.14928380e-01]
[ 6.64254301e-04 1.50758967e-01]])
applyGradientDescent
public func applyGradientDescent(input: Tensor, alpha: Tensor, delta: Tensor): Tensor
public func applyGradientDescent(input: Tensor, alpha: Float32, delta: Tensor): Tensor
通过从 input 中减 alpha * delta 来更新 input
$$ input = input - \alpha * \delta $$
$$ \alpha 代表 alpha, \delta 代表 delta $$
输入:
| 名称 | 含义 |
|---|---|
| input | 要更新的变量。 支持 Float32 类型,需要设置为 parameter |
| alpha | 系数,支持 Float32 类型的数字和 Float32 类型的标量 Tensor |
| delta | input 的 Delta,shape 和 dtype 和 input 一致 |
输出:
| 名称 | 含义 |
|---|---|
| output | 更新后的 input, 与 input 的 shape 和 dtype 相同 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(onesTensor(Array<Int64>([2, 2]), dtype: FLOAT32), "input")
let delta = Tensor(Array<Float32>([0.1, 0.1, 0.1, 0.1]), shape: [2, 2])
let out = applyGradientDescent(input, 0.001, delta)
print(out)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 9.99899983e-01 9.99899983e-01]
[ 9.99899983e-01 9.99899983e-01]])
applyRMSProp
public func applyRMSProp(x: Tensor, meanSquare: Tensor, moment: Tensor, learningRate: Tensor, gradOut: Tensor, decay: Float32, momentum: Float32, epsilon: Float32, useLocking!: Bool = false): Tensor
public func applyRMSProp(x: Tensor, meanSquare: Tensor, moment: Tensor, learningRate: Float32, gradOut: Tensor, decay: Float32, momentum: Float32, epsilon: Float32, useLocking!: Bool = false): Tensor
均方根(RMSProp: Root Mean Square prop)算法优化器,实现算法如下:
$$ s_{t+1} = \rho s_{t} + (1 - \rho)(\nabla Q_{i}(w))^2 \ m_{t+1} = \beta m_{t} + \frac{\eta} {\sqrt{s_{t+1} + \epsilon}} \nabla Q_{i}(w) \ w = w - m_{t+1} $$
其中,$w$表示要更新的权重 input;$s_{t+1}$表示待更新的均方 meanSquare,$s_t$表示前一次的均方;$m_{t+1}$表示 moment,$m_t$表示前一次的 moment;$\rho$表示 decay, $\beta$表示 momentum;$\epsilon$表示 epsilon,用于避免除 0;$\eta$表示学习率 learningRate;$\nabla Q_{i}(w)$表示梯度 gradOut。
参数列表:
| 名称 | 含义 |
|---|---|
| useLocking | 如果为 true,x 和有累加 tensors 的更新将受到锁保护,Bool 类型,默认为 false |
| decay | decay rate,meanSquare 更新衰变速度。 支持 Float32 类型 |
| momentum | moment 更新参数。 支持 Float32 类型 |
| epsilon | 避免除 0,支持 Float32 类型 |
输入:
| 名称 | 含义 |
|---|---|
| input | 要更新的变量。 支持 Float32 类型,需要设置为 parameter |
| meanSquare | 梯度的均方值。与 input 的类型和 shape 一致 |
| moment | input 的变化量。与 input 的类型和 shape 一致 |
| learningRate | 学习率。支持 Float32 类型标量 Tensor 和 Float32 类型的标量 |
| gradOut | 梯度。与 input 的类型和 shape 一致 |
输出:
| 名称 | 含义 |
|---|---|
| output | 更新后的 input, 与 input 的类型和 shape 一致 |
支持平台:Ascend, GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(Tensor(Array<Float32>([1.0, 1.0, 1.0, 1.0]), shape: Array<Int64>([2, 2])), "input")
let meanSquare = parameter(Tensor(Array<Float32>([1.0, 1.0, 1.0, 1.0]), shape: Array<Int64>([2, 2])), "meanSquare")
let moment = parameter(Tensor(Array<Float32>([1.0, 1.0, 1.0, 1.0]), shape: Array<Int64>([2, 2])), "moment")
let gradOut = Tensor(Array<Float32>([1.0, 1.0, 1.0, 1.0]), shape: Array<Int64>([2, 2]))
let learningRate = Tensor(Float32(0.01))
let decay = Float32(0.0)
let momentum = Float32(0.0)
let epsilon = Float32(0.001)
let res = applyRMSProp(input, meanSquare, moment, learningRate, gradOut, decay, momentum, epsilon)
print(input)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 9.90005016e-01 9.90005016e-01]
[ 9.90005016e-01 9.90005016e-01]])
argmax
public func argmax(input: Tensor, axis!: Int64 = -1): Tensor
函数 argmax 实现 Argmax 算子功能,用于对输入 Tensor 的值沿着某个轴进行比较,返回最大值的索引。如果 input 的 shape 是 (x_1, ..., x_N),那么 output 的 shape 为 (x_1, ..., x_{axis-1}, x_{axis+1}, ..., x_N)。
【注意】:由于后端的限制, input 暂时只能为 1 维或 2 维。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,Float32 类型的 Tensor。 |
| axis | 要施行 Argmax 的维度,默认值为 - 1,如果 input 的维度数为 rank,那么 axis 的取值范围为 [-rank, rank)。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 最大值的索引,Int32 类型的 Tensor。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointArgmax(input: Tensor, axis!: Int64 = -1)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]), shape: Array<Int64>([2, 3]))
let output = argmax(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Int32, value=
[2 2])
argMaxWithValue
public func argMaxWithValue(input: Tensor, axis!: Int64 = 0, keepDims!: Bool = false): (Tensor, Tensor)
函数 argMaxWithValue 实现 ArgMaxWithValue 算子功能,用于对输入 Tensor 的值沿着某个轴进行比较,返回最大值及其索引。
【注意】:在 auto_parallel 和 semi_auto_parallel 模式下,不能使用第一个输出索引。
参数列表:
| 名称 | 含义 |
|---|---|
| axis | 要施行 ArgMaxWithValue 的维度,默认值为 0。 |
| keepDims | 是否保留 axis 对应的维度,默认值为 false。 |
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,支持 Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| index | 最大值的索引 Int32 类型。 |
| output | 输入 Tensor 的最大值,与 input 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU
反向函数:
public func argminOrArgmaxGrad(x: Tensor, axis: Int64, keepDims: Bool, op: String, out: Tensor, gradOut: Tensor): Tensor
微分伴随函数:
public func adjointArgMaxWithValue(input: Tensor, axis!: Int64 = 0, keepDims!: Bool = false)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 6.0, 5.0]), shape: Array<Int64>([2, 3]))
let (index, output) = argMaxWithValue(input)
print(index)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Int32, value=
[1 1 1])
Tensor(shape=[3], dtype=Float32, value=
[4.00000000e+00 6.00000000e+00 5.00000000e+00])
argMinWithValue
public func argMinWithValue(input: Tensor, axis!: Int64 = 0, keepDims!: Bool = false): (Tensor, Tensor)
函数 argMinWithValue 实现 ArgMinWithValue 算子功能,用于对输入 Tensor 的值沿着某个轴进行比较,返回最小值及其索引。
【注意】:如果存在多个最小值,输出第一个最小值的索引位置。
axis 的索引范围是[-dims, dims - 1],其中,dims 是输入 input 的维度。
参数列表:
| 名称 | 含义 |
|---|---|
| axis | 要施行 ArgMinWithValue 的维度,默认值为 0。 |
| keepDims | 是否保留 axis 对应的维度,默认值为 false。 |
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,支持 Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| index | 最小值的索引 Int32 类型。 |
| output | 输入 Tensor 的最小值,与 input 具有相同的 shape 和 dtype。 |
支持平台:GPU
反向函数:
public func argminOrArgmaxGrad(x: Tensor, axis: Int64, keepDims: Bool, op: String, out: Tensor, gradOut: Tensor): Tensor
微分伴随函数:
public func adjointArgMinWithValue(input: Tensor, axis!: Int64 = 0, keepDims!: Bool = false)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 6.0, 5.0]), shape: Array<Int64>([2, 3]))
let (index, output) = argMinWithValue(input)
print(index)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Int32, value=
[0 0 0])
Tensor(shape=[3], dtype=Float32, value=
[1.00000000e+00 2.00000000e+00 3.00000000e+00])
asin
public func asin(input: Tensor)
函数 asin 实现 Asin 算子功能,用于计算输入的反正弦。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,支持 Float16\Float32 数据类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与 x 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU
反向函数:
public func asinGrad(x: Tensor, gradOut: Tensor): Tensor
微分伴随函数:
public func adjointAsin(input: Tensor)
二阶伴随函数:
public func adjointAsinGrad(x: Tensor, gradOut: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = Tensor(Array<Float32>([0.23, 0.44, -0.13, 0.58]), shape: Array<Int64>([2, 2]))
let res = asin(x)
print(res)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[2.32077688e-01 4.55598682e-01]
[-1.30368978e-01 6.18728697e-01]])
asinh
public func asinh(input: Tensor)
函数 asinh 实现 Asinh 算子功能,用于计算输入的反双曲正弦。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,支持 Float16\Float32 数据类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与 x 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU
反向函数:
public func asinhGrad(x: Tensor, y: Tensor): Tensor
微分伴随函数:
public func adjointAsinh(input: Tensor)
二阶伴随函数:
public func adjointAsinhGrad(x: Tensor, y: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = Tensor(Array<Float32>([-5.0, 1.5, 3.0, 100.0]), shape: Array<Int64>([2, 2]))
let res = asinh(x)
print(res)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[-2.31243825e+00 1.19476318e+00]
[1.81844640e+00 5.29834223e+00]])
assign
public func assign(input: Tensor, value:Tensor): Tensor
函数 assign 实现 Assign 算子功能,用于给参数赋值。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入的参数, 需要设置为 Parameter, GPU & CPU 支持 Float32\Float64\Int32, Ascend 支持 Float32\Int32。 |
| value | 要分配的值, 数据类型与 input 一致。 |
输出:
| 名称 | 含义 |
|---|---|
| output | Tensor,与原始变量的类型相同。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointAssign(input: Tensor, value: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(Tensor(Array<Int32>([1, 2, 3]), shape: Array<Int64>([3])), "input")
let value = Tensor(Array<Int32>([4, 5, 6]), shape: Array<Int64>([3]))
let output = assign(input, value)
print(input)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Int32, value=
[4 5 6])
Tensor(shape=[3], dtype=Int32, value=
[4 5 6])
assignAdd
public func assignAdd(variable: Tensor, x: Int32): Tensor
public func assignAdd(variable: Tensor, x: Float16): Tensor
public func assignAdd(variable: Tensor, x: Float32): Tensor
public func assignAdd(variable: Tensor, x: Float64): Tensor
public func assignAdd(variable: Tensor, x: Tensor): Tensor
函数 assignAdd 实现 AssignAdd 算子功能,用于做参数的自增计算。
输入:
| 名称 | 含义 |
|---|---|
| variable | 自增参数, 需要设置为 Parameter, GPU & CPU 支持 Float16\Float32\Int32 类型; Ascend 支持 Float16\Float32\Int32\Int64 类型。 |
| x | 自增数值,类型为 Tensor 时必须与 variable shape 和类型相同,为 number 时类型必须与 variable dtype 相同。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出,与 variable 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointAssignAdd(variable: Tensor, x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let variable = parameter(Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2])), "variable")
let x = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let output = assignAdd(variable, x)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[2.00000000e+00 4.00000000e+00]
[6.00000000e+00 8.00000000e+00]])
atan
public func atan(x: Tensor): Tensor
函数 atan 实现 Atan 算子功能,用于计算输入 Tensor 的三角反正切值。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,仅接受 Float16\Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出,与 x 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU
反向函数:
public func atanGrad(x: Tensor, y: Tensor): Tensor
微分伴随函数:
public func adjointAtan(x: Tensor)
二阶伴随函数:
public func adjointAtanGrad(x: Tensor, y: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Float32>([-178.0730743408, -125.8694152832, -13.1253213882, -64.0065612793]), shape: Array<Int64>([2, 2])), "x")
let output = atan(x)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[-1.56518078e+00 -1.56285179e+00]
[-1.49475467e+00 -1.55517423e+00]])
atan2
public func atan2(x: Tensor, y: Tensor): Tensor
函数 atan2 实现 Atan2 算子功能,用于计算 x/y 的三角反正切值,该算子反向不支持 Float64 类型的输入。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,仅接受 Float16\Float32\Float64 类型,Ascend 不支持 Float64 类型。 |
| y | 输入 Tensor,仅接受 Float16\Float32\Float64 类型, shape 与 x 一致。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,shape 与 x 和 y BroadcastTo 之后相同, 数据类型与 x 相同。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointAtan2(x: Tensor, y: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Float32>([-233.6013336182, -166.4370422363, -264.0430297852, -100.0823135376]), shape: Array<Int64>([2, 2])), "x")
let y = parameter(Tensor(Array<Float32>([-96.0830841064, -204.3753814697, -51.6355972290, -98.7397003174]), shape: Array<Int64>([2, 2])), "y")
let output = atan2(x, y)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[-1.96101642e+00 -2.45815134e+00]
[-1.76391673e+00 -2.34944177e+00]])
avgPool
public func avgPool(input: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, padMod!: String = "VALID"): Tensor
函数 avgPool 实现 AvgPool 算子功能,用于在输入 Tensor 上应用二维平均池。操作如下:
$$ output(Ni,Cj,h,w)={1\over hker∗wker}\sum_{m=0}^{hker−1}\sum_{n=0}^{wker−1}input(Ni,Cj,s0×h+m,s1×w+n) $$
参数列表:
| 名称 | 含义 |
|---|---|
| ksizes | 滑窗大小。内核大小用于取平均值,为长度为 2 的 Int64 数组,分别表示滑窗的高度和宽度, 数值不小于 1。 |
| strides | 滑窗跳步。为长度为 2 的 Int64 数组,分别表示移动的高度和宽度, 数值不小于 1。 |
| padMod | padMod 模式,可选值: "SAME", "VALID",忽略大小写。默认值:"VALID"。 |
输入:
| 名称 | 含义 |
|---|---|
| input | shape 是(N, C, H, W)的 Tensor, 支持 Float16\Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (N, C, H_out, W_out) 的 Tensor。 |
Ascend 平台暂不支持反向
支持平台:Ascend, GPU, CPU
反向函数:
public func avgPoolGrad(gradOut: Tensor, input: Tensor, value: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, padding!: String = "VALID"): Tensor
微分伴随函数:
public func adjointAvgPool(input: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, pad_mode: String)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([-0.00379059,-0.00749117, 0.00654396, 0.00295572, 0.00235576,-0.0118451, -0.00893178, 0.00429676]), shape: Array<Int64>([1, 1, 2, 4]))
let output = avgPool(input, Array<Int64>([2, 2]), Array<Int64>([1, 1]))
print(output)
return 0
}
输出为:
Tensor(shape=[1, 1, 1, 3], dtype=Float32, value=
[[[[-5.19277528e-03 -5.43102250e-03 1.21616491e-03]]]])
batchMatMul
public func batchMatMul(input: Tensor, weight: Tensor, transposeA!: Bool = false, transposeB!: Bool = false): Tensor
函数 batchMatMul 实现 BatchMatMul 算子功能,用于两个 Tensor 批量相乘。两个输入 Tensor 的 shape 维度数 n 必须相等且 n >= 3。 设 input 的 shape 为 (*B, N, C),weight 的 shape 为 (*B, C, M),input 的 shape 中的 C 必须等于 weight 中的 C,并且 input 的 shape 中的前 n - 2 个元素必须与 weight 中前 n - 2 个元素相等。
参数列表:
| 名称 | 含义 |
|---|---|
| transposeA | 如果取值是 true,就需要先对 input 的最后两维做转置后再跟 weight 相乘。默认值: false。 |
| transposeB | 如果取值是 true,就需要先对 weight 的最后两维做转置后再跟 input 相乘。默认值: false。 |
输入:
| 名称 | 含义 |
|---|---|
| input | 如果 transposeA 是 false,要求 shape 是 (*B, N, C) 的 Tensor。 如果 transposeA 是 true,那么要求 input 转置后的 shape 是(*B, N, C),GPU & CPU 支持 Float16\Float32\Float64 类型的 Tensor; Ascend 支持 Float16\Float32\Int32 类型的 Tensor。 |
| weight | 如果 transposeB 是 false,要求 shape 是 (*B, C, M) 的 Tensor。 如果 transposeB 是 true,那么要求 weight 转置后的 shape 是(*B, C, M),GPU & CPU 支持 Float16\Float32\Float64 类型的 Tensor; Ascend 支持 Float16\Float32\Int32 类型的 Tensor。 |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (*B, N, M) 的 Tensor,其值是 input 和 weight 相乘的结果。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = onesTensor(Array<Int64>([2, 4, 1, 3]))
let weight = onesTensor(Array<Int64>([2, 4, 3, 4]))
let output = batchMatMul(input, weight)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 4, 1, 4], dtype=Float32, value=
[[[[3.00000000e+00 3.00000000e+00 3.00000000e+00 3.00000000e+00]]
[[3.00000000e+00 3.00000000e+00 3.00000000e+00 3.00000000e+00]]
[[3.00000000e+00 3.00000000e+00 3.00000000e+00 3.00000000e+00]]
[[3.00000000e+00 3.00000000e+00 3.00000000e+00 3.00000000e+00]]]
[[[3.00000000e+00 3.00000000e+00 3.00000000e+00 3.00000000e+00]]
[[3.00000000e+00 3.00000000e+00 3.00000000e+00 3.00000000e+00]]
[[3.00000000e+00 3.00000000e+00 3.00000000e+00 3.00000000e+00]]
[[3.00000000e+00 3.00000000e+00 3.00000000e+00 3.00000000e+00]]]])
batchNorm
public func batchNorm(input: Tensor, scale: Tensor, bias: Tensor, mean: Tensor, variance: Tensor, isTraining: Bool, epsilon!: Float32 = 1e-5, momentum!: Float32 = 0.1): (Tensor, Tensor, Tensor, Tensor, Tensor)
函数 batchNorm 实现 BatchNorm 归一化算子功能。
批处理规范化广泛用于卷积网络中,用于解决 “Internal Covariate Shift” 问题,原理详见论文 Accelerating Deep Network Training by Reducing Internal Covariate Shift。它使用每个 mini-batch 的数据和可更新参数对特征做重新缩放和更新,计算公式如下:
$$ y = \frac{x - mean}{\sqrt{variance + \epsilon}} * \gamma + \beta $$
每个 batch 处理时,mean 和 variance 的值都会变化,计算公式如下:
$$ new_running_mean = (1 - momentum) * running_mean + momentum * current_mean $$
参数列表:
| 名称 | 含义 |
|---|---|
| isTraining | 为 true 时, mean 和 variance 会随着训练过程进行计算。为 false 时,mean 和 variance 从 checkpoint 文件中加载。 |
| epsilon | 为保证数值稳定性而加的一个小数, 默认值为 1e-5。 |
| momentum | 之前的 batch 计算得到的均值对本次 batch 计算的影响因子, 默认值为 0.1。 |
输入:
| 名称 | 含义 |
|---|---|
| input | Tensor,形状(N,C,H,W), 支持 Float16\Float32 类型。 |
| scale | Tensor,当 isTraining 为 true 时需要设置为 parameter。shape 为 (C), 支持 Float16\Float32 类型。 |
| bias | Tensor,当 isTraining 为 true 时需要设置为 parameter。shape 为 (C), 与 scale 数据类型一致。 |
| mean | Tensor,当 isTraining 为 true 时需要设置为 parameter。shape 为 (C), 与 scale 数据类型一致。 |
| variance | Tensor,当 isTraining 为 true 时需要设置为 parameter。shape 为 (C), 与 scale 数据类型一致。 |
输出:5 个 Tensor 的元组, 归一化的输入和更新后的参数。
| 名称 | 含义 |
|---|---|
| output | 形状(N,C,H,W),与 input 有相同的类型和形状。 |
| updatedScale | 更新后的 scale 值,dtype 为 Float32。 |
| updatedBias | 更新后的 bias 值,dtype 为 Float32。 |
| reserveSpace_1 | 预留空间 1,dtype 为 Float32。 |
| reserveSpace_2 | 预留空间 2,dtype 为 Float32。 |
支持平台:GPU
反向函数:
public func batchNormGrad(dy: Tensor, x: Tensor, scale: Tensor, saveMean: Tensor, saveInvVariance: Tensor, reverse: Tensor, isTraining: Bool, epsilon!: Float32 = 1e-5, momentum!: Float32 = 0.1)
微分伴随函数:
public func adjointBatchNorm(input: Tensor, scale: Tensor, bias: Tensor, mean: Tensor, variance: Tensor, isTraining: Bool, epsilon!: Float32 = 1e-5, momentum!: Float32 = 0.1
)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let scale = onesTensor(Array<Int64>([2]))
let bias = onesTensor(Array<Int64>([2]))
let mean = onesTensor(Array<Int64>([2]))
let variance = onesTensor(Array<Int64>([2]))
let input = onesTensor(Array<Int64>([2, 2, 2, 2]))
let (output, updatedScale, updatedBias, reserveSpace1, reserveSpace2) = batchNorm(input, scale, bias, mean, variance, false)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2, 2, 2], dtype=Float32, value=
[[[[1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00]]
[[1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00]]]
[[[1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00]]
[[1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00]]]])
batchToSpace
public func batchToSpace(input: Tensor, blockSize: Int64, crops: Array<Array<Int64>>): Tensor
对于排列为 NCHW 维度的数据,将 batch 对应的维度 N 的数据按照 blockSize 的大小对应分到 H 和 W 对应的维度,并对结果进行裁切 crops。裁切之前对应维度计算公式:
$$ \begin{split}\begin{aligned} nOut &= nIn//(blockSizeblockSize) \ cOut &= cIn \ hOut &= hInblockSize-crops[0][0]-crops[0][1] \ wOut &= wIn*blockSize-crops[1][0]-crops[1][1] \end{aligned}\end{split} $$
参数列表:
| 名称 | 含义 |
|---|---|
| blockSize | 将 batch 按照 blockSize 对应分割。Int64 类型,必须不小于 2。 |
| crops | 对转换后的数据进行裁切, 第 0 维的两个数组分别对应 H 和 W 的裁切值。 Array<Array<Int64>>类型,2*2 大小 |
输入:
| 名称 | 含义 |
|---|---|
| input | Tensor,数据排列为 NCHW, N 必须是 blockSize*blockSize 的整数倍,支持 Float32\Float16 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | Tensor,数据排列为 NCHW,与 input 有相同的类型,shape 为转换之后的 shape。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointBatchToSpace(input: Tensor, blockSize: Int64, crops: Array<Array<Int64>>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let blockSize: Int64 = 2
let crop0 = Array<Int64>([0, 0])
let crop1 = Array<Int64>([0, 0])
let crops = Array<Array<Int64>>([crop0, crop1])
let x = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([4, 1, 1, 1]))
let out = batchToSpace(x, blockSize, crops)
print(out)
return 0
}
输出为:
Tensor(shape=[1, 1, 2, 2], dtype=Float32, value=
[[[[ 1.00000000e+00 2.00000000e+00]
[ 3.00000000e+00 4.00000000e+00]]]])
batchToSpaceND
public func batchToSpaceND(input: Tensor, blockShape: Array<Int64>, crops: Array<Array<Int64>>): Tensor
用块划分批次维度,并将这些块交错回空间维度。此函数会将批次维度 N 划分为具有 blockShape 的块,即输出张量的 N 维度是划分后对应的块数。 输出张量的 H 、W 维度是原始的 H 、W 维度和 blockShape 的乘积从维度裁剪给定。 如此,若输入的 shape 为 (n,c,h,w) ,则输出的 shape 为 (n′,c′,h′,w′) 。
$$ \begin{split}\begin{aligned} nOut &= nIn//blockShape[0]blockShape[1] \ cOut &= cIn \ hOut &= hInblockShape[0]-crops[0][0]-crops[0][1] \ wOut &= wInblockShape[1]-crops[1][0]-crops[1][1] \end{aligned}\end{split} $$
输入:
| 名称 | 含义 |
|---|---|
| input | Tensor,数据排列为 NCHW, 必须等于四维。批次维度需能被 blockShape 整除。支持 Float16\Float32 类型。 |
| blockShape | Int64 类型的数组,分割批次维度的块的数量,取值需大于 1。长度必须等于 2。 |
| crops | 空间维度的裁剪大小, Array<Array<Int64>>类型,2*2 大小。 |
输出:
| 名称 | 含义 |
|---|---|
| output | Tensor,数据排列为 NCHW,与 input 有相同的类型,shape 为转换之后的 shape。 |
支持平台:Ascend
微分伴随函数:
public func adjointBatchToSpaceND(input: Tensor, blockShape: Array<Int64>, crops: Array<Array<Int64>>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let blockShape = Array<Int64>([2, 2])
let crops = Array<Array<Int64>>([[0, 0], [0, 0]])
let input = Tensor(Array<Float32>([1.0000000000, 2.0000000000, 3.0000000000, 4.0000000000]), shape: Array<Int64>([4, 1, 1, 1]))
let out = batchToSpaceND(input, blockShape, crops)
print(out)
return 0
}
输出为:
Tensor(shape=[1, 1, 2, 2], dtype=Float32, value=
[[[[ 1.00000000e+00 2.00000000e+00]
[ 3.00000000e+00 4.00000000e+00]]]])
biasAdd
public func biasAdd(input: Tensor, bias: Tensor): Tensor
函数 biasAdd 实现 BiasAdd 算子功能,完成对 input 和 bias 的加法运算,并返回计算结果。input 的维度必须大于 2,bias 必须为 1 维 Tensor,且 input 的第二维的长度必须与 bias 的第一维的长度相等。
参数列表:
| 名称 | 含义 |
|---|---|
| input | Tensor,接受 Float16\Float32 类型,shape 是 (N, C) 或者(N, C, H, W), Ascend 平台 rank 必须为 2D 至 4D。 |
| bias | Tensor,接受 Float16\Float32 类型,shape 是 (C)。 |
输出:
| 名称 | 含义 |
|---|---|
| output | dtype 和 shape 跟 input 相同的 Tensor。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func biasAddGrad(input: Tensor): Tensor
微分伴随函数:
public func adjointBiasAddGrad(input: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = randomNormalTensor(Array<Int64>([32, 16, 32, 32]))
let bias = randomNormalTensor(Array<Int64>([16]))
var output = biasAdd(input, bias)
print(output.getShape())
return 0
}
输出为:
[32, 16, 32, 32]
boundingBoxDecode
public func boundingBoxDecode(anchorBoxes: Tensor, deltas: Tensor, maxShape: Array<Int64>, means!: Array<Float32> = [0.0, 0.0, 0.0, 0.0], stds!: Array<Float32> = [1.0, 1.0, 1.0, 1.0], whRatioClip!: Float32 = 0.016): Tensor
对边界框的位置解码。
参数列表:
| 名称 | 含义 |
|---|---|
| maxShape | Array<Int64>类型,解码计算后框的取值范围, maxShape 的 size 必须等于 2。 |
| means | Array<Float32>类型,size 必须为 4,deltas 计算用的均值。 |
| stds | Array<Float32>类型,size 必须为 4,deltas 计算用的标准差。 |
| whRatioClip | Float32 类型,解码框计算的宽高的比例。 |
输入:
| 名称 | 含义 |
|---|---|
| anchorBox | 输入 Tensor,锚点框。Float32 类型,shape 必须是[n, 4] |
| deltas | 输入 Tensor,box 的 delta 值。Float32 类型,shape 与 anchorBox 一致 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,解码后的框。Float32 类型,shape 与 anchorBox 一致。 |
支持平台:Ascend, GPU, CPU
示例代码如下:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let anchorBox = Tensor(Array<Float32>([4.0, 1.0, 2.0, 1.0, 2.0, 2.0, 2.0, 3.0]), shape: Array<Int64>([2, 4]))
let deltas = Tensor(Array<Float32>([3.0, 1.0, 2.0, 2.0, 1.0, 2.0, 1.0, 4.0]), shape: Array<Int64>([2, 4]))
var maxShape = Array<Int64>([768, 1280])
var output = boundingBoxDecode(anchorBox, deltas, maxShape)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 4], dtype=Float32, value=
[[4.19452810e+00 0.00000000e+00 0.00000000e+00 5.19452810e+00]
[2.14085913e+00 0.00000000e+00 3.85914087e+00 6.05981483e+01]])
boundingBoxEncode
public func boundingBoxEncode(anchorBoxes: Tensor, groundtruthBox: Tensor, means!: Array<Float32> = [0.0, 0.0, 0.0, 0.0], stds!: Array<Float32> = [1.0, 1.0, 1.0, 1.0]): Tensor
对边界框的位置编码。
参数列表:
| 名称 | 含义 |
|---|---|
| means | Array<Float32>类型,size 必须为 4,deltas 计算用的均值。 |
| stds | Array<Float32>类型,size 必须为 4,deltas 计算用的标准差, Ascend 平台上 stds 中不能含 0。 |
输入:
| 名称 | 含义 |
|---|---|
| anchorBox | 输入 Tensor,锚点框。Float32 类型,shape 必须是[n, 4] |
| groundtruthBox | 输入 Tensor,真实框。Float32 类型,shape 与 anchorBox 一致 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,编码后的框。Float32 类型,shape 与 anchorBox 一致。 |
支持平台:Ascend, GPU, CPU
示例代码如下:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let anchorBox = Tensor(Array<Float32>([2.0, 2.0, 2.0, 3.0, 2.0, 2.0, 2.0, 3.0]), shape: [2, 4])
let groundtruthBox = Tensor(Array<Float32>([1.0, 2.0, 1.0, 4.0, 1.0, 2.0, 1.0, 4.0]), shape: [2, 4])
let output = boundingBoxEncode(anchorBox, groundtruthBox)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 4], dtype=Float32, value=
[[-1.00000000e+00 2.50000000e-01 0.00000000e+00 4.05465126e-01]
[-1.00000000e+00 2.50000000e-01 0.00000000e+00 4.05465126e-01]])
broadcast
public func broadcast(input: Tensor, rootRank: Int64, group!: String = "nccl_world_group"): Tensor
将输入 Tensor 广播到整组
输入:
| 名称 | 含义 |
|---|---|
| input | 输入,支持 Float32,Int32 类型 |
| rootRank | 源进程,发送数据的进程。单卡设备只支持输入 0。取值范围: [0, 设备节点数) |
| group | 通信组类型,GPU 设备支持输入 "nccl_world_group"。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出,shape 和类型与 input 相同 |
支持平台:GPU
微分伴随函数:
public func adjointBroadcast(x: Tensor, rootRank: Int64, group!: String = "nccl_world_group")
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import context.*
main(): Int64
{
g_context.setBackend("nccl")
let x = Tensor(Array<Int32>([2, 2]), shape: [1, 2])
let output = broadcast(x, 0)
print(output)
return 0
}
输出为(单 gpu):
Tensor(shape=[1, 2], dtype=Int32, value=
[[ 2 2]])
broadcastTo
public func broadcastTo(input: Tensor, shape: Array<Int64>): Tensor
函数 broadcastTo 实现 BroadcastTo 算子功能,用于把输入 Tensor 广播成指定的 shape 的 Tensor。要求输入 Tensor 的 shape 维度必须不大于指定广播的 shape 的维度。并且,对于输入 shape 和指定广播 shape 的每一个维度值对,其维度值还需满足以下三个条件之一:
- 当输入 shape 的维度值是 1。
- 输入 shape 的维度值跟广播 shape 的维度值相同。
- 广播 shape 的维度值是 - 1。
当指定广播 shape 的维度值是 - 1 是,其广播后的 Tensor 对应维度的维度值保持输入 shape 的维度值不变。
参数列表:
| 名称 | 含义 |
|---|---|
| shape | 指定广播的 shape。 |
输入:
| 名称 | 含义 |
|---|---|
| input | 需要广播的 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32\Int64\Bool 类型, Ascend 支持 Float16\Float32\Int32\Bool 类型。 |
| 当 BroadcastTo 算子在可微函数中调用时,仅支持 Float32 数据类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输入 Tensor 广播之后的结果,其 shape 即是 BroadcastTo 指定广播的 Tensor。 |
支持平台:Ascend, GPU, CPU
用户可以直接使用 broadcastTo 函数实现 Tensor 的广播,示例代码如下:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.23, 4.56, 0.0]), shape: Array<Int64>([3]))
let output = broadcastTo(input, Array<Int64>([2, 3]))
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[1.23000002e+00 4.55999994e+00 0.00000000e+00]
[1.23000002e+00 4.55999994e+00 0.00000000e+00]])
cast
public func cast(x: Tensor, toType: Int32): Tensor
函数 cast 实现 Cast 算子功能,转换输入 Tensor 的数据类型。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入要进行数据类型转换的 Tensor。 |
| toType | 指定转换的数据类型。支持常量值或数据类型输入。支持的常数值范围是 0 ~ 7 和 9 支持的数据类型包括 Float16\Float32\Float64\Int32\Int64\Uint8\Uint16\Uint32\Bool。 数据类型和常数值的对应关系见 附录 F: dtype-类型 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,shape 与 x 相同。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointCast(x: Tensor, toType: Int32)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let output = cast(input, INT32)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Int32, value=
[[ 1 2]
[ 3 4]])
checkValid
public func checkValid(bboxes: Tensor, imgMetas: Tensor): Tensor
CheckValid 算子用于检查边界框是否满足要求。
对于输入 imgMetas = [height, width, ratio], 要求边界框小于(height * ratio, weight * ratio)。
输入:
| 名称 | 含义 |
|---|---|
| bboxes | 输入 Tensor,Float16\Float32 类型,shape 为[n, 4]。 |
| imgMetas | 输入 Tensor,Float16\Float32 类型,shape 为[3]。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,Bool 类型,shape 为[n]。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let bboxes = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]), shape: [2, 4])
let imgMetas = Tensor(Array<Float32>([9.0, 8.0, 1.0]), shape: [3])
let output = checkValid(bboxes, imgMetas)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Bool, value=
[true true])
concat
public func concat(input1: Tensor, input2: Tensor, axis!: Int64 = 0): Tensor // 可微函数
public func concat(input: Array<Tensor>, axis!: Int64 = 0): Tensor // 不可微函数
public func concat(tupleInput: Tensor, axis!: Int64 = 0): Tensor
函数 concat 实现 Concat 算子功能,用于对输入 Tensor 在指定轴上进行合并。
假设输入 Tensor 有 N 个,第 i 个 Tensor 维度为 (x_1, x_2, ..., x_{mi}, ..., x_R) ,对第 mi 维进行合并,则输出维度如下:
$$ (x_1, x_2, ..., \sum_{i=1}^Nx_{mi}, ..., x_R) $$
也就是说, 只允许被 concat 的 axis 那一维不相等,元素 shape 的其他位置上必须都对应相等。
【备注】:由于仓颉 TensorBoost 自动微分尚不支持数组可微,当前输入是 Tensor 类型数组的函数 concat 是不可微函数。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32\Bool 类型,Ascend 不支持 Float64。 所有输入的 dtype 类型必须一致。 |
| input2 | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32\Bool 类型,Ascend 不支持 Float64。所有输入的 dtype 类型必须一致。 |
| input | 输入 Tensor 列表,GPU & CPU 支持 Float16\Float32\Float64\Int32\Bool 类型,Ascend 不支持 Float64。所有输入的 dtype 类型必须一致。 |
| tupleInput | 多个 Tensor 合成的 Tuple,GPU & CPU 支持 Float16\Float32\Float64\Int32\Bool 类型,Ascend 不支持 Float64。所有输入的 dtype 类型必须一致。 |
| axis | 参考轴,默认是 0,如果 input 的维度数为 rank, 那么 axis 的取值范围为 [-rank, rank)。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 合并后的 Tensor。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointConcat(input1: Tensor, input2: Tensor, axis!: Int64 = 0)
代码示例 1:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input0 = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let input1 = Tensor(Array<Float32>([5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 2]))
let output = concat(input0, input1)
print(output)
return 0
}
输出为:
Tensor(shape=[4, 2], dtype=Float32, value=
[[1.00000000e+00 2.00000000e+00]
[3.00000000e+00 4.00000000e+00]
[5.00000000e+00 6.00000000e+00]
[7.00000000e+00 8.00000000e+00]])
代码示例 2:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input0 = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let input1 = Tensor(Array<Float32>([5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 2]))
let input:Array<Tensor> = [input0, input1]
let output = concat(input)
print(output)
return 0
}
输出为:
Tensor(shape=[4, 2], dtype=Float32, value=
[[1.00000000e+00 2.00000000e+00]
[3.00000000e+00 4.00000000e+00]
[5.00000000e+00 6.00000000e+00]
[7.00000000e+00 8.00000000e+00]])
conv2d
public func conv2D(input: Tensor, weight: Tensor, outChannel: Int64, kernelSizes: Array<Int64>, mode!: Int64 = 1, padMod!: String = "valid", pad!: Array<Int64> = Array<Int64>([0, 0, 0, 0]), strides!: Array<Int64> = Array<Int64>([1, 1, 1, 1]), dilations!: Array<Int64> = Array<Int64>([1, 1, 1, 1]), group!: Int64 = 1): Tensor
函数 conv2D 实现 Conv2D 算子功能,用于对输入的 2D 卷积运算。
参数列表:
| 名称 | 含义 |
|---|---|
| input | 卷积算子的输入,接受 Float16\Float32 类型的 Tensor,shape 是 (N, C_in, H_in, W_in)。 |
| weight | 卷积算子的权重,接受 Float16\Float32 类型的 Tensor,shape 是 (Cout, C_in, K_h, K_w)。 |
| outChannel | 输出通道数。 |
| kernelSizes | 卷积核大小,长度是 2 的数组,必须为正数。 |
| mode | 0:数学卷积,1:互相关卷积,2:反卷积,3:深度卷积。默认值:1。 |
| padMod | padding 模式,可选值为:"same"、"valid"、"pad"。默认值:"valid"。 |
| pad | 输入的隐含 pad, padMod 是 "pad" 时生效。默认值:Array<Int64>([0, 0, 0, 0])。 |
| strides | 滑窗跳步,长度是 4 的数组。默认值: Array<Int64>([1, 1, 1, 1]) 。 |
| dilations | 卷积核之间的间距,长度是 4 的数组。默认值: Array<Int64>([1, 1, 1, 1]) 。 |
| group | 权重分组数。默认值:1。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 dtype 为 Float32 类型的 Tensor,shape 是 (N, Cout, Hout, Wout)。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func conv2DBackpropInput(gradOut: Tensor, weight: Tensor, shape: Array<Int64>, outChannel: Int64, kernelSizes: Array<Int64>, mode!: Int64 = 1, padMod!: String = "valid", pad!: Array<Int64> = [0, 0, 0, 0], padList!: Array<Int64> = [0, 0, 0, 0], strides!: Array<Int64> = [1, 1], dilations!: Array<Int64> = [1, 1, 1, 1], group!: Int64 = 1): Tensor
public func conv2DBackpropFilter(gradOut: Tensor, input: Tensor, shape: Array<Int64>, outChannel: Int64, kernelSizes: Array<Int64>, mode!: Int64 = 1, padMod!: String = "valid", pad!: Array<Int64> = [0, 0, 0, 0], padList!: Array<Int64> = [0, 0, 0, 0], strides!: Array<Int64> = [1, 1, 1, 1], dilations!: Array<Int64> = [1, 1, 1, 1], group!: Int64 = 1): Tensor
微分伴随函数:
public func adjointConv2D(input: Tensor, weight: Tensor, outChannel: Int64, kernelSizes: Array<Int64>, mode: Int64, padMod: String, pad: Array<Int64>, strides: Array<Int64>, dilations: Array<Int64>, group: Int64)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = randomNormalTensor(Array<Int64>([32, 1, 32, 32]))
let weight = randomNormalTensor(Array<Int64>([6, 1, 5, 5]))
let output = conv2D(input, weight, 6, Array<Int64>([5, 5]))
print(output.getShape())
return 0
}
输出为:
[32, 6, 28, 28]
conv3d
public func conv3D(input: Tensor, weight: Tensor, outChannel: Int64, kernelSizes: Array<Int64>,
mode!: Int64 = 1, padMod!: String = "valid", pad!: Array<Int64> = [0, 0, 0, 0, 0, 0],
strides!: Array<Int64> = [1, 1, 1, 1, 1], dilations!: Array<Int64> = [1, 1, 1, 1, 1], group!: Int64 = 1) : Tensor
函数 conv3D 实现 Conv3D 算子功能,用于对输入的 3D 卷积运算。
参数列表:
| 名称 | 含义 |
|---|---|
| outChannel | 输出通道数 C_out,必须为正整数。 |
| kernelSizes | 卷积核大小,长度是 3 的数组,必须为正整数,且不大于输入的 shape (C_in, H_in, W_in)。 |
| mode | 适配不同的卷积,当前未使用。默认值为:1 |
| padMode | padding 模式,String 类型。可选值为:"same"、"valid"、"pad"。默认值:"vaild"。 same:采用补全的方式。输出的深度、高度和宽度分别与输入整除 stride 后的值相同。如果设置了此模式,则 pad 数组的元素必须等于 0。 valid:采用丢弃方式。输出的可能最大深度、高度和宽度将在没有填充的情况下返回。多余的像素将被丢弃。如果设置了此模式,则 pad 数组的元素必须等于 0。 pad:在输入的深度、高度和宽度方向上填充 padding 大小的 0。 则 pad 数组的元素必须大于或等于 0, 且 pad[0] 和 pad[1] 小于 kernelSizes[0] - 1) * dilations[2] + 1; pad[2] 和 pad[3] 小于 kernelSizes[1] - 1) * dilations[3] + 1; pad[4] 和 pad[5] 小于 kernelSizes[2] - 1) * dilations[4] + 1。 |
| pad | padMod 是 "pad" 时生效。默认值:[0, 0, 0, 0, 0, 0]。 |
| strides | 滑窗跳步,长度是 5 的数组, 前两维取值仅支持 1,其余取值需大于等于 1。默认值: [1, 1, 1, 1, 1] 。 |
| dilations | 卷积核之间的间距,长度是 5 的数组,前三维取值仅支持 1,其余取值需大于等于 1。默认值: [1, 1, 1, 1, 1] 。 |
| group | 权重分组数。默认值:1。目前仅支持取值为 1。 |
输入:
| 名称 | 含义 |
|---|---|
| input | 卷积算子的输入,接受 Float16\Float32 类型的 Tensor,shape 是 (N, C_in, D_in, H_in, W_in)。 |
| weight | 卷积算子的权重,接受 Float16\Float32 类型的 Tensor,dtype 要求与 input 一致,卷积核大小设置为(K_d, K_h, K_w), 则 weight 的 shape 是 (C_out, C_in//group, K_d, K_h, K_w)。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出与 input 类型一致的 Tensor,shape 是 (N, Cout, Dout, Hout, Wout)。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func conv3DBackpropInput(weight: Tensor, gradOut: Tensor, shape: Array<Int64>, outChannel: Int64, kernelSizes: Array<Int64>, mode!: Int64 = 1, padMod!: String = "valid", pad!: Array<Int64> = [0, 0, 0, 0, 0, 0], strides!: Array<Int64> = [1, 1, 1, 1, 1], dilations!: Array<Int64> = [1, 1, 1, 1, 1], group!: Int64 = 1): Tensor
public func conv3DBackpropFilter(input: Tensor, gradOut: Tensor, shape: Array<Int64>, outChannel: Int64, kernelSizes: Array<Int64>, mode!: Int64 = 1, padMod!: String = "valid", pad!: Array<Int64> = [0, 0, 0, 0, 0, 0], strides!: Array<Int64> = [1, 1, 1, 1, 1], dilations!: Array<Int64> = [1, 1, 1, 1, 1], group!: Int64 = 1): Tensor
微分伴随函数:
public func adjointConv3D(input: Tensor, weight: Tensor, outChannel: Int64, kernelSizes: Array<Int64>, mode!: Int64 = 1, padMod!: String = "valid", pad!: Array<Int64> = [0, 0, 0, 0, 0, 0], strides!: Array<Int64> = [1, 1, 1, 1, 1], dilations!: Array<Int64> = [1, 1, 1, 1, 1], group!: Int64 = 1)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = randomNormalTensor(Array<Int64>([1, 16, 40, 24, 40]))
let weight = randomNormalTensor(Array<Int64>([32, 16, 3, 3, 3]))
let output = conv3D(input, weight, 32, Array<Int64>([3, 3, 3]),
strides: Array<Int64>([1, 1, 1, 1, 1]), dilations: Array<Int64>([1, 1, 1, 1, 1]))
print(output.getShape())
return 0
}
输出为:
[1, 32, 38, 22, 38]
cos
public func cos(input: Tensor): Tensor
函数 cos 实现 Cos 算子功能,用于计算输入数据的余弦。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, GPU & CPU 支持 Float16\Float32\Float64 支持, Ascend 支持 Float16\Float32。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输入数据对应的余弦值。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointCos(input: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([0.62, 0.28, 0.43, 0.62]), shape: Array<Int64>([4]))
let output = cos(input)
print(output)
return 0
}
输出为:
Tensor(shape=[4], dtype=Float32, value=
[8.13878477e-01 9.61055458e-01 9.08965766e-01 8.13878477e-01])
cropAndResize
public func cropAndResize(x: Tensor, boxes: Tensor, boxIndex: Tensor, cropSize: Array<Int64>, method!: String = "bilinear", extrapolationValue!: Float32 = 0.0): Tensor
CropAndResize 对输入的 image 进行裁剪,然后调整图片尺寸大小。
参数列表:
| 名称 | 含义 |
|---|---|
| method | resize 时候的采样方法,String 类型,可选值有"bilinear","nearest"和"bilinear_v2",默认值为"bilinear"。 |
| extrapolationValue | 如果采样值越界,可以用来推断应该输入的值 ,Float32 类型,默认为 0.0。 |
输入:
| 名称 | 含义 |
|---|---|
| x | 输入数据,支持 Int32,Float32 与 Float64 类型,4D 格式:[batch, imageHeight, imageWidth, channels]。 |
| boxes | shape 为[n, 4],表示 n 组裁剪方式的取值, 每组裁剪值表示为[y1, x1, y2, x2],类型为 Float32。裁切值取值[0, 1]表示对应图片的高度[0, imageHeight-1]或者宽度[0, imageWeight-1]的位置。[y1, y2]成比例裁剪得到图片新高度为 (y2-y1)*(imageHeight),允许 y1>y2,此时图片会上下翻转,宽度方向同理。如果裁切值越界,越界位置的值根据 extrapolationValue 外推。 |
| boxIndex | shape 为[n],每个元素取值范围为[0,batch),表示 boxes[i]用于对第 boxIndex[i]个 image 进行裁剪,Int32 类型。 |
| cropSize | Array<Int64>类型,长度为 2,对应宽高的大小[crop_height, crop_width]。仅支持常量输入 |
输出:
| 名称 | 含义 |
|---|---|
| output | 返回一个张量,shape 为[n, crop_height, crop_width, channels], 类型为 Float32。 |
支持平台:Ascend, GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let batchSize = 1
let numBoxex = 5
let imageHeight = 256
let imageWeight = 256
let channels = 3
let x = randomNormalTensor(Array<Int64>([batchSize, imageHeight, imageWeight, channels]))
let bboxes = uniformTensor(Array<Int64>([numBoxex, 4]))
let boxIndex = Tensor(Array<Int32>([0, 0, 0, 1, 1]), shape: [numBoxex])
let cropSize = Array<Int64>([24, 24])
let output = cropAndResize(x, bboxes, boxIndex, cropSize)
print(output.getShape())
return 0
}
输出为:
[5, 24, 24, 3]
ctcLoss
public func ctcLoss(x: Tensor, labelsIndices: Tensor, labelsValues: Tensor, sequenceLength: Tensor, preprocessCollapseRepeated!: Bool = false,
ctcMergeRepeated!: Bool = true, ignoreLongerOutputsThanInputs!: Bool = false): (Tensor, Tensor)
函数 ctcLoss 实现 CTCLoss 算子功能,用于计算 CTC 的 loss 和梯度。
参数列表:
| 名称 | 含义 |
|---|---|
| preprocessCollapseRepeated | 如果为 true ,则在 CTC 计算之前折叠重复的标签,默认为 false 。 |
| ctcMergeRepeated | 如果为 false,则在 CTC 计算期间,重复的非空白标签将不会合并,并被解释为单个标签,默认为 true 。 |
| ignoreLongerOutputsThanInputs | 如果为 true ,则输出比输入长的序列将被忽略,默认为 false 。 |
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 3-D Tensor (max_time, batch_size, num_classes),仅支持 Float32 类型。其中 num_classes 代表 num_labels + 1 个类,num_labels 是实际标签的数量,空白标签被保留,默认为 num_classes - 1。 |
| labelsIndices | 标签索引 2-D Tensor,仅支持 Int64 类型,第一列表示 batch,第二列表示 time,labelsValues[i] 以 labelsIndices 的第 i 行 (batch, time) 为索引存储对应的 id。 |
| labelsValues | 1-D Tensor,仅支持 Int32 类型, labelsValues 的取值范围必须在 [0, num_classes) 的范围内。 |
| sequenceLength | 序列长度,仅支持 Int32 类型,形状为 (batch_size),其中的每一个值必须不超过 max_time。 |
输出:
| 名称 | 含义 |
|---|---|
| loss | 包含对数概率的张量,形状为 (batch_size),数据类型与输入 x 相同。 |
| gradient | 损失的梯度,与输入 x 具有相同的形状和数据类型。 |
输入要求:
- sequenceLength[batch] <= max_time
- labelsIndices 的第一列的最大值必须等于 batch_size - 1
支持平台:GPU
微分伴随函数:
public func adjointCtcLoss(x: Tensor, labelsIndices: Tensor, labelsValues: Tensor, sequenceLength: Tensor, preprocessCollapseRepeated!: Bool = false, ctcMergeRepeated!: Bool = true, ignoreLongerOutputsThanInputs!: Bool = false)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Float32>([0.3, 0.6, 0.6, 0.4, 0.3, 0.9, 0.9, 0.4, 0.2, 0.9, 0.9, 0.1]), shape: [2, 2, 3]), "x")
let labelsIndices = parameter(Tensor(Array<Int64>([0, 0, 1, 0]), shape: [2, 2]), "labels_indices")
let labelsValues = parameter(Tensor(Array<Int32>([2, 2]), shape: [2]), "labels_values")
let sequenceLength = parameter(Tensor(Array<Int32>([2, 2]), shape: [2]), "sequence_length")
let (loss, gradient) = ctcLoss(x, labelsIndices, labelsValues, sequenceLength)
print(loss)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[7.96280026e-01 5.99515796e-01])
cumProd
public func cumProd(x: Tensor, axis: Int64, exclusive!: Bool = false, reverse!: Bool = false): Tensor
函数 cumProd 实现 CumProd 算子功能,用于计算输入张量 x 沿轴的累积积。
参数列表:
| 名称 | 含义 |
|---|---|
| exclusive | 如果为 true ,则执行独占的 CumProd ,默认为 false 。 |
| reverse | 如果为 true ,则 CumProd 将以相反方向执行,默认为 false 。 |
输入:
| 名称 | 含义 |
|---|---|
| x | 输入数据,支持 Int32 与 Float32 类型。 Ascend 反向不支持 Int32 类型 |
| axis | 用于计算累积积的维度,类型为 Int64 ,取值范围为[-rank, rank)。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 返回一个张量,与 x 具有相同的 shape 和 dtype 。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointCumProd(x: Tensor, axis: Int64, exclusive!: Bool = false, reverse!: Bool = false)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Int32>([2, 1, 3, 2, 3, 3, 0, 1, 2, 1]), shape: Array<Int64>([2, 5])), "x")
let output = cumProd(x, 0, exclusive: true)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 5], dtype=Int32, value=
[[1 1 1 1 1]
[2 1 3 2 3]])
cumSum
public func cumSum(input: Tensor, axis: Int64, exclusive!: Bool = false, reverse!: Bool = false): Tensor
函数 cumSum 实现 CumSum 算子功能,用于计算张量 x 沿轴的累积总和。
参数列表:
| 名称 | 含义 |
|---|---|
| exclusive | 如果为 true ,则执行专用的 CumSum ,默认为 false 。 |
| reverse | 如果为 true ,则 CumSum 将以相反方向执行,默认为 false 。 |
输入:
| 名称 | 含义 |
|---|---|
| x | 输入数据,支持 Float16\Float32\Float64\Int32 类型, Ascend 不支持 Float64 类型。 |
| axis | 用于计算累积张量值的维度,类型为 Int64 ,取值范围为[-rank, rank)。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 返回一个张量,与 x 具有相同的 shape 和 dtype 。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointCumSum(input: Tensor, axis: Int64, exclusive!: Bool = false, reverse!: Bool = false)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Float32>([-11.0726070404, -2.7946569920, -47.6111984253, -186.2480163574]), shape: Array<Int64>([2, 2])), "x")
let output = cumSum(x, 0)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[-1.10726070e+01 -2.79465699e+00]
[-5.86838074e+01 -1.89042679e+02]])
depthToSpace
public func depthToSpace(input: Tensor, blockSize: Int64): Tensor
对于格式为 NCHW 维度的数据,将 Channel 对应的维度 C 的数据按照 blockSize 的大小对应分到 H 和 W 对应的维度。对应维度计算公式:
$$ \begin{split}\begin{aligned} nOut &= nIn \ cOut &= cIn//(blockSizeblockSize) \ hOut &= hInblockSize \ wOut &= wIn*blockSize \end{aligned}\end{split} $$
参数列表:
| 名称 | 含义 |
|---|---|
| blockSize | 将 batch 按照 blockSize 对应分割。Int64 类型,必须不小于 2。 |
输入:
| 名称 | 含义 |
|---|---|
| input | Tensor,数据排列为 NCHW, C 必须是 blockSize*blockSize 的整数倍,支持 Float32\Int32\Int64\UInt32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | Tensor,数据排列为 NCHW,与 input 有相同的类型,shape 为转换之后的 shape。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointDepthToSpace(input: Tensor, blockSize: Int64)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let blockSize: Int64 = 2
let x = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([1, 4, 1, 1]))
let out = depthToSpace(x, blockSize)
print(out)
return 0
}
输出为:
Tensor(shape=[1, 1, 2, 2], dtype=Float32, value=
[[[[ 1.00000000e+00 2.00000000e+00]
[ 3.00000000e+00 4.00000000e+00]]]])
divNoNan
public func divNoNan(x: Int32, y: Tensor): Tensor
public func divNoNan(x: Float16, y: Tensor): Tensor
public func divNoNan(x: Float32, y: Tensor): Tensor
public func divNoNan(x: Tensor, y: Int32): Tensor
public func divNoNan(x: Tensor, y: Float16): Tensor
public func divNoNan(x: Tensor, y: Float32): Tensor
public func divNoNan(x: Tensor, y: Tensor): Tensor
函数 divNoNan 实现 DivNoNan 算子功能,用于计算 x/y 的值,如果 y 为 0,则返回 0。
输入:
| 名称 | 含义 |
|---|---|
| x | 第一个输入。类型为 Float16\Float32\Int32 的 tensor 或 number。 |
| y | 第二个输入。类型为 Float16\Float32\Int32 的 tensor 或 number,dtype 类型与 x 一致 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,shape 跟 input1 和 input2 相同(或者跟两者 broadcasting 之后相同),数据类型与 x 相同。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointDivNoNan(x: Tensor, y: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x: Int32 = 1
let y = parameter(Tensor(Array<Int32>([0, 1, 1, 0, 0, 0, 0, 0]), shape: [2, 1, 2, 2]), "y")
let output = divNoNan(x, y)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 1, 2, 2], dtype=Int32, value=
[[[[0 1]
[1 0]]]
[[[0 0]
[0 0]]]])
dropout
public func dropout(input: Tensor, keepProb!: Float32 = 0.5, seed0!: Int64 = 0, seed1!: Int64 = 0): (Tensor, Tensor)
函数 dropout 实现 Dropout 算子功能,用于将输入经过 dropout 处理,输出两个形状和输入一致的 Tensor,一个是根据 keepProb 生成的 mask,另一个是根据 mask 和 keepProb 计算得到的输出。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入的 Tensor,只接受 Float32 类型。 |
| keepProb | 进行 mask 的概率,value 在 (0.0, 1.0] 之间,默认值:0.5。 |
| seed0 | 随机种子,默认值:0。 |
| seed1 | 随机种子,默认值:0。 |
输出:2 个 Tensor 的元组,dropout 计算输出和 mask。
| 名称 | 含义 |
|---|---|
| output | dtype 是 Float32,mask 对应的位置上为 0 则该 Tensor 的元素为 0,否则为输入时对应位置的元素 keepProb, shape 与输入的 shape 相同。 |
| mask | dtype 是 Float32,元素的值为 0 或 1,shape 与输入的 shape 相同。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func dropoutGrad(gradOut: Tensor, mask: Tensor, keepProb!: Float32 = 0.5): Tensor
微分伴随函数:
public func adjointDropout(input: Tensor, keepProb!: Float32 = 0.5, seed0!: Int64 = 0, seed1!: Int64 = 0)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([2.0, 2.0, 3.0]), shape: Array<Int64>([3]))
let (output, prob) = dropout(input, keepProb: 1.0)
print(output)
print(prob)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[2.00000000e+00 2.00000000e+00 3.00000000e+00])
Tensor(shape=[3], dtype=Float32, value=
[1.00000000e+00 1.00000000e+00 1.00000000e+00])
dropout3D
public func dropout3D(x: Tensor, keepProb!: Float32 = 0.5): (Tensor, Tensor)
函数 dropout3D 实现 Dropout3D 算子功能,用于在训练期间,以概率 1 - keepProb 从伯努利分布中随机将输入张量的一些通道归零。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入的 Tensor, shape 是 (N, C, D, H, W),支持类型 GPU 支持 Float32,Ascend 支持 Float32 与 Int32。 |
| keepProb | 进行 mask 的概率,value 在[0, 1] 之间,默认值:0.5。 |
输出:2 个 Tensor 的元组,dropout 计算输出和 mask。
| 名称 | 含义 |
|---|---|
| output | 与 x 的 shape 和 dtype 一致。 |
| mask | 与 x 的 shape 一致,dtype 是 Bool 类型。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointDropout3D(x: Tensor, keepProb!: Float32 = 0.5)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Float32>([3.0, 3.0, 1.0, 0.0, 0.0, 0.0, 3.0, 0.0]), shape: Array<Int64>([2, 1, 2, 1, 2])), "x")
let (output, mask) = dropout3D(x, keepProb: 0.5)
print(output.getShape())
return 0
}
输出为:
[2, 1, 2, 1, 2]
dynamicShape
public func dynamicShape(input: Tensor): Tensor
返回输入 Tensor input 的 shape,应用于动态 shape 场景。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor。支持 Int32、Float32、Bool 类型 |
输出:
| 名称 | 含义 |
|---|---|
| output | input 的 shape,Int32 类型 Tensor |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointDynamicShape(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
var input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let out = dynamicShape(input)
print(out)
return 0
}
输出为:
Tensor(shape=[2], dtype=Int32, value=
[2 2])
elu
public func elu(input: Tensor, alpha!: Float32 = 1.0): Tensor
计算指数线性
$$ \begin{split}\text{ELU}(x)= \left{ \begin{array}{align} \alpha(e^{x} - 1) & \text{if } x \le 0\ x & \text{if } x \gt 0\ \end{array}\right.\end{split} $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入,支持 Float32 类型 Tensor |
| alpha | 负面系数,Float32 类型的数字,目前仅支持 1.0, 默认值:1.0 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出, 与 input 的 shape 和 dtype 相同 |
支持平台:Ascend, GPU, CPU
反向函数:
public func eluGrad(x: Tensor, y: Tensor): Tensor
微分伴随函数:
public func adjointElu(input: Tensor, alpha!: Float32 = 1.0)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([-1.0, 4.0, -8.0, 2.0, -5.0, 9.0]), shape: [2, 3])
let output = elu(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[-6.32120490e-01 4.00000000e+00 -9.99664545e-01]
[ 2.00000000e+00 -9.93262053e-01 9.00000000e+00]])
embeddingLookup
public func embeddingLookup(inputParams: Tensor, inputIndices: Tensor, offset: Int64): Tensor
通过索引从输入 Tensor 中取数据,索引通过 offset 做偏移,偏移后的 Indices 为 inputIndices - offset。索引值超过 input 张量的 0 维索引部分,对应位置值取零。如果索引值为负数,则对应输出张量部分是未定义的。 Ascend 平台只支持静态图模式。
输入:
| 名称 | 含义 |
|---|---|
| inputParams | 输入 Tensor。支持 Float32、Bool 类型 要求 dim 为 2 |
| inputIndices | 索引 Tensor。支持 Int32、Int64 类型 |
| offset | 对索引 Tensor 做偏移。Int64 类型标量 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,数据类型与输入 Tensor 一致 |
支持平台:GPU
微分伴随函数:
public func adjointEmbeddingLookup(inputParams: Tensor, inputIndices: Tensor, offset: Int64)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0]), shape: Array<Int64>([8, 2]))
let idx = Tensor(Array<Int32>([5, 2, 8, 5]), shape: Array<Int64>([2, 2]))
let offset: Int64 = 4
let out = embeddingLookup(x, idx, offset)
print(out)
return 0
}
输出为:
Tensor(shape=[2, 2, 2], dtype=Float32, value=
[[[ 3.00000000e+00 4.00000000e+00]
[ 0.00000000e+00 0.00000000e+00]]
[[ 9.00000000e+00 1.00000000e+01]
[ 3.00000000e+00 4.00000000e+00]]])
eps
public func eps(input: Tensor): Tensor
函数 eps 根据输入 Tensor 的 dtype 返回一个全是该数据类型下最小值的 Tensor。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, 可选数据类型:Float16\Float32\Float64 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出的 Tensor, 其 shape 和 dtype 和输入的一致 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointEps(input: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 5.0]), shape: [3])
let output = eps(input)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[1.52587891e-05 1.52587891e-05 1.52587891e-05])
equal
public func equal(input1: Tensor, input2: Tensor): Tensor
public func equal(input1: Tensor, input2: Float16): Tensor
public func equal(input1: Float16, input2: Tensor): Tensor
public func equal(input1: Tensor, input2: Float32): Tensor
public func equal(input1: Float32, input2: Tensor): Tensor
public func equal(input1: Tensor, input2: Float64): Tensor
public func equal(input1: Float64, input2: Tensor): Tensor
public func equal(input1: Int32, input2: Tensor): Tensor
public func equal(input1: Tensor, input2: Int32): Tensor
函数 equal 实现 Equal 算子功能,用于计算 x==y 元素的 Bool 值。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32, Ascend 支持 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
| input2 | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32, Ascend 支持 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
输出:
| 名称 | 含义 |
|---|---|
| output | Tensor,与广播后的形状相同,数据类型为 Bool。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input1 = Tensor(Array<Float32>([3.0, 2.0, 1.0]), shape: Array<Int64>([3]))
let input2 = Tensor(Array<Float32>([2.0, 2.0, 3.0]), shape: Array<Int64>([3]))
let output = equal(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Bool, value=
[false true false])
equalCount
public func equalCount(x: Tensor, y: Tensor): Tensor
函数 equalCount 实现 EqualCount 算子功能,用于计算 x == y 元素的个数。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,接收 Float16\Float32\Int32 类型的 Tensor,两个输入必须为同一 dtype 类型,shape 也必须相同。 |
| y | 输入 Tensor,接收 Float16\Float32\Int32 类型的 Tensor,两个输入必须为同一 dtype 类型,shape 也必须相同。 |
输出:
| 名称 | 含义 |
|---|---|
| output | Tensor,与输入的 dtype 相同,shape 为[1]。 |
支持平台:GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = Tensor(Array<Int32>([1, 0, 1, 1, 0]), shape: Array<Int64>([5]))
let y = Tensor(Array<Int32>([3, 0, 0, 2, 2]), shape: Array<Int64>([5]))
let output = equalCount(x, y)
print(output)
return 0
}
输出为:
Tensor(shape=[1], dtype=Int32, value= [1])
erfc
public func erfc(x: Tensor): Tensor
函数 erfc 实现 Erfc 算子功能,即 1 - 高斯误差函数。以 element-wise 的方式进行计算,计算公式如下:
$$ erfc(x) = 1 - \frac{2} {\sqrt{\pi}} \int\limits_0^{x} e^{-t^{2}} dt $$
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,支持 Float16\Float32 类型的 Tensor,且 rank 需要小于 8。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor, 与输入 Tensor 的数据类型和形状相同。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointErfc(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = Tensor(Array<Float32>([-0.9332344532, 0.5735540390, 0.1609500945, 0.5236085653]), shape: [2, 2])
let output = erfc(x)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[1.81309581e+00 4.17292267e-01]
[8.19943309e-01 4.59000111e-01]])
exp
public func exp(input: Tensor): Tensor
函数 exp 实现 Exp 算子功能,用于计算一个 Tensor 逐个元素的以欧拉数 ($e$) 为底的指数, 即: $e^{x}$。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,支持 Float16\Float32 类型的 Tensor。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 计算指数后的 Tensor, 与输入 Tensor 的数据类型和形状相同。 |
支持平台:Ascend, CPU
微分伴随函数:
public func adjointExpOp(input: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 4.0]), shape: Array<Int64>([3]))
let output = exp(input)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[2.71828175e+00 7.38905621e+00 5.45981483e+01])
expandDims
public func expandDims(input: Tensor, axis: Int64): Tensor
函数 expandDims 实现 ExpandDims 算子功能,用来对输入在指定维度扩维。
参数列表:
| 名称 | 含义 |
|---|---|
| input | 输入数据。 |
| axis | 需要扩展的维度位置,如果 axis 是负数,则代表后往前的第 axis 个维度(从 1 开始)。如果 input 的维度数为 rank, 那么 axis 的取值范围为 [-rank -1, rank]。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出维度在指定轴扩展之后的 Tensor,与 input 的数据类型相同。 |
支持平台:Ascend, CPU
微分伴随函数:
public func adjointExpandDims(x: Tensor, axis: Int64)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([2.0, 2.0, 2.0, 2.0]), shape: Array<Int64>([2, 2]))
let expandDims = expandDims(input, -1)
print(expandDims.getShape())
return 0
}
输出为:
[2, 2, 1]
flatten
public func flatten(input: Tensor): Tensor
函数 flatten 实现 Flatten 算子功能,用来合并 Tensor 除第 0 维外的其他维度。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入形状为 [N,...]的 Tensor 。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor 的形状为[N, X],其中 X 是剩余维度的乘积。 |
支持平台:Ascend, GPU
反向函数:
public func flattenGrad(x: Tensor, shape: Array<Int64>): Tensor
微分伴随函数:
public func adjointFlatten(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = onesTensor(Array<Int64>([1, 2, 3, 4]))
let flatten = flatten(input)
print(flatten.getShape())
return 0
}
输出为:
[1, 24]
floatStatus
public func floatStatus(input: Tensor): Tensor
函数 floatStatus 实现 FloatStatus 算子功能,用于对输入 Tensor 进行判断,是否存在下溢或者上溢。
输入:
| 名称 | 含义 |
|---|---|
| input | 正向计算的输入 Tensor, 目前支持 Float16,Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出形状为 Array<Int64>([1]),dtype 为 Float32。 |
支持平台:GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([10000000.0]), shape: Array<Int64>([1]))
let output = floatStatus(input)
print(output)
return 0
}
输出为:
Tensor(shape=[1], dtype=Float32, value= [0.00000000e+00])
floor
public func floor(input: Tensor): Tensor
函数 floor 实现 Floor 算子功能,用于将 Tensor 向下舍入到最接近的整数元素。
输入:
| 名称 | 含义 |
|---|---|
| input | (Tensor) 输入 Tensor,GPU & CPU 支持 Float16\Float32 类型 Tensor; Ascend 支持 Float16\Float32 类型 Tensor。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与原始变量的类型相同。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointFloor(input: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([2.5, -3.7, -1.4, 7.8, 6.3]), shape: Array<Int64>([5]))
let output = floor(input)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[2.00000000e+00 -4.00000000e+00 -2.00000000e+00 7.00000000e+00 6.00000000e+00])
floorDiv
public func floorDiv(input1: Tensor, input2: Tensor): Tensor
public func floorDiv(input1: Tensor, input2: Float32): Tensor
public func floorDiv(input1: Float32, input2: Tensor): Tensor
public func floorDiv(input1: Tensor, input2: Int32): Tensor
public func floorDiv(input1: Int32, input2: Tensor): Tensor
函数 floorDiv 实现 FloorDiv 算子功能,用于计算第一个输入与第二个输入逐个元素相除,并向下取整。输入可以是 Tensor 或者标量,但不能同时为标量。当输入为两个 Tensor 时,其 shape 必须可以进行 broadcast。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 第一个输入。支持 Float32 或 Int32 类型的 number 或 tensor,两个输入的 dtype 必须相同。 |
| input2 | 第二个输入。支持 Float32 或 Int32 类型的 number 或 tensor,两个输入的 dtype 必须相同。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 相除的 Tensor,数据类型和形状与 broadcast 后的输入相同。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointFloorDiv(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = Tensor(Array<Float32>([0.5965690017, 0.7835913897, 0.3291122615, 0.7661116719, 0.5438582897, 0.0798860192]), shape: Array<Int64>([3, 2]))
let input2 = Tensor(Array<Float32>([0.0275930110, 0.7529847026, 0.4509352744, 0.1639176756, 0.2969887257, 0.4561915398]), shape: Array<Int64>([3, 2]))
let output = floorDiv(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[3, 2], dtype=Float32, value=
[[2.10000000e+01 1.00000000e+00]
[0.00000000e+00 4.00000000e+00]
[1.00000000e+00 0.00000000e+00]])
floorMod
public func floorMod(input1: Tensor, input2: Tensor): Tensor
public func floorMod(input1: Tensor, input2: Int32): Tensor
public func floorMod(input1: Int32, input2: Tensor): Tensor
public func floorMod(input1: Tensor, input2: Float32): Tensor
public func floorMod(input1: Float32, input2: Tensor): Tensor
函数 floorMod FloorMod 算子功能,按元素计算除法的余数,向下除法。输入可以是 Tensor 或者标量,但不能同时为标量。当输入为两个 Tensor 时,其 shape 必须可以进行 broadcast。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 第一个输入。支持 Float32 或 Int32 类型的 number 或 tensor,两个输入的 dtype 必须相同,Tensor 的 shape 的维度不能超过 7。 |
| input2 | 第二个输入。支持 Float32 或 Int32 类型的 number 或 tensor,两个输入的 dtype 必须相同,Tensor 的 shape 的维度不能超过 7。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 相除的 Tensor,数据类型和形状与 broadcast 后的输入相同。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointFloorMod(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = parameter(Tensor(Array<Int32>([2, 4, -1]), shape: Array<Int64>([3])), "x")
let input2 = parameter(Tensor(Array<Int32>([3, 3, 3]), shape: Array<Int64>([3])), "y")
let output = floorMod(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Int32, value=
[2 1 2])
gather
public func gather(inputParams: Tensor, inputIndices: Tensor, axis: Int64): Tensor
函数 gather 实现 Gather 算子功能,用于根据轴和索引获取 Tensor 中的某些值。
输入:
| 名称 | 含义 |
|---|---|
| inputParams | 输入 Tensor, GPU & CPU 支持 Float32\Float64\Int32\Int64\Bool, Ascend 支持 Float32\Int32。 |
| inputIndices | 索引, 整型类型 Tensor。 当执行设备为 CPU 时,值必须在 [0, inputParams.getShape()[axis]) 范围内。GPU & CPU 支持 Int32\Int64, Ascend 支持 Int32 |
| axis | 轴。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointGather(inputParams: Tensor, inputIndices: Tensor, axis: Int64)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let inputParams = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]), shape: Array<Int64>([2, 3]))
let shape:Array<Int32> = Array<Int32>([1, 2])
let inputIndices = Tensor(shape, shape: Array<Int64>([2]))
let output = gather(inputParams, inputIndices, 1)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[2.00000000e+00 3.00000000e+00]
[5.00000000e+00 6.00000000e+00]])
gatherD
public func gatherD(x: Tensor, dim: Int64, index: Tensor): Tensor
沿着一个指定的轴获取 Tensor 中的数据,输出新的 Tensor。获取数据的方式如下:
output[i][j][k] = x[index[i][j][k]][j][k] // if dim == 0
output[i][j][k] = x[i][index[i][j][k]][k] // if dim == 1
output[i][j][k] = x[i][j][index[i][j][k]] // if dim == 2
除 dim 所在的维度,x 和 index 的其他维度对应的 shape 值需保持一致。定义 xShape 为 x 的 shape,xShapeDims 为 x 的维度,dim 的取值范围是:[-xShapeDims, xShapeDims), index 中每个元素的取值范围在[-xShape[dim], xShape[dim])。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor。支持 Float32\Int32\Int64\UInt32\Bool 类型。 |
| dim | 指定获取数据的轴的位置。标量,支持 Int64 类型。 |
| index | 索引 Tensor。支持 Int64、Int32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor,与输入 Tensor 具有相同 dtype。shape 和 index 一致 |
支持平台:GPU
反向函数:
public func gatherDGrad(index: Tensor, gradOut: Tensor, dim: Int64, xshape: Array<Int64>): Tensor
微分伴随函数:
public func adjointGatherD(x: Tensor, dim: Int64, index: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let idx = Tensor(Array<Int64>([0, 0, 1, 0, 0, 1]), shape: Array<Int64>([2, 3]))
let dim: Int64 = 1
let out = gatherD(x, dim, idx)
print(out)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 1.00000000e+00 1.00000000e+00 2.00000000e+00]
[ 3.00000000e+00 3.00000000e+00 4.00000000e+00]])
gatherNd
public func gatherNd(input: Tensor, indices: Tensor): Tensor
函数 gatherNd 实现 GatherNd 算子功能,用于从 input 中根据 indices 进行取值,得到特定 shape 的 Tensor,输出 shape 的计算公式为:
$$ indices_shape[:-1] + x_shape[indices_shape[-1]:] $$
其中 input 的 rank 必须大于等于 indices shape 的最后一维。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,接受 Float32\Float64\Int32\Int64\Bool, Ascend 支持 Float32\Int32\Bool 类型的 Tensor。 |
| indices | 索引构成的 Tensor,接受 Int32\Int64, Ascend 支持 Int32 类型的 Tensor。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出,数据类型与 input 一致。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointGatherNd(input: Tensor, indices: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([-0.1, 0.3, 3.6, 0.4, 0.5, -3.2]), shape: Array<Int64>([2, 3]))
let indices = Tensor(Array<Int32>([0, 0, 1, 1]), shape: Array<Int64>([2, 2]))
let output = gatherNd(input, indices)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[-1.00000001e-01 5.00000000e-01])
gelu
public func gelu(input: Tensor): Tensor
函数 gelu 实现 GeLU 算子功能,GeLU 是一种常见的激活函数。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,支持 Float16, Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func geluGrad(gradOut: Tensor, input: Tensor, out: Tensor): Tensor
微分伴随函数:
public func adjointGelu(x: Tensor)
二阶伴随函数:
public func adjointGeluGrad(gradOut: Tensor, input: Tensor, out: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([1.0, 0.5]), shape: Array<Int64>([2]))
let output = gelu(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[8.41192007e-01 3.45714003e-01])
getTupleItem
public func getTupleItem(input: Tensor, index: Int64): Tensor
函数 getTupleItem 实现 TupleGetItem 算子功能,用来获取 Tensor 元组中的某个 Tensor。
输入:
| 名称 | 含义 |
|---|---|
| input | Tensor 元组,通常是 makeTuple 的输出, 支持所有类型的 Tensor。 |
| index | 获取第几个 Tensor。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出,返回 input 对应索引下标 index 的 Tensor。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointGetTupleItem(input: Tensor, index: Int64)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input0 = Tensor(Array<Int32>([1, 2, 3]), shape: Array<Int64>([3]))
let input1 = Tensor(Array<Int32>([4, 5, 6]), shape: Array<Int64>([3]))
let input = makeTuple([input0, input1])
let index = 0
let output = getTupleItem(input, index)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Int32, value=
[1 2 3])
greater
public func greater(input1: Tensor, input2: Tensor): Tensor
public func greater(input1: Tensor, input2: Float64): Tensor
public func greater(input1: Tensor, input2: Float32): Tensor
public func greater(input1: Tensor, input2: Float16): Tensor
public func greater(input1: Tensor, input2: Int32): Tensor
public func greater(input1: Float64, input2: Tensor): Tensor
public func greater(input1: Float32, input2: Tensor): Tensor
public func greater(input1: Float16, input2: Tensor): Tensor
public func greater(input1: Int32, input2: Tensor): Tensor
函数 greater 实现 Greater 算子功能,用于对输入 Tensor 进行 element-wise 的比较,第一个 Tensor 位置上元素大于第二个 Tensor 对应的元素则返回 Tensor 上对应位置为 true,否则为 false。
两个入参至少有一个是 Tensor。当两个都是 Tensor 时需要保证 shape 可以进行 broadcast。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 输入 Tensor,GPU & CPU 接受 Float16\Float32\Float64\Int32 类型的标量或者 Tensor; Ascend 接受 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
| input2 | 输入 Tensor,GPU & CPU 接受 Float16\Float32\Float64\Int32 类型的标量或者 Tensor; Ascend 接受 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 比较计算的结果 Tensor,Bool 类型,shape 跟 input1 和 input2 相同(或者跟两者 broadcasting 之后相同)。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointGreater(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = Tensor(Array<Float32>([1.0, 2.0, 3.0]), shape: Array<Int64>([3]))
let input2 = Tensor(Array<Float32>([1.0, 1.0, 4.0]), shape: Array<Int64>([3]))
let output = greater(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Bool, value=
[false true false])
greaterEqual
public func greaterEqual(input1: Tensor, input2: Tensor): Tensor
public func greaterEqual(input1: Tensor, input2: Float16): Tensor
public func greaterEqual(input1: Float16, input2: Tensor): Tensor
public func greaterEqual(input1: Tensor, input2: Float32): Tensor
public func greaterEqual(input1: Float32, input2: Tensor): Tensor
public func greaterEqual(input1: Tensor, input2: Float64): Tensor
public func greaterEqual(input1: Float64, input2: Tensor): Tensor
public func greaterEqual(input1: Tensor, input2: Int32): Tensor
public func greaterEqual(input1: Int32, input2: Tensor): Tensor
函数 greaterEqual 实现 GreaterEqual 算子功能,用于对输入 Tensor 进行 element-wise 的比较,第一个 Tensor 位置上元素大于等于第二个 Tensor 对应的元素则返回 Tensor 上对应位置为 true,否则为 false。
两个入参至少有一个是 Tensor。当两个都是 Tensor 时需要保证 shape 可以进行 broadcast。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32 类型的标量或者 Tensor; Ascend 支持 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
| input2 | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32 类型的标量或者 Tensor; Ascend 支持 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,Bool 类型,shape 跟 input1 和 input2 相同(或者跟两者 broadcasting 之后相同)。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointGreaterEqual(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = Tensor(Array<Float32>([2.0, -3.0, -1.4, 7.0, 6.0]), shape: Array<Int64>([5]))
let input2 = Tensor(Array<Float32>([3.5, -4.0, -0.4, -5.0, 6.0]), shape: Array<Int64>([5]))
let output = greaterEqual(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Bool, value=
[false true false true true])
hardsigmoid
public func hardsigmoid(input: Tensor) : Tensor
Hard sigmoid 的激活函数
Hard sigmoid 定义为:
$$ \text{hsigmoid}(x_{i}) = max(0, min(1, \frac{x_{i} + 3}{6})) $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, 支持 Float32 类型 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 与输入 的 shape 和 dtype 相同 |
支持平台:Ascend, GPU, CPU
反向函数:
public func hardsigmoidGrad(input1: Tensor, input2: Tensor)
微分伴随函数:
public func adjointHardsigmoid(input: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([-1.0, -2.0, 0.0, 2.0, 1.0]), shape: Array<Int64>([5]))
let output = hardsigmoid(input)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[3.33333343e-01 1.66666672e-01 5.00000000e-01 8.33333313e-01 6.66666687e-01])
hardswish
public func hardswish(input: Tensor): Tensor
Hard swish 的激活函数:
Hard swish 定义为:
$$ \text{hardswish}(x_{i}) = x_{i} * \frac{ReLU6(x_{i} + 3)}{6} $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, 支持 Float32 类型 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 与输入 的 shape 和 dtype 相同 |
支持平台:Ascend, GPU, CPU
反向函数:
public func hardswishGrad(input1: Tensor, input2: Tensor)
微分伴随函数:
public func adjointHardswish(input: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([-1.0, -2.0, 0.0, 2.0, 1.0]), shape: Array<Int64>([5]))
let output = hardswish(input)
print(output)
return 0
}
代码示例:
Tensor(shape=[5], dtype=Float32, value=
[-3.33333343e-01 -3.33333343e-01 0.00000000e+00 1.66666663e+00 6.66666687e-01])
inTopK
public func inTopK(x1: Tensor, x2: Tensor, k: Int64): Tensor
给定一份样本 x1(Tensor),再给定一组索引 x2(Tensor), 检测索引对应的元素是否在 A 组元素的前 k 大的数中,是返回 true,否返回 false
输入:
| 名称 | 含义 |
|---|---|
| x1 | 一个 2 维 Tensor,表示待检测的样本值。支持 Float32, Float16 类型 |
| x2 | 一个 1 维 Tensor,指定检测索引。x2 的 shape 与 x1_shape[0]相等。支持 Int32 类型。 x2 取值不可为负且必须小于或等于 x1 第二维度的大小, 超出范围未定义。 |
| k | 指定检测的范围 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, shape 与 x2 相同,Bool 类型,如果 x2 下标所表示的 value 在 x1 的前 k 个元素中,返回 true,否则返回 false |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x1 = Tensor(Array<Float32>([1.0, 8.0, 5.0, 2.0, 7.0, 4.0, 9.0, 1.0, 3.0, 5.0]), shape: Array<Int64>([2, 5]))
let x2 = Tensor(Array<Int32>([1, 3]), shape: Array<Int64>([2]))
let output = inTopK(x1, x2, 3)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Bool, value=
[true false])
iou
public func iou(anchorBoxes: Tensor, gtBoxes: Tensor, mode!: String = "iou"): Tensor
计算两个矩形的并交比
IOU 代表两个矩阵的交集在并集上的比例,IOF 代表两个矩阵的交集在正确的矩阵上的比例
$$ \begin{align}\begin{aligned}\text{IOU} = \frac{\text{Area of Overlap}}{\text{Area of Union}}\text{IOF} = \frac{\text{Area of Overlap}}{\text{Area of Ground Truth}}\end{aligned}\end{align} $$
输入:
| 名称 | 含义 |
|---|---|
| anchorBoxes | 待检测矩阵(Tensor) ,shape 为 (N,4) , x, y 代表横纵坐标, "4" 元素分别代表 "x0"(x 轴最小值), "y0"(y 轴最小值), "x1"(x 轴最大值), and "y1"(y 轴最大值)。支持 Float32, Float16 类型 |
| gtBoxes | 真实的有效值矩阵(Ground truth), shape 为(M,4), x, y 代表横纵坐标, "4" 元素分别代表 "x0", "y0", "x1", and "y1"。支持 Float32, Float16 类型 |
| mode | 计算方式。可选值:"iou","iof" 。默认值: "iou" |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, shape 为(M,N), dtype 与 anchorBoxes 相同 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointIou(anchorBoxes: Tensor, gtBoxes: Tensor, mode!: String = "iou")
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let anchorBoxes = Tensor(Array<Float32>([1.0, 1.0, 4.0, 5.0]), shape: Array<Int64>([1, 4]))
let gtBoxes = Tensor(Array<Float32>([3.0, 2.0, 3.0, 6.0]), shape: Array<Int64>([1, 4]))
let output = iou(anchorBoxes, gtBoxes)
print(output)
return 0
}
输出为:
Tensor(shape=[1, 1], dtype=Float32, value=
[[ 1.90476194e-01]])
identity
public func identity(x: Tensor): Tensor
通过拷贝,返回一个跟输入 shape 和内容相同的新的 Tensor。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor 支持 Float16\Float32\Float64\Int32\Int64\Bool。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与输入 x shape 和 dtype 一致。 |
支持平台:GPU
微分伴随函数:
public func adjointIdentity(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = Tensor(Array<Int32>([1, 2, 3, 4]), shape: Array<Int64>([2, 2]))
var out = identity(x)
print(out)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Int32, value=
[[ 1 2]
[ 3 4]])
isFinite
public func isFinite(x: Tensor): Tensor
判断 Tensor 中每个元素是否为 finite,finite 表示有限的数,inf 和 nan 都不是 finite。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,支持 Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与输入 x shape 一致,Bool 类型。 |
支持平台:GPU
微分伴随函数:
public func adjointIsFinite(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = Tensor(Array<Float32>([1.0, 1.0/0.0]), shape: Array<Int64>([2]))
var out = isFinite(x)
print(out)
return 0
}
输出为:
Tensor(shape=[2], dtype=Bool, value=
[true false])
isInf
public func isInf(input: Tensor): Tensor
函数 isInf 实现 IsInf 算子功能,判断输入 Tensor 的每个元素是否为无穷数,返回一个 Bool 类型的 Tensor。
输入:
| 名称 | 含义 |
|---|---|
| input | 输出 Tensor, 可选数据类型:Float32 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 其 shape 与输入 Tensor 一致,数据类型为 Bool 类型 |
支持平台:GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
from std import math.*
main(): Int64
{
let input = Tensor(Array<Float32>([Float32.NaN, 2.0, Float32.Inf]), shape: [3])
let output = isInf(input)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Bool, value=
[false false true])
isNan
public func isNan(input: Tensor): Tensor
函数 isNan 实现 IsNan 算子功能,判断输入 Tensor 的每个元素是否为非数,返回一个 Bool 类型的 Tensor。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, 可选数据类型:Float32 |
输出
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 其 shape 与输入 Tensor 一致,数据类型为 Bool 类型 |
支持平台:GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
from std import math.*
main(): Int64
{
let input = Tensor(Array<Float32>([Float32.NaN, 2.0, Float32.Inf]), shape: [3])
let output = isNan(input)
print(output)
return 0
}
输出:
Tensor(shape=[3], dtype=Bool, value=
[true false false])
indexAdd
public func indexAdd(inputX: Tensor, indice: Tensor, inputY: Tensor, axis: Int64, useLock!: Bool = true, checkIndexBound!: Bool = true): Tensor
函数 indexAdd 实现 IndexAdd 算子功能,把 inputX 中沿 axis 维度 indice 位置的元素分别与对应的 inputY 相加,返回相加后的 Tensor。
输入:
| 名称 | 含义 |
|---|---|
| inputX | 输入 Tensor, 可选数据类型:GPU 支持 Float16、Float32、Float64、Int32,反向不支持 Float16;Ascend 支持 Float32、Int32, 维度大于 0, 必须是 Parameter |
| indice | 索引信息, 可选数据类型:Int32, 必须是 1D 的 Tensor, indice 的值应在 inputX 沿 axis 方向的长度范围内, 即 [0, shapeX[axis]), 超出范围则不进行计算 |
| inputY | 需要相加的 Tensor, 数据类型与 inputX 一致,除 axis 方向外 shape 与 inputX 一致,而在 axis 方向的长度等于 indice 元素的个数 |
| axis | 索引方向,表示沿 inputX 的哪个维度进行索引,数据类型必须是 Int64, 数值范围必须在 InputX 的 rank 之内 |
| useLock | Bool 类型, 是否开启 lock mode 以保护变量 Tensor 的更新过程, 默认值 true |
| checkIndexBound | Bool 类型, 是否进行 index 边界检查, 默认值 true |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 其 shape 和 dtype 与输入 Tensor 一致 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointIndexAdd(inputX: Tensor, indice: Tensor, inputY: Tensor, axis: Int64, useLock!: Bool = true, checkIndexBound!: Bool = true)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let inputX = parameter(Tensor(Array<Int32>([0, 0, 0, 0, 0, 0]), shape: [2, 3]), "inputX")
let indice = parameter(Tensor(Array<Int32>([0]), shape: [1]), "indice")
let inputY = parameter(Tensor(Array<Int32>([1, 2, 3]), shape: [1, 3]), "InputY")
let axis: Int64 = 0
let output = indexAdd(inputX, indice, inputY, axis)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Int32, value=
[[ 1 2 3]
[ 0 0 0]])
invertPermutation
public func invertPermutation(x: Tensor): Tensor
对于是索引的一组排列,交换其索引和值,仅支持动态图。其计算过程如下:
$$ y[x[i]] = i, \quad i \in [0, 1, \ldots, \text{len}(x)-1] $$
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,取值范围是[0, len(x) - 1],不能有重复值。支持 Int32 类型,shape 为 1D。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与输入 x shape 和 dtype 一致。 |
支持平台:GPU
微分伴随函数:
public func adjointInvertPermutation(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = Tensor(Array<Int32>([3, 4, 0, 2, 1]), shape: Array<Int64>([5]))
let out = invertPermutation(x)
print(out)
return 0
}
输出为:
Tensor(shape=[5], dtype=Int32, value=
[2 4 3 0 1])
klDivLoss
public func klDivLoss(logits: Tensor, labels: Tensor, reduction!: String = "mean"): Tensor
计算 logits 和 labels 之间的 Kullback-Leibler 散度
KLDivLoss 算法的更新公式如下:
$$ L = {l_1,\dots,l_N}^\top, \quad l_n = y_n \cdot (\log y_n - x_n)\ Then, \begin{split}\ell(x, y) = \begin{cases} L, & \text{if reduction} = \text{'none';}\ \operatorname{mean}(L), & \text{if reduction} = \text{'mean';}\ \operatorname{sum}(L), & \text{if reduction} = \text{'sum'.} \end{cases}\end{split}\ x 代表 logits. y 代表 labels. ℓ(x,y) 代表 output. $$
输入:
| 名称 | 含义 |
|---|---|
| logits | 输入,支持 Float32 类型 |
| labels | 标签,shape 和 类型 与 logits 相同 |
| reduction | 指定以上公式中 reduction 的类型。GPU 可选值: "none", "mean", "sum"; Ascend 可选值: "none", "batchmean", "sum"。 默认值: "mean". |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出,如果 reduction 为 "none",输出为 shape 和 类型 与 logits 相同 的 Tensor,否则输出为标量 Tensor |
支持平台:Ascend, GPU
反向函数:
public func klDivLossGrad(logits: Tensor, labels: Tensor, gradOut: Tensor, reduction!: String = "mean")
微分伴随函数:
public func adjointKlDivLoss(logits: Tensor, labels: Tensor, reduction!: String = "mean")
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let logits = Tensor(Array<Float32>([0.2, 0.7, 0.1]), shape: Array<Int64>([3]))
let labels = Tensor(Array<Float32>([0.0, 1.0, 0.0]), shape: Array<Int64>([3]))
let output = klDivLoss(logits, labels, reduction: "none")
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[-0.00000000e+00 -6.99999988e-01 -0.00000000e+00])
less
public func less(input1: Tensor, input2: Tensor): Tensor
public func less(input1: Tensor, input2: Float16): Tensor
public func less(input1: Float16, input2: Tensor): Tensor
public func less(input1: Tensor, input2: Float32): Tensor
public func less(input1: Float32, input2: Tensor): Tensor
public func less(input1: Tensor, input2: Float64): Tensor
public func less(input1: Float64, input2: Tensor): Tensor
public func less(input1: Int32, input2: Tensor): Tensor
public func less(input1: Tensor, input2: Int32): Tensor
函数 less 实现 Less 算子功能,用于对输入 Tensor 进行 element-wise 的比较,第一个 Tensor 位置上元素小于第二个 Tensor 对应的元素则返回 Tensor 上对应位置为 true,否则为 false。
两个入参至少有一个是 Tensor。两个都是 Tensor 时需要保证 shape 可以进行 broadcast。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32, Ascend 支持 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
| input2 | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32, Ascend 支持 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 比较计算的结果 Tensor,Bool 类型,shape 跟 input1 和 input2 相同(或者跟两者 broadcasting 之后相同)。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = Tensor(Array<Float32>([9.0, 16.0]), shape: Array<Int64>([2]))
let input2 = Tensor(Array<Float32>([1.0, 26.0]), shape: Array<Int64>([2]))
let output = less(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Bool, value=
[false true])
lessEqual
public func lessEqual(input1: Tensor, input2: Tensor): Tensor
public func lessEqual(input1: Tensor, input2: Float64): Tensor
public func lessEqual(input1: Tensor, input2: Float32): Tensor
public func lessEqual(input1: Tensor, input2: Float16): Tensor
public func lessEqual(input1: Tensor, input2: Int32): Tensor
public func lessEqual(input1: Float64, input2: Tensor): Tensor
public func lessEqual(input1: Float32, input2: Tensor): Tensor
public func lessEqual(input1: Float16, input2: Tensor): Tensor
public func lessEqual(input1: Int32, input2: Tensor): Tensor
函数 lessEqual 实现 LessEqual 算子功能,用于对输入 Tensor 进行 element-wise 的比较,第一个 Tensor 位置上元素小于等于第二个 Tensor 对应的元素则返回 Tensor 上对应位置为 true,否则为 false。
两个入参至少有一个是 Tensor。两个都是 Tensor 时需要保证 shape 可以进行 broadcast。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 输入 Tensor,GPU & CPU 接受 Float16\Float32\Float64\Int32 类型的标量或者 Tensor; Ascend 接受 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
| input2 | 输入 Tensor,GPU & CPU 接受 Float16\Float32\Float64\Int32 类型的标量或者 Tensor; Ascend 接受 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 比较计算的结果 Tensor,Bool 类型,shape 跟 input1 和 input2 相同(或者跟两者 broadcasting 之后相同)。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointLessEqual(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = Tensor(Array<Float32>([9.0, 16.0]), shape: Array<Int64>([2]))
let input2 = Tensor(Array<Float32>([1.0, 26.0]), shape: Array<Int64>([2]))
let output = lessEqual(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Bool, value=
[false true])
logicalAnd
public func logicalAnd(input1: Tensor, input2: Bool): Tensor
public func logicalAnd(input1: Bool, input2: Tensor): Tensor
public func logicalAnd(input1: Tensor, input2: Tensor): Tensor
函数 logicalAnd 实现 LogicalAnd 算子功能,用于计算两个输入的 “逻辑与” 运算。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 输入 Tensor,接收 Bool 类型的标量或者 Tensor,不能同时为标量。 |
| input2 | 输入 Tensor,接收 Bool 类型的标量或者 Tensor,不能同时为标量。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor,Bool 类型,shape 跟 input1 和 input2 相同(或者跟两者 broadcasting 之后相同)。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointLogicalAnd(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = Tensor([true, false, true], shape: Array<Int64>([3]))
let input2 = Tensor([true, true, false], shape: Array<Int64>([3]))
let output = logicalAnd(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Bool, value=
[true false false])
logicalNot
public func logicalNot(input: Tensor): Tensor
函数 logicalNot 实现 LogicalNot 算子功能,用于对输入 Tensor 进行 element-wise 的取反计算。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,支持 Bool 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointLogicalNot(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Bool>([true, false, true, false, false]), shape: Array<Int64>([5]))
let output = logicalNot(input)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Bool, value=
[false true false true true])
logicalOr
public func logicalOr(input1: Bool, input2: Tensor): Tensor
public func logicalOr(input1: Tensor, input2: Tensor): Tensor
public func logicalOr(input1: Tensor, input2: Bool): Tensor
函数 logicalOr 实现 LogicalOr 算子功能,用于计算两个输入的 “逻辑或” 运算。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 输入 Tensor,接收 Bool 类型的标量或者 Tensor,不能同时为标量。 |
| input2 | 输入 Tensor,接收 Bool 类型的标量或者 Tensor,不能同时为标量。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor,Bool 类型,shape 跟 input1 和 input2 相同(或者跟两者 broadcasting 之后相同)。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointLogicalOr(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = Tensor([true, false, true], shape: Array<Int64>([3]))
let input2 = Tensor([true, true, false], shape: Array<Int64>([3]))
let output = logicalOr(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Bool, value=
[true true true])
log
public func log(input: Tensor): Tensor
函数 log 实现 Log 算子功能,用于对输入 Tensor 进行 element-wise 的 log 计算。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64 类型, Ascend 支持 Float16\Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointLog(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([9.0, 16.0]), shape: Array<Int64>([2]))
let output = log(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[2.19722462e+00 2.77258873e+00])
log1p
public func log1p(input: Tensor): Tensor
函数 log1p 实现 Log1p 算子功能,用于对输入 Tensor 进行 element-wise 的计算。计算公式如下:
$$ out_i = {log_e}(x_i + 1) $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,支持 Float16\Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台: Ascend, GPU, CPU
微分伴随函数:
public func adjointLog1p(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([0.5284928083, -0.5617582798, -0.7654479146, -0.3952527642]), shape: Array<Int64>([2, 2]))
let output = log1p(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[4.24282163e-01 -8.24984670e-01]
[-1.45007765e+00 -5.02944708e-01]])
logSoftmax
public func logSoftmax(input: Tensor, axis!: Int64 = -1): Tensor
函数 logSoftmax 实现 LogSoftmax 算子功能。
将 LogSoftmax 函数应用于指定轴上的输入 Tensor。 假设给定 axis 中的一个单维度切片,对于每个 $x_i$,LogSoftmax 函数计算如下所示:
$$ output(x_i)=log({exp(x_i)\over \sum_{j=0}^{N−1}exp(x_j)}), $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,目前只支持 Float32 类型。 |
| axis | 需要计算 softmax 的轴,默认值为 -1,即计算最后一维。 如果 input 的维度数为 rank,那么 axis 的取值范围为 [-rank, rank)。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func logSoftmaxGrad(input1: Tensor, input2: Tensor, axis!: Int64 = -1): Tensor
微分伴随函数:
public func adjointLogSoftmax(input: Tensor, axis!: Int64 = -1)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([9.0, 16.0]), shape: Array<Int64>([2]))
let output = logSoftmax(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[-7.00091171e+00 -9.11712646e-04])
layerNorm
public func layerNorm(input: Tensor, gamma: Tensor, beta: Tensor, beginNormAxis!: Int64 = 1, beginParamsAxis!: Int64 = 1, epsilon!: Float32 = 1e-7): Tensor
函数 layerNorm 实现 LayerNorm 算子功能,用于在本层的各个特征之间,对 batch 中的每一个样本进行激活之前的正则化。 输入之间的限制:设 input 的维度数为 rank,则 beginNormAxis 的取值范围为 [-1, rank),beginParamsAxis 的取值范围为 [-1, rank)。gamma 和 beta 的 shape 必须完全相等,如果 beginParamsAxis 为 1,那么 input 从第二维起,gamma 从第一维起,两者的每一维度的值都应完全相等。
$$ y = {x− \text{mean} \over \sqrt {\text{variance}+ϵ}}∗\gamma+\beta $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,目前只支持 Float32 类型。 |
| gamma | gamma 参数,可跟随网络进行训练,对输出结果进行缩放,目前只支持 Float32 类型。 |
| beta | beta 参数,可跟随网络进行训练,对输出结果进行平移,目前只支持 Float32 类型。 |
| beginNormAxis | 对输入开始执行正则化的维度,value 必须在 [-1, rank(input)) 区间中,默认值为 1。 |
| beginParamsAxis | 对参数开始执行正则化的维度,value 必须在 [-1, rank(input)) 区间中, 默认值为 1。 |
| epsilon: | 为了数值计算稳定而加入的小 number,默认为 0.0000001。 |
输出:
| 名称 | 含义 |
|---|---|
| output | layernorm 计算的结果 Tensor. 与输入 Tensor 具有相同的 shape 和 dtype |
| mean | layernorm 计算的均值 |
| variance | layernorm 计算的方差 |
支持平台:Ascend, GPU, CPU
反向函数:
public func layerNormGrad(input: Tensor, gradOut: Tensor, variance: Tensor, mean: Tensor, gamma: Tensor, beginNormAxis!: Int64 = 1, beginParamsAxis!: Int64 = 1): (Tensor, Tensor, Tensor)
微分伴随函数:
public func adjointLayerNorm(input: Tensor, gamma: Tensor, beta: Tensor, beginNormAxis!: Int64 = 1, beginParamsAxis!: Int64 = 1, epsilon!: Float32 = 1e-7)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = randomNormalTensor(Array<Int64>([2, 2, 3]))
let gamma = onesTensor(Array<Int64>([2, 3]))
let beta = onesTensor(Array<Int64>([2, 3]))
let (output, mean, variance) = layerNorm(input, gamma, beta)
print(output)
print(mean)
print(variance)
return 0
}
输出为:
Tensor(shape=[2, 2, 3], dtype=Float32, value=
[[[ 1.04573095e+00 2.81799555e-01 1.54612660e-02]
[ 1.62202418e-01 2.83852386e+00 1.65628195e+00]]
[[ 1.95735395e+00 5.20567179e-01 2.25229478e+00]
[ 1.56564367e+00 2.58231640e-01 -5.54091096e-01]]])
Tensor(shape=[2, 1, 1], dtype=Float32, value=
[[[-6.47745386e-04]]
[[-3.89819220e-03]]])
Tensor(shape=[2, 1, 1], dtype=Float32, value=
[[[ 1.17331721e-04]]
[[ 3.14546378e-05]]])
linSpace
public func linSpace(start: Tensor, stop: Tensor, num: Int64): Tensor
函数 linSpace 实现 LinSpace 算子功能,用于创建起始值为 start,终止值为 stop 的等差数列。
输入:
| 名称 | 含义 |
|---|---|
| start | 输入 0-D Tensor,仅支持 Float32 类型,表示起始值。 |
| stop | 输入 0-D Tensor,仅支持 Float32 类型,表示终止值。 |
| num | 大于 0 的 Int64 类型,表示起始值与终止值中间的刻度数,包括起始值与终止值。 |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (num) 的一维 Tensor。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointLinSpace(start: Tensor, stop: Tensor, num: Int64)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let start = parameter(Tensor(Array<Float32>([1.0]), shape: []), "start")
let stop = parameter(Tensor(Array<Float32>([10.0]), shape: []), "stop")
let num: Int64 = 5
let output = linSpace(start, stop, num)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[1.00000000e+00 3.25000000e+00 5.50000000e+00 7.75000000e+00 1.00000000e+01])
lrn
public func lrn(input: Tensor, depthRadius!: Int64 = 5, bias!: Float32 = 1.0, alpha!: Float32 = 1.0, beta!: Float32 = 0.5, normRegion!: String = "ACROSS_CHANNELS"): Tensor
函数 lrn 实现 Local Response Normalization 功能,用于数据的归一化。计算过程如下:
$$ b_{c} = a_{c}\left(k + \frac{\alpha}{n} \sum_{c'=\max(0, c-n/2)}^{\min(N-1,c+n/2)}a_{c'}^2\right)^{-\beta} $$
其中,$a_c$表示特征图上 c 对应的像素值;$n/2$表示 depthRadius;$k$表示 bias;$\alpha$表示$alpha$;$\beta$表示 beta。
参数列表:
| 名称 | 含义 |
|---|---|
| depthRadius | 归一化窗口的一半的宽度,需要大于等于 0, 支持 Int64 类型,默认值为 5 |
| bias | 一个偏移量(通常为正数为避免除 0),支持 Float32 类型,默认值 1.0。Ascend 反向仅支持正数 |
| alpha | 一个标量值,支持 Float32 类型,一般为正,默认值为 1.0。Ascend 反向仅支持正数,前向支持非负数 |
| beta | 指数值,支持 Float32 类型,默认值为 0.5 |
| normRegion | 特别的归一化区域,String 类型,可选值为“ACROSS_CHANNELS”, 默认值为“ACROSS_CHANNELS” |
输入:
| 名称 | 含义 |
|---|---|
| input | 输入,4-D Tensor,仅支持 Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出,归一化结果,dtype 和 shape 与 input 一致 |
支持平台:Ascend, GPU, CPU
反向函数:
public func lrnGrad(grads: Tensor, x: Tensor, y: Tensor, depthRadius!: Int64 = 5, bias!: Float32 = 1.0, alpha!: Float32 = 1.0, beta!: Float32 = 0.5)
微分伴随函数:
public func adjointLrn(input: Tensor, depthRadius!: Int64 = 5, bias!: Float32 = 1.0, alpha!: Float32 = 1.0, beta!: Float32 = 0.5, normRegion!: String = "ACROSS_CHANNELS")
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = parameter(Tensor(Array<Float32>([0.1, 0.2, 0.3, 0.4]), shape: Array<Int64>([1, 2, 2, 1])), "x")
let res = lrn(x)
print(res)
return 0
}
输出为:
Tensor(shape=[1, 2, 2, 1], dtype=Float32, value=
[[[[ 9.53462496e-02]
[ 1.82574183e-01]]
[[ 2.86038756e-01]
[ 3.65148365e-01]]]])
lstm
public func lstm(x: Tensor, hx: Tensor, cx: Tensor, w: Tensor, inputSize: Int64, hiddenSize: Int64, numLayers: Int64, hasBias: Bool, bidirectional: Bool, dropout: Float32): (Tensor, Tensor, Tensor, Tensor, Tensor)
函数 lstm 实现 LSTM 算子功能,用于对输入执行 Long Short-Term Memory (LSTM) 的计算。
在 LSTM 模型中,有两条时间连续的 pipeline,分别对应两个单元。一条对应 Cell state 单元, 一条对应 Hidden state 单元。 记两个连续的时间节点 $t-1$ 和 $t$,$t$ 时刻的输入记为 $x_t$,$t-1$ 时刻的 layer,其 Hidden state 记为 $h_{t-1}$,Cell state 记为 $c_{t-1}$。 使用门机制来计算 $t$ 时刻的 Hidden state 和 Cell state。输入门 $i_t$ 用于避免输入的扰动,遗忘门 $f_t$ 则保护 Cell 受到上一个时刻 $h_{t-1}$ 过多的影响。 输出门则保护其他单元免受当前非相关记忆内容的扰动。候选 $\tilde{c}_t$ 由输入得到,再和 $i_t$ 一起得到当前的 $c_t$。 $c_t$ 和 $h_t$ 都是用当前时刻的门计算得到的,详见论文: [https://www.bioinf.jku.at/publications/older/2604.pdf https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/43905.pdf](https://www.bioinf.jku.at/publications/older/2604.pdf https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/43905.pdf)
输入:
| 名称 | 含义 |
|---|---|
| x | 输入的 Tensor,只接受 Float32 类型的 Tensor。 |
| hx | 初始的隐状态,通常为 0,shape 为 (numDirections * numLayers, batchSize, hiddenSize)。只接受 Float32 类型的 Tensor。 |
| cx | 初始 Cell state,通常为 0,shape 为(numDirections * numLayers, batchSize, hiddenSize),只接受 Float32 类型的 Tensor。 |
| w | 权重,即 LSTM 中的各种门的权重矩阵按顺序合并在一个 Tensor 中。只接受 Float32 类型的 Tensor。 |
| inputSize | 类型为 Int64,输入的特征数。 |
| hiddenSize | 类型为 Int64,隐藏层的特征数。 |
| numLayers | 类型为 Int64,LSTM 堆叠层数,默认为 1。 |
| hasBias | 类型为 Bool,是否使用 bias。 |
| bidirectional | 类型为 Bool,是否使用双向 LSTM。 |
| dropout | 类型为 Float32,每一层 lstm 的网络之后的 dropout (最后一层除外),默认为 0.0,取值范围为 [0.0, 1.0)。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出,Float32 类型的 Tensor。shape 为 (seqLen, batchSize, numDirections * hiddenSize)。 |
| hN | 最后一个时刻的隐状态,Float32 类型的 Tensor。shape 为 (numDirections * numLayers, batchSize, hiddenSize)。 |
| cN | 最后一个时刻的 Cell 状态,Float32 类型的 Tensor。shape 为 (numDirections * numLayers, batchSize, hiddenSize)。 |
| reserve | Float32 类型的 Tensor。shape 为 (r,1) ,供反向计算使用。 |
| state | 随机数生成状态,Float32 类型的 Tensor。shape 为 (1, 1),供反向计算使用。 |
反向函数:
public func lstmGradWeight(x: Tensor, hx: Tensor, y: Tensor, reserve: Tensor, state: Tensor, inputSize: Int64, hiddenSize: Int64, numLayers: Int64, hasBias: Bool, bidirectional: Bool, dropout: Float32): Tensor
public func lstmGradData(y: Tensor, dy: Tensor, dhy: Tensor, dcy: Tensor, w: Tensor, hx: Tensor, cx: Tensor, reserve: Tensor, state: Tensor, inputSize: Int64, hiddenSize: Int64, numLayers: Int64, hasBias: Bool, bidirectional: Bool, dropout: Float32): Tensor
微分伴随函数:
public func adjointLstm(x: Tensor, hx: Tensor, cx: Tensor, w: Tensor, inputSize: Int64, hiddenSize: Int64, numLayers: Int64, hasBias: Bool, bidirectional: Bool, dropout: Float32)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let inputSize = 10
let hiddenSize = 2
let numLayers = 1
let seqLen = 5
let batchSize = 2
let input = randomNormalTensor([seqLen, batchSize, inputSize])
let h0 = randomNormalTensor([numLayers, batchSize, hiddenSize])
let c0 = randomNormalTensor([numLayers, batchSize, hiddenSize])
let w = randomNormalTensor(Array<Int64>([112, 1, 1]))
let (output, hn, cn, reverse, state) = lstm(input, h0, c0, w, inputSize, hiddenSize, numLayers, true, false, 0.0)
print(output)
return 0
}
输出为:
Tensor(shape=[5, 2, 2], dtype=Float32, value=
[[[5.71691152e-03 -2.18112604e-03]
[5.49678551e-03 -6.48714742e-03]]
[[6.91998517e-03 -4.01305873e-03]
[6.87390612e-03 -5.91153279e-03]]
[[7.69769028e-03 -4.71466361e-03]
[7.68993190e-03 -5.57636376e-03]]
[[8.00751708e-03 -5.03855059e-03]
[8.05460289e-03 -5.63370017e-03]]
[[8.17715563e-03 -5.22785494e-03]
[8.41557886e-03 -5.57166804e-03]]])
l2Normalize
public func l2Normalize(x: Tensor, axis!: Int64 = 0, epsilon!: Float32 = 0.0001): Tensor
public func l2Normalize(x: Tensor, axis: Array<Int64>, epsilon!: Float32 = 0.0001): Tensor
函数 l2Normalize 实现 L2Normalize 算子功能,使用 L2 范数沿维度 axis 标准化。
参数列表:
| 名称 | 含义 |
|---|---|
| axis | 标准化的维度,如果输入 Tensor 的维度数为 rank, 那么 axis 的取值范围为 [-rank, rank), 目前支持 Int64 与 1-D Array<Int64> 类型,默认值:0。 |
| epsilon | 为了数值计算稳定而加入的小 number,支持 Float32 类型,默认为 0.0001。 |
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor, 支持 Float32, Float16 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与 x 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func l2NormalizeGrad(x: Tensor, out: Tensor, dout: Tensor, axis!: Int64, epsilon!: Float32 = 0.0001): Tensor
微分伴随函数:
public func adjointL2Normalize(x: Tensor, axis!: Array<Int64> = [0], epsilon!: Float32 = 0.0001)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = parameter(Tensor(Array<Float32>([-133.8271636963, 134.3088836670, -176.9140930176, 16.7510051727, 19.5274810791]), shape: Array<Int64>([5])), "x")
let output = l2Normalize(x)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[-5.13547182e-01 5.15395701e-01 -6.78888559e-01 6.42801598e-02 7.49345794e-02])
matmul
public func matmul(input_x: Tensor, input_y: Tensor, transpose_a!: Bool = false, transpose_b!: Bool = false): Tensor
函数 matmul 实现 Matmul 算子功能,完成两个二维矩阵相乘运算。
输入:
| 名称 | 含义 |
|---|---|
| input_x | 如果 transpose_a 是 false,shape 是 (N, C) 的二维 Tensor。如果 transpose_a 是 true,则需要 input_x 转置后的 shape 是(N, C)。CPU、GPU 支持 Float16\Float32\Float64 类型, Ascend 支持 Float16\Float32 类型。 |
| input_y | 如果 transpose_b 是 false,shape 是 (C, M) 的二维 Tensor。如果 transpose_b 是 true,则需要 input_y 转置后的 shape 是(C, M)。数据类型必须和 input_x 一致。 |
| transpose_a | 如果取值是 true,就会先对左矩阵做转置后再跟右矩阵相乘。 默认值: false。 |
| transpose_b | 如果取值是 true,就会先对右矩阵做转置后再跟左矩阵相乘。 默认值: false。 |
支持平台:Ascend, GPU, CPU
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (N, M) 的二维 Tensor,取值是 input_x 和 input_y 相乘的结果。 |
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input_x = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let input_y = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let output = matmul(input_x, input_y, transpose_a: true, transpose_b: false)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[1.00000000e+01 1.40000000e+01]
[1.40000000e+01 2.00000000e+01]])
maxPool
public func maxPool(input: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, padMod!: String = "VALID"): Tensor
函数 maxPool 实现 MaxPool 算子功能,在输入的 Tensor 上进行 2D 最大值池化操作。
输入:
| 名称 | 含义 |
|---|---|
| input | Tensor, shape 是(N, C, H, W), 数据类型支持 Float16, Float32。 |
| ksizes | Array<Int64>, 滑窗大小。 长度为 2 的数组,value 必须小于输入 shape 的宽和高并且大于 0。 |
| strides | Array<Int64>, 滑窗跳步。 长度为 2 的数组,value 必须大于 0。 |
| padMod | String, padding 模式,可选值:"VALID", "SAME"。 默认值: "VALID"。 |
| 注:Ascend 平台运行反向,在 ksizes 或 strides shape 值不可过大的;如接近 input 的 shape。 |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (N, C, H_out, W_out) 的 Tensor。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func maxPoolGrad(gradOut: Tensor, input: Tensor, value: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, padding!: String = "VALID"): Tensor
微分伴随函数:
public func adjointMaxPool(input: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, pad_mode: String)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let inputx = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 1, 1, 2]))
let output = maxPool(inputx, Array<Int64>([1, 1]), Array<Int64>([1, 1]))
print(output)
return 0
}
输出为:
Tensor(shape=[2, 1, 1, 2], dtype=Float32, value=
[[[[ 1.00000000e+00 2.00000000e+00]]]
[[[ 3.00000000e+00 4.00000000e+00]]]])
maxPool3D
public func maxPool3D(input: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, padMod!: String = "VALID", padList!: Array<Int64> = [0, 0, 0, 0, 0, 0]): Tensor
函数 maxPool3D 实现 MaxPool3D 算子功能,在输入的 Tensor 上进行 3D 最大值池化操作。
输入:
| 名称 | 含义 |
|---|---|
| input | Tensor, 支持 Float16/Float32 类型, shape 是(N, C, D, H, W)。 |
| ksizes | Array<Int64>, 滑窗大小。 长度为 3 的数组,value 必须大于 0,并且小于等于输入 shape 的深、宽和高加上对应 padList 的值。 |
| strides | Array<Int64>, 滑窗跳步。 长度为 3 的数组,value 必须大于 0。 |
| padMod | String, padding 模式,可选值:"VALID", "SAME", "PAD"。 默认值: "VALID"。 |
| padList | Array<Int64>, padMod 为"PAD"模式时,用于指定 pad 数值,长度为 6 的数组,value 必须大于等于 0,其余模式 value 取值必须为 0。默认值:[0, 0, 0, 0, 0, 0] |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (N, C, D_out, H_out, W_out) 的 Tensor。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointMaxPool3D(input: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, padMod!: String = "VALID", padList!: Array<Int64> = [0, 0, 0, 0, 0, 0])
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let data = parameter(initialize([32, 1, 32, 32, 32], initType: InitType.NORMAL, dtype: FLOAT32), "data")
let out = maxPool3D(data, [2, 2, 2], [2, 2, 2], padMod: "PAD", padList: [1, 1, 1, 1, 1, 1])
print(out.getShape())
return 0
}
输出为:
[32, 1, 17, 17, 17]
makeTuple
public func makeTuple(inputArray: Array<Tensor>): Tensor
public func makeTuple(inputArray: ArrayList<Tensor>): Tensor
函数 makeTuple 实现 MakeTuple 算子功能,用来把多个 Tensor 合并成一个元组。
输入:
| 名称 | 含义 |
|---|---|
| inputArray | 类型为 Tensor 的数组或 ArrayList。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出。 |
支持平台:GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input0 = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let input1 = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let output = makeTuple([input0, input1])
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 1.00000000e+00 2.00000000e+00]
[ 3.00000000e+00 4.00000000e+00]])
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 1.00000000e+00 2.00000000e+00]
[ 3.00000000e+00 4.00000000e+00]])
matrixInverse
public func matrixInverse(input: Tensor, adjoint!: Bool = false): Tensor
函数 matrixInverse 实现 MatrixInverse 算子功能,返回输入 Tensor 的逆, 如果输入 Tensor 不可逆,将会报错或返回未知结果
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, 可选数据类型:Float32\Float64, 维度必须大于 2,并且最后两个维度的长度相等 |
| adjoint | Bool 类型,表示是否支持复数,当前还未支持,默认 false |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 形状和数据类型与 input 一致 |
支持平台: GPU, CPU
微分伴随函数:
public func adjointMatrixInverse(input: Tensor, adjoint!: Bool = false)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 5.0, 6.0]), shape: [2, 2])
let output = matrixInverse(input)
print(output)
return 0
}
输出:
Tensor(shape=[2, 2], dtype=Float32, value=
[[-1.50000000e+00 5.00000000e-01]
[ 1.25000000e+00 -2.50000000e-01]])
maxPoolWithArgmax
public func maxPoolWithArgmax(input: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, padMod!: String = "VALID"): Tensor
函数 maxPoolWithArgmax 实现 MaxPoolWithArgmax 算子功能,用于计算最大值池化运算。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,shape 是 (N, Cin, Hin, Win),数据类型支持 Float32。 |
| ksizes | Array<Int64>, 滑窗大小。 长度为 2 的数组,value 必须小于输入 shape 的宽和高并且大于 0。 |
| strides | Array<Int64>, 滑窗跳步。 长度为 2 的数组,value 必须大于 0。 |
| padMod | String, padding 模式,可选值:"VALID", "SAME"。 默认值: "VALID"。 |
【注意】:
- same:采用完成方式。 输出的高度和宽度将与输入的高度和宽度相同。 填充的总数将在水平和垂直方向上计算,并在可能的情况下均匀分布在顶部和底部,左侧和右侧。 否则,最后的额外填充将从底部和右侧开始。
- valid:采用丢弃方式。 可能的最大输出高度和宽度将返回,而不会填充。 多余的像素将被丢弃。
输出:
| 名称 | 含义 |
|---|---|
| output | 池化结果,shape 是 (N, Cout, Hout, Wout)的 Tensor。dtype 和输入相同。 |
| mask | 最大值索引,Int32 类型的 Tensor。 |
支持平台:GPU
反向函数:
public func maxPoolGradWithArgmax(input: Tensor, gradOut: Tensor, gradient: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, padding!: String = "VALID"): Tensor
微分伴随函数:
public func adjointMaxPoolWithArgmax(input: Tensor, ksizes: Array<Int64>, strides: Array<Int64>, pad_mode: String)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let inputx = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 1, 1, 2]))
let (output, mask) = maxPoolWithArgmax(inputx, Array<Int64>([1, 1]), Array<Int64>([1, 1]))
print(output)
print(mask)
return 0
}
输出为:
Tensor(shape=[2, 1, 1, 2], dtype=Float32, value=
[[[[ 1.00000000e+00 2.00000000e+00]]]
[[[ 3.00000000e+00 4.00000000e+00]]]])
Tensor(shape=[2, 1, 1, 2], dtype=Int32, value=
[[[[ 0 1]]]
[[[ 0 1]]]])
maximum
public func maximum(input1: Tensor, input2: Tensor): Tensor
public func maximum(input1: Tensor, input2: Float64): Tensor
public func maximum(input1: Tensor, input2: Float32): Tensor
public func maximum(input1: Tensor, input2: Float16): Tensor
public func maximum(input1: Tensor, input2: Int32): Tensor
public func maximum(input1: Float64, input2: Tensor): Tensor
public func maximum(input1: Float32, input2: Tensor): Tensor
public func maximum(input1: Float16, input2: Tensor): Tensor
public func maximum(input1: Int32, input2: Tensor): Tensor
函数 maximum 实现 Maximum 算子功能,用于计算两个 Tensor 取逐个元素最大值。输入必须是两个 Tensor 或者一个 Tensor 和一个标量。当输入是两个 Tensor 时,它们的 dtype 不能同时是 Bool,它们的形状可以被 Broadcast。当输入是一个 Tensor 和一个标量时,这个标量只能是一个常数。 该算子 Float16 类型的精度为 0.01,后续会精度提升到 0.001。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 第一个输入, 支持 Float16\Float32\Float64\Int32 类型, 可以为 Tensor 或者标量, 两个输入不能同时为标量。 |
| input2 | 第二个输入,数据类型与第一个相同, 可以为 Tensor 或者标量, 两个输入不能同时为标量。 |
支持平台:Ascend, GPU, CPU
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor, dtype 与输入一致。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointMaximum(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input0 = Tensor(Array<Float32>([1.0, 5.0, 3.0]), shape: Array<Int64>([3]))
let input1 = Tensor(Array<Float32>([4.0, 2.0, 6.0]), shape: Array<Int64>([3]))
let output = maximum(input0, input1)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[4.00000000e+00 5.00000000e+00 6.00000000e+00])
meshgrid
public func meshgrid(input : Array<Tensor>, indexing!: String = "xy"): Tensor
从给定的坐标张量中构建坐标矩阵
给定 N 个一维的坐标向量,返回一个由 N 个 N-D 坐标张量组成的元组输出,用于在 N-D 网格上计算表达式
输入:
| 名称 | 含义 |
|---|---|
| input | N 个一维 Tensor 对象的数组,数组长度必须大于 1。支持 Float64,Float32, Int32, Int64 类型 Tensor |
| indexing | 输出索引选项。可选项: "xy","ij", 默认值"xy"。在输入 Tensor 长度分别是 M 和 N 的二维情况下,输入为"xy"时输出形状为(N,M), 输入为"ij"时输出形状为(M,N)。在输入 Tensor 长度分别是 M,N 和 P 的情况下,输入为"xy"是输出形状为(N,M,P),输入为"ij"时输出形状为(M,N,P) |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出,N 个 N-D Tensor 类型的 tuple,dtype 与输入相同 |
支持平台: Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Int32>([2, 3]), shape: [2]), "x")
let y = parameter(Tensor(Array<Int32>([2, 3, 4]), shape: [3]), "y")
let z = parameter(Tensor(Array<Int32>([5]), shape: [1]), "z")
let input = Array<Tensor>([x, y, z])
let output = meshgrid(input)
print(output[0])
print(output[1])
print(output[2])
return 0
}
输出为:
Tensor(shape=[3, 2, 1], dtype=Int32, value=
[[[2]
[3]]
[[2]
[3]]
[[2]
[3]]])
Tensor(shape=[3, 2, 1], dtype=Int32, value=
[[[2]
[2]]
[[3]
[3]]
[[4]
[4]]])
Tensor(shape=[3, 2, 1], dtype=Int32, value=
[[[5]
[5]]
[[5]
[5]]
[[5]
[5]]])
minimum
public func minimum(input1: Tensor, input2: Tensor): Tensor
public func minimum(input1: Tensor, input2: Float64): Tensor
public func minimum(input1: Tensor, input2: Float32): Tensor
public func minimum(input1: Tensor, input2: Float16): Tensor
public func minimum(input1: Tensor, input2: Int32): Tensor
public func minimum(input1: Float64, input2: Tensor): Tensor
public func minimum(input1: Float32, input2: Tensor): Tensor
public func minimum(input1: Float16, input2: Tensor): Tensor
public func minimum(input1: Int32, input2: Tensor): Tensor
函数 minimum 实现 Minimum 算子功能,用于计算两个 Tensor 取逐个元素最小值。输入必须是两个 Tensor 或者一个 Tensor 和一个标量。当输入是两个 Tensor 时,它们的 dtype 不能同时是 Bool,它们的形状可以被 Broadcast。当输入是一个 Tensor 和一个标量时,这个标量只能是一个常数。 该算子 Float16 类型的精度为 0.01,后续会精度提升到 0.001。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 第一个输入,支持 Float16\Float32\Float64\Int32 类型,可以为 Tensor 或者标量,两个输入不能同时为标量。 |
| input2 | 第二个输入,数据类型与第一个相同,可以为 Tensor 或者标量,两个输入不能同时为标量。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor,数据类型与输入一致。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointMinimum(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input0 = Tensor(Array<Float32>([1.0, 5.0, 3.0]), shape: Array<Int64>([3]))
let input1 = Tensor(Array<Float32>([4.0, 2.0, 6.0]), shape: Array<Int64>([3]))
let output = minimum(input0, input1)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[1.00000000e+00 2.00000000e+00 3.00000000e+00])
mirrorPad
public func mirrorPad(input: Tensor, paddings: Tensor, mode!: String = "REFLECT") : Tensor
通过 paddings 和 mode 对 input 进行扩充
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, 支持 Int32 和 Float32 类型, 只支持 2, 3, 4 维的输入 |
| paddings | 填充的 Tensor, 只支持 Int64 类型。paddings 的值是一个矩阵,形状是(N,2), N 表示输入 Tensor 的秩,对于第 D 维的 input, paddings[D,0]表示在第 D 维的 input 前扩充 paddings[D,0]个,paddings[D,1]表示在第 D 维的 input 后扩充 paddings[D,1]个。mode 为 REFLECT 时, paddings[D,0] 和 paddings[D,1]必须小于 input_shape[D], mode 为 SYMMETRIC 时, paddings[D,0] 和 paddings[D,1]必须小于等于 input_shape[D] |
| mode | 指定的填充方式,可选项:"REFLECT", "SYMMETRIC" 默认"REFLECT" |
输出
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor。dtype 与输入 input 一致 如果输入 mode 是 "REFLECT", 表示通过采用对称轴的方式复制填充。如果输入是[[1,2,3], [4,5,6], [7,8,9]], paddings 是 [[1,1], [2,2]], 输出是 [[6,5,4,5,6,5,4], [3,2,1,2,3,2,1], [6,5,4,5,6,5,4], [9,8,7,8,9,8,7], [6,5,4,5,6,5,4]]. 如果输入 mode 是"SYMMETRIC", 也表示通过对称轴的方式填充,但不包括对称轴,如果输入是[[1,2,3], [4,5,6], [7,8,9]], paddings 是 [[1,1], [2,2]],输出是 [[2,1,1,2,3,3,2], [2,1,1,2,3,3,2], [5,4,4,5,6,6,5], [8,7,7,8,9,9,8], [8,7,7,8,9,9,8]]. |
支持平台:Ascend, GPU, CPU
反向函数:
public func mirrorPadGrad(input: Tensor, paddings: Tensor, mode!: String = "REFLECT")
微分伴随函数:
public func adjointMirrorPad(input: Tensor, paddings: Tensor, mode!: String = "REFLECT")
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Int32>([1, 2, 3, 4, 5, 6, 7, 8, 9]), shape: Array<Int64>([3, 3]))
let paddings = Tensor(Array<Int64>([1, 1, 1, 1]), shape: Array<Int64>([2, 2]))
let output = mirrorPad(input, paddings)
print(output)
return 0
}
输出为:
Tensor(shape=[5, 5], dtype=Int32, value=
[[5 4 5 6 5]
[2 1 2 3 2]
[5 4 5 6 5]
[8 7 8 9 8]
[5 4 5 6 5]])
mod
public func mod(x: Int32, y: Tensor): Tensor
public func mod(x: Float32, y: Tensor): Tensor
public func mod(x: Tensor, y: Int32): Tensor
public func mod(x: Tensor, y: Float32): Tensor
public func mod(x: Tensor, y: Tensor): Tensor
函数 mod 实现 Mod 算子功能,逐元素计算第一个输入张量除以第二个输入张量的余数,输入 x 和 y 的 shape 需要满足 broadcasting 要求,如果输入是一个 Tensor 和一个标量,那么标量只能是一个常数。
【说明】:
- 该操作输入不能为 0
- 由于运行平台的体系架构不同,该操作结果在 NPU 和 CPU 上结果可能不同
- 如果输入的形状表示为(D1,D2,Dn),则 D1*D2*Dn<=1000000,n<=8。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,数据类型为 number 或 Tensor。 |
| y | 输入 Tensor,数据类型为 number 或 Tensor。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,shape 跟 input1 和 input2 相同(或者跟两者 broadcasting 之后相同)。 |
支持平台:Ascend, GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = parameter(Tensor(Array<Float32>([-189.5108184814, -213.9907989502, -129.7547760010, -256.0727233887, 53.2714538574]), shape: Array<Int64>([1, 5])), "x")
let y = parameter(Tensor(Array<Float32>([-95.8178634644, 19.0195846558, 65.1648788452, -160.8015136719, -76.9250640869]), shape: Array<Int64>([1, 5])), "y")
let output = mod(x, y)
print(output)
return 0
}
输出为:
Tensor(shape=[1, 5], dtype=Float32, value=
[[-9.36929550e+01 -4.77536774e+00 -6.45898972e+01 -9.52712097e+01 5.32714539e+01]])
mul
public func mul(input1: Tensor, input2: Tensor): Tensor
public func mul(input1: Float16, input2: Tensor): Tensor
public func mul(input1: Tensor, input2: Float16): Tensor
public func mul(input1: Float32, input2: Tensor): Tensor
public func mul(input1: Tensor, input2: Float32): Tensor
public func mul(input1: Float64, input2: Tensor): Tensor
public func mul(input1: Tensor, input2: Float64): Tensor
public func mul(input1: Int32, input2: Tensor): Tensor
public func mul(input1: Tensor, input2: Int32): Tensor
函数 mul 实现 Mul 算子功能,完成 Tensor 的 element-wise 相乘运算,输入 input1 和 input2 的 shape 需要满足 broadcasting 要求,如果输入是一个 Tensor 和一个标量,那么标量只能是一个常数。
输入:
| 名称 | 含义 |
|---|---|
| input0 | Tensor 或者 Number,GPU & CPU 支持 Float16\Float32\Float64\Int32 类型,Ascend 支持 Float16\Float32\Int32, dtype 或者类型要求与 input0 一致 |
| input1 | Tensor 或者 Number,GPU & CPU 支持 Float16\Float32\Float64\Int32 类型,Ascend 支持 Float16\Float32\Int32, dtype 或者类型要求与 input0 一致 |
输出:
| 名称 | 含义 |
|---|---|
| output | 相乘后的 Tensor。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let inputx = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let inputy = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let output = mul(inputx, inputy)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 1.00000000e+00 4.00000000e+00]
[ 9.00000000e+00 1.60000000e+01]])
multinomial
public func multinomial(x: Tensor, numSample: Int64, seed!: Int64 = 0, seed2!: Int64 = 0): Tensor
算子 multinomial 输出对输入张量的对应行进行采样的张量,采样的方式服从多项式概率分布。
参数列表:
| 名称 | 含义 |
|---|---|
| seed | 随机种子,必需为非负整数,Int64 类型,默认值为 0。 |
| seed2 | 随机种子,必需为非负整数,Int64 类型,默认值为 0。 |
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor, 包含概率总和的输入张量,支持 Float32 类型,shape 要求 1D 或者 2D。 |
| numSample | 要采样的样本数,支持 Int64 类型, 必须大于 0。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,行与输入 x 的行一致,每行包含 numSample 个采样索引,Int32 类型。 |
支持平台:GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = Tensor(Array<Float32>([0.0, 9.0, 4.0, 0.0]), shape: Array<Int64>([4]))
let numSamples: Int64 = 2
let output = multinomial(x, numSamples, seed: 1, seed2: 1)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Int32, value=
[1 2])
neg
public func neg(input: Tensor): Tensor
函数 neg 实现 Neg 算子功能,用于对输入 Tensor 进行 element-wise 的取负值。
输入:
| 名称 | 含义 |
|---|---|
| input | 正向计算的输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32 类型; Ascend 支持 Float16\Float32\Int32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 正向计算的结果 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointNeg(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([1.0, 5.0, 3.0]), shape: Array<Int64>([3]))
let output = neg(input)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[-1.00000000e+00 -5.00000000e+00 -3.00000000e+00])
nmsWithMask
public func nmsWithMask(bbox: Tensor, iouThreshold!: Float32 = 0.5): Tensor
在计算机视觉领域中进行目标检测问题时,目标检测算法会产生多个边界框。按降序排序选择一些边界框(目前 Ascend 平台不支持降序排序)。使用得分最高的边界框计算其他边界框与当前边界框的重叠部分,并根据一定的阈值(IOU)删除该边界框。iou 计算公式为:
$$ \text{IOU} = \frac{\text{Area of Overlap}}{\text{Area of Union}} $$
参数列表:
| 名称 | 含义 |
|---|---|
| iouThreshold | 指定与 IOU 相关的重叠框的阈值,默认值:0.5。 |
输入:
| 名称 | 含义 |
|---|---|
| bbox | 张量的形状是 (N, 5) ,N 是输入边界框的数目。每个边界框包含 5 个值,前 4 个值是边界框的坐标(x0、y0、x1、y1),表示左上角和右下角的点,最后一个值是该边界框的分数, 支持 Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出由三个张量组成的 tuple ,分别是 selected_box 、selected_idx 和 selected_mask 。 selected_box 形状为 (N,5) ,表示非最大抑制计算后的边界框列表;selected_idx 形状为 (N) ,表示有效输入边界框的索引列表;selected_mask 形状为 (N) ,表示有效输出边界框的掩码列表。 |
支持平台:Ascend, GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = parameter(Tensor(Array<Float32>([1.5246382952, -61.6349449158, -30.6520633698, -30.2967433929, -283.8182678223]), shape: Array<Int64>([1, 5])), "x")
let res = nmsWithMask(x, iouThreshold: 0.5)
print(res)
return 0
}
输出为:
Tensor(shape=[1, 5], dtype=Float32, value=
[[ 1.52463830e+00 -6.16349449e+01 -3.06520634e+01 -3.02967434e+01 -2.83818268e+02]])
Tensor(shape=[1], dtype=Int32, value= [0])
Tensor(shape=[1], dtype=Bool, value= [true])
notEqual
public func notEqual(input1: Tensor, input2: Tensor): Tensor
public func notEqual(input1: Tensor, input2: Float32): Tensor
public func notEqual(input1: Float32, input2: Tensor): Tensor
public func notEqual(input1: Tensor, input2: Float16): Tensor
public func notEqual(input1: Float16, input2: Tensor): Tensor
public func notEqual(input1: Int32, input2: Tensor): Tensor
public func notEqual(input1: Tensor, input2: Int32): Tensor
public func notEqual(input1: Float64, input2: Tensor): Tensor
public func notEqual(input1: Tensor, input2: Float64): Tensor
函数 notEqual 实现 NotEqual 算子功能,用于计算 x!=y 元素的 Bool 值。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32 类型的标量或者 Tensor, Ascend 支持 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
| input2 | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64\Int32 类型的标量或者 Tensor, Ascend 支持 Float16\Float32\Int32 类型的标量或者 Tensor,两个输入必须为同一 dtype 类型,不能同时为标量。 |
输出:
| 名称 | 含义 |
|---|---|
| output | Tensor,与广播后的形状相同,数据类型为 Bool。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointNotEqual(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = Tensor(Array<Float32>([3.0, 2.0, 1.0]), shape: Array<Int64>([3]))
let input2 = Tensor(Array<Float32>([2.0, 2.0, 3.0]), shape: Array<Int64>([3]))
let output = notEqual(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Bool, value=
[true false true])
oneHot
public func oneHot(indices: Tensor, depth: Int64, on_value: Float32, off_value: Float32, axis!: Int64 = -1): Tensor
函数 oneHot 实现 OneHot 算子功能,用于将输入转换成 oneHot 类型的 Tensor 输出。
输入:
| 名称 | 含义 |
|---|---|
| indices | indices 中的元素指示 on_value 的位置,不指示的地方都为 off_value。仅支持 Int32 数据类型的 Tensor。 |
| depth | depth 表示输出 Tensor 的尺寸, Ascend 平台 必须大于等于 1。 |
| on_value | on_value 一般为 1.0,如需标签平滑 (label smoothing),可以设置为比 1 略小的值。 |
| off_value | off_value 一般为 0.0,如需标签平滑 (label smoothing),可以设置为比 0 略大的值。 |
| axis | 将指定维度转变为 onehot。假设 indices 的维度为 [n, c],axis = -1 时,输出的 shape 为[n, c, depth]。axis = 0 时,输出的 shape 为[depth, n, c]。默认为-1。 |
输出:
| 名称 | 含义 |
|---|---|
| output | dtype 是 Float32 的 Tensor,shape 比输入 indices 的维度高一维,高的维度取决于 axis 的值。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointOneHot(indices: Tensor, depth: Int64, on_value: Float32, off_value: Float32, axis!: Int64 = -1)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let data: Array<Int32> = Array<Int32>([0, 1, 2])
let input = Tensor(data, shape: Array<Int64>([3]))
let output = oneHot(input, 3, 1.0, 0.0)
print(output)
return 0
}
输出为:
Tensor(shape=[3, 3], dtype=Float32, value=
[[ 1.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 1.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 1.00000000e+00]])
ones
public func ones(input: Array<Int64>, dtype: Int32): Tensor
public func ones(input: Int64, dtype: Int32): Tensor
根据给定的 shape 和类型创建全 1 张量
输入:
| 名称 | 含义 |
|---|---|
| shape | 给定的 shape, 支持 Array 和 Number |
| dtype | 输出 Tensor 的类型, 支持 Int32, Int64, Float32, Float64, Bool 类型 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出, shape 为输入的 shape,dtype 为输入的 type |
支持平台: Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let output = ones(Array<Int64>([2, 2]), FLOAT32)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 1.00000000e+00 1.00000000e+00]
[ 1.00000000e+00 1.00000000e+00]])
onesLike
public func onesLike(input: Tensor): Tensor
函数 onesLike 用于根据输入 Tensor 的 shape 和 dtype 构造全 1 Tensor。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,其 shape 和 dtype 跟 input 相同。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointOnesLike(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]), shape: Array<Int64>([2, 3]))
let output = onesLike(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[ 1.00000000e+00 1.00000000e+00 1.00000000e+00]])
pad
public func pad(input: Tensor, paddings: Array<Array<Int64>>): Tensor
通过 paaddings 对 input 进行扩充
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, 支持 Int32 和 Float32 类型 |
| paddings | Array<Array<Int64>>类型。paddings 的值是一个矩阵,形状是(N,2), N 表示输入 Tensor 的秩,对于第 D 维的 input, paddings[D,0]表示在第 D 维的 input 前扩充 paddings[D,0]个,paddings[D,1]表示在第 D 维的 input 后扩充 paddings[D,1]个, |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor。dtype 与输入 input 一致。 dtype 为 Int32 类型填充 0, dtype 为 Float32 类型填充 0.0 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointPad(input: Tensor, paddings: Array<Array<Int64>>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Int32>([1, 2, 3, 4, 5, 6]), shape: [2, 3])
var paddings1 = Array<Int64>([1, 1])
var paddings2 = Array<Int64>([1, 1])
var paddings = Array<Array<Int64>>([paddings1, paddings2])
let output = pad(input, paddings)
print(output)
return 0
}
输出为:
Tensor(shape=[4, 5], dtype=Int32, value=
[[ 0 0 0 0 0]
[ 0 1 2 3 0]
[ 0 4 5 6 0]
[ 0 0 0 0 0]])
pow
public func pow(x: Tensor, y: Float16): Tensor
public func pow(x: Tensor, y: Float32): Tensor
public func pow(x: Tensor, y: Float64): Tensor
public func pow(x: Tensor, y: Int32): Tensor
public func pow(x: Tensor, y: Int64): Tensor
public func pow(x: Float16, y: Tensor): Tensor
public func pow(x: Float32, y: Tensor): Tensor
public func pow(x: Float64, y: Tensor): Tensor
public func pow(x: Int32, y: Tensor): Tensor
public func pow(x: Int64, y: Tensor): Tensor
public func pow(x: Tensor, y: Tensor): Tensor
函数 pow 实现 Pow 算子功能,用于计算以 x 为底,y 为指数运算。
输入:
| 名称 | 含义 |
|---|---|
| x | 正向计算的输入 Tensor 或 标量, GPU & CPU 支持 Float16\Float32\Float64\Int32\Int64; 反向仅支持 Float16\Float32\Float64。Ascend 支持 Float16\Float32\Int32; 反向仅支持 Float16\Float32。 |
| y | 正向计算的输入 Tensor 或 标量,与 x 具有相同的数据类型。 |
注意:x, y 的 shape 需要买满足可广播的要求;且 x, y 只能有一个为标量。
输出:
| 名称 | 含义 |
|---|---|
| output | 正向计算的结果 Tensor,与输入 Tensor 具有相同的数据类型。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointPow(x: Tensor, y: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = Tensor(Array<Float32>([9.0, 16.0]), shape: Array<Int64>([2]))
let y = Tensor(Array<Float32>([2.0, 1.0]), shape: Array<Int64>([2]))
let output = pow(x, y)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[8.10000000e+01 1.60000000e+01])
prelu
public func prelu(input: Tensor, weight: Tensor): Tensor
函数 prelu 实现 PReLU 算子功能,实现 PReLU 函数。
$$ prelu(x_i)= \max(0, x_i) + \min(0, w * x_i) $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,dtype 为 Float16\Float32,shpae 为任意数量的附加维度。(N,C,*)。Ascend 不支持 0-D 或 1-D Tensor |
| weight | 第二个输入 Tensor,dtype 为 Float32。 只有两个 shape 是合法的,1 或 input_x 的通道数。 通道指是 input 的第二个维度。 当 input 为 0-D 或 1-D 张量时,通道数为 1。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,shape 与 dtype 和 input 一致。 |
支持平台:Ascend, GPU
反向函数:
public func preluGrad(gradOut: Tensor, input: Tensor, weight: Tensor): Tensor
微分伴随函数:
public func adjointPrelu(input: Tensor, weight: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = parameter(Tensor(Array<Float32>([-6.0000000000, -5.0000000000, -4.0000000000, -3.0000000000, -2.0000000000, -1.0000000000, 0.0000000000, 1.0000000000, 2.0000000000, 3.0000000000, 4.0000000000, 5.0000000000]), shape: Array<Int64>([2, 3, 2])), "x")
let weight = parameter(Tensor(Array<Float32>([0.1000000015, 0.6000000238, -0.3000000119]), shape: Array<Int64>([3])), "y")
let output = prelu(input, weight)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3, 2], dtype=Float32, value=
[[[-6.00000024e-01 -5.00000000e-01]
[-2.40000010e+00 -1.80000007e+00]
[ 6.00000024e-01 3.00000012e-01]]
[[ 0.00000000e+00 1.00000000e+00]
[ 2.00000000e+00 3.00000000e+00]
[ 4.00000000e+00 5.00000000e+00]]])
randomCategorical
public func randomCategorical(logits: Tensor, numSample: Int64, seed!: Int64 = 0, dtype!: Int32 = INT64): Tensor
算子 randomCategorical 输出对输入张量的对应行进行采样的张量,采样的方式服从分类分布。
参数列表:
| 名称 | 含义 |
|---|---|
| dtype | 用于指定输出 Tensor 的数据类型,支持 INT64 和 INT32,默认值为 INT64。 |
输入:
| 名称 | 含义 |
|---|---|
| logits | 输入 Tensor, 包含概率总和的输入张量,GPU 支持 Float16\Float32\Float64, Ascend 支持 Float16\Float32 shape 要求 2D。 |
| numSample | 要采样的样本数,支持 Int64 类型, 必须是正整数。 |
| seed | 随机种子,必需为非负整数,Int64 类型,默认值为 0。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,行与输入 x 的行一致,每行包含 numSample 个采样索引,由输入 dtype 指定数据类型。 |
支持平台:Ascend, GPU
代码示例:
from CangjieTB import ops.*
from CangjieTB import common.*
main(): Int64 {
let x = Tensor(Array<Float32>([0.0, 9.0, 4.0, 0.0]), shape: Array<Int64>([2, 2]))
let numSamples: Int64 = 2
let res = randomCategorical(x, numSamples, seed: Int64(1), dtype: INT32)
print(res)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Int32, value=
[[ 1 1]
[ 0 0]])
randomChoiceWithMask
public func randomChoiceWithMask(inputX: Tensor, count!: Int64 = 256, seed!: Int64 = 0, seed2!: Int64 = 0): (Tensor, Tensor)
randomChoiceWithMask 输出对输入张量的对应行进行采样的索引张量以及一个掩码张量。
参数列表:
| 名称 | 含义 |
|---|---|
| count | 要采样的样本数,采样数>0,支持 Int64 类型,默认值为 256。 |
| seed | 随机种子,必需为非负整数,Int64 类型,默认值为 0。 |
| seed2 | 随机种子,必需为非负整数,Int64 类型,默认值为 0。 |
输入:
| 名称 | 含义 |
|---|---|
| inputX | 输入 Tensor, shape 必须>=1D,并且<=5D,支持 Bool 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| index | 输出 Tensor,shape 为 2D,行与输入 x 的 dims 一致,每行包含 count 个采样索引,Int32 类型。 |
| mask | 输出 Tensor,shape 为 1D,对应 count 个采样索引的掩码,Bool 类型。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = Tensor(Array<Bool>([true, true, false, false]), shape: Array<Int64>([2, 2]))
let count: Int64 = 2
let seed: Int64 = 1
let seed2: Int64 = 3
let (res0, res1) = randomChoiceWithMask(x, count: count, seed: seed, seed2: seed2)
print(res0)
print(res1)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Int32, value=
[[ 0 1]
[ 0 0]])
Tensor(shape=[2], dtype=Bool, value=
[true true])
rank
public func rank(input: Tensor): Int64
返回给定 Tensor 的秩
返回一个 0-D Int64 类型数字来表示输入 Tensor 的 rank,
输入:
| 名称 | 含义 |
|---|---|
| input | Tensor, 支持所有类型 |
输出:
| 名称 | 含义 |
|---|---|
| output | Int64 类型,表示输入 Tensor 的秩 |
支持平台: Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = onesTensor(Array<Int64>([1, 2, 3, 4, 5]))
let output = rank(input)
print("${output}\n")
return 0
}
输出为:
5
randperm
public func randperm(n: Tensor, maxLength!: Int32 = 1, pad!: Int32 = -1, dtype!: Int32 = INT32): Tensor
根据 n(Tensor 类型)指定的元素个数 N,构建 N 个从 0 到 N-1 的不重复的随机样本,如果给定的 maxLength > N,最后 maxLength-N 个元素使用 pad 代替
输入:
| 名称 | 含义 |
|---|---|
| n | shape 为(1,)的张量,其唯一的值必须在[0, max_length]之间,支持 Int32 类型 |
| maxLength | 期望获得向量的长度,该值必须大于 0,默认值:1 |
| pad | 填充值,默认值:-1 |
| dtype | 返回 Tensor 的类型,可选项:Int32, Int64, UInt32 默认值:Int32 |
【注意】: UInt32 取值范围为[0,4294967295], 当 dtype 为 UInt32, pad 输入在取值范围外时, pad 被 UInt32 最大值(4294967295)代替。
支持平台: Ascend, GPU
输出:
| 名称 | 含义 |
|---|---|
| output | 输出, shape 为(maxLength,), dtype 为输入 dtype 的张量 |
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let n = Tensor(Array<Int32>([1]), shape: Array<Int64>([1]))
let output = randperm(n, maxLength: 5)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Int32, value=
[0 -1 -1 -1 -1])
realDiv
public func realDiv(input1: Tensor, input2: Tensor): Tensor
public func realDiv(input1: Tensor, input2: Float16): Tensor
public func realDiv(input1: Float16, input2: Tensor): Tensor
public func realDiv(input1: Tensor, input2: Float32): Tensor
public func realDiv(input1: Float32, input2: Tensor): Tensor
public func realDiv(input1: Tensor, input2: Float64): Tensor
public func realDiv(input1: Float64, input2: Tensor): Tensor
public func realDiv(input1: Tensor, input2: Int32): Tensor
public func realDiv(input1: Int32, input2: Tensor): Tensor
函数 realDiv 实现 RealDiv 算子功能,用于计算第一个输入与第二个输入逐个元素相除,数据类型可以是浮点类型或整型。输入可以是 Tensor 或者标量,但不能同时为标量。当输入为两个 Tensor 时,其 shape 必须可以进行 broadcast。两个输入的数据类型需一致。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 第一个输入。GPU 支持 Float16\Float32\Float64\Int32 类型的 number 或 tensor; Ascend 支持 Float16\Float32 类型的 number 或 tensor。 |
| input2 | 第二个输入。GPU 支持 Float16\Float32\Float64\Int32 类型的 number 或 tensor; Ascend 支持 Float16\Float32 类型的 number 或 tensor。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 相除的 Tensor,数据类型和形状与输入相同。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = Tensor(Array<Float32>([9.0, 16.0]), shape: Array<Int64>([2]))
let y = Tensor(Array<Float32>([2.0, 1.0]), shape: Array<Int64>([2]))
let output = realDiv(x, y)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[4.50000000e+00 1.60000000e+01])
reduceAll
public func reduceAll(input: Tensor, keepDims!: Bool = false): Tensor
public func reduceAll(input: Tensor, axis: Int64, keepDims!: Bool = false): Tensor
public func reduceAll(input: Tensor, axis: Array<Int64>, keepDims!: Bool = false): Tensor
函数 ReduceAll 实现 ReduceAll 算子功能,用于将指定维度上的元素根据 logical AND 的规则进行降维操作。
输入:
| 名称 | 含义 |
|---|---|
| input | 需要降维的 tensor,只接受 Bool 类型,输入维度要求小于 8。 |
| axis | 需要降维的维度,可以不输入,输入 Int64 类型或输入 Int64 类型数组。如果不输入表示对所有维度取 logicalAND。必须在 [-rank(input),rank(input)) 范围内。 |
| keepDims | 降维后,维度是否保留为 1,true 表示保留,false 表示不保留,默认 false。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 降维后的 Tensor,与 input dtype 相同。 |
【注意】:
- 如果 axis 是空,且 keepDims 为 false,则输出为 0-D Tensor,表示输入 Tensor 中所有元素取 logical AND 的结果。
- 如果 axis 是整型,设置为 2,而 keepDims 为 false,则输出的形状为(x1,x3,...,xR)。
- 如果 axis 是数组,设置为 [2,3],而 keepDims 为 false,则输出的形状为(x1,x4,...,xR)。
支持平台:Ascend, GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Bool>([true, true, true, false, false]), shape: Array<Int64>([5]))
let output = reduceAll(input, 0)
print(output)
return 0
}
输出为:
Tensor(shape=[], dtype=Bool, value= false)
reduceAny
public func reduceAny(input: Tensor, keepDims!: Bool = false): Tensor
public func reduceAny(input: Tensor, axis: Int64, keepDims!: Bool = false): Tensor
public func reduceAny(input: Tensor, axis: Array<Int64>, keepDims!: Bool = false): Tensor
函数 ReduceAny 实现 ReduceAny 算子功能,用于将指定维度上的元素根据 logical OR 的规则进行降维操作。
输入:
| 名称 | 含义 |
|---|---|
| input | 需要降维的 tensor,只接受 Bool 类型,输入维度要求小于 8。 |
| axis | 需要降维的维度,可以不输入,输入 Int64 类型或输入 Int64 类型数组。如果不输入表示对所有维度取 logical OR。必须在 [-rank(input),rank(input)) 范围内。 |
| keepDims | 降维后,维度是否保留为 1,true 表示保留,false 表示不保留,默认 false。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 降维后的 Tensor,与 input dtype 相同。 |
【注意】:
- 如果 axis 是空,且 keepDims 为 false,则输出为 0-D Tensor,表示输入 Tensor 中所有元素取 logical OR 的结果。
- 如果 axis 是整型,设置为 2,而 keepDims 为 false,则输出的形状为(x1,x3,...,xR)。
- 如果 axis 是数组,设置为 [2,3],而 keepDims 为 false,则输出的形状为(x1,x4,...,xR)。
支持平台: Ascend, GPU
微分伴随函数:
public func adjointReduceAny(input: Tensor, axis: Array<Int64>, keepDims!: Bool = false)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Bool>([true, true, true, false, false]), shape: Array<Int64>([5]))
let output = reduceAny(input, 0)
print(output)
return 0
}
输出为:
Tensor(shape=[], dtype=Bool, value= true)
reduceMax
public func reduceMax(input: Tensor, keepDims!: Bool = false): Tensor
public func reduceMax(input: Tensor, axis: Int64, keepDims!: Bool = false): Tensor
public func reduceMax(input: Tensor, axis: Array<Int64>, keepDims!: Bool = false): Tensor
函数 ReduceMax 实现 ReduceMax 算子功能,用于计算输入 Tensor 在指定维度上的最大值。
输入:
| 名称 | 含义 |
|---|---|
| input | 需要降维的 tensor,GPU & CPU 接受 Float16\Float32\Float64 类型; Ascend 接受 Float16\Float32 类型,输入维度要求小于 8。 |
| axis | 需要降维的维度,可以不输入,输入 Int64 类型或输入 Int64 类型数组。如果不输入表示对所有维度取最大值。必须在 [-rank(input),rank(input)) 范围内。 |
| keepDims | 降维后,维度是否保留为 1,true 表示保留,false 表示不保留,默认 false。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 降维后的 Tensor,与 input dtype 相同。 |
支持平台:Ascend, GPU, CPU
【注意】:
- 如果 axis 是空,且 keepDims 为 false,则输出为 0-D Tensor,表示输入 Tensor 中所有元素的最大值。
- 如果 axis 是整型,设置为 2,而 keepDims 为 false,则输出的形状为(x1,x3,...,xR)。
- 如果 axis 是数组,设置为 [2,3],而 keepDims 为 false,则输出的形状为(x1,x4,...,xR)。
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 4]))
let output = reduceMax(input)
print(output)
return 0
}
输出为:
Tensor(shape=[], dtype=Float32, value= 8.00000000e+00)
reduceMean
public func reduceMean(input: Tensor, keepDims!: Bool = false): Tensor
public func reduceMean(input: Tensor, axis: Int64, keepDims!: Bool = false): Tensor
public func reduceMean(input: Tensor, axis: Array<Int64>, keepDims!: Bool = false): Tensor
函数 reduceMean 实现 ReduceMean 算子功能,用于在指定维度上对 Tensor 进行取平均运算。
参数列表:
| 名称 | 含义 |
|---|---|
| input | 需要降维的 Tensor, 接受 Float16\Float32 类型,输入维度要求小于 8。 |
| axis | 需要降维的维度,可以不输入,输入 Int64 类型或输入 Int64 类型数组,如果不输入表示对所有维度取平均。必须在 [-rank(input),rank(input)) 范围内。 |
| keepDims | 降维后,维度是否保留为 1,true 表示保留,false 表示不保留,默认 false。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 降维后的 Tensor,与 input dtype 相同。 |
支持平台:Ascend, GPU, CPU
【注意】:
- 如果 axis 是空,且 keepDims 为 false,则输出为 0-D Tensor,表示输入 Tensor 中所有元素的均值。
- 如果 axis 是整型,设置为 2,而 keepDims 为 false,则输出的形状为(x1,x3,...,xR)。
- 如果 axis 是数组,设置为 [2,3],而 keepDims 为 false,则输出的形状为(x1,x4,...,xR)。
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 4]))
let output = reduceMean(input)
print(output)
return 0
}
输出为:
Tensor(shape=[], dtype=Float32, value= 4.50000000e+00)
reduceMin
public func reduceMin(input: Tensor, keepDims!: Bool = false): Tensor
public func reduceMin(input: Tensor, axis: Int64, keepDims!: Bool = false): Tensor
public func reduceMin(input: Tensor, axis: Array<Int64>, keepDims!: Bool = false): Tensor
函数 ReduceMin 实现 ReduceMin 算子功能,用于计算输入 Tensor 在指定维度上的最小值。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,接受 Float16\Float32 类型,输入维度要求小于 8。 |
| axis | 需要降维的维度,可以不输入,输入 Int64 类型或输入 Int64 类型数组。如果不输入表示对所有维度取最小值。必须在 [-rank(input),rank(input)) 范围内。 |
| keepDims | 降维后,维度是否保留为 1,true 表示保留,false 表示不保留,默认 false。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出的 Tensor,与 input dtype 相同。 |
【注意】:
- 如果 axis 是空,且 keepDims 为 false,则输出为 0-D Tensor,表示输入 Tensor 中所有元素的最小值。
- 如果 axis 是整型,设置为 2,而 keepDims 为 false,则输出的形状为(x1, x3, ..., xR)。
- 如果 axis 是数组,设置为 [2, 3],而 keepDims 为 false,则输出的形状为(x1, x4, ..., xR)。
支持平台:Ascend, GPU
微分伴随函数:
public func adjointReduceMin(input: Tensor, axis: Array<Int64>, keepDims!: Bool = false)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = Tensor(Array<Float32>([-0.9895743132, -2.3158619404, -1.8102313280, 0.3145818710, -2.8364603519, -0.1768671125]), shape: Array<Int64>([2, 3, 1, 1]))
let output = reduceMin(x, 1, keepDims: true)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 1, 1, 1], dtype=Float32, value=
[[[[-2.31586194e+00]]]
[[[-2.83646035e+00]]]])
reduceProd
public func reduceProd(input: Tensor, keepDims!: Bool = false): Tensor
public func reduceProd(input: Tensor, axis: Int64, keepDims!: Bool = false): Tensor
public func reduceProd(input: Tensor, axis: Array<Int64>, keepDims!: Bool = false): Tensor
函数 reduceProd 实现 ReduceProd 算子功能,用于计算输入 Tensor 在指定维度上的乘积。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,接受 Float16\Float32 类型,输入维度要求小于 8。 |
| axis | 需要降维的维度,可以不输入,输入 Int64 类型或输入 Int64 类型数组。如果不输入表示对所有维度取最小值。必须在 [-rank(input),rank(input)) 范围内。 |
| keepDims | 降维后,维度是否保留为 1,true 表示保留,false 表示不保留,默认 false。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出的 Tensor,与 input dtype 相同。 |
【注意】:
- 如果 axis 是空,且 keepDims 为 false,则输出为 0-D Tensor,表示输入 Tensor 中所有元素的乘积。
- 如果 axis 是整型,设置为 2,而 keepDims 为 false,则输出的形状为(x1, x3, ..., xR)。
- 如果 axis 是数组,设置为 [2, 3],而 keepDims 为 false,则输出的形状为(x1, x4, ..., xR)。
支持平台:Ascend, GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x = parameter(Tensor(Array<Float32>([-81.2111434937, -117.9023818970, 209.5803375244, -161.2210693359]), shape: Array<Int64>([2, 2])), "x")
let output = reduceProd(x, 1, keepDims: true)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 1], dtype=Float32, value=
[[9.57498730e+03]
[-3.37887656e+04]])
reduceScatter
public func reduceScatter(input: Tensor, op!: ReduceType = ReduceType.SUM, group!: String = "nccl_world_group"): Tensor
按照输入的 group 方式减少和发散 Tensor
输入:
| 名称 | 含义 |
|---|---|
| input | 输入,支持 Float32 和 Int32 类型 |
| op | 规约类型,支持四种输入,分别是 ReduceType.SUM、ReduceType.MAX、ReduceType.MIN, ReduceType.PROD。默认为 ReduceType.SUM。 ReduceScatter 在微分时只支持 ReduceType.SUM 类型 |
| group | 通信组类型,GPU 设备支持输入 "nccl_world_group"。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointReduceScatter(input: Tensor, op!: ReduceType = ReduceType.SUM, group!: String = "nccl_world_group")
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import context.*
main(): Int64
{
g_context.setBackend("nccl")
let x = onesTensor(Array<Int64>([3, 3]))
let output = reduceScatter(x, op: ReduceType.SUM, group: "nccl_world_group")
print(output)
return 0
}
输出为(单 gpu):
Tensor(shape=[3, 3], dtype=Float32, value=
[[ 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[ 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[ 1.00000000e+00 1.00000000e+00 1.00000000e+00]])
reduceSum
public func reduceSum(input: Tensor, keepDims!: Bool = false): Tensor
public func reduceSum(input: Tensor, axis: Int64, keepDims!: Bool = false): Tensor
public func reduceSum(input: Tensor, axis: Array<Int64>, keepDims!: Bool = false): Tensor
函数 reduceSum 实现 ReduceSum 算子功能,用于在指定维度上对 Tensor 进行求和运算。
参数列表:
| 名称 | 含义 |
|---|---|
| input | 需要降维的 Tensor,GPU & CPU 接受 Float16\Float32\Float64 类型; Ascend 接受 Float16\Float32 类型。输入维度要求小于 8。 |
| axis | 需要降维的维度,可以不输入,输入 Int64 类型或输入 Int64 类型数组,如果不输入表示对所有维度取和。必须在 [-rank(input),rank(input)) 范围内。 |
| keepDims | 降维后,维度是否保留为 1,true 表示保留,false 表示不保留,默认 false。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 降维后的 Tensor,与 input dtype 相同。 |
支持平台:Ascend, GPU, CPU
【注意】:
- 如果 axis 是空,且 keepDims 为 false,则输出为 0-D Tensor,表示输入 Tensor 中所有元素的和。
- 如果 axis 是整型,设置为 2,而 keepDims 为 false,则输出的形状为(x1,x3,...,xR)。
- 如果 axis 是数组,设置为 [2,3],而 keepDims 为 false,则输出的形状为(x1,x4,...,xR)。
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 4]))
let output = reduceSum(input)
print(output)
return 0
}
输出为:
Tensor(shape=[], dtype=Float32, value= 3.60000000e+01)
relu
public func relu(input: Tensor): Tensor
函数 relu 实现 ReLU 激活函数功能,即实现 max(0, input) 运算,并返回计算结果。
参数列表:
| 名称 | 含义 |
|---|---|
| input | 接受 Float16\Float32 类型的 Tensor 输入。 |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 与 input 一致的 Tensor。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func reluGrad(gradOut: Tensor, out: Tensor): Tensor
微分伴随函数:
public func adjointRelu(input: Tensor)
二阶伴随函数:
public func adjointReluGrad(gradOut: Tensor, out: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, -4.0, 5.0, -6.0, 7.0, -8.0]), shape: Array<Int64>([2, 4]))
let output = relu(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 4], dtype=Float32, value=
[[ 1.00000000e+00 2.00000000e+00 3.00000000e+00 0.00000000e+00]
[ 5.00000000e+00 0.00000000e+00 7.00000000e+00 0.00000000e+00]])
reshape
public func reshape(input: Tensor, shape: Array<Int64>): Tensor
函数 reshape 实现 Reshape 算子功能,基于给定的 shape,使用相同的值重新排布输入张量。
参数列表:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,shape 是 $${x_1, x_2, ..., x_R}$$, dtype 支持 Float32\Float64\Int32\Bool, Ascend 支持 Float32\Int32\Bool。 |
| shape | 调整后的 shape $${y_1, y_2, ..., y_S}$$, 只能是常量。 如果它有几个 - 1;或者如果其元素的乘积小于或等于 0,或者不能被输入张量形状的乘积整除,或者它与输入的数组大小不匹配, 则报错。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor。 |
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 4]))
let output = reshape(input, Array<Int64>([2, 2, 2]))
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2, 2], dtype=Float32, value=
[[[ 1.00000000e+00 2.00000000e+00]
[ 3.00000000e+00 4.00000000e+00]]
[[ 5.00000000e+00 6.00000000e+00]
[ 7.00000000e+00 8.00000000e+00]]])
resizeNearestNeighbor
public func resizeNearestNeighbor(input: Tensor, size: Array<Int64>, alignCorners!: Bool = false): Tensor
根据最近邻算法调整输入 Tensor 大小
根据最近邻算法调整输入 Tensor 到指定的 size 大小。最近邻算法仅考虑最近的 point 的值,完全忽略其它的邻居 point,并生产一个分段的 interpolant。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, shape 分别代表(N,C,H,W)(N: batch; C: channel; H: height; W: width),GPU 支持 Float32, Int32, Ascend 支持 Float32 |
| alignCorners | output 是否与 input 的角落元素对齐, 默认值:false (alignCorners 为 true 和 false 的具体差别可参考代码示例 1,代码示例 2) |
| size | 目标调整的大小,必须为 2 维数组 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 类型与 input 相同,shape 为(N, C, size[0], size[1]) |
支持平台: Ascend, GPU, CPU
反向函数:
public func resizeNearestNeighborGrad(gradOut: Tensor, size: Array<Int64>, alignCorners!: Bool = false): Tensor
微分伴随函数:
public func adjointResizeNearestNeighbor(input: Tensor, size: Array<Int64>, alignCorners!: Bool = false)
代码示例:
代码示例 1:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Int32>([1, 2, 3, 4, 5, 6, 7, 8, 9]), shape: [1, 1, 3, 3])
let output = resizeNearestNeighbor(input, Array<Int64>([2, 2]))
print(output)
return 0
}
输出为:
Tensor(shape=[1, 1, 2, 2], dtype=Int32, value=
[[[[ 1 2]
[ 4 5]]]])
代码示例 2:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Int32>([1, 2, 3, 4, 5, 6, 7, 8, 9]), shape: Array<Int64>([1, 1, 3, 3])), "x")
let output = resizeNearestNeighbor(x, Array<Int64>([2, 2]), alignCorners: true)
print(output)
return 0
}
输出为:
Tensor(shape=[1, 1, 2, 2], dtype=Int32, value=
[[[[ 1 3]
[ 7 9]]]])
reverseSequence
public func reverseSequence(input: Tensor, seqLengths: Tensor, seqDim: Int64, batchDim!: Int64 = 0): Tensor
反转可变长度的切片
输入:
| 名称 | 含义 |
|---|---|
| input | Tensor,被反转的 Tensor, 支持所有类型 Tensor |
| seqLengths | Tensor, 必须是 Int32 或者 Int64 类型的一维向量。 最大值必须小于等于 input.shape[seqDim] |
| seqDim | 执行反转的维度,取值范围在[0, len(input)) |
| batchDim | input 执行切片的维度。取值范围在[0, len(input)), 默认值:0 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 与 input 的 shape 和 dtype 相同 |
支持平台: Ascend, GPU, CPU
微分伴随函数:
public func adjointReverseSequence(input: Tensor, seqLengths: Tensor, seqDim: Int64, batchDim!: Int64 = 0)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Int32>([1, 2, 3, 4, 5, 6, 7, 8, 9]), shape: [3, 3])
let seqLengths = Tensor(Array<Int32>([1, 2, 3]), shape: [3])
let output = reverseSequence(input, seqLengths, 1)
print(output)
return 0
}
输出为:
Tensor(shape=[3, 3], dtype=Int32, value=
[[ 1 2 3]
[ 5 4 6]
[ 9 8 7]])
reciprocal
public func reciprocal(input: Tensor): Tensor
函数 reciprocal 实现 Reciprocal 算子功能,用于对输入 Tensor 进行 element-wise 取倒数计算。
输入:
| 名称 | 含义 |
|---|---|
| input | 正向计算的输入 Tensor,支持 Float16\Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 正向计算的结果 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointReciprocal(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 4]))
let output = reciprocal(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 4], dtype=Float32, value=
[[ 1.00000000e+00 5.00000000e-01 3.33333343e-01 2.50000000e-01]
[ 2.00000003e-01 1.66666672e-01 1.42857149e-01 1.25000000e-01]])
round
public func round(input: Tensor): Tensor
函数 round 实现 Round 算子功能,用于对输入 Tensor 进行 element-wise 的取整计算,取整规则为四舍五入。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,支持 Int32 和 Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointRound(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([-0.5889578462, 0.6572893858, 0.9656294584, 0.8302891254, -0.4508400559, 0.1614982486]), shape: Array<Int64>([3, 2]))
let output = round(input)
print(output)
return 0
}
输出为:
Tensor(shape=[3, 2], dtype=Float32, value=
[[-1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00]
[-0.00000000e+00 0.00000000e+00]])
rsqrt
public func rsqrt(input: Tensor): Tensor
函数 rsqrt 实现 Rsqrt 算子功能,用于对输入 Tensor 进行 element-wise 的开方,然后取倒数。
输入:
| 名称 | 含义 |
|---|---|
| input | 正向计算的输入 Tensor,每一个元素必须 >=0,支持 Float16\Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 正向计算的结果 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU
反向函数:
public func rsqrtGrad(out: Tensor, gradOut: Tensor): Tensor
微分伴随函数:
public func adjointRsqrt(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 4]))
let output = rsqrt(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 4], dtype=Float32, value=
[[ 1.00000000e+00 7.07106709e-01 5.77350259e-01 5.00000000e-01]
[ 4.47213560e-01 4.08248276e-01 3.77964467e-01 3.53553355e-01]])
sameTypeShape
public func sameTypeShape(input0: Tensor, input1: Tensor): Tensor
检查输入 Tensor 的 dtype 与 shape 是否相同
输入:
| 名称 | 含义 |
|---|---|
| input0 | 第一个输入 Tensor |
| input1 | 第二个输入 Tensor,与第一个输入的 dtype 和 shape 相同 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 与 input0 的类型和形状相同 |
支持平台: Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input0 = Tensor(Array<Float32>([10.0, 9.0, 8.0, 7.0]), shape: Array<Int64>([2, 2]))
let input1 = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let output = sameTypeShape(input0, input1)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[ 1.00000000e+01 9.00000000e+00]
[ 8.00000000e+00 7.00000000e+00]])
scatterAdd
public func scatterAdd(input: Tensor, indices: Tensor, updates: Tensor, useLocking!: Bool = false): Tensor
通过加法运算更新输入 Tensor
使用给定值通过加法操作更新 Tensor 值以及输入索引。每一次运算结束后 input
$$ \text{input}[\text{indices}[i, ..., j], :] \mathrel{+}= \text{updates}[i, ..., j, :] $$
Note:
这是一个就地更新运算符。因此,input 将在操作完成后更新。
输入:
| 名称 | 含义 |
|---|---|
| input | 将要被更新的 Tensor,必须是 parameter,支持 Float32\Int32 类型, 不支持 scalar Tensor |
| indices | Tensor, 指定要进行计算元素的索引, 必须是 Int32 类型 |
| updates | 与 input 进行相加操作的 Tensor, updates_shape = indices_shape + input_shape[1:], 类型与 input 相同 |
| useLocking | 是否使用锁保护运行任务。默认值:false |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 更新后的 input,与 input 的 shape 和 dtype 相同 |
支持平台: Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(zerosTensor(Array<Int64>([2, 3])), "input")
let indices = Tensor(Array<Int32>([0, 1, 1, 1]), shape: Array<Int64>([2, 2]))
let updates = Tensor(Array<Float32>([1.0, 1.0, 1.0, 3.0, 3.0, 3.0, 7.0, 7.0, 7.0, 9.0, 9.0, 9.0]), shape: Array<Int64>([2, 2, 3]))
let output = scatterAdd(input, indices, updates)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 1.00000000e+00 1.00000000e+00 1.00000000e+00]
[ 1.90000000e+01 1.90000000e+01 1.90000000e+01]])
scatterSub
func scatterSub(input: Tensor, indices: Tensor, updates: Tensor, useLocking!: Bool = false): Tensor
通过减法运算更新输入 Tensor
使用给定值通过减法操作更新 Tensor 值以及输入索引。每一次运算结束后 input
$$ \text{input}[\text{indices}[i, ..., j], :] \mathrel{-}= \text{updates}[i, ..., j, :] $$
Note:
这是一个就地更新运算符。因此,input 将在操作完成后更新。
输入:
| 名称 | 含义 |
|---|---|
| input | 将要被更新的 Tensor,必须是 parameter,支持 Float32\Int32 类型 |
| indices | Tensor, 指定要进行计算元素的索引, 必须是 Int32 类型 |
| updates | 与 input 进行相减操作的 Tensor, updates_shape = indices_shape + input_shape[1:], 类型与 input 相同 |
| useLocking | 是否使用锁保护运行任务。默认值:false |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 更新后的 input,与 input 的 shape 和 dtype 相同 |
支持平台: GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(Tensor(Array<Float32>([0.0000000000, 0.0000000000, 0.0000000000, 1.0000000000, 1.0000000000, 1.0000000000]), shape: Array<Int64>([2, 3])), "input")
let indices = Tensor(Array<Int32>([0, 1]), shape: Array<Int64>([1, 2]))
let updates = Tensor(Array<Float32>([1.0000000000, 1.0000000000, 1.0000000000, 2.0000000000, 2.0000000000, 2.0000000000]), shape: Array<Int64>([1, 2, 3]))
let output = scatterSub(input, indices, updates)
print("input:\n")
print(input)
print("\noutput:\n")
print(output)
return 0
}
输出为:
input:
Tensor(shape=[2, 3], dtype=Float32, value=
[[-1.00000000e+00 -1.00000000e+00 -1.00000000e+00]
[-1.00000000e+00 -1.00000000e+00 -1.00000000e+00]])
output:
Tensor(shape=[2, 3], dtype=Float32, value=
[[-1.00000000e+00 -1.00000000e+00 -1.00000000e+00]
[-1.00000000e+00 -1.00000000e+00 -1.00000000e+00]])
scatterUpdate
public func scatterUpdate(input: Tensor, indices: Tensor, updates: Tensor, useLocking!: Bool = true): Tensor
使用给定值以及输入索引更新输入 Tensor 值。
$$ \text{input}[\text{indices}[i, ..., j], :] = \text{updates}[i, ..., j, :] $$
Note:
这是一个原址更新运算符。因此,input 将在操作完成后更新。
输入:
| 名称 | 含义 |
|---|---|
| input | 将要被更新的 Tensor,必须是 Parameter;GPU 平台支持 Float16,Float32,Int32, Int64 类型, Ascend 平台支持 Float16,Float32 类型 |
| indices | Tensor, 指定要进行计算元素的索引, 必须是 Int32 类型;注意,如果在索引中有重复项,则更新顺序未定义。 |
| updates | 与 input 进行更新操作的 Tensor, updates_shape = indices_shape + input_shape[1:], 类型与 input 相同 |
| useLocking | 是否使用锁保护运行任务。默认值:true |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 更新后的 input,与 input 的 shape 和 dtype 相同 |
支持平台: GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input_x = parameter(Tensor(Array<Float32>([-0.1000000015, 0.3000000119, 3.5999999046, 0.4000000060, 0.5000000000, -3.2000000477]), shape: [2, 3]), "input_x")
let indices = Tensor(Array<Int32>([0, 1]), shape: [2])
let updates = Tensor(Array<Float32>([2.0000000000, 1.2000000477, 1.0000000000, 3.0000000000, 1.2000000477, 1.0000000000]), shape: [2, 3])
let output = scatterUpdate(input_x, indices, updates).evaluate()
print("input:\n", input_x)
print("\noutput:\n", output)
return 0
}
输出为:
input:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 2.00000000e+00 1.20000005e+00 1.00000000e+00]
[ 3.00000000e+00 1.20000005e+00 1.00000000e+00]])
output:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 2.00000000e+00 1.20000005e+00 1.00000000e+00]
[ 3.00000000e+00 1.20000005e+00 1.00000000e+00]])
scatterNdAdd
public func scatterNdAdd(input: Tensor, indices: Tensor, updates: Tensor, useLocking!: Bool = false): Tensor
通过稀疏加法运算更新输入 Tensor
使用给定值通过加法操作更新 Tensor 值以及输入索引。每一次运算结束后输出更新后的值,使我们更方便使用更新后的值
输入:
| 名称 | 含义 |
|---|---|
| input | 将要被更新的 Tensor,必须是 parameter,支持 Float32\Float64\Int32 类型。昇腾平台不支持 Float64 类型 |
| indices | Tensor, 指定要进行计算元素的索引,假设 indices 的 rank 为 Q, Q 满足 Q >= 2。假设 input 的 rank 为 P,indices shape 的最后一个元素为 N, P 和 N 满足,N <= P。indices 只支持 Int32 类型 |
| updates | 与 input 进行相加操作的 Tensor, updates 的 rank 为 Q-1+P-N,shape 为 indices_shape[:-1] + x_shape[indices_shape[-1]:] , 类型与 input 相同 |
| useLocking | 是否使用锁保护运行任务。默认值:false |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 更新后的 input,与 input 的 shape 和 dtype 相同 |
支持平台: Ascend, GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(Tensor(Array<Int32>([1, 2, 3, 4, 5, 6]), shape: Array<Int64>([6])), "input")
let indices = Tensor(Array<Int32>([2, 4, 1, 7]), shape: Array<Int64>([4, 1]))
let updates = Tensor(Array<Int32>([6, 7, 8, 9]), shape: Array<Int64>([4]))
let output = scatterNdAdd(input, indices, updates)
print(output)
return 0
}
输出为:
Tensor(shape=[6], dtype=Int32, value=
[1 10 9 4 12 6])
softplus
public func softplus(input: Tensor): Tensor
SoftPlus 激活函数
SoftPlus 是对 Relu 功能的平滑近似。它可用于限制机器的输出始终为正。计算公式如下所示:
$$ \text{output} = \log(1 + \exp(\text{x})), $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入,支持 Float32 类型 Tensor |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出, 与 input 的 shape 和 dtype 相同 |
支持平台:Ascend, GPU, CPU
反向函数:
public func softplusGrad(x: Tensor, y: Tensor): Tensor
微分伴随函数:
public func adjointSoftplus(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0]), shape: [5]), "x")
let output = softplus(x)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[1.31326163e+00 2.12692809e+00 3.04858732e+00 4.01814985e+00 5.00671530e+00])
spaceToBatch
public func spaceToBatch(input: Tensor, blockSize: Int64, paddings: Array<Array<Int64>>): Tensor
函数 spaceToBatch 实现 SpaceToBatch 算子功能。
将空间尺寸的(h,w)按 blockSize 划分为相应数量的块,输出 Tensor 的 h 和 w 尺寸是划分后的相应块数。在划分之前,如果需要,输入的空间尺寸根据镶嵌零填充。 注意:SpaceToBatch 算子反向现在仅支持 Float32 类型。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor。shape 为 (n,c,h,w)。GPU 平台支持 Float16,Float32,Int32, Int64 类型, Ascend 平台支持 Float16,Float32 类型。 |
| blockSize | 划分块的大小,值大于或等于 2; 类型为 Int64。 |
| paddings | 指定 h 和 w 填充值的位置;类型为数组,其中包含两个子数组,每个子数组包含两个整数,每个整数都必须大于 0,要求 input.shape[i+2]+padding[i][0]+padding[i][1]可被 blockSize 整除。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, dtype 与 input 相同,shape 为 (n′,c′,h′,w′)。 |
$$ n' = n*(blockSize*blockSize) $$
$$ c' = c $$
$$ h' = (h+paddings[0][0]+paddings[0][1])//blockSize $$
$$ w' = (w+paddings[1][0]+paddings[1][1])//blockSize $$
支持平台:Ascend, GPU
微分伴随函数:
public func adjointSpaceToBatch(input: Tensor, blockSize: Int64, paddings: Array<Array<Int64>>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(Tensor(Array<Float32>([1.0000000000, 2.0000000000, 3.0000000000, 4.0000000000]), shape: Array<Int64>([1, 1, 2, 2])), "input")
let output = spaceToBatch(input, 2, [[0, 0], [0, 0]])
print(output)
return 0
}
输出为:
Tensor(shape=[4, 1, 1, 1], dtype=Float32, value=
[[[[ 1.00000000e+00]]]
[[[ 2.00000000e+00]]]
[[[ 3.00000000e+00]]]
[[[ 4.00000000e+00]]]])
spaceToBatchND
public func spaceToBatchND(input: Tensor, blockShape: Array<Int64>, paddings: Array<Array<Int64>>): Tensor
函数 spaceToBatchND 实现 SpaceToBatchND 算子功能。
将空间尺寸的(h,w)按 blockSize 划分为相应数量的块,输出 Tensor 的 h 和 w 尺寸是划分后的相应块数。在划分之前,如果需要,输入的空间尺寸根据镶嵌零填充。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor。shape 为 (n,c,h,w)。支持 Float16,Float32 类型。 |
| blockShape | Int64 类型的数组,分割批次维度的块的数量,取值需大于 1。长度必须等于 2 块形状描述空间维度为分割的个数,取值需大于 1。 |
| paddings | Array<Array<Int64>>类型,2*2 大小 空间维度的填充大小。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, dtype 与 input 相同,shape 为 (n′,c′,h′,w′)。 |
支持平台: Ascend, CPU
微分伴随函数:
public func adjointspaceToBatchND(input: Tensor, blockShape: Array<Int64>, paddings: Array<Array<Int64>>)
$$ n' = n * (blockShape[0] ∗ blockShape[1]) $$
$$ c' = c $$
$$ h' = (h + paddings[0][0] + paddings[0][1])//blockShape $$
$$ w' = (w + paddings[1][0] + paddings[1][1])//blockShape $$
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float16>([1.00000, 2.00000, 3.00000, 4.00000]), shape: Array<Int64>([1, 1, 2, 2]))
let output = spaceToBatchND(input, Array<Int64>([2, 2]), Array<Array<Int64>>([[0, 0], [0, 0]]))
print(output)
return 0
}
输出为:
Tensor(shape=[4, 1, 1, 1], dtype=Float32, value=
[[[[ 1.00000000e+00]]]
[[[ 2.00000000e+00]]]
[[[ 3.00000000e+00]]]
[[[ 4.00000000e+00]]]])
sparseGatherV2
public func sparseGatherV2(input: Tensor, indices: Tensor, axis: Int64): Tensor
函数 SparseGatherV2 实现 SparseGatherV2 算子功能,用于根据轴和索引获取 Tensor 中的某些值。 此算子暂不支持反向。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, dtype 为 Float32。 |
| indices | 索引 Tensor,dtype 为 Int32 必须在 [0,input.shape[axis]) 范围内,若不在范围内,返回值对应位置补 0。 |
| axis | 指定轴, 类型为 Int64, 必须在 [-input.shape.size,input.shape.size) 范围内。 |
| 注:Ascend 平台不支持输出 shape 的 dimension 大于 8 的输出。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor。 |
支持平台: GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input_params = Tensor(Array<Float32>([1.0000000000, 2.0000000000, 7.0000000000, 42.0000000000, 3.0000000000, 4.0000000000, 54.0000000000, 22.0000000000, 2.0000000000, 2.0000000000, 55.0000000000, 3.0000000000]), shape: [3, 4])
let input_indices = Tensor(Array<Int32>([1, 2]), shape: [2])
let axis: Int64 = 1
let output = sparseGatherV2(input_params, input_indices, axis)
print(output)
return 0
}
输出为:
Tensor(shape=[3, 2], dtype=Float32, value=
[[ 2.00000000e+00 7.00000000e+00]
[ 4.00000000e+00 5.40000000e+01]
[ 2.00000000e+00 5.50000000e+01]])
spaceToDepth
public func spaceToDepth(input: Tensor, blockSize: Int64): Tensor
函数 spaceToDepth 实现 SpaceToDepth 算子功能。将空间数据块重新排列为深度。
输出张量的高度维度为 h / blockSize
输出张量的权重维度为 w / blockSize
输出张量的深度为 blockSize ∗ blockSize ∗ c
输入张量的高度和宽度必须能被 blockSize 整除。数据格式为“n,c,h,w”。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor。shape 为 (n,c,h,w)。dtype 为 Float32\Int32\Int64。 |
| blockSize | 划分块的大小,值大于或等于到 2。类型为 Int64 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, dtype 与 input 相同,shape 为 (n, (c ∗ blockSize ∗ 2), h / blockSize, w / blockSize)。 |
支持平台: GPU
微分伴随函数:
public func adjointSpaceToDepth(input: Tensor, blockSize: Int64)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(Tensor(Array<Float32>([0.5003513098, -0.3798691332, -0.3341046572, 0.7740871310, 0.2986998260, 0.7112543583, -0.8665986061, 0.5443865657, -0.9524301291, -0.4871452749, 0.6529405713, 0.8801626563]), shape: Array<Int64>([1, 3, 2, 2])), "input")
let output = spaceToDepth(input, 2)
print(output)
return 0
}
输出为:
Tensor(shape=[1, 12, 1, 1], dtype=Float32, value=
[[[[ 5.00351310e-01]]
[[ 2.98699826e-01]]
[[-9.52430129e-01]]
...
[[ 7.74087131e-01]]
[[ 5.44386566e-01]]
[[ 8.80162656e-01]]]])
resizeBilinear
public func resizeBilinear(input: Tensor, size: (Int64, Int64), alignCorners!: Bool = false, halfPixelCenters!: Bool = false): Tensor
public func resizeBilinear(input: Tensor, size: Array<Int64>, alignCorners!: Bool = false, halfPixelCenters!: Bool = false): Tensor
函数 resizeBilinear 实现 ResizeBilinear 算子功能,使用双线性插值将图像调整为指定大小。。
输入:
| 名称 | 含义 |
|---|---|
| input | 正向计算的输入 Tensor,支持 Float32 类型,必须为 4-D tensor,shape 为 (batch,channels,height,width)。 |
| size | 图像的新 size, 类型:由 2 个 Int64 元素组成的元组或 Array, 每一个元素必须 >=0。 |
| alignCorners | 是否按比例调整图像大小,若为 true,则按比例调整 input,这将精确对齐图像的 4 个角并调整图像大小。 |
| halfPixelCenters | 是否几何中心对齐。如果设置为 True, 那么 alignCorners 应该设置为 False。默认值:False。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出的图像。shape 为 (batch,channels,new_height,new_width),dtype 与 input 相同。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointResizeBilinear(input: Tensor, size: Array<Int64>, alignCorners!: Bool = false, halfPixelCenters!: Bool = false)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = parameter(Tensor(Array<Float32>([1.0000000000, 2.0000000000, 3.0000000000, 4.0000000000, 5.0000000000, 1.0000000000, 2.0000000000, 3.0000000000, 4.0000000000, 5.0000000000]), shape: [1, 1, 2, 5]), "input")
let output = resizeBilinear(input, (5, 5))
print(output)
return 0
}
输出为:
Tensor(shape=[1, 1, 5, 5], dtype=Float32, value=
[[[[ 1.00000000e+00 2.00000000e+00 3.00000000e+00 4.00000000e+00 5.00000000e+00]
[ 1.00000000e+00 2.00000000e+00 3.00000000e+00 4.00000000e+00 5.00000000e+00]
[ 1.00000000e+00 2.00000000e+00 3.00000000e+00 4.00000000e+00 5.00000000e+00]
[ 1.00000000e+00 2.00000000e+00 3.00000000e+00 4.00000000e+00 5.00000000e+00]
[ 1.00000000e+00 2.00000000e+00 3.00000000e+00 4.00000000e+00 5.00000000e+00]]]])
relu6
public func relu6(input: Tensor): Tensor
函数 relu6 实现 ReLU6 算子功能,计算输入 Tensor 的 ReLU(修正线性单元),其上限为 6。公式如下: $$ \rm{ReLU6(x)} = \min{(\max{(0, x)},6)} $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,支持 Float32,Float16 类型 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 与 input 的类型和形状相同 |
支持平台: Ascend, GPU, CPU
反向函数:
public func relu6Grad(gradOut: Tensor, input: Tensor): Tensor
微分伴随函数:
public func adjointRelu6(input: Tensor)
二阶伴随函数:
public func adjointRelu6Grad(gradOut: Tensor, input: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 4]))
let output = relu6(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 4], dtype=Float32, value=
[[ 1.00000000e+00 2.00000000e+00 3.00000000e+00 4.00000000e+00]
[ 5.00000000e+00 6.00000000e+00 6.00000000e+00 6.00000000e+00]])
reverseV2
public func reverseV2(input: Tensor, axis: Array<Int64>): Tensor
反转给定 Tensor 指定维度的元素
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,支持 Float32,Int32,Int64 类型 |
| axis | 被反转维度的索引。索引值在[-dims, dims-1]范围内,dims 表示 input 的维度 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 与 input 的类型和形状相同 |
支持平台: Ascend, GPU
微分伴随函数:
public func adjointReverseV2(input: Tensor, axis: Array<Int64>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Int32>([1, 2, 3, 4, 5, 6, 7, 8]), shape: Array<Int64>([2, 4]))
let output = reverseV2(input, Array<Int64>([1, 0]))
print(output)
return 0
}
输出为:
Tensor(shape=[2, 4], dtype=Int32, value=
[[ 8 7 6 5]
[ 4 3 2 1]])
rint
public func rint(input: Tensor): Tensor
对输入 Tensor 的每一个元素,返回最接近的整数。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,支持 Float32 类型 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 与 input 的类型和形状相同 |
支持平台: Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([-1.6, -0.1, 1.5, 2.0]), shape: Array<Int64>([4]))
let output = rint(input)
print(output)
return 0
}
输出为:
Tensor(shape=[4], dtype=Float32, value=
[-2.00000000e+00 -0.00000000e+00 2.00000000e+00 2.00000000e+00])
roiAlign
public func roiAlign(features: Tensor, rois: Tensor, pooledHeight: Int64, pooledWidth: Int64, spatialScale: Float32, sampleNum!: Int64 = 2, roiEndMode!: Int64 = 1): Tensor
函数 roiAlign 实现 ROIAlign 算子功能,计算感兴趣区域 (RoI) 的 align 运算符。算子通过双线性插值从特征图上附近的网格点计算每个采样点的值。 不对任何涉及 RoI、其 bin 或采样点的坐标执行量化。
输入:
| 名称 | 含义 |
|---|---|
| features | 特征 Tensor,shape 必须为 (N,C,H,W),支持 Float32 类型。 |
| rois | 目标区域 Tensor,shape 为 (rois_n,5)。支持 Float32 类型。 rois_n 表示 RoI 的数量。第二维的大小必须为 5,5 列分别表示 (image_index,top_left_x,top_left_y,bottom_right_x,bottom_right_y)。 |
| pooledHeight | 输出特征高度,类型为 Int64。 |
| pooledWidth | 输出特征宽度,类型为 Int64。 |
| spatialScale | 将原始图像坐标映射到输入特征图坐标的比例因子。假设 RoI 的高度在原始图像中为 ori_h,在输入特征图中为 fea_h,则 spatial_scale 为 fea_h / ori_h。类型为 Float32。 |
| sampleNum | 默认值:2。采样点的数量。类型为 Int64。 |
| roiEndMode | 默认值:1。值必须为 0 或 1。类型为 Int64。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 正向计算结果 Tensor, shape 为 (rois_n,C,pooled_height,pooled_width). |
支持平台: Ascend, GPU
微分伴随函数:
public func adjointRoiAlign(features: Tensor, rois: Tensor, pooledHeight: Int64, pooledWidth: Int64, spatialScale: Float32, sampleNum!: Int64 = 2, roiEndMode!: Int64 = 1)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let features = parameter(Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: [1, 1, 2, 2]), "features")
let rois = parameter(Tensor(Array<Float32>([0.0, 0.2, 0.3, 0.2, 0.3]), shape: [1, 5]), "rois")
let output = roiAlign(features, rois, 2, 2, 0.5, sampleNum: 2)
print(output)
return 0
}
输出为:
Tensor(shape=[1, 1, 2, 2], dtype=Float32, value=
[[[[ 1.77499998e+00 2.02499986e+00]
[ 2.27499986e+00 2.52500010e+00]]]])
squaredDifference
public func squaredDifference(input1: Tensor, input2: Tensor): Tensor
public func squaredDifference(input1: Tensor, input2: Float32): Tensor
public func squaredDifference(input1: Float32, input2: Tensor): Tensor
public func squaredDifference(input1: Tensor, input2: Float16): Tensor
public func squaredDifference(input1: Float16, input2: Tensor): Tensor
public func squaredDifference(input1: Tensor, input2: Int32): Tensor
public func squaredDifference(input1: Int32, input2: Tensor): Tensor
函数 squaredDifference 实现 SquaredDifference 算子功能,用于计算第一个输入与第二个输入逐个元素相减并对结果求平方。输入可以是 Tensor 或者标量,但不能同时为标量。当输入为两个 Tensor 时,其 shape 必须可以进行 broadcast。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 第一个输入。支持 Float16\Float32\Int32 类型的 number 或 tensor,两个输入的 dtype 必须相同。 |
| input2 | 第二个输入。支持 Float16\Float32\Int32 类型的 number 或 tensor,两个输入的 dtype 必须相同。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,数据类型和形状与 broadcast 后的输入相同。 |
支持平台: Ascend, GPU
微分伴随函数:
public func adjointSquaredDifference(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = Tensor(Array<Int32>([8, 9, 4, 3, 4]), shape: Array<Int64>([5]))
let input2 = Tensor(Array<Int32>([6, 1, 2, 5, 8]), shape: Array<Int64>([5]))
let output = squaredDifference(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Int32, value=
[4 64 4 4 16])
sign
public func sign(x: Tensor): Tensor
函数 sign 实现 Sign 算子功能,用于对输入 Tensor 进行 element-wise 的求符号计算,x 的元素为正数时返回 1,负数时返回 -1,元素为 0 时返回 0。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,支持 Int32 和 Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointSign(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([-0.5889578462, 0.0, 0.9656294584, 0.8302891254, -0.4508400559, 0.1614982486]), shape: [6])
let output = sign(input)
print(output)
return 0
}
输出为:
Tensor(shape=[6], dtype=Float32, value=
[-1.00000000e+00 0.00000000e+00 1.00000000e+00 1.00000000e+00 -1.00000000e+00 1.00000000e+00])
sub
public func sub(input1: Tensor, input2: Tensor): Tensor
public func sub(input1: Tensor, input2: Float16): Tensor
public func sub(input1: Float16, input2: Tensor): Tensor
public func sub(input1: Tensor, input2: Float32): Tensor
public func sub(input1: Float32, input2: Tensor): Tensor
public func sub(input1: Tensor, input2: Float64): Tensor
public func sub(input1: Float64, input2: Tensor): Tensor
public func sub(input1: Int32, input2: Tensor): Tensor
public func sub(input1: Tensor, input2: Int32): Tensor
函数 sub 实现 Sub 算子功能,用于对输入逐元素做减法运算。输入必须是两个 Tensor 或者一个 Tensor 和一个标量。当输入是两个 Tensor 时,它们的 dtype 必须一致,并且它们的 shape 可以被广播。当输入是一个 Tensor 和一个标量时,这个标量只能是一个常数。
输入:
| 名称 | 含义 |
|---|---|
| input0 | Tensor 或者 Number,GPU & CPU 支持 Float16\Float32\Float64\Int32, Ascend 支持 Float16\Float32\Int32 类型, dtype 或者类型要求与 input1 一致 |
| input1 | Tensor 或者 Number,GPU & CPU 支持 Float16\Float32\Float64\Int32, Ascend 支持 Float16\Float32\Int32 类型, dtype 或者类型要求与 input0 一致 |
输出:
| 名称 | 含义 |
|---|---|
| output | 结果 Tensor |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointSub(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input0 = Tensor(Array<Float32>([1.0, 5.0, 3.0]), shape: Array<Int64>([3]))
let input1 = Tensor(Array<Float32>([4.0, 2.0, 6.0]), shape: Array<Int64>([3]))
let output = sub(input0, input1)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[-3.00000000e+00 3.00000000e+00 -3.00000000e+00])
stack
public func stack(input: Array<Tensor>, axis!: Int64 = 0): Tensor
public func stack(input: Tensor, axis!: Int64 = 0): Tensor
函数 stack 实现 Stack 算子功能,用于在指定轴上对 Tensor 进行数值堆叠。
给定具有相同秩 $R$ 的 Tensor 列表,输出一个秩为 $R+1$ 的 Tensor。假定输入的 Tensor 个数是 $N$,Tensor 的 shape 是 $(x_1, x_2, ..., x_R)$ ,如果 $axis \ge 0$,那么输出 Tensor 的 shape 是 $(x1, x2, ...,x_{axis}, N, x_{axis+1},...,x_R)$。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入类型是 Array<Tensor>时, GPU & CPU 支持 Float32\Int32\Bool 类型的 tensor 数组, Ascend 支持 Float32\Int32 类型的 tensor 数组; 它们具有相同 shape 和 dtype;输入类型是 Tensor 时,其必须是 makeTuple 的输出。 |
| axis | stack 参考轴,默认是 0。范围 $$[-(R + 1), R + 1)$$。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,和 input 具有相同的 dtype。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointStack(tupleInput: Tensor, axis!: Int64 = 0)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input0 = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let input1 = Tensor(Array<Float32>([5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 2]))
let input: Array<Tensor> = [input0, input1]
let output = stack(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2, 2], dtype=Float32, value=
[[[1.00000000e+00 2.00000000e+00]
[3.00000000e+00 4.00000000e+00]]
[[5.00000000e+00 6.00000000e+00]
[7.00000000e+00 8.00000000e+00]]])
stridedSlice
public func stridedSlice(input: Tensor, begin: Array<Int64>, end: Array<Int64>, strides: Array<Int64>, beginMask!: Int64 = 0, endMask!: Int64 = 0, ellipsisMask!: Int64 = 0, newAxisMask!: Int64 = 0, shrinkAxisMask!: Int64 = 0): Tensor
函数 stridedSlice 实现 StridedSlice 算子功能,用于提取 Tensor 的跨步切片。从给定的输入 Tensor 中,提取出 (end - begin)/ strides 大小的切片。此算子 Ascend 平台暂时仅静态图支持反向。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 tensor,GPU & CPU 支持 Float32\Float64\Int32\Bool 类型, Ascend 支持 Float32\Int32\Bool 类型,。 |
| begin | 元素是常量的数组,代表切片开始的位置,begin,end,strides 的元素个数必须相等。 |
| end | 元素是常量的数组,代表切片结束的位置,begin,end,strides 的元素个数必须相等。 |
| strides | 元素是常量(非 0)的数组,代表切片步长,begin,end,strides 的元素个数必须相等。 |
| beginMask | slice 起始索引的掩码,默认 0。 |
| endMask | slice 结束索引的掩码,默认 0。 |
| ellipsisMask | 省略掩码,默认 0,只有有 1bit 是 1。 |
| newAxisMask | 新轴掩码,默认 0。 |
| shrinkAxisMask | 收缩轴掩码,默认 0。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func stridedSliceGrad(gradOut: Tensor, shape: Array<Int64>, begin: Array<Int64>, end: Array<Int64>, strides: Array<Int64>,
beginMask!: Int64 = 0, endMask!: Int64 = 0, ellipsisMask!: Int64 = 0, newAxisMask!: Int64 = 0, shrinkAxisMask!: Int64 = 0): Tensor
微分伴随函数:
public func adjointStridedSlice(input: Tensor, begin: Array<Int64>, end: Array<Int64>, strides: Array<Int64>, beginMask!: Int64 = 0, endMask!: Int64 = 0, ellipsisMask!: Int64 = 0, newAxisMask!: Int64 = 0, shrinkAxisMask!: Int64 = 0)
二阶伴随函数:
public func adjointStridedSliceGrad(gradOut: Tensor, shape: Array<Int64>, begin: Array<Int64>, end: Array<Int64>, strides: Array<Int64>, beginMask!: Int64 = 0, endMask!: Int64 = 0, ellipsisMask!: Int64 = 0, newAxisMask!: Int64 = 0, shrinkAxisMask!: Int64 = 0)
【注意】:
以下面示例中的数据为例
- 在第 0 维中,begin 为 1,end 为 2,strides 为 Array<Int64>([1, 1, 1]),因为 1 + 1 =2≥2,间隔为 [1,2] [1,2)。 因此,返回第 0 维的 index = 1 的元素,即 [[3,3,3],[4,4,4]]。
- 类似地,在第一维中,间隔为 [0,1)[0,1)。 根据第 0 维的返回值,返回 index = 0 的元素,即 [3,3,3]。
- 类似地,在第二维中,间隔为 [0,3)[0,3)。 根据第 1 维的返回值,返回索引 = 0,1,2,即[3,3,3] 的元素。
- 最终,输出为 [3, 3, 3]。
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let data: Array<Int32> = Array<Int32>([1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 6, 6, 6])
let input = Tensor(data, shape: Array<Int64>([3, 2, 3]))
let output = stridedSlice(input, Array<Int64>([1, 0, 0]), Array<Int64>([2, 1, 3]), Array<Int64>([1, 1, 1]))
print(output)
return 0
}
输出为:
Tensor(shape=[1, 1, 3], dtype=Int32, value=
[[[3 3 3]]])
standardNormal
public func standardNormal(shape: Array<Int64>, seed!: Int64 = 0,
seed2!: Int64 = 0): Tensor
函数 standardNormal 实现 StandardNormal 算子功能,用于生成符合标准正态分布的随机数。
输入:
| 名称 | 含义 |
|---|---|
| shape | 生成随机数的形状。 |
| seed | 随机数种子。必须 >=0,默认值:0。 |
| seed2 | 随机数种子 2。必须 >=0,默认值:0。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 shape 跟输入的 shape 一致,dtype 为 Float32 的 Tensor。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let shape = Array<Int64>([2, 3])
let output = standardNormal(shape, seed: 2)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[8.51138175e-01 -9.68754649e-01 -2.28183597e-01]
[1.99522287e-01 4.66489911e-01 1.12157691e+00]])
squeeze
public func squeeze(input: Tensor, axis!: Array<Int64> = []): Tensor
函数 squeeze 实现 Squeeze 算子功能,输出一个 Tensor,其 dtype 跟输入 Tensor 相同,其 shape 等于输入 Tensor 的 shape 去除维度是 1 的轴。
【注意】:维度索引从 0 开始,并且必须在 [-input.ndim, input.ndim) 范围内。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor。 |
| axis | 指定要删除的形状的维度索引,默认删除所有等于 1 的维度。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与原始变量的类型相同。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointSqueeze(x: Tensor, axis: Array<Int64>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let data = onesTensor(Array<Int64>([3, 2, 1]))
let output = squeeze(data)
print(output)
return 0
}
输出为:
Tensor(shape=[3, 2], dtype=Float32, value=
[[1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00]])
Switch
public func Switch(cond: Tensor, input1: Tensor, input2: Tensor): Tensor
仓颉 TensorBoost 尚不支持将仓颉原生的 if 语句转换成计算图中的控制流,如果用户需要在神经网络中使用 if 语句,可以使用仓颉 TensorBoost 提供的 Switch 算子实现该功能。函数 Switch 实现 Switch 算子功能,用于根据条件在计算图中创建控制流。
输入:
| 名称 | 含义 |
|---|---|
| cond | 输入条件 Tensor,cond 中只需要一个 Bool 类型元素,对应 if 语句 condition 判断逻辑。 |
| input1 | 控制流的 true 分支,对应 if 语句分支。 |
| input2 | 控制流的 false 分支,对应 else 语句分支。与 input1 具有相同的 shape 和 dtype |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 跟输入 input1 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointSwitch(cond: Tensor, input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input1 = Tensor(Array<Float32>([0.0, 1.0, 2.0, 3.0]), shape: Array<Int64>([2, 2]))
let input2 = Tensor(Array<Float32>([5.0, 6.0, 7.0, 8.0]), shape: Array<Int64>([2, 2]))
let cond = Tensor(true)
let output = Switch(cond, input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[0.00000000e+00 1.00000000e+00]
[2.00000000e+00 3.00000000e+00]])
select
public func select(condition: Tensor, x: Tensor, y: Tensor): Tensor
函数 select 实现 Select 功能,用于根据 condition 中元素的符号来选择结果输出来自 x 还是来自 y。
输入:
| 名称 | 含义 |
|---|---|
| condition | 条件判断 Tensor,Bool 类型,其 shape 跟输入 x 和 y 相同。 |
| x | 输入 Tensor x ,GPU & CPU 支持 Float16\Float32\Float64\Int32\Int64 类型, Ascend 支持 Float16\Float32\Int32 类型。 |
| y | 输入 Tensor y,与 x 具有相同的 shape 和 dtype。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,跟输入 x 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointSelect(condition: Tensor, x: Tensor, y: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let condition = Tensor([true, false], shape: Array<Int64>([2]))
let x = Tensor(Array<Float32>([2.0, 3.0]), shape: Array<Int64>([2]))
let y = Tensor(Array<Float32>([1.0, 2.0]), shape: Array<Int64>([2]))
let output = select(condition, x, y)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[2.00000000e+00 2.00000000e+00])
softmax
public func softmax(input: Tensor, axis!: Int64 = -1): Tensor
public func softmax(input: Tensor, axis: Array<Int64>): Tensor
函数 softmax 实现 Softmax 算子功能,用于对输入 Tensor,在 axis 指定的轴上进行 softmax 计算。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,dtype 是 Float32。 |
| axis | 需要计算 softmax 的维度,其元素取值应在[-input.getShapeDims(), input.getShapeDims())之间,默认值为 - 1,即计算最后一维。 |
输出:
| 名称 | 含义 |
|---|---|
| output | softmax 之后的结果 Tensor。与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointSoftmax(x: Tensor, axis: Array<Int64>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0]), shape: Array<Int64>([5]))
let output = softmax(input)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[1.16562294e-02 3.16849165e-02 8.61285329e-02 2.34121650e-01 6.36408567e-01])
sqrt
public func sqrt(input: Tensor): Tensor
函数 sqrt 实现 Sqrt 算子功能,用于对输入 Tensor 进行逐元素开方运算。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,GPU & CPU 支持 Float16\Float32\Float64 类型, Ascend 支持 Float16\Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func sqrtGrad(out: Tensor, gradOut: Tensor): Tensor
微分伴随函数:
public func adjointSqrt(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([9.0, 16.0]), shape: Array<Int64>([2]))
let output = sqrt(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[3.00000000e+00 4.00000000e+00])
square
public func square(input: Tensor): Tensor
函数 square 实现 Square 算子功能,用于对输入 Tensor 进行逐元素平方运算。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,dtype 是 Float16\Float32。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointSquare(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([2.0, 3.0]), shape: Array<Int64>([2]))
let output = square(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[4.00000000e+00 9.00000000e+00])
squareSumAll
public func squareSumAll(x: Tensor, y: Tensor): (Tensor, Tensor)
函数 squareSumAll 实现 SquareSumAll 算子功能,返回输入 Tensor 的平方和。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor,dtype 是 Float32。 |
| y | 输入 Tensor,shape 与 dtype 与 x 一致。 |
输出:
| 名称 | 含义 |
|---|---|
| output1 | 输出 Tensor,与输入 x 具有相同的 dtype。 |
| output2 | 输出 Tensor,与输入 x 具有相同的 dtype。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointSquareSumAll(x: Tensor, y: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Float32>([0.0, 0.0, 2.0, 0.0]), shape: Array<Int64>([2, 2])), "x")
let y = parameter(Tensor(Array<Float32>([0.0, 0.0, 2.0, 4.0]), shape: Array<Int64>([2, 2])), "y")
let res = squareSumAll(x, y)
let tuple = makeTuple([res[0], res[1]])
print(tuple)
return 0
}
输出为:
Tensor(shape=[], dtype=Float32, value= 4.00000000e+00)
Tensor(shape=[], dtype=Float32, value= 2.00000000e+01)
sigmoid
public func sigmoid(input: Tensor): Tensor
函数 sigmoid 实现 Sigmoid 激活函数功能,Sigmoid 定义为:
$${sigmoid}(x_i) = \frac{1}{1 + \exp(-x_i)}$$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,dtype 是 FLOAT32。 |
输出
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,shape 和 dtype 与 input 相同。 |
支持平台: GPU
反向函数:
public func sigmoidGrad(input: Tensor, gradOut: Tensor): Tensor
微分伴随函数:
public func adjointSigmoid(input: Tensor)
二阶伴随函数:
public func adjointSigmoidGrad(input: Tensor, gradOut: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = randomNormalTensor(Array<Int64>([32, 10]))
let output = sigmoid(input)
print(output)
return 0
}
输出为:
Tensor(shape=[32, 10], dtype=Float32, value=
[[4.97435033e-01 4.95399296e-01 4.99560505e-01 ... 4.96425629e-01 5.00373304e-01 4.96130377e-01]
[5.00792205e-01 5.02004087e-01 4.99814272e-01 ... 5.00120342e-01 4.99071419e-01 5.04202366e-01]
[4.94585782e-01 5.01240373e-01 5.04908741e-01 ... 4.98411238e-01 5.00000536e-01 5.00362337e-01]
...
[5.00727594e-01 4.98013198e-01 4.96974528e-01 ... 4.93593991e-01 5.01453340e-01 5.00634849e-01]
[5.04909337e-01 5.02907217e-01 4.99907285e-01 ... 5.02277315e-01 4.97044623e-01 5.00786901e-01]
[5.01355529e-01 5.00793278e-01 4.97799337e-01 ... 5.01390338e-01 5.02621114e-01 4.97769445e-01]])
sigmoidCrossEntropyWithLogits
public func sigmoidCrossEntropyWithLogits(x: Tensor, y: Tensor): Tensor
使用给定的 Logits 来计算 Logits 和 Label 之间的 Sigmoid 交叉熵。
在离散分类任务中测量分布误差,其中每个类是独立的,不使用跨熵损失相互排斥。
假设 logits 输入为 X ,lable 输入为 Y ,output 为 Loss,计算公式为:
$$ \begin{split}\begin{array}{ll} \ p_{ij} = sigmoid(X_{ij}) = \frac{1}{1 + e^{-X_{ij}}} \ loss_{ij} = -[Y_{ij} * ln(p_{ij}) + (1 - Y_{ij})ln(1 - p_{ij})] \end{array}\end{split} $$
输入:
| 名称 | 含义 |
|---|---|
| logits | 表示 logits 的输入,支持 Float32 类型 Tensor |
| label | 表示 label 的输入,支持 Float32 类型 Tensor |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出, 与 input 的 shape 和 dtype 相同 |
支持平台:Ascend, GPU, CPU
反向函数:
public func sigmoidCrossEntropyWithLogitsGrad(x: Tensor, y: Tensor, dout: Tensor): Tensor
微分伴随函数:
public func adjointSigmoidCrossEntropyWithLogits(x: Tensor, y: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let logits = Tensor(Array<Float32>([-0.8, 1.2, 0.7, -0.1, -0.4, 0.7]), shape: [2, 3])
let label = Tensor(Array<Float32>([0.3, 0.8, 1.2, -0.6, 0.1, 2.2]), shape: [2, 3])
let output = sigmoidCrossEntropyWithLogits(logits, label)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 6.11100674e-01 5.03282428e-01 2.63186008e-01]
[ 5.84396660e-01 5.53015292e-01 -4.36813980e-01]])
slice
public func slice(input: Tensor, begin: Array<Int64>, size: Array<Int64>): Tensor
函数 slice 实现 Slice 算子功能,用于从 input Tensor 中抽取一部分数据。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor。 |
| begin | Int64 的数组, 取值大于等于 0, 第 i 位元素值 begin[i] 表示 input 第 i 根轴上从 begin[i] 位开始抽取数据。 |
| size | Int64 的数组, 取值大于 0, 第 i 位元素值 size[i] 表示 input 第 i 根轴上抽取 size[i] 个数据。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与输入 Tensor 具有相同的 type,shape 为输入中的 size。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func sliceGrad(dy: Tensor, x: Tensor, begin: Array<Int64>, size: Array<Int64>): Tensor
微分伴随函数:
public func adjointSlice(input: Tensor, begin: Array<Int64>, size: Array<Int64>)
二阶伴随函数:
public func adjointSliceGrad(dy: Tensor, x: Tensor, begin: Array<Int64>, size: Array<Int64>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]), shape: Array<Int64>([2, 3]))
let begin = Array<Int64>([0, 1])
let size = Array<Int64>([2, 1])
let output = slice(input, begin, size)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 1], dtype=Float32, value=
[[2.00000000e+00]
[5.00000000e+00]])
split
public func split(input: Tensor, axis: Int64, outputNum: Int64): Tensor
函数 split 实现 Split 算子功能,用于把 input 沿 axis 指定的轴划分成 outputNum 个子 Tensor。input 在划分轴的维度必须能被 outputNum 整除。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor。 |
| axis | 指定要切分的轴, 取值在 [-input.size, input.size) 之间。 |
| outputNum | 表示将指定的轴切分成 outputNum 份。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与 input 具有相同的 dtype。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointSplit(input: Tensor, axis: Int64, outputNum: Int64)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]), shape: Array<Int64>([6]))
let axis = 0
let outputNum = 3
let output = split(input, axis, outputNum)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[1.00000000e+00 2.00000000e+00])
Tensor(shape=[2], dtype=Float32, value=
[3.00000000e+00 4.00000000e+00])
Tensor(shape=[2], dtype=Float32, value=
[5.00000000e+00 6.00000000e+00])
sparseApplyProximalAdagrad
public func sparseApplyProximalAdagrad(x: Tensor, accum: Tensor, lr: Float32, l1: Float32, l2: Float32, grad1: Tensor, indices: Tensor, useLocking!: Bool = false): (Tensor, Tensor)
public func sparseApplyProximalAdagrad(x: Tensor, accum: Tensor, lr: Float32, l1: Float32, l2: Tensor, grad1: Tensor, indices: Tensor, useLocking!: Bool = false): (Tensor, Tensor)
public func sparseApplyProximalAdagrad(x: Tensor, accum: Tensor, lr: Float32, l1: Tensor, l2: Float32, grad1: Tensor, indices: Tensor, useLocking!: Bool = false): (Tensor, Tensor)
public func sparseApplyProximalAdagrad(x: Tensor, accum: Tensor, lr: Tensor, l1: Float32, l2: Float32, grad1: Tensor, indices: Tensor, useLocking!: Bool = false): (Tensor, Tensor)
public func sparseApplyProximalAdagrad(x: Tensor, accum: Tensor, lr: Float32, l1: Tensor, l2: Tensor, grad1: Tensor, indices: Tensor, useLocking!: Bool = false): (Tensor, Tensor)
public func sparseApplyProximalAdagrad(x: Tensor, accum: Tensor, lr: Tensor, l1: Tensor, l2: Float32, grad1: Tensor, indices: Tensor, useLocking!: Bool = false): (Tensor, Tensor)
public func sparseApplyProximalAdagrad(x: Tensor, accum: Tensor, lr: Tensor, l1: Float32, l2: Tensor, grad1: Tensor, indices: Tensor, useLocking!: Bool = false): (Tensor, Tensor)
public func sparseApplyProximalAdagrad(x: Tensor, accum: Tensor, lr: Tensor, l1: Tensor, l2: Tensor, grad1: Tensor, indices: Tensor, useLocking!: Bool = false): (Tensor, Tensor)
函数 sparseApplyProximalAdagrad 实现 SparseApplyProximalAdagrad 算子功能。根据 adagrad 算法更新张量,与 ApplyProximalAdagrad 算子相比,输入多了额外的索引张量。
$$ accum+=grad1*grad1 $$
$$ prox_v=x-lrgrad1\frac{1}{\sqrt{accum}} $$
$$ x=\frac{sign(prox_v)}{1+lr*l2}max(|prox_v|-lrl1, 0) $$
参数列表:
| 参数名称 | 含义 |
|---|---|
| useLocking | 如果为 true,x 和 accum 的更新将受到锁保护,默认为 false |
输入:
| 名称 | 含义 |
|---|---|
| x | 要更新的 tensor,支持 Float32 类型,需设置为 parameter。 |
| accum | 要更新的 tensor,shape 和 dtype 与 x 一致,需设置为 parameter。 |
| lr | 学习率,支持 Float32 类型的 number 或 tensor。 |
| l1 | 正则化系数,支持 Float32 类型的 number 或 tensor。 |
| l2 | 正则化系数,支持 Float32 类型的 number 或 tensor。 |
| grad1 | 梯度,dtype 与 x 一致,且当 x shape 的维度大于 1 时,x 与 grad1 的 shape 除第 0 维外一致。 |
| indices | x 和 accum 的第一个维度的索引向量,支持 Int32 与 Int64 类型,且 indices 与 grad1 的 shape 第 0 维相同。 |
输出:
| 名称 | 含义 |
|---|---|
| x | 输出 Tensor,与输入 x 具有相同的 dtype 与 shape。 |
| accum | 输出 Tensor,与输入 accum 具有相同的 dtype 与 shape。 |
支持平台:Ascend, GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Float32>([4.1, 7.2, 1.1, 3.0]), shape: Array<Int64>([2, 2])), "var")
let accum = parameter(Tensor(Array<Float32>([0.0, 0.0 , 0.0, 0.0]), shape: Array<Int64>([2, 2])), "accum")
let lr: Float32 = 1.0
let l1: Float32 = 1.0
let l2: Float32 = 0.0
let gradient = parameter(Tensor(Array<Float32>([1.0, 1.0, 1.0, 1.0]), shape: Array<Int64>([2, 2])), "grad")
let indices = Tensor(Array<Int32>([0, 1]), shape: Array<Int64>([2]))
let tuple = sparseApplyProximalAdagrad(x, accum, lr, l1, l2, gradient, indices)
let output = makeTuple([tuple[0], tuple[1]])
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[2.09999990e+00 5.19999981e+00]
[0.00000000e+00 1.00000000e+00]])
Tensor(shape=[2, 2], dtype=Float32, value=
[[1.00000000e+00 1.00000000e+00]
[1.00000000e+00 1.00000000e+00]])
sparseApplyFtrl
public func sparseApplyFtrl(x: Tensor, accum: Tensor, linear: Tensor, gradOut: Tensor, indices: Tensor, lr: Float32, l1: Float32, l2: Float32, lrPower: Float32, useLocking!: Bool = false): (Tensor, Tensor, Tensor)
根据 FTRL 方案更新输入,FTRL 表示一种在线凸优化算法,根据损失函数自适应选择正则化函数。可参考在线凸优化的自适应边界优化论文:a View from the Trenches for engineering document。其计算过程如下:
$$ \begin{aligned} m_{t+1} &= m_{t} + g^2 \ u_{t+1} &= u_{t} + g - \frac{m_{t+1}^\text{-p} - m_{t}^\text{-p}}{\alpha } * \omega_{t} \ \omega_{t+1} &= \begin{cases} \frac{(sign(u_{t+1}) * l1 - u_{t+1})}{\frac{m_{t+1}^\text{-p}}{\alpha } + 2 * l2 } & \text{ if } |u_{t+1}| > l1 \ 0.0 & \text{ otherwise } \end{cases}\ \end{aligned} $$
其中,$m$表示 accum,$g$表示 gradOut,$t$表示迭代步数,$u$表示 linear,$p$表示 lrPower,$α$表示学习率 lr,$w$表示待更新的输入 x。
输入:
| 名称 | 含义 |
|---|---|
| x | 要更新的变量。 支持 Float16\Float32 类型,需要设置为 parameter |
| accum | 梯度的均方值。shape 与 dtype 与 x 一致,需要设置为 parameter |
| linear | 线性增益。shape 与 dtype 与 x 一致,需要设置为 parameter |
| gradOut | 梯度 Tensor。shape 与 dtype 与 x 一致 |
| indices | 表示 x 和 accum 的第一维中的索引 Tensor。dtype 为 Int32 或 Int64, indices.shape[0] = grad.shape[0]; 注意,如果在索引中有重复项,则更新顺序未定义。 |
| lr | 学习率。类型为 Float32, 必须大于 0.0 |
| l1 | L1 正则化强度。类型为 Float32,必须大于等于 0.0 |
| l2 | L2 正则化强度。类型为 Float32,必须大于等于 0.0 |
| lrPower | 学习率下降的速度控制参数。Float32 类型,必须小于等于 0.0 |
| useLocking | 如果为 true,x 和有累加 tensor 的更新将受到锁保护,Bool 类型,默认为 false |
输出:
| 名称 | 含义 |
|---|---|
| x | Tensor,更新后的 x 具有 与 输入的 x 相同的形状和数据类型 |
| accum | Tensor,更新后的 accum 具有 与 输入的 accum 相同的形状和数据类型 |
| linear | Tensor,更新后的 linear 具有 与 输入的 linear 相同的形状和数据类型 |
支持平台: GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let x = parameter(Tensor(Array<Float32>([-0.6458890438, -0.5430433154, -0.4407467842, -0.4004685581, 0.6915576458]), shape: [5]), "x")
let accum = parameter(Tensor(Array<Float32>([0.1707346588, 0.1966998577, -0.9218196869, 0.8483691812, 0.8923599124]), shape: [5]), "accum")
let linear = parameter(Tensor(Array<Float32>([-0.4502078593, 0.2068482637, -0.2828353047, 0.6220275760, 0.3832996786]), shape: [5]), "linear")
let gradOut = Tensor(Array<Float32>([0.5018641949, 0.5371343493, 0.8976003528, 0.6669725180, -0.7595016956]), shape: [5])
let indices = Tensor(Array<Int32>([5, 7, 4, 1, 3]), shape: [5])
let (res0, res1, res2) = sparseApplyFtrl(x, accum, linear, gradOut, indices, 3.01, 0.0, 0.0, -0.5)
let res = makeTuple([res0, res1, res2]).evaluate()
print(x)
print("\n")
print(accum)
print("\n")
print(linear)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[-6.45889044e-01 -3.52612305e+00 -4.40746784e-01 2.55120188e-01 -2.76851344e+00])
Tensor(shape=[5], dtype=Float32, value=
[1.70734659e-01 6.41552210e-01 -9.21819687e-01 1.42521203e+00 1.69804633e+00])
Tensor(shape=[5], dtype=Float32, value=
[-4.50207859e-01 9.38311398e-01 -2.82835305e-01 -1.01185441e-01 1.19854653e+00])
sin
public func sin(input: Tensor)
函数 sin 实现 Sin 算子功能,用于计算输入的正弦。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor。GPU & CPU 支持 Float16\Float32\Float64 支持, Ascend 支持 Float16\Float32。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointSin(input: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([0.62, 0.28, 0.43, 0.62]), shape: Array<Int64>([4]))
let output = sin(input)
print(output)
return 0
}
输出为:
Tensor(shape=[4], dtype=Float32, value=
[5.81035197e-01 2.76355654e-01 4.16870803e-01 5.81035197e-01])
scatterNd
public func scatterNd(indices: Tensor, update: Tensor, shape: Array<Int64>): Tensor
函数 scatterNd 实现 ScatterNd 算子功能,用于根据指定的 indices,将 update 分散到大小为 shape 的 ZeroTensor 中。
indices = [v1, v2, ... vn], vm 是一个 k-vector,表示一个 index, k 是 shape 的维度。
update = [a1, a2, ..., an]
则输出的 tensor 中 v1 的值为 a1,v2 的值为 a2...,其余值均为 0。
输入:
| 名称 | 含义 |
|---|---|
| indices | 要取数的 indice,dtype 是 Int32\Int64。indices shape 的 rank 至少为 2,且 indices shape 的最后一维必须小于 shape.size |
| update | 输入数据,dtype 是 Float32\Float64\Int32\Int64, Ascend 支持 Float32\Int32。update shape 需要满足: update shape = indices shape[:-1] + shape[indices_shape[-1]:] |
| shape | Int64 的数组,表示输出 Tensor 的 shape。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor。该 Tensor 的 shape 与 输入的 shape 相同,dtype 与 update 的 dtype 相同 |
注:Ascend 平台不支持 indices 为 Int64 类型
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointScatterNd(indices: Tensor, update: Tensor, shape: Array<Int64>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let indices = Tensor(Array<Int32>([0, 0, 1, 2, 2, 0]), shape: Array<Int64>([3, 2]))
let update = Tensor(Array<Int32>([1, 2, 3]), shape: Array<Int64>([3]))
let shape = Array<Int64>([3, 3])
let output = scatterNd(indices, update, shape)
print(output)
return 0
}
输出为:
Tensor(shape=[3, 3], dtype=Int32, value=
[[1 0 0]
[0 0 2]
[3 0 0]])
scatterNdSub
public func scatterNdSub(input: Tensor, indices: Tensor, updates: Tensor, useLocking!: Bool = false): Tensor
函数 scatterNdSub 实现 ScatterNdSub 算子功能,用于根据指定的 indices,对 input 中的单个值或切片应用稀疏减法,从 input 对应位置减去 update 的值。
输入:
| 名称 | 含义 |
|---|---|
| input | 将要被更新的 Tensor,必须是 Parameter,支持 Float32\Float64\Int32\Int64 类型, Ascend 平台支持 Float32 和 Int32 类型。 |
| indices | 要取数的 indice,dtype 是 Int32。indices shape 的 rank 至少为 2,且 indicesShape 的最后一维必须小于 inputShape.size |
| updates | 要更新到 input 中的张量,dtype 与 input 相同。 shape 为 indicesShape[:-1] + inputShape[indicesShape[-1]:] |
| useLocking | 是否通过锁保护分配,类型为:Bool, 默认值:false。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor。 shape 与 dtype 和 input 相同。 |
支持平台: GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(Tensor(Array<Float32>([1.0000000000, 2.0000000000, 3.0000000000, 4.0000000000, 5.0000000000, 6.0000000000, 7.0000000000, 8.0000000000]), shape: Array<Int64>([8])), "input_x")
let indices = parameter(Tensor(Array<Int32>([2, 4, 1, 7]), shape: Array<Int64>([4, 1])), "indices")
let updates = parameter(Tensor(Array<Float32>([6.0000000000, 7.0000000000, 8.0000000000, 9.0000000000]), shape: Array<Int64>([4])), "updates")
let output = scatterNdSub(input, indices, updates)
print(output)
return 0
}
输出为:
Tensor(shape=[8], dtype=Float32, value=
[1.00000000e+00 -6.00000000e+00 -3.00000000e+00 ... 6.00000000e+00 7.00000000e+00 -1.00000000e+00])
scatterNdUpdate
public func scatterNdUpdate(input: Tensor, indices: Tensor, updates: Tensor, useLocking!: Bool = true): Tensor
函数 scatterNdUpdate 实现 ScatterNdUpdate 算子功能,用于根据指定的 indices,更新 input 中的值,将 input 对应位置更新为 update 的值。
输入:
| 名称 | 含义 |
|---|---|
| input | 将要被更新的 Tensor,必须是 parameter,支持 Float32\Float64\Int32\Int64 类型,Ascend 平台支持 Float32 类型。 |
| indices | 要取数的 indice,dtype 是 Int32。indices shape 的 rank 至少为 2,且 indicesShape 的最后一维必须小于 inputShape.size; 注意,如果在索引中有重复项,则更新顺序未定义。 |
| updates | 要更新到 input 中的张量,dtype 与 input 相同。 shape 为 indicesShape[:-1] + inputShape[indicesShape[-1]:] |
| useLocking | 是否通过锁保护分配,类型为:Bool, 默认值:true。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor。 shape 与 dtype 和 input 相同。 |
支持平台: GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = parameter(Tensor(Array<Float32>([-0.1000000015, 0.3000000119, 3.5999999046, 0.4000000060, 0.5000000000, -3.2000000477]), shape: Array<Int64>([2, 3])), "input")
let indices = parameter(Tensor(Array<Int32>([0, 0, 1, 1]), shape: Array<Int64>([2, 2])), "indices")
let updates = parameter(Tensor(Array<Float32>([1.0000000000, 2.2000000477]), shape: Array<Int64>([2])), "updates")
let output = scatterNdUpdate(input, indices, updates)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 1.00000000e+00 3.00000012e-01 3.59999990e+00]
[ 4.00000006e-01 2.20000005e+00 -3.20000005e+00]])
tanh
public func tanh(input: Tensor): Tensor
函数 tanh 实现 Tanh 算子功能,用于对输入 input 进行逐元素的 tanh 运算。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,dtype 是 Float32。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,与 input 具有相同的 shape 和 dtype。 |
支持平台:Ascend, GPU, CPU
反向函数:
public func tanhGrad(out: Tensor, gradOut: Tensor): Tensor
微分伴随函数:
public func adjointTanh(x: Tensor)
二阶伴随函数:
public func adjointTanhGrad(out: Tensor, gradOut: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0]), shape: Array<Int64>([5]))
let output = tanh(input)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[7.61594176e-01 9.64027584e-01 9.95054781e-01 9.99329329e-01 9.99909222e-01])
tensorScatterUpdate
public func tensorScatterUpdate(input: Tensor, indices: Tensor, update: Tensor): Tensor
函数 tensorScatterUpdate 实现 TensorScatterUpdate 算子功能,把 input 中 indices 位置的数据更新为输入的 update, 返回为更新后的 tensor。 注:此算子暂不支持反向。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入的 tensor, 数据类型 GPU 支持 Float16\Float32\Float64\Int32\Int64\Bool; Ascend 支持 Float32 |
| indices | 需要更新的位置索引,数据类型 GPU 支持 Int32,Int64; Ascend 支持 Int32, Int64,维度不小于 2,并且最后一个维度长度不大于 input 的维度大小, 即 indices.shape[-1] <= input.shape.size |
| update | 需要更新的数据,数据类型必须和 input 一致,并且形状要满足 update.shape=indices.shape[:1]+input.shape[indices.shape[−1]:] |
输出
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, 形状和数据类型和 input 一致,但 indices 位置的数据变为 update 提供的数据了 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointTensorScatterUpdate(input: Tensor, indices: Tensor, update: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([-0.1, 0.3, 3.6, 0.4, 0.5, -3.2]), shape: [2, 3])
let indice = Tensor(Array<Int32>([0]), shape: [1, 1])
let update = Tensor(Array<Float32>([6.0, 6.0, 6.0]), shape: [1, 3])
let output = tensorScatterUpdate(input, indice, update)
print(output)
return 0
}
输出:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 6.00000000e+00 6.00000000e+00 6.00000000e+00]
[ 4.00000006e-01 5.00000000e-01 -3.20000005e+00]])
tile
public func tile(x: Tensor, multiples: Array<Int64>): Tensor
函数 tile 实现 Tile 算子功能,函数按照给定的次数复制输入 Tensor。通过复制 multiples 次 x 来创建新的 Tensor。输出 Tensor 的第 i 维度有 x.getshape()[i] * multiples[i] 个元素,并且 x 的值沿第 i 维度被复制 multiples[i] 次。
输入:
| 名称 | 含义 |
|---|---|
| x | 输入的 Tensor, 支持 Float16, Float32, Float64, Int32, bool 类型;反向仅支持 Float16\Float32\Float64。 |
| multiples | 指定复制的次数, 参数类型为 Array,数据类型为整数。如$[y_1, y_2, \cdots, y_S]$,multiples 的长度不能小于 x 的维度,反向暂时只支持最大维度为 4。 |
输出:
| 名称 | 含义 |
|---|---|
| Tensor | 与 x 的数据类型相同。 |
支持平台:Ascend, GPU, CPU
代码示例 1:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let multiples = Array<Int64>([2, 3])
let output = tile(input, multiples)
print(output)
return 0
}
输出为:
Tensor(shape=[4, 6], dtype=Float32, value=
[[ 1.00000000e+00 2.00000000e+00 1.00000000e+00 2.00000000e+00 1.00000000e+00 2.00000000e+00]
[ 3.00000000e+00 4.00000000e+00 3.00000000e+00 4.00000000e+00 3.00000000e+00 4.00000000e+00]
[ 1.00000000e+00 2.00000000e+00 1.00000000e+00 2.00000000e+00 1.00000000e+00 2.00000000e+00]
[ 3.00000000e+00 4.00000000e+00 3.00000000e+00 4.00000000e+00 3.00000000e+00 4.00000000e+00]])
topk
public func topK(input: Tensor, k: Int32, sorted: Bool): (Tensor, Tensor)
函数 topK 实现 TopK 算子功能,用于在最后一个轴上查找 k 个最大项的值和索引。
输入:
| 名称 | 含义 |
|---|---|
| input | 要计算的输入,只支持 dtype 为 Float32 类型的 Tensor。 |
| k | 要沿最后一个维度计算的顶层元素数,类型为 Int32 的常量;范围要求大于 0,小于等于 input 最后一个维度的 size。 |
| sorted | 如果为 true,则结果元素将按值降序排序。 |
输出:
| 名称 | 含义 |
|---|---|
| values | 输出 Tensor,dtype 与 输入 input 一致。沿最后一个维度切片的 k 个最大元素。 |
| indices | dtype 为 Int32 类型的 Tensor,输入的最后一个维度内的值的索引。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointTopK(input: Tensor, k: Int32, sorted: Bool)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([2.0, 4.0, 1.0, 5.0, 6.0]), shape: Array<Int64>([5]))
let k = 3
let sorted = true
let (values, indices) = topK(input, k, sorted)
print(values)
print(indices)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[6.00000000e+00 5.00000000e+00 4.00000000e+00])
Tensor(shape=[3], dtype=Int32, value=
[4 3 1])
tensorScatterAdd
public func tensorScatterAdd(input: Tensor, indices: Tensor, updates: Tensor): Tensor
函数 tensorScatterAdd 实现 TensorScatterAdd 算子功能,通过将 input 中由 indices 指示的位置的值与 updates 的值相加来创建一个新的张量。当为同一个索引给出多个值时,更新的结果将是所有值的总和。对于每个 indices,updates 中必须有对应的值。updates 的 shape 应该等于 input_x[indices] 的 shape。 此算子反向暂不支持 4-D 以上的输入,且反向暂不支持 indices 为 Int64 类型。 此算子 indices 的值不可为负数;
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,dtype 为 Float16\Float32\Float64\Int32\Int64, input 的维度必须不小于 indices.shape[indices.shape.size -1]。 |
| indices | 输入 Tensor 的索引,dtype 为 Int32 或 Int64。rank 必须至少为 2。 |
| updates | 用于更新输入 Tensor 的 Tensor,dtype 与 input 相同,updates.shape 应该等于 indices.shape[:-1] + input_x.shape[indices.shape[-1]:]。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,shape 和 dtype 与 输入 input 一致。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointTensorScatterAdd(input: Tensor, indices: Tensor, updates: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input_x = parameter(Tensor(Array<Float32>([-0.1000000015, 0.3000000119, 3.5999999046, 0.4000000060, 0.5000000000, -3.2000000477]), shape: Array<Int64>([2, 3])), "input_x")
let indices = parameter(Tensor(Array<Int32>([0, 0, 0, 0]), shape: Array<Int64>([2, 2])), "indices")
let updates = parameter(Tensor(Array<Float32>([1.0000000000, 2.2000000477]), shape: Array<Int64>([2])), "updates")
let output = tensorScatterAdd(input_x, indices, updates)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 3.09999990e+00 3.00000012e-01 3.59999990e+00]
[ 4.00000006e-01 5.00000000e-01 -3.20000005e+00]])
tensorScatterSub
public func tensorScatterSub(input: Tensor, indices: Tensor, updates: Tensor): Tensor
函数 tensorScatterSub 实现 TensorScatterSub 算子功能,通过将 input 中由 indices 指示的位置的值与 updates 的值相减来创建一个新的张量。当为同一个索引给出多个值时,更新的结果将分别减去这些值。对于每个 indices,updates 中必须有对应的值。updates 的 shape 应该等于 input_x[indices] 的 shape。 此算子反向暂不支持 4-D 以上的输入,且反向暂不支持 indices 为 Int64 类型。 此算子 indices 的值不可为负数;
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,dtype 为 Float16\Float32\Float64\Int32\Int64,input 的维度必须不小于 indices.shape[indices.shape.size -1]。 |
| indices | 输入 Tensor 的索引,dtype 为 Int32 或 Int64 。rank 必须至少为 2。 |
| updates | 用于更新输入 Tensor 的 Tensor,dtype 与 input 相同,updates.shape 应该等于 indices.shape[:-1] + input_x.shape[indices.shape[-1]:]。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,shape 和 dtype 与 输入 input 一致。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointTensorScatterSub(input: Tensor, indices: Tensor, updates: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input_x = parameter(Tensor(Array<Float32>([-0.1000000015, 0.3000000119, 3.5999999046, 0.4000000060, 0.5000000000, -3.2000000477]), shape: Array<Int64>([2, 3])), "input_x")
let indices = parameter(Tensor(Array<Int32>([0, 0, 0, 0]), shape: Array<Int64>([2, 2])), "indices")
let updates = parameter(Tensor(Array<Float32>([1.0000000000, 2.2000000477]), shape: Array<Int64>([2])), "updates")
let output = tensorScatterSub(input_x, indices, updates)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[-3.30000019e+00 3.00000012e-01 3.59999990e+00]
[ 4.00000006e-01 5.00000000e-01 -3.20000005e+00]])
tensorScatterMax
public func tensorScatterMax(input: Tensor, indices: Tensor, updates: Tensor): Tensor
函数 tensorScatterMax 实现 TensorScatterMax 算子功能,通过将 input 中,indices 指示的位置的值与 updates 中的值进行比较,选择最大值更新到指定位置上。 对于每个 indices,updates 中必须有对应的值。updates 的 shape 应该等于 input_x[indices] 的 shape。 此算子反向暂不支持 5-D 以上的输入,且反向暂不支持 indices 为 Int64 类型。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,dtype 为 Float16\Float32\Float64\Int32\Int64, input 的维度必须不小于 indices.shape[indices.shape.size -1]。 |
| indices | 输入 Tensor 的索引,dtype 为 Int32 或 Int64 。rank 必须至少为 2。 |
| updates | 用于更新输入 Tensor 的 Tensor,dtype 与 input 相同,updates.shape 应该等于 indices.shape[:-1] + input_x.shape[indices.shape[-1]:]。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,shape 和 dtype 与 输入 input 一致。 |
注:反向暂不支持 Float16\Int64 类型
支持平台:GPU
微分伴随函数:
public func adjointTensorScatterMax(input: Tensor, indices: Tensor, updates: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input_x = parameter(Tensor(Array<Float32>([-0.1000000015, 0.3000000119, 3.5999999046, 0.4000000060, 0.5000000000, -3.2000000477]), shape: Array<Int64>([2, 3])), "input_x")
let indices = parameter(Tensor(Array<Int32>([0, 0, 0, 0]), shape: Array<Int64>([2, 2])), "indices")
let updates = parameter(Tensor(Array<Float32>([1.0000000000, 2.2000000477]), shape: Array<Int64>([2])), "updates")
let output = tensorScatterMax(input_x, indices, updates)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 2.20000005e+00 3.00000012e-01 3.59999990e+00]
[ 4.00000006e-01 5.00000000e-01 -3.20000005e+00]])
tensorScatterMin
public func tensorScatterMin(input: Tensor, indices: Tensor, updates: Tensor): Tensor
函数 tensorScatterMin 实现 TensorScatterMin 算子功能,函通过将 input 中,indices 指示的位置的值与 updates 中的值进行比较,选择最小值更新到指定位置上。 对于每个 indices,updates 中必须有对应的值。updates 的 shape 应该等于 input_x[indices] 的 shape。 此算子反向暂不支持 5-D 以上的输入,且反向暂不支持 indices 为 Int64 类型。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,dtype 为 Float16\Float32\Float64\Int32\Int64, input 的维度必须不小于 indices.shape[indices.shape.size -1]。 |
| indices | 输入 Tensor 的索引,dtype 为 Int32 或 Int64 。rank 必须至少为 2。 |
| updates | 用于更新输入 Tensor 的 Tensor,dtype 与 input 相同,updates.shape 应该等于 indices.shape[:-1] + input_x.shape[indices.shape[-1]:]。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,shape 和 dtype 与 输入 input 一致。 |
支持平台:GPU
微分伴随函数:
public func adjointTensorScatterMin(input: Tensor, indices: Tensor, updates: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input_x = parameter(Tensor(Array<Float32>([-0.1000000015, 0.3000000119, 3.5999999046, 0.4000000060, 0.5000000000, -3.2000000477]), shape: Array<Int64>([2, 3])), "input_x")
let indices = parameter(Tensor(Array<Int32>([0, 0, 0, 0]), shape: Array<Int64>([2, 2])), "indices")
let updates = parameter(Tensor(Array<Float32>([1.0000000000, 2.2000000477]), shape: Array<Int64>([2])), "updates")
let output = tensorScatterMin(input_x, indices, updates)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[-1.00000001e-01 3.00000012e-01 3.59999990e+00]
[ 4.00000006e-01 5.00000000e-01 -3.20000005e+00]])
transpose
public func transpose(input: Tensor, inputPerm: Array<Int64>): Tensor
函数 transpose 实现 Transpose 算子功能。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor, 支持所有类型的 Tensor。 |
| inputPerm | Int64 的数组,表示调整规则。inputPerm 的长度和 input 的 shape 维度必须相同。 取值必须在 [0, rank(input)) 范围内。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,dtype 与 input 相同,输出 Tensor 的 shape 由 input 的 shape 和 inputPerm 的值确定。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointTranspose(x: Tensor, inputPerm: Array<Int64>)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let intputPerm = Array<Int64>([1, 0])
let output = transpose(input, intputPerm)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[1.00000000e+00 3.00000000e+00]
[2.00000000e+00 4.00000000e+00]])
truncateDiv
public func truncateDiv(input1: Tensor, input2: Tensor): Tensor
public func truncateDiv(input1: Tensor, input2: Int32): Tensor
public func truncateDiv(input1: Int32, input2: Tensor): Tensor
public func truncateDiv(input1: Tensor, input2: Int64): Tensor
public func truncateDiv(input1: Int64, input2: Tensor): Tensor
public func truncateDiv(input1: Tensor, input2: Float16): Tensor
public func truncateDiv(input1: Float16, input2: Tensor): Tensor
public func truncateDiv(input1: Tensor, input2: Float32): Tensor
public func truncateDiv(input1: Float32, input2: Tensor): Tensor
public func truncateDiv(input1: Tensor, input2: Float64): Tensor
public func truncateDiv(input1: Float64, input2: Tensor): Tensor
public func truncateDiv(input1: Tensor, input2: Bool): Tensor
public func truncateDiv(input1: Bool, input2: Tensor): Tensor
函数 truncateDiv 实现 TruncateDiv 算子功能,用于计算第一个输入与第二个输入逐个元素相除,当输入为 Int32 类型的 Tensor 时,结果并向 0 取整。输入可以是 Tensor 或者标量,但不能同时为标量。当输入为两个 Tensor 时,其 shape 必须可以进行 broadcast。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 第一个输入 Tensor。GPU 支持 Float16\Float32\Float64\Int32\Int64\Bool 类型的 number 或 tensor, Ascend 支持 Float32\Int32 类型,两个输入的 dtype 必须相同。 |
| input2 | 第二个输入 Tensor。两个输入的 dtype 必须相同。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 相除的 Tensor,数据类型和形状与 broadcast 后的输入相同。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointTruncateDiv(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let input1 = Tensor(Array<Int32>([1, 2, 3, -1, -2, -3]), shape: Array<Int64>([6]))
let input2 = Tensor(Array<Int32>([3, 3, 3, 3, 3, 3]), shape: Array<Int64>([6]))
let output = truncateDiv(input1, input2)
print(output)
return 0
}
输出为:
Tensor(shape=[6], dtype=Int32, value=
[0 0 1 0 0 -1])
truncateMod
public func truncateMod(input1: Tensor, input2: Tensor): Tensor
public func truncateMod(input1: Tensor, input2: Float16): Tensor
public func truncateMod(input1: Float16, input2: Tensor): Tensor
public func truncateMod(input1: Tensor, input2: Float32): Tensor
public func truncateMod(input1: Float32, input2: Tensor): Tensor
public func truncateMod(input1: Tensor, input2: Float64): Tensor
public func truncateMod(input1: Float64, input2: Tensor): Tensor
public func truncateMod(input1: Tensor, input2: Int32): Tensor
public func truncateMod(input1: Int32, input2: Tensor): Tensor
函数 truncateMod 实现 TruncateMod 算子功能,用于计算第一个输入与第二个输入逐个元素求模,支持 Float32 和 Int32 类型。当输入为 Float32 类型时,因为 Float32 的有效数字只有 6 位,计算结果打印出来 6 位之后的数据可能不准确。输入可以是 Tensor 或者标量,但不能同时为标量。当输入为两个 Tensor 时,其 shape 必须可以进行 broadcast。
输入:
| 名称 | 含义 |
|---|---|
| input1 | 第一个输入。GPU 支持 Float16\Float32\Float64\Int32 类型的 number 或 tensor, Ascend 支持 Float32\Int32 类型。 |
| input2 | 第二个输入。类型必须和 input1 一致。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 相除的 Tensor,数据类型和形状与输入相同。 |
支持平台:Ascend, GPU
微分伴随函数:
public func adjointTruncateMod(input1: Tensor, input2: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64 {
let x1 = Tensor(Array<Float32>([0.0347052291, -0.6000000, 0.5798667073, -0.55000, 0.0335827433]), shape: [5])
let y1 = Tensor(Array<Float32>([-0.2082750499, -0.250000, 0.7290703654, 0.050000, 0.2802773118]), shape: [5])
let output1 = truncateMod(x1, y1)
print(output1)
let x2 = Tensor(Array<Int32>([1, 2, 3, -1, -2, -3]), shape: [6])
let y2 = Tensor(Array<Int32>([3, 3, 3, 3, 3, 3]), shape: [6])
let output2 = truncateMod(x2, y2)
print(output2)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[3.47052291e-02 -1.00000024e-01 5.79866707e-01 -3.72529030e-09 3.35827433e-02])
Tensor(shape=[6], dtype=Int32, value=
[1 2 0 -1 -2 0])
uniformInt
public func uniformInt(shape: Array<Int64>, low: Tensor, high: Tensor, seed!: Int64 = 0, seed2!: Int64 = 0): Tensor
函数 uniformInt 实现 UniformInt 算子功能,用于生成整形均匀分布随机数。该整数值 i 均匀分布在闭合间隔 [low,high)上,即根据离散概率函数分布:
$$ P(i|a,b) = {1\over b−a+1}, $$
输入:
| 名称 | 含义 |
|---|---|
| shape | 指定输出 Tensor 的 shape。 |
| low | 均匀分布下界,dtype 是 Int32,仅支持 scaler tensor。 |
| high | 均匀分布上界,dtype 是 Int32,仅支持 scaler tensor。 |
| seed | 随机数种子。必须 >=0, 默认值:0。 |
| seed2 | 随机数种子 2。必须 >=0, 默认值:0。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,dtype 是 Int32,shape 是输入的 shape。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let shape = Array<Int64>([5])
let low = Tensor(Int32(1))
let high = Tensor(Int32(10))
let seed = 2
let output = uniformInt(shape, low, high, seed: seed)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Int32, value=
[3 2 7 6 8])
uniformReal
public func uniformReal(shape: Array<Int64>, seed!: Int64 = 0, seed2!: Int64 = 0): Tensor
函数 uniformReal 实现 UniformReal 算子功能,用于生成实数型均匀分布随机数。
输入:
| 名称 | 含义 |
|---|---|
| shape | 指定输出 Tensor 的 shape。 |
| seed | 随机数种子。必须 >=0, 默认值:0。 |
| seed2 | 随机数种子 2。必须 >=0, 默认值:0。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,dtype 是 Float32,shape 根据输入的 shape。 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let shape = Array<Int64>([5])
let seed = 2
let output = uniformReal(Array<Int64>([5]), seed: seed)
print(output)
return 0
}
输出为:
Tensor(shape=[5], dtype=Float32, value=
[3.04325491e-01 1.38403744e-01 7.46221542e-01 5.87218642e-01 7.81347454e-01])
unsortedSegmentMax
public func unsortedSegmentMax(input: Tensor, segmentIds: Tensor, numSegments: Int64): Tensor
函数 unsortedSegmentMax 实现 UnsortedSegmentMax 算子功能,对比 input 中相同 segmentIds 的 segment, 取最大值,返回一个 Tensor
注:如果 input 中找不到 segmentIds 中对应的 segment, 则对应的输出为该数据类型下的最小值,见例 2。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入的 Tensor,shape 为 [x1, x2, ..., xR], 数据类型 GPU 支持 Float32, Int32; Ascend 正向支持 Float32,Int32, 反向支持 Float32 |
| segmentIds | 必须是 1 维 Tensor,且长度等于 input 第一个维度的长度,即 shape 为 [x1], 数据类型只能是 Int32。cpu 平台中 segmentIds 的值必须在 [0, numSegments) 范围内。 |
| numSegments | segmentIds 中不重复数据的个数, 数值非负。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, shape 为 [N, x2, ..., xR], N = numSegments |
支持平台:Ascend, GPU, CPU 注:Ascend 平台时,numSegments 值过大时,可能因内存不足而运行失败。
反向函数:
public func unsortedSegmentMinorMaxGrad(input: Tensor, segmentIds: Tensor, numSegments: Int64, out: Tensor, dout: Tensor): Tensor
微分伴随函数:
public func adjointUnsortedSegmentMax(input: Tensor, segmentIds: Tensor, numSegments: Int64)
代码示例 1:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 4.0, 2.0, 1.0]), shape: [3, 3])
let segmentIds = Tensor(Array<Int32>([0, 1, 1]), shape: [3])
let numSegments = 2
let output = unsortedSegmentMax(input, segmentIds, numSegments)
print(output)
return 0
}
输出:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 1.00000000e+00 2.00000000e+00 3.00000000e+00]
[ 4.00000000e+00 5.00000000e+00 6.00000000e+00]])
代码示例 2:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Int32>([1, 2, 3, 4, 2, 0, 4, 5, 6, 4, 2, 1]), shape: [4, 3])
let segmentIds = Tensor(Array<Int32>([0, 0, 0, 5]), shape: [4])
let numSegments = 2
let output = unsortedSegmentMax(input, segmentIds, numSegments)
print(output)
return 0
}
输出:
Tensor(shape=[2, 3], dtype=Int32, value=
[[ 4 5 6]
[-2147483648 -2147483648 -2147483648]])
unsortedSegmentMin
public func unsortedSegmentMin(input: Tensor, segmentIds: Tensor, numSegments: Int64): Tensor
函数 unsortedSegmentMin 实现 UnsortedSegmentMin 算子功能,对比 input 中相同 segmentIds 的 segment, 取最小值,返回一个 Tensor
注:如果 input 中找不到 segmentIds 中对应的 segment, 则对应的输出为该数据类型下的最大值,见例 2
输入:
| 名称 | 含义 |
|---|---|
| input | 输入的 Tensor,shape 为 [x1, x2, ..., xR], 数据类型 GPU 支持 Float32, Int32; Ascend 正向支持 Float32,Int32, 反向支持 Float32 |
| segmentIds | 必须是 1 维 Tensor,且长度等于 input 第一个维度的长度,即 shape 为 [x1], 数据类型只能是 Int32 |
| numSegments | segmentIds 中不重复数据的个数, 数值非负 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor, shape 为 [N, x2, ..., xR], N = numSegments |
支持平台:Ascend, GPU, CPU
注:Ascend 平台时,numSegments 值过大时,可能因内存不足而运行失败。
反向函数:
public func unsortedSegmentMinorMaxGrad(input: Tensor, segmentIds: Tensor, numSegments: Int64, out: Tensor, dout: Tensor): Tensor
微分伴随函数:
public func adjointUnsortedSegmentMin(input: Tensor, segmentIds: Tensor, numSegments: Int64)
代码示例 1:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 4.0, 2.0, 1.0]), shape: [3, 3])
let segmentIds = Tensor(Array<Int32>([0, 1, 1]), shape: [3])
let numSegments = 2
let output = unsortedSegmentMin(input, segmentIds, numSegments)
print(output)
return 0
}
输出:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 1.00000000e+00 2.00000000e+00 3.00000000e+00]
[ 4.00000000e+00 2.00000000e+00 1.00000000e+00]])
代码示例 2:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Int32>([1, 2, 3, 4, 2, 0, 4, 5, 6, 4, 2, 1]), shape: [4, 3])
let segmentIds = Tensor(Array<Int32>([0, 0, 0, 0]), shape: [4])
let numSegments = 2
let output = unsortedSegmentMin(input, segmentIds, numSegments)
print(output)
return 0
}
输出:
Tensor(shape=[2, 3], dtype=Int32, value=
[[ 1 2 0]
[2147483647 2147483647 2147483647]])
unsortedSegmentSum
public func unsortedSegmentSum(input: Tensor, segmentIds: Tensor, numSegments: Int64): Tensor
函数 unsortedSegmentSum 实现 UnsortedSegmentSum 算子功能,用于对输入 input 按照 segmentIds 进行累加计算。
【备注】:如果输入的 numSegments 不在 segmentIds 中,将用 0 填充。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,GPU & CPU 支持 Float32\Float64\Int32 类型,Ascend 支持 Float32\Int32 类型。 |
| segmentIds | 指定累加的 segment,dtype 是 Int32,shape 的长度 > 0 小于等于 input 的长度。 |
| numSegments | 设置累加的字段。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 累加的计算结果。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointUnsortedSegmentSum(input: Tensor, segmentIds: Tensor, numSegments: Int64)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([4]))
let value: Array<Int32> = Array<Int32>([0, 0, 1, 2])
let segmentIds =Tensor(value, shape: Array<Int64>([4]))
let numSegments = 4
let output = unsortedSegmentSum(input, segmentIds, numSegments)
print(output)
return 0
}
输出为:
Tensor(shape=[4], dtype=Float32, value=
[3.00000000e+00 3.00000000e+00 4.00000000e+00 0.00000000e+00])
unstack
public func unstack(input: Tensor, axis!: Int64 = 0): Tensor
函数 unstack 实现 Unstack 算子功能,用于在指定轴上对 Tensor 进行拆分。和 Stack 的操作相反,两者互为反向算子。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 tensor, GPU & CPU 支持 Float32\Int32\Bool, Ascend 支持 Float32\Int32。 |
| axis | Unstack 参考轴,范围 [-R, R),其中 R 是 input 的 rank,axis 默认取 0。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 拆分后的 Tuple Tensor,和 input 具有相同的 dtype,rank 是(R - 1)。 |
| 支持平台:Ascend, GPU, CPU |
微分伴随函数:
public func adjointUnstack(input: Tensor, axis!: Int64 = 0)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0]), shape: Array<Int64>([2, 2]))
let axis = 1
let output = unstack(input, axis: axis)
print(output)
return 0
}
输出为:
Tensor(shape=[2], dtype=Float32, value=
[1.00000000e+00 3.00000000e+00])
Tensor(shape=[2], dtype=Float32, value=
[2.00000000e+00 4.00000000e+00])
While
public func While(cond: Tensor, body: Array<Tensor>, tail: Tensor, vars: Array<Tensor>): Tensor
函数 While 用于生成循环控制流。
条件与限制:
1)当前 While 仅可对接单 While,不支持 While 内部包含 While 和 If 的情况。
2)当前 While 不支持自动微分。
3)当前结果可以与 mindspore while 用例结果保持一致。
4)当前不支持 Eager 模式运行,使用时需要将环境变量 CANGJIETB_GRAPH_MODE=true 设置为静态图模式。
输入:
| 名称 | 含义 |
|---|---|
| cond | 循环终止条件,Tensor 类型,通常是比较运算的结果。 |
| body | 循环体。 |
| tail | 循环尾计算。 |
| vars | 循环需要的变量。 |
输出
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor |
vars 是 while 所需要的初始变量的值,body 是进入 while 循环体后,返回的一组新的变量列表的值,与 vars 个数以及类型要保持一致,相当于更新了一遍 vars 的值。
解释说明:(与限制冲突无法得到正确的结果)
- vars 包含的初始变量和 body 返回的更新后变量必须一一对应。
- vars 要包含所有循环需要使用的变量,包含循环条件和循环体的变量。
- vars 不可以包含非 Parameter 的 Tensor
- 如果 while 循环需要的变量没有修改,也需要将变量写到 body 的 return 中。
- body 不可以捕获闭包外面的变量,body 的入参即是 vars 变量的值。
- 如果 z 使用 x 进行初始化,需要将 z 初始化为 x 的初始值,如示例 3。
下面提供 4 个示例代码:
运行下面的示例代码前,需要先导入依赖包,并将 context 设置为非 eager 模式。
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import context.g_context
main(): Int64 {
let ret = TestWhile()
print(ret)
return 0
}
示例 1:
仓颉 While:循环变量 x,y,循环体内 x 更新,y 不更新,返回 x。
func TestWhile(): Float32
{
var x = 1.0
var y = 10.0
while (x < y) {
x = x + 2.0
}
return x
}
对应的 While 实现:
func TestWhile(): Tensor
{
var x = parameter(Tensor(Float32(1.0)), "x")
var y = parameter(Tensor(Float32(10.0)), "y")
var body = {x: Tensor, y: Tensor =>
var x_new = x + Float32(2.0)
return [x_new, y]
}
var whileRes = While(x < y, body(x, y), x, [x, y])
return whileRes.evaluate()
}
输出为:
Tensor(shape=[1], dtype=Float32, value= [1.10000000e+01])
示例 2:
仓颉 While:循环变量 x,y,循环体内 x 更新,y 更新,返回 x + 5。
func TestWhile(): Float32
{
var x = 1.0
x = x + 2.0
var y = 10.0
while (x < y) {
x = x + 3.0
y = y + 1.0
}
return x + 5.0
}
对应的 While 实现:
func TestWhile(): Tensor
{
var x = parameter(Tensor(Float32(1.0)), "x")
x = x + Float32(2.0)
var y = parameter(Tensor(Float32(10.0)), "y")
var body = {x: Tensor, y: Tensor =>
var x_new = x + Float32(3.0)
var y_new = y + Float32(1.0)
return [x_new, y_new]
}
var whileRes = While(x < y, body(x, y), x + Float32(5.0), [x, y])
return whileRes.evaluate()
}
输出为:
Tensor(shape=[1], dtype=Float32, value= [2.00000000e+01])
示例 3:
仓颉 While:循环变量 x,y,z,循环体内 x 更新,y 不更新,z 更新,返回 x + z。
func TestWhile(): Float32
{
var x = 1.0
var y = 10.0
var z = x
while (x < y) {
x = x + 2.0
z = z + 1.0
}
return x + z
}
对应的 While 实现:
func TestWhile(): Tensor
{
var x = parameter(Tensor(Float32(1.0)), "x")
var y = parameter(Tensor(Float32(10.0)), "y")
var z = parameter(Tensor(Float32(1.0)), "z")
var body = {x: Tensor, y: Tensor, z: Tensor =>
var x_new = x + Float32(2.0)
var z_new = z + Float32(1.0)
return [x_new, y, z_new]
}
var whileRes = While(x < y, body(x, y, z), x + z, [x, y, z])
return whileRes.evaluate()
}
输出为:
Tensor(shape=[1], dtype=Float32, value= [1.70000000e+01])
示例 4:
仓颉 While:循环变量 x,y,循环体内 x 更新,y 更新,返回 x。
func TestWhile(): Float32
{
var x = 1.0
var y = 10.0
while (x < y) {
x = x + 2.0
y = y + 1.0
x = x + y
}
return x
}
对应的 While 实现:
func TestWhile(): Tensor
{
var x = parameter(Tensor(Float32(1.0)), "x")
var y = parameter(Tensor(Float32(10.0)), "y")
var body = {x: Tensor, y: Tensor =>
var x_new = x + Float32(2.0)
var y_new = y + Float32(1.0)
x_new = x_new + y_new
return [x_new, y_new]
}
var whileRes = While(x < y, body(x, y), x, [x, y])
return whileRes.evaluate()
}
输出为:
Tensor(shape=[1], dtype=Float32, value= [1.40000000e+01])
zeros
public func zeros(shape: Array<Int64>, dtype: Int32): Tensor
函数 zeros 用于根据输入的 shape 和 dtype 构造全 0 Tensor。
输入:
| 名称 | 含义 |
|---|---|
| shape | 输出 Tensor 的形状,必须是正整型数据 |
| dtype | 输出 Tensor 的数据类型,可选类型 FLOAT16,FLOAT32, FLOAT64, INT32, INT64, BOOL |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出的 Tensor, 其 shape 和 dtype 和输入的一致 |
支持平台:Ascend, GPU, CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let shape = Array<Int64>([2, 2])
let dtype = Int32(FLOAT32)
let output = zeros(shape, dtype)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 2], dtype=Float32, value=
[[0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00]])
zerosLike
public func zerosLike(input: Tensor): Tensor
函数 zerosLike 用于根据输入 Tensor 的 shape 和 dtype 构造全 0 Tensor。
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,其 shape 和 dtype 跟 input 相同。 |
支持平台:Ascend, GPU, CPU
微分伴随函数:
public func adjointZerosLike(x: Tensor)
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
main(): Int64
{
let input = Tensor(Array<Float32>([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]), shape: Array<Int64>([2, 3]))
let output = zerosLike(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[0.00000000e+00 0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00 0.00000000e+00]])
附录 E NN API
仓颉 TensorBoost 中 NN 包提供优化器,网络层和损失函数的构造方法。
构造优化器、网络层或损失函数时,如果输入不符合要求,会抛出异常,有以下几种类型:
- 初始化数据类型不支持
- 初始化参数选项不支持
- 初始化参数值不符合要求
- 初始化 Tensor 的形状不符合要求
Cell 接口
Layer 和 Loss 结构都继承以下接口,如需使用,要导入 nn package (from CangjieTB import nn.*) 。
接口定义:
public interface CellUnary {
operator func ()(input0: Tensor): Tensor
}
public interface CellBinary {
operator func ()(input0: Tensor, input1: Tensor): Tensor
}
public interface CellTernary {
operator func ()(input0: Tensor, input1: Tensor, input2: Tensor): Tensor
}
public interface CellQuaternarynary {
operator func ()(input0: Tensor, input1: Tensor, input2: Tensor, input3: Tensor): Tensor
}
public interface CellQuintuplenaryToTuple {
operator func ()(input0: Tensor, input1: Tensor, input2: Tensor, input3: Tensor, input4: Tensor): (Tensor, Tensor, Tensor)
}
public interface CellSevenTuplenary {
operator func ()(input0: Tensor, input1: Tensor, input2: Tensor, input3: Tensor, input4: Tensor, input5: Tensor, input6: Tensor): Tensor
}
public interface CellUnaryToTuple {
operator func ()(input0: Tensor): (Tensor, Tensor, Tensor)
}
public interface CellBinaryToTuple {
operator func ()(input0: Tensor, input1: Tensor): (Tensor, Tensor, Tensor)
}
optimizer
仓颉 TensorBoost 的 优化器 使用 struct 表示,用户只要导入 nn.optim package (from CangjieTB import nn.optim.*) 即可直接使用仓颉 TensorBoost 已经封装好的优化器。
优化器基类
public abstract class BaseOptim<T0> where T0 <: OptDiff {
public func getParameters()
public func getOptParameters()
public func update(gradients: T0): Tensor
}
所有优化器的基类,不要直接使用此类,实例化它的子类。OptDiff 接口定义详见 第四章:创建和收集 parameter
优化器基类提供以下方法供用户使用:
| 名称 | 作用 |
|---|---|
| getParameters | 获取模型参数 |
| getOptParameters | 获取优化器参数 |
| update | 用于更新网络权重 |
其中 update 方法参数列表:
| 名称 | 含义 |
|---|---|
| gradients | 更新网络权重所需的梯度,类型与需要更新权重的网络模型一致。 |
Adam 优化器
public class AdamOptimizer<T0> <: BaseOptim<T0> where T0 <: OptDiff {
public init(net: T0, learningRate!: Float32=0.001, beta1!: Float32=0.9, beta2!: Float32=0.999, eps!: Float32=0.00000001, weightDecay!: Float32 = 0.0, lossScale!: Float32 = 1.0, useLocking!: Bool = false, useNesterov!: Bool = false)
public init(net: T0, learningRate: Tensor, beta1!: Float32=0.9, beta2!: Float32=0.999, eps!: Float32=0.00000001, weightDecay!: Float32 = 0.0, lossScale!: Float32 = 1.0, useLocking!: Bool = false, useNesterov!: Bool = false)
}
使用的算子:
public func adam(parameter: Tensor, moment1: Tensor, moment2: Tensor, beta1Power: Tensor, beta2Power: Tensor, learningRate: Tensor, beta1: Tensor, beta2: Tensor, eps: Tensor, gradOut: Tensor, useLocking: Bool, useNesterov: Bool): Tensor
Adam(Adaptive Moment Estimation) 算法,是在论文 Adam: A Method for Stochastic Optimization 中提出的一种优化方法,利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。公式如下:
$$ \begin{split}\begin{array}{ll} \ m = \beta_1 * m + (1 - \beta_1) * g \ v = \beta_2 * v + (1 - \beta_2) * g * g \ l = \alpha * \frac{\sqrt{1-\beta_2^t}}{1-\beta_1^t} \ w = w - l * \frac{m}{\sqrt{v} + \epsilon} \end{array}\end{split} $$
m 表示第一个矩向量;v 表示第二个矩向量;g 表示梯度;l 表示比例因子;
$\beta_1, \beta_2$ 表示 beta1,beta2;t 表示更新步骤;
$beta_1^t beta_2^t$ 表示 beta1Power 和 beta2Power;
$\alpha$ 表示 learningRate;w 表示 parameter;
$\epsilon$ 表示 eps。
构造方法参数列表:
| 名称 | 含义 |
|---|---|
| net | 需要更新权重的网络 |
| learningRate | 学习率,支持 Float32 的数字(>= 0.0)和非 Parameter 类型的 Tensor(必须为 1 维,且每个元素都>=0),Tensor 的 dtype 必须为 Float32。数字表示静态学习率,Tensor 表示动态学习率。默认值:1e-3 |
| beta1 | 第一个矩估计的指数衰退率,Float32 类型,范围是 (0.0, 1.0)。默认值:0.9 |
| beta2 | 第二个矩估计的指数衰退率,Float32 类型,范围是 (0.0, 1.0)。默认值:0.999 |
| eps | 加到分母增加数值稳定性的极小项,Float32 类型,大于 0。默认值:1e-8 |
| weightDecay | 权重衰减,Float32 类型(>= 0)。默认值:0.0 |
| lossScale | Float32 类型,大于 0,默认值:1.0 |
| useLocking | 是否加锁以让 tensor 不被更新。Bool 类型,默认值:false |
| useNesterov | 是否使用 Nesterov Accelerated Gradient (NAG) 算法更新梯度。Bool 类型,默认值:false |
支持平台:GPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import nn.*
from CangjieTB import nn.optim.*
from CangjieTB import nn.loss.*
from CangjieTB import nn.layers.*
from CangjieTB import context.*
from CangjieTB import macros.*
@OptDifferentiable
public struct Net {
let dense1: Dense
init(dense1_: Dense) {
dense1 = dense1_
}
@Differentiable
operator func ()(input: Tensor): Tensor {
input |> this.dense1
}
}
@Differentiable[except: [lossFn, input, label]]
func train(net: Net, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor): Tensor
{
var output = net(input)
var lossTensor = lossFn(output, label)
return lossTensor
}
func gradient(net: Net, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor): (Tensor, Net)
{
var adj = @AdjointOf(train)
var (loss, bp) = adj(net, lossFn, input, label)
var gradout = bp(Tensor(Float32(1.0)))
return (loss, gradout)
}
main(): Int64
{
let weight_init = initialize(Array<Int64>([16,2048]), initType:InitType.NORMAL, dtype:FLOAT32)
let dense = Dense(2048, 16, weight_init,has_bias: true)
let net = Net(dense)
// var optim = AdamOptimizer<Net>(net, learningRate: 0.001) // 初始化优化器,learningRate 采用静态学习率
var lrArrary: Array<Float32> = Array<Float32>([0.01, 0.008])
var learningRate = Tensor(lrArrary, shape: [lrArrary.size])
var optim = AdamOptimizer<Net>(net, learningRate) // 初始化优化器,learningRate 采用动态学习率
let input = parameter(initialize(Array<Int64>([16,2048]), initType:InitType.NORMAL,dtype:FLOAT32), "data")
let label = parameter(initialize(Array<Int64>([16,16]),initType:InitType.NORMAL,dtype:FLOAT32), "lable")
var lossFn = SoftmaxCrossEntropyWithLogits(sparse: false)
var num = 0
var epoch = 1
while (num < epoch) {
var (loss, gradout) = gradient(net,lossFn, input, label)
optim.update(gradout) // 网络更新,gradient 表示模型梯度,由自动微分获得
print(loss.getShape())
print("\n")
print(net.dense1.weight_.getShape())
num++
}
return 0
}
输出为:
[]
[16, 2048]
Momentum 优化器
public class MomentumOptimizer<T0> <: BaseOptim<T0> where T0 <: OptDiff {
public init(net: T0, learningRate: Float32, momentum: Float32, weightDecay!: Float32 = 0.0, lossScale!: Float32 = 1.0)
public init(net: T0, learningRate: Tensor, momentum: Float32, weightDecay!: Float32 = 0.0, lossScale!: Float32 = 1.0)
}
使用的算子:
public func applyMomentum(parameter: Tensor, accumlation: Tensor, learningRate: Tensor, gradOut: Tensor, momentum: Tensor): Tensor
Momentum 算法,是在论文On the importance of initialization and momentum in deep learning 中提出的一种优化方法,主要为了降低梯度更新的高敏感性,使得梯度更新方向趋于一致,加快收敛速度。公式如下:
$$ accum = accum * momentum + grad $$
$$ w -= lr * accum $$
其中,$w$ 是待更新的参数,$grad$ 是更新到 $w$ 的梯度,accum 是 grad 的累加 tensor。
构造方法参数列表:
| 名称 | 含义 |
|---|---|
| net | 需要更新权重的网络 |
| learningRate | 学习率,支持 Float32 的数字(>= 0.0)和非 Parameter 类型的 Tensor(必须为 1 维,且每个元素都>=0),Tensor 的 dtype 必须为 Float32。数字表示静态学习率,Tensor 表示动态学习率 |
| momentum | 动量,Float32 类型(>= 0.0),用于更新梯度。 |
| weightDecay | 权重衰减,Float32 类型(>= 0.0)。默认值:0.0 |
| lossScale | loss 缩放,Float32 类型,大于 0.0,默认值:1.0 |
支持平台:GPU
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import nn.*
from CangjieTB import nn.optim.*
from CangjieTB import nn.loss.*
from CangjieTB import nn.layers.*
from CangjieTB import context.*
from CangjieTB import macros.*
@OptDifferentiable
public struct Net {
let dense1: Dense
init(dense1_: Dense) {
dense1 = dense1_
}
@Differentiable
operator func ()(input: Tensor): Tensor {
input |> this.dense1
}
}
@Differentiable[except: [lossFn, input, label]]
func train(net: Net, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor): Tensor
{
var output = net(input)
var lossTensor = lossFn(output, label)
return lossTensor
}
func gradient(net: Net, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor): (Tensor, Net)
{
var adj = @AdjointOf(train)
var (loss, bp) = adj(net, lossFn, input, label)
var gradout = bp(Tensor(Float32(1.0)))
return (loss, gradout)
}
main(): Int64
{
let weight_init = initialize(Array<Int64>([16,2048]), initType:InitType.NORMAL, dtype:FLOAT32)
let dense = Dense(2048, 16, weight_init,has_bias: true)
let net = Net(dense)
var lrArrary: Array<Float32> = Array<Float32>([0.01, 0.008])
var learningRate = Tensor(lrArrary, shape: [lrArrary.size])
let momentum: Float32 = 0.9
var optim = MomentumOptimizer<Net>(net, learningRate, momentum) // 初始化优化器,learningRate 采用动态学习率
let input = parameter(initialize(Array<Int64>([16,2048]), initType:InitType.NORMAL,dtype:FLOAT32), "data")
let label = parameter(initialize(Array<Int64>([16,16]),initType:InitType.NORMAL,dtype:FLOAT32), "lable")
var lossFn = SoftmaxCrossEntropyWithLogits(sparse: false)
var num = 0
var epoch = 1
while (num < epoch) {
var (loss, gradout) = gradient(net,lossFn, input, label)
optim.update(gradout) // 网络更新,gradient 表示模型梯度,由自动微分获得
print(loss.getShape())
print("\n")
print(net.dense1.weight_.getShape())
num++
}
return 0
}
输出为:
[]
[16, 2048]
SGD 优化器
public class SGDOptimizer<T0> <: BaseOptim<T0> where T0 <: OptDiff {
public init(net: T0, learningRate: Tensor, momentum!: Float32 = 0.0, dampening!: Float32 = 0.0, weightDecay!: Float32 = 0.0, nesterov!: Bool = false, lossScale!: Float32 = 1.0)
public init(net: T0, learningRate!: Float32 = 0.1, momentum!: Float32 = 0.0, dampening!: Float32 = 0.0, weightDecay!: Float32 = 0.0, nesterov!: Bool = false, lossScale!: Float32 = 1.0)
}
使用的算子:
public func sgd(parameters: Tensor, gradient: Tensor, learningRate: Tensor, accum: Tensor, momentum: Tensor, stat: Tensor, dampening!: Float32 = 0.0, weightDecay!: Float32 = 0.0, nesterov!: Bool = false): Tensor
SGD 算法,实现随机梯度下降。 momentum 是可选的。Nesterov 动量基于论文 On the importance of initialization and momentum in deep learning.中的公式:
$$ v_{t+1} = u \ast v_{t} + gradient \ast (1-dampening) $$
If nesterov is true:
$$ p_{t+1} = p_{t} - lr \ast (gradient + u \ast v_{t+1}) $$
If nesterov is false:
$$ p_{t+1} = p_{t} - lr \ast v_{t+1} $$
在第一次执行时:
$$ v_{t+1} = gradient $$
其中 p, v and u 分别表示 the parameters, accum, and momentum.
构造方法参数列表:
| 名称 | 含义 |
|---|---|
| net | 需要更新权重的网络 |
| learningRate | 学习率,支持 Float32 的数字(>= 0.0)和非 Parameter 类型的 Tensor(必须为 1 维,且每个元素都>=0),Tensor 的 dtype 必须为 Float32。数字表示静态学习率,Tensor 表示动态学习率 |
| momentum | 动量,Float32 类型(>= 0.0),用于更新梯度。默认值:0.0。 |
| dampening | 动量阻尼,Float32 类型(>= 0.0)。默认值:0.0。 |
| weightDecay | 权重衰减,Float32 类型(>= 0.0)。默认值:0.0。 |
| nesterov | 是否启用 Nesterov 向量,如果启用,dampening 必须为 0.0,Bool 类型。默认值:false。 |
| lossScale | loss 缩放,Float32 类型,大于 0.0,默认值:1.0 |
支持平台:Ascend、GPU
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import nn.*
from CangjieTB import nn.optim.*
from CangjieTB import nn.loss.*
from CangjieTB import nn.layers.*
from CangjieTB import context.*
from CangjieTB import macros.*
@OptDifferentiable
public struct Net {
let dense1: Dense
init(dense1_: Dense) {
dense1 = dense1_
}
@Differentiable
operator func ()(input: Tensor): Tensor {
input |> this.dense1
}
}
@Differentiable[except: [lossFn, input, label]]
func train(net: Net, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor): Tensor
{
var output = net(input)
var lossTensor = lossFn(output, label)
return lossTensor
}
func gradient(net: Net, lossFn: SoftmaxCrossEntropyWithLogits, input: Tensor, label: Tensor): (Tensor, Net)
{
var adj = @AdjointOf(train)
var (loss, bp) = adj(net, lossFn, input, label)
var gradout = bp(Tensor(Float32(1.0)))
return (loss, gradout)
}
main(): Int64
{
let weight_init = initialize(Array<Int64>([16,2048]), initType:InitType.NORMAL, dtype:FLOAT32)
let dense = Dense(2048, 16, weight_init,has_bias: true)
let net = Net(dense)
// var optim = SGDOptimizer<Net>(net, learningRate: 0.001) // 初始化优化器,learningRate 采用静态学习率
var lrArrary: Array<Float32> = Array<Float32>([0.01, 0.008])
var learningRate = Tensor(lrArrary, shape: [lrArrary.size])
var optim = SGDOptimizer<Net>(net, learningRate) // 初始化优化器,learningRate 采用动态学习率
let input = parameter(initialize(Array<Int64>([16,2048]), initType:InitType.NORMAL,dtype:FLOAT32), "data")
let label = parameter(initialize(Array<Int64>([16,16]),initType:InitType.NORMAL,dtype:FLOAT32), "lable")
var lossFn = SoftmaxCrossEntropyWithLogits(sparse: false)
var num = 0
var epoch = 1
while (num < epoch) {
var (loss, gradout) = gradient(net,lossFn, input, label)
optim.update(gradout) // 网络更新,gradient 表示模型梯度,由自动微分获得
print(loss.getShape())
print("\n")
print(net.dense1.weight_.getShape())
num++
}
return 0
}
输出为:
[]
[16, 2048]
layer
仓颉 TensorBoost 的 Layer 使用 struct 表示,用户只要导入 nn.layers package (from CangjieTB import nn.layers.*) 即可直接使用仓颉 TensorBoost 已经封装好的 Layer 结构。
2D 卷积层
Layer 定义:
public struct Conv2d {
public let weight_: Tensor
public let bias_: Tensor
public var in_channels_: Int64 = 0
public var out_channels_: Int64 = 0
public var kernel_sizes_: Array<Int64> = []
public var strides_: Array<Int64> = []
public var pad_mode_: String = ""
public var padding_: Array<Int64> = [0, 0, 0, 0]
public var dilations_: Array<Int64> = []
public var group_: Int64 = 0
public var has_bias_: Bool = false
public init(in_channels: Int64, out_channels: Int64, kernel_size: Array<Int64>, stride: Array<Int64>, pad_mode: String, padding: Array<Int64>, dilation: Array<Int64>, group: Int64, has_bias: Bool, weight: Tensor, bias: Tensor)
public init(in_channels: Int64, out_channels: Int64, kernel_size: Array<Int64>, stride!: Array<Int64> = Array<Int64>([1, 1]), pad_mode!: String = "same", padding!: Array<Int64> = Array<Int64>([0, 0, 0, 0]), dilation!: Array<Int64> = Array<Int64>([1, 1]), group!: Int64 = 1,has_bias!: Bool = false, weight_init!: InitType = InitType.NORMAL, bias_init!: InitType = InitType.ZERO)
public init(in_channels: Int64, out_channels: Int64, kernel_size: Array<Int64>, weight_init: BaseInitializer, bias_init: BaseInitializer, stride!: Array<Int64> = Array<Int64>([1, 1]), pad_mode!: String = "same", padding!: Array<Int64> = Array<Int64>([0, 0, 0, 0]),dilation!: Array<Int64> = Array<Int64>([1, 1]), group!: Int64 = 1, has_bias!: Bool = false)
public init(in_channels: Int64, out_channels: Int64, kernel_size: Array<Int64>, weight_init: Tensor, bias_init: Tensor, stride!: Array<Int64> = Array<Int64>([1, 1]), pad_mode!: String = "same", padding!: Array<Int64> = Array<Int64>([0, 0, 0, 0]), dilation!: Array<Int64> = Array<Int64>([1, 1]), group!: Int64 = 1, has_bias!: Bool = false)
}
extend Conv2d <: CellUnary {
@Differentiable
public operator func ()(input: Tensor): Tensor
}
Conv2d 是 2D 卷积层。输入 tensor 的 shape 是 (N, C_in, H_in, W_in),其中 N 是 batch_size,C_in 是 input channel number。对于每一个 batch 的数据 (C_in, H_in, W_in),Conv2d 卷积层按照如下的公式进行计算。
$$ out_j = \sum_{i=0}^{C_in - 1}ccor(W_{ij}, X_i) + b_j $$
其中 ccor 是互相关运算符,$C_{in}$ 为输入通道数, $j$ 的取值范围为 $0$ 到 $C_{out} - 1$, $W_{ij}$ 对应 第 j 个 filter 的第 i 个通道, $out_{j}$ 对应输出的第 j 个通道. $W_{ij}$ 的 shape 为 (kernel_size[0], kernel_size[1]), 其中 kernel_size[0] 和 kernel_size[1] 是卷积核的高度和宽度。完整卷积的 shape 为 ($C_{out}$, $C_{in}$ // group, kernel_size[0], kernel_size[1]), 其中 group 代表 input 在 channel 维度上被分组的数目。
当 pad_mode 为 valid 时,输出的高和宽分别为:
$$ \left \lfloor {1 + \frac{H_{in} + padding[0] + padding[1] - kernel_size[0]−(kernel_size[0]−1)×(dilation[0]−1) }{stride[0]}} \right \rfloor $$
和
$$ \left \lfloor {1 + \frac{W_{in} + padding[2] + padding[3] - kernel_size[1]−(kernel_size[1]−1)×(dilation[1]−1) }{stride[1]}} \right \rfloor $$
参数列表:
| 参数名称 | 含义 |
|---|---|
| in_channels | 输入通道数,支持 Int64 类型,必须是大于 0 的数值。 |
| out_channels | 输出通道数,支持 Int64 类型,必须是大于 0 的数值。 |
| kernel_size | 滑框大小,支持 Int64 类型 Array。 长度为 2 的数组,值必须小于输入 shape 的宽和高并且大于 0。 |
| stride | 滑窗跳步,支持 Int64 类型 Array。 长度为 2 的数组,值必须大于 0。 默认值:Array<Int64>([1, 1]) |
| pad_mode | padding 模式,String 类型。可选值为:"same"、"valid"。默认值:"same"。 same:采用补全的方式。输出的高度和宽度将与输入 x 相同。padding 的总数将在水平和垂直方向计算,并尽可能均匀地分布在顶部和底部,左侧和右侧。否则,最后一个额外的填充将从底部和右侧完成。如果设置了此模式,则 padding 必须为 Array<Int64>([0, 0, 0, 0])。 valid:采用丢弃方式。输出的可能最大高度和宽度将在没有填充的情况下返回。多余的像素将被丢弃。如果设置了此模式,则 padding 必须为 Array<Int64>([0, 0, 0, 0])。 pad:输入 x 两侧的隐式填充。填充的数量将被填充到输入张量边界。 padding 数组的元素必须大于或等于 0。 |
| padding | 输入的隐含 padding,支持 Int64 类型 Array。默认值:Array<Int64>([0, 0, 0, 0])。 |
| dilation | 内核元素之间的间距,支持 Int64 类型 Array。默认值:Array<Int64>([1, 1])。 |
| group | 权重分组数,支持 Int64 类型。默认值:1。 |
| has_bias | 是否有 bias,Bool 类型。默认值:false。 |
| weight_init | 权重初始化方式,支持三种方式: 1)支持 InitType 方式。可选值:ZERO、ONE、NORMAL。默认值:NORMAL。 2)BaseInitializer 随机初始化方式(RandomNormalInitializer,XavierUniformInitializer) 3)支持 FLOAT32 的 Tensor 初始化方式,非 Parameter 类型的 Tensor。 |
| bias_init | bias 初始化方式,支持初始化方式同 weight_init |
输入:
| 输入名称 | 含义 |
|---|---|
| input | shape 是 (N, $C_{in}$, $H_{in}$, $W_{in}$) 的 Tensor,dtype 为 Float32 |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (N, $C_{out}$, $H_{out}$, $W_{out}$) 的 Tensor,dtype 为 Float32 |
支持平台:Ascend、GPU、CPU
代码示例,权重初始化采用默认值,其他初始化方式参考 Tensor 的 API 的章节:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
main(): Int64 {
let input = randomNormalTensor(Array<Int64>([32, 1, 32, 32]))
let conv = Conv2d(1, 6, Array<Int64>([5, 5]))
let output = conv(input)
print(output.getShape())
return 0
}
输出为:
[32, 6, 32, 32]
3D 卷积层
Layer 定义:
public struct Conv3d {
public var inChannels_: Int64
public var outChannels_: Int64
public var kernelSizes_: Array<Int64>
public var strides_: Array<Int64>
public var padMode_: String
public var padding_: Array<Int64>
public var dilations_: Array<Int64>
public var group_: Int64
public var hasBias_: Bool
public let weight_: Tensor
public let bias_: Tensor
public init(inChannels: Int64, outChannels: Int64, kernelSizes: Array<Int64>, strides: Array<Int64>, padMode: String, padding: Array<Int64>, dilations: Array<Int64>, group: Int64, hasBias: Bool, weightInit: Tensor, biasInit: Tensor)
public init(inChannels: Int64, outChannels: Int64, kernelSizes!: Array<Int64> = [1, 1, 1], strides!: Array<Int64> = [1, 1, 1], padMode!: String = "same", padding!: Array<Int64> = [0, 0, 0, 0, 0, 0], dilations!: Array<Int64> = [1, 1, 1], group!: Int64 = 1, hasBias!: Bool = false, weightInit!: InitType = InitType.NORMAL, biasInit!: InitType = InitType.ZERO)
public init (inChannels: Int64, outChannels: Int64, weightInit: BaseInitializer, biasInit: BaseInitializer, kernelSizes!: Array<Int64> = [1, 1, 1], strides!: Array<Int64> = [1, 1, 1], padMode!: String = "same", padding!: Array<Int64> = [0, 0, 0, 0, 0, 0], dilations!: Array<Int64> = [1, 1, 1], group!: Int64 = 1, hasBias!: Bool = false)
public init (inChannels: Int64, outChannels: Int64, kernelSizes: Array<Int64>, strides: Array<Int64>, padMode: String, padding: Array<Int64>, dilations: Array<Int64>, group: Int64, hasBias: Bool, weightInit: Tensor, biasInit: Tensor)
}
extend Conv3d <: CellUnary {
@Differentiable
public operator func ()(input: Tensor): Tensor
}
Conv3d 是 3D 卷积层。输入 tensor 的 shape 是 (N, Cin, Din, Hin, Win),其中 N 是 batchSize,Cin 是 input channel number。对于每一个 batch 的数据 (Cin, Din, Hin, Win),Conv3d 卷积层按照如下的公式进行计算。
$$ out(N_i, C_{out_j}) = bias(C_{out_j}) + \sum_{k=0}^{C_in - 1}ccor(weight(C_{out_j}, k), X(N_i, k)) $$
其中 ccor 是互相关运算符,$C_{in}$ 为输入通道数, $out_j$ 对应输出的第 $j$ 个通道,$j$的取值范围在 [ $0$ , $C_{out} - 1$] 内, $weight(C_{out_j}, k)$ 是 shape 为 (kernel_size[0], kernel_size[1], kernel_size[2]) 的卷积核切片, 其中 kernel_size[0] , kernel_size[1], kernel_size[2] 是卷积核的深度、高度和宽度。bias 为偏置参数,X 为输入 Tensor, 完整卷积的 shape 为 ($C_{out}$, $C_{in}$ // group, kernel_size[0], kernel_size[1], kernel_size[2]), 其中 group 代表 X 在 channel 维度上被分组的数目。
当 padMode 为 valid 时,输出的深度、高度和宽度别为:
$$ D_{out} = \left \lfloor {1 + \frac{D_{in} + padding[0] + padding[1] − (dilation[0]−1) × kernelSize[0]−1 }{stride[0]}} \right \rfloor $$
$$ H_{out} = \left \lfloor {1 + \frac{D_{in} + padding[2] + padding[3] − (dilation[1]−1) × kernelSize[1]−1}{stride[1]}} \right \rfloor $$
$$ W_{out} = \left \lfloor {1 + \frac{D_{in} + padding[4] + padding[5] − (dilation[2]−1) × kernelSize[2]−1}{stride[2]}} \right \rfloor $$
参数列表:
| 参数名称 | 含义 |
|---|---|
| inChannels | 输入通道数,支持 Int64 类型,必须是大于 0 的数值。 |
| outChannels | 输出通道数,支持 Int64 类型,必须是大于 0 的数值。 |
| kernelSizes | 滑窗大小,支持 Int64 类型 Array。 长度为 3 的数组,值必须大于 0 且不大于 [Din, Hin, Win], 默认值:[1, 1, 1]。 |
| strides | 滑窗跳步,支持 Int64 类型 Array。 长度为 3 的数组,取值必须大于 0。 默认值:[1, 1, 1] |
| padMode | padding 模式,String 类型。可选值为:"same"、"valid"、"pad"。默认值:"same"。 same:采用补全的方式。输出的深度、高度和宽度分别与输入整除 stride 后的值相同。如果设置了此模式,则 padding 数组的元素必须等于 0。 valid:采用丢弃方式。输出的可能最大深度、高度和宽度将在没有填充的情况下返回。多余的像素将被丢弃。如果设置了此模式,则 padding 数组的元素必须等于 0。 pad:在输入的深度、高度和宽度方向上填充 padding 大小的 0。 则 padding 数组的元素必须大于或等于 0, 且 padding[0] 和 padding[1] 小于 kernelSizes[0] - 1) * dilations[0] + 1; padding[2] 和 padding[3] 小于 kernelSizes[1] - 1) * dilations[1] + 1; padding[4] 和 padding[5] 小于 kernelSizes[2] - 1) * dilations[2] + 1。 |
| padding | 输入的深度、高度和宽度方向上填充的数量, 支持 Int64 类型 Array。默认值:[0, 0, 0, 0, 0, 0]。 |
| dilations | 卷积核元素之间的间距,长度是 3 的数组, 支持 Int64 类型 Array。第 1 维仅支持取 1, 其余值需要大于等于 1。默认值:[1, 1, 1]。 |
| group | 权重分组数,支持 Int64 类型, 当前仅支持 1。默认值:1。 |
| hasBias | 是否有 bias,Bool 类型。默认值:false。 |
| weight_init | 权重初始化方式,支持三种方式: 1)支持 InitType 方式。可选值:ZERO、ONE、NORMAL。默认值:NORMAL。 2)BaseInitializer 随机初始化方式(RandomNormalInitializer,XavierUniformInitializer) 3)支持 FLOAT32 的 Tensor 初始化方式,非 Parameter 类型的 Tensor, shape 为 [outChannels, inChannels / group, kernelSizes[0], kernelSizes[1], kernelSizes[2]]。 |
| biasInit | bias 初始化方式,支持初始化方式同 weightInit, 当使用 Tensor 初始化时, 支持 FLOAT32 类型, shape 为 [outChannels]。 |
输入:
| 输入名称 | 含义 |
|---|---|
| input | shape 是 (N, $C_{in}$, $D_{in}$, $H_{in}$, $W_{in}$) 的 Tensor,支持 Float32 数据类型 |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (N, $C_{out}$, $D_{out}$, $H_{out}$, $W_{out}$) 的 Tensor,数据类型与输入一致 |
支持平台:Ascend、GPU、CPU
代码示例,权重初始化采用默认值,其他初始化方式参考 Tensor 的 API 的章节:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
main(): Int64 {
let input = randomNormalTensor(Array<Int64>([32, 1, 32, 32, 32]))
let conv = Conv3d(1, 6, kernelSizes: [1, 1, 1])
let output = conv(input)
print(output.getShape())
return 0
}
输出为:
[32, 6, 32, 32, 32]
BatchNorm2d 层
Layer 定义:
public struct BatchNorm2d {
public let moving_mean_: Tensor
public let moving_variance_: Tensor
public let gamma_: Tensor
public let beta_: Tensor
public var num_features_: Int64
public var eps_: Float32
public var momentum_: Float32 = 0.0
public var affine_: Bool = false
public var use_batch_statistics_: Int64 = -1
public var isTraining_: Bool = true
public init(num_features__: Int64, eps__: Float32, momentum__: Float32, affine__: Bool, use_batch_statistics__: Int64, moving_mean__: Tensor, moving_variance__: Tensor, gamma__: Tensor, beta__: Tensor, isTraining__: Bool)
public init(num_features: Int64, eps!: Float32 = 1e-5, momentum!: Float32 = 0.9, affine!: Bool = true, gamma_init!: InitType = InitType.ONE, beta_init!: InitType = InitType.ZERO, moving_mean_init!: InitType = InitType.ZERO, moving_var_init!: InitType = InitType.ONE, use_batch_statistics!: Int64 = -1, isTraining!: Bool = true)
public mut func setTrain(mode: Bool)
}
extend BatchNorm2d <: CellUnary {
public operator func ()(input: Tensor): Tensor
}
4D 输入上的批量归一化层。仓颉 TensorBoost 只支持 'NCHW' 数据格式。
批处理规范化广泛用于卷积网络中。它使用少量数据和学习到的参数来重新缩放和更新功能,具体可参考如下公式。
$$ y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta $$
参数列表:
| 参数名称 | 含义 |
|---|---|
| num_features | 输入(N,C,H,W)中的 C |
| eps | 分母中增加的值,以保证数值稳定性。默认值:1e-5 |
| momentum | 用于 running_mean 和 running_var 计算的动量的浮动超参数。默认值:0.9 |
| affine | 设置为 true 时,可以学习 gamma 和 beta。默认值:true |
| gamma_init | gamma 权重的初始化。包括 ZERO,ONE 等。默认值:ONE |
| beta_init | beta 权重的初始化。包括 ZERO,ONE 等。默认值:ZERO |
| moving_mean_init | 移动平均值的初始化。包括 ZERO,ONE 等。默认值:ZERO |
| moving_var_init | 移动方差的初始化。包括 ZERO,ONE 等。默认值:ONE |
| use_batch_statistics | 取 1 时,则使用当前批处理数据的平均值和方差值,并跟踪运行平均值和运行方差;取 0 时,则使用指定值的平均值和方差值,不跟踪统计值;取 -1 时,当 isTraning 为 true 时,则使用当前批处理数据的平均值和方差值,并跟踪运行平均值和运行方差,当 isTraning 为 false 时,则使用指定值的平均值和方差值,不跟踪统计值。必须为以上三种取值,默认值 -1。 |
| isTraining | 仅在 use_batch_statistics 为 -1 时有效,默认值 true ,可通过成员函数 setTrain(mode: Bool) 来设置。 |
输入:
| 输入名称 | 含义 |
|---|---|
| input | shape 是 (N, C, H, W) 的 Tensor, 支持 Float16\Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (N, C, H, W) 的 Tensor |
支持平台:GPU
代码示例:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
main(): Int64 {
let input = randomNormalTensor(Array<Int64>([1, 3, 224, 224]))
let bn = BatchNorm2d(3)
let output = bn(input)
print(output.getShape())
return 0
}
输出为:
[1, 3, 224, 224]
BatchNorm3d 层
Layer 定义:
public struct BatchNorm3d {
public let movingMean_: Tensor
public let movingVariance_: Tensor
public let gamma_: Tensor
public let beta_: Tensor
public var numFeatures_: Int64
public var eps_: Float32 = 1e-5
public var momentum_: Float32 = 0.0
public var affine_: Bool = false
public var useBatchStatistics_: Int64 = 0
public var isTraining_: Bool = true
public init(numFeatures: Int64, eps!: Float32 = 1e-5, momentum!: Float32 = 0.9, affine!: Bool = true, gammaInit!: InitType = InitType.ONE, betaInit!: InitType = InitType.ZERO, movingMeanInit!: InitType = InitType.ZERO, movingVarianceInit!: InitType = InitType.ONE, useBatchStatistics!: Int64 = -1, isTraining!: Bool = true)
public mut func setTrain(mode: Bool)
}
extend BatchNorm3d <: CellUnary {
public operator func ()(input: Tensor): Tensor
}
5D 输入上的批量归一化层。仓颉 TensorBoost 只支持 'NCDHW' 数据格式。
批处理规范化广泛用于卷积网络中。它使用少量数据和学习到的参数来重新缩放和更新功能,具体可参考如下公式。
$$ y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta $$
参数列表:
| 参数名称 | 含义 |
|---|---|
| numFeatures | 输入(N,C,D, H,W)中的 C |
| eps | 分母中增加的值,以保证数值稳定性。默认值:1e-5 |
| momentum | 用于 running_mean 和 running_var 计算的动量的浮动超参数。默认值:0.9 |
| affine | 设置为 true 时,可以学习 gamma 和 beta。默认值:true |
| gammaInit | gamma 权重的初始化。包括 ZERO,ONE 等。默认值:ONE |
| betaInit | beta 权重的初始化。包括 ZERO,ONE 等。默认值:ZERO |
| movingMeanInit | 移动平均值的初始化。包括 ZERO,ONE 等。默认值:ZERO |
| movingVarianceInit | 移动方差的初始化。包括 ZERO,ONE 等。默认值:ONE |
| useBatchStatistics | 取 1 时,则使用当前批处理数据的平均值和方差值,并跟踪运行平均值和运行方差;取 0 时,则使用指定值的平均值和方差值,不跟踪统计值;取 -1 时,当 isTraning 为 true 时,则使用当前批处理数据的平均值和方差值,并跟踪运行平均值和运行方差,当 isTraning 为 false 时,则使用指定值的平均值和方差值,不跟踪统计值。必须为以上三种取值,默认值 -1。 |
| isTraning | 仅在 useBatchStatistics 为 -1 时有效,默认值 true ,可通过成员函数 setTrain(mode: Bool) 来设置。 |
输入:
| 输入名称 | 含义 |
|---|---|
| input | shape 是 (N, C, D, H, W) 的 Tensor, 支持 Float16\Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (N, C, D, H, W) 的 Tensor |
支持平台:GPU
代码示例:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
from CangjieTB import common.*
main(): Int64 {
let net = BatchNorm3d(1)
let inputX = Tensor(Array<Float32>([1.5, -1.0, -0.5, 2.5]), shape: Array<Int64>([1, 1, 2, 1, 2]))
let output = net(inputX)
print(output)
return 0
}
输出为:
Tensor(shape=[1, 1, 2, 1, 2], dtype=Float32, value=
[[[[[ 6.11591339e-01 -1.13581240e+00]]
[[-7.86331654e-01 1.31055284e+00]]]]])
Dense 层
Layer 定义:
public struct Dense {
public let weight_: Tensor
public let bias_: Tensor
public var has_bias_: Bool
public var activation_: String
public init()
public init(has_bias: Bool, activation: String, weight: Tensor, bias: Tensor)
public init(in_channels: Int64, out_channels: Int64, weight_init!: InitType = InitType.NORMAL, bias_init!: InitType = InitType.ZERO,has_bias!: Bool = true, activation!: String = "NOACT")
public init(in_channels: Int64, out_channels: Int64, weight_init: BaseInitializer, bias_init!: InitType = InitType.ZERO,has_bias!: Bool = true, activation!: String = "NOACT")
public init(in_channels: Int64, out_channels: Int64, weight_init: Tensor, bias_init!: InitType = InitType.ZERO, has_bias!: Bool = true, activation!: String = "NOACT")
}
extend Dense <: CellUnary {
public operator func ()(input: Tensor): Tensor
}
Dense 是全连接层。Dense 全连接层按照如下的公式进行计算。
$$ outputs=activation(inputs∗kernel+bias), $$
其中 activation 是 Dense 层指定的激活函数(目前支持的激活函数包括 "RELU", "RELU6", "TANH", "GELU", "SIGMOID" 和 "SWISH"),kernel 是 Dense 层的权重矩阵,bias 是 Dense 层的偏置向量。
后续计划支持的其他激活函数列表: 'softmax': Softmax, 'logsoftmax': LogSoftmax, 'fast_gelu': FastGelu, 'elu': ELU, 'prelu': PReLU, 'leakyrelu': LeakyReLU, 'hardswish': HSwish, 'hsigmoid': HSigmoid, 'logsigmoid': LogSigmoid
参数列表:
| 名称 | 含义 |
|---|---|
| in_channels | 输入通道数,支持 Int64 类型,必须是大于 0 的数值。 |
| out_channels | 输出通道数,支持 Int64 类型,必须是大于 0 的数值。 |
| weight_init | 权重初始化方式,支持三种方式: 1)支持 InitType 方式。可选值:ZERO、ONE、NORMAL。默认值:NORMAL。 2)BaseInitializer 随机初始化方式(RandomNormalInitializer,XavierUniformInitializer) 3)支持 FLOAT32 的 Tensor 初始化方式, 非 Parameter 类型的 Tensor |
| bias_init | bias 初始化方式,支持初始化方式同 weight_init |
| has_bias | 是否有 bias。Bool 类型,默认值:true。 |
| activation | Dense 层指定的激活器,使用 String 类型表示。目前支持 "NOACT","RELU","RELU6","TANH","GELU","SIGMOID" 和 "SWISH", 后续会补充更多激活函数。默认值:"NOACT"。 |
【备注】“SWISH” 按照如下的公式进行计算:
$$ y = \frac{x}{e^{-x} + 1.0} $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入的 Tensor,必须大于或等于 2 维。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出的 Tensor |
支持平台:Ascend、GPU、CPU
代码示例,权重初始化采用默认值,其他初始化方式参考 Tensor 的 API 的章节:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
main(): Int64 {
let input = randomNormalTensor(Array<Int64>([9, 8, 32]))
let dense = Dense(32, 16, has_bias: true, activation: "SWISH")
let output = dense(input)
print(output.getShape())
return 0
}
输出为:
[9, 8, 16]
Dropout 层
Layer 定义:
public struct Dropout {
public var keepProb_: Float32
public var seed0_: Int64
public var seed1_: Int64
public var training_: Bool = true
public init(keepProb!: Float32 = 0.5, training!: Bool = true)
}
extend Dropout <: CellUnary {
public operator func ()(input: Tensor): Tensor
}
Dropout 是一种正则化手段,根据丢弃概率 1 − keepProb,在训练过程中随机将一些神经元输出设置为 0.0,通过阻止神经元节点间的相关性来减少过拟合,在推理过程中,此层返回与 input 相同的 Tensor。
参数列表:
| 参数名称 | 含义 |
|---|---|
| keepProb | 输入神经元保留率,取值在 (0.0, 1.0] 之间,默认为 0.5 |
| training | 是否处于 training 状态。当 Dropout Layer 处于 training 状态时会对输入进行随机的 drop,否则对输入不做处理,默认为 true |
输入:
| 输入名称 | 含义 |
|---|---|
| input | Float32 类型的 Tensor |
输出:
| 名称 | 含义 |
|---|---|
| output | Dropout 操作之后的结果,Float32 类型的 Tensor,shape 和输入相同 |
支持平台:Ascend、GPU、CPU
代码示例:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
main(): Int64 {
let input = randomNormalTensor(Array<Int64>([2, 8]))
let dropoutLayer = Dropout(keepProb: 0.2)
let output = dropoutLayer(input)
print(output.getShape())
return 0
}
输出为:
[2, 8]
Embedding 层
Layer 定义:
public struct Embedding {
public let embeddingTable: Tensor
public var vocabSize_: Int64 = 0
public var embeddingSize_: Int64 = 0
public var useOneHot_: Bool = false
public init(vocabSize__!: Int64 = 0, embeddingSize__!: Int64 = 0, useOneHot__!: Bool = false, embeddingTable_!: Tensor = Tensor())
public init(vocabSize: Int64, embeddingSize: Int64, initType: BaseInitializer, useOneHot!: Bool = false, paddingIdx!: Option<Int64> = None)
public init(vocabSize: Int64, embeddingSize: Int64, initType!: InitType = InitType.NORMAL, useOneHot!: Bool = false, paddingIdx!: Option<Int64> = None)
}
extend Embedding <: CellUnary {
public operator func ()(inputIds: Tensor): Tensor
}
Embedding Layer 是一个简单的查表层,记录了固定大小的嵌入向量。
该层常用于记录词向量,用索引来查词。layer 的输入是一系列的索引值,输出为索引值对应的词向量。
参数列表:
| 参数名称 | 含义 |
|---|---|
| vocabSize | Int64 类型,嵌入向量的词库大小 |
| embeddingSize | Int64 类型,每个嵌入向量的大小 |
| initType | BaseInitializer 类型或 InitType 类型,layer 中嵌入向量的初始化方式,默认为正态分布。 |
| useOneHot | Bool 类型,表明是否使用 One Hot 的方式来进行初始化,默认为 false |
| paddingIdx | Option |
输入:
| 输入名称 | 含义 |
|---|---|
| inputs | 输入的索引 Tensor,shape 为(batchSize, inputLength),dtype 是 Int32,索引值应在(0, vocabSize) 之间,否则索引所对应的输出向量为 0 向量。 |
输出:
| 名称 | 含义 |
|---|---|
| outputs | 嵌入向量 Tensor,shape 为(batchSize, inputLength, embeddingSize),dtype 是 FLOAT32 |
支持平台:Ascend、GPU
代码示例:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
from CangjieTB import common.*
main(): Int64 {
let indexs: Array<Int32> = Array<Int32>([4, 7, 5, 0, 3])
let inputIds = parameter(Tensor(indexs, shape: Array<Int64>([5])), "inputIds")
let embeddingSize: Int64 = 4
let vocabSize: Int64 = 8
let embeddingLayer = Embedding(vocabSize,
embeddingSize,
initType: InitType.XAVIERUNIFORM,
useOneHot: false)
let forwardOutput = embeddingLayer(inputIds)
print(forwardOutput.getShape())
return 0
}
输出为:
[5, 4]
Flatten 层
Layer 定义:
public struct Flatten {}
extend Flatten <: CellUnary {
public operator func ()(input: Tensor): Tensor
}
Flatten 是数据展平层,按如下公式进行计算。
$$ input shape:(N, dims) \\ output shape:(N, \Pidims) $$
输入:
| 名称 | 含义 |
|---|---|
| input | shape 是 $(N, *dims)$ 的 Tensor |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 $(N, \Pi*dims)$ 的 Tensor |
支持平台:Ascend、GPU
代码示例:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
main(): Int64 {
let input = randomNormalTensor(Array<Int64>([32, 1, 32, 32]))
let flatten= Flatten()
let output = flatten(input)
print(output.getShape())
return 0
}
输出为:
[32, 1024]
LayerNorm 层
layer 定义:
public struct LayerNorm {
public let gamma_: Tensor
public let beta_: Tensor
public var beginNormAxis_: Int64 = -1
public var beginParamsAxis_: Int64 = -1
public var epsilon_: Float32 = 1e-7
public init(beginNormAxis__!: Int64 = -1, beginParamsAxis__!: Int64 = -1, epsilon__!: Float32 = 1e-7, gamma__!: Tensor = Tensor(), beta__!: Tensor = Tensor())
public init(normalizedShape: Array<Int64>, beginNormAxis!: Int64 = -1, beginParamsAxis!: Int64 = -1, gammaInit!: InitType = InitType.ONE, betaInit!: InitType = InitType.ZERO, epsilon!: Float32 = 1e-7)
}
extend LayerNorm <: CellUnary {
public operator func ()(input: Tensor): Tensor
}
根据给定的轴对输入的 Tensor 进行归一化。计算公式如下:
$$ y = {x− \text{mean} \over \sqrt {\text{variance}+ϵ}}∗\gamma+\beta $$
其中,$\gamma$是$gamma$,$\beta$是$beta$,$\epsilon$是$epsilon$。
输入:
| 输入名称 | 含义 |
|---|---|
| input | 输入 Tensor,目前只支持 Float32 类型。 |
参数列表:
| 参数名称 | 含义 |
|---|---|
| normalizedShape | 指定 shape 对 gamma 和 beta 初始化,支持 Array<Int64>。 |
| gammaInit | gammaInit 参数,可跟随网络进行训练,对输出结果进行缩放,支持 InitType 初始化方式,默认值是 InitType.ONE。 |
| betaInit | betaInit 参数,可跟随网络进行训练,对输出结果进行平移,支持 InitType 初始化方式,默认值是 InitType.ZERO。 |
| gamma | gamma 参数初始化的 Tensor,可跟随网络进行训练,对输出结果进行缩放。 |
| beta | beta 参数初始化的 Tensor,可跟随网络进行训练,对输出结果进行平移。 |
| beginNormAxis | 对输入开始执行归一化的维度,value 必须在 [-1, rank(input)) 区间中,默认值为 -1。 |
| beginParamsAxis | 对参数开始执行归一化的维度,value 必须在 [-1, rank(input)) 区间中, 默认值为 -1。 |
| epsilon | 为了数值计算稳定而加入的小 number,默认为 0.0000001。 |
输出:
| 输出名称 | 含义 |
|---|---|
| output | layernorm 计算的结果 Tensor. 与输入 Tensor 具有相同的 shape 和 dtype |
支持平台:Ascend、GPU、CPU
代码示例:
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import nn.layers.*
main(): Int64 {
let input = randomNormalTensor(Array<Int64>([2, 2, 3]))
let normalizedShape = Array<Int64>([2, 3])
let layerNorm = LayerNorm(normalizedShape, beginNormAxis: 1, beginParamsAxis: 1, epsilon: 1e-7)
let output = layerNorm(input)
print(output.getShape())
return 0
}
输出为:
[2, 2, 3]
MaxPool2d 层
Layer 定义:
public struct MaxPool2d {
public var kernel_sizes_: Array<Int64> = []
public var strides_: Array<Int64> = []
public var pad_mod_: String = ""
public init(kernel_size!: Array<Int64> = Array<Int64>([1, 1]), stride!: Array<Int64> = Array<Int64>([1, 1]), pad_mod!: String = "VALID")
}
extend MaxPool2d <: CellUnary {
public operator func ()(input: Tensor): Tensor
}
MaxPool2d 是最大值池化层,按照如下公式进行计算。
$$ output(N_i, C_j, h, w) = max_{m=0,..,kH-1}max_{n=0,..,kW-1}input(N_i, C_j, stride[0]*h+m,stride[1]*w+n) $$
其中 input size 是(N, C, H, W),output size 是 (N, C, H_out, W_out),kernel size 是(kH, kW)。
参数列表:
| 名称 | 含义 |
|---|---|
| kernel_sizes | Array<Int64>,滑窗大小。长度为 2 的数组,值必须小于输入 shape 的宽和高并且大于 0。默认值:Array<Int64>([1, 1]) |
| strides | Array<Int64>,滑窗跳步。长度为 2 的数组,值必须大于 0。默认值:Array<Int64>([1, 1]) |
| pad_mod | String,padding 模式,可选值:"VALID","SAME"。默认值:"VALID"。 |
输入:
| 名称 | 含义 |
|---|---|
| input | shape 是 (N, C, H, W) 的 Tensor,dtype 只支持 Float32 类型. |
输出:
| 名称 | 含义 |
|---|---|
| output | shape 是 (N, C, $H_{out}$, $W_{out}$),dtype 为 Float32 类型的 Tensor |
支持平台:Ascend、GPU、CPU
代码示例:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
main(): Int64 {
let input = randomNormalTensor(Array<Int64>([1, 2, 4, 4]))
var maxPool = MaxPool2d()
let output = maxPool(input)
print(output.getShape())
return 0
}
输出为:
[1, 2, 4, 4]
Relu 层
Layer 定义:
public struct Relu {}
extend Relu <: CellUnary {
public operator func ()(input: Tensor): Tensor
}
Relu 是 Relu 网络层,按照如下公式进行计算。
$$ output=max(0,input) $$
输入:
| 名称 | 含义 |
|---|---|
| input | 输入的 Tensor |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出的 Tensor |
支持平台:Ascend、GPU、CPU
代码示例:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
main(): Int64 {
let input = randomNormalTensor(Array<Int64>([32, 6, 28, 28]))
let relu = Relu()
let output = relu(input)
print(output.getShape())
return 0
}
输出为:
[32, 6, 28, 28]
Softmax 层
Layer 定义:
public struct Softmax {
public var axis_: Array<Int64>
public init(axis!: Array<Int64> = Array<Int64>([-1]))
}
extend Softmax <: CellUnary {
public operator func ()(input: Tensor): Tensor
}
Softmax 网络层,按照如下公式进行计算。
$$ softmax(x_i)=\frac{exp(x_i)}{∑^{n−1}_{j=0}exp(x_j)} $$
参数列表:
| 名称 | 含义 |
|---|---|
| axis | 需要计算 softmax 的维度,其元素取值应在[-input.getShapeDims(), input.getShapeDims())之间,默认值为 - 1,即计算最后一维。 |
输入:
| 名称 | 含义 |
|---|---|
| input | 输入 Tensor,dtype 是 Float32。 |
输出:
| 名称 | 含义 |
|---|---|
| output | softmax 之后的结果 Tensor。与输入 Tensor 具有相同的 shape 和 dtype。 |
支持平台:Ascend、GPU、CPU
代码示例:
from CangjieTB import nn.layers.*
from CangjieTB import ops.*
main(): Int64 {
let input = Tensor(Array<Float32>([3.41188848e-01, 2.06148401e-01, 1.33806154e-01, 2.96444386e-01, 4.45214391e-01, 2.77494937e-01]), shape: [2, 3])
let softmax = Softmax()
let output = softmax(input)
print(output)
return 0
}
输出为:
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 3.72246891e-01 3.25224876e-01 3.02528232e-01]
[ 3.18305582e-01 3.69363725e-01 3.12330663e-01]])
Loss
仓颉 TensorBoost 的 Layer 使用 struct 表示,用户只要导入 nn.loss package (from CangjieTB import nn.loss.*) 即可直接使用仓颉 TensorBoost 已经封装好的 Loss 结构。
BinaryCrossEntropy 层
Loss 定义:
public struct BinaryCrossEntropy {
public let reduction: String
public init(reduction!: String = "mean") {
this.reduction = reduction
}
public operator func ()(x: Tensor, y: Tensor, weight: Tensor): Tensor
}
使用的算子:
public func binaryCrossEntropy(x: Tensor, y: Tensor, weight: Tensor, reduction!: String = "mean"): Tensor
public func adjointBinaryCrossEntropy(x: Tensor, y: Tensor, weight: Tensor, reduction!: String = "mean")
public func binaryCrossEntropyGrad(x: Tensor, yGrad: Tensor, y: Tensor, weight: Tensor, reduction!: String = "mean"): Tensor
计算 logits 和 labels 之间的二值交叉熵。令 logits 为 x ,labels 为 y ,output 为 l(x, y)
$$ L = {l_1,\dots,l_N}^\top, \quad l_n = - w_n \left[ y_n \cdot \log x_n + (1 - y_n) \cdot \log (1 - x_n) \right] $$
L 表示所有 batch size 的损失,l 表示一个 batch size 的损失,n 表示在 1 到 N 范围内的其中一个 batch size
$$ \ell(x, y) = \begin{cases} L, & \text{if reduction} = \text{'none';}\ \operatorname{mean}(L), & \text{if reduction} = \text{'mean';}\ \operatorname{sum}(L), & \text{if reduction} = \text{'sum'.} \end{cases} $$
参数列表:
| 名称 | 含义 |
|---|---|
| reduction | 指定缩减类型,类型为 String,它的值必须是"none"、"mean"、"sum"之一。 默认值:"mean"。 |
输入:
| 名称 | 含义 |
|---|---|
| logits | 输入 Tensor,dtype 为 Float32 类型,shape 是 (N, *)。 |
| labels | 标签 Tensor,dtype 与 shape 需要与 logits 一致。 |
| weight | 权重 Tensor,应用于每个 batch 元素损失的重新调整权重, dtype 与 shape 需要与 logits 一致。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出 Tensor,如果 reduction 为 "none",则输出是 shape 与 logits 一致的 Tensor,否则,输出为含有一个元素的 scalarTensor。 |
支持平台:Ascend、GPU
代码示例:
from CangjieTB import nn.*
from CangjieTB import common.*
from CangjieTB import ops.*
from CangjieTB import nn.loss.*
main(): Int64
{
let logits = parameter(Tensor(Array<Float32>([0.2000000030, 0.6999999881, 0.1000000015]), shape: Array<Int64>([3])), "logits")
let labels = parameter(Tensor(Array<Float32>([0.0000000000, 1.0000000000, 0.0000000000]), shape: Array<Int64>([3])), "labels")
let weight = parameter(Tensor(Array<Float32>([1.0000000000, 2.0000000000, 2.0000000000]), shape: Array<Int64>([3])), "weight")
let loss = BinaryCrossEntropy()
let output = loss(logits, labels, weight)
print(output)
return 0
}
输出为:
Tensor(shape=[1], dtype=Float32, value= [ 3.82404834e-01])
BCEWithLogitsLoss 层
Loss 定义:
public struct BCEWithLogitsLoss {
public var reduction: String
public var weight: Tensor
public var posWeight: Tensor
public init(weight: Tensor, posWeight: Tensor, reduction!: String = "mean")
public operator func ()(logits: Tensor, labels: Tensor): Tensor
}
使用的算子:
public func bceWithLogitsLoss(logits: Tensor, labels: Tensor, weight!: Tensor = Tensor(), posWeight!: Tensor = Tensor(), reduction!: String = "mean"): Tensor
public func adjointBceWithLogitsLoss(logits: Tensor, labels: Tensor, weight!: Tensor = Tensor(), posWeight!: Tensor = Tensor(), reduction!: String = "mean")
计算 logits 经过 sigmoid 激活函数处理后与 label 之间的二值交叉熵。
令 logits 为 X,label 为 Y, weight 为 W,output 为 L。计算公式如下:
$$ p_{ij} = sigmoid(X_{ij}) = \frac{1}{1 + e^{-X_{ij}}}\ L_{ij} = -[Y_{ij} \cdot log(p_{ij}) + (1 - Y_{ij}) \cdot log(1 - p_{ij})] $$
i 表示第 i 个 sample,j 表示分类,则
$$ \ell(x, y) = \begin{cases} L, & \text{if reduction} = \text{'none';}\ \operatorname{mean}(L), & \text{if reduction} = \text{'mean';}\ \operatorname{sum}(L), & \text{if reduction} = \text{'sum'.} \end{cases} $$
参数列表:
| 名称 | 含义 |
|---|---|
| weight | 每个 batch 的权重。shape 可以被广播到与 logits 一致。 dtype 为 float32。 |
| posWeight | 正例的权重。shape 可以广播到与 logits 一致。 dtype 为 float32。 |
| reduction | 指定缩减类型,类型为 String,它的值必须是"none"、"mean"、"sum"之一。 默认值:"mean"。 |
输入:
| 名称 | 含义 |
|---|---|
| logits | 输入 Tensor,dtype 为 Float32 类型,shape 是 (N, *)。 *号表示可以追加任意的维度。 |
| labels | 标签 Tensor,dtype 与 shape 需要与 logits 一致。 |
输出:
| 名称 | 含义 |
|---|---|
| output | Tensor 或标量,如果 reduction 为 "none",则输出是 Tensor 并且 shape 与 logits 一致, 否则,输出为含有一个元素的 Tensor。 |
支持平台:Ascend、GPU
代码示例:
from CangjieTB import nn.*
from CangjieTB import ops.*
from CangjieTB import common.*
from CangjieTB import nn.loss.*
main(): Int64 {
let logits = Tensor(Array<Float32>([-0.8, 1.2, 0.7, -0.1, -0.4, 0.7]), shape: Array<Int64>([2, 3]))
let labels = Tensor(Array<Float32>([0.3, 0.8, 1.2, -0.6, 0.1, 2.2]), shape: Array<Int64>([2, 3]))
let weight = Tensor(Array<Float32>([1.0, 1.0, 1.0]), shape: Array<Int64>([3]))
let posWeight = Tensor(Array<Float32>([1.0, 1.0, 1.0]), shape: Array<Int64>([3]))
let loss = BCEWithLogitsLoss(weight, posWeight)
let output = loss(logits, labels)
print(output)
return 0
}
输出为:
Tensor(shape=[1], dtype=Float32, value= [ 3.46361160e-01])
L2Loss 层
Loss 定义:
public struct L2Loss {
public init() {}
public operator func ()(x: Tensor): Tensor
}
使用的算子:
public func l2Loss(x: Tensor): Tensor
public func adjointL2Loss(x: Tensor)
不使用 sqrt 计算输入张量 L2 范数的一半,计算公式如下:
$$ loss = sum(x**2)/2 $$
输入:
| 名称 | 含义 |
|---|---|
| x | 输入 Tensor, 支持 Float32 类型。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 输出标量 Tensor,与 x 数据类型一致。 |
支持平台:Ascend、GPU、CPU
代码示例:
from CangjieTB import nn.*
from CangjieTB import ops.*
from CangjieTB import common.*
from CangjieTB import nn.loss.*
main(): Int64 {
let x = parameter(Tensor(Array<Float32>([1.0, 2.0, 3.0]), shape: Array<Int64>([1, 3])), "x")
let loss = L2Loss()
let output = loss(x)
print(output)
return 0
}
输出为:
Tensor(shape=[], dtype=Float32, value= 7.00000000e+00)
NLLLoss 层
Loss 定义:
public struct NLLLoss {
public let reduction: String
public init(reduction!: String = "mean")
public operator func ()(x: Tensor, target: Tensor, weight: Tensor): (Tensor, Tensor)
}
使用的算子:
public func nllLoss(x: Tensor, target: Tensor, weight: Tensor, reduction!: String = "mean"): (Tensor, Tensor)
public func adjointNllLoss(x: Tensor, target: Tensor, weight: Tensor, reduction!: String = "mean")
public func nllLossGrad(x: Tensor, yGrad: Tensor, target: Tensor, weight: Tensor, totalWeight: Tensor, reduction!: String = "mean")
计算 labels 和 logits 的负对数似然损失,通常和 softmax、log 一起使用。
Tensor x(input) 是 shape 为 (N, C) 的张量,目标 Tensor t(target) 是 shape 为 (N) 的张量,其中 N 为 batch size,C 为类别数量。
对于每个 $N_i$ loss 的计算公式如下:
$$ \large l_n = - w_{t_n}x_{n,t_n},\quad\quad\quad w_c = weight[c]\cdot1,\ $$
nllloss 的计算方式有三种:none、mean、sum,默认方式是 mean,计算公式如下:
$$ \begin{cases} \large\ell(x, t) = L = - {l_1,...,l_N}^T, \quad\quad if\ reduction = 'none'; \ \large\ell(x, t) = \sum_{n=1}^N \frac{1}{\sum_{n=1}^Nw_{t_n}}l_n,\quad\quad\quad\ \ if\ reduction = 'mean';\ \large\ell(x, t) = \sum_{n=1}^N l_n,\quad\quad\quad\quad\quad\quad\quad if\ reduction = 'sum'. \end{cases} $$
注意:目标分类是相互排斥的,即目标中只有一个分类是正的,但预测的概率不需要是排斥的。只要求预测的概率分布是有效的,概率分布和为 1。
参数列表:
| 参数名称 | 含义 |
|---|---|
| reduction | 指定输出使用的 reduction 方式,包括 none、mean、sum。默认值:mean |
输入:
| 输入名称 | 含义 |
|---|---|
| input | 输入 Tensor,shape (N, C), dtype 是 FLOAT32 |
| target | 目标标签 Tensor,shape 为(N), dtype 是 INT32 |
| weight | 类别加权 Tensor,shape 为(C), dtype 是 FLOAT32 |
输出:
| 名称 | 含义 |
|---|---|
| loss | loss Tensor,reduction 为 none 时,shape 为(N),否则为标量 Tensor,dtype 与 input 相同 |
| total_weight | 标量 Tensor,dtype 与 weight 相同 |
支持平台:Ascend、GPU
代码示例:
from CangjieTB import nn.loss.NLLLoss
from CangjieTB import ops.*
from CangjieTB import common.*
main(): Int64 {
let input = parameter(Tensor(Array<Float32>([0.5488135219, 0.7151893377, 0.6027633548, 0.5448831916, 0.4236547947, 0.6458941102]), shape: Array<Int64>([3, 2])), "input")
let target = parameter(Tensor(Array<Int32>([0, 0, 0]), shape: Array<Int64>([3])), "target")
let weight = parameter(Tensor(Array<Float32>([0.3834415078, 0.7917250395]), shape: Array<Int64>([2])), "weight")
let nllloss = NLLLoss(reduction: "mean")
let (loss, totalWeight) = nllloss(input, target, weight)
print(loss)
print(totalWeight)
return 0
}
输出为:
Tensor(shape=[1], dtype=Float32, value= [-5.25077164e-01])
Tensor(shape=[1], dtype=Float32, value= [1.15032458e+00])
SmoothL1Loss 层
Loss 定义:
public struct SmoothL1Loss {
public let beta: Float32
public let reduction: String
public init(beta!: Float32 = 1.0, reduction!: String = "none")
public operator func ()(logits: Tensor, label: Tensor): Tensor
}
使用的算子:
public func smoothL1Loss(logits: Tensor, label: Tensor, beta!: Float32 = 1.0, reduction!: String = "none"): Tensor
public func adjointSmoothL1Loss(logits: Tensor, label: Tensor, beta!: Float32 = 1.0, reduction!: String = "none")
计算 SmoothL1Loss 函数。 在设置 beta 值之后,当|x_i - y_i| < beta 时,为一个二次函数;否则的话,为一个线性函数,缓解了梯度爆炸。
SmoothL1Loss 可以看作是 L1Loss 的修改版,或者是 L1Loss 和 L2Loss 的组合。 L1Loss 计算两个输入张量之间的元素绝对差,而 L2Loss 计算两个输入张量之间的平方差。 L2Loss 通常会导致更快的收敛,但它对异常值的鲁棒性较差。
给定两个长度为 N 的输入 x、y,SmoothL1Loss 的描述如下:
$$ L_{i} = \begin{cases} \frac{0.5 (x_i - y_i)^{2}}{\text{beta}}, & \text{if } |x_i - y_i| < \text{beta} \ |x_i - y_i| - 0.5 \text{beta}, & \text{otherwise. } \end{cases} $$
输出结果的计算方式有三种:none、mean、sum,默认方式是 none,计算公式如下:
$$ \begin{cases} L(x, y) = {L_1,...,L_N}^T, \quad\quad\quad\quad\ \ \ if\ reduction = 'none'; \ L(x, y) = \sum_{n=1}^N \frac{1}{\sum_{n=1}^Nw_{t_n}}L_n,\quad\quad\quad\ \ \ if\ reduction = 'mean';\ L(x, y) = \sum_{n=1}^N L_n,\quad\quad\quad\quad\quad\quad\quad if\ reduction = 'sum'. \end{cases} $$
参数列表:
| 名称 | 含义 |
|---|---|
| beta | 用于控制分段函数从二次函数变为线性函数的点。默认值: 1.0, 类型: Float32。 |
| reduction | 指定应用于输出结果的计算方式,比如“none”、“mean”,“sum”,默认值:“none”。对于 Ascend 平台仅支持“none” |
输入:
| 名称 | 含义 |
|---|---|
| logits | 输入 Tensor,shape (N,∗),类型是 FLOAT32 的 Tensor |
| label | 标签 Tensor,shape (N,∗),shape 和 dtype 与 logits 一致 |
输出:
| 名称 | 含义 |
|---|---|
| output | 损失 Tensor,shape 和 dtype 与 logits 一致 |
支持平台:Ascend、GPU
代码示例:
from CangjieTB import nn.*
from CangjieTB import ops.*
from CangjieTB import common.*
from CangjieTB import nn.loss.*
main(): Int64
{
let logits = parameter(Tensor(Array<Float32>([1.0, 2.0, 3.0]), shape: Array<Int64>([3])), "x")
let label = parameter(Tensor(Array<Float32>([1.0, 2.0, 2.0]), shape: Array<Int64>([3])), "y")
let loss =SmoothL1Loss()
let output = loss(logits,label)
print(output)
return 0
}
输出为:
Tensor(shape=[3], dtype=Float32, value=
[0.00000000e+00 0.00000000e+00 5.00000000e-01])
SoftmaxCrossEntropyWithLogits 层
Loss 定义:
public struct SoftmaxCrossEntropyWithLogits <: CellBinary {
public let sparse: Bool
public var ignoreIndex: Int32 = -1
public init(sparse!: Bool = false, ignoreIndex!: Option<Int32> = None<Int32>)
public operator func ()(logits: Tensor, label: Tensor): Tensor
}
使用的算子:
public func softmaxCrossEntropyWithLogits(logits: Tensor, label: Tensor): (Tensor, Tensor)
public func adjointSoftmaxCrossEntropyWithLogits(logits: Tensor, label: Tensor)
public func sparseSoftmaxCrossEntropyWithLogits(logits: Tensor, label: Tensor, isGrad!: Bool = false): Tensor
public func adjointSparseSoftmaxCrossEntropyWithLogits(logits: Tensor, label: Tensor, isGrad!: Bool = false)
计算 softmax 交叉熵损失函数。
使用交叉熵损失测量输入(使用 softmax 函数计算)的概率和目标之间的分布误差,其中分类是互斥的(只有一个分类是正的)。
此函数的典型输入是每个分类的非标准化分数和目标。分数 Tensor x 是 shape 为 (N, C) 的张量,目标 Tensor t 是 shape 为 (N, C) 的张量,其中包含长度 C 的 one-hot 标签。
对于每个 $N_i$ loss 的计算公式如下:
$$ \ell(x_i, t_i) = - \log\left(\frac{\exp(x_{t_i})}{\sum_j \exp(x_j)}\right) = -x_{t_i} + \log\left(\sum_j \exp(x_j)\right) $$
$x_i$ 是一维的张量, $t_i$ 是标量.
注意:目标分类是相互排斥的,即目标中只有一个分类是正的,但预测的概率不需要是排斥的。只要求预测的概率分布是有效的,概率分布和为 1。
参数列表:
| 参数名称 | 含义 |
|---|---|
| sparse | 指定标签是否使用稀疏格式, Ascend 平台必须为 false。默认值:false |
| ignoreIndex | 计算损失时忽略值为 ignoreIndex 的标签,默认为 None,即对所有标签值进行计算。不为 None 时,sparse 必须为 true,loss 值的计算与梯度传递只会考虑未忽略的维度。 |
输入:
| 输入名称 | 含义 |
|---|---|
| logits | 输入 Tensor,shape (N, C), Tensor 类型是 FLOAT32 |
| label | 标签 Tensor,shape 为(N)。如果 sparse 为 true,则 label dtype 为 INT32。 如果 sparse 为 false,则 label 的 dtype 和 shape 必须与 logits 相同。 |
输出:
| 名称 | 含义 |
|---|---|
| output | 返回 shape 为空的 tensor,value 为损失值,dtype 与 logits 相同。 |
支持平台:Ascend、GPU、CPU
代码示例:
from CangjieTB import nn.loss.*
from CangjieTB import ops.*
from CangjieTB import common.*
main(): Int64 {
let logits = randomNormalTensor(Array<Int64>([10, 1]))
let label = onesTensor(Array<Int64>([10]), dtype: INT32)
let loss = SoftmaxCrossEntropyWithLogits(sparse: true)
let output = loss(logits, label)
print(output)
return 0
}
输出为:
Tensor(shape=[], dtype=Float32, value= 1.38155103e+00)
附录 F Utils API
介绍
此包提供一些常用接口,包括检查接口,日志接口,随机数接口。
主要接口
checkScalar
检查输入的标量 value 与临界值 thres 之间的关系是否满足输入条件 rel,满足则检查成功,否则抛出异常。
/*
* 检查输入的标量是否有效
* 参数 value - 需要检查的标量
* 参数 thres - 临界值
* 参数 rel - 比较方式,支持的种类有"REL_EQ", "REL_NE", "REL_LT", "REL_LE", "REL_GT", "REL_GE"
* 参数 argName - 参数名称
* 参数 primName - 函数名称
* 异常 ValueException - 当标量无效或输入的比较方式不在支持范围内时,抛出异常
*/
public func checkScalar<T>(value: T, thres: T, rel: String, argName: String, primName: String): Unit where T <: Comparable<T> & ToString
checkScalarRange
检查输入的标量 value 与下限值 lower 和上限值 upper 之间的关系是否满足输入条件 rel,满足则检查成功,否则抛出异常。
/*
* 检查输入的标量是否在给定的区间
* 参数 value - 需要检查的标量
* 参数 lower - 区间的下限
* 参数 upper - 区间的上限
* 参数 rel - 比较方式,支持的种类有, "REL_INC_NEITHER", "REL_INC_LEFT", "REL_INC_RIGHT", "REL_INC_BOTH"
* 参数 argName - 参数名称
* 参数 primName - 函数名称
* 异常 ValueException - 当标量无效或输入的比较方式不在支持范围内时,抛出异常
*/
public func checkScalarRange<T>(value: T, lower: T, upper: T, rel: String, argName: String, primName: String): Unit where T <: Comparable<T> & ToString
checkTwoScalar
检查输入的标量 value1 与 value2 之间的关系是否满足输入条件 rel,满足则检查成功,否则抛出异常。与 checkScalar 检查逻辑相同,但如果失败输出的错误信息不同,checkScalar 检查输入与一个已知标量的关系,checkTwoScalar 强调两个变量之间的关系。
/*
* 检查两个输入的标量是否有效
* 参数 value1 - 需要检查的第一个标量
* 参数 value2 - 需要检查的第二个标量
* 参数 rel - 比较方式,支持的种类有"REL_EQ", "REL_NE", "REL_LT", "REL_LE", "REL_GT", "REL_GE"
* 参数 arg1Name - 第一个标量的参数名称
* 参数 arg2Name - 第二个标量的参数名称
* 参数 primName - 函数名称
* 异常 ValueException - 当标量无效或输入的比较方式不在支持范围内时,抛出异常
*/
public func checkTwoScalar<T>(value1: T, value2: T, rel: String, arg1Name: String, arg2Name: String, primName: String): Unit where T <: Comparable<T> & ToString
checkStr
检查输入的字符串 str 是否包含在 validTypes 中,包含则检查成功,否则抛出异常。
/*
* 检查一个字符串输入是否在有效的字符串数组里
* 参数 str - 需要检查字符串
* 参数 validTypes - 有效的字符串数组
* 参数 argName - 参数名称
* 参数 primName - 函数名称
* 异常 ValueException - 当字符串无效时,抛出异常
*/
public func checkStr(str: String, validTypes: Array<String>, argName: String, primName: String)
checkBool
检查输入的 value 与 validMode 是否相同,相同则检查成功,否则抛出异常。
/*
* 检查一个字符串输入是否在有效的字符串数组里
* 参数 value - 需要检查布尔值
* 参数 validMode - 有效的布尔值
* 参数 argName - 参数名称
* 参数 primName - 函数名称
* 异常 ValueException - 当布尔值无效时,抛出异常
*/
public func checkBool(value: Bool, validMode: Bool, argName: String, primName: String)
checkArray
检查数组里的每一个元素与输入的临界值 thres 的关系是否都满足 rel,满足则检查成功,否则抛出异常。
/*
* 检查输入数组中的每一个元素是否有效
* 参数 arr - 需要检查的数组
* 参数 thres - 临界值
* 参数 rel - 比较方式,支持的种类有"REL_EQ", "REL_NE", "REL_LT", "REL_LE", "REL_GT", "REL_GE"
* 参数 argName - 输入数组的名称
* 参数 primName - 函数名称
* 异常 ValueException - 当数组中的元素无效或输入的比较方式不在支持范围内时,抛出异常
*/
public func checkArray<T>(arr: Array<T>, thres: T, rel: String, argName: String, primName: String): Unit where T <: Comparable<T> & ToString
/*
* 检查输入数组中的每一个元素是否有效
* 参数 arr - 需要检查的数组
* 参数 arg2 - 临界值
* 参数 rel - 比较方式,支持的种类有"REL_EQ", "REL_NE", "REL_LT", "REL_LE", "REL_GT", "REL_GE"
* 参数 argName - 输入数组的名称
* 参数 arg2Name - 临界值的名称
* 参数 primName - 函数名称
* 异常 ValueException - 当数组中的元素无效或输入的比较方式不在支持范围内时,抛出异常
*/
public func checkArray<T>(arr: Array<T>, arg2: T, rel: String, argName: String, arg2Name: String, primName: String): Unit where T <: Comparable<T> & ToString
/*
* 检查输入数组中的每一个元素是否有效
* 参数 arr - 需要检查的数组
* 参数 thres - 临界值数组
* 参数 rel - 比较方式,支持的种类有"REL_EQ", "REL_NE", "REL_LT", "REL_LE", "REL_GT", "REL_GE"
* 参数 arg1Name - 输入数组的名称
* 参数 arg2Name - 临界值数组的名称
* 参数 primName - 函数名称
* 异常 ValueException - 当数组中的元素无效或输入的比较方式不在支持范围内时,抛出异常
*/
public func checkArray<T>(arr: Array<T>, thres: Array<T>, rel: String, arg1Name: String, arg2Name: String, primName: String): Unit where T <: Comparable<T> & ToString
checkArrayRange
检查数组里的每一个元素与下限值 lower 和上限值 upper 之间的关系是否满足输入条件 rel,满足则检查成功,否则抛出异常。
/*
* 检查输入数组中的每一个元素是否在给定区间
* 参数 arr - 需要检查的数组
* 参数 lower - 区间的下限
* 参数 upper - 区间的上限
* 参数 rel - 比较方式,支持的种类有,"REL_INC_NEITHER", "REL_INC_LEFT", "REL_INC_RIGHT", "REL_INC_BOTH"
* 参数 argName - 输入数组的名称
* 参数 primName - 函数名称
* 异常 ValueException - 当数组中的元素无效或输入的比较方式不在支持范围内时,抛出异常
*/
public func checkArrayRange<T>(arr: Array<T>, lower: T, upper: T, rel: String, argName: String, primName: String): Unit where T <: Comparable<T> & ToString
checkTensorDtype
检查输入的类型 argType 是否包含在 validTypes 中,包含则检查成功,否则抛出异常。
/*
* 检查输入 Tensor 的元素类型是否有效
* 参数 argType - 需要检查的 Tensor 的元素类型
* 参数 validTypes - 支持的类型数组
* 参数 argName - Tensor 名称
* 参数 primName - 函数名称
* 异常 TypeException - 当元素类型无效时,抛出异常
*/
public func checkTensorDtype(argType: Int32, validTypes: Array<Int32>, argName: String, primName: String)
checkTensorDtypeSame
检查输入的类型 arg1Type 与 arg2Type 是否相同,相同则检查成功,否则抛出异常。
/*
* 检查两个 Tensor 的元素类型是否相同
* 参数 arg1Type - 第一个 Tensor 的元素类型
* 参数 arg2Type - 第二个 Tensor 的元素类型
* 参数 arg1Name - 第一个 Tensor 的名称
* 参数 arg1Name - 第二个 Tensor 的名称
* 参数 primName - 函数名称
* 异常 TypeException - 当两个 Tensor 的元素类型不同时,抛出异常
*/
public func checkTensorDtypeSame(arg1Type: Int32, arg2Type: Int32, arg1Name: String, arg2Name: String, primName: String)
checkTensorRank
检查输入 value 与输入的临界值 thres 是否满足输入条件 rel。满足则检查成功,否则抛出异常。
/*
* 检查输入 Tensor 的秩是否正确
* 参数 value - 需要检查的 Tensor 的秩
* 参数 thres - 临界值
* 参数 rel - 比较方式,支持的种类有"REL_EQ", "REL_NE", "REL_LT", "REL_LE", "REL_GT", "REL_GE"
* 参数 argName - Tensor 的名称
* 参数 primName - 函数名称
* 异常 ValueException - 当输入 Tensor 的秩无效或输入的比较方式不在支持范围内时,抛出异常
*/
public func checkTensorRank(value: Int64, thres: Int64, rel: String, argName: String, primName: String)
/*
* 检查输入 Tensor 的秩是否在给定区间内
* 参数 size - 需要检查的 Tensor 的秩
* 参数 lower - 区间的下限
* 参数 upper - 区间的上限
* 参数 rel - 比较方式,支持的种类有, "REL_INC_NEITHER", "REL_INC_LEFT", "REL_INC_RIGHT", "REL_INC_BOTH"
* 参数 argName - Tensor 的名称
* 参数 primName - 函数名称
* 异常 ValueException - 当输入 Tensor 的秩无效或输入的比较方式不在支持范围内时,抛出异常
*/
public func checkTensorRank(size: Int64, lower: Int64, upper: Int64, rel: String, argName: String, primName: String)
checkTwoTensorShape
检查输入 arr1 与 arr2 是否相等,相等则检查成功,否则抛出异常。
/*
* 检查两个 Tensor 的形状是否相等
* 参数 arr1 - 第一个 Tensor 的形状
* 参数 arr2 - 第二个 Tensor 的形状
* 参数 arg1Name - 第一个 Tensor 的名称
* 参数 arg2Name - 第二个 Tensor 的名称
* 参数 primName - 函数名称
* 异常 ValueException - 当两个 Tensor 的形状不等时,抛出异常
*/
public func checkTwoTensorShape(arr1: Array<Int64>, arr2: Array<Int64>, arg1Name: String, arg2Name: String, primName: String)
checkValueDebug
判断 condition 状态,输入 condition 为 true 时,程序继续执行;condition 为 false 时,程序终止,并抛出输入的异常信息 message。只在 CANGJIE_TENSORBOOST_DEBUG 选项打开时生效。
/*
* 用于实现断言功能,debug模式有效
* 参数 condition - 判断条件
* 参数 message - 错误信息
* 异常 ValueException - 当判断条件为假,抛出异常
*/
public func checkValueDebug(condition: Bool, message: String): Unit
checkValue
判断 condition 状态,输入 condition 为 true 时,程序继续执行;condition 为 false 时,程序终止,并抛出输入的异常信息 message。
/*
* 实现断言功能,检查数值
* 参数 condition - 判断条件
* 参数 message - 错误信息
* 异常 ValueException - 当判断条件为假,抛出异常
*/
public func checkValue(condition: Bool, message: String): Unit
checkType
判断 condition 状态,输入 condition 为 true 时,程序继续执行;condition 为 false 时,程序终止,并抛出输入的异常信息 message。
/*
* 实现断言功能,检查类型
* 参数 condition - 判断条件
* 参数 message - 错误信息
* 异常 TypeException - 当判断条件为假,抛出异常
*/
public func checkType(condition: Bool, message: String): Unit
checkRuntime
判断 condition 状态,输入 condition 为 true 时,程序继续执行;condition 为 false 时,程序终止,并抛出输入的异常信息 message。
/*
* 实现断言功能,检查运行状态
* 参数 condition - 判断条件
* 参数 message - 错误信息
* 异常 RuntimeException - 当判断条件为假,抛出异常
*/
public func checkRuntime(condition: Bool, message: String): Unit
checkOverride
判断 condition 状态,输入 condition 为 true 时,程序继续执行;condition 为 false 时,程序终止,并抛出输入的异常信息 message。
/*
* 实现断言功能,检查重载
* 参数 condition - 判断条件
* 参数 message - 错误信息
* 异常 NotImplementationException - 当判断条件为假,抛出异常
*/
public func checkOverride(condition: Bool, message: String)
DType 类型
public let UNDEF_DTYPE: Int32 = -1
public let FLOAT32: Int32 = 0
public let FLOAT64: Int32 = 1
public let INT32: Int32 = 2
public let INT64: Int32 = 3
public let UINT8: Int32 = 4
public let UINT16: Int32 = 5
public let UINT32: Int32 = 6
public let BOOL: Int32 = 7
public let STRING: Int32 = 8
public let FLOAT16: Int32 = 9
public let DTYPE_MAP = HashMap<Int32, String>(
[
(0, "FLOAT32"),
(1, "FLOAT64"),
(2, "INT32"),
(3, "INT64"),
(4, "UINT8"),
(5, "UINT16"),
(6, "UINT32"),
(7, "BOOL"),
(8, "STRING"),
(9, "FLOAT16")
]
)
数据类型 SIZE
定义了不同数据类型的大小
public let BOOL_SIZE: Int64 = 1
public let INT8_SIZE: Int64 = 1
public let UINT8_SIZE: Int64 = 1
public let INT16_SIZE: Int64 = 2
public let UINT16_SIZE: Int64 = 2
public let INT32_SIZE: Int64 = 4
public let UINT32_SIZE: Int64 = 4
public let INT64_SIZE: Int64 = 8
public let UINT64_SIZE: Int64 = 8
public let FLOAT16_SIZE: Int64 = 2
public let FLOAT32_SIZE: Int64 = 4
public let FLOAT64_SIZE: Int64 = 8
enum LogLevel
LogLevel 是表示打印日志等级的枚举类型。
public enum LogLevel {
| DEBUG // 调试信息
| INFO // 普通信息
| WARNING // 告警信息
| ERROR // 错误信息
| EXCEPTION // 异常信息
}
cjLog
此函数用于打印日志信息
/*
* 打印日志信息
* 参数 level - 日志等级
* 参数 info - 日志信息
*/
public func cjLog(level: LogLevel, info: String)
setSeed
设置全局随机数种子,用在初始化,随机算子中。如果不设置种子,随机正态初始化(RandomNormalInitializer)和随机算子会使用默认种子值 0,其他初始化会随机选择一个种子值。
/*
* 设置全局随机数种子,用在初始化,随机算子中。如果不设置种子,随机正态初始化(RandomNormalInitializer)和随机算子会使用默认种子值 0,其他初始化会随机选择一个种子值。
* 参数 seed - 随机数种子
*/
public func setSeed(seed: Int64)
getSeed
此函数用于获取随机数种子
/*
* 获取全局随机数种子
* 返回值 Int64 - 随机数种子
*/
public func getSeed(): Int64
getGraphSeed
此函数用于获取图级别的随机数种子
/*
* 获取图级别的随机数种子。在一个程序中,调用两次设置相同的随机数运算,会生成随机数序列,保证两次随机数运算结果不同同;同时,同样的程序运行两次,结果会和上一次相同。
* 参数 opSeed - 随机运算的随机数种子
* 参数 kernelName - 随机运算内核名称
* 返回值 (Int64, Int64) - 当前图级别种子,算子级种子
*/
public func getGraphSeed(opSeed: Int64, kernelName: String): (Int64, Int64)
TypeException
此类用于抛出类型错误异常
public class TypeException <: Exception {
public init()
public init(message: String)
public override func getClassName(): String
}
ValueException
此类用于抛出数值错误异常
public class ValueException <: Exception {
public init()
public init(message: String)
public override func getClassName(): String
}
RuntimeException
此类用于抛出运行错误异常
public class RuntimeException <: Exception {
public init()
public init(message: String)
public override func getClassName(): String
}
NotImplementationException
此类用于抛出未执行错误异常
public class NotImplementationException <: Exception {
public init()
public init(message: String)
public override func getClassName(): String
}
setSaveGraphs
public func setSaveGraphs(saved: Bool): Unit
函数 setSaveGraphs 用户设置保存计算图功能,当入参是 true 时,启用保存计算图功能,入参是 false 时,则不保存计算图。
如开启保存计算图功能,则网络在运行前向计算时会在当前目录保存 ir 图,即产生后缀名为 .ir 和 .dot 的文件。ir 图的说明见 MindSpore IR 文档。
也可以通过设置环境变量 CANGJIETB_IR_LOG = true,保存仓颉 TensorBoost 计算图; 如果需要更多计算图信息,可以设置环境变量 CANGJIETB_IRPASS_LOG = true,保存优化前后的计算图。
【注意】:该功能仅对静态图模式有效,动态图模式无影响。